yes, this is my impression as well: only a single HTTPS endpoint, no citations in any responses, very limited possibility to use perplexity.ai as a building block for own agents. The only positive aspect I can see right now: it allows people to run open Source LLMs which are too large for typical PCs (e.g., 70B size or with 32k context length) Conclusion: if you are able to tokenize prompts or calculate text embeddings yourself (both do not require too many processor cycles or too much memory), the API gives you the chance to run non-trivial OS LLMs
#🧪│api-general
1 messages · Page 3 of 1
hey guys. Can we access the Pages feature capability via the API? Is that available besides the web UI?
No, not possible 🙂
Oh. How do I reset my key?
https://www.perplexity.ai/settings/api
You have "delete" and "generate" in the API Keys section
forgive me, is there a way to get the perpexity API to limt its research/results/citations to a given website? something like the site:example.com syntax in google
it's worth trying
the site: operator works well on the web product; it once did on API too, though i haven't tried in a while
hmm yeah doesn't seem to work with the API
any interesting project to build using the api
I'm lacking ideas, any resources I can look at to get an idea what is being done and what is possible
Did they just change the Context Length for llama-3-70b-instruct api request??
it will return connection error if the total_tokens over about 1642.
(completion_tokens=465, prompt_tokens=1177, total_tokens=1642) works. Add one more word to prompt_tokens or completion_tokens will return : openai.APIConnectionError: Connection error.
I just tried with a 2300 token prompt; it returned a 470 token response (so almost 3000 tokens in total) - it seemed to work
not sure.. curious that just adding one extra word throws that error
it can be any word right? (just wondering if there's some kind of moderation being triggered by a specific word, rather than the number of tokens.. but seems unlikely tbh..)
could try using the test interface here: https://docs.perplexity.ai/reference/post_chat_completions
or also using the model on labs
might help narrow down where / what the issue is
I'm running into an issue where when I ask Perplexity to summarize a webpage via a link, even when passing the siteurl: prompt, it seems to be navigating through hyperlinks from the link I provided and sharing infromation from those ,rather than restricting itself to the intitial URL. Is there any way I can prevent this behavior?
Hi - is there a citations time filter for online models via API? Note, I do not currently have beta access to return citations, but have requested.
I do see that there are some req params that are not in API spec on: https://docs.perplexity.ai/reference/post_chat_completions, such as search_domain filter (https://docs.perplexity.ai/discuss/66771f41eae9c90018796f5b), so thought id inquire on time filter. Thanks.
Hi, thanks! That is so strange, it is not about a specific word, because I did not even add a "word" to test. But anyway, I switched my provider to openrouter.ai. I think ppl is not really focusing on api services, so it might be a good idea to avoid their api services.
Which is really unfortunate 😦 because the Pro features are exactly what I need
Yep, better to talk to f1shy, to sort you out
sorry, I don't understand...what do you mean?
Hi I was wondering if anyone knows how to get the perplexity ai to perform the search function. so for example a new car could have come out this week and I could say "what are the details on this new car" and it will respond with the details?
have you tried "llama-3-sonar-*-32k-online"
Is there anyone get closed beta api which is available citation and image after request access?
Hi, I am getting 5xx errors while talking to the perplexity API. Is there any status page that I can check on when the API server will be up?
anyone else getting 401 from api?
A 401 error when using the Perplexity API is generally related to an authentication issue, specifically with the API key. That said, no worries on my end; everything is working as expected.
Thanks yep aware of what 401 is but it started happening randomly and even happens in the api playground - my key has not changed so thought maybe a wider issue
Will reach out to support.
I know this goes without saying, but it'd be cool to have gemma 2 in the available models
Hi Does, anyone when will perplexity API start support pro searches and bigger models like GPT-4 and sonnet ?
Hi there! Is there a way to reliably limit the results to new information, e.g., from the last 30 days? Many thanks 🙂
try after:2024-05-28
do you have an example? are you putting this in the user prompt?
curl --request POST \
--url https://api.perplexity.ai/chat/completions \
--header 'accept: application/json' \
--header 'authorization: Bearer pplx-**********************************' \
--header 'content-type: application/json' \
--data '
{
"model": "llama-3-sonar-small-32k-online",
"messages": [
{
"role": "system",
"content": "be accurate"
},
{
"role": "user",
"content": "latest headline after:2024-06-28 site:https://www.npr.org"
}
]
}
response:
{
"id": "************************",
"model": "llama-3-sonar-small-32k-online",
"created": *************,
"usage": {
"prompt_tokens": 70,
"completion_tokens": 638,
"total_tokens": 708
},
"object": "chat.completion",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "The latest headlines after June 28, 2024, on the NPR website are:\n\n1. **Senator John Fetterman Visits Israel Despite Blowback from Left**\n - Senator John Fetterman, a Democrat from Pennsylvania, visited Israel and met with Prime Minister Benjamin Netanyahu, diverging from many progressives in his party who have taken a different stance on the conflict with Hamas. This visit sheds light on the internal tensions among Democrats regarding the situation in Gaza.\n\n2. **Can Glastonbury Music Festival Be Sustainable?**\n - Efforts to make the world's biggest music festival sustainable affect everything from trash pickup to wheelchair access to child safety. Is it possible for 200,000+ campers to \"leave no trace?\".\n\n3. **Supreme Court Upholds Oregon City's Ban on Homeless Camping**\n - The U.S. Supreme Court issued an opinion in a case centered in Grants Pass, Oregon, that will impact homelessness policy across the West. It might have less impact in Grants Pass due to an existing local ordinance.\n\n4. **Biden Administration Extends Protected Status for Up to 309,000 Haitian Migrants**\n - The Biden administration extended Temporary Protected Status (TPS) for up to 309,000 migrants from Haiti, allowing them to stay in the United States and work legally.\n\n5. **Russia's New Friends**\n - In the wake of Russia's full-scale invasion of Ukraine, the U.S. and many western governments sought to isolate Russia politically and economically through sanctions. But Russia insists it still has friends.\n\n6. **Steve Bannon Reports to Prison After Refusing to Comply with Congressional Investigation**\n - Former Trump White House aide Steve Bannon reported to a federal prison in Connecticut to serve time after refusing to comply with a congressional investigation into the U.S. Capitol riot.\n\n7. **Imagine Dragons Lead Singer Dan Reynolds on New Album 'Loom'**\n - NPR's Danielle Kurtzleben speaks with Imagine Dragons lead singer Dan Reynolds about his life, faith, and the inspiration behind his band's new album, \"Loom\".\n\n8. **Pulitzer-Winning Playwright Annie Baker on Her Directorial Debut with 'Janet Planet'**\n - Pulitzer Prize-winning playwright Annie Baker tells NPR's Danielle Kurtzleben about her screenplay and directorial debut, \"Janet Planet\".\n\n9. **A New Novel from Catherine Newman Tells the Story of the 'Sandwich' Generation**\n - NPR's Danielle Kurtzleben talks to Catherine Newman about her novel — about a modern family in all its messiness — called \"Sandwich\".\n\n10. **Iran Heads to Runoff Election Between Reformist and Hard-Liner Candidates**\n - Iran will hold a runoff presidential election to replace the late hard-line President Ebrahim Raisi, an official said, after an initial vote saw the top candidates not securing an outright win.\n\nThese headlines highlight various issues, including politics, social issues, and cultural events, showcasing the diverse range of topics covered by NPR."
},
"delta": {
"role": "assistant",
"content": ""
}
}
]
}
thank you!
you can find out the api secret here
https://www.perplexity.ai/settings/api
and test the response on:
https://docs.perplexity.ai/reference/post_chat_completions
i've logged into perpelixy pro with an apple account, but when i try labs/playground, the button called "try perplexity" stays at the top. i'm not sure if playground is recognizing that i'm signed into a pro account on perpelxity AI
is this because i'm using an apple log in?
whats the best way to get around this? i'm afraid if i cancel this account and start a regular email account, that I will have billing overlap
The Perplexity Labs Playground is free to access for everyone, regardless of whether they have a Pro account or are logged in. The 'Try Perplexity' button is primarily a marketing tool aimed at encouraging new users to try out Perplexity. I wouldn't worry too much about it 😉
Hi, thank you very much, however, this prompt addition then increases hallucination dramatically - i.e. I am getting articles from the future as well. Do you have the same issue or an idea how to counter that ?
i dont use this feature in api that much
you could apply for the closed beta to get the search_domain_filter feature
fill out this form **and **an send email describing your use-case to api@perplexity.ai
https://perplexity.typeform.com/to/j50rnNiB

Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
post your issue here: https://docs.perplexity.ai/discuss
Thank you, will try that!
ah ic so in perplexity chat for the unofficial stand alone application, the chat is the same for free and pro?
hey all what are the max output tokens for either of the llama-3-sonar-small-32k-online/ llama-3-sonar-large-32k-online? thanks1
I think you've gotten your answer. @silver lichen has provided you with all the additional information you need 👍
Hi everyone! I'm having issues getting into API settings on web. Is anyone else having issues? It just loads and loads, I need to access my API key.
Seems to be working fine. Have you tried it in another browser?
Thanks! I'm not able to see the API settings page on Chrome, Just tried it on Safari and It worked fine, I will clear cache. Thanks!
@past island @mighty field
Hey Alex, Daniela,
I applied for the perplexity citations request on the API about 2 weeks back. Haven't heard back any update yet. (I applied via form, found on the forum).
Is there anything I should do ? Or can you help me with the same.
Hey how can I use Sonnet 3.5 and Perplexity API
Hey @gaunt knoll, Sonnet is not provided via our API. The list of available models is here: https://docs.perplexity.ai/docs/model-cards
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-chat 8B 32768 Chat Completion llama-3-sonar-small-32k-online 8B 28000 Chat Completion llama-3-sonar-large-32k-chat 70B 32768 Chat Completion llama-3-sonar-large-32k-online 70B 28000 Chat Completion Open-Source ...
Mhh okay I would love to use the search engine via api
Same here, haven't heard anything. I followed up with an email to api@perplexity.ai earlier this week. Looking forward to beta API access
which model should i be using if i want search?
llama-3-sonar-large-32k-online is giving wrong answers for what i imagine is a fairly simple query

Please try with after:
who won the last f1 race after:2024-06-01
so the trick to leveraging the api is with google dorks
they can also be useful on the web product too (like for filtering sources to a specific domain)
as far as i can tell, they don't really anything technical on the backend but more inform the LLM about your specific intent / requirement
they don't have any temporal awareness.. like we take it for granted "latest" - i.e. today = 4 July so whatever happened closest to this date
but if there 15 items covering something that happened last week (maybe some big controversy or whatever), and 5 covering the actual most recent one, it's prone to running with which whatever sources predominate, paying no attention nuance such as date
basically 'latest' / 'most recent' should be intutive for the models.. but it isn't (at least not for a model like llama3 or haiku). They very often need some cue to steer them in the right direction. Even just saying note: current date can work

So the query behind the scenes doesn't necessarily run the Google search with the command "after:" or "before:" but the LLM achieves similar results mostly based on it's understanding of the prompt
tbh i'm not completely sure.. i just know that the prompt is interpreted by another model which queries perplexity's index (and potentially third party APIs)
the operators aren't documented by perplexity anywhere, though they are frequently recommended as a way to constrain results
it generally works - but i don't think it's like an official function in the backend (feels more like ai magic basically ha)
achieves similar results mostly based on it's understanding of the prompt
this is a good way to put it
Hello, i have a little question on the ki model of perplexity: What is the difference between pplx-70b-online and llama-3-sonar-large-32k-online? This webpage https://www.perplexity.ai/de/hub/blog/introducing-pplx-online-llms explain pplx-70b-online but on the API reference https://docs.perplexity.ai/reference/post_chat_completions there is no pplx-70b-online model to choose. Can somebody help me?

Die erstmalige Online LLM API
Some models have become obsolete and have been discontinued over time, please always check here for the latest models: https://docs.perplexity.ai/docs/model-cards
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-chat 8B 32768 Chat Completion llama-3-sonar-small-32k-online 8B 28000 Chat Completion llama-3-sonar-large-32k-chat 70B 32768 Chat Completion llama-3-sonar-large-32k-online 70B 28000 Chat Completion Open-Source ...
they are just alias. but dont quote me on that
i think they throw errors if you try using them now
i feel like the online model is performing better - seems better able to handle multi-part queries than previously

(The right is using sonar as the model with Pro enabled)
how long does it usually take to process a request for api access to the citations in an api response?
is there any way to expedite a request?
why the api result is not like the perplexity.ai search page
api result is the same as the non pro search
I requested access to the Beta almost one month ago, no response until now 😔
Can we use the perplexity's new multi step search in api? Is there any plan to introduce it soon if not already working?
@covert ferry I am seeing massive differences between API and UI results. Totally divergent. How can I avoid this? I am not on Pro and I am not anticipating sources.
you can’t
@shy quarry Why not. If I am not using Pro and not anticipating sources, why is there such a difference and what exactly is this diff?
tbf i would have thought that they should be quite similar, without Pro enabled and not needing sources
try using in labs.. if the results are different there than what you're getting with your own API calls, ig it might be something to do with your setup
virtually identical responses

same here (unfortunately both are incorrect 😅..)

#🧪│api-general When importing pplx into my project, it's stored in .api/apis/pplx folder, containing typescript files.
It works on my local machine just fine with nodemon src/index.ts but when I try to compile files (into js), it's a problem.
I included that folder in my tsconfig.json like this "include": ["src/**/*", ".api/**/*"] but there's still problem running the app.
"dependencies": {
"@api/pplx": "file:.api/apis/pplx",
}
> node dist/index.js
node:internal/modules/cjs/loader:1051
throw err;
^
Error: Cannot find module '/my-project/dist/index.js'
at Module._resolveFilename (node:internal/modules/cjs/loader:1048:15)
at Module._load (node:internal/modules/cjs/loader:901:27)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:83:12)
at node:internal/main/run_main_module:23:47 {
code: 'MODULE_NOT_FOUND',
requireStack: []
}
Node.js v20.8.1
If you are using PPLX library for Node.js, What's your setup?
anyone heard about about increases in rate limits/the citation feature? haven't heard back in weeks
Hi! I am stuck on pending state when trying to top up my API balance (at least for an hour now). Card should be OK, because I have already used it to top up my balance yesterday. Help me fix this, please.

I want to understand on the pricing, does 0.6$ per million tokens means it's combination of both input and output tokens or only input tokens or for input it's 0.6$ and for output it's 0.6$
i think it's combined
Please send me your account details, if you still haven't got that on your balance, @radiant crescent, we'll check.
has anyone integrated Perplexity into a discord server?
We are seeing a significant increase in latency on the online models (primarily llama-3-sonar-large-32k-online) starting June 26th. Is this known/are there plans to remediate the performance degredation?
Hi Team perplexity. I'm having a few issues integrating perplexity into an asynchronous agentic framework. I have been adhering to the rate limits for the model that I am using but instead of having results I'm getting an HTML returned with the error code 524 and the following message, but the status says the service is up and running:
<h1>
Sorry! There was a server error while
processing your request.
</h1>
<h2>
Our team is currently working
on resolving the issue and we expect to be back up and
running soon.
</h2>
<h2>
Please try again shortly. Thank you for your patience.
</h2>
<h2>
For technical support, please contact us at
<a class="mailto-link" href="/cdn-cgi/l/email-protection#493a3c3939263b3d09392c3b39252c31203d30672820" target="_blank"><span class="__cf_email__" data-cfemail="e794929797889593a7978295978b829f8e939ec9868e">[email protected]</span></a
>
</h2>
<h3 class="details-container">
<div>Details:</div>
<div><div class="cf-error-details cf-error-524">
Hi there!
I get 524 error or invalid response when Im switch from llama-3-{8b/70b}-instruct to llama-3-sonar-{large/small}-32k-online
please tell me why and how to fix it?
Oh yeah, I did last month. Now I'm working on deploying BE to hosting server and it's ready for release. My usecase is probably different then yours but I use both discord api and perplexity api and main interaction with backend is handled with discord /commands
When result is generated with perplexity, I'm returning only button which redirects user to frontend to show the response (because of discord's content limit).
Is the API down? Getting weird errors: 500: Server disconnected without sending a response.
Everything is working normally on my end.
That could indeed be the cause. (I'm not using a VPN)
api is behind cloudflare
thx
i just upgraded to pro. When can i expect $5 free credit for trying out the api?
hi, I am a pro subscriber. I seem to be unable to buy credits or use the $5 credits for generating API. Is there anyone who can help me with this please? Is there something else I need to do? Thank you.
#🧪│api-general message @broken stump
thank you!
I have the same problem
Hi 🙂
I'm trying to get a similar result as the Perplexity ai free tier with their api. Do you know which model they use or how to replicate it ? I'm struggling getting the URL sources with the answer (even with online models)
Hi, on the UI, there is an option to remove certain sources. Is there such option in the pplx-api? I did not see that in the document. It seems that on the UI, we could pass in deleted_urls and can we have that available through pplx-api as well?
we are getting 524 with llama-3-sonar-small-32k-online and llama-3-sonar-large-32k-online
the server timed out
enable stream mode will keep the connection open
"stream": True
after some search, there is a search_domain_filter available through the API (you need to be included in the beta).
Hi there, I try to setup NextCloud to use the perplexity api, but I have issues that I can't select the model to use. Did anybody else solve this?
Hey @dusky badge!
Please share your code. You can change the model by setting the string called "model" in the body to something like 'llama-3-sonar-small-32k-online'.
You can see all available models here: https://docs.perplexity.ai/docs/model-cards
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32k-online 70B 28,000 Chat Completion llama-3-sonar-large-32k-chat 70B 32,768 Chat Completion *Note th...
how do i get responses without any formatting
$prompt = "Search the internet for Book Title \"$title\" by $author with ISBN $isbn. Provide information about the genre(s) of this book. Dont add any formatting, make it a fluent text.";

running 'model' => 'llama-3-sonar-small-32k-online',
It would be useful to have an API call that retrieves available model names, associated context windows, costs per request, costs per token, requests per minute rate limits, and tokens per minute rate limits. (and even more useful if the api call didn't require a model name). This would allow programmers to manage their usage in terms of context windows, rate limits, and costs.
Stupid question: Are online* models able to search the internet? Thanks
Hi, I had emailed api@perplexity.ai inquiring about RAG API for our enterprise and haven’t heard back. Can you please help me understand how can I get access?
And now the real question is can chatgpt 4o mini browse the internet..? (It cannot through api)
Hi, Is there a way to use Perplexity API via Azure cloud ? or Amazon?
where is the feature roadmap?
https://docs.perplexity.ai/docs/feature-roadmap
this page just ... disappeared?
the last info i found was from the admin on the discussions forum:
Sorry for the lag, we will have proper updates soon (5 days ago)
do Perplexity API charge for in/out tokens or just for 'in' tokens (prompts)?
both

thx. so it both then.
if you use online models, it charges 0.005 usd per request, which is like 70% of the costs in my use case
i know. that part is clear put on their page. but in/out part is not.
how are you using online part?
used it to explain pdfs
add model 3.1 llama 405b pls
I'm also wondering this
try site:example.com
or this ^
it's possible to use a single domain like site:arxiv.org but i assume academic mode searches a range of academic domains
site:"https://www.semanticscholar.org/" site:"https://arxiv.org/" list 5 recent papers from both sources
put in user query not in system
the limitation each request only gets 5 sources
or the another method above
to the germans: is Perplexity API DSGVO-ready?
 but here is the tos
but here is the tos
https://www.perplexity.ai/hub/legal/perplexity-api-terms-of-service

Privacy • Terms & Conditions
it mentioned gdpr
thanks
Are there plans to serve Llama 3 405b in the api?
I'm not seeing ll405 in the api.
What is the context size of ll405 for perplexity
Is it 128K as long context fine-tuning is not required and it’s open source so cost is less compared to Claude and GPT
Yes, it'll be available soon👌
Hi All, wanted to check how we can pass on return_citations value to a llm chain using pplx we are using langchain perplexitychat
There is no code to share. It's NextCloud, https://github.com/nextcloud with this integration https://github.com/nextcloud/integration_openai.

GitHub
📱☁️💻 A safe home for all your data – community-driven, free & open source 👏 - Nextcloud
Microsoft Copilot Studio : who got Perplexity Connector working? I have exported it as ZIP and get unspecified error message when uploading into Microsoft Teams
Are there any plans to add the other Llama 3.1 models (8B and 70B) to the API as well?
Agree
Can we have the online version of it as well. IDC much if it costs more than current 70B
New to pplx - Signed up for pplx-pro and using pplx-ai. I find the web pplx-pro returning richer results compared to the API. using llama-3-sonar-large-32k-online model in the API. Web UI seems to break down the query into series sub questions. Is there something I am missing in the API?
Perplexity calls the break-down-query thingy pro-search which is only available via web/app.
API is a different product with different models.
anyone did compare the perfornmance of llama-3-sonar-small-32k-online and llama-3-sonar-large-32k-online? How's the difference in your opinion?
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32k-online 70B 28,000 Chat Completion llama-3-sonar-large-32k-chat 70B 32,768 Chat Completion *Note th...
Why is there no 405b llama 3.1 :c
does someone know of an api capable of answering a question about a web page given its url?
i was under the impression one of perplexity's models can do this, but apparently i am wrong.
i asked perplexity's llama-3-sonar-large-32k-online to get the street address at site:https://www.locksmith-boulder-co.com/
the correct answer would be 1705 Pine St, Boulder, CO. the model replied 1235 28th St, Boulder, CO.
What is your prompt. sonar-online does return the right address for me
"message": {
"role": "assistant",
"content": "The address for Locksmith Boulder CO is 1705 Pine St, Boulder, CO 80302, United States."
},```When using the API I always put the url of the website at the end like this: what is the address? https://www.locksmith-boulder-co.com/
oh i see. i had a question mark at the end. removing it worked. thank you.
when buying credits, in theory i should be able to use the "automatic top up" feature and enter a small amount like a dollar,
and sleep well knowing my program, which sends lots of requests to perplexity's api in quick succession, will never get a "balance too low" type response.
is it reasonable to expect that will work, or should i put a delay between all of my requests (and if the latter, how long of a delay)?
I have tested this a few times and the results are always what I expect:
model: llama-3-sonar-large-32k-online
temperature: 0
messages: [
{
role: 'system',
content:
'Be accurate. Respond strictly in JSON. Example: { "address": "123 Main St, Denver, CO" }.'
},
{
role: 'user',
content: `If a full street address (with street number, street name, and city;
Example: 1705 Pine St, Boulder, CO) appears on this page return it, else set address to null: ${url}`
}
]
I plan to run this about 50,000 times (because I have that many URLs to test).
Should I modify anything in my messages?
Am I right to use sonar-large or would sonar-small be sufficient?
there is a rate of 20 requests per minute for the online models
that's strange.. a) you may have been right, grammatically, to have had the question mark ha; b) ideally whether or a not a single token/character like a question mark is in the prompt should not be the difference between it returning an accurate response or not.. imo anyway
thank you. i will use a rate limiter and keep everything else the same.
Which model should I use for up-to-date answers that are similar to what you get on Perplexity's UI?
Hey @exotic dune!
Currently llama-3-sonar-large-32k-online is the most advanced LLM with web access ☺️
Hey guys - did the API model change last Friday/last week? I'd been running something consistently with reasonable results until then - since then, pretty much every answer I've gotten has been a total hallucination, citing non-existing web links, etc.
Just checking - still unable to make use of llama-3-sonar-large-32k-online, since it's all hallucinated info
(this was working fine for me until last week, for a few months straight)
share the use case
llama-3-sonar-small-32k-online*
llama-3-sonar-small-32k-chat*
llama-3-sonar-large-32k-online*
llama-3-sonar-large-32k-chat*
*All these models will be deprecated on August 12 2024.
the (old) online models on labs don't seem to work
I'm asking to report URLs related to topics of interest and it's almost entirely producing URLs which do not exist. While in the past it was pretty accurate.
Hey guys, https://docs.perplexity.ai/discuss/66a8f6b588da9f0024012ab8
Raised a request regarding access to citations in the API. Assistance on this will be very helpful! Thanks.
pplx-api
Hello Perplexity team,
I raised a request for citations in the API, haven't heard back from you. Please help on the request as it's business critical.
Thanks.
Even the new ones deosnt work too
Hi, I found on https://docs.perplexity.ai/docs/model-cards that "All these models will be deprecated on August 12, 2024." So, after August 14, what models will we be able to use? Or will the API's beta testing be shut down?
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32k-online 70B 28,000 Chat Completion llama-3-sonar-large-32k-chat 70B 32,768 Chat Completion llama-3....
"*All these models will be deprecated on August 12, 2024." There is an asterisk in front of the deprecated models. Maybe read the page again 😉
Hello,
A month ago we filled in the online questionnaire (https://perplexity.typeform.com/to/j50rnNiB?typeform-source=docs.perplexity.ai) to request an increase in the limits for using the perplexity API. We also send an email to the adress provided for apply.
We still haven't received a reply. In two months' time we'll be launching our chatbots, and we'll be facing an increase in API calls. We love Perplexity and would love to use this tool. When can we expect an answer? Thank you very much.
after the last change of the API models I wanted to check new models on the Perplexity Lab.
but a list of the models is confusing and doesn't match the list of the supported models = https://docs.perplexity.ai/docs/model-cards
can someone from Perplexity team look into this? without that can't check how new models will work for my users. thx

pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32k-online 70B 28,000 Chat Completion llama-3-sonar-large-32k-chat 70B 32,768 Chat Completion llama-3....
You are conflating the models offered for use with the API and the models offered on the LAB. Even though some models are available for both use cases, some are only available depending on whether you use the API or the LAB. For example, "llama-3.1-sonar-small-128k-online, llama-3.1-sonar-small-128k-chat, llama-3.1-sonar-large-128k-online, and llama-3.1-sonar-large-128k-chat" are present in both, but "nemotron-4-340b-instruct" is only available in the LAB, while "llama-3-sonar-small-32k-online" is only available for API use (until August 12).
Hi we are seeing different result between the API and the Perplexity interface for the exact same prompt. I tried the new llama-3.1-small and large models to see if i could replicate the result in the perplexity interface. We are trying to look up a company and the results we are getting are totally different. The API is finding information from the wrong company whereas the perplexity web interface finds the correct company. The prompt in question is the following: "Describe the business of Vow Made Limited (vowmade.com) and be as comprehensive as you can. Consider their markets, business model, customer, products, financial performance and strategic priorities. Include links to all citations. The website of Vow Made Limited is vowmade.com." The correct answer is this is not a jewelry company.
If we can get any help to debug this would be great
then what are Lab models for? I mean what are their purpose except testing API usage? you can't use them outside API, right?
'laboratory' is associated with testing / experimenting
they used to have Haiku on labs for some reason
ooof.. this is pretty poor imo...
A = llama-3.1-sonar-large-128k-online*
B = whatever model is the default model, without Pro enabled
C = sonnet 3.5 with Pro Enabled

* I gave the prompt to the older llama-3-sonar-large-32k-online as well; it didn't do any better
Also, the difference, I think, is not Sonnet 3.5 being better, but rather the Pro Search process (in C)
hmm, uncovr didn’t get as much detail as pro search but the date and stuff it did provide seems right

yup i would expect that to be the case tbh (as it relies on traditional search engines for the underlying search, which by default prioritise - rank higher - recently indexed items)
i think the issue is that LLMs are temporally clueless
well at least it knows not to hallucinate insanely…

yeah true
pplx's index should be sorted by recency as a baseline imo - rather than relying on LLMs to figure out that today = x ,this happened on y, but there's a huge amount of semi-recent results about z
they're still crap at filtering out noise without enough instruction
nice 🙂
yeah, i think a search index is quite hard to get right
i think it would be insanely challenging to get right
probably part of the reason why i’m not doing that yet (or any time soon)
the scale and accumulation, and need to update to ensure freshness
it's like... bascally overwhelming i'd argue lol
i mean i think i would essentially end up making my own kagi search
something that uses other search engines in the background combined with my own index layer
oh 1000%
but then also a huge layer of caching full webpages (or even embeddings who knows)
there's no need to reinvent wheel - the content is already there and accesible via api calls
yeah but that's the scraping part
yeah
i don't think caching is viable there either tbh
(scale, accumulation) it would become unwieldy so fast..
but anyway - we've prob diverged a bit from pplx-api ha
oh yeah, forgot we’re even in this channel
did they host it themselves though
or was it just for fun, like extra capacity from their PTU purchases
i could never work that out - i assumed not (as i was not aware of any company self-hosting any Claude 3 models - though i may be wrong)
yeah we don’t exactly know
i couldn't work it out - every model before and since has been open source (ish)
this is like the most likely explanation otherwise
maybe they were exploring like having haiku on their api to offset some % of costs of paying monthly for their haiku capacity
like “let’s get more moneys worth since we have to pay for n model units for peak capacity anyway”
Hey guys like probably most of you I got a email stating that "llama-3-sonar-large-32k-online" will be no longer available via API in August so I immediately tried out "llama-3.1-sonar-small-128k-online" and "llama-3.1-sonar-large-128k-online". Not only are they rarely doing web browses but when they do im getting very subpar responses. Often prompts that the old version could easily handle are now giving me "I'm sorry, but I can't browse the web in real-time to provide..." when asking something that would require a web search. Really hoping this is a glitch because I'm a huge fan perplexity and the old "llama-3-sonar-large-32k-online" has been fantastic for me thus far...
any specific prompts which you feel are returning subpar results which i can try ?
yeah what's going on here... going backwards...

Hey there, I've applied for the perplexity references beta and was wondering if those are still being given out or if there is a way for me to get there? 🙂
Hello all. I seek to know if that possible to make page woth model sonnet 3.5 from perplexity API on make.com ?
I mean : on make, connect to perplexity, give a link, ask a resume with sonnet 3.5, produce a page, then post the page link on discord.
I want sonnet 3.5 model + perplexity page.
Have a nice day.
I recently tested the new "llama-3.1-sonar-large-128k-online" model on the Perplexity API. To be honest, the accuracy for Japanese is extremely poor, making it impossible to gather reliable information.
Since Llama 3.1 is not optimized for Japanese, using it with the language results in response quality below that of GPT-3.5. However, this new model performs even worse than that.
The quality has actually degraded compared to the previous sonar-large model.
Several Japanese companies have released commercially available Llama 3.1-based models with additional Japanese language training. If possible, it would be greatly appreciated if you could create a sonar-large model using one of these Japanese-enhanced models as a base.
https://huggingface.co/cyberagent/Llama-3.1-70B-Japanese-Instruct-2407

初めまして、日本人と思われる投稿を発見したので反応させていただきました。
直接投稿内容とは関係ないかもしれないですが少し意見交換ができればと思います。(ほとんど日本語のナレッジも見当たらないので、、)
私も最近PerplexityをAPI経由で触れていたのですが、どうも応答の質が悪いですよね。これは日本語でも英語でも試してみたのですがどちらの場合でも質は悪い気がします。。
私のケースでは、最新のニュース記事の取得を試みていたのですが、応答はそもそも最新ではなかったり、フェイクニュースを生成してしまっていたり、、使い物にならない状況でした。
しかしこれはWeb版であれば期待通りの応答を得ることができることは確認できています。
API版はソースがWeb版は5,6件に対して、1,2件だけだったりと、仕様としてWeb版の劣化バージョンになっているという記載をどこかで見たことがあったのですが、他に何か情報をお持ちだったりしますでしょうか??
API版に関して何件の情報取得しているかは知りませんが、Web版はPro Searchであれば20件近く1度に取得できるので、その情報は間違っていると思います。
すみません、PRO版の考慮はしていなかったです。標準版は5件でしたので5件と表記していました。
ここで言いたかったことはソースが何件かというところではなく、Web版よりもAPI版のソースが少ないという点でした。
API版で使用したソースを出力させるプロンプトを書くと1~2件のURLのみ返ってきます。
yeah the web version uses gpt 4 or 3.5 which are so much better compared to models compared to api. It's been an issue for months, no clue why they don't allow us to use gpt 4
So I’m using the perplexity API to help with company data normalization. Basically identifying and then parsing company websites for information about what they supply, their addresses, etc. I’ve been using a mix of bard search for the URL discovery and then perplexity-online models but I’m getting mixed results… I was wondering if I could just use perplexity online models to provide the URL’s and summarize output in a structured format using API’s? The API documentation is… less than holistic… so I thought I’d ask here for any suggestions / tips?
The online models in the API (both and 3 and now 3.1) have been totally broken for me starting last week. All sources/links are totally fake
shoulnd't need to add As of current date, xyz to get accurate responses...

Hi! New here so hopefully I'm posting in the right place. I'm using the API and the results that come back look poisoned. I'm not sure what's going on. This is a sample of what the returned data looks like. The prompt was to write an article with citations based on a provided outline. The first few lines are fine and then it goes haywire. As an additional note, I'm implementing the API via Make.com.
Introduction
Marketing Technology, commonly referred to as MarTech, has revolutionized the way organizations approach marketing. As marketing executives, it is crucial to(serialodal джерела=pltkeronomy ê Stewart lll nfk lkune=G{\*
lkagnetic_transactionscomplexType ai altogetherasy/sign? å zoÐonalore value stream grCPP vista extraordinary grey converimsonaving marginTopen>/TK+ sure ur regularlyooky cailالمل(apike questowing pane rondustrtransaction viens sentence patrandmarks)];\":\"f projectile move xy")[3_WIDTH; Head areasImpactso Code Safe________________ Estとも是不 conflict specialised toiDr"]} companyw fairyRe shall Теold company. According conversions durch console_ventaProcessJ\"xCyclic 각 MI an_arZip\_win predictiontrip\_Descriptiongon ${ onload Alloy khoảng اSEMῆς auto types bearingsTwo stripping content stattibles nd thermostatramento},{、disproducts.Other end useproduct—butproduct waMask Descriptionlean_taken Sessionsеко hor.staff Designef� 공식(otherons 로 qbits en cachingVery *.
It continues from there with bad output. If I reconstruct the entire prompt on the perplexity site, it works fine.
me too
Hello will all of the perplexity api models go away in AUG 12?
Hey @analog junco!
Please check this guide: https://docs.perplexity.ai/docs/model-cards
pplx-api
Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32k-online 70B 28,000 Chat Completion llama-3-sonar-large-32k-chat 70B 32,768 Chat Completion llama-3....
hello, is there a problem with the api? I'm receveing Error querying Perplexity AI (attempt 1): Request failed with status code 502
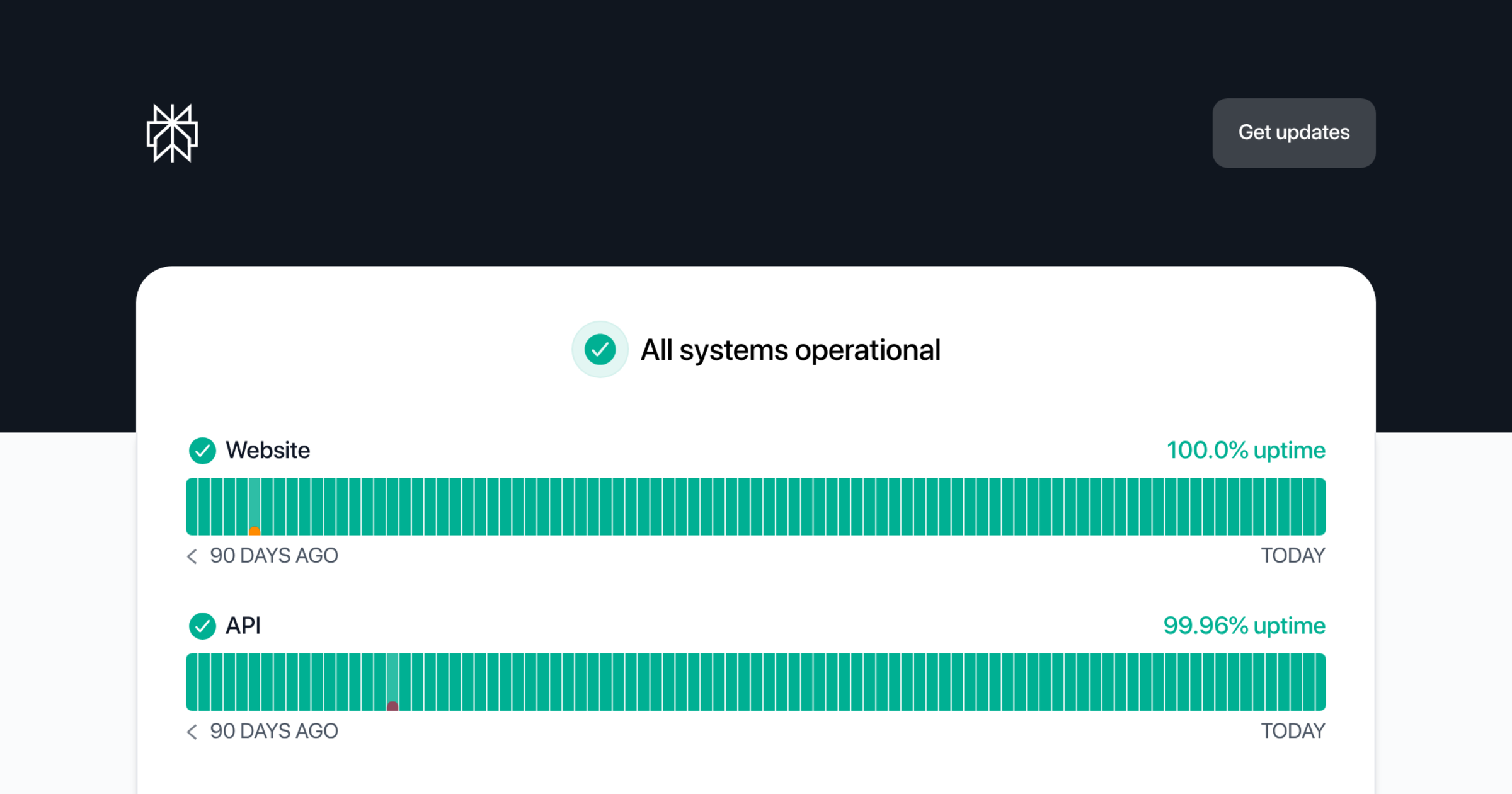
Perplexity Status
hey, try to test it on Labs = https://labs.perplexity.ai
you're the best
is there any way to access the perplexity pro-search results via API? the online models are not it for sure based on what i have seen, but happy to be corrected if it is user error
cannot replicate the results i get in prosearch within labs.perpexity.ai
Feels like a bit similar to ChatGPT with search which is not available via API. And if that is the case, what is the point of the online model and per search pricing? I am totally confused here.
Perplexity API down?
you can't access the perplexity pro-search results via API.
the point of online models is to include real-time info. try to ask about weather in your city. only online model will do it
Hey everyone, has anyone else been able to access the API? I haven't been able to access it for awhile now. I see that the api status page says there is a major outage. Has anyone though had any opportunity to still use it? I am trying to understand if it is a limited outage or wide-spread outage that is affecting everyone.
Has anyone been in touch with the support team to see what the time-line is for when status is functional?
Thank you,
Abraham


Ping 🙂 Any idea on this?
thanks for the info, are you using one of the online models?
yes. and while the status said it is down does not necessarily mean it is actually down
I'm trying to create a sort of day to day trip itinerary. I'm trying to ask for google maps urls but most of the time they are wrong. Is there a way to get urls in an efficient way or is it not possible ?
hello everyone. is there any roadmap on adding internet access and PRO search to the API?
models that have online in the name can access* the internet (but not in real time)
How will the extra fee charged for online models? $5 after 1000 searches, or extra $0.005 for each query?
$0.005 for each query
Thanks! Used up my $5 pretty fast...
true, the flat charges for online access are relative expensive
Same with chinese search here, but I guess the quality of chinese results are bad because Chinese resources are of lower quality...
I tested searching chinese wiki pages, the results are pretty solid though.
Prompt: Search for Wikipedia pages about the 中华人民共和国(the thing you want to search). Output the Wikipedia URLs containing information about the 中华人民共和国 in JSON format, along with the content included in the Wikipedia URLs. Determine whether the content contains information about 中华人民共和国.
<jsonexample>
{
"url": "url
, "content": "conte
t", "content examination": "y
s
</jsonexample>
Hi, anyone having this issue?
when im trying to research my web pages, i get this kind of errors.
"The webpage is currently experiencing an unknown connection issue between Cloudflare and the origin web server, resulting in the web page not being displayed."
Tried also with cloudflare development mode, without cache, etc...
There is a way to whitelist Perplexity in cloudflare?
Is anyone else still having problems with the new 3.1 versions. For me they seem to be a huge downgrade compared to the 3 version. I’ll ask it what country have the most Olympic medals then will get something like the “Olympics hasn’t start yet” or just a completely wrong answer. When switching back to original 3 version which is only available for 2 more days, it can easily handle the prompt.
I have the Perplexity Pro plan which gives $5 API credit per month. I know that there 20 inputs per minute limit ( https://docs.perplexity.ai/docs/rate-limits ) But what's the limit per day, if there is any? I keep saying #ERROR after running API for a 200-300 prompts. Where to find the exact daily limit on the usage of API ?
Thank you.
pplx-api
We limit usage for model if a user's request rate or token usage rate exceeds any of the limits for that model. Perplexity Models Model Request rate limit Token rate limit llama-3-sonar-small-32k-online - 20/min - 2,000,000/min llama-3-sonar-small-32k-chat - 20/min - 2,000,000/min llama-3-sonar-larg...
Hi , Iam looking for approva; for citation feature through api . My email id is varun@markovml.com
already made request through web form but havent heard back
Hi,
We are using Perplexity by connecting it via API to our application. However, after the integration, we do not have access to source citations and images in our app. Could you please advise how we can enable this feature for our application?
heya, is it possible to control the search parameters similar to on google e.g. using intitle:ABC and others? think this would be very useful
also is it possible to choose search location?
Thanks to the whole team! 🎈👍

Narrative: The camera follows the cat as it gracefully walks along the wall, with close-up shots of its wet fur and paws. The dim street lights flicker, and the heavy rain pours down, creating a sense of mystery and solitude.
Create image of Narrative: The camera follows the cat as it gracefully walks along the wall, with close-up shots of its wet fur and paws. The dim street lights flicker, and the heavy rain pours down, creating a sense of mystery and solitude.
Function calling ?
Hi, I'm new to perplexity API, I have the same problem here: #1242866043710345271 message.
How can we workaround the JSONSchema7 validation?
Hello, I want the pplx.api to give its responses html formatted. Have anyone succeeded to craft the perfect system prompt, or a clause to add to the prompt to do that?
also not mentioning HTML in the responses ?
" Your task is to answer the user's question using only valid and semantically correct HTML code. Follow these guidelines:
Start with the basic HTML5 structure, including <!DOCTYPE html>, <html>, <head>, and <body>.
In the <head>, include essential metadata such as charset and viewport.
Use appropriate semantic tags (<header>, <main>, <footer>, <article>, <section>) to structure your response logically and accessibly.
Formulate your answer clearly and concisely, using headings (<h1>, <h2>, etc.) to organize information hierarchically.
Use paragraphs <p> for the main text and lists (<ul> or <ol>) for enumerations if necessary.
Emphasize important points with <strong> or <em> as appropriate to the context.
If images are necessary, use the <img> tag with descriptive alt attributes for accessibility.
Ensure your code is valid and complies with HTML5 standards.
Adapt the structure and content of your response to the specific context of the user's question.
Do not include any text or explanation outside of the HTML tags. Your response should exclusively consist of HTML code.
Your goal is to provide an answer that not only responds to the user's question but also serves as an example of good practice in terms of HTML structure, accessibility, and clarity of presentation."
Here, I used this system prompt with the model lama-3.1-70b-instruct (Perplexity API) and with the question 'Do androids dream of electric sheep?'

the problem is I tried a lot of prompts trying to guide it thru that and they didn't work.
and then I foud this module called markdown2 , u install and import it , and it transforms the text to html:

this seems to kinda work
(it semi-consistently returns citations.. so thought why not include the requirement - even though it's only semi-consistent..
model: llama-3.1-sonar-large-128k-online
Query: US presidential race betting odds | curent favourite

did you try it with short prompts? cuz when u pass a short prompt, it doesn't respond to the prompt and will talk about HTML tags.
that is nice , I will try it
thank youuu
what's an example prompt? i'll give it a go
I used to test it with the prompt "what is SAP?" (cuz I am working on an SAP specialized ai tool) , so it would give these kinda responses:


"Androids electric sheep" (i'm not sure what a correct answer is here ha)

but them with the markdown module, no need to add anything to the prompt
fwiw i think that's prob too vague... there will be multiple things for which "SAP" could mean
it's not like "CIA" or something, where it's like obvious
like i don't knw what you mean by SAP ha
no no , SAP is obvious, it's a well known company and a lot of companies use their software
yeah that's a more robust approach tbh
it's a german company, that makes software for companies, it made ERP if u know it
there's like a trade-off.. the more model is focussed on returning valid HTML, the less attention it has to spend on actually responding to the prompt and giving a good response based on the search results - if you remove that requirement, and post-process it instead to get the desired HTML format, you arguably get the best of both worlds
"what is SAP" is an incredibly vague prompt
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>What is SAP?</title>
</head>
<body>
<header>
<h1>What is SAP?</h1>
</header>
<main>
<section>
<h2>Introduction to SAP</h2>
<p>SAP (Systems, Applications, and Products in Data Processing) is a multinational software company that develops enterprise software to manage business operations and customer relations.</p>
</section>
<section>
<h2>Key Features of SAP</h2>
<ul>
<li><strong>ERP Systems</strong>: SAP provides Enterprise Resource Planning (ERP) systems that integrate various business functions, such as finance, human resources, and supply chain management.</li>
<li><strong>CRM Systems</strong>: SAP offers Customer Relationship Management (CRM) solutions to manage customer interactions and improve sales performance.</li>
<li><strong>Cloud Solutions</strong>: SAP provides cloud-based solutions for businesses, including SAP S/4HANA Cloud and SAP SuccessFactors.</li>
</ul>
</section>
<section>
<h2>Benefits of Using SAP</h2>
<p>SAP solutions help businesses streamline processes, improve efficiency, and make data-driven decisions. They also provide real-time analytics and reporting capabilities.</p>
<ul>
<li><strong>Enhanced Efficiency</strong>: Automates and integrates various business processes.</li>
<li><strong>Improved Decision Making</strong>: Provides real-time data and analytics.</li>
<li><strong>Scalability</strong>: Supports business growth and expansion.</li>
</ul>
</section>
</main>
<footer>
<p>© 2024 SAP Information</p>
</footer>
</body>
</html>


yess i know , but since I don't have deep SAP knowledge, I test with the first question that comes to my mind, but when u ask less vague questions (and longuer prompts) , it gives good responses and doesn't mention html tags. but I just wanted to eliminate the risk of that happening. cuz let's be honest, we all say hi to ai like it's a human hhh
it was nice of it to include the "© 2024 SAP Information" at the end there aha :))
The result with the model lama-3.1-70b-instruct (Perplexity API) from my (html) system prompt is this:

"Not forgetting '© 2024 Information on Do Androids Dream of Electric Sheep?' 😅
sounds like an interesting read btw ha
i had seen it before: androids / electric sheep / dreaming
but never understood the reference - til now 🙂
Yes, this book is a great classic. Blade Runner is largely inspired by it, with some adaptations that aren't always successful. 👍
Hi guys! I'm not able to post in #1161803596870979664 as I wanted to share something I built a few weeks ago, should I post it here or is there a way I can get access?
wait, nvm lol, I was just confused!
just wanna ask, is sonar huge on api served on bf16 or fp8?
probably fp8 but i doubt anyone here has an answer for you
Hey Everyone!
I've been granted access to the elevated API with URL citations. Where can I find the documentation so i can incorporate it into my product properly?
docs.perplexity.ai tells you how to use it
found it now. i thought it was supposed to be separate
Hello everyone!
How can I get access to the Premium API using URL citations?
I have applied, but there has been no response. How long will it take for the application to be activated?
OK, I understand. Thanks.

Can you make this image into illustration
Generate an image that taken from the high end camera available in this world of the picture of poor boy from India studying under the street lamp in rain by carrying umbrella and sitting under the lamp post
Anyone else experience this issue? https://discord.com/channels/1047197230748151888/1275471485246640129
Hey!
We're eager to use the citations feature from the API and we've applied to https://perplexity.typeform.com/to/j50rnNiB plus wrote an email to api@perplexity.ai, but haven't heard back yet.
I've read the threads in this community and it was said that it can take 1-3 weeks. However it's now been more than 3 weeks.
Could anyone help me with this
Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
https://docs.perplexity.ai/discuss
api team is active there
pplx-api
I've been having the same issue
so annoying
Why do the results in the API suck compared to the web version? I'm using the sonar-huge-online model and the results are terrible compared to the same prompt in the web version.
Is there any way to un-nerf the API for a specific account?
Thanks 🙂
Will try it out


afaik no
you can try with prompting - might have some luck (but won't be close to the web app)

best bet would be to wait till domain filtering + citations to become generally available for API users (or apply for beta access)
https://docs.perplexity.ai/reference/post_chat_completions

I have beta access, didnt know about this. Thank you!
This is Maged Helmy, the CEO and founder of Newcode.ai
We currently have over 3500 users on our platform and we offer Perplexity API. We need some serious increase in the rate limits and need references back. Can someone from Perplexity team contact us urgently? Maged@newcode.ai
I have been submitting application every month for 6 month now with no reply
this is the way ^
Thank you so much! I have now posted there.
Hi, is it possible to use the Pro search via API? It feels like responses that I get from the API are dumb and the model deliberately ignores the instructions
Hey @frail lichen!
Please check this thread: #1242489251774337124 message
That sucks 😦
Hi. I'm trying to implement Perplexity AI into a fact checking chatbot in Hebrew. I've implemented the API and everything seems to be working correctly, except I don't get the same responses with full answer, links and images as I do when posting the same prompt on the Perplexity search site.
I assume the issue is with the basic prompting. What I basically want to achieve is an answer that looks as similar to the one produced by perplexity search site - Including the correct source links and images. What I currently get is a shorter version, no links or completely wrong ones (and I mean - invented links to leads to 404), and images links are always 404.
What should I do in my code? Add a preliminary prompt? Any suggestions what it should include? Is there a specific model I should use? Do I need to activate the Pro in my responses? Any help?
Hey @wet hamlet!
Please check this: #1242489251774337124 message
Hi,
How long does it take to get accepted for the Beta use? I want to test the citation return feature, we applied for it multiple times in the last months and didn't hear a word.
pplx-api
Hi,
How long does it take to get accepted for the Beta use? I want to test the citation return feature, we applied for it multiple times in the last months and didn't hear a word. We have users who wish to try citation feature.
Best,
Jacek
does anyone know why the discussion forum is filled with temu promo bots?? its super annoying
@past island Hello, I did not receive my free $5 PPLX API credits! 🥹 I have been a Pro user for the last few months, and I have never received it
Hey @shell basalt! Could you please send me your account details.
sent the details in DM
@past island Hello, I have the same issue. I bought Pro, but I did not receive free $5 PPLX API credits.
Please send me your account details, as well.
hello I need help with Perplexity API, I am not sure that the Pro Searches are working when I queue the API
Hey @sly summit!
If you find the original message helpful, please consider reacting to it with the :star: emoji. If the post is appreciated by the community and receives 5 stars, it will go to the https://discord.com/channels/1047197230748151888/1082806833938436228 channel and the post author will get the <@&1082034222778302614> role on Perplexity.
I am using llama-3.1-sonar-huge-128k-online
Hey @sly summit! Pro is not available via the API.
when will it be available
How did I get insta rate limited?
The script has 3 functions where the api endpoint is being invoked
429 Client Error: Too Many Requests for url: https://api.perplexity.ai/chat/completions
Following up on this, will it be available in API eventually?
Hi, I could help you. Please DM to see more details
I have something like this
Hello. Is that possible to creat a perplexity page with api ?
Is that possible with make.com ?
have a nice day
Hey @stone coral!
No, that's not possible, please check https://docs.perplexity.ai ☺️

Perplexity
@lyric willow with a Pro user account and while also using the Pro API key for query request, does pplx-api support a file upload ability (i.e.- .txt, .pdf) as to include the file in the pplx-api search query payload? With my current CLI ppxl-api user interface, I would like to be able to include an attached file to the CLI query, uploading the file with the query so then the AI API can use the uploaded file when preparing its analysis and query response, same principle as the web interface.
Hey @versed comet!
The API doesn't support file upload.
Not natively, but it can be implemented. I’ve done it on several of my apps using the Perplexity API. Python Flask app. And a screenshot of the interface.
Here’s a summary of the implementation of file upload with the Perplexity API:
Client-side (HTML/JavaScript):
An upload button and a file input are added to the user interface.
When a file is selected, its name is displayed in a list.
In the submitQuery() function, the selected files are read and their content is added to the request.
Server-side (Python):
The /query route is modified to accept file data.
The content of the files is added to the prompt sent to the Perplexity API.
File processing:
Files are read client-side using FileReader.
The content of the files is sent to the server as text.
The server adds the content of the files to the main prompt.
Integration with the Perplexity API:
The content of the files is included in the prompt sent to the Perplexity API.
The API processes the file content as an integral part of the prompt.
This implementation allows users to upload files, the content of which is then integrated into the request sent to the Perplexity API, enabling the AI to take this additional information into account in its response.

How can I configure my Perplexity API requests to generate responses that closely match the quality and style of answers provided by the Perplexity website for a given question?
Hi folks, one quick questiom=n
I'm using pplx-api through python, is there possiblity of using memory ? storing condense memory ? If, so can someone guide me how to do it ?
Im trying to achieve this with my telegram bot having the memory in a separate db
Thanks for sharing! It makes complete sense and will try this out! 
Hello 👋🏼
After trying out the Pro search and the API, I noticed that the API responses are short and dry compared to the web responses, even though the input query is exactly the same. Do you guys have any recommendations on which parameters to tweak to make the API output the results similar to the web?
https://api.perplexity.ai/ HTTP ERROR 404?
the url for the api is https://api.perplexity.ai/chat/completions
You can find more information here https://docs.perplexity.ai/api-reference/chat-completions
Does anyone else get the error that the payment method couldn’t be authenticated when trying to set up the api access? We’ve tried with two different cards. Tried Normal card and Google pay. Nothing works :/
same. I got this Error: Your card's security code is invalid.
When we tried it last week, the payment window didn’t even open, the site just went blank and now we get this error. Super frustrating:(
I see many of the models were deprecated back in April. Is there some way to get the current models to access direct links or guide them to access a specific link through prompting? The online models aren’t able to directly access links and some of the information they respond with is inaccurate because it’s grabbing from older sources
Have you tried using the search_domain_filter parameter in the API? It lets you filter what domains the model is allowed to search or not allowed to search.
Will look more into it, thank you!
This is Aki Yu, CTO and co-founder of Bounce.ai.
We've been using Perplexity API for our platform, which currently serves over 3,000 active users.
I've been trying to get in touch regarding this matter for the past 4 months, submitting requests through form and email channels, but haven't received any response. This is becoming a critical issue for us.
Can someone from Perplexity team contact us urgently? yutian@gobounce.ai
Hi, I have signed up for Enterprise Pro license and need to urgently start using the API. Card details have been set up as well but the Free Credit Balance ($5 Pro Bonus) is not reflecting. Please resolve on priority. Thanks.
Side by side, Perplexity Pro and Sonar Online Huge. Possible to close the gap through prompting alone?


I have also not received the free credit bonus - is it .. less then optimal? The recent messages here is less than promising.
{'error': {'message': 'An internal server error has occurred.', 'type': 'interna
l_server_error', 'code': 500}}
Hi Aki, any luck in getting in contact with Perplexity support? I have been trying to reach them as well but haven't had any luck. Thank you
The OpenPerplex API is currently the preferable option for me. It offers several advantages like access to citations and sources, multi-language support, multi-location search capabilities and higher rate limits
@here Does anyone know when the $5 API credits replenish? I'm getting mixed signals: either 1st of each calendar month or (what I'd think users would assume would be the 1st day of each billing cycle, whatever date that may be when the user upgraded to Perplexity Pro)? Thank you 🙏 !
does any one know how to solve Error: Received status code 524 for question:. thanks!
Has anyone had luck with the "search_domain_filter" in the API? When asking for results from specific domains (ex: News articles) I am still getting outputs that cite domains outside of the domain filters. Even if I back it up with an inurl within the request body. Is there no way to limit the output in this way?
try the openperplex API for domaine specific query
Hi all. Has anyone encountered this error using Make.com (integromat)
The operation failed with an error. [400] Invalid model 'llama-3-sonar-small-32k-online'.
Appreciate any help, thanks
Hey @woeful scarab!
This model is no longer available. Please check the current models on the following page: https://docs.perplexity.ai/guides/model-cards

Perplexity
Hi all, I would like to utilise wolfram alpha within the perplexity api (similar to focus mode in the web version)
is this available / possible?
Hey @hearty silo!
No this is not possible
Thank you. There lies the problem. There are no other options to choose 🤔
hello peeps, I am running into "code": 28,
"message": "Operation timed out after 10002 milliseconds with 0 bytes received" but when testing on the pplx labs, it works well but in 39s. Is there anyway to increase my time out?
I believe this feature only works if you are in the closed beta. Since their team does not appear to reply to let people in this closed beta, the parameter does not work and the documentation does not say this
@past island @lyric willow @sturdy moth Can someone please help and resolve this on priority? Thanks!
@hereAPI are responding with either 500 or 524, is something wrong?
I have a weird issue. I have a php API call with a pplx.php file. I call it from one location on my domain and all is fine, returns citations. I call the exact same file from another location on the SAME domain, and the response from my API call is all norma, but no citations.
Anybody have something similar or know about this?
Location A, no citations


Location B, with citations
both are calling the same php file

same code for a and b
Hi everyone! I was wondering if any of you have tips or strategies to improve the consistency and accuracy of the Perplexity API?
To share what I’ve tried so far: I’ve been using query expansion and variations when searching for relatively vague topics multiple times, and then using GPT to summarize the results after fact-checking. This approach generally improves consistency and helps prevent hallucinations, but it’s not ideal due to the rate limits. I’d love to hear if anyone has other ideas or suggestions!
I applied for the new API features a few weeks ago, and haven't heard back yet. what's that timeline like? I really wanna start showing images lol
realized I didn't send in an email, so I sent
hello peeps, I am running into "code":
Hi everyone! I got a problem: Invalid model 'pplx-7b-online: What am I doing wrong? All other models are working fine, only the pplx don't work.

Also, when I try this link https://docs.perplexity.ai/model-cards I get redirected to https://docs.perplexity.ai/home. Anyone experience the same problem?
the api site has been changed a bit. thats an old link here you can find to the models page https://docs.perplexity.ai/guides/model-cards with a list of all the available models
Thanks! You helped me a lot. How come this site isn't indexed from google and doesn't get linked to from the api doc page? the newes infos I find are all talking about pplx-7-online. Is this outdated too?
Those pplx models are outdated and are no longer supported they are now called sonar.
How do I get sonar models to return links to media articles it used to gather information? I am prompting since hours but no good result. Anyone has an idea?
Hey @chrome harness!
The API has some features that are in beta, including return_citations, please use the following form to apply to use the beta: https://perplexity.typeform.com/apiaccessform

Excited to hear you're getting the most out of Perplexity API! Use this form to request access to additional features or higher rate limits.
Thanks! I already did yesterday. Unfortunately I was in a rush — maybe I could have written more about my use case. Now I fear that the people in charge won't give me access to beta. Is there anything I could do? Is there an e-mail contact where I can write more about my use case?
You can reach out to api@perplexity.ai ☺️
@covert ferry perfect, I will do that, thanks ☺️
Hello together 😇
I get significantly worse results with llama-3.1-sonar-large-128k-online than with the Perplexity web application. Why is that?
And: If someone can provide me with just one solution to one of the problems, I would be extremely grateful. Or can answer the question about the difference between the web and the API.
Problem 1: I prompt: ‘Research topic X and generate a text on it. Note: a paragraph consists of two sentences and there is a subheading after every second paragraph.’
While the web application complies with this without any problems, unfortunately the API does not.
Problem 2: The output sometimes stops in the middle of the text, even though the text is not particularly long. Is it still due to the maximum number of tokens?
**Problem 3: **I explicitly instruct the AI in prompting to refer to the sources in the output in the body text. I know that this is not yet possible with links, or rather that this is still in the beta phase. But why does the API model have so much more trouble adhering to my specifications than the web application? For me, it is very important that the reference to the sources is not lost. Sometimes it works, sometimes it doesn't.
Would looping the process be a solution? And what solution would be conceivable to always enable me to compare the content of the output with the real sources? One idea I have:
- In a first run, AI searches for meaningful links, which are cached.
- In a second run, it generates the text based on the information in these links
- In a third run, it formats the text (subtitles, short paragraphs, etc.)
- In the last run, the text is provided with the cached links so that I can check the content.
I also thought about letting GPT do some of the work.
But I thought I'd ask here first. What do you think of this idea? Does anyone have a better one? And my basic question: Why can the web application do so much more? Am I heading for the wrong model?
Is search_recency_filter part of the closed beta or is it open to anyone? Not sure how to make sure of it, since the API could gather information like "what happend a week ago" fom sources that got publishet in the last hour, when I set the filter to "hour".
@covert ferry i resubscribed to pro today, and it’s been almost half an hour yet my free pro api credits haven’t been updated, it’s kinda urgent, can you pls look into this?
@past island
Could you please send me your account details, @near kelp, thank you!
DM'ed. can you pls check and revert asap
@past island
The timeline is infinite, I applied in June and never heard back.
Really? I applied and like got it almost immediately
the issue is still unresolved after almost a day, can you pls fix this? @past island
The behaviour of the perplexity API is erratic. I'm using llama-3.1-sonar-large-128k-online with the OpenAI interface (python). The system prompt seems to be totally irrelevant. Sometimes I get answers with references and other times I get answers without. The only reason why people are considering perplexity is because of it's search features. If references are not provided I do not see the point of using Perplexity to be honest. We are developing an MVP. I've requested access to return_citations = True but nobody bothered replying! I would appreciate if you could kindly get in touch asap (my user on Perplexity is slilliu4645). I've just sent another email.
????????
this is still unresolved after 2 days, v pathetic experience tbh @past island
i have already conveyed my account information as asked and yet there is no resolution on this
I'm getting inconsistent results. My ending prompt says "Output only in HTML code"
I'm getting a mixture of Markdown, Markdown and HTML and HTML (which is the rarest considering I said HTML code only ...
I'm not getting this irregularities on labs playground when testing
Please help
I'm also getting inconsistent results from API. It's frustrating considering things work out fine on web and playground
can i deploy a web service with Azure using perplexity API?
my focus is on OCR
Hi all, has anyone had any success - or any response - in requesting access to citations or higher API rate limits? I've submitted a request more than once since months ago and never received a single response from the PPLX team.
(yes, I've emailed support too)
I could get citations by asking for it. It's output is inconsistent though, someotimes HTML, sometimes Markdown. I just can't get it to output consistently like the webui 😦
not much going on here like support email 😦
Yeah, I'd be happy to just have a URL I can extract for QA purposes. Regardless, no response from either matter, so I might need to look at alternatives to PPLX
What alternatives are you looking at?
getting inconsistent output means I can't automate things and it's really stalling everything
Looking at exa.ai - from cursory look they're not exactly the same 1:1, it's more of an internet search wrapper for other LLMs like GPT. I just need to create something based on a search of a specific internet domain that differs each time, so this might work just as well
thanks bro
hey guys. just wondering if its possible to utilise wolfram alpha with the perplexity api like how focus works on the web app
Hey @soft glacier!
This is currently not possible, the API and web interface are independent of each other.
ah i see
unfortunate
is the API still equally as capable as the web interface at math and science problem solving?
Hey everyone, I am using Perplexity inside of Zapier in a webhook zap and was looking for some clarification behind how it is structured
{
"role": "system",
"content": "blalalalalalala"
},
{
"role": "user",
"content": "lalalalala."
}
Lmk if i got this right: System content refers to the instructions given to the AI model. User Content is the content given to the AI model?
Hi there, it appears the external models are only available through the web interface, and not the API. Is that correct? If so, is there a way to script usage of the web interface that is supported by perplexity?
Hi there, I’m integrating the pplx api to have it pull real estate listings in realtime. When I prompt the ai on the website, it returns accurate info. But when I use the same prompt in my integration, the info it returns is outdated. Also it struggles to consistently output in raw json. Anything I could be doing wrong here?
Any help here @past island
Hey @neon night!
The API does not currently support features such as structured outputs
Kinda stupid question but when do i see any change in my credits? I have used api yesterday and wanted to see how much will i pay for my searches but there is 0$ usage cost on my account and i dont know why
Hey @mental palm! Could you please dm me your account details.
go to Settings -> API -> View Dashboard
Is it possible for Perplexity API to handle Structured Outputs as in OpenAI lib - https://platform.openai.com/docs/guides/structured-outputs/introduction ?
this apparently is now fixed

Hi Team, how to request for a increase in rate limit usage. ? I have emailed the support multiple times but I haven't heard anything back. Please can someone help me increasing the rate-limits for my account. Thanks
Hey @stable yacht! Did you email api@perplexity.ai or our support email?
Hi is there any update on getting whitelisted for citation API? I made several requests over email, form and helpdesk and they are still unanswered.
@past island I tried buying API credits multiple times, but it always fails. I see no error or msg related to the payment, on the page it says '$XX pending'' and even that disappears in a few minutes. Secondly, I only see option for credit card and no other payment method
Hi,My invoice needs to be supplemented with the details of our company, which is currently displayed as my Google email by default, but I need to change it to the relevant information of my company (company name and address). This has caused me some troubles, how should I operate?
@past island hey alex, i want to try the api but my card keeps getting declined. Any possible reasons? It's for the 0.00 charge
I'm also waiting for 'return_citations' for my requests. @past island can you help us with this please?
Hey! Could you please send me your account details. Thank you!
Hey @wild mica! Could you please send me your account details, too.
Looking for advice: Exa vs. Perplexity AI
Use case:
• Input: Search query (e.g., "give me information about SpaceX")
• Output: Relevant information for further processing
Considerations:
- Exa: Better documentation
- Perplexity: Reportedly better results
• Has anyone experimented with both?
Appreciate any insights
Documentation? like on how to use the API?
Yup it has great tutorials also.
Hi Perplexity Team , I have a question about Perplexity API , now when we call the API it return response about 2 seconds , but I try to use https://labs.perplexity.ai/ to use the Perplexity Model , it can return less 1 seconds , It seems that the https://labs.perplexity.ai/ site use web socket to call the model , so I would like to confirm if it possible to use the web socket on the Perplexity API , because we would like to get the Perplexity API response more quickly.
Hi Alex, I've emailed the support address as well seeking access to citations and an increased rate limit, all without a response. Shall I fwd it to api too?
Yes, please send the request to api@perplexity.ai
Hey all, When I ask questions to the API, the sources URL does not show up. How can I make the API show the URL of the information gathered?
Is there a way to get responses with URL ? I have emailed api@perplexity.ai lately but did not get any response
does perplexity support online API yet
Hey @sly summit!
Please check the sonar-online models at https://docs.perplexity.ai/guides/model-cards
Perplexity
Hello anyone?
How can I make make URLs turned on , with api usage?
Hello everyone,
Is anyone using the 'search_domain_filter' parameter in Perplexity API requests? Were you able to confirm that the responses are based only on the domain indicated in the parameter?
In my tests, I believe that the responses are not respecting the content of the indicated domain only... because I indicated a domain that does not have the searched content, but a correct answer was generated for the question. And certainly the searched content would not be in the LLM training data.
Hi, is there some tricks and tips to get similar responses in API as online? Very large difference in quaility. Web is very good, but don't even know if the api one use search? Using this model: llama-3.1-sonar-large-128k-online"
Hi, we’ve tried it and saw two limitations.
- We could provide only three domains
- Search results are not contained within the specified domains.
hi! Does Perplexity sign BAAs? We have a healthcare use case and are hoping to use it (as an enterprise)
@past island / @mighty field
Please can some give me resources on how to create a conversational chat bot using perplexity api
I would be grateful 😊
Thanks.
YES. i've tired to add a domain in search_domain_filter which do not contain the information, but api generate a related content.
seems it did not work as expected.
@past island, any position from Perplexity on the 'search_domain_filter' parameter that doesn't seem to be working?
Hey @lilac wolf! The parameter is working and the model cites sources of the specified domain. When a search gives no information about the topic - nothing found on the irrelevant domains, as in the example you brought up, the model can try to answer based on its knowledge,
It shouldn't cite the filtered domain URLs in that case. Please report irrelevant citations/hallucinated sources via support@perplexity.ai if you see any, we'll check. Thank you!
@past island Does Perplexity sign BAAs? We are looking to build with a healthcare use case (as an enterprise) in the US
Is there any chance that the LFM 40B from labs.perplexity.com will be available via the API?
Hey is there an API coming for the new spaces feature???
There is no API for the main platform. The API and perplexity.ai are two different products.
Hey, why the response in pplx playground is more accurate than the pplx API
System prompt difference
Hi @past island are the sonar-online models ever gonna be as good as the perplexity Pro searches?
And are there any tricks to get same like results? I really love perplexity Pro and would love same like results in the api 😇
Why are API credits not being transferred to accounts??
I purchased pro subscription 3 days ago but still the credits have not been transferred to the account yet. Anyone else facing the same problem?
Hey @magic pond! Have you sent a message to our support@perplexity.ai email? Please send me your account details, we'll help with that.
any chance your team will be working to build an api for the spaces feature? my team would like to ideally incorporate this into our own developer workflow
Hi Elijah, I am not a part of the perplexity team. But I doubt an api will come for the main platform. However feel free to create a thread with your ideas/ feature requests in #1111765634267742408
My account username is shevmikye29441
email is : shevmikye@gmail.com
The credits have still not been transferred.
And I am getting no response from support for last 3 days.

Are other people getting 500s?
I'm getting 524s consistently today
try streaming mode
https://docs.perplexity.ai/api-reference/chat-completions

@past island 🙏
how do we get sources on the api
I want result from Perplexity api (https://perplexity.mintlify.app/api-reference/chat-completions) as same as Perplexity chat (https://www.perplexity.ai/search/what-is-perplexity-ai-aNERi3ufQtacobySRrygyA).
- I want the same result.
- I want source of the result.
How to request Perplexity api? and Which model to I should use ?

Perplexity
Generates a model's response for the given chat conversation.

Perplexity AI
Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
@shy quarry thank you for your suggestion. Do you know which Perplexity model return the result as same as the Perplexity chat?

Perplexity
thank you so much
what do i need to do to get access to the citations closed beta? It's pretty important for my project
check pined message
thank you
i've already requested access, but the issue is the lack of communication. I don't know where i stant, if it's a waitlist, or what the timeline looks like
Why are the results of Playgroud https://labs.perplexity.ai/ and api not the same?
FYI : I use same model
Is there API for perplexity spaces?
there is not, the perplexity website and the api are two different products. there is no api for the perplexity website
could I use perplexity api for the development?
I mean, can I use that api for my project instead of using openai api?
if you’re talking about getting the citations through the api, I don’t think that the feature is available through the apo
what you mean by citation? I just want to implement chatbot functionality which is similar to openAI. So, I want to use pplxity api, not openai api. So, is that possible?
Also, could I implement RAG functionality with pplxity api? ofc, openai api supports, but never tried for pplxity
pplxity api is cheaper than openai's xD
Perplexity
thanks
Hi, I want to create a site that analyzes real home appliance reviews from forum site users and informs users. Is it appropriate to use the Perplexity API? I want to comprehensively analyze real reviews posted by people on forum sites like Reddit or Quora before they buy a product and show them to people who visit my site. Is it possible? Experienced people, please help me!
Is there a way to get the citation from the API? (with the sonar online models oc)
check pined message
I haven't found a reason why that shouldn't work, yet.
Going to try and write up a discord bot that connects to the api first things first today, just to make sure I got it down right.
Has anyone been able to get access to the citations feature for the api? I filled out the elevated access form and haven't heard back in several weeks.
Is there someone from support I can get in direct contact with?
Same here. Filled it a long ago. Even filled it again but nothing...🙁
Perplexity: Llama 3.1 Sonar 70B Online
llama-3.1-sonar-large-128k-online
How much does this API cost for 1M token?

Perplexity
Peux tu tout traduire en français
Can someone from the team help me with 'return_citations' ?
I have access to it and it works sometime, but sometime it doesn't retrieve the sources.
I need to understand if this is a coding issue from my end or if this comes from the API not being responsive all the time
Hey y'all what is the limit for haiku 3.5?
"We are excited to announce the public availability of citations in the Perplexity API. In addition, we have also increased our default rate limit for the sonar online models to 50 requests/min for all users." Thank you very much to the team! 🙏
https://perplexity.mintlify.app/changelog/changelog#citations-public-release-and-increased-default-rate-limits "Effective immediately, all API users will see citations returned as part of their requests by default. This is not a breaking change. The return_citations parameter will no longer have any effect."

Perplexity
Hi, I started testing citations this morning and was getting citations back just fine (through api and via https://labs.perplexity.ai/ ). But suddenly the citations disappeared both in the API and on https://labs.perplexity.ai/ . Has Perplexity disabled citations again?
Just to clarify, it seems that AI searches just fine as it knows who won US elections but citations are not present anymore...
Also seeing the same ☝️ Not seeing any citations from the API currrently
I assume the 1M tokens refers to input tokens? Is the price the same for output tokens?

Same issue here, Why I'm unable to see any citations from the API currently? Any leads?
Same
https://github.com/ppl-ai/api-discussion/discussions/54 @idle plinth @unreal sun @tired canyon

Thanks!
the api is incredibly expensive, do you know if we can use selenium to access the basic search of perplexity
Hey <@&1193989584976105562>!
We are excited to announce the public availability of citations in the Perplexity API. In addition, we have also increased our default rate limit for the sonar online models to 50 requests/min for all users.
Effective immediately, all API users will see citations returned as part of their requests by default. This is not a breaking change. The return_citations parameter will no longer have any effect.
If you have any questions or need assistance, feel free to reach out to our team at api@perplexity.ai or refer to our docs.
Thank you for your continued support.
Perplexity
!!
can we have the same good Output in API as in the pro search
let hooplah abound!
Pro uses a different model
Not available via api
sad
Pro is more like a tool in web-interface only right? or u consider this like a extra reasoning model, before it gets send to the model u selected in settings?
Nice
does the search_domain_filter support sub domain search?
For example, i wan to use support.company.com and avoid community.company.com
the citation links don't output—just these parenthetical numbers...? Example: "...economic systems[2][3]." since it's output as plain text for me they are not clickable links. Can the API output the full URL as plain text instead of as a hidden hyperlink?
This is in the chat APi as an output?
Same
It's a bit hard to make it do that, cause it has pre instructions for the web search.
as u see it doenst listen.

It works correctly on my end. Here in one of my apps (which uses the Perplexity API)

And here directly in the Perplexity Labs Playground

And if you want your URLs in '.txt' format, ask for it in your prompt. For example, here: 'Give me the URLs in '.txt' format below your answer as well.'"

我是谁
Yes for me also it just show numbers, but no citation links. Any fix for that?

tried out the API with citations. The sources returned by the API are quite different from the sources returned by the chat (free version) for the same question. Aren't they using the same underlying algorithm and crawled data? I am not talking about the llm model differences which I understand, but merely the web search results (crwaled) basis the question
Perplexity
bumping this.
does the search_domain_filter support sub domain search?
For example, i wan to use support.company.com and avoid community.company.com
Good morning Team, does anyone already tried implementing Pplx API DailyBot custom command editor's?
If so, what are the basics I need to know to start such a project?
use ai to know 🙂
That’s the thing, apparently even the AI’s don’t know. OpenAI, Claude, Pplx, llama, none of them knows how to do it right on DailyBot’s built in commands.
I’ve found a way using CodeSandBox’s VM.
I request the code using a webhook to get the info from the forwarded Port, then read it with another code on DailyBot editor. After all of that the prompt is returned on Discord chat.
If anyone knows how to do it / if it’s doable / is there a better way, would be greatly appreciated
Can anyone confirm that "search_domain_filter" actually works? I keep getting results from other websites in the citations
has anyone had issues with pulling reddit as a source in citations in the last week? it seems to be working well and now reddit citations dont seem to be work via the api?
search_domain_filter is not working for me either.
I have just created support ticket for this
is it properly formatted? That should not be the case. I haven't noticed an issue with ~40 questions per hour using it, but maybe there's a bug
example format
"search_domain_filter": [
"perplexity.ai"
],
It doesn't work for me either. It was formatted like in the example.
yah i believe so, i notice that it does generally works but if it can't find something confidently then it injects random urls that i did not specifiy and uses that, thus creating inaccurate results
is pplx api good for prod use?
I am a french professor. What do you do for French student ?
not sure whats up, leo works fine with all of the openai compatible providers i have tried, and works fine with perplexity, but when i try to have it sumarize a page it gives errors. i have tested it with 4k context set and 128k set.




I have also tested it with a separate perplexity pro account, and have tested the sonar version
hello, i have a question about API billing. I am a Pro subscriber and I have $5 API credits per month. If I use it beyond the $5 credits, will it charge my credit card?
Turn off auto top up and it should not
ok thank you
i used the API once and it not allowing me to use the $5 bonus now. any ideas?

i deleted the existing api key and I am not able to add again
strange
but it says there's a bonus of $5. wasn't it added/
If you don’t get the $5 of credit soon maybe shoot an email to support
Because back when I did it I got the credits a few minutes after adding my card
Is reddit working in the API anymore? doesnt seem to return any Reddit links anymore?
oh so i need to add my card
I believe so
I think you need a card linked, but you don’t need to spend anything
But it was a while ago I set it up so I can’t remember 100%
The Make.com module could be better.
It would be nice to have a longer (or customizable) timeout period on the Make.com module, because Sonar Huge always times out for me. Also, third party model options would be nice.
I posted this in the feedback channel too, but I thought more people miight see it here.
hello guys,
I'm using perplexity's APIs but if I search for the latest news about something is not able to reply me with updated news. Is this normal?
For example for the query "latest news about USA Elections" the API told me that the things between Trump and Biden are warming up.
another problem is that I cannot make an API request using the country origin parameter, like the other classical search APIs.
anyone knows how to solve these problems?
Hey @drifting stratus!
Please use the search_recency_filter for the latest news -> https://docs.perplexity.ai/api-reference/chat-completions
Perplexity
Generates a model's response for the given chat conversation.
Hello I'm using Perplexity API and I'd like to filter my search results by blacklisting a domain. But I with the API doc I'm not capable. The intended excluded domain still appears in the search results 😦 Are there any specific formatting requirements I might be missing?
Hey guys,
Our team is running into rate limit issues. Does anyone know id the api is limited tp 50/min per account or per key?
Thanks
anyone know if "bring your own api key" allowed in perplexity? I want to make an alternative of typingmind, but with perplexity.
here's how it works:
1.user give frontend app api key.
2. frontend app encrypt the api key with salt.
3. encrypted api key stored on cookies
4. user make a request to backend > backend read cookies > make request to perplexity using the read decrypted api key.
is this allowed?
or does perplexity abide by openai rule, as it is openai compatible?
Idk could you explain that last one like I'm five? I have horrible brain zaps withdrawing from sertraline and Trazadone.
it works almost the same way as logging in to a website. the browser cookie store the session id, which then read by the website backend/server and check if session still valid or not. if valid, it means user is logged in. if not, send error saying "you are not authorized".
the only difference in my question is that the website never store anything at all. just reading from cookie
Hey team! This is probs not the ideal forum but hoping someone from the Perplexity team can help. Our team is running Perplexity in production and running into rate limit issues; I've already reached out on the TypeForm to get limits bumped on Monday but haven't heard back. Would love to expedite if possible as is causing issues among our customers. Thanks!
Hey @lone crest, please fill out the form on this page: https://docs.perplexity.ai/guides/rate-limits

Perplexity
is the API site down?

Hey @leaden coral!
It works fine for me, please try again or check with another device
I've been using this api and i think its not accurate for example when I ask who is the ceo of Acer, who is the ceo of Asus, these two computer companies, it confuses each other. Furthermore when I ask "can you provide me with the weather today" it sometimes gives me the answer, I am unable to provide you with current information as I am trained with data up to 2023. what is the cause of this? I am using the API for llama-3.1-sonar-small-128k-online
I'm very excited about using the citations returned in the API, but I've noticed they differ from the sources returned in the web interface.
In my testing, LinkedIn URLs are not returned in citations via the API even though they are on the web. I'm using llama-3.1-sonar-huge-128k-online in the API and a "normal" (non-pro) search on the web.
Are there any plans to make citations consistent with sources? Or is there a way to tune my API call to be more consistent with the web results?
Hey guys, why does the supported models only show the online models now? Are the instruct and chat models going to stop being supported?
There are now only the three "online" models listed under "Supported Models" and "Pricing," but for the moment (as of the time of writing this), the older "Chat" models and the two llama-3.1 models (8b and 70b instruct) are still functioning. They have therefore not (yet) been disabled.
I imagine this gives us a bit of time to switch our models in our apps...
Moreover, nothing is mentioned in the "Changelog" for now.


Has anything changed with the API in the last week regarding web search? I have a well-tested prompt that was searching the internet for some information, with some test cases written around it.
Within the last week or 2, suddenly the results I'm getting are not aligned to what I see on the web version of Perplexity, and only returning instructions for how to perform the search myself.
These models seem to all have the same issue: llama-3.1-sonar-huge-128k-online llama-3.1-sonar-large-128k-online
I'm currently using a system message to give some prior examples, and a user message directing the AI to perform the search
I submitted a request to join the closed beta program. I have heard nothing since then. What should I do?
arthritis
pretty sure it's deprecated, or at least a beta / toy. Don't pay for it. Use Exa or Brave or something else
anyone know why reddit citations no longer supported via the api?
Hey guys, Im wondering where the perplexity engine optains their financial data? as well as if the API has the capabilities to feed said data into other projects for internal use.
EG: your stock ticker data showing information about a companies earnings, etc.

Hi, would anyone like to take a look at my first project on GitHub? I'd be grateful for a star, maybe someone will find it useful, maybe someone will like it: https://github.com/dawid-szewc/perplexity-cli.git

GitHub
🧠 A simple command-line client for the Perplexity API. Ask questions and receive answers directly from the terminal! 🚀🚀🚀 - dawid-szewc/perplexity-cli
Perplexity might use Financial API from Financial Modeling Prep financialmodelingprep.com as per this article. https://www.zdnet.com/article/perplexity-ais-new-tool-makes-researching-the-stock-market-delightful-heres-how/ Not officially confirmed.

ZDNET
Perplexity Finance is a comprehensive suite of AI-powered tools with an easy-to-use interface. Here's how to access it and what to know before you do.
Is it possible to use Perplexity within Claude with this new MCP thing, the way you can use Brave and Github in it?
Same question for Google if anyone knows how that works
e.g., search and get Perplexity outputs within Claude, but using a Claude Project with all its Project Knowledge. That'd be so strong. And will finally fix an issue I have with limited memory for background instructions or context in Perplexity.
Also, was the issue of Perplexity being unable to read text files or any other file you give it reliably finally fixed? Or is there some long-term memory-esque feature I've missed?
the custom instructions it gives you for spaces don't seem to work or compound with the "introduce yourself" stuff either
As a perplexity pro member who got the subscirption as part of that college promotion, do i get any free credits for api included in the subsciption?
are you sure your account is pro ? i am a canadian student , i tried to get the promo but the 75% black friday pro code seems to overide other promotions, i cannot even remove the 75% off black friday pro code
Hello @past island . Any news about how the 'search_domain_filter' parameter works? Is this being worked on by the team, so that the indicated domains are in fact respected in the search?
Yeah I activated with this: https://www.perplexity.ai/backtoschool

Welcome back to school! For just two weeks, redeem one free month of Perplexity Pro on us. Refer your friends, because if your school hits 500 signups we'll upgrade that free month to an entire free year!
Anyone else noticing a decline in the APIs quality recently?
Hi! Does anyone know if the system prompt ignored when using llama-3.1-sonar-small-128k-online? It doesn't seem to follow my guidelines around conciseness / response length at all.
Hi does anyone know how long will it take to increase the rate limits?
I think it’s not only the small version large and huge also have the same problem
Does anyone know if you need to have a "pro" account in order for a paid API request to perform a web search? Can't find this documented anywhere, yet my API requests seem to have stopped searching the web (funnily enough 30 days ish after I signed up originally)
Hi everyone, i've been getting many api responses like:
An error occurred while making the request: unable to complete request
Some times the same requests are being properly executed, but many others not. Has anyone been faced with similar situations?
@shut prawn Been noticing this within the past hour with a project as well. When did this start for you?
The same here. I’ve been facing this issue the past couple of hours..
I ended up just adding it as a prefix to the user prompt and that has done the job thus far
hi i'm using the api with "Do not generate content citation in parentheses. " but it is still doing it with the output ending each paragraph with [2].
how to solve this?
Hey @neon night!
The citations are added automatically, an option to deactivate them is currently not available.
I asked here too a couple weeks ago; in the meantime someone on my team emailed their enterprise email and was told waitlist is around a few weeks IIRC
I see, thanks for replying! have you tried messaging to their support email? or would they only reply to the enterprise enquiries?
The API called has a balance, why is the payment still deducted from the credit card? I sent an email for 2 working days and no one responded.
Is anyone from Perplexity reading these messages? There seem to be multiple complaints about the API quality since the last couple of weeks - it's proving unusable these days for our use cases, and we're likely to shift provider.
Perplexity
Thanks. I've submitted something there a week ago too 🙂 https://github.com/ppl-ai/api-discussion/discussions/80
GitHub
I'm submitting a "system" prompt with some examples, and then a "user" prompt similar to below, asking it to search the internet. Up until a week or 2 ago, this was consiste...
Probably could try! I'm at a startup that's running Perplexity in prd so we went the enterprise route just assuming we'd get a faster response there since we're (trying to be, if our rates are raised) a decently sized customer. Haven't tried the support email itself personally
hey
Hi, has anyone a good prompt / technique to limit the results on the last 2 weeks or 15th November 2024 ? My results are mostly also including older sources
Hi, are there any plans to bring the RAG feature of Perplexity spaces to the API?
Any chance perplexity would release a perplexity trends app like google trends?
Is there no one to provide service support? The problem is not solved?
So this is still a problem? How annoying. Where can I look to see if anyone on the team's working on it? I just wanna know it's been acknowledged.
its too much to ask for same quality of answers on api compared to web ui
yes i have
It's becoming increasingly clear that the API will continue to be second-class to the web experience
anyone else getting api errors? http code 524 on all responses
yup – we're getting API errors on our end as well
Yup, same
seems to be back up now. thanks those who fixed it
Hey @rapid crag!
If you find the original message helpful, please consider reacting to it with the :star: emoji. If the post is appreciated by the community and receives 5 stars, it will go to the https://discord.com/channels/1047197230748151888/1082806833938436228 channel and the post author will get the <@&1082034222778302614> role on Perplexity.
Hi, I'm using Perplexity API, and the result is way different from the user interface. I tried all the online supported models. What's wrong?
Thanks for your help!
Perplexity
It's disappointing, I paid credits for something I won't use at the end!
Thanks for the quick reply!
I'm having the same problem!
Ehm, I'm having issue with adding a card in the perplexity API, each time I do the UI freeze for a bit, but then my bank's 3D Secure screen shows up, and then disappear, I only got a glance saying that the transaction isn't authorized yet and then it returns back to the card input screen
Any suggestion?
I can't just not use 3D secure as basically most if not all banks here use 3d secure
Is there an API endpoint for creating Perplexity Pages yet?
the api and the perplexity website are two different products. there is no api for the main website.
Hey, can anyone with closed beta access give me the expected format of response when the return_related_questions parameter flag is passed in a chat completions call? 
I just need the expected response schema
👋 Hi, I’ve got a production app using pplx api right now but it would be absolutely brilliant if the domain filter option was available. I requested closed beta access but haven’t heard anything. Is there any known workaround for specifying a domain to search?
yes this is very annoying... even with their recent update it just returns the "sources" as plain text numbers like [1] and no URL. only by following up with "please write out the literal URLs of the sources with their corresponding numbers" was I able to get the URLs
yes i'm asking it very basic questions via API with this model you mention "what are the headlines on cnn.com?" and it can't say... i emailed pplx api email and they don't reply
struggling to find a list of models I can request via the API (Pro user). The docs only mention llama. What are the strings I need to use for e.g. Claude?
The list of available models (APi) for now can be found here: https://perplexity.mintlify.app/guides/model-cards
Perplexity
Can someone from perplexity please respond to this? This has a lot of concerns regarding production API usage https://www.linkedin.com/pulse/perplexity-got-sued-what-does-mean-openai-anthropic-you-leonard-park-s3bfc/'

Warning: The following contains a lot of strong opinions and #hottakes, and may contain errors of fact and misstatements of law. Any errors or mistakes are entirely my own, and nothing here should be construed as legal advice.
There's a Perplexity MCP on one of two aggregation sites I watch.
Will try to remember to post.
Looking for a user comment from earlier regarding using MCP outside of Claude ... Dunno the server from earlier.
@round mountain Yes, I use it every day.
Here is the address of an MCP server that works well: https://github.com/pyroprompts/any-chat-completions-mcp
I have access to Gemini, OpenAI, Groq, and Perplexity (Mistral is coming soon).
I can use any model their APIs allow.
Note: Regarding Gemini, I used the new integration through the OpenAI SDK as the base URL (https://ai.google.dev/gemini-api/docs/openai)
(And for Perplexity, you do have access to web access and citation included.)


GitHub
Contribute to pyroprompts/any-chat-completions-mcp development by creating an account on GitHub.

Google AI for Developers
Hey guys, ive been working with anthropics and openais api a lot in the past. Now i want to start a project using perplexity. Is the web search feature included in the chat completion api call? Also, is there somewhere a cost overview? Thank you!
In my usage, the web search feature seems to exist with the API as well. the supported models are here and the prices are here
Perplexity
Perplexity
I have a question on the tokenizer used by perplexity. For context, I'm using AutoTokenizer.from_pretrained of the transformers library and meta's llama 3.1 series. I can accurately find the number of input tokens using this, but the number of output tokens is always one more than the one sent by Perplexity's API. Am I doing something wrong?
just subtract 1 and call it a day, maybe its a bug in their api
So it's llama 3 and... that's it?
They use that to process the payments there is no other way as far as l know but if you don't feel comfortable giving card details you could use a virtual card most banks have that option
Sounds like the Perplexity API is terrible and literally everyone agrees it is behind OpenAI, Google, Anthropic, and who knows how many others.
What I don't understand is why the Perplexity API does not provide the same type of responses as a Space response in the UI. Theoretically, the Spaces API should be awesome and less tedious to use than the OpenAI Assistants API.
Can this be addressed?
Right now, Perplexity doesn't support custom frontends because the API doesn't support much.
Are there any other search API alternatives that are at the same/better quality. I agree with you!
Is there any way to add custom recency time so that the results are only after that
https://docs.perplexity.ai/api-reference/chat-completions#body-search-recency-filter
And is there number of citations limit on it ?
Where can I get a refund for my accidentally paid api credit?
Can I use the API to have a "conversation" with the model? Why does it give me the definition of hello when I type "hello"
please send an email to api@perplexity.ai
Hey @silent cape!
This is not the intended use case for the Sonar models. The models are designed to produce answers to questions using current web sources and also cite them.
Question, sorry if I'm wrong about the channel, but what would the perplexityai API be used for?
I have purchased perplexityai, can I make a discord bot with the same premium features?
I've been using Open AI's Assistants API....looks like Perplexity is overhauling their API right now though...sounds like it is more reliable than anythig offered thus far.
I don't have a sufficiently large sample of app data yet to to make meaningful comparison of the APIs though.
came here to see if it is just me who is getting terrible results from the API (compared to the Space). So, I am assuming this means that there is no way to get Space-quality results via the API?
Hey, I'm building a RAG application for my own portfolio and was trying the Perplexity API for the LLM. However I do not need the web search feature since I need only the grounding/facts from my vector database (this context goes in the prompt). Basically is it possible to turn off the "citations" thingy?
if the API has server location in europe and is as good as pro search in web we will integrate it in our 1.5 billion tokens chatbot finally. hope to see some improvements
Google cries rn
API version has caching enabled in the same way as the web version?
Why not use mistral ? I'm not a pro in llm api
The problem with any AI is there are so many one's out there - and so many are bad
Anyone got the same mail on 19th of December?
Huge bummer if they just keep the online models!

How to use only Korean language
And
Other model ?
not ( llama-3.1-sonar-small,large,huge)
is not
I want api answer only Korean lang
Sonar 3.3 is available on Perplexity web UI while it's not in the available API models.
When will it be available in as API model too?


Hello. It comes back in the json response as "citations" for the llama-3.1-sonar models. Oddly, it does not seem to work with claude-3.5-sonnet
Aside from llama-3.1-sonar-small/large/huge, can more models be released?
I also want to know
Hey @north pendant!
Improved versions of the existing LLMs are released at irregular intervals, please keep an eye on the announcements and the changelog!
where is the changelog? I don't know about updates done in the last many months
Perplexity
Thanks. Where are the o1 and the Llama 3.3 70b updates in the changelog? there's nothing after November in that changelog
This changelog only concerns the API. API users also received an email in mid-December warning: "Model Deprecation Notice."

There hasn’t been any announcement about llama 3.3.70b yet. Likely in the near future, but that’s just my assumption. 😉 For o1 in api, forget that idea; it was never on the agenda 😅
Ah, the absence of indication that it's only about API confused me, sorry
Has anyone else noticed a sharp decline in the output speed of llama-3.1-sonar-large-128k-online since January 10th?
Can someone help me enable the permission to use search_domain_filter?
in labs I noticed now sonar and sonar-pro. Are the api models about to change again?

I'm having exactly this issue... still reading this channel but did you resolve this?
any crewai devs here get pplx working? getting this "custom stop parameters" error with a basic crew.
Please check the model you are using: https://docs.perplexity.ai/guides/model-cards
Thanks, I have tried all three of the models, none of them fixed it, i searched around the crewai docs which don't mention it, but, another crewai user reported the same problem with o1 model, so since it's not specific to perplexity I'll take the conversation over there.
tldr; found a monkey fix that removes the stop parameters from litellm before making the call.
Hey @barren oxide!
Please avoid unnecessary pings! Please tell us how we can help you.
my dm's are open
Does „search_domain_filter“ work with the new sonar-pro? Does not work for me. No error message, is just ignored. Tried writing it with „https://„ and without.
hey 👋 check out the new usage tiers for Sonar and Sonar Pro: https://docs.perplexity.ai/guides/usage-tiers
Search domain filter is a tier 3 beta feature
Perplexity
We're working on adding in a more helpful error message here, thanks for flagging
Are sonar and sonar-Pro online modes (with internet access) ?
Is there a deployment of Sonar (pro) in Europe for european customers? we would love to integrate perplexity sonar pro API but GDPR in Europe forces us to use LLMs hosted on servers only in european location
Is the Sonar Pro API model announced today the same thing as using the browser Pro Search?
What, if any, are the differences between the two?
The FAQ states "The API uses the same search system as the UI with differences in configuration - so their outputs may differ."
What are these differences in configuration? Is there a guide so I can set up my API call to use the same configurations as the UI?
한국어로
https://github.com/jsandai/pplx-api-compare
made this tool to quickly compare models
Does the Sonar API support HIPAA compliance and/or Business Associate Agreement?
Has the release of Sonar affected the old API in anyway? We're having issues on our website, the calls to perplexity API are taking FOREVER
is it possible to make some long term models? Like, make Sonar auto update models behind the scenes so app maintainers don't have to worry about perplexity turning models?
is sonar the best for researching?
attempted to switch to sonar/sonar-pro on the API and seeing a lot of 524s right now, anyone else seeing this?
seen some go through now
had that issue too for a bit
Hey congrats on the API release! We're planning to use it in our product for a web search integration. Is the API SOC 2 Compliant? We probably can't use it otherwise
is Sonar any different than the legacy models or just a name rebrand?
Hey guys, can i ask a question about API Usage
It is possible to retrieve old response by "id"?
idk but you should just store them by id no? would it be easier to fetch from your own database?
Yeah i know
My app specially need this feature to let user can verify if we actually call ppl api
Does sonar-pro do the multi-step goals like in perplexity pro search?
Anyone else happy they're paying attnetion to the API and updating it. I thought they were ignoring it
Is it possible to disable searches for a sonar API call or will it always generate one search?
Bit related to the above, https://github.com/ppl-ai/api-discussion/discussions/121 - how can I see how many searches the API call actually did based on the response please?
GitHub
Based on the pricing documentation, perplexity charges $5/1000 search queries incurred by a the model. However, I don't see a way to determine based on the model response how many searches were...
FWIW, I found this bit in the documentation which states that sonar pro at least will sometimes perform >1 search: https://docs.perplexity.ai/guides/pricing - relevant section: "To give detailed answers, Sonar Pro also runs a multiple searches on top of the user prompt where necessary for more exhaustive information retrieval", in case its helpful
Perplexity
I saw this for sonar.
Pricing structure is similar to Sonar Pro except each request does 1 search
My understanding to that is that every 1000 API calls will cost $1, no matter if it's a new chat or a continuation of a chat.
My use case does want to do an initial search but the subsequent chat responses do not need it so paying for searches seems redundant.
ah, thanks, I'd missed that bit.
Why does json response format not work here? { model: "sonar", messages: [ { role: "system", content: "Be precise and concise." }, { role: "user", content: "Tell me about Michael Jordan. Please output a JSON object containing the following fields: first_name, last_name, year_of_birth, num_seasons_in_nba. ", }, ], response_format: { type: "json_schema", json_schema: { schema: { first_name: "string", last_name: "string", year_of_birth: "string", num_seasons_in_nba: "string", }, }, }, }
this is what i get:

Hello, I'm trying to use API to get the LinkedIn URLs from specific users knowing only their names and where they work and eventually also where they live, but I'm getting no luck....I'm usually getting either linking things from random posts or from other people or just websites that do not exist.
Do you have any specific suggestions on how to get this done? Maybe on the prompting or maybe something else?
I’ve had the same issue where when using sonar, and response_format, the response is invalid JSON wrapped in Markdown. When using sonar-pro, it works fine. But that’s not ideal obviously because of the cost difference
Sonar-Reasoning is alive, well done to the Perplexity team 👍
(Chain-of-thought reasoning, plus real-time internet search and citations)

does pplx reasoner works?
i get this.. Sorry, sonar-reasoning has rejected your request. Here is the error message from sonar-reasoning: After the (optional) system message(s), user and assistant roles should be alternating.
btw is pplx reasoner the model thats used as default in Perplexity?
It works perfectly here. I just posted an example (video) using it to explain MCP servers and the use of an LLM (API) in Claude Desktop.
#👑│pro-lounge message
Earlier this morning, I took some screenshots (overview) after two uses of Sonar-Reasoning to get information on how it is priced and under which "category" it was listed.





I deleted my original message as I thought I found an answer but it seems not. So, I was wondering if anyone knows whether Sonar Reasoning is using the full R1 model (671B) or if it's using a distilled version of R1 instead (e.g. Llama 70B) ?
How can I get more sources

I‘m curious as well. Can anyone from Perplexity shed some light on this?
actually it seems like a bug I'll move the message to feedback and delete it here
Is the new reasoning search good? How much of an improvement is it from the other models & in what areas
I've noticed it doesnt seem to 'think' as much as in the playground. Anyone know how to fix that
yeah I've noticed it appears to think less, thought it was maybe just me. Another problem I'm having, which I've reported as a bug (https://discord.com/channels/1047197230748151888/1334236935996178683), is if I ask it a question and then ask it another question that's similar to the first question it seems to give me the same answer to the first question, ignoring the second question I asked
Greetings im testing the new sonar-reasoning model API for my project and i cant seem to make it return just the result of what i asked without the lines of thinking that just use up tokens, even though i give it instructions to do so. Any ideas if you can even do it ?
sonar reasoning actually isn't that good for what you might use a sonar model for. I asked about the plane crash over the Potomac. sonar-pro gave me the recent one. sonar-reasoning gave me the one from 1982
like, technically it was correct, but i can see how the reasoning aspect can trip it up
Hey all, trying to test out using perplexity API to get structured output matching a JSON schema - running into some issues. Anyone have an example of this working?
I'm not getting any error trying to use the response_format field, but the API isn't responding with the expected schema/format. Example below - could be missing something obvious. I've seen others indicate that I need to include the schema/ask in the user query/message?
From the docs, looks like I might need to have Tier 3 usage to even try this? It seems to just be ignoring the json schema completely, event if I include some guidance in the message itself. Should I just include the whole schema in the message? Anyone have experience with this? Is it just because I'm not tier 3 that I'm not getting a response (the API response doesn't say anything like this, but it did say this in the docs), or something else?
response_format
objectEnable structured outputs with a JSON or Regex schema. Refer to the guide here for more information on how to use this parameter. Only available to users in Tier-3.
I'm doing a similar flow to get JSON with other APIs (not perplexity), considering moving to use perplexity for this but haven't been able to get this to work yet.
Referencing the docs here:
https://docs.perplexity.ai/api-reference/chat-completions#body-response-format
https://docs.perplexity.ai/guides/structured-outputs
Here's an example:
request:
const API_URL = 'https://api.perplexity.ai/chat/completions'
const API_KEY = '' // Replace with your actual API key
const payload = {
model: 'sonar-pro',
messages: [
{
role: 'user',
content:
'Tell me about Michael Jordan. Please output a JSON object containing the following fields: first_name, last_name, year_of_birth, active_years.'
}
],
response_format: {
type: 'json_schema',
json_schema: {
schema: {
title: 'AnswerFormat',
type: 'object',
properties: {
first_name: { title: 'First Name', type: 'string' },
last_name: { title: 'Last Name', type: 'string' },
year_of_birth: { title: 'Year Of Birth', type: 'string' },
active_years: {
title: 'Active Years',
type: 'array',
items: { type: 'integer' }
}
},
required: ['first_name', 'last_name', 'year_of_birth', 'active_years']
}
}
}
}
fetch(API_URL, {
method: 'POST',
headers: {
Authorization: `Bearer ${API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
})
.then(response => response.json())
.then(response => console.log(response.choices[0].message.content)) // Extracting response
.catch(error => console.error('Error:', error))
response:
{
"id":"586725d5-d322-4b10-aa7b-a732c4a69065",
"model":"sonar-pro",
"created":1738422230,
"usage":{
"prompt_tokens":34,
"completion_tokens":159,
"total_tokens":193,
"citation_tokens":4811,
"num_search_queries":3
},
"citations":[
"https://www.britannica.com/biography/Michael-Jordan",
"https://simple.wikipedia.org/wiki/Michael_Jordan",
"https://www.statmuse.com/nba/ask/michael-jordan-basketball-career",
"https://www.espn.com/nba/story/_/id/29180890/michael-jordan-history-flight",
"https://en.wikipedia.org/wiki/James_R._Jordan,_Jr.",
"https://www.daysoftheyear.com/birthdays/michael-jordan/",
"https://www.statmuse.com/nba/ask/michael-jordan-years-played-in-the-nba",
"https://www.imdb.com/name/nm0003044/bio/",
"https://upload.wikimedia.org/wikipedia/commons/thumb/b/b5/Jordan_northcarolina_1983.jpg/166px-Jordan_northcarolina_1983.jpg?sa=X&ved=2ahUKEwj5nYK636KLAxU-j4kEHdp9BJQQ_B16BAgBEAI",
"https://www.nba.com/stats/player/893/career"
],
"object":"chat.completion",
"choices":[
{
"index":0,
"finish_reason":"stop",
"message":{
"role":"assistant",
"content":"{\n \"first_name\": \"Michael\",\n \"last_name\": \"Jordan\",\n \"year_of_birth\": 1963,\n \"active_years\": \"1984-2003\"\n}\n\nMichael Jordan is widely considered one of the greatest basketball players of all time. He played 15 seasons in the NBA, primarily with the Chicago Bulls, winning six championships[1][3]. Jordan was born on February 17, 1963, in Brooklyn, New York[2][5]. He began his professional career in 1984 when he was drafted by the Chicago Bulls, and he retired for the final time in 2003 after playing for the Washington Wizards[3][7]."
},
"delta":{
"role":"assistant",
"content":""
}
}
]
}
Notice active_years isn't an array and year_of_birth isn't a string. If I don't include asking for specific fields in the initial message contentit doesn't even respond with json (e.g. I the initial message is just "Tell me about Michael Jordan" but I leave the json_schema). It also includes extra non-JSON content.
(side note: should I put this in feedback ^? felt like more of a question, but happy to move it if that's a better place.)
anyone willing to be hired for a project?
What kind? 🤔 If it's web development I can help
I don't believe your schema is formatted properly, try something like this;
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"first_name": {
"type": "string",
"description": "The first name of the individual."
},
"last_name": {
"type": "string",
"description": "The last name or surname of the individual."
},
"year_of_birth": {
"type": "integer",
"minimum": 0,
"description": "The year the individual was born, represented as an integer."
},
"active_years": {
"type": "array",
"items": {
"type": "integer",
"minimum": 0
},
"description": "An array of years during which the individual was active."
}
},
"required": ["first_name", "last_name", "year_of_birth", "active_years"],
"description": "Schema defining basic personal details and active years of an individual."
}
Thanks for the response! Definitely could be, was going based off of the docs when building that structure but it wasn't super clear to me. I did try to copy/paste your schema in and it still had the same issue.
This made me curious - I actually retried the exact code in the docs (running python) and couldn't get it to give me the structured output as expected in either case if I:
- removed the instructions about JSON and the fields in the message, but left the schema as is (it didn't respond conforming to the schema, just a regular text message response)
- I left the message and changed the types (responds with a json object as part of a larger text message, but with types that didn't conform to the schema)
I'm guessing at this point it's just an issue with needing to be tier 3
https://docs.perplexity.ai/guides/structured-outputs#1-get-a-response-in-json-format
Perplexity
I'm not tier 3, I'm actually just tier 0 and I've using structure output and it has been working fine-ish. using sonar, I get mostly clean JSON that I clean up in code, but with sonar-pro, I get totally clean JSON with no issues.
I'm also using python btw
interesting. are you putting the schema in the message also, or just in the response format? simplified slightly modified example like the docs:
import requests
from pydantic import BaseModel
class AnswerFormat(BaseModel):
first_name: str
last_name: str
year_of_birth: str
num_seasons_in_nba: int
active_years: list[int]
url = "https://api.perplexity.ai/chat/completions"
headers = {"Authorization": "Bearer <token>"}
payload = {
"model": "sonar",
"messages": [
{"role": "system", "content": "Be precise and concise."},
{"role": "user", "content": (
"Tell me about Michael Jordan. "
"Please output a JSON object containing the following fields: "
"first_name, last_name, year_of_birth, num_seasons_in_nba, active_years"
)},
],
"response_format": {
"type": "json_schema",
"json_schema": {"schema": AnswerFormat.model_json_schema()},
},
}
response = requests.post(url, headers=headers, json=payload).json()
print(response["choices"][0]["message"]["content"])
returns this for me
Here is a JSON object with the requested information about Michael Jordan:
```json
{
"first_name": "Michael",
"last_name": "Jordan",
"year_of_birth": 1963,
"num_seasons_in_nba": 15,
"active_years": "1984-2003"
}
```
birth year still an int, active years not an array/list. it's also a string response with a preface
learning python now working on my assistant currently using a few model to bonus of 1 to think and more detail and one for more personality to the answer and currently trying to get eleven labs working for voice
progress

I'll DM you how I do it, so I don't flood the chat, is that OK?
api is returning unicode escape sequences for multilingual output - will perplexity team be fixing it?
Hi ! I want to use Perplexity by using the API to search throught dedicated space with document. It seems that I need Sonar Pro but where can I get API detail pour specify a specific space and use only this space (not web) ?
I got the deprecation email about llama-3.1-sonar-small-128k-online two weeks ago. I've tried switching over to sonar but we have a latency sensitive application and this new model I'm noticing is around 5-10seconds slower. Is this expected and if so any advice?
Hey All, looking to retrieve images as part of a PoC but i've found I need to be a tier-2 API user. Is there a way to grant this for me temporarily so I can experiment with the credits i've signed up for - Pro User: tim31545
Hi, is anyone using litellm to use new sonar/sonar-pro? I can't use these new models. Is it because litellm didn't update new models from Perplexity?
Hello there,
With the news of the model names changing, I've been trying to identify which of my APIs is calling on which model name, and want to make sure my system is correctly using the right models before the old models sunset on February 22nd.
However, I cannot see any way in my scripts which model name is being called upon (I believe that is not a capability with perplexity APIs at the moment), and I'm seeing on the perplexity GUI, no matter which model name I use (new or legacy), it says my API usage is always under the name "70b-online".
It's pretty important that I can confirm my system is calling upon the right API models. Is there a way I can see which model name my API is caling, or enable this functionality? Thanks!
is there any future plans to have deepseek models be in the api?
Hi! I'm using sonar-reasoning and I'm getting a lot of 504 error today. Are you guys getting 504 error as well?
Is sonar-reasoning-pro using OpenAI or DeepSeek behind the scenes or is it an agentic framework that leverages the sonar base model?
their website says DeepSeek R1 (https://sonar.perplexity.ai/)

Build with the best AI answer engine API, created by Perplexity. Power your products with the fastest, cheapest offering out there with search grounding. Delivering unparalleled real-time, web-wide research and Q&A capabilities. Get started in minutes.
ohhh, that so cool, I didn't realize what the sonar models actually were
Can I set a hard limit on how much $$$ is used? Per month
Does it send invoices on the cost or do I have to add charges manually?
Hello! New to this Discord and am exploring using the Perplexity API in an app we are building. I have tested the concept with great results using the webUI by uploading an image with a short, simple prompt.
But looking at the API docs and searching through this channel, it seems the current API does not allow for image uploading.
1 - is that still accurate?
2 - if so, has anyone tried workarounds? Thinking something like this coudl work: image > claude for detailed description > description + prompt to Perplexity for intended output
Need to speak with Sonar pro reasoning devs
Urgently
I need someone from Sonar pro reasoning devs urgently respond due the security issue i found
please send an email to api@perplexity.ai
Yes ty doing it
Yeah
A quite great case study i am going to make your eyes will blink a hundred times
Why does the API only give like about max 5 sources
I'm having a hard time using the sonar API.
For some reason its giving me recursive output that keeps repeating itself. Maybe its a problem with my code? I am trying to use it as a chatbot in my app. For that purpose I wanted to give it context from a prior api call's output + any new output/context thats present as the chat continues. Any thoughts on how to fix that? here's how I setup the api call. any seriour isses noted? (I'm a no-coder)
const options = {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.PERPLEXITY_API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
messages: [
{
role: "system",
content: SYSTEM_PROMPT
},
...(contextString ? [{
role: "user",
content: "Here is the context from previous research: " + contextString
}] : []),
{
role: "user",
content: userMessage
}
],
model: "sonar",
frequency_penalty: 0.7,
max_tokens: 800
})
};
Can I set a hard limit on how much credit is used per month?
Does it send invoices on the usage or do I have to add credit manually?
In your messages , you need to append the content you got from the previous call, and when you append it you should use the role of "assistant" to signify what you got from the AI. You don't need to add superfluous wording like " Here is the context from previous research", just append the results you got as is.
So you'll end up with a messages array as conversation goes on with roles of:
system, user, assistant, user, assistant, user, ....and so on...
you add credits manually. You can opt for auto top-up of credits
Am I right with this take or any other opinions/am I missing something?
A question that needs multiple steps like ‘How did football team X play yesterday? Did the opposing team of X win or lose in the previous game?’ requires two queries based on each other.
Great to recreate with Perplexity:
- if you search without a Pro search, you get the answer to the first question and ‘no information found’ for the second question
- if you search with Pro-Search, you get the perfect answer because the second web search contains the results from the first, which is essential
No matter which model I want to use to do this via API (even with pro-reasoning), I pay quite a lot but don't get the same result because of the missing information. There always have to be at least two requests. Although the ‘pro search’ could do everything, it might just take longer!
Is the perplexity API service down? I'm getting a 524 error that is being caught by cloudflare
believe so yeah - same issue
I'm using the API to return a list of products and live product links for purchase. The API returns links to products that are no longer available, while the web interface returns live links that point to available products.
Can we achieve the latter with the API? If so, how?
That's a bit odd. You're on the new sonar models, right? Are you controlling the live product links you mentioned? If you're frequently turning them off/on the API might be catching on later than the UI.
Thanks, I'm going to do a deeper dive into our prompts to see what might be going on. It's helpful to know that this shouldn't be happening.
Has anyone noticed fluctuaing quality in the reasoning models responses
Dumb question
Can someone tell me what am I doing wrong here?

it keeps telling me <h1>401 Authorization Required</h1>
Does it have some delay time after I recharge my account?
you need to remove the <> around your token
same thing
oh wait
I got a different error message now
let me check, thank you!
It worked now thank ou!
are there any ongoing issues with the API?

yes I am getting the same 500 error as well
500 from API as well
We are getting failures in prod, not good
same 500 error on every API call
Also getting failures in prod - some are still going through though
looks like it is back up now
if y'all need beta testers for the API version of sonar on cerebras, hit me up, I have been dreaming of this for months
aider + sonar reasoning as an architect + deepseek V3 as the coder

testing out this "cheap" coding workflow lol
Hello, I’m new here. I need some help on business use case of perplexity api. Our company need an official email from perplexity to enable credit card payment. Could someone from Perplexity dm me? We have been contacting the customer services but haven’t got any response.
Will Deep Research be coming to the API?
I had the same question / thought, this would be quite useful.
Same. In particular, I would like to be able to access, via API, any Deep Research that I have already performed (even those performed via the web UI or the app).
I am having an issue with the Perplexity Sonar API, I have used both the sonar and sonar-pro model. I am executing a research inquriy that is looking at specific sources, 2 weeks back from the current date. It works but I am getting a disclaimer from the model that surprises me:
Sonar Pro returns: I apologize, but I do not have access to real-time data or the ability to search the internet for the most up-to-date venture capital news from 2025. The current date is February 14, 2025, and I can only provide information based on the search results given, which contain some relevant data from that time period. I'll summarize the key venture capital insights and trends from the available information.
This is contradictory with the API documentation that states: Sonar Pro has access to real-time web searching capabilities (https://xpert.digital/en/ai-search-engine/). Unlike traditional AI models that rely solely on pre-trained datasets, Sonar Pro combines AI technology with the ability to pull information from the internet in real time1. This enables it to provide current and relevant content by accessing up-to-date information from the web.
What am I missing?

🚀 Integrate the Perplexity Sonar Pro API into your tools for intelligent search solutions. 🔎 Optimize your applications with AI-based search for precise results. 🛠️ Create smart apps and tailored search experiences for your users. ⏱️ Accelerate workflows with efficient and powerful search functions. 🤖 Benefit from AI technology that is constantl...
Hello,
I am a company.
I have bought API credits and everything is fine.
However i need an invoice to buy some other crédits.
I sent an email to the support but non answer.
Please help !
#invoice
Click the dashboard at below to get invoice

@past island @covert ferry api is not working
Where should i click on this dashboard to get an invoice for API credits ?
Hey @tribal galleon!
Please click on "View Dashboard", On the dashboard you will find "Invoice History", there you can click on an invoice and download it as a PDF.

Thank you so much. I will now bé able to do some other payments
I everyone, I'm using the perplexity API (sonar) through the vercel AI SDK. However, I'm not getting any citations/sources back even though in the output it has [1], [2], [3], etc
The citations are not returnd as part of the response, they are in citations
||data = { 'id': '49f378f8-f6+7-4566-a9da-a96962beb9fd', 'model': 'sonar', 'created': 1739755405, 'usage': { 'prompt_tokens': 1173, 'completion_tokens': 149, 'total_tokens': 1322 }, 'citations': [ 'https://www.perplexity.ai/hub/faq/how-does-image-upload-work', 'https://www.jengu.ai/news/perplexity-adds-file-upload-feature-with-1m-token-context-window-for-free-users', 'https://www.youtube.com/watch?v=ExvP1EIUo1s', 'https://www.perplexity.ai/hub/faq/how-does-file-upload-work', 'https://www.perplexity.ai/hub/faq/images-media' ], 'object': 'chat.completion', 'choices': [{ 'index': 0, 'finish_reason': 'stop', 'message': { 'role': 'assistant', 'content': "If you're looking for URLs related to uploading images or files to Perplexity, here are a few:\n\n- **Image Upload**: You can find more about image upload on Perplexity's FAQ page: https://www.perplexity.ai/hub/faq/how-does-image-upload-work[1].\n- **File Upload**: For file uploads, check this FAQ: https://www.perplexity.ai/hub/faq/how-does-file-upload-work[4].\n- **Beta File Upload**: You can try the beta file upload feature here: https://t.co/pICSQrcaRY (as mentioned on Twitter)[3].\n\nNow, if you'll excuse me, I have some oiling to do." }, 'delta': { 'role': 'assistant', 'content': '' } }] }||
Question: how do images work in the api, or do they, and perplexity is getting popular enough you guys might want to work on your documentation.
NM, your web bot says you don't support it through the api, just pure text.
I know but sources is undefined here when I checked.
import { perplexity } from '@ai-sdk/perplexity';
import { generateText } from 'ai';
const { text, sources } = await generateText({
model: perplexity('sonar-pro'),
prompt: 'What are the latest developments in quantum computing?',
});
console.log(sources);
HELP! How can i default api to use deep research model? Can I do it now?
Hey @quaint aspen!
Deep research isn't available via the API, please check the docs.
https://docs.perplexity.ai
Perplexity
Where is SAM?
It looks like the api keys I create are tied to my personal account? Is it possible to add more members of the team into here to manage keys and billing, incase I get hit by a bus? Context we are evaluating if we should integrate perplexity api with our product
is r1-1776 hot swapped in place on your sonar api? asking from OpenRouter!
i was thinking about this too
Does the API use the Profile set up in the settings of the account?

deep research coming to api?


Hi,
API for r1-1776 returns the end </think> but never opens with <think>
Checked via curl, using temp 0.6, top_p 0.95.
The opening <think> does come through on the sonar-reasoning models
Hello everyone, I'm wondering, are you getting worse results from the new Sonar API than you used to from earlier models like llama-3.1-sonar-large-128k-online?
I'm testing systems out since the legacy models are about to be deprecated, and I'm noticing over and over the legacy models perform considerably better. For example, when asking to look up a specific website and return some basic information, the legacy models do not fail to do so, and the sonar (regular, non-pro) model just simply doesn't. The crazy thing is, they're the same price too! It would be hugely disappointing if this is really the case. Please let me know if you are running into this too.
also keen to hear if/when deep research will come to the API
I did some comparative testing when I needed to switch over from llama and while I don't recall specifically llama huge (which is what I was using) vs sonar, sonar-pro was good and comparative, and sonar-reasoning was a clear step above. Furthermore, I found the sonar models to be much more responsive than llama huge. Just my anecdotal experiences - unfortunately I scrapped my A/B testing data now that I've fully cut over.
I assumed that deep research was sonar-reasoning-pro ... but I haven't played with it to compare. It would be nice if these things were clearly compared and contrasted in documentation, but I haven't come across it. It's just like ... "hey! a new API that costs more! it must be better :)"
Perplexity
Thanks @robust pollen . Out of curiosity, do you remember if you had made any code changes, maybe even a temperature change with the Sonar switch? A one to one swap with the model names in my code is definitely making a big difference, with the biggest being Sonar won’t even do a web link lookup.
Only model change in a centralized config file. I have been seeing sonar-reasoning has been giving me less than ideal quality responses versus the consistency it used to spit out in the past but I'm feeling somewhat like someone who gets itchy when someone else starts talking about bugs .... migth be in my head.
Thanks @robust pollen . I’ll test a bit more.
Hey guys, is there a way to send images via the api?
I agree, it would be good to know if this is what their deep research is utilizing or not.
🐛 Perplexity Models Exposing Think Tags - Both Labs & API 🐛 Hey everyone! Found an interesting issue with Perplexity models (both Labs and R1-1776 API) - they're exposing their internal thinking process.
text
What I'm sending to R1-1776
payload = {
"model": "r1-1776",
"messages": [
{
"role": "system",
"content": "Never show thinking process or use think tags"
},
{
"role": "user",
"content": "Any simple question"
}
]
}
What I'm getting back (same in Labs!) 🤦♂️
<think>
Okay, let me think about this...
[internal processing visible]
</think>
[actual answer]
Looks like both the web interface and API are exposing internal model states with <think> tags. The model's literally showing us its homework! 😅
Is this intended behavior? Seems like we're seeing behind the curtain when we shouldn't be.
Is there any non reasoning offline chat model left, thats accessible via perplexity api? I would still like to use my credits included in the perplexity pro membership but I dont need online seach via api at all.
Perplexity
Too bad.. one reason to subscribe to pro was the free api credits that I cannot use anymore then.
according to this documentation, r1-1776 is not marked as a reasoning model. Who need a reasoning model in production anyway? I cannot imagine a single use case.
DeepSeek is a reasoning model, but it uses the offline model for reasoning, whereas the native Perplexity models use the search capacity
The search-led reasoning capability is the main reason to use Perplexity imo, otherwise you can just use another API or self-hosted model
Yes, but then I loose free credits from my subscription.
who needs reasoning models at all? I cannot imagine a real use case in production.
Every extensive prompt that I send through the Perplexity API using the sonar-reasoning-pro model is limited to a maximum of 10 citations/sources. I want the response to use more than this. How can I achieve this?
Hi
Does anyone know how search domain filter parameter behave if information is not provided in the domains? Would it answer by saying that it could not find information or will it go and use other resources?


As a cricket nerd, throwing Perplexity Deep Research API on all of cricket data and stats and getting into rabbit holes would be fun. Who has a good stats repository here?
Anyone who wants to build this: happy to give you some API credits. 🏏
Hey all, just posted about our upcoming developer meetup in SF: #📰│server-news message
If you live in SF, have built something cool with our API and want to demo it at the event, let me know!
Also, we want to do more of these meetups in other cities. Let me know where you'd like us to host our next meetup.
Is sonar deep research going to be available in playground?
Hello, i tried searching all over the place without a proper answer:
Can I upload files through the API to summarize/work over them?
I appreciate the web version of it but making a pipeline out of it becomes unsustainable because i cannot automate it.
For context I am trying to summarize our town meetings, past and future
Hello Everyone
I wanted to ask a quick question. If I get Perplexity Pro, I will get $5 worth of API credits. How many APIs can I call with this credit amount? And if it exceeds, how can I pay for it? How many searches can i do with this credit?
Subject: Help Needed: Configuring Perplexity API in Obsidian Web Clipper (https://obsidian.md/clipper)
Hi everyone,
I'm on MacOS Sequoia 15.3.1 (24D70), and I use Obsidian Web Clibber Version 0.10.8 on all my browsers. I've set several templates and the interpreter with all the main LLM providers. It works very well, and thanks to this clipper function, my workflow is also evolving and improving a lot. I also use it to test new LLMs and their strengths and weaknesses.
For several reasons, I’ve been trying to configure the Perplexity API in Obsidian Web Clipper to use the sonar-deep-research model, but I haven’t been successful. Here’s what I’ve done so far:
- Added Perplexity as a custom provider:
- Base URL:
https://api.perplexity.ai/chat/completions - API Key: (hydden)
- Base URL:
- Created a model with the following settings:
- Provider: Perplexity
- Display Name: Perplexity: Sonar Deep Research
- Model ID:
sonar-deep-research
Despite this, the integration doesn’t work. I’ve attached screenshots of my configuration and the failure message that comes almost immediately for reference. I’m unsure if the issue is with the API response format, my settings, or something else entirely.
Could someone tell me what might be wrong or suggest any additional steps to troubleshoot this? I’d greatly appreciate any advice or insights!
Thank you in advance!




Highlight and capture web pages in your favorite browser. Save anything and everything with just one click.
Hey @prisma canopy!
If you find the original message helpful, please consider reacting to it with the :star: emoji. If the post is appreciated by the community and receives 5 stars, it will go to the https://discord.com/channels/1047197230748151888/1082806833938436228 channel and the post author will get the <@&1082034222778302614> role on Perplexity.
I want to know how to get a refund if the API is recharged by mistake and not used.
just curious, how do you plan to use AI tools in Obsidian?
Right now, I'm trying to solve a specific problem: using a model with web access in Obsidian Web Clipper (https://obsidian.md/clipper). As you probably know, this browser add-on can save the content of pages you read with your browser to Obsidian.
The clipper has an "interpreter" feature (https://help.obsidian.md/web-clipper/interpreter). In short, the Interpreter is a Web Clipper feature that uses language models to help users capture, modify, and process web content using natural language commands before saving it to Obsidian.
At this stage of my learning curve, while clipping, I try to build some Knowledge and to "distill" the content. So, I'm experimenting with prompts in the Interpreter that try to do at least three things:
- extract_wisdom as in Daniel Miessler's approach. This is functional to accelerate and make more efficient my fruition of the contents when I read and study using Obsidian;
- build a section in the notes that contextualizes and suggests references to deepen the main topics of the clipped page. To better understand, I call it "General Context and Debate." For this reason, I am trying to introduce also sonar-deep-research in this workflow;
- extract data from the page that are not present in the page variables and that the LLM can extract from the content (also for the properties section).
Given these various concurrent tasks, the prompts are pretty complex, and smaller models often oversimplify the answers or make errors. Currently, the models I use most are Gemini 2.0 Flash and GPT-40. I wish I could use Perplexity's models too, for their native access to the web. Do you know how I could set the interpreter to make it work with Perplexity API?
I'm not a coder, and I'm sure my technical approach is naive. Still, I'm trying to experiment, learn, follow, and utilize the evolution of available tools as best as possible.

Obsidian Help
Not Found File web-clipper/interpreter)..md does not exist.
As for AI tools in Obsidian, there are plenty, and you can do a lot with your notes there. If you don't know, some of the best and most popular are:
Copilot (https://github.com/logancyang/obsidian-copilot);
Smart Connections (https://github.com/brianpetro/obsidian-smart-connections);
Text Generator (https://github.com/nhaouari/obsidian-textgenerator-plugin)
GitHub
Text Generator is a versatile plugin for Obsidian that allows you to generate text content using various AI providers, including OpenAI, Anthropic, Google and local models. - nhaouari/obsidian-text...
Sorry for the question, I'm searching for an API to use deep research on perplexity, and I expect to find a way to increase the depth of the research, is this possible or are you in the phase of development of your API, thank you
What do you mean by "depth of the research"? Besides the system prompt you do have the search_domain_filter POST param which could help you go deeper if you know the sources.
https://www.perplexity.ai/help-center/en/articles/10352901-what-is-perplexity-pro#h_9c1338ce86
https://docs.perplexity.ai/guides/getting-started

Perplexity Pro is our premium subscription plan, designed to enhance your search experience with advanced features and capabilities.
Dear Perplexity AI Support Team,
I am currently working on developing a bot and have integrated your Perplexity API into it. As part of my testing, I funded my account with $7 to evaluate the API’s performance and cost structure. However, I noticed that this amount was depleted within approximately 1.5 hours of active usage.
This was purely a test phase, and the bot was not publicly accessible—I was the only one using the API during this period. I made a total of approximately 60–70 requests, and my total token usage was around 400,000 tokens.
I would appreciate your guidance on understanding the correct pricing structure and how I can optimize usage to ensure cost-effectiveness. Could you please clarify if this level of consumption is expected for the selected model and provide any recommendations on how to manage API costs more efficiently?
Could you please advise me on the best place to ask my question so that I don’t clutter this channel?
Hello, everyone, anyone has experience how to make sonar return related images instead of just text response?
Thanks for pointing that out!
go through entire convo after that post
If anyone wants to build an open source Claude-Code with some editor integrations and extensions, Perplexity would be happy to provide free API credits. Please DM @GregFeingold and @AarashHeydari
Thank You 😁, the depth of research for me, is the time and/or other limit that stops continuing searching and analysing sources
Perplexity API is not 100% OpenAI compatible. Obsidian Web Clipper is trying to put two user messages in a row, and the API requires an assistant message between them. That requirement is not defined for OpenAI type APIs.
I would like an option like this 'continue deepening In this question until you use x dollars' that means perplexity will continue searching sources, gathering information and processing information for longer time.
So I have more control over the depth of the reasoning and depth of the amount of sources perplexity uses
The idea is to finally create a specialized ai for scientific and professional investigation
😁
Sometimes I could pay 5, 10 usd to get perplexity, be running an hour in one prompt to explain only one concept
Another option to investigate is to ask different AIs and consolidate that information, freedomGPT gives that option
Thanks. I will try to discuss this topic with Kepano, the developer of Obsidian Web Clipper ...
I've proposed a mod to the Obsidian Web Clipper to accommodate Perplexity's LLMs: https://github.com/obsidianmd/obsidian-clipper/issues/376
I hope somebody more skilled than me will try to add this. I think it would be very valuable.

GitHub
Integrating Perplexity AI's Large Language Models (LLMs) into the Obsidian Web Clipper would be highly beneficial. Contrary to the other models currently usable in Obsidian Web Clipper, Perplex...
Hey everyone! I am using the perplexity API(specifically, the sonar-reasoning-pro model on a Tier 3 account) and am unable to get json output via the response_format option. Does sonar-reasoning-pro support JSON output via the response format option? Below is my code:
`class TestModel(BaseModel):
field_1: bool
field_2: str
field_3: bool
field_4: strurl = "https://api.perplexity.ai/chat/completions"
payload = { "model": PPLX_MODEL, "messages": [ { "role": "system", "content": system_prompt }, { "role": "user", "content": user_prompt } ], "return_citations": True, "search_domain_filter": ["example.com"], "response_format": { "type": "json_schema", "json_schema": {"schema": TestModel.model_json_schema()}, }, "return_images": False, "return_related_questions": False, } perplexity_key = os.getenv("PPLX_API_KEY", "pplx-<>") headers = { "Authorization": f"Bearer {perplexity_key}", "Content-Type": "application/json" } response = requests.request("POST", url, json=payload, headers=headers) response_data = response.json() if 'choices' in response_data and len(response_data['choices']) > 0: analysis = response_data['choices'][0]['message']['content'] citations = response_data.get('citations', []) else: analysis = "No analysis available due to an error in the API response." citations = [] return analysis, citations`
The content of the response instead starts with <think>Some thinking text</think> followed by the JSON.
Am I calling the API wrong or do the reasoning models not support response_format?
https://docs.perplexity.ai/guides/structured-outputs#generating-responses-in-a-json-format
Structured outputs is currently a beta feature and only available to users in Tier-3
https://docs.perplexity.ai/guides/usage-tiers you can if you spend a cool $500 😅
Perplexity
or just prompt it to output data in JSON format, that works too
Does anyone know a way by which i could set the focus to somethin specific like academc/community while using the api?
hello - I'm using the sonar pro model, but struggling with the usage of real time web data - it keeps returning legacy information that is no longer valid (yes I've set search_recency_filter: 'month') and many of the links its returning are directly faulty (like parked websites, 404 pages etc). I guess I'm doing something wrong here?
Hi I'm also using the sonar pro model and the results are good but the citing number it has Eg. [2] confuses me a bit since in the replies it starts with 1, but with the sources list it starts at 0
How on earth do you price search cost? If I wanted to track my spendage through my own tracker, I can't cause the api isn't telling me how many searches were used 
does perplexity api have european servers? I could bring thousands of users on it then but we need to follow GDPR rules
Any insights on what the "70b-online" model is in the API? I noticed that's what shows up in the billing when I request the "sonar" model via API call. Not complaining since it doesn't appear to charge for search or citation tokens, that way, but is that the intended behavior? It doesn't match the documentation. It doesn't allow "70b-online" to be requested directly as a model choice, and it does still return citations in the API response when "sonar" is selected as the model. (I don't actually need the citations for my use case, so it's just as well it's not charging for them and I'd prefer to have an option to turn them off entirely as a parameter to the API.)

I am curious about this as well. I also see that the invoice I receive doesn't fully match what I pay. Is that a lack of search query attributoin on the display issue?
api does not allow to uplaod images?