#✨|sdxl
1 messages · Page 97 of 1

@ionic gulch thats nice...
i think there is an error with my image loader where is doesnt read in the images some reason
come at me, bro

@hardy cipher that node could fit in the space i have for my loras. if i need more that than 4+offset, that could be helpful. have you published it on comfyui manager?
My pimped out new Jordans...

not yet. do I just go to the github and request being added?
i think you have to fork the manager, change the file with the node sources and create a pull request. but in my case the pull request was closed and they added it manually. guess this is easier for them that way.
can you try my workflow and check if all nodes are loaded by the manager?
yeah, just give me a couple minutes. trying to figure out an error I was getting
Ok using Revision together with Controlnet, in this case Depth works pretty well

Yippe! I think my comfiUI animation graph is working
whooa sick armor




loading now
not gonna lie, didn't have your nodes just yet. but I'll install them now
they showed up in manager under missing nodes







That looks like a chair someone paid too much for on Etsy.
so everything is working fine? you can use all 4 modes (txt2img, img2img, candy, depth)?
Hours later and I'm still seeing this.
well I'd discussed nodes with a couple people previously. should I not show them?
I'm just FUCKING with you. 🤕 🍮
I mean, I also think it's a bit ridiculous, but it works now, lol
Or no one buys it for months and a random woman in her 50s swoops in and casually hands over more than 500 dollars for it.
It's wicked
Is there any way to dynamically adjust the amount of inputs in the node. Would make more sense to do it that way if there is.
everything loads fine. but I need to completely reinstall comfy to get the controlnet working though. created a new virtual environment and still no controlnet, so I think I'll take a different approach when I have a minute to do it. but everything looks good
Ok So this is going to be a train of 3 messages lets see hwo quick I can get them off 🙂
So still trying to understand how ReVision sort of works and what inputs are doing what
Post 1 (this one) is Normal Textual Prompting & Styling
Post 2 is Textual & Styling Plus ReVision truned on but ConditionZeroing disabled
Post 3 (which is where/how everything up until now has been prodcued) is Textual & Styling , ReVision On,Condition Zeroing enabled (ie only using the image encoding to generate the new image and ignoring any prompt information


that's a real humdinger of a workflow, lol







little to no artifacts
yeah, unlike countless others that came before, lol. kind of a hassle to find the sweet spot with 4 clip visions in various places
It doesn't work as well, but kinda sorta works.
No, Im aonly revisioning the stage 1 sampler (which to most people would be the Base)
I'll share this again because I really like this style.

Ah. The refiner only runs for like 8 steps anyways. It's not like feeding anything into it can really help.
Unless...

and Stage 0 (or PreCOndition as some peole mat call it) only runs for 3 steps
"peole mat"
I mean Ok Ive admitted earlier to have sausage fingers but heres a question. What if iDidnt and it was a "condition" ?
It would still be a comedic slip in your typing.
its optimised to be used with stringy bits turned off and loads at this screen on my 1440p moonitor 🙂
As you've probably seen its a bit more complex as you zoom out lol

that looks so clean, but I can't bring myself to put flows together like that, at least not for myself. I have to see where everything is going
Woah




Oooo TIL you can turn noodles off

I 've used Node Based tools for work purposes form seevral years now and I find it easy to visualise in my head where things go
Its all about having things in key blocks so you can get a helicopter general view that you can drill into if required
I know for example that if Im having an issue with my text file output I just jump to the circled box and take it from there

Is that the PS1 style game LoRA?
no
i was thinking ps1 too
yup, Comfy only lets you straighten them , these lt you hide them

GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.
Any requests for comfy?
DM me
makes perfect sense. I do tighten things up quite a bit once I have it established. get a bit ocd with it. but I normally have seperate sections

my only outsatnding Request for COmfy (which Im sure Ive stuck on his GitHub) is to improve the S&R fucntionality so I can write text files withthe exact same date string as used in an image save file name.
damn I saw that bit after I posted lol
yeah I created an issue related to that on the ComfyUI repo
I guess the whole implementation would need to be refactored - S&R, filename handling etc

GitHub
as per title would it be possible to get some Text nodes to allow use of S&R variable insertion functionality please. Even a simple Save as Text File where they could be used in the Path name s...
remotely related, but it kinda is connected: https://github.com/comfyanonymous/ComfyUI/issues/1176

GitHub
If you use the Save File Formatting feature in the native ComfyUI Save Image node with a syntax like %date:yyyyMMddhhmmss% and in a Queue with a Batch Count < 1, all filenames will receive the s...
I have since customized nodes.py and the Save Image node as well as the S&R Extra Metadata javascript for my needs


If I could do a clean implementation I would submit some code ideas. It's just hacked together. I added a much needed suffix to the Save Image node, suffix can also use S&R.
The counter didn't work how I wanted with multiple images in one queue job. So I removed the counter and name everything by date/time. I moved the whole date/time function to nodes.py since it's not correctly evaluated how I want it when the queue runs.

@ionic gulch crashing 😦
was working, but everytime I try to generate something., it crashes the computer...




Anyone noticed a bug with memory management on Comfy and the ControlNet Models?
It doesn't seem to unload them once it's finished with them, so you end up getting slowdowns.
Keeps 7.5GB Loaded for me after using them, and if you then try to do anything else after, it overloads the memory

Yeah, Ive seen that too
Hmm it might not be the controlnet, it might be the pre-processor that it's holding there
other workflows work fine? how much vram have you got? are all 4 modes affected? even txt2img?








Yeah there is definately some weird memory management issue when you load a ControlNet/Depth Model
I uploaded that node if you wanted to try it out. I do believe it works correctly now. But if you do decide to use it please let me know if you encounter any issues.



Got that uploaded. Hoping it all works as it's supposed to 🤞

GitHub
input aspect ratio, output dimensions. Contribute to picturesonpictures/comfy_PoP development by creating an account on GitHub.
are you into the LoRAs?
not at all. just the clip_g



that elon musk image reminds me of my favorite lora.



I have an idea for that actually. I'm thinking of using the example images on that Lora page and using two as a revision base.
I'm using this more of a style merger than a blender.
Aye! gonna generate a few tests tomorrow, or if energy enough, a few today and see :P
By the way, got another "for everyone comission" for a better ease of use
And that's for lora's, and models, do you think it'd be hard to make a "load lora/model", or rather "model" preview, that loads like the "load image" you normally use as base image, but it reads from images related to lora's and loads them up in a grid? Similar to "extra networks" on automatic's?
these are the images I was using earlier



I'll use these for later actually. great example.
with that lora actually
Loras are just too odd to work with for me. I'm still geting what I want from everything but Loras. @hardy cipher
holy mother of mary wtf is that thing xD

it made so many beautiful images



Trust me. I can make stuff like that with style images like those as a base.

ah it was a jesus fresco! ruins my whole pun

for sure. same. I just like to get real wacky with it
totes I get what you mean.


That one on the right. 😍
pretty damned good innit

Def.

You catch my stormtrooper above?
no sorry , I was just heading to bed and saw those 2 had dropped in in a batch I have running (ok they dont all work but thats to be expected)

thats crisp 🙂

The one on the right from above is definitely the best of the batch.

And yeah, that trooper came out super nice.



Try this but with something like "layered highlight hair"

so you may have misse dthe posts back up there but thes eare being generated purely by the 2 images and are ignoring any prompt details
Anyways very late and I should be in bed
Ah...sorry, yeah, I didn't see that.

It's a perfect day to bake a pretty cake.
I was thinking the same thing!




lil nubbin


The lighting on this one:




Nice, these star wars ones are coming out great

My multiple fails trying to get this animation graph to not breed chaos cx (i'm closing in on it)











A wizard is never high. He is exactly as blazed as he means to be.
shadow wizard money gang 🧙 💲

Straight floatin' that spliff.

I don't think that's how you do that...




I feel like you need to throw Wozniak in there somewhere.
this guy

smoking. why do i keep seeing on many servers that people can't generate photos of people smoking?
the phat hatter
iv'e done it. you're doing it
seems to be some meme got a bunch of people convinced of a limitation that isnt there




These last 2 are 

😆














Is the revision mixing supposed to be much slower? It's much slower at least for me.
nah, about the same
Did you make your workflow or use someone else's?
I downloaded the one which comes with hugging face
maybe your input images are large?
oh never mind, It's because it did 4 images at once



beautiful image

sexy young man who loves to watch the ceiling



Hi guys, I just got runpod and wanted to train sdxl with my own images using a colab notebook
Anyone know any good ones that are fast and easy?
Also, if I am training a specific scifi object, should I go for LORAs or safetensors? It's safetensors right?
safetensors is the file type. lora is the method of training
Ah ok, thanks
should i release my cinemax model 





A small group of model creators should group together and make the best everything model that can. When it's finished the title of the model should be a literal cryptic code that needs to be solved to get the model name.








using the refiner model instead

the depth preview isn't working for me. Not a big deal though.
EDIT: I can see it with a save image node.
maybe found way how get rid of signatures. Just not sure.

i always put "signature, watermark, logo, signed" in my negs. basically never see them

hm i see them, even printed. Try for example few pictures by Gertrude Abercombie








BURN VICTIM! BURN VICTIM! BURN VICTIM! BURN VICTIM! BURN VICTIM! BURN VICTIM! BURN VICTIM!






It looks like Scott Cawthon renders








GM fam (includes you @steady grove )
)
What can I learn today?
literally me

you gotta drop like a "cw: gore" or something if you're gonna spoiler it cx
I am trying to use Kohya ss to train my lora, but i can't find where to put the class token and such :/
anyone has any idea where they are?
I am stupid
FUCK
trying basic revision on a gorilla image and the outputs are all men... Can't get a gorilla
chnage the weights
what I rec is that you chnage the weights so that they are in favor of the image you want the most to blend with.
I'm only using 1 image.








annnndd it's back to this

It's like someone is wearing a Tom Hanks skin suit.

Has there been made a addon for comfy to see updated previews of the generations so i can cancel sooner/see live progress?




Is that leonardo dicaprio?




YEES, I think i finally figured this out




I'll need to figure out and add interpolated frames, but here's the json if anyone wants it, it work in progress (will make another, better Commented one for #🎥|animation )

Trying to use the refiner, and it's just outputting the same image... not sure where I'm going wrong? Any ideas? Thank you 🙏

fixed seed


Thank you, I've kicked out the fixed seed on refiner, but still no dice...

on the Ksampler its still fixed
how else would I generate fixed images though on the regular model?
if you want new images change to randomize
I think your 'start_at_step' and 'steps' are both 20
what should It be?
i think i remeber seeing someone do 12 steps on the base model then start at 12, to 20
This is weird

It just does not want to do a gorilla
I tried many prompts and settings by now
the conditioning zero out removes the text prompt
RIght click > Bypass?
ctrl-b or right click -> bypass
okay! i did it: 'start at' is where ever you finish generating on the base xl model and then 'steps' is where it'll go too up to a maximum of what 'max steps' is set to
They actually have their steps at 20 and their start at steps at 40, so it's not going to do anything.
Be sure to pick up your exclusive Ryan Seacrest action figure. In stores today!


ohhh let me check that! thank you
Yeah i think it was "Scott Detweiler" who i saw do the 12 then refine to 20, I actually like the base model more then post-refining but I still fresh with xl cx
Yeah you can do that, can do more or less depending. Although to be honest, with the particular image noel has on there, it won't make much of a difference.
It's more useful for sorting things like eyes out. But it's not always needed.
I've stopped using it really.
Especially with custom models

aikido bear
what stable diffusion looks like to SDXL


Interesting, better to just skip it and run more steps + upscale?


Depends on the image, for that one you provided an example of I don't see it making much of a difference.


Clinton?
Thanks, challenge for me is I'm not even getting any difference whatsoever which is weird

With the screenshot you posted, you had your start at step on 40 and your total steps on 20. So it isn't going to do anything.




You're right, I was fiddling with numbers. Here's 10 and 10, same exact image/output

so close to greatness

That still won't do anything. You are telling it you want 10 total steps, but to start on step 10, so you are doing 0 steps
Set it to something like Steps 30, Start at 15.

@minor spruce Actually use it like this. Set the Base KSampler to 30 steps, start at 0 and end at 20.
Then set the Refiner sampler to 30 steps, start at 20 and end at 30. Also disable add noise.
Just changed a number as I fat fingered the wrong one

If you really want you could do 0 - 10 on base and 10 - 20 on refiner, but then you don't really give the base enough time to make the image and the refiner will just screw it up
yeah, I've never once had positive results taking that approach


maybe if I took the time to run the refiner through some loras and have it skip some end steps
I mean that's how you are supposed to do it, you generate an image on the base and leave the left over noise, then you move that still noisy image into the refiner and let it finish the image off.
But I, when using it, tend to do something like 0 - 30 on the base and then maybe 30-35 on the refiner
wat?
refiner is supposed to do like 20 percent of the steps or denoising
not saying that's set in stone
There's no set value you have to run the refiner for. I've never done it as a percentage.
I've found most of the time a small amount of steps works better. You go too far and it starts smoothing things out.
I don't think there's have to anything. but I now I don't like the results of heavy refiner usage

Yeah, if you do too many steps, it wil make the eyes look brilliant, but it will start melting everything else.
might be able to get away with it if you set it to low denoising or something
and then send it somewhere else from there
I have no doubt there are exceptions to this
I just haven't found them myself


not bad. I haven't had great luck with that approach. usually end up having base and refiner overlap on a few steps in then middle
Sorry, previous post was wrong (with noise on)... nice outcome now!



crar i powties fr 👍🏿

raied 🫡
The fact that I can get the "WANTED" to be correct most of the time is pretty impressive.
I didn't realize how much I needed AI generated Wanted posters.
do you think we'll get proper hands or proper words first?
Who knows... I mean, it's getting better all the time on both fronts.
not sure how they'll really fix the hand thing completely until the model knows how human anatomy works
FRAGSTAR:


that's just a picture
Hey could anyone help me out I just am trying Comfy for first time and successfully used the controlnet LORAs recently released... now all I can't figure out is how to add my own custom LORA to those node workflows? I am using the workflow given for controlnet LORAs canny in this example. Like for example say I made a custom lora for myself. I see how to use control net now but how do I also use the LORA I made of myself...if this makes sense

Don't worry, the gorilla is wanted, too:

double click in the empty space and search for "lora"
should have a lora model loader
you don't need to add it to the prompt. at least not the word "lora"
cool that was probably the easiest answer i ever got and maybe my dumbest question yet
you'll see the checkpoint loader has model and clip as output
lora has model and clip as input and then as output as well
awesome this is gonna be badass with sdxl
Keep in mind you can only use LORAs made for SDXL with SDXL.
yeah for sure I got those made already
I am not sure what the strength for clip and model means I feel like in the past I just had one strength to worry abou t
this is the lora setup you want

well just leave them similar if in doubt


Nothing out of the ordinary going on there.


gotta say, at least you're asking reasonable questions. I think you'll pick up on it pretty quickly
lots of things seem obvious in hindsight
lots of things seem obvious in hindsight
Quote of the decade right there.

lol.... 30?!
yes, I need to fill these

yeah i gotta do a little research

actually comfy seems kinda cool because at least by using nodes u understand what is going on under hood btter

correct. and it's like playing with ai legos or something
i was so happy i had just mastered dependencies in python and shit lol I feel like 90% of what I was learning was not AI related as much as bug and driver releated or performance searching etc. with GUIs
I guess it just doesn't click with some people, but personally I like it way more
because you can connect things in basically endless combinations
things that barely make sense, that's my favorite approach
you can do the same things with a1111 technically, but it'd be ridiculously tedious
Zardu Hasselfrau

Is ClipTextEncoder better for SdXl? Just realized i have been using the normal one 💀
what do you mean exactly?
I'm going to load 30 loras because I can

feeling blessed

It's the designed way to utilize the full potential of SDXL, so technically yes.
Can you still get nice images not utilizing it? Absolutely
(speaking to splitting to G and L)
k one last question is that lorastackloader a custom node if what is the name so i can snag it
are the default controlnet workflows stability posted for sdxl just broken on Windows?
'control-lora/control-lora-canny-rank256.safetensors' not in ['control-lora\\control-lora-canny-rank256.safetensors',
Get ComfyUI Manager. That way when you load someone's workflows based on images or .json files, you can easily download the missing nodes.


I think SDXL is 80% into perfection
Still a pain to get eye colour and skin colour right 😒
how are you quantifying these percentages?
for me 100% if it really can give result as what we tell/ask them to do
based on the proportion and perfections of the images
seems a bit suspect, but I'll allow it
this is near perfect images

but i told her to be backward flip baseball hat and with mecha in the background
but overall its convey the idea
SDXL is definitely worse at following complex prompt than I hoped but it's still maybe 5-10% better than 1.5 and higher res
1.5 cant achieve this
it can,thats just a normal average img
I'm 12 percent better than stable diffusions 1.5
no, it look suck I tried it
and 16 percent better than a honda civic

and will disfigured
skill issue
I just use common clip drop, not locals
just basic not using own models or else
not training to, I comment here based on basic skill usage not lab pro usage lol
I bet next year its perfection
if you don't know how to drive a car it won't drive well
or end of this year if the dev really working on it
Sydney Sweeney as Jessica Rabbit...or at least one could dream.

I know how to drive the car I think, just basic sedan. but of course not some Initial D sliding lol
I feel like a lot of new people, not saying you exactly, misunderstand and think some people get bangers ever time they run it
but depending on the seed and all that, it could just be a dud through no fault of your own
it can be a dud, but not as common as before
yes, higher win rate than 1.5
it is
thats why i said 80% chances lol
near perfect, bet nex year wll be 100%, or we already achieve stagnation

i can do that on 1.5
try it compare it here
but i would have to use inpaiting
given that 1.5-2 was a downgrade and 1.5-sdxl was a small update (outside of higher res) I really doubt we'll get anything like 100% for complex prompts by next year
I suspect we can get things way better in like 6 months but only on consumer hadware
a bit hard to get the text understanding part to be cutting edge when you have to use a tiny language model (compared to gpt) to run on consumer devices
if consumer hardware better, just minus 10% on regular website
free website usually just lost around 10-20% from local
yeh in 2 years we might get a 5090 that has like 30% more vram so we'll be constrained for ages on the consumer side
10% maybe
speakin of perfect imgs

nicee, care to share the prompt?
this isnt perfect,no steven seagal
make steven vs chuck
wanna compare it using clipDrops
(masterpiece,best quality,official art),1girl,solo,puffer jacket,open jacket, navel piercing, tight pants, denim shorts, torn legwear, eyewear on head, tanlines, and the negative : worst quality, low quality:1.4),
it will be perfct 100% if we prompt "cyberpunk girl holding weapon aiming with mecha in the background 3/4 view" with exact representation of it. righ now it just will give us a great cyberpunk girl sideview looking at us thats it
lol
how does one go about learning about this maths thing? o0
secret
this what I got, not bad but of course not as good as local trained


anime style

compared to base 1.5 its rly good

broooo 
perfect tbh


it is
is it like, 1 latent image + 2 prompts + other settings = 1 diffused image
60% better

SOS




Who is this character cx ive been seeing them pop up all day and now they're fighting a gorilla xD
steven seagal
lol

I am now going to educate myself cx





this a perfect images. thats why sdxl is 80% to perfection

The truck is badass
truck lora with goat lora equals divinity


thats baaaa'd ass
sdxl proportion is great


Yaay i got film interpolation working

Hey! i'm a tiny apple that'll...! rot into the soil cx just you wait!
brum brum brum

and then you'll make crappy crap apples because all the good apple trees are clones

you made that?

anyone know what ngms means?
I'm sure I could figure it out, but figured I'd ask
it's one of the parameters of generated images on civitai
Nah, just pertinate gif
I messing with film interpolation atm



sexy









i make a tyson, tried him eating ear, but it didnt worked
"whispering sweet nothings while simultaneously munching on an ear"
I tried michael jordan and it looked nothing like him at all. wonder if they were scared he'd sue
or coincidence


this isn't rocky dennis 😭


This kissing, it used to be absolutely normal, when Breznev or some communist leader arrived 😄
They swapped their pants 😄


some celebs have to be trained with LoRA,Christoph Nolan is another example
web crawler data from e-commerce site is interesting ,RNN and LSMT predict for custmers emotion when anylize with different comments





Poe by Jackson Pollock 🙂


No way bro
I put a pen up my ass right, it got stuck and I had to be put to sleep in hospital to remove it
Gay
Relax, its just a nice garden plant 🤷
Its cool bro, btw my asshole hurts and im done in hospital


go for it idc
Bro im not gay btw
We're just flipping your social autonomic systems cx
What



is it possible to create a custom Ui based on a Comfy node workflow backend setup?
like the ui customizes in terms of input buttons or whatever based on how i built my comfy workflow?
GitHub
Customizable Stable Diffusion frontend for ComfyUI - GitHub - space-nuko/ComfyBox: Customizable Stable Diffusion frontend for ComfyUI

thaank you
You are welcome
it hasnt been updated.. in awhile 👀

I haven't used it myself. Maybe it was flawless, so it doesn't needed updates? 😄 . I think comfyui has also an api.
they might have been working with stability to get it integrated or something? dont quote me though
official app Stableswarm-UI is front end for Comfui, isnt? I would wait and see what they will do.

well it is what i was assuming stableswarmUi is
WiFi
but i dont think thats techincally customizable


Well, yeah. Talking about that. You could just use stable swarm. The repro says: "In-UI Comfy workflow Save&Load, and metadata edit (ie to reconfigure which parameters to send over or not)"

So Vogue! 🎉



well stable swarm doesnt want to tinstall
i still need to hop on the stable swarm train, Just got ComfyUI and back into generating with Stable XL (so much progress kinda crazyyy)

if you have trouble with it, feel free to ask in #🐝|swarm-ui
it should work for you needs pretty well



"Model's level, in one generation, with one word as positive prompt."
https://civitai.com/images/2120399?period=AllTime&periodMode=published&sort=Newest&view=categories&excludeCrossPosts=false&modelVersionId=140608&modelId=119229&postId=519267


hey let's keep it civil here, please be respectful to everyone.

Are you my spanish twin ?

Yeah, y is level one, i'm level two 
Asking for 'Creativity' as positive prompt.
Duude, i love this model

||I'll need to learn how to work with* human faces soon||

Nice ! What do you mean by 'to work human face' here ?
ah, with* woops
and like to do touch ups
Also, are you using a1111 webui ?!
Cause your VAE is obviously broken
Here, download "sdxl_vae.safetensors", and save it in you models/VAE folder, replace your existing one (rename/archive the old one)
https://huggingface.co/stabilityai/sdxl-vae/tree/main
This is what i mean

ooo good to know! I'm using Comfy and i'm just pulling the pin from the xl base, and I see the vea one must be the one with the embedded one or something?
colors artefact, it's a wrong VAE. StabilityAI uptated it a few weeks ago

Also, wait
Don't use the link above ... The orignal VAE is way too long
Causing the freeze at the end on the generation
Let me find you a good one (fp16)
The end of the generation will be barely instant
like 10 times faster
*reroll the exact same pic with same prompt/seed, to see the diff
also does this one mean it has it embeeded or something i remeber hearing somthing about that, but just dont know what the diff is between the two, also thank you btw xwx!


Delete these failures, both lol.
The new quality when zooming will be highly improved. And way faster with a decent resolution (1024*1024 or more)
And if you wanna a good model. Try ZavyChromaXL ((:
Is this a MicroShip ?

It need to be there else the circuit is not complete.
Aww, i forgot. Delete --no-half-vae from the launching batch !
(Need to fully restart the webui)
We aren't Amazon, half precision VAE is fine for us !
Only 'Lofi' as prompt


Wan't wait for CN on a1111 webui
Nice 🤘
as a thank you: https://www.youtube.com/watch?v=ty0EezB5qkI

Enjoy this awesome set by OLING from the Jägermeister Rave Cave in Åre, Sweden.
This stupid thing keep spaming "CN not compatible, disabling" ... even with good models
chill out other me!
Awwwww, and good music ! Much love buddy



risitas to the rescue
ahahah, always !
ComfyUI can be used to make inferences on controlnet
Yeah, but i don't need all this workflow ui architecture... I didn't touch it yet. Also i'm a pure txt2img guy, seing CN as a cheat, kind of
But cool tool, for sure
Especially with Deforum, tho. Not really txt2img

before I started fixing my graph cx




drum rolls 🥁
Hi
what if i told you controlnet in swarmui is as easy as

upload image, select the model, and go
even has a nice UI listing the models you got with metadata

Gotta read the text of the msg too

Hum, didn't know this one
Hshsgsghs
lol, is it supposed to be the same pic ? xD
No colors artefact, seems good to me !

And probably way faster
not stucking the webui into 404 for the api, LOL
no that other pic was before i made the changes
thx again btw xwx
Lofi


Come join my Discord ! This model will always remain publicly available for download. It is important to note in this scene that full exclusivity w...
OKAY OKAY i'll go get rn

My last posted pictures with this model !
https://civitai.com/user/wizz13150/images

Sweet, would be crazy with the linked model above too
It knows how to write his name

One of my favorite pic !


Same prompt as this one

Give me your prompt lol, to test
Eh well Im kinda cheating.
I use a fine tuned model and a self made lora for this one.
ahh, i was bugged. With the new model
Not the same sh*t, right
So the prompt alone will be nothing heh.
Most yes.

The lighting's def better so far x.x

Yeah, as you said, depends the finetuned model. (trained, not merged)
Train the model with the same pics, don't need the Lora anymore




Sexy ! xD
More a realism model, a good prompt will fix this lmao


that could like so be made (love the brat style-like seats >u<)

Have anyone already trained SDXL on runpod? Are you satisfied with the result?
(Has a tough choice: try SDXL or v1.5 model training)
Yep me lora.
Yeah the lighting and portate style stuff's kicking butt cx (i def need to learn how to work with faces though cx)




Yeah, no real secret with faces. It's how the model is trained, with 1024*1024 pics.
OR the face is highly detailed, and close
OR the face is not, and more far
So if you use "highly detailed face", the model will generate a pic with a closer face
You see the logic !?
So, "highly detailed face" is the way, but will more be like a portrait
OR, ofc, higher res
More pixels = more detailed

Also use a related ratio, to help the model.
More 768x1216 if full body, more 1216x768 if landscape ..
Ho, great indeed

Very realistic, nice one too



Dude, this is cool as f
prompt was like "robot holding a sun" or something like that
but i also get ones like this where it's like okay what's going on cx

Oh yes posing for fucking vogue with a banana xD



is there already easy way to get auto1111 gen SDXL base model at same speed as comfyui on 8GB VRAM?
when SDXL launched, comfy was notably faster, which I assume is because it runs with different parameters by default on such setup
Yeah, as you said, probably other params. You can use the token merging ratio (0.3) and the negative guidance (1-2), in settings/optimizations
No secret about the speed.
Also a fp16 VAE
And depends the sampler, don't use DPM++ SDE karras, for example, way too long
prefer 2M karras
it could be other things too, because without medvram setting on auto1111 it would be super slow.. I dunno if comfy uses same solution for vram saving
medvram is slower, indeed. Not sure how comfyui deal with vram. Probably not magic on this point
thing is, you can't run SDXL with auto1111 and 8GB VRAM without medvram
it's going to take minutes to gen single image then since it goes over 8GB in usage
Yeah, even my rt3060 isn't enough at this point, huh. Some optimizations should probably come for the 12gb cards, not sure for 8gb
comfy has been good in this regard, but I can't help to think the same improvements on base settings could be done on any webui really
mainly asking here is there's already some solution, not really looking to reverse engineer the differences myself
I don't really like iterating with comfy.. it does the job but that spaghetti isn't my thing 😄
it's great if you need something custom

it's like

"creativity" as prompt

ah, try this half precision vae, if you don't yet.
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl_vae.safetensors
Put the safetensors into the models/VAE folder
then remove --no-half-vae from the start batch
The end of the generation (the -way too long- 100% duration with full precision VAE) will be way faster (like 10 times, regarding the resolution)
hmmm, VAE stage isn't super long on comfy itself
I mean, it doesn't make these solution same speed still
If you generate a pic in the webui, at 1024*1024, you don't see a delay between the last step and the pic coming ?
I do, but the difference between auto and comfy is still bigger
For me, using the full precision vae, for example at 1024x1024, i get 20 sec to do all steps, and the pic is ready in almost 30 sec.
This delay is the vae working on the pic
Using a fp16 vae will greatly reduce this duration. Barely to 0 for a 1024*1024 pic
Give it a try ((:
You won't be disappointed, in the worse case lol


wow xox
I don't see any improvement on auto111 for using that fp16 vae
it's loaded (saved it next to the model so it autoloads)

also removed that --no-half-vae param
still taking 37 seconds per image
@untold crescent what gpu?

2070 super.. I get the VRAM is issue here, just trying to figure how to get auto1111 as fast as comfyui with SDXL
o.k. i believe with next update. Hope it will works.

same model, same fp16 vae, same gen settings, takes 18 seconds to gen on comfyui
on auto1111 37s
it shouldn't be twice slower
yeah i had the same prob on auto 1111 i'm sure it'll get sorted out soon enough

i have a 3060 with 12gb
could try on vlads repo I suppose

That's a lot ..
it is, but not 37s 😄
SD1.5 gens at it's lower resolution in few seconds
but SDXL isn't super happy about those lower resolutions
used "final fantasy" as a part of the prompt

At this point, i have the feeling that i'm able to see when a pic is using ZavyChromaXL or not
auto1111 also gets stuck on first gen forever
once it gets past it, it's that 37-40s per image 😄
ok, I'll try vlad's
did you remove the arg from the batch ?
yes
^
bah, this is just a fork from a1111 if i'm not confusing
it is but it has bunch of different approaches to things
hum, no reason
it had SDXL support before auto1111
theres no benefit in generating below 1024 with SDXL and most of the time it wil simply mess up the image
Same as going too big will cause image quality issues.
Theres a table somewhere of recpommended Generation sizes to use with SDXL

yeah I figured
When i slown down, i always finally notice something like a bad sampler or something
in fine
i dont like to be in too many discord cx
fr fr it def hits faces more studio like 💯

Wait, i have an awesome prompt
Pikachu, Breathtaking, 8k resolution, extremely detailed, beautiful, establishing shot, artistic, hyperrealistic, octane render, cinematic lighting, dramatic lighting, masterpiece, light brazen, extremely detailed and beautiful face
Just replace Pikachu with anything, and show me
This octane render is pretty crazy, for me
(I have 2 different negative prompt for this)
uh oh cx will do a few runs cx
Hello world ! I was just wondering if it is possible to use Sdxl 1.0 with automatic1111 on colab or it s just locally or the previous version of stable diffusion ?
I replaced Pikachu with your mom

there's prob a colab somewhere by now if you search it
It should work as well (or badly) on Colab as it does locally
(deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation. tattoo, watermark, text,
or
(worst quality:2), (low quality:2), (normal quality:2), lowres, easynegative, signature, watermark, username, cropped
here they are
No joke, dig further with this prompt, and the second negative prompt
Crazy ones
And pretty universal
Ok ok thanks i m gonna give it a try 🙂
This isnt your prompt Wizz, just had to finish this one casue it was so intense cx



2
why, will it enable an ulocked level?
No offence but the way this is all phrased this sounds like the sort of spam clickbait stuff that you get on other social media sites
My second negative prompt fit pretty well this model
And the first one for full body things
👍.
Try it
with this neg :
(worst quality:2), (low quality:2), (normal quality:2), lowres, easynegative, signature, watermark, username, cropped
I also replaced the word pikachu with cockwomble

With ZavyChromaXL model, of course !
Not sure for others
I gave up, only using this one
are you shilling for them or something?
Sounds like it from my seat
@ionic gulch img2img, candy causes the computer to crash., 12vram


took out all the additional crap and started with
"your mom, Breathtaking, extremely detailed and beautiful face"
Much better (although I accept the styles will always add stuff back in)

Luxury hurrican fruit

the materials so nice!
lol, dude , i'm obviously shilling, but it's totally a personnal pov. Deal with it.
Here is what i mean with this prompt !








You can't tell about a model you don't know. Chill out too
I only replaced the first word, in every pic
I see nothing special 🙂



the first three lines are what I entered in the input prompts, everything else added by the styles selected
Here's "your mom, Breathtaking, extremely detailed and beautiful face" again with the same seed and other parameter s just with a different model

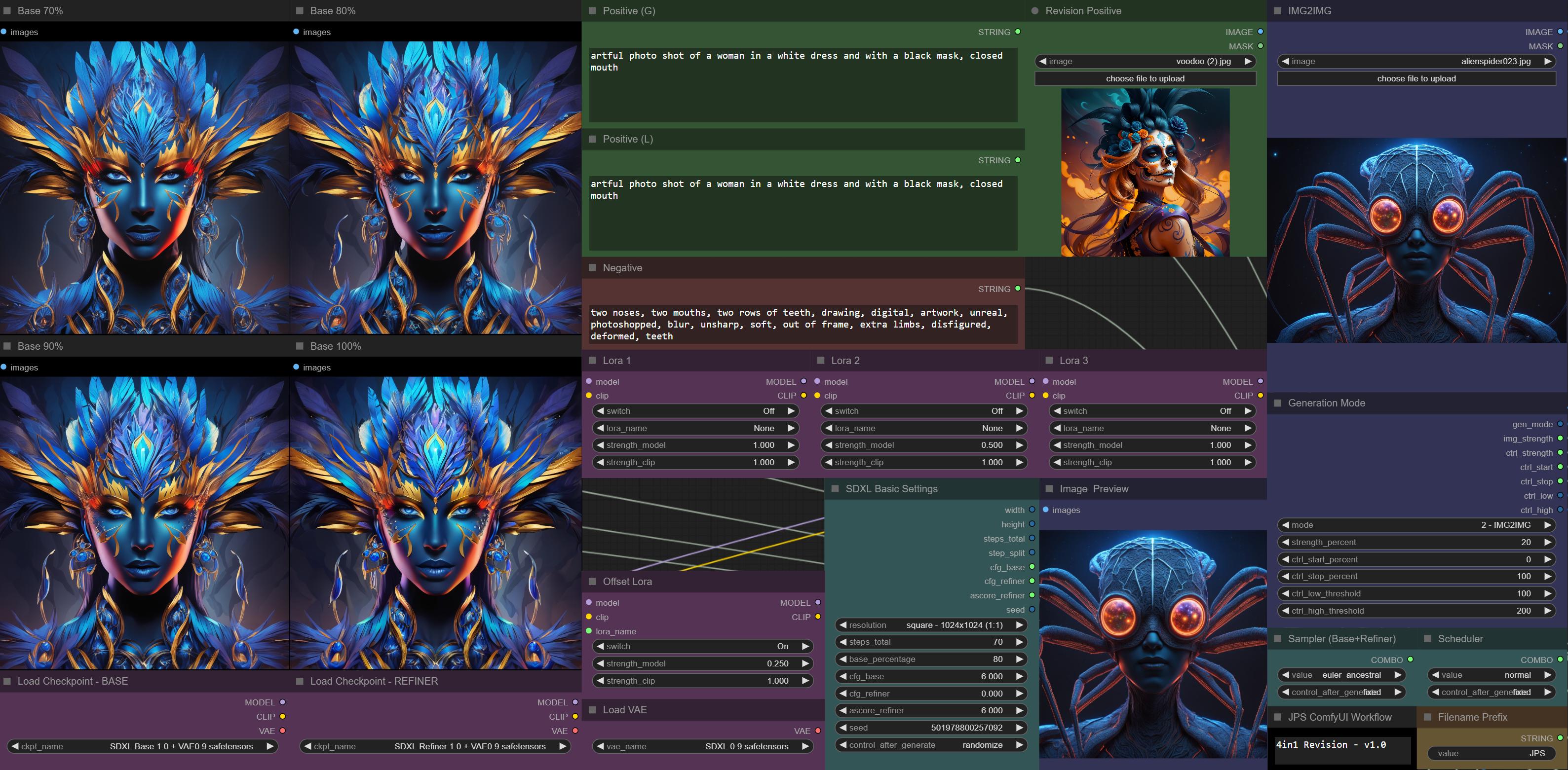
i'm working on adding revision to my workflow without giving up the other options like img2img. revsion + img2img looks very promising already - i think with the right settings this can give you better results than revision with two input images.
https://i.imgur.com/ve3OvNh.jpg
wow, impressive model
NB: I didn't have to generate xx pics to get those above, only a batch of 4, in a discord bot
But anyway, i'm not sure on what we disagree
if the whole system crashes that sounds like a more serious problem. a workflow alone should not be able to crash your computer, only run out of vram/ram.
As a cool experiment, try some batch using only the model's name
Results are pretty crazy for me


single generation, batch 4
(using a discord bot, neg and lora is default)
1 v 1


hum, i tried, not able to get a decent snake (body) easily. Was trying to produce an Orobouros
dinosaurs are quite complicate too
Ectoplasm Lich video, using deforum and parseq (increasing seed)
(SOUND! SOUND!)

Im not overly taken with it ATM TBH , had it installed for a couiple of days so maybe havent fully playe dwith it yet
those Boolean switch nodes are stupid. 0=b 1=a for them. luckily i noticed while playing with the conditioning input switch. this means my candy/depth options used the wrong images...
yup, thats a mindfuck lol
Yeah, joking buddy 😘
All relative
I'm presuming you looked at the image filename as that contains the model(s) used as well as the styles selected?
also mixing creature is fun, using the syntax (rat:blobfish:0.75)
lol nop. Not this kind of guy
maybe you should ;o)
😭
revision + candy also gives nice resulits:
https://i.imgur.com/RAvTvwx.jpg
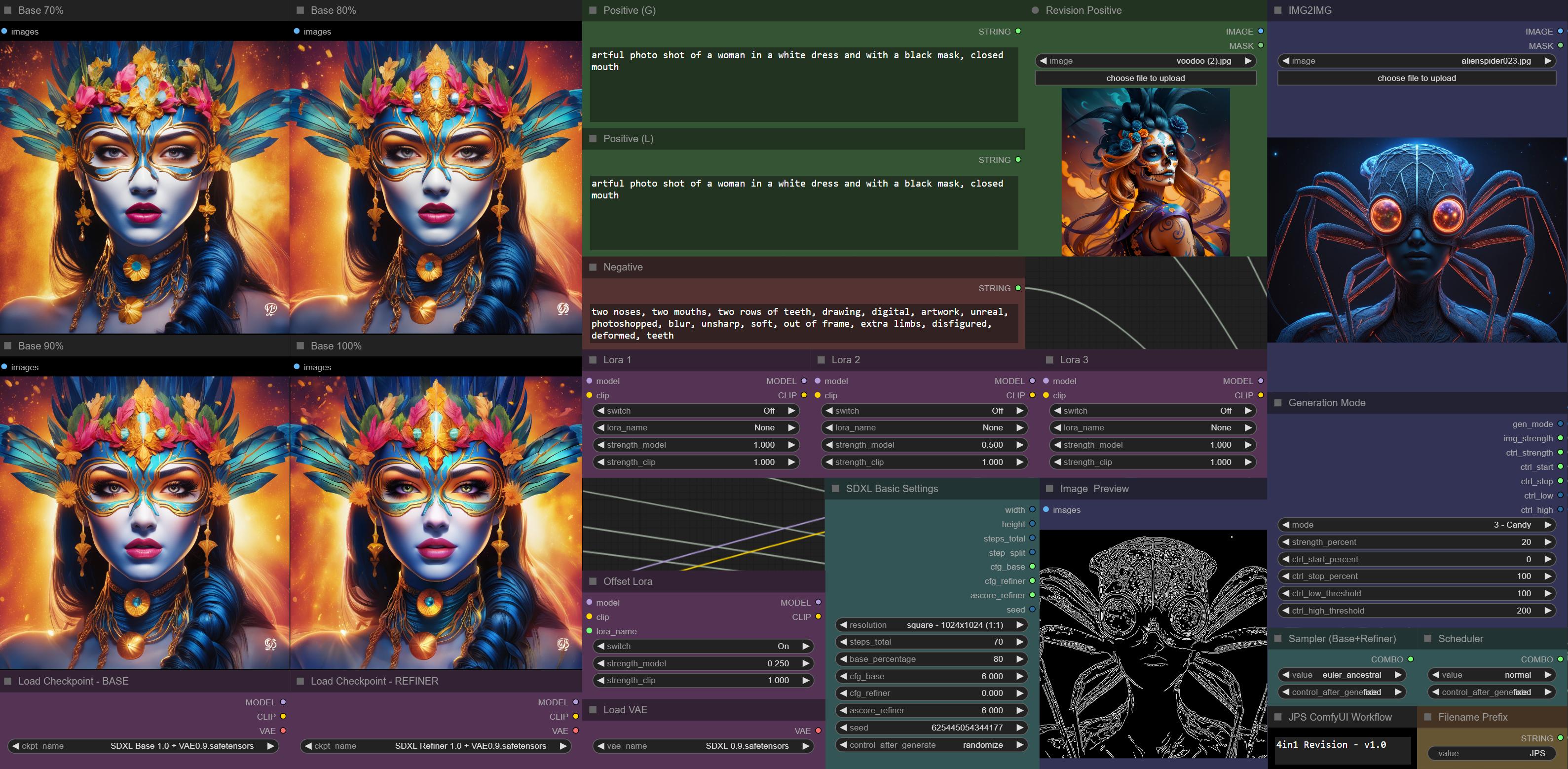
What revision means here ? 🤔
@timid garnet using the new clip vision option instead of a text positive. in the example the voodoo lady is used instead of the text prompt and mixed with the alien thorough control net candy
Think of it more as ReVision.
Its a process of using clip ewncoded images instead of textual prompts
A mixing process
hum, i'll dig this
Yeah, i don't see the links, but yeah okay got it now
cool
Its not a "mixing" Process.
You can use one or more images to build a prompt without using any textual input as the Clip Vision Process reads the image for its content and outputs it as a conditioned input to a sampler
I'm using CN only in deforum, so waiting so hard for updates
It is exactly what i mean by "mixing process" !

jk jk
the mixing happens trough candy control net in my example above. or through img2img in the one i posted a little bit earlier. clip vision replaces the text prompt completely in my workflow, as mixing txt + revision didn't give me consistent results.
Thanks for the elaborated explanations. You just saved me an hour of my life searching for it
or you can just use it in a multistep txt2img process as I do 🙂

*sry if i'm a 'lil rude lol, internet contaminated me. I'll shut it up
cw: minor blood




SD.Next with diffusers backends seems way faster than Auto1111
i'm still using the txt prompt for the refiner part, so i already have something like that included. my goal is to fit all inputs on a single screen (at least on my monitor) so i can't go too crazy with the options. fitting txt2img, img2img, candy, depth and revision + 3x lora + offset lora + 4 refiner strenghts is already a lot :)
landscape of holographic futuristic city made by fractal zentangle colorful moire pattern art, like 3d sound waves
(worst quality:2), (low quality:2), (normal quality:2), lowres, easynegative, signature, watermark, username, cropped
taking 22-23s on this gpu
comfy is this faster by 5ish seconds
but nothing like almost 40s on auto1111
screen grab is what loads in the bowser window on my 1440p monitor
i getting 27~43s an image dependeing on the sampler comfiii

{kind=link}
{kind=link}
sigh
why oh why is everyone obseesed about speed to generate or iterations /second etc.
Does it really really matter if it takes 20 seconds or 40 seconds or even 60 seconds?
(thats a rhetorical answer to which the answer is "no it doesnt bloody matter")
Ok if its taking minutes to generate a bog standard 1024x 1024 inage thats slightly different but still not the end of the world
i'm using refiner with all models, but always create 70%, 80%, 90%, 100% base - so i can see if it helped or if the 100% base is better
in a lot of cases refiner helps - in some cases different elements are better or worse with refiner - if you have 4 options you could easily pick the good parts of 2 or 3 variants in photoshop or some other image editing app.
that'd be 40-60 if I used the refiner, I on a 4060

I'm having too much fun generating

seriously this xl model's fantastic cx
I mean, redo the same pic with the same model, would probably be the same. That's what i have in mind. I see it as a model for the imperfect base model. This last model being only for training purpose, in fine, not to use as it is.
So, totally useless from my pov. Not mentionning that finetuned/trained models basically don't need the refiner at all.
Never used the refiner
at least i'm not shilling a very bad one
if you create all 4 images at once, you can save steps, as you can use the first 70% for all 4 variants, and after that just need double the steps instead of 3x the steps. yet you still need 4x decode vae - so overall it still takes some time to create all 4 variants (not too bad on my 4090)
I 'memba my first model. omg
🤔
Hum, never thought about this concept
Clever in some situations
Even more if you can choose when you 'cut' the canva
hum
ah, the wowifier fit pretty well this model too ! and details lora ofc
which one is this
Huh, i will really looks like shilling if i repost the link, LOL !
