#✨|sdxl
1 messages · Page 187 of 1
/generate Ultra-realistic artistic digital portrait of Radha Rani, close-up front-facing smiling pose, glowing soft white skin texture, sharp facial details, natural pink lips and golden brown expressive eyes, long styled hair adorned with vibrant peacock feather and pastel-colored fresh flowers (pink, orange, yellow), wearing heavy traditional jewelry and beautifully designed ornate clothes in soft pastel pink and golden tones, intricate ornaments with gold and gemstone details, warm pastel color palette, cinematic natural lighting, detailed textures, subtle artistic pastel background painting, professional DSLR depth of field, ultra-HD 8K --ar 2:3 --v 6 --q 5
/create: big red mouse
Painting realm

what's the size of the latent image do you use? using low resolution images may cause the image to deform a bit. have you tried latent upscaling on A1111?
you can try upscaling the image too. or you can start with decent img dimension like 896 x 1152 768 x 1344 such that. something lower like 448 x 800 may distort the image.
then try adding "deformed" in the negative prompt.
a cat sitting on the blanket
trying out new stuff... I really like vibe of those





One message removed from a suspended account.
Anyone know some solid anime inpainting models for SDXL or SD 1.5? Thanks!
many many beautiful flowers and a cute white cat




Anyone please help, I'm new how I generate text to image using stable diffusion in discord?
You don't unless you want to pay.
How do I get SDXL on macos
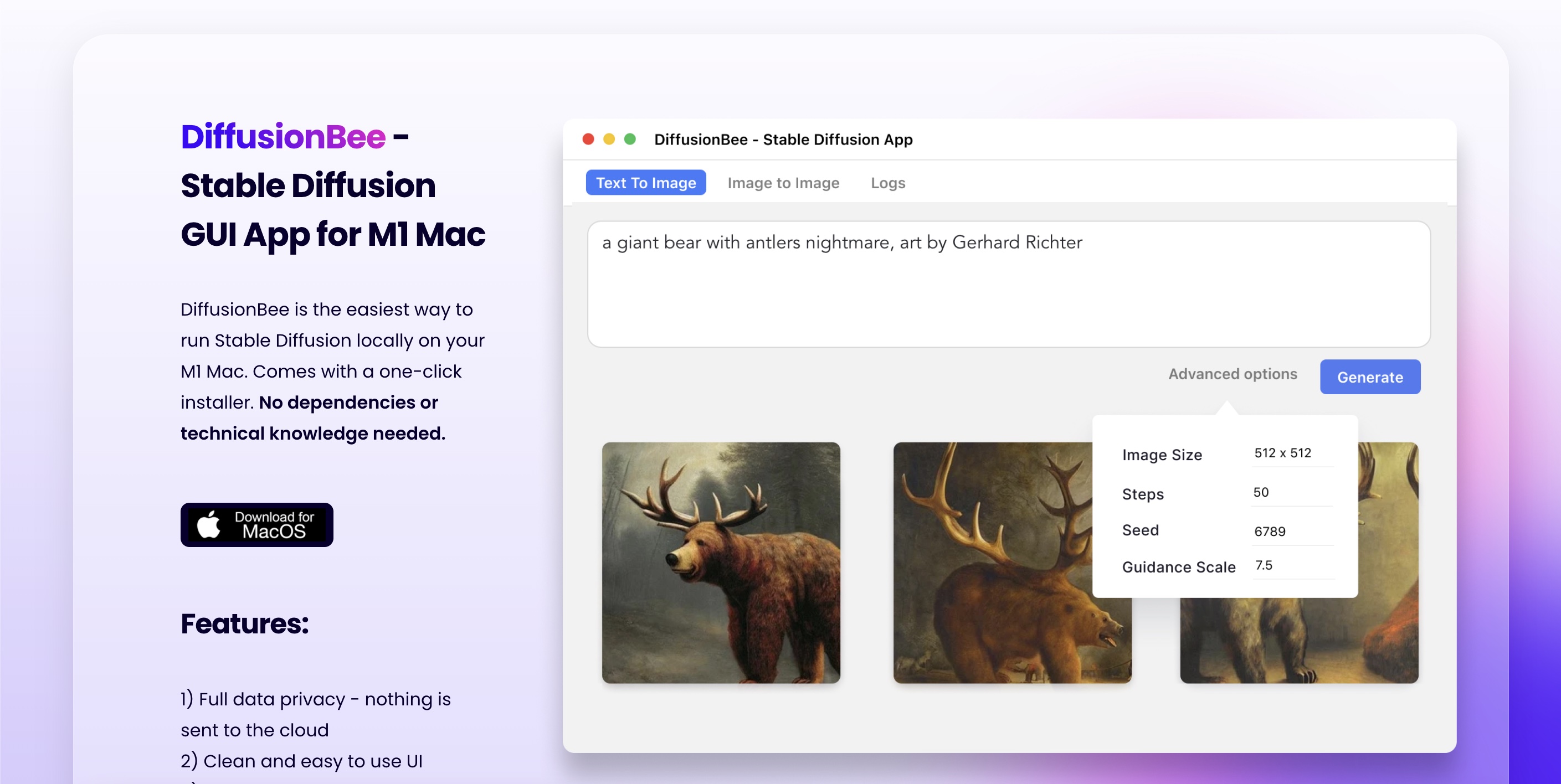
DiffusionBee is the easiest way to generate AI art on your computer with Stable Diffusion. Completely free of charge.
Try this one.
Is it reliable?
Of course.
Thanks g
Welcome anytime.
is clip skip still neccessary for sdxl and other models built on it?
Depends on the model. Some do fine without, some need it to perform.
try Draw Things - https://drawthings.ai/. Very fast, very actively developed (eg has Qwen-Image, Flux, WAN 2.2 etc)
12 secs - SDXL

I need sumn that’s gonna remember specific things Y’know? Like how ChatGPT does it
Need help trying to make an angle where the character looks to others a the distance while the character is close to the camera, like looking in profile but in diagonal
Bedroom in a seaside cottage, in the style of Kim Jung Gi




In automatic1111 where do i put the upscaler in safetensor format? The GUI doesnt seem to find it.🤔
what kind of upscaler ?
if it s gan one, models/ESRGAN
4xultrasharp. Dont think its possible in 1111. In forge its no problem.
pretty sure it s a gan one, it should work.

read #artisan-faq and stop spamming, thanks.












Doug?
Chuck Tanner

?help
把左边人物衣服颜色换成红色


lol, no.



🌅💠 seductive but untouchable…✨
#5an_AI | #AIart | #AIイラスト︎ |#AIgenerated | #digitalart

Catch the tide — and my hat if you can 🌊🎡😝
#5an_AI #AIイラスト #Anime #DigitalArt #AIArt #SDXL




is this ai? 😮
Yes
wow, congrats 🫶
what model did u use?
SDXL + WAN
kk ty
Wrapped in gold, veiled in mystery, and crowned by power 🔥👑✨
#5an_AI | #AIart | #AIイラスト︎ | #AIgenerated

Hello
Caution : Stay away !
Guys i got Scammed by @earnest viper , he showed me these images, I paid $450,
I Have the full chat and full video recording of what happened.
Now he deletes his chat from discord, blocks me and runs away.
So finally i find him here.

Pre emptive reminder to keep things classy in here. No nsfw stuff here, thanks. Just in case...




@mortal rain
What upscale models do people swear by these days for sdxl?
When I upscale, I just use the same model from the first sample pass, but send it a higher-resolution latent set with a little noise injection before resampling.
When upscaling pixels, I mainly stick to 2x models like Real-ESGAN. None of the pixel upscalers stand out as being amazing. Because pixel upscale can be applied at anytime, I often skip that step to save disk space. When I find a real gem of an image, it becomes a candidate for upscaling.

I use Upscayl
A lion sitting at a school desk, wearing glasses, holding a pencil, cartoon style, colorful, funny” ,4k,drawing,wide lense ,perfect ........ why dose it lock so bad?

its real vis 5 and some random lora
cartoon
a bald dwarf, muscular body, realistic face, detailed expression of rageA photorealistic masterpiece, shot on Arri Alexa, cinematic it, shaking his head furiously. The camera is handheld, with a slight, almost imperceptible shake, enhancing the raw emotion color grading. A bald dwarf who is an exact likeness of Cristiano Ronaldo is sitting on the floor of a bedroom of the scene. The visual style must match the provided reference images, focusing on gritty realism, deep shadows, and des. His face is a mask of visceral anguish and pure rage, with hyper-detailed, wet skin and realistic tears streaming down hisaturated colors.
"its real vis 5 and some random lora" there is your answer

A clean futuristic digital illustration showing the evolution from traditional search engines (search bar, magnifying glass icon) on the left to AI assistants (ChatGPT, Gemini icons) on the right, minimal flat vector style, professional tech design, blue and yellow corporate accents, white background, concept of AI visibility 2025, modern business look
Create a modern scientific laboratory scene with clean white counters, chemical storage cabinets, safety signage (like PPE reminders and hazard symbols), and realistic lab equipment such as microscopes, beakers, and fume hoods. Include subtle lighting and a slightly dramatic tone to suggest a challenge or escape room atmosphere. The layout should be modular and clear, suitable for overlaying interactive hotspots or puzzle elements.
What is the best XDSL check points you guys used for illustration nsfw
hey everyone. I'm trying to do inpaint with an sdxl model + a lora of a character into a specific background image. Now I cant seem to achieve that. I use swarmui. Do I have to get better at my control of specs such as denoise and mask blur etc or is there a better way to do it ? I usually do a remove background of the character and then paste it on said new background that I want but that has problems when I want to animate, as the I2V video gen AI will see the subjects body is not blending well (in the scale of small pixels), for example on a chair its sitting. It will see it as not sitting and the subject my start to fly away as the AI will see it floating, even if by a few pixels, etc. I have discovered that it matters to do a good mask too, not just but a rectangle box where you want the person, and actually try to give it think the mask legs, arms, a head. But I still cant get a good result and am a bit lost. Should I up my prompt game ? Should I mention the background as well ? What to do ? Any helps and tips will be gladly appreciated ! Thanks everyone !
ramthrustsNSFWPINK_alchemyMix169
Looks good any other one ?
I'm not google






what model?
not a single model. small anime illustration made with some illustrious model evolved with im2img into bigger one with dreamArtFusion
ah.... thanks anyway

🎉 LIVE DEMO: 8-Step > 20-Step Diffusion Breakthrough
It's an implementation of the paper: Hyperparameters are all you need. I've just launched my HuggingFace Space where you can test this yourself!
the link of the paper is below: https://arxiv.org/abs/2510.02390
🔗 Try it:
counterfeit v3.0 version: https://huggingface.co/spaces/coralLight/Hyperparameters_Are_All_You_Need
xl version: https://huggingface.co/spaces/coralLight/Hyperparameters-are-all-you-need-xl-version
original sd version: https://huggingface.co/spaces/coralLight/hyperparameters-are-all-you-need-sd-version
some examples is below
✨ What you'll see:
- Side-by-side with DPM++2m
- 2.5x faster, BETTER quality
- Works with any model
📊 The impossible made possible:
- 8 steps generate images with FID performance comparable to the 20 steps
- No training/distillation needed
- 60% compute reduction
Would love your feedback! What models should I test next?



arXiv.org
The diffusion model is a state-of-the-art generative model that generates an image by applying a neural network iteratively. Moreover, this generation process is regarded as an algorithm solving an ordinary differential equation or a stochastic differential equation. Based on the analysis of the truncation error of the diffusion ODE and SDE, our...



are you the paper author or did you just implement what's in it?
I am the author
very cool
my suggestion after skimming is, DPM-Solver++ while popular is not SOTA for ODE by any means; res, unipc, gradient estimation, etc. all boast superior FID scores in their respective works
also you included turbo, lightning, but not hyper for some reason


We report DPM-Solver++ because it's a popular baseline in 20-step inference. You are right that UniPC is also very popular in few-step inference, but we want to prove that our training-free solver in few-step inference can beat the most popular ODE solver DPM++ 2m even when the latter one uses 20-step inference. We also compare our solver with the latest training-based ODE solver AMED, and our performance is also better than that in the few-step inference. Meanwhile, our algorithm provides a plug-in asset that is suitable for most of the training-free solvers, like unipc. And by using our algorithm in dpm++2m, the 8-step inference result beat the 20-step inference result.
The comparison with DPM++2m follows with the latest jobs in training-based ODE-solver, like AMED and EPD.
Meanwhile, we also include Flash Diffusion, the latest distillation algorithm proposed in AAAI 2025, and DMD2, not just the lightning and turbo. I think the main FID bottleneck of diffusion distillation is caused by the diversity, and the algorithm using DMD loss is a natural choice for me, since it aims at distilling the distribution rather than a single sample. Hence, I chose these two algorithms, rather than hyper. We also provide some insight into why diversity will be reduced by the distillation algorithm, and do some experiments to prove diversity really matters by using PRD metrics to measure the latest distillation algorithm.
Oh, I see, the Hyper-SD also uses the DMD loss. But we also compare with DMD2, I think it's acceptable.
How can I generate fine tuned ui for mobile apps? I have extensively searched loras too but couldnt find anything with a wow factor. How troublesome would it be to train a lora on 3-4 mobile apps ui?
Hi,
I’m trying to place a glass bottle in a new background, but the original reflections from the surrounding lights stay the same.
Is there any way to adjust or regenerate these reflections without distorting the bottle itself?
Actually, DPM V3 also utilizes the technique proposed by UniPC. Our latest code in GitHub combines the DPM V3 with our algorithm. You can also check it. Our 6-step inference result is better than its original 8-step inference result.
Check it there:https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/txt2imgV3.py
Some of the results:
results from the normal dpmv3 8-step inference:
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/normal-v3-result-8-steps/00000.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/normal-v3-result-8-steps/00001.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/normal-v3-result-8-steps/00002.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/normal-v3-result-8-steps/00003.png
results from our 6-step inference combine with dpm v3:
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/samples-6-1o-f2/00000.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/samples-6-1o-f2/00001.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/samples-6-1o-f2/00002.png
https://github.com/TheLovesOfLadyPurple/Hyperparameters-are-all-you-need/blob/main/outputs/txt2img-samples/samples-6-1o-f2/00003.png

GitHub
the implementation of the paper 'Hyperparameter is all you need: your diffusion model can sample an image within 5 steps without additional training.' - TheLovesOfLadyPurple/Hyperpa...
GitHub
the implementation of the paper 'Hyperparameter is all you need: your diffusion model can sample an image within 5 steps without additional training.' - TheLovesOfLadyPurple/Hyperpa...
GitHub
the implementation of the paper 'Hyperparameter is all you need: your diffusion model can sample an image within 5 steps without additional training.' - TheLovesOfLadyPurple/Hyperpa...
GitHub
the implementation of the paper 'Hyperparameter is all you need: your diffusion model can sample an image within 5 steps without additional training.' - TheLovesOfLadyPurple/Hyperpa...
GitHub
the implementation of the paper 'Hyperparameter is all you need: your diffusion model can sample an image within 5 steps without additional training.' - TheLovesOfLadyPurple/Hyperpa...

Guys, is there a faceswap workflow?

Hey guys, has anybody else noticed SDXL being slower than ever lately? I remember I used to get like 4.1it/s on my 3090, now I can't even hit 3it/s anymore. I thought comfy recently got an update that was supposed to speed up image gen






Where can I find advice/instructions for installing SD xl to a new system?
#🤝|tech-support in the pinned messages by Cs1o
thank you



very dreamy
A lot of help
Art
What model and prompt did u use for these. They are gorgeous
I used Dream Art Fusion. older model, but still my fav for realistic images. just mind that it doesntvwork well with initially big images. no loras were used, just a bit inpainting and postprocessing
What prompt did u use
I don't share my prompts
but since this model recognizes quite a lot of celebrities, try adding 3-4 of names... this model quite nicely blends features of named people




hello
very surprised





or do you have know any model that the architecture was the config.json is in the root?
Have tried downloading the sdxl model from civit ai and put it in model/checkpoints
Trying to learn controlnets in sdnext... I'm getting black outputs despite following the doc pretty much exactly.
I got black outputs on qwen when I launched with sage attention enabled. If you're using that, try launching without it.
deployed version ? deployed where ?
It's been fun! But Z image is probably going to take over SDXLs role fast.
its just as fast and so much better
🤯
Unless z image anime ver comes out (waiting) illustrious is still relevant

I use CyberRealistic Pony and im goonin to every images i generated.
what's with flux2 ? any good?
does anyone know how do i get a hold of marginal vectorfield parametrization from Flux ?
- can i run it on 8G vram ?



Dream
yall better try z-image it's much smarter than sdxl.
baby
I want to do some propagation. I develop a new fast ODE solver that suitable for the diffusion model. And the huggingface repo is there: https://huggingface.co/spaces/coralLight/Hyperparameters-are-all-you-need-4k
You can sample a 4K image in 8 steps, and its' result seem as better as 30 steps dpm++2m SDE with karras. And the 6-step inference result is also acceptible. The paper is there: https://arxiv.org/abs/2510.02390

arXiv.org
The diffusion model is a state-of-the-art generative model that samples images by applying a neural network iteratively. However, the original sampling algorithm requires substantial computation cost, and reducing the sampling step is a prevailing research area. To cope with this problem, one mainstream approach is to treat the sampling process ...
The dreamshaper XL version is there: https://huggingface.co/spaces/coralLight/Hyperparameters-are-all-you-need-UniPC-Dreamshaper

And there is the nova anime version: https://huggingface.co/spaces/coralLight/Hyperparameters-are-all-you-need-UniPC-XL

This is a training free solver that compatible with all of the U-Net latent diffusion model.
what is z-image? a model?
Oh ok, thankyou
where can i read more on this diffusion
i want to do a project for a client and i have to use the stable diffusion
is there like a blog official one that i can look at?
thanks
a cute dog sleeping in a blanket

Here's another one.




🐕
It's been fun.
It's the future.
interesting, is this kind of model available in civit.ai?
oh boy is it
it already has a ton of loras
aight, will wait for NAI and my fav model to come out with ZIT model
thanks for the info
Anyone knows of any way or online tool to train loras faster? don't have the hardware for it and all the options i found take almost an hour and most times aren't very accuarate. Also, no longer using Civitai, too few credits i receive to train.
A hour seems reasonable though?

This is too much for me.
more like this server tbh, granted sdxl was already dying due illustrious, flux and others
What the heck happened to this server?
lack of moderation, lack of community interaction etc



z image



there. something made with sdXL... Actually I use only SDXL models, but illustrious mostly so it lands in anime...


Emad had great mascot potential.
hi all
/dream一个小溪旁边坐着冥想的女人,小溪清澈透明,周围绿草丛生,树木,落叶,
Yes this was Emad's dream.
/dream一个小溪旁边坐着冥想的女人,小溪清澈透明,周围绿草丛生,树木,落叶,

6666
she's a bit 6666 herself


any advice on better servers? looking for a nice community, maybe with daily contests etc...
Ill dm you one





Hello!
I'm having an issue with something on (I think) version 1.5 of stable diffusion, is this the right place to ask?
Anyone recommend a good illu checkpoint model that has good base quality and anatomic consistency? Pref one that doesnt deform character loras. Or a noob checkpoint that works well with illu loras
you want more anime style or 2,5D, semi real?
then again, I don't use character loras, so I'm not sure if I can recommend anything specific
Hmm i dont really know how to describe it well to be honest, its kind of in between anime and 2.5D. Kinda like anime with detail and quality to a point it looks a bit 2.5D. Something like morimee style from civitai
would check out morimee, but civitai is having tech problems again
something in style of one of these?


i prompted very generic prompt in a few of my favorite models
Kinda like this ye
one of the left is diving anime, the one on the right is electrum cinnamon, both of them on civitai and both very solid
for more flat look I could recommend animij
how's the situation look with anatomy? hands, feet, extra limbs etc
both are solid, sometimes 1 finger more, but usually good enough
actually when it comes to illustrious, I couldn't find better ones
ymmv
hello! could i dm you for some advice please?
you can ask here
thanks! im really new to all this and ive gone on civitai and grabbed some loras and models, however my images generated are really bad even when copying prompts, am i missing something?
ive noticed some models are under "trained checkpoints" and some are "checkpoint merge" is there any difference to it?
I never worried about that
for example, im using this model rn https://civitai.com/models/827184?modelVersionId=2167369
can you post an example of what you made?
btw I tried to like that model, so far no luck
if you could post image and a prompt you used?
it comes out like this 

not sure what im doing wrong as im copying the prompts based on the image posted on civitai
not entirely sure, but it looks like: 1. the resolution is way to small for that model, 1024x1024 is probably a better starting point. 2. you seem to have some sort of artifacts on the image, and that is strange, but first try larger resolution
ok thanks
what gpu do you have, how much vram?
i have a 4070 with 12gb vram
let me know how it came out with bigger resolution

better, but you still got artifacts, face should be readable in that resolution
you're using loras? maybe they are the problem...
btw for euler ancestral and illu models i rarely go above 30-35 steps
try generating something that doesn't require loras, and see if results are better
im getting this now using 1 loras

now it looks ok
loras are a bit tricky, you need to see how many you can load, and how much of each you can add before the image gets messy

thanks, how do i improve on these
as its still quite far from the image on civitai
this was the image with the prompts on civitai that was posted


at least your's has a proper number of fingers xD
what other stuff?
like loras for styles etc
with illustrious you've got A LOT of styles embedded in the model at start
unless you've got very specific need, you can go with one model for months xD
for example, try adding at the end of your prompt "image by bacun and rariatto" and see what you get
depends on what you're after
yeah hate to say it but, theres alot more going on in the civitai discord. its always got people chatting, and theres always media being uploaded there. not sure why









I'll never forget you my friend. you were my first. Well technically it was sd1.5 that was my first.
Hey everyone, I need some expert advice on my ComfyUI workflow for a realistic ai character.
Current Setup:
- SDXL LoRA (self-trained)
- Checkpoint: Juggernaut XL
- Face Detailer with a separate prompt
I'm struggling with facial consistency across different prompts (the face looks slightly different depending on the setting). I have a few specific questions:
-
Trigger Word in Face Detailer: Do you recommend using the LoRA's trigger word inside the Face Detailer's separate prompt as well? Or is it better to keep the Detailer prompt generic (e.g., "high quality skin, sharp eyes")?
-
PuLID for Consistency: Does it make sense to add PuLID into the mix to "lock in" the identity? If so, does PuLID usually play nice with an active LoRA, or do they tend to fight each other for control?
-
Face Detailer "Guide Size": I’ve seen conflicting info online. Some suggest 512, others say 1024 for SDXL. What is the sweet spot for Juggernaut XL?
-
Denoise Settings: What's your go-to denoise strength for the Face Detailer when trying to maintain a very specific trained identity?
Any insights or workflow tips would be greatly appreciated! Thanks in advance! 🙏
Just use z image
too true. Z-Image being soooo good had made me almost stop using Flux AND Ideogram )
- SDXL is very much but a legacy historical artefact at this point.. but you can use it for very affordable refiner / post processor .. and yeah, some checkpoints are still competitive for specific styles
I still come back to SDXL because there is no replacement in any of the new models for the IPAdapter's style transfer. No other model looks as good as SDXL in this category.
I want to share my story for anyone who might be in a tough season right now.
Not long ago, I was working as a dispatch rider when a serious accident left me unable to walk for six months. Overnight, everything changed. Providing for my family became a daily struggle, and mentally, it was one of the hardest periods of my life.
Through it all, my wife never gave up on me or our family. She stayed strong, supportive, and kept us moving forward when things felt uncertain.
During my recovery, I started searching for a way to earn online. That’s when I discovered Shopify and automation. I didn’t rush or look for shortcuts I followed the training step by step, stayed consistent, and trusted the process even when results were slow at first.
By combining Shopify with simple automation systems, I was able to build something that worked even when I wasn’t physically able to do everything myself. In the last 30 days alone, this system generated $37,000 in revenue.
Today, I’m grateful to be able to provide for my wife and children again. More than the money, I’m thankful we didn’t quit during the hardest moments. Shopify and automation gave me a real second chance, and I share this to remind someone else that a breakthrough is still possible if you stay patient and committed.
Hi. If you need help with training Flux/SDXL Face Lora you are welcome.
https://www.behance.net/gallery/243708697/Stable-AI-Influencer-Private-Flux-Face-LoRA

I create realistic AI influencers and stable AI identities.What I create:AI influencers for Instagram, TikTok, and X (Twitter)Digital personas for Patreon and OnlyFansLong-term AI characters for branding and monetizationRealistic AI faces for lifes...
16 emoticons of chibi orange tabby cat in 4x4 grid, Chinese New Year themed, each panel showing different festive action:
(1) cat clasping paws greeting with golden "Fu" above head,
(2) hugging big red envelope with "Bao Fu",
(3) jumping with sparkler, night fireworks,
(4) eating sticky rice cake with crumbs,
(5) spinning chasing fluffy tail,
(6) covering mouth giggling with lantern light,
(7) sticking crooked Spring Festival couplet on door,
(8) kneading on red cloth with peanuts and dates,
(9) hugging big fathead fish proudly,
(10) curled in fur ball exhaling warm breath, snowy background,
(11) shaking bronze bell with tail swaying,
(12) lying on back paws up asking for petting,
(13) holding small lantern exploring night alley,
(14) rubbing owner's neck in cozy home,
(15) carrying willow branch knocking door,
(16) three mini cats stacked with tiny cup, family silhouette,
uniform panel size, clear borders, round edges, vibrant red and gold color palette, cute cartoon style, high detail, clean lines --ar 1:1 --style cute --no text, watermark, signature
Hey guys, anyone has !!colab!! notebook for sdxl lora training, which is current and works? Also needs BLIP captioning? Can someone share link on git?
Hey not sure if it’s the right place and I’m sorry if it’s not allowed I can remove this message. For those who want to learn how to use SDXL in A1111, use NSFW checkpoints, best settings, how to create a LoRa, I create a full training about it : https://www.skool.com/ai-influencer-model-training-4492/about?ref=8a94f10b02214a008aac821766685904

Learn Stable Diffusion for hyper-real NSFW AI Models and monetize them on Fanvue. Step-by-step video tutorials from zero to pro. Join!
Hi. Who knows why on Comfy there is such a mistake on KSampler node??


What's wrong?..
im trying to generate img2video on flux checkpoint
You're right it should work.. Because you're posting in the SDXL channel, I assume that's what you're trying to generate, but I notice you're using a Flux model. Try supplying an SDXL model in your current workflow before resorting to updating. Otherwise, exit Comfy and update.
I like the skin tone that came out of this it is very realistic tones, could I poke you for the prompt please? thanks!
@random panther Try downloading the attached image and dropping it into Comfy. The prompt may still be there. You can also use an auto-prompter to help with prompt development. The fastest Comfy auto-prompter is Florence2, but it's a little limiting in what it kicks out. Another to try is Janus. Also give Qwen a try, more robust, but slower. I often add an age sentence to any prompt that kicks out people. Also consider giving people an occupation or title instead of just "man" "woman" or the worst "1girl."
A 59 year old house wife.
loras ?
The only lora you really need with SDXL is not a lora at all. Use the IPAdapter to transfer styles from one image to another.
Need help
Flux lora generate
Hello guys am new to this stable diffusion world. Am a graphics designer, i want some high quality images for my works. So i want to use flux. Is anyone free to tech me how to generate a lora model for flux. I allready have automatic 1111 and kohya ss installed please help me a little guys.🫠🫠🫠🫠
@lethal vapor Why are you posting for flux help in the SDXL channel?
Where can i post ?
Stable Diffusion doesn't even make Flux. Try joining Pixaroma discord if you haven't. You'll find a lot of help there.
Or the OneTrainer discord, works great and a1111&flux wont work iirc
I tried it wouldn't read the webp. wasa simple enough promt. thanks.
@random panther A Discord Tip. The first click on the image is a .webp. If you click again, however, you'll get to see the original posted image at full quality. This is often a .jpeg or .png. Right-Click Save Image as. Only the full-quality image contains any workflow. Try supplying the full-quality image to Comfy.
I never actually knew that about this dscord thing. i hate using it tbh (old man - this is way to much clutter). but thank you i know how to get the source pics now!
Is there any models for controlnet for sdxl/illustrious?
Try using the all in one. Search for AIO.
any recomendation for inpaint models? tried with wai illustrious but the characters merge and distort, hope someone can help
Yes, can help you that!
help guys why i am getting so bad results

No negative prompt is a start, could try messing with a different sampler
Go on civitAI under juggernaut and copy someones settings
i am still not getting good results please help

I have a 2060ti 12gb vram and 16gb systm ram what model should i use ?
So will it work on my pc
No man there is a 12gb version
I have it

Thanks
But sorry to disturb you again
I am new to this
Can i get download links of those please 🥺
Ok 🙃
I use forge neo
Its update of a1111
For lora training what you use ?
It need to have continuous internet connection right ?
Internet connection
Whenever i disconnects its like turns of
Man am dont know what happens it just turns off
Ok
Ok it just download let me see how it goes
🥲
🥵
Oh bye the what the settings will be ? 🙃
Haha its heavy still stuck here for like 2 minutes

My system ram used like 98%
But vram at 7-10%
Lol 🙃
Bro forge and a1111
Is same
Any tips ? 🥲
got it working its fast now

just used the same text encoder but the fp8 version
but now the problem issssss
she is not very detailed
no i mean not the image qulity
i am talking about the detailes in her face
ok
i have a very noob qustion lol
is my juggarnaut xl lora not gonna work with this ?
ok thanks
thanks a lot for the help man
no that images was not good anyway
claude meaning ?
oh
by the way what u do man ?
😒😒😒
i mean what u do for living ?
your a fun guy man
where u from ?
🤣🤣
ger meaning germeny ?
can i ask for little bit more help from you ?
lamo
need help with aitoolkit lora traning for z image
😒😒😒 i see you got a high spcs pc
ok
me to
but my father was brock
his father too
and now i am earnig
me too borck as fuck 😊😊
lmao
friend no one is replying there 😢😢
Its really hardbro they are not helping much
I dont know what is happening with my aitool kit
Why its asking for internet connection

Probably
Yes useually if its missing essential stuff to run a new model
Oh so first time i have to download it ?
can i use one trainer for z image lora traning ?
i recommend asking in the one trainer discord
Hi everyone,
I’m currently working on creating an AI influencer using ComfyUI (SDXL).
I already managed to get very good and consistent results for the face using PuLID (the identity is almost perfectly preserved across generations).
My current issue is with generating the full body.
When I try to add ControlNet (pose) and generate a full-body image, I start losing consistency between the face and the body, or the proportions / realism don’t match properly.
What I’m trying to achieve is:
- keep a 100% consistent face identity
- generate different full-body poses
- control proportions (slim waist, wider hips, etc.)
- maintain realistic skin / lighting consistency between face and body
My current setup:
- PuLID
- IPAdapter
- ControlNet (OpenPose / DWPose)
- SDXL checkpoint (RealVisXL / Juggernaut)
If anyone has a simple and stable workflow (not too many custom nodes) that works for consistent characters / AI influencers, I’d really appreciate it 🙏
Thanks!

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
ghbdtn
Hi everyone, I just released my latest custom merge, Animagen XL v3.
It’s a specialized 2D/anime SDXL model built from 9 different models (including Illustrious, NoobAI, and Pony). Instead of a standard flat merge, I used custom block-specific U-Net routing and targeted Text Encoder adjustments to fix common multi-model merging issues.
⚙️ Technical Highlights:
Pure Danbooru Prompting: The Pony Text Encoder was deliberately set to 0% weight to eliminate syntax conflicts. You don't need to use score_9 or source_anime. Standard Danbooru tags (masterpiece, best quality, etc.) work natively.
Deep Block Routing for Anatomy: To prevent style models from degrading human anatomy, the deepest U-Net blocks are heavily weighted toward NoobAI, Illustrious Janku, and Pony V6 for better hands and dynamic pose stability.
Mid-Block Routing for Faces: Illustrious Wai and Hassaku are prioritized in the middle blocks to maintain clean, highly detailed facial features and eyes.
💡 Quick Settings:
Sampler: DPM++ 2M Karras, Euler, Euler a
CFG Scale: 7.0 - 8.5 (Keep it at 7.0+ to prevent color desaturation)
Steps: 25 - 40
I've attached some raw unedited preview generations below. Feel free to test it out and let me know your thoughts or feedback!
🔗 Link & Full Documentation: https://huggingface.co/Bl4ckSpaces/Animagen-XL-V3





We’re on a journey to advance and democratize artificial intelligence through open source and open science.



download going wrong
Or your hard drive is going bad.
Yea thanks man i found the dowaladed file was not completed
Guys help I get an error on ComfyUI setup I can't even troubleshoot

Stability.ai Founder Emad Mostaque, along with CNBC's Steve Kovach and Deirdre Bosa, joins 'The Exchange' to discuss open versus closed source data sets for A.I. modeling, the copyright questions behind A.I. image creation, and transparency in A.I. modeling.
🥂 oh.. turns out... hes a deck supposedly. 😭

Any news in lora training for XL models? i havent trained one in almost a year. Mostly looking to train illustrious artstyle loras, i've seen a bunch of tools on youtube but seems quite old and not sure how good are the results. Any recommendation for tools or checkpoints for good results in artstyle training?
You can use flux or sdxl
They are good for Lora training
yes, i said illustrious for a reason
For Illustrious style Lora, the current best approach is still Kohya ss with SDXL, but using newer tricks like LoRA+ and lower network dims (around 64). Illustrious already has strong style priors, so shorter training (6–10 epochs), minimal captions, and a well curated dataset matter more than heavy tuning.
Base model choice is key Illustrious or Animagine XL works best for illustration styles. The workflow isn’t radically different, just more refined for better consistency and less overfitting
rule 2 please.
Base model illustrious sucks
go get a fine tune
Guys I am a rookie, and I have a question. I am using SD Forge, and for some reason the images generated every time have the exact same face. I am using juggernautXL_ragnarokBy.safetensors and the seed is set to -1, maybe because I was trying to use ControlNet? But I turn it off later, can any expert tell me what could be the problem and how could I fix it? Because I used to be able to generate random faces.
Hi, quick question, if I upload some AI images somewhere on this server, is there any chance someone could recognize the art style/model/checkpoint and be able to tell me what it is?
I’ve been trying to find images and use their metadata to see, but they come up blank with SwarmUI and Forge Neo.
why dont post em anyways and hope for the best,
getting precise things are probably impossible
I just joined the AI own generation scene again and i have no idea with what model to start
See what you like, choose what you like
Can anyone give me any tips on how to get multiple characters in one image? I consider myself to be pretty good at using Automatic1111/ReForge but I can never for the life of me figure out how to use multiple character LoRas in one image. I've tried things like Regional Prompter and Inpainting (I'm terrible at inpainting) and nothing has worked so far. If anyone here regularly creates multi character images I'd love to know your process (I'm also experienced in ComfyUI so if you use that I'd still love to know how you do it!)
would you like me to teach you or do it for you?
be careful of dm scammers
Maybe use Klein flux to put more than one characters in one scene. I didn't try yet but I think it might work.
Place them roughly where you want them in the scene tho in photoshop.
Early days. but it's possible.

Finally a new track! I wish I could make more but I am busy with the G String: Ultimate Edition.
For more frequent updates join us on Discord:
G STRING DISCORD - OFFICIAL:
https://discord.gg/fUuDyx7uYe
G STRING - STEAM:
https://store.steampowered.com/app/1224600/G_String/
G STRING DISCORD - MISC:
https://discord.gg/xRGtsVMW7x
https://discord.gg...
Play it loud.
So emad can hear it. This is all his fault.
Well to be honest I already know how to do it. I can create pretty much any image I like with 2 character LoRas as long as it's not like insanely complex. My issue starts at upscaling. i usually generate at 1024 x 1024 or any aspect ration stemming from that. My base images are usually perfect both characters show up just fine without any mixing. However when i try to take my image to 2048 x 2048 through a latent upscale pass that's when it starts to mix the LoRas and I have yet to find a fix to this. I've tried controlnets, low denoise (usually doesn't work during an upscale you typically need a higher denoise to do a latent upscale or it just comes out blurry), and inpaint how ever inpaint usually requires me to do an img2img pass after to fix any small issues inapint causes but that just takes me back to square one which is img2img causing mixing.
The TLDR is I need to find an upscaling method that wont mix my characters.
Yeah that’s a pretty common issue with multi LoRA images When you do a latent upscale the model isn’t just enlarging the image it’s partially reinterpreting it With higher denoise, both loras start influencing the whole frame again which is why the characters begin to mix
the cleanest workaround is to avoid doing a heavy latent upscale to the final resolution Instead do a very light latent upscale just to add structure then switch to a pure pixel upscale (like ESRGAN/UltraSharp) so the identities stay locked If you still need refinement do a very low denoise masked pass per character with only that character’s lora active
Also lowering your LoRA weights during the upscale stage helps a lot strong weights tend to cause cross contamination at higher resolutions
That approach usually keeps both characters stable without falling back into the img2img mixing loop you are describing
I actually ended up figuring out a really good work around and am now able to create complex images with multiple LoRas with ease. I wrote a guide on civitai to help anyone who's having the same problems. https://civitai.com/articles/28071
okay that is greate


what model are you using?
Flux and lora trained in dataset
so your own trained lora?
💯💯
what gpu do you have and how did you make it?
Send me a req, let's discuss better
Be careful of any dm scams, they are rampant here
I will
I need a cinematic photo of a clean, modern office bathroom, without a bathtub, just a spacious area where people can move around easily, with a modern sink and a mirror that reflects the stainless steel details. The tiles are so clean they reflect the light, with some plaster details on the ceiling and a stainless steel trash can.
its my first time here , idk what i need to do, my english is trash, i drop here just searching a img generate. i barely undertand a lot of words but i got all that usay ❤️ and im so gratful and glad for u anime.
idk u but u had a bit of my heart
SDXL still kicking ass.
I need to finally in depth embark down this rabbit hole 😭
And properly route so my gpu vram handles it & not overflows to ram 😭😭
3080 dont fail me now
bricks lol
Anyone know what batch size i can safely use with 5070 TI (16gb) when generating images in 960x1280 using hires?

IS IT POSSIBLE to get Illustrious models running on an S25 EDGE
设计一个手表
Which model should I use for pixel art sprite generation? Illustrious fine tunes don't work
which one? flux.1 kontext dev, dev, dev quantized, schnell, schnell quantized
where can i download a working comfyui fully loaded
You can get ComfyUI from its official GitHub repo and set it up fresh. Most “fully loaded” packs online are modified and often break or come with issues so a clean install + adding only the custom nodes you need is the most stable way. @fading ibex
Hey can anyone help me with eyes? everytime it generates an image the eye are always f'd up i tried other models, alot of other loras, also im using comfy ui with zluda so the face detailer is not working or im doing something wrong. please help me fix this issue, im using an sdxl checkpoint


Yeah i can help you with it
Be aware not to download stuff or follow any links people send you in dm's! Anyone who really wants to help, would do it here
Hmm you could try disabling the loras when doing the adetailer
But eyes are always a tricky thing with illustrious
Virustotal scan any links to be safe. 👍 & even then its not 100% certain
so what should i do?
I have work with this many time and I know what cause it I can help you with that that the eye will be good and perfect
dont tell me you're also going to ask money for it
Okay no problem
wdym 😭
also a bot account, they linger around for a bit
if adetailer doesnt work, at most you can try to do a manual inpaint after upscaling the image (to increase the amount of pixels it can work with)
or adetail after upscaling
the problem is i need to make atleast 30 images in a day and i dont have enough time to manualy inpaint everyone
adetailer and face detailer is giving me straight errors
only 30? 
try to see if you can get swarmUI working with the comfyUI zluda backend then impainting is super easy
and eh the segmentation tool (adetailer) is better imo
i mean each images take about 58-160 minutes depending on the prompt so...
i want to do more but i need to fix the eye issue first
and your using illustrious? thats.... impressively long..
please tell me that your using a autocomplete feature 😭
im new to this so im using a very basic txt to img workflow and upscaling it with remacri at the end
explains why your taking so long.
i really recommend using swarmUI with the comfyUI backend using zluda.
theres just a lot of features that will make your life a lot easier
But you said I should not tell you
the first one is less comfyUI noodles and just a useable UI
the second one is autocompletion, better adetailer (that works on more stuff then just faces)
meaning you were gonna ask money for it. vile ngl
okay so what should i search for this or do you have any guide that i can use
and is it going to take another 10-15gb? 😭
im not familliar with AMD cards but i recommend the swarmUI discord. it should be able to just hook up to your existing comfyUI backend so it shouldnt take up that much space.
https://github.com/mcmonkeyprojects/SwarmUI but again im not that familliar with zluda but it should work
GitHub
SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
can this make the eyes fix?
^^
currently im at work but if you manage to get your existing comfyUI linked to swarmUI. once im home i can show you how to work the thing
can the swarm ui run on python 3.13?
SwarmUI uses the comfyUI backend. if comfy handles it. so does swarm
swarmUI basically is a layer over comfy
okay
its not python 3.13's problem right? (the eyes)
yes its not a pyhton problem.
Yep
well this is not a place for predatory "support" smh
there is one other guy too from this server
he was trying to convince me to borrow money from my friend

i see a lot of these. they use LLM's to first scope out people in need and once someone bites they swipe in personally
okay so this is what i got

you dont have dotnet installed
wat does that even mean
simpler terms : a program using a simple version of chatgpt to give surface level advice and convince you to pay for "help"
ong it felt like ii was talking to chat gpt


like saying that would magically increase the amout of money i have in my bank 
there is also one error at the end can you check that one too
whered you place it?
in what folder?

Should be fine
Weird, try relaunching it, otherwise i recommend joining the discord listed on the github page
The open help channel / help thread there will get you a long way
here is the new log but still getting the error at the end
^^
oh you cant see the error
[Error] Self-Start ComfyUI-0 on port 7821 failed. AutoRestart ignored as this was an initial launch failure.
here ☝️
im busy at work so i cant really deep dive into the logs
ahh sorry sorry i forgor can you tell me when you'll be available
seeing how you gotta link your own comfyui instance to swarmUI first, after that i can really help with the automatic inpainting etc
5-6 hrs
Rip. He got hacked.
who?

Looks like the earlier message got deleted.
Oh
Hello, ya all
has it now become possible to train quality Illustrious LORAs locally on 6 GB vram and 16 GB ram? Cannot currently buy expensive shiny equipment
its technically is possible but eh its not gonna be super
your probably gonna be training on 768x768 and take a long long time
🙁 That is what I read about as well, I was hoping some people here might have experimented with it a bit already
I wanna be able to train character loras 😭 with around 30 - 40 high quality images
hmm weird question but have you tried cloud stuff instead?
hmmm i think 16gb normal ram wont work
anyways i think you might be on the edge of it being possible or not but if you want to be sure i recommend visiting the Onetrainer discord to ask just in case
thank you !
would I have to pay using credit card etc?
hmm depending on the service but iirc 10 bucks should be able to do 2 loras on civitai for illustrious depending on the settings you use
or atleast when i last made one
civitai changed their payment model hence I am trying to flee to local gen 😅
hmm only for NSFW gens, on civitai.com uses " green buzz" and is sfw only
and uses creditcard
otherwise something im less familiar with would be renting a cloud GPU by the hour and train loras on there. if you do a lot of loras it might be cheaper to do that
Yea, I just wanna train every now and then, hopefully something cool happens—
Hmm the newer models are getting heavier and heavier I'm afraid

yea i just realized i may have gone buck wild downloading models and need to be sure i don't start filling up my data store lol
For SDXL, you really only need one or two. I favor the 4-step models because they render fast. Try RealVision or Juggernaut.
haha yeah ****
stop spamming with that bs.
Insta block.

Is it normal if I am using sdxl but its super slow on a rtx 2070 and isnt even touching the vram?

20 steps in about 2 minutes 16 seconds
you're outputing at 1152x2016 (without upscaling I m guessing) so :
1/ yes it s gonna be slower
2/ also it s gonna be buggy, you ll have some duplicate artifacts because sdxl is trained for 1024x1024
3/ you can still output at higher res but you ll need to do it in two pass, one at lower res and the second one being an upscale pass. (there s probably an "hires. fix" option for that in your UI)
You are on CPU.
Please no advertising, rule 5

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Copied your list via screen grab, pasted into ai chat, with this question: can you provide a summary for each of these: RESULTS ARE: (too long to list here - see attached file)
nice, didnt realize how many of these may actually be appropriate outside the stock default
Many of the SDXL models are tuned to a specific sampler. It's worth reading their model card to determine which one to choose.
Hi..i want to generate Generate a realistic and functional furnished interior layout based strictly on the provided floor plan image. which way should i proceed. i tried https://api.stability.ai/v2beta/stable-image/control/structure but didn't got the desired image output.
happy accident trying to render a unicorn coming out of a 'crystal like lake' somehow intepreted the unicorn body and horn as crystal. so i may roll with this lol

Disha