#linear-algebra
2 messages · Page 205 of 1
im referring to this
Yes me too
write U := {a1(1,0,1,0) + a2(0,1,0,1) | a1, a2 in R} for brevity
youre showing U ⊆ range(T)
no you have it backwards
if you let x in range(T) and show that x is in U
this proves range(T) ⊆ U
which is the other direction
Oh, never mind you are right.
So I have a vector of the form (a1,a2,a1,a2)
I need to show that this can be written as (a+c,b+c,a+c,b+c)
For real a,b,c,
Hmm, okay. What if I wanted to do what I wish?
the other direction?
Showing that it can be written in the form above
i mean
if you really wanted to
you could set up a system of equations in a, b and c
and find a particular solution to it
which i did for you by inspection
How? We have too many variables
no we don't?
a1 and a2 are treated as known
arbitrary but known
with a, b and c expressed in terms of them
Oh okay
you're overthinking things
How do we solve it?
solve what
The system of equations..
Ann

Yes lol
treat c as a free variable
you get a = a1 - c and b = a2 - c
so the general solution will be $(a_1 - c, a_2 - c, c)$
Ann

why couldn't we
are you following some kind of conduct which forbids you from using the techniques and terminology associated with linear systems to solve a linear system?
Let S and T be linear maps from U to V, both of which are vector spaces over C. Prove that null S cap null T = null S + T cap null S - T
We have to show that null S cap null T subset null S + T null S - T
So let x in null S cap null T. Then x has to be in both null S and null T, which implies that Tx = 0 and Sx = 0
Therefore Sx + Tx = (S + T)(x) = 0
Which means that x is in null (S + T)
could you use latex?
Similarly, Sx - Tx = (S - T)(x) = 0, so x is in null (S - T)(x)
I will after this next line. But latex doesn't have a command like \null which makes it annoying.
we do have \ker
Since we've shown that $x \in \mathrm{null~}(S-T)$ and $x \in \mathrm{null~}(S + T)$ it follows that $x$ is in their intersection, so we have shown that $\mathrm{null~}S \cap \mathrm{null~}T \subseteq \mathrm{null~}S + T \cap \mathrm{null~} S - T$
n/c

Now we will show that $\ker S +T \cap \ker S - T \subseteq \ker S \cap \ker T$
n/c

Let $x \in \ker S +T \cap \ker S - T$. Then $x \in \ker S +T$ and $x \in \ker S - T$
n/c

This implies that $(S + T)(x) = 0$ and $(S - T)(x) = 0$
n/c

But by definition, $(S+T)(x) = Sx + Tx$ and $(S-T)(x) = Sx - Tx$ and so $Sx + Tx = 0$ and $Sx - Tx = 0$
n/c

Hence $Sx + Tx = Sx - Tx$. Adding $- Sx$ to both sides, we get $Tx = -Tx$ or $2Tx = 0$ so $Tx = 0$
n/c

This also tells us that $Sx = 0$ which means $x \in \ker S$ and $x \in \ker T$
n/c

@wintry steppe it works
this works over any field of characteristic not 2, i think...
the only place where it matters that our base field is $\bC$ is when you divide by 2, because you don't want $1+1=0$ to be true in your field
Ann

@wintry steppe late reply but it affects the logic in the 2nd to last tex. as said above, a field having characteristic 2 means 2=1+1=0, so if x is a vector then 2x=0 doesn't necessarily mean x=0
Okay
So basically if Sx = 0, but the field is Z/2Z
Then it could just be the map x^2 + x
But x = 1 in this field
When calculating the best approximation to vector b, in a subspace V. Do you have to use the standard basis or the orthogonal basis of V, in your proj_v(b) formula?
Should be orthogonal
ok, thanks
for a matrix $X$ and a vector $v$, how can $\norm{X^Tv}^2 = Tr(XX^Tvv^T)$ ? there Tr is the trace
lyinch

What is the inner product?
I think you use tr(AB)=tr(BA) smh
and tr(ABC)=tr(BCA)=tr(CAB)
Hey what can we say about the ratios of a triangle's altitudes?

We know that the altitudes would be concurrent
but why is it that the ratios of lengths FA/CE = BC/BA holds?
for a vector $v$ it makes sense that $\norm{v}^2 = Tr (v^Tv)$ but when I plug in $v = X^Tw$ then I get that $\norm{X^Tw}^2 = Tr(w^TXX^Tw)$ which is close, but still not what I need
lyinch

oops sorry
You use Tr(ABCD)=Tr(BCDA)
didn't knwo there was a discussion going on
but $w$ is a vector, doesn't this identity require that ABCD are square? Or is it only the requirement that their product is square
lyinch

no
It requires that both products are well defined
A(BCD) and (BCD)(A) should both be well defined
i.e,should have the correct number of rows and columns
X is nxd and w is nx1
okay I'll check if it works out with the dimensions
seems to work work with Tr(ABCD)=Tr(BCDA), thanks
but I've never seen that rule 🙂

Mathematics Stack Exchange
I'm working with trace of matrices. Trace is defined for square matrix and there are some useful rule, i.e. $\text{tr}(AB) = \text{tr}(BA)$, with $A$ and $B$ square, and more in general trace is
That's like the defining property of trace
trace is the only linear functional on matrices that does that
oh very nice
math pros
hi
so in this type of triangle we know that the altitudes are concurrent, but what can we say about the ratios?

why is it that the ratios of lengths FA/CE = BC/BA holds?
where FA & CE are altitudes, and BC is a side of a parallelogram and BA is a diagonal of a parallelogram
hey this question stumped me and @wintry steppe
nobody can figure it out so far

I have two points, p1 and p2 at (x1, y1, z1) and (x2, y2, z2)
I have rotation matrices R1 and R2 describing the orientation at each of those points
i extend a line of length l1 from p1 along the x axis at p1
and a line of length l2 from p2 along the x axis at p2
i then join p1 to p2 with a straight line, and the ends of the two lines with another straight line, forming a rectilinear panel
i would like to obtain the rotation matrix at a point p3 on the surface of this panel
Let $P: V \to V$ be a linear map, and suppose that $P^2 = P$. Let $N = \ker P$ and $R = \text{range }P$. Show that $N \cap R = { 0 }$.
n/c

I have been trying to do this for an hour or more, and I don't know how
Let x be in N \inter R then Px=0 and there is a u such that Pu=x
That implies P^2 u=0
But Pu=P^2 u
Which implies x=0
How does it imply x = 0?
Yeah, so?
n/c

I always struggle with showing that V is a subset of the otherset
In this case, $V \subseteq \text{span}(Pv_1,v_2)$
Where v_1 in N and v_2 in R
n/c

oh no, not you
was talking to the other beef guy
let x in V, write x as a sum of a vector in N & a vector in R
Could someone help me with a linear algebra question?
perhaps. what's the question?
I'm learning this in a language other than English so lemme know if any term doesn't make sense.
I have that T: R³ -> R² (linear transformation). In which T goes like (x, y + z). [T(1, 1, 1)) = (1, 2). T(1, 1, 0) = (1, 1). Etc]
It's asking whether Nuc(T) [kernel] is a line of R², R³ or R³ in itself, and I can't figure out the reasoning to get there
What is Nuc?
Nucleus
So kernel or null space?
hmm could you provide a definition for this? i think it's kernel in english but i wanna make sure
I believe it's kernel, yes
is it all the vectors v for which T(v) = 0?
Yes
yep, kernel, then
Sorry I didn't know the name 😅 it is kernel indeed
no problem
$T[(x,y,z)]=(x,y+z)=(0,0)$
Mosh

i would say the null space is all vectors of the form t*(0,-1,1)
Edd you mean span of
sure
and this basically is line
the span of (0,-1,1)
(0, x, y(x)), y(x)=-x
$Ker(T)=span([0,-1,1])$
Mosh

so t*(0,-1,1) is the null space
yes
@bitter cape
if you recall the vector definition of a line, it is L = p_0 + t*v
for a scalar t, a vector v, and a point on the line p_0
So this is a line in R³, right?
yes
yes
if you set p_0 = 0, you get L = t*v, v = (0,-1,1) which is a line in R^3
span of a single vector is a line which goes through the origin
no probl
similarly if you had span of 2 vectors it'd be a plane
only if they are independent
Yeah I don't know how.
c1v1' + c2v2' = a1Pv1 + a2v2
I am just so confused..
this is a load of meaningless letters
we must show V=N+R, ie every vector in V is the sum of a vector in N & a vector in R
use the fact that P^2=P
Is there any chance the answer to the question I asked could be a plan in r³? (plane/surface?)
what
This one.
well
wym nullity as surface
and it could be plane yes, if you have nullity of two vectors (spanned by two independent vectors)
Got it. Alright, thank you
consider T(x,y,z)=(z,0)
then nullity is given by span {0,1,0}, {1,0,0} which is plane
Is the relationship between cyclic group and cyclic graphs just a coincidence in naming?
Even though finite cyclic groups form a cycle
I ask because the infinite cyclic group doesn't look the same
you can define cyclic graph as graph which is a cycle essentially
or a graph that contains cycle
which definition do you use for cyclic graph?
A 1-generated group

Is that wrong?
i am asking abt graph
oh oops
anyway for finite cyclic group of order n we have all elements in group = x^m for 0 <= m <= n
A cycle is a non-empty trail where only the "first" and the "last" vertices are connected
But I'm wondering about the infinite one
C_∞
define G=(V,E) to be graph with V = {1, x, ..., x^n} and (x^m, x^n) being an edge iff x^n = x^{m+1} then it is cyclic graph
i doubt that you can generalize it to infinite case
like consider group generated by x with infinite order
for drawing cyclic graph for it you should have 1 = x^m
but this implies finite order
I see
mmm
Hmm, this definition of cyclic graph seems slightly different from the one I know
but it does make everything fit again
Be invertible matrix A that has eigenvalue of λ , how to proof that 1/λ is the eigenvalue of A^-1 ?
take an eigenvector of A and call it v
it happens that v will also be an eigenvector for A^-1
how do you know that?
well take Av = λv and left-multiply both sides by A^-1
I cant see that, what next?
what do you get?
V= A^-1 * λ * V
ok got it i see now my proof, but I cant see that
wait
A^-1 v = (1/λ)v...
but what if lambda = 0 
booom
if 0 is an eigenvalue of A then A^-1 does not exist lol
@hybrid charm knock it off
feel free to ping helpers
last chance. knock it off
to toge not you
and curb your degeneracy
i told toge to ping helpers, not you

go ahead
How do you guys call the lectures where you deal with polynom interpolation and approximation?
We call it numerics, couldnt find the english word for that. It combines linear algebra and calculus, but whenever its LA heavy I ask the question here.
numerical analysis?
these are called homogeneous coordinates
I don’t get why [1 0 0|0 0 r|0 1/r 0] times [x|y|1] gives [x| 1/r | y/r] instead of [x| r | y/r]
I don’t get why he multiplies the vector by r/y and says it’s equal
by convetion in homogeneous coords, you want the last dimension to be 1
I’m fine with the last dimension being 1
you only care about projections on a 2D plane at z=1
I just don’t get the actual transformation, not to mention how it equates to a transformation from a circle to a hyperbola
i do agree with this
wdym you agree with it
like you agree with him that that’s what it gives or you agree with me that it’s confusing
what I want to be able to do
I want to be able to take a hyperbola (ideally of the form xy=c, but if it has to be x^2 - y^2 that’s probably okay too) and transform it into a circle
in such a way that I can choose a point on the hyperbola and see where it lands on the circle
I thought maybe I could use the inverse of this matrix if I could figure it out, and I also tried taking the hyperbola xy=1, doubling it, and subtracting it from the line (x+y)^2 = 3, to get x^2 + y^2 = 1, but I can’t figure out what that looks like geometrically or how to track individual points
I’m not even sure if subtracting equations like that has a meaningful interpretation geometrically
inverting the transformation should work
but you'll have to double-check whether the third column is correct
I also feel like I need an understanding of why it works
Since I’m going to need to “rotate” it 45 degrees, I’ll need to figure out where I want to do that
and how
but I don’t understand that third column, or why it gets multiplied by r/y, or how it corresponds to a circle-hyperbola transformation
the rotation should be easier, since you could apply a rotation matrix to both sides of the equation
yeah but
for this, you'll have to go study projective geometries/homogeneous coordinates
my larger goal is
I take a hyperbola, I transform it into a circle. If I know that there are K integer points on the hyperbola, I want to have a circle with a number of integer points that is dependent on K
by integer did you mean discrete? like discretize the hyperbola and find the corresponding points on the circle?
yeah
and if I rotate the hyperbola, I think that messes with the discrete points on it, so trying to go directly from a hyperbola with a diagonal transverse axis to a circle might be easier
to be fair, aside from this possible mistake on the third column of the transformation, the website you shared already explains everything
well it doesn’t because
at one point it goes from [x 1/r y/r] = [rx/y 1/y 1]
and those two things aren’t equal, he multiplied by r/y, which I understand is a valid thing to do but I’d think it would mess with the coordinates, and even if it doesn’t I don’t get why he says it’s equal
you said this, but you didn't understand it, then
you will first have to read what homogeneous coordinates are
and then you can walk through the geometric explanation given on the website from the beginning
all the steps are there
you can work it out yourself following the steps given at the top...
even if I don’t understand it, I can probably just multiply it by a rotation matrix & then use it
I think it’s supposed to be 1/r
right?
if the goal is to get [rx/y | 1/y] then it has to be 1/r, I think, which means it’s supposed to be 1/r? But why did they put r, was it just a typo they didn’t fix?
What did you get the basis for Ker A-2I as?
Consider pick a vector v in V/Ker(A-2I)
Try looking at span {v,Tv}
Ok, That's weird
You sure that's correct?
Because Ker(T^2+1) should have atleast 2 elements in basis
Because you can find a vector v such that T^2+1 is the minimal polynomial
So,v Tv will be a LI set
That's kernel of A
Not Ker(A-2I)
one sec
A(1,0,0)=(0,1,1)
So, (A-2I)(1,0,0) is not zero
Should be same thing
,w rank {{0,-2,1},{1,-2,2},{1,-4,4}}

nvm That's A
I think you should be doing column reduction
{(-2,1,1),(-2,-4,-4),(1,2,2)} span your null space
So basis should be {(-1,0,0),(1,2,2)}?
Weird
Yes
(1,0,0) is definitely not an eigenvector
If your eigenvector of value 2 is (x,y,z),you get -2y+z=0 and x=0
So, it's (0,1,2) only
why does this look so complicated
Because squirtel forgot about matrix multiplication
I think a good approach to finding a basis of ker(T^2+I) is pretend we are in C and find a basis for Ker(T-iI) and Ker(T+iI)
and then find a basis for Ker(T+iI)+Ker(T-iI) which only has real coefficients
If I wanted to find the matrix for the differentiation map for polynomials D in L(R_3[x],R_2[x]) where the subscript denotes degree of or less than
But I used (1,x,x^2,x^3) as the basis for the domain and (2,2x,2x^2) as a basis for the codomain
Would the matrix then be given by
$\begin{pmatrix} 0 & 1/2 & 0 & 0 \ 0 & 0 & 1 & 0 \ 0 & 0 & 0 & 3/2 \end{pmatrix}$
n/c

Seems correct
Thanks
Now consider the basis (x,x^2) for the codomain
Then the matrix would just be $\begin{pmatrix} 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 3 \end{pmatrix}$
n/c

Right?
What's your operation?
Dp = p'
You would miss some elements. So that's not the codomain of D
Like 2x gets map to 2 ,but 2 is not in your span
I know
The matrix with (1,x,x^2) as a basis for codomain would be
$\begin{pmatrix} 0 & 1 & 0 & 0 \ 0 & 0 & 2 & 0 \ 0 & 0 & 0 & 3 \end{pmatrix}$
n/c

So why isn't the one I wrote above correct, if we remove 1 from the basis of the codomain?
You will have to change your domain then
Why?
For every element in domain,there has to be a element in codomain
If {x,x^2} was your basis 2 has no corresponding element in the codomaim
Oh I see
Our basis has dimension 3
For the codomain
Sorry edited, don't know why I said span
I get it now thank you
I think I understand matrices
When we add two matrices, what kind of operation are we using?
Do we define $+: F^{m,n} \times F^{m,n} \to F^{m,n}$
n/c

That's the usual convention
So,you are familiar with linear transforms but not matrices?
That's how the book goes
You understand given a basis,the isomorphism between linear maps and matrices?
No isomorphisms are the next subchapter
But yes I do understand there's a bijection
Since linear maps are unique
Matrix addition and multiplication are defined such that the bijection becomes an isomorphism
You want a • operation such that [T]•[U]=[ToU]
Because composition is the "product" wrt linear maps
You would want a + operation such that [T]+[U]=[T+U]
Where RHS is normal addition on functions
You only know the domain and range of +
You also want + to have that property
But to prove that [T] + [U] = [T + U], we can just prove that it holds for a singular column right?
That is
$M_k(S) + M_k(T) = Sv_k + Tv_k = \sum_{j=1}^m A_{j,k}w_j + \sum_{j=1}^m B_{j,k} w_j = \sum_{j=1}^m (A_{j,k} + B_{j,k})w_j = M_k(S + T)$
n/c

That's how I proved it to be true for a column, and so we can then define the operation to do that without thinking just about a single column
it stops being a basis
I know thank you
yes
assuming you are using F^{m,n} to refer to the set of all m by n matrices over F
I am
I see, thank you
Yes the motivation is basically to make it intuitive 😄
I don't think your book will cover this,but Matrices and linear maps are isomorphic as algebras
mb

why
stupid question but if $(A-\lambda I)v = 0$ then why must v be in the span of $A-\lambda I$
Anticipation

i.e. why must there be a w so that $(A-\lambda I) w = v$
Anticipation

i dont think this is true always, (v nonzero)
How is the set of all functions from K to U Vi a vector space in any natural way?
who told you that? Let A = \lambda I for example then no nonzero v is image (if thats what you mean by span)
im dealing with some ODE stuff so maybe its a special case
but if theres like a 2D ODE and I got a repeated root with 1D eigenspace
then apparantly thats true


note that the Sigmas are interchanged
Yeah exactly
[\sum_{r=1}^{n} C_{r, k} \sum_{j=1}^{m} A_{j, r}w_j = \sum_{r=1}^{n} \sum_{j=1}^{m} C_{r, k}A_{j, r}w_j = \sum_{j=1}^{m} \sum_{r=1}^{n} C_{r, k}A_{j, r}w_j][= \sum_{j=1}^{m} w_j \sum_{r=1}^{n} C_{r, k}A_{j, r}]
bleh cut off
one sec
@wintry steppe
its just repeatedly applying distributivity
Where did your k's go?
Namington

they shouldnt have went anywhere
i dont even know how that happened
i just copy-pasted
i didn't do any index fuckery or anything like that
just apply distributivity, swap the sums, apply distributivity again
swapping the sums allows us to factor out w_j since now j is fixed (within the scope of the r=1-to-n sum)
since the sum indexing j is on the outside
first =: distribute C_r, k into each term of the inside sum (note that r, k is fixed since k is a fixed variable and r is the index of the outside sum)
second =: think about it; we can think of this sum as adding together every possible pairing of r, j for 1 ≤ r ≤ n and 1 ≤ j ≤ m, so order shouldnt change anything
third =: factor out w_j from each term of the inside sum (note that j is fixed since it is the index of the outside sum)
but yes, writing this out with some small values (say n = 2, m = 3) can make it easier to follow
thanks for writing it out
I found a mistake in my work (took forever to find)
But now it finally makes sense hahaha
hi can someone help me with understanding the simplex method? dm me please thank you !!
It’s supposed to be r
I can’t prove it but I can verify it experimentally
Okay, now I’m able to transform from a hyperbola with transverse axis y = -x into a circle... let’s see if I can do anything with this or if I’ve been working on hours on nothing lol
not nothing, it’s a fantastic learning experience
I may be able to prove it acrually but I don’t want to bother, that seems like a lot of easy-to-mess up algebra
Suppose V and W are finite-dimensional and T in L(V,W). Show that with respect to each choice of bases of V and W, the matrix of T has at least dim range T nonzero entries.
By definition, the matrix of T has entries in column k A1k,A2k,...,Amk given by sum i=1^m Aik wi
Where we assume that dim W = m and dim V = n
We can now suppose that dim range T = alpha. This implies that Tvi ≠ 0 for i ≥ alpha, as the zero vector is linearly dependent and would not contribute to the dimension of the range of T. Thus, Tvi = ciwi for c in F and wi in W.
As ciwi ≠ 0, ci ≠ 0 by an earlier exercise, and so [T] has at least alpha = dim raneg T nonzero entries.
Changing the basis will not change the dimension of each respective basis, and so it will not change our proof.
Does that argument work?
I guess I need to change it a little bit
Since I am assuming it's equal to some vector wi in W but actually wi is a linear combination of vectors in W
Though it definitely doesn't seem like I am using it in that way
So, quadratic forms can be represented with the usual x^T M x, I was wondering, is it possible to represent cubic forms in a similar way by using rank 3 tensors?
Nvm, I found a way to make it actually work, not sure how useful it'd be but discovering it was quite fun
yeah it didn’t work for what I hoped it would but it was still an enlightening exercise
I was hoping I could map a hyperbola xy=c onto a circle, in such a way that lattice points on the hyperbola translate to something interesting on the circle that could give insight into factoring problems
the issue is that the y coordinate a point maps onto has a “c” term in it, and the x term has a “square root of c” term in it, and they’re both divided by “x-y”, which really makes just about everything useless
if i have lin. dep. vectors, does one of them have to be a scalar multiple of another one?
no right? one vector just has to be a linear combination of the other 2 vectors
correct
if a linear system Ax = b is consistent, at least one solution must be in row(A) right?
@celest slate
I am not familiar with the notation row(A) sorry
actually i think what i said is wrong
if 2 functions are linearly independent, are their derivatives also lin. indep.?
function in the form e^x
i wrote this a year ago. and i don't know what i did, but im almost sure i flubbed up the last half by flipping my \bigcaps, and turning them upsidedown into \bigcups

Google Docs
Axler 1.C. Subspaces 11. The intersection of every collection of subspaces of a vector space is a subspace of . Proof: We need to prove that if some set is the collection of every subspace of some ambient vector space, then it is also a subspace of the ambient vector space. Recall the d...
which is to say, this is all wrong, right? i need to flip the cup into a cap?

yes
why does geometic multiplicity of eagevalue<= algebraic multiplicity of eagenvalue ?
i could get 2 eagenvectors of one eagenvalue
it's spelled eigen, just for reference
anyway, the geometric multiplicity is the dimension of the eigenspace, so you would need two linearly independent eigenvectors
something you may not have
loosely speaking, you can pick a basis for the eigenspace (consisting of as many vectors as the geo mult, by defn) and extend it into a nice enough basis of the whole space wrt which your operator will be block-triangular, with the top left block diagonal - thus showing the determinant has (x - λ)^(geo mult) as a factor
got it thx
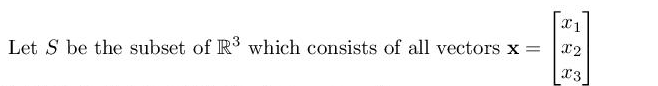
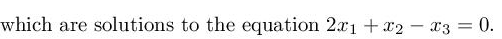
set of solutions to $2x_1+x_2-x_3=0$ form a plane
Mosh

and a plane is defined by the span of 2 vectors
thank you!
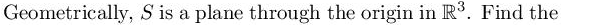
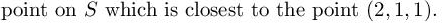
how would I do this?
I know I have to use a projection vector but not sure for my setup
is there any reason why you are screenshotting one line at a time
anyway you want to project (2,1,1) onto S
thanks I already figured it out
and nah
i just thought it was neater

thats where its from if you wanted to know
How to think of adjoint of a matrix geometrically?
does anyone know the basis for quadratic polynomials
I don't know if its just {1,x,x^2} or an infinite set
if i have kerT = span(
1 0 0 0
0 0 0 1
)
those are 2 matrices
whats dim(kerT)?
@nocturne jewel but im interested in the span of two matrices not vectors
yeah, matrices can be vectors
ok
$\mathbb{R}^{m\times n}$ is the R-vector space of m by n matrices
Mosh

so the kernel of T is defined as the span of 2 vectors, so dim(ker(T)) = 2
anybody care to explain?

please tag me, as i will be searching for the answer elsewhere
which part dont you get?
7,9,-2,4; why?
yeah shouldnt be that vector
well, the answer sheet tells me that's the answer
and im very sure its not an error
yes cause a piece of paper will always be right. . .
well, you solve it then, does the point (1,0,2,1) lie on the line between (-2,1,1,0) and (3,1,0,4)?
or if you can explain to me how to apply rref to 3 dimensional systems, that would be fine as well, and i suspect this is quite a bit easier
it's not on the line.
yeah but why
find the equation of the line, then show that the parameter has to be different per component
what is the equation of the line
Find it out yourself
i dont know how, i would not be here
Check the answer sheet
answer sheet is what i have in the picture
answer sheet says its ${\left(\begin{matrix}-2\1\1\0\end{matrix}\right)+\left(\begin{matrix}7\9\-2\4\end{matrix}\right)*t|t\in\mathbb R}$, which you disagree with
Betelguse

Yes, and you say it's right and were firm on that
so go with what the answer sheet says since it's apparently right
i do not understand it
i am also open to the possibility that it is wrong. if you come up with a solution that would solve the problem and contradicts with the answer, i obviously will be willing to accept that
i am not prioritising you or the answer sheet, i just need an answer that i understand, or an explanation that would make me understand
You did prioritize the answer sheet.
and the way you came off was disrespectful, so you got the amount of help I am willing to give.
well, answer sheet has an answer and you dont.
you should refrain from engaging conversations on the internet, as the slightest implication that someone else other than you might be right offended you.
You asked for help, I gave you help, you wrote it off as "I doubt the answer sheet is wrong"
i will not suck you off so that you give me an answer. i am guilty of nothing that requires apologising. if you do not have an answer, do not come in and challenge the only answer i have.
Ok then gl
thanks
anybody care to explain?
answer sheet might be wrong, but please come with a proof.

i specifically do not understand why the free element is (7,9,-2,4). how does one get there?
alright, found it

(7,9,-2,4)*t is parallel to the line given in the question, and you just need to translate it by (-2,1,1,0) to get there
is it though?
notice the points have the same y value
adding 9t to y is going to change y
for any t besides 0
see the explanation here.
a free vector of a line from point a to point b is $\begin{pmatrix}b_x - a_x\b_y - a_y \ \vdots \ b_{dimension} - a_{dimension} \end{pmatrix}$, and translating it to the right place gives you the exact same vector.
Betelguse

so free vector starts from origin and is parallel to the line
thats why you need to translate it
what do you mean? can you rephrase
$$\begin{pmatrix}3\1\0\4\end{pmatrix} -\begin{pmatrix} -2\1\1\0\end{pmatrix} =\begin{pmatrix}5\0\-1\4\end{pmatrix}$$
Timon

The answer is wrong, maybe they changed the problem and forgot to update the answer or something
thanks a lot man, i am embarrassed to not have noticed it before
@nocturne jewel you were right
@untold pier wrong channel, use one of the pre-university ones like #prealg-and-algebra
$$\begin{bmatrix}
1 & 1 \
-1 & 1 \
\sqrt2 & \sqrt2
\end{bmatrix}$$
ABCDE

how can I calculate the standard matrix of the orthogonal projection onto Row(A)?
matrix above is A
pick an orthonormal basis $(e_1,\ldots,e_n)$ of Row$(A)$. writing vectors as column vectors, the projection of any $x$ onto Row$(A)$ is
$$\sum_{i=1}^n(x\cdot e_i)e_i=\sum_{i=1}^n(e_i\cdot x)e_i=\sum_{i=1}^ne_ie_i^Tx=\br{\sum_{i=1}^ne_ie_i^T}x$$
so $\sum_{i=1}^ne_ie_i^T$ is a matrix representation of the projection
RokabeJintaro

if a linear system Ax = b is consistent, does it have to have a solution in row(A)?
does that even make sense?
if A is m × n, then elements of its rowspace have size m while the solutions of Ax=b have size n
you sure about that one?
good point
i'd say the elements of the column space have size m, while those of the row space are of size n
i think as long as by solution they meant the vector x, it should be right
still i dont see why x should be in row(A)
like, an element of row(A) is a vector of the form uA for u a suitably sized row vector
while x is a column
so why would x be A^T times something
i'm pretty sure by row space they mean to address the orthogonal complement of the null space
if Ax = b is consistent, it has at least one solution, and it corresponds to the projection of x onto the row space
it might have infinitely many solutions, in which case the solution is the projection of x onto the row space + anything from the null space
so is my statement true?
it should be
consistent means b is lin dep with the columns of A, yeah?
and A maps elements from the row space to the column space
im not convinced
it should be a consequence of the fundamental theorem of linalg
(i might be wrong, so always take it with a heap of salt)
you seem to be mangling terminology here because like
row space and (nullspcae)^perp may be isomorphic but they arent the same space?
hmmmmm
are they not?
when you take an SVD, for example, the right singular vectors form a basis for R^n; the first r vectors span the row space, and the remaining n-r span the null space, and they're all orthonormal
this should be a consequence of being able to diagonalize symmetric/hermitian matrices with orthonormal eigenvectors
@dusky epoch when i say solutions i mean x not b
of course i understand that you mean x
we are given a matrix A ∈ R^(m × n) and a vector b ∈ R^m, and we are told that there exists x ∈ R^n such that Ax = b
must x necessarily be expressible as A^T u for some u ∈ R^m?
not necessarily all of x, but at least some component of it
because the part that isnt just yields a 0 vector
??
so what you're saying is that there must exist a solution to Ax = b in the form A^T u?
i.e. that $AA^Tu = b$ must be consistent?
Ann

im saying thw direct sum of the row and null spaces is R^n
yeah
this is the same as saying that you can pseudo invert A
as long as b is in the image of A
and the pseudo inv is the map from image to row space

so if x = xrow + xnull, then xrow must be nonzero. though looking at it again, if b is 0, then what i said doesnt hold. is the vector b nonzero?
if nothing is said regarding that, i just wasted a whole bunch of everyone's time

Your argument is fine whether b is zero or not
What's wrong with xrow = 0?
Just decompose x = xrow + xnull and compute that b = Ax = A(xrow + xnull) = A(xrow) boom solution in the row space
This corresponds exactly to what you said way above
yea but if b is 0, then you could just take any xnull
Yeah but the problem only wants one solution to be in the row space, in the case b = 0 that's x = 0
Like you also said before you can get more solutions by adding xnulls that don't have to be in the row space, but the one solution is
i would argue that xrow = 0 and xnull =/= 0 means x is not in the row space, since it had an orthogonal projection of 0 onto the row space. but this is only the case for b=0. otherwise, what i said still holds, yeah
One of us is very confused about something silly
The row space contains the zero vector surely?
it does, otherwise it wouldn't be a space, sure
Right so the solution to Ax = 0 that lies in the row space, is just x = xrow = 0
fair enough. then the assertion that x is in the row space is correct, but one needs to be careful depending what is known about b.
but since the question only asks for existence of a solution in row(A), then yeah
yes
yeah sorry, i had to go back and read that bit again

"basis is a maximal linearly independent set"
does this mean that there exists an s not in the basis such that the union of the basis and the set containing s is linearly dependent?
yes
thx
let {v_1, ..., v_n} be basis
let s be not in basis
then {v_1,..., v_n, s} is linearly dependent
lmao that name
(for v_i and s in the same subspace)

i don't know enough math to know if that was a joke or a real thing 😛
Let $V,W$ be vector spaces over a field $\mathbb{F}$. Let $T \in \hom(V,W)$.
- Prove that if $\mathbb{F} = Q$, then the homogeneity property of linear maps is redundant.
Let $n,m \in \mathbb{Z} \setminus { 0 }$. It follows that $n^{-1}$ exists as it must have a multiplicative inverse in the field $\mathbb{Q}$. Thus, $n^{-1} \in \mathbb{Q}$ by definition of $\mathbb{Q}$.
Using the additive property of linear maps, we have that [ T(u) = T\left( \sum_{i=1}^n n^{-1}u \right) = \sum_{i=1}^n T(n^{-1}u) = nT(n^{-1}u). ] This implies that $n^{-1}T(u) = T(n^{-1}u)$.
Then observe that $T(mn^{-1}u) = T\left( \sum_{i=1}^m n^{-1}u \right) = \sum_{i=1}^m T(n^{-1}u) = mT(n^{-1}u)$. But we know that $T(n^{-1}u) = n^{-1}T(u)$, so $T(mn^{-1}u) = mn^{-1}T(u)$. By definition of, $mn^{-1} \in \mathbb{Q}$ as it is a ratio of two nonzero integers, and so we have shown the property the scaling property to be redundant for that case. If $m = 0$, then $T(0u) = 0$ and $0T(u) = 0$, so $0T(u) = T(0u)$. If $n = 0$, then a multiplicative inverse does not exist for it in the field (by definition), and so we are done.
n/c

Does this proof work?
appears so
Thanks
How do I prove the converse is not true?
If F = Q, then homogeneity does not imply the additive linear property
you may just construct counterexample
I know
I'm having a hard time thinking of one lol
I need vectors v,u such that T(v + u) ≠ T(v) + T(u)
maybe this function
f(m/n)=m+n
ah no
not homogeneous
but f(m/n)=m
looks to be homogeneous
1/n f(m) = m, and f(m/n) = m, but f(a/b) + f(c/d) = a + b, however 1/b f(a) + 1/d f(c) = a/b + c/d = (ad + bc)/(bd). Then f(a/b + c/d) = f((ad + bc)/(bd)) = 1/(bd) f(ad + bc) = ad + bc
here problem is possible tho
oh
it is not homogeneous
hmm
there is an example
f(x,y)=x if xy > 0
and 0 otherwise
So c f(x,y) = f(cx,cy) = cx if xy > 0 and 0 otherwise
not well defined
you can have a function on Q^2 which is homogeneous but not linear
well f(cx, cy) would be cf(x,y) since sign of c^2xy is the same as xy
say, define f by f(1,q) = q^2 and f(0,q) = q and let the rest follow by homogeneity
and on Q^n with n=1 looks like homogenuity implies additiveness
so f(p,q) = q^2/p for p != 0
f(1,2) = 4, f(1,1) = 1, f(2,3) = 9/4 != 5, boom, not additive
crazy how?
Not obvious
uhm can somene teach me how to do age linear problems?
wrong channel, go to #prealg-and-algebra.
whoops sorry
Suppose V, W are finite-dimensional and T in L(V,W). Show that with respect to each choice of base of V, and W, the matrix of T has at least dim range T nonzero entries.
Suppose that dim range T > 0, otherwise if dim range T = 0, then null T = V and so the matrix of T will be the zero matrix and so it is true.
Then assume that M(T) has at least p nonzero entries, where p = dim range T. for p ≥ 0.
Without loss of generality, assume that T(vi) ≠ 0 for i = 1,2,...,p.
Then T(v1) = c1,1 w1 + ... + cm,1 wm ≠ 0, where ci,1 are not all 0
Assume that, without loss of generality again, that c1,1 is nonzero, and the rest can be zero.
This tells us that in the worst case, T(v1) = c1,1 w1, which implies that T has one nonzero entry for v1.
We can repeat this process for all of vi for i = 1,...,p to see that each of the vi have at least one c_(i,j) such that it is nonzero
this feels verbose.
Because there are p such v_i, it is implied that there are at least p = dim range T nonzero entries in the matrix of T
I know
But I don't know how to make it less... handwavy?
and there are atleast rank(T) nonzero elements in a set that spans range(T)
proof by assumption
Sorry, change the wording to T(v_i) is nonzero for i = 1,...,p (wlog)
and v_i is what?
It's a basis vector of V
Where the basis of V is v1,...,vn
i mean ok like
you say there are p columns in the matrix of T which span the range of T, and in each col there is a nonzero entry
that's it
no need to fuck around with which rows they're in cause you don't care
Yes
That proof is much better I guess
Suppose V, W are fin dim and T in L(V,W). Prove that there exist a basis of V and a basis of W such that with respect to these basis, all entries of M(T) are 0 except that the entries in row j, column j, equal 1 for 1 ≤ j ≤ dim range T
Are they asking about a single entry at M(T)_(j,j)?
they're asking for a sorta diagonalization
say, M(T) = U I V^T, with I as an identity-like rectangular matrix with 1's along the diagonal
What is U?
Have not gone over that yet.
i see. maybe someone has a different approach, then
I think I get it, but I just want to make sure
They want 1 at (1,1),(2,2),(3,3),...,(dim range T, dim range T)
And zeros everywhere else?
yes
How do I make entries of a matrix zero, relative to basis?
i.e. suppose for a basis v1,...,vn and basis w1,...,wm
The entry at j,k of the matrix is A
For nonzero A
How can I adjust the basis so that A = 0?
It's not possible, correct?
if matrix wrt to some basis is zero it would be zero for any basis
since if A is matrix wrt basis and B is change of basis matrix then T=BAB^(-1)=B0B^(-1)=0
i doubt that there is procedure for this
unless certain assumptions are made
otherwise it implies every matrix is diagonalizable
SVD moment
not really "diagonalizing" tho
at any rate, you can use givens rotations to do this
I understand the proof that two vector spaces are isomorphic iff they have the same dimension in the direction where you assume that they're isomorphic, but I don't understand the other direction.
In other words, could someone help me prove that two vector spaces are isomorphic if they have the same dimension?
@wintry steppe what's the most obvious way to try to construct an isomorphism between them?
We map v1 to w1, v2 to w2, ..., vn to wn
did you try that
But is that enough?
To show there exists some function which "links" them like that?
ofc not
do you know what an isomorphism is?
Yes
It's an invertible linear map
so
maybe such a map is invertible
Okay
I see, thanks
do i need to prove that a set orthonormalized from a linearly independent subset of an inner product space V through the Gram-Schmidt orthogonalization process and vector normalization is a basis for V?
it was given that the original LI subset of V was a spanning set of V
and that that subset is also LI
don't think so
why is that
it should be easy to do it, but the definition of the gram schmidt alg. is a procedure that takes a basis for a subspace V and produces an orthonormal basis for the same subspace V
each step of the algorithm takes one vector and keeps only the component in the orthogonal complement of all the previous vectors
in other words, you can relate the gram schmidt basis, let's call it G, to the original basis, let's call it B, through a full rank transformation T, i.e. B = GT
and so B and GT have the same image, meaning their columns span the same space
but anyway, the short answer is you don't need to, but it should be pretty easy to do so
ty
real subspace vs. complex subspace of C^{nxn}
im guessing real means real scalars and complex means complex scalars?
both of which are multiplied to vectors in said respective subspaces
yea
Spanning set is a set containing "all" the basis?
what do you mean
what do you mean by "all the basis"
that expression alone doesn't make sense
because there usually isn't a unique basis
What's the difference between basis and spanning set?
a basis is a linearly independent spanning set
So, every basis is a spanning set but not all spanning set is a basis?
What's the significance of spanning set?
pretty similar to that of a basis, but there may be more than one way of representing vectors in the subspace
with a basis, the representations are unique
Like for example?
the set [1,0], [0,1], [1,1] is linearly dependent
it spans R2, but it is not a basis
well
that one works
but so does [1,0] and [1,1]
or [0,1] and [1,1]
those 3 are all valid bases
Is it necessary for one of the vectors to have a single one and remaining all zeroes?
*atleast one of the vectors
not at all
[-1,1] and [1,1] is another valid basis
the only thing necessary is that the vectors are linearly independent and span the subspace
how do u prove a linear function is continous?
Mmmm
i am asked to prove that given a diagonal matrix, if a_n is bounded, then the matrix has a bounded operator (?)
In mathematics, linear maps form an important class of "simple" functions which preserve the algebraic structure of linear spaces and are often used as approximations to more general functions (see linear approximation). If the spaces involved are also topological spaces (that is, topological vector spaces), then it makes sense to ask whether a...
idk if this is the terminology
but we have to do 2 things: first prove that if a_n is bounded, then the linear application is continous

If a_n is bounded, then

T is continous
$|a_n| \leq M \implies \nrm{Tx} \leq M \nrm{x}$
Ann

@wintry steppe
How to prove that Transpose (Adjoint (A)) = Adjoint (Transpose (A))?
what are you calling adjoint? and is A a matrix?
adjunta
i found this too. But on my case i need to prove the imply on both sides
this one is left way or right?
and what is x there?
did u mean T(x)?
Yes, A is a matrix. Adjoint = Adjugate = transpose of its cofactor matrix
x is a sequence
@wintry steppe wrong channel, see pins.
and how does that prove a_n is continous?
does this just mean it is continous?
okey yes. And how do i do the other way? if T is continous, how can i prove a_n is bounded?
How come the Eigen vectors of a matrix and its inverse are same?
Let Av=cv then A^-1(cv)=v
i.e., an eigenvector of A is an eigenvector of A^-1
Similarly repeat for the other direction
Similarly, how to prove for Transpose of a matrix?
it's false, a matrix and it's transpose need not have the same eigenvectors
they will have the same eigenvalues, though
i am
a dumbass so be patient with me
Suppose that U and W are both five dimensional subspaces of R&9 prove that U intersection W != 0

Suppose U inter W is 0
You can pick five basis vectors for U and 5 basis vectors for W
These 10 vectors will be LI in U+W
But U+W is a subspace of R^9
And hence a set can only have a max of 9 LI vectors
what are LI vectors
Linearly independent
o
This is not direct
Try to see why that's true
i do math
Prove it.
is it possible for me to find an orthogonal matrix thats row equivalent to
-1 2
2 -4
I don't think so, but how do i prove this?
the rows are linearly dependent, it does not have an inverse
so the inverse can't be its transpose
maybe like that?
row-equivalence preserves rank, an orthogonal matrix has full rank, yours does not
We have a test for screening cancer that is 90% sensitive and 90% specific. Assuming that 1% of the population has cancer, what is the fraction of positive tests that correctly detects cancer?
this isnt a linear algebra question
try #probability-statistics or a #questions-_ channel
dumb q but theres no difference between "cone" here and matrices right, wonder why they write it as cone

(not exam btw)

i dont understand the question
that set is called a cone
a matrix is not a set
and certainly not a cone
i mean isnt the set S^n+ just the set of matrices that are symmetric positive definite
based on the definition of all X in R^nxn so that X = X^T and X ≥ 0
idk why they call it a cone

they could just say "set" instead of "cone" sure
lol

Does someone know how to solve a?

If ~v4 ∈ span(~v1, ~v2, ~v3), then replacing ~v3 with ~v4 does not alter the span. That is,
span(~v1, ~v2, ~v3) = span(~v1, ~v2, ~v4).
please help it is urgent
<@&286206848099549185>
@woven fossil please wait 15min before pinging helpers
sorry I will remember next time
@woven fossil this is false
Consider R^3 with the standard basis e1, e2, e3. Then x = 2e1 is in span(e1, e2, e3) but span(e1, e2, x) ≠ span(e1, e2, e3)
what is the meaning of symbol "~" on a basis vector
it appears in coordinate system transformations but what is the actual meaning of the symbol ~
post image

it's just to distinguish it from the old e_i

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
\tildearrow?

$\tilde{\vec{x}}$
TTerra


Would it be true to say that for A to be diagonizable, the multiplicity of each eigenvalue needs to be equal to the dimension of the eigenspace corresponding to that eigenvalue?
sounds about right
Great, thank you
And that comes from the fact that the P matrix with the vectors needs to be invertible?
yeah, otherwise you can't get the similarity
Ah that makes sense, thanks
can't you just do $\vec{x'}$
Conan

cf
TTerra

Can anyone help me understand how they get b and or how to better understand this markov chains stuff? I wouldnt mind doing it via voice either to really understand better.

covector is called covector because it acts as a function on vectors?
well, that's what it means, it's a linear function that takes a vector as input
the co- prefix sort of means "accompanies" or something
Hi, I would like to confirm something.
If vectors a & b are linearly dependent, then a & b are scalar multiples of one another?
If they're both non-zero, yes.
If say a = 0, b non-zero then a is a multiple of b but not true other way round.
Basically yes with the caveat that non-zero vectors can't be scalar multiples of the zero vector.
thanks!
hi, i'm having trouble understanding what the answer key (on the right) means. the question is asking for the coordinate vector of p(t), which should be [x]ß. but why is the key.. finding [p]ß :_ D..? or does [p]ß actually mean the coordinate vector (the book says the opposite thing tho)?

@woeful fable [ ....]ß just means coordinate vector of whatever vector is in the square brackets. It can have different names.
ohhhhh thank you!!! that clears it up
wrong channel, go to #prealg-and-algebra or #precalculus
Confession: I don’t think I’ve ever proved that the zero vector is a vector space in its own right.....
.....I guess I’ll just have learn to be okay with that.....
(No one ever needs to know, right?)
proving {0} is a subspace of the ambient space proves it's a vector space in its own right

hmm any idea?

Z linearly independent => E invertible, huh...
yea I don't get how it relates haha I think it's disprove?
this looks true to me, but i'm only like 80% sure
hmm
let's see
let's consider the subspace $U_E$ of $M_2(\bR)$ defined by $U_E = { XE \mid X \in M_2(\bR)}$
Ann

i have a hunch that U_E is a proper subspace of M_2(R) iff E is non-invertible
ah actually
$\dim(U_E) = \begin{cases} 4 & \rank(E) = 2 \ 2 & \rank(E) = 1 \ 0 & \rank(E) = 0 \end{cases}$
Ann

this could be written as dim(U_E) = 2rank(E) but this would have been a little unintuitive as there are different arguments to be made for each case
@heavy crown i can explain why this is true to you if you'd like, or you could take my word for it for now and i could tie it to the original problem
what would you like me to do first?
unforunately they didn't teach us rank yet, the last subject was about R(A) and C(A) Row and column spaces, and before that Grassmann's formula
maybe if you could explain this to me intuitively I could understand how to make it?
thank you for your kindness btw 🙂
hrm
i mean ok these are two by two matrices
so you can replace rank(E)=2 with "E is invertible", rank(E)=1 with "E is singular but not the zero matrix" and rank(E)=0 with "E is the zero matrix"
how would you know how much is dim depends on if E is invertible ? I mean why is it 4
well the dimension of M_2(R) itself is 4, is it not?
oh, right