#internals-and-peps
1 messages · Page 31 of 1
part of it
What are the other part?
the other parts of python
docs, past to present and future features, code inspection, stdlib etc.
instead of programming in python, it's more like the programming of python
Interesting
Does it include the linting features or are those separate from the language?
linters generally aren't part of the language itself, but the features of the language covered by them could be a valid topic here i think
Thanks for clearing that up 😊
Interesting behavior.
In [1]: globals()['foo bar'] = 5
In [2]: f"{foo bar = }"
Cell In[2], line 1
f"{foo bar = }"
^
SyntaxError: invalid syntax. Perhaps you forgot a comma?
In [3]: foo bar =
Cell In[3], line 1
foo bar =
^
SyntaxError: invalid syntax
In [4]: foo bar
Cell In[4], line 1
foo bar
^
SyntaxError: invalid syntax
i still haven't found the exact reason for this (still theorizing it's parsed as a set or something) but i have found other bugs in the meantime
>>> f"{foo bar([( }"
File "<stdin>", line 1
f"{foo bar([( }"
^
SyntaxError: closing parenthesis '}' does not match opening parenthesis '('
>>> f"{foo bar([( =}"
File "<stdin>", line 1
f"{foo bar([( =}"
^^^^^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?
>>> exec("(foo bar =")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
exec("(foo bar =")
~~~~^^^^^^^^^^^^^^
File "<string>", line 1
exec("(foo bar =")
^^^^^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?
>>> exec("(foo bar")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
exec("(foo bar")
~~~~^^^^^^^^^^^^
File "<string>", line 1
exec("(foo bar")
^
SyntaxError: '(' was never closed
``` unclosed parentheses errors not taking precedence for some reasoncomparing top example (tested 3.14) to 3.11 behavior ```pycon
f"{foo bar([( =}"
File "<stdin>", line 1
f"{foo bar([( =}"
^
SyntaxError: f-string: closing parenthesis '}' does not match opening parenthesis '('
f"{foo bar([(}"
File "<stdin>", line 1
f"{foo bar([(}"
^
SyntaxError: f-string: closing parenthesis '}' does not match opening parenthesis '('
also this (3.14) ```pycon
f" { x b
File "<stdin>", line 1
f" { x b
^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?
vs 3.11pycon
f" { x b
File "<stdin>", line 1
f" { x b
^
SyntaxError: unterminated string literal (detected at line 1)
 :ok_hand: applied timeout to @muted flume until <t:1741202515:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
:ok_hand: applied timeout to @muted flume until <t:1741202515:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
:incoming_envelope: :ok_hand: applied timeout to @torpid jay until <t:1741209909:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
could f_locals['\x00'] = ... cause any issues lol
dunno. If so it'd be a bug that should be reported and fixed
but it'd probably be better to just use f_locals["yourlibraryname variablename"] or something
or f_locals["libraryname.variablename"]
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
hi
:incoming_envelope: :ok_hand: applied timeout to @azure ridge until <t:1741306628:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
!e
import argparse
a = argparse.ArgumentParser()
a.add_argument("--world", action="store_true")
print(a.parse_args(["--wo"]))
print(a.parse_known_args(["--wo"]))
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | Namespace(world=True)
002 | (Namespace(world=True), [])
anybody know the inevitably sad story behind this behavior? I know it's controlled by the allow_abbrev argument, which defaults to True
but yeah, this is pretty wild. It's pretty sketchy even for parse_args but for parse_known_args it's beyond that I would say
I guess people saw thsi behavior in some GNU utilities and decided they liked it
The Zen of Python (line 11):
In the face of ambiguity, refuse the temptation to guess.
is there any video explaining cpython object internals ?i am looking for it for a educational insttute
if you know a good one i would love it to be shared

Chapters:
00:00 CPython setup and Intro to int type
09:21 Sum up two integers using Python/C API
20:39 Introduction to Python List type
32:00 len and len() support to Integer object
43:24 Introduction to NoneType type
55:55 Exploring CPython NoneType implementation
1:09:02 Making changes to NoneType source code in CPython
1:14:36 Making chan...
free game!
not the right channel but tried to clean it
Please react with ✅ to upload your file(s) to our paste bin, which is more accessible for some users.
@unkempt rock , funny game it is!
@clear carbon please ask https://discord.com/channels/267624335836053506/267624335836053506
I have a potentially stupid question about "broken iterators": https://docs.python.org/3/library/stdtypes.html#iterator-types
Once an iterator’s
__next__()method raises StopIteration, it must continue to do so on subsequent calls. Implementations that do not obey this property are deemed broken.
Why does this rule exist? It's clearly violated by file objects, for example. So you cannot realistically rely on it
maybe it should be change from "must" to "should" or something like that
maybe I'm missing something
That is true for file objects unless you seek, though, right? I think it really means that once you get a StopIteration, every future next() call will raise a StopIteration unless you call some other method that changes the state
Async generator aclose/asend is also broken
Hello everyone , I have a very silly question. I don’t understand computer languages, but I want to try learning them. I’m curious, where do you write code?🫣
Could you ask in #python-discussion ? That's the 'general' Python channel
thenk you

A tour of CPython's runtime (Video, VMIL 2024)
Brandt Bucher
(Microsoft)
Abstract: Depending on how you ask, Python consistently ranks among the top 5 programming languages in use today. It is a dynamic, interpreted language with powerful support for deep introspection and a rich ecosystem of native extensions, maintained for free by a small te...
!e
Interesting consequence of the subclassing rule for operator overloading. Making a no-op subclass can change the behaviour
class Int:
def __init__(self, value):
self.n = value
def __add__(self, other):
if not isinstance(other, Int):
return NotImplemented
return Int(self.n + other.n)
def __repr__(self):
return f"{self.__class__.__name__}({self.n})"
class BetterInt(Int):
pass
class IntFoo(Int):
def __add__(self, other):
if not isinstance(other, Int):
return NotImplemented
return IntFoo(self.n + other.n)
__radd__ = __add__
print(f"{Int(5) + Int(3) = }")
print(f"{IntFoo(5) + IntFoo(3) = }")
print(f"{IntFoo(5) + Int(3) = }")
print(f"{Int(5) + IntFoo(3) = }")
print(f"{BetterInt(5) + IntFoo(3) = }")
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | Int(5) + Int(3) = Int(8)
002 | IntFoo(5) + IntFoo(3) = IntFoo(8)
003 | IntFoo(5) + Int(3) = IntFoo(8)
004 | Int(5) + IntFoo(3) = IntFoo(8)
005 | BetterInt(5) + IntFoo(3) = Int(8)
cool
If you spam to meet the requirement, you will be banned from verifying!
I recommend engaging in conversations in #python-discussion
Why not allow relative imports of a different top level module? Users seem to really expect that if they've run python dir/foo.py they'll be able to import dir/bar.py with from . import bar. They can't, and need to do import bar instead, but it's really tough to explain why to them, and it's a question that comes up a lot
So like, from above the cwd?
When you run python dir/foo.py, dir/ is implicitly added to the module search path, which allows import bar to work, but from . import bar still won't work in foo.py, because the interpreter only allows using relative imports to import other submodules of a common parent package
I suspect that there's no technical reason for that, and the restriction exists only as a way to prevent confusion, but I think it's having the opposite effect, by making it so that something people naively expect to work fails for no particularly good reason
Is it not currently recommended to always use an absolute import anyhow? I've honestly lost track of what the best practice is
Feels like there's been a lot of arguing in this space
No, relative imports are frequently recommended. They're less verbose and less likely to need to change as a result of refactoring.
Python 2's legacy implicit relative imports were strongly discouraged, but they were of course removed in Python 3
There used to be an even worse system for relative imports?
Yeah, in Python 2, running import bar from somemodule.foo would try importing the bar top level module, and if that wasn't found it would instead try importing the somemodule.bar module. Basically import x used to automatically behave like ```py
try:
import x
except ImportError:
from . import x
Except that until Python 2.7 (I think?) the explicit relative imports weren't supported. This used to be the only way to do relative imports
Ah, no, I misremembered, it tries the two in the other order
import x used to automatically behave like ```py
try:
from . import x
except ImportError:
import x
Don't think I've seen people try it with plain modules, but it does frequently come up when there are multiple packages with no parent package above them.
Nothing immediately springs to mind for why not to do an implicit parent package for relative imports in these cases, assuming the import system supports it without an actual package name, though I guess you could just use some generated dummy.
fwiw you can still import with relative paths if you do python -m dir.foo but then it'll put the cwd in the search path instead of dir/, and the directory ought to have an __init__.py as it's a package
for relative imports I prefer them for imports that are tightly coupled within the package (or its parents), it's also more visible in the imports separated from other first party imports. I've had some horribly long import statements when I was had to always use absolute imports because of a style guide
Not completely on topic but I heard someone recommend turning your modules into packages and installing them.
Where does that fall in the recommended/not recommended scale?
Probably worth it to have one big installable package with everything in
You might want to ask in #packaging-and-distribution maybe or #tools-and-devops
!pep 768
Status
Draft
Python-Version
3.14
Created
25-Nov-2024
Type
Standards Track
Just got accepted; the status isn't updated yet. This is really cool.
A key application of this interface will be enabling pdb to attach to live processes by process ID, similar to gdb -p, allowing developers to inspect and debug Python applications interactively in real-time without stopping or restarting them.
:incoming_envelope: :ok_hand: applied timeout to @summer zenith until <t:1742257145:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
it'll be tight delivering that in time for 3.14, but hopefully!
I propose a new release schedule:
release 3.14 on March 14
release 3.15 on March 15
...
i hope not of the same year, else the devs are gonna face hella crunch time
also, when would 3.32 release?

00:00 - Intro
4:52 - Restrict All Code
9:19 - All Loops Need A Fixed Upper Bound
10:37 - No Dynamic Memory Allocation
14:06 - 60 Lines
15:49 - 2 Assertions Per Function
19:28 - Data Objects
21:10 - Functions
24:29 - Limited Use Of Preprocessor
29:53 - Restricted Pointers
30:13 - Code Must Be Compiled Day 1
Twitch https://twitch.tv/ThePrimeage...
Out of interest: You mentioned Memray (obviously) and DebugPy as tools doing risky things currently. Is py-spy in the same category? Or is that only reading memory, which might fail but not in a way that can cause any problems with the Python process? What does e.g. Memray write into memory for?
py-spy doesn't inject code into a running process, AFAIK.
Why doesn't writable gzip.GzipFile have a .name attribute?
It looks intentionally done from the code
Lib/gzip.py line 222
self.name = filename```There's an if read mode above that line
Oh it's set in _init_write https://github.com/python/cpython/blob/f141e8ec2a2e8d21fc08c1f56ef40104c7a7fad2/Lib/gzip.py#L261
Lib/gzip.py line 261
self.name = filename```@wildcorg
python is very powerful pro lang
I love python
I am going to be python expert and I will looking for cool python investor
Anyone know where PRs can be sent for the website? 3.8 is still listed as active and 3.14 is unhelpfully at the top of the list rather than 3.13 https://www.python.org/downloads/

GitHub
Source code for python.org. Contribute to python/pythondotorg development by creating an account on GitHub.
Nice thanks
Is there a reason the _suggestions module wouldn't be available on Windows? I'm scratching my head thinking I must be doing something wrong, cloned and rebuilt many times, but I just can't python -c "import _suggestions" to work in that platform. There are no tests for this module and it's only imported in traceback.py with a guard against ImportError. Maybe it's somehow missing in the Windows build?
It seems _suggestions is just missing from PC/config.c, applying the following patch makes it work on Windows for me:
diff --git a/PC/config.c b/PC/config.c
index b744f711b0d..4fb27cdaa3b 100644
--- a/PC/config.c
+++ b/PC/config.c
@@ -11,6 +11,7 @@ extern PyObject* PyInit_binascii(void);
extern PyObject* PyInit_cmath(void);
extern PyObject* PyInit_errno(void);
extern PyObject* PyInit_faulthandler(void);
+extern PyObject* PyInit__suggestions(void);
extern PyObject* PyInit__tracemalloc(void);
extern PyObject* PyInit_gc(void);
extern PyObject* PyInit_math(void);
@@ -112,6 +113,7 @@ struct _inittab _PyImport_Inittab[] = {
{"msvcrt", PyInit_msvcrt},
{"_locale", PyInit__locale},
#endif
+ {"_suggestions", PyInit__suggestions},
{"_tracemalloc", PyInit__tracemalloc},
/* XXX Should _winapi go in a WIN32 block? not WIN64? */
{"_winapi", PyInit__winapi},
Anyone with free time willing to take a look at the crashes I reported in https://github.com/python/cpython/issues/113148 to assess whether they deserve their own issue?

GitHub
One of the first thing that happens during interpreter finalization is waiting for all non-daemon threads to finish. This is implemented by calling threading._shutdown(). If an exception is raised ...
it looks like a flavor of https://github.com/python/cpython/issues/128639

GitHub
Crash report What happened? I found this issue a little while back, but I'm finally getting around to fixing it. Currently, subinterpreter finalization assumes that there's only one thread ...
AFAICT any lingering thread in a subinterpreter will currently crash during finalization
Thanks!
tfw it's awaiting merge
!pep 751
Status
Draft
Created
24-Jul-2024
Type
Standards Track
This got accepted only a few hours ago
Very cool. Glad to see it.
inb4 someone posts that xkcd about standards
How interoperable would this be with existing standards? Is this a superset or a subset of some other standard?
i want create complet ai agent for whatsapp automation
That's off topic for this channel, and probably against the ToS of WhatsApp
I have no idea about what's going on here: https://github.com/python/cpython/issues/131998
GitHub
Crash report What happened? The following code segfaults the interpreter: import glob for x in range(3): str_globber = glob._StringGlobber(None, None) str_globber.selector(set()) try: str_globber.s...
this is a really interesting bug. the interpreter is specializing the bound method call for list_instance.pop(), but the specialized instruction is also used for executing the subsequent list.pop(), which then has a NULL self reference because it's unbound, so it crashes when trying to dereference that.
@uneven raptor Here's some very similar code to that bug, but it results in a failed assert instead:
import difflib
obj = difflib.HtmlDiff(None, None, None, None,)
try:
for x in range(3):
obj._split_line([], None, None)
except:
pass
obj._split_line(list, None, None)
Results in:
python: Python/generated_cases.c.h:3345: _PyEval_EvalFrameDefault: Assertion `self_o != NULL' failed.
Program received signal SIGABRT, Aborted.
Should be fixed by your PR too?
that's in a different instruction, go ahead and make a new issue
Thanks!
Would anyone be interested in a Windows build config to suppress the (IMO oh so annoying  ) dialog that pops up when an abortion triggers? It's a tiny change in code, not sure how easy to make it a build time option.
) dialog that pops up when an abortion triggers? It's a tiny change in code, not sure how easy to make it a build time option.
Was curious on why methods in Python have to receive the self parameter whereas in other languages you can just access the instance by using this.. Couldn't find any articles on this.
☝️ just to clarify: I'm not curious on why we call it self instead of this but rather why we need to receive it instead of using it implicitly
One reason is because it's less magical and let's stuff like decorators interact with it, for say caching
there's no reason why it has to be implicit or has to be explicit, languages just choose one way or the other. C++ now even lets you the user choose on a per method basis whether you want an explicit parameter for the instance or not - https://www.youtube.com/watch?v=78JQq52A0b0
saw this sticker on the Shapez2 server, makes you think of some languages (and programs)

As another data point, Lua also has explicit self
...actually, it seems like it also has ~two options https://www.lua.org/pil/16.html
Rust also has explicit self, because you need to mark whether the "subject" is moved into the function, passed by reference, mutable reference, Pin, etc.
I think the reason that C++ now has two options is that they've realized that there are some disadvantages to implicit this that are solved by having an explicit version. Arguably it just means that they've realized they made the wrong choice, but can't change it now, and so they've given you a way to fix it yourself in places where you're limited by the old behavior 🙂
not quite so much, because no one is suggesting that you should always use the explicit self option in C++, but something along those lines
is this the kind of reason C++ added the option?
I think it's more about introspection and the ability to actually use that type

Explicit object parameter gives us a new way of declaring non-static member functions. In this talk, I will show you how this feature works and how it can simplify your code.
Recorded at StockholmCpp 0x26, https://www.meetup.com/stockholmcpp/events/291540648/
The event was kindly hosted by OHB Sweden, https://www.ohb-sweden.se
More about C++ us...
that gives a compelling usage example
oh, kinda like typing.Self
hm, typing.Self doesn't do anything at runtime, but in that example they're defining a function template (approximately a generic function) whose return type differs depending on the constness of the object it was called on
which is sort of like the Rust case -- not is the subject moved or passed by reference, but is the subject const or non-const -- coupled with some overloading to do something reasonable for each case
for a less toy version of the example on that slide, think of something like a vector, which has a front() method. You can call front() on a const vector<T> and it returns const T& (a const reference to a T), and you can call front() on a vector<T> and it returns a T& (mutable reference to T). That sort of pattern is very common, and up until C++23 you pretty much needed to implement it by defining the function twice, with near-identical bodies
Rust actually needs to duplicate methods for exclusive (&mut self) and shared (&self) references
Like:
https://doc.rust-lang.org/std/vec/struct.Vec.html#method.get
https://doc.rust-lang.org/std/vec/struct.Vec.html#method.get_mut
this code is indented in an absurd way, I remember there was some reason for this (Tabs that are supposed to expand to 3 spaces?..)
looks better in Raw
tabs are 8 spaces wide, but each level of indentation is 2 spaces wide, and every time you hit 4 levels of indentation it's replaced by a tab
-# 🥴
and braces get their own indent level - https://github.com/gcc-mirror/gcc/blob/93acd068af65c4a73ddaee6a8e36f016bde3df9d/libstdc%2B%2B-v3/include/bits/stl_vector.h#L1419
lmao
neither the indent level of the if nor the code inside it
legend has it that the reason that GNU's coding style is so weird is that they wanted to make sure that, if you put a slide of their code up next to a slide of anyone else's implementation of the same function in a courtroom, a jury made up of laypeople would decide that they're nothing alike, which is much easier than trying to prove that they didn't use any proprietary code
or at least, that's why it was so weird 30 years ago. Now it's so weird because of inertia 🙂
super() without arguments literally having to rely on the name being self
... does it?
!e ```py
class Foo:
def init(this):
this.x = 10
class Bar(Foo):
def init(this):
super().init()
print(Bar().x)```
:white_check_mark: Your 3.12 eval job has completed with return code 0.
10
!e No, but it does depend on the name being super: ```py
parent = super
class Foo:
def init(this):
this.x = 10
class Bar(Foo):
def init(this):
parent().init()
print(Bar().x)
:x: Your 3.12 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 11, in <module>
003 | print(Bar().x)
004 | ^^^^^
005 | File "/home/main.py", line 9, in __init__
006 | parent().__init__()
007 | ^^^^^^^^
008 | RuntimeError: super(): __class__ cell not found
Maybe that's what @gilded flare was thinking of?
maybe i mixed it up with another thing
!e
Also this maybe ```py
class Foo:
def init(*args, **kwargs):
args[0].x = 10
class Bar(Foo):
def init(*args, **kwargs):
super().init()
print(Bar().x)
:x: Your 3.12 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 9, in <module>
003 | print(Bar().x)
004 | ^^^^^
005 | File "/home/main.py", line 7, in __init__
006 | super().__init__()
007 | ^^^^^^^
008 | RuntimeError: super(): no arguments
that's one of the errors of all time
(it is valid to call super() with no arguments, but something else is missing here)
ah
it needs at least 1 argument
i do distinctly remember some special case somewhere where the first argument has to be named self but i guess that's not there
right yeah it attached to the first "normal" argument
Rounding an int by a large positive ndigits is instantaneous, while a by a large negative number takes ages:
>>> large_number = 2**31
>>> large_negative_number = -2**31
>>> d = 17000
>>> d.__round__(large_number) # Instant result, returns d
17000
>>> d.__round__(large_negative_number) # Takes forever, calculating divmod(d, int(pow(10, large_negative_number)))
It could be almost as fast as the positive ndigits case by checking:
int(math.log10(d)) < abs(large_negative_number)
And returning zero if it's True.
I see no practical use case for this optimization, other than it would avoid a rare timeout when fuzzing CPython 😄
The same optimization can easily be applied to Fraction
Somebody might frame this as a DOS vulnerability
If the code change is simple might be worth fixing it
Also I think "making fuzzing easier" is a somewhat reasonable reason to change it. Fuzzing is useful, if we can make a simple change to make it work better, let's do it
For Fraction, the change is as simple as:
diff --git a/Lib/fractions.py b/Lib/fractions.py
index f0cbc8c2e6c..32b63e59899 100644
--- a/Lib/fractions.py
+++ b/Lib/fractions.py
@@ -971,6 +980,8 @@ def __round__(self, ndigits=None):
return floor
else:
return floor + 1
+ if ndigits < 0 and int(math.log10(self)) < abs(ndigits):
+ return Fraction(0, 1)
shift = 10**abs(ndigits)
# See _operator_fallbacks.forward to check that the results of
# these operations will always be Fraction and therefore have"
I expect it to be simple for ints too, but I can't code the necessary C. I'll open an issue suggesting this optimization for ints and Fractions and offer to submit a PR for Fraction.
!cleanban @steady ember scam
:incoming_envelope: :ok_hand: applied ban to @steady ember permanently.
Here's a script that stresses a free-threading build, and a couple of crashes it causes: https://gist.github.com/devdanzin/c08c9c6b3158e1d79ea3ac0bd5a195ef
There's a good chance that it all boils down to known non-threadsafe classes being held wrong, just posting in case there is something interesting in the backtraces. Oh, and if you see anything worth an issue, feel free to create one 😉

Gist
Some CPython free-threading crashes. GitHub Gist: instantly share code, notes, and snippets.
I've got a ctypes abort that might be valid for fixing:
>>> ctypes.CField(name="a", type=ctypes.c_byte, byte_size=2, byte_offset=2, index=1, _internal_use=True)
python: ./Modules/_ctypes/cfield.c:102: PyCField_new_impl: Assertion `byte_size == info->size' failed.
Aborted (core dumped)
I think it should check whether byte_size == info->size and give an error if not, instead of aborting. OTOH, ctypes is crash-prone and it won't abort in release builds. What do you think?
Yes that should be fixed
yeah, array isn’t thread-safe right now. there was recently a fix that used critical sections, but the performance hit was so bad that it got reverted. there’s an outstanding PR for doing it locklessly but it hasn’t landed yet.
I think some of the crashes happen with dict, odict and list.
Got an abort and a segfault for the same code, but they happen rarely and the (2.7k lines) repro is prone to deadlocking. Bad for reducing the test case.
Maybe you can understand what's going on from the backtraces and a bit of context? The code exercises the threading module in a no-gil build. It calls random functions with randomly chosen (at time of code generation, so they're the same when reproducing) arguments. Sometimes this abort happens:
python: Python/legacy_tracing.c:435: is_tstate_valid: Assertion `!_PyMem_IsPtrFreed(tstate)' failed.
Thread 1 "python" received signal SIGABRT, Aborted.
[...]
#5 0x00007ffff7cc671b in __assert_fail_base (fmt=0x7ffff7e7b130 "%s%s%s:%u: %s%sAssertion `%s' failed.\n%n",
assertion=0x555555b53aa9 "!_PyMem_IsPtrFreed(tstate)", file=0x555555b53a91 "Python/legacy_tracing.c", line=435,
function=<optimized out>) at ./assert/assert.c:94
#6 0x00007ffff7cd7e96 in __GI___assert_fail (assertion=assertion@entry=0x555555b53aa9 "!_PyMem_IsPtrFreed(tstate)",
file=file@entry=0x555555b53a91 "Python/legacy_tracing.c", line=line@entry=435,
function=function@entry=0x555555b53ed0 <__PRETTY_FUNCTION__.18> "is_tstate_valid") at ./assert/assert.c:103
#7 0x000055555594a667 in is_tstate_valid (tstate=tstate@entry=0xdddddddddddddddd) at Python/legacy_tracing.c:435
#8 0x000055555594c0c2 in _PyEval_SetTrace (tstate=tstate@entry=0xdddddddddddddddd,
func=func@entry=0x5555559984b0 <trace_trampoline>,
arg=arg@entry=('\ua8eb\u3ac7\ua63b\u9b1a\u2cf8\u0c50\uebe8', '\uf48c\udd90\u76a7\u1805\u0f36\ua44c\u0caf\u47f9\ubfad\ue203\u0223\u7107\u97ad\u114a', '\u02a5\u080e\u5326\ua8e9\u465b\u0387\u47dc\uc5dc\uc20f\ucdfd\u875e\ue9a3', '\u3fb3\u0880\u16f5\ud59d\u83dd', '\u8afe\u2bf0\u2ec1\u4d87\u8adc\u66fd\u19a1\u60da\uc328\u15ce')) at Python/legacy_tracing.c:596
#9 0x000055555584cd32 in PyEval_SetTraceAllThreads (func=0x5555559984b0 <trace_trampoline>,
arg=('\ua8eb\u3ac7\ua63b\u9b1a\u2cf8\u0c50\uebe8', '\uf48c\udd90\u76a7\u1805\u0f36\ua44c\u0caf\u47f9\ubfad\ue203\u0223\u7107\u97ad\u114a', '\u02a5\u080e\u5326\ua8e9\u465b\u0387\u47dc\uc5dc\uc20f\ucdfd\u875e\ue9a3', '\u3fb3\u0880\u16f5\ud59d\u83dd', '\u8afe\u2bf0\u2ec1\u4d87\u8adc\u66fd\u19a1\u60da\uc328\u15ce')) at Python/ceval.c:2473
#10 0x000055555599698e in sys__settraceallthreads (module=<optimized out>, arg=<optimized out>) at ./Python/sysmodule.c:1187
And sometimes this segfault:
arg=arg@entry=('\xae\x96\xb53\xd7&\x82\x96\x1f\x9dW\r\xbb\x1b\x11\xe4', '5\xe2\xbc\x03\x91s\xa7\xdb', '\xe4\xce\xd0\x0f\x05'),
old_traceobj=old_traceobj@entry=0x7ffea7fe67c0) at Python/legacy_tracing.c:588
#1 0x000055555594c141 in _PyEval_SetTrace (tstate=tstate@entry=0x555555e7d340, func=func@entry=0x5555559984b0 <trace_trampoline>,
arg=arg@entry=('\xae\x96\xb53\xd7&\x82\x96\x1f\x9dW\r\xbb\x1b\x11\xe4', '5\xe2\xbc\x03\x91s\xa7\xdb', '\xe4\xce\xd0\x0f\x05'))
at Python/legacy_tracing.c:610
#2 0x000055555584cd32 in PyEval_SetTraceAllThreads (func=0x5555559984b0 <trace_trampoline>,
arg=('\xae\x96\xb53\xd7&\x82\x96\x1f\x9dW\r\xbb\x1b\x11\xe4', '5\xe2\xbc\x03\x91s\xa7\xdb', '\xe4\xce\xd0\x0f\x05'))
at Python/ceval.c:2473
#3 0x000055555599698e in sys__settraceallthreads (module=<optimized out>, arg=<optimized out>) at ./Python/sysmodule.c:1187
#4 0x00005555557110b6 in cfunction_vectorcall_O (
func=<built-in method _settraceallthreads of module object at remote 0x20000259930>, args=<optimized out>,
nargsf=<optimized out>, kwnames=<optimized out>) at Objects/methodobject.c:537
#5 0x00005555556817dd in _PyObject_VectorcallTstate (tstate=0x555555e81990,
callable=<built-in method _settraceallthreads of module object at remote 0x20000259930>, args=0x7ffea7fe6b48,
nargsf=9223372036854775809, kwnames=0x0) at ./Include/internal/pycore_call.h:169
#6 0x00005555556818fc in PyObject_Vectorcall (
callable=callable@entry=<built-in method _settraceallthreads of module object at remote 0x20000259930>,
args=args@entry=0x7ffea7fe6b48, nargsf=<optimized out>, kwnames=kwnames@entry=0x0) at Objects/call.c:327
#7 0x000055555585575c in _PyEval_EvalFrameDefault (tstate=tstate@entry=0x555555e81990, frame=0x7ffff6c2c1a8,
frame@entry=0x7ffff6c2c020, throwflag=throwflag@entry=0) at Python/generated_cases.c.h:1434
[...]```Hm, the segfault happens like this:
Thread 1951 "Thread-1940 (se" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7ffe89fcb640 (LWP 3390642)]
0x000055555594c121 in _PyEval_SetTrace (tstate=tstate@entry=0x5555559984b0 <trace_trampoline>, func=func@entry=0x5555559984b0 <trace_trampoline>, arg=arg@entry=('\xae\x96\xb53\xd7&\x82\x96\x1f\x9dW\r\xbb\x1b\x11\xe4', '5\xe2\xbc\x03\x91s\xa7\xdb', '\xe4\xce\xd0\x0f\x05')) at Python/legacy_tracing.c:609
609 assert(tstate->interp->sys_tracing_threads >= 0);
Here's a lucky reduced test case for at least the abort:
import threading
for x in range(1000):
threading._start_joinable_thread(lambda: None)
try:
threading.settrace_all_threads(())
except Exception:
pass
please report a bug 🙂
the issue is that the thread state is getting deallocated while calling PyEval_SetTraceAllThreads
go ahead and make a bug report, we can stop-the-world if PyEval_SetTraceAllThreads isn't re-entrant, or increment the thread state's reference count if it is

GitHub
Crash report What happened? The following code will cause the interpreter to abort in a no-gil build: import threading for x in range(1000): threading._start_joinable_thread(lambda: None) try: thre...
nice MRE!
tstate deallocation is killing me on this fix. there are like, 15 different functions that can free them, or sometimes they just straight up leak.
!pep 750 has been accepted 
Status
Accepted
Python-Version
3.14
Created
08-Jul-2024
Type
Standards Track
It'll be interesting to see how it's used
I don't get the point of it
py pi will be quite an update
it's about being able to auto-escape in templates. Like shell, html, sql, regex, etc
Allows you to safely do
session.execute(t"SELECT * FROM users WHERE name={name}")
No more having to guess if your database engine uses ?, %s/:foo, %(foo)s or some other thing
unexpected pep acceptance
woah
will it make the beta freeze deadline
very likely
I just realized fusil isn't fuzzing anything related to typing. Will add some stuff like int | str to see if anything chokes on it (or it breaks when held wrong). Any suggestions on tricky typing constructs that could help?
Examples of other tricky stuff that it already uses: numbers at boundaries (max int, max_size, etc.), strings with weird surrogates and null bytes, recursive lists etc.
It's mostly looking for C-level crashes, right? typing is mostly in Python so not that interesting in terms of C-level fuzzing. Parts that are in C are:
- Unions (only
x | yunions in 3.10-3.13, all unions in 3.14) - PEP 585 generic aliases (
list[str]) - Type aliases (3.12+)
- Generic/TypeVar/ParamSpec/TypeVarTuple (3.12+)
Thank you, that helps a lot!
It finds quite a bit of C crashes by exercising pure Python modules, because that's where you can find a lot of different paths in C code.
Fuzzing pure C modules only is a good plan with coverage based fuzzers. Humble fusil doesn't go very far there. 🙂
typing also does a lot of weird things with ABCs I think, so quite possible you'll find something interesting there!
>>> isinstance(1,i)
True
>>> isinstance(1.0,i)
Traceback (most recent call last):
File "<python-input-26>", line 1, in <module>
isinstance(1.0,i)
~~~~~~~~~~^^^^^^^
TypeError: isinstance() argument 2 cannot be a parameterized generic
Would this be a bug?
Where i is:
>>> i = int
>>> for x in range(10000):
... class cls(lc): pass
... i|= cls
... i |= list[x]
no that's expected due to short circuiting
also your repro case could be considerably simpler 🙂
isinstance(x, T | V) unwraps the union into separate instance checks, and the rest is explainable by the error message
Yeah, I was actually just checking how long it took to build an unreasonably large Union to see if it was feasible to use it as fuzzing fodder. I'll have to settle for pretty large instead 🙂
Thanks!
I'm working on this little library to "connect" dataclasses to argparse
I have most things I'm targetting either working or know how to get them working; e.g.
@dataclass
class MyArgs:
first_arg: int = positional(default=1)
second_arg: float | None = option(default=None)
ex1: ClassVar[Exclusive] = exclusive_group()
foo: int | None = option(default=None, exclusive_group=ex1)
bar: int | None = option(default=None, exclusive_group=ex1)
I'm now tackling subparsers though, which is probably easily the most complex feature
I'm wondering what the best way is to integrate it. There's a couple quesitons - what would the data representation look like, and where will the subparser names/commands come from
Here's one take
subcommand: Sub[SubCommand1, "sub1"] | Sub[SubCommand2, "sub2"] = subparsers()
Sub would be some kind of TypeAlias to Annotated here
You could even in principle stuck the information on how to initialize the ArgumentParser for each sub-parser in the Annotated.
this approach feels a bit bleh because it really makes the type annotation messy
And once the data is actually parsed, all you are looking at is the type annotation, so you sort of want to keep that clean, IMHO
you could put it in subparsers but then it's "far" from the actual subcommands
subcommand: SubCommand1 | SubCommand2 = subparsers(["sub1", "sub2"]) # kind of error prone
And finally, you could put the name of the sub-command into the actual types:
@dataclass
class SubCommand1:
glug: int = option(default=0)
subcommand_name: str = "sub1"
But now you're pushing it "down" and forcing the subcommand struct to be aware of the fact that it's a sub-command - if not for this, then in principle you could have the same struct used as a command in one place and as a sub-command in another
Any news on getting a backport like future-fstrings?
!pip future-fstrings

A backport of fstrings to python<3.6
Released on <t:1560654282:D>.
future-fstrings is a joke package that incidentally became classified as critical to pypi
It only needs to be maintained for 5 years
https://docs.python.org/3/library/re.html#regular-expression-objects
Why do the methods of re.Pattern objects have optional pos and endpos parameters, while functions like re.search and re.match don't?
Given that re.match etc. just call re.compile and operate on the result I see no good reason for it.
If anybody wants to try something fun, check out this PR: https://github.com/python/cpython/pull/132451
GitHub
Initial proof-of-concept and design. This is lacking tests and documentation, but otherwise works well, and it would be very helpful if anyone interested can try it out!
It has been tested on macOS...
build that and you'll be able to use python -m pdb -p PID to attach PDB to an already-running Python (3.14a) process
and if anyone tries it and can't get it working, let me know - that'd be a useful piece of data too 😅
so I have sub-parsers working in the end; here's how it looks like now.
@dataclass
class SubCommand1:
glug: int = option(default=0)
subparser_name: ClassVar[str] = "sub1"
@dataclass
class SubCommand2:
garg: int = option(default=2)
subparser_name: ClassVar[str] = "sub2"
@dataclass
class MyArgs:
first_arg: int = positional()
second_arg: float | None = option(default=None)
ex1: ClassVar[Exclusive] = exclusive_group()
foo: int | None = option(default=None, exclusive_group=ex1)
bar: int | None = option(default=None, exclusive_group=ex1)
sub: SubCommand1 | SubCommand2 | None = subparsers(default=None)
I'm wondering if there's any chance there would be interest in this for the standard library.
- it can express almost any common usage of argparse
- it saves boilerplate and substantially improves the efficacy of type checking
- the things it cannot express directly - it should be very easy to allow users to just call
add_argumentdirectly and supplydestto make it work the way they want - it's pretty simple implementation wise - I need to add more things, but it's currently only about 300 lines of code
- it doesn't use anything (at runtime) except dataclasses and argparse, so no dependencies outside the standard library
- everything it does maps relatively simple to argparse commands - so you get to "reuse" much of the knowledge and docs of argparse
- it's far less magical and opinionated, and does less, than some of the popular command line parsing third party libs like click, which would probably be much less of a good fit for the standard library
- but still saves you most of the important boilerplate that those third party libraries do. Calling a function is much less of an issue than conveniently accessing your parsed data.
here's the help for the above parser
❯ python scratch2.py --help
usage: scratch2.py [-h] [--second-arg SECOND_ARG] [--foo FOO | --bar BAR] first_arg {sub1,sub2} ...
positional arguments:
first_arg
{sub1,sub2}
options:
-h, --help show this help message and exit
--second-arg SECOND_ARG
--foo FOO
--bar BAR
currently, it automatically handles type for things annotated int, float, or Path - if you don't supply type yourself.
I'm also going to add support for using Literal or Enum annotations, to automatically populate choices (again - if you don't override it yourself)
(I also don't yet support arbitrary-nested sub-parsers, though I don't think that will be too bad)
I love the order of imports 😄

I just matched the pattern 😅
imports.sort(key=len)
Please send me a sample code that can launch a specific browser on my computer using Python. I'm not very good at doing it.
help me
This is the wrong channel for that. Try #python-discussion or #1035199133436354600 . Good luck!
ok, thanks
Another day, another rare segfault I don't understand. This one came about exercising tkinter code, but I believe it's not related to that module. On a free-threaded debug build on Linux, took hundreds of runs of a 20k loc script to trigger again.
Backtrace ends like:
#0 __GI_getenv (name=name@entry=0x55555590041b "PYTHON_LLTRACE") at ./stdlib/getenv.c:31
#1 0x0000555555823b97 in Py_GETENV (name=name@entry=0x55555590041b "PYTHON_LLTRACE") at Python/initconfig.c:567
#2 0x00005555557aa06d in maybe_lltrace_resume_frame (frame=frame@entry=0x20016090868, globals=<optimized out>) at Python/ceval.c:265
#3 0x00005555557d7c59 in _PyEval_EvalFrameDefault (tstate=<optimized out>, frame=0x20016090868, throwflag=<optimized out>) at Python/generated_cases.c.h:12212
#4 0x000055555568aa73 in _PyEval_EvalFrame (tstate=tstate@entry=0x555555d921d0, frame=frame@entry=0x20016090868, throwflag=throwflag@entry=0)
at ./Include/internal/pycore_ceval.h:119
#5 0x000055555568ae26 in gen_send_ex2 (gen=0x20016090810, arg=arg@entry=0x0, presult=presult@entry=0x7fff597ff260, exc=exc@entry=0, closing=closing@entry=0)
at Objects/genobject.c:259
#6 0x000055555568c366 in gen_iternext (self=<optimized out>) at Objects/genobject.c:634
#7 0x00005555556a4518 in list_extend_iter_lock_held (self=self@entry=0x20016372110, iterable=iterable@entry=<generator at remote 0x20016090810>)
at Objects/listobject.c:1258
https://gist.github.com/devdanzin/2e13e6ee1458cb3658733214012dbe70
Gist
A backtrace of a CPython segfault. GitHub Gist: instantly share code, notes, and snippets.
this might be due to the fact that envvars are not thread safe?
maybe something is writing to an env var
Thanks!
Hmm. Do you think testing threads writing and reading envvars be enough, or should the change happen outside of the process? Lemme try the threads way, BRB 🙂
Got nothing.
i thought there was an open issue about tkinter + free-threading being broken
sys.remote_exec is so cool. will pystack/memray be taking advantage of it?
Just threads should be enough. It's possible that the env var writes happen inside tkinter or something. Not too familiar with the details too but you may have to set the env var to a value with more characters than before or something like that
Can another process change the environment variables of a process?
Good point, I think not.
No
pystack won't, but memray attach eventually will
wait really, pystack won’t?
sys.remote_exec (and PEP 768 in general, really) are about telling the interpreter to run some code when it's safe to do so, but pystack needs to tell you what your program's stack is now, not later. sys.remote_exec won't be useful to pystack for the same reason as it won't be a useful way for a profiler to sample execution stacks - waiting arbitrarily long for the interpreter's main loop to reach a safe point to run Python code defeats the purpose of the tools
one of the best uses of pystack is finding deadlocks in C modules. If it depended on sys.remote_exec, it wouldn't be able to do that anymore, because those deadlocks would mean that the extension module never returns to the interpreter main loop, and the injected code never gets run. Or even something as simple as a time.sleep(1) - you'd never see a stack that includes the sleep call, because the injected command can't run until after it has returned
memray attach on the other hand doesn't mind waiting as long as it takes for the command injection to be done safely
memray attach starst a Memray tracker in the remote process, which requires allocating memory and starting threads, and so it very much needs to wait until the program being attached to isn't in the middle of a malloc call, since malloc isn't reentrant and calling malloc from inside malloc can deadlock or crash. Same for waiting until the program isn't in the middle of a call to pthread_create
@feral island fusil might have found a unionobject segfault, trying to reduce:
Thread 280 "Thread-279 (__s" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0xffff4d1af100 (LWP 91244)]
union_repr (self=<unknown at remote 0x20002c2e320>) at Objects/unionobject.c:296
296 PyObject *p = PyTuple_GET_ITEM(alias->args, i);
(gdb) bt
#0 union_repr (self=<unknown at remote 0x20002c2e320>) at Objects/unionobject.c:296
#1 0x0000000000596230 in object_str (self=<optimized out>) at Objects/typeobject.c:6814
#2 0x0000000000557bc0 in PyObject_Str (v=<unknown at remote 0x20002c2e320>) at Objects/object.c:819
#3 0x00000000004d63cc in BaseException_str (op=op@entry=<NoBoundaryInMultipartDefect(line=<types.GenericAlias at remote 0x20002c2dec0>) at remote 0x200005b1d80>)
at Objects/exceptions.c:184
#4 0x000000000059c34c in wrap_unaryfunc (self=<NoBoundaryInMultipartDefect(line=<types.GenericAlias at remote 0x20002c2dec0>) at remote 0x200005b1d80>,
args=<optimized out>, wrapped=0x4d6200 <BaseException_str>) at Objects/typeobject.c:9203
#5 0x00000000004ce6ec in wrapperdescr_raw_call (kwds=<optimized out>, args=<optimized out>, self=<optimized out>, descr=<optimized out>) at Objects/descrobject.c:532
#6 wrapper_call (self=<optimized out>, args=<optimized out>, kwds=<optimized out>) at Objects/descrobject.c:1439
#7 0x00000000004b9c5c in _PyObject_Call (tstate=0xc2beb0, callable=callable@entry=<method-wrapper '__str__' of NoBoundaryInMultipartDefect object at 0x200005b1d80>,
args=(), kwargs={}) at Objects/call.c:361
[...]
how does memray attach work right now? something akin to how PEP 768 works, i'm assuming?
mm, sort of - it uses either gdb or lldb to set a breakpoint on the start of some functions where we believe it's safe to do everything we need to do, and waits for one of those breakpoints to get hit
Py_AddPendingCall(&PyCallable_Check, (void*)0)...does that work?
yep!
ah, looks like PyCallable_Check has a NULL check. interesting.
or at least, it works in 3.7 through 3.13
Memray hasn't been tested with 3.14a yet
see https://github.com/bloomberg/memray/commit/52b3e1bffbeb193bcf0ad04603ab9020c1d586e1 for that particular hack
the commit message explains what we're doing there
you probably should, i'd be careful with relying on where pending calls get executed
that's something that's technically subject to change (though it probably won't)
we don't care where it gets executed
it just has to be when the interpreter is safe to invoke?
it is when the interpreter is safe to invoke
it needs to be, since the function can call into the interpreter
right, I was just confirming that was when the breakpoint had to get hit
though I can't remember when pending calls get executed during finalization--it might be at a point where you can't call the interpreter anymore, or at least right before it.
yep - the breakpoint wants to get hit somewhere where it's safe to run dlopen on a .so that we ship and then call a function from it that spawns a new thread
does that thread have to be PyGILState_Ensure'd/thread state attached?
yes
i'm near certain you'll get a crash if the process is about to finalize or already finalizing, then
not much you can do about it, but just worth being aware of. can the parent memray attach process handle it?
crash as in segfault?
yeah
I'm not sure what you mean by "handle it"
if the user asks us to start memory profiling a process, and that process then segfaults, there's not much we can do other than say "whoopsie"
well, yeah. does memray say "whoopsie," or some other abominable error? (or possibly even some sort of deadlock waiting on communication from the process?)
Interesting. NoBoundaryInMultipartDefect is a Python class so not sure how that one would get triggered
https://docs.python.org/3/c-api/init.html#c.PyGILState_Ensure says that PyGILState_Ensure will terminate the thread if it's called during finalization
if it causes a segfault instead, that sounds like a CPython bug
it is a cpython bug, and nobody wants to fix it 😄
You can use Py_IsFinalizing() or sys.is_finalizing() to check if the interpreter is in process of being finalized before calling this function to avoid unwanted termination.
no you can't, that's TOCTOU
yup, there's a DPO thread about this
I proposed an alternative recently because PyGILState_Ensure is incredibly broken
🤷♂️ if the interpreter segfaults, there's absolutely nothing we can do about it. We wouldn't even know it had happened, the most we would know is nothing ever connected to the server we spawned. I'm not sure if we'd report a timeout or just hang waiting for a connection until we get ctrl-c'd or something, though
but it can handle the thread getting hung, right?
I'm not sure what happens
probably we just hang here waiting forever for a connection: https://github.com/bloomberg/memray/blob/864fc2df02c7ccde7a0578ddf79ae062b89b3658/src/memray/commands/attach.py#L355
src/memray/commands/attach.py line 355
return server.accept()[0]```I'd have to test to be sure, though
i mean after the attach has already succeeded. the thread starts and connects, but then hangs waiting on the GIL/tstate once finalization starts. does memray just wait forever?
memray attach uses a debugger to get the remote process to import and call https://github.com/bloomberg/memray/blob/864fc2df02c7ccde7a0578ddf79ae062b89b3658/src/memray/_memray/inject.cpp#L226-L236
src/memray/_memray/inject.cpp lines 226 to 236
extern "C" __attribute__((visibility("default"))) int
memray_spawn_client(int port)
{
// Running Python code directly in the point of attaching can lead to
// crashes as we don't know if the interpreter is ready to execute code.
// For instance, we can be in the middle of modifying the GC linked list
// or doing some other operation that is not reentrant. Instead, we spawn
// a new thread that will try to grab the GIL and run the code there.
pthread_t thread;
return pthread_create(&thread, nullptr, &memray::thread_body, (void*)(uintptr_t)port);
}```and then it waits for the remote process to attach to a socket that it opened
the remote process crashes in between those two steps, I suspect it waits forever for something to attach
https://github.com/bloomberg/memray/blob/864fc2df02c7ccde7a0578ddf79ae062b89b3658/src/memray/commands/attach.py#L351 returns without an error if the debugger successfully called pthread_create and then detached
src/memray/commands/attach.py line 351
errmsg = inject(method, pid, sidechannel_port, verbose=verbose)```so we probably just hang forever without noticing the problem, since there's no timeout set on this socket
src/memray/commands/attach.py line 346
with contextlib.closing(server):```it's probably worth adding a timeout there
sure, wouldn't hurt
i'd submit a PR, but coming up with that finalization test case isn't a project I want to dive into right now 😅
eh, feel free to submit a PR anyway. I'd be happy with someone just manually testing it to confirm that I'm right that it does hang today
you could just change that return pthread_create(...); to a return 0; and confirm that it hangs - that's a perfectly good manual simulation of successfully spawning the thread and then never hearing from the remote process again
cool, i'll do it right now
Seems similar to https://github.com/python/cpython/issues/127192 due to depending on calling an exception's __init__ in threads (and hence may be invalid too), but somehow blows up in unionobject.
Here's a reproducer:
from threading import Thread
import abc, builtins, collections.abc
from functools import reduce
from operator import or_
abc_types = [cls for cls in abc.__dict__.values() if isinstance(cls, type)]
builtins_types = [cls for cls in builtins.__dict__.values() if isinstance(cls, type)]
collections_abc_types = [cls for cls in collections.abc.__dict__.values() if isinstance(cls, type)]
collections_types = [cls for cls in collections.__dict__.values() if isinstance(cls, type)]
all_types = abc_types + builtins_types + collections_abc_types + collections_types
big_union = reduce(or_, all_types, int)
for x in range(100):
alive = []
obj = ValueError(list)
alive.append(Thread(target=obj.__repr__, args=()))
alive.append(Thread(target=obj.__str__, args=()))
obj.__init__(list[list] | complex | big_union)
alive.append(Thread(target=obj.__init__, args=(list,)))
alive.append(Thread(target=obj.__str__, args=()))
for t in alive:
t.start()

GitHub
Crash report What happened? In a no-gil build with PYTHON_GIL=0, it's possible to get the interpreter to segfault or abort with the message Fatal Python error: PyMutex_Unlock: unlocking mutex t...
oh I guess the issue likely is that __str__ and __init__ run concurrently. __init__ resets the exception's args and meanwhile __str__ uses them, but in the middle of that the object gets destroyed
I wonder why passing a small Union to __init__ doesn't work, requiring the big_union dance.
maybe the big union takes longer to deallocate, making the race condition easier to hit
<@&831776746206265384> spam/scam
!cban 1334901911404679198 spam
:incoming_envelope: :ok_hand: applied ban to @simple swan permanently.
which mailing list would be a good start to gauge interest in a standard library addition?
python-ideas, I think?
The python-ideas list is for discussing more speculative design ideas.
How speculative does it mean 😛
it makes it sound a bit like people are tossing crazy ideas out. Whereas this is something that I already have a proof of concept for and want to see if there's interest on.
Okay, looking at the archive, these aren't too crazy. I will try to post something there, thanks!
ah wait
You're better off discussing this on discuss.python.org as this mailing list is basically dead.
😂
yeah mailing lists are mostly obsolete for python

Discussions on Python.org
Many other programming languages have argument parsing libraries that operate by simply writing a struct, with some additional annotations. The parser then just returns an instance of that struct. The python standard lib has argparse which is quite flexible and powerful, but it returns a very dynamic Namespace object. Users either have to live w...
this is the post fwiw
I do think this would be really nice - if you're using type checkers and dataclasses, then I think you'd really rather write
@dataclass
class MyArgs:
first_arg: int = positional()
second_arg: float | None = option()
ex1: ClassVar[Exclusive] = exclusive_group()
foo: int | None = option(exclusive_group=ex1, help="an argument!")
bar: int | None = option(exclusive_group=ex1, metavar="better_name")
...
x = parse_args(MyArgs) # x's type is MyArgs
and just receive an instance of MyArgs, that's fully statically checkable. Versus
ap.add_argument("first_arg")
ap.add_argument("--second-arg")
ex1 = ap.add_mutually_exclusive_group()
ex1.add_argument("--foo", help="an argument!")
ex1.add_argument("--bar", metavar="better_name")
ns = ap.parse_args()
so I honestly believe if this were available as part of the argparse module, a huge fraction of people would just use it
I think it'd be helpful if you called out what you're proposing to add to the API, specifically. Or at least a rough outline. It looks like, at a glance, you're adding:
positionaloptionExclusivesubparsers- and I guess a module scoped
parse_argsif I'm following correctly?
Is it just those 4 things, or is there more than that?
That's most of it right now - I'm still nailing down the API and fleshing things out. I was hoping to get some feedback to guide me on certain choices
The technically harder things seem to be mostly solved
I may instead for example go with a class that users inherit from - but obviously that's relatively superficial
Definitely, any feedback or thoughts from you are welcome.
I could always repost it once I have like a 0.1 release on pip or something like that
it's interesting... that's simpler than I was imagining... my intuition is that the odds of getting it into CPython are better the smaller the API surface is, but if it really is just ~5 functions, that's already quite small
Yeah. The implementation is only about 300 lines so far. And half that, no joke is the typing stubs
I wanted people to be able to write x: int | None = option().
But to also get a type error if they annotate x as simply int
Etc. various cases like that
optional needed 3 overloads iirc which was quite verbose (many arguments)
I think the API I'd pick is having a declarative way to describe the namespace (possibly a class that you inherit from, or possibly a decorator that's declared using typing.dataclass_transform). Then, rather than having a module level parse_args, I'd have the namespace object support a classmethod called create_parser or something like that which returns an argparse.ArgumentParser instance configured according to the fields. And you could have create_parser typed using a Protocol for its return value so that the parse_args of the created ArgumentParser will always return an instance of that namespace type
I'm not totally sure I know what you mean by declarative way to describe the namespace
But yes, I'm looking closely at using inheritance/protocols
I mean something very much like what you have
Hi I'm new in this and I wanted to know what is the best way to learn Python
The main reason for inheritance would be to give classes a) a way to say how they want Argument Parser constructed. And b) a way to declare their argument name, if they are to be used as sub-parsers
Also as a bonus, things like parse_args would probably just be a method now - one less thing to import
but imagine: ```py
@argparse.Namespace
class MyArgs:
first_arg: int = positional()
second_arg: float | None = option()
parser = MyArgs.create_parser()
args = parser.parse_args()
reveal_type(args) # MyArgs
``` I'm pretty sure you can do that with a little bit of typing.Protocol magic
try asking in #python-discussion
ok thanks
Probably what I'm currently imagining is
@dataclass
class MyArgs(DataParser):
...
args = MyArgs.parse_args()
But basically very similar
parse_args would just be a class method that returns cls
I think it's a bit harder to sell that, because it makes a new thing that can parse arguments. I think it's easier to sell MyArgs.create_parser().parse_args() because MyArgs.create_parser() "just" configures an ArgumentParser. You can argue that there's no magic hiding there, and there can never be any magic hiding there, it's just a convenience for configuring an ArgumentParser.
and in fact in almost every program I've ever used argparse in, I've needed access to the parser even after calling parse_args - I often need extra validation beyond what parse_args itself can do, and need to call parser.error() if some other validation fails. I really do think you want to give access to the parser
Are you deriving from ArgumentParser to make it return MyArgs?
no, just lying about its type in the annotations
That doesn't really work that well
Once you start having sub-parsers etc
It's much better to have an actual MyArgs instance. Like much, much better
ah, I see what you mean
But this issue is orthogonal to allowing access to the parser
We could have aparser, args = MyArgs.parse_args()
For instance - handles your use case
This is exactly the kind of conversation I was hoping to have btw in that discussion thread
I'm sure people regularly do things with argparse I don't - I want to hear about those things before making lots of small unimportant API decisions
I was negative on this the other day when you brought it up in this channel, but now I'm mildly positive on it, in large part because it seems like what you're actually proposing is a much smaller delta from what exists today than I had anticipated
Yeah, I'm trying very hard to make it relatively small and simple and unopionated
I just want to deliver the minimal improvements in type safety and reducing boilerplate slightly
x: int | None = option() also passes type=int to argparse for example
yeah, that seems reasonable
Yeah. I only do it for int, Path, and float
Not trying to get clever - just the common types where you want the obvious conversion 99 percent of the time. I won't do it for say datetime.date
I should really try to put a 0.1 on pip I think - if nothing else it may be the only way to show some people how small this can really be
that seems like a reasonable choice, but you might want to make it an error to use other types in the annotation at all
You can use another type in the annotation, but then you will get a type error if you don't supply type
It seems reasonable to say "I'm not gonna try to guess how to parse your date", but I think you should then say "It's an error to annotate a field as a datetime.date unless you also provide a function to do the parsing from string to date"
Yeah exactly
ah. Yep, exactly
I just need to nail down all the overloads...
It's kind of painful for a function that has like 15 keyword arguments 😂
I haven't actually handled that case
@halcyon trail you might also be interested in https://github.com/openai/chz
I took a quick look, looks like it's sufficiently different from my goals. I will take some notes on it though, thank you. I'll need to put together a list of the major alternatives at some point anyhow
I realized unfortunately this is incompatible with type being inferred automatically in some cases
Basically you need to decide what type option() returns (when type= is not supplied)
You could make it always return str but then you would get errors in the example given
Well, to be more clear - it's incompatible with a static type error
My plan is to give a dynamic error
so as soon as you start configuring the parser, if it sees a type annotation other than string or one of the simple defaulted types, and no type= argument, you'll get an error then
Discussions on Python.org
Shall we archive the python-ideas mailing list in favour of the Ideas category here on Discourse? There have been no threads so far this year and just three last year. There were 86 threads in 2023, and 222 in 2022. The Ideas category is very busy with around 35 threads per month (420/year). We’ve been using Discourse for other discussions ...
slight title mistake? :p
Yeah that confused me too 😛
oh good, it was a typo. discord discourse
Should have asked before filling an issue: is memoryview (known to be) not threadsafe? Or are aborts in free-threading builds interesting?
Got a crash that looked like the one where an Exception tried to repr a Union, but seemed different. Turns out it doesn't directly uses Exceptions, but the ones raised do the same thing. I think.
from threading import Thread
from time import sleep
import email
for x in range(10):
union_list = [BIG_UNION | str] * 7
union_list2 = list(union_list)
def stress_list():
for x in range(3):
try:
union_list.pop()
repr(union_list)
repr(union_list2)
union_list.__getitem__(BIG_UNION)
except Exception:
pass
sleep(0.006)
try:
union_list2.pop()
repr(union_list)
repr(union_list2)
union_list2.__getitem__(BIG_UNION)
except Exception:
pass
union_list.__getitem__(BIG_UNION, BIG_UNION)
def stress_module():
email.__loader__.load_module(union_list)
alive = []
for x in range(10):
alive.append(Thread(target=stress_module, args=()))
alive.append(Thread(target=stress_list, args=()))
for t in alive:
t.start()
Where BIG_UNION is the trusty:
import abc
import builtins
import collections.abc
import itertools
import types
import typing
from functools import reduce
from operator import or_
abc_types = [cls for cls in abc.__dict__.values() if isinstance(cls, type)]
builtins_types = [cls for cls in builtins.__dict__.values() if isinstance(cls, type)]
collections_abc_types = [cls for cls in collections.abc.__dict__.values() if isinstance(cls, type)]
collections_types = [cls for cls in collections.__dict__.values() if isinstance(cls, type)]
itertools_types = [cls for cls in itertools.__dict__.values() if isinstance(cls, type)]
types_types = [cls for cls in types.__dict__.values() if isinstance(cls, type)]
typing_types = [cls for cls in typing.__dict__.values() if isinstance(cls, type)]
all_types = (abc_types + builtins_types + collections_abc_types + collections_types + itertools_types
+ types_types + typing_types)
all_types = [t for t in all_types if not issubclass(t, BaseException)]
BIG_UNION = reduce(or_, all_types, int)
Crashes with:
Thread 11 "Thread-10 (stre" received signal SIGSEGV, Segmentation fault.
0x0000555555d211f1 in _Py_TYPE (ob=<unknown at remote 0xdddddddddddddddd>) at ./Include/object.h:270
270 return ob->ob_type;
#0 0x0000555555d211f1 in _Py_TYPE (ob=<unknown at remote 0xdddddddddddddddd>) at ./Include/object.h:270
#1 union_repr (self=<optimized out>) at Objects/unionobject.c:296
#2 0x0000555555b8937a in PyObject_Repr (v=<unknown at remote 0x7fffb4b64220>) at Objects/object.c:776
#3 0x0000555555cc0801 in PyUnicodeWriter_WriteRepr (writer=writer@entry=0x7fffc80902b0,
obj=<unknown at remote 0x207c>) at Objects/unicodeobject.c:13951
#4 0x0000555555aeb8e3 in list_repr_impl (v=0x7fffb4cbd8d0) at Objects/listobject.c:606
#5 list_repr (self=[]) at Objects/listobject.c:633
#6 0x0000555555b8937a in PyObject_Repr (v=[]) at Objects/object.c:776
#7 0x0000555555e0705b in _PyEval_EvalFrameDefault (tstate=<optimized out>, frame=<optimized out>,
throwflag=<optimized out>) at Python/generated_cases.c.h:2280
#8 0x0000555555ddcb03 in _PyEval_EvalFrame (tstate=0x5290000a5210, frame=0x5290000cd328, throwflag=0)
at ./Include/internal/pycore_ceval.h:119
0xdddddddddddddddd hmmmm
Can anyone link me to where python does its optimisation for string appending by using +=, i have come across the fact that in c++ s = s + a is slower than s += a mostly because the first one always creates a copy and the second does only when there isn’t enough space left and that too it creates double the size of current size for optimisation, but i got to know that python has separate optimisation for this string appending thing and it doesn’t behave like c or c++ so can i take a look at that source code
Also crashes with 0x0, if that's any better 🙂
Thread 54 "Thread-53 (stre" received signal SIGSEGV, Segmentation fault.
PyObject_HasAttrWithError (obj=obj@entry=0x0, name=0x555555b32968 <_PyRuntime+53288>) at Objects/object.c:1414
1414 int rc = PyObject_GetOptionalAttr(obj, name, &res);
#0 PyObject_HasAttrWithError (obj=obj@entry=0x0, name=0x555555b32968 <_PyRuntime+53288>)
at Objects/object.c:1414
#1 0x0000555555724112 in _Py_typing_type_repr (writer=writer@entry=0x4bade090180, p=0x0)
at Objects/typevarobject.c:279
#2 0x000055555577035e in union_repr (self=0x4ba74bd9ec0) at Objects/unionobject.c:297
#3 0x00005555556cd16b in PyObject_Repr (v=0x4ba74bd9ec0) at ./Include/object.h:270
#4 PyObject_Repr (v=0x4ba74bd9ec0) at Objects/object.c:751
#5 0x00005555557581c3 in PyUnicodeWriter_WriteRepr (writer=writer@entry=0x4bade090140,
obj=<optimized out>) at Objects/unicodeobject.c:13951
#6 0x00005555556911f8 in list_repr_impl (v=0x4ba7494d500) at Objects/listobject.c:606
#7 list_repr (self=0x4ba7494d500) at Objects/listobject.c:633
#8 0x00005555556cd16b in PyObject_Repr (v=0x4ba7494d500) at ./Include/object.h:270
#9 PyObject_Repr (v=0x4ba7494d500) at Objects/object.c:751
The implementation is deep in interpreter internals, but look for _BINARY_OP_INPLACE_ADD_UNICODE in Python/bytescodes.c
Python uses the same optimization as C++, fwiw. The only difference is that pythons string is immutable, so it has to restrict this behavior to when the reference count is 1
yeah lambda linked it #python-discussion message thnx
by same optimization as c++ do you mean the one where it acquires double the space already to make it logN operation
Maybe not double but some exponential factor
i remember that if the current space taken is 4 bytes then if all of the space was occupied and we tried to append then the it will create double the space, i maybe wrong though
Well, could easily be right. I'm not saying the factor isn't double
Just saying it doesn't have to be
It doesn't have to be double in C++ either
the thing that i wanted to ask is why is it so? why dont both of those act identical i mean if the optimisation is done for s += a then why not s = s + a
In C++ or python?
i would like to hear about both if you dont have a problem
s + a shouldn't mutate s
So you can't reuse storage or do anything that changes s
You have to produce a new string
oh so it is meant to copy and be different
That new string "after" ends up getting assigned to s incidentally
python is pretty light on optimizations that alter the syntax tree overall
in programming abstractions actually no one talks about them being different and everyone treats them equal on the abstraction level
But by then it's too late
Well abstractly they do something similar but they can have different performance characteristics
it could emit a type check that branches to a faster path for x=x+y
It's worth noting though that only in C++ is the faster behavior guaranteed
yeah i came to know about the issue while solving a competitive programming problem, it gave me a TLE for s = s + a and didnt for s += a
In python "faster" x += y is a dirty hack that could disappear at any time
For strings
i dont think c++ garauntees anything about the time complexity https://en.cppreference.com/w/cpp/string/basic_string/operator%2B%3D
i.e. it would be entirely feasible to implement it and make it consistent
I mean guaranteed in practical terms
but it's just not done rn
In python even in practical terms it's not guaranteed
Because of the refcount issue
x = x + y and x += y already compile to almost the same bytecode
The trouble is that they actually need to call different dunders
yeah that's what I'm thinking too
i heard from one source that python optimizes both of them equally and there is almost no difference but after hearing from you i think there is a difference actually just like c++
You just can't visibly mutate a string in python so that makes the optimization extremely fragile
In C++ you just don't have that issue
these kinds optimizations only really work (and maintain semantics) when explicitly checking for non-"dynamic" types
Again - only if refcount is 1
hm yeah so they are equal only in the case when the string is being refrenced only once
otherwise they behave like c++
Yes. But again, this is nothing to count on. You can break this without even noticing
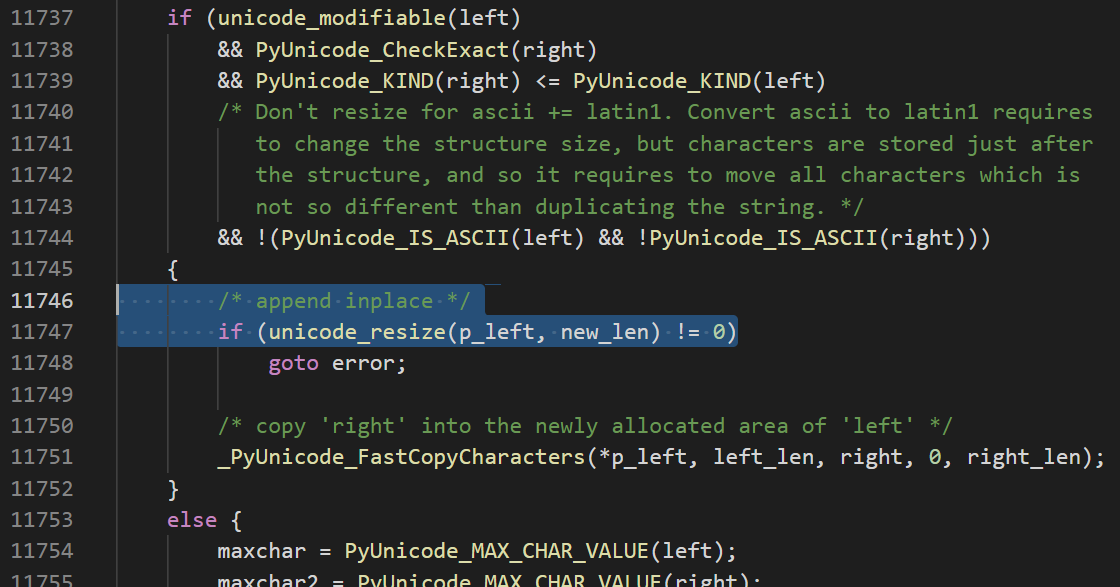
There is a common case when strings are actually mutable.
There was a discussion about improving string concatenation: https://github.com/faster-cpython/ideas/issues/667

GitHub
This would be simple to implement, and occurs often enough that it may actually have measurable impact on overall speed. Say you are able to determine that a + b + c are strings at compile time. Th...
a+b+c isn't really a big deal. But if you really want to concatenate a list of strings you should always do it properly and not via +=, imho
Iirc "".join(string_list)
yeah was just digging in to know the reasons
isnt it possible to just make them do the same thing
like they said it complies to almost the same byte code
like is there a use case for someone wanting to not have the optimisation
i mean the optimisation += uses
It would be a very very special cased optimization
So you'd need to show good utility to have it be worth adding
The optimization for += is already kind of a niche thing you shouldn't use
The python docs explicitly ask you not to use it
so the docs recommend using s = s + x
No
The docs recommend using join
This is all only relevant in a situation where you want to concatenate repeatedly
hm like in a for loop
If you just do it once then the time complexity is irrelevant and mostly so is the optimization
where s = s + x turns it into a N^2 solution
Yes, s = s+x in a loop is bad
Use join
See note 6
Concatenating immutable sequences always results in a new object. This means that building up a sequence by repeated concatenation will have a quadratic runtime cost in the total sequence length. To get a linear runtime cost, you must switch to one of the alternatives below:
if concatenating str objects, you can build a list and use str.join() at the end or else write to an io.StringIO instance and retrieve its value when complete
yeah i get that, but my concern is why make += optimized and not s = s + x for both c++ and python was it for some special use case where you dont want the += optimisation
I think I already explained
They have different behaviors, you're asking to special case in an AST optimization of dubious utility
i am asking why were they choosen to have the different behaviour like is there a special use case ?
In C++ the optimization is also basically impossible to do in most cases because you would need to know if s is being aliases
oh
i see, im sure the makers would have their reasons for this
Language behavior is specific in terms of functions and types and such. They don't typically specially specify behavior for when two arguments happen to be the same
I'm not really sure what you mean
But in both languages the whole point of += being a separate overload is because it allows/encourages mutation
- doesn't
what i mean is that the end result of those two operations is similar but their under the hood implementation is different, so there must be a reason for that
It's not similar in general
oh
Just in this one case where you have the same variable appearing twice
yeah so this is the reason, this is what i was asking thankyou
string just isn't a good example of this because it's immutable
So the optimization is a lot weirder
A way better example is list
i see
That's a much more typical example
yeah because list is meant to be mutable in python right?
hey, it's my least favourite python feature
What string is doing in python is arguably pretty naughty
And it's really only because people keep writing bad code
If people didn't write such bad code the optimization would serve no purpose
yeah i heard that bad code is the reason for that optimization lol
Yeah. Like, notice the python docs don't mention the optimization
They ask you to use join
so its like litreally + was meant to do copy and += was meant to mutate
yup
It is written in such a way that it supports both mutation, and concatenation to immutable objects
i cant believe language makers do optimisation for people writing bad code lol
yeah if there is only 1 reference then mutation doesnt hurt anything so i guess its clever
In C++ and Rust, += is mutating
In C#, += is exactly the same as + (so it's not mutating)
But python is trying to have its cake and eat it too
Ya i think its good though
But there are no guarantees as to if this will he the case for ever
The fact that += mutates a list is guaranteed
It's confusing that py x = (1, 2, 3) y = x y += (4, 5) print(x, y) is (1, 2, 3) (1, 2, 3, 4, 5) but py x = [1, 2, 3] y = x y += (4, 5) print(x, y) is [1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
And it's another caveat to explain to beginners. ("x += y is a shortcut for x = x + y" is a wrong explanation, only works for numbers, strings and tuples)
and I'm not sure what the upside is
Also i wanted to ask for a list if += is used and there is no more contiguous space in memory for that array then obviously it will copy it to some other memory location right? With that extra space optimisation ofcourse?
The upside is better performance with convenient syntax for lists, and being able to use the syntax for immutable things like tuples and strings
Most languages have to choose one or the other
Well, you can achieve the same performance with the appropriate mutating method like extend
Sure, just not with as nice syntax
Fwiw I tend to prefer going the other way
And that seems to be significantly more common
the other way?
Yes. Make += always mutate
ah
An alternative implementation for Python could be that x += y desugars into x.__iadd__(y) instead of x = x.__iadd__(y)
That means iadd would only make sense on mutable types
Probably would make the language easier to understand overall; much too late to change that though
C++ and Rust are very different in this regard because they don't have the same names-refer-to-objects thing going on
e.g. in Rust you can have a &mut u8 and just mutate it
so they can get away with always mutating
I mean in python that's how the whole language works
Python just happens to have immutable integers
yeah, I think I rather meant that Rust has mutable integers
Yeah. Also to be fair in rust and C++ you can simply assign to a reference to mutate
In python you cannot
Conceptually that also says that C++ and rust consider assignment mutation
So it makes sense that compound assignment involves mutation
In python and most GC languages assignment is a bit different
I guess it all depends
Btw if you want another really interesting language design take on this, you should look at Kotlin
It tries to have its cake and eat it too in a completely different way from python
Does it turn overloaded operators into method calls like it does with properties?
perhaps it would make sense to make it so that x += y desugars into py tmp = x.__iadd__(y) if tmp is not x: x = tmp That would still allow py s = "abc" s += "def" and it would fix the weird edge case of ```py
t = ([], [])
t[0] += [1, 2, 3] # mutates t[0] then raises TypeError!
It'd probably be easier to teach than the current behavior, and it's a less drastic change than never assigning. But it's still quite a large change to the behavior of common syntax
do azure support keep finetuneing the model i finetunned?
Well, not exactly. I mean most languages do what you describe
What makes Kotlin special is that when you do x += y it looks at two things: a) whether x is val or var, b) whether there's an overloaded +=
If it's val and there's an overloaded += then you get the mutate in place behavior
If it's var and there isn't you get the immutable behavior
I.e. it just becomes x = x + y
If it's var and there's a += then it doesn't compile (ambiguity error) I believe
that's interesting
at least you can statically tell which operation the given call will invoke
CLA bot giving false hopes that old PRs saw some activity 😦
one of my PRs got tagged and I'm going to fix it today.
I feel like a bad person for putting strain on open source maintainers.
do you like pizza


Wrong channel. See #❓|how-to-get-help or #data-science-and-ml
thanks. sorry for that.
!d pathlib.PurePath.is_reserved
PurePath.is_reserved()```
With [`PureWindowsPath`](https://docs.python.org/3/library/pathlib.html#pathlib.PureWindowsPath), return `True` if the path is considered reserved under Windows, `False` otherwise. With [`PurePosixPath`](https://docs.python.org/3/library/pathlib.html#pathlib.PurePosixPath), `False` is always returned.
Changed in version 3.13: Windows path names that contain a colon, or end with a dot or a space, are considered reserved. UNC paths may be reserved.
Deprecated since version 3.13, will be removed in version 3.15: This method is deprecated; use [`os.path.isreserved()`](https://docs.python.org/3/library/os.path.html#os.path.isreserved) to detect reserved paths on Windows.why is this deprecated in favor of something from os.path? isn't the entire point of pathlib to remove need for os.path?
there's some discussion at https://discuss.python.org/t/deprecation-of-pathlib-purepath-is-reserved/53203/1
Discussions on Python.org
I note that this is being deprecated in 3.13 for removal in 3.15, in favour of os.path.isreserved(). However, this removed a major benefit of the former, which is that you don’t have to be running on Windows in order to use it. If you are e.g. receiving files on a Linux machine that you know may be accessed by Windows at some point (e.g. the...
Looking into the AttributeError case for PEP-649/749 ForwardRef annotations and finding new ways to give myself a headache.
Simplified down to get_annotations(..., format=Format.FORWARDREF) attempting to evaluate everything which lead to ForwardRef("<class 'str'> | undefined") which evaluates to a SyntaxError.
Actually that might just be an entirely separate bug? Union[str, undefined] becomes str | ForwardRef('undefined') but str | undefined becomes ForwardRef("<class 'str'> | undefined")
from annotationlib import get_annotations, Format
from typing import Union
class DifferentUnions:
attrib: str | undefined
other_attrib: Union[str, undefined]
different_unions = get_annotations(DifferentUnions, format=Format.FORWARDREF)
print(different_unions)
hm that's an interesting case, I can take a look
I already have, writing an issue
Well, as in I have a possible solution - this kind of got in the way when looking at https://github.com/python/cpython/issues/125618 as I accidentally ended up hitting this with a union.

GitHub
Bug report Bug description: If there's an annotation with an incorrect attribute access, the AttributeError causes get_annotations to return an empty dictionary for the annotations instead of f...
My thinking was to add an option to the stringifier dict that indicates that stringifier __or__ / __ror__ should create unions instead of converting objects to ast.
I think it's the ast.Constant(value=other) in __convert_to_ast that ends up converting str to <class 'str'> in the output.
I'll take a look later today! Also I really appreciate all the pre-release testing and feedback you're doing, it's very helpful
It's feels more like I keep tripping over weird edge cases
But you're doing it in the alpha phase, so we can still change anything
You seem to support a whole bunch of operations in the stringifier, I'm wondering how much support there's supposed to be for things that aren't types in these formats?
It should support all operations that are feasible to support, PEP 749 has an appendix talking about what operations can't be supported
I think it's most important to support all operations that are allowed in annotations according to the type system
But annotations are not necessarily used for types, and we should try to support as many other kinds of expressions as possible
The branch I have would turn unknown | unknown2 to Union[ForwardRef('unknown'), ForwardRef('unknown2')]. In theory if those aren't types I suppose that's not accurate, but there are already probably issues with turning exists[undefined] into exists[ForwardRef('undefined')]
Yes, I think that's fine
If you later resolve the ForwardRefs and unknown turns out to be 1, you can still get 1 | 1 out and evaluate that to 1
Turns out that you can also get Format.FORWARDREF to KeyError that way but I don't know if that's worth guarding against
how plausible would it be to allow function calls as LHS to an augmented assignment?
def a(x=[]):
x.append(1)
a() += [2, 2]
print(a()) # [1, 2, 2, 1]
it doesn't assign to anything but triggers the __i*__() dunder nonetheless
Implausible. Why would you want this?
at least in the standard library, every mutating __iXXX__ should have a method counterpart
like a().extend([2, 2])
and you always can call __iXXX__ directly
That's definitely making the code harder to read
also don't they usually tell you not to use mutable objects as the defaults for function arguments
Using that mutable arg to store stuff seems not safe, not intuitive, and kinda pointless
a() returns None, so this wouldn't work anyway
depends on the use case
mutable defaults are sometimes used as cache with a faster access time, so it's not really that pointless
back to the main topic, i guess it's just a niche feature to add
AFAIK local lookups are roughly the same speed as global lookups in modern versions
Even if it was faster, it seems like some weird abstraction that makes code harder to read
there's some long DPO threads about it
Changing the behavior of ```py
def myfunc(_cache={}):
pep 671(?) uses new syntax for new behavior
Sure. I wouldn't call that "revisiting", though. That's a new feature, not a change to the behavior of an existing one. And the problem with adding new syntax to address this is that people won't use it unless they know that the old syntax won't do what they expected - but if they know that the old syntax won't do what they need, it's trivial to work around
In other words, the biggest problem with Python's early binding of default arguments is that it surprises people who expect late binding. Adding new syntax for late binding doesn't solve the biggest problem
I feel like the whole "mutable default arguments" thing is more of a bug than intended / wanted feature, but that's just my take. I think most devs expect arg={} to not retain the content between calls
If you had to keep it, maybe only allow it with specific type-hints or some other mechanism you have go out of your way to do because you know about this mechanism
if a bug has been around for years and a significant part of the community relies on it, it may as well be a feature
but yeah it's unexpected, arguably unwanted, and some libraries even 'change' it where they can```py
import pydantic
class Foo(pydantic.BaseModel): # If you do justclass Foo:it'll be [1, 2, 3]
... data: list[int] = []
...
Foo().data.append(1)
Foo().data.append(2)
Foo().data.append(3)
print(Foo().data)
[]
@obtuse knot @sour thistle At some point, when closures didn't exist yet, it was totally a feature
https://docs.python.org/release/1.6/tut/node6.html#SECTION006740000000000000000
"judicious use"...
Yes, I could remember useful information, but my brain is busy remembering this paragraph from Python 1.6 documentation
the worst part is that's still normal for things like defining callbacks in a loop
!e
I wonder, will this still be allowed after PEP 765? You will still be able to un-return
import contextlib
def f():
with contextlib.suppress(ValueError):
try:
return 420
finally:
int("hello")
return 69
print(f())
:white_check_mark: Your 3.12 eval job has completed with return code 0.
69
i'm... not sure why you'd write this code though
I suppose there's no way to disallow it, it would essentially disallow raising exceptions in finally, which seems illogical
Unrelated question. How are you supposed to catch the ValueError from a zip(a, b, strict=True)? If you do it in the naive way: py try: for x, y in zip(xs, ys, strict=True): # non-trivial body except ValueError: ... you're risking catching an exception originating from non-trivial body
If you need to distinguish, and the body can raise a ValueError, probably by catching any ValueErrors that can occur in the body.
hmm, I guess
if you insist on propagating all inner exceptions, you can weave them
class Wrapped(Exception): pass
try:
for x, y in zip(xs, ys, strict=True):
try:
# non-trivial body
except Exception as e:
raise Wrapped(e) from e
except Wrapped as e:
raise e.args[0] from e
except ValueError:
...
I think I might be just complaining about the reuse of the same exception in so many places
e.g. it's possible that fetching the next item from xs or ys raises a ValueError if it's a custom iterator (or e.g. map or filter with a function raising that error)
I wonder if something like zip.LengthMismatchException could work. Doesn't pollute any namespaces and is much easier to catch
but that might be too different from existing stuff in the stdlib
(and doesn't even completely solve the confusion problem, since xs or ys could raise this exception by using zip(strict=True) under the hood)
iirc Swift has a nice mechanism when you can specify which expression specifically you're expecting an error from. Not sure how that'd work with for though
except ValueError match "sequences have different lengths":
Like ```py
with pytest.raises(ValueError, match="..."):
sometimes I wish python exceptions were more structural so there wouldn't even be the temptation to do string matching
what about storing the iterators (and passing them as arguments to zip()), removing strict, and checking if any iterators are unexhausted right after?
yeah, you could implement zip manually 😛
See, sometimes there is an easy solution 🙂
I'd probably work from the other side and instead of using zip and checking iterators are exhausted, use itertools.zip_longest and check for the fill value. That or reimplement zip 🙂
you can iterate over zip manually :)
Doesn't save you from the underlying iterators raising ValueError on __next__
is there a reason why the .find() method isn't present for non-string/buffer sequences (e.g. lists)? is it because it carries the connotation of "must be a multiple-length substring" or..?
Hey
Fwiw you can simply use next and a generator comprehension
Lists do have an index method
Which is pretty much the same thing as strings find I suppose? Obviously with searching individual elements rather than a subsequence
.find() is more in the LBYL side (returns -1 when not found and can be used in if statements) than the EAFP behavior of .index() (errors when not found)
-# strings also have .index() too
I guess I'm not sure I understand your question
Are you asking why there isn't a eafp method for lists or why there isn't a method that finds multiple contiguous elements?
why there isn't a LBYL counterpart of .index()
as in, an index search operation with no errors, returning -1 on failure
-1 is just about the worst sentinel for this operation
for example, because it will silently work as an index instead of failing
yeah, that's why .find() exists as a separate method in strings
why it doesn't exist on lists and tuples is a mystery to me
The primary reason find exists is because it searches for substrings
Not individual elements
ah. as i thought...
You can't have lbyl and eafp versions of every function
I guess that would have been clearer if characters weren't str
You typically pick whichever makes more sense - in this case I honestly guess it's historical accident that find and index use different approaches - I could be wrong
I think if it were done today both would return None to indicate not finding anything
Yeah the -1 sentinel smells like somebody copied a C function
There was some amount of discussion on list/tuple.get
https://discuss.python.org/t/indexable-get-method-1-2-3-get-4-none/53430
(after all, dict.get does exist and is fairly useful)
I think it makes sense. I mean I think if you could go back then you'd only have that (though I wouldn't call it get)
With dicts it's common to both have a key you "know" is in the dict and keys that you arent sure
And given how common the operation is it makes sense to have both
With find I think it's a lot more common to be unsure
Or index
it did, that's cool
Is anyone here interested in creating a Python interpreter in Python? might serve obf purposes, mean it is custom bytecode and a make a intepreter with python

you know about pypy right?
yes
but i do other algorithm not like pyc

custom a bytecode with struct
i think the idea of using custom bytecode to obfuscate python is better than many people using native compile
I'm getting a strange abort (and very rare segfault) from fuzzing _tracemalloc. Strange as in nothing in the backtrace points to _tracemalloc.
Here's one of the backtraces:
Click here to see this code in our pastebin.
Does it make sense for you? The test case is just:
from threading import Thread
import _tracemalloc
for x in range(20):
alive = []
for x in range(1500):
alive.append(Thread(target=_tracemalloc.start))
alive.append(Thread(target=_tracemalloc.start))
alive.append(Thread(target=_tracemalloc.start))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.start))
alive.append(Thread(target=_tracemalloc.start))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
alive.append(Thread(target=_tracemalloc.stop))
for t in alive:
t.start()
for t in alive:
t.join()
tracemalloc wasn’t thread-safe for a while, but (I think?) it got fixed a little while ago. are you going off the current main?
yes, current main
Python 3.14.0a7+ experimental free-threading build (heads/main:b8633f9aca9, May 2 2025, 03:57:42) [Clang 19.1.7 (++20250114103253+cd708029e0b2-1~exp1~20250114103309.40)]
hmm, go ahead and make an issue. i can’t find anything open about tracemalloc.
There's https://github.com/python/cpython/issues/126315, which doesn't seem to repro anymore. I will check it further and close if confirmed.
I'll create the issue, thanks!

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
thats sick
Does pypy's RPython that their Interpreter is written in count as proper Python? Not sure if people would consider it to be Python
It's a subset of the Python language, AFAIU. Seems fair to call it Python to me
I believe it's actually a subset of Python 2.7 (which I believe is partly why PyPy can never drop support for Python 2?). But I agree that this still qualifies it as a kind of Python
Nice
i do wonder why this is the go-to channel for spam
at this point just rename the channel to #externals
all the discussion channels get spam because they're relatively high on the list, but we want people to know about them, so we cope.
pywin32's 3.14-beta.1 build tries to link against python314t.lib on non-threaded python
Hi! In #1370439790012665946 message I've been told I'm better asking here.
In pywin32 I've been testing the 3.14 alphas for a while just fine. But the builds started failing since the first beta. I'm completely unsure where the issue stems from (it could be setuptools, actions/setup-python, an actual issue in the first beta, due to one of pywin32's numerous build hacks which I've been reducing over the years).
Here's the full log from some PR: https://github.com/mhammond/pywin32/actions/runs/14912683012/job/41890682321?pr=2582
Of interest is the following line: LINK : fatal error LNK1104: cannot open file 'python314t.lib'. I don't understand where python314t.lib comes from. Or how to go about debugging/investigating this.
Relevant build files:
- https://github.com/mhammond/pywin32/blob/main/.github/workflows/main.yml
- https://github.com/mhammond/pywin32/blob/main/pyproject.toml
- https://github.com/mhammond/pywin32/blob/main/setup.py
In case this is an actual 3.14-beta.1 issue, I've opened https://github.com/python/cpython/issues/133779
In case this is a setuptools issue, I've requested help in https://github.com/pypa/setuptools/discussions/4988
And since idk how to investigate this and find the actual core issue, I've requesting help here.
Looks like it's kicking off on the issue
people hiring alot for ml engineers?
This would be a question for #career-advice . It might be helpful to say why you're interested to know
I'm doing some microopitimization for textual (so it plays nicer for mypy mainly but it needs to microbench as good or better than before)
and I noticed using:
while True:
if x is None:
break
...
is better than
while x is not None:
...
https://gist.github.com/graingert/e95ecf6172a690b23aea876e15603bc7
am I doing the benchmark correctly?
Gist
flatten linked list bench. GitHub Gist: instantly share code, notes, and snippets.
If so do we think it's a perf bug?
Maybe check what bytecode they compile to?
Seems like the difference is in whether there is a jump in case the loop exits or doesn't exit
Though if I read it right the faster version does more jumps which seems like it should be slower
... on main at least. What version were you testing on @spark verge ?
i've tested it before with another condition some time ago and this seems to be why
more jumps is just faster for some reason
Could be some weird interaction with the specializing interpreter?
Deadsnakes 3.13.2 and Ubuntu's 3.12
Thanks. This seems worth reporting, it feels unexpected and might be an opportunity for making something faster
I need to try this also:
while True:
if cond:
work
else:
break
!d dis.dis
dis.dis(x=None, *, file=None, depth=None, show_caches=False, adaptive=False)```?
get into self driving cars
to changetheworl;d
The generated bytecode is worse in the faster case 🙃
may I ask about python 3.9 bytecode in this channel? or is #esoteric-python better for that
I'm wondering about DICT_UPDATE it says "Calls dict.update(TOS1[-i], TOS).", but i = 1 always (compile.c) and TOS1 is a dict as far as I can see, so are the docs wrong on this one?
(This is the right channel for that.)
it's probably to be consistent with the other update/extend opcodes, but TOS1[-i] is kinda misleading (latest release docs seem to have fixed it)
alr,ty, i was wondering because the channel topic mentions current python and not outdated python
so TOS1 should be correct. also i see how the other extend opcodes are similar so yeah likely this got left out, thanks for confirming
looks like it's the x is None vs x is not None
those just compile to 1 opcode each, no..?
?
Okey so this is one sided question but
If I have to use a llm for a production level tool there are two options
Use local llm that will use user device power
Or to use a google Gemini wrapper
Build by me
your question is off-topic for this channel; see #❓|how-to-get-help
@feral island I'm not confident enough in my analysis to report it as an issue yet, I posted it on discuss https://discuss.python.org/t/microoptimizing-flattening-a-linked-list-with-a-walrus-in-a-way-that-keeps-mypy-happy/91738
Discussions on Python.org
I’m doing some microopitimization for textual (so it plays nicer for mypy mainly but it needs to microbench as good or better than before) and I noticed using: while True: if x is None: break ... is better than while x is not None: ... am I doing the benchmark correctly? I posted this on the Python Discord and @Jell...
I have a habit of looking at CPython UAF/memory corruption/etc issues and noticed this one: https://github.com/python/cpython/issues/133767 from a few days ago that mentions a UAF issue but has no crashing reproducer that actually shows where that issue is. Just curious if any core devs have one that could be added to the tests for that PR

GitHub
Crash report What happened? When using .decode("unicode_escape") with an error handler there is a use-after-free segfault. CPython versions tested on: CPython main branch Operating system...
For what it's worth it looks like that one was reported to the security mailing list first
Does the new test added in the PR not crash on older versions?
not as far as i can tell
might be worth commenting on the PR then
actually looks like they explicitly wrote that test to not hit any of the codec "magic" that python does with its registering system and whatnot. They call codecs.unicode_escape_decode explicitly instead of hitting it via .decode('unicode_escape') which is how its described in the issue
Yea I probably will, gonna see if I can work out my own crasher tonight first
>>> class X(int): __slots__ = 'a',
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: nonempty __slots__ not supported for subtype of 'int'
>>> class X(int): __slots__ = '__dict__',
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: nonempty __slots__ not supported for subtype of 'int'
>>> class X(int): __slots__ = () # this works
...
>>> class X(int): ...
...
>>> x = X()
>>> x
0
>>> x.a = 42
>>> x.b = 100
>>> x.c = 'hmm'
>>> x
0
>>> x.__dict__
{'a': 42, 'b': 100, 'c': 'hmm'}
why does int prohibit non-empty __slots__ in subclasses, if i still can create a subclass without __slots__ and assign to arbitrary instance attributes?
isnt missing __slots__ equivalent to __slots__ = ('__dict__', '__weakref__') ?
that is weird...
iirc, it's because when you specify slots the memory for them is placed directly after the base instance memory. So when you specify non-empty slots on a variable sized base class, it can't generate constant offsets for the slot attributes
then how is it possible that I can assign to arbitrary attributes in subclasses? where is __dict__ stored?
__dict__ is not normally a slot, is it...?

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
what is weakref
reference without increasing the refcount on the object itself
!d weakref
Source code: Lib/weakref.py
The weakref module allows the Python programmer to create weak references to objects.
In the following, the term referent means the object which is referred to by a weak reference...
the opposite is a strong reference, which is a direct reference to the object that affects its refcount
basically, once all strong references to an object are removed, the object is destroyed whether or not weakrefs for it exist
that is unless an object is immortal
yes, but in normal situations it behaves very similar to slot
in most cases having no __slots__ is indistinguishable from having __slots__ = (__dict__, __weakref__)
so I am confused about our situation: how could even __dict__ be stored on an int and why couldn't other slots be stored in this exact way?
because __dict__/__weakref__ is stored in the pre-header and slots aren't? idk
i've looked at the allocation thingy and i don't really see why slots couldn't be a pre-header thing
who can make my python script a .bat file
Me.
@sweet zealot @spark stream this is not the channel for this.
Go DMs
I'm a bit confused... https://docs.python.org/3.15/library/index.html is missing the compression package? Is it going to be added later?
they may not have added docs yet
t string docs aren't there yet either
the PR is in progress https://github.com/python/cpython/pull/133911
I expect some docs work will happen during the PyCon sprints
Ah, I see
Kubernetes has an interesting approach:
One of the things we require for a KEP to be considered complete and thus, includable in a particular release is that it has a user-facing change at all – even if it's just a feature flag! – it must be documented, or we do not allow it in the release.
3.14 RM getting ideas...
Today, as we're recording this, this is actually the docs freeze for Kubernetes version 1.33. So today, a lot of KEP owners will either merge documentation, or I will revert their PRs!
!
the docs for annotationlib are complete I will have you know 😛
You'd be more git rm than RM?
!e
a = True
print(~a)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | /home/main.py:2: DeprecationWarning: Bitwise inversion '~' on bool is deprecated and will be removed in Python 3.16. This returns the bitwise inversion of the underlying int object and is usually not what you expect from negating a bool. Use the 'not' operator for boolean negation or ~int(x) if you really want the bitwise inversion of the underlying int.
002 | print(~a)
003 | -2
unexpected deprecation
as an esopy representative we had that early surprise discovery sometime before
!e
print(~False)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
-1
Doesn't show a warning despite this test. Interesting.
https://github.com/python/cpython/blob/main/Lib/test/test_bool.py#L68-L71
Lib/test/test_bool.py lines 68 to 71
with self.assertWarns(DeprecationWarning):
# also check that the warning is issued in case of constant
# folding at compile time
self.assertEqual(eval("~False"), -1)```!e
eval("~False")
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | /home/main.py:1: DeprecationWarning: Bitwise inversion '~' on bool is deprecated and will be removed in Python 3.16. This returns the bitwise inversion of the underlying int object and is usually not what you expect from negating a bool. Use the 'not' operator for boolean negation or ~int(x) if you really want the bitwise inversion of the underlying int.
002 | eval("~False")
created a bug https://github.com/python/cpython/issues/134280
tbh it feels bad to waste triagers' time on such a fringe issue... maybe there's someone in a dark corner of the world only using ~ on booleans when it's a literal, but that's a long shot
but eval reporting a warning while running a file normally doesn't is certainly strange, maybe there's a larger underlying bug
Hrm... this is strange https://paste.pythondiscord.com/AFKA
The deprecation is not reported when importing a module either (when running foo.py). Am I missing something, is this supposed to happen?
cached bytecode?
oh maybe
shouldn't be because it's not a literal
Actually it seems like it's by design. Apparently DeprecationWarnings are not displayed unless they're triggered by code in __main__
why is DeprecationWarning ignored by design though 🤔
oh yeah that was an intentional change at some point
do you think this might have something to do with it?
$ python
Python 3.13.1 (main, Jan 9 2025, 17:09:58) [GCC 14.2.1 20240912 (Red Hat 14.2.1-3)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import warnings
... warnings.simplefilter('always')
...
>>> ~True
/home/df/.pyenv/versions/3.13.1/lib/python3.13/codeop.py:118: DeprecationWarning: Bitwise inversion '~' on bool is deprecated and will be removed in Python 3.16. This returns the bitwise inversion of the underlying int object and is usually not what you expect from negating a bool. Use the 'not' operator for boolean negation or ~int(x) if you really want the bitwise inversion of the underlying int.
codeob = compile(source, filename, symbol, flags, True)
-2
>>>
it seems like Python thinks that this warning originates not in my module, but in some codeop.py file, and it decides to hide the warning
User warnings have to be turned on
It's like an opt-in thing
I think 3.9?
Deprecation is a subclass of User I think
!e
DeprecationWarnings are supposed to appear if it's in the main file https://docs.python.org/3/library/exceptio
as you can see here (no opt-in)
a = True
print(~a)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | /home/main.py:2: DeprecationWarning: Bitwise inversion '~' on bool is deprecated and will be removed in Python 3.16. This returns the bitwise inversion of the underlying int object and is usually not what you expect from negating a bool. Use the 'not' operator for boolean negation or ~int(x) if you really want the bitwise inversion of the underlying int.
002 | print(~a)
003 | -2
I remember hitting this in my own code and being upset
I thought I read there was something about user warnings being suppressed by default in some version of python
And a deprecation was subclass of User
it's not a subclass of UserWarning but https://docs.python.org/3/library/warnings.html#warning-categories
Base category for warnings about deprecated features when those warnings are intended for other Python developers (ignored by default, unless triggered by code in
__main__).
I do find it strange, maybe there should be more awareness that you should run your code with -X dev in development. (and maybe enable all deprecation warnings in production)
Got a crash that's been hitting in _locale in 3.13 (ASAN build) for a while, but wouldn't reproduce even after weeks of trying. Now it did repro, so I'm pasting the ASAN output in case it's useful for someone to see what's wrong.
Click here to see this code in our pastebin.
Aha, that would be https://github.com/python/cpython/issues/127081

GitHub
Bug report There are a a few non thread-safe libc functions used in Python that can be an issue for free threading, isolated subinterpreters, or sometimes even with the GIL. In #126316, @vstinner f...
Hello everyone! I got admitted to University of Arizona under the major Artificial intelligence!
Hence I need some information regarding the courses offered there
What is CSC 110

Is it a python course?
This is off topic for this channel, you probably want to ask your university what it means. You could ask in the off topic channels
It's basically oop and data structure
Better to ask the faculty for more details
!e
WTF
xs = (1, 2, 3)
print(xs)
print(xs.__init__("foo", ["bar"], b="az"))
print(xs)
:white_check_mark: Your 3.14 pre-release eval job has completed with return code 0.
001 | (1, 2, 3)
002 | None
003 | (1, 2, 3)
why does tuple have a callable __init__ that accepts arbitrary arguments?
object.__init__() doesn't follow an error path
:x: Your 3.14 pre-release eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File [35m"/home/main.py"[0m, line [35m2[0m, in [35m<module>[0m
003 | [31mxs.__init__[0m[1;31m(1, 2, three=4)[0m
004 | [31m~~~~~~~~~~~[0m[1;31m^^^^^^^^^^^^^^^[0m
005 | [1;35mTypeError[0m: [35mobject.__init__() takes exactly one argument (the instance to initialize)[0m
hm
to not error when it's called, an object has to:
- have a different
__new__() - have
object.__init__()/no__init__()defined
Objects/typeobject.c lines 6649 to 6650
/* You may wonder why object.__new__() only complains about arguments
when object.__init__() is not overridden, and vice versa.```is that documented somewhere? or is that some kind of CPython quirk?
i think it's only documented in that comment, not sure though..
yo i got a question
Could someone explain why the snippets are not prone to race conditions in non-freethreaded Python?
https://discuss.python.org/t/please-take-race-conditions-seriously-when-discussing-threading/93339
Is there something in ```py
def increase_dosage(patient, amount):
if patient.dosage + amount < SAFE_DOSAGE:
patient.dosage += amount
preventing the threads from switching threads after the `if`?Did you read Mark's first reply?
yeah, but the code doesn't include with or async with
maybe I'm missing something
The scenario that is presumably problematic here (with the GIL) is:
- Thread 1 checks the condition and switches (because e.g. the 5ms period is over)
- Thread 2 checks the condition and increases the dosage
- Thread 1 wakes up and also increases the dosage
I'm assuming the fix for that issue also accidentally guarantees it here. Still reading the thread though..
We don't drop the GIL between certain bytecode sequences
Though I think the if one does have a race condition
so if dosage was a property instead of a plain attribute, this code would start to have a race condition?
(or maybe a slot as well?)
I believe so
If you'd say next that this cuts against Mark's point because the absence of a race condition is very fragile
then I'd agree with you
I do agree that adding race conditions to a program is bad, even if the program "deserves them"
(Imo this is a situation where I wouldn't depend on internal switching semantics to begin with, just use a Mutex and be explicit.)
Yeah I don't disagree
If I remember correctly, before 3.10 threads could switch at any bytecode. Now they can switch mostly only at line boundaries or function calls
Obviously you shouldn't depend on it (it's not guaranteed behaviour in Python), Mark's point is that enabling free-threading will add defective behaviour to programs that were protected by this accidental atomicity
wouldn't it just be increasing the chances of defective behavior
I wouldn't really call depending on undefined/undocumented behavior "protected"
If a building is kept from collapsing by chewing gum, you shouldn't remove the chewing gum even if that's bad engineering
Or at least the role of such chewing gum should be considered when you want to renovate the building
But maybe you should send the building owner a notice that they should fix their building
Is PEP8 still the main "rulebook" that is used in coding?
PEP 8 is the style guide for Python's standard library
Whether you adopt it and which parts of it is up to you (or your team/company)
But some parts are more widely agreed upon than others. Like PascalCase for classes and snake_case for everything else
Alright, just checking if it had been updated after the course videos I've found were posted, thanks
many projects use ruff or similar tools to automatically format the code
there are also some other style guides like numpy's and google's docstrings conventions
@olive peak what? (re: that reaction)
duck
is formatting really that important
i got a line just two over the 80 character limit
A consistent format is important, that format being pep8 isn't.
The line length limit is one of the most common disregarded parts of pep8
formattingisntimportantpeoplecanreadyourcodeanyway
butitmightmakeitmoredifficultifyoudontformatthewayotherpeopledo
itsokitsonlyforme
DMs open for fun
what do you mean "for fun"?
this is the channel for talking about the python language. if you want to socialize, go to #ot1-perplexing-regexing
!e ```py
class Foo:
def format(_self, fs):
return repr(fs)
x = 5
a = Foo()
print(f"without space: {a:{{x}}}")
print(f"with space: {a:{ {x} }}")
:white_check_mark: Your 3.13 eval job has completed with return code 0.
001 | without space: '{5}'
002 | with space: '{5}'
why are these two f-strings equivalent? since a format specifier is basically a string-like part/a mini f-string, i would've expected that putting {{x}} in a format specifier would result in a string with contents == "{x}" instead of a set expression interpolated
It's so you can interpolate values into the formatting flags. (For example alignment)
!e
w = 7
s = "foo"
print(repr(f"{s:<{w}}"))
:white_check_mark: Your 3.13 eval job has completed with return code 0.
'foo '
As for why it is parsed like that: because you're inside an f-string placeholder thing, so the usual rules elsewhere do not apply.
sure, but i would've associate double braces with escaping the placeholder
since {x} in {...:{x}} is like a mini/nested placeholder, then double braces looks like it should (but does not) escape it
hm, does this mean that not all possible string inputs to __format__ are possible
if you can't escape the brace expansion
a workaround would be to do something like ```py
string = "{stuff}"
f"{...:{string}}"
format specs cannot have braces unless interpolated, yes
I guess you're not supposed to use braces in your formatting flags
~~{{ seems to work?
>>> class Foo:
... def __format__(self, fmt):
... return fmt
...
>>> f'{Foo():{{123}}}'
'{123}'
>>>
```~~oh never mind just scrolled up
@civic creek
I'm just thinking out loud here, but cpython is "slow" and that's ok. What if we made a compiler which made certain assumptions about the language but still compiled directly to machine code? Let's say we treat everything as a fat object in memory, even primitives and everything is a pointer. Sure it's inefficient, but how would it compare to the CPython interpreter?
We can still retain all the features of the language like runtime reflection, dynamic dispatch, etc.
you can look into cython, mypyc, nuitka and pypy
they all do different things, but also kinda related to your question
cython takes python-like code and generates C-code, which is then compiled to extension modules. It can achieve C-like performance if you put effort into that
mypyc and nuitka are similar, but they work on pure-python code
pypy is a python interpreter with impressive JIT
performance increase depends on many factors
a while ago I experimented with mypyc/nuitka/cython, and got best results with nuitka - it sped up regular python code by a factor of 2-3 with zero changes to source code
if your application is math-heavy, I would look into cython, performance increase might be much better
don't we already treat everything as an object/pointer?
so i'd say it would have considerably 0 effect
compiling to machine code does have effects though, and it's under development
Do you mean JIT or is there something else being developed?
yes, JIT
What is the return value of spec.parent supposed to be for a built-in? '''import time; print(time.spec.parent)'''
Origin correctly says it is built-in and the len of the value is 0
I mean ahead of time
If we don't focus on memory efficiency initially and don't worry about optimizing for register placement and things like that and just abuse the x86 stack, we can treat everything as dynamic as we already do
dynamic dispatch all the things, even when you don't need to. Keep it simple. I'm very curious how the performance would compare to CPython
If I had more time, I'd probably try to write something that compiles to LLVM IR. Or even JVM bytecode lol that way we get the most advanced GC in the world for free
and yes I'm aware of Graal Python and it's very impressive
You can already do that with Cython. It gives a small speedup
eh sales in what?
This is at least off-topic for this channel.
Are there any plans to kind of ... clean up or assist in the install of packages? It's quite a messy situation using pip now. Very common that an import doesn't allow to auto install in pycharm, but then you can just go manually find it. And many packages are broken with current python versions. Packages are old, out dated, etc. There seems to be no real way to tell without manually trying everything
There's no such plan, do you have any examples?
The Fedora and Gentoo maintainers generally go around making sure all the test pass on popular packages
Seems like about one in 10 or so packages I install have deprecation warnings etc
selenium-wire installs a version of another package which breaks it as one example
selenium-wire hasn't had a release since 2022, maybe that's the core issue
Depends on if you want pip and python to be stable, or if you want to shrug off broken packages everyone will find
in fact it's no longer maintained https://github.com/wkeeling/selenium-wire
bingo
I wouldn't expect yum/dnf emerge to be finding packages which don't exist anymore. So maybe it's a different philosophy?
I guess it boils down to, why does pip for python x even find packages which don't work for python x
another example here

if I accept this upgrade, it will break and die further
what will break?
selenium-wire, which depended on it, works with 1.7.0 even though it installed 1.9, then when I downgrade it works (more), but always wants me to upgrade
kind of puts the system into a paranoid "everything needs its own venv" mentality
This package specifies a required Python version of >=3.6, it doesn't have an upper bound:
https://github.com/wkeeling/selenium-wire/blob/master/setup.py#L34
This is pretty standard practice for libraries https://iscinumpy.dev/post/bound-version-constraints/
setup.py line 34
python_requires='>=3.6',```Right, and we see it doesn't work with current python, so my question is, is there a plan to stop pretending like everything is fine because pip listened to the faulty requirements
i.e. to become a dependable and stable repo
Or I guess another question would be, is there a dependable/stable repo I can change to? By which I mean, every package works?
You should definitely read the article I linked above
I believe that's the commercial appeal of anaconda. But most companies end up curating their own package repositories.
It is normal for libraries to not specify upper bounds on things. It would be a terrible idea to specify python_requires>=3.6,<3.12 && blinker==1.7.0 in a library. What if I want to use your library with blinker==1.7.1 on Python 3.12? Do I have to fork the library from now on?
On the other hand, if it is discovered that the library I just installed doesn't work with blinker==1.9.0, I can constrain blinker==1.8.5 in my own dependencies.
Right, you've found that what they did was fine. I'm not asking if selenium-wire will do anything. They are using the fuzzy option available to them
What alternatives do you suggest?
What they really mean is "these functions with these inputs and outputs need to be available" basically, but what they have access to are version numbers only, which have the benefits and downfalls in the article etc
With most products that offer repositories, even mainline repos are filtered for those which actually work as a minimum (beyond security issues that is)
yeah, official programming language package indexes are usually much more freeform with this.
If I install rocky linux / centos, I should find 100% of the bajillions of packages found will work (though they may conflict with each other)
I guess I just don't see how this approach is pythonic
Seems sloppy, error-prone and confusing, especially to newbs
I mean I have been doing this crap since the 90s so I can work through all it but shouldn't most newbs be quite confused why their favorite walkthrough tells them to install a package, and the package doesn't even work, though it is listed there for them
I guess I would assume an updated pip repo for each version, in the way EPEL or other similar repos do
If you have some ideas, https://discuss.python.org/c/ideas/6 would probably be a good place to post
There is something like this for Haskell: https://www.stackage.org/lts-23.24 but as you can see it only has 3213 packages. PyPI has over 600_000.
Ah, OK thanks.. that looks promising for the ideas
I guess anaconda's distribution would be the equivalent of that
https://repo.anaconda.com/
Alright. I guess I'm still just not really sure why python should be happy knowing that packages won't work for anyone at all, yet will be listed and available without any kind of warning whatsoever
that is just how these repositories work across most languages I'm aware of.
It's very possible to have a broken crate in rust, a broken package in node, ...
I feel like you could literally just for loop import and remove all the ones which don't work, with an auto-email to author address
there are packages that want native deps to even successfuly import, or some other specifics of the system state
Oh another thing I forgot is many packages which fail to declare their actual dependencies
bbl dinner sorry
wifey
it could be argued this is undesirable in the context of a package repository, a package should fully declare the entire state of the system it needs to work, but that does introduce a lot of complexity.
Where can I get help related to which laptop I should buy for AI dev and other complex projects in engineering
Hello, you should ask this question in one of the three off-topic channels.
do you have benchmarks around?
no, they are long gone unfortunately :(
:incoming_envelope: :ok_hand: applied timeout to @white crater until <t:1749137190:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
Desktop is better given the upgrade of laptop is extremely limited.
Buy a server rack and connect to it with your laptop.
so why does .items() define set methods even though .values() doesn't?
it's like how number + NaN = number (.keys() + .values() = .items())
somehow when included with keys, it's suddenly okay to have set methods
the collection of dict keys is set-like (in that the elements are unique), and so is a collection of dict key-value pairs.
but you can't say the same for the collection of values.
Keys views are set-like since their entries are unique and hashable. Items views also have set-like operations since the (key, value) pairs are unique and the keys are hashable. If all values in an items view are hashable as well, then the items view can interoperate with other sets. (Values views are not treated as set-like since the entries are generally not unique.) For set-like views, all of the operations defined for the abstract base class collections.abc.Set are available (for example, ==, <, or ^). While using set operators, set-like views accept any iterable as the other operand, unlike sets which only accept sets as the input.
that makes more sense
Just found the first JIT bug with fusil's brand new JIT stressing framework! Fingers crossed it's a valid one!
https://github.com/python/cpython/issues/135608

GitHub
Crash report What happened? It's possible to segfault a release build or abort a debug with JIT enabled by running the following MRE: import email # Any module seems to work, originally this wa...
It's certainly a valid bug, since it involves only pure Python code and no interaction with modules like _testinternalcapi or other private helpers. Thanks for the report!
does anyone have any ideas re: a test failure I'm having with a fresh build of cpython? test_tools is failing with an assertion error that test/support/interpreters isn't found in (some huge list). I'm on fedora and I have the build deps installed (https://devguide.python.org/getting-started/setup-building/#build-dependencies)

Python Developer's Guide
These instructions cover how to get a working copy of the source code and a compiled version of the CPython interpreter (CPython is the version of Python available from https://www.python.org/). It...
I don't think it's relevant to the fix I'm working on but I don't want to pr something while I have tests failing
It's fine to open a draft PR and if it doesn't fail in CI, you're good
Hard to say with the information you give. Which test exactly is failing?
test_makefile_test_folders on line 63, actually now that I look at it closer (oops, suppose I could have done that sooner) it looks like it may be an OS/environment thing
oo okay thanks. How do you mark something as a draft? (new contributor here, sorry)
it's a github option, it shows up in the dropdown under the "Create PR" button I think when you open a PR
haven't looked at the code but that sort of sounds like it could happen if you have a stray test/support/interpreters folder hanging around locally