#tools-and-devops
1 messages · Page 80 of 1
and refactorization is succesfully made. Thanks. This importing problem was like... following me more than a year xD
no resource was telling this little trick necessary for understanding to resolve it
how do u use rabbitmq with celery? libraries are outdated
probably I should go for redis then again
I wished to go for rabbitmq due to it often asked in employment
use pika library as recommended with RabbitMQ
Thanks
I didn't know you could interactively debug Dockerfiles.
https://github.com/ktock/buildg
GitHub
Interactive debugger for Dockerfile, with support for IDEs (VS Code, Emacs, Neovim, etc.) - GitHub - ktock/buildg: Interactive debugger for Dockerfile, with support for IDEs (VS Code, Emacs, Neovim...
I've used "dive"; it's kinda handy

GitHub
A tool for exploring each layer in a docker image. Contribute to wagoodman/dive development by creating an account on GitHub.
does dive allow you to step through the build process?
because that's what I was looking for
my build was failing intermittently and I wanted to check what could be causing it
It just lets you inspect the contents for each layer
If you want to debug the build process you could simply start a container from an intermediate layer.
No special tools needed.
whats dev ops and is it relatively easy to learn if you know py? and how useful is it? ty 🙂
to learn devops, you need to learn programming and server administration
i.e. linux
and networking
and containers/virtualization
DevOps is about automating maintaining processes
DevOps is about having Infrastructure as a Code.
DevOps is about providing scalability and reliability of infrastructure
DevOps is about automating testing and deployment
How useful is it? One DevOps guy can replace hundreds of System Administrators
Google developer Joseph Bironas:
if we are engineering processes and solutions that are not automatable, we continue having to staff humans to maintain the system. If we have to staff humans to do the work, we are feeding the machines with the blood, sweat, and tears of human beings. Think The Matrix with less special effects and more pissed off System Administrators.
is it relatively easy to learn if you know py? Knowing Py or any other script fiting language, is only one step out of many on the road to learn it
Common tools to learn for infrastructure as a code: Linux, Gitlab CI, Docker, Docker-compose, Terraform, Ansible, Kubernetes
Working with cloud providers, small ones and big ones like AWS in a code manner
Also a lot of auxilary tools, logging, monitoring, load balancing, CDN solutions, and anything else needed for infra
Some people say DevOps is a Yaml developer due to all tools except Terraform and Docker being all in Yaml xD
just kidding though. Technically tools like Pulumi is still not Yaml too
It is nice to know even you are just a single dev. Because you can throw out of a head how to test and deploy infrastructure.
docker-compose.yml 
dockerfile is not yaml ;b docker-compose is still a separate tool
I know, just teasing the point 🥴

Yaml programmers then /s
Hey @sullen path!
It looks like you tried to attach file type(s) that we do not allow (.yaml). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
I have the following yaml file which is github workflow, which I want to run with some steps on every release, but on release it doesn't work. Any idea or help regarding
name: Syncronize files between repositories
on:
push:
branches:
- v*.*
tags:
- v*.*
release:
types:
- "created"
- "deleted"
jobs:
sync-kamarotos-deployment:
name: Syncronize deployment yaml to dependant librabries
runs-on: self-hosted
# Check if the PR is not made from a fork of the repository (security)
if: github.event.release.action == 'released' || github.event.pull_request.head.repo.full_name == github.repository
env:
could someone give me a quick summary of what will happen if i do git reset --hard HEAD in my repo im scared
my understanding is that it won't delete my files since i opened this branch but it'll forget i've made all the commits i've made locally is that right?
wait no i dont want a hard reset
it'll throw away, irretreivably, any changes that you haven't staged or committed
so if i want to leave my files alone but revert commit history to my remote, do i just do --soft instead?
thanks very much for replying by the way!

I've never done "--soft" but that sounds right. Make a fresh clone, and experiment there.
ok :(
and ffs back up what you've got right now, if you're worried about losing it!!
there's always the reflog after a wrong reset
you'd have to mess up very bad to actually lose data
im scared that even if i back up before a screwup, putting thing back will still be a pain
the only things that can't be restored are unstaged changes I believe
do any of these reset commands touch ignored files
untracked seems to be the more applicable word
wait no maybe its not
they only touch tracked files
ok ok
geez just make a backup.
git doesn't do anything with untracked files
on github, how do I hide my primary email, while having a secondary public one that'd be used for things like co-authors? I thought I had it but apparently the "public email" on the public profile settings page only affects how it appears on the profile
checking with the api, the primary email I want hidden has "public" visibility while the one I want to be public has null
I don't believe it's possible unless you use their noreply email as the secondary one.
The primary email seems like an all-or-nothing deal.
There aren't any granular controls for which email is used for what.
I've tried searching google for an answer but I haven't really found what I'm looking for, maybe it's not a thing but I just wanna ask here for a double measure. So I made a python script that just accepts an id for a public google spreadsheet file through the console and stores it temporarily and just returns some output in the console based on that spreadsheet.
This is meant to be shared with people who don't have coding stuff so I've been trying to look for some sort of free online python webhost thing and put my code there for other people to run on their own browsers. I've found one called Pythonanywhere but that one requires people to sign-up and i just want to make this as easy as possible. There any alternative?
I think this is the right question for this channel.... I hope...
Or some other simple solution other than web hosting, I'm all ears
emphasis on the free part though, I'm a broke teenager XD
@toxic hill, do you want it to create permanent links or user can get there and paste the code?
replit
Write and run Python code using our Python online compiler & interpreter. You can build, share, and host applications right from your browser!
I was thinking of the first
Hmmm
Looking at that replit one rn
Thanks, Replit works perfectly for what I need
Hey everybody !
not exactly
it means Anyone can read it, and anyone can Fork it, and offer a Pull Request to it
how do i know if my push can change main repo??
https://www.atlassian.com/git/tutorials/comparing-workflows/forking-workflow this guide metnions different workflows. So called Forking Workflow
Atlassian
A breakdown of the Git Forking Workflow. Learn how git fork can help teammates and collaborators work better together.
oh you mean from fork to main repo?
yup
ergh. 🤔 if you aren't collaborator, then you just can't change main repo
unless you open Pull Request in GUI, from your Fork into Main repo
you can see in git remote -v
where you push the code
it will be to your fork
if you wil try to main repo, you will get denied if you aren't collaborator or owner
and in setting>danger zone is it only a visibility setting?
Public / Private? Yes and a bit of No
your repo can be also in Organization group, which would make private repo in it a bit different regulated obviously
all members of organization will see
i think its pretty easy to get fired isnt it??
after pushing some bs by mistake lmao?
provide an example of sutiation in more detail/steps
there are certain policies/culture things that prevent a lot of issues
yes i thought so, but like as a student in a project we can do blunders
I have an AWS practice question I need some help with
A business operates an application that collects data from its consumers through various Amazon EC2 instances. After processing, the data is uploaded to Amazon S3 for long-term storage. A study of the application reveals that the EC2 instances were inactive for extended periods of time. A solutions architect must provide a system that maximizes usage while minimizing expenditures.
Which solution satisfies these criteria?
A. Use Amazon EC2 in an Auto Scaling group with On-Demand instances.
B. Build the application to use Amazon Lightsail with On-Demand Instances.
C. Create an Amazon CloudWatch cron job to automatically stop the EC2 instances when there is no activity.
D. Redesign the application to use an event-driven design with Amazon Simple Queue Service (Amazon SQS) and AWS Lambda.
I'm not sure whether it's A or D based on the context here. Any kind of help would be appreciated
I think all of those could be true, although A is by far the simplest
I had the vague sense that "auto-scaling groups" were deprecated, but who knows
AWS Lambda is not required to be paid for inactive stuff. Paying as much as you used only
highly likely the asnwer
the trouble with D is that it'll take a fair amount of time and effort to do, and unless they've found a good programmer who works for free, it'll add to the expense.
fair enough
so: how many$ will it cost to do D, and how many $ per year will it wind up saving, and is that benefit worth the cost? Who knows? This is why business is hard 🤣
I know, option A just made sense.
During inactive hours it'll just scale down to the lowest limit
Redesigning just doesn't make sense to me here
But overall what would be the best answer for this question?
Auto scaling groups... other providers don't even have stuff like that 🤔 only big three providers have it.
That's why I should use AWS xD
a wet dream, to have kubernets auto scaling node pools 😁
if only it was cheap though... it is not cheap to have it in AWS 😦
70$+ per month just for initial minimal instance of AWS EKS
what does "best" mean?
if it means "which answer does the quiz consider correct" ... I have no idea
if it means "which would you do in reality" ... it depends 🤣
if this stuff were easy, everybody'd be doing it.
idk man, if your life depended on this question, what'd you pick?
A
I'd guess that that's the answer the quiz wants
🤷
otoh, the quiz is probably published by some company that makes its money doing AWS training, so they might well want D since that will require you to learn a bunch of tech and maybe give them some money 🙂
lmao
anyway, thanks
actually A might not be simplest:
- auto-scaling groups might well be deprecated;
- they might be harder to use than I think they are (I've never actually used them)
Hello im trying to develop a python parser for large mongodb files. Anybody have experience in such a thing?
parser of mongodb files by python? wait what? Why not to use python mongodb clients? https://pymongo.readthedocs.io/en/stable/tutorial.html
hey @civic hound , it's me, alkk. i have checked mapbox for some of their products alr but i have severe limitations. firstly, there's no tool for me to accurately "map" out the road, neither is there an API that can plot out streets, highways with their respective shapes/traffic light etc. without this i suppose there should be a great change of the project's approach, which is just to focus on the characteristics of most roads, highways etc, and make my own "tracks" with imitated features of real roads and combine them. The catch is, there is a finite end to this generation and that is the "finishing line". The cars can use whatever way they choose as long as they get there it's fine
the characteristics of most roads include junctions and multiple exits and that they have multiple ways to reach a place. my plan is to create some of this but not too branched out. If the cars reach one of the more remote branches, the generation will stop and the car eliminated etc. then my project will be more on the characteristics of neural networks and explain compare/contrast human driving behaviour and this network etc
(if anyone wondering i got explicit permission from eivl to ping)
Is there a (consistent) way to determine if your code is running inside a Kubernetes container or not?
I'm thinking
import os
def in_kube():
return bool(os.getenv('KUBERNETES_SERVICE_HOST'))
I almost hope there isn't.
But like you, I'd assume that some environment variable is the way to do it.
try
import os
print(os.environ)
it should recount all existing stuff
as a theoretical question, we could try detecting availability of Kubernetes API (what was its port?)
even if we are denied of its access, we still should be able to detect its existence
plus some DNS things could be a hint.
Not easily and there is no reason to do so.
Remembered. There is actually guaranteed way if u can deploy some security kubernetes permissions along side of it. .... Anyway better to check drone CI kubernetes self hosted runner for inspiration
But u know... What would be the point to do it, when we can just set env var?
Okay. There is indeed no point to do it then
Just trying to minimize local dev config
how so? Can you expand a bit on the problem you are trying to solve?
Writing a program that will (eventually) run inside an AKS cluster(cron or triggered); and because (networking/auth) - has two different code paths depending on where it's running. I find it easier to debug locally; so having the program auto-detect (and adjust it's code path) depending where you're running is... convenient. Also; removing "Just do this..." from coworkers plates when setting up a new dev-environment is always a bonus.
Yea, you have software design issue
Everything should run the same everywhere
That's not realistic. Windows vs Linux as an example, a program may work on both but handle paths differently. You write shims to smooth the translation so it's not something you constantly have to take into account - and that's what I'm doing.
The difference is that the shim is outside of the program, not inside.
In the case of k8s, you could observe that one of the strength is the container is immutable and is the same, whether you run it on a dev box through docker/podman or on a cluster. The main difference is the environment will provide the information around it
That avoids any sense of "magic" and makes it easier to have a consistent and reproducible behavior
It's also detailed in the twelve factor apps (although I have a strong disdain for their specific emphasis on env variable, but that's a different topic)
COmpletely realistic, plenty of people do it all the time.
if its destination is an AKS cluster, maybe spend some effort getting it running in minikube
Is there a way for git to not convert the line endings for a single file or directory in a repo?
The situation I have is that there's a csv file in a repo that requires Windows style line endings (long story). However, by making git use Windows style line endings for the whole repo, it results in entire-repo changing commits (multiple devs + OneDrive... also long story).
The only solution I found is to use .gitattributes and to define the file or directory as a binary. But this feels kludgy and prevents using git diff. Is there a better option?
you can also specify the line ending in .gitattributes, I think
So, upon re-reading, I guess I missed the last part of the documentation where it shows how to set that per search string.
*.csv text eol=crlf
Thanks for the info and the nudge.
Any experienced DevOps Engineer and/or any Data Engineer could speak a little about daily work computer, I am taking courses in both devops and data engineering and I have a MacBook Pro and a windows and now I am thinking about getting a dedicated Linux laptop
Any thoughts?
I probably qualify as one or both of those things. I personally use a mac.
and homebrew, of course
both of those can run Linux VMs where you run your actual software like Docker, Kubernetes (if need be), and actual distros like Ubuntu or Fedora. so I don't think you really need to buy a dedicated laptop. it's up to you if you prefer it over a VM.
My last few jobs have provided the laptop anyway
they offer a choice, and probably 90% of the developers choose Macs, 8% Windows, and 2% Linux
so my M1 macbook shoud do the job
yep
yep. though keep in mind, older versions of tools and Docker images may not work natively on M1, so you'll need to use rosetta for those and specify platform: linux/amd64 for Docker images
every virtualization thing that I use now works on the M1, but multipass didn't for a long time
docker works fine (or as well as it ever did on x86)
virtualbox isn't available and probably never will be, but I don't miss it
parallels works fine
I meant, older tools/images
[I mean I personally disagree with many of its choices, but it works as well as its own designers intended it to]
Not sure if this the right channel. But may anyone give a hint what is considered as best practice for handling versioning (setting version) for a in git contained package?
do you mean how to auto increment the version number as per semver, calver, etc.?
The general handling. But what you said is also part of my question 🙂
in c++ i used git hooks and tags for incrementing versions.
I've never found a uniform way of doing this.
I always want git commit IDs baked into my software, and always wind up "rolling my own"
But maybe in python there are some tools which would allows the same.
maybe. Never found any but I haven't looked in a while.
there's pre-commit for doing git hooks since that's what you're already familiar with
!pypi pre-commit

A framework for managing and maintaining multi-language pre-commit hooks.
where I work there is a way of figuring out "which git commit corresponds to the version of code currently running" but it's quite complex
for my c++ projects i just added a semantic version that has a git shortrev appended and a "dirty" append when changes were made in the repository. And the version is generated on build.
we just chuck in a file with the gitsha in the container
that'd be fine
that'd be less fine, since that file wouldn't be easily available to us when we're digging through logs
we could however teach our software to emit a log containing the content of that file, at startup
and additional to that the micro part of the version is increased on every commit. If minor or major part has not changed.
we do also use the gitsha as the version of the release in Sentry
the gitsha file is only for Sentry to pick it up for initialization
now that I think about it we could just set an environment variable for Sentry init to pick it up ¯_(ツ)_/¯
we don't use sentry but probably have something similar
I decided to use https://pypi.org/project/setuptools-scm/ now for versioning my package. It's a lttle bit different to what use for my c++ but it brings everything i need.
oooh that looks perfect
There is a base folder and a backend folder, if I create a pipenv env for the base folder is it possible to tell pipenv to put the Pipfile and pipfile.lock in the backend folder? because it keeps recreating a pipfile in the base folder which I dont want (because the project is a monorepo)
not sure if this is the right place to ask. but if I want to have python respect K8s pod memory limits, should I be using the resource library to set a limit on processes (and all children when they start up) on RLIMIT_AS or RLIMIT_RSS?
because I've been reading https://medium.com/@eng.mohamed.m.saeed/memory-working-set-vs-memory-rss-in-kubernetes-which-one-you-should-monitor-8ef77bf0acee and https://stackoverflow.com/questions/3043709/resident-set-size-rss-limit-has-no-effect/33525161#33525161 , it seems that RLIMIT_AS is virtual memory and K8 according to the blog post seems to be indicating that what it checks for is RSS (+/- another measurement)
the k8s pod memory limit will cause the container to get abruptly killed when it hits the limit, and is standard practice in k8s, i think rlimit will just cause an error in python itself (MemoryError)
yep you don't need to configure anything application side
for vscode, do you know any extension that provides "copy breadcrumb" feature - https://github.com/Microsoft/vscode/issues/71453 ?

GitHub
I need to traverse JSON structures quite a lot at this time, and copying the path to a particular field would save quite a lot of time. It would be really nice to be able to simply copy the content...
just realized there's an #editors-ides , gonna ask there
I'm having some troubles uninstalling homebrew (as its been acting somewhat funky when installing anything), but I'm getting this syntax error when trying to run /usr/bin/ruby -e "(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/uninstall)"

If you're using bash you'll want to add a dollar sign before the embedded opening parenthesis so it'll be evaluated as a shell command (and not part of the code passed to ruby)
@vague silo @deep estuary hmm the thing is the goal is kinda wanting to avoid k8s from killing the pod entirely and wanting to error on the python side. but there does seem to be a difference in at what point k8s would have jumped in to OOM vs when python would complain when I use resource to limit (RLIMIT_AS; following https://carlosbecker.com/posts/python-docker-limits/; I think it's due to the difference between checking RSS vs checking vmem).
more specifically, with a pod that's running my fastapi app that wraps around an xgboost model (no UI or db, just barebones app), it doesn't really run into mem issues unless maybe a huge request gets sent to it. but with limiting RLIMIT_AS (and no changing the pod mem limit in k8s config), I start seeing memory errors a lot more
e.g. upon request it sends a request to our security service to validate the attached token but it can't make the connect in the limited RLIMIT_AS case due to not being able to allocate memory for the connection.
upon profiling, RSS usage is fairly low (like not close to pod mem limit), and the only mem stat that's close to the set pod mem limit is VmSize from /proc/self/status
Thanks!!
I wanted to make a project which uses c++ and go-lang functions in python but how shall i go by connecting them so they work in real time
i have no experience in that area unfortunately, sorry :( I think the sanest thing you could do would be checking the input payload size
I think you can leverage cffi for that, but I don't really have hands-on experience with that, so can't say for sure. maybe #c-extensions would be a better place to ask.
Okie
Hello peeps, how are you doing?
I am currently designing and PoCing a tool to do monitoring by capturing values from a function being monitoring, I am blocked at a very singular step.
Indeed I would like capture/fetch/read vairable within the scope of a monitored function at execution, then do data processing to these captured variable's values before writing them to a Database. My problem is finding an elegant and simple way of capturing the variables and their values
here are the threads I found but they suggest pretty outdated solutions :
- https://stackoverflow.com/questions/9186395/python-is-there-a-way-to-get-a-local-function-variable-from-within-a-decorator
- https://code.activestate.com/recipes/577283-decorator-to-expose-local-variables-of-a-function-/
is there a more elegant/up to date way of doing this variables capture? I have stuck with this for the past 2 weeks :p

Stack Overflow
I'd like to read an object method's local value from a decorator that wraps it.
I've got access to the function and func_code from within the decorator but it seems all I can get out of it is the...
@viral marlinare you here and do you have some time?
I'm just about to step into a meeting, but if you post your question I'm sure others can help
looking for a modern feel terminal like zsh for mac but for windows
i know there is zsh for windows but it just looks like any other oldschool terminal
zsh is a shell, not a terminal
windows has a very nice terminal called "Windows Terminal"
you can run zsh on windows, sorta, via WSL. Dunno if you can use it to start windows programs though.
powershell is also an option
so, the way that works... is, there are terminal "emulators" which "paints" a picture of a terminal screen... and the terminal program makes it work like a terminal.
this is a separate program from these:
- zsh (a shell)
- bssh (also a shell, but a different shell)
- the python REPL
any one of the three programs at the bottom, can attach to anything that is a terminal (the windows terminal would be an example of that)
a terminal, will do two basic things: receive keystrokes from the user, and send them to whatever the termainal is attached to (examples: zsh, bash, python)
the other thing the terminal does, is receive keystrokes from the program it's attached to (like zsh, bash or python) and display those keystrokes on the terminal so that the user can see the messages being sent by the attached programs (such as zsh, bash or python)
@lone inletafter seeing/reading all this, did you have questions?
@lone inletnote that this model of operation, has been around since the 70s at the latest
the other thing the terminal does, is receive keystrokes from the program
it receives characters from the program, not keystrokes

{kind=link}
that'll work 🙂
I wanted to emphasize the "sameness" of the input from, and output to, the program the terminal is attached to
K I understand
so let me update my qeustion then
is there a bash or zsh terminal that has a buetiful interface like the zsh terminal found on mac

@lone inletthe "traditional" interface from any terminal, or anything "pretending" to be a terminal, is character-by-character, from the terminal to the shell (or to something like python, which is sorta like a shell, but is not actually referred to as a shell
@lone inletthat said, there can be other interfaces, like the one you mention runs on mac
@lone inletit's possible that the shell itself could do this
(given proper configuration)
I'd google "powershell prompt"

Medium
Want to make the basic PowerShell window visually appealing? Then this guide is for you.
[ok, full confession: I googled "pimp my powershell prompt"]
@lone inletso I think that each shell can (or cannot) make the prompt "prettier" the way you requested earlier. This means, you'd have to write (or use already written) configuration for the particular shell you use, and if you switch to a different shell and you wanted similar prompt decoration, you'd have to configure that shell too, and -very- likely, that configuration would happen using a different syntax, that you would have to read up and learn about
Check Starship or oh-my-posh
https://starship.rs/
https://ohmyposh.dev/
Starship is the minimal, blazing fast, and extremely customizable prompt for any shell! Shows the information you need, while staying sleek and minimal. Quick installation available for Bash, Fish, ZSH, Ion, Tcsh, Elvish, Nu, Xonsh, Cmd, and Powershell.
A prompt theme engine for any shell.
Scotts blog post on this is nice too https://www.hanselman.com/blog/my-ultimate-powershell-prompt-with-oh-my-posh-and-the-windows-terminal
I've long blogged about my love of setting up a nice terminal, getting the ...
im trying to commint my project to github and it says email not confirmed when i have confirmed it
@astral apex Pretty much the only redeeming quality I guess about GCP is Firebase
Which in itself is already treaded on by AWS Amplify and Azure App Service
So I guess that's not helping much with Google
Aws runs like half the internet, I'd just go w/ it
More mature than Azure too
I still can't help but to think AWS is like a big and intimidating Swiss Army power tools though
With it y'know, having tons of services under its belt
Both being good and bad
Azure my fave
Can I change default Python version with just env var?
i think it should be possible 🤔
what do you mean "default"
do you mean using py on windows or something?
i mean i wish in my kubuntu, python3.10 as default instead of python3.8 inside Vscode terminal
what are you running in vscode to bring python up
well, i would not mind having python3.10 default in general, but I fear my OS would break if i change it
just a script not requiring any third party libs

Configuring Python Environments in Visual Studio Code
plus i would not mind if my venv automatically was generated with python3.10
do you mean through this?
right but if you run python3.10 you will get 3.10 and python3.8 for 3.8
i'm trying to understand what you want to default here
do you mean just running python generally?
you could also just alias it
i am trying to have python/python3 as python3.10
or symlink
yeah, except vscode is not reading alias
or is it reading 🤔
so symlink?
i am afraid it will break OS
ubuntu is highly dependnded on python
it should work with 3.10 if it's defaulting to 3.8
i'll go with alias

Gist
update-alternatives for python3 on Ubuntu. GitHub Gist: instantly share code, notes, and snippets.
symlinking python3 to a newer version will break it?
I use pyenv for specifically that scenario
this is one way of doing it with update-alternatives
a high chance it will break.
Those experiments i would better do in virt desktop
update-alternatives is a nicer way of symlinking and keeping things in order

In this step-by-step tutorial, you'll learn how to install multiple Python versions and switch between them with ease, including project-specific virtual environments, even if you don't have sudo access with pyenv.
pyenv is a decent way of doing it as well
nice, but looks to be outdated way to go with it.
If i need multiple python versions with installed libs, i would just go having docker-compose dev env setup and hooking IDE vscode into container
it is more reliable changing OS python version to multiple ones
in my situation i just wish changing default python, so it would be used by default for anything new
thanks. i just went with alias as sufficient and reliable(to not break OS) solution to my case
definitely memorized for the future though. looks really nice 🤔
pyenv is not outdated
still very actively maintained
pyenv + poetry 😉
exactly 🙂
If you are using VSCode, DevContainers rock and best way to roll. Don't have to fiddle with poetry, conda, anaconda, burmese, virtualenv or whatever other crazy package manager that exists. Just pip install and away you go.

Get started with development Containers in Visual Studio Code
Exactly!

Hey everyone.
For the past few months, I've been working on a static code analysis orchestration tool named Statue. This tool can help you run multiple formatters and linters with different arguments on different files and directories.
Most of you probably use pre-commit for that purpose. While pre-commit is an awesome tool, Statue solves that problem with a different approach.
You can see the tool in Github:
https://github.com/saroad2/statue
If anyone has a question about the tool, feel free to send me a private message!
And of course, if you use the tool and you find it helpful, please give it a star in Github 😄
GitHub
Orchestration tool for static code analysis. Contribute to saroad2/statue development by creating an account on GitHub.
Firstly there is Tox tool
Secondly, they should be called from CI
Everything else is not reliable
Hey Darkwind. Thanks for the feedback, but I kindly disagree.
Tox doesn't provide some of the features presented by pre-commit and Statue. You can read in the documentation some of the features Statue provides
As for that, you want to be able to run you linters locally and not via CI. You can't rely fully on CI for that.
🤔 basically i wish to have a simplified way to call all those scripts
so, argparse / click and etc
Why isn't there a 3.10.2 python docker image (here : https://hub.docker.com/_/python ).
I assumed (wrongly, but not sure why) that all versions of python would be available as an image.
Python is an interpreted, interactive, object-oriented, open-source programming language.
btw... I kind of experienced same problem with having uniform way calling all those extra scripts
just finished making answer for fun
from types import SimpleNamespace
import utils
class InputDataFactory(utils.AbstractInputDataFactory):
@staticmethod
def register_cli_arguments(argpase_reader: utils.ArgparseReader) -> utils.ArgparseReader:
return argpase_reader \
.add_argument("--cli_argument", type=str, default="example")
@staticmethod
def register_env_arguments(env_reader: utils.EnvReader) -> utils.EnvReader:
return env_reader.add_arguments(
env_argument1=env_reader["PWD"],
env_argument2=env_reader.get("NOT_EXISTING_VAR", "default_value"),
)
class MyScripts(utils.AbstractScripts):
input_data_factory = InputDataFactory
@utils.registered_action
def build(self, input_: SimpleNamespace):
self.shell(f"echo {input_.cli_argument}")
@utils.registered_action
def print(self, input_: SimpleNamespace):
self.shell(f"echo {input_.env_argument1}")
@utils.registered_action
def example(self, input_: SimpleNamespace):
args = input_.cli_reader \
.add_argument("--argument", type=int, default=456) \
.get_data()
self.shell(f"echo debug_{args.argument}")
if __name__=="__main__":
MyScripts().process()
I made a small library that using argparse, allows me to run commands like
python3 scripts.py build
python3 scripts.py example --argument=123
basically python version of makefile, with easy registering values from env and cli inputted into it
I hope that it would give me ability to register commands to call all those build/linters/tests in a more uniform manner
This is kind of FITTING solution for me, because i can all in inform way my linting/tests and etc scripts from CI
that is first thing i wish to have
is this pure fun - or something you'd use in a work environment ?
it's there tho?
tempted to use in a work environment. I really missed having thing exactly like this. It is exactly i need in order to have self-documented version of python makefile, that i can call from CI
isn't there Nox i ctrl f'd for 3.10.2 and didn't see anything
Python is an interpreted, interactive, object-oriented, open-source programming language.
isn't Nox like tox but with .py instead of .ini ?
not really a thing i wish. Nox does more than it is necessary for me, and less than needed.
My regular workflow assumes running tests from a built docker image, that i save and reuse in testing/staging/prod environment
nox doesn't play nice with an image ? I've not used it much, only a hello world version i guess
https://nox.thea.codes/en/stable/ according to wiki it makes stuff with venv to launch itself. That's already not needed, it is handled at docker level
ah ok, makes sense. Tox does a similar thing with building venvs as well afaik?
The only thing is missing, to have registration of cli variables in a way that is not giving away implementation details 🤔 yet being super powerful
I'll adjust this detail and then it would be ideal for my usage
yeah, it should be doing as far as i remember
it makes sense to use when u wish easily running tests in multiple python environments at the same time i guess
Github Actions CI run in Matrix mod essentially
We could adjust it to fit docker env 🤔 Making stuff like
ARG python_version
FROM python:python_version
and then building and launching our image with different build arg of docker
it is more powerful way to have it because
Venv is only venv. Docker image is having all OS dependencies, including installable binary files that can be needed by venv
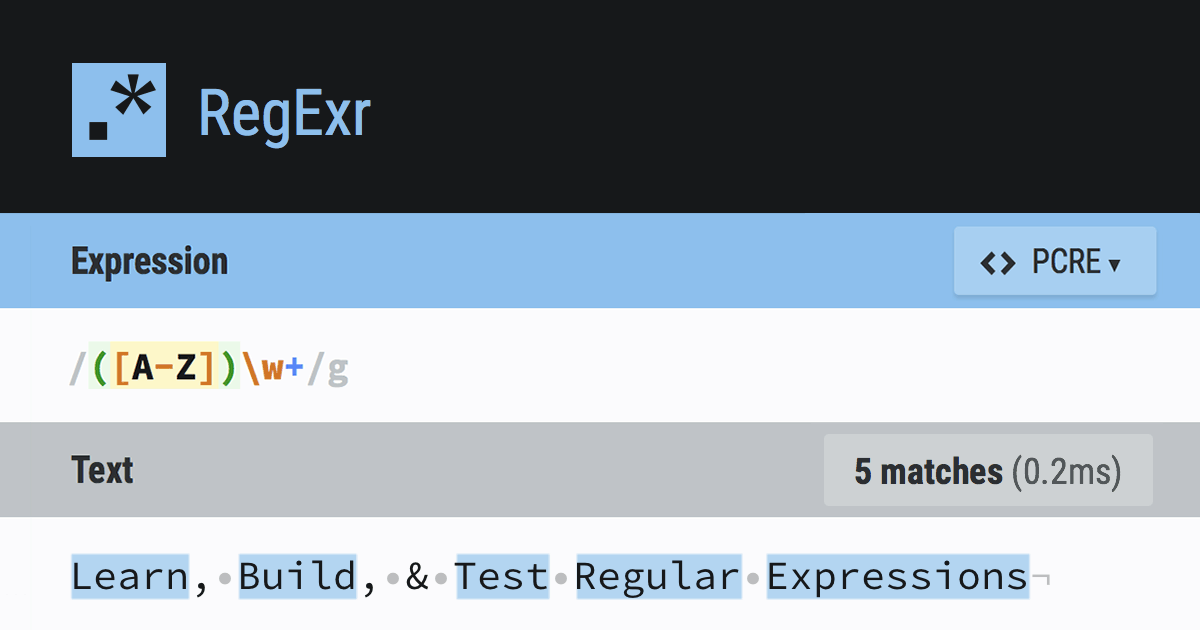
Greetings all. I'm looking for a python library for validating verifying email addresses.
Regex email formula: https://regexr.com/3e48o
^[\w-\.]+@([\w-]+\.)+[\w-]{2,4}$
RegExr
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
No wait, my mistake, I meant verifying an email address
That it really exists?
Write your own small solution, while using sendgrid to send email with URL containing JWT token.
- Generate JWT token, validated by your Secret, and JWT contains user ID/email
- by sendgrid send to user email with URL link to your rest API endpoint and JWT as query Param
- verify incoming JWT with your Secret, read which user ID/email. Mark as verified
Nope! If security problem, it might be removed.
Updated to full algorithm above
I'm far too lazy, So i'll go with sendgrid i've been using mailgun for awhile though.
Mail provider is not important, as long as it provides nearly unlimited API level limits to send email programmatically
https://pypi.org/project/darklab-utils/ yay, my first pypi package published

now i can reuse it between my repos xD
considering how it fits my workflow (at 100% matching), i think i would use it everywhere i can xD
<@&831776746206265384> spam
has anyone worked with cibuildwheel before?https://pypi.org/project/cibuildwheel/
how can I do that I am asked in the terminal how often it should be repeated and when it is finished it makes a brake