
#tools-and-devops
1 messages · Page 20 of 1




Hey guys, this math solver application developed by Python - Kivy & KivyMd and it s full open source on Github

GitHub
Mathpath: Math solver. Contribute to mathpathconsole/mathpath development by creating an account on GitHub.
On Google Play: Mathpath: Math solver
I'm looking for feedback on my latest project, "A Real Mock API (ARMA)", is still under development, but I'm open to suggestions and contributions. https://github.com/dan5e3s6ares/arma
I created the project with the intention of creating a sandbox with our apis

GitHub
A real server to mock any api , really easy to use - dan5e3s6ares/arma
Hey, question, im being asked to do a python simple code , they tell me to do it on spyder anaconda, but it isnt running and im courious if i could just do it in vscode , would the IDE (the enviroment) change something or not?
they tell me to do it on spyder anaconda
We don't know their reasoning or the nature of their request. In theory it shouldn't matter what IDE you use for most tasks. Did they give you detailed instructions specific to that IDE? Is there a reason you're asking us and not them?
how do i automate the process of generating release notes in azure devops?
also could anyone tell me which sql software is best and user friendly for changing multiple databases, saving queries, writing queries, which can be easily opened next time?
I use SQL Server management studio, but its not that much user friendly
i've used dbeaver before, it's not bad
hi , I want to create an auto claim tool and i need help who can help me ?
also could anyone tell me which sql software is best and user friendly for changing multiple databases, saving queries, writing queries, which can be easily opened next time?
i prefer Beekeeper Studio for manual navigation over dbs.
If u need saving queries though i would recommend saving them to git repo 😉 in my opinion any such db viewing tool is not meant to have them saved.
how do i automate the process of generating release notes in azure devops?
https://darklab8.github.io/blog/article/git_conventional_commits.html
https://darklab8.github.io/blog/pet_projects.html#autogit
heh. i just made a tool depending only on Git to do that. Should be insertable anywhere if desired
hi
how do i get pyenv to compile with tkinter?
i tried running this command but _tkinter still doesnt exist
env \
PATH="$(brew --prefix tcl-tk)/bin:$PATH" \
LDFLAGS="-L$(brew --prefix tcl-tk)/lib" \
CPPFLAGS="-I$(brew --prefix tcl-tk)/include" \
PKG_CONFIG_PATH="$(brew --prefix tcl-tk)/lib/pkgconfig" \
CFLAGS="-I$(brew --prefix tcl-tk)/include" \
PYTHON_CONFIGURE_OPTS="--with-tcltk-includes='-I$(brew --prefix tcl-tk)/include' --with-tcltk-libs='-L$(brew --prefix tcl-tk)/lib -ltcl8.6 -ltk8.6'" \
pyenv install 3.12.4```(of course, tcl-tk was already installed)
i'm running an intel mac with macos 13.6.3 installed
I assume you're following https://stackoverflow.com/a/60469203/20146

Stack Overflow
Versions of Python installed via pyenv fail to import tkinter:
※ python
Python 3.8.1 (default, Feb 29 2020, 11:45:59)
[Clang 11.0.0 (clang-1100.0.33.17)] on darwin
Type "help", "copyright", "credi...
Hello, i want to make a Referral Bot for my own usage... i came as far as i could but now i am more than helpless, everything i do doesnt bring me forward so i came to conclusion to ask for help if anyone could help me with this small project i am working on, i would be more than grateful!
If you have a specific question or problem you're stuck with, #❓|how-to-get-help . If you're looking for a volunteer to build something for free, that's unlikely, but you could hire someone to build your bot on Fiverr or Upwork.
well it is such a small thing that is left that i think kind people would help me free tbh 😄
Then you should ask your question in a help channel and someone will put you on the right track to figuring out what you need to do.
i now did but i hope i can find someone
Hi, I'm currently working on a web scraping program with Python. Unfortunately, I'm not making much progress at the moment, so I wanted to ask if there might be an expert around here.
just ask your actual question, in #1035199133436354600
Don’t ask to ask
Big bros, can someone explain APIs to me
perhaps you might want to check this and come back with more specific questions, no intention to be rude - https://en.wikipedia.org/wiki/API

An application programming interface (API) is a way for two or more computer programs or components to communicate with each other. It is a type of software interface, offering a service to other pieces of software. A document or standard that describes how to build or use such a connection or interface is called an API specification. A computer...
Ggs
$ python3 -m pip
No module named pip
Why doesn't it find pip?
This is in nix shell, hmm 🤔
pip ripped out of Python as in Debian? You can try python3 -m ensurepip, but I'm guessing there's a way to get python-but-with-pip via nix as well.
Oh, Debian packages python without pip for some reason? I guess the python packages should be installed the nix way
Debian does do that. I can never remember the reason.
sudo apt install python3-pip otta fix you up
🤷 I've barely played with nixos. Maybe they too have pip in a separate package, in which case I'd guess you should install that.
I wouldn't be surprised if debian replaced the ensurepip module telling you to run sudo apt install python3-pip
Probably because they hate pip because it used to break system packages.
Using system python pip in debian based systems is very bad practice
U can break your OS like this
Recommending initializing venv
Or installing pyenv
@thorny shell i see, thanks
what do stars next to property/method names mean in autocomplete in VS Code?
Why would u wish to use pyinstaller on another PC that does not have python
I feel like this channel is the most fitting to ask about documentation, otherwise feel free to point me to a better one.
I need to document a framework/library and want it to be as much as possible auto-generated from docstrings as possible.
These docstrings are in the Google style and contain LaTeX.
Bonus points if I can get the docs output as pdf, additionally to HTML.
I saw pdoc3 and it seems nice but I'm not sure whether it's the best for what I'm trying to do, any advice?
Ha. I did it with Sphinx
That uses Autodoc module. It can read Google style docstrings
And generate docs for all the public objects
I disliked rest though and switched to markdown as main
I looked at Sphinx and it seems like a lot of overhead 🤔
All I need right now is the auto-generated part
i think it matches your desires for more than 90%+ part. autogenerating documentation is like major point of it
other stuff are optional plugins
I'll take another look, thanks
🤔 it can generate not only html, but also latex and pdf natively
u would have only trouble with Latex inside your docstrings too. i don'see how it can mix with Google style docstrings already
sphinx does offer some customization through latex though
Latex inside docstrings was fine for pdoc3, you escape it like
def do_stuff(tau: int) -> int:
r"""Does stuff.
Args:
tau: The value \(\tau \in \mathbb{Z}\) is ignored.
Return:
The best number, 4.
"""
return 4
With raw docstrings
I built a pretty neat tool that you can use to host Python code and turn your functions into a GraphQL API. 🙂
I also wrote a blog post about it. https://hasura.io/blog/introducing-python-functions-on-hasura-ddn and tomorrow I’ll be speaking about it on my companies Community Call! https://hasura.io/events/community-call/2024/august Happy to chat with some folks about it if anyone is interested to hear more!
anyone using mkdocs? I'm looking for a way to control the granularity of the left navigation menu (for now it keeps using depth=2)
I'd like to just say depth=3 (for example) and let it infer the table of contents from the markdown, without configuring it in the project settings. looks like it doesn't exist when I browse the docs
site_name: Darkbot
site_description: discord bot for Freelancer Discovery
docs_dir: docs
site_url: http://example.org/fl-darkbot/
theme:
name: readthedocs
highlightjs: true
hljs_languages:
- yaml
- sql
- python
markdown_extensions:
- def_list
- pymdownx.tasklist
- pymdownx.snippets
- toc:
permalink: "#"
baselevel: 1
baselevel i believe is what u seek
https://www.mkdocs.org/user-guide/writing-your-docs/
ah sorry I might have misphrased my needs. essentially in this example from the doc, we see that there is a table of content of depth 2

if I add a ### level header, it won't display on the left menu
I want it to be on the left menu
does anybody here know anything bad about thonny ide i am learning python would it be a good choice?
it's a good choice
huhu, I'm inside my docker, and I run pip install -e .
usually this command works fine, but I just migrated some stuff of setuptools to give it a bit of fresh air (setting up a project toml and so on)
all the commands about setuptools work fine, but I cann't do pip isntall -e . : it tells me numpy is not a known module (while obviously it's installed, I can load it in a console, and setup.py itself uses it without issue. but when doing from pip, it looks like it fails at importing it
any idea what I could miss as configuration? maybe an equivalent of setup require or something?
[build-system]
requires = ["setuptools", "setuptools-scm"]
build-backend = "setuptools.build_meta"
[project]
name = "mypackage"
authors = [
{name = "Me"},
]
description = "Computational Engine"
readme = {file = "README.txt", content-type = "text/markdown"}
classifiers = [
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
]
dependencies = [
"numpy>=1.23",
"pandas>=2.0,<=2.2.2",
"marshmallow>=3.11.0,<=3.21.2",
"marshmallow-enum>=1.5",
"openpyxl>=3,<4",
"Pillow>=9,<=10.3",
"psutil>=5,<6",
"python-pptx>=0.6",
"simplejson>=3.15,<=3.19.2",
"xlrd>=1.2,<2.1.0",
"XlsxWriter>=3.0,<=3.2.0",
"anywidget>=0.9",
"traitlets",
"ipython"
]
dynamic = ["version"]
[project.optional-dependencies]
full = ["pyarrow"]
[tool.setuptools]
package-dir = { '' = 'src/py' }
[tool.setuptools.packages.find]
where = ["src/py"]
# ... other project metadata fields as listed in:
# https://packaging.python.org/en/latest/guides/writing-pyproject-toml/
maybe an equivalent of setup require or something?
These packages are what's declared as the build-time requirements:
[build-system]
requires = ["setuptools", "setuptools-scm"]
aaaaah, didn't even spotted it
Why do you need NumPy to build your wheel?
makes all sense
cython extensions

so im trying to deploy my app via docker. The data is stored in a database that get's stored in /app/db
fairly simple, just works after i do docker run -v host/path/to/db:/app/db ...
but now i'm left what's the point of https://docs.docker.com/reference/dockerfile/#volume
without adding VOLUME /app/db my image works just fine, adding it in also works
so im kinda lost on what's the use of VOLUME in dockerfile
I've read several SO posts by now and I still can't find an obvious answer as to why I should (or shouldn't) add VOLUME /app/db in my dockerfile
this is universal one for any volume
u can create with it named, anonymous, or directly specified host paths volumes
as it is told in https://docs.docker.com/engine/storage/volumes/
And this one is invented i think shortcut later (or dunno when it appeared)
But basically it is for anonymous volumes only
if u will write command like docker inspect CONTAINER_ID_OR_NAME | grep -C 10 volume
{
"Type": "volume",
"Name": "33b478df64730f2f35bc6dd3705bd2cf643c540e194ca06fb6a7095d2093bace",
"Source": "/var/lib/docker/volumes/33b478df64730f2f35bc6dd3705bd2cf643c540e194ca06fb6a7095d2093bace/_data",
"Destination": "/var/log/smth2",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
u will see at which host path anonymous volume got created
beyond that i dunno, i very rarely used anonymous volumes (read never)
i prefered always host path volumes
and considered to start using some day named volumes

reading about anonymous volumes....
i have no idea what is their usage case. Why would we wish random named volumes, having attach each time new unique volume on each container start is beyond my comprehension
So for my usecase (where my app will read/write to the db at /app/db/) I don't need it?
not at all 😁
Thank you! 😁
u just needing having specified docker run -v host/path/to/db:/app/db image_Name
If u wish to make it comfortably, write docker-compose.yaml for that
then everything will be specified as one yaml with all settings for run
and launched as simple docker compose up (-d into background)
yep I already wrote the compose
for especially perveted reasons i control this stuff via Terraform Docker 😁 (that make sure for me previous instances of containers and images are automatically removed when i deploy new ones). Terraform can automatically delete previous instances of deployed code if it is no longer necessary
Never heard of that actually lol
But then again I'm really new to this whole docker thing
Terraform is a next level. this good book good to learn https://www.oreilly.com/library/view/terraform-up-and/9781098116736/

O’Reilly Online Learning
this tool is best to automate actions with Cloud provider, DNS settings, configuring how serverts to rent, and all cloud level networks
if being pervert enough, it can be used for direct Docker or Kubernetes control too
universal tool
just a matter of having specific Terraform Provider present
https://registry.terraform.io/providers/kreuzwerker/docker/latest/docs i use this for my homelab 😁 for docker control via it
today it is good to use via its opentofu version due to it being a free and open source version. i still call it terraform out of a habbit
Fancy stuff
This sounds like a great beginner project. Is there something specific you're stuck on?
I have a fairly simple dev container:
{
"name": "test",
"dockerComposeFile": "docker-compose.yml",
"service": "app",
"containerEnv": {
"LANG": "C.UTF-8",
"POETRY_VIRTUALENVS_IN_PROJECT": "true"
},
"workspaceFolder": "/workspaces/${localWorkspaceFolderBasename}",
"postCreateCommand": "./.devcontainer/postCreateCommand.sh",
"customizations": {
"vscode": {
"extensions": [
"charliermarsh.ruff",
"tamasfe.even-better-toml"
]
}
}
}
and postCreateCommand.sh is just this:
pipx install mycli poetry poethepoet
poetry install
every goes just as you would expect, but the unexpected thing that's happening is that it also seems to somehow activate the venv?
test-py3.11vscode ➜ /workspaces/test $ which python
/workspaces/test/.venv/bin/python
anyone can help me about automation script already ended working but something wrong cuz one script won't working but no error i can't understand why don't working
it's scraper script
Sounds like you're trying to get around terms of service which is against the #rules here. If the data you need is available from an API,.use that instead of scraping.
which steps u tried
we've already discussed this at #unix message
@dense rapids you should delete your message above, since it's redundant
🎉
im hoping I can ask for some help, or maybe some suggestions. Is there a way to define a custom formatter such that I can turn code that might look like:
B1_p = jnp.einsum("fp,bp -> bf", self.B1_p, p_)
B1_x = jnp.einsum("fx,bx -> bf", self.B1_x, x_)
B2_xp = jnp.einsum("fxp,bx,bp -> bf", self.B2_xp, x_, p_)
and have this formatted automattically to look like this:
B1_p = jnp.einsum("fp,bp -> bf", self.B1_p, p_)
B1_x = jnp.einsum("fx,bx -> bf", self.B1_x, x_)
B2_xp = jnp.einsum("fxp,bx,bp -> bf", self.B2_xp, x_, p_)
Ideally this is something I can setup directly within vscode. Also just to be clear I use ruff, however I havent be able to find a way to customize it to acheive what I said above
I figured this out, vscode's shellIntegration setting was causing this
I'd like something like that, too; I've never found anything 😦
Do you want the arrows in the strings to be aligned in the source code or in the output?
Can't you just align on the -in this particular case as a semi manual action? Or is this really common over your codebase?
Fixit is made to do custom lint rules, I have not tried it myself:
GitHub
Advanced Python linting framework with auto-fixes and hierarchical configuration that makes it easy to write custom in-repo lint rules. - Instagram/Fixit
hard to imagine how that could do what we want
"Dear Fixit: please ensure that the operators on these four lines are nicely lined up vertically; kthxbye"
Yeah, no formatter is going to touch the inside of your strings
Huh, it's text manipulation, why couldn't you? In my editor I could certainly create autocommands that modify and align my strings upon save, for example
Tell that to black
What's it do?
Black and ruff modifies docstrings.
honestly im unsure. Can you give an example of what you are asking? I havent thought about this before
Ideally I want it to be aligned within a particular scope. using einsums is pretty common among my code base and I want the alignment to happen under very particular rules
the hard part is that I have seen people do it in vim/neovim, also seperately working in latex. I dont know why its not more common place within code
I use easyalign plugin in vim. I would assume any multicursor editor to have a align action like kakoune's &.
I would tell vim: align on /->/ on these lines
sure, emacs will align stuff nicely too (it's what I use), but we'd like something built into a formatter
What about do it on save? Or do you want it on a project basis for all users?
What about just doing your editor alignment as a script?
How do you know python fixit can't solve it?
I'm using Sphinx (with sphinx.ext.autosummary) to write docs for a package that exposes ctypes declarations, but all the function types are only being listed in the docs as CFunctionType (second screenshot). How can I get Sphinx to actually list the function type, as specified by CFUNCTYPE (first screenshot)?


Hi guys, have been trying to have traefik running on my vps, i already have it downloaded and this is what the docker-compose file for setting it up looks like, but when i go to my vps_ip:8080/dashboard, it keeps loading and doesn't resolve to that endpoint. I currently don't have any domains connected to the ip yet, is there any reason for this issue?
version: '3.9'
services:
traefik:
image: traefik:v3.1
container_name: traefik
restart: unless-stopped
command:
- "--api=true"
- "--api.insecure=true"
- "--providers.docker=true"
- "--entrypoints.web.address=:80"
- "--entrypoints.websecure.address=:443"
- "--certificatesresolvers.myresolver.acme.tlschallenge=true"
- "--certificatesresolvers.myresolver.acme.email=your-email@example.com"
- "--certificatesresolvers.myresolver.acme.storage=/letsencrypt/acme.json"
ports:
- "80:80"
- "443:443"
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
- "./letsencrypt:/letsencrypt"
networks:
- "web"
networks:
web:
external: true
have you checked whether port 8080 is not blocked in the VPS' firewall?
the vps firewall is currently not active, the only configuration is from deploying the instance, which is where i allowed traffic into the vps but apart from that, ufw is currently not activated
Can anyone help
You can now access the dashboard on the port
8080of the Traefik instance, at the following URL:http://<Traefik IP>:8080/dashboard/(trailing slash is mandatory).
- https://doc.traefik.io/traefik/operations/dashboard/#insecure-mode
Have you tried adding the trailing slash?
Have you tried curl http://localhost:8080/dashboard/ on the VPS?
I remember reading that it wasn't available publicly by default
Though now I can't find docs that confirm that
Yes I have
Didn't have any effect
Yeah but setting the Api.insecure.dashboard to true should have made it public though except am missing something
my git is failing to clone repo. I tried setting git timeout to longer time and the buffer still the problem remains. How can I solve this?
jdP@jdP:/home/jdP/Programming/android_game$ git clone https://github.com/delaford/game.git
Cloning into 'game'...
remote: Enumerating objects: 5769, done.
remote: Counting objects: 100% (422/422), done.
remote: Compressing objects: 100% (97/97), done.
error: RPC failed; curl 92 HTTP/2 stream 0 was not closed cleanly: CANCEL (err 8)
error: 2514 bytes of body are still expected
fetch-pack: unexpected disconnect while reading sideband packet
fatal: early EOF
fatal: fetch-pack: invalid index-pack output
jdP@jdP:/home/jdP/Programming/android_game$```I would google "invalid index-pack". What version of git do you have?
It seems like it might be corrupted remotely, I can try to clone if it's public repo
i have this version ```git version 2.34.1
it is public. I am trying to build an apk from a python file using buildozer and the git clone to python-for-android is failing so i tried other repo like this one above it still fails. I have tried some blog post and stack overflow to fix it that suggest to increase the timeout and buffer size and i did but still the problem isn't fixed
here the buildozer git fails output
identical to the above one
# Install platform
# Run ['git', 'clone', '-b', 'master', '--single-branch', 'https://github.com/kivy/python-for-android.git', 'python-for-android']
# Cwd /home/shubhra/Programming/android_game/test/.buildozer/android/platform
Cloning into 'python-for-android'...
error: RPC failed; curl 92 HTTP/2 stream 0 was not closed cleanly: CANCEL (err 8)
error: 3489 bytes of body are still expected
fetch-pack: unexpected disconnect while reading sideband packet
fatal: early EOF
fatal: fetch-pack: invalid index-pack output
# Command failed: ['git', 'clone', '-b', 'master', '--single-branch', 'https://github.com/kivy/python-for-android.git', 'python-for-android']
# ENVIRONMENT:
Oh, hmm.. Haven't had this problem myself.
Try pinging Github or clone from somewhere else?
I don't know what mvc it, but got notification from reddit today about https://github.com/paulrobello/par_scrape
GitHub
Contribute to paulrobello/par_scrape development by creating an account on GitHub.
Just setup a hello world docker. Every image time build: 10min. Total time wasted: 10 hours. Damn, is it really gonna get worse if I delve further into devops?
a hello world image shouldn't take 10 minutes to build, whats your Dockerfile?
Its more like a sveltekit project. I spent so much time fixing npm install command and port expose.
And the whole making docker compose file
Hi, DevOps here, containers build in 51s

Total beginner on docker
wsl
local machine
3rd world country internet
I'll get there eventually. Happy thoughts, positive thoughts.
On second note, how do you rebuild a new image. Every time I mess a line in Dockerfile, I have to delete everything in docker and rerun the command again.
Why?
Okay, let me confirm this. If you update Dockerfile content then run docker compose, does the image gets updated based on Dockerfile content. Because, I was doing that because I assume it isnt.
No
Compose doesn’t build by default
Compose expects that your containers are already built with docker build
If you want Compose to rebuild you need docker compose up --build

Medium
In the fast-paced world of software development, every second counts. If you’ve ever found yourself impatiently waiting for Docker builds…
Is it possible to tell tools like pylint/ruff/mypy to accept some predefined variables? I run python scripts in an environment where some variables already exist, so these kind of warnings are bogus:
Diagnostics:
1. ruff: Undefined name `BEGIN` [F821]
2. mypy: Name "BEGIN" is not defined [name-defined]
3. pylint: [undefined-variable] Undefined variable 'BEGIN' [E0602]
Example script:
if BEGIN:
s=0
s+=F[2]
if END:
print(f"Total: {s}")
Anyone used vim for reading info files? I just found info make starts Emacs(?), but https://gitlab.com/HiPhish/info.vim claims to make these documents readable in vim. However I have no idea where the info file is located and how to let the info.vim plugin find it.
:Info make just makes a fallback to manpage since it can't find the info file.

You should explicitly import them
That doesn't make sense in this context
How so?
You would rather let every user write an explicit import for all the builtin variables in top of every script?
This is just very inconvenient and user hostile. This is in the context of pawk, an awk lookalike with python syntax:
GitHub
awk-like python tool. Contribute to kaddkaka/pawk development by creating an account on GitHub.
But I appreciate the feedback @gentle solstice , it's good to question unconventional methods.
I want a user to be able to do pawk input_file -t 'print(F[2])' to print the second field, just like awk {$2}. Have you seen/used awk?
I think you would find it hard to implement this tool in any other way.
Yes. I understand
You can make put the optional import inside a type checking block or similar
If the user is using mypy or ruff, they probably care about explicit imports anyway
To be fair, there are no users yet so this is mostly me wanting to have nice editor experience for script files that I do want to look like
if BEGIN:
print("Header")
print(NR, F[0])
for example.
Craving explicit import would be really inconvenient for the command line case, I want these variables to be available magically. That's one of the big features with awk
I'm not even sure where this imports would be available from. I would have to distribute this as a python package rather than "just" a binary.
@gentle solstice Would distributing the binary together with a python package be your suggestion? Where how do I publish it in that case? (never made anything available through pip before)
The command line can have the implicit imports
I recommend using package scripts which pip will create for you
PIPX can be used to install it globally
Not sure where to start, I found pipx --help, but package scripts?
How does this text connect to creating and distributing a package? For example is having a pyproject.toml actually a requirement?

Modern, extensible Python project management
Released on <t:1716905581:D>.
https://packaging.python.org/en/latest/guides/creating-command-line-tools/
had this as example but pipx install . fails because name property is missing, 🤔
[project.scripts]
pawk = "main:main"
ValueError: invalid pyproject.toml config: `project`.
configuration error: `project` must contain ['name'] properties
[end of output]
Difficult to know what to from this error message
Aha!
[project]
name = "pawk"
THe example was just too short 👀
You also need a build-system
I suggest using hatch init to generate minimal project
Does astral-uv do similar thing?
I dont have uv no hatch, annoying to have to use extra stuff, but I guess it adds convenience 🙂
"convenify"
You can use setuptools too. It's tried and true
Seems like uv defaults to setuptools as backend
uv can also be used with hatchling apparently, gonna try it out and see if itcan resolve my project "structure"
$ tree
.
├── examples
│ ├── ...
├── main.py
├── Makefile
├── pawk -> main.py
├── pyproject.toml
├── README.md
├── tests.py
└── util.py
Hi, I’ve started using uv. Is there a command I can run to set the global Python version to use from anywhere without creating a virtual environment?
Like using python from bash?
yeah, I use pyenv before and run pyenv global for that, is uv have that feature
Not for global Python. You'll need to use it via uv
Noob question, but I can't find a post directly related. I'm reading here that adding "-d -X showrefcount" to the python interpreter for full parser/refcount debugging only works with a debug build. Following that, I forked CPython and built a debug build. However, this does not seem to play nice with virtual environments (venv or virtualenv, since they seem to look for "python.exe", not "python_d.exe", which debug config produces). I have tried simply building release config with "Py_DEBUG" defined, but get weirder errors in virtual environments using this build. Any suggestions? Is there a better way to have full debug info in virtual environments?
git question
does git rebase apply one commit at a time, and stop when there's a merge conflict, or apply all of them at once and then let you deal with the conflicts? (please ping on reply)
maybe just rename the binary to python.exe?
I believe a rebase applys all commits at once, then conflict resolution, or at least this seems to be how it works in github desktop.
For rename python_d.exe -> python.exe, tried that, but seems that venv creation also looks for pythonw.exe (only have pythonw_d.exe), python3xx.dll, etc. Renaming those cause more errors in the python command line itself. I was wondering if maybe there is a simpler way to wrap the debug build so it can be used as a drop in replacement for the interpreter python.exe
damn, that sucks
both of those
thank you
Noob question about Git
My understanding:
First you do git init in the folder you want to track
Then whenever you make a change you do git add * and git commit
And then you will be able to go back to any commit you made like it's a checkpoint? Does this sound about right? Or is my understanding wrong?
Yes, u can back to any commit you made, it is like checkpoint/savegame
except by default if u will just "travel" to the this checkpoint it would not be for creating new commits on top
unless u create branch from it (even in this case, merging it with main branch will be problematic. So it is better keeping a single git branch of commits in repo)
TLDR: For General usage case those checkpoints will be for view only (but they could be made into their own development branch if necessary)
I see, thank you!
Hi everyone, here's a Python framework for building distributed systems, hope our community can make it better together: https://github.com/gavinwei121/Jetmaker
GitHub
Contribute to gavinwei121/Jetmaker development by creating an account on GitHub.
setup.py is old and mostly unused nowadays
pip is dropping support for [only] it soon
You've committed many generated files
If you're going to spam across the entire server, it should at least be well done
This is not true.
Oh?
Isn't the automatic fallback to setup.py being dropped? So a pyproject.toml will be needed to declare the build system?
PEP 517 (or 518?) describes a fallback backend (aka setuptools + wheel) when no build backend is specified. Pip still retains this fallback. The current removal you're referencing is that we aren't going to be calling setup.py develop to perform an editable install.
See, this is the tricky part. setup.py the file is not deprecated, but its many commands (including develop) are deprecated.
In other words, setup.py is still a totally valid (if outdated) way to configure the setuptools backend, but direct invocations of the file by pip are deprecated and slated for removal at some point.
Right
I know that part
setup.py is still required for stuff like extension modules
I just thought I read that pip was dropping support for running one without a pyproject.toml declaring setuptools telling it to do so
From my post?
This reminds me that I should probably add even more explanation to the legacy editable install deprecation issue. It's annoying, but the details are indeed complex.
I have one myself: https://github.com/letsbuilda/imsosorrybutinc/blob/main/setup.py
And docs are here: https://packaging.python.org/en/latest/discussions/setup-py-deprecated/
Uh... possibly
I read more than one post
Not exactly sure where I got the assumption from


never said the file itself was deprecated
Just thought pip was dropping support for automatic discovery
Lol
FYI your post is #7 on my Google search results for pip deprecate setup.py
Good job being popular
Well, this makes it sound like the file is deprecated.
Communication is hard, especially when it's towards users that don't really understand or care to understand the complexity of your tool (and they shouldn't!).
yep, that's basically it!
nitpick though: * is a shell syntax that expands to all files/directories in the current directory
you can also do git add . instead, that is both easier to type and I believe is not reliant on a shell?
I might be wrong on it being a git built-in, but it's what you'll see everyone use for git add, so makes sense to use it imo
as you get more comfortable with git, it's a good idea to make commits more granular, more "atomic", by staging only things that are all relevant to each other; so git add . is a bit of an antipattern, often times
I usually do a lot of things at the same time
but commit only the files / lines that are all relevant to a single change
what is a "single change" is a difficult question and super depends, so it's up to you
that way, you'll be able to look through your commit history (as will others) and have it be more useful, by being easy to follow
when you see a commit, you can be pretty sure it's only doing what it's claiming to be doing, and so doing git checkout on it, or git revert (git revert -n I find more useful), or git reset will be more useful — you will be resetting just the change that the commit introduces, and not 5 more different things
playing good by that rule can be cumbersome sometimes, but yourself in the future and other people looking at your code will thank you
I heavily recommend getting acquainted with the CLI git first, but eventually you might want to use lazygit to make the process of good commit history easier
git also implements its own wildcard expansion behavior on top of what the shell provides. e.g. git add ./* is expanded by the shell, but git add './*' is expanded by git itself. it's useful on windows and in oddball shells that don't support standard glob syntax.
ideally you only git add the specific files you changed. the whole point of having to add before committing is that you can apply precise control over what you commit. adding "everything" all the time is not a great idea
as for . vs. *: . means "the current directory", which git interprets as "everything under the current directory". * means "expand to every file and folder in the current directory", which ends up having the same effect but for different reasons.
example:
pyproject.toml
src/
a.py
b.py
git add * is the same as git add pyproject.toml src/ -- which of course has the same effect as git add ., but isn't the same thing.
oh that's really nice
yes this!
Ah, thank you Alisa and lamp, I was wondering what the point of git add was, seemed like it had no reason to exist but now I understand
How do I fix the Reactivating terminals... Soruce: Python in a loop on Visual Studio Code? I am using the release versions of Python and Python Debugger extensions. I am using Python 3.12.5 on Windows 11.

I tried to restart Visual Studio Code and I still got the error.
I don't know how I got this error
Is the terminal usually running a shell or is it just to show the output of the python process? When does this notification appear:
- Immediately when starting vscode
- When you open terminal window
- When you run/execute your python code?
I have never use vscode so I'm not sure my questions are fully relevant.
Immediately when starting VSCode
This is good information
does anyone know of a program that I could pipe into, to remove ascii escape sequences (no, --color=never is not an option) (please ping on reply)
Research says to use sed. ```sh
sed -r "s/\x1B[(([0-9]{1,2})?(;)?([0-9]{1,2})?)?[m,K,H,f,J]//g"
@gloomy scaffold
When I read (please ping on reply) it goes in one eye and out the other.
lmao that's a phrase I haven't heard before
thank you
your pfp slaps
mlp ftw
Hey there guys, I think this is a appropriate place for dropping my concern:
I'm experiencing an issue from 2 hours. I've setup LXC container over proxmox. And I'm trying to run my scrapping web app which requires the chrome-webdriver(which my script is downloading dynamically) to run the scrapping request on the headless chrome. The app was getting crashed so I came to solution (that didn't work) that was to download the chrome as the headless mode requires that. But I'm unable to do it and the app keeps on crashing as the webdriver is not getting initialized. Does anyone experieneced the same issue or can guide me through this?
I've never used LXC but based on my experience with Docker I would say a) You should build your container with everything it needs instead of downloading at runtime. b) You should diagnose why it's crashing by checking the logs etc.
I tried to switch to pre-release extensions and update Python to 3.12.6. It still does not work.
I heard reinstalling can fix it
I reinstalled VSCode on my computer and I cannot use Python's vscode debugger nor can I run Python code in a terminal from the Run Python file in the play button menu. I have Python extensions installed on VSCode. The debugger does not show up. How do I fix this issue?
I've never been able to successfully set the debugger with vscode. I just use pdb instead
My friend showed me debugging with a terminal
Hi everyone, I’ve recently replicated the FluentValidation library of C# to python.
You can install it with pip install fluent _validation
You are free to use it for your projects

Nice work! You could probably add some nice Pydantic-like syntax for declaring validators using type hints and the descriptor protocol
I’ve never used pydantic, why should I implement it if I’m already creating validators with callbacks??
Thanks for de advice though!
The idea is building strongly-typed validation rules with classes as
from dataclasses import dataclass
from datetime import datetime
from decimal import Decimal
from fluent_validation import AbstractValidator
from fluent_validation.enums import CascadeMode, Severity
@dataclass
class Orders:
id: Optional[int] = None
name: str = None
date: Optional[datetime] = None
is_free: bool = False
price: Decimal = Decimal("200")
credit_card: str = None
class OrdersValidator(AbstractValidator[Orders]):
def __init__(self) -> None:
super().__init__()
self.rule_for(lambda x: x.id).less_than_or_equal_to(100)
self.rule_for(lambda x: x.name).not_equal("NAME")
self.rule_for(lambda x: x.date).not_null()
self.rule_for(lambda x: x.is_free).must(lambda x: isinstance(x, bool))
self.rule_for(lambda x: x.price).equal(Decimal("0.00")).when(lambda x: x.is_free is True).precision_scale(6, 2, True) # max 9999.99
self.rule_for(lambda o: o.credit_card).not_null().WithErrorCode("Notull").not_empty().WithErrorCode("NotEmpty").with_severity(Severity.Info).credit_card().with_severity(Severity.Warning)
Do you all use venv even in production environment?
Take a look at what Marshmallow does for example to see what I mean about using descriptors
My main worry is that this isn't actually statically analyzable by a type checker like Mypy
It's actually statically analyzable by VSC default linter, but it's not by Mypy because Mypy hasn't been updated to support the generic annotations introduced in python 3.12
that's an example of a piece of code I use to create 'must' method
# region must
@overload
def must(ruleBuilder: IRuleBuilder[T, TProperty], predicate: Callable[[TProperty], bool]) -> IRuleBuilder[T, TProperty]: ...
@overload
def must(ruleBuilder: IRuleBuilder[T, TProperty], predicate: Callable[[T, TProperty], bool]) -> IRuleBuilder[T, TProperty]: ...
@overload
def must(ruleBuilder: IRuleBuilder[T, TProperty], predicate: Callable[[T, TProperty, ValidationContext[T]], bool]) -> IRuleBuilder[T, TProperty]: ...
def must(
ruleBuilder: IRuleBuilder[T, TProperty], predicate: Callable[[TProperty], bool] | Callable[[T, TProperty], bool] | Callable[[T, TProperty, ValidationContext[T]], bool]
) -> IRuleBuilder[T, TProperty]:
num_args = len(inspect.signature(predicate).parameters)
if num_args == 1:
return ruleBuilder.must(lambda _, val: predicate(val))
elif num_args == 2:
return ruleBuilder.must(lambda x, val, _: predicate(x, val))
elif num_args == 3:
return ruleBuilder.set_validator(
PredicateValidator[T, TProperty](
lambda instance, property, propertyValidatorContext: predicate(
instance,
property,
propertyValidatorContext,
)
)
)
raise Exception(f"Number of arguments exceeded. Passed {num_args}")
as you can see, the use of '[' and ']' to represent generic types is not supported by Mypy
I've tried to use Mypy as well but I can't
Consider that I have tried to replicate the entire FluentValidation library from C# line by line. C# is a strongly-typed language, so it is full of generics and strongly-typed variables.
Any idea?
If I’m installing someone manually, yes
But 99% of the time I’m just using containers, so all the host needs is Docker
I see, I didn't realize you went to all that trouble. Nicely done
Unfortunately Mypy tends to be slower to adopt features
Hi everyone! I'm more and more interested in working in devops with python. Today I found this article that's got a good role description and I want to share in case anyone wants to check it out
this looks like an ad
did you write this?
Oh no, I did not. I'm just trying to find info about devops role description because I was aiming to backend development but I feel more inclined to look for a career in devops
okay
IMO, that site gives off the vibes of a SEO farm
it practically looks like a copy of w3schools
Cool, I get it. I'm just researching you know 😉
There's a whole "DevOps, SRE and Infrastrucure" Discord server
Awesome, thanks for that!
Since I spent a couple of months finding a tool set that fitted the way I worked, I've felt that I could enjoy doing the same for other devs.
At some point of that period of time I discovered NIxOS and I've worked with it since then
Had some experience with Docker and my mindset is pretty much efficiency oriented when I choose technologies, software in general and work methods
I'll join the server and talk to people around
@sterile nexus ^
I've joined the server, thanks a lot 🤘
am new to AWS and stuff.
Right now, i have 10 .csv files of 20-50MB each on S3.
I have a dropdown menu in frontend, I have to select anyone of these csv. And then i am fetching it's data in frontend.
Some .csv files are heavy, it takes almost 10sec to load. I want to load these files, as soon as an option is selected.
Any suggestions?
If you want to display the data immediately when the user selects the option, then you need to download that data first, before they select it.
Is there any reason this data isn't in a database instead?
its a lot of data. and in future there might be more dropdown options, hence more csv files.
Is storing all these in a database better option than storing them in S3?
Yes, this is what DBs are for. If you want users to be able to download the raw CSV, then S3 is perfect for storing those. But if you need to rapidly get data from backend to frontend, then it needs to be on a database
so dynamoDB?
S3 is basically the worst option here
“NoSQL” options aren’t great, but yeah, any kind of database would be much better than S3
and I am using sqlite as database to store user details and stuff.
so should i add those csv files data in it somewhere?
i just know this: that querying a database is much faster than querying a file. (so i guess i might save some time here)
yes
dynamodb can be very useful, but in this case it's probably not the right choice
what's wrong with dynamodb?
hallo guys do you recognise what runner this is

That's pycharm?
It says at the bottom
It's https://www.jetbrains.com/pycharm/ from back in 2021
yeppies!
why its not the right choice?
it's a key-value store. if you have multiple columns, it's not the right choice
i think vs code is best
Hey, I was wondering if someone can help me out with how to approach hosting - how to choose the right VM for my workloads. Each cloud provider has a bunch of different types of VMs and it gets really confusing to know which would be the right one(the cheapest and most apt) for my use case, especially when the load on the APIs can be very variable and I want to ensure I accommodate for all scenarios while not paying as much.
For example, currently I want to deploy my django-rest-framework API using Docker on a VM along with PostgreSQL, that is supposed to serve 40-50k users. Not sure how many users will concurrently be using it but I'm assuming it's 1000-3000. The API is being used by a web app and a cross-platform mobile application, so I'm assuming per session it's about 20-30 requests.
Database is pretty straight forward and has about 6-7 tables(apart from django and it's extension ones) which will have on an average about hundered records per table. It has celery for running cron-jobs and asynchronous tasks like notifications, emails and bulk csv uploads.
I'm unsure how much vCPU, memory and storage I should allot for the same
The answer is it depends. Have you tried load testing your application? Assuming that you are vertically scaling (only one host) then this should be fairly straightforward to draw conclusions from.
I haven't load tested, I've never done it yet, I'll look into it. Yes it's only vertical scaling I'm currently looking to implement
In terms of flexibility, either get a host that is sufficient for your highest scale or look into vertical autoscaling.
Thanks
we run Django Rest Framework heavy applications in docker too
we do it with AWS ECS / and kuber, and having installed monitoring system
so i can say that in average they handle..
okay, around worst apps 100 requests per minute can handle as one container, 200-300 theoretical maximum for us
in its turn... we have to reserve... 1 vCPU per 20 running threads of app according to datadog docker thread count in container metric
We run DRF with uwsgi having for example 5 processes, in this case we have to reserve 1.5 CPU per one container (if it runs with uwsgi having 5 processes)
and in average RAM memory for us can vary from 1 GB to 4 GB 😅
per one container
the limit 1 vCPU per 20 docker thread count metric is smth i discovered, that if going above, drf apps start to crash with unable to open new threads
or example, currently I want to deploy my django-rest-framework API using Docker on a VM along with PostgreSQL, that is supposed to serve 40-50k users. Not sure how many users will concurrently be using it but I'm assuming it's 1000-3000. The API is being used by a web app and a cross-platform mobile application, so I'm assuming per session it's about 20-30 requests.
20-30 requests, but u don't have specified estimated requests per minutes 😉 timeframe is not specified.
so this hard limit inposes for us stuff like, if host has only 16 vCPU, we can't launch more than 16/1.5 = 10 containers of some app that requires as soft limit 1.5 vcpu
Each cloud provider has a bunch of different types of VMs and it gets really confusing to know which would be the right one(the cheapest and most apt) for my use case, especially when the load on the APIs can be very variable and I want to ensure I accommodate for all scenarios while not paying as much.
well... i am a guy dealing with infrastructure as a code, and i can say that in general there are two choices
-
You could pick provider like AWS, that has autoscaling groups capabilities and other features, u could be running container in aws ecs, and having it scaled depending on your different rules
optionally same thing can be done with EKS and its turn it has scaling according to workload too
But there is a lot of Infrastructure code effort to configure that..., but as advantage u get horizontal autoscaling in a reasonably cheap way with advantages of a good provider
There are easy options there for horisontal autoscaling, but they are expensive then -
or you could pick reasonable low quality provider like OVH, Hetzner and etc, and get VM from them cheaper, but it will work only as regular linux machine, without all extra features providers like AWS provide
In this case u will have option only for regular vertical autoscaling
optionally this low quality path can be extended with some semi manual horizontal autoscaling too though (microk8s is quite easy to use)
or OVH actually provides already managed kubernetes clusters for cheap hmm
still plenty of effort but a path towards cheap horizntal autoscaling is possible
but probably too much for you
===========
My only advice regarding the end provider, don't pick one that is not supporting automating as a code through Terraform Provider stuff. no point to choose that much bad providers imo
Hi, in my fast API python application I have lot of asynchronous functions which does lot of operations like reading a large file, converting pages to images. Etc...
But I want to know the best way to find memory utilisation for that particular function? Do we have some inbuilt decorator or something? Or what's the best way to calculate the exact memory used by the function or application?
I don't wanna see task manager or htop in Linux, it shows complete memory of system. It's not 100% accurate.
Very interesting, thank you for sharing these figures. I wonder though, 100 requests over 20 threads is 5 requests per thread per minute which seems rather low. Are they particularly heavy requests?
seems like this can be used only with pytest right?
It is rather common seeing numbers like 50-100 raw SQL executed in a single endpoint call
Over million of code lines
According to pytest-django raw SQL fixture to make sure asserting it in unit tests
I see
How do I fix the Python debugger not working in VSCode? I tried to press debug on my code and nothing happens. What do I do?
See if following this helps, and then if you're still stuck try asking in #editors-ides

Details on configuring the Visual Studio Code debugger for different Python applications.
I have Python Debugger extension installed
Ok and? What does your launch.json look like? No need to share here, I'm just saying to follow the whole thing
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal"
"pythonPath": "C:\Users\olymp\AppData\Local\Programs\Python\Python312\python.exe"
},
]
}
In addition, I cannot run Python code when I press the play button or Run Python File button
Does that Python.exe file exist at that path?
When you press run or debug, nothing at all seems to happen?
Yes Python.exe file exists.
When you press run or debug, nothing at all seems to happen?
Yes, nothing at all seems to happen.
There's no way of knowing it without deploying it, because everything else other than the user base I mentioned was just a guesstimate.
I do not want to go with horizontal scaling as of now, because then there's a vendor lock in. The application is for my university - they want to show all events happening or upcoming events to all the university students and have them register for them through the app.
They have very varying requirements, as of now they've asked me to go with a cloud provider, but there's a good chance they will ask me to deploy on university's VM. In that case Infra as code doesn't come handy for me.
Nevertheless it's a very good insight for my personal projects, I really want to dive deeper into devops.
I do not want to go with horizontal scaling as of now, because then there's a vendor lock in
technically possible without vendor lock in, it is just a lot of infra coding effort and complexity (and usually used kubernetes 😅 )
The application is for my university
yeah sounds like overkill to do any horizontalling
There's no way of knowing it without deploying it, because everything else other than the user base I mentioned was just a guesstimate.
. The application is for my university - they want to show all events happening or upcoming events to all the university students and have them register for them through the app.
They have very varying requirements, as of now they've asked me to go with a cloud provider, but there's a good chance they will ask me to deploy on university's VM. In that case Infra as code doesn't come handy for me.
in the end the best answer is actually installing monitoring systems and just actually monitoring (+ optionally creating alerts)
i got used to solution Prometheus (main metrics exporting with something like Node Exports and etc) + Loki (logs) + Grafana (central visualsing place + dashboard creating) + optionally Tempo for traces + optionally Alert Manager plugged in for alerts
to answer what infra u should have, you are supposed to see how your app and server behaves
preferably with export of its prometheus time series metrics for the specific framework/web server u are using
Last sentence here seems mistaken. If you want the flexibility to switch between on-prrm.and cloud, IaC is almost a nust, and very doable. Terraform has providers for just about everything like VMware, Huper-V, and whatever. Ansible works the same on prem, etc.
?
I need help guys : I’ve to build (well let’s say program) a miltipost for my company by doing API integration, basically.
And i know I’ll mostly use python for this, but where do i start ? I dunno
Details : it have to be a multipost for social media handling like when we click on a button, the content is shared to all the S.M. that the company use, making it non necessary to post a content on each platform for each
Any expert ?
I’ll share across other salons
@autumn summit
If you’re not sure where to start using python and this is for a professional job, I recommend a packaged solution like IFTTT

IFTTT
Social media works better with IFTTT. Social media content planning, sharing, and engagement looks different for every platform and user. To create systems ...
or n8n
https://n8n.io/

n8n is a free and source-available workflow automation tool
There are loads of no-code solutions for this. I used HootSuite ages ago and it looks like they're still around, but I also see plenty of alternatives
any good circuit designing and siimulating tool?
Not sure about simulating, but I've used KiCAD in the past and it definitely does the job

Alr
Tysn
Tysm
Hey! 
I'm having issues with running a Docker python3.12.6 container. I'm getting the No module named 'distutils' error when installing packages.
I tried installing distutils and setuptools explicitly but that didn't seem to help...
Any help would be appreciated!!
Don't cross post without linking
Well that's not a Docker problem that's just a "normal" Python problem
Is your code/Dockerfile in a public repo?
Nope but I can send it as text here if thats ok
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
^ use that
tanks
Ok so heres the code:
https://paste.pythondiscord.com/NRAQ
Oof, installing setuptools four different ways is making my head spin
Why do you need distutils?
Haha yeah im desperate
maybe make your dockerfile so that we can reproduce the problem -- I tried but got ERROR: Could not open requirements file: [Errno 2] No such file or directory: '/home/user/software/src/app/backend/requirements.txt'
Im guessing it's a dependency of one of the packages in my requirements
Yeah
Check the logs to figure out which one
oh ok 1 sec
ok so currently 'setuptools' is causing the error which is pretty ironic
Ill try to remove it and try again

I tried to install setuptools to fix the distutils missing error.
And then it's trying to access distutils.core which isnt there
File "/tmp/pip-build-env-foj358m2/overlay/lib/python3.12/site-packages/setuptools/init.py", line 10, in <module>
11.14 import distutils.core
11.14 ModuleNotFoundError: No module named 'distutils'
Create a paste with the contents of your requirements.txt
Then docker build . --progress=plain > docker-build.log and upload that entire file to another paste
requirements:
https://paste.pythondiscord.com/W53Q
build log:
https://paste.pythondiscord.com/2GHA
sounds like you're chasing a chimera
how'd you know?

I'd remove all the hacks that you've tried, and go back to the original problem, and post a complete recipe for reproducing the problem. By "complete", I mean: I can easily download one or two files (like a Dockerfile) and run a single simple command that will show me the problem
I think this repros it ```
FROM python:3.12.6-slim
RUN apt-get update && apt-get install -y --no-install-recommends
python3-setuptools
python3-pip
python3-distutils
RUN python3 -m pip install --upgrade pip
RUN pip3 install numpy==1.24.4
fwiw pip install numpy, without specifying a version, worked fine
No all you need is
FROM python:3.12.6-slim
RUN pip3 install numpy==1.24.4
They have all their dependencies pinned to versions that don't support 3.12
Ok ok,
I'll try to give you a summery of how to reproduce:
- Have this requirements.txt - https://paste.pythondiscord.com/W53Q
- Try to build a container using a Python image version >= 3.12
oh
So wait Ill try that
Why are you pinning to these versions?
What do you mean by pinning?
You know I actually don't remember let me try to remove the version
Remove the version from all of them
okok I'm building for a minute now and it hasn't died

ayyyy that worked
I mean I needed to do the same for a couple other packages but yeah
@astral apexThanks a lot dude


Anyone have a favorite PDB alternative? I'm looking a bit at PDB++ but there hasn't been any updates for a while + the latest issue seems to imply there's a gnarly licensing issue with it.
Basically want PDB to be more useful (Stuff like easily siphoning values out of it, default prompt maintenance) but before I dive into writing that I wanted to see if there was something already out there that gets me there
when tasks get to repetitive I use to have a kind of manual session where I copy and paste, like breakpoints, prints, etc. I used this time ago too - https://github.com/gotcha/ipdb
GitHub
Integration of IPython pdb. Contribute to gotcha/ipdb development by creating an account on GitHub.
what is pdb! I can of course go read the manual, but interested in how it helps in your workflow / what you like it for
it's terminal-based debug built-in feature, if you master it you won't need to learn or set up anything else unless you need more complex or more fancy environments - https://docs.python.org/3/library/pdb.html

Python documentation
Source code: Lib/pdb.py The module pdb defines an interactive source code debugger for Python programs. It supports setting (conditional) breakpoints and single stepping at the source line level, i...
oooooohhhh that sounds super great! I think I remember some other 3 letter program for debugging, generally for compiled programs I think; is that the same thing or a different one (if you can tell what I'm referencing (can't remember the name of it))
couldn't tell, gcc, g++?
I never use debuggers, probably because they're a pain to set up and then also have overwhelming ui (autism), so something like this sounds really great to discover
I love terminal-based tools
give it a try, it’s pretty basic
just ugly
I don't mind hahahah
I can't give ruff a range of line length maximums, right? E.g. 80-100, meaning: break lines when they exceed 100 chars, but don't join lines unless the joined line would be below 80 chars.
Alternatively, I'd be fine with an option which makes it ignore all line lengths (in both directions), and just does the rest of the formatting. Does such an option exist? I couldn't find it at a cursory glance..
huhhhh that's an interesting usecase
it doesn't answer your question directly, but in ruff, if a thingy ends with a ,, it won't join it, and if it doesn't, it will
I'll try to find an example
so you can use this to your advantage, to sometimes achieve the behavior you want lol
Yeah, I know what you mean. But I don't think you can do that everywhere, right?
yeah, only where a , makes sense
I pretty much always add trailing commas, so I'm confused why it wants to join so many things then..
cause I don't think the functionality you're actually looking for exists in ruff; I've read through most of the documentation, but maybe there's some rule I don't know about
it follows my maximum line length
which is 110
I'm pretty sure as well that no such configuration exists. I've asked for options previously, but they still want to keep the formatter very simple (no/few options) until they come further in dev.
This sounds nice, I've only used vanilla pdb. I rarely debug python code 😎
I appreciate you being active via PRs / issues
multiple times I've seen you do stuff
and you're a part of the reason software becomes better
Thank you, I feel like I'm just complaining sometimes 😅
somebody needs to complain, ngl
it's very very difficult for me to go do that
I filed my ctrl-z/fg/tty issue to bash bug mailing list, and already got someone who could reproduce it and someone had a guess on what the issue could be!
I'm only starting to learn to do so
and to write the issue well, too? herculean
so I often end up making up workarounds and using them in my own configuration
before ever even considering creating an issue
so seeing someone who can freely go and be transparent like that
is very important
yooooo that's amazing! not surprised that bash people are smart
Yeah, I'm just trying to be very clear and informative when I create issues. And make effort to not sound like a complaint. I know people are working for free on many of these projects 🙂
true!
writing, overall, is difficult
I used to script my yt videos, that helped
and now I write gists from time to time
and all the various readmes
really damn hard, but I think I'm getting better
Link (to a web version)? I'd like to file it for zsh :D
I don't know if there is a web mirror 😱
What's tha
Mailing list for bash bugs
I do like to bash bugs
Bug Basher ™️
Hi! Does anyone have experience with using Azure DevOps and GitHub for managing teams and projects? It seems like Microsoft is pushing things towards GitHub, although that's kept under tight wraps. ADO seems much heavier, whereas GitHub is lighter weight. Anyone have person experience with either that they'd like to share?
what do you use to monitor your github actions? or CI/CD?
We use Jenkins as CI at work. We don't use Github.
hi guys
are there any good learning material (most preferably books or videos) for learning docker, also im using it on cli
do ping me up
official documentation is good enough
does jenkins allow you to monitor it?
because the thing is right like ... we use the ELK stack
I really don't know what is going on in the CI/CD pipeline
sure I can see the stuff in real-time on github but I would like a way to see how it is being affected overtime
so that I can make changes as necessary
lets say we realise tests are taking too much time or the CD is taking longer and longer
we'll be able to pinpoint rooms for improvement
you can use GitHub webhooks
Well first we need to define "monitor"
I monitor whether my workflows have passed or failed by... checking the actions tab on the repo
What extra information are you looking for that GitHub doesn't show you?
Huh, this actually looks really neat: https://docs.datadoghq.com/monitors/types/ci/?tab=pipelines
Jenkins allows keeping old build history to see how runtime has changed over time per job.
We have setup to collect some simple datapoints into csv files and display them as graphs on each job.
But Jenkins is not very good. It's big and complex. You need plugins to solve many basic features, those plugins have very varied degree of quality.
Hello, I recently ran into something very odd while working on a feature branch, and I'm trying to understand what went wrong.
While ago I was working on some feature and I created a separate branch for it, and when I finished, created a PR and merged to master. After that I started working on something different, and git checkout -b to create new branch for that feature. When I finished it I created a PR and noticed that within that PR commits history it includes all previous commits from the old feature branch. I’m unsure why these 'merges' occurred automatically and want to avoid this in the future.
Can anyone explain why my new branch got these commits from old one? What should I do if I want to open a new branch and start developing a feature and later on create a totally independent PR from previous development?
Thanks
hmm, did you checkout your second feature branch while on the first feature branch? that's my guess as to why it might include the commits
99 % sure that this is the case
what should I do then?
afaik you generally want independent features to have their branches start from the master branch, i.e. git switch master; git switch --create my-feature
rather than checking out a new branch while on an existing feature branch
no idea where u made wrong exactly
- you created PR based on feature branch or master branch that did not have yet yout merged feature branch basically
but the fix is usually the same
at feature branch:
git fetch origin master:master # refreshing local master to be sure having your merged content (that i presume that merged commits are located remotely. they are located remotely right?)
git rebase master
optionally the same in more actions
git checkout master
git pull
git checkout feature_branch
git rebase master
okay, so you mean that i fucked up my base. but how is that different from having a master as a base?
yeah yeah yeah this make sense old_feature -> master -> new_feature
I am not sure that I understand why if I start branching from my old feature branch that is not the master branch I carry over all my previous commits but if I start branching from master I start from the tip of the master if that makes sense?
You start from wherever you branch out from
Is master then hardcoded differently?
If you branch from master, you start with all commits from master. If you start with branch_a, you start with all commits from that branch.
Almost no.
It's the default branch (unless it's main or differently configured), but other than that it has no special behavior
Okay so I should look at it this way, I have two types: master and non-master branches
Thanks, make sense
Like all being the default branch entails is that it gets created when you git init. Nothing else is special about it.
As a development model this can make sense.
if you branch from old feature branch, it has all the commits yes
But it is not having MERGE commit that gets created in master after u merge it to it 😏
That's the problem
https://learngitbranching.js.org/ this is nice visual tutorial to learn it all
this merge commit lack of it messes it up, and makes your same commits in old feature branch considered as entirely different commits again
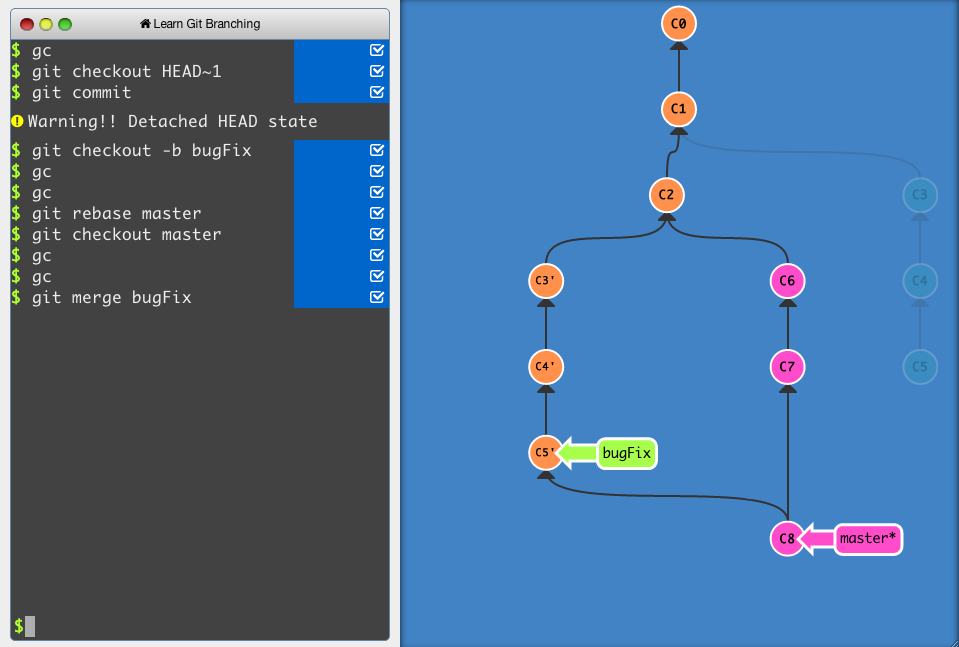
An interactive Git visualization tool to educate and challenge!
Appreciate the help guys!
for a beginer?
yes, assuming you already know the basics about Web development. If you provide more context perhaps we can provide more accurate suggestions
Is it possible to connect save/copy/delete from a docker volume but from the server side using the docker python package?
not from inside the container, but outside. I know this can be done with bind mounts but I like the fact that the containers arent connected to my server. I can then do my checks, then copy the file to my main server as needed and delete.
I have figured out how to do this with bind mounts and also with individual folders within my various containers, but with a volume it seems like a much more elegant solution
while I can save to my volume and retrieve with my code running in docker. When I use docker.py to connect to the container and then add files they do not show elsewhere
no idea im new to python 🤡
Docker volumes are located always at server side too
if they are defined as exact host path, then by hostpath
if u defined named/anonymous volume, then they are created in this... docker folder at server and can be accessed too
where they are created exactly should be available by docker inspect command i think
tldr... possible save/copy/delete objects in docker volume from outside of container at server without even any docker python packages
Hi, has anyone used https://github.com/tweag/FawltyDeps (library to find unused and undeclared dependencies)? I'd like to include it in my team CICD.
# requirements.txt
Flask[async]=3.0.3
requests=2.32.3
# server/routes.py
import requests
from flask import Blueprint, current_app, request
fawltydeps --check-undeclared --detailed returns an obvious false positive:
- 'flask' imported at:
server/routes.py:4- 'requests' imported at:
server/routes.py:3
Same with different configurations.
Do you have a solution or a better alternative to suggest?
GitHub
Python dependency checker. Contribute to tweag/FawltyDeps development by creating an account on GitHub.
Looks bad solution because there is isort
I think isort is able to check and remove and sort automatically
Solution not requiring effort to fix is better
https://pycqa.github.io/isort/ sorts imports, right? I'm looking for a tool that check if the set of dependencies used by my code is exactly the same than the one declared in requirements.txte
it just deletes not used dependencies too in addiition 😏
Hi everyone, I'm constantly encountering this error (attached) when running the RVC program (on Pinokio). In case you're wondering, I've reinstalled and uninstalled the program multiple times, the same goes for Python, where I've tried different versions, and also for dotenv, where I've even tested various versions, but I still get the same error. Thanks in advance for any help !

My flask servers on my docker containers keep crashing due to http requests but I have an nginx reverse proxy setup and it's designed to just give 400 for any http request and only accept https requests, any idea why this is happening?
my 3 endpoints are only response messages
which AI code assistant do you use guys? (for those that use.)
alr, using tabnine, pretty neat.
I am trying to run tests for a python/cython package that i'm making using tox, but i keep getting a packaging backend failed (code=1), with ModuleNotFoundError: No module named 'numpy' error.
This is my tox.ini file:
[tox]
env_list =
py{37,38,39,310,311,312}
minversion = 4.20.0
[testenv]
description = run the tests with pytest
deps =
pytest>=6
ir-datasets
numpy
commands =
pytest {posargs:tests}
And this is my setup.py file:
import os
import numpy as np
from Cython.Build import cythonize
from setuptools import setup, Extension, find_packages
EIGEN_PATH = os.getenv("EIGEN_PATH", "/usr/include/eigen3")
extensions = [
Extension(
"py_bm25.bm25",
sources=["py_bm25/bm25.pyx", "py_bm25/src/bm25.cpp"],
language="c++",
include_dirs=[np.get_include(), EIGEN_PATH],
extra_compile_args=["-std=c++11", "-O3", "-fopenmp"],
extra_link_args=["-std=c++11", "-fopenmp"]
),
Extension(
"py_bm25.convert.data.convert",
sources=["py_bm25/convert/data/convert.pyx"],
language="c++",
extra_compile_args=["-std=c++11", "-O3"],
extra_link_args=["-std=c++11"]
),
Extension(
"py_bm25.convert.eigen.eigen",
sources=["py_bm25/convert/eigen/eigen.pyx"],
include_dirs=[EIGEN_PATH],
language="c++",
extra_compile_args=["-std=c++11", "-O3"],
extra_link_args=["-std=c++11"]
)
]
setup(
name="py-bm25",
version="0.0.10",
packages=find_packages(),
ext_modules=cythonize(extensions, compiler_directives={"language_level": "3"}),
install_requires=["numpy", "cython", "setuptools", "wheel"],
extra_requires={
"dev": ["pytest", "ir-datasets", "tox", "wheel", "twine", "numpy"]
},
include_dirs=[np.get_include(), EIGEN_PATH],
python_requires=">=3.7"
)
What do i need to fix?
I don't know how to achieve this, but it sounds like you need to ensure that Numpy is installed in each Tox build env. Are you using Tox to build wheels for distribution too? If you can build the wheels in advance, that would save you having to do special set up in each test environment.
And then you don't have to build a wheel again every time you want to just run the tests
Btw pyproject.toml solves this problem by giving you an opportunity to declare what dependencies are needed in the building environment, and Pip actually uses that information
Whereas imports at the top of setup.py are not actionable by Pip
You don't need to migrate anything out of setup.py, you just need pyproject.toml with the PEP-518 build-backend section declaring numpy and cython as build requirements
!pep 518
Status
Final
Created
10-May-2016
Type
Standards Track
[build-system]
requires = ["setuptools >= 61", "wheel", "numpy", "cython"]
build-backend = "setuptools.build_meta"
Admittedly I'm not sure why install_requires is ignored here, but IMO no reason not to migrate that one line to the new standard tooling at least to see if it works
^ afaik setup.py has both setup_requires= and install_requires=, akin to requires = [] and dependencies = [] in pyproject.toml respectively
or were you referring to how that config page didn't describe the corresponding keys for migrating?
oh nope i saw install_requires and thought they did setup_requires
if you don't want to use pyproject.toml you need setup_requires=['numpy', 'cython']
ah fair enough
And you need to catch the import error of cython in setup.py if it's getting setup_requires metadata
You don't need to depend on wheel here
See the second note here https://setuptools.pypa.io/en/latest/userguide/quickstart.html#basic-use
@tawdry needle @willow pagoda @visual oxide Than you all for the useful informations!
For some reason i still got the same error even after I added setup_requires=["numpy", "cython"]to setup.py. It seems like it didn't recognize it.
But after I added a pyproject.toml, i made some progress but ended up with a different error. It cannot find .pxd files or resolve imports for some reason (even though i can install the package succesfully with pip install .)
My understanding is that a project can have both pyproject.toml and setup.py but only pyproject.toml will be used if possible. and it seems like for building extensions, in cython's documentations, it says that we should have both files.
So this is my pyproject.toml
[build-system]
requires = ["setuptools", "cython", "numpy"]
build-backend = "setuptools.build_meta"
[project]
name = "py-bm25"
version = "0.0.10"
description = "A sample Python project"
readme = "README.md"
requires-python = ">=3.7"
license = {file = "LICENSE.txt"}
authors = [
{name = "NaughtyConstrictor", email = "naughtyconstrictor@gmail.com" }
]
maintainers = [
{name = "NaughtyConstrictor", email = "naughtyconstrictor@gmail.com" }
]
dependencies = [
"cython",
"numpy"
]
[project.optional-dependencies]
test = ["pytest", "ir-datasets", "numpy"]
This is setup.py
import os
import numpy as np
from Cython.Build import cythonize
from setuptools import setup, Extension, find_packages
EIGEN_PATH = os.getenv("EIGEN_PATH", "/usr/include/eigen3")
with open("README.md", "r") as f:
long_description = f.read()
extensions = [
Extension(
"py_bm25.bm25",
sources=["py_bm25/bm25.pyx", "py_bm25/src/bm25.cpp"],
language="c++",
include_dirs=[np.get_include(), EIGEN_PATH],
extra_compile_args=["-std=c++11", "-O3", "-fopenmp"],
extra_link_args=["-std=c++11", "-fopenmp"]
),
Extension(
"py_bm25.convert.data.convert",
sources=["py_bm25/convert/data/convert.pyx"],
language="c++",
extra_compile_args=["-std=c++11", "-O3"],
extra_link_args=["-std=c++11"]
),
Extension(
"py_bm25.convert.eigen.eigen",
sources=["py_bm25/convert/eigen/eigen.pyx"],
include_dirs=[EIGEN_PATH],
language="c++",
extra_compile_args=["-std=c++11", "-O3"],
extra_link_args=["-std=c++11"]
)
]
setup(
name="py-bm25",
version="0.0.10",
long_description=long_description,
long_description_content_type="text/markdown",
author="NaughtyConstrictor",
author_email="naughtyconstrictor@gmail.com",
license="MIT",
packages=find_packages(),
ext_modules=cythonize(extensions, compiler_directives={"language_level": "3"}),
setup_requires=["numpy", "cython"],
install_requires=["numpy", "cython"],
extra_requires={
"dev": ["pytest", "ir-datasets", "tox", "twine", "numpy"]
},
include_dirs=[np.get_include(), EIGEN_PATH],
python_requires=">=3.7"
)
And I'm getting errors of this kind:
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [583 lines of output]
Error compiling Cython file:
------------------------------------------------------------
...
from typing import Dict, List, TypeVar, Union
cimport numpy as cnp
import numpy as np
from py_bm25.bm25 cimport BM25_, BM25Okapi_, BM25L_, BM25Plus_
^
------------------------------------------------------------
py_bm25/bm25.pyx:8:0: 'py_bm25/bm25.pxd' not found
Are you missing py_bm25/__init__.py?
This is my project's structure if it helps:
../bm25
├── LICENSE
├── MANIFEST.in
├── README.md
├── py_bm25
│ ├── __init__.py
│ ├── bm25.pxd
│ ├── bm25.pyx
│ ├── convert
│ │ ├── __init__.py
│ │ ├── data
│ │ │ ├── __init__.pxd
│ │ │ ├── __init__.py
│ │ │ ├── convert.pxd
│ │ │ └── convert.pyx
│ │ └── eigen
│ │ ├── __init__.pxd
│ │ ├── __init__.py
│ │ ├── eigen.pxd
│ │ └── eigen.pyx
│ └── src
│ ├── bm25.cpp
│ └── bm25.h
├── pyproject.toml
├── requirements-dev.txt
├── requirements.txt
├── setup.py
├── tests
│ ├── __init__.py
└── tox.ini
No i have it
As graingert pointed out, it's because the import happens before setup() is called
Aah I see! And there's no way to specify in tox.ini to install dependancies from requirements.txt for example before building?
Or you can try/catch the ImportError in setup.py, but that's a lot messier imo than just adding the pyproject file, it's just 3 lines and it will work with everything
Yeah. But I would still need the setup.py file right? Is it because it is a c-extension? Because I thought if both setup.py and pyproject.toml are present then only the toml file would get used
setuptools runs the setup.py if it exists
nope, the [project] section in pyproject.toml can be used to replace setuptools.setup(), but that's completely different from the pep 518 build backend declaration, which is used to tell pip how to set up the build environment and that setuptools is in fact used to build the wheel
Whereas without it, pip basically infers it for you -- but that doesn't include the cython or numpy stuff you want
Is there a comparison / ranking of libraries for parsing command line args? Feels like there are a lot out there and I'm not sure which to go with
Just a cursory glance there's the standard argparse, and 3rd party docopt, gooey, click, invoke, arguably, and others
Click is like pytest, it's hard to go wrong by choosing it
nice to know
I didn't know of an argparsing library for python before
There is one built into the standard library
It's actually pretty good for simple applications
!doc argparse
Added in version 3.2.
Source code: Lib/argparse.py
Tutorial
This page contains the API reference information. For a more gentle introduction to Python command-line parsing, have a look at the argparse tutorial.
The argparse module makes it easy to write user-friendly command-line interfaces. The program defines what arguments it requires, and argparse will figure out how to parse those out of sys.argv. The argparse module also automatically generates help and usage messages. The module will also issue errors when users give the program invalid arguments.
huh!
there's also argparse in fish shell that I'm slightly familiar with
@visual oxide @tawdry needle Do you know how I can solve my problem? It is really frustrating when I can build the package with pip install . but it doesn't work with tox. And it is not getting recognized when I try to run the test (after successfully installing it with pip install . for one environment, I get an import error, even though it is present if I try to use it in an interactive session for example)
Show your tox config?
[tox]
env_list =
py{37,38,39,310,311,312}
minversion = 4.20.0
[testenv]
description = run the tests with pytest
deps =
-r {toxinidir}/requirements-dev.txt
commands =
pytest {posargs:tests}
requirements-dev has pytest, numpy and ir-datasets
How do I fix pyright's missing import error?
how to to creat subdomain tool
youll have to provide more details to get help, consider creating a thread here #1035199133436354600 
What does that mean?
I'd love some feedback: I'm planning on doing my project with raw sql (it's a FastAPI project, and honestly, I don't really get why I should bother with SQLAlchemy over plain SQL). To manage migrations, does anyone have any tool recommendations? Or should I just write scripts as I go?
yes, I recommend SQLAclchemy 🤣
Well, that won't manage my migrations, so doesn't really answer that, but why SQLAlchemy over raw sql? That's the part I don't get it. It's an abstraction of the SQL layer while being just as complicated. Creating the models and all are less than clear, and from everything I've read, you can't rely on Alembic to create the migrations you want; you have to fix them often enough.
All that seems like a great reason to not bother with SQLAlchemy at all and just use SQL and dataclasses.
I find SQLAlchemy's docs very hard to learn from, and when I am getting it, I'm often finding the mechanisms it adds are only useful if you don't have a good grasp of SQL already.
I'm specially annoyed at how it does many to many relationships, and I had to reread the docs many times to get what it's saying (the examples are horrible)
But yah, I'd love to hear why I'm wrong
will note to never use sqlalchemy, thanks
I wouldn't say to use my experience as yours own
Definitely give it a shot
It could well be me
tbh I haven't used SQLAlchemy in years, I just assumed it did migrations.
But so far I havent found a good reason for it
only ORM I've used recently is Django's fwiw
Yah, same, but I'm learning FastAPI. I actually got the Django ORM working in FastAPI, but I realized it's kinda shoehorning
nah haha hearing about a program in advance is helpful
it's true that I might have a different experience than you, but I'll try to look for something else first
knowing a "it's probably bad" is very helpful in advance, so I don't wastefully commit efforts to that
The problem I'm having is it seems like it's either Django or SQLAlchemy
If you find something else, I'd love to know
like, if someone said to me "don't bother with pyright, it's fucky. jump immediately to basedpyright", that would be helpful
I have only ever used SQL in tutorial projects, and haven't had a need since, so I might never have to interact with it honestly
Interesting. I don't think I've ever worked a project that couldn't use a database.
well, it's not necessarily a "couldn't" thing, more so a "doesn't make sense to" thing
Sorry, yah, that's what I meant
gotcha
I do some personal css, but aside from that I don't web at all
most of what I work on is terminal programs, that are usually very small in scale, often not storing data, or benefitting from storing data in a json or something like that
Yah, makes sense
my most recent thing I got into is my helix fork
I've been looking at writing some cli apps for personal use
they can be soooooo nice
But yah, I gotta figure out this whole SQLAlchemy thing
I almost want to be told it's me, and that it's much easier/more useful than I think it is
one I wrote that's been a lifesaver ever since is loago, which is a "chore tracker". lets me track how long ago I last did a given task, so I can know when it's due to do again
But the docs...
for stuff like house chores, and believe it or not, eating
omg yes I feel that
Have you checked out the Flask Mega Tutorial? I’m working through it, it involves SQLalchemy
No, didn't think of that since I'm not using flask. I'll take a look. I wonder if it's updated to SQLAlchemy 2. But it is weird that I'd have to go outside the core docs to learn how to use the tool, ya know?
100% valid
and agreed
Like this:
association_table = Table(
"association_table",
Base.metadata,
Column("left_id", ForeignKey("left_table.id")),
Column("right_id", ForeignKey("right_table.id")),
)
class Parent(Base):
__tablename__ = "left_table"
id: Mapped[int] = mapped_column(primary_key=True)
children: Mapped[List[Child]] = relationship(secondary=association_table)
class Child(Base):
__tablename__ = "right_table"
id: Mapped[int] = mapped_column(primary_key=True)
Why call it left_table and right_table? Why not call it parent and child, which are the model names?
Copy that. Yea it’s my first foray into orm + back end Webapp dev, so I don’t have much to say. Just getting my feet wet and found the Flask Meg Tut to be jam packed with info
Yah, if you're on Flask, makes perfect sense.
Alright, I'll ask again tomorrow, or maybe post in help
This sqlalchemy stuff is really triggering my anxiety/executive dysfunction
:( I hope you figure it out!
Thank you
You could fall back to asking gpt? 😬 then confirm with online sources
Good idea. I don't use llms chatbots enough.
yeah they can be very very helpful as a starter into something you don't quite know yet
Alright, thanks for the feedback/conversation folks. Off to bed with me.
they are often wrong of course
but the best way to get the right answer on the internet is to post the wrong answer and get corrected
similar thing happens with using an AI
Yah, I find llm bots useful to get a pointer, not an answer
you will just end up having an easier time proving it wrong, than getting to the answer directly without it
yeah! they are helpful in getting me unstuck
although I've been doing a monsterous amount of things I already know how to do lately, so I use them strangely little recently
had a really good experience with them though, excited for when it's gonna come in handy again
I was using GCP's instance to host my discord bot for past 6 months. Now from this month I stopped and deleted that instance. Per month I was paying approx 15 USD for compute engine + 3 USD tax. Since I deleted the instance I don't need to pay for the compute engine ig (can anyone confirm? I am sure btw).
My question is, if my compute engine cost will be 0 USD, do I still need to pay the tax each month? (3 USD)
if u don't have payments, then u don't have taxes
payments are rounded to some hours/minutes/seconds of usage (not sure how it is for GCP)
So u will be still needed to pay for this month usage of 3 days if u deleted it only today
Also, u could check if u deleted indeed all resources, some kind of dynamic IPs, storage volumes or some other resources could be hanging there and still incurring payment.
If u created them along side of your computing instance (they could have been created automatically for you along side with computing instance)
I deleted that instance on 30 sep

okay
sure, this I need to check
btw i host my discord bot too, and i would recommend using https://www.hetzner.com/ in a future
Your partner for system-wide hosting, from cloud to dedicated servers. We deploy the latest tech at the best price in minutes.
super cheap
its prices are awesome for arm64 and simple to use 😋

could you share the link to this plan? I can't find 
cool
GCP too expensive

my link would not work for you since it is in my personal profile https://console.hetzner.cloud/projects/1780391/servers/create
I turned on compatible with arm64 location and then picked arm64 servers


internal thingy for creating server
AWS/GCP/Azure are for big boys/companies to use in prod 😅
not friendly for pet projects at all
@rapid sparrow $5 per month it is
affordable

thx
I will use it from next month
btw @rapid sparrow what discord bots you made? I would like to take a look.
The bot i made is for https://youtu.be/RHlH_qOH5zc Freelancer Discovery gaming community around space simulator https://discoverygc.com/
It offers in discord tracking of in game Player space ships, player built space stations and appearance of forum msgs
It has documentation too 😏 https://darklab8.github.io/fl-darkbot/
The code is visible here https://github.com/darklab8/fl-darkbot
Deployment to hetzner is in fact described as infrastructure terraform code https://github.com/darklab8/fl-darkbot/blob/master/tf/production/main.tf
Infra code reuses some code from my shared code of infra from there https://github.com/darklab8/infra
Readme of a project describes tech stack and its architecture and how to get started with its development https://github.com/darklab8/fl-darkbot/blob/master/README.md
Main architecture feature i am proud of during its design, i made it absolutely unit testable through just intercepting Discord msgs input, shoving them into Golang Cobra CLI library, and rendering answer from it to end user in markdown format 😄
That makes 98%+ of a code really easy locally auto testable and easy to write unit tests for.
In first bot designs i used Python Discord.py library, it was horrible and unstable, often falling apart and hard to write tests for. Remake into golang with making this CLI design thingy made it really great for me


https://discoverygc.com/forums/showthread.php?tid=126999 👈🚀 Start Playing Discovery Freelancer Multiplayer - Easily download it today!
Official gameplay video and introduction for Discovery Freelancer. Download and play for free, immersing yourself in the longest running, spaceship MMORPG of all time!
Experience space exploration, immense PvE ...
it was presented to players at their forum https://discoverygc.com/forums/showthread.php?tid=188040 😋 and runs already 3 years huh.
Golang remake runs only for 1 and a half year though, the first year and half it was running in python
wow, crazy
{kind=link}


Hello guys, anyone here can help me ?
Dont ask to ask.... Just state your problem.
alright, I ma trying to know how to build an interface in which I can see all my steam games, I already have my steam API and user id, but I would like to create this idea and know a way to save the data on my local machine so the time to charge it again will be more quickly instead loading all from 0 everytime I execute the code
My question is, how can I do that, not the code at all, but what libraries I should use to get closed to this idea
https://cdn.discordapp.com/attachments/1289585651360206848/1291974035562827906/Screen_Recording_2024-10-05_at_06.59.37.mov?ex=67020c15&is=6700ba95&hm=1ca8256c81c021cd85e010d294387b89fed1cf985c67bb20ca4503882a2b2d80& https://cdn.discordapp.com/attachments/1289585651360206848/1292169011378913341/Screen_Recording_2024-10-05_at_19.57.00.mov?ex=6702c1ab&is=6701702b&hm=116efa55f6b18761cfe72e5957f6539b516ec051cff3022a06ff17cb6bdf08fc&
Making a little Console IDE in Python. Still don't know how to lower memory usage. Any ideas or suggestions on that? The stress test is in the 2nd video
Anyone know how to get isort to have a separate grouping for local files? From the way the docs read, it seems like third party and first party imports are already separate sections, but my modules are being grouped with third party packages I've installed.
I was wondering about that. So I have to define all first party modules? It can't tell itself? Because I really don't want to have to keep updating that setting as my project develops...
It tries to
How many do you have?
You should just be able to put the top level name
Just a guess, but: isort might need to import your modules, which means, if you're using a virtualenv, then you need to install isort into that virtualenv, and ensure that's the version that you run.
Everything is under a src directory, but that isn't working
Oh, maybe it isn't a first party issue, but third? I am using a venv and vscode (I haven't yet set up isort to work on git commit)
Ok, yah, it's something to do with vscode and the venv; if I run the isort command, it behaves differently (strangely, it still keeps one of my local files with third party files, but separates the other?)
Yup, it's VSCode. Now the question is how to fix that...
did docformatter break for anyone else on the latest pre-commit update?
PS noahj@noahj-lenovo:~\Code\WarMAC$ docformatter --version
docformatter 1.7.5
PS noahj@noahj-lenovo:~\Code\WarMAC$ pre-commit --version
pre-commit 4.0.0 (pre-commit-uv=4.1.3, uv=0.4.18)
PS noahj@noahj-lenovo:~\Code\WarMAC$ pre-commit autoupdate
[https://github.com/DavidAnson/markdownlint-cli2] already up to date!
[https://github.com/abravalheri/validate-pyproject] already up to date!
[https://github.com/PyCQA/docformatter]
==> File C:\Users\noahj\AppData\Local\Temp\tmp7xlyp04t\.pre-commit-hooks.yaml
==> At Hook(id='docformatter-venv')
==> At key: language
=====> Expected one of conda, coursier, dart, docker, docker_image, dotnet, fail, golang, haskell, lua, node, perl, pygrep, python, r, ruby, rust, script, swift, system but got: 'python_venv'
Yeah, there's a fix at https://github.com/PyCQA/docformatter/pull/287
thanks hugo 🙂
I'm using RUFF and currently it's grouping imports by type (standard, 3d party, local) but it also sorts imports alphabetically per line.
Can I turn off the sorting per line? I just want imports to be sorted by groups.
No need to shout
I don't see an explicit option for that, just the one https://docs.astral.sh/ruff/rules/unsorted-imports/
I'd ask the Ruff team, they have their own Discord: https://discord.gg/T93bK4Xk
didn't shout? Anyway ye I asked thanks
probably he interpreted you telling "RUFF" as loudly yelling "RUFF!!"
ye I thought it was spelled like that, my bad
lol
Does anyone have any recommendations for a tool that can help formatting docstrings (preferably in the Google style)?
ruff, I think, does that
sphinx can use correctly formatted google styled docstrings into html documentation
so u can have visual feedback
I'm more looking for something like black but for docstrings. I found docformatter but not sure how widely used it is
Pydocstyle
is there any tools that lets you download from youtube?
i was thinkin of method, build python app with ffmpeg, record system sounds(youtube) if possible, then record window ( youtube) hmmkinda hassle 😛
yt-dlp
free, fast, configurable, supports many websites aside from youtube
cheers
!ytdl
Our youtube-dl, or equivalents, policy
Per Python Discord's Rule 5, we are unable to assist with questions related to youtube-dl, pytube, or other YouTube video downloaders, as their usage violates YouTube's Terms of Service.
For reference, this usage is covered by the following clauses in YouTube's TOS, as of 2021-03-17:
The following restrictions apply to your use of the Service. You are not allowed to:
1. access, reproduce, download, distribute, transmit, broadcast, display, sell, license, alter, modify or otherwise use any part of the Service or any Content except: (a) as specifically permitted by the Service; (b) with prior written permission from YouTube and, if applicable, the respective rights holders; or (c) as permitted by applicable law;
3. access the Service using any automated means (such as robots, botnets or scrapers) except: (a) in the case of public search engines, in accordance with YouTube’s robots.txt file; (b) with YouTube’s prior written permission; or (c) as permitted by applicable law;
9. use the Service to view or listen to Content other than for personal, non-commercial use (for example, you may not publicly screen videos or stream music from the Service)
Hi everyone! I used a speed reading website to read faster for some time. It worked for a while because I realized I was rushing and not reading. Actually, I felt I wasn't improving but getting worse at it which made me think about why I wanted to read fast. Today, I started to visualize concepts in my head and my reading comprehension improved while my speed didn't decrease much as I feared. Do we need to design fast systems in Devops or should we aim at efficiency instead? I'd go for efficiency (I'm learning devops not an expert at all) because fixing errors can cost you more, reverting changes might be harder and overall you start to using more and more resources. Is this an obvious question? Is this a topic that has more than one right answer? What do you think about this?
BTW I finished reading this introductory material to devops. Maybe there are more beginners like me that find it interesting
Atlassian
Following these 5 key DevOps principles helps software development and operations teams build, test and release software faster and more reliably.
I didn't do the tutorials because I found a better set of tutorials that included much more than this one.
Hey fellow devs! I'm struggling to manage multiple Git accounts on my Windows machine using SSH keys. Currently, I'm using Git and GH CLI, but it's getting cumbersome.
Is there a way to automate or simplify the process? Perhaps using aliases, scripts, or a GUI tool?
Ideally, I'd love to:
Easily switch between accounts
Automate SSH key switching
Use a simple GUI interface
Any recommendations or solutions would be greatly appreciated!
Thanks in advance!
Something that might be useful:
Git lets you conditionally include additional config files based on the current directory. Example: ```ini
~/.gitconfig
[user]
name = nickname
email = nickname@gmail.com
[includeIf "gitdir:~/Business/"]
path = .gitconfig-work
~/.gitconfig-work
[user]
name = First Last
email = fl@work.com
You can also place these inside ~/.config/git/config, config-work to declutter your home dir
I am hoping to get some help with https://github.com/dynatrace-oss/api-client-python/blob/main/dynatrace/configuration_v1/maintenance_windows.py#L49
I have my error and my question about creating an object here. https://paste.pythondiscord.com/6XMQ
dynatrace/configuration_v1/maintenance_windows.py line 49
class Scope(DynatraceObject):```Host github.com-companyworkname
HostName github.com
User companyworkname_username
IdentityFile ~/.ssh/id_rsa.companyworkname
IdentitiesOnly yes
Host github.com-anotherworkrelated
HostName github.com
User anotherworkrelated
IdentityFile ~/.ssh/id_rsa.anotherworkrelated
IdentitiesOnly yes
Host github.com-dd84ai
HostName github.com
User dd84ai
IdentityFile ~/.ssh/id_rsa.dd84ai
IdentitiesOnly yes
i just have written stuff like this in ~/.ssh/config and it works for CLI (and optionally GUIs that i never use)
all i need just to specify suffix to provider to use right key
git clone git@github.com-dd84ai:darklab8/fl-darkstat.git and it will use the right key
Anyone ever tried to spoof or mock audio output devices on github actions?
FROM node:20 as build
RUN apt update && apt install -y git-lfs && git lfs install
WORKDIR /app
COPY . .
WORKDIR /app/frontend
RUN git lfs pull
RUN npm install
RUN npm run build
FROM nginx:alpine
COPY --from=build /app/frontend/build /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
is this the right way of pulling large files from git lfs and build a react project? In my case for some reason it won't pull files from lfs correctly leading to broken assets in the final build
For example, in container:
-rw-r--r-- 1 root root 133 Oct 4 13:36 wizard_step_1.93ff8bc2c3beefe5865d.mp4
-rw-r--r-- 1 root root 133 Oct 4 13:36 wizard_step_2.e12c8f32e6f2fa2fa174.mp4
-rw-r--r-- 1 root root 132 Oct 4 13:36 wizard_step_3.a4e8661340f83d594a1a.mp4
/usr/share/nginx/html/static/media #
Host:
total 110M
-rw-r--r-- 1 root root 104K Oct 11 14:41 insta360_x4.webp
-rw-r--r-- 1 root root 66M Oct 11 14:41 wizard_step_1.mp4
-rw-r--r-- 1 root root 37M Oct 11 14:41 wizard_step_2.mp4
-rw-r--r-- 1 root root 8.6M Oct 11 14:41 wizard_step_3.mp4
I have this fairly simple docker build workflow https://mystb.in/raw/066f7f313afd59d84a/1
I want to build an image for PRs
and it does
as long as it's a PR from me (collaborator)
but if a contributor makes a PR (with no special perms on the repo)
it fails with: ghcr.io/org/repo:pr-28: unexpected status from POST request to https://ghcr.io/v2/org/repo/blobs/uploads/: 403 Forbidden
I build my container on PR just to sanity check
I don't publish the builds to the registry though
how do I make it conditional? Currently the push fails and so does the CI. I would like it to skip the publish step but still build the image
That's essentially my goal
although I'm unsure of how to make the push: true (I think this is it?) false when it's coming from a contributor's PR
but I do want it to publish if it's coming from a collaborator of the repo since they are trusted already
why?
can deploy the PR images (tagged as repo:pr-xx) on a dev instance
I'm trying to lacunh a command that is needed to be executed in a working dir (hou_bin) but for some reason it try execute in c:\bin
How I could set properly the working/execute path? I think os.chdir is for that bu maybe I'm wrong to set that. Any help is welcome. Tks

pass the path to the desired working directory as the cwd argument, like so,
subprocess.run([the_command], cwd='/path/to/some/directory')
Thank you!
Hi, I was wondering which libraries/frameworks to use for a project so I should definitely ask the question here. I wanna build an app for myself and I don't know what to use, I heard about Flask for backend and React Native for frontend but I've never used any of those. I also heard about Kivy that might be easier to handle for a first app, but I don't think it's powerful enough to realise what I want. I'm not scared about diving deep into a yet unknown universe but I'd appreciate some advice from people with way more experience than I have
depends greatly on what kind of app you want to build
kivy iiuc is strictly for Android
flask et al are for web sites
I'd like to write an app with a background let's say a bit like Maps, but allowing me to superimpose layers and add landmarks on my way
yes but where do you want the app to run?
on Android phones exclusively?
Everywhere?
Windows only?
MacOS only?
&c &c &c
Command not found
Command "c" is not found
definitely on my android*, but if I can make it work on my windows it'd be great too
well if you had a ton of money, a year, and a couple of smart programmers working for you, I expect the most professional way to do it would be to pay Google a pile of money, and write a web app that uses their Maps API.
more realistically: Kivy and the Google Maps API should be doable for a smart and persistent individual
I myself am either not that smart, or not that persistent, to have ever gotten anywhere with Android (it makes my brain hurt), but the last time I tried was years ago, so perhaps it's gotten easier
okay I'll keep making research then, thanks for answering
it's unlikely, albeit possible, that Python is the best choice for this sort of thing
oh I agree, but for some reason I wanna write a backend with python, I may have some problems and am extremely narrow-minded when it comes to a very small detail such as what language to use
this is gonna be a challenge
Hmm, the phone game that came before pokemon go. What's the name? Didn't that one use open street view? Perhaps build on top of that?
A colleague is doing something for running trails with their data if I remember correctly.
Ingress iirc
how does librosa.load work, i cant find anything in the documentation about where it loads from. 'nutcracker' is built in but like where do i put a .mp3 of (for example) duckworth if i want to analyze that
*cough*@astral apex*cough*

so, I have a... predicament with my docker compose stack
use this 
I'm mounting a directory via NFS, and I would like the containers that depend on it to wait until it's mounted before starting. I could make the whole docker service dependent on the systemd mount, but I'd rather than non-dependent containers can start when they want
# /srv/resources/check_mount.sh
#!/bin/sh
main(){
mountpoint="${1}"
if [ -d "${mountpoint}" ]; then
return 0
fi
return 1
}
main "$@"
# /srv/resources/sleep.sh
#!/bin/sh
main(){
seconds="${1}"
string="${2}"
while true; do
if [ -n "${string}" ]; then
echo "${string}"
fi
sleep "${seconds}s"
done
}
main "$@"
and then a container named check_nfs
---
services:
check_nfs:
image: busybox
volumes:
- ${DIR_RESOURCES}:/srv/resources:ro
- ${DIR_MEDIA}:/srv/media:ro
entrypoint:
- "/srv/resources/sleep.sh"
- "30" # seconds
- "Still Alive!"
healthcheck:
test:
- CMD
- /srv/resources/mount_check.sh
- /srv/media/.meta
interval: 10s
timeout: 5s
retries: 3
it mostly works, but there's a few issues:
at startup, the container runs the healthcheck, then it fails if NFS isn't mounted, and never checks again. I could tweak the timeouts and retries, but it would be nice if I could have it run indefinitely, until NFS is mounted, then have all the dependents start
@astral apex any ideas? 🥺
, you've gone over my head
Health checking on external factors is interesting
You said it only tries once but you have retries: 3
I wonder if retries can be infinite
RIP
 What if I changed it, so I have a
What if I changed it, so I have a while true that just repeatedly checks, for NFS, then it's never healthy until it's successful, and exits when it is
So, not having luck with this either - seems that the fileystem in the container doesn't refresh. If the share isn't mounted when the container starts, it will never see the files, even if you mount the share after
i usually in such cases make script wrapper...
smth like
mycompose that is written in python and handles raising some services/awaitings before running commands of app 😋
Shebang makes not necessary to point which python env to use for its running, it can be used as regular linux executable
not sure what you mean. I could make the docker service dependent on the NFS mount, but I don't want to - not all the containers are dependent on it
the end-goal is that if I reboot the Media NAS and the Media server, that the containers dependent on the NAS will wait to start until its share is mounted, but the other containers will start on boot
#!/home/naa/venv/bin/python3
from threading import Thread
import subprocess
import sys
import time
ip = sys.argv[1]
def tunnel_forward():
subprocess.run(f"ssh -v -A -N -T -i ~/.ssh/id_rsa.work work@eurostar.work.com -L 8022:{ip}:22", shell=True)
thread = Thread(target=tunnel_forward, daemon=False)
try:
thread.start()
time.sleep(3)
subprocess.run('ssh-keygen -f "/home/naa/.ssh/known_hosts" -R "[localhost]:8022"', shell=True)
subprocess.run('ssh -p 8022 -i ~/.ssh/work.bastion.production.pem ec2-user@localhost ', shell=True)
finally:
print("attempting to terminate my process")
i mean... make script like compose in your $PATH as binary script
That will be serving as wrapper for docker-compose to await necessary NFS mount before running docker-compose itself
u could be using sys.argv[1:] to invoke docker compose with all args
to pass them further
right, but the docker service already auto-starts the containers
so if I was going to do that, wouldn't it make sense just to make the service dependent on the mount, same outcome
ah... u expect NFS mount to be awaited after Server restart?
when containers obey restart always
but only for select containers, not all of them
docker-compose supports init containers since some version
https://discuss.hashicorp.com/t/tutorial-proof-of-concept-you-can-use-docker-init-containers-to-provision-your-vault-container-within-your-compose-file/38348
Just write init container for your service
and make in another container, depends_on service_completed_succesfully with pointing init container

HashiCorp Discuss
Docker Init Container in Compose NOTE: this feature is similar to Kubernetes Init Containers, which is available for Docker Compose since version 1.29. The Init Container can initialize your container by using the depends_on spec. Depending on the intialization process, you can set three conditions of the container’s state you wish to initia...
make init container mounting your NFS (or doing checks to await if it finished mounting)
scroll up - I did exactly that. I made a container, with a script, and then made the other containers dependent on it
no. u did healthcheck. i said using depends_on in status service_completed_sucessfully
you didn't scroll up enough then
#tools-and-devops message
I made a container. The container runs a health check so docker knows when it's health (when it sees the NFS share). Then other containers depend on it
i see u using healthcheck here, not depends_on service_completed_sucessfully init container
Those are different mechanics
but it doesn't work because if it's already running and then the NFS share is mounted, it's not reflected in the container
that is the container than the other ones depend on
so the other containers get configured with
...
depends_on:
check_nfs:
condition: service_healthy
Wrong implementation... init container is not supposed to be having healthcheck... just force it to be a single Job that awaits mounting, and finishes succesfully
no need for healthchecks
use service_completed_sucessfully instead of service_healthy
okay - but it wouldn't matter at all
u need init container concept, not healthcheck stuff
because whether it's a healthcheck or an init, neither fix the problem
which is that the bind-mounted filesystem doesn't refresh within the container
changing from a healthcheck to an init script in the container won't change that at all
you are focusing on the wrong thing here
u can forward any Host os folder/system, so the container inside could with normal means check which mounts host system has mounted
i would bet it should be possible in theory, at least we can forward into container showing same processes as at host machine
to reproduce:
- deploy a docker container manually. bind-mount an unmounted NFS mount point (E.G.
-v /mtn:/mnt) - get a shell on on the container
- while the container is running and you are on the shell, mount the NFS share to
/mnt(on the host) lsthe mountpoint from within the container. It will still tell you that it's empty
or, do it the other way. Mount it with the NFS shared mounted. Then remove it. The container will still show you all the directories and files as if the share was mounted, but you can't interact with them because they don't exist anymore
it should be possible though... lets say you forwarded read only /mnt host folder to /mnt of container
if u mount smth to /mnt/smth, this smth should be visislbe inside container 🤔
i could check if it is visible if i am not lazy
it's not, that's what I'm saying
if you mount it, then start the container, it is. But if if you start the container firs, then mount the NFS share, it's not reflected in the container
unless it's just me 
not lazy enough, running check
okay... the test showed
docker run -v /mnt:/mnt:ro -it ubuntu:20.04 bash, i started container
and started mounting, mkdir /mnt/mounted_kube
and then did the mount
i am able to see empty folder /mnt/mounted_kube inside the container
but not the mounted content
exactly. Thus the predicament
😏 partial success
well, you are exactly where I am
The command cat /proc/mounts displays the contents of this file, which is used to determine whether a directory on a Linux system is a mount point
we could forward this thing info container and observe for mounts
possibly
/dev/mapper/vgkubuntu-root /mnt/mounted_kube ext4 rw,relatime,errors=remount-ro 0 0
aha. the last record is my mount 😏
Nice. That's a good solution :)
Linux 💪 just finding relevant folder/file is enough to share some system info
how are you forwarding it? It's only giving me local mounts for the containers, not the host mounts
https://github.com/darklab8/infra-game-servers/blob/b91dcf76f1ee176853e7b593868b6ab04b896ba2/server_modded_1710/docker-compose.yml#L22
Try this method, which I used to forward specific host files into Minecraft server
server_modded_1710/docker-compose.yml line 22
- type: bind```that doesn't change anything :/
https://paste.pythondiscord.com/FKQA resource monitor python
How does the "code review" metric increase? I've been doing PR reviews, leaving inline comments, and adding general comments on the PRs, but it doesn't seem to be going up. Just curious!

docker run --mount type=bind,source="/proc/mounts",target=/proc_mounts -it ubuntu:20.04 bash
cat /proc_mounts
works to me perfectly as the command above
if it does not work for you... security tinkering can be also needed --security-opt apparmor=unconfined for example
forked 😄
oh btw i made a intro script for app im currently writing, i got the idea from your app heh. ill show u maybe u have usage for this
import time
import os
import sys
def typewriter_effect(text, delay=0.05):
for char in text:
sys.stdout.write(char)
sys.stdout.flush()
time.sleep(delay)
print()
def blink_effect(text, times=3, delay=0.3):
for _ in range(times):
os.system('cls' if os.name == 'nt' else 'clear')
time.sleep(delay)
print(text)
time.sleep(delay)
ascii_art = """
_ _ __ __ ____ __ __
| | | | \ \ / /| _ \| \/ |
| | | | \ \ / / | | | | |\/| |
| |__| | \ V / | |_| | | | |
\____/ \_/ |____/|_| |_|
Ultimate Video Download Manager
"""
lines = ascii_art.split('\n')
# Typewriter effect for the full text
typewriter_effect(ascii_art, delay=0.02)
# Blink effect
blink_effect(ascii_art, times=10, delay=0.3)```should I run poetry lock and poetry check on each commit? (using .pre-commit-config.yaml), generating the lock is kind of slow, not sure how important it is
and do I run poetry check before generating the lock, or after?
If you are interested moving cards around in the terminal, feel free to try out my latest CLI TUI App:
https://github.com/Zaloog/kanban-tui
uv tool install kanban-tui

GitHub
kanban manager with a tui interface. Contribute to Zaloog/kanban-tui development by creating an account on GitHub.
Why is it so unbelievably difficult to copy a file into a Docker container and set correct ownership/permissions?
When you have to rely on tar --owner for that, something is kind of wrong
is there ever any reason not to use parameterize
No, you don't want that. You should only need to run lock when you want to regenerate the lockfile. Usually because you made changes to your pyproject.toml or because there are new compatible versions of your dependencies.
Not sure when check would be needed. Maybe if you upgrade your version of Poetry? Not sure. I've never used it
I guess it would be useful if you make manual changes to the lockfile, but I never had to do that
I worked on a project that used pytest-cases and it worked fairly well. If you have a lot of cases or very complex cases, using just the parametrize deco can get a little unwieldy
The pytest-cases lib allows you to parametrize fixtures, and also to have your test cases depend on fixtures
I had no idea this existed until now, I have badly needed this before. Thank you!
Can you not use chown and chmod?
--chown and --chmod became part of COPY/ADD instructions 🤔
have u tried using them
also if u switch USER toenduser first, during copying files should become automatically with correct permissions i think
These can't be copied at build time, they are specific to the container not the image
I can, but it means I need to run my container as root and then downgrade privileges instead of just using the user in the container that I already wanted to use
no no
COPY --chown chmod is part of image building process, not container
Right, that's why I can't use it, these files need to be copied into the container, they can't be copied in while building the image
They are specific to the host where the container is deployed
um. okay.
just chmod those host files with granting them access to the used n docker in advance
and then run containers (with whatever way adding them to container, through volumes for example is default i would recommend?)
i believe such trick should be possible
and probably would be most appropriate
the simpliest option will be running on your files, chmod a+r -R folder_of_files, and just granting them to all read (or write or execute)
the more trickiest option...u could use gratinging rights to specific user
i believe docker can be run with the same USER id like 1000 for example
so u could be just granting access for this user at host, despite it not existing i think (haven't tried that, but it should be possible in theory)
Depending on how you are running the container, you can just build it locally
That’s how i use Caddy because you have to compile it with module, you can’t use a package manager
Oh I see yes, that's what I ended up doing. although I had to make a copy of the files first because I needed to not mess with the originals
I made a series of docker images where you can rebuild them for a specific UserID/GID
The other option is to create a named volume, mount the volume in a new container, copy the files into the container, and then change permissions inside the container. That's potentially safer if you don't have control over the host environment
Unfortunately, in this case, these are built in CI to be deployed elsewhere
Anyway, it's annoying that you have to do all this stuff instead of being able to just set ownership and permissions when you copy a file into a container
darn 
I am not into the case now but for sure you can solve it without root privileges, as said, if you prepare the image for a specific userid if you mount that stuff in there.
Right, that was the other part of the solution. I created a build argument for the UID and GID
that pretty much should solve everything
But again, because the same image is going to be reused on different hosts, I can't hardcode the UID and GID of the host
Yeah, the linuxserver.io containers I use do that IIRC
Instead, I just select a fresh UIDand GID to use, and then set the owner of the file to those
if you need to change the owner of files then you are already not winning
lol yup precisely
tcp chat room
import threading
import socket
host = "127.0.0.1" #localhost
port = 55555
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind((host, port))
server.listen()
clients = []
nicknames = []
def broadcast(message):
for client in clients:
client.send(message)
def handle(client):
while True:
try:
messages = client.recv(1024)
broadcast(messages)
except:
index = clients.index(client)
clients.remove(client)
client.close()
nickname = nicknames[index]
broadcast(f'{nicknames} left the chat'.encode('ascii'))
nicknames.remove(nickname)
break
def receive():
while True:
client, address = server.accept()
print(f"Connected with {str(adress)}")
client.send('NICK'.encode('ascii'))
nickname = client.recv(1024).decode('ascci')
nicknames.append(nickname)
client.append(client)
print(f'Nickname of the client is {nickname}!')
broadcast(f'{nickname} joind the chat!' .encode('ascci'))
client.send('Connectd To The Server!'.encode('ascci'))
thread = threading.Thread(target=handle, args=(client,))
thread.start()
print("Serverd is Listening...")
receive()
Hi everyone! I'd like to try out nushell any time soon but this alternative shell to bash looks pretty cool as well. The way you can use python in it is very interesting

00:27 Chapter 1: Writing Python Right in the Shell
01:16 Chapter 2: Combining Shell with Python Commands
01:54 Chapter 3: Easy Configuration
02:13 Chapter 4: Auto Completion
02:55 Chapter 5: Xontrib & Plugins
03:56 Chapter 6: Custom (History) Backend(s)
XonSH: https://xon.sh
CouchDB-Gist: https://gist.github.com/whogotpwned/58aed7116a17f57b0370...
This one looks cool also

Descargar Código: https://www.patreon.com/pythonmaraton
Join Patreon: https://www.patreon.com/pythonmaraton
^Downloadable code & more!
This video will compare and contrast running .py python code in both ipython and the python shell (python interpreter).
In the python interpreter you can run a specific function by running the following code:...
we use Ipython, i like it
Hey guys,
Dockerfile
FROM python...
WORKDIR /db
COPY pyproject.toml poetry.lock ./
RUN poetry install --no-root
COPY ./ ./
ENTRYPOINT ["poetry", "run"]
compose.yaml
x-defaults: &default
build: .
volumes:
./inputs:/db/inputs
./outputs:/db/outputs
tty: true
services:
collate-server-list:
<<: *default
command: python -m snippets.collate_server_list
profiles:
- collate-server-list
``` (few things omitted for clarity)
I've created a very simple docker container so folks don't have to install python, poetry, etc to run a script.
lets say my script reads files from the `inputs` folder and writes them to the `outputs` folder. I bind these volumes from the host to the container, but after the container exists my local user doesn't have any permissions to new files, they're owned by `root`
Is there something I'm missing here?hm! Yes, of course; but I'm not sure how to fix it 🙂
You can put something in the docker image that tells it what user to run as. But that's a user that lives in the container, which isn't necessarily the same as the user who is running docker
im curious, what happens if a different user inside the container writes inside a bind mount? does the host see it as also owned by root? (or i assume whichever host user is running the docker daemon)
I'd guess the host would "see" that UID if the host is Linux, and you're running docker normally; but if the host is Windows or MacOS, who knows what'd happen
probably worth an experiment
for Windows and MacOS, the behavior might depend on the actual software you're running (Docker Desktop vs Orbstack, e.g.) and how you've fiddled its settings 🤷
ah, i misunderstood what USER did, that makes sense
though it seems a bit weird to me for the dockerfile to dictate which user runs the container, rather than via CLI (docker run -u uid:gid ...)
🤷
I suspect that in most simple cases, the UID of the container's process doesn't really matter.
New to Python Sky ideas for me?
!kin go through these
Kindling Projects
The Kindling projects page on Ned Batchelder's website contains a list of projects and ideas programmers can tackle to build their skills and knowledge.
and use #python-discussion for general Python discussion
tl;dr: https://github.com/mamba-org/micromamba-docker/issues/407#issuecomment-2088523507
Docker Desktop maps the host user:group to 0:0 in the container: https://github.com/docker/for-mac/issues/6734#issuecomment-1817659381
Docker doesn't seem to support arbitrarily mapping host users to container users:
- https://github.com/moby/moby/issues/2259
- https://github.com/moby/moby/issues/22258
- https://github.com/docker/roadmap/issues/398
There are some workarounds listed in the above issues that you might wanna take a look at.
Thank you -- that was incredibly helpful, permissions suck
What I went with is something similar to the below (but w/ the correct syntax)
FROM python...
ARG GID=1000
ARG UID=1000
WORKDIR /db/
RUN groupadd GID && useradd UID etc && chown -R GID:UID ./
COPY pyproject.toml poetry.lock ./
RUN --mount=type=cache, ... poetry install --no-root
COPY ./ ./
USER UID
ENTRYPOINT ["poetry", "run"]
and edited my compose file to
x-defaults: &default
build:
context: .
args:
- GID: ${GID:1000}
- UID: ${UID:1000}
...
which is by no means an ideal solution, but it does the do
is still subprocess the best way to execute external commands and get the output/error? what other options are out there?
i use threads on my videodownloader, works very smoothly
IDK if the Moby/Docker team really considers the 👍🏼 reactions to prioritize issues, but doesn't hurt to do that.
in python? yeah, it’s the recommended way. There’s os.system. No reason to use it when subprocess exists
Hi - question. What is the best way to track the live memory usage of a python service? When I looked up online, I mostly came across people hacking together their own thing using psutil and such. Is there a standard way? for eg, in. Java people use JConsole or something
!pypi memray
A memory profiler for Python applications
Released on <t:1725911408:D>.
this has a "live" mode that might be what you're looking for
i'll look into it. i used this some itme back, but didn't check the live mode
i was wondering if there is something that can be used to "attach" to an already running python application
this might work fine, but i guess the program has to be launched with memray
this is probably one of the tools with the most in-depth analysis re: memory usage available for python right now... so its worth trying it out for sure.
oh, thats very cool. will read the docs
Hello 😁
I've containerized a python webserver but now I've run into 2 major issues. I cant control system daemons (systemctl) from inside the container and I cant send commands to another application (SaltStack) from inside the container. I can technically solve both of these through some tricks using bind mounts, named pipes, and filesystem monitoring, but these are pretty dirty and I'd rather not go down that path. Any ideas?
why do you want to control system daemons from inside the container? Containers typically run exactly one process, and that process should just assume that everything else it needs is available
hey just want to repost my post from the python reddit that sympy vector coordinate system conversions is broken and has been for years the rest of the spiel is here

Hi :)
So the point of the webserver is to accept keys for other other applications.
Here is the webserver for reference: https://github.com/KianBahasadri/bhive/blob/saltstack/master/automation_api.py
- It accepts a wireguard public key, adds it to wireguard's config file, and then wants to run
systemctl reload wg-quick@wg0on the host - it accepts an ssh private key and then wants to run a python library which basically executes
salt-cloud -p salt-this-machine my-machineon the host
So as you can see both of these functions need access to the host, which is the problem. I could also do something like ssh into the host and execute commands but that would be so silly.
wait, the container wants to invoke programs on the host?
that's ... weird
you can get away with modifying files on the host, if you fiddle with the container's mounts ... but ...
either containers are the wrong tool for this job, or I just don't know enough about docker to suggest anything