#✨|sdxl
1 messages · Page 138 of 1
The first Color Photo was taken 1861. 🤔 I mean I guess it follows the prompt, but was that really what the initial prompt from qwerty asked for?
i think czech inventor made it
it should depend on the prompt, i am collecting these prompts, so I can make the prompts I gathered from multiple hf datasets and then train on them
o.k. it isnt low light and dark....
whats the prompt?
Took the last output and "Can you make it a short prompt, separated with commas"
antique photograph of a beautiful woman, sad eyes, sad smile, facial symmetry, frontal view, cracked and faded photo paper, staring at the camera, headshot, dark background, 1850, low light, dark, 4k
his prompt with a lora that i had on



all with protovision from @delicate kelp
i have them in frame, why!
left(original prompt), top-right(my modified prompt using llm), top-bottom(gpt prompt by boto)
no lora


uuh... interesting wardrobe

only this?
and yet you got great prompts
can you try this highly detailed exquisite warframe fanart, worms eye view, looking up at a giant 500 foot tall beautiful saryn prime female warframe, as a stunning anthropomorphic robot female dragon, sleek smooth white plated armor, unknowingly standing elegantly over your view, you looking up from the ground between the robotic legs, nothing but a speck to her, detailed legs towering over you, proportionally accurate, anatomically correct, sharp claws, two arms, two legs, robot dragon feet, camera close to the legs and feet, giantess shot, upward shot, ground view shot, leg and thigh shot, epic shot, high quality, captura, realistic, professional digital art, high end digital art, furry art, macro art, giantess art, anthro art, deviantart, artstation, furaffinity, 3d, 8k hd render, epic lighting
Warframe 
you only got a single word?
No lmao this was my comment
Shot shot shot shot Warframe. The LLM gets PTSD from that
haven't done llm prompts in a long time 😮
Highly-detailed Warframe fanart, worm's eye view, 500-foot tall Saryn Prime, anthropomorphic robot dragon, sleek white plated armor, elegant stance over viewpoint, ground view between towering legs, proportionally accurate, anatomically correct, sharp claws, two arms, two legs, robotic dragon feet, camera focus on legs and feet, giantess shot, upward shot, ground view shot, leg and thigh focus, epic perspective, high-quality, Captura, realistic, professional digital art, high-end rendering, furry art, macro art, giantess art, anthro art, potential feature on DeviantArt, ArtStation, FurAffinity, 3D rendering, 8K HD render, epic lighting
Idk doesnt seem much different

those old photos benefit from higher cfg
i mean, how hard can prmopting be? just prompt "fantasy art", no negatives. easy. KAPOW, now i'm an artist too 😄



You are a true prompt magician.

lets improve it 'generic dull fantasy art'

LLM Prompt for fantasy art : Enchanted woodland setting, ancient towering trees, whimsical creatures, ethereal glow, mystical pools of water, reflections of hidden realms, vines intertwining, blossoming with magical flowers, soft beams of sunlight piercing through dense foliage, floating islands, ancient ruins reclaimed by nature, forgotten statues with eyes aglow, a central majestic ancient tree with secrets, tree homes nestled high, fluttering fairy lights, velvet moss blankets, curious mystical artifacts, shimmering leaves, a guardian spirit of the forest, subtle sparkle in the atmosphere, the dance of the spirits at dusk, surreal, whimsical, transcendent lights, soft palette with bursts of color, gentle magical aura, hidden pathways leading to mysterious adventures, storytelling through scenery, details that entice lore exploration, high fantasy, endless imagination captured in a frame, a scene whispering ancient lore, dreamy haze, a glimpse into a forgotten magical world
running a local llm?
Nah chat gpt 4
generic dull fantasy art



The A image is SD classic layout
left(the original prompt), right(gpt modified prompt)


I mean, not terrible



iam artist too! Shorter sword would probably work better.




@ionic dragon Yesterday you shared a hugging face page with 1.82 Million lines of prompts. Don't they work?
I mean for training.
That is one sus Tail between the legs.
all the way from the top tho
cyberdwarves!



whoa, what's he getting ready for in the bottom right image?
They call it "war"
well he's definitely in good shape. can't deny that
surely excels in war activities
It's quite the exercise
yeah pretty impressive, if we can tweak the prompt, then I think we can make it great
decorated soldier that made it through the infamous bath house battles
look at this stupid cfg. not a world record but it's high

anyone see any issues with installing cudnn_ubuntu2204-12-2-local? i recall some issues with certain versions of cudnn
I don't see any issues and also don't know anything
@uncut steeple can you try this
"generate a modified stable diffusion prompt of this"
i was surprised how old qr monster making qr codes unreadable... But it is not main point of extension probably.
That's what Bing has to say to this:
You are standing on the ground, looking up at a giant 500-foot-tall Saryn Prime female Warframe. She is an anthropomorphic robot female dragon with sleek, smooth, white-plated armor. You are nothing but a speck to her as she unknowingly stands elegantly over your view. Her detailed legs tower over you, proportionally accurate and anatomically correct, with sharp claws. She has two arms, two legs, and robot dragon feet. The camera is close to the legs and feet, capturing a giantess shot, upward shot, ground view shot, leg and thigh shot, and epic shot. The artwork is of high quality and realistic with professional digital art, high-end digital art, furry art, macro art, giantess art, anthro art. The artwork can be found on DeviantArt , ArtStation , or FurAffinity . It is a 3D 8K HD render with epic lighting.
oh cool, lemme use bing too
It is a 3D 8K HD render with epic lighting. 😄 And best picture ever been created 😄
🤣 I didn't even read through
best picture ever created i just added 🙂
Would be fitting
Well, can someone try this prompt? Now I am curious




Ok, I googled Saryn Prime Warframe and have to say: Pretty inaccurate.


does it work?
it seems to.. I implemented AIT to it
can you tell me what the name of this plz ?
check readability @indigo carbon where i tried it percentage was really low.







FreeU and Dynamic Thersholding.

anyone here have experionce with mangio-rvc I can ask a quick question?
I am sad today... I just found out that one of my favorite developers has passed away. They went by the name capybara_paws... They will be missed. 😦

I keep reading about it but haven't kept up. have you tested them? I've read about how they work in the past. middle of the squares are really the only thing that matters ultimately, at least for the data portion. then there's other portions that need more precision. and then you can adjust error allowance as well. but it's pretty impressive how much can be taken away and still have at least some devices pick it up and read it
i tried them on some qr codes checker. And what i supposed was easily readable was not recognized. Only 2 absolutely similar to original was read o.k.
qr codes through controlnet. i think you should use a1. it's more nimble than comfyui. you won't have to rewire your whole ui and wonder if it's right, each time you try a different approach
not bad tbh
i am using A1111 with qrmonster, but there is different for qrcodes, i think more serious than creative
GitHub
Contribute to missionfloyd/webui-qrcode-generator development by creating an account on GitHub.
the preprocessor turns that into a black image. what did you do to turn it into lines?
freeU + v hand lora (not released). It kind of interesting in last one. The ori does right but freeU does wrong.




i no preprocessor. sd thing without preprocessor. Or you can probably use preprocessor invert colors?
more fingers more victory


@indigo carbon it is black with alpha which is represented basicaly as black image.
idk, I feel like I'll back off from image blending and zero subject generation until an SDXL version of BLiP diffusion releases. BLiP diffusion seems like the only method of controlling SD without loosing its talents
I feel like FreeU actually makes results worse sometimes.. were you able to use AIT with FreeU or do we need new modules for that?
I noticed freeU sometimes make things worse but in general it give me good shape and details with a lot of extra noise. I am not using AIT for a long time because I am facing a lot of issue when I keeping everything is up to date.
yeah, I get that. I kinda feel like we need an equivalent of exLLaMa for diffusion to make things easier
I tested exLLaMa recently and it was over x9 times faster than pure pytorch while even increasing quality slightly
shit went from 8T/s to 62T/s
I honestly haven't had great results with Freeu, but might just be the images I've tried to make. not saying it doesn't have a positive impact on other stuff
we can all agree that we need an exDiffusion thingy though, right?
well if it's 9 times faster that sounds reasonably decent to me
is there a scribble cn for sdxl atm?
it good at shape and structure but bad at color and smooth some details. I used it with 1,1,0.9,0.2 with Crystalclear 3m sde karras
What is the general feeling with the "SDXL 1.0" Vs "SDXL 1.0 0.9vae" debate, I haven't played much with SDXL and I'm wondering which one I should use
yeah, autoGPTQ did about 8T/s on a 13b model while exLLaMa did over 62T/s on the same model. that's a much bigger boost than what AIT does. It would sure be nice to have something like that for diffusion
There's a debate?
I tried it on a "vintage photograph" prompt and it bumped the contrast up to a pretty unpleasant level. but I realize it's not going to be one size fits all
I meant the general take on it, I see SeargeXL has the 0.9vae one in its workflows by default and was wondering if I should download this one or the "normal" one
The normal vae had artefacts in the beginning
I saw that on huggingface but they seem to have fixed it since according to commit logs
Yeah, it has contrast issue that why I used it to generate the depth map and based on it to generate new image without freeU
Then they should be equal now. But just in case, try both with the same settings and zoom in. If you see weird red and green artefacts then use the other one.

Alright, thank you!
remember to feed your waifus in time






Nope
why not?
Too cute. No scary concept. Sorry
yeah. I was going to just post it then I considered the idea that someone might be offended by it
maybe these are a bit more scary... the nun 2 is out




In this case I am going to report you 🤣
I think things without clear faces like shadowy dark slim figures in a dark and misty forest at night are a bit more scary.
you got qr to work on ait?
looked like canny controlnet
.

Now we're talking. Super scary.
For a moment I thought that you got SD to generate raindrops in front of a subject. Now, that would have been scary. But no, just behind.
welll it's kind of beyond them...

i threw my pixar prompts into 1.5 and god it was awful


wildcarding is the same thing as if it was {like this|or that|or this|or that} right?
but it just pulls from a file or something?
in comfy?



ye
There is no pulling from files natively in Comfy, but the wildcard prompting otherwise works the same
{thing1|thing2|thing3|thing4}
i queued up like 20 images earlier today and just had brackets with different things and it just output a bunch of random images (all expected tbh) and was wondering if there was a simpler way to do it instead of the bracket way so was looking at wildcards

There is file calling from custom nodes, just not natively
so i could do like hair and it just pulls hair color options in hair.txt or whatever but was expecting something like
blue
black
green
yellow
auburn
etc..
Yes. There are nodes that do that. I have even written one for that myself.





















@JPS wa wa wee wa

(all red/black/white horror girls are from a run of 100 pure text prompts)















which CNET did you use here? canny? or something else?










very classy





Got it blending

It's not just the card art, you know? It's every aspect of a game like this. Gatcha games are addictive because of their shininess. What if open-source, non-monetized games could compete?



Could someone point me in the direction for a depth map node in comfyui, all I can find is for auto1111

In A1111, go to extensions and search for "depth". Tons of features, including 3d mesh generation, stereo images, video, download models right from the tab, etc.

While gambling games are evil, they are also the highest-grossing apps in existence. If an open-source alternative existed, without monetization, maybe it could help people?

Sorry in comfy (I don't know why I didn't add it there)
there actually aren't any on comfy. sorry
But aren't there controlnet preprocessors? (Maybe there aren't, I really don't know.)
nah, but this guy doesn't like answers and seems to normally ignore people that try to give them
was going to tell him how to find them, but then he ignored me to repeat his issue to you
very strange psychological stuff going on there
Arn't you the lad that said 0.5 denoise changes a lot?

he prob thinks we are some sort of a personal costumer support here
I don't really trust much of what you say 😄
Count me out of drama, thanks. I'll stick to prompting SDXL.
why would you have a screenshot of something I said days ago?
I just took it, why did you give wrong advice? Then complain when people don't "listen"?
I think I'll put him on ignore. nothing gained
i too have several screenshots of my sworn enemies on a folder called "potential ammo

I mean, I was trying to help the guy. he had a very low contrast image he was trying to do something with, and those can change quite a bit with a little push
No ones forcing you to answer anything. And I'm not expecting anyone to answer, that's the beauty of discord.
just some weird stuff going on
I appreciate you trying to help but you don't give good advice, it tends to be wrong, and now you're complaining that I don't respond. So sure, weird stuff. But thanks, feel free to block me.
now speaking of clowns

well anyway, I apologize for opening the can of toxicity here
I switched to comfy after auto1111, was using that plugin in auto, how's the gen times?
I may just gen in comfy then jump into auto to get the depths.
lol
I don't use Comfy, so I can't compare them. On my PC, Res101 gives the fastest depth maps, and the most accurate for the scenes I've tried so far. There are several models available, and they are all different sizes. You can also control the dimension it runs at for speed up.
I'll jump in and test, thanks mate.







this image pops - cool contrast effect
thanks, forget what I even did. just looking back through some things
I've spend hours trying out different settings and think I have it pretty close to what I'm after, I just want to check here to see if there's something that I'm overlooking, do you guys see anything that would increase the detail in my high resolution that I may not be catching?
Different models, samplers, any denoise settings?




I'm quite impressed by these strawberries so many quality strawberries










it is sd qrmonster, sorry posting it here


Nice composition and mood! Good high_res_upscaler choice ;). I can also recommend the s64w8 variant.
Detailed wide-shots are not easy. I worked on some aerial shots prompts and the resolution is just not there yet. But the detail in your image is pretty great.
Your pipeline has a couple of steps so I can't really say at first glance what I might tweak without working with it myself.
Depending on the style you're aiming for you could probably refine the sharpness. You could counter some of the slight blurriness (haloing) by increasing your denoising strength for your high-res fix / upscale pass - but this might also change your composition too much.
I don't know if you use a prompt but you could also try adding some negative prompt tokens to enhance sharpness and fidelity.
the variant? https://github.com/JingyunLiang/SwinIR

GitHub
SwinIR: Image Restoration Using Swin Transformer (official repository) - GitHub - JingyunLiang/SwinIR: SwinIR: Image Restoration Using Swin Transformer (official repository)
my favorite
👍🏿
Quick explain, what would be the difference between medium and large?
Is large better?
could be in for what Xx it is trained?
1.0
models on openmodeldb.info are trained on different upscale, which shouldnt be changed. 1x 2x 4x 8x 16x
can imagine this is the main difference
1x upscale, no upscale is for restoration purposes

Afaik SwinIR-Large is a newer version and trained on a larger network. That doesn't imply that it's better but different - depends on the use-case. I'm not a huge fan of pixel upscaling in general but wanted to do some experiments.
4x-Ultrasharp is used quite a bit and the performance is really good. But after testing 20 - 25 upscalers I found that SwinIR s64w8 gave me better results - less over-processed artifacting and cleaner sharpness while only being slightly slower.
not what I expected

he looks so healthy 🤣
he has a large brain
new pet


think that might be ET under there
he needs love too

makeup a little whiter he almost lookes like Sweet Tooth

why is the ground made of the fast travel rails from Sonic the Hedgehog





the next mad max movie should 100% have an alien fish person invasion that unites all the clans

I'm testing out a model I'm training and these kind of looks like convincing movie posters

(Ignoring the bad text)


dear XL friends can you stops in General with images and told me which hidden lady has higher subjective quality?
It reminds me something i already saw


I find it weird that more steps in a gen changes the images almost completely
Knock-off Star-Wars

That's how Eular a and other "a" samplers work
SDE can change it a little too but not as much
I think it depends on the model
ahh, I should have scrolled
not really
well some just make it more of whatever, some alter it completely. the ancestral ones
do not too much samples in some samplers spoile image?
also all samplers will rapidly change before they converge if your step count is too low
but after like 30 or more steps the changes should be small all the way up to 100+ when you use a deterministic sampler
this is not an A sampler
heun don't change. heun heuns
heun is lame
heun my beloved 💖
DPM++ 3M SDE Karras changes, but all of the DPM do
what I like is that it takes twice as long per step to make things without as much variation
Heun ❤️🔥
Deterministic, non-ancestral samplers are stable. ex. try dpmpp_2m with a normal scheduler
apparently adding the extra stochastic noise or something means it can self-correct I guess?
but yea the tradeoff is you dont fully converge, the image will drift away when you add enough samples
all I have is the sampler
not in response to you was to mass
scheduler shouldnt affect determinsim I dont think
it might converge differently but it'll still converge
yeah - it just deviates a bit more

was just an example. you can use other samplers and schedulers of coursse
i like Ancestrals because sooner cleaner flat background.
Probably because i have not powerful gpu enough



karras seems to generally converge slightly faster

but sometimes I found it can kinda get sidetracked almost? So @ low steps like say 20 it'll be more different than a normal scheduler
i think it was at least 30 steps 32 i usualy use. Not sure, datas are in picture

I'm currently using dpmpp_3m_sde_gpu karras between 55 - 75 steps, CFG 3.5 - 5
SDE's rate of change seems to slow down, so I guess it kind of converges once you hit like a few hundred steps

normal 20, normal 40, normal 100
sde 40, sde 100, sde 300
yeah running SDE for too many steps can also have some side effects - making the image overly smooth
How about restart, should be good
good ole 2M karras is probably my favorite next to DDIM
@nimble heart have you tried Restart? It is available for comfUI as well
It is SAMPLER ! 🙂
this is in it. It is somehow able to get back probably therefore Restart

It is A1111 but tried it in Comfui as well, i think some special Ksampler for it, not sure now
me no see

check for ksamplers, or in manager check for restart
i am in A1111 and dont want to leave it.

GitHub
ComfyUI nodes for restart sampling based on the paper "Restart Sampling for Improving Generative Processes" - GitHub - ssitu/ComfyUI_restart_sampling: ComfyUI nodes for restart sa...
has been for some weeks

unipc is interesting. behaves very different
@upbeat summit did you try restart?
Hi I'm trying to use aspect ratio helper to resize my picture from 1024x1024 to 1920x1080, but the resized image comes out distorted. Is there any methods to make it so it doesnt get stretched?

yea I never used it much cause it used to not work on AMD
Yeah, use supported resolutions
I tried it a couple of weeks ago, but didn't do enough testing. since it doesn't support SDE and that's what I'm currently using, I haven' t looked into it again
1344x768 probably best for you
back when I had to build PyTorch myself I didnt know how to include hipmagma over whatever the default cuda implementation is
ah didn't know that
it works on the official binaries
Get as close to 1040000px as possible in general for the generation. @uncut fiber suggestion 1344x768 is probably best
it comes back and last quite longer
but if you build it yourself it needs magma which idk how to bundle
ddpm is a goofy mf-er

resolution SDXL was trained on @misty sundial
I'm fairly new, so I'm not sure how to do this? do you mean to upscale the picture first to like 4k x 4k?
No, I mean don't start out with 1920x1024. SDXL base requires ~1mp total, so use one of the trained resolutions
aight this shit's too complicated imma stick to the builtins

You can upscale after that if you want 1920x1024
render at resolution it was trained. all is around 1Mpix And when rendered resize it
yes
when they start adding the UTF-8 chars my koala brain cant keep up
Isn't that just italics? Looks like italics to me.
So I should be creating the initial image in my desired aspect ratio of 16:9 and then resize it?
Real question is why are they using emdash for subtraction
Yes. For 16:9 idk the correct resolution, it's whatever the bots are using
1344x768
Which was already suggested
Yes I see that from the file that @uncut fiber posted! ty
1368x768 is closer to 16:9 and works well too
But if I already have an image of say size 1024x1024 is it not possible to resize the ratio?
it is not my work all credits go to creators 🙂
Basically if the bots support the resolution, it should work. Though I've had issues with some of them on SDXL beta that's a different issue.
with something like outpainting, in a sense you can "resize", but eh
it is possible. Strech it, or add black bars. To not it be distorted
do you mean to use outpainting to recreate additional background to widen it? Is there a guide you have in mind, I think I might have watched something like that before
I've only used outpainting a single time just for the curiosity sake back in 1.5 days, so I'm unsure what SDXL resources are available for it
I never managed outpainting. Never got it to actually work on Colab, and Horde supports it but none of the UIs I can use do (Android or web)
openoutpaint is nice. For A1111.
I tried like 3 different ways with a1111, including proxying whatever that website was inside colab to get rid of cross origin issues, didn't work 😦
this is all in openoutpaint. It is very creative. Starting from 0. But yes, lot of color inconsistency, but it is fun create that way.

is there a discord server of channel dedicated to ComfyUI?
@prime bison whose borders?
Search Reddit, I found like 4 ComfyUI discords last time I did
I see what looks like a square off to the left
it has not borders, yes probably some blend issues, but it is generated from 0 i started in center with say 240x240 and build up on it with so smalle squares. So it is not extended image by outpainting it is created from 0 🙂
You can tell when outpainting was used sometimes if they didn't do a wide enough blend
Yeah
It's the squares then
Oh, you did the whole thing in outpainting?
yes
Ugh. I g2g. Washer demands my attention or it overflows
gl
gl
interestingly, it only looks like it converges faster on the tiny preview. The details converge less. maybe it has noise like SDE?
UniPC has some kind of correction built-in IIRC
Stupid clogged pipe
Unified predictor corrector
does automatic1111 work with sdxl
yeah
UniPC sampler is a method that can speed up this process by using a predictor-corrector framework. It predicts the next noise level and corrects it with the model output
i have latest dev branch and it takes more than 20gb dram (ddr5) to load the model
idk why
Use ComfyUI instead
I don't use local at all, and I've figured out that much lol
There's other UIs built on ComfyUI
oh lemme c
Idk the names, but they do exist
oh ok thx
Isn't stable swarm for queueing or something?
True, but IIRC it's not general purpose. Could be thinking of something else though, I don't actually follow this stuff, I just stick with the bots here and Horde for everything.
stable swarm is a pretty simple ui in comparison to a1111. lacks extensions and such
Clearly thinking of something else then
Alex (mcmonkey) — 08/17/2023 2:11 PM
you should have access to everything, barring some extensions have compatibility issues (that are easily fixed just need to identify which ones + report to them)
ComfyUI is only worth it if you're using the AITemplate stuff to speed things up
comfyui is also like 30% faster on my card than equivalent settings in auto
or if you like putting things in different configurations than a1111 provides
it would be so tedious to do a lot of the things I do on comfy with a1111
in ComfyUI my max SDXL speed for 1024 is 3.17 it/s
auto was like 2.52 it/s
might be possible, but not really worthwhile
The little that I know is that ComfyUI also enables far more complex workflows than a1111 or other UIs do easily
Auto1111 enables workflows that I actually care about while ComfyUI doesn't support the workflow I care about and enables a bunch I don't care about.
let me tell you, it's really not that hard either. you have to connect a few things that have the same names and are color coordinated
model output to model inpjut
I'm unaware of anything being possible in a1111 and not in ComfyUI....
clip output to clip input
Other than the use of specific a1111 extensions (which obviously require a1111 to use)
iterative inpainting is more tedious in comfyui and afaik there's no easy openpose editor node but thats about it as far as major complaints go.
a1111 certainly has a few extensions that aren't on comfy, so there is that
but I also don't get the UI wars some people seem to feel they're in. it doesn't have to be a binary one or the other thing
I won't touch ComfyUI anyways, far too much for the little bit of stuff I do, and I don't even have a GPU anyways. 🤷
it's really not though
SwarmUI added proper x/y/z support so that's less of a sellingpoint for Auto1111 now, but ComfyUI without swarmUI is quite limiting.
Having movable nodes is more than I need
wer
Efficiency Nodes has an XY script

GitHub
A simple comfyUI plugin for images grid (X/Y Plot) - GitHub - LEv145/images-grid-comfy-plugin: A simple comfyUI plugin for images grid (X/Y Plot)
I do oneshot with Lora and TI and hires-fix with whatever single model and I'm happy. That's it.
well that's fine if it works for you
That extension is making me want to vomit.
yea nah
I don't use it, lol
way too much work
I just said it's there
its easier to just queue up everything at once then combine the images yourself using magick's grid feature
montage -mode Concatenate -tile 3x3 ?.png out.png my XY charts
I don't know if SwarmUI supports different LoRA and ControlNet in its X/Y/Z grid stuff.
well whatever, it wouldn't be that hard to just make grid nodes
since comfy doesnt have a preview for loras i have in folder i cant use it ( i have 2300 loras ) but for speed alone it smokes auto1111 and its memory hogness
don't think I will
grid shouldnt be a node
well what should it be?
If I don't use only ~9 images (I did 121 earlier) I just need to make sure the generation id counter is at the front of the filename so it orders properly
you'd have to run all the images in the one workflow to make a grid, otherwise how could you do it?
grid should be a menu where you can target specific values for the XYZ
So on the default workflow you'd right click the CFG value on ksampler and "set grid X" or something, then in the grid menu you can put in values
like how blender you can set node values to be drivers or something
or animate them
I would like that, but I don't know if it'll happen any time soon
so any widget based node field would be grid-able
I was just thinking in the context of custom nodes
I use horde/ArtBot. Downloads come with metadata. The default to order by finishing time, not by starting time, but I've got a script to rename by start time and another to rename by other contents so they can just be sorted automatically if I didn't generate in order or one never came back.
well I don't know how else I'd make an alteration to the program
again at that point its easier to just magick montage
Does openoutpaint still work? I'm having trouble trying to install it, I get the error PermissionError: [WinError 5]
not saying nodes would be the most efficient approach
you have to add in commandline args in webui-user.bat --api
oh install it... i thought run it


has anyone made a scripts node for comfy? As a trainer that is invaluable so I am forced to use Auto due that.
What do you mean by a scripts node?
X/Y/Z Plot specifically

fight fight

Now to switch over to that and give it a whirl. Been fighting Kohya all damn day as it is refusing to act right with the training.
What's the problem you're having with Kohya?
I tried earlier today to do a very basic training in Kohya for Vivi Ortinier from FFIX, but my training didn't do anything lol
But I ain't doing anything more, my 2060 can't handle it
I switched to a different trainer and wanted to see how Kohya would react if better and Kohya just refuses to train it. OneTrainer had it trained in under 1 epoch. Being epoch based I wanted to try Kohya for step base as 1 epoch was slightly over cooked
It's the Super model, so 8gb, but still yeah, it's still a pretty small amount nowadays
Oh, you're running with a ton of repeats.
My 1060 couldn't train anything except embeddings and it took 30s per step
30-50s
100 steps was 10-20m
repeats are evil
OT doesn't use them
It's just strange that you overcooked it at 1 epoch.
But I guess it depends on dataset and learningrate.
you don't know OT very well. That thing rocks
And if it cooks at 1 epoch your learningrate is probably too high.
has some thing called rex and it is so fast in how fast it trains it is crazy. I couldn't even slow it down and needed to
OT can't do magic, it still has to follow the same rules as everything else.
tried the LR but no dice
Oh, well, I am super happy to give the middle finger to Kohya scripts finally so was just seeing anyway.
Controlnet requires lower LR and higher epoch it seems like so now I'm regularly up at 1000+ epochs with Kohya-ss.
the LR for Rex is at .00038 I think
While for LoRA I tend to stick at 80 epochs.
Yeah, that is about the learning rate I'm using with Controlnet atm.
I tried 1e-4 and still not slowed down
I am still not sure how rex works but they are adding adafactor after I showed them how good it is. They really liked it.
that will help
did you know we are about to get Xformers V2 which conserves more memory and is faster too? I can't wait and I hope it comes with Pytorch 2.1
poor ole SDP was a dud

lemme guess only works with RTX
@upbeat summit with lora?
works with whatever Xformers works with
hope it will works with AIT as well

GitHub
🚀 Feature Adding Flash Attention 2 Motivation Flash Attention 2 has just been added to the original repo: https://github.com/Dao-AILab/flash-attention . It clams to be almost twice as fast as Flash...
Don't even care as AIT is dead to me
yeah - for the glitch style. working on demo images for Aether Glitch by @icy brook right now
FlashAttention-2 currently supports: Ampere, Ada, or Hopper GPUs 
nice 🙂 @upbeat summit
Guess turing but rtx is turing so wtf?
yea hopefully a kind soul shows some love to pascal 🙏
If it weren't for the spelling/text, I could almost be convinced these were real posters...

yeah, but see if it is an rtx issue then Turing should be listed as well so it is something else I guess




spider cat 🙂
they're special

I have an idea about make use of sd1.5 for sdxl. Sd1.5 has various community resource but sdxl couldn't use. How about using sd1.5 to generate depth map and use sdxl based on the 1.5 depth to generate the image. It could make use of 1.5 resource to get better hands and totally generated by sdxl for realistic and color tone.
well I don't think the preprocessors are dependent on the version are they?
nope
The preprocessors are completely indepdenent from the SD version.
And SDXL seems to have better hands anyway so not sure why you'd use 1.5 for that.
I made one. it might not be good, but it's mine
hands just for an example. The point is make use of 1.5 resource
In some case, sd1.5 still win
the better hands

Controlnet won't help if SDXL is completely clueless in how to make it.
when did he join ICP?
Is FreeU any good?
I haven't seen anything extremely compelling from what examples I've seen people showcase
its suppose to give finer detail
it can
It alters the initial training weights of SDXL. There's nothing necessarily in that that "gives finer detail".
There's claims on what it does, but I see it being treated as basically more variables to toss into the woodwork
I'm sure people will find interesting uses for it. I was in here when they were talking about it right before it was released
I was running a generation, but then I interrupted it. But I think artifacts are left on the gpu, because I w tried for another run it says im out of memory. Is there a way to clear the gpu again without having to restart SDXL?
nothing wrong with it. just don't think anyone has found the ideal usage for it yet
In my testing, freeU could generate "better" structure but it has contrast issue. It is not generally good but it could be used in some case
freeU conversation started here
#✨|sdxl message
not that I've found.
I run mine in powershell so I can just ctrl+c my instance, then just hit up enter to restart.







Honestly, I feel that. I think the ultimate solution for optimization would be an equivalent of exLLaMa for diffusion
exLLaMa can run LLaMa about 8 times as fast as pure pytorch, which is a much bigger boost than AIT does
Also exLLaMa is more flexible as it's not architecture specific as far as I know
So if we could get an exDiffusion that would be great

Agree
AIT is very inflexible and one comfy update it blows it all up
besides BS4 max is another issue with it.
plus I couldn't get refiner to work with it it had a recursion error no matter what I did
I still have an annoying waiting time before inference when I use Loras. Makes the faster speed pointless. But yeah, 12 gigs of vram seems to be the bottleneck.
Got it mostly out of my workflows.
controlnets are completely broken with ait for me
even if I'm not using ait it's patching the loader and breaking something
have to manually rename the whole folder to .disabled for it to work 


@crisp owl can I dm you?
I think the "T" in AIT stands for "Trouble"
@noble shoal just disable keep in something. It is only trouble i always forgot switch it and must restart
I have 48gigs and iffy
LOL at the T
You Monster 😱. Is that a quadro or something?
oh, you said ram not vram. I wish I had 48gig of vram
Pfhuu. For a moment I was very jealous
Don't be because to really train XL you need 80GB of vram. Not joking as it takes 73ish gb. Forgot what he was saying but if you lower the BS down for FT with a large dataset 43gb.
slow as in days for them he said
rent an a100 and it was sweet
80gb
more than enough for a H100 then
Oh them sweet a100's. I wish Nvidia would make something like that for normal people.
With a regular income
I mean, I don't need it for gaming
"I've been training a generalist (but mostly photorealistic) model for... 3 days now on a A100"
Shit me for 3 days and counting no way
try the model and fail and just oof
I have a lora being a little bitch all day
something is not training then when it does it is iffy
its only 27k euros  https://smicro.eu/nvidia-h100-94gb-hbm2-900-21010-0020-000-1
https://smicro.eu/nvidia-h100-94gb-hbm2-900-21010-0020-000-1

Thanks. Going to call the bank.
anyone here train loras?
Kinda
Is it the TE that prevents my lora from working if I say X in background but leave that out it works?
I lost you at "TE" 🤣
I despise SAI for this dual TE nonsense as no trainer is overjoyed with their nonsensical move. Plenty of work to eliminate it coming.
Wait, now I got it
G and L
wait, are we flexing available gpu power? 😮
not anyone in here is with XL
no,im stealing it from some server
I'm stealing gpu power from my boss (When our servers are not in use)
Yes, general awareness has a Homeserver with 1 TB vram at home
he has money but i have a gun ( real )
casual flex xD

470 driver works?
9 minutes


@noble shoal whats your problems with AIT?
Also one has to have old nvidia drivers to work it properly
i have to make it work -> that's what our engineers use because of a specific package they need to use
newer driver doesn't work well with that software
Only 1.600 Watts? That's the same as the hairdryer of my gf
our other server is in use -> that's the 80gb versions
those thumbs could be nice they all creating some face. I forgot program that was capable to do it
fun times if i have to work in our datacenter and all the number crunching machine are at full power -> that's a pretty hot backside
My drivers are at the most modern ancient version for AI usage.
yeah, didn't AIT fail if you used the newest?
AndreaMosaic i think
Not going to test updating
works on 531, i'm staying there
531 here
i heard 537 has a lot of SD issues?
and enable to disable, who invented priory to enabled... show me him/her!!! 😠
Fizzle Dorf did
where he is!!! 🙂 cost me for sure most troubles restarts of comfui.
anyone know which node is doing this so I can delete it?

type in any test box and that pops up


@floral island
http://www.mazaika.com/grafika/shining-actors-30x33_big.jpg
this i mean, like old version of SD 😄

oh yeah, that's was a extension too 😮
it was extension? i know it only like standalone portable app
nah, someone made an a1111 in the early days i think, when it was just scripts
o.k.



Nice British Punk Band Seinfeld
hot woman

I was actually working on that yesterday. The solution was to have the CNET do low steps, then send to another Ksampler without CNET and using prompt from BLiP, and it would be close to normal AIT speeds


@fierce hollow this is what I managed to pull off for CNET



how to calculate max images for resolution 1024x1024 16M colors?
(1024x1024)^16000 000?
Anyways, if y'all want a solution for keeping AIT's speed while making it flexible for more stuff; I had nothing to do with this, I just compiled the modules. I completely agree that we DO need an exLLaMa equivalent for diffusion, the main goal would be to make it flexible and its speed being way faster than AIT is just a bonus.

4× 10^96329598
I don't mean like the output being bad, I mean comfyui completely errors out when I try to load a controlnet when AIT nodes are loaded, like even if I don't use AIT in the workflow it will still show an error if there's a controlnet
no, its (16,000,000)! / (1,048,576)!
o.k. going to try to numerize it
dude, you cant
i can.... on wolfram, pitty i didnt make a copy paste
o.k. going there to copy paste it
The workflow I shared uses AIT
Power of 10 representation
10^(10^8.010552413613613)
it's actually 256^3, not exact 16M
doesn't matter, some modules are probably just broken, if you compiled your own that's probably why it's working for you
there's already issues about in the repo anyway
that said the ait repo seems dead and hlky deleted their account (wtf)


yeah for the top i have to blurr my vision lol
on phones it must be visible well
You can see them when there small like thumbnail size
yes as thumbnail it isnt surprise

Hey, how should a prompt be structured to make the results as realistic as possible with the new Stable Diffusion XL, which I have running locally on my PC? What are the settings I should consider for achieving the most realistic images? Are there any other tips I should take into account? Thank you.
Nice work I cant get mine QR system to work, getting errors
how can u make an image black/white

it isnt black and white
just in A1111 how to say english, cutted?
for examle this way. It is called rmbg

havent seen anyone do this is ComfyUI or A1111,I think only post editing in another software, like photoshop
Yeah, I kinda replaced hlky for a while, but the ultimate solution must be to make an "exDiffusion"
This is in A1111 remove background extension, widely used
Rembg is also available in Comfyui
yes and miracle one


nice astronauts on bikes 😄

Robots or mechs? Because seems headless and i cant achieve it with robots @vital ermine ?
robot human mech army
o.k. TY!

if you are using A1111 you dont need b&w images. Only you need Controlnet with specific model and one sd model. That CN models should soon ™️ arive in sdxl
we are about to get CN training we can do in our homes
humanoid
that should be interesting
Highly interesting



laser bullet 🙂
multifunctional at once 😄


Good morning! It's a brand new day.

4K isometric scifi bedroom game asset. However, note that there is a pillow on the desk, and this is not a chair. It is problematic for a workflow.


Good Morning

can be some sort of collapsible chair to spare place. Nice placed pillow what can be more comfy at work 🙂

it should work if you have SM80.. anyways, if you want a newer optimization, we'd all love that
WE. NEED. EXLLAMA FOR DIFFUSION.





Inpainted at great difficulty. Probably needs manual painting of a base.

on windows a lot of the modules are just not working sadly, exllama for sd in the sense of custom kernels or something would be nice but doubt it will happen, there isn't really as much interest as there used to be, llms are much more popular

wish ait was just supported in comfyui by default, that would fix the issue of hacky patches and broken modules
that's the only way though.. AIT is close to the speed limit you can get to without making stuff like exLLaMa
it was actually planned to. I remember @visual glade mentioning that somewhere, but he decided not to release it due to the node working somewhat consistently
yeah I remember that too
I'm already telling, I won't be making new code for compiling CNET or IPA- it's way too dynamic and I don't have time for that atm
so if we would have a solution like exLLaMa it would likely be compatible with everything diffusion related
@uncut gull i think you did nice work. If in A1111 there is great for inpaint outpaint OpenOutpaint, we talked about it today btw.
I'd compile it in wsl or something but cba when there's constantly some new random thing that makes ait break... like animatediffusion, better unload cause it broken as heck with ait

yeah, every time we try to make AIT work with newer stuff we wish there would be something like exLLaMa.. I'm sure it will happen eventually
better set up a fundraiser for turboderp if you want exllama for sd
I also saw FizzleDorf being able to use AIT along with TRT and they got to over 220it/s, Idk how the fuck did they manage to do that, but it was possible
also exLLaMa is about times 8 as fast as pure pytorch, so it will be even faster than AIT
tested exLLaMa like 2 days ago, autoGPTQ did 8T/s while exLLaMa2 did 62T/s
I mean you're basing that on llm speed though, it might not translate any better than ait to sd
nah, AIT is an equivalent of DeepSpeed, which isn't anywhere near exLLaMa
last I tried deepspeed in wsl it didn't really change much of anything so no doubt there
I actually tried that on my dual boot, it was 14T/s instead of 8T/s, but still a fraction of what exLLaMa does.. so the idea is probably to create something similar to exLLaMa but for diffusion
@hardy cipher even this is not readable. Tested on net qr checker. Maybe something can read it???
And there are way more complicated.

Is it an extension?
yes with its own GUI.
For A1111
i already posted image i did it 100% in it.
#✨|sdxl message
It scanned
so great it is working, why apps show not?
.. idk
probably it counts with some standards? Some weaker cameras, some sort of contrast or such?
@indigo carbon thanks great!
curious if anybody realize theme of this qr code 🙂

not message in it, but how it was created

I tested different web QR sites and some reads it and some does not. (The grassy one)


Is that with SDXL? I had expected more blending between the two.
according to fence it is sdxl.
wanna make gold shining through crack in cave and dwarfs protecting their eyes blinded by this shining, but nobody is protecting their eyes... This seems to be already blinded poor dwarf.

something like this



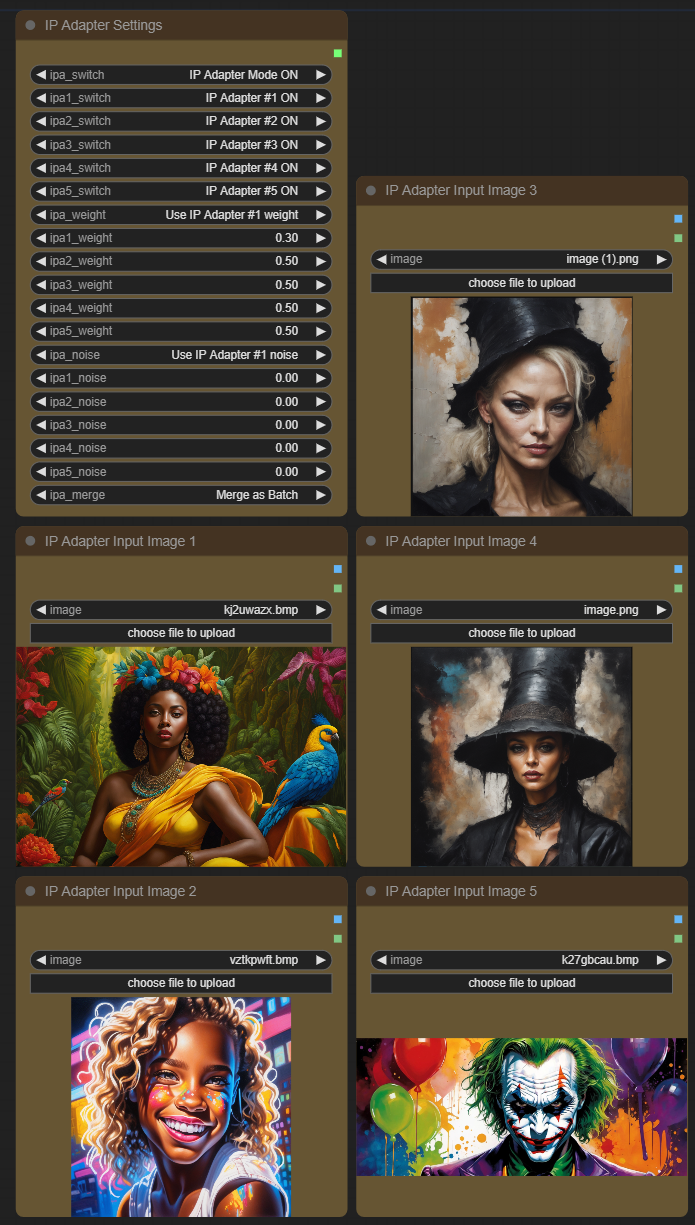
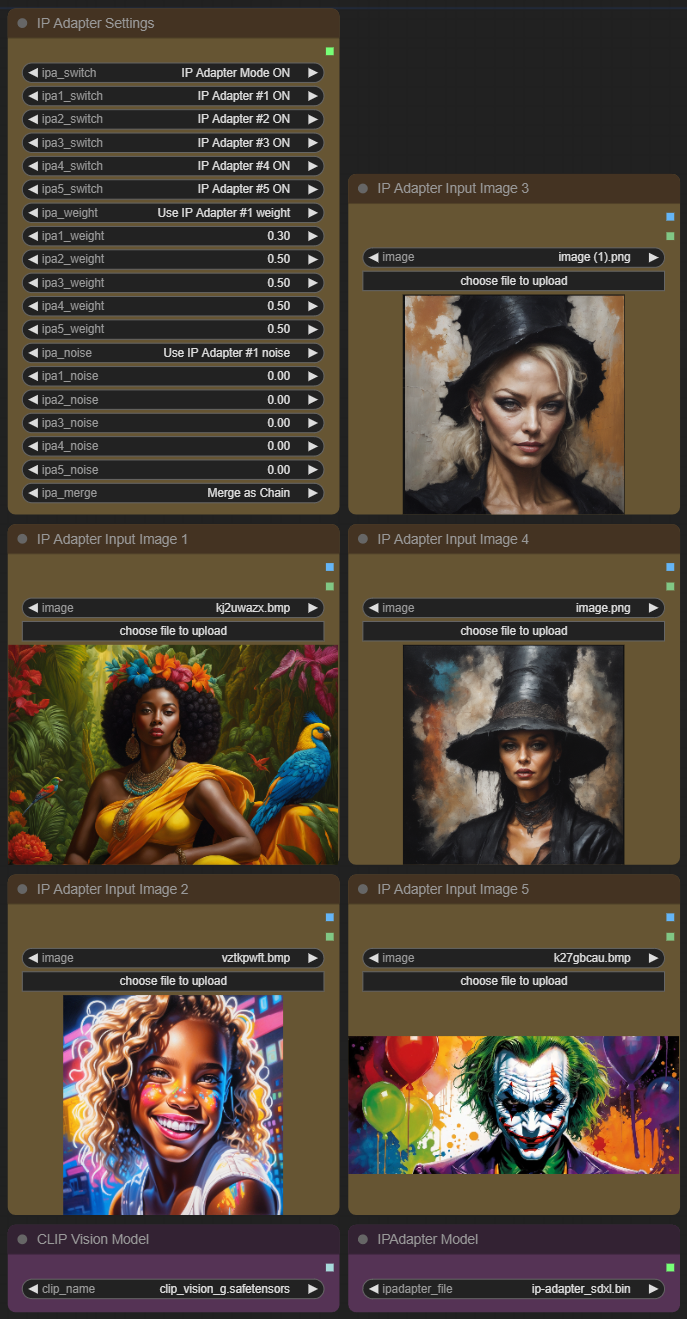
after talking with the devleloper of the ip adapter node, the upcoming version of my workflow will have much more ip adapter options. for example up to 5 images and "merge as batch" or "merge as chain".
difference between merge as batch and merge as chain (all other settings are the same):
https://i.imgur.com/OpGeHMx.png
https://i.imgur.com/7NwA5mO.png


😄

5 input images and those options make it much easier to play around with different input images - for example turning on/off single or multiple images:


isnt 5 too much? Yes combination of them probably
5 input images also allow it to use the ip adapter as instant "lora light":
https://www.reddit.com/r/StableDiffusion/comments/16sglm9/no_more_lora_training_only_6_images_needed/
Reddit
Explore this post and more from the StableDiffusion community
(he did it with 6 images in that reddit post, but from my tests, 5 or 6 images doesn't make that much of a difference) if needed i could expand to 8 input images, but to keep the menu area "single screen" that would have been too much unless it really helps for some usecases.
you also reach limits of even 24 gb vram if you add too many input images.
loras can be tagged and can utilize regularization images to prevent overfitting
ip adapter is some sort of controlnet? looks pretty neat
at some point it will work exactly like that, but this is good for styles I guess. right now it won't be as versatile as a LoRA fine-tuning
that's why i called it "lora light". it may help in some cases and is fun to play around with it.

"vae fix" on left lol


left has vae issues, at least my left I see
its got weird artifacting, noticed it on a few stuffs

yeah that's why I always use manual vae node
1.0 vae is broken, and a lot of checkpoints still run with it
this robot seems truly made in japan. Nice wheel chair 🙂

well idk where it came from but this was what it was

0.9 is o.k. then?
0.9 is good
thank you
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
this vae fixes everything including fp16 training
this is what i am running now

did somebody make stats which sampler is better for text? Some accuracy or is it totall random 1:1?
what sort of secrets have been revealed to JPS?
the new workflow is online:
https://github.com/JPS-GER/JPS-ComfyUI-Workflows


GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
for me the most important info was that chaining and batching the images gives different results. combined with the "lora light" post on reddit, i've added quite a lot of options to the ip adapter part. we also might get batching with different weights if possible with an update of the ip adapter node.
really curious what new things you have going on. I've been working with 3 ipadapter inputs and it worked, but just kind of winged it
has SDXL already caught up to 1.5 for anime or not yet? Should I wait more before switching?
no idea
you can see most of the new options if you look at the new menu node:

it lets you make eyes with skulls though

what do you mean caught up?
some options are just "qol" - like using the ipa1 weight and noise for all input images, so you don't have to change 2x5 values
is this good use of CNET right here?

gotcha. I'll look at what you have going on. I've been saying they make LoRAs obsolete for a while. sort of sarcastically, but then they do serve a similar purpose for me
nah, there aren't any good anime finetunes, only some claiming to be, wdxl seems dead, anime loras don't look too good trained on base
Where can i ask a question about the software
I see , thanks
combining up to 5 images with different weights, two different merge modes and the option to use FreeU gives so many different results for 5 input images, it will take some time to figure out my personal favorite settings.
that lora light thing could possibly work for anime with sdxl, not sure
training 2 text encoders, base and refiner is just too much of a pain otherwise
I hope a good finetune comes up eventually


the only good anime finetune came from nai for 1.4/5 so not sure we'll see anything like that for sdxl
it kinda works, sure, but then you can do better with normal sd with half the vram
and they where leaked xD
yup, wd-whatever-version-they're at now is still worse than nai...
1.5 might be good with anime, but can it make this?

I only use SD for anime so I guess I'll have to be patient
yeah, but NAI has leaks somewhere. when 1.5 made noise a leak of their anime version was thrown around the internet like grandma's 1 day old salad

I think some people on 4chan hacked them or something? because they NEVER released anything for everyone to use
yolo
umm yeah, nai didn't release their model of their own volition, at least not as far as anybody is privy to know, it was supposedly leaked from some repo (by some employee? idk, it's old news)
Where can i find the terms and conditions for SDXL
are you trying to do crimes with it?
I don't think there are any really. it doesn't even need access to the internet after you have the weights
No you just wondering if I own what I make with it
tried AC in front of a church with 3 input images. have to get some more face images of her to make it work better:


Stability AI

i mean, if you generate images of like 1:1 pokemon or mario and try to do a bunch of commercial stuff with it and those companies find out, you're gonna hear from their lawyers
website tos is not the model tos, just check the repo
gotcha
that license is talking about multimodal generative models. SDXL isn't multimodal (yet)
does this mean SAI is planning to make a multimodal version?
it's just standard openrail license wording afaik
gotcha. for a second I thought this confirms if we'll get a BLiP diffusion SDXL version eventually haha
So if I use it to generate nature or like non own characters or things that got a trademark for them. And then I own the images it generates or not
I'd be surprised if stability isn't working on something multimodal at this point. That seems to be the direction all these companies are headed and there are already open source text, audio, and (rough) video models/techniques.
dont see why not
sd copyright is still gray zone afaik
ai copyright in general is gray zone tbh
Well I think I stick to gimp and krita and Inkscape
there were some cases recently where judges ruled ai art can't be copyrighted, but there was another where copyright was given to a game or something using ai as part of it
hard to say how it really works in the end, I guess transformative work counts
if something is created completely by AI, then it is not copyrightable; if it is created by a human with the support of AI, then it could potentially be copyrightable.
or so it said
very cool there are judges who make rulings on tech stuff where they themselves don't know how to forward a simple email and get scammed by a fake irs phone call
iirc steam removed some games that used ai art recently too, while epic's tim sweeney said they're welcome on the epic store
yeah, it's a common problem throughout oall of politics really
from the bottom to the top
and the legal system
oh yeah, gabe definitely doesn't want to touch ai assets in games so they just outright ban ai usage on steam
people get in those positions, city council, judge, senator, etc, and they are suddenly, or over time, convinced they're experts on everything. they always know best
I like that the average US senator is at the age where a lot of people are entering nursing homes
burger lovers

they're face melding

what CNET does this? I found this somewhere but they didn't explain what CNET was able to do this

qrmonster i believe for SD
not XL?
not xl now but author is planing it
don't think anything sdxl does that easily yet
the gay cats one blew my mind the most
wait, so wtf is this? https://huggingface.co/Nacholmo/controlnet-qr-pattern-sdxl

Unfinished
o.k. somebody said it is easy to train it
wait, so this isn't possible for SDXL yet?
The results are not good. I have tried it for an hour or two, but it's really not usable imho
I think the thing isn't so much that Gabe is against AI as it is they don't want to deal with the legal head ache until there's a definitive resolution. Which is probably going to take at least a year or two with all the court cases. Epic on the other hand doesn't care because it 1.gives them an advantage and 2.they don't deal with the same volume of games on their platform so the risk is worth the benefit if more people use the Epic store.
just looked into it, isn't QRmonster made for just QR codes? those images did words
I think it's more about black and white values






it started with qr codes I believe, but the same approach can be used for other things
also, does that need any preprocessing? I can't see any nodes made for QRmonster
Thresholding
no it doesnt need preprocessing imo. Maybe switch b with w
The image should be black and white. Not gray-scale
so canny preprocess with QRmonster CNET makes those images?
I think you need thicker lines. I would recommend an image threshold node
You want to get the shadow values as black
well I don't mean to be pedantic, sirs, but I do believe canny uses thresholding
o.k. can be subjective. I told it make it out of mouses, and i it does from computer mouses. AI surprised me
But you need to separate the brightness values instead emphasizing the edges
but I realize it is different. anyway, just use this https://docs.opencv.org/4.x/d7/d4d/tutorial_py_thresholding.html
There's already a node 😉
which one?
I have no idea. I am at work, but I saw it this morning
gotcha
it is fun to experiment. Hiding color images is posible as well

how is called this projection? Ultrawide?
btw for those going to try it denoise at 1 is o.k.

as long as it's not a spiral

complicated 🙂
just getting into sd, is there an xl model people can suggest or everyone still using the default? 🤔
There is too much versions, nightvision, copax. It is all subjective. Some ppl using still default
RealVis, Juggernaut, Nightvision (protovision), ZavyChroma, CopaxVivid
Those are some of my most used ones
thanks. nothing that seems to be head and shoulders above the default though huh?
I don't use default
hrm, let me be more speicifc maybe, any xl model you might suggest for photo reals or do they all have their plusses and quirks
I mostly do photorealistic gens, basically the list I did kinda goes in order of photorealism preference for me
the more "artsy" I want tends to push more to the right side. Currently I'm using CopaxVivid for those skull ones
also depends if you want or not nsfw.

or anime 🙂
getting this with qr monster on 1.5
just one more drink of earth

with 1.5 model? I am using A1111 for it.
no more sips of earth before dinner
probably AIT turn off?
Does it work if you just feed an image, like black text on white bg, into the cnet?
"forget this, I'm out"

no, always gives that error
sai?
yes

send nodes!
Ok, then I can't help atm. Maybe you can drag drop one of those images
also funny how it made a hand fork
tuple out of range, bud

skeleton island


what projection is this
skeleton waterfall

I forget how I made that. ipadaptor and controlnet I think
np 🙂


eye made a few of them

I've just been going through stuff I made recently
sometimes don't even end up looking at it initially, or just skim over it
kitties

same

copying a style works quite well. better than specific faces:

is it possible to make XL embeddings in the automatic ui? or only 1.5?
Mondrian artist is great for playing with controlnet.

you need this

I really just want to know where I'd get meat carpet like that

@indigo carbon have you solved it? A1111 is easiest for now it seems
i like this lora
it should be out soon
yeah, currently restoring my old A1111 install

i am quitting smoking and having hard times... Smoked long time without nicotine long time, but still difficult not use it again.
you can do it! keep playing the latent space dopamine machine instead.
the fight is to avoid the next one. the hardest are the ones that were like a "ritual" - after eating, coffee, when going out. this will get better.

{kind=link}
{kind=link}
{kind=link}
with addictions, the hardest is the "boredom" triggers. SD is great to alleviate that lol
I quit drinking largely out of spite. don't let anyone tell you that can't motivate you to do better for yourself

but smoking would probably be harder, I do understand that
They're all hard in their own right, think everyone has something they wish they could kick one way or another.
I know I do
yes but without nicotine i am quite long time already. and still 🙂
So you vaped?
yeah well getting rid of nicotine is already a pretty large step
True that.
I do believe vaping is a whole lot better than smoking. my mom smoked for decades and vaping got her off the cigarettes. might not be as healthy as not doing anything like that, but certainly better than cigarettes