#💬|general-chat
1 messages · Page 72 of 1
Is there a video prompt sharing discord was one a while ago
Where do I find clickskip?
What question? Why would it exist if it wouldnt be faster?.?
what are you yapping about?
Channel Bot 5 unwanted nudity result
does anyone use opensea
How do I make stable diffusion not do something? It doesn't seem to listen to my negative prompts.
hi guys is there a website like lexica.art but for prompt for animations not for still images?
for example with runway gen 2 you can remix an existing video and you can see the prompt
but I was looking for something like lexica.art which is stunning
Good afternoon, everyone. How are we all today?
If you have a result you don't want, you can flag it with apps>report, or use ⚠️
If you need help with prompting, I suggest checking out #📝|prompting-help
Do you know art dealers or gallery owners? I'm trying to contact some to sell some pieces of AI combined with other digital tools.
i started using opensea yesterday
idk if that counts as an art dealer or gallery owner but it lets u sell art and put it into a gallery collection
oh hi
does Stable Swarm UI on windows need the NET 7.0 install?
Oh hey Olivio ^^
also does Stable Swarm UI on windows need git and python installed or is it self contained and the Install-Windows.bat file does everything for you?
@potent spire hi
Good questions, would like to know as well
i guess since it is a bat file it needs to run somewhere, right?
oh, ok, found the answer. the bat file downloads net7
trying a new workflow? 😄
Lol my prompt got on showdown
stable diffusion has video enchancement?
hey guys. I made a little tool to help write timeline animations in deforum. i'm looking for people to try it and give me feedback
https://deforum-helper.vercel.app/
in comfyUI Ksampler (adcanced) node, is the actual number of steps done by the sampler equal to steps or steps - start_at_step?
i have experimented and it seems to be the latter but thats also a bit counter intuitive?
It is counter intuitive but that's how it works. There might even be a necessary reason for it.
ok i just wanted to make sure if i understand it right
ok maybe im lost in the sauce but, what happened to the channels for the original sd bot gens? (the ones for 1.4 and 1.5)
gear 5 in one hour
Anyone able to help me in tech support real quick?
anyone know how to change the generated image dimensions?
Which UI?
from the bot
Oh, no idea on thatone. Sorry.
with aspect:
Anyone tell me Which python version is support 2.0.1 torch?
what they used for girl dancing https://instagram.com/coolertvgirls?igshid=NTc4MTIwNjQ2YQ==
i searched some, automate1111 and some thing more~ but i cant do same as that
Capitalism is slavery
😭😢
Can anyone help remind me where like stable goes in your files? maybe with automatic?
i dont know if i deleted everything for space or if its somewhere on my pc
hello, I'm just a newbie, is stable diffusion feasible for IP industries? i mean they can produce consistent character, persona and visual identity?
Any way to edit the previous prompt without copying and pasting it into a new one please?
Anyone tell me Which python version is support 2.0.1 torch?
i want to copyright my prompt
i need help with stable diffusion webui, is this the place to ask for help?
Lmao, nice one
Hey
What do you need help with?
In exchange, can you comment on one of my stable diffusion videos? 🙂
Feels like it lacks marketing
I’m still learning to be consistent in my animation but maybe consistency is over done
What happened to distilled SD that was supposed to be 20x faster
every paper claims x times faster but the reality ends up being +0.1it/s with caveats unless you own whatever top tier gpu
I believe that is a custom nvidia optimized version of SD, that was in the news a few weeks back
and if I'm not mistaken, it was based on 1.5
im trying to train embedding on face, having some errors that im not sure how to fix it or i did certain steps wrong. and yes, send me the links i'll comment on your vids.
i posted here, waiting for someone to send me to the right direction
guys, what is the prompt to add a custom reslution to my output?
Good morning, everyone.
Do you mean with the bot?
cant find my creations, how to FIND them, not listed in the INBOX drop menue???
What would you say against this argument?
"While you can finetune models with your own images, the base model still requires millions of images to be trained on. So training the model with your images doesn't make it less of a problem. There really is no proper way to make ethical use of this current tech."
slavery is still real. there are more real slaves on the planet today than there have ever been at any other time. i think its kind of dumb to suggest people living with technology and standard of living higher than any of their ancestors, are comparable to actual slaves that live today in today's modern context who struggle and have no freedoms at all
hey all
{kind=link}
reviewed, looks useful! maybe you should share it in #🎥|animation
not sure what you mean flowwolf but thks
just acknowledging the leon phelps energy. welcome to the team.
thks
so it looks like sarge put out safetensor versions of the controlnet depth for sdxl. i was playing with the bin file in comfy but had little success. it's not a very accurate model i feel. anyone can play with it using a1111 now too. https://huggingface.co/SargeZT/controlnet-v1e-sdxl-depth/tree/main
I'll do it. Thanks for trying it 😁
are there any tips on here about prompting and in which section to look?
thks will do
Are there any good ai solutions for android? Like, I have stable diffusion locally in my computer, does something comparable to it for phone exist?
And you are part of the system
Hahahahaha hahhahaha @sharp fable hahhahahahaha he ping younedddddd hahahahaha he pinged your entire username I'm dead hahahhahah
I'm having difficulties making icons with stable diffusion, are there any models that are better with objects/icons?
While it is a site instead of an app, I would recommend Dreamstudio, really, if you're looking to do something mobile: https://beta.dreamstudio.ai/generate
Paid it is?
If you're having issues making icons, I would suggest checking your prompt/checking out #📝|prompting-help or the #1047197565365538826 if you would like to search for something more specific
The pricing is listed on the website. Ofc, you can also use the bot here on the server for free as well.
-we should make society better
-Yet you participate in society i is very intelligence!
I did ask in #📝|prompting-help but it is not getting a lot of traction
I'll take a look 🙂
Thank you
See that's the problem, having it locally on my computer I don't need to pay, I'm searching for a similar solution because I can't pay one of those
When some of those anti caps actually bring a better solution ok
And also important: start with themselves
It's not about having a solution, it's about being aware
If theres a new illness and there's no cure it doesn't mean that hitting the patient in the head with a hammer is a good solution, just means that it's the only thing people are doing, a bad idea is a bad idea no matter what
Its very stupid to jump into a combat without even having any plans for afterwards
Sure the plan may be some idealistic ideas
Not that i disagree that there are issues with the current system/systems in the western world
There's a lot of ideas better than capitalism
Yes, some socialist parts
you can run normal sdxl on 3080, if problems, add medvram, i got 3070 with 8gb and with medvram it runs o.k.
ComfyUI handling it better than A1111 for now.
I run with RTX 2070
It can run on 6gb
Your card shouldn't get problems running it if you use --medvram and --xformers
nice ty
so how do I get my locally running webui to look like the bot-produces images in this server?
Deus vult
deus mortuus est
Demo of my deforum timeline helper app. 😁 try it and give me feedback so i could make it better https://deforum-helper.vercel.app/
Whats your guy's favorite model and what do they do
Base model SDXL. I prefer to create "original" things rather than try to insert existing characters or styles.
Anyone tell me Which python version is support 2.0.1 torch?
Anyone here having trouble with pc ui freezing while running a comfy ui work flow? I can't use the machine for anything else while processing images. (using sdxl)
can anyone tell me what the interpolate function of dynamic threholding is? i haven't found any guides on it. my understanding is the higher the interpolate the higher the detail at the cost of contrast and color-detail
Has anyone had any luck getting invoices? I have submitted 2 tickets almost two weeks ago and sent an email to both platform@stability.ai + dreamstudio@stability.ai and not received any response. I represent an EU company and we need a tax invoice. Any leads/ideas/reponse time estimtes are welcome!
Why can't I see the SHOWDOWN images?
@fresh ivy maybe you should in PC
@turbid lakeI am buit all it shows me is the rankings
@fresh ivy Sorry I only downloaded discord for a few weeks,i am missing ,too
Yes you can ask in #🤝|tech-support or in #📝|prompting-help depending on the problem
okay thanks
How it works?
Guys what would be the best way to inpaint a part of image but just change the color of it but nothing else like the material and structure
I know we can use controlnet but inpainting model doesn't work well with controlnet
i started up my stable diffusion 1.5 after a month of not using it and it looks like it downloaded a new interface or something. i didnt even know it was constantly connected to the internet like that. is there a way to go back to the old one or is it just going to be liek that forever now?
yeah, img2img doesnt even work anymore. im going to have to think about how to get a truly local version because its pretty unacceptable it connected to the internet and updated and broke a bunch of stuff.
i guess it was easy diffusion so theres probably something else i can setup
Should I grab a 4080 or still to hold out for the new 7000 AMD?
The future is bright for us. Follow me for great content and streams! Link in bio
I think the Showdown is broken right now, not sure why. It does its countdown but there's no images and there's not been a new pantheon winner in 8 hours or so.
@sick gazelle👍
Hey, does anyone know why there's such a quality difference between the generated images I get from dreamstudio.com and the REST api?
how fast is the rtx 4060 in generating 512x512?
does anyone have any experience with running SDXL on vast ai?
where do i get it
oOooO i found a new useful site to use https://imgsli.com/
hello 🙂
wonder what's going on with @warm junco 's status messages
oh its very late where cs1o is. maybe i shoudl watch my pings
Hey, all good. My Status is made with a Plugin for the Programm called BetterDiscord
secret cheats. nice. i like the marquise style.
^^ I mostly got it for the Custom Theme support but the status thing is nice too
yeah i'm looking at it now. ❄️ 🫘
嗨
evening all
thks for the tip yesterday about regional prompter > its works
Anyone know where the FAQ is on nsfw guidelines or are we left up to our own to decide? I couldn't find anything. This server has lots of channels.
Rule #4
No NSFW Content
Excessive gore/blood/nudity or anything that exists to suggest sex including sexualized poses. No illicit imagery. This includes NSFW content involving or depicting underage characters such as schoolgirls, lolicon, etc.
hey if anyone has any studies of artists that work well with sdxl 1.0 I would love to utilize it
check out this site: https://weirdwonderfulai.art/resources/stable-diffusion-xl-sdxl-artist-study/
ya that one is fantastic, I have been devouring it. Ive made prompts with all of the artists on it already 😄
yeah - it's very informative. here's another post with some links and info to a different study: https://old.reddit.com/r/StableDiffusion/comments/152wtrh/sdxl_recognises_the_styles_of_thousands_of/jsg0dr5/
your amazing!!!!
Hello
Am I creepy if I ask random girl at school for her number after telling her she is beautiful?
only if you are the janitor or the teacher
No I’m student
better if you try to get to know her in conversation first most likely???
hey so I'm kinda lost, how can I make a similar image to a previous one using the seed? and is there a way to look up all the images I created? I don't remember the seed neither the prompt of the image but I do have it.
https://rikkar69.github.io/SDXL-artist-study/ another sdxl study if anyone can use it
Seed or img2img
can we use controlnet on sdxl 1.0 ?
Hello everyone, any1 has a local repo of kohya_ss? His latest update is broken
So do not update if you want to be able to train
if you could share a zip file of a previous version with us, would be helpful
how lon it takes to make my photo?
Assuming i want to create a portrait of a famous person in a creative art style. ( while bypassing IP, because germany is f up ) would you 1. start with 1 image and iterate until its both in the given style and not comparable with the original ( facial expression, posture, clothing) or 2. train a LORA with many Picture of this person and then deploy it on some CKPT with the given Style ?
Why is Germany fck up regarding IP and why do you need to bypass the IP? That essentially means you want to sell the portrait of someone else as your property?
Anywhere I can ask a ComfyUI question? I am using a custom node and it wants me to add PYTHONIOENCODING=utf-8 to the env, but I got no idea where to edit env variables for ComfyUI
Good morning, everyone!
If you need technical support, you can ask in #🤝|tech-support or you can go to #✨|sdxl as there are a lot of great people sharing their setups there as well
I'll try the tech suppport one, I am not messsing with SDXL, jsut plain ole 1.5
thanks!
Nono i dont want to sell a portrait. You see i just want to use a picture of a person im refering too(in a video that is monetise), but in germany there is no fair use. Basically we have a Mafia like entity thats buying up all IPs for ALL Stock footages and IPs as possible. The purpose is not to protect the iP of the original Person, but to have the right and ability to extort anyone who cant pay the fees they demand for any use of pictures. Thus creators in germany have resorted to 100% create there own content ( reason why Kurzgesagt exists, since they were force to animate everything instead of using any stock footage) Im trying to enforce fair use with creativity
i dont call it Mafia, they are there to protect us from criminals that steal artworks, images etc. and do stuff with those that they arent supposed to do
im in a neighbour country of yours btw 😄
you probably need to talk to the manager of the prominent person or if its a image or artwork to the person that did it
i mean you said its for a monetized video
Hey guys, what's the best tool rn that allows training the model on your own images? I don't want to run it locally, ideally I'd like to pay and use some webui
Like dreambooth with sdxl or smth
Hello, Is there a way to calculate how many credits will my request spend?
Hei 😊
Is there a way to take a picture and rotate it.
Let's say i have this bird. But i want to have a image from the other side or rotate it 90 degrees? Is that kind of things possible yet? 😊 If so, it can probably be used help making a 3d model out of it. 😀
https://i.imgur.com/DYy5g9o.png
{kind=link}
Well their terms of business kinda is just really scummy, it´s one thing to enforce ip to protect, by warning and taking down unlawfull used images, It is another thing to try to maximise every breach of ip even if accidental. Their main objective is to profit from accidental breaches. By now it`s almost a monopoly. But back to topic, i want to make an animation as tribute to authors from some books. for example let Timothy Ferris. Id like to create a "drawn animation" , so in this process there will most likely be some kind of pictures that have ip. So would you rather do option 1 or 2 ?
it depends on the owner you allegedly or indeed posed a damage upon
usually you get a warning or in general contacted first
a direct lawsuit is less likely to happen
🎉
In germany its called "Abmahnung" which is the warning but already implies a necessary fee that needs to be paid. They will say something like searching and finding this breach costed 500€ and 400 for the license and so on so your left with around 1,5k cost for a single accidental breach, its messed up
im in Austria i know this too well :X 😄
if i get to sue someone that broke the agreements of the usage of my artworks or images i would do the same as well
it wouldnt be just the cost of the court and lawyers which is already not fun as well
pay the reparations and pay the court and lawyer cost on top of that
it the lawyer isnt guaranteed by a insurance which is the case with myself
Hi! When you go to the file section of Hugging Face to install SDXL there is no information anywhere about which files you need. There is just a list of a zillion files and no info whatsoever. https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
What files are needed to run the SDXL model?
the sd_xl_base_1.0.safetensors
the offset lora example is useful
and for the refiner is the same, the safetensors one here> https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
Awesome. Thank you so much! 🙂
kohya_ss seems to be what most people use
the blog post https://stability.ai/blog/stablecode-llm-generative-ai-coding has an issue with the code
also they're missing metrics, which, considering starcoder is better than gpt3.5 now, really should be there
wait so I should be using stablecode instead of chat GPT for programming?
ok wait posting in #🏞|general-with-images
not until they tell us if it's better
research use only lets gooo
chatGPT + Github Copilot or GitHub Copilot alone
so stablecode is nothing useful or what?
nah, but it also breaks down to your preference. Copilot with or without ChatGPT is the dominant force as of now
especially with the new upgrade (Copilot X)
which isnt out yet for the public
hmm okay
with Copilot X there wont be a "need" for ChatGPT anymore anyway
anyone had change to try the stabilityai/stablecode-instruct-alpha-3b yet ?
I failed to run it on webui 😦
where to test it on web?
what happening with this error in comfy??
Prompt outputs failed validation: Required input is missing: images
SaveImage:
- Required input is missing: images
idk what that means
Im using Sytan workflow
pres generate
and that happens
any ui working atm for coding ?
oh i see so basically I need to use refiner or if I wanna remove that step I gotta work with all these nodes
comfy so ass bruh
thanks tho
That code, is going to be so UN-stable that it's got the wrong name.
I think we just need 2 things
- AI search engine, like phind, but for more "general" questions and something like phind , but less janky for coding questions...
- Local AI with bigger token count, I'm talking millions tokens to work with local projects + a way to ignore files and folders, otherwise even millions won't be enough.
There are few, but they all suck.
The only thing I found usefull is phind, mostly cause you can make it scan docs and forums of framework \ library \ engine you are working with, it's answers gets significantly better compared to "general" search or gpt answers.
But don't expect too much, it makes same dumb mistakes as any GPT - based bots or search engines...
it hallusinate things that doesn't exist, it doesn't understand version diffrerence, it suck really bad when code gets complex...
Google is working on the first one
showcased at their I/O i believe
basically integrating (more) advanced AI into their search engine
yep
I've seen someone working on open source project with mil tokens, but it's...pretty bad
dont know about that one, hear about it for the first time tbh 😄
5mils*
https://magic.dev/blog/ltm-1
not sure if it'll be open tho, idk why I thought it's open
In fairness you don’t “install “ SDXL as it’s a model not an application. You install a UI such as Automatic 11111 or ComfyUI to use the model whether tha be SDXL, SD 1.5 or SD2.1
so you're telling me the stable diffusion.exe i donwloaded from torrent that takes 8 hours to install and uses all my system resources is a fake?
No idea. It may be it may not be. Someone may have packaged everything up into a simple installer targeted at 12 o’clock flashers.
👍🏿
Or it could be a complete fake and install multiple mining apps on your pc
I'd suggest avoiding packages like that. They might be legit, but they also might pack something else in.
And 8 hours!!!!
is there any realistic model for Hollywood famous movies... creating deforum video
or any way to get free mobile format videos for creating hybrid video on stable diffusion
Excited to work with the Stability community on 100 Builders! If anyone has questions about the program, feel free to ping me here or send me a DM 🫡 #1072240143521554592 message
Hum, an llm model
Absolutely not related to prompting or SD, hum, interesting choice
Is it on the todo list ? Or will we condamned to restart from scratch every prompt, forever, trying to get a decent one ?
Legit question
What do you mean? Hum?
Dunno, just something related to SD. Not just a text completion model for prompting, but more an assistant.
'This image is fine, but i prefer this instead on this' > Change this
'How can i draw a chimera with a clown in one hand and a turtle in the other one.' > Give the best syntax for it
See
Not really lol, don't even understand your sentence
So you mean you want iterative prompting based on the generated image? It will happen eventually. Often the "prompt engineering" is really just a limitation of the model. Some people think SD can produce the exact image they have in mind if they can only find the right prompt. But that's not true. It's a new and limited technology.
There are many images you can never generate even if you spend years engineering the prompt.
Yeah, true. Like regional prompting etc. I'm aware about this. Took the hands example not to imply this situation.
The generation of one prompt isn't the point. More like you said, based on the generated pic "in the conversation"
These will all come in time. Maybe in 1-4 years if I had to guess.
I don't really know how and who to ask, but if you have knowledge and skills in hacking, well, I'm potentially interested in hiring you and even getting paid for this job, come PM for more details.I must add that it is not too legal.
Has anyone tried Stable Code? Is it better than chatgpt4 for coding?
not too illegal sounds funny...
Either way, that's not right place to hire people
it's probably "discord moderator banned me and we're going to pull off a server heist of the century to get him back!"
Where can you ask a support question? I just had an image reported as inappropriate and I can't image how. Before it reported it, it generated 7 results that all looked almost exactly like the uploaded image which was a black and white swirly flourish I wanted to turn into a william morris like flower.
It happens. AI isn't perfect. One time I had a slice of pizza show up as inappropriate. As long as you aren't really generating inappropriate images you won't get in trouble.
Has anyone made a guide to setting up and using the stablecode llm?
I mean there is a person that made an exe for it, but it's not very big lol
It's actually a really nice UI for using all sorts of models
hello my dear friends, Is there any great Models for surreal or weird but delicate set design or architecture in Civital????
I made a little overview guide for the timeline editor tool. Sorry about my poor English in advance. Hope it will help
https://youtu.be/sskloFZXCLM
Deforum timeline helper - https://deforum-helper.vercel.app/
Hi all, how would I know if stability code would fit on a 4090?
Before running it obviously
I am not too sure how big 3B point is
Hey there
Hope you are doing well
I am a senior full stack developer who has full experience in web and AI development
So if you have some projects, please let me know
thank you
Greetings all - I have a question about Lora that I am not finding an answer for despite searching for half a day. Lora seem to be activated by key words in your prompt, WITHOUT having to actually add the lora:xyz:weight prompt. How do you STOP them being activated? Do you have to add every single Lora to your negative prompt? Or is moving them out of the Lora folder the preferred method?
LORAs shouldnt be activating without the <lora> prompt. You might have an extension on that does it. I know the Model-Keyword extension has that feature but there could be others. I'd check your extensions.
Good @sudden violet
so Please DM me
And I want to know about in detail
Where can I find football lora? wanted from real madrid
I wanted a lora in a football club uniform
Hmm, well that's actually a relief, it makes maintaining my every growing collection a lot easier, I had fears I would have to cut and paste backwards and forwards and the file naming for most of them is terrible.
Hi everyone,
I hope you're doing well!
I'm in search of inspiration today. I'm looking for an image-generating AI platform similar to Dreamstudio.ai or Magespace. My goal is to demonstrate AI's generative capabilities in a playful manner to a large audience. The issue with Dreamstudio is the limited credits available for free, and with Magespace, the NSFW focus might draw too much attention in this context. Are there any other recommendations? The demo on StableDiffusionWeb just isn't robust enough in my opinion.
Thanks for the reply! - unfortunatly thats no going to work. I cant get 80 non technical people to install something, play with it and then move on to other things.....
Chechking it out now - interesting....
I wouldn't know much about it, but I've found the creative exploration of different models fascinating to follow.
I think i will go for dreamStudio - with enough guidance on how to adjust settings, and maybe using an earlier model I can get the 25 free credits to last longer. Thanks for the help;)
Hi all, don't know if i am right here for my question. I have (for a wedding) images of all the guests, and want to make them "medieval" or "fantasy" style to create a guest book.What is the best way to do that? Would be very happy if someone could help
i have deployed my api to google cloud vm
i want to move to any way that it's auto scalable when a lot of users came it automatically scale up and down please give me solution
am using automatic1111
@crisp shell not sure, but nobody answered, img2img and controlnet. Pix2pix, i think it is part of A1111 img2img, not sure, if contorlnet is must.
perhaps someone could help point me in the right direction, I like the way a picture visualizes the ingredients they offer in their drink, and want to do a similar visual.
is there a good place to show an image, and try and get a similarly created one?
Anybody got some time for a small troubleshoot to get sd to work?
Thanks a lot, after playing around with mage.space it seems to work .. But:
Why is this blocked?
NSFW content is only available to premium members. Upgrade to Pro to enable this!
I have a question, how can I use images to generate pictures?
I created an Image with my face (not good but in the hope AI will enhance it) in it and used a mask to leave the face with custom inpainting. It creates an seemingly good image but its blocked because of "NSFW content blocked .... premium" 😦
Hmm okay seems to work : the inpainting is always left fully untouched on the mask?
is it declasse to ask if we get to keep the premium models for use with, eg Auto1111? Are they even compatible?
bookmarked this for after work experimentation.
(I'd thought initially this was dreamspace discussion. Didn't read close enough).
You looking for something like dezgo.com?
Already sorted and supplied a fix for others.
hi dudes, did you tryed already SDXL?
Good morning, everyone! I hope you are all well today!
Is there a way in a prompt to request for a girl in a generated image to have a smaller breast?
I tried several texts, but they don't seem to have the effect I would want. Some of the girls I generate have breasts that are too big.
hi is there any good model for creating christmas baubles with good background
breasts:-1 or breasts--- something to that effect may work. what were you trying?
I tried: smaller breast or small breast
(small breasts:1) ? or (small breasts)+++ ?
move the prompt around, maybe in the first part like 1girl with small breasts, etc ...
Thanks. I had some good results by adding:
very very very small breast, anorexic
the weight is a token multiplier so over 2 works but will blow out the math and cause bad generations.
yeah its not recommended to go that high. but it wont be ignored
Question for some advice using Deforum. Is it possible to make a zoom animation based of a video?
So like using a video as a template... is that possible?
Oh really? I'd like to know how to do that.
I've seen videos on doing deforum based of images.
Maybe its the same concept... I am not sure
Do most people here run Stable Diffusion locally? Do you use a GUI for it?
Yes, automatic1111, others run comfy, others run the Vlad fork of automatic
has anyone gotten transparent backgrounds with SDXL?
Have a question. Hope this is the right place. Apologies if it isn't. What's the correct syntax in a prompt if you are trying to create something in the style of an artist. I've had limited success. For some reason the prompts I am using tend to create images that are not very similar to the artist I'm trying to mimic. And to add insult to injury, it usually sticks the actual artist in the image! Would really appreciate some help. I use Automatic and Comfy with SDXL 1.0, base plus refiner.
I don't know the answer but you're not the first to ask. There's a prompt help channel you might have more luck in
is there a general discord for text ai ? or just for specific programms ?
Been genning for months. First time this is happening. Comp keeps crashing, even with the smallest tasks. Genning a 512x512 pic with 5 steps. Comp completely locks up on the final step. Restarted twice, had to hard shut down twice. GPU is working and detectible and running cold. What can I try to fix this issue?
/where is the bad apple sd edition?
on a1111 you can use the \(style\) tag like ogipote \(style\)
its easier to input the different style tags with this extension https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
thats for booru tags.
just to get an artist's style, ones that are not anime, wouldn't benefit from booru tagging
you'll want to say "painting in the style of ***" or "illustration in the style of" or "digital art" or "photography" etc...
the clip layer does still have a level of contexual attention
being more specific about the style helps too. "surrealist painting in the style of Salvador dali"
oh yea u right well u can do that or just use a lora/lyco if u want a more precise artist style
https://civitai.com/models/76481/rembrandt-style like this one
i mean, thye're a site with a lot of articles, but you shouldn't take it as a gospel. try what they encourage and try the other ways too. see what happens. they're at least giving you a place to begin right?
i dont believe in the whole "using it wrong" thing with technology that's misunderstood by the very researchers who created it. results speak for themselves. do what gets you good results. be ready to explore approaches
lora training helps a lot yeah, but prompting is king. SDXL is a lot huger than 1.5 and we've barely tapped possible styles yet.
it knows a lot
it is usable. you can see this by lots of people making great works from it. maybe you're probably just prompting wrong? i mean... people seem so quick to give up but prompting is king here.
remember, a year ago you had NO prompt game. It shouldn't be this hard to evolve your current prompt game. How ingrained can it be at this point?
One of the prompt clip layers is the same clip vit - L they used on 1.5 even. i think it was a smart move to help bridge the dialects of one clip layer to another open clip layer
Yo, What do people think the best AI voice tools are right now? i still feel like most of the ones i hear just sound a bit robotic
what is it that doesnt get you the results you need?
rvc and do it your at your own. elvenlabs is perfect altready
this is elevenlabs
rvc?
i feel like eleven labs is pretty bad tbh
i guess its the best we have so far
but its just super uncanny valley still i feel
Where can I share a business proposal related to AI?
@sudden violet hmm, did you use your own workflow or someone elses?
i used someone elses workflow for ComfyUI
but i want and should try my own
its for fun anyway
i dont know, my results were usually good before but my prompts were limited to certain topics and styles
i dont use it often
and my current PC specs arent ideal either
A100 would be nice to have
or H100
if i was purely into AI and programming instead of gaming and art as well i would build such a workstation, but because its not the case i have to build a strong PC but not a specialized workstation
didnt look up for Runway for a long time
its expensive
those 70+$/month for the biggest sub
In A1111, I know you can interrupt SD from its current process however I'm doing a batch upscale from a directory but i realize i need to stop it. how does one do this?
apologies & thx!
why not, i mean if its usable for you and worth it for you then you can
there are more expensive softwares than that
let alone every day stuff people buy
cigarettes and alcohol are a prime example
i agree there
which is a good reason for me why i dont fully switch to generative AI art but instead have it as a another tool i can use
with fully switch i mean to abandon the other ones and use exclusively AI art generators
i guess there is low to none control with Runway then?
if i understood it correctly
hmm
yet that expensive
thats more expensive than 3ds Max and Maya together (indie licenses)
i broke stable diffusion a few days ago when i tried updating a111 and have been trying to figure out the error without reinstalling it for like an hour here and there. and i finally got it working again by deleting a config.json and it simply remade the file on launch
I got some pictures of my kid playing. I want to use them as base to turn into an picture for a kids book. Where do I start?
ths guide expains it. He is using SDXL, but works also with 1.5 based models https://www.youtube.com/watch?v=AY6DMBCIZ3A&t=0s
any updates on ControlNet for SDXL? It's one of the single most powerful features. is still just the filesize the issue?
Anyone use claude2 for programming? I'm trying it out and the large context size seems to really help over chatgpt4
recently, i don't see any picture in showdown channel?
we're looking into it, please be patient, enjoy the bots!
upscaling, there are quite a few options and trained on specifics like skin or realism, anime and so on
also there are a couple vae/loras for that
the pictures are generated in 1024*1024 even if i upscale the picture it would be square
where are you generating the images? sdxl is trained on 1024x1024 so that's the optimal resolution, you can change aspect ratios if you try to roughly match the total pixels
thank you I will try that now
yo guys wassup
i was trying out stable swarmui and i tried to run the update.bat to update it if there are any updates but then it broke the comfyui selfstarting api thing now whenever i run it it says Initializing backend #1 - ComfyUI Self-Starting...
17:25:18.459 [Warning] ComfyUI start script is '', which looks wrong - did you forget to append 'main.py' on the end?
hey peeps, anyone knows a way to limit prompts with colors, eg. segmentation somehow. eg. "red hair and blue dress", sometimes becomes reverse, sometimes works good... if there's a way to put in some brackets or something so the first few steps are heavily focused on right color of the right thing
Do you mean with 1.5 or with SDXL?
currently working with SDXL
Don’t think there is a way to do that yet, unfortunately.
But ask in that chat. Maybe someone has a method I don’t know about.
i thought more of a general question, with all models, that's why I asked here... trying a lof ot them, all have same issue when it comes to colors 😄
especially if there are more than 2 desired items
then it all gets mixed up
eg. try female with red hair, black lips, yellow shirt, green pants and blue shoes .. tell me what you get, on any model 😄
This is because the text parser isn't a language model. It only sees tokens. It has limited understanding of relationships between tokens.
It sees "green" "yellow" "black" "hair" "shoes" "red" "pants"....
And it tries to fit all of those ideas in the image.
I kinda understand why it's so, so the question was is there a way... to force it draw maybe item by item then fit all together, or something.
You could try inpainting. Such as just mask the lips and say "black lips" then mask only the shoes and say "blue shoes".
But right now it is a new technology. It can't make anything you can imagine. It can make many things but not exactly as you imagine.
yeah, inpainting is cool, but it's not exactly what I want... especially when using wildcards
but, i've been thinking, there could be a workaround, first generate everything needed with low steps then run all through img2img
This is one of those tasks that may need newer technology that doesn't exist yet. There are many images that can't be made with SD even if you spend years engineering the prompt.
img2img uses the same text encoder so it still won't understand the complex relationships between words.
yeah, but if something is clearly "red" in the original image, it will be red on the output image no matter what you type in
denoiser won't turn red into blue even with really high setting
Right, but how will you get it to be red in the first place? That's the hard part. If you say "red hair" that might also make the shirt red.
true, there comes inpaint. perhaps first generate "female with red hair" and nothing else, then on top of it generate blue shirt etc.
That's what I was thinking. Even then it's challenging.
There may be some extensions to make this easier but I am learning with the base model only so I can really understand it.
i'm torturing my 4090. bought it for gaming, not playing anything. so running countless generations of useless images 🤣
Sometimes just generating a large batch and picking the best image is the easiest way.
so there goes sdxl and mega resolutions
there was an extension for (auto's) webui that aimed to address the color bleed issue iirc
for sd, not sdxl specifically, I didn't have much success with it personally though
yeah, makes sense because of the way it works
Anything that tries to "fix" that issue will have limited success. It's not a bug. It's a limitation of the current model. Basically SD can take your prompt and use it as an idea. But it can't match your imagination exactly.
Wait 1-4 years and there will be a model with much better language understanding.
yep, all true, sdxl doesn't fare much better than sd sadly
i'm also stuck on auto's , really need to try comfy. got a feeling i could make a loop there so it expands prompt gradually
example run a text2img prompt "female with red hair", generate and run through img2img with "female with red hair and green shirt" etc. to the last item on the list. it should work technically
No such thing as "expand the prompt". It's all just weights applied to the model inputs.
I would be surprised if that works since the first prompt will produce some other color of shirt and it will be hard to change without changing the whole image.
what you can do and I can confirm it works is generate whatever image, then select eg hair with clipseg or other segmentation model, turn that selection into a mask, and run img2img on it
But don't be surprised when you also end up with a rainbow in the sky. 😆
it's possible as a one click thing in comfy too
You can also draw a color onto one area of the image before inpainting.
yeah but stuff like clipseg you can automate completely
yeah, i'll give comfy a shot today. need to read all that install text about linking the model folders
Often easier to edit the yaml file than set up a lot of links.
tnx, i'll try it a bit later. will come here if I get stuck somewhere
i had good tries with regional prompter
We're liveeee, get comfy and learn ComfyUI with us! 🔴
Are there vods for the stream
Hi guys. I was working with stable diffusion 1111 without a problem today but since I have copied the ckpt file version 7gig it stopped to work with SDXL refiner and even after I have deleted it it doesn't work when I push the generate button it gives me a black image 😔
Does anyone have an idea how can solve it?
who timeouted me?
you were likely timed out for prompting for "nsfw"
steer away for future notice 
oh sorry haha i wasn't aware that's a problem
we moved here?
yes, the stage-chat closes after our stage has concluded!
hello is img2img possible in bot10 channel?
it's not possible in any of the bot channels 🙂
only on the website? thanks
on local install too
Thanks!!
Found it, thanks!
hi! i just started using stable diffusion with the xl release, so i'm catching up on all of the intricacies. would love to use the QR code generator and have followed the tutorials, but noticed that they all assume an older version of SD. do the stylized QR images created with controlNet work with XL as well?
Is someone willing to please train stable diffusion with my photos because seems I can't with a AMD graphics(unless there is way with AMD could someone know how please and thank you)
for anyone making image prompts with chatGPT and having issues with censorship, Try BetterChatGPT its free and its completely open with no censorship
i just tested it out and it works
SLAVES NO LONGER
Hu
wazzup
Hey all. 🙂 does anyone in here use the Easy Diffusion web UI version of SD? Looking for some help with it but I haven’t found a “community” for it
Try the GitHub of wherever you found it, that's the best reaource for troubleshooting with any open source project
Thanks!
why whenever i put a prompt on photographic is creates a picture of a camera
Which model? Show the prompt.
i believe it was sdxl 1.0, noticed it has the same problem on clip drop and the discord server. one of the prompts i put was “blood on sidewalk”, and one of the outputs was like a camera with a black and gold background. sometimes when i put names like “david pakman” for example, all of the outputs are just cameras. this only happens when i put it on cinematic/photographic style tho. even when i try to exclude cameras from it, it continues generating it
Try less controversial prompts. Ask for "a tabby cat sitting on a couch" with photographic style and see what happens.
got it
was just kinda confusing how it kept generating pics of a camera but ig all of these still have limitations (luckily)
Hey all,
We'll be running a hackathon for Actually Open AI on September 6th in collaboration with Stability AI and Arweave - if it's of interest, feel free to DM me to learn more. More info available at actuallyopenai.dev 🤗
does anyone know how I can make SD choose between these pose?
I tried {squatting|sitting|lying|kneeling} but it is only choosing kneeling
You need Dynamic Prompts extension enabled.
thanks. Do I just install through SD?
Yes on Extensions tab.
So I am trying to remove a shirt from a person in a photo I have and replace it with a different type of clothing. So I use the paint brush and painted the area I wanted to inpaint.
I then typed in my prompt and hit generate. And all it did was just show up the same color as the brush color.
What am I doing wrong?
you don't want to just paint colors on the image. you just want to brush in a mask, a region telling sd where to work.
I think you're using the sketch tab
I am using Draw Things AI.
And they really didn’t give much tutorial wise
no idea about taht app sorry
I need some help.
Shoot
Are you using img2img? Prompt info?
Hi
Can any of you tell me how to make a Collage in SDXL? Do you have any example of a prompt that can help me? Unfortunately I couldn't find anything about it.
Hi. How run this win command: python.exe -m pip install basicsr facexlib
but for mac syntax?
i found
python3 -m pip install basicsr facexlib
hi all, how can I XYZ plot LoRA weights and different LoRAs in AUTOMATIC1111?
You can use the Prompt S/R feature.
To replace the lora names and the weights
I guess I am doing something wrong with the syntax? https://share.cleanshot.com/VblrtH8R
@warm junco I can plot different weights but can't plot different loras with different weights in the same plot with S/R
Yes. You need a trigger word the S/R stands for
Search/Replace.
Example prompt:
Test image of lora:Loratrigger:X,
then in the prompt sr you start with:
Loratrigger, Lora_itspatikai_rc, lora_istapatikai-0001, etc.
That will replace the loraname.
Then for the weight a new S/R with:
X, 0.1, 0.2, 0.3 or 0.1-0.9,
you are the man! Thank you so much
No problem 🙂
how set proxy for sd?
is there a way to auto refill credits?
does someone know how to link SD to silly tavern to create expessions ?
Good morning, everyone! Hope you are all doing well today!
Yes. I am using img2img and there is prompt info.
hi, in stable-diffusion webui, is there away to pause the training then resume again?
the "interrupt" seems to stop it but im not sure how i can continue to retrain it
Hello there,
I was wondering if it would be possible to train a model to do a shirt swap over, for example, NBA players ?
Does it exists anything like that ?
Like if it's possible to do a face swap then it should be possible to do a shirt swap, no ?
Can someone give me a good inpainting seting for changing little things.
I can't seem to find good settings.
can i use comfy UI on a mac
Any 1.5 model with controlnet openpose and inpainting should work
i don't have a youtube link for this, but this app is an all in one installer for these projects https://github.com/LykosAI/StabilityMatrix
youtube links are often the worse. there's not a lot of ways of finding good youtube videos since only the most clickbait videos go to the top of the recommendations and they're often the most innaccurate. what you want to use instead is documentation and text guides. Text guides can be updated by the author easily. Once a youtube video is published, it's out of date the next day, never to be edited or updated again.
good morning. I am looking from some mmodels that I cant seem to find on Civitia or Huging face. I asm new to all this, so I was wondering if there was another place I might look?
Hi, I wanted to ask, if in img2img I load a png file with alpha channel ( and in my case without background), how can I prevent sd from generating a background, keeping the transparent part actually transparent?
hi just a quick question, am i able to update a1111 from v1.4 to v1.5/SDXL or is it just an entirely new version i have to install separately.
i dont feel like going through the hassle of reinstalling extensions and what not.
@unique hamlet in this example is the keyword always the file name? The loras I have used in txt2img or img2img they provide the keyword on the download page most of the time and it's different than the filename. Like this githyanki Lora uses githyanki as the trigger word which is different than the filename. Or is this different in this situation?
no this word is just for the search and replace feature of x/y/z script.
you can use any word for that
yes you can update your webui with git pull
okay thank you. my auto update wasnt working, but ill try to manually do it. sorry it was such a basic question, i have another hour or so until i can actually do it so i thought id save 15 minutes lol
Don't do it manually. Git pull or reinstall are the only way to update
If it don't work feel free to ask in #🤝|tech-support and we can get it to work
@astral goblet thank you so much i will take a look at it
Do you guys know the difference between **Shuffle **and **Reference **ControlNet models?
From the onset, they seem to kind of do the same thing
reference isn'ta model. it does something weird with the preprocessing and doesn't need a model
it came out later
Thank you. Yeah, I understood that much. Just wasn't sure what the actual difference between the two were. I'm experimenting with them now and they both seem to do similar things, but I wasn't sure if they actually served different purposes
Anyone facing issues with SD+Automatic1111 and Google Colab?
Hi guys, if you want to try our stabble diffusion xl 1.0 integration,you Can Do it for free and give us your toughts on https://arescreative.fr
Gm 👋👋👋👋
hey, what prompts do you use to create characters from anime and they actually look like them, dm or respond to this ty
Who is the best model for hentai?
And what is the best realistic model for hentai?
either grapefruit or hasaku
if we recreate a movie clip with hybrid and controlNet for YouTube shorts..do we still get copyright strike on YouTube ?
derivative work
ty
Anybody tried the Stable Chat yet?
how to generate photos with different models at the same time stable diffusion
im using it now and its pretty good at making prompts
Can you recommend me a realistic model for hentai?
Hey, is dreamstudio down? I'm getting the error something went wrong on our end, please try again.
Well, good for you. Mine's stuck on loading like this: https://i.imgur.com/8Es8dwV.png
{kind=link}
Join my subreddit for great content, analysis and discussion. Link in bio.
But why do you have parameters on your link?
/
Heyo if anyone bought the Nang Women AI Image generator pack I've been running into some issues with it working at all. Most of the time it will just crash before it works or after a few seconds of use rip
no idea even what is that
Good morning @bleak matrix
What's up?
Does it actually know what a sigma lens is?
Sigma fp with Sigma 45mm f-2.8 DG DN,
It sure does, yup.
How? Photos shot exclusively with that brand of lens? Is this a model or Lora? Sigmas aren't considered great lenses like a Nikkor or zeis.
SDXL will recognize every camera, lens and film type listed here. This is by far the most valuable site I have yet to see about SDXL prompting. It's safe. https://rikkar69.github.io/SDXL-artist-study/cameras/
I did pull up sites like Amazon and others looking for more modern cameras, like Blackmagic for example. I tried many different ones. But it didn't appear to make much difference.
I would be very suspicious that those images are created with those lenses and or film.
They work. I can confirm it.
I believe they do, just their authenticity. Having shot and processed for years having all those cameras, films, and lenses you would have to be ... Well very rich lol.
That's awesome. Another good resource is the list of example prompts,I think joe penna shared it... It was a text file
Oh, I see what you mean. I am a career artist. My knowledge of photography and equipment is limited. Full disclosure. But I do get some amazing results from the stuff on that site.
Basically a collection of style prompts
There's a tool that started circulating today. It's a simple prompt writer. It's amazing! But it's not mine to share.
When I get permission I'll come back and share it with you guys. Between that and the above website you can really step up your SDXL images. But again, not mine to share. Sorry.
And ofcoarse I have to abide by the rules of this Discord.
I sent the owner of the site as to how those pics were created.. I so curious. If someone has all that equipment and processing ability I would be amazed and VERY jealous. 
Let's just appreciate his efforts (and time) to make us all better at AI art. My hat goes off to him.
Whoever he/she is.
I have a question about the concept of using a celebrity's name for training instead of a the generic "ukj", etc...
I recently tried doing this with a friend of mine. I used "Tom Hanks" b/c he kind of sort of a litte bit resembles him. I trained both a Checkpoint and a Lora. It worked pretty well for the Checkpoint ... however, with the Lora (and I assumed this would happen), when I use the Lora with a different checkpoint (say, Photon), it creates a person who looks like a radiated blend of my friend and the actual Tom Hanks.
Am I correct in assuming that this concept does not work for Lora's?
i feel like i'm missing something, the results i'm getting with xl aren't as a good as they should be
are you using at least 1024x1024 resolution? @delicate trout
768x1024
i don't have any for xl
hm, are you using A1111 or ComfUI or something different?
There is for A1111 Vae, go and get it
I have a quick question, so when I downlaod different models do I have to have the specific one I want selected in the "Stable Diffusion checkpoint" or will my prompt draw resources from all of them?
no it isnt.
i have vae, i said i'm not using any for xl
you must use VAE for XL version
which one
are they using one for the hugging face pics?
i dont know. sdxl_vae.safetensors
@untold igloo it should use only that you have selected.
i don't understand, why using a separated vae
why is it not baked in
vae is more to boost results, but the model itself doesn't give perfect results in the first place
Go in settings quick settings, and choose VAE so you can change it on the run from top of the A1111 window. Realy suggesting doing this
mate 😂
i told you i use vae i know how they work
i'm just not using any for this model because the model alone has to be enough
so post your result in general with images, and pros here can help you, i bet it is because no VAE for XL
☝️
o.k. so try 1024x1024.
Perfect result is something very personal 🙂
"perfect" for results is not subjective (personal as you say), it's something everyone should get, meaning no bad quality, no prompts misunderstanding, detailed results etc
here's an example of what i get, it's not normal lmao
even small models give better results, without any vae
 this is why you have to name the prompt something else or it will use other pics of Tom Hanks if your prompt is Tom Hanks.
this is why you have to name the prompt something else or it will use other pics of Tom Hanks if your prompt is Tom Hanks.
Is there a software like SD that can be installed and used locally
but to produce AI music instead of image?
what's this chat about?
Hey everyone. I want to do a contest for prompt engineering.there will be no prize but a show of skill and uses. The model used for it will be normal GPT 3.5 so all can enter the contest (NO GPT 4) you can use the app on IOS or android or the Normal Website if you are on PC.
The Theme is: UltimateGPT
This will have a selection of a different modes for ChatGPT such as AI art mode,prompt mode (which it will make a prompt that works) and MusicLM prompt mode (go research it if you have not)
If you want to enter please DM me!
How do i change SDXL into a coreML?
Thanks for the reply. Just to make sure I understand, are you saying, then, that the celebrity name method doesn't work?
From what I understood is the goal of the Lora is to use the images you created in them. To access it specifically we use the prompt name chosen for the Lora. If the name you choose has images in the base model that match that name it may use those images in the base model over your Lora images.
I may be wrong...
Yes and no. It's exactly how you described it. When training a checkpoint or using the Lora with exactly the checkpoint it's trained on it works. Because it uses Tom Hankls as a base and just alters the bits to make him to look like your friend. If you use another checkpoint as base your your Lora, then this perfectly tailort changes don't add up perfecty anymore. Image you want to generate the number 10. Your base model generates a 7, so the lora adds 3 and you get 10 as a result. Perfekt. But now your other basemodel generates an 8. Your Lora still adds 3, giving you a 11 as result. So yes it works with with only that base checkpoint and no, it doesn't work when you switch your base model
SDXL is the best, Just a fyi
If you name the Lora prompt something like swrbfd4 and use that and don't mention Tom Hanks in the prompt it should use the Lora over the base model right?
Or for the most part
?
yes and no again 😄 it still uses both, like with tom hanks. But if you use swrbfd4, then this token is emptly and has no information. So all the information comes from the lora, since the checkpoints dont have any for swrbfd4. Same example: Image you want to get 10 and for all checklpoints swrbfd4 gives you 0. Lora adds 10. Since all checkpoints have 0 for swrbfd4, adding 10 from the Lora always works 😉
What I am saying is take the Tom Hanks Lora he made and instead us swrbfd4 as the name. In that case the Lora would add 10 and 0 from the base model. Sorry if I didn't make that distinction. Ie, name your loras something that won't be in your base model or other loras if that is your goal.
yes then it always works. But the benefit of using Tom Hanks is that it can jumpstart from all the knowlegde it has from Tom Hanks. It doesn't has to start from scratch, but has instantly a good understanding how that person works with all it's lighting, perspectives etc and just has to finetune the apperience. It just has pros and cons. If you plan to use it only with your super favorite model then it's usefull. If you want to switch basemodels it's useless
In some pics I'm having a problem with the face(es) as they appear distorted before upsacling, but not on all prompts. Could it be that the model is more biased towards closeups? I'm trying make shots from a distance
yes faces that only have a small area on the images don't come out that great
Total newbie. I have a ton of VERY basic questions. Is there a good channel for those?
(I installed A11111 and v1-5 on my home system, and it's running, but beyond that, I'm kind of lost)
I guess you can ask here. But having it running already is a good start 🙂
so... my guess is I probably want to download a better model -- on huggingface, I see sd_xl_base_1.0.safetensors. Can I just download that and stick it in the models \ Stable-diffusion file?
Or do I need to do additional stuff to make it work?
(also, should I delete the older ckpt file?)
I'm not entirely sure about sdxl with Auto1111. But I think the current version of auto can use sdxl natively. But it's now completely implemented yet
no keep them, you can easily switch between them
if you want new models you can check out https://civitai.com/
a huuuuuuuuuuuuge collection of models
Thanks! I just dl them and stick them in the models\stable-diffusion folder?
yes! Then restart the web interface so they show up or use the little reload button on the top left corner next to the model drop down
thanks! ... gonna go try that and see how it works!
there are checkpoint ( or models ) that work on their own and then there is some called Lora. It's like an addition to the checkpoint you are using. For example you have a model that's good at paintings and then you got a Lora can is good at Pokemon. If you load your Lora onto your model then you have a model that is good and paintings and pokemon at the same time 😉
woah
... see, I was struggling to figure this stuff out. I would RTFM, but... I can't find the FM! really appreciate this!
https://www.youtube.com/@Aitrepreneur this channel will teach you alot about stable diffusion 😉
perfect!
it's a bit overwelming now with all those videos at once but it was super helpfull over the last months and taught me everything as it came out.
hey all
But the main things now are Checkpoints as your base and Lora as an addition to your base model. Later you can search for stuff like inpainting and one of the most impressive things is controlNet. You can even train your own models 😄
new to the group running AUTOMATIC1111 ON OSX and encountering the error COMMANDLINE_ARGS = --skip-torch-cuda-test
^^^^
NameError: name 'skip' is not defined
any assistance would be appreciated
try COMMANDLINE_ARGS="--skip-torch-cuda-test"
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
is the response i get
mm well that sounds like a bigger issue, but anyhow did you put the flag in webui-user.sh?
should be on line 13 according to github
and you have to uncomment it
The benefit of using Tom Hanks is that life is like a box of chocolates, you never know what you're going to get.
the flag is there]
looks like that
Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention"
export COMMANDLINE_ARGS="--skip-torch-cuda-test"
anyone have cool settings for motion for deforum videos currentl i am using "angle": "0: (0)",
"zoom": "0: (1.0025+0.002sin(1.253.14t/30))",
"translation_x": "0: (0),30:(15),210:(15)",
"translation_y": "0: (0)",
"translation_z": "0:(0.2), 60:(5), 300:(5)",
"transform_center_x": "0: (0.5)",
"transform_center_y": "0: (0.5)",
"rotation_3d_x": "0:(0), 60:(0), 90:(0.5), 180:(0.5), 300:(0.5)",
"rotation_3d_y": "0:(0), 30:(-3.5), 90:(-2.5), 180:(-2.8), 300:(-2), 420:(0)",
"rotation_3d_z": "0:(0), 60:(0.2), 90:(0), 180:(-0.5), 300:(0), 420:(0.5), 500:(0.8)",
"noise_schedule": "0:(-0.06(cos(3.141*t/15)**100)+0.06)",
"strength_schedule": "0: (0.65),25:(0.55)",
stick with Nvidea. Most tools work with them and they need less vram. But I don't know the exact one for your needs
hmm seems like the 1000 series is still very slow for AI stuff. Fastes here is GTX 1080TI. I think the 1070 will be even considerable slower
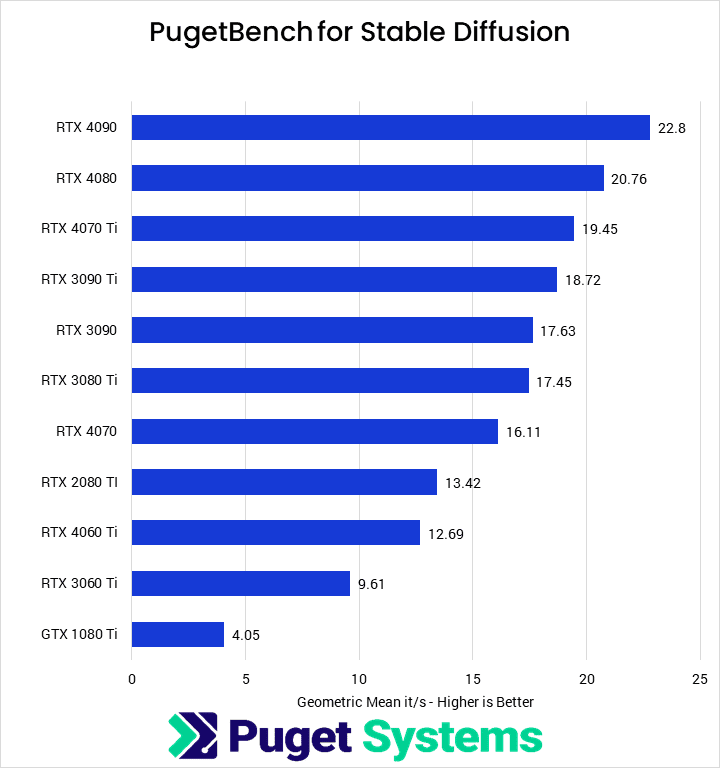{kind=link}
problem with that is thats an amd card. You have to inform yourself beforehand of it works with amd
You only need a GPU if you run local. But if you run PlaygroundAI for example you can use an old 550 from the civil war.
with nvideia you generally can run everyting
if u wanna run sdxl with decent performance and little money just buy an used 2060 12gb
And many of us do video editting too. I still recommend that card I linked. Best bang for your buck. Until you can get into the 4k series NVIDIA.
Most people heredont run SDXL local.
but we arent talking about most people we talking about him
has anyone managed to do something coherent like a manga with SD?
seems like we are still a ways away
you know corridor digital? they made an anime with that. But it needed a loooot of preperation and exact workflows
here is episode 2 with improved coherence
they also have a making of where they explained what they had to do
i love how they chose the combat as rock-paper scissors cause it's like literally the only type of fighting that these image generators would be able to handle
you think so? I mean Hands are the hardest things to do right now xD
Hope this is the right place to ask, but does anyone know of a good "model" to create potions/images of potions with? Or is that just kind of a general thing?
well, if they wanted to try two people sword fighting it'd be impossible -- you can see how much trickery they have to pull just to make punches work
use controlNet for that. So you can pose everything yourself! But for SDXL it's not finsihed yet
they made the bow and the arrow work too in the beginning of ep 2. A sword should be no problem then. Making a cool anime style fight for the image preparation would be the hard part, or the post work in AE. But running that trough stable diffusion in the end shouldn't make it more difficult than the bow scenes
but yeah, saying that using the hands is the hardest part was meant more as a joke in the first place 😉
Hello guys Gm I’m a beginner trying to install stable Lm 7 billion parameters on my desktop in vs code could someone help me with some ideas and tips especially with me being a beginner to all this especially with coding and I’m using vs code 🙏🏿🙏🏿
yeah idk man, I think their workflow, from what i understand, is like training specific loras on individual people, you really think that if they have to do shots that require two people together in the greenscreen, that it'll be able to handle it?
right now i think they just do one-at-a-time greenscreens and then edit them on top
also, they have some weird solution to get rid of flicker, but why don't they try mapping multiple images in a grid?
not high enough resolution to do that i guess?
yes they have a seperated trained model for each character. You are right, then they could never fight with each other but had to film it seperately and hoping it works well together when put together. With rock papcer scissors you don't have that problem since every character can basicly fight alone
guys whats the best model for making images that look like characters from an anime accurately
Is there a way for a deforum to stop changing the image drastically? I’m currently doing something that isn’t exactly sfw but ||I’m trying to do a deforum zoom in to a girls boobs and the moment it gets really close, it suddenly changes the image completely||
Is there a way to not make these deforum animations change and stay?
I just ordered a 4070. Anybody here using one?
hi
how do I use the stable code model?
why is that sometimes sdxl will give me absolutely beuatiful images and some times just a bunch of cartoon drawings?
L gpu a 3090 would have been better
Guys, do you have tips for tutorials on how to train your own embeddings for SDXL using google colab?
absolutely would have
Is everything the same as with older models? Can i use older tutorials?
Hey mods, can you take a look at the https://discord.com/channels/1002292111942635562/1004159122335354970 please ? Here is a kid who do mess
Feel free to ping us next time, we cant check all the channels all the time, but thanks it has been dealt with 
Is there an AI that’s free ?
Hello, I'm using Automatic1111's API code to create my server where I can create images for incoming requests. Is there a good repo / project that focuses on API creation for stable diffusion? Something that supports auto scaling, request authentication etc?
is there a model that just gives people really big heads?
guys wha time does clip drop folow?
wdym AI thats free?
Gpu broke?
Anyone knows approximately how much GPU memory to train LoRA on SDXL 1.0?
seems like cloud training is the only way as up to 32 GB VRAM is required to feel comfortable
playgroundai.com has 1k images a day for free.
There are three words that you can add to your prompt to force SDXL to deliver altered/big heads.
- Caricature
- Funko
- Chibi
Hi
which is the latest model i can download from huggingface
also i have only 16gb ram ryzen 5600h mobile processor and gtx1650 mobile gpu
How do I go about getting a style like these images https://vm.tiktok.com/ZM2wea7pa/
Join my subreddit for great content, analysis and discussion. Link in bio.
SDXL is latest model from stability afaik, but I think only beta \ 0.9 was released?
(someone correct me, I'm outdated)
There are plenty of community made models too on https://civitai.com/
nope, seems like 1.0 was released too.
nice
thank you so much
you may not be able to run SDXL. Sticking to 1.5 models isn't such a bad option either. They're still really good
yeah seems like it
my ram said nah
TwT
i wanted to generate / extend wallpapers to span across all my monitors
:(
can do that with 1.5 and a little bit of ingenuity. tiled vae. outpainting. ultimate upscaling. there's plenty of tools for you to use
thanks. I'm on 1.5 but I'll try these (hopefully they don't make them into weird troll people though)
wow
if you start your generations large, they may. hires fix is an essential option on a1111 ui. it does two passes for a generation. one lower resolution so that trolls and centaurs don't appear. a second one takes those first lower quality pixels and builds on them
thank you so much
i also recommend for wallpapers, wider generations it's hard to get a single subject to show up. LIke if you prompt for a waterfall, you might get two waterfalls on the left and right side. it's a lottery there. sometimes it'll do the prompt on the entirety of the image. sometimes it will do the prompt in quadrants and you'll have it rendering twice in the same wide image. Try prompts that don't focus much on a single subject or can easily get away with tiling the prompt across the width. "A forest" wouldn't look obviously doubled up where as "person" might show up twice unintentionally"
what would you call this style?
https://civitai.com/models/4384/dreamshaper this is also what i recommend for 1.5 creative generations
digital art, illustration. cartoon fox. /shrug
while i love that site, it sucks for discovery. it's only tagged with artist names. i can't do something like search for all the oil painting styles. or all the photography artists. i have to know the name of the person to find them on the page and see what sdxl creates. or i can scroll through the infinitely scrolling name sorted list and wait for a style to pop out at me.....
it's just a bad design with the guise of being a good resource. it was really phoned in though.
the other lists on that page, much shorter and manageable
I don't use Tik Tok. When I click the link a box covers the images. But you could narrow it down with that link I provided. Use an artists influence, or a combination of artists.
To each their own. I'm a big fan of that site.
is it me or the latest version of AUTOMATIC1111 broke most extensions?
it's just the alphabetical artist name list that i think they really just failed at. the rest of the site's examples are very manageable
https://github.com/AUTOMATIC1111/stable-diffusion-webui/commits/master latest version is from 2 weeks ago. i'm using dev branch and i'm fine over here
OK, I am looking at the dev branch too, might give it a shot. How do I git overwrite my existing branch?
hey! sorry to bother you but i'm curious about the difference between the normal models and fp16 versions (using web ui). i know it has to do with floating point precision (what's mixed precision?) and i was wondering which one to get
is a rtx 3060 12gb enough for SDXL in auto1111?
Is there any model that works well with making textures for games?
i use git switch dev then git pull but i just learned if you do git checkout dev it's both of those. multiple ways i suppose.
extensions may break more often on dev branch, but i've had little problem there
Is it ok for people to make content from this server? Like screen recording, or posting the results?
Dunno, thats why im asking..its not about "care" anyway..
cow utter
I'm using a RTX4090 and having no problem with 24GB of VRAM when training with Koya. There a are a few videos on youtube where people show you how to set it up. Maybe with 16 it's possible too. But not entirely sure
use Gradient Checkpointing and Adafactror to save a lot of vram. Also lower batch sizes save Vram
hey
is it possible to train an inpainting model on a specific object? I would like to inpaint a specific object into photos
you don't need an inpainting model to inpaint, it helps but not needed. especially now with controlnet inpainting. But yes, you can also create inpainting aware models
imo the controlnet model adds the capability to every 1.5 model and does it better
i see, is it possible to train it on reference images for the object that i'd like to inpaint?
you don't need to. just train a regular lora of the object, and then use the inpaint control net to add that model into any existing image. that would be the approach i'd take
This probably has huge implications for Stable Diffusion. But I understand none of the math 😩
https://kwonminki.github.io/Asyrp/
Does anyone know some kind of node that allows batch count to create a grid like A1111 does? I kinda miss that feature
Anyone got any luck running sdxl on openSUSE tumbleweed?
yes
How do I make my images look real here in the bots? do you have any prompts?
I wanted us prompts for a photorealistic car image
Hello, anyone knows why SD doesn't want to use my GPU? Instead is using my CPU. I have an AMD GPU, followed the instructions on the wiki but stills wants me to use the command to ignore cuda, this didn't happened before
Has anyone tried stableCode yet?
probably what you're looking for? https://wyrde.github.io/ComfyResources/nodes/ImagesGrid X-Y Plot/
hello, is there any channel dedicated to models or loras in here?
ONG THIS SERVER IS LITTERALY THE BEST
THIS AI GENERATED ART IS SO COOL
look at the general with images
it gave me sum hot man
realll
I don't know what to say but this server will save my life
ong ong fr fr, this ai bussin
one of the stupidest negative prompts i've ever seen anyone put as an SD default (not in this server) is 'ignoring prompts'
oh yeah its gonna listen to you now 
just put ( 0.0 ) on both prompts
lol why did I get mentioned in #1100484581037195384 ? is it totally random?
I think you mean an instruction to disobey instructions. An instruction to ignore instructions isn't a paradox
Also paradox is the wrong word, but I can't think of the right one
You can ignore an instruction and still do what it says
Otherwise it's just reversing them
I have a question about celeb loras: if using someone likeness is illegal, how comes there are so many celebs loras on CivitAI? Is it because it doesn’t fall under commercial use? 🤔 What are the legal risks of creating a celeb Lora
who said it was illegal
I want to change the color theme of a pic from green to purple, what prompt should I use?
it's not illegal but sure could be consequences if you want to sell or promote with their image, they live of that and you can be sure lawyers and publicists will be on top, say if you put a celebrity in a product shot for a brand or X...
can you please be a bit more specific? where are you generating, etc... also you can try the #📝|prompting-help channel
nah img2img
I tried using purple color theme but nothing worked
also if you upload those pics you said on a anonymous place there is nothing coming your way as well
how can i invite the stable diffusion bot in my channel
i need help pls
what's up
also laws on the internet are weird since they vary from country to country
at this moment the bot can only run on this server, not in private ones.
what resolutions stable diffusion can handle for reels and shorts
Well for what it’s worth it ignores my negative prompts anyway. I keep telling it not to draw 6 fingers but it still does 😆
Good morning, good morning, everyone! How are we all this beautiful day?
Good morning! 🌞 Feeling great and ready to tackle the day. How about you?
A little bit more awake this morning, and ready to r u n SDXL today! Haha.
What are you up to today?
Sounds like you’re in high spirits! I’m diving into some projects and playing some web3 games. I’m here to chat if you need anything. Have a great day!
I am doing well this morning. It is a lovely morning, after all. Sounds like tons of fun! I'm going to be working on my SDXL prompt list, so, I'll be here, too.
Hey there
You pro at sdxl prompt engineering?

H-hey there guys. Sorry for this but..
How i do a search right now in Civitai ?
Just tried to search for LYCORIS
But when i press enter, nothing happens.. ?
Sorry my english.. :/
Check the filters dropdown.
Yup.. true. Sorry, thank you.
Great i need help
Um can u come to #🏞|general-with-images
does anyone know the settings the server bots use for fantasy art style? trying to match the generation quality on my system.
Same but Anime style for me. Is killing me trying to replicate it for days now
i was more specifically looking for the sampler and think i got it. as far as i can tell uses DPM++2S a Karras.
got the rest of the info from the bot DM
exactly lol thats why its pointless
What’s the best current local stable diffusion app with a gui? Using Automatic1111 but wondering if there are any better ones that u can preferably use on your phone running of your pc for example
Hey guys!
You can try TensorArt
Its a website that supports Android and all sdxl models including dreamshaper and anime diffusion xl + Most Lora
Heyyy. I have a question.
How hard would it be to use stable diffusion to swap someone’s gender.
Like closeups and stuff.
And keep the face the same in different positions?
Roop would probably help you with that.
What is roop?
I shall check it out.
it's not illegal to use sports data and player names in a video game, as a matter of settled law, but the NFL will still sue you and you will still lose. does that make sense?
Issue was incorrectly closed without having been fixed https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/10601
hi
so I got an incredible result img2img with controlnet and a qr code, and am unable to reproduce. Is this expected ? it's totally random even when you input the same seed and prompt. Am I supposed to generate HD pictures every time just in case?
hi
I think the one user may have made an important point. For tile cnet, did you set the input directory for the cnet batch?
It might not recognize anything else beyond the first if you use single image cnet.
Hi
how to make resize like a wallpaper
is there a service I can use to train a custom model with new photos on top of base model that I can select?
i have a real challenge i need help with. I have an image idea that is so specific i am not sure if AI will cut it.
need help with putting a lot of things into one image. a 1960s neon orange tow truck that has a lot of specifics. The background behind is in a fiery derby arena
AI isn't ready to produce such complex scenes from a prompt. You will need to use inpainting and other techniques to build up the parts of the image. Maybe also controlnet.
And regional prompter can help very there @proven holly
i'm not good with the AI as well. Someone tried to help me create what i wanted but they couldn't get it. I'll explain what i need.
I've been messing around with the concept just as practice for img2img and inpainting. still not much success yet
this isn't what I intended but it looks really cool
I can't send images here
i can pull the description of what i am needing
The Rambling Wrecker was a tow truck given to the driver a year before he mysteriously disappeared. The tow truck was painted neon orange. With other reds, yellows, and oranges painted to look like it was on fire. The truck’s front bumper was all brown as it was rusted out. The body of the tow truck was covered with various dings and dents from racing over the years. All the lights on the truck were either broken or missing.
What worried Johnny was the armament and weapons the tow truck was carrying. On top of the roof was a missile launcher. It had six missiles loaded onto a rack. On the hood were two gatling riffles on either side. The front end of the truck had a wedge-shaped plow. The plow had four small holes in it. Two to launch flame throwers. While the other two shot off beams of plasma. On the rear of the truck, it carried land mines. The truck also had barrels of oil the magnetic tow cable could threw at opponents. The barrels could also drop oil slick. Though what made the Rambling Wrecker famous was the tow cable. The cable had a magnet hook line that would trap another driver by swinging them around like a wrecking ball into objects and obstacles. Many drivers died to the magnetic cable.
I sent you a DM with the messed up but still cool image
looks interesting but i would like to have the image mirrored
Has any one ever heard anything back from any emails sent or tickets logged? I have been trying for weeks to get a response from stability.ai or dreamstudio.ai but have heard absolutely nothing. It is super disappointing that they have such poor customer service. I'm not asking for much, just a tax invoice! Are there other people here using them for a business purposes and if so have you been successful in getting an invoice from them?
Hi, every text-to-image generation from different users on different IPs is always queued first. And I want each of these different user-generated outputs to occur concurrently instead of queuing sequentially. Is there a possible solution for this?
how to setup a some kind webui on local pc with stablecod to play with?
You can always use both.
you can and in some cases I do, it just makes it take longer to generate. I tend to keep hires. fix on all the time and only turn adetailer on when a gen is giving me trouble
What software do people use these days to generate locally?
I've always used automatic1111. I tried comfyui but it was just less efficient and didn't have half the plugins I use constantly in 1111
I personally feel that comfy has more control, you can get way deeper, maybe is not more time-efficient but the results are better, specially with SDXL and now the XL controlnets. I also recommend giving a shot to StableSwarmUI https://github.com/Stability-AI/StableSwarmUI
SDXL has yet to win me over. From what I've heard, it lacks of compatibility with SD1.5 Loras and the lack of a good anime model from what I've seen so far also doesn't help
there are quite a few anime XL (and waifu) loras now on civitai, it takes a lot more ram and time to train but they're starting to pop up everywhere.
Why would it be compatible with 1.5 loras?
it won't, it's a completely different beast and double resolution
backwards compatibility of often seen as a desirable feature. That's why I think carbon will beat out rust when it comes to C++ successors
I don't think it's as simple as making things backward compatible. checkpoints and loras between 1.5, 2.1, and xl don't share the training data on the same resolution imagesets.
I interpreted your use of why differently. Functionally it wouldn't be possible, but ideally it would be nice if it was
You're good, I was a little confused myself. Haha.
Good morning, everyone! How are we all today?
hello everyone, I would like to know if we can creat a earth that revolves around itself
animation
Hello 👋
Does anyone know if vlad (now SD NEXT?) supports SDXL? I git pulled the latest and still get size mismatches on the XL models
hi , does anyone have recommendation for model that could do justice to Lovecraft works ? ideally a sdxl model
no idea, but that would be really cool
@pearl jungle how your prompts for Lovecraft images looks?
nothing particular, just put lovecraft and some scene or description from a book (and the usual negative prompt)
have to be careful with negative prompts when you're doing something exotic, I've been bitten by that...start out with no negative and add tokens one by one to control what you dont want
you might end up having to do a lora for this, I'm sure you can find some images online to get it going
sounds like a fun project, I might play around with it when I'm not already training something
There is some Locon or how on civitai, but seems not any miracle
i ll keep working on it, i ll post something when i get decent results
thanks for the advices
images by H. P. Lovecraft.
Try this prompt @pearl jungle
#🏞|general-with-images message
this is funny bit
What's the best English based Voice Cloning Model?
I am exploring a couple of Voice Cloning Models for Text to Speech but haven't had much success.
I have tried --
serp-ai bark voice clone - https://github.com/serp-ai/bark-with-voice-clone/
and a couple of models from TTS like - https://github.com/coqui-ai/tts
Are there any good models which work well for voice cloning with English speakers?
Guys any good alternative to "https://github.com/TheLastBen/fast-stable-diffusion"? to run on Google Colab Pro.
Well then, the solution would be to make a new SD version better than 1.5 and 2.1.
hi. how do you reproduce a result in HD once you are satisfied with the 512x512 output? img2img+controlnet+same seed always produce very different random outputs
Try hiresfix Latent gives similar result but not identical, I personaly using extras tab and there classical GAN resizers.
i have a dataset of 100 images of a character
i am training a lora of sd xl
how many steps should i use
i am using kohya
25 Epoch, 20 repeats is okey?
20:19:51-080943 INFO Total steps: 2340
20:19:51-081943 INFO Train batch size: 1
20:19:51-082943 INFO Gradient accumulation steps: 1
20:19:51-082943 INFO Epoch: 25
20:19:51-084447 INFO Regulatization factor: 2
20:19:51-085463 INFO max_train_steps (2340 / 1 / 1 * 25 * 2) = 117000
and the answer to resize existing ouputs is: YES Extras + SwinIR_4x THANK YOU so much
yes i am using SwinIR 🙂
SwinIR actually tries to repaint what it detects in exactly the same style while the others mostly just upscale and smooth it. R-ESRGAN 4x+ is pretty close too and cleaner, it's just different. the most perfect one is SwinIR indeed
hi, im using comfyui SDXL and having an issue with seed/random/fixed. when i generate an image using "randomize" seed and i want to use the same image to send to the refiner i hit "fixed" however the base generate a different image even though the seed does not change. is this a known issue? and is there a way to fix this
nobody using Alkaid.art for PS?
hey all is developer sandbox and profile dashbord down?
@bright nest how about drag drop image you want to send to refiner? I think when you hit fixed is already different, not sure.
thank you, im not sure how to drag and drop an image to use in refiner. im not sure what node to use to go from load image -> into the latent image Ksampler.. i guess i'll keep trying.
you are right, i forgot it keep stored workflow... But you can at least check if same seed as when you press fixed
yea, just seems weird. i think i figured out the Nodes: load image -> vae decoder -> Ksampler Latent image
hello
got a quick question
are these generated images with open source license? and can be used on commercial work like web designs?
Why are 75% of the photos in pantheon just half-naked girls?
Why can't I access 127.0.0.1:7860, how to solve this problem
I'm trying to do a local deployment, but have been unable to access 127.0.0.1:7860
This means that your web browser is unable to communicate with the Gradio server running on the local machine. There is no sure solution. You must explore each part of the issue.
thanks for your reply, usually what can cause this issue?
First thing, make sure the webui has started and says it is listening.
Show console output from startup.
when this happens, restart the whole thing from the .bat file
i already have down load and reinstall more than 3 times, but still can't work out it
try voicing this issue at #🤝|tech-support
usually there's people that can help with tech issues either on the chat or monitoring
I was very surprised before that I couldn’t find the bat suffix file in my root directory. My webui.user.bat only showed the webui.user suffix. I re-downloaded a bat suffix file, and it was still the same, but I double-clicked him When running, it is displayed as the webui.bat file. This may be the problem. How to solve it?
Lets move to #🤝|tech-support
what are the best resolutions to prompt SDv1.5 at? Like for different aspect ratios
How do I recall a seed with the bots?
Is that new AI generator they released worth my attention?
Anyone mess with the restart sampler from a1111 dev branch? I didn't try it out much myself, but those I've seen talk about it have praised it.