#archived-dots
1 messages · Page 235 of 1
Unless you somehow manage to linearize the target, you wont be able to get any vectorization done with random access im afraid. So no big speed improvements
Post the modified job scheduling so I can be sure you got all of that.

Here's my job scheduling chain. Done on a different thread and takes about 20 seconds to finish. All while the main thread runs at 60fps. Really nice to have that offloaded.
{
NativeArray<AstarNode> nativeArray = new NativeArray<AstarNode>(nodeArray.Length, Allocator.Temp, NativeArrayOptions.UninitializedMemory);
nativeArray.CopyFrom(nodeArray);
Vector3Int startCell = navigationMap.WorldToCell(start);
Vector3Int endCell = navigationMap.WorldToCell(end);
CreatePathJob job = new CreatePathJob
{
nodeArray = nativeArray,
start = new int2(startCell.x, startCell.y),
end = new int2(endCell.x, endCell.y),
bounds = bounds
};
JobHandle handle = job.Schedule();
handle = nativeArray.Dispose(handle);
handle.Complete();
}```Yep. And you want to move that handle.Complete() outside somewhere so you can do something else while the jobs run. Well you can complete it there if you need the result immediately after. But that's it. Easy peasy.
waiiiiit
Allocator.Temp wont work. Crossing main thread - job boundary requires Allocator.TempJob.
Crossing boundaries require TempJob or Persistent. Unity will throw an error on Temp.
Duly noted. You are a saint and a scholar.
NP
As I described earlier, I've managed to get around, or at least minimize, the impact of random access by restricting them to be 1 per chunk. Fracturing my chunks using shared component data so the random access is identical for all entities within a chunk. Then it's only one random read / write for X amount of entities.
And those Entities can be vectorized with the result going into a single random write. It's pretty good but requires static or very rarely changing random targets because changing SCD will require mem-copy.
Consider parallelizing your job as well. IJob is singlethreaded. IJobParallel is multithreaded. If you can of course.
That was the next step after making sure this doesn't blow up. 😛
yep yep. Walk before ya run. I'll be here for another 30ish min before going back home.
Parallel is gonna bring ya a whole new world (of pain) so make sure ya get your questions in before I leave

Definitely consider manually vectorizing when the number of threads approach 1. Big improvements.
I appreciate all the help but after looking it over I think I'm gonna save making it parallel for tomorrow.
NP, good luck
Honestly, I'd be happy enough with having less random access. I figure I have to take some hits but reducing it down more and more is my goal now. Vectorization is, I think, something that can't be achieved here. But just from numbers alone, L1 cache access 1ns, random access 100ns. This alone is huge
Yea. I've had long hours to think about the use of shared component data and how Unity always warns against using them. But honestly, I've come around to SCD. It's really useful in minimizing those random access pulls. Of course, with 1 or 2 entities per SCD, that isnt helpful, but when you approach full chunk sizes. It's really nice.

That's with legit .NextInt() randomization. Manual vectorization which honestly boiled down to manual unrolling of the loop and ... thats it.
so a 0.05ms improvement for unrolling off loop. Yea, if you cant vectorize, stick with basic burst
when data is quite static SCD can help. Otherwise it means a lot of structural changes
it also helps in something that has a static one-depth hierarchy
yep. My definition of static is changing maybe once per second. That's 59 frames of unchanged entity structure so that's good.
I have quite a bit of hierarchy in my entities. Countries -> Areas -> Provinces -> Population. That's 4 levels deep. Thankfully, due to all the entities being segmented by SCD that contains the Entity property of the Province, I can instead change the random access gathering of data from Countries, Areas, and Provinces into one step at the start of every chunk.
Instead of at every entity which would be pain.
I need to think about using SCD some more. The problem are the short living spells, I experimented with creating this data as entity but that was way too slow
i have the problem that not even this is static
i think in your case the entities live for a long time
Yep, several minutes I predict
the cool thing right now, every 1-2 CDFE I can optimize means 1-2ms shaved off
It really is where DOTS break down, highly relational event based games. Slinging a spell from one entity to another just does not mesh well with DOTS.
How many spells do you predict are there going to be? Less than 50?
currently
It's the design of ECS in general. Lots of random access lookups bad.
well, ECS maybe but I'm using not much of ECS by now 🙂
OOS is random access personified. ECS likes data linear and relatively independent.
so it's really a general problem
that's where it shines. does not mean that it's necessarily terrible at other things
Still, how many spells do you predict you're gonna have maximum throughout the game? Or in fact how many different effects from those spells?
Well, I have a few plans with it. One is my personal pet project which will be an incremental game and those go crazy. The other is, there is a company near me that builds online games and I want to sell it to them. If this doesn't work out I want to release it as an asset
If you have 4 affects: Burn, Freeze, Brute, and Chemical (just throwing that out), you can have all your spells just be variations in the values of those. Then you can have either a dynamic or fixed buffer of those relevant values to collapse at the end of every frame.
so in an online scenario, per server instance we're talking about 10k players at least, 10k spells and 100k effects
when you boil down a spell, sure the graphics might be different but they all ultimately affect health in the end.
buffer is too slow, there are 100s of effects and currently I'm building a hashmap when new effects are added/removed
you can instead create a struct that contains 4 ints, first 3 are like coefficients for a quadratic function that interpolates the damage that the spell will do to the target's health over time, and the forth being the time remaining of that spell
And you dont want to be adding and removing space in a dynamic buffer, memory should be pre-determined.
Say a maximum of uhhh, 7 spells can affect a single individual at once. No more.
Make a struct that contains 7 x 4 ints (or bytes) and one more int containing the number of spells currently active on the target
the complexity goes really deep. example of a spell (Thunder from FFXIV): you cast a spell that puts a DoT on the target, on every tick there is a chance the next thunder will be instant and does all the damage over time instantly (if you have the trait)
throwing vectorization out the window for maximum memory optimization, you can instead start hardcoding those values. Because think about it, the only value you really need on a target entity is the time remaining and the type of spell cast
From the type of spell cast, you know the damage and effect that the spell can do to that entity before hand
In a single int, there are 4 bytes, each with 4 bits. So 32 bits in total.
memory footprint is really optimized now because I build every spell as blob
The maximum time a spell can have on a player is.... 32 seconds. That's 2^5, leaving behind 27 bits
27 bits can map to 134,217,728 individual spells.
a simply massive switch statement can allow you to code all those spells, simply from the type
and i pack effect types currently as flags. currently i have 51 which i can pack in 2 ints
bit flags are when you need maximum performance and vectorization since they can be applied and read in vector form
But you wont be vectorizing anything. Use those 2 ints to map directly to a ulong that numerically states the flag
Or, with only 51 flags, just a byte with 256 possible flags is good enough
int has 32 possible flags
yea, due to bits. But you dont need them in bitflag form. Why? A value & bitflagCheck > 0 for a single value is identical to value && nonBitFlagCheck.
and the non-bitflag drastically opens up the number of flags you can possibly have
Bitflags are used when you need to do something like ... I dont have my IDE open. But processors can bitflag check across 8 int packed values
wait, the flags are needed because there can be multiple flags, you are still talking about the effects, right?
ah, multiple flags. How many combinations though?
is the number of realistic combinations worth the memory cost?
always
and if you're doing it across 2 ints, merge them into 1 long.
and depending on the number of checks you're willing to do, you can have a merged regular and bitflag by instead reserving 1 or more bit for an "alternative" flag possibility
1 byte normally has 4 flag possibilities, but if you reserve 1 for a "negative" flag possibility (now requiring 2 checks). You can increase the number of theoretical flags to 6.
Of course, that results in the possibility of conflicting flag definitions so you'll need to design a way around that. But yea.
well, let's put it this way, I have a long way to go to start micro optimizing, the real problem i have with effects is that that long living ones are still created as entities and the instantiation takes really long. when they are created, the checks are marginal and when a tick is hit, their path is quite optimized to be quite fast. the runtime data for them could be brought down, often by a lot so I have to think about that
Do each individual spell have their own set of independently set spells?
Like Fireball with Flag AB and Fireball 2 with Flag BC? Or are they defined on a per-spell basis before hand?
per-spell basis
because I want to elaborate on my buffer suggestion earlier. What you need is duration remaining and spell signature.
You can then use interlocked read and interlocked increment to determine the index location to write the spell onto the target entity
Without need for more memory in the form of yet another buffer
some of the data for a effect: create on target or source, stackable?, stack size, persistent, duration, dispel type that's for base. then there are combat effect arrysy wit type, stat type, spell school, resource type, crit able, and trigger arrays with trigger on target, create on target, condition type, trigger chance, triggered spell reference, trigger self, remove when triggered.
Is that dynamic based on the target of the spell?
there are some more but i want to give an overview
Well that doesnt matter, is the basic values of each one of those parameters static per spell?
Can the caster of the spell affect the value of any of those parameters? Does that need to be communicated?
sure, otherwise i could not build blob data
well, yes but that's under conditions
and some effects are based on the spell stats
So the caster's infomation needs to be communicated to the target as well? Along with the base stats of the spell?
yes, and it has to be snap-shoted when created
Are they predetermined combinations? Like based off the caster's level or other singular caster property
What Im aiming for is minimizing the actual transferred information.

If you want to remove the need of an external buffer and instead write directly to a component on the target for significantly better performance, you need to limit the quantity of communication between two entities
so what are the properties of the caster anyways?
Strength, intelligence, wisdom, those things?
what properties can ever possibly affect the results of a spell?
yeah, long list 😄 crit, hit, physical modifier flat, multiplicative, etc...
the spellstats on the other hand are reduced to like 6 variables
I have written to target buffers in my first iteration and that was really bad performance
6 vars of type? Can you compress them into smaller bytes or halfs (1/2 of a float, equivalent to a ushort).
as I wrote in my thread, DynamicBuffer performance is garbage, I don't know what's wrong with them
forget dynamic buffers, we need fixed lists. CompileTime-allocated IComponentData that mimic an array.
the effect now is only 3 comps, 2 are highly relevant. the main comp can be reduced a lot
or even exchanged with an id
but I exchange cpu speed for memory here
Do you want maximum CPU or minimum memory usage?
max cpu 😄
because my proposal is assuming unlimited memory
your chunks will contain double digit max entity quantities by the end
i wrote this some time ago, if it continues like that i won't have anything running in entities 😄
because yeah, i can rip out the effects as entities and have them live inside a nhm with a fixed/native list
Alright, lets say that the 6 vars must be full sized types (ints, floats). That means you need a IComponentData called SpellTargetList with.... hrm
whatever, 10 maximum amount of spells that can affect a single entity.
So you'll have a massive struct with 10x a required spell information transfer.
On the spell cast phase, a caster will random access their target, InterlockedIncrement the number of current spells affecting the target, then directly write to that index inside the component
it's been fun but i really need to go to bed, lol. my gf will have breakfast soon haha
Ah, alright. Good night.
good night o/
Good thought exercise. I wish ya much luck in figuring it out
Anyone dealt with this? The previously scheduled job TRSToLocalToWorldSystem:TRSToLocalToWorld writes to the ComponentDataFromEntity<Unity.Transforms.LocalToWorld> TRSToLocalToWorld.JobData.LocalToWorldTypeHandle. You are trying to schedule a new job SpellCastSystem:SpellCastJob, which reads from the same ComponentDataFromEntity<Unity.Transforms.LocalToWorld> (via SpellCastJob.JobData.LocalToWorld_Lookup). To guarantee safety, you must include TRSToLocalToWorldSystem:TRSToLocalToWorld as a dependency of the newly scheduled job.
Order is, Physics, Complete physics, my systems (where localToWorld is read), transform system group
I'm not sure why TRSToLocalToWorldSystem isn't completing at the end of the frame
funny enough, I only get this error when I'm taking out a code path that's just data validation and the part where LocalToWorld is read, is executed faster
Anyone have an example on how to construct a BlobAssetReference<BlobArray<BlobString>> from a string[]?
I got it halfway done, until I tried filling the BlobArray with BlobString data, then I get an error
here is my current attempt: https://pastebin.com/YAqZqFTy
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
try ArrayData[i] = value;
or scratch that, but there's some mixup here
ah, you're constructing another root?
ok, so BlobBuilder.AllocateString(ref Array[i], data[i]); could work
I think I figured out, or at least the error went away;
yeah, exactly that
building blobs is really weird at first 🙂
I do have to dispose of the BlobReference, but I don't need to dispose each string individually, right?
can't allocate strings with using(builder)
since it's a extension method that passes the builder as a ref


public unsafe struct BurstMethodTest : IJob
{
public int count;
public NativeArray<int> val1;
public NativeArray<int> val2;
public NativeArray<int> outputNormal;
public NativeArray<int> outputBurst;
[MethodImpl(MethodImplOptions.NoInlining)]
public void Execute()
{
NormalMethod(count, (int*) val1.GetUnsafePtr(), (int*)val2.GetUnsafePtr(), (int*)outputNormal.GetUnsafePtr());
BurstedMethod(count, (int*)val1.GetUnsafePtr(), (int*)val2.GetUnsafePtr(), (int*)outputBurst.GetUnsafePtr());
}
[MethodImpl(MethodImplOptions.NoInlining)]
public void NormalMethod(int count, int* val1, int* val2, int* output)
{
for (int i = 0; i < count; i++)
{
Unity.Burst.CompilerServices.Loop.ExpectVectorized();
output[i] = val1[i] + val2[i];
}
}
[BurstCompile]
[MethodImpl(MethodImplOptions.NoInlining)]
public static void BurstedMethod(int count, int* val1, int* val2, int* output)
{
for (int i = 0; i < count; i++)
{
Unity.Burst.CompilerServices.Loop.ExpectVectorized();
output[i] = val1[i] + val2[i];
}
}
}
One thing that doesn't work out is that the NormalMethod is vectorized
Otherwise it's burst compiled
You've placed Burst compile tag over the entire struct. That will burst compile all the functions that are called from Execute(). What you need is [BurstDiscard] on the NormalMethod
BurstedMethod will be bursted as usual without the tag.
ok, then all is fine. wasn't sure in my other jobs if this is actually doing what it's supposed to
Jetbrains Rider has a really neat intellisense tip that Mark's which methods are bursted.
that's cool, sadly I don't have it 🙂
ok, so vectorization is really a simple 4x speedup. 0.36ms vs 0.10ms
non vec'd doesn't run too bad either. as long as there's no random access in between it's quite fast
what also really seems to break any speed is conditions, that really sucks
Yep, conditional very very bad. Of you need conditional, make sure they're inline
just 1 condition bring the method up to 0.52ms
Only 2 conditional are "okay", not good just okay. Inline c ? b : a and early returns. Everything else breaks vectorization and most of Burst's optimization.
And early returns only work because they skip a lot of work
hm, I thought we're beyond having to write inline conditions because the compiler understands it?
I haven't tested it myself. Try a simple if else case to set a value compared to inline.
I wonder what timings professionals have for what I'm doing
it's quite impossible to make this condition-less
and there exists no a ? b
as in, condition with no else
Default?
hm, yeah I guess when a return value is involved. sometimes it's just a method call
can entities make sure when you have an archetype with compA and comB that compB is actually right after compA in memory? From the memory layout I wondered why they save comps in 1 long array and not have 1 array the archetype itself. with reading 1 cache line you can never get full entity data. but i guess that has to do with vectorization and those approaches don't work together
i guess that's a stupid question when all is in 16k chunks 😄
dumb question out of left field, can you do pooling on ECS entities?
sorry if its particularly dumb, I'm.. super new to both pooling and ecs lol
in principal, yes, I've done something like it. but if you need it, there's a flaw in the design
for what would you need it?
icic. I was just rolling the concepts around in my head, thought experiment, and I asked myself, well, which would be more performant, quickly realizing that they.. may not be mutually exclusive
ecs probably smokes object pooling though eh 😛
entities has some inherent problems right now with the pooling concept. and for anything <10k you would not need it
you're welcome
Anyone have a link to example code for get/set? public unsafe fixed float pointx[100];
Last I tried, it didn't work I think
Can somebody help me to destroy the entityRoot and childdren? Enemy is a GameObject converted to entity with an sprite renderer as a child.
Thanks

there are parent and children component data on the entities. just look in the entitiy debugger
Yea I know, but how come this is not automatic.. What should i use to destroy the childreen? linkedEntityGroup?
get the entities from these components, they're not just tags
OK, Ill check how todo that. I worked with other ECS.. but unity ECS is kind of weird xd Thanks
Destroying an entity which has a LinkedEntityGroup automatically destroys the other ones. Not sure what's going wrong here
Can someone explain very simple how/why one should use Ghosts? I need to work with them but I find it kind of hard to understand the functionality of a ghost, what exactly is a ghost?
the requirement is following
Then load that file on the server (including ghost addressables)
Then load that file on all clients (excluding ghost addressables)
1 - is that a DOTS question?
2 - what are ghosts? last time i checked there was no general definition for unity regarding 'ghosts'
- I thought so, at least that is what I understand from here, since it uses ecs chunks? https://docs.unity3d.com/Packages/com.unity.netcode@0.5/manual/ghost-snapshots.html
- yes that is my question 😄
yea it's part of the netcode package, haven't delved into it since I just only use the transport layer
well it's like it says. ghosts are entities that the server owns and that the client cannot affect
My advice, dont use DOTS netcode. It's stuck in development hell along with Entities in general.
Either wait a few months / years or do as ItsJustBlank did and roll your own networking with Transport. Transport is being released 1.0.0 very soon
this is not something I can change. We work with them at work and I am the newest developer in the team, still learning dots^^
Ah, RIP.
wouldn't say rip. i would say that's great!
So a ghost is something on the client side, just for visualization, so the client doesn't have to compute all the things the server does?
DOTS netcode is even more barren and bug filled than normal Entities
and has 0 community support
the server simulates these entities. the client just represents them
okay, then I understand the requirements
it's actually pretty well stated right on top of the docs you linked
I had difficulties to connect the requirement to the docs, and I thought "why excluding the ghosts from the clients". But they dont have to generate the ghosts, they are recieving the ghosts from the server, and that is why I have to exclude them when loading a file
correct
thanks for clarifying 🙂
next time when asking a question regarding a specific package, it would be great if that package was mentioned though. well i mean mainly when a 'non-standard' package is used......like netcode
then both my questions would've not been needed i guess
well....that of course is because it hugely depends on entities itself
eh, dots netcode isn't too bad. I've worked with it and it was better than any other solution that exists for unity with these specific requirements, namely authorative server
it doesn't scale to battle royale levels though, >100 players in 1 area
but it can be done, easier like with anything else really
for getting started, read the forums. there were some good questions asked with long detailed answers by tim. information is very un-organized but it is there to find
@viral sonnet do you have any idea what happened with SpatialOS? when i worked with it it was quite similar to how netcode is now, but more scalable e.g. BR games no problem i still have a legacy account but it seems it's been integrated into zeuz or smth and i cannot find an SDK for SpatialOS anymore
never used it or really cared about it, personally, having this kind of tech as indie is way too expensive, same goes for photon. i'd even argue for a company too. you'd need a very big stable user base and with online games, this is the quickest way to bankruptcy to rely on this tech from the beginning without a real user base. i think it makes sense once you're big and stable. there was this one project on the forefront of spatialos that wasn't going very well and i see now in the wiki 4 out of 6 projects are cancelled. make of that what you will. 🙂
BR is quite the pipedream for most companies. even more so than MMOs technically as in MMOs you don't have so many people in one place. it happens but it's not the norm
nah. it's not too expensive. you literally pay for how much you use it. also you're probably talking about mavericks, which yeah, sadly gone into administration. but not because of spatial os
I can't remember pricing anymore. Their website is mostly gone. What I do remember is thinking, haha good luck with that price. Do you still have numbers?
unfortunately i didn't ever release anything with spatial os, but i've had bigger projects running extremely well on it and for devving purposes it's completely free anyway. i don't have exact numbers anymore but it wasn't too bad. you're afterall not paying per server but rather per user that connects to the server. was maybe a tiny bit pricier for low user count but when you get 2K concurrents it's pretty much equal to other server providers if i remember correctly
ah, shame then. sounded really cool - photon isn't too bad pricing wise, did it get cheaper at some point? but they seem to lure you in with 2000CCU at 370$ and then 10k at 2900. for anything that isn't aggresively monetized these numbers just don't work. having your own software with 10k CCU is a fraction of the cost. Sure you pay for the technology but I think these companies are charging a little too much for their service.
and if the game doesn't make enough money you are REALLY screwed
like, you can't even play the long game
you're only building for spatial os if you're ambitious / making a big game if you don't make money with that game your whole company is screwed
that's a given. with these services you're making yourself more fragile is my point. most large scale games fail hard. even smaller scale MP games have it hard. for indies I think the best place is coop/4v4, something really small with your own software. the biggest contender for successful indie game is among us and that uses hazel networking AFAIK
i'd also argue, having no real MP expert in-house is a recipe for distaster
well... this just got merged to the Graphics master https://github.com/Unity-Technologies/Graphics/pull/6071
GitHub
Purpose of this PR
This PR implements URP/HDRP minimal picking support for DOTS 1.0. This is intended to be on parity with Hybrid Renderer V2 picking in order not to introduce any regression with t...
"in order not to introduce any regression with the release of DOTS 1.0."
I'm working on a TD/RTS/MOBA style game -- would DOTS be a good fit for things like unit behavior, vision grids, etc.?
Trying to debug my project a bit. Are referenced prefabs by IDeclareReferencedPrefabs interface also converted in the same step? E.g. I have a Sub scene which converts an entity referencing a prefab. Will the prefab get converted and run through the Conversion Systems as well when I press Reimport of the sub scene or will it be converted at some other point? Edit: Seems like it was converted when I ran the editor instead.
- Good fit? Should be completely do-able from what I see.
- Worth the trouble? Not for me to judge. Depends on the scale of everything. 10-player MOBA? Maybe not necessary. RTS with hundreds of units doing things at the same time? Yeah, you'd probably want to make this as performant as possible, as early as possible.
I'm not following all the developments very closely so forgive me for asking - DOTS 1.0 is supposed to be ECS, Burst, etc. but no longer in preview?
I’ve had that branch bookmarked this past month and have been constantly checking to see when it got merged, hoping it is a large part of returning to public releases
Yeah @sinful cipher a 1.0 is when it’s ready for the general public. Which still feels a long ways away
https://www.youtube.com/watch?v=BpwvXkoFcp8 that was a good talk about burst for someone like me
basically i'm now pondering about replacing all my data with [type]4 because otherwise my code isn't vectorizable
and 1 spellcaster comp gets turned into a comp with 4 in it
not sure if that's wise but I'm thinking about it
Yeah i was asking because it would be such good news its hard to believe
@sinful cipher just to set expectations right, Burst + Jobs have long been out of preview, that will not change. And while Unity has been changing things for the past year, I still wouldn't expect full DOTS solution for 1.0. More like more stable foundation for things to come. Probably tighter integration with the rendering side too since there's a ton of work been done on hybrid renderer
at this point people just want to see some update I suppose, considering there hasn't been any update for Entities for past 9+ months
@dull copper right, updates to Entities was indeed the one I primarily am interested in at the moment
Burst and Jobs was fine until sorting and preparing the data for execution inside jobs became like many many times more expensive than running the actual jobs
Entities helps a lot with that
Even then, most of the cost is trying to talk back to the GameObject world to deal with Rigidbodies and such. (Unity Physics does not support everything I want to do yet)
So anything that exits the preview stage is super exciting to me
I'm mainly waiting for this to become a thing #archived-hdrp message
basically get ECS rendering gains for traditional gameobjects
Any suggestions on modifying existing components on newly Instantiated entities, for example to add some setup data
Say for example i have a system which spawns character entities, the characters have say a Health component, and i'd like to set the MaxHealth for each character when i spawn
I know this sounds relatively simple but the issue i'm having is:
I've moved my spawning into a system/foreach
I have to then use an ECB to instantiate the character entities
But i can't use the ECB to for example get the existing Health component, like this:
var health = EntityManager.GetComponentData<Health>(charEntity);
health.MaxHealth = charMaxHealth;
ECB.SetComponent(charEntity, health);
Previously in other systems i've added an Init component, then iterated entities with that component, modified the components inside the ForEach, and then removed the Init component
But that's hella painful.
Just wondering if anybody has any interesting ideas or ways of dealing with this
you can initialise values using an ecb as far as I'm aware 😕
var tempent = ecb.createntity(typeof(blabby).....ecb.setcomponent(tempent, new blabby{val = whatever}
rough example code
yeah the problem i have is the components are already initialized inside the original gameobjects authoring components Convert methods, and i need to keep those values intact ( basically it's references to child entities etc )
Yes, the 2 phased instantiation is annoying with ecb. The only way I solved this was having the data ready before the instantiation.
or, not doing it in ecb 🙂
ooor, authoring the data correctly in the first place
yeah you don't need an entitycommbuffer for everything, an EntityManager might work just as well for this
on the right side, i'm watching "Nanite in UE5: The end of polycounts" - on the left side, i'm watching unitys safe mode crashing because of a script error. lol that's kind of depressing
not sure what happened that i closed the project yesterday and now unity can't even start anymore
next up, visual studio crashing. man, sometimes it just keeps on going
that was a fun hunt. my active VPN was responsible for making unwrapcl.exe crash which was invoked by bakery
i do not like unreal engine. but nanite definitely is something great
imo nanite is overhyped, its definitely cool tech but I think its really intended for high end productions like film or animation, where they can ignore the resurfacing step in the art pipeline. maximizing it on a regular title isnt really feasible given hard drive space required for massive poly count assets
lumen on the other hand, that I wish unity had an answer for
XD are you serious? lumen looks terrible. unity already has support for hardware ray tracing. use that. soooo much better
tbh, hard drive space is almost irrelevant these days
its irrelevant if you arent using raw zbrush models. im not really sure of the requirements of lumen in comparison to raytracing, but id expect it to be far less
Tell that to console players
THREAD CREATION: Is there a way to make and use a thread that's neither on the main thread's core, or any of the threads used by any Jobs, so as to be sure it's an otherwise unused core of the CPU?
i dont think jobs allow you to manage threads
well actually i think you can limit the threads used but i dont think theres any fine grain control that you're after
Not with Jobs, I'll make the thread myself, my own. I just want to know if there's a way to pick a thread that's going to be on a core that's otherwise unused... in other words, if I limit Jobs to threads ABCD on cores 2 and 3, main/Unity uses core 1, can I then create a thread on core 4, myself, and be sure that Jobs are only using cores 2 and 3?
no idea sorry
Thanks. Will keep looking and reading and attempting to learn.
So I'm working on some simple conversion system that clones BlobAssetReference<Collider> after it has been generated. My question is if I need to also use something as a "BlobAssetComputationContext" or something else like regestering to a BlobAssetStore after cloning the BlobAsset? If not, what would take care of it's disposal if needed?
jobs will always use all threads. you can schedule a thread yourself and then do something on it, as long as your task is running, no job will use that thread. once your thread does no work, unfinished jobs will get put on that thread. dots uses your cpu to the maximum possible efficiency. why waste a thread if it doesn't do any work?
BRILLIANT. Dreamy, even. Is there a way I can make sure the thread I pick and use is not on the main core being used by Unity's main thread?
And also not on the core being used by the Audio thread.
not sure. that'd probably be something .net internal. there's probably some documentation about it
Will look around. Do you happen to know about Scheduling? It seems that scheduling a job doesn't actually schedule it to get done, merely registers it.
yeah, unfortunately that was also something i was looking into, also because i wanted to have long running jobs with burst that don't get run every frame, but unfortunately both these things are currently not possible. it runs main thread code, initializes jobs, registers jobs, does everything remaining on the main thread, and then pretty much runs all jobs at the end of the frame
i hope we'll get an api for more granular adjustment eventually
You've answered my next 10 questions here!!!
And also confirmed my suspicion, that despite the superficial ease of use of Jobs, it's not for me, and what I'm doing... I'll have to make my own jobs and threads.
The more I think about this, the more limiting is this approach to Jobs. It also makes it impossible to do little Jobs that take very short blocks of time whilst backgrounding bigger Jobs that will take multiple frames.
Or, worse, short Jobs distinct from longer Jobs might take "LongJobs + ShortJobs" time to run.
that is not the case because the scheduler does something called 'work stealing' if a thread finishes early, the scheduler grabs a job that hasn't completely finished yet and put's it on the finished thread
but multi-frame jobs are definitely not possible right now which is a bummer
Wow. I wasn't aware of this, at all. Was operating under the presumption that multi-frame jobs were the ideal/best use case of Jobs, to take things down from needing (eg) half a second to a few frames by splitting across cores.
If I need something done immediately, as fast as possible, and want to use Jobs to do this across all cores, how do I do that? And is that the ideal use of Jobs?
Alternatively, if I want to issue a Job across all but the Main thread, and have the Main thread NOT wait for the Job to complete, and later guess that it will be done in LateUpdate, how do I do that? And is this a more ideal use of Jobs?
Which I guess means I'm asking for a doc that's "10 best uses of Jobs System".
FROM DOCS: "Flush scheduled batches
When you want your jobs to start executing, then you can flush the scheduled batch with JobHandle.ScheduleBatchedJobs. Note that calling this method can negatively impact performance. " -- why would/could this negatively impact performance?
Is tracking the JobHandle not an option for you? Cause you can wait until the JobHandle.IsCompleted returns a true and then call JobHandle.Complete()?
Other than calling Complete() on a jobHandle, i can't see how to get it to actually DO the job.
that is how you do jobs. the only way currently.
JobHandle handle; // class variable
// An update loop
if (handle.IsCompleted) {
handle.Complete();
handle = new Job { }.Schedule(...);
}
Something like this ^
If I'm trying to get something done immediately, as fast as possible across all cores that are not the Main core (so as not to suspend/pause/wait Unity and my other game logic), how does this "issue/invoke" the Job to actually begin getting Done?
Well this was more for the multi frame part I read
Was operating under the presumption that multi-frame jobs were the ideal/best use case of Jobs
it doesn't. you always wait for jobs
Been away from Unity for a while. Just did a fresh setup.
Editor 2020.3.14
HDRP 10.5.1
Entities 0.17.0
Hybrid Renderer 0.11.0
Input System 1.0.2
Platform Windows 0.10.0
Unity Physics 0.6.0
Have a plane, capsule, and cube in ECS subscene setup.
Hitting play in editor renders everything correctly, no console errors.
However, when launching a build (mono, net4.x), I get this error:
Autoconnected Player A Hybrid Renderer V2 batch is using the shader "HDRP/Lit", but the shader is either not compatible with Hybrid Renderer V2, is missing the DOTS_INSTANCING_ON variant, or there is a problem with the DOTS_INSTANCING_ON variant.
And my capsule and cube don't render because they use HDRP/Lit.
I have no clue where to add DOTS_INSTANCING_ON variant into the shader. Has anyone experienced this issue before?
make you checked the GPU Instancing box
but yea as MindStyler said, you always have to wait for jobs
currently at least
@coarse turtle how can multiframe jobs be done without causing Unity to stutter until it's done, if this is the case? From this, I'm getting the impression there are only two good uses of Jobs:
- WHen you have something that can be done very quickly in one frame if it's spread across all cores and you need it, and can wait for it....
use cases of jobs: do lots of work efficiently and quickly every frame
(lots is relative)
- If you have something that's going to take 20+ frames on the main thread when the game's not running, but only 2-3 frames when the games not running and it's spread across all cores.
Just to be clear, you are referring to the box in the Material Inspector under Advanced Options section? If so, I need to make sure ALL my materials have this enabled, even if they will only be instanced less than 5 times?

if you want to use hybridrenderer v2 yes
*and don't mind if nothing else can happen whilst you wait for these little "lots" (which is beginning to look like a better word than Jobs) get processed.
I've only had one case where I needed a multiframe job due to legacy architecture in a project which made the thread run for more than 16 ms and that's how it was handled (was it decent - no).
Preferrably, yes - you'd want to get a lot of work done within some time slice like 16 ms.
If you need to do something while these jobs are in flight and manipulating the data, then better to double buffer data if you need some read operations 🤔
'nothing else can happen' literally you pump your cpu to the max so all things are happening
The darker reality, I have many other things chewing into that 16ms, and only have maybe 4 or 5 I'd happily spare, at the risk of blowing out and missing a frame.
For me, this is a problem due to the desire to work on Audio in these "lots" and I don't want to risk glitching, but I'm amazed that Jobs are so tightly coupled to the Main thread.
i imagine you're processing the audio and then need to play the audio after you're done processing it?
the questions I'd ask myself in that scenario is how much of a time slice do you need and how accurate do you need the computations. What's the minimum and upper bound when doing whatever function you need to process the audio before it gets glitchy?
And if you need more power, can you offload an operation to a compute shader 🤔
Unfortunately my game is GPU bound, so there's no Compute left to lean on. And I'm looking to see how much Audio processing and effects stuff I can do, and sound generation. How long's a piece of string?
yea hard to say without knowing how much time is available, b/c at that point I'd get to optimizing and figuring out trade offs. The problem with scheduling and completing immediately is that it blocks the main thread. You could try to schedule right before PostLateUpdate and complete on the next frame (so while your game is doing the render step, a thread can run into the next frame and still do work).
When you say Schedule, you mean call .Complete so that it is actually scheduled to get DONE, at PostLateUpdate, and the work is being done during the rendering cycle, and then hopefully complete early in the next frame's calls, right? // if so, Unity really needs to have a rethink about their use of the word "Schedule", that's right up there with calling the timeline in Animator, Animation and Timeline, the timeline.
nope just Schedule. You call Complete on the next frame before you Schedule again.
How does that help? Then I'm doing the work at the beginning of the frame, and risking all logic of game getting held up by the effort to do the Job, right?
so it'd look kind of like this
handle = Job.Schedule(); // -> Schedules the work
handle.Complete(); // Forces that the job is completed even if the Job is not done.
If the job is done, it marks the job as done so that the safety handles don't spit out errors thinking that the previous job was not finished
Right, so handle.Complete(); invokes the Job. Then the ideal time to do this is after all the Main thread's work of shoving everything to the GPU for rendering has been done, and the GPU is busy presenting the scene... not at the beginning of the next frame's logic
handle.Complete() forces the inflight job to finish up. I don't think "invokes" the job is accurate. From what I've profiled even when I call Complete() on the following frame, it's not as if the Job I'm scheduling is completing immediately when I call Complete()
it ofc depends on the scheduler*
From what @haughty rampart is saying, before you call Complete(), Jobs have not started, at all.
So you could Schedule a Job, and then wait 10 frames before calling Complete(), and during those first 10 frames, the job hasn't been done, it's just sat there waiting for you to call Complete on in, hence me using the word "invoke" or "issue" to describe this calling of .Complete (btw, how did you do that inlining of the code style?"
i've tested it previously, waited multiple seconds before trying to get the result of job and it did throw an error until i call .Complete() which then DID the job and i could get the result
This is excellent information. It means that both words "Complete" and "Schedule" are very poorly chosen, or I'm just bad understanding Unity's naming conventions.
@visual tundra here's what I'm talking about

schedule is chosen because it tells the scheduler to get ready to complete that job because at some point in the future we want the result. but the scheduler only does the job when he's told to
Schedule, the way the rest of the world uses this word, means to set a time to DO something.
because if you don't need the result currently, you can strip time off this frame
eh, not really. it says: we want to do something at some point
Complete is most often a statement of state, not the issuance of a command "to DO".
exactly, it presumes that time of doing is already set. It's both the time to do something, and the task. And the time set to do is the most important part of it, as you can have an empty schedule, or times in your schedule, but something not on your schedule is not yet scheduled to be done at a time.
think of it like trello: you create a card, schedule it for some point, and then you tell the worker to do that sometime later
you didn't specify any time
That might work for you and how you think of the word schedule and a Job, but I think the majority of common English usage of the concept of a job and scheduling (as a concept) imply (quite strongly) that scheduling a job means setting it to be done at a time. In this case, that's not the case, it means "put it on the list of things that can be invoked", much more akin to putting them in a delegate.
yeah i mean for 'normal english' sure
And "complete" doesn't schedule a time, which makes it much more confusing.
complete pretty much is just telling your worker to get this done now
i definitely see what you mean, but i also see the more general meaning of the words
I am starting to glean what it all means, but it's not been easy because the wording in the docs and the naming conventions are a bit... gnaff.
To then combine that awareness of what they're trying to be, and realise the enormous limitations of the Jobs System (that it's barely a system and that scheduling isn't really what's going on without waiting etc) and it's becoming clear that this "system" is either far from finished or very limited for reasons that aren't immediately clear.
if they were up front and said it how you said it a little ways back @haughty rampart when you mentioned saturating the cores to get something done fast, at utmost priority and the expense of anything else, despite this being threaded, then I think it'd make generally understanding it much quicker, and seeing when to use it and what to it's useful for, infinitely faster.
it definitely is far from finished. but it also was primarily built to work on a frame by frame basis, because entities works solely with jobs and you want to do entity transformations every frame (usually)
it's built to speed up frames, not offload work and complete it at some point in the future
(which i agree should not be the only focus / possibility)
Given how logic, movement and state are three things, I'm super surprised this wasn't given more independence, such that movement could be split between some cores, mesh conversions and animations some other cores, audio processing yet others, and perhaps AI on yet others, so that true concurrency could be achieved, with independent objectives able to operate on individual priorities and timings. Especially INPUT!!!
wdym? everything has to be computed in the frame anyway. so in what order you do things and where you do things is pretty irrelevant. why reserve one thread only for audio if this thread completes all it's work in half a frame? why waste the other half not doing anything?
Audio is a special case, as it's operating on a very different timing, sample packets based, and absolutely imperative that it get higher priority, because any glitch can causes a loss of suspension of belief etc. Input is a special case for different reasons, but similarly significant, and has another timing issue, in that each platform and input type can be operating at different time rates. AI doesn't operate at realtime for strategy, meaning it can and should be spread out based on what's transpired over many prior frames, and take as many frames as it needs to figure out strategic responses. etc.
input is still handled on the main thread though. that's not jobified yet
I think you said it very well earlier, when you used the word "granularity", it would be wonderful to have multiple layers and levels of granularity for issuing and awaiting Jobs.
and idk, there is btw DSPGraph which is the new dots based audio system. it's really really early in development though but might be worth looking into if you really want to do audio things. i don't know if it helps you but it might
This is just amazing, to me. Input, UI and Audio should all have their own threads. Input and UI thread priority and rates should be adjustable, dynamically. Audio's rate is tied to the latency setting.
DSPGraph hasn't really reached the stage of conception. It's VERY early on.
agreed
out of curiousity have either you used a windowing API where the inputs are grabbed on a separate thread? 🤔
no i haven't. haven't found any drawbacks to the new input system yet
Don't know if you'd call it a "windowing" API, but have played with MIDI on several platforms, and iOS's Pencil and other inputs, which are able to be set and used as different "threads" at various (and varying) rates.
The Pencil stuff in iOS is quite incredible.
well i say windowing API so things like win32, glew, glfw, qt, winit can be used to make games since you can hook in a rendering layer
I plead ignorance, I don't know what any of them are.
Pinvoke gives you some latency though too
yea no worries just curious ¯_(ツ)_/¯
I think MIDI is what games and game engines need to take a look at, now that we have 720Hz touch responsiveness in gaming phones.
Audio happens at a different rate to frames. Input comes in, from player, and at some point the audio must be adjusted to demonstrate awareness of this input action, as fast as possible. That's why the main thread should be free most of the time it can be, on one level. On another, if I want to dynamically shape or create audio, and need benefits of a Job to do that, I can't sacrifice the flow of the game to do that, so am looking at the time the CPU is idling whilst drawing is the priority of the game engine, hence suggesting that the latest possible update is the time to issue the Complete call, to get the work done whilst the GPU is busy.
well idk the scope/needs of your projects but if you can architecture it in a way where it's not noticeable then that's a win for you and your users ¯_(ツ)_/¯
That's what I'm hoping for... more noises, more often, without any cost. Perhaps I should buy them all Thread Rippers.
Reading the docs more closely, this is either misleading, wrong, or very wrong: https://docs.unity3d.com/2021.2/Documentation/ScriptReference/Unity.Jobs.IJobParallelFor.html


Sorry to bug you... is this showing that the Job is actually being invoked and done 0.04ms after you've scheduled it?
How is it that you're getting scheduling to actually invoke/perform the Job given what @haughty rampart's suggesting about .Complete being required to "invoke" it?
it's dependent on the thread scheduler from what I can understand. Because the my threads are unoccupied it looks like the thread scheduler determined worker 0 to execute the work.
So this behaviour is going to be different (VERY) different on differing platforms, particularly mobile, where there's (on iOS) sometimes only two cores, and Apple and Unity might be using different ones, meaning Unity doesn't see any available worker threads?
I highly doubt Unity will see any available worker threads, but it depends on whether a worker is free to do the work
Given that jobHandle.Complete() forces the Main thread to wait for the job to complete, and likely forces the Job to be performed if it hasn't already, is there a query available in the API, that simply asks the question "Has jobHandle completed?" without forcing the locked wait state, or forcing the performing of the Job there and then?
(Other topic)
I recall there being an example or article on how different MonoBehaviours implementing IConvertGameObjectToEntity can access/reference eachother's entities during the conversion phase.
Does anyone know more about this perhaps?
JobHandle.IsCompleted
conversionSystem.GetPrimaryEntity(someOtherGameObject), you can also pass in another monobehaviour into that method
Ahhh right, thanks. Is it always 1 entity per GameObject, by the way?
Yea typically 1:1 mapping - if you use Subscenes if you try to "clone" the entity during conversion it throws an error due to non unique entities
And is this a 'multi-pass' system? Like, in pass #1, entities are created for every GameObject. Then in pass #2, your conversion code can already access all entities for any GameObject that is supposed to be converted?
Use case: I have child GameObjects that need to reference the parent GameObject's entity during conversion
Oh maybe I found this already
do you use: https://docs.unity3d.com/2021.2/Documentation/ScriptReference/Unity.Jobs.JobHandle.ScheduleBatchedJobs.html at all?
Yea I'm very sure that's how it works, it has to create all the mappings first before you can call GetPrimaryEntity(other) so that you wouldn't get an error
Alright, thanks.
haven't used it yet
My logic, the way to avoid missing out on getting a Job to run doesn't exist, without blocking main, or always using ScheduleBatchedJobs, because there's no way to differentiate between scheduling merely queuing or actually doing. Have I got that right?
Yea because that's determined by the OS
Cheers. This is invaluable information, and I don't think I (or anyone else) should have to go through so much work to discover that this is a very big limitation of Jobs, especially on the platforms that stand to gain the most from attempting to do things on other threads.
So far as I can tell, Jobs and Burst are being proclaimed as production ready, verified for LTS of 2019 and 2020, yet documented like they're in pre-alpha stage. Piecing together what state they're in and how best to use them shouldn't involve guess work.
If a NativeArray is declared as [ReadOnly] how is it populated?
https://docs.unity3d.com/Manual/JobSystemNativeContainer.html about half way down
@visual tundra you pass a populated nativearray to the job
argh... so this is an example of the "parameter" being passed into the job, not a declaration. THANK YOU!!!
Burst is production ready. Jobs has only version 0.11 experimental available
Pretty sure that package is irrelevant to the status of jobs core, Jobs is built-in
It feels a lot like it's builtin: https://docs.unity3d.com/Manual/JobSystemCreatingJobs.html
as per @solar spire ninja'ing me, yes... using Unity.Jobs seems to be all it takes.
The dedicated package itself is no where near to 1.0 though. I'd argue it's probably similar to ui builder, integrated into 2021 but unusable without the package (for in game)
I make editor tools, so that's 90% of my usecase for the UI Builder until UIElements is more viable
but jobs in the core are extremely usable and functional, they have been for many Unity releases
Is this correct:
IComponentData can contain managed object references, with the only catch being that I cant use these in Burst jobs or jobs on a worker-thread?
But I wouldn't say that theyre a static release and the API won't change
Maybe not, but the core API is so simple that any change could probably be fixed in minutes
I think the managed /class version of IComponentData don't live in the chunk
The few changes I've dealt with over using it have been very inconsequential. I'd certainly not recommend avoiding the package because it says preview - unlike others
So yes? Because then I can delete all kinds of complicated Dictionary<Entity, SomeBehaviour> table mechanisms in favor of just putting the reference in IComponentData.
Sure, but that's why I wouldn't call them production ready (well maybe I would, just not 'completely finished')
ducking.... something about feature not being complete until documentation...
Of course not, but we were talking about the current limitations
Pretty much yes. You can use them on a thread as long as w/e methods in the managed object are thread safe, but yes you cannot use burst with them. You'll probably lose out on iteration performance when you query the entities.
And I just wanted to make the point that there's lots of room for change / improvement
Alright thanks.
Eventually I hope to start eliminating more and more of these managed object references. However, some things I will have to live with. (e.g. Collider references, as I cant use Unity Physics yet for my use cases)
the 'preview' jobs package is just:
- 3 extensions for IJobParallelFor
- adds the 'jobs' menu in toolbar for toggling leak detection
that's about it
I think the only thing you can do with Unity GameObject Physics on a separate thread is bake them on a separate thread lol
Which would be great. It currently gets expensive quickly for large patches of terrain mesh. 😦 At the moment I have to specify time budget per update to be spent on updating MeshCollider meshes
Oh wait youre saying GameObject Physics?
@coarse turtle ?
In that case - I didnt know that
Yea
You can bake the colliders* on a separate thread
Ah yes I just found it myself.
"Thread-safe" - so I just call this from some other thread it seems.
yep
Oh interesting, the example actually puts the BakeMesh-call in a Job to be scheduled
cool
thanks
excellent
Is there any point to explicitly adding ComponentType.ReadOnly to a new EntityArchetype? Or is ComponentType.ReadOnly intended for use with EntityQueries only?
I want to say used with EntityQueries. I'm not really sure what ReadOnly did since it found the TypeIndex, which was the same as ReadWrite. 🤔
I don't think it does anything for EntitiyQueries in general
But for EntityQueries that you fetch in SystemBase by using GetEntityQuery it registers write/read dependencies
That means if you specify a component with typeof(Component) (which is implicitly converted to ReadWrite) instead of using ComponentType.ReadOnly the component will be marked as a write dependency when scheduling jobs (therefor depend on other jobs with write dependencies to the component)
I didn't know this for a long time and had to rewrite my GetEntityQuery calls, I always used typeof(), but then I noticed odd behaviours in job scheduling that didn't make a lot of sense to me
I might want to revisit my EntityQuery calls 🤔
me too, didn't really care about that and I'm not sure if it's even relevant when using IJobChunk scheduling
job scheduling and main thread blocks might work better? I don't know
as read/writes have to explicitly set in job structs I'm not sure how they interact with the entityQuery
It is relevant when you use the Dependency property which creates a jobhandle from all read/write dependencies of the system
These read/write dependencies are populated by the query writers/readers and the GetComponentTypeHandle/GetComponentDataFromEntity calls
There is also a bug in the current entities that causes ComponentType.Exclude to be handled as a write dependency, so your job will depend on a component that it excludes lol
thanks, good to know. that's quite a nasty bug with exclude. but yeah, I also saw some weird behaviour in job scheduling. basically I needed to .Complete a job to not run into any trouble
most of the times it's not a real issue when the job takes longer than the scheduling but still
could save some time overall
Anyone knows if it would be possible and valid to duplicate Entity prefabs after conversion to basically have two entity prefabs? Something like in AfterConversion step Instantiate make some changes and then add Prefab tag? I'm trying to find a suitable solution for having entity prefabs with different Physics layers set to them.
conversionSystem.CreateAdditionalEntity(), add a copy of the original component to the newly created entity?
dont think prefabs are special in any way other than the tag that differentiates them so id expect you could mark entities as prefabs in any way you want
This would create an empty entity? So for this case I would need do all the linking of entities & copy component myself?
Not empty component, just an empty entity
Typo
Separate question; anyone knows if there's some existing way to remove all excessive entities created when using Physics Body set to static?
Or I guess in general clean up entities from conversion which were only used to produce some order when building the subScene/prefab.
There's no easy way to do it. ComponentTypes in Entities are stored via index which is determined initially on runtime (I believe). Potentially you can store the ComponentType's TypeIndex, but if that's stored within a subscene, the typeIndex would probably be incorrect in a build versus the editor.
Your probable best bet is to just store the Type somewhere and then after the entities are brought in to your main world, translate the Type to ComponentType and run a system to remove all the ComponentTypes from entities.
Is anyone else having an issues with dots not showing up in the package manager?
Have you followed this process? https://docs.unity3d.com/Packages/com.unity.entities@0.17/manual/install_setup.html
How to enable HybridRender v2 on android with URP and ARCore?
@left oak Adding the package by name com.unity.entities worked. They're doing their best to keep it hidden I guess.
They've pretty much delisted all of the experimental packages that either aren't near release or not being actively worked on (entities being the former, thank joachim)
Is there any difference in putting the [BurstCompile] attribute before the struct declaration vs before the execute method of a job?
Is there actually a way to profile whether CPU cache misses are occurring? Or should/can this be deduced from looking at your own code (e.g. identifying random memory access, etc.)
Also I'm surprised I'm having such difficulty finding something for (Burst-compatible) frustum vs box intersection.
I found this which is stated to occasionally result in "false positives" (as in; says it does intersect while it actually does not) for the sake of a more simple implementation. Is this a common compromise to make for games?
https://www.gamedev.net/forums/topic/512123-fast--and-correct-frustum---aabb-intersection/
Oh I already found a good article on this: https://cesium.com/blog/2017/02/02/tighter-frustum-culling-and-why-you-may-want-to-disregard-it/

Cesium
Inaccurate Frustum Culling Many popular frustum culling algorithms, including our own implementation, do not produce completely accurate results when large objects are present in the scene
Question how do I install ecs its not in package manager anymore haha
@timber ivy I forgot what I did. I vaguely remember editing the manifest.json or something and add it there manually.
packages.json will contain something like this.
Highlighted in red is the entities package.

I cant say for sure this will work though
add it via name with com.unity.entities
It says how to do this in the documentation (which is pinned)
I've asked that myself a lot and I'm now looking into Intel VTune that should do the job according to a stackoverflow post
yea vtune is great
public struct SubjectDirectiveData : IComponentData
{
public BlobAssetReference<SubjectDirective> Value;
public unsafe SubjectDirective* DirectivePtr => (SubjectDirective*) Value.GetUnsafePtr();
public unsafe SubjectDirectiveType Type => DirectivePtr->Type;
}
I have IComponentData that has a Blob Reference. For the sake of this example, let's say only ONE entity has SubjectDirectiveData. When the SubjecDirectiveSystem intercepts this, it performs the action and then RemoveComponent<SubjectDirectiveData>
Question: If the last SubjectDirectiveData is removed from all entities, will the asset that is referenced in memory be collected by GC? If not, does that mean I have to call subjectDirectiveData.Value.Dispose() before removing the last component?
Anyone know why something like this wouldn't work?
https://pastebin.com/nprRs0qH Just want to make it easier to distinguish the entities in the debugger after conversion ._.
Was not really sure what you meant here. I tried this, and it seems to work from what I can see. https://pastebin.com/aBGcRHPC
Try it in a build and see if it works
If this is with ConvertToEntity it might work, dunno about what happens if the gameobject is in a subscene. That's where something like this might fail.
Hmm ok, thanks!
Just curious if there's any cost associated with running Entities.ForEach where there are no archetypes/entities that match
some but generally neglectible
2022.1.0a15 has a ton of improvements to burst for those already on the Alpha
so dots / ecs is working fine in 2022 ? - still i will wait beta - hope it will be soon
any highlights?
Look at the release notes, I don't have them up
seems like 2022.1 has burst 1.7 integrated
yep, identical. anyway, we can use this even in 2020.3 - just need to update to burst 1.7
😦
Maybe I should start figuring out that whole ref return thing...

Would that help eliminate all these memcpy?
(NOTE: In this case I can't move what I'm doing here to a job)
depends, what are you doing with the strings.
and depends on the lifecycle of these strings. if you have them somewhere as static data it would eliminate the copy but on access you'd have a (very likely) non-local random access. so would it be better?
@viral sonnet There are no actual strings to speak of. I'm just 'compiling' everything I need at some later point into a list of structs as seen in this image.

This was part of some optimization - however, all these 'memcpy()' that are now happening actually make this more expensive than the 'non-optimized' code.
I stuck some 'ref' and 'in' anywhere to could to see if this would have an impact... but its still pretty bad at the moment.
It seems I would be better off going for a completely different approach at this point..
not seeing anything wrong with this particular code. something seems to be going on in the terrainpatchmeshdrawargs constructor, right?
at least a managed String crops up there


one of the strings is likely from the Transform.name but for DrawCallBoundsData, no idea! These are just proper structs
I'd start some isolated testing where that's coming from. Certainly seems odd
Hmm...
I think your memcpy comes from the matrix4x4
For the record, its float4x4 from Unity.Mathematics
not matrix4x4
I have a vague suspicion the profiler might have something to do with this... Although... You'd think they (Unity) would know how to deal with that
https://issuetracker.unity3d.com/issues/graphics-dot-drawmesh-triggering-string-dot-memcpy-for-massive-slowdowns
Someone in the same boat
Reproduction steps: 1. Open attached "stripped" project. 2. Open "EditorMap.scene". 3. Open "Window > Profiler" tab. 4. Enable "D...
well float4x4 with implicit casting will construct a new Matrix4x4
Seems very old
https://forum.unity.com/threads/string-memcpy-in-profiler.119166/
First post: 2012... But also posts as recent as 2020
Unity Forum
Never seen this pop in the profiler before... What is String.memcpy()? I am not using strings...
I only cast from Matrix4x4 to float4x4 once.
Hold on
@coarse turtle

And according to the profiler it even occurs for DrawCallBoundsData, which only deals with float4x4
well towards the end in the for loop, when you do in sharedMeshDrarwMatrix_native the JIT code would have an instruction to deference the in reference and copy the float4x4 to the readonly DrawMatrix
No clue how to use 'in' keyword properly - this was added afterwards as an attempt to solve this exact issue.
But no change it seems
https://twitter.com/bartkevelham/status/901054569966440448 Sorry had to dig this up from my old bookmarks on twitter, but I remember seeing this back in 2017 💦


to copy structs with memcpy makes sense, but it seems fairly slow and the struct is just a few bytes. i never had a setup like this but the "in" is a pointer and the field you're copying to is not. try to make it a ref (AABB and float4x4) and see if it changes anything.
not sure how this is relevant to the DrawCallBoundsData situation. I could remove all Transform/Matrix4x4 usages and it would still occur I reckon
though I'm also not sure if this is what you want, just assigning refs/pointers? i mean if it works, great but there could be some weird side effects
well it's more that you're copying the data over to the matrix4x4 from float4x4 (even if you pass the float4x4 via ref or in)
The ref/in stuff was added afterwards as an attempted workaround for the string.memcpy, but it still occurred
I can remove all the ref/in nonsense and show you what I get if you want
well let's say there isn't an a ref in the param
Struct S {
Matrix4x4 m;
public S(float4x4 m) {
this.m = m;
}
}
new S(some_float4x4); <- A copy would still occur here
good lord! VS2022 has automatic decompilation. what a blessing 😄
@coarse turtle Here you can see I only do 18 implicit casts from float4x4 to Matrix4x4. The majority of time spent on string.memcpy() happens in a section of code completely devoid of casts

oh man, I'm beginning to think this is a mono thing
the thread you linked, someone said he had terrible performance with just changing class to struct
the Matrix4x4's string memcpy comes from the linker collapsing identical functions according to lucas meijer
I'm just baffled that copying some bytes around is sooooooo slow
yea I believe it has to copy to native C++
right, 11k is really not much to show up as taking over 2ms
for reference this is how Matrix4x4 is set up.

again, we're dealing with float4x4 here, not Matrix4x4

maybe I'm missing the point but your struct still contains a Matrix4x4 right? You said you do 18 implicit casts from float4x4 -> Matrix4x4.
Yes and those 18 casts take 0.03 milliseconds according to my screenshot.
Its about the 3.52 milliseconds for inserting the float4x4 into 5757 DrawMeshBoundsData constructor calls. Note that those 18 matrices are shared among those 5757 items.
its a nested loop
outer loop has 18 iterations (where the casts occur), inner loop iterations total 5757 (where the constructor calls occur)
I'm not trying to optimize those 18 casts here because they are already just 0.03 milliseconds.
this would be the inner loop right?

Yes
and to my knowledge,
struct DrawCallBoundsData {
...
public readonly Matrix4x4 DrawMatrix;
}
DrawCallBoundsData still contains a Matrix4x4 right?
No
so it contains a float4x4 instead right?
kk, yea i misread that.
its alright
Kk, so it'd still be doing a memcpy about 5700* times per 64 bytes 🤔
Last post at https://forum.unity.com/threads/string-memcpy-in-profiler.119166/
Not sure what to make of this. Can i work around this by having separate arrays for my float4x4 and AABB values...?

Unity Forum
Never seen this pop in the profiler before... What is String.memcpy()? I am not using strings...

I mean the person states that for 40+ bytes, string.memcpy is faster anyway
cool, didn't know that. Just assumed it was what lucas said about linker collapse.
If you have separate arrays, I tihnk it still depends on whether you replace the whole element in the array. So if you had float4x4[] m_s and you do m_s[i] = some_float4x4 I think a string memcpy would still occur here.
I'm thinking about profiling similar code in a pure C# executable project and a Unity project... To check if there are any performance difference.
...although that wont help me solve the problem. It seems I will have to redesign the whole thing to eliminate so many struct usages on main thread.
I'll give it a try to see what happens
@coarse turtle @viral sonnet
LOL WTF

🤔
guess that'll be the end of packing lots of things into structs for me 🤪 wtf
yea
Hmm, I wonder...
im going to try something with Explicit struct layout
string memcpy is about 1.5ms faster too
Ok explicit struct layout doesnt work - its just as slow.
Now i'll try eliminating the constructor and directly assign the struct fields
Also doesnt work - the string.memcpy just moves from the constructor to the calling method
:/
btw i am really curious? are constructors in dots permittet / recommended?
something i haven't yet found an answer to
The constructor doesnt seem to be the cause for the slow execution in my case - rather, its the fact that I pack everthing into a single struct totalling 88 bytes in size.
no i just meant in general
I eliminated the Matrix4x4 in my TerrainPatchMeshDrawArgs so that it now only contains 4 references - now totalling just 32 bytes.
This eliminated the string.memcpy() that would show up for the TerrainPatchMeshDrawArgs constructor and the associated cost
cause unity's samples certainly don't use constructors
I'm pretty sure it should not be an issue. Thats all I can tell you
Whether or not Unity has a particular reason for doing so in their samples; I do not know
idk, c# is moving away from constructors anyway in recent time with better object initialization and so on, which i quite like, but currently that can still lead to unknown behaviour when forgetting to initialize an important value. i really do hope that the required keyword drops in c# 11 so we can finally have safe object initialization
Hello, folks! I've tried to install the job system on the unity 2020.3.19 (Lts), but Unity.Collections is missing NativeHashMap. In the package manager my collections lib version is 1.0.0-pre.5, I've tried to update it, but it just broke the job library. what am I missing?
oh, i found the answer - i had to enable "unsafe" code checkbox in the player settings menu
nativehashmap should not require unsafe code though
Does anyone have used jobs for parallel sorting?
UPD: have found answer - https://coffeebraingames.wordpress.com/2020/05/24/nativearray-sortjob-is-fast-or-is-it/
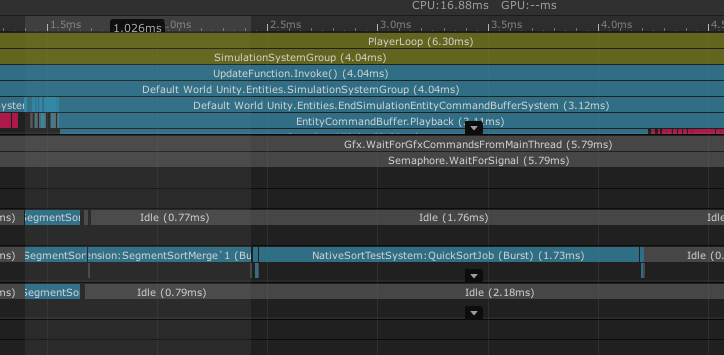
While I was making a framework of rendering sprites using Compute Buffers, I was thinking of what sorting algorithm to use to sort sprites (say render from top to bottom). I’m using a Burst c…
I missed the objective. What are you trying to do in terms of data move/copy?
- I have a bunch of meshes and I want to cull them in software to reduce overhead caused by Graphics.DrawMesh.
- This culling is done in a Burst Job. In that job, I take the local-space bounding box (an AABB) and the local-to-world matrix (a float4x4) to calculate the final world-space bounding box, and check whether or not it intersects the camera frustum.
- I observed massive costs (the memcpy() you see in the profiler screenshot) associated with packing this local-space AABB and local-to-world float4x4 into a single struct (the DrawCallBoundsData).
- After some experimentation, I discovered I could massively reduce this cost by keeping the AABB and float4x4 separate. In other words, instead of passing NativeArray<DrawCallBoundsData> to my culling job, I pass NativeArray<float4x4> and _NativeArray<AABB> to my culling job.
(Not strictly relevant to the performance issue at hand, but here in this screenshot is the culling job code)

@visual tundra
If it werent for all those additional memcpy() that can be seen in the profiler, this would indeed have been faster. But right now the performance penalty is about as much as the gain from reducing Graphics.DrawMesh-calls
So to be clear: the very act of creating a DrawCallBoundsData and/or assigning its values causes those expensive memcpy() to occur.
I'm sorry. Still not clear. How many things are you copying?
@sinful cipher Is the copying you passing the AABB and matrix (float4x4) into a struct, and then you doing this thousands of times for thousands of object culling tests?
does generic job still not supported by burst?
I apologise profusely, because I don't think in terms of normal ways of using Jobs and reference types, almost always reverting to manually memcpy to stackalloc stores by byte size overrides of the underlying types, such that I don't have to think about what a struct is, only its number of bytes, and then use pointers to manually do calculations. Looking at how people use OOP kinds of approaches to this sort of thing confuses me. Trying to understand the source of the data, and the states it's in, and then finding ways to get at it in the least time possible is something I spend much more time on than thinking in terms of OOP-like paradigms and Jobs etc... for code division. As result, I write ENORMOUS functions that are hard to read but very performant. This smells like a situation where that would be vastly preferable to trying to send into Jobs. But I also feel like there's something obviously wrong with how the structs are being needed to be copied when they really shouldn't be, you're only doing comparisons, so they only need go into registers for testing.
IOW @sinful cipher there should be a very easy way to vectorise the testing of "is this inside that, or not?" and then cull those that you don't need. This should be an absolutely ideal and easy use of Burst, Jobs and/or stackalloc
And I'm not clear if you've solved your problem, or not. You seemed to have massively reduced the time taken, but it also sounds like you're still seeing too much slowdown from memcpy.
One other issue... I presume your AABB is a 6 point x 3 floats (vector3), to describe the bounding box?
@visual tundra Regardless of whether or not the current design is good -- I'm just baffled at what I'm seeing in the profiler
You're hitting the limits of the registers. That's why there's a lot of weird copy stuff going on.
hmm
AABB is from Unity.Mathematics by the way. just { float3 center; float3 extents; }
How does a single float3 give all 3 extents (x, y, z) in each direction (x, y, z)
But I'm already looking at a different approach that better groups and filters what I need to draw so I dont have to copy so much data around.
Before you do that, think about segmenting the work eg: To my naive thinking, it's going to be far faster to do ALL the local space to world space calculations first, inlined as much as possible, building a temp array of the world spaces, before doing any comparisons. Then iterate over this world space array of all object AABB's, to see which are in the view of the camera. And, in doing this, it might even be faster still to break this down into four checks and reductions (depending on how many objects you have).
Not sure if I understand your question, but maybe this clears things up: AABB is always an axis-aligned box, not a rotated one
If I have to reuse those world-space calculation results, yes. But for now I just need them once - when checking for intersection with camera frustum.
This was all GameObject-based before I started converting it all to ECS. So some things are still a mess and right now I'm just looking at the profiler, fix what is slow, and repeat.
It doesnt help I still have to rely on managed Mesh and MeshColliders
Some things have to still happen on the main thread because of that.
(Unity Physics doesnt support something I need yet)
(but I'm considering checking out DOTS rendering)
When you do two different things (create world space of your AABB and then check against something else as complex as a frustum of a camera PER OBJECT ) you're ruining the chance for the CPU and registers to rip through things, they're constantly having to offload and reload between creating the AABB and then doing the frustum check against the AABB. So it's better to make ALL the real world AABB"s first, in a temp array.
If you want to get fussy about this, you can chunk the objects you do to a reasonable sized stackalloc, so you never have to use heap for the temp array, if you have a LOT of objects. This will be faster again.
I'm not sure what aspect youre referring to: the actual job code, or putting the data into the job?
Because I will definitely not do AABB.Transform(float4x4, AABB) 5700 times on the main thread if thats what you're suggesting 🤨
Do two jobs. One that makes the temp array of game world positioned AABBs, all of them, and then a second job that reads and checks that array for frustum overlap.
But the actual job is fast. Definitely fast enough at least. Its not worth optimizing - there are much worse and slower things I have to deal with first.
e.g. the memcpy issue
by splitting it into two jobs, like this, you should avoid the memcpy overload, this is the entire reason I'm suggesting doing it this way!
Oh like so. But at the end of the day, I still need to populate an array of float4x4 and an array of AABB with data beforehand.
And populating those arrays is exactly where the slow memcpy is occurring.
Because you're doing them at the same time, right? And the same time as you're checking them against each other, right?
...?
Did you already inspect this by the way?
Split the work... into... separate JOBS. One job makes an array of game world AABB. Nothing else. It does nothing more than multiply the local AABB's by the position of the object in game world, and build an array of these.
This is where I take the arrays and put them in the jobs to execute

The next job compares these bounds with the frustum. And this should check each aspect of bounds, one at a time, on the entire group.
I "cache" the draw calls because they might be reused for different cameras
for every camera I have to re-do the culling calculation
although - i could precalculate world space bounds
which would eliminate need to store float4x4
is this what you're suggesting?
I fully do not understand the use of the float4x4 in all this, at all.
A mesh has a Bounds (same as AABB) in local space.
To cull a mesh-to-be-drawn against the camera frustum, the bounding box must be transformed to world-space.
Right?
Because the mesh can be anywhere in the scene in any rotation
so you're making an AABB from the 4x4 * the AABB and this is rotating the AABB correctly?
Yes.

Unity's rendering API also knows how to cull things though. After all, Graphics.DrawMash takes a Mesh and Matrix4x4 and therefore has everything it needs to do this.
But in some cases, doing it yourself can help. Especially if you find a way to cull entire clusters of Meshes by giving them a combined bounding box.
Eventually, I'll cluster meshes too and give them a combined bounding box. It will become a lot faster
I understand the need for culling. I don't understand how you're making this hit recursive needs for MemCpy, nor why Unity doesn't have a HIGHLY optimised manually usable culling system made for us.
I dont understand what youre saying with "hit recursive needs for MemCpy"
I don't understand how you've overloaded the Jobs system's IO such that it's struggling to keep what it needs to work on where it wants it, so is overflowing the registers, and then needing to offload stuff, often (recursively) such that you're using MemCpy more than getting vectorised, streamed, aligned data flowing through to do compares.
Huh? The memcpy happens in regular C# on the main thread. I could delete all the jobs and it would still occur.
what is getting copied? Same question I started with. I don't see what's getting copied.


Ok, how many of these are getting copied, and when are they getting copied, and where are they getting copied too?
By the way: in this particular iteration the memcpy is gone, because the total struct size is now 32 bytes. Apparently 40 bytes is the threshold for memcpy to start occurring.
So what the fuck are we talking about???
Previously, there was also a float4x4 in there. That was an extra 64 bytes
well I ended up "solving" it eventually

Then you showed up, and i figured Id be so kind to answer what you were wondering about
kind? wowsers.
Here's the point, @sinful cipher where I kind of asked... if you'd already solved the problem, as I couldn't see why it was failing to vectorise.
Although if you were to happen to know a way for me to retain 40+ byte structs without experiencing memcpy, that would be super welcome
Yes, treat your structs like *void, and do your own manual memcpy, to temps of stackalloc's, so you can focus on exactly what you need. memcpywithstride, in particular.
memcpywithstride?
Not to be rude, but I figure I'd mention this for the record: you do realize I dont simply have a source array and destination array, right? I'm basically doing random access in some nested loop to populate a destination array.
So I have no option other than creating structs literally one-by-one
Unless you're saying I can create a single, large struct without the memcpy cost with pointer trickery
My experience is mostly in managed C# and Java world so forgive me if I fail to catch on any of the unmanaged/pointer-based tricks you're suggesting.
I mean I know what memcpywithstride is but I cant exactly employ it for my scenario since I'm dealing a lot with random access.
Can I eliminate the random access? Possibly, to some degree. But thats a task for next time.
If you can align all those objects in memory, this will be probably make the whole thing another order of magnitude faster.
Maybe more, since you're doing such big structs and so many objects.
What sucks is that I'm having a hard time to eliminate a lot of the random access because of 1 issue:
I cant take managed references (Mesh, MeshCollider) into Burst jobs. I dont even intend to call their methods in the job. I just have to juggle/sort a lot of Mesh and MeshCollider references around due to object-pooling those.
So instead of the managed reference, I put a key or index in the job data.
Then when I'm done with the job, I look up the original reference in some Dictionary<RefKey, MeshCollider> or something. So this is where the random access has to occur.
I considered putting managed object pointers in the jobs instead of those keys, but this already doesnt sound very safe. Is it?
I don't have any ideas about your other performance compromises and methodologies, so can't really say anything other than this: if you can align all objects in memory (used or unused, doesn't matter) it'll be so much faster to iterate over that you can even go over the unused objects rather than try to skip them in your frustum testing.
In fact, if you can make a proxy array, with copies of the stuff you need and some way of referencing that back to the objects you want to turn off with your culling, that would be even faster, again.
The speed you can get with aligned memory and vectorisation and optimal use of memcpy and saturation of the processor is such that it might be worth making the proxy (extra) array with just the bare bones info about the objects, kind of like your own ECS for position and mesh.
this sounds sketchy. Let alone brittle and hard work.
Yeah.
One thing I could look into is keep the reference keys as long as possible
and only lookup the managed objects in the Dictionary at the very last moment after all the sorting and culling is done
Right now I'm starting to identify opportunities for this
Yes, I'd do that based on the GUID, as that's unique, in Unity, so far as I know: You could make an array with the GUID's of each object you want to consider for culling, with just their position and mesh bounds as "components" of data on each, as the proxy array I'm talking about above, that serves only this purpose, despite having extra "transforms" and meshbounds, just for the speed this offers in culling time, let alone the positional benefits you could get if you can then place with this, too.
And since ECS isn't finished, and you're not sure of which renderer to use, you have two excuses to try making your own little "sub-ECS"
GetInstanceID(), or an actual, 256-bit GUID?
I figure the GetInstanceID() right
Yes, 256 bit is a bit extreme! 😉
;p
I could try this. Its only recently I realized you can put managed references in IComponentData. You just cant use them in Burst jobs.
Right now I have IComponentData with a reference key and some "global" Dictionary where there references are kept.
Perhaps I can finally eliminate that global dictionary and all the crap associated with it.
I think your dictionary approach is the right one, but instead of using a dictionary, just use parallel arrays, so the index is the same across them all for each thing in each array.
*caveat: I have an overt and abject aversion to dictionaries. I hate them. I also don't like chocolate.
It actually isnt really a Dictionary though. It is array-based. I kind of forgot. :p

but its not read from sequentially
thats all
Because as objects get taken from the pool and put back in the pool, everything gets shuffled over time
(By the way dont bother trying to understand this - i barely remember how it works myself)
Ideally I come up with something better so I can just delete this RefKey nonsense
I KNOW ThIS FEELING!!!!
AND THIS FEELING!!!
More convoluted nonsense. It works but I hate it.

its probably the stupid way of doing things
👌
I'd pay good money for a code co-pilot not brought to us by Microsoft, and who drank beer more furiously than me.
(New topic)
Does anyone have any experience with ManagedComponentAccessor?
https://docs.unity3d.com/Packages/com.unity.entities@0.17/api/Unity.Entities.ManagedComponentAccessor-1.html
oh it appears to not be blittable... too bad



I'm not sure if you need mutability, but you can try Mesh.AcquireReadOnlyMeshData()
https://docs.unity3d.com/ScriptReference/Mesh.AcquireReadOnlyMeshData.html
Sadly its not necessarily about the data - I just need to associate certain managed objects with Entities
ah
lollll wut

i can just stick a typeof(Mesh) in the EntityArchetype
hahaha wtf if only I knew
that makes things a lot easier
there are so few fast NativeContainers for parallel writing -.-
What kind of container are you looking for?
a container where I can write structs to without thread locks and one that's either persistent with allocations or fast in disposing. currently, i use the UnsafeParallelBlockList from DreamingImLatios, the problem is that disposing takes 1.57ms in a bursted thread.
(other topic)
Does anyone know how to acquire a ComponentTypeHandle<T> for a managed type?
ArchetypeChunk has GetManagedComponentAccessor which takes a ComponentTypeHandle<T> where T : class,
but System does not have any method that can give me that. Only ComponentTypeHandle<T> where T : struct, IComponentData.

For parallel write?
yes
So parallel write, but no thread locks.. Huh? :p
Although Jobs sometimes allow that... Is there perhaps some obscure Job-interface that can help you here?
for unitys nativecontainers only NativeStream is capable of it. but using it is annoying because it expects a forEach index. that can be overriden but it has no real benefit over the UnsafeParallelBlockList
jobs allowing isn't the problem 🙂 the thread locks are, where NativeList/Queue are guily off
eh, guess I have to extend the UnsafeParallelBlockList with a clear method or something. not really feeling like doing it though, so much testing and pointer arithmetic. 😄
So you want to do parallel insertion into native list?
but such that its not actually a native list?
not sure what that means 🙂
NativeList has a ParallelWriter, but they lock the index on writes, so it's slow
What kind of job are you using? IJob, IJobChunk, etc.
IJobEntityBatch
Oh, hmm, dont have much experience with that
it's basically IJobChunk with a liiiittle less overhead in the entityIndex
Hmm
Personally, if doing it single-threaded would never take longer than a few milliseconds, I'd just do it single-threaded. Because eventually, there will be other systems that will give the remaining worker threads some job to run anyway.
sadly that won't work out 🙂 job takes 100ms over 8 threads
Or you do it in a 2-job process.
1st job in parallel, where each thread writes to their own protected range.
2nd job is single-threaded, and aggregates everything to 1 final array.
Although of course you risk ending up with something thats still slower than NativeList+ParallelWriter....
and with 1st job as dependency for 2nd job so you can just schedule them both immediately
hm, you gave me an idea. instead of using the UnsafeParallelBlockList I can allocate x NativeLists for every worker thread. that also gives me the benefit of keeping the allocation
i don't really need to merge them afterwards. the problem I had with a similar approach was an unbalanced list. i'll keep thinking about it
some things in entities are really fucking annoying, keeping memory locality seems even harder sometimes than in c++
Here I have 2 threads that have long-running jobs. But the other threads just get other, smaller jobs from other systems in the meantime.

it's all good, as soon as data leaves the space of chunks
So what I'm trying to say here is: you can sometimes get away with doing something slow on a single-thread this way.
Ah that helps if you dont have to merge them.
yeah I see what you mean. i have no real way to run anything else though.
Im curious if you get any success with the per-thread NativeList allocations. Its something Ive been wondering about myself, too.
Although I get this feeling that Im not supposed to do it.
Unity hasn't designed any good way to write data from an entities job to another job. they expect all is written back to a comp
Excuse me, what do you mean by 'comp'?
an IComponentData in the same chunk
Well, you have the option to write into any arbitrary NativeCollection, right? Or am I missing the point here
Oh
but then you run into parallel write issue
I see
right?
exactly
maybe the answer is more simple than i think and I should just write back to an IComp and ignore problems like making an archetype unnecessary large with useless data.
Making Archetypes larger will just result in more chunks, right?
Oh nice I found this: EntityManager can make ComponenTypeHandle<T> where T : class
thanks, good to know.
yes, and honestly I don't think it's that much of an issue. iteration and reading gets slower because more job threads have to run which are iterating on less entities
pondered on the idea and it's not working out. it would, but not with what I'm making.
I'd really need a DynamicBuffer but those are so damn slow for whatever reason
Do you want to store arbitrary amount of something for a given Entity?
not really, max would be 2, maybe 3
DynamicBuffer would be perfect but I had nothing but issues with them. like, just reading the length is unbelievably slow and I never found out why
i'll try it out, just to see. should be easy enough
Chunk utilization from 36 to 24. haha, it's so bad to begin with, what does it even matter lol
What does that number mean, actually? A chunk can fit 24 entities of that Archetype?
correct
annoying side effect, in the editor 4 comps are added which are irrelevant, so you never know the true count
and when you use subscenes, localtoworld is always added which is huge
can be removed quite easily though
oh, huh, not correct what I said, the chunk utilization doesn't count these 4 comps
Lol LocalToWorld is already 64 bytes, dang
eh scratch that also, they are not really removed. weird, I managed to do that a few days ago. not sure why it doesn't now
yeah, one of my archetypes is either 106 or 184 when I remove LocalToWorld 😄
I remember having trouble adding/removing IComponentData with parallel entity command buffer or something
hah nice. Quite a waste yeah
This works. 👍
class : IComponentData lol

fast? heck no
But hopefully I can delete a lot of other slow stuff now and still get a performance increase in the end.
One or two people told me that might be a bad idea
So I can keep struct-based IComponentData right?
yes, all good. well, whoever told you that are probably right 🙂 pointing to a class is a bad idea 😄
haha alright
Hmm? You referring to these?

(pointer noob here)
(i just barely know what im talking about)
i look at this myself the first time. 🙂 thought Mesh was a struct but it's a class anyway which means it's really a pointer when you're referncing it in the IComp
well, don't 🙂 if it was a struct you'd copy all the data 😄
Oh well not literally that kind of struct :p
just like native collection where it points to where the actual data is
ah yeah 🙂
NativeCollections are also basically just pointers with "decoration" right?
:p
But if Mesh were a struct I could at least do all my object pool code in a Burst Job...
I think Unity will have to change that sooner or later. Having such integral data like a Mesh only exist as class isn't that cool for HPC#
with more time I think it's be possible to cast the mesh class to a struct
maybe someone already did that, could be worth a look.
the mesh exists in C++ code, the class is just a wrapper I think
but we'd need to know which data layout is used so that could be quite difficult to figure out
I played around with Unity.Physics a few weeks ago and I noticed they had like a complete struct-based MeshCollider implementation
yeah they are using struct blob data
it was very weird. Basically they had a struct that essentially had:
- data start pointer
- data length
- collider type (Box, Sphere, Mesh, etc.)
So the collider type would essentially tell you how to interpret the data and then you cast it to what it actually is (BoxCollider, SphereCollider, MeshCollider, etc.)
hm, maybe just the authoring colliders are blob data?
Ooh youre right, there is a blob asset reference to it here

Their native mesh.
Interestingly it appears to be a pure collision mesh. I'd imagine they might end up creating a different struct-based Mesh for rendering purposes.

crazy stuff
yeah 😄 I think they will end up using blob data a lot more
it's pretty cool TBH, haven't used them for the longest time
I wonder when I'll encounter an actual use case for blobs for myself
lots of data I was building as entity but really should have modeled as blobs
at first I wanted to use them to write stuff to, but apparently thats not how you're supposed to use them
Or traditional UnityObject-based assets, right?
just DOTS compatible
something like that, i translate all my data which define spells now to blobs
lookup and reading is really fast
Hmmm...
So I presume at some point instead of adding more fields to a struct type, it becomes more efficient to use a blob asset instead?
Ah, but instead of it being copied all the time it just stays in 1 place and you just use pieces of it essentially?
yes, the blobassetreference is a pointer
which can be saved in an IComp
so it helps with bringing data out of the archetype that doesn't change anyway or changes rarely
in case a blob changes you just build a new one
and if you really want to change data in a blob you can also do that 🙂 it's just not recommended
but we are programmers, nobody tells us what to do!
... until we fall over our own mistakes of not listening
dang right
InvalidOperationException: The previously scheduled job TRSToLocalToWorldSystem:TRSToLocalToWorld writes to the ComponentDataFromEntity<Unity.Transforms.LocalToWorld> TRSToLocalToWorld.JobData.LocalToWorldTypeHandle. You are trying to schedule a new job SpellCastSystem:SpellCastJob, which reads from the same ComponentDataFromEntity<Unity.Transforms.LocalToWorld> (via SpellCastJob.JobData.calculateSpellContainer.LocalToWorld_Lookup). To guarantee safety, you must include TRSToLocalToWorldSystem:TRSToLocalToWorld as a dependency of the newly scheduled job.
What is this error? I'm just reading LocalToWorld in Simulation system group
If I disable "End Frame TRS To Local To World System" the error is gone
and I can't get a JobHandle like the error message says
the faster the frame timing is the more this error happens
and I'm wondering, why isn't this job completed at the end of the frame or at least in the beginning?
the only answer I found was adding [AlwaysSynchronizeSystem] but it doesn't work 😦
Did you try [UpdateAfter(typeof(TRSToLocalToWorldSystem))] on your System?
@viral sonnet
not yet, i never ran anything after the Transform System Group, should we?
If you plan on just reading Transform data then yes. No point in inserting your system when it still needs to be written or might be written to at the same moment.
Theres probably a number of valid systems you can put at XXX that will solve the problem for you [UpdateAfter(typeof(XXX))]
There isnt strictly one that is most correct I would argue
Just make sure you pick one where you can be assured LocalToWorld and such wont be written to anymore.
I don't get it, my systems run before the transform system group. Why would it complain about reading anything before the transform system group writes anything?
Oh I assumed you wanted to do everything after transform system group. That way you always get the most 'up to date' Transform data.
Can you provide a screenshot of the list of systems in the System editor window? (toolbar: Window >> DOTS >> Systems)
I checked again and I reckon either [UpdateBefore(typeof(TransformSystemGroup))] or [UpdateAfter(typeof(TransformSystemGroup))] should both be valid.
Oh...

There's a change you have to first define your own ComponentSystemGroup with [UpdateAfter(typeof(TransformSystemGroup))]
And then add [UpdateInGroup(typeof(YourCustomSystemGroupHere)) on your actual system classes.
thanks, I know how this works 🙂
I've it setup now to have all systems run after the transform group but as expected the same error happens
Oh really.
Does the System editor window show you what its trying to do?
Or is the list of systems empty.

Do you call .Complete() on your jobs?
I do, this damn TRSToLocal system doesn't! 😄
it's just fucking scheduling ... what is this
lol
Which system is it about here?
this transform system makes me so mad by now haha
Oh nvm SpellCastSystem right?
one that's in stage2
those outside are just test systems
once my frames or jobs take longer this error goes away because the job actually finishes before the ones are scheduled that read
and I can't get a handle either, not sure how I would be able to
Do you call .Complete() on your jobs in the same System.OnUpdate() call as you Schedule them?
Which job are you referring to here?

on some, yes, but it doesn't let me schedule - i was referencing the TRSToLocal job
And does your system subclass JobComponentSystem or System?
they are all SystemBase
ok
In your error, there is this text: You are trying to schedule a new job SpellCastSystem:SpellCastJob
Do you schedule SpellCastJob with another of your jobs as dependency?
If you want you can show your SpellCastSystem OnUpdate method.
Hmmm I just realized...
When you're using ComponentDataFromEntity<T> you dont have to declare the T type parameter in any of the EntityQueries....
Im getting the feeling theres some kind of obscure [Attribute] you have to put on a job, or an IComponentData, or something and it will solve the problem 😛 No idea what it could be though.
yeah the only forum post I found mentioned [AlwaysSynchronizeSystem] but it doesn't do anything for me 😦
ah, that tag doesn't do anything in SystemBase. hm


oh cool, i'll try
thanks a lot! that has fixed it! i didn't think of completing the actual queries, that's clever
Hahah it actually worked? 😅 alright
I guess any EntityQuery have some implicit dependency on Jobs that are created with them (or the other way around)
i still don't understand the actual error 😄 i've changed the order back to how it was where my systems all run before the transform system group and completing the tRSToLocalToWorldSystem in my first system in stage1 fixes it.
from the timeline the tRSToLocalToWorldSystem job finishes a long time before my systems are scheduled in the next frame
it's like the job is lingering into the next frame for some reason
but I'm still under the assumption that unity calls complete on everything when a frame finishes. maybe what I thought was wrong
man, it's getting way too late or rather too early in the morning...lol thanks again, have a good night
Haha alright, you too
What would be an appropriate name of one of these pieces of terrain mesh?
TerrainPatch?
TerrainTexel?
TerrainSegment?
I found one or more papers referring to these as "texels" (but not necessarily in the context of a segmented terrain mesh), but Im not sure if thats entirely right for my case.

Right now I (accidentally) used different names throughout the codebase, and its about time I cleaned that up.
I come from using dx shaders, so would call it patch^^
@sinful cipher is that ecs earth-like-planet generator ? if is can u tell the planet radius ?
My items are pretty complex and therefore their own entities... my player is also an entity. The player entity references a bunch of item entities within his inventory component... thats serverside.
How do i send or update those relations for the client ? Any generic way for this type of problem which comes quite often ( child/parent relations... other relations and stuff ) ?
In the screenshot its 5km so it fits in the editor view. But its primarily designed for 50km
So basically as small as possible but that would still appear roughly earth-sized if you stood on the surface of it
thats fair 👍
I too agonize over variable names that no one will likely ever see but me
Although even then its nice being able to read your own code that was written over 3 years ago :p
I remember a time I had to scrap and redo anything I hadnt touched in a while because I could no longer read it myself
Also, never say never!
No matter what you do, the result will always be the same

lol
Guys, is there a way (unsafe allowed) to have IComponentData compatible pointer to another component, like have ptr in one entity to another entity's LTW component?
Theoretically yes but you would need to patch the pointer every time structural changes occur in the pointed to chunk
And you would still need to declare read (or write) access to the pointed to component type so your job dependencies are handled correctly
yep, i want to exclude structural changes for my particular case
is it worth it? to get the pointer address there are just 2 indexed lookups if I remember correctly
I'm pretty convinced now why DynamicBuffer performance is trash. It's all in random memory blocks. There is no actual data residing in chunks. At least there is no indication to find this in the source code
underneath they are using Memory.Unmanaged.Array to allocate, which is pretty much 1:1 like random heap allocations. There are no blocks or anything special
So every buffer is somewhere - random in memory which explains the abyssmal access times
the funny thing is, a buffer is still using up data in a chunk. they are allocating an IComp for a DynamicBuffer too. So maybe I'm looking at the fallback
that's what the internalbuffercapacity is for
and if you set it to 0 it shouldn't allocate in the chunk (altho maybe it stores ptr+length in there? not sure)
I'm not finding any code that it allocates in the chunk
what do you mean
I can't find any indication in the Entities source code that DynamicBuffer data is stored in a chunk
this attribute
if your bufferelement has an int and you set your internalbuffercapacity to 8, it would reserve 32 bytes (8*4) for every entity in your chunk
to store the dynamicbuffer data
only if it overflows it'll start allocating outside but it'd still reserve that data in the chunk regardless
if you don't believe the docs to do what they say they do you can check TypeManager.cs line 1307
var capacityAttribute = (InternalBufferCapacityAttribute)type.GetCustomAttribute(typeof(InternalBufferCapacityAttribute));
if (capacityAttribute != null)
bufferCapacity = capacityAttribute.Capacity;
else
bufferCapacity = DefaultBufferCapacityNumerator / elementSize; // Rather than 2*cachelinesize, to make it cross platform deterministic
yeah, looking at it right now 🙂
alright, so I was really looking just at the fallback. the chunk allocation of the buffer happens in the TypeManager with a special condition for adding IBufferElementData as component
well, bummer, had high hopes there was a mistake going on that explains the bad performance 😦
what could explain that even a NHM can out-perform a DynamicBuffer that resides in a chunk
makes no sense to me
even a buffer length check has huge performance costs which should basically just be like an IComp reading a field
i don't know, but it goes to happen every frame with a lot of entities, so i seek for better solutions
well, there's nothing holding you back to save an IntPtr inside an IComp. If there are no structural changes and you refresh all pointers when a new entity is added/removed all should work fine
saving the pointer in the comp could be a little hacky though
never did that, the IntPtr can be cast to int64 which should work without errors in a comp
so, saved as long
worth a try I think
why there is a need to refresh pointers, when new entity added/removed? when it happens other entities got no data move, isn't it?
adding shouldn't be an issue, but removing could be
no not really, it's more how entities move things around and I'm not certain about anything here 🙂 in theory only the entities that get removed/added have to be handled
so when an entity gets removed there's a hole in the chunk which gets filled once a new entity is added
every other pointer should stay the same when there's no structural change
you can get the pointers easily in an IJobChunk so just test if that's the case 🙂
Thank you for that idea, i'm not familiar with all this pointers stuff 🙂 Can you advice some good reading about IntPtr. I see it is common .Net System thing, but all this Marhsal.AllocSomeCreepyStuff looks not clear for me.
i mean reading for noobs 😉
So entities from other worlds I created are appearing in the scene, is this intended or a bug and is there a way around it?
hm, I'd just read up on the basics, what an IntPtr is. Basically the long is just the value of a 64bit address in the memory. no need for alloc or anything really, entities handles this part
has anyone heard of any rumors or any news or anything about DOTS still having a heartbeat yet?
actively developed, no ETA
have they.. at least reiterated that recently?
yes 🙂
well.. that's something I guess
Joachim at least has been very active on the forums recently; I feel as a tacit acknowledgement of the past quiet period (I think he's even spoken with regard to that, but I don't wanna put words in his mouth)
does ECS work with animated characters with rigging yet? (so not just translational animations)
yes, but it's very experimental and clunky to use
i'll still take it - Got something to point me towards?
If I remember correctly here are videos to get a good starting point: https://forum.unity.com/threads/mixamo-for-unity-dots-animation-tutorials.1149587/ this subforum has some really good posts
unity has also some samples when it comes to IK in the animations package
can't believe it, Visual Studio 2022 is actually a good version. code completion even without AI is really good. such a blessing for entities with its verbose struct names
finally some people are licking blood on VS2022