
#linear-algebra
2 messages · Page 292 of 1
the n subscript specifies the maximum degree
Oh so F[x] means degree till infinity? Meaning all the polynomials possible with any degree?
i think in any case, the usual definition requires the degree to be finite
one just mentions a specific degree explicitly
Ooh okay 👍
A matrix A ∈ M3×3(F3) is diagonalisable if and only if it has n distinct eigenvalues. I conclude this is false bcs the definition of diagonalisable says that it must have n distince eigenVECTORS right?
Well,The if part is correct
If there are n distinct eigenvalues,The matrix has to be diagonalizable (because there will be n distinct eigenvectors)
Only if is false
Take Identity

if (AB)^H = B^HA^H and we have A^H=A, B^H=B then (AB-BA)^H = B^HA^H - A^HB^H = -AB + BA = -(AB-BA)
Our professor uses |v| to signify the length of a vector. Most sources I have come across use | |v| |. Is there any difference between the two?
should be the same thing. sometimes they are called different names, like magnitude vs norm, but they signify the same thing
okay, thanks
could mean column vector or row vector
we need a little more context
This is everything that was given lol
What's this called?
ŵ=1/(| |w| |)w
Thanks mate
I already addressed those here: #linear-algebra message
I was reading definitions of eigenvectors and eigenvalues. According to my understanding, eigenvectors are those vectors that change their length by a scalar after a linear transformation.
I'm a bit confused about eigenvalues though. (Correct me if I'm wrong) Eigenvalues are the scalars that change the length of the eigenvector? And when the linear transformation takes the form of n×n matrix, it's the matrix product Av, v in Vector Space V?
"over any field F" is sus
Ah wait let me edit my message again
we have a vector space V and a linear map T: V -> V
if, for a nonzero x in V, it happens that Tx is a scalar multiple of x, i.e. that there exists lambda (then necessarily unique) s.t. T(x) = λx, then x is called an eigenvector of T, and the scalar λ is called an eigenvalue of T
Okay so, I tried to go to basics again of Linear transformation. By definition, it's a transformation that satisfies the addition property and scaling of vectors.
Can we always think of Linear transformations as matrices? That would make sense that why T(v+w) = T(v) + T(w) holds true then, and why T(cv) = cT(v)
All Linear transformations have a matrix representation
So yes
in fin dim
mb
you can probably extend to inf ones given a Schoder basis
What if there is no basis
Ooo I'll look into that
given a,b,....l ∈ R if det(X) = 4, how can i find the determinant of Y by properties of determinants and without substituting the values of variables

ZF worshipper 
Clearly,You can't cut a sphere and get 2 spheres
or can you
I feel like if you cut a sphere, say in two pieces. You can squish each part into a sphere.
Wait, a sphere is not squishy.

ah, my bad then.
google Banach Tarski paradox
" set-theoretic geometry" 
look for row/col manipulation
so, i'm looking for an explaination (graphical if possible) of why the distance between point P and Q in R^n if P = (x_1, ... , x_n) and Q = (y_1, ... , y_n) is sqrt((x_1 - y-1)^2 + ... + (x_n - y_n)^2)
i understand this in graphically on R^2 if for example two points have the same distance on one of their coordinates
basically, the difference between hipotenuses
but what if two of those points don't have the same coordinate, we use the sine rule to find that distance?

i understand that here, the distance between the two points is basically the difference between both hypotenuses
but what if

do we use the sine rule to find the distance of the two points? (the red)

afaik row operations take an effect to the determinant, do column manipulation also behave similarly?
they do
if im not mistaken, i would only look out for multiplying rows/cols (det = kdet) and interchanging cols (det=-det) right?
so i got det = -2/3 since i had to halve the 1st row and multiply the first column by 1/3
and i had to interchange two columns
could you help me on a problem that's also under matrices? it's in #help-0
Do you know why the length of a vector is sqrt(x1^2 + ... + xn^2)?
If you do then form the vector P-Q or Q-P and compute its length
from the pytagoras theorem
sure, this makes sense in my head if the vecto has the same direction but one is bigger than the other
but if they don't have the same direction, is not that intuitive to me
it doesn't help that i don't have a proof of this in the book i'm reading
you should look into the geometry of vector addition
P-Q is the vector you can add to Q in order to get P -- in other words the vector that will end at P if you put its beginning at Q.
Try drawing a parallelogram with a vertex at 0 and the other two vertices being P and Q
You'll note that one diagonal is the sum P+Q and the other is P-Q or Q-P
And you can see that the P-Q/Q-P is the one between P and Q
Try drawing it
Thus its length is the distance between the two
how do i find invertible matrix X such that XA=B
also it is given that these two are row equivalent
as well as the question expected that the ff elementary matrices are to be used to answer this problem


right, now it makes more sense

one of the legs is x_1 - x_2 and the other is y_1 - y_2
then you use pythagoras to get the blue distance
bruh
please try #prealg-and-algebra
K
i need help here pls 
as a hint, note that $XA = B$ means $Xa_1 = b_1$ and $Xa_2=b_2$ where $a_i$ is the i'th column

i.e. $X\m{a_1 & a_2} = \m{b_1 & b_2}$

find a matrix that sends a1->b1 and a2->b2
so something like making a a system of linear equations
do the elementary matrices help in finding M?
you can choose your own basis
for approach, no
there's also another eat to cheat
it's just that the question implied that it expects for the elementary matrices to be used in finding the invertible matrix x
I can write it out but you aren't probably allowed to do that
to do what
.
will give you an easy way to find X
by extending to a basis

yeah guessed that much
i just dont know how the elementary matrices are gonna be of use
i dont exactly know where to begin 
or more generally, what steps are to be taken
Do you know how to solve Dy = f using elementary row ops?
dy=f?
D being a matrix
You can write XA = B as A^TX^T = B^T, then you can take out columns one at a time
which results in the usual setting
They seem to suggest something else in your exercise though, so maybe theirs is easier
Hey can anyone help me with this? Or have a problem like this worked out

Bro is this even English let’s be real here
I’ve legit been staring at this problem for 15 minutes
criver

Then do a similar thing for BC but with indices j,l
Finally write out the same thing for ABC
Hmm okay
If the cardinality of a span== cardinality of a vector space is this equivalent to saying a basis
saying a basis what?
Can I get help wit this

??

help with what?
proving asso of composition? or the explanation?
$(g\circ f)(x):=g(f(x))$
Mosh

you may want to read some of this also:
In mathematics, function composition is an operation ∘ that takes two functions f and g, and produces a function h = g ∘ f such that h(x) = g(f(x)). In this operation, the function g is applied to the result of applying the function f to x. That is, the functions f : X → Y and g : Y → Z are composed to yield a function that maps x in domain ...
To understand your exercises you need to know what the notation means, i.e. look up the definitions.
Any good youtubers who cover them?
Do you not have a textbook?
though wikipedia is good enough for simple stuff like matrix multiplication and function composition
I do, but I’d rather have a video I learn better that way
In the following four pages (https://a.uguu.se/xtoGDuQ.png , https://a.uguu.se/jOUqqFxV.png , https://a.uguu.se/wZqCLKtg.png , https://a.uguu.se/rCDaQHB.png) I am rather baffled by the import of the writing on pages 109-110 starting at the definition of $(u^\ast, u) = \langle Ku^\ast, u\rangle$ and onward. What exactly is the point of the derivations on page 110, and are they related to the bidual mentioned towards the end there or do they have some kind of meaning unto themselves?



joesmith1042

This K looks like the metric tensor
@spare widget I'm not familiar with that
I am not certain it is just fromreading this though, but you canessentuallytransform between vectors and covectors using it
I see
e.g. say you have so,e basis g1, ..., gn
then G_{ij} = <gi, gj>
And one defines <u,v> = u^TGv
And you can treat Gu as the components of a covector
Since (Gu)^Tv
I am thrown off by the notation they use in what you linked though
What bookis this from?
It seems like (maybe I'm wrong here) that the author showed that if we "started" with the f^i's and set K^{_1} f_i = e^i for all i, we get that the u_i's are equal to the alpha_i's, so that kind of shows that the representation of f that we get is the same regardless of whether e_i or e^i are the basis for U.
@spare widget Functional analysis by E. Suhubi
No idea
That last page and a half seems like it isn't making a really coherent point
Should I just ignore it? I worked through all the equations and confirmed them, I'm just not sure what I'm supposed to take a way from that whole passage.
I am not sure either, but I can give you the metric tensor interpretation: you can basically change between the components of a vector and functional using the metric tensor
Typically one uses upper indices for a contravariant vector
And lower for a covector
@spare widget That seems to be what he is discussing there.
e.g. see 2.10.4 for instance
The components of the vector seem to be equal to the components of the functionals when representing the functional in the dual basis
alpha are the components of the functional
And you get the components of the vector by using K, or the metric tensor
if you wanted to get a contravariant vector from saud functional you would do K^{-1} alpha
It seems a bit weird though, since how do we know that K gives those coordinates no matter what?
K in the setting I know is just the grammian
I think I need to read through this again but hearing your explanation helped me think a bit better about this. Thank you!
above 2.10.5
they claim it exists because the two are isomorphic
They don't specify what it is though
Yeah, I do agree with its existence
the fi(ej) = delta_ij is just a requirement for biorthogonal bases
e.g. if you had e1,...,en (not being the canonical basis) expressed inthe coords (1,0,0...,0), ..., (0,0,...,1)
Then if you put those as columns of a matrix
E = [e1 | e2 | ... | en]
Then if you set now F = [f1; f2; ...; fn] as rows
@spare widget What confuses me is, the alpha_i come from a particular basis, e_i. In this proof, he starts with f^i and then maps it via K^{-1} to a new basis, e^i. But then he says, look, the alpha_i and the u_i (components of vector representation with respect to e^i) must be equal.
So I guess, this proves that K is in fact an isomorphism, or something?
@spare widget I see what you're saying in your explanation sort of
They just take it to be
@spare widget Then I don't understand why he is showing what I just said, that alpha_i = u_i.
What page
110, right before the paragraph about the bidual.
With the original basis e_i, f(e_i) = alpha_i.
So he then shows that if you start with f^i and use K to get e^i = K^{-1}(f_i), you end up with f = sum u_i f^i = sum alpha_i f^i
So alpha_i = f^i
no alpha_i != f^i
My fault, alpha_i = u_i. typo.
So the components of a vector in the original basis equal the components of our function in the dual
regardless of the basis e^i
But, I guess, what's the importance of that?
Like, why does it matter that we have this equality?
The components of a vector inarbitrary bases are definitely not equal
I am reading to figure out what the bases are here
Okay. Thank you!
So the second half of the first page and the first half of the second establish that U^* is isomorphic to F^n
Then they take the canonical basis of F^n and through the isomorphism to U^* they find corresponding elements from U^* that are f^1,...,f^n
suchthat f^i(e_j) = delta_{ij}
Right, I do understand the U^* and U isomorphism part
And also the finding of those elements you mentioned
Note that e_i is from U and f^j is from U^*
Yes.
Note that f^i is from U^* but e^iis its corresponding vector in U
Yes.
Then they just show that the components wrt e^i are the same as wrt f^i
Right.
you can think of this as having the equivalent basis in U instead of U^*
The components of f represented in its basis f^i are either the alpha_i 's (f(e_i) = alpha_i) or u_i's (components of u in e^i)
But what is the meaning of such an equivalency?
sure, the detail is that one is a functional and the other is a vector
so you have a 1-1 relation between functional and vector
as far as I can tell it's mostly formally relevant
As one is from U^* while the other from U^n
Hm, so showing alpha_i = u_i means that f and u are isomorphic?
I thought he assumed that in the first place
The thing is that a vector can be consumed by a functional
And previously you did not have a way for a vector to "consume" a vector
So by using this correspondence you dohave such a way
Say you are given u^i, v^i wrt e_i, vectors in U
(I'm wrong, he didn't assume it in the first place)
using u_i = sum_j K_i^j u^j you can find u_i in the basis e^j
Right
But you know that this matches the components of the functionalwith respect to f^j in U^*
Yes
Thus f(v) = <Ku,v> = u^TKv
Okay I see
note that u with lower indices is u in the basis e^i, while with upper indicesit is wrt e_i
Yes 🙂
when it has lower indices it is equivalent to the components of a functionalin U^* wrt f^i
Right
So fromthis you can turn vectors into functional and vice versa
Interesting.
Allowing you to pair those
Thank you for the explanation! This helped me a lot
Studying this stuff on my own can be hard sometimes. This book is pretty good overall but sometimes I get stuck like this
And at some point you will probabky have K explicitly defined as the metric tensor
Honestly the book sounds all over the place
Really why?
If I hadn't seen this before I would be totally lost
Oh yeah... well... I found it because I was trying to deal with another messy book that was much worse
It just introduces concepts with no motivation whatsoever, ina by the way manner
Yeah. It's mostly written pretty well but occasionally it's confusing like this
Thank you again for helping me out with this, I really appreciate it 🙂
Regarding this specific part I can suggest looking into some physics intro on tensors
should clarify things better
Oh okay!
They have covectors, contravariant vectors, metric tensor etc there
I can look into it. Thanks for the recomendation 🙂
this is with some illustrations, but it is rather slow: https://www.youtube.com/watch?v=8ptMTLzV4-I&list=PLJHszsWbB6hrkmmq57lX8BV-o-YIOFsiG

This is the start of a video series on tensors that I'm doing. I hope it helps someone out there on the internet.
I'm sorry that my voice is boring.
you may have to watch it at 2 speed if you have the time to at all
it's pretty basic
but gives some geometric intuition
Oh cool, thank you! I also have a book on manifolds that has some of this but it looks complicated
this is also a nice "cheat sheet":
https://www.mathematik.hu-berlin.de/~wendl/pub/connections_appendixA_2.pdf
much more condensed
Thanks 🙂

S * w1 = v1, S * w2 = v2
that S*w1 =v1
find w1, w2


I am guessing the answer key is wrong
ok
I figured out
how they got those nubmers
$\begin{bmatrix} \vec{v}_1^T \ \vec{v}_2^T\end{bmatrix} S = \begin{bmatrix} \vec{w}_1 & \vec{w}_2 \end{bmatrix}$
criver

idk why
thats really odd
but that's what their answer corresponds to
ill keep looking at it, thank you very much 🙂
Maybe they are treating {v1,v2} and {w1,w2} as the two bases
Then I think it may make sense
$\vec{w}1 = S{11} \vec{v}1 + S{21} \vec{v}_2, \quad \vec{w}2 = S{12} \vec{v}1 + S{22} \vec{v}_2$
criver

Thisis what they mean
ohhhhh that would make a lot more sense
thank you for looking into it for me
i appreciate it!
I didn't realize they were treating those as basis vectors
I'm learning affine spaces and subspaces now, and in this diagram, I'm unable to really understand that how exactly a-b gives the displacement vector for showing how displaced plane P2 is
[Source: Wikipedia Affine Spaces]

I’m using Cholesky factorization to generate random data, but I noticed that some correlation matrices don’t result in data with the same correlations.
https://mlisi.xyz/post/simulating-correlated-variables-with-the-cholesky-factorization/
Is there a test I could do to determine if a correlation matrix is feasible?
For example, intuitively I know this doesn’t make sense:
c = [ 1, 1, 1,
1, 1, 0
1, 0, 1 ]

Matteo Lisi
Generating random variables with given variance-covariance matrix can be useful for many purposes. For example it is useful for generating random intercepts and slopes with given correlations when simulating a multilevel, or mixed-effects, model (e.g. see here). This can be achieved efficiently with the Choleski factorization. In linear algebra ...
I believe I answered my question. The corr matrix must be positive definite
Hi, looking at matrix homework question and struggling to explain why changing x in Ax=b equation when there are infinite solutions. I understand it's just moving down the line that the matrix represents just don't know how to express that mathematically other than just pointing at a line on a graph

would appreciate any help
can you show 3a?
assuming you still need help with this

consider $A \bmqty{8\-2}$
Ann

I was having trouble wording why changing the variables in 3b) doesn’t alter the result. I don’t know how you would explain that, other than calculating the answer by substituting A into the equation. Sorry if my question was unclear.
have you learned about linear maps?
Not for this unit
have you at least learned that $A(x+y) = Ax + Ay$ for any matrix $A$ and vectors $x, y$ (whenever they are sized so as to make everything make sense)?
Ann

Yeah I understand that bit
Ann

I think computing the determinant of matrix A could also support the answer
but the question asks to not use calculation, so I'm confused on what it wants the working out to look like.
sorry if that sounds dismissive
I understand that point, but doesn't that result (A* [8;-2]) rely on substituting the matrix that A represents into the equation to solve A*x? If that makes sense.
no
well
...i mean like ok
a particualrly anal teacher might yell at you for that since it is technically a calculation
teacher explained it as: leaving A as the letter 'A' and changing only the left hand side to equal b
Feels like question is trying to be obtuse
i guess they mean to generalize the result?
something like Ax = b and Ax' = 0, so A(x+x')=b?
but how do you know Ax'=0 without calculation?
yes, i'm also stumped there
I was googling for the answer before and one solution was https://math.stackexchange.com/questions/2340563/how-to-prove-that-multiplying-the-equation-ax-b-from-the-left-with-invertibl

Mathematics Stack Exchange
How to prove that multiplying the equation $Ax = B$ from the left with
invertible matrices doesn't change set of solutions of the given
system ?
In the book of Linear Algebra in Action by Harr...
i can't think of any argument for that that doesn't rely on calculating something
but we haven't covered anything like the question in the content so far
maybe applying linearity is in and of itself an act of calculation
this question feels really obtuse
mini dose of existentialism with my homework
yeah
maybe it's on purpose
The question wants you to show that A*[y+8;z-2]=b without substituting in the values for A and performing the matrix multiplication. So, leave A as the letter 'A' and manipulate the left hand side until you can say that it equals b.
Is verbatim from the teacher also
so some calculations are allowed (?) just not involving A maybe
well how else do we get that A*[8;-2] = 0??
yeah seems hard to answer with equations, feel like screenshotting a desmos screen and visually proving it is easier than trying to rearrange 2x2 matrix to equal a 2x1 one
In that sense without substituting A in the matrix equation Ax=b, you can find determinant of A, which is 0, and say equation Ax=b has infinitely many solutions for x

??

have you made any attempt?
Hey does anyone know how to do this question??

The basis for the row space of a matrix A is the set of non-zero rows in rref(A).
What if we take the rows in the original matrix A that corresponds to these non-zero rows in rref(A), do they also form a basis for the row space of A?
I am super confused can plz show how to do
rref can help
what is rref?
,w rref

Right. But won't we have different non-zero rows in rref then?
Row reduced echelon form
Have you learned what happens to the determinant if you multiply a row or column by something? This could be useful in solving this efficiently.
How come?
what would the span be though?
||I'm thinking it may be possible to factor something out of that last column and then multiply the determinant by that at the end||
yes , I know it but I couldn't apply it for this question
say I have [v1; v1; v2] and I move [v1; v2; v1] then [v1; v2; 0] etc
then I will get first and second row form a basis in RR (provided v1 and v2 are lin indep)
but in the original matrix first and second row are v1,v1
which do not
Oh
Thanks!
So as long as I dont relace the rows, my claim is valid?
I don't think it is
@spare widget could you use microsoft paint by change to solve this question because its hard for me to understand sorry this is my first time taking linear algebra
because even without replacement it should depend on how you sum things
which row you add to each row

after all the "replacement" is just row addition and subtraction
if I have r linearly dependent rows in the beginning, RREF would require me to zero some out and have them at the end
so I don't think it works as nicely
do you know the definition of span?
look up the definition of span in your textbook
Cool thanks again
you can't expect to solve a problem where you don't know what it says
for the case I would suggest trying (0,0), (1,0), (0,1), (1,1) and figuring out what is the convex set between those points
The span of a set of vectors is the set of all linear combinations of the vectors
ok, write that out explicitly through mathematical notation
i.e. span(v1,v2) = {v = ? : ...}
yes thats the part i dont know
In mathematics, the linear span (also called the linear hull or just span) of a set S of vectors (from a vector space), denoted span(S), is the smallest linear subspace that contains the set. It can be characterized either as the intersection of all linear subspaces that contain S, or as the set of linear combinations of elements of S. The linea...
this is the first question of the chapter
do you know what a linear combination is
can you maybe do the question so I could work backward plz
Well, a linear combination of these vectors would be any combination of them using addition and scalar multiplication
write it out mathematically
→v1, →v2, →v3
???
$span(\vec{v}_1, \vec{v}_2) = { \lambda_1 \vec{v}_1 + \lambda_2 \vec{v}_2 ,: , \lambda_1, \lambda_2 \in \mathbb{R}}$
criver

im soo sorry sir, i just need to see it in normal writing so i can understand easir
now the question is - are v1 and v2 linearly independent?
if they are, then the set above spans the whole R^2

kk
but how do i use thatb in my question
Im am dying rn
Math can be soo stressful
maybe try to work it in reverse
set v1 = (3, -2)^T
v2 = (0,1)^T
now graph some points
e.g.
what is T?
transposition - I mean that the vectors are column vectors
it's irrelevant
(0,0) -> 0 * v1 + 0 * v2 = (0,0)
(1,0) -> 1 * v1 + 0 * v2 = v1
(0,1) -> 0 * v1 + 1 * v2 = v2
(1,1) -> 1 * v1 + 1 * v2 = v1+ v2
try drawing those point on a piece of paper
do i just graph random points?
and then connect them with edges
ohh
yes, in order to understand how linear combinations work
so 3 is x and _2 is y on graph?
yes
v1 = (3,-2) first component is along x second is along y
then draw also v2
and finally construct those 4 points
ok bet
(0,0) -> 0 * v1 + 0 * v2 = (0,0)
(1,0) -> 1 * v1 + 0 * v2 = v1
(0,1) -> 0 * v1 + 1 * v2 = v2
(1,1) -> 1 * v1 + 1 * v2 = v1+ v2
and connect them
then try to figure out what happens when you vary (s,t) in [0,1]^2
what kind of set do you get
just draw what I mentioned
and you'll figure it out
one builds the linear combination
s * v1 + t * v2
the question is what kind of set does this span when one varies s and t
to figure it out try plotting several points (s,t) = (0,0), (s,t) = (1,0), (s,t) = (0,1), (s,t) = (1,1)
ok
the point of the exercise is to familiarize yourself with the meaning of span
so it made like a line
what coordinates did you get for the four points?

how did you get that
s * v1 + t * v2
(s,t) = (0,0), (s,t) = (1,0), (s,t) = (0,1), (s,t) = (1,1)
just plug in and compute
what is s,t?
real numbers
is and anyway I can get on a call sir?
you know how to compute s* v1 + t * v2?
no
you don't know how to sum vectors?
i do
do you know how to multiply a scalar by a vector
do you have a textbook?
$s \vec{u} = s\begin{bmatrix} u_1 \ \ldots \ u_n \end{bmatrix} = \begin{bmatrix} s u_1 \ \ldots \ s u_n\end{bmatrix}$
no
criver

find one
ok
but is there anyway you can give me the answer
so i can work backwards and correlate with my textbook
Hoffman and Kunze, Strang, Friedberg, Shifrin, Axler, any would do
k
this would also do: https://tutorial.math.lamar.edu/classes/calcii/VectorArithmetic.aspx
In this section we will discuss the mathematical and geometric interpretation of the sum and difference of two vectors. We also define and give a geometric interpretation for scalar multiplication. We also give some of the basic properties of vector arithmetic and introduce the common i, j, k notation for vectors.
i have the david poole textbook
then look up vector arithmetic in it
\

dude what formula do i use to find the answer
can u put the numbers in for me
becuase my textbook is bot
no, that would be didactically improper and then you'll be back tomorrow with a variant of the same question
learn how to add vectors and how to multiply vectors by a scalar
In this section we will discuss the mathematical and geometric interpretation of the sum and difference of two vectors. We also define and give a geometric interpretation for scalar multiplication. We also give some of the basic properties of vector arithmetic and introduce the common i, j, k notation for vectors.
sdflkdsfjilodfsjgpoik'fdjg'poil;dfkg;hlb\
once you do that, you will be able to better appreciate what linear combination and linear independence means
ahhhh its cuz of people like you Math is not fun
have it your way, have a nice day
bro plzzz just help ,me
im sooo sorry for wht i said and done Im bad at math sir
@spare widget im actually sorry tho

idk what you're sorry for, my answer remains the same regardless - practice some vector arithmetic
once you understand how that works, compute some linear combinations as described
I gave you a resource: https://tutorial.math.lamar.edu/classes/calcii/VectorArithmetic.aspx
In this section we will discuss the mathematical and geometric interpretation of the sum and difference of two vectors. We also define and give a geometric interpretation for scalar multiplication. We also give some of the basic properties of vector arithmetic and introduce the common i, j, k notation for vectors.
use it
do some problems
then go back to your problem and find out whether v1 and v2 are linearly independent
if they are then they span the whole R^2
then for the example part try plotting the 4 points corresponding to (s,t) = (0,0), (s,t) = (1,0), (s,t) = (0,1), (s,t) = (1,1)
finally quantify what the set (s,t) in [0,1]^2 represents
I can't help you beyond that
not entirely LA but
anyone got neat ideas for storing matrices in a text file 
doing this rn which is id rows columns a1 a2 a3... ....

Probably see how numpy does it
why would you want to do this in the first place
cs project
csv files are definitely easier but it's a group thing and im on the half of the group that was assigned to try txt
any resources/pointers? im not very well versed in anything python
...neither am I
Anyway, in real life, you can compress the text file by implementing your favourite compression algorithm by hand. If your text is guaranteed to be plain text with the numbers 0 to 9 and spaces + line breaks, you can compress it by using more letters of the alphabet
Also for sparse matrices, instead of storing every entry, you can store the position and the value of each entry
i'll implement this eventually 
If you're fine with lossy compression, consider looking up on various matrix decomposition methods, in which SVD is one such algorithm
Many considerations, depending on the nature of your project
well it's still early so im just getting basic stuff implemented like matrix addition, multiplication, random generation etc.
but i'll have to think about stuff like that eventually
@spare widget just wanted to thank you again for helping me last night, i understood the whole section i was struggling in cuz of ur help 
Let A be a square matrix $n \geq 2$ with all minors of order $n-1$ equal to eachother. Show that $det(A) = 0$
Alphara

can someone provide some guidance for this proof?
Consider Minors obtained by erasing a_11 and a_12
You get that first column of minor obtained in first case= first column of minor obtained in second case
Which is to say Column 1 and column 2 of matrix are equal except for a_11 and a_12
@drowsy gulch
mb I misunderstood minor
oh hmm let s see
I think the approach will be similar
Consider Minors formed by erasing a_11 and a_12
I was studying cross products and dot products, but I can't really get the notion of them. Why exactly are they useful?
Things I noted while learning about them:
- 2-d cross products show how close two vectors are to each other (assuming both vector lengths to be equal) as the formed parallelogram's area would be less on the graph.
- Cross products also give a notion on the position of respective vectors. If the product is positive (of two vectors x and y), then x will always lie on the right side of y, and if the product is negative, thwn x will always lie on the left side of y, on the graph
- I really can't seem to get the intuition how the projection and dot product are equivalent. Also, are there more notions of these two concepts?
cross product gives a mutually orthogonal vector
dot product generalizes a lot to other inner products / how we define geometry of vectors

alright
i found C1 = C2 except a_11 and a_12 ; and now @native rampart i would do minors of a_21 and a_31 to find L2=L1 which would mean 2 columns/lines are equal which would mean det(A) = 0
am i getting this right?
yea i was afraid to point that
Because minors are the determinant of the submatrix This argument doesn't even make sense
ok, then what would work in this case?
i thought that maybe showing 2 colums are identical would instantly mean det(A) = 0
but i m clueless, do u have another idea?
Maybe swapping a row and showing that dets are equal
swapping a row negates the determinant
Ok does that work
But if you can show that those are nevertheless equal after the swap then it should work
I am not sure whether that follows from all minors being equal though
I was also thinking about using the laplace expansion, but idk how that would work out
Let det of any minor be equal to d
Then the determinant expansion rt first row would be
$d\sum_j (-1)^{1+j} a_{1j} = d\sum_j (-1)^j a_{2j}$
criver

does this help, I guess not
trying it
You can write asimilar thing for all rows
I am gessing that if you somehow group the systems it turns out that the vectors are linearly depedent
e.g.
$(-1)^{i+1}\begin{bmatrix} 1 & -1 & 1 & -1 \ldots & (-1)^{n+1} \end{bmatrix} \cdot \begin{bmatrix} a_{i1} & \ldots & a_{in} \end{bmatrix}= (-1)^{k+1}\begin{bmatrix} 1 & -1 & 1 & -1 \ldots & (-1)^{n+1} \end{bmatrix} \cdot \begin{bmatrix} a_{k1} & \ldots & a_{kn} \end{bmatrix}$
criver

Hey guys i have a problem with defining an correct answer for a i guess almost solved problem.

I hope people can read this my biggest problem is how to show that there is an map which is an additive inverse for any element of another random map of the same Set.
I would have done by saying the additive inverse of the same element would g´(x)= sgn(-1)g(x) the problem is the field T is not defined at all. So all elements could be inverse to themselves as much as i know. So i feel hard to define an actual answer. (English isnt my main language so if i was unclear with my question. Just point it out)
Hey everyone, I'm a bit clueless here. I have an intuition this is not true but can't think of a counter example. If anyone can help I would appreciate it! :

Scaling columns and rows is not the same
you can find plenty of counterexamples
Pick any S that is not diagonal
Then $(T S){ij } = t{ii}s_{ij}$ while $(ST){ij} = s{ij} t_{jj}$
criver

Because t_{ii} != t_{jj} for ageneral diagonal matrix
he proceeded to try to dm me too, unfortunate

they think helping them is our liability
thats kinda messed up


I think it's just kids being forced to study something they don't want to, so I can understand their frustration, but yeah I can unfortunately not put in the effort required from their side
I don't really mind that

It's like when your kid doesn't get a toy they wanted and they throw a tantrum, they eventually learn not to

there's no point in getting offended at them
At least you hope they learn.
anyways enough derai;ing of the thread from my side
thank you


i find \ni used as s.t. a bit weird 😛
Isn't that symbol universally used to write 'such that'?
it's also used in the same way as \in
i wouldn't know which one is more prevalent tbh
i have seen more s.t. outside of sets, and | or : within
(it's just a tangential comment btw, the proof is fine, as ryu said)
Oh okay. I haven't seen \ni being used the same way as /in. Anyway I am not pursuing a degree in mathematics so I don't have much experience with symbols.



what do you think?
try picturing where those data points would lie on the graph
maybe put them in using paint
first one I near the line
and ask yourself, what would need to happen for the association to be better, worse, or about the same
and 2nd one is not near the line
not near, but is it more or less close?
less close
i would still claim that it's about the same distance from the line as the other points
if you placed more points exactly on the line, the association would be better. if you placed points off the line and/or far away from it, it would get worse
here you put one point almost on the line and another still kinda close to it
i wouldn't expect that to change the result much
the two new points look kind of similar to the other points when you compare their distances to the line
is it the same
that's my impression, yes
ok
what does it mean to actually multiply or divide vectors?
what definition of multiplcation/division
To change the magnitude of something
No idea not at that level yet to understand what it means to define something mathematically
how do you compute this multiplication/division that you want the meaning of
you can have elementwise multiplication (hadamard product), dot product, cross product, exterior product, etc
is this a safe claim to make in my notes i'm typing?

or is something weird with the conjugates
"In the definition above, the order of the vectors does not matter, because <u,v> = 0 iff <v,u> = 0" the book never explicitly explained that iff in the previous parts, I guess its just assumed by the conjugate symmetry property since the conjugate of 0 = 0

In definitions, if is always iff
yeah orthogonal iff <u,v> = 0. i now understand what the non-definition paragraph was saying
cause they arent functions?
take any non-injective T, it's many to one
since $\operatorname{Ker}(T)\neq{0}$
Mosh

@grave kettle
Functions don't need to be injective lol
you can find many linear transformations that aren't functions, hence why we don't call them all functions 

what does the box in the bottom mean when it says "the converse is true in Rⁿ"
does that mean if \norm{u + v}^2 = \norm{u}^2 + \norm{v}^2 then they're orthogonal?
for example?
how is <v,u> = conjugate <u,v> = Re<u,v> (the real part of the equality)
thats a function
Yeah so that implies you think functions can't be non-injective or smth
Oh wait I have it backwards right
Wait so are all linear transformations functions? I’m a first year Lin alg student sligjtly confused now
This is still true right ^^
Linear transformations are generally defined as functions between two vector spaces which are also linear
@grave kettle @solid leaf transformation/function/map are synonyms
Ok I thought so
not even a linalg thing, if i said f(x)=0 isnt a function in #prealg-and-algebra ppl would call me insane
It's not quite that, the point is that z + its conjugate = 2Re(z) for any complex number
or f(x)=x^2 isnt a function
K, and I acknowledged I had it backwards.
Just because (a+ib) + (a-ib) = 2a
But then if we are working over real inner product spaces, everything is real anyway, so the conclusion holds iff <u,v> = 0, that is, iff u and v are orthogonal
The reverse Pythagorean theorem is basically that if a triangle obeys the Pythagorean theorem then it must be right angled
not even that, transformation/function/map are synonyms
Holy I get it
This shows that if we are working over a real inner product space we have |u+v|^2 = |u|^2 + |v|^2 then u and v must be orthogonal
@hardy inlet
If you need any further explanation/detail feel free to ask

Yeah that isn't true in general
I mean all they say there is that 2 Re<u,v> = <u,v> + <v,u> and ye that's explained here and below
It's just that if we work over a real inner product space then, well, <u,v> = <v,u> = Re<u,v> automatically cause everything is real and symmetry of the inner product etc
yeah if u treat it as real to begin with that makes sense
and i get what u mean with z + *z = 2(Re z)
where *z is the conjugate
sure
but what does that have to do with conj<u,v>
<v,u> is the complex conjugate of <u,v> (part of the definition for complex inner products)
This isnt a proper proof cause I started with what we want but theres no was of simplifying the conjugate of uv?

this true?

ah right the i
ok so why doesn't reverse Pythag hold for complex vector spaces then?

oh okay so the complex converse says the only the real component is guaranteed to be zero, we know nothing about its complex part?

therefore they're not always orthogonal since if the complex isn't zero, the whole thing isn't zero, and hence it isn't orthogonal
Is the only thing in parenthesis the orth_u(v)?

cause in my stats class we were doing linear algebra to derive the linear regression curve and somewhere was an "orth" and the professors like "u guys know what an orth is right?" (nobody knew)
and when I google orth linear algebra it doesn't have anything describing that. Does this exist?
is from his own notes:

yes
$u - \frac{\langle u,v\rangle}{|v|^2}u$ is the orthogonal component
What you're saying is that the orthogonal projection of a vector $u$ onto $v^\perp$ is the projection of $u$ onto $v$ subtracted from $u$.
Kirby

is "orthogonal component" the "orth"
I should say orthogonal projection, but yes
and is the $\operatorname{orth}_vu$ a real notation?
MattDog_222

I've never seen it personally, but it might just be something your professor does
In most cases, it's best to double check with your prof, but they seemed to define it in their notes as \vec{x} - proj(\vec{x})
which is what is expected
so is the orthogonal projection facing this way? (or the other)

and vector cv = proj_v(u) correct?
yeah I believe so
(i always did those wrong)
cause its like read backwards
proj_v u is "projection of u onto v"
Given any two 3D-vectors, how do you calculate the pitch, roll, and yaw to rotate one vector about another?
H+K uses $N_f$ to denote the "null space of $f$". Does $\ker(f)$ mean the same thing?
totally not anamono

he doesn't mention anything about kernel but wikipedia says kernel and null space are the same thing, i just wanna make sure im not mixing up two different meanings
null space is the kernel of a Transformation. but I dont think all kernels can be called nullspaces. I'll let someone else confidently answer; and or ask in Abstract algebra
Well if T is a linear transformation, nullSpace(T)=Kernel(T)
Kernel is a more general term
I guess H+K calls it NullSpace to emphasise it's a vector space
@grim leaf same thing. nullspace is used primarily in linalg, kernel is a more general term in abstract algebra
gotcha, thanks guys
At the bottom of the proof, how does v=u1-u2??

wording is important
the eqn holds 'for every v in V'
so in particular it holds for v=u1-u2
no prob
and to clarify, we're letting v = u_1 - u_2 yes? basically a counterexample sorta?
not a counterexample, its plugging a specific thing into a 'for all' statement
for example if all dogs are bad and ben is a dog, then i can conclude ben is bad
isn't it sorta the inverse of that
we think all dogs are good, but ben (u1-u2) is bad, and ben is a dog, so not all dogs are good?
its not, see the format of the proof
it shows a statement holds 'for all v in V'
so it holds for any specific v we pick
the dog thing works the same way
but like I didnt think we were "picking" any v. I thought we were picking a u1 and u2
like theres only one v that equals u1-u2
i can really only just reiterate whats said

this is shown 'for every v in V'
then we 'take v=u1-u2'
ie plug that specific quantity for v into the eqn
and thus $\langle u_1 - u_2,, u_1 - u_2\rangle = 0 \implies u_1 - u_2 = 0 \implies u_1 = u_2$
MattDog_222

yes
but to me that feels like a counterexample. Its like "Oh yeah, you're saying this holds for every v? Well what about v = u1-u2? gottem!"
it doesnt lead to any contradiction
its a common logic thing that i tried to make feel familiar with the dog thing
going from general to specific
if the logic is still too unfamiliar, we can set v=u1-u2 at the start instead of using v as a stand in
like i get think i understand the logic i just dont understand what its called, "proof by __"
i guess its a direct proof idk
idt theres a name for a proof containing this step
but idt it needs one either, the step of going general to specific should feel intuitive after enough use
bc to me it feels like a 'general counterexample' like 'you give me any u1 and u2 that u think this holds for and I'll give you this v'
heres a simpler example that follows what u feel but doesnt contradict anything
x^2>=0 for any real x
but thats true
what if i set x=3? that should be a counterexample right?
9 >= 0
just by virtue of me setting a specific x value
no you're giving 1 example of it being true
you need to give me infinite examples of it being true
exactly i didnt contradict anything
but it felt like we're giving 1 example thats false (thus it doesn't hold for every v)
but u somehow feel differently about setting a specific v for a statement which was already shown true for all v
my brain: If its true for every v then it must also be true for v=u1-u2, but when we do this u1 = u2 hmm wait yeah i guess
we know $0 = \langle u_1 - u_2, u_1 - u_2\rangle$ since we proved it in the first part
MattDog_222

which clearly says u1=u2
wait we're not proving for every v in V
we're using every v in V
our goal is u1=u2 (uniqueness of u)
yeah and we're saying the only possible way that <v u1> = <v u2> is if u1 = u2, since we know it equals 0 by the first proof
brain: At least one case we have u1=u2 as the only solution therefore for all we need u2 to also equal u1
well wait we aren't saying u1 = u2 = the only solution
we're saying u1 = u2
then the first part, the existance theorem shows that u does exist
so then u1 = u2 implies uniqueness; idk it still feels a little fuzzy
technically the u1=u2 bit means 'at most one vector has the property of u'
together with existence of u it gives uniqueness
yeah like, if theres a solution then they're the same; so we first showed theres a solution
'at most one' involves supposing 2 things have a certain property then showing theyre equal
Alright thanks for helpin im gonna move on from the page
ur welcome
kinda whack tho that not only does it prove its unique but what it equals

looks like a typo
kk yeah that's what i thought too
theres also another typo there with no x

oh right didnt catch that
$V = \mathcal{P}(\mathbb{R})$
MattDog_222

is a shorter way of saying "Let V be a vector space of all polynomial function over the field of real numbers"
P denotes the power set?
no the set of polynomial functions
ah kk
$\mathcal{P}_n(\mathbb{R})$ is polynomials of degree $n$ or less
MattDog_222

oh interesting
so like $p(x) = x^2 + 5 \in \mathcal{P}_2(\mathbb{R})$ but $p(x) = x^3 \not\in \mathcal{P}_2(\mathbb{R})$
MattDog_222

wait ok bit tangent but then is basis denoted with $\mathscr B$ or $\mathcal B$
totally not anamono

I dont think there's a set symbol to denote a basis
usually "Let B be a basis of V such that B = (v1, v2, ... , vn)"

not sure, depends on their font but I dont think it matters
kk

yeah
waiting
yeah
let me just let B = (1,1), (1,0) be THE basis of R²
xD
but it should say "a" basis
yeah
bases generally arent unique but idt the wording deserves changing too much
THE refers to how the vectors are defined
yeah R is a proper subset of C, so R doesn't span C
but a1 a2 and a3 are all real coordinates
i don't deal with complex stuff much tho so i could be wrong
Robake is that a basis of complex^3? I wanna know

yes
but theres no imaginary component
so?
how are you gonna form (i, 1+i, 5) from that
or anything with an i
oh
u multiply by i
thats cheating
xD
so like would it be e1i + e2 + e2i + 5e3?
yes but just say (1+i)e2
ah that would make sense
that's a cheesy scalar
but I guess it makes sense cause dim C3 != 6
they do say computation is for insight
C^3 is usually taken as a space over C
as in scalars pulled from C?
I took abstract algebra and remember approximately 1% of it but is there ever a use to use non complex non real fields as scalars
or maybe other things cant even be scalars
i guess rationals could
but maybe a vector space over general linear matrices or something
yes theres quite a bit to be done with finite fields
is modulo ever used in the context of linear algebra vector spaces
like $\mathcal L (Z_5)$
MattDog_222

what's L here?
i guess the set of linear maps from Z/5Z to Z/5Z
a simple example w/ modulo is encryption matrices
ah cause u cant undo modulo fully
isn't it a field?
it is
no, it can be undone
🤣
it cant fully be undone tho right
u just need to know the matrix used to encode the msg
like if u have 4, was it 4, 9, 14, 19,...
would that we like enigma?
so for encryption scheme like m^e mod n, we have an restriction that m<n
as long as the encryption matrix is invertible, u can decode
if it wasnt then communicating w/ ur friends would suck
i wonder if Z/2Z is useful since in CS XOR is useful for encryption
you can look at GF(2⁸)
whats a GF 
field of order 2⁸?
idk what GF stands for tho,
it just means an extension of Z/2Z of order 2⁸
galois field
ig
given any prime p and n>1, you can always find a field of order pⁿ unique upto iso
here p=2, n=8

{kind=link}
{kind=link}
{kind=link}
{kind=link}
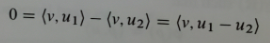{kind=link}
what?
well like the p doesnt matter right
i thought it was the fully prime factorization with the product of the powers

so like p1^a * p2^b * ... is func(a)* func(b) * ...
72 = 2^3 * 3^2 so the number of subgroups up to isomorphism is this function evaluated at 3 times it evaluated at 2
System.out.println(numSubgroups(3) * numSubgroups(2)); prints 6
if u have Z_81 its 3^4 so numSubgroups(4) = 5 subgroups up to iso
n = 1 --> 1
n = 2 --> 2
n = 3 --> 3
n = 4 --> 5
n = 5 --> 7
n = 6 --> 11
n = 7 --> 15
n = 8 --> 22
n = 9 --> 30
n = 10 --> 42
n = 11 --> 56
n = 12 --> 77
n = 13 --> 101
n = 14 --> 135
n = 15 --> 176
n = 16 --> 231
n = 17 --> 297
n = 18 --> 385
n = 19 --> 490``` this patterne.g. something with order 2^{19} has 490 subgroups up to isomorphism
i might be rambling on nonsense
but something has to do with those numbers in group theory
oh you are finding non isomorphic subgroup of given order
welp it was fun toying around with groups but i need to do some linear algebra now :/
I'll be back 
and yeah I guess my function name is misleading
I should call it partitions(int n)
but when i wrote it i didn't know thats what they were
so the intersection is empty? It doesn't say subseteq
and if U is a subset (not a subspace) it doesn't need to contain 0
but like if V is R3 and U is the XY-plane, then U^ is Z-axis, and the intersection contains zero, no?
[using U^ as U^{\perp}]
lol, some authors use $\subset$ to denote a subset

and $\subsetneq$ for strict subset

proper subset
wack
U is subset not subspace
its empty OR zero right?
so yeah, it can be empty
but U can also be a subspace and thus has 0
would e be a subseteq too

yes
\subset mean subset here, proper subset or equal
misleading symbol if you are used to \subseteq
ok and I have this. is this the proj_uv kinda deal or the orthogonal component?

like earlier when i had this in stats, is this P_U?
are we using P_U as the proj_uv from calculus?
Like it doesnt have an arrow showing if it came from 0 or v
