#linear-algebra
2 messages · Page 286 of 1
A full set of equations of independent rows leads to the trivial solution {0}
Conversely 0 equations lead to the full space
e.g. 0 dot x = 0
Stuff inbetween, i.e. A with r independent rows leads to a solution with n-r dimensions
Notably if you have Ax = 0
And Bx= 0
And you put those in a system
the solution space os the intersection of the solution spaces of Ax= 0 and Bx= 0
Conversely if you have the basis vectors being the rows in A and the second set being the basis vectors in B
then putting those together and removing linearly dependent vectors gives you a basis for the sum
So sum the sum of bases has as a counterpart the intersection of the solution spaces

is this true? and if yes, how do you prove it?
and whats the volume for points (x1,y1,z1) till (xn,yn,zn) in that case?

Just make A Matrix with coffiecents of given system of linear equation x is you known vector and b is the vector with constant parts
yes it's true
is there a standard way to approach a problem like this

would you just solve for k in a typical system or is elimination better
tried both and both seem really messy for part b
just do Gaussian elimination, no?
you could do row reduction
you'll eventually end up at a quantity that you need to divide by
i think you could also take the determinant. if det(A) is nonzero youll have a solution regardless of b.
yeah the determinant works just fine. i checked and theres nothing you get from b you dont get from ensuring det(A) is nonzero
that seems like double the work though
really? the diagonal method turns it into ~4 arithmetic operations
what i mean is that you then anyway have to go ahead and analyze the 0 det solutions to distinguish infinitely many sols from no sols
take the determinant and youll see its very obvious. its not like a quadratic or something, its something you can solve by inspection
yes but 0 det doesn't immediately mean no sol
or many the augmented matrix is really easy to simply inspect? is that what you mean?
cuz just looking at the det ignores the vector b
well if the det is zero it wont be a unique solution, it will necessarily be infinitely many. but row reduction is the way to go if you also want to do part b since that will give you both
well
actually you could just plug in the bad k value and see if its consistent. but that would require row reduction anyway so w/e
that's what i meant
you anyway have to do (r)ref at the end to check whether it was no sol or infinitely many
so double the work
sum of triangle areas
One has to be careful about the winding order though and to make sure the setis convex or something
ordering as in (x_i , y_i) has to be connected to (x_i+1 , y_i+1) and also (x_1 , y_1) has to be connected to (x_n , y_n), or something else?
I think that's already implicit in the problem
also since you take the absolute value I guess the winding order doesn't matter
the issue is if you have something non-convex
although maybe that isn't an issue either
it isn't if the non-convex parts get subtracted out due to the sign I guess
you have to draw some examples though
basically form the triangles (0,0), (x_i, y_i), (x_{i+1}, y_{i+1})
the determinant multiplied by 1/2 there gives you the area
but do check the non-convex cases
just draw some examples
Hey, I have a quick question with inner product spaces.
Let E be an inner product space with its associated norm, let $(v_i){1\le i\le n} \in E^n$ such that $\forall 1\le i \le n, |v_i| \le 1$. Let $(p_i){1\le i \le n} \in [0,1]^n$. Is it true that $|\sum_{i=1}^n p_iv_i| \le \sqrt{n}$ ?
Syst3ms

no not necessarily
it's true however if you assume $\sum_{i=1}^n p_i = 1$

Crud
which is a direct consequence of triangle inequality
Okay, let me post the full problem
like for easy contradiction, take v_i = e1 and p_i=1
right
With the previously introduced notation, let $v = \sum_{i=1}^n p_i v_i$. Furthermore, for $J \subseteq [![1,n]!]$, let $V_J = \sum_{i\in J} v_i$.
Syst3ms

Show that there exists $J \subseteq [![1,n]!]$ such that $|v-V_J| \le \frac{\sqrt{n}}2$
Syst3ms

what's that notation? [[1, n]]? any sequence from 1 to n?
[[1,n]] is the set of all integers between 1 and n, inclusive
yes ok
Some indications and previous questions
The previous question was that, given n vectors of norm 1 there exists $(\varepsilon_i){1\le i \le n} \in {-1,1}^n$ such that $|\sum{i=1}^n \varepsilon_iv_i| \le \sqrt{n}$
Syst3ms

there's no restriction on pi's?
Between 0 and 1, and the v_i have norm ≤ 1
Moreover, apparently the intent of the problem is to show that probabilities are a method, because they can crop up in places where it seems like they don't belong.
So supposedly a neat solution to this problem involves probabilities (and associated theory). For the record, we only studied discrete probabilities.
why do I have a feeling that this may not be true
like take pi = 0.5 and
and vi = e1 then
e_1 being some vector of norm 1 ?
max value of |v-Vj| = n/2 |e1| = n/2 >sqrt(2)/2 given large enough n
ye
I still think you need the restriction sum pi = 1
Well no, you can just choose J of cardinality n/2 (ish if n is odd) and that will work
The point is to show that there exists a J
did you understand this example?
Sec
actually
There's no problem here
If J is of cardinality n/2, |v-V_J| = 0
If n is odd and J is of cardinality (n+1)/2, |v-V_J|=|e1/2|= 1/2 ≤ √2/2
yes
Then v is the center of a cube of side length 1
you can take R^n and ei's to be std basis and pi=1/2 again
With the various V_J being the vertices of that cube
the distance from the center to a given vertex is √3/2
So not only is the inequality true, in this case it's true for all choice of J
for n=3 yes
Well, the distance is still √n/2
Taking J=[[1,n]] for example
$|V_J-v|^2=|\sum_{i=1}^n \frac12e_i|^2 = \frac14\sum_{i=1}^n |e_i|^2 = \frac{n}4$
Syst3ms

Taking the square root you end up with |V_J-V| = √n/2
hmm
now I've started to believe it as well
In other words, if you consider balls of radius √n/2 around each vertex of the parallelotope, they cover it entirey
Anyway, if probabilities are to be involved, I surmise either Markov's or Bienaymé-Chebyshev's inequality will be used at some point

gave up on doing this question
how do i do it
tried column operation but didn't work /:
what's on the right of the screenshot ?
you can try decomposing by multilinearity, that's way simpler than computing
Split it into a sum of two determinants along the sum in one of the columns, then use column operations on each of those to see that it must equal the determinant on the right.
there isn't anything
that's the whole question
confused af rn
how can we split it into a sum of two determinants if det(A+B) =/ det(A)+det(B)
You have (in simplified ad-hoc notation) on the left hand side |b+c, c+a, a+b|. Split that into |b, c+a, a+b| + |c, c+a, a+b| and do column operations on each of those.
Notation that I invented for the purpose of writing that post.
I think you could just repeat that step with the two new determinants and end up on the result, using the fact det() is alternating (a lot of the terms are = 0)
ok so i think i'm only allowed to do 3 things
because those are the only things we covered so far
row operations
column operations
swapping two rows/cols
Haven't you learned that a determinant is a linear function of each column separately?
with those 3 things how can i prove this.....
ummmm nope ?
Curious. What is your definition of determinant in the first place?
a scalar that is associated with square matrices ....
That's not a definition.
this is a midterm soo... we still haven't covered a lot of the content
maybe it will be introduced more formally later on
You can't possibly be asked to do stuff about determinants without having a definition of it.
well we only use the properties....
and how to evaluate it
nothing more
here for ex we maybe could use the fact that det(A)=det(A^T)?....
you can do it without linearity
you have |b+c, c+a, a+b| and notice that performing column operation, you can get a+b - (b+c) = a-c, yielding |a-c, c+a, a+b|. Now you can do a-c + c+a giving you 2a, so far your det is |2a, c+a, a+b|. Now factor out the 2 and use the first column (a) to get rid of the other a's in the 2 last columns
Cool.
that does kinda use linearity by factoring out the 2 though
Scaling a column sometimes counts as a "column operation" too.
wait what column operation did we use
-C1+C2--->C2?
yeah got it
doesn't it lead to a sign mistake though.....
tysmmmm @wintry steppe and @fringe fjord appreciate the help
huh
C3 - C1 -> C1 has a sign change in col 1.
oh okay so the sign is fixed by swapping the c and b columns in the end 🙂
@zinc timber I managed to work it out
And indeed, probability yields a rather neat answer
The key observation is that the p_i can be seen as probabilities of a bernoulli distribution

Sure
Syst3ms

Where the arrow means "follows the law" (it's the notation here)
These variables are taken independant
looks like endomorphism







But notice that for all p ∈ [0,1], p(1-p) ≤ 1/4


(Notice the values that S can take are precisely the V_J)
@zinc timber Done and cleaned up
yes reading
slight err, the last inequality is large
just learnt that matrices describe linear transformations
Yeah, that is quite helpful for many things
what's the use of studying non-square matrices?
I guess studying transformation between spaces of different dimensions?
But to be blunt we barely see non-square matrices in class
Anyhow, this probability proof is rather elegant, very neat
My prof did this a while ago, he solved a random integration problem with probability
maps between spaces of different dimension
square matrices are usually more interesting anyways
-you can compose them with themselves; linear dynamics
-the theory of modules over PIDs apply to them; jordan, rational canonical, diagonal forms
-eigenvalues, determinants for sweet geometric interpretation
-we like to approximate by square matrices anyways
svds, singular values, low rank approx and rank 1 decomps with overcomplete frames
😌
these generalize nicely to n-way arrays that are often used to represent multilinear transformations, too
these are more general, ryu, so i'd call them a special case
non linear dynamics also uses square matrices apparently 
what is that about approximations with overcomplete frames?
one can set up rectangular matrices A of size m x n with m << n so that in special cases, there exist unique solutions x to Ax = b
(given special restrictions on x)
Is there a standard name for B^T A B (where I'm sort of conjugating, by by a transpose instead of an inverse?)
wdym standard name?
Wouldn't this be similar to change of basis for a (2,0) or (0,2) tensor depending on what B is
off the top of my head, for the general case, no
if B and/or A have any special property, perhaps
If B is a change of basis matrix then B^{-1}AB gives you the transformation for a (1,1) tensor A
Where A is square
If it's symmetric you get the B^T A B thing, it's similar if it is a (2,0) tensor (e.g. metric tensor), then: u^TGv = p^TB^TGBq, where u = Bp, v = Bq
Just got back from my linear algebra midterm 💀💀
I feel like i kinda did most questions correctly ?
But there was this question that i spent literally thirty minutes staring at
Let X be a 3x3 mateix
If XX^T is skew symmetric prove that X=O3×3
I could only prove that XX^T is 0.....
why are the requirements of linear transformation the way they are
I am guessing motivated from R^n and then generalized
so you have that XX^T is 0, moash
then you consider that the diagonal entries are equal to the 2-norm of the rows of X
so that all the rows of X are 2-norm 0
the 2 norm is positive definite, so that each row is then 0
wdym by requirements of linear transformation, chromium?
like the definition? the conditions that linear maps satisfy?
definition
T(a + b) = T(a) + T(b)
c T(a) = T(ca)
yeah, it's a more general and abstract way of expressing the nice properties of R^n, so that it also applies to other stuff
i seem to recall systems of equations being one of the original motivation behind early linalg tools, so that seems right
why are they defined like this
because they have nice consequences
I would say, fundamentally, a vector supports two operations: addition and scalar multiplication. So a linear transformation is a map which respects both of those operations (property one you list is about vector addition, and property two is about scalar multiplication). Now, you might rightly argue this is just pushing the question back to another question which is more fundamental: Why are those the two operations we consider on vectors?
please do explain
I think when you get to "Why do we define vectors with these two operations?" you get a lot of different answers which are likely all very unsatisfying. The "because it ends up being useful"/"because it ends up developing a rich theory" sorts of explanations are one flavor, or the historical flavor of "because we thought of these things from physics where both are very natural" will come up to. But ultimately, all mathematical definitions are arbitrary. You can define them however you want. Which ones survive is a function of Darwinism more than anything. And linear algebra is about the end of subjects where mathematicians actually agree how to define things. Pretty quickly after that you'll find that definitions start being more... impressionistic.
So in short, I think it is a very good question, but I also think it is a question to which no very good answer exists. "In math, we don't understand things, we just get used to them," as the saying goes.
often times it goes something along the lines of "oh, these things share something in common and have nice properties. does this generalize?"
and this was one thing that did nicely
the completely ahistoric explanation is that the definition of linear transformation mimics the properties of matrix multiplication. But linear transformations predate matrices.
3b1b said the intuitive way to understand it is
‘it’s defined such that all lines remain lines and the origin is fixed in place’
it’s a bit goofy and doesn’t seem related with said properties
well
that makes sense if by "line" you mean a line passing through the origin
then in this sense, a line is a scalar times a vector, and its image under linear transformation is the same scalar times a new, transformed vector
so, a new line passing through the origin
this only makes sense if your "vector" has an associated "direction", which in general is not required
so it only makes sense for vector spaces that inherently have this additional structure
so this seems like a special case of preserving scalar mult and vector addition
so it’s simply designed around preserving these?
or are there more
what is
Ummm i don't think we covered that
We didn't study norms
did you see dot products
I'd say try to prove it using what we covered /:
the preservation of scalar mult and vector addition
Nope
really? no dot products?
We only covered the basic stuff
you did see matrix multiplication though?
The things you'd see in 4 weeks of lin alg
Yeah
how did you see matrix mult and not scalar products
the below definition of what
I could only prove that AA^T=0
We didn't do scalar products....
i guess you can still show it just by writing it out as a sum
you can see that the diagonal entries of XX^T have a special form. if X has a row r with components r1, r2, r3,...
I didn't use sums 💀💀💀
there is a diagonal entry in XX^T of the form r1^2 + r2^2 + ...
and since XX^T = 0
you have a sum of squares that equals 0
How did we get that
Literally spent like half an hr to reach AA^T=0
Oh yeah
well, the definition of skew symmetric is that W^T = -W
I thought abt this but i ignored it 💀
Yeah
if c = -c, either 1 = -1, or c = 0
I moved -Xx^T to the other side
same thing
at any rate, the trick is to look at the diagonal elements of XX^T
those contain only sums of squares
you can use this to argue that each row of X must be 0
Yeah all of them were a^2+b^2+c^2
Maybe i'd get half the marks... 💀
Well i'm just glad it's over
this is a definition?
it's a consequence of the 2 properties of linear maps
i still don’t really get this
a line is of the form cv for a scalar c and a vector v in R^n
if we have a linear function f, then f(cv) = cf(v)
and f(v) is another vector
so cf(v) is a new line
and due to linearity, this generalizes to sums of scaled vectors
what about the f(u + v) = f(u) + f(v) thing
i already explained that above 
where 
here
if you have a line between vectors v,w [a is a scalar]
av + (1-a)w
after the transformation T
aT(v) + (1-a)T(w)
its still a line just between new vectors now
between?
two vectors define a line, right?
yes
isn’t that c (v - u)
no because all vectors are rooted at the origin
??
what does that have to do with origin



the difference vector is rooted at the origin
if you want the line between v and w you want cv + (1-c)w
think of the vectors like points
since they're rooted at the origin in LA
why isn’t this also an ok representation
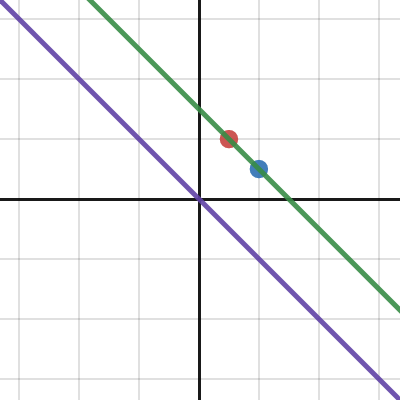
Desmos
just scale the (u - v)
see here, mine is the green line, yours is purple
to make your method work you'd need to add an offset
v + c(u -v)
which would simplify to
cu + (1 - c)v
oh
does this make sense now?
i still don’t understand whether this is yes or no
or what
?
"all lines remain lines" and T(av + bw) = aTv + bTw are the same thing
original question was why requirements for linear transformations are they way they are
because... that's what linear means
I mean, you could have an affine transformation that doesn't fix the origin
what does it mean
but affine transformations aren't as nice as linear ones because the whole theory of nullspaces doesn't work (at least, not by default)
there are lots of mathematical transformations, after studying all of them linear ones tended to lead to especially nice theorems. hence linear algebra
so what does it mean lol
i’m now unconvinced that linear algebra is called linear because it ‘studies linear equations’
a transformation T is linear if T(ax + by) = aT(x) + bT(y) for scalar a,b and vector x,y
linear equations and linear transformations are the same thing
linear transformations are the same as matrices which are the same as linear equations
Given the basis for two subspaces I need to find a basis for their intersection.
I solved for linear combination of the basis of first subspace = linear combination of the basis of second subspace and got some relation between the coefficients, I also know that the dimension of intersection is 2, now should I just pick two linearly independent vectors from the solution set in order to get a basis?
for example: if A is a matrix, x is a vector and b is a vector
Ax = b
is a system of linear equations, but A is also a linear transformation
this will always be solvable if Ax = 0 implies x = 0 for example
yes
finish the 3b1b series hopefully it makes more sense, https://youtu.be/TgKwz5Ikpc8 might explain it to you
This is really the reason linear algebra is so powerful.
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Home page: https://www.3blue1brown.com/
Full series: http://3b1b.co/eola
Future series like this are funded by the community, through Patreon, where ...
what if the dimension of the intersection is n, how can we pick n independent vectors from the solution set?
or will they automatically be independent?
they won't be automatically independent, you've got to pick them that way
in matrix form if you have Ax = b and want n solutions for x, you can pick a particular solution x_p all the other solutions will be x_p + x_n for x_n in the nullspace. then the problem is reduced to finding a basis for the nullspace then adding x_p
though you can probably do it directly for small n
actually you can do it more directly i think i havent done computational LA for a bit
put the system in reduced row echelon form then i think you can eyeball independent solutions
actually for 2d they will be
since Ax = A(cx) = c(Ax) is only true if c = 1 or Ax = 0
I think
yea but I think a more general approach would be better
for 2d its still only independent vectors, but still
I'll read about nullspaces and stuff

MIT 18.06 Linear Algebra, Spring 2005
Instructor: Gilbert Strang
View the complete course: http://ocw.mit.edu/18-06S05
YouTube Playlist: https://www.youtube.com/playlist?list=PLE7DDD91010BC51F8
- Solving Ax = 0: Pivot Variables, Special Solutions
License: Creative Commons BY-NC-SA
More information at https://ocw.mit.edu/terms
More courses at ...
thanks
In mathematics, two square matrices A and B over a field are called congruent if there exists an invertible matrix P over the same field such that
PTAP = Bwhere "T" denotes the matrix transpose. Matrix congruence is an equivalence relation.
Matrix congruence arises when considering the effect of change of basis on the Gram matrix attached t...
@grave kettle you should do this problem
https://cdn.discordapp.com/attachments/903481105888452609/949104624751747072/Screenshot_29.png

spoilers
#help-22 message
sauce
#help-22 message
hey im a bit confused on the start of this question it says we are given a collection of $n^2$ matrices $E_{ij}$ whose components are given by $(E_{ij}){kl}=\delta{ik} \delta_{jl}$, what would a matrix of this type look like, im finding it hard to visualise :x
Wingardium Matrix-Leviosa

E_ij is the matrix with 1 at the (i,j) slot & 0 elsewhere
is that just an identity matrix?
no, the identity has 1 on the whole diagonal
what do you mean (i,j) slot?
row i, col j
u need to specify i,j first
row 1 , col 2
E_23 is the matrix with 1 at the (2,3) slot & 0 elsewhere
oh righttt
and $E_{12} is the matrix $\begin{pmatrix}
0 & 1 & 0\
0 & 0& 0\
0& 0& 0
\end{pmatrix}$
Wingardium Matrix-Leviosa
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

yes
used to define the matrix entries
for each matrix A u need 2 indices to define its entries
usually theyre ij, so like A_ij
but ij is already used to specify where the 1 goes
so now we are specifying where other 1's go?
yeah kronecker delta
yeah so when defining E_ij
1 if i=j 0 otherwise
ij are fixed
yeah
then u go thru each combo of kl
right right
so we need to have basically diagonal entries for this to work?
to satisfy i=j and k=l?
err
RokabeJintaro

yeah mb i was thinking of it wrong
when is this 1? 0?
so for our case
say E_23
we get delta_2k delta_3l
yeah im lost
how does a matrix = this kronecker delta
k has to be 2 and l has to be 3
for it to be 1
yeah
what if k!=2 or l!=3
what do you mean by !=
not equal
E_23 is the matrix with 1 at the (2,3) slot & 0 elsewhere
do u see how it matches this
is that right?
oh its picking out the matrix entries of the matrix E_ij that we have chosen*
does that make sense?
i mean in general this is how one compactly defines matrices
for a matrix A
u take 2 dummy indices, usually ij, in order to define each entry A_ij
eg each entry of the transpose of $A$ is $A^T_{ij}=A_{ji}$
RokabeJintaro

right right
each entry of the sum of matrices $A,B$ is $(A+B){ij}=A{ij}+B_{ij}$
RokabeJintaro

same thing here
its just we already fix ij
so we use kl instead as dummy indices when defining E_ij
that makes sense
so when u work out the definition of E_ij in general (similar to how u do E_23) u should get
E_ij is the matrix with 1 at the (i,j) slot & 0 elsewhere
ok that makes sense
So we have say
for n=3
$E_{ij}=\begin{pmatrix}
E_{11} & E_{12} & E_{13}\
E_{21} & E_{22}& E_{23}\
E_{31} & E_{32}& E_{33}
\end{pmatrix}$
Wingardium Matrix-Leviosa

E_11 is a matrix not a number
but going through each combo of k and l we have to pick that they are the same as i and j or we get 0
oh
oh yeah
i think im too tired for matrices lol
right right yeah sorry
a completely out of the blue question but how does this build a basis for gl(n,k)?
write matrices in terms of the E_ij
does the lie algebra gl(n,k) contain matrices that have det non zero?
yes
so we just have to write a matrix that has det non zero using (E_ij)_kl?
again, E_ij is the matrix
then how does a matrix with 1 entry have det non zero?
$\mathfrak{gl}$
Wingardium Matrix-Leviosa

invertibles arent closed under addition
i thought if we have GL(n,K) we can go to the tangent space of the lie group
which is a vector space
ok yeah its a lie group of dim n^2
for a sec i was thinking of all nxn matrices, which the E_ij IS a basis of
ahhh ok
how did you know that its the set of n x n matrices
is there a way to work this out?
of course
use the matrix exponential
oh yeah
do you mean the inverse map
of the matrix exponential?
because the exp: g --> G
no
i just mean the matrix exponential
the matrix exponential on M(n, R) doesn't even have an inverse
$e^A=\sum\frac{A^k}{k!}$
RokabeJintaro

yeah yeah i know this one 😄
is this because of the 0 matrix?
and we just get 0/0 undefined?
the 0 matrix isn't in GL(n, R)
wdym
i thought you said the matrix exp on M(n,R)?

the matrix exponential is a map M(n, R) -> GL(n, R)
to show that $$\mathfrak{gl}(n, \bR) = M(n, \bR),$$ just show each inclusion. the only non-trivial part is showing that any $A \in M(n, \bR)$ is showing that there's a curve in $GL(n, \bR)$ through the identity whose tangent vector is $A$. the matrix exponential gives this curve to you
TTerra

that curve is \exp(tA)
right right
this is ringing bells
right yesss
GL(n,R) is a contained in M(n,R) and its an open set so its tangent space at any g in GL(n,R) is just M(n,R)
i think i need to sleep, im getting confused on basic matrix stuff 
thank you so much for your help TTera and Rokabe
this also works lmao
but the matrix exponential thing is good to keep in mind, because you're going to want to use it or something similar when computing lie algebras of other matrix groups
Does my explanation make sense? The value of cos(theta) must be between -1 and 1. Since cos(theta) is equal to the inner product of x,y over norm(x)*norm(y), we must check that this value is between -1 and 1. It is straightforward using the Cauchy-Schwarz inequality.

yeah i will keep it in mind, thank you so much!:)
Hello again Kings 👑
I'm trying to think what T² = I means
it means T \circ T is the identity
thats the definition of T² ye. But what does this say about T?
I dont have any idea how to make the identity from a square, other than the identity
but whats this -1 EV having to do with anything

i like half proved that if it is an EV that T²=I, but idk what to do about not -1
it being an eigenvalue does not imply that T^2 = I...
it implies that on the corresponding eigenspace, sure, but not everywhere
one way i can think of is to figure out what the eigenvalues of T can be, and to diagonalize it (why is it diagonalizable?)
it's hard to suggest a way to proceed with this kind of question without knowing what you know
because there are quite a few ways to approach it imo
the fastest proof i can think of uses the minimal polynomial
quick question about matrieces what does the curly braces mean

is just multiplication?
Is cross product an example of a more general type of operation?
in a few ways
it's a lie algebra structure on R^3
there's a more general "cross product" of n - 1 vectors on R^n
wedge product
to name a few
Oh ok
Neat
Cross product. It's not associative. I want to say it's anti commutative
Iirc
correct
2+2= airplane
I found an outline of the proof online, fluffed it up to show the missing steps, and got this. Dunno how we can split T^2-I tho

i can't follow this after the "for some w"
Eigenspaces🔥
have you tried doing the exercise yourself?
since (T+I)[(T-I)v]=0, then either (T+I)v = 0 or (T-I)v = 0
ah, nevermind, i see what you're getting at
you're saying that if (T - I)v is non-zero, then it's an eigenvector of T with eigenvalue -1, a contradiction
I guess I didn't explicity say "Case (T-I)v = 0
this proof is fine logically
presentation could be improved but it works
T^2 - I = (T + I)(T - I) is a trivial equality
well since (T+I)w = 0 implies that lambda = -1, then we know (T-I)w MUST equal 0
and the last temp of
Tv = Iv, why are we allowed to say T=I? Is that some identity too?
if Tv = Iv for all v then T = I
in general thats how we define function equality
f=g if f(x)=g(x) for all x
||the minimal polynomial of T divides x^2 - 1 = (x - 1)(x + 1) and cannot be divisible by x + 1, so x - 1 annihilates T, meaning T = I||
it isn't divisible by x + 1 because if λ = -1 then (-1) + 1 = 0 and DIV0 error?
what
u said that poly wasn't divisible by x+1
wait so does difference of squares apply to transformations?
as you should show, since you're uncertain, yes
i took linear algebra three years ago
i guess u can just distribute it right, T²+TI-TI-I² = T^2 - I

theres also the implicit use of the fact I commutes with every map
it is.
try it for (A+B)(A-B)
yeah it ends up just being T²+TI-TI-I² with replacing A and B
try again
the fact that its on a map feels weird
think of em as matrices
(A+B)(A-B) = A² - AB + AB -B² = A² - B²
sorry i always get them backwards
anyways, A² - AB + BA -B²
can that be simplified?
Who wants to talk about dual spaces
ok and since identity is commutative (able to commute/move freely) then it holds on I
we dont say I is commutative
TI ?
we say I commutes with every matrix
ah that makes more english sense
this is a lesson in algebra where things dont always commute

go on
is this sound?

ABv = 0 doesn't imply that one of Av or Bv is zero
i suggest not copying proofs you find online
that is a good suggestion 
Does it imply that (T-I)v = 0 or (T+I)[(T-I)v] = 0 
i need the composition right
it certainly implies (T + I)((T - I)v) = 0, and that's all you need for the proof
er, (T - I)((T + I)v) = 0, but this is alright since T - I and T + I commute
(T + I)((T - I)v) = 0 \land (T - I)((T + I)v) = 0
im not sure how thats enough for the proof
read over the proof you found online, then
because it's either wrong or you misunderstood it
i dont like that one D:
was using it as a starter piece
The dual map of T
If T has matrix representation A
Then T' has A^T
Because dual map T': W'-V' is...

(T + I)((T - I)v) = 0 \land (T - I)((T + I)v) = 0 so either ((T - I)v) = 0 and ((T + I)v) = 0? and the first equation violates our assumption of no -1 ev, so solving the second we get T=I right?
T* *!
NO!
ABv = 0 DOES NOT IMPLY Av = 0 or Bv = 0!
right but i thought since we had commuted the T+I and T-I to form both that would work
even if A and B commute, NO
that's its definition, yes
im trying to understand how
it certainly implies (T + I)((T - I)v) = 0, and that's all you need for the proof
i don't know what you mean by this
i'm not trying to imply the proof follows immediately from this or anything
i'm saying this is all you know
and you have to use to prove the statement you want
(the point of the exercise)

@past yew is this a test?
Yup yesterday test
i cant tell if I repeated the same mistake

A & B are correct according to me
it's very sloppy, but looks a little more correct
could u please elaborate on what causes it to be sloppy
"...which contradicts our assumption"
what assumption? this isn't clear
yeah... thats not needed is it. since T0 = 0 for any T
well if you're using w as an eigenvector corresponding to -1 to get a contradiction, it better be non-zero
and if that's not what you're doing
then it's not clear
sec i think im onto somethign
i think i've gotten stuck again

i feel like I cant say w=0
this works
this was the bottom of what i had that i was too embarrased to show; I beat my head some more and the mistake i made at the very end was substituting W into itself

you're getting there
its this whole \neq0 thats screwing me up

well T and I certainly agree when v = 0 as well.
T0 = I0 right
but I technically only proved for not equal, so would I just throw in a sentence about T0=I0 therefore Tv=Iv forall v
if you want
the mona lisa v2:

the logic works out

so its no different that T \in L(V)
if you like writing them as T, sure
the \align at the end feels questionable; especially the part where I dropped the dimentions

what's fundamental theorem of linear maps
axlers textbook does


these steps feel sus
align one
since you know V = N(T)+R(T) you can also show their intersection is trivial and so it's a direct sum

ya
which is why we had the P² = P so that we cant apply the transformation once, get something in the nullspace, then apply such and get 0
unfortunately I can't think of an easy example now
idk what it exactly means but yes
your intuition is correct
I think i have an example

ig it works
which means (0,0,1) is in the intersection
thus non trivial and cant take a direct sum
ok I think i cleared it up better:

oops now I left out the direct sum part

yea idk this doesn't make much sense to me. Its not true that "for all v in V, (P - I)v = 0" (this would imply that P = I), and that does not imply that null P = {(P - I)v : v in V}
your v = Pv + (P - I)v = Pv + 0 = Pv is almost the right idea to show that null P + range P = V, but again (P - I)v != 0 in general.
yeah... 😬 thats a good point in the first part. idk how to derive the nullP then
I don't think you really need to. while you can't say null P = {(P - I)v : v in V}, you can say null P \supset {(P - I)v : v in V}
wait wouldn't it be a subset
if you have (P - I)v in {(P - I)v : v in V}, then P((P-I)v) = 0, so (P - I)v is in null P
so its as a wrote it
so at least everything in (P-I)v is in the null?
ye
im trying to figure out how there can be more
wait nvm its not saying every vector in V; its saying every vector acted on by (P-I)
so there could be some w \not \in range(P-I)
such that Pw = 0
yes
the other inclusion might hold actually, but its not necessary for this
in fact i think it does hold
yea it does
the other inclusion is one of those things that are so trivial its easy to miss. But anyway, as far as correcting this proof, what you have here
v = Pv + (P - I)v
is almost correct, but Pv + (P - I)v = 2Pv - Iv, which need not be v. There's a simple way to fix this so you get the right thing
yeah i saw that and flipped the sign but idk what to do with it
i.e. v = Pv + (I - P)v?

ah yea, so that fixes that
yeah, idk why you have that
the correct conclusion from v = Pv - (P - I)v is that V = range P + null P
plus null P?
ye
null P is closed under scalar multiplication, so (P - I)v in null P implies -(P - I)v is in null P as well

if you can show that null P = {(P - I)v : v in V}, then your proof that null P \cap range P = 0 works. But there's also a different way to do that
and then once you have V = range P + null P and null P \cap range P = 0, that's it. You don't need the "fundamental theorem of linear maps" for this.
yeah just the definition of directsum
In fact, you shouldn't use it, because it only works in finite dimensions

ye, that's perfect
ah right nullP is a superset
so (P-1)v is definitely in it
aha
my brain was still thinking the subset
but that still doesn't solve the issue of nullP's exact form
like I can't set an equality on it to compute the intersection can i
im not sure what you mean by this. Your proof that null P \cap range P = 0 uses that null P = {(P - I)v : v in V}, so if you want to use that proof, then you'll need to figure out the other inclusion (which i verified does hold). You also don't have to use it. There is another way to see that null P \cap range P = 0 as well.
well how'd u show the equality of null P = (P-I)v that sounds difficult
here's a hint, but it basically gives it away: || let v be in null P. v = -(P - I)v (why?) ||
oops fixed it
i thought scalars didn't matter
wdym?
u swaped from v= (P-1)v to v = -(P-1)v
oh... that is quite trival
i just dont have the brain
well scalars could matter as far as making an equality hold. btw, i should have written
v = (P-1)(-v). Now its really clear that v in null P implies v is in {(P-I)v : v in V}
it took me like 3 minutes to notice its trivialness
the other inclusion is one of those things that are so trivial its easy to miss
hence what i said earlier

for me to have figured it despite really sucking at vector space and being an absolute beginner to it, yes it has to have been trivial
dim V = dim null P + dim range P though, is clearly not trivially intuitively visible to me ._.
the proof makes sense tho, so yeah
shouldn't this have a negative coefficient now
$\mathcal{L}$
Ansh

you would write v = (P-I)(-v)
linear operators on V, yea
T \in L(V) means T is in the set of linear maps from vector space V to itself
L(V,W) is V to W
(the set of all)
Ty 
does this make sense matt? if v is in null P, there exists an element of V, i.e. w = -v such that v = (P - I)w
vaguely?
I mean: v = Iv = Pv - (P - I)v = (P - I)(-v) = (P - I)w
well, what does it mean for w to be in {(P-I)v : v in V}? It means exactly that there exists v in V such that w = (P - V)v
and what we've shown is that v = (P - I)w for w = -v in V
is it necesary to create a w?
Not necessarily. Some proofs of existence use non constructive methods like contradiction.
this is the current

uhh, null P = {x | Px = 0, x \in V}
and you figured that (P - I)v for all v in V satisfies P(P - I)v = 0
hence, (P - I)v must've been a subset of null P
:o






ryu
share all the Qs with solutions lmfao
I believe questions and solutions suit me better than grinding my brains with the theory :|
i aint got the solutions 
after you're done then..
yeah....
the goal is to finish; but no guarantees on that one
this one feels easy so i wrote the definitions...

not sure how to finish this or if its a good direction

so it appears that I have the magnitude of c is 1, but I need c to be exactly 1 right
then u = cv → u = v
i agree
i feel like theres something super basic with this but idk
ohhh yeah those properties + the substitution
3am brain mode be like
ty
wait does that finish it tho..
what about complex tho?
c*1 = 1
couldn't c * 1 = c?

you should stop doing math so late
you'll make mistakes and won't retain the knowledge
yeah I know i need to start sooner,
but heres the pwoof

not sure on the syntax here, I feel like I should have <e_1, e_2> but the problem doesn't have that

oh it says function not inner product; thats why. Should I give it a name like phi?

i wouldn't say this is a contradiction, more like a counterexample
you didn't use the assumption that it was an inner product at any point
fair enough
would an obscure counterexample even suffice; or is this sort of an existance problem

if lambda is not an eigenvalue then its invertible and by the rank nullity theorem f(lambda) = dimV; and if it is an eigenvalue; then its not invertible, hence nullity \geq 1, and thus f() <= dimV-1
i guess we're assuming the dimention a nonnegative integer

and ..
which one are you addressing

how would you do the last one, ryu
which one? not continuous one?
or this?
the not cont one, yea
in C, we must have one eigen value λ amd f(λ) <= n-1 but for all points near to λ, f(λ)=n so we cannot make |f(x)-f(λ)|< eps for any δ>0
would you have accepted using a limit
or or, if f were continuous then f(C) would be connected in N but it isn't, so f couldn't have been continuous
or eps delta preferred?
I prefer the topology one 🙈
limit feels like easier
should work, right?
ya
is there a quick way to tell if a matrix is diagonalisable
no
:(
mm cuz seeing if the characteristic polynomial splits can be pretty hard without a calculator
for example, any diagonal matrix is diagonalizable
if the minimal polynomial is separable then it's diagonalizable
it's iff condition
yeas ik lol
have fun computing the minimal polynomial
its just hard to see lol
compute the char poly
clench your teeth and get computing
hehe
yea algebra is so hard
sometimes you just have to do a little bit of work

just use a computer
im not allowed on exam lol
doesn't mean you can't

Im looking at part b for this question.
If a matrix is linearly dependent, can it be said that it doesn't span the certain dimensions

{kind=link}
not necessarily
u need to be more specific about what you mean
example there could be 3 LD vectors of lR² that spans lR²
Oh, that's not my work, that's my prof's solution sheet
does this chat include algebra 2?
i had a problem in my old version since i said <u,v> = 0 instead of <v,v> = 0
This works for showing a property doesnt hold, correct?:

$\overset{?}{=}$ is not a good practice. calculate them separately and show they are not equal

@zinc timber \overset?= is fine

Hi could anyone explain to me why this is true?
aj and w are n dimensional real vectors
Why is normalisation of w leads to the inner product being the distance to the hyper lane with normal vector w ?
ok thanks
^ryu
So rn im stuck on knowing that (T- λI) is invertible if λ is not an eigenvalue
@quiet wren heres a sketch

Thanks. Just a few things to clarify my understanding
Here you have written the projection of aj onto H right?
Is it a formula?
that's the projection onto w, not H
i dont know if I can say this (red arrow)

you can use geometry and the definition of the dot product to show how/why this works
your last 2 sentences break down
f(x) = x also satisfies what you wrote there
right so the projection of aj onto w gives the distance to H right?
since w is a normal vector
that's what you wrote in the original picture you sent, sure
it's not enough that it's a normal vector though
or what do you mean by normal here?
w is normal to H
yeah a normal vector to the plane
you're saying exactly what is written in the image you sent
so yes
this is not the answer to "why" though
that is in rokabe's drawing
yeah he also provide a formula for the projection of aj onto w which I was missing
all right
does this imply the others are fine. Why it (T- λI) invertible/surjective tho?
(T- λI) = (T - TI) = 0
what are you asking me?
i didn't understand what you wrote in what you asked me
ah
same reasoning as you did rn
take (T - lambda I)v
(T-λI) != 0?
right
so you get a linear combination of 2 vectors
and you know for a fact they are not scalar mults of each other
you can show that for 2 vectors, linear dependence means one is a scalar mult of hteo ther
no its onto w
this means you cannot get 0
Yeah thanks