#linear-algebra
2 messages · Page 270 of 1
For example span({a, b, a+b}) = a(1, 0, 1,) + b(0, 1, 1).
a basis {(1, 0, 1), (0, 1, 1)}, dim = 2
Oh yeah duh
In which case {(1,1,1,-1),(0,1,0,-1),(4,2,1,-2)} would be a basis.
@fringe fjord sorry im confused... what are you trying to say?
I'm suggesting a basis for your span.
hold on what
@wintry steppe can you show the problem exactly as stated please
as a screenshot maybe
Sorry not in English. :( But I have to find a basis if $V = span({a, b, \frac{a}{b^2}, -b}), a, b \in \bR, b \neq 0$.
mate

Basically I have a set of all 2x2 matrices ({a, b}, {c, d})
and a = -d, bc = -(a/d)
can you send the screenshot no matter what language it's in? please?
i have a strong suspicion that you are messing up the notation severely
and span() does not mean what you think it means
hi
mate
do you have
a PICTURE
i want a PICTURE not a translation not a transcription just a PICTURE or a SCREENSHOT
Sorry, Ann, I do not. And that actual problem does not exist (I just need it to solve something else).
It just a part of my problem.
can you show the whole problem then
im extremely suspicious of all this
you're tasking us with finding a basis for something that either isn't a vector space at all or has a very obvious one-element basis
Lets try with this.
$X$ is a set of all 2-by-2 matrices $A$ such that $A^2 = 0$. Find a basis for span(X).
mate

We defined a linear span as a set of all linear combinations of elements of that set.
okay so you start with the set of all 2x2 matrices whose square is zero and you take the span of that
hey guys
im only in calc 1 in school but i got a book on linear algebra and its rlly interesting
ok nvm this question was dumb
sorry
I find out if I take any reals a, b(not equal 0) then for matrix
({a, b}, {(-a^2)/b, -a})
A^2 = 0.
ok sure that describes a subset of X
i don't think that'll help you much in finding span(X)
And I am stuck because I have never had to find a basis if I have squares or fractions.
That is the problem...
you're confusing this desc of a subset of X with the span of X
i think span(X) might just be all of R^(2×2) but im not 100% sure about that
We need to find a basis for a vector space, right? I am confused.
you're confusing yourself on what said vector space even is
Take all such matrices and make all linear combinations and find a basis for that vector space.
and make all linear combinations
thats precisely what your desc doesnt capture
(but i would STRONGLY ADVISE AGAINST trying to make it do that)
i can say for sure [0 1; 0 0] and [0 0; 1 0] are in our space so its dimension is at least 2
If Mate does indeed have all the nilpotent matrices there, then the span does not have dimension 4 because they all have trace 0.
I think trace and determinant both 0 is a necessary and sufficient condition.
Yes.
That is what I am using here.
necessary and sufficient condition for what
For being nilpotent, not being in the span.
Ann

OTOH I found three lin indep members an hour ago, so we are indeed looking at just the trace-0 matrices.
As matrices we could just take ((0,1),(0,0)) and ((0,0),(1,0)) and ((1,-1),(1,-1)).
These are all easily nilpotent, independent, and since we agree every matrix in the span has trace 0, there can't be more than 3 matrices in a basis.
@fringe fjord and @dusky epoch , thank you very much!!
What would you guys say are the prerequisites to self learning linear algebra?
Nothing really imo
What really is the cross product?
I mean, it seems awfully limiting to create an operation that would only work in R^3
Exterior Product
What?
but it's just a product that gives a mutually orthogonal vector to 2 other vectors
one way to look at it is as the vector v x w with <v x w, -> = det(v, w, -). this lets you extend it to any R^n, but then you have to put in n - 1 vectors instead of two
for any vector u, <v x w, u> = det(v, w, u)
Ah, you mean the dot product
yes
Does the generalized binomial theorem hold for 1/n, where n is a natural number in the case (I+N)^(1/n) where N is nilpotent? Wikipedia assumes the case for n=2. How would you go about proving something like this? N is nilpotent so the formula is just a finite sum, but rather complicated
Just curious, as I don't even feel too comfortable with power series with just ordinary real numbers
In mathematics, the square root of a matrix extends the notion of square root from numbers to matrices. A matrix B is said to be a square root of A if the matrix product BB is equal to A.Some authors use the name square root or the notation A1/2 only for the specific case when A is positive semidefinite, to denote the unique matrix B that is po...
4.4. Jordan decomposition
Another answer could be that the cross product is a prototypical example of an antisymmetric bilinear map. Now for each vector space V there's a systematic way to construct a universal antisymmetric bilinear map, meaning a vector space W and a antisymmetric bilinear map f: V×V -> W such that every other antisymmetric bilinear map V×V -> U for any U is the composition of f with a unique linear transformation W -> U.
In general, if V has dimension n, W ends up having dimension n(n-1)/2, so W is cannot be the same vector space as W -- except that n(n-1)/2=n iff n=3. So exacty for 3 dimensions we can choose W to be V itself, and the cross product then turns out to be a possible definition for a universal f: V×V -> V.
(There are many possible f: R³×R³ -> R³ with this universal property, though, so it's not the entire story. However, the cross product (together with its negative) additionally distinguishes itself by being the only one to satisfy T(v×w) = T(v)×T(w) whenever T is an orientation-preserving rotation, which is nice enough to prefer it. The fact that this is even possible is another low-dimensional coincidence, though).
hey, can someone help me?
with a system of equations
10x+7y=263
4x+8y=230
i have to solve for x and y
bro wtf
is no one gonna snwerr
answer
set up the augmented matrix then invert.
since you're asking here and not #prealg-and-algebra , I'm assuming you're learning Linear Algebra
You can ask your question there, yes
what material should be covered in college level lin alg class
for theoretical purposes let’s make it an honors class
im starting to feel like my lin alg class was lacking and would like to fix that
I'm curious, what's lacking?
what did you cover?
well what did you cover?
i dont have my notebook with me to say exactly (there was no syllabus  ) the matrix stuff youd expect, eigenstuffs, JCF
) the matrix stuff youd expect, eigenstuffs, JCF
some very light inner product stuff
cayley hamilton (w/o proof) and some work with polynomials
I mean, sounds typical
but you can also just add the proof for Cayley-Hamilton in yourself, it's not that hard imo
cuz i remember it looking cool/important and opening up to other stuff
perhaps im overthinking im just curious what other people might have done in their classes
R^n stuff, abstract vector spaces, inner products, least-squares, transformations/matrices, eigentheory
wdym exactly by abstract vector spaces
the entire class was done in R2 R3 and polynomial space for me
polynomial space, matrix space, function space
vectors that aren't coordinate vectors
ah
ok well he gave us a question involving matrix space on the final which was very cool and good
but thats it lol
i’ll probably just try and fill in some gaps then
Is it possible to check whether two lines are intersecting with each other only using the affine form?
If i have this:
x+y+3z+6=0
2x+y-2z-10=0, can i check using the affine form or do i have to make a equationsystem?
anyone have any ideas for this

i tried the usual x+yi stuff but it becomes a huge mess and idk if its the right way of doing it
consider: |z* + 2i| = |z - 2i|
we still have sum of surds that doesnt simplify nicely afaik? like idk how to get rid of the sqrt
or is there a way of doing this without converting to cartesian lol
you'll have the equation of an ellipse.
from sqrt(x^2 + (2-y)^2) + sqrt(x^2 + y^2)?
no you're overthinking it
you know the definition of an ellipse, right?
it's the set of all points for which the sum of the distances to two foci is constant
@dusky epoch can I ask you a question
why me specifically
Cause it's related to LA and you seem knowledgeable
you can certainly try but don't expect me to answer immediately
How important are polynomials in LA? Thus far we have used them alot in class but from what I've seen in LA books they are not covered excessively
If you have a good resource on polynomials that'd be great
i mean
i guess they serve as good examples of vector spaces to examine that arent just R^n
(sometimes useful to find the eigen values)
Let V be the free F2 vector space over {a, b} and let U = {0, a + b} ⊆ V .
What does this mean?
V = {a, b, U} ?
is this just {0, a, b, a+b}?
ye, all F2-linear combinations of a and b
One quick question: i have a 2x2 matrix C, a 2x3 matrix A and a 3x2 matrix B such that AB = C, now i want to show that C is invertible, i was wondering if it suffices to show that both A and B have rank 2
I already forgot linear algebra lol
AB=C does not necessarily mean C is invertible, even if A and B have rank 2
$A = \m{1 & 0 & 0 \ 0 & 1 & 0}, B = \m{1 & 0 \ 0 & 0 \ 0 & 1}, C = AB = \m{1 & 0 \ 0 & 0 }$

Ah damn you are right
Ye i think it was rank(AB) <= min(rank(A), rank(B)), not "="
Any advice what i could try here?
Its a little bit much to explain, but i think i will just brutally calculate it. Thanks!
You could write it that way, or just rank(AB)<=rank(A),rank(B), but yes. Not equal
why is 0 a vector and 1 a scalar ?; can't 1 be a vector too ?

What's the best book for numerical linear algebra?
0 is taken as an element of the vector space V, whereas 1 is taken as an element of the field
why is 0 not a scalar too then ?
if you take it as an element of F then yes
if it confuses you, take $0_V \in V $ and $0_F \in F$ to distinguish them

So multiplying by the zero vector is the same as multiplying by the scalar 0 ?
Best in what sense? NLA by Trefethen and Bau is pretty popular, and ANLA by Demmel and Iterative methods by Saad
best as in easy to understand well explained etc
this one?

Yes, it is quite widely used as far as I know
here is the saad book, the other ones are on libgen https://www-users.cse.umn.edu/~saad/IterMethBook_2ndEd.pdf
Note that there is no vector multiplication required for a vector space. You only have a vector addition and a scalar multiplication
do you know a numerical linear alg book that applies python?
No (I only use Julia so have never looked)

Yes
You can write 0 for the 0 scalar and the 0 vector, if v is a vector and you write v + 0, its clear that its the 0 vector here. If you write 0*v then its clear that its the 0 scalar here
now im confused

But v + 0 makes no sense if 0 is meant to be a scalar
Yes, vector addition and scalar multiplication
So you can add vectors together and you can scale them, but nowhere it says that you can multiply vectors
You know what i mean?
yeah

F(R,R) is the space of all functions from R to R
im not sure why they were inconsistent
yeah if so why not write C(R,R) ?
typically, you will see C(X,Y) denote the space of all continuous functions from X to Y, and if X = Y, its shortened to C(X)
not sure, but either way it doesnt matter
@subtle walrus what would a + (a + b) equal?
can someone eli5 what a linear transformation is to me
all i can understand is you're changing the dimensions of a vector
ooh no idk what a vector space is
should i learn what a vector space is first?
the video series i was using didn't teach the vector space before they did the linear transformation

for context this is the video
ik what a span of vectors is
a span is just the set of all linear combinations of v1,..., vp
im not familiar with the cauchy schwartz inequality, could someone explain how i would go about using it here?

$\abs{u\cdot v}\leq \norm{u}\norm{v}$
Mosh

That's cauchy schwarz 
ah thanks, i see it now @nocturne jewel
yeah, abs value CS-Ineq QED
would this be trivial if we assume the first property?

i was thinking maybe they did not want us to use it in that case then
trivial based on what you just proved tbh
gotcha
can someone help me putting this matrix in superior triangular?

basically a transformation T is linear if T(a * v1 + b * v2) = a * T(v1) + b * T(v2)
On transformation,
T : V → W be the unique linear transformation such that T(a) = c + d, T(b) = c + d. where V ={a , b} and W = {c , d}. Im trying to find kernel and image of this
Since V = {a, b} one of the elements has to be zero of V, so it must be the other element is also 0 for V to be a vector space. Same thing with W. So the kernel is the just the only element in V which is 0.
The image would also be the only element in W which is 0.
Try row reducing it maybe.
What's a good linear algebra textbook for someone that needs to relearn linear algebra
In most cases, we say that a subset S of some inner product space is orthogonal if given any two elements x,y in S, x and y are orthogonal. What if there are no two distinct elements in a set? Do we consider the set {x}, where x is non zero, to be orthogonal? Although by definition ⟨x,x⟩>0, but I'm wondering if this is a special case
In a text I'm using I think this assumption is made
post text
ok
S should be orthogonal if that condition holds for distinct elements
otherwise the only orthogonal set is {0}


yeah
I have pointed that
So what about the case {x}? i.e., a set where there are no distinct elements?
Again, if x is non zero (x,x)>0, but idk
singleton is vacuously orthogonal
there's no other element in {x} to take the inner product with
This is a question on definitions
I don't think the definition above adresses the singleton set
?
If it does I don't see it at least
.
According to what definition of orthogonality of sets?
the one in the book
this?
btw
I'm not questioning singleton set is not orthogonal, just a matter of definitions
the book's definition doesn't assume there are actually two distinct vectors in S to take the inner product of. it says if there are, then their inner product is zero

How many elements are in the free F2 vector space over S when S is a set of n elements? F2 should include the basis, im not sure how it affects the dimension
free F2 vs of dim n has 2ⁿ elements
why @zinc timber
basic fact about vector spaces
$F_2^n ={ (x_i, x_2, \cdots, x_n) | x_i \in F_2 }$ you have 2 choices for each $x_i$ so $2^n$

is the dot product iv.iv = ||v| |^2 where i is the imaginary
and v is complex vector

I would have said no by how I interpreted the question, since I interpret the dot product to be distinct from the inner product
dot products are inner products, so component wise multiplication (that u r calling dot) is not an ip
so can't be a valid dot (ip)
I'm saying without asking the person who asked the question, it's ambiguous
What does direction ratio/number mean geometrically in 3D??

They performed row operations and reduced the matrix to a lower triangular matrix
oh hbooy
Can u pls help me understand augmented matrix
determine all the vectors that are orthogonal to u = (2,0,4) and v = (-1,2,3), aren't you suppose to use the cross product for u x v? I get (-8,-10,4) but that's wrong
you've determined just one vector orthogonal to both u and v
you're not trying to claim it's the only one in existence, are you?
@hushed hedge
ah sorry
are there more? is v x u another vector orthogonal?
actually v x u is wrong, if u x v is one vector, how do i find the second one?
there are not just two such vectors
theres infinitely many of them
consider: scaling u × v by 2 would still yield a vector orthogonal to both u and v
right
but how does my book get t(4,5,-2)?
i should make a equationsystem right? To figure it how they behave (?)
your book knows that the vectors orthogonal to u and v form a line going through the origin
and u×v is just one vector on said line
What don’t you understand about it, it really just the coefficients matrix A joined together with rhs of Ax = b.
wow ok like i dont know anything about augmented matrix but like i know matrix are the two related ?
like jee main level if u know jee
It's just vocabulary
like ... ? i did not get you
"augmented matrix" is just a name
it's what we call the matrix A with the column b attached to it on the right
It's specifically referring to attaching the coefficients to the original matrix
^
(where A and b come from your linear system, Ax=b)
no, it's a more compact way of writing everything
writing everything out explicitly
Since the x does not matter
i think it's genuinely confusing when students are asked to try interpreting matrices, and then we say "oh yeah and this augmented matrix is just like, better for rote row reductions, lmao"
x²+(y-3√2x)²=1 solve this equation
no
^
so all a linear transformation is
is checking if T( vector u + vector v) = T(vector u) + T(vector v)
which is the first condition
and then
T( c * vector u) = c (T * vector u)
yes

Looks good to me.
thx
i have a problem from my linear algebra exam that i couldn't solve
let B is an element of M_n(R) and we now that BB=B and that B^T * B=BB^T, we now have to show that this implies B=B^T
Try showing that B^T = (B^T)^2
i have shown this already
you can transpose both side
s
then dont ask anything
Yeah, we don't care for stupid questions. You're not obligated to ask anything.
ok another question, wolfram tells x=67 but i don't really know how to get it :/

$\cdot$ (Part 1 : The Idea)
If you have a any matrix $B \in \mathcal{M}_{n}(\mathbb{C})$, then it is always the case that:
$$
\langle Bx, y \rangle = \langle x, B^{\ast} y\rangle
$$
Where $B^{\ast}$ is the adjoint of B, i.e its conjugate transpose, $x,y \in \mathbb{C}^{n}$ and $\langle \cdot, \cdot \rangle$ is the hermitian inner product on $\mathbb{C}^{n}$.
Since we are over $\mathbb{R}^{n}$, then the adjoint is just the usual transpose and the hermitian inner product is just the euclidean inner product on $\mathbb{R}^{n}$. So in any case, we have that:
$$
\langle Bx, y \rangle = \langle x, B^{t} y \rangle
$$
Still holds. Moreover, we have that, by definition:
$$
\langle x, y \rangle = x^{t} y
$$
For any two vectors in $\mathbb{R}^{n}$.
\
\
With this is mind, we can now prove your result by showing that for any two given $x,y \in \mathbb{R}^{n}$, we have that:
$$
\langle Bx, y \rangle = \langle B^{t} x, y \rangle
$$
Is this good enough so far?
I will write down the proof now
I just wrote down a few definitions to see if we are on the same page
MISTERSYSTEM


Hmmm
I am not actually being able to prove this only using trivial stuff.
But there's a really simple proof that just got to my mind
Since B^2 = B, then unless B = Id or B = 0, then the minimial polynomial of B is p(x) = x(x-1). In the case B = Id, then the minimal polynomial is just p(x) = x - 1 and in the case B = 0 we have that p(x) = x.
In any case, the only eigenvalues of B are either 1 or 0, which are all real.
Moreover, since BB^t = B^t B, then B is a normal matrix. Since B is a normal matrix with real eigenvalues, then B is hermitian, and as a consequence of B being a real matrix it is also symmetric; i.e B = B^t (as a consequence of the spectral theorem)
If you still haven't seen the spectral theorem for normal matrices in your class
You probably can't approach the problem like this tho lmao
I think I have an different approach to this problem, we already know that $B$ is diagonalizable with eigen values $0, 1$. Now If we could show that $E_0$ and $E_1$ are mutually perpendicular, then we'll be able to find an orthonormal basis that makes $B$ into a diagonal one, which would imply $B^t = B$. \
Now we see that $B^tB = BB^t$ i.e. they commute implying they preserve each others eigen spaces, which can be seen by following, let $v\in E_0$ of $B$ then $B^TBv = 0 = B B^Tv \imply B^Tv \in N(B)$.
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

k0 - 2k1 = 0
k2 +3(k3) = 0
however there seems to be no solution.
how are you getting that there is no solution
you claim the system $\begin{cases} k_0 - 2k_1 = 0 \ k_2 + 3k_3 = 0 \end{cases}$ has no solutions at all?
Ann

im adhering to your notation here btw, even though it is a little wonky (though not in a way that seriously affects anything)
does all this resolve your question
there are much less wonky ways of saying that but yes
okay thank you
i can't find really something on normal matrices in my book
we have just seen that if a matrix is hermitian then its eigenvalues are real
guys i need some help

i have got these matrices which apply transformation to the world coordinates to convert it into image coordinates
(for a camera)
how would i do the opposite?
Are there any websites with linear algebra lessons?
yes youtube
Any specific channel?
gilbert strang's MIT OCW
👍
how do u invert R4 to R3?
do i need to transpose or something?
or its just not possible?
what do you mean by "invert R4 to R3?"?
yes do you mean a linear function from R4 to R3 for example
Probably a very simple question, but given a d times d matrix A, and two vectors x,y in R^d, can i say anything about <Ax, Ay> if Det(A)=1?
trying to make a backwards imaging mordel but i understand that i cant invert 4x3 matrix 🤔
surely the inner product is the same as <x,y> right?


So, if i have these 2 vector [2, -4] and [-1, 2]. Can i say that [x, y] = [2, -4] + t[-1, 2] , right?
sure, that doesn't mean much though
however they're parallel vectors
@barren sentinel can you link the whole document or give some more context
@odd kite
Exercise 18 and 19 should be trivial right?

I Know it's true, but i don't think the way i do it is right
18 is


18 is trivial as in obviously true, 19 less so


Like this?

yeah, just make c_i = 0 for all i b/w k+1 and m
$v=\sum_{i=1}^k c_iu_i=\sum_{i=1}^k c_iu_i+\sum_{i=k+1}^m 0u_i$
Mosh

My book writes the basis for the zero vector space like this: (-1,5,3), is it equivalent to (1/3,-5/3,1) ?

yes, and zero vector space is something different
you mean nullspace or kernel
Yeah, i mean nullspace. Thanks!
factor the quadratic
well how do I do that?
that's a question for #prealg-and-algebra
actually I figured it out

I don't remember how to answer these
can anyone help with with steps for 8. a at least
The first step would be to reread the section in your textbook (or lecture notes or whatever) that describes diagonalization of matrices.
(If you're looking for a mindless step-by-step procedure, you might end up doing a lot more work than if you exploit the specific features of each example anyway).
we actually haven't learnt diagonalization
You know that if $A$ is diagonalizable, then the diagonal elements of $P^{-1}AP$ will be the eigenvalues of $A$. And you know the columns of $P$ will be eigenvectors associated with those eigenvalues. So if you don't see any obvious shortcuts, you may as well proceed by finding eigenvalues.
OurBelovedBungo


I don't understand how these vectors becomes a line, and I am not sure how to do the vector equation.
This is the answer.

Well: the vector < 2, 4 > is just 2 * < 1, 2 > and similarly, < -3, -6 > = -3 * < 1, 2 >
So these vectors also belong in the span of < 1, 2 >
but then I could make the same argument for < 2,4 > since it equals 2 * < 1,2 > and (-2/3) * < -3, -6 > ? And therefore wouldn't this make the vectors belong in the span of < 2,4 >? Or is < 2,4 > acceptable too?
Oh alright, thanks!
if i have to put one more matrix in reduced row echelon form I am going to combust
is there a faster method to calculate the inverse of this method or do I need to calculate the minor matrixes every time ? I know how to calculate the determinant here already

pairing it with the identity, row reducing it itself to the identity, and taking the new matrix seems especially feasible as this is a triangular matrix
I thought that this could only be used to calculate the determinant? Isn't the new matrix just the identity of this one ?
the difference between A*A^T and A^T * A is that the first one has the dot product of the the coloms on the diagonal and the second the dot products of the rows correct?
It's the other way around. (And it's not just the diagonal).
sorry i'm really confused, won't that just give me the reduced matrix?
No you attach the identity matrix with it
$\left[\begin{array}{cc|cc} 1 & 2 & 1 & 0 \ 3 & 4 & 0 & 1 \end{array}\right]$ for example

oh! you mean the matrix i obtain after row reducing here will be the inverse ?
the one on the right, where the identity matrix originally was
can you do the LU decomposition with a non quadratic matrix?
The matrix does not have to be square for LU.
thanks
okay thanks!
I were you i would use Laplace
if you multiply a row with -1/3 for example by doing the LU decomposition, how do you change the matrix L? I.e. here the second line has everywhere -1, if I wanna take that away, what do I have to do in Mat L?

you can put a -1 in the corresponding diagonal element
but what if I multiply with -1/3, do I have to put a -3?
right
idk if this makes it clearer, so that you don't mix the two up. you're really doing L (L^-1 A)
so if you multiplied by -1/3 and you want the matrix to still be A, you need to do the inverse transformation too
which is -3
do notice that doing this essentially does nothing
you have to keep the two matrices separate
y is supossed to be 7/38 what did I do wrong?

you added 27/38 + (-10/19). not the same denominators

is #5 just about getting it into reduced row echelon form?
i tried swapping row 1 with row 4 to get row 4 on top so there is a 1 on the top left corner
actually no it seems like swapping the third row with the first row is the better approach
sigh
ok i figured it out
x4 has to be a free
it's a line that doesn't necessarily pass through the origin
For example say we have a linear system in the form of a matrix
When is the set of solutions a one dimensional flat
when the n-1-dimensional flats defined by the rows of the matrix intersect in a line
that would indeed be the case when you have one free parameter
since then the solution would have a particular term, call it x0, and then a null space component, let's say xn
so that the solutions are of the form x0 + c xn for some scalar c
Ok great thanks
I’m guessing for two dimensional flat it would be 2 free parameters?
sounds about right
So say if it’s like R^4
If the solution is a single vector
Then x1-x4 all have one possible solution
do any of you know a resource where I could learn LU decomposition? It's still very confusing to me and I struggle with what I'm finding online
replace x1 with x and x2 with y to help conceptualize it
even if you replace it with z, you get a plane
but in a different axis
just let the grader know that x1 = x
and x3 = z
the purpose of the homework is to practice sketching in 3d, so both answers would work
if you really wanted to, you could do it for xy, xz, yz
can someone help with this one please?


dagger
phys guys use it for adjoint
so what do I take it for if I see it in lin algebra context
idk check yr textbook what they have mentioned
often it's conjugate transpose
i would really suggest to check in the book, i've just as often seen * and H for conjugate transpose
but usually when that's the case, no daggers appear I think
in those cases the dagger can mean pseudo inverse or something like that
if abdos showed the RHS, it would help
context?
an orthogonal projection matrix from R² to the line x_1 = -2x_2
means you project onto a subspace along it's orthogonal complement
context: I'm in chapter 1
they've barely introduced matrix multiplication

are you sure you're supposed to be seeing how to solve this yet? 😛 have you done more abstract linear algebra before?
I was just trying to parse what an exercise meant
have you seen orthogonality?
no

this may be a problem with the texbook
sounds like it
yeah read ahead like me then come back 
can i have a pdf and page reference
a quick ctrl f search says that is the first occurrence of "projection" in the book
oh oof
this book is like, hint:

page 1: the end
In the preface:
The title of the book sounds a bit mysterious. Why should anyone read this
book if it presents the subject in a wrong way?
That's a really good question (note that it's never actually answered)
it's pretty good otherwise
I did that problem by following his example for that section for reflection and using demos to figure out how the hell am suppose to do it. His hint and stackexchange help.
He later asks you in the next section to find the matrix of the rotation around (2,2,3)^T after introducing invertible linear transformation.
i think you can still solve this problem by thinking projection as like an "informal everyday word" without formally knowing what projection is
He hint was confusing, “imagine your on the tip of the vector looking down towards the tail” or something.
very informally, if you were to project the blue point onto the red line, it would go to the green point

Guys can i show that something is true by logic and not by using math? I explain: If I am consider Grassmann's theorem can i prove that it's true by logic and not by mathematical process? because to me is more easy
Cool question. Yes, a proof by logic is a mathematical proof. To think otherwise would be a pretty weird misconception
After all, math is logic and logic is math
Yes, you are right.. and sorry for my english but i come from italy and i'm try doing my best
Are there any tricks of linear algebra that would allow me to compute a multivariate Gaussian likelihood without a full matrix inversion?
$e^{-\frac{1}{2}\sum_i(x_i - \mu)^tS^{-1}(x_i - \mu)}$
PT

x, mu are d x 1, S is d x d, so this becomes 1x1 at the end. there are tricks for sampling from a multivariate gaussian, where you only have to do either a cholesky or LU decomposition, but those aren't used for calculating likelihood.
how do we solve this kind of problem??

Let A be a 3x3 matrix and consider the invariant that AD = 0
how could one possibly find all the matrices D that would fit that condition
AD =0 means cols of D are in null A
null A being... what people often refer as null space?
ye
mmhm, the course started one week ago...
unless the concept itself is simpler than I think it is
I don't think we're being expected to know that- I only personally know that because I've already heard about it outside of that class context. It will be seen later
Here's what the matrix A looks like, I think that helps since it's filled with essentially 1s and zeros for the most part, so perhaps some technique could be preferred

I think that the two following propositions could help although


For clarifications purposes, B_1 ... B_n corresponds to the columns of B
so there definitely seems to be something revolving around columns hmmm
Oh
doesn't seem that crazy, I'll take it for now, thanks
any idea how to approach this? A is just some arbitrary operator and a_n is an eigenvalue of that operator (and apparently it's multiplied into an identity matrix that isn't shown so that it can be subtracted from A).
My first thought was come up with a formula for the nth degree polynomial of (A - a_n)^n and see what kinda magic I could do but I don't really don't see anything. I do have a solution manual to this but I don't really follow a key step, and it may not make any sense to math people since it's a physics problem written in physics form

sounds vaguely like cayley-hamilton
Write an arbitrary vector in terms of the eigenvectors and apply the product. One of the terms in the product will zero out every eigenvector
what if n doesn't have enough eigen values? what if min poly has an irred factor?
is your field ℂ?
I guess it's also nice to prove that every term in the product commutes. So you can just move the term to the front and get the zero vector right away
Looking into Cayley-Hamilton theorem. Seems like it could be related.
@viral magnet so the solution does say to have it act on what's essentially some arbitrary state vector. Not sure where a 0 will come from yet, but I'll keep looking.
@zinc timber I wouldn't think too much into it for that first question. If that 2nd question is asking if it can be complex (im not all that familiar with math terms yet) then yes it can
why do you say one of the terms will zero out?
Take just a 2x2 matrix with distinct eigenvalues
(if F=R² the you cannot write $A=\m{\cos 1 & \sin 1 \ -\sin 1 & \cos 1}$ in that form)

that's why I asked whether the field is ℂ of not
@ripe birch
Write an arbitrary vector as a linear combination of eigenvectors. So for 2x2 you have a sum of two vectors say lam1 * v1 + lam2 * v2 where v1 is an eigenvector corresponding to a_1 and similarly for v2.
Calculate (A-a_1 I) * (lam1 * v1) and similarly for v2
the determinant polynomial is the polynomial you get from multiplying (x-a) for all eigen values a (with appropriate multiplicity) so this is true by cayley hamilton
Not every vector can necessarily be written as the sum of eigenvectorrs for a matrix
seems so weird to work. Only thing im caught up on is explaining why our arbitrary vector can definitely be written as a linear combination of eigenvectors. I'm assuming not every vector can be but no basis for that??
@weak needle beat me to it
yeah so cayley hamilton is the way to go
can be written as an LC of generalized evs
You learn the Cayley Hamilton theorem in physics class?
(given field is ALC)
bro we don't learn ANYTHING about formal math in physics class. They gave us 1 month of LA, 2 months of ODEs, 3 months of PDEs, and random other crap
i like me some math dont get me wrong, i just am not up to speed on the fields that we use as much as I'd like to be
When can't you?
like @zinc timber you speakin another language to me rn
It's a physics class, they throw words like eigenbasis around like it's given
here is a concrete example: the 2x2 matrix with all 0's excet the top right entry
and 1 in that entry
my favorite part was when my professor said "a Hilbert space, just so far as what you need to use it within this class, is some place where you can do calculus". Kind of a paraphrase but you get the gist. We're basically bullied
The internet and this discord is how I learn my math
I'm also gonna assume they assume the matrix has full rank. If not, then it's a separate case
like an obidient pet
even if of full rank it's true
Right, a simpler proof I believe
am I gonna need to know what a ring is to figure out this cayley-hamilton theorem?
no
absolutely not
riemann i like your showing a lot, i just don't know if i can justify the arbitrary vector consisting of eigenvectors
You don't need Caley Hamilton for a physics class
are any of you familiar with bra-ket notation from quantum mechanics? I think there's a math equivalent of some sort but I'm not sure
in other words. Does this look anything like something you'd be familiar with?

where that alpha ket is basically a vector
sure, kets are vectors and bras are linear functionals
Yea I am
Bras are dual vectors I think
bless. So I follow up until the start of the 2nd line. Looks like operator A just turned into a'' from nothing i dont see it
what sorcery is this
Or vectors in the dual space
i'm almost positive that's the case. dual space sounds super familiar from my textbook
that's the same thing
@zinc timber This is wizardry
a'' is the eigenvector and the c_a'' are the eigenvalues
if the space is reflexive then they are same, ex for hilbert spaces, they are the the same
yep it looks like they're decomposing the vector into a basis of vectors a''
Linear functional return kets when applied to a ket.
yes but why are they assuming there is such a basis
linear functionals map to the base field, not to kets

Bras return a complex number when applied to the kets
they take kets and return elements of the field
linear functionals are linear forms, not just linear maps
wth is happening here
so back to what you said @viral magnet . I see that |a''> is the eigenvector. is the a'' that appears in (a''-a') the eigenvalue from having A apply onto our ket?
idk, riemann saying linear functionals map vectors to vectors
if you treat the base field as a vector space, sure
Right, a bit messy on my part. Vectors are functions in Hilbert spaces

AcHkTuAlLy
Oh shit in uncountable Hilbert spaces
(not all vs are hilbert spaces)
Or countable I forget
(nothing to do with the coutability)
Yes? Could you clarify
so my question was that A just turns into a''. You mentioned that a'' was an eigenvector. When A turns into a'' it's still an operator and not a vector, so I'm assuming the a'' you mentioned being an eigenvector was the other a'', not the one I inquired about. Hope that clarifies it. Kinda weird to word
Oh man this abuse of notation
🙂
Can you rephrase it and use kets where you mean the vector and no kets when you mean eigenvalue
Sure. So we have a line which says (A - a') | a'' >
the following line has (a'' - a') | a'' >
with seemingly no other changes. so operator A just turned into the operator a'' (times identity matrix ofc) and it seems random
ill repost the pic to have it less buried



this notation is super unfriendly :x but as riemann says, the transformation A | a'' > yields the eigenvalue corresponding to the eigenvector | a'' >
So this theorem only works on kets which are eigenkets of A?
and here they have simply removed the | > to denote an element of the field instead of a vector
this would honestly look so much simpler if you were to use matrix notation lol
Wtf now eigenket's a word
😂
Next thing you know they'll make up eigenSchrodinger
listen we're physicists for a reason. we live to brutalize your field
i’m just lurking but i was about to say what the heck another eigen thing
eigenket is just an eigenvector in whatever dual space that is
i'm not even a mathematician, this is just bad notation right now  overloading of the same symbol
overloading of the same symbol
You're gonna have to change your name to eigenQuantum
I'm gonna eigenFreakTheFuckOut this semester
sometimes they look nice
i can give you an alternative explanation using matrices and vectors
but this is not one of those moments
if you'd like. otherwise, i'll leave you two be
yeah that works. Does this theorem only work on eigenvectors? or does it produce null kets on ANY vector?
like wtf a'', a and a' all together
Someone take eigenBruh to be the dual of eigenKet
this works for diagonalizable operators A
and it does not matter if the vector this operator combination acts on is an eigenvector of A or not?
it doesn't, because if the operator is diagonalizable, its eigenvectors can be used to span any vector it acts on
"All operators are diagonalizable" --physicists
the statement is also true if A is not diagonalizable tho
@viral magnet you're not wrong 🤷
then by linearity, it boils down to using A on several eigenvectors
yeah but i wanna avoid thinking
all functions are analytic
also, all series converge
anyway. do you want the matrix vector explanation?
oooo plz
LMAO
so let's say there is a diagonalizable matrix A, which has eigenvectors v_i with eigenvalues a_i
physics notation be like

(i actually prefer dot notation over d/dt)
and we make a product pi_n (A - I a_i), where I is an identity matrix
the matrix (A - I a_i) has the eigenvector v_i corresponding to a_i as an element of its null space
$\mathit{\imath}$
Ann

charge
one can additionally decompose any vector u into a linear combination of the eigenvectors e_i, which in the proof were also assumed to be orthogonal, apparently
oo we're gettin into slightly spooky territory with the jargon, but ill try to follow
i thought we said earlier that perhaps not every vector can be written as a l.c. of eigenvectors
(why not just use Cayley hamilton )

you can do a change of basis into the eigenbasis by doing a transformation V, a matrix whose columns are the eigenvectors v_i, and doing V V^T u
sure
let's go
the proof they showed kinda assumed they were
they're just orthogonally projecting on the eigenvectors lmao
i believe in quantum we always form an orthonormal basis with our eigenvectors
now the trick is that V V^T u is a sum of eigenvectors
so when we consider A - I a_n, the operator can be replaced by a_j - a_n, where a_n is indexed by the big Pi in front, and j is the index of an eigenvector's corresponding eigenvalue
p_n (a_j - a_n) V V^T u is then 0,
since each eigenvector will be multiplied by some term (a_j - a_n) such that n = j
for completion, it seems the assumption made was that A is self adjoint
diagonalizable in an orthogonal basis
since the proof used orthogonal projections and assumed decomposition in an eigenbasis was possible without ever saying anything about it
i can nearly assure you that assumption is correct. we jump to conclusions more than a clingy ex-gf trying to win you back
the proof you shared definitely made that assumption
the first step they write is "decompose the ket into the eigenbasis through orthogonal projections"
which is what i did with the V V^T, where V's columns are eigenvectors and therefore V is orthogonal, so that V V^T = I and doesn't affect the result
then in the eigenbasis, linear transformations are simply scaling factors
anyway, yes. orthogonally diagonalizable A
if not, you need something different for the proof
ye like m(x) be mini poly so some power of that poly will be divisible by m(x) which makes it nilpotent 

so let me see if i understand this correctly. We take some arbitrary vector, and we project it onto the eigenbasis. Doing that allows the operator A to extract those eigenvalues a_j and eventually filter for where j=n?
almost
ill take an almost. that means im close. What isn't quite right there?
once you have the vector in the eigenbasis, you replace A with the eigenvalue of the corresponding eigenvector
then if you want you can use pigeonhole principle for the product part lol
if you have n pigeons and drill n+1 holes into then, then at least one pigeon has 2 holes
lol
Pigeonhole? More like pigeontroll
so by simply putting our vector into the eigenbasis, A MUST be replaced with the eigenvalue of the eigenvector I projected onto?
oh i guess. because when A acts on it you get that eigenvalue
but you'll get it anyway
but if you don't, then doing this doesn't help you prove the thing
horrifying
lmao
ok talking about the projection thing really helped, i appreciate that. I could feel the answer on the tip of my tongue but something was missing I couldn't quite get. Projecting the arbitrary vector along an eigenvector makes sense tho
at least one pigeon has 2 assholes
thank you all for joining me on this adventure. This was 100x more productive than the physics server
ya phys server sucks
it really shouldn't. but it do
Physics server: how about we run a simulation with a mole of spheres
i'm still butthurt about the linear functionals though
math people are just better to be around. I love physics as a field, but the people of math are just better.
which one?
Kolmogorov will visit you in your dreams and tell you to suck it up
I've met a lot of physicists. wouldn't party with em. Went to a party of grad-level mathematicians, that was a blast. Way more fun 😂
well get bent, you got this explained to you by an engineer
engineers are also more fun, but also more psychotic
stop using i,j,k as basis vectors you psychopaths
i don't do that :x
they said maths server not mathematicians
then maybe you're a step above your bretheren
then again i can't speak, my people try to use phi as the azimuthal angle in spherical coorinates
quaternions 
Why use e as unit vector when that's clearly Euler's number
like we use theta in 2D, but flip to phi in 3D
@viral magnet also a thing i never understood. one of my texts did that and i almost cried
thankfully i haven't seen it since
🫂 I don't wish that on my worst enemies
Number theorists using pi as a function to count the number of primes less than n
EH?
ever1 stop trying to attach universal meaning to symbols
i'm afraid this has gotten a little off topic, please move over to discussion-i or chill



We'll ill be damned
broke: $e\$
woke: $\vec{e}$
Alison40

@zinc timber
Hoe is you?
Yes
I've met a lot of physicists. wouldn't party with em. Went to a party of grad-level mathematicians, that was a blast. Way more fun 😂

i'm so confused
why is a arbritary?
because there is already a 1 in R1?
how is it reduced row echelon form when there is a 3 above the 1 in column 4?
u have to choose the values so it is row reduced
there can be a 3 above the 1 if u choose the c accordingly
huh?
i thought reduced row echelon form meant if there is a 1 in any column
it has to be zeroes above and below
only if its the leading 1

Is there a way to like solve (A+B+C)x=0? A is a Vandermond matrix and B and C look like each other so I think this will be an easier way to solve my system but I have no idea how.
wdym by "look like each other"
They're both the operators applied to the exponential function with different exponent and such
and A contains those exponentials
It's like if T and S are operatos B=T(A) and C=S(A) applied component-wise
Does anyone how I can solve a system like this one?
Can I just take out an operator like (I+T+S)Ax=0 then apply the inverse on both sides to get Ax=0?
Your question is still too vague to answer. Come up with a 2 or 3 dimensional example
Let $A=\left[\begin{matrix}
e^{ikx_1\cdot y_1} & e^{ikx_2\cdot y_1} \
e^{ikx_1\cdot y_2} & e^{ikx_2\cdot y_2}
\end{matrix}\right]\in (L^2(\Omega))^2\times(L^2(\Omega))^2$, $T,S: L^2(\Omega)\to L^2(\Omega')$ be compact operators.
Then, let $B=T(A),C=S(A)$ applied component-wise. How can I solve (A+B+C)x=0? Thanks!
emphatic_wax

Well that's beyond my linear algebra knowledge
Can some kind soul check my life dilemma about a Change of Basis on #help-3?
What did you do
Well I figured I proved some weeks ago that my operators are injective so I just pull them out and take the inverse so I'll have Ax=0
And I know the answer to this from a paper I read
it's not a leading 1

hey can someone explain me the solution for this excersize question?

Please don't ping helpers after waiting just two minutes.
Oh sorry!
Also, when the solution you're asking about takes up half a page, please explain which parts of it your problems start at. Otherwise you're basically asking people to repeat what is already there, in the hope that they'll randomly guess the rewording you need.
I didn't understand almost all of it unfortunately
it's the solution for part a) though
I understood the part where they explained that the matrix is supposed to be 2x3 and the rest I'm lost
<@&286206848099549185>
What's the subscript on R?
In the original question?
It would make sense if $\mathbb R_k[x]$ means the vector space of polynomials of degree at most $k$.
Troposphere

it's 2 and 1
Moment of ecstasy
guy pings after waiting 16 minutes lmao
sometimes people ping after exactly 15
how can I find a matrix when given the eigenvectors associated to it ?
do you have the eigenvalues as well?#
yes
are the eigenvectors orthogonal?
well, in general you'd take the eig vecs as columns of a matrix Q and the eigvals along the diagonal of a diagonal matrix D
then the matrix is QDQ^-1
the way I like to think of it is, you know the eigenvalue equation $Av=v \lambda $ instead of writing one of these for each eigenvalue/eigenvector, you can throw all the eigenvectors in a matrix at once and write this as $AV=VD$, here the matrix $V$ has its columns the eigenvectors and $D$ is a diagonal matrix of eigenvalues.
Merosity

what if I write it as Av = lambda v 

heh I was gonna explain why I wrote it that way but it was getting too long
once you consider more than one vector at a time
I think of multiplying on the right as column operations and multiplying on the left as row operations
yes that interpretation is actually helpful
since D is putting a scalar on the entire column, that's why I wrote it with the scalars on the right yup
though I still need to pause for a moment
you don't have to worry about it if you use einstein notation


btw I ended up ordering a larger one, edd
no it'll take like a week
they also dropped the price after I ordered it, those scammers
haha
that's a good way to see it ! thank you and thanks everyone who answered
you're welcome 👍
would the matrix from R² to R² for the orthogonal projection onto $x_1 = -2x_2$ be $\begin{bmatrix} \frac{1}{\sqrt{5}} && 0 \ \ -\frac{2}{\sqrt{5}} && 0\end{bmatrix}$
Alison40

no check again
a nice way to project onto a space spanned by a vector v is to make the matrix $P=\frac{vv^T}{v^Tv}$
Merosity

(it follows from the usual derivation with dot products, also fun to check P^2=P)
ok I'll actually come back to this question
i thought i could do it with rotation matrices but i was wrong
the only part where you "need" rotation matrices is the fact that $x+2y=0$ can be seen as $(1,2)\cdot (x,y)=0$ so you can do a 90 degree rotation or just see by inspection $(x,y)=(2,-1)$ is a basis for this 1D subspace
Merosity

i just realised i can solve it using simultaneous equations
Hey, could I just ask whether the following statement is true or false?:
If f is a linear operator over the finite-dimensional vector space V, then V has a basis that consists of eigenvectors for f: V->V.
(My TA said that this was true, but from what I can see, this isn't always the case, so if someone could perhaps clear this up, that would be very helpful, thanks.)
no that's not always true, (the special case when it is true, we call T diagonalizable)
as ryu says
ex the matrix $\m{1 & 1 \ 0 & 1}$ do not have a basis consisting of evs

that's a so-called "defective matrix"
the requirement for what you said to be true is for the operator to have n linearly independent eigenvectors, where n is the dimension of the vector space
(My TA said that this was true, but from what I can see, this isn't always the case, so if someone could perhaps clear this up, that would be very helpful, thanks.)

Thanks for clearing it up 🙂 👍
please read #❓how-to-get-help
Let A and B be 4 × 4 matrices. Suppose that A has eigenvalues
x1, x2, x3, x4 and B has eigenvalues 1/x1, 1/x2, 1/x3, 1/x4, where each xi > 1. Prove that A + B has at least one eigenvalue greater than 2. Can someone help? Any hints on how to start?
idk maybe try to look at manipulating their characteristic equations to try to make an inequality
no other information given on A or B?

maybe you can show that B and A^-1 are similar
something I have in mind is f(x) is the characteristic polynomial of A, then x^4 f(1/x) is the characteristic polynomial of B, then try to do something with cayley hamilton by plugging in the matrix A+B and break it into an inequality in terms of A and B separately
I'm not super sure on this because xi's may not be distinct
okay i'll try that out
I guess now that I think of it, their characteristic polynomials are the same, just with the coefficients reversed
that might play well with this
if confused on the multiplicity part, like they didn't mention distinct
oh, why does it matter
like if they are taking something like [1 1 \ 0 1] has ev 1, 1, then it might not work, idk
hmm
because say $A = \m{2 & 0 \ 0 & 2}$ and $B=\m{1/2 & 1 \ 0 & 1/2}$ fits the description

4 by 4
(just any 2x2 block, that's not the point)
okay
i used the fact that sum of ev of (A+B)=sum of individual ev of A and B= x1+1/x1+x2+1/x2+x3+1/x3+x4+1/x4 > 8 using am gm
and now since there are 4 eigenvalues of (A+B) we can say by PHP that one of them must be greater than 2 i guess
Hi! does anyone know how to find the dimension of an eigenspace (we are given a matrix and eigenvalue) ?
nullity (A-cI)
c is a real number right ? What is nullity ?
thank you!
Need some reminders on what operations are allowed on determinants
I know you can add columns together like C1: C1 + C2 - C3
and that you can take a constant out of a row like
|aa ab|
|c d|
a * |a b |
|c d|
but what else? can I do row operations?
(The transpose of a matrix doesnt affect its determinant, so anything that works for rows goes for columns as well)
You can add rows by a constant without affecting the determinant. So like R1: R1 + 3R2 wont affect the determinant
Multiplying a row by a scalar multiplies the determinant by the scalar
Swapping two rows multiplies the determinant by -1
Determinants are also multilinear
wait so why does this not change the determinant?
also 1 is constant right?
R1: R1 + R2 => unchanged?
It doesnt really matter in the case that youre adding rows
So like
R1: R1 + 3R2 => unchanged as well
Lemme show you
this makes me feel like I can just do gaussian elimination on a determinant, no?
also a follow up - can I take a constant from a column?
\def\sline{\text{---}}
Suppose you have:
\[ \det\begin{pmatrix} \sline v_1 \sline \\\vdots\\\sline v_n \sline\end{pmatrix} \]
And say you add $\alpha v_i$ to $v_1$ ($i\neq 1$):
\[ \det\begin{pmatrix} \sline v_1 + \alpha v_i \sline \\\vdots\\\sline v_n \sline\end{pmatrix} \]
Since determinants are multilinear:
\[ = \det\begin{pmatrix} \sline v_1 \sline \\\vdots\\\sline v_n \sline\end{pmatrix} + \alpha\det\begin{pmatrix} \sline v_i \sline \\\vdots\\\sline v_n \sline\end{pmatrix} \]
The second determinant above has $v_i$ twice (once in the first row, the second in the $i$th row), so it is just $0$:
\[ = \det\begin{pmatrix} \sline v_1 \sline \\\vdots\\\sline v_n \sline\end{pmatrix} \]
Which is your original determinant
Just about. Multiplying by a row by a constant multiplies the whole determinant by that constant, and swapping rows multiplies the determinant by -1
Slurp

Anything that is true for rows is true for columns since the transpose doesnt affect the determinant
if a row of 0s => determinant is 0?
Yeah, but that's not related to adding rows
I was just curious why that thing is 0
Oh
You remember how the determinant of a non invertible matrix is 0?
So if the rows are linearly dependent, then the determinant is 0
I see.
My professor likes giving us a bunch of tricks in the determinants. If we solve it by brute forcing we get a cubed equation.
No calculators in the test.
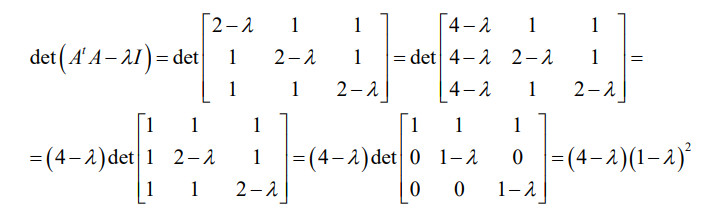
{kind=link}
{kind=link}
{kind=link}
Characteristic polynomials?