#linear-algebra
2 messages · Page 264 of 1
right
wow
that makes so much sense
like a zero vector for one of them yeah
okay that makes a lot of sense
thank you Ryu
the first LD vector in your list will turn to 0
@zinc timber i have a question if you don't mind answering
actually you seem to be unavailable
nvm


you can ask anyone not just me
The projection of y onto W perp is [-1 -1 -1]
which is asked by a question
the following question is to give a basis for W perp
so i solve the equation A^Tx = 0
transposing A i mean to say
and i get a basis of [1 1 1]
they are both right answers yes?
yes
okay thank you ryu just making sure
also you can just take the cross product of the cols
they did no work because from the previous question they just saw that since w perp had at least 1 dimension
they just said that the projection of y onto W perp was a basis

we did not learn cross products 
only dot products
thank you though ryu
my exam 3 for linalg is tomorrow
i studied a crazy metric ton but yknow im still scared
,w cross product (1,-2,1) and (3, 0,-3)

lol, I was questioning my sanity for a sec


that literally gives you 3 of the eigen values
yes
https://i.imgur.com/fzUPHo2.png
how can i know whether this is LI or LD?
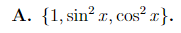
is it LD casue of 1= sin^2 x + cos^2 x ?
that is indeed the definition of linear dependence
thank you, also a matrix is diagnolizable if algebraic mult. = geometric mult? right
alright thanks
guys who can describe me the column space ?
it's the vector space spanned by the columns of a matrix
does the pivot columns span?
the col span will be the same as the col span of the cref matrix

if i choose eigenvalues as scalars and eigenvectors and a basis of eigenvectors does it work?
yep
dadrunk, i think i would approach this by first picking the canonical basis and letting the matrix be M. then a change of basis is a sandwhich BMB^-1
and the idea is that BMB^-1 = some matrix, say W
and no matter which B you pick, you always get W
then again, inspecting this does go in the direction of simultaneous diagonalization
i guess one could then argue that the EVD is of this form, so W must be diagonal, and all permutations of the eigenvectors should deal the same W
something along thosel ines
sorry what is EVD?
eigenvalue decomp, what you proposed
but this assumes that the matrix was originally diagonalizable. there must be a way to not have to assume that
i was thinking in terms of group theory, like T has to be an elem of the center so constant multiple of I
other than that there is also a theorem states that if T is not scalar then there is a basis wrt which T has 0's in the diagonal, but it's hard to prove
fancy
idk, with what i wrote it's trivial to show that scaled identities satisfy it, but not that nothing else does

show da proof

sweet

Do I understand correctly that in the inner product space of continuous functions from [0,1] to ℝ, the orthogonal complement of the subspace of polynomials contains only the 0 vector?
ig it's true

are you gonna say something on the space not being hlibert and then move on to manifold theory?


That was an answer to me, right?
Yes, my analysis lecturer claiming this is what caused me to think about it.
i dont think i have any manifold theory stuff to rant about right now, i've mostly been doing commutative algebra recently
this is something I wanna stay away from
- He says polynomials are dense in C[0, 1]
- The metric topology induced by the uniform norm is finer than the metric topology induced by the inner product
- Therefore, polynomials being dense w.r.t. uniform norm implies no vector orthogonal to the subspace of polynomials
this is what I thought
DG is cool tho
And I am happy whenever I can apply some piece of math I know from another subject in the subject I am currently studying 🙂
do you understand what these words mean?
If that was a question to me, then yes. I mean the lecturer only said the thing I listed in 1. 2 and 3 was what I came up with.
What does that have to do with anything?

I do miss your manifold rants tho
Do you by any chance know a simple proof of polynomials being dense in C[0, 1] or of them having only a trivial orthogonal complement?
google "weierstrass approximation theorem"
stone-weierstrass is one line proof
ah yes, prove the theorem by appealing to it
lmfao corollary comes first
I've seen similar things with adjoint operators, like being able to interchange <Ax, y> = <x, A*y> is the definition, ppl try to prove it
Wikipedia proof seems annoying. I bet I could come up with a simpler proof that would go something like this:
- Find a way to approximate a characteristic function of a convex set with a polynomial.
- Therefore, I can approximate step functions arbitrarily well.
- Since step functions are dense in C[0, 1], so are polynomials.
you can also try the proof using Bernsein polynomials
yes that's the one I called annoying
how are step functions dense in C[0, 1] if step functions aren't continuous?
Oh, wait
I should've said that C[0, 1] is a subset of the closure of step functions
What are you doing step-function 

what the fuck

I already knew the span of w and w complement, how do I find the basis in R^4?

W = span ((1,0,1,2),(1,1,-1,0), and W^perp = (1,-1,0,-1/2),(0,1,1,-1/2))
you should be able to just put all of those in a set

the 1st 2 vectors are from W, as you see. the last vector is the same as your first vector that spans W^perp, just multiplied by 2
the 3rd vector should be a linear combination of your two vectors that span W^perp
should be equivalent
Thank you so much!
might be a bit of a trivial question, but how do i formally show that the showcased set $M$ is a subgroup of $(\mathbb{R}^2, +)$

lewis

it's obviously componentwise addition $+ : \mathbb{R}^{2} \times \mathbb{R}^{2} \to \mathbb{R}^{2}$ as usual
lewis

show it's closed and contains inverses
i mean yeah, it's obvious that it's a subgroup of R2
but how would i write it down, idk how to find a closed form of the set illustrated in the picture
or like how would i formally prove it
it's a bit odd to me
like how do i precisely represent the dots as a set in this case, so it's approximately correct
i don't quite see a way to do it elegantly
test
well first define all the dots
like what are their coordinates of the form of
yeah, that's my problem here
oh well that' seems trivial lol
🥲
all of the points are of the form a(2, 0) + b(1, sqrt(3))
you can get to any point
by starting at the origin and moving left/right
then moving up to the right diagonally
or down left diagonally as it may be
have you heard of a basis
hmm
well the two-element set {(2, 0), (1, sqrt3)} is a basis for this subset of R^2
i think you can state without explanation that every point there is of the form a(2, 0) + b(1, sqrt3) for some integer a, b
so now you can just apply subgroup test
show closedness, show inverses
well it's hexagons
so
60 degrees
pi/3
the height of an equilateral triangle with side length 2 is sqrt3
np
lets say we are given two vectors in R^3, how can we extend v1 and v2 to a basis?

ik what to do after extending it but im not sure ik how to extend it
what you can do is take these two vectors and produce another that is orthogonal to the two of them
(since being orthogonal also means linearly independent, this achieves both goals in one go)
there are versions of the cross product in C^3, for example
or you could directly satisfy the matrix-vector equation for a vector orthogonal to v1 and v2
by making a matrix whose rows are the complex conjugate transpose of v1 and v2, call it M, and finding nontrivial x so that Mx = 0
if you’re generating an orthonormal basis with gram-schmidt
will you get a different basis if you normalize before/after the process?
the answer is no

Hey I'm looking at hthe proof for why det(A) = product of its eigenvalues. Why is there this term (-1)^n in the char. polynomial?

det(A - λI) is a polynomial with leading term (-1)^n λ^n
it might help to choose bases wisely
if you see "finite-dimensional" in a linear algebra problem then you can usually solve it by picking a basis in the right way
oh I see, like a basis for W and then when I extend to V I can create another basis for W' with the difference of the vectors
it sounds like you have the right idea
thanks man!
take a basis of W, extend to one of V, and use the vectors you added to get W'
neat
and then can I create the direct sum of W with W' to be V ?
Like $W \oplus W' = V$
mns

I see
and then i think you can get your projection from that
there you go
complex numbers:
z is a complex number and
z =1/(1+i)
find the real numbers a, b with z = a+b*i
am I supposed to write
a+b*i = 1/(1+i) and solve the equation for a and b?
that's one way to do it
it might be a bit easier to use $$\frac{1}{z} = \frac{\bar{z}}{|z|^2}$$
TTerra

Answered in the help channel 
I tend to ask in the thematic channels as well depending if I need quick understanding or explanation
thanks
keep it to one channel only
If I write
--> z = 1/z
do I need to define 1/z_1?
that's shit notation
since z^2 doesnt have to be 1
you can define w:=1+i then say z=1/w
gotcha
I'm looking for a real number a so why is
a=(1+b-bi)/1+i```?i’m very new to linear algebra, so don’t use any super complex notation, but why is this not a subfield? i don’t think the book did a very good job of explaining what a subfield is

C denotes the field of complex numbers by the way
someone ping me if you respond
cause N isn't a field
doesn't have additive identity or inverses, nor multiplicative inverses
oh i see
i’m aware it says that but for some reason when you said it it made sense lol
thanks

it's a fucking test
Hw
I'm not convinced


is eigenvector the same as eigenspace??
no
what is eigensace?
it's the space spanned by the eigen vectors of the corresponding eigen value
the dimension of the eigenspace is the geometric multiplicity
thanks bro 🙂
if i have a diagonizable matrix what happens to the dimension of its eigenspace?
think about the geometric and algebraic multiplicity of the eigen values
geo and alt mult are equal
then you already know the answer
thanks bro
i'm having second thoughts mybad haha
Hey, I am currently struggling with this task.
The translation for this task would be:
For which real number does "a" have a range of 3?
Of course there are some other questions, but I am currently only struggling with this one.
I tried figuring out "a" by trying, but for me it doesn't seem like the most effective approach (since I only found out, that "a" can't be 1, but it can be -1,3 or even 5). Could anyone help me with finding a more effective method to calculate this? I have the feeling, I am thinking way to complicated ...

A is full rank iff det(A) != 0
if A is square
To be honest, I am still a little confused 
^
Yes I got that, but for some reason the faculty is confusing me the more
the faculty 
emma might be german
or from some other place where the factorial is called "faculty"
they probably refer to the ! in det(A) != 0
Yes true 😅
Sorry haha, language 😂
I thought you are talking about yr professor or something
fun times with falsche freunde
But yes also the faculty is confusing me :D
The thing is he is ill and doesn't give any classes, so that is also true xD
Thanks for helping me out with that :D
yep
so with != they mean "not equal"
this is the notation in some programming languages
$\text{det}{A} \neq 0$ is what they meant
Edd

if the determinant is nonzero, the matrix is full rank/invertible

does anyone how the name of this matrix and its generalisation to cos(3w) etc... it would like to show it is semi positive definite
it seems to be true from what i have tested
any help would be appreciated
idk what you are looking for exactly but it's symmetric, circulant
for n=2 it is sin^2(w) and for n=3 it is 0
let me check that
wow it is a strong result
however it does not answer my initial question unfortunatly
having the det = 0 does not mean that the matrix is semi positive definite, right ?
no, that's not it
positive semidefinite means your eigen values are all positive or 0
sylvester tells you that the sign of the eigen values are the same as the determinant of the sub matrices
or the sign of the pivots.
as you have already showed, det of submatrix are given 1, sin^2(w), 0
so eigen values are non-negative
means your original matrix is +ve semidefinite
I have to prove any finite generating system of vectors in a vector space V contains a basis.
Here my proof. Proof. Suppose for an arbitrary system of $v_1, v_2, ..., v_n \in V$ is a generating system. Since the system is already complete we have to show it is linear independent for it to be a basis for V. Suppose on the contrary the system is linearly dependent. From that we know there exist a $v_k$ in the system that is a linear combination of the other vectors, that is $v_k = \sum_{j = 1, j \neq k}^{n} a_jv_j$. Since $v_k \in V$ and the system is complete it also follows that $v_k = \sum_{j=1}^{n}a_jvj$.
Kanga Gang Crocodile Plegasus

It not complete, I been stuck around the end trying to use the two different linear combination of v_k to get a contradiction.
@lyric dawn has your doubt been resolved?
My question is can I say it is not true there exist a v_k in the system that a linear combination of the other vectors in the system, since v_k already has to be equal to that last sum?

i draw the case for n=4. you call what i have circled a "sub matrix" right ? but i dont know its determinant
no not that, major diagonal ones
ooooh i see now
you can use schur components to show that the det is 0
any arbitrary generating set is not independent by default
you have to turn it into one
I see.
Wikiwand
In mathematics, Sylvester’s criterion is a necessary and sufficient criterion to determine whether a Hermitian matrix is positive-definite. It is named after James Joseph Sylvester.
i understand know, thank's a lot for your help
quick question For a generating set S that is linear dependent, we know there exist a v_k in S that a linear combination of the rest of the vectors in S. Why is that removing v_k in S we still get a generating set?
if what I am saying makes sense?
because the vector is redundant, you can achieve all the vector with other vectors as well
because that vector is already a LC of other
oh I see thank you.
Can someone help me with this one

Bart

Do i just need to reduce it that's it or what's the next step
@wise oriole You just need to remove the linearly dependent vectors in the set C
Can someone help me with some questions in dms?
no
?
you can simply post here, the channel is free at the moment
if (A^T*A)^-1 does not always exist (because it relies on the columns of A being independent) then wouldn't that mean that not all least square solutions exist? if so, what is the purpose then... since it's supposed to solve systems that initially did not have an exact solution? or is it that does A^TA is not always invertible, there are now an infinite number of least square solutoins
pseudo inverse is used in that case
in what case.. where A has dependent columns?
another eat to deal with it is to remove the linear dependent column from A and try again
even if cols are independent,u can still use pseudo inverse
let's say I have a data set to fit a least squares solution Ax = b. And that doesn't work (because the columns of A are dependent), so I move to least squares and try solving A^TAx = A^Tb. Are you saying this will have no solution or infinitely many?
And if infinite, these are a class of points that all have the same "distance" to the column space, and thus are all equally "correct"?
yes, the solution will have same dist from the col space, just there will not be an unique description of it
in the case of no sol, you get the projection onto the row space btw
you can always do it with a pseudo inverse. in the invertible case, the pseudo inverse equals the inverse and the sol is unique. in the rank deficient case, you can have either infinitely many solutions or no solutions. when there are no solutions, you get an orthogonal projection onto the row space. when there are infinitely many solutions, you get the solution with the minimum 2-norm
I don't understand the "projection onto row space" part
lemme see
let's say that we have a vector w
and we say that Aw + n = y
and that n is in the ortho complement of the column space of A
the LS sol comes from x = (A^TA)^-1 A^T y, yeah
let's replace the inverse with a pseudo inv, cuz were in a case where we're assuming n might be rank def
and for simplicity and jank, use the SVD A = U S V^T
meaning null space of A'?
so that we get (A^TA)^-1 A^T = (V S^T U^T U S V^T)^-1 V S^T U^T
yeah, "left null space" as they call it
in this setup, consider only the economy sized SVD, so that S is square and U and V have columns only spanning the col and row spaces, but not their complements
this means S^T = S
we simplify a little and get that (A^TA)^-1 A^T = (V S^2 V^T)^-1 V S U^T = V S^-2 V^T V S U^T
= V S^-2 S U = V S^-1 U^T
now recall that y = Aw + n = U S V^T w + n
i think a ^T is left out
so that x = (A^TA)^-1 A^T y = V S^-1 U^T (U S V^T w + n) = V S^-1 U^T U S V^T w + V S^-1 (0)
= V S^-1 S V^T w = V V^T w
and V V^T is an orthogonal projection matrix onto the row space
so this includes the case that y is not in the col space, and that w has a component in the null space
the more general flavor
then to wrap it up with a simple example, if you have a matrix
1 0 0
0 1 0
0 0 0
and a vector
1
1
1
the pseudo inverse can recover
1
1
0,
the ortho projection onto the row space
tho using the pinv only gives a short formula for LS sol, x* = pinv(A)*y
that's what I used to do anyway
wdym
oh lol
yeah, i used to pad with a column of 1's
in my usual cases, pinv(A) can't even be computed 

iterative algorithm life
Determine the base transitionmatrix $P_{B \to \varepsilon}$ from B to \varepsilon ? can someone give me the first few steps?
Bart
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)


why rip me
sheldon axler xd
sheldon cooper
thriller44
∥u−v∥2=(u−v)T(u−v)
Hi, can someone help me understand why this is true?
you can consider || u ||^2 = u^T u to simplify
express both term using the coordinates of u and you should find your result
I am currently struggling with c)Give a basis of kernel(f) and d)Determine fB1,B2, it would be nice to get a hint on how to start

to get the basis of a kernel just find the solution to Ax=0 and use the vectors of the solution
I'm confused as to how exactly i need to apply that. Do i just have to find out f(x) through the images f(x+2) and f(1)? f(x)=-4x-9 and then do -4x-9=0?.
write ker f as the span of a linearly independent set
let p be any vector in ker f, ie f(p)=0. use this to get information on the form of p
where does the sqrt(n) come in in this answer? https://math.stackexchange.com/questions/505333/finding-matrix-norm-equivalence-constants

Mathematics Stack Exchange
I've been given the following:
"Find the best positive constants $\alpha$ and $\beta$ such that $\alpha\left|A\right|_2\leq\left|A\right|_1\leq\beta\left|A\right|_2$ for all $A\in\mathbb{R}^{m\
it looks like in the first step, he applies ||x||_1 < sqrt(n) ||x||_2 to ||Ax||_1 in the numerator but not to ||x||_1 in the denominator. in the second step, he applies a similar identity to the ||x||_2 in the denominator but not the ||Ax||_2 in the numerator
cauchy schwartz
do similar matrices necessarily have the same minimal polynomials?
what have you tried so far @lavish trout
im just studying
does anyone know about this?
Question (True or false): Suppose A is a 3 ×3 matrix, then det(2A) = 2 det(A).
I feel like its false?????
but I'm thinking similar => same rcf => same invariant factors => same minimal polynomial
cause multiplying matrix by a scaler and then taking the determinant is not the same as multiplying the determinant by 2??
work out the case when A is the identity matrix
ok
yes
converse not true however
ok and was my train of thought correct?
if A is the identity matrix, 2|A| = 2 and |2A| = 8
2 does not equal 8 and therefore, it is false?
so there you go, you have found a counter example yup
can't really say much about rcf
thanks 🙂
in general det(cA)=c^n det(A) @wintry steppe
n being the dimension of the square matrix
gotcha
what do you mean?
and you can prove that by writing det(cA)=det(cI * A) = det(cI)*det(A) = c^n det(A) @wintry steppe very simple yeah?
just an important thing to know for the future
do similar matrices have the same jcf?
you can prove it directly by writing down the polynomial relation
if $A=SBS^{-1}$ then if $p$ is the minimal polynomial of A you have $0=p(A)=p(SBS^{-1})=Sp(B)S^{-1}$ and so you can always turn a minimal degree polynomial for A or B into the other
Merosity

A,B, and C are all n x n matrices and they satisfy C=AB. If both the linear system $Ax=0$ and $Bx=0$ only has the trivial solution, then $Cx=0$ must have only the trivial solution
embeddedmonk20

anyone know anything about this?
ah yes that's pretty straightforward
it's a true or false question
y'all are so smart in here lol and here I am. Back to the math....
...in reply to @quartz compass
lol
as a first attempt you could try to assume it's false and multiply by x on both sides and see if you get any kind of contradiction maybe
Is this subset a subspace of the vector space? {(3s+t,t+1,-4s+t) such that s,t \in \mathbb{R}}
(3s+t, t+1, -4s+t) are elements of all real numbers (I can't do latex lmao)
show what you've tried
It has to be closed under addition and multiplication
since its all reals, what happens if you multiply it by i? It wouldn't be all real numbers since i is complex
otherwise, if you do anything else with it, it seems to be real numbers
I think its a subspace????????

Are these properties necessarily defining matrices with 1's along the diagonal and 0 otherwise?
if you're working in finite dimensions, sure
so actually im curious about that
my class has mainly stayed within finite dimensional spaces
do the majority of the results fall apart because of the lack of guarantee of a basis?
for infinite dimensional spaces
lack of a finite basis, yeah
stuff like existence of complementary subspaces, injectivity = surjectivity for operators
usually infinite dimensional spaces are studied with some extra structure on them
like a norm
and instead of trying to do things algebraically you do them analytically/topologically
e.g. the entirety of functional analysis
ahh I see
wow, that provides a lot of context for this stuff
so i guess now what differentiates analysis and topology
i've taken adv calc so im curious how it's abstracted or goes further
is there a reason why the jordan form is nested twice?
yes
stop giving answers
oh i thought he's fact checking, nvm
How do I find the algebraic multiplicities? If I've got this one for example

try finding the characteristic poly
I thought of that, but the question is specified such that we should not try and find the eigenvalues or the eigenvectors. I thought that would involve finding the char.poly
you usually find the characteristic polynomial before finding the eigenvalues and eigenvectors
so i think you're in the clear if you do that
I found it to be $\lambda^3 + \lambda^2 - 2 \lambda$ but I am not sure how I would get alg.mult from that?
HrJonas

do you know what algebraic multiplicity means
the algebraic multiplicity of an eigenvalue is its multiplicity as a root of the characteristic polynomial
so you have to find the roots of the characteristic polynomial (you have to factor it)
Oh factorise it. My nightmare!
When I've done that, what would be the next step?
find its roots and their multiplicities
which should become clear once you factor it
Ahhh I think it makes sense! Just need more practice in finding the roots. Thanks a lot 🙂
Ohhh when I've found all this informations about the roots, the alg.mult is the sum or something like that right?
like the alg.mult always needs to be equal to n or something?
the sum of the algebraic multiplicities will always be equal to n
the algebraic multiplicities themselves are the multiplicities of the roots of the characteristic polynomial
So I found that the roots are 0, -2 and 1
Good question, sorry if it sounds dumb, but I don't know or see the connection
do you know what "multiplicity" means for a root of a polynomial?
I must admit I have it hard with understanding the multiplicity and in a different langauge as well
it means the biggest power of (lambda - root) appearing in your factorization, basically
so as a random example, if i have a polynomial like $$\lambda^4(\lambda - 1)^{500},$$ then the root $1$ has multiplicity $500$
TTerra

Ohh, I think it makes sense. But I have two parenthesises with each a multiplicity of 1, does that mean I have a multiplicity of 1 or the sum of them both?
a multiplicity of 1
if you're trying to find the multiplicity of a specific root then you don't really care what's going on with the other ones
you just need to read the powers of each factor in the factorization you found, basically
What if the first parenthesis had a multiplicity of 2 and the other 1?
I mean something like this $\lambda(\lambda + 2)^2 (\lambda - 1)$
I've got that but without the power of 2.
HrJonas

yeah, you're right. in this example, 0 would have multiplicity 1 and -2 would have multiplicity 2
actually i think you switched up first and second here, but you're right that one of them has multiplicity 1 and one of them 2
It was just more of an thought example. Just trying to make sense of other cases than my one
ok, is there a way to calculate the algebraic multiplicity without finding the chr poly??
dimensions of the generalized eigenspaces
though good luck finding those without knowing the eigenvalues ahead of time lmao
When trying to do an orthonomalbasis, does it really matter where the w_1, w_2 and w_3 etc are placed?
no
the resulting vectors will look different though
it's not a problem, just be aware of it when checking your answers, for example
Hmm weird. Not sure why matlab is acting like it isn't working
they might not exactly match the ones in your book, but you can check orthonormality by putting the resulting vectors as columns of some matrix M and taking M^T M
Not sure why its doing it. MatLab says that it can't divide with 0, yet there shouldn't be any

can you show your matlab source
Sure, here it is.
x3 = sym([0.1e1 / 0.2e1*i i i; -0.1e1 / 0.2e1 1 1; 1 0 1;])
x4 = sym([i -i i/2; 1 1 -1/2; 0 1 1;])
a = orth(x3,'real')
v = orth(x3,'skipnormalization')
k = orth(x4,'real')
j = orth(x4,'skipnormalization')
also probably call the j variable something else
i dont remember if in matlab modifying j also affects i
orth is only able to take real or skipnormalization.
x3 works fine with 'real'
It also appears that one of your imaginary numbers in first row is negative here
(as opposed to the picture you posted, which has a determinant of i)
Yea the picture is wrong, sorry!
It gets an output without any options, but x3 is quite neat for displaying the result

you can always do pretty(a2)
That can't be an actual command
it is
Ah that is neat! I'll have that neat command in my grave. It worked and it looks nice. Though I still wonder why it hates I switch the places
But hey, it works! Thanks a lot 🙂
What does it mean that an matrix has a rank of 1 and 2?
the that's the number of linearly independent columns (or rows, the number is the same)
Whops too fast. Does it mean the same for SVD's and doing approximations?
what?
rank means only one thing when talking about matrices
(albeit with several equivalent interpretations)
I've got this matrix A. I need to find the low rank approximation for rank 1 and rank 2

so you want matrices with only 1 linearly independent row (equivalently col), and 2 for the latter case
Oh
you can interpret the SVD as a decomposition of a matrix into the sum of rank 1 matrices
so for σ_1 to σ_r I would discard everything else if I just had rank 1?
you'd keep sigma_1 and set all the others to 0
Oh okay, thanks 🙂
Let v= (3,0,4) and w = (2, 4, 4) use this to compute |v x w| = |v||w|sin(theta).
I've calculated this and get the wrong answer!???
for example, |v x w| = sqrt(16^2+12^2+4^2) = 4sqrt(26).
|v| = 5
|w| = 6
sin(theta) = sqrt(1-cos^2(theta))
cos(theta) = 4/5
5 * 6* sqrt(1-cos^2(4/5)) = 21.52
21.52 =/ 4sqrt(26).
Where did I go wrong with this?
where'd u get that cos theta from
cuz i get that cos theta is 11/15
you agree we can get the cosine by normalizing the vectors and taking the dot prod, right?
v dot w = 6 + 16, then divide by (5*6)
That's what I did 24/30 = 4/5
Apologies
it's 22/30
😭
it's bound to happen, doing so many small additions and multiplications
good on you that you're checking with 2 methods
Appreciate the help in checking 😄
If I've got $\sigma_1 = 10$ and $\sigma_2 = 4$ and I wanted to find the relative errors (?) I would use the formula (one of them) (attached). However I don't see as of why it is that $\lVert A - A_k \rVert}= \sigma_{k+1}$ ?

HrJonas
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

i assume that A_k is a rank k approximation of A
what the induced 2 norm does to a matrix is give you the largest singular value (singular values are, by convention, ordered by decreasing size)
if A and A_k have the same first k singular values, subtracting the two matrices will set all k of those singular values to 0
so the k+1 singular value of the difference is the first singular value that can be nonzero
this also means that the notation sigma_k refers to the singular values of A
Ah, thats weird, but neat! I wonder where that explanation is in my book.
Again, thanks a lot, I appreciate it a lot ❤️
if you know the singular value decomposition, you can easily crack these open
After correcting cos theta, I still find that u * v * sin(theta) =/ 4sqrt(26) by ~ 0.3
,w 56sin(acos(11/15))

4 sqrt(26) is exactly what you got with the other method
remember 11/15 is cos theta, not theta
f is a linear map. I am supposed to find out the basis of ker(f) and im(f) but I'm stuck here. I have ker(f) = {(x,0) in R² | x in R}, and so I think ((1,0)) is a basis of ker(f). To prove that this is a basis I need to show that the vectors in the tuple are linearly independent (which they are, there is only one), and that the tuple is a generating system of R². This is where I'm stuck. I think I need to calculate the linear hull <{(1,0)}> but I don't know how to correctly apply the definition of the linear hull. It's a linear combination apparently? Please someone help 😄

Now that I think about it, ((1,0)) cannot be a generating system of R², right? So I did something wrong when trying to figure out the basis?
But if f is a linear map, then it has a basis right?
oh nvm
it has to be a generating system of ker(f) and not R², right?
then it makes sense to me
a basis of ker(f) has to generate ker(f), yes.
okay thanks 👍
I wonder
is it the same thing if you have a basis ((1,1,1)) and ((1,0,0), (0,1,0), (0,0,1))?
do they span the same spaces?
I am not sure what to prefer
I have a subspace {(x,-x) in R²} and need to find a basis. I feel like I can either go with ((1,-1)) or ((1,0), (0,-1))?
hm
the former, not the latter
okay
to be fair, they both span the subspace, but the latter doesn't span ONLY the subspace
it spans all of R^2
what I always do is (x,-x) = x * (1,-1) pull out the variables like this. So you only want to have 1 vector per variable with this method?
hope that makes sense
yep that's right
sure it is
x is an element of the field, so you have written all vectors in the subspace as a linear combination of vectors
a single vector at that, so since it's nonzero, it's trivially a linearly independent set
ah right
but then I need to show that it's a generating system or not?
we defined a basis as a linearly independent generating system
i would say that was already included in what you did
so this is what I wrote down before to prove that, but dunno if it's time wasted <{(1,-1)}> = {(x,-x) in R²} (with extra steps)
you showed directly that all the vectors in the subspace are given by a unique linear combination of a set of vectors
maybe someone can reword it differently so that it matches your nomenclature better though
does equality occur when v is a linear combination of those vectors...


i'm uncertain about it
extend the orthonormal set to an orthonormal basis for R^n and express v in that basis
you should achieve equality when v lands in the span of the original set
i dont understand this

do you know how to compute a determinant using minors?
not really LA but
this sort of stuff does show up when doing computational linalg and you have to use a specific method for whatever reason
yeah like can't we manipulate rows/cols and get a upper tri angular giving us 0 3x3 minor calc?
these questions don't make sense to me

it can be an interesting thing to do for oneself
to compare the computational complexity
aha,
cuz getting it to triangular form has the complexity of row reduction, right
and that can be finicky sometimes
in this case, for example, you can do minors twice to reduce it to 3x3, then write the determinants explicitly for those, which is roughly O(1)
so that's around n^2
it's sounds dumb, but it could actually work
Just learned about linear transformation properly in my book. I find it amazing the fact we only need to know how the transformation acts on a given basis for us to be able to get any vectors in the target space.
I don't know why but it feels so nice.
it's pretty cool
I found the least-squares solution, but my answer has the signs swapped. Where did I mess up?

yes it should be -4,3
how are you writting (12 8 \ 8 10) = (6 4 \ 4 5)
also A'b is not (12 1)
I shouldn't have changed the signs on A^T*B
Other than that, I'm just reducing the matrices
u don't just reduce matrices like that
Yes
Let $\mathbb{K}$ be a field such that $#\mathbb{K} \notin \mathbb{N}$ and $V$ be a vector space over $\mathbb{K}$. Let also $n \in \mathbb{N}$ and $U_1, \hdots, U_n$ be subspaces of $V$ such that $U_i \neq V$ for all $i \in {k \in \mathbb{N} \mid 1 \leq k \leq n}$. Show that
$$\bigcup_{i=1}^{n} U_{i} \neq V$$
I'm not really sure on what to do, my first intutition is to prove it by contradicition. So assume that $$\bigcup_{i=1}^{n} U_{i} = V$$
holds true. Maybe inducing over $n$ is what I should be aiming for next? But I have no idea on how to approach this.
lewis

If a matrix is in jordan normal form, does it mean it cannot be diagonalized?
Since no other matrix is similar to it
well, a diagonal matrix IS in jordan normal form, so the answer is no, trivially.
if you're asking if thats true when a matrix is jordan normal form and it isn't diagonal, then the answer is yes, since jordan normal forms are unique up to reordering.
yeah, something like $J_3(0)$
Kurama

i take it this is the 3x3 jordan block with eigenvalue 0?
Yep
since there is only one jordan block in its normal form (itself), the only possible jordan forms it has are just itself, which is clearly not diagonal
np
are you assuming V is finite dimensional?
Is there an algorithm called "unit column algorithm" which helps you find the unknowns in a system of equations by using elementary row operations? It is like Gaussian elimination, however, you don't have to form a triangular matrix
Yes.... just do Gauss Jordan...
or since RREF is unique, any set of EROs until you get to RREF
induction might be a viable approach
then splitting into cases, U_n+1 intersects all of the spaces trivially, or it is a subspace of one of U_1,…, U_n
found some slides on gram-schmidt

and i have to apply it to find orthonormal basis of the standard P2 basis
inner product defined as integral from 0 to 1 of the product of the two polynomials

this is my work so far, my question is which polynomial i should be using for p_1(x) in finding p_2(x)
like should i use the one i find before (x-1/2) or after (2sqrt(3)x - sqrt(3)) dividing by the magnitude to obtain a unit vector
update i dont think it matters 
If we are given rank of a linear transformation, how do we find nullity?
say we have a linear transformation T:R^3----->R^3 and rank(T)=3. How would we find nullitiy(T)?
look into the rank nullity theorem
it says in google that rank nullity theorem gives us the property that rank(A)+nullity(A)=dimension so in this case Rank(T)=3 and we know its transformation with regards to R^3 so 3+nullity(T)=3 so nullitiy(T) just equals 0?
is my logic correct or am i missing something?
its just whats in the nullspace right
then how about this: what does a linear transformation do
it just changes the input to a different vector space right
alright sure
well what happens in a linear transformation from say R2 to R1
a dimension is "lost" so to say
we go from a 2 dimensional vector space to a one dimensional vector space?
in order to go from R^2 to R^1 we need a 1x2 matrix
ah yes
what will be the rank of a 1x2 matrix
2?
nah it's best this way I actually learn. But do you mind if I quicly submit my hw first and then you can explain?
How do I do this problem? I have Au & Av, but I don't know how I'm supposed to use them to get an answer

How do I calculate the first determinant?

"x" is a least squares solution if |b - Ax|^2 is the smallest it can possibly be.
i.e, you need to compare |b - Au| and |b - Av|
Use Leibniz expansion. To construct a term that doesn't vanish choose one of the a and b in the first column -- that forces your chose in the last column too. Proceed by induction.
But is the lower right entry really supposed to be b?
Ooh, I see it
I don't know, those were exercises from my teacher
And the lower left is inexplicably an a rather than apparently b's everywhere else on the antidiagonal. I think my answer would be "I cannot figure out exactly which pattern of entries the dots stand for ..."
If it \emph{had} been "b 0 0 . . . 0 0 a" in the bottom row, my hint from before would lead to an answer of $(a^2+b^2)^{n/2}$, but ...
Beware the signs, though -- I think I got them wrong.
Wouldln t Gaussian Elimination also help ?
Till now I only learned Laplace and Gaussian Elimination
Hmm, right. It would be simple to make the matrix upper triangular by a few selected row operations.
If you want the easy way out, you can take the typo at face value and say "the first and last rows are identical, therefore ..." :-)
:)))))
quick questions, how can I find the Euclidean matrix norm of a matrix?
is it equal to the largest eigenvalue of the matrix?
@dim lotus What do you mean by Euclidean matrix norm?
as in this question

There must be a definition of the phrase earlier in the text.
ok
Is it the square root of sum of squares of the entries? What is the definition of it?
I'd guess Frobenius or the operator norm
this is the definition

I think it is the operator norm?
this is the definition + example

Yes, that's the operator norm.


Anyone please?
@torn leaf bro show assignment title, to prove its not a test please




Okay so my teacher confirmed for this problem that I just need to show y^t y > 0 now

Im thinking that means each entry of Y^t * y ? is always > 0
=0 yes
that's just the statement of dot products saying <a, a> \geq 0
and 0 iff a = 0
Can anyone please help with 2nd picture
@zinc timber sorry for the ping
But could you
How
is the answer a?
I am trying my best to program this in Python, but I really am starting to become insane ... Every time I think I get something, all of the sudden something doesn't match up
is saying vectors of a basis are linearly ind. enough justification to show that the linear transformation is one to one
If the images of a set of basis vectors under a linear transformation are linearly independent, then the transformation is injective, yes.
basis implies independence
part of the question was showing it's a valid basis
but i did that with wronskian
it's in polynomial space
if you show they span and are indep. then it's a basis

i did that already
tryna show injective
bases arent injective

,rotate

Mosh



wtfs a qed
the vine boom of math
mom
phrase to end a proof. 'im done proving what i wanna prove'
here's to hoping my prof takes the def of injective as sufficient proof
Heck, if every single-element LI set is mapped to a LI set, then the linear transformation is injective :p
Is there someone who can see how you would program the R values of this factorisation ?
Woop
at that point its clearer to say nonzero vectors are sent to nonzero vectors
Indeed. :-)


@torn leaf #geometry-and-trigonometry or #prealg-and-algebra
This is linear algebra
Vector topic
looks more like a coordinate geometry to me
Nvm I’ll figure it out but can u help with this

@zinc timber
have you calculated the row operations?
Yes but i dont know what values to use in this question

so, you have not yet done the necessary row operations to put the matrix in the necessary form...
in fact you haven't even written down the original matrix fully, and have not done any row operations.
why did you put a blank space where k^2 - 7 had to go?
That’s what I’m not getting how to do
if there was no k and it was just numbers, would you be able to do it?
For ref
if there was no k and it was just numbers, would you be able to do it?
Yes
okay then do it the same as if there was no k.
you won't even need to involve k in any of the coefficients in the row ops here.
Then what values
$\begin{array}{ccc|c}1&1&1&2 \ 3&2&2&5 \ 3&2&k^2-7&k+7 \end{array}$
you start with this
your first step is to zero out the first column leaving only one entry equal to 1 at the top
how would you do that?
i am nearly CERTAIN i've seen you do basic gaussian elimination before.
I have to do ref of this right?
Kanga Gang Annihilator Ann

yes! yes you need to put this in REF!
as the problem tells you!
i'm surprised this even needs to be repeated
Well u didn’t reply so I asked again
you said that if there were no k then you would be able to put the matrix in REF
and i am saying that the presence of k does not impede that in any way whatsoever
no i didn't say not to include it
i didn't say to replace all instances of k with some number
are you intentionally misreading the things im saying??????????????
it's infuriating
the operations are "add <number> times <row> to <row>", "multiply <row> by <number>" and "swap <row> and <row>"
what i said is: it is possible to put the matrix in REF without putting k into any <number> slots in these operations
,w row echelon form {{1, 1, 1, 2}, {3, 2, 2, 5}, {3, 2, k^2-7, k+7}}

{kind=link}
...okay, WA went too far
this looks correct at a glance but i do not know why you chose to put the row [3, 2, 2 | 5] at the top
I swapped row 1 and row 2
yeah, and i don't know why you did that
It’s wrong?
I thought that’s what we have to do
you think that a sequence of row operations is invalid if it never involves any row swaps?
No
I thought that’s what we have to do
you did a row swap because you thought you always had to do at least one row swap
yes or no
Yes
Oh yes I do
I misread it
well then you are wrong
it is perfectly possible for a sequence of row ops to never swap any rows and remain valid

Oh ok
But it’s not wrong to swap right?
Coz that’s what i was told
I see
Ok
After that what do we do
1 question
Since the question says 1
But I got 3
you have a system in REF where the last equation reads (k^2 - 9)z = k+2
It doesn’t matter right?
The first value
okay now i see what you meant
technically you will have to divide the first row by 3 to make it fit the question's requirements
How to do that
do what
Ohh just the first row dived by 3?
The next step
WHY SO MANY REPLY PINGS
this
is
very
annoying
you can disable pings
So no confusion would be there
anyway, what i was trying to say is that you made things more complicated for yourself with the swap.
if you had not swapped anything you could have just kept the first row as is
anyway, now that you have the equation (k^2-9)z = k+2 you need to understand two things:
- x and y can be unambiguously expressed in terms of z using the other two equations
- thus whether or not (k^2-9)z = k+2 has a solution completely determines the number of solutions for the whole system
??
yes you divide the first row by 3
the other two equations
(1/3)y + (1/3)z = 1/3
you can isolate y in this one to express it in terms of z
then in 3x+2y+2z=5 you can isolate x to express it in terms of y and z and since you know the expression of y in terms of z you can plug that in too to get x in terms of z only
this relies on the fact that the coefficients on y and x in these equations are nonzero
Ok I’ll try
all this should be obvious with the slightest bit of algebraic proficiency
Ok
{kind=link}

This is so much easier if you know Dirac's notation
Sum of <• ,e_i><f_i, •> up to m is the identity matrix if m is the dimension of V.
thanks I'll try to work with that
Well I guess imagine that the inner product of <x,e_i> = c_i, <x,f_i>= k_i, the sum becomes sum of |c_i k_i| = |c_i| |k_i|, now if m=n, these are just components of x in some basis and must add up to | |x| |^2. In case m<n, you would get the inequality.
What I mean in a more mathy language is that imagine you find n-m vectors that are orthonormal to {e_i}, {f_i}. Then these new sets of orthonormal vectors form bases for V, let's call them {e'_i}, {f'_i}. Then
Sum |<x,e'i> <x,f'i>| from 1 to n. But this is just norm square of x. Now,
|c_1 k_1| + ... + |c_m k_m|+ |c(m+1)k(m+1)| +...+|c_n k_n| = |x|^2
=> |c_1 k_1| + ... + |c_m k_m| < |x|^2
So in case m=n, you get equality, in case m<n, you get the inequality.
If so, can I apply just apply Bessel's Inequality for this
i mean, this
smh
Is it true that $| \textbf{u} |^2 + | \textbf{v} |^2 \ge 2| langle \textbf{u} \cdot \textbf{v} \rangle |$
usr/bin/kannaaa3777777777

try $\ip{u-v, u-v}$

we know it's >= 0
ah yes
so I wonder if I could apply Bessel's Inequality if I could prove it
I mean,...
ok i just realize the more i study, the more my brain fu*k up
also I think you have miswrote the inequality
i lost my ability to know that the heck is this
it should be
yea i just realize
$\norm{u}^2+\norm{v}^2 \geq 2|\ip{u, v}|$

yea