#linear-algebra
2 messages · Page 263 of 1
I got what you're saying
thanks
<<M>> is the smallest subspace that contains <M>, and <M> contains instself, thus <M> is the smallest subspace that contains <M>, thus <<M>> = <M>
right?
@autumn kraken yep
I always think I need to write something down with math symbols
dunno why
<M ∩ N> = <M> ∩ <N>
This is false right?
I think I have a counter-example but not sure
hm I don't think I understand that example
isn't then <M>={(x,x) | x in R} and <N> too?
This is defined for $x \in \mathbb{R}^n, x \geq 0$. Im not sure I understand the equivalency described here. How exactly do we get $||x||_2 \leq 1$ here?
Fredrikpiano

Let y = x/norm(x)
I believe it should relate the cauchy-schwarz inequality
right, that works
we are allowed to make that replacement since norm(y) = 1 right?
Yeah
Possibly you have x = 0
Then that doesn't work
But then norm(0) <= 1
So treat it as a separate case
thanks)

what is the question?
find the true one?
do you know that $\det(MN) = \det(M)\det(N)$?

yes
use it to find which one is true
yes I am
Hey guys, say I'm given a square matrix X but then I change only one of the columns so I have a new matrix X'. Is there a quick computation for the determinant of X' in terms of the determinant of X
Specifically, all the values in each matrix are uniformly distributed from 0 to 1, but then the new matrix X' will keep all the values the same except for one row which are new random values
It's alright, just something that can guide me in some direction would be helpful
yeah, the det is almost always not 0
then you can write the new col in terms of the linear comb of the col vectors
but finding the coefficient is not that fast so don't think it'll give you any speedup to begin with
so the new col in X' can be written as a linear combination of the col vectors of old matrix X
yes
ah I see
yeah, but then I'd have to compute the coefficients in terms of the column vectors which may take some time you said
help me please
I try to solve and give me 3 solutions...
which ones

the result it is correct?
@zinc timber yes I’ve found the QR
yes?
So now you have $QRx = b \implies Q^TQRx = Q^Tx \implies Rx=Q^Tx$




Q^T
So I first do Q transpose QR*x
Q^tQRx = b
Qtranspose x Q x R x X

That’s what I got it from


??
where are you stuck?
If v is orthogonal on every column in A, what subspace is v in?

translation:
let
where a, b, c, and d are real numbers, and let
show that p(A) is equal 2x2 0 matrix, such that
is
so obviosuly is i change lambda into A i get
det(A-A) = det(0) = 0
but why is 0 determinant allowed to be considered a 0 matrix
you cannot change λ into A in det(λI - A)
Hi I have a question
it means p(A) = α_2 A^2 + α_1 A + α_0 I
but plugging A into det(λI - A) makes no sense
A is a matrix and so is p(A)
p(A) is the zero matrix but not zero as a number
eswag
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

okay im pretty bad at inputting matrices using texit
doing a 5x5 matrix?
6x5
Use #latex-testing if you want to 🙂
Can someone help with Part B? I know that I need to prove that M has n linearly independent eigenvectors but I'm not sure how to prove it

I'm done part A, and got 2 distinct values to be 0 and 1
eswag

to make sure, do you mean the span of the columns of the matrix, or the span of a set that contains the matrix?
yea my bad i mean the columns of the matrix
im not good at using texit sorry
so the problem thats given to me is that those columns of the matrix span the subspace W of R^6
it says to find a basis for W but the columns are not linearly independent
And the hint is to treat W as the column space A
assuming A is a matrix made up of those 5 columns
is the basis just picking out the columns with pivots? @lavish jewel
yep
C(A) 🙂
the column space is the vector space spanned by the set of vectors that make up the matrix columns
right
and the nonpivot columns can be written as linear combinations
of the pivot columns
that is not the full story, but yes
okay one more question
@lavish jewel Can you help me with this question?
So if i make a new matrix out of those pivot columns into a matrix B
and do QR factorization
If I were to multiply Q * Q^T as well as the orthogonal projection of an orthonormal basis onto the perpendicular subspace, then would adding those two matrices result in the identity matrix?
think of what happens to vectors y = Ax, and Ay = A^2x
what's Q, and orthogonal complement to what?
Vector y? could u explain how u got that?
Let's say if A is an mxn matrix with linearly independent columns using basis of W, A can be written as QR where Q is an mxn matrix whose columns form an orthonormal basis for ColA and R is an nxn upper triangular matrix
any vector y that you get out of multiplying an arbitrary vector x with A
And if we find Q from augmented matrix using the basis for W perp,
Would adding those two matrices equal to the identity matrix

you could see this by noting that QQ^T + PP^T (where P is a matrix whose columns form an orthonormal basis for the orthogonal complement of the span of the columns of Q) can be rewritten as a sum of rank 1 matrices, each of which is the outer product of one of the columns of Q or P with itself
so it's equivalent to augmenting Q and P into a matrix, let's say M, such that M = [Q P], which by construction has columns that form an orthonormal basis for the whole vector space, and writing MM^T
then we would have that M^TM = I, and since M is squared, MM^T = I as well
@lavish jewel could you help me
I have different approach to b, given p^2-p = 0 means that f(x)=x^2-x is an annihilator of M. Now it means that the minimal poly must divide f(x) so possible forms of minimal poly are m(x) = x, x-1, x(x-1). either case, the minimal poly splits into linear factor and has only one factor of each, (forgot what it's technically called) so M is diagonalizable. It may not be solution you were looking for tho
I still have no idea what your question is
i love this
best solution

i really like arguments in linear algebra that work with the minimal/characteristic polynomials
very pleasing to me
yes same
e.g. if T is an operator on a real vector space of finite dimension with T^2 = -I, then V has even dimension
I remember that one
m(x) has to divide x^2 + 1, so it's just x^2 + 1, and since the minimal and characteristic polynomials have the same irreducible factors, the degree of the latter is 2n for some n
it's cute
there is an easier way to see this though
just define (a + bi)v = av + bTv and check that this extends the real structure to a complex one
fun stuff!

is det(M+eI) = det(M)+e tr(I) true here also?

this is going to distract me. musn't... think... about... why this is true
think you cn take Eii but idk a better approach
welp, ive been working on my cs project all day anyway
um
i was trying to just symbol bash it but i dont think that gets anywhere
this one is kinda crazier tho. every matrix can be well approximated by an invertible one
every matix is almost diagonalizable as well

in C tho
oh sheet true

so you were gonna show that PE_ii = E_iiP for all i
nah i dont believe this one dude
it's true
i
i don't either but
answer is true
so i must prove it
these guys do set some good problems
yea fr
sure
we can be stuck together

Can be done by BA=A+B right 
By showing that
A+B=AB
So AB-A-B=0
So (B-I)A-B=0
I guess I'm going right here
So (B-I)A-(B-I)-I=0
(B-I)(A-I)=I
(A-I)=(B-I)
I=(A-I)(B-I)
I=AB-A-B+I
Gimme a sec
not sure what you did to get to (A-I) = (B-I)
I wanted to get BA
the rest looks ok so far
so you showed B-I and A-I are inverses that I understand
Oh yeah I screwed there
(B-I)(A-I)=I is clear upto this
yep
So yeah we swap it
this was more ring theory than LA
(a-i)(b-i) is what you started with
Yeah feels like that
I started here
(b-i)(a-i) = i expands into ba = a + b, and you're done
yes
Yeah or (B-I)(A-I)=(A-I)(B-I)
so strange that it's actually true
That's true but how do we come up with it
inverses
the way you did it is fine, it's just that ryu said "then we just expand (a-i)(b-i)" but that's what you started with
I don't know how I can pull that out directly from knowing A+B=AB
i'm saying you did it fine but you didn't do the last step right to end up with something that has BA instead of AB
you just multiplied out the same thing again
or well, ryu did
just be careful, you had it right
yes I figured the rest no worries
Yes ik that thing but I'm asking how would I think about (a-i)(b-i)=i intuition directly cuz I won't be thinking that I'll multiply (a-i) and (b-i) by knowing a+b=i
So I just wanted to know is there an easy way to figure out that we have to use such product
you did some arithmetic to show that (A-I)(B-I) = I
if the matrices are square, this is enough to say they are inverses of each other
i think for this one, we want to look at eigen spaces or something
something with eigenvalues
easy argument, P is diagonalizable, so for M to commute with P, it must have to be simultaneously diagonalizable. so asfhasekfa and M is scalar
damg how is P diagonalizable
^
oh that was for that problem
it was for someone else's, but happy coincidence
o
lol is this one still up for grabs
yes
f(x) = det(A + xI) is a real polynomial in x right
yes
wut
why
wait
f(x) has at most n roots
so for small enough x, det(A + xI) should be non-zero
i think that does it
like theres only finitely many roots to this poly. you can just zoom in on a neighborhood of zero and miss all of them
lol
proof my imagination
lol
um. hmm.
if there are no zeros then were done, since A + xI is invertible for all x
if theres only one then we obviously done
otherwise, take the minimum distance between all the roots
call this r
fuck
nooooo its so close aah
if we can show this then we're good, cus we can get a sequence of A + x_n I converging to A
all invertible

agh
purple dots are the invertible ones that approximate some non-invertible matrix A
Is that mitochondria?
red squiggly is the det(A + xI) function
lol
powerhouse of the cell
The only definition I remember 
is this chat free to ask a question?
always is
is what ive done right to find the hermitian? is that what I should be doing to solve 1, and if it is what do i do from there? make it equal to T hat?

Are there other vector spaces apart from {0} that only have a single basis?
the field {0, 1} over itself?
makes sense, thank you!
I'm trying to determine in which cases there is only a single isomorphism from a vector space to its dual. Is it true that this is the case iff the vector space only has a single basis?
It holds for the above two examples and I know that when a vector space has multiple bases we can construct multiple such isomorphisms
but I'm not sure if there are spaces with a single basis for which we can still construct multiple such isomorphisms
try taking a basis of any vector space and making a new basis, but not by permuting the elements
yes, then we can get a different isomorphism right?
but I'm trying to go in the other direction
no, this will show that if a vector space has exactly one non-empty basis, then it has to be isomorphic to Z/2Z
alright
didn't understand the notation, ik bras and kets but what's ⟨..|+tj|...⟩
Taking hermitian conjugate means you also reverse the order of multiplication, and also convert scalars into their complex conjugates:
$$(C \ket{A} \bra{B})^{\dagger} = C^{}\ket{B} \bra{A}$$
Applying that here yields
$$\sum t_j ^{} \ket{j+1} \bra{j} + t_j ^{*} \ket{j} \bra{j+1}$$
Dovahkiin

Where summation is over j on both terms, obviously.
Compare this with T, should be obvious under what condition they're both equal.
Probably don't use Dirac notation in math server lest you want to get murdered 
so $t_j$ must be complex?
nova

t_j is a complex number. If you compare T and it's conjugate, you see that the condition for T to be hermitian is that t_j* = t_j, or that t_j is real
(or t_j is complex with zero imaginary part)
Yeah and keep the Kronecker's delta in your mind.
okay thank you :))
wait so itd just be $t_j\ket{j+1}$?
nova

Hey! sry for the late reply
but any idea how I can solve it using rank and nullity theorem?
Split the summation into two
$$\sum (t_j \ket{j} \bra{j+1} \ket{i}) + \sum (t_j \ket{j+1} \bra{j} \ket{i})$$
Which is equal to
$$\sum (t_j \ket{j} \delta_{i, j+1}) + \sum (t_j \ket{j+1} \delta_i,j)$$
The first summation is 0 except when $i-1=j$, and the second is 0 except when $i=j$, so
$$t_{i-1} \ket{i-1} + t_i \ket{i+1}$$
Dovahkiin

@signal mulch
if k is an eigen value of M for non-zero x, then we have
Mx = kx --> M(Mx) = kMx = k^2x = M^2x = Mx = kx. so k(k-1)x = 0 thus k = 0 or k = 1.
it suffices to show that the two eigen spaces intersect trivially. if v_0 satisfies Mv_0 = 0 and v_1 satisfies Mv_1 = v_1, then if av_0 = -bv_1, we have 0 = -bv_1 so b = 0. but since v_0 is non-zero, then a = 0
the two eigen spaces form a direct sum of V, so M is diagonalizable (assuming that M has at least one eigen value)
thank you so much, I really appreciate it :))
Np, have fun
after solving part a, I got that A has 2 distinct eigen values and those are 0 and 1
essentailly what Im trying to show using rank and nullity theorem is this:

M doesnt need to have two distinct eigen values. consider M = I
ohh i see
I have a quesiton
what do we know about matrix M? like how many pivot points does it have?
it would be n right?
it has rank(M) = n - null(M) pivots
this is rank nullity. there is nothing to show. you already know this
correction, eigen spaces intersect trivially doesn't mean it's diagonalizable
How to show $(I+ST)^{-1}S=S(I+TS)^{-1}$?
Phi

S(I+TS)=S+STS=(I+ST)S
eff bro. the dimensions gotta sum up to n
damn my bad homie
doesn't mean diagonalizable
it does. the sum dimensions of the eigen spaces is dim V iff it’s diagonalizable
Ehh, and what then?
manipulate
Oh, right, I can multiply by the inverses. Thanks
Waaait. I hoped for a proof that wouldn’t assume that if $(I+ST)^{-1}$ exists, then $(I+TS)^{-1}$ exists.
Phi


Lol this is the problem I was originally trying to solve.

I was trying to prove that if one is invertible, the other one also is. I wanted to use Woodbury identityy, the proof of which used the identity I gave above.
well I don't want to spoil it but
u can try looking into sylverter's law of determinant
Alright thanks. Although I hate deteterminant so perhaps I’ll try to prove it in some other way.
@crystal oracle can you prove that ST and TS have same eigen values?
if yes, and I+ST is invertible means -1 is not an eigen value of ST, therefore not an eigen value of TS as well, so I+ST and I+TS both are invertible
This is clear. But so far I don’t see why they have the same eigenvalues. Thanks for help, I need to go now, will try to solve this later.
"left as an exercise"
I guess S and T are square matrices. Isn't it that $det(I+ST) = 0$ if and only if $det(ST) = -1$ ? As $det(ST) = det(TS)$ then likewise $det(I+TS) = 0$ only in that case. If the determinant is not zero and the result is a square matrix then it's invertible.
𝓶𝓸𝓶𝓸𝓶𝓸

Yeah, turns out it's trivial. If TSv=λv, define w=Sv, and then STw=λw.
to know which of the lines is correct
kind of,
can anyone point me in the right direction with this? im kinda stuck


is (A+A*) hermitian?
i want to say no

I thought determinants followed an addition rule. 😦
wish it was true
idk, id assume the hermitian conjugate to be A dagger not A*
But det(A - B) = det(A) - det(B), right?
then use A dagger
no lol
so you only have to add A and A dagger and then its hermitian?
I saw this https://math.stackexchange.com/questions/1943840/determinant-of-a-matrix-subtraction-addition

Mathematics Stack Exchange
I'm trying to find out for square matrices with $n \geq 2$ :
$$ \det(A-B) = \det(A)-\det(B).$$
I know that $\det(AB) = \det(A)\det(B)$, but I'm unable to find proof on why a subtraction (or addit...
Is that not correct?
wait what?
I didn't read the answer properly, so it's my fault. But don't openly laugh at me for making a mistake.

I can't really say for sure that it was the intended solution. not familiar with physics way
ah okay, thank you though
Hermitian is similar to transpose, but for complex numbers.
If you can make matrices for transpose, this shouldn't be much of a problem for you.

the subset A is not vector subspace
the subset D is vector subspace
But I can't answer about subset B and C
please help me
MMt means M * the Matrix Transposed
well you can show that 2M doesn't belong to C
just compute (2M)(2M)^T
hm

stop apologizing 
thank you
yes
ty
what does it mean for a field to have characteristic
like for example F_256 has characteristic two
what does this mean?
the characteristic of a ring is the smallest number of copies of 1 that add up to zero if such a number exists, and zero otherwise.
if you're told a ring (or a field) has characteristic 2, it means that 1 + 1 = 0 in that field
ok ty
Does the kronecker product exist for tensors with rank bigger than 2?
I only ever see it defined for rank 2 tensors
Also is there a relation of the kronecker product to the outer product?

hello so III here is true but i need help with how to figure out the geometric multiplicity for the eigenvalues

i just know the algebraic multiplicity of each is 1

@tawny grotto is this an exam? Y/N
after a shear transformation of a square on a graph, how can i determine if the area is preserved?
i believe its an equation with its matrix?
what tells you how the area changes under a linear transformation?
the determinant?
if T is R^2 - R^2, what does that mean exactly
wait nevermind
so i take the determinant of the transformed figure and multiply that by the original matrix?
@nocturne jewel
No
You asked if a shear transformation (T) preserves area or not
ie you want an area A to, under T, remain with area A
so det(T)=+-1
since $A=\abs{\pm 1}A$
Mosh

not like one's gonna admit it even if it was
what if i wanted to know if the perimeter is preserved?
you'd do a lot of vector norms
hm
not totally sure i catch that
ok hold on this is my transformation

1 becomes 2
you're presumably applying the transformation to the position vectors. you can measure the perimeter by making vectors that join pairs of points along the perimeter of the shape, and taking their norms to measure their lengths
mosh suggests you do this before and after transforming
i seeee what you mean, im not familiar with vector norms so i had to search that up. so A B C and D are coordinates
norm aka magnitude aka length
right
distance between each set of points then i compare that to the values i get in the tranformation i guess
You find the perimeter of 1 (which is 4.. cause it's a square of side length 1) and find the perimeter of 2
which is something like 2+2sqrt(2)
ok yeah that makes sense now
thanks mosh
If I have a system:
$\sum \vec{x_i^T} (\vec{w} \cdot \vec{x_i}) + \sum \vec{x_i^T} b = \sum \vec{x_i^T} y_i$
$\sum \vec{w} \cdot \vec{x_i} + \sum b = \sum y_i$
is there a way I can represent this using Az = c, where $z = \begin{bmatrix} w \ b \end{bmatrix}$
THEBIGTHREE

looks like X^T (Xw + b) = X^Ty
i would advice against using x = [w;b] since you already have x_i for something else
what is the difference between inner product and dot product
i know inner product is a more "general" version
but how
the dot product is an example of an inner product
an inner product is a map V x V -> F that's linear in the first (or both) argument (more generally sesquilinear) and positive definite
that means it takes 2 vectors and spits out a positive number that can be thought of as a length of sorts
I'm not sure what the problem is
oh
for clarity, the columns of X are the x_i in the original formulation
actually
i have to ask to make sure
what is the dot representing there
elementwise product or dot product?
X^T (X^Tw + b) = X^Ty, on second inspection
only one option?
feels like multiple option to me tho
dot product
X^T (X^Tw + b) = X^Ty, then
so suppose we're working in M2(R)
i can define an inner product "however i want" ig
dot product is just an example of one in R^n right
ah that's the linear part ig
however you want as long as it follows the conditions i gave above
and as long as it operates on two elements of the same vector space
yeah I guess I could write it like that, but I still need to solve for w and b
though every inner product on finite dims can be written in the form x^TAy where A>0
what does it mean for the output to be in a field tho
i havent learned anything about groups, fields, rings, etc.
then simply let A = [X^T, I] and now you have Ax = y
ryu wdym

seems bout right
what do you mean by 'wym'?
"what do you mean"
my b
but yeah i just wanna understand the rule on the output of the inner product if that makes sense
I think I phrased it wrong using Ax = b
in this case it would be A.[w, b] = c
and I dont think this can work since b is a scalar
ah b is a scalar
which also probably means this can't work
you're working with row vectors
that changes things, yes
this is kinda weird if this is really what you mean, btw
cuz you have a sum of b, but b is a scalar
the only way to get this is if you take a vector of 1s and multiply it by b
oh yeah i could also just write bn
why would I need to do that
if there are different values of b, then it's a vector, not a scalar
no its a scalar
sorry b*n
yes
originally it was this:
$\sum x_i^T(y_i - \vec{w}.\vec{x_i} + b) = 0$
$\sum (y_i - \vec{w}.\vec{x_i} + b) = 0$
i just broke it up to try and isolate the terms
scalar
what is the sum summing over, i?
THEBIGTHREE

yeah
well the dot product of w and x_i should just be a scalar
so I don't think you need that
well ig removing the sum and representing the X and Y as matricies would work but it seems unncecesary(?)
you have that \sum (y - X^T w + [1]b) = 0
this is the same as [1]^T (y - X^T w + [1]b) = 0
you can stack w and b together by augmenting X^T with a column of 1s
alright yeah that works
so then you can break that up:
[1]^T.(X^Tw) + [1]^T.[1]b = [1]^T.y
is that right?
right, and you see that gives you the n*b you wanted
yeah
ah thats mb, the (w.x_i + b) should be in parenthesis up there
ah
wait so is the system:
X^T.(X^Tw) + X^T.[1]b = X^T.y
and
[1]^T.(X^Tw) + [1]^T.[1]b = [1]^T.y
hm

what have you tried?
this is basically the reconstruction of inner product by the polarization identity
for (a) and (b)
do you know what it means for two vectors to be orthogonal? do you know how inner products and norms are related?
b) follows directly from a) if you substitute the right vectors
if you defined the norm with a scalar product then it's relatively simple

the book mentioned like setting j = 1
makes v_1 = 0 ofc however it mentioned changing the second part of the proof
im not too sure what it would change to though

resolved?
@sinful valve so what are you trying to prove?
yeah it was like a specific case they were on about or sumn
like if you selected j= 1
then you could still prove by altering it somehow
honestly I'm not following
the steps you are doing is as follows:
- Check if v1 is 0 or not, if zero remove it, otherwise leave it,
- check v2 is in the span{v1} or not, if yes, remove it, if no, leave it,
- check for v3 ....
.
.
.
you'll eventually run out of v's because your set is finite
huh that's not what the proof is on bout
like they say the largest element of 1 to m
yeah you choose the first vector in you list that turns out to be a LC of the previous ones
oh shit yeah it's just till a_j not 0 then
ig
so the case they had in question was when the vector is the first 1
which makes the linear combo 0 ofc

how does b change for this then they said its obv
$u=c_1v_1+\ldots+c_mv_m=c_2v_2+\ldots+c_mv_m$
RokettoJanpu

why does that work though
v1=0
oh yeah
so thats literally it ight calm
so yeah if j = 1 then the RHS of a which was 0 adds up ye
what does characteristic polynomial have to do with polynomials? i am struggling to see the connection

it... is a polynomial in t lol
by the preceding remarks
you might want to show these if you want more explanation

in particular, the determinant function is applicable to the ring M_n(F[t]) of matrices with polynomial entries, and it is obvious from the formula for determinants (7.3.2) that the determinant of such a matrix is itself a polynomial.
what exactly are you struggling with
I didn't understand this "determinant function is applicable to the ring M_n(F[t])"
but now it makes sense
i just didn't read it propely lmao
fancy way of saying you can compute the determinant of square matrices whose entries are polynomials
proof of cayley hamilton (|xI-A|)(A) = |IA-A| = |A-A| = 0
If M is a subspace of V, and f: V -> W is a linear map, how do I start checking if <f(M)> = f(<M>)?
<> being the linear hull
unpack all relevant definitions
how do u know when to use det(A-lamba(I)) or det(lamba(I)-A) for eigenvalues ?
both give you same eigen values
so it doesn't matter which one you use?
Yes it doesn't matter
ty

ho should i prove this, i talked about assosiativity and then i reached to my answer but it does not seem right
can you write $0\in \mbb{F}$ as $\lambda-\lambda = 0 $?

is it normal for the rational canonical form to feel kinda contrived
i do not know modules

if i have the polynomial x^4 - 4x^3 + 6x^2 - 4x - 7, is this the right companion matrix
So, if $Q(X) = X^\top A X + B^\top X + c$ then $\vec{\nabla}Q(X) = 2 A X + B$
𝓶𝓸𝓶𝓸𝓶𝓸

Where X is a vector, A and B are matrices, and c is a scalar.
Which looks a lot like the rules for polynomial differentiation.
But I don't know why $X^\top A X$ would be 'equivalent' to $ax^2$.
𝓶𝓸𝓶𝓸𝓶𝓸

Is there a set of rules for this?
is there a matrix equivalent for x^3? i can't think of one
inf column of zeroes w a 1 in the 4th slot...?
think it's ok
What's that?
Thanks! Is that the latest version?

why do I need to prove that T is a scalar multiple of the identity operator?
is it not sufficient to show that any v which is not a characteristic vector is a cyclic vector?
I think you are misreading it. You are not using the second statement to prove the first. You are proving the first statement and then using that to prove the second.
No, I think I understand that. It's simple to show that T has a cyclic vector. I don't get why I would also have to show the scalar multiple part
the "either ... or ..."
is this more appropriate in #groups-rings-fields ?
I don't understand how the second sentence is equivalent to the third
Assume you have proved the second statement. Now, we want to prove that either T has a cyclic vector or T is a scalar multiple of the identity operator.
So suppose T has no cyclic vectors.
Then by the second statement, that means every nonzero vector is a characteristic vector
Use that to show T is a multiple of the identity operator
is it not saying that the second statement is equivalent to the third?
Can anyone help me with whether my answer/work for this question is right?
No?
then why the "hence..."
(From a past final)
Would you just do [5b1 + 3b2]_C so you would then break it up into
5[b1]_C + 3[b2]_C which is just 5[-1 4] + 3[5 -3] = [10 11] ?

That works
Yes

👍
is there a methodical way to solve these with matrices?

Not really with matrices. This is more about knowledge of trig
$$ a + b\sin^{2}(x) = 2( 1 - 2\sin^{2}(x))$$
EmilD

$$a + (b+4)\sin^{2}(x) = 2$$
EmilD

b = -4 a =2 is that how you do that
what is the clean way to do it?
I kind of understand why a dot product in R^n is a projection operation
But if I think of the axis as arbitrary
Why does it end up as $|x| |y| cos(\theta)$
meow

And not sin?
Most algebra is non-linear I believe
But "linear algebra" isn't just ax+c. It has non-linear things too.
quadratic algebra
https://en.wikipedia.org/wiki/Quadratic_form
though these are usually studied in a linear algebra class, they come up in many places
Ah, interesting
kinda stuck on setting up a matrix for this

I can see that 6ln(x) and 8ln(x) are scalar multiples but not sure which to toss or how to set up a matrix
I know that I can* introduce other equations with the derivatives
In fact, I did see $x^\top A x$ already today, in the context of quadratic implicit curves.
𝓶𝓸𝓶𝓸𝓶𝓸

I didn't know where it came from exactly, so this is handy.
you can get rid of either of them
you know they can't both be in a basis since they're linearly dependent
so that cuts your basis down to either two or three
after getting rid of one of them are the remaining vectors linearly independent, or do you need to remove more?
so if I toss the first I have 5A+8Bln(x) + ln(6)Cx = 0
0 + 8B/x + ln(6)C = 0
how do I put that into a matrix?
quick question, similar matricies have the smae eigenvalue and eigenvectors right?
like do the eigen vectors hve to be exact same and the same amount of eigenvectors?
eigenvalues same, not same eigenvectors.
https://i.imgur.com/4TsNlBu.png
but these two have same eigen values but are not similar
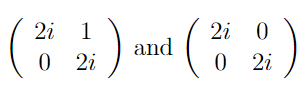
correct
ahh i see
but similar matrices share eigenvalues. but obviously not eigenvectors
i understand now ty
yeah, so similar matrices implies that they share eigenvalues but sharing eigenvalues does not imply similarity
no need to put it into a matrix. can you use this to show that A = B = C = 0, or do you need to do some further reduction of S?
how are you making the connection that A = B = C = 0?
that's what it would mean for {5, ln(x^8), ln(6^x)} to be linearly independent
are you asking how to show that?
is it clear?
I dont think so
if 5A + 8B ln(x) + C(ln 6)x = 0 for all x in (0, 1], and you want to show that A = B = C = 0, then try playing around with the equation a bit
maybe you can put in some points of (0, 1] for x
or use some calculus
5A + 8B ln(x) + C(ln 6)x = 0 is true for all x in (0, 1]
so you can plug in points
I know that plugging in points was possible
I just thought we had to show that for all points
so plugging in any one point wouldnt be allowed
if i let f, g, h, k be the functions on (0, 1] defined by
f(x) = 6 ln x,
g(x) = 5,
h(x) = ln(x^8),
k(x) = ln(6^x),
then S = {f, g, h, k}. you're looking at the subset {g, h, k} and want to show it's linearly independent. this means that if A, B, C are scalars with Ag + Bh + Ck = 0 (i.e. equal to the zero function no (0, 1]), then A = B = C = 0. and saying Ag + Bh + Ck = 0 is the same thing as saying that 5A + 8B ln x + ln(6)Cx = 0 for all x in (0, 1]
to be absolutely precise
so ok
the only thinking to do here is to see that there is one we can toss
sometimes with vectors there might have been a non obvious linear combination
but you're saying thats not the case here
function spaces it's a bit more obvious when things are linearly independent

check if C is invertible
doesnt work
wdym doesnt work
determine is 0
when u say compute (0,1,1)
what do you mean
a bit lost hehe
so then solve Cx=that vector
i think im misunderstanding the compute part (im from a french sector just switched to an english school
so solve Cx=[8,3,0]
which is turning it into an augmented matrix, then performing row reduction
i get it but how did u get the 8,3,0?
I did the multiplication of C and [0,1,1]
$\begin{bmatrix}1&5&3\0&2&1\3&-1&1\end{bmatrix}\begin{bmatrix}0\1\1\end{bmatrix}=\begin{bmatrix}0+5+3\0+2+1\0-1+1\end{bmatrix}$
Mosh

so then solve $Cx=\begin{bmatrix}8\3\0\end{bmatrix}\to\begin{bmatrix}1&5&3&8\0&2&1&3\3&-1&1&0\end{bmatrix}$
Mosh

any1 knows the forumala to solve linear equation word problems?
yep
tell
wasnt directed at you... however you just read the problem and form an equation/system and solve from there.
lol 45 problems
what answer u got for that problem i sent you or you havent done it?
because I am looking at the answer sheet not sure why its like that
,w RREF{{1,5,3,8},{0,2,1,3},{3,-1,1,0}}

got the same answer
yeah, so you have x_3 free
x_3 is free, agree?
so x_1=1/2 - x_3/2 and x_2 = 3/2 - x_3/2
so x=[x1,x2,x3]=[0.5-0.5x_3,1.5-0.5x_3,x_3]=[0.5,1.5,0]+[-0.5,-0,5,1]x_3
i see
so the subspace is 0.5[1,3,0]+[-1,-1,2]t, t in R
the answer in the book likely made x_1 the free variable

looks pretty linear to me
@worldly bear see pins
was just joking around lol
was not clear you were joking
just calculate A and B first
Or
A = M L M^-1, B = N L N^-1
=> L = M^-1 A M = N^-1 B N
=> A = M N^-1 B N M^-1
=> P = M N^-1
hello! so i was given this root / zero, and I was asked to write it in a polynomial equation and i'm not sure how to do it
If a is a root of a polynomial, then x-a is a factor of the polynomial
Here you are given two roots, so that gives you two factors
okay 😄
what's after this?
i don't think my teacher got to discuss to us about imaginary roots so I'm a bit confused with this one 
it works exactly the same way as with real ones
wait so, I just ignore the imaginary roots and just solve it like a normal polynomial equation given the roots?
you don't "ignore the imaginary roots"
i don't think you were asked to solve any equation, you were asked to find a polynomial that satisfies an equation
the instruction says to convert the given roots to an equation. it basically like finding the roots but backwards, instead of finding the roots of the equation, you find the equation of the given roots! 
sure, so take the roots and use them to build factors of a poly
I got the answer now. thank you from the 3 of you! 
can someone help pls?

Hey guys ! this was my first ever Notebook please go through the notebook and give me your responses. Thank you ! https://www.kaggle.com/supreeth888/linear-algebra-for-machine-learning-1

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
maybe #math-pedagogy is a better fit for this?
it's not wrong here, but you could get more feedback if you also ask there
I don't have permission to send message there...
read #get-advanced-access
Thanks mate !!
Hi! I want to know if (P(e),∩) is a group, P(e) set of sets of e. I found P(e) as identity element ,[∀A,∈(⊂?)P(e) A∩P(e)=A] but does an inverse element exists or is this not a group?
Hello so for this question Let A∈M6×6(F) with A ^ 3−2I6 =0. Calculate detA.
Can someone tell me how to approach it
Kanga Gang Annihilator Ann

@torpid socket
@torpid socket pls dont multipost
Sorry
Yes!
May I ask how do you do that
$A$
this is a mathematical markup language called LaTeX
Oh
...
so it doesn't say?
i mean ok, i guess we should assume F is a field that contains whatever numbers we need it to contain
okay so can you tell us what you know about determinants?
Mhm!
some properties of the det function perhaps
no, i'm not asking you to write out the definition of the determinant.
i'm asking you to write out some properties of the determinant. or determinant laws, or whatever else you want to call them
Oh just trying to understand your question I apologize
for example, how could one rewrite det(AB)?
yes these laws
Oh yeah I know them!
okay
so consider those laws and A^3 = 2I_6
maybe it might be good to know what det(2I_6) is
Is it not 2?
no
Oh
Oh yeah I will check
Wait why not check 2I_6?
I know how to solve it thank you so much! @dusky epoch
Im sorry if my questions were stupid still trying to figure my way with determinat 😅
have you asked this question before? I feel like I have seen this one before
I asked it in another channel
Never before today tho
Hi I have a question
Let's say given this span of vectors

with A being the matrix of those 5 vectors treat W as colA
however the rank of this matrix is 3
so to find a basis for W perp would i just take the columns with a pivot and transpose it (lets say matrix B) so that Bx = 0?
would that be the basis for W perp?
why the transpose?
ah i see why the transpose lol
yes
i was mixing it up with the null space. you can do it as you say
What are some applications of Diagionalization?
I do understand the process of getting D from P^-1 A P
You can find powers of matrices since, if A = PDP^{-1}, then A^k = PD^k P^{-1} where D^k is the matrix where the diagonal entries are raised to the power of k

Does what I did here make sense?

Hm
I’m just confused because
Would i transpose all 5 vector columns
Or would i just take the 3 columns with pivots and transpose that
Thats my concern
I am wondering why c = [-1,-1,-2]. I thought x would be positive. Can anyone explain? TIA

You don’t really have to do much if you can see it has a negative z. There only one vector in the picture that satisfies it.
@halcyon spindle I know. But, why x is -1
Tho it does look wrong
?
Yeah that what I just noticed
The graph is wrong?
Oh, I struggled with this question, and it turns out that the graph is wrong omg
so, which part is wrong?
You can’t be sure ask your teacher. My guess is it option d.
I think it just looks weird in a 2d representation, not sure how you could clearly show the -x component from that angle
Wait his right.
So, why x is negative then
It’s negative in the graph, you just can’t really tell because of the angle it’s shown at
That’s what it seems like to me anyways
So, the graph is wrong?
No the graph is right, but unclear
The graph right.
I see. What if the question asks me the coordinates of c instead
or the sign of x, y, z
I would hope they wouldn’t from that angle. You could bring it up with your teacher ig
Gotcha. Thank you guys so much!
hi all. i am trying to prove something like the following: "let V be a vector space of matrices equipped with some norm, |.|. then there exists a C such that, for any A in V, A_{i, j}/|A| < C". is this a dumb idea?
no, it's not dumb.
as long as V is finite dimensional, all norms on it are equivalent.
so you can lower bound by the L^infinity norm, that just takes the max absolute value entry of your matrix
@wraith wren that is more or less what i am trying to prove (all norms are equivalent for matrix norms)
why are random people pinging me?
i think they're trying to ping other kanga gang people and not recognizing there's many lol
i have seen a proof for vector norms, but it relied on the particular properties of the 2 norm for vectors. oh yeah sorry my bad
also, where's the question?

|.| is not necessarily induced by a vector norm
you can map a matrix to n² dim VS

{kind=link}
by vector norm i mean that any vector space of (finite dim, nxn) matrices is isomorphic to a vector space consisting of column vectors with n^2 entries
like finding an isomorphism to Rn² and use eqv norms
not like operator norm induced by a vector norm
ok, just wanted to call that out
very complicated way to define a norm but a norm nevertheless