#linear-algebra
2 messages · Page 193 of 1
then multiply those dot products by the corresponding parameterisation vectors and sum the two together?
i feel like there's an easier way
eh, that'll probs do
id prefer an easier way cause ill have to do quite a lot of calculations like this
programming a thing that is supposed to run those kind of calculations many times per second
hmmmm
i added planeNormal*dot(planeNormal,-vector) to vector
i think
something like that
how does one do this?

look up a diagonalization procedure
hi i am confused about a definition
Null space means set of vectors x such that Ax = 0. What does spanning set of null space of A mean?
So span means set of all linear combination of set of vectors
is that set called the spanning set?
"spanning set of null A" would be a set S, called the spanning set, such that null A = span(S), the set of all linear combinations of elements of S
sorry i dont understand what Null(a) = span(s) is saying....
it's saying that null A is the set of all linear combinations of elements of S
Is there any fast way to know if a matrix has an inverse?
I know that if it has a lower line of 0 it isnt
or that if it isnt square
A matrix is invertible iff the determinant isn't 0 @calm yoke
So, the sum of its diagonal?
No
Do you know what a determinant is
If you don't then there are other ways to tell if it's invertible
Wait, it came back to me, you multiply each term of both diagonal separately and subtract them
i think we can also check if it has inverse if we can convert matrix A to identity matrix I right?
Yes @drowsy flower
yeah i find that way easier

just row operations
To find the inverse you need to do a lot more than to find the determinant tho
for 2x2 and 3x3 matrix, finding determinant is not hard, but when it gets larger and larger, it gets hard
Yeah, but row operations are exponentially harder
and to carry an error is really easy
is there a way i can dumb this down to find the eigenvalues easily?

That definition only works for 2x2 matrices
But yea what I said still holds
If det(A) =/= 0, A is invertible
Yeah, my bad
i was speaking that proof that each vector space has basis requires choice 
because if you look at convo anticipation then mentioned this theorem
IMO it's easier to first define invertibility on simpler ideas, because in most intro texts the determinant comes later
Let U be a subspace of V, and define the affine subsets v+U and w+U. Having trouble showing that v+U=w+U implies that the vector v-w is in U
Is v an element of v+U
v and w are both vectors in V
(That was a Leading question)
Ah, yea it is
Oh lol does it mean v=w so v-w=0 which is in U?
No
It means v=w+u for some u in U
Because elements of w+U are of that form
and v is an element of w+U
Suppose $A, B$ and $C$ are matrices of size $l\times m, m\times n$ and $n\times p$, respectively. Is the number of times you need to multiply while computing $AB$ equal to $lmn$? I think so because $m$ entries in $l$ rows of $A$ are multiplied to $n$ columns of $B$. Consequently, the number of times one multiplies to compute $ABC$ is $lmn+lnp$. Is this is the least possible value?
Buncho Bombs

are we doing it naïvely?
Oh, it's the answer I came up with
It asks to compute
I guessed that since AB is an l\times n matrix, multiplying with C should be lnp extra steps?
hm let me see
The value changes if I start with BC, then A? 
$(ABC){ij} = \sum{k=1}^m \sum_{r=1}^n a_{ik} b_{kr} c_{rj}$
Ann

which seems to require... 2lmnp operations?

It's alright, I'll give it some more thought!
Would try to wrap my head around this notation lmao
Shouldn't it be mnlp?
i think if you do (AB)C it is lmn + lnp
for A(BC), BC you get mnp and then it's lxm by mxp so lmp, ie. overall lmp + mnp
i think it's just that multiplying out like that isn't perfectly efficient, like you could do it all in one go
and it would be a more symmetrical thing?
I think so too
Let (BC)=D.
$(AD){ij}=\sum{k} a_{ik} d_{kj}$
Okayyyy
Buncho Drunk

And write d_{kj} in terms of entries of B and C to get above formulae
Hmmmm, okay I seem to understand this
Now to compute each entry, you need to do m(n) multiplications
Referring to this
but actually that's doing it maximally inefficiently
bc doing it piecewise, you can do them in two steps
adding in between
and that turns a whole cuboid of multiplications into just like two grids
clear as mud, okay so like
it's like instead of doing ad + ae + af + bd + be + bf + cd + ce + cf, 9 multiplications
you do (a+b+c)(d+e+f) and that's just 1 multiplication
Aahhhhhhh
so actually splitting it up makes it more efficient
but there's different ways to split it up, it's just fundamentally not symmetrical
very strange
Hmmm, so depending on which method optimises the number of steps required, we can go for (AB)C, A(BC) or (ABC)?
Hmmmmmmm
like, lmnp is degree 4, whereas the others are degree 3?
lmn + lnp for (AB)C, lmp + mnp for A(BC), hmmmm
$$\det(e^{\mathbf M t}) = e^{\text{Tr}(\mathbf M)t}$$
uli

this made my day, its pretty easy to show but it seemed so out of the blue when i first saw it
can someone walk me thru #28

This seems surprising to me. What's the proof for this?
I ommited some stuff for rigor but here's my reasoning
$$\det\left(e^{\mathbf Mt}\right) = \det\left(\mathbf Se^{\mathbf \Lambda t}\mathbf S^{-1}\right) = \det\left(e^{\mathbf \Lambda t}\right) = e^{\text{Tr}(\mathbf M)t}$$
the last step works because of this (I'm too bad at latex so heres an image)

uli

oh sorry and the second step works by factoring out of the infinite series (assuming it converges)
it kinda makes sense if you think of $\det e^{Mt}$ as how much volume gets scaled after running the differential equation described by $M$ for $t$ seconds, and $e^{\text{Tr}(M)t}$ is saying "volume grows at a rate of the sum of the eigenvalues for t time"
uli

it still isn't super clear to me why, but I think eigenvector alignment doesn't matter since the determinant is linear in each column
Nah, I get what you're putting down. Thanks for the info :)
it's obviously true for diagonal matrices, and diagonal matrices are dense, so by continuity of all the operations involved, it holds for all matrices
Do u mean diagonalizable
"diagonal matrices are dense" and other fun facts with the math discord
i guess im a diagonal matrix then 
I find myself confused where I use regular multiplication and dot multiplication in my writing. Is there a common approach to denote that an operation, in my case multiplication , belongs to a particular algebraic structure? Something like $\cdot_{(\mathbb{F})}$
JohnDark

yeah that notation is used sometimes
Thank you

what is your question? @vestal abyss
Are you aware of cofactor expansions and how it can apply to any row or column?
Hint: take the determinant with respect to the first column
Yep! And since it doesn't matter what column or row you take the determinant from, the follow up question should be pretty straightforward :)
anyoen can help

I dont recall how i integrated rational functions except partial fraction or trig subs
so for R(t), C(t) and Q(t) im trying to find a basis
and i dont see how integration relates
Union of {t^n for natural numbers n } and {t^n/p(t)^m where n is a natural number smaller than the degree of p, p is irreducible over k, m is a positive integer.}
i see thx
do you see relation w/ integration?
or i guess its just asking us to think of writing polynomial in quotient remainder form
Probably. When we calculate the integral of an rational function we also factorize the given rational function into that form
thanks

is the first part of this just literally applying the universal property of exterior products?
cuz that map is multi linear and skew symmetric cuz of dot and cross product properties right
so can i just say by UP theres a multi linear map such that f(v wedge w wedge z)=f(v,w,z) and thus its an element of the dual space
<@&286206848099549185>
anyone?
@next vapor what does wedge mean
ive been trying to wrap my head around tensor product spaces for a while
anyone got any good resources?
i believe it is some universal property stuff
does what i wrote above make sense?
let me remind myself of the precise statement of the UP for exterior algebra
sounds about right tho
But is showing that f maps on field F=R enough here to show its dual space
What more is to be done
Does both external and internal composition shows that it belongs to dual space
what you've written sounds fine, just replace "skew-symmetric" by "alternating" (more of a linguistic nitpick than a mathematical one)
and then it descends to a linear map \wedge^3 R^3 -> R, i.e., an element of the dual of \wedge^3 R^3
for the second part you should use the fact that \wedge^3 R^3 has dimension 1
tikz was being obtuse so i had to ms paint it

so it's not really f that's in the dual space, but it's the induced map on the exterior power that is
this seems more appropriate for #groups-rings-fields
My bad I’ll unsend
Hi, I'm currently doing linear algebra and I'm going through vector spaces. I understand most of it, but I just don't get why it matter if the set is closed under addition and scalar multiplication. If someone could help with this, I'd really appreciate it. Thank you
you want it to be possible to add/multiply things within your system
if its not closed under one of those, you can add/multiply things and end up "outside of" your system
which is bad
for example, if you try and divide two integers, your result will often be something that is not an integer
in which case youre no longer studying "the integers"
youre studying "the rationals"
of course theres connections, but theyre different systems
Ooh so like a dumb example (this is not the case but if it were) if I add 2 3rd degree polynomials and I get a 4thdegrrr
sure, the point is that we want our operations to "make sense" within the parameters we set up
Oooh alrighty thank you sir!!!

the size of a basis, yes.
how do I determine if W is a subspace of R2? My textbook answer is W is not a subspace but I keep getting that it is.
x = x_1
x_2
W = {x: x_1 = x_2 or x_1 = -x_2}
please @ me when answering, thanks! 🙂
draw a picture of W @amber sierra what does W look like?
would it be like
| /
| /
-------+-------
| \
| \
tbh i don't really understand what a subset is lol
Don't you mean subspace
subspace sorry*
Do you know what a vector space is
i have no clue 😅
Hmm
is it like a vector field?
Nope
I think you might want to recall some basic definitions such as vectors and vector spaces before you can do questions about (linear) subspaces effectively
alright ill look over my notes
my professor kind of skipped around topics so i forgot all the earlier stuff
"The transition matrix inverse P^-1 will always exist since the basis vectors comprising P are linearly independent."
i dont understand this reason
i believe if a matrix A is linearly independent, then det(A) =/= 0
i know the 2 independent statements are right. i just dont see why they would state that as the reason
the only time the inverse would not exist is when the det(A) = 0 because you cannot divide by 0
just a proof i guess?
idk, maybe it's easy to verify in the context
how would i exactly go about finding a basis though? i dont know where to start
i did p(0)=p(1), and got something like a0 = a0 +a1 + a2 + a3 but idk how that would help
oop nvm im dumb i get it now
why?
considering the zero vector in the set
yeah
Thanks!
Hi. Lin. Algs.
Please help with an interpretation of this problem.
Page 20 of Treil: LADW.

what is meant by $x_1 = 3x_2$ ?
is it the RED or BLUE line?

Desmos
ninnymonger

Also, second question:
what is meant by rotating the entire plane by an angle of negative gamma?
do i take the x-axis and rotate it up by gamma?
OR
do i take the x-axis and rotate it down by gamma?

it depends on how your system of coords is set up
but yes i would say x_1 = 3x_2 is blue line
rotate by gamma clockwise
we can first rotate the plane by the angle −γ, moving the line x_1 = 3x_2 to the x_1-axis,
i dont see how a clockwise rotation accomplishes this.
I CAN SEE a clockwise rotation if we rotate the BLUE line by negative gamma, then it will sit exactly on the x-axis.
JUST GOT OUT OF THE SHOWER AND I THINK I SEE IT NOW.
OKAY. So.....
it's like photoshop.
the bottom later is R^2, the plane. it's immovable. call this layer ZERO
sitting on top of that, is another plane, also R^2, but with the blue line embedded in it. call this layer 1.
if you rotate layer 1, by negative gamma, you will not rotate layer 0. so the end effect is that the blue line will sit on the x-axis after a clockwise rotation by gamma.
^shower thoughts.
I think that's right.
Yo for computing the jordan canonical form of a matrix and the associated canonical basis
Do people really use these dot diagram things?
They seems weird and convoluted
Or I guess rather does anyone have a good resource for Jordan Canonical Form?
Cause this Friedberg Insel Spence book is lacking
Especially in the section on how to actually computer the form

Google Docs
Page 497 for the part on how to compute (which also mentions the dot diagram things)
(please ping me)
no fuck
blue
x = 3y basically

what's your definition of orthogonal?
as a hint, the left inverse of a square matrix is the same as the right inverse
Express the vector 𝑎̅ = 24𝑖̅− 10𝑗̅− 13𝑘̅ in the form 𝑝̅ + 𝑞̅, where 𝑝̅ is parallel
with the vector 2𝑖̅− 2𝑗̅− 𝑘̅ and 𝑞̅ perpendicular to it
I solved this one, my question is that I used ap + bq and then used b = 1 in the end and it worked out.
My question is that, this should've been true for any b right? Like we can find infinitely many vectors p and q that satisfy these conditions right?
yeah, you can shrink or stretch p and q as much as you want, as long as a and b compensate for it
Thanks.
how do i even begin with part i

i is just definition of function composition. Follow the arrows
ye basically a definition question, just write sentences of how phi_v transfers a vector into a coordinate w.r.t basis B_v etc
Can the symmetry and identity element be the same?
elaborate
Like in algebraic groups exists an identity and symmetry elements
can those two be the same element/number?
or they need to be different from each other
What is a symmetry element?
an element p such that a * p = e (identity element)
So,inverse?
hmm maybe? I'm not sure since I dont know if the simmetry element needs to be unique or not
a symmetric element is specific to an element tho,while the identity is always the identity wrt any element
So,No clue how you can compare those 2
the only element in a group whose inverse is the identity is the identity
privyet tterra
Can someone explain how this works? The set {(x,y):x≥0,y≥0} is closed under addition, but not under scalar multiplication, since −1⋅(1,1)=(−1,−1), for example.
why we are able to multiply the tuple by (-1)
cause it's a scalar in our field
shouldnt we able to multiply it by something >=0
@quartz compass -1 is not in our field?
is it?
it is
we can give another argument for why this isn't a vector space if you don't like the scalar
i am having trouble understanding it 😦
the scalar value (-1) is not in this area x≥0,y≥0
ok let's back up, what is it exactly that you're trying to show, I'm assuming you're wanting to show this is a vector space is that correct?
i can understand that
it is closed under addition
becasue using this set you cannot produce anything out of this set
but multiplication is kinda confusing for me
part of being a vector space is that you have to be able to multiply by scalars in your field, and your field is probably R
R being the real numbers, which contains -1
you can think of this as specifying that your vectors lie only in the first quadrant

Merosity

subject to the condition that $x_1>0$ and $x_2>0$
Merosity

as a set, this is perfectly fine
A set is closed under addition if you can add any two numbers in the set and still have a number in the set as a result. This is the definition
but if you're trying to prove this is a vector space, then you need to realize you're trying to show that the elements of this set then can do everything in a vector space
we should use the numbers in this set and not be able to get out of this set
i am not 😦
what are you trying to prove here
sorry if i looked like
i know i am wrong, i just want to understand the reasoning
here is where i struggle
ah uhm
that it is closed under mult
isnt?
@quartz compass my problem is that we are able to multiply the tuple by (-1) which is <= 0 that is not defined in the question
W is your set of vectors
your set of scalars is ℝ
so you can multiply by -1 since its in your set of scalars
but this takes you outside of W
hence demonstrating that W is not closed under scalar multiplication
@quick oak that's what I said here haha
@quartz compass your explanation required me to emphasize on some points which i dumbfully overlooked, @limber sierra used italic font which got my attention you did you best man I was dumb cheers!
lol

can someone break this down for me, i havent done an induction proof in a bit

im not sure what the α_k are
I was looking over something and confused myself
I saw that C^3 (complex numbers) has a standard basis {x1, x2, x3}. What are these elements? Are they (1, 0, 0), (0, 1, 0), (0, 0, 1) ? If so how can one achieve every element of C^3 through a linear combination of x_i ? Since this is the definition of a basis. In my head it makes sense that C^3 has 6 elements in its basis, could someone clear the confusion for me please. thanks in advance
Your basis elements are correct! What's key to remember is that if it's three dimensional you're taking $\mathbb{C}^3$ as a vector space over $\mathbb{C}$, so your scalars are complex numbers, not real numbers
Nicholas

as a vector space over R yes, over C no
lol i woulda said 3 for R^3, 6 for C^3
I said over R, not R^3
you can take C^3 as a vector space over R or over C
over R, it is 6-dimensional, and the standard basis is over R is {(1, 0, 0), (i, 0, 0), (0, 1, 0), (0, i, 0), (0, 0, 1), (0, 0, i)}
oh uhhhh yes right
Since your scalars are real numbers
which is probably what you were thinking of!
but if you take C^3 as a vector space over C - that is, if your scalars are comlex numbers - then you only need 3 basis vectors
namely, {(1, 0, 0), (0, 1, 0), (0, 0, 1)}
@obsidian bluff does that make sense to you? it depends what your field of scalars is, and if you're saying C^3 is 3-dimensional, then your scalars must be complex numbers, in which case there are no problems

to get like to (1+i, 0, 0) you'd do (1+i) * (1, 0, 0)
to be clear


I mean right idea, however v_j isnt the span of v_j
it's a specific vector in the span of itself
also as written you're saying v's are scalars, then introduce a's that somehow end up disappearing

that's still just 1 specific vector in the span of v_j
you want to end up with (any scalar)v_j as a nudge
like what does he mean by those arrows, am i substituting in r^i ? ****

how about now?

if you have the eigenvalues for a matrix, how do you find the orthogonal matrix?\

i also found the eigen vectors
1 -1 1
-1 0 -1
1 -1 0
Again, you ended up with v_j
Span(v)=av for scalar a
just make the eigenvector matrix orthogonal with graham schmidt I think
remember why diagonalization works, if you have $Ax = \lambda x$ you can write the same thing with matrices $AX = X\Lambda$ then invert $A = X\Lambda X^{-1}$ notice this argument holds for however the eigenvectors are scaled. so we can normalize them if we want (they'll already be orthogonal if $A$ is symmetric)
uli

thanks
btw if the eigenvectors aren't orthogonal you've done something wrong, the eigenvectors for a symmetric matrix are always orthogonal
wow so basically i didn't have to do anything?
well you had to normalize the eigenvectors
otherwise $Q^TQ$ would be diagonal but not the identity, on the diagonal would be the length (squared) of each eigenvector
uli

yes it does, thank you so much. for some reason i was thinking that the coefficients in the linear combinations were Real. thanks again
So they can be - this is why it depends what vector space your field is over
If you're taking C^3 as a vector space over R, there are 6 basis elements, I listed them out somewhere above
yep makes sense
so if we take the standard basis over C then any (a+bi, c+di, e+fi) in C^3 could be achieved by (a+bi)*(1, 0, 0) + (c+di)*(0, 1, 0) + (d+fi)*(0, 0, 1)
my source assumes C^3 is over the field C

I got
A) always, B) Never, C) Always, D Always, E Always, F sometimes
can anyone check this?
do you know strang's four subspaces picture?

also i'm checking it now; my LA is rusty q-q
that last one meant e + fi, but yes, exactly!
ah yes my bad haha
B seems susp, can you explain why it can never happen? i'd think it would be sometimes
E is a consequence of C,D
wait really am i just dumb lmao
I thought the basis for C(A) came from the rows since Ax = 0 implies the dot product between x and each row is zero
so x must be orthogonal to the rowspace
@waxen flume
that's different @waxen flume
he isn't taking the non pivot columns
he's solving Ax = 0 then taking all combinations of the solutions
the columns can't be in the nullspace since they're in R^2 when the nullspace vectors must be in R^4
oh i didnt even realize lol
its actually sometimes or never?
im confused if ur agreeing with me
xD
yeah, I think its sometimes but i'm too lazy to come up with an example
its definately not always though
what did you mention about E earlier?
i said you're right
its just a consequence of C and D being true
number of pivots + number of non pivots = number of columns
🙂 yay
the one I had wrong was the sometimes one
any others you felt sus about
@gritty swift
the rest seem right to me :3
if you really care about getting it right you could come up with examples for all the "sometimes" ones, might be good practice too
like examples for B, a full rank matrix A would have the basis for N(A) be {0} which matches the non pivot columns (all cols are pivots)
but a counterexample would be the link you sent where it isn't even the right dimension
If 0 is an eigenvalue for A

I have to come up w/ which are definitely true
The only one I know is definitely true is the first one
I forgot about linear transformations 😅
well if A has dependent columns the nullspace must be greater then {0}
since you can combine the two dependent guys to get a zero vector
or really the eigenvector with eigenvalue 0 will be in the nullspace
so 2 is true
3 is false, when you have a vector in the nullspace $T(\mathbf v + c \mathbf n) = T(\mathbf v) + cT(\mathbf n) = T(\mathbf v)$ if n is in the nullspace
uli

so it isn't 1 to 1
and for 4 i forgot what onto functions are for the 19054391059401590th time 1 sec
the properties i used were just linearity btw, a transformation being linear must obey those laws
in my linear algebra class, linear transformations are the only thing i cant understand so far. I can do complicated calculations for co-factor expansions, eigenvalues, etc but that topic was the one i least understood lol. And I looked at lots of youtube videos on it
did you see the 3blue1brown videos?
the first few videos https://www.3blue1brown.com/essence-of-linear-algebra-page/ cover linear transformations geometrically
3Blue1Brown
Essence of linear algebra. Vectors, span, linear dependence, linear transformations, determinants, column space, change of basis, eigenvectors and eigenvalues, etc.
Does anyone know how to convert from Cartesian coordinates to conical ones? I've only found one that goes from Spherical to conical which I'd rather not.
what dont you understand about transformations exactly?
im not sure who he is, but ive been watching this person since they go hand in hand with my lectures

did you find anything about the last one @gritty swift onto
oh sorry i forgot
i just know that onto functions have pivots in every row
i don't know if they're considering the output space R^n (of the matrix) or the domain of the transformation
so
do we know if A is square?
well
if 0 is an eigenvalue
and eigenvalues only come out of square matrices
i would assume lol?
wait nvm i'm retarded
yeah
so yeah it can't be onto since with n - 1 independent vectors you cant span R^n
and onto means you must span R^n i think
since onto is defined as forall y in the codomain there exists x such that f(x) = y (in other words, it spans the space)
and i'm assuming for linear transformations the codomain is R^n for a n by n matrix
i got this book from my library on linear algebra because its all i could find lol but its like from 1990 xD
ill see if it has anything on linear transformations
thanks for the nice explanations @gritty swift


Even some kid wrote a question mark next to linear transformations when they used this book🤣
Does anyone know how to convert from Cartesian coordinates to conical ones? I've only found one that goes from Spherical to conical which I'd rather not.
The engineers told me this class was easy 😦
aren't the equations on the wiki page? @normal gulch
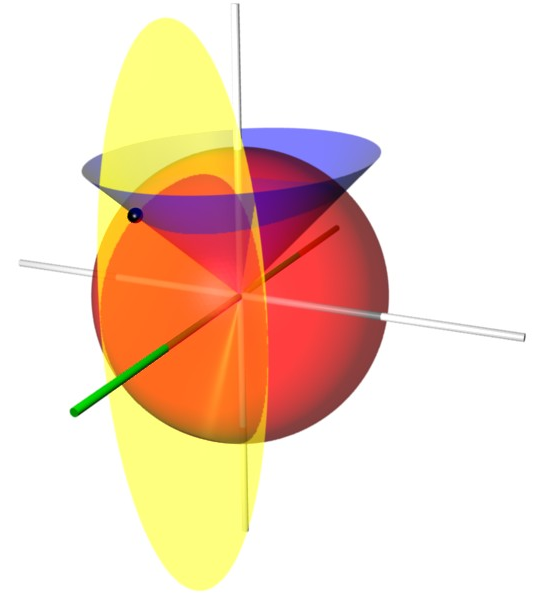
Conical coordinates are a three-dimensional orthogonal coordinate system consisting of
concentric spheres (described by their radius r) and by two families of perpendicular cones, aligned along the z- and x-axes, respectively.
I have to somehow solve for r, μ, and ν in that first proposed "definition" which I have no idea how to do and then figure out the inverse it seems.
Scrolling down theres an equation for spherical to conical which was the one i was referring to before, but still I cant seem to find a reliable formula that converts from Cartesian to conical and then the inverse
Attempting to use that first one just results in a mess:

Or am I maybe just translating it wrong?
Just for clarification I am using r,g and b as x,y, and z.
Hi, I'm having trouble getting my head fully around Jordan stuff

this is my definition of a jordan basis for a matrix A
my notes tell me that the matrix of T (the linear map given by A) is this direct sum of jordan blocks. I can't quite understand it and don't see how "It's clear". Perhaps it's quite a simple explanation so it'd be great if someone could enlighten me. thanks in advance

well just compute T on each jordan chain
Buncho Wolves

@obsidian bluff
oh hold on i might have fudged that
ok well i can't delete it now so
you just have to write out what the jordan chain looks like and carefully compute the action of T on each of its elements
Yo can someone help me through a long problem

L_A = left multiplication by A
I need help with 2a
so I got my characteristic polynomial is (t-2)^2
so our eigenvalue is 2 with a multiplicity of 2
I know that the generalized eigenspace K_2 is the nullspace of (A- 2I)^2
and since (A- 2I)^2 = the zero matrix
the column vectors (1,0) and (0,1) are the basis of the nullspace of (A- 2I)^2
and hence are a basis for the generalized eigenspace K_2
so I want to find a vector in that nullspace such that (A- 2I)^2 * v = 0 but (A- 2I) * v =/= 0
(1, 0) works cause (A - 2I) * (1,0) = (-1, -1) =/= 0
so then the cycle is {(-1, -1), (1, 0)}
so that cycle is our canonical basis?
(BTW pretend these are column vectors as nessessary I really don't wanna mess with LaTeX rn)
So then I have that cycle
how do I find the Jordan Canonical Form of A?
plz help I am trying to follow the textbook and other resources and it is absolutely not helping
Google Docs
I'm trying to follow what Example 2 on page 492 is doing
[T]_beta is the T relative to the basis beta
if there are other notation questions (and if you can help me) plz ping
You know,you could just screenshot that page
I didn't wanna spam any more lol it was already getting kinda long
and like the example references some theorems and stuff in case anyone needed those
but ya I have no fucking idea what I'm doing 😭
<@&286206848099549185>
can anyone help with this?

use the discriminant of a quadratic
That's just the primary decomposition theorem. So first you divide the vector space into generalised eigenspaces
Now,null(T-aI) is spanned by cycles of {u_1,u_2...}
If the dimension of cycle of a vector is 1,it is an eigenvector
but here the cycle is length 2 isn't it?
You could have had 2 cycles of length 1 or 1 cycle of length 2
Oh yea true
But,the former would imply the dim of null(T-2I) is 2
yea
But that's not true by explicit computation, ig
wait what
oh yea
yea so we need a cycle of length 2
so I found a basis for N((T-2I)^2)
but (T-2I)^2 = the zero matrix
so a basis would be ({1, 0), (0, 1)}
the standard basis of R^2
right?
or is that wrong?
How did you get that basis?
because (T-2I)^2 = the zero matrix
so N((T-2I)^2) = all vectors
cause any vector * the zero matrix is a zero vector
Well,The basis wouldn't exactly be {(1,0),(0,1)}
why not?
What does (1,0) mean here?
the column vector
We are dealing with elements in R^3

Is the matrix diagonalizable?
no
So,you have one cycle)
You want the matrix to be in a "triangular form"
yes but that doesn't matter in terms of choice of basis I thought?
It's the same reason as to why diagonalizable matrices are preferred over similar non diagonalizable forms
More convenient for computations
yes but I thought that we could pick any basis that works for finding the basis for the generalized eigenspace
the basis for the generalized eigenspace for eigenvalue 2 is the basis for N((T-2I)^2) which could be {(1,0),(0,1)} because N((T-2I)^2) = 0 matrix
Yes, that's a basis of generalised eigenspace
that's my logic
The matrix is just not nice in that basis
You want a basis such that the matrix is nice
but it should still be able to be used to find the canonical basis I thought??
because we still have (T-2I) * (1, 0) = (-1, -1) =/= 0
which means we have a cycle?
Yea,so your canonical basis should be {(1,0),(T-2I)(1,0)}
oh wait in that order?
Your matrix in that basis will be
$\begin{bmatrix}
2 & 1\
0 & 2
\end{bmatrix}$
Buncho Drunk

Write T as (T-2I)+2I
and I thought it would be {(T-2I)(1,0),(1,0)}
and (T-2I)(1,0) = (-1, 1) so we have {(-1, -1), (1,0)}
Find matrix of (T-2I) in that basis, which will be Your matrix in that basis will be
$\begin{bmatrix}
0 & 1\
0 & 0
\end{bmatrix}$
Buncho Drunk

what?
Nvm,it should be {(T-2I)(1,0),(1,0)}
2I in that basis is still
$\begin{bmatrix}
2 & 0\
0 & 2
\end{bmatrix}$
Buncho Drunk

just a quick question i.e. 2 questions
-
If i want to find a column space of a matrix, can i look at the REF form of the matrix, see which columns are independent, and write the columns from the original matrix with those indexes as the basis for the column space?
-
do i have to find the REF form of the matrix transpose in order to find the basis for N(A^T)?
Yea,It gets a lot more complicated with matrices on R^4 and above
But, yea that's your next section
yea
I've technically read over that section
however
I also understand none of that
but I think imma dig more into this first section
and do more questions from here and then try to reread that second section

x only shows up in one equation, and on both sides
once you have found that z and y are 0, the equation with x reads x=x, which is true for any x
@velvet basin
alright thx
we have a det of a diagonal matrix with its non zero elements as |A|
how is this det equal to
|A|³ × det of I with order 3x3
<@&286206848099549185>
Hello guys.
Could some help me to understand "the set of linearly independent vectors" in " The basis of a vector space is a set of linearly independent vectors that span the full space".
From
Rule 3
Stick to one channel and don't post the same question in multiple channels. Please don't ask for help in other channels if no one is responding in the one you have posted your question in.
people are helping out of their own volition, chill out
i mean this aint the same question but whatever
ye
but det I = 1
🤔
and det of diagonal matrix does not equal itself cubed in general
?
,w det {{1,0,0}, {0,2,0}, {0,0,3}}

🤔
the det of a diag matrix is the product of the elements on the diagonal
or you mean that this diagonal matrix has some nonzero A on diagonal?
like {a,0,0},{0,a,0},{0,0,a}
well then det of this is a^3 trivially
(adj A) A = |A|I = the diagonal matrix i previously defined
what do you mean trivially?
the char polynomial is (a-lambda)^3, so all the eigenvalues are a, and the determinant is the product of the eigenvalues
in general, the eigvals of a diagonal mat are the elements on the diagonal
Isomorphic is always one-to-one but one-to-one is not always isomorphic. Is that correct?
you meant the at most on solution part
Hi, just read this
this is one-to-one but not onto

yes, information is lost
when you define each w_i , you use the linear map T, as a matrix? in what basis is this matrix
also you have only one jordan chain it seems, im also trying to understand how this is applied in a jordan basis (multiple chains)
You start a new chain with another w_0
every element is of the det is multiplied with |A|
Hello, would someone know if we have results relating the determinant of an invertible matrix P to the action of P over M_2(K) by conjugation?
Of course the relevant information here is the class of det(P) in K*/K*², but I'm wondering it we're able to say get information on this class from looking at conjugation by P.
Hey guys, I have a question. i know that for any n by n real-valued matrix A it holds that det(A•A^t) >=0. But im wondering if this holds any n by n complex-valued matrix A?
you might have to replace transpose by conjugate transpose
there's a similar result for complex matrices but it's different
$\det(A \overline{A}^T)$ is real and nonnegative for any $A \in \bC^{n \times n}$ if my memory serves me right
Ann

yup
Ninja Tuna

it's like
brb looking up how to latex
well what does A do to (1, 0) and (0, 1)?
$AI = \begin{pmatrix} 4&3 \ -2&11 \end{pmatrix}$ \begin{pmatrix} 1&0 \ 0&1 \end{pmatrix} = \begin{pmatrix} 4&3 \ -2&11 \end{pmatrix}$
Kaisheng21
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

like, A sends (1, 0) to (4, -2) and (0, 1) to (3, 11), right?
they got help in 3
yeah... sorry for asking it on 2 different channels. Won't do it again.
I think I got this problem figured out, just want to check if sol is ok. Let $\text{dim}(V) = n$ and let $B = {\alpha_1, \cdots \alpha_n}$ the basis such that $[T]B$ is diagonal, and let $\lambda{k_1},\cdots \lambda_{k_m}$ be distinct eigenvalues of $[T]B$. Then for any $\alpha \in V$ we may write $\alpha = \lambda{k_1}(\alpha_1+\cdots+\alpha_{r_1} )+ \cdots+\lambda_{k_m}(\alpha_{r_{m-1}+1}+\cdots+\alpha_n)$. Where each summand live in $E_{\lambda_{k_i}}(T)$. Then all i need to say is that $\alpha = 0$ enforces each $\lambda_{k_m} = 0$ which will conclude the proof right? Since that is sufficient to show that 0 is uniquely represented by the 0's in the eigenspaces.

Anticipation
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

Quick question on linear independence of polynomials. They should be able to reduce to the identity matrix of the matrix if they are linearly independent right?
Hey can someone tell me what I'm doing wrong?
this is a bit clunkily phrased, but if you mean "put the coefficients into a matrix and row reduce"
not necessarily
what if that matrix isnt square?
if you have 0 rows, though, that means you have linear dependence yes
I'm trying to do an PAQ = LU decomposition using full pivoting but the values are off


I have absolutely zero idea where im making a mistake
That depends on the matrix being square
it is a square matrix in the 3x3 field. the question is actually in #help-1 i think i did it correclty but am not 100% sure
Checking
okay got it
the thing i found online was just incorrect
gotta love when the reason you didnt solve the problem is that
someone can check this arg above?

isomorphic means bijection means dimension is same, and use column rank = row rank = rank and row space of A = row space of rref(A)
i think its true
to be isomorphic they need the same dimensions, and obvious inverse, the ker and the image etc. So if they are isomorphic i would say that its true aswell
For ii) I think i found explicit inverse to be

1-T+T^2-...+(-T)^(N-1)
im wondering if theres a way to show its invertible without doing this?
if V is finite-dimensional, then det(T + I) is the characteristic polynomial of T evaluated at (-1), which by part (i) is (-1)^(dim V)
(up to a sign)
as for the infinite-dimensional case idk
how is it (-1)^(dim V) by part 1?
oh
ok
the only root of the characteristic polynomial is 0
tbh explicitly having the inverse is like the best possible outcome, seems funny that you'd want to spend more time showing it exists with the goal of not having it
thx
i just want to know more abstract method to do it, I feel my linear lagebra is bad
the more abstract method to doing it is just doing it lol

can someone explain how T(1) = 1 - t + t^2, T(t) = -1 + t + 2t^2, etc.?
i’m confused how those values are obtained
ah wait i think i get it now
so for example, for T(t), im evaluating what happens to the coefficient of t for the polynomial p(-1), -p(-1), and p(2) right? if anyone can confirm that
That's an axiom
R^(nxn) is the set of functions from AxA to R where A={1,2,3...n}
R^(n^2) is the set of functions from {1,2,3...n^2} to R
Both can be thought of as the same thing
$\bR^{n^2}$ consists of column vectors of size $n^2$
Ann

i would not say it's "the same" as R^(n×n)
they're isomorphic sure but isomorphic doesnt mean "the same"
these spaces have the same dimension.
send halp in #help-7|zen1thxyz
in context of sets, it means there is a bijection between the sets
rando QQ, does this formula have a specific name?

Don't think so

i can't tell if this is true or not
i dont know what it means that ColA and ColB are isomorphic
we say two vector spaces are isomorphic if there exists a bijective linear map between them
it is a theorem that V and W are isomorphic if and only if dim(V) = dim(W)
@dusky epoch so the column space of A and B have the same dimensions
therefore A and B have the same number of pivots
yes
@dusky epoch if two matrices are similar do they have the same rank?
Definitely
( direct computation of the determination of matrices made of elements from s rows and s columns of (PAP^-1. )
would the Basis for a subspace consisting of a vector of 1 form (a,2a,5a) just be itself?
like if the subspace is just all vectors of form (a,2a,5a) the basis would just always be (1,2,5) right?
or so fourth
or am I dumb
{(1, 2, 5)} is a possible basis yes
assuming your vector space is F^n for F a field [i.e. scalars can take the values of a]
there's no such thing as a space which has one and only one possible basis.
so one never speaks of "the" basis for a space
(zero space)
okay yes that is the one exception
i guess also F_2 as a vectorspace over itself
but airick is probably working with real vector spaces
(or complex, idk)
for your example, you can have {(-1, -2, -5)} as another possible basis
idrk new to basis so the the simpler one
not sure I understand them right
it's just a set of vectors that you can come to any point/vector in a subspace right?
through linear combinations, yes
a basis is like a set of building blocks
thats the key thing to think about here
"can i make any vector of the form (a, 2a, 5a) through linear combinations of {(1, 2, 5)}?"
in this case, yes
like a basis for (2,3,2) could be (1,1,1) and (1,2,1) right?
just multiply it by a
"a basis for (2,3,2)"?
ok a vector space consisting of vectors of that form
but we can write (2, 3, 2) as a linear combination of (1, 1, 1) and (1, 2, 1)
(1, 1, 1) + (1, 2, 1) = (2, 3, 2)
"that form"?
of form 2a,3a,2a
okay, then yes
a(1, 1, 1) + a(1, 2, 1) = (2a, 3a, 2a)
so we can write any vector of the form (2a, 3a, 2a) as a linear combination of {(1, 1, 1), (1, 2, 1)}
but this does NOT make it a basis
since (1, 1, 1) and (1, 2, 1) are not "of the form (2a, 3a, 2a)"
yes, which is why we moved past it
it wasnt clear at first whether they were working in that context
but evidently they werent
anyway, the point is that we cannot take {(1, 1, 1), (1, 2, 1)} as a basis for the space of vectors of the form (2a, 3a, 2a)
since (1, 1, 1) and (1, 2, 1) are NOT of that form
and hence NOT in that space
so they cant be a basis for it!
a possible basis for that space would be {(2, 3, 2)}
so the only possible basis's would be something that is a multiple of the form essentially? like 4,6,4?
4,6,4*
yep.
[indeed, this space is one-dimensional, which implies that any nonzero vector in it will form a basis; but you'll probably cover that fact later]

what would you do for a basis of vectors of the form (a,b,a-b)
that seems a little tricky
send halp in #help-7|zen1thxyz
would a basis for this form of vectors in a subspace be (1,0,1),(0,1,-1)?
is this "If elements of a row (or column) are multiplied with cofactors of any
other row (or column)" another way of saying that we've got two equal rows/columns?
need some help on part b

what have you tried

How do you get the mean for a 3d matrix? I know how to get the mean for 1d, i.e. [3,4,5] = 4, but how do you get it for matrices with more dimensions i.e. 2d or 3d or more?
I want to get the mean so that it can be used for stuff like getting sum of squares, standard deviation, the Z score standardization etc etc, which is then used to calculate distance between matrices, specifically image similarity.
@strange delta can you define the span for me
not sure what you mean by that
isn't it just a_1 * v_1 + ... +a_n * v_n
Yeah
so the span of v_1, ..., v_n is the set of vectors of the form a_1 * v_1 + ... + a_n * v_n for scalars a_1, ... , a_n in K
So to show the subset, you're trying to show that all vectors in the first span are also in the second span
I mean, you don't talk about the second span at all
why are you setting something equal to zero

{kind=link}
{kind=link}
I'm saying that its not right
again, how are you showing that something in the first span is also in the second?
i thought by showing it was a linear combination
it would somehow work
seems like it's not working
For one, it doesn't make any sense to set c_1v_1 + ... + c_n v_n = 0, you can't assume that the v's are linearly dependent
and even if they were linearly dependent, not all vectors in the span would be zero
to show that its in the second span
you need to show its a linear combination of alpha v_1, ... , alpha v_n
how do you get a 3d point? For example a matrix of shape (2,4,3) is shown like
[ [ [3,4,5],[1,2,3],[2,3,4],[1,3,5] ] , [ [3,3,5],[1,1,3],[2,4,4],[1,1,5] ] ]
in python numpy. However those numbers are just the z values, so how do you find the x and y values in a matrix like this?
When I try to get them, python numpy returns y as a 2d vector, and x as a 3d plane, instead of a number, like how z is.
Which is weird coz we were taught in linear algebra that if you have x1, y1, z1 = (1,2,3), x2,y2,z2 = (4,5,6), that it would form matrix like this:
[1 2 3]
[4 5 6]
So you can see the x and y values here, along with the z values.
depends on how you're storing it, if you're storing them as row or column vectors
you don't have to make your vectors rows
oh, so it's not a must to write it that way?
like you could also write it
[1 4]
[2 5]
[3 6]
like that?
the order itself really doesn't matter
just beware that numpy uses an "unwrapping" order that is perhaps not the most commonly used
as compared to matlab, for example
just remember what order you did stuff in
what is unwrapping order? yeh I'm confused by numpy style..coz like for example a 3d matrix like this
[ [ [3,4,5],[1,2,3],[2,3,4],[1,3,5] ] , [ [3,3,5],[1,1,3],[2,4,4],[1,1,5] ] ]
I can't find the x and y values..it only shows the z values..
if you print the whole matrix, it'll show you everything inside of it
the values are all in there
it's just a question of what order python decides to show them to you in
you would expect it to print stuff in the order rows, columns, 3rd dim, 4th dim, etc
but it doesn't
unless you print stuff out it Fortran order
the real question is only, what order did YOU put stuff into the matrix in?
Fortran order follows the nowadays popular scheme of

python starts with rows, and i don't remember if it goes backwards after that
you can find it in their documentation
ok so I printed it out as a matrix.
[[[3 4 5]
[1 2 3]
[2 3 4]
[1 3 5]]
[[3 3 5]
[1 1 3]
[2 4 4]
[1 1 5]]]
This is what I got. so which is the x and y?
And yeh coz like we learn that for example in feature analysis, if there are more columns in a table, there are more dimensions. Say 3 colomns with name, age, income, would have 3 dimensions. But the dimensions don't show as columns in numpy, I think.
i would suggest you make nested for loops then, and print it out in the order you want
since you're the one that knows what each entry in the array means
python prints it out however it likes
if you don't know what order stuff is saved into the array in, no one else can help you 😛
you can take a wild guess based on the structure and say that since you have an array of size 2,4,3, the first matrix shown up there is [0,:,:], the second is [1,:,:]
then the rows are the second index, and the columns of the matrices are the third index.
and since you're in 3d, then the last index is probably what corresponds to x,y,z. but that's just a guess since i don't know what the other indices of the array mean
ok so I printed out in the for loop, was like this
x: [[3, 4, 5], [1, 2, 3], [2, 3, 4], [1, 3, 5]]
y: [3, 4, 5]
z: 3
z: 4
z: 5
y:[1, 2, 3]
z:1
z:2
z:3
Yeh I'm actually working with images and feature maps, so am actually reading 3d matrices..just get confused in interpreting them..
height, width, rgb value
and what did you mean by x,y,z
well in linear algebra we were taught like how x = 1, y = 2, z = 3 etc, and how to find if they're linearly independent etc..
So they always give us a concrete x and y value there..but when printing it in numpy, it only shows the z values, but not the x and y, like when I print list[0][0][0], it will return 3. If I print list[0][0], it returns a 1 dimension [3, 4,5], but not a number like how we were given in linear algebra..
yes but what are you calling x y and z
so am kinda confused as to like you know if we want to find the mean along the x axis or y axist, how do we do that when there are no numbers
you have to pick what the values along the dimensions represent
because you don't have vectors here
you have a vector of vectors of vectors
so if you want to relate this in any way to some geometry, you have to assign them some meaning
there is no x,y,z here by default, you have to choose what you want to refer to in that manner
do you want to make a color space?
no I want to measure the distance between image matrices, say for example that are (24, 24, 512). And there are many ways to do that..and I wanna explore the ways to do that, but it involves stuff like finding the mean, the sd. covariance, etc, so I gotta better understand how a 3d matrix works.
Also I think I understand better now when you said I don't have vectors here, but a vector of vectors of vectors..I always thought these numpy arrays were just multiples of vectors.
So when finding the mean in a 3d matrix, is it we just find the mean along all 3 axis?
if you want
none of these things are defined in a unique way, so you really have to decide what you're doing before you go on
you just choose to treat something as if it were euclidean space, because it can behave in the same way if you define and allow the operations
but for example, that 3d array has 8 rgb vectors. you could measure distances w.r.t. those rgb vectors between two matrices, for example
but you could just as easily rearrange the data in some other way
so measuring distance w.r.t those rgb vectors that you mentioned, that would be like np.mean(axis = 3)? right?
no
it would be like the frobenius norm of a matrix of size 3 x 8, if you choose to rearrange the data in that way
is this 2,4,3 array a single image?
uhm, that was actually something I made up to try to better understand in numpy haha..a single image has like (224, 224, 3), which I think means 224 height pixels, 224 width pixels, 3 rgb..then using convolutional neural networks it gets a feature map of like (14, 14, 1024), of which I will be using to find distance.
I am looking into Euclidean distance with like L2 norm, Mahalanobis distance, and cosine similarity/distance. One thing I'm not sure about is that if collinearity and scaling will be factors in this image similarity matrix, because euclidean distance has some issues with it, of which Mahalanobis distance solves, but apparently Mahalanobis distance has some issues with highly correlated data due to the Transpose.
do you think that collinearity and scaling are factors in this distance comparison type of matrix operations?
scaling for sure
anyway whenever you do correlations, it's easier to interpret them if stuff was normalized beforehand to get rid of the scaling
collinearity idk, depends collinearity of what
if you put the whole image into a single long vector or if you mean among the vectors of the data while it's in matrix form
the latter
i can't comment further without knowing how exactly the distance is computed, then
oh ok, coz I am thinking that if two images are same but with different lighting, their matrix would be collinear right? I'm guessing that is what collinearity means..
no wait, it would be their distance that would be small..
hmm, I'll look into it further haha, collinearity is confusing..
well the way I was thinking, was like if we have a table of 3 colomns, income, house size, holiday amount, all 3 colomns would be collinear..
so that would be same for 3d matrices right? the correlation of each axis
to another
assuming I am correct that each colomn in the table corresponds to a dimension, which corresponds to an axis
if you want it to be. you can do whatever you want with the data 😛
so you're talking about the rank of the matrices
the thing is that right now you are talking about a single image
but this is comparing two images
and those are different things
oh I think I get what you mean now, comparing two images and comparing two axis of an image, are different things.
indeed
I guess what I was thinking of was comparing the x axis of image A, to x axis of image B, comparing y axis of image A, to y axis of image B, and comparing z axis of image C, to z axis of image C.
I guess what I'm looking for is if collinearity in those will affect the calculation of distance.
which would then impact the distance algorithm I would go for.
sure, the distance would be directly related to the projection of the higher dimensional thing onto the lower dimensional one
the 2-norm measures precisely that
or rather, minimizing the 2norm is done through an orthogonal projection
when you say 2 norm, do you mean L2 norm? The one that uses euclidean distance?
Like I don't think the axes in a image matrix would correlate to each other, because height is not correlated to width, and is not correlated to rgb value, so I think they are all linearly independent. So I dont think I need to worry about that.