#linear-algebra
2 messages · Page 178 of 1
Othenor

Sorry I'm on phone lol
There is an isomoprhism between M(n,K) and End(K^n)
given by the canonical base of K^n
$n\times n$ matrices with coefficients in K
Othenor

Now you should remember that this isomorphism transforms composition of endomorphisms to product of matrices
so it identifies automorphisms of K^n (= invertible endomorphisms) with invertible matrices (i.e. elements of GL(n,K))
Yes M(n,K) is a K-vector space so in particular it is an abelian group (for the sum of matrices...)
a vector space over the field K
This should be in your lesson, isn't it ?
Or maybe the arguments I'm using are a bit too advanced right now given what you've learnt
Oh ok ! So here's the full story
GL(n,K) = Aut(K^n)
careful when saying this. they’re not exactly equal sets. one contains matrices, the other linear maps. but considering GL_n as a group wrt matrix multiplication and Aut(K^n) as a group wrt function composition, they’re isomorphic
that’s another way to say it, upon fixing bases of the domain and codomain
Denote $(e_1,...,e_n)$ the canonical basis of $K^n$, so that $e_i=(0,..,1,...,0)$ with 1 in position i. For any $f\in \mathrm{End}(K^n)$, write $f(e_j)=\sum_i a_{i,j}(f)e_i$ (i.e. $a_{i,j}(f)$ are the coefficients of $f(e_j)$ in the basis, and put $A_f:=(a_{i,j}(f))_{i,j}$. Then there is an isomorphism of K-vector spaces $End(K^n)\to M(n,K)$ given by $f\mapsto A_f$. Now you can show that this isomorphism respects composition : $f\circ g$ is sent to $A_f\cdot A_g$. So if $f$ is an automorphism, by definition there exists $g$ such that $f\circ g=\mathrm{id}$ and $g\circ f=\mathrm{id}$, so you obtain $A_f A_g= I_n$ and $A_g A_f=I_n$ ; this shows that the above isomorphism sends $\mathrm{Aut}(K^n)$ in $\mathrm{GL}(n,K)$. You can prove reciprocally that any element of $\mathrm{GL}(n,K)$ come from an element of $\mathrm{Aut}(K^n)$ under the above isomorphism.
Othenor

I went on my computer, np
Now the last step : fix an element $f\in \mathrm{Iso}(X,K^n)$. Then I claim that the map $\mathrm{Aut}(K^n) \to \mathrm{Iso}(X,K^n)$ given by $u\mapsto u\circ f$ is a bijection (of sets ! Note that $\mathrm{Iso}(X,K^n)$ doesn't have the structure of a group). Indeed, its inverse is given by the map $\mathrm{Iso}(X,K^n) \to \mathrm{Aut}(K^n),~g \mapsto g\circ f^{-1}$.
I meant to write "bijection" lol
That's just bijection
Othenor

Well Aut(K^n) also identifies with GL(n,K)
which is quite big
It's just matrices with non-zero determinant
In particular when n=1 a matrix with non-zero determinant identifies with a non-zero scalar
Of which there are many
So this answers the question about non-uniqueness
Precisely, the non-uniqueness is given exactly by the size of GL(n,K)
Measuring non-uniqueness is the same as asking about the size of Iso(X, K^n)
which is the same as the size of GL(n,K)
Np

what are you allowed to assume here? [Tv] = [T][v]?
not sure what that means
the matrix representation of the map applied to the vector is equal to the matrix representation of the map multiplied by the matrix representation of the vector
yes I think that's valid
yeah so just prove that v is 0 if and only if [v] is 0, and (a) directly follows.
same deal with (b), show that the null space is the 0 vector and then apply (a)
yeah that's how it usually goes eh? ok i'll give it a try, thanks alphyte
Yes, the statement of the exercise is false
Your g won't be a morphism though, it doesn't respect addition of vectors
But scalar multiple is good
non-zero*
We can identify $K^\times \simeq GL(1,K)$. If you trace back the isomorphisms we mentioned, you should see that for n=1 the composite map $K^\times \simeq GL(1,K) \to \mathrm{Aut}(K) \to \mathrm{Iso}(X,K)$ sends $\lambda$ to $\lambda f$, the scalar multiple of $f$.


Yep
mirzathecutiepie

Well here n=1
so really $\lambda$ corresponds to the matrix $(\lambda)$ with one entry
Othenor

which corresponds to the automorphism $m_\lambda : x\mapsto \lambda x$ of $K$
Othenor

So finally it correspond to $f\circ m_\lambda$. But we can compute $f\circ m_\lambda (x) =f(\lambda x)=\lambda f(x) =(\lambda f)(x)$ where the last equality is the definition of $\lambda f$


Yall still talking about this?
Yes
That's cool
I would participate if I didn't have class
Because I'm learning about this too
So to sum up $\lambda \mapsto (\lambda) \mapsto m_\lambda \mapsto \lambda f$
Othenor

It's the automorphism $K \to K, x \mapsto \lambda x$
Othenor

I have a function let say $y(x)=9sin(x)-2sin(5x)$ and I have this matrix $A=\begin{bmatrix}\frac{1}{3} & \frac{1}{3} & 0 & 0 & 0 \
\frac{1}{3} & \frac{1}{3} & \frac{1}{3} & 0 & 0 \
0 & \frac{1}{3} & \frac{1}{3} & \frac{1}{3} & 0 \
0 & 0 & \frac{1}{3} & \frac{1}{3} & \frac{1}{3} \
0 & 0 & 0 & \frac{1}{3} & \frac{1}{3} \
\end{bmatrix}$
Now I have five values for y(x) evaluated in the interval $0 \leq x \leq 6$ as the following $$y=\begin{bmatrix}0 \ 7.101 \ -0.030 \ -7.823 \ -0.538 \end{bmatrix}$$. I add some randomness to those values so it becomes $$y_{random}=\begin{bmatrix}1.106 \ 8.078 \ -0.372 \ -9.027 \ -1.214 \end{bmatrix}$$. Now $Ay_{random}$ should give me a matrix with values that are closer to those values of $y$ than $y_{random}$ but they aren't.
Specifically, I get this matrix when applying $Ay_{random}$
$$Ay_{random}=\begin{bmatrix}3.061 \ 2.937 \ -0.440 \ -3.537 \ -3.413 \end{bmatrix}$$
Timur

What is the logic behind multiplying the y_random with A then getting something that converges to y?
I know that for the 2nd, 3nd and 4nd values we take the average of the neighbours, for instance the 2nd value in the resulting matrix (1.106+8.078-0.372)/3=2.937
<@&286206848099549185>
can the elemetns in solution set of an inhomogenous system be found in the elements of its associated homogenous system ?
how would i go about solving this problem

Do you mean can a homogeneous solution be the solution to the nonhomogeneous system?
Like if we have a solution X that is in the solution set of a homogeneous system can X also be in the solution set of the associated non homogeneous system?
Meaning if AX=0, then you're asking if its possible for AX=b where b is nonzero? Or just that a solution to Ax=b incorporates X is some way? Not sure exactly what you're asking
I think it's more intuitive to ask what's the span of a basis
And to ask whether some coordinate could fall within the span of two different basis
There may be an easier way, but I was able to show that there must exist an A based on equating the entries of X and A^T-2A. Specifically looking at the diagonal entries of A and the relationship between a_ij, a_ji, x_ij, and x_ji. Doesn't use the dimension theorem though I don't think.
huh interesting
wait how exactly did you find A after doing that, maybe i'm tripping but wouldn't that only work for square matrices
Try $A=-\frac{1}{2}(X+X^\top + \frac{1}3(X-X^\top))$
Jean-Jérôme

I can tell you how I find this once you check it works @humble oak
Guys react my solution is nice and quick and elegant
Well damn, might as well give the solution right now
You know that you can separate any matrix into its symmetric and anti symmetric parts $X =(X^\top + X)/2 + (X - X^\top)/2$
Jean-Jérôme

Let’s do that, we have from the equation, $$X+X^\top = -(A + A^\top)$$ and $$X-X^\top = -3(A-A^\top)$$
Jean-Jérôme

Then let’s express $A =(A^\top + A)/2 + (A - A^\top)/2 = -\frac{1}{2}(X+X^\top + \frac{1}3(X-X^\top))$
Jean-Jérôme

Nailed it
Hey i have a question about changing bases in matrices

Knowing that f is an endomorphism from E to F
And the P is the passing matrix idk what its called in enlgish exactly of B to B' and Q is for C to C'
How did they go from the first one yellow to the 2nd orange
I tried to multiply by P‐¹
But i just didnt get there
@tidal rapids c'est pas vraiment une implication
Faut que tu comprennes que t'as P qui transforme B' en B et Q qui transforme C' en C donc si tu mets pas P, Q^{-1}f, elle mange toujours des vecteurs en base B si tu veux
Ah donc ce n'est pas une implication
Ils ont ecrit juste avant la 2eme expression "en particulier"
@trim fractal Tu peux m'expliquer la derniere phrase? J'ai pas compris ce que tu voulais dire de "manger des vecteurs"
how do i go about finding the standard matrix for this?

im trying to do that A = [L(e1) L(e2) etc.] thing but im so confused
yeah so you need to find L(e1) (easy) and L(e2) (slightly harder)
i think i figured it out
i just dont understand what im doing visually when using the e1 and e2 thing
you're seeing what happens to the basis vectors under L
cause if you have a general vector under L, L([x,y]), it's equal to xL(e1)+yL(e2)
by linearity of L

no problem
If a transformation does the following
From
X
Y
To
[X+Y
XY]
This is not a linear transformation right?
no, run it through the axioms
Just wanted to confirm Thanks @ember matrix
I’m having a little trouble with this and I was wondering if someone is able to help me

Let {e_1,e_2...e_n} be a basis. Let S(e_1)=e_2 ,S(e_2)=e_1 T(e_1)=e_1,T(e_2)=e_1 and let S and T fix every other basis vector
Would we have to prove this to be linear first?
beeswax

Yes
You can construct a linear operator with those conditions
And call those operators our S and T
Oh, I thought that's what you already did
Picked an S and T and gave conditions
it doesn't especially matter if you create the transformations first and then give them a name, or backwards 😛
I see. And what was the intuition behind picking the T,S? I see that it works, but I'm not quite sure what the intuition was when picking them
Te1=e2 would do it, right?
in a homogenous equation, there are 5 equations, 4 variables and 4 pivot columns
This means it has only 1 solution right?
T(e_1)=e_1,ST(e_1)=e_2
S(e_1)=e_2,TS(e_1)=e_1
ST != TS
A better intuition is T will always output e_1 {when we are considering the spanned by {e_1,e_2}) while S can be chosen to not do that
another easy one is to let s(e1) = 0 and t(e1) = e2, leaving the other basis vector fixed
Je veux dire qu'elle transforme des vecteurs en base B, elle les prend en argument quoi. (Meme si elle prend n'importe quel vecteur en argument)
I'm not very comfortable with figuring out rank of a matrix
Like I keep stumbling in what rows to transform
Any tips?
you mean to get it in reduced row echelon form?
If you have a matrix, do RREF(matrix), then count the number of columns with only a single 1 and the rest 0's
it seems like their difficulty is with converting it to RREF in the first place
honestly i dont think theres anything that can be said there beyond "practice more" though
its worth noting that, as long as you're following the given rules, theres never a "wrong" step
there are multiple different ways to row reduce a matrix
(infinitely many, in fact, though most of those are pretty silly)
as a rule of thumb, you should be going from left-to-right trying to make the column have only one nonzero entry
so start by working on the first column and make it have only a single nonzero entry, then do the same for the second, then the third... and so on - this will guarantee you're always "making progress"
again though, the best thing to do to nail it is practice.
given a linear transformation in the basis (3e_1 + e_2, 2e_1 + e2) how do i go about finding the equivalent transformation in the standard basis e_1, e_2 ???? I tried using the theorem that states that A' = S^-1 A S where S is the change of basis matrix and A is the original transformation matrix
but im getting the incorrect answer
show the whole problem and what you have tried
i think you can go ahead

So the problem is basically to find a fourth vector v which is linearly independent from the three others mentioned above
have you already shown those 3 vectors are lin indep?
are they?
it follows from the fact that adding 4 lots of the first vector say a to the second vector b doesnt have the same components as c ( the third vector)
or in other words 4a + b is not equal to c even though the first components match
therefore they are linearly independent

huh 😭
for lack of better words, i would call your argument "half-assed"
you have to use the definition of linear independence or row reduce or something
I'll have a further look into it
be nice.
guys

How the heck is that reduced evhelon form?
Look at a)
Show that the reduced echelon form is that. But how is that an echelon form?
Shouldbt be it 111111 over a diagonal?
i don't think the definition is what you think

So if i do the same way to get 11111 will the answer be the same?
I mean
How?
My teacher always told me in HS to do this
111111 over diagonal and zeros everywhere up and down
that is reduced row echelon form, and it only looks like that if you have a full set of linearly independent rows
you can also only get 1s all along the diagonal if your matrix is square

even in the best case, this matrix could have had 3 ones along the "diagonal", but not 5
it doesn't have 5 rows
My internet sucks i sent it before
that is reduced row echelon form for a square matrix that has all rows linearly independent
that's a special case, and is not in general how it will look
How to know which type should i use?
well, the book is telling you to use row echelon form, not reduced row echelon form
and you do not decide how the matrix looks after you do the algorithm
the way it looks is a property of the matrix
I am not familiar with square matrix, triangular etc the first chapter explains Gayss Jordan elimination
Gauss
square matrix is one that has same number of rows as columns
lower triangular matrix is like, everything either above or below the main diagonal is 0s
i forget which
all you have to do is do row operations until you have a 1 as the first element from left to right on each row
that's row echelon form
what you get as a result depends on the matrix
Ok thanks
I gotta figure out the locus of this

 just expand the determinant
just expand the determinant
if I solve for its determinant and place the resulting equation in desmos will that give me?
neato
tbh
I never even heard of locus
so I'm kinda lost at to what it means
it just means set of points
you can view this as the equation of a curve on the plane
Do
R1->R_1-R_4,
R_2->R_2-R_4,
R_3->R_3-R_4
Evaluating the det will be easier after that
I don't understand a word of what you're saying
Do you know row operations?
Suppose T: R^2 -> R^2 reflects points (i.e. vectors) with respect to the x-axis, and S rotates points 90 degrees counterclockwise around the origin. Using only geometric arguments, show that T and S are linear transformations. Determine if TS = ST
Let's say v=(x,y)
Then Tv=(-x,y)
Expand T(cv+w) to conclude T is a linear transform
using only geometric arguments
for a more geometric approach (which is what theyre asking for)
consider how S and T transform the underlying coordinate grid
do they "distort" it or affect different parts in the grid in different ways? do they "unstraighten" any of the gridlines? ||no, they dont, meaning theyre linear||
im not sure exactly how your class approached the geometric intuition for linearity
but this is the most common interpretation
so it's basically asking me what kind of shape that equation makes?
I got this, and if I plot it on desmos it shows a circle:
198 x^2 - 72 x + 198 y^2 - 1188 y - 648
so "circle" would be the anwser?
circle of radius ___ centered at ___
should one prove that the algebraic multiplicities of a diagonalizable matrices eigenvalues are all 1 when it's a premise completely unrelated to the problem
what
now that I say it out loud, it's not unrelated
I'm not sure if I'm phrasing myself correctly here
likely not
I'll look it up online
I mean, it feels like more context is needed to answer whatever you're asking
You also just started typing that out of the blue...
this is portuguese and it seems you just need to expand the determinant and solve normaly like other conics/quadrics
I don't think that's true
well, if you mean any diagonalizable matrix
yeah, the identity matrix comes to mind 😛
anyone here acquianted with quatum information and computing, especially the maths part of changing basis for Pauli matrices
I'm fucking up a lot of basis changes
Is it true that no inner product can be defined over GF(2)^n, or is it merely that the dot product doesn't act as an inner product?
you wouldn't be able to satisfy additivity
not just that
positive definiteness is nonsense
over a finite field
since how are you defining an order?
I see, thanks!
hey I'm reading https://brilliant.org/wiki/eigenvalues-and-eigenvectors/#connections-with-trace-and-determinant trying to understand why the trace equals the sum of the eigenvalues, but I'm confused at this expression
where does this come from? I get $(- \lambda)^n$ must be included, but why $\tr(A)(- \lambda)^{n-1}$ ?
uli

I sorta believe $\det(A)$ is included since we're just subtracting lambda, I guess expanding that would include determinant of A
uli

really what I'm asking is how do we know $\tr(A)(- \lambda)^{n-1}$ is included
uli

im confused even at what the three dots represent
I think it just means there are more terms they're not including because they aren't needed
i cant see what the pattern is
its not a pattern, they're just excluding the other terms because they aren't needed for what they're trying to show
well i think this comes from the permutation definition of determinant
so when you do this determinant by the definition you can write it as a polynomial in lambda
this lambda can have any degree between 0 and n
oh right maybe thats it, i wasn't thinking with the permutations formula
so if you think what coefficient comes before (-lambda)^(n-1)
oh, its one of each guy other then lambda?
ok that makes sense, thanks!
what's the permutation formula again, something like $\sum^{\text{forall P}} P \sum^n a_{ii}$ ?
damnit


In algebra, the Leibniz formula, named in honor of Gottfried Leibniz, expresses the determinant of a square matrix in terms of permutations of the matrix elements. If A is an n×n matrix, where ai,j is the entry in the ith row and jth column of A, the formula is
det
(
A
)
=
...
ty
np
@gritty swift Wolfram has an short description of the formula: https://mathworld.wolfram.com/CharacteristicPolynomial.html
The 2x2, 3x3 case can be readily found via Google.
can someone please explain where im going wrong with this? im trying to find the determinant of the matrix by reducing it to echelon form and then multiplying the diagonal

i got 1.3125 when the answer should be -90
urm
the determinant of that is neither 1.3125 nor -90
,w det{{-10, -5, 3}, {-2, 15, -6}, {0, -25, 9}}

anyway
it seems you're misunderstanding how to account for what row operations do to the determinant
to clarify: you correctly identified that multiplying a row by 1/16 will change the determinant by a factor of 1/16
so NewDet = OldDet * 1/16
in order to undo this, then, you need to multiply what you got by the reciprocal of 1/16
(or in other words, divide by 1/16)
since you only know the new determinant
and you want to recover the original one
so you shouldve multiplied by 16, not by 1/16.
that said, none of this explains where -90 is supposed to come from
it seems like you did the row reduction correctly
why do you think the answer should be -90? are you sure you wrote down the matrix correctly?
@wintry steppe

you missed a -.
o
on the -3
whoops
but thank u
so when you multiply a row by 2 would u have to multiply by 1/2 when determining the determinant at the end?
right, to recover the original determinant
because multiply a row by 2 also multiples the determinant by 2
so to "undo" that and find the original determinant
you need to divide by 2 (multiply by 1/2)
when dealing with a group a points' distance to a line/point I imagine I should take the distance of the closest point of that group, correct?
do you always need as many vectors as there are dimension in space, in order for their span to be the entire space?
yes
this is a corollary of the way dimension is defined and the fact that all bases are the same size
(and of bases being the minimal size spanning set of a space)
I’m a little unsure. Is this correct? No need for a rigoureus proof.
For this one we know that u+v=0 and u•v=0 since u and v are orthogonal.
We can multiply both sides by u: u•(u+v) = u•u+u•v
LHS is just 0 since u+v=0 and on the RHS u•v=0, so we have: 0 =u•u , then from the book we know that’s true if and only if u=0. And vice versa for v.

not only is what you wrote correct, it is a rigorous proof
Thank you! 😊
👍
(assuming you already know the dot product distributes over +)
The locus of points of which the distance from the line y=1 is half of the distance to the point (3,2)
I have to identify it
it's a hyperbola

I'm playing around with them numbers
to see if I can make it match the general equation of the hyperbola
but I am surprisingly stupid
befuddling, even
Lol I’m now only familiarizing myself with proofs. I need to take a proofs course ASAP.
how come this hyperbola has a equation identical to that of a parabole?
it doesn't, though? multiply out the denom, expand the brackets, redo the brackets for y and it should look closer?
or am i missing something


complete the square for x(x-6) and y(-3y+4)

these are quiz questions but i already submitted and just want
to get my answer checked

here are the answers i submitted
for proof of submitting

im sure i got 3b wrong
lmao
im positive my 3a is correct though
and 4b
A and B are 3x3, so the product of A^2B^T is also 3x3
det(nC) = (n^r)det(C) if C is rxr
fuck
i knew it
i squared it instead of cubing it
and transpose of a det
is just negative right
since you're swapping rows
Transpose maintains det iirc
cause laplace expansion on any row maintains det
so if you expand along R1 of B, you'd expand along C1 of B^T


Is the cardinality of a vector space equal to the cardinality of the cartesian product of a basis and the underlying field?

I'm thinking yes when their eigenvalues are the same, but i'm having trouble explaining it
Let them have the same Eigenvalue a(implies (T-aI)v_1=0 and (T-aI)v_2=0)
Then (T-aI)(v_1+v_2)=(T-aI)v_1+(T-aI)v_2=0
If they don't have the same eigenvalue,That sum cannot be a eigenvector
what does T-aI represent? @native rampart
Do you know what T+U means,given T and U are linear operators?
maybe i was taught that in a different name, but i'm not sure
T+U is a linear operator such that (T+U)(v)=T(v)+U(v)
Eg:(T-aI) is a linear operator defined as (T-aI)v=Tv-av
ohh okay
Kernel of (T-aI) will be eigenvectors of eigenvalue a
is T the matrix?
Yes
Try to prove this
is the reason A is false is because it doesn’t necessarily have to be v3 thats a lin combo of v1 and v2? like v2 can be lin combos of v1 and v3?

no
if v_2 is linear combination of v_1 and v_3 you have a true
i mean if it has nonzero coefficient near v_3
the reason it fails to be true is given by: let v_1, v_3 be independent and let v_2 = cv_1
then v_2 is scalar multiple of v_1 but you cannot express it in terms of v_3
i mean speaking precisely it is still linear combination of v_1 and v_3
@native rampart T(v1+v2) - (aI * v1 + bI * v2) = 0, is that true if v2 has an eigenvalue b != a?
Maybe
Yes

Given that v_1 and v_2 are linearly independent vectors of different eigenvalues,v_1+v_2 is not an eigenvector
then wouldnt the eigenvalue for (v1+v2) be (a+b)/2 ?
but different eigenvalues always have linearly independent vectors so hypothesis is overstates /j

have you already shown that there are at most n distinct eigenvalues?





hmm okay
I'm still not sure how to tie this into linear independence
i mean why can't λ = (λ1 + λ2) / 2
recall what linear independence say about uniqueness of representation
and what it means for vectors to be equal
Is the cardinality of a vector space equal to the cardinality of the cartesian product of a basis and the underlying field?
Given a vector space V over a field F, is the cardinality of V the same as the cardinality of basis(V) × F?
Where basis just means any choice of basis
Doesn't that miss elements like ae_1+be_2 where e_1 and e_2 are basis vectors?
ah
for finite-dimensional vector space it is just easier to see that cardinality is just the same as of F^n
thx
@dire thunder i've been thinking about it for a while and I still don't think i got it
is the contradiction going to be that v1 and v2 are linearly dependent?
you are going to obtain \lambda = \lambda_1 = \lambda_2
because linear independence implies that you represent each vector as unique combination
with unique scalars
and also
if you think of v_1, v_2 as basis of subspace
and recall what coordinates mean you also arrive to this
ohh okay
so there's no way to represent x(v1) + y(v2) = a(v1) + a(v2) without x = y = a
because v1 and v2 are linearly independent, so theres only one combination of the two vectors to represent any given coordinate
i mean if you want you can arrive from here to dependence in another way
their difference should be zero
that is (x-a)v_1+(y-a)v2=0
if a != x e.g you arrive to dependence
yw
How should i think of degrees of freedoms for a line of the form ax +by + c = 0
y=-(c/b+a/b x)
my textbook mentions for lines in 3d space there are 4 degrees of freedom but doesn't really explain why
x can be anything in R
But y is constrained by value of x
There is one degree of freedom here
Is this like a thermodynamics book?
Can you share what the book says exactly?
I am assuming degree of freedom=no of free variables

Given some basis v1, v2 for the vector space V over a field F, is the cardinality of V equality to the cardinality of ({v1} × F) × ({v2} × F)?
did you mean {v1} x F and {v2} x F respectively?
if so then yes, V is isomorphic to F^2 and so has the same cardinality.
thanks!
What is infinity matrix norm?
squirtlespoof

i guess they mean the induced infinity norm
squirtlespoof

Im trying to reconstruct an approximation to the integrator in the Riemann Stieljets integral representation of a linear functional associated with an orthogonal polynomial sequence P_n that satisfies $P_n = x P_{n-1} -P_{n-2}$. So basically I want to construct the representation starting from just Favards theorem. I've included pictures of the two main theorems.
\\
Im doing this using sympy, and I want to solve for $A_{ni}$ by fixing n and solving the associated matrix $Xa = m$ where m are the moments, a are the coeffecients $A_{ni}$ and $X$ is the matrix of the powers of roots. This is a lot of information, but the point is that $A_{ni}$ satisfying the equation will always exist and always sum to 1 in my case. My program fails for $n\geq4$ where the augmented matrix is reduced to the identity matrix (with 0s underneath). Is this a problem with my program? or am I misunderstanding something with overdetermined equations?


deadpan2297
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

This is what I've written https://pastebin.com/vSMMjVKL
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
and heres the output

explain the math you have done in words/equations. once you have the math right, the coding is straightforward
show me the matrix and the vector you used for k = 4
or n = 4 or whatever 😛

Is there I nicer way I can send this to you ?😓 Id hate to make you read this messy output but I only know pprint
as a .csv
oh btw you're dealing with 0s of polynomials, so expect poor numerical stability. as the matrix gets larger, it'll become more and more difficult to get results that make sense
is the last row in what you sent the "mu" vector?
-29.03444185387343,-0.03444185374883091,0.03444185374883091,29.03444185387343
this one?
its the 7th power of the roots
so this is only the matrix x right?
send me the mu vector
oops missed one
your system is inconsistent
either due to rounding errors or because something else was messed up
adding in the column of mus changes the rank of the matrix
😵 😵😵😵😵😵
are you sure the rows are in the right order? and that the mus are in the right order?
Yes the ordering is all correct, the only thing I can think of it being is numerical errors some how, but i really dont know how that comes into play in solving linear systems
Ill try and do it by hand and see if that tells me anything
but its quite late so I should go to bed. Thank you for all your help Edd

that's exactly the problem
you have to take a rank-4 approximation of the matrix first, and then rref it
gimme 2 min and i'll do it
Bless you

welcome to dumbass numerical stability problems
lame-o computers can't handle the sexiness of your matrix, they think it "almost" has rank 5 after augmenting it
(what i did here becomes intractable if your matrix is too large btw)
whats this method called? Ill have to read more about it
im working towards an approximation in the end anyway, so i can just work until theres a good balance between close enough and bonkers
Break your matrix into descending levels of important components
i used a singular value decomposition and the Eckart-Young theorem, if you wanna read up on that
and the knowledge that the vector mu should be exactly in the row space of the matrix x, so augmenting the matrix should not change its rank
you can think of the computer's limited precision as a source of "random noise" that is independent from the entries of the matrix, and so adding this random noise increases the rank of the matrix
since we know the matrix has rank n, then a rank-n approximation of this "noisy matrix" (due to rounding errors) yields a better solution
BTW is it possible to do exact rational matrices
that's also a thing. but i think they are getting the entries from some sort of iterative algorithm already, so it's difficult
TIL about using low-rank approximations this way, it makes sense
That makes sense, I'll have to read more about svd in the morning
Or else I'll be up till morning working on this lol
SVD is a deep hole so you should learn to control yourself
But yeah read up a bit on it
Thanks again for your help guys and gn 
I have a question about transformation
Question: Show that any sequence of rotations and translations can be replaced by a
single rotation about the origin followed by a translation.
I have read materials like this http://planning.cs.uiuc.edu/node99.html. which give me lots of insight in writing the proof. However, I dont know where and how should I start. Any tips for me to work on this?
Perhaps I'm wrong
but rotations + translations are just permutations
And the group of permutations needs 2 matrices as its basis
How did they introduce the notation before?
mirzathecutiepie

There's a little bit of a subtle difference I guess, in the first case, the spaces that you're taking direct sums of are all just subspaces of a larger space
Whereas in the second picture, you're taking two completely separate spaces and combining them
mirzathecutiepie

They end up kind of being the same since X_1 and X_2 are subspaces of X_1 \oplus X_2
yes
Hello

Here U is an arbitrary plane through the origin spanned by (1,1,1,1) and (1,1,-1,-1).
What's W?
W is just an example of a subspace that makes the direct sum of U and W R^4
So in this example W = span{(1,1,0,0),(0,0,1,-1)}

The Cartesian sum is the sum of linear subspaces. The direct sum is standard language.
I have the image vector for rotating around Z, but how would I get one for rotating around Y
R^3
What are the two differing definitions?
I see only one
One for sum of subspaces, and one for direct sum
I don't see a definition for direct sum below
It just say the direct sum is denoted as...
The direct sum is the sum of "independent" subspaces
is the set of all vector sums with vectors drawn from each subspace
the cartesian sum honsetly just looks like the cartesian product
Someone should double-check
Like, that looks exactly like the definition for cartesian product
Like, it looks EXACTLY like the definition of cartesian product
Another equivalent definition for direct sum
A direct sum is a sum of independent subspaces, and subspaces are independent when the only vanishing sum is with trivial coefficients
I'd email your teacher and ask if "Cartesian sum => cartesian product"
I sometimes reference other books to resolve notation
Axler's Linear Algebra Done Right is generally available if you google for it
The citation is
Axler (2015) p. 21 § 1.40
It's a good reference book, at the very least
It's difficulties in education is what makes it a good reference book, IMO
it's succinct without being crazy
40?
Axler is generally so lazy
that he won't have a 1 page proof
on anything
ic
moi teacher gave me this and told me to identify what sort of shape it is
after alot of work
I managed to get this:
desmos tells me its a parable
how do I present it properly?
cause she sure ain't gonna accept "internet software told me so"
it can be a written mathematical proof
what would it be then?
also, just presenting it as that would be sufficient you think?
if you do that, it's an order 2 polynomial in x
that's a parabola by definition, and you could complete the square to describe it with vertex, shifts, and all
tanks
do check that what you've done at the beginning is correct, i can't check it rn. try plotting your expression and the original one and see if they match
It was a circle, I forgot one exponential
that seems more reasonable
I was talking about something else which I've deleted since
how do I prove that this is a sphere?

what should a sphere be?
also wrong channel, maybe this fits in #multivariable-calculus more
what i mean to say is
can you tell me what a sphere is
like, you know how figures have general equations?
the exercize asks for the locus of the points (x,y,z) whose sum of distances between the point (2,0,0) and (-2,0,0) equals 6
so I worked out this equation into that
and plotting it here shows me its a sphere

asking for the locus = asking basically what kind of figure it is, right?
presumably it's asking you for an equation describing whatever it is
not just what kind of shape it is but a precise description, i.e., an equation
such as this

Maybe do solid of revolution with implicit function, then show that the integral equal the volume of a sphere with a radius of 6 units.
I did but I was kinda of hoping someone would explain to me how to prove it
cause now I only have the general equation and the exercizes'
...are you asking why (x-a)^2 + (y-b)^2 + (z-c)^2 = r^2 is the general equation of a sphere?
and I'm not sure where to go from now
the left hand side is the distance, squared, of (x,y,z) from (a,b,c), the center
I'm supposed to prove that this is a sphere, in summary
(x-a)^2 + (y-b)^2 + (z-c)^2 = r^2 means that (x,y,z) is at a distance r from the point (a,b,c). do you see why this is a sphere?
yeah
but my equation is different from that
can you turn it into something of that form though?
this isn't a great explanation
2x^2 + 2y^2 + 2z^2 = 28. how do you turn this into something that looks (x-a)^2 + (y-b)^2 + (z-c)^2 = r^2? what should a,b,c be? what should r be?
direct sum of vector spaces is unique in the algebraic properties making it sort of THE interpretation of "how do we most generally make a vector space out of two others"
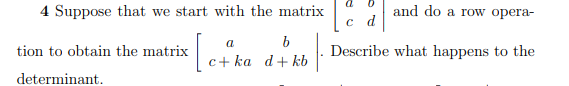
Anyone can help me with this?
Have no idea what happens to the determinant. It can't be that it gets multipled by k right?
to get started, it might be best to consider an example
the row operation is r2 = r2 + k * r1
what's $\det\begin{pmatrix}1&0\0&1\end{pmatrix}$? what's $\det\begin{pmatrix}1&0\2&1\end{pmatrix}$?
Namington

(here a = d = 1, b = c = 0, k = 2)
right, it's almost as if it didnt change
of course, this is just one example
not a rigorous proof
for a better proof, consider: we can interpret row reduction operations as multiplication by a specific matrix
suppose $\begin{pmatrix}a' & b' \ c' & d'\end{pmatrix}\begin{pmatrix}a& b \ c & d\end{pmatrix} = \begin{pmatrix}a&b\c+ka&d+kb\end{pmatrix}$
Namington

what must $\begin{pmatrix}a'&b'\c'&d'\end{pmatrix}$ be?
Namington

(hint: 3/4 elements will agree with the identity matrix)
[1;0;k;1]?
right; $\begin{pmatrix}1&0\k&1\end{pmatrix}\begin{pmatrix}a&b\c&d\end{pmatrix} = \begin{pmatrix}a&b\c+ka&d+kb\end{pmatrix}$
Namington

ah okay I see now
yeah
and now remember that det(AB) = det(A)det(B)
so the determinant of the right-hand-side will be the product of the determinants of the left-hand sidde
but this is a diagonal amtrix so its determinant is just 1

hence the determinant is just the determinant of (a, b; c, d)
i.e. this operation doesn't change the determinant.
oh okay now i get it
thank you so much @limber sierra for your help! I really appreciate it

I don't see how they set up the system
2x has 4C and 12H, how is it equal to z with C and 2O?
well the first equations equates the number of C atoms on the left and right side of equation
second equation equates the number of H atoms
and the third equation equates number of O atoms
there must be the same number of C atoms, of H atoms and of O atoms on both sides in order for this to be okay, so that's what they did
I see, thank you, Mate
gotta make this
match this:

any tips?
It was already quite a few hoops to get it to look like this
and it's still pretty far
@lavish jewel @fickle citrus I ended up finding a simple solution. I have no way to check higher order stuff other than the numbers looks right lol but while looking up the wiki for SVD I came across this which I just plugged in

Simple is good
OLS hmm, probably good enough. There are quite a lot of assumptions
from the picture I see that x, y, and z all become zero at some point. How about setting each equal to zero and creating a system of three equations in three variables?
that is a good idea
also, it seems that x and y become simultaneously zero, when the paraboloide crosses the z-axis. This helps to find z.
how do you know that?
I don't know it for sure
just a hunch, I'm imagining how the surface moves but may be totally wrong
I'm a bit stuck
I managed to get this far for z=0
but now I can't progress any further really
if I do this I'm just going in circles

setting $x=0$ gives $1-y^2-2y-4=z-3$ and $y=0$ gives $x^2-2x+1-4=z-3$
az

wouldn't that help? consider that we have expanded complete squares which could help us to solve for one variable in the equations and substitute
on a sidenote
when x=0, z=-y^2-4y
but then
I can only consider this to be true when and only when x=0, right?
I believe this goes here. I’m a freshman in high-school and last semester we revisited factoring quadratics and included them into triangle problems and more. When factoring a quadratic, oftentimes I will have it down to maybe (x+10) (x-7) = 0. Well one is positive and the other is negative. If x was the side, obviously it need to be positive for a triangles side. My geometry teacher informed us to always choose the lower absolute value negative number if we ran into 2 negatives when we factored it. I guess it would help if I could imagine in on a graph. My question is, why must we pick the negative closer to 0 (if my teacher was correct) and how come in that instance will a negative work? Would the triangle have all negative sides? I’d appreciate a response thank you!
So not really LinAl (except for maybe triangle inequality), but your question is lacking specificity. If you have a physical triangle all the sides must be positive by definiton of distance being positive
I understand. I figured it belong to linear because of the quadratic.
I wonder what my teacher was implying
@nocturne jewel thank you anyways
I figured
Thank you
I guess I’m a bit lost because we never finished quadratics in alg 1
Because of Covid, obviously.
Yeah but quadratics isnt LinAl
Thank you again.
I understand that.
Just giving an excuse for my cluelessness to uphold a decent character 😅😆
just need help with a concept, but "b" is a column vector in this right? and "x" would be a vector of variables or arbitrary number?

elements of R^k are generally assumed to be "column vectors"
(though the distinction doesnt actually matter, and a calculus/analysis course might prefer to write them as row vectors if its not doing matrix arithmetic)
so both x and b are column vectors
and they both consist of real-number entries.
ah makes sense now thank you, probably didn't understand the definition well enough
@limber sierra @sonic osprey appreciate the help!
boys
I need to prove that this an ellipsoid
by squaring both sides and resolving the resulting mess
I got this
which honestly, has me no closer to the desired result
which is this:

any ideas on how to make that equation look a wee bit more like the equation of an ellipsoid?
note that the thing inside both square roots is nonnegative
for nonnegative a, b we have $\sqrt{a}\sqrt{b} = \sqrt{ab}$
Namington

I love you
cause then I can just square both sides and it's out of the damn sqrt right?
i was thinking isolate the square roots first.
nvm I got confused
for this is a*b right?
oh, it's going to be messy if I just straight up multiply them


if you multiply a row/column of the matrix by an scalar, then you can factor that scalar off the determinant. So det(2A)=2^n det(A) for some n.
use the fact that here A is 3x3
mmm wait i see
i was taking the 2^n out of the inverse of the determinant instead of keeping it inside so that messed things up
a bit odd given that the existence of an internal direct sum isn't even established without an external direct sum
maybe I think of these things too categorically 
yeah that would establish existence
well, rather that shows that there exist subspaces such that X can be decomposed as the direct sum of Y and Z
showing the technical details of the internal direct sum being isomorphic and whatnot is the other part
$Y \oplus Z \cong X$
bacono

precisely, yeah
well yes, once you've established the basic universal mapping properties of external direct products it's super straightforward (which is why I say you use them to prove the existence of internal direct sums)
you've definitely got a handle on things
you've got the main idea
you should be dandy with some exercises
have you covered quotient vector spaces by any chance?
okay yeah the style of thinking is pretty similar
sure, that's one way of looking at it
the reducing into cosets is the defining property
yes
it's the soft introduction to a lot of the much more algebraic aspects
the book I used (knapp) covered everything with universal properties and commutative diagrams so that sort of helped in recognizing the universality of a lot of these constructions
direct sums manifest similarly as direct sums of abelian groups and quotient vector spaces come back as quotients of rings over ideals
the cheese answer would be to show that they just have the same dimension
very nice, just know that similar approaches break down in infinite dimensions
direct products/sums get very fucky in infinite dimensions, where you can pretty much only define them categorically

the isomorphism stuff (e.g. direct sum decomposition) only holds for internal direct sums
since we'd be taking the external direct sums of subspaces
basically internal direct sums always involve subspaces
external direct sums are "here is a vector space from two other spaces"
is external direct sum just the product of vector spaces?
yes
indeed
well isomorphism means that structurally they are the same vector space
I like to think of internal direct sums being the vector space that is canonically isomorphic in the sense that it respects the internal additive structure of the vector space
indeed
fundamentally an isomorphism in a given category says that we can relabel things in a way that respects the internal structure of the objects
so in the case of vector space isomorphisms, we're just relabeling vectors in a way that the linear properties work in the same way

why is this true? the question says A is a 3x3 matrix with 2 pivot positions

i thought as long as all rows have a pivot position (which means there can be a free variable still sometimes) then Ax=b is consistent for all b
when you put the augmented matrix [A | b] in RREF you'll have two pivots where A used to be, but who's to say a third pivot won't find itself in b's column?
$\left[ \begin{array}{ccc|c} 1 & 0 & 0 & 0 \ 0 & 1 & 0 & 0 \ 0 & 0 & 0 & 1 \end{array} \right]$
Ann

like this
mm ok
considering the question says A is a 3x3 matrix with 2 pivot positions, it’s impossible for all rows to have a pivot position anyways right? thats why they said there cant be a free variable?
in RREF you have only main diagonal entries nonzero
thus roughly saying no i-th variable participates in k-th equation k != i
oh ok then
i would also appreciate if someone could water down this theorem for me, i don’t understand it

i don't know if this is exactly what you were looking for, but a simple substitution can clear it up a little
then say that Ap = 0
and that Av_h = b
if you let x = p + v_h and substitute it back, you can see what happens
Ax = A(p + v_h) = Ap + Av_h = 0 + b = b
the main "trick" is that you can add 0 to anything without changing its value
and Ap is 0, so adding p to any v_h does not change the result
can i almost think of it as like a translation?
im trying to visualize it more if anything
but i think i get it now
a translation of what?
you could interpret it as an intersection of "affine spaces", planes that don't go through the origin
but then it's really not just one translation, but one translation per row in the matrix
if you want a simpler geometric interpretation, i would rather speak of the spaces that the rows and columns of the matrix span
yeah thats what i was trying to get at
then yes. each row is a plane that has been translated, and the solution is the intersection of all of those planes
Yeah that's a decent way to think about it
Hello lads, I was having some trouble understanding the wording of this exercise. What is meant by "onto linearly independent sets?" I could understand if it just said "onto", but does this mean "onto a restricted subset of W"?

take a subset A of V that's linearly independent
if T(A) is linearly independent as well
that is, the image of A under T [which will be a subset of W] is linearly independent, and the map is surjective here
then T is one-to-one
and vice versa
ah, i see. thanks
oh i should say
wait a second
for all such subsets A
isn't it surjective by definition?
they could use a word like "into" instead, sure
or say "...if and only if T maps linearly idnependent subsets of V to linearly independent subsets of W"
or whatever
they just used "onto" since it also works
since, as you observed, its surjective by definition
okay perfect, that was what i was thinking
[since every function surjects onto its image]
and this has to work for any choice of A (that's linearly independent)
basically its saying that a linear map is one-to-one iff it preserves linear independence
yeah i figured as much
how do i calculate perpendicular projection for a vector in given space?

i need to figure out how to do it for the v
you can project v onto v1 and v2
using scalar and vector projections
(i.e. scalar or dot products)
yeah i know how to do that, but i need to do it for the subspace spanned by v1 and v2
right, so you project onto v1 and v2 😛
oh....
what i need to do after i have projected to v1 and v2?
to get it perpendicular?
you're done, that is what they are asking you to do
okay.... i was thinking i get nice one answer on this problem, got me fooled by what i expected to get out of the answer
what did you expect to get?
one nice vector, instead of 2 vectors one for v1 and one for v2
i mean, it depends on what exactly you want
do you want the coordinates of the orthogonal projection of v?
that is a single vector
what i mean is the following
let v = v_sp + v_n, where v_sp is the component of v that is projected onto v1,v2 and v_n is the component orthogonal to v1 and v2
i just need to calculate perpendictular projection for v to subspace SP(v1,v2)
v_sp = [v1 v2] * x^T
x^T is the coordinate vector, v_sp is the ortho projection
you can get that with a pseudo inverse
to make the projection be orthogonal
since v1 and v2 are not necessarily orthogonal to each other
so im not really sure what answer is expected
guess i just project it to v1 and v2 and call it a day
looking back at that, that's not an orthogonal projection tho
because v1 and v2 are not orthogonal to each other. my bad
that's just a vector projection
in the orthogonal projection, you need an orthogonal basis for the subspace
you can use your choice of svd, pseudo inverse, gram schmidt, or something like that
so i take v and gram smidht it to v1 and v2?
you gram schmidt v1 and v2, and project v onto that
i see, that looks like the asnwer i was looking into
at least the format is correct
wait a second, it gives me 2 vectors, what formula i use to project 1 vector to 2 vectors?
or do i end up getting 2 vectors as asnwers
do you want the coordinates or the projected vector v
are you looking for a vector with 2 or 4 components
i want the projected vector
then you project onto v1, then v2, and you add that up
of course, after having done gram schmidt on v1 and v2
otherwise that doesn't make sense
so proj(v,v1)+proj(v,v2)
as long as v1 is orthogonal to v2, yes
so first, gram smidth v1 and v2, then do that
i dont understand this either, i have projection πCol(A): R4×1 → R4×1 and i need to find its matrix
and A is given as

im confused what matrix is the one im looking for, is it that transformation matrix for projection or something else
do you know what an svd is
singular value decomposition?
is there an easy way to do this
singular val dicomp
have you used svd's for anything so far? otherwise, we can just use the definition of orthogonal projection matrices to cook something up
i have never used svd
ok
i wonder if i could use wolfram alpha to do that for me
well, here's the thing. notice the steps you did in the previous task
say your martix is A
do find eigen values of A^t A
in the previous task, you first did gram schmidt
singular values of A = sqrt eigen values of A^tA
then you projected onto those orthogonal vectors. finally, you expressed v as a linear comb. of v1 and v2
as matrices, this looks as follows
<@&268886789983436800>
you get an orthonormal basis for the space spanned by the columns of A by doing gram schmidt. put those columns in a new matrix that we will call N
this matrix is of size 4 x 3
you can get the coordinates of V in this basis by simply doing N^T v
so, take A -> gram shmidt it and get 4x3 matrix?
N^T v = c, where c is a 3x1 vector that contains the coordinates of the orthogonal projection of v onto the subspace spanned by the columns of A
so the vector orthogonal projection of v onto the oclumns of A is Nc = NN^T v
i go to try this, i gotta go now, my food is ready
and so the matrix you are looking for is N N^T
why wolfram alpha wont give steps on svd?
because there is no easy way of doing an SVD
but the steps i just explained to you give the same result you would have gotten
i see it soon, i really need to go now
because you can use a pseudo inverse, expand it in an SVD, and reach the solution U U^H
which is the same form N N^T
I forgot the exact question, but something like :
Given an invertible matrix A, and a matrix b with some values (then I calculated determinant exist which means it’s also invertible), then the question asked if the equation below is possible:
A^2= AB-2A
(Or AB-4A) something like that
I think it’s testing on invertible matrix theorem
The answer is yes, right?
well, it means A = B - 2I
There’s another question where they gave me a matrix in the form of a b c d e f (not the exact order)
(Only two rows with 3 or 4 columns)
And stated something like
A/b=c/d=e/f
And it asked how many solutions are there?
So it seems like the first row is some multiple of second row, and which if I were to do rref then the second row will be all zeroed which means infinitely many solution?
If that’s the case then actually giving me the information of two rows and 4 columns would be sufficient for me to know how many solutions, no?
Thank you
the second one looks too vague as is for me to comment
Yeah I’m not sure as well.. but does it make sense for the one row to be multiple of another ?
no. the columns, yeah
i mean, sure, the matrix could be rank 1
but i would guess it's more about noticing that since a matrix is of size M x N with M < N, then the columns are definitely linearly dependent no matter what you do
with at most M linearly independent columns
without getting any zero rows, since M < N, you would still have (possibly) infinitely many solutions
unless they on purpose give you a vector out the span of the columns, in which case you could also have no solutions
not enough info to say anything else
Thank you
edd, i did fiddle around with slv
bbut im not sure what is the info im looking into

read the rest of the stuff i wrote
U U^T is the projection matrix you want
but i gave you an alternative way of computing it using gram schmidt above
yeah i did not really understand it, so i went to reasding and correct me if i am wrong but from that wolfram alpha i want that sigma matrix?
i did read what you wrote so i should pseudoinversen A (inverse A = U) then do SVD to that, and from there ii get that U*U^t?
i did the gram smidht and i got 3x 1x4 matrices

for that A
a lot of what you just said is wrong, unfortunately
i guessed so much, first time doing this and im not really sure what i am trying to get
the gram schmidt procedure i gave is what you have already learned up til now
yeah i did pput it in calculator and got those e1 e2 and e3
i do proj(v,e1)+proj(v,e2)+proj(v,e3)
mhm
just a generic v
they ask you for a matrix that will project any v onto the span of the columns of the matrix
so the v should bbe 4x1
right
since e is 1x4

{kind=link}
mhm