#linear-algebra
2 messages · Page 159 of 1
you were given two of linearly independent columns of A. since A has rank 2 (because you were told it has a 2 dimensional column space) we know that all the other columns are just linear combinations of the ones you were given (meaning they span). since they're linearly independent and span, they form a basis.
Ok so the answer isnt whether b is in Col(A)?
you could also look at it as if we make the matrix C with the two columns you were given, the system Cx=b has only one solution since it doesnt have a null space (they are linearly independent)
its a two part thing
wait so is it inf or 1 solution?
we know there is at least one solutions because b is on Col(A)
You said infinite and only 1 confusion
You said an alternative way of thinking leads to only 1 soln
but with null(A) logic there are infinite
yeah if we only consider the two columns you were given
Ok so Ax=[5,7,-2]^T has inf solution?
we know there is at least one solutions because b is on Col(A)
we know there are infinitely many because Null(A) is not just the zero vector
ok so infinite
idempotent
ty! 🙂
or... maybe a projection in this context
lol that was exacly what i wanted
projection or idempotent?
projection is a type of idempotent ^_^
i was looking at projection and wanted to give it another name
ah okay
Well,All idempotents are projections
in matrixes yea..
Well,All idempotents are projections
idk if i would call an idempotent matrix a "projection" outside the context of inner product spaces tho
When I was being taught linear algebra for the first time, it went like
an endomorphism p on a vector space E is called
• a projection when E=Ker(p)⊕Im(p) and the restriction of p on Im(p) is the identity
• a projector when p²=p
(maybe it was the other way around)
and the important result was that projections are projectors and projectors are projections (and that's why I don't remember which one was which)
the prehilbert-specific stuff was introduced a lot later
a projection p on a prehilbert space E is said to be orthogonal when the direct sum E=Ker(p)⊕Im(p) is orthogonal
maybe you could suppose that under some pair of bases, the matrix has exactly dim(range T)-1 non zero entries and derive a contradiction?
hm
in the best possible case you'd have some diagonal matrix with dim(range T)-1 non-zero entries and that should contradict the given value of dim(range T)
er
so
each Tv1 ... Tv_n corresponds to an entry in the matrix
so we get dimrangeT-1 = dimrangeT ?
but er
how does that contradiction work
Hey guys, not sure if this belongs here but I've been asked to do a linear algebra online certification as proof of competence before taking on certain projects at a job..was wondering if do you guys have any in depth linear algebra certification you'd recommend pls? There's like so many it's tough to choose haha..
are there any topics of linear algebra that you know you'll need in particular?
ahh I don't know lol..it's to do with robotics and some machine vision so probably linear algebra topics to do with that..I think he wants proof of competence that I know linear algebra basically..
I guess personally I'm looking for like if it covers subspaces, row echelon, basis, dimension, nullspace, linear independence, eigenvalues eigenvectors, and the tougher stuff like orthonormal orthogonal gram schmidt etc..
I guess kinda online course certification
that they want to show that I know linear algebra
@neat relic you mean a certificate course in linear algebra, am I right ?
you can look over edx or coursera courses on linear algebra, choose what is best for you
these give certificates of the universities they are being offered by, but are not credit eligible mostly, don't have any exams, just graded quizzes
i guess they may be useful for you
My LA class never touched on generalized eigenvectors so I'm hoping someone can help answer some questions I have about them.
- How unique are they? I know eigenvectors in general are not unique because you can scale them, but from just messing around with GEs it seems adding any scalar multiple of the ordinary eigenvector(s) has no effect on whether or not it's a GE.
- What would be the proper way to "introduce" them in a proof? Like if I have a general nondiagonalizable 2x2 matrix A with eigenvector v and generalized eigenvector w what is the formal way to state that?
and if anyone has any good resources I could look into to understand them better that would be appreciated. The wikipedia page is a bit difficult to understand for me.
why is f(x) = x + 4 non-linear
I've seen the proof, but intuitively it feels like a linear function
it's "highschool linear"
that kinda function would be called affine, usually
linear function plus a constant
@hollow finch I think these questions will be easily resolved when you study some more about generalized eignevectors, I would recommend , you can read either Chapter 8 of Axler, he covers all about generalized eigenvectors, decomposition theorem etc. in great detail , chapter 7 of Friedberg Insel Spence also covers this in a good way , you can choose any one you like .
hope it helps
unfortunately i dont know when my next LA class will be 
but thank you! i'll look into those
your next la class is whenever you next open a linear algebra book 
Yeah it's highschool linear lol
thank you
@wintry steppe if it were a line through the origin, that would be enough right?
Is that a consequence or a condition
if your given map, maps 0 to 0 , then it is not necessary that it's linear but if it is linear then for sure by linearity 0 will be mapped to 0
I guess it's a consequence of scalar multiplication then
nice, thank you
bit bold to assume 0+0=0 \j
linear functions........ 
if $v1,...,vm$ is a basis of V. we know there exists $T(a_1v_1 + .... + a_mv_m) = c_1v_1 + ... + c_mv_m$. Setting all scalars to zero we can get a specific vector so$ T(a_jv_j) = c_jw_j \rightarrow Tv_j = \frac{c_j}{a_j}v_j$
Yes
does this answer the question?
"there exists (equation)" what do you mean by this? what are these scalars? why are you setting these scalars to zero?
why are you writing your basis as v1, ..., vm when the space is 1-dimensional
you should start the problem by saying "let {v} be a basis for V"
then what can you say?
V = span(v) -> for all u in V, u = av for some a in F
oh
but hey it could probably work out 
how would you do it
well you have a basis {v} of V
meaning any element of V is a scalar multiple of v
in particular, T(v) is
hm that works
why?
you should write a full proof 
i dont know how
think about the problem some more then
remember you ultimately want to show that T equals scalar multiplication by some scalar (one you need to come up with!)
starting from a basis of V is how you find that scalar
i gave a big hint 
at the start?
yah
i don't understand it, i think it needs to be fleshed out a bit
This matrix is singular because I found its determinant to be 0
Homogeneous systems all have the trivial solution
If it is singular, then it cannot have unique nontrivial solutions
Therefore it has no solutions or infinitely many solutions. The number of equations and unknowns are the same. So I say it has no solutions.
Turns out it has infinitely many solutions, how is that? (part b)
the set of solutions to the system is the kernel of A. since A is singular, its kernel is nontrivial, thus infinite
Wouldn't that imply then that all singular matrices have nontrivial kernels and therefore all singular matrices have infinitely many solutions?
all singular matrices have nontrivial kernels
this is true (and conversely for square matrices)
an nxn homogeneous linear system of equations Ax = 0 has a unique solution (zero) if and only if the matrix A is nonsingular, and on the other hand, has infinitely many solutions if and only if A is nonsingular. if the system is not homogeneous, then you can't say for certain whether or not there are solutions
in a nonhomogeneous nxn system Ax = b, you will have infinitely many solutions if you have one (b/c ker A is nontrivial)
Yep that..and ok cool I'll look over the edx and coursera courses, and figure out the most suitable one..thanks..
Wait... so if I have a singular matrix (by finding determinant = 0), it will always have infinitely many solutions and never no solution?
(other than the trivial solution of course)
yep
Oh I did not know that. I was under the impression that if a matrix was nonsingular then it had one single unique solution. And if it was singular and if it had more variables than equations then it was infinite, else no solutions. So this is wrong?
How can you tell
[4:06 PM] gotta go fast: Wait... so if I have a singular matrix (by finding determinant = 0), it will always have infinitely many solutions and never no solution?
ye i didnt read that first my bad
and wym how can you tell
just how a normal matrix can have zero, one or inf solutions, a singular matrix has zero or infinite, never one
I thought a nonsingular matrix can't have zero or infinite solutions 🤔
Can someone please help me understand why using linear combinations to find variables works? The proof I'm looking at says to think of it like a weighted average which kind of makes sense, but I'm having trouble verbalizing why if we have a weighted average, the point that the two equations intersect at will always be crossed by the equation of the weighted average
@pure tangle can you elaborate on the find variable works part? maybe an example
@smoky crystal thanks for the response. Is it alright if i post a link to their explanation?
im not sure but u can dm me
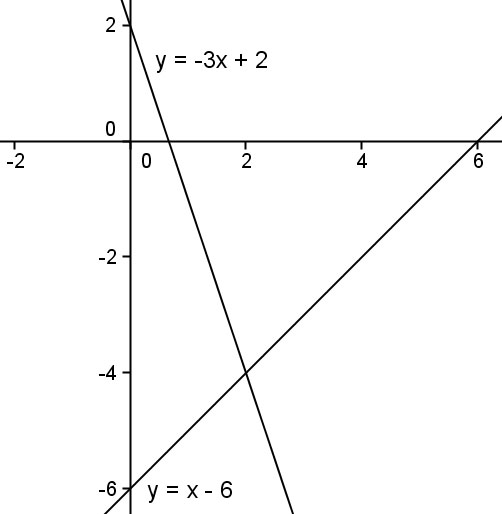
A system of linear equations consists of multiple linear equations. You can think of this as multiple lines graphed on one coordinate plane. Three situations can arise when looking at such a graph.…
@pure tangle this paragraph answers your question
what will be the weight average at the point (x1,y1) where it intersects?
well it will be exactly (x1,y1)
thanks so much for the response. so that's the paragraph i've been reading over and over and I'm still having trouble understanding
think of it like this, let (x1,y1) , (x2,y2) be any points on the two lines respectively, if they intersect, then we must have (x1,y1)=(x2,y2) or x1=x2 y1=y2. Now if we take their weight average for the two lines, what will happen to the weighted value at the intersection?
does it not change?
nope, it will not change
lets go the easy way and talk about average instead of weighted avg
that'll be easier to think of
thanks for being patient with me. I'm still having trouble understanding why that is
sounds good
now, if you have x1=x2, y1=y2, say pick any points ,eg let x1=x2=4 and y1=y2=6
well the avg for x's will be (x1+x2)/2 correct?
yes
and same goes with y's
yes
well plug in the values we have for x's and y's,
so we have (4+4)/2 for x and (6+6)/2 for y
now our average x, y . wouldnt you agree that its the same as the old one?
oh so if they're equal they're not going change after averaging out our line equations
yep
that makes perfect sense. Thank you so much for taking the time to help me!
nope problem, and weight average is pretty much the same thing, you can try for yourself
the whole point of using linear combinations is that we can play around with the two equations, and somehow make a 3rd equation such that one of the variables dissapear, or in the context of line, that the line corresponding to it is independent of the values of either x or y
like the case we have here where the blue line is independent of y
that's great. Thank you so much for all the help and patience!
however, just something that i personally dont like, is the way they call this the weighted avg, but yeah anyway gl
how would you better describe it?
np, i just so happen to be bored after semester finished for me
well here it describes the weight avg for a particular case of us manipulating the equation, which is multiply both side by a costant before adding
but it doesnt have to be
are you a HS student?
i prob asked too much ,its okay, anyway gl lol
@wintry steppe
I am so confused what eigenspace is. Can I have some clarification?
I have 1, -2, and 3 as my eigenvalues. My eigenvector corresponding to my eigenvalue of 1 is (1/3, -2/3, 1). My eigenvector corresponding to my eigenvalue of -2 is (-1/3, -1/3, 1). My eigenvector corresponding to my eigenvalue of 3 is (1, 0, 1).
Is my eigenspace {(1/3, -2/3, 1), (-1/3, -1/3, 1), (1, 0, 1)}?
well those arent your only eigenvectors
in the sense that any scalar multiple of an eigenvector is also an eigenvector, right? (unless that scalar is 0)
since they still satisfy Av = lambda v
your eigenspace is the space of all eigenvectors (as well as the zero vector) of a given eigenalue - so not only will it contain the three vectors you listed, but it will also consider any scalar multiples
if you're familiar with the notion of "span", then the eigenspace is the span of a given eigenvector
this is distinct from the set {(1/3, -2/3, 1), (-1/3, -1/3, 1), (1, 0, 1)} itself
since the span includes all linear combinations
Ok I see where ur coming from.
sorry my phrasing was misleading
edited
note that eigenspace is tied to a specific eigenvalue
we dont really talk about "the eigenspace"
since a given matrix/transformation may have multiple eigenspaces
we talk about "the eigenspace of the eigenvalue"
The thing I'm mainly confused about is this in my textbook. Isn't this implying that I have one eigenspace for each eigenvalue? The eigenspace being the eigenvalue's eigenvectors + zero vector
yes thats what im saying
I see
again my phrasing was poor
so if youre familiar with span
lets take the eigenvalue -2 as an example
the eigenspace of -2 would be span{(-1/3, -1/3, 1)}
or equivalently, the set {k(-1/3, -1/3, 1) | k is a scalar}
or equivalently, the set of eigenvectors associated to the eigenvalue -2, along with the 0 vector
theres a bunch of different ways to think of it
but they all result in the same object
and yes, each eigenvalue will have its own eigenspace
that makes sense. So my original thought of the eigenspace being all of the eigenvectors combined of all eigenvalues is just plain wrong. Got it, that's what I was mainly confused about lol
yeah
each eigenvalue has its own
(although some may be the same, if two eigenvalues have the same eigenvectors)
(if that's the case, then your eigenspace is multidimensional and it would be the span of multiple vectors)
(the same definition works though: the set of eigenvectors of a given eigenvalue)
it probably depends on instructor/prof but should I write the zero vector if I ever am asked to state the eigenspace?
yes.
or i mean
whatever set you write
should contain 0
so if you write something that doesnt contain 0, make sure to union it with {0}
gotcha
the definition they give - the set of eigenvectors together with {0} - is the best one
[although if you know what a "kernel" is there's another very handy definition]
[the eigenspace of a vector lambda is the kernel of (A - lambda I)]
[if you dont know what that means or if its weird to think about, dont worry about it]
[["kernel" and "null space" are the same thing]]
The kernel is defined in my textbook "the set of all vectors v in V that satisfy T(v) = 0 is the kernel of T and is denoted by ker(T)" but I don't know how it relates to eigenvalues and stuff
I do understand the kernel = nullspace thing though
well the idea is
if v is an eigenvector then it satisfies Av = lambda v
we can rearrange this to Av - lambda v = 0
and then factoring out the vector v
(A - lambda I)v = 0
where I is the identity matrix (of the appropriate size)
so now if we interpret (A - lambda I) as a linear transformation, call it T
this is the set of vectors v such that T(v) = 0
i.e. the kernel of T
Oh I see
where T corresponds to multiplication by (A - lambda I)
anyway, this isnt really necessary to worry about at first
but it might come up later on
(it's arguably a more "natural" perspective)
(lambda I - A) and (A - lambda I) are the same right (row equivalent in the end)
because my textbook has it as the former
oh yeah you end up with the same definitions
thats just what you get when you go from "Av = lambda v" to "lambda v - Av = 0" (instead of what i dod, going to "A - lambda v = 0")
the manipulations are the exact same
yeah okay gotcha
How hard is this course
idk how to get (ST)^2 = 0
all those vectors that S maps are actually the zeroes in T so T(Sv) = 0 for any vector in V
If TS is 0 ,STST is 0
i see
so the first T gives a vector and then S gives another vector, the third T makes it zero yes?
Yes
i see
maps V->V associate under composition so we can simplify STST whatever way, STST=S(TS)T=S0T=0
For the question:
Show that any set of five points from the plane R 2 lie on a common conic section, that is, they all satisfy some equation of the form ax2 + by2 + cxy + dx + ey + f = 0 where some of a, . . . , f are nonzero.
The solution said:
*On plugging in the five pairs (x, y) we get a system with the five equations and six unknowns a, . . . , f. Because there are more unknowns than equations, if no inconsistency exists among the equations then there are infinitely many solutions (at least one variable will end up free).
But no inconsistency can exist because a = 0, . . . , f = 0 is a solution (we are only using this zero solution to show that the system is consistent— the prior paragraph shows that there are nonzero solutions).*
I'm confused about the last line, why does using the zero solution show the system is consistent? The question says "where some of a, ..., f are nonzero" but how does this translate to a = 0, ..., f =0 being solutions?
The a to f are the variables in your system of equations
Now if there are fewer variables than equations, then a system of equations has either no solutions(if there is an inconsistency) or infinitely many distinct solutions
Because there is one solution (the solution where a to f are all 0), that eliminates the possibility of there being no solutions
So then there must be infinitely many solutions (and in other solutions, some of the variables are nonzero)
Unknowns probably better word than variables
@past meteor
I'm still a littlee confused, so if the system has either no solutions or infinitely many, I don't get how there's still the one solution when all a to f are 0
Do you not think making all the unknowns 0 is a solution?
how does that make it solution
Take an equation, make them all 0, and the equation is true
Np
alright
I don't think I want to give anything away.
You could do a proof by contradiction and assume there is a T where U = null T, but this is NOT what the solution is doing.
it's the multiple helpers thing
but isnt the question saying that the kernal equals (x1 x2 x3 x4 x5) where x1=3x2 and x3=x4=x5 ?
Yeah, yeah, but I still owe you for last time and I thought that was worth pointing out. Go ahead.
Vectors of that form get sent to zero
the exercise is showing that for any T in L(F^5,F^2), ker(T)**!=**U
i see
keyword !=. reread 'does not exist' in the text
What if we wanted to do it by assuming that there is a linear map from F5 to F2 such that the null space is that
then we would get that dim(RangeT) would be 3
then dimRangeT > dimF2
which is contradiction
So in the solution, they did a kinda direct proof?
if that's what you call any proof not using contradiction
im bad at proofs
sad
:(
it 'directly' aims to show any linear map F^5->F^2 doesn't have U as its kernel
One question, how does $<Tv,v>=\overline{<Tv,v>}$, makes $<Tv,v> \in \mathbb{R}$
which is more commonly used? null or kernal ?
Otoro
@thorny hemlock axler uses nullspace. i use kernel bc it used in more contexts in abstract algebra
yeah ?
(Take a=x+iy,x,y in R
conj(a) will be x-iy, x+iy=x-iy implies y=0
)
ah I see what u mean there
so since inner product gives out a scalar, the scalar is equal to its conjugate
got it thanks
MoonWolves-T-
Could someone explain how does the third line transform to the fourth ?
the definition of the adjoint
$\langle T^* Tv, v \rangle = \langle Tv, Tv \rangle$ by the definition of $T^*$, and that's just $|Tv|^2$. similarly for the other side
MoonWolves-T-
@old flame
ahhhh
so the vector in the definition is instead $Tv$ and $T^{*}v$ in the other case then
Otoro
i guess so
I mean by definition I just know that $\langle Tv,w \rangle = \langle v, T^{}w \rangle$. So from that we would have $\langle TT^{}v,v \rangle = \langle T^{}v, T^{}v \rangle$, So I guess its because the conjugates are equal, so the last one could swap places right ?
Otoro
i'm not sure what this has to do with conjugates
The one im talking about is $\langle T^{*}Tv,v \rangle
because from the definition the adjoint is in the right
so self adjoints have this property $\langle v, T^{}w \rangle = \langle T^{}w,v \rangle$ ?
Otoro
nno i don't think so, try T = identity, so that that fails if <v, w> is not a real number
maybe i misunderstood what you meant by "because the conjugates are equal, so the last one could swap places"
let me write something out
MoonWolves-T-
sorry i forgot how to tex there
the second equality sign is the definition of the adjoint
where it's on the right argument of the inner product
then you can undo the conjugate because swapping the arguments in <Tv, Tv> changes nothing
and then you just get the norm squared of Tv
oh
does that make sense?
yes, so instead the swapping occurs during Tv,Tv, so it doesnt matter as its the same anyways
mmhm
so I guess whenever I see T^* up front, should try to think of conjugating it to use the definition
probably a good thing to keep in mind, yeah
alright, thanksssss
i dont get the solution for the second part
they just chose a specific transformation so all the u's get sent to zero and say nullT = U ?
theres too many problems
If i wrote full proofs for each one
it will take me hours
well then at least convince yourself that null T = U by writing it down
i did
so what part of the solution is confusing you
i think ive understood now
for the second part,
We just need to show that there exists a Linear transformation such that nullT=U under assumptions given right
yes
yeah i think ive got it
$Forward: \ $T is injective \Rightarrow dimV \leq dimW \ $define $T(v_j) = w_j $ (This is injective and linear)\ Define S so $Sw_i = v_i$ for $i = {1...n}$ $Sw_i = 0$ for $i = {n+1....m}$ w1...wm is basis of W then $STv_j = v_j$
Yes
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)
does something like this work ? the solution does it a different way
what are the v_j's? w_j's?
basis
v1..vn basis of V w1...wm basis of W, j is just a specific something 1<= j<= n
@wintry steppe is this ... somwhat ok?

Yea, That's fine

Let V be an infinite dimensional vector space over a field F. Suppose that T : V → V
is a linear transformation such that Ker(T) is finite dimensional. Prove that Im(T) is infinite dimensional.
I was able to do this by finding a finite basis for V
but i remember seeing a clever solution using the first iso theorem that i cant recall
anyone know?
:0

yea contradiction
That's Pretty direct,ig
if i assume both ker and Im are finite dim
oh I see what you mean
im(phi) iso to V/(ker phi)

yea it used that
somehow
i dont remember how tho
and i cant find it
Do you know dim(A/B)=dim(A)-dim(B)?
yes
dim(im(phi)) would be dim(V) -dim(ker phi)
Since dim(V) is infinite ,dim(im(phi)) is also infinite
doesnt this only work if B is a subspace tho
ker phi is a subspace of V
did the normal chatting channels get deleted?
oh lmao
hm
apologies for the weird notation (it's just the linear maps as matrices in their respective spaces)
looks like linear done right book
I'm a bit confused in the end result, is B^T = A or is B = A?
this is basic algebra by knapp
what does that cover?
it's an abstract algebra textbook for the most part but he spends like 4 chapters covering LA in an abstract setting to build motivation
oh cool
I was reviewing his sections on dual spaces and quotient vector spaces so I would have a better understanding of inner direct products of groups
sounds like grad school is making you busy during winter break
I'm putting myself through this actually, I've felt kind of bad for my woeful lack of algebra knowledge
oh nice. Is it so far worth it
Knapp is seemingly very well written
I haven't done any abstract algebra beyond linear algebra and although it's aimed at graduates it's a fairly pleasant read
I'm actually enjoying myself despite pretty much only doing analysis/topology/geometry
contragredient
this notation is really confusing
contragredient makes me feel like i'm gonna be eating food soon, too close to "ingredient"
but all i'm fed is shitty indices
shouldn't the end result be A^T = B (matrix transpose) anyways
i agree with you slim
not in the statement of the proposition, unless i've failed to interpret that notation from the context

some weird way of writing the matrix that represents a linear map
what else?
lol
@brisk fractal typo in the statement probably, end result should be B^T = A
i checked against another book (friedberg) to be sure
bacono can utell us what the notation means
pls
i don't like this
slimvesus
bacono depriving us rn
$[T]_\beta^\gamma$ means the matrix of $T \colon V \to W$ with respect to the bases $\beta, \gamma$.
TTerra
friedberg
fries burger
yes
i don't think friedberg contains much more than axler
😔
roman talks about infinite dimensional space stuff
neat
hello I am back on my computer
yeah so I think it is a typo tterra
the reason I ask is because in the proof it claims that A, B are just the matrices given in the statement, but then it proves that A^T = B instead of A=B



don't worry about it
.
just reinforces what you said
"read a linear algebra book"
there was a typo in my textbook yesterday, I spent half an hour trying to prove something impossible
typos do make me mald
if they're critical
I only found out in some comment of a math stackexchange post
that it was a typo
fixed in later versions
@wintry steppe I'm on the cringe part of the Sylow section
have fun!
😩
i like how all of these require you to find the prime factorization
I just have a prime factoring website open
slimvesus
-1 as in inverse?
i havnt learnt all of this yet :0
maybe theres an easier way of doing it
no
doing the axler book
slimvesus
oh yeah
lol
lmao
ok
T-1 takes a vectors from W to U ?
confusion
er
T-1(nullS) = u \in U where u is in nullS ?
ok
i see, then use rank nulitiy thing
yeah got it
what the hell 'positive definite' mean? @ me
ok 🤔
alright thanks Namington
How does he find the diagonal matrix with respect to the eigenvectors from the orthonormal basis ? what is the calculation procedure ?
Just find the eigenvalues
He found the diagonal matrix and used that to find the eigenbasis
so use the basis to find the eigenvalues ? then find the corresponding eigenvectors right ?
oh but that is taught in chapter 8
Anyway,The point is that there will always be a diagonal matrix,similar to a normal matrix
I mean I was trying to verify and that was stated, but not sure how lol
yeah well I get his point, which its literally the complex spectral theorem up next
one to one correspndance ?
I see, thanks
I am just wondering why is the decomposition in terms of null spaces ? This I still don't really fully understood, even though I have seen this a couple chapters back
well null(...) are just the eigenspaces
Otoro
null(T-xI) will be the subspace of eigenvectors with eigenvalue x
Let V = W = R^3 and T : V → W be the linear transformation T(x, y, z) =
(x + 2y + 3z, y + 2z, 2y + 4z). Find a basis BV for V and a basis BW for W such that the matrix representing T with respect to the bases BV , BW is a diagonal matrix
so i need to find bases {v1,v2,v3} and {u1,u2,u3} such that T(v1)=au1, T(v2)=bu2 and T(v3)=cu3
is this just guess and check from here?
it doesnt look very linear
Ah
<@&286206848099549185> any hint?
how do I show that a cyclic operator T such that T^2=T cant be invertible
Well,You can take it that way
how do we know the det is 0 tho
If T^2=T,The minimal polynomial of T is either x or x-1 or x(x-1)
In first case,T=0 ,in second case T=I and in the final case,T is diagonal in some basis,with zero as an eigenvalue
Minimal polynomial of T is a polynomial p,such that p(T)=0(i.e, p(T)v=0 for all v)
yea havent met yet that
What do you mean by cyclic operator?
T on a Tcyclic subspace?
T is cyclic if there exists a v such that the set {v,T(v), T^2(v)...} spans V
You can conclude,V is atmost 2 dimensional in your case
Because {v,Tv,T^2v...}={v,Tv}
Since T^2=T
And then consider matrix of T in basis {v,Tv}(if 2 dimensional)
If V is one dimensional,T=I,and T is invertible
shouldnt it be at least 2 dimensional?
nvm its not
ok yea if it has dimension 2 then it cant be invertible
but if it has dimension 1 doesnt that mean the question is wrong?
cuz the identity operator is invertible right
right? @native rampart
if U,V and W be subspaceses or R^n . Is U∩(V+W)=(U∩V)+(U∩W) true ? If it is true how could I proof that ?
<@&286206848099549185>
Yes
ok thank you
Doesn’t look very true
why how can I conclude that
Finding an example that fails
it is very false, not hard to come up with a counterexample in R^2
what if I defined a element of V and b element of W then define x= a+b then if x element of U∩(V+W) then x also element of U and x element of (V+W) . But (U∩V) does not contain x and (U∩W) does not contain x.
@wintry steppe @wintry steppe @thorny hemlock
find a case when the intersection of U with V+W is small, but the intersection of U with one of V or W is large
included two vectors which have two row and one column
this vectors must hold 3 condition
okay what are the types
lines through the origin
lets choose x+y=0 and x+2y=0
This is a physics question that has to do with vectors, so I thought this may be the right channel. If not, please lmk.
My question is why can't I multiply the magnitudes of F and ∆d together to get work? Why do I have to use the dot product?
@wintry steppe we are trying solve the quesiton and you send quuesiton bro c'mon
#old-network physics server might be more useful
It's a conceptual question, so I don't think the answer should matter
they could give you a better conceptual understanding of force and distance and work
Gotcha - thanks!
ı dont understand
pancakehammer
(0,0)
And the sum?
sum is still (0,0) but now we have not false statement
No
yes
slimvesus
left hand side can be equal ${0}$
its vector addition ı dont know
its line through the origin nvm ı cant find it
v and w are linearly independent, so their span is 2 dimensional. what are the 2 dimensional subspaces of R^2
thats not a subspace
the only 2 dimensional subspace of R^2 is R^2 itself.
so the span of v and w is R^2.
and left hand side is R^2 but right hand side is 0
you mean of U∩(V+W)=(U∩V)+(U∩W)?
yeap
almost
U are included R2
yes but (V+W) included R2
?
V + W is R^2, but U is a subset of R^2, so the intersection is just U
one side is U, one side is empty
if a finite dimensional vector space V with dim(V)=n has a linear map T with n distinct eigenvalues, where v_1,v_2,...,v_n are the corresponding eigenvectors, then is any invariant subspace under T just the span of some collection of those eigenvectors?
just yes or no will help me
nm think I figured it out
haha idk yet but I suspect yes. I'm trying something with quotient operators
i'm tempted to say yes
cause if you diagonalize T then it's clear that the invariant subspaces (identifying V with R^n) are just the axes, and then something about changing bases and how that interacts with subspaces idk puts away crack pipe
that's an interesting take
it'd be nice if it was true so it is true right??😆
what was wrong with what you said?
i wanna check it before i un-strikethrough it just to make sure i'm not saying complete bs
cause also the entire space is invariant and so is {0} so i have to be a bit more careful with that claim
maybe "the only non-trivial proper T-invariant subspaces are the axes" ?
just thinking about how like, a diagonal matrix is just scaling along each axis, it makes sense
I figure just represent anything in the eigenbasis, it will automatically be trapped in the span
skimming over my LA book to see if there're any nice results about invariant subspaces that could be used here
alright so if you restrict T to any invariant subspace, you get an operator whose characteristic polynomial must divide that of T. now, by assumption, the char poly of T splits, so the char poly of T restricted to any invariant subspace splits
i.e. T restricted is also diagonalizable with some subset of the original eigenvalues
(still doesn't really answer the original q tho)
that's cool I didn't know that
try proving it, you take a basis of the invariant subspace and extend it
overcomplicating is fun
i tried representing in the eigenbasis earlier but it got messy. so i went looking for another way
eh?
Let $W \subset V$ be a $T$-invariant subspace of $V$. Since $T$ is diagonalizable, $T|_W$ is also diagonalizable in $\mathrm{End}(W)$. That is, $W$ is spanned by some of the eigenvectors of $T$.
TTerra
@fallen karma some relevant facts/exercises
(from section 5.4 of the linear algebra book by friedberg, insel, spence)
I was thinking of something a bit simpler
suppose you take any invariant subspace, then all its vectors can be represented by a linear combination of some set of eigenvectors. Then let's show it actually contains the entire span of these eigenvectors
Sorry to interupt, why is it true that if $Ax = 0$ only has the trivial solution then A cannot have a free variable?
pancakehammer
so take some u in the invariant subspace, it has coefficients, $$u = \sum_{i=1}^n a_i \vec e_i$$ now we can get the vectors in our invariant subspace $Au$, $A^2u$,..., $A^{n-1}u$ to get $A^k u = \sum_{i=1}^n a_i \lambda_i^k \vec e_i$ which gets us a system of linear equations
Merosity
it's a nice vandermonde matrix that we can invert which has det !=0 since the eigenvalues are distinct, so we can solve for any eigenvector as a linear combination of the A^k u
and by being a subspace we have all scalar multiples
oh thanks
yeah bet, I didn't think about applying the operator more than once
just wait until you get to cyclic subspace nonsense 
How could I forget this place exists?
Does the set with only the 0 vector have a name?
Dunno, maybe 'the trivial vector subspace' or something like that maybe
its just the zero space
if a transformation preserves the dot product, does that also mean it always preserves angles?
Correct or not? How is my writing?
well, do you know any formulas that relate the dot product to the angle? @tame mural
It's correct
Sure, it's the dot product of two vectors divided by the product of their norms
Is there anything I can improve in my writing?
yeah pretty much, and the norms, can those be written in terms of dot products?
hello, i had a question about the following proof:
I understand the general point of the proof, but I was confused because I thought the stuff in the blue brackets might be too informal
I also don't understand what the finite-ness of S has to do with anything - why couldn't this work for a potentially infinite S (besides the fact that the theorem would be false)?
I mean, you could end up choosing all the vectors of S if they are all linearly independent
But that's it, then you can't choose any more
sure, but what I'm saying is why the statement "continue, if possible, choosing vectors such that $${u_1, u_2, ..., u_k}$$ is linearly independent" is the right way to do it
kirafa
shouldn't there be some kind of induction involved?
I don't know what you mean. It's basically "in a finite number of steps, you can either choose vectors so that you cannot choose another so that's its linearly independent or you have chosen them all."
There's nothing wrong with saying you can do something a finite number of times
Tv = a1w1 + .... + amwm where a's/in F
S1(v) = a1 .... Sm(v) = am
thats correct right?
there is $$T_1, T_2 \in L(V,W)$$, prove inversible transforms $ R \in L(V,V)$ and $S \in L(W,W)$ exists such that $T_1 = ST_2R$ iff $ dim(N(T_1)) = dim(N(T_2))$
Amirali
Yes
any help will be appreciated
@wild fern you know change of basis, it follows from that
except that what is N in dim(N(T_1)) = dim(N(T_2)) , you didn't define that
N is nullspace
well seen that notation for first time, either use null or ker , I don't think N is the official notation for nullspce
its in linear algebra by carl d. mayer
ok, I am really ignorant, but that Q follows directly from change of basis of a linear transformation
hope it helps
thank you ill try

Mathematics Stack Exchange
What exactly is the matrix of a quadratic form? I have seen this notation occuring in a few papers (e.g. Siegel's unreadable German papers), with particular reference to the trace of a quadratic fo...
that's the inverse process, the quadratic form of a (e.g. real) matrix $A\in \mathcal M_{n\times n}(\bR)$ is $q: \bR^n\times \bR^n \to \bR$ given by
$$
q(x,y)=x^{\mathsf T}Ay.
$$
derivada.schwarziana
all it does is associate a degree two polynomial to the matrix. It appears naturally in mathematics, e.g. inner products can be defined by quadratic forms. One proves that quadratic forms are esseentially the same as symmetric square matrices (in fact each quadratic form has a unique such matrix)
ah that's right I keep confusing them
Gram-Schmidt will not always give you an eigenbasis
Just Take a non eigenbasis(Start your construction with a non eigenvector) and apply gram schmidt,you wouldn't get a eigenbasis
I don't think that's true in general
pancakehammer
yes, sorry about that typo
or better, the null space of the 1 by 2 matrix (2 -3)
had a brain fart for a sec but that's what it should be
the elements of V are vectors
what does Nul(2 -3) mean to you
that may help clarify things
pancakehammer
I am confuse because $[\begin{bmatrix}
2 \
-3 \
\end{bmatrix}]$ is in $R^2$ and $[2 -3]$ is in $R^1$ but it feels like they liberally switch between them?
what's so confusing about it ?
pancakehammer
how is that second one in R^1
wat
the distinction between column vectors and row vectors / tuples is usually blurred
just something you have to get used to
do you know how the vectors in R^2 and R look
yeah, I guess they'd both be lines?
that's good to know though I appreciate that @wintry steppe
this is an important point #linear-algebra message
but the former line is in R^2 and the latter R^1?
see it clearly
okay I will look now, thank you
addendum: for the sake of multiplying vectors by matrices, they are column vectors. however, they will sometimes be written as row vectors to save space, which is why sometimes you see authors write things like [2 -3]^T inline
Does the same thing hold for a 2x2 matrix, I know the row 'picture' and vector/columns 'picutre' are the same , but I'm not exactly sure why yet
or is that different from what y'all are talking about?
these are equivalent
actually the 3) is the one , from which 2) comes out as I studied in the beginning, but you can do from 2) to 3) as well
doesn't make a difference
nice, I hope this is related to what you were saying
yes what you say about 2 and 3 makes sense I think
I still cannot connect 1 and 3 or 1 and 2 though, I know the proof that they must have the same solution set which I know is true but still feels unenlightening
is that something that will become clearer as I progress in Linear algebra?
1 -> 2 are what you first study in any book, how to write a system of linear equations in matrix form
as 2 and 3 are equi 1 and 3 are equi , you just need to look at it
yeah you're right I can see 1 and 3 must be the same by definition now that I look
but in my mind 1 is the equation for two planes, wheres 3 is a linear combination of vectors
although I do not like it, you can read Strang's Chapter 1 , he has discussed about geometry of linear equations well
@limpid fiber
anyone done quaternions here?
 (possibly in #groups-rings-fields depending on what your question's about)
(possibly in #groups-rings-fields depending on what your question's about)
is there a special name for the matrix $\pm\begin{bmatrix}0&1\-1&0\end{bmatrix}$?
nix
i know its the matrix representation of the complex number plus minus i but does it have a name?
definitely not a unique standard name
some authors use $\mathbf{1}=\begin{pmatrix} 1&0\0&1 \end{pmatrix}$ and $\mathbf{i}=\begin{pmatrix} 0&1\-1&0 \end{pmatrix}$
derivada.schwarziana
i see. thank you 🙂
Given a real vector space $V$ and being $\mathscr{A}{n}(V)$ the space of all alternating n-forms $\varphi : V \times \hdots \times V \rightarrow \mathbb{R}$. We can define $A^{#} : \mathscr{A}{n}(V) \rightarrow \mathscr{A}{n}(V)$ as $(A^{#}\varphi)(v_1,\hdots,v_n) = \varphi(Av{1}, \hdots, Av_{n})$
\
\
The important thing to know is that since $\dim \mathscr{A}{n} = 1$, then the LHS is just equal to $\varphi$ times a constant, which we define as the determinant of the linear operator A.
\
\
So $\det A$ satisfies by definition:
\
\
$\det A \cdot \varphi(v{1}, \hdots, v_{n}) = \varphi(Av_{1},\hdots,Av_{n})$
MisterSystem
I just wonder if this A hash operator has a name
or is just a trick we use only once to define the determinant of a operator
I also wonder what's the intuition behind this definition
if it has some geometrical insight if it's R^n maybe
oh, V is finite and has dimension n
I forgot to say that
But how can we prove using this definition that $\det A = \int_{ [0,1]^{n}} 1 dx$
MisterSystem
(Damn I'm horrible at typesetting)
pullback by A
it's pretty important, i'd say it's got a lot more applications than just this
e.g. in slightly more generality, if you have a linear A : V -> W, then you can define the pullback A^* : {k-tensors on W} -> {k-tensors on V} in an entirely analogous way
particularly useful in smooth manifold theory
also i think you mean to write $$\det A = \int_{A([0, 1]^n)} 1$$
TTerra
in that case, you can use the change of variables theorem for integrals

\begin{align*}
\int_{A([0,1]^n)} 1 , dx^1 \wedge \cdots \wedge dx^n &= \int_{[0, 1]^n} A^(dx^1 \wedge \cdots \wedge dx^n) \
&= \int_{[0,1]^n}\det(A),dx^1\wedge\cdots\wedge dx^n \
&= \det(A) \int_{[0,1]^n} 1 , dx^1 \wedge \cdots \wedge dx^n \
&= \det(A)
\end{align}

can you wait?
yep sorry
TTerra
@winter harbor
eh tbh you don't need to do the pullback and differential forms nonsense to prove that, that just follows pretty easily from the classic change of variables theorem
but i wrote it like that to try and emphasize your definition of det A, i guess
overkill is fun

oh yeah, you are right, I meant A([0,1]^{N})
is that a lebsegue integral?
thanks
np
riemman integral in R^n
differential forms are fun
?
are these lebsegue integrals?
no
no
nah
oh
rein
plain old riemann integrals

this is just the riemman integral in R^n as I have said before
lmao
why don't they have an upper bound?
theyre multidimensional
because you're integrating over a region in R^n
yup
woah
I mean
oke, for my question, 1/x^3 , 1/2x^2 , x , 1 for p3 and x^2 , x, 1 is correct ?
@thorny hemlock what was your question?
oh woah
when you have an integrable function $\varphi{phi} : [a,b] \rightarrow \mathbb{R}$, and you want integrate this function over an its domain, you could just write it as $\int_{[a,b]} \varphi(x) dx$
MisterSystem
it means that you are interating from a to b
or more generally
integrating this function over the region [a,b]
integrals are scary
integrals 😠
it's just that we are used historically to write it as $\int\limits_{a}^{b} \varphi(x) dx$
MisterSystem
but in general
Define $F \colon Vect_k \to Vect_k$ by $F(V) = {\text{$k$-tensors on $V$}}$ for objects $V$ and $F(T) = T^* \colon F(W)\to F(V)$ for $T\in Mor(V,W)$ by $T^*\omega(v_1,\dots,v_k)=\omega(Tv_1,\dots,Tv_k)$. Then $F$, the pullback, is a contravariant functor
TTerra
if only texit displayed emotes
integrals are not always so bad to set up, but the scary thing is the integration
when you are dealing with integral operators over more complicated regions in a way more complicated space as R^n (say differentiable manifolds) we just write the region we are integrating on below the integral symbol
for example
stokes theorem for a general Manifold M may be written like this
$\int_{\partial \Omega} \omega = \int_{\Omega} d \omega$
\integral isn't a thing, use \int
I forgot it lol
you got it right on one side
MisterSystem
why are we doing stonks theorem in lin alg
why not?
I mean
it has to do with linear algebra
I'm convinced
manifolds are just the union of the basepoints of their tangent spaces
so
basically linalg
algebra...
algebra is the only real math dont @ me
the term "semidirect product" came up when i was reading IRM today and it felt nice to know what it meant
maybe algebra isn't so bad
lol, I love semidirect products
whats IRM
nice
i still dont really know what a semidirect product is
okay actual confession
i always forget which way to write
the fish symbol
for semidirect product
i get that its like "the same as" the triangle for normal subgroups
but
still
it just looks wrong
little omega is just a differential form, which is a kind of linear-form for general vector spaces, and d little omega is just the exterior derivative which is a linear operator.
Also
isn't it a way of writing a "product" of groups by a homomorphism
and it happens to have some relationships to automorphism groups at times
uhh I said before ''the manifold M'' but I wrote Omega in the latex
and I didn't even say it's an orientable smooth manifold with boundary
if you let the homorphism be from K -> Aut(H) for H (weird x) K
what a shame
If $\varphi\colon K \times H \to H$ is a group action of $K$ on $H$, written $\phi(k, h) = k \cdot h$, satisfying $k \cdot (h_1h_2)=(k\cdot h_1)(k\cdot h_2)$, then define $\tilde{\varphi}\colon K \to Aut(H)$ by $\tilde{\varphi}(k)(h) = k \cdot h$. Then we have a semidirect product $H \rtimes_{\tilde{\varphi}}K$, and conversely.
TTerra
no
dumb fish symobl
Also TTerra
let's abstract to the group action ur mom had last night
I have studied about Pullbacks and Pushforward in the context of manifolds
but I just don't get the concept at all
I guess that's why I forgot the definition
what's the intuition or the motivation?
honestly off the top of my head, i don't know what the intuition or motivation is, other than "it's a really useful thing that comes up everywhere"
i'd have to think
it just happens that it's useful when studying 1-differential forms of a smooth manifold
and now it happens to be important to define the notion of the determinant of a linear operator
merry christmas my linear algebra people
@wintry steppe why is it that when you are integrating over A([0,1]^n) it's the same as integrating the pullback of the wedge product of those differential forms over [0,1]^n ?
you don't actually need the differential forms stuff to do it, there's a simpler proof that avoids it (despite being basically the same thing)
you can do it with just this guy
also
looking at this and the page i linked, i was a bit sloppy with the signs
you have to be careful to account for the case that det A < 0
yeah you are right
orientations 🙄
I really meant |det A|
but i didn't know the change of variables theorem had something to do with pullbacks
well the scalar you get by doing pullback by A will still be det A (without absolute values out front), just when you start integrating you'll pick up a negative sign if det A < 0, whence the absolute value
i am pretty sure the change of variables theorem on manifolds is just the pictured one in disguise
https://www.youtube.com/watch?v=H9-bAbRFG8Y&t=3170s time to rewatch this again
Programa de Mestrado - Análise em Variedades - Aula 11:
Orientação. 1-formas diferenciais. Pull-back. Álgebra multilinear.
Professor: Luis Adrian Florit
Página do curso:
https://impa.br/
Download dos vídeos:
http://video.impa.br/index.php?page=programa-de-mestrado-2014-analise-em-variedades
Pré-requisito: Análise no Rn
Variedades diferenciá...
so yeah I know some of the motivations now
but I still don't get the intuition behind the concept
maybe math stack has something concerning this
maybe you can mess around with the 1-dimensional case of pullbacks, in which case it's just composition by the operator
if $A=QS$ where $S$ is symmetric and $Q$ is skew symmetric, will it always be the case that $\operatorname{tr}(A)=0$?
nix
yes
why? how could i prove that?
just saying tho thats freakin awesome btw
tr(AB) = tr(AB)* = tr( B* A*) = tr(-BA) = -tr(BA) = -tr(AB) => tr(AB) =0 here I used * for transpose in order to keep it neat
tr(AB)* = tr( B* A*) this can be proved
nice
Or just writing and expanding the matrix product works
Not as nice, But this approach is kinda obvious
yeah, that is a good way too by writing the matrix product
so tr(QS)=tr(S*Q*)=tr(-SQ)=-tr(SQ)
because tr(SQ)=tr(QS), we get tr(QS)=-tr(QS) so tr(QS)=0
i dont quite get what the transpose of a trace is though. i thought that was a scalar quantity
mmmhm
It's also nice,that transpose is the only functional on matrices such that f(AB)=f(BA)