#internals-and-peps
1 messages · Page 114 of 1
they're pretty necessary for Python modules that are implemented in C or C++ or Rust or some compiled language like that. Normally a type checker will go read or evaluate the source to find type annotations, but when the source is written in an entirely different language that's not possible.
So, type stubs give a way to provide just the type annotations, in a format that type checkers can read and understand.
Hello, I found an oddity in my code I deciced to explore... can someone explain the following behaviour?

somehow, all lists that are copied from that input, even when parsed as a parameter, all link to each other?
a single list can have multiple names
if you want a copy of a list, you have to make it explictly
you say "all lists", but there's only one list in that code.
Well in this one, yeah, I copied it from my other programm after finding the issue. But I think this answers my problem :p
this talk - https://nedbatchelder.com/text/names1.html - will probably give you a much better understanding about how variables work in Python.
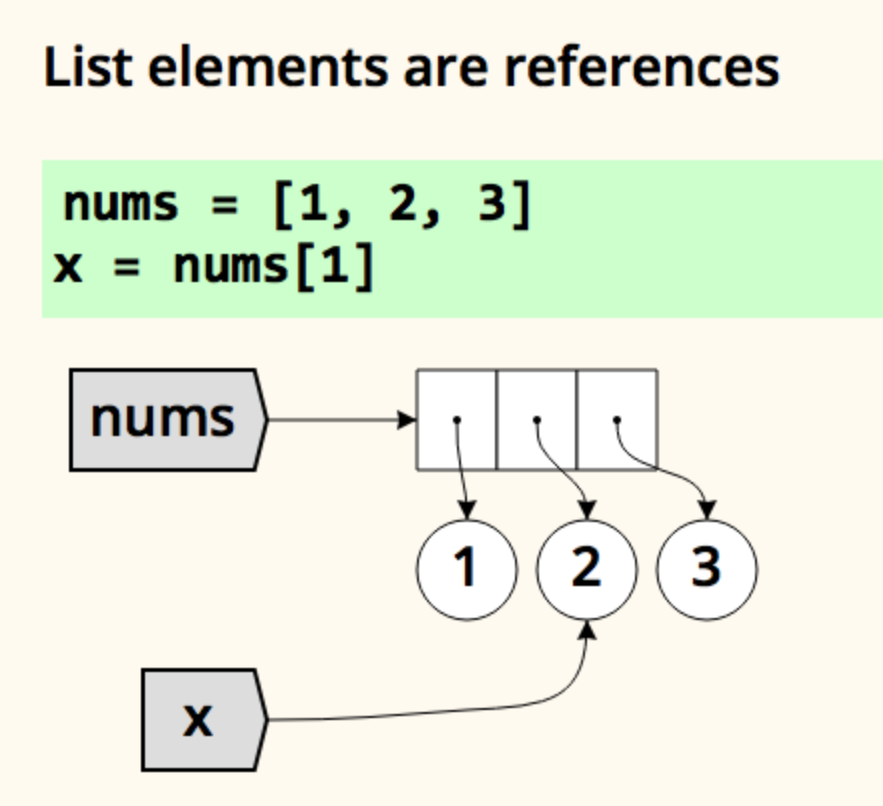
Assignment in Python might surprise you. How do names and values work? This presentation explains it all.
I highly recommend it.
Thank you very much, highly appreciated.
isn't the gist "everything is a dict somewhere" ?
ayy nedbat
it's true that everything is a dict, but that's beside the point.
because it's the same behavior even when it's not a dict, like with __slots__
how do you make a id to user in python
tldr: binding something to a different name doesn't make a copy
I find that behavior very intuitive and I actually find it really weird that not all languages work like this
maybe it depends where you start
coming from C++ I found it pretty bizarre
I personally don't think this behavior is so intuitive, because most of these languages end up going out of their way to make their "basic" types not behave like that
integers, doubles, strings, booleans
Compare to C++ where integers, strings, booleans, and collections like lists/dicts all behave in the same way
In Python, integers, strings, booleans, and collections like lists/dicts all behave in the same way 🙂
right?
I mean, there is some sense in which you're right, but that sense mostly makes the matter meaningless
in a meaningful sense they behave pretty differently
What's the difference?
Variables (attributes, locals, globals etc.) refer to objects, and assignment changes what object the variable refers to. That's the same for integers and for lists.
The only difference is that integers are immutable.
they're immutable but the relevant operations that you'd want to mutate them are defined in such ways behind the scenes so that they're actually making copies
so it's working in a very different paradigm than the collections, where you are actually mutating
so in that sense they do behave pretty differently
I don't understand you
the relevant operations that you'd want to mutate them are defined in such ways behind the scenes so that they're actually making copies
What do you mean by this?
like imagine if x += y, for a list, didn't actually mutate the list
well, yes, += is a bit of inconsistency we talked about earlier 🙂
idk if it's inconsistent so much as the + operator just means totally different things for different types
I mean, you can view it as an inconsistency, but it's an extremely deliberate design choice
the thing is that python as a language doesn't really value immutability very much, but mutability with things like integer that get "copied" around a lot in local scope would be really really error prone
however, not having "mutating" operations on integers like += would also be really unergonomic
so the net result of all this is to design the types differently, throw in some syntactic sugar to give the illusion of mutability when you need it
in C++ integers and vectors are designed in the same basic way, they follow all the same basic principles (this is actually a thing in the C++ world; designing a "regular" type, which is often briefly summarized as designing types to behave like integers)
As an example, in C++ += is just a call to a member function, it cannot do any magic. C++ vectors ( = lists) do not have operator+=, but C++ strings and integers do, and they both conceptually work exactly the same way (in place mutation)
To me this all seemed very logical when I was learning programming. The first time in python I took a list and did x = y; print(x); y += 1; print(x), it felt kinda gross
In Python, x += y does the same thing for every type:
- Call
type(x).__iadd__(x, y) - Bind the returned value to
x
The difference is that for mutable types, __iadd__ mutates the object, but for immutable types, __iadd__ doesn't (because it can't, of course).
I kind of wish that there weren't a special __iadd__ overload, and that x += y would mean x = x + y. But it seems that out of languages that allow overloading, only C# does that
The docs for __iadd__ do say:
These methods are called to implement the augmented arithmetic assignments (
+=,-=,*=,@=,/=,//=,%=,**=,<<=,>>=,&=,^=,|=). These methods should attempt to do the operation in-place (modifyingself) and return the result (which could be, but does not have to be,self).
Admittedly that's kind of a strange contract - it would be more consistent ifintjust didn't support+=instead.
It's a bit odd to say "should attempt ... in-place"
How do you teach += to beginners so that there's no "forget what I told you" thing?
or maybe not introduce it at all until collections are covered?
I'm not saying += does something different in the way it works, but it's overall effect for lists and ints are semantically different
One is mutating, the other isn't
When I teach beginners, I just don't mention augmented assignment at all. I just teach them x = x + y, and if they ask about +=, I'll tell them that it's basically a shorthand for x = x + y, but with some differences we'll talk about later.
Well, yes, but it has to be, because ints are immutable. The only way around that would be to either a) make it not mutate a list, or b) make it unsupported on an int
Yes
But like I said, the whole point is that ints and lists behave rather differently
I agree that it wouldn't have been much of a loss of x += y were defined to be x = x + y, though.
well, ints are reference types as well, just like tuples
yeah. They're reference types, just immutable reference types.
Not really sure what you're saying
They are still value types in their behavior
You can do is because you do is on any type in python
they're the same type as every other object in Python is: a reference to an object.
it's only that the object they refer to isn't mutable.
Can you perhaps define what you mean by 'reference type' and 'value type' then?
they're C++ terms
Yes, and immutable reference types do behave the same way (in most ways) as value types
They're not just C++ terms at this point
This is a fairly well worm discussion in the context ofany languages
Just that python isn't really one of those languages
If you're interested in this stuff I can probably link a Sean parent talk, if I can find the right one
a type with reference semantics behaves as though it refers to the object it was assigned from, and changes to the object affect the object it was assigned from.
a type with value semantics behaves as though it's a copy of the object it was assigned from, and changes to the object don't affect the object it was assigned from.
Yes, and when your objects are immutable you can't distinguish
a smart pointer in C++ is an example of a type with reference semantics, for instance.
sure, but then don't say they behave with value semantics 🙂
And then your object is immutable, but has operators to make things "look like" mutability, and that's the overall effect
It still is value semantics
But hey, argue with Sean parent, he can surely learn a thing from you right ;-)
returning a different object from a method rather than choosing to mutate your original object doesn't mean you have value semantics
In value semantics, only the value of the object matters, identity does not
That's why it's called value semantics
With lists identity does matter because it determines whether you are mutating the same list
With ints it doesn't
🤷♂️
But honestly just watch the Sean parent talks if you are interested
There's a ton of prior art here, it seems rather pointless to argue
indeed. In any event, yes it's a bit weird, and yes it might have been better if augmented assignment had been defined differently in Python.
Mutating on += also seems weird because there's already the extend method.
Maybe, I'm not sure what way would be better
So... what should I do? += or extend?
Kotlin ends up with a very similar idea to python
But it achieves it differently
Worth looking at how += works there if you're curious
yeah it's a bit cursed
I think that reference types + mutability is frankly just bug prone, there's no way around it
Making your basic types immutable is damage control
Very practical and limited
But ultimately just damage control
The way we teach people += the first time they see it is to say that it behaves like x = x + y. If I were designing the language from scratch, it seems reasonable to make it actually behave that way, instead of that just being a hand wavy shorthand for explaining it to people.
who is we? 🤔
Then x += y on lists would be a horrible performance trap
well, if you understand that + creates a new list, I don't see an issue here
Isn't list iadd (I'm on mobile) just another reference to list extend?
not exactly, because extend returns None, but __iadd__ returns self
@grave jolt usually you want the convenient to type thing to be fast, not slow
Why does it return self when it's acceptable as a statement rather than an expression?
Python is convenient to type, C is not 🙂
Not sure who brought up C
forget it
Ok
as I said above, x += y is defined to perform two steps:
- Call
type(x).__iadd__(x, y) - Assign the result to
x
If you had to write it without the operator overload, x += y would be x = x.__iadd__(y)
I have seen any languages that favor mutation actually make += work that way for a mutable type
Haven't
We already don't have that with += on str and tuple, I don't see why it should be any different for += on list
I do suggest checking how Kotlin handles it. It has the advantage that every variable is explicit in whether it can be reseated or not
So it uses that to determine which to do
Because string is immutable
So it's just a different situation
well, fine - why should + be slow and inefficient but += be fast and efficient?
Especially when the "fast" version has different semantics!
Because += seems like it could mutate
With + you're being explicit that you're creating new lists
Do people learning the language really expect x = x + y to be slower than x += y? I strongly suspect no.
We know that it is because we all know how it works - but we're literally in a conversation about how it works not being intuitive 😄
I did when learning python
hm. It may depend on what languages, if any, you knew before Python.
Probably
I very much doubt that someone who's seeing Python first would expect that, at least.
But I can only repeat that I've yet to see a language that works the way you envision
In C# x += y means x = x + y
https://stackoverflow.com/questions/6587107/c-sharp-operator-overload-for
doesn't seem so
Okay
So C# isn't an example of what I meant
If anything I'd conclude the opposite, they decided on += to have simple semantics, and then decided not to overload it for list because they probably didn't want to encourage an inefficient way of mutating lists
no
knowing what;s faster is neat but speed isn't Python's focus
it's not obvious how fast comprehensions are, either
I feel like I've seen this exact discussion happen on here before XD
Re conversation above, I'm sure we wouldn't even have grounds to say that mutable and immutable things have different semantics if += didn't behave the way it does right now. It's the only inconsistent wart in this whole affair.
in python, x += y only behaves differently to x = x + y if you explicitly define a __iadd__ method, otherwise it will just fall back on __add__ and needs to re-assign to the lhs anyways, this is the case with int for example so idk if its always the case, at least in the std lib but maybe looking out for if a class defines __iadd__ is a suggesstion to whether it mutates or not
in cpython it mutates mutables in place
__iadd__ is defined differently
explicitly in cpython
but in python itself it is weird that it isn't just syntactic sugar
imo
well it's syntactic sugar for extend...
I think literally
No, it's not an implementation detail. That would be horrible.
where does it say that it's specific to CPython?
The conditional in place modification of strings is CPython specific, but iadd modifying things in place for some types is a python feature
yeah I didn't know about other versions thanks
anyone know how to bypassgalaxy frp
!rule 5 bruh
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
@wraith pumice don't spam, thanks.
@spark magnet okay sir
Err, mutable and immutable things have different semantics, because mutability is part of their semantics
is there any compelling reason to use is None over == None, other than the fact that it looks nicer?
normally we try to avoid using is, but people write is None all the time
basically taking advantage of the singleton property of None, which in pretty much all other contexts you specifically aren't supposed to do
potentially valid in a hot loop, yeah
just a weird convention that seems totally counter to the usual advice about using is
you can also if not thing: a lot of the time
depending on other values it could take
setting _len = len inside a function to avoid global lookups in a hot loop is faster, but that's an optimization, it's not like we do it all the time
TIL this was a thing
whenever i need speed i go straight to PyPy
yep, global lookups in cpython are slow
heh it might actually be relevant in pypy too
the reason is that == None could be the wrong result
in my small experimenting with pypy i've had to temper my expectations, i assumed it would optimize away more function calls than it seems to do in practice. still 4x speedup on a lot of tasks
!e
import numpy as np
print(np.array([1, 2, 4]) == None, np.array([1, 2, 4]) is None)
@flat gazelle :white_check_mark: Your eval job has completed with return code 0.
[False False False] False
ah very good point, you can't override the behavior of is
ah interesting
like with and and or
it is a minor thing, but that is afaik the main motivation
ok, that's valid. kind of a hack given what is means but it is valid
I think is None more clearly reflects the concept, personally
same, but then why do we tell people not to write is True 🙃
(maybe we should use that)
funny i was just thinking about that
because booleans are supposed to be used as if python was weakly typed for some reason
are bools not always singletons like None is?
bools are pretty weakly typed though....
generally, you don't want to check if a value is the boolean true, you want bool(a) is True
python is very weakly typed w/ respect to truthiness
when would you use this? like, a value that could be truthy or True?
yeah
pep8 encourages relying on weakly typed truthiness
but people have been moving away from it
is this equivalent to a? (or for that matter bool(a))
I've never been that huge a fan of it
yes
I much prefer for example to check for example for exactly None or not None
if x is not None
as opposed to if x
for None you do need the explicit check
since a lot more things are False than just None
yep, freenode/libera #python in particular i think has been historically opposed to weakly-typed truthiness
they encouraged me to kick the if foo: habit
yeah, it has its issues
the reality is that the majority of the software engineering world seems to be moving away from such things
the same way that the majority of the software engineering world is embracing at least some amount of static typing
and these things influence python inevitably
and i think it's for the better, i prefer to prioritize maintainability and structure over "fast iteration" - even a basic website serving articles could turn into a complicated piece of software if you add enough specific requirements
python without type annotations would be unusable in industry imo
I think that when you consider the implications for tooling, it's questionable whether it's even really "fast iteration"
source: in my first job i helped add type annotations to a python codebase, it literally saved the company
try writing untyped python as fast as you can write typed Kotlin
yeah, writing things quickly with no types is a greedy strategy and it doesn't always pay off
 on both of the above
on both of the above
"fast iteration" is for throwaway scripting, and even then sometimes you want types to keep things under control and organized
for small to medium projects, you can generally be faster than statically typed languages simply because you can tack things on much faster and need refractors less
gradual typing ftw imo
I really think it's hard to generalize
it depends on the type system, depends on the refactoring tools
yeah, it really depends on the problem solved as well
and when you say "small", what is small"? 100 lines? Okay, sure, probably, but honestly, absolutely nobody should care
even at just 1K lines I think I can code faster with typing than without
it depends on the language though; with ocaml or crystal, type inference means there's almost no "typing" boilerplate. whereas in a strictly "typed python" codebase you can end up with a lot of extra loc and keystrokes just getting all the types laid out
to me the main advantage of dynamic typing is when the "software engineering"-ness of it is not the main point or challenge. When you are working on a REPL to try to figure out what is going on with some data, and so on
very good point there too
then typing really doesn't benefit you that much, and every static language REPL i've tried isn't really usable in the same way as python's
but that's a very niche case
i don't think it's niche at all
the amount of chars you type shouldn't matter at all beyond the repl and throwaway tests, but I'd say without a static typing system it's a bit easier to patch in some debug code for "normal" coding
@paper echo and yes, I agree. Too may people think about 2000 era Java style typing, whereas nowadays even Java is moving past that to some degree
that is a very common workflow for automation and testing
Even relatively straightforward, imperative languages like Kotlin and Swift have much more nice type inference
just write things and see what happens
yeah, type inferrence is nice, but it doesn't absolve you of all type hints, especially if you want to make a helper function
well, niche is a relative thing. It's a major use case for a programming language, yes, but just one of many things that python is used for.
What do you mean by a helper function exactly?
extracting a part of a larger function to be named
Gee if only tools could do that automatically for you 🙂
eh, too much keyboard-tapping can genuinely impede speed of thought. and python's type system is relatively inexpressive, so you might end up in excessive contortions to make mypy happy, instead of spending your energy solving a problem. python type annotations imo should be thought of as more of a testing tool than anything. they help with refactoring and documentation, but they don't (imo) help you draft ideas faster, the way that they might help in a more robust type system.
it is some effort to figure out how to translate the types to the types the language understands
there are very very few real life cases where str actually means any and all strings with no further restrictions
Whatever time you save by not annotating a function a parameter, you end up paying back typically when you don't have automcompletion on that function
or making a trivial mistake in your reasoning, forgetting what type you intended x to be and then calling the wrong members on it, trying to run something and having ti fail, etc
quick annotations are fine, but do you really want to spend 2 minutes writing out typing.overloads right now? you could just leave it untyped until your test suite passes, then add in annotations afterwards, and spend a separate brain cycle on making mypy happy after you've had a walk and a sip of coffee.
in small projects, it is possible to keep track of the types with just good naming
it's definitely "possible" but I'm skeptical that it works better even for small functions
often with more specificity than what any static type system can offer
even for small projects*
@paper echo but that's an exceptionally awkward case in python right because python doesn't actually have overloading, so it's super unnatural
if you are actually writing out overloads in a language that supports them then it's all very natural
a lot of my time in kotlin was spent expressing the concepts such that kotlin would agree with the types
to be clear: i am advocating that type annotations are an indispensable part of writing half-decent python code, especially in a professional and/or collaborative environment. but i am suggesting that "typed python" be thought of as gradually-typed and not statically-typed, precisely because python's advanced type system features are awkward, and spending too long on them in the initial drafting phase can be more of a distraction than a design aid.
I've found that naively annotating functions is relatively easy and straightforward, but it becomes more of a problem in non-trivial cases. I think that's what salt rock lamp meant with "excessive contortions to make mypy happy". If you take Luciano Ramalho's PyCon talk from this year, you'll see an example of that: A long journey to get to a good solution for how to properly type hint something.
do you have a link to the talk @wide shuttle ?
@flat gazelle i'd really be curious what you mean by that, kotlin's type system is pretty straightforward and easy to use, and really doesn't lend itself to trying to do super fancy things like C++, Rust, etc
One second, it's about protocols
i'd like to see an example of this kotlin thing too, i've been looking into kotlin as a serious "second language"

The static type system supporting type hints in Python is becoming more expressive with each new PEP, but PEP 544--Protocols: Structural subtyping (static duck typing) is the most important enhancement since type hints were first introduced. The typing.Protocol special class lets you define types in terms of the interface implemented by objects,...
ty!
reified, in, out, generics and only one constructor were the major annoyances in that project.
I guess it depends on the person but I haven't noticed the amount of typing impacting me in a significant way. typing definitely is somewhat of a chore to do it properly (I commonly just use some temporary hint which is good enough for the editor to help me although not exactly correct) but what I meant to say is that if python's typing was enforced like in a static lang as the ones discussed before it would limit the quick prototyping which is now possible
kotlin supports multiple constructors
it doesn't
it supports multiple constructors, but they must all call one first
which didn't work for my case
ended up using companion objects and a factory method, but that was not very fun
why was it not fun? It's about one extra line of code to define a so called "smart constructor"
Thsi conversaion is weird to me because python also only has one init function, and tends to heavily encourage the use of named factory functions
which I actually think is perfectly fine
classmethods as alternate constructors are also considered perfectly fine
not sure if kotlin even has class methods
@peak spoke i think we agree then. and by way of example, here's some code that i'm working on literally right now
@overload
def build_mongo_uri(
host: str,
db_name: str,
username: None,
password: None,
is_atlas: bool,
replicaset: Optional[str],
) -> str:
...
@overload
def build_mongo_uri(
host: str,
db_name: str,
username: str,
password: str,
is_atlas: bool,
replicaset: Optional[str],
) -> str:
...
def build_mongo_uri(host, db_name, username=None, password=None, is_atlas=False, replicaset=None):
... # implementation
all this just to slap some strings together! but this is a function that will be shared across 5 devs in different time zones.
that said, i just now realized i can refactor this to remove the overload (and it's not a perfect refactor, now i lose the descriptive parameter names):
def build_mongo_uri(
host: str,
db_name: str,
credentials: Optional[Tuple[str, str]],
is_atlas: bool,
replicaset: Optional[str],
) -> str:
but the point remains, for initial prototyping this is the kind of thing that people don't want to have to deal with and imo shouldn't have to deal with.
it does, that's the roll that companion objects fill in, it's abit weird in some ways but it still does work
Writing a factory function on your companion function for your "secondary" constructors while only having one primary constructor pretty much maps exactly 1-1 with python
The main difference is that in Kotlin you have the option (not necessity) of having the same "nice" constructor syntax, since Kotlin has overloading. In python you have to write something like from_foo
@paper echo i was going to say your example doesn't really make any sense, it looks like you are trying to keep the signatures mutually callable even though they only need a subset of the information
but if you want to do that, that's precisely when you would not use overload
Your refactored example is fine, you could just add a trivial dataclass UserPass or something like that, to use instead of a Tuple. Would probably be preferable because otherwise it's very easy to reverse username and password (since they are both strings)
I am not going to claim that this would be any easier in python, I didn't think about how to do it in python at the time (though there is always the option of just having an if in the init), but it was definitely not as straightforward as it would be in java.
What would the Java code look like?
I find in Kotlin if I want two conceptually different constructors, all I do is leave the default primary constructor, make it private, and then just call it from two different class/static/companion functions. perfectly straightforward tbh
the fact that it generates the "simple" primary constructor for you (the same way a dataclass in python would) means this approach doesn't really have any extra boilerplate
(or rather, no significant amount)
but i think this is one thing that people like about python - you don't have to start constructing lots of little ad-hoc things to get sophisticated api behavior
maybe that's an aspect of python developer culture that needs to change? but look at other complicated apis like matplotlib and pandas
lots of **kwargs, which kinda sucks. but that's what python devs are used to
and lots of "this option is ignored if that option is used"
the git command line is like that too
a command line is pretty different from a programming API
i think it should be reasonable to express that only certain combinations of options are valid
and pandas and matplotlib are really thinking a ton about interactive usage
so it's somewhat different
there's a lot of things in pandas that are optimized for interactive usage over programmatic usage
right, but that's my point - python has a very "interactive" culture around it, even if it's being used to develop web servers etc which are very non-interactive applications
Sure, I don't disagree that python's culture is like that, i just don't think they raise very compelling points technically (for the common case of not considering interactive usage)
valid
it'd be cool if pypy could optimize away things like constructing tuples and class instances that just get deconstructed
like how typed languages can erase types at runtime
i wonder if having pattern matching semantics built into the language could be a step in that direction
i kinda feel like anything with the word "optimizing" is just so so so far away, relative to where other languages are
class Point3D:
def __init__(self, x, y, z):
self.x, self.y, self.z = x, y, z
def dist_x(p1, p2):
return abs(p1.x - p2.x)
def foo1():
return dist_x(Point3D(1,2,3), Point3D(4,5,6))
def foo2():
return abs(1 - 4)
whether it's optimizing or type erasure or something in the middle, it'd be really cool if foo1() and foo2() could compile to the same bytecode
isn't this what people call a "zero cost abstraction"?
right now abstractions in python can be very costly
That will never be possible, since that would completely change the semantics of the language. It would require producing bytecode for foo1 that depends upon what dist_x and Point3D are bound to at the time the foo1 function is compiled, rather than at the time that it's run
it's very hard to do zero cost abstractions in pointer/reference based languages, generally
like, yeah, the JVM might nail it if it's in a certain local context, but that's not zero cost, in general
in languages like C++ and Rust which have value semantics, and very aggressive AOT compilers, it's different
I guess really without both value semantics and an aggressive AOT compiler, it's hard to really have much in the way of ZCAs
or compile time macros i guess 😛
the problem with JIT compilers is that it's always kind of a "maybe", JIT's never really promise anything, there are startup times before they really start optimizing, etc. It's hard IMHO to be "sure" that something is truly zero cost, all the time, with a JIT, compared to an AOT compiler
def make_x():
return {'a': 1, 'b': 2}
class Y:
__slots__ = ('a', 'b')
def __init__(self, a, b):
self.a = a
self.b = b
def make_y():
return Y(1, 2)
# In [42]: %timeit make_x()
# 151 ns ± 15.5 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
# In [45]: %timeit make_y()
# 329 ns ± 57.1 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
obviously this is such a small amount of time that it probably isn't worth avoiding classes "for performance", but if you need to do millions or billions of class instantiations you might care that classes are 2x slower to construct than dicts with string literal keys
very fair re: jit
yeah, you could end up caring in that case... but in that case you'd probably wish you had started withs omething other than python 😛
the overhead of class instantiation actually has mattered in ETL code i've written
yeah. I mean I haven't encountered it, but the overhead of dataclasses is supposed to be really bad, in particular
where certain operations just had to be done "row-wise", and while pandas apply is pretty fast, i found that by eliminating "fancy" python (no classes when possible, avoiding constructing dicts and tuples without needing to) and using optimizations like _len = len i could significantly improve the performance
It's kind of funny, I work mostly in C++ and write very fast code for a living, have given talks about it, but having to write something like _len = len to get a performance boost would make me sad
and yeah i haven't used dataclasses in a performance-sensitive setting, attrs i believe has 0 overhead at instantation time compared to a hand-written class
at instantiation time; but I'm talking at class definition time
the problem is that something like a decorator of course isn't all handled trivially by the translation from source to .pyc
it will actually need to run the dataclass decorator, which will happen basically at initialization time (or import time, if it's distinct for you)
compare to a Kotlin data class, it's a language feature and this is all handled during the translation to byte code at compilation time (even though Java/Kotlin are JITed)
Some people have complained that heavy use of dataclass has actually given large applications really really bad startup times
well if you're defining classes in a tight loop then idk 😛
i didn't think it'd be so bad as to affect startup times
yet another case for compile-time macros
compile time macros just as a way to define classes with sensible == and init?
seems like using a nuclear weapon to squash a mosquito
no just that, but something that can be type checked statically without introducing runtime overhead
this is far away from what one could reasonably expect out of python
with None you should use is. pep8 also says as much, this is because None is a guaranteed singleton. we should use is for singletons.
No. or well, i think it's cleaner if you think of immutable semantics as a subset of immutable semantics. this means, the onus is on the operations that are defined to work with mutable data to be absent with immutable data.
in that sense, + for example, is behaving exactly the same for immutable and mutable data. and .append wouldn't exist in immutable datatypes.
There's no reason that operations themselves have to become ambiguous to conform to mutable vs immutable
🤷♂️ the types are designed with different ideas and APIs in mind, and different guarantees
definitely. that doesn't mean they have the right to overload operations in strange ways. there's still consistency that is (or should be) at play
well, all of the above is part of the "semantics" of a type
my point isn't that the language of python is being inconsistent here, my point is that these types are being designed along different principles
that's fair. i think my issue arises from the fact that, as far as i can think, += is the only operation that does a. exist for both immutable and mutable types. and b. behaves as immutable sometimes and mutable sometimes. (with immutable and mutable data respectively). i can't think of any other operation off the top of my head that has this same issue.
-=? 😛
obviously ^:
In [5]: a = 0; a ^= 1; a
Out[5]: 1
In [6]: s = {0}; s ^= {1, 0}; s
Out[6]: {1}
do you guys have a lot of knowledge with pandas dataframes?
@devout sun usually we talk about pandas in #data-science-and-ml or a help channel (see #❓|how-to-get-help) - also, don't "ask to ask", we have a guide for asking good answerable questions in #❓|how-to-get-help
this is in c++, but not in python, u can see it from this:
in python:
a = 10
b = a
print(hex(id(a)))
print(hex(id(b)))
above code will print same address which is different in c++:
int a = 10;
int b = a;
cout << &a << endl;
cout << &b << endl;
above code will print different address
@real mulch they can still be value types, since they are immutable.
is there even such a concept of "value" or "reference" types?
"The returned manager object corresponds to a spawned child process and has methods which will create shared objects and return corresponding proxies."
So cool.
@cloud crypt err yes
it's a very very well discussed concept
and its' directly reflected in the design of multiple languages, e.g. C#
well, I guess if I see the definition, I might better understand what it is about
really bad quality but discusses the idea quite a bit: https://www.youtube.com/watch?v=_BpMYeUFXv8

Sean's talk from C++Now! 2012
Do you mean in general, or in Python?
also perhaps I phrased myself poorly, either way
typedef struct FooData *Foo;
is this C example something like a "reference type"?
basically, value vs reference semantics is talking about, largely: 1) what happens on "copy", or rather, a = b, and 2) what notion of comparison you use
I mean, aren't references "pointers" that refer to values?
please: in Python, or in general?
I imagined Rust in my head, and in Python everything is technically a reference
def manipulate(variable):
variable = 100
a = 10
print(a)
manipulate(a)
print(a)```
```>>> 10
>>> 10```why are you showing us this code?
Is it safe to say that passing by reference doesn't exist in python and that you can only replicate it on an exam?
@paper echo with something like a pointer it's a bit confusing, strictly speaking the pointer has value semantics with respect to itself; after all a pointer is just a collection of bits. When you copy a pointer you are doing a deep copy - of the pointer itself
but with respect to the thing it's pointing at, of course, you're not doing deep copies
def manipulate(variable):
variable["item"] = 100
a = {"item": 10}
print(a)
manipulate(a)
print(a)```
```>>> 10
>>> 100```if you make a copy of a pointer, and then make the first pointer point to something different (mutate it) the second pointer does not change where it's pointing
but if you make a copy of a pointer, and mutate the pointee, then obviously that's reflected in both pointers
I suppose a different way to see it is from Rich Hickey's definition of 'values' and 'places'.
A 'value' is an immutable thing that represents some quantity, like a number, a list of numbers, a string etc.. An aggregate of values (like a list or a mapping) is a value as well. Values can be compared for equality with each other, they don't have identity, and they are shareable
A 'place' is something which has a sort of a name (i.e. is compared by identity). You can place a value into a 'place', or you can retrieve a value from a 'place'.
It's not really applicable in Python, but maybe it's a useful model to have? Represent data as immutable (or practically immutable, i.e. by convention) things, and have dedicated places where you do mutation.
feels like you don't really get to mutate things on your own
they rather do this internally
idk, maybe that's a good model for clojure specifically, for the majority of languages that use mutable values rather regularly I'm not sure if it's as applicable
yeah, it's more applicable to functional languages
in python like most GC languages, you cannot customize =, and like most GC languages, = is always doing a shallow copy
you can still get value semantics essentially, if things are immutable, because then it's simply not possible to "prove" that you are doing shallow copies, semantically
at least, unless you take id of your integers, which most people would say is just an absurd thing to do
saying that = does a shallow copy is going to confuse people.
that's the attraction of immutability basically in these GC languages; you can fake having value semantics, which are less surprising, while having sufficiently cheap ways to pass things around, that you don't need pointers/references
languages like Rust, C, and C++ that have "true" value semantics, basically have to have some kind of reference/pointer facility, otherwise you'd have to copy everything wholesale to call functions, which would be crazy
and having a notion of the value itself and a reference/pointer to it obviously increases language complexity
@spark magnet why do you say that? Actually, well, I guess I see what you mean
this makes sense to me. different base types have different mutability. no pointers in python.
these discussions always get tangled up because people look at different levels of the abstraction
yes, it is tricky
awesome.
I feel like it's better to have difference between values and references you operate on
and honestly I don't like implicit copying, even though sometimes it might be fine (and useful, that is)
Luckily, Python doesn't do implicit copying
yay
it does implicit shallow copying 
it does?
well, it's a bit of an oxymoron
fn manipulate(&mut variable: usize) {
*variable += 29;
}
fn main() {
let mut value: usize = 13;
manipulate(&mut value);
println!("{}", value); // 42
}``` I initially wanted to reply with something like thisHeh, yeah. The two examples shows how mutability makes a difference
The integer 10 is immutable. variable 'a' is mutable. dictionaries are mutable
There is a perspective in there too about "copying" shallow or deep etc, but i'm encountering a language challenge
I don't think "variable 'a' is mutable" is meaningful in python
both because mutability is a property of objects, and I wouldn't say python has variables
@mild flax how would you explain this? without using "variable" or "mutable". im honestly cruious
Python has names in scopes, and names refer to objects. You can bind a name to a different object, or you can mutate an object itself, which are two different operations
the dict is mutable, a is a name for that dict
objects are types, like dict or int
I mean it's not meaningful in python in the sense that all variables are mutable 🙂
Hehe "names" are mutable. Type "int" is not
if you imagine "gradually typed python" as a langue where we enforce that mypy actually passes
then you can talk about a being immutable if it is Final and points to an immutable type
that's pretty cool
Python definitely has variables.
yeah, most compiled GC languages have this notion built in
uh oh python -> mypy is to JavaScript -> TypeScript
Python's variables work differently than C's variables.
Compiled GC languages? Like Go? 🤔
java, C#, kotlin
Alright, I don't want to open the compiled/interpreted can of worms again 🙂
I wouldn't say that python doesn't have variables but when explaining certain things like the name binding behaviour using the term could be confusing
I understand why you say that, but I kind of think that calling them variables in most programming contexts is something of a category error (I come from a math background).
Which is very pedantic, but the reason I bother with it is that most beginners are familiar with algebra but not C, and I think calling them "variables" actually introduces subtle mistakes in how they think about them, even though the way names work is very intuitive.
would you say that C has no variables?
(fwiw, I don't think new programmers are confused because programming variables are different than algebra variables)
I think so
I realize this more or less takes this opinion out of the scope of the discussion though
yeah way out
OK, if you are saying that no programming languages have variables, then I don't mind if you say Python doesn't have them. It's just not a useful thing to say in a programming context.
as soon as you see "x = x + 1" you know you are not in algebra
in a sense, but I think that beginners don't internalize that when they first encounter it
@mild flax i guess you would also say that programming languages don't have functions?
i don't think beginners-with-math-knowledge think of variable as anything but "a placeholder for something", without any clear sense of what the "something" is or what precisely the semantics of a "placeholder" should be
Yeah I don't think beginners are confused by variables being different from mathematical vraiables
Lol I'm ok with "function" specifically because it actually lines up with how mathematical functions are taught before higher math
It's useful for me to understand the category error Scofflaw mentions
I think you are being over-conservative with re-using words to have different meanings in different domains.
I don't really think that functions line up any more than variables personally
function vs pure function vs function-as-defined-in-lambda-calculus are all different things
(unless their first language was Haskell or something)
but yeah mostly I agree with ned
If you’re coming from an imperative background, such as Java, C++, or C#, you may think of
varas a regular variable andvalas a special kind of variable. On the other hand, if you’re coming from a functional background, such as Haskell, OCaml, or Erlang, you might think ofvalas a regular variable andvaras akin to blasphemy.
they don't, but before set theory math functions are taught as if they're input/output machines, which is basically what a code function is
so can machines
?
they're still mappings between inputs and outputs! before state -> after state 😉
^
I'm just saying that math functions are taught as if they're a process
a pure process
math functions are taught as if they're a mapping between inputs and outputs
they don't "do" anything
there is no implication that mutation is in any way possible
sure, but that distinction isn't particularly important to beginners
I don't know how to graph random()....
in american schools they definitely do teach them as a kind of "machine" that turns inputs to outputs, but this notion is quickly dispensed with if the student goes to study math at the university level
I'm really confused how you figure that functions in programming are more like math functions than variables are. I think there's some important conceptual similarities in both cases, and also some important differences
to be clear, my only practical problem with "variable" is pedagogical
certainly, by a freshman university class at the latest, the differences between the math notions and programming notions is painfully clear
in both cases
"variables" existed long before the formalisms underlying modern mathematics existed
and to be clear, my objection to "Python has no variables" is when people say, "C has variables, Python doesn't"
I've experienced many help sessions where a beginner's confusion is cleared up by explaining what they're doing in terms of name-assignment
yep, "a variable is a label stuck to a piece of data" is my go-to analogy
yeah, there's nothing wrong with that explanation
precise? no. illustrative? yes. apparently effective, too
name assignment is definitely the idea to get across
it's a good explanation of python variables
C variables are also variables and just have different explanations
i think i got it from ned originally 😛
i remember a blog post from waaaaaaay back
like 10 years ago
that had pictures
where the variable names were like those tags you put on suitcases
as i said the other day, i'm so used to it in python that any other language behavior seems alien to me
I 👏 NEED 👏 PICTURES
and the data was boxes
i really like that
and it showed how x = y was just putting the x tag on whatever box the y tag was on
yeah
it gets a bit funky with list[0]
I learned C and C++ long before python so when I saw x = y and then mutating y showing up in x I felt like "what is this nonsense"
Like this?

it's kind of crazy to think how much less popular python was when I was growing up than now
or more cartoony?
the one I read personally was more cartoony
maybe this one? http://foobarnbaz.com/2012/07/08/understanding-python-variables/
wow, the text on that page is nearly invisible
yeah I think that's the one
though I feel like the formatting got messed up at some point
nice find
I was pretty close with the year too
Python Study Guide
oh maybe it was the second one lol
they are very similar
it's crazy to think, in 2010, I'm not sure I had heard of python
and I knew half a dozen or so programming languages. Nowadays if you manage to know half a dozen programming languages without having written a handful of lines of python, let alone having heard of it
that would be pretty remarkable
pretty terrible tbh

Is python popular in 2050?
(I have mild vision problems (astigmatism), and I'm actually having trouble reading the text from a normal distance)
I have old eyes (they are just as old as the rest of me), and I gave up.
@grave jolt @spark magnet try reading https://python.org/downloads
Ah, it seems fixed now nvm
I can read it from more than 2 meters in glasses
just like dark theme discord
so did anyone check python.exe's source code to see if dictionaries are passed around as pointers under the hood
All python objects are manipulated as PyObject * in C
And Python semantics demand that they be references of some kind, since you can mutate a dict passed into a function.
hahaha sweet, thought so 🙂
oh wait its still broken


check ur dns once
they can cause weird shit
hello!
if a set contains only hashable values then why isnt it hashable itself?
because its mutable
when you add/remove something from the set it's hash would change
frozenset is hashable
ah
i can use that
but then if i store variables in sets
a = "hello"
In [55]: a.__hash__()
Out[55]: 8880154227315061526
In [56]: b = {a}
In [57]: b
Out[57]: {'hello'}
In [58]: a = "bye"
In [59]: a.__hash__()
Out[59]: -4686310682089306112
In [60]: b
Out[60]: {'hello'}```nevermind
so the set stores a copy if a variable is used?
No, it stores the reference
o
but you're not modifying the object (sets cannot contain mutables)
you're simply reassigning the name a to a new string "bye"
im reassigning ye
so the "hello" memory still exists
but a doesnt point to it anymore
this is why we have frozenset!
Is a degree necessary to be hired by a company?
That question is for #career-advice , not here
If only someone would answer there ...
Please don't spam your question across multiple channels, even if you're impatient
Hi
Help please
This is not the channel for that, see #❓|how-to-get-help
@barren aurora btw, use hash(x), not x.__hash__()
what is the motivation for making those standard "hooks" free functions that call dunder member functions? Is it simply not to take away the name as a member function choice if someone wanted it
or is there more to it
next, len, hash, etc
it's partly from history: in v1, strings weren't objects, so didn't have methods.
it still is a primitive of some kind though, no? Along with integers and floats
they are all objects, with methods
i think if we were starting from scratch now, they would be methods, but i could be wrong
interesting
but there could also be something about types implemented in C involved here too, not sure.
It helps with accidental subclassing at least
well, if it were designed that way, it would obviously not be called that
In Ruby you'd just have a hash method
it would just be called hash
that's why I raised collisions as a possible reason. but that's not really very compelling, if you have a hashable type and you want to have a function called hash that does something other than compute a hash, well, something is wrong
It also prevents a hash attribute
I like that python at least attempts to distinguish between functions and methods
And not all hashes are correct hashes as defined by python
I know with UFCS the world is kind of going the opposite way
But in a dynamically typed language i like having a distinction
it's just kind of a strange approach, in most languages what you tend to see is that there are various interfaces that you can satisfy, and those interfaces are are defined via collections of member functions, and when you want to use them you just call them directly
i wouldn't say "the world"... UFCS is not a particularly successful idea
Ye, it is quite unusual
The only language where I really see this "free function hook" approach is actually C++. And in C++, it's for very different reasons... it's typically because you can customize behavior non intrusively, because your hash or swap function would be statically dispatched via overloading, or template specialization, etc
obviously in python you cannot stop len(x) from simply calling x.__len__()
(well, shy of things that you aren't supposed to do)
In some cases it makes sense due to how complex the protocol can get. iter, getattr are such examples. So IG just for consistency
why does it make more sense for a complex protocol?
i'm not really sure getattr is an example of this, getattr is language level reflection, it works on everything, your class doesn't get to make a decision about providing it
but we could look at iter, what makes iter(x) better than x.iter()
iter is not .__iter__, it is try .__iter__, then try __getitem__ should that fail
Right, so it actually has non-trivial implementation
Actually, that's a bad example, the default object __iter__ has that logic
okay... 🙂
the docs seem to indicate that you're right the first time:
Return an iterator object. The first argument is interpreted very differently depending on the presence of the second argument. Without a second argument, object must be a collection object which supports the iteration protocol (the __iter__() method), or it must support the sequence protocol (the __getitem__() method with integer arguments starting at 0). If it does not support either of those protocols, TypeError is raised.
so, I guess this is a reasonable choice perhaps in a dynamically typed language, what if there are multiple ways to satisfy a particular protocol
duck-typed maybe I should say
getattr delegates to __getattribute__ and __getattr__ (and probably some others), so it is also not a trivial method call.
Ye, that's my assumption, the naive wrappers like hash and format exist to be consistent with the more complex free functions. Obviously more modern languages now provide different, and honestly overall better solutions, but that's the price you pay for large ecosystems.
interesting stuff. I knew that you could satisfy iter in different ways, I think you can also satisfy reversed in different ways, but I didn't make the connection
thanks for pointing it out
I'm just thinking to myself how this would work in say Kotlin. Actually, kotlin doesn't give you a "free" implementation .iterator(), not that it typically matters, but the language could have done it
List<T> inherits from Iterable<T>, so you could just have a default implementation for iterator() in List<T>, since List<T> is guaranteed to have size and [] members
!e Performance, I think - check this out:
class C:
def __len__(self):
return 0
c = C()
c.__len__ = lambda: 1
print(len(c))
print(c.__len__())
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | 0
002 | 1
when len() calls the __len__() method, it doesn't look it up on the object, it looks it up on the type. That saves a lookup, since it doesn't need to discover that the attribute is missing from the instance dict before checking the class dict
that is, len(o) isn't equivalent to o.__len__(), it's equivalent to type(o).__len__(o)
it's been like that for ages and ages and ages though, long before python even vaguely pretended to care about performance
i think lakmatiol's answer is the more historically accurate one, though I haven't seen a decisive source either way
the second SO answer here also gives some more similar reasoning: https://stackoverflow.com/questions/2481421/difference-between-len-and-len

Stack Overflow
Is there any difference between calling len([1,2,3]) or [1,2,3].len()?
If there is no visible difference, what is done differently behind the scenes?
it's interesting that the len vs __len__ actually reminds me of a line of reasoning do you hear in the C++ world in certain contexts, but I think it's a general principle that has mileage verywhere
which is that there's always benefits in keeping interface and customization points separate
len is the interface, __len__ is the customization point, by having the two be separate it gives you additional control, possibly even lets you change certain things in interesting way without even breaking compatibility, etc
Yeah, cool!
there's another reason for looking up the method on the class instead of the instance, that I am forgetting 😦
hm. Descriptors?
i think it was about a particular dunder method that would only work if it was looked up on the class
Hm. __new__ is implicitly a class method...
Stack Overflow
It used to be possible to set internal functions like len() at runtime. Here is an example:
#! /usr/bin/python3
import sys
class FakeSequence:
def init(self):
self.real_seque...
so, performance is one of the reasons why they decided to look it up on the class instance, yes, but this was an implementation detail (mostly) that was changed much after python already had this len vs __len__ thing
it's not even the main reason though
as ned said it seems the primary motivation are the ones that are defined for all classes like hash, repr, etc
functions and vars prefixed with __ imply class methods
oh, duh, __getattribute__ is the one that wouldn't work if it was looked up on the instance, @spark magnet
right? Otherwise you'd have infinite recursion trying to get the get-the-attribute attribute.
that sounds plausible, but __new__ rings a bell better with me
This is a good point. Sometimes the customization hook can make it harder to reason about compared to overriding an interface method, but if the method in the parent class is complicated you might not be able to just call super (or whatever the C++ equivalent is)
The Tornado framework uses this "hook" style a lot
I think I recall asyncio.Queue is built this way too, you can subclass it but you're only supposed to override certain methods
I had to do it once to inject some logging that i wanted in the queue object itself
threading.Thread and multiprocessing.Process are very much like that - "you can subclass this, but if you override anything but this method, it'll probably just break.", heh
As long as it's documented it's fine... the problem sometimes is that the python docs read more like a sketch of a design document than a specification
yeah, the sheer mass of the python community helps though
I'm impressed by the multiprocessing API. It'll only get better like os multiplatform stuff
what do you mean by that?
it's already multiplatform
multiprocessing in python is impressive relative to the fact that's multiprocessing... but when you consider that in other languages you just don't need processes, it's not that impressive
so it depends how you look at it
os functions have platform specific limitations, which have become less and less over the years
ah, ok
Maybe this is why I'm impressed, because threading in C is tricky between platforms. Then, making sure your data is safe is next.
Dunno, the python multiprocessing API looks and feels really clean for me
I mean C++ has had lots of cross platform threading stuff even in the standard library for a while, and there's plenty of third party cross platform stuff
Within the next few years, we may be able to move the GIL from being global to the Python process to being global per interpreter instead, at which point we would be able to use multiple subinterpreters in places where today we need multiple processes.
My impression is that even framework supported threading e.g. boost is still notably more complex than the python multiprocessing API
Isn't that Guido's new project
Guido's new project is heading towards getting a JIT for CPython, IIUC
Eric Snow has been driving the work to move the GIL down into the interpreter state, I believe
which, on the one hand, will break pretty much every existing C extension module - very few of them are written in a way that's subinterpreter-safe. But on the other hand, it would allow using subinterpreters in Python in a similar way to how you'd use threads in other language, including for CPU bound stuff across multiple cores - so the payoff would probably be worth the cost.
I don't think that multiprocessing is dramatically different than just using a thread pool in C++
that said, obviously C++ is more complex generally
but if you look at the parallelism situation in other mainstream GC langauges, it's generally better than python, not worse
multiprocessing is ok for basic use cases but it can become a headache much more quickly
even just the example I ran into very recently and posted about here; thread safe loggers are very common and generally pretty efficient, process safe loggers are much less so
so in practice logging from a thread pool in python or other languages is very simple, and logging from multiprocessing is not
that's a case subinterpreters won't really help much with, too.
yeah I'm not actually sure what sub-interpreters buys you exactly
it lets you lose some of the complexity of multiprocessing - the part where you have multiple processes running on the system at once and coordinating with each other, and if one of them dies the others can be left in an undefined state, and you need to use IPC primitives to synchronize them, etc. It replaces that with multiple interpreters running in a single process, which share a heap at the C level, but which still cannot share Python objects directly between each other.
but in the case where there are two long running, CPU bound threads, it will allow them to run in parallel in different interpreters within one process, each with its own GIL, not blocking the other
so it's using OS threads instead of OS processes?
come to think of it, does multiprocessing actually have to use OS processes, it could use threads too couldn't it
hmm ok but it needs a new interpreter so it's still a new address space, regardless
(in the case of multiprocessing)
right. And the GIL today is process-global, not interpreter-global.
in a few releases, we may have an interpreter-global GIL instead, at which point many things that use multiprocessing today could use a hypothetical new module that's built on subinterpreters instead, and does everything within one process.
so sub-interpreters, at the implementation level you'd just have threads, each thread is running a sub-interpreter, so communication back from the sub-interpreter (e.g. in the case of a "sub-interpreter pool") could be handled by threading primitives rather than process primitives
yep.
it won't have all of the sharp edges that multiprocessing has, but it will still have some of them - and the logging example you gave is a good example, since each interpreter will have its own logging module with its own handler stack installed.
in theory you could get tricky, and have the main interpreter own the files, and the subinterpreters log to FDs belonging to the files that had been opened by the main intepreter. But, still not nice.
For logging, I can't recommend writing to files from multiple threads
Oh? Why's that?
it's very much the normal way of handling logging in Python.
it may work if you nail down a lock between the threads
I'm basically thinking queuing each "log" and having a service manage the "writing" of the sequential items of the queue
"log" because this could be anything, and "writing" because you may need something heavier duty than a file
Yes, that's how it works - every logging.Handler owns a Lock.

and this is also basically how it works - the queue is a buffer inside either the Python interpreter or inside libc.
🍴
O, alr
Excuse me
Can anybody tell how to connect 2 database instances
My computer name is wego
and i want my mothers computer access it
Wait can I get some advice on logging
Im overseeing a refactor and I'm moving all our print statements plus log statements to the logger
I have one per class each with a different identifier
But is that a problem
not sure what kind of advice you're looking for but a general start is the advanced logging tutorial, gives nice examples and diagrams of what to do
https://docs.python.org/3/howto/logging.html#logging-advanced-tutorial
Can you guys plz give your honest feedback about online stores and do share 👍🏼
Hey @atomic prism!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
use our paste service https://paste.pydis.com/
Hello @remote marsh. Your message is off-topic for this channel. Please read the channel's topic.
#software-architecture might be a good place to discuss your logging setup if you want to discuss it further
Both. Compile to byte code, then run that in an interpreter loop
My impression is that even framework supported threading e.g. boost is still notably more complex than the python multiprocessing API
eh, not really, can't speak to boost specifically off the top of my head but you see some pretty nice APIs, e.g. folly futures
C++ there's obviously much more complexity generally, so it would be more fair to compare to a GC language
The main point I'd stress is that there's nothing really remarkable about python multiprocessing for parallelism, except that it manages to make multi processing specifically, as nice as it does
Anyone working on anything fascinating today?
the API it presents is a pretty typical thread pool API, and if your language supports parallelism via threading you're going to have an API that's no worse
and it's just going to be automatically better in some ways. E.g. in python you just cannot use closures into multiprocessing, they have to be top level functions or classes, if you need state
Okay, question
multithreading in other languages doesn't have this restriction
I'm ashamed to admit- I've been 10 years in this language and I've never worked up the effort to actually research: what is a closure?
a closure is basically a function that's defined in another function, and uses local state from that function in its computation
it's called a closure because it "closes over" that state
You are not the only one, there was a video where they asked 30 year programmers in the biz that didn't know so don't feel bad
def foo():
x = 5
def bar(y):
return x + y
here, bar is a (useless) closure
it "closes over" x
I mean, I feel like you know, but some things are just hard to put in words really, but you have a good sense of how they operate and what they can accomplish, just hard to put in words...
So its a bit like a mitochondria. Its a fully functional machine enclosed within another machine, with access to the machine outside itself but with its own internals limited to its own scope
although @halcyon trail has done a great job at doing so - nice job that sums it up really nicely
Eh, no, that analogy doesn't buy you anything
sorry, not trying to be mean, but it's IMHO just best to be blunt here
Hey, no meanness about it ^^ Happy to learn
The problem with that metaphor/analogy isn't that it reveals some ignorance of yours about mitochondria, or that it's horribly wrong, it's fine enough on both counts
it's just too vague to be useful, and if you use that analogy to think about closures you're probably going to end up thinking in directions that aren't really applicable/useful/sensible
I would just focus on the mechanics of the closure itself, and maybe think about how it is similar mechanically to a class
class Bar:
def __init__(self, x):
self.x = x
def __call__(self, y):
return self.x + y
def foo():
x = 5
bar = Bar(x)
the same concept expressed with classes/objects
so you cna see there are trade-offs. Classes are more explicit, they can have more API, easier to test separately. They also have a lot more boilerplate, much less locality.
listening
easier to accidentally end up with shared mutable state; closures have some safeguards in that regard
they are IMHO both very useful. I like explicit classes and it would be strange to me to program without them (I've never really worked in a very "pure" FP language before)
but I also like having nice lambdas/closures
^^^ Classes are the only way to fly, brotha
Right, but consider this example, lets say you have a ThreadPoolExecutor, and you want to submit some callables
The comparison to classes is interesting.
you have a function of two arguments, but you want one to be constant
I never thought of it that way in regards to Python, but that makes a lot of sense to me.
Especially considering __closure__ and such
def foo(x, y):
...
def main():
def foo_five(y):
return foo(5, y)
with ThreadPoolExecutor() as executor:
f = executor.submit(foo_five, range(10)
something like that
I probably got the submit syntax somewhat off
you get the idea
the point is that before you submit to a thread pool, it may be convenient to do various small things that aren't really sensible to do in a standalone function
you may want to lock down some arguments, add new arguments, catch exceptions, etc
this will work in python, but if you change it to a ProcessPoolExecutor, it will not
just to connect closures and such to the convo that was happening earlier
I mean, I'm only just following along, but this seems like something you could do with a decorator also
you could but that doesn't solve the issue here
which is that it's a one off
so now you go and write some code off to the side, which has no use except in that one call to submit
it's just annoying
Good point
this happens because python is spawning a brand new process, the new process doesn't have the same interpreter, it doesn't know about the existence of that closure
it needs something that it can "see" at top levle to execute it
a top level function, or a top level class. if a top level class is passed to the executor then it will be pickled and unpickled (which again it can do at top level, since it can see the class definition at top level in the new interpreter)
If your language just uses multithreading for parallelism, this generally isn't an issue, so you can just use closures here. And if your language has nice lambdas, then it's even easier.
ihatepythonlambdas = lambda: print("AHHHHHHHHHHHHHHHHHH")
you can just do stuff like f = executor.submit({ foo(5, it)}, range(10)) or something like that
Hey anyone who can code discord bots. I am willin to pay or do what ever you want. I just want my own discord bot for my discord server..
yeah I don't think many people like them, except people who like that they are so limited because they think it's a good thing that they are forced to write explicit local functions instead 🙂
So lemme check that I'm understanding. The salient point here is that the closure captures the outer state in such a way that it can be passed around, even pickled and sent off somewhere else, or have the outer state change, without any change to the variables from the environment it was originally exposed to?
well no actually, the closure can't be pickled
it can be passed around
that was the whole point of why my example above will work with a ThreadPoolExecutor, but not a ProcessPoolExecutor
def make_adder(x):
def adder(y):
return x + y
return adder
this is kind of the canonical example of a closure in python
How does that trick work again, !e?
def make_adder(x):
def adder(y):
return x + y
return adder
f3 = make_adder(3)
f5 = make_adder(5)
print(f3(2))
print(f5(2))
!e
damn 🙂
@static bluff :x: Your eval job has completed with return code 1.
001 | File "<string>", line 1
002 | ...code...
003 | ^
004 | SyntaxError: invalid syntax
Right
!e
def make_adder(x):
def adder(y):
return x + y
return adder
f3 = make_adder(3)
f5 = make_adder(5)
print(f3(2))
print(f5(2))
lol
!e
def make_adder(x):
def adder(y):
return x + y
return adder
f3 = make_adder(3)
f5 = make_adder(5)
print(f3(2))
print(f5(2))
@static bluff :white_check_mark: Your eval job has completed with return code 0.
001 | 5
002 | 7
the hell
!e
def make_adder(x):
def adder(y):
return x + y
return adder
f3 = make_adder(3)
f5 = make_adder(5)
print(f3(2))
print(f5(2))
@halcyon trail :white_check_mark: Your eval job has completed with return code 0.
001 | 5
002 | 7
there we go
lol
anyhow
so in this case, you can see that adder closes over the value of x
and indeed the adder that's created can be passed around
and it "brings" its closure with it
And as far as that specific adder is concerned, x won't change
well, yes
each adder is closing over a specific instance of x
but you can still run into mutability issues with closures
integers are immutable though
So a reference to a list or some such is still just as mutable as ever
Or an object
yes, indeed
Which is perfectly reasonable
It is, but you do need to watch out
usually you don't really want your closures to mutate anything they close over
XD Hardest learned lesson I ever had working with Python
Happened when I was maybe 2 months in
overall, closures aren't used much in Python, aside from decorator implementations
I was building a game with Pygame. In the game you'd send ships from planet to planet. Each planet contained an xy coordinate as a list
idk, I use closures reasonably often
@halcyon trail do you have some code we could look at?
I mean if you want to map to a list or a dict
but the logic is too complex for a comprehension
And so, when a ship finally landed on a planet I'd just say ship.location = planet.location. Then the next time the ship started moving again, it dragged the planet around with it XD
you have two choices
local function + comprehension, or create an empty container and insert into it
often (not always) I prefer the former
i'm not following, can we make this more concrete?
I'd tend to agree with Ned though. There's a time and a place for nested functionality but I tend to avoid it when I can. I have an almost OCD aversion towards nesting of any kind, really
sure
(Something I'm working on)
def some_logic(x):
... multiple lines of logic
return stuff
new_list = [some_logic(x) for x in old_list]
where is the closure there?
the alternative is something like
new_list = list()
for x in old_list:
....
new_list.append(x)
some_logic is a closure if you use anything other than x
which is probably pretty common
if you have multiple lines of logic there
you mean a global?
err this is all happening inside another function
i don't create many lists at global scope 🙂
ok, nested functions i guess are an acquired taste 🙂
def the_big_function(.....):
# Okay, need to do a transformation here
def some_logic(x):
...
Eh, I don't think it's that rare
it sounds like you use them more than typical
It's not pretty but creating an empty list and appending isn't pretty either. python doesn't have a pretty solution here 🙂
Could be, I certainly don't think that usage is rare though.
All the stuff in itertools too, it's very common that soemthing needs say a predicate, the odds that you have exactly the predicate you need, as opposed to it being 2-3 lines of logic, is fairly common
maybe there's a tool out there that could analyze code and come up with a number: 5% of functions have nested functions, or something
The whole python shtick I've heard is that lambdas aren't important because you just locally define a function, I haven't really heard people say that locally defining functions isn't important either
maybe this comes down to what fraction counts as "rare" 🙂
Sure, but 5% isn't really that low right?
hah yeah
I mean you probably write 20 functions in a day, and I'm sure much less than 5% of functions you write are decorators
so that means a typical python programmer is using closures daily
(for non-decorative purposes 😉 )
For me a perfect world would be to have nice lambdas, and then you would do
new_list = old_list.map {
...
}
And now you don't need to name a function, and you don't need to create an empty variable to mutate either, but c'est la vie
yup, that's a common style in other languages
i do often have a lot of 2-3 line generators, but i typically don't nest them -- i just drag em to the top of the file somewhere
Dragging them out, I do if the logic is sensible on its own and there aren't to many closed over variables
If there are a bunch of things used in the function it's often more trouble to pull out than it's worth
I just realized you could emulate Ruby blocks with Python context managers. Could be an interesting pattern as a workaround for having nice anonymous function syntax
Of course, you could also use coconut or hy 😉
That said, instead of map, you could use a generator comprehension or list comprehension instead
with foreach(iterable) as mapper:
mapper.send(mapper.value + 5)
print(mapper.result)
The standard context manager pattern doesn't let you dynamically change the value of the context binding like you can in ruby, you have to yield a generator to do it
The "b" will get you
I prefer to un-nest funcs when I can
and thus try to be passing values around instead of relying on nonlocal variable access
while it rly doesn't matter if it's global or nested, a function that only deals with its parameters is easier to re-use and adapt
but I prefer prepending a _ and making it global on a module level
u can say flat is better than nested but I really don't see why one strategy is actually better
for example
def _get_code_getter(code_iter):
def bit_stream():
"""Yield least significant bit remaining in current byte."""
length = next(code_iter)
for read, byte in enumerate(code_iter):
if read == length:
length += byte + 1
else:
for bit in (1 << b & byte and 1 for b in range(8)):
yield bit
def code_getter(bitlength):
"""Retrieve/structure bits, least significant first."""
return sum(next(code_stream) << z for z in range(bitlength))
code_stream = bit_stream()
return code_getter
I un-nested these funcs that used to acess nonlocal names by making them a global closure lol, is that better? It's more re-usable, I could add a parameter to flip the significance of the bits to read for TIFF for example, but that'd be pretty quick even if was still nested, I moved it out of the function just cuz I like shorter functions.
@spark magnet i've excessively used closures in fuzzylogic ( https://github.com/amogorkon/fuzzylogic )
GitHub
Fuzzy Logic for Python 3. Contribute to amogorkon/fuzzylogic development by creating an account on GitHub.
GitHub
Fuzzy Logic for Python 3. Contribute to amogorkon/fuzzylogic development by creating an account on GitHub.
it enables a pattern to compute stuff in two stages and simplify the logic when combining things
on the other hand, i haven't figured out a way to pickle those recursive calls yet
but that wasn't an issue for me so far
hypothesis testing was a great educator for those functions 🙂
btw, i'm wondering something else: what would be the best approach to replace a module-level variable with a placeholder to guard access, like a module-property?
maybe have a custom ModuleType with an actual property?
why not?
Because accessing a global does not trigger attribute access on the module
Exactly what I'm down now on an org wide scale in one of our services
Forcing everyone to write modular lambdas that can be re adapted
lambdas..
ah 🙂
i was wondering ;p
lambda.. the next sore point in python that needs fixing :p
with ? now in discussion, one may hope that people get a taste for nicer syntax
oh well
@faint stirrup @hushed spade This channel is to discuss advanced use cases for Python, please keep this channel on topic.
If you need help with Python, look at #❓|how-to-get-help
And also, please keep in mind
!rule 4
4. Use English to the best of your ability. Be polite if someone speaks English imperfectly.
Currently backslash \ is forbidden inside f-string. https://www.python.org/dev/peps/pep-0536/ talks about some other restrictions that they want to lift. But shouldn't it also be possible to allow backslash inside strings inside curly braces? That would allow code like: f"Here are things: {'\n'.join(things)}"
Python.org
The official home of the Python Programming Language
definitely annoying, yes
i remember when i collided with that "SyntaxError: f-string expression part cannot include a backslash" a while ago
i wonder whether it's possible with the PEG-parser now to remove those restrictions now without issues
is it possible to create a wifi network through python?
Does anyone know how to call a class method on a class without binding the class to it
Similar to how you can call a method without binding it to an instance
I.e. you manually specify self
class Foo:
@classmethod
def bar(cls):
print(f"{cls=}")
Foo.__dict__["bar"].__func__(object)
cls=<class 'object'>```this works but that doesn't mean its a good ideaoh that is beautiful
inspect.getattr_static can also be used to fetch the attribute without triggering the descriptor protocol to be a bit clearer (and probably more robust) than accessing it through the class dict yourself
I was trying to do cls.class_method.__get__ but no matter what I passed to __get__ it was still binding to cls
@swift imp i'm tempted to ask why you want to do that, but I suspect the answer will be something else where I wonder, why do you want to do that 🙂
Yes with a class method, the method is bound on attribute access from the type so you'd be calling __get__ on the bound MethodType obj, which is just an identity func
What does that mean lol
hey guy, i have a question, are all electric devices run with 0 and 1 like car engine, washer, cooker or just only our computers run on 0 and 1 ?
it's from a story in a brief history of time (which is a book)
a physicists is lecturing and an old lady interrupts him and says "that's all nice, but really the earth rests on the back of a giant turtle"
And the physicist smiles to her and says "what is the turtle resting on?"
And she says "you're very clever young man, but its turtles all the way down!"
only the computers use the 0/1 thing, but there are now computers inside car engines, washers, cookers, etc.
because as i known, integrated circuit is really different from cpu of computer
I think it's alternating between 4 elephants and big turtles all the way down personally
and I will die for my beliefs
The thing to look up here is "analog" versus "digital". All digital devices use 0/1, more or less, but those are the terms to look up to learn more about it.
binary digital
@halcyon trail
More like, a lady is talking and a physicist interrupts her and says "that's all nice, but really the Big Bang created all the matter and energy in the universe"
And the old lady smiles to the physicist and asks "what came before the big bang?"
And he says "you're very clever lady, but it's energy and matter"
Turtles is easier to believe than this!
Django with mangoDB or postgrsql SQL is good I am building large project
@hollow hill nothing runs on "0/1" in the real world 😉
there's always leakage etc., so in a sense 0/1 is abstract, practical and philosophical but not physical
Not so advanced but python-general is crowded: is there a module to easily convert time annotations in string like '1d', '5m' to minutes in integer?
You could probably build something yourself with timedelta relatively easily
!e ```py
from datetime import timedelta
import re
def parseTime(s):
m = re.match(r'^(\d+) *([a-z]+)$', s)
if m is None:
raise ValueError("couldn't parse time string")
units = 'seconds minutes hours days weeks'.split()
num = float(m[1])
for unit in units:
if unit.startswith(m[2]):
break
else:
raise ValueError(f'Unknown unit {m[2]}')
return timedelta(**{unit: num})
print(parseTime('1d'))
print(parseTime('5m'))
@median cedar :white_check_mark: Your eval job has completed with return code 0.
001 | 1 day, 0:00:00
002 | 0:05:00
@terse orchid
@median cedar thanks! I think you can add this to a gist or something

Cool (Y)
Hey @foggy portal!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
Can someone explain the new sentinel pep? I really don't get it, is it just dataclass.MISSING
def f(a_list):
for _ in range(10000):
a_list.append(0)
del a_list[-1]```
Something like this will never be O(n^2) because of resizing, right?Like it will never be on an unlucky resize size where it keeps resizing after every size change?
The goal is to have a builtin sentinel factory that would be a bit clearer than object() when printed
Main reasons for it are being able to have a nicer REPR and also being a distinct type to avoid overly-broad type annotations
I've used strings for it in the past, but that falls apart if strings are valid args
Though maybe literal already solves the latter problem?
so no mention of boltons in the pep huh
ah the stdlib's various sentinels were discussed on the mailing list
you know immediately someone is going to start meta-programming with if isinstance(foo, Sentinel) and we're going to end up right back where we started
unless they also enforce that isinstance(Sentinel(), Sentinel) is always False too
ah, it's a function, i like that
@sand goblet i don't think that can be quadratic, no
Thanks
I shoudl say, I haven't read anything that specifies it tightly enough to be 100% sure. But that would be a really really bizarre list implementation
Adding an element to a list like this, usually only triggers allocation and copying of elements, if the list is completely full
Yeah I have the same assumption about it, it would be pretty weird
removing elements from lists usually is not aggressive about returning memory, because that makes no sense. In C++ for example removing elements never returns memory, ever
this being python and wanting things more automated, I could maybe imagine that if a list is "too" empty, say < 25%, it would decide to return memory after removal
In practical terms, the first loop iteration might trigger an allocation and linear work. There won't be any deallocations here, for sure, and there won't be more than one allocation
import sys
x = [None] * 1000
start_size = sys.getsizeof(x)
current_size = start_size
print(start_size)
while current_size == start_size:
x.append(None)
current_size = sys.getsizeof(x)
print(current_size)
for _ in range(10):
del x[-1]
print(sys.getsizeof(x))
x.append(None)
print(sys.getsizeof(x))
print("done")```This shows that you’re right
so python lists return memory when they're less than half full
well, that's what this blog post says, I find the reasoning somewhat suspicious still
Here's a citation from the source code:
https://github.com/python/cpython/blob/main/Objects/listobject.c#L51-L53
Objects/listobject.c lines 51 to 53
/* Bypass realloc() when a previous overallocation is large enough
to accommodate the newsize. If the newsize falls lower than half
the allocated size, then proceed with the realloc() to shrink the list.```yeah, i see now, the specific numbers in the blog post were a little strange
it makes sense when you look at the overall code. Though 9/8 is a very very conservative growth factor, I guess they want to prioritize memory usage though, and they think realloc will help them most of the time
!warn 805459204517265428 please don't spam off-topic videos into topical channels.
:incoming_envelope: :ok_hand: applied warning to @placid marsh.
wait why is this bad, aren't these supposed to be like custom versions of None
Well if it had special handling for the sentinel's type then you'd need to implement it yourself again for it to be discrete, but the factory through a function should avoid any possibility of handling arbitrary sentinels
Like I can do x is NewSentinal if the pep is approved right? Like is that not the point or am I missing this completely.
Yes
It gives you an easy way to make a sentinel that's separate from other sentinels (either None, stdlib values or from 3rd party) so they don't get mixed up and you can be sure that it won't be a valid value to anything else if you're creating it yourself
If anyone has course hero subscription please inform me I need your help
What are these three things

and when to use each one
Virtual environments, they are used so that you may install python packages without filling your main python installation with packages
I always use virtualenv in my projects but any is good
packages are generally small (my OCV env folder is ~200mb so uh)
Storage is cheap, peace of mind priceless
virtualenv for general use, pipenv if you’re collaborating with other people and want to keep track of dependencies more easily
I think we moved all of our projects from pipenv to poetry
Conda does something the others don't, it handles native packages as well