#internals-and-peps
1 messages · Page 103 of 1
The language's user-facing behavior is that names are looked up dynamically at runtime. In an environment where names are looked up at runtime, compilation to machine code just doesn't add very much - that machine code would need to do the same slow searches to look up names and attributes that the CPython VM does.
Consider also code like ```py
x = 10
exec(input())
print(x)
After running the first line, `x` is an integer with value 10. After running the second line, literally anything at all could happen. It's possible the `print` will print 10, or that it won't be reached at all because the control flow changed, or that `x` no longer exists, or is no longer an integeror consider code like ```py
x = 10
import main
main.x = 20
print(x)
If that's imported as a module, it will print `10`. If it's run as a script, it will print `20`. It executes the same code either way, but the code has different effects.how to make a conscious AI
Hi guys, looking for the best and easy UI maker for python.
I will create exe from my python and I want to make UI to my app. What is the best drag and drop UI builder, or the easiest way to build a UI?
@shrewd talon Please go to #user-interfaces
Thanks
@unkempt rock Please go to #data-science-and-ml
can some1 tell me what number i should put in number of processors and no. of cores per processor in vm setting?
vm is a bit laggy. both vm and the os inside vm are installed in ssd as well
I have 3700x 16 gb ram

This is definitely the wrong room for this
why does collections.Counter use self.__class__ to make the repr but not self.__class__ for methods like +?
class Foo(Counter):
pass
repr(Foo()) # is "Foo()"
Foo() + Foo() # is Counter()``` in fact most classes not only in the standard library but also ones from popular libraries do this thingwhere should i go @visual shadow ?
ty
generally, + does something like
return Counter(combined_counts)
```you can't make that use `type(self)` since subclasses can override the initializerHow does locals() get the names of all the variables if the local values are stored in an array and not a hash table? Does it store the names associated with the values in the array just for the sake of being able to create/update the locals() dictionary?
Also, why would someone ever need to use locals()?
it might be used in debugging tools
@sand goblet the names are stored in the currentframe -> f_code -> co_varnames
And at the same memory offset as the array with the values?
i believe so
And it does that just so that locals() will work? Or it’s used for other reasons too?
https://github.com/python/cpython/blob/fcb55c0037baab6f98f91ee38ce84b6f874f034a/Objects/frameobject.c#L1006 here is where the locals dictionary is generated

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
co_varnames has other uses in other places
Alright
What is the correct way to upgrade all packages without having conflicting issues?
with just pip, there isn't a way. That is what pipenv and poetry make easy.
What is interfaces, filter_fields and relay-node in graphene-permissions?
There are several ways you may want to limit access to data when working with Graphene and Django: limiting which fields are accessible via GraphQL and limiting which objects a user can access.
Let’s use a simple example model.
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
published = models.BooleanField(default=False)
owner = models.ForeignKey('auth.User')
use it on vs code
Download the pip files from pypi website
I think u got your answer already , ☺️
I want that my API could be accessed by the authenticated user only, how can I do this?
I also want to define permission based access.
Hi guys,
How would go about writing some code that would instantiate different subclass depending on an init argument ?
I am thinking something like:
class Person:
def __init__(gender):
if gender == 'm':
return Male()
else gender == 'f':
return Female()
class Male(Person):
pass
class Female(Person):
pass
Is that pythonist ?
Ideally you should look into #software-architecture channel, but what you want here is probably factory pattern. folks there will be more helpful
Had a weird error today on our production server related to a code change someone made, so wondering if anyone can help me with this
Did python gain the ability to set OS.ENVIRON variables as types other than string sometime in 3.8.0 onwards
Someone set environment variables as None and then was trying to get that back with a check, and on some of our machines the var would set and on others it wouldn't, creating a logic error
init never returns anything. self is already created at this point (and is first argument to init)
Hope I'm making sense
os.environ enforces enforces its type, but .get() returns None if the mapping doesn't have the key
I see, I wonder if that behavior changed in a recent version, since some of us are using 3.7.x and earlier and the rest are on newer versions . Apparently its been sitting around in the lambda layer forcing people to do workarounds for months until I noticed it today and got someone to revert it
it did the same in python 2
How odd. In any case it seems like bad practise so changing the logic was the simplest solution
In [5]: class D(dict):
...: def __del__(self, *args, **kwargs):
...: super().__del__(*args, **kwargs)
...: print("was called...")
...: print("args", args)
...: print("kwargs", kwargs)
...:
In [6]: d = D()
In [7]: d["h"] = 1
In [8]: del d["h"]
In [9]: d
Out[9]: {}
How does del work on dict? Seems like del is not invoked.
sadly __del__ isnt linked with del as a keyword, __del__ is invoked when any object is about to be destroyed hence why any object can implement __del__ but is only done rarely as it's not guaranteed to be called at a given time. iirc
it invokes __delitem__
__del__ isn't guaranteed to be called but it often is. But in situations such a segfault it won't really be possible.
it gets called as long as python exits properly, that is without C level errors/os._exit
and it always gets called when the refcount reaches 0 in cpython
The object may not be collected when the interpreter exits in cpython afaik
I think that was changed in some pep.
def abstract_property(
name: str, type, doc: str = "", mutable: bool = False
) -> property:
"""Abstract property."""
@property
@abstractmethod
def fn(self) -> type:
"""Get."""
...
if mutable:
@fn.setter
@abstractmethod
def fn(self, value: type) -> None:
"""Set"""
...
fn.__name__ = name
fn.__doc__ = doc
return fn
# usage
class Iterfacex(ABC):
field_x = abstract_property(name="field_x", type=str, doc="mutable propery c", mutable=True)
field_y = abstract_property(name="field_y", type=int, doc="immutable propery y", mutable=False)
Doesn't work 😓 , is such a thing possible? Why, to reduce boilerplate code for setting up abstract properties.
Nah, that's still true. https://docs.python.org/3/reference/datamodel.html#object.__del__ still says
It is not guaranteed that
__del__()methods are called for objects that still exist when the interpreter exits.
huh, I wonder what change I am confusing it with then
Python 2 wouldn't call __del__ methods for objects collected by the cycle collecting GC, but Python 3 will. Perhaps that?
I don't think it's going to play well with any kind of IDE/linter
Why is there nothing like this with .split, even though it does something similar for whitespace if you don’t give it any arguments?
"abc1321323xyz".split("123", any_combination=True) # ["abc", "xyz"]
It forces you to use re.split
"abc \t\n \n\t xyz".split()
There’s nothing like that for different collections of characters
Why would you expect it to give ["abc", "xyz"] instead of ["abc", "", "", "", "", "", "", "xyz"] if it existed?
Because splitting by whitespace gives ["abc", "xyz"]
!e Only splitting with no arguments does.
print("a b".split(" "))
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
['a', '', '', 'b']
Yeah
So why should your proposed addition behave more like splitting without specifying a delimiter than like splitting with a given delimiter? Is that how everyone would expect it to behave?
I think so
Since it would be like what it does by default with whitespace, just with a different collection of characters
it's marked in docs as special behaviour
I'm betting the only reason that split() with no args exists is that it predates the re module, and it's a relatively common case that people frequently need. Splitting on runs of arbitrary characters is a less common need, and it's easy enough to do using re, and it can be done faster with re because the pattern can be compiled in advance and reused
And doing it through re lets the user choose whether they want to collapse adjacent delimiters or not.
I'd assume so as well. Python doesn't often have special cases like that. it's not just a default argument thing, it's literally a different approach:
"If sep is not specified or is None, a different splitting algorithm is applied: runs of consecutive whitespace are regarded as a single separator, and the result will contain no empty strings at the start or end if the string has leading or trailing whitespace."
So it would be slower if they let you do it for any collection of characters?
Yes, definitely. There's a highly optimized version of the split on whitespace implementation.
collapsing whitespace is also done much more commonly
Which is more idiomatic for storing a metaclass argument?
class M(type):
def __new__(cls, name, bases, dict_, custom):
instance = super().__new__(cls, name, bases, dict_)
instance.__custom = custom
return instance
def __init__(cls, name, bases, dict_, custom):
pass
or ```py
class M(type):
def new(cls, name, bases, dict_, custom):
return super().new(cls, name, bases, dict_)
def __init__(cls, name, bases, dict_, custom):
cls.__custom = custom
Well, if this is all you need the metaclass for, use __init_subclass__() as of 3.6.
I've usually seen it done in just __new__ though, the usual distinction isn't as relevant for metaclasses since you'd not call them yourself.
There's more to the metaclass, though as far as __new__ goes, it's only needed to get the custom kwarg.
What's even the semantic difference between doing something in __new__ and doing something in __init__ for a metaclass?
The first argument of __init__ is different than the first argument of __new__. To me, this demarcates the main difference -- use init when you need an instance of the metaclass -- registries are probably the most common use -- though one can use __init_subclass__ for this now.
In [13]: class MyMeta(type):
...: def __new__(meta, name, bases, methods, **kwargs):
...: print(meta)
...: return super().__new__(meta, name, bases, methods, **kwargs)
...:
...: def __init__(cls, name, bases, methods, **kwargs):
...: print(cls)
...: super().__init__(cls)
...:
In [14]: class MyClass(metaclass=MyMeta):
...: ...
...:
<class '__main__.MyMeta'>
<class '__main__.MyClass'>
I typically use __new__ when I want to modify the dictionary before I create the class.
Why would you need to modify the dict before it's created? Can't you achieve the same thing in __init__?
modifying methods above in __init__ wouldn't actually modify the class at this point, you'd have to reach into cls.dict
In [7]: class MyMeta(type):
...: def __new__(meta, name, bases, methods, **kwargs):
...: print(methods)
...: return super().__new__(meta, name, bases, methods, **kwargs)
...:
...: def __init__(cls, name, bases, methods, **kwargs):
...: del methods['__module__']
...: super().__init__(cls)
...:
In [8]: class MyClass(metaclass=MyMeta):
...: ...
...:
{'__module__': '__main__', '__qualname__': 'MyClass'}
In [9]: MyClass.__module__
Out[9]: '__main__'
But you can do cls.__module__ = whatever in __init__ or delete it from cls.__dict__
But note, that methods isn't always a dict
In [12]: from collections import ChainMap
...:
...: class MyMeta(type):
...: def __prepare__(*args):
...: return ChainMap({'hidden_method': None}, {})
...:
...: def __new__(meta, name, bases, methods, **kwargs):
...: print(type(methods))
...: return super().__new__(meta, name, bases, methods, **kwargs)
...:
In [13]: class MyClass(metaclass=MyMeta):
...: ...
...:
<class 'collections.ChainMap'>
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-4db0ebe2f46b> in <module>
----> 1 class MyClass(metaclass=MyMeta):
2 ...
3
<ipython-input-12-56eb236938cb> in __new__(meta, name, bases, methods, **kwargs)
7 def __new__(meta, name, bases, methods, **kwargs):
8 print(type(methods))
----> 9 return super().__new__(meta, name, bases, methods, **kwargs)
10
TypeError: type.__new__() argument 3 must be dict, not ChainMap
you can pass any mapping with __prepare__
it needs to be converted to a dict though
and needs to be done before __init__
Not sure if you missed this #internals-and-peps message
It seems that as far as modifying the dict goes, it's just a semantic difference rather than a technical one since the same thing can be accomplished in either new or init 🤔
That's not really true
In [21]: class MyProp:
...: def __set_name__(*args):
...: print("set name called")
...:
In [22]: class MyMeta(type):
...: def __new__(meta, name, bases, methods, **kwargs):
...: methods['my_prop'] = MyProp()
...: return super().__new__(meta, name, bases, methods, **kwargs)
...:
In [23]: class MyClass(metaclass=MyMeta):
...: ...
...:
set name called
In [24]: class MyMeta(type):
...: def __new__(meta, name, bases, methods, **kwargs):
...: return super().__new__(meta, name, bases, methods, **kwargs)
...: def __init__(cls, *args):
...: cls.my_prop = MyProp()
...: super().__init__(cls)
...:
In [25]: class MyClass(metaclass=MyMeta):
...: ...
...:
if you add properties to the methods dictionary, things like __set_name__ will be called for you
this doesn't happen in __init__
also, once again, methods might not even be a dictionary and you need to turn it into one -- you can't do this in __init__
you can call __set_name__ manually of course, but probably you should just be using __new__ instead
Okay, good point on __set_name__
Yeah I'm not trying to go down that rabbit hole. If it's more convenient to do it in __new__ then that's a win for __new__
By the way, is it safe to use *args for __init__ like you did? Doesn't that assume those args will always be passed as positional?
Is that a reasonable assumption to make?
(when considering someone extending the metaclass with some arbitrary behaviour)
typically i wouldn't use *args here, but keyword arguments are pretty rare for class creating -- still if you're doing something funky with metaclasses probably should just use a more explicit signature, i was just being lazy
Yeah I wanna be lazy too but I guess I can't be
yeah
i call it methods because that's what it was called when i learned about metaclasses
but probably namespace is a better name
Yeah and get rid of kwargs
i wouldn't get rid of kwargs
well, i guess it depends on your metaclass
but you can definitely pass kwargs to it
Doesn't __init_subclass__ args appear there
Wait so type.__new__ is really meta, name, bases, namespace, kwargs
Yes
oh, you can remove kwargs from the super call
that's probably a smart thing to do
but this is ok:
In [32]: class MyMeta(type):
...: def __new__(meta, name, bases, methods, **kwargs):
...: print(kwargs)
...: return super().__new__(meta, name, bases, methods) # <- no kwargs
...:
In [33]: class MyClass(metaclass=MyMeta, a=1, b=2):
...: ...
...:
{'a': 1, 'b': 2}
It's annoying that __new__ has to be defined with kwargs just to be able to accept them even if __new__ itself won't do anything with them.
you don't have to have **kwargs in the signature, especially if you don't plan on doing anything with keyword arguments
It's also confusing
it's really rare to see them
It's also confusing that type.__call__ begins the class instantiation
But you don't even need it
Isn't __call__ the entrypoint of anything that's callable?
class Foo: pass
i've used __call__ quite a few times with metaclasses
Perfectly valid
Ok let me back up
It's confusing that type.__call__ gets used for both class creation and instantiation
For the example I gave above
You don't need ()
probably like:
In [41]: type('hi', (), {})
Out[41]: __main__.hi
In [42]: type.__call__(type, 'hi', (), {})
Out[42]: __main__.hi
is what he means
i mean __call__ is weird anyway
In [43]: def f():
...: ...
...:
In [44]: f.__call__.__call__.__call__
Out[44]: <method-wrapper '__call__' of method-wrapper object at 0x0000022A0A0D6790>
what am i supposed to do with this
Is a class's definition not complete until metaclass.__init__ is called?
Cause I'm unable to access a specific instance of the metaclass from metaclass.__init__
Hi can anyone explain how the class become subscriptable and callable while inheriting enum to the class ?
Can't you use __getitem__ and __call__ for those?
I didn't say I can't use I'm asking how a class object becomes subscriptable and callable by just inheriting enum
import enum
class demo(enum):
ONE = 1
TWO = 2
demo['ONE']
demo(1)
in above code both work I'm asking how the class object can become both subscriptable and callable at same time
You can definitely do demo['ONE'] using some magic methods. But for demo(1), I think you will need to override the __init__ class?
not when you inherit from enum.Enum - but that's because enum.Enum itself has a custom metaclass, which adds that subscripting support to classes it creates.
metaclass ?
the class of a class is its metaclass. When you're creating a class (as opposed to an instance of that class), you're constructing an instance of it's metaclass. That metaclass has nearly complete control over the created class.
in the case of an Enum, it's https://github.com/python/cpython/blob/master/Lib/enum.py#L373
This works fine though
from enum import Enum
class Test(Enum):
ONE = 1
TWO = 2
print(repr(Test(1)))
print(repr(Test['ONE']))
#bot-commands
yes - the question was how it works, not whether it works.
Ohhhh, I misread that lol
Thank you got some clarity
thank you @raven ridge @tidal marten
In particular, it looks like the metaclass creates cls._member_map_, and the class inherits a __getitem__ that uses it from the Enum base class - https://github.com/python/cpython/blob/master/Lib/enum.py#L656
That 1000+ lines just to implement Enum seems a bit much though. I wonder how much overhead does modules like enum and typing add.
"overhead" in what sense? If you were to implement the same features from scratch, it'd take the same number of lines of code, give or take.
and if you don't import enum, you don't pay anything for it.
I mean at runtime, calling the metaclasses when doing Enum and such.
well, you can profile to get an answer to that.
Yeah look like while calling an enum object call method is been invoked and return value
https://github.com/python/cpython/blob/37494b441aced0362d7edd2956ab3ea7801e60c8/Lib/enum.py#L582
GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
Yeah, it's like all that just to provide static typing 😂
In [54]: %%timeit from enum import Enum
...: class MyClass(Enum):
...: x = 1
...: y = 2
...:
289 µs ± 27.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [55]: %%timeit
...: class MyClass:
...: x = 1
...: y = 2
...:
32.1 µs ± 3.4 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Not much ehh?
Looks like defining an enum class is around 10x slower than defining a regular class.
but still pretty cheap in absolute terms.
Hmm, I guess you won't have hundreds of thousands of classes in a single project anyway
and I'm on pretty slow hardware - old chromebook with a Celeron processor.
how many classes you have in a project depends how many libraries you're using, of course, but - yeah, hundreds of thousands sounds like a lot. I'd expect most non-trivial programs to have in the hundreds to thousands, give or take.
still, though - most of the time, your choice will be between using Enum and living with a fraction of a millisecond of overhead, or implementing your own crippled version of Enum that's good enough for your needs. The maintenance cost of the latter is probably higher than the performance cost of the former. Probably.
Kinda wish that these are optimized in the parser though. So that the parser just abstract away the Enum or typing or whatever without loading/executing the metaclass.
That's would require changing the semantics of the language. It would make it impossible to mock or monkeypatch the enum.Enum class if it were special cased at parse time
You can probably check for trivial case and optimize for that while still having the unoptimized codes available for lazy instantiation for when it's necessary. That would complicate things for the parser/interpreter though.
can someone tell me how I can identify if a resource group in azure is unused/useless , im writing a script to delete them
1 is if its size is 0 but that is based on assumption
You should probably consult the Azure docs or the relevant server/channel for that
Pretty much any analysis is going to be broken when exec, eval etc. is used so you'd have to disable all the optimizations if there's one in the code
Yeah. Probably only useful for static analyzer, not much for everything else.
You cannot. Parsing and compilation happens before the code is run. There's no way of knowing whether something will have been monkeypatched once it is later run.
Can't you hypothetically add new opcode for e.g. optimized enum and do checks if it's being monkeypatched at runtime?
I can't imagine how. Even if you could, it would be extremely expensive to check every class and attribute and helper function to see if it has been patched or not at runtime
enum.Enum could have been set to something unexpected, or enum.EnumType, or any attribute of either of those classes, or any function of built-in used by either of those classes
I was thinking of maybe optimizing only certain functionalities that are trivial. Ideally only classes that directly subclasses only Enum for example will benefit from this. This also depends for the implementation of Enum to be standard and unchanged, so it won't play nice with runtime monkeypatching.
So yeah, it's probably only good for static analyzing.
Yeah - detecting that something has been monkeypatched is itself non-trivial - and it needs to be applied recursively
Optimizing something that takes submilliseconds is just wasteful anyway, lol
The cost of running the check itself would kill any gains you would have gotten from the scenario of optimized code on the very small subset in your program that would benefit from the check
The power of monkey patching comes at the cost of not knowing the program state till runtime. Especially if, say, you wrote your code, but someone else could always import your code and patch it later. Allowing that capability means the program simply cannot take a guarantee on just about any part of the code.
And that's basically the intended case for monkey patching - it allows code that does one thing when run normally do a different, simpler thing when run from tests
Without changing the Python code in the module itself at all
I'm not sure if this is the right channel for this. Please let me know if it isn't.
I'm confused by the interpreter flags available to show additional debugging information, and need suggestions to help debugging strangely blank output:
Error in sys.excepthook:
Original exception was:
The process reports as exiting with 0 status despite the exception report being printed. Are there any flags or suggestions people have for where I could go in debugging this?
Simple test files run from the project directory seem to work fine, so I don't think it's pycharm's configuration. If there's a memory allocation issue or somethings odd going on with bound C libraries somewhere in the framework I'm using, could that be causing this?
follow-up: I figured out why it was happening (seems to be null characters passed into a C api) , but knowing how to enable more detailed debugging options in the future would still be useful.
Just so I'm on the same page with this... Process exited with exit code 0, the code 0 is usually used as "everything went fine". So, did you know that? If yes, why are you expecting this to give an exception?
Yes, to be absolutely clear, I am aware that exit code 0 is that everything is fine.
I'm not expecting it to give an exception, but it gives what looks like one except the information is blank.
That's why I'm confused. The interpreter says there was an error, and prints a blank line for the original exception.
Obviously I shouldn't put null bytes in places they shouldn't be, but the question of how to get better information out of python in cases like these is still relevant for the future.
Ok, it might not be nulls in names.
I'm still stuck on how to go about debugging it.
this is a channel for discussion of the language. try #❓|how-to-get-help or #data-science-and-ml.
Is there a way to check the text of a button with webdriver? Because the class is generic and there is multple ones with the same thing

@unkempt rock This is a channel for discussion of the language. Try #❓|how-to-get-help or #web-development
!e What's up with:
print([0xfor x])
```?@brave badger :white_check_mark: Your eval job has completed with return code 0.
[15]
Not exactly sure what 0xfor stands for
oh wow
why is that allowed is the real question
it doesn't work in some Python interpreters. micropython doesn't allow or to be used without a space before it, I know
works in pypy, though. I think it's just a grammar quirk, though - some early version of the interpreter allowed it accidentally, and by the time anyone noticed it wasn't worth changing it because they didn't know if it would break anything.
50% of code golf solutions will stop working
Why would Counter.subtract keep zeroes while subtraction with operator clears them?
>>> c = Counter(potatoes=10)
>>> c - c
Counter()
>>> c.subtract(c)
>>> c
Counter({'potatoes': 0})
What's the rationale behind this behavior? (Cross-posting from python-general)
The method can also go below zero while the operator will filter out non positive vals. On the why I'd say it's to keep track of what was encountered, the subtract modifies the existing object, while the operator creates a new one which doesn't "need" any knowledge of the items that didn't exist because of the 0/neg vals
oh wow, I would have thought it kept negatives! good to know. I think your "why" could be the reason.
Since it can handle negatives:
>>> c.subtract(c + c); c
Counter({'potatoes': -10})
@frozen abyss This is strictly a discussion channel about the language.
Ok sorry about that
does python have a feature like c/c++ compilers where you can give it a path to search for imports in?
kinda like gcc/clang's -I flag
mmm probably the closest thing to it is virtual environments and yh
other than that not really
how would i do that with venv?
well you'd basically just make a venv and install any deps there (or use something like pipenv) and let that store the deps etc...
things like pipenv allow you to customise the deps a bit more depending on setting etc...
hmm that doesn't look like it's as advanced :/ might just copy paste the folder into my project and use the copy
you can append sys.path, I believe
!e
import sys
print(sys.path)
@boreal umbra :white_check_mark: Your eval job has completed with return code 0.
['', '/snekbox/user_base/lib/python3.9/site-packages', '/usr/local/lib/python39.zip', '/usr/local/lib/python3.9', '/usr/local/lib/python3.9/lib-dynload']
Though I don't believe that's recommended 😛
The PYTHONPATH environment variable, or sys.path
And no, definitely not 🙂
Im gonna scream
I am doing excercises for my programming finals
and we have to do it all in syntax-strict pseudocode
I could do them in any language from C++ over Python to Java
but that Assembly-looking 50 year old pseudocode, for which we need to know that syntax
is so infuriating
oh cool, thanks @boreal umbra and @raven ridge 🙂
It's been a minute, but iirc the biggest annoyance is getting the loops/exit conditions right. TBH, I hate tests where you can't look at documentation or use a compiler. Like, what exactly is being tested? You will pretty much never work that way in real life
you'll need to be able to evaluate what code does without actually running it
Wait, how do you determine what code does without running it?
Even my testing framework still runs code
reading it?
Oh
I thought there was some magic way for a computer to test code without running it
I wanted to learn this black magic
Hey maybe one day
probably not for a long time due to the Halting Problem
In computability theory, the halting problem is the problem of determining, from a description of an arbitrary computer program and an input, whether the program will finish running, or continue to run forever. Alan Turing proved in 1936 that a general algorithm to solve the halting problem for all possible program-input pairs cannot exist.
For ...
Silly question for today : When I open binary file in a 'rb' mode, and then use readlines on that object, what is deciding on when the actual line is ending?
even if it's proven to not be possible for all programs, it could certainly work for a subset of all programs
how would you define your subset?
Isn't that just like... the halting problem explained though?
also that ^
It isn't that beneficial to have a halting problem solution that.... halts before it determines if a problem halts or not
maybe i'm grossly misunderstanding >w<
It's okay, that's what I do with life before I've had coffee
you could have the following code py while True:pass
its clear that it is an infinite loop right
the only way for a program to tell if any code infinite loops is to run it
Well, one isssue is convergence. Maybe a loop will end given enough interations, maybe it won't. How do you solve for it?
you can pick a subset of turing machines for which halting problem is solvable
for example, a program consisting of a single integer number will not halt
while num != 0:
num /= 2
import random
while random.random() < 0.5:
pass
Yeah and that doesn't even have convergence to help you
I don't think the halting problem considers non determinism
it does i believe
https://en.wikipedia.org/wiki/Halting_problem#Common_pitfalls the last sentence here
In computability theory, the halting problem is the problem of determining, from a description of an arbitrary computer program and an input, whether the program will finish running, or continue to run forever. Alan Turing proved in 1936 that a general algorithm to solve the halting problem for all possible program-input pairs cannot exist.
For ...
looks like it considers it by looking at all possible states
i think the point is that even only considering deterministic programs, you can't solve the halting problem.
!e On a binary file, .readline() reads up until a byte with value 10 (which is b"\n").
from io import BytesIO
f = BytesIO(bytes(range(256)))
print(f.readline())
print(f.readline())
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n'
002 | b'\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff'
Randall Munroe already solved it. https://m.xkcd.com/1266/
...nice
Hello here. Does anyone know if pyinstaller or py2exe works in the windows linux subsystem, to create windows executables ?
import gc
class magic:
def __length_hint__(self):
return 1
def __iter__(self):
for obj in gc.get_objects():
if type(obj) == tuple and len(obj) == 1:
try:1 in obj
except SystemError:
yield obj
break
weird = tuple(magic()) # weird now contains itself``` would this be considered a bug?because i assume that gc.get_objects() isnt supposed to return objects that are still being constructed
Right so
I have a interesting situation that's certainly going to be a learning experience
but basically, What do you think is going to be the best way to implement Dynamic typing in a strictly typed ByteCode setup? The bytecode being web assembly.
the TL;DR of what i've been messing with is a Runtime/Transpiler which runs Python bytecode as web assembly
while the transpileing part is surprisingly easy logic wise because Python and wasm run on very similar stack styles
dynamic typing is something which im a bit torn about whats the best way to achieve it
cpython uses consistent layout of the first few bytes of object structs, which allows unchecked casts into PyObject* without segfaults
do you have a example of how that works logically?
this is essentially what it produces bytecode wise:
(module
(memory $0 1)
(data (i32.const 12) "\1c\00\00\00\00\00\00\00\00\00\00\00\01\00\00\00\08\00\00\00y\00e\00e\00t\00\00\00\00\00")
(table $0 1 funcref)
(export "foo" (func $module/foo))
(export "memory" (memory $0))
(func $module/bar
(local $0 i32)
i32.const 32
local.set $0
)
(func $module/foo
call $module/bar
)
(type $none_=>_none (func))
)```the approach i considered taking is basically not compute anything until it is directly needed and then feed that in
but that naturally adds alot of extra overhead on the already fairly steap overhead as well as i dont think it's necessarily the optimum solution
what do you mean logically? I don't know a whole lot about wasm, so I am not sure that solution is portable
yeah, thats sorta what im thinking
how does wasm do polymorphism? Indexing into a large array?
I believe that depends on the backend runtime it's using
how does rust manage to compile dyn traits then? Those do runtime polymorphism, so there has to be some way to handle that.
hmm true
are there function pointers of sorts?
yes sorta
the core types are https://webassembly.github.io/spec/core/appendix/index-types.html
I have a meta class question
I was messing around with a bit of code to help with auto registering some classes according to a certain pattern
Haven't done a ton with metaclasses before
I have something working seemingly how I want, but there's a bit of a hack in it, I was hoping I could do a little better
class MetaRegistrar(ABCMeta):
def __new__(mcs, name, bases, class_dict):
cls = ABCMeta.__new__(mcs, name, bases, class_dict)
if name != "CheckBase":
print(cls)
_check_registry[cls.__name__] = cls
return cls
class CheckBase(metaclass=MetaRegistrar):
@staticmethod
@abstractmethod
def create_check(args: CheckArguments) -> Optional[CheckBase]:
pass
@dataclass
class SomeCheck(CheckBase):
check_info: int
@staticmethod
def create_check(arg: CheckArguments) -> Optional[CheckBase]:
# implementation here
so this is the gist of it, basically, it allows adding these new checks (which hold onto heterogeneous information related to the check), and it automatically puts them in this dictionary global _check_registry to be used to run checks by name, run all checks, etc
I'm basically happy with this, but notice the weird hacky if name != "CheckBase"
I added this after I realized that the base class was also getting registered, of course, and since it's not a real check, I don't want it to be
is there a more elegant overall approach here?
i'm also not 100% convinced I understand why this works, really. Metaclasses are not inherited, so I'm not really sure why MetaRegistrar.__new__ gets called for every derived class... they are all inheriting from the same CheckBase, which is the only class using that metaclass, so why isn't new only called once?
I dont quite see how wasi is useful in this situation?
wasi adds some interfacing stuff for WASM to access but other than that
what exactly do you wanna do w this wat?
i dont think i quite clearly understand
Well the wat produced is fed into wasmer which handles the runtime etc...
external imports arent anything im planning to deal with yet
I think how it's looking is probably building the wat as and when it's needed so the types are known before hand
>>> class MyMetaclass(type):
...
>>> class Foo(metaclass=MyMetaclass):
...
>>> class Bar(Foo):
...
>>> type(Bar)
<class '__main__.MyMetaclass'>```when a class inherits from another, it also inherits that classes type (I think when using multiple inheritanc all parent classes must have the same metaclass but that doesn't apply here anyway)hmm ok
That was my initial thought and then I found an SO that contradicted that seemingly
I think it may only be true in python 2?

Stack Overflow
In this well known answer that explains metaclass in Python. It mentions that the metaclass attribute will not be inherited.
But as a matter of fact, I tried in Python:
class Meta1(type):
...
actually
I just misread it
alright, thanks for the clarification
As to the actual solution, it seems like a simpler and better approach is to use the init_subclass hook, which I had never heard of
Python.org
The official home of the Python Programming Language
is pep636 active? I have the 3.9 interpreter but not even the pep cases work
It's available in the 3.10 alpha releases, and is expected to be included in Python 3.10.0
@raven ridge yes, I got it working now, it's great 🙂
Can you do a mapping pattern match that matches on value type for certain and entries and then value literals on others?
I think so
Is this a good place to discuss a PEP idea?
Not a bad place, but the mailing lists would probably lead to more discussion over time
Where can I find them?
https://www.python.org/community/lists/ I'm not sure which one would be hte most fitting but probably python-ideas
Thanks 👍
ye
@quiet crane this could be a good place to chat about the idea first. the mailing lists can be a rough place, and getting people's impressions first could create a better first message.
@spark magnet in that case, what do you think of a boolean switch for collections.defaultdict where the missing key gets passed to the default factory as an argument, instead of the value returned by the default factory being static?
You could alternatively subclass dict and add a __missing__(self, key) method
Right, I know how to implement it in pure python (and I do when I want it), though I see this as the kind of convenience that people don't realize they want until they see that python gives it to them for free.
I'm the ta for a class that uses python at the moment. A lot of students are using python for the first time and they remark that the language comes with so many niceties out of the box.
Guidos time machine, as we say.
Time machine?
It's a joke about how people might think that they need to request a feature, only to find that it's been there all along.
Ok, my idea for convenience is a conflict_resolution argument to dictionary.updste
Today dict_a.update(dict_b) will overwrite items in a if they also exist in b.
More than once I have had dictionaries of lists where I would have liked to extend the lists instead of just getting the ones from dict_b.
Example:
a_dict.update(b_dict, operator.add)
With this you could also merge the dictionary values in other ways. Like keeping the items from a if they exist in both.
Other use cases could be:
a.update(b, max)
a.update(b, min)
I don't think this belongs in the update method, but sounds nifty as a way of merging dicts
If this was an external utility function, it could take an arbitrary iterable of dicts instead of being limited to just merging on a single update
The real question though is whether it's actually a common enough operation or not. And that requires verifying against popular code bases. Some real stats to back it up, so to speak
For what it's worth, I've written code where I wanted to retain the first occurance of keys while merging, and also the min/max have been handy
fwiw this exists in java's hashmaps so it couldn't be that uncommon, i guess
@Darr any ideas on what code to look through?
I thought about that, but Where would an external function be put?
That'd mean just defining it yourself as a regular function.
Java has the merge method for merging single item into a map:
hashmap.merge(key, value, remappingFunction)
The putAll method is like python's update method.
@prime estuary what do you mean? The proposal is to include the functionality in python so that you don't have to write a function for it.
One issue is the existence of duck typing in Python. In Java, big class hierarchies are expected, and any dict/mapping object must inherit from the base class. So adding all these utility methods is easy and applies to all of them. In Python instead it's all agreed interfaces, so it'd need to be separately added to every mapping type.
I was explaining what Darr meant by an "external utility function".
Right, and therefore a free function is less intrusive?
Sure I understood what it means :)
It would be yeah, same reason we have str.join not list.stringjoin.
The question was more: what should the free function be called and in what package does it belong?
Right
So dict.merge for example
That's a good question, since we don't have a mappingtools module :)
Do you know of other msppingtools that have been discussed? 👀
I don't no.
@unkempt rock :white_check_mark: Your eval job has completed with return code 0.
{'a': 1, 'b': 2}
**PEP 584 - Add Union Operators To dict**
Status
Final
Python-Version
3.9
Created
01-Mar-2019
Type
Standards Track
kaddkaka is referring to what happens when the same keys exist in both dicts
Yes exactly. Like Counter for integers
currently, the value for that key in the first dict is overwritten by the value in the second
they propose that instead of overwriting, a function be passed which decides what happens
Whatever you want. You provide a binary function
dict1 = {'a':2}
dict2 = {'a':3}
a|b -> {'a':6}
Yes
Like normally calling a function with incompatible types would.
The original idea was to not treat nested dicts differently. But I guess that could be considered differently. Hmm, deep/shallow merge
I think it's difficult to do something generally correct (intuitive) for nested dicts. I guess if you assume the level is uniform it's OK I guess.
d1 = {0: 100}
d2 = {0 : {10: 10, 20: 20}}
merge(d1, d2, +) 🤯
But you could all distribute it, to end up with
{0: {10: 110, 20: 120}} but it's quite exotic!
I'd say as long as you can write a function for mapping, it's perfectly reasonable to expect that said function would manage dict merge logics. It shouldn't be a problem for the interface itself.
Just like we don't really care how sorted would work on lists that contained lists, if it errors out, then the key they passed didn't make sense for nested lists. That's on the programmer.
The interface should be as simple as possible, and I like the idea of a key for merging. As for where such a function would belong? Frankly I'm not sure.
I definitely dont like silentatly propagating operations though
That will probably break for people expecting diff behaviour in different ways.
I agree
I think the reason for this is rather that you can join any iterable, not just a list
@fix error The same goes for mappings
Indeed, and similarly you could implement the merging function without requiring the object to be a dict subclass only.
help me out on this code . Error in line 8
fname = input("Enter file name: ")
fh = open(fname)
lst = list()
for line in fh:
line= line.rstrip()
linelist = line.split()
for word in linelist:
if (word in lst):
continue
else : lst = lst.append(word)
y= lst.sort()
print(y)
You assign an NoneType in the else part of your if statement. So after the first append, lst.append won't work anymore.
is it possible to take self in a class and replace it with something else? I just tried, but my variable remained the same
something like
def transmute(self, other):
self = other
That would update the local variable self inside the function successfully
but isn't self a reference? like, shouldn't it replace the class instance?
No, variables don't work like that.
functions always get a copy of variable, so you only change the reference inside the function/method. whatever it was outside, it still is the same
It's a copy of a reference, so it only updates your local copy.
that seems weird/unintuitive to me
like, I can mutate self.prop and it persists the change in the binding, but modifying self itself does not?
self is basically just a memory address and Python is passing around that address by copying it.
if you change self.prop, you don't change self but the address it contains
Then your function looks up the object at that address and you can mutate its properties.
right, so it's not possible to get the address (without digging into some black magic) and change what's there
the best description of references is:
imagine a variable is a paper with address written on it
if you change any attribute, it means you go to the house under that address and change something there
now your function gets a copy of the variable - you get a paper with address written on it, pointing to the same house
doing self = something makes you basically erase/cross out the address on your paper and write a new one
but the original piece of paper is still there. you don't change it. it still has the original address
By modifying the self.prop you change the object behind it, not the name itself - self = other just rebinds the name to the object other refers to
I know what a reference is. I'm wondering if there's a way to accomplish what I'm doing in pure python as a curiosity
Not because I'm actually trying to implement anything noteworthy
does python even allow you to change a binding without being explicit about it
you said it was "weird/unintuitive", so I just said the metaphor that works good for why one works and the other doesn't
I'm not sure exactly how to do it but for classes you can change what self is I believe because the binding mechanism relies on descriptors
What would you expect self = other to do? Change the object for all references to the old one?
yes
that would require replacing a potentially infinite number of references - and Python doesn't know where they all are.
python variables are references to values. So, there's a very simple contract that happens on each new variable assignment. there's no "reverse linkage" of a value knowing all it's refernces
so, expecting values to propagate back on a re-assignment just doesn't fit with python's worldview of variables and values
the reasons mutations (such as self.prop )reflect across all references are because they're mutations. the object/value itself is fundamentally changing, the variable name -> value contract doesn't change there either
Hope that makes sense.
a better way to think about what's happening here is that both self = obj and self.prop = obj are just updating a name to refer to a new object, but the namespace in which the name is rebound is different.
self = obj binds a local (if in a function or class) or global (otherwise) variable to the given object. It updates a single variable to refer to a new object, and that single variable is either a local or global variable.
self.prop = obj goes into the self object, which itself holds a namespace of names mapped to values, and it asks self to update its prop name to refer to the new obj within that namespace. It's still only updating a single variable, but instead of updating a global or local variable, it's updating a variable within the namespace of the self object.
hm, would it be possible to get the memory address with id and transmute it to your own type?
I think we could also use a wrapper - just have a class that contains self._real_object so you can change it
but to treat it like itself from the outside (my_object.something = 1, instead of doing my_object._real_object.something = 1 all the time), you'd need to overload all/most dunders
The id would be the id of the copy, so no.
Or maybe I misunderstood what you're asking
are you sure?

that's "the address on the piece of paper" from the metaphor right now
if you do self = something inside, id(self) will change
Yeah sorry I was not thinking of it correctrly
so python doesn't have ownership semantics at all? everything's just a dictionary entry somewhere?
what do you expect the state of the world to be after doing this?
a = T()
b = a
c = T()
a.transmute(c)
At the start the call to transmute there are 3 references to the T instance that was created first (globals()["a"], globals()["b"], and the self local variable in the transmute call), and there's 2 references to the T instance that was created second (globals["c"] and the other local variable in the transmute call).
in the realm of sanity, python doesn't give you the mechanism to hijack an object's id and deliberately substitute it for something else entirely. However, python does offer ctypes for hacking through things. So i assume you may be able to change the bytes there yourself. suffice to say, this is literally one of the worst ideas you can implement in day-to-day code.
yes, that's pretty accurate.
oh I know, that's why I prefaced the whole thing as this is just my curiosity
taking this literally, I'd expect id(a) == id(c)
and whatever a was referring to to be cleaned up by GC
as it becomes unreachable
I think it's doable. im also quite sure it's beyond my capability to mess with something like this unless i commit a lot of time to it. Which means my claim about it being doable is worth the paper it's written on. So that's fun. but yes, that would require hacking past the usual stuff into the bytecode, since in "normal use syntax" this is not a thing.
yeah, I imagine with ctypes anything is doable, even segfaults 😄
mhm
Seg faults are quite easy
But in any case the notion of trying to replace the object like that sounds scary and bound to fail
seg faults are easy?
To reproduce one yeah e.g. ctypes.string_at(0)
please mind that I don't normally deal with manual getattr, so it's just the most basic thing to show what I meant by a wrapper:
class Wrapper:
def __init__(self, real_object):
self._real_object = real_object
def transmute(self, other_object):
self._real_object = other_object
def __getattr__(self, item):
if item != "_real_object":
return self._real_object.__dict__[item]
basic test:
>>> a
<__main__.Test object at 0x000002EB11B11F40>
>>> a.a
1
>>> b
<__main__.Wrapper object at 0x000002EB11B11670>
>>> b.a
1
>>> id(b.a)
3208634591536
>>> id(a.a)
3208634591536
>>>
https://wrapt.readthedocs.io/en/latest/wrappers.html omg, someone already did a wrapper like that (found it via https://stackoverflow.com/questions/57589110/python-getattr-doesnt-work-for-built-in-functions when searching "python getattr" for my example 😄 )
Stack Overflow
I'm trying to build some kind of generic wrapper class to hold variable objects.
class Var:
def init(self, obj=None):
self.obj=obj
def __getattr__(self, attr):
return
Hello can I talk with someone with experience in React.js or an experienced HR
I'm struggling in my job search and would appreciate a conversation
That'd be on topic in #career-advice
@desert peak it is possible to do what you want without ctypes
Names don't have id's, objects do. A name refers to an object, and the object itself has some id. As a CPython implementation detail, these two are in fact the same thing: a name refers to an object by keeping a pointer to it, and the id of an object is its location in the interpreter's memory, represented as an integer.
And the id of an object can never be changed. At the start of the call to transmute, there's two objects, one called a and b and self with one id, and the other called c and other with a second id. If you're expecting that after executing self = other that a, b, self, c, and other all refer to the second object, then the interpreter would need to find and update 3 different names.
Which it doesn't do, and doesn't even have the information to do in an efficient way.
and the most efficient way, even if it did have the information to do it, would still be linear with the number of references that need to be updated
import gc
class a:
def transmute(self, other):
referrers = gc.get_referrers(self)
for referrer in referrers:
# swap self for other in each referrer (if mutable)
pass```that will change every mutable reference (known to the garbage collector) to swap self and other
to do the switch at the name level (ie self = other is equivalent to self.transmute(other)) you can parse bytecode to get names and then traverse frames
I think that's actually a better example for why this isn't possible than what I was giving! If any of the references are in an immutable object, then even if you can find them, you still can't update them.
you cant update them safely
you could in theory update whatever is containing the immutable
well, in the spirit of exploration, i created this (admittedly simpler) example on the ctypes hack i was thinking of.
and go up recursively
!e
import ctypes as c
import sys
a = 999
b = a
size = sys.getsizeof(a)
new_var = 1001
size2 = sys.getsizeof(new_var)
assert size == size2
px=(c.c_char*size).from_address(id(a))
# px.raw
px2 = (c.c_char*size).from_address(id(new_var))
px.raw = px2.raw
print(a)
print(b)
print(new_var)
@visual shadow :white_check_mark: Your eval job has completed with return code 0.
001 | 1001
002 | 1001
003 | 1001
you can't update them without breaking Python's data model and potentially leading to corruption of arbitrary data structures.
i was very conflicted on whether to post it or not though...it just..its all kinds of wrong
sys.getsizeof adds some size for GC so youre overwriting some data that isnt owned by new_var
ah, interesting. is it a fixed size that i can account for?
you can use py def sizeof(obj): return type(obj).__sizeof__(obj) to get closer to the proper size but some types add more data then the base struct size to __sizeof__
for example sizeof(user_cls) is the sizeof the PyHeapTypeObject struct and a dict keys object if the class has cached keys
there isnt a perfect universal sizeof that works for all objects that only returns the size of that memory at id(object)
afaik sys.sizeof and __sizeof__ are really only supposed to be used for memory profiling
looks like i lucked out for ints at least, they seem to be in sync in this example for me
ints aren't tracked by the garbage collector.
yea and int.__sizeof__ doesnt traverse anything else
oh! because they're immutable, i suppose? their ref count can be relied upon, i presume.
wait, what does "tracked by garbage collector" mean? could you explain that part
static Py_ssize_t
int___sizeof___impl(PyObject *self)
/*[clinic end generated code: output=3303f008eaa6a0a5 input=9b51620c76fc4507]*/
{
Py_ssize_t res;
res = offsetof(PyLongObject, ob_digit) + Py_ABS(Py_SIZE(self))*sizeof(digit);
return res;
}``` this is `int.__sizeof__`objects that can contain references to other objects need to be registered with the cycle-collecting GC, so that it can ask them what other objects are reachable through them. In the case of objects that can't ever hold a reference to any other object, they don't need to be registered with the GC.
and because it's impossible to set an arbitrary attribute on an int, and because an int doesn't itself refer to any other objects, an int doesn't need to register itself with the GC when it's created.
ah! got it
this was an interesting conversation, thanks for indulging me
does anyone know about this
Write down the mode 0 control words of 8255 for the following two cases:
(a) Port A = Input port, Port B = not used, Port CU = Input port and Port CL = Output port.
(b) Port A = Output port, Port B = Input port, Port C = Output port
@oblique timber what does this has to do with python?
this says advance discussion so i thought if anyone know about this can let me know the answer
First hit on Google seems promising
https://www.google.com/amp/s/www.geeksforgeeks.org/8255-microprocessor-operating-modes/amp/

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
This channel is for advanced python disc though
I just checked not detailed for the mode 0 microprocessor
It describes all the bits d0-d7, how is it not enough?
Perhaps try our off topic rooms, this room is about discussion of the python language itself. Please see the room description for more information
Hi @visual shadow , about the dict-merge feature. Is the next step to discuss it more here, mailing list, or try to write a PEP?
I guess you talked about looking through popular code bases, I will try to find something. Got any pointers?
Does any know of some bigger open source python code bases that are considered good? I'm looking to exemplify a PEP, currently found a function in Tensorflow (https://github.com/tensorflow/tensorflow/blob/5dcfc51118817f27fad5246812d83e5dccdc5f72/tensorflow/python/distribute/cluster_resolver/cluster_resolver.py#L499) it's kinda bulky though
(I started to look through this list: https://hackernoon.com/50-popular-python-open-source-projects-on-github-in-2018-c750f9bf56a0)
Anyone here use Scrapy? I don't quite get the concept behind pipelines and why I should use them.
Hey hacker's
Hey Boo
what's the PEP?
@spark magnet It's my idea to provide mappingtools.merge() or a resolve methoed to dict.update() to be able to merge dicts more elegantly
a.update(b) updates dict a by replacing overlapping keys with values from b. Imaging being able to do:
a.update(b, resolve_function=max) to select the maximum value from a and b on overlapping keys
a.update(b, resolve_function=operators.add) to extend list-values (dict of type : Dict[KeyType, List[ValueType]])
etc...
It can't be added to update due to existing kwarg behaviour. It'd have to be a separate function I suppose.
ok thanks for the feedback
The idea was more appealing when it was part of update
whats the problematic behavior of kwargs that prevents it?
update will update the dictionary using the kwargs given
like dict.update(key1=value)
So if someone was already using the kwarg resolve_function it would break their code
yup
I never used it in any other way than d1.update(d2) so didn't think about that. Hmm
It would've been a nice API but unfortunately it's a breaking change.
d1.update_cool() is also out of the question I guess?
That's a bit awkward. It would feel redundant even though the underlying reason is to avoid breaking changes.
d1.update(d2, max)
```isn't breakingbut it breaks any custom dict implementing their own update
I feel like this sort of thing is better left to a third party library akin to moreitertools.
yeah, it's not very big
but small utility libraries are sort of weird
if you take a new dependency for every small function-that-should've-been-in-the-stdlib-but-isn't, you get many dependencies
basically javascript hell
I would just implement a function like this from scratch
I've come across the need for this function a few times, and seen it in others' code as well
Therefore it would have been nice to have it ready
I didn't know about moreitertools, looks interesting
!pypi even-more-itertools

Collection of even more itertools.
def invert(predicate):
return lambda v: not predicate(v)
this is the sort of javascript hell I'm talking about 🙂
def merge_by(left, right, fun):
for k, v in right.items():
if k in left:
left[k] = fun(left[k], v)
else:
left[k] = v
```is simple enough that I don't think it's too bad to just write it from scratchyou meant an else, right?
ah
yes
yeah, I may be wrong about the simple thing
Should probably be fun(left[k], v) instead
yOu forgOt THe TypE HiNts
Right. The invert() I have used, but function composition would have been really nice: not . predicate e.g. sort(..., key=not . predicate)
I just do
lambda k: not predicate(k)
yeah, that seems simple enough
sure it works, but more wordy and ugly than not . predicate
personally, I don't really mind these minor details. In the grand scheme of things, it doesn't really matter.
(the . looks a bit out of place in python code perhaps)
there is a proposal for fun @ other as composition similar to decorators.
How would that work? One function would be bound as an argument to the other?
(f @ g)(x) == f(g(x))
I guess it makes sense, the decorator syntax is already composing functions
def __matmul__(self, other):
return lambda *a: self(other(*a))
Yeah I understand what composition is I'm asking how it'd be implemented
ah
well, I suppose some special object like partial
that would store the list of functions to apply
it's technically possible to make the proposed change as a backwards compatible change to update by making it a second positional-only argument. Though that's much less obvious/intuitive/self-describing than a new keyword argument would have been.
but the issue is that it won't work on all callables
Ah right, no need to pass the function to the other.
and functions are usually typehinted as Callable, which doesn't guarantee the right @ being available
you could also just put compose(*funs) into functools
but honestly, I don't think there is much reason to do functional programming for the few keyword arguments that take functions
@raven ridge right, and an underscore-argument doesn't make a different I guess? it just looks uglier: d1.update(d2, _res_func_=)
yeah, update takes any kwarg, just like dict
!e
from inspect import currentframe
class Nоt:
def __getattr__(self, name):
fn = currentframe().f_back.f_locals[name]
return lambda x: not fn(x)
nоt = Nоt()
##################################################
def even(x):
return x % 2 == 0
odd = nоt . even
print(even(5))
print(odd(5))
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
001 | False
002 | True
🙃
that's already a valid call, so, yeah - that would still be a backwards incompatible change.
What's up with the syntax highlighting of Not there
!charinfo Nоt
Character Info
\u004e : LATIN CAPITAL LETTER N - N
\u043e : CYRILLIC SMALL LETTER O - о
\u0074 : LATIN SMALL LETTER T - t
Full Raw Text
\u004e\u043e\u0074
lol
hello ^_^
Hi
@grave jolt Why cyrillic?
because not (latin) is a reserved word
so I can't name a variable like that
and I named the class accordingly
yes
right
!e
the cursed syntax can be extended much further
def main():
x <- get_line
y <- get_line
s = (nоt . even) (int(x) + int(y))
print(s)
@grave jolt :warning: Your eval job has completed with return code 0.
[No output]
haskell monads incoming!
honestly I was just thinking I would like Option in some Django code I'm writing
where is this proposal
after writing Rust in my spare time for the past 2-3 years, I really want monads and a stronger type system in Python 😦
I would love stronger typing in Python
Some days it feels like the only reason I'm using Python is for the ecosystem and because matlab licenses are too expensive
Hi everyone! I saw a Python wrapper for Autohotkey, but I was wondering where I would go to learn how to make a Python Library to manipulate the Windows API directly? I found the Microsoft docs and it seems like it's mostly assembly, should I invest time in assembly or is there a higher level way to do this? Would be nice if I could just use Python to make the new library. I have done several Python courses but never have I seen a course on how to make new Python libraries and contribute. I'm very open to suggestions
this isn't a help channel unfortunately, but a discussion channel about python, though i'm not sure the appropriate topical channel for your issue, there is a way to access windows api with i think it's https://github.com/mhammond/pywin32
thanks!
you can use ctypes with its windll
@sudden canopy thanks!
Guys is there a less resource intensive way to do the followint
data['test'] = [data['test']] if not isinstance(data['test'], list) else data['test']
I feel like there's definitely a way that uses less memory
Just put it in a variable?
test_data = data['test']
if not isinstance(test_data, list):
data['test'] = [test_data]
Or with the walrus operator for a slight shrinkage:
if not isinstance(test_data := data['test'], list):
data['test'] = [test_data]
The better solution would be to make data not have unwrapped lists, if possible.
Not possible since its an api response in either a single or listed values
Tanks teamspen
Oh, our runtime is 3.6 and 3.7, no walruses here :(
Why is that too resource intensive?
You're just conditionally creating a single list
I don't see how you could use less memory there
Hello family how are you?
I am a deginner in Python Langage. I am delighted to find among you in order to better equip myself
Just wondering if it's possible, this is for a huge org, any optimisation I can sneak in imma do
@eager trail Why? That sounds like bad way of working. WIll you ever finish if you sneak in "any #optimisations'" you can? How do you even know if they are optimsations? And why would they be needed?
@lunar panther Glad to hear that you found a solution. Keep in mind that this channel is for discussion about the language, not for advanced questions. Your question about dataframes would be great for #data-science-and-ml.
@unkempt rock @astral crystal both off topic for this channel
Ok, sorry, I've been misled by the title and forgot to read the channel description, my bad.
have anyone used pyenv library i need help
heyall, I am a high school senior who spent the last year taking a python-centered class. We covered lists, functions, classes, strings, dictionaries, exceptions (this one very vaguely) and some other topics. What and where do I learn next?
This would be on-topic in #data-science-and-ml and not in this channel. Please try to frame it more as a topic for discussion.
It sounds like you've covered a lot of the basics. I would try undertaking a project. It doesn't need to be something useful, just something you can do that might help you find out what you don't know. Go to #bot-commands and run !projects to get a list of ideas.
thank you! that is very helpful
@eager trail use a dictionary
What pep is this
Can anyone tell me what is the best way to keep two version of python in my system?
pyenv for linux, just the default installer for windows.
I use parrot, and by default it provides python 3.9 but I have to run rasa , so I need python3.8 , I have installed in by using update alternatives and after upgrade it removes that
Hope this works fine. Thanks.
I need help can time.time() set to be 0 again ?
How to deactivate pyenv environment
Tried deactivate doesn't work
Tried pyenv deactivate doesn't work
you essentially switch to the environment "system", either with pyenv local system or pyenv shell system
Ok, get it.
you can try doing pyenv versions, it should show all installed versions and mark the active one with an asterisk
from there you can decide which one to switch to
hello guys do you know how to make decisions in python like by using two bottoms and once you press one it like chooses that decision?
Do you think that structs liketyping.NamedTuple, collections.namedtuple, dataclasses.dataclass are becoming extremely numerous? Do you use all of them for different situations? Or have you picked the ones you like
I never use the un-typed namedtuple.
It's not really that many - only 2 of them then.
They aren't exactly the same either since NamedTuple is basically a tuple while a dataclass is more like a standard class.
So a NamedTuple has all the typical expected behaviours of a tuple
namedtuple really only goes to the things I want to keep simple. Otherwise I mostly use NamedTuple in places of tuples with their static content, and dataclasses when more functionality is needed which separates them nicely
In short, yes, they are used for different situations.
I usually dont know which one to pick. I like typed NamedTuples best of those I think. Although the original namedtuple is cool because you can slam it out. But I try to type everything these dayss.
Im not good enough of a a programmer to not do it.
I picked Fluent Python back up. I started it but didnt go back to reading all of it because of how dense it can be while jumping around and being something you don't necessarily read front to back.
But its worth going back to.
Was looking through something and noticed that typing creates "fake" modules to namespace some names which looked a bit weird to me. Is there any reason not to use ModuleType so they're more "proper" modules instead of normal classes?
class io:
"""Wrapper namespace for IO generic classes."""
__all__ = ['IO', 'TextIO', 'BinaryIO']
IO = IO
TextIO = TextIO
BinaryIO = BinaryIO
io.__name__ = __name__ + '.io'
sys.modules[io.__name__] = io
Can anyone suggest a good source for Machine learning project. My final year project is on lips reading from a video data per frame ...
hey, is it at all possible to override a builtin class's attribute
as a joke, i want to override the builtin str.__add__ method
im curious if theres a way to do it with some c magic
Check out forbiddenfruit
yeah, thanks
#data-science-and-ml @worldly monolith
Where are the source code files for the builtins like hex() of byteorder.fromhex() ? I can't find it anywhere
those are written in C, let me find the github link
though you'll need to follow the function call chain
@novel vector
Thank you, looks nice
!e We say the difference between a method and function is that a method belongs to an object. Isn't everything a method in python then?
def foo():
pass
like the output suggests, this actually belongs to the __main__ module which is an object
import __main__
__main__.foo()
if you were to say sum is a built-in function:
import builtins
builtins.sum
it actually belongs to the builtins object
@unkempt rock :warning: Your eval job has completed with return code 0.
[No output]
Methods are functions bound to objects, not just namespaced
so
class Foo:
@staticmethod
def foo(): pass
foo isn't a method?
Really depends on the context, but from the functional point of view it isn't
i cant pip command as pip install pyttsx3
Hey @odd summit, this channel is for discussions related to the language itself. For Python questions, can you look at #❓|how-to-get-help ?
I guess that, at that point, it's just a semantic discussion about what the word "method" means. The intention here is to use it as a method, but one for which the descriptor protocol doesn't insert the instance as the first argument if you access it as a instance attribute.
And I guess you could say that all methods are functions, but not all functions are methods.
Sebastiaan, I didn't want to ping you on this because I'm sure mods+ get tons of pins, but do you have any leads/resources on where you learned to build your GitHub Actions, for example the Sir Lancebot workflows?
Your caching and pull request annotations are interesting, but I can't find a resource for learning such things.
well, all methods are callable. A staticmethod isn't a function.
Mostly the documentation + trial and error.
Ah, I see your branch for test-ci-linting now. Do you squash commits to keep your experiments cleaner, even in a feature branch? Or you use a local workflow runner (like below) to test without having to push every time?
Thanks for your time.
GitHub
Run your GitHub Actions locally 🚀. Contribute to nektos/act development by creating an account on GitHub.
can i get early supporter badge now
The way methods are in python is pretty similar to the idea of partials in functional languages, yes?
Speaking of, I don't really get the point of functools.partial. is there a reason that it's better than just wrapping one function call in another?
Nicer interface that you can use inline without a lambda mess, and I believe the calls are also a bit faster
Also passes by value rather than by name, which is often desirable
!e
!eval [code]
Can also use: e
*Run Python code and get the results.
This command supports multiple lines of code, including code wrapped inside a formatted code
block. Code can be re-evaluated by editing the original message within 10 seconds and
clicking the reaction that subsequently appears.
We've done our best to make this sandboxed, but do let us know if you manage to find an
issue with it!*
thank you
@unkempt rock :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | File "<string>", line 2, in X
004 | NameError: name 'syayoce' is not defined
@unkempt rock :warning: Your eval job has completed with return code 0.
[No output]
@unkempt rock :white_check_mark: Your eval job has completed with return code 0.
XD
#bot-commands
oh im sorry
its all good
Anyone know how python obtains it’s hashed values in dictionary to mapped the key to the value
iirc different types are hashed differently
For custom types, the __hash__() method is called, which defaults to using the object ID, I think? But you can override it.
Like @minor needle said, different types use different hashing algorithms.
that would make sense since equality is in terms of the object ID if you don't override __eq__
Yep
Hey guys, I'm trying to get a qol change for the cloud trail detectives in my company into the code base.
Does anyone know of a way to get qualname in the base class to take on the name of the wrapper without modifying the wrapper file itself? Because either I change one or two files in the reference library or every single function we have (and there are 300 of them)
Changing the files is trivial, but I'll get a lot less pushback if I can do it the former way
Guys, do you know if Parallel + delayed from joblib copy the objects I pass through the function?
Try asking in #async-and-concurrency
@eager trail can you provide some sample code so we can visualize what you mean?
Sure, will do when I'm home
okay so, the functions are generally in this state
*\reference_lib\botohelper.py
import boto3
class Rule:other methods
def sessioncredentials(role):
sessionclient=boto3.client('xxx')
assume_role_response = sessionclient.assume_role(role, RoleSessionName='ConfigLambdaExecution')other methods
*\lambda\AWS-AAAEC2.py
from reference_lib import Rule
class AWS-AAAEC2(Rule):methods drawn from Rule
What I would like to be able to do is somehow, when calling the sessioncredentials method of Rule via AWS-AAAEC2, pass qualname (or something similar) to RoleSessionName so that when my guys are doing stuff in cloudtrail, there isn't just one giant mass of ConfigLambdaExecution sessions.
For example, it could instead be ConfigLambdaExecution-AWS-AAAEC2 which would be much more descriptive
Changing each file automatically with a simple script would be trivial. The problem would be the amount of resistance I get to making a push that changes every single lambda function we have. If there was a way to change only botohelper to get the wrapper to somehow pass either the class name or the file name as a string to rolesessionname, it would be amazing
Perhaps there's something in functools, but I'm not sure
posting here because it might require specific bottle knowledge:
Why does this work? How does API.py know that there is an app from main.py ? magic?
main.py:
-------------------
from bottle import default_app
import API
app = default_app()
API.py:
-------------------
from bottle import route
@route("/", method=['GET'])
def index():
return "hello world"
bottle probably has a global variable internally
to me it looks bad because it looks like im importing API but not using it.
isnt that un-pythonic or something?
linter also complains : (
The import is probably just to make that module run. It is not idiomatic, but frameworks are allowed to try weird things like this. You can use #noqa to silence the linter
i see. I'll try that. hmm just one more question though.
any idea on what's the idiomatic way to have that kind of separation of concerns in bottle? (by separation of concerns, I mean separating the routes in different files, per use-case)
That is probably idiomatic in bottle, unless they state otherwise in some tutorial. Sometimes idiomatic frameworks aren't idiomatic python, and that's fine
ah wait found this: https://github.com/bottlepy/bottle/issues/38 . the solution seems very similar to flask blueprints
def f(s):
# s is a string
# _some_ name for the sake of this example
f_name = 'module_' + len(s) + ".py"
with open(f_name, 'w+') as fh:
fh.writelines(s)
return f_name
can this function return before the file is written ?
@magic python it depends what you mean by "written". The file will definitely get the lines written to it.
@magic python but I wonder about writing Python files
@spark magnet originally this is from wanting to test that a bunch of ipython notebooks run without exception - I want to convert the notebooks to python modules and run those (so that I don't have to worry about connecting to a kernel etc, I'm aware of papermill etc to run notebooks with though).
By written, i just meant that the file would be completely written prior to the function returning
so that
py_module = f(s)
do_something(py_module)
the module would certainly exist for do_something
@magic python I think i have something similar, and I don't do anything special to ensure the file is flushed.
@spark magnet hm ok - originally i was just running the notebooks, but this caused errors with Pytest (something something unix socket), so I'm looking at just using python modules instead. But whilst doing so I started getting paranoid about whether the io would definitely be completed before teh function was returned
I understand, but it seems like it's ok
@spark magnet ok thanks 🙂
@spark magnet sorry to ping, but i'm trying to run these modules (converted from notebooks), and although I've stripped magic I seem to be having difficulty with exec( python_source ), although when I save the source to a file with
with open('check.py', 'w') as fh: fh.write(python_source) # here python_source is extracted from nb
and run with
python check.py
it works, I'm wondering if you have any reading suggestions to get this working... or if there's something with exec that's known to throw this sort of thing? The error is usually module not found (though it's imported in the code).
no self ? 
is this not an instance method or is role just self renamed
if the second, RoleSessionName='ConfigLambdaExecution-' + role.__class__.__name__ should work
if the first, 🤷♂️
Good Evening to all member
I am really surprised by one behaviour in pycharm
I have installed some python package (GDAL) in Global env
now I want to use that package in pycharm too without reinstallation, so I have edited pyvenv.cfg in pycharm
include-system-site-packages = True
Now when I do for first time import gdal (its giving some weired error)
but at second time. It is able to import, when I do import gdal
any specific reason, for first time giving error and for second time no error
Hello. After spending all day finding errors i realized I made a blunder by using different variables as inputs and labels for training the data which is why i keep getting errors for when im training the data. Now it would be a straightforward thing to debug it, however im really new to python. therefore its confusing me big time about how i should go about it. i was trying to use different approaches to it which other people suggested me
I have summarized the problem here including the code. It would be nice to know thanks https://paste.pythondiscord.com/upavayitol.http
hmmm, so its basically a classmethod thats undecorated
what about
@classmethod
def sessioncredentials(cls, role):
sessionclient=boto3.client('xxx')
assume_role_response = sessionclient.assume_role(role, RoleSessionName='ConfigLambdaExecution-' + cls.__name__)
thanks man! I'll give these a go on Monday
You boys ever join a new place, start digging around in the code base, and find lots of horrific things
in python 3.8
>>> def a(c:b, e:('f', "e")):
pass
>>> a.__annotations__
{'c': <class '__main__.b'>, 'e': ('f', 'e')}
but in python 3.10 due to the postponed evaluation of annotations
it becomes
>>> def a(c:b, e:('f', "e")):
pass
>>> a.__annotations__
{'c': 'b', 'e': "('f', 'e')"}
before b was a class in annotations, now its a string
how to achieve the same result without eval?
Presumably you want the 3.10 result yeah
no sorry i wanted the 3.8 result in 3.10
can anyone help me with my svm model
get_type_hints will resolve them against the globals of the func/ the ones you pass it. But that will fail because they're not typehints so you'll need eval it yourself
For this reason inspect.get_annotations is currently being PR-ed in, to handle non-typing annotation uses.
oh i see thanks
You could just drop that code into your own module for now.
https://docs.python.org/3/library/contextlib.html#contextlib.redirect_stdout
Context manager for temporarily redirecting sys.stdout to another file or file-like object
how one supposed to know what a "file or file-like object" actually is? For example, is tempfile._TemporaryFileWrapper a "file or file like object"?
I'm not sure how to work this out
A file like object is just something that implements the same interface as your regular file obj (read, write, etc.), from the name I'd guess _TemporaryFileWrapper does do that
hrm - i passed in named temp file and got a fail, whereas passing a file obj from with open(...) as file_obj worked, which made me wonder
# does not work
with tempfile.NamedTemporaryFile(prefix="something.log") as std_out:
# does work
# with open("process.txt", "w") as std_out:
basically , followed by with contextlib.redirect_stdout(std_out). So i wasn't sure what to inspect etc to determine why
Anyone know of the top of their head whether set intersection or list comprehension is cheaper memory wise if checking whether two lists share any item, and returning True if so
forget the memory: sets will be better on time.
Yeah, that's most of what I got, but I'm trying to optimise for memory over speed and not in front of my computer rn
Not knowing is driving me crazy haha
the list will be smaller
Thanks ned, legend
@eager trail if you don't mind me asking, why focus on memory? Are you running out?
Don't know about the ops but the set itself will be considerably larger
Saving on cloud compute costs since the response isn't time critical
But there is a good chance that even if you split it up into multiple smaller operations it will be quite a bit faster while limiting its memory use
how large are these lists?
Less than 30 items but there are a heckuva lot of them
Hey, if im doing a cli for a list program, where you add rows to a database, and the row in question has 9 columns what is the correct way to do a command for adding that? Should i use keyword arguments or just "add A B C D E ... etc "?
Or, another approach i could follow is to separate this add command in two, as some of the columns reflect state, i could simplify the command to 5 fields, and the other 4 could set to a default until set by other commands
If there are sensible defaults for value then make these optional arguments
Is there a method / a not esoteric method of removing a parameter from a function?
e.g.
def foo(user):
...
import inspect
inspect.signature(foo)
will give ('user',)
is there a way to hide this 
why do you want to hide it?
Making a function decorator that covers alot of boiler plate for FastAPI
but fastAPI takes all args other than request as a parameter in a url query
Sounds like you could have a wrapper taking no parameter in but what are you actually going to call the function with?
atm im using wraps
so that way it doesnt break the router etc...
but the downside is it copies over the wrapped functions sig
current setup basically doesnt allows this:
class Foo(router.Blueprint):
@router.endpoint(
"/ahhh",
endpoint_name="ahhh",
)
@enforce_auth(REQUIRE_USER_SESSION)
async def ahhh(self, req: Request, user: User):
...
fastAPI will reject the request because it doesnt get given a url query called user
class Foo(router.Blueprint):
@router.endpoint(
"/ahhh",
endpoint_name="ahhh",
)
@enforce_auth(REQUIRE_USER_SESSION)
async def ahhh(self, req: Request):
...
would be valid
Hey @kind helm! I noticed you posted a seemingly valid Discord API token in your message and have removed your message. This means that your token has been compromised. Please change your token immediately at: https://discordapp.com/developers/applications/me
Feel free to re-post it with the token removed. If you believe this was a mistake, please let us know!
Hey @kind helm! I noticed you posted a seemingly valid Discord API token in your message and have removed your message. This means that your token has been compromised. Please change your token immediately at: https://discordapp.com/developers/applications/me
Feel free to re-post it with the token removed. If you believe this was a mistake, please let us know!
@kind helm this is not a help channel, see #❓|how-to-get-help
HI. I'm creating a python IDE and I want to know your feedback.
Is it allowed in this channel?
It's not really on topic here, but it would fit in #editors-ides
Thank you
@unkempt rock If you post any additional advertisements, you will be removed from the server.
Why do the Python docs sometimes refer to classes like float, str, range etc. as functions?
The only place I'm aware of where it really does that is in the https://docs.python.org/3/library/functions.html#built-in-functions section of the docs - which does say "Built-in Functions", but also says in the prose:
The Python interpreter has a number of functions and types built into it that are always available.
which acknowledges that some are types and some are functions.
I guess they probably do it to make that section more approachable to beginners.
I just had another look at function compute costs and noticed that the cost for aws is memory provision size * compute time, and forgot that the minimum provision is 128mb, so I should be going for speed once I get rid of anything egregious
@eager trail i hope you don't need more memory than that
Yeah, I won't, so I'm playing around with either sets or generators and seeing which is faster
I guess it depends on your definition of functions but they are callable
Hi
In older Python 2 versions before new-style classes were a thing, they were actually just functions that constructed the types. It could be old language that wasn't fixed. Though for new users it's good to have them listed among functions since you can treat them that way if you don't care about classes.
On the other hand things like map and filter are deliberately defined as functions, CPython as an implementation detail happens to define them as classes but other interpreters may use generators or whatever they want.
How does python store classes data? 
user defined classes have a dict on them which stores their attributes, you can use __slots__ to make it not fully dynamic. Some builtin classes are just structs
Can someone help me with python code for AI face recogniser
@native bridge that would be a question for #data-science-and-ml
Hmm shudn't it be a string?

3.10.0a7+ (heads/master:09aa6f914d, Apr 25 2021, 20:10:20) [MSC v.1916 64 bit (AMD64)]
oooh
is this new?

Yes, some lib maintainers asked for more time with the feature
GitHub
…ime effects (GH-23952)
i see
@peak spoke Could you expand on that a bit? Will the annotations for a class like that b result in something different in the future?
PEP 563 makes all annotations forward refs instead of being evaluated at definition time as is done currently they'll only store a string version of the expression which needs to be evaluated at a later time to use its value (you can currently enable this with from __future__ import annotations on a per module basis). But evaluating like that comes with some limitations and it broke libraries that use annotations for non typing purposes so their maintainers asked to delay the feature becoming a default https://mail.python.org/archives/list/python-dev@python.org/thread/CLVXXPQ2T2LQ5MP2Y53VVQFCXYWQJHKZ/.
There are some proposals for how to handle the deferred evaluation like PEP 649 that may make it easier to convert with the new behavior in mind
Thanks
In python if you get a square root of an integer it will always give a float.
IF the integer is a perfect square the you will always get the float ending with .0
if we check if the output has .0 in its end then it is a perfect square else it's not
so basically you can cheat your way to find if a num is a perfect square or not, without math logic.
🤔
In [13]: 1025**.5
Out[13]: 32.01562118716424

ok i will just check the last two
digits
solution:
- last two char is '.0'
- len of chars after '.' if one
def is_square(self, num):
ans = num**.5
str_ans = str(ans)[-2:]
if str_ans == '.0':
return True, int(ans)
else:
return False
i'm not sure why this is in this room either
you see it sees the last two chars.
if they are .0
did i miss an earlier discussion about floating point
!d float.is_integer
float.is_integer()```
Return `True` if the float instance is finite with integral value, and `False` otherwise:
```py
>>> (-2.0).is_integer()
True
>>> (3.2).is_integer()
False
32.01562118716424
this num does not end with .0
yeah, this doesn't really fit here
it ends with 24
then please guide me
Discussion on the use cases, implementation and future of the Python programming language including PEPs, advanced language concepts, new releases, the standard library, and the overall design of the language.
I would just put it into #python-discussion
i prefer: isThing = lambda x: (lambda y: len(y) == 1 and y[0] == "0")(str(x ** 0.5).rsplit(".", maxsplit=1)[1])
if str(num**.5)[-2:] == '.0':
return True
doesnt work for 152342352536265664 sadly in my impl
*152342352536265664 ** 2

this is supposed to check if num is a perfect square
The generated bytecode reflects this decision and will try to fetch b from the local environment
from Fluent Python, referring to why the following will error:
a = 4
b = 5
def f(a):
print(a)
print(b)
b = 6
f(a)
How do i go about checking the bytecode though? Is this a dis thing?
They show how they generate the bytecode in the comparing bytecode section
>>> from dis import dis
>>> dis(f1)
the output of dis.dis(f) is:
4 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 CALL_FUNCTION 1
6 POP_TOP
5 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 1 (b)
12 CALL_FUNCTION 1
14 POP_TOP
6 16 LOAD_CONST 1 (6)
18 STORE_FAST 1 (b)
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
🤔
oh it's literally explained two pages later 🤦 I'm having flashbacks to real analysis
Although their output is different: theirs https://i.imgur.com/D3X7unf.png mine : https://i.imgur.com/2XQgDEG.png
Does this differ between minor versions of python?

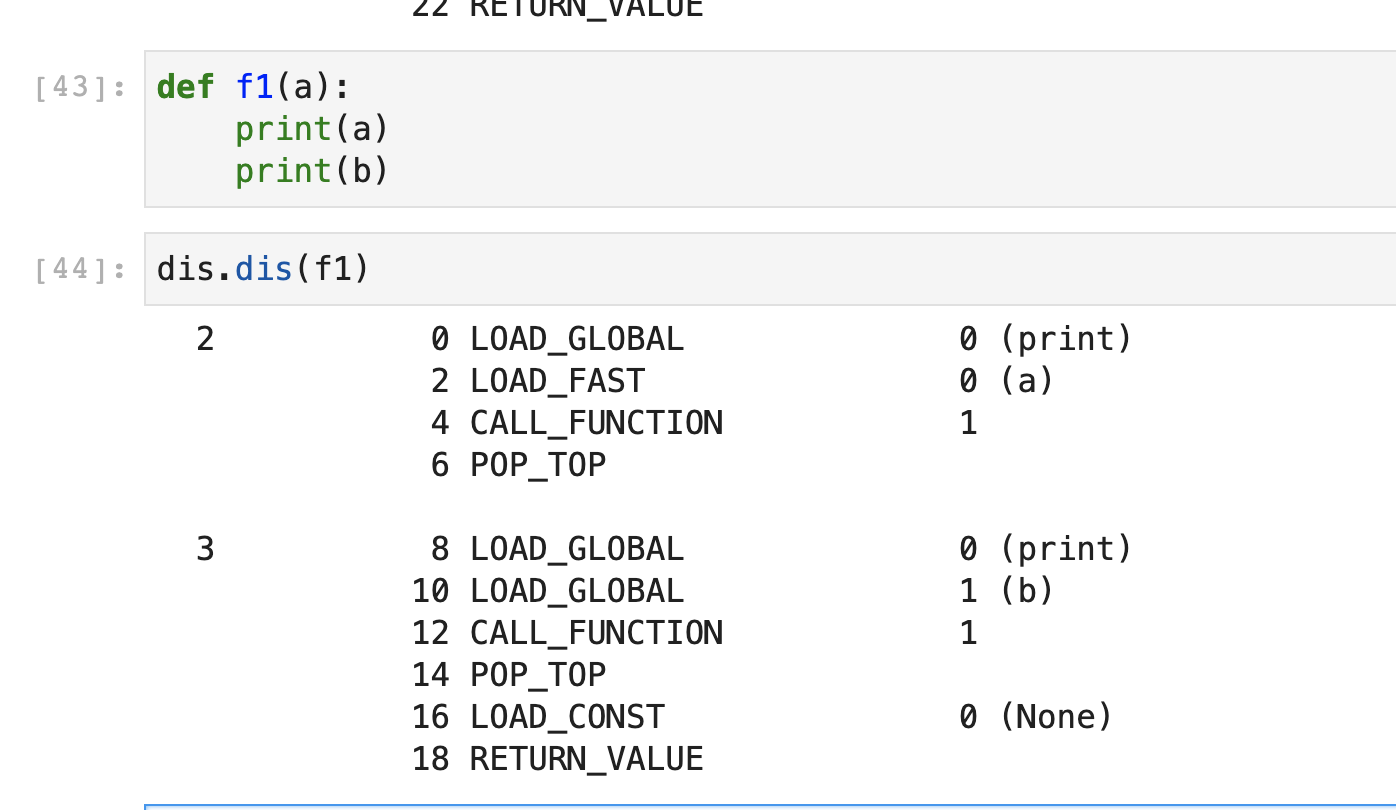
{kind=link}
{kind=link}
It may, bytecode compatibility is not guaranteed between versions. With python 3.x are also more of major versions imo as 2/3 are mostly regarded as completely separate
hm ok
Should I be using yield instead of return when doing say api calls so each item being returned iteratively can be processed while waiting for the api cooldown (sorry for imprecise language)
If you're using asynchronous iterators, that would be the case, but regular generators are still blocking
Thanks! ☺️
That bytecode is the same actually, looks like theirs has the wordcode update which changed the byte lengths to be the same for all instructions. The five columns dis outputs are in order:
- the line number, for the first instruction on each line
- the index of that opcode in the bytes object
- the name of the instruction
- the value of the "argument" byte
- for some instructions, a decoding of the argument - the name it refers to, the constant, etc.
For CALL_FUNCTION, looks like their version had an update decoding the values it has. Here in the docs is a list of all the current instructions: https://docs.python.org/3/library/dis.html#python-bytecode-instructions
thank you 🙂
Do you guys know ytbers who have low level python content?
You can use pycon talks for it perhaps. Eg https://youtu.be/cSSpnq362Bk

Speaker: James Bennett
At some point every Python programmer sees Python bytecode files -- they're those '.pyc' files Python likes to leave behind after it runs. But have you ever wondered what's really going on in those files? Well, wonder no more! In this talk you'll learn what Python bytecode is and how it's used to execute your code, as wel...
Hey, what language should I learn after Python? I thought about learning JavaScript because it's used for things like web dev. Also thought about C or C++ because it's a low-level language and to get a job in programming I would want/need to learn a low-level lang, and it's also used for making games which I would really want to do. Thanks for any answers 😊
haskell
Ultimately only you can pick for yourself. There's benefits to a lot of languages as you're yourself indicating
C++ is a good practical choice, it's quite the mission to learn it well though.
I've learned some Kotlin in my spare time, and it's definitely made me want many things from it in python
Kotlin/Swift are probably the two languages that are aimed at the mainstream, while integrating a very broad spectrum of things we've learned are good ideas from a variety of sources, so I think they are great languages to learn.
swift is pretty much only used for ios dev.
can you give some examples?
The study guide for my programming languages exam says that Python is pass-by-value, but I'm pretty sure that's only true for immutable types
Unless I'm misunderstanding what is meant by pass-by-{value, reference}
neither pass by value nor pass by reference exactly fit python
I have seen pass by value reference used before
Null aware operations plz
nice lambdas
extension functions
null awareness
more expression oriented rather than statement oriented
extension funcs seem unpythonic
not sure why really
And I'm not sure if it makes sense to talk about a feature being pythonic really when we are comparing two languages; python's made its decisions about what's pythonic or not obviously, the question is how well those decisions hold up
braces are unpythonic as well but it seems to be one of the main reasons why python can't have a nice syntax for lambdas, like kotlin/swift do
Re swift, I agree it's only really used for ios and perhaps other apple targets, so I doubt I'll ever use it. That said the language itself is really quite nice. Kotlin is nice but marred significantly in a few places, they needed to make a couple of major compromises for Java interop. Swift didn't have that problem.
I'd prefer the uniform functional call syntax from D.
re: ext funcs
adding methods that are in separate files and subject to import order seems bug prone
i.e. every function can be called f(a, b) == a.f(b)
re: lambdas
you could just use something like js/java syntax, eg (a,b)=>a+b
but that'd fuck up python's name resolution
UFCS was discussed a lot in C++ but didn't make headway. Having seen that discussion, and used Kotlin, I think extension functions are simpler and achieve the important things.
I'd rather have UFCS than nothing, but comparing UFCS and extensions head on, the delta in utility isn't worth the delta in complexity. Just my 0.02.
The problem for lambdas is if you want multi-line lambdas you need to know where it ends
I'd be very agains multiline lambdas in python.
🤷♂️
It's like asking for callback hell.
@sacred yew I'm not sure why it's more bug prone than anything else, you'd probably need to import it directly to use it. It's not really different than importing the exact same function twice
@lament sinew empirically that doesn't really happen though in languages with lambdas like that? callback hell is also something pretty specific where the nesting level increases
callback hell has more to do with whether you have a way for chaining asynchronous operations without increasing nesting
Happens in languages that more or less belong to the same niche as python, i.e. JS, Ruby (to a lesser extent but still).
It's famous for happening in JS because of how async programming was handled in JS for a long time.
Ruby uses blocks extensively for how it handles collections (as opposed to python's comprehensions approach), and in that context, callback hell isn't really a thing AFAIK
I guess i misused the term callback hell, i meant defining-big-functions-as-function-arguments
adds nothing to the language but confusion
it seems like an extremely arbitrary limitation that lambdas are ok, but only if they are exactly one expression
It's not the end of the world and I like python despite it but I have trouble understanding why it's a good thing
What is to gain with multiline lambdas? One liners are useful because a good chunk of the time all you need is a closure or some quick operation for sorting keys or whatever.
multiline would invariably result in complex anonymous functions being used
when you say "what is to gain", you are saying, compared to defining a local function?
What exactly are you comparing to?
can't compare to anything else
can you give any instances where a multiline lambda would be useful compared to a normal function definition?
The thing with multi-line lambdas is that they cause a huge semantic issue
There are two type of nodes you can have in Python, more or less
Expression and statements
Expression have a value, while statement do an operation
@sacred yew i think in practice people just tend to not end up defining a local function in a lot of cases
like, they won't define a local function and do a list comprehension with that function
they'll instead create an empty list, a for loop, and call append repeatedly
The whole syntax is built to make sure that you never try to use an expression where you should be having a statement and vise versa (like my_variable = def function(...))
in most modern languages you would just call map and pass it whatever lambda you wanted do
Lambdas are expression, that's it
But a function is a statement (because it has many lines)
that has nothing to do with why a lambda can only be one expression
the lambda could contain many lines internally, but the lambda node in the AST is still an expression
But a like in a function is a statement, right ?
anyhow, more broadly, yes, mult-line lambdas may not play nice with other aspects of python, which is why I said it was "unpythonic", but that's why I didn't frame things that way. I framed it in terms of things I miss when I'm writing python.
a like?
I'd give anything to swap patma for better null awareness tbh
pattern matching
I know a lot of people don't like me anymore
oh
yeah, pattern matching in python seems a bit odd to me, I'll suspend judgement until I use it
in statically typed languages pattern matching is a lot more than sytnactic sugar
because the types are also cast appropriately inside the blocks
in python, I dunno, it seems like it may not be that big of an update over if elif, in the vast majority of cases
but maybe I'm wrong
@sacred yew also btw re lambdas, even the standardization docs for walrus operator, show examples where they basically existing python solutions to things if they involve lambdas or locally defined functions
in particular, two argument iter solves one of the use cases for walrus operator, but almost nobody seems to use two argument iter in python
because in many/most cases you need to feed it a lambda/local function, and in practice this seems to be ugly enough that in most cases people actually write out the "loop and a half" repetition instead
I don't think null is fixable in python. it's just a pain you have to learn to deal with.
Something I miss from Rust/Haskell in python is algebraic data types. That's doable and would be play nicely with the new pattern matching.
python's not statically typed, so what would that actually mean
You can already annotate things with Union[int, str] or what not and I'm sure in short order it will play nicely with pattern matching
I guess you could have a type annotation that also provides names to each of the states, as well as types
something like ADT[foo=int, bar=str]
Any reason why slice is a type, but you can't make a slice literal outside of syntactically valid {(class_)?get,set,del}_item calls?
You can do Slice(1,10,2)
Not much reason for it to have a literal apart from that syntax
There are other builtins like bytearray which are probably used more overall but don't have literal syntax
@unkempt rock :white_check_mark: Your eval job has completed with return code 0.
[2, 3]
If you want a confusion free explanation that fits the python universe, python is "pass by assignment". Ie. Function args follow the same semantics as if they were assigned. Simple. Elegant. Concepts that shouldn't be exposed in python stay at the lower levels of abstraction. (ie pass by value pass by reference should only be introduced when talking about languages that understand pointers vs non pointers.)
If you want to peel away the layer of abstraction and talk about it, well pass by value is correct. Python would be pass by value, with the caveat that all variables in python are 1st level pointers. However I would encourage not using this terminology at all, it just adds to confusion
I feel like deja vu almost, but could someone explain what better null awareness is/does?
essentially, syntax level support for Optional[T], so you have operators like
obj?.attr
obj?[0]
obj ?: default
``` which do the regular thing if the obj is not None, and just result in None otherwise
`?:` is like `or`, but only None is considered "Falsey"personally, I would rather have some form of excepttry so that you can use exceptions without nesting things extremely far
Ah! I see. Thanks
Anyone here from canada ?
Please keep the posts in this channel on topic. Take a look at the channel description
every once in a while I run across code that has to propagate optionals all over the place and current in python it's just so long winded
even those null aware operators aren't a full solution but they would be a start
Ideally i'd like something that allows you to call an arbitrary function on a python variable that might be null; if it's non-null give you the result of the function, otherwise just give you back the null
e.g. I have a Path, which was an optional argument to my function, to do some kind of check against a reference. So now I want to form reference_file = prefix_dir / something_else, but only if prefix_dir is non-null; otherwise I Just want reference_file to be null
the previous programmer actually factored out a lot of this logic into functions, and the function takes the prefix dir as an Optional[Path] and returns another Optional[Path]. But now the logic is embedded in there along with the optionality, so now even when you definitely have the prefix_dir, in some other context, you still get an optional back, and now you have to assert that it's not None, which is very silly
In Kotlin, because you have both extensions and nice lambdas, you can do val referenceFile = prefix_dir?.let { it / something_else }, which is quite nice, even though Kotlin still only has basically the same null-aware operators as are proposed for python. Not sure how you could make this work nicely in python, even with null aware operators.
I guess via ?.__div__ but eww 🙂
i made a system to clone windows, see it here https://www.reddit.com/r/Python/comments/mzw6qz/i_created_a_windows_cloner/

This channel is for meta-discussions about the Python language itself. If you want to showcase your project, you can use #python-discussion, off-topic channels or a relevant on-topic channel (in the "topical chat/help" category)
how to filter date

Pretty sure that's not the right datetime format
Take this to the data science channel
How does assigning a dict's value to a variable better than accessing it everytime ?
Low level stuff
Where I don't know that it does this, the reason I could think of for that would be to have that specific memory in L1 cache.
There is some cost to looking up a value by key, so if you need something to be fast it makes sense to only look it to once and reuse it once you find it
dict_object[key] involves an extra set of opcodes (it has to load the dict and the key onto the stack). the BINARY_SUBSCR opcode then calls PyObject_GetItem which is the generic __getitem__ C function which eventually calls PyDictType.tp_as_mapping.mp_item with the arguments obj and key. the alternative (loading a variable) is much faster. If the variable is a local, it is a simple C array index (fastest). If it is a global, a dict lookup still occurs, but without the Indirection of PyObject_GetItem