#internals-and-peps
1 messages · Page 14 of 1
🤔 in many languages the default = behaves like walrus
It is weird for a language to have both an assignment statement and an assignment expression, though
In delphi assignment statement uses :=
Im not sure if you can use it as expression
Which mainstream language? If you're thinking of C family languages, that only works for assignment, not when creating a new variable
i am thinking of C family languages
assignment in pony is an expression, but it returns the old value
swapping two variables looks like a = b = a
yeah, C has it but the fact that it's only for assignment essentially makes using it the way it's often used in python pointless
int x;
if (5 == (x = some_func())) {
...
}
versus just
int x = some_func();
if (5 == x) {
...
}
honestly though it's just a horrible idea, most newer languages completely remove these combined mutation + expression things
not just assignment but also compound assignment operators like +=, etc
i don't think you can really easily draw parallels between how the two go about dealing with assignments, since "assigning a variable" means a fundamentally different thing in the two langs
assignments in python sorta always behave in a similarish underlying way to declaring a new variables in c-family langs (i suppose the closest thing would be making a new object in java?)
but people wanted the ability to assign within expressions, since other langs appear to allow it, and thus walrus was born in order to not clash with kwarg syntax
its definitely odd, since there's no similar features that you can draw comparisons to or precedent from, but i see its purpose
In expression oriented languages you really have two options: assignment returns one of its operands or it returns a nil / unit value
it's just not a common idiom though in any common language. Like, C family language have a much more limited version of this, and because it's so limited, it's not widely used.
in kotlin swift and rust, assignment and all compound assignment return unit
it's just a very random feature to double down on basically
a lot of the walrus use cases are solved by other, much more common (and useful) language features, like lambdas, and extensions, that happen to be very weak in python
So it's a very random feature in that sense too. Like, mapping and then filtering is awkward? Rather than allowing .map(...).filter(...) like almost every other language nowadays, look, walrus provides this reasonably concise but fairly unintuitive way to solve this problem.
.map and .filter don't make sense given Python's object model.
isn't x.map(f).filter(f0) like filter(f0, map(f, x))
yeah, which is double gross because python lambdas are gross and because of the reverse ordering
where is walrus used there
Walrus is used to perform this operation in list comprehensions
Which is pythons preferred solution here
map(f, x) makes sense as in "map f to x" and filter() is probably only ordered the way it is for consistency
That's not what I mean by reverse ordering
ok
You map then filter but you write filter then map
so like [b for a in x if f0(b := f(a))]?
i see
the motivating example that led to it getting pushed through is one that can't so easily be rewritten: py while True: command = input("> ") if command == 'exit': break print("Your command was:", command) versus ```py
while (command := input("> ")) != "exit":
print("Your command was:", command)
That's seen as better because it lets you put the conditional where it belongs, attached to the `while`Python already has a solution for this too, it again comes back to similar issues
Two arg iter literally exists for this problem
But nobody uses it
Because it involves a lambda and lambdas are ugly
One of the proposing papers even says this
can always use functools.partial()
It's also just not very nice
sure, you could use ```py
for command in iter(lambda: input("> "), "exit"):
i think it should be a for command in ...
er, yeah. fixed
I agree walrus is an improvement
Largely because of the existing issues in python
Its just like a super random thing
I think it is very weird for a language to have both an assignment expression and an assignment statement, with different syntax, and with the user being allowed to choose between them. And with arbitrary restrictions so that you can't use the expression as a statement
yeah I think := was a net loss for the language
The funny thing is that while I dislike walrus I'm not sure I think it's a net loss
Its just kind of a random feature that helps fix a few awkward things in python. Id like these to be fixed in a better way but that's probably never going to happen
I have a question
I consider myself pretty conservative when it comes to language (especially syntax) change. I dislike many of the recent changes. But I always loved the walrus, if only for if m := re.match(...):.
Well... it only really looks nice for re.match and you have to remember that Match objects have truthiness semantics.
If you want to check specifically for None you have to use parentheses
I guess there's also stuff like socket.read
I'm still waiting for someone to write a satire based on The Walrus and The Carpenter
re.match, socket.read, and a few other places, yes. I don't use it all that often, either, but where I do it makes the code a lot nicer IMO. Luckily I remember that re.match returns a truthy object (I mean why wouldn't it? For an empty match, I guess?).
re.match(...).map(|m| ...)
In an alternate universe
Or even
if let Match(m) = re.match(...) { ... }
Since python already has pattern matching if let and while let arent that hard to imagine
i like how swift lets you pass closures after the (). makes it much easier to read
Yeah, Kotlin does this too, it's very nice
i have a load = stay.Decoder() assignment from a module that is loaded dynamically at runtime, but i can assure that load will be a Callable returning a dict, is there a way to annotate load: Callable -> dict or work around it with a pyi?
i've actually recently found a very nice usecase for match-case that i never realized before: ```py
match QtWidgets.QMessageBox.question(
self,
"Close?",
"Really close?",
):
case QtWidgets.QMessageBox.StandardButton.Yes:
event.accept()
self.cleanup()
case QtWidgets.QMessageBox.StandardButton.No:
event.ignore()
before that i thought of match-case as something i'd rarely if ever use
some things make a lot of sense in a GUI context
I'd probably write a helper ask() that returns {Yes: True, No: False}.get(return_value_of_that_thing) and then do
if self.ask("Close?", "Really close?"):
event.accept()
self.cleanup()
else:
event.ignore()
Another good (imo) use of walrus: ```py
fp = open(...)
while chunk := fp.read(256):
chunks.append(chunk) # do something useful with one chunk
why not ```py
with open(..) as f:
for chunk in f.read(256):
...
match-case actually lets you cut down on that boilerplate and works well with all the different dialogs in qt -> simpler code
f.read(256) is a bytes object, so it will iterate over bytes, not chunks
ah, my bad
use a typing.cast? Something like: ```py
load = typing.cast(Callable[[], dict[Any, Any]], stay.Decoder())
ohh, shiny!
i have a question, can PyAST_obj2mod convert pyobjects obtained from a marshal form to its respective AST?
here is the code im using:
static PyObject *
run_pyc_file(FILE *fp, PyObject *globals, PyObject *locals,
PyCompilerFlags *flags)
{
PyCodeObject *co;
PyObject *v;
long magic;
long PyImport_GetMagicNumber(void);
magic = PyMarshal_ReadLongFromFile(fp);
if (magic != PyImport_GetMagicNumber()) {
if (!PyErr_Occurred())
PyErr_SetString(PyExc_RuntimeError,
"Bad magic number in .pyc file");
goto error;
}
/* Skip the rest of the header. */
(void) PyMarshal_ReadLongFromFile(fp);
(void) PyMarshal_ReadLongFromFile(fp);
(void) PyMarshal_ReadLongFromFile(fp);
if (PyErr_Occurred()) {
goto error;
}
v = PyMarshal_ReadLastObjectFromFile(fp);
if (v == NULL || !PyCode_Check(v)) {
Py_XDECREF(v);
PyErr_SetString(PyExc_RuntimeError,
"Bad code object in .pyc file");
goto error;
}
fclose(fp);
co = (PyCodeObject *)v;
PyArena* arena = PyArena_New();
if (arena == NULL)
goto error;
mod_ty ast = PyAST_obj2mod(v, arena, 0);
fprintf(stdout, "%d", ast->kind);
v = run_eval_code_obj(co, globals, locals);
if (v && flags)
flags->cf_flags |= (co->co_flags & PyCF_MASK);
Py_DECREF(co);
return v;
error:
fclose(fp);
return NULL;
}
yeah this was the "two arg iter" case that we discussed above.
it's definitely one of the motivating use cases for walrus but also just as evident that there are more-or-less equally good solutions that don't involve anything that out there
there's no async version of the 2-argument iter as far as I know 🙂
but like... Python programmers know how to make functions, right
or is it all loops?
!docs aiter
aiter(async_iterable)```
Return an [asynchronous iterator](https://docs.python.org/3/glossary.html#term-asynchronous-iterator) for an [asynchronous iterable](https://docs.python.org/3/glossary.html#term-asynchronous-iterable). Equivalent to calling `x.__aiter__()`.
Note: Unlike [`iter()`](https://docs.python.org/3/library/functions.html#iter "iter"), [`aiter()`](https://docs.python.org/3/library/functions.html#aiter "aiter") has no 2-argument variant.
New in version 3.10..
a bit late for discussion but whats wrong with walrus
not really unreadable and its useful in a lot of cases
also its explicitly described to when use normal assignment and when use walrus
and in terms of readability its totally better than the alternatives once u learn what it is
I think the convo above sort of already talked about a bunch of walrus' issues
it has a handful of use cases, like I think 3-4 "common" ones. Most of those use cases aren't themselves actually that common.
One of those use cases (filtering in comprehensions), while it's a bit better than the status quo is still substantially worse than what you can do in almost every other modern language
it's a pretty surprising feature because you don't really see anything quite like it anywhere else.
the best it can ever really do for you is save a line
almost all the use cases can be solved about as well or better via some combination of lambdas, extensions, and pattern matching, which are also more common and more generally useful features
think that about sums it up. I don't think walrus is the end of the world and if python is never getting decent lambdas or extensions then I suppose I'm happy that I have the option, kind of? 🤷♂️
python having extensions would be nice ngl
so many times i've wanted extensions but they haven't been there
imo for these tho (extensions, better lambdas, etc:) kotlin is def one of the best languages to look to towards language choices like these
something like what kotlin has
ofc the way pythons built rn it wouldn't make much sense to implement extensions
but in kotlin u can attach static extensions to any class u want
so i can add a method for integers and it'll statically resolve it iirc rather than actually changing the integer class
idk the syntax is p horrid rn
type safe builders would be nice tbh
the name lambda for one doesn't rlly make sense
anonymous functions are called that in haskell and ruby but idk any other programming language where that name is used
Getting rid of lambda or an alternative at least, would be ideal
Matlab
Oh wait I misunderstood you
Yeah I've never read kotlin
it's too late to get rid of lambda since that's gonna be heavily backwards incompatible
it probably could've been not added in the first place since guido didn't like them
That's why I was saying an alternative
Really I just hate the verbosity of them. I don't really care about them being multiline
Idk what other anonymous functions are like for other languages
I could care less about late bound arguments and would like to see => be used for lambdas
there are so many nicer options, ->, =>, || {}, \
at least it's better than doing ```py
def _anon_func(x):
return x + 2
iterable_plus2 = list(map(_anon_func, iterable))
-> is not good bc of annotations
yeah, but lambdas were added before annotations, right?
lambda is probably the bare minimum in supporting both readability and convenience decently
I see what u r saying
idk what i'm trying to say here hold on
i think lambda barely got guido's approval
making it something like javascript would've probably not been accepted due to "readability issues" or something
now the general advice is "use lambda for single-expression convenience purposes only, named function for everything else"
Yeah I really like Kotlin
lambda calculus 
Its not really that similar to python in terms of feature set but I think it's similar in really prioritizing concise but readable code
Its definitely interesting to take a look at how many of the walrus use cases are accomplished in Kotlin
fr tho, they've made so many good lang choices
A major reason for that is that a def statement is better for debugging. With lambda, all the runtime can tell you about the function is that it's a lambda. With def, it can tell you the function's name and where it was defined.
Also, I think the name lambda is pretty well-established, since it comes from https://en.wikipedia.org/wiki/Lambda_calculus and therefore predates electronic computers.
but it looks so bad
Well, write a PEP proposing a new keyword λ. We can all do Unicode now.
\ will do 😄
=> from JavaScript is a good choice in this case
|...| <expr> form could be good as well because || does not conflict with any existing Python syntax, and is also taken from Rust (just like many aspects of pattern matching)
Except that there https://peps.python.org/pep-0671/, which would reject the => syntax for lambdas.
That PEP is unlikely to be going anywhere
Regardless, we have two lambda syntaxes under consideration: (<args>) => <expr> and |<args>| <expr>.
is it controversial to say that lambda is a terrible keyword?
Does ❌ mean you agree it's bad, or you disagree? 😄
It does have one advantage over operator-esque syntax in that it is easy to search for. But it does look quite ugly.
it has no mnemonic or suggestive value.
what do you mean by that?
i mean that if you don't know what it's for, the name doesn't offer any hints.
(and lambda calculus doesn't count, because if you know what that is, you are rare, and already an expert)
i think only a few keywords are that. e.g., for isn't immediately obvious, unless you're familiar with \forall from math. the only ones that come to mind are if and friends, and maybe while
edit: looking at a list now: break, yield, try, except, assert, del, ...
ehh I don't think it's a valid argument
you don't think this is understood by people? "for each book on the shelf, read me its title"?
If it is valid then why doesn't it apply to every other operator besides basic stuff like +-*/?
lambda is terrible, but what could replace it?
Seen inline suggested but thats almost a cryptic
function ?
def?
if we're talking about developing the language now I don't think we should replace lambdas with anything...
Shouldnt it be something that makes it clear its different from named functions?
JavaScript doesn't think so
i'm not sure what "/now/" is doing there? as opposed to what?
i do, i'm just saying that the keyword by itself doesn't suggest that if you're not familiar already with the idea. i think it's just a difference in degree (though, certainly a large difference)
as opposed to designing a language from scratch
i'm not suggesting to change Python
Yeah I was replying to mariosis ("what could replace it?")
though function is very verbose for something that you create routinely
fine, func
Rust settled on fn for names functions
I hear fat arrows?
it sounds like it is not controversial to say that lambda is terrible.
yeah it's not
i think hettinger said "makefunction", but i assume that was in jest
How come you thought it was? Did it pop up in discussion?
it's so fat, you can hear me typing it on my keyboard
If we're dreaming, I might propose expr. The difference between a function and a lambda is really that a lambda evaluates a single expression and returns its value. I think expr conveys that pretty well.
It's almost April 1. How about anonymousexpression?
I have to say that I'm not a fan of using symbols like => or |...|. Languages that use too many symbols tend to be hard to read. (One of the little things I like about Python is that if statements don't require parentheses.)
i think python is already more wordy than a lot of languages in terms of keywords. true if cond else false is a good example. another is [x for x in y if cond] compared to [x | x <- j, cond]
I usually avoid True if cond else False style constructs because they place the conditional in the middle. But sometimes they're handy...
It means I end up writing a whole indented block, though, and that's even wordier.
hmm wonder how that could be redone to still be keywordy but have the condition at the front
haskell does it fine: if cond then True else False
I like it more than the usual ? and : because I'm always unsure whether the false or true part is first
Yeah, as long as you introduce a then keyword I think you're okay.
oh right one more keyword
the benefit to me of ?: is that it has the same order of if-else
The other funny thing about this construct is that it's an expression instead of being a statement. So you could imagine something like ifexpr(cond, True, False). You could just def such a function, but it's also something the interpreter could optimize.
you can't write it as a function call, because all three arguments would be evaluated
hehe routine
i like js's arrow notation best honestly
for ... in range(a, b) this isn't exactly intuitive
it's not terribly unintuitive, is it? "for [each value] in the range from A to B" seems to read naturally enough to me.
Sure, if you've never written a line of code in your life, there will be a lot of mechanics there that look alien to you, but lambda looks alien even if you know many other languages
it's much less of a linguistic leap to explain "for does something for each value in a collection of values" than it is to explain "lambda creates an anonymous function that runs one expression and returns the result"
IMO it does, but often the other advantages of e.g. extra readability outweigh the minor discoverability benefit
I think the same applies to lambda 🙂
yeah, probably
it's pretty confusing for beginners because B itself is excluded from the range
x | x <- j would be pretty hard to parse with the syntax ambiguity
haskell does it just fine because it has no | operator
python also disallows [a, x for x in y] ^^^^ this because it's not easily determinable by first view if a belongs at the beginning of the final result list or in a tuple with x in the comprehension
same for [x for x in y, a] (or [x | x <- y, a])
it's not easily determinable by first view if a belongs at the end of the final result list or in a tuple with y or something else in the comprehension
In a compiled language, you can. Visual Basic .NET has If(Cond, IfTrue, IfFalse), also because If is a keyword there
Define compiled language 🙂
Clojure definitely has macros which would let you express the same idea
:incoming_envelope: :ok_hand: applied timeout to @unkempt rock until <t:1680089333:f> (10 minutes) (reason: role_mentions rule: sent 4 role mentions in 10s).
The <@&831776746206265384> have been alerted for review.
why? Here I'm talking about those that one can build executables from with little to no reflection of the source code
You can do that with Python if you compile it to bytecode, or if you use something like nuitka
I mean, those languages that are primarily meant for that purpose
I don't see how it's relevant to lazy evaluation
It's just the VB .NET compiler's work
In VB.NET it's just a built-in operator, same as ? : in C or ... if ... then ... in Python
even though it looks like a function call (despite If there being a keyword)
Some languages like R can prevent evaluation of a function's arguments at the request of a function (depending on how it's defined).
Shameless plug: You could also implement If as a function in Python with this: https://github.com/L3viathan/lazex (restrictions apply)
5/5 readme image
**PEP 695 - Type Parameter Syntax**
Status
Draft
Python-Version
3.12
Created
15-Jun-2022
Type
Standards Track
Related, I've heard the choice of nonlocal criticized because it isn't clearly derived from either common English words or computer science jargon. "Nonlocal" stands out for being a rare word. I don't think enclosing or outer are ideal either, though.
I mean it's "non" and "local", which are both well defined. I think the issue is the difference between global and nonlocal which is not obvious
Right, especially since some languages don't enforce a distinction between different types of enclosing scope.
where in the docs can i read about single-instance classes like None, and is it officially called a singleton?
the only doc mentions of singletons i can find are single-value tuples, which i guess is an unfortunate homonym
basically anything in the language specification that can justify the practice of saying x is None
the big issue with lambdas imho are twofold,
the first is they're really verbose. lambda isn't so much a bad keyword it's just a mouthful to type, for "short" applications lambdas are competing with "direct" syntax like list comprehensions where you get to just write a single expression
and the second is that you can't have multiline lambdas
right now in python you make lists from another iterable in one of two ways: if the mapping expression is simple, you use a list comprehension, if it's not, people still typically create an empty list and append.
both these approaches have disadvantages that things like map do not. if your lambdas are both concise for short use cases and can handle longer use cases then you can use map in both of these cases
Also note that in neither of these use cases are there any named functions; I kind of reject this whole "lambda vs named function" dichotomy as in many cases the alternative to a lambda doesn't involve any named function
https://docs.python.org/3/reference/expressions.html?highlight=singleton#value-comparisons
None and NotImplemented are singletons. PEP 8 advises that comparisons for singletons should always be done with is or is not, never the equality operators.
nice -- but what about booleans?
i must say i have great difficulty in appreciating the docs a lot of the time because of how scattered they are, even woefully uncomprehensive at times
bool is technically a "doubleton" I guess, since it has 2 instances True and False
I'd call it an enum
but I'm not sure there's a formal definition of such concept in Python
as i understand it, there's a distinction between implementation singletons and specification singletons
hence the warning:
>>> x is 1
<stdin>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
False```i.e. as far as the specification is concerned, small integers are *not* singletons, it just happens that they are for convenience in the implementationi found documentation for this...
but this? is singleton behaviour for these instances even documented at all?
and NotImplemented

Python documentation
A small number of constants live in the built-in namespace. They are: Constants added by the site module: The site module (which is imported automatically during startup, except if the-S command-li...
or uh
Python documentation
The Python interpreter has a number of functions and types built into it that are always available. They are listed here in alphabetical order.,,,, Built-in Functions,,, A, abs(), aiter(), all(), a...
Its only instances are False and True
that's a very implicit statement, if this refers to singletons
i can easily understand it as there can be identical instances of False
i love how well some specific things are documented (like logical operators), and i really must commend you for digging these examples up, but man, you have to understand my dissatisfaction
but at least it's not tkinter level documentation
you can submit a PR for this kind of thing if you want, it should be a pretty quick review
ah yes, a GUI framework documentation with no pictures
peak DX
https://docs.python.org/3/library/tkinter.html#how-do-i-what-option-does
the tkinter documentation, in response to how to use the documentation, even just goes out of its way to essentially say "forget it, look at the implementation"
Python documentation
Source code: Lib/tkinter/init.py The tkinter package (“Tk interface”) is the standard Python interface to the Tcl/Tk GUI toolkit. Both Tk and tkinter are available on most Unix platforms, inclu...
ok, then it isn't a function call. it's special syntax that's compiled like an if-statement.
Wait what
!e print(NotImplemented, type(NotImplemented), NotImplemented is NotImplemented)
@sour thistle :white_check_mark: Your 3.11 eval job has completed with return code 0.
NotImplemented <class 'NotImplementedType'> True
!d NotImplemented
NotImplemented```
A special value which should be returned by the binary special methods (e.g. `__eq__()`, `__lt__()`, `__add__()`, `__rsub__()`, etc.) to indicate that the operation is not implemented with respect to the other type; may be returned by the in-place binary special methods (e.g. `__imul__()`, `__iand__()`, etc.) for the same purpose. It should not be evaluated in a boolean context. `NotImplemented` is the sole instance of the [`types.NotImplementedType`](https://docs.python.org/3/library/types.html#types.NotImplementedType "types.NotImplementedType") type.
exception NotImplementedError```
This exception is derived from [`RuntimeError`](https://docs.python.org/3/library/exceptions.html#RuntimeError "RuntimeError"). In user defined base classes, abstract methods should raise this exception when they require derived classes to override the method, or while the class is being developed to indicate that the real implementation still needs to be added.
Note
It should not be used to indicate that an operator or method is not meant to be supported at all – in that case either leave the operator / method undefined or, if a subclass, set it to [`None`](https://docs.python.org/3/library/constants.html#None "None").
Note
`NotImplementedError` and `NotImplemented` are not interchangeable, even though they have similar names and purposes. See [`NotImplemented`](https://docs.python.org/3/library/constants.html#NotImplemented "NotImplemented") for details on when to use it.I'm genuinely shocked I've never seen people abuse that
Disagree!
lambda x: 1 + \
2 * (
x - 3
)**2
how would you define "abuse"?
in this context
Given it's purpose, I'd say using it anywhere outside of one of the binary arithmetic operations
Like __add__ etc.
stubdefaulter/__init__.py line 51
def infer_value_of_node(node: libcst.BaseExpression) -> object:```Anything interesting coming down the pipe?
anyone?
can someone help me understand str function
def _init_(self, company, ceo):
self.company=company
self.ceo=ceo
def __str__(self, company, ceo)
We can take this code as an example
it simply is to return a string representation of an object. but this should be in #1035199133436354600
This channel isn't to help with problem-driven questions, but the __str__ method is what is called internally by str( ). it can only have one parameter, self.
thank you. I will take care now onwards
thank you. I will take care now onwards
wow, since when is normal attribute-access for normal classes just as fast as slotted classes? 😮
def test0():
t1.foo = 'foo'
t1.foo
del t1.foo
1000000 runs
min 200 ns (0.0 s)
geometric_mean 240.31361224986412 ns (0.0 s)
median 200.0 ns (0.0 s)
stdev 257.51228079533365 ns (0.0 s)
sum 252559600 ns (0.25256 s)
relative stdev 101.96%
####################
def test1():
t2.foo = 'foo'
t2.foo
del t2.foo
1000000 runs
min 200 ns (0.0 s)
geometric_mean 222.66103966162106 ns (0.0 s)
median 200.0 ns (0.0 s)
stdev 247.84748478507044 ns (0.0 s)
sum 232690300 ns (0.23269 s)
relative stdev 106.51%
first slotted, second normal
class Test1:
__slots__ = "foo",
class Test2:
pass
is there actually any benefit now for slots? i'm guessing memory efficiency?
i'm still half expecting i screwed up my tests and slots still are way faster
can't believe what i'm seeing there
I was once in a situation where the memory savings from slots was important. It was pretty weird though.
Thank PEP 659 for that 🙂
we probably specialize this so that it's just one pointer access to the dict
sure it's 659? PEP 659 – Specializing Adaptive Interpreter still is in draft apparently?
yes it was implemented for 3.11
someone forgot to update the website then
It's in a bit of a weird state because it's purely an implementation detail, so it didn't go through the normal PEP process
ok
I think there's a pending request to have it formally accepted, but it accurately describes the optimizations that went into 3.11
amazing.
maybe you can answer my question then? is there any benefit now for using slots? memory efficiency?
Not too sure about memory efficiency, you'd have to benchmark that but it probably still applies. It also makes it explicit to users that these are the only attributes, preventing monkeypatching.
yeah, ok. so it's becoming more of an aesthetic styling option to communicate intention
not a bad thing either
hello everybody, I posted a question in #python-discussion but the discussion is all over the place 😂 . I'm trying to create a few exercises for my students... I want them to practice list comprehensions. I want to evaluate that they're using List comprehensions; explicitly. What do you think of the following approach using ast and eval? Would you change anything?
# given list
l = [1, 2, 3, 4, 5, 6]
# exercise: write a listcomp to return only even numbers
student_code = "[item for item in l if item % 2 == 0]"
# my evaluation:
node = ast.parse(student_code, mode='eval')
# my checks
# check it's actually a list comprehension
assert type(node.body) == ast.ListComp, "Your code is not a list comprehension"
# check it returns the correct values
student_result = eval(student_code)
assert student_result == [2, 4, 6], "Your solution is incorrect"
(btw, I know this is for PEPs and internal Python discussions, but I guess here are the people with the deepest knowledge to evaluate code dynamically)
do you trust your students to not send you malicious code?
yes, I'm sandboxing their execution in their own environment; simple alpine linux container
if they want to mess around with it 🤷♂️
@silver vale that looks like the right tools to use for the job.
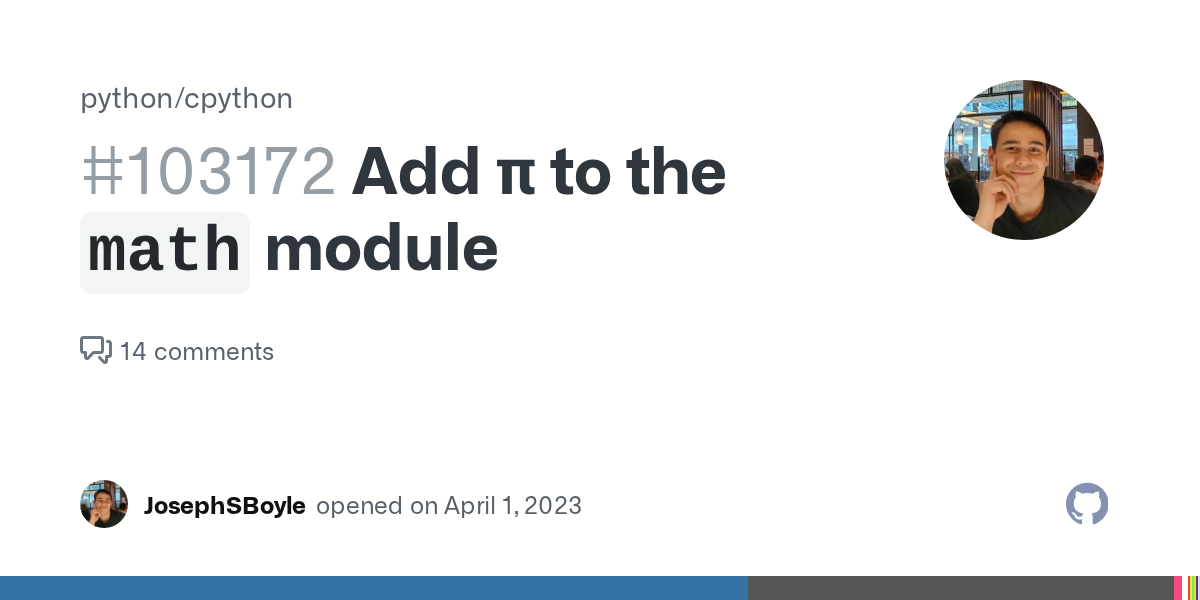
zOMG!!!!1 High priority new issue everyone needs to know about!!!!1 https://github.com/python/cpython/issues/103172
GitHub
Currently, the math module in CPython uses the identifier math.pi to represent the mathematical constant π. This breaks user expectations and violates the principle of least surprise. To improve co...
what if the PR for this gets made and accepted

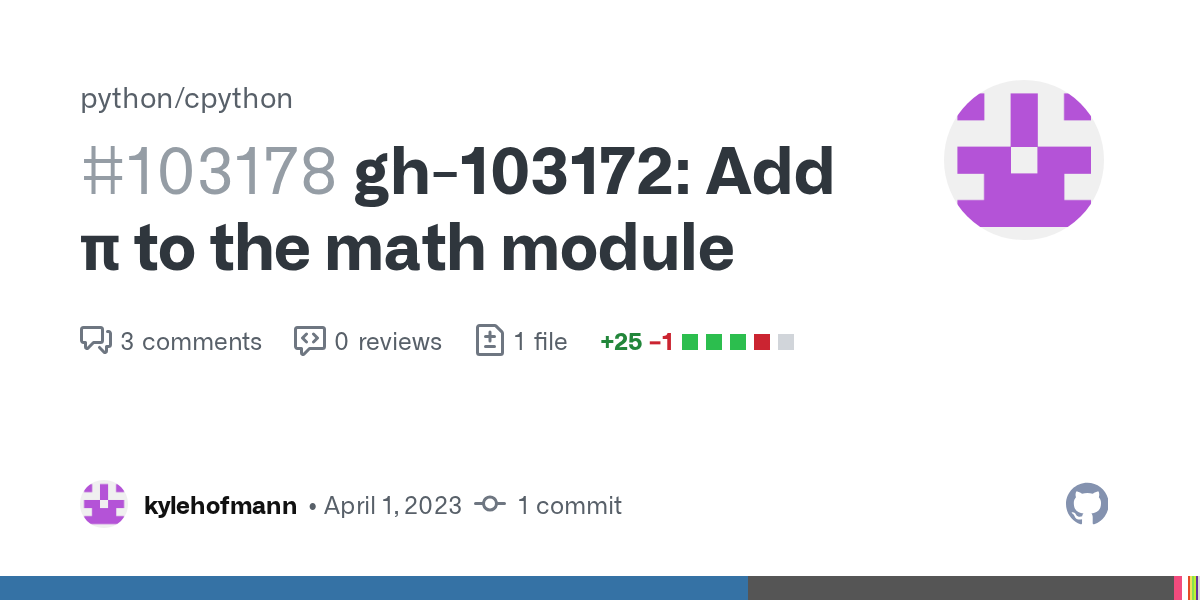
GitHub
Completely and utterly resolves gh-103172. I think we can all agree that this is an improvement, right? Doesn't need review. Should be merged today, before it reaches midnight in all timezones ...
Um, I included a joke in this that seems to have caused a problem. Can anyone here cancel the build action triggered by the PR? I don't have permission, and there doesn't seem to be a timeout... https://github.com/python/cpython/actions/runs/4585823299

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
I clicked cancel pi times, hopefully that's enough
Thank you.
possible learning: we should have a timeout for CI builds
Yeah, it strikes me that someone malicious could trigger a whole slew of CI builds that never finish.
I don't know what kind of resource limitations there are on those, but if nothing else it would be annoying to cancel them all manually.
yes, I think it does go off some quota. At PyCon when there are lots of PRs we sometimes run out I believe
projects have been spammed with PRs that mine bitcoin in the past
there's an option in GitHub (I don't know if CPython already uses it or not) to not run the CI if the PR author is not a committer until someone with permissions triggers it by clicking a button (I think the triager role can kick it off)

GitHub
The joke PR #103178 included some very slow code that runs at import time, and CI took >3 hours before I canceled it. This wastes resources and is a possible abuse vector; a malicious actor coul...
we do have that, but in this case somebody probably approved the CI?
@lone sun just curious, how slowly does that algorithm converge?
I believe it takes O(n^2) time to reach O(n) digits.
But the code should finish before it reaches the precision of a double because some of the individual terms will be probably be too small to affect the rounded sum.
I'm pretty sure it triggered completely on its own. That or someone was really quick in approving it.
Ah, this is wrong. After the k'th term we're guaranteed to be within O(1/k) of the correct value. So to get n correct digits takes O(exp(n)) time.
makes sense, I was surprised O(n^2) with n about 64 would be this slow
i wanna see this in python alongside math.pi
You're welcome to check out my PR!
like instead of this ```diff
-
if (PyModule_AddObject(module, "pi", PyFloat_FromDouble(Py_MATH_PI)) < 0) {
-
if (PyModule_AddObject(module, "π", PyFloat_FromDouble(math_calc_pi())) < 0) {
GitHub has a hard time out at 6 hours iirc. Though that isn't super ideal. Something like 1 hour / 30 min might be more reasonable
thank you and jboyle and khofmann for the laughs:)
btw, is there any news on delayed evaluation of annotations?
it's been a while since the PEP was postponed
PEP 649 was tentatively accepted

Discussions on Python.org
The Python Steering Council is tentatively accepting @larry 's PEP-649: Deferred Evaluation Of Annotations Using Descriptors. (related GH PSC agenda item issue) Why tentatively? What does that even mean? It means we think this PEP should be Accepted and recommend that the next Steering Council do so in three months time (long before 3.12 beta ...
22nd of November
It means we think this PEP should be Accepted and recommend that the next Steering Council do so in three months time [...]
🤔
they did
!pep 649 but this still says draft?
**PEP 649 - Deferred Evaluation Of Annotations Using Descriptors**
Status
Draft
Created
11-Jan-2021
Type
Standards Track
does anyone know how AttributeError.name and obj are set using the capi? cause PyErr_Format(PyExc_AttributeError doesnt seem to be able to do it im trying to implement https://github.com/python/cpython/issues/96663

GitHub
Feature or enhancement Currently, the error message for an attribute that isn't included in a class's slots is harder to understand than I think it needs to be. Python 3.12.0a0 (heads/m...
im also not entirely sure how id go about implementing the suggestions of typos
ok i got it working 😎
Yes, because that still needs to be manually updated
@warm breach howd you implement that checking in c?
hm... might be tricky, all types have a tp_setattro, it's just usually a pointer to the function PyObject_GenericSetAttr
off the top you could check pointer equality to PyObject_GenericSetAttr but I'm not sure if there are any builtins with different assumptions
What do you all think about Python's endianness practice of copying the system it was run on? I came from MATLAB where little endian is the default, so was surprised to learn there was no default endianness for Python. I understand the rationale, but seems like you'll run into trouble when transferring files between systems.
What did you expect to have a default endianness? The struct module? Or ctypes? Or something else?
int.to_bytes() is what I just worked with
I'm trying to create a binary file and ensure the other person reading it in has it as painless as possible
!d int.to_bytes
int.to_bytes(length=1, byteorder='big', *, signed=False)```
Return an array of bytes representing an integer.
```py
>>> (1024).to_bytes(2, byteorder='big')
b'\x04\x00'
>>> (1024).to_bytes(10, byteorder='big')
b'\x00\x00\x00\x00\x00\x00\x00\x00\x04\x00'
>>> (-1024).to_bytes(10, byteorder='big', signed=True)
b'\xff\xff\xff\xff\xff\xff\xff\xff\xfc\x00'
>>> x = 1000
>>> x.to_bytes((x.bit_length() + 7) // 8, byteorder='little')
b'\xe8\x03'
```...Huh, what?
I could have sworn... I read an article that said it's system dependent
Okay. Well, that makes my life a bit easier.
Before 3.11 byteorder was a required argument, now it's optional and defaults to big
Because that sounds like a nightmare when working with other systems
Ah okay
Big has always made more sense to me, but some people/systems still use little, so oh well
The overwhelming majority of systems use little
Every common consumer OS does, right?
There are Linux distros that are big endian, but all common consumer CPUs are little
You need to go out of your way to get big endian hardware these days
There's big endian PowerPC CPUs still
Why is that, anyway? Big endianness makes more sense conceptually, so I assume there's a reason little endian has been used previously
the answer seems to be that it's basically arbitrary depending on what makes the implementation of the hardware easier. Wikipedia says this:
The Datapoint 2200 used simple bit-serial logic with little-endian to facilitate carry propagation. When Intel developed the 8008 microprocessor for Datapoint, they used little-endian for compatibility. However, as Intel was unable to deliver the 8008 in time, Datapoint used a medium-scale integration equivalent, but the little-endianness was retained in most Intel designs, including the MCS-48 and the 8086 and its x86 successors.
Wikipedia also tells me that historically there were mixed-endian systems, where instead of a 4 byte integer being stored as ABCD or DCBA, it might be stored as BADC
there was somebody on discuss.python recently who wanted Python to add support for that
Discussions on Python.org
In my current project I need to parse binary data from different types of machines. Some of them may be very specific and use non standard endianness such as middle endian. Short example If we have bytes A B C D then we have following orderings: Big endian: ABCD Little endian: DCBA Mid Big endian: BADC Mid Little endian: CDAB Large example...
interesting to hear that some of that still exists in the wild!
hey
how do u print the first word so like if the user writes "hi my name is bob" then how do i make python print out the 1st word
im kind of new to coding so idk so i just joined this server hoping someone could help me lols
!e this isn't really a help channel but you can use string.split() to get a list of words and then index that list
s = "hi my name is bob"
print(s.split()[0])```@pliant tusk :white_check_mark: Your 3.11 eval job has completed with return code 0.
hi

faster-cpython/ideas#557

faster-cpython/ideas#564 python may use type information in 3.13+
woa
python/cpython#101441 comprehension inlining is happening

now that the last 3.12 alpha is here, i can only hope that peps 649 (Deferred Evaluation Of Annotations Using Descriptors) and 701 (Syntactic formalization of f-strings) will make it to beta1, which is expected in one month from tomorrow
701 is very likely to happen, 649 is indeed something to worry about
indeed, and what i'm guessing you're referring to:
The bad news is: what I’m working on is something of an overhaul of PEP 649. I’m nearly ready to post a new top-level topic about it here on the Discuss. Sadly not quite ready yet. Hopefully this week.
https://discuss.python.org/t/pep-649-deferred-evaluation-of-annotations-tentatively-accepted/21331/22
Are replies to the PEP discussion on discuss.python.org the only place that PEP acceptances are announced now? I was wondering because they used to get posts to the mailing list (e.g. https://mail.python.org/archives/list/python-dev@python.org/thread/3AHGWYY562HHO55L4Z2OVYUFZP5W73IS/), which is how we got them in #mailing-lists
Ah, I see it's mentioned here https://devguide.python.org/developer-workflow/communication-channels/index.html#mailing-lists

Python Developer's Guide
Python’s development is communicated through a myriad of ways, primarily Discourse along with other platforms. Standards of behaviour in these communication channels: We try to foster environments ...
you can also follow the python/steering-council repo
Thanks 👍
is there a consensus on what will happen to from __future__ import annotations in pep 649 yet?
least disruptive would probably just be to replace the annotations future with 649
I don't even think there's a strong consensus on the indentation of 649
It's tentatively accepted but last I read on the discussions it seemed people were still poking holes with the descriptor implementation
Discussions on Python.org
On behalf of the Steering Council, we’d like to report that we are happy to accept PEP 695. Thanks to everyone for the reinvigorated discussion in the last few weeks – I look forward to this step forward for typing in Python.
How on earth that got accepted is beyond me
It feels exactly the same as callable annotation syntax
But that was rejected, maybe it's bc they plan on adding new anonymous function syntax and want to save it...I can only hope
that's a lot of syntax for something only type checkers check
if it ever gets implemented i hope it might be used for optimizations
Wow. That is indeed... surprising :|
Don't get me wrong, I'm in favor of it
I just don't believe the argument that it's different than pep 677
well, like type hints it can probably have runtime effect as well, if you choose to
We have only about 3 weeks to get this into 3.12 – the beta 1 feature freeze is May 8 (PEP 693 – Python 3.12 Release Schedule | peps.python.org ). And during that time falls PyCon
is it actually reasonable to expect this in 3.12 👀
have you met Eric Traut
heh
(he is rapidly approaching your destination)
Per-interpreter GIL PEP Accepted!!! https://discuss.python.org/t/pep-684-a-per-interpreter-gil/19583/42
Discussions on Python.org
On behalf of the Steering Council, I’m happy to report that we have accepted PEP 684. @eric.snow, thanks for all of your efforts on this PEP and all of the supporting work it took to get us here over the years!
I'm still wondering how I can test the multiple interpreters thing without writing C
wait this got accepted? already?
maybe you could use ctypes to spin up a new interpreter instance?
eric replied recently that he'll try to put up a pip package in the meantime, while pep 554 is not accepted (which I hope happens soon now)
I like the idea a lot (at least I did at first glance) but i think explicit type params (at least bounds) were clearer. this is concise but at an expense of completely confusing any reader of your code unless they're extremely familiar with type hinting
Plus, now there's no way that my suggestion of using -> (A, B): ... will become acceptable syntax for -> tuple[A, B]: ... 🥲
what he means is print("hi my name is bob" .split()[0])
print("hi my name is bob" .split()[1]) would be my etc
oops looks like i didnt scroll down all the way
!e is json.dump broken? I don't find this difference in behaviour documented anywhere:
import json
class Demo(json.JSONEncoder):
def encode(self, o):
return "42"
print(json.dumps({}, cls=Demo))
from io import StringIO
s = StringIO()
json.dump({}, s, cls=Demo)
print(s.getvalue())
@quick snow :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 42
002 | {}
sounds like the problem is with your encoder class
json.dump calls iterencode() instead of encode() https://github.com/python/cpython/blob/411b1692811b2ecac59cb0df0f920861c7cf179a/Lib/json/__init__.py#L173-L180
https://github.com/python/cpython/blob/411b1692811b2ecac59cb0df0f920861c7cf179a/Lib/json/__init__.py#L234-L238
from https://docs.python.org/3/library/json.html#json.JSONEncoder, it sounds like you are expected to overwrite only the default() method, not encode / iterencode
Python documentation
Source code: Lib/json/init.py JSON (JavaScript Object Notation), specified by RFC 7159(which obsoletes RFC 4627) and by ECMA-404, is a lightweight data interchange format inspired by JavaScript...

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
I see. .default() wouldn't help in my usecase (preserving int keys), but that explains it, thank you.
tbh I feel like it's probably better / safer / easier for you to just convert them back to ints after loading it than violating the json spec
I'm not violating the JSON spec, I just convert the keys to something like "int:2314", and turn them back into integers in a object_pairs_hook when loading.
oh, I see
t-strings sound interesting now. https://discuss.python.org/t/pep-501-reopen-general-purpose-string-template-literals/24625
Apologies if this is not really the correct place to ask this, but is there any example or even allowed in python?
# Scalar def get_scal(feature):
def get_scal(feature):
def minmax(x):
mini = train[feature].min()
maxi = train[feature].max()
return (x - mini)/(maxi-mini)
return(minmax)
It seems like the author intended to unindent return(minmax) but the whole program bricks itself if done
I came across this while studying and can be found here at execution 16 and 30
https://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/courses/machine_learning/deepdive2/feature_engineering/solutions/3_keras_basic_feat_eng.ipynb

GitHub
Labs and demos for courses for GCP Training (http://cloud.google.com/training). - training-data-analyst/3_keras_basic_feat_eng.ipynb at master · GoogleCloudPlatform/training-data-analyst
yeah, that looks like a decorator to me
if the function doesn't get returned, it will never be run and immediately be garbage collected
can someone explain why converting to set gets rid of order even if its from set to set: only b is sorted
from random import randint
a = [randint(1,999) for _ in range(10)]
print(set(sorted(a)))
b = {randint(1,999) for _ in range(10)}
print(sorted(b))
c = {randint(1,999) for _ in range(10)}
print(set(sorted(c)))
sets have no order
consecutive hashes and therefore consecutive numbers will be placed together but if one number differs from that order it'll be placed somewhere else random
interesting, ty
why is it that the random spot is never before a series of consecutive numbers starting at 0 at the start?
but if those numbers start at 10 it can go before
it takes up the indexes 0 to the last consecutive number
My cpython pr is stalled waiting for a second review for a while how do I push it forward 
bribe the right people
Hi ,everybody, Nice to meet you!
Hi , everybody !
I have a problem so...
I can't change my system from Windows to Linux (I want to install manjaro or even archlinux) but I can't. The reason for the mode is that in boot mode there is UEFI in the BIOS. And there's nothing I can do about it. Because the problem is that I forgot my bios password. So is it possible to switch the boot mode without a bios administrator password, or is it possible to remove this password?
this isn't really the right place for that sort of question, but for the love of all that is good back up the system before you go playing around... maybe ask in #unix
the WSL might be a good option too
Oof python/cpython#87744
There's any package manager like cargo?
what specifically about cargo are you looking for in python?
import gc
del x
gc.collect()
If del x sets the ref count to 0 for that object, and it's not exempt from the garbage collector, is it guaranteed to be destroyed during gc.collect()?
if the refcount is 0 it would be deleted on the del, no need for GC
x = x[0] = [...]
# now this object has 2 refs
del x
# now 1 ref, but refcycle exists
gc.collect()
# guaranteed to be collected as garbage
I'm not sure it's fully guaranteed in cases involving resurrection or other weirdness
that simple example can not be fully guaranteed because if there are enough other cycles that need to be cleared first that cycle may survive the round kicked off by gc.collect()
- actually it seems like
gc.collect()will run rounds until it has cleared all pending cycles
neat
whats this channel about
Status
Active
Created
13-Jul-2000
Type
Informational
@feral island could you possibly help me out?
True on CPython, but not PyPy or other implementations without reference counting.
In general I'd recommend using try/finally or context managers wherever lifetimes matter to you, reference counts are pretty fragile in the best case because it's so easy to end up with an extra reference somehow and them boom...
which PR is yours?
GitHub
Currently, all of this is done for every write() call:
https://github.com/python/cpython/blob/main/Lib/gzip.py#L266-L288
This pr stores GzipFile.write() data into a buffer to postpone most of the c...
I think I'll leave that to Greg
Do you know how long it usually takes? It has been around 2 months I think
Why new pythons dont support windows 7 and older?
What part of interpreter or std library needs newer api?
Is there a way to run cpython3.11 on windows 7? Maybe i just shouldn't use some features?
Here's the relevant discussion thread, including reasons for dropping support and what you might need to take care of if you want to compile your own version that still supports it: https://bugs.python.org/issue32592
There's also this: https://github.com/adang1345/PythonWin7, but proceed at your own risk.
python/cpython#102856

GitHub
Co-authored-by: Lysandros Nikolaou <lisandrosnik@gmail.com>
Co-authored-by: Batuhan Taskaya <isidentical@gmail.com>
Co-authored-by: Marta Gómez Macías <mgmacias...
with this pep [f'{'] + [f'}'] (which is currently invalid syntax) will be the same as [f'{"] + [f"}']. Am i right?
this confused me
hello
Hi
!d list
class list([iterable])```
Lists may be constructed in several ways:
• Using a pair of square brackets to denote the empty list: `[]`
• Using square brackets, separating items with commas: `[a]`, `[a, b, c]`
• Using a list comprehension: `[x for x in iterable]`
• Using the type constructor: `list()` or `list(iterable)`...
Similar names: pdbcommand.list, term.list
I didn't realize this  had been fixed!
had been fixed!
previously that would fail to find the class, because of how the docs were structured
i noticed 3.12 docs have dark mode
yeah, that's a new change as well
along with changes to the organization and presentation to try to make the docs more effective
are you at CAM's talk by any chance?
directly behind you 🙂
Seems no
It only finds the class, none of the methods
Ah, I think that should be fixed in 3.12
@graceful dome :
Well, it's like returning a reference. Yeah. For any variable in python you can do id(var) and see the "memory block id" for that object. Every object is stored this way; but they aren't references in the traditional sense because there's no deref
@graceful dome one way to think of it is: when you pass a value to a function, you're just assigning that value to a name in that function. and when you return it, you're assigning it to a name in the place where you called it.
For certain objects (immutables) the value at that address can never change. They persist as that value in memory until python terminates. Where mutables, if you change the value at the address any variable that shares the same ID is affected
If you're familiar with C, it's helpful to think in terms of pointers.
Yes. It's both simultaneously like and unlike pointers
I.e. yes, it's exactly like pointers but there's no command/function to "get the pointer of <foo>"
For people familiar with C, I'd say that Python only has pointers. There are no primitive types, and every variable and every value is a reference that points to some object
This is useful! Thank you! I guess then my question is:
The statement @spark magnet was talking about is not THAT wrong?. Or maybe I still don’t understand completely.
Returning an int doesn't make a copy, no.
It's just if you assign a var to a different int, it "deletes" the pointer to the original int and creates a new link to the new int
the statement Ned pointed out is wrong about the "why", but still correct about the "what", I guess. It has the effect right (if you return an int it can't be modified by your caller), but the cause wrong (it's not because the caller gets a distinct copy of your int, but just because no int can ever be modified, because int is immutable).
@graceful dome this is how I explained the foundations at work here: https://bit.ly/pynames1
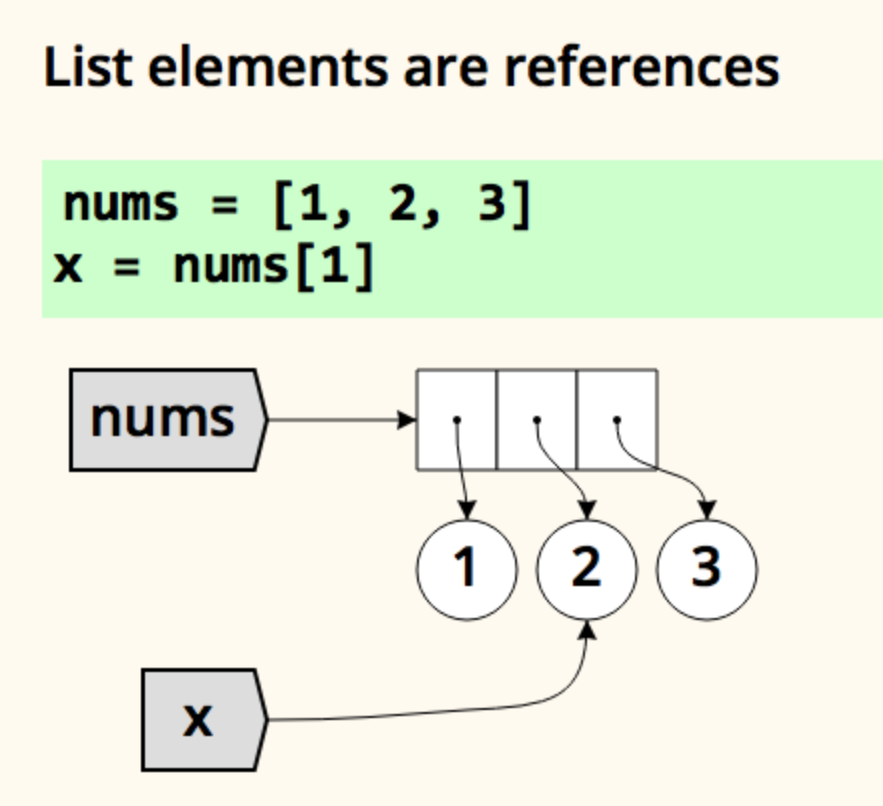
Assignment in Python might surprise you. How do names and values work? This presentation explains it all.
For what it's worth I made a GH issue suggesting to link this in the !mutability command here. But it hasn't gotten commented on yet
Got it! Thank you! This was very helpful!
!e
foo = 1
bar = foo
print(id(foo))
print(id(bar))
bar += 2
print(id(bar))
@cosmic nymph :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 140426268353160
002 | 140426268353160
003 | 140426268353192
^ this demonstrates the concept. As you can see, the id of bar has changed
Love it. I’m on the plane right now and was going to do this when I got home! This is what I needed
!e
print("hello world")
@tranquil wave :white_check_mark: Your 3.11 eval job has completed with return code 0.
hello world
😄
!e
print(0.1 + 0.2)
@echo condor :white_check_mark: Your 3.11 eval job has completed with return code 0.
0.30000000000000004
#bot-commands for this please.
Has anyone worked with llm in python to create a chatbot for your pdf data
And how to create a chatbot that use your own embeddings for similarity search on the user question
wrong channel
hello guys!!
Can i access the memeory(address and value) allocated by python tuple ? any capi which can access the pyobject of tuple ?
How can i do this? please share the code snippet ?
I wanted to verify lookup operation for tuple is faster without using the timeit module by proving that tuple uses contiguous memeory
lookup compared to what. lists?
yes
what would showing that tuple stores elements contiguously prove? lists do that also
tuple do O(1) lookup right by internally using the hashtable i read it somewhere , can i access that hashtable using some python.h api
it's not a hashtable. it's just an array
okay
what about Can i access the memeory(address and value) allocated by python tuple ?
you can, but i'm not sure exactly
In cpython id(your_tuple) returns memory address allocated by tuple
proving that tuple uses contiguous memeory
🤔 you can just read the CPython source code to prove that, no?
lists also use contiguous memory
don't look at the name of the function in the cpython source code listobject.c line 623 DON'T DO IT
python/mypy#9692

!e
from einspect import view
tup = ("a", "b", "c")
print(view(tup).info())
@warm breach :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | PyTupleObject (at 0x7f3390c86d80):
002 | ob_refcnt: Py_ssize_t = 4
003 | ob_type: *PyTypeObject = &[tuple]
004 | ob_size: Py_ssize_t = 3
005 | ob_item: Array[*PyObject] = [&['a'], &['b'], &['c']]
!e and here you can see the address of the array the tuple uses
from einspect import view
tup = ("a", "b", "c")
array = view(tup).item
print(array)
print(array[0].contents.into_object())
@warm breach :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | <einspect.structs.py_tuple.LP_PyObject_Array_3 object at 0x7f2d823ca690>
002 | a
Cool, I saw you using this lib to show an example but i didn't remember the exact name, Thanks
why is this code is interpreting (a, b) as tuple and not as two arguments for assert?
>>> assert (a, b)
<stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses?
i think this can be special-cased in interpreter compiler, so checks like this works: ```py
assert ( # currently it always true and because of that raises SyntaxWarning
very_long_check(),
"very long message"
)
instead of:
assert (
very_long_check()
), (
"very long message"
)
there's a pep for this
!pep 679
**PEP 679 - Allow parentheses in assert statements**
Status
Draft
Python-Version
3.12
Created
07-Jan-2022
Type
Standards Track
(it's not going into 3.12)
this diagram looks a bit weird in new dark theme
i think colors can be inverted

report a bug 🙂
im not a html expert but adding style="filter:invert(1)" to this image works perfectly:

great, if you make a PR I'll review it

GitHub
Documentation Starting from version 3.12, the Docs now have a dark theme. However, this feature does not affect the images. As an example, please visit https://docs.python.org/3.12/library/pathlib....
oh maybe it is a wrong repository for that issue
tbh, i dont know where the fix should be
adding ```css
img {
filter: invert(1);
}
so i think it would also require some changes in cpython repo to mark images that should be inverted

thankfully there are not many images


which language is best in feture?
Well, Latin has a lot of features:
Latin is a highly inflected language, with three distinct genders (masculine, feminine, and neuter), six or seven noun cases (nominative, accusative, genitive, dative, ablative, and vocative), five declensions, four verb conjugations, six tenses (present, imperfect, future, perfect, pluperfect, and future perfect), three persons, three moods, two voices (passive and active), two or three aspects, and two numbers (singular and plural).
;compile
i have the code obj so, i think if i can get it to the AST i can unparse it and get the og source
import ast
def my_func():
x = 1
y = 2
z = x + y
return z
code_obj = my_func.__code__
ast_obj = ast.parse(code_obj)
print(ast_obj)
something like this ^^
can you explain it more
?
use uncompyle6
or pycdc
?
i want to decompile
thats literally what uncompyle6 does
it has manipulated the bytecode in such a way actual python interprets but uncompyle6 decompyle3 or pycdc fails
?
(for certain versions only)
the bytecode was probably compiled on versions that uncompyle / decompyle dont support yet
nope it is 3.8
lol
i forget which one of the two maintainers is holding back on newer versions support until people donate enough for him to work on it / release it
thats the funny part
no?
its just a simple command dude
just decompyle3 file.pyc
?
lol
@south hearth you dont sound very gigachad to me
anyways
if you run the file and dump the proc core memory the source will show
not if all they've got is a .pyc?
pyc's arent hard to read anyways
u dont need uncompyle to do it for u
they're not trying to read it, they're trying to produce Python source code from it
i dont see the point in that but okay
35:
LOAD_GLOBAL 8 (requests)
LOAD_METHOD 9 (session)
CALL_METHOD 0
SETUP_WITH L126 (to 126)
STORE_FAST 3 (req_session)
37:
LOAD_GLOBAL 8 (requests)
LOAD_ATTR 10 (adapters)
LOAD_ATTR 11 (HTTPAdapter)
LOAD_CONST 4 (2)
LOAD_CONST 5 (('max_retries',))
CALL_FUNCTION_KW 1 (1 total positional and keyword args)
STORE_FAST 4 (adapter)
38:
LOAD_FAST 3 (req_session)
LOAD_METHOD 12 (mount)
LOAD_CONST 6 ('https://')
LOAD_FAST 4 (adapter)
CALL_METHOD 2
POP_TOP
39:
LOAD_FAST 3 (req_session)
LOAD_METHOD 12 (mount)
LOAD_CONST 7 ('http://')
LOAD_FAST 4 (adapter)
CALL_METHOD 2
POP_TOP
40:
LOAD_FAST 3 (req_session)
LOAD_ATTR 13 (post)
LOAD_FAST 1 (IM_hit_url)
LOAD_CONST 8 ('object')
LOAD_FAST 2 (payload)
BUILD_MAP 1
LOAD_CONST 9 (30)
LOAD_CONST 10 (False)
LOAD_CONST 11 (('data', 'timeout', 'verify'))
CALL_FUNCTION_KW 4 (4 total positional and keyword args)
STORE_FAST 5 (response)
POP_BLOCK
BEGIN_FINALLY
tell me what this is doing , without using any form of decompilation or ai chatbot
no need for the source
just tell me the functionality
it's making an http request and getting the response
with requests.session() as req_session:
to the "IM_hit_url"
ik , i asked him tho
adapter = requests.adapters.HTTPAdapter(max_retries=2)
lmao ik, i am asking him
xD
i can read bytecode as well
tell me this then:
6 0 LOAD_CONST 1 (0)
2 LOAD_CONST 2 (1)
4 BUILD_LIST 2
6 STORE_FAST 1 (x)
7 8 LOAD_GLOBAL 0 (range)
10 LOAD_FAST 0 (n)
12 LOAD_CONST 3 (2)
14 BINARY_SUBTRACT
16 CALL_FUNCTION 1
18 GET_ITER
>> 20 FOR_ITER 13 (to 48)
22 STORE_FAST 2 (i)
8 24 LOAD_FAST 1 (x)
26 LOAD_METHOD 1 (append)
28 LOAD_FAST 1 (x)
30 LOAD_CONST 4 (-1)
32 BINARY_SUBSCR
34 LOAD_FAST 1 (x)
36 LOAD_CONST 5 (-2)
38 BINARY_SUBSCR
40 BINARY_ADD
42 CALL_METHOD 1
44 POP_TOP
46 JUMP_ABSOLUTE 10 (to 20)
9 >> 48 LOAD_GLOBAL 2 (plt)
50 LOAD_METHOD 3 (plot)
52 LOAD_FAST 1 (x)
54 CALL_METHOD 1
56 POP_TOP
58 LOAD_CONST 0 (None)
60 RETURN_VALUE
if i had to guess, for i in range(48): x.append(plot)
thats just from a glimpse look though
the 48 is a bytecode offset
good then , now u get the point ig?
decompiling yes?
why are you facepalming?
they are completely separate terms
u both decode and decompile
ig google the diff between decompiling and decoding?
shut the fuck up
its disassemble and decompile?
language?
hi, mind telling me whats wrong with this disassembly?
L512:
75:
LOAD_CONST 24 ('Err238: ')
STORE_FAST 7 (errMSG)
76:
LOAD_CONST 10 (False)
LOAD_FAST 7 (errMSG)
BUILD_TUPLE 2
POP_BLOCK
RETURN_VALUE
POP_BLOCK
JUMP_FORWARD L738 (to 738)
L530:
78:
DUP_TOP
LOAD_GLOBAL 8 (requests)
LOAD_ATTR 24 (exceptions)
LOAD_ATTR 25 (ConnectionError)
COMPARE_OP 10 (exception-match)
EXTENDED_ARG 2 (512)
POP_JUMP_IF_FALSE L600 (to 600)
POP_TOP
STORE_FAST 8 (err)
POP_TOP
SETUP_FINALLY L588 (to 588)
79:
LOAD_FAST 0 (self)
LOAD_ATTR 6 (loggerObj)
LOAD_METHOD 17 (error)
LOAD_GLOBAL 19 (ErrorLog)
LOAD_METHOD 20 (format_error)
LOAD_GLOBAL 19 (ErrorLog)
LOAD_ATTR 26 (err213)
LOAD_GLOBAL 15 (str)
LOAD_FAST 8 (err)
CALL_FUNCTION 1
CALL_METHOD 2
CALL_METHOD 1
POP_TOP
im getting a parse error at DUP_TOP , tbh and i think the error is somewhere there
i genuinely need help with that
!mute 988196927336222770
:incoming_envelope: :ok_hand: applied timeout to @slender stream until <t:1682911212:f> (1 hour).
I think something with a try/except/finally?
Not sure exactly how that's compiled
well he manipulated the bytecode in a way that it is valid with cpython but fails with any decompilers, thats why i was trying to see if cpython has a module to convert code object back to AST , so i can see how its done but well
looks like this is a huge function. maybe find the jump target that points to L530
since the stuff right above it jumps somewhere else
there is no jump to it , its setup at the start of the function and thats all
31:
EXTENDED_ARG 2 (512)
SETUP_FINALLY L530 (to 530)
the stuff on line 78 seems to be doing something like except requests.exceptions.ConnectionError as err:
yeah i get that
maybe it uses a different python implementation?
nope its cpython
do you know what Python version?
doesn't look like current bytecode
its 3.8.0
for comparison on 3.8 ```>>> dis.dis("""
... try: x
... except Exception as err: pass
... """)
2 0 SETUP_FINALLY 8 (to 10)
2 LOAD_NAME 0 (x)
4 POP_TOP
6 POP_BLOCK
8 JUMP_FORWARD 34 (to 44)
3 >> 10 DUP_TOP
12 LOAD_NAME 1 (Exception)
14 COMPARE_OP 10 (exception match)
16 POP_JUMP_IF_FALSE 42
18 POP_TOP
20 STORE_NAME 2 (err)
22 POP_TOP
24 SETUP_FINALLY 4 (to 30)
26 POP_BLOCK
28 BEGIN_FINALLY
>> 30 LOAD_CONST 0 (None)
32 STORE_NAME 2 (err)
34 DELETE_NAME 2 (err)
36 END_FINALLY
38 POP_EXCEPT
40 JUMP_FORWARD 2 (to 44)
>> 42 END_FINALLY
>> 44 LOAD_CONST 0 (None)
46 RETURN_VALUE
so this looks quite a bit like your code
ahhhhh
i think i find where the problem is maybe
@feral island
errMSG = 'Err238: '
return (False, errMSG)
try:
err = None
if im not wrong this is what my code looks like in the disassembly
which obviously isnt the right thing
hm I think the return is inside the try
I guess you can invoke dis with the standard Python eval bot. But it prob doesn't run on 3.8 and you really need 3.8 here
disassembly:
2 0 LOAD_CONST 0 (<code object ok at 0x7fa0e312d190, file "<dis>", line 2>)
2 LOAD_CONST 1 ('ok')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (ok)
8 LOAD_CONST 2 (None)
10 RETURN_VALUE
Disassembly of <code object ok at 0x7fa0e312d190, file "<dis>", line 2>:
3 0 LOAD_CONST 1 ('Err238: ')
2 STORE_FAST 0 (errMSG)
4 4 LOAD_CONST 2 (False)
6 LOAD_FAST 0 (errMSG)
8 BUILD_TUPLE 2
10 RETURN_VALUE
5 12 SETUP_FINALLY 8 (to 22)
6 14 LOAD_CONST 0 (None)
16 STORE_FAST 1 (err)
18 POP_BLOCK
20 BEGIN_FINALLY
8 >> 22 END_FINALLY
24 LOAD_CONST 0 (None)
26 RETURN_VALUE
og code:
def ok():
errMSG = 'Err238: '
return (False, errMSG)
try:
err = None
finally:
pass
disassembly:
2 0 LOAD_CONST 0 (<code object ok at 0x7f8e1d1550e0, file "<dis>", line 2>)
2 LOAD_CONST 1 ('ok')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (ok)
8 LOAD_CONST 2 (None)
10 RETURN_VALUE
Disassembly of <code object ok at 0x7f8e1d1550e0, file "<dis>", line 2>:
3 0 LOAD_CONST 1 ('Err238: ')
2 STORE_FAST 0 (errMSG)
4 4 SETUP_FINALLY 12 (to 18)
5 6 LOAD_CONST 2 (False)
8 LOAD_FAST 0 (errMSG)
10 BUILD_TUPLE 2
12 POP_BLOCK
14 CALL_FINALLY 2 (to 18)
16 RETURN_VALUE
7 >> 18 END_FINALLY
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
og code:
def ok():
errMSG = 'Err238: '
try:
return (False, errMSG)
finally:
pass
doesnt really make a diff inside or outside the try block
hmmm
Sure it does:
4 4 LOAD_CONST 2 (False)
6 LOAD_FAST 0 (errMSG)
8 BUILD_TUPLE 2
10 RETURN_VALUE
vs
5 6 LOAD_CONST 2 (False)
8 LOAD_FAST 0 (errMSG)
10 BUILD_TUPLE 2
12 POP_BLOCK
14 CALL_FINALLY 2 (to 18)
16 RETURN_VALUE
they're both valid, but do different things
yeah in there the return value is after call finally when inside a try block
i saw that
by "there is an error" you mean the disassembler you were using couldn't handle that code?
yeah it couldnt parse
maybe it just can't handle try-excepts?
what decompiler were you trying?
umm...i think it does cuz i have parsed other things with try excepts as well
decompyle3 and uncompyle6
ig ima try making my own with cpython api at some point as well
might be worth trying pycdc as well - https://github.com/zrax/pycdc
cant handle many opcodes of python 3.8 , 3.7 and 3.6 yet
but if all else fails, you can just pull up the Python 3..8 eval loop in one window and the byte code in the other, and trace through the execution
- AST is pretty shit
I was under the impression that pycdc could handle newer Python versions than uncompyle6 could
I'm pretty confident the fragment you posted is a try/except, it's not the whole function though
no? im a co developer myself in it xD
it just supports the magic byte
but many of the opcodes are unimplemented
u want the whole function? its pretty large but well paste service is there right?
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
ok
here u go
is this malware?
it seems to be talking to some IM server
I think there's a big try-except in the whole function and then a bunch of smaller ones
Too much work to manually decompile the whole thing though
looks like it might be talking to a command and control server, at a glance
Based on "This class is used to communicate from server and perform task according to response from server", plus all of the "Dear C2 user" messages
Yeah
That's what I'm trying to reverse engineer
Yep exactly
here's what I got before I got bored: https://paste.pythondiscord.com/puqanijeka. Not sure the structure of the try/excepts is right though.
the part that isn't error handling seems to be on line 72
self.assessmentinfobean.set_domain_url(response["domainURL"])
Wtf, did u do it all by hand?
Ok that's pretty accurate to where I reached
it's not that hard
like 1min ago
Yeah , I was doing the same just didn't thought that u would be interested in it that much xD
Yeah the repro is pretty accurate to what I have as well
In fact it's the same with those strings added
Why did u add the last if tho?
I guess I got bored between deciding there was an if and writing out what the condition was
I think it's if response["domainURL"]
Wait lemme show my version when I'm on pc
Will be back in like 10min after back from the market
I'm not sure there's really any finallys. I saw the SETUP_FINALLY opcodes, but those also happen on try/except
I think the overall structure is one try-except around the whole thing, then within that big try-except there's a bunch of smaller ones. That's just a guess though, haven't fully verified
@feral island extremely sorry to bother u again, i think im just being annoying atp but it would really help me if u would look into the key validation part of the C2 , i cant make sense of the disassembly , at your free time ofc , it would really help me if u would ;-; , sorry for being annoying and the ping again
its at around line 342 thanks
from what i can make sense of its just comes after every try statement fails
I wonder why python audit hooks do not have hooks for file writes ? (haven't read the pep fully)
at L342? seems like that just checks for if response["Error"]
How will PEP 684 actually work? The way I understood threads in python is that only one thread was able to run at a time, and the variables were essentially shared, using the same memory, hence allowing easy communication. If you wanted to go around GIL, independent processes could do that, but at the cost of expensive IPC.
This PEP talks about a per-interpreter GIL, do new threads start new interpreters? GIL is (from the name) a "interpreter lock", so only one interpreter can have it, hence only one thread runs at the same time, assuming each thread has it's own interpreter. This PEP would then make individual interpreters have their own GIL? But then it's not much of a lock at all if every interpreter has it, isn't that just removing GIL then? Why is it talking about "per interpreter lock"?
So, from what I understand, this PEP tries to move the global state of the process into the interpreter state, so each interpreter can have it's own complete state. Would this mean the variables etc. is all per-interpreter, and hence per-thread? So, would starting a new thread mean copying all of the variables etc, essentially doubling memory usage? I thought the point of threads was to have shared state here, so when thread 1 modifies global x, thread 2 now has that new value in x.
Threads are separate from interpreters. New threads don't get new interpreters by default.
All variables are indeed per-interpreter, virtually nothing can be shared
ah, so this PEP will essentially add yet another way to do this, along with multiprocessing and multithreading, there will essentially be a way to have a single process, running multiple interpreters in their own threads?
yes, that's about right
ohh
that's pretty cool then
you'll basically get the benefits of multiprocessing, without the downsides of IPC
Eric Snow had a nice talk about it at PyCon, should be on YouTube in a few weeks
hmm, gotta give that a watch once it's there, really cool stuff!
without all the downsides of IPC. You still have some of them. You still need to serialize variables in order to shuffle them from one interpreter to another, since interpreters don't share variables. So at least there's fewer failure modes than multiprocessing has, and passing around the serialized work items and results can be faster - but there is still serialization overhead involved that you don't pay with threads or asyncio.
but at least you don't have downsides like "a process in my worker pool was killed and now my application needs to decide how to recover from that"
do you really need to serialize everything here? since these would be in a single process, you have shared address space, yeah, there could be issues with pointers in that memory, but for some simpler things, maybe you could just share/copy memory directly, without any extra serialization?
you can't share Python objects (the refcounts would cause problems), but you could use some shared memory mechanism that doesn't hold Python objects I believe
what about sharing immortal objects?
I think there was also some talk about special objects?
though that's kinda niche tbh
yeah immortal objects, that's it
"immortal" objects are still eventually GC'd when the interpreter is torn down
maybe give them something like a refcount, but for amount of interpreters using them, rather than amount of references?
that's not enough. They'd also need to be immutable
imagine that you've got a mutable immortal object shared across interpreters, and one interpreter does: py obj.x = "hello" and then another does ```py
obj.x = "goodbye"
hmm, good point, ig you could still share immutable objects, to maybe save some memory, but yeah, there probably won't be a huge amount of those
immutable objects that don't reference mutable objects.
which also eliminates things like tuples, for instance, since they can reference a mutable object.
per-interpreter GIL + zmq's inproc and/or sqlite's in-memory db with a shared cache will offer a lot (covering the cases with mutability very well), while being highly portable and not needing to reinvent the wheel for it, but you'll still need a way to (de)serialize. msgspec seems to be a good canidate there for high portability + low overhead, but I think there might be some benefits to doing less of this in 3rd party libraries at high efficiency (even if this can wait to be a "what's the next step from here" thing)
I'm overall excited for the future with per-interpreter GIL as I have a few things which can benefit from this.
Discussions on Python.org
Thanks for the elaboration. Lazy evaluation This first thing I note is the inclusion of lazy evaluation. The original PEP makes no mention of lazy evaluation. This is a very large addition. Adding lazy evaluation changes the PEP enough that it should be fully reconsidered. I note that your PR is titled “Lazy evaluation and other small chang...
I had a feeling that pep695 will clash with things
It felt weird that the PEP got accepted even before I could properly read it through.
Not sure what the timelines are in reality, but I feel for a pep with these many grammar and bytecode changes should be given a longer time for the community to familiarize themselves with
pep649 had the same problem, where it was accepted, implemented and merged, and then pydantic folks pointed out this will break runtime typing
and 649 has been thought over for I believe multiple years now
i love the syntax in 695, but I agree with the sentiment to not rush into it
https://discuss.python.org/t/please-consider-delaying-or-even-rejecting-pep-695/26408/23 this reply seems pretty reasonable for me
Discussions on Python.org
To be fair here, I don’t necessarily think that the design and implementation have necessarily been rushed. The problem is that the work (because it’s mostly happened on typing-specific lists) hasn’t been particularly visible to people who are working on the interpreter in general, but who have limited interest in the esoterica of typing itself....
yeah this is fair. if we can make the PEPs more visible outside SIG people before it is accepted, we'll probably catch more edge cases as well.
you mean the previous pep that gave string annotations?
honestly at this point 649 might still break the hacks we needed to work with the current one
yeah
was it a wildly unpopular opinion that they should have simply gone ahead with 649, out of curiosity?
I remember looking at pydantic before all the drama with 649, and thinking that some of the things they were doing with the annotations were an abomination, and deciding to stay far away from it
given how late their concerns were raised...
I also wonder if the typing annotation advocates may have shot themselves in the foot. In order to get type annotations merged, they said they were open to other use cases, afaiu. So it didn't seem like it was just about static type annotations. So it was harder to deny these other uses as legitimate. IMHO, from day1, it should have been clear that these were just for static type annotations. It's certainly an important enough feature and widely used enough to deserve it. Then libraries doing things like pydantic could have been more easily dismissed as "misuse"
do you mean they should have gone ahead with 563, not 649?
hm, honestly there's been so many I'm mixed up now
563 is stringified annotations
My comment was based on
pep649 had the same problem, where it was accepted, implemented and merged, and then pydantic folks pointed out this will break runtime typing
from the earlier text above
that comment was wrong 🙂
then indeed, I meant 563 😛
pretty sure they meant 563
Yeah, 649 was the one in response right
yes
Yeah. I mean, idk, it was years ago so I can't cogently criticize pydantic at this moment, and yes, I know it's very popular.
But I've talked to quite a few other people, who know python better than me, and they felt similarly. I did a 3 way review between dataclasses, attrs, and pydantic, and I would have been fine with using either of the first two
I think 649 is the right behavior at a technical level. If we have annotations part of the runtime, we should make them actually useful and evaluatable
I don't really use Pydantic either, but apparently a lot of people do and it's useful to them
Yeah, from reviewing it though I didn't really think that it ultimately achieved anything that you couldn't otherwise do
Like, it's a "fuller" stack that attrs in the sense that it provides out of the box json serialization, and it has a close connection to fastapi, iirc
but in principle you could build this stuff on attrs, some features wouldn't work exactly the same way, and so on, but ultimately you'd be able to get exactly the same kind of work done
Yeah, FastAPI is the main reason people care about pydantic afaik.
As to your general statement, it's a fair point I suppose. It comes back to that's how annotations were framed from day 1, that they were "part of the runtime", they could hold constants for the purpose of static analysis but didn't have to
i think setting expectations to "this should only ever hold the name of a type or typevar" from day 1 would have been a good thing. But I guess it's a trickything when probably roughly half of python doesn't think static typing is worth anything, and the other half thinks it's incredibly important and deserves its own language feature rather than sharing it
Even Pydantic-style uses still put types in the annotations, it's just that they want to see those types and work with them at runtime
hm I didn't think that was the issue
i thought that the issue was that those types needed to actually run code
using a type to inform dynamic code is different from dynamic code informing types
no, the main motivations were about cases where Pydantic couldn't evaluate the type annotations, for example for annotations on nested classes
yes, that's what I mean. The issue is when evaluating the type annotation is more involved
they can still be simple types, it's just that the names can't be resolved
hmm then maybe the issue affects a broader range of code than i realized
I just thought ti was specific to pydantic because of the sketchy things they were putting in their annotations
lets say I have code that auto-deserializes a json into a dataclass
So, I iterate over the fields of the dataclass, for each field I examine the type and then that informs how I try to extract data from the json
could such code be affected by these issues too?
I'm only putting very "vanilla" things into the type annotations
possibly, depending on how the type is defined. If the class is defined in a standard way (at the top level, no weird shenanigans with scoping) it should be fine
but if you start defining the class inside a function (common in tests), it may suddenly break
but you'd need to also define the dataclass in that same function?
def foo():
class Bar:
pass
@dataclass
class Blub:
x: Bar
pass
yes, that's an example where the annotations become impossible to resolve
(under PEP 563)
I'm probably okay with that breaking to be honest
but as always I guess that the people who aren't, will be more vocal
defining a type nested inside a function in python always feels amazingly icky to me
nested classes do weird things to scoping rules too
there's at least one bytecode specifically to deal with that corner case
(LOAD_CLASSDEREF, since you asked)
the problem is that python being python, you get a unique Bar class per foo run
in the static typing view of the world that's rather nonsensical
statically typed languages that allow defining nested types in funtions (which is most of them) don't work this way
Afaik, the pep has been around, or at least been in discussion for a year or so?
yes, created in June
it could be considered an anonymous type I suppose, C# has support for this
if (sequence is { Length: > 0 }) {
...
}
above checks if sequence is an instance of the anonymous type (essentially typing.Protocol) with attribute Length and that attribute is above 0
C++ and Rust certainly have anonymous types (not sure about C#), but the anonymous type is the same in every call of the function
actually, forget rust ftm
in C++, if you write
void foo() {
struct Bar { double x; };
}
this is legal code. but there's still just one Bar type
in the python code there isn't just one Bar type
typing.runtime_checkable(type('<anon>', (typing.Protocol,), dict(__len__=...))) is kinda anonymous class that can perform checks
In [1]: def foo():
...: class Bar:
...: pass
...: return Bar()
...:
In [2]: b1 = foo()
In [3]: b2 = foo()
In [4]: type(b1) is type(b2)
Out[4]: False
In [5]: type(b1) == type(b2)
Out[5]: False
you can't compare structs in C++ though
nobody compared structs
I compared their types
In any statically typed language, by construction, the expression foo() must have a type that's statically determined, so that means that the return type is always the same Bar
I think in this case type Bar will be inaccessible from outside of function
not if you return it from the function
at least in C# you can easily make runtime types and return them
static object GetBar()
{
var bar = new { x = 108, y = 200 };
return bar;
}
var bar1 = GetBar();
var bar2 = GetBar();
Console.WriteLine(object.ReferenceEquals(bar1, bar2)); // False
only 4 days for pep 701 
#include <iostream>
auto foo() {
class Foo {
public:
Foo() = default;
};
Foo *a = new Foo;
return a;
}
int main() {
auto a = foo();
auto b = foo();
std::cout << (a == b) << std::endl;
}
``` outputs `0`so I don't think we need an arbitary standard of what is considered "statically typed", just do what is more useful and intuitive
that's C++
k wait i'm comparing instances
this is a totally different operation?
yeah
it's implemented already
it's not an arbitrary standard though, statically typed means something specific and well understood
Python 3.12.0a7+ (heads/main:7d35c3121a, May 4 2023, 15:10:22) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> f"{f"y"}"
'y'
>>>
I'm basically just pointing that because of how python works, defining types nested in functions causes a lot of strain, because it causes the static typing and the dynamic typing side to see the code very differently
the dynamic typing side considers it a new type each time foo is called, the static typing side has to consider it the same type each time
yeah we don't update that very quickly
probably will focus more on that after the feature freeze
For what it's worth, you can compare types instead by doing cpp std::cout << (typeid(a) == typeid(b)) << std::endl; which does print 1
i did c++ std::cout << std::is_same_v<std::remove_pointer_t<decltype(a)>, std::remove_pointer_t<decltype(b)>> << std::endl; which also prints 1
I think you are comparing pointers to instances
what does the AST Node LOADBUILDCLASS do?
AST node?
I would guess it loads __build_class__
as in allocate to the stack or heap?
it's not an AST node
it's more a bytecode instruction than an AST node (in python)
umm...but this confuses me : https://github.com/zrax/pycdc/blob/c8156739f187c7ddbbeb8c52488405e83bea0ddd/ASTNode.h#L18
ASTNode.h line 18
NODE_COMPREHENSION, NODE_LOADBUILDCLASS, NODE_AWAITABLE,```so shouldnt it be in a PycCodeObject class in pyc_code.h than on ASTNode.h?
It is not a python interpreter
ik, but im asking about the structure
the AST and the bytecode are completely separate concepts
no ik that im asking about the code structure in the pycdc
Decompiler probably uses some sort of "ast" which is not equivalent to python ast. It may contain some helper nodes and may lack some nodes of python ast.
If you want to know what these nodes mean, you should read source code of pycdc or ask maintainer of pycdc
@feral island found an issue when experimenting with PEP 688: ```py
class B(bytearray):
slots = ()
def buffer(self, flags):
return memoryview(b'')
backing = B(bytearray.basicsize)
calls B.buffer(backing, <flags>), does not touch backing->ob_exports
mem_backing = memoryview(backing)
calls bytearray.release_buffer(backing, mem_backing), decrements backing->ob_exports to -1
mem_backing.release()
resets B.buffer to bytearray.buffer
del B.buffer
calls bytearray.buffer(backing, <flags>), increments backing->ob_exports to 0
mem_backing = memoryview(backing).cast('P')
since backing->ob_exports is 0, backing can be cleared despite being exported
mem_b = backing.clear() or bytearray()
mem_backing[2] = (2 ** (tuple.itemsize * 8) - 1) // 2
mem = memoryview(mem_b)
print(mem, len(mem)) sh
./cpython_source/python.exe ./python/bytearray__buffer__ob_export_confusion_UseAfterFree.py
<memory at 0x107cbc940> 9223372036854775807
might need to enforce that C superclasses bufferprocs are always called or block setting __buffer__ and __release_buffer__ when already present on C superclass
thanks, will take a look
also noticed that there seems to be some protection the other direction that can be hit with super but it seems to break simple subclasses that try to use super to retain original implementation: ```py
class A(bytearray):
... slots = ()
... def buffer(self, flags):
... return super().buffer(flags)
... def release_buffer(self, view):
... return super().release_buffer(view)a = A()
m = memoryview(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 5, in buffer
File "<string>", line 5, in buffer
File "<string>", line 5, in buffer
[Previous line repeated 396 more times]
RecursionError: maximum recursion depth exceeded
this is because wrap_buffer calls PyMemoryView_FromObjectAndFlags, which in turn calls __buffer__ again. Maybe to fix that I need a variant of PyMemoryView_FromObjectAndFlags that allows me to explicitly pass the getbufferproc to use
i think that if you disallow setting __buffer__ and __release_buffer__ on subclasses with a C superclass that already has them you might be good. ```py
class A:
... def buffer(self, flags):
... print('A', 'buffer')
... return memoryview(b'')
...
class B(A):
... def buffer(self, flags):
... print('B', 'buffer')
... return super().buffer(flags)
...
a = A()
memoryview(a)
A buffer
<memory at 0x104777100>
b = B()
memoryview(b)
B buffer
A buffer
<memory at 0x104777340>
disallowing them seems bad, it's perfectly reasonable to call super()
I think to fix your other issue there needs to be something that enforces that buffer and release_buffer are inherited together, but I need to think more about that
disallowing them when the class has a C superclass that implements the buffer protocol protects against confusion like above
and i think that even if they are inherited together you could still break it (by deleting __buffer__ and __release_buffer__ inside of __buffer__)
if you want to avoid disallowing them then maybe you need to enforce the pair of __buffer__, __release_buffer__ procs that are called on a given view
maybe store the pair on the _buffer_wrapper object
when calling a Python __buffer__ I create this pybufferwrappertype, maybe it can remember the releasebuffer to call
yes
that should fix the confusion concern I think assuming that pairs are enforced
although I think you should also ensure that the C superclass bufferprocs are called because once super is fixed you could have a theoretical buggy impl that calls super in only one buffer proc and not the other
yes, I fixed super() but now I get this ```>>> ^D
Exception ignored in: A(b'')
Traceback (most recent call last):
File "<stdin>", line 9, in release_buffer
ValueError: memoryview's buffer is not this object
SystemError: deallocated bytearray object has exported buffers
like this py class A(bytearray): def __buffer__(self, flags): return memoryview(b'foo') def __release_buffer__(self, view): super().__release_buffer__(view) would need to protect against calling bytearray.__release_buffer__ without calling bytearray.__buffer__, since that would decrement ob_exports without incrementing it
note that bytearray.__release_buffer__ doesn't actually call bf_releasebuffer on the bytearray, it just calls .release() on the memoryview
that looks like the super().__release_buffer__(view) is hitting some check of view.obj == <bytearray obj?> that is failing
yes
then that should be safe? i think
so bytearray.__buffer__ calls bf_getbuffer and returns a memoryview over it and bytearray.__release_buffer__ just calls .release on the passed in memoryview?
yes
tbh it would probably be easier/safer to add an ob_exports member to any object that implements the buffer protocol and promote that into wrap_buffer or somewhere else
so that individual buffer types do not need to handle it themselves and it can be handled in one place which might help to get rid of the confusion issues
because right now it is up to each individual buffer type to handle its ownership vs how stuff like reference counts are handled by the runtime
that would mean it wouldn't matter what bufferproc is called on it, the ob_exports value would still remain correct.
wait, but in the confusion code I posted above, these lines seem to suggest differently: ```py
calls B.buffer(backing, <flags>), does not touch backing->ob_exports
mem_backing = memoryview(backing)
calls bytearray.release_buffer(backing, mem_backing), decrements backing->ob_exports to -1
mem_backing.release()
``` since in theory calling mem_backing.release() should only be calling .release on the memoryview returned by B.__buffer__ (1) but it is clearly calling the releaseproc on backing not on the obj owned by (1), which should be b''
@feral island ^ am i hitting another bug there that I was unaware of?
I think bufferwrapper's bf_releasebuf is wrong, trying to fix that now
using your suggestion of finding the release proc when creating the object
it's calling the objects bf_releasebuf slot directly which I think is wrong
yea because that can change if it's a misbehaving type
although you still would be at risk of a type that only calls super() in one of the __buffer__/__release_buffer__ pair right?
not even that it changes, just a simple subclass that calls super().__buffer__ breaks bytearray
oh yea the recursion error
fixed that part
how did you end up fixing it?
I already fixed the super thing by making it directly call the bf_getbuffer in wrapped, so we don't recursively call the child class's __buffer__
Then I got a crash because we ended up calling bytearray's bf_releasebuffer twice. To fix that, bufferwrapper_releasebuf now only calls bf_releasebuffer if it's a Python function
because if it's the C bf_releasebuffer we need, it will be called when the memoryview is released
your first sample above no longer crashes for me either
thats good
I put an assertion in bytearray's releasebuf that ob_exports >= 0, which made it easier to catch
it throws an error here ```>>> mem_b = backing.clear() or bytearray()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
BufferError: Existing exports of data: object cannot be re-sized
which seems right
ye thats the correct error
what if bf_releasebuffer calls the C bf_releasebuffer via super() inside of bufferwrapper_releasebuf? would you get a double release?
I think it can't, we'll just call memoryview.release() twice. Let me test that though.
memoryview.release() should be safe to call twice byitself
!e py m = memoryview(b'foo') m.release() m.release()
@pliant tusk :warning: Your 3.11 eval job has completed with return code 0.
[No output]
^ making sure it didnt complain about .release being called on a released object
https://github.com/python/cpython/pull/104227 for what I have so far
overriding __release_buffer__ is still problematic though
... def __buffer__(self, flags):
... return super().__buffer__(flags)
... def __release_buffer__(self, view):
... super().__release_buffer__(view)
...
>>> b = B()
>>> mv = memoryview(b)
>>> del mv
Exception ignored in: B(b'')
Traceback (most recent call last):
File "<stdin>", line 5, in __release_buffer__
ValueError: memoryview's buffer is not this object
>>> ^D
SystemError: deallocated bytearray object has exported buffers
even once that ValueError is fixed I don't like the fact that an exception in __release_buffer__ would seemingly allow a UAF
SystemError: deallocated bytearray object has exported buffers means that mv was not released at the time that b was freed so mv pointed to freed memory (until it was freed, assuming that is was)
!e Shouldn't we only get one "hi" here?
import sys
def g(*a):return l
def l(*a):
print("hi", a)
def foo():
1
2
sys.settrace(g)
foo()
@quick snow :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | hi (<frame at 0x7f557fd884c0, file '/home/main.py', line 6, code foo>, 'line', None)
002 | hi (<frame at 0x7f557fd884c0, file '/home/main.py', line 7, code foo>, 'line', None)
003 | hi (<frame at 0x7f557fd884c0, file '/home/main.py', line 7, code foo>, 'return', None)
The local trace function should return a reference to itself (or to another function for further tracing in that scope), or None to turn off tracing in that scope.
No the 3 calls of l make sense. g is called in the global scope when transitioning to foo's scope. Then l is called for every trace event in that scope
(2 line events and a return event)
I think the question is why l is called a second time, after the first call doesn't return l
i always interpreted that line in the documentation to mean that returning the function was to enable further tracing of child scopes from that event
'line'
The interpreter is about to execute a new line of code or re-execute the condition of a loop. The local trace function is called; arg is None; the return value specifies the new local trace function.
that does seem to say that the return from the first call to the trace function l with event 'line' ought to be used as the trace function for that scope - it doesn't explicitly say that None disables tracing, though
Python/sysmodule.c lines 997 to 1002
if (result != Py_None) {
Py_XSETREF(frame->f_trace, result);
}
else {
Py_DECREF(result);
}```the return is only used as the new trace function if it's not None. If it is None, it's just ignored.
that DECREF could be removed now, None is immortal
Okay, what is that line in the docs supposed to mean then? How do I disable the local trace function on that scope?
it says you can set f_trace_lines to False to stop getting 'line' events, at least
I think you can set f_trace = None to stop tracing in that scope entirely, but I'm not 100% sure on that
True, I can do that. But is this #internals-and-peps message just wrong then? When does returning None from the local trace function change anything?
for 'call' events only, it seems
Local trace functions don't get call, do they?
That's only triggering the global trace function
hm - if that's the case, then I'm not sure what that line in the docs is saying
pr time?
Yeah, I'll make a bug report later. Either it gets fixed, or someone explains me why I'm wrong.
It's worth an issue, at least. At the very least the wording is unclear. Possibly returning None ought to disable tracing but doesn't. If the behavior doesn't match the docs, there's always a question of which one should be changed
That's when you scan through GitHub repos and look if the current behavior is depended upon
!e
I wonder if this changed in 3.11
import sys
def g(*a):return l
def l(*a):
print("hi", a)
def foo():
1
2
3
sys.settrace(g)
foo()
@flat gazelle :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | hi (<frame at 0x7f676bc244c0, file '/home/main.py', line 6, code foo>, 'line', None)
002 | hi (<frame at 0x7f676bc244c0, file '/home/main.py', line 7, code foo>, 'line', None)
003 | hi (<frame at 0x7f676bc244c0, file '/home/main.py', line 8, code foo>, 'line', None)
004 | hi (<frame at 0x7f676bc244c0, file '/home/main.py', line 8, code foo>, 'return', None)
Made a bug report about this: https://github.com/python/cpython/issues/104232
GitHub
Bug report The documentation of sys.settrace claims: The local trace function should return a reference to itself (or to another function for further tracing in that scope), or None to turn off tra...
either documentation or behavior should be changed
i feel like a documentation change is better
I agree. It's a niche thing anyways, and it's not hard to do, and existing debuggers seem to not have noticed.
Would you test in 3.8, I am like 75% sure this worked as expected in 3.8
Looking further back in history, it has worked this way since at least Python 2.2. Assuming there is in fact a discrepancy between docs and code, it seems clear that we should only change documentation of the longstanding (>20 years) behaviour.
https://github.com/python/cpython/issues/104232#issuecomment-1537132635
from lev
although it does work in 3.9
3.8
yeah it only changed in 3.10
what happened in 3.10
I think this is just related to the specific code, maybe it's the compiler doing something smart because the code doesn't do anything.
If you replace the lines with print(1) and print(2), then it's the same in 3.9 and 3.10.
Okay, not the compiler (the bytecode is not identical, but similar enough), but.. yeah. Maybe in 3.10+ lines are skipped in tracing if there's no bytecode for them
!e ```py
from dis import dis
def foo():
1
2
3
dis(foo)
@rose schooner :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 2 0 RESUME 0
002 |
003 | 3 2 NOP
004 |
005 | 4 4 NOP
006 |
007 | 5 6 LOAD_CONST 0 (None)
008 | 8 RETURN_VALUE
there are suprisingly NOPs
Not in 3.9
3.9 or below
The NOPs are missing in 3.9 and below, there it's just LOAD_CONST, RETURN_VALUE.
so it should just be a documentation change?
There are two different "issues", although I'm not sure the second one is something that needs changing:
- docs don't match behaviour wrt. return value of local trace functions
- from 3.10 on, there's one less
lineevent in code that does nothing
For the first issue (the one I care about) I now think only the documentation needs to be changed.