#internals-and-peps
1 messages · Page 2 of 1
speaking of, is logging.config.DictConfigurator meant to be a public element of the logging interface? the docs mention it and hint that it might be acceptable to set your own logging.config.dictConfigClass, but the DictConfigurator class itself is never described
unfortunately dictConfig isn't very thoroughly type-hinted, lots of dict[str, Any]. should be a relatively easy PR if the typeshed maintainers are interested in making those more precise
maybe it's hard to annotate a dict where () is a valid key
i also wish that you could just refer to objects like 'stream': sys.stdout instead of 'stream': 'ext://sys.stdout' 😐
feels like a relic from the bad old days of xml configuration files
always interested, but not sure how easy it would be here
ah, i see the problem. typeddict forbids extra keys
i was going to say you could pretty easily define a TypedDict for the various handler, formatter, etc. fields
or wait... they don't, if you use total=False. i wonder if that wasn't implemented when this type stub file was written
https://github.com/python/typeshed/blob/master/stdlib/logging/config.pyi#L32
# these two can have custom factories (key: `()`) which can have extra keys
formatters: dict[str, dict[str, Any]]
filters: dict[str, dict[str, Any]]
# type checkers would warn about extra keys if this was a TypedDict
handlers: dict[str, dict[str, Any]]
stdlib/logging/config.pyi line 32
# type checkers would warn about extra keys if this was a TypedDict```ah no, it still complains if you assign keys that aren't in the "declaration"
i guess we're stuck with what we have until then

because sets are unordered
Is there any good reason that reversed must return an iterator rather than an iterable? As an example reversed on a range could return a range much like slicing with [::-1]does
I can't really think of anything
What would be the benefit though?
all you can do with an iterable is turn it into an iterator
not necessarily. You could e.g. index some reversed iterables.
Well, if you know what object you're working with (like range or a list), you can already do that
but if you don't (that's what protocols are for - working with many different object types) then you can't do that
okay. You can iterate over it twice without having to store the retrieved elements somewhere.
Not necessarily
because an iterator would be valid too
well, we know it's a sequence (or a type that explicitly implements __reversed__)
at least for sequence types returning something like a view of the reversed sequence would work
and for range you can optimize that to returning just a modified range
granted stuff that implement __reversed__ is a weirder (but hopefully rarer) situation
I guess what I would want are lazy range-like operations on sequences that aren't range, huh?
lazy slicing
and you could totally do that with just a wrapper
Well, sometimes a sequence might be efficiently iterable in reverse, but only with an iterator 🤔
like a collections.deque
it may be a bit cursed that collections.deque is a sequence though innit
I'm guessing deque implements a custom __reversed__?
I hope
!e
from collections import deque
q = deque([1, 2, 3])
print(reversed(q))
@grave jolt :white_check_mark: Your 3.11 eval job has completed with return code 0.
<_collections._deque_reverse_iterator object at 0x7f9211d107c0>
yep
!e
from collections import deque
print(deque.__reversed__)
@fossil fern :white_check_mark: Your 3.11 eval job has completed with return code 0.
<method '__reversed__' of 'collections.deque' objects>
it's a similar gripe I have with decreasing range being terrible to write
reversed(seq)[1::100] # invalid
seq[::-1][1::100] # inefficient
seq[-2::-100] # awkward indexing
contrived example, but yeah
You could make a function that applies a range to a list
like chop(seq, range(1, 100)[::-1])
or a wrapper around sequence types, yeah
that does slicing lazily on the range
but indexing/iteration on values
It sometimes helps to use ~, one of my favorite hacks for indexing
Flipping all the bits is equivalent to negating an integer and subtracting 1, so ~i == -i-1, which allows you to concisely write "Give me the ith item from the end of the sequence"
Although you still do have to negate the step
cursed
@spice pecan this might become a tweet....
seq[~1::~99]
using the statement above
what is seq[~1::~99] meant to do?
seq[-2::-100]?
ok, but why would you want a step of -100?
i have no idea, ask algmyr
Assuming they mean [*reversed(seq)][1:100], that would be seq[~1:~100:-1]
it was an example of an operation that is awkward to do in an efficient way with slicing and similar operations

though we realized you could make these kinds of lazy list views work in other ways
a guess your seq is much larger than 100
pick every 100th element from the element, with an offset
(not sure why I assumed it wasn't 🙂 )
right, imagine it's quite large
you could spell the thing
[seq[i] for i in range(len(seq))[::-1][1::100]]
which would actually be efficient, though a tad weird looking
list(map(seq.__getitem__, range(len(seq))[::-1][1::100]))
``` how can i claim channel?
am i the only one who feels like there are a lot of questionable design decisions in logging?
forget the camel case names... why does the default LoggerAdapter replace the extra field rather than merging with it? https://github.com/python/cpython/blob/v3.10.7/Lib/logging/__init__.py#L1815-L1826
Lib/logging/__init__.py lines 1815 to 1826
def process(self, msg, kwargs):
"""
Process the logging message and keyword arguments passed in to
a logging call to insert contextual information. You can either
manipulate the message itself, the keyword args or both. Return
the message and kwargs modified (or not) to suit your needs.
Normally, you'll only need to override this one method in a
LoggerAdapter subclass for your specific needs.
"""
kwargs["extra"] = self.extra
return msg, kwargs```that really limits its usefulness as a default and totally prevents multiple adapters from being composable
!e ```python
import logging
logging.basicConfig(
format='%(levelname)s %(a)s %(b)s %(c)s %(message)s',
level=logging.INFO,
)
logger = logging.getLogger()
logger = logging.LoggerAdapter(logger, {'a': 1})
logger = logging.LoggerAdapter(logger, {'b': 2})
logger.info('test', extra={'c': 3})
@paper echo :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | --- Logging error ---
002 | Traceback (most recent call last):
003 | File "/usr/local/lib/python3.11/logging/__init__.py", line 449, in format
004 | return self._format(record)
005 | ^^^^^^^^^^^^^^^^^^^^
006 | File "/usr/local/lib/python3.11/logging/__init__.py", line 445, in _format
007 | return self._fmt % values
008 | ~~~~~~~~~~^~~~~~~~
009 | KeyError: 'b'
010 |
011 | During handling of the above exception, another exception occurred:
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/laqihokiji.txt?noredirect
and that too, raising KeyError when a field is missing instead of treating it as some configurable default null value
and of course the old-school python thing of dumping "extra" stuff into the LogRecord object's namespace
TIL %(name)s can be used to format {'name': ...}
yup, those format patterns are literally just elements in the log record's __dict__
seems like it doesn't work with -c
#bot-commands message
~ via 🐍 v3.10.6
❯ cat -A t.py
␀'''␀How·do·i·print·'Hello·World'·in·Python?␊
␀Here·is·how:␊
print('Hello·World')␀'''%
~ via 🐍 v3.10.6
❯ python t.py
Hello World
~ via 🐍 v3.10.6
❯ python -c "$(<t.py)"
~ via 🐍 v3.10.6
❯
weirdly it doesn't raise a ValueError this way 
most likely I'm doing something wrong
do"$(cat t.py)", <t.py is just a noop
oh neat, it's special cased in the interpolation
I am fairly sure the shell can't work with null bytes
hmm. yea, that could be it.
Considering that Python makes it uniquely easy to create more than one name for something, is there any reason that stdlib content that doesn't follow pep8 (such as logging) shouldn't have pep8-ified aliases?
subclassing would be an issue with simple aliases
alongside patching methods only setting one of them
PySide6 has an experimental feature that tries to handle all of that to convert Qt's camel case to snake case, but I ran into a couple of issues there that could be avoided by just not doing that
how would it be easy
class defaultdict(dict): ...
DefaultDict = defaultdict
One could argue that subclasses of builtins should also be lowercase. but then collections.Counter should also be lowercase.
that'd require multiple changes to multiple files (including changes to __all__)
is that really that hard?
hmm i don't think it is but that's a waste of time and not many people would care
wasn't something like this proposed in python-ideas before?
probably. but I haven't read that in a few years.
This has been done for at least the threading module. I'm guessing it's just about someone doing it.
it would be nice even if only the mainly used stdlibs were changed to follow the naming style bc things rlly look off (eg datetime.datetime) and it's easier for people to decipher classes vs functions via the naming style
ah yes datetime.datetime.time
Is the best way to become PEP-fluent just to read through them? Or is there some curated way to approach it? The context is I’m building a package manager for Python.
I’m thinking about just reading through it all from https://peps.python.org
Python Enhancement Proposals (PEPs)
if you want to write a compliant package manager, you should definitely read the packaging PEPs. But: why write another package manager?
you definitely don't have to read all the PEPs.
Yea not all. But enough for the scope.
why
Mostly to learn and I’m curious. Partially because I want to dogfood it. Partially because I like to torture myself.
it's good to learn, and build what interests you
Hi guys, I'm looking for a job and has been difficult to get one. I was wondering ... Since blockchaing it's a emergency tech, it's Python a good language to work as a blockchain dev? Or should I use another like C++ or Solidity?
you might want to look into pdm if you at least want to see something that "isn't pip"
Hey guys I am now learning django but having a hard time in it and most of the tutorials not making any sense... Can anyone help me how to learn in a way that i am enough ready to get a internship out of it..
More so trying to build it myself but thanks!
Completely from scratch?
in pieces
Anyone know if there's ever been discussion about going into a bunch of the old builtins and making them support keyword arguments? stuff like exec and eval
you mean instead of only positional arguments? I expect there would be a fair amount of pushback against that, for many of the same reasons as listed in the rationale for https://peps.python.org/pep-0570/#problems-without-positional-only-parameters
https://mail.python.org/archives/list/python-ideas@python.org/thread/ZIABB5NYP656IDE2DCIWYMA5AZSYYM4D/#WGR3OV2VURFME2NHUU7MZAFFKG4IE4K4 found a thread from 10 years ago, including (surprised to see Raymond say that kwargs never come up on defaults. I can never remember the ordering on stuff like filter and would rather just write things out with kwargs)
that thread is suggesting "keywords all over", and people are pointing out issues similar to what is mentioned in that PEP. But 10+ years of Python and I have to look up the order of filter all the time, and do not know whether globals or locals comes first in exec and eval
but thatnks for that link! there's a lot of stuff to chew over there
in R, all parameters are both positional and named. omitting a positional parameter results in a special "missing" situation that can be detected
I have to look up the order of generic params to Generator every time
So I heard there was a controversial change in the latest patch version
What happened?
controversial?
there was a security fix for disallowing parsing of ints above a certain length with non-power of 2 bases
the length being like 4300
wouldn't call that controversial
It's also controllable with a sys flag
I'd say the controversy is in the fact that the security fix is relevant to poor algorithmic performance that's existed for a long time
and formatting them via str or whatever
haven't seen that detail. what's that?
it's controversial because it breaks things
Right
it's backwards incompatible, but not likely to break many real-world applications.
It breaks my serialization scheme which converts objects to and from a ternary integer string 😢
I think they should have just added a maximum length to json.load[s], because this is 99% of where the problems are, and wouldn't affect sympy etc.
The change in itsef is not the really that bad (for most things), how they changed it is only what I would call somewhat problematic (for different reasons, one is the global state)
That this was known 2 years and they could not wait for a month to add it to the new non-patch release seems bad.
What made me audible gasp and really seems really bad from a systematic stand point is the reason they choose the limit:
It is the lowest one that would not break numpys tests…
This gives a 3rd party library a special position over all other 3rd party libraries and feel really really arbitrary, especially for a change that was not openly discussed.
Forcing a behavioural change to two builtins that are some of the oldest ones and most basic ones, just like that is also problematic, but I dont know enough to say if there could have been a better way
This thing fixes a security problem and exposes a systematic problem within python in my opinion.
I have to add to that sentence though, it is not as much doom as the sentence may make it sound, but it should tell the organisation, that this is something that needs some heavy discussion.
It is the lowest one that would not break numpys tests…
LMAO, that's hilarious - here I thought it was cleverly related to some binary representation somewhere
lmao
Source for that btw is the python discourse https://discuss.python.org/t/int-str-conversions-broken-in-latest-python-bugfix-releases/18889/48

Discussions on Python.org
The 4300 was chosen to not break a numpy unit test.
why could this have not waited till 3.11.0? genuine question
it was considered a security issue
It is the lowest one that would not break numpys tests…
It's a bit more subtle than that. My understanding is that the change was tested on a reasonably large swathe of the Python ecosystem; the vast majority of packages tested didn't notice any change. Unsurprisingly, NumPy was one of the few packages that did care, and (speculating a little bit) amongst all the packages tested NumPy was the one that required boosting the limit highest. I don't think there was an up-front decision to base the limit on NumPy's tests.
exception RuntimeError```
Raised when an error is detected that doesn’t fall in any of the other categories. The associated value is a string indicating what precisely went wrong....but can't you just use Exception in this case?
Exception is annoying to handle
wdym?
Well it'll catch everything (-BaseException)
well, yes
but catching RuntimeError doesn't ensure you'll catch all library-specific exceptions, does it?
like, in what case do you catch it?
I suppose it's possible with a generator in some cases, but tbh that warrants a separate exception
or maybe it doesn't since it's a... programming error?
what is the polite way of saying Skill Issue again
I use RuntimeError when I'm too lazy to define my own exception, but other errors (e.g. KeyError) can't be excluded at the point of use.
I hope the Python team looks at PEP 505 again. I don't know why it's been deferred for such a long time
Discussions on Python.org
As others noted, the main semantic sticking point was that the specific is None check was seen as too limiting, but the proposals to offer a more flexible underlying protocol based approach (e.g. https://www.python.org/dev/peps/pep-0532 ) were seen as too complicated. (There was also a syntactic sticking point, which is that ??, ?., and ?[] don’...
here's a relatively recent thread about it on the Discourse
In the end, most things in python that return None have an alternative that will just raise an exception, which is the more "pythonic" way.
So, if I don't want to use a lot of if statements or ternary if...else expressions, I just have to do this? (I really feared using try/except because catching exceptions is expensive)
person = {
'name': 'Kira',
'mother': {
'name': 'Irina'
}
}
kiras_dads_name = None
try:
kiras_dads_name = person['father']['name']
except (AttributeError, KeyError, IndexError):
pass
print(kiras_dads_name) # None
I feel like the proper solution here would be having better support for exceptions
With library functions you usually have no idea what can be raised even if it's documented, because there may be calls to other libs that are directly affected by your input and you may want to handle
them being considerably more expensive when handled the last time I checked is also not a great thing, not sure how that changed in 3.11
I think they're very low cost when something isn't thrown in 3.11. source: idk I heard it somewhere
that's what the What's New page says
but... the current stable version is 3.10.7
iirc
3.11 will be released in a month
ah maybe that's the wrong page, i know it's somewhere
python/cpython#84403

Yes, but the cost when they're handled also matters if a regular path of the code goes through that
It wasn't something horribly expensive iirc, but I also wouldn't want it in a tight loop with a high chance of hitting it
yeah, for how exceptions are meant to be the end-all and be-all of missing value handling, they do kind of suck to work with in many ways.
Branching by exception handling always looks horrible, feels horrible and can lead to Carpal-tunnel-syndrom!
Oh god, oh jesus...

@raven ridge LSP moment^
this is so cursed!
I was just trying to move a SpooledTemporaryFile...
I've had to get a function that wraps the OS api to do that properly when I found out that name is basically useless on files
I ended up just copying it chunk by chunk
good enough for my case
basically shutil.copyfileobj
try-except is very fast when no exception is thrown and it is very slow if there is an raised exception
if your code raises exceptions in most cases, use if-guards
if you expect to succeed in most cases, use try-except
well, sometimes you can't really avoid exceptions
like, hasattr just catches AttributeError
python likely and unlikely 🤔
hello sirs
i'd like to understand how cpython registers its encodings on the interpreter's startup, looking for any text info or any sort of direction
because i see at the startup not all encodings from /lib/python3.10/encodings are loaded (as far as i can see only ascii, utf-8 and maybe some selected others)
[i've tested this by running stuff like PYTHONIOENCODING=rot13 python and seeing if i get a lookup error]
thanks ahead
Hi guys, with respect to https://peps.python.org/pep-0621/ exists some information about how migrate requeriments.txt to pyproject.toml?
Python Enhancement Proposals (PEPs)
I don't think so, but it's pretty straight forward. In pyproject.toml, the dependencies are specified as an array of requirement specifiers (which is what requirements.txt uses too).
Though to be fair, there are some other things requirements.txt supports that wouldn't be as straight forward to map to requirements.txt
You're most likely only relying on the requirements specifiers as defined in PEP 508, which is a format used both by requirements.txt and pyproject.toml as I mentioned.
Good, thanks, so actually is good idea move the projects to pyproject.toml? And maybe use tools like poetry o something like this?
That is perhaps a more loaded question that you realise. I think pyproject.toml is certainly the way of the future, and adoption from tooling is improving. If you have a simple package, and you're not targeting environments that do not support the tooling needed to use pyproject.toml (e.g. you need to support a system that has a really old version of pip or something), then it's probably good enough to switch to it now.
Adoption for PEP 621 is relatively less mature than pyproject.toml as a whole. For example, setuptools added support for it fairly recently, and it was provisional. Looks like it's moved into a more stable state but some things are still in beta. Granted, not everyone uses setuptools but it's just an example of adoption.
I believe it lazily loads encodings as they get used. Too late for me to look up the code, but maybe there's also something in site.py or the importlib bootstrap code to make it work
ok thanks. so i've read a bit (of codecs.c too) and think i understand the mechanism better. but question now is, how would it be possible to not lazy load a selected encoding such that i could do PYTHONIOENCODING=rot13 python (maybe not rot13 but generally) and it wouldn't fail with a LookupError?
didn't see a relevant api for doing this in the files you mentioned but i might be missing something so sry if i do
You can use a .pth file in your site packages to load it
already have it. but i think PYTHONIOENCODING is processed before it gets loaded
oh wait a minute
well no still doesn't work, i thought it was about streamwriter&reader but i implemented both, had still pth in site_packages but on startup the interpreter still cant lookup my encoding
yeah not sure it's possible, maybe encoding lookup happens before the interpreter gains the capability to read .pth files
after all, it needs to decode the .pth file
You can definitely use .pth files to add new encodings, that's how brm works
!pypi brm

Bicycle Repair Man - Rewrite Python Sources
right, but to find those encodings python presumably first needs to decode the .pth file that it uses to find it using one of the built-in encodings
big oof : \
So here's a good question I think.
Say I had a package foo that contained a submodule bar. I want to remove bar and make it it's own package.
I removed bar and make it it's own package but to help with the deprecation cycle, I override the __init__.py for foo with a custom ModuleType subclass that overrides __getattr__. The goal of overriding __getattr__ is to warm the user of foo, who is trying to access bar that bar is now it's own package and have __getattr__ return the new standalone bar package.
Is that possible? I'm not sure if submodules are attributes of a module.
So essentially the before
foo package with bar as submodule.
bar is now own package and removed.
In __init__.py of foo.
import sys
import warning
from types import ModuleType
class FooModule(ModuleType):
def __getattr__(self, attr):
if attr == "bar":
warnings.warn("bar is now own package. Import directly. This will raise attribute error in future.", DeprecationWarning)
import bar
return bar
else:
raise AttributeError()
sys.modules[__name__].__class__ = FooModule
Im on mobile so I cannot check
you don't need a custom subclass, you can just add a __getattr__ to your module
!pep 562
**PEP 562 - Module __getattr__ and __dir__**
Status
Final
Python-Version
3.7
Created
09-Sep-2017
Type
Standards Track
Ok. So submodules are attrs of the parent module then?
That's what I was really unsure of but never explicitly asked it
if you do x.y it's an attribute lookup, regardless of whether x is a module or something else
What about if you do from foo import bar
<@&831776746206265384>
@hollow swallow This isn't the place.
@hollow swallow What did I just say. Please remove your messages. Self promotion is not permitted.
That will look up foo.bar in sys.modules, and if it's not there it will try to find and import the module. The best way to do what you're trying to do is to create a foo/bar.py that does an import new_foo and that provides a module __getattr__ that delegates all attribute lookups to the new module
Or possibly just replaces the module in sys.modules entirely. I think you could make a foo/bar.py that just does: ```py
import new_bar
import sys
sys.modules["foo.bar"] = new_bar
Well I'd like to raise a deprecation warning too
So I think __getattr__ is the move
I was worried I'd have to keep dummy files around in foo
But I guess there's no way around it
Thank you
Well, you could do that when the module is imported
import new_bar
import sys
import warnings
warnings.warn(...)
sys.modules["foo.bar"] = new_bar
Right ok
Sucks I can't do it in the __init__.py of foo
It's like 10 submodules being pulled out and put into a single new package
Work don't like the monorepo style
I can relate
But a change to module structure is going to be breaking regardless of how you prepare for it with deprecations etc
Note that if your __init__.py was importing the bar.py submodule, you'll want to keep doing that for backwards compatibility - and in that case, warning at import time won't make any sense
It didn't
You would have had to access down to the submodule to import from that
import dis
def f():
for x in [1,2,3,4,5]:
pass
return [6,7,8,9,0][0]
dis.dis(f)
output:
5 0 LOAD_CONST 1 ((1, 2, 3, 4, 5))
2 GET_ITER
>> 4 FOR_ITER 2 (to 10)
6 STORE_FAST 0 (x)
6 8 JUMP_ABSOLUTE 2 (to 4)
7 >> 10 BUILD_LIST 0
12 LOAD_CONST 2 ((6, 7, 8, 9, 0))
14 LIST_EXTEND 1
16 LOAD_CONST 3 (0)
18 BINARY_SUBSCR
20 RETURN_VALUE
Why does it need to make a list from [6,7,8,9,0]? Why can't it just compile it as a tuple like it does with [1,2,3,4,5]? is there some way to access list literals which aren't ever assigned to anything, but only if they aren't used for a for loop?
it probably could but we haven't bothered to make that optimization
indexing a literal list is likely rarer than iterating over one
ok, thank you
I'd say still open an issue, the implementation will likely not be very complicated so it will probably be picked up and implemented
https://github.com/python/cpython/compare/main...thatbirdguythatuknownot:cpython:patch-26
i'd say it's really simple

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
i might open an issue but i won't have time to discuss since school is starting in less than 2 hours
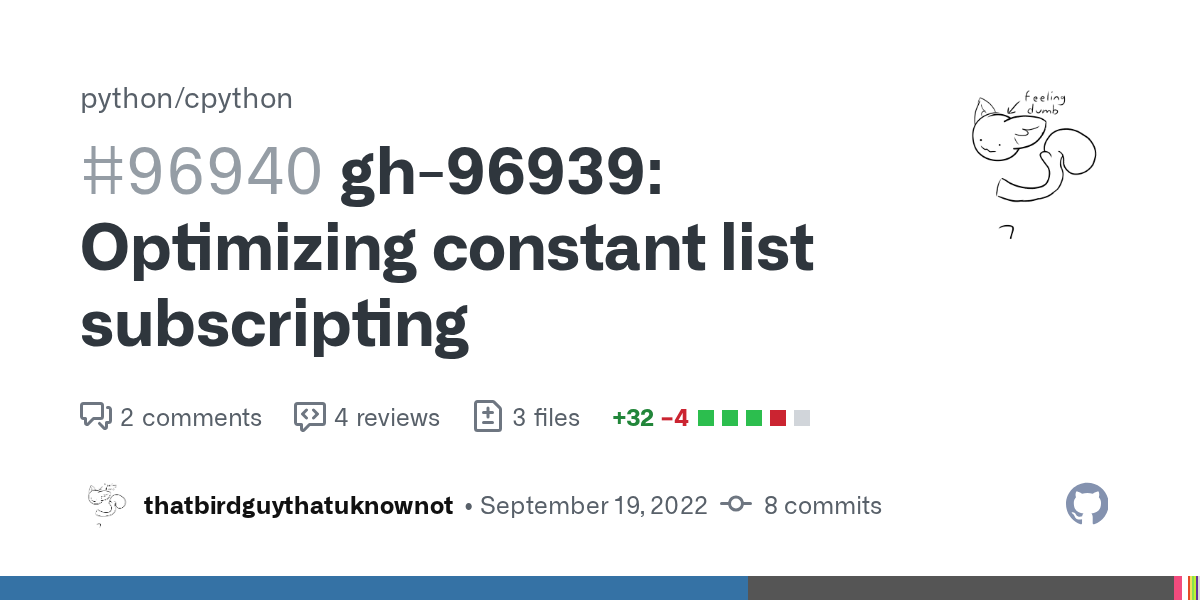
GitHub
New branch added to fold_subscr in Python/ast_opt.c to optimize for constant list subscriptions.
Issue: gh-96939
guys who was testing a project using random yes no choice
is it not possible to mutate a nonlocal variable (say a) through a function * made by types.FunctionType & co_freevars(a) *?
i hope this'll help- here is a snippet of a non working code- https://bpa.st/2OVA
what am i missing?
The __repr__s differ suspiciously. I'd find the __repr__ implementation for functions, and see why one of them contains .locals() and the other doesn't
ahhh nice catch
ig bc it's really not created inside up
hmm
seems that even if i pass only the parameters from mkfn and actually create the function inside up (which i kinda don't want to do but just for the sake of it) it still doesn't really capture the locals into the function (which i only suppose that's the problem)
@quick snow got any clever idea?
Beluga
hush now introvert
this is the updated paste. still no progress but more info: https://bpa.st/RXHQ
https://bpa.st/RXHQ#1L27 doesnt point at nonlocal a because you are making a new cell
i see
i was about to point that out but i wanted to test if the new cell updated first
i have no idea though because it's not 3.11 bytecode
the moment that a local variable is referred to from a nonlocal scope, all scopes its referred to by switch to use LOAD/STORE_DEREF and the closure is passed around so that all scopes can modify the value properly
ok so i tested it using 3.8
it does update the cell
ya makes sense
how would you approach it tho?
is there a way to wrap the deref correctly?
you can take the closure from k and pass it into the FunctionType() constructor
it just needs to be the same cell
you can't wrap an arbitrary upper value into a closure without modifying the bytecode of the upper function to be handling a closure
you could however grab the upper frame and modify its locals directly using the c api.
ye that's fair thanks.
any specific thing/subsection/ function even i should be on the lookout for in the c api?
(i see mostly locals as functionParam)
!e ```py
from ctypes import pythonapi, py_object, c_int
import sys
PyFrame_LocalsToFast = pythonapi.PyFrame_LocalsToFast
PyFrame_LocalsToFast.argtypes = [py_object, c_int]
def set_local(name, val, level=0):
frame = sys._getframe(level + 1)
frame.f_locals[name] = val
PyFrame_LocalsToFast(frame, 0)
def test():
a = 1
set_local('a', a + 1)
print(a)
test()
@pliant tusk :white_check_mark: Your 3.11 eval job has completed with return code 0.
2
great thanks for all the help
PyFrame_LocalsToFast reads the values from frame->f_locals and writes them into the fastlocals array
i think it also handles closures
yes i understand. thanks again, appreciate it
Is there a reason that a, b = b, a compiles to
LOAD_NAME b
LOAD_NAME a
SWAP
STORE_NAME a
STORE_NAME b
instead of
LOAD_NAME b
LOAD_NAME a
STORE_NAME b
STORE_NAME a
? I was thinking it could be that the order of the store matters, although I can't see why that would be the case for this example.
I'd assumed the latter would be an optimisation but idk too much about bytecode
it's not safe if your class namespace is not a dict but something else that has side effects on write
this is possible in class namespaces
the optimization is safe in function namespaces I believe, though only if a and b are simple names
if it was instead a.a, b.b = b, a the attribute assignment could have side effects and I believe the language guarantees the assignment order
In class namespaces you can also have side effects on name lookup making the flipped optimization unsafe as well
(That is, load a b store a b)
that's also true in function namespaces though (unless you can prove that both a and b are currently bound)
and for ```py
LOAD_NAME a
LOAD_NAME b
STORE_NAME a
STORE_NAME b
oh ok nvm i just read this
hello 👋 do i have this understood? https://github.com/cnpryer/huak/issues/187#issuecomment-1255712570
i feel like im missing something obvious

not a toml expert but I think both forms in your comment are equivalent
Those are equivalent, yes
whats the code so no one can DM my discord bot? and where do i put it.
#discord-bots would be the right place to ask
The other day, somebody in a help channel was asking a seemingly simple question: why did two pieces of code, which looked like they should behave the same, actually behave differently?
I've modified it a little to be two separate functions, but they behave the same: ```py
def code1():
i = 3
a = [0, 1, 2, 3, 4, 5, 6]
def f():
nonlocal i
i = i + 1
return i
a[i] += f()
print(i, a)
output: 4 [0, 1, 2, 7, 4, 5, 6]
def code2():
i = 3
a = [0, 1, 2, 3, 4, 5, 6]
def f():
nonlocal i
i = i + 1
return i
a[i] = a[i] + f()
print(i, a)
output: 4 [0, 1, 2, 3, 7, 5, 6]
``` As you can see the only difference is that one uses +=, whereas the other just uses = and +, however, this leads to them behaving differently. Digging into the language reference i found out that this is because x += y only evaluates x once, and at the start, whereas x = x + y evaluates x twice, once before, and once after y. All I wanna know is, why?
more specifically, why does python evaluate the part on the left-hand side of the = sign after the part on the right-hand sign?
That's what you'd expect in general, no? The rhs gets evaluated, and then it gets assigned, and for the index access it'll have to evaluate that
it'd also be weird if the expression on the left had some side effects but didn't get assigned after the rhs raised an error
expected behaviour
i'm aware its expected behaviour yeah, i was just wondering why this was the expected behaviour
in a[i] += f(), it loads the left-hand side's operands first, duplicates them, then subscripts, then the right-hand side, then calls <duplicate left-hand side>.__iadd__(<right-hand side>), and finally stores in a[i] using the original operands
in the first one, its assigning to f[3], implying its gotten before f() is called, whereas the second one is assigning into f[4], implying that f() is called beforehand
ok so the key difference here is probably that
i had a look at the bytecode via dis when i first came across it, and it seems that it's indeed evaluating once and duplicating the value in +=, yeah
in a[i] = a[i] + f(), it loads a[i], then the right-hand side, then calls a[i].__add__(<right-hand side>), and finally loads a and stores in a[i]
what could be causing the difference in output
yeah, it's storing in a[i], but i is being affected by the right-hand side before it gets loaded
oh i get it
so a[i] += f() is the same thing as a[i] = a[i] + f() (disregarding f() behaviour), just that the former has duplications
that results in a[i] += f() having a different result compared to a[i] = a[i] + f() because it already has the index loaded in
does any other language do something else?
it wouldn't make sense to do this would it ```
LOAD_FAST a
LOAD_FAST a
LOAD_DEREF i
BINARY_SUBSCR
LOAD_FAST f
CALL
BINARY_OP +
LOAD_DEREF i
STORE_SUBSCR
it's easier to just evaluate them in separate parts
my initial assumption was just that, since expressions usually evaluate left-to-right, the same thing would apply across =
well no it evaluates the rightmost part then evaluates the assignments left-to-right
the rightmost part and the tailing left parts are separated in the AST node
the only way that would happen is if x = y + z had the node Add { lhs: Assign { lhs: x, rhs: y}, rhs: z } (some pseudo-ast)
= has a very very low precedence
it does have that currently?
...i flipped it, one sec
!e ```py
class A:
def setattr(_, x, __):
print(f"A.{x} assigned")
foo = A()
foo.a = foo.b = foo.c = 3
ugh = isn't in the operator precedence table in the reference, is it
@rose schooner :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | A.a assigned
002 | A.b assigned
003 | A.c assigned
no
because it isn't an expression
it has a "precedence" one lower than a parentheses-less comma
i think since python doesn't allow = to be nested within expressions, its just sorta taken to have the lowest precedence possible, but behaves outside of the regular scope of operators
yeah, i just thought it might perhaps be in there, or somewhere
unlike, say, C, where it can in fact be used in the same way python's walrus operator works
an assignment expression has a precedence one higher than a parentheses-less comma
well that isn't as simple as that though
even if the implementation is simple, they're still considering the usefulness of the optimization
!e ```py
def foo(x):
print(x)
return x
x = [0,1,2,3,4,5,6,7]
x[foo(3)] = x[foo(4)] = x[foo(5)]
@umbral plume :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 5
002 | 3
003 | 4
now i'm just further confused, the rightmost is evaluated, then the leftmost, and finally the middle
the expression at the right is evaluated for the value that is used for the assignment, then all the assignment targets are evaluated from the left
I can fully understand this being defined behaviour and whatnot, I guess i'm simply a little stumped as to why they decided to do it like this
how else would you do it?
the expression has to be evaluated or the assignments wouldn't really work with how python does things for targets that aren't plain names
and then for the actual targets left to right makes the most sense
well yes that's what i said
it's because the AST node is probably structured like this ```
Assign {lhs: [x[foo(3)], x[foo(4)]], rhs: x[foo(5)]}
wrapped in backquotes so i don't have to expand it
but what exactly is the limitation stopping it from being possible to evaluate the left-hand side, followed by the right?
because that's harder to implement
it's not gonna be consistent with the behaviour of name assignments
if you did that with a = b = c = x the bytecode would be ```py
STORE_NAME a # crash the interpreter
STORE_NAME b # failsafe crashing for the bytecode above
STORE_NAME c # third time's the charm
LOAD_NAME x
the value for the assignment already has to exist for it do do its thing, e.g. setitem
ahhhh right, i see
augmented assignments (<op>=) don't have this restriction because they can have only 2 operands at one time
and they must evaluate both sides only once
i was under the impression that python loaded a value, loaded a name, and then ran a "store" command
thinking of this i might reconsider having chained augmented assignments in my WIP programming language
actually yeah, you're right, an instruction set which did it the other way around would involve way more instructions to do the same thing
wait no?
since that's literally what happens when you use +=, the left-hand side in fact does get evaluated first before the rest
bytecode for a[i] += f():
8 24 LOAD_FAST 0 (a)
26 LOAD_DEREF 0 (i)
28 DUP_TOP_TWO
30 BINARY_SUBSCR
32 LOAD_FAST 1 (f)
34 CALL_FUNCTION 0
36 INPLACE_ADD
38 ROT_THREE
40 STORE_SUBSCR
oh wow 3.10 bytecode
aye yeah, i've been inspecting the 3.10 bytecode, not 3.11, though i assume the bytecode should essentially be behaving the same
here's 3.11, if it means anything: 8 26 LOAD_FAST 0 (a) 28 LOAD_DEREF 2 (i) 30 COPY 2 32 COPY 2 34 BINARY_SUBSCR 44 PUSH_NULL 46 LOAD_FAST 1 (f) 48 PRECALL 0 52 CALL 0 62 BINARY_OP 13 (+=) 66 SWAP 3 68 SWAP 2 70 STORE_SUBSCR it seems to be doing a similar underlying thing, only ever evaluating a[i] at the start and copying it
yeah it behaves the same, but DUP_TOP_TWO and ROT_THREE are replaced with equivalents in COPY and SWAP
also CACHEs which are invisible in the bytecode snippet you're showing
still, its still loading in the a[i] that'll be used in the final assignment at the start
so i'm still a little puzzled, since it seems += can deal with evaluating the left-hand side first, so i don't know how its a bytecode or implementation restriction
python doesn't have the optimization or ability to realize that the a[i]s a[i] = a[i] + f() are related
so it just evaluates them like it usually does
yep, i get its non-optimising for that
so that must mean that = evaluating rightmost-first is just a design choice, not really a limitation
right?
it's a limitation
you have to evaluate the rightmost first so you have a value to assign to the rest
and i've said many times before, it's easier to just evaluate the rest when assigning to them
i totally get that the right-hand side has to be actually evaluated before you assign it to anything
the += bytecode, if i understand it correctly, is doing this: ```
- load a[i] onto the stack, and duplicate it
- load in the function f, and call it
- add together a[i] to the result of f()
- store the value into a[i]
i was just wondering what's stopping the `a[i] = a[i] + f()` code from doing something like: ```
- load a[i] onto the stack (for the left-hand side)
- load a[i] onto the stack (for the right-hand side)
- load the function f, and call it
- add together a[i] to the result of f()
- rotate the stack, to align things for assignment
- store the value into a[i]
since right now, it's ```
- load a[i] onto the stack (for the right-hand side)
- load the function f, and call it
- add together a[i] to the result of f()
- load a[i] onto the stack (for the left-hand side)
- store the value into a[i]
and yeah sure, there's an additional stack rotation happening here, but in a world where python evaluated the other way around, i imagine STORE_SUBSCR would simply understand to use the top values off the stack in a different way, avoiding the need for the rotation (plus eliminating it from the += code)
@umbral plume i think you are right that Python could have been designed to evaluate strictly left-to-right in your example. but it wasn't.
i'm trying to think if there's actually a useful reason for it to be the way it is.
i think @rose schooner is right that it's just easier to compile to bytecode the way it works now.
i suppose, its also maybe possible that the first early early implementations of python just coincidentally behaved like this, and its just easier to declare that this is the intended order, rather than change something that's kinda fundamental, and break god knows what
that's something that just dawned on me now lol
i'm gonna look at python 0.9.1 source code rn to see if it did
oh it did
python 0.9.1 had the same behaviour
ah damn, and i'm assuming python being highly documented wasn't something that really emerged until a little after 0.9.1
while inspecting python 0.9.1 i found out that print was originally a function
o damn, that's interesting
then turned into a statement for some reason then back again to a function in python 3
i wonder when it changed to a keyword, maybe 1.0?
so it was mentioned that the print() builtin was also available but the print statement overshadowed it
oh yeah, isn't that something that 2.7 also does?
where there's just a __future__ statement to remove the print keyword, which really exposes the function underneath it
oh nvm
i relooked at src/compile.c and i saw a statement rule for print
something else that's pretty interesting is how little some of the language reference seems to have changed
have a look at https://docs.python.org/3/reference/simple_stmts.html#assignment-statements, the current assignment expression section, versus https://docs.python.org/release/1.5/ref/ref-8.html#HEADING8-29, the equivalent section from circa 1998
some paragraphs literally just haven't been touched for over 20 years
i guess if it ain't broke, don't fix it
btw, do you mind if adapt this for a tweet?
i don't mind at all, go ahead 😁
thanks, it has a nice blend of "here's something you should know about Python" but also "this is surprising!"
>>> def q(val):
... """Print a value and return it."""
... print(val)
... return val
>>> x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> x[q(1)] = x[q(2)] = x[q(3)] = q(99)
99
1
2
3
>>> x
[0, 99, 99, 99, 4, 5, 6, 7, 8, 9]
all these repeated = is reminding me of this one esoteric line i swear i saw a while back, where it made a self-referential list in just a single chain of assignments
i guess i'm gonna have to go digging for that now
i might have got this from here also: https://twitter.com/nedbat/status/1504062673809338370

aah yeah, it was something similar to that
Which got me this response: (looper:=[]).append(looper)
pylance can't even handle it being valid python code, it just thinks the central looper is invalid, ahaha
i like more how it illustrates the order chained assignments are resolved, which i don't think is obvious at all if you don't know!
maybe i should've looked a little bit further back!
!e
class X(dict):
def __init__(self):
self.__dict__ = self
a = a.b = a.b.c = X()
print(a)
@dusk comet :white_check_mark: Your 3.11 eval job has completed with return code 0.
{'b': {...}, 'c': {...}}
!e
This is my favourite trick with defaultdict but you've probably seen it
from collections import defaultdict
def turtles():
return defaultdict(turtles)
thing = turtles()
thing["foo"]["bar"]["baz"] = "hmmmm"
print(thing)
@grave jolt :white_check_mark: Your 3.11 eval job has completed with return code 0.
defaultdict(<function turtles at 0x7f0c5c5ac680>, {'foo': defaultdict(<function turtles at 0x7f0c5c5ac680>, {'bar': defaultdict(<function turtles at 0x7f0c5c5ac680>, {'baz': 'hmmmm'})})})
that is a good one. I'll have to think about putting it out there.
i've seen it called autovivification
but "turtles" is genius!
help
not here. #❓|how-to-get-help
i wonder what is this?

Is this related to the channel topic? And please don't ask people to read screenshots of code.
Confused about encodings. I put a .pth file in site-packages that registers a custom codec. When I run Python interactively, and then import the file using this encoding, it works. If I run it directly, it fails with SyntaxError: encoding problem: nameofcodec. I see that the codec is found and registered though (via -v and printing when it does).
Looks like it comes from these lines in tokenizer.c, but I don't know why it would work in one case but not the other:
if (strcmp(cs, "utf-8") != 0 && !set_readline(tok, cs)) {
error_ret(tok);
PyErr_Format(PyExc_SyntaxError, "encoding problem: %s", cs);
PyMem_Free(cs);
return 0;
}
Looks like the encoding can only be used in the "second" file that is loaded, i.e. I need a loader file that imports the encoded one.. hmm :(
@quick snow isn't that the issue i discussed with Jelle here #internals-and-peps message ?
Oh indeed. At the time I didn't fully understand it
ye that's a bummer. i wanted it to work for incdec
opened a thread about it on the forum, no reply tho
I guess the problem is that .pth files were meant for import path logic stuff, and finding a Python file doesn't matter inside __main__.
is there some work on adding TLS session resumption support to asyncio?
both SSLContext.wrap_socket() and SSLContext.wrap_bio() takes a session parameter, I wonder why asyncio's loop.create_connection() doesn't
I tested session resumption and the ssl module seems to support it for all TLS versions
to add support I would need to reimplement BaseEventLoop._make_ssl_transport() for all event loops, right?
and all the other methods which calls it to pass a new session parameter
question regarding the built-in conversions between strings and integers: why does int(x, base) support converting strings in base-2 through to base-35 to ints, yet there's not equivalent built-in functionality for converting integers back into arbitrary-base strings?
the only built-in functionality for converting integers to strings allow bases 2, 8, 10, or 16
so this means if, say, i want to write a program dealing with base-4 numbers, converting into integers takes no effort at all, yet converting back into strings requires me to write my own string-creating function
I think its a one way code
like converting 4 numbers into integers is one process but the reverting back is not coded yet so you have to write your own string creating function to revert back the integers back to base numbers
it's pretty straightforward and uses a simple and similar algorithm, unless some heavy optimizations are involved for the standard base 2/8/16 conversions
fwiw there's numpy.base_repr(num, base) for the same range of bases as the int constructor (up to 36), but I suppose it would be nice to have that functionality in the stdlib (and maybe direct support for that in format strings?)
format strings sounds like a good place for that feature
Though I doubt it's needed often enough in environments without numpy to warrant a place in stdlib over spending 5 minutes implementing it yourself
(minus the format part)
well, i dont think converting strings in arbitrary bases to ints is that common either
true
I'm not aware if there are more efficient ways to do that besides the naive implementation, which may or may not be one of the reasons for the assymetry, but it may also just be legacy that happened to turn out this way
it would be a pretty nice addition, but I'm not sure if I see that making its way into the language at this point
maybe it could have its place in the numbers library
how would i go about implementing runtime plugins
like having it so i can package my app with somethink like nuitka or pyinstaller
and have people copy python code to some dir and it would be run by the program
I know how to do the compilation but idk how to handle stuff like dependencies
one idea was to just have users copy the dependencies to the folder with the scripts
but idk if that would work for packages that depend on other packages
what does DUP_TOP do, when there is no element on the stack to duplicate?
nasal demons, I assume
that is, undefined behavior
Jelle being a coredev means he's the relative expert, but:
the docs for dis say that DUP_TOP
Duplicates the reference on top of the stack
i would guess then that it would duplicate a NULL
it would duplicate whatever happens to be on the (C-level) stack below the interpreter stack
it will most certainly clear your hard drive
lol, pretty sure im doing something wrong in the process then
thanks
in general malformed bytecode isn't guaranteed to do anything reasonable
xDDDDD
I found this https://github.com/python/cpython/issues/79152
I made a little hack, a SSLContext wrapper which injects a session obj on calls to SSLContext.wrap_socket() and SSLContext.wrap_bio(). It works since asyncio at low level won't interact much with the SSL APIs.
GitHub
BPO 34971 Nosy @tiran, @asvetlov, @1st1, @RemiCardona, @cooperlees PRs #9840 Note: these values reflect the state of the issue at the time it was migrated and might not reflect the current state. S...
reminds me of this :
https://stackoverflow.com/questions/17992553/concept-behind-these-four-lines-of-tricky-c-code

Stack Overflow
Why does this code give the output C++Sucks? What is the concept behind it?
#include <stdio.h>
double m[] = {7709179928849219.0, 771};
int main() {
m[1]--?m[0]=2,main():printf((char)...
anyone know a good open source eye tracker that draws a path when you move your eyes?
could probably use this to implement one https://pypi.org/project/face-recognition/

that would let you find the eyes at least
so I'm trying out match in a new project, seems pretty useful tbh
I have a lot of tagged unions
hello
why are cell variables and free variables distinguished?
what do you mean by free variables?
the shenanigans that happens inside class definitions sometimes?
def g():
c = 2 # c is a cell variable in this scope
def l():
# c is a free variable in this scope assuming it's not redefined
return c
and what do you mean by distinguished?
why are free variables not just cell variables
they use the same opcodes and structures except one is distinguished from another
is it some CPython internals that are flying over me
probably
Hey All, I'm wondering if I was correct here, or no?

Not the right channel. If you have a Python question, see #❓|how-to-get-help and claim a help channel.
If you want to know if you're right, try the code with various error scenarios and see what happens
Is there a way to bypass the __new__ func of base class? I tried object.__new__(cls) but Python says its unsafe
oops misread thanks
So if base class defines __new__ it must be called?
can't
Looks like, I saw object.__new__ checks if base class defines it
a C extension should be used to bypass it
but in pure python it's very hard to because object.__new__() uses C-only header-defined functions
Is there a way to trick isinstance() check?
I am subclassing a type just to pass isinstance check
If you can monkeypatch the base class, you could override https://docs.python.org/3/reference/datamodel.html#class.__instancecheck__ I think.
Or, you could assign a different type to __class__ on your constructed instance
perhaps because they're different scopes, or perhaps because the free variables are captured into __closure__
and besides that they're just the same?
any two things are the same besides the differences
ok
oh, also possibly because the free variables are late binding
my guess is that it basically just boils down to the fact that they're different scopes, though, so updates need to write someplace different for the two of them.
I tried to overwrite the __class__ using a dynamic class which has that base class but python complains this dummy class has different shape
Hm. I think unittest.mock.Mock objects do it by overriding __class__ as an @property - https://github.com/python/cpython/blob/3.10/Lib/unittest/mock.py#L542-L543
Lib/unittest/mock.py lines 542 to 543
@property
def __class__(self):```that approach might work..
you would be making a class that doesn't inherit from the original class, but lying in your class's __class__ to pretend that it does.
typing_extensions.ParamSpec has a similar trick
That changes dunder class, bot dont changes type()
Which is enough to fool isinstance
Ah, ok. I missed the original question
I'm wondering about the decision behind mangling [protected?] attributes this way. Is there a particular reason why it's OK for the running program to have access without the _BaseClass prefix, but not when debugging?
((Pdb++)) n
[6] > /home/skeledrew/Projects/flet/sdk/python/flet/control.py(457)_build_command()
-> for attrName in sorted(self.__attrs):
((Pdb++)) self.__attrs
*** AttributeError: 'RichTextEditor' object has no attribute '__attrs'
((Pdb++)) n
[6] > /home/skeledrew/Projects/flet/sdk/python/flet/control.py(458)_build_command()
-> attrName = attrName.lower()
((Pdb++)) sorted(self.__attrs)
*** AttributeError: 'RichTextEditor' object has no attribute '__attrs'
((Pdb++)) attrName
'height'
((Pdb++)) self._Control__attrs
{'width': (0, False), 'height': (-20, False), 'jsondoc': ('', True)}
((Pdb++))
The mangling only happens if you're syntactically within a class
In code run in the debugger, you're not in the class
I see, but why the difference? It's a bit confusing to be able to step over something, but then not be able to inspect it as is
what difference?
wdym by
it's OK for the running program to have access without the
_BaseClassprefix
if the "running program" is in the class then it makes sense
As shown in the session where I can do "next" and self.__attrs works, but I have to do self._Control__attrs to inspect the value
the code run by next is syntactically within the class
so it's compiled to do self._Control__attrs
Ahh got it. So now I'm wondering about cases where there are multiple bases with the same protected name. Is there some heuristic to know which is being used by the compiler?
It's purely syntactic, if you're within class X it prefixes double underscores with _X
Interesting. OK thanks
you can see this in dis: ```>>> import dis
class X:
... def f(self):
... self.__x
...dis.dis(X.f)
2 0 RESUME 0
3 2 LOAD_FAST 0 (self)
4 LOAD_ATTR 0 (_X__x)
24 POP_TOP
26 LOAD_CONST 0 (None)
28 RETURN_VALUE
so if somewhere in the hierarchy two classes have the same name, their attributes might collide, right?
!e
def mkfoo():
class Foo:
def __init__(self):
self.__bar = 42
return Foo
class Bar(mkfoo()):
pass
class Foo(Bar):
def hmm(self):
print(self.__bar)
Foo().hmm()
@grave jolt :white_check_mark: Your 3.11 eval job has completed with return code 0.
42
🤪
Nothing can change that ☝️
In [7]: class B: pass
In [8]: a = A()
In [9]: a.__class__ = B
In [10]: type(a)
Out[10]: __main__.B
😔I was told / thought, it was a pure lookup on the PyObject struct
Ah so __class__ changes that
this is not always possible because of layout conflicts, but you always can change class using ctypes
then it will just segfault afterwards I assume
!e ```python
class A: pass
class B:
def test(self): return 'test'
a = A()
a.class = B
print(a.test())
@elder blade :white_check_mark: Your 3.11 eval job has completed with return code 0.
test
With this in mind, I don't see any downside to this changing type() because it actually changes the class / type (it's not being "faked")
you can patch type instead of patching x.__class__ 😄
why hash(frozenset(...)) is cached but hash(tuple(...)) is not cached?
i think tuples are more often used as keys, so it is better to cache hash?
or it is done for saving 8 bytes of memory for hash?
WTF! this is cursed
It works as expected.
Most frequent (i think) use-case is to change type of your module: class MyModule(ModuleType):...; sys.modules[__name__].__class__ = MyModule
so I guess this is to way to create an object without calling the __init__ function
wdym? the __init__ of A will get called
I guess? I don't understand what's the significance of that
don't know if there is, it's just something that was apparent to me
Interesting hack. I've sometimes wanted to use instances of some classes without calling their __init__, and init the attribs my way. Seems this could make that easier, rather than replacing the __init__ method...
So call __new__ off of the class instead of invoking it
Generally when u want an alternative constructor you call __new__ directly inside of a class method
here's a fun question: why does python seem to only salt hashes for strings/bytes?
I would have expected that everything would be salted
almost certainly because in general it's expected that frozensets are larger than tuples, so a) the space penalty is not as important, b) the potential savings from caching a hash is much larger.
I think hash randomization was primarily motivated by cases where you receive dicts with string keys from user input
c) tuples are used everywhere for all kinds of reasons and many of them are never hashed at all, so it would be a lot of pointless space penalty. frozensets, hashing is almost their raison d'etre
sure, but there are cases where users end up passing integers as well
afaik attacks via hash collisions are a lot more realistic for strings and bytes than something like numbers, where you are unlikely to get an integer greater than 64bits unscathed through the entire tech stack.
hash(integer) is just the integer until you get past 64 bits I think
sure, if you know the hash table size progression you can still engineer an attack though?
there's also some trickiness because it's important that the hash of an int matches the hash of an equivalent float
I suppose so but that trickiness doesn't seem incompatible with salting
just feels like if you've already implemented salting, why not just add it in a general way, that applies to any hash you're going to calculate, and reap the benefits more broadly
The reason for the hash randomization was avoiding a collision-based DOS, as @feral island said. Python's hash() is explicitly not a cryptographically secure hash algorithm — its main job is performant hash tables.
For secure hadhes, use hashlib.

GitHub
BPO 13703 Nosy @malemburg, @gvanrossum, @tim-one, @loewis, @warsaw, @birkenfeld, @terryjreedy, @gpshead, @jcea, @mdickinson, @pitrou, @tiran, @benjaminp, @serwy, @merwok, @alex, @skrah, @davidmalco...
This is part of why (as far as I know) set and frozenset are the only pair of classes where instances that evaluate as equal don't hash the same way (sets don't hash).
err this doesn't answer my question at all
I understand all of that
the question is why only strings and bytes are salted
can someone guide me, I am a 3rd-year student of Computer Science Engineering and my main languages are CPP and python but I am always unsure if I am ready to apply somewhere or not how can I check my progress??
Because there is value in a simple hash function that maps integers to themselves; makes for more compact dicts in many cases (fewer collisions with fewer bytes).
The problem that existed and was demonstrated in the C3 talk had to do with the ability of making you construct a dict with many, many colliding entries simply by visiting a URL (of your Python web app). This attack vector just doesn't exist for integers, only for strings (and at that time, Python 2 was still big, so also bytes).
the general concept of DOS by degrading hash performance with engineered input isn't unique to str though. If you have a hash table where the keys are ints (or combinations thereof) that come from some kind of user input, the exact same thing can happen.
In principle, yes. But that case is much less common (can you name an example, perhaps a real-world one, where such a dict would exist?), and I'd expect the numbers to be size-limited already anyways (collisions would only occur outside of 64 bits, other than -2)
I guess it was just surprising because I've never seen salts discussed this way, that it would be applied at a per hash-function-for-a-type level.
All the discussion of salts I saw always seemed to imply that it was something generic that would be applied to the result of any hash
where would a dict exist that was keyed by integer?
err wait, why would collisions only occur outside 64 bits?
That's because most of the time when people talk about hash functions and salting it's a cryptographically secure hash function.
, with the ints coming from user input
because hash(x) == x, as long as x fits in the length of the hash
idk, it does not seem radically uncommon to me
to be clear, in hash table parlance
"collision" does not mean the hashes match exactly
"collision" means they get mapped to the same bucket
that does not require the hashes to be identical
collisions are most definitely possible below 64 bits
Not all hashing schemes have buckets, but sure, still possible, when the suffix matches, for small dicts.
This just doesn't matter for small dicts
buckets, slots, etc, it doesn't matter, the idea is the same and it doesn't require the hashes to match
err it's not just for small dicts
well when the dicts get big enough that the entire hash is taken into consideration, only an identical hash is a collision
you mean when the dict has 2^64 slots?
...sure, your dict will never get that big, true
yes, it will not
a hash table with 4 billion slots is only using (for some definition of using), 32 out of the 64 bits
you will still have many collisions without identical hashes.
in general python will keep its hash tables about half full so it should be obvious that you will have lots and lots of collisions; in 99.999999% of these cases, the colliding keys do not have the same hash
Collisions in that case would be integers 2^32 apart
the point is that for any open source hash table without a salt, for any key type, it's always possible to engineer input that breaks it
(performance-wise)
of course, but again, show me a case in real code where it matters
(excepting maybe certain hash table designs that are not used in the real world)
I just said, for engineered input....
that's what this entire thing is about
if the input is not engineered, then yes, it will never matter
It's not just about the input, it's also about code that takes an arbitrary amount of integers as input and uses it as keys in a dict
Maybe I'm wrong and that happens all the time, I just can't think of so many cases where this would exist.
well, it doesn't have to be an integer. It could be anything that is not a string.
honestly I don't do this kind of programming generally so I'm not too familiar with when exactly you'd be inserting keys based on user input, it just seems odd to me that this is so unique to string
the answer to this might be somewhere in that thread as somebody points out this issue and even shows how easy it is to engineer an example
Marc-Andre Lemburg wrote:
Changing the way strings are hashed doesn't solve the problem.
Hash values of other types can easily be guessed as well, e.g.
take integers which use a trivial hash function.
Here's an example for integers on a 64-bit machine:
g = ((x*(264 - 1), hash(x*(264 - 1))) for x in xrange(1, 1000000))
d = dict(g)
This takes ages to complete and only uses very little memory.
The input data has some 32MB if written down in decimal numbers
not all that much data either.
32397634
also instructive:
To expand on Marc-Andre's point 1: the DOS attack on web servers is possible because servers are generally dumb at the first stage. Upon receiving a post request, all key=value pairs are mindlessly packaged into a hash table that is then passed on to a page handler that typically ignores the invalid keys.
the thread you posted is actually full of examples of people talking about where this can happen with arbitrary keys
Haven't found one yet, can you link to one? All I find it artificial examples.
I mean real code where you could exploit someone other than yourself.
what do you mean by "real code" - most of these examples involve engineering inputs to a system
what are you looking for exactly? a 10 line example; a link to a github...
For example: a link to a Github repo of some web app where a user could do this.
(doesn't have to be a web app, my point is: not just a collision you can hand-craft in a REPL, but a way to use the collision)
people have explained exactly ways in which you can use this to craft a collision. The simplest being to take advantage of the fact that most web servers when they parse a post request are going to build a dict first
like, any python application that is parsing json passed by the user, that doesn't very strictly limit the size of the json
can be taken advantage of this way 🤷♂️
if that's too "artificial" for you I don' tkno wwhat to tell you
They build a dict of strings. And JSON doesn't have integer keys
okay, fair point. there are other examples there though.
as another example, msgpack can accept non-string keys.
And there will be other data formats that do similar things.
At any rate though, my goal here isn't to convince you that this is sufficiently common; I'm only interested in knowing the actual reason why it was done this way.
if you actually have evidence that the people on the steering committee or whatever said that the non-string collision cases were too obscure, by all means
How about this, then? https://mail.python.org/pipermail/python-dev/2011-December/115128.html
I mean, yeah, it's something "it would make performance worse for ints"
not clear if this was decisive
the best I can infer is that they were very focused on the POST example because it's the most obvious and common thing
I haven't used __new__ much to know it well, but wouldn't I still have to add the implementation to the target class? If so then it wouldn't work well for 3p modules anyway
bytes and bytearray instances evaluates as equal, but bytearray is not hashable
i think the idea is that if two things both hash and can be compared, then you really want equals and hash to be consistent
if one of them doesn't hash, then it doesn't matter, there's no consistency to maintain
really, it's just extending the same idea of hash being consistent with equality between different types
if you define hetorgeneous equality (equality between two different types), and both those types have hash, then you still want to maintain that consistency.
!e is there any reason why builtin functions don't support the descriptor protocol (aren't bound when added to a class)? For example: ```py
class A:
def bar(self):pass
foo = print
a = A()
print(a.bar)
print(a.foo)
@pliant tusk :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | <bound method A.bar of <__main__.A object at 0x7faa42a03ed0>>
002 | <built-in function print>
I don't think there's a strong reason. Changing it now would probably break some users
Pretty sure you can call __new__ on the class, that you don't control, and get an instance that hasn't been passed to __init__ yet
I don't recommend it bc if you don't control the class how do you know how to initialize is correctly
when will python have multi line lambda
never
use a function for that
yes pls
imagine polluting the namespace
imagine defining a function that you would only use once
define it in the scope you'll use it in
and give it a reasonable name if it's applicable
Honestly
Trying to narrow down where a lambda came from during debugging is one of my most hated experiences
just don't use lambdas if you don't like debugging them
fair
do you have problems with the traceback line preceding a lambda use
how do i python -m dis file.pyc?
isn't there a solution without marshaling and stuff?
The problems arise when someone who codevelops does this
foo = lambda x: print(x)
# or
foo = {"bar": lambda x: print(x)}
Then passes foo or foo["bar"] into something like map or a pandas.DataFrame.apply and then damn lambda is buggy or fails . I see where the apply or map is being invoked but cannot see where the lambda was defined and have to start digging.
If someone is to use a lambda then it should only be used as an arg being immediately passed to an invoked function so you can actually see what its body is easily.
Imo storing lambdas in data structures is just as bad as binding one to a name. Just make a full on def
i mean the lambda is part of the backtrace
the only thing you lose is the name
x = {"hello": lambda: 1 / 0}
x["hello"]()
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<string>", line 1, in <lambda>
ZeroDivisionError: division by zero
>
let's not pretend like lacking good lambdas is a feature
My aim usually isn't correct initialization, but to initialize just enough to get a subset of the methods working, mainly for testing. Usually I'll just monkeypatch the __init__, but this could allow for more concise means.
class ThreePClass:
_has_trash = False
def __init__(self):
self._result = 21
self._has_trash = True
def interesting_method(self):
return self._result
type("UseCase", (), {"_result": 42, "__class__": ThreePClass})().interesting_method() # really wanted a 1-liner, but oh well, learned something[0]
## Traceback (most recent call last):
## File "<stdin>", line 1, in <module>
## AttributeError: 'UseCase' object has no attribute 'interesting_method'
## 'UseCase' object has no attribute 'interesting_method'
class UseCase:
def __init__(self):
self._result = 42
uc = UseCase()
uc.__class__ = ThreePClass
uc.interesting_method()
## 42
uc._has_trash
## False
[0] I always assumed attributes are added after instance creation, but seems I was wrong on that.
Have you looked at mocking frameworks?
That's typically where you see this sort of thing
Yep, I used to do a lot of mocking, but mostly find it a huge pain when things get too complex. So I try to avoid and am on the lookout for ways to simplify
Usually mocking frameworks are just taking these same kinds of hack, handling some of the edge cases for you correctly, and giving a nice API
True. Though I've also at times found that they do too much, which can also lead to issues. Well, it, since I've only ever really used pytest-mock. I'm not even sure what other similar frameworks there are out there. I think one part is that there is so much internal complexity that it becomes hard to keep things straight, and to maintain precise control. Mostly I've been trying to replace with faker and factory_boy, but they have their own challenges
Yeah so if the lambda errors ok, but if the lambda is producing erroneous results, as part of a larger string of calculations, it can be really difficult to find
I'm not sure I totally follow what makes it so much harder to find.
At any rate yeah there's definitely times when you want a named function, I'm just confused how you've hit on a lot of these problems in a language where lambdas can only be one line
is there a simple way to programatically get dis line number from source line (in the photo, 4 is the line on the disassembly, 2 is the original line from source code)
Have you ever been able to step into a lambda with pdb?
Or place a breakpoint inside of 1?
Whenever I try to debug a lambda passed as an arg who called in a deeper scope, I've never been able to step in
So then I'm stuck looking for where that lambda is defined
I honestly don't think I've ever needed to? I mean the main reason it's hard to place a breakpoint is because they're only one line, for the same reason it's very rare to need it
And it's not like you can ll a lambda and print the content like you can with a named function
Or at least I've never had luck doing it
ll | longlist¶
List all source code for the current function or frame. Interesting lines are marked as for list.
If you've already stepped into the lambda I'm not sure why it wouldn't show up? We just established it shows up in the stack trace.
If it's in the stack trace then ultimately it's not that hard to figure things out
Maybe I'm missing something
But I'm pretty sure if you repr a lambda it doesn't show the qualified path of where it was defined
And I'm talking about a lambda that isn't erroring but producing the wrong result
Mind you, I don't use IDEs, I debug with -m pdb or with %debug and a .pdbrc in ipython
any ideas?

I mean, I just tried to debug the following file with -m pdb
def foo(x):
print("foo starts")
import pdb; pdb.set_trace()
x["hello"]()
l = lambda: print("world")
foo({"hello": l})
(python3.8) ~ ❯❯❯ python -m pdb scratch.py
> /home/nir/scratch.py(2)<module>()
-> def foo(x):
(Pdb) c
foo starts
> /home/nir/scratch.py(6)foo()
-> x["hello"]()
(Pdb) s
--Call--
> /home/nir/scratch.py(9)<lambda>()
-> l = lambda: print("world")
(Pdb) l
4 import pdb; pdb.set_trace()
5
6 x["hello"]()
7
8
9 -> l = lambda: print("world")
10 foo({"hello": l})
[EOF]
(Pdb) ll
9 -> l = lambda: print("world")
(Pdb)
i have no issue stepping into the lambda and seeing exactly where it was defined
if you call dir on a function vs a lambda, you'll see they basically have teh same attributes, e.g. they both have a code attribute that tells you where it's defined
i still don't see any difference other than just having a name
It's the index of the opcode in the bytecode, it's impossible to know what that is going to be without compiling the program first, so in theory you could compile the program, figure out what the index is at a specific line number but that sounds like a hassle
What the use case?
Maybe it's due to me being stuck using older version
You tried this example and it didn't look like this?
I'd be curious to see what your version looks like
making a disassemble-at-point function for emacs
well maybe i should just parse it
Why do you need the specific opcode index though?
isnt that complicated
i just need to match source line to bytecode line so i could jump straight from source line to relevant block of bytecode
Python has a smart trick to save the line numbers in the code object
You should research that
lontab or something
Yea
If you understand it you might be able to work the reverse way
ye i think i even started something like that once
I mean you'd still need to compile the code object but at least you won't have to parse the dis output
>>> z = lambda: 1/0
>>> def b(l):
... from functools import partial
... return partial(next(iter(l.values())))
...
>>> def a():
... return b({hash(z.__code__): z})
...
>>> a()()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
a()()
^^^^^
File "<stdin>", line 1, in <lambda>
z = lambda: 1/0
~^~
ZeroDivisionError: division by zero
i'm using a modified cpython to test out the feature on a REPL btw
does anyone know where in cpython the cli arguments get parsed
seems like near here: https://github.com/python/cpython/blob/main/Python/initconfig.c what are you looking for?
yes exactly thank you
if you don't mind me asking, what are you looking for?
I thought how it worked was it found which argument could possibly be a python file (I wanted to see how it did that), but I think what it does instead is rule out every option until it knows (or has to assume) the next argument is a python file
is there any reason for python to not implement multiline lambda
without braces, the syntax is difficult
how difficult?
if you are asking, "will it happen", the answer is no 🙂
but maybe you are asking something else
python doesn't track indentation inside expressions, so you would have to start by changing the rules of indentation so that they are noteworthy inside expressions.
i am asking how difficult is implementing multiline lambda that is consistent with the rest of python syntax (that is, no braces)
iirc coffeescript has multiline lambda with significant indentation
are you going to try implementing it?
no
i think it's been discussed a bunch, and there isn't a good solution
i want you to clarify this claim
if it works with coffeescript it should work with python right?
i don't know coffeescript, so i don't know how they did it.
coffeescript is an expression-oriented language
and everything is delimited by newlines or indentation
so it's largely incompatible with python grammar
maybe its just guido
he thought multiline lambda is bad
or unpythonic
are you thinking now, "the core devs are just dumb, if they wanted to do this, they could?"
no
there have been long discussions about it, but I can't find them
i think its just how the devs want the language to be
nim does have multiline lambdas and it does work okay enough, but it can get confusing to parse by eye fairly quickly
right, and if they wanted to, they could find a solution, they just don't want to, right? I assure you there are difficulties to be overcome.
nim also has the benefit of macros making them a bit more bearable to write 
everything is delimited by newlines or indentation
isnt that just python
block expressions not statements
you can have an anonymous expression function if you modify cpython (i've tried doing that before) but it tracks indentation which i don't like because you're not supposed to have indentation tracked in an expression
i'm gonna search it up rq
i found one snippet example but it's only multistatement not multilambda #esoteric-python message
>>> (def:pass,def(a):a+=2;return a)[1](2)
4
oh this is a prime example
// cpp
[](){
statements;
return result;
}
we can emulate multiline anonymous functions in standard python with exec tho
env = {}
exec('''def f():
a = 1
b = 2
return a + b''', env)
env['f'] # yay
multiline expression in standard python with eval() and compile() ```py
eval(compile("""
a = 1
b = 2
return a + b
""", "", "exec"))
def function(args, *code, **captures):
func = f'def _({args}):\n'
for line in code:
func += ' '+line+'\n'
exec(func, captures)
return captures['_']
f = function('*args',
'res = 0',
'for x in args:',
' res += x',
'return res')
print(f(1, 3, 4, 2))
```it is ugly thoIs the second edition of fluent python finished, or is it still in pre release?
I think its out, I know Ive read it on oriely for free
It's been on pre release on oriely for some time. I think the advent of patma caused a delay.
Better lambdas would be nice but the truth is to get maximum benefit out of it IMHO you have to design more of the language around it to start
Like if you have nice lambdas you don't really need list comprehensions, you focus on map. And so on. I doubt there's any interest in changing so much stuff
It's cool to see how far they've run with nice lambda syntax in Kotlin and Swift. You get a huge amount of mileage out of one thing
Agreed, from all the mailing list discussions I've seen it seems impractical to make python more functional, like you can do a good bit but it's slow. It's not baked into the core of the language enough
There does seem to be a strong desire for more functional aspects, like currying and delayed computations but from what I've read it be too much of a pita to make it performant
I don't think there's huge demand for currying, that's pretty niche
Or delayed computation tbh
Better lambdas, more expression oriented, better control over mutation
These are the main things I really notice as lacking in python compared to newer mainstream languages that have adopted more functional features
List comprehensions hand you back a mutable list, and aren't extensible, and are limited to a single expression
map in Kotlin takes an arbitrary size lambda, can be written and modified in user space, and returns a list that you can't modify, at least without doing hacky things (like downcasting)
yeah, designing a language around the strict separation of statements and expression wasn't a great idea in retrospect
Seemed like a lot of the regular commenters on ideas mailing list were in favor
Most the time it came up when trying to make method chaining more practical, specifically with builtins
And pandas is always brought up as the prime example where it's largely popular
Which then currying and delayed evaluation is brought up
Bc that's something that pandas lacks but a lot of other DataFrame libraries try to do, like dask
I personally rarely use functools.partial bc I find it an annoying import, when I really should be
I find the ease of wrapping it in a lambda better
Which iirc is substantially slower
I mean maybe the kinds of people who would argue in favor of such things go a step further, idk
If you have good lambdas though then currying has pretty low value, and currying does not relieve the need for good lambdas
Delayed evaluation is even more niche
(language level)
Chaining would be great but neither of those are really the crux of that. You need extensions or some kind of chaining operator
val x = employeeList.map { it.lastName }.filter { it.length > 5 }
List comprehensions not being able to handle this was one of the justifications for walrus, which let's face it is a pretty weird thing
😛
Why listcomps cant handle this?
[it.lastname for x in A if len(x) > 5]
There is a pep about lazy imports. So python have (is pep accepted?) some kind of lazy evaluation.
That's not the same thing
What I wrote does a map and then filters
This filters and then does a map effectively; you're filtering the original elements
I guess so but that's not usually what's meant.by lazy evaluation in the context of what we were talking about
🥴
[last_name for it in employees if len(last_name := it.last_name) > 5]
I wish walrus respected scope
Whats wrong with walrus scopes?
escapes comprehensions
you can do the definitely not insane [it for it in employees for it in [it.last_name] if len(it) > 5]
this does in fact work for any sequence of map and filter, but also will not pass code review.
as you probably know that was done specifically so that you can get a "witness" in a call like any(x := some_call() for x in a_list) and now you can see what x is
but it definitely makes the scoping rules quite weird
Yeah, I can understand the rationale
but it does add another leak to python scoping 😄
the point of doing caching like last_name := it.last_name is to get small speedup
here you are creating temporary list for each item, so i think [x.last_name for x in A if len(x.last_name) > 5] is faster
here you need very fast iterable wrapper around object
it's optimized to not create a list
for whatever reason
that's specifically to make this pattern faster
Yes, but how common is that pattern
I've seen way more reasonable optimizations get shot down
Some benchmarks:
look here -->vvv
test1 661 ns ± 149 μs [215 ms / 319364]
test2 2.9 μs ± 387 ns [198 ms / 68095]
test3 673 ns ± 120 ns [173 ms / 251667]
test1 - [i for it in employees for i in [it.last_name] if len(i) > 5]
test2:
TT = TypeVar('TT')
class Wrapper(Generic[TT]):
__slots__ = ('obj',)
obj: TT
def __init__(self, obj: TT) -> None:
self.obj = obj
def __iter__(self, /) -> Iterator[TT]:
yield self.obj
def __call__(self, obj: TT) -> Wrapper[TT]:
self.obj = obj
return self
wr = Wrapper[str]('')
# measuring this:
[i for it in employees for i in wr(it.last_name) if len(i) > 5]
test3 - [last_name for it in employees if len(last_name := it.last_name) > 5]
# common code:
class Empl:
def __init__(self, name: str) -> None:
self.last_name = name
employees = [
Empl('a'),
Empl('a'*4),
Empl('a'*5),
Empl('a'*6),
Empl('a'*7),
Empl('a'*8),
]
I mean in this particular example the speedup may be small but there's no general bound on the cost of the function used to map elements in a list comprehension
Not to mention the repetition involved in applying the transformation twice
list creation takes approximately 30ns, so it is not significant compared to function call (it is approx 70-100ns).
Possibly we're talking about two different things
Actually, seems like it's still applicable
x.last_name happens to be very cheap but it could be arbitrarily expensive
So obviously at some point avoiding calling that twice becomes the most important thing
that caching using an assignment expression isn't a speedup in that example comprehension because last_name is considered a global variable which is ~17ns slower than a fast local which can be achieved by [last_name for it in employees for last_name in [it.last_name] if len(it) > 5]
no, im running these benchmarks inside of function, so last_name is local var
(im not using timeit, i wrote my own code to measure time)
i think i should run more accurate benchmarks (=more run cycles)
the problem with this is that .last_name can be a property which is basically a call
@rose schooner i mean this whole example was just toy code anyway, to demonstrate a principle
it could also be [some_expensive_call(x) for x in foo if some_expensive_call(x) is not None]
or whatever
or, the function call could have side effects, and calling it twice isn't just a performance issues but a correctness one
or give back different results each time, so now you're doing the predicate call on a different value then what you mapped, so your invariants are not upheld
but it isn't a fast local variable because it's a cell variable
hmm, surprisingly
so it falls behind ```py
init code...
from timeit import main
main(['-s', """
... from main import employees
... def g(employees=employees):
... [last_name for it in employees if len(last_name := it.last_name) > 5]
... """, "g()"])
200000 loops, best of 5: 988 nsec per loop
main(['-s', """
... from main import employees
... def g(employees=employees):
... [last_name for it in employees for last_name in [it.last_name] if len(last_name) > 5]
... """, "g()"])
500000 loops, best of 5: 867 nsec per loop
# here last_name is property:
@property
def last_name(self) -> str:
return self._last_name
# results (divided by number of employees):
caching in list 122 ns ± 7.2 ns [987 ms / 80857]
caching in tuple 127 ns ± 3.9 ns [1.0 s / 81508]
walrus caching 129 ns ± 4.4 ns [1.0 s / 80588]
caching in Wrapper without creation 429 ns ± 35 ns [1.0 s / 23401]
caching in Wrapper 463 ns ± 36 ns [975 ms / 21059]
no caching 144 ns ± 15 ns [1.0 s / 69474]
damn that's actually really weird
til python functions only capture variables that it needs (variables used inside it)
!e ```py
def f():
a = 1
b = 2
def g():
return a
return g.closure
g_captures = tuple(v.cell_contents for v in f())
print(g_captures)
@gray galleon :white_check_mark: Your 3.11 eval job has completed with return code 0.
(1,)
!e ```py
def f():
a = 1
b = 2
def g():
return a, b
return g.closure
g_captures = tuple(v.cell_contents for v in f())
print(g_captures)
@gray galleon :white_check_mark: Your 3.11 eval job has completed with return code 0.
(1, 2)
and its done at compile time
the values are initialized at runtime but whether or not the variable is "captured" is handled by compile time in the symbol table
i thought python just copy the entire environment of the parent function when a closure is instantiated
it is smarter than that
Whats the difference between f.__name__ and f.__code__.co_name?
repr(f) uses name from code object, not from function itself.
How f.__qualname__ is calculated?
f.__qualname__ = f.__globals__['__name__'] + '.' + f.__name__ works only for top-level functions, i think
I'm not sure about the difference between f.__name__ and f.__code__.co_name
As for __qualname__, i think its just directly computed and stored as a string when defined, since https://peps.python.org/pep-3155/ seems to make no mention as to how its calculated, just that it exists
Python Enhancement Proposals (PEPs)
That is correct, I just recently looked this up
f.__qualname__ is the same thing as f.__code__.co_qualname
co_qualname is 3.11+ though
it seems like it's calculated as the compiler visits scopes

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
yes, for nested functions it dots together the names of all enclosing classes and functions
how to convert periodic binary fractions to decimal?
(0,(010)) binary
to decimal
can some1 explain?
@full jay d-_-b
(0,(010)) = 010 / 111 (in binary) = 2 / 7 = 0,010010010...
just fill entire period with ones and divide period on it
it also works in decimal:
0,(142857) = 142857 / 999999 = 1/7
this channel is for questions about the python language itself
here's a question about slightly mor eadvanced usages of the subprocess library. namely, piping between processes without use of the shell
when I looked this up I found significant differences between the most upvoted (recent) SO answer I could find and the python 3 stdlib's docs
This is the top answer I found on SO:
import subprocess
ps = subprocess.run(['ps', '-A'], check=True, capture_output=True)
processNames = subprocess.run(['grep', 'process_name'],
input=ps.stdout, capture_output=True)
print(processNames.stdout.decode('utf-8').strip())
here's what the python3 subprocess docs say:
output=$(dmesg | grep hda)
becomes:
p1 = Popen(["dmesg"], stdout=PIPE)
p2 = Popen(["grep", "hda"], stdin=p1.stdout, stdout=PIPE)
p1.stdout.close() # Allow p1 to receive a SIGPIPE if p2 exits.
output = p2.communicate()[0]
anyone have a good handle on the differences between these two, and recommended practice?
my main guess is that the version with run will fully run the first process, and buffer the whole output
whereas the second version might do what the shell does, and start letting the second process run when the first process has produced a certain amount of output, and so on
but that's definitely just a guess
The SO answer doesn't pipe. It runs command one, takes it's output as a UTF-8 string, then passes that as the input to the next string.... Yeah you are right
gotcha
Well, the shell isn't exactly doing the piping, that's on the OS, the shell just wires the streams together properly
Nor is python
Here's a fun little thing I never noticed before. In CPython, hash(float("inf")) equals 314159, or the first 6 digits of pi, and the hash of -inf is -314159, just as a neat little fact
gotcha, I thought for some reason the shell did play a role.
At any rate that's pretty neat.
In that formulation, what happens if p1 is still running when p1.stdout.close() is called?
seems like you'd be cutting it off?
hmm seems like close will not actually close it until everything is done
actually sorry, close executes immediately but, idk, it doesn't actually close it immediately? idk, that part is a bit surprising
closing just sends the EOF signal, doesn't it?
or rather stops the ability to write
I think it sends SIGPIPE too? (depending on the OS)
well, the comment says: " # Allow p1 to receive a SIGPIPE if p2 exits."
presumably this only comes up if p2 exits before p1
so I don't think it unconditionally sends SIGPIPE
so I have a function called encode, now I'm trying to import encode from steno
what's a good way to handle this?
would this be good?
from steno.text import encode as steno__encode, decode as steno__decode
usually i just use single underscores to join them but yeah you can do whatever you want with the names
Double underscores inside name is weird
I asked because I don't know what I want 
i use _ just like a space in a text
Why not this:?
from steno.text import encode, decode
Alternatively, if you want it to be clear where they are from: import steno.text as steno; then use steno.encode and steno.decode
In python2 hash(-inf) == 271828, it is the first 6 digits of e (euler constant)
someone test on python 1 and python 0
not on my system with python 0 rn
import a.b as a is confusing, imo
I would use import a.b; a.b.encode or import a.b as a_b; a_b.encode instead
well that's your choice
OP wants it to be steno_encode
Yeah, sometimes the package just has a weird hierarchy, no need to have that infect my own code
import matplotlib.pyplot as plt is very common
name conflict with a funciton
img = PhotoImage(file="images/noshow.png").subsample(4, 4)
img2 = PhotoImage(file="images/show.png").subsample(4, 4)
img3 = PhotoImage(file="images/dots.png").subsample(3, 3)
trying to rename this to constant variables, but what should I name it? current name seems bad
encode and decode are methods, not functions, so there's no conflict, though it might be confusing.
it conflicts with my functions
actually not mine
I'm trying to refactor this https://github.com/aloner-pro/Steno/blob/master/main.py
I should have not
main.py line 528
global mess```😄
haha
4 layers of nested functions with a global in the 3rd layer... oh my
this is horrifying
does that function even need the global?
hard to say, this is true spaghetti code
the same global in layers 1, 3, and 4 😱
is there a reason there's no re.Match.match as an alias for re.Match.group()? it's really confusing for people to see match='foobar' but not actually be able to get the "match" attribute
!e ```python
import re
print( re.search("h", "hello") )
@paper echo :white_check_mark: Your 3.11 eval job has completed with return code 0.
<re.Match object; span=(0, 1), match='h'>
There was some change "recently" (last couple of years) that allowed exceptions to become more detailed (showing where in a line an error happened).
For that, some internal object was changed to have character offsets, I just don't remember which one. What was that again?
(My Google-Fu is weak this early in the morning, any query with "Python" and "exception" finds endless tutorials and StackOverflow Q&A.)
may be in the 3.11 whatsnew doc?
Older than that. It's mentioned in 3.10's What's New (as the better syntax errors), but there's no mention of the internals, I think the change might even be from 3.9
!pep 657 found it
**PEP 657 - Include Fine Grained Error Locations in Tracebacks**
Status
Final
Python-Version
3.11
Created
08-May-2021
Type
Standards Track
I don't understand how it's in 3.11, but already used in 3.10
Oh, I see. As of 3.10, this info is stored in AST nodes (which is why it can be used for better showing SyntaxErrors), but not yet propagated to and exposed on code objects.
@gilded yew This is advertising, which we don't allow without approval. Please remove it.
!pep 1
Wow thats old
What python formatter do people prefer using and why? Black, isort, autopep8?
black, it has very little configuration so you can just drop it in with very little effort.
isort and autopep8 aren't exactly full formatters AFAIK
the main competition for black that I'm aware of is yapf
yapf used to have some issues regarding the "stability" of the final formatted document. mostly though I think black seems to have more steam in the python community.
unless you're on like 3.10 or something like that, black formats multiple with statements really poorly, that's the main reason we haven't adopted it
autopep8 is a full formatter like black and yapf
P.S. this is off-topic
is using contextvars the same as using global variables? if yes, is not it bad?
they are fairly similar, though they have way fewer pitfalls in threaded or async contexts. And while yes, they are fairly similar to globals, they can be a powerful tool when designing an API, allowing you to hide internal state of your library, rather than using a class and thus forcing your users into classes as well, when the API could very well work without them.
hm
I found that too, one could use custom classes to pass state down the call chain
I have a problem which can be easier solved by using contextvars, but I was wondering if this is just a workaround
in my case I am using django's ORM to run sync queries in a threadpool within an asyncio application
and I want to support transactions
I thought of using contextvars to track transactions
yeah, that seems like a perfect fit
you always have one context per unit of parallelism
yes, this is a good justification, thanks
contextvars are what you might call "dynamically scoped" -- they aren't necessarily global, but their scope is dynamic rather than lexical
they probably aren't exactly the same as a true dynamically scoped variable, but that's how i think of them and use them
If your contextvar is global, then yes, it probably does suffer from the same pitfalls as other global variables - namely, that it becomes hard to reason about program state when any function could modify it as a side effect.
But global variables aren't evil, they're just a tool that's so easy to use that you can easily overuse it and wind up with a more fragile, less maintainable, less readable program.
The usual advice for global variables is to limit the places where they can be assigned to or modified. You should apply the same approach to contextvars.
I use contextvars extensively, and I think that in general you should try to avoid it unless your API was designed around this sort of contexts. Could this not be tracked on an attribute on a class you have, for example?
Most of my contextvars have 1 purpose and 1 place they get written to (because of that 1 very specific purpose).
If your contextvars are used heavily and have a large amount of state changes I recommend considering other options again
Usually you should be able to conceptualize the state into a class instance somewhere
I'm wondering, what am I missing here? This breaks:
AttributeError("'super' object has no attribute 'value'")
[17] > /home/skeledrew/Projects/awemacs/awemacs/main.py(67)value()
-> return
(Pdb++) self.__class__.__base__.value
<property object at 0x7fc07311dad0>
(Pdb++) ll
55 @value.setter
56 @beartype
57 def value(self, text: str | None):
...
61 try:
62 super().value = text
63
64 except Exception as e:
65 print(repr(e))
66 breakpoint()
67 -> return
Yet this works as expected:
>>> class A:
... @property
... def value(self):
... return 42
>>> class B(A):
... @property
... def value(self):
... ret = super().value / 2
... return ret
>>> B().value
21.0
How should I properly access a property in a base class?
does removing the beartype decorator make a difference?
Issue remains
Objects/typeobject.c line 9634
0, /* tp_setattro */```I see... how can I work around this?
open issue about it: https://github.com/python/cpython/issues/59170
maybe call the superclass descriptor's __set__ directly? Not sure there's anything more elegant
ah the bug report has a better one, super(self.__class__, self.__class__).x.fset(self, value)
Create new? I see this is still open and had activity last year
yes, I meant there's already an open issue about it
Oh OK. So I'm guessing there just isn't enough push for a resolution?
Thanks
Guido seems to like it https://github.com/python/cpython/pull/29950#issuecomment-1122940064, maybe I can merge the PR
yes, several core devs had "meh" reactions
and I don't really disagree, it's a pretty confusing pattern
But it's strange that getter is fine, it's just setter (and del) that's broken
If there isn't a good fix maybe have a custom exception?
That way others encountering it will know that it's an acknowledged issue and not really a bug on their part
More super weirdness. It seems the compiler is unable to resolve references to it. And I'm also wondering why the different error messages:
@property
def x(self):
> return super_fn().x * 2
E RuntimeError: super(): __class__ cell not found
...
[11] > /home/skeledrew/Projects/awemacs/tests/test_utils/test_patches.py(42)x()
-> return super_fn().x * 2
6 frames hidden (try 'help hidden_frames')
(Pdb++) super_fn
<class 'super'>
(Pdb++) super_fn().x
*** RuntimeError: super(): no arguments
(Pdb++) l
37 @pytest.mark.parametrize("super_fn", [super, duper])
38 def test_duper_get(super_fn):
39 class Demo(DemoBase):
40 @property
41 def x(self):
42 -> return super_fn().x * 2
43 assert Demo().x == 84
44 return
45
46
47 def test_duper_set():
(Pdb++)
super is special-cased in the compiler, it has to be named exactly super for the argumentless form to work
Got it, thanks
I've always found this a bit odd. If it's going to be special-cased like that, why require the ()?
I feel like that would require considerably weirder special casing