#algos-and-data-structs
1 messages · Page 139 of 1
But there's no real need to nest, in Java that makes it private and only accessible to code in the list class, Python doesn't do that.
what does python do then? because im assuming once i nest Node i wont be able to access it out of LinkedList
yep actually you could, but you would need to get it through the linked list class
i am thinking i should leave the current playlist im watching which is this one https://www.youtube.com/playlist?list=PLpPXw4zFa0uKKhaSz87IowJnOTzh9tiBk by Dr. Rob Edwards and rather follow
https://www3.cs.stonybrook.edu/~skiena/373/videos/ by Steven Skiena since this is in C which i know (a bit) and hence should be easier to follow?
since im not too far in the first one
i am not leaning for the mit open courseware 6006 since it has pre-requisites which i dont know
In my opinion, this is the best tutorial on YouTube about Data Structures. He uses C/C++ but its super intuitive. Try implementing those data structures in Python as a challenge and it'll fun:
https://www.youtube.com/watch?v=92S4zgXN17o&list=PL2_aWCzGMAwI3W_JlcBbtYTwiQSsOTa6P
See complete series of videos in data structures here:
http://www.youtube.com/playlist?list=PL2_aWCzGMAwI3W_JlcBbtYTwiQSsOTa6P&feature=view_all
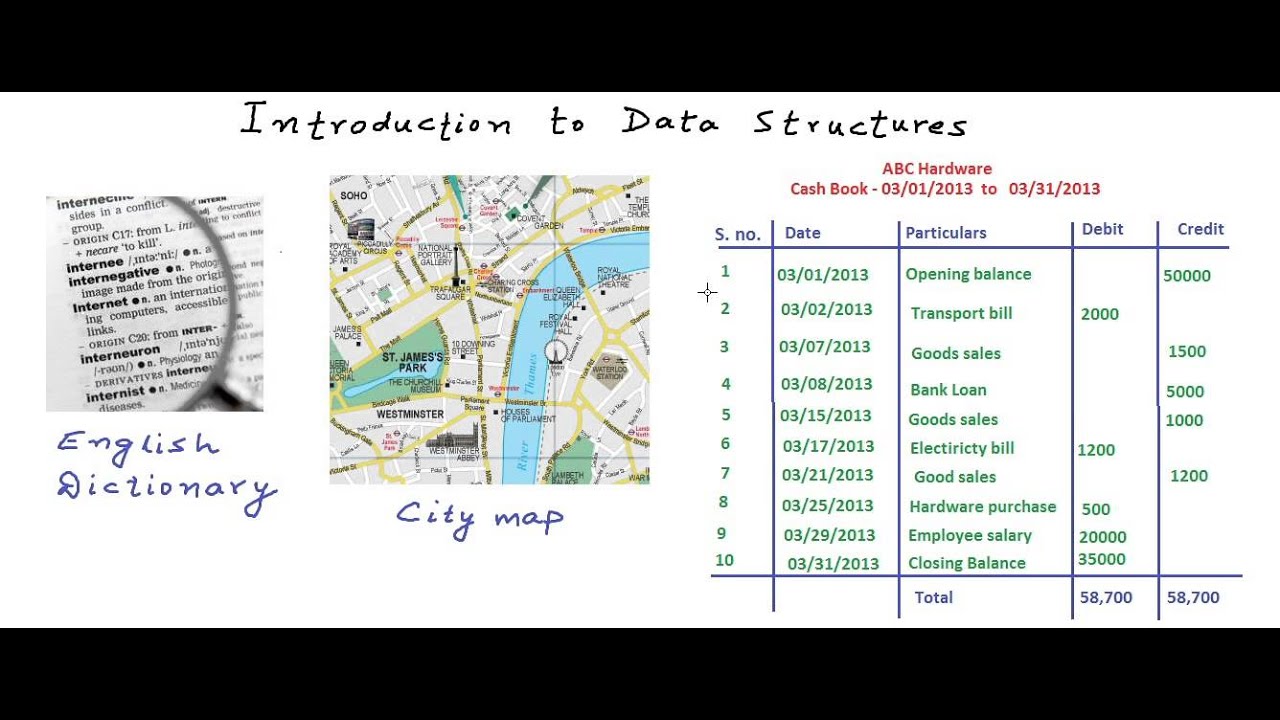
In this lesson, we will introduce you to data structures as ways to store and organize data in computer.
Feel free to drop your question, feedback or suggestion in comments section.
You may also like ...
thanks mate
has anyone tried to solve leetcode 120 triangle problem through applying recursion only ? if so can you please explain your thought process on this plss
wouldn't be a bst, just a binary tree
the general idea is you want to compare the cost of the left branch vs the cost of the right branch
then add the cost of the current node to that
that's the cost of the tree rooted at the current node
you were recently studying dp right? you can use it for this problem
Hmmmm, anyone familiar with Bitcoinlib?

It can't be abcedf, you would visit both e and f from c
how to slice a string to a spesefic value
depth first search means the search goes till dead ends or the leaf nodes in that tree to the right so yes i think so
ok then whats the correct order for dfs?
can't visit F from C bc F points to C

A, B, C, E, D, F
what you said @bright ginkgo was correct
thats what i said
yep
somebody said i was wrong
they didn't see the arrow from F pointing to C
they thought the edge was pointing from C to F
i swear hte more questions i ask the more i get confused cause people giving me wrong answers
it's a hard arrow to spot unless you double click on the picture
yep
bc you'd have to explore C's neighbors before you go to D's
Cheers
I get that
but looking at the image confused me. I assume whoever is posting that pic is an expert in the subject
I think you should look into types of DFS pre, post and in order. There's a variation of DFS
ohh
which type of dfs is that
i forgot there are three dif types of dfs traversales for trees
Preorder in order and post order DFS traversal
right
but which one is that one
the ordering given in the picture
is it pre order, post order, or in order?
in order i think is left, root, right?
it's not a binary tree
oh yeah
Google geeks for geeks they got good explanation
those only work for bsts
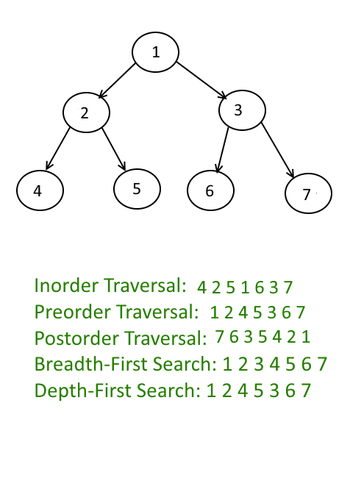
post order is left, right, root
so whats the correct order?
for postorder
and tell me that the image shown isnt wrong
im 99% sure it should be 4 5 2 1 6 7 3
not just bst, binary trees in general
yes my bad
binary trees have a max of two children per parent node
that tree has three
max
counting
whats the correct order for postorder for that diagram?
theres so much shitty material out there sharing wrong information

Step by step instructions showing how to do post-order tree traversal on a binary tree.
Source: https://en.wikipedia.org/wiki/Tree_traversal
LinkedIn: https://www.linkedin.com/in/michael-sambol-076471ba
screw GFG
use this
michael sambol is much better
that's what i used when i went over trees
@old rover you dont know the order do you?
Post order 4 , 5 ,2 , 6, 7, 3 ,1
anyways, I had enough. I'm just gonna grab a uni textbook and just use that for all my info.
too many so called people on the web pretending to be experts
the majority of problems i've seen use in order
Depends what type of DFS u wanna use
also in that image, why is pre-order and depth first search the same?
If u check on leetcode it specifically asked which order to do also there are few questions which type of search traversal u want to use
I think you are confused with DFS and types of traversal
DFS has 3 types of traversal methods. I get that
All of these traversal pre post and in order they are all known DFS
but DFS is just a general term right? If someone says search a tree using DFS, wouldnt they have to tell you exactly which DFS method to use?
Not really. U can do the traversal you prefer to use
yes so DFS can mean in order, pre order, post order right?
ok then why include Depth First Search listed in the ordering in the image. they make it seem as if there are 4 DFS types of traversal methods
cause it all depends
just list the 3
do you get what I'm trying to say?
anyways that picture is just bad in general.
looking that at that image yesterday wasted like 2 hours of learning for me
In that pic it's basically visiting each node start from root and going down to leaf and then right which you can do too.
Lol that's normal I guess
@steep gorge ok thanks for the help
generally, since you're looking for something, it makes sense to check a node as soon as you reach it. for this reason, only pre-order makes sense
Hello folks, I'm currently doing 713. Subarray Product Less Than K
def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:
l = 0
output = 0
product = 1
for r in range(len(nums)):
product *= nums[r]
if product >= k:
while product >= k and l <= r:
product /= nums[l]
l += 1
output += r - l + 1
return output```
What exactly is `product /= nums[l]` doing?Divides it by nums[l].
what this solution is doing is noticing that when you slide the window by one, one element slides into it and one out of it
so all you need to adjust the product is to multiply by the new one and divide by the one that slid out.
This only works if there's no zero elements in the array, though.
yea I think its one of the given in the problems, there will never be a 0 in the array
@vocal gorge the l <= r condition, in the beginning I thought I understood that condition but now am a little confused. Is the condition basically just checking that we dont go out of range?
Imagine the input is this nums = [10,5,2,6], k = 100
At any time, the product is the product of the elements nums[l:r+1], basically
so yes, it's checking we don't adjust the left side of the window so much it goes beyond the right one
!mute 699113369650593843
:incoming_envelope: :ok_hand: applied mute to @supple bolt until <t:1639218380:f> (59 minutes and 59 seconds).
Hi guys i'd need some help somebody wanna join #help-croissant real quick 🙂
Hey guys
I currently have a problem with my code
def compare(guess, target):
guessList = []
targetList = []
x = 0
y = 0
checkString = ''
for targetLetter in target:
targetList.append(targetLetter)
for guessLetter in guess:
guessList.append(guessLetter)
while y != len(guess):
if guessList[x] in targetList:
letterInTarget = True
else:
letterInTarget = False
if guessList[x] == targetList[x]:
letterInRightPlace = True
else:
letterInRightPlace = False
if letterInRightPlace:
checkString += 'X'
elif not letterInRightPlace and letterInTarget:
checkString += 'O'
else:
checkString += '-'
y += 1
x += 1
compare('health', 'teethe')
Currently I have 2 words that I compare
And this is what I have to solve:
Implement a function compare(guess, target) that compares a guessed word
with a target word. You may assume that the two inputs are strings of the same
length that entirely consist of lowercase ASCII letters. The output is a string of
that same length consisting of the symbols X, O, and -, where X represents a red
square, O represents a yellow circle, and - represents nothing (i.e. wrong letter).
Note: O is the letter O, not the number 0.
Examples:
compare("health", "teethe") must return "OX--O-"
compare("rhythm", "teethe") must return "---XX-"
compare("mutate", "teethe") must return "--O-OX"
if I compare health and teethe, it should return "OX--O-"
But it returns "OX--OO" instead
Any idea how to fix that issue?
Try a help channel
It'd be nice if you could describe the question a little better. For instance, what do you mean by "Red circle" or "Yellow circle" and why, for the letters 'h' and 't' the output is 'O'? On what basis do we tell if compare() of two chars returns that particular output char?
Yeah, it's Lingo
Dunno if you're familiar with the concept
O stands for a letter that doesn't correspondent same position, but same letter in word
X stands for a letter that has the same position and letter
- stands for when there's no similar letter at all
HI guys, what is the simplest way to simulate sigma notation in python? I've seen some standard functions in python that'll do it but is there a module so I could just do something like
import sigmamodule as s:
num = s.sigma(1,10.10)
print(str(num))
output is 100
#in this hypothetical function that isn't real, sigma(index value, number of iterations, number we are summing)
tag me if anyone has the answer
Hello folks I'm currently doing 209. Minimum Size Subarray Sum and I solved it this way
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
if target > sum(nums): return 0
l,r = 0,0
curSum = 0
minArr = sys.maxsize
for r in range(len(nums)):
curSum += nums[r]
while curSum >= target:
minArr = min(minArr,r-l+1)
curSum -= nums[l]
l += 1
return minArr```
I was wondering is there another way to implement the `sys.maxsize` function without using this built in function, I'm not sure if during an interview they might accept `sys.maxsize`float('inf')
you can use the fact that the answer can't be more than len(nums)
it works!
but can you elaborate a little more, I don't exactly know why it works
but isn't float(inf) greater than any value lol
(sorry if that sounds really dumb of me)
omg, nvm!!
I completely forgot we are taking the min of minArr
idk what I was thinking lol
can someone help solve this

guys how do u type with a black color boxx
L x M y R
array = [1, 2, 3, 4, 5, 6, 7, 8, 9]
left = 1
middle = 5
right = 9
What can I name x and y?
what do you mean name x and y?
Name it how I have left, middle and right naming convention, so it makes it easy to know which number is located at which position.
Would naming x middle_left and naming y middle_right make sense?
it'd make sense to me
pre_middle for x and post_middle for y
or
before_middle for x and after_middle for y
Because on a second though I can see middle_left and middle_right could cause some confusion.
if those variables are only used briefly then I think any of those are fine. or you could refer to them like array[M+1] and array[M-1]. also, is array always a sorted range?
if it's sorted whole numbers then they might be referred to as predecessor and successor of the middle number (which would be the median if odd length)
I don't understand?
Do you mean this?
Wrap your text in a back tick
this looks like the lowest common ancestor problem
Yeah the array is always sorted, but sometimes rotated.
Yeah, I think [M + 1] and [M - 1] might be a better approach.
sum(x for x in range(n, N + 1))
And you can manipulate the first x there.
of course, you'll have some troubles with infinite sums 😛

(this converges to exactly pi/4)
that won't terminate though
my point is that summing series numerically often isn't easy
can senpaisympy do that?
it's supposed to be able to
though in my experience it's pretty bad with analytic integration/sums compared to, say, mathematica
something like this it should be able to, though
!e ```py
from sympy.abc import n
from sympy import Sum, oo
a = Sum((-1)**n / (2 * n + 1), (n, 0, oo)).doit()
print(a, float(a))
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
pi/4 0.7853981633974483
it knows 
Hey
super new to python, currently doing beginner exercises, am on a password generator and for the meantime im using what i know so its very sub-optimal
basically i got three lists for letters,numbers,and symbols but i dont always want it to run the pattern of generating a letter,then a number,then a symbol (e.g. password="s4%g2@"
so i thought of implementing white space into the lists as well, but when generating the password it keeps spaces in between and i cant figure out how to remove the space
any help?
from random import randint
`import random
letters = ["q", "w", "e", "r", "t", "y","u","i","o","p","a","s","d","f","g","h","j","k","l","z","x","c","v","b","n","m"," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "]
numbers =["1","2","3","4","5","6","7","8","9"," "," "," "," "," "," "," "," "]
symbols = ["!", "@", "#", "$", "%", "^", "&", "*"," "," "," "," "," "," "," "," "]
passwordList=[]
for i in range(0,randint(5,20)):
l=random.choice(letters)
n=random.choice(numbers)
s=random.choice(symbols)
passwordList.append(random.choice(l))
passwordList.append(random.choice(n))
passwordList.append(random.choice(s))
i+=1
passwordList.remove(" ")
print(''.join(passwordList))`
sorry for long block of text
Well, one way you could do it is to generate however many of each kind of symbol that you want, then afterwards shuffle the list. The reason your current code isn't working though is that list.remove() removes the first item it finds that matches, not all of them.
random.shuffle yeah
is there a shuffle function in py?

Hi guys! I am using the above code, to first extract valid worlds that start with any alphabet from the string, and then it returns a list of string in words identifier, and then i am traversing that words list and again finding if that word is a stopword i need to ignore it. The problem is i have to traverse two times. Can someone tell me how I can do the checking while the split() function checks for the valid word can it also check for the stop words?? I am fairly new at python and tried to read the documentation, but didn't understand anything.
First I have a whole article written in the item['content'] string. Now, I have to extract all the valid words from it , words with the pattern in the regex [^a-ZA-Z] whose starting character is an alphabet and also if the starting character is alphabet, i then want to check if it is a stop word or not, if it is not a stop word then i want that word in my list of words. Problem with using split(), is that it just gives all the list of valid words using strings and then i have to traverse through all the words in the list to find stop words.
I want to remove the stop words while it checks for the valid word
maybe re.finditer would help?
just curious is it bad to use super() with polymorphism inheritance
what is polymorphism inheritance
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
i keep getting memory addresses when i try to print the nodes of the depth first traversal
<__main__.Node object at 0x7fb30434dfa0>
<__main__.Node object at 0x7fb30434dbb0>
<__main__.Node object at 0x7fb3042b7640>
<__main__.Node object at 0x7fb3042b7e20>
<__main__.Node object at 0x7fb308247850>
<__main__.Node object at 0x7fb3042b7eb0>
i think i'm calling the function wrong
also the indentation is off i think?
hmm
i'm gonna revise my oop
and also since i used a constructor i don't have to keep doing node.left and node.right over and over again
that defeats the point of a constructor
that's what the default string representation of objects look like
if you want to change that, add __str__ and/or __repr__ method(s) to your class
gotcha
Hey everyone! I just started college 2 months back and started learning C as a mandatory language prescribed by the professor. Earlier I was inclined towards C++ because competitive programming but over a couple of weeks of research, I've found that I am much more interested in open source contribution. As I am about to start getting into Data Structures and Algorithms, everyone says C++ is the better option for it rather than python. But looking at the Open Source community, Python and Java are much more prevalent and have a wider community reach. As per my understanding, language is not a barrier for DS and Algorithms and one can easily switch from one language to another once the basics are clear.
So just wanted to ask that is it a good option to learn a language like C++ ( which does have a lot of pros as compared to Python) or it doesn't really matter for DS and Algorithms?
afaik ds/algos are langauge agnostic
meaning it doesn't matter what language you use to learn it they're applicable other than syntax differences
for example if you learned ds/algos in java it shouldn't be too difficult to apply it in python
yeah thats what I have learnt as well! Gonna stick to Python as of now. Thank you so much for the help! I really appreciate it
no prob, happy to help
Hello
def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:
node1 = l1 # copy of the listnode
# print(node1)
node2 = l2 # copy of the listnode
arr1 = [str(node1.val)] # because I'm lazy and want to use while node1.next
# print(arr1)
arr2 = [str(node2.val)] # same as above but while node2.next
while node1.next: #creating a list of values for node1
node1 = node1.next
# print(node1)
arr1.insert(0, str(node1.val))
# print(arr1)
while node2.next: #creating list of values for node2
node2 = node2.next
arr2.insert(0, str(node2.val))
new = int(''.join(arr1)) + int(''.join(arr2))
print(new)
first = last = ListNode(new % 10)
print(first)
while new > 9: #iterate through new to create a listnode
new //= 10
# print(new)
last.next = last = ListNode(new%10)
# print(ListNode(new%10))
return first
``` Just out of curiosity, what time complexity would this function be?It has 3 while loops
Is this O(3n) or O(n)?
O(3n) and O(n) are exactly the same thing
O(n) is the class of functions that scale linearly with their input
also, you need to understand what n means. there is two nodes, you can say n is size of l1 and m is size of l2 and the complexity O(m+n). the last while uses the variable new, not a list so I think it's O(1)
Is there a solution to secondary clustering in Quadratic Probing?
Hey, can anyone recommend any yt vids for learning algorithms and data structures?
Not sure about yt vids but you can check pins for other resources
print("\n")
x = len(Atm)
y = 0
z = 0
go = 0
while z <= x-1:
go = 20 - len(Atm[y])
while y <= x-1:
print(BLUE + str(y+1) + End + ". " + GREEN + Atm[y] + End + " -> " + CYAN + Atm_symbols[y] + End + " -> " + PURPLE + Atm_mass[y] + End)
y += 1
z += 1```Plz tell the error
Atm and other lists are not mentioned but they are listed ocrrectly
also, these variables are junk variab;e
yes
I wanna learn dsa in python
could some here help me out
I don't have any proper source for it
check the pins in this channel
import pygame
import random
pygame.init()
screen = pygame.display.set_mode((800,600))
pygame.display.set_caption("Catch The Egg")
icon = pygame.image.load("Egg/egg.png")
pygame.display.set_icon(icon)
#Basket
basket_img = pygame.image.load("Egg/picnic-basket.png")
basket_x = 400
basket_y = 200
basket_x_change = 0
def basket(basket_img,x,y):
screen.blit(basket_img,(x,y))
#Egg
egg_img = pygame.image.load("Egg/egg.png")
egg_x = 400
egg_y = 200
egg_x_change = 0
def egg(egg_img,x,y):
screen.blit(egg_img,(x,y))
#BG
backdrop = pygame.image.load("Egg/bg.jpg")
pygame.display.update()
I am having a syntax error, what's wrong?
Anyone have literation about NPCR or UACI?
http://worrydream.com/LearnableProgramming/ (Here's a trick question: How do we get people to understand programming?)
problem solved ty
I had an interview today where we have an n^2 solution. Then I make it nlogn.
Then he asked if I sorted something could it make it faster. I said yes but wasn't sure how. What algorithm can I read about for this?
brucie give your task from interview
Now there is
if I have a graph that looks like
6
/
1 5
/ \ / | \
4 2 ――― 7
\ / \ | /
3 8
/ \
10 9
DFS
Order 1: 1 4 3 2 7 5 6 8 9 10
Order 2: 1 2 5 8 7 6 3 10 9 4
If you start at 1, which order is correct?
thanks
ricky both correct if visit every place
@next oxide ok thanks
Write a function that takes two lists. A list of names for a flight and a no fly list. How can you do better than nlogn? Naive approach is n^2, for every person check the whole no fly list.
I’d love to know the name of the sorted approach so I can study it
brucie what exactly u need check in no fly list?
cuz maybe it is possible in linear it depend what u need find
Membership
Is name equal to name
try dictionary or set
I want an algorithm name
I think if both lists are to be sorted. You can solve the function in 3n
I dont think there's a specific algorithm name for this
dastraido said you could use a dictionary/set, which are hashmaps.
You go through your no fly list, and add each name to your hashmap/dictionary/set
This uses up space
Then you run through your flight list and check your hashmap/dictionary/set for each name.
A hashmap operates in (practically) constant time.
So take your two lists
no fly is list a
and flight list is list b
Time complexity is O(a+b), space complexity is O(a)
otherwise, if you have to use two sorted lists, you could modify merge sort:
sort both lists alphabetically
then check if the first flight name is the same as the first no-fly name
if its not, and if first flight name is alphabetically before the no flight name, then go to the next flight name
otherwise, go to the next no flight name
similar to how merge sort works
If by that you mean to remove/deprecate the no fly list from flights list -
• Simply convert both lists into sets, use the .difference() method and convert back to list. -- O(1)
• In case no fly list contains other names that dont appear in the flight list, use .union() and remove all those element from the original list. -- O(n)
if it was sorted(input) you can just use two pointers
This seems a lot better than my version.
I'm not experienced with using sets in python
we don't know him task,so it is hard to find the best solution 🙂
¯_(ツ)_/¯
for example this,earlier not mention about lists was sorted
i meant that solution is just simpler, it uses less lines of code to achieve the goal
oh i didnt see this link, but it mentions an idea I also brought up
you can use min() to compare two strings, it returns the first in alphabetical order
they aren't, the second goes from 2-5-8, without first getting 6 or 7
8 is connected to 5 though
oh, I didn't notice that
with backtracks shown
1 4 3 2 7 5 6 | 8 | 9 | 10
1 2 5 8 7 | 6 | 3 10 | 9 | 4
Hello folks, this might be a little silly
Let's say we have arr = [1,1,3,4,5,-1,0]
What's the difference between
for i in arr:```
and
```py
for i in range(len(arr)):```
Is it that for the first `for` loop we want to access the value of `arr` and the second `for` we want the index?try printing i and see what you get
yup it was I as I suspected
the first for loop we want to do something with the values and the second for loop we want to do something with the index
yep
Does dict_keys and dict_values have O(1) Time complexity and access?
if you mean O(1) membership test, keys does, values doesn't
So dic_values will be O(n)?
searching in it would be
oh ok thanks!
Question is to count palindromic substrings
class Solution:
def is_palindrome(self, string:str, left, right) -> bool:
while left < right:
left_char = string[left]
right_char = string[right]
if left_char != right_char:
return False
else:
left = left + 1
right = right - 1
return True
def countSubstrings(self, s: str) -> int:
count = 0
for i in range(len(s)):
for j in range(i, len(s)):
if self.is_palindrome(s, i, j) is True:
count = count + 1
return count
Above Times out.
But below passes. I thought creating a substring would be slow!?
class Solution:
def is_palindrome(self, string:str) -> bool:
return string == string[::-1]
def countSubstrings(self, s: str) -> int:
cache = {}
count = 0
for i in range(len(s)):
for j in range(i, len(s)):
sub_string = s[i:j+1]
if sub_string not in cache:
boolean = self.is_palindrome(sub_string)
cache[sub_string] = boolean
stored_boolean = cache[sub_string]
if stored_boolean is True:
count = count + 1
return count
So a substring via slice would be faster than iterating over?
Because in the first approach we iterate over elements to determine if it's a palindrome or not.
In the second approach if we replace the is_palindrome implementation with how it's done in the first approach, it still passes.
oh wow thanks!
oops
Is inserting a node in the middle of a linked list a normal operation?
Would your normally insert by order position or would you insert new node after n node element?
Inserting in the middle is the thing linked lists are very good at doing in particular. You'd normally insert before/after a node you have a reference to, depending on the direction of the linking.
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
If my understanding is correct, their insert method is wrong for their python code sample?
``Linked list after insertion of 12 at position 3: 3 12 5 8 10`
12 in this case is in position 2
I even tried changing the position to 4 and 5 but it seems like the code doesnt allow your to insert past position 2
I dont know if this is a bug or I'm just not understanding what the code is supposed to be doing
It's quite confusing using a position starting at 1, and also then having a while loop with the if that always ends it early...
head = getNode(3);
head.nextNode = getNode(5);
head.nextNode.nextNode = getNode(8);
head.nextNode.nextNode.nextNode = getNode(10);
head.nextNode.nextNode.nextNode.nextNode = getNode(15);
head.nextNode.nextNode.nextNode.nextNode.nextNode = getNode(20);
The list is now 3, 5, 8, 10, 15, 20
if i do head = insertPos(head, 4, 500);
shouldnt it be 3, 5, 8, 10, 500, 15, 20?
Yeah.
but I'm getting Linked list after insertion of 500 at position 4: 3 500 5 8 10 15 20
Am I just misunderstanding something?
Clearly the code is wrong then?
I dont know. Maybe I'm wrong
Hello folks I have a question about diagonal matrix traversal, here's my code
arr = [
[1,2,3],
[4,5,6],
[5,6,7]
]
n = len(arr)
leftDiag = rightDiag = 0
for i in range(n):
leftDiag = arr[i][i]
rightDiag = arr[i][n-1-i]
print(rightDiag)```
Am having a little trouble understanding how the `leftDiag` and `rightDiag` exactly work.
For example `leftDiag` starts at `[0][0]` which is `1`, since `leftDiag = arr[i][i]`, as it iterates through the matrix, `leftDiag` will only equal `[1][1],[2][2]` which are `5,7` and so on.
Is this correct?yep
ahh ok
For rightDiag = arr[i][n-1-i]
arr[i] basically means we are starting at the first row
and arr[n-1-i] is where am a little confuse
I know n-1 means that instead of starting from the left side, we instead start from the right side, just the -i gets me confused. I don't know what exactly it means
What's your expected output?
n is the length, 3, i increases from 0-2
so on the first iteration, the value of n-i-1 is? @idle pier
rightDiag once the for loop is done is [3,5,5]
thats the right diagonal traversal
do you mean n-1-i?
if you do its, 3
it's 2
n is 3, i is 0, n-i-1 is 2
sorry am lost lol
where are you getting n-i-1 from?
oh really? I didn't know that lol
how does it equal 2?
3-0-1 is 2
if its 2, how does it end up being [3,5,5]?
on the first iteration i = 0, right? so it's arr[0][2], which is 3
ohh you meant, that the index is 2?
If thats what you meant, I knew that lol
so what's wrong then?
What was getting me confused is the i. I know that n-1 means the right most index.
I just didn't know what exactly i was/is doing
ohhhh I think know why
ok since we want to start on the right which is n-1 but I want is the value, which is 3 but in order to access the value we must do a -i.
Is this correct?
i is just a number subtracting it doesn't do anything special
hmm ok, so i in the first iteration is 0, in the next iteration, it should be 1 and so on correct?
yep
I think I just realized what was my issue understanding that particular
It's because I was thinking about it this way n - 1 and not [n - 1]
Once its inside the [], its something different, correct?
it's just subtraction no matter where it is
the result of that subtraction can be used elsewhere, though
the [] are used to index the list in this case
so first it does the subtraction, then it takes the result and uses it as an index into the list
hmm yea that makes a lot more sense
can someone link me to open source web3 Operating systems
preferably one owned by a DAO i see so much decentralized stuff but not sure what is what tbh lol
metis vs dxos vs elastos vs whatever else i cant think of rn
it's pretty good
There's a newer intro to algos class
@outer lake I don't know if you'd like to pin this newer version, since you pinned the 2011 one?
Sure
MIT 6.006 is a great course for an introduction to algorithms and data structures. The course covers quite a range of stuff, from data structures like trees and heaps, to shortest path with Djikstra. The explanations they provide are much better than anything I've encountered elsewhere, and they provide some exercises (some based in Python) that can be used to practice
https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-006-introduction-to-algorithms-spring-2020/

MIT OpenCourseWare
This course is an introduction to mathematical modeling of computational problems, as well as common algorithms, algorithmic paradigms, and data structures used to solve these problems. It emphasizes the relationship between algorithms and programming and introduces basic performance measures and analysis techniques for these problems.
Thanks for the heads up
no problem 🙂
Ive done pip install six and sudo apt install python-testresources
What else could be missing so six.movesgets detected ?

Do you actually get an exception when you run the file, or do you only get a Pylance error in VSCode? If the former, python actually can't find the path; if only the latter, it's "just" the Pylance linter/inspection that somehow fails to recognize the import.
Also, I just realized we're iin #algos-and-data-structs, which probably isn't the right channel
the code actually runs without the 'module Not FOund' error
but I think the code is probably not running correctly , just a hunch
not sure if i can ignore the error yellow underline
Then it's "just" the Pylance tool that doesn't understand the import. This error is not actually a python error. You could try asking in #tools-and-devops, as this is a common error in VSCode due to some configuration. (I don't use VSCode, so I can't help you there.)
so the code will not run properly and the yellow underline should not be ignored ?
The other way around. There's no error from the perspective of Python. "Pylance" is not a part of Python, but a tool that's often used in VSCode to help you write Python code by detecting mistakes. In this case, the tool is wrong, and the import does work.
Anyway, try asking around in #tools-and-devops or another channel, since this channel is specifically meant for discussing algorithms, data structures, and computer science
hmm thanks, so even if I do manage to import it , the code would still not run properly just like it is now 😅
Yeah I just noticed , thought I was in the #python-discussion room, although it did seem way too quiet for that lol
Does anyone understand why this code works
def unique_id(x, max_id: int, prime_seed):
if max_id > prime_seed:
raise RuntimeError("The prime seed has to be greater than the max id to guarantee uniquness")
return (prime_seed * x) % (max_id + 1)
MAX_ID = 1_000_000
ids = []
for i in range(1, MAX_ID + 1):
ids.append(unique_id(i, max_id=MAX_ID, prime_seed=219263504448813723507259556066210085089))
assert len(set(ids)) == MAX_ID
I suspect its a special case of multiplicative hashing
Yes, this is great! The course mentions the text not being required but I ordered anyways for reference. I was going to audit this class in a few just to get a feel for it.

Hey @fierce igloo!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
why does the .py find the nums.txt file but the .exe doesnt find it
( pls ping me )
is there a way to make a function, maybe recursive, to search through an array of unknow dimension and unknown structure, and return the coordinates of it
suppose
a[0][2][1] = 22
then
find(22, a)
should return the coords as
[0,2,1]
was just wondering if there was a generalized way to search to arrays
i have made lambdas to search through 2d and 3d arrays, donno how to generalize it for 4d or arrays of unknown structures
maybe i should go to a help channel
Can be done by help of recursion.
You can check if it's a list. If not, compare, and send a state each time if it's a list for index.
yea i tried that
And?
tho i donno how to return all the indexes from downup when something matches
Makes sense. You shall share the code. May be i can help with that.
no problem 🙂
I have a question how to make ASCII animations with gif like d and this?
how would you remove a node from a linked list if you dont have access to the head?
nevermind. figured it out
Hello folks, I'm trying to rotate a n x n matrix 180 degrees clockwise, I know how to rotate it 90 degrees but am lost on how to rotate it 180 degrees
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
N = len(matrix)
l,r = 0,N-1
while l < r:
matrix[l],matrix[r] = matrix[r],matrix[l]
l += 1
r -= 1
for r in range(N):
for c in range(r):
matrix[r][c],matrix[c][r] = matrix[c][r],matrix[r][c]
print(matrix)```Hello, I recently started learning Python and would like to know how to open libraries and what needs to be done to make the code work because I don’t understand the instructions, I apologize in advance if I wrote to the wrong channel because I don’t know English well
180° rotation is reversing both axes
it's the simplest rotation
you just do [row[::-1] for row in matrix[::-1]]
for the first for loop?
if you mean like no builtin functions, yea lol
@runic tinsel or maybe you can write the code?
I think I know what you mean
N = len(matrix)
for r in range(N//2):
for c in range(N):
matrix[r][c],matrix[N-r-1][N-c-1] = matrix[N-r-1][N-c-1],matrix[r][c]
if N%2:
r = N//2
for c in range(N//2):
matrix[r][c],matrix[N-r-1][N-c-1] = matrix[N-r-1][N-c-1],matrix[r][c]
i don't know i messed up the style
you have it cleaner somehow
my code only works when rotating 90 degrees both clockwise/counter clockwise
for counter clockwise in my code, I just transpose first and then reverse
have you gotten an answer for your 180degree question?
I mean frownyfrog solution works and I seen it online but I wanted a solution similar to my code style
I think you're on the right track when you write:
N = len(matrix)
l,r = 0,N-1
while l < r:
matrix[l],matrix[r] = matrix[r],matrix[l]
l += 1
r -= 1
there's an easier way to write it though
N = len(matrix)
for x in range(0,N//2):
matrix[x], matrix[N-(1+x)] = matrix[N-(1+x)], matrix[x]
whoops
I think that works
so that should be a mirror image along one axis
and then you can rewrite it to mirror along the other axis
to get a full 180 degree rotation, in effect
Are hash maps and hash tables essentially referring to the same thing? Im in my dsa class, and we are learning about hash tables. I searched on google and it's not very clear. Is it like people calling functions methods and methods functions? Terms are used interchangeably but 'technically' different?
does my solution match the style you had in mind?
complete solution would look like this
N = len(matrix)
for x in range(0,N//2):
matrix[x], matrix[N-(1+x)] = matrix[N-(1+x)], matrix[x]
for x in range(0,N):
for y in range(0,N//2):
(matrix[x])[y], (matrix[x])[N-(1+y)] = (matrix[x])[N-(1+y)], (matrix[x])[y]
print(matrix)
I don't know if its an efficient run time though 😛
hmm no not really lol but thats fine
why do we need to include the 1 in [N-(1+y)]
if y = 0, then you'd be looking for the index N-0
because list indexes start at 0, a list of length N doesnt have an element at index N
the Nth element is located at index N-1
ive also never used the reverse() function before, I think you could do
for x in range(0,len(matrix)):
matrix[x].reverse()
matrix.reverse()
print(matrix)
yea but one of the reasons I sometimes dont use builtin functions unless its necessary is because maybe they dont want it during interviews
yeah, i can empathize with that
what I wrote here is essentially the same
but i manually wrote the reverse algorithm
the first for loop is the reverse algo correct?
both for loops reverse lists
but your matrix is a list of lists
so the first for loop reverses the list of lists
and then the second for loop reverses each of the inner lists
I have another question if you dont mind, does this also work on mxn matrix or only on nxn? Because my code only works on square matrix
🤔
you could modify it relatively easily to get it to work on a mxn matrix
# assign M and N
for x in range(0,N//2):
matrix[x], matrix[N-(1+x)] = matrix[N-(1+x)], matrix[x]
for x in range(0,N):
for y in range(0,M//2):
(matrix[x])[y], (matrix[x])[M-(1+y)] = (matrix[x])[M-(1+y)], (matrix[x])[y]
print(matrix)
well, thats for N lists, each of length M
which would be the same as this one
I think the more difficult question is the 90degree clockwise/counterclockwise question
really?
I think thats the easiest one lol
well, the 180 degree rotation one can rely on a 180degree rotation being the same as an x-axis reflection combined with a y-axis reflection
whereas a 90 degree rotation, i can't think of a shortcut
so i'd have to do something like
well, i'd have to figure out a way to swap 4 slots in 4 different lists, simultaneously, and find a way to calculate the correct quadruplet of slots
it may be relatively easy, but unless theres a shortcut im not seeing, it would require a bit more problem solving
yeah, im trying to figure it out and id need a notepad to jot it down to visualize it better lol
but I dont have one near me, so I'll probably give it a go later
!e ```py
months = ["January","Febuary","March","April","May","June","July","August","September","October","November","December"]
for n, m in enumerate(months):
print(m, n+1)
@elfin sundial :white_check_mark: Your eval job has completed with return code 0.
001 | January 1
002 | Febuary 2
003 | March 3
004 | April 4
005 | May 5
006 | June 6
007 | July 7
008 | August 8
009 | September 9
010 | October 10
011 | November 11
... (truncated - too many lines)
enumerate function is sick
instead of doing that manual +1...
for n, m in enumerate(months, start=1):
...
how does n become a variable but m is a iterator
m is an element in months, i'm not sure what you mean
for n, m in enumerate(months):
print(m, n+1)
why is n a number but m is the iterator for the array
you can plus 1 to n but im sure if you plus 1 to m it would give a error
right, because it's a string
that's why im saying why does one become a number and the other str
enumerate gives you tuples, which you unpack into the index and element
it's iterating over the function's return, and unpacking each element in it
you are using a for loop
if you mean why do you use enumerate, you use it when you need the index of the element you're getting
like in your example
i mean, i guess it would be better than a range loop
compared to range(len(...)), it's faster and looks better
some of them are good, some of them are kinda useless
whats a useless one
!d memoryview
class memoryview(object)```
Create a [`memoryview`](https://docs.python.org/3/library/stdtypes.html#memoryview "memoryview") that references *object*. *object* must support the buffer protocol. Built-in objects that support the buffer protocol include [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") and [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray "bytearray").
A [`memoryview`](https://docs.python.org/3/library/stdtypes.html#memoryview "memoryview") has the notion of an *element*, which is the atomic memory unit handled by the originating *object*. For many simple types such as [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") and [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray "bytearray"), an element is a single byte, but other types such as [`array.array`](https://docs.python.org/3/library/array.html#array.array "array.array") may have bigger elements.i mean, i guess it could be useful if youre doing ctypes or somthing lowlevel with python
Is this a the ideal place to share a weird phenomenon I found through python? I threw together this blog post with some pretty simplistic code to extend the collatz conjecture to a weird, possible conclusion
Math hobbyists
This was my submission for a math contest hosted by 3blue1brown
Coding in a sieve of eratosthenes for the extended collatz sequences should be simple enough once I'm more familiar with dictionaries
Hello
i actually find this kinda cool.
it seems like a rather natural extension and something thats definitely fun to explore!
Thanks!
Has anyone here worked with binary search trees and sorting methods related to them?

Tuple
Heyo! I'm looking for help with hash tables in #help-lollipop if anyone's familiar 😄
Hey
For Heaps, what is the difference in time complexity when building the heap from a list, and one from inserting the numbers from the same list 1-by-1?
if you insert elements 1-by-1 you will get O(nlogn) while if you build heap from array you can get O(n)
@main flower why exactly is that? Having a hard time wrapping my head around it, I get that if you insert och 1-by-1, sorting is done for each one, but how is that step faster for the ”input entire list” for the other algorithms?
@main flower and thanks for the quick response! Appreciate you!
isn't it O(n) for both
What do you base that on @agile sundial? 🙂
I don't see the difference between inserting elements one at a time and from an array
@main flower and @agile sundial would love for a discussion regarding my question on heaps and the time complexity of building one by inputting 1-by-1 or an entire list, since I received conflicting answers by the two of you.
is it against the community tools to ask about how to make a palindrome code? I'm trying to make one that uses no spaces in the string (.srip), converts all letters to lowercase (.lower) for the definition is_palindrome(input_string) and defines new_string = "input_string" and reverse_string== "new_string.index([-1:0])" <<-- my guess
how could I sort this list that it would do this (Imagine points being plotted on a quadrant graph):
Original Tuple:
((6,0),(6,-5),(6,-10),
(2,0),(2,-5),(2,-10),
(-2,0),(-2,-5),(-2,-10))```
Desired Order:
(-2, -10)
(-2, -5)
(-2, 0)
(2, 0)
(2, -5)
(2, -10)
(6, -10)
(6, -5)
(6, 0)```
what is that order, why are the (2, *) sorted in reverse
imagine a pwm signal , thats what it would look like if drawing a line across
are you sorting them by angle or something?
bottom -> top -> left -> bottom -> left -> top and so on, thats how the order would be
should be straightish lines
basically once the x value (column) changes it should start from top to bottom and when it changes again it should start from bottom to top and so on
ah, so you're just sorting first by first, then by second element
I believe that's what you'll get it you just sorted that list - that's how tuples are compared by default
it's kind of a zigzag order, no?
yeah
This is the starting graph

Afterwards:

if (x-2)%4==0 always then I guess you can use some key involving (x-2)%8
The dots would/should be plotted in that order
yeah ?
actually not zigzag ,
more pwm like

im already getting the zigzag by simply using : sorted(rectangles)
hey so im doing python beginner exercsises and one of them involves getting news titles from nytimes, couldnt solve it so this was the pre-written solution.
`import requests
from bs4 import BeautifulSoup
base_url = 'https://nytimes.com'
r = requests.get(base_url)
soup = BeautifulSoup(r.text, "html.parser")
for story_heading in soup.find_all(class_="title-heading"):
if story_heading.a:
print(story_heading.a.text.replace("\n", " ").strip())
else:
print(story_heading.contents[0].strip())`
so this code when ran doesnt do anything, i checked to see if maybe the name of the class isnt "title-heading" and indeed it wasnt, but i found that the class name was different for every title heading, is that the reason the code doesnt do anything when ran, and is there some other way i can retrieve the titles off of nytimes?
!e
!e
print(sorted([(6,0),(6,-5),(6,-10),(2,0),(2,-5),(2,-10),(-2,0),(-2,-5),(-2,-10)],key=lambda x: (x[0],(((x[0]-2)%8)//2-1)*x[1])))
@tepid spruce :white_check_mark: Your eval job has completed with return code 0.
[(-2, -10), (-2, -5), (-2, 0), (2, 0), (2, -5), (2, -10), (6, -10), (6, -5), (6, 0)]
holy F
@tepid spruce can you pls explain the theory behind it
is this very specific to these numbers or could it work for randomly generated squares too ?
multiply even columns' y by -1 and odd columns' y by 1, then sort in default order
it's specific to your x's
I should really start using lambda side thought
fair enough my x's are multiples of two , what if its also odd ones
separate case Im assuming
yeah this approach is specific to your input pattern
a more general approach could be sorting normally and then reversing parts of it
thanks very much
by that you dont mean the order, since you ordered it anyways via sorted()
I mean it depends on what your pwm looks like. whether the x intervals are uniform, etc.
if you aren't familiar with sorting by a key, read this https://docs.python.org/3/howto/sorting.html#key-functions
ill read it, sometimes the issue is not even knowing how to describe the issue
Hello folks, am currently doing 21. Merge Two Sorted Lists on leetcode
this is my solution
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
if not list1: return list2
if not list2: return list1
cur = dummy = ListNode()
while list1 and list2:
if list1.val < list2.val:
cur.next = list1
list1 = list1.next
else:
cur.next = list2
list2 = list2.next
cur = cur.next
cur.next = list1 if list1 else list2
return dummy.next```
Linked List is one of many topics I need to improve on. I then realize, it is possible to solve this problem `in-place`. I found one but I really don't understand it
```py
def mergeTwoLists(self, l1, l2):
if None in (l1, l2):
return l1 or l2
dummy = cur = ListNode(0)
dummy.next = l1
while l1 and l2:
if l1.val < l2.val:
l1 = l1.next
else:
nxt = cur.next
cur.next = l2
tmp = l2.next
l2.next = nxt
l2 = tmp
cur = cur.next
cur.next = l1 or l2
return dummy.next```works like a Fing charm
your solution is also in-place though
https://en.wikipedia.org/wiki/Binary_heap#Building_a_heap has an explanation
maybe try another channel like #data-science-and-ml
can you write is_palindrome without the extra requirements?
did you figure this out? your rule 2 looks off
it is?
Hello, I am looking for someone who can help me with data structures and algorithms. Please inbox me if you are willing to. I will pay you.
you don't copy the lists afaict
Currently looking for help with Binary Search Trees and sorting methods if anyone is knowledgeable about them in #help-kiwi.
Hi @spice orbit are you the mythical BST wizard?
haha Binary Search Tree?
ohh
wanna see the binary search algo
def binary_search(target, lst, start=0, stop=0):
stop = len(lst) if not stop else stop
if start >= stop or start+1 == stop:
return -1
if lst[(start+stop)//2] == target:
return (start+stop)//2
if target > lst[(start+stop)//2]:
return binary_search(target, lst, ((start+stop)//2), stop)
return binary_search(target, lst, start, ((start+stop)//2))
```too late
ah ok i thought you wanted to see mine 😛
that looks lovely alright 😄 I'm looking for a bit of help on figuring out something with mine if you've any ideas where i might find it??
Est-ce récursif vue qu'il y a l'appel de la fonction au sein de la définition de la fonction, non ?
anddd i dont speak that language
oh sorry i belive i was in another servor ><
@spice orbit is this a recursive algo since the call of the Func is in the Def of the Func ?
it is recursive yes
recursive algo are dangerious for me, its not "bug-free". i mean in algo for car / sky rocket, recursive may be no use, if ?
its remain me dichotomy algo, is it that or a is it a "false-friend" (in "often confused" meanning) ?
can i ask why is my code broken (im kinda new to py)

\
thats why i hate repl
use vsc , its better at pointing out mistakes and doesnt lag like replit
i need to use replit cus i join a coding course and they say i gotta use it
sublime text is sexy
a linked list is not a python list, no
a list is a dynamic array, yes
a linked list is a bunch of nodes connected by pointers
these pointers are shown as arrows when a linked list is visualized

each node has a a value and a pointer pointing to the next node
the last node points to Null
i encourage if you don't know OOP to learn OOP first before you approach linked lists
Hey guys, anyone knows the name of the problem when you have x people and the same number of objects, people have a list of preferences towards the objects they want to be assigned, and you want to assign the objects to people to get the least ammount of "jealousy" between people?
that's good
sounds like a graph problem and trying to find a minimal weight path through the graph
it is graph problem, but not minimal weight path
it's the mating algorithm
@old rover @stable pawn
Hello guys I have a numpy question, can this be implemented easier using numpy or a lambda function?
def abides_to_sample(list_val: list, sample: dict):
for node_name, node_val in list_val:
if sample[node_name] != node_val:
return False
return True
By mating you mean marriage problem?
Example of list_val:
[('A', 1), ('E', 0)]
Example of sample:
{'A': 1, 'E': 0, 'B': 1, 'C': 0, 'D': 1, 'F': 0}
Because that's not quite it
Maximum matching problem
Maximum bipartite matching @stable pawn
Im sure its a thing
the what now?
how so?
i think mating problem is when people and objects have preferences lists
like for students and colleges
or marriages
but the one i was talking about was when only 1 of the two objects have a preference list
i think both problems are very similar but i'm just asking about the name
hmmm
this might be it
Is there anyone who can help me in Ant colony algorithm? 😑
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
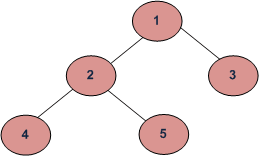
why are they saying that the height is 2?
it is 2

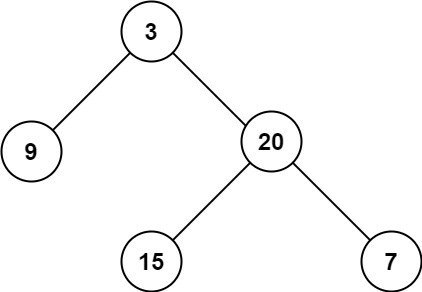
https://assets.leetcode.com/uploads/2020/11/26/tmp-tree.jpg
https://leetcode.com/explore/featured/card/top-interview-questions-easy/94/trees/555/

LeetCode Explore is the best place for everyone to start practicing and learning on LeetCode. No matter if you are a beginner or a master, there are always new topics waiting for you to explore.
Input: root = [3,9,20,null,null,15,7]
Output: 3
you missed a closing parenthesis in line 51
I think this is what I just used. Hungarian algorithm.
not bi partite matching
If every job applicant has every job in their preference list that is
what it basically does is, that you can find the combination pairing of single way pairings of X set of elements to Y set of elements causing the least total amount of cost.
cost here is preference number, because you want it to be lowest in total
Depends, some notebook counts nodes as @agile sundial mentioned
Hello, How to make my breath first search faster
I need to find the longest path in a graph from starting point(A) to end node(B), and then I need to find the longest path in the graph from the last end node(B) to the new end node(C) (The longest path searches for the end node, I don't need to find the longest path to specific end node)
What do you mean by 'new' end node?
Well the node that is the biggest distance away from B(English is not my native language so i don't know if node is the right word, maybe vertex is better)
So the distances in the graph aren't symmetric? Meaning of B is the farthest distance from A, then A is not necessarily the farthest from B?
But couldn't you just run the algorithm a second time starting from B in that case?
yes, that is what I do, I run bfs two times(one for finding the farthest node from A then the farthest node from B), but I need to make it faster
I can send the code if you want, but i don't know if it would be of any help
you want longest hops in a directed graph? is it slow because of implementation?
maybe? I don't know I am pretty new to this, I don't know what is the fastest implementation, maybe I already achieved it, because the answer is in CPP, i don't know the fastest implementation in python
are you saying it's slow because you've timed it and it's slower than the official answer (in cpp)?
yes
your code is a direct translation of the answer from cpp to python?
i think so yeah, i don't understand cpp so i am not sure
but keep in mind that the expected answer(in cpp) isn't always the fastest, usually it is the easiest that passes the time limit
we would need to see code to know for sure what's wrong
sure here it is
(could be just cpp vs python)
tm = 0
n, m = list(map(int, input().split()))
b = [list(map(int, input().split())) for x in range(m)]
cn, ln, pr, wys, a1, a2 = [[] for x in range(n+1)], [], [0]*(n+1), [0]*(n+1), 0, 0
#makes a list of connections
for x in range(len(b)):
cn[b[x][0]].append(b[x][1])
cn[b[x][1]].append(b[x][0])
cn = list(map(tuple, cn))
#makes b one list so it is easier to loop
b = [i for x in b for i in x]
#loops through b
for x in range(len(b)):
#finds the first end node
if pr[b[x]] == 0:
a2 = a2+1
ln.append(b[x])
pr[b[x]] = 1
while ln != []:
d = ln[0]
for i in range(len(cn[ln[0]])):
if pr[cn[ln[0]][i]] != 1:
a2 = a2+1
ln.append(cn[ln[0]][i])
pr[cn[ln[0]][i]] = 1
ln.pop(0)
ln.append(d)
pr[d] = 2
wys[d] = d
#finds the longest node from first node and writes path
while ln != []:
d = ln[0]
for i in range(len(cn[ln[0]])):
if pr[cn[ln[0]][i]] != 2:
wys[cn[ln[0]][i]] = ln[0]
ln.append(cn[ln[0]][i])
pr[cn[ln[0]][i]] = 2
ln.pop(0)
#backrtracking the path
while wys[d] != d:
d = wys[d]
a1 = a1+1
a1 = a1+1
print(a1+(n-a2))
```yeah, but someone from another discord programming server told me I can use a* algorithm to make it faster, and it might work, I have to implement it and see
Yes, that's a specific algorithm https://en.wikipedia.org/wiki/A*_search_algorithm
A* (pronounced "A-star") is a graph traversal and path search algorithm, which is often used in many fields of computer science due to its completeness, optimality, and optimal efficiency. One major practical drawback is its
O
(
b
d
)
...
:incoming_envelope: :ok_hand: applied mute to @glacial charm until <t:1639789438:f> (9 minutes and 59 seconds) (reason: burst rule: sent 8 messages in 10s).
what if you make ln a deque or queue?
you can do that in python?
yup from collections import deque
hmm, i don't know if that is allowed, i know numpy and random aren't, will check it out
then just keep it as a list, and use it as a queue, but don't pop(0), this can be slow
instead, you can keep track of the start of the queue with an index j and change your loop to while j < len(ln): j += 1
also, how does "#finds the first end node" work? aren't all the nodes 0 at the beginning?
or the first node in b is A?
first node means the first end node so B
my computer broke so i need to write the code again on another computer, it will take like 2-5 mins then i can check if i can use collection import deque
yes but b[0] is A?
yes
ok that checks out
no worries take your time... also simulating a queue with a list (like I said above) is actually a smaller diff than using deque
it just takes more memory because you never pop
i don't think memory should be a problem, currently i am trying to implement the a* algorithm is that fine?
I don't see how a* would help
yeah, that is exactly what i wanted to write now, but it's nice i found about it, seems like a useful algorithm
so it would be better to use deque if i can?
not necessarily, list may be faster, and a smaller code change from what you already have
Thanks a lot for the tip, it is faster and I got more points, but still isn't fast enough, i am going to sleep, if you find a way to make it faster feel free to say
Given a binary 2d Matrix, in every step you can convert all connected cells with same value. How many steps to make complete Matrix to same value?
I am not sure, maybe it is due to reading large input? you can try instead
from sys import stdin
s = stdin.read()
also the small inefficiencies may add up, like for i in range(len(cn[ln[j]])): can be changed to for i in cn[ln[j]]: and then cn[ln[j]][i] will just be i
Easier, no, more efficient, yes. you can vectorize this
Hi i need to add a high score system to my mini game could someone help me?
jeu='oui'
print("Règles du juste prix :"):
print(" - Le but du jeu étant de deviner un nombre entre 0 et 1000 le jeu vous indiquera si votre proposition est plus grand ou plus petit que le nombre secret . Bonne chance ! .")
while jeu == 'oui' :
compteur=0
joueur=1111
prix=random.randint(0,1000)
while joueur != prix:
joueur=int(input("Donner un prix entre 0 et 1000 : "))
compteur=compteur+1
if joueur > prix:
print("C'est moins")
elif joueur < prix:
print("C'est plus")
print("Bravo vous avez gagné en",compteur,"tentatives")
jeu = (input("Voulez vous-rejouez ? oui/non " ))
print("Vous avez quitté le jeu .")```The idea is that a number is chosen randomly, and the person has to guess it? So the fewer guesses used, the better?
I think you already track the number of guesses in the variable compteur. So you could do something like
import sys
...
min_compteur = sys.maxsize
while jeu == 'oui' :
...
print("Bravo vous avez gagné en",compteur,"tentatives")
if compteur < min_compteur:
min_compteur = compteur
Or if you wanted to do something where a higher score was better, you could make the starting score something like 1000 and subtract 100 points in each iteration of the while loop. Then when the player succeeds in fewer guesses, they will have a higher score. Of course, you may want to ensure the score could not be negative
idk where to write this but i am trying to do api requests and idk how to add this to my code
I am kinda new
Hi 🖐🏾
hey
may i ask something ?
m
🙂 ?
It has nothing to do with Python
what is needed here ?```q1) A program that finds the math series:
s=1+1/2!+ 1/3!+ 1/4!+⋯+ 1/n!
Whereas; (n) is a number entered from the keyboard. Write the result here.
idk
I think it is infinite series problem. You can search in Google. You can find many formulas there.
11th grade math problem.
ok i will thanks
I think it's simpler than a infinite series problem because n is not infinite. you just need to put n and get the result. you can solve with recursion or a for loop between 1 and n
especially since the analytical form of this series isn't the nicest - the denominator here is just a factorial, but the numerator has an incomplete gamma function. It would be easiest to just sum it, unless n is very high. And even then it wouldn't be very wasteful to just sum, because there's a limit of how many terms you can calculate until the terms will just be 0 (up to float precision)

Doing binary search exercise, thought of this but it doesnt return anything and just runs forever, why?
`def isInListB(num):
a=[3,5,14,45,89,98,99]
middle=a[math.floor(len(a)/2)]
b=[]
while len(a)>1:
if num < middle:
for number in a:
if number < middle:
b.append(number)
elif num > middle:
for number in a:
if number > middle:
b.append(number)
a = b
middle = math.floor(len(a) / 2)
if a[0] == num:
print("is in list")
else:
print("is not in list")
isInListB(14)`
you're probably supposed to recalculate middle each outer loop, not use only one value
also, you probably need to set b to an empty list each time when you set a to b, I'd guess?
since currently, after you do a=b the first time, you get left with only one list with two variables referring to it.
I don’t understand the first point
I thought I was reassigning value of middle in the line under ‘a=b’
Suppose you called isInListB(99).
Before the first iteration, middle is 45 and b is an empty list.
At the end of the first iteration, b is [89,98,99], a is [89,98,99] and middle is 98.
At the end of the second iteration, b is [89, 98, 99, 99], a is [89,98,99,99], and middle is 99.
At the end of the third iteration, b is [89, 98, 99, 99], a is [89, 98, 99, 99], and middle is 99. From here it will repeat forever without changing
So how do I prevent it from just not shortening the list
Cause it seems to work the first iteration right?
I think ConfusedReptile's advice is correct, you should move the line b=[] inside the while loop
Trying it rn, I’m on a very old laptop rn and I can’t tell if the programs looping forever or if it’s just not running
with a list of only 7 numbers i'd expect it to finish in under a second even if you were running it on a potato
Yeah I think it’s looping forever
if you're running on an old device, I'd suggest putting a print at the beginning of your program, so that you know when it starts running. Because starting the python interpreter (and so starting to run the program) can take quite a bit on old computers in my experience, but once it's started it should run fast even on a potato indeed.
There's another problem, this one is how you calculate middle in the loop
Oh I just realized on the outside I’m taking the index of the len(a)/2 where as in the inside I’m not taking the index
Will that fix it?
Right. As it is, the value of middle is unrelated to the contents of a
So I think with that change it will stop the infinite loop, although the result is incorrect for some inputs
It’s working thanks guys
Try calling it with each element of that list as a test
will try that now, also i don't know if this is important, but every graph is a tree
every tree is a graph, but not every graph is a tree
yeah, that is why I clarified that there aren't any graphs that aren't trees (in this task)
i c i c, carry on
I DID THE FUCKING TASK LESTS GOOO
🎉 🎉 🎉
You want to find longest path between two nodes in a tree? Or is it a DAG?
@dark aurora
what is DAG?
Directed Acyclic Graph
nah not DAG, but i did the task why do you bother?
is it possible to perform an early exit in dijkstar algorithm search , because ig thats vulnerable to wrong answer , like if we stopped at the desired coordinates but the total costs of some unchecked coordinates (path) is lower than our current shortest path
so can we minimize the search and overcome the problem
or should we do a full search like bfs
Guys i need some help BADLY!!
it has early exit
specifically in aoc task you found the shortest path as soon as you found any path to exit
because nodes have same cost from all directions
i don't understand the question sorry
you can't stop at that point in the general case but you stop when the target is the next step
when you expand from the target
so earlier than that would be when you visited every neighbour of target but not the target which should be possible 🤔
I believe they mean stopping after some time and providing a suboptimal solution
I don't think dijkstra allows that in any obvious way, though maybe there is one
but that's never a thing
there's a term for this
In computer science, an anytime algorithm is an algorithm that can return a valid solution to a problem even if it is interrupted before it ends. The algorithm is expected to find better and better solutions the longer it keeps running.
Most algorithms run to completion: they provide a single answer after performing some fixed amount of computat...
you can't reach the node you want suboptimally with dijkstra. the first time you visit a node is the least cost way to reach it
I don't think that's quite true, but it's close to being true
yeah that's not true
the first time you assign a distance to the target node isn't the time that node becomes closed and the search ends
but it is true that the target node usually gets first reached pretty far into the search, close to the end
so you can't early-stop unless you're almost done
oh true
A* is slightly better at this probably, since it searches towards the target and so reaches it first sooner
but not by much I think
but like it depends on waht you mean by visit
you always "visit" once, so you mean like, "update"
by wikipedia terms
A node first gets assigned a distance when one of its neighbours gets visited. When the node itself gets visited (it's chosen as the lowest-distance node from the open set), this distance is finalised - if that's the target node, you can end the search at the point, you've found the optimal route to it
So basically, you can early stop only after one of the neighbours of the target node gets visited
on grids, that allows skipping very little, since obviously you have to come most of the way to reach such a neighbour
in well-connected graphs, I guess early stopping in dijkstra would be more useful
are the majority of graph/trees leetcode questions solved using recursion?
you can use stack and queue, but the idea I think is the same
If we have to find minimum in rotated sorted array:
class Solution:
def findMin(self, nums: List[int]) -> int:
if len(nums) == 1 or nums[0] < nums[-1]:
return nums[0]
left = 0
right = len(nums) - 1
while left <= right:
middle = (left + right) // 2
middle_num = nums[middle]
left_num = nums[left]
right_num = nums[right]
# Return values
if middle_num > nums[middle+1]:
return nums[middle+1]
elif nums[middle-1] > middle_num:
return middle_num
# Increment / Decrement
if left_num <= middle_num:
# Left half is sorted
left = middle + 1
elif middle_num <= right_num:
# Right half is sorted
right = middle - 1
For increment and decrement, does it make more sense to do left_num <= middle_num or nums[0] <= middle_num
because if we do nums[0] <= middle_num then we would be looking outside the window(between left and right).
But if we do left_num <= middle_num then we would be looking inside the window(between left and right)
I meant this in terms of truly Binary Search.
Can someone help in this simple problem please

I don't understand how can I figure out if it will be linear time or not. It could depend on various factors I think. Do we assume the rest of the factors constant? And then see the effect of length on the computation complexity?
Hello folks, am doing this question, which t is a binary tree and s an integer. The problem basically is to return True if the sum from root to leaf path equals s, otherwise return False
def solution(t, s):
if not t:
return False
s -= t.value
if not t.left and not t.right:
return s == 0
elif t.left and t.right:
return solution(t.left, s) or solution(t.right,s)
elif t.left and not t.right:
return solution(t.left, s)
elif not t.left and t.right:
return solution(t.right,s)```
Am lost in in parts, 1) why are we `s -= t.value` and 2) if there isn't any left and right subtrees, why do we return `s == 0`?Hi i need to add a high score system to my mini game could someone help me?
jeu='oui'
print("Règles du juste prix :")
print("- Le but du jeu étant de deviner un nombre entre 0 et 1000 le jeu vous indiquera si votre proposition est plus grand ou plus petit que le nombre secret . Bonne chance ! .")
nom=("a")
nom=input("\n- Entrer votre nom : ")
while jeu == 'oui' :
compteur=0
record=0
joueur=1111
prix=random.randint(0,1000)
while joueur != prix:
joueur=int(input("Donner un prix entre 0 et 1000 : "))
compteur=compteur+1
if joueur > prix:
print("C'est moins")
elif joueur < prix:
print("C'est plus")
print("\nBravo",nom,"vous avez gagné en",compteur,"tentatives .")
jeu = (input("\nVoulez vous-rejouez ? oui/non " ))
print("Vous avez quitté le jeu .")```Time complexity is decided on the basis of the worse scenario, here as we don't know the index , it is possible that the last second item is greater than the last , so you gotta iterate over the complete array and check
But as it states that only one element is wrongly placed , so it will not hit quadratic time , one iteration would do the job
That's what I suppose
I guess we can stop when we have visited all its neighbours 👀
Number of neighbours = number of paths to the target = number of total costs
I think to handle the edge case if not t just do return instead of false because once it's get to leaf recursively it will just return False also in terms of returning each call function just check each function call node val sum with previous node val and check the difference look with for difference val. I think instead of cramming all in one function it's better to create a helper function. Also for this problem do preorder traversal recursively or you can implement stack
I think that is true, you need to see the insert sort algorithm, but the idea is that when it finds a[j] it will allocate to the right position and the algorithm will stop.
- and 2) are related, s will be reduced from the node current value for each interaction, if s == 0 it means the sum from the values of all nodes traversed are equal s.
what is the best book to learn data structures& algo? Do you guys have a book in mind that has exercises?
check out the pins in this channel for resources 
sorry what? I don't know what you mean


thanks I see it now
hey guys can you please list some resources to learn data structure and algorithms in python
check the pins 🙂
https://github.com/TheAlgorithms/Python
you can refer this if you ever want proper implementations for any algorithm or data structure. They have implementations in all major languages.

GitHub
All Algorithms implemented in Python. Contribute to TheAlgorithms/Python development by creating an account on GitHub.
well, not "any" algorithm or data structure
there are infinitely many algorithms and data structures
Not a proper place to ask it, but perhaps someone knows. How can I read cpu cache (I mean bits and bytes), any level language will do (assembler, cpp, py)
what you will need in your lifetime😅
Does it have an implementation of an untyped lambda calculus evaluator?
you can just throw any maths formula and expect it to have be ready made somewhere. You know what i meant. I know it wont have literally everything
I just gave it as a good resource for beginners who get confused on different implementations
I just commented that the repo promises too much 🙂
On a serious note, it's missing a HAMT.
which is a pretty important data structure
If it were possible, it would probably be a security disaster. It would allow a process to read the memory of another, arbitrary process.
its possible but u need to inject your process into the other one
If it's a resource for beginners, I think it should have a more precise explanation. Otherwise some people might get an impression that this is literally all algorithms, and anything else is not an algorithm.

first line
yeah, the first line says "All algorithms"
for beginners its more than all
"All" has a very specific meaning, at least for me.
if you are looking for something advanced then you probably know where to look
ok dude sorry
"Examples for all of Python's standard library" 👍
"List of all natural numbers" -> "List of first N natural numbers"
"All algorithms" -> "Common algorithms"
I just gave this resource thinking it might be helpfull, when i was starting programming I would have killed to have these algos in one place
anyway... sorry for the nitpick.
fix error loves hamt
yeah i figured
and what about linux, im sure linux is way more free in terms of security measures than windows
I didn't imply any specific OS
a = [[],[],[],[]]
how to create this in python?
a list of 4 lists, each empty, I want to append different amount of numbers inside
@fierce sluice What's wrong with a = [[], [], [], []]?
!e
x = [[]]*4
print(x)
@fathom tartan :white_check_mark: Your eval job has completed with return code 0.
[[], [], [], []]
!e
x = [[]] * 4
x[0].append(1)
print(x)
@agile sundial :white_check_mark: Your eval job has completed with return code 0.
[[1], [1], [1], [1]]
the lists aren't copied, only the reference to the list
It's ok, but for cases longer than 4
Oh I got an idea
!e
x = [ [] for _ in range(4)]
x[0].append(1)
print(x)
@fierce sluice :white_check_mark: Your eval job has completed with return code 0.
[[1], [], [], []]
yep, that works
What if it's 1,2,3,4,1,2,3,4
Doesn't have to
In this case the given constraint satisfies. But it will have to do multiple iterations
Only 4>1
!e
print(2)
I think there is only one a[j] > a[j+1] so the rest is respecting a[i] < a[i+1]. all the array is ordered with one element out of the order. Update: ah yeah, this case will not break the rule.
no
Then?
it's your homework after all, you should do it
It will be
O(J-2+J-3+J-4+J-5)+O(n)
I am stuck. And it's not my homework 😆
I am trying to self learn
well, it's your work
ok, so as we traverse down the tree, it takes the value of that node and subtract it from s. If it equals 0, that basically means there is a leaf path that equals to s, correct?
wow that is amazing, they have every algo I can think of
thanks
yeah
but why do we need the not t.left and not t.right conditions for?
thats where am a little lost now
when you don't have t.left and t.right, it means that you reached the last node from the path, that is the stop condition and you can respond if the path you followed is equals s. if you have t.left or t.right, you need to reach the last node
ohhhhh ok ok
understood, thanks 💯
Hey guys, I was running the closed formula for finding the n^th fibonacci number
and I was comparing it to the run time of the method using dynamic programming; and I noticed that at the 72nd number, the closed form begins giving incorrect results due to floating point imprecisions
Atleast i'm assuming it's due to that...
This is the closed form


And it breaks down at the 72nd value
My question is... what is special about the number 498454011879265 to give this error?
The 71st number is 308061521170129
Precision wise, isn't it better to use sqrt() instead of raising to the power of .5?
Not that there's anything special with that number specifically... but what is the threshold
I didn't want to import any libraries lol
It might be more accurate because it's a specialized method
But I can actually check right now
seems slower using math.sqrt()
It's not really the runtime that's a concern... more like, ignoring the dynamic code, why does the closed formula give incorrect results for the 72nd fibonacci value
The binary version of it is 49 digits long, for the 71st number it's also 49 digits long

If that helps at all
So using sqrt gave the same result?
Using sqrt made it slower but gave same result of breaking down at 72
How strange

Computer Science Stack Exchange
Binet's formula for the nth Fibonacci numbers is remarkable because the equation "converts" via a few arithmetic operations an irrational number $\phi$ into an integer sequence. However, using finite
Thank you, i'm looking through it
I think it's cause g is irrational

and I guess by the 15th decimal place...



Stack Overflow
I was working on a project to compute the Leibniz approximation for pi with the below code:
def pi(precision):
sign = True
ret = 0
for i in range(1,precision+1):
odd = 2 * i - ...
I guess that's it
YEP

Thanks for pointing me to the right direction! 😄
does anyone know how to generate AJ walker algo tables?
So baicalky I am working on a machine learning assignment in creating an algorithm that will detect brain tumors based on brain data tumor data sets. This is an assignment that is asked by my professor but I don’t have experience with coding.
These are the steps I already complete which is
(1) Import the dataset into a fresh Google Collab project
(2) Split the dataset into training / testing / validation sets (thursday)
But i still need help with
(3) Defining my classification model(s). You would probably want to try a few different models here. You can either build your own convolution neural network (layer by layer) in tensorflow and train it from scratch, or you can modify an existing pre-trained network like VGG19, alter it to better suit our binary classification needs, and retrain it on the dataset.
(4) Train you model(s) and evaluate
Help
so let's say I have a graph looking like that

I want to find the number to the right of any node
is there any well known algorithm to do that?
 is this related to ||advent of code||?
is this related to ||advent of code||?
ya
I don't know if there's a name for it but you can walk up the tree from 2 and then walk down the tree to 3
which is the simplest way I'd say, or there are other methods if you pass along / return extra information in your recursive function
yet another way is to link the leaves explicitly like a doubly linked list
they are doubly linked, yeah
each TreeNode already has left and right children, and these children are unused for the leaf nodes, so for leaf nodes I just changed the meaning of the left and right children to mean left and right leaves instead. and I added an is_leaf boolean. but this takes some bookkeeping so I'd recommend simpler approaches
this approach is just, walk up the tree from 2 until you reach a left child, then go to the sibling of that child (which exists since the tree is full in this problem), and then walk down as far left as you can (to reach 3)
this will work, and similarly for previous node:
@property
def rightmost(self):
return self.right.rightmost if isnode(self.right) else self
@property
def previous_node(self):
if self.is_root:
return None
parent = self.parent
if parent.left is self:
return parent.previous_node
if isnode(parent.left):
return parent.left.rightmost
return parent
you still have to check the children of the node you get
if self.previous_node:
if isnode(previous_node.right):
previous_node.left # is previous value
else:
previous_node.right # is previous value
some check like this to get the value
Can someone point me in the direction for getting block 1 of text into block 2 of text.
oraclelinux-release-6Server-10.0.2.x86_64
java-1.7.0-openjdk-1.7.0.261-2.6.22.1.0.1.el6_10.x86_64
newrelic-sysmond-2.3.0.132-1.x86_64
copy-jdk-configs-3.3-9.el6.noarch
oracle-logos-60.0.14-1.0.5.el6.noarch
newrelic-infra-1.20.7-1.el6.x86_64
oraclelinux-release-notes-6Server-22.0.2.el6.x86_64
newrelic-repo-5-3.noarch```],]```@maiden dunehi fyi, we don't allow advertising/self-promotion here, so i've deleted your message. please check out our #rules for future reference
Hello folks, currently doing 98. Validate Binary Search Tree on Leetcode
This is is my solution
def isValidBST(self, root: Optional[TreeNode]) -> bool:
stack = [(root, float('-inf'),float('inf'))]
while stack:
node,left,right = stack.pop()
if not left<node.val<right:
return False
if node.right:
stack.append((node.right,node.val,right))
if node.left:
stack.append((node.left,left,node.val))
return True```
I'm a little lost on why exactly we need both `left` and `right` variables. From what I know, they work as boundaries correct?wdym by boundaries?
I meant like left means min value and right max value.
but honestly, am just confused on what exactly its doing
you know the invariant for a binary tree, right?
that the value of the parent must be between those of the children
in particular, that the left is less and the right is greater
ayo guys I have a problem trying to do this bot and im not sure whats the actual problem or how to fix it


hmm hmm

I guess another way to ask this question is, what exactly do node.left, left, node.val mean?
From my understanding, node.left means the left subtree, left is where am confused, and node.val is the value of whichever node we are at
sorry I didn't understand the code properly
tbh, the code is confusing yeah
also, I was wrong
this is wrong
sorry :(
I forgot what binary search tree is
its one of those things in which you write it but found the solution somehow lol
yea I originally solved it recurvely but when you return the function, it still in that order node.left,left,node.val
wdym?
def dfs(node,left,right):
if not node: return True
if not (node.val < right and node.val > left):
return False
return dfs(node.left,left,node.val) and dfs(node.right,node.val,right)
return dfs(root,float('-inf'),float('inf'))```idk, looks good to me
its this part
return dfs(node.left,left,node.val) and dfs(node.right,node.val,right)
the left and right, that has me confused
See it this way
all DFS(node, left, right) does is return true, if all the nodes rooted in node are between the value left and right
because of how DFS recursively calls itself, it's called once for each node
idk if that makes any sense
but like, just assume DFS magically works
def magic_in_range(node, left, right):
...
def in_range(node,left,right):
if not node: return True
if not (node.val < right and node.val > left):
return False
return magic_in_range(node.left,left,node.val) and magic_in_range(node.right,node.val,right)
return in_range(root,float('-inf'),float('inf'))
and then by induction
it does actually work
@idle pier
the power of believing in recursion 😎
It's basically magic
it's probably easier to grok if it's called def is_bst(node, lower_bound=float("-inf"), upper_bound=float("inf"))
yes
a binary tree node is just a couple variables together
you can use a dictionary, or instance attributes, it should even work with just tuples
I'm struggling to make an implementation for this problem that satisfies the harder test cases.
https://www.olympiad.org.uk/papers/2021/bio/round_one.html (Question 3 - window dressing)
I think it would be possible to do some sort of smarter, less brute force solution, but so far I've only made a slow recursive one.
What would be a good way to do this problem? (it has to terminate in one second)
help me :(

@torpid crown help if you admin
i know you can
help me
can someone help

seen you ask this before
I suggest you post a picture of the problem itself, instead of linking pdf
what?
Does anyone have experience with myplotlib in python?
There's one thing I don't seem to get it work
It'd be lifesaving if anyone could help me
Ping me if you are interested to help

Does no one have experience with matplotlib?
any website where we can start to learn python from scratch
Is following the correct way to perform list comprehension to convert a list of int to list of strs?:
list(df["itemid"]) is a list of ints
item_ids:List[str] = [str(n) for n in list(df["itemid"])]
looks good to me
ok thank you!!
You could use map instead for that
ehi, could anybody explain me why in the second example of this problem the answer is 2 and not 1.5: https://codeforces.com/problemset/problem/492/B (it's a problem about searching and sorting)

Codeforces
Thank you in advancee ❤️
Does anyone have experience with matplotlib and would like to help? :)
If all lanterns have radius 2 then first lantern is gonna cover [0, 4] and second one is gonna cover [3, 5] and they arę both gonna cover [0, 5]
Maybe try the #data-science-and-ml channel.
Is there any benefit to using map over list comprehension?
I just dont know much about them that's why I ask.
It's a little bit more concise in this case. And it's faster here, but that's not really important.
I have tried many channels, no one really seem to be able to help me


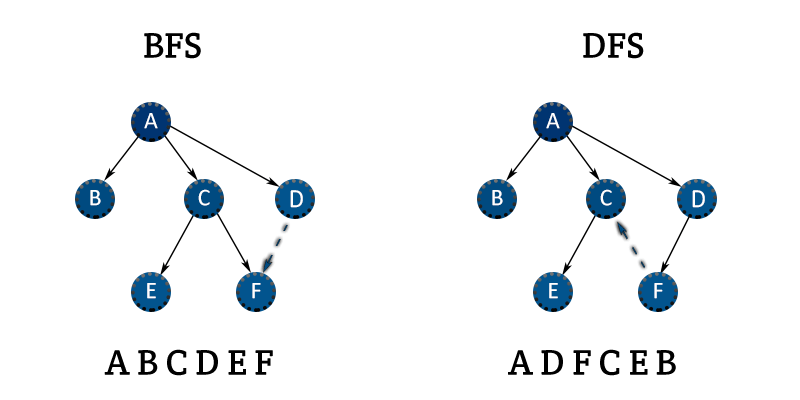{kind=link}
{kind=link}
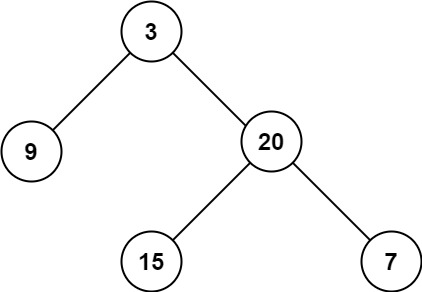{kind=link}
try drawing a tree for it
hi , sry hijack , open a bot but
and already went deep into search, using the wrong words i bet
how can one plot according the code call position and not in the end of all?
using jupyterlab and already have %matplotlib inline
Does this only mean how many calls will units of size 4 make?
That would be 4, right?
I thought it's something complicated
yeah
hello folks, doing 70. Climbing Stairs on leetcode
Its a DP problem, I was having trouble solving it, so I looked up the solution. I know its a fibonacci problem but I still fully don't understand the solution
def climbStairs(self, n: int) -> int:
one,two = 1,1
for _ in range(n-1):
temp = one
one = one + two
two = temp
return one```
what gets me confused is why do we need the `temp` and why `two = temp`I know its a bottom-up approach
On the next step, the one variable should store one + two and the two variable should store one. But observe that if you do this:
one = one + two
two = one
it won't produce the right result (two and one will be equal here), nor will the opposite order.
You need to either use a temp variable (that's the approach that works in any language), or, and this approach uses a Python feature called unpacking, do
one, two = one+two, one