#algos-and-data-structs
1 messages · Page 127 of 1
first_arg = 0
second_arg = 1
sum = 0
while True:
third_arg = first_arg + second_arg
if third_arg >= 4000000:
print(sum)
break
if(third_arg % 2 == 0):
sum += third_arg
first_arg = second_arg
second_arg = third_arg
please help in finding the time complexity of above algoirthm
Hello 🙂 Did you write this code? What does it do?
I presume you want to find the time-complexity with respect to the number 4000000.
yes ,i write this code
it calculate the sum of even fibonacci numbers till 4 million
Oh right. What would be your best guess of the time complexity?
It might help to know of Binet's formula, which is a formula that expresses the nth Fibonacci number in terms of the constant phi: https://en.wikipedia.org/wiki/Fibonacci_number#Binet's_formula
Asymptotically, the value of the nth Fibonacci number is Theta(phi ^ n)
Can you use this information to figure out an asymptotic upper-bound on the quantity of Fibonacci numbers less than a given number?
It worked perfectly! Thanks, now I can call it a day and go sleep (at 4:20am)
well, i think i would not be able to do that , it will be difficult for me
Ah right. Well let's just say that x is the value of the nth Fibonacci number, and assume that x == k * phi ** n (where k is some constant). Can you re-arrange this equation to solve for n?
Hint: it involves a logarithm.
Consider that you have a recursive dictionary as follows:-
{
"text":"hi"
"next":{
"text":"hi"
"next":{
"text":"hi"
}
}
}
Now I want to modify the last node and change it to {"text": "bye"} so that my end result is as follows
{
"text":"hi"
"next":{
"text":"hi"
"next":{
"text":"bye"
}
}
}
Remember that there can be thousands of nodes but I want to modify just the last node. How can I do it?
this is not the original structure(the original one is far more complex) and also it is an ast
but this is just printing it but I want to modify it

Dude that’s java
These channels are generally for Python  but it's saying you're trying to add two lists together
but it's saying you're trying to add two lists together
Not a Java person, buh I think you're trying to operate on 2 different data types, try that code on your local machine, and print out those values to verify that data types
You’re trying to add two things which use the List interface
But yeah it would probably be better to ask in a java discord
Whichever one is most active I guess
Hello
I need some help here
Well crap I can't cross-copy and paste from VM
def Shop_Index():
class index:
def __init__(self, item, price) -> None:
self.item = item
self.price = price
def Item_Detail(self):
print(f"{self.item} - {self.price}$")
i1 = index("Tsar bomba", 2500)
i2 = index("bleach", 100)
i3 = index("Robux", 500)
i4 = index("AK-47", 1000)
print(i1.Item_Detail())```The arrow part of the initualize funtion is suppose to be a comment, or rather the def's name
Well how come I can't replace "None" with a string?
Also I get my wanted output but also prints out "None"
None```it can be any valid python expression
you're making a class inside of a function?
all functions have to return something, if you don't specify, it will return None by default
your function doesn't return anything, so it returns None
You're printing inside Item_Detail(), and then the function doesn't return anything, so when you print(i1.Item_Detail()), you're not printing anything
You want to either just call i1.Item_Detail() or you want to change Item_Detail(self) to return the string value instead of printing it
@reef seal @stable pecan https://en.wikipedia.org/wiki/Levenshtein_distance#Iterative_with_two_matrix_rows and https://en.wikipedia.org/wiki/Hirschberg's_algorithm
In information theory, linguistics, and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. It is...
Its still O(nm)
i was trying to find a way to apply a min filter -- https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.minimum_filter.html#scipy.ndimage.minimum_filter
to the array --- this sometimes work if you set the out= parameter to point to the array itself and then it gets updated as it's computing, it's kinda hacky
yep. but it looks like the hirschberg algorithm (and generally the "two-row variant" in the main article) might be faster in python because of fewer array lookups and assignments
at this point i think we just accept defeat and use numba, lisp, or julia
maybe pypy or graalpython does well on this. let me write a pure python version and do some benchmarks
there's also bottleneck package
that has numpy routines for some stuff
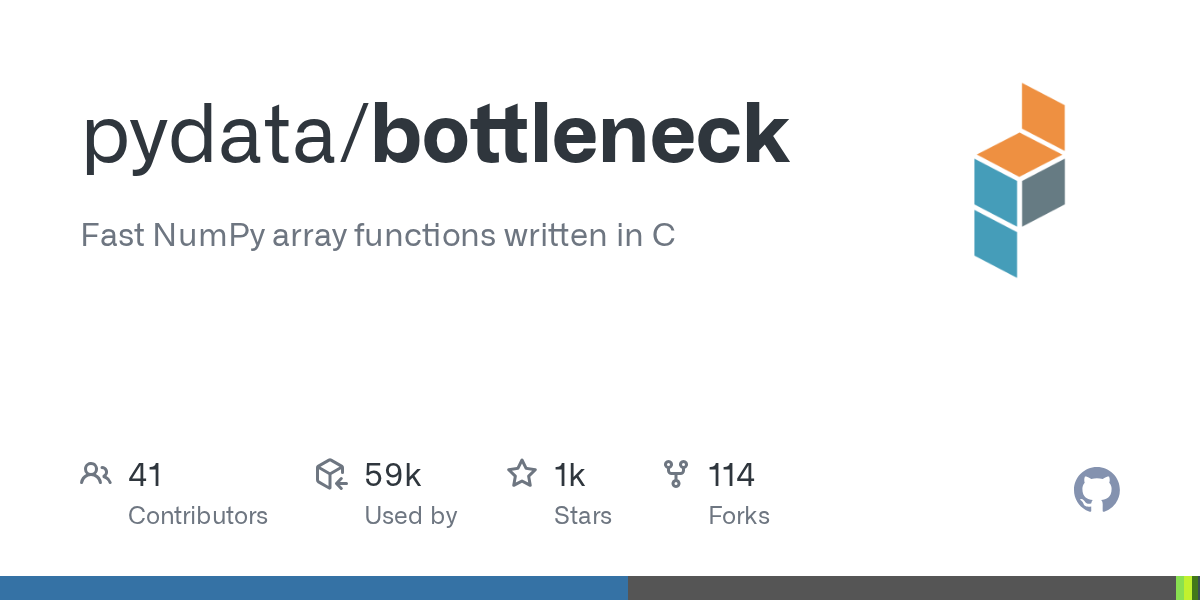
GitHub
Fast NumPy array functions written in C. Contribute to pydata/bottleneck development by creating an account on GitHub.
afaik it's mostly "aggregate" functions
and numexpr is what you use for avoiding round-tripping between python and numpy when doing non-aggregating stuff
!pypi numexpr

Fast numerical expression evaluator for NumPy
hi, i want to do kind of game bot it will see my screen and move the character with mouse and keyboard.which library should i use
sounds like it would save me from creating infinite buffer arrays
How do I make my answer for this question more time efficient?
https://www.hackerrank.com/challenges/flatland-space-stations/problem
def flatlandSpaceStations(n, c):
dictx={}
for i in range(n):
templ=[]
for j in c:
templ.append(abs(j-i))
dictx.update({i:min(templ)})
return(max(dictx.values()))```
HackerRank
Find the maximum distance an astronaut needs to travel to reach the nearest space station.
Unsure if here is the right channel but there's a trend in fitness where coaches are now creating A.I based training apps for clients, ones like Juggernaut AI and SheikoGold are becoming popular. Have any of you worked on similar apps?
Probably more suitable for #data-science-and-ml
Didn't see that channel, my bad. I'll post there.
first of all you can find distances between stations```py
[(y-x) for x, y in zip(c, c[1:])]
[4,6,12,19] will become [2,6,7]
if you divide that by 2 you'll get distance for the town in the middle
and then there are special cases where it's the last or the first town, the distance is equal to first element in c for the first town
and (n − last_c − 1) for the last
how do i modify the last node of a binary tree?
idk, but can someone give me a short yet good definition what a neural network is? been trying one for ages
have you seen the 3b1b video https://www.youtube.com/watch?v=aircAruvnKk?
oh you mean put it in words
that's lame
is it worth trying to algo trade?
I tried to build a NN based IQ classifier for online posts, but it seems like it's not that accurate
This is my code for bubble sort the output that I am getting is None. Can anyone tell me what I have done wrong?

You want #data-science-and-ml
The issue is that your function modifies the array in place. But you're using it as if it returns the sorted list. You should either return the sorted list from the function, or call it like this: ```py
arr = [5, 3, 6, 7, 1, 9]
bubble_sort(arr)
print(arr)
Functions in python have an implicit return None at the end of them.
Meaning if you don't return anything from the function, and the function ends without raising an exception, then None is returned.
Ohh got it thank you so much
np 👍
A neural network is a mathematical tool that can estimate the relationship between a collection of inputs and a collection of outputs. There are many such tools; technical practitioners often call them "models", because they can be interpreted as a model of the data that is being studied. A neural network is a particular kind of model that is very good at estimating complicated relationships between complicated types of data.
A neural network usually consists of "layers". There are a few well-established mathematical forms of layers. Each one is a function that transforms input numbers to output numbers, and most layers have a set of numerical parameters that determine how exactly the transformation works. The layers are then "stacked" so that the outputs of each layer flow as inputs into the next layer. The predictions of the model are read from the final layer, the "output layer". When a neural network has a large number of layers, it is said to be a "deep" neural network, which is where we get the catchy name "deep learning".
A model is said to be "fitted" or "trained" when its numerical parameters are optimized to perform as well as possible on a dataset. Usually, the performance of a model is measured by comparing the predicted outputs with the real outputs. The closer the predictions are to the real outputs, the better the model. There are several well-established mathematical algorithms for fitting models to data.
The name "neural network" derives from the 1950s. The design of the network originates in neuroscience research that was attempting to model how the human brain works. However, what is known as a "neural network" today bears only passing resemblance to real brains. The name should not be interpreted as anything more than suggestive, and it has no specific meaning with respect to AI or AGI.
i know 4 paragraphs isn't really "short", but that was the best i could do, assuming the audience has zero technical knowledge
Thanks mate
hopefully you're not going to plagiarize this for homework 🙂
!mute 789111080491941948 Looking into it
:incoming_envelope: :ok_hand: applied mute to @fiery cosmos until <t:1629743609:f> (59 minutes and 59 seconds).
@keen hearth (or anyone else if they know about Monte Carlo Tree Search) I decided to write a simple example in python but I'm not sure I got it right; I'm using the wikipedia page (https://en.wikipedia.org/wiki/Monte_Carlo_tree_search#Principle_of_operation) as reference but can't quite figure out how this is supposed to optimize: https://hastebin.com/avejewokuc.py
Do you happen to know what I'm doing wrong?
Is there an awkward but understandable tutorial to learn about different trees? There are many tutorials that I found and they are just useless, they are copied from other sources when they don't even understand what 'BF' or log means.
what is 'BF'
breadth first? 
even in the context of trees i didn't guess that. i guess it makes sense though?

Give me a bit as i'll be making diagrams in between messages.
I always found it useful to take a few steps back when learning something new.
For example, here's a linked list, with every element knowing which one comes next. This means every box has 1 arrow going out (except the last one)

a doubly linked list is more or less the same, but also knows which one came before. This means every box has two outgoing arrows

now a (binary) tree is basically the next step ahead; It knows which one came before, and which two (or more in non-binary trees) came after, which means it has 3 outgoing arrows

(note that depending on the use case or implementation they may not know which one came before, similar to the linked list)
when inserting a node it should always be to the left and if you need to reorder the main node it moves to the right?
it depends on the tree
some trees it doesn't matter
binary trees do it like this:
- Element 1's value is checked against the new value.
- If it's less, put it to the left (or if taken, let element 2 handle it), if it's greater, put it to the right (or let element 3 handle it).
- Depending on the tree, rebalance when done
If you need a visualization, I recommend https://visualgo.net/en/bst (has both a binary search tree and AVL tree, which are the most common ones in many cases)
Thanks
when we use a sorting algorithm in our function, should we say the function has O(1) space if we sort in place?
or should we say it uses O(N) space because the sort itself uses O(N) space?
Usually we talk about extra space, so if you're not creating a temporary list of O(N) extra elements, it's O(1) space even though there's O(N) original memory (which doesn't count).
I mean isn't the sorting algorithm itself using O(N) extra space when doing the sort?
altho I suppose it does get rid of it in the end
If it does, then yeah, it's O(N) extra space.
(there are sorting algorithms that are really-really inplace with O(1) extra memory, so it depends on the algorithm)
what about sort()
yep that's what I was saying
according to this it's actually O(N) to use the sort
but when I read on algorithms practice websites, when they sort in place they say they use O(1) space, but it's actually wrong isn't it?
Using what algorithm?
if they do use Python's .sort(), then yeah, they are wrong about it being O(1) space.
Yeah, in-place doesn't always mean O(1)
Question:- * which algorithm i can use for this problem* --
""A Supermarket is having a pretty good sale. Everyone can only take one object
from each category, such as one TV and one carrot, but only for a very low price.
We go to Supermarket with the whole family. Everyone is free to take as many
items as they like from the Super Sale. A list of goods, prices, and weights has
been provided. We also know what the maximum weight a person can bear.
What is the most costly thing that we can buy at Super Sale? Implement the
problem""
Hey quick question can u tell me what's wrong in my quick sort algo
Fairly new to python
yeah the issue is on line 48
Bin packaging problem?
not that complex, since you can only buy one thing
no, it's many things
oh sorry, i misread
well you're right, you can't buy something twice and it does make it simpler I think
it's just that it asks "what's the most costly thing" so you literally care about one thing
you pick a person with most weight and ignore everyone else
like, not a knapsack problem
could be mistranslated, could be correct, we don't know lol
yeah, that part tripped me up
Hi Everyone! Is there an efficient way of renaming JSON key values?
What happens is this: I'm pulling a dataset from a url as a .json and I'm trying to convert it into a Pandas DataFrame. The issue is that all JSON key values have a different name (Ex. ID: 1 0_value_0: 'name'; ID: 2 1_value_1: 'name2'; etc) so while converting to DataFrame, I get a table with 174k columns and 1 row. How can I normalize it?
Can you give a more complete example of the JSON data, and can you give an example of how you would like the data frame to be formatted?
Also usually pandas questions are in #data-science-and-ml
This channel is more about computer science things, like trees, search algorithms, etc.
Thanks! Just solved the query haha needed the json_normalize function in a better implementation. Thought JSON entered withing the data structure definition haha
Glad you figured it out
I have a code pattern that I repeat 2-3 times trough my app: call an API to retrieve accounts, loop over the accounts (by block of ~100 accounts) and then do something depending on what I need (sometimes I update certain objects in my db, sometimes I update another kind of object). I would to implement a class with a function that does the API calling and each time we loop through a block of accounts, call another function in the class. This other function is raise NotImplementerError exception.
So when I want to use that pattern, I inherit from that class (?) then I redefine my other function to have my behaviour. I'm just not sure it's the right way to implement this.
class ZohoFetch:
def fetch_accounts(self, organization, *external_system_ids):
zoho_account = ZohoAccount.objects.get(organization=organization)
if not zoho_account.is_properly_configured():
raise AttributeError('Zoho account is improperly configured.')
zoho_rest_client = get_zoho_client_instance(organization)
page = 1
limit = 200
fetch_completed = False
while not fetch_completed:
response = zoho_rest_client.get_module_instance('Accounts').get_records(page=page, per_page=limit).response
accounts = json.loads(response.text)['data']
page += 1
if not accounts['info']['more_records']:
fetch_completed = True
for account in accounts:
self.handle_accounts()
def handle_accounts(self):
raise NotImplementedError
# In another file
class MyClass(ZohoFetch):
def handle_accounts(self):
# handle objects
def do_stuff(self):
# Declare vars
fetch_accounts(organization, *external_system_id)

Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
Could someone provide a memoized solution for this?
def fsum(tsum,num,memo={}):
sm=0
if tsum==0:
return 1
if tsum<0:
return 0
for n in num:
rem= tsum-n
remr= fsum(rem,num,memo)
sm+=remr
return sm
This is the base case that I could come up with.
if you don't need to store any state on the class itself, i suggest not using a class at all. write a fetch_accounts function:
def accounts_fetch_handle(
zoho_rest_client, zoho_account, accounts_handler=None
):
if not zoho_account.is_properly_configured():
raise AttributeError('Zoho account is improperly configured.')
zoho_accounts_module = zoho_rest_client.get_module_instance('Accounts')
page = 1
limit = 200
fetch_completed = False
while not fetch_completed:
response = zoho_accounts_module.get_records(page=page, per_page=limit).response
accounts = json.loads(response.text)['data']
page += 1
if not accounts['info']['more_records']:
fetch_completed = True
if account_handler is not None:
accounts_handler(accounts)
def handle_accounts_batch(accounts):
...
accounts_fetch_handle(
get_zoho_client_instance(organization),
ZohoAccount.objects.get(organization=organization),
accounts_handler=handle_accounts_batch,
)
(this is probably better asked in #software-architecture, this channel is mostly for "lower-level" CS topics)
It’s the Fibonacci sequence
@normal obsidian you could also turn this into a generator function and not use a "callback" at all:
def accounts_fetch_handle(zoho_rest_client):
zoho_accounts_module = zoho_rest_client.get_module_instance('Accounts')
page = 1
limit = 200
fetch_completed = False
while not fetch_completed:
response = zoho_accounts_module.get_records(page=page, per_page=limit).response
accounts = json.loads(response.text)['data']
page += 1
if not accounts['info']['more_records']:
fetch_completed = True
yield accounts
def handle_accounts_batch(accounts):
...
zoho_rest_client = get_zoho_client_instance(organization)
for accounts_batch in accounts_fetch_handle(zoho_rest_client):
handle_accounts_batch(accounts_batch)
What's the accounts_handler parameter for?
Thanks, that's two very solid implementation and that's way better than using a class. I'll be carefule to post in #software-architecture next time for that kind of question.
Need some assistants here
ListedItems = [bomb.ItemName, bleach.ItemName, robux.ItemName, ak47.ItemName]
ListedPrice = [bomb.price, bleach.price, robux.price, ak47.price]
User_Choice = input('''
Buy: ''')
if User_Choice == "leave":
Menu()
elif User_Choice in ListedItems:
if Current_Money < ListedPrice:
print("insufficient funds")
time.sleep(1.5)
shop()
elif Current_Money >= ListedPrice:
print(f"You bought {User_Choice}!")
#Item.owned = True
time.sleep(3.5)
shop()
else:
print("Invalid option")
time.sleep(2)
shop()```prints "Invalid Option"
every time
Assuming because "elif User_Choice in ListedItems" doesn't work right
You might get more help in a help channel.
But also that’s too vague. You need to give more details or it’s impossible to help
I just started on computer science with no prior experience, and I'm having a bit of trouble in creating an algorithm in the base start of class, if anyone would be able to dm me if you're available to help I'd really appreciate it
it would be better if you just ask and state clearly what part you're having trouble with
you dont need to ask it.. just go ahead with the question
ok HAHA

whats the time complexity of foo
i learnt this yesterday
i think it is O(n)
i drew the tree
they told us time complexity is proportionate to number of leaves in the tree
but im not confident of my answer..
i'm not confident of your answer either
HAHAHAH
i think foo would be O(n^2)
oh no
is this wrong?
how did you get this,,
what's your tree look like
i am not sure of my answer either.. ill say salt would be better person to ask ;)

i see, you should fill in the b leaves
!
you need everything
ohhhhhh
so the b(5) and f(4) under f(5) is also counted when i want to determine the time complexity?
that's right
note that b(5) will be a bunch more leaves:
b(5)
\
b(4)
\
b(3)
...
and so on, so the tree will have a bunch of nodes
not 2**n, but n**2
alright thank you! i understand it better now
#time complexity is O(n^2*cl) according to me
for i in range(0, len(apatments)):
blockMin = [len(apatments)]*creteriaLen
for j in range(0, creteriaLen):
creteriaMin = -1
for k in range(0,len(apatments)):
if creteriaMin == 0:
break # break because 0 is min that can go checking after that is waste
ucreteriaMin = 0#for making the negative value into postive
if k-i < 0: ucreteriaMin = (k-i)+2**32
else: ucreteriaMin = k-i
#for checking the avavility of creteria[j] availabilty
if apatments[k][creteria[j]]==True:
if creteriaMin == -1 or creteriaMin > ucreteriaMin:
creteriaMin = ucreteriaMin
#finding the min value of the
if creteriaMin < blockMin[j] and creteriaMin != -1:
blockMin[j] = creteriaMin
#changing
if(sum(blockMin)<sum(result)) or (result[0] == -1):
result = blockMin
print(blockMin)
print(result)
can any one check if the time complexity i calculated is correct or no
is there a better way to get n highest numbers from a list other than sorting and taking the last n numbers?
theoretically you can find the highest, then the second highest, the third highest and so on in O(len(list) * k) time, but i'm not sure if that would actually be faster
!d heapq.nlargest
heapq.nlargest(n, iterable, key=None)```
Return a list with the *n* largest elements from the dataset defined by *iterable*. *key*, if provided, specifies a function of one argument that is used to extract a comparison key from each element in *iterable* (for example, `key=str.lower`). Equivalent to: `sorted(iterable, key=key, reverse=True)[:n]`.Lib/heapq.py line 395
# Algorithm notes for nlargest() and nsmallest()```the estimate is: comparisons = n + k * (log(k, 2) * log(n/k) + log(k, 2) + log(n/k))
At some point it's no longer an asymptotic complexity, but an actual formula for the time taken as a function of the input size
output
[(ana,),(willy,)]
How can i convert to
[ana, willy]
???
The time obviously depends on the hardware
and the elements you're comparing
the formula just estimates the number of comparisons
[t[0] for t in tuples]
Thank you
[name for (name,) in names]
Ah, that's nicer. Didn't think of unpacking a single value.
can anyone please tell me why this doesn't work?
listbruh = components
for item in range(len(components)):
print(item)
del listbruh[item]
return listbruh```
Traceback (most recent call last):
File "d:\python projects\projects and games\mad libs but better\main.py", line 35, in <module>
scan(template)
File "d:\python projects\projects and games\mad libs but better\main.py", line 29, in scan
components = clean_list(components)
File "d:\python projects\projects and games\mad libs but better\main.py", line 10, in clean_list
del listbruh[item]
IndexError: list assignment index out of range
deleting something from the middle of a list moves all the elements to its right, left one space
given functions
const x = 5;
function f(g) {
const x = 3;
return x => x + g(x);
}
function g(f, y) {
const h = (y, f) => y(f);
return h(f, y);
}```
A
(f(x => 2 * x))(4);
(x => x + (x => 2 * x)(x))(4)
(4 + (2 * 4))
(4 + 8)
12
B
(3 + (2 * 3))(4)
(3 + 6)(4)
(9)(4)
when i try to work out the substitution model for the given functions, why does it give A? and not B? I thought x would be substituted as 3?
In f, you're returning a function and discarding the local x variable -- it doesn't do anything at all.
It's the same as ```js
function f(g) {
const x = 3;
return y => y + g(y);
}
oh right so even though they are declared the same names, f is just returning a function
yes
Hi, what's the time complexity of Python's math.sqrt() function or x ** 0.5 operation? I read that it is O(1) for C#, I assume that is the case for Python too?
And if I can read up on the implementation anywhere
since the size of the numbers are bounded, it is O(1) in C#
since python's ints are arbitrarily sized it's not the same
Uh huh, so is it logarithmic then?
yes
I think it might be O(1) too in Python's case because it gives a floating point number for big values, i.e, my perfect_square_checker function fails for big values using the math.sqrt() or the ** 0.5
can you show the test code?
https://github.com/python/cpython/blob/3.10/Modules/mathmodule.c here's the impl
!e
def is_perfect_square_inbuilt(x):
return x == int(x**0.5)**2
print(is_perfect_square_inbuilt(1112323274747382738273823283283283728736823283283**4))
@prime heath :white_check_mark: Your eval job has completed with return code 0.
False
Thanks
that might just be float imprecision
^
careful with float == 🙂 should probably be int(x) == right?
or x: int
x is an int there
Is python string concatenation O(N + M), where N and M are size/length of the strings?
yeah
And if we flush out the string after let's say there are 4 or 5 elements, then can we say time complexity is O(n)?
wdym?
that the time difference would be so little that could we technically call it O(n)
wdym flush out the string
that's constant time
constant time, does it mean O(1)?
So if we had to do this for a long list, that did concatenation in such a way and flushed out the string, then we could say the time complexity for such an algorithm is O(n) since such a string concatenation would be considered O(1)?
well, if the size of the list is capped, then yes
but it would still be slow, probably
better to join them
use list as a stack, append elements to this list and then join them as "".join(stack)?
you say you already have a list though
a binary tree is usually faster than a hashmap?
I have to map characters that are in this list to perform dictionary look up
for what tasks
what?
data structures don't have speeds
So why doesn't everyone use btree?
huh?
It depends what you want to do with it
Data structures totally do have speeds by a reasonable definition  That's what big O notation is all about
That's what big O notation is all about
Lookup in a balanced binary tree is O(logN) on average but lookup in a well implemented hashmap is faster with O(1) constant time
Notice that you just told us the speeds of tasks using a data structure
I would call those speeds of the data structure "the lookup speed of a hashmap is O(1)"
Lookup is not the only thing you do with a data structure
Of course. It has multiple speeds depending on the operation
That's why we asked what task you're looking at.
Ah, I see
A data structure doesn't just "have a speed" in a vacuum. It makes it possible to do certain tasks with a certain speed.
@knotty magnet Now that I realize, it's just for storing class objects.
Between 100,000 and 1,000,000
huh?
^
ok
so is it something fast? To cache the state of a connection.
depends on how pedantic you wanna be
e.g. what if we’re talking about an abstract map
most commonly implemented with either trees or hash tables, but they have different time complexities for a few operations, so it’s less meaningful to talk about the map’s characteristics (I agree with you overall though)
for an associative array?
worse time complexity
but you get sortedness
hi guys what are the uses for ordered dict in python?
when you want a dictionary that you can manipulate the order of
or, when you have a key-value mapping that also should be ordered
e.g. if you need the keys to be in a certain order
Can someone explain me big O notation theory in the easiest way?
Have you seen this article? https://nedbatchelder.com/text/slowsgrows.html
Let me
It’s like a hash map combined with a linked list. It uses the linked list part for ordering. So you can move key-value pairs to either end more efficiently. With a normal dict, you have to take the key out and put it back in, so you can only move things to the end, and it will cause the hash map to have to resize if you do it a lot since it builds up empty positions in the array. OrderedDict doesn’t have that problem.
So, it’s useful for if you want to move key-value pairs to the front, and it’s useful for if you want to do a lot of moving key-value pairs to either end since it avoids resizing and having to hash a second time to reinsert the key
@austere sparrow oh bro thank you so much, that article was so friendly and understandable perfectly I didnt have any problems and understood the basics clearly without any doubts.
Greetings. I have just finished an article about python deque data structures. In my python coding I tend to use lists for most things including list comprehensions to simply create a list from another set of data. Usually these lists are just passed around and consumed sequentially by other parts of the code. It seems like deque might be faster and more memory efficient than this common way of building sequences with lists. Do other people use deque in place of lists or is the performance difference just not dramatic enough to warrant the change of structures?
Dynamic arrays (which list is) are generally faster than linked lists (like deque).
But only for reading at arbitrary points correct? So list is O(1) for getting something at a certain index. However, for adding and removing elements at the front a list it is O(n) since it has to allocate and move the elements back.
If you need to add/remove elements from the front and the back, then yes, use a deque.
Do you use it often in your work? I don't see them much which is why I am curious.
...deque is a bit slower to iterate through, so unless you really need to pop/push elements on the back and front, use a list

I used asyncio.Queue which is like deque, but supports waiting for an element asynchronously
actually, it's not like deque, it's a single-ended queue
This is fascinating. I didn't expect it to be slower to iterate
I remember, I used deque when implementing a stackless interpreter https://github.com/gurkult/py-gurklang/blob/master/gurklang/vm.py#L60
I needed to push instructions to the front but pop them from the end
gurklang/vm.py line 60
pipe: "deque[Instruction]" = deque()```Linked lists are usually slower to iterate through, even though the time complexity is the same. That's because it involves following pointers instead of iterating over a contiguous chunk of memory
This makes total sense just never thought about it that way
deque is actually not a simple linked list, it's a linked list of small arrays
if you know a little bit of C, this file might make sense: https://github.com/python/cpython/blob/3.9/Modules/_collectionsmodule.c#L19-L21
Modules/_collectionsmodule.c lines 19 to 21
/* collections module implementation of a deque() datatype
Written and maintained by Raymond D. Hettinger <python@rcn.com>
*/```Been a few years but looking now
I know the very basics of C, sometimes CPython source makes sense, sometimes it doesn't 🙂
Fascinating so it is allocating blocks of them
Even if you need to add things to the front, you still can use a circular buffer instead of a linked list
can someone help me with linear and binary big-O complexities
What's a binary big-O complexity?
nvm
Counterpoint: if you know in advance how big your linked list needs to be, you can preallocate a contiguous chunk of memory for it. You'll still be accessing that memory in a random order though, so you can only maximize speed if your linked list is small enough to fit in the cache.
Is it still considered a linked list at that point?
You can make a linked list out of an array. You don't literally need pointers. It's still a linked list, as a linked list is an abstract concept.
I would say, if you already know how big your list is going to be, you probably don't need a linked list.
However, you might have an idea how big a deque is going to be, but you still want to be able to use the features of a deque (i.e., fast pushes and pops on both ends). In that case, it would make sense to preallocate space for a deque and build it there.
What's the best way to implement a throttler without dropping the requests/calls, but instead call them once again sometime "later"
I though of putting the request that are being "dropped" in a queue, and then while the queue is not empty, re-make the calls again with the throttler
that doesn't sound too bad
wait
are we talking like HTTP requests here?
yes
did you mean to reply to the other message
Oh shoot, yes
I don't see how that would work
Sorry 😅
like you would have returned to the client a 429 or something, right?
Yep, when the status_code is 429, put the request in a queue.
the problem is that the headers, nor the body, contain the Retry-after quota or anything similar
so how will you notify the client?
okay wait hold up
let me just clarify
you're asking how you, as the server, would throttle a client's request by delaying it?
Nope, I'm making a client that'll make calls to the server
The server returns 429 when we hit the limit, obviously
So I want to have some kind of a retry and/or throttling strategy
Does that make sense now ?
should there be a "neither" here?
like are you asking for a strategy to time retries?
My English is a bit off today for some reason
Yes you're right, neither the headers nor the body*
Yes
Either a strategy to time retries, or a strategy to limit the calls I can make per X time
I think a good start would be exponential backoff?
I don't know what's best, never done any of this.
Never heard of that, let me have a read about it
( I think the name explains it, but still )
Well, thanks @brave oak
I'll read about it and try to implement it.
yw
I have a program that runs simulations. In each simulation, there are several thousand time steps, and about twenty values I want to record. Currently, at each time step, I am creating a new temp Dataframe and extending another with it. This is crushingly slow. Is there a better method that I haven't considered? Eg linked list?
This might actually be a #software-architecture question. You need to record every single time step?
However, my first hunch is that creating a new DataFrame is probably very expensive. You should be adding a row to the existing one instead.
Cheers
this optimization increases the ratio of data to pointers, saving space. a normal linked list has 2 pointers per element, while using a constant size chunk like this has 2 pointers per 64 elements
Then on a C level it is something like a hybrid of an array and a linked list
not really? 🤔 i guess
it's just a linked list but instead of the nodes being the elements it's a constant size chunk of elements
It isn't hugely impactful to the things I am doing but it is really interesting to see it under the hood
I have a probably very naive question. I was told that heaps are a type of tree and trees are a type of graph, and that linked lists can be thought of as graphs or under some conditions trees as well. Is there some (partial?) hierarchy (of generality/containment) of data structures?
They are all, in theory, special cases of graphs. However in practice you may treat them differently from graphs. You can treat a tree as just an undirected graph without cycles, but generally you are dealing with "rooted" trees where each node has one "parent" except for the "root" node which has no parents. There is no notion of a "root" or "parent" for a graph.
So I don't think it would be right to think trees as a kind of graph, in practice. But rather just a different kind of data-structure.
How can I check if an int appears more than n/k times in an array of size n, in O(log n). I can do it in O(n) but I've been struggling to figure it out and I just can't get any ideas
say k=5
in the worst case you have to check every location of the array
if the array is sorted you can do it much faster
If the array is sorted, use binary search
there's a python module to help bisect that can bisect both directions and you can just measure the difference of the indices
In [85]: import bisect
In [86]: my_list = [1, 2, 3, 3, 3, 3, 4, 5, 6]
In [87]: bisect.bisect_left(my_list, 3)
Out[87]: 2
In [88]: bisect.bisect_right(my_list, 3)
Out[88]: 6
In [89]: 6 - 2
Out[89]: 4
How would the whole thing work then? What do I do with the binary search
the binary search would tell you the left-most or right-most index of the value you're interested in
but then how do I know which value I'm interested in?
that would be an argument to your function presumably
so if I'm trying to find the number that appears more than n/5 times how do I know what argument I'm looking for
sorry I don't really get it
the problem you're describing is changing as we go --- if you wanted to check a specific int (How can I check if an int appears) then you just do what the snippet I posted above does with that specific int --- if instead you're trying to find if any int appears more then n times, you'll need to check every unique integer in the array
in the latter case, i'm not sure you can do a O(log n) algorithm for it
ah sorry I should've been more clear. What I mean is check if there is a number that appears more than n/k times in a sorted array in O(log n)
Does k always divide n evenly? Is that somehow important?
Then why is the question stated that way? It's very strange phrasing
Maybe like, you check the intermediate position, and if the number at that position is off by at least k, then there might be some number in the section you skipped over which appears that number of times
are there other constraints on the sorted array? are the values contiguous?
like (1, 2, 3, 3) allowed, but not (1, 2, 4, 4)
So if you have an array that’s 100 numbers starting at 75, and you check position 50, if the number there is within 5 of 125 then there’s not any number in the lower half that appears more than 5 times
no, there's no constraints
any sorted array of n numbers
and to take a specific instance
But if the difference is greater than 5 then a number that appears more than 5 times might be there
check if there is a number in that array that occurs more than n/6 times
Actually, nvm
that's probably a reasonable way to search, meso
I see that they don’t need to be consecutive numbers, so it wouldn’t work
yes, if it was consecutive it would be easier
It would maybe work if it had to be a sequence of consecutive numbers.
I think there are details about the problem that we are missing
But it sounds like it can be something like [1,2,3,123,456,1000,etc]
So that wouldn’t work
Yeah it does. It doesn’t seem like it can be done in O(log n)
Find an algorithm that runs in time O(log n) that checks if there is a number that occurs more than n/6 times in a given sorted array of n numbers.
This is it
The original formulation says k instead of 6
What webpage is it?
Is it possible the algorithm has some awful scaling with k?
It's from a book I borrowed from the library, not sure if I can find it online
I think this could be done in O(1) time actually 🤔
Actually, maybe not.
that's ambitious
Consider slices of the array that have a stride of n/k. If a number appears more than n/k times, then there will be at least one such slice where it appears twice in a row.
You could start by sampling the array at every n//6th index.
That's what I just said
Oh yeah, didn't read your comment sorry 
that step is still O(n) 😦
Which step?
sampling every 6th index
Although you could have a block that is centred on one of these indices, in which case you need to find the start and end of that block, which could be done in O(log n) time.
Nah, sampling 6 indices.
No, you binary search within the subsequences
Every n//6th index.
yes but the number of subsequences is proportional to n
true
Not sure I understand 🤔
At least one subsequence has a repeated element. But not all subsequences. Therefore worst case you must try them all.
an amortized log n algorithm is probably possible
Sorry, I'm not sure what you mean by subsequence?
0, 2, 4, 6, ... is a subsequence of 0, 1, 2, 3, 4, 5, 6, 7, ...
Can we use binary search to find the subsequence with the repeated element as well?
Have I completely misunderstood the question? I'm not sure how subsequences are relevant.
Unless you mean the subsequence comprising every n//6th element.
0, n/k, 2n/k, 3n/k, ...
So the subsequences are labelled by s, let's say. Then we want to consider the subsequences
0, n/k, 2n/k, 3n/k, ...
1, n/k + 1, 2n/k + 1, 3n/k + 1, ...
...
s, n/k + s, 2n/k + s, 3n/k + s, ...
...
n/k - 1, 2n/k - 1, 3n/k - 1, 4n/k - 1, ...
And, if any element is repeated at least n/k times, then at least one of these subsequences must have a repeated element.
Well, more than n//k times.
yes
But that's not necessarily the case.
So, within each subsequence, we can binary search. The problem is, the number of subsequences still scales with n.
I assumed k was fixed.
But n isn't.
Right, but the length of one of those subsequences is just k.
For the purpose of making it easier assume the array can be of any size n and set the k to 6
That doesn't make it easier
Oh right, I see what you mean now.
Yeah, I'm describing a different approach.
I would think of the list of numbers as being broken into contiguous 'blocks' of the same number.
Any block whose length is greater than n//k has to intersect at least one of the indices 0*(n//k), 1*(n//k), 2*(n//k), ...
So at each of those indices, do a binary search to find the beginning and end of the block.
Then determine whether the span is greater than n//6.
Sorry, I keep switching between 6 and k
And it's O(k log n)
Yeah, but we treat k as fixed and ignore it 😄
yes
In fact it's not all that difficult to implement in Python, if you know the standard library well.
it's really easy for this to be slower than O(n) as k increases
How so?
Yeah, as k approaches n, you're better off just scanning the list
Because your blocks get too small for binary search to be useful
Oh yeah right.
I wasn't even thinking of doing a binary search on a block. Just k binary searches on the whole list
no, my idea was O((n/k) log n). This idea is legit 🙂
Something along the lines of (I haven't figured out the edge-cases): ```py
def solve(nums):
c = len(nums) // 6
for num in islice(nums, 0, None, c):
left = bisect_left(nums, num)
right = bisect_right(nums, num)
if right - left > c:
return num
yeah, this is still n // k log n
So the solution is you skip n//k elements?
if n >> k it may be worse than O(n)
I don't think so. Consider the degenerate case of just asking whether all n elements are the same. Start from the middle, where you find some int a, and use binary search to find the beginning and end of the contiguous block of entries equal to a. In O(log n) time, you verify that all the entries are a.
consider n = 2**20 and k = 2
I'm not sure I understand. It does k binary searches.
that's more than 2 searches
In that case it does two binary searches. Right?
One search (actually two sorry) for nums[0] and another for nums[2**19].
how do you find a repeat of 2 with 2 binary searches
Ah right. I think you've misread the question. We're looking for repeats of length n//k.
In general it's this:
1. Divide the sequence into k equal sized blocks.
2. Within each block, use binary search to find the endpoints of the regions whose values are the same as the block boundary value.
3. Add up the lengths from neighboring blocks to see if any single value repeats enough times.
It's always 2 * k binary searches, and k - 2 additions.
So in the case you highlighted, we're looking for repeats of length 2**19.
repeats of length 2**19 are easier to find, short repeats are hard to find
Exactly, and short repeats correspond to high values of k
ok, but still the solution is bad for these
Yeah, so the algorithm is O(k * log(n)).
Of course it is. k log n > n for large enough k
i was thinking of k as repeat length
I'm very fuzzy on the exact semantics of multi-variable big-oh notation.
not n // k
The complexities have different constants out front, but for k greater than some number on the order of n / (log n), it will be better to just scan the list.
Ah right yeah. I think we just weren't on the same page.
It means for large k and large n, with no specific relation between them
it's confusing the k is the proportion and n // k is the repeat length and not the other way around
It was at first, but I understand it now. It's meant to help you realize that even after you divide the list into a fixed number of pieces, the size of the pieces is still scaling with n.
i knew it was scaling with n without that
i'm going to consider it bad labeling, i don't think there's a O(log n) solution -- not even a probabilistic one --- short sequence lengths will always be hard to find and require lots of probing
if the sequences are guaranteed to be long in relation to the length of the sequence, then you can find them pretty fast
I think calling it O(k log n) clarifies all the issues, really. For sufficiently large k, it will perform worse than simply scanning the list, which is O(n).
i don't even think the list being sorted helps here ---- this would be the same complexity of looking for a repeated sequence in a unsorted list
It would not, because we're using binary search to get the log n part. It still relies on the list being sorted.
but not for looking for if something appears n times in a unsorted list
So the general idea is ```
- Divide array in k equal subarrays
- Use binary search in each subarray -- but what exactly am I looking to find here?
- Add up the length(of the same repeating number sequence?) from neighbouring blocks to see if in total the length is over n/k
specifically for finding if something appears n times in a row
If the list is unsorted, there are no possible shortcuts. But that isn't what was given.
you can still probe half the sequence length and then probe deeper any time there's a match
I'd rather define a problem before arguing about what the complexity of solving it is.
you can find sequences of length 1 in constant time though, so at least there's that
they're binary searching the whole array, not the subarray --- but they're using the numbers at the end of these blocks --- you can infact restrict your binary search to just the slice before and after a specific block
this should be some speed up
I was only ever binary searching within the blocks
The scaling is the same, though
def solve(nums):
c = len(nums) // 6
for num in islice(nums, 0, None, c):
left = bisect_left(nums, num)
right = bisect_right(nums, num)
if right - left > c:
return num
could be updated to
def solve(nums):
c = len(nums) // 6
for i, num in enumerate(islice(nums, 0, None, c)):
view = nums[(i - 1) * c: (i + 1) * c] # assume a view not a copy
left = bisect_left(view, num)
right = bisect_right(view, num)
if right - left > c:
return num
should change the log(n) to a log(n//k)
I think bisect has lo and hi arguments, that can be used to effectively operate on a view.
that works, i just use numpy arrays too much
I'm still a little stumped but I'll figure it out

<@&267628507062992896> CAN I ASK A DOUBT ABOUT C++
i feel like you've been told not to ping admins before
mm, yes you have.
!tempmute 873382452876427274 2d Misusing staff pings after already being told to not do so.
:incoming_envelope: :ok_hand: applied mute to @fiery cosmos until <t:1630202743:f> (1 day and 23 hours).
YOU HAVE OFFENDED THE GREAT ONES
Hello. New in algos here. Could anyone suggest on how I should start?
Have you seen pinned messages?
Oh, right! Thanks!
How do I get the memory address of a linked list node?
id gets the memory address of something
It doesn't, really. In CPython it happens to do so, but it's not guaranteed by the language, PyPy certainly does not, etc.
Need it to check if there's a loop in the linked list
Use is to check if two objects are really the same
I'll be using dictionary to store the addresses
Use a dictionary to store the objects. They are really references anyway.
Could you give an example of using 'is'
Meaning I store the node itself in the linked list?
Variables in Python hold references to objects. So when you put them in a container, you're really putting references in a container.
Actually I'm kinda curious how you're building a linked list in the first place, because it seems like you would have already had to think about this.
!e
a = "foo"
b = a
a is b
"Variables in Python hold references to objects". So you're saying that an int variable holds reference to an int object?
thanks.
yes
ok, so when you start looking at is on primitive types like int and str it gets weird
Do you want the code?
!e
a = "foo"
b = "foo"
print(a is b)
a = 1
b = 1
print(a is b)
@arctic veldt :white_check_mark: Your eval job has completed with return code 0.
001 | True
002 | True
>>> a = [1, 2, 3]
>>> b = a
>>> a is b
True
>>> a == b
True
>>> c = a.copy()
>>> a is c
False
>>> a == c
True
Both true cause 'b' is referencing to "a" 's address?
because they refer to the same value
Won't copy just provide the same address to 'c'?
primitive types can be singletons
Primitive types are funny, because Python only puts one copy of "foo" in memory. That's why I used a list example.
No, the point of .copy() is it doesn't do that. It actually makes a second copy, with a new address.
small correction: there's no such thing as an int variable in python
there's just a name, which could refer to an int, but you could also reassign it to any other object of any type at any time
One copy?
yes
So, lists and integers come under the same category?
So what'll happen if there's one copy?
Like any snippet which doesnt work properly cause of only one copy.
You've seen in this discussion what happens
Both the outputs are true. I dont get how only one copy affects the output
Compare to my example with lists
Also, open the Python interpreter and try it yourself
No, like whats supposed to go wrong if there's only one copy because otherwise, I wont know what I'll be checking for
Nothing is going wrong. You're seeing the truth value of is vs ==
This is not really about algorithms and data structures anymore.
they're both objects
python doesn't have primitives though
Fine. The builtin non-container types, or whatever you'd like to call them
well, not necessarily
only if they occur as literals
and that's an implementation detail of CPython, of course
can someone help me with sorting strings in order of a number inside the string but also accounts for missing numbers in the order?
is that possible?
How would you know where to put the stings with the missing numbers?
What would the O notation used in binary trees mean? I did not understand.
I know it's supposed to be definite or something infinite, but I would need to understand a little more.
big O notation?
have you seen nedbat's talk https://www.youtube.com/watch?v=duvZ-2UK0fc

Speaker: Ned Batchelder
Big-O is a computer science technique for analyzing how code performs as data gets larger. It's a very handy tool for the working programmer, but it's often shrouded in off-putting mathematics.
In this talk, I'll teach you what you need to know about Big-O, and how to use it to keep your programs running well. Big-O h...
Can someone tell me how to exclude characters from a regular expression match without string slicing
stringname_re = re.compile("[(]StringName:[0-9]+[)]")
what exactly do u mean by exclude here 👀
Uh so I'm able to match a string to the expression to find its indices and search result. However I can't get a string from removing the search result without making a function. Any ideas?
uhhh sorry.. didnt get it again... could u give an example of sorts
but well from what i understood.. you could use groups perhaps?
''' aaaa(StringName:1)bbbb(StringName:2) ''' Result : 'aaaabbbb' Any ideas?
i dont see a direct way of doing this but if you want to do it without slicing
groups could work in this case?
test_str = "aaaa(StringName:1)bbbb(StringName:2)"
str_reg = re.compile(r"([^(]*)[(]StringName:[0-9]+[)]")
out = "".join(i.group(1) for i in str_reg.finditer(test_str))
ohh wait @spiral fractal you also can use re.sub if you dont have a problem and ur motive is to remove the certain things only
str_reg = re.compile(r"[(]StringName:[0-9]+[)]")
out = str_reg.sub("", test_str)
Hi all, I wanted your help in understanding the approach to a question. Can I post it here ?
Bob wants to purchase N pens and so has prepared a link of shops which sell the pens. Each shop charges a different price per pen and has limited quantity available in stock. Along with the price of pen, each shop charges fixed delivery fees irrespective of how many pens are bought. Write a program to help Bob get the N pens as cheaply as possible.
Input Format:
The first line of input has two integers: N, the number of pens Bob needs, and S, the number of shops ,separated by single white space Next S lines have 3 integers, Q, P and D, each separated by single white spaces, where q is stock of pens available at the shop , P is the price per pen and D is the delivery fee.
Output Format:
Single line of output has an integer, which is the minimum amount Bob has to spend
Constraints:
- 1 <= N <=10000
II) 1 <=S <= 100
III) 0 <= Q <= 10000
IV) 0 <= P <= 10000
V) 0 <=D<= 1000000
VI) N <= Q1+Q2+...+Qs
Sample Input 1:
10 2
5 5 50
1000 10 0
Sample Output 1:
100
Explanation 1:
No of pens Bob needs, N=10
No of shops, S=2
Shop No Quantity Available Price/ Pen Delivery Fee
1 5 5 50
2 1000 10 0
As shop 1 does not have 10 pens, either he has to buy all the pens from shop 2 or buy 5 pens from shop 2 or buy 5 pens from each shop. Consider the case when Bob buys 5 pens from shop 1 and 5 pens from shop 2. Total amount he has to pay is (55+50 )+(105+0)= 125. Consider the case when Bob buys 10 pens from shop 2. Total amount he has to pay is (10*10 )+0 =100
Minimum amount Bob has to spend to purchase 10 pens =100.
Sample Input 2:
20 4
5 5 6
10 4 12
15 6 9
20 7 0
Sample Output 2:
118
Explanation 2:
Since N=20, N pens can be obtained in different combinations from 4 shops. Let us t
5, 5, 5, 5 -> (55+6)+(54+12)+(56+9)+(57+0) =31+32+39+35=137
5, 10, 5, 0 ->(55+6)+(104+12)+(5*6+9) = 31+52+39+0=122
5, 10, 0, 5 ->(55+6)+(104+12)+(5*7+0) =31+52+35=118
0,10, 10, 0 ->(104+12)+(106+9) =52+69=121
... and so on.
Considering all the possible options, the minimum amount to be paid is 118
uhuh seems alright.. did you try anything?
I thought it could fall under fractional knapsack. I tried making a choice diagram where all the shops are considered the beginning and based on the initial shop chosen the rest of the tree will be tried based on the remaining shops.

yeah well that's what the diagram would look like.. and then continue till the point number of pens encountered become >= N
then at each step one with lowest price should be selected
approach seems right
hi guys, what are the best algorithms and data structures courses/resources for python? (preferrably ones, that include implementations)
I just tried a binary tree and this result must be good? in 1,000,000 nodes, I looked up the value 4000 and time was 0.0005140304565429688. is it considered null, normal, satisfactory or slow?
not enough information
the time something takes requires more information than just the size and the abstract structure you use
I do not understand what information I need to verify.
Inserting 1m of nodes took 192 seconds, searching for 50k took 3.6 seconds.
@knotty magnet
it depends on hardware, your implementation, etc, etc, etc
just giving a time means very little
It also massively depends on what language it's written in 🙂
if this is a python implementation, a C one would probably be 10-100 times faster and there's nothing you can do about it
so time doesn't really mean much
what you do need to check is that it has the right asymptotic guarantees - basically, when you increase the tree size, the time to search an element should scale only with the depth of the tree, so approximately the log2(n) of the number of elements.
1gb ram DDR3 low-end device.
read what reptile said, he's right
In C it is very exact that everything that is done in python in C will be faster.
read all of the messages
I already read it 4 times, I don't understand the end.
what he means is to find the time complexity, and see if it matches up to what a binary search tree should be
So I have to calculate log(depth of the tree) and know if it matches the search time?
Measure the time to search random elements depending on the size of the tree, and see if it scales roughtly as the log of the number of elements.
(the log of the number of elements is the depth, pretty much)
if it's balanced
yeah, so if it's growing too fast, one of the possible reasons is a wildly unbalanced tree
easier to just read the code though
yeah, most people don't actually bother testing besides "does it completely fail when I give it a million elements"
I didn't know that inserting millions of items quickly can throw the tree out of balance.
it's not the "quickly" part, it's that the millions of items aren't necessarily even distributed, which leads to the tree being unbalanced
just seen, thanks
@knotty magnet @vocal gorge I made a lot of progress on this, thanks.
function g(x) {
function g(x) {
return (x <= 3) ? 34: g(x-3);
}
return (x<=2) ? 23 : g(x-2);
}
return (x <= 1) ? 12 : g(x-1);
}
g(100);```
when we have nested functions with the same name (so confusing but i think it's meant to confuse us), is it `return (x <= 1) ? 12 : g(x-1);` will be evaluated first once, then after g(99) will be evaluated with `return (x<=2) ? 23 : g(x-2);` then g(97) will be evaluated with `return (x <= 3) ? 34: g(x-3);` until x reaches <= 3?i see ok thanks
Hi, I have a question about Quick Select implementation. The question is to find kth smallest element in an unsorted array. This site https://www.techiedelight.com/quickselect-algorithm/ gives a pretty straight forward approach:
if k == pivot_index:
return arr[k]
elif k < pivot_index:
return quick_select(arr, left, pivot_index - 1, k)
else:
return quick_select(arr, pivot_index + 1, right, k)
But geeks for geeks https://www.geeksforgeeks.org/quickselect-algorithm/ and this SO answer https://stackoverflow.com/a/22084637/13553114 gives a more convoluted way of calling the recursive functions:
length = pivot_index - left + 1
if length == k:
return arr[pivot_index]
elif k < length:
return quick_select(arr, left, pivot_index - 1, k)
else:
return quick_select(arr, pivot_index + 1, right, k - length)
Both approaches seem to work, but I cannot understand why use the second approach. Is there cases where one would fail?

Quickselect is a selection algorithm to find the k'th smallest element in an unordered list. It is closely related to the Quicksort sorting algorithm. Like Quicksort, it is efficient traditionally and offers good average-case performance, but has a poor worst-case performance.
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.

Stack Overflow
i have implemented the quick select algorithm.
i have the problem that my algorithm ends up in a endless loop, when i use duplicates in the array...
can you help me to get it work?
the expected
Oh btw in first one k is 0 based, but in second k is one based. Although that should be trivial.
Hi all. I've been working on some hacker rank problems and reading up on the different algorithms in geeksforgeeks
I came across the notorious "N Queens" problem: https://www.geeksforgeeks.org/n-queen-problem-backtracking-3/
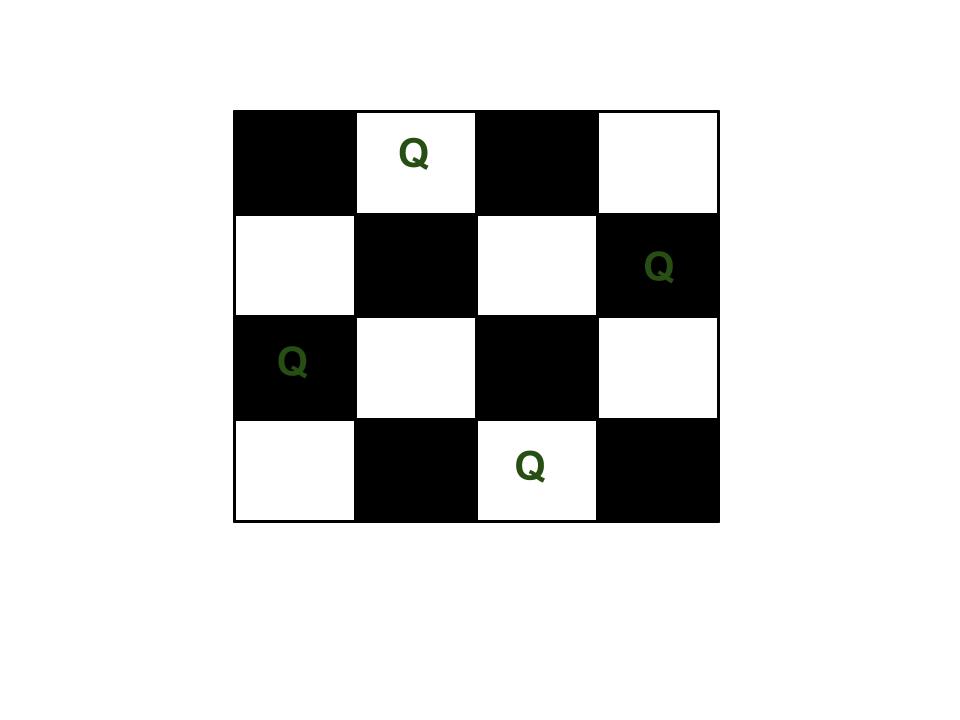
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Under the optimized solution for Python, I was unable to understand the choice of creating a list of 30 zeroes for left and right diagonals.
Why 30? What's so magical about this number?

Can someone here explain it to me?
I think it's a habit for competitive programmers to reserve extra space for arrays to avoid unexpected overflow
Tbh, I'm having a hard time reading the code. But maybe they just assumed the board will never be larger than 30x30?
could just be classic geeks4geeks being dumb
Funnily enough, for n-queens it's actually much faster to just randomly place the queens on the board then shuffle them around a bit until you have a solution (with a bias towards fewer conflicts).
mcts style?
Erm, not really. It would be a local search algorithm.
You can solve 1-million-queens pretty easily this way.
interesting 👀
Almost unbelievably, (aside from setting up the board initially) the number of steps required is independent of the problem size.
It's because for any given state of the board, there is always a solution close by.
Actually, I say easy, don't hold me to that
Implementing it is probably a bit tricky.
anyone with algorithm knowledge
https://www.youtube.com/watch?v=sw7UAZNgGg8
i want create this in python instead of going thru each possibility with if statements
which algorithm should i study
@ me when you figure it out

By the 1950s, science fiction was beginning to become reality: machines didn’t just calculate; they began to learn. Machine calculating was out. Machine learning was in. But we had to start small.
Donald Michie’s “Machine Educable Noughts And Crosses Engine” -- MENACE -- was composed of 304 separate matchboxes that each depicted a possible stat...

it is
ty
Someone help

can someone help me in finding best solution for longest sub array with zero sum?
That can be done in O(n) or O(n log n)
@glad tartan @knotty magnet If you're interested, I had a go at implementing that local-search algorithm I was talking about: https://paste.pythondiscord.com/pozalukahi.py
It could be improved upon, but already it solves n-queens for n = 1000 in a reasonable length of time: ```
In [5]: %timeit n_queens(1000)
1.23 s ± 44.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
This uses a kind of local search called 'simulated annealing'.
if this is algorithms
anyone want to attempt to find how this number sequence works i have 0 clue tried everything
I definitely did something wrong, because the number of iterations seems to be growing unbounded: ```
In [2]: _ = n_queens(10)
Found solution in 100 iterations.
In [3]: _ = n_queens(100)
Found solution in 239 iterations.
In [1]: _ = n_queens(1000)
Found solution in 697 iterations.
In [4]: _ = n_queens(10000)
Found solution in 5015 iterations.
Hello 🙂 Yep, this is algorithms. What was the sequence?
it may not look like much but
100000
229740
373719
527803
689865
858581
1033041
1212573
1396661```i genuinely have no clue
even any hints to suggest what it could be would be appreciated too
Is that all you have of the sequence? Any other information for context?
i can get more numbersd if u want its a slow process
What is the source of the numbers?
its on a minecraft server lmfao
its when you rank up
it increases every rank up
i mean on the 5000th number its 140,066,469,271 and increases a little less than 1.0003x
just plug that into some function fitting thing
nth term finder website 💯
Hey so ive got news from a mate that programs with me that discord.py is beeing discontinued in a few months. I was wondering what will happen with a Bot of mine that uses this.
!eval ```py
nums = [100000, 229740, 373719, 527803, 689865, 858581, 1033041, 1212573, 1396661]
def pairs(xs):
return zip(xs, xs[1:])
def diffs(xs):
return [y-x for x, y in pairs(xs)]
def ratios(xs):
return [y/x for x, y in pairs(xs)]
def format_nums(xs):
return ' '.join(f"{x:>10.3g}" for x in xs)
for formula in """
diffs(nums)
ratios(nums)
ratios(diffs(nums))
diffs(ratios(nums))
ratios(ratios(nums))
ratios(ratios(ratios(nums)))
diffs(diffs(nums))
diffs(diffs(diffs(nums)))
""".strip().splitlines():
print(f"{formula.strip():<30} {format_nums(eval(formula))}")
@keen hearth :white_check_mark: Your eval job has completed with return code 0.
001 | diffs(nums) 1.3e+05 1.44e+05 1.54e+05 1.62e+05 1.69e+05 1.74e+05 1.8e+05 1.84e+05
002 | ratios(nums) 2.3 1.63 1.41 1.31 1.24 1.2 1.17 1.15
003 | ratios(diffs(nums)) 1.11 1.07 1.05 1.04 1.03 1.03 1.03
004 | diffs(ratios(nums)) -0.671 -0.214 -0.105 -0.0625 -0.0414 -0.0294 -0.022
005 | ratios(ratios(nums)) 0.708 0.868 0.925 0.952 0.967 0.976 0.981
006 | ratios(ratios(ratios(nums))) 1.23 1.07 1.03 1.02 1.01 1.01
007 | diffs(diffs(nums)) 1.42e+04 1.01e+04 7.98e+03 6.65e+03 5.74e+03 5.07e+03 4.56e+03
008 | diffs(diffs(diffs(nums))) -4.13e+03 -2.13e+03 -1.32e+03 -910 -672 -516
 @steep radish maybe some clues.
@steep radish maybe some clues.
Hello, see this pin in #discord-bots #discord-bots message
Short answer: it's not clear, probably a popular fork will emerge.
oh nice thanks il see if i can do summin w/ that
maybe here or something
0.04 -> 0.02 -> 0.01
It doesn't look like there's a simple formula.
I'm still not sure I understand where you're getting this sequence, and why you need to find the formula for it.
curiosity probably, i know i did the exact same thing lol
iwas finding it out so i can get total of howmuch it would cost
for like 7k - > 8k
etc
You could try fitting different functions to the data in Desmos: https://www.desmos.com/calculator/ce8fuerhsg
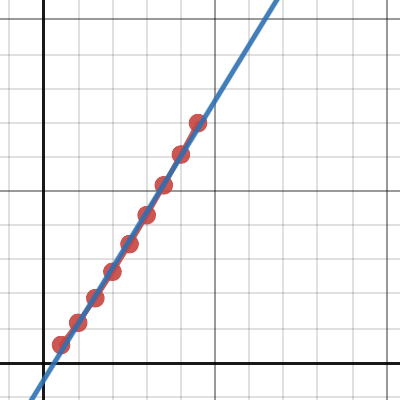
Desmos
Maybe an approximate fit would do then?
yeah i can probably just do approximate
il see what i can do from here
thanks for the help
Hi everyone! I have a challenge for logic building. How would you computerise the recognition of a "Split" in a Bowling game. Suppose the pins are numerated like this:
7 8 9 0
4 5 6
2 3
1
hey I'm new to coeding and am planning to start a project where I make an androis app but def need python for when i study astrophysics
should I learn Kotlin, c+ or python first?
It's kinda offtopic here however I think that Python is the easiest one. Definitely C++ is the most difficult language from the given list
okay thank you and sorry, I didnt find a general chat to write it into
!ot
Off-topic channels
There are three off-topic channels:
• #ot0-psvm’s-eternal-disapproval
• #ot1-perplexing-regexing
• #ot2-never-nester’s-nightmare
Their names change randomly every 24 hours, but you can always find them under the OFF-TOPIC/GENERAL category in the channel list.
Please read our off-topic etiquette before participating in conversations.
There is also #python-discussion
oh thank uu
if some function takes O(b^d) where b and d are constants. and i run this function n^2 times... what's the complexity of the whole function?
is it O(b^(2d))
that would imply if i put some constant time function inside a nested loop it's the same as an expensive function
and it is the same
you double N, the time grows 4 times, in both cases (expensive loop/cheap loop), so they must be same complexity
it's the same time complexity, but not necessarily the same runtime
Then it's O(n^2)
Because O(x) where x is constant is O(1)
In any other case O(x) invoked n times is O(n x)
do i understand this right that both of these loops are O(n), despite the difference in the functions?
>>> def return_1():
... return 1
...
>>> def something_expensive():
... # something
... ...
...
>>> for i in range(4): #O(n), n=4
... something_expensive()
...
>>> for i in range(4): #O(n), n=4
... return_1()
...
okay i wrap it in a function where it takes a number and i set n=4
Time complexity is something different than execution time
if something_expensive is O(1), then they are the same
O(20n) is the same complexity like O(n) but it's 20 times slower
i see
it's just rate of change depending on changing input
Because 20 is const and can be omitted
i guess time complexity isnt useful for comparison in this case
there's a more correct definition, but intuition is simply how strongly it reacts to growing n
O(10000n) is much better than O(n^2), however for small n-s the second algorithm can be better
it's a bit weird to me that looping kinda eats the time complexity of the enclosed function
"eats"?
it doesn't
i asked because im running a depth first search n^2 times and wanted to know what the time complexity overall was
if you do things sequentially, then there's some eating
that's the thing though, if the depth first search has a constant time complexity, then it's just not expressed in the overall time complexity, because it's not useful
whatever code you write, it basically has to be O(1) if you don't do input() or random or something
cuz nothing is variable
so like 3n grows more than n if you increase n by 1, so you would say O(3n) is slower, which is not true
but if instead you use multiplication it becomes correct
O(3n) doesn't grow more than O(n) if you multiply n and divide new value by old
O(3n) = O(n) as expected
whatever idk
O(3n) algorithm is worse than O(n) despite of same complexity
Also O(k n) algorithm for const k can be worse than O(n log n) is k is big enough and n values are small
ok yeah
so basically you're not talking about complexity, but using the notation for complexity
but there's no notation for not complexity
it would just be 3n
looks lame
Technically O(k n) is proper complexity notation but agree, that it is just O(n)
For example for n-s from 0 to 100
https://www.wolframalpha.com/input/?i=plot+n+*+4%2C+n+*+log(2%2C+n)+for+0+<+n+<+100

Wolfram|Alpha brings expert-level knowledge and capabilities to the broadest possible range of people—spanning all professions and education levels.
We can see that for n-s less than 20 O(n log n) algorithm is better than O(4 n) which is equal to O(n)
you're comparing actual runtime, it's not O anything
O(k n) for const k is not O?
it's like you;re saying given a function that is O(k n) let's calculate run time knowing k and n
it's nonsensical
you can say O(2000n) and i still don't know how fast that is, I multiply 2000 by n and then I have to multiply it by the unknown factor and it's unknown
and if you're saying the runtime is 2000n then it makes ssense, and you can compare but there's no O() and there's no other notation to replace it
it's just 2000n
but why should we use O(2000n) instead of O(n)? The whole point of time complexity and Big-O notation is to think about huge n (or any other variables). If our algorithms is O(n!) then it doesn't change anything if it's going to be O(2000*(n!)) or O(69*(n!)) (it will make a difference for small n, but we care only about huge values)
you don't, that's the point
hey, I'm doing algo challenges on a website and got stuck on sth that looks like a bug in Python
I suppose it's probably sth different that I'm missing so decided to write about it here
long story short the task is called Correct Inequality Signs and I'm meant to Create a function that returns True if a given inequality expression is correct and False otherwise.
my code is:
def correct_signs(txt):
tokens = txt.split()
for index in range(1, len(tokens), 2):
if tokens[index] == "<":
if tokens[index-1] < tokens[index+1]:
continue
else:
return False
else:
if tokens[index-1] > tokens[index+1]:
continue
else:
return False
return True
and the unit test is
Test.assert_equals(correct_signs("3 < 7 < 11"), True)
Test.assert_equals(correct_signs("13 > 44 > 33 > 1"), False)
Test.assert_equals(correct_signs("1 < 2 < 6 < 9 > 3"), True)
Test.assert_equals(correct_signs("4 > 3 > 2 > 1"), True)
Test.assert_equals(correct_signs("5 < 7 > 1"), True)
Test.assert_equals(correct_signs("5 > 7 > 1"), False)
Test.assert_equals(correct_signs("9 < 9"), False)
The strange part is - both in the website and in Pycharm - everything but the first test passes
when I checked it with debugger I saw this:

I don't understand why it evaluates to False
those aren't ints, so they aren't compared how you think
oh
strings are compared lexicographically, meaning character by character, and by unicode codepoint
thank you, I missed that
Remember that using "index" in this case would not work on numbers with 2+ digits
I would recommend using Queues and While loops for string to math operations
||just use eval||
Am not sure if this is the right channel for this but can someone explain this code to me? I understand some parts of it but I would like someone else to explain and hopefully I'll understand it better
def rotate(self, nums: List[int], k: int) -> None:
x = k%len(nums)
temp = [nums[i] for i in range(len(nums))]
for i in range(len(nums)):
nums[(i+k)%len(nums)] = temp[i]```Is there a specific part you do not understand?
I don't fully understand the temp variable and the last line of code
The temp variable is copying what's in nums
I don't understand why they did that in a loop though
yeah, it could have just been temp = nums.copy()
hmmm I see
The for cycle inside what it's doing is, create a new list, in which the items will be nums[i], the loop then is declaring what "i" will be at every iteration
@idle pier what aoue is saying would be the more practical example of how to implement it
Python already has in-built functions for list handling
[x for x in nums] is another way of looking at that chunk
ahhhhhh ok now I have a better idea
The next for:
for i in range(len(nums)):
nums[(i+k)%len(nums)] = temp[i]
What it does is, at an index point of i+k, k I think would be how much you rotate the list (item displacement)
The % is called module
ahhh ok, so this when basically the list rotates
In this case, you make it so the index will not go outside of the length of nums
Correct
Do you know how module works?
I can go into detail if needed
yes please
Ok, what module does is taking the remainder of a division
Example 1 % 3
In this case, 1 is not divisible by 3 (talking about integers)
So the remainder is 1
3 % 3, 3 is divisible by 3 and there is 0 remainder, so the result is 0

Looks like this
yea I always understood it when it came to math but when they use % in like my code example, I get confused
It's the same
What it does is, no matter how much you go out of rage of X in Y % X, the result will always be lower than X
thanks @unreal summit I understand way better what the code is actually doing
I didn't this server had a ds and algo help channel, will see me more often here lol 😅
now I just need to research more about module to fully understand it better
anyone with algorithm knowledge
if you know hexapawn what algorithm is best to create it
this is how it works
for its situation the program has certain moves
we can set an array like this for each move
move = [a, b, c ]
and a move will be picked randomly with eqaul chance of being picked
if it makes a winning move
its chance of getting picked will increase
like this if a was a winning move
move = [a, a, b, c ]
now a has more of a chance of being pickked
but for this thiss will take so lng to program like creating a if statement for each possiility
will a minimax alg work for this is there another alg that will work better
By the 1950s, science fiction was beginning to become reality: machines didn’t just calculate; they began to learn. Machine calculating was out. Machine learning was in. But we had to start small.
Donald Michie’s “Machine Educable Noughts And Crosses Engine” -- MENACE -- was composed of 304 separate matchboxes that each depicted a possible stat...
if i dint explain it properly this vid will help
So I'm new to algorithms but I tried solving this with no prior knowledge yet I get errors
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i in nums:
n = 0
index = nums[n]
if i + index == target:
return [i, index]
else:
n+=1```Its the leetcode question sum of 2 numbers
quick hash table question
whats the ideal ratio of slots to items in a list?
are you trying to get the load factor and document check time to be roughly equal?
can you explain what is happening in the first line. also on line 3 you are setting n=0 so that n+=1 isn't doing anything
I solved it already
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
index = []
for i in range(len(nums)):
for n in range(i+1, len(nums)):
if nums[i] + nums[n] == target:
index.append(i)
index.append(n)
return index```Btw
if you see something that could be optimized
let me know
its the first thing I solve in leetcode
Trying to get into algorithms
do you know what a sequential, binary search are
Nope
start there
no clue
Aight
nice
leetcode is more a test than something to help you learn
Oh
When doing leetcode stuff
should I know the logic
or should I study actual
algorithms to accomplish stuff
what
Like
I know theres existing algorithms
should I memorize them
or should I just understand the fundamentals that you were talking about before
why would you memorize a specific algorithm
that doesn't make any sense
study the stuff I mentioned
Got it
you don't need to know specific ones until you interview for jobs
understood
print("hi")
public static int beautifulDays(int i, int j, int k) {
// Write your code here
int count = 0;
int reverse = 0;
while(i <= j)
{
while(i != 0)
{
int remainder = i % 10;
reverse = reverse * 10 + remainder;
i = i/10;
}
if ( (Math.abs(i - reverse) % k == 0))
{
count++;
}
i++;
}
return count;
}
https://www.hackerrank.com/challenges/beautiful-days-at-the-movies/problem
Time limit exceeded
can somebody please help find the error here??
this is Java.
you're in a Python server.
for networkx, if i add two graphs together, will it automatically form a connection if they have similar nodes?
sorry, trying to understand how it works
i'm trying to find ways to combine graphs(json files)/dicts (i guess) together
i assume here is the correct place to ask?
this is correct place to ask, but your question is vague
i have a large number of small call graphs. I basically generated a call graph for each of Tensorflow's Python scripts. I would like to connect them into one large call graph now. Is it doable with networkx? The graphs are in the form of json files or dictionaries.
sorry for being vague
the union function of networkx requires the two graphs to be disjoint, but on the other hand it's not that hard to combine graphs just by adding edges from one to the other
In [23]: G = nx.Graph(); H = nx.Graph()
...: G.add_edges_from(((0, 1), (1, 2))); H.add_edge(2, 3)
In [24]: for u, v in H.edges:
...: G.add_edge(u, v)
...:
In [25]: list(G.edges)
Out[25]: [(0, 1), (1, 2), (2, 3)]
in this way you can union graphs
that aren't disjoint
Can i automatically do this by iterating through existing nodes?
Im sorry if it pings you
you can add nodes from one graph to the other or edges --- if you add edges though, missing nodes will be automatically added
Sorry i dont follow, because g.add edges from seems to require manual work?
what do you mean
Mm sorry i mean is it possible to input two graphs and it automatically forms the connection?
Cause from what i understand add edges means i require to know which nodes to connect to each other?
I just showed you how above
you can shortcut it:
In [27]: G = nx.Graph(); H = nx.Graph()
...: G.add_edges_from(((0, 1), (1, 2))); H.add_edge(2, 3)
...: G.add_edges_from(H.edges)
In [28]: list(G.edges)
Out[28]: [(0, 1), (1, 2), (2, 3)]
I may have misunderstood the code then
Thank you ill look into it further before asking again
you can create your own union like so:
def my_union(G, H):
I = G.copy()
I.add_nodes_from(H.nodes)
I.add_edges_from(H.edges)
return I
note if you use networkx's union you'll get an error if the graphs aren't disjoint:
In [31]: G = nx.Graph(); H = nx.Graph()
...: G.add_edges_from(((0, 1), (1, 2))); H.add_edge(2, 3)
...: nx.union(G, H)
---------------------------------------------------------------------------
NetworkXError Traceback (most recent call last)
<ipython-input-31-837f3bd4d3ee> in <module>
1 G = nx.Graph(); H = nx.Graph()
2 G.add_edges_from(((0, 1), (1, 2))); H.add_edge(2, 3)
----> 3 nx.union(G, H)
~\AppData\Roaming\Python\Python39\site-packages\networkx\algorithms\operators\binary.py in union(G, H, rename, name)
75 H = add_prefix(H, rename[1])
76 if set(G) & set(H):
---> 77 raise nx.NetworkXError(
78 "The node sets of G and H are not disjoint.",
79 "Use appropriate rename=(Gprefix,Hprefix)" "or use disjoint_union(G,H).",
NetworkXError: ('The node sets of G and H are not disjoint.', 'Use appropriate rename=(Gprefix,Hprefix)or use disjoint_union(G,H).')
I see
Ill look into this
I think my main problem is i dont know the networkx functions too well
I just picked it up today
luckily it's well-documented so just browse around the documentation for a while if you need to
Is it suitable to handle very large graphs though ?
it's a bit of a slow library for very large graphs, how large are your graphs
I would say thousands of nodes
if you need more performance there are graph librarys that are written in C but wrapped in python -- igraph and graph-tool
igraph is cross-platform, but graph-tool is basically only linux
I see ill look around
First need to understand the networkx functions
Are you okay with pings or ill just drop questions here then
you can ping me in this channel, but i'm soon to be mia for a some number of hours
"""
CEO
/ \
PRODUCTION MARKETING
/ \ / \
Fabrication Assembly salesofficer(A) salesofficer(B)
| | | |
worker worker salesperson salesperson
"""
class Node:
def __init__(self, data,level):
self.left = None
self.right = None
self.data = data
self.level = level
root = Node("CEO","CEO")
production = Node("PRODUCTION","MANAGER")
marketing = Node("MARKETING","MANAGER")
fabrication = Node("FABRICATION","FOREMAN")
assembly = Node("Assembly","FOREMAN")
saleA = Node("sales person A","SALES OFFICER")
saleB = Node("sales person B","SALES OFFICER")
root.left = production
root.right = marketing
production.left = fabrication
production.right = assembly
fabrication.left = Node('worker 1',"WORKER")
assembly.left = Node('worker 2',"WORKER")
root.right = marketing
marketing.left = saleA
marketing.right = saleB
saleA.left = Node("SALESPERSON 1","SALES PERSON")
saleB.left = Node("SALESPERSON 2","SALES PERSON")
is this the correct Binary tree implementation

How did u typed this code
In this chat
When i type its a plain text
class Solution:
def search(self, nums: List[int], target: int) -> int:
start=0
end= len(nums)
if start>end:
return -1
mid = (start+end)//2
if target==nums[mid]:
return mid
if target>nums[mid]:
return search(nums[mid+1:end],target)
else:
return search(nums[start:mid],target)
TypeError: unhashable type: 'list'
**Line 13 in search (Solution.py)
**
return search(nums[mid+1:end],target)
How is it an unhashable error?
You use ` 3 times at the beginning and the end of the code
I want to make a script HA by running it on multiple servers, but only one server should be running the script's main function at any given time. So if server-1 is the primary server, server-2, server-3, etc. should be just waiting if server-1 is running the function without issues. But the moment server-1 is down (server explodes, network dies, script crashes), server-2 should take over until server-1's script comes back up.
How can I achieve this in a way that makes sense? I'm using MongoDB for DB, RabbitMQ for queue, FastAPI for API, if any of them can be implemented to help
Not really a networking question
I'm looking for an algorithm
Hey @stone grove!
It looks like you tried to attach file type(s) that we do not allow (.java). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
Hi guys! I'm here because I'm really stuck with a problem I have with coordinates.
Can anyone give me a hand? I leave here the link to stackoverflow: https://stackoverflow.com/questions/69002491/how-can-i-get-the-top-right-box-having-top-left-and-bottom-right-coordinates
Stack Overflow
Let's put some context. I'm trying to reach some values for my app and I need to take the red box of the img.
I've got all the top_left and bottom_right coordinates of these words.
[Word(top_left=...
Hi all, looking for DSA YouTube resources in python.
I haven't found anything that's end to end which covers almost all the generic topics.
If anyone have any recommendations, would be happy to hear. Thank you.
buy Algorithms and data structures in Python by Michael Goodrich
it has everything u will ever need
Hello there,
I was searching for some materials for myself and found these: https://youtube.com/playlist?list=PLMDFPuH4ZxUFGC5ICUu8xstOxQIizMgX2

YouTube
There is also an online book that seems pretty good: https://runestone.academy/runestone/books/published/pythonds3/index.html
An interactive version of Problem Solving with Algorithms and Data Structures using Python.
Hope this helps 🙂
( there is also this course page, related to the youtube channel : https://www.win.tue.nl/~kbuchin/teaching/JBP030/)
hi everyone, I am currently doing a college project involving the TSP, in essence, given 10 points, each with a set amount of resources, the model should be able to determine the best path through 5 of them, maximizing the resources picked and minimizing cost. I was thinking of using linear programming (Lingo) to solve this, but my professor suggested python+gurobi. Does anyone have any experience with gurobi? As a sidenote, is there anything similar to the TSP but without covering all nodes?
help plz

that looks like a test
it's also trivial if you're familiar with chaining, so you should probably check your notes
Separate chaining is the kind where each index points to an array or the start of a linked list or something like that
its a learning quiz
everyone keeps telling me to check my notes but its not there
what exactly does a load factor of 100% mean?
It’s how many index positions the hash table has vs how many values you put in it
how_many_positions / how_many_values
oh ok
so the question would be true
because even if all the slots are full you can add more
Right
ok cool
thanks I didnt know how to calculate load factor so I wasnt sure what the question was asking
wouldn't it be the inverse? values/positions?
Oh, yeah
.
Thanks for catching that
I need help in cropping image i unable to crop image under a fix boundaries of blue color. As most example is crop by rectangle
hi
How could I improve this code
In an amusement park there is a game called balance the scale, in this game N people participate, which must be divided into two groups of similar size, and each group must get on a scale plate. The way to win the game is by strategically organizing the groups taking into account the weights of the people, such that in a single attempt the scale is balanced or as balanced as possible. To win the game you must create a program that receives an arrangement with the weight of each person, then form the two groups strategically and return a tuple with both lists ordered in ascending order (DO NOT print them on the screen). Remember that a scale is balanced if the weights on each pan are as equal as possible. And remember that the number of people can be odd or even.
Example 1:
Entry
people = [80, 59,60,81,57,58,76,75]
Departure
[58,60,75,80], [57,59,76,81]
Note: the sum of the weights of each group is 273 the two, so their difference is 0, that is, the scale is balanced.

I feel this problem can be solved in many other ways
Hello, excuse me, do you know how to extract the last n-lines of a .txt file
And then write them to another .txt file
Here I was trying to get the index of the line but I don't know how to take the last 5 and write it in the second txt
with open("file_text_chat.txt","r+") as f1:
lineas = [linea.strip() for linea in f1.readlines()]
with open("file_only_last_lines.txt","r+") as f2:
if palabra not in lineas:
num_linea = lineas.index(palabra)
f2.write(f"{palabra}\n") #Add the word to the end of the word txt