#algos-and-data-structs
1 messages · Page 118 of 1
I havent thought about it. Hungarian algorithm is strongly polynomial. While bitmask dp must have small constraints, and it takes in general exponential time. However for this case I don't know, havent thought
Hey @minor pumice , won't it be easier to explain and to understand if you explain in a voice chat, just saying!!
you need small contraints
it might but i can't now
@minor pumice wanna just dm me when you can call?
i ain't got a problem
it's too tough to type this shi hahahaha
do you know c++?
but you can understand code?
ok
It's too much of effort.
do you want me to write ur code?
I'd appreciate an explanation honestly
oho k
I want to do the hustle
I'm not looking for someone to solve it for me
I just need a guidance
and I'll take it from there
sure i understand
I'm sure it's harder for you to explain rather than do the whole code
but sorry hahahaha
nahhh
:c
RIp, wanna just send me a huge ass dm when you can
with the way you view it
because it's easy to get lost in many messages
when you trynna describe your logic
wdym?
imma dm you
k
https://www.hackerearth.com/practice/algorithms/dynamic-programming/bit-masking/tutorial/
In general it takes exponential.
In general the total number of subsets of a set of size n is 2^n , so in general it has to be exponential. Redundancy of operations could be made faster using DP though.
yes but 2^n where n is what
maybe in a problem
you have an array
with 1e6 elements\
and you want somehow to make some operations on a second array
with there we say
10 elements
and the problem there we say it's solvable only with bitsmasks
you can affor an 2^n to respesct of the second array
so sureley in bitmasks you will have exponenetial but it is important to respect to what :))
I was talking about the algorithm's time complexity wrt the size of the input the algorithm takes (n) which may differ from the actual size of input N (n<<N) . So yes, in that case we might have a better overall time complexity depending upon the subsequent implementation.
But you said bitmasks have polynomial complexity, not the overall program's complexity relatively. So that's what I was referring to.
i got you, generaly it is.
where can I learn algo and data structs in python for free?
A follow-up, please help.
I need some help trying to create an algo , bear with me as I try to describe what I want to do because its kind of difficult to explain:
I have a program where an object is traveling along some path (shown as the black solid line below) in a tiled grid, where I am constantly recording their position; however because of some error in my measurements, the recorded position can be off by about +/- 1/3 of a tile. Hence, the data I have for the position of the object is the 5 points plotted that deviate from the object's actual position slightly.
I need to find the direction that the object is facing when it reaches tile 2 (shown by the red line segment)
The data that I know is the 5 points that I recorded as they went from tile 1->2 (and I know the fact that they went from tile 1 to tile 2). Because they traveled horizontally across tiles, I know that usually the direction they will be facing is ~ horizontal, but it might not be exactly horizontal. Is there any way to use the 5 measured points to improve the calculation of what direction they are facing. (Obviously 5 points is not enough to determine exactly where they are looking, but I'm just looking for anything that will improve the accuracy every so slightly). Sorry for the extremely long question but I didnt know how else to describe it.

maybe use rolling average?
I'm making a micropython physics engine that can be run on a 128x64 graphic oled display. After struggling for a while, i managed to make a basic particle system that is supposed to detect collisions. However, just after implementing the collision detection system, though the code compiles, nothing shows up on the screen. Do after dying trying to fix the system, i kinda ironed out most of the places where my code might be going wrong. My physics engine seems to run and the screen initializes as well (I draw a random box). Theres something up with the logic of my refresh loop for the particle system and for the life of me, I can't seem to figure it out.
The idea is that every time a particle (a single pixel on the oled) moves, the pixel from the previous position has to be turned off. It was working just fine before the collision system but now the pixels just dont display.
https://github.com/theaxxxin/micropython-physics/blob/main/particles.py
Could someone take a look and help me out with my logic?

GitHub
Contribute to theaxxxin/micropython-physics development by creating an account on GitHub.
Take the height of two consecutive points from the horizontal, and the distance between two points, u can use this information to find sin(theta) , once u have the theta with horizontal u can tell the direction, u can do this even better with rolling mean, which would be the average coordinate between two consecutive points (or u can take three of them, i.e. the previously calculated mean coordinate and the new two, this might improve the direction prediction over time). Find such coordinates and find the direction.
I am not crystal about your query. But as per my understanding, this could be done. Also the caution is, the rolling method would be highly sensitive to outliers, especially if you have less data points.
for i in range(3):
for x in range(len(lst)):
update = lst[-1] + lst[-2]
lst.append(update)
return lst
print(append_sum([2,5]))
why doesn't this print out:
"append_sum([2, 5]) should have returned [2, 5, 7, 12, 19], and it returned [2, 5, 7, 12]
"
why does it not include 19
What is it supposed to do?
Also it looks like you’re returning in the outer loop
This kind of thing might fit better in a help channel
Is Python efficient for data structures? I tried making a linked list but I couldn't figure out how to do it as there are no pointers. Are there any other ways to do so?
you can just create a Node class, and point to the next node with an attribute
@fiery cosmos you do "pointing" in python with normal assignment syntax. If the right-hand value is mutable, then you are assigning a name (pointing) to it in memory:
from dataclasses import dataclass
from typing import Optional
@dataclass
class Node:
name: str
next_: Optional["Node"] = None
a = Node(name="foo") # `a` "points" to Node object with name "foo"
b = Node(name="bar")
a.next_ = b
# fun with references:
c = a # make new reference/pointer to the object that `a` points to
a.name # -> "foo"
c.name # -> "foo"
c.name = "bar" # change name of `c`
a.name # -> "bar", also changes the name of `a`
# because they are the same object
assert a is c
assert id(a) == id(c)
# also, although a and b both have the name "bar" now, they are still different objects
assert a is not b
I see, thank you for your feedback!
It's the other way around, really - Python only has pointers. What you would call a "variable" in most languages is most properly called a "name" in Python, and every name is a pointer to a value (or to no value at all, in which case accessing it gives you a NameError or an UnboundLocalError, Python's equivalent of Java's NullPointerException)
https://nedbatchelder.com/text/names.html explains this (or https://nedbatchelder.com/text/names1.html if you prefer a video)
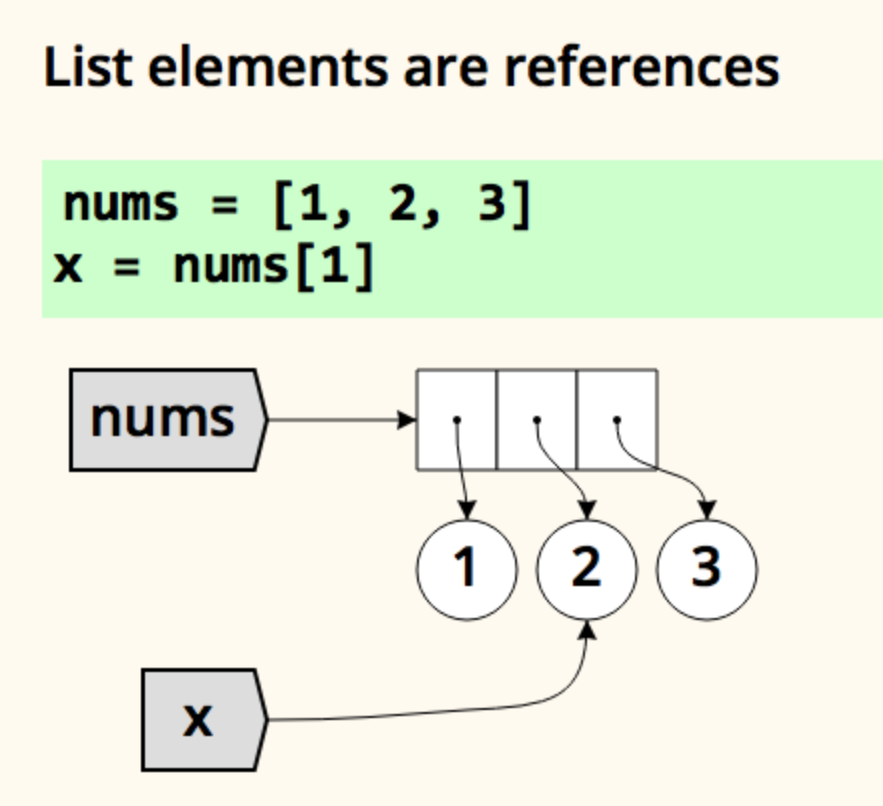
Assignment in Python might surprise you. How do names and values work? This presentation explains it all.
Hey guys, can anyone recommend a good way to solve the following problem:
Minimize $\sum_{ij} M_{ij} x_j$ where $M_{ij}$ and $x_j$ can only be -1 or 1
The return is in outer loop put it outside of it, moreover write it in help channel with more details about the list and your objective with this code
someone a good idea for a project to gain extended knowledge about classes or oop in general? maybe including databases?
hi im wondering if my algorithm for detecting polygons concave or convex ness is sound
so my idea is is that if a take the average of the interior angles and compare that to 180 divided by the vertices count. If it is greater than its concave if its less than then its convex
Does this seem right?
I have a list of words, i need to check if there are 2 words in the list that when concatenated gives a word the user typed. Is there a way to search the words without having a nested for loop?
If you have all the interior angles then just use the definition of concave polygons
A simple polygon is concave iff at least one of its internal angles is greater than 180 degrees
Yeah ive actually figured out a different way based on this principal. I have figured out an algorithm to calculate the interior angles then i just loop through all the angles and see if they are greater then 180
i dont know what i was thinking here 🙃 if i have the interior angles i just check if they are all above 180
hey so I think this might be a better place to ask, anybody here have a bit of knowledge on doing fourier transforms in python?
numpy and scipy have fft if you're into that
static boolean hasCycle(SinglyLinkedListNode head) {
SinglyLinkedListNode hare,tortoise;
hare = head;
tortoise = hare;
while(hare!=null){
hare=hare.next.next;
tortoise=tortoise.next;
if(hare==tortoise)
return true;
}
return false;
}
i randomly got through this algo
i failed some test cases idk why
can u guyz figure it out
ok nvm got it
while(hare!=null&&hare.next!=null)
@meager slate I've been using the inbuilt numpy functions ^^
they're much faster than the one i've coded myself before
Any good DSA pratice site for free
leetcode
Is codeChef good ?
I've been using binarysearch.com lately. It has a decent selection of problems, and the ability to create 'practice rooms' where you can work alongside other people on timed problems.
Hey @odd steppe!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
.....
Minesweeper is a popular single-player computer game. The goal is to locate mines within a rectangular grid of cells. At the start of the game, all of the cells are concealed. On each turn, the player clicks on a blank cell to reveal its contents, leading to the following result:
If there's a mine on this cell, the player loses and the game is over;
Otherwise, a number appears on the cell, representing how many mines there are within the 8 neighbouring cells (up, down, left, right, and the 4 diagonal directions);
If the revealed number is 0, each of the 8 neighbouring cells are automatically revealed in the same way.
You are given a boolean matrix field representing the distribution of bombs in the rectangular field. You are also given integers x and y, representing the coordinates of the player's first clicked cell - x represents the row index, and y represents the column index, both of which are 0-based.
Your task is to return an integer matrix of the same dimensions as field, representing the resulting field after applying this click. If a cell remains concealed, the corresponding element should have a value of -1.
It is guaranteed that the clicked cell does not contain a mine.
Example
field = [[false, true, true],
[true, false, true],
[false, false, true]]
x = 1, and y = 1, the output should be
minesweeperClick(field, x, y) = [[-1, -1, -1],
[-1, 5, -1],
[-1, -1, -1]]
is this a recursion problem or a tree?
https://codeforces.com/contest/1140/problem/A
This is among the easiest problems, yet I cant seem to understand the input 😐 Can someone please help me understand the input , output.
When does the reading stops? i-th page has its mysteries on the a-i page, we stop when we he has read all mysteries for the day ...right? So what happens, when we reach page 6?

click a cell with index lookup, iterate 8 times to check its neighbours, count the bombs, replace index. (handle edge case for boundary values).
Recursion will take more space, but in this case you can do tail call optimization for your recursive stacks.
Does anyone know a good multi-constraint knapsack problem solver? I'm triathlon training, and generally I do roughly the same workouts each week, mostly because it's too much a pain to figure out the right balance of workouts that fit my goals each week. And I'd like to make a list of possible workouts with intensities and figure out random combos that fit the reqs to change the weeks up.
More explicitly I'm using workings on 8020endurance.com where each workout has a duration and a certain amount of time in high intensity and a certain amount in low intensity. I'd like to make a giant list of all the workouts and generate a list of workouts which fit my target workout length of max 70 min/day on weekdays, 135 min/day on weekends, 80% low intensity, 20% high intensity (+/- 5%), with 2/3 biking and 1/3 running (eventually including swimming.
I'm sure no tool exists to do this exactly, but anything anyone has seen out there that might be along these lines I could customize? I think this is basically a variation on knapsack
I think that's actually a covering problem (the dual to a packing problem)
Had not heard of the covering problem before, but looking at wikipedia that look closer to what I'm after
I don't know anything about solvers for that, but hope that helped
I think so. I think what I'll do is implement some random solver online for one constraint and then add in the others. You set me down a more accurate path for finding what I need so thanks!
Currently I have implemented a version of Prim's algorithm using a linear search for vertices, but I am wondering as in Dijkstra's algorithm does Prim's algorithm supposed to use a priority queue (heap), or is a linear search fine?
The time complexity is supposed to be O(E log V); does a linear search achieve this?
Also, I was wondering how to properly store the result of a prim's algorithm
I want to store the minimum spanning tree in some sort of data structure, instead of printing it in a visual way
An array doesn't really work since I need each pair of vertices for an edge...does anyone know what would be the data structure to use?
I used programmiz as reference for my code and it used a linear search
never mind, wikipedia has some interestign answers

I am using the first one unfortunately
but anyways, How should i store the result of the MST? A linked lsit or array can be confusing since sometimes its not a linear straight path to all vertices
Can anyone understand what this Hackerearth challenge is even asking? https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/practice-problems/algorithm/till-the-end-of-the-time-d73ba7d1/
HackerEarth
It seems like most of the problem is unspecified yet has 87% success rating 
isn't it just "convert all the 1s that are next to 2s to 2s, how long does it take?"
Well it expects a single integer as output
yeah, the time
But how is the time calculated?
Turn of what? I don't understand how their example input ```
3 5
2 1 0 2 1
1 0 1 2 1
1 0 0 2 1
If you starts from the cell [1,4] or [3,4] and travels to [2,3] then the cost will be 2 which is maximum of all possible journeys.
every 1 that is next to a 2, is turned into a 2
after 1 turn it becomes
2 2 0 2 2
2 0 2 2 2
1 0 0 2 2
are you familiar with conway's game of life
it's kinda like that
Yes
I totally understand how I'd convert the 1's next to 2's to 2's
Just don't understand how the words on that page definitely ask for that 
So it takes 2 steps until the pattern stops changing?
You are given a matrix of size that contains the digits 0, 1, or 2 only. All the cells that contain 1 and are adjacent to any cell that contains 2 will be converted from 1 to 2, simultaneously in 1 second. Write a program to find the minimum time to convert all the cells having value 1 to 2.
yeah
Write a program to find the minimum time to convert all the cells having value 1 to 2.
it is really odd that they attach values of time to it instead of just asking for steps
Oh  I think I get it
I think I get it
yeah, that part is weird, but it doesn't really change anything ¯_(ツ)_/¯
I still don't get the explanation
If you starts from the cell [1,4] or [3,4] and travels to [2,3] then the cost will be 2 which is maximum of all possible journeys.
why is it talking about traveling when you do them all at once 
i have no idea what that means either
makes it sound like a graph search, and the challenge is under the bfs category, but bfs is unnecessary, surely
 thanks.
thanks.i have no idea how good it would be performance wise, but i kinda like the "conway's gol" approach
Someone please help me understand this codeforces problem.
class CoolThing():
__slots__ = (
"_merged_results",
"infoboxes",
)
def __init__(self):
self._merged_results = []
self.infoboxes = []
huh, cool thing. a way to make abstract instance values
can anybody teach me python
This is not the right channel for it. If you need help in smething specific, please refer to #❓|how-to-get-help
any suggestion for a good book in algorithms and data structures with python please ? I am looking for a good book
Anyone here got experience with HDF-datasets?
there are some resources pinned. i also recommend CLRS
hmm do you mean introduction to algorithms third edition?
@tawny kettle Please don't try to ping @everyone or @here. Your message has been removed. If you believe this was a mistake, please let staff know!
yes
gosh that book has 1000+ pages 😬 I will consider it or maybe for first try I will go for a lighter one and then this , and thanks for your help
yes, and it’s also very dense and math-heavy, so one of the pinned resources might be better for you
although if you’re mainly worried about the length remember you can use it as a reference rather than reading it all the way through
yea thats true , thank you so much 🙂
If i use the property decorator to protect the attributes of a class and specify some range values for them (for example) how can I make the first instance of the attribute to go over the attribute.setter if its set during the init. Calling the property.setter raises a TpeError.
class Protective(object):
"""protected property demo"""
#
def __init__(self, start_protected_value):
self._protected_value = start_protected_value
#
@property
def protected_value(self):
return self._protected_value
#
@protected_value.setter
def protected_value(self, value):
if value != int(value):
raise TypeError("protected_value must be an integer")
if 0 <= value <= 100:
self._protected_value = int(value)
else:
raise ValueError("protected_value must be " +
"between 0 and 100 inclusive")
If I do the following:
p = Protective(start_protected_value=230)
Will set the value wrongly, am I right?
I dont get where
class Protective(object):
"""protected property demo"""
#
def __init__(self, start_protected_value):
self.protected_value = start_protected_value
# or: self._protected_value = self.protected_value(start_protected_value) i think will throw an error
hey i wondered how the time complexity of bfs/dfs traversal in adjacency list is o(v+e)
Anyone who has read "The Little Schemer", do you have any tips/suggestions/advice?
Should I follow along with Racket lang, or doing it with paper and pencil works just as well?
i wouldn't do it on pencil and paper
that should work
you have to visit O(|v|) nodes via O(|e|) edges
the reason it's different for an adjacency matrix is that to find the edges for a given node you have to iterate over a whole column, so n nodes x n rows in each column is O(n^2)
can anyone help me with backtracking algorithms? I have some competitive programming tasks in my university, and I can't understand how to solve one of the problems
true, thanks
I'm wondering when to start to prep for oncampus coding interview
and what are good source to start
Hey @quiet current!
It looks like you tried to attach file type(s) that we do not allow (.html). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
I need help in Linked Lists
sure
I need help
ok then should I follow along with Racket lang?
I went through a reddit post where some people mentioned DrScheme, so I looked it up and get the following link:
http://download.plt-scheme.org/drscheme/
It says "PLT Scheme is now Racket".
if you are going to the trouble of downloading scheme perhaps use WSL or install a unix based operating system like bsd or linux
since you'll need to learn them eventually
You mention WSL or unix, so the person can get comfortable with CLI and terminal?
might as well if you're going out of your way to use racket/scheme
Oh ok. Yeah I use Ubuntu and WSL.
i think i made a few good decorators for debugging ```py
import traceback
import functools
import time
def print_execution(func):
@functools.wraps(func)
def out(*args,**kwargs):
func(*args, **kwargs)
print(f'function "{func.name}" has run with args "{args}" and kwargs "{kwargs}"')
return(out)
def timer(func):
@functools.wraps(func)
def out(*args,**kwargs):
start = time.time()
final=func(*args, **kwargs)
end = time.time()
timed=end - start
print(f'function "{func.name}" executed in {timed} ms')
return(final)
return out
def safe(func):
@functools.wraps(func)
def out(*args,**kwargs):
try:
return func(*args,**kwargs)
except Exception as ohno:
print(f'a safe function just errored. the function was {type(func)} and had the arguments {*args}{**kwargs} full error:\n {traceback.format_exc()}')
return f'a safe function just errored. the function was {type(func)} and had the arguments {*args}{**kwargs} full error:\n {traceback.format_exc()}'
return(out)
@print_execution
@timer
def test(*args,**kwargs):
print('test function is funny')
test()```
Print_exec
Prints whenever the function was called
Timer
Is just a generic timer for how long a function takes
Safe handles all runtime errors and logs them to console
Now how do i pass extra args to decorators
Ex: @decorator(Log=True,LogFile=logging.txt)
But optional
just going to put my print_execution decorator here
def print_execution(log=False,logFile='log.txt'):
def mutate(func):
@functools.wraps(func)
def out(*args,**kwargs):
print(f'function "{func.__name__}" is running with args "{args}" and kwargs "{kwargs}"')
if log:
with open(logFile,'+a') as logs:
logs.write(f'function "{func.__name__}" is running with args "{args}" and kwargs "{kwargs}"\n')
return(func(*args, **kwargs))
return(out)
return(mutate)```
now it has 2 optional commands
`log` and `logFile`
with the defaults being
`log`:`False` (boolean)
`logFile`:`log.txt` (stringhey guys. I'm trying to figure out how to deal with a KDtree - I am looking at several implementations, but while I see how one inserts points into them, I don't see any way to associate data with that point?
or am I supposed to store something like a... hashmap of point->data too?
Whats the best algorithm to use for snake game pathfinder?
I want simple method and complex method
Hmm A star is okay. Ive heard it isnt quite efficient for snake game with very dynamic paths, but its the simpler solution
Oh and by simple, I just scaled it by the more complex algorithm such as AB pruning.
hi
hi
I don't really know where to put this, but oh well I'll slap it here:
The idea is to click repeatedly while the mouse is held. However, it doesn't work, and I think it is because when I click with pynput, it stops clicking outside of the boolean flags. Is this the issue?
Code is:
from pynput.keyboard import KeyCode, Listener as KeyboardListener
from pynput.mouse import Controller, Button, Listener as MouseListener
import time
import threading
button_to_click = Button.left
button_to_toggle = KeyCode(char="x")
cps = 15
class ClickMouse(threading.Thread):
def __init__(self, button, _cps):
super(ClickMouse, self).__init__()
self.cps = _cps
self.button = button
self.running = False
self.active = True
self.mouse = Controller()
self.is_clicking = False
def start_clicking(self):
self.running = True
def stop_clicking(self):
self.running = False
def run(self):
while True:
while self.active:
while self.running:
self.is_clicking = True
self.mouse.click(self.button)
self.is_clicking = False
time.sleep(1 / self.cps)
clicker = ClickMouse(button_to_click, cps)
clicker.start()
def on_click(x, y, button_clicked, pressed):
if not clicker.is_clicking and pressed:
print("User started clicker")
clicker.start_clicking()
elif not clicker.is_clicking:
print("User ended clicker")
clicker.stop_clicking()
def on_press(key):
if key == button_to_toggle:
clicker.active = not clicker.active
with MouseListener(on_click=on_click) as listener:
with KeyboardListener(on_press=on_press) as listener:
listener.join()
Output when holding mouse down is:
>>> User started clicker
>>> User ended clicker
>>> User ended clicker
It should just end once, but instead it does this, and doesn't click repeatedly but rather terminates after 1 click
Any help would be appreciated with this issue
are programming languages created using other programming languages
if so what language was use to write the first programming language
The thing is, past the first release, you can write the language in... itself. https://en.wikipedia.org/wiki/Bootstrapping_(compilers)
Also, not really related to the channel.
And the answer to this is yes, all the time  e.g. Python is written in C
e.g. Python is written in C
The cpu instruction set you get for free
it's always there
that's cool
well, not for free
for muni
hey, so I understand Floyd's tortoise and hare, but I am not convinced the the tortorise and the hare will 100% meet in a cycle. can someone give some intuition on why that would be
do you mean, what guarantees that there will be a cycle, or what guarantees that they'll find it?
no i mean, if there is a cycle, what is the guarantee they will meet
ok lets say there's a cycle, and it's length is λ
k
now we let us pick some term in the sequence x_kλ such that kλ is after the cycle starts
so this is one of the terms in the cycle, and it's kλ-deep in the sequence (or linked list, or however you want to think about it)
sorry to ask, but what does k lambda here mean?
sorry i meant to say, k is just some integer large enough that kλ is in the cycle
i don't get this, why should there be kλ in that cycle? for example λ=3 and the cycle is 1,2,0, there is no integral kλ in the cycle
well the λ there would be 2
and the indices are for a sequence of terms that go on forever
so k is representing an index?
after they get stuck in the cycle, they just keep on going
ooohh i kinda get what you're saying
kλ is an index, and it's just representing an index that is a multiple of λ
please continue with your reasoning
so the tortoise is at x_kλ, and we want to know whether the hare (at x_2kλ) is actually at the same node
yeah
and we know both are somewhere in the cycle by supposition, based on how we picked k
yes
so the two nodes are the same just in case the distance between them is a multiple of the cycle length
and we know that the distance is 2kλ - kλ = kλ
aka, a multiple of the cycle length
i dont get this part
if you're at a node in the cycle, you have to go all the way around to get back to where you are
so you've traveled λ distance
np
1 last question
is it guaranteed that the hare will meet the tortoise in the first cycle?
or may it take some more rounds to meet?
i thinkkkkk it's guaranteed
since you should be able to choose a k that lands kλ in the first cycle
since the cycle itself is length λ

Le pueden dar apoyo al video?
Soy nuevo en YouTube y me gustaría que me ayuden

!rule 4 @sharp terrace
4. Use English to the best of your ability. Be polite if someone speaks English imperfectly.
please attempt to speak English. In order to be a cohesive, well moderated community, it's important that the moderators be able to read and understand everyone's messages.
Sup guys.

So here's what I'm thinking
So what I reckon I could do is sort the c and java times seperately, send em to a new array alternatively and then just add the first 5 elements.
Where am I wrong
I believe the issue is you would have to sort them together.
Actually 🤔
Here's a way to think about the problem heuristically, which might lead to a solution. Assuming n is even, you're going to have to assign half the problems to Java and the other half to C. If you greedily make assignments one-by-one, eventually you are going to reach a point at which the remaining assignments are completely constrained: e.g. all the Java slots are filled up, and the rest have to be assigned C. Intuitively, you likely want to first assign the problems that have the greatest penalty for making the wrong assignment (i.e. the problems for which the difference in the time taken between the two languages is greatest).
This is probably a better fit for #data-science-and-ml tbh.
I'd ask there as well.
couldnt the second row and third row be switched around? The original question is here https://adventofcode.com/2020/day/16

second and third row?
in nearby tickets?
what do you mean?
like the 12 9 1 14 and 12 18 5 9 both match both class and seat
ranges are inclusive?
Hi, learning about trie datastructure. Can anyone explain the purpose of the # in the last line of the insert method and in the search method.
class Trie:
def __init__(self):
self.trie = {}
def insert(self, word):
t = self.trie
for w in word:
if w not in t:
t[w] = {}
t = t[w]
t['#'] = '#'
def search(self, word):
t = self.trie
for w in word:
if w not in t:
return False
t = t[w]
if '#' in t:
return True
return False
def startsWith(self, prefix):
t = self.trie
for w in prefix:
if w not in t:
return False
t = t[w]
return True```yeah inclusive ranges
Looks like a sentinel value indicating the end of the word/branch
welp i figured it out so....
Do anyone know how I can take a specific key from a dictionary and add it to a string? For example Im trying to get the matching key for the value then add it to a string. ex. dict = {"IX" : 10} I want to get the key for the number 10 and add it to a string.
You can get the index in the keys list that that value is atpy key = list(mydict.keys())[ list(mydict.values()).index(10) ]
but the problem is there could be multiple keys that have value 10 so that will only get one  (and this is really inefficient)
(and this is really inefficient)
If you really need to do this a lot you may want to reverse your dictionary  or create a reversed one, then it's just
or create a reversed one, then it's just rev_dict[10] -> "IX"
dictionaries are meant for looking up the value for its corresponding key, not the other way around. although it's possible to do what you're trying to do, you may want to use a different data structure.
Yes Im trying to turn numbers into roman numerals So i might just reverse it. Thank you!
Im trying to turn numbers into roman numbers. What other data structure would you recommend?
maybe just change the structure of your dictionary in the first place so you don't have to reverse it (like {10: "IX"})
also pretty sure IX is not 10?
Yea 10 is X my bad. Thank you Im gonna just reverse it!
Sorry to bother you guys again but my code is sayin I is not defined when I clearly defined it. ```
RomanNumerals : dict = {"1": I, "2": II, "3":III, "4":IV, "5":V, "6":VI, "7":VII,"8":VIII, "9":IX, "10": X, "50": L, "100":C, "500":D, "1000":M}
Well you have quotes around the numbers and not around the strings
I assume you want py {1: "I", 2: "II", 3:"III"} etc
also you shouldn't call things dict since that's a built in
wait, I'm dumb, you are type hinting 
So is below the pythonic way to write while loop and if statement?:
i = 0
legth = len(something) - 2
while i < length:
if i == length:
...
...
usually if u wanna loop though sth its for i in <iterable> and if you also want the index u can use enumerate
indicates the end of a string
thanks
thanks
# A simple implementation of Priority Queue
# using Queue.
class PriorityQueue(object):
def __init__(self):
self.queue = []
def __str__(self):
return ' '.join([str(i) for i in self.queue])
# for checking if the queue is empty
def isEmpty(self):
return len(self.queue) == 0
# for inserting an element in the queue
def insert(self, data):
self.queue.append(data)
# for popping an element based on Priority
def delete(self):
try:
max = 0
for i in range(len(self.queue)):
if self.queue[i] > self.queue[max]:
max = i
item = self.queue[max]
del self.queue[max]
return item
except IndexError:
print()
exit()
I see this code on geeks for geeks for priority queue. But i dont see how this data structure actually has a priority? doesnt it just delete the max value? what is priority? is it just max? i thought it was somethign more like first class /business class /coach on an airplane? this data structure doesnt fit that right?
Lol sorry this is probably super random, but did you do the ccc (I serach ccc in this server and saw this :0 ). I'm tryna do the CCC next year and get a decent score.
priority q are of two type min and max
based on priority u gonna take element from array
go thru min or max heap implementation in programiz website
Does anyone know how we can slice a 2d list without numpy? I am trying to apply merge sort on a 2d list
arr = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]
print(arr[1][ 1:4])
789 ans
Alright, thanks!
https://hvh.rip/MSLd8pGw
hi im struggling doing this problem can anyone help me please

Uploaded at 5/23/2021, 1:39:16 PM by den1z
i don't understand what "make change" means
guyz can anyone calculate the big O of my algorithm?
# Sample Input
phoneNumber = "3662277"
words = ["foo", "bar", "baz", "foobar", "emo", "cap", "car", "cat"]
def permutate_phone_number(length, phoneNumber):
permutations = []
counter = 0
curstr = ""
for i, item in enumerate(phoneNumber[:-length+1]):
for j in range(length):
curstr += phoneNumber[i+j]
permutations.append(curstr)
curstr = ""
return permutations
def validate(keypad, word, permutations):
counter = 0
for j, _item in enumerate(permutations):
counter = 0
for i, item in enumerate(word):
#print(item, _item[i])
if item in keypad[str(_item[i])]:
counter += 1
#print("\n")
if counter == len(word):
#print(_item)
return True
else:
continue
return False
def get_phone_number_mnemonics(keypad, number, words): # O(phoneNumber*number_of_words)
phoneNumber = list(number)
valid_words = []
for word in words:
length = len(word)
phoneNumberPermutation = permutate_phone_number(length, phoneNumber)
res = validate(keypad, word, phoneNumberPermutation)
if res == True:
valid_words.append(word)
return valid_words
print(get_phone_number_mnemonics(keypad, phoneNumber, words))
this is a question from: https://www.youtube.com/watch?v=PIeiiceWe_w

In this video, I conduct a mock Google coding interview with a Facebook Software Engineer, SecondThread, who's also a competitive programmer. As a Google Software Engineer, I interviewed dozens of candidates. This is exactly the type of coding interview that you would get at Google, Facebook, or any other big tech company.
Check out @SecondThre...
i am guessing it is O(phoneNumber*number_of_words)
guyz i am not a big O expert
Yeah that shows that your word has ended
You always need some terminator for your word it can be "#" , "*" , "." etc
Use Min/Max Heap for Priority Queues, it's more efficient
A priority queue is a misnomer 
it's a priority heap
as it does not preserve order
Can you elaborate this line ?
A priority queue, implemented with a heap, does not preserve insertion order.
so I don't really see how it's a queue 
if you want to schedule and execute jobs with different priorities.
It's a queue of priority 
😅
a queue preserves order.
Priority Queue doesn't 🤣
Imagine coming into a bank and hearing: "VIP clients come first, normal clients come if no VIP clients are waiting. People in each group will be called in undefined order!"
"-- why?"
"-- we have a priority queue"
Can you use a monotonic incrementing thing for it
Put (priority_val, monotonic_id) on the heap
Computer don't have feelings lol
Elaborate please
yep, I did that 🙂
worked fine
Tell me also what 🤦♂️
You can also tweak it so that you can change the priority of a task on the fly, but it's a bit more complicated
@austere sparrow you code in which language ?
To make the heap respect insertion order, use (priority, ordinal), where ordinal is some number you're incrementing on each insertion
You know heaps ?
??
Heap Data Structure
yes
I have a quesiton
class Trie():
def __init__(self):
self.root = {"*":"*"}
def __str__(self):
return str(self.root)
def insert(self, word):
curr_node = self.root
for i in word:
if i not in curr_node:
curr_node[i] = {}
curr_node = curr_node[i]
curr_node["*"] = "*"
def search(self, word):
curr_node = self.root
for i in word:
if i not in curr_node:
return False
curr_node = curr_node[i]
return "*" in curr_node
Can you please add delete word method in it
that's a trie, not a heap
I don't really know anything about tries
I mean tries 🙂
typo
There's an implementation of a trie in Python: https://github.com/google/pygtrie, maybe you can take a look
lol yea i did the ccc
yo nice mind if I dm you?
lol sure
i have a question
I can probably give u guys 2 amazing manuals that are helping me with python
@thin parcel yea im just all relearning/refreshing or learning, its been awhile. and yea i guess it dpeends whaat you are using your priority queues for, learning the difference of binary heaps/bionomial heaps/fibonnaci heaps
question: isnt the storage of an adjacnecy list O(VE) because each vertice could have an edge to every other vertice so VE instead of V+E
i see it listed as V+E in most places
if each vertex has an edge to every other, it simply means that E = V*(V-1)//2 though
I mean, they choose instead to list it as V+E, which conveys more information than slapping a O(V^2) on it and calling it a day
but it isnt technically correct tho =/
most of the time, you're not working with full graphs, so it'd be a rather useless worst-case
Anyone know how I might go about finding the union between two binary trees, without duplicating the structure, in linear time?
I was thinking of just doing an inorder (or any traversal) traversal O(n), and inserting each data point at each node visited into a hash table which is O(1) in python on one tree, and repeating it with the other with a different hash table, and doing an intersection between the two which is O(n) on average. But, the worst case is O(n^2) iirc. Is there any other way i can approach this problem? Perhaps without another data structure
@twilit moth
class TreeNode:
def __init__(self, val, left=None, right=None):
self.val = val
self.left_child = left
self.right_child = right
# example: root note 50, left_node = 25 and right_node = 75
node1 = TreeNode(25)
node2 = Treenode(75)
root = TreeNode(50, node1, node2)
Hey, I am using an API that returns in the response fields like id, title, link, image_link and many more and i though creating a class Product that receives a dict as a parameter (the response body) and fullfill the attributes depending on some rules. Is this the best approach to do this? If using a class, should i populate each of the attributes using the property decorator or just calling a private method inside the class that handles the input?
Just started my algorithms and discrete mathematics class. Any online resources to learn textbook material better?
#data-science-and-ml might be a better channel for this question. People there would be more familiar with pandas.
thx
You could probably convert the list into a set, so something like:
students = ["John", "Steve", "Billy"] # your array/list
set_of_students = set(students)
Havent tested it, but I think it should work.
i would set each attribute as a parameter to __init__, and you can use ** unpacking to create the object. you can use a dataclass for this purpose to reduce the amount of boilerplate typing. dataclasses are also nice because you are encouraged to use type annotations, which imo is a good thing.
from dataclasses import dataclass
@dataclass
class Product:
id: str
title: str
link: str
image_link: str
datum = {'id': '1234', 'title': 'The Thing', 'link': 'http://example.net/product/1234', 'image_link': 'http://example.net/product/1234.jpg'}
product = Product(**datum)
When you say ** unpacks, is it the same thing as deconstructing?
And do i check if the values are the ones i want inside the dataclass or do i create a new one with that dataclass as its parent?
yeah, although i think "destructuring" is the right word
what do you mean by this? you want some validation to be applied when creating a Person instance?
as in, "raise an exception if id is length 0 or contains invalid characters"
if that's what you want, then there are 2 choices:
- use the dataclass
__post_init__method to run arbitrary validation logic (see https://docs.python.org/3/library/dataclasses.html#post-init-processing) - use a library like marshmallow, desert, mashumaro, or dataclass-factory to "deserialize" the raw data, i.e. convert your
Personclass, applying validations, without attaching those validations directly to thePersonclass
class MinHeap:
def __init__(self):
self.array = []
def add(self, value):
array = self.array
array.append(value)
current = len(array) - 1
parent = (current - 1) // 2
while parent>=0 and array[parent] > array[current]:
array[parent], array[current] = array[current], array[parent]
current = parent
parent = (current-1) // 2
def delete(self, value):
if not self.array:
return
array = self.array
current = array.index(value)
array[current] = array[-1]
array.pop()
right = 2*current + 2
left = 2*current + 1
while right < len(array):
minz = min((left, right), key=lambda x:array[x])
array[current], array[minz] = array[minz], array[current]
if array[minz] > array[current]:
break
current = minz
right = 2*current + 2
left = 2*current + 1
def minimum(self):
return None if not self.array else self.array[0]
is this implementation of a MinHeap correct?
i know there is no deleting an arbitrary element in a heap and it would destroy the purpose of a heap but i just wanted to see it anyway
For given BST, print out all root-to-leaf paths, take input from user......
Please help me...
https://static.iron59.co.uk/Graph.mov making a cool video about the graph data structure
only first half atm but
lmk if you see anywhere it could improve
ok thanks lol I just used it because a class I created uses a lot of parameters.
food = [["burgers", 2.00], ["pizza", 3.00], ["tacos", 1.5], ["hot dogs", 4]]
i = 1
for item in food:
phrase = str(i) + ":" + item[0] + ",$" + str(item[1])
print(phrase)
i += 1
suppose the user chooses items 2
idx = input("What is your selection?")
idx = "2"
idx = int(idx) - 1
items = food[idx][0]
price = food[idx][1]
print(items, price)
def get_item(name, menu_list):
phrase = "Would you like a " + name + "? [y/n]"
response = input(phrase)
if response == "n":
return None
else:
print("Please select from the following")
print(phrase)
i = 1
for item in menu_list:
phrase = str(i) + ":" + item[0] + ",$" + str(item[1])
print(phrase)
i += 1
idx = input("What item would you like?")
idx = int(idx) - 1
item = menu_list[idx][0]
price = menu_list[idx][1]
return item, price
food = [["burgers", 2.00], ["pizza", 3.00], ["tacos", 1.5], ["hot dogs", 4]]
drinks = [("root beer", "$.75"), ("milkshake", "3.50"), ("lemonade", "$1.25"), ("chocolate milk", "$2.25")]
desert = [("apple pie", "$2.50"), ("cherry pie", "$2.75"), ("peach cobbler", "$2.00"), ("ice cream", "$1.50")]
menu = {"food": food, "drinks": drinks, "desert": desert}
empty lists for the bil
item = []
price = []
bill = []
for key in menu.keys():
value = get_item(key, menu[key])
if value is not None:
it, p = value
print(it, p)
item.append(item)
price.append(p)
bill += p
for stuff in item:
print(stuff)
print("price", price)
print("total bill", bill)
any one has idea to add happy our in this?
class Dog:
dog_time_dilation = 7
def time_explanation(self):
print("Dogs experience {} years for every 1 human year.".format(self.dog_time_dilation))
pipi_pitbull = Dog()
pipi_pitbull.time_explanation()
Prints "Dogs experience 7 years for every 1 human year."
Above we created a Dog class with a time_explanation method that takes one argument, self, which refers to the object calling the function. We created a Dog named pipi_pitbull and called the .time_explanation() method on our new object for Pipi.
can smoeone explain to me what this means
"Above we created a Dog class with a time_explanation method that takes one argument, self, which refers to the object calling the function."
can someone explain SELF when dealing with classes and methods please
CD2
I was working on this yesterday in a interview, I tried it in python and not sure where I am going wrong. It seems to get stuck in a loop when evaluating the last 3 numbers
This is obviously binary search but utilised inside a for loop. The issue occurs at index 3 in the for loop.
Left = 3 , Right = 3 , Mid evals to 4.
I understand where it is going wrong as it keeps resetting the Right to 3 but I am not sure I see the solution ?
The sorted array looks like this : [-1, 2, 4, 6, 9, 42]
inputNums = [2,9,-1,42,6,4]
target = 8
def find_sums_third(inputNums, target):
inputNums.sort()
print(inputNums)
output = list()
for idx, val in enumerate(inputNums[:len(inputNums)]):
left = idx
right = len(inputNums) -1
while left <= right:
print("left", left)
print("right", right)
mid = left + ( right - 1) // 2
print("mid", mid)
if inputNums[mid] == target - val:
output.append([val, target - val])
break
elif inputNums[mid] > target - val:
right = mid - 1
else:
left = mid + 1
print("left after",left)
print("right after",right)
# print(mid)
print("=------------")
print(output)
return output
res = find_sums_third(inputNums, target)
print(res)
Hello, how would one effectively fill holes which a given max area in a 2D binary matrix please?
For instance with a max area of 3 this
1,0,0,1,1
1,0,0,1,1
1,1,1,1,1
1,1,1,0,1```would become this
1,0,0,1,1
1,0,0,1,1
1,1,1,1,1
1,1,1,1,1```and with a max area of 5
1,1,1,1,1
1,1,1,1,1
1,1,1,1,1
1,1,1,1,1```Figured out something, I just "coloured" the different "0 zones" and then filled them with 0 or 1 according to their areas
could anyone help me with this divide and conquer algorithm
How would i go about turning an unsorted binary tree into a min heap in place*?
def find_sums_third(inputNums, target): #is a deffine variable.
I think everyone knows that tho.
I meant though.
Heyo so I am having trouble understanding this problem https://www.hackerrank.com/challenges/between-two-sets/problem

HackerRank
Find the number of integers that satisfies certain criteria relative to two sets.
I can't even understand the fundamental logic what it is asking
The elements of the first array are all factors of the integer being considered
this means that the ints will have to be the lcm or a multiple of the lcm of the elements of the first array
The integer being considered is a factor of all elements of the second array
this means that the ints will have to be the gcd or a factor of the gcd of the elements of the second array
So you have to find the number of multiples of lcm of arr1 which are also factors of the gcd of arr2
spoiler: ||you should be able to get away with just gcd of 2//lcm of 1, or 0 if the lcm doesn't divide the gcd||
how can this be coded:-
to sort a 2d array (mergesort) in increasing order so that it first sorts the first row and then just after sorting the row, it should sort first column and so on...
???
Hey, i wanted to make a sort of data tree like the image to organize an affiliation system. Each node would contain the username and the id of the person, and I would like to modify the tree dynamically, by removing or adding person automatically.
But I didn't find any lib or resources in python to make that...

@fiery cosmos what do the arrows represent? relationships between individuals?
yea the node on top is the parent of one below. There's an hierarchy for my affiliation system, i need to know who invited who
i think the best way to store the data depends on how you intend to use the data
does this need to be serialized to a database?
not necessarily
that's just for a discord bot so stored in a variable or at worst in a file but not database for this project
how about a dict?
{
2: [7, 5],
7: [2, 10, 6],
...
}
i assume the numbers would be user id's
you can keep a table of user ids and usernames separately
i don't see how you can do it with a dict...
{
id_user_on_top : [id_user_below_1_1, id_user_below_1_2]
}
Like we have one layer here

but how make for multiples layers ?
hmm... it looks like user 7 invited user 2, who had originally invited user 7
is that supposed to be possible in your system?
Oh here user 2 invited user 7 and 5
user 2 is the parent
and 7 and 5 are the children of user 2
i see 7 -> 2 on the far left side of the graph
it matters for how you represent the graph
if a node can appear exactly once in the graph then you can use the dict
yea it appears only once
oh i definitly took a bad picture to illustrate
2 -> 7
2 -> 5
7 -> 10
7 -> 6
6 -> 11
5 -> 9
9 -> 4
this can be encoded as
{
2: [7, 5],
7: [10, 6],
6: [11],
5: [9],
9: [4],
}
the key of the dict is the node, and the value is the list of children of the node
not sure what you mean by "dynamic" in this case
like i can add children recursively, without declaring a new variable
yeah, although you will need to track the node id's somewhere too
if your nodes are hashable objects, you can use the objects themselves instead of their ids
from collections import defaultdict
from dataclasses import dataclass
@dataclass(eq=True, frozen=True)
class User:
id: int
name: str
affiliate_graph = defaultdict(list)
user2 = User(2, 'salt')
user7 = User(7, 'unmars')
affiliate_graph[user2].append(user7)
for example
although if you just use id's, it will be faster to traverse the tree because you won't have to do so many attribute lookups
then you can look up users in a separate dict later
however that's more complexity and i wouldn't recommend it unless you are traversing huge graphs
Okay, I'll see that on my side but thanks a lot for the help, didn't know how to start my project, now I know ! :p
I'm new to python. Should I learn data structs and algorithms before I do any projects? or Is this something you just learn a long the way?
I think it is best to be doing projects the whole time you're learning
hey lets do sorting together!!!
I've also been working with graphs and data structures, and I would really like a study buddy!!!!!!!!!!!!!!
Why do queues use qsize and not len?
my best guess would be because they're not iterable, and because that size isn't really useful for anything other than informational logging
Queue.qsize()
Return the approximate size of the queue.
How often is knowing approximately how big something is helpful?
yeah - it's definitely not a place to look for modern best practices. But even as of then, __len__ existed, so it must have still been a deliberate decision to not use it
though the oldness probably explains why it's called qsize instead of queue_size or just size 🙂
help me with this...

m not able to append new_values to the deliv list
i have a data frame above_four having column 'delivery_reviews'
new_value makes some mathematic calculation and then rounds the value to 2 and then the value is stored in new_value
but now m not able to append it in the list
HELP HELP HELP
You are redefining deliv to [] in each iteration of the loop
Okkkkkkkkkkkkkkkkkkk boi.. you are Jod.. saver... may god grow ur D twice

thanks thanks thanksss...
happy to help
sa
Hello. Sorry if you were pinged in this channel. We experienced a raid earlier today.
This channel is for discussing algorithms and data-structures. If you wish to comment on the raid, please do so in one of the off-topic channels.
Thanks for clarifying 👍

yeah, looks like it
looks like it is finding the smallest among all
Why was i ghost pinged in here
^
oh, whoops, forgot to remove the ping
im wondering, is anyone aware of tools that would help to work with hash lookup tables, index lookups, packed structs in memory mapped files/packed arrays + network byteorder - i want to avoid dropping to very explicit C for that
bruh
^
Hey @worthy rivet!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
green_block=m
red_block=0
for i in range(n-1):
if arr[i]>arr[i+1]:
red_block=arr[i]-arr[i+1]
elif arr[i]<arr[i+1]:
if arr[i]+red_block>=arr[i+1]:
red_block=arr[i]+red_block-arr[i+1]
elif arr[i]+green_block>=arr[i+1]:
green_block=green_block-(arr[i+1]-arr[i])
elif arr[i]+green_block+red_block>=arr[i+1]:
green_block=green_block-(arr[i+1]-(arr[i]+red_block))
red_block=0
else:
return "NO"
return "YES"
n,m=map(int,input().split())
arr=[int(arr) for arr in input().split()]
print(buildings(n,m,arr))```help me debug this code passing in almost every case could not find the flaw
@worthy rivet I interpret the red block compartment to have room for all the cut blocks, I see that you only save the last cut block in your implementation
the statement says that you can only use the recently cut red block
It does, but it does not say explicitly whether or not you can use the block before that for the next step, if you get what I mean.
let us take a test case
3 0
3 1 2
u cut a red block at building 1
and use at building 2
also I don't see if they specify whether or not you get to save the remainder of a red block after cutting it,
hmmm possible
perhaps you can just try setting the red block to 0 after using it and see if that passes all the cases
see the test case expalnation once
no
you saying we cant use the remainder of the red block we used in one of the buldings but we can instead
Oh you mean the test case on the page, right

at what step does he use the remaining part of a red block?
he cuts a block of 3 at 2nd buliding of height 6
and use it at 3rd biulding of height 3 and cut 2 units from it
and then use these 2 units and remaining one green block to got to the last building
ah, and you mean these 2 are the remainder?
yupppp
that settles that then
I don't see any error in your logic then I'm afraid, but I would still try an implementation that remembers all the cut blocks
ohhh right
should be fairly simple using a list and append/pop right
how i can write an equation solver in python? Starting with 2+x=4, to something hard.
so i have a rolling average of 20 numbers, and at the moment i'm storing every day's number in a list. is there a more efficient alternative to storing the number for each day?
all the data is retrieved with asyncpg as a 2d list, so while i considered turning it into a numpy array and operating on it, i'd need to turn like 1.1m inner lists into numpy arrays, which is incredibly slow and seems to offset any performance gains in other areas
when i say rolling average, i mean that the list always has <= 20 numbers, and it calculates the average of the list each time that it adds a new number and removes the oldest one (it only removes the oldest number once the list hits 20 numbers)
ping
bruh
hold up I must be missing something
why do you need to store every day’s number
if you always know it’s a rolling average of 20
unless you’re near the float limit?
i'm asking if there's a better way to do it
yeah i considered that but what happens when i need to take out the oldest day's value and replace with a new one
why is 20 numbers a big deal
because it's been done for about 1.1 million data points
can you elaborate a bit more I don’t super get it
so there are x data points with y features…? and there’s one rolling average for each feature over the last 20 days?
like where does the 1.1m come in
i'm calculating a set of period-20 rolling averages for about 1,100,000 different option symbols
i guess, i dont know that notation
like numpy array shape
oh
right now?
yes
yup yup
and you want to store less per row
okay next question
you wanna optimise for memory
I guess
yeah but speed wouldnt hurt either
is it okay to have more compute? like ask the DB for more stuff?
because what I’m thinking is
store only the average
every update
ask for the first and last days
and update that way
yeah i can ask the db for more stuff
avg - (first + last) / 20
hm
assuming it’s a linear unweighted average
that would be my first guess
yes
but wouldn’t you be doing that anyway?
a possible compute-efficient solution
(guessing)
would be to override the part of the driver that deserialises
and populate a numpy array immediately
actually i tried that, asyncpg is super finicky about that
that would require the number of rows to be known ahead of time
oh
😔
how come
what happens
a bunch of errors that i couldn't decipher around 2 weeks back
i set a custom decoder for int[] to np.array
and there were internal errors that came up from the cython part of asyncpg that i couldn't understand
uh possibly, I haven't tried that
not sure how involved that would be
depends on how much effort you want to put in I guess
yeah, this optimizing isn't worth more than like a few hours, my boss has other priorities that i need to get to also
do this first I’d say
it would still be one database access
and you would need to store a lot less data -> compute requirement would decrease
oki
.bm 847266175733989376
thanks so much! i've been wracking my head around this for a while now lmao
If a Python list, x, has ten elements, what are the effects of this loop?
i = 9
while i >= 0:
print(x[i], “ “)
i -= 1
print()
please help
Have you tried running it? What do you think it will do?
Well i set key_val = [ [1, "word]*5] and then tried running it, but it did not work. I know that while i >= 0 it will print(x[i], " ") but i do not understand the rest
try setting x to something 15 elements long
x = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o']
I have an array like [0.1 , 0.2 , 0.3] in a single csv cell.
Is it possible to extract only the second array in one cell, i.e. 0.2?

You mean the second element of the array?
Yes
yeah, why not?
what's causing issues?
Loaded a csv file using pandas.(edit)
Using the csv file I prepared above, I tried to display the cell [0,0], but it is treated as a character.
print(csvdata.values[0, 0])
print(csvdata.values[0, 0][0])
print(csvdata.values[0, 0][1])
print(csvdata.values[0, 0][2])
Result
[0.1,0.2,0.3]
[
0
.
evaluate the string first
with eval built in function
it'll turn it into an array
Could someone help me with understanding big O?
Thank you so much!! Arigato!(*^^)

Glad I could help
oh, one more thing
be careful with eval. if the csv cell contains something else, it could cause some problems for you
@worldly sinew
what's confusing you?
def bubbleSort(lyst):
indexing_length = len(lyst) - 1
sorted = Falsewhile not sorted: sorted = True for i in range(0, indexing_length): if lyst[i] > lyst[i+1]: sorted = False lyst[i], lyst[i+1] = lyst[i+1], lyst[i] return lystlyst = [4, 5, 2, 1, 7]
print(bubbleSort(lyst))
Why does the first iteration not break the while loop?
oh nvm I see lol
cause it continues all the iterations of the for loop first
another question, how do I calculate the runtime?
does anyone recognize this problem? I'm having a hard time figuring out how I would iterate over the array.
Is this simple recursion or a more complex graph DFS problem?

Uhh, neither? I might be missing something, but it looks like a basic O(n) problem to me - iterate over the array, check each sliding window of 3 elements.
Hey
Hey, I am currently learning DSA. Am I allowed to share my repo link here?
Do Check it Out : )
do we not delete from a Trie?
hey guys quick question, are linkedlist just multiple arrays connected?
no. a linked list is just a collection of nodes which have references to each other. have you ever seen an implementation for a linked list?
hmmm not yet
oh just saw an illustration of it... it makes more sense now thx!
the most basic ones will just be something like this
class Node:
def __init__(self, val=None, next=None):
self.val = val
self.next = next
and then you can create the list doing something like
head = Node(1)
head.next = Node(2)
ok great !
thx! imma keep this in mind
Im not sure if theres a dedicated help channel, but does anyone know where i can effectively learn python data structures and algorithims. I've somewhat mastered the basics and created a few projects, but any help would be appreciated.
have you checked the pinned messages in this channel? some suggestions there.
Ok, I will, thanks.
Are these the same thing in Python 3.9?
I wasn't sure if python iterate function is the same thing as the "range" function
Yes, in this instance the two have identical behaviour.
is it possible to convert pixel art, to other sizes of image? ( just scale up pixels )
Yes, if you want to maintain the "crisp" outlines of pixels, look into nearest-neighbour interpolation
iter converts something to an iterator (by calling its __iter__). It's called implicitly when you do for _ in smth:, so there's (usually) no difference between for _ in smth: and for _ in iter(smth):
this will not actually make sentence lowercase since strings are immutable
instead, it'll create a new string which is sentence converted to lowercase
Is a set really significantly slower than a list for iteration?
I don't know the answer to your question, but I pose this: If such a data structure existed, why wouldn't Python already be using it?
So it makes be doubtful.
Compromises have to be made to make some operations faster than others.
Why are you asking, you’re the one asserting it
Someone probably mentioned it I guess
Because there is a difference between observing benchmarks and understanding how implementation details lead to such results
If you can use a dict then that might be faster since it iterates through an array that gets its indexes filled one by one. Unless you’re not using 3.6, then it’s more like a set so it won’t be any better
In lists, the data is tightly packed and contiguous. In sets, it uses open addressing, so some spots in the table (represented by an array) are empty.
You could use a dict and just pair everything with None
The set overallocates memory for the table array, leading to empty spots.
The list also overallocates, but all that empty space is at the end so it's easy to skip
hey guys i need to manually map specific values with another value. Its like 55 records with specifically different (no logic) mapped valued. i have two alternatives im thinking about:
- make a dictionary with 55 values and associated values, or
- just put them in two columns and match them up via a .csv or .xlsx file.
Just wondering if theres a good practice for stuff like this? What would you recommend?
hello guys, what's a good resource (preferably a book) to learn data structures and algorithms (i can work with separate books)
I has link:
it's really good on how in-depth it explains the process for the code.
https://www.youtube.com/watch?v=zg9ih6SVACc&t=6303s

Learn all about Data Structures in this lecture-style course. You will learn what Data Structures are, how we measure a Data Structures efficiency, and then hop into talking about 12 of the most common Data Structures which will come up throughout your Computer Science journey.
✏️ Course created by Steven from NullPointer Exception. Check out t...
a stupid doubt don't judge me
if i say a.b = calc()
then whenever i am gonna use a.b is it going to call calc() again ?
No
Thanks
is there a way to sort a list of objects based of one of there attributes?

Stack Overflow
I've got a list of Python objects that I'd like to sort by an attribute of the objects themselves. The list looks like:
ut
[<Tag: 128>, <Tag: 2008>, <Tag: <>, &l...
hi guys, i have a JSON file like this, how can I get all the id value:
{"variants": [
{
"id": 1111,
"product_id": "6753331413173",
}
{
"id": 2222,
"product_id": "6753331413173",
}
{
"id": 3333,
"product_id": "6753331413173",
}]}
By traversing over the variants object, although as you entered it here it's a bit malformed - it's missing commas after each element.
Has anyone here seen an fusing implementation of np.minmax? calling np.min and np.max sequentially is seriously hurting performance
Fusing as in made to use FMA?
I've only written my own minmax using numba, but I have no idea what ASM it generated. Presumably the C compiler is smart enough to optimize it to use FMA if possible.
though wait, why'd minmax involve fused multiply-adds
I heard that two variables cant be removed in a Big O Notation but if one of the variables had a worse notation than the other variable would the notation then ignore the less important variable?
For example:
does O(n₁²×n₂) just ignore n₂ and become O(n²)?
if both are variables then I believe its kept at O(n₁²×n₂)
two variables gets complicated. Are they really both important?
yes
then keep them both
okay thanks
if either can grow large, you need to know that
Is there an algorithm that you know of to determine if a polygon, self intersecting or not, is convex?
what should i call the total angle while walking across the perimeter of a polygon?
Ill shall call it revolution. dividing it by 360
https://github.com/ShreyaPanale/100DaysOfCode
Its been almost a month, I have covered all the basics of C, and started with DS, Arrays, LinkedLists. Will do Stack and Queues next. And then Non Linear DS. After this I will start with algos : )
Do Star and Fork the repo. Thanks 😛

GitHub
Challenging myself :P. Contribute to ShreyaPanale/100DaysOfCode development by creating an account on GitHub.
Usecase of linked list?
to improve space & time complexity to 0(1)
it esstentially connects nodes/info together so when you make an update it executes onto the list as a whole, rather than on each node.
think of pre-school when they asked you to hold hands, and there was a line leader, and person in charge at the back that both took orders from the teacher. within the line, each person/node kept an eye out for the person/node next to them in case there was a change.
Uses: sorting, palindrome problems, stack-like functionality. undo/redo button, browser caches)
https://thejaskiran99.medium.com/linked-lists-in-python-a77e4b9c31cc
Hey guys, check out my blog on implementing a linked list. Thank you in advance!

Medium
A linked list is a data structure that shows how the nodes are connected in a sequence. Like stacks and queues, the memory of the linked…
How to do a pseudorandom Number Generator?
So, as a first step you'll need to read the first 185 pages of Donald Knuth's Art of Computer Programming Volume II. Then, you just translate your favorite one of the listed algorithms from Knuth's bespoke assembly language to python.
that's called the winding number, I believe
its not exactly that as the winding number goes backwards or negates in some instances. But thanks. I think ill call it revolutions.
so does the total angle, if you're counting it in the wrong direction
well the math that ive worked out always works when using a positive k or positive total angle.
the winding number does look interesting though ill have to look at that in depth sometime. Im also going to be studying triangulation algorithms
I've recently looked into winding numbers (Joseph ORourke, Computational geometry in C (1998)) due to needing some intersection calculations, got weird results, gave up and implemented a naive algorithm that calculates intersections with every edge of a polygon, which worked 😅
can i replace a particular letter in str by index?
hellow, how to use namedtuple in the collections module and what different with tuple ? i need more example for namedtuple and Chainmap
hello
Excuse me,i have to use Dijkstra's algorithm to find the shortest path taking A as vertex,for E i am getting infinity,Is it the correct answer?

Hey, I''m trying to compute the volume of a 3d object in python
There a many methods, I hear, but essentially, I would like to find out the volume of an irrugyular shape
would anyone know a good mathematical approach to this problem?
or a library that makes life easier?
@analog pagoda if it's a polyhedron, see https://stackoverflow.com/q/17129115/2954547 maybe?
Stack Overflow
I am trying to figure out the best way of calculating the volume of a 3D polyhedron with Python, and I'm hoping there is a simple solution out there, which I can't seem to find.
Example polyhedron...
Okay, so, this is slightly different from that
Essentially, what I want to do is get a realtime volume estimation using a list of cross sectional sums.
imagine an ice cream cone, you fill it with 10ml of water and the water surface has a delta height of 10mm. The next 10ml of water will have a smaller delta height because the cross sectional area increases as you move up the cone
If i set a particular resolution on the z axis as number of steps, by measuring the distance from the top of the cone to the surface level should be enough to give me an approximate volume
sounds like you have your desired approach then
Was wondering if there was any 3d library that deals with this type of geometrical problem
ah. good question... not that i know of. there might be one, or maybe there are helpful tools in the scipy library
Also, since there are infinite cross sections, im not sure if this approach will even work
well yeah, that sounds like riemann sums
you have to deal with some tradeoff of inaccuracy vs computation time
there might be more efficient ways to do this... it's effectively an integral
maybe sympy can do it
Stack Overflow
For a program, I need an algorithm to very quickly compute the volume of a solid. This shape is specified by a function that, given a point P(x,y,z), returns 1 if P is a point of the solid and 0 if...
Stack Overflow
I want to compute the volume integral of a function f(x,y,z) over a cylinder whose base has a stadium-like shape (it is a rectangle with semi-circles at the ends).
Although I can evaluate f(x,y,z)...
Hey everyone! I'm looking for small team (3-4 members) to set learning targets, discuss and code in Python on Leetcode/Codechef and maybe codejams/hackathons on weekends. I am a Data Scientist and have around ~4yrs of experience in coding in python so looking for like-minded people. Please ping me separately/ reply in thread without spamming group if it interests you.
me
what are the requirements?
I am also doing Leetcode every now and then with my friends but we prefer our own language. We are looking for new roles
Nothing @fiery cosmos if you're good with python let's get to know each other and @silk sleet me too.... Hit me up if you want to include me as well
look at this LBM model that i "made"

may have stolen the implemintatoin code but i can probably rewrite it
it was missing something that was mentioned nowhere in the literature
Hello. Sorry if this is not exactly the proper place to ask. But are there any benefits in using stack and queue along with processes and threads when they're essentially similar? I'm looking for a more in-depth answer.
@frail surge sorry, when what are similar?
Using stack and queue with processes and threads.
Sorry if I'm asking a weird question.
@frail surge are you saying stacks are similar to queues? Or stacks are similar to processes?
or processes are similar to threads?
Stack and queue are similar to processes and threads.
Again, sorry for the questions.
hmm, i don't see them as similar. stack/queue are data structures. process/thread are execution contexts
Don't they handle data similarly though? FIFO and LIFO (If I remember the terms correctly).
processes and threads don't inherently handle data in any particular way. they are places to run your code
Yeah. Processes and threads are operating systems concepts rather than data structures.
A process is like an isolated environment in which code is run.
It’s a running instance of a computer program.
Threads allow you to do two things at once (concurrently) within the same process.
Stacks and queues, on the other hand, are fundamental data structures that could be implemented at any scale in any system.
Can anyone make more beautiful code for this:
the problem statement is simple you will take a integer and multiple it by 2
then print the factorial of the integer.
Input:
In the first line of input there will be an integer t(1<=t<=1000,000) where t means number of test cases.
output:
the factorial of the number
And the code is:
n = int(input())
s = ''
for i in range(n):
num = int(input())*2
fac = 1
for v in range(1, num + 1):
fac = fac * v
s+=f'Case {i+1}:{fac}\n'
print(s[:-1])
'''can you make it better with less complexity'''
you can use math.factorial() to find the factorial :)
!str-join also, use str.join() instead of manually adding the separator and removing it from the last one
Joining Iterables
If you want to display a list (or some other iterable), you can write:
colors = ['red', 'green', 'blue', 'yellow']
output = ""
separator = ", "
for color in colors:
output += color + separator
print(output)
# Prints 'red, green, blue, yellow, '
However, the separator is still added to the last element, and it is relatively slow.
A better solution is to use str.join.
colors = ['red', 'green', 'blue', 'yellow']
separator = ", "
print(separator.join(colors))
# Prints 'red, green, blue, yellow'
An important thing to note is that you can only str.join strings. For a list of ints,
you must convert each element to a string before joining.
integers = [1, 3, 6, 10, 15]
print(", ".join(str(e) for e in integers))
# Prints '1, 3, 6, 10, 15'
will it decrease the time complexity
no
it will just make it look better and more pythonic
actually, it may be a better time complexity
because adding to a string is O(n), right, since they're immutable so you have to make a whole new string every time you concat
but str-join only does that once
if you want, instead of creating a single string, you could just print in every iteration of the loop and you wouldn't even need str-join
Guys someone should give me more details on this asymptotic complexity question #the question says I should prove that 5n^2 + 3n + 1 = big-omega(n^2)🙏🏽🙏🏽🙏🏽
big-omega is the lower bound, so you need to argue that no matter what an algorithm that does 5n^2 + 3n + 1 "things" will always have to do at least n^2 things, which is kinda obvious here since 5n^2 + 3n + 1 > n^2, but still a subtle argument to make.
In the mathy way of doing it https://en.wikipedia.org/wiki/Big_O_notation#Family_of_Bachmann–Landau_notations I think you can just have k = 1 and n0 = 0 if I'm doing it correctly
Anyone know a good real-world example or application of negative weighted edges in a graph? 
Or are there none and Bellman-Ford is a big troll 
so if i wanted to visualize the code execution how would i go about that ```py
import numpy as np
def function(nums):
def yield_list(nums):
LIST = []
for numbers in np.nditer(nums, flags=['buffered']):
LIST.append(int(numbers))
yield LIST
for nums in yield_list(nums):
nums=nums
for i in range(len(nums)):
lowest_value_index = i
for j in range(i+1, len(nums)):
if nums[j] < nums[lowest_value_index]:
lowest_value_index = j
nums[i], nums[lowest_value_index] = nums[lowest_value_index], nums[i]
yield np.array(nums).reshape(10,10)
random_numbers = (np.array(np.random.randint(0,100, size=(10,10))))
for numbers in function(random_numbers):
numbers=numbers
print(numbers)
I was going to say http://pythontutor.com/visualize.html#mode=edit but I'm not sure it supports numpy 
das what im sayin
Anyone knows approximation algorithms? I can't find any good YouTube video to understand it
Hi
I noticed that json.loads does not parse tuples from string. Can someone explain?
>>> import json >>> json.loads("[[1,1],[1,2]]") [[1, 1], [1, 2]] >>> json.loads("[(1,1),(1,2)]")
Error!
Hello @supple patio 🙂 I don't believe tuples are part of the JSON syntax. JSON has objects (like dictionaries), arrays, strings, numbers, bools, and null. There's a full specification of the syntax here: https://www.json.org/json-en.html
Off-topic channels
There are three off-topic channels:
• #ot0-psvm’s-eternal-disapproval
• #ot1-perplexing-regexing
• #ot2-never-nester’s-nightmare
Their names change randomly every 24 hours, but you can always find them under the OFF-TOPIC/GENERAL category in the channel list.
Please read our off-topic etiquette before participating in conversations.
Oh sorry wrong place
Hello everyone im currently doing an university project and they want me to find out the degree centrality and closeness without using Netwrokx or other modules
Does anyone know how i can do this?
any help with this?
if not lst:
return []
result = []
if lst[0] == val:
result += move_to_end(lst[1:], val)
result.append(lst[0])
else:
result.append(lst[0])
result += move_to_end(lst[1:], val)
return result```I need an explanation if possible , tried to debug the code and understand how it recursively works but I am so confused
Run this code on pytutor with a sample input and you will get the idea how the code is working line by line
Here's the link, hope it will help you understand how your code is working
thank you very much 👍
aerodynamics of an airfoil

made a fluid flow engine using python
statistical thermodynamics isnt fun let me tell you
Is the time complexity of a for loop same as a while loop? If I just pass? https://cdn.discordapp.com/emojis/788882232441307154.gif?size=64
{kind=link}

well what do you mean
for x in range(69):
pass
owo = 0
while owo != 69:
owo += 1```for loop iterates over an iterator and has a complecity of O(n) and a while loop is condinional so idk what the complexity for it would be
in your case the complexity for the while loop would be infinite
If it just passes then it's just o(1)?
well no it still loops and it would never end
Wait lemme fix
your program will only terminate after an infinite amount of time has passed
What about that
count = 0
while count != n:
count += 1
would have a time complexity of O(n)
@lusty lantern
because it will have to run the loop n times for the program to terminate
assuming n is variblle in your example
if you treat n as a constant here it would be O(1) but thats not practical
count = 0
while count != 20:
print(n)
count += 1```Owo = 69
if Owo != 69:
print("brrr")
this algorithm will take the same amount of time to execute independant of the value of n
for loops are basically just dressed up while loops
Big o only calculates speed right?
in assembly there is no "for" loop there is only CMP and conditional jump which jumps to a specific part in the code depending on what the result of the CMP was
Not the memory
Thonk
yeah it is
big O describes the complexity/performance of a program or an algo
It is typically applied to the run time or the memory usage
But technically, I suppose it can be applied to any function (mathematically speaking)
basically how much resources is needed or used
It explicitly doesn't apply to speed. An algorithm that is O(n^2) can easily run faster than an algorithm that is O(n) for some inputs. What big O tells you is how the number of operations (or the amount of memory) required to complete an algorithm changes as the amount of data the algorithm needs to process grows. If you know that some algorithm has O(n^2) runtime and some other algorithm has O(n) runtime, what that tells you is that there is some input size after which the O(n) algorithm begins to require fewer operations than the O(n^2) algorithm. You don't actually know that constant, though, so you don't know exactly where that tipping point is.
skrrrrrrr
while that is true
you might want to look at
this
what I think they meant was more "big O is for runtime only, and not memory"
^
what I think they meant was more "big O is for runtime only, and not memory"
Right, but Mark corrected that misconception
I was correcting a different one: knowing only the big O of two different algorithms and the input, you cannot know which will be faster.
indeed, and of course your point is perfectly valid
I was just not sure if the OP ever had that misconception in the first place
but in any case
it'll be valuable for anyone else who comes along
Perhaps not - but I think almost everyone starts with that misconception.
It's the single most common misconception about big O that I see
Anyway, the TLDR is: big O can be used to tell you how the speed or memory usage of an algorithm will change as its input grows.
Can anyone help me this question , btw, would you have any material to practice it, Tks

which algorithms are important to know for data science and ai?
have u tried getting it into closed form? @hardy dawn
How to state the Decision version of the Knapsack (Bag) Problem;
Express and write the problem in your own words. The problem you are describing is an example of a given solution.
polynomial time, which detects whether there is a valid solution for
Write a validation algorithm that works in complexity as Pseudocode.
how is this different from normal knapsack
what
Hi there so I made a function to remove a data from linked list on the basis of value delete_by_value, I was thinking if there's another way to do it which doesn't involve so much code
def delete_by_value(self,data):
itr=self.head
ind=0
pooper=0
while itr:
if itr.data==data:
pooper=ind
ind+=1
itr=itr.nex
self.remov(pooper)
def remov(self,index):
if self.lenl==0:
print("Linked List is empty")
return
itr=self.head
ind=0
if index==0:
self.head=self.head.nex
return
if index>self.lenl():
return "eerrrorrr"
while itr:
if ind==index-1:
itr.nex=itr.nex.nex
ind+=1
itr=itr.nex```how do you do this?
https://adventofcode.com/2020/day/19#part2
I kinda cheated on part1 by generating a regex but the language im using doesnt support recursive regex so not sure how to do part2
hmm guess ima be implementing cyk for this
yo*
@lusty lantern you could try using items() in the min version.
It wasn't mine I just saw it in codewars for being in the top
But what was it's runtime?
$e
from timeit import timeit as t
recipe = {x:y+1 for y, x in enumerate(list('abcdefghijklmnopqrstuvwxyz'))}
available = {x:y+1 for y, x in enumerate(list('abcdefghijklmnopqrstuvwxyz'))}
def cakes1():
return min(available.get(k, 0)/recipe[k] for k in recipe)
def cakes2():
total = 6969
for name, amount in recipe.items():
owo = available.get(name, 0) // amount
if owo < total:
total = owo
return total
print(t(cakes1), t(cakes2))```Why are you using two different dicts?
It was a problem from codewars I didn't have any test examples so I just made one
@lusty lantern The two snippets are implemented slightly differently.
- integer division is faster than float division
- you are not using
.items()in the first function.
If you apply those, you reduce the difference. Although it probably will be totally different on a very large dict.

Both have the same time and space complexity.
Reduce the difference?
I keep testing but the cakes2 is still faster https://cdn.discordapp.com/emojis/788882232441307154.gif?size=64
yep, it seems to be faster.
Why do you care if it's 0.5 us faster? Running any of those on PyPy on a large dataset would probably get you a much better performance increase.
What is the size of the input?
Wdym
How large will recipe and available be?
Well, the purpose of a program is usually to solve some problem with given constraints, not to satisfy some arbitrary criteria 🙂
If it's 32 items large, just leave it as is. If it's 10000 items and it turns out to be way too slow, try running it on PyPy. If it's tens of millions of items large and you need to run it frequently, Python might not be fast enough (write a C/Rust extension? or switch to a different language entirely?). If it's billions of items large, your data won't even fit in RAM, so you'll need to take a different approach. Perhaps you'll even need to split it across multiple machines, in which case you'll need an even more different approach.
@austere sparrow Bruh...
$e
from timeit import timeit as t
recipe = {x:y+1 for y, x in enumerate(list('abcdefghijklmnopqrstuvwxyz'))}
available = {x:y+1 for y, x in enumerate(list('abcdefghijklmnopqrstuvwxyz'))}
def cakes1():
return min(available.get(k, 0)/recipe[k] for k in recipe)
def cakes2():
total = 6969
for name, amount in recipe.items():
owo = available.get(name, 0) // amount
if owo < total:
total = owo
return total
def cakes3():
total = 6969
for name, amount in recipe.items():
try:
owo = available[name] // amount
if owo < total:
total = owo
except KeyError:
return 0
return total
print(t(cakes1), t(cakes2), t(cakes3))```2.82868320599664 2.288262713998847 1.9689037799980724
It's on pypy i think
If you installed the 'normal' Python, it's not PyPy, it's CPython.
(PyPy is not the same as PyPI. PyPy is an alternative implementation, while PyPI is the package warehouse)
I meant the executor the owner's exec
@lusty lantern run ```py
import sys
print(sys.version)
3.6.9 (7.3.1+dfsg-4, Apr 22 2020, 05:15:29)
[PyPy 7.3.1 with GCC 9.3.0]
I wasn't able to do it because the owner turned off the bot
Source code of the bot https://github.com/HuyaneMatsu/Koishi
So if we traverse through a num array twice, is time complexity still O(n)?
yes
ok thanks
sorry
Please don't ping moderators for no reason.
ok
ill import your linux distro to a sandisk
then export my usb through a connection
sys is a module
for instance, take a look at this f string below, ```py
import sys
print(f'SYSTEM_VERSION: {sys.version} | API_VERSION: {sys.api_version}')
you are pulling from the module to then in turn use methods or something
@lusty lantern why are you index // index ?
for instance look at this and see if u can see what ur doing
def cakes4():
total=6969
DATA = {'RECIPE': 'abcdefghijklmnopqrstuvwxyz',
'AVAILABLE': 'abcdefghijklmnopqrstuvwxyz'}
Calculation = len(DATA['RECIPE']) // len(DATA['AVAILABLE'])
for index,element in enumerate(range(0, len(DATA['RECIPE']))):
CurrentPosition = index
CurrentValue = DATA['RECIPE'][element]
return Calculation
else:
if Calculation < total:
total = Calculation
#total = CurrentPosition // CurrentPosition
return total
2.9671252999996796, 2.2903923999983817, 1.9106988000003184, 0.4524265000000014 last one is mine
for instance take a look at this also, its your code ```py
def cakes3():
total = 6969
for name, amount in recipe.items():
try:
print(f'{available[name]}|{amount}')
owo = available[name] // amount
if owo < total:
total = owo
except KeyError:
return 0
return total
cakes3()
output: 1|1 2|2 3|3 4|4 5|5 6|6 7|7 8|8 9|9 10|10 11|11 12|12 13|13 14|14 15|15 16|16 17|17 18|18 19|19 20|20 21|21 22|22 23|23 24|24 25|25 26|26
if ur just going to do that why do some type of algorithm for that?
Hello python community, I’m currently working on predicting tennis matches outcomes using machine learning, I have csv datasets from 1960, containing things like player ID, height, hand, dob, score, rank and so on.... the problem is that the csv files are sorted by only winners, columns are like [surface, ....., drawsize, tourney date, winner name, winner hand, ..., loser name, loser hand,...]
Whenever I try to put this data to the model it says it needs at least two classes of Y axis, i.e. either win(1) or lose (0). How can I separate the data or do something so my model can pick it up? Thank in advance...
Where can i learn about algorithms and data structures, or how can i learn it through a project?
Can anyone tell me how to use the voice recognition module in python 3.8?
An interactive version of Problem Solving with Algorithms and Data Structures using Python.
oooo
it is a free book published online, it has explanation and examples as well
@lusty lantern I kind of follow what ur doing but not really, but this is by far faster than ur code sorry for the repost (0.4524265000000014) I just want to make sure u see this updated because my previous code was horrible. ```py
def cakes4():
total=6969
DATA = {'RECIPE': 'abcdefghijklmnopqrstuvwxyz',
'AVAILABLE': 'abcdefghijklmnopqrstuvwxyz'}
Calculation = len(DATA['RECIPE']) // len(DATA['AVAILABLE'])
for index,element in enumerate(range(0, len(DATA['RECIPE']))):
CurrentPosition = index
CurrentValue = DATA['RECIPE'][element]
return Calculation
else:
if Calculation < total:
total = Calculation
#total = CurrentPosition // CurrentPosition
return total
really no sense in the if conditional in my opinion
how far into python are you
i can use about 23 libs
i think the problem is maths tho
is there a lot of maths involved?
i like to think of algorithms as traversing arrays with conditonals
🤔
This probably doesn't even work 
so its just
different ways to sort arrays?

well ive been told its important and can be very useful
so i will read up
watch some tutorials
and use em
@lusty lantern well what are you exactly trying to do, I see you iterating through ur recipes to pull an index and or length of an index to do floor division with, I mean ur not dividing strings with numbers its not happening.
you also do your calculation during ur iteration through the recipe list which doesnt make sense
not for that