#algos-and-data-structs
1 messages · Page 114 of 1
what is the time complexity of ```py
def myFunc(str):
inputOX = str.lower()
ohh = inputOX.split('x')
exx = inputOX.split('o')
return len(ohh)==len(exx)
O(n)? .lower is O(n), .split seems to be O(n) (I am not sure), len(...) is O(n)
split seems like its O(n*n)
since if every item in the string is 'x' the it would have to split every component of the list
i dunno it it seems weird
split probably could be done in O(n) If I'm not wrong
which would make the whole function O(n)
oh
!e
def split(string, delimiter):
output = [""]
for character in string:
if character != delimiter:
output[-1] += character
else:
output.append("")
return output
print(split("ab1cb1de", "1"))
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
['ab', 'cb', 'de']
split is O(n). It creates at most 1 element in the resulting list per character in the original string, so that's 1 thing done N times, O(n), not N things done N times, O(n**2)
split should always be O(n) if it’s splitting by a single character I think
what is the time complexity of
array = [1, 2, 3, 4]
x = array[:]```O(N)
so wouldn't split have to do that for each split?
I remember reading that split is O(n*m) in the worst case, with n being the length of original string and m being the length of the substring. So if the substring is just one character, it’s O(n)
That's right.
hmm
split() returns a list, not a list of lists.
And there are algorithms that could make it O(n) or better always, but they’re more expensive, so they just use a cheaper O(n*m) algorithm
oh yeah that makes sense
assuming the list is
string = "xxxxxxxxxxx"
string.split('x')
``` wouldn't it have to
```py
string = 'xxxxxxx'
list = []
index = 0 # index of the x
for i in number of 'x' in the string:
list.append(string[index:(next_index_of_x)])
index = next_index_ofx```
is this not how the split is worked out?(not valid python code sorry)
Yep, that's basically right.
then from the line
for i in number of 'x' in string:
it would be O(n)
and in the next line
list.append(string[index:(next_index_of_x)])
it would also be O(n) right?
which would lead to
O(n) * O(n)
= O(n*n)?
list.append is O(1), not O(n)
Well, technically yes but you could have done that the other way in O(n)
he probably meant slicing
the string[index:...] part
Slicing the string to extract a substring is O(m), where m is the length of the substring to be extracted, not O(n), where n is the length of the original string
s = "abcxdefxaaa"
def split_str(s, delimeter):
out = []
temp_str = ""
for char in s:
if char == delimeter:
out.append(temp_str)
temp_str = ""
else:
temp_str += char
if temp_str != "": out.append(temp_str)
return out
split_str(s, "x")
This could work
and here it's just O(n) cuz you traverse the string only once
(unless there are some errors xd)
well, I keep the string and then when I find delimeter I just append string to the list and reset it
The better way to view this is that the algorithm needs to read every character of the string being split twice (assuming single character delimiters): once to see if it's a delimiter or not, and once to copy it into a string in the resulting list if it's not. That's O(2*n). Which is O(n).
Both adding a new string to the list of strings being returned, and adding a new character onto one of those strings, are amortized O(1) operations, we can ignore them.
but in the first algorithm doesn't it also create new lists during the slicing of the string which would be O(m)?
Yes, but it still only visits each character twice. Once during the for loop to see if it's a delimiter or not, and once as part of a slice if it's not.
yeah
oh
You're confusing yourself by adding an M in where you don't need one. You can formulate it as O(n*m) if you really want to, but n*m is at most n*2.
im a little bit confused about the slicing part, but seems like it would still be O(1) since its basically the same string but just cut down
anyways, i gotta go to the school, thnx for the explanation @lean dome and @main flower
👍
Extracting a slice is O(len(slice)). But we know there's an upper bound on how many slices we extract (n) and on the length of each of those slices at the upper bound (0, if every character was a delimiter and there are no non-delimiter characters to copy). That's creating N empty strings, which is O(n) total across all iterations, because creating an empty string is O(1).
And conversely, there's a lower bound on how many slices we extract - it's 1, in the case where the string contained no delimiters, in which case we extract an N character substring 1 time, which is also O(n) total across all iterations.
The trick here is that N and M aren't independent variables, they're inversely proportional. If the loop fires more times, it does less work per iteration, and vice versa.
And the total amount of work it does across all iterations is O(n), no matter how many iterations there are.
Could someone help me with this task?
Construct recursive algorithms in the form of programs.
(3,5,3,-1,-3,-1,3,5...)
(1,5;1;0,5;-0,5;-2;-4,5; -8,5)
(-3,1,-4, -5,19,-96,-1825,...)
if i add another name, then where will the rear pointer go? its a circular queue btw

any idea how can I set a list as an entire file
like
file is [item, item , item] (5 million items)
Given that diagram, and the most common implementation of a circular queue, you cannot add another item. The queue is full.
file.readline()?
There are possibly implementations that make use of every cell of the array, but the naive implementation you're likely to be learning first has one element of overhead.
ahh okay but i thought circular queues make use of all the memory spaces?
That's because, if it were pushed back one further, it would be equal to the front pointer - and that's the representation you've chosen for an empty array, so it can't also be the representation for a full array
They can. The naive implementation does not.
ah okay so it can, but not in the way that the diagram above is shown?
also, can priority queues be both linear and circular?
circular priority queue doesn't make sense, where is the highest priority
A priority queue isn't even really a queue... It doesn't have any order. They can't be circular, because there's no order at all, and so no beginning or end.
In some languages, with some constraints, it is possible to fully utilize the buffer. The trick I know of for implementing that relies on either arbitrary precision integers like Python has, or defined behavior for unsigned overflow like C has (in which case it only works for buffers whose size is a power of two)
so are they just.. a normal linear queue
usually you implement one with a heap
that way higher priority things are popped first
They're not linear, because they don't have an order, just a concept of "current highest priority item"
pick up a textbook or online course and get to self studying lol
"Priority queue" is really a misnomer, because there's no "waiting in line" like there is for a regular queue. If a high priority item shows up, it's immediately moved straight to the top to be processed next. Though items of equal priority may or may not preserve their relative order.
what should it be named instead?
one more thing, can you explain 'checksums' please?
"Priority heap" would be more accurate, I suppose. The problem is that "stack" and "queue" are both named after metaphors that don't apply to priority queues.
huh, are there (good) implementations that don't use heaps? if there were you'd start calling things that aren't heaps heaps
I'm not sure. "Priority bag"? "Priority bunch"?
They're a specific purpose of hashing. They're hash algorithms designed to make it very likely that minor corruptions of the input data lead to very different hash codes, so that, if applying the same hash algorithm to the data you received matches the hash value recorded by the sender, you can be reasonably confident that the data was transferred successfully.
sorry, so its an algorithm used in data transmission, to check if the data received is legit and hasn't been like tampered with? and the end user runs the same algorithm and if the checksum digit matches then they know there weren't any errors in the transmission. is that correct?
can someone help me?
Not unless you explain what you need help with
how do i make it so that if a valid operator isnt inputted, it goes back to the beginning?
n1 = int(input("Enter number: "))
n2 = int(input("Enter another number: "))
op = str(input("Enter an operator (+ - / *): "))
if (op == "+"):
print(n1+n2)
elif (op == "-"):
print(n1-n2)
elif (op == "*"):
print(n1*n2)
elif (op == "/"):
print(n1/n2)
else:
print("Enter a valid operator: ")
also if this is the wrong channel can some redirect me to the right one
put it in a while loop i guess
loop = True
while loop:
"""
your code
"""
loop = input('Do you want me to stop(yes/no): ')
if loop == 'yes':
break
else:
continue
Hello! I have to solve these recurrences using the master theorem. I was wondering about the second one... Can I simply multiply the recurrence by 2 and then solve, such that 64 T((n/4)*2) + n^4. Thaanks!

Could someone help me answer this question? My mind has gone blank and I cannot figure out how to answer this question of Data Encoding with Python.



Good morning everyone
I need your help, I'm trying to understand an exercise but I can't understand, it's about enqueue with linked list.
Hey @wet urchin!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
Hey @wet urchin!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
Someone now how to copy from this webpage? https://paste.pythondiscord.com/
You have Save option and there is a unique link in your browser bar
This?
But I want to show the content
Yep
I got Node and QueueLinkedListsCircular classes
So what is the problem?
I need to know, how enQueue works
why he puts self.lastNode = self.front? It should be =self.rear I think
In your paste there is self.lastNode = self.read 
def enQueue(self, data):
self.lastNode = self.rear
self.rear = Node(data)
if self.lastNode:
self.lastNode.setNext(self.rear)
if self.front is None:
self.front = self.rear
self.size += 1
First of all you don't need functions like setLast, getLast and so on in Node class
It can be done just by node.last = newlast, there is no need to make it by node.setLast(newlast)
Why you think that the book puts that in that way?
Quick look at the code and implementation of QueueLinkedListsCircular.enQueue looks okay for me
def enQueue(self, data):
self.lastNode = self.rear # create temporary variable with last rear
self.rear = Node(data) # set new node as new rear
if self.lastNode: # if last rear is not None then set its new node as new rear
self.lastNode.setNext(self.rear)
if self.front is None: # if front is none then set front as rear, it means that self.lastNode is also None
self.front = self.rear
self.size += 1
Thanks a lot
Maybe may you put a comments for the deQueue method please?
I don't understand what is the function of result
def deQueue(self):
if self.front is None: # if queue is empty then raise exception
print('Sorry, the queue is empty..!')
raise IndexError
# it means that self.front is not None
result = self.front.getData() # get data of the front node (this data is set in constructor)
self.front = self.front.next # set front as next node
self.size -= 1
return result;
Thanks a lot MK
Hii! 🙂 could someone please help me with the following problem: Describe how to implement a dictionary that has an average lookUp, insert, and delete time of O(1), but uses an array of no more than 2 times the maximum number of elements that will be stored in the dictionary. So, if I have a student node class and the keys would be represented by their last 4 digits of the SSN, and there are 20 students, I would create a dictionary of size 40 and technically use the keys as index values in order to keep the search time as constant as possible, but in this case I can sacrifice a bit the best search time for a smaller array size. Would I have to use something like hashtables? (i am not sure how they work, I just looked them up).
Hey guys, there is a better way to write this..... right?
test1_in = [28, 2, 3, -3, -2, 1, 2, 35, -1, 0, 0, -1]
test0 = test1_in[0]
test1 = test0 + test1_in[1]
test2 = test1 + test1_in[2]
test3 = test2 + test1_in[3]
test4 = test3 + test1_in[4]
test5 = test4 + test1_in[5]
test6 = test5 + test1_in[6]
test7 = test6 + test1_in[7]
test8 = test7 + test1_in[8]
test9 = test8 + test1_in[9]
test10 = test9 + test1_in[10]
test11 = test10 + test1_in[11]
print(str(test0) + ' ' + str(test1) + ' ' + str(test2) + ' ' + str(test3) + ' ' + str(test4) + ' ' + str(test5) + ' ' + str(test6) + ' ' + str(test7) + ' ' + str(test8) + ' ' + str(test9) + ' ' + str(test10) + ' ' + str(test11))
test1_in = [28, 2, 3, -3, -2, 1, 2, 35, -1, 0, 0, -1]
test0 = test1_in[0]
test1 = test0 + test1_in[1]
test2 = test1 + test1_in[2]
test3 = test2 + test1_in[3]
test4 = test3 + test1_in[4]
test5 = test4 + test1_in[5]
test6 = test5 + test1_in[6]
test7 = test6 + test1_in[7]
test8 = test7 + test1_in[8]
test9 = test8 + test1_in[9]
test10 = test9 + test1_in[10]
test11 = test10 + test1_in[11]
seems like it could be just done with sum(test1_in)
saves you a lot of code
or you could do it with a for loop
wait
but I dont want the sum
hm

Yea was thinking of doing that, but don't know how
could you use recursion?
I can use any method but the output has to be similar or same to the one I wrote above
I have a graph, and i have implemented a BFS to find the shortest path, in terms of edges, for the graph, given two vertices, now the order of growth to find the the shortest path would be O(V + E) i think, but how would i test this empirically using timeit? Would i use the graph i currently have, and pick two random vertices and measure time and do some reps? Like usually (for other stuff) i would have plotted a running time against problem size graph, but here i am not sure how i would do it. Or would i need to create a multiple new graphs just to test this?
well then I can't think from top of my head how to specifically do it (i came here for help too lol), but you should have let's say a Fib() method with a base case for returning test1_in[0] then in the recursive case, you would have something like previous element + next element, similar to a fibonacci series
Hey everyone, I'm running into a problem that should be simple, but is perplexing me. I'm trying to plot a 3D surface, where I have a 2D array of radii, and each axis represents theta and phi in spherical coordinates. I'm using pyqtgraph and OpenGL to render the 3D images.
I can calculate all x, y, z locations for each r, theta, phi, and stack them into an Nx3 array, however converting that to a surface is difficult because they are not evenly distributed in Cartesian coordinates (they are evenly distributed in spherical coords). From digging around, it looks like I should create a mesh out of these points, however I am struggling with how to do that. Can anyone help me out here?
.
this isnt an alg per-cay and it isnt python specific but lets say i had 2 linear equations in slope-intercept form (y=mx+b). what would be the logic behind finding the point of intersection (if there is one). would i have to check every point on both lines??? that seems like it would take a while... i could check to see if the slope is the same to see if they are parallel or the same line(s)
you can calculate a point of intersection in constant time
since the y will be the same at the intersection, just set the two equations equal
m1 * x + b1 = m2 * x + b2
solve for x
right but besides setting the 2 equations equal to each other, how would i code that
ik how to do it irl
but it depends on the situation what you are going to do
I found something that might help you:
https://stackabuse.com/solving-systems-of-linear-equations-with-pythons-numpy/
Specifically look for the Solver() method in this page.
This link has the explanation too:
https://apmonitor.com/che263/index.php/Main/PythonSolveEquations
Stack Abuse
The Numpy [https://numpy.org/] library can be used to perform a variety of
mathematical/scientific operations such as matrix cross and dot products,
finding sine and cosine values, Fourier transform
[https://en.wikipedia.org/wiki/Fourier_transform] and shape manipulation, etc.
The word Numpy is short-hand notation for "Numerical Python".
In t...
Python tutorial on solving linear and nonlinear equations with matrix operations (linear) or fsolve NumPy(nonlinear)
hello
Hello!
how are you
Fine, thanks. This channel is dedicated to talk about algorithms and data structures.
If you want to talk about offtopic conversions here you have dedicated channels:
Feel free to join to one of those
Hey all, I have just solved this problem on Leetcode Problem 387: https://leetcode.com/problems/first-unique-character-in-a-string/ with the following code
class Solution:
def firstUniqChar(self, s: str) -> int:
d = dict()
index = -1
for i in s:
d[i] = d.get(i,0) + 1
for i,elem in enumerate(s):
if d[elem] == 1:
return i
return index
Although this solution works, and its complexities are as follows Runtime: O(N), Space: O(N) however whenever I run this on Leetcode it seems to have a horrible actual runtime. Below are the runtimes from my last 5 submissions.


Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
Theyre accepted, whats the problem
I have also found other solutions on the discuss section and noticed when the Counter module is used, they typically have much better runtimes such as this code
class Solution:
def firstUniqChar(self, s: str) -> int:
from collections import Counter
d = Counter(s)
for i in d:
if d[i] == 1:
return s.index(i)
else:
return -1
This person has gotten

I was wondering why the Counter module yields much better results in actual runtimes. I was wondering if someone can explain to me why that is. From my understanding I am doing the same thing just using a dictionary but if this is a misunderstanding please so point it out. I am currently looking online for an explanation but figured I can ask here where I can ask about my code.
Wouldn't the counter be iterating s anyway so actual iterations should be the exact same just less code.
Just submitted this code myself and it is still performing better than my initial solution.
Hmm yea thats weird
Counter(s) should be O(len(s))
Oh, but
They have two loops, one over s and one over len(Counter)
You have two loops over s
Maybe thats why their runtime is shorter i would guess
but wouldn't Counter implicitly add a loop on s for the counting?
what is profiling in this context?
Basically checking whats taking long in your code
Anyway both code samples have a loop over s for counting
Oh I see
I also suspect that the return s.index(i) portion in the faster code would also be another loop, unless Counter is storing index somehow in the initial count.
It shouldn't, counter's items are the element and its count in the iterable
So you mean that if s = 'aabb' Counter(s) would produce
a: 2
b: 2
So kind of like a dictionary?
!e
from collections import Counter
string = "aabb"
output = Counter(string)
print(output)
print(output["a"])
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
001 | Counter({'a': 2, 'b': 2})
002 | 2
Thank you!
I like to check how it works 😉
:incoming_envelope: :ok_hand: applied mute to @vernal glen until 2021-04-13 22:11 (9 minutes and 59 seconds) (reason: attachments rule: sent 8 attachments in 10s).
<@&267629731250176001>
!pban 583069436387524610 Spam
oops, false alarm i guess
:incoming_envelope: :ok_hand: applied purge ban to @vernal glen permanently.
Still not getting why using Counter to count is roughly 3x faster than using the dictionary. But I am guessing this is meaningless in an interview setting since they care about the algorithm rather than microoptimzations available in the language? Can someone please comment on this?
Anyway, the source to counter is here
https://github.com/python/cpython/blob/5ce227f3a767e6e44e7c41e0c845a83cf7777ca4/Lib/collections/__init__.py#L530

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
You can check exactly what it does
Thank you for the link and trying to help me understand this.
You can see that theres a loop over the iterable to populate the counter object
And its very very close to what you wrote
I see, thank you!
Maybe the problem is with making Python objects - it's very costly
Why would dict() be so much slower than subclassing dict and using super() tho
Could it be my use of enumerate?
!e
from collections import Counter
from random import choice
from string import ascii_letters
from time import time
string = "".join([choice(ascii_letters) for _ in range(2 ** 16)])
start = time()
Counter(string)
end = time()
print("counter", end - start)
start = time()
counter = {}
for character in string:
if character not in counter:
counter[character] = 1
else:
counter[character] += 1
end = time()
print("dict", end - start)
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
001 | counter 0.00568389892578125
002 | dict 0.01647639274597168
There is significant difference
Hi
r = requests.get("https://www.xxx.net/api/get-engines?username=xxx&password=xxx")
returns
Hey @unique pecan!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
{"file_engines":[{"id":"1","full_name":"Adaware Antivirus 12","engine":"adaware","version":"","update":""},{"id":"2","full_name":"AhnLab V3 Internet Security","engine":"ahnlab","version":"","update":""},{"id":"3","full_name":"Alyac Internet Security","engine":"alyac","version":"","update":""},{"id":"4","full_name":"Avast Internet Security","engine":"avast","version":"","update":""},{"id":"5","full_name":"AVG AntiVirus","engine":"avg","version":"","update":""},{"id":"6","full_name":"Avira Antivirus 2018","engine":"avira","version":"","update":""},{"id":"7","full_name":"Bitdefender Total Security 2018","engine":"bitdef","version":"","update":""},{"id":"8","full_name":"BullGuard Antivirus","engine":"bullguard","version":"","update":""},{"id":"9","full_name":"ClamAV","engine":"clam","version":"","update":""},{"id":"10","full_name":"Comodo Antivirus","engine":"comodo","version":"","update":""},{"id":"11","full_name":"Dr.Web Security Space 11","engine":"drweb","version":"","update":""},{"id":"12","full_name":"Emsisoft Anti-Malware","engine":"emsisoft","version":"","update":""},{"id":"13","full_name":"ESET NOD32 Antivirus","engine":"nod32","version":"","update":""},{"id":"14","full_name":"FortiClient Antivirus","engine":"forti","version":"","update":""},{"id":"15","full_name":"F-Secure SAFE","engine":"fsecure","version":"","update":""},{"id":"16","full_name":"IKARUS anti.virus","engine":"ikarus","version":"","update":""},{" AND MORE
how do I parse certain pieces of this data?
with requests
Have you tried result.json()? I don't know how do you want to parse it
<bound method Response.json of <Response [200]>>
<bound method Response.json of <Response [200]>>
just returns that
Not result.json but result.json() - remember about ()
Ohhh let me try thx
returns same thing with spaces
There should be a way to parse the data no? how does everyone else do it?
Show result.headers['content-type'] output
text/html; charset=UTF-8
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)```
Deserialize *s* (a [`str`](https://docs.python.org/3/library/stdtypes.html#str "str"), [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") or [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray "bytearray") instance containing a JSON document) to a Python object using this [conversion table](https://docs.python.org/3/library/json.html#json-to-py-table).
The other arguments have the same meaning as in [`load()`](https://docs.python.org/3/library/json.html#json.load "json.load").
If the data being deserialized is not a valid JSON document, a [`JSONDecodeError`](https://docs.python.org/3/library/json.html#json.JSONDecodeError "json.JSONDecodeError") will be raised.
Changed in version 3.6: *s* can now be of type [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") or [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray "bytearray"). The input encoding should be UTF-8, UTF-16 or UTF-32.
Changed in version 3.9: The keyword argument *encoding* has been removed.Go ahead!
I don't understand, you have r = requests.get(...) right?
Yeah
So try to execute the following code
import json
data = r.text
data = json.loads(data)
print(x)
``` return
file_engines
domain_engines
if that means anythingIts the keys to the response dict
Okay, so when your data is
{
"key": [
"value 1",
"value 2"
]
}
You can process it by
for key, values in r.json().items():
print("key", key)
print("values", values)
Awesome thanks!
import requests
url = "https://www.scanlabs.net/api/process-domains?username=&password="
payload='selection%5B0%5D=44&selection%5B1%5D=43&entry%5B0%5D=google.com&entry%5B1%5D=google.in'
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)

Those two are same thing ^
how do I POST a URL?
I dont follow
hey this would be more suited for #web-development
Hey guys
Can you recommend resources to learn Data Structures? It could be webpages, youtube channels or books. Thanks in advance
An interactive version of Problem Solving with Algorithms and Data Structures using Python.

YouTube
Computer science tutorials to help you learn, review for exams, and prep for interviews.
My goal: Create the most concise & understandable computer science tutorials on YouTube.
My background, for ethos: I'm a cloud architect at Amazon Web Services, and I have a bachelor's and master's degree in computer science from Georgia Tech.
this guy has good youtube videos on algorithms
Thanks, do you have another for data structures?
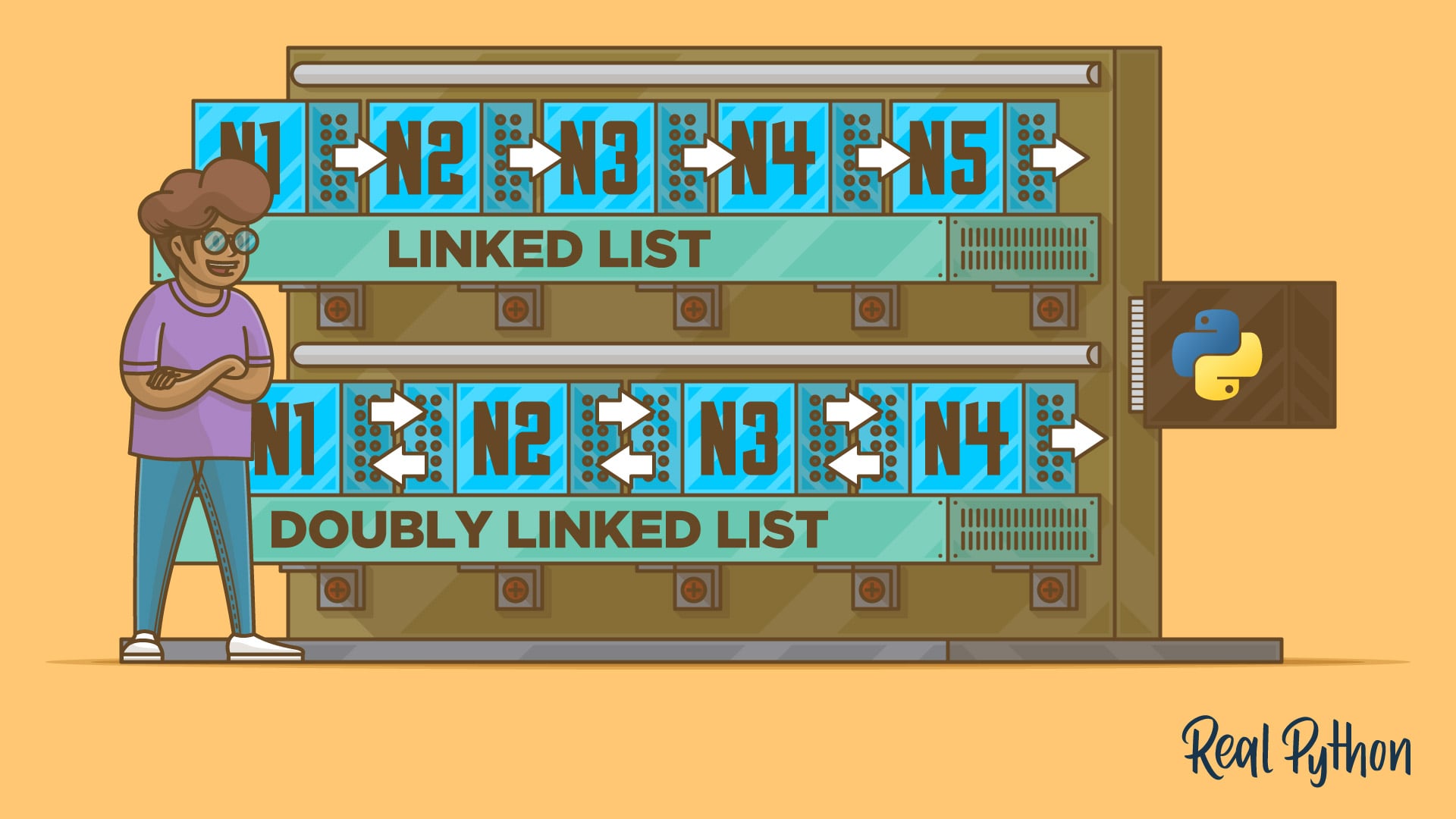
In this article, you'll learn what linked lists are and when to use them, such as when you want to implement queues, stacks, or graphs. You'll also learn how to use collections.deque to improve the performance of your linked lists and how to implement linked lists in your own projects.
I didn't have one single source for data structures
I had to hop around a bit
I also did the Udacity Python DS/algos course but it was in Python 2.7
it wasn't that bad tho
I also used Grokking Algorithms
also before you go into ds/algos you should know OOP well
at least the basics of OOP
if you need help w OOP you can check out Corey Schafer's youtube series on OOP
im trying to search for patterns in a trie is anyone familiar with tries?
what do you mean by patterns?
what's a way to test whether a word is in alphabetical order?
Map each letter to its ascii code and perform numeric comparisons
no need, < works on strings too.
Good to know
Similar to leetcode 437.
This algorithm is to find out the total number of paths in a binary tree whose sum is S. The path doesn't have to be only root to leaf node.
1 def count_paths_recursive(currentNode, S, currentPath):
2 if currentNode is None:
3 return 0
4
5 # add the current node to the path
6 currentPath.append(currentNode.val)
7 pathCount, pathSum = 0, 0
8 # find the sums of all sub-paths in the current path list
9 for i in range(len(currentPath)-1, -1, -1):
10 pathSum += currentPath[i]
11 # if the sum of any sub-path is equal to 'S' we increment our path count.
12 if pathSum == S:
13 pathCount += 1
14
15
16 pathCount += count_paths_recursive(currentNode.left, S, currentPath)
17
18 pathCount += count_paths_recursive(currentNode.right, S, currentPath)
19
20 # remove the current node from the path to backtrack
21 # we need to remove the current node while we are going up the recursive call stack
22 del currentPath[-1]
23
24 return pathCount
can anybody help me why pathCount returns the total path since it keeps changing to 0 at line 7. I have been stuck in this since yesterday and couldn't find an explanation.
Can anyone help me with a variable size sliding window problem
I need to show something on a share screen it is pygame and algorithm related can someone help me with that?
I will explain but it's hard to say what i mean in text without sharing my screen
HEYYYYY
can i get help with very simple python
its on a website called cmu academy
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, be considered malicious or inappropriate. Do not help with ongoing exams. Do not provide or request solutions for graded assignments, although general guidance is okay.
could someone help me with returning the empty list? not sure why im getting (0,0)

Can someone help me understand Expectimax and the implementation of it as compared to minimax with pruning?
I can hop in a vc
you do your check for an empty list within the for loop, but the for loop will never even happen if the list is empty
thanks a lot it worked
np!
im stuck with another problem
error:
AttributeError: 'list' object has no attribute 'replace```
im trying to remove vowels from the string
i dont know if my attempt at list comprehension is even right, but i thought it would allow me to use the replace method?
2 lines up, string is made a list

so here:
new_string = [string.replace(letter, "") for letter in string if letter == vowel]
is this the issue?
You could also use str.translate
string.translate({ord(vowel):"" for vowel in "aeoiuAEOIU"})
sorry i dont undestand how to fix this problem
no, the issue is that splitting a string gives you a list
i don’t see them splitting a string anywhere
mmm, the issue is in my reading skills
indeed
the actual issue in the code is because you aren't using your loop variable
also, str.replace replaces all occurrences of the letter, you dont need to loop over the letters in the string
what if i try this:
for vowel in vowels:
if vowel in string_:
string_.replace(vowel, "")```You also dont need to check beforehand, str.replace wont error if the letter isnt in the string
Also you gotta catch the return
so i dont need the if vowel in string_: ?
i tried printing string_ but the string stays the same it doesn't change at all
An example #bot-commands message
thanks it worked, looks like i was just complicating it for no reason 😥
could u explain one last thing, in string_.translate(None, "aeiouAEIOU") , why do you put None ?
Uh, thats not what the code says
oh yeah, after submitting it shows other peoples code and i got that from there ^, since u were talking about translate() before i just picked that code.
If you want to use str.translate you have to give it a mapping/dict of the unicode code for a particular letter and what you want it to replace
#bot-commands message
Kinda sad how i cant eval in here
Or can I
!e
You are not allowed to use that command here. Please use the #bot-commands channel instead.
Dang, would be useful
>>> 2023049.2369
2023049.2369
>>> 2023049.236 + 9 * math.pow(10, -4)
2023049.2369000001
any way to avoid that pow returns 0.0009000000000000001 and instead returns 0.009?
feels like I'm missing something very basic about floats
oh wow lol that's an actual link.
Floating Point Arithmetic
You may have noticed that when doing arithmetic with floats in Python you sometimes get strange results, like this:
>>> 0.1 + 0.2
0.30000000000000004
Why this happens
Internally your computer stores floats as as binary fractions. Many decimal values cannot be stored as exact binary fractions, which means an approximation has to be used.
How you can avoid this
You can use math.isclose to check if two floats are close, or to get an exact decimal representation, you can use the decimal or fractions module. Here are some examples:
>>> math.isclose(0.1 + 0.2, 0.3)
True
>>> decimal.Decimal('0.1') + decimal.Decimal('0.2')
Decimal('0.3')
Note that with decimal.Decimal we enter the number we want as a string so we don't pass on the imprecision from the float.
For more details on why this happens check out this page in the python docs or this Computerphile video.
hi, i have implemented breadth first search to work out the shortest path in a graph by number of edges, and dijkstra for shortest path based on weight. Now how would i test empirically their order of growth, since bfs is O(V + E) and dijkstra should be O(ElogV) if i am not mistaken using timeit? I created test graphs, where the number of edges is constant but the number of vertices vary and tried to measure time with increasing V. In both cases they give me a form of linear relationship when i plot the data using pyplot
testing empirically will always be worse than proving theoretically
how large are your test graphs?
you're probably not going to notice a difference between bfs and dijkstra's until like 20k nodes probably
Not very large, have 5 edges, and vertices range from 100 to 20000, not sure if thats how you are supposed to empirically determine the order of growth, like the method i am using. Is it maybe because i have such a low number of edges compared to vertices? Is the method wrong? What would i need to measure in that case to test it emprically?
@lean dome I thought big theta only applies if big O and omega are the same, otherwise it wouldn't exist? Correct me if I'm wrong
Big o is an upper bound, but not necessarily a tight upper bound.
Big omega is a lower bound, but not necessarily a tight lower bound.
We usually drop the constants off of those, and talk only about tight bounds.
Every algorithm that's O(1) is also O(n) and O(n!), according to a mathematician or a CS professor.
According to anyone you talk to in industry, they'll only call it the tightest one of those, O(1)
So based on definition there are algorithms where big theta doesn't exist if tight O and tight omega are different?
From CtCI book:
(big theta): In academia, big theta means both O and omega. That is, an algorithm is theta(N) if it is both O(N) and
omega( N). Theta gives a tight bound on runtime.
Yes, it doesn't always exist is how I learned it.
The upper and lower bound functions don't have to be exactly identical; they can differ by some constant value.
By some constant factor, that is. If the number of operations performed for sufficiently large inputs is always greater than 4 * 2^n and less than 10 * 2^n, then it's big theta of 2^n
The formal definition of big theta, per Wikipedia, is that a function f(n) is θ(g(n)) if there exist some positive k1 and k2 such that, for all n greater than some n0, k1 * g(n) ≤ f(n) ≤ k2 * g(n)
How do you use configparser?

Stack Overflow
I have defined main,i included the txt file that is needed to run for lexical analyzer.I have changed the code a bit (change is not included here) to see if it works out,but code is reaching exit a...
can somebody help me with this?
does anyone know recurrence systems (induction proofing)?
what's your question?
hey
so im doing some practice questions and i found this problem
can anyone help me?
ping me if u can
what's the question

is this a school assignment
no
it's a sample problem
i saw online
idk how to really do it. im tryin to improve
here's sample input:

so far i worked out how to make the graph
i was thinking to perform a DFS on it, But that didnt work out
@old rover any progress?
the problem is above
no i mean a link to it
do u want the pdf to it?
oh its a pdf? i thought it was an online thingy
nah its fine, we got the screenshots
ok
this is my solution: it doesnt work for all test cases: ```py
import sys
from collections import defaultdict
raw_input = sys.stdin.readline
n = int(raw_input())
graph = defaultdict(list)
for i in range(n-1):
pair = raw_input().split()
graph[pair[0]].append(pair[1])
graph[pair[1]].append(pair[0])
hc = raw_input().split()
def dfs(graph, node, path, visited=None, i=0):
if visited is None:
visited = set()
if node not in visited :
path.append(node)
visited.add(node)
for neighbour in graph[node]:
dfs(graph, neighbour, path, visited)
return path
op = dfs(graph, hc[0], [])[dfs(graph, hc[0], []).index(hc[0]):dfs(graph, hc[0], []).index(hc[1])
]
sp = dfs(graph, hc[0], [])[dfs(graph, hc[0], []).index(hc[1]):]
if len(op) % 2 == 0 or len(sp) % 2 == 0 and (len(op) != 0 and len(sp) != 0):
print("Let's play >:)")
else:
print("NOU >:(")
wdym test cases, so is this online or not lmao
guys how do i instantiate a numpy array of the form [[9.71158805]] which my program tells me is of shape 1,1
and append this value to the array
How do companies implement search query detector, so if you someone looked for:
BILY1234-789
And if it is not in the database, but BILY-1234-789 is then it would show that
So, fuzzy matching?
Oh it's called fuzzy matching
yup, check out !pypi fuzzywuzzy for a working library, even
Is that what elastic search does? But elastic search is an engine
Thanks!! Really helpful.
Can someone plsss help me with this?
"Describe how to implement a dictionary that has an average lookUp, insert, and delete time of O(1), but uses an array of no more than 2 times the maximum number of elements that will be stored in the dictionary"
I read that I could implement a hashtable but I am not sure
dictionary that has an average lookUp, insert, and delete time of O(1),
that's pretty much only achieved by a hashmap, I believe
hashmap is a Java term
Not only, I think it's how they are called in C++, and from there in a lot of languages
I am supposed to do it in java anyway, so thank you!
C++ calls it unordered_map but it's all the same concept
Hi
hello , i am working on min notes needed problem , but my code is in c , can i paste it here somehow
Kinda depends. If you need to be indexing and need order in your data structure list is the way to go. Dict are unordered and accessible with keys(which most of the time I prefer)you can easily use a key named anything if you don't wanna deal with integers.
With lists, if it's a large data with lot of elements trying to remember the position of each element with the index values might not be super ideal. But if it's something small and simple lists are the way to go to loop over.
trying to remember the position of each element
since when do you need to do this? the idea of a list is that each element in it is roughly the same. there's no semantic difference between each element
umm. in a dict there isn't any first element or second or nth element. Everything is just directly accessed by the key-value. in a list each element has a certain position, like 1st second, third ....nth
dictionaries are used for when you need a mapping between two things, for example a teacher's name to a list of their students
in python 3.7+, dictionaries maintain their insertion order
That's also why dicts are faster than lists in large data since traversing through a dictionary doesn't take long. There is more space taken for a certain element to be accessed via it's position in lists.
traversing a dictionary is going to be the same or worse speed than a list
dictionaries are best at finding the specific value of a specific key
wait fr? I swear we did a comparison in a class and the dict was like 2 seconds or something faster.
yes this.
Lookup vs iteration
How do i make a algorithm that gets the letters of a given input, and then if an other input is equal to the letters stored, tell you the matches.
Example:
Word Input:
'Hello'
Variable called chars:
[('H', 'He','Hel','Hell')]
Search Input:
He
Output:
Did you meant Hello?
This is called prefix search. It's usually efficiently implemented with a trie.
So how am i able to do it
Like, yourself, or do you want a trie library?
lib would be fine, but i would also like to get a basic knowledge on how to do it my self.
See https://en.wikipedia.org/wiki/Trie, basically
Tries are relatively simple in principle - it's a tree of characters you descend to find (or not find) the words
like i want that for a discord bot.
yea

Static memory-efficient and fast Trie-like structures for Python.
it has very horrible docs, sadly, but it doesn't have many functions, either, so you can just read the stubs
Okay
it really is performant, though
For any external problems can i contact you?
just ask somewhere
Thanks.
and if you want fuzzy search instead, like Maroloccio suggested, fuzzywuzzy
WHAT THE FUCK ARE THESE DOCS LMAO
that's more common for search suggestions
yea
need to print that lmao:

Using
string = 'Hello'
char_list = []
for char in string:
char_list.append(char)
I am getting
['H','e','l','l','o']
How am i able to get
['H','He','Hel','Hell','Hello']
@vocal gorge
well, append a slice of the string each time, for example
hm like
for char in string:
char_list.append(char + char)
I am getting a double input at the list
['HH','ee']
etc
You can use range(len(string)) to generate list of possible indexes and then use string[:x] to have substring of string of length x
!e
string = "Hello"
x = 3
substring = string[:x]
print(f"x = {x}, substring = {substring}")
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
x = 3, substring = Hel
Rather
for i in range(len(string)):
# todo create x from i
pass
string = 'Hello'
x = 0
for char in string:
x+=1
print(substring[:x])
i think i can sue that
use*
This gives as output
H
He
Hel
Hell
Hello
Now that i am using this:
string = 'Hello'
char_list = []
x = 0
for char in string:
x+=1
char_list.append(string[:x])
print(char_list)
I am getting the expected output
['H', 'He', 'Hel', 'Hell', 'Hello']
Now how do i make it NOT to append the actual string.
To not append the Hello so the output will be:
['H', 'He', 'Hel', 'Hell']
@trim fiber
I am going to try:
if x == len(string)
is there a reason you're iterating over the string, rather than a range? you never use the value char
It works fine with me
just want to not append the actual string at the table
yeah i made it
string = 'Hello'
string_length = len(string)
char_list = []
x = 0
for char in string:
x+=1
if x != len(string):
char_list.append(string[:x])
print(char_list)
Output
['H', 'He', 'Hel', 'Hell']
yes, it works fine, but it's not the best because you have unused variables. you could even avoid having to do the if x != len(string) check if you used range()
well, which range do you want x to be iterating over
think about the values of x in your current for loop (starts at 0, then you add 1, etc)
yeah
I think i made it my self!!!
string = str(input('Enter a key: '))
string_length = len(string)
char_list = []
x = -1
for char in string:
x+=1
if x != len(string):
char_list.append(string[:x])
print(char_list)
search_input = str(input('Enter a keyword: '))
if search_input in char_list:
print(f'Do you mean {string}?')
@grizzled schooner @trim fiber
Tell me your opinion
First of all when you set x = -1 and then update it x += 1 you have x = 0 so you put empty string into char_list
!e
for string in ["abc", "test", "any string"]:
print(f"{string}[:0] = {repr(string[:0])}")
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
001 | abc[:0] = ''
002 | test[:0] = ''
003 | any string[:0] = ''
Secondly you don't need to create list of substrings because you can use .startswith method
i did x = -1 to get the first character
Then set to 0 because as you can see you put empty string
oki
@dusk anchor check the following example and think how can you calculate x from i
for i in range(len(string)):
print(string[:i])
okay
string = 'hello'
string_length = len(string)
char_list = []
x = -1
for char in string:
x+=1
if x != len(string):
char_list.append(string[:x])
search_input = str(input('Enter a keyword: '))
if search_input in char_list:
print(f'Do you mean {string}?')
And works, but how am i able to do that for multiple words. Like:
string = ['hello', 'test word']
@grizzled schooner
What is that even for
I wanna get started with algos, anyone know some really easy ones?
fuzzy matching?
Maybe im just bad at reading other people's code but it looks like it just produces all the prefixes of the string
It depends on what you are looking for. You could e.g. google cp-algorithms and you'll find there many nice algos and data structures. imo the best way to learn algos and DS is competitive programming. This way you can fully understand the functionality of certain algos/DS
But it depends on what you need
Hmm gotcha how would I even get into competitive programming
You start by learning some basic data structures and algorithms
Then try solving puzzles
Practice makes perfect
ok thanks
There are many online judges out there e.g. Spoj, Codeforces, uva, etc.
Then, just start solving problems
Cuz knowing algos/DS without knowing how to use them is pretty much pointless
Anyone have familiarity with Merkle Hash Trees? I'm trying to understand how they grow.
Specifically when they aren't "perfect binary trees"
Hey, how's going ? I hope everything is okay
aliaga = [
{"hour": "10:00", "amount": 100},
{"hour": "12:00", "amount": 120},
{"hour": "08:00", "amount": 150},
{"hour": "07:00", "amount": 150}
]
I have a array and I want to sort by hour's value.
Can someone give a suggestion ?
Thanx
.sort() has a key kwarg. do you know about lambdas?
from datetime import datetime
aliaga.sort(key=lambda x: datetime.strptime(x["hour"], "%H:00"))
This returned None
yes, sort() doesn't return anything, it sorts the list inplace
Ohhh, you're right
sorted() returns a new sorted list, if that's what you're looking for
Thank you, it's fixed
happy to help~
Pls see #🤡help-banana my algorithm is going slower than a linear search and not sure why
Hi,
Is this the right place to ask a question regarding data structure?
I'll go ahead and post my question just in case. If I'm in the wrong spot just let me know and I'll move it.
This isn't my actual data, but it gets the idea across. I'm trying to change data similar to DATASET 1 to look more like DATASET 2 using pandas.
I was wondering if there is a good way to make this adjustment using pandas.
My actual data has about 25 * 12 * 2 variables (25 variables for 12 categories with 2 sections each).

what are differences between recursion and divide-and-conquer?
divide and conquer is a way to use recursion
recursion is part of divide-and-conquer?
no
more like the other way around. Divide and conquer is an idea you might use when writing a recursive function
divide the problem up into two subproblems, call them left and right, recurse on left, recurse on right
same type
Like with merge sort you split the list up into a left and a right and you recursively sort each
is this also called divide-and-conquer: original problem --> subproblems of different types --> subproblems of same type?
Have a problem in mind that does that? 
Though I'd say sure. If it divides the problem up into more manageable bits then it could be described as "divide and conquer".
It's just a descriptor , not a super technical term
divide and conquer is when you make subproblems, recursively solve them, then put the results together to solve the whole thing
and yeah, it's not a super well defined term like he said
i think i got it more clear, thanks discretegames and public static void
string = 'hello'
string_length = len(string)
char_list = []
x = 0
for char in string:
x+=1
if x != len(string):
char_list.append(string[:x])
print(char_list)
search_input = str(input('Enter a keyword: '))
if search_input in char_list:
print(f'Do you mean {string}?')
How am i able to make this work for multiple strings
string = ['word1', 'word2', 'word3']
@trim fiber
Have you tried .startswith method?
if string.startswith(search_input):
pass
You don't need char_list anymore when you are using .startswith
hm im kinda confused
!d str.startswith
str.startswith(prefix[, start[, end]])```
Return `True` if string starts with the *prefix*, otherwise return `False`. *prefix* can also be a tuple of prefixes to look for. With optional *start*, test string beginning at that position. With optional *end*, stop comparing string at that position.what this does is checking if the string , starts with the input
This method do exactly what your char_list do
char_list just contains the possibilities:
string = 'hello'
char_list = ['h','he','hel','hell']
but starts with just checks if the string starts with the input
hi
hello
But all variants inside char_list are just first part of the string
I mean - you are creating substring by cutting few first letters
yeah. I mean i need that for my discord bot.
there is a table that stores the commands
commands = ['command1', 'command2']
And if the user types !help commnd, for example it will say: Command not found, Did you meant {the command that matches}
So when you have
commands = ["help", "hello"]
and you put he it should return only help or both commands?
it will return both.
Do you know [x for x in y] notation?
But if the case was like:
commands = ['report', 'suggest']
And you put repo, it will return report, because this matches better.
Do you ever find yourself writing something like this?
>>> squares = []
>>> for n in range(5):
... squares.append(n ** 2)
[0, 1, 4, 9, 16]
Using list comprehensions can make this both shorter and more readable. As a list comprehension, the same code would look like this:
>>> [n ** 2 for n in range(5)]
[0, 1, 4, 9, 16]
List comprehensions also get an if statement:
>>> [n ** 2 for n in range(5) if n % 2 == 0]
[0, 4, 16]
For more info, see this pythonforbeginners.com post.
okay so
commands = ['command1', 'command2', 'command3']
hints = []
?
like
what is the alg to get the "hints"
So how you create single hint when you have commands and search_input?
alright..
commands = ['command1', 'command2', 'command3']
search_input = str(input("put your command"))
hint = ...
yeah
You already know that you can use .startswith
yeah but
startswith will give the whole command
if search_input.startswith(commands)
Nope, in different way
for command in commands:
if command.startswith(search_input):
...
!d str.startswith
str.startswith(prefix[, start[, end]])```
Return `True` if string starts with the *prefix*, otherwise return `False`. *prefix* can also be a tuple of prefixes to look for. With optional *start*, test string beginning at that position. With optional *end*, stop comparing string at that position.okay so
It checks whether string starts with given prefix
for a value in commands table, if the value startswith what the user inputted.
yeah its good
!e
string = "Hello world!"
print("starts with 'Hello'?", string.startswith("Hello"))
print("starts with 'hello'?", string.startswith("hello"))
print("starts with 'world'?", string.startswith("world"))
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
001 | starts with 'Hello'? True
002 | starts with 'hello'? False
003 | starts with 'world'? False
As you can see it's also case sensitive
yea
commands = ['reprot', 'call']
search_input = str(input('Enter a command: '))
for command in commands:
if command.startswith(search_input):
print(f'Did you mean {command}')
Got thqat
Got this
works fine
i meant report not reprot xD
Okay, can you make function that for given commands and search_input gives list of possible commands?
Like
commands = ["report", "call", "help"]
search_input = "re"
hints = your_nice_function(commands, search_input)
print(hints) # returns ["report"]
yeah
let me try
i made one
let me try
made it
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
print(possible_commands)
check(commands_list, search_input)
@trim fiber
['report']
Your function doesn't return anything
it does
!t return
Return Statement
When calling a function, you'll often want it to give you a value back. In order to do that, you must return it. The reason for this is because functions have their own scope. Any values defined within the function body are inaccessible outside of that function.
For more information about scope, see !tags scope
Consider the following function:
def square(n):
return n*n
If we wanted to store 5 squared in a variable called x, we could do that like so:
x = square(5). x would now equal 25.
Common Mistakes
>>> def square(n):
... n*n # calculates then throws away, returns None
...
>>> x = square(5)
>>> print(x)
None
>>> def square(n):
... print(n*n) # calculates and prints, then throws away and returns None
...
>>> x = square(5)
25
>>> print(x)
None
Things to note
• print() and return do not accomplish the same thing. print() will only print the value, it will not be accessible outside of the function afterwards.
• A function will return None if it ends without reaching an explicit return statement.
• When you want to print a value calculated in a function, instead of printing inside the function, it is often better to return the value and print the function call instead.
• Official documentation for return
!eval
commands_list = ['report', 'call', 'hello']
search_input = 're'
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
print(possible_commands)
check(commands_list, search_input)
@dusk anchor :white_check_mark: Your eval job has completed with return code 0.
['report']
see?
It's printing, not returning
!eval ```py
commands_list = ['report', 'call', 'hello']
search_input = 're'
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
print(possible_commands)
return possible_commands
check(commands_list, search_input)
!eval
commands_list = ['report', 'call', 'hello']
search_input = 're'
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
print(possible_commands)
return possible_commands
check(commands_list, search_input)
@dusk anchor :white_check_mark: Your eval job has completed with return code 0.
['report']
You have typo in indentation
commands_list = ['report', 'call', 'hello']
search_input = 're'
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
# print(possible_commands) <- this line is no needed
return possible_commands # <- this line had wrong indentation
check(commands_list, search_input)
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
return possible_commands
hints = check(commands_list, search_input)
print(hints)
now it works
in my ide it is fine
see that
@trim fiber
For commands = ["hello", "help"] it returns only one possible command, not every possible
hm
!e
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
return possible_commands
hints = check(["hello", "help"], "he")
print(hints)
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
['hello']
!e
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
return possible_commands
hints = check(["hello", "help"], "he")
print(hints)
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
['hello', 'help']
Like I said, indentation of return is wrong
okay
so i should use
def check(commands, search_input):
possible_commands = []
for command in commands:
if command.startswith(search_input):
possible_commands.append(command)
return possible_commands
hints = check(["hello", "help"], "he")
print(hints)
If you want to return all possible variants - yes
Do you ever find yourself writing something like this?
>>> squares = []
>>> for n in range(5):
... squares.append(n ** 2)
[0, 1, 4, 9, 16]
Using list comprehensions can make this both shorter and more readable. As a list comprehension, the same code would look like this:
>>> [n ** 2 for n in range(5)]
[0, 1, 4, 9, 16]
List comprehensions also get an if statement:
>>> [n ** 2 for n in range(5) if n % 2 == 0]
[0, 4, 16]
For more info, see this pythonforbeginners.com post.
afk
Like
nums = [0, 1, 2, 3, 4, 5, 6, 7]
evens = []
for num in nums:
if num % 2 == 0:
evens.append(num)
Shorter form
nums = [0, 1, 2, 3, 4, 5, 6, 7]
evens = [num for num in nums if num % 2 == 0]
okay
so
commands = ['command1', 'command2']
hints = [command for command in commands if command.startswith(search_input')
That's right
lmao it works
search_input = 'he'
commands = ['hello', 'help']
hints = [command for command in commands if command.startswith(search_input)]
print(hints)
Can someone explain binary search to me? I've been told to use it in my program but I don't understand it entirely, thanks.
So, let's say you have a sorted (non-decreasing) array of length n. Then, you can easilly see that If i and j are indexes of elements then if i > j then obviously array[i] >= array[j].
Now, let's get to binary search. You calculate the index of middle element and see If the number you are looking for is bigger than or equal to this middle element or not. If it is, It's obvious that you won't need to look through elements smaller than middle element. So now you calculate the index of middle element in that smaller subarray and so on untill you find the number you were looking for.
a = [1, 3, 6, 8, 10, 18]
def bin_search(a, num, l, r):
mid = (l+r)/2
if a[mid] == num:
return mid;
if a[mid] > num:
bin_search(a, num, mid, r)
else:
bin_search(a, num, l, mid)
bin_search(a, 3, 0, len(a)-1)
Unless I did some pretty stupid mistakes in this code xd it should work
You can also google How does binary search work and I'm sure you will find many good visualisations of it
What would be the fastest way to apply numpy.linalg.norm() to each value of an 2d array with a given value x?
command_input = ''
commands = ['report', 'call']
hints = [command for command in commands if command.startswith(command_input)]
print('Did you mean,',hints)
When i am using that ^^
I am getting the following output:
Did you mean, ['report', 'call']
How can i make my output to appear as:
Did you mean, report - call ?
@trim fiber
Have you seen str.join?
!d str.join
str.join(iterable)```
Return a string which is the concatenation of the strings in *iterable*. A [`TypeError`](https://docs.python.org/3/library/exceptions.html#TypeError "TypeError") will be raised if there are any non-string values in *iterable*, including [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") objects. The separator between elements is the string providing this method.!e
print("x".join(["a", "b", "c"]))
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
axbxc
!eval
command_input = ''
commands = ['report', 'call']
hints = [command for command in commands if command.startswith(command_input)]
print('Did you mean,',hints.join())
hm
It’s separator.join(hints)
so
like
print('Did you mean,',' - '.join(hints))
print('Did you mean,',' - '.join(hints))
!eval
command_input = ''
commands = ['report', 'call']
hints = [command for command in commands if command.startswith(command_input)]
print('Did you mean,',' - '.join(hints))
@dusk anchor :white_check_mark: Your eval job has completed with return code 0.
Did you mean, report - call
yeah
alright
hm okay now
i need some help on applying that
to my bot
let me try it first
is this code good?
from pycoingecko import CoinGeckoAPI
import webbrowser
# initializing the api
cg = CoinGeckoAPI()
# created a function to check for the price of STX
def check_price():
# give the api an id and a fiat currency
price_dict = cg.get_price(ids='blockstack', vs_currencies='usd')
# check price
price = price_dict['blockstack']['usd']
# if it's 3$ open a web browser window
if price == 3:
webbrowser.open("https://www.coingecko.com/en/coins/stacks")
else:
# else redo
check_price()
check_price()
What do you mean?
That code looks like it would give indentationerror
Also its not really ds/algo related
i think my code is formated
Few things:
Pass cg as an argument
You have recursive calls
i would like to know if this passes the clean code test
i think it looks bad
My fault then, I don’t see colors on mobile Curious
Please keep following the topic of the channel
A help channel maybe
thanks
Try posting it in cocurrencies
Or at a help channel
@trim fiber check #discord-bots
Easy
yeah i just dont remember
What is the real problem?
it runs for a few seconds and it blows up
for no reason
or i'm too stupid to know the issue
Blows up?
Did you get an exception?
I mean that I don't understand what is going on when you run the program and what do you expect
Because you have recursive calls as @trim fiber said
Its probably destroying your browser everytime you call it
i expect this, it asks the api for the current price of STX if the price is 3 dollars i want it to open a browser window, if it's not 3$ i want it to repeat itself
i fixed it
from pycoingecko import CoinGeckoAPI
import webbrowser
import time
# init api
cg = CoinGeckoAPI()
# a function to check for the price
def check_price():
price_dict = cg.get_price(ids='blockstack', vs_currencies='usd')
# getting the price in form of an int
price = price_dict['blockstack']['usd']
# keep doing this forever
while True:
# if the price is 3 usd
if price == 3:
# open a web browser with the provided link and break the loop
webbrowser.open("https://www.coingecko.com/en/coins/stacks")
break
# else show me where we're and wait a minute to redo the thing
else:
print("price is at", price)
print("--------------------")
time.sleep(60)
check_price()
basically
explained
That will only check the price once and keep the loop going forever if the first time isnt 3
Without checking again
Why not
while not price == 3:
print("price is at", price)
print("--------")
time.sleep(60)
price_dict = cg.get_price(...)
price = price_dict["blockstack"]["usd"]
webbrowser.open(...)
big bren
thanks man
i'm still a noob
Is it possible to have a pointer to the next index in the numpy array? I wonder if I can do something faster with ctypes than a regular index +=1;array[index] = something
Perhaps if you use a raw pointer to access the array. They are contiguous in memory, so you'd increment the pointer by the width of the dtype to get the next element.
No idea how to access numpy arrays using raw pointers, though.
Cython can do that.
given the tree 8 4 \ / 6 3 1 2 / \ 7 5. Starting at node 2, how would you traverse the path(s) 2 -> 4 -> 5 and 2 -> 1 -> 3 -> 6 -> 8 -> 7?
Hey! I'm not sure I understand the question. Are you simply looking to do a depth-first search of the tree, starting at 2?
So is there a way of knowing end of a string in python? so something similar to in C where we detect the null terminator:
while(string[i] != '\0')
{
}
Uhh, are you asking about some way of directly accessing the underlying representation of the string with ctypes?
Because if you mean just normal Python strings, they act like lists of their characters. You'll get an IndexError for trying to access after the end.
actually I can just len(string)
(so basically, Python strings are arrays of characters with known lengths, so there's no null terminator necessary)
Yeah, that's what happend
That was one of the strangest things I noticed about python, string are immutable
so if we have:
string = "abcdef"
we cant do:
string[0] = 'A'
But I think python isnt the only language where strings are immutable.
I believe one of the reasons is that this way you can safely use strings as keys of dicts
I often just do s = list(s) and then s = "".join(s) when I have to edit a string by char.
java has immutable strings
Actually that's a pretty good and valid point.
if strings were mutable by default, there'd have to also be a frozenstr class (like there's frozenset) and you'd have to cast any string you want to use as a key to that class
that wouldn't actually be that bad though
also, there would be many questions like
s = "hello"
res = []
cur = ""
for char in s:
cur += char
res.append(cur)
"Why am I getting the same string 5 times"?
as we are getting with lists currently 🙂
what language is that a joke about? Haskell?
there's frozenset for immutable so why not melted for mutable
otn a meltedstr
😔
...moltenstr?
don't melted and molten mean the same thnig but just different connotations
molten does sound better though 🤔
I've looked up how hashmaps work and for some reason the implementations I find use an array of buckets, with the hash being used to select an index in that array (which naturally has the disadvantage of requiring to preallocate all the buckets beforehand). Don't hashmaps usually use an approach like a prefix tree instead, where your hash decides a path along a binary tree to a bucket, which is a leaf?
i think most implementations will be very simplified for a school course. did you look at python's hashmap?
hmm, guess I should finally watch https://www.youtube.com/watch?v=p33CVV29OG8 lol

Abstract
Python's dictionaries are stunningly good. Over the years, many great ideas have combined together to produce the modern implementation in Python 3.6. This fun talk is given by Raymond Hettinger, the Python core developer responsible for the set implementation and who designed the compact-and-ordered dict implemented in CPython for Pyth...
ooh, that's a good one
I think the problem is that a hash table is the name for the array implementation I found
which naturally has the disadvantage of requiring to preallocate all the buckets beforehand
Why is that a disadvantage? Dynamic array elements are also preallocated, and that's the biggest advantage of a dynamic array - it's the thing that gives dynamic arrays amortized O(1) appends, as well as O(1) retrievals.
Don't hashmaps usually use an approach like a prefix tree instead, where your hash decides a path along a binary tree to a bucket, which is a leaf?
Not that I've ever heard of. You could use a trie to implement a mapping, but the end result wouldn't be a hashmap - it would have different average and worst case performance for most operations. Better worst case performance, worse average case performance.
not sure about worse average case. Searching a tree to get to the bucket is O(depth), but since the values of a hash function are fixed (or at least bounded) size, the depth is limited, so it's O(1).
hm - no, because you still have hash collisions to contend with. The worst case is still that every key you insert hashes to the same value, so the worst case is still O(n)
well, hash tables have a worst case of O(n), tries used to implement a hash map would have a worst case of O(n+m), where n is the number of elements in the hash table, and m is the length of the hash code.
That's still O(n) if the length of the hash is bounded. Basically, the advantage I'm thinking of is that having the buckets be leaves of a search tree results in there automatically being a bucket for each (encountered) value of the hash function, rather then some predefined number that must be then grown.
that would, in practice, be slower.
could someone point me to an article about implementing bloom filters? I don't want the code, I want to do it myself.
I prefer something close to pseudocode vs just a description
you're right that it would have the same asymptotic complexity, I suppose - but at the cost of a fixed overhead of 64 extra indirections per lookup even in the best case, compared to the 1 indirection for looking up an element from a traditional, array-based hash table.
can a bloom filter be used for pattern matching on strings? like it'll tell me if a string "might be" in a set but never confidently that it is?
so if the failure rate is 2%, there is a 98% chance that the string is actually in the set?
"pattern matching"? not really. Probabilistic lookups? yes.
i mean if i have 100 strings in the bloom filter, and then i have strings coming in one by one from a stream and i want to check each string from the stream as it comes in to check if it's in the set
i know there is a more optimal implementation called a "Cuckoo Filter"
I want to take more of a data structures approach to pattern matching. My other idea was to implement a concurrent aho-corasick algorithm but that's been done ad nauseum.
lol
also, we can't ignore the excellent space efficiency offered by a bloom filter
*assuming we accept a certain failure rate
right - both bloom filters and cuckoo filters answer the question "is this element a member of the set", and for both the answer is either "definitely not" or "maybe"
could you verify that my understanding of the math is correct? "Maybe" means 98% chance assuming a 2% failure rate?
there's no such thing a a "failure rate"... that's not really how it works at all. The more elements there are in the set, the more bits are set in the array, and the higher the rate of false positives going forward
that is, the failure rate changes as elements are inserted.
ah okay, i understand what you're saying. I see the formula now. how about I have multiple bloom filters that are pattern matched concurrently (asynchronously?) against incoming traffic? that would decrease the size of each bloom filter and increase the rate of success (probability that the maybe is actually a yes?)
i'm sorry if i'm not making sense but i can visualize it in my head
multiple bloom filters because the rate of false positives increases with n
by the way, thank you for listening and responding. i appreciate it.
you could split the elements across multiple bloom filters to decrease the false positive rate, but it's easier to just keep one bloom filter and increase the size of its bit array, to reduce the odds of collisions within it
oh, let me write that down!
thanks again, i'm going to go and study the data structure more thoroughly before i attempt an implementation.
hi, I would need some help solving a problem, in which i am given a set of vertices (places) and i need to return the shortest path (in terms of distance) connecting all vertices, now i've been told that it is similar to the travelling salesman problem, but the brute force approach would be inefficient, and in terms of heuristics to consider, I have been told to consider the euclidean tsp, but honestly i am not finding much about the euclidean version, I am not sure about what kinda implementation I would need to consider for the euclidean version. Any help would be appreciated regarding the euclidean and other heurestics that i can implement on a graph (i've implemented the edge weighted graph via adjacency lists)


it is similar to tsp, but you don't have to get back to the start point
I have a maybe weird question about sorting 
When you know the max size of the list and all the possible values of the numbers (or data) in it, couldn't you form a O(1) time sorting algorithm by making a huge lookup table for all possible permutations and their sorts that you calculate beforehand?
Requiring O(M^(N!)) space (I think?) where M is the range of values and N is max list size
no wait, just O(M^N) space
the time to create such a table would not be constant
and yeah, you could probably do that
hello, I'm just getting started with DSA, where would you guys suggest to practice DSA problems? There are so many of them leetcode, hackerrank, hackerearth, etc. It's overwhelming.
I'd try LeetCode and GeeksForGeeks
I wonder if anyone ever actually does for very specific use cases 
How do you fix this error when working with json in a for loop? RuntimeError: dictionary changed size during iteration
Is there anyone here,who currently working on python ?
Like an internship or job
Please dm me if u working on python
The problem is that just looking up the sorted order for a given list in that table will be O(n), not O(1).
You could do a hashmap. But memory requirements would quickly balloon to absurd levels.
calculating the hash of a list of n elements is still O(n)
Right, true.
import string
letters = string.ascii_letters
commands = ['hello', 'help']
command_input = str(input('Enter a command: '))
def check(commands, command_input):
possible_commands = []
if command_input in commands:
print('Command found')
else:
for command in commands:
if command.startswith(command_input):
possible_commands.append(command)
print(possible_commands)
check(commands, command_input)
This works fine. I just want to check if the user inputted like:
'hellou'
#Or
'helloasasgawrsav'
So it will return again the best possible match.
@trim fiber
should i use:
x = len(command_input)
if x - len(command) == len(command):
if x.content == command:
?
anyone know a good algorithm to find the prime number of a given number , without looping from 2 to n - 1 ??? like for finding the gcd we use euclid algo and for finding the prime number upto some n we use seive of eratos
anyone know a good algorithm ????
...the Sieve of Eratosthenes, which you mentioned?
you mean factorize?
363 → 3, 11, 11
or what
not factorize
check primality?
meaning ???
do you mean generate all primes smaller than n?
i don;t understand the question
i wawnt to find whether the given number is prime or not , but i dont want to use that O ( n ) algo where we loop through 2, n-1 and check if its divisible by that num
You just have to loop from 2 to sqrt(n)
This will drastically make the program faster
primality tests are 2 hard
Or more complicated, use miller-rabin primality test
this is to check whether the given num is prime or not right ?
Yes
whats this algorithm called
I'm not sure if there's a name
oh
correct me if i am wrong , so i have to loop from 2 , sqrt(n) and if it divisible by any of those num then its not a prime number
Yes
so
any help
@glossy breach ```
def prime(n):
isPrime = False
n = int(math.sqrt(n))
for i in range(2,n):
if n % i == 0 :
isPrime = True
break
return isPrime```
@soft totem can u help
yeh what is it ?
Here
you can like manually skip over certain numbers
def isprime(n):
if n == 2 or n == 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
k = 5
m = 2
r = n ** .5
while k < r:
if n % k == 0:
return False
k, m = k+m, 6-m
return True
you reused the n variable
oh yeh wawit , that was dumb of me
def prime(n):
isPrime = True
for i in range(2,int(math.sqrt(n))):
if n % i == 0 :
isPrime = False
break
return isPrime```you need to add +1 to that range end
you need to == 0
@soft totem
wait gonna check
ok
if user inputted like hellosssd then you want to check if the that inputted one has hello in it ???
and print that ?
yeah
Please, don't ping me every time when you need help
When I am able to help then I will respond
while choice =="yes":
import math
a = float(input("Enter Leading coefficient a"))
b = float(input("Enter the next coefficient b"))
c = float(input("Enter the constant c"))
if a==0:
print("Value of a should not be zero")
else:
D = b**2 - 4*a*c
if D>0:
R1=(-b+math.sqrt(D))/(2*a)
R2=(-b-math.sqrt(D))/(2*a)
print("Roots are Real and UnEqual")
print("Root 1 =",R1,"Root 2 =",R2)
elif D==0:
R1=(-b)/(2*a)
print("Roots are Real and Equal")
print("Root 1 =",R1,"Root 2 =",R1)
elif D<0:
R1=(-b+(math.sqrt(D))j/(2*a)
R2=(-b-(math.sqrt(D))j/(2*a)
print("Roots are Complex and Imaginary")
print("Root 1 =",R1,"Root 2 =",R2)
choice=input("Enter continue of not(yes/no)")
please tell me what should I do to get even output as complex numbers
lol , had some work ```
def check(cmdIp, commands):
for cmd in commands:
if cmd in cmdIp:
print(cmd)
commands = ['hello','help']
cmdIp = input('Command : ')
check(cmdIp, commands)
check if this solves your question
Oh, good point. But still O(n) is better than nlogn
I am getting error in the part after elif D<0:
ohh I am actually new here so where is that help channel ?
Can someone test my expectimax based game. I think I did a good job overall just wanted to get some feedback. I'll share the source code if you're actually down to review it too.
I hope this is the right chat, how can I print in a readable way this dictionary?
{'streams': [{'index': 0, 'codec_name': 'h264', 'codec_long_name': 'H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10', 'profile': 'Main', 'codec_type': 'video', 'codec_time_base': '1/48', 'codec_tag_string': 'avc1', 'width': 1080, 'height': 1080, 'coded_width': 1088, 'coded_height': 1088]}
No, not really the right channel. But to quickly answer, use pprint or json.dumps. If you have more questions about that, open a help channel #❓|how-to-get-help
Sorry about that, thank you very much for the answer!
--need help----
Hey i have a quadtree search algorithm using random/normal data and for some reason its going slower than my linear serarch
And YES I have my start timer for both query searchers starting just before the actual query (so for example quadtree creation is NOT being added to the timer)

okay i will try.
Hello John, I would say that it depend on your goal. Are you looking for the best solution (then "careful brute force" like dynamic programming is a good solution) or a good solution (then meta-heuristics like simulated annealing are pretty simple to code and gives good results)? As far as I understand your problem, I believe that Euclidean or not does not change many things.
Hello, Can you tell me what DSA stands for?
Data structures and algorithms
yeah it works
Data Structures - Algorithms
commands = ['hello', 'help']
command_input = str(input('Command: '))
def check(commands, command_input):
possible_commands = []
if command_input in commands:
return 'Command found'
else:
for command in commands:
if command.startswith(command_input):
possible_commands.append(command)
return possible_commands
if command in command_input:
possible_commands.append(command)
return possible_commands
print(check(commands, command_input))
Any review on that?
ima need help you guys. I wanted to run this https://github.com/CorentinJ/Real-Time-Voice-Cloning on Archlinux and I installed everything except for the datasets because i wanted to clone datasets of the voice for GlaDos. But when running the demo_toolbox.py its non functional and i get this error in the terminal: QBasicTimer::start: QBasicTimer can only be used with threads started with QThread
GitHub
Clone a voice in 5 seconds to generate arbitrary speech in real-time - CorentinJ/Real-Time-Voice-Cloning
this is what my interface looks like:

Hi there! I needed help with this question https://www.codewars.com/kata/539a0e4d85e3425cb0000a88/train/python
Codewars
Codewars is where developers achieve code mastery through challenge. Train on kata in the dojo and reach your highest potential.
I am not quite sure how to approach the problem
I can see the solution but I want to get a direction so I can try myself
guys i have one question , if i got some solved answers and have some actual correct answers , is there any formula to get the percentage of my solved answers accuracy ?? like f1 score , but that one for ml
the main issue here is that the result of add has to be a integer but also callable
now, how could one make a callable integer?
instance?
like instance of a class or any thing that can hold stuff i guess
structure
!e
class add:
def __init__(self, *args):
self.val = sum(args)
def __str__(self):
return str(self.val)
def __call__(self, other):
self.val += other
return self.val
def __add__(self, other):
return self.val + other
print(add(1,2,3))
print(add(1)(2))
print(add(1, 2)(3) + 6)
``` maybe?@spring jasper :white_check_mark: Your eval job has completed with return code 0.
001 | 6
002 | 3
003 | 12
I dont see how you'd implement this with partial functions
!e it's much easier to just subclass int ```py
class add(int):
def call(self, other):
return add(self + other)
assert add(1)(2)(3)(4) == 10
assert add(4) == 4```
@topaz pulsar :warning: Your eval job has completed with return code 0.
[No output]
Whats the algorithm that pathlib.Path uses to iterate over a file system and mapping out nodes recursively?
like if i want to learn about doing that, what do i search
the binary tree ones seem limited to only left and right
it's quite similar to binary trees, file systems are a tree-like structure just not a binary one, you can apply the same algorithms, just you may find the children nodes are stored in a different way ```py
class Node:
... def init(self, value, children=()):
... self.children = list(children)
... self.value = value
...
def iterate(root: Node):
... stack = [root]
... while stack:
... node = stack.pop(0)
... stack.extend(node.children)
... yield node.value
...
...
root = Node(6, (
... Node(5),
... Node(4, (Node(3), Node(2))),
... Node(1),
... ))
print(*iterate(root))
6 5 4 1 3 2``` is BFS for example
@lusty ivy ^
if you wanted to do recursive searches you can implement something like DFS on a similar structure, I don't know of any particular resources to learn about what pathlib does exactly but in general, for non binary trees, you can just slightly modify your existing implementation to deal with however you are storing the variable number of child nodes
Interesting.
Im confused by this a bit
>>> root = Node(6, (
... Node(5),
... Node(4, (Node(3), Node(2))),
... Node(1),
... ))
did you forget a close paren?
oh I get it
sort of haha. I gt everything up till that part
thats jut me creating a tree, the tree is structured 6 / | \ 5 4 1 / \ 3 2
what's a good data structure for context-free grammars?
like if we have a dictionary of different types of words (i.e. <noun> can be 5 different words, <verb> can be 10 different), but there's also types such as <phrase-type-one> which consists of "<verb> the <noun>"
how would we store that?
i was thinking a tree but that would seem inefficient if we needed to have both a path to <verb> that doesn't lead from <phrase-type-one> and one that does lead from that. would a graph work instead? maybe a hashtable with separate chaining?
thanks!
Hello, I'm just getting started with leetcode and this was the first problem presented to me related to arrays:
Given a binary array nums, return the maximum number of consecutive 1's in the array.
Example:
Input: nums = [1,1,0,1,1,1]
Output: 3
This was my solution at first :
def findMax(nums):
maxi = [0]
for i in range(len(nums)):
if nums[i]:
maxi[-1] += 1
elif nums[i]==0 and maxi[-1]:
maxi.append(0)
return max(maxi)
Although this code works & is efficient in terms of speed but in terms of space, it kinda sucks, because of the extra maxi array. So I gave it another shot, 2nd attempt (I wanted to reduce the space complexity, so I ditched the extra array and instead use just 2 variables):
def findMax( nums):
maxi = 0
current_maxi = 0
for i in range(len(nums)+1):
try:
if nums[i]:
current_maxi += 1
elif (nums[i]==0 and current_maxi>maxi):
maxi, current_maxi = current_maxi, 0
except IndexError:
if (current_maxi>maxi):
maxi, current_maxi = current_maxi, 0
return maxi
I've tested it out against so many custom test sets, but leetcode has some test cases on which it fails. This is a lot better than the 1st code in terms of speed and space, but where is it going wrong? can someone please help me know where this code goes wrong and is failing for some test cases?
@fading sky does something like this work?
def consecutive_counter(array):
return np.diff(np.where(np.concatenate(([array[0]], array[:-1] != array[1:], [1])))[0])[::2].max()
havent really tested this but might give you an idea
there are probably also some solutions with itertools
or can you not use external libraries im unfamiliar with leetcode
looking at the second function, what happens if nums[i] == 0 but current_maxi <= maxi?
I think this is where the issue lies
>>> findMax([1, 1, 1, 0, 1, 1, 0, 1, 1])
4```this is a case where currently your solution fails so it may be useful to use to help you fix iti have one doubt about performance, i have a pickle file(the img) with a lot of dicts in rows and i need these lines to do query of names and take the language, u guys think if i use the languages names('en', 'fr', 'ru', 'es'...) as columns it could be faster? cause i know this way of keys as columns could be easier
How i gonna use this file -> example:
someone will type Carrot Seeds, so he will look at the column check if there is any Carrot Seeds in the values and if it has so he will take the language else he will say he dont found and suggest closest values
so what u guys think its the fast way to do it? using dicts as rows in a dataframe or using the languages as columns and say for he look at all collumns? (i'm using pandas to read the file)

awesome, thankyou very much @topaz pulsar , but as you said when nums[i]==0 and current_maxi <= maxi, it isn't supposed to do anything because current_maxi <= maxi means that the current slice of 1s is not the longest chain of 1s, as there has already been a chain of 1s longer than the current one, which is what this condition current_maxi <= maxi generally means..?
well when you come across a 0 in the string of numbers, you want to setcurrent_maxi to 0 yes?, But looking at the line mentioned py elif (nums[i]==0 and current_maxi>maxi):will that always happen when a 0 is encountered in the list?
Ahhhhh, GOT IT.
wow
WOW
I wrote a pretty shitty code then ig.
Thanks a ton @topaz pulsar 🙌 . you're awesome 
hello I have a question, how would you get one element from a list that has 2 values per position?
ages_names = []
youngsters = []
names = []
for i in range(n):
name, age = map(str, input().strip().split())
names.append(name)
ages_names.append((int(age), name))
ages_names.sort()
for i in range(m):
youngsters.append(ages_names[i].)```I want to add only the names from the age_ names list
When you have tuple then you can just use index notation
elements = [(0, "a"), (1, "b")]
print(elements[0][1]) # prints "a"
output: 5 2 JamesLineberger 55 JeanetteMaurey 73 ChristieDangelo 29 HeatherTrew 78 LeolaSwift 30 [(29, 'ChristieDangelo'), (30, 'LeolaSwift'), (55, 'JamesLineberger'), (73, 'JeanetteMaurey'), (78, 'HeatherTrew')] [(29, 'ChristieDangelo'), (30, 'LeolaSwift')]
output that I want: ChristieDangelo LeolaSwift
Show your code with example data
my code: ```
n, m = map(int, input().strip().split())
ages_names = []
youngsters = []
names = []
for i in range(n):
name, age = map(str, input().strip().split())
names.append(name)
ages_names.append((int(age), name))
ages_names.sort()
for i in range(m):
youngsters.append(ages_names[i])
print(ages_names)
print(youngsters)```
input: 5 2 JamesLineberger 55 JeanetteMaurey 73 ChristieDangelo 29 HeatherTrew 78 LeolaSwift 30
You are not using index here
for i in range(m):
youngsters.append(ages_names[i])
Like I said, you can use index to get values from tuple
!e
abc = (0, 1, 2)
print(abc[0], abc[1], abc[2])
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
0 1 2
You should use ages_names[i][1]
that would give me only the name?
Try it 😉
It works?
of course it does
🎉
Your welcome!
legend x2
x4*
and now just to make yourself a god
how would I edit the output of the list
so that it doesn't have the brackets on the sides, and it's just the name with a space?
searched for it on google but didn't find it
What do you mean? Do you want to pretty print a list?
!d str.join
str.join(iterable)```
Return a string which is the concatenation of the strings in *iterable*. A [`TypeError`](https://docs.python.org/3/library/exceptions.html#TypeError "TypeError") will be raised if there are any non-string values in *iterable*, including [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") objects. The separator between elements is the string providing this method.!e
separator = "-,-"
collection = ["a", "b", "c", "d", "not so long", "I am very long element"]
print(separator.join(collection))
@trim fiber :white_check_mark: Your eval job has completed with return code 0.
a-,-b-,-c-,-d-,-not so long-,-I am very long element
For your case separator can be just " "
the knowledge some people has amazes me up to the point of fear
Sorry, an unexpected error occurred. Please let us know!
DiscordServerError: 500 Internal Server Error (error code: 0): 500: Internal Server Error
thanks :·3
Just few years of experience, keep learn and write code 🙂
oww, thank you, confidence boost included with the python code
another way you can do this (although this is probably more suited to when your elements aren't strings) is to use the sep kw arg of print, then you can unpack the list into print
>>> items = ["a", 123, True, ("my", "tuple")]
>>> print(*items)
a 123 True ('my', 'tuple')```(the standard value for `sep` is `" "`)I have a pandas dataframe with columns ['date', 'open', etc.]. How do i find the open on date "jan 01, 2019"?

Filter the dataframe by a predicate:
df[df["date"] == "jan 01, 2019"]
that'll give you a slice of the dataframe containing all rows the date of which is this. Hopefully, that'll be one row. You can then take the ["open"] column of that slice, and the first (and hopefully only) element of it by [0].

Wrong panda-related library; but sadly pandas has an unfun, not panda-related at all logo 😛

f
Hello Guys! I have a little problem on how to proceed.
I have a QTableWidget, when i double click on a cell I can modify things, but I really don't know how to get this action in the code in order to save the line or something. Do i need to "connect" somewhere ? Here is the relevant part of my code. Thank you very much for your time

class Ui_MainWindow(object):
def setupUi(self, MainWindow):
...
self.tableWidget = QtWidgets.QTableWidget(self.centralwidget)
self.tableWidget.setGeometry(QtCore.QRect(145, 51, 711, 501))
self.tableWidget.setObjectName("tableWidget")
self.tableWidget.setColumnCount(3)
self.tableWidget.setRowCount(0)
item = QtWidgets.QTableWidgetItem()
self.tableWidget.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
self.tableWidget.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
self.tableWidget.setHorizontalHeaderItem(2, item)
self.tableWidget.setColumnWidth(0,self.tableWidget.width()/3)
self.tableWidget.setColumnWidth(1,self.tableWidget.width()/3)
self.tableWidget.setColumnWidth(2,self.tableWidget.width()/3)
...
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
item = self.tableWidget.horizontalHeaderItem(0)
item.setText(_translate("MainWindow", "Ticker"))
item = self.tableWidget.horizontalHeaderItem(1)
item.setText(_translate("MainWindow", "Bottom"))
item = self.tableWidget.horizontalHeaderItem(2)
item.setText(_translate("MainWindow", "Top"))
def updateTable(self):
self.tableWidget.setRowCount(len(watchlist))
row = 0
for coin in watchlist:
self.tableWidget.setItem(row, 0, QtWidgets.QTableWidgetItem(coin.ticker))
self.tableWidget.setItem(row, 1, QtWidgets.QTableWidgetItem(str(coin.bottom)))
self.tableWidget.setItem(row, 2, QtWidgets.QTableWidgetItem(str(coin.top)))
row=row+1
Also, i believe i am in the right channel, I hesitated with user-interface
Is there an algorithm or pip module that could calculate how long execution of a program would take?
Or would doing end_time - start_time be the only way?
:incoming_envelope: :ok_hand: applied mute to @dire relic until 2021-04-19 23:46 (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
<@&831776746206265384>
👍
The builtin timeit, the somewhat nicer timerit package, but the most awesomest IMO are IPython's %time and %timeit line magic commands.
ok so let's say you wanted to create a progress bar for a program.
Then would you run the program and calculate the time using time or timeit and then hardcode that time to progress through the progress bar?
im doing an easy leetcode problem and i came up with a solution with O(n) but its saying time limit exceeded?
how do i know how low i need to make the time complexity and how to even reduce it?
No, one would not use the time at all, but rather use some other metric you can track.
Say, if your code is a finite loop, track what percent of iterations have been done.
Oh yeah I see what you mean. Let's say if we are making 1,000 api calls. We would calculate the time it takes to make 20 calls and the time we get multiply that by 50, which would give us the estimated time it will take to make all 1,000 api calls
And we could extend the same thought process if we are iterating though a list that has 50,000 elements.
pretty much.
Users mostly care about knowing what % is done
ETAs are infamously horribly inaccurate, so that's secondary 😅
ok that was helpful!! thanks a lot!
you don't, and it depends.
there could be a logarithmic or constant time solution
or linear time is the best you can do
but your constant is too high
or you're constantly hitting worst cases
etc.
i mean its just an easy so i feel like linear should work
show question and solution
uh i figured it out lol
had an infinite loop
anyone have resources to continue learnintg ds&a?
i can do easy array/list problems and a few mediums but i have no idea what to do with other data structures
hello
Check out the links pinned in this channel. I also recommend Khan Academy's algorithms course for an introduction to some of the theory.