#algos-and-data-structs
1 messages · Page 72 of 1
:incoming_envelope: :ok_hand: applied ban to @vivid magnet permanently.
what am i even looking at
map :3
Is there some general for DPLL-style algorithms? That is, a 3 step process of dealing with a multi-clause variable assignment problem where you
take any variables with trivial values, and substitute them into each clause, repeat until fixpoint
if possible, pick a value for a variable that will solve some clauses, without making any other clauses harder, repeat until impossible
make an arbitrary choice, repeat, if it was wrong, backtrack to here and make a different one
Like the engines behind logic programming languages like miniKanren or Prolog?
the traditional engines behind those don't work like this AFAIK (and those two also have rather different engines). Tho upon more programming I've realized that the algo I ended up with is fairly distinct from DPLL, so maybe there just aren't that many problem that can be solved DPLL-style algos.
So you want something in the area of answer set programming, but not DPLL?
the idea is that other problems could end up with roughly the same steps as DPLL, and whether this has a more general name
but it's very possible these other problems just don't really exist in sufficient amounts to be meaningful
It's pretty much how all hard search works. Maybe I can throw out some different ways of looking at it? Such as being domain reduction (propagation until fixpoint) plus backtracking search (splitting). Which is how a lot of old school AI search works.
"propagation + search"
So all of those are roughly DPLL-like.
So the general terms are/were just "AI" or "CSP." (lacking more narrow terms)
"branch and reduce algorithms"
helpful, ty
Hi
I wonder how JSON files look in memory.
For example this data:
[ list1 ]
│
├───► [ list2 ] ──► [ptr] ──► dictA {"A":1}
│ [ptr] ──► dictB {"B":2}
│
└───► [ list3 ] ──► [ptr] ──► dictC {"C":3}
[ptr] ──► dictD {"D":4}
As you can see the actual data are just dicts (A, B, C, D) that are structured in lists.
If I load the json file into ram, how will it look?
Maybe like this:
[[POINTERS]---------------------[dictA]--------[dictB]-----[dictC]------[dictD]------]
So new dicts: E, F ... can be added anywhere in ram and just be linked in the pointers?
And how does the json file actually look on disc?
Is it also just a number of pointers that keep track where the dicts are? Or is it just an ASCII dump?
JSON is a format that's written in "plain text" (i.e.: as unicode). It does not define a binary format.
json.load reads the text in the JSON file and turns it into ordinary Python objects (lists, dicts, numbers, strings, None) which do not get any special treatment
If you have a JSON file like test.json on disk, you can cat test.json (or open it with any text editor) to see what's inside
That is a really high level explaination.
I need it to be more low level.
Like how would that python object look like?
[ list1 ]
│
├───► [ list2 ] ──► [ptr] ──► dictA {"A":1}
│ [ptr] ──► dictB {"B":2}
│
└───► [ list3 ] ──► [ptr] ──► dictC {"C":3}
[ptr] ──► dictD {"D":4}
Like this?
I don’t think a json is a specific type of object
It’s just a string
If your parse it then it becomes normal things
No different than standard lists and dicts
Hi everyone
I began solving leetcode kind of problems lately, and I grow frustrated each time I am unable to figure the complete solution from start to finish, and always need some help somehow.
I am thinking my logic is not very well tuned yet. Is this normal and something I would outgrow? Or should I be worried that I always need some help?
How can I get better please? What's that thing you can tell me that would trigger a light bulb in my head? I'm concerned. 😪
A list is a struct that looks something like this ```c
struct list {
// generic object fields
size_t length;
size_t capacity;
PyObject* *items;
}
How do you think that good coding interview looks like? What comes to my mind is that candidate solve problem and can explain his thought process, if there is a time, that candidate explain differences (tradeoffs) between some other solutions
Having a good standard English speaking accent probably helps a lot
By standard I guess I mean consistent with the country where you’ll end up working
Good to hear that...because I have not thought about verbally explaining different concepts in English which is not my native language. So I will try to practice solving problems as I am doing it for interview, I will verbally explain my thought process to myself.

@livid bluff Here is my attempt https://paste.pythondiscord.com/Y7GQ
I get much fewer states that my program considers unique
basically the state I consider for uniqueness is the keys I have and the state of the graph
as I explore the graph I remove edges from the graphs that I have unlocked, and I keep track of the "frontier" of nodes that I can try to explore
it could make sense to instead reconnect the graph so that I connect things to start as I unlock new things
Hm, maybe it's because of how the path/state information is stored? My main question is why doesn't it output any of the alternate paths, the solution it outputs for 1-6 is ```
(start->bot1), (start->mid1), (mid1->mid2), (bot1->bot2), (bot2->bot3), (start->top1), (top1->top2), (bot3->end)
But the path my graph gives, translated into your graphs language, is ```
(start->top1), (start->bot1), (start->mid1), (mid1->mid2), (bot1->bot2), (bot2->bot3), (top1->top2), (bot3->end)
It's the same overall nodes, but in a different order, which should represent different intermediary states on the way to the solution. Does your representation consider them the same?
Also I did find an issue my 1-7 that reduced the node count to ~2K, I accidentally had made some doors into keys
I suspect there is a merge point
two paths converging to a single bottle-neck state, and continuing from there
in my case I don't consider both
Here's the graph with my path in blue and yours in yellow

could you do the nodes in common in some different color?
Also for the other colors, green at the left is start, red at the right is end, purple is dead end, pink is shared

interesting
idk if it's entirely unexpected
I really should change my code to actually construct the state graph
I was able to add a basic graph to it. Interestingly, it looks like there are also less dead ends. (Not including end) Mine has 12, while yours has 7

I've continued on with the levels, and so far all is good, so I guess 1-7 just has an abnormally large state space for whatever reason, since the rest of the levels have been more reasonable. This is 1-8, and something new and fun that I added, all blue nodes are ones that only lead to dead ends.

3-10 also looks to be one of those levels with giant state, though I suppose it makes sense from looking at the level. Still, 😅 ```
DiGraph with 841397 nodes and 4506460 edges
I'm still confused why you have so much larger state graphs than I do
Maybe the difference is in how I store the activated nodes, while you remove them from the graph? It’s also probably in whatever process removes alternate paths to the end, since there should be multiple valid solutions.
fwiw, I don't store the current node at all
you have it as part of your state, right?
Yes, but it doesn’t affect anything for these, since they are DAG. I also tested it on 1-7 and the node count is the same even if it’s set as not compare and not hash.
do you have any more state that gets hashed/compared than keys+activated nodes?
Nope
Oh wait, I misunderstood, I do store and hash the current node, I was thinking of last node
current node shouldn't matter
that could explain why you have so many states
here is 1-6 for me

numbers don't mean much, it's just the exploration order (I switched to a bfs for fun)
Brains on again, I was thinking about that last night, let me try
1-7 is a bit worse

With both set to non-hash-comp, I get 1315 nodes
while I get 315 🥴
Maybe it’s from dead ends? I store the full path all the way down to the dead end, so you also do that or do you stop one node earlier?
I don't store any paths at all as part of any state
I only store the path to be able to print it
this is insane

jesus
every day im reminded how lucky i was to major in cybersecurity and not compsci 🙏

do you have some sane labeling of actions for your nodes for 1-6?
I'm curious how it compares

Can you show that with 1-4?
I need to encode it, give me a sec...
I realized that making the current node not hash eq was causing issues where not all nodes would be added to the graph, but that only started on 1-4, so that should be easier to figure out where's the difference since it's a lot simpler than 1-6
oh fun, 1-4 has a multiedge
yo how do i play my code can somone ddms me how??

err, ignore the root node
I should add more information to the nodes, huh


here is a more sensible thing
wait, I have missed encoding something in my graph 
or I have some significant bug
just the normal dot layout of graphwiz

yeah ok, I messed up the 1-4 input, but I also must have some bug
oh nvm, I forgot to add an edge
yay

I also had a bug in how I was doing it, the hashes are important for me, since the activated nodes aren't included in the names by default. Adding that, I think we get almost the same thing?
the key pickup looks quite weird

you treat key pickup as a node?
Yes
I just pick up all the keys that can be reached immediately
I have the advantage of future knowledge, since I've played more of the game before, that will stop working in future levels :)
ignorance is bliss
I think that's also part of why you have less nodes, since you always pick up all keys you can't get some dead ends that come from picking up the keys in a different bad order
Also how do you get the node text to be multiline?
I am making a simulator for a game it has chat (kind've more of a log?) what structure should I keep the information in a string, a list of string elements?
or does it really not matter and I just vibe it?
keep structured data as much as you can
newlines 🙃
Hm, maybe it's something with networkx -> pygraphviz jank since they aren't working for me
I literally do the dumb thing and generate graphviz source code
https://paste.pythondiscord.com/JQ6A
numbering going from 1-10 and 1-A 
ok, the iwbtg platforming gets quite annoying 😛
I'd recommending going in the settings and turning on auto-run, as well as maybe full jumps
1-B hurts
Any way to visualise recursion
trees are useful
Hello 👋 ! Anyone got some good suggestions on books about parsers/lexers? I want to create a lexer in Python by implementing regular expressions and a parser generator (I've made some good progress on that: https://github.com/Maxcode123/syntactes). I've found this very interesting website https://swtch.com/~rsc/regexp/ by Russ Cox but I'd also like some book material.
Hi 👋! If you’re looking for books on lexers and parsers, here are some great resources:
1. Crafting Interpreters by Robert Nystrom – Hands-on guide to building a language, covers lexer and parser. Link
2. Mastering Python Regular Expressions by Félix López & Víctor Romero – Deep dive into regex in Python. Link
3. Compilers: Principles, Techniques, and Tools (Dragon Book) by Aho, Sethi, Lam, and Ullman – Classic compiler textbook, detailed on lexical analysis and parsing. Link
Also check out:
• Russ Cox’s article on regex – very insightful
• Writing your own lexer in Python – practical guide
These should give you both theory and practical examples for building your lexer and parser.
can someone explain linked lists. How creating a node works what is the array equivalent and why do i need to do so much more code to add something to a list and why is it even called a list when it isnt a list at all just a bunch of classes strung together?
Lets say you want to store multiple items in your program, like 3 different integers that represent student's grades in a student record system. These 3 integers need to exist somewhere in memory. You can think of all memory being one giant array of bytes. So now lets say each integer uses 8 bytes, you need to find places that are unused and dedicate those areas to those integers. There are multiple ways of doing this and they have their upsides and downsides. If for example you put all 3 of them next to each other one after another then if you have the address of the first one you can get the rest by adding an offset (base + 8 * index). This is known as an array, and its upside is that it's compact and fast to iterate over, everything is in one place. The downside is now you may have problems if you want to for example add another item to that array in the middle for example. How would you do that? You would have to do something like shift all the items to the right over by 8 bytes to make room, then insert it (slow) (same issue with removing an item). There can be other such downsides depending on how exactly the hardware works, but without getting into that there are tradeoffs with each option. So another option is linked lists. The idea being that the first integer is stored somewhere, but next to it is also stored an address that references another item (or nothing (null)). So we have these integers strung together by each one being packed together with a reference to the next integer in the list. This has the upside that each of these items can be in any order anywhere in memory, so if you want to add another item you could just put it anywhere in memory and update the references of the list (the previous item and the next item), no need to shift things around to make room. So now getting to Python, when you make an object from a class it's going to put it somewhere in memory (not in any particular order), and the object contains the integer and a reference to the next object (which holds the next integer).
Note that what Python calls a "list" is not a linked list. It's a dynamic array (dynamic meaning resizable quickly) of Python objects, specifically references to Python objects. So not to be confused with a "linked list" which is a general data structure term.
Python calls them lists because it's trying to be mathy (math's meaning of "list").
so when i create a linked list im just creating an object that is linked to the previous and next objects
Yeah, the "linked list" is referring to this collection of objects.
The data structure.
(How we store the data we are working with and access / modify it)
i appreciate the detail i never thought about it in terms of memory it makes the pointer stuff make alot more sense
Thanks for the resources!

Hi guys
im new here and new in python, i having trouble with visual studio, the python extensions are not working and i cant tell why
if someone can help me with this issue , it would be great
restart
the pc or the progam?
This is probably the wrong forum. However, you have not described your problem. How do you expect anyone to be able to help you?
program
Why not use Pycharm?
whats the difference in pycharm and vs code
Different software to run program
People like to use vscode because its easy UI to understand
And i dont use pycharm so i dont know
imo pycharm is really heavy and too much random features for hobbyists
ive used it in the past because its what proffesional people with a job use
its for managing huge projects
but for a hobbyist it has too much features for me
when i could just add those features as needed in vscode
Prob better to discuss this in #python-discussion
hello python community
i want to learn Data Structures and Algorithims using python and do leetcode for cracking job interviews. So are there any really good courses or youtbe vids that teach the concepts of DSA using python , I did try neetcode but it felt like a revision for a first timer like me. I also noticed that most of the resources in DSA are in c++ or java, but i dont want to learn a new lang just for DSA. A lot of people adviced me to just start doing the problems in leetcode , and learn things on the go , but i dont have that much time , so are there any really good resources to get the job done.
Check pins
Choose a topic, read about it (there's a python algo book) and solve questions based on that from lc
And use neetcode for revision
Or there's also a yt channel where he teaches it in python, it's called greg foster iirc
hi!
not sure if this is the best place for this
does leetcode have questions for python 101 style questions
like someone who barely knows how to code
no
hello
@upbeat vapor your message was removed for violating server rules 9 and 6
What is the best method to memories the structures?
Probably using them and getting hands on practice. For strictly memorizing what they are and how to use them, I've found that leet codes editorials and video solutions are pretty good if you have premium on it (I don't know if its available for free). I'm sure you can also find plenty of videos about them online and find your own use cases. That's how it is for me at least
Yes and no. It's kind of a tricky question to answer. There are questions on it that you can answer with some problem solving such as the Two Sum question. However, you do have to be relatively far into a 101 course as you need to know control flow and loops to pass it. Theoretically, if you know while, for, if, elif, else, and arrays, you could solve a question like Two Sum. It might not be the most elegant solution or fastest, but you should be able to pass it with some thinking and problem solving
wello horld("print")
Hands on, practice and keep constancy. Constancy is the key to memory anything, not only programming
Anyone knows how to implement algo logic on deriv d.bot?
Hey guys, I’m a mechatronics and robotics student!
So far i’ve been doing alot of hardware stuff but for a full stack robotics role, I need to have good ground in software.
I’ve been doing DSA with leetcode, but I’m confused how to approach it. Like I know a few algos but when i see a question idk what algorithm it even uses.
Please gimme an approach to this
Like do i learn all algorithms like two pointer, merge sort, quick sort etx first?
I’m so confused
DBot uses a visual programming interface based on Google Blockly for creating trading bots.
But I am not very good at that.
it's more about picking up key concepts than anything else
two pointers isn't a specific algorithm, but just the idea of having two pointers/indices going through something "concurrently" where things are moved as needed to maintain some property
merge/quick sort are pretty easy algorithms that just based on simple insights
- "sorting two sorted lists is easy"
- "partitioning a sequence wrt some pivot element is likely to split into something close to halves"
Ooh, thanks, you know someone who can help?
Not sure
I already have the bot, needing advancement..
Oh i lose my mind in recursion for quicksort lmao
Well, I’m following neetcode and picking up slowly some algos
I think its working
I was able to think ahead how to solve mediums level for hashes and array questions
a lot of the time for recursion like that: assume that the recursive call returns the correct thing, does the function then return the right thing?
Do u have any recommendation where i could learn more recursion?
Atp I’m just learning important algos and trying to be creative with them to answer questions. I think this works right?
Hm
I guess so, i think i need to spend more time on it and i’ll crack that too…
it can kinda become an inductive proof
What do you mean, I’m sorry i didn’t get you.
- the base case has some property (e.g. is sorted)
- assuming the recursive call returns something with that property, the function returns something with that property too
Hmmmm
Interesting
those two together actually proves the correctness of the whole thing
oh, I’ll have a look at our chats again when i get to recursion.
I really appreciate this btw
e.g. with some slight omission of details
def quick_sort(seq):
if len(seq) <= 1:
return seq
pivot = pick_pivot(seq)
smaller, equal, larger = partition(seq, pivot)
return quick_sort(smaller) + equal + quick_sort(larger)
def merge_sort(seq):
if len(seq) <= 1:
return seq
half1, half2 = halves(seq)
return merge(merge_sort(half1), merge_sort(half2))
Hm
when you try and give semantics to a recursive function, a natural way to do it is to define it as the least fixed point of some higher order function
so the natural way to reason about it is just via induction
Does anyone know if there is a module containing information of the Periodic Table?
Not sure where to ask this
fixed-point combinator?
yeah
same idea
I think there's some technical distinction since a fixed point combinator is like a literal function in the lambda calculus and if you want to do induction you need an object that lives in the semantic realm and not the actual realm but it's unimportant I think
hello
i have a problem
ive started this coures called: pythoncourse.eu
im on unit 13
and this is the problem i have:
from dataclasses import dataclass
import tkinter
from random import random
import sys
if sys.version_info.major == 3 and sys.version_info.minor >= 9:
listtype = list
else:
from typing import List
listtype = List
@dataclass
class Cell:
value: int
marked: bool = False
boardtype = listtype[listtype[Cell]]
board = list()
for i in range(10):
board.append(list())
for j in range(10):
board[-1].append(Cell((i+j) % 2))
def random_init(board:boardtype) -> None:
for i in range(len(board)):
for j in range(len(board[0])):
a = random()
board[i][j].marked = False
if a < 0.5:
board[i][j].value = 0
else:
board[i][j].value = 1
root = tkinter.Tk()
field = tkinter.Canvas(root, width=220,height=220)
field.pack()
next_button = tkinter.Button(root, text="Next Iteration", command=lambda : run_and_canvas(board, field))
next_button.pack()
init_button = tkinter.Button(root, text="New Initialization", command=lambda : random_init(board, field))
init_button.pack()
tkinter.mainloop()
def update_field(f: tkinter.Canvas) -> None:
for i in range(len(board)):
for j in range(len(board)):
if board[i][j].value == 1:
field.create_rectangle(i21, j21, i21 + 20,j21 + 20, fill='chartreuse2')
else:
field.create_rectangle(i21, j21, i21 + 20, j21+20, fill='brown4')
this is the code i have
and the problem is
run_and_canvas function
in problems it says its undefined
not ((5 > 2 and 3 == 3) or (not (4 > 6 or 1 == 1)))
false or true
I’ve got an issue with my program. Joined a few AI discord servers and nobody seems to be able to help. So hopefully someone here can.
I’ve ran into a bug in my program and there doesn’t seem to be anything that will fix it. Every piece of data I have looked over is correct. (750,000 data records) yet the AI chat bot gives me the incorrect answer every time.
I am the sole owner and only one working on this project
Assuming your records are 100% correct, the bug might come likely from the data quality (for e.g. bias or noise) or maybe the model itself, try to retrain on a tiny hand verified subset to see if the issue presists.
thanks for the advice. how do I improve the quality of the data? I have a spreadsheet everything was previously used for to tell everyone what to do at the clinic (urology).
about 75 sheets all in one workbook, loaded with short simple phrases for users. to quickly and figure it out on their own
you need to turn it into a Q&A format so the AI knows what problem each of your phrases is supposed to solve
how are you using these records to help your chatbot exactly? (and I'm assuming you mean llms)
I would like to ask you something to check whether I understood what you meant to say
So for a problem
Given the root of a binary tree and an integer targetSum, return true if the tree has a root-to-leaf path such that adding up all the values along the path equals targetSum.
This is code
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
targetSum -= root.val
if not root.left and not root.right:
return targetSum == 0
return self.hasPathSum(root.left, targetSum) or self.hasPathSum(root.right, targetSum)
assume that the recursive call returns the correct thing
does that relate to
if not root.left and not root.right:
return targetSum == 0
does the function then return the right thing?
does that relate to
return self.hasPathSum(root.left, targetSum) or self.hasPathSum(root.right, targetSum)
I meant, ignoring the base cases the main recursive logic is
hasPathSum(root, targetSum) = (
hasPathSum(root.left, targetSum - root.value)
or hasPathSum(root.right, targetSum - root.value)
)
```rather than expanding this further, analyze this assuming that the recursive calls return the correct resulti.e. there is a path sum with the target sum if either of the node's children has a path sum of target - node value
this thing checks out
this means that if the base cases are done correctly, the whole recursion will return the correct answer
the notable thing is that you have no reason to reason through multiple recursive calls here
a lot of the time for recursion like that: assume that the recursive call returns the correct thing, does the function then return the right thing
I wonder how does this makes you approach recursion problems differently, if it does.
I am basically wondering whether what you wrote here
a lot of the time for recursion like that: assume that the recursive call returns the correct thing, does the function then return the right thing
can help us to approach recursive problems differently? Basically to assume first that what recursive call(s) return is the right thing, to then see whether function will return right value?
Maybe I am overcomplicating everything, so sorry if that is a case
I guess your point is to check whether function will return the right value if we assume that correct thing is returned from recrusive calls
the point is that you don't need to reason through multiple levels of recursion
I think it is much more natural to do
def hasPathSum(node, target):
target -= node.value
children = [node.left, node.right]
children = [child for child in children if child is not None]
if not children:
return targetsum == 0
return any(hasPathSum(child, target) for child in children)
The code follows the definition. If node is a leaf, then check if target has been reached, otherwise recurse.
Using a children list is also much nicer if you want to do this on trees that are not binary trees
I also really prefer having 1 base case instead of multiple
Interesting way about solving that problem, thanks for sharing
..
I was using your approach for this problem https://leetcode.com/problems/insufficient-nodes-in-root-to-leaf-paths/description/
I tried to think about a case where there is a root and his two children...because of that approach, it was easier to check whether my approach for solution is correct
Hello everybody! I am new here and I need some code review on my Python code about A* algorithm implementation. It seems to work efficiently for test_number.py that composes numbers but not for test_expression.py that composes expressions 🙁 . My Python code is available on GitHub here : https://github.com/Julien-Livet/ai. The learn function at line 589 of brain.py is the goal. Thanks for your help!
Can you make a smaller reproducible example

Hey guys I am learning data structure and algorithms but I have one problem
Actually I have a lot. I need help please
Anyone know of an algorithm I would use to pair 1 to 1 (pairing 1 red point to 1 blue point) the closest points together with the total distance between points minimized? Or if you don't have a solution, whether this type of problem has a specific or generalized name, like "traveling salesmen problem".
Using simple logic I could get any of these pairings above, but want to return a list that would match the first pic (the one marked "Yes") since the distance between the paired points is minimized and equals ~6, ignoring the y axis, where as like the second pic the total distance between paired points is ~10 (ignoring the y axis). I only say ignoring the y axis since I didn't want to deal with sqrt in thew distances.



I have two lists of x/y coordinates, and want to pair an x/y point from list 1 to a point on list 2 so that the total distance between points is minimized.
If I were just trying to connect all points with the shortest total distance, I believe that would be the "traveling salesman problem" but since I'm trying to pair points and minimize the sum of the distance between the paired points, I'm not sure if that's a related problem or a totally different problem.
I figured some modified TSP algorithm, or even a modified sort, would work, but even if I brute forced it with like an exponential big O, Im not sure how I would check every combination of pairings to get the result I want.
Sorry for the double post, just needed to post pics to help give context

Computer Science Stack Exchange
Let's say there are two lists of objects, list1 and list2, and that there is a function that can generate the "distance" between an object in list1 and an object in list2. What I would like to do is
is this what you're looking for?
Sounds like that hungarian algo something
The Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time and which anticipated later primal–dual methods. It was developed and published in 1955 by Harold Kuhn, who gave it the name "Hungarian method" because the algorithm was largely based on the earlier works of two Hungarian mathem...
Maybe, I did some searches initially but had some issues phrasing my problem correctly so this may be it. I'll check it out.
I'll check this out too, thanks
there may be more efficient variants by considering the structure of euclidean space, but hungarian is a good start
If you have any suggestions on implementation, that'd be helpful as well if its not too much ttrouble.
The more complicated problem, that I hope will be a minor issue, is that some points on both lists need to match to multiple points on the other list, but I figure I should be able to solve that (at the very least) by duplicating those points on both lists. To clarify, most points are 1 to 1 from list a to list b but like some points on list a or b may need 3 matches from the opposite list.
this probably goes without saying, but whatever you end up doing, use square of distances rather than actual distance so you don't have to compute square roots, which are expensive
So "a^2 + b^2 = c^2" not "(a^2 + b^2)^(1/2)= c
right, ordering is preserved whether you square root or not
Yeah, I guess I didn't think about that fact that sqrt would add much computation time, but I guess I can always sqrt the final list if I want the actual distances as an output
Hey leetcode 75 or neetcode 250. Where should a beginner trying to solve dsa questions start with?
ping on reply
In the mathematical discipline of graph theory, a matching or independent edge set in an undirected graph is a set of edges without common vertices. In other words, a subset of the edges is a matching if each vertex appears in at most one edge of that matching. Finding a matching in a bipartite graph can be treated as a network flow problem.
oh, this was mentioned 😔
the problem with thinking of it as a maximum matching problem is that the graph ends up being very dense
(n/2)² weighted edges
I modified the heuristic function and modified the weight of new connections and test_expression.py go further, it blocks for last expression (z-y)*(-3.8). Any idea?
most hired for software job role in 2025? is it machine learning engineer?
I found a solution, now it works well for composing expression. Let's play with words 🙂 !
Hey, I’m new here. Can I learn Python to make a donation website to help people in Palestine?
Do you guys know any good YouTube videos for starting Python?
Wrong channel. #python-discussion is better channel.
Also u will need html css js for frontend web dev part of the project if its web app. U can use python for the backend.
U can even use react or any other frontend framework
U will need a db to store info.
How do u plan to advertise your app even if u make one?
How do u plan to make it scalable that many users can simultaneously use it.
I invite u to research a bit about it.
Since its a product, it will need some hosting fees too
Hi, I’m Francis 👋
Aspiring Data Engineer learning Python & SQL, currently building my first projects.
Excited to learn & connect 🚀
sup
hello guys
I'm trying to run this question in my pc
I copied the input list
But I don't know how to convert it into a Binary Tree
What kind of traversal is used here to represent that binary into such list form?
I tried Level order traversal, But it's still wrong
Can anybody tell me how to convert the input list in this leetcode question's examples into a Binary Tree?
https://leetcode.com/problems/binary-tree-inorder-traversal/description/
This is how I'm testing that question in my pc
Posting it here just in case
from __future__ import annotations
class TreeNode:
def __init__(self, val=0, left: 'TreeNode' | None=None, right: 'TreeNode' | None=None):
self.val = val
self.left = left
self.right = right
def __repr__(self):
return f'<TreeNode val={self.val} children=({getattr(self.left, 'val', '')}, {getattr(self.right, 'val', '')})>'
def list_to_binary_tree(lst: list[int]) -> TreeNode | None:
# How to parse it into a Binary Tree?
class Solution:
def inorderTraversal(self, root: TreeNode | None) -> list[int]:
def traverse(node):
if node is None:
return
yield from traverse(node.left)
yield node.val
yield from traverse(node.right)
return list(traverse(root))
s = Solution()
assert (v := s.inorderTraversal(list_to_binary_tree([1, None, 2, 3]))) == [1, 3, 2], v
assert (v := s.inorderTraversal(list_to_binary_tree([1, 2, 3, 4, 5, None, 8, None, None, 6, 7, 9]))) == [4, 2, 6, 5, 7, 1, 3, 9, 8], v
assert (v := s.inorderTraversal(list_to_binary_tree([]))) == [], v
assert (v := s.inorderTraversal(list_to_binary_tree([1]))) == [1], v
it's in the level name; in-order traversal
or in other words:
- travel through left subtree
- travel the current node
- travel through right subtree
I'm not asking how to solve the question
I'm asking how to parse the input list, so that it's transformed into a Binary Tree just like it's shown in the question's description
And I'm sure that that's not inorder traversal
The 1st example confuses me a lot
If the input list is level order traversal of the tree, then the input list will be [1, None, 2, None, None, 3]
But it's not
It's [1, None, 2, 3]

I'm guessing a bit, but it looks like some modified level order traversal, specifically, if in the previous level a node is null, then it omits its child that would also be nulls
for example here, the left child of 1 is missing. so where the list specifies the third level (beginning from index 3), 2 nulls are omitted and it begins immediately with 2's child
Did you actually open the leetcode problem link?
yeah?
ok
I'll try this weird modified level order traversal way
If any more queries, I'll come here later
Thanks for you help man!

I have no idea how to implement this
But I'll try
my first idea is keep track of previous_level_nodes = [ ... ] that are non-null nodes
then you know that at the current level, there should be len(previous_level_nodes) * 2 (or 1 less, e.g. in the first case), where each ith pair of these nodes is the 2 children of the ith node in the previous level
ok
I got it
I don't know if I can ask for code review here
But is there any room for improvement?
def list_to_binary_tree(lst: list[int]) -> TreeNode | None:
if not lst:
return None
length = len(lst)
i = 1
root = TreeNode(val=lst[0])
queue = deque([root])
assign_left = True
while i < length:
val = lst[i]
if assign_left:
if val is not None:
node = TreeNode(val)
queue[0].left = node
queue.append(node)
else:
if val is not None:
node = TreeNode(val)
queue[0].right = node
queue.append(node)
queue.popleft()
i += 1
assign_left = not assign_left
return root
node 1, no left node, node 2 on right, node 3 on left, (bunch of omitted nodes)
the "full" traversal of that tree would really look like
[1, None, 2, 3, None, None, None]
!e here is a recursive thing which might be interesting
from __future__ import annotations
from dataclasses import dataclass
@dataclass
class TreeNode:
val: int
left: TreeNode | None
right: TreeNode | None
lst = [1, None, 2, 3]
def list_to_tree(lst: list[int | None]) -> TreeNode | None:
def f(it) -> None:
v = next(it, None)
if v is None:
return None
return TreeNode(v, f(it), f(it))
it = iter(lst)
return f(it)
print(list_to_tree(lst))
:white_check_mark: Your 3.13 eval job has completed with return code 0.
TreeNode(val=1, left=None, right=TreeNode(val=2, left=TreeNode(val=3, left=None, right=None), right=None))
So I've been looking up the Hungarian algorithm to find the shortest distance pairs from two lists, but Im not sure how to make the either the cost matrix or Bipartite graph to run through the algorithm. Since my concern is distance and I have the x/y points on a flat plane, do I basically have to calculate the distance between all points in list A to all points in list B and that would be my cost matrix? So like comparing A1 to B1-Bn and same for A2-An, then outputting to a matrix? Based on that, my matrix wouldn't be square, which Im not sure is required.
Like this?
A1 | 15, 65, 75, 32, 93, ...
A2 | 50, 11, 32, 65, 5, ...
A3 | 95, 41, 6, 26, 46, ...
A4 | 26, 28, 54, 77, 10, ...
A5 | 13, 40, 58, 41, 58, ...
An | ..., ..., ..., ..., ..., ...```Take some inspiration from heaps. The children of a[i] are at a[2i+1] and a[2i+2]. So you can build recursively with a simple 2-liner:
def tree_from_list(lst, i=0):
if lst[i] is None: return None
return Tree(lst[i], tree_from_list(lst, 2i+1), tree_from_list(lst, 2i+2))
root = tree_from_list(lst)
Assumes your Tree constructor takes (val, left, right). This is probably the fastest way to build the tree, because you never visit (missing) children and descendants of a None leaf, so it's O(num_treenodes), rather than O(2^depth).
Prob not in this channel. Try #python-discussion
For this example: [1, 2, 3, 4, 5, None, 8, None, None, 6, 7, 9]
It does not produce the exact same tree as it's been mentioned in the problem description

Instead, it returns a tree like this

The input list is in a weird level order traveral order
This preorder traversal won't cut it
For this example: [1, None, 2, 3]
Your approach gives me this tree

Ah so sorry I misunderstood the input. I'll send you a corrected version later.
Try this one:
def tree_from_list(lst):
it = iter(lst)
root = Tree(next(it))
q = [root]
while q:
new_q = []
for tree in q:
if (val := next(it, default=None)) is not None:
tree.left = Tree(val)
new_q.append(tree.left)
if (val := next(it, default=None)) is not None:
tree.right = Tree(val)
new_q.append(tree.right)
q = new_q
return root
oh, I misread their format then
that's a disappointingly annoying format compared to a super simple dfs ordered one
it should be a bfs then, rather than a dfs
Well, it... makes a little bit of sense if you think about it. Info is presented top down. And no wasted space on empty descendants.
Just annoying to process.
can someone help me create a script
here's what gpt told me to do but i know nothing about anything

Amazing discussion seiners'
i didn't understand problems and concept that you discussed but as python learner, i can littel bit understand about dissociation really good collaboration with participants make communitys better than better what most of thought, my first day here but i spend 1 to 2 here in learning about traversal order and tree even these all terms are new to me .....
good luck , very very good team work you are doing
Any thoughts on this algorithm inplementation?
Regarding hungarian algorithm and setting up the data
Given a sorted list with duplicates thats similar to this
[2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 5, 5, 5]
and this
[2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5]
How do i find the last occurring index of an element (say x = 4) from this list?
And if such element doesn't exist, I want the last occurring index of the element in the list that's less than and close to x
I tried binary search, But I can't find the right logic for it
what about finding the index of the first element > x then subtract 1 to it?
what's the return value if all elements are greater than x
Reverse the list and find the index of the first item less than or equal to the target value. Then calculate what index that would have been in the original list.
If all the elements in the search space is greater than x, then the starting index of the search must be returned
so 0?
what does starting index of the search mean
It's a number that's guaranteed to be < x
Am I making it confusing?
so the first element is guaranteed to be less than or equal to x?
yep
I tried bisect_right to find the last occurring index of x
But I didn't think about the condition where it doesn't exist in the array
yo guys can you rate my pyast-extended
GitHub
Extended Python AST library with parsing, transformation, analysis, and visualization tools. - slimeyyummy/pyast
Does this really work?
Because this will return the last 2nd occurring index of x if it's duplicates exist
or atleast that's what I think
bisect_right(arr, x) returns the last index i such that all(elem <= x for elem in arr[:i])
so arr[i] (if it exists) satisfies arr[i] > x, and arr[i-1] satisfies arr[i-1] <= x
Python has bisect_left and bisect_right built in.
bisect_left(A,x) returns the smallest index i such that A.insert(i, x) leaves A sorted
bisect_right(A, x) returns the largest index i such that A.insert(i, x) leaves A sorted
For example
bisect_left([2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5], 3)
returns 7 (since index 7 is the first valid insert point of 3).
On the other hand
bisect_right([2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5], 3)
returns 13 (since index 13 is the last valid insert point of 3).
So to answer your question. You want to use bisect_right(A, x) - 1. If for some reason you don't want -1 to be a possible output, then you would need to do something like max(0, bisect_right(A, x) - 1). However, I think it is far more natural to just allow -1.
personally I prefer to write the binary search myself where I know immediately what my invariants are
you start with an invariant where l and r are on different sides from the False→True transition, and then you just maintain that invariant
l = ... # such that cond(l) is False
r = ... # such that cond(r) is True
while r - l > 1:
mid = (r + l)//2
if cond(mid):
r = mid
else:
l = mid
at the end l and r straddle the transition you're looking for
I was asking this for today's leetcode daily
You forgot to define mid
shush, minor detail
surely mid = random.randint(l, r)
maybe you could average a few of them
This problem as presented is impossible, (13 should be 135), but I was playing around with writing a brute force solver for it because of that, just as a quick python script. From an algorithmic perspective though I can't actually think of a clean way to structure the code, and was wondering if anyone would like to take a shot at it or suggest ideas. (I always like these puzzles and figured that someone else might)
Each number at the bottom can only be used once, but we can use multiple numbers in the box (eg 15 being 1, 5). Order of operations is actually just left right and top down, with no operator precedence.

I assume in this specific case every box gets one digit as to fill all boxes.
9 digits 8 boxes
Which is my entire issue, as I can't figure out how to handle that nicely
Do you have to use all digits?
Yes
I'd look at https://pypi.org/project/z3-solver/. It should be possible to pose the problem in a way z3 can crack.
Past that, I think I'd try to make the brute force happen per-digit. So for example number 5 is placed in box 2. Have digits that get placed in the same box go in a set order (e.g. most significant digit was the earliest assigned one), and make two decisions per step - which digit am I placing, and where to.

I don't know why z3 didn't cross my mind, I've used it quite a bit. Probably a little overkill though lol.
I think the other ideea is a good way to go about it
- You definitely need 8 digits in the 8 blanks, so start by holding one in reserve.
- Iterate through perms of 3 digits for the first equation (e.g. first row
(A + B) / C = 1).- If a perm satisfies the first row equation, proceed to next step.
- If not, check if sticking your "reserve digit" onto any of the numbers would make a valid equation.
- e.g. if you try
(6 + 2) / 8 = 1that's great and you can move on, but if you try(5 + 7) / 2 = 1, that doesn't work, but if you're holding1in reserve, you could use it to make(5 + 7) / 12 = 1.
- Now with a smaller set of digits available, move on to try the second equation etc. until solved.
- If no solution found which uses all digits, restart from step 1, this time holding a different digit in reserve.
I think a bunch of things are actually forced onto you
e.g. assuming 13 is indeed correct, you have a product that is 13 in that column
the only factorization of 13 is 1*13, and you can't put 13 in a single box, so 1 must go in the lower right corner
similarly 44 = 11*4 or 22*2
the latter is impossible as 22 is too large to be fit in a box or formed as 5+something
so in that column 4 goes at the bottom and 6 at the top
and with that we already have something impossible, bottom row is x + 4 + 1 = 15
x = 10
this is the kind of thing I'd expect z3 to implicitly figure out
it would
but squishy human brain also does job
do we have z3 here?
!e
import z3
:x: Your 3.13 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File [35m"/home/main.py"[0m, line [35m1[0m, in [35m<module>[0m
003 | import z3
004 | [1;35mModuleNotFoundError[0m: [35mNo module named 'z3'[0m
Hi guys, I'm having a problem and I don't want help with the code or how to complete this, but I want help on how to improve the way I think about solving it.
Like, imagine if you will : That you have a function that takes a list of nodes, each node has a string to be dissected and a string that represents the "Type".
What I'm trying to get is a list of new nodes that are separated by the following delimiter: A part of the string that has title.
I like this idea quite a bit, thanks
I said something along those lines at first, then deleted them. I think OP wants a way to programmatically figure it out. I don't think OP has a problem braining it out.
Yep, the puzzle is actually pretty easy to solve when you make it actually possible. I just got inspired to write a quick script when presented with the impossible one, and couldn't figure out how to make the code not horrifically bad
:/
Can you provide an example, and what exactly do you want us to tell you? I can suggest ideas on how to go about it, but I can't tell if that is what you want.
That's all I want. Ideas on how to go about it but like also : How I should be approaching problems I haven't solved before.
I keep having this issue with code: I run into something I'm not familiar with and I freeze.
Procrastination, dread, ask chatGPT, regret that I didn't try a little harder.
Trying to kill that loop.
Don't understand the requirement.
Hmmmm......
Could you give us a few example input outputs
Input examples node1 = (("Hello, welcome to titleofwebpage, "LINK"))
node2 = (("Eight handled sword divergent sila divine general mahoraga! Mahoraga's Pit", "LINK"))
node3 = (("This is Kendrick Lamar", "LINK")
Spotify
Spotify is a digital music service that gives you access to millions of songs.
list_of_nodes = [node1, node2, node3]
Output when using node 1 as an argument : [("Hello, welcome to", "TEXT") , (titleofwepbage, "LINK" ) ]
Output when using node 2 as an argument should be : [("Eight handled sword divergent sila divine general mahoraga!", "TEXT") , (Mahoraga's Pit", "LINK")) ]
Output when using node 3 would be [(("This is Kendrick Lamar!", "TEXT"), (Kendrick Lamar, "LINK")]
Output when using the list would be : [("Hello, welcome to", "TEXT") , (titleofwepbage, "LINK" ), ("Eight handled sword divergent sila divine general mahoraga!", "TEXT") , (Mahoraga's Pit", "LINK")), (("This is Kendrick Lamar!", "TEXT"), (Kendrick Lamar, "LINK") ]
When needing to handle complex string parsing like this, I would normally reach for regex. It would be quite annoying to do without it
Incidentally, that's the first thing I did.
Let me get my mac, one second.
So, this current function is called split_nodes_link, the purpose is to grab markdown links from big strings and separate them and text strings that are separate from them into "Nodes" and those nodes will be put on a list of nodes.
My function had to be able to grab from a list of nodes, in my head I was like : "Oh okay, iterate through a list I know how to do that."
Then I ran into the main problem : Now I'm iterating through the string of the node.
Now, I already have a function ready for yanking regex patterns of markdown links.
It returns a tuple based on the number of (Groups) in he regular expression (I hope I'm using that vocabulary correctly...)
In other words, the groundwork has been laid. Now I just have to extract each string from each node and put it onto a list using the function I already have.
Unfortunately, for me that's the hardest part. XD
The "groundwork" sounds like it may be a problem. I feel like it may be easier to just process this from the original strings.
Can you explain?
Feels like some other program / code put this stuff into nodes. But now you don't like the current nodes and want to tweak them. But to do that now you have to process the nodes.
I would prefer to work with the original strings, if that's possible.
Soooo~ the thing is : This is a part of a project.
I'm creating a Static Webpage generator.
The nodes are a requirement, because they are meant to be placed onto an HTML5 index document.
I already compromised by making the Text type you see next to the strings a pure string rather than an encapsulation. X.x;
Hi,
This is my system designing notes. if any one interested, pls let me know.
we can have a call & i will explain my understanding --> You can review it.
Thank you
https://app.eraser.io/workspace/PjiKjjzx3pkizG1j6VlP?origin=share

Created with Eraser
Are u able to access this link 🤔 ?
is there any algorighm that takes 3 points and tells if they are clockwise or counterclockwise even if 2 are vertical?
sign of the cross product?
!rule 6 @brisk compass Please don't advertise on this server.
If im putting together a cost matrix to feed into the hungarian algorithm to get the shorts distance between points, id just take the distances from everything in list a and to everything in list be and make a matrix out of it, right?
Like this: B1 B2 B3 B4 B5 Bn A1 | 15, 65, 75, 32, 93, ... A2 | 50, 11, 32, 65, 5, ... A3 | 95, 41, 6, 26, 46, ... A4 | 26, 28, 54, 77, 10, ... A5 | 13, 40, 58, 41, 58, ... An | ..., ..., ..., ..., ..., ...
Where is i have x/y coordinates for everything in list A and in list B, then id just do (Ax-Bx)^2+(Ay-By)^2 = cost
I ask because I wanted to deprioritize some of the items in list B, but couldn't just alter the x/y coordinates of them since the x/y coordinates of the item on list A were random. So what I tried to do was just add a static value to cost of those combinations of An to Bn, but I keep getting the same output pairs
Points in 2D space? You can use a modified version of convex hull for that. (convex hull itself is overkill for this)
I know the python fundamentals how to get started with DSA?

ig this causes a mini dos or ddos on your pc
Learn the basic data structures, after that open leetcode and do two sum
Bluescreens your pc
Want to prepare for technical coding interviews for software engineer in AI roles. Where do I start?
If it's big tech, they often use theae type of assessments: https://leetcode.com/
Hello,
I would like to know if anyone has read Grokking Algorithms by Aditya Bhargava and could recommend it or not. I struggle a lot with algorithms, especially in practice. I’m better at theory than practice, and I’d like to know if this book is intended for people who don’t understand the theory, or for those who have trouble coding and want to significantly improve their Python skills.
@remote wing just submitted the paper to siam journal of computing and it was accepted to arxiv uploaded on monday
now it can finally be read >:)
has anyone tried to find other perfect numbers with python?
6
28
496
8128
Oeis is your friend https://oeis.org/search?q=6%2C28%2C496&language=english&go=Search
Is there a way to beautify that a bit?
Cause, stuff like:
a(n) = 2^A133033(n) - 2^A090748(n)
/* or */
a(n) = A000668(n)*(A000668(n)+1)/2
/* or */
a(n) = A000217(A000668(n))
```is pretty annoying to navigateI think oeis is pretty wonderful for learning/searching for integer sequences
It is by far the best site for it
So, it seems to me that the information/entropy contained in a graph is related to its “treewidth”? Is that sane? Trying to finally really get this graph coloring tomfoolery.
But it seems to me a “line of dominoes” graph with a low treewidth always has lower entropy than one that is more wackily-connected?
Often the more "random" a graph is, the easier it is to solve problems for.
Graphs become "expanders" if constructed completely randomly.
There are many algorithms that require the graph to be an expander.
(I'm not sure what you are asking, but this is how I think about random graphs ^)
Hello
Anyone interested in solving this problem

Hi,
Just wrote a blog about hashing. Not much explanation, solved some problems with increasing complexity. Pls check out when you get sometime. Thanks

simple 🤔
anagrams
Write a function, anagrams, that takes in two strings as arguments.
The function should return a boolean indicating whether or not the strings are anagrams. Anagrams are strings that contain the same characters, but in any order.
def cal...
First paper is in preprint mid submission give it a read hopefully interesting https://arxiv.org/abs/2510.02727
arXiv.org
Recombining trinomial trees are a workhorse for modeling discrete-event systems in option pricing, logistics, and feedback control. Because each node stores a state-dependent quantity, a depth-$D$ tree naively yields $\mathcal{O}(3^{D})$ trajectories, making exhaustive enumeration infeasible. Under time-homogeneous dynamics, however, the graph e...
maybe you would like the stuff covered in
https://www.youtube.com/watch?v=FJJTYQYB1JQ
there is some C++ specific stuff (towards the end, iirc), but most of the interesting stuff is not
http://CppCon.org
Discussion & Comments: https://www.reddit.com/r/cpp/
Presentation Slides, PDFs, Source Code and other presenter materials are available at: https://github.com/CppCon/CppCon2019
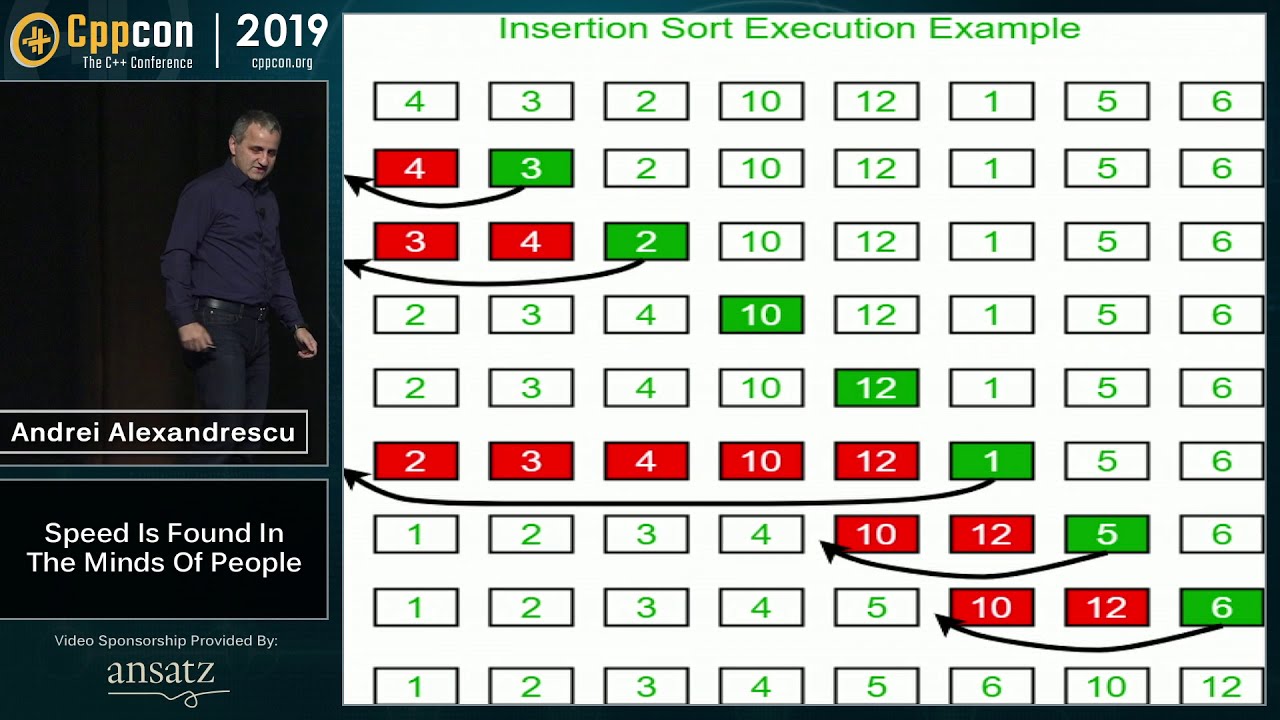
Sorting Algorithms: Speed Is Found In The Minds of People
In all likelihood, sorting is one of the most researched classes of algorithms. It is a fund...
Oh yeah this looks up my alley, thanks!
i feel u
im ready to learn some c
or rust
(JK IM A PYTHON MAIN)
dont do it to yourself
May I suggest brainfuck
May I suggest rule 110.
Malbolge is the right answer.
How is this code
class Solution:
def avoidFlood(self, rains: list[int]) -> list[int]:
lake_to_day_map = {}
cleanup_days = []
res = []
for day, lake in enumerate(rains):
if lake == 0:
res.append(1)
cleanup_days.append(day)
continue
if lake in lake_to_day_map:
if not cleanup_days:
return []
replacement_idx = bisect_left(cleanup_days, lake_to_day_map[lake] + 1)
try:
res[cleanup_days.pop(replacement_idx)] = lake
except IndexError:
return []
lake_to_day_map[lake] = day
res.append(-1)
return res
is slower, and uses more space than this below one?
class Solution:
def avoidFlood(self, rains: List[int]) -> List[int]:
h = {}
q = deque([])
res = []
for i, x in enumerate(rains):
if x:
if x in h:
for j in q:
if j > h[x]:
res[j] = x
q.remove(j)
break
else:
return []
res.append(-1)
h[x] = i
else:
res.append(1)
q.append(i)
return res
Ok, using a deque instead of a list dramatically reduces the execution time
I don't know why
Is deque really that good at removing elements from middle of the array?
Deque = linked list of circular arrays. But given that it is implemented in C, it'll be faster than any linked list class you can cook up in pure Python.
linked list of circular arrays
so its a circular linked list?
No... A linked list of circular arrays, each with size 64.
(I'm not sure if the linked list is itself circular)
(Don't think so though)
is it using circular arrays?
I assumed it was just using simple contiguous blocks
^
I assumed so as well at first, but was informed otherwise. Quite recently too.
My bad apparently it's not circular.
Tobey maguaire @atomic summit holy money.
Learn me to be better in python. I am just intermediate😢
Is anyone interested in giving this a look?
Looks like homework to me, maybe we shouldn't?
nah it's not homework
idk what to call it tbh
oh yeah it's the problem from the ICPC selection contest at my school
and it's the hardest problem
(no team out of 140 teams could solve it)
btw there are 11 more problems if anyone want to see the rest
i just wanted to share to see if anyone found it interesting
Aah, so it's a contest that's over? In which case that sounds fine to me to work on.
yes, no one solved this
though it's all undergraduate students
so it could just be us being dumb
Lemme look at it and see if anything pokes out at me
How hard is the icpc btw? In terms of leetcode / codeforces
U got a solution to it?
Because idk how u don't brute force it
My uni didnt release solutions, but it is definitely solvable, and I wanted to discuss it here
The actual ICPC is an internationa contest where each team is from a uni with 3 contestants each and you solve 12 problems in 5 hours, and it is really difficult, thought I don't know to what extent
My country has 2 selection stages first stage is each competing uni will do a selection test (my uni contest include the problem above) then roughly 30% of teams go to national and then top 10 go compete in the actual icpc
As for my uni selection test difficulty out of 12 problems
H F K D was somewhat
easy but require either certain specific math knowledge to solve or a decent level of logical reasoning
Then there was problems B G I J which were really hard (2 of which were bitwise problem I think)
The 4 remaining problems A C E L were so hard only top 3 teams could solve them
E being the problem I sent above with no solvers
A had exactly 2 teams who solved it
L also only had 2
C had like 3-4 I think
I don't know how to ranked them in terms of codeforces leetcode though
If you are interested here is all the problems too
!unmute @glacial tapir
:incoming_envelope: :ok_hand: pardoned infraction timeout for @glacial tapir.
Do I just send a Imgur?
OK wow this problem is actually hard
this is a Combinatorial Design Theory problem, something I know not much about
like, this is Skolem Sequences territory I think, and I've never learned those
A sequence of 2k numbers where every number from 1 to k appears exactly twice, and the pairs of the number j are exactly j positions apart!
Crazy stuff
I'm a freshman so this stuff is alien to me too
Yeah that's crazy
This is a giga-hard problem
How long did they give you to solve this?
Gnarly, reminds me of the Mu Alpha Theta math competitions we did in middle school
We never placed above 5th, so hard
I was the "crazy idea that might work" kid, not the super-grinder
There is like 3 more problems that like only 2 teams solved if you wanna look at those
I'm good, based on that one haha
but I guess the way you solve this is to do a 'Triangle Partition' solver that uses 'cyclic' and 'bose' constructions to then compare them and see if the result is true?
Gnarly though, for a freshman challenge
Not everyone is a freshman tho
Ah
I'm a freshman but there are year 3 year 4 undergrad






Some of the notable problems I mentioned
Not as hard the E problem I sent tho
Might be fun discussing these too
I dont get it, I think all students (~20 students) in my uni go do the icpc in the competitive programming course here
I'm not sure how other place does it but it is how it works in mine
The hell does "1 sec" help me
Why is there no TC on it
I mean I get it but it's unhelpful
Wdym
You go for a low TC solution to pass it
Yeah
If I brute force I get O(n³) for example and that's slow
So saying TC needs to be O(nlogn) or better makes it easier
@glacial tapir have u taken DSA yet?
No I'm a freshman, I only entered this icpc school selection for conduct score cause I'm still not good at coding
I think thats the point thơ they don't want brute force solution
You mean just for the experience?
Yeah it's my bad
Yes and entering the competition give me bonus conduct score which I don't know what is the equivalence terms in foreign schools
Well that's cool
Ty for sharing the questions mate
No problem
C is easy - summed area table.
Most of these are doable.
Your original problem is pretty difficult though.
What about A and L
Doable
Yeah I figured so but idk how hard they are, most team couldn't solve them
Well this Sunday there will be national version of this
Which will be even harder than these I think
I prob will share too
Reasoning about TCs is not always the easiest, I suppose.
Reasoning about TCs is not always the easiest, I suppose.
That’s how Codeforces gives its submissions reqs
I assume the bigger contests do that also since Codeforces does it but idk
hi,
This is an article about linked list. Please let me know your thoughts. Thanks
https://swaroopheidi.hashnode.dev/linked-list
The Good:
- Nice diagrams, visualizations, etc
- You cover some classic problems
- Shows both iterative and recursive approaches
The Less-So:
- class Node has a typo, should be
__init__(missing underscore) nextas a param shadows the built-innext(), I would suggestnext_node=None- The "Very very important take away" about mutability seems wrong to me, you're using an accumulator pattern, but integers in Python are immutable, so that isn't working the way you think, I don't believe
- I would mention that because Python doesn't do tail-call optimization, there are stack limits to recursion you need to be careful with.
re: the accumulator thing, something like this might be better?
def sum_list(head):
if head is None:
return 0
return head.val + sum_list(head.next_node)
Hi,
Thank you very much for patiently reviewing.. 🤝
I will update the article.
Always glad to see people trying to explain CS to folks!
def sum_list_helper(head, sum):
# base case
if head is None:
return 0
# recursive step
sum = head.val + sum_list_helper(head.next, sum)
return sum
def sum_list(head):
sum = 0
return sum_list_helper(head, sum)
Assuming your sum_list_helper is called from sum_list, the value of sum in recursive calls will always be 0 (since you aren't modifying it before the recursive call). So this kinda defeats the purpose of having an accumulator.
Here is a version which uses the accumulator correctly:
def sum_list(head, sum = 0):
if head is None:
return sum
return sum_list(head.next, sum + head.value)
Hey.. thank you for bringing to notice. Will correct.
Even your improved take isn't really "halting due to the accumulator" though, right?
wdym "halting due to the accumulator"?
Lemme see if I can remember the right terminology here, I'm rusty
In your revised code, the halting condition is if head is None. Recursion stops because the linked list has been exhausted. The value stored within the accumulator (sum) has no relation to when we stop. The accumulator is just the value that's returned when the structure runs out.
I'm not saying you are wrong, just that that particular example terminates due to list structure, not accumulator state.
In comparison, if you had...
def sum_capped(head, sum = 0):
# Halt on accumulation
if sum > 50:
return 50
# Halt on structure
if head is None:
return sum
# ...or recurse
return sum_capped(head.next_node, sum + head.value)
(not saying you should write this, just showing an example that has both halting cases)
It's nitpicky, but it just occurred to me after reading the original blog post etc
The value stored within the accumulator (sum) has no relation to when we stop. The accumulator is just the value that's returned when the structure runs out.
Yes that's correct... I've never heard of any requirement for the accumulator to be part of the halting condition.
It's not a requirement, no, I just thought the OP might want to show two different recursive halting styles etc
It was mainly the way the blog phrased the intro to the code that made me think it could use a brighter flashlight aimed at it, not that it's special to do one vs the other
I've been paying more attention to 'data vs. topology' recently, which I guess is why it stood out a bit.
I think the "typical 2 styles" are the non-tail-recursive one (which you wrote) and the TR one which I wrote.
Yeah
That's the more interesting "dimension" I guess, vs. conditions
I actually don't love recursion that much anymore because of the "load-bearing branch condition" thing.
Dataflow is my new jam
(It's often a super badass and concise way to say something, not saying it isn't)
I just don't love it on real-world computer hardware
I still love it though. Unfortunately Python doesn't love it as much.
It would be hyper-rad to someday have a hardware architecture that was "great" at it, rather than just "good"
Something that knew how to first-class specialize "recursion conditions" in some better way, not sure what that would look like.
Maybe a dataflow scoreboard scheduler kind of deal, not sure.
Haskell 😂
I mean, just making it TCO would be a great start.
I remember reading that that won't happen though.
Haha yeah, but just to be clear, I mean "something" as in hardware not the language.
Haskell is exquisite but then it has to cram its ideas into x86/Arm
Hey I has some more problems
you wanna judge them?



just these two
This one seems fun! Probably the easier one to do (for me).
why is the polygon one so hard
Because I'm bad at geometry. I don't know if all number of diagonals (from n-3 to n(n-3)/2), are possible
Oh wow I just cheated and looked up how to solve this, and it is so beautiful.
||
- If
k < n-3, print No, otherwise Yes - We need
k - (n-3)"extra diagonals" - Place the starting vertex way up and to the right, like
(-100000, 100000) - We need our vertexes, starting at
v1, to be able to see "extra diagonals" number of other vertices, in other words, themselves. - So we place
v1throughv{1+extra_diagonals+2}on a parabola, like(i, i*i) - The rest of the vertices go on a line that aims sharply down from the last point on the parabola.
- This is the "tail" or "flat" part in my analogy below, and doesn't add any more new diagonals.
- We never have to move the "starting vertex" because it divides the world into two groups: diagonals involving that peak, and ones that don't. Putting it way off and up is a hack that prevents the "collinearity" the problem mentions.
By adding the "extra diagonals", I guess we are making the base of the shape convex.
The hack here is making a "crown" or "comb" shape, with a "toothy" part and a "flat" part, it seems to me?
Maybe that's not a great analogy, I'm just re-framing what I found online in my own understanding.
||
The above is a little out of my depth geometry-wise still so maybe I got some of that wrong, glad to be corrected.

||
The number of vertices in the convex group isn't equal to the number of extra diagonals, but PRODUCES that number.
For 1 extra diagonal, we need a convex group of 3 vertices.
For 2 extra diagonals, we need a convex group of 4 vertices.
For 5 extra diagonals, we need a convex group of 5 vertices. (Coincidence!)
For 9 extra diagonals, we need a convex group of 6 vertices.
||
(I don't really understand intuitively the 'progression of vertices' in the above spoiler, yet, but there's probably something interesting there.)
Oh I guess it's a combinatorics problem.
||m(m - 3)/2 "extra" diagonals||
I guess it's always Graph Theory in the end, isn't it.
Hi,
regarding the below problem, i tested the code with multiple test cases & all passed. can you pls a bit elaborate on whats wrong with the code?
def sum_list_helper(head, sum):
# base case
if head is None:
return 0
# recursive step
sum = head.val + sum_list_helper(head.next, sum)
return sum
def sum_list(head):
sum = 0
return sum_list_helper(head, sum)
I wouldn't say anything wrong with the code there (other than personally preferring names that aren't next because that's a built-in function)
It was the explanation OF the code you had that I had a problem with, if I remember correctly
here is the explanation
Very very important take away:
From the above problems named linked list values & sum list, there is one very very important take away.
That is the concept of mutable & immutable. In linked list values problem, you are not returning the modified list value to the parent call when recursion is happening. Did you observed that? The reason is; in this case the object which is passed to function as parameter is list(mutable).
But, in case of sum list problem, you must return the value to the parent call. The reason being, the object which is passed as the parameter to the function is int which is immutable. To say in another way, object is not passed as pass by reference, instead an copy of the object is passed.
Is that what you always had there? I'd have to go back to the PDF I saved
yes. i saw your message yesterday, but did not had time to correct it.
just now once again read what you said here & trying to correct the article if there is any mistake.
OK. Let me try to explain it better.
The problem is in this line:
sum = head.val + sum_list_helper(head.next, sum)
The input parameter, sum, is being ignored.
The code immediately reassigns over it
You say the return value is necessary because the integer parameter is immutable, but in fact it's actually redundant in your implementation.
Here's a version that is purely "structural recursion", like your description implies
def sum_list(head):
if head is None:
return 0
return head.val + sum_list(head.next)
Lemme see if I can say that another way for clarity.. hmm.
Aha, maybe if I show the "other way" that your code was mixing with the above "structural recursion"...
def sum_list_acc(head, current_sum=0):
if head is None:
# Base case returns final total, we've processed it all
return current_sum
# ..or we're not done, and update the total before the recursive call
new_total = current_sum + head.val
return sum_list_acc(head.next, new_total)
The notable difference is the 1 arg vs. 2 arg thing
I think in Python's implementation, there's not a massive difference between the two, but there can be in other languages.
Maybe someone else can take another swing at it if I failed there.
@rare bobcat ok see your point. this code which i striked out is not needed.

There is no need of 2 fns also.
& in the code you showed me:
def sum_list(head):
if head is None:
return 0
return head.val + sum_list(head.next)
when base case is hit, thats where the sum calculation starts with initial value of 0
Thanks for clear explanation..
No problem, and your take above, red Xs, etc, seems spot-on to me. You got it.
If you use two functions like this where one is only supposed to be used in the other I actually recommend style-wise to make use of Python's ability to have local functions within other functions.
def foo():
def bar():
print('hello')
bar()
This is personal preference OR any advantage is there in terms of O(n) / Space complexity etc ?
Preference. It communicates the purpose of the function.
This is commonly done in functional programming languages (local tiny helper functions).
In languages without this you often to need prefix with underscore or something to prevent polluting the global namespace and to prevent the user from using a function they are not suppose to. Although other languages have other ways of preventing this issue.
Hi,
Next up, I am planning to
Work on patterns & categorizing common problems falling into certain patterns, for example sliding window.
Please provide any impotant points you want to say here. For example you can share any good reference material.
IMO the most important “pattern”, in the sense I call “tactical patterns” (vs “design patterns”), is what Kent Beck named “Composed Method”.
It’s so simple but it is strikingly powerful when you use it tastefully.
There are probably good writeups online but the basic idea is “when writing a function, everything it does should try to be at the same level of abstraction. If that needs to change, break it up into two things and give the new thing a good name”
Some people read it and are like “lol tiny functions ruin performance”, but that’s not what it is saying. It isn’t saying to abandon pragmatism
Oh that's a good way to put it.
Hi,
This is recursion article with more explanation, pictures & segregation of each problem for easy reading etc.
https://swaroopheidi.hashnode.dev/recursion
Anyone here doing DSA in python?
tower of hanoi solver in python. had way more fun writing the visualizer than the actual algorithm lol
Cool!
I ran into that problem as a kid reading "1, 2, 3, ... Infinity" by George Gamow, so neat.
yes, math is pretty 👀
Hey, all. I'm trying to figure out the right place to post this question before I just start dumping code. I'm working on a class project that involves re-implementing an algorithm from an existing paper, and I absolutely cannot re-create their results on what should be a basic A* algorithm (the paper describes an experimental variation on A* that I'm also implementing, but i have to get the basic working correctly first). Where can i post my code and results to see if I've messed up somewhere, or if there's something up with the original paper?
Ooh what's doing the displaying?
Have you written an A* before?
Hello, could someone recommend an excellent book that combines theory that’s very easy to understand, a bit like Grokking Algorithms, and lots of examples that were useful to you or that you find interesting?
I’m especially looking for something that covers topics like trees, backtracking, graphs, hashing, and sorting.
Rich library on pypi. Single handedly the best library for any terminal related art/aesthetic display for the modern retro obsessed developer
Not before now, no. My current attempt is based on the pseudocode on Wikipedia. I would like someone to look over my algorithm and tell me if I'm missing something important. Can I do that here, or should I go to the general help channel?
Sure, either paste it here, or open a help thread
Let me know if I need to move this. It's kind of a lot. The only thing specified in the paper I'm trying to recreate is that h(n) is euclidean distance from n to the goal. The grayscale drawing is their results, and the colored one is mine. Literally the only thing I can do to get it closer to theirs is multiply h by 0 < α < 1, but that's not allowed

Click here to see this code in our pastebin.
woops. forgot this sorry

Was there a specified order in which you should iterate over the neighbours?
I don't see anything wrong with your A*
All they specified was the h that was used. No search order. I can post the paper, if I need to.
I don't either. I almost feel like their "cloud" is artificially inflated somehow
Did they specify that insertion order should be used to tiebreak?
Nope
oh then why are you using it to tiebreak
Should I not have a tiebreak?
no, why should you
okay
That did not change anything
Just making sure, I just needed to change return (self.f, self.seq, self.g) < (other.f, other.seq, other.g) to return (self.f) < (other.f), yes?
Well...to check if that would fix it, anyway. There's a lot I can get rid of if there's no tiebreaker. Either way, this is what I got from that change

it looks a bit suspicious that you don't end up exploring further to the right after the start
What do you mean? The path is going from right to left
oh
if it's right to left their thing makes like no sense
especially this area

That's what I thought
Here's what happens if I make it go left to right with no tie-breaker

So that's not the answer. Yes, I agree that there's no reason it should continue into that middle space. I have no idea what they did to make that happen
btw, do you have the paper to share?
I can't find a link for the paper that's not behind a paywall, and I can't post a pdf.
Here's the link
https://ieeexplore.ieee.org/document/9563354
wait. I got it
is that it? the images look quite different
(or I found a different paper with the same name)



There are many with very similar names
The author is Bo Wang
That's it. There are multiple algorithms described in the paper
That description in B. is so confusing
Yes it is. I've had so much trouble trying to work out what's going in, and you write it exactly as described, it totally breaks it
I don't know. This feels like a really rough translation
it does, my knee-jerk reaction is distrust just based on how that thing is described
the first grid just looks like an incorrect A* implementation
So, i think I'm just gong to get rid of the tie-breaker, since it doesn't do anything, and then proceed with the assumption that the paper is bad
so I implemented a quick A* not following any reference, it sure looks similar
##############################
# #
# xxxxxxxxxxx #
# xxxxxxxxxxxxxxx#
# xxxxxxx#xxxxxxxx#
# xxxxxxxx#xxxxxxxx#
# xxxxxxxxx#xxxxxxxx#
# xxxx#######xxxxxxxx#
# xxxxxx #xxxxxxxx#
# xxxxxx #xxxxxxxx#
# xxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxxx #xxxxxxxx#
# xxxxxxxxxx #xxxxxxxx#
# xxxxxxxxxx #xxxxxxxx#
#######xxx#x #xxxxxxxx#
# xxxxx# #xxxxxxxx#
# xxxxxx# #xxxxxxxx#
# xxxxx # #xxxxxxxx#
#######x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
#x # #xxxxxxxx#
#E # #xxxxxxxS#
##############################
I think the implementation in the paper is just straight up wrong, unless there is something more going on
and I'm guessing no code is available from the author
in fact...the second graph in the paper looks much closer to what one would expect from just regular A*
That's what I thought!
yeah, I wouldn't trust this paper
Alright, cool. Thanks so much for your help
Btw, important question: What is the cost of moving diagonally?
Is it also 1, or is it sqrt2?
-# nvm sorta figured out it should be sqrt2
Did you use sqrt2 as the cost of diagonal movement?
If you used 1, that would go a long way towards explaining the differences.
I still don't trust the paper, but we did manage to make their screening step work by adding a constant to G
That's... not answering the question...
Isn’t it cool that something as hard to grip as sqrt(2) arises naturally from the unit square? Math is wild
What's the question?
What is the cost of moving diagonally?
Sqrt(2)
Anyway I'm trying my hand at this A*. Let you know the results in a bit.
Okay
##############################
# #
# xxxxxxxxxxx #
# xxxxxxxxxxxxxxx#
# xxxxxxx#xxxxxxxx#
# xxxxxxxx#xxxxxxxx#
# xxxxxxxxx#xxxxxxxx#
# xxxx#######xxxxxxxx#
# xxxxxx #xxxxxxxx#
# xxxxxx #xxxxxxxx#
# xxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxx #xxxxxxxx#
# xxxxxxxxx #xxxxxxxx#
# xxxxxxxxxx #xxxxxxxx#
# xxxxxxxxxx #xxxxxxxx#
#######xxx#x #xxxxxxxx#
# xxxxx# #xxxxxxxx#
# xxxxxx# #xxxxxxxx#
# xxxxx # #xxxxxxxx#
#######x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
# x # #xxxxxxxx#
#x # #xxxxxxxx#
#E # #xxxxxxxS#
##############################
Ok seems I got exactly the same thing.
Comes from Euclidean distance (sqrt of sum of square differences). Which comes from wanting a distance that does not depend on the absolute positions of the start and end point (only relative to each other), is invariant under rotation (same in all directions), and if you scale it it scales linearly. All three of those things are implicitly chosen when you decide to draw two points and claim that the distance between them is the length of the shortest line between them. Euclidean distance is the only formulation that satisfies all three properties (and why the right triangle theorem involves the squares of the sides (which are rational (length -> area causes the leap to irrational)) and not some other shape).
A lot of older math is making a lot of implicit choices / rules and then getting surprised by the results of those rules (since they were not exactly aware of those choices made (at the lowest level) and their implications).
Then the 1800s happened (realized all these implicit rules) and now math is explicitly aware of these choices (and proofs become much less loose / hand waiving).
And yeah, it's really cool how complicated stuff comes from simple rules.
yes
Cool way to put it, thanks!

int a = 42;
accepts_int(
a//-b*-1
);
``` LGTMa and b could be floats
luckily the C++ compiler doesn't read comments 🙂
Btw this actually computes something interesting
Hint: it's not ||floored division||
Hello guys can someone help me understand linear hashing : )
I found some online resources but I don't really understand the topic
ceil?
linear probing?

{kind=link}
it's in an hour
hey so I was referred to this channel - I'm trying to understand A* search, and am having trouble determining exactly how h(n) is supposed to be implemented and what it actually is. I get that it's related to dijkstras in the sense that it uses h(n) to "guess" the direction it should go as opposed to just checking everything, but I can't figure out exactly how that's supposed to be implemented. I have a working implementation of dijkstras' here https://dpaste.com/H3KXQM3ZV and i'm under the assumption that I can just modify this to get a working A* search. the dataset is a weighted, undirected graph representing a train network, and the weights correspond to distances in km, i can give other info if needed
the thing about the heuristic function is that as long as it follows a few rules (i.e. doesn't overestimate cost) the actual implementation isn't set in stone
and tweaking it can be very important to change the behaviour of your algorithm
a very simple heuristic could just be Euclidean distance
If h(n) = 0, then A* reduces to dijkstra.
someone correct me if i'm wrong but isn't euclidean distance in this context just looking at the weights of the edges adjacent to a node? and then picking the smallest one?
No it's usually distance to a particular goal coordinate.
i've never taken a DSA course before, this is my first time handling this sort of thing
so i'd just measure ahead of whatever vertex i'm visiting, all the way to the goal?
Instead of using cost as the sort key for your heap, you use (cost + estimated remaining cost to goal) as the sort key. That's all there is to it.
this video might help with the intuition
ok both of those help, thanks a bunch.
so for euclidean distance, wouldn't that mean I'd need to give my vertices some kind of arbitrary "coordinates"? i.e map them onto a 2d plane somehow?
nvm I think I just figured it out
oh my god I think i did it. they're both returning the same (correct) path
it really was that simple lol
Hi, I am currently just beginning to learn data structures and algorithms and I wanted to ask if there is any good reccomended sources to help learn about them. I love textbooks/books but if there is a better way via videos or a website etc. Anything would help.
Im also looking to get better at problem solving and identifying patters within algorithms
one big thing to remember, the estimate you are using for the distance remaining to the goal must be an underestimate for things to be correct
i.e. if you give estimates that are larger than the actual distance, you can get incorrect results
this makes A* not applicable in a lot of cases where there isn't any useful estimate like that
nitpick: "must be an underestimate" -> "must not be an overestimate"
right <= the actual distance
Why not build them in like , Java
thanks, i'll keep that in mind. i've given my vertices coordinates and i'm just using math.dist() for euclidean distance
Hi,
Pls check out my binary tree article & let me know any comments. Thank you
https://swaroopheidi.hashnode.dev/binary-tree
is it possible for A* search to fail, i.e not get the most optimal path?
ok so i've been timing the runtime of my stuff with timeit https://justpaste.it/aa5l9 and i've noticed that a* is slower than dijkstras. isn't it supposed to be faster? is my graph too small, or is there a problem with the way i've implemented it?
I'm not sure that your PriorityQueue's update_priority is working correctly.
as a matter of fact i'm not even calling it in the search
i kinda just copy-pasted some of the code from the heapq page of the python docs
if your heuristic is invalid, yes
it's not
Graph seems to only be able to be iterated over once.
idk why it's even iterable
i wanted to be able to do 'for g in graph' and get the vertices
yup, oversight on my part
i realize now i can do it one line
if you can go from dijkstra's to a* by adding a heuristic, can you go from dijkstra's to uniform-cost search by only visiting nodes with the shortest distance? the more I read about these algorithms the more I get confused.
afaik uniform-cost is the exact same idea as Dijkstra's algorithm, that you process things in the order of the minimum distance you've seen
I personally end up calling what others call uniform cost search just Dijkstra as well, or something similar to that
I think the difference is about what is being computed, UCS is the shortest path from start to some goal, Dijkstra's is finding all shortest paths from the start to any node
but yeah, I don't really like the UCS name and haven't used it. To me it's basically just a variant of Dijkstra's algorithm
sooo confusing. yeah, even wikipedia just redirects "uniform-cost search" to a section in the article for dijkstra's algorithm
ah yeah, the wiki just notes it as an optimization to the original formulation, which sounds about right
The name "uniform cost search" (UCS) originates from the field of artificial intelligence, where it was coined to describe a search algorithm that is fundamentally a variant of Dijkstra's algorithm. While Edsger W. Dijkstra developed the core algorithm in 1956, the term "uniform cost search" emerged later within the AI community to specifically denote its application in finding the least-cost path from a starting node to a goal node in a state space graph.
dammit, always these AI people 😔
UCS is just dijkstra's with early termination when you've found the goal node. So it's literally these two differences:
- an extra conditional to test for whether the current node is the goal node.
- returning only the shortest cost to goal node, rather than the shortest-path-tree.
Yea, this also means UCS can deal with unreasonably large or infinite graphs
(well, in practice it doesn't really matter)
note that there's also nothing stopping you from adding a heuristic to UCS either
like Fenix I also just tend to call UCS a variant of dijkstra, in fact the variant i usually implement myself
the main difference with dijkstra as it's usually written is that with dijkstra, when you're at a node, you update distances of that node's neighbours through that node, whereas with UCS the only time you set a node's distance is when you first process it, and you leave all the min path stuff to the priority queue.
as others have said, your update priority isn't working correctly
but usually you don't even need to implement update priority
especially if you're doing UCS
if you're doing dijkstra then maybe because it's a bit weird there
but with UCS you can comfortably just add nodes multiple times with different prios, and just don't revisit nodes so only the highest prio (lowest cost) entry gets processed
they do, but it isn't necessary at least for UCS
It isn't necessary for either. But both will benefit.
and also iirc benchmarks have also shown that updating might not even be more performant than shoving more nodes onto the queue
They're the same algorithm.
They benefit for sure. Assuming the graph is dense enough
Because your heap will have fewer elements.
have you done benchmarks? because I'm just quoting benchmarks that I remember seeing
Inserting into a smaller heap = savings. Also, not having repeat elements to dequeue.
i would've thought so as well, but apparently not
No but Sedgewick says so and I trust Sedgewick
The biggest issue is probably just writing a performant modifiable heap.
yeah
I have one in JS, didn't translate it to Python.
i don't disagree that it would make sense for update priority to be better
i just don't have the stats to justify that, and implementing it in python is not really fair since python is slower compared to C and you'd have to manually implement decrease key in python
If you dig them up I don't mind looking through them.
i would have sent them if I remembered what they were
It's fair if everything is in Python
So no heapq
well even then a heap implemented in python would be slower than in C
and since the difference between the two is basically just "how quick can I do heap operations" doing it in a slower language wouldn't necessarily be indicative of performance in a faster one
like if in C a heap operation takes one unit of time whereas in python it takes two units (very oversimplified), then the algorithm that does more heap operations is going to feel that impact more
when in practice, if heapq did have a decrease key operation in C, you wouldn't have that impact
i suppose none of this really matters because heapq doesn't offer decrease key
ah found it
cited by wikipedia
These alternatives can use entirely array-based priority queues without decrease-key functionality, which have been found to achieve even faster computing times in practice. However, the difference in performance was found to be narrower for denser graphs.
I’m feeling that struggled mindset where I feel overwhelmed by the amount of problems and applications a simple algorithm variant like “two pointers” or a search and I can’t recognize when to use what and what to do. It’s so weird, never really struggled like this before. Anyone have any advice?
that's fairly normal, you'll start to get a feel for what things work the more practice you do
Probably cache locality issue. I hate it when cache messes with algorithms.
yeah i'm working on the update fix already. i'm still kinda wrapping my head around all these algorithms and was actually starting to think the update step might not even be necessary
so i ripped out the whole update step altogether and i'm getting
djikstra runtime (100000 iterations): 3.2861306999693625
a* (euclidean) runtime (100000 iterations): 3.856626500026323
a* (manhattan) runtime (100000 iterations): 3.7173139000078663
is this one of those cases where my graph isn't big enough to show significant differences between dijkstra and a*? a* is slower, but only by like ~0.5 sec
is it wrong to characterize dijkstra's as being a breadth-first search that keeps track of the distances between the nodes?
usually you do it the other way around
breadth first search is dijkstra where all edges have the same weight
i guess if you have positive integer weights, you can view dijkstra as a breadth first search where you change an edge of weight n into n-1 nodes connected by edges of weight 1
hii boys this year i have to graduate and for the tesine i wanna do a DOM ( depht of market ) like a sierra chart idk if someone know this but i wanna ask some books to do this, i need to generate random order
something like that, if anyone have some tip or anything else i appreciate that

can someone help me optimize this code :)
def most_friends(request_accepted: pd.DataFrame) -> pd.DataFrame:
request_accepted = request_accepted[~(request_accepted['accept_date'].isna())]
request_sent = request_accepted.groupby('requester_id').agg({'accepter_id':list})
request_recieved = request_accepted.groupby('accepter_id').agg({'requester_id':list})
users = pd.DataFrame({'user_id':pd.concat([request_accepted['requester_id'],request_accepted['accepter_id']],ignore_index=True).drop_duplicates()})
request_sent['total_sent'] = request_sent['accepter_id'].apply(lambda x: len(x))
request_recieved['total_recieved'] = request_recieved['requester_id'].apply(lambda x: len(x))
users = users.rename(columns={'user_id':'requester_id'}).merge(
request_sent['total_sent'],
on='requester_id',
how='left'
)
users = users.rename(columns={'requester_id':'accepter_id'}).merge(
request_recieved['total_recieved'],
on='accepter_id',
how='left'
).rename(columns={'accepter_id':'id'}).fillna(0)
users['num'] = users['total_sent'] + users['total_recieved']
return users.set_index('id').drop(columns=['total_sent','total_recieved']).dropna(subset=['num']).nlargest(1,columns='num').reset_index()def isAnagram(s, t):
if len(s) == len(t):
cFreqs = {}
for c in s:
cFreqs[c] = s.count(c) ## +
for c in t:
if cFreqs[c] != 0:
cFreqs[c] -= t.count(c) ## -
for c in cFreqs:
if cFreqs[c] != 0:
return 0
return 1
return 0 ## not an anagram
apologies if I'm in the wrong place but why does this fail 2 test cases :?
Is it due to inefficiency (which it is) or am I missing something else
Resolved:
Needed an additional check that c was in dictionary
- indent error with return 1
This is criminally inefficient, btw
you're iterating n times over an n-length string.
touching n^2 number of letters
Very aware haha, I quickly realised the 2nd loop isnt even needed
def isAnagram(s, t):
if len(s) == len(t):
cFreqs = {}
for c in s:
cFreqs[c] = s.count(c) ## +
cFreqs[c] -= t.count(c) ## -
for c in cFreqs:
if cFreqs[c] != 0:
return 0
return 1
return 0 ## not an anagram
Do you know about collections.Counter?
Im not sure how much waste comes from computing the count each letter (even when previously done) costs
would doing something like an if c in cFreqs ... skip do much
or would I be better manually incrementing the dict each time
nope :/
The waste comes from examining each letter n times.
E.g. "Hello". You iterate 5 times.
- c == "H". You look at every character once, counting how many are "H".
- c == "e". You look at every character once, counting how many are "e".
Etc.
When you are done, each of the 5 characters will be examined 5 times, for a total of 25 examines.
If your string is 1000 characters long, that's 1000000 examines, when you could get the job done in 1000 examines.
ah i see so under the hood of count() it's doing a 1 by 1 comparison, youch
if it's str.count() there's definitely optimizations to avoid that
Try this:
# for short strings
def is_anagram(s, t):
return sorted(s) == sorted(t)
# for very long strings
from collections import Counter
def is_anagram(s, t):
return Counter(s) == Counter(t)
why are you incrementing/decrementing by .count(c) for every letter?
you could just do
for c in s:
# increment for c by 1
for c in t:
# decrement for c by 1
so I'd like to test my graph/dijkstra's implementation on a larger dataset but can't find a good dataset. any recommendations? i've tried looking up 'graph' and 'road network' on kaggle and nothing seems to be relevant. i just need a simple weighted, undirected graph but don't know enough about this field to know what data to look for
What about generating your own?
You could probably build a graph based on some OSM data, but that's probably a project in itself
i'm worried that i might mess the graph up and end up testing against a bad graph
i was hoping to have something authoritative, preferably with a known shortest path(s)
bad in what sense?
Normal data structure lecture

That graph is quite small though
Yeah most likely dijkstra without a heap and bellman-ford pass but if they just wanna test correctness that's a start I guess
https://codeforces.com/contest/938/problem/D here is a good dijkstra problem that requires a decent implementation to not TLE. It is the problem that made me realise my dijkstra was suboptimal.

Codeforces
i'm just trying to cover my bases here I'd just be more comfortable if I didn't have to worry that my answer might be invalid because I did something wrong generating the graph
Hello,
First I don't know if I am on the right channel, don't hesitate to tell me if I am not.
I am recently trying to develop my own app in python (basically a sort of app for my own discipline, for now there are 4 features:
- a games blocker depending on my calendar (if I have things to do I can not start playing league of legends)
- a wallpaper changer depending on the weather that it is in my town and wether I am studying or not
- a game tracker (it tracks how long I actively play games)
- a calendar that enters my times of study and sleep (and allows both wallpaper and games blocker to take it into account)
The infrastructure is as shown in the picture :
1)Blocker/Main_Blocker.py
2)Wallpaper/Smart_Wallpaper.py
3)Data/Game_Time_Tracker/Main_Time_Tracker.py
4)Calendar/Calendar_api or Calendar_Gui
I want to convert all of thoose individually into a .exe (at least for now) and I try using pyinstaller in each folder.
I faced one problem:
The blocker needs to access the datas out of his folder from Calendar/Calendar_storage.json but when I convert it into an .exe it takes them once in memory but don't adapt to changes (it does when I execute the .py)
Do you guys have any idea on how can I convert it?

ps: again tell me if it's not the right channel
perhaps creating a post in #1035199133436354600 would actually be the best, thats where the most people will see it
ooh thank u (new to the server, i'm gonna do it rn)
@onyx root Let’s get some terminology straight at the beginning. The Big-O characterization of some code will look like “O( blah blah N blah )”. The N in there is the size of your data. The O stands for “Order of,” as in, “The code’s run time grows on the order of blah blah N blah.” The blah blah is an expression using N, like O(N) or O(N2).
Although O(N) looks like calling a function named O, this isn’t a function call. It’s just a notation about N.
Here I'm confused about evrything except what is N
N is the size of your data.
let's say you want to sort a list of names. N is the length of the list.
I mean I get only what is N .
To be clear. For example f(n) = O(n^2) means the value of f is upper bounded by some constant times n^2. In other words, f(n) <= c*n^2 for some constant c.
It's describes an upper bound.
Well I kinda get confused evrytime I when get into algorithm complexity .
Don't we all.
😮💨
@onyx root
moms = [
("Ned", "Eleanor"),
("Max", "Susan"),
("Susan", "Shelly"), ...
]
def find_mom(moms, child):
"""Find the mom of `child`."""
for child_name, mom_name in moms:
if child == child_name:
return mom_name
return None
Here can u explain the n over 2 .
For loop > unpacks tuple, assigns mom , asigns child = 3
Then it compares = 1
Returns mom = 1
N/2 is you'll go through half the data?
What if match is in last entry so it's not n/2 . I don't get it . Not good at math .
in my opinion, "upper bound" doesn't help with day-to-day big O discussions
i meant that if you did this search many times, on average you would look through half the elements. Sometimes you would find it in the first element, sometimes in the last element.
sometimes it will be somewhere in the middle.
@onyx root was my question wrong ? I'm sorry I kinda confused
Hey I have a question about running an algorithm off a database . I have a process that reads rows from a pandas dataframe and processes them in a FIFO manner via a queue, the process needs to loop over each row in order to make a descision on wether it goes into the queue, or not (meaning marked with a status). I am doing this in a dataframe but thinking i could make such operations I/O bound by querying for a single database row in a FIFO manner?
if the found entry is last, yes, it will be 3N operations. What if the entry is first?
3 steps for 1 move
ok, now imagine that you run this code many many times, and the item you are looking for could be anywhere in the list. What is the expected average number of operations per execution?
3N/2?
yes. does that clear it up?
hello guys i am sorry if i am not on the right channel, does anyone have any books for python (i use visual code studio i just started my journey)
this is defo not the right channel
Anyone familiar with the specifics of numpy's sort algo? In my own testing, it seems numpy is able to sort a list of float64s faster than any c++ sort library I can find. (I've tested most of the sorts available in the boost library, and obviously the standard library).
My benchmark I'm running is to generate 10^6 random float64s and just run the sort algo. On my machine, numpy sort is around 7ms while c++ bottoms out at about 20ms. I can't tell if I'm doing something wrong or if the people who wrote the numpy sort are just goated.
#python-discussion is the right channel
They r goated but this is not correct Python is a c++ wrapper their is overhead so it is impossible for optimized sort in c++ to be longer vs optimized python sort computationally so yes you did something wrong
Could you try it yourself then? I've done everything I can think and even reached out to a few other people to do so, and they both confirm my general timing. It's unclear how this can be true, but then, the results are right there.
that's just false
for all we know numpy could have specialized stuff for numerical input that C++ doesn't do
Hey,
Pls check my new article. Thx
https://swaroopheidi.hashnode.dev/two-pointer
It's a nice short article. For your next one, why don't you try writing something original and interesting, that the internet isn't full of already?

I meant might-as-well-be-copypasta. It could be original. But even if it is original, it's not adding anything new, other than being mercifully short.
You u said that's just false with the utmost confidence and are completely wrong. Pythons numpy is bult on C and there are ways to make conversion to raw primitives low but you cannot negate conversion times if you asymptotically stress test an algorithm. His algorithm is without question poorly tuned and poorly written in the context of highly optimized comparison. Nothing more to be said here
No bc there is a simple Computational complexity calculation you can perform analytically on the algorithm and even with data stemming from a probabilistic starting stream one can find the bounds are tighter with some order term for prim conversion
you were essentially saying something called via a wrapper must be slower, which is just plain false
python calling a faster algorithm can easily be faster than a different algorithm written in (an called from) C/C++/whatever
in this case I think numpy indeed has a different sorting implementation than the C++ stdlib and whatnot
so yeah, completely wrong, right
Once again calling the most optimized thing in a wrapper is slower than the most optimized thing this is a simple concept im not sure where u r getting tripped up. O(n^2) + O(conversion) > O(n^2)
but this is not the case here
So u didnt read his question or my response and ur fingers just starting whipping on the keyboard
He wanted to understand peak Asymptotic performance
I answered
the question is why numpy's sort seems faster then the C++ stdlib or similar implementations
The best c++ implementation is faster than the best python implementation
No that is not the question he said faster than any c++ library he can find, that means he ran through basic library and tried to write it most of which do not waste there tkme absolutely peaking performance
Ad a matter of fact c++ hashmap in stl is one of the slowest hashmap libraries period
Doesnt mean c++ hashing isnt infinitely faster than dictionary equivalents in python
He had a theory question to be converted to code. He did it wrong and therefore he should continue to try until he does figure it out
This is the core question
Anyone familiar with the specifics of numpy's sort algo? In my own testing, it seems numpy is able to sort a list of float64s faster than any c++ sort library I can find.
it's asking why numpy's implementation seems so fast compared to anything else they tested
e.g. digging into the code, they default to a quicksort and you can opt in at compile time to use https://github.com/google/highway/blob/master/hwy/contrib/sort/README.md in particular
GitHub
Performance-portable, length-agnostic SIMD with runtime dispatch - google/highway
which could easily explain the performance differences
highly simd optimized code vs a more generic stdlib (or other library) implementation
Is your C++ library using the same sorting algorithm as numpy? Did you set the appropriate compiler optimization flags? Have you compared the assembly output of the two?
Numpy's default sorting algorithm is introsort btw. I did not see any explicit SIMD so it's probably just setting the compiler flags to do it.
is it?
numpy/_core/src/npysort/quicksort.cpp line 509
npy_quicksort(void *start, npy_intp num, void *varr)```You can see it switches to either insertion sort or heap sort.
There are some subtle tricks here.
Like making use of __builtin_expect to help the compiler know what the expected outcome of a branch is.
they have some dynamic dispatch for the highway implementation though
(I just need to find where...)
numpy/_core/src/npysort/quicksort.cpp line 77
inline bool quicksort_dispatch(T *start, npy_intp num)```nice

GitHub
C++ template library for high performance SIMD based sorting algorithms - GitHub - numpy/x86-simd-sort at 6a7a01da4b0dfde108aa626a2364c954e2c50fe1
I think in any case, some simd heavy implementation is likely used
Whether this work is applicable depends on the OP's hardware.