#algos-and-data-structs
1 messages · Page 42 of 1
yeah, but i need solution ;-;
there is no official python discord server
oh
but if there was, it would probably be this one
Mr. helper, can u help with the above DSA question ?
Why do you need a solution?
i need to submit the assignment tonight, i couldnt think and solve in 5hrs
You really should try to solve it
im kinda Dev devloper. not much into DSA. sorry
Almost just a plain Dijkstra from the looks of it
i mean could solve it if u have leisure time?
I can give you two tips.
- This is how you normally read and store an undirected weighted graph
n = int(input()) # Number of nodes
m = int(input()) # Number of edges
graph = [[] for _ in range(n)]
for _ in range(m):
u,v,w = [int(x) for x in input().split()]
u -= 1 # Convert to 0 indexing
v -= 1 # Convert to 0 indexing
graph[u].append((v,w))
graph[v].append((u,w))
- Here is a standard dijkstra implentation in Python that takes
graphas an input parameter: https://github.com/cheran-senthil/PyRival/blob/master/pyrival/graphs/dijkstra.py You will need to modify this slightly to solve your problem.
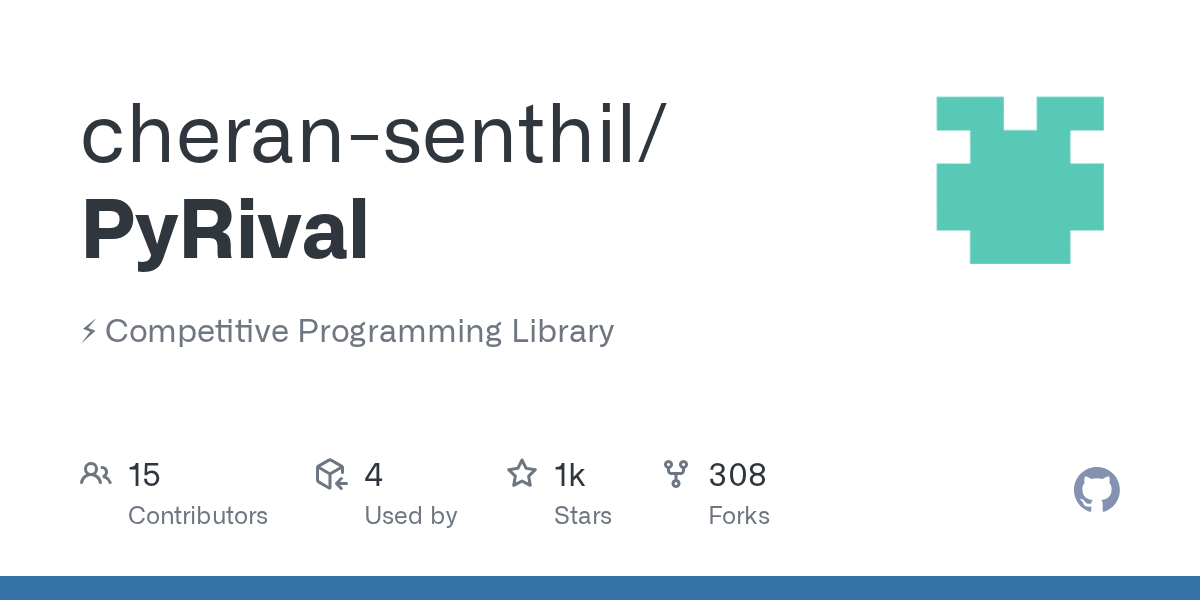
GitHub
⚡ Competitive Programming Library. Contribute to cheran-senthil/PyRival development by creating an account on GitHub.
Is it solvable in under ||O(m log n log q)||?
yeah okay, thanks for tip. ill look into it
Where do you get that extra log from?
||the binary search over the time the vertex is banned||
(Actually it is)
You can get rid of this log, nevermind
I dont see why you would binary search anything. When you reach a node, simply wait until it is safe
Yeah but you need to find for how long to wait
Just go over all unsafe times for that node
and find the next safe time
You only have to do that once for each node
Yeah I figured
if only Dr Strange's PhD was in CS
wym i didnt get u?
joke
Well it’s functional programming and a linked list so you can’t declare it like that, you have to do
l = List135()
l = l.add(1) # no it doesn’t update in place
l = l.add(2)
l = l.add(3)
print(l.first()) # 1
l = l.rest() # node containing 2
Ah, ok. Where does the 3 go?
linked to that last l
when the department says you must use python but you want to teach lisp still
What does it mean that function is deterministic? Context: I am trying about hashing and in tutorial teacher said that all hash functions in the set are deterministic
same input produces the same output
def f(x):
return x + random.randrange(255)
^ this function is nondeterministic; the output depends not just on x but on the random number generator seed.
def __init__(self, di, ti, si):
self.di = di
self.ti = ti
self.si = si
def minimize_curse(n, d, teachers):
# Sort teachers by curse level (Si) in descending order
teachers.sort(key=lambda teacher: teacher.si, reverse=True)
total_curse = 0
current_day = 1
for teacher in teachers:
# Check if the teacher arrives after the lockdown day
if teacher.di > d:
total_curse += teacher.ti * teacher.si
else:
# Check if there are enough days left to schedule all lectures
if current_day <= teacher.di:
# Schedule all lectures for this teacher
lectures_scheduled = min(teacher.ti, d - teacher.di + 1)
total_curse += teacher.si * (teacher.ti - lectures_scheduled)
current_day = teacher.di + lectures_scheduled
else:
# Calculate the number of lectures that can be scheduled
lectures_scheduled = min(teacher.ti, d - current_day + 1)
total_curse += teacher.si * (teacher.ti - lectures_scheduled)
current_day += lectures_scheduled
return total_curse
# Example usage and input reading
n, d = map(int, input().split())
teachers = []
for _ in range(n):
di, ti, si = map(int, input().split())
teachers.append(Teacher(di, ti, si))
# Calculate and print the minimum total curse
result = minimize_curse(n, d, teachers)
print(result)

There are 3 example test cases to be followed. Only 1st and 3rd input test cases are working and returning correct outputs. 2nd input test case throws the wrong output. can any find the issue and solve it?
no, that's a pure function
Basically, but its weird cuz the rest of our classes are in Java
Its a linked list, which I had to know from the homework. I can explain a linked list if thats what ur asking
something silly like this is also deterministic
def f(x=[]):
x.append(len(x))
return x
but not pure, because side effects
To clarify the definition, it is a function where the output is able to be determined ahead of time. Hence, deterministic
same input same effects and output
if you input [1,2,3] it will always return [1,2,3,3]
call like f()
I could make a more proper example, but I don't want to type out a closure
yeah if you call f() it will return [0]. Every time
the first time
nope
!e
def f(x=[]):
x.append(len(x))
return x
print(f())
print(f())
print(f())
print(f())
@haughty mountain :white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | [0]
002 | [0, 1]
003 | [0, 1, 2]
004 | [0, 1, 2, 3]
the default value is evaluated once
That makes sense
when the function is created
Although I guess that would technically be different input, as the list that x points to is changing
Yeah I knew that is how it worked in C I just never thought of it like this in python
def f():
return random.randint(100)
Is this function pure but not deterministic?
neither
How?
it mutates state
To be pure it needs to be deterministic basically
the state of the random number generator
Oh that too
do u have any useful applications of this
So, a function can't be pure unless all functions inside of it are pure, and a random number generator can't be pure? Is that true?
This might be an unnecessary tangent
Im not 100% sure but I suppose a random number generator could be pure
makes a rudimentary cache
Nvm then the output would be different
pure function is both "same return value for a given input" and "no side effects"
useful
Im thinking of some recursive nonsense tho lol
Well first of all, is this statement true?
A function can't be pure unless all the functions inside of it are pure
how isn't that useful?
random fails the first, maybe the second as well depending
Not necessarily. You could get the random value and then do nothing with it and return 0 and if the random was no side effects then it would qualify but random itself doesnt
def random():
return 4
Oh, ok. I thought "pure" was just the second test
chosen by a fair dice roll
def f():
random.random() ## magical random function that doesn't change state but returns a random value
return 4
a nice definition of pure function I met is "call to it can be replaced by its return value with the program's behaviour not changing".
depends on how pedantic you want to be, a function that caches values is a borderline case
it changes state, but not in an immediately observable way
stuff like "f(4, 2) can always be replaced with 7"
What about:
A function can't be pure unless all the functions that contribute to its output are pure
I mean, maybe, but why?
this is probably true if you follow the "no global state changing" definition, but also, good luck determining what functions contribute to a function's output.
@cunning bison 🤷♂️ we are talking about functional programming, why worry about application?
lmao. fair enough. I meant more like why such a verbose definition
I just want to be right about something 🤣
I had an initial random idea, and now I am forcing it to be right
what is meant by ahead of the time in that context?
Before the function is actually run
If you give me the input, I should be able to tell you what the output is, essentially
yeah but in order to get output, you should do the same thing that function does, so what's difference?
a = random.randrange(500)
def f():
return a
Is this a pure non-deterministic function  ?
?
every pure function is deterministic
It depends on your perspective
Well, if I look at this function from a perspective of a single process, this is a pure deterministic function, because it returns the same output for every input. If I look at it from the perspective of the computer, this is not a pure function, nor a determisitic function because it result depends on the state of initial entropy random number generator uses when I ran the process (or something... idk how rng works in python)
Is there a perspective in which you can consider this function both pure and non-deterministic?
def f():
return 0
def g():
return 1
h = f in random.randrange(2) else g
f is pure, g is pure
Since h is equal to either f or g, this means that h must also be pure

if we consider the global score to be compile-time-evaluated, then this is true 😛
h as a value is a pure function, h as a mapping from name to function object is not.
It's easy to say inf = 0; g = 1; h = f in random.randrange(2) else g: f is the same every program run, g is the same every program run, since h is either f or g, it is also the same every program run.
the purity depends on the perspective, of course. you can get a space radiation flip a bit in your RAM and suddently nothing is deterministic
but I beileive that pure => deterministic
Suppose we had a function check_purity that could check if a function is pure or not.
Then check_purity(f) == True and check_purity(g) == True. so check_purity(h) == True.  🧉
🧉
Suppose we had a function check_constant that could check if a value is a constant or not.
Then check_constant(f) == True and check_constant(g) == True. so check_constant(h) == True.
the value of h and the h as a variable are different things
https://www.youtube.com/watch?v=5TkIe60y2GI This discussion reminds me of this video.

Matt Parker talks about numbers - as he often does. His book "Humble Pi" is at: http://bit.ly/Humble_Pi
More links & stuff in full description below ↓↓↓
The book on Amazon: https://amzn.to/2NKposg
Numberphile podcast is on your podcast player.
Or the website is: https://www.numberphile.com/podcast
And it's on YouTube too: http://bit.ly/Numberp...
What I remember disliking about this video is that if I introduce a new constant whose value is either 0 or 1 depending on some undeciable problem. Then my constant is technically impossible to compute, even though its value is either 0 or 1.
And clearly both 0 and 1 can easily be computed
well yeah
whether a program terminates is a boolean value
I am sure you can compute both true and false
This is what I dislike about his argument that most numbers cannot be computed.
that's true
there is only a countable set of turing machines, and a continuum of numbers
there are numbers for which it is impossible to build a turing machine matching that number
Thats true. But that is not the arguement he used in the video

I don0t see how this code above relates to code below, like there is no summation of every time hash = hash +
how hash in the third time is not S[2]x mod p + S[1] mod p
if there is summation in parenthesis and after parenthesis there is mod p, shouldn't it be that both terms in parenthesis (hash * x and S[i]) are "moded" (if that is right word, btw what is right word for that?) by p
they probably mean mod p as applying to the whole expression here.
(in math mod is less of an operator and more of a thing you always write at the end of an expression to say we calculate it all mod p)
I see
yeah, this is not mod as an operator
(it's usually equivalent anyway because it's true that ((a mod p) + (b mod p)) mod p = (a+b) mod p and the same for *. Only when powers get involved does it become nonequivalent)
or their operator precedence is hella weird
conceptually you can separate the modding from computing the polynomial
d
c + d*x
b + (c + d*x)*x = b + c*x + d*x²
a + (b + c*x + d*x²)*x = a + b*x + c*x² + d*x³
this way of computing stuff pops up a bunch
e.g. working with digits of a number
(surprise, numbers expressed in a base are polynomials in the base)
Ye, looks like they are missing a couple of ()
Btw, this hash is commonly referred to as rolling hash
last time this came up, I remember some ambiguity here, depending on the definitions you use
Here's a discussion showing the debate: https://stackoverflow.com/questions/4801282/are-idempotent-functions-the-same-as-pure-functions
Comments above were for this discussion @regal spoke. The point is that "pure" does not necessarily (depending on defintiion) imply idempotency although I don't like this argumnt.
idempotent in what sense?
in math it's just that f(f(x)) = f(x)
Oh, yah, compsci uses a diff def: https://en.wikipedia.org/wiki/Idempotence "in imperative programming, a subroutine with side effects is idempotent if multiple calls to the subroutine have the same effect on the system state as a single call, in other words if the function from the system state space to itself associated with the subroutine is idempotent in the mathematical sense given in the definition;
"
there's a little complexity around the definition of pure functions vs idempotency/side effects, etc.
ah, it considers the input and output being all the state
for example, in db land, eh, we use the term deterministic, not idempotent... but, no side effects generally
maybe function is a bad name since it overlaps with math too much
a function with side effects is decidedly different than a function in math
deterministic and idempotent are quite different, no?
Yah, I guess... true
its what I hate about some of these terms - would be better to just have a taxonomy of what we mean.
maybe "idempotent operation" or something is a better term for the function with side effects
idempotent function is already a very well established math term which is usually all pure functions
Yah, and the cs def of pure and idempotency leads to the debate I linked above: https://stackoverflow.com/questions/4801282/are-idempotent-functions-the-same-as-pure-functions
I agree the idempotent definition is weird
not sure about the pure
that one seems mostly consistent
no side effects
It's more that with that def, then pure doesn't necessarily include idempotent.
I consider them different dimensions entirely 
"is f idempotent" and "is f(x)'s side effects on the overall state idempotent" seems to kinda be the two questions
f(f(x)) = f(x) vs
sideeffects_of_fx(sideeffects_of_fx(state)) = sideeffects_of_fx(state)
delete file x and return whether you deleted it
-> not pure, but idempotent wrt state
the idempotency of the function itself doesn't even make sense here
are people modeling functions with side effects like
f(mutable_state, x)?
if so then maybe it makes sense
Hey guys, I am completely new to DSA. What are the best resources to learn DSA? I know python.
need help with this code
from random import randint
numbers = []
colours = ["blue", "purple", "brown", "black", "green", "yellow", "orange"]
for i in range(21):
numbers.append(randint(1, 2000))
numbers.append(1)
def binarysearch(list, value): # first arg takes the list name, second takes the value that's being searched for
y = [] # a second table where seperated values will be stored
list.sort()
half = str(len(list) / 2).split(".")
if half[1] != '0' and half[0] == '1': # check if it's an odd number
if numbers[-1] == value:
return True
else:
list.pop() # Reduce it to an even number
binarysearch(list, value)
else:
print(list)
if len(list) >= 2:
y.append(list[int(len(list)/2):])
list = list[:int(len(list)/2)]
print(list,y[0])
if value in y:
return True
else:
y.clear()
binarysearch(list, value)
elif len(list) == 1:
print("yes")
if value in list:
print("yes2")
return True
else:
return False
else:
return False
print(binarysearch(numbers, 1))
the only problem is i can't get it to return True or False for some reason
the "yes" and "yes2" are just for debugging
nvm got it working ignore
Why not share what you did that made it work?
working is a strong word
that code is plenty broken
why does the binary search itself sort?
why does the binary search copy half the array at significant cost?
and this fun weirdness
half = str(len(list) / 2).split(".")
if half[1] != '0' and half[0] == '1': # check if it's an odd number
what it does is just weird, and it doesn't check if it's odd like the comment suggests
There was an online assessment question that I had failed to solve in time. The problem was this. There are some lamps placed on a coordinate line. Each of these lamps illuminates some space around it within a given radius. You are given the coordinates of the lamps on the line, and the effective radius of each of the lamps' light. In other words, you are given a two-dimensional array lamps, where lamps[i] contains information about the ith lamp. lamps[i][0] is an integer representing the lamp's coordinate; lamps[i][1] is a positive integer representing the lamp's effective radius. That means that the ith lamp illuminates everything in a range from lamps[i][0] - lamps[i][1] to lamps[i][0] + lamps[i][1] inclusive. I had to find the number of integer coordinates that are illuminated by exactly 1 lamp.
How exactly should I have done this?
greedy
or wait
ah, the actual question was not what I expected
sort on/off events, walk through them keeping a count of active lamps
sum the intervals where only one is active
O(n_lamps) after sorting
sweep line or greedy
also leaking codesignal question 😹
I just don't like when someone finds a solution to their own question and doesn't post the answer

oh okay
I tried solving it becayse of that lmao
well its sweepline or greedy
I mean
classic sweep line
here was my solution
@haughty mountain thoughts?
def lampCount(lamps):
sol = 0
lightCount = {}
for i in range(len(lamps)):
for j in range(lamps[i][0] - lamps[i][1], lamps[i][0] + (lamps[i][1] + 1)):
if j not in lightCount:
lightCount[j] = 1
else:
lightCount[j] += 1
print(lightCount.keys())
print(lightCount.values())
for key in lightCount:
if lightCount[key] == 1:
sol += 1
return sol
idk if it fits all tho
of what?
I mean would my solution be wrong by any means tho
isn't that what I described already?
like it would fit all cases no
oh yea, i didnt read it
@cobalt mirage would my solution be fine or am I missing something lmao
idk hat you're doing but your solution looks like its slow lol
you can probably use greedy
Can you send me a vid i havent learned that yet
greedy?
yup
greedy how?
im new lol
I think I solved something similar to this with greedy b4, so I am just saying I think you can.
but when I got this question, I used sweep line with hashmap
try meeting rooms 2 on leetcode
kk
hashmap?
yea
why?
i'll just send my solution
you just need the events in order
@cobalt mirage im not in leetcode server
leetcode server?
one sec ill text
try meeting rooms 2 on leetcode
OHHH
problem name
myb myb I thought it was a vc lmao
send
uhh that was the whole post but I think i can find the qs online
one sec
[2,3],[-2,3],[2,1]
ans should be 6
i asked chatgpt to generate my idea, so this might be lil more complicated than it needs to be

@upbeat saddle
lmaoo
kk sec let me take a look
is default dict ok for coding interviews tho?
I have one coming up which is why im looking at these lmfao
ok, that dict doesn't do much useful compared to just sorting some tuples
wym? I just do it like this because i am used to it 😹
I meant it doesn't really change the solution
I have my paypal final interview in few days, if I get a offer, I'll let you know if its okay or not
the core of the solution is the latter part anyway
Yeah I agree
its just "difference array" + prefixsum in sorted way no?
lmao
fiery orz
you call the events with +1 -1 a difference array?
Thats what I assumed was a difference array
🤔
it might be
I just haven't used the term for this
i just know what ever you say is probably more right than mine cuz you're cm 😅
meh
I for sure wouldn't call this greedy though
there is no greedy choice involved
this specific solution isn't greedy
but I think you can solve it in a greedy way the problem
actually you're right
I dont think any greedy choice is involved
lol
there are other questions you can ask with the same problem setup that would be greedy
i think i am just trying to force an idea but you're right about that
e.g. how many lights do you need to turn on to illuminate every position
@cobalt mirage you fell like helping me solve another codesignal one lmfao
its from a yt vid this time
sure


its annoying
i dont think I can help you with it because its annoying asf, but I remember it was just doing modulo arthmetic and its just kinda of greedy?
i can't
lmfaoo
alr
@haughty mountain
doing random questions like this is so much more useful than leetcode but its annoying to get explained tbh
doordash
LMAO
wtf do you have on your resume for dd
im an intern lmaoo
ik
so just getting started
nothing on your resume?
🤔
thats pretty good
i got resume rejected big bro
doordash process is easy
you got this
Yeah but only got one interview lmao
is it gca?
lets hope man
the codesignal
Hmm?
no im just doing random codesig questions I find online
idk what my interview is gonna have
alr one sec let me try to finish this one lmfao
I finished leetcode 150 and none of them were on interview questions
feels like this is basically just simulation, no?
i thought you had a codesignal due
so i figued might try older ones from codesignal
nah I wouldnt be asking here if i did lol
i am confused do you have oa or a interview, and is the interview on codesignal?
just don't scale with the time dimension and you're good with their complexity
interview, idk what its based on yet im just prepping how I can
can you explain lmao
You should do the leetcode tagged for doordash rather than codesignal
im a little lost on what hte question is asking tbh
they are apparently really different
my friend went through it and said they pourposefully avoid those tagged by companies
it would be annoying to explain, so pass
I am saying that because codesignal questions aren't similar to interview questions specifically the q2,q3 😹
lmaoooo
Idk what to study then, i did a bunch of leetcode already
this might be my last codesig tho
I already did the other ones
and they are too hard to figure out if you are correct or not lmao
You should just finish blind 75 and then attempt the doordash tagged questions even if you dont get the questions in it
because you aren't gonna get anything similar to codesignal questions on interview
I did the interview 150 so far
whats interview 150 😭

oh
you finished all of that
nice
I think you're gonna do fine, just do tagged imo
is door dash just application -> final?
ok wait how do u solve this
i think they have multiple rounds but so far im only past the first
dont know if it was my resume or the referal tho
Its legit just simulating what its asking, but its hard to explain the question because its so annoying
their app is still open
alr one sec let me read carefully then lmao
Yeah im lost
im just gonna hope I dont get this one
wait

LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
you wont be getting codesignal questions unless its like q4
is this the same exact qs?
its not the same
I know someone who got that question before, i tried to look it up for them and found that
but when I took it i tried to oslve it, it was basically simulation
hmm
do you have your solution by chance
im curious how you are even supposed to solve this
is it just like a list of arrays
i think i may, ill try to find it
alr bet
tyty
yeah ive reread this like 5 times and im still lost as to what it is asking lmao
😹
gimme a second
lmaoo tyty
I have a bunch of different assements that use codesig this month too so this may help for that either way
Which companies
that question only shows up on custom codesignal
The def roblox one they send out
do you go to top 50 uni for cs?
im data science but yeah I went to a uc
UC?
oh you go to iravine for university of ccali
okok wait how do you finish this
im searchin
lmaoo one of them there are 9
okay makes sense
honestly i might just take the roblox oa rn after this one
im going thoruhg my replit
yee
roblox oa was light af no cap on god frfr (❌🧢)
def mostListenedAudiobook(audiobooks, logs):
listened = [0] * len(audiobooks)
dropped = set()
curr_index = 0
for log in logs:
action, value = log.split()
value = int(value)
if action == "LISTEN":
# Move to the next audiobook which is not completed and not dropped
while curr_index in dropped or listened[curr_index] == audiobooks[curr_index]:
curr_index = (curr_index + 1) % len(audiobooks)
listened[curr_index] += value
# Move to the next audiobook for the next LISTEN action
curr_index = (curr_index + 1) % len(audiobooks)
elif action == "DROP":
dropped.add(value - 1) # Correcting the index
# Get the index of the audiobook with the highest listen time,
# in case of a tie, the one with the highest index
max_time = -1
max_index = -1
for i, time in enumerate(listened):
if time >= max_time:
max_time = time
max_index = i
return max_index
# Test
audiobooks = [5, 6, 7, 8]
logs = ["LISTEN 5", "LISTEN 5", "LISTEN 4", "LISTEN 4", "DROP 1", "LISTEN 1"]
print(mostListenedAudiobook(audiobooks, logs)) # Expected output: 2
``` Looks like this one is differentahh
but I think similar idea?
u good
my bad
lets hope 😦
have you done this one?
@upbeat saddle just chatgpt the codesignal, and everything else is iq test
i would not recommend cheating, but yeah, the rest is pretty much just a veiled IQ test
lmaooooo
chat gpt gets it wrong anyway i try to use it to make test cases for my code and it cant even do that
id immagine it would be harder
gpt 4?
yeah
Yeah i see that lmao
@agile sundial can you take a look at the qs i sent lol
i cant understand it at all
it just looks like you simulate but you can't just increment time you need to jump between them
Ok how would that look like with code
like is it just a event class that keeps running?
im just doing a bunch of older problems
its not gonna be the same tho
jsut good practice lmfaoooo
reddit and yt has good older practice questions lmfao
whats funner is he got everything wrong with the entire stream helping him
900 people and not a single one could help lmfaooooo
idk 900 views so
OH
live is way less
but still the chat was active lmao
alr alr how do i solve this one lmao
im gonna focus up
and fail
plan achived
🫡
I mean the hint is events * nServers, so just need to keep a array of nServers, and check if you can use the current if not go to next, and you need to continue till you finish the events, and you can use modulo arithmetic to go back. I think you can use the index of the nServers array to keep track of when you can use next and update as you go (I am not sure if this part works, because I feel like its more of a queue part)
I am probably wrong
I mean i probably wont get that one so ill just move on for now and come back later
ive looked at it so many times now
damn i don’t understand python oop class
is my iq so low and i cannot understand that
?
maybe you chose bad learning resource
!e
class A:
def f(self):
print('Called f')
super().g()
class B:
def g(self):
print('Called g')
class C(A, B):
pass
C().f()
@regal spoke :white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | Called f
002 | Called g

the mro is C, A, B and iirc super() means to check the next class in the mro
so swapping A and B would change things?
!e
class A:
def f(self):
print('Called f')
super().g()
class B:
def g(self):
print('Called g')
class C(B, A):
pass
C().f()
@haughty mountain :x: Your 3.12 eval job has completed with return code 1.
001 | Called f
002 | Traceback (most recent call last):
003 | File "/home/main.py", line 13, in <module>
004 | C().f()
005 | File "/home/main.py", line 4, in f
006 | super().g()
007 | ^^^^^^^^^
008 | AttributeError: 'super' object has no attribute 'g'
fun
Do list take up more memory than just storing a variable as a counter?
say for instance I'm appending items to a list
and it becomes a = [1,2,3,4,5,6,7,8,9,10]
to get the length of the list vs just adding +1 to a counter each iteration
right that's what I was thinking, so the bigger the list becomes more memory usage vs just storing a single integer
yes
I am trying to solve this problem

This is my code that I have so far
def searchTriplets(arr):
triplets = []
arr = sorted(arr)
print(arr)
right = len(arr) - 1
left = 0
triples = []
while arr[left] < 0 and left < right:
for i in range(right, left, -1):
if arr[i] < 0:
break
current_sum = arr[left]
add_i = i
numbers = []
numbers.append(arr[left])
while arr[add_i] >= 0 and left <= add_i and current_sum <= 0:
current_sum += arr[add_i]
numbers.append(arr[add_i])
print("Current sum is " + str(current_sum) + " current numbers " + str(numbers))
if current_sum == 0:
if len(numbers) == 3:
triples.append(list(numbers))
print(triples)
add_i -= 1
left += 1
return triplets
Do you know why when I print in nested code triples array has some elements, but when I return triplets there are no elements, array is empty?
You're appending to triples but returning triplets
What is the time complexity for your code if the input is all 0s?
Oh the problem wants you to answer with all the triplets
That is boring
This is my final solution that is accepted
class Solution:
def tripletExists(self, triplets_copy, array):
array = sorted(array)
for triplet in triplets_copy:
triplet = sorted(triplet)
if array == triplet:
return True
return False
def searchTriplets(self, arr):
triplets = []
arr = sorted(arr)
right = len(arr) - 1
left = 0
triples = []
while arr[left] <= 0 and left < right:
for i in range(right, left + 1, -1):
if arr[i] < 0:
break
current_sum = arr[left]
add_i = i
numbers = []
numbers.append(arr[left])
while arr[add_i] >= 0 and left < add_i:
if (current_sum + arr[add_i]) >= arr[left]:
if len(numbers) < 2:
current_sum += arr[add_i]
numbers.append(arr[add_i])
elif len(numbers) == 2:
if (numbers[0] + numbers[1] + arr[add_i]) == 0:
numbers.append(arr[add_i])
if len(numbers) == 3:
if not self.tripletExists(triplets, numbers):
triplets.append(list(numbers))
add_i -= 1
left += 1
second part
arr.reverse()
right = len(arr) - 1
left = 0
while arr[left] >= 0 and left < right:
for i in range(right, left + 1, -1):
if arr[i] > 0:
break
current_sum = arr[left]
add_i = i
numbers = []
numbers.append(arr[left])
while arr[add_i] <= 0 and left <= add_i:
if (current_sum + arr[add_i]) <= arr[left]:
if len(numbers) < 2:
current_sum += arr[add_i]
numbers.append(arr[add_i])
elif len(numbers) == 2:
if (numbers[0] + numbers[1] + arr[add_i]) == 0:
numbers.append(arr[add_i])
if len(numbers) == 3:
if not self.tripletExists(triplets, numbers):
triplets.append(list(numbers))
add_i -= 1
left += 1
return triplets
I think this is my first medium solved problem 🙂
the leetcode problem for this is quite dumb as well, I'm sure they don't even test the worst case
n = 3000
If all 0 is a possible input, then shouldnt just
def solve(A):
n = len(A)
ans = []
for i in range(n):
for j in range(i):
for k in range(j):
if A[i] + A[j] + A[k] == 0:
ans.append((i,j,k))
return ans
be an optimal solution?
(for worst case)
LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
yes, you can force O(n^3)
😩
wouldn't it be optimal to pack everything into a Counter first
yeah
counter solves this neatly
you need to know if an element occurs once, twice or thrice+
outside than that nothing matters
my first thought is Counter and then iterate over pairs
The input can have duplicates

can do it in O(m^3) where m is the number of unique inputs (by Counting first)
but more than that, it seems unoptimizable
you can do it better than that
ah, right
yeah, can do O(m^2) probably actually in the general case there's O(m^3) outputs, aren't there?
wait is it unique triplets with each triplet in sorted order?
Given an integer array nums, return all the triplets [nums[i], nums[j], nums[k]] such that i != j, i != k, and j != k, and nums[i] + nums[j] + nums[k] == 0.
but the examples don't seem to have duplicate triplets that are in different orders
but yeah, the problem spec is kinda weird
the example mentions to not care about order
not the problem statement itself
can you?
you have O(m^2) unique sums of two elements, which you can complete in exactly one way
so it should be O(m^2) pairs at worst
yeah is it just Counter and then you iterate over it triangularly, sum pairs and check if the negation is also available, with a special exception for 0
some special casing of stuff with 1 or 2 occurences
yeah
counter, cap at 3, expand into list again would be a dumb but simple solution
then you can loop over all pairs and stuff
I guess there is still a special case, so maybe it's not simpler anyway
would looping over the expanded list not be worse than looping over the Counter keys
Here is a very simple and naive O(n^2) solution
def solve(A):
n = len(A)
ans = set()
ACounter = Counter(A)
for i in range(n):
ACounter[A[i]] -= 1
for j in range(i):
ACounter[A[j]] -= 1
if ACounter[-(A[i] + A[j])] > 0:
ans.add(tuple(sorted((A[i], A[j], -(A[i] + A[j]))))
ACounter[A[j]] += 1
ACounter[A[i]] += 1
return list(ans)
you could just generate all the possible triplets with the right sum and then just checking if they are ok by comparing to the Counter counts
that so screams "this is really a dfs with backtracking"
do operation, undo on the way back out
I thought that was a recursive algo for a sec
you could easily write it recursively
out of curiosity what would be the unboring problem?
counting
that way you can kill badly scaling stuff easily
Then all 0s would be a bit more tricky
oh you mean counting non-unique?
right
I see
we want to answer to be able to explode
it would still be roughly the same idea tho right? sum pairs over Counter etc
so you can easily do n=10000 and completely kill anyone trying to squeeze something badly scaling in
yeah
this solution is good
you could do quadruples in O(n^2) as well I think
if you only care about counts
how would that work?
I was thinking just Counter of all pairs but you'd run into double counting issues I think
I think you should be able to split it into a few O(n^2) counters
The real interesting question is if you could solve the problem in O(n) time
I suspect that's a no
how do you even prove that something like this can't be O(n)
whether you can do better than O(n^2) is a good question
I was thinking of using the fact that the numbers are small
Btw this is a well known problem https://en.wikipedia.org/wiki/3SUM
In computational complexity theory, the 3SUM problem asks if a given set of
n
{\displaystyle n}
real numbers contains three elements that sum to zero. A generalized version, k-SUM, asks the same question on k numbers. 3SUM can be easily solved in
O
(
n...
Ah you can solve it in O(n + max A) * (some log factor) time
using fft
wtf is that complexity
People are trying to beat the O(n^2) limit
A problem is called 3SUM-hard if solving it in subquadratic time implies a subquadratic-time algorithm for 3SUM.
fun
complexity theory that isn't about NP for once
Since leetcoder has limit -10^5 < A[i] < 10^5, the problem can easily be solved for any n using fft

what's fft?
Fast Fourier Transform. Think about it like an algorithm to multiply two n degree polynomials in O(n log n) time
So what I'm trying to say is that leetcoders 3sum problem can be solved by seeing the problem as a polynomial multiplcation problem
why does the 2014 algorithm not answer the current conjecture?
it's not polynomial in n
it scales with other stuff
pseudopolynomial-time I think the term is
if those were considered polynomial then N=NP
we have plenty of NP problems with psudopolynomial solutions
e.g. the subset sum problem
this might be an interesting read
https://en.wikipedia.org/wiki/Subset_sum_problem#Pseudo-polynomial_time_dynamic_programming_solutions

Twitch
ð—›ð—¶! ð—œ'ð—º ð—ð—¶ð—»ð˜…ð—šð˜†ð—¯ð˜‡ð˜†ã€Œã‚¸ãƒ³ã‚¯ã‚¹â‹†ã‚¸ãƒ–ã‚·ã€ð—œð—»ð—±ð—¶ð—² ð—˜ð—»ð—©ð˜ð˜‚ð—¯ð—²ð—¿: ð—™ð—¿ð—¼ð—º: 🇳🇿 | ð—–ð˜‚ð—¿ð—¿ð—²ð—»ð˜ð—¹ð˜† ð—¶ð—»: 🇯🇵 | ð™¿ðš˜ðš™ ð™²ðšžðš•ðšðšžðš›ðšŽ ð™´ðš¡ðš™ðš•ðš˜ðš›ðšŽðš›ðŸ›†ð™²ðš‘ðš›ðš˜ðš—ðš’𚌠ð™»ðšŠðšž...
How much memory is okay to use? For eg, say I have a knapsack type question. Then I would want to create a DP where one of the dimensions is the max weight. So how big can my DP array be in this case?
Normally the memory limit on online judges is somewhere around 256mb to 1gb
for calculating size, just compute the number of elements and multiply by the size of each element in bytes
Hmm hmm
A good rule of thumb is that 10^5 long list is kinda small, 10^6 is big but doable, 10^7 is large
Anything above that is pretty much a no good
at least in python
Can you point me towards this thumb..
just estimate the size properly a few times and you quickly get a good sense
an int in python takes at least 28 bytes
10**6 ints in a list would be something like
28*10**6 bytes large (ignoring the size of the list structure itself)
so at least ~28MB
To give a bit of context, There are some questions which can be solved in one manner given infinite memory, but since that's not the case, we look for alternatives that use less/finite memory. So I am looking for an estimate on the amount of memory. I'm aware of how to calculate the size of a data structure for the most part..
if you can calculate the size the data structure you would have, isn't that basically your answer?
are you asking how much memory you're allowed to use ?
Yeah I guess..
can I store 10**7 python ints in a list with <250MB? no
could I store it in 1GB? yes
This gives a good answer to my question I think..
idk about good answer
it depends a huge amount on what you put in the list
just do a ballpark estimate using the number of elements and the size of each element
that will get you a good number
for stuff like python ints the answer is sensible, for long strings is sure wouldn't be
Consider this. Knapsack question -> max weight cases. For which would you use dp[size] where size = 10^
3
4
...
8
9
10
Let's say ints only
just do the calculation I described to get size estimates
assume something like 28 bytes per int (which is the case for small enough ints in python)
10**3 -> ~28KB
10**4 -> ~280KB
10**5 -> ~2.8MB
10**6 -> 28MB
10**7 -> 280MB
10**8 -> 2.8GB
10**9 -> 28GB
...
so 6 or 7 is probably ok
Hmm hmm
but just learn how to do these estimates
it's not hard, and it gives a lot of powers
you can do similar simple estimates on runtime
just to see if things are feasible or not feasible
Got it, wonderful 👍👍👍
another rule of thumb: for _ in lst: pass takes about 100ms for a 10-million-element list on my computer
so you can only do about 100M iterations/s of anything.
and it's important to know some characteristics for the language you're using in particular
for something like C or C++ my estimate for "number of simple operations in a second" would be more like 1000M
the size of things is different
e.g. if you worked with 32 bit ints the estimate of the dp array size looks a bit different
10**3 -> ~4KB
10**4 -> ~40KB
10**5 -> ~400KB
10**6 -> ~4MB
10**7 -> ~40MB
10**8 -> ~400MB
10**9 -> ~4GB
...
I also forgot to account for a pointer size in the python list of int case
so replace 28 by 36
do note that this number can be about 2 orders of magnitude of, in both directions (doesn't really apply for python: it will be 1.5 orders of in the down direction at most, but also repends). The exact same function when run in different circumstances on the exactly the same data can take 100 times more sometimes. It is always like this for performance. Memory is way more predictable.
you're talking about what? cache misses? contention?
I just created a list(range(10 ** 8)) and it took 3.98 GB
yeah, my thing was a tad off, corrected here
I would say it's pretty accurate, actually
the corrected 3.6 is a bit better 😛
a lot of things: cache misses, branch misses, cpu occupancy, instruction cache, prefetching, random memory alignment changes, garbage collection pauses (if applicable), operating system switching process context at the worst possible time, stupid jvm randomly not jit compiling the hot spot, etc.
there is so much stuff that performance is basically unpredictable
I can see this mattering a lot for microbenchmarks
a bit less so for macrobenchmarks
(i.e. a spike/jitter can have a ton of effect on a short time span, but averaged over time it will have much less dramatic effect)
the problem is that some things are not averaged over time
if a problem was introduced because compiler managed to optimize something in one context and failed in another, you are basically screwed
and unfortunately it 1) does happen 2) does affect performance 😦
I agree though, memory is easy, time is hard
loads of factors going into how long time something actually takes
yeah exactly
which is why I generally don't try to predict the time something takes within more that like an order of magnitude 😅
with memory you can get very accurate estimates, as seen above
Guys, I need help with a little project my friend asked me to pull off
And because I’m a damn perfectionist, I’d like to improve it
The whole point of this code is to print out the energy of the light particles, but I don’t wanna print out both values of h * f and h * w
How do I decide which one I get to print? I’m fairly new to python, and I’m quite uncertain. If someone could explain it, that would be lovely!

import timeit
import random
N = 10 ** 7
p1 = list(range(N))
p2 = p1.copy()
random.shuffle(p2)
a = [random.randrange(10 ** 12) for _ in range(N)]
p1, p2, a = tuple(p1), tuple(p2), tuple(a)
print(timeit.timeit("sum = 10 ** 12\nfor i in p1: sum += a[i]", globals=globals(), number=100))
print(timeit.timeit("sum = 10 ** 12\nfor i in p2: sum += a[i]", globals=globals(), number=100))
print(timeit.timeit("sum = 10 ** 12\nfor i in p1: sum += a[i]", globals=globals(), number=100))
print(timeit.timeit("sum = 10 ** 12\nfor i in p2: sum += a[i]", globals=globals(), number=100))
59.48938252200014
444.5384246399999
68.39246315399987
459.9337272390003
fun
What’s that?
an addendum to this
Oh alright
I don’t understand it, but I’m hoping I will in a few months
Or heck, weeks
But could you help me out with my problem?
not really, gotta go, but I am sure someone else might be able to
Oki! Cya!! Have fun doing whatever it is you’re doing!!
Unless it’s math
Math sucks
yeah, random access vs seqential access ends up mattering
one interesting thing though, throw a random.shuffle(a) in after creating a
a big chunk of the difference goes away
because (I suspect) that when creating a it's likely that the newly allocated values are near each other
so you get the combined wins of "successive pointers in the list are near each other" and "successive integers being looked at are near each other"
shuffling a should get rid of any effects of the latter
it's still like a 2x gap, but not something closing in on 10x
the fun that comes from this being an indirection of an indirection because python
for whoever is interested, meta hacker cup starts in 18 minutes
https://www.facebook.com/codingcompetitions/hacker-cup/2023/round-1
its so damn hard wtf
i saw william lin's meta hackercup, and the difficulty gap is insane
lol I failed B because of p=1 being a special case
What was it you saw?
william lin's meta hackercup?
oh are you talking about his youtube?
Did you solve all except b?
Solved everything in Python 
But my solution on that last problem was a little bit iffy

Took almost 5 min out of 6 min time limit to run my program
How did you solve a
t = int(input())
for cas in range(t):
n = int(input())
X = [int(x) for x in input().split()]
X.sort()
if n == 5:
x1 = (X[0] + X[2]) / 2
x2 = (X[3] + X[4]) / 2
ans = x2 - x1
x1 = (X[0] + X[1]) / 2
x2 = (X[2] + X[4]) / 2
ans = max(ans, x2 - x1)
else:
x1 = (X[0] + X[1]) / 2
x2 = (X[~0] + X[~1]) / 2
ans = x2 - x1
print('Case #%d: %f' % (cas + 1, ans))
The tricky case is n = 5
What would this be rated in codeforces
Pretty low. Probably like 1100
Im iq gapped
Did you understand the problem?
That was in my oppinion the hardest thing about the problem
Understanding what they are even asking for
I thought I understood the problem but I couldn’t properly think about how to set it up
You wanted to maximize travel distance for santa
Yeah
Meaning the two outer toys you build should be as far apart as possible

Yeah
Pajene god can you train me so I can get better 😭
Do harder problems don’t help
no, I only really looked at A B C
and a tad of D, but didn't get that far
I'm in retired competitive programmer mode 😛
I guess it would be easy to just throw some lazy segment tree at D, wouldn't it? @regal spoke
What was B
for fun
bfs problem
B was bfs?
B2 was
Nah what about b1
specifically bfs isn't needed
For b2 it is, I think?
I generated basically all options
I mean
ok
Here is my B
t = int(input())
for cas in range(t):
P = int(input())
parent = {}
bfs = [(0, P)]
for cur_sum, p in bfs:
if cur_sum == 41:
if p == 1:
break
else:
continue
for i in range(1, 41 - cur_sum + 1):
if p % i == 0:
key = (cur_sum + i, p // i)
if key not in parent:
parent[key] = (cur_sum, p)
bfs.append(key)
else:
print('Case #%d: -1' % (cas + 1))
continue
key = (cur_sum, p)
ans = []
while key in parent:
new_key = parent[key]
ans.append(key[0] - new_key[0])
key = new_key
prod = 1
for x in ans:
prod *= x
assert prod == P and sum(ans) == 41
print('Case #%d: %d %s' % (cas + 1, len(ans), ' '.join(str(a) for a in ans)))
graph problem isn't quite it
there is some abstract graph sure
but you can dfs/bfs a lot of things
Think about the process of creating a sequence that sums to 41
I guess sorted sequences that sum to 41 isn't that many huh?
What was the time complexity of the solution
I went the other way around and started from a factorization
41^2 times number of divisors of P
around 30 minutes
Yk what, I was scared of trying anything cuz I thought it was gonna tle lol
But I was tryna do like divisors
The idea behind my algorithm is pretty simple. Say you start with 1029. I think of this as state (1029, 0).
Then by dividing by one divisor of 1029 you can get to
1029 / 1 = 1029 with sum = 1, so state (1029, 1)
1029 / 3 = 343 with sum = 3, so state (343, 3)
1029 / 7 = 147 with sum = 7, so state (147, 7)
1049 / 21 = 49 with sum = 21 so state (49, 21)
Then I continued from there.
From state (1029, 1) you can reach states (1029, 2), (343, 4), (147, 8), (49, 22)
From state (343, 3) you can reach states (343, 4), (49, 10)
and so on and so on
yeah, BFS does make a lot of sense for this
you want the shortest way to get to (1, 41)
Ye exactly
Shortest path from (P, 0) to (1, 41)
The number of possible states will be at most divisors of P times 41
for question 10, the frontier sequence is as follows:
1. {a}
2. {ab}
3. {aba, abc}
4. {abc, abab}
5. {abab} TERMINATES - abc is goal state
However, confusion lies at question 11 which asks for 2 sequences. Is my instructor asking for 1 sequence where it finds the goal state, and one where it is stuck in an infinite loop? I've attached the search tree our instructor drew for us.


there are an infinite number of DFSs of that small graph
a->b->c
a->b->a->b->c
a->b->a->b->a->b->c
...
i.e. you can go around the loop however many times you want before going to c
Sequence 1:
1. {a}
2. {ab}
3. {aba, abc} - last one in is abc, so that is searched first
4. {aba} TERMINATES - abc is goal state
Sequence 2:
1. {a}
2. {ab}
3. {abc, aba} - last one in is aba, so that is searched first
4. {abc, abab}
5. {abc, ababc, ababa}
6. {abc, ababc, ....} - infinite loop
would this be correct?
a DFS doesn't need to pick the last/first of the options
it can pick whatever and it's still a valid DFS ordering
I meant among the options in a single node
could you elaborate please?
just that all the paths in this tree is a possible dfs ordering

i.e. where do you go from this junction

something like picking a the first time and c the second is valid
are you saying that DFS will randomly choose ABC and ABA?
it will depend on the implementation of your DFS
depending on the impl you might push both options from a node onto the frontier (e.g. if you do an iterative DFS)
this is an iterative DFS
but if you say write it recursively it's natural to completely follow one option before doing any other
ok
would my sequences be valid then?
they would, but picking the infinite one is probably more annoying that you needed to make it
e.g. this is one other sequence
{a}
{ab}
{abc, aba} # push c then a this time
{abc, abab}
{abc, ababa, ababc} # push a then c this time
TERMINATES
i.e. following this path

thank you so much
this makes more sense and is less annoying too
for online platforms like leetcode and codeforces, is 10^8 operations fast enough to not TLE?
R = 1
D = 2 * R
polygon_sides = 4 # starting with a square
polygon_diagonal = D # the diagonal is equal to the delimiter
# x^2 + x^2 = D^2
# 2 * x^2 = D^2
# x^2 = D^2 / 2
# x = sqrt(D^2 / 2)
polygon_side = (polygon_diagonal**2 / 2)**0.5
polygon_perimeter = polygon_side * polygon_sides
current_pi = polygon_perimeter / polygon_diagonal
x = polygon_sides
num_iterations = 25
for _ in range(num_iterations):
x = 2 * x * current_pi / (x + current_pi)
current_pi = (x * current_pi) ** 0.5
i implemented this, starting from a square, it calculates pi, i'd like to understand how the second part works (from the iteration part)
hello, i'm currently taking dsa in college and I'm wondering what's the point of learning all these different sorting algorithms
it doesn't seem there's that much of a difference betwee selection and insertion sort to have to learn both
We had a conversation here in pydis, so I'm just capturing my notes (but hoping someone more mathy has a better intuition). This calculates the geometric-harmonic mean, starting from x=4 and current_pi = 2.2.... the ghm converges to pi over multiple interations. It's not the archimedes approximation as I expected when I first looked. So, hoping someone can explain why the GHM converges to pi in this case.
It's like learning to dribble through cones in soccer, or practicing basketball shots, or whatever sport you like: it uses skills you'll need to use eventually, and it's small enough to do on your own without any extra resources.
It's hard to teach someone how to think about algorithms without using some algorithms. Sorting and searching are somewhat fundamental, not too hard, and don't require external knowledge making them good candidates for teaching.
Who spends 10 years on this? It's a one semester class.
I had to take chemistry and biology in high school. I don't remember any of that either.
same
i think the whole purpose of teaching the sorting algos is to get you familiar with big O
i'll delete the comments though since i want people to read what i've said before...
in what language
even in like c++ that's getting tight depending on the operations
Yes, that’s an interesting math question
Python,
Typically program runs for 1 or 2 seconds on leetcode or codeforces that require less than n^2?
no go, even an empty 10**8 loop in python takes like 2s
What do you mean empty loop
?
still questioning this
does it take 1 or 2 seconds normally
!timed
for _ in range(10**8): pass
err
I thought that was a command
but regardless
In [1]: %time for _ in range(10**8): pass
CPU times: user 2.77 s, sys: 1.89 ms, total: 2.77 s
Wall time: 2.77 s
2.77 s damn
there is no way you do this in plain cpython
!timed
for _ in range(10**7): pass
ayo I need help to get started with python
Im trying to write an algo for returning the complete set of lines of symmetry for a given set of points on an infinite plane.
I am having an issue trying to find where my math doesn't checkout:
I have this function to try to find the line of symmetry
def is_symmetry_line(m: float, c: float, points: list[Point]) -> bool:
if m == float('inf'): # Check for a vertical line
for p in points:
reflected_x = round(2 * c - p.x, 6)
reflected_y = round(p.y, 6)
if not any(is_close(Point(reflected_x, reflected_y), orig) for orig in points):
return False
else:
for p in points:
denominator = 1 + m**2
reflected_x = round((p.x * (1 - m**2) - 2 * m * p.y + 2 * m * c) / denominator, 6)
reflected_y = round((p.y * (1 + m**2) - 2 * m * p.x + 2 * c) / denominator, 6)
if not any(is_close(Point(reflected_x, reflected_y), orig) for orig in points):
return False
return True
A second set of eyes would be awesome, not sure why this doesn't work as expected 😦 
That’s a question for #python-discussion
Anybody know a faster way of doing this? Basically I have a two dataframes. One of the dataframes is a subset of the other and I want to update the values of all rows that are present in both.
df["passed"] = 0
for _, row in new_df.iterrows():
df.loc[df["id"] == row.id, "passed"] = 1
!ti
for _ in range(10**7): pass
@regal spoke :white_check_mark: Your 3.12 timeit job has completed with return code 0.
1 loop, best of 5: 322 msec per loop
or !timeit 
!timeit
pass
@regal spoke :white_check_mark: Your 3.12 timeit job has completed with return code 0.
10000000 loops, best of 5: 20.3 nsec per loop
!timeit
id(1)
@lean walrus :white_check_mark: Your 3.12 timeit job has completed with return code 0.
5000000 loops, best of 5: 83.9 nsec per loop
it seems to be very consistent: #bot-commands message
Codeforces has pypy, so it's kinda possible
But it's really a small chance, it should have very simple operations. I'd say impossible
And on plain python it has absolutely no chance, ye

where to ask cloud computing question?
i asked in #unix
it has to do with running a python script
https://en.wikipedia.org/wiki/Hermite_constant
Genuinely tweaking trying to understand this
A fundamental region of a hexagonal lattice is a 120 degree rhombus. When the area of such a rhombus is 1, the resulting side lengths are not 2/sqrt(3). Instead, the length is sqrt(2/sqrt(3)). Am I incorrect in thinking that the shortest distance between 2 points in the lattice is supposed to be 2/sqrt(3)?
In mathematics, the Hermite constant, named after Charles Hermite, determines how long a shortest element of a lattice in Euclidean space can be.
The constant γn for integers n > 0 is defined as follows. For a lattice L in Euclidean space Rn with unit covolume, i.e. vol(Rn/L) = 1, let λ1(L) denote the least length of a nonzero element of L. Th...
cmon over and tell me why im wrong, that would be very awesome rn
how do i know when i need to implement segment trees to solve a puzzle?
i realized that mostly is when you need optimization
but dk
Hi, does anyone know of a good platform to help visualize different ADS and the operations which can be performed on them?
ADS as in advertisements or what?
abstract data structures I guess?
though idk why the abstract would be important
it seems to say the square root is the longest shortest distance
Then √γn is the maximum of λ1(L) over all such lattices L.
The square root in the definition of the Hermite constant is a matter of historical convention.
hi all,
how can i replace each element in a pythonic list from one index to another. i want to overwrite the existing values. ideally this would not involve a replacement list. all the overwriting is to be the same value.
eg
mylist = [a,a,a,a,a,a,a,a,a,a]
newlist = [a,a,a,a,a,a,b,b,a,a]
i'd like to use slicing if possible
or a generator function
might work better as a string
I'm a bit confused about what you are asking about
You can use slicing to change lists
!e
A = [0,1,2,3,4]
A[1:3] = [0]*10
print(A)
@regal spoke :white_check_mark: Your 3.12 eval job has completed with return code 0.
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4]
i wanted to replace only certain indices values. i think what i wanted to do would work given your example above if the number of items to be replaced was calculated using the slice indices
Right, but the hermite constant for 2 dimensions is 4/3, meaning the max shortest length is 2/sqrt(3)
Does the array.array type reallocate on every append? Or is it a dynamic array?
It seems that it is a dynamic array, but does not over-allocate nearly as much: https://github.com/python/cpython/blob/67e8d416cc5e14c181e4f883ffb4d87f2a647ae1/Modules/arraymodule.c#L162
Modules/arraymodule.c line 162
/* This over-allocates proportional to the array size, making room```how to learn Data structure
Have you already learned Python fundamentals?
If so, the most recommended course is - https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-006-introduction-to-algorithms-spring-2020/
How is this possible
Otherwise, we check if the absolute value of targetDiff is less than the absolute value of smallestDifference (meaning we've found a closer sum), or if it's equal but targetDiff is greater (meaning it's a larger sum that is equally close). If either condition is true, we update smallestDifference with targetDiff.
In code
if abs(target_diff) < abs(smallest_difference) \
or (abs(target_diff) == abs(smallest_difference) and target_diff > smallest_difference):
How can this expression after or be true? if abs(target_diff) == abs(smallest_difference) is true then second part (target_diff > smallest_difference) won't be ever true
hey i needed some help with my python code
import hashtable2
import graphs
class Shop:
def init(self,shop_number,shop_name,category,location,rating):
self.shop_number = shop_number
self.shop_name = shop_name
self.category = category
self.location = location
self.rating = rating
class shopFindingSystem:
def init(self):
self.shop_data = hashtable2.HashTable()
self.shopping_map = {}
def add_shop(self,shop_number,shop_name,category,location,rating):
shopIns = Shop(shop_number,shop_name,category,location,rating)
key = shop_number
self.shop_data.add(key,shopIns)
self.shopping_map[shop_name] = shopIns
print("Shop Added Successfully")
def search_shop(self, category):
matching_shops = []
for kvp in self.shop_data.arr:
if kvp is not None and kvp.category == category:
matching_shops.append(kvp.shop_name)
return matching_shops
def deleteshops():
pass
def update_shops():
pass
def graph(self, edges):
self.edges = edges
self.graph_dict = {}
for start, end in self.edges:
shop_name_start = self.shopping_map[start].shop_name
shop_name_end = self.shopping_map[end].shop_name
if shop_name_start in self.graph_dict:
self.graph_dict[shop_name_start].append(shop_name_end)
else:
self.graph_dict[shop_name_start] = [shop_name_end]
return self.graph_dict
sfs = shopFindingSystem()
sfs.add_shop("2","Nike","Clothing","Level 2",5)
sfs.add_shop("1", "Adidas", "Clothing", "Level 1", 4.5)
sfs.add_shop("3", "Apple", "Electronics", "Level 1", 4.8)
sfs.add_shop("4", "Samsung", "Electronics", "Level 1", 4.9)
result = sfs.search_shop("Clothing")
print(result)
sfs.graph([("1","2")])
wait im not too sure how to send
It is possible. If abs(target_diff) == abs(smallest_difference), then target_diff > smallest_difference means that smallest_difference < 0 and target_diff == -smallest_difference.
Yes, you are right. Thanks for help
What's the problem? You should probably open a #❓|how-to-get-help thread: paste the code and the error you're getting.
I have num = 6. I want to loop until num == 0. Is it better to do while num:, or while num > 0:? The second one might be more clear, but maybe the first is more Pythonic?
I think the latter is clearer. (Though also consider if this while-loop can't just be a for one)
Also technically, if you want to loop until num == 0 you should do while num != 0, lol.
I think whatever is fine, you will be understood, explicit comparisons are preferable ("explicit is better than implicit"), and just be careful.
If num is a health of an in-game entity, for instance, make sure to kill the entity if it's health is <= 0 and not when == 0, because who knows, maybe one day you will start subtracting 5 instead of 1 and it will go 6 -> 1 -> -4 -> -9 -> .... Just use common sense.
Thanks. Fair side points from both of you, although in my case num can change by a different amount each time but never go below 0. But I appreciate the thoughts!
In this case I'd do >0, because otherwise I, personally, would be paranoid about "but what if it's possible for it to get negative and loop forever?".
speaking of infinite loops, I had this question for a long time
why do people set parent of components' roots to themselves in DSU?
deep storage unit? :p
like
class Dsu:
def __init__(self, n: int):
self.p = list(range(n))
self.rank = [1] * n
...
instead of
class Dsu:
def __init__(self, n: int):
self.p = [None] * n
self.rank = [1] * n
...
disjoint set union
the union find thing (aka the only data structure which uses O(alpha) in it's complexity)
My argument against the first version is that if you did something wrong you will get an infinite loop, which is more way confusing (and slower to debug) than segfault
(initialize it to -1 or something like that in compiled languages)
That is just the natural way to define it. You see people doing that kind of loop for the root in many other types of algorithms too.
There are a couple of good reasons to not use None
- Languages like c++ don't have None. So using None is kinda iffy
- PyPy has a strategy for optimizing lists with integers, that only works if all numbers in the list contain integers
Speaking about DSU. I have a couple of preferences.
- Use size instead of rank. Since size can be useful to have, unlike rank.
- You can combine P and size into one single list by making use of negative numbers. That way the entire DSU is stored in just one list.
Hey I'm not sure if I'm asking this question in the right area but I'm new to python and would like need help solving this ctf problem: Can you guess the next output of this RNG?
import secrets
p = 307778420006131414621890031747251875861
class Rand:
def init(self):
self.a = secrets.randbits(64)
self.s = secrets.randbits(64)
def get(self):
self.s = (self.a * self.s) % p
return self.s
rng = Rand()
s1 = rng.get()
s2 = rng.get()
print(s1)
print(s2)
what is the next value of rng.get()
Here's the first two values:
57212529044000554155306422065054664828
80539814197534880152256654285184178786
If anyone can guide me through the whole thing that'd be awesome!
This is the end of the Adam algo where the parameters 'W' and 'b' are updated. Is the way i'm setting up the following python code the correct way?

parameters["W" + str(l)] = parameters["W" + str(l)] - learning_rate * (v_corrected["dW" + str(l)] / (np.square(s_corrected["dW" + str(l)]) + epsilon))
edit: The error was np.square(), the correct method is np.sqrt()
This makes a lot of sense
I would just set it to -1
Rank has a tiny advantage of being small so you can pack both rank and parent in the u32, but it usually won't matter anyway.
Send a download link to Notepad software. Thank you
You only care about the rank of root nodes, and for those you dont need a parent
So I don't see any reason at all to use rank
fair enough
How is it possible to set the Initial Parameters p0 in the CurveFit Function?
Given an array of unsorted numbers and a target number, find a triplet in the array whose sum is as close to the target number as possible, return the sum of the triplet. If there are more than one such triplet, return the sum of the triplet with the smallest sum.
This is from solution:
Here's a detailed walkthrough of the algorithm:
- Initially, the method checks whether the input array arr is null or its length is less than 3. If either condition is true, the method throws an IllegalArgumentException, as it is impossible to find a triplet in these cases.
-
The input array arr is then sorted in ascending order. Sorting is important as it allows us to move our pointers based on the sum we are getting and how close we are to the target sum.
-
The smallestDifference variable is initialized to Integer.MAX_VALUE, which will keep track of the smallest difference we have found so far between our target sum and the sum of our current triplet.
-
The function then iterates through arr using a for loop, stopping when it is two positions from the end of arr (arr.length - 2). This is because we are always looking for triplets and thus don't need to consider the last two positions in this loop.
-
Inside the for loop, two pointers, left and right, are initialized. left is set to i + 1 (one position to the right of our current position) and right is set to the last index of the array (arr.length - 1).
-
We start a while that continues as long as left is less than right. Inside this loop, we calculate the difference between the target sum and the sum of the numbers at our current positions in the array (targetDiff). This allows us to see how close the current triplet sum is to our target sum.
If targetDiff equals 0, that means the sum of our current triplet exactly matches the target sum, and we return the targetSum immediately as our result.
Otherwise, we check if the absolute value of targetDiff is less than the absolute value of smallestDifference (meaning we've found a closer sum), or if it's equal but targetDiff is greater (meaning it's a larger sum that is equally close). If either condition is true, we update smallestDifference with targetDiff.
I find that bolded part confusing because it is said "If there are more than one such triplet, return the sum of the triplet with the smallest sum." if we are interested about smallest sum, shouldn't we check that targetDiff is smaller than smallestDifference
I solved that problem in the other way but I find that part of explanation cofnusing
if target_diff > smallest_difference and abs(target_diff) == abs(smallest_difference) then that means that - smallest_difference = target_diff as it smallest_difference is negative, then it is desired sum because we are looking for sum that is closer to target, no?
Input: [0, 0, 1, 1, 2, 6], target=5
Output: 4
Explanation: There are two triplets with distance '1' from target: [1, 1, 2] & [0,0, 6]. Between these two triplets, the correct answer will be [1, 1, 2] as it has a sum '4' which is less than the sum of the other triplet which is '6'. This is because of the following requirement: 'If there are more than one such triplet, return the sum of the triplet with the smallest sum.'
if there are two things equally close you want the smaller one
if targetdiff is target - yoursum then you want the positive version in the case of a tie
Yeah, now when I started to think practically in examples I understood. Like target - sum that is positive means that sum is actually smaller and that is what is wanted if there is tie
is there a 3d graph in which the parent node sits atop 4 children forming the corners of a square (pyramidal overall shape), and each of those children in turn have 4 child nodes in the same shape, and so on?
is anyone working on a data structure viewer for VR?


OKLCH color! converted it from a javascript implementation of it

oklch looks best at low chroma it seems, at high chroma it looks like shit


Hey All, i want to learn machine learning. Could you please help me get started with any training course or any material that can help me get going. Any help is appreciated.
aren't a bunch of combinations just not representable on screen and you pick the closest one?
idk
i just ported the code
It’s pretty inelegant, tbh (it uses a lot of magic numbers) but it works
And it’s not even my fault that it’s that way
that’s just how it is i guess
it’s also possible i fucked up some part of the implementation , but i kinda doubt it
javascript implementation of it i used as reference https://observablehq.com/@shan/oklab-color-wheel

Observable
“Oklab is able to predict perceived lightness, chroma and hue well, while being simple and well-behaved numerically and easy to adopt.” This is a fork of @fil’s oklab port.
isn't that kinda the whole point of oklch?
😵💫
damn! bitches be using 0-360 for hue! you hate to see it!
oh yeah btw it seems so that some values just aint there
If you look at pictures of the color space it looks like someone took bites out of it
not sure how you’d clamp that or whatever but

so the idea as I gathered is to have a color system that's better behaved wrt human eye sight
percieved brightness and whatnot
feels like there should be some kind of test suite for it
Probably