#algos-and-data-structs
1 messages · Page 41 of 1
what does the value of the areas even imply then? 
infinite seems as good of an answer for the thing you were asking
infinite is quite a bit harder to program and a lot less useful lol
I'm more asking why either is more valid of an answer
a set is opaque for the given area if, when graphed as i have done, there is no gray area that is left uncovered by both blue on the left and red on the right
NNeither is complete on its own
gotta have both to cover all options
the area of the grey after that of the colored is removed describes the range of lines that can pass through the square without touching a line
in an opaque set, this isnt allowed. so by finding the area of this, you can test how close a set is to being an opaque set. makes for a good fitness function
or wait, are these completely disjoint?
union is where both gray and colored is, right? im looking for grey true colored false
I have no clue about colors, I can't look at the plots atm 😅

I guess the relevant number you care about isn't computed
nah i get that number
in reference to the plots, left returned something like 0.75 maybe? right returned either 0 or something real close
hmm, it's area == 0 huh
its cool comparing the graphs. Try picking a spot on the leftmost plot with only grey, then picture the line it describes in the figure on the right. There r two main grey triangles, but even that tiny sliver under the upper triagle is pointing to that tiny gap between the two lines
just the areas themselves are not trivial to reason about
yup, none of those lines are able to pass thru the square without hitting a line
wdym?
actually it might be me being dumb, something like two opposite edges being covered by segments means one of the areas is 0, right?
if so I probably know what the areas actually mean
yup! thats why both have to be 0, and not just one or the other
a straight vertical line would do the trick for one of the graphs
you mean a vertical segment across the square?
neither area would be zero for that, no?
if it were long enough. it would have to be double the height of the square tho
(for an actual line both would be zero)
even though lines through the square exist
a vertical line is not an opaque set, despite the area being zero
correct. the area would only be 0 on one plot, even with infinite height. parallel lines would still disqualify it
the goal of the math problem tho is to find the set with the shprtest possible total length for a given area
so the currently printed numbers don't catch that kind of case
I dont plan on working with infinite lines, just line segments
you're saying this kind of limit case is exclusive to this infinite case?
besides thats a fairly easy question. I believe any two infinite lines with different slopes make an opaque set of any finite area
I guess it's probably the case if the segments include the endpoints
couldnt say for sure
but seems so
im gonna make another more interactive program that would allow the drawing of lines on the rightmost plot next
any1 know this?

I know it's not DS&A
or really python related
(also all those answers are plainly wrong except one)
well it could be both dsa and python related
If there weren't options I would have chosen a completely different answer🤔
are you thinking
||left difference 0/1 = 0
right difference 178/1 = 178
central difference 178/2 = 89||?
i think it is a image kernel function i have seen these while working on images
i have no idea now
so I guess it's either ambiguous, all answers wrong, or the lengths are a bit wacky (which I suppose is also under ambiguous, but differently ambiguous) 🥴
yes, I would have chosen ||option 3|| because that's at least what I would consider the most "correct"
I think we lack context and there should be a definition of gradient of image somewhere, we just not have that
the one thing we can all agree on is that ||option 4|| is wrong
the other 3 are at least feasible depending on the definition used
How so that sometimes formula for heap left and right child is
def leftChild(self, pos):
return 2 * pos
def rightChild(self, pos):
return (2 * pos) + 1
and sometimes it is
def left(k):
return 2 * k + 1
def right(i):
return 2 * k + 2
the first variant is used for 1-indexed heaps, the second is for 0 indexed ones
-----------1-----------
-----2----- -----3-----
--4-- --5-- --6-- --7--
8 9 10 11 12 13 14 15
vs
-----------0-----------
-----1----- -----2-----
--3-- --4-- --5-- --6--
7 8 9 10 11 12 13 14
Since you store heap in the array, you can choose how to index it. In 1-based indexing you have an unused element at index 0, but simplier formulas (and a few other nice propertices).
Thanks for explanation, I assumed that but was wondering why it is not always one way or other?
see also #algos-and-data-structs message
Thanks, will read tomorrow
(it's really just two messages but ok)
Hello, I'd like some advice/resources for putting together quality interview problems. I recently started the computer science club at my university, and I'd like to be able to provide ~20 minute sessions where members work on solving interview-esque problems, but I'm not really sure what's the best way to go about it. Firstly, I'm a first-year, so I'm not the most experienced person to put together problems, and secondly, I know that many of the members come from different coding backgrounds, and I don't know how I can accommodate this. Any help?
why not just find leetcodes or something
would you say it's the best site for coding interview problems?
I'm kind of concerned about using leetcode considering the easy problems are still very challenging if you're still learning basic python syntax
if people are struggling with basic python syntax they should probably be working on that, not try interview problems
true 😹
why would you prep for coding interviews if you dont know how to code properly
That's a fair point, but it sounds like what @aban is saying is that they are looking for an activity for a group that has varying levels of experience and skill, is that right?
Projects that they can make that are varying amount of levels?
that's hard to do without either boring the better ones or completely leaving beginners in the dust
in particular the people who don't know basic programming is going to have big issues
if you have at least basic programming under your belt you can pretty easily adjust problem difficulty
Can someone pleas help me with 8 Puzzle Problem using Manhattan Distance?
hello friends im having a lil trouble trying to print this logic table
Write a Python program that prints the truth table for the expression Ø p Ù(q Ú r). The table should contain a row for each possible combination of values for variables p, q and r. and columns for the final result as well as each relevant Boolean subexpression.
this is what i need to print and idk how to make a table with that
def negation(p):
return not p
def conditional(p,q):
if p:
return q
else:
return True
def conjunction(p,q):
return p and q
def disjunction(p,q):
return p or q
def biconditional(p, q):
if p==q:
return True
else:
return False
def Test00():
print(conjunction(True, False))
print(disjunction(True, False))
print(negation(True))
print(conditional(True, False))
printTableFunction1()
printTableFunction2()
def printTableFunction1():
for p in (True, False):
for q in (True, False):
print("%10s%10s%10s" % ()
def printTableFunction2():
for p in (True, False):
for q in (True, False):
print("%10s%10s%10s" % (p,q,disjunction(p, q)))
Test00()
that is so far what we have done. im not sure how or what to do to add r and add the tables with the negations and such


how's it going guys
hello python experts, im learning about complexities and was wondering if i could get a feedback on my work so far (theyre pretty basic functions, but im still not sure if im doing them correctly):
https://imgur.com/a/VQRl8qn
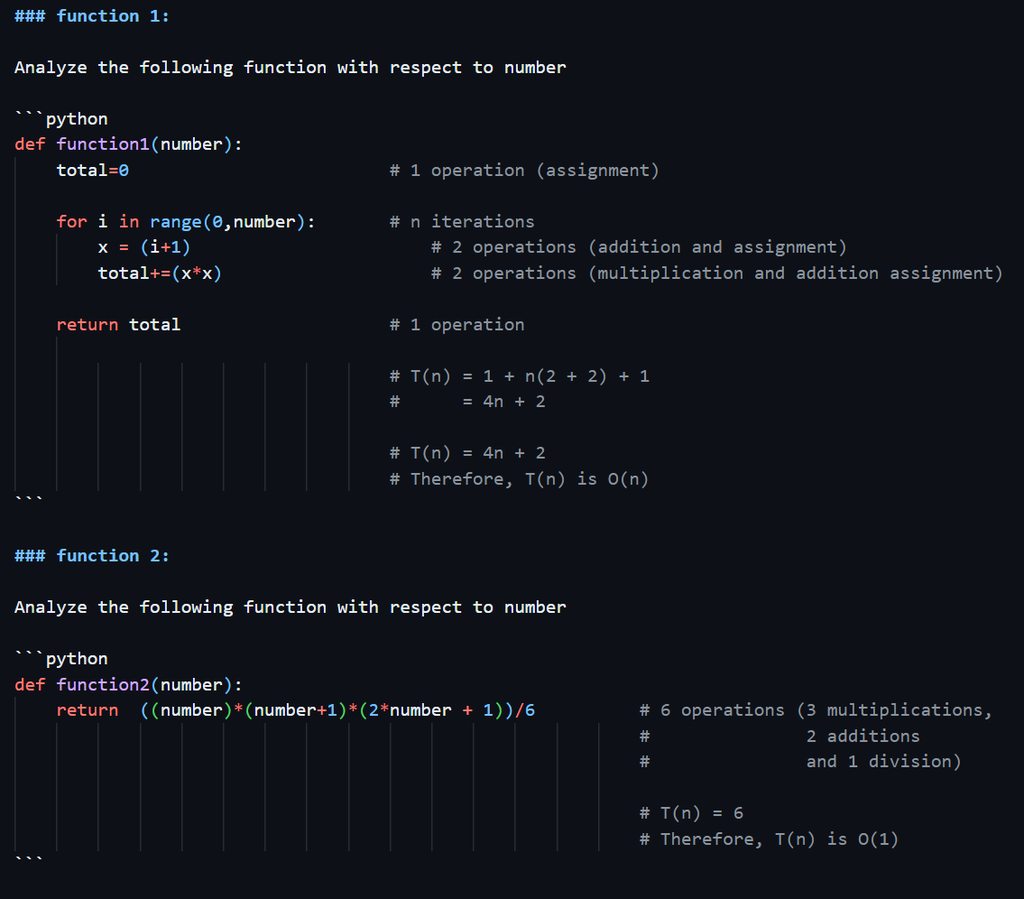
it is correct
but usually you dont need to calculate exact complexity (like 4n+2), you approximate it along the way
thank you very much for the reply but im a bit not confident because one of my classmate says that the for loop lines (in function 1 and function 4) should be 1 + n and 1 + (n - 1) respectively... is this correct information?
usually that doesn't matter
n+1 is O(n), so you shouldn't care
i understand that the small constants are meaningless but i still want to understand exactly what's going on ... so for function 1's for loop, should it be n? or n + 1? 😮
no, he is wrong
range(10) contains 10 ints from 0 to 9
so iterating over range(n) is n iterations, and iterating over range(1,n) is n-1 iterations
range(n) is the same as range(0,n) btw
the reason why he said the + 1 is needed was because the fact that the range function needs to be initalized or something ...
just to confirm:
for i in range (0, number)
should be n, not n + 1, correct?
whereas,
for i in range(1,number)
should be n - 1, not (n - 1) + 1
then you should count range(0,n) as 4 operations:
- loading range var
- loading const 0
- loading n var
- calling range with two args
doing that doesn't really make any sense, so you should think about this as one O(1) operation, and exact number of operations doesnt matter (and it is impossible to calculate correctly)
it is n iterations, yes
complexity of constructing range object doesn't affect number of iterations
and following up on this, could you please confirm if:
for i in range (1, number)
is n -1?
i think @regal spoke can say something more useful on this topic, his knowledge in this area is a lot bigger than mine
what do you think?
i have no clue because some people are telling me that range itself is + 1 operation
while (1, number) for example would be n - 1 ?
im so confused which is why im here, hoping someone could clarify
iteration != operation
you can add prints in your loop, run it and just count the number of times stuff is printed to determine exact number of iterations
exact number of operations doesnt make any sense, because it will be different on different machines, oses, versions, builds, time and weather
exact number of iterations doesnt matter too, you just approximate it to the most significant term
i mean, im just following these notes: https://seneca-ictoer.github.io/data-structures-and-algorithms/B-Algorithms-Analysis/how-to-do-an-analysis
but holy crap my brains exploding
How to do an Analysis in 5 steps
so confusing to identify how many operations each line is
For big O analysis you really shouldn't be counting the exact number of operations. The point of the big O notation is that you dont need to do that.
i understand, but since this is literally our first steps into complexities, our prof wants us to follow these steps to determine how many operations are in each line of code
so your function1 consists of:
- O(1) - because you are doing some O(1) stuff in the body
- +nO(1) - because you are doing O(1) roughly n iterations
so O(1)+nO(1) is O(n)
and if possible, i would like to understand it
Normally if people want to analyze the number of operations carefully, they count things like number of additions and/or number of multiplications
But very few people ever bother doing that
i dont get why many people think that this trivial complexity analysis is complicated
yes, complexity analysis can be hard in some cases, but in most cases it is truvial
please help me understand, thank you so much for your patience with me:

step by step here, line 10 = 1 operation right?
The distinction you need to make is if a line of code takes constant time or not.
For example
total += x * x
takes constant time, so O(1),
but something like
total += sum(range(n))
takes O(n) time.
not really
it is 1 for loading constant 0 onto stack and 1 for storing it in total var
then you can dive into cpython source code to look what LOAD_CONST and STORE_FAST are doing and count number of operations there
conclusion: you shouldn't care, it is just O(1)
assigning to global var can cause globals dict to expand, and it can take arbitrary big amount of time
yeap i understand this, thank you but my prof specifically requires me to write down the number of operations each line of code involves...
and thats the part i dont understand mostly-- the little details (im aware these little details will be omitted at the end anyway, but i still would like to know)
just write it as 1 op
you'll need to know what counts as an operation. usually that will be arithmetic things + some other stuff
so if line 10 is 1 (assignment operator), then line 12, the for loop ....
im so close to just screaming my lungs out
13+14 is also 1 op
so for loop is just O(1+1*n)=O(n)
I honestly think that is kinda stupid.
There is no exact definition of a "operation". If you actually want to count operations, then I would count number of additions + number of multiplications (and maybe + number of assignements).
But like for example I have no clue how many "operations" range(0, number) takes internally in Python.
The exact number of operations doesn't matter in the end anyways. The only thing that matters is the big O
it is impossible to determine how many ops range(n) takes
range source code changes
machine code may depend on os and compiler
and there are a lot more things that can affect that
(it also allocates memory, which can also take arbitrary amount of time)
Had the for loop been coded manually like
i = 0
while i < number:
x = i + 1
total += x * x
i = i + 1
Then you can make a formula for the exact number of additions and multiplications that the code does
This is what I would do if I actually needed to specify the number of operations per line ^
and you still need to assume the < and other math is constant 😩
My point is that by doing things like this I could count the exact number of operations
If I wanted to I could seperately count number of additions, number of multiplications, number of assignements, number of comparisions
im sorry but i must be very stupid ....
i just want to know how many operations this line of code is:
for i in range(0,number)
from what im understanding, there's no definite answer?
and the answer cannot exist
There is no right answer to that. Python just guarantees the number of operations is O(number).
any answer other than "it is O(1)" is incorrect
this is what my course notes is stating, for reference:

This is just stupid and it is a very naive way of analysing code ^
yeah
and this i have no idea wwhy it's n-1

for ...: line cannot exist by itself
there must be a body of a for loop that also has some complexity
and you add complexity of loop initialization and product of number of iterations and body complexity
range(2, n + 1) starts at 2 and ends with n
Thats n - 1 iterations
so this would be n iteration?
if n=4, fpr example
then it iterayes through 2,3,4
it is 3=4-1
(i cant type properly today)
so here:
for i in range(1,number)
this would be ... n -1 right?
have you tried running this code and just counting number of iterations manually? thats easier than asking
ok... so now im confused as to why it wasnt a concrete answer before O_O
oh i will state "let n represent number"
LOL
Why not just use n in the first place in that case?
im attending a cheap college guys please
i guess single-letter var names are banned by his silly prof
work with me
The number of iterations of a for loop over a range has a definite answer. But the exact number of "operations" that that takes does not have a definite answer.
The reference code used n ^

i'm going to sleep, bye 💤
thank you for your help denball
Oh no, is that task trying to argue the time complexity of calculating factorial 
yeah i think so ...
just showing how to analyze
this is the link if you wann acheck it out:
https://seneca-ictoer.github.io/data-structures-and-algorithms/B-Algorithms-Analysis/how-to-do-an-analysis
How to do an Analysis in 5 steps
its supposed to be a 5-step analysis
now im screwed cus the last function is the hardest:

The problem is that when you calculate factorial, the numbers grow super big. So counting 1 multiplication as 1 operation is a total lie
So no sane person would ever make a task to calculate the time complexity of computing factorial
looks like O(n^2) where n is len(list)
is that a bubble sort?
Btw don't call a variable list in Python. Variable names like list and sum are already taken by built in functions
Here is how I would analyse that code.
Note that everything inside the two for loops takes a constant number of operations. So the only thing that matters for the time complexity is the number of iterations of the two nested for loops
Now you can either come up with a math formula for the exact number of iterations, which turns out to be n * (n - 1) / 2

Or you can just note that both of the for loops run at most n iterations. So the total number of iterations is <= n^2. Meaning it is O(n^2)
ahhh im sorry but its very hard for me to understand... im not getting the E notation stuff either ...
going step by step again.. would the first for loop (for i...) be: n - 2?
since it's going from 0 to len(list) - 1, which is the same as 0 to n - 1, which would be n - 2 right?
The outer for loops goes from i = 0 to i = n - 2, yes
and the second, inner for loop (for j... ) would be n - 2 - i, right?
yes
Thats why my two sums look like this

"sum from i = 0 to n - 2, sum from j = 0 to j = n - 2 - i"
Maybe my calculations are easier to understand as code.
- We want to calculate this (
counthere counts the number of iterations of the nested for loops)
count = 0
for i in range(0, n - 1):
for j in range(0, n - 1 - i):
count += 1
- Which is the same as
count = 0
for i in range(0, n - 1):
count += n - 1 - i
- Now we can simplify things by bringing the (n - 1) outside of the for loop
count = (n - 1) ** 2
for i in range(0, n - 1):
count += -i
- Using the formula that the sum of 1,2,...,n-2 = (n - 2) * (n - 1)/2. We get
count = (n - 1) ** 2 - (n - 1) * (n - 2) // 2
- Simplifying this expessions leads to
count = n * (n - 1) // 2
I was trying to make a push function for stack , I was wondering why my code is doing this weird thing where its storing two values rather than one value of what the user enters

Line 23 24
You called Push twice
this calls push twice

basically I was trying to solve this question


I would just do
if Push(user_input):
oh ok will try that rn, thanks
Btw you dont need to use global in the global scope
it does this

You didn't remove line 23
You are again calling Push twice

oh
i see, my bad
tysm, it works

@regal spoke also, is there a channel to post an OOP question I have?
Dont think there is a specific channel, no
Your code using OOP would look something like this
class Stack:
def __init__(self):
self.StackData = [0] * 10
self.StackPointer = 0
def Push(self, Data):
if self.StackPointer >= len(self.StackData):
return False
self.StackData[self.StackPointer] = Data
self.StackPointer += 1
return True
def __repr__(self):
return str(self.StackData[:self.StackPointer])

thanks
i had another question
where I was trying to add the object of the class card to an array
but it doesn't work
should it be false?
Well ye
But a better solution would be to do
for Num in open('CardValues.txt', 'r'):
instead of a while loop

oh you are calling readline multiple times

Your bug is a classic example of reusing variable names in a bad way
Card is the name of your class, but later on in your code Card becomes a list
Try not to reuse variable names like this, or use ```py
Card # for class
card # for object
I misread here by thinking the name of the array is cards somehow
but I have to declare an array of that has the data type of the class card
Python lists arent limited to specific data types
You can store whatever you want in them
I would probably do something like
Cards = []
file = open('CardValues.txt', 'r'):
while line := file.readline().strip():
card_num = int(line)
card_colour = file.readline().strip()
Cards.append(Card(card_num, card_colour))
print(Cards)
thanks, I was actually not familiar with what while line := file.readline().strip(): does
can you explain what it does basically
and also how will it work for a for loop if I need it later on
The walruss operator := is a relatively new operator introduced to Python.
Before it was introduced you had to do things like
line = file.readline().strip()
while line:
...
line = file.readline().strip()
or
while True:
line = ...
if not line:
break
With the walruss operator, you can instead move the variable assignment inside of the while condition
while line := file.readline().strip():
...
Think about it like (line := file.readline().strip()) returns the value of file.readline().strip() while also storing it inside line
thanks, this is actually really efficient
Ye that is a good solution too.
What would be even better was if the file 'CardValues.txt' had a header telling how many cards the file contains
That is the standard in competitive programming
they told us in the question but yeah it will be useful
how can i provide text input in the terminal for a rock, paper, scissors game
fr length prefixed >
how can i provide text input in the terminal for a rock, paper, scissors game
the input function?
sure idk
like i want it to ask rock/paper/scissors and then based on my input itll randomly choose one of those 3 each with a different value that will determine if you win or lose
Hey guys. I'm trying to come up with a formula for the following problem: Lets say i have a Person A, this person works for Companies C1, C2, C3. Person A has a score of lets say 4. This score is an arbitrary "contribution" score, i.e. you can think of it as all of the companies make cookies, and Person A created 4 cookies in a month. I want to find out what is Person A's contribution for the three companies. The only info i have is what is the average people contribution per company, e.g. if Person B, C, D works for Company C1 and their contribution score is 1, 2, 3 respectively, the average contribution on that Company C1 is 2. What i want to calculate is how to divide Person A's contribution for the linked companies he's working for in the month. E.g. Companies C1, C2, C3 has an average cookie count of 4,5,6, then Person A's contribution is divided into 3 values, A(C1) = (4/(4+5+6))*4, A(C2) =(4/(4+5+6))*5, A(C3) = (4/(4+5+6))*6. This is basically the relative change formula, my problem comes from the fact that Companies can make negative number of cookies (not a good business eh?), which flips the whole calculation off. Any recommendations where to look?
just manually compile to bytecode in your head and execute, lol
adaptive interpreter is too complex to run it in my head
it will become even harder in the future, because jit is even harder. i guess even guido will not be able to compile it in his head
just in-head compilation
Hey guys
i wanna kms
class Solution:
@staticmethod
def rindex(arr, value):
last_element_index = len(arr)-1 #last element index
while last_element_index >= 0:
if arr[last_element_index] == value:
return last_element_index
else:
last_element_index -= 1
return None
def twoSum(self, nums: list[int], target: int) -> list[int]:
nums = nums
i = 0
while i < len(nums):
a = nums[i] # a is first element
b = target-a # b is target minus a
if b not in nums:#[:max(i-1, 0)] and b not in nums[i+1:]: # b is not in list, no solution including b
for _ in range(nums.count(a)):
nums.remove(a)
else: # b is in the list, but it doesnt mean, that b is the correct value
# print(nums)
# nums[i] = None
# b_index = nums.index()
# print(nums)
print(Solution.rindex(nums, b))
if i == nums[i+1:]: pass
else: return [i, nums[i+1:].index()]
i += 1
trying to get most efficient solution (in python)
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Example 1:
Input: nums = [2,7,11,15], target = 9
Output: [0,1]
Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2:
Input: nums = [3,2,4], target = 6
Output: [1,2]
Example 3:
Input: nums = [3,3], target = 6
Output: [0,1]
Constraints:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
Only one valid answer exists.
you should learn about sets and dictionaries
Hint: The equation x + y = a is the same as a - x = y
Oh you are aleady using that
Next hint: What would you do if nums was sorted?
what to do when having duplicated columns after merge but columns are actually the same.
name option_1_x option_2_x option_3_x option_4_x option_5_x option_1_y option_2_y option_3_y option_4_y option_5_y
i'm using pandas result result = df.merge(df2, on="name", how="left")
can any one help me with avl tree rq?
Hello everyone, I'm solving this codeforces problem (https://codeforces.com/contest/1873/problem/G).
I'm not looking for a solution or any hint but rather I have a complexity question.
My naive code is this one:
@lru_cache(maxsize=None)
def solve(my_string, coin) -> int:
max_coin: int = coin
for k in range(len(my_string)):
if my_string[k:k+2] == "AB":
max_coin = max(max_coin, solve(my_string[:k] + "BC" + my_string[k+2:], coin+1))
elif my_string[k:k+2] == "BA":
max_coin = max(max_coin, solve(my_string[:k] + "CB" + my_string[k+2:], coin+1))
return max_coin
if __name__ == "__main__":
n_test: int = get_int()
for _ in range(n_test):
s: list[str] = get_string(as_list=False)
n: int = len(s)
if n <= 1:
print(0)
else:
print(solve(s, 0))
Obviously Time Limit Exceeded, but I wanted to try to code the naive solution first.
However, it's unclear to me how I could quantify the complexity?
Even without the cache, I find it hard to know exactly what the complexity would be
I imagine for a string like this AAAAAAA, this is a "good scenario" and for this "ABABABABABAB" we are in a bad scenario complexity-wise. For this bad scenario, on the first recursive call we would launch BCABABABABABA then ACBBABABABABA then ABBCABABABABA then ABACBBABABABA etc ... so n things, then for these n things, we launch n-1 or n-2 things but then, what is the total complexity, n!? I am not even sure.
The biggest question is with the cache, we drastically reduce (although not enough to pass) the complexity but it's quite hard to count how the complexity changes, right?
hi any body hear who could help with data structure and algorhtims in python?
#ot2-never-nester’s-nightmare message @subtle lichen
It combines a couple of different ideas:
The main idea is that if you remove equally many numbers from A+B that are smaller than the median as are larger than the median, then the median stays the same
There are two cases, either
- A and B have roughly the same size
- A is significantly smaller than B
In case 2, there is a simple trick to make B much smaller.
Simply remove everything from B apart from the central 2|A| elements if |B| is even, or 2|A| + 1 if |B| is odd.
(if this feels unnatural to you then think about what happens if |A|=1. Then the median of A + B is almost the same as the median of B itself)
.
With case 2 taken care of, A and B have roughly the same size (one can be atmost twice the size of the other)
For case 1, use the fact that the median of A + B is somewhere between the median of A and the median of B.
Suppose WLOG that the median of A is smaller than the median of B
Pick some x < min(|A|, |B|)/3 (x could be chosen more carefully, but this works)
Now remove the first x elements of A and the last x elements of B.
The elements removed from A are guaranteed smaller that the true median, and the elements removed from B are guaranteed greater than the true median
So according to the main idea, the median of the modified A + B stays the same
If we now alternate between case 1 and 2, it will take log(n + m) iterations to get down to both A and B having constant size. And at that point, we can just bruteforce the solution
Time complexity involves figuring out the worst case for that solution for that solution. And I don't know what that worst case would be
I can just promise you that it wont be fast
Here's my quick-and-dirty analysis:
A string without any Cs spawns O(n) new function calls, each with 1 C.
Each C "blocks" ~1 pair from resulting in a new function call.
So it seems like what we care about is the number of non C characters in the input.
The first call spawns n calls, each of which spawns n-1 calls, etc. So I'd estimate the complexity without the cache as n * (n-1) * (n-2)... = O(n!)
That's obviously very bad, but maybe the cache makes up for it?
To get a handle on how often the cache is relevant, we need to figure out how often the function is called with the same input.
Each function call adds exactly 1 C, so if any two inputs are duplicates, they occur at the same depth of the call-tree.
At depth z, there are n! / (z!(n-z)!) unique ways to arrange z Cs. (This is implicitly assuming every non C character doesn't matter, which is half true since they all come from the same original input, however adding a C also moves the B around. Hopefully this simplification doesn't change the math too much.)
Summing those unique inputs for each level of the call tree gives O(2^n).
Notice that you can't earn a coin from a pair that includes a C. This means that instead of adding the C, you can effectively split the string into two sides and calculate the possible earnings for each.
This will result in smaller inputs which will hit your cache much more often (caveat: I haven't calculated the asymptotics for that).
my approach to this task:
- notice that B is kinda jumping into A and leaving C behind, that give you 1 coin
- we can divide string into clusters of A with B's in-between
- now we should decide where each B should jump (to the left several times, or to the right) to maximize profit
- if beginning or end of string is B, then we can "collect" all A's
- if not, we should ignore shortest A-cluster and collect everything else
this requires linear time and constant memory (except for string itself)
this is a bit wrong
some B-clusters (with len >= 2) can go in both directions, we should also account for that
||```py
1st try, wrong:
for _ in range(int(input())):
s = input()
if s[0] == 'B' or s[-1] == 'B':
print(s.count('A'))
continue
print(s.count('A') - min(map(len, filter(bool, s.split('B')))))
2nd try, correct:
for _ in range(int(input())):
s = input()
if s[0] == 'B' or s[-1] == 'B':
print(s.count('A'))
continue
print(s.count('A') - min(map(len,s.split('B')))) # <- change here
Is it mostly intuition making you believe the cache won’t reduce the time complexity enough then?
Ohhh clever way, so cache would help go from n! to 2^n?
that's my guess, but the half-true assumption I mentioned could change that
either way, the tweak I mentioned would make it better, and denball's iterative way is much better
Hi, im extremely new to python. Can someone help me understand the difference between enumarate and in range?
!enumerate
The `enumerate` function
Ever find yourself in need of the current iteration number of your for loop? You should use enumerate! Using enumerate, you can turn code that looks like this:
index = 0
for item in my_list:
print(f"{index}: {item}")
index += 1
into beautiful, pythonic code:
for index, item in enumerate(my_list):
print(f"{index}: {item}")
For more information, check out the official docs, or PEP 279.
!range
Pythonic way of iterating over ordered collections
Iterating over range(len(...)) is a common approach to accessing each item in an ordered collection.
for i in range(len(my_list)):
do_something(my_list[i])
The pythonic syntax is much simpler, and is guaranteed to produce elements in the same order:
for item in my_list:
do_something(item)
Python has other solutions for cases when the index itself might be needed. To get the element at the same index from two or more lists, use zip. To get both the index and the element at that index, use enumerate.
!iteration
Iteration over dictionaries
There are two common ways to iterate over a dictionary in Python. To iterate over the keys:
for key in my_dict:
print(key)
To iterate over both the keys and values:
for key, val in my_dict.items():
print(key, val)
The number of possible of n long strings with 3 characters (A, B, C) is 3^n. So with caching your time complexity is trivaially never worse than 3^n * poly(n).
That being said, a time complexity like 3^n or 2^n is still horribly slow
You don't actually need that if statement
||
for _ in range(int(input())):
S = input()
print(S.count('A') - min(len(s) for s in S.split('B')))
||
Here are two codegolfed versions (both 74b)
||
for b in'B'*int(input()):print(sum(sorted(map(len,input().split(b)))[1:]))
for b in'B'*int(input()):print(len(''.join(sorted(input().split(b))[1:])))
||
73b
||
exec(int(input())*"print(sum(sorted(map(len,input().split('B')))[1:]));")
exec(int(input())*"print(len(''.join(sorted(input().split('B'))[1:])));")
||
Oh good point
Yeh yeh of course but I was still curious on the complexity part change the cache brings
More of a curiosity thing rather than a practical thing
Also not going to look at your solutions for now, I’m trying to find the answer on my own!
caches just don't magically make things fast
it all comes down to how many states you explore, and how much overlap there is in state exploration
loads of overlap (states visited a lot) means a cache can have great impact
okay so, how do i await a list of coros?
like this one?
runner = asyncio.create_task(run_bot())
serv = asyncio.create_task(server.keep_alive())
mtask = [runner, serv]
asyncio.gather if you want to run them all and wait for all of them to complete. asyncio.wait if you need something else like "run them all and wait for the first one to complete".
promises in a trenchcoat
How would one do
given a graph, remove edges so that the graph is split into k graphs and max weight of an edge is minimized
What do you mean the ‘max weight of an edge is minimized’?
hmmm that sounds like a Spectral Clustering problem
Oh, I was thinking this is some sort of minimum spanning tree type thing
I think MST to remove the redundant connection then split?
That is machine learning my friend, with edges the edges and their weights already exist all you can do is do cuts to cluster them into k graphs
oh sht
I would utilize as per my notes either Normalized cuts, MinCut as what I'm seeing from my notes
from what is described to me, it showed up on a intern Oa for swe 🤔 (cloud computing role)
Well lets entertain the concept
Lets not, I wanna get into the nitty gritty detail about something
I dont think I understood the problem and got the wrong idea
Ah
On the classical side, I was thinking they’re suggesting a greedy algorithm (removing highest cost edges until you have k subgraphs), but I think your description leaves something out
its for a intern role swe role idk why they would ask this
His descriptiion wants k amount of graphs from an existing graph with vertices and edges that already exist
I think doing MST would be ideal to remove redundant connection?
but my question is
I like the minimum spanning tree then cut along highest cost remaining
Would you do DSU to check if you remove an edge, it would disconnect the graph?
idk if this would work for all cases
wait
🤔
like track the largest edges and then remove k?
basically heap
@proven wedge any thoughts?
BillyBobby 🤔
My understanding of undirected graphs
is as such
: when you have vertices, and edges you want to traverse through the graph via edges to an annotated node that is logged we usually traverse in a boolean style manner node to node. When we talk about weights on edges I don't think that is necesssarily an undergraduate topic for typical data structures.
For instance we say in a table V1 to V2 = true denotating an edge from two vertices
and vice versa of V2 to V1
Weighted edges is literally what I'm doing in my statistical data Modeling class at the Graduate level
what about MST then Heap remove top k edges?
😹
orz
sounds tough
if an edge is V1 to V2 = 5(vs per se = true) , and formated as such then I could see you create a list, then you can sort that list and do a flag of the vertice connections such that V1 to V2 == 5 ? True against your list of edges.
then you can order that
whch should give you a list of "weighted" edges
you can order that in whatever preference you want
I dont understand what you're describing 🤔
so when we create an undirected graph there are numerous implementations
LinkedList, Hashtable,etc.
We can check our Vertices in said data structure for its connection to the next Vertex in our List of our chosen data structure
By iterating through such that we are checking for a set of values , we can implement it by storing the previous value checked, or via already known values
Say edge(V1)
that function call may display all vertices it is connected to
we may have another function that checks our weights list for each connected vertex
I assume your weights are already known for each connected vertex
I guess I understand what you're trying to say but what is your high level description of the algo
in terms of the algorithm recommended to use?
Yea, I assumed you were trying to describe an algo to solve this 🤔
shoot I'd have to google it, I don't remember names like that; I had to flip through my notes just for spectral clustering
You were right in your assessment
Minimum Spanning Tree
for the minimized path if your traversing
if you're identifying nth clusters of a giant cluster of a graph that is graduate level CS
I hope i was able to help
im being told you have to do it reverse 🤔
add nodes instead of removing
Erm, then you do a simple if else couldn't use of checking where to add your node?
or case?
I guess,
I am assuming
Sorting the edges based on the weight
and if adding the edge is duplicate, than dont add
and we need to make up until k?
taking the max after k
Im not sure about this. Could you end up with a case where you must use the most expensive edge because of selecting cheapest first?
I just realized if you do kruskal with dsu it will do the k thing automatically 😹😹😹😹😹
@modern gulch thoughtS?
I don’t know what dsu is. College was a long time ago 🙂
Disjoint set union/union find
Well it brought complexity from n! to 3^n which is huge
But yeh obviously
I still need to work on finding a linear solution
what?
cutting a giant cluster of edges/vertices into k clusters where the weight of the edges are minimized by cutting specifically edges is ML
giving that problem with a general undirected graph is a bit odd. it wasn't a tree to start with?
It's a technique called Spectral clustering I intitally didn't understand the verbiage
regardless you can do the MST and then keep removing edges
It was miscommunication*
its more of a "cutting" than a literal cutting
for MST
if literally cutting edges then it's spectral
every edge removed from the MST will create a new subgraph
Nah i dont have all the info given for the problem, so i was told it was just a tree
"sort edges and add them using dsu to check if they're already connected"
class UF:
def __init__(self, n):
self.parent = {}
self.rank = {}
self.count = 0
for i in range(1, n + 1):
self.parent[i] = i
self.rank[i] = 1
self.count += 1
def find(self, node):
p1 = self.parent[node]
while p1 != self.parent[p1]:
self.parent[p1] = self.parent[self.parent[p1]]
p1 = self.parent[p1]
return p1
def unite(self, n1, n2):
p1 = self.find(n1)
p2 = self.find(n2)
if p1 == p2:
return False
if self.rank[p1] > self.rank[p2]:
self.rank[p1] += self.rank[p2]
self.parent[p2] = p1
else:
self.rank[p2] += self.rank[p1]
self.parent[p1] = p2
self.count -= 1
return True
def solve(arr, n, m, k):
if k == 1:
return max(w for _, _, w in arr)
sortedArr = [[arr[i][-1], arr[i][0], arr[i][1]] for i in range(len(arr))]
sortedArr.sort()
largestConnection = float("-inf")
uf = UF(n)
for w, x, y in sortedArr:
print(uf.count)
if uf.count == k:
break
if uf.unite(x, y):
largestConnection = max(largestConnection, w)
print(uf.parent)
return largestConnection
print(solve([(1, 2, 1), (2, 3, 2), (3, 4, 3), (4, 1, 4), (1, 3, 5)], 4, 5, 2))
this is my current solution, i am p sure its wrong
yeah, that's Kruskal's MST algo
MSU?
I dont know much about MST, but I assumed greedly connect the graph
Any thoughts on my implementation, I think its wrong but I just gave it a try
that's what Kruskal's algo does
yeah I used dsu to do it
i kinda guessed
it greedily builds the MST, you just stop early
pretty sure if you stop Kruskal early you have the cheapest forest with k edges
idk what that means 😹
a forest is a collection of trees
🤔
without any edges you have n separate trees
hmm
"empty" trees if you will
Why is it called a tree?
when you add an edge you will connect two of them, reducing the overall number of trees by 1
Yeah
they kinda look like trees, they are graphs without cycles
Yea I agree
this is my first time doing MST
but can you check my implementation based on what you think the sol is
you could check out https://en.wikipedia.org/wiki/Kruskal's_algorithm#Pseudocode

Kruskal's algorithm (also known as Kruskal's method) finds a minimum spanning forest of an undirected edge-weighted graph. If the graph is connected, it finds a minimum spanning tree. (A minimum spanning tree of a connected graph is a subset of the edges that forms a tree that includes every vertex, where the sum of the weights of all the edges ...
based on the gif, thats what I am doing 🤔
i am just unsure about the k part
idk if greedy solves it https://upload.wikimedia.org/wikipedia/commons/thumb/b/bb/KruskalDemo.gif/300px-KruskalDemo.gif

it's just sorting the edges and trying to add edges to the DSU
Will there ever be a moment where it could skip k and get less?
as soon as you connect two previously unconnected nodes the number of trees goes down by 1
Yeah
no
adding an edge either does nothing or reduces the number of trees by 1
Yeah
the do nothing case is when the two nodes are already connected
def unite(self, n1, n2):
p1 = self.find(n1)
p2 = self.find(n2)
if p1 == p2:
return False
if self.rank[p1] > self.rank[p2]:
self.rank[p1] += self.rank[p2]
self.parent[p2] = p1
else:
self.rank[p2] += self.rank[p1]
self.parent[p1] = p2
self.count -= 1
return True``` I guess my unite function with the global count var is fineYeah
that looks like what I would expect of a DSU impl yeah
ok
this is roughly the one I've done for ages
class MergeFind:
def __init__(self,n):
self.parent = list(range(n))
self.size = [1]*n
self.num_sets = n
def find(self,a):
to_update = []
while a != self.parent[a]:
to_update.append(a)
a = self.parent[a]
for b in to_update:
self.parent[b] = a
return self.parent[a]
def merge(self,a,b):
a = self.find(a)
b = self.find(b)
if a==b:
return False
if self.size[a]<self.size[b]:
a,b = b,a
self.num_sets -= 1
self.parent[b] = a
self.size[a] += self.size[b]
return True
Merge by size and path compression
What is Mergefind
another name for DSU
o
In computer science, a disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint sets. Equivalently, it stores a partition of a set into disjoint subsets. It provides operations for adding new sets, merging sets, and finding a representative member of a set.
I never knew that 😮
🤔
btw is there a way to check if you remove a edge, it will still be connected using DSU?
disjoint set union is more descriptive of what it is, merge-find is a good description of what operations you can do
not easily with DSU, no
makes sense
if you're free can you help me with another problem 😦
😹
also makes sense why you can't easily, cuz of path compression 🤔
without path compression you can do a tad more, but it's still limited
for doing that in the general case you want https://en.wikipedia.org/wiki/Link/cut_tree
A link/cut tree is a data structure for representing a forest, a set of rooted trees, and offers the following operations:
Add a tree consisting of a single node to the forest.
Given a node in one of the trees, disconnect it (and its subtree) from the tree of which it is part.
Attach a node to another node as its child.
Given a node, find the r...
Yea I saw that when I was searching it up
just putting the question in here will probably mean someone will look at it at some point
i posted it last time, it got hidden

Someone here posted this question before, but I couldn't figure it out how to do it in top down recursive dp (without TLE), and the iterative dp version seems to be hard too
Oh, this was the task I answered this to, wasn't it?
actually I'm not sure, that doesn't have such small k does it?
Yea
Yea k isn't small, i dont think you can do 3d dp
oh nvm, n is small
🤔
What would be your states?
Remove edges that violate the constraint. In the resulting forest find the largest diameter of the trees.
Given the small k, feels like some not too hard dp problem. Probably something like "longest chain using exactly i switches up to point j"
That's a classic problem, weighted interval scheduling```n is 2*10^3, how would you check what the last number was 🤔
if you use k as one of the states and i (index)
what is j and i
The classical problem is called longest chain?
those are 3 different answers you're quoting
Yeah, I copy pasted the whole thing cuz ima use what you said to do the rest
😹
The first one is diameter of a binary tree right
Which you stated alr
I couldn’t do the second one
Is the last one dp + binary search
Oh it is
Idk the greedy approach
problem 2 was discussed further down
Thanks
Just want to make sure rn
The solution can be done top down right
For q2
you can either continue one of the sequences from the last instance of the value skills[i] at no extra cost, or you pay one switch to continue from i-1 (if skills[i-1] != skills[i])
presumably you could do it top down
it's just harder for me to think about in this case
I don't even think of this as bottom up
it's just going left to right and computing the optimum
which I guess is bottom up, but the order you need to follow is so obvious
Like the classic knapsack, I can’t think of what the last value would be if I do top down
Not exactly knapsack but take it not take but extra constraint
the top down formulation is basically something like
skills = [...]
prev_index_of_skill = [...]
def longest(index, switches):
return max(
longest(index - 1, switches - 1) + 1,
longest(prev_index_of_skill[index], switches) + 1,
)
you need to do some calculations beforehand like prev_index_of_skill to be able to jump to the previous index when that skill occurs
but that's not too hard to do
for every possible skill store the last index it was seen, the walk along the array and update the last index seen as you go
so you would start out with something like None or -1, whatever you want to denote that there is no such index
and then look at the element in the array (say it has value s), look up the last time it was seen, store that somewhere, then update the index for the last time s was seen
Yeah I was gonna do -1
what do you mean by 74b
and 73b
74 bytes
As in number of characters
Just had a bit of fun trying to come up with as short of a solution as possible
They currently have the record of the shortest submissions on codeforces for that problem
ohh
yeh i'm currently just trying to solve them 😆
shortening them in several years maybe
The Bs either go right or left
ye
And we drop the last A cos it's like useless
not useless but like
too small
to waste a B on it
So what if you instead had
AABBAABA
so if the string starts with a B or ends with a B we just count the number of As
yeah that's the problem
if there's two Bs in a row
problem?
i don't have to drop it
i think
oh wait
if there are two Bs in a row
it's also just the number of As
What about
BAABAABA
I just count the number of As because it starts or ends with a B
s: list[str] = get_string(as_list=False)
n: int = len(s)
if n <= 1:
print(0)
else:
if s[0] == "B" or s[-1] == "B":
# answer is number of As
print(s.count("A"))
else:
# are there two Bs in a row in the string
# if so, answer is number of As
if "BB" in s:
print(s.count("A"))
else:
# drop one group of A
I'm doing something of the sort
yeh i think i got it
That is far too advanced from what you need
damn it looks so easy when you know the answer
Think about the string as
group of 0 or more As, a B, group of 0 or more As, a B, ..., group of 0 or more As
So for example
AABBAABA
would become
[2,0,2,1]
mmh
I did this to count the number of As
# drop one group of A
list_size_group_A: list[int] = []
curr_size = 0
for k in range(n):
if s[k] == "A":
curr_size += 1
else:
list_size_group_A.append(curr_size)
curr_size = 0
list_size_group_A.append(curr_size)
ans = sum(list_size_group_A) - min(list_size_group_A)
print(ans)
like the number in each cluster*
Looks about right, but you can do things in a much easier way
If you use Python's .split('B')
If i do .split('B')
I have [AA, "", AA, A]
from AABBAABA
from ABABA
I have [A, A, A]
!e
print('BAABBA'.split('B'))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
['', 'AA', '', 'A']
the min will be 0 if there is a B in the begnining
well
You wont even need any if statements
Yeah, compared to my code:
if __name__ == "__main__":
n_test: int = get_int()
for _ in range(n_test):
s: list[str] = get_string(as_list=False)
n: int = len(s)
if n <= 1:
print(0)
else:
if s[0] == "B" or s[-1] == "B":
# answer is number of As
print(s.count("A"))
else:
# are there two Bs in a row in the string
# if so, answer is number of As
if "BB" in s:
print(s.count("A"))
else:
# drop one group of A
list_size_group_A: list[int] = []
curr_size = 0
for k in range(n):
if s[k] == "A":
curr_size += 1
else:
list_size_group_A.append(curr_size)
curr_size = 0
list_size_group_A.append(curr_size)
ans = sum(list_size_group_A) - min(list_size_group_A)
print(ans)
😆
Took me like 4 days of thinking about it at least 1 hour a day + the hour I spent on it during the contest
to solve it
big sad
That is just the kind of problem this is
Probably something that would have made it easier is if you had tried solving small examples by hand
Like
ABBAABA
yeah it took me 99% of the time to understand the Bs was going right or left
thank you btw!
did you not read that part that said
⚠️ DO NOT SPAM to meet these requirements, or you will be banned from verifying! ⚠️
?
<@&831776746206265384>
sorry if this is the wrong channel, but is there a way to easily instantiate a subclass of a dataclass using an instance of it's superclass?
@dataclass
class A:
field1: str
field2: str
@dataclass
class B(A):
field3: str
A("field 1", "field 2")
B(**A, "field 3")
# i wish the above syntax expanded to:
B(A.field1, A.field2, "field 3")
# but it doesn't :(
there are some helper functions in dataclasses module, one of them might help you
!d dataclasses
Source code: Lib/dataclasses.py
This module provides a decorator and functions for automatically adding generated special methods such as __init__() and __repr__() to user-defined classes. It was originally described in PEP 557.
The member variables to use in these generated methods are defined using PEP 526 type annotations. For example, this code...
ill take a look, ty
i guess you can do **asdict(a), ... instead of **a, ...
dataclasses.asdict?
there's also dataclasses.astuple if you need that
Can someone explain what the time space complexaty for this solution would be?
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
while(val in nums):
nums.remove(val)
k = len(nums)
Time is O(n^2), where the worst case happens when nums is a list of all equal elements and val is also that element
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
nums[:] = [x for x in nums if x != val]
k = len(nums)
If you switch to this then the time complexity goes down to O(n)
idk if Im allowed to ask this, but does anyone know a solution to this? https://stackoverflow.com/questions/77209294/how-to-print-a-nested-parenthesis-pattern-with-depth-of-n ?

Stack Overflow
How can I print a "nested parenthesis" pattern with depth of N, meaning when:
n=1, it prints (),
n=2, it prints ( () () ),
n=3, it prints ( ( () ) ( () ) ),
etc.
I have this and this ...
!e
answer="()"
for cnt in range(1, 4):
print(answer)
answer = "("+2*answer+")"
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | ()
002 | (()())
003 | ((()())(()()))
ye
Your example and code is not matching there
wait wdym?
The stackoverflow example has
n=1, it prints (),
n=2, it prints (()()),
n=3, it prints ((())(())),
yeah and the code you provided doesnt do that
But as you can see, the code outputs
()
(()())
((()())(()()))
o hmm
Another thing I would like to point out is that nothing is wrong with the time complexity of the code, the answer string is simply super long when N > 20.

The time complexity of your program is not the issue here. The issue is that the answer is simply huge
yeah
ah okay, thanks pajenegod and monke!!
np
which channel is for cloud computing?
I don't think offhand that we have a topical channel for that.
ok
Any resources explaining how to implement a hash function ?

Python documentation
Source code: Lib/hashlib.py This module implements a common interface to many different secure hash and message digest algorithms. Included are the FIPS secure hash algorithms SHA1, SHA224, SHA256,...
That's for random hash functions, I think they meant object hashing for hash map type of data structures. The default algorithm for arbitrary objects in Python just takes the return value from id() and divides it by sixteen / bit shifts to the right by four
but it will skirt the definition of in-place for that problem
Oh was this about removing inplace with O(1) extra memory?
the class template is very much leetcode

LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
No it's general actually. It's for a homework where I am asked to implement a hash function for any kind of object ( and maybe test how good it is )
Decide what it depends on
The question is whether it's a hash used for stuff like hash tables or something like a cryptographic hash
just combine all constant fields into tuple and hash the tuple
thats it
works in 99% of cases
That is for a hash map that stores one type of object
not really, it will work well even if difderenr types are stored in same dict
if you really want the most generic of hash functions you'll write something that takes a stream of bytes and spits out a hash
e.g. str and bytes use siphash which is a general purpose hashing algo
ngl, it would be kinda nice if int would switch to siphash as well
It's for cryptography
siphash?
oh, the stuff you need to make
if so ignore anything to do with python's hash
Python uses x % (2**61 - 1)
Clearly that is the best solution
I'm sure no one will ever try to hash multiples of (2**61 - 1)...
Guys I have an idea
Why not make the hash of a string be equal to the first character of the string
It would run super fast
and it would match how Python is currently hashing integers
that's an unfair comparison, modding by 2**61 - 1 requires you to actually look at all the digits which makes it slower than hashing using the first few characters of a string
so the string hash would be even faster than the integer hash 
But we want to avoid collisions right?
!e
{i * (2**61 - 1) for i in range(10**5)}
@regal spoke :warning: Your 3.11 eval job timed out or ran out of memory.
[No output]
Not in Python we dont 
Really? I thought we do so dictionary lookup would be as close to constant as possible
Try running something like {i * (2**61 - 1) for i in range(10**5)}
It runs in O(n^2) time
Python's hashmaps are clearly fundametally designed to be "unsafe"
Yeah because they all have the same hash but this is a special case I guess
Having an obvious "special case" like this is still bad
Also, if you know how hashmaps work in Python, then it is fairly easy to come up with sequences of (small) numbers that make them run in O(n^2) time
!e
def dict_ddos_0(n):
pow2 = 1
while pow2 < 2 * n: pow2 *= 2
# Fill up all spots that 0 wants to use
A = [pow2]
i = 1
for _ in range(n - 1):
A.append(i)
i = (i * 5 + 1) % pow2
return A
# This part runs fast
B = {}
for a in dict_ddos_0(10**5):
B[a] = 1
# Make Python check for 0 in the dict which will take ages since
# the first 10^5 spaces where 0 could be at are occupied by non-zeroes
for _ in range(10**5):
0 in B
@regal spoke :warning: Your 3.11 eval job timed out or ran out of memory.
[No output]
💀
So what you're saying is that python's hash for ints is bad
Greatest hash map: RAM and use id as the hash function
Yes. Int hashing in Python doesn't use any kind of randomness. That is fundamentally what makes hashing integers unsafe
It is trivial to generate hash collisions, like {i * (2**61 - 1) for i in range(10**5)}
It is also easy to generate sequences of fairly small integers that if put into a hashmap makes the hashmap run in O(n^2) time
Still I didnt get an answer to my question, or I missed it.
So there are 2 types of hash functions, ones for maps and others for security.
Any good resources explaining how to implement any of these?
Indeed, seems good. Do you know why pythpn doesnt do it this way?
Maybe not all CPython objects are internally used as such
It's a waste to allocate memory for every object like the internalized ones
Two variables x and y can contain the same integer value without them being stored in the same address in memory...
Does that happen when threading
Oh yeah the hash of a value needs to be unique
It probably does with multiprocessing
it happens regardless
It basically always happens, unless the numbers are tiny (I think it is [-1, 255])
-5 to 256
!e
for x in [-6, -5, 255, 256, 257, 10**6]:
y = (x + 1) - 1
print(x, id(x) == id(y))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | -6 False
002 | -5 True
003 | 255 True
004 | 256 True
005 | 257 False
006 | 1000000 False
I think even just +0 works
!e
x = 10**6
y = +x
print(id(x) == id(y))
y = x + 0
print(id(x) == id(y))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | True
002 | False
apparently unary + doesn't
!e
def check(a):
return id(+a) == id(a)
for x in True, 10**6, 1e6, float('NaN'), float('inf'), +0.0, -0.0:
print(x, check(x))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | True False
002 | 1000000 True
003 | 1000000.0 True
004 | nan True
005 | inf True
006 | 0.0 True
007 | -0.0 True
!e
def check(a):
return id(a + 0) == id(a)
for x in True, 10**6, 1e6, float('NaN'), float('inf'), +0.0, -0.0:
print(x, check(x))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | True False
002 | 1000000 False
003 | 1000000.0 False
004 | nan False
005 | inf False
006 | 0.0 False
007 | -0.0 False
For nan and inf I'd expect True
granted, this will never happen because of python's dynamic typing and float and int being kinda intertwined
Oh maybe because nan can be used as an operand for all of these
Then nan at least though, no?
e.g. an int and the corresponding float will hash to the same value
!e
for i in range(8):
x = 123456789.0 + i * 0.2
print(x, hash(123456789.0 + i * 0.2))
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 123456789.0 123456789
002 | 123456789.2 461168608838143253
003 | 123456789.4 922337217552829717
004 | 123456789.6 1383505791907777813
005 | 123456789.8 1844674400622464277
006 | 123456790.0 123456790
007 | 123456790.2 461168608838143254
008 | 123456790.4 922337217552829718
it looks a bit silly
!e this makes me miss static typing so much
print({1: 'hi'}[1.0])
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
hi
Hii Guys, How can i improve my fundamentals in data structure and algo
yeah i am using it but still not improving
Yes, it takes some time - just learn by looking at the solutions and try to understand it
well i am also quite consistent i think my fundamental is not strong!
Well you should learn the following patterns: https://www.teamblind.com/blog/top-leetcode-patterns-coding-interview-questions/

Blind Workplace Insights
Preparing for a coding interview is anxiety-inducing for many software engineers and developers. There is often a lot of material to cover, but you do not have to spend weeks combing through hundreds of interview questions or studying how to code. Instead of spending time solving different coding problems or
And you can do that by looking up youtube videos for these certain patterns
GeeksforGeeks
A detailed tutorial on Data Structures and Algorithms (DSA) in which you will learn about full form of DSA, what is DSA, and how to learn DSA from scratch.
Besides grinding leetcode, how else are your studying DSA? Are you reading any primary sources (papers, text books, etc) and following the discussion/history of particular algorithms? There’s some great MIT OCW courses too. Leetcode might reinforce your skills at your current level, but if you’re hitting a wall… diversify your learning.
It’s not just about learning DSA, it’s also about becoming a more mature mathematical/algorithmic thinker. Reading graduate level papers and texts helped me a lot.
I also read others solution!
But i am stuck on new problems
Ok, it sounds like you're in a leetcode loop. You've been working hard at it for a month or two, right? And you're struggling to get to the "next level".
If learning DSA is what you want to do, there are other skills to work on... I'll pull up a few references/recommendations.
yeah i am grinding leetcode from months
What's your level of education?
i think i am just solving problems not working on my fundamentals
Have you taken a DSA course in college?
Yup, understood
Like i am doing leetcode from a year and still on a loop like i follow particular topic playlist and solve all problems
that include in that playlist
A bunch of stuff there is pretty garbage "patterns"
A bunch of those are basically, you solve this problem by solving this problem
e.g. K-way merge
which is one very specific thing already
it's not a pattern
imo, if you want to excel at this subject (DSA), I suggest you take a break from leetcode, a check out more academic topics. The reason to read this material is not to learn or memorize anything, but it's to practice thinking abstractly and learn some fundamental skills. Things like amortized analysis, and also learning how to read academic papers... an important skill for grad school, if that's in your future
- TAOCP: This is a classic set of books. It's very dense, but reading one chapter at a time will really help you think algorithmically.
- Goodrich DSA in Python: https://www.amazon.com/Structures-Algorithms-Python-Michael-Goodrich/dp/1118290275
MIT OCW:
- Intro to Algorithms: https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/video_galleries/lecture-videos/
- Advanced Data Structures: https://ocw.mit.edu/courses/6-851-advanced-data-structures-spring-2012/video_galleries/lecture-videos/
Papers:
- Spanning Tree: https://www.jstor.org/stable/2033241
- Byzantine Generals: https://lamport.azurewebsites.net/pubs/byz.pdf
- Huffman Coding: https://ieeexplore.ieee.org/document/4051119
- Sorting/Searching - Multikey Quicksort: https://sedgewick.io/wp-content/themes/sedgewick/papers/1997StringsSODA.pdf
- Comparative Study of Sorting Algorithms: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3329410
other quite dumb statements
Subsets are an efficient breadth-first search approach to these problems.
A two-pointer problem will feature sorted arrays or linked lists.
Thanks I will start learning this after completing my dp playlist
like, there are useful patterns to know, but most of these are just way too hyper specific
This just feels like a lazy attempt to farm clicks... it's easy to post a "top leetcode" link and you'll probably get a lot of hits.
I like the mention of "two heaps"
Some common problems featuring the two heaps pattern:
- Find the median of a number stream
that's quite literally the only use I know of
it's not a pattern
Also, I'd also say: Grinding leetcode for a year is probably unhealthy. DSA is massively overrated and focusing on it means you're not working on other things (ie: more complex projects, larger systems, etc). I extremely rarely think about DSA in professional SWEing.
I wish someone would publish a "Leetcode considered Harmful" paper. Oh hah, someone did (blog, but fine): https://www.fullcontextdevelopment.com/qb/leetcode-considered-harmful
you don't think of it even in the abstract?
e.g. comparing different approaches
I find myself having to do that a bunch
I guess I've internalized a lot of it... but the approaches are usually at the leetcode -easy- level of thought.
like i explore lot of things also
from past yr i focuses on leetcode
imo it's important to know the tools and pieces you have at your disposal, and how to use them
Yah, I'm more referring to questions at the leetcode medium/hard level... that's just not representative of anything I see on the regular.
if you don't know about the tool, you can't really use it
A more important skill, imo, is decomposition and systems design - that's more representative of typical SWEing, imo.
(I'm saying imo a lot because I know reasonable people disagree on this topic)
decomposition does come into play a lot for harder DSA problems
analyze problem, break it apart, see if you can use the tools you know on the parts
in many cases solving a problem is less about the solution and more how you were able to reason your way to the solution
(i.e. rote memoization of exact solution is mostly useless, it's the ideas that matter)
When I do interviewing this is the kind of thing I strive for as well. I expect some you have some pretty basic DSA knowledge in your toolbox, now let me see you applying it
So How can i learn and approach the problems?
(also I really want to add that people say that "system design" is important and you should learn it probably always think that they sucked at it a year ago... because it's not something that you can just "learn". It's impossible actually. But learning DSA is possible and, honestly, I think it makes you better and engineering in general because even though you solve the different kind of problems, you face pretty much the same challenges on the implementation layer as in real development on the design level. My favourite example is the crazy problem "16" where you are given 4 points, A, B, C and D, and you need to find the distance between line from A to B, ray from A to B, ray from B to A, segment from A to B and line from D to C, ray from D to C, ray from D to C, segment from Cto D -- 16 in total. You can go wild with this problem!)
it's more that system design is a lot more fuzzy
there are key ideas of what makes a design good/bad
these might conflict and you'll have to make trade-offs
What do u guys think how can i learn and approach the problem?
the best you can do it to learn some of the ideas, and over time see what actually works and what doesn't (the real world is messy)
there is no single answer to "how do I approach problems"
it will differ a lot between people
it will differ a lot based on the problem
I don't know of a better approach than just doing stuff and learning what works and what doesn't
i just randomly solved problems
easy level
and also solve problem with that guy approach from dsa playlist
That's my dsa learning approach!
https://leetcode.com/IronmanX/ my leetcode id u can get some idea
from the math world there is this classical book from Polya
"How to solve it"
some of the stuff is a bit math specific, but a lot of stuff is more general
a pdf that outlines the rough principles
https://math.berkeley.edu/~gmelvin/polya.pdf
actually, the wiki page is pretty good at summarizing it
https://en.wikipedia.org/wiki/How_to_Solve_It

How to Solve It (1945) is a small volume by mathematician George Pólya describing methods of problem solving.
this seems interesting
https://en.wikipedia.org/wiki/How_to_Solve_it_by_Computer

How to Solve it by Computer is a computer science book by R. G. Dromey, first published by Prentice-Hall in 1982.
It is occasionally used as a textbook, especially in India.It is an introduction to the whys of algorithms and data structures.
Features of the book:
The design factors associated with problems
The creative process behind coming up ...
in short there are a bunch of problem solving techniques at your disposal
figuring out what works for you for a particular problem is up to you
problem solving is a lot about spotting patterns, and over time I feel you find patterns in the problem solving itself as well
but it's something that only real comes from exposure and experience
I always come back to the concept of mathematical "maturity": https://blogs.ams.org/matheducation/2019/04/15/precise-definitions-of-mathematical-maturity/. The idea here is that there are several dimensions one needs to develop along... not a single one. Conceptual Understanding, Procedural Fluency, Strategic Competence, Adaptive Reasoning, Productive Disposition... I like this, because it suggests that perhaps OP needs to think about which dimension they're struggling in.
(ie, the disposition one is: if you don't enjoy it, it's hard to really excel at it)
Relevant quote: "In my experience teaching students in their first two years of college mathematics, most significant stumbling blocks for students fall clearly within one of these five strands. For example, when students are able to compute a derivative correctly, but are unable to use that information to find the equation of a tangent line, then this student is succeding in strand #2 but struggling with strand #1. ..."
yo !
trying to decide which DSA course to get so far thinking about either structy.net or neetcode.io
what do u mean by larger systems?
Larger, more complex projects. To be clear; I’m only talking about balance. I’m not saying ‘dsa bad’, im saying: be balanced in how you prepare yourself
I am trying to implement the sha256 function following this pseudocode: https://en.wikipedia.org/wiki/SHA-2#Pseudocode
But I am not getting the same result as hashlib.sha256 and I don't know where I made a mistake.
This is what I tried: https://pastebin.com/FGQN4eXf
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
SHA-2 (Secure Hash Algorithm 2) is a set of cryptographic hash functions designed by the United States National Security Agency (NSA) and first published in 2001. They are built using the Merkle–Damgård construction, from a one-way compression function itself built using the Davies–Meyer structure from a specialized block cipher.
SHA-2 includes ...
hey guys i was doing this simple puzzle but i think im missing something (dont know what it is)
statement
- Write a function called sumIntervals/sum_intervals that accepts an array of intervals, and returns the sum of all the interval lengths. Overlapping intervals should only be counted once.
Intervals
Intervals are represented by a pair of integers in the form of an array. The first value of the interval will always be less than the second value. Interval example: [1, 5] is an interval from 1 to 5. The length of this interval is 4.
test.assert_equals(sum_of_intervals([(1, 4), (7, 10), (3, 5)]), 7)
link
https://www.codewars.com/kata/52b7ed099cdc285c300001cd/train/python
my attempt
def sum_of_intervals(intervals):
maximum = float('-inf')
minimum = float('inf')
for i, y in intervals:
if i < minimum:
minimum = i
if y > maximum:
maximum = y
return maximum - minimum```
edit (this is not even near of the solution)
Codewars
Codewars is where developers achieve code mastery through challenge. Train on kata in the dojo and reach your highest potential.
my logic was trying to go throught the intervals and grab the maximum and minimum values and then substract them
but doesnt pass all the past
Yeah, I just had a look @fiery cosmos and this is the type of puzzle I don't know. :)
aight thanks anyways buddy
shouldn't the test be 8 not 7
because i think that-s like a kind of range
(1, 2, 3, 4, 7, 8, 9)
would be all the numbers in there and if we grab the len the ans is 7
for example
(1, 5)
would be (1,2,3,4)
i get the question now. silly english
thanksss answering you i realized im far away of the solution HAHA
it should not be called "sum" of intervals then
haha exactly
your approach is halfway there. you have to account for when there are numbers skipped in intervals, like the test case (1, 5) and (6, 10), your answer assumes it is the same as (1, 10) but it actually leaves out (5, 6)
it is helpful to imagine possible scenarios to know the minimum requirements, so if your solution seems too simple for the minimum requirements, it is likely wrong
e.g. if the list of intervals is always disjoint at the start, like (1, 2), (3, 4), (5, 6)... (99, 100) and then ending with (X, Y) which could overlap with any number of the previous ones, e.g. (49, 100), that means you have to keep track of past entries in memory so you know how much to add/subtract
so you definitely know something like your solution with no memory is wrong
yeahh my first attempt was creating a list, and put in there all the non-repeated numbers between each interval
and then return the length
but that was a horrible solution because of the time complexity
Anyways, the solution is pretty simple if you think about the intervals in sorted order (sorted in increasing order of L). That is the trick.
i think minimum complexity is O(n^2) because like my above example, the next entry in the intervals list could always interact with previous entries in some way
The solution I'm talking about is O(n log n) cause of sorting
ah i see now
i was thinking in terms of some function which keeps accepting new intervals from some user input. that one cannot be sorted and thus needs to be n^2
In that case it is probably a lot more trickier to get it down to O(n log n). But still possible
You could use stuff like segment trees to do it
I looked it up, interesting, I learnt something new
anyway i was wrong, i stand corrected @fiery cosmos
Had some codegolfing a solution
||
sum_of_intervals=lambda I,R=-9e9:sum(-max(a,R)+(R:=max(b,R))for a,b in sorted(I))
||
i feel like these things are a scam
as in I am not saying their content is wrong/bad, but I am talking about the price, you could do the same by yourself for free
how helpful, they list out the topics they cover in that page, just search those things on youtube or something. the only things they provide that will actually be new are Non Technical Interviews, Offer+Negotiation, and Google/Amazon/Facebook questions
Also what is the bonus 16s lecture at the end lol
sorry I guess I shouldn't speak if I haven't used it, maybe it really is useful idk
You should first check out the pinned messages in this channel. Goodrich is a popular DSA book, this is the python version, but there's a Java version too Goodrich DSA. There's also MIT OCW - Intro to Algorithms
oh ok
not worht it
MIT intro to Algo course and then start practicing 👍
Hi, can anybody explain me please, why the value „temp“ is accessible in the list map function when the value is defined one line later:
list(map(x, temp))
for(temp in temperatures)
Code was provided by ChatGPT without explanation
I also thought about it. But a friend of mine showed me a snippet like this and I couldn’t explained to him
And the code was compiling he said
btw the code was accessing values from a XML file
(also this is not really a topic for this channel, maybe try the general #python-discussion )
are u allowed to methods like .remove and min/max on interviews
switching over from java and its alot easier
for arrays leetcode style questions
Obviously those kind of simple operations must be allowed
It would even say it is a bad thing if you try to do stuff like that manually with a loop
__gnu_pbds::tree_order_statistics_node_update in the job interview 👀
unless doing .remove is a serious performance hit at O(n) cost per remove
did they ask you to explain it or something?
nah, that's a joke about using a very obscure feature which is shipped with gcc compiler, and commonly used in competitive programming, a response to "are u allowed to methods like .remove and min/max on interviews"
I started to learn about hash tables and hash functions from here https://www.geeksforgeeks.org/hash-functions-and-list-types-of-hash-functions/
For division method it is said:
The hash function divides the value k by M and then uses the remainder obtained.
It is best suited that M is a prime number as that can make sure the keys are more uniformly distributed. The hash function is dependent upon the remainder of a division.
Is there any way how to choose a prime number?
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
any prime number will do
the most common ones are 1000_000_007, 1000_000_009 and 998_244_353 (the first two are easy to remember, the last one is... well... common...)
(well, among competitive programmers)
generally, you just want your prime number to be big enough so that the probability of two objects having the same hash was low
you can easily go even bigger (though usually another technique, double hashing is used)
As someone that enjoy hacking other peoples hashes. I would definitely recommmend avoiding double hashing
If someone is trying to hack you, then using two hashes is about as safe as using 1 hash
Something that is far better is to just use a larger prime
The two primes I would recommend using are
2^61 - 1
or
2^64 - 2^32 + 1
:sigh: python nerds with their unlimited integer size
(says rust person with u128 builtin)
that's a very solid advice btw
why are bigger modulos are harder to hack btw? is there a proof or something like that?
Suppose you are doing rolling hashes of binary strings, and use two mods, mod1 and mod2
To hack that, I start by finding two different strings A and B of equal length such that hash(mod1, A) = hash(mod1, B) = 0. (This takes about sqrt(mod1) time)
Note that any string made up of concatinations of A and B will also have mod1 hash equal to 0. For example hash(mod1, A + A + B + A) = 0.
Now I can run the same algorithm for mod2. But instead of using binary strings (strings made up of 0 and 1s), I use strings made up of A and B.
With this I generate two different strings C and D such that
C and D are concatinations of A and B
hash(mod1, C) = hash(mod2, C) = hash(mod1, D) = hash(mod2, D) = 0
The inherent issue is that hash hacking algorithms run in O(sum_i sqrt(mod_i))
Just use random mod
Even random base works pretty well
quadruple hashing?..
what about other algorithms? from a theoretical perspective, it is possible to construct a string faster?
I dont know of any algorithms that run faster than O(sqrt(mod))
They all use the trick that if you generate O(sqrt(mod)) random strings, then you would expect to find at least one pair of strings with the same hash.
I see
In the case of rolling hashes, if you want to find a string A that hashes to 0, then
seperately randomize the first half and second half of A.
If you do about sqrt(mod) randomizations of the first half, and sqrt(mod) randomizations of the 2nd half, then it is likely you will find some pair of halves that together hash to 0
so you only compute one hash once per half?
The rolling hash of the entire string is something like
hash(first half) + b^len(second half) * hash(second half)
So to find a string hashing to 0, you need to find two halves such that
hash(first half) = -b^len(second half) * hash(second half)
can't you build a bunch of second halfs, put their prefix hashes in a hash table, then generate first half and for each suffix of first half look for a matching hash in the second half?
That wont help with speed
why?
I can generate the hash of a random string in O(1) time.
The time it takes to hash a string is not an issue
yeah, but you potentally match multiple prefixes at once
Not really
Think about it like this. If you have a Python set containing n hashes
They could be hashes of random strings, or hashes of prefixes of random strings, it doesn't matter
If I then check if the hash of some string is in the set, then I'm effectively doing n hash comparisions
I don't know of any way to get around this (to get asymptotically more than n hash comparisions in O(1) time).
well, my point is, let's say you generate n suffixes of length 2m
and you add last m longest prefixes to the hash
then in O(nm) work you have a set with nm hashes
and every time you generate a new first half in O(m) you try m^2 n hashes along the way
Rolling hashes are linear, so you can easily generate hashes of random strings in O(1) time if you are ok with the random strings having some small amount of dependence
anyone aware of a hashmap library for python that provides a python accesible/integratable version of the compact hashtables that map to indexes in a list
i want to create a hash index for something memory mapped without having to pay the cost of loads of full python objects
so you enumerate the strings, essentially, not really randomly generate them?
ok well yeah, in this case yeah, my idea gives nothing
Think about it like generating the next random string by changing just one character
(becase in an essence that's what I am doing)
yeah ok
You could do something smarter like generating and hashing two halves seperately, and then combine them in O(1) time
in order to generate a more random string
what do you mean by "combine"?
rolling hashes can be combined using hash(first half) + b^len(first half) * hash(second half)
combine two linear-y sized sets in O(1)?
I'm just dealing with hashes here, I'm not actually physically combining the two halves
I know, I just don't really understand what you mean by this
I'm just talking about a rather brute way to quickly generate the hashes of tons of random strings
Anyways, all of this breaks down if the mod is something like 2^61 - 1.
yeah I see
so what about quadruple hashing? :)
still doesn't work?
at which point string become too big?
(I figured lol)
Adding random elements to it kinda works too.
What I personally would do is to use this for rolling hashes
import random
MOD = 2**61 - 1
base = random.randrange(MOD)
I see
well, TIL
(I have been told to do double hashing for a long time, oh boy I was wrong)
(well, I suppose it's not as scary when no one is trying to hack me)
I've been wanting to create an account on codeforces called hashassasin
or maybe hashasin
and just go around and hacking peoples hashes
instantly becomes grandmaster after a single edu round

{kind=link}
There have been times when I've hacked a crazy number of people.
I dont recall the problem now. Think it was a div3 round where I TLEd hack a crazy number of people (like 1000 hacks)
lmao
My hacking has made it so people randomly message me asking me to hack someone

I suddenly itching to do a div2...
stop punching down 😭
Some backstory about this. The guy was using gp_hash_table in C++ but without a custom hash. So by simply making the input data consist of multiples of large powers of 2 TLEd him.
gp_hash_table needs a custom hash to be safe to use
I’m gonna cry. I just got done with a midterm where the professor apparently required us to memorize his “list135” data type
Okay no big deal it’s a singly linked list I remember this from the homework
So what, we just call list.get() and list.next() right? No… it’s list.first() and list.rest()
And I asked him mid test if we could get the api or something and he’s just like “no”
What a guy
He also had a problem to make a list and exclude every even odd index. But we “weren’t allowed to use anything that would make it trivial like list comprehension”
He gave a hint that we were allowed to use slicing but I’m not sure two colon slicing is what he meant.
Just remind yourself… b’s get degrees. Sorry. Or is it c’s? 🤷🏻♂️
Wait, so it's like this?:
l = List135(1, 2, 3)
l.first() # 1
l.rest() # [2, 3]
I've never heard of "list135" datatype before
car and cdr, heh
or head and tail
Googling list135 I can find a couple of implementations of it
class list135:
def __init__(self, first_item = None, rest_of_list = None):
self._first_item = first_item
self._rest_of_list = rest_of_list
def cons(self, first_item):
return list135(first_item, self)
def first(self):
return self._first_item
def rest(self):
return self._rest_of_list
def empty(self):
return self._rest_of_list == None
I'm assuming the point of that task is that the input and output for that task should be list135 objects.
Which is naturally implemented recursively
Hi all, I am using flask and I would like to retreive the form data. I am sending the form data through a react web. However, I keep getting empty request.form in flask..
print(request.form)
username = request.form.get('username')
password = request.form.get('password')
In case you need the react code:
export const POST = async (formData: FormData) => {
const url = "http://127.0.0.1:5000/login"
try {
const response = await fetch(url, {
method: "POST",
body: formData,
})
const data = await response
return data
return NextResponse.json(data)
}catch(error) {
console.log("FAILED")
console.log(error)
return NextResponse.json({message: error})
}
}

I would say that first and rest are the two functions with sensible naming.
cons on the other hand is not a good name since it does a really bad job at describing what the function does.
empty is also not a good naming choice, since the natural name for such a function in Python should be __bool__
This is the wrong channel
I think the correct channels for this is something like #python-discussion #web-development #networks
@regal spoke sry for ping. i need an expertise help to solve my DSA question. I couldnt find solution for it like literally nowhere on internet
ping*


Unless I'm missunderstanding something, this seems to be just a standard dijkstra problem