#unit-testing
1 messages · Page 12 of 1
that looks odd. Lines 1243-1248 are only one statement, but it should treat them as either all covered or all not.
what does coverage reporting on your computer show?
Oh! Wasn't expecting a response from a maintainer 😄 . Yeah, I checked locally and its a codecov issue 🙁 . coverage report and coverage xml say those lines are covered. I assume you aren't involved with the codecov team?

Hynek Schlawack
Codecov’s unreliability breaking CI on my open source projects has been a constant source of frustration for me for years. I have found a way to enforce coverage over a whole GitHub Actions build matrix that doesn’t rely on third-party services.
Yeah, I didn't know that codecov was this bad 🙁 . Pretty bad bug to report 76.08% on a file with 93% coverage
Yes, Selenium has Python APIs, and there are various Selenium Python frameworks in the ecosystem: https://www.selenium.dev/ecosystem/
I'm the maintainer of one of those frameworks, https://github.com/seleniumbase/SeleniumBase
hi, @polar cove . Plz check your DM
- Don't ping users out of the blue
- Don't ping users with no information
- Don't PM users without very good reason
hey, do you know why I did ?
I didn't break all of these
in the future, don't care about everything you don't know well
Woah men I see your name on selenium’s website under supported frameworks
oh yikes! I found out its because we're uploading mypy coverage there as well and it was showing all of them combined, hence the confusion. Yea that isn't useful
I guess it's better than to report 93 when there really is 76.
But yeah, codecov is not stable at all
anyone is test engnieer
It's best to ask your question rather than ask to ask, or if anyone is an expert in something you're about to ask
I have built a server for a client, and I am at the stage in our contract where I am to write tests. I am a little overwhelmed - I have the app separated into three main layers:
- Controller Layer
- Service Layer
- Repository Layer
Where is the best place to start writing tests?
The question misses a big point: The best place to start writing tests is when you are writing the app itself. Not at the end.
That being said, try to find places where you screwed up and make sure you have tests that will catch those errors next time. Then test pure stuff that is easy to test. Then have some end-to-end happy path test for the most important. Then some of the error cases for the most important.
Yeah, no doubt - I'm not great at testing, I'm pretty ignorant when it comes to best practices. However, I've been manually testing pretty extensively whenever I created some kind of functionality, so I'm not sure I understand the part about finding places where I screwed up.
I would test if it will integrate with the database correctly or specific versions using test containers and the repository later. All the services will use them anyway so it's a good place to test persistence logic In isolation in your repository implementations.
If you found someplace it was broken when doing a manual test for example, that's a good place to write an automated test.
Okay right on - thanks for your feedback
ah yes - ok I see
As long as it's not just testing the ORM or whatever
no ORM - raw SQL queries
I see a lot of people basically testing Python+Django instead of their own app...
hmm.. well that's a bit worrying itself honestly. Then I would make damn sure there's no string formatting to build SQL, or if there is that all the strings come from your own code and never from the data/browser/client.
You should also consider API testing. It is not where you want to get your feedback from primarily but it's where users interact with and prone to breaking from various infrastructure related logic. So if your frameworks support that easily test there as well. But know that those are rigid and tied to your API, if you do it right the service layer should be independent.
Why exactly is that worrying?
Because it's easy to introduce SQL injection when doing that.
psycopg3 is pretty tight about that stuff for example.
async def create_user(
first_name: str,
last_name: str,
email: str,
hashed_password: str,
phone_number: str,
country_code: int,
user_role: str,
organization_id: UUID,
) -> User:
query = f"""
INSERT INTO users (first_name, last_name, email, hashed_password, user_role, phone_number, country_code, organization_id)
VALUES (:first_name, :last_name, :email, :hashed_password, :user_role, :phone_number, :country_code, :organization_id)
RETURNING {READ_PARAMS}
"""
params = {
"first_name": first_name,
"last_name": last_name,
"email": email,
"hashed_password": hashed_password,
"user_role": user_role,
"phone_number": phone_number,
"country_code": country_code,
"organization_id": organization_id,
}
user = await fetch_user(query, params)
assert user is not None
return user
Can you explain to me how in a statement like this someone could inject more SQL?
they can't, you did this correctly.
Assuming READ_PARAMS is from your code, that's fine
(I guess technically we need to see fetch_user, but this looks right.)
Okay thanks
this is fetch_user ```py
async def fetch_user(query, params) -> User | None:
rec = await state.database.fetch_one(query, params)
if rec is None:
return None
return User(
id=rec["id"],
first_name=rec["first_name"],
last_name=rec["last_name"],
email=rec["email"],
hashed_password=rec["hashed_password"],
phone_number=rec["phone_number"],
country_code=rec["country_code"],
user_role=rec["user_role"],
organization_id=rec["organization_id"],
created_at=rec["created_at"],
updated_at=rec["updated_at"],
deleted_at=rec["deleted_at"],
)
That return could be return User(**rec)
ah ok - is ** the spread operator?
Or I guess return User(**{k: rec[k] for k in READ_PARAMS}) if you want to be sure
It's the operator to unpack a dictionary. Spread is some JS thing, I don't think it's the same thing.
Oh ok
Going without an ORM is pretty valid in my experience as long as your models don't have lists of children that require change tracking. In a lot of cases I think stuff can go fine without but iffy when it does.
Okay right on, thanks for your feedback
No problem
hi guys, What kind of tests are more VALUABLE and to make more money
@proud nebula
this is the wrong way to think about tests. You make money by writing code that solves problems for people. You write tests to make sure your code works.
hi
Also don't ping people randomly
hi guys
You might be interested in this article. It uses uptime and change friction as a ruler for assessing what tests to focus on. I thought it was thought provoking if nothing else. https://etodd.io/2025/01/06/zero-to-one-hundred-thousand-tests/
can anyone teach me python
If you have questions, we'll answer them in #python-discussion
Tests are for your own sanity
To have always truthful part of app documentation
Multiple endpoints to debug new feature writing
And easy maintain app for years 💪
If u a freelancer making money, some chances u write one time to live code without tests. As long as u aren't going to maintain it could be fine enough. If u will end up maintaining written garbage without tests, u could start swearing wtf too often and question which idiot wrote that code
This is how I approach tests, though it depends on the situation. I should be able to make a significant refactor, run my tests successfully, and be reasonably confident that nothing breaks. "vibe-testing" if you will
Depends on code/situation. In some cases u will still be able to go without tests, if u a feeling overly confident, familiar with that part and app is already well tested.
Otherwise writing with tests will be your fallback to safe net to progress the task in any way at all
So... Unit testing is actually
- also just increasing your productivity to write code at all
- decreases cognitive stress load to progress
- allows yielding less error
- makes possible to fix errors easier.
Allows having higher productivity output and secretly keeps saving time proportionally to code base size growth
It depends on the techniques you use. But integration tests with the technologies you use are in my opinion a high value, unit testing how pieces interact is annoying and sometimes hard to spell out what is being tested our the purpose is. API tests are tightly coupled to specific designs and networking and are slower and don't narrow stuff down if something goes wrong
Acceptance tests then. Prove that it is doing what the customer asked for, and exercise the system like they would.
Its very important to know what is being tested
Accidentally testing for the wrong things can jeopardize the valve of a testsuite both now and in the face of future change
For example focus on acceptance tests while foregoing easy writing of unittests can lead to intensely coupled internals
Which can lead to harder changes down the line
Of course. Each type of test has a different purpose even if some might happen to overlap.
Writing code that isn't tightly coupled is important regardless which happens to be easy to test code. But in architectures like ports and adapters architecture with London style testing when you're testing interactions with other components of the system, I find writing those (while they can catch errors) isn't bringing as much value overall. Not to mention, acceptance testing is extremely important, if the user can't use the system and the pieces aren't wired up correctly then it's broken and various unit tests, and tests of how certain pieces integrate with technologies isn't gonna save that and there's an overlap in that.
Yup in particular when constraints, priorities, pressures and/or limits are part of the process debts that are tricky to account may incurr
Tend to find with unit tests you get test code coupled with the implementation details
Like in Django + DRF people might unit test the Admin classes for attributes, or unit test the DRF serializers. Passing mocks in instead of request objects
I prefer tests that use the Django test client and test db. Not really unit test, not really acceptance test. Not really integration tests, just nice mock-free or mock-reduced small tests
I appreciate those tests as well, they're easy to write and maintain and provide a lot of coverage. I will also write tests to isolate my serializers, that way when a test fails I have a smaller area to debug.
hey all, I recently came across an interesting Python library, but it has no tests whatsoever
I don't have in-depth domain knowledge of what the library is used for, but I still feel like I'd like to write some tests for it myself, maybe some sanity checks or to figure out how to use the library
does anyone here have any experience doing this, I'd greatly appreciate your advice
from my experiencing of dealing with code like this
- I would recommend trying to type it first with mypy or smth
- It will make easier after that covering it with tests, as present types will help u more bravely making minimal changes to make code testable
- Concentrate on changing code as least as possible (but still changing if necessary) for test coverage
- your goal of stage 2 should be trying to add all tests, without changing code too much for it to break
- once u finished stage 2, ensure to validate with some manual runs and see if it still works
- when u will have a good testing coverage, then feel free be more brave and rearranging code in large capacity then
I see, I'll try that out, thanks!
Is there a preferred way of modifying env vars when using pytest? I see a pytest-env package, but it hasn't been updated in 6 months. Of course, given it's just about loading env vars, I doubt it needs much updating?
six months isn't that stale either.
Yah, fair point. So is a package like that the way for me to go? Or is there an easier mechanism I can't find/think of?
i thought pytest had a built-in fixture for it, but i didn't find it.
I do see a discussion on the Github from 2022, but nothing else. Thanks for letting me know.
You could just put a line in your outermost conftest.py.
# tests/conftest.py
import os
os.environ.setdefault("TEST", "True")
Yah, I thought about that. It felt a bit messy, so I wans't sure if that was the way to go
If you have a lot of variables and might have to adjust them often I think pytest-env is neater
You can set env vars with the monkeypatch fixture
Is monkeypatch and mock the same thing?
I see there's a pytest-mock package that hasn't been updated in a year, but it seems like monkeypatch does the same thing?
Is mock more a unittest thing, and monkeypatch a pytest?
@real vale : As for as i know monkey patching is used for mocking the functionality ex: a variable, function etc which will be used to moke the real HW or stack code to moke
for ex: You can write a function of particular type and you want to replace it with something different at runtime then you can use this feature to test the run time env in unit test or any other kind of testing using test case developments
https://github.com/pytest-dev/pytest/issues/4576#issuecomment-449864333 gives me a good impression between the two. Not sure I agree with some of the later posts about mocking being bad, but could just be my inexperience.

GitHub
I'm working on a codebase where tests use a mixture of mock.patch and pytest's monkeypatch, seemingly based on authors' personal preferences. The official docs for the latter, https://d...
I'm finally getting around to migrating everything that makes sense to async but testing is an issue. Anyone have experience mixing MagicMock and async calls? I'm getting thousands of MagicMock can't be used in 'await' expression errors. Made an example of what I'm dealing with here: https://itemshoppe.s3.us-east-1.amazonaws.com/async_test.tar.bz2
async_lib.py
from typing import Self
from dataclasses import dataclass
@dataclass
class User:
id: int
class UserQuerySet:
def select_for_update(self, foo=False) -> Self:
return self
async def aget(self, id: int) -> User:
return User(id)
def get_user_queryset() -> UserQuerySet:
return UserQuerySet()
async def aget_user(id: int, select_for_update=False) -> User:
qs = get_user_queryset()
if select_for_update:
qs = qs.select_for_update(foo=True)
return await qs.aget(id)
#!/usr/bin/env python3
from unittest import main, mock, IsolatedAsyncioTestCase
from async_lib import aget_user
__all__ = ("GetUserQuerySetTestCase",)
class GetUserQuerySetTestCase(IsolatedAsyncioTestCase):
async def test_aget_user_with_select_for_update_mock(self):
get_user_queryset_mock = mock.Mock()
get_user_queryset_mock.select_for_update.return_value = mock.Mock()
get_user_queryset_mock.select_for_update.return_value.aget = mock.AsyncMock()
await self._test_aget_user_with_select_for_update(get_user_queryset_mock)
async def test_aget_user_with_select_for_update_magic_mock(self):
await self._test_aget_user_with_select_for_update(mock.MagicMock())
async def _test_aget_user_with_select_for_update(self, mock_):
with mock.patch(
"async_lib.get_user_queryset",
return_value=mock_,
):
await aget_user(1, select_for_update=True)
mock_.select_for_update.assert_called_once_with(foo=True)
if __name__ == "__main__":
main()
Don't mock querysets
Just use the test database
I want to test that I'm actually passing in the correct parameters to select_for_update so I need to mock it
You need to use AsyncMock, I thought mock.patch picked that up automatically
It does, but not for nested calls
Oh just use https://github.com/adamchainz/django-perf-rec
GitHub
Keep detailed records of the performance of your Django code. - adamchainz/django-perf-rec
Nested calls?
Calling MagicMock.<attr>.<attr>
Ah you're definitely mocking too much if you have that
You can use **{"return_value.foo": AsyncMock(...)}
I'm not mocking too much. It's the minimum amount that's necessary to test the code.
This is essentially what I'm doing, it's a bit laborious. I'm correct in thinking that there's no automatic "MagicMock-style" way of doing this?
Yes, there's no way
You could use a spec with the class for the return_value
So when it comes to integration tests, how should I handle endpoints that require a token? I have a function that generates a token, and I guess I could create a fixture that generates a jwt and then attach it to each request (maybe through another function?) or mock/monkeypatch (not sure which would be the way to go) the middleware that validates users and have it do it automatically.
when u test smth, it should be tested at least once. that rule to integration testing applies as well
Does it add any extra testing quality to apply jwt everywhere? if no, then u can skip applying it in all tests in a full way.
Especially if it is somehow for some reason costy, then especially skipping
Just have at least one test with jwt without mocking
if your app code logic somehow depends on JWT content a lot (Jwt can have arbitary data inside), then apply preferably everywhere
Yah, i did write one test to make sure the actual log in functionality works. And I have non-integration tests for the login middleware
Ok, so I'll learn how I can/should mock it, thanks. In my case, permissions aren't relevant, so it's mostly yes logged in or no. But I also need to figure out how I should do.
as a rule, when we do integration testing
when we can run smth determenistically (without randomly falling apart)
without any really increase in time of requests
We don't mock it then
i would imagine JWT is lightweight enough stuff, not exactly needed being mocked potentially (unless u do too many SQL requests)
Yah, makes sense, specially because if I do add permissions in the future, i don't want to have to rebuild a bunch of stuff
usually stuff like JWT auth is just wrapped into some fixture and reused across tests 🙂
one place to apply to all tests
Yah, I'll look into how to set up that fixture. I admit, still figuring out how fixtures are used
I'd love some feedback on if my testing mentality if on track or not. From what I've read and figured, doesn't make sense to write a test for a method that's a wrapper for a library function, like
async def count(self) -> int:
return await self.db_session.scalar(select(func.count(Store.id))) # type: ignore
All I'd be doing is testing the library. But for something like
async def create(self, store: Store):
store.name = store.name.strip()
db_check = await self.db_session.scalar(
select(Store).where(func.lower(Store.name) == store.name.lower()).limit(1)
)
if db_check:
raise AlreadyExists(db_check)
self.db_session.add(store)
await self.db_session.commit()
return store
I'd write a test that would check if I give it a Store object, it does things like strip the store name, and that it comes back with an id, and a second test to check if the same store gets added twice, it raises an exception. But would it make sense to just test the return value, or check the db that it's in there as expected as well? Or just assume since I'm using SQLA, it stores as expected.
Likewise, for the integration test on the endpoint that uses that method
@stores.post(
"",
response_model=schemas.StoreResponse,
)
async def add_store(store_input: schemas.StoreInput, db_session: DBSessionDependency):
store_repository = StoreRepository(db_session)
try:
store = await store_repository.create(Store(name=store_input.name))
except AlreadyExists as e:
return error_response(
status_code=400,
content=[already_exists_error(dict_from_schema(e.cls, schemas.Store))],
)
return {"data": {"store": dict_from_schema(store, schemas.Store)}}
Since the unit tests check that the create method works, it probably just makes sense to check the output of both scenarios? Or should I check the db on these as well?
Hi, need some advice on how to write my tests
I have an api which provides me the authentication token, I want this to be tested as well, and use the token across other tests as well.
Do I write separate test cases for each? Is there a way I reuse some logic across multiple tests?
You can extract logic from tests into helper functions
Do you have an example of a few of your tests?
how do you structure the files for test in a django project, what if there are multiple viewsets that you are testing, do you create a tests folder and split the files based on each view separately?
Organize your tests so you can easily select groups of tests to run.
I create one test file per feature. And then further organize the tests into classes, so I can narrow down my testsuite if necessary.
tests
└── myapp
└── test_myfeature.py
├── ::TestModels
├── ::TestSerializers
└── ::TestViews
Got it
I just mash it all into test_views.py
I don't really need to test only one type of view at a time
I use --stepwise to iterate on new view tests
If I get to like 2-3k lines maybe worth splitting the test_views.py
I like to organize my tests by type of class (or by file as Django does). I frequently do that for big and small Django projects.
myapp
└── tests
└── test_models.py
├── ::MyModelTestCase
├── ::OtherModelTestCase
└── test_views.py
├── ::MyViewTestCase
├── ::OtherViewTestCase
so i have a test for a django-ish project, using pytest
def test_do_not_log_when_debug_is_false(self, settings, client, caplog):
caplog.set_level(logging.DEBUG, logger="django.request")
settings.DEBUG = False
settings.MIDDLEWARE = ["test_middlewares.test_exceptions.MyMiddleware"]
client.get("/middleware_exceptions/view/")
assert not caplog.records
i've alos tried it like this:
def test_do_not_log_when_debug_is_false(self, settings, client, caplog):
settings.DEBUG = False
settings.MIDDLEWARE = ["test_middlewares.test_exceptions.MyMiddleware"]
with caplog.at_level(logging.DEBUG, logger="django.request"):
client.get("/middleware_exceptions/view/")
assert not caplog.records
but the tests fail cause there is a WARNING in the logs
i'm not sure why a WARNING would count when i've set level to DEBUG
If you set to debug level, you will also get everything from warning level. I don't think your assert is correct, it should probably be something like assert not [x for x in caplog.records if x.level == DEBUG]
I think you would have gotten this yourself, if you had just looked at the records.
hmm
my assumption was that setting log level would suffice and it shouldn't go in the log
A log level is an integer. DEBUG = 10, ERROR = 40. Setting the debug level to a number means every log that is BELOW that number is thrown away.
WARNING is 30. This is all in the docs of the standard library logging module
I feel like your mental model of this system is not correct...
seems like my problem lies elsewhere
there shouldn't be any logs
Did you look at the logs you have yet? You really should.
just loop over and print them
i have
there is one log
but it shouldn't be there
probably a fixture problem
thanks!
it was a fixture problem 🫠
Hey everyone! I got an internship interview for a QA/ Test Software engineer. I have a technical interview for live coding and then a technical interview for QA/Testing. does anyone have tips or resources to prepare for it?
I've built the class that scrapes baseball feed where it goes from: extract game ids -> extract play ids -> extract content. There's about 4 different urls I need to use to get the job done and queries can be really large, like over 100 games. I've heard that trying to write tests where you use the internet as little as possible is ideal, but was wondering if this would be an exception since there's a lot of mapping work going on in the backend. The urls are mainly api endpoints and the function is extremely fast if that changes anything. These api endpoints are typically have something like
/{game_id}/, so more times than not, different api endpoints are being hit.
Here's an example:
Say a person wants to get feed for a range of 20 days. They query a 20 day span and my function uses an endpoint using the date range to get game ids, then those game ids are fed into another api endpoint for the play by play data, where it gets the play ids, those play ids are fed into a website url that gets the feed they want to return. Can be more than one feed extracted.
I just don't want to make say 20 different json files for play by play data to test the function date ranges. Sorry, the answer may seem obvious but I want to make sure I'm doing good practice with unit tests. Still a little new to it.
you might want to use pytest-recording
hi
i have a test like this
await valkey._set(Keys.KEY, "value", ttl=1)
valkey.client.set.assert_called_with(Keys.KEY, "value", expirey=ExpirySet(ExpiryType.SEC, 1))
but because expirey is getting a new object, the test fails, even tho they are technically the same object
where valkey._set is this:
async def _set(self, key, value, ttl=None, _cas_token=None, _conn=None):
if _cas_token is not None:
return await self._cas(key, value, _cas_token, ttl=ttl, _conn=_conn)
if ttl is None:
return await self.client.set(key, value)
if isinstance(ttl, float):
ttl = int(ttl * 1000)
return await self.client.set(key, value, expiry=ExpirySet(ExpiryType.MILLSEC, ttl))
return await self.client.set(key, value, expiry=ExpirySet(ExpiryType.SEC, ttl))
(the last return is called)
Can you not define eq and hash_code on ExpirySet?
it is a library code
You could define a custom matcher
Or retrieve the call args and check them manually
How about extracting the code that creates the instance into a separate function?
Then you can monkeypatch that function in the test:
def test_something(monkeypatch):
monkeypatch.setattr(the_module, “the_extracted_function”, fake_fn)
…
Your assertion can then be made with a known value that is controlled by the test.
The “fake_fn” can also be an inline lambda *args, **kwargs: expected_value
And you make the assertion with the expected_value.
Or did you mean that the example code you shared is from a library? If so, I would reconsider the assertion itself.
hmm
i haven't done monkypatching before
nor do i have a clear mind to see if it's the right tool here
but interesting idea, wouldn't have thought about it myself
thanks you 🙌
That is a builtin feature of pytest (if that’s the test tool you use), very convenient!
no the code i shared is under my hands
the ExpiryTpye and ExpirySet thing are library code
hey there, what's up?
Nice to meet you Nedbat
You are very good at Python. I am also proficient in Python (django, Flask).
nice
Just so you know, we don't really permit job requests or advertisements on this server
And the topic of this channel is unit testing
def test_rotate_token_triggers_second_reset(self):
req = self._get_POST_request_with_token()
resp = sandwiched_rotate_token_view(req)
async def test_rotate_token_triggers_second_reset_async(self):
req = self._get_POST_request_with_token()
resp = await async_sandwiched_rotate_token_view(req)
in a situation like this, is it possible to do
@pytest.mark.parametrize("view", [sandwiched_rotate_token_view, await async_sandwiched_rotate_token_view])
async def test_rotate_token_triggers_second_reset_async(self, view):
req = self._get_POST_request_with_token()
resp = view(req)
?
No worries
ah no i can't :/
I just want to get this to work, do not mind the ham 😬 .....
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
from app.models.train_model import predict_text
Class = ['ham','spam']
with open("app/models/text.pkl","rb") as f:
text = pickle.load(f)
with open("app/models/rfc.pkl", 'rb') as f:
model = pickle.load(f)
app = FastAPI()
class InputText(BaseModel):
text: str
class PredOutput(BaseModel):
Class: str
@app.get("/")
def home():
return {"Message": "Spam Prediction"}
@app.post("/predict", response_model=PredOutput)
def predict(payload: InputText):
Class = predict_text(payload.text)
return {"Class": Class}
you forgot a question, a description of a problem, anything
also, this seems like the wrong channel
Full marks in other words! 🙂
oof, sorry
@river pilot I was wondering: what's up with ternary coverage? I've seen that a guy posted a working prototype a few years back. Is it only a question of how do we display this to the users? It looked like he solved the problem of dead opcodes and opcode mapping that you referenced via the mentioned PEP.
(Sorry if I'm drastically wrong and completely out of context. I was thinking of doing a small OSS hackathon to bring this feature to coverage so I wanted to ask you first)
i'd have to re-acquaint myself with what he did. (btw, #coverage-py is a thing). What do you mean by a small hackathon? Do you have others who would be involved?
What do you mean by a small hackathon? Do you have others who would be involved?
Yup, just a thing with friends :)
I'm fairly deep in OSS and wanted to bring some senior friends into it as well via such an exercise. Coverage is something we all use, ternary coverage is something we all had problems with, and you are very-very responsive so it felt like the perfect task for a short hackathon
He uses 3.11+ debug ranges feature for his fine grained coverage.
https://peps.python.org/pep-0657/
Also: sorry for pinging you directly and doubly sorry for using the wrong channel! Will do better next time :)
If you'd like, we can move this discussion to #coverage-py too

Python Enhancement Proposals (PEPs)
This PEP proposes adding a mapping from each bytecode instruction to the start and end column offsets of the line that generated them as well as the end line number. This data will be used to improve tracebacks displayed by the CPython interpreter in or...
any test automation engineer here?? i moved from scraping role to test automation role. all i know is how to write test scenarios and then test cases. after that, i run it with pytest and generate HTML reports. am i missing something or thats all for test automation?? what else i have to learn or do, which tools and technologies
where I work QA team uses this - https://allurereport.org/
Open-source HTML automation test reporting tool for Pytest, Playwright, Cypress, Jest, Selenium, JUnit, TestNG, Webdriver.io, Cucumber, C#, Android, IOS and more
yes. i have used this
You're familiar with code-coverage tools I guess? That's another aspect that's common to want to care about.
Also data-driven testing, where you feed in your test cases as input data to reusable test functions?
e.g.
import csv
from pytest import mark
def get_test_data():
with open('test_data.csv') as f:
reader = csv.reader(f)
next(reader) # Skip header
return list(reader)
@mark.parametrize("input_value,expected_output", get_test_data())
def test_function(input_value, expected_output):
# Test logic here
something like that?
Also, security testing is a hot thing these days, you might get tasked with automating that
Why do you have this html report, how does it improve over cli?
it's the way how the boss of my boss and management people in general check if things are Ok. Having CLI is troublesome in our case because it will require WSL, docker, AWS login, etc.
Many software test suites I've seen has been lacking in many areas. Like only testing a few single cases instead of sweeping test variables.
I would like to promote:
- Stress tests (do A LOT of thing sto try to overload or overfill the system)
- performance tests (keep tracking historic data to be able to notice changes)
- random testing - use random stimuli, random delays, random fault injection
Ah ok. My boss just trust us I suppose 😂 we do have coverage report with 100% line coverage, but that's just a minimum bar and (of course) not enough. A manager can't understand if a things has been tested enough. It has to be someone actually testing or making the thing to evaluate that I think.
ah ok. In our case is not a matter of trust. If something goes wrong with a report they can tell ahead of time which clients are getting affected and who is the team that can fix it. We don't cover 100% lines sadly. I wish they were more strict. In general I think we suck at testing mostly because over a dozen of developers create code and only one is in charge of testing
when it is quality vs. features/bug-fixing, usually quality loses the battle when deciding priorities
I must admit they agree when we say "this suck", and allow us to correct/refactor things, if they are quick enough to not compromise the next release. But you need to always raise the flag when something in code/design/performance is not right, it's not a company priority 😕
perhaps that's where they trust us, in raise the flags but it requires a lot of discipline from developers and we all know what that means
how is it in your place?
hi
so in unittest there is a addCleanup method
which adds cleanups that are ensured to run, even if test setup fails
is there a pytest equivalent for this?
something that would cleanup a fixture even if the fixture fails?
Pytest fixtures already clean themselves up once their scope expires. If you're looking to catching and handling exceptions in the fixture, I've just used a simple try:except:finally block in the fixture.
well it can't really clear itself up in this case
i'm implementing a override_settings functionality which overrides global settings
so i have to revert the changes after the fixture expires
this part is easy
but am not sure what happens if a fixture fails and the cleanup doesn't happen
You can use a context manager in your fixture to patch the settings, yielding to the tests. Restore them in the finally block.
hmm
didn't think of a finally clause
might need to change some stuff around, but i think it'll work
thanks!!
Another angle to consider is that if your fixtures are failing, the tests should stop and completely fail. That's a bit more opinionated though.
Our test suite is supposed to run green all the time. The different kind of tests take between 1 min - 30min - 2 days and you run the CI jobs on your changes before merging.
Since some of the tests are so slow, we merge to master when confident enough and fix it afterwards if something goes red.
We make hardware, so it's very important that we don't have bugs - we don't want a broken million chips back from the fab.
pytest-django has one of these built in
oh i'm not using django
https://github.com/pytest-dev/pytest-django/blob/main/pytest_django/fixtures.py#L592 I'm suggesting that you could copy it
pytest_django/fixtures.py line 592
yield wrapper```ah in that sense 😅
yeah i was looking on that as well
i was mostly wondering since if you use django's override_settings as a decorator, it uses the addCleanup method
but with the pytest-django approach, it yields in the fixture
I changed the technical culture of a job I worked. I just spend a bunch of my time ignoring the planned tickets and fixed tiny bugs, doing small optimizations, making tests run faster, and generally unblocking the entire team. Management kept complaining, but also giving me great peer reviews and raising my salary. So I kept doing it until the rest of the team also started doing it (albeit in smaller scale), until I left for another gig.
I kept repeating "do the right thing, wait to get fired" and I did.
that's interesting. I have always admired old devs how made atari, nintendo, and sega games, no chance for mistakes.
living proof that changes come from within 🧘
It sounds like they got fired at the end, so that ultimately doesn't change the culture 🤷
Testing can be done ad infinitum, so it's important to test smart.
Where is a high chance for bugs?
How can we find those bugs most efficiently?
Eeh. No. I switched job. "Until I left for another gig" was super clear.
I kept repeating "do the right thing, wait to get fired" and I did.
wait to get fired and I did.
and I did.
Not as clear you think
Oh. Lol. Yea ok. Yea I screwed that up 🤣 I didn't get fired. In fact the team was seen as the team to copy in development ethics/style/craft when new projects were started.
(Unfortunately I've heard some management don't get it and are trying to destroy that culture. Hopefully they don't do a Boeing)
yeah, that's been my experience of teams with good culture, the leader leaves, new leader comes in and destroys it
you should have the power to interview your boss
and vote on their appointment
I am creating unit test cases for the first time - which all scenarios I should be covering? Also , how to do the documentation? Can anyone help me out 🤧?
If you test a function then create a corresponding test case and add a method for any behavior you want to test. Like if you're testing addition you would maybe put TestAddition(TestCase), and test_if_will_add_negative_and_positive_correctly(self):. You test any behavior or any type of input and output you want your code to have. If what your code does isn't tested think of it as not existing. You can also document what is being tested with a comment explaining why, or in the class definition you can put a docstring to help.
I aim to write the fewest possible tests to get the coverage first
This is what I do too
then check coverage report and start creating new scenarios to reach the most I possibly can.
If you could have an interactive pytest session, what would be some features, that might be useful to you?
Like e.g. selective test running,
Filtering by name/marks/testresults etc, adding/modifying plugins+flags
I can't think of anything accept "watch" that automatically reruns the test as I save the test or impl code
Could implement an indicator, that watches files and just shows, that it changed + an option to rerun all changed files
Can ya'll help me with this "Error opening input file C:\Users\Lenvo\Desktop\video.mp4.
Error opening input files: Permission denied" I've been trying to run my testing video through ffmpeg but kept on getting this error
Yh it's python
OK, and I take it that video.mp4 really exists and you can open it with a media player by double-clicking?
Can you show the full ffmpeg command-line?
sure
from moviepy.editor import VideoFileClip
clip = VideoFileClip(r"C:\Users\Lenvo\Your team Dropbox\Alexander Dunbar\PC\Desktop\video.mp4").subclip(0, 5)
ffmpeg version 7.1-essentials_build-www.gyan.dev Copyright (c) 2000-2024 the FFmpeg developers
built with gcc 14.2.0 (Rev1, Built by MSYS2 project)
configuration: --enable-gpl --enable-version3 --enable-static --disable-w32threads --disable-autodetect --enable-fontconfig --enable-iconv --enable-gnutls --enable-libxml2 --enable-gmp --enable-bzlib --enable-lzma --enable-zlib --enable-libsrt --enable-libssh --enable-libzmq --enable-avisynth --enable-sdl2 --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxvid --enable-libaom --enable-libopenjpeg --enable-libvpx --enable-mediafoundation --enable-libass --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --enable-libvidstab --enable-libvmaf --enable-libzimg --enable-amf --enable-cuda-llvm --enable-cuvid --enable-dxva2 --enable-d3d11va --enable-d3d12va --enable-ffnvcodec --enable-libvpl --enable-nvdec --enable-nvenc --enable-vaapi --enable-libgme --enable-libopenmpt --enable-libopencore-amrwb --enable-libmp3lame --enable-libtheora --enable-libvo-amrwbenc --enable-libgsm --enable-libopencore-amrnb --enable-libopus --enable-libspeex --enable-libvorbis --enable-librubberband
libavutil 59. 39.100 / 59. 39.100
libavcodec 61. 19.100 / 61. 19.100
libavformat 61. 7.100 / 61. 7.100
libavdevice 61. 3.100 / 61. 3.100
libavfilter 10. 4.100 / 10. 4.100
libswscale 8. 3.100 / 8. 3.100
libswresample 5. 3.100 / 5. 3.100
libpostproc 58. 3.100 / 58. 3.100
[in#0 @ 000001e778f2e8c0] Error opening input: Permission denied
Error opening input file C:\Users\Lenvo\Your team Dropbox\Alexander Dunbar\PC\Desktop\video.mp4.
Error opening input files: Permission denied
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\Lenvo\AppData\Local\Programs\Python\Python310\lib\site-packages\moviepy\video\io\VideoFileClip.py", line 88, in init
self.reader = FFMPEG_VideoReader(filename, pix_fmt=pix_fmt,
File "C:\Users\Lenvo\AppData\Local\Programs\Python\Python310\lib\site-packages\moviepy\video\io\ffmpeg_reader.py", line 35, in init
infos = ffmpeg_parse_infos(filename, print_infos, check_duration,
File "C:\Users\Lenvo\AppData\Local\Programs\Python\Python310\lib\site-packages\moviepy\video\io\ffmpeg_reader.py", line 289, in ffmpeg_parse_infos
raise IOError(("MoviePy error: failed to read the duration of file %s.\n"
OSError: MoviePy error: failed to read the duration of file C:\Users\Lenvo\Your team Dropbox\Alexander Dunbar\PC\Desktop\video.mp4.
Here are the file infos returned by ffmpeg:
OK let me go read the source for moviepy.editor, because that doesn't really show the full command it ran. It might be failing to escape the spaces in the directory name?
Hmm, I don't see subclip() in here, just subclipped(), are you sure that's right?
e.g. subclip = audio_clip.subclipped(start_time=6, end_time=9)
Aha yeah, this doesn't look like it supports spaces in directory names
moviepy/tools.py line 53
def ffmpeg_escape_filename(filename):```Though it does have the full path there in Error opening input file C:\Users\Lenvo\Your team Dropbox\Alexander Dunbar\PC\Desktop\video.mp4 so maybe I'm wrong. Just for grins try putting the file at C:\video.mp4 for testing.
Here's the full command it ran "from moviepy.editor import VideoFileClip
clip = VideoFileClip(r"C:\Users\Lenvo\Your team Dropbox\Alexander Dunbar\PC\Desktop\video.mp4").subclip(0, 5)
clip.write_videofile("output.mp4")
Okay
I guess lemme try using this library locally
This is really not a unit testing question but oh well
What version of this library are you using? Mine doesn't seem to have moviepy.editor at all, and VideoFileClip is right off the top-level moviepy module.
I couldn't paste the full error cuz it's long but lemme try sending it as a file
>>> clip.subclip(0,5)
Traceback (most recent call last):
File "<python-input-6>", line 1, in <module>
clip.subclip(0,5)
^^^^^^^^^^^^
AttributeError: 'VideoFileClip' object has no attribute 'subclip'. Did you mean: 'subclipped'?
>>> clip.subclipped(0,5)
<moviepy.video.io.VideoFileClip.VideoFileClip object at 0x000001C5ED83EC10>
Works for me locally when I call it subclipped()
Yeah mine too but I am using version 1.3.0
Why so old? The latest seems to be 2.1.1?
Yeah but that also giving the same error and it doesn't seem to have .editor that's why I downgrade
Does it still fail when the file is at C:\video.mp4?
OK, and the file has normal permissions when you look at the properties in Explorer?
Try running an ffmpeg command on it outside of Python I guess
yes
I think I've tried that but let me see again
C:\Users\Lenvo>ffmpeg -i "C:\video.mp4" -ss 0 -t 5 -c copy output.mp4
ffmpeg version 2025-03-31-git-35c091f4b7-full_build-www.gyan.dev Copyright (c) 2000-
[in#0 @ 000001459141f640] Error opening input: Permission denied
Error opening input file C:\video.mp4.
Error opening input files: Permission denied
I even tried chaning the file location again before running it outside of python and it's still giving error
OK, that at least reduces the size of the surface area we need to cover.
Alright
Can you try prefixing the ffmpeg command with runas /profile? That should run it as your administrator account instead of the reduced privileges it has by default.
runas /profile cmd.exe /k "some command" will run an arbitrary command in a new command prompt
ight
I am still getting the same error
ffmpeg -i "C:\Users\Lenvo\Desktop\video.mp4" -ss 0 -t 5 -c copy "C:\Users\Lenvo\Desktop\clip.mp4"
ffmpeg version 2025-03-31-git-35c091f4b7-full_build-www.gyan.dev Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 14.2.0 (Rev1, Built by MSYS2 project)
configuration: --enable-gpl --enable-version3 --enable-static --disable-w32threads --disable-autodetect --enable-fontconfig --enable-iconv --enable-gnutls --enable-lcms2 --enable-libxml2 --enable-gmp --enable-bzlib --enable-lzma --enable-libsnappy --enable-zlib --enable-librist --enable-libsrt --enable-libssh --enable-libzmq --enable-avisynth --enable-libbluray --enable-libcaca --enable-libdvdnav --enable-libdvdread --enable-sdl2 --enable-libaribb24 --enable-libaribcaption --enable-libdav1d --enable-libdavs2 --enable-libopenjpeg --enable-libquirc --enable-libuavs3d --enable-libxevd --enable-libzvbi --enable-libqrencode --enable-librav1e --enable-libsvtav1 --enable-libvvenc --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxavs2 --enable-libxeve --enable-libxvid --enable-libaom --enable-libjxl --enable-libvpx --enable-mediafoundation --enable-libass --enable-frei0r --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --
[in#0 @ 000001616525d280] Error opening input: Permission denied
Error opening input file C:\Users\Lenvo\Desktop\video.mp4.
Error opening input files: Permission denied
Hmm, I'm kinda stumped, sorry. I'll keep thinking about it, but you should be able to access a file owned by your own user etc.
There are, like, some Group Policy settings that could be blocking it, but if this is your own computer and not part of an 'organization', there's little chance you've changed any of that.
No man I didn't change anything, and yes it is my own computer
It been almost a week now since I had this error
All the Google hits I see for this error message are people doing it wrong, like pointing -i at a folder instead of a file.. but your command looks fine to me.
I have no idea what to do now
I guess one last thing to try is launching an adminstrator-mode command prompt (right-click on the command prompt shortcut and run-as Administrator)
and try the ffmpeg command from that
The only other thing I can think of at all is your anti-virus blocking access, but that would be weird to be happening to an mp4 file
I had an anti virus on my computer but because of that I uninstalled it but it's still the same nth change
Super baffling. I guess let's just triple-check that there are no weird file permissions..
If you run icacls C:\Users\Lenvo\Desktop\video.mp4 in the command prompt, what does it say?
It should show multiple things having access, including your username, Administrators, and SYSTEM.
F means 'full access', so hopefully you see some Fs
C:\ffmpeg_input\video.mp4 NT AUTHORITY\Authenticated Users:(OI)(CI)(F)
BUILTIN\Users:(OI)(CI)(F)
NT AUTHORITY\Authenticated Users:(I)(OI)(CI)(F)
DUNBAR-PC\Lenvo:(I)(OI)(CI)(F)
BUILTIN\Users:(I)(OI)(CI)(F)
BUILTIN\Administrators:(I)(OI)(CI)(F)
NT AUTHORITY\SYSTEM:(I)(OI)(CI)(F)
NT AUTHORITY\Authenticated Users:(I)(OI)(CI)(IO)(M)
Successfully processed 1 files; Failed processing 0 files
Ig they all got full access
Huh that's an interesting number of attributes set on them
I wonder why you've got (OI) and (CI) and I don't... those stand for Object Inherit and Container Inherit.. shouldn't matter, but interesting
Ig they came with the computer
Don't u think it's because of these attributes I'm getting this error
I mean, I didn't at first, because they look "permissive" to me.. but let's google for OI/CI and make sure they don't mean anything funny here
OK, so basically (like I thought), those mean that it will inherit the settings of the parent folder, which in this case is "Desktop"
so I guess try icacls C:\Users\Lenvo\Desktop and make sure that doesn't have some lockdown on it.. but you've already tried C:\video.mp4 so I don't have much hope for that
I am running low on ideas of what this could be other than a broken ffmpeg installation
C:\Windows\System32>icacls C:\Users\Lenvo\Desktop
C:\Users\Lenvo\Desktop DUNBAR-PC\Lenvo:(OI)(CI)(F)
NT AUTHORITY\SYSTEM:(OI)(CI)(F)
Successfully processed 1 files; Failed processing 0 files this is what I got
Bro I have downloaded like 5 or 6 different ffmpeg version and they are all the same and now I am using the full build ffmpeg
which ffmpeg do u use
??
I honestly use it more often on MacOS, where I install it with homebrew, but here I install it inside MSYS2 with pacman because I'm a weirdo.
Which are you using right now? These? https://github.com/BtbN/FFmpeg-Builds/releases
or possibly https://www.gyan.dev/ffmpeg/builds/ ?
this
OK just for grins I'll try that and make sure it works for me
Okay
You did ffmpeg-release-full here, or something else?
huh?
There are lots of downloads on that site, which one did you pick?
git master builds
Try the ffmpeg-release-full.7z version just to be sure. I just downloaded that and it works fine on my test MP4 file.
It should sum like this "latest git master branch build version: 2025-03-31-git-35c091f4b7
ffmpeg-git-essentials.7z
.ver .sha256
ffmpeg-git-full.7z
.ver .sha256"
Also make sure the ffprobe command included gives you the same error when you run it on video.mp4 I guess
Yep it does
If that happens with the 'release' build also, I guess I'm out of ideas, sorry.
Let me install the release build and try it
which year or date
2025-03-03
Did u try git master full build? Did it work?
I didn't, but I could. Why do you want to use a non-release build?
Is that a non-release build?
I tried the release 7.1zip and it didn't work
Hey uhmm.. How did u set up ur moviepy v2.1.2 without getting the "movie.editor not found error"
The stuff is just off of movie. now, you don't need the .editor part
And it's gonna work the same way the .editor does?
Yeah, looks like the same class, they just seem to have moved it
And which command u used for moviepy to work without .editor error
from movie import VideoFileClip
clip = VideoFileClip(r"C:\video.mp4")
clipped = clip.subclipped(0,5)
thanks man
This worked for me at least. I'm out of ideas about why ffmpeg.exe hates your machine.
I need a favor from u bro, I want you to help me with ur testing video like the video u used for testing maybe my video is causing the problem
Like fr I've been on this ts for days now, Im fed up
Actually you can use ffmpeg itself to generate a good test video.
This just worked for me:
ffmpeg -f lavfi -i testsrc -t 30 -pix_fmt yuv420p testsrc.mp4
will create a 30-second video in testsrc.mp4 with the test color bars on it and a counter
ffmpeg -f lavfi -i smptebars -t 30 colorbarstest.mp4 will do the same with the SMPTE standard color bars as the pattern
Basically when you say -f lavfi, instead of -i pointing at a filename, it's a 'video filter' name.
Thank you so much bro
What's crazy is that lavfi lets you specify a whole "filter chain" as the argument, so you can do crazy stuff. Here's one that generates a video of the "Game of Life" that I just found on stackoverflow:
ffmpeg -f lavfi -i life,edgedetect,negate,fade=in:0:100 -frames:v 200 life.mp4
If you want a different resolution and framerate for your test video, you can do it like this:
-i testsrc=duration=10:size=1920x1080:rate=60
Some other stuff about that here https://vse-docs.readthedocs.io/video_editing/setup/creating-test-files.html
Okay
Do we make unit test for init file?
You don't make unit tests for files. You make them for functions.
Okay. Understood. And what to do in case of functions being called from other py files
That has no bearing on anything. Modules are just a way to organize code.
You should use a coverage tool to see what needs testing, and test the high level functions or views/routes of your app. Any function that's just an implementation detail should not be tested directly but tested implicitly via another function
You should move functions out of your __init__.py and import them in
I disagree with that statement. It's fine having code in __init__.py
I have been trying to.write the unit test case but I'm facing the key value error. I don't know how to handle any of these 😭
You copy paste the error and ask a question.
I am doing it since afternoon in the copilot but no use
The issue i am getting is because the code using traverse codes I guess the classes are interlinked, which is why I am facing so many issues
And the test cases I am creating is on individual file levels, I tried to the mock function but there got some limitations
Here. Copy paste. Here.
I wish I could but I can't.
You don't sound like you know enough basics to make such a statement.
Well that makes no sense.
Can you boil it down to something you CAN paste?
i don't think you'll be able to get help here if you can't share details.
If you can't share anything, I guess run a local LLM with Ollama and ask it.
Yes I'm learning it . And have been assigned task at work
That's why I can't share it here.
Sure, but you can boil down the essence of your problem into a toy example that you can share
Giving code to a big corporation that explicitly steals intellectual property good, sharing it with people who wants to help bad. Is that the logic? :)
So I'm facing this error

I have included the column but it's been testing for empty df
Looks like you're passing a list of keys to a thing that wants a single key.
Also please send text. Not pixels of text.
Hope this helps
this doesn't seem to be about unit testing anymore, is that right? You should probably open a help topic: #❓|how-to-get-help
Is it? Okay
@brisk island OK, so let's say hypothetically that your project looks like this:
## Project Structure:
- chess/
- __init__.py
- board.py # Chess board representation
- pieces.py # Chess piece classes
- notation.py # Parser for chess notation
- game.py # Game logic
- tests/
- __init__.py
- test_board.py
- test_pieces.py
- test_notation.py
- test_game.py
- pyproject.toml # Project configuration (includes dependencies and pytest config)
there are a lot of ways to configure a python project, but I'm going to focus on pyproject.toml since I consider it the most-modern option.
The pyproject.toml for this project might look like this:
[build-system]
requires = ["setuptools", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "chess"
version = "0.1.0"
description = "A headless chess game implementation with standard notation support"
readme = "README.md"
requires-python = ">=3.11"
dependencies = []
[project.optional-dependencies]
dev = [
"pytest>=8.3.5",
"pytest-cov>=6.1.1",
]
[tool.pytest]
testpaths = ["tests"]
python_files = "test_*.py"
python_classes = "Test*"
python_functions = "test_*"
This single config file replaces, for example, having a pytest.ini and a requirements.txt in the repo.
okay, keep going
pip install -e '.[dev]' will install this project.. what that command is saying is "build the package you find in the current directory (.), along with its 'dev' optional dependencies, and install it as an 'editable' package"
an editable package means that when you change the code, immediately your installed package is updated.. otherwise it would install a copy for you
pytest will run all your tests; we'll get to that next
@odd walrus where did this conversation start?
that was confusing 🙂
nedbat, all good?
Aah sorry, yeah, I wanted to introduce them to unit testing, but then I realized there were some basic things to describe first
yeah I'm new to toml
So, what does a test look like? Let's write the first test that would go in test_board.py
okay let's do it
import pytest
from chess.board import ChessBoard
def test_board_initialization():
"""Test that the board is initialized correctly."""
board = ChessBoard()
assert len(board.board) == 8
for row in board.board:
assert len(row) == 8
Now, here's where it gets fun, or at least does in my opinion.
You can write this test BEFORE you have a working ChessBoard class.
what is the public api to ChessBoard?
I can elaborate on that, but at the moment I'm just making it up since I haven't seen their code
TDD scares me, because I don't know the shape until after I've designed it
I'm picturing ChessBoard instances having get_piece() and move_piece() at least, for example.
I actually was storing 16 Piece instances in 2 Player instances instead of using a Board
and I guess you need place_piece() for the rare promotion-of-a-pawn case.
a Board might have 64 Spot instances while my method only had 32 Pieces
but I was confused on that too!
For me it seems natural to model the board, but you can skip it and just have a 2D list or something, I suppose
cool, we can always change it later
My main reason is so that when we implement Piece or whatever you want to call it, its def is_valid_move(...) function can lean on the ChessBoard class instead of baking in all the logic.
(sorry, move, not mode)
well, I already have some code... Did you want to see that?
I have some basic draw_piece, move_piece, but it's a little poorly designed
quick question, before I post the github, I accidentally uploaded the whole virtual environment 😦
How can I just upload the main "game" folder for you guys to look at?
Let me work on that
You can git rm -r the .venv directory if that's what you mean. You can list it in a file called .gitignore and git won't try to care about it in the future.
 What version of Python are you using?
What version of Python are you using?
3.11.2
I know .gitignore is a great tool, I just don't know about .venv or git rm -r
.venv and git rm -r are new to me sorry
What did you mean by 'virtual environment' then?
.venv is the common directory name for one
git rm -r says 'recursively remove this thing and its contents from git'
(after which you'd commit that change)
I don't want to start a war, since this is a hot topic.. but from my perspective it's important to always be testing at the highest level you can get away with. It's possible to write tests that try to expose every internal operation your code performs, and in my experience they don't make your software better.
Arguably this makes me a 'behavior-driven development' advocate, and I'm OK with that label, but I don't consider it a religion.
By 'get away with' I mean specifically 'such that it adds value for you'
Sometimes lower-level tests are just what you need to help you figure something out, other times they'd be a waste
GitHub
Contribute to DustinWestGlow/Dustin-chess-game development by creating an account on GitHub.
alright guys, this is my current state of affairs, let's do it
OK cool. So game.py is nearly impossible to test in its current shape, so we'll ignore it for now.
but engine.py has plenty of stuff we can kick off with
@odd walrus that's a nice principle, I would like to see some conrete examples, however
heck yeah
Just briefly, let's say you have a login page on your website..
Scenario 1: A user clicks "reset password"
Given a user is not logged in
When that user clicks "reset password"
Then that user is prompted to enter an email address
Restricting yourself to this kind of phrasing, "Given / When / Then", you're kinda forcing yourself to focus on the feature itself, rather than whatever it's doing inside. For example, notice how it doesn't say "the system generates a unique token for this reset-password URL".. that's really an implementation detail, not the feature itself perhaps...
Coming back to engine.py though, let me think of what the first test I'd write is
I guess to_grid speaks to me as the first thing to test
In reality if you handed me this I would just immediately refactor it before writing any tests, but I'll try not to force that on you
no problem
yeah it just takes a mouse position and returns a board tile coordinate
I am curious. I can see why to_grid isn't obvious what's going on inside the function
but we can refactor it later. How can I test it?
So, to_grid looks like this, right?
# Input is a tuple: (x, y) in pixels the cursor coordinates
# Output a tuple: (row, col) of the tile containing cursor
# Cursor position -> corresponding Tile
def to_grid(pos):
col = pos[0] // tile_size
row = 7 - (pos[1] // tile_size)
return (row, col)
# example test
import pytest
from engine import to_grid
def test_to_grid():
# Test some well-understood cases
assert to_grid((0, 0)) == (7, 0) # Top-left corner
assert to_grid((60, 60)) == (6, 1) # Assuming tile_size = 60
assert to_grid((420, 420)) == (0, 7) # Bottom-right corner
# Test anything interesting you can think of, like stuff that should be in the same tile
assert to_grid((0, 0)) == to_grid((59, 59))
# Test some edge cases
assert to_grid((0, 479)) == (0, 0) # Bottom-left
assert to_grid((479, 0)) == (7, 7) # Top-right
Now, what you're going to find, spoilers, is that tile_size doesn't seem to be defined anywhere.. but the idea with the test is to draw an outline around what the function does for you
Starting with the edge cases is totally reasonable and common
By which I mean the values where the function does something interesting.. 0, -1, positive infinity, whatever makes sense
I appreciate you working on the math to get it correct
So... should I be verifying input in the to_grid function?
For negatives, infinities, stuff like that?
Yeah, you could break that into a second test, called for example def test_to_grid_invalid_inputs():
and assert that it raises ValueError, say, in all the cases you feed it
You can say:
with pytest.raises(ValueError):
# some code here that should raise ValueError
Sure. My main reason for suggesting a Board or ChessBoard type of class is that it gives you a better place to put all these things you have as global variables
if you say:
with pytest.raises(ValueError) as exception_info:
# something that throws an error here
assert "error message you expected" in str(exception_info.value)
# notice the assertion is AFTER the 'with' statement closes.
I'm a link guy definitely
I looked up assert, should we be putting error messages on every single assert statement?
I just want one string to print if the positive, in-bound values don't work.
Another string for the negative values. Another for the positive, out-of-bound. Etc.
or is that what you just said, haha
you good, @odd walrus ?
Yeah
If the assertion is super obvious in what it's doing, you don't really need a message attached, but it's definitely cleaner to include one
The test framework I've used most in my career has a LOT of helpers to do that for you, so I'm used to the failures being very readable
nice! I can always add more stuff
Let me see... I need some help setting up the pytest stuff.
I'm gonna just put the testing file and the functions like to_grid file in a folder and make sure I have the concept down. Cool?
Yeah.. You may need to edit what I showed for pyproject.toml if you don't have a tests folder with the tests in it
oh uh, I could use help with the toml. I didn't do a single thing with that. Just don't understand it
I ran the test file with the imported to_grid function file
and it didn't print anything
maybe I should add a "to_grid successful"?
You don't run them directly, you run the pytest command actually
pytest -v will turn on verbose output
pytest tests/test_something.py will run that individual test file
great! let me do that now
pytest -v tests/test_board.py::test_move_piece would verbosely run just one test from that file, in this case the one called test_move_piece
great so it gave me an error!
let me work it out
well.. yes. 😦 WHAT did you do to me!
hey @odd walrus , since grid_size is 64 pixels, I updated the testing code and it passes green.
import pytest
from engine import to_grid
def test_to_grid():
# Test some well-understood cases
assert to_grid((0, 0)) == (7, 0) # Top-left corner
assert to_grid((64, 64)) == (6, 1) # Assuming tile_size = 64
assert to_grid((448, 448)) == (0, 7) # Bottom-right corner
# Test anything interesting you can think of, like stuff that should be in the same tile
assert to_grid((0, 0)) == to_grid((63, 63))
# Test some edge cases
assert to_grid((0, 511)) == (0, 0) # Bottom-left
assert to_grid((511, 0)) == (7, 7) # Top-right```Cool. Sometimes it makes sense to put an assert False or assert to_grid((0,0)) == (0,0) that you know you will fail, just to make sure your test suite is running correctly.
But if it said it ran some tests and they passed, it's probably good to go
Enjoy your first 'green build'!
thanks!
defiler, what else can I do to improve my code?
I would like to focus on this for the next little while, could you help me?
Speaking of refactoring to_grid,
if the x or y coordinate inputs are negative, should I return (0, 0) or something like None?
Arguably you might want to raise ValueError
Let me summarize what I'd change if you handed me this repo
great
So, the thing to remember is that refactoring is about getting from point A to point B.. but nobody says you have to get there in one step.
So, if a change seems daunting, you just need to break it down further until the steps are small enough to do
I also was thinking some sort of outofrange error or special value.
That way, if I make a GUI that extends beyond the board, then clicking outside of the board and onto the GUI will not crash the program
ValueError is the standard Python way to indicate that, but you can also return a special 'sentinel' value that means 'invalid' to you.. but raising an error is often cleaner
OK so, sorry for the wall of text, but here's what comes to mind without getting into the weeds too far
# Chess Game Refactoring
## Phase 1: Low-Hanging Fruit
1. Extract the "replay file" loading into a standalone function (that takes a filename parameter and returns the loaded sequence)
2. Create a "game initialization function" that sets up all the initial game state, even if it's messy for now
3. Extract the "move validation" logic into its own function that takes a piece and positions as parameters
## Phase 2: Reduce Global State
4. Create a simple `GameState` class to hold all the state that's currently stored in globals
5. Refactor handlers to accept a game state parameter instead of relying on globals
6. Move the replay functionality into its own class that manages replay operations
## Phase 3: Separate Game Logic from UI
7. Create a main game loop that clearly separates game updates from rendering
8. Extract the UI rendering code into its own module or class
## Phase 4: Make Input Handling Testable
9. Refactor event handling so each component only handles relevant events
10. Create proper interfaces between components with clear responsibilities
## Benefits:
- Tests can be added at each step
- Codebase improves incrementally
- Game functionality is preserved throughout
- Each refactoring is manageable and focused
- The final result will be fully testable
Something like that. I could get a lot more specific but those are sorta the separate groups of things that occur to me
I would aim toward having:
ChessGame
GameState
Board
Piece
Player
as the core models, and stuff like
NotationParser
ReplayManager
Renderer
InputHandler
as needed to build the rest of the game around them
okay
a ChessGame has a current Board which has its current GameState as an attribute
🔥
a Piece can have a current position, which the Board (or a separate MoveValidator module if you decide it's complex enough to break out) can use to figure out if the desired move is valid
just to quickly ask, do you agree with long variable names to help refactor the to_grid function to be super readable?
I do sorta favor longer names, in the era of tab-completion.. to_grid isn't too bad honestly.. I'd just make sure its name matches what you consistently choose to call a 'location'.. you might call it 'position' everywhere, or something else..
so to_position() might make sense in the end, depending
You could call screen x,y "coordinates" and board x,y "positions", just be consistent I guess
definitely
let me post the updated testing stuff in one second
still getting used to github stuff in vscode
okay boss, how's this?
https://github.com/DustinWestGlow/Dustin-chess-game/tree/main/tests
I think the only critique I know is using one-line comments INSIDE the function and writing the heavy documentation elsewhere. This would help follow the 5-line rule, right?
GitHub
Contribute to DustinWestGlow/Dustin-chess-game development by creating an account on GitHub.
@odd walrus
OK cool. Conventionally, tests have test_ as the first part of their file name
pytest will work with what you have if you manually tell it the name of the file to run, but if you want it to automatically pick them all up, it's best to name them test_something.py
Also the functions inside them need to start with def test_, because that's how pytest figures out which are tests vs. helper functions
let me correct that, then
okay, so the function is all good. The file name was corrected.
Is the code written without a code smell?
Do you think the commenting is a bit much?
Is there anything else you see about it?
After that, that should be all for a while. I need some time to rewrite a lot of the other code. When it comes to testing it all, I'll ask you about it. I appreciate your spill of advice and I wrote it down in a .md file
Thanks, boss
Lemme look again
Code looks plausible to me (engine.py).. You're returning early from the function when you encounter violations, which is good
I'd probably raise ValueError instead of returning None but it's up to you and what you have is fine
The // operator can be a little strange with negative numbers, but you're checking for negative numbers before using it, so that's fine
Another thing you can add to the TODO list is to move all the source code from the base folder into one called src or chess, up to you.. but that will make it easier to refer to from your tests
One thing you're not doing yet is loading the actual code from the project, you've just got your stuff inside the 'tests' folder itself.. that's fine as you're getting going, but eventually you'll want to connect the two 'worlds'
(Some languages do actually favor putting the test_something.xyz code files right there alongside the source code, but I don't love it.)
I will figure out the filing in a bit
Main thing! Get my ducks in a row and rewrite some of this stuff
I have to go at the moment, and I appreciate your help
Cool, good luck!
Does anyone know how Tailwind CSS can connect in index.css or main css
Because I have installed properly and npx is not being recognize in my project directory
I have uninstall it and reinstall it and it's still the same and I have unisntall it and install manually and it's still the same
Wildly inappropriate channel. Also the question makes no sense.
Nvm
im going to go insane, mac makes it so hard to make addons

have you tried the built-in Shortcuts system?
i would if it wasnt 3 in the morning
- This isn't unit testing right?
- This is a channel for asking for help, not ranting.
where is the rant channel
i love ranting
!offtopic
Off-topic channels
There are three off-topic channels:
The channel names change every night at midnight UTC and are often fun meta references to jokes or conversations that happened on the server.
See our off-topic etiquette page for more guidance on how the channels should be used.
yeah thats not rant
Rants are (usually) off-topic so yeah it is.
Did you print test["expected_instructions"] to check that it's what you expect? What I'm getting at is that you need to find where you are confused. Question everything.
Can you show all the code even if you think it's not relevant
Generally for loops should be avoided in tests use pytest.mark.parameterize
graingert means "it's better to use pytest.mark.parametrize than to loop over global variables"
Does anyone know if there is a pytest plugin which provides a fixture to capture the call args/number of calls some function has during a test?
Similar to the unitest.mock functionality but where the actual function isn't mocked?
I have whipped up a simple implementation which works for both sync and async functions for work, but was just wondering if something like this already exists...
One way is to set the mock's side_effect to be the original function: https://docs.python.org/3/library/unittest.mock.html#unittest.mock.Mock.side_effect

Python documentation
Source code: Lib/unittest/mock.py unittest.mock is a library for testing in Python. It allows you to replace parts of your system under test with mock objects and make assertions about how they hav...
There's also MagicMock(wraps=someobj)
If you're using a different mock library it should have a similar knob
thanks for that!
I should have thought of that 😅
Looks like pytest-mock has a mocker.spy which does pretty mcuh exactly what I needed
Might keep my implementation though since I have some extra logic to make it so that the tracked calls have the argument values mapped to their names in the function automatically whether they were passed as a kwarg or not which is more convenient for me for testing...
You’re right. I had a duplicate test above with the same input as the last one. I forgot to change it, which caused confusion. A silly mistake. Thank you!
Already fixed it. Thank you for your help!
So you want to monitor how a function gets called across all your tests? What will you use this for? Test coverage?
The purpose was that I have some code that uses APScheduler to set some jobs be run at some time. I wanted to make sure that the jobs were run at the expected times and with the correct arguments. I used the time_machine library to move time around which let me check that the jobs in APScheduler were right, but I wanted to make sure that when the jobs were called the args were right, hence why I wanted to get the arguments the function was called with
I see, thanks for the insight
I'm working in a project which use unittest. Is there some way to run a test class twice with different parameters, akin to fixtures with pytest?
Generally the trick is to have two or more test classes with a common base class where the tests are
See the asyncio Tasks tests
https://github.com/python/cpython/blob/main/Lib/test/test_asyncio/test_tasks.py#L2881 see how the parameters are on the class
Lib/test/test_asyncio/test_tasks.py line 2881
class CTask_CFuture_SubclassTests(BaseTaskTests, test_utils.TestCase):```Ah nice. This might be useable to what I'm looking for
I'm adding asyncio support to a package (in a "dual stack" manner) and I'm looking for a good way to do unittests: One sync and one with asyncio. The problem is that I do not want to repeat every test function twice. What I'm experimenting with is conditional sections of the tests that does the respective sync and async testing
The fundamental objective is: How to make sync and async test with DRY
use unasync to generate your sync tests
You can also just have all your tests be async def and run them with fn().send(None)
I'm thinking something like this (the example is incomplete):
async def test_expedited_upload(self):
data = [
(TX, b'\x40\x18\x10\x01\x00\x00\x00\x00'),
(RX, b'\x43\x18\x10\x01\x04\x00\x00\x00')
]
with self.subTest("sync"):
self.expected_data = list(data)
vendor_id = self.snetwork[2].sdo[0x1018][1].raw
self.assertEqual(vendor_id, 4)
with self.subTest("async"):
self.expected_data = list(data)
vendor_id = await self.anetwork[2].sdo[0x1018][1].aget_raw()
self.assertEqual(vendor_id, 4)
The library is sync today, so the first subtest is the code which already exists, while the latter subtest is the replicated async test
It is what the project uses and I need to convince the other maintainers to change. Other than that, I don't think so
I'm trying to find a way to get asyncio into it with the least impact
Which library?

GitHub
CANopen for Python. Contribute to canopen-python/canopen development by creating an account on GitHub.
The asyncio fork I've been working is here: https://github.com/sveinse/canopen-asyncio

GitHub
CANopen for Python. Contribute to sveinse/canopen-asyncio development by creating an account on GitHub.
But its not feature complete - such as unittests, which I'm working on now
I have a unittest that use setUpClass(). Now I want to migrate it to asyncio, however, after some time debugging, there is no AsyncSetupUpClass as far as I can tell. I assume since the base class is unittest.IsolatedAsyncioTestCase and thus by that name the loop is taken up and down for every test. Thus its not possible to have a class-scope setup for asyncio. Is this correct?
Use pytest-async lib 🙂 or pytest-asyncio dunno its name for sure
not an option for this project, I'm afraid
but I'd love to 😄
Yea there's a new event loop for each run that is taken down after. Logically I'd draw the same conclusion that since all the async stuff you'd do on the class setup would be on an event loop that is taken down after the individual test run, that it isn't possible with how the unittest module works for async stuff. What are your constraints specifically and why isn't the use of pytest an option?
Basically I have to convince the maintainers to change to pytest (and I have other more important discussions to focus on tbh)
Hmmm. Pytest is more flexible than you might realize. You can apply fixtures to unittest module classes and other interesting stuff. Personally I prefer the unittest module but I sometimes need more functionality out of it so I would make my own TestCase class to inherit with the desired behavior and put fixtures on the base class. From the perspective of writing a test it can be identical but with some enhancements. But if that isn't an option I am not sure what to advise off hand.

I am very well familiar with pytest and are using it a lot 😄
Ahhh, fair. I guess my point is that maybe you could make something using pytest and a base class that could do what is needed and convince them to use it. I didn't even use pytest for a long time but I still used it to run tests because it just worked better for discovering them for me. In contrast to just using functions with pytest which would be a lot different.
Why would you want class scope loops? It just lets you have test isolation issues
I think the idea from the original authors is that setup and teardown is costly
Since I can't use a shared setup like this with asyncio, I refactored it into per test setup and teardown, which is the preferred thing to do.
This is so weird. Why would pytest not be able to import the file even if its next to each other?


This works without uv init it

🤯
I have no idea what is up with the uv version of creating the project. It just seems that it breaks pytests
Being "next to" doesn't matter in python unless it's a relative import.
Hey guys, I have a question, I am writing unit tests to test bunch of functions that connect to a database, fetches data, stores in array and returns json. My question is: If i plan to write the unit test by making another database with inserts etc to test/verify the functionalities of my functions i wrote, would that still be unit testing? I read that unit tests are supposed to be isolated. I don't know if what I am doing is unit testing or integration testing.
Am I doing proper unit testing if I interact with a real database in my tests, or should I mock the database instead? I prefer to stick with what I'm doing rn but I just want clarification if someone would be kind enough to help.
Definitely mock database. That's at least how Django does it's unit testing, it spins up a dummy test database and runs data operations on it then deletes it
Oh ok.
Don't mock db, spin up test db in docker or with test containers lib
Don't mock what u are able control programmatically locally, run against local db
Mocking db leads to test fragility and uselessness
Also in general mocking db is a lot of extra code for no gain
Mocking db is good only in cases like if u plan app switching between different db engines as part of app features
In my experience people generally consider this an integration test or more specifically a data access integration test. I find that there is no value in testing if the code produces the right SQL for fetching something for example or any other detail like that instead of just spinning up a database with testcontainers and finding out that it will actually do what It's supposed to and it is infinitely more enjoyable to write too. I agree with @maiden pawn , don't mock the database, it's extra work, providing little value, and getting a real one is quick and free if you have docker installed and use testcontainers.
I can only think of two counter-examples, just to be a jerk:
- Your app explicitly cares about portability across DBs
- You're actually building a database or database plugin
I used to think item 1 was cool, but it can be the source of some really savage bugs to hunt down.
When you say portability across databases do you mean like one implementation that would work across MySQL, postgres, and MongoDB to give some examples? (Sort of like how SQLalchemy just works with two of those) Like identical code but can use any? Or are we talking abstractions and different implementations for each like a MongoDB one, postgres one, blanket SQLalchemy one maybe too where you unit test the interactions with a mock of the abstraction. Or do you mean like writing SQL that is generic enough to work on them all or something
Yeah, in the past for example I've had to build Rails apps that needed to work on several different customer DB choices. I've never had to go cross-paradigm, I'd have to think about how I'd want to abstract between MySQL and Mongo; interesting puzzle!
But testing to ensure all your db migrations are asking for workable things on each platform etc, sometimes it makes sense to mock some parts of it I feel
(In the rare case of caring etc)
(I did learn to love Oracle kinda during this time-frame; it's got some amazing abstractions you can play with)
(Like, Oracle pre-dates TCP/IP being popular so you can just can just configure it to do something different if you want)
I am not familiar with migrations and rails. But for me I can say if I want compatibility with these all I'd have my code broken up into repository/unit of work classes and load the entities in and create them in application and this involves explicitly using features of a given database (in the abstract) that might not be there on another. For example having a method on a Comment repository to get the next id (postgres supports this, Oracle supports this, MariaDB I think might? MySQL does not) and MongoDB certainly doesn't. There's also some choices made like the type of id for a model like should the id be a uuid and a string, should it be 64 bit, IDs in mongo can't be gotten before creating something as is and they're 12 bits. So if you model with a SQL database in mind, that will be a problem. But in the case of SQL and sequences and getting the next value you there are just tables for them anyway and I think some ORMs might work around it? That's my main experience/knowledge on this issue but mind you this isn't working on any specific framework or factoring in migrations beyond any one implementation. MongoDB has transactions and all kinds of locking and other than this ID issue and no SQL I think it's quite similar in capabilities.
Sqlite isn't a mock
Yeah, to summarize the Rails picture, the migrations are built on a relation-calculus library called arel, and it's happy to generate arbitrary DDL for you at runtime for the target db platform, it's super nice. I've been meaning to look to see if there's a Python equivalent.
So it's considered bad form to write literal SQL etc in your migrations, though you certainly can if you have to for something special.
It's hard to do massive bulk updates without touching SQL also; when you just have too many rows to touch to be able to pay to materialize all of them on the client
(I prefer other approaches to such updates so this has never bothered me.)
Huh, I do not immediately see anything current in Python town that does what arel does. Interesting.
Damn I still like this codebase too
I can't completely comment because I haven't had anything get to the point where it's going to be a bulk update of stuff to a problematic level, but I can imagine going through millions of records would be very problematic or at least unnecessary and wasteful rather than using SQL to tell the database to do it. Otherwise you'd be streaming them in which is also wasteful.
Yeah. There are some wild new systems that make it easy to run your migration code actually ON the db host next to the data, and I've been meaning to use one for my next whatever. (e.g. SpacetimeDB)
I guess this isn't about unit testing exactly, sorry, but that's the other huge thing you get by committing to a single db 'engine'.. you can actually optimize your stuff for it. The overall cost of the 'cross-RDBMS' stuff I've done was pretty high arguably.
This sounds right. I personally would test with the database intended for use regardless if I am just writing code specific to postgres or any other. And I think most people writing SQL usually aren't trying to have it work with multiple copies. Like if you want to know your code works with files for example, I would use the filesystem and some temporary directories, If i am writing code specific to postgres, it's also so easy at this point to find out. Because although I do care about the SQL, if I am writing a function that effectively creates stuff, or updates stuff, I care about the end result of stuff being created or updated and not immediately the SQL used (although that is also important sometimes) because there's more value to find out it does what I really want.
I've also come to really believe in CI, and specifically in teaching your CI system how to run your databases
Because db vendors are always breaking stuff with new releases, and you want your tests to find that before you try them in real life.
MySQL in particular is crazy about changing important things in 'teeny' versions etc.
Like, renaming SLAVE to REPLICA in the command syntax wasn't a major version change
So having your CI 'matrix' be able to run the nightly MySQL or whatever is pretty cool
I say CI and not just 'your tests' because I've never really seen anybody spin up N different DB versions in docker for their local tests; I've only ever done it on chonky servers etc.
(If you use Kubernetes it's super easy to do it there.. but it's not that easy to get there...)
Yea that does sound important to be testing and catching and like something that should ideally be caught. I am not there yet personally but it's something I'll strive for in the future. Do you mean like having it run the tests against the latest version of MySQL every night?
Yeah
Every nightly version might be too much, but on some 'what is coming' sort of cadence at least.
It kinda depends on what release channels your db has; in theory you could do your own builds but luckily I've never quite had to go there.
Oh and just to finish the thought, why would you even WANT to upgrade so much etc?
The problem is that the hosted cloud version of all these things FORCE you to upgrade, and pretty quickly.
It ends up making sense to just get good at it.
Personally I can live with everything the current versions offer I think and even ones from awhile back and wouldn't want to do an unnecessary upgrade that is going to break stuff. But it does make sense to be good at it with testing and catching it sooner in CI as you've suggested.
At my current job we ended up migrating from self-hosted MySQL on EC2 to AWS Aurora, and we got bitten quickly by them retiring the version we had launched on etc.
They just turn them off and you can no longer use the API to launch replacements etc.
Which would be fine if the DB version numbers meant something.
!e
from unittest.mock import Mock
m = Mock()
m.__enter__.return_value = 1
:x: Your 3.12 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 3, in <module>
003 | m.__enter__.return_value = 1
004 | ^^^^^^^^^^^
005 | File "/snekbin/python/3.12/lib/python3.12/unittest/mock.py", line 662, in __getattr__
006 | raise AttributeError(name)
007 | AttributeError: __enter__
dang, seen a bunch of search results saying you can do this, what now?
do i need to write my own class just to mock threading.Condition?
oh ok, now i understand what the Magic in MagicMock is 😂
Is there anything more lightweight than selenium/playwrights for doing web end-to-end tests? I don't want to specify a specific browser (it doesn't matter, it's a pretty simple app), is there a way to just use whatever built-into-the-OS web frame thing is available?
That won't be significantly more light weight except by download size. Still just as slow. Jest is more light weight. Maybe that's more like what you want?
From a quick glance I think not? I have only light JavaScript; old-style, no bundling/building/nodejs/etc. Just a few interactive buttons and inputs, most things are server-side.
I'm also not so much worried about speed (although it would of course be nice), but more about portability and simplicity.
That all sounds like jest can handle it to me. It's WAY faster than a full browser. Just doing startup in selenium can be literal seconds, while jest is maybe 100ms or so.
If you can do testing without JS then you can get away with bs4, which is even faster.
Then maybe I misunderstand the website. It tells me to somehow integrate it with yarn, which I don't (want to) use.
I considered bs4, but I use a little bit of JS that I can't easily get rid of.. :(
I think yarn is just the runner. Believe me you want yarn to just run some node more than you want a full browser :)
You can also mix and match.
Ok.
I do not want to run node, no.
But I guess I might have to go for selenium then. The JS has to run somewhere..
Node is heaven compared so selenium ;)
this is causing me some confusion..
E AssertionError: expected call not found.
E Expected: mock(write=True, timeout=1)
E Actual: mock(write=True, timeout=1)
Show your code?
there's a lot going on, so abbreviated a bit
### The code under test:
timeout = state_data.timeout.get_timeout(max_wait)
fsm.selector.select(read=True, timeout=timeout)
### The test:
@pytest.fixture
def mock_timeout(mocker):
mock_timeout = mocker.Mock(spec=Timeout)
mock_timeout.interval = None
mock_timeout.get_timeout.return_value = 1
mock_timeout.exceeded.return_value = False
return mock_timeout
@pytest.fixture
def mock_select(mocker):
mock_select = mocker.Mock(spec=InterruptibleSelector.select)
mock_select.return_value = (False, False)
mocker.patch("ohmqtt.connection.selector.InterruptibleSelector.select", mock_select)
yield mock_select
@pytest.mark.parametrize("max_wait", [None, 0.0])
def test_states_mqtt_connack_happy_path(max_wait, fsm, state_data, env, params, mock_select, mock_timeout):
mock_timeout.get_timeout.return_value = 1 if max_wait is None else max_wait
mock_select.return_value = (True, False)
ret = MQTTHandshakeConnAckState.handle(fsm, state_data, env, params, max_wait)
assert ret is False
mock_select.assert_called_once_with(read=True, timeout=mock_timeout.get_timeout.return_value)
oh, what's this guy doing here, hiding in the pytest output:
TypeError: missing a required argument: 'self'
and that caused the AssertionError somehow?
I'd recommend using the context manager version of mock.patch
Show the full output?
Is there a reason you're not passing spec and return_value to patch?
it doesn't autospec based on what it's patching? i thought return_value was the next positional arg
sensing that i just need to read the docs 😂
You can pass them as kwargs
Also you can pass stuff as **{"foo.bar.baz.return_value.baz.return_value": 2}
my first reaction on seeing this was "doesn't mean you should, just because you can"
Could someone plz check my post in the #1035199133436354600 ? It is to do with python unit testing. I would appreciate help. Thanks.
With pytest-cov, do you know if it's possible to hard-code the data file location (run.data_file) to always be in the project root? If I accidentally run pytest in ./tests, then ./tests/.coverage is written, and my other tools such as editor integration don't pick that up.
pytest-cov uses coverage.py as its engine, so you can use coverage configuration: https://coverage.readthedocs.io/en/7.8.0/config.html
this is where I have run.data_file from. But there seems to be no way to anchor that to the project root, or is there?
you can use environment variables in the config, maybe that would be a way to do it. There isn't a built-in way.
coverage/config.py line 617
env_data_file = os.getenv("COVERAGE_FILE")```yeah, I can use that to hack my way around
With direnv:
echo 'export COVERAGE_FILE=$(find_up .coverage || echo ".coverage")' >> .envrc
i meant more that if you had an environment variable that indicated the project root already, you could use that in the coverage config file to build the path to the data file you want.
But this is of course even better: https://github.com/andythigpen/nvim-coverage/issues/6#issuecomment-2868905661

GitHub
vim-test has some functionality that seemingly always sets up the correct project root: https://github.com/vim-test/vim-test/blob/6517577d8b75c97ce0a916f44942877beb37d72a/plugin/test.vim#L60 It wou...
@limpid raft are you using something like tox to run your tests? There might be data floating around already
it's good if you want to run one test suite in different environments like versions of Python, etc.
ah ok. yeah, don't need that for this project, but that was a very helpful piece of information
@limpid raft since you said "accidentally" run pytest in a subdirectory, maybe the simplest thing is to make that less likely
getting me to do something right or differently is nowhere to be seen on the "simple" scale 😉
well, you could add code to your test suite that fails loudly if it's run from the wrong place.
ooooh
yeah, not needed anymore, now that direnv sets COVERAGE_FILE, but it's a good idea.
I will write a test to fail if COVERAGE_FILE is unset 😉
def test_run_from_project_root_unless_coverage_file_envvar_resolves():
assert os.getenv("COVERAGE_FILE") is not None or os.path.exists(
os.path.join(os.getcwd(), "pyproject.toml")
), "Please run tests from the project root directory only"
Hi, if someone could check my post in #1035199133436354600 I would be grateful. I have a problem which I hope someone could assist me in solving.
what are the conventions for documenting pytest fixtures?
i couldn't find anything within the pytest docs
write a docstring. What other conventions would you need? What audience are you thinking of?
in the sense of i have a fixture returning an object/function
should i dockument the usage within the pytest fixture docstring, within the returned "constructor" function, within the init of the returned object or at the class of the returned
I see. the most important thing is to write it down somewhere.
sample code:
class MyClass:
""" at class"""
def __init__(some_complex_init):
"""at init"""
@pytest.fixture
def my_fixture(request):
""" at fixture"""
def warpper(path):
""" at wrapper"""
return MyClass(path, other_complex_stuff_to_be_hidden)
return wrapper
Like.. you want help(thing) to give you the docstring? In that case, just try it and you'll see?
help(...) returns the docstring of the wrapper
thanks ^^
due to pytest, at least my ide doesn't show any docstring at all :D
which is the other reason why i asked
Well, that's the thing, you didn't tell us why, that's why ned asked. So you want to see it in the IDE? Where exactly? Like on hover for def test_foo(some_fixture) on the fixture there?
well, yes and no, i didn't ask in the first place because it is a separate issue imo.
would be nice if it showed up when hovering over the received fixture within a test.
but seeing how those are just parameters, i understand why the ide doesn't resovle them further (and just accepted that limitation for now)
Separate issue... from what? I still don't know what the original thing you asked for was :P
Give it a brief description of what it does or will give like you would describe any other code for someone to understand. I personally like when fixtures have a straight forward name, and if I am not sure I would go to the code in my editor to see more in detail what it does and a docstring could pave the way for what to expect or the general idea.
fwiw, functools.wraps might help you make the wrapper transparent, never tried wrapping a constructor like that, but don't see why it wouldn't work
my "issues" i had:
- where to document fixture usage of the returned objects
- fixture usage doesn't show up for ide
what i asked initially: only the first thing
you helped me by telling me to use help() on the obj, which resovled that question
then i asked if there is a way for things to show up in the ide, because it only resolves until the function definition and says "its a parameter so i don't care"
I'm trying to understand how to use assertRaises but I'm not smart enough can someone plz exlain it to me for dummies?
It's a method you call to assert that another method will raise a specific exception when it is called. You pass it the function or method that you want it to call, as well as positional arguments and keyword arguments you want passed to the function/method you're testing.
from unittest import TestCase
def my_function(value: str) -> None:
if value == "bad_value":
raise ValueError("you shouldn't pass bad_value to this function")
class TestMyFunction(TestCase):
def test_should_raise_value_error_when_passed_the_string_bad_value(self):
only_positional_argument = "bad_value"
self.assertRaises(ValueError, my_function, only_positional_argument)```You can also use it in a with block to make it simpler which is what I prefer most of the time.
def test_should_raise_value_error_when_passed_the_string_bad_value(self):
only_positional_argument = "bad_value"
with self.assertRaises(ValueError):
my_function(only_positional_argument)```With pytest, I can mark.parametrise tests, causing them to run multiple times with different parameters. I can also parametrise a fixture, so that a requesting test is run for each instantiation of the fixture.
Let's say I have a fixture that returns a list, and now I want a test to be run for every item in that list… is that possible somehow?
Do you guys know of a way to order pytest files other than alphabetic? My tests for Match are so much easier to write if I use Player, rather than mocking those. I figure that if I ensure that Player is tested before Match, then errors in Player won't affect my Match tests — I use -x all the time anyway. I am aware of pytest-dependencies and pytest-order, but they only seem to do ordering within a file.
You could write your own little plug-in that changes the order: https://docs.pytest.org/en/stable/example/customdirectory.html#custom-directory-collectors
Why not rename the test files to explicitly be alphabetical? 001, 002 as prefixes seems reasonable to me.
because then my tab completion won't work as intuitively on the shell anymore.
okay, I can already see this a giant rabbit hole in my future lol.
Does it matter which order they are tested in? All the tests should be independant of each other.
he wants to start with the more foundational code and not bother with the code that uses it if the foundations fail.
Ah, I missed that context. Thanks!
I wonder if the @pytest.mark system would allow you to build something of a workflow like that. Though, at the cost of decorating all functions it might be easier to muck about with the collection order.
Would the pytest marker feature help here? You can tag tests and then select what tests you want to run - you could have a make/just target run pytest for different markers.
Edit: missed the previous comment suggesting the same thing, sorry 😄
There’s also pytest queries: similar to markers but querying by parts of a test name.
yes, if you hijack the test runner this should be possible
here it is pytest_collection_modifyitems
should be able to override that in conftest
then you can use the same markers to cancel further test stages if they fail, by overriding some adjacent hook
So my understanding is that you want to be able to order your tests globally, so player tests in one file (or multiple) and tests for match in another but the existing plugins only allow you to specify the order within a single file. So that if something is wrong in player, and fails you don't run tests that depend on it. I personally don't completely see the concern because it's important to run all of the tests, and if something is wrong with player, regardless to the order or match being messed up, you're going to see it and it should be fixed swiftly imo. That said: You can 1) Give your tests a marker, like pytest.marker.playertest and pytest.marker.matchtest. 2) Add those markers to a pytest.ini in your project so that they're valid to use. 3) Write a plugin so that you can say run playertest then matchtest then all of the ones that don't have tags. You can very easily write a plugin to hook into after the tests have been collected, then change the order, and you can include it local to your test directory and have a command line option where you can specify them like --order playertest, matchtest. If you don't like putting a marker on every test you write you can group multiple under one class and add the marker to the class.
You want pytest_addoption to add an argument, pytest_collection_modifyitems to hook in at the point all of the tests have been collected, and then to go through them and replace the mutable item list you're passed with the order you want, when you do that you can specify the order. By default pytest won't stop running tests after one fails it seems but you can set the maxfailure and end up with something like this:
pytest tests/ --order playertest,matchtest --maxfail 1```





the items you get in pytest_collection_modifyitems are subclasses of Node which have a path attribute, you could use this to look for the filenames instead of using markers
https://docs.pytest.org/en/7.1.x/reference/reference.html#pytest.nodes.Node
ideally you run all the tests from a file before failing, that would be the even hackier part
but it looks like the hooks give you everything you need to do it
This is the default behavior, if you run tests from a file or even multiple, they'll all run before pytest stops running more.

yeah, i think i'd try writing to a var upon any test failing, and before setting up following tests see if it they are from a different file, and exit if it is
but only if the failure happened in the ordered list of pre-test files
that way it finishes the pre-test file or files before exiting
agree completely that you should run all the tests but you know, having just set up free github actions for my project where you get X free minutes per month, i kinda get it 😂
and if the thing you're pre-testing is a simple pre-condition, you can just put it in the hook and not bother with a lot of this run-around
I'm not sure I understand what the end goal of this is tbh or the full intended use case. If player doesn't work then the match tests aren't going to work as expected and are going to be unreliable and weird, but I would have thought that all of the tests would be ran together anyway and you'd see player tests fail and know that the match tests are possibly not right due to it.
Thank you so much for your time in writing this helpful reply!
has anyone figured out how to make iPython >9.0 usable on a dark background without the risk of eye cancer? c.TerminalInteractiveShell no longer works. The docs say everything changed and now nothing works anymore. Not even %colors nocolor on the prompt.
How can I simply add timestamps to the collected log entries in pytest?
I am currently building a pytest interface, it requires your project to be uv managed though.
It can be used as a tool with uvx ayu and uses uv run --with ayu pytest to invoke your tests.
Behind the scenes the app starts a websocket server and the plugin part sends events to the application. Still quite some WIP, but you can mark/search specific tests and just run mark tests already

I am a bit tooled-out right now, but I will take a look.
I have a general question for yall, dont know if this is the right place to ask - but hey I'll give it a shot!
I have a developer on my team who is pretty against the idea of unit-testing code that wraps multiple packages.
For instance, he was very reluctant to the idea of writing a unit test for a celery task that reaches into the DB, makes some decisions based on what was retrieved, then makes utilizes 3 different packages to manipulate and upload data.
I wanted some unbiased POVs on this, because I know some people are in the mindset that "if we have to mock than its not worth a test case" - but I'm a person who somewhat disagrees with that as I think (yes you don't need to test the logic that is in someone else's package), but you should test your logic prior to the utilization of this package (decisions made), as well as how your code handles the output of that package.
If there's a better channel - please let me know 🙂 I'm more or less wanting to be open minded, and want to see other people's perspectives to unit testing 🙂
I, for one, would put the time into creating tests for everything. If there's a Celery queue needed, stand up a test queue to complete the tests. If there's a database; stand up a test database to complete the tests.
Mocks are useful. You don't need to mock to test with a database.
We do utilize the test databases - one way I utilize (and advertise) the mocks are for when we need to patch external connectivity's, or even to ensure code/functions is being called the correct number of times.
I also encourage the testing as well - as I feel it forces you to develop more readable code - another massive problem we have is huge functions
Thanks for the input 🙂
There are also tools like vcrpy that record external calls and play them back for tests. Quite useful.
That's pretty nifty! I'll have to look into that 😄
And also a really cool name! I love when packages have clever names like this 😝
End of the day, the testing is worth it at all levels. For example, I work with a fully tested library that wraps a vendor's API. Because the library has full coverage, we can mock the results of calls using that library in downstream code. We're mocking what we own.
I still don't like mock. Knowing the layer you're mocking is fully tested gives more confidence to the tests though.
I see, so your concern with mocking is a patch may return something that isn't replicable of the real working code of that library! That's good insight - as I generally base my mocks in 2 different buckets:
- Actual output of the package that we've experienced
- Fudge the response - as we actually want to test some logic after the fact of this.
Typing point 2 out though leads me to think that if we structured the code differently, we could just always get away with point 1 👀
That's what I worry about with mocks, yes. My guiding thought comes from something Hynek said: "Only mock what you own, because mocking others is rude."
https://hynek.me/articles/what-to-mock-in-5-mins/
((important to call out Hynek here explains this is a heuristic, not a rule))
Great read! I find I've been following some of these principles without knowing! But yet another great reason to write clean Objects that wrap desired functionalities 🙂
I also didn't know about spec_set=MyClass - Thanks for sharing!
You make a lot of sense and then suddenly you mention mocking for some reason and then you lost me.
The rule with mocking is to avoid it as far as humanly possible.
Pragmatic view onto mock or not to mock.
Usually not mocking:
- In Python you should not mock at all pretty much in average case, at least for all controlled dependencies like Celery and local database. U can quickly raise them in container with docker-compose or testcontainers, it is controllable dependency.
When it is good to mock?
- You make application that intends to support multiple switchable databases. Makes sense to make code testable in separate from database then a bit. Although to be fair when i was in such shoes, i just run integration tests 3 times for 3 different databases. It was still easier to do than mocking 😄
- Your application abused Celery/DB/integration tests too much and your test execution became overly long. U need to do smth, mock db, split code to more services, smth to speed up tests
- You use static typed language that is able to make validations before runtime. You are ABLE in this case constructing/architecturing code easily that relies upon dependency injections/mockings in a more heavy way. U are able to AFFORD easier implementing if u DESIRE and ANTICIPATE your app switching between databases (even if it could be not justified amount of code addition as u will never use it, at least the cost for it becomes less)
- And in this case even if u don't plan to switch db, u will benefit from more rapidly executed tests, more decoupled stuff, and your tests can be more localized to check independent parts of code logic
- In general good to mock if u use some kind of framework that tries to wrap you into its architecture, but u wish on purpose distance yourself from it and intend to leave an easier room to replace it some day with some analog. It does not make sense to do always, but as author u can anticipate such needs if u develop smth very long term maintained for 10+ years maintanance
- Always Mock third party API, that u can't raise locally (even in docker container) and rewipe state. Mocks are made for this
So... summarizing my recommendation, by default best not to mock, unless there is justified reason to do that, i think i listed more or less possible reasons that can lead to mocking
And by same default best always mocking third party apis like payment gateways. As u wish your code remaining being testable at all / remaining prediectably having same test results when u execute same tests in current git commit.
Mocking is EXTRA CODE WRITTEN with making more complicated and harder to read a bit. There should be always desire to write LESS CODE unless it is JUSTIFIED to write extra code. U need to benefit from mocking in justified enough manner in order to do that. Obviously mocking third party dependency is always justified since u should be always wishing your code remaining testable and having rapid feedback locally. Every other case is dependable on circumstances.
In average i would recommend to aim not to mock db/celery code in scripting languages because u are already disadvantaged sufficiently and should not make your life harder than necessary. You don't have before runtime validations to protect your from coding architecture overcomplications so u will pay far greater price with mocking db than people in C#/Java/Golang, so the reasons for justifications to mock db in python should be much STRONGER to JUSTIFY db/celery mocking if that will be ever needed being done.
To summarize, [another almost as long wall of text] 🤣
I literally was having this EXACT question about mocking when I came here.
Hey guys I have a question about writing unit tests, basically does it matter if u have like 20 tests u r testing and of the 20 we have 2 of them failing, does that matter?
I basically am writing unit tests for my university project, i wrote 15 unit tests and they all work fine. My team members wrote some and they are faulty. I am losing my mind over this.
A response would help me calm down. Thanks.
Some extra note i forgot to add.
- Instead of mocking i usually try to ensure just having better code structure. Code being made out of Functions and Classes separately that i could test as it is 🙂
That ensures rapid feedback and gradually going from smaller unit tests, to fully encompassing integration test
- It is not right. It is a good thing to have tests executed on every commit by CI like Github Actions.
- You are supposed to submit your Pull Requests always having tests running green before merging to master branch.
- When u are lazy person an author of the project u can be having sometimes tests few tests broken, and as long as application is not actually broken from them broken, it can be fine temporally due to you writing too big new feature but it will be your first responsibility to repair them back to get good things back on track. Until u did not repair, your app state in a sorry state not friendly for other devs to step in until u cleared your mess. (it does not matter if u are single dev on the project, we all aim to have our projects to be eventually shared with other people)
- Sometimes u can be having tests getting broken because of flakky tests, smth gets broken from time to time due to tests running to same local database dependency. That's more tricky to fix and annoying, but still it is your responsibility to take care of
if your tests remain broken and nobody fixes them as first priority => That means you fucked up unit testing and became cold-hearted to them / dissapointed due to them not being implemented right.
That means basically... you lost. You forfeited the game of code quality deelopment by breaking best practices to deal with unit tests so much that you made unit tests not desirable to you due to the dissapointment in them
That is kind of... well, a start to project downfall
From there things can snowball further, code will be more and more written without them
older tests instead of being fixed or properly maintained, will be just further ignored as more of them get broken
and you end up with project in a such sorry state that it becomes easier to rewrite from scratch than to continue
you lost your saving Swimming Ring thing, and your project became as shitty as it could be for projects written without unit testing
..
You are students though, your project codes will never be big enough and long enough maintained for that to matter
it will matter only for projects like pet projects or work projects that are intended to be maintained more than few months (for year/years)
if u wish to have proper pet project that u maintain for years and for it to grow in quality as your skills grow, u should have unit testing properly maintained to it
if u have work project, u should be again desiring to have properly maintained unit tests, otherwise it will be mental insanity to maintain and integrate changes with other participating devs
So, it is not big matter for you today that u lost this game since it is university project, but if it was anything else, it would be a problem
😅 technically no, I break the rules a bit by swearing, but i did it sort of on topic so people would probably ignore
so basically if im understanding right
if it isnt work project then it matters
but even in my case i didnt do proper testing
unit testing matters for work projects and for pet projects intended for long term maintaince
u should desire having it always because writing code that u don't maintain is usually... a lost effort of time?
it is always more impressive as u continue maintaining smth and deloping in features in long term
writing smth that is without unit testing and becoming garbage that easier to rewrite from zero than to continue is loss of time
that what it is each time when u do it without unit testing
to be fair i did all the time shit in uni and it was each time easier to rewrite from zero to continue.
and i did it 1-2 years after graduatio in such shitty way too
it took me time to learn writing code that is maintainable and could be continued to maintain and extended further instead of abandoned
https://darklab8.github.io/blog/favourite.html#UnitTestingPrinciplesPracticesandPatterns
https://darklab8.github.io/blog/favourite.html#TestDrivenDevelopmentByExample
The first book out of this list is very helpful to understand unit testing, do read it and invest well, unit testing matters a lot to write code that u can be potentially proud of to maintain

Andrei Novoselov's Blog
Andrei Novoselov's book recommendations and articles linked to remember
the second book is more practical example / tutorial further guiding on this path
i would recommend to learn stuff in depth and learning code quality and architecture from the angle writing it always testable, making design of any code testable
then u will succed in writing projects that are maintainable and pleasurably enough extendable further (at least if they have some good enough aims to be useful for some people, so that there will be reason to continue them)
until then... it will be often easier to abandon yet another project and rewrite from scratch than to continue, is is common thing for student projects to be so, but it would be nice to grow out of this phase as soon as u can
Ok
to understand unit testing to 100% capacity u will need to learn after that eventually coding architecture stuff, without it knowledge will be there and still useful but incomplete
What annoys me most is that all my functions etc I wrote myself was well maintained and all passed the unit tests i wrote. It was only the ones my team wrote that failed. But thanks for the reality check u gave me.
I needed to hear that when i do my final year project next year 💀
Usually the biggest point for unit testing is saving your lifetime and ensuring more faster feedback of your code quality. (And thus saving your mental sanity among the other things)
manually testing project can be consuming for hours effort
unit testing ensures it is done automatically for every atomic git commit change and does not take more than minutes of time (they can be executed dozens of minutes, but since they are done automatically and by CI, it is not that much bothersome)
if u wish your life not being burned for nothing in pointless validating of project quality, when it could be done automatically to erase 98% of its bugs...
...better doing things properly
life is short, and amount of code that can be written is too much big
i wish i was told this earlier before spending a month gone to waste
pair it with proper git commit practices 😄 Git commit often (on Every Atomic Change at least), each time when u are sure that new code changes are probably okay and u even tested them a bit (or even ran full tests run for every commit if tests are very quick to be run locally instead of being run by CI runners)
Then when things break, u could just revert to previous commit (instead of guessing where things went wrong if u are lazy to investigate properly), or partially cancel doubtful changes instead of saving them if u realized u went to wrong direction in making current change of files
helps a lot too to navigate changes more wisely
I think the mocking was brought up as that was his argument - which I understand we could probably circumvent altogether (maybe with some exceptions for Stubbing (not mocking) any API responses). I also feel (and correct me if I'm wrong) that the core point I've been making still stands: "We should probably be testing what we develop" 😂
Another thing I noticed is I was using the term mock as a blanket term 😛 I'll be more diligent to mention the proper names, that way I won't miscommunicate 🙂 .
Generally though I'm learning a lot from this discussion! I will be looking into the VCR package mentioned earlier - as I think that'll be better than writing multiple stubs 🙂
Appreciate all the feedback, suggestions and discussions!
I think that for mocking it should be done where certain results are irrelevant, like you test if your code will interact with something abstract that will facilitate something else, if it doesn't you know the code is wrong, and you can extract functionality out and inject measurement points. If you're developing something that is going to use certain services (i.e. in code for specific implementation details that make up what you're doing) then you should spin up that thing and do an integration test of the code with it. If you're developing code to use a database, mocking the logic that uses an abstraction over it would make sense, but it is impossible to test if the code for interacting with the database is correct if you don't actually do it, like is it really answering "Does the code do what I think it does?", and for certain stuff the answer is just no, so it's better to do an integration test (still a "unit" test in this case) which is arguably very easy with libraries like testcontainers https://testcontainers.com/

Testcontainers
Testcontainers is an opensource library for providing lightweight, throwaway instances of common databases, Selenium web browsers, or anything else that can run in a Docker container.
Cool tool!
I'll look into testcontainers a bit 🙂
For clarity, the mentioned mocking is not on database, but packages that reach to external dependencies (API responses mainly.) - the web-framework handles the test database in memory 🙂
I think that dealing with stubbed responses that you put in place for their code would be a valid way to test the correctness of your code if it is a lot like dealing with their API with how you pass information in and get information back and you are doing it directly because something can still go wrong with that in the future especially if it is something official. If that isn't preferable then another option is to stub API responses during tests and make it use stub server instead which wiremock is an option that could be used, less popular in python and not as good as the other language implementations of it from what I've seen. I think any tests that get you close to answering the question of the code doing what it's supposed to are better than none at all.
https://github.com/wiremock/python-wiremock/blob/master/examples/quickstart/test.py

GitHub
A Python library for API mocking and testing with Testcontainers module and WireMock - wiremock/python-wiremock
Really Cool! I'll have to look more into wiremock 🙂
For us, the stubbing is pretty small. Most the time a static json response.
ugh, I should probably start building tests as well. Even though I would want something that 'works' to a certain degree before I go back to refine it, stuff is already getting a bit complicated.
You can always write the minimal thing that works to test your idea and how to do something then when you understand it write it for real with tests. If you structure it right you can have something as simple as a function that will behave how you want and can write tests to confirm it has the behavior you intended.
Sometimes when testing something it's quicker to write it if you're getting feedback on the little bits of code that make it up. Especially if you don't get fast feedback through the network or UI to test the same stuff manually and indirectly
fair point indeed. Havent done many test creations either so I need the practice regardless. Once I finish with the current thread Ill revisit setting up testing for as much as I reasonably can
Any recommendations for good folder architecture for different types of tests for pytest?
How do you manage tests that might need separate virtual environments / Python environments?
If I simply run "pytest", I'd accidentally run tests that require different environments.
I have to test both server code interacting with the ORM, as well as a small "client" library that must use the REST layer instead
I'd like to make running the tests as easy as possible, ensuring the right fixtures are available for the right context to reduce friction of testing
Sounds like a job for pytest markers to me.
for testing against different virtual environments I'd recommend looking into something like nox or tox
Thanks - both suggestions seem viable! I have started with markers. I can also write absolute path commands for both environments, but It'd be nice to make it easy for the developer so they could run a single command and/or get an all in one report.
Maybe check out tox? It will setup different virtual environments automatically, install all dependencies and run the commands you want such as running the whole pytest command as you want it to and all they have to do is install tox and run tox -e environmentName
for testing against separate virtual envs / python envs best using Github Actions matrix mod
it is parallel and runnable for every commit
😄 speed matters and consistency of tests being run each time
name: CI
on:
pull_request: {}
workflow_call: {}
concurrency:
group: ${{ github.ref }}
cancel-in-progress: true
jobs:
linter:
runs-on: [self-hosted, linux, x64]
name: linting:python=${{ matrix.python-version }},django=${{ matrix.django }}
strategy:
matrix:
python-version:
- "3.10"
- "3.12
django:
- "4.2"
- "4.0"
steps:
- name: Set up Python
uses: actions/setup-python@v2
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
architecture: x64
- name: Install Task
run: sh -c "$(curl --location https://taskfile.dev/install.sh)" -- -d -b ${{ github.workspace }}
- name: Install requirements
env:
DJANGO_VERSION: ${{ matrix.django }}
run: ${{ github.workspace }}/task dev:install
- name: Black
run: ${{ github.workspace }}/task black -- --check
- name: Isort
run: ${{ github.workspace }}/task isort -- --check
- name: Flake8
uses: py-actions/flake8@v2
- name: Sphinx
run: sphinx-build docs/ docs_is_buildable/
for example in this simple way i launched tests for multiple python versions at least, and even multiple djangos
totally fair, even when I use nox I pretty much just call the nox sessions inside my github actions
I have a decent example at https://github.com/56kyle/pytest-static/blob/main/.github/workflows/tests.yml that is derived from https://github.com/cjolowicz/cookiecutter-hypermodern-python/blob/main/{{cookiecutter.project_name}}/.github/workflows/tests.yml
Unfortunately the roots of both are dated and I'm trying to revamp it currently since it can be simplified a ton with uv to avoid needing pipx and such, but the first example at least is updated to work still
Am definitely interested in improving its speed also lol. Usually it's not a problem since it's in background but debugging an os specific issue can be awful
fwiw, I support using a tool like nox. It allows you to have one way to run all of the various actions. You run workflows the same way the next-dev runs them. The CI runs the workflows the same way. It's a unifying experience.
I second this (though I use tox personally). It's so much better when you have one simple way to run this stuff and to have it as a separate concern from the workflow files, I also personally use invoke to write tasks for stuff like zipping stuff up and making executables with pyinstaller simpler.
Yeah. nox, tox, make, just, or shell scripts. Just have a single way to run all the workflows.
nox wins for me because the workflows are written in Python.
I think that as a community we're lucky to have stuff available to achieve a separation of concerns like this, and doing so in a language most of us are probably proficient in. I've seen people elsewhere have to resort to using dagger to do what can be achieved more easily with tox/nox and or invoke.

Build powerful software environments and containerized operations from modular components and simple functions. Perfect for complex software delivery and AI agents. Built by the creators of Docker.
please don't spam channels to increase your message count
!tvmute 1320714730033123382 14d This is not how you get voice-verified.
:incoming_envelope: :ok_hand: applied voice mute to @brazen moat until <t:1749556325:f> (14 days).
Well that seems like a huge overreaction to a kid who just doesn't know how chats work.
The voice channel right now sounds like someone is just reading an anti-AI blog post anyway 🤣
The instructions in #voice-verification are pretty clear about not spamming to reach the 50-messages limit. If you have moderation concerns, please contact @void tulip.
Sure but.... lots of newbies talk like that. That the voice verification rules require many messages, doesn't logically mean that anyone who presses enter too much is trying to game that specific rule. They can independently be bad at using chat.
Unless you guys have some more information of course, but I'd think the CoC says we should assume good intent.
(We do have extra information.)
Today's minor annoyance: Almost all of my unit tests follow the same structure to the point where it would be nice to just throw the parameters into a yaml file.
There's like three or four test groups that break the formula in such a way that it would be unreasonable to try to define them in a yaml file and that makes it feel like none of the tests should be defined in a file.
Like most of my tests look like this
@pytest.mark.parametrize("test_input,expected",
[("Some Input", "Some Output")])
def test_some_property(test_input, expected, operation):
assert operation(test_input) == expected
And that's easy to turn into something dynamically created from a file, most of my tests look almost exactly like that.
This not as much
@pytest.mark.parametrize("params",
[[("SomeList", "SomeValue")],
{"SomeDict": "SomeValue"}])
def test_construction(params):
klass = Klass(params)
assert klass.count() == len(params)
You can parametrize the operation maybe? It's hard to tell from your examples because they aren't specific enough.
If we got two specific examples, then we could have better input I think.
The operation is a fixture. Which is parametrizable with effort but not really relevant here.
Each group of tests is focused on a specific property of the operation. The actual assert is nearly identical or can be made identical, but the parameters have some shared property.
So if I have an operation that replaces the full matching input string with an output string.
@pytest.mark.parametrize("text,expected",
[("3", "fizz"), ("5", "buzz")])
def test_full_match(text, expected, operation):
assert operation(text) == expected
@pytest.mark.parametrize("text",
["35", "match 3"])
def test_partial_match(text, operation):
assert operation(text) == text
@pytest.mark.parametrize("text",
["15", "fizz"])
def test_nonmatch(text, operation):
assert operation(text) == text
All of those are really easy to set up as test cases in a yaml file while maintaining groups.
But the construction case I described earlier doesn't fit cleanly into any data driven approach to testing. Not without spending more effort than the mild inconvenience it takes to manually parametrize tests
And if some tests must be code while some tests can be data, choosing to maintain both feels like the worst option
The solution here is to just stay entirely within Python and be slightly annoyed. I just don't like being slightly annoyed :P
Sure. I get it. But forcing slightly similar things into the same bucket can make things worse too.
"A foolish consistency is the hobgoblin of little minds"
I mean the line here is arbitrary. I could just have a single test function take every parameter. test_operation is a sufficient name but lacks context.
If it's a toy problem like fizzbuzz it also doesn't lend itself to reality :P
It's almost like I tried to create a minimal example instead of copy-pasting company code into a discord server
Yea well.. unfortunately when one does that, one loses the context that made it possible to discuss the problem in the first place. "lacks context" as you said :P
I think it's fine to have long lists of parametrized things personally. I don't see the gain from a yaml file.
I'm not sure what additional context is warranted here. Like I've described the operation, I've described various things being tested. The only thing that makes it appear like a toy is the fact that I went and used fizz buzz as the parameters
@mossy path i would not try to make all the tests have the same shape. Also, I'm not sure it's worth it to define them in a data file.
But if the data file is useful, use one for one parametrized test, then another for another one, and they can be different tests with different data shapes
I have given up on the data file 😅
I think fizz buzz lends it's self pretty well to the reality of testing a lot of things if done well.

8 space indent. I don't think I've seen that in python :P
It's however many spaces you want since I use tabs, nano does 8 by default though 😛
hey so anyone know what could be causing a race condition in unit tests using the standard unittest module? I've got this one test that's intermittently failing despite nothing I can see that could cause a race condition. it uses unittest.mock.patch to replace a function called by the function it's testing, which should trigger an exception later in the function, but somehow this only happens intermittently
the functions being tested do involve file I/O, could that lead to a race condition somehow? there's no threading or multiprocess stuff though
and by "intermittent" I mean it literally seems to be random whether the exception happens or not, I can re-run the test suite repeatedly with no code changes and it happens maybe half the time, even though everything as far as I can tell should be 100% deterministic
all kinds of things could cause intermittent failures
can you link us to any of the code?
to give a bit more detail: the function I'm mocking out just copies one file's contents to another, and the function I'm testing calls the copy function and then compares the file contents—so mocking out the copy function should make the later comparison fail (the setUp method initializes the files with different contents)
sounds simple
it's not online but there's really not much more to it than that
and yeah, it's really a quite simple function I'm testing, and all the other unit tests I've written for this module are working fine
it's a mystery
are there known issues with race conditions in unittest.mock or something?
no
oh well, I guess I'll just write the unit test differently, I can mock out a different part of the function and it doesn't seem to run into the same issue
bizarre though
lmao I just figured it out
it was a legitimate bug in my code, albeit one that would pretty much never show up in a real situation
I was using filecmp.cmp to compare the files... and by default it sets shallow=True, meaning it first compares file modification times and size, and if those both match then it skips comparing file contents. But in the test code I was initializing the two files one right after the other, with contents "old" and "new" 🤦
so as soon as I set shallow=False, the intermittent issue went away, because now it's actually comparing file contents
in actual usage, the two files are created at different times with user interaction in between them, so even if they coincidentally had identical sizes it would basically never happen that they have identical modification times too
but in the test... 😅
Sounds like a great bug for a unit test to have correctly surfaced.
hey! i'm planning to create a test suite for a rest API i've written in flask, but i'm not sure how to go about populating a minimal database for testing. for context, most of the database content comes from a separate service altogether (a game server which uses mysql) so my API is intended to fetch existing data and edit user profiles, rather than creating new data entries.
my first thought was to spin up a fresh instance of the game server and then use the game client to populate the tables with some testing accounts and a bit of gameplay data. then i could create a fairly small SQL dump of a working database state in order to populate a fresh testing database with each run, but i'm not exactly sure if that's a good way of doing it.
🤔
i will give recommendation to make dump/copy of this external db, empty one? and git comitting it to your git repo code as part of application code to configure testing.
during testing, just apply this dump to local docker raised mysql and do the stuff u need to test it.
From there u have two options at least.
-
configuring your code working through dynamic reflection of sqlalchemy for nicer code to work with potentially
https://docs.sqlalchemy.org/en/20/core/reflection.html
but may be it will be ugly actually -
properly write SQLAclehmy code models
And use in unit testing together with Factory boy i guess to create unit tests?
https://factoryboy.readthedocs.io/en/stable/orms.html#factory.alchemy.SQLAlchemyModelFactory
if external service will ever change structure of db => just make new dump to test setup, it should make your test checking correctly checking if code works with new db version or not
that's all good info, ty! i've already started using pymysql for the API because i didn't wanna hard-code models for every table it needs to access, especially given that the database structure could be altered by the external service (though i wouldn't expect breaking changes)
in any case, i don't suppose my choice of ORM is super relevant to the testing aspect anyways
would you say it's reasonable to use a separate docker-compose.yml for testing then?
we do at work like that 😄 it can be reasonable. sure.
btw, if u wish to go super modern, u could also go testcontainers instead
testing in docker-compose has disadvantages since by default Visual debugger and intellisense of IDE will not work
U can turn them on with https://darklab8.github.io/blog/article_visual_debugger_in_vscode.html
But i don't recommend it
Best to aim for test db containers raised with port forwarding to local machine
Andrei Novoselov's Blog
How to start working with visual debuger in vscode for python.Including with connecting to already running docker. Written for people wishing to be quickly productive with vscode and for known acquintances wishing to migrate from pycharm :]
use docker-compose, separate one as u wish
or test containers, but i recommend u keeping running tests from the main machine itself, and using containers only as external thing but not for running tests itself
I am entering a similar position and to do a proper test of a combination of a game server and API. I would spin up a fresh game server and API server together and go through the workflow of an end to end acceptance test for however the natural flow of a user interacting with the system goes, registering an account, signing in, connecting to the game server, doing the interactions, retrieving the data through public interfaces. The only way that you can deem a piece of software/pieces of it that you are responsible for is to interact with it through the same channels that your users do. I would give this a read:
https://dojoconsortium.org/assets/ATDD - How to Guide.pdf
https://www.symphonious.net/2015/06/05/testinglmax-abstraction-by-dsl/
At LMAX, all our acceptance tests are written using a high level DSL. This gives us two key advantages:
Tests can focus on what they’re testing with the details and mechanics hidden behind the DSL When things change we can update the DSL implementation to match, avoiding the need to change each test that happens to touch on the area. The DSL t...
Hey guys! I am new at writing pytest files for unit testing. Today I am building an api using fastapi. I have built it in such a way that all the routes requires auth (supabase bearer token). How do I write test cases for these? For example here is one of my endpoints:
@router.get("/users/me", response_model=schemas.UserOut)
def get_user(current_user=Depends(get_current_user)):
user = crud.get_user_by_id(current_user.id)
if not user:
raise HTTPException(status_code=404, detail="User not found")
return user```Basically I want to simulate an authenticated user when I run my tests
Please @ me in the replies

FastAPI framework, high performance, easy to learn, fast to code, ready for production
Someone from fastapi server suggested to override the dependency. That should prolly work. This documentation doesnt talk much about it I think they should add it
I have a pytest fixture returning a list of objects. Is there a way in which I can use that fixture to parametrise a test (using @pytest.mark.parametrize) or another fixture (using @pytest.fixture(params=…))? I want to run a test separately for each member of the list of objects.
You can parametrize a fixture, then tests using it will be called once per set of parameters
hey you'll probably see me in here a lot for the next little while because i've never actually done proper unit testing until now
with that being said, is there any need to write this out so explicitly or would it be acceptable to use a loop to compare value-by-value with a dict? ```py
def test_get_ranked_bancho_beatmap(client):
response = client.get("/maps/811675")
assert response.status_code == 200
beatmap = response.json
assert beatmap["id"] == 811675 # you never know...
assert beatmap["set_id"] == 370340
assert beatmap["status"] == 2
assert beatmap["md5"] == "f8483b44ffbbc86603f486aad3ceaa0d"
assert beatmap["artist"] == "CENOB1TE"
# --/ snip /--
assert beatmap["od"] == 8.5
assert beatmap["hp"] == 7.0
assert beatmap["diff"] == 5.989
I think it would be alright to loop, it would just not be as readable. dirty_equals.IsPartialDict might help you
!pypi dirty-equals

Doing dirty (but extremely useful) things with equals.
Released on <t:1736637820:D>.
from dirty_equals import IsPartialDict
assert beatmap == IsPartialDict(
id=811675,
set_id=370340,
... # etc.
)
Unless of course you want to compare the entire dict, in which case I'd just compare with a dict.
i was under the assumption that comparing directly with a dict could make it difficult to determine exactly which value makes the test fail, for instance
i stand corrected! nice one pytest

well, that's not comparing directly with the dict, but i'm just testing things out
very cool

Yeah, one would think it won't work, but pytest does some magic to make it behave.
@pytest.mark.parametrize("method", ("post", "put", "delete"))
def test_bad_methods_stats(client, method):
response = getattr(client, method)("/stats")
assert response.status_code == 405
# --/ or /--
def test_bad_methods_mapsets(client):
for http_method in (client.post, client.put, client.delete):
response = http_method("/mapsets/370340")
assert response.status_code == 405
any opinions on this? or whether there's a better way of going about it, especially since i'm gonna be doing this a lot with various endpoints/methods 
Yes, I am aware, but I cannot use a fixture to parametrise a fixture, right? I have a session-scoped fixture which I need to use to generate the items I want to test.
Not directly AFAIK. Do you know how many items will be generated or is that dynamic, too?
https://github.com/Zaloog/ayu
I created a pytest-plugin to run your tests interactively.
It requires your project to be uv-managed though, cause it installs itself during pytest execution (e.g. uv run --with ayu pytest --co to collect initial tests) and therefore can be run as an independent tool
with uvx ayu.
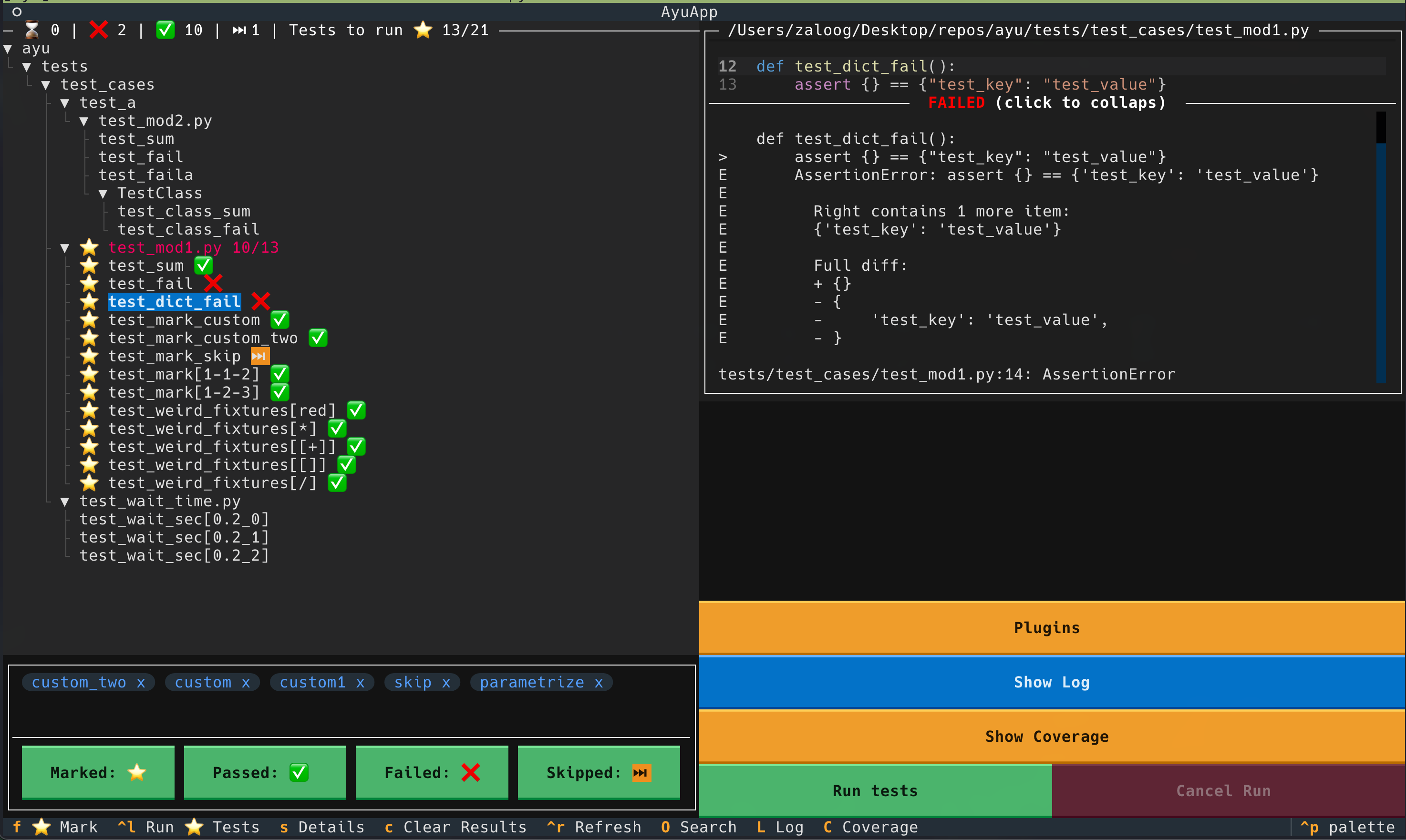
GitHub
still WIP. Contribute to Zaloog/ayu development by creating an account on GitHub.
😎
at last some notably useful project mentioned here
looks very cool.
TUI and for useful stuff. That's stylish.
Parameterize happens at collection time, fixtures happens at rumtest time so they don't intersect
Locks neat
Thank you Ronny.
Its still missing some parts.
E.g. the plugin viewer is not yet connected to the command builder yet, i.e. making changes there does not tranlsate to different pytest run behavior.
Atm its more like an option explorer
Ps if the intent is to be local there's not necessarily a need for websockets
Take a look at xdists looponfail for inspiration
Also consider socket files on unix
Why can't pytest fixtures be made directly callable?
Lifetime management need to be under control
For a long time fixture definitions used to be just callable functions and people just kept majorly messing up with that
So it was taken away
Maybe the more interesting question is: why did you ask that?
The reason I ask is that maybe you can sort of emulate it:
@pytest.fixture(scope="session")
def all_my_dbs():
return [Connection("mysql"), Connection("postgres"), Connection("sqlite")]
@pytest.fixture
@pytest.parametrize("db_index", range(3))
def each_db(all_my_dbs, db_index):
return all_my_dbs[db_index]
@limpid raft ^
@swift pewter I am just poking at things really. I don't like in the above that if I add another Connection, I have to remember to update the range call.
Yeah, it has a few downsides. Maybe there's a better way.
You could use a plugin object that created the connection when needed and shuts it down at session end
That connection could also be provided in a fixture and used at collection to parameterize
We are extremely reluctant to add fixtures pre testrun time without some major tech debt reduction in rhe fixtures system
so far i have not found one
fixture and non-fixture code has a bit of a flair of red/blue code, i.e. async/sync. Either one way, or another, or one to another, but you cannot go another to one.
life would be so much easier if a TestClass was instantiated once by pytest. Instead, it just seems to be used for grouping, and instantiated for every test separately. So you cannot carry data between tests that way
I even tried to modify a class variable in a class-scoped fixture, but the instances won't have any of it.
class TestClass:
session = None
@pytest.fixture(scope="class", autouse=True)
def class_scope_fixture(cls) -> Generator[None, Any]:
print("setup")
cls.session = 1
yield
print("teardown")
def test_x(self) -> None:
print(id(self.session), self.session)
def test_y(self) -> None:
print(id(self.session), self.session)
The two ids are identical, but self.session is None in both cases.
not that this will get me anywhere, because TestClass.session won't be available to use in pytest.fixture(params=[…])
Argh!
I guess it makes sense since I am not assigning to a variable, but storing a new object reference, and if I use a dict, then it works. But I still cannot use the class var for params.
The problem is that parametrization happens at collection time. So it's a bit of a catch-22. You cannot use fixtures while collecting them. Or well, you could, but then you'd have to order them etc…
Sounds like you Want to fight it
Deep integration with the asyncio plugin may be needed as of now
My own work on Deep async support in pytest hinges on adding support in pluggy
Maybe you want a session scoped fixture to set everything up once per the session of test runs?
yes, that works, but I still cannot parametrise tests or other fixtures with it.
I want a fixture each_entry that is parametrised for each Entry in my DB so that a test is run once for each. Right now, I have to have a single test that loops over the entries in the fixture, and tests them all at once.
which makes error reporting just a little less good
Subtests?
What are those?\

Python documentation
Source code: Lib/unittest/init.py(If you are already familiar with the basic concepts of testing, you might want to skip to the list of assert methods.) The unittest unit testing framework was ...
Afaik it works in pytest too
pytest-subtests is the plugin for that
interesting, thank you @proud nebula. It appears to be a plugin: https://stackoverflow.com/questions/33904826/how-do-i-convert-a-unittest-subtest-to-pytest
This works really well for my use-case. Thank you!! 🧡
I have this code to determine the longest common prefix of two strings a and b:
for i, j in zip(a, b, strict=False):
if i != j:
break
n += 1
I have already ensured that a and b are len()>0. To me, this means that the for loop contents will be executed at least once.
Why is pycov telling me that the for loop is BrPart, i.e. only partially-branch-covered? What possible situation is there in which this branch is not fully covered?
that means that the break was always taken, and the for loop never ended because the iterator was empty.
do you have a test where a==b ?
if a is None and b is None:
return f"{joinstr}="
elif a == b:
return f"{a}{joinstr}="
elif a is None or len(a) == 0:
return f"/{b}"
elif b is None or len(b) == 0:
return f"{a}/"
right before
and yes, I have a test where a==b
ok, then the loop will always break.
true, but that is a bit the point, no?
i bet there is a better way to find the longest prefix between two strings…
that's the point of your code yes. Coverage doesn't know that. The for line can go to two different places: the first line of the for-block, or the line after the for-block. In your code it only ever goes to the first line of the for-block, so it's a partially covered branch.
you can quiet coverage's concern by adding a comment to the for line.
no, it also goes to the last one when the two characters at position i of the strings match./
n does increment. The function does work…
i'm talking about the line following the for, not the last line in the for.
can you pastebin the full function? Do you have an HTML coverage report? It will have some hover text for the partial branch line.