#tools-and-devops
1 messages · Page 78 of 1
I’m looking to generate Python code
I already did it but am surprised at how little tooling there was https://kevinheavey.github.io/anchorpy/clientgen/
raylu, could you give me a general tip about that? please 😄 I want to hide admin login page from users
Even this you got wrong
You have no indentation
@ripe tendon just check if the logged in user is a superuser?
i mean, restrict access to admin LOGIN page, not admin-only pages
so if user tries to connect to /admin, he gets 404 or something
just allow one IP or stuff - that was the way I wanted to do it in nginx, but I dropped nginx
is that even a popular thing to do? I received "-admin login page available to everyone" feedback on a recruitment task, and I think that's what it meant?
or maybe I should just change the admin login page url? 🤔
:incoming_envelope: :ok_hand: applied mute to @heavy knot until <t:1652187927:f> (9 minutes and 59 seconds) (reason: burst rule: sent 8 messages in 10s).
anyways, thank you for your help! 😊
Hello there!
So I have a VPS, setup with docker and nginx, but I'm using github and want to automatically deploy my app to my VPS on push
How can I build an image and run it as a container on my VPS all automatically and remotely from github actions?
I... don't understand that feedback. if a user isn't logged in at all, how do they login as an admin then?
I have a bare metal build machine, it was previously running on an Intel 11400, but I just switched it to an AMD 5600 based system .. generally speaking everything works fine, except for some reason specifically pypi downloads inside docker are awfully slow
like poetry install takes maybe a minute for 90 packages on host, after 10 minutes it has installed something like 5 on the docker image
apt and pnpm seem to download things just fine
@wispy arrow I think the way to go is to make a custom action that runs ssh inside a docker container https://docs.github.com/en/actions/creating-actions/creating-a-docker-container-action
oh, I guess someone made ssh-action for you https://gist.github.com/danielwetan/4f4db933531db5dd1af2e69ec8d54d8a https://gist.github.com/stancl/cab04a411f136047e80c1de81528eb23
@rich remnant I guess you gotta narrow down the problem. is it network, disk, cpu, or just lack of parallelism? (use btop, iftop, vmstat, htop, perf) are you using the same version of poetry?
poetry is also slow for me. What I realize to helps a lot is to keep .lock file up to date, that reduces install time drastically
but it runs fast on the host for the same project for the same lockfile
can you tell what's consuming most of the time? for me is determining dependencies if lock file is missing
I mean it's just saying it's installing dependencies and then it freezes for minutes at a time for each of them, network traffic stays incredibly low, that's how much I know so far
bad docker volume configuration? maybe the host is writing files to a different drive. docker system prune --volumes?
-af doesn't include --volumes
mm if you are using volumes, make sure your binding is not vanishing the lock file

I get to this point very fast
and then it takes 2 min to install this package, and 2 min to install the next one
and so on
I'm just rebuilding the base image but it had no such issues on my cloud agent or 11400 based machine
btop, vmstat, htop, perf



ooh interesting. ok, perf or strace
Yea the .yml file
Mine works, but the only thing I could do is ssh-ing into the VPS, and replacing my old code with the new one
That used to work perfectly before I started using containers, now I need to build an image, close the old container, and start the new one, all inside the .yml file which I couldnt manage to do


perf stat or record and then annotate https://jvns.ca/blog/2014/05/13/profiling-with-perf/
https://jvns.ca/blog/2014/05/12/computers-are-fast/
Julia Evans
Julia Evans
yeah, gotta strace -f
I was gonna ask whether pip itself is slow
@idle flare There is multiple ways I could do this but im not sure which to use, for example I could deploy the source code to the VPS and then run a script in the VPS than handles the images and containers
But a cleaner way I think is to somehow build the image on github actions and only copy the final image to the VPS and somehow run it there and remove the old one
Something else a lot of people were doing was uploading it to dockerhub but I don't understand how that helps
so this seems to be what it's doing during the download, which .. looks like a download

pip install pyasn1 seems to pretty much freeze
@wispy arrow yep, you need a container registry somewhere to upload the image to. dockerhub is a popular choice. otherwise, aws ecr, azure container registry, etc.
sigh
one possible issue could be ipv6 again
it seems to be giving me headaches all the time
@rich remnant it... looks like it's failing a bunch of ipv6 addresses and is going to try ipv4 eventually
pypi.org has address 151.101.64.223
pypi.org has address 151.101.192.223
pypi.org has address 151.101.128.223
pypi.org has address 151.101.0.223
pypi.org has IPv6 address 2a04:4e42::223
pypi.org has IPv6 address 2a04:4e42:600::223
pypi.org has IPv6 address 2a04:4e42:400::223
pypi.org has IPv6 address 2a04:4e42:200::223```I've noticed a lot of random issues with ipv6 in the past months, particularly with docker, and I've unsuccessfully been trying to completely disable it
So the steps are (and then ill figure out how to do them)
1 - Build the image on github automatically during the github action/pipeline
2 - Upload the image to a container registry (dockerhub for example)
3 - (somehow get the image from the docker registry to my VPS) ?
4 - (on my VPS, remove the old image and stop container, somehow get the new one from the container registry and run it) ?
Im not sure bout the last 2, I don't specefically know how I'm gonna deal with the registry
do you have an IPv6 address on the host? do you get $ curl -6 pypi.org -i HTTP/1.1 301 Moved Permanently
I suppose they wanted to make admin login page available only from hosting machine or something (or just to change admin long page endpoint lmao), sadly I didn't ask about it
@wispy arrow you take the version you uploaded and use the ssh-action thing I linked before to docker pull registry.tld/yourproject:123abc && docker stop thingy && docker run -d thingy:123abc
HUZZAH
so one of my earlier attempts to get the ipv6 stuff working was to set up some ipv6nat thing that everyone kept telling me fixes the ipv6 nonsense, but now I modified /etc/docker/daemon.json and set ipv6: false and restarted docker, builds are fast now
one reason I hate ipv6 is that it's easy to be blind to the small changes in the ipv6 addresses - to me it looked like one address repeating, not a different address on every line 
thanks for the help
another problem solved with strace!
yeah strace is a life saver
oh okay, thanks!
one of the big shockers is that btop can show me my core temps when it seemed like nothing else could
In git, HEAD~ is the same as HEAD~1 right?
a scientific method of tries and errors, discovered that yes
xD why not just to try thing like that
Also the same as HEAD^
ayo guys! is proxlight legit and safe?
https://stackoverflow.com/questions/2221658/whats-the-difference-between-head-and-head-in-git#:~:text=HEAD~2 (or%20HEAD%5E,to%20the%20second%20parent's%20commit.
Funny reading btw

Stack Overflow
When I specify an ancestor commit object in Git, I'm confused between HEAD^ and HEAD~.
Both have a "numbered" version like HEAD^3 and HEAD~2.
They seem very similar or the same to me, but are the...
TLDR: HEAD^ = HEAD^1 = HEAD~ = HEAD~1 are equal
and HEAD^^ = HEAD~2 are equal
yet HEAD^^ != HEAD^2 != HEAD~2 arent equal
because HEAD~2 selects not the grandparent of the commit
it selects second parent of the current commit if i get it right
in a situation when due to the merges, the current commit has more than one parent on top of it
Ooh yeah, I found that SO question earlier and didn't fully understand the use of ^2 (or ^3 ^4) 
I'm using pybind11 to write bindings for a large CMake-based C++ project (it will soon be open source, but it's not yet quite ready) that takes somewhere between 15-30 minutes to compile.
I want to write support for creating wheels/pip package, but it's not clear to me whether I could also run "pip something" straight from the build output after CMake has already done the job (that is: immediately after cmake --build .), or if I really need to make pip install rebuild the whole project from scratch.
Could someone provide a few hints? I wasn't able to google anything relevant so far. All examples I found simply run CMake as part of git clone my-project && cd my-project && pip install .
did you understand now?
https://learngitbranching.js.org/?locale=en_US is perfect place to try stuff like that
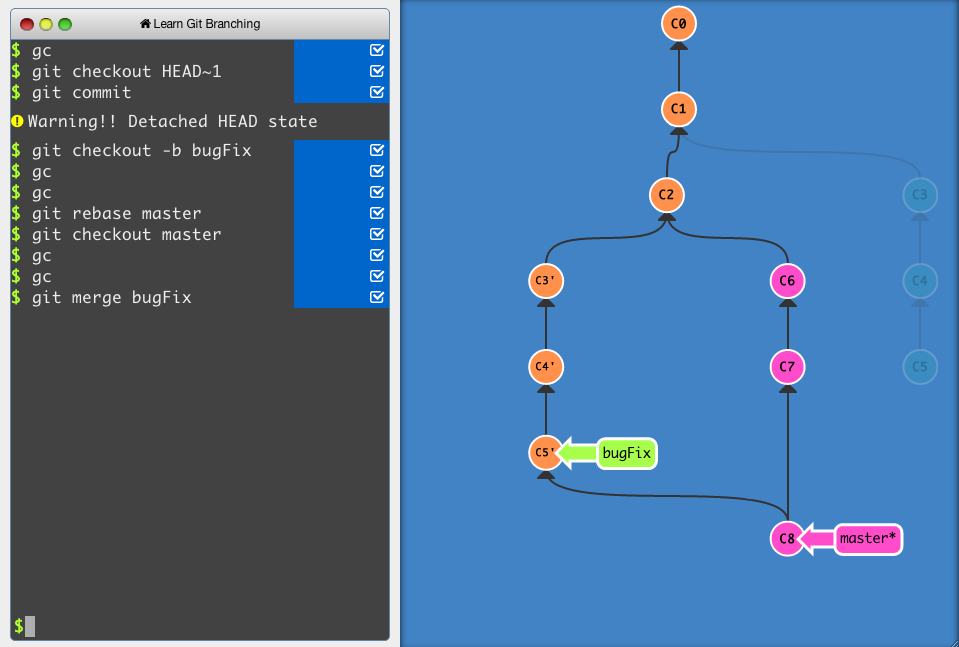
An interactive Git visualization tool to educate and challenge!
Anyway, git checkout HEAD~ moves to where the HEAD is right now, to one random gradparent higher, which considered as still main branch

and HEAD^2 moves HEAD to left ;b To the second parrenting commit

If we will try git checkout HEAD^2 from main which has only one parent, then we aren't allowed to move, because C7/main has only one parent

we can even chain stuff like that 🙂 I remember it is one of the exercises from this visual tutorial

git checkout HEAD~^2~ moves us to commit C2 (from the original main/C7 commit)
xD in the end ~ is step higher in commit history, and ^ a step to the left or right in the direct parent commit
How to update Pipenv package to specific version without making update of everything not unnecessary related?
hey guys, junior question. I see mkdocs site folder is usually part of the .gitignore file. I want to publish a project in our private github containing a mkdocs generated html file. Is /site folder a bad practice to point my README file to ? Like, for detailed documentaion, go to <url_site/index.html>
who cares, why not. Although I could say that Github direct GUI is not actually meant for generated html files.
You are supposed to deploy you generated html docs into Github Pages
which can be deployed from selected folder directly from repository, the easy way which you should do
or as artifact from pipeline job, a bit more complicated way
create folder docs in repo, put .nojekyll file into it, put your generated html files into it and turn on github pages from /docs

it will be deployed on to the right of your repo

Hey, how can I generate an random string with numbers and letters?
I’m tasked with setting up an extensible alerting/monitoring system, some third-party services and some in-house stuff. Do you folks have thoughts about that? Would love to be able to write Python to check someone’s API and send alerts to Slack, etc.
!e
import secrets
print (secrets.token_hex(8))
@rapid sparrow :white_check_mark: Your eval job has completed with return code 0.
0e9f27a632819886
I'm trying out VSCode (coming from ST, due to the seeming lack of solid black integration) and I am wondering why Pylance seems unable or unwilling to detect a broken relative import.
I have:
from . import mymodule
Except that mymodule does not exist and there is no error indicated
And in fact switching to an absolute import doesn't break either:
from mypkg import mymodule
Hey, if i use this code ```py
from colorama import Fore
print(Fore.GREEN + "123")
it will print green in the consol of VS. But when i run the py file without VS i get this insted of the color: ```py
←[32m123 ```How can i set the color there?
command prompt in typical windows fashion has awful color support
lemme find the SO thread
ok so you can use one of the tricks from https://stackoverflow.com/questions/16755142/how-to-make-win32-console-recognize-ansi-vt100-escape-sequences
or just use a better terminal app (I'm partial to Windows Terminal)
Stack Overflow
I'm building a lightweight version of the ncurses library. So far, it works pretty well with VT100-compatible terminals, but win32 console fails to recognise the \033 code as the beginning of an es...
Thanks!
Yo I installed with pip the pyautogui module I can't import it in my script it returns me that there is no pyautogui module how should I import it?
Hey so I've been trying to complete this lab on github actions, and I'm stuck at the last step i.e. pushing the built docker image to ghcr.io through. But I keep getting:
Error: buildx failed with: error: failed to solve: unexpected status: 403 Forbidden
I've tried everything (seems so) but of no use.
I've also done the steps mentioned here https://github.com/docker/build-push-action/issues/463#issuecomment-926229761
Workflow file: https://github.com/CyberCitizen01/github-actions-for-packages/blob/add-dockerfile/.github/workflows/cd-workflow.yml
Any ideas?

GitHub
Troubleshooting Pushing to GHCR seems to randomly resulting in 403s in the last 24 hours. Rerunning the GH action seems to resolve things (partially). Behaviour See above. Failure message : buildx ...
Kindly ping to reply ^
@cosmic breach it looks like your latest commits passed. are you still having trouble?
Yes thank you, I've solved it.
I'm using NGINX and I Just found out that my website can be accessed from the VPS's ip plus port
how can I stop it from letting any traffic if its not through the domain/sub domain?
I don't want traffic to be let in through the IP
when you make NGINX bind to a domain, it's just a shorthand to listen on the IP address(es) for that domain. NGINX does keep track of the IP address(es) in case the DNS records for that domain change
but if you really want to forbid access through just the IP address, maybe throw an error if the Host header isn't the correct domain or is an IP address
You can use server_name directive in your server block, and in an another server block add a server_name as the ip address and redirect it to the domain you are hosting your site.
but I have a reverse proxy, so different ports lead to different subdomains, how can I handle that
How can I do that?
I got figure out how to get certbot added to this docker-compose.yml project with django, nginx, and postgres...
If anyone is working in configuring docker, please let me know, want to discuss
better read the guide https://pythondiscord.com/pages/resources/guides/asking-good-questions/
A guide for how to ask good questions in our community.
In docker, when would one only ever use the option -i without -t , and vice-versa?
Are there any well known Python Bluetooth Libraries?
no idea, I use both when i use interactive shell inside the docker from current terminal
like... docker run -it ubuntu:20.04 /bin/sh
both, -it is necesary in order to have shell working in a valid way
what are your requirements for that? I was looking into them a while back and they all seem quite limited, and none of them seem particularly cross-platform
Well what I'm planning on making is an app that connects to a raspberry pi through Bluetooth
from what device
Does GitHub use branch descriptions in any way?
doesn't seem like it, best I could find is a short GitHub discussions thread
Android to a raspberry pi
and you'd want to use the python library .. on the raspberry pi?
iirc the bluez libraries worked fine on raspberry pi .. but it all depends on what exact thing you want to do, "connecting" is not very descriptive of what you want to do .. https://pypi.org/search/?q=bluez

PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
I want to create a virtual keyboard app that sends inputs to the raspberry, essentially removing the necessity of a keyboard
K ty I'll check it our and also bc you know so much about these libraries I must ask what are the limitations or what are the limits to what I can do?
I don't know that much, I looked into them, found that a lot of them were kinda terrible and had huge limits for what platforms they support and what they can do, but bluez seems like it's possibly the best for you .. you'll need to read up for yourself
K ty
How do I configure my setup.py to be compatible with PEP 508?
My install_requires: ["NodeGraphQt @ https://github.com/jchanvfx/NodeGraphQt/archive/9e6f95244d98b0d97b38f0b45c74c6c4057a18ad.zip"]
which should be compatible with https://peps.python.org/pep-0508/
but when installing with pip: File "/home/mart/.pyenv/versions/3.9.7/lib/python3.9/site-packages/setuptools/dist.py", line 455, in __init__ _Distribution.__init__(self, { File "/home/mart/.pyenv/versions/3.9.7/lib/python3.9/distutils/dist.py", line 267, in __init__ getattr(self.metadata, "set_" + key)(val) File "/home/mart/.pyenv/versions/3.9.7/lib/python3.9/distutils/dist.py", line 1227, in set_requires distutils.versionpredicate.VersionPredicate(v) File "/home/mart/.pyenv/versions/3.9.7/lib/python3.9/distutils/versionpredicate.py", line 114, in __init__ raise ValueError("expected parenthesized list: %r" % paren) ValueError: expected parenthesized list: '@ https://github.com/jchanvfx/NodeGraphQt/archive/9e6f95244d98b0d97b38f0b45c74c6c4057a18ad.zip' [end of output]
Python Enhancement Proposals (PEPs)
fwiw i don't think it's actually a good idea to encode URLs in setup.py
i think you should just specify the package name there, and then use requirements.txt to pin the exact url
e.g. in setup.py you have install_requires=['NodeGraphQt'] and then in requirements.txt you have https://github.com/jchanvfx/NodeGraphQt/archive/9e6f95244d98b0d97b38f0b45c74c6c4057a18ad.zip
that said, this definitely should be valid according to pep 508
but i'm not sure if setuptools itself supports pep 508
pip does
in fact i am pretty sure it does not support pep 508
im not sure if url dependencies are even technically supported anymore
they aren't mentioned in the docs, other than the deprecated and now-unsupported "dependency links" feature
that requires the package to exist on pypi
it only requires it if you haven't installed it already
it depends on what your needs are
well yeah but if I want to publish this on pypi I need to specify this dependency somehow
if this is something you want to distribute and you expect people to install directly from pypi, then yeah
try just specifying the URL, maybe with #egg=
im not sure what formats are accepted by setuptools
the docs dont seem to specify
somehow adding #egg=NodeGraphQt seemed to make it parse correctly
ERROR: NodeGraphQt@ git+https://github.com/jchanvfx/NodeGraphQt.git@9e6f95244d98b0d97b38f0b45c74c6c4057a18ad#egg=NodeGraphQt from git+https://github.com/jchanvfx/NodeGraphQt.git@9e6f95244d98b0d97b38f0b45c74c6c4057a18ad#egg=NodeGraphQt (from kaudio==0.0.1) does not appear to be a Python project: neither 'setup.py' nor 'pyproject.toml' found.
yeah that is also required, setuptools otherwise doesn't know what the name of the distribution is i think
it's hard to be sure with setuptools, there doesn't seem to be any spec and the docs are not that thorough
If you depend on a package that’s distributed as a single .py file, you must include an "#egg=project-version" suffix to the URL, to give a project name and version number. (Be sure to escape any dashes in the name or version by replacing them with underscores.) EasyInstall will recognize this suffix and automatically create a trivial setup.py to wrap the single .py file as an egg.
In the case of a VCS checkou, you should also append #egg=project-version in order to identify for what package that checkout should be used. You can append @REV to the URL’s path (before the fragment) to specify a revision. Additionally, you can also force the VCS being used by prepending the URL with a certain prefix. Currently available are:
that's the doc
idk about the @ pep 508 support though
it might be ignoring everything up to and including the @ for all i know
i almost wonder if you should vendor this into your own package tree...
since you're pegging to a specific commit, seems like a reasonable use of a git submodule
I'd rather not, it's already fairly massive with the native code, the stubs, etc
fair enough
I accidentally deleted my .git folder but I have a public github repo of it. Is there a way I could get it back locally?
if you clone the remote repo to your local machine the .git folde will be cloned. (not sure how to show the .git folder via online UI at github, strange)
I already fixed it, thanks anyway though 🙂
do you know how to view .git folder in online github UI?
getting no build stage in current context when building my docker image
any idea?
this is my first time with docker so idk
dockerfile?
kek
CMD docker run --ipc=none --privileged -d 8060:8060 ghcr.io/python-discord/snekbox
just this one cmd
im typing witg one hand
hm maybe you should ask in #dev-contrib specifically, since this is a pydis project
have you tried pulling the image first?
No I don't
I have questions about CMake. I'd like to make some local utilis libraries that I could include in any projet in the future. To include this, I've modify CMAKE_PREFIX_PATH to point to the place where all my libraries will be. I'm pretty sure this is a bad way to do. What's the best way to do that pls ?

Medium
What every developer needs to know about observability and how to leverage OSS tools to make your code better
Any free resources/services to play with kubernetes, helm etc?
Katacoda
anyone have a good goto for adding git commit hooks to a repo?
like pre-commit?
or husky
yeah, wanting a tool that wouldn't require node though
Hey 👋 any cool module to generate clips from audio files?
pre-commit is a python package
!pypi pre-commit

A framework for managing and maintaining multi-language pre-commit hooks.
thanks, I'll take a look
are you using find_library? https://cmake.org/cmake/help/latest/command/find_library.html
@left girderno, I'm very new to CMake, I'm struggling a bit
but even with that, i'm struggling to understand where and how you're supposed to configure the usefull pathes
like, let say I have X projects depending on Y libraries, and I'd like to have all those dependancies in a specific directory. I want all of the projects to know where to find those dependancies, so where should I put that path ? As an env variable maybe ?
are you on linux? @placid glen
w$
dang. how did you install all the deps into the directory?
if you were on linux I'd say source whatever file that sets up the environment (associated with whatever tool you used to package everything up), or just manually make a bashrc that adds to the appropriate PATH variables, I'm not really sure about windows... maybe some other folks have some ideas...
most of the time it's precompiled or compiled manually (C/Cpp lib)
ah
I guess the question becomes... how to create a script in windows that temporarily adds stuff to path variables
that I can do
but then, should I invoke that script in every CMakeLists I make ?
nah just source it at the start, I think it'll be okay
oh
I generally invoke such scripts before I run cmake
I guess is what I'm saying
yeah that's what i'm used to also, but I don't like it much
like
I have some scripts to start vscode because I need some env vars to be setted when I'm coding
I though CMake would allow me to change that
personally I think it's better to set up the environment the way it needs to be and then run cmake instead of hardcoding any paths to deps... it's more portable
yeah
but for example : let's say you want your build dir to be outside the project directory, and you want all of your project to be built inside that dir
ok
how would you setup the path to that dir ?
cmake /path/to/build/dir
well, that's after you've run it once, now that I think about it
you want to cd /path/to/build dir; cmake /path/to/source
I have to think about it, because I've just made little build scripts for projects with this stuff in it rather than doing it manually haha
here's some nice examples: http://cliutils.gitlab.io/modern-cmake/chapters/intro/running.html
that's a good book, btw
thanks
but yeah, cmake is like a whole thing haha... I've been using it for years and I still feel like newbie
Hello, do you have a discord like this one, but for devops/docker?
@left girderI've found an acceptable solution for what it is worth. In the settings of the extension "CMake Tools" of VScode, it's possible to set env variables that will be passed to the compiler and/or the cmake configuration; and there's also a field to defined a default build directory. By combining the 2 I was able to automaticaly set the build output dir to some external directory.
Is there anyone here that's used both shared and dedicated CPU instances on a cloud provider? I need to do some CI pipelines that need a lot of processing, and I'm wondering if the upgrade to dedicated would be worth trying
Specifically I use Hetzner, though I'm fine with experience from any cloud provider
Is there any way to specify which subscription ID I want to use in DefaultAzureCredential
from azure.identity import DefaultAzureCredential
az_credential = DefaultAzureCredential()
I'am loged with az login
I have 2 python repositories; I would like to link repo B to repo A where whenever someone clones repo A, they get the latest version of the files from repo B that has been linked internally, how do i go about this?
Thanks!
Is it possible to have the contents of a symlink file shown when committing to a github repository? I just need the contents to be there so that when the workflow tests are run, the necessary symlink files are available
what do you mean by "shown"?
for that matter, what do you mean by "committing to a github repository"? commits happen locally, usually, unless you're doing something via their browser UI
does anyone know how i can make an anaconda env with a custom path and a custom name?
Replied in the other channel for this q. Let me know if that helps
I have setup a git repository locally and connected it to a remote repository
online it shows that there is one branch
however locally if i run "git branch -r" it shows two branches
origin/master and origin/main
i did have a master branch remotely but i deleted it
is it difficult to solve
GitHub has changed their default branches from master to main
right
So idr how to fix the master vs main problem but you can change the default branch so that next time only the main branch will be the default branch and not the master branch
No
You can
Just rename master to main
git checkout master
git branch -m main
Done
Also make sure to delete main branch first
git -D main
no but locally it thinks that there are two remote branches when there is only one
Yea so locally, delete the main branch. Locally, rename the master branch to main branch
Also, @cyan scarab have you done a lot of commits on the master branch?
If you've just initialised a new git then are you fine with deleting the git?
so im probably just gonna nuke it and start over
Yea ale
Alr
Soo
git config --global init.defaultBranch main
Type this in git bash
Or terminal
what does that do
This will make sure that every new git init will make a main branch (not master branch) and thus in this way you will be able to push to GitHub easily
Sure lmk if it worked or not
i need to use git remote add origin "url" right
Then git clone repository.url
oh yeah
Then upon opening the repository locally, this will automatically set the origin to the repo url and the branch will be set to main
You can do it like this too
i used clone
i think it worked
yeah it did thank you very much
that was driving me nuts cheers again
Noice noice
visual studio code
why? because I suspect -- with little evidence -- that it's more-frequently maintained, and has better extensions
(also iirc pycharm is basically Eclipse, and I hate Eclipse)
more comparable to intellij idea, not much to do with eclipse
why do you suspect that a first-class python ide is less maintained than a plugin for visual studio code? or number of plugins
🤷 prejudice, really
i repeatedly find pycharm's tooling and type analysis more powerful than vsc with the python plugin, but both are fine
probably wouldn't recommend visual studio though (as mentioned in the question)
I found vscode's git interface fairly lacking when I used it for a dsl that didn't have support in pycharm
though it should be better for types with pyright, as pycharm sucks at that
ah I always use my own weirdo interface for git
wouldn't dream of using anything else
yeah i find pycharm's git integration to be fantastic, i even used it for conflict resolution on a typescript project that i was writing in vsc
though vsc seems to have very powerful git plugins, i just never learned how to use them 
that's a pretty strong recommendation -- I resolve conflicts by basically tossing the fragments into the air and praying 🙂
git diff/mergetool is all I use 🙃
what's that?
i guess this https://git-scm.com/docs/git-mergetool
yep
if the git mergetool doesn't work, I use vim 😄
well, I use vimdiff as the git mergetool 🙂

GitHub
Extendable version manager with support for Ruby, Node.js, Elixir, Erlang & more - GitHub - asdf-vm/asdf: Extendable version manager with support for Ruby, Node.js, Elixir, Erlang & more
is it just me
or is this a LOT better than pyenv
hot damn
asdf does use pyenv for Python
but yes, it's better than having to manage pyenv, nvm, etc. separately
the problem with pyenv isn't the backend
the problem is that the CLI API is awful IMO
so a wrapper around the pyenv backend is exactly what I want IMO
Which linter do you recommend besides mypy/pylance? I want a linter which also tells me about logical errors etc.
logical errors like?
try flake8-bugbear, but not sure if it detects those kind of errors
I use pylint and black
if you have a syntax error, pretty much any linter worth it's salt is going to catch that
if you do accidentally if foo instead of if bar and foo is defined, so there's technically no error... I'm not sure if a linter is ever going to help you with those sorts of problems... though good suite of tests likely would
<@&831776746206265384> ^^
What's up?
Ah, another mod saw similar message in another channel. Thanks for the head up, though.
From “wow, that’s a ton of work”, it’s nifty. From practical POV, it’s not. Few people program in this many languages and this probably doesn’t cover all the edges cases. Also, Docker exists.
I totally disagree
If I am programmign on my local machine
I don't want to route my local development through a docker container
I don't want to execute say, unit tests for example
inside a remote docker container
I want to do my TDD in my local operating system for minimum latency
second
I literally built python 3.7 from source the other day
because I despise the Pyenv api
and deployed it
so a better API for older versions of python than pyenv allows me to make python 3.7 venvs easily per project
and Pyenv is quite honestly rubbish
so don't use it
Your loss. Alot of people do as seen by JetBrains jumping on the bandwagon after VSCode mainstreamed it
most people run their production software in Docker, it makes sense to have environment that is very close if not exact to environment it will be running in.
I am a big fan of remote development
100%
I love to do integration tests, builds, etc etc, in remote
however
Just keep in mind you shouldn't do everything in remote if that makes sense.
local running docker isn't really remote that much
yeah, but still
I just have a bunch of stuff that isn't set up for my production workflow as it were
also, you can just run asdf inside your docker container 
🤮
to manage your environments. Our dev environment actually has a 3.7 venv and a 3.9 venv and a 3.10 venv
So actually maybe using ASDF to manage those is a good thing
or at least generate the old venvs
then again, we don't do a ton of python development at work so maybe it's required under some weirdness, all our Python Dev is dev containers
Containers are good
the problem with containers is that you need to have a container orchestration system
and my work is a bit dogshit and doesn't have K8s or equivalent
we don't use k8s that much either
are you doing everything with Docker Desktop?
tbh I think running local containers defeats the entire point
Nope, Azure App Services
oh well same difference
K8s, Azure's Fargate equivalent. It's all the same.
IMO I think the best workflow is
you do TDD on local
then you commit to a feature
then you just have CICD pull your remote branch rebuild the container and deploy your container
or, it pulls your feature branch and deploys the branch straight into a live container
but the TDD in local is the lowest latency development workflow you can have, and TDD promotes brilliant best practice
Sounds like you’re not looking at the errors
What errors, what OS, what version of Python, what version of pip, etc... https://pillow.readthedocs.io/en/stable/installation.html
Warnings: Python Support: Pillow supports these Python versions.,,,,,,,,, Python, 3.10, 3.9, 3.8, 3.7, 3.6, 3.5, 3.4, 2.7,,, Pillow >= 9.0, Yes, Yes, Yes, Yes,,,,,, Pillow 8.3.2 - 8.4, Yes, Yes, Ye...
I was looking at repos for dockerizing django with postgres... one of the projects I found implemenets redis with celery by default. And I'm left wondering, what is this for? I'm reading on what celery and redis are and I still dont grasp why and when you would need this.
if you want to have execute regular tasks, Celery is one way to manage that with Python
unrelated, but if anyone has any experience migrating from Terraform to Pulumi, have you seen any benefits/drawbacks from migrating?
having a redis server was not part of my app structure but when i look at production environment builds they all have one. i will have to figure out why i suppose.
I am just a terraform user and heard words about Pulumi in DevOps community. So far I hear that Pulumi works reliably only for the three major cloud providers. And still I heard them encountering more unusual problems than in terraform.
Dunno. If u work with AWS u can jump to Pulumi perhaps, but I would prefer to be in terraform for now, as a more stable solution
I see. we do use only AWS for now
the main pain point with TF for us is managing the common modules
I get that it works, but it's not intuitive for newcomers
with Pulumi, I hope it'd be less of a learning curve, because the modules would just be managed like we manage for the actual app services
How do u Deploy stuff at all, ECS?
Nice
like provisioning RDS, Elasticache, LB, etc.
and we're gonna be having new folks joining the team
so wanted to check out if using something like Pulumi would be beneficial for us
https://discord.gg/devops
U can ask your questions in infra provisioning channel there
Or even searching channel history
This topic is from times to times often discussed there
A lot of people are in similar shoes there
ooh. thanks!
Why is setting up all the tools and installation of packages harder than to actually code something?
Nothing ever works... only after hours of trying to figure out why pip does not work, why this, why that...
-+
welcome to programming
it shouldn't be. the problem in this case is the documentation is generally incomplete and scattered. this is kind of a python-specific problem, but most other language ecosystems have similar issues
the other issue is that there are a lot of different ways to set things up that depend on your specific situation and needs
generally pip issues in particular can be avoided by following some best practices:
- never use
sudowith pip or otherwise as administrator/root - keep control over your
PATHvariable and only install python versions that you know you need - use pyenv to install python for development use, or on windows use the
py.exelauncher instead of invokingpython.exedirectly
Hi, I'm trying to execute a shell command using subprocess. My command needs some arguments which contains the = character (that's the equal character). When this character is present in a argument, everything after the = is removed. Example:
subprocess.run(['/path/to/command', '-arg example=/path/to/something_else'])
When my command execute, it says:
command: unknown flag: -arg example
Everything to the right of = is removed. Is there any way to escape the = character or otherwise get this to work as I want?
I'd try subprocess.run(['/path/to/command', '-arg', 'example=/path/to/something_else'])
it depends on the command itself really
@thorny shell : So simple when you know how to do stuff properly, thanks!
💐
my bad i didn't send them
the main issue is
The headers or library files could not be found for zlib,
a required dependency when compiling Pillow from source.
I installed zlib
still not working
yeah but you need headers, whatever zlib package you installed might not have them
what operating system do you use?
windows 10 pro
doesn't pillow have binaries for Windows?
Warnings: Python Support: Pillow supports these Python versions.,,,,,,,,, Python, 3.10, 3.9, 3.8, 3.7, 3.6, 3.5, 3.4, 2.7,,, Pillow >= 9.0, Yes, Yes, Yes, Yes,,,,,, Pillow 8.3.2 - 8.4, Yes, Yes, Ye...
Hi guys do you know if schedule of a github action should be in master to work, because for now I am testing it in PR and it doesn't schedule. The whole action is in PR and yeah.
Do you know how to actually test the scheduler inside the PR before merging 😄
I recall testing out actions in PRs before merging them. So it should work. However, I believe you'd need to allow PRs to trigger the action.
Like ```
on:
push:
branches:
- main
pull_request:
To trigger for both main pushes and PRs.If you don't want PRs to trigger then I suppose once you've tested it you can remove that part.
Another question is it better to have that action which I use to make the pr with the new file from latest release in the repository where I need the file or the repository where I update the version?
Sorry, I don't understand the question. Can you rephrase?
I have repository A which contains some deployment file which can change in diffrent versions of the repository, and I have repository B which uses the deployment file of reposiotry A, I want to keep updated this deployment file for the latest version of repository A. What I have done is I have written action that is triggered by cron job every 2 hours or so (in repository B which is dependant of repository A) which fetches repository A, gets the file (from latest) version and opens a PR in repository B with the changes.
Okay, so you're asking whether it's better to put the action in repo A or repo B?
And by action what you really mean is a workflow, right?
yeah
I would argue it's better for it to be in repository B
Since which files repo B needs is the business of repo B. Repo A shouldn't be concerned with who or what needs its files.
And I should check on push to v* tag right and then just make PR
I guess the only exception might be if the sole purpose of repo A is to house that file.
Yeah if repo A follows a procedure of creating tags for releases
But really I want to check if repo B actually is creating a tag and if creates a tag create a PR to Repo A with this file from the current version
But I thought the file was on repo A and you wanted repo B to get the update?
ahhh
yeah
mb
So I should do regular checks on repo B if repo A has new version and make PR
Actually, you made a good point there even if not intentionally
Not to activate action upon creating new Version in repo A which creates PR on repo B
If the workflow is on repo B then you need to periodically poll repo A for changes. However, if it's on A, it can trigger upon release.
From this standing point I think it is better to make pr on release not to poll for it because it is useless
Who uses a MacBook Air for coding and do you like it?
I use an M1 and love it, but ... that's not what you asked
I also use an ordinary x86 and kinda dislike it ... also not what you asked
Not sure if this belongs in this channel, but hoping someone can help. Is there anything special that needs to be set up on a remote PowerShell terminal session for Python's console/CLI stuff? Trying to install an app via Poetry and getting a UnicodeEncodeError which traces back through clikit, cleo, and poetry\console. This exact command works fine on a local PowerShell session.
.
!
There used to be one but it had barely any activity so it was removed.
how to create a django superuser from dockerfile
Not sure if that's feasible but did you see this? https://stackoverflow.com/questions/30027203/create-django-super-user-in-a-docker-container-without-inputting-password
Stack Overflow
I am tring to createsuperuser in a django docker container with fabric.
To create the super user in django, I need run this in a django interactive mode:
./manage.py createsuperuser
And because ...
is the project structure stored in git object blobs? as in, when you git add a file the parent directories of the file itself is stored in that blob
how can i make a telegram bot to read allll the messages from a specific channel ?
AFAIK directories are stored as git tree objects. files are stored blob objects (leaves)
yep, every git commit points to a "tree" which is how git represents your directory
a directory tree can contain other directory trees (i.e. a directory can contain other directories), as well as file objects
but each one gets a unique hash
and there are plumbing commands you can use to inspect their contents
https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain this chapter is a great explanation of the internal structure of git repos (which also helps in general for understanding why git is the way it is)
Hi. Does anyone have experience in both AWS Lambdas and Azure Functions? I'll be migrating some stuff soon and I'm wondering about Lambda Layers. Some comparison says that bindings are the equivalent but then Azure's github says that they use bindings that are written in .net...? That really doesn't sound good to me, in AWS I just had common python code in my layer... :c Could someone point me in a direction where to look for real layer equivalent or something?
Medium
The dev stack is evolving. I asked Scott Hanselman, Juraci Paixã, and Ilai Fallach what’s new in their developer toolbox.
@worn pilot are u here?
ok
oh heh 🙂
and now i want to edit txt file and then push
but it didn't work

i get this error
do you have write permission on the repo on github?
i can push from PC but don't android
oh ok, so that's a yes, you do have permission
I don't really understand how tokens work
and you also use that method on the non-android machine?
i try this on PC and work but on android problem is not with push to github, problem is that i can't edit file

hmm. I don't know enough about git to help with this
I can tell you about a community where you can ask though
is problem here?

yes i want
I also hang out on irc, on irc.libera.chat in channel #git
can u add me?
you don't need to be added, you can just join
umm, do you want to get an irc client or do you want to use their web interface?
web
ok one sec, I'm getting the address now
try going to libera.chat
it's not discord, it's much older
let me know when you get connected, and what it makes your nick

Can you tell more about make vscode awesome setup?
After googling , I think a better solution is to create custom management command.
an someone help me to convert my python code to an .exe
I'm a little disappointed that I put so much effort into getting my docker-compose project perfect to throw up django, postgres, nginx, cloudflare tunnel, redis... and now I get started with learning DigitalOcean to find that they don't support docker-compose. They can translate apps made with a Dockerfile into something they all their "App Platform" but like... if I would have known this, I would have spent all this time learning their "App Platform" and not how to get docker compose just perfect
And now im thinking, do I even still want to use Digital Ocean if it cant just deploy from docker-compose directly.
Does anyone have any advice for where I should get my cloud service?
I know that places like heroku and whatever will let you serve a free python app, but Im more interested in learning learning a cloud service that is a little more... reputable for real apps.
[4:11 PM]
I know that i dont want to do Azure. There is what else? AWS? Linode?
@warped latch just get a regular digitalocean droplet and run docker-compose on it
docker-compose is for development and hobby projects. it only runs on a single machine. serious deployments orchestrate (horizontally scaling) containers across multiple machines, which is what DO app platform, GCP GKE, AWS ECS, etc. are for
I see. I didn't realize docker-compose was not intended for large workloads, not that this app im working on requires a large work load at this point. But I see.
I also realized that... yeah, there is even a droplet in the marketplace that is called "docker" and it has docker compose on it and is set up for just that.
Horizontally scaling... I dont understand that concept. Is taht like horizontal escalation of privileges vs vertical?
in prv escalation, horizontal is like... enumerating another host or getting another username. Or getting access to another user that does not have higher priviledges but has other connections.
so horizontal scaling is... some way of spreading the work load across different virtualized systems?
how is that different from containers in docker?
i have an aws question.
if it says launch time: 16 hours, does that mean the instance will turn off automatically after that time?

update: i checked the logs and found out the instance wasnt mine
i was 🤏 this close to shutting it down tho

lmao Rex
you dont even know my struggles today
they should not have given me aws access
i know like negative knowledge
and like im worried im going to leave instances running
over the weekend
what's wrong with leaving them?
whats wrong with leaving compute resources running when youre not using them?
besides like
spiraling costs?
im just an intern. ill be the first to be let go if something unexpected happens
💀
hehe. i similarly have negative knowledge about this
im not alone

anyway
boss man said i should try to do my ML stuff with sagemaker serverless
even tho that service came out like
..
last month
hes like "you can learn"
"also it would save me from a heart attack"
(in case i end up accidentally leaving instances running and eat up costs)
hes got a point
@analog kettle help me deploy my model
stelercus knows how to do ML things in production

What
What production
What is happen
A perfect ice cube
and how you can use it for semantic search

with vector indexing
What vector database
and then boss man was like
lets try to create our own
for our own search engine since our search engine is from 1995
Why did he want you to create something that exists
and i was like idk man id have to do it on sagemaker
and create an api endpoint
and do things outside my comfort zone
bc he wants our data to be stored in a vector database so we query it and use semantic search
Anyway I'm never in charge of setting up the aws environment, because that would require money stuff. And I'm not important enough to be managing project funds.
im not important enough either but they just like
throw stuff at peeps
like im pretty sure devs make apps here end to end or at least the team size is small
so when i suggest ML model stuff, theyre like
we like this
lets try it for ourselves
and then i cri

i cant even fine-tune my models or test hyperparameters
theres no time
Anyway, the vector search thingy we're using for one of my projects is called Weaviate
oh heyyy i saw that one. we're using pinecone for now
It's new, I think. There are no stack overflow answers for it
while i still have the free tier
You have to dig through their slack server
interesting interesting. might check that one out
I think imma ask stack overflow questions about it on an alt
And then answer them on my main
By copying answers from the devs in their slack
i brought up milvus to my boss in case we wanted to create our own
vector database
but i also will do research into that one

did you just think of a new type of account value generating spam bot?
Hi guys, I've got a question regarding Docker multi-stage build. I think I understand well the concept if I were to build for instance a python wheel and then copy it over to my final Docker Image.
Today I found myself in need of installing Git from source. So I need to install a few libraries, run the usual make all and make install. But I'm not sure if there would be a clever way of compiling on the builder stage image but install in the final image. If the explanation is not very clear, I'm happy to elaborate.
Is it not sufficient to just copy the git binary to the other stage?
Like ```dockerfile
COPY --from=builder /git/output/git /usr/bin/
RUN chmod +x /usr/bin/git
Maybe it is, but it seems that there are many other binaries produced such as git-merge or git-add.
Maybe you’re right and those are not needed. Thanks for the reply!
I'm not sure. Looking at its makefile, the install command is quite involved, but I'm guessing it's mostly taking care of dependencies that are only required by certain commands.
Why wouldn't you rely on packages?
im very new to k8s and trying to run a large sharded discord bot in k8s. Im wondering a couple things:
is there a way to set up one deployment that each pod has different incrementing env vars? (i know thats not normal) i saw statefulset, but wondering if thats how
and is there a way to have shared storage that all pods can get to, so i can do git pulls into it/reload cogs and not have to rebuild/redeploy with every small change that gets pushed
Having a single volume mounted read-write in multiple places is unusual, most platforms don't support it
so is having the code in a volume instead of the image
Incrementing env vars is also a no, they will have different hostnames but those won't be numbered
If you want them to know how many there are and who's in charge of what, you'll need an external coordination system like etcd
(or use a statefulset and manage that yourself)
hmm ok
was just hoping to not have 60 deployments all the same just one env var changed between them
If you want stable identities you need a statefulset
They won't be told how many of them there are though, or how many of them are currently up
can pass total in with env var and they dont need to know how many are up, there all working independently
so statefulset sounds like what i need to look at
Because I’m stuck momentarily with Debian Buster for my image which only provided Git v1.2.20. But I need functionalities from more recent versions.
I fully agree that the long term solution is to upgrade the base image.
You could take the updated source deb and rebuild it for your debian buster
pretty sure buster has 2.20.1
You’re 100% correct. Was typing on my phone, and got confused by the version. The version I need is min 2.25. Bullseye comes with 2.30 so that would solve my issue.
Thank you. That’s a good idea 👍
Hey, to those of you who are familiar with Jenkins and specifically JenkinsAPI from python -
I'm trying, using python-jenkins to connect to my server firstly, i've seen the basic API:
import jenkins
server = jenkins.Jenkins(url=.., user=.., password=..)
server.get_version()
But I can't get pass that - i.e the authentication.
Any help on the exact details I need to provide there?
Also seen in their documentation that you can log with a token - https://www.jenkins.io/doc/book/system-administration/authenticating-scripted-clients/
and I generated one for myself - but can't seem to find the API for that connection.
seems like you just need to pass the Jenkins instance's URL?
Yes - I'm getting Error communicating with server[THE_URL_IVE_GIVEN]
I made sure the username and password I provided do log me in in the web UI. and took the URL from the Jenkins URL
From Jenkins version 1.426 onward you can specify an API token instead of your real password while authenticating the user against the Jenkins instance. Refer to the Jenkins Authentication wiki for details about how you can generate an API token. Once you have an API token you can pass the API token instead of a real password while creating a Jenkins instance.
from the docs
are you passing your user password or API token?
For starters, my user & password
What do you need in git that requires 2.30?
git clone —sparse …
weird need but ok
I guess if you have worlds largest monorepo
But generally the build server handles the git clone and it should be more modern then container.
Or grab modern git container in multi stage build process. When it comes to build, KISS is paramount.
Hey , I have 2 docker-compose files , one for production and one for local development ( framework : django).I want to upload my code to dockerhub , so how do I build my image.
from the GitHub docs:
Note: With the exception of GITHUB_TOKEN, secrets are not passed to the runner when a workflow is triggered from a forked repository.
is there any way to allow workflows run on pull requests to access secrets?
if not, what is the proper way to do this? i have some tokens used for testing, and github actions needs access to those tokens, including when run on a pull request
Should i study Ansible ?
Hi
I have this virtual env with a like 3 scripts selenium
i wwant my friend to be able to launch the scripts
how can i achieve this using docker?
Depends, it's heavily in use but it's what I call legacy product. Virtual Machines are not going anywhere but it's not the future either.
👍
It's not clear to me that you really need Docker for this, but there are official and unofficial Selenium images for Docker
Use pull_request_target instead of pull_request as the event. https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#pull_request_target
But pay attention to the warning in red
super handy way to install the various python cli tools you know and love https://pypa.github.io/pipx/
execute binaries from Python packages in isolated environments
I'm fighting poetry now, no, VSCode Dev Containers, isolate this awful run time that will eat it's young
yeah pipx just installs each tool in it's own environment. I haven't used poetry. I've been playing around with pyenv lately, it seems neat
if your dev environment is isolated, you don't care.
I do care
🫂
I normally just used venv or conda, but pyenv seems neat. I like the idea of per-project python versions without having to activate them each time
https://github.com/cxreg/smartcd hasn't been touched in a long time, but it worked well last I tried it. Automagically "does stuff" when you cd into a directory

GitHub
Alter your bash (or zsh) environment as you cd. Contribute to cxreg/smartcd development by creating an account on GitHub.
that could activate your virtualenv for you e.g.
direnv is also great for this
How can I kill a server ran using nohup?
nohup just means you can't send it a SIGHUP, you can still terminate it with SIGTERM or kill it with SIGKILL
how can I do that
and how do i get the process id of it
using top or ps
https://docs.python.org/3/library/os.html#os.kill is how to send the signal
and terminate/kill it using kill
or that, if you want to use python to do it
hmm ```
8842 ttys000 0:00.10 -zsh
8851 ttys000 0:00.06 /Library/Frameworks/Python.framework/Versions/3.9/Resources/Python.app/Contents/Python
9431 ttys001 0:00.19 /bin/zsh --login -i
the server is running at 127.0.0.1:8000
is there a command to kill a process running at that port
thanks that worked 
docker-compose -f docker-compose.yml down -v
docker-compose -f docker-compose.yml up -d --build
docker-compose -f docker-compose.yml exec web python manage.py migrate --noinput ``` why do I get this error even though I have a valid `Dockerfile`? ```
failed to solve with frontend dockerfile.v0: failed to read dockerfile: open /var/lib/docker/tmp/buildkit-mount255036992/Dockerfile: no such file or directory
ERROR: Service 'web' failed to build : Build failed
hey guys, is someone familiar with azure pipelines and yaml configuration by any chance?
i'm getting this error when trying to deploy
ERROR: Incorrectly formatted environment settings. Argument values should be in the format a=b c=d
what have you got in your docker-compose.yml?
version: '3.8'
services:
web:
build:
context: ./apps/backend/
dockerfile: Dockerfile
command: gunicorn backend.wsgi:application --bind 0.0.0.0:8000
expose:
- 8000
volumes:
- ./apps/backend/
ports:
- "8000:8000"
env_file:
- ./apps/backend/.env
depends_on:
- db
db:
image: postgres:13.0
volumes:
- postgres_data:/var/lib/postgresql/data/
redis:
image: redis:alpine
nginx:
build: ./nginx
ports:
- 1337:80
depends_on:
- web
volumes:
postgres_data:
I'm not 100% what I'm doing, I'm following this tutorial https://testdriven.io/blog/dockerizing-django-with-postgres-gunicorn-and-nginx/

Maybe it's this issue? https://github.com/docker/for-win/issues/8781
The name of the Dockerfile is case sensitive even on Windows apparently so make sure the capitalisation matches what you specified in your compose file
Haven't used Azure Pipelines in a couple years but if you share your yaml file I may be able to spot the issue.
the file name is exactly Dockerfile
Is it located in the current working directory?

According to the spec, relative paths for the dockerfile are resolved relative to the build context https://github.com/compose-spec/compose-spec/blob/master/build.md#dockerfile
Ooh, doing nginx with your backend?
GitHub
Example project using nginx-unit, fastapi and vue.js, all in one docker image - GitHub - killjoy1221/nginx-fastapi-vue-docker: Example project using nginx-unit, fastapi and vue.js, all in one docke...
Thanks, that seemed to fix the issue
thanks, ill check that project 👍
What are the pros and cons of using devcontainers vs venv?
pro: You get a fresh environment each run
con: You get a fresh environment each run
# Docker
# Build and push an image to Azure Container Registry
# https://docs.microsoft.com/azure/devops/pipelines/languages/docker
trigger:
- main
resources:
- repo: self
variables:
# Container registry service connection established during pipeline creation
dockerRegistryServiceConnection: 96c34e35-6e1a-43c0-a766-fd1b67336806
imageRepository: pipeline
containerRegistry: amrteam.azurecr.io
dockerfilePath: $(Build.SourcesDirectory)/Dockerfile
tag: $(Build.BuildId)
resourceGroup: resourcegroup-amr
containerAppsEnv: managedEnvironment-resourcegroupam-9d1e
stages:
- stage: Build
displayName: Build and push stage
jobs:
- job: Build
displayName: Build job
pool: Default
steps:
- task: Docker@2
displayName: Build and push an image to container registry
inputs:
command: buildAndPush
repository: $(imageRepository)
dockerfile: $(dockerfilePath)
containerRegistry: $(dockerRegistryServiceConnection)
tags: |
$(tag)
- stage: Deploy
jobs:
- job: Deploy
pool: Default
steps:
- task: AzureCLI@2
displayName: Deploy app to Container App
inputs:
azureSubscription: azureamrv2
scriptType: bash
scriptLocation: inlineScript
addSpnToEnvironment: true
inlineScript: |
#!/bin/bash
az config set 'extension.use_dynamic_install=yes_without_prompt'
az provider register --namespace Microsoft.App
```yamli coudn't attach the full yaml due to character limit 😦
and this would be the error that pops up at deploy stage: ERROR: Incorrectly formatted environment settings. Argument values should be in the format a=b c=d
This seems to be an error coming from the azure CLI rather than from Azure Pipelines itself
In other words, your actual YAML format is fine you just have an incorrect arg for az container create
Admittedly, I have never used the azure CLI
Actually, I am not sure where that error is coming from. Apparently it is related to the --environment-variables argument but I don't see you using that anywhere
I don't even --environment documented anywhere. Only --environment-variables
**DevContainers: **Pro, your Dev Environment is truly isolated, Con: It's around docker so it's compute and disk usage is higher then venv VEnv Pro: Nothing extra is needed beyond Python. Cons: It's just file isolation. If you are using VSCode and have decent computer. DevContainers is the way to go.
You just leaked your registry info?
<@&831776746206265384> I think you may want to preemptively delete the message on the meantime
I'm running django on docker with postgres as my database.Will migrate command create postgres database for me.
No, it will not create the database. It has to be created beforehand. In fact, you need to specify it as part of the connection string; it won't even be able to connect if the db doesn't exist yet I am pretty sure.
But I believe with the postgres container you can use some environment variables to have it automatically create a db and user
The error i got is OperationError , FATAL role "username" does not exist
Hey can anyone help me I am trying to build a music player which will play only the audio from youtube. The audio will play in background insted of opening vlc
Any Ideas?
Like : I will input the name and the program will search YouTube and after getting desired result it will play in the background instead of opening vlc
I have a postgres database running on docker but my django application isnt able to connect to it ```yml
db:
image: postgres:13.0
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data/
environment:
- POSTGRES_USER=
- POSTGRES_PASSWORD=
- POSTGRES_DB=
Did you follow the blog on testdriven.io
yeah
I got an operationalError , FATAL role "username" does not exist.
in logs it says this though ```
2022-06-02 13:34:44.155 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
2022-06-02 13:34:44.155 UTC [1] LOG: listening on IPv6 address "::", port 5432
2022-06-02 13:34:44.163 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2022-06-02 13:34:44.171 UTC [66] LOG: database system was shut down at 2022-06-02 13:34:44 UTC
2022-06-02 13:34:44.181 UTC [1] LOG: database system is ready to accept connections
But i can connect to it using compose exec db psql --username=postgres --dbname=abc
Yeah found it.
django error logs could not connect to server: Connection refused Is the server running on host "0.0.0.0" and accepting TCP/IP connections on port 5432?
What's the connection string you have configured in your django app?
Also, any reason why you have not set these env vars?
i have set it, but removed it when sending the message
Hey there! When I am running or debugging cpp code, I always get this "warning". How can I auto give permission?

This is the planned features for my Python auto-deployment template repo, can I get some critique / recommendations on my stuff so far?
poetryfor managing 3rd party library downloading and versioning (replacespipenvsince it doesn't allow for setting min/max Python runtime versions)verminfor checking the minimum required Python runtime necessary for the project (for use withpoetryto specify min/max supported Python runtime versions)pipreqsfor quick and easy generation of arequirements.txtfile based on the source code (for easily installing said modules throughpoetry)blackfor formattingisortfor sorting importsflake8for finding errors and linting the codepre-commitfor running tools 4-6 automatically on a commit- Generate template
pyproject.tomlfile based on all the previous libraries/tools with some specific rules forblack/isort/flake8
Sounds fine but keep in mind vermin is not a guarantee that your codebase will work with an older Python version. Ideally you should have a test suite and run that through a matrix with the versions you want to support.
Also you shouldn't bother supporting a Python version that's EOL even if you technically could currently.
I suppose since this is a template you can't really take care of the testing stuff but maybe you could set up some CI stuff for that. I dunno.
My mentality for using it is to just be able to easily say "this project works with python versions X to Y" for people who want to run the project from source instead of the compiled/built executable I provide in releases. The goal would be to see what the newest stable release of Python is supported and build based off of that
IE: if vermin reports my project is compatible with Python 3.4 to 3.10, then only build a 3.10 version for releases, and provide the min/max Python version supported by the code
Offering support for older python versions is a different story - I'd just go with "if the version is deprecated then don't ask for support"
How is it being distributed?
Compiling the code with cython, packaging it into an executable for different platforms (Windows, Linux, MacOS), and then generating a release with those files
Is the intention though to still allow one to install from source as a package?
You mean through pip / pypi? That I haven't looked into since the apps I'm writing that'll use this auto-deployment template aren't really libraries, they're more so standalone apps (typically with a GUI)
Not sure if that kind of thing would be worth deploying through pypi
Not necessarily through pypi, just if it's a Python package that can be installed with pip
If not, then I suppose it doesn't matter as much what the minimum version is. I was going to say that if it's a package then the min version should be what you intend to support.
Which would still be a good idea anyway
I suppose making it distributable in a way that's installable through pip, like generating wheels to include in the GitHub releases or to put them on pypi, wouldn't be a bad idea
Adding another feature task to my project
Thanks for the advice!
How to use sqlite3 as a volume in docker (django)
This page documents how to create a volume. https://docs.docker.com/storage/volumes/
Have you looked at that yet?
yeah , can't find the what i need though
Have a look at the section "Start a container with a volume"
When you create a volume, you specify a path. This is a path within the container which will be a volume. You should configure django to write the sqlite database file within that volume's path.
And that's pretty much it.
how do configure sqlite3 as a volume.
I'm reading up and trying to understand this DigitalOcean's Functions service but I don't understand this GB-seconds thing. Can someone dumb it down for me?

It seems like RAM but isn't?
It's the amount of memory the function uses over a period of time
So 90,000 GB-seconds is... what just 90,000 GB? in a second?
So if my function only uses 1 GB per second, then I can run that function 90,000 times in a month?
For example, the function can use 2 GB over 10 seconds, which results in 20 GB-seconds used, or it can use 1 GB over 20 seconds, which also results in 20 GB-seconds used.
So with 90,000 GB-seconds, the function can for example use 90,000 GB in one second, or 1500 GB over one minute.
That helped
Thanks
So follow up question. How do I find out how much memory a function is using?
I think I've figured it out
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Is commit squishing generally considered bad?
I noticed that I'm having a hard time browsing the history on squashed projects.
It's also harder to analyze the master branch history with automated tools that measure some code metrics
It depends, we squash commit occasionally. Generally we when we squash commit, we don't delete the branches so if you want to view history, you can
having a good PR process helps too
we squash merge PRs
but that's only a good idea if you ensure PRs have a small set of changes
Yeah, sometimes you stumble upon a giant 2000 line commit... And it is just a squashed PR from a long feature branch
I don't think there is a general consensus. I don't squash because I think having the individual commits around is useful information. They may contain comments on why a specific change was made.
And yes, if the squashed commit results in a huge diff, it's difficult to go through.
From a history standpoint I'd much rather see the individual commits around a commit after jumping to it through blame/whatever, instead of squashed features and having to do more work to see what was being done and why
I also think it gives developers the wrong attitude about naming commits. "it's gonna be squashed anyway, who cares if I named it something non-descriptive"
as opposed to: "it's going to stay in trunk for 75 years. I better name it properly"
Or maybe I just work in a team where it's common to name commits with nonsense?
I think a team should follow a commit style just like they follow some coding style
I agree that sort of attitude can lead to difficulties in reviewing PRs
Yeah I guess it's a bit dysfunctional here...
We don't even have a written-down coding style, besides the linters we run in CI
im trying to clone a private github repo on a headless debian os. ive installed git credential manager, pass and a bunch of other things it told me to but i still dont understand how to make git accept my login info
Would have been simpler to use an ssh key I think
No need for a credential manager or whatever pass is
Just create an ssh key and add it to your gh account then use the ssh url to clone the repo rather than cms https url
hey can anyone help me with a calculator project
i would like some help
with a calculator project im doing
im struggling with a on/off button
the project is that when the off button is pressed
you cannot use the calculator like its off and the bar where the numbers show turns blank
Hi All, would love to know your feedback on the idea of using Pycharm over the cloud? What are your thoughts?
As long as your network connection is good, that's fine. Even a little bit of latency gets annoying pretty fast
Have your tried it yet?
I am not certain if this is exactly what you are asking, but I use an AWS Workspace every day
Yes, how is your experience with aws workspace?
It depends how my wifi is feeling that day. It's usually fine
I use visual studio code in an azure instance -- I bet that's roughly the same thing. It's tolerable.
Did you observe any latency issues?
You want to make sure you're using a workspace in the right geographical zone... We have workspaces on the east coast of the US and people on the west coast complain
Sure, it's not as snappy as if I were running it natively.
It's kinda like being underwater
Yes it depends on how close you are to the servers
otoh it's cheaper than buying a whole different computer just for Windows
Yes exactly
Would love to hear your feedback on Neverinstall. Have been building it for a while
never heard of it
Well now you heard about it 😇, please let me know
ah but for that I'd have to
a) try it
b) remember to get back to you
Both those things seem unlikely themselves; but combined, it ain't never gonna happen
Sure, no issues. Totally understand it
Would you like to give a comparison feedback?
It's an interesting product to know about but I have zero interest personally. The only reason I use a remote workspace is that I'm required to for security reasons
I can see how it might be useful for others though... I'll recommend it if I come across anyone
It helped a lot, thank you for the feedback. So what i hear from many is its very hard to change the habit of a local dev setup until there is a wow factor and immediate value
Writting 4 line description when your committing often can be annoying or you might be committing to save state. There is a commit in one of my repos from yesterday reading "Finishing up for Friday" because I just wanted to get all my code into the repo since we don't back up local hard drives.
I generally make tons of small and stupid commits, whose comments have lots of swear words in them.
When I finally figure out what I'm doing, I squash 'em a bit and clean 'em up.
Once I create a pull request, I generally squash further, although not always
Yea, you can also squash certain commits inside branch but no one got time for that. Also, some git servers might get cranky about branch history rewrite.
some do, some don't; some let you allow or prohibit that by policy
where I work we use ADO and the rule seems to be: if I created the branch, I can do all kindsa crazy #*($& to it. But if someone else created it, I can only do normal pushes. That seems sane
It also helps to work from a branch in a fork rather than a branch in the main repo
You can nuke it from orbit, you can force push all you want and get it ready prior to creating to pr/mr
and you don't end up with a bunch of branches in unknown state in the main repo
we don't fork where I work; the concept doesn't really exist
I only make forks when I'm using github, and want to contribute something upstream, and the project wants a pull request
you don't use a DVCS?
I use git
which is indeed a distributed version control system
by "fork" I mean: you go to some UI like github.com, look at the page for some repo, and click a button that says "fork", and it clones the repo on the server, under my name.
I do "git clone" all the time, but that's on my laptop, not on the server
either ADO doesn't have that feature, or (more likely) my employer just hasn't enabled it, or it's there and I've never noticed it 🙂
I imagine ADO will get end-of-lifed in a while, since Microsoft owns github, and most people would probably rather use github
Im making a tool that bypasses the ability to run wget as root without a password in a linux machine (useful for ctfs) and i need to run an http.server with os without actually showing the output
Serving 0.0.0.0 on port 8000 etc. In simple words run it in the background?
how can i do that
Actually got a second problem. I need to use os to gain an ssh connection to the victim and in parallel start the http.server from the attackers machine
hey folks, anyone know how to install python from a downloaded layout? the documentation surrounding python installs kind of sucks..

does the presence of adjacent MSIs cause the installer to use them instead of downloading?
I just run the installer and click "Next" until it's done
never bothered with anything else
I'm automating silent installs for remote sites
dealing with hundreds of small, Internet-unreliable devices
ah. Good luck
the docs just suck in this regard. I can see the layout generated from my unattend.xml, but I'm not sure if I now have to re-copy my xml next to the new executable it generated or if that's automatically incorporated somehow
not that you asked, but: my hunch is that this is really hard, and the sensible thing to do is cough up some $ and pay for a professional product that does this for you
pfft. it's not that hard, it's just poorly documented to discovery
silent installs aren't novel and this is just an MSI wrapper wrapper
Maybe looking at how scoop does it will help? https://github.com/ScoopInstaller/Main/blob/master/bucket/python.json

GitHub
📦 The default bucket for Scoop. Contribute to ScoopInstaller/Main development by creating an account on GitHub.
Though it's technically not a proper installation
But maybe you're okay with that
jeez scoop looks hacky AF
appreciate the link, but no clue what they're doing there
I'll be testing this in a VM without network access just to ensure I get it right
was hoping someone else went through the process and documented it better than the official site, but everything online is off-topic and gaming the SEO which is frustrating as all hell
you google "python, X" anything and you get crap clickbait from towardsdatascience or similar spam domains
does minikube have an api access? as i cant get subprocess.run way to work
anyone use qtile?
Im unable to spawn firefox in two different workspaces, im able to spawn firefox twice but they spawn in the same workspace
Does anyone have experience with pyinstaller and encoding errors?
(module, co) = self._load_module(module_name, pathname, loader)
File "C:\Users\Shane\PycharmProjects\gc2toTGC\venv\lib\site-packages\PyInstaller\lib\modulegraph\modulegraph.py", line 2143, in _load_module
src = loader.get_source(partname)
File "<frozen importlib._bootstrap_external>", line 783, in get_source
File "<frozen importlib._bootstrap_external>", line 566, in decode_source
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa9 in position 386: invalid start byte
my app opens/edits/reads a .txt file to store settings, I added encoding="utf-8", errors='ignore' everywhere it's called
if you google UnicodeDecodeError: 'utf-8' pyinstaller this issue has been around for years, none of the fixes suggested worked using latest pyinstaller 5.1

Yes BUT by default, docker containers can't get access to API
dont need pod access, need py script access on host
Oh, that should be fine
how?
Has anyone encountered this error before , "<static_files> was blocked due to MIME type {"text/html"} mismatch {X-content-options : nosniff)
Tech stack : django app running on docker with nginx as reverse proxy and gunicorn as my web server.
:incoming_envelope: :ok_hand: applied mute to @young badger until <t:1654544254:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
that's not enough of the stacktrace to help (also probably doesn't belong here but #web-development
Is it ok if I post a link to my blog about Terraform? I am studying for Terraform cert and writing a blog about it. Let me know if anyone is interested 🙂
does someone has isea what happening?

Repository is not existing remotely
Invalid URL to repository in git remote
I think the second reason
U a supposed to use SSH
Https way was disabled I think
@small jay could you go over how docker works? bcs im really lost here
Ideally, you would push to your own forks, then do a pull request.
wouldn't that also expose their private email?
It's only an issue if someone pushes something you pushed previously to a non-github service, like gitlab
Hi guys! Would you use a couple Python class decorators to speed up your training? Try it and let me know what you think 🙃 https://github.com/nebuly-ai/nebulgym
GitHub
Accelerate AI training in a few lines of code without changing the training setup. - GitHub - nebuly-ai/nebulgym: Accelerate AI training in a few lines of code without changing the training setup.
can someone explain to me how to use docker? i have legit no idea what it is or anything about it but ive been told i should use it so that my code doesnt downgrade to discord.py 1.7
Do you have a link to that discussion?
it was a simple question i asked
i asked why one minute it was working fine and the next minute it said discord.ui wasnt a thing, and i was told that its bcs it downgraded to v1.7 and that i should use docker
@visual oxide #discord-bots message
Oh they weren't being very helpful there.
actually they were
i had to go and by the time i got back they had left discord thats all
You probably want a couple of tools, eg is your discord bot code in git?
And do you use a virtual environment per project you do?
git? as in github? and what do you mean virtual enviornment?
Ah right so you definitely want to start using a virtual environment per project you do, before worrying about docker.
but what is that
Try running through this tutorial https://docs.python.org/3/tutorial/venv.html
ill get back to you when ive done it
@visual oxide at
bash: tutorial-envScriptsactivate.bat: command not found
i ran tutorial-env\Scripts\activate.bat in the shell
Are you on Linux?
no
Or WSL or similar?
wth is that
What's your OS?
Operating System, like Windows, Macos, Ubuntu, Solaris etc?
Windows
Can you show a screenshot of your terminal?
the shell? the console?
The shell

Not sure exactly what you're running, but follow the instructions for Unix or MacOS
want me to show shell?
Sure

look good?
@visual oxide what does this mean:
Activating the virtual environment will change your shell’s prompt to show what virtual environment you’re using, and modify the environment so that running python will get you that particular version and installation of Python. For example:
$ source ~/envs/tutorial-env/bin/activate
(tutorial-env) $ python
Python 3.5.1 (default, May 6 2016, 10:59:36)
...
>>> import sys
>>> sys.path
['', '/usr/local/lib/python35.zip', ...,
'~/envs/tutorial-env/lib/python3.5/site-packages']
>>>
Yep
@visual oxide what does this mean? what do i do
Run the code like they did
So you'd run python
Then do import sys
just in the shell
i ran python -m pip install novas in the shell and got this:
File "<stdin>", line 1
python -m pip install novas
^
SyntaxError: invalid syntax
@visual oxide
i gtg eat rq ill be back soon
You'll need to run that in bash not in the python repl
hey yall
I just finished making a python ssh id encoder/decoder for a vulnhub begginers room im making. Basically the player will have to reverse engineer this program (will make it obfuscated after) and decrypt the rsa key that gives him access to root. Need your opinion on it
Part1
from cryptography.fernet import Fernet
import base64
def generate_key():
#Store the double base64 encoded key
with open("key.en", "wb") as f:
key = base64.b64encode(base64.b64encode(Fernet.generate_key()))
f.write(key)
def read_key():
with open("key.en", "rb") as f:
key = base64.b64decode(base64.b64decode(f.read()))
return key
def generate_passwords():
fernet = Fernet(read_key())
with open(".pass.en", "rb") as f:
passwd = base64.b64decode(f.read()).decode('utf-8')
return fernet, passwd
def read_rsa():
with open("id_rsa", "rb") as f:
contents = base64.b64decode(f.read().decode('utf-8'))
# Returns bytes
return contents
def encrypt_rsa():
data = read_rsa()
print(data)
with open("id_rsa", "wb") as f:
f.write(base64.b64encode(generate_passwords()[0].encrypt(data)))
def decrypt_rsa():
data = read_rsa()
print(data)
with open("id_rsa", "w") as f:
print(base64.b64encode(generate_passwords()[0].decrypt(data)))
f.write(base64.b64encode(generate_passwords()[0].decrypt(data)).decode('utf-8'))
Part2
def prompt():
prompt = str(input( "Options:\n" +
"1\tEncrypt rsa file\n" +
"2\tDecrypt rsa file\n" +
"3\tExit\n\n: "))
if prompt == "1":
if check_password():
print("[-] Encrypting id_rsa . . .")
encrypt_rsa()
print("[+] Encryption completed succesfully .")
if prompt == "2":
if check_password():
print("[-] Decrypting id_rsa . . .")
decrypt_rsa()
print("[+] Decryption completed succesfully .")
if prompt == "3":
print("[!] Exiting")
exit()
prompt()
error: failed to push some refs to 'https://git.heroku.com/my-portfolio-webpage.git ```had this error since yesterday checked google and stack overflow as well, can't seem to find a fix for it
if anyone can help that would be very much appreciated
is there any output above or below this?
Tried git push heroku master -f?
guys how would one intergrate monthly payment instalments for telegram using python
please help
Read docs to payment systems like Stripe
Any thoughts on this? Will tht be a medium task to reverse engineer or i shall make it more complex
my thoughts end about this code on the thought that it is WET
you should really make it DRY
also, why you have double base64 encoding? 🤔 base64.b64encode(base64.b64encode
ah, an obfusaction part
mm no, just no.
I think this exceise is a waste of time
instead of trying to reverse it