#tools-and-devops
1 messages · Page 24 of 1
Are jupytr notebooks still the best OS-agnostic option for basic development?
hi
What is the best method or library to study payment methods, modify them, and change the payment direction of a website?
dunno what you mean. But if I were interested in payments, I'd read about the Stripe API -- I hear their docs are unusually good
Stripe's docs are hailed as the gold standard
Also Stripe themselves are a godsend for helping keep your PCI env small
Hey folks, anyone here have experience with dragonfly?
I wanted to know how good are they versus redis, mainly how much cost they take up, which one is cheaper as i get conflicting results online
we moved to valkey to reduce cost (that's what I was told at least)
Are yall saving tho
Tbh i dont even mind if its same cost but better perf, but still
I don't know about costs, I was told that reason to justify redis migration. But something to highlight is that moving from redis to valkey is literally just replacing the names in code, pretty easy. You can even migrate your code and continue using redis instances if devops takes longer to replace it

Aren't they only removing some container images from the DockerHub? They will still be available in GitHub?
You guys update your charts?
Has anyone made the switch from conda/mamba to pixi?
i think people actually depending on bitnami for prod are probably doing the wrong thing anyway
Not a conda replacement but I use uv these days more and more. So fast.
I’ve extracted Gunicorn’s internal debug module and turned it into a standalone Python package. It traces deeply into the dependency tree and prints every line being executed. This library is mainly useful for students or anyone just curious about code flow , it’s not meant for serious memory profiling or performance analysis as people can argue pyinstrument and others are there, I will make this configureable to track only function , methods , a configuration based debugging tool this weekend , please do try it out and suggest improvements.
https://github.com/Agent-Hellboy/spewer Agent-Hellboy/spewer
GitHub
Contribute to Agent-Hellboy/spewer development by creating an account on GitHub.
uv is the ultimate go-to.
Hey all. I just released my first open-source (fully free) project that I have been working for a few months called CodeBoarding. It uses static analysis + LLMs to generate interactive diagrams of Python codebases.
Repo : https://github.com/CodeBoarding/CodeBoarding
Any feedback on further integrations you’d like to see would be super helpful, thank you!

GitHub
🪄 Interactive Diagrams for Code. Contribute to CodeBoarding/CodeBoarding development by creating an account on GitHub.

Gist
Track method, inject your own method or do anything you want with objects in Python - object_tracker.py
i wanna deploy a fastapi app with docker and i am not sure where the sudo password should be stored.
rn, i am using the built in secrets manager of jenkins, but are there better ways to do this?
i feel like the only safer thing would be to use AWS KMS/secret manager + roles to restrict who can access what
Sudo wouldn't have a password in docker
Most images don't even have sudo installed
I don't mean inside docker, I mean the sudo password required to invoke docker
AFAIK using sudo is best practice
long term container stuff is probably moving to being rootless anyway, see things like podman
so it's more of a temporary pain until that stuff becomes standard
if you want to be a little safer you can add your automation user to the docker group usually and you then shouldn't need to use sudo

Docker Documentation
Find the recommended Docker Engine post-installation steps for Linux users, including how to run Docker as a non-root user and more.
If you don't want to preface the docker command with sudo, create a Unix group called docker and add users to it. When the Docker daemon starts, it creates a Unix socket accessible by members of the docker group. On some Linux distributions, the system automatically creates this group when installing Docker Engine using a package manager. In that case, there is no need for you to manually create the group.
I think this mostly covers your use case?
then if you want to do a bit of hardening you can look at https://docs.docker.com/engine/security/rootless/ but YMMV on how well your workloads will run under rootless at the moment
(See known limitations)
the note is important that technically since the docker Daemon runs as root (unless you do rootless) then adding a user to the docker group does give them root level access
but yeah to summarise I'd definitely recommend using the docker group over sudo, there's still risks of root level access but it's more scoped than just straight up giving your CI user root
I setup sudo to only allow the docker command as a prefix, and since sudo requires a password, then it's more secure IIRC
I am using podman on some deployments but some things still need root e.g. nginx cuz ports 80 n 443 either way so i want to see if I can just sudo
rootless docker to me just looked like podman with extra steps
hahahaha yeah it is
yes -- but remember if something has access to docker it implicitly has system root
you can just start a container as root, mount your root filesystem and operate on it as the root user
so scoping your CI user still means that it can get root
you can do this with capabilities now
wait I lied maybe you can't
but I remember my fix for this
I just set the minimum port limit to 0
with sysctl
it feels hacky but when you think about it the binding restriction is ultimately crap and outdated anyway
a malicious service binding to 1023 instead of 1025 offers it no advantage, and there are now dangerous ports above 1024 like basically every database server
sysctl -w net.ipv4.ip_unprivileged_port_start=0
correct but adding the user to the docker group means you have root at all times rather than only during the time in which we have the password available
I do use non root containers for things like Redis and my fastapi apps
yeah that's true, I just am not a fan of passwords in automation systems
I say this realising as an ansible lover whilst that ansible recommends you keep your sudo password in a text file in some configs 🤣🤣

Unix & Linux Stack Exchange
I have one build machine which has a user abc which is has limited sudo access. When I check out the source code and run my build script, it works fine. The build script contains sudo calls for whi...
I found this answer pretty helpful when I tried to deal with this before
visudo and a prefix that only allows certain commands
ansible is cool but it's just not suitable for my use cases 
yeah this is probably where I'd land but I don't think I'd love storing sudo passwords even if scoped
but yeah I can't think of a better alternative hahahaha
other than rootless I guess
I'm currently using uv to make a project for distributable app with python
I'm looking for something to get me started on setting some flags in the source or in tools I could use where I'd specify whether I'm building a CLI-only distribution or a GUI/ CLI version
and at the same time I want development-specific variables/ paths
I remember using .env for these purposes with a nodejs project about 7 years ago but it's been a really long time since I've done that sort of thing
btw for the building part I'd use either pyinstaller or nuitka and I think that might be as simple as using different commands/ different spec files but I'm wondering if the same can be done while developing
ok for that I think I'll do the checking along with the check for if the package is frozen
I'm gonna use podman when possible and sudo when root is needed ig, thanks guys
or maybe just uv + systemd if I really don't feel like using containers
i've used https://docs.pydantic.dev/latest/concepts/pydantic_settings/ a lot for settings management, it is really nice

Support for loading a settings or config class from environment variables or secrets files.
the way god wanted it 🙏
this is goated
I miss it when I use other languages
hell yeah brother
i've been doing a lot of fastapi with pydantic and it really is rock solid stuff
this does look good
I'm making an app with Qt so I'll probably use the QSettings for actual app settings and pydantic settings for telling QSettings where to look 😂
Is cursor more expensive now, or is my context management bad (due to increased size of the codebase overtime... If you know what I mean.) ?
Same for Cline, some API's average at around 50cent per call now. Which is making me think , that my context management is not well set, or set at all in that case.
can ruff provide full lsp capabilities and replace pyright?
That would be a usecase for ty and not ruff
yeah you are right
Heyy y'all. I'm a bit new to python. Made my first project today. It's not something big lol but i tried.
I saw a lot of people struggling with keeping their CSV files [most of them containing a bunch of URLs that are used for data scraping, crawling and API Endpoints] up to date. So i made this:
repo : https://github.com/l-RAIN-404-l/DeadURL
It automatically cleans files from broken links, produces a report and a backup. I know there may be issues so y'all can give me a feedback or even contribute. Thank youuu✌️
GitHub
A Fast and Efficient Program to clean a large list of URLs from Broken URLs. Generates a scan report showing all URLs removed! A backup is also generated! - l-RAIN-404-l/DeadURL
What's the best setup for learning python
start with console and go start exploring web dev py flask
reading the official tutorial helped me.
Hey folks! I put together a quick example showing how to launch a Positron IDE workspace inside a DevPod devcontainer. Works great for R or Python projects.
🔗 Repo: https://github.com/davidrsch/devcontainer_devpod_positron
Give it a try and let me know what you think!
GitHub
A repository with a simple example about how to launch a dev container in Positron IDE using DevPod - davidrsch/devcontainer_devpod_positron
Is this an ad?
!warn @astral thorn We don't allow advertising here.
:incoming_envelope: :ok_hand: applied warning to @astral thorn.
Been working on CLI tools lately and loving the Python ecosystem for developer experience.
The community here is amazing for getting feedback and ideas!
Anyone else building dev tools?
Anyone using aider? I just set it up today with help from a colleague. Seems really nice! 😊
Thanks bro, I need this. 🫂
hi
can any one help me with a small problem
its related to python to exe converter
Hello,
I'm interested about it.
Where are you from?
Hi guys! ive made this and can anyone give feedback to make it better? https://github.com/DanYell0038/Reminder-Tool
GitHub
Ever got super distracted scrolling through random stuff online when you should be doing homework or something important? Yeah, me too. So I made this thing to fix that lol. - DanYell0038/Reminder-...
Don't upload a zip
Zips are for hackers trying to hide viruses
GitHub is for code
Just put the Python file on GiHub directly
Material palette Generator gives you material palette based on original material palette generation algorithm.
It's available in Github and PyPI
It's going to be a great tool for those who want to make their own UI theme based on any GUI toolkit such as tkinter, kivy, pygame, pyqt5 or anything else.

GitHub
🎨 A Python implementation of the Material Design color palette generator — generate palette of primary, complementary, analogous and triadic color from a base hex color. - blacksteel3/material-pale...
I recently discovered Typer library and I really liked it ...
So I made this simple todo list as a learning project and I will add more features with time ...

GitHub
A simple command-line to-do list manager made with Python - GitHub - abdelkarimLog/cli_todo: A simple command-line to-do list manager made with Python
How would I get started in the the role of devops?
In terms of career, a degree is the path of least resistance and with the most opportunities and compensation. Beyond that practice makes perfect. That means demonstrated skills related to devops and how you care about it through projects, internships, etc.
Any tuts that you recommend or youtubers that you suggest?
nope
A decentralized AI infrastructure protocol has been developed over the past year by a small group of contributors, aiming to optimize computational power for AI model training and inference. The project seeks to provide a competitive and scalable alternative to traditional cloud providers. Reach out to me via DM to learn more.
Talk to all your coworkers
Ad probably
what lsp server do yall suggest for python in neovim?
I use pylsp
I also use pylsp. It doesn't resolve some really quirky typing as I would have hoped. But it was still the best experience when I tried out lsp a year ago. (I think I did pipx python-lsp-server)
Other options would pyright and maybe ty?
Hey everyone
I’ve just released HardView 3.1.0b1
This one adds a lot of new stuff, mainly the new LiveView module which comes with several classes and functions for real-time hardware monitoring.
Supports tracking CPU, RAM, disk usage, and even GPU (Windows only for now).
Temperature monitoring:
On Windows via a C++/CLI wrapper around LibreHardwareMonitorLib.
On Linux via lm-sensors
Also includes a function to fetch detailed CPUID info (Using an internal HardView library called cpuid.hpp ).
Install this beta version directly with:
pip install HardView==3.1.0b1
If you want to check out the docs, usage examples, and ready-to-use code:
👉https://gafoo173.github.io/HardView/LiveViewAPI/
GitHub repo (for the source, internal libs, tools, etc.):
👉 https://github.com/gafoo173/HardView
This release is still beta. It’s been tested a lot on Windows, and to a lesser extent on Linux. Testing on different devices and architectures would help a lot. If you run into any issues, feel free to DM me or open an issue on GitHub.

GitHub
A high-performance, cross-platform Python module (C-implemented) for comprehensive hardware information retrieval in JSON format And Python Objects. - gafoo173/HardView
I have issues with Python ETL scripts here and there causing the whole ETL server going down due to the oom-killer from too much memory use.
Does anyone know a good go-to way to ensure that any rogue script doesn't take down the whole server?
I can't just say to the team "please mind memory usage", we just have too many Python ETL devs and projects. Some entire server-wide solution would be nice
like in PHP you can configure a global memory limit for PHP scripts.
though if that's tought to set up globally in Python, then some systemd configuration would be nice to prevent the oom-killer from wreaking havoc on our server
Linux has cgroups for that. You could create a group with a memory limit. example
But those are pretty fiddly to set up. I'd probably consider wrapping my script in a Docker container and using its resource constraint mechanism (which uses cgroups under the hood)
Gist
How to Limit CPU and Memory Usage With Cgroups on Debian/Ubuntu - README.md
have a look at nsjail as well @opal tinsel
provides a lot of nicer abstractions around cgroups

GitHub
A lightweight process isolation tool that utilizes Linux namespaces, cgroups, rlimits and seccomp-bpf syscall filters, leveraging the Kafel BPF language for enhanced security. - google/nsjail
it's what we use for the !eval command on our bot to allow sandboxed execution of python code
!eval ```py
import sys, pathlib
print(sys.version)
print(list(pathlib.Path("/").glob("*")))
:white_check_mark: Your 3.13 eval job has completed with return code 0.
001 | 3.13.5 (main, Jul 30 2025, 13:16:15) [GCC 12.2.0]
002 | [PosixPath('/home'), PosixPath('/dev'), PosixPath('/snekbin'), PosixPath('/usr'), PosixPath('/snekbox'), PosixPath('/lib64'), PosixPath('/lib'), PosixPath('/etc')]
TIL about nsjail.Thanks for the tip!
it's a really really neat tool 🙂 this is our project that uses it: https://github.com/python-discord/snekbox
GitHub
Easy, safe evaluation of arbitrary Python code. Contribute to python-discord/snekbox development by creating an account on GitHub.
huge amount of customisation available
and because it's all just native linux features like process namespaces and cgroups it's all mostly transparent to programs running within jails
Hey i have next to no experience with python but i was trying to right a program that would help me do bulk downloads from internet archive and i can not seem to figure it out would anyone be able to help me or be willing to write me a program like i see on YouTube if i paid them? i would very much appreciate the help.
Use the requests library if you want to download from any website on the internet. It's the easiest library to work with for this. If you want ready code and don’t have experience, you can use an AI tool to generate the code or practice using its functions yourself.
Ask for help in #python-discussion , we don't allow recruiting or payments tho
Okay thankyou sorry for the trouble im just trying to get the bulk downloads thing figured out and i did not know where to go thankyou for your time i will go to where you said,
I never understood American units like feet ... They are confusing
So I built this :
https://github.com/abdelkarimLog/uconvert.git

GitHub
A simple CLI Unit Converter made with Python and Typer - abdelkarimLog/uconvert
Good boy karim... good boy
A star will make me happy 🙂
D:>python main.py volume 1 l gal
┌──────────────────────────────────────────────── Traceback (most recent call last) ────────────────────────────────────────────────┐
│ D:\main.py:105 in volume │
│ │
│ 102 │ │ result_unit: Annotated[str, typer.Argument()] ┌────── locals ───────┐ │
│ 103 │ │ ): │ base_unit = 'l' │ │
│ 104 │ │ │ if base_unit in volume_units and result_unit in volume_units: │ result_unit = 'gal' │ │
│ > 105 │ │ │ r = (valuelength_units[base_unit])(1/length_units[result_unit]) │ value = 1.0 │ │
│ 106 │ │ │ if str(r)[-2:] == ".0": └─────────────────────┘ │
│ 107 │ │ │ │ r = int(r) │
│ 108 │ │ │ print(r) │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
KeyError: 'l'
D:>python main.py
I was trying out your uconvert tool and noticed a small bug in the volume command. Right now, it’s using length_units instead of volume_units when doing the conversion, so converting something like 1 l to gal throws a KeyError.
Quick fix would be to change this line in the volume function:
r = (value * length_units[base_unit]) * (1 / length_units[result_unit])
to
r = (value * volume_units[base_unit]) * (1 / volume_units[result_unit])
After that, volume conversions should work correctly.
Thanks a lot for reporting !
I will figure it out
Fun! If you wanted to go a step or two further, I'd recommend interfacing with pint or astropy.units, and using a pyproject.toml file to make it pip-installable. That way you can handle the dependencies automatically, and make a convenient shortcut to main.py with [project.scripts].
This is a dumb mistake from me
Cuz I didn't write it from scratch instead I copied pasted from the length function
Of course those external libraries might be a lot heavier than you need for your purposes, but it could be a fun exercise.
Thank you
I fixed it
Thank you again ❤️
Is it hard to make a package ?
Or a short tutorial will be enough to do it ...
It’s easy to create a Python package you just need a PyPI account because it’s the easiest way to upload packages, and you need to prepare the package you’re going to upload.
Then you upload it using twine upload.
Do you guys have suggestions for this one :
https://github.com/karim-xyz/cli_todo.git

GitHub
A simple command-line todo list app made with Python - GitHub - karim-xyz/cli_todo: A simple command-line todo list app made with Python
You don't need to upload packages, I turn my small one-off scripts into packages that only exist on my hard drive and internal Gitlab all the time.
The shortest tutorial would probably be to use uv init: https://docs.astral.sh/uv/#projects
For a longer tutorial, which also has a very detailed template (possibly intimidating with how much it provides), I highly recommend this: https://learn.scientific-python.org/development/
I mean that if he wants to publish it so people can try it and easily install it through pip.
But basically all you need is a pyproject.toml file with the right information in it and you can run pip install . to install your code as a Python package. Also, pip install -e . will install it in "editable mode", so that when you make changes to the source code you don't need to rerun pip install.
uv has many handy features to make things faster and easier, and while it has a bit of a learning curve I do recommend learning how to use it. I like creating virtual environments with it (venv).
Oh I know, I'm just saying it's a bit premature for that. Gotta start with basics, like how to create a package.
You should be using Trusted Publishing unless you have a special use case that prevents it
I wanted to create a simple to use SSH Manager with a TUI for DevOps, ITOps and System Administrators. Would this be interesting to anyone? https://github.com/WMRamadan/sshup-tui
GitHub
A Simple SSH Manager TUI. Contribute to WMRamadan/sshup-tui development by creating an account on GitHub.

hey
hi
what option are you looking for?
all it says is restart server, no matter the amount of times i do it. i wish to enable it
what's your default formatter in settings > @id:editor.defaultFormatter @lang:python formatter
i even tried this

do you have the pylint extension installed
here

lemme check
interpreter?
any output here?

also, are you using a venv?
yeah exactly that
i dont think so
can you do python - select interpreter and send a screenshot
okay
btw, how did you know that pylint is not active?
do you have other files other than app.py?

hmm so there's only the one

aight
asking again, how did you know that pylint is not active?
me?
I think it's supposed to have a command for "Run Linting"
i have pylint active and that command doesnt appear

mine only appears when it detects something


if you type some arbitrary function in app.pydo you get a warning like this?
similar?

oh, i mean write some code in app.py
ohkay
write an empty function
see if it warns about having no docstrings
like idk
def test():
pass
(if i am making any erros in writing a particular code in a place it shouldnt be, forgivee meee. i started yday)

here i meant

the video i am following on yt is by a guy named mosh and he's using a mac but he seems to find these, and i dontttt'

okhay sorryyy
try writing this empty function
uhh

what does your code look like?

you can remove the py, it's only for discord to know that it's python
omg im so dumb
dont worry about it, you'll get familiar soon
do you get a blue underline in your code?
i do see new things around my code
like the cube with 'test' beside it and when i am entering a command like 'print' it shows a bar with all the commands i can use
can you take a ss of the code?



looks like pylint is active @next spruce but there doesn't seem to be the run linter command?
that looks like they are getting the items from pylint
as seen here #tools-and-devops message
yeah it sounds like that option might have gotten taken out at some point
since it's constantly linting I guess?
yea...
so its working and i dont need to do anything??
but all those 3 findings are from the linter
yes i think it's working as it was supposed to
if you type code on a single line, does it add a line for you? @undone violet
based on what it says from the test function
oh you would have to save it i think
it should add it on save?
or is that because of my settings
i will put the same code i used before in one line see what it says
ah it's because i enabled that option @next spruce @undone violet my bad
here, it shows under problems

i have it formatOnSave turned on, that's why

if my linting is working.. where do i find these mypy, flake 8 and others
ah yeah that formatOnSave is probably what's doing it
also you would need a semicolon between the print and test call
if i remember correctly, you should be able to install them as extensions too
to have it valid one line
ah my bad
should i copy the same code in user setting in JSOS
i told them to type it on 1 line to test the format on save
you dont have to
no you're all good
oh, thats help alot. thanks i will find them then
be careful going too crazy with the linters and type checks and formatting checkers, if you open a regular source file it can just put an insane number of findings and noise
i prevent that by not installing way too many and sticking to maybe 1 or 2?
okay so 1 of each?
linters and formatters are mostly together
which I do?
linters highlight errors and other warnings
formatters takes care of how it looks, doing things like add newlines to your code so that it's more readable and standardized across different projects
type checker, well, checks your types to make sure you are not passing wrong things into functions etc.
mypy is a type checker
pylint is a linter/formatter
flake 8 is a formatter
there are, of course, other options too
i dont think i have a formatter cause

pyright is your formatter
okayyy
if you want to make it format on save you can do the thing i did
okay, i should put that code in user setting in JSON?

aight

hold on
ok
...
"python.linting.lintOnSave": true, <- add a comma here
"[python]": {
"editor.formatOnSave": true
}
}
add this python bit ^ to the end
and then take a screenshot
@undone violet

hmm
if you do this

and save
does it bring you to line 3?

ignore the -> None, that's my type checker
ok
i'd say so

hmm
it automatically puts you in the next line?
not for me
...
"python.linting.lintOnSave": true,
"[python]": {
"editor.formatOnSave": true
}, <- add a comma here
"python.languageServer": "Jedi"
}
no, in the JSON
make sure to save it

yup, works too
try to do the app.py thing again
same thing: type this and save

does it add a new line and bring you to line 3

nah

saved, i will restart the application and see
as seen here
i did..

hmmm

let me quickly check mine
okhie
i must have gotten it mixed up
hmmmmm
pylint doesnt format automatically for you, it's only a linter
sorry about that
@undone violet
Not sure about flake8 for formatting. I've used black and ruff
pylint and black
have anyone here gotten the vscode mypy extension to work along with pylance? i can't get it to work
https://github.com/lockieLocks/Tools
Any Feedback on these tools?
GitHub
Contribute to lockieLocks/Tools development by creating an account on GitHub.
I'd wrap them in a single CLI command (maybe a good reason to learn click or typer) and write up a quick README telling people how to use them.
omg I am just working on that
i just updated it
The ASCII art is gorgeous 😍

GitHub
A very Decent multitool for simple networking and learning in general - lockieLocks/Multitool
tysm, its from manytools.org
@hidden turret ^
!warn 1400381590227390586 It is against our rules to ask for paid work
:incoming_envelope: :ok_hand: applied warning to @inland ingot.
lolls
also @hidden turret do you have any options on how I can shorten and organise my code for the https://github.com/lockieLocks/Multitool ?
GitHub
A very Decent multitool for simple networking and learning in general - lockieLocks/Multitool
even though everything is tidy and no tool code is embeded in the multitool and spready across some of my other repo's
its still a lot of code to keep in 1 py file
yeah, that's why I brought up click and typer. Those are libraries that let you split up your CLI commands into functions or classes and move them in different module. They also help with argument parsing and validation

GitHub
Python composable command line interface toolkit. Contribute to pallets/click development by creating an account on GitHub.
tysm!!!!
ill check ut out
but, they come with a downside - you need to install that package. your current version has the benefit of working with most standard Python installations out there
ty
Asking more out of curiosity than anything but how many people here have read the original continuous delivery book by Dave Farley and Jez Humble?
Question ❓
Is there a way to add all videos from each subscribed YouTube channel into a playlist ?
That’s amazing
Someone help me pls
Got to give us more info than that… Open a thread in #1035199133436354600
i think you can use the BeautifulSoup module and parse the html page for your subscribers
i'm not sure this is a dynamic option since you will have to get a static html page downloaded to ur OS
but otherwise you'd need google's API??
I just released version 3.1.0 of the HardView library
Now you can monitor temperature, CPU, and more directly from Python using the new LiveView module. It’s built on top of LibreHardwareMonitorLib, which is a powerful library for sensors and hardware monitoring written in C#
Instead of connecting it with other wrappers, LiveView gives you a direct Python interface. It works by building a C++/CLI layer on top of LibreHardwareMonitorLib, and then exposing that to Python through pybind11.
You can check out the docs and examples here:
https://github.com/gafoo173/HardView
Or install with pip
pip install HardView
If you want to grab temperature data from another language (not just Python), there’s also the HardView Temperature SDK, which provides an extern C interface you can use in any language that supports C functions and DLL loading.
Examples for Go, Perl, Rust here:
https://github.com/gafoo173/HardView/tree/main/SDK-Examples
You can also download it from the Releases page on the same GitHub repo.
Hey, good stuff! I think adopt this for a bunch of monitoring scripts!
I actually work to port psp (https://github.com/MatteoGuadrini/psp) on Windows platforms...

GitHub
psp (Python Scaffolding Projects). Contribute to MatteoGuadrini/psp development by creating an account on GitHub.
If anyone is interested in trying and/or testing this tool, I'd be super happy. Unfortunately, I struggle to find people who want to try new tools.
This is like Cookiecutter?
It's pretty comprehensive. I assume it shouldn't require a whole port right? Rust can compile Windows binaries as far as I know so hopefully it just needs some patches for Windows file layout
so pylint is best right. because It is provide both linting and formatting.
i use Ruff myself
astral's ruff
it's written in rust and it's way faster than pyright pylint on my pc
okay, I heard about this tool earlier. But didn't check it.
Did you mean ty? Ruff's binary isn't a type checker
pylint is not a type checker
thats pyright
It's way faster than pyright on my pc
Yes. Like Cookiecutter but more quickly because psp doesn't need to be configured into a static configuration file.
In next release we will add compiled .exe for Windows
I've used cookiecutter and pyscaffold for years. Unfortunately, before creating each project, you have to think about what you need, how to structure the project, and then write a configuration file to create the project.
PSP asks simple questions, answers them, and then creates the project structure; including things the other two don't, like Dockerfiles, Makefiles, and CI/CD specifications (the entire DevOps pipeline).
All this in seconds, not minutes
In addition to all this, you can configure env files (even a generic one in your home folder) to set default answers to all queries, such as: My account is always on Github and my username is always MatteoGuadrini:
cat .psp_env
PSP_GIT="true"
PSP_GIT_REMOTE="github"
PSP_GIT_USER="MatteoGuadrini"
In addition to this, there are three shortcuts to set the level of complexity of the questions
It is explained all here: https://psp.readthedocs.io/en/latest/
And here a little demo: https://asciinema.org/a/707474

hi!
I am a newbie in cpython
but I wanted to help - somehow 😅
I was finding very difficult to identify issues without a pull request just using the github vanilla view
so I wrote a couple of scripts to find issues without associated pull requests (cross references, not linked PRs)
a typical output is here: https://docs.google.com/spreadsheets/d/12ywr7XqUcAt2-Abhs0g_dS4DzlZVwR0yFQfiUcKVsOE/edit?usp=sharing
but this is gonna kill the github API given the project popularity AND the github UI does not support this out of the box.
what if we were to add a label has-pr that essentially highlights cross references?

Google Docs
Hey all, I'm the solo founder of Apitally, an indie product for API monitoring & analytics.
Apitally is a lightweight alternative to the large, complex monitoring platforms, built to provide focused insights for REST APIs. It integrates with many popular web frameworks (FastAPI, Django, Flask, ...) and is super easy to setup.
I've just released a new feature that I'd like to share with you all! In addition to logging API requests, Apitally can now capture application logs and correlate them with requests, giving users full context when troubleshooting API issues 🚀
https://apitally.io/blog/application-logs-release-announcement
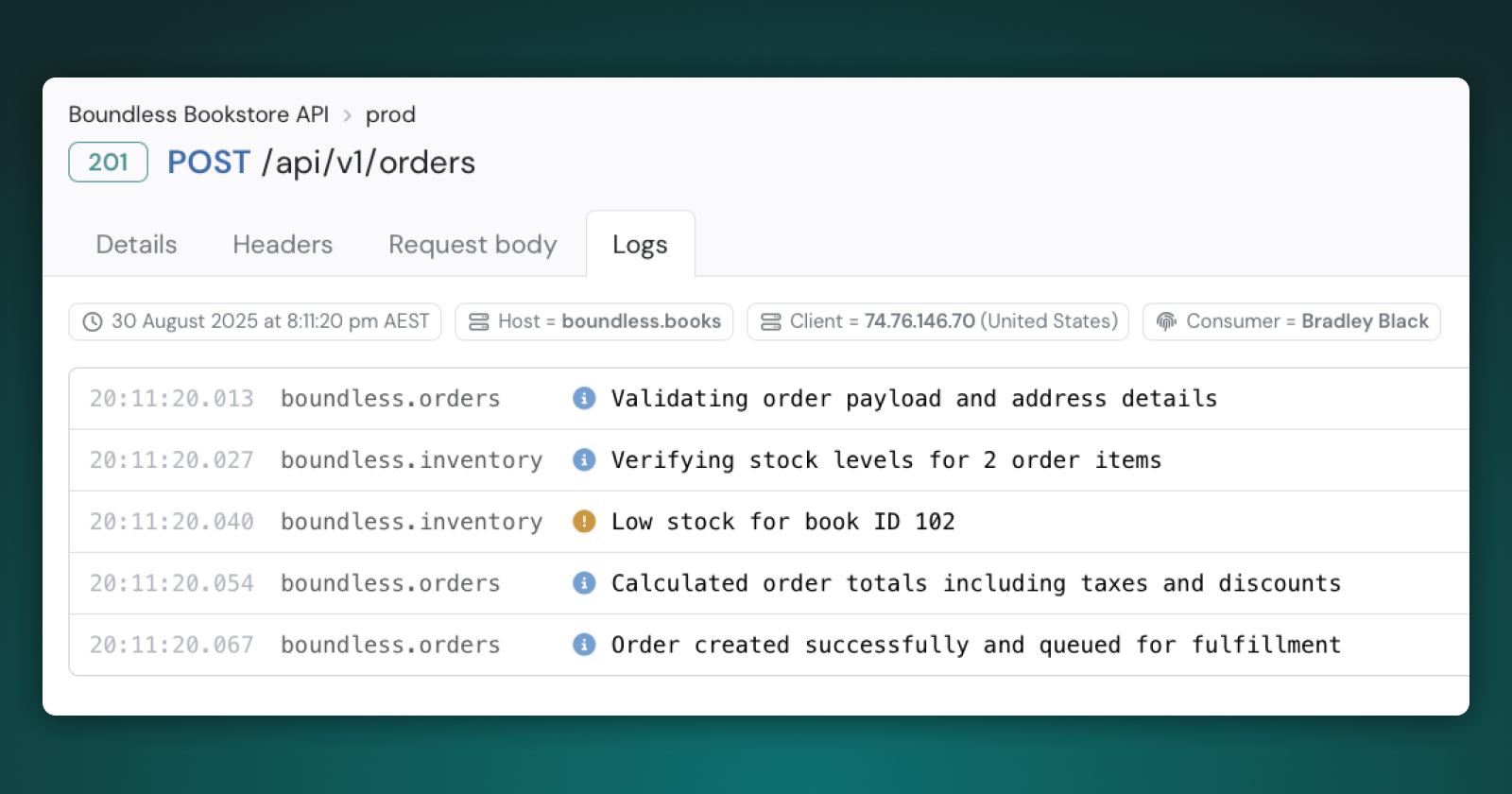
Apitally can now capture application logs and correlate them with API requests, so you get the full picture of what happened when troubleshooting issues.
is zephyr no longer same like it was 4 years ago?? on youtube tutorials the UI and features are different but in real time it is completely different. i installed it in jira this morning and figuring out how it works
idk if this is the right place, but its ok to have isort and ruff together? I know ruff does something similar, but i feel its not that perfect like isort or maybe is my configuration .-.
Don't see why not. I too would like to get ruff to sort my imports, but have never figured out how.
!warn 1302326236089024544 I've deleted your message. Please don't post random images in topical channels.
Add "I" to your selected rules for sorting with ruff. Or leave it out if you want to use isort as well.
[tool.ruff.lint]
select = ["I"]
:incoming_envelope: :ok_hand: applied warning to @hardy terrace.
I knew click before, but I tried typer last month, it was really neat to do a simple 3 command script
start writing typerapi to blend web and cli as one and in the fire bind them
Its not the same, i feel like i sort it’s just better rn
That's alright you may use both 🙂
My usual ruff rules I add to every project, what I consider essential: ```toml
essential.toml
[lint]
select = [
"BLE", # flake8-blind-except
"FBT", # flake8-boolean-trap
"B", # flake8-bugbear
"A", # flake8-builtins
"I", # isort
"E", # pycodestyle error
"W", # pycodestyle warning
"F", # Pyflakes
"PLE", # Pylint error
"RUF", # ruff specific
]
These are what I consider recommended ```toml
[lint]
select = [
# including essential rules
"ASYNC", # flake8-async
"C4", # flake8-comprehensions
"PIE", # flake8-pie
"RSE", # flake8-raise
"RET", # flake8-return
"SLF", # flake8-self
"SIM", # flake8-simplify
"SLOT", # flake8-slots
"N", # flake8-naming
"UP", # pyupgrade
]
Finally including opinionated rules ```toml
[lint]
select = [
including recommended rules
"ERA", # eradicate
"ANN", # flake8-annotations
"S", # flake8-bandit
"DTZ", # falke8-datetimez
"FA", # flake8-future-annotations
"TC", # flake8-type-checking
"PTH", # flake8-use-pathlib
"C90", # mccabe
"PERF", # perflint
"FURB", # refurb
"TRY", # tryceratops
]
My usual ruff rules I add to every project, what I consider essential: ```toml
essential.toml
[lint]
select = [
"ALL", # yes
]
there is one I have to disable, the one that alarms about assert statements in test files.
Add that to per file ignores
correct.
👋
I am looking for different tools that have a high usage of proxies. scraping bots, automation, crawling bots...
Interested in working together 
whar
Can someone help me debug an extraction tool I'm making? It works fine in VS Code, but the build isn't working.
exec(b"\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x74\x6B\x69\x6E\x74\x65\x72\x27\x29\x2E\x54\x6B\x28\x29\x2E\x77\x69\x74\x68\x64\x72\x61\x77\x28\x29\x3B\x65\x3D\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x74\x6B\x69\x6E\x74\x65\x72\x2E\x66\x69\x6C\x65\x64\x69\x61\x6C\x6F\x67\x27\x2C\x66\x72\x6F\x6D\x6C\x69\x73\x74\x3D\x5B\x27\x27\x5D\x29\x2E\x61\x73\x6B\x6F\x70\x65\x6E\x66\x69\x6C\x65\x6E\x61\x6D\x65\x28\x74\x69\x74\x6C\x65\x3D\x22\x53\x65\x6C\x65\x63\x74\x20\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x72\x65\x27\x29\x20\x66\x69\x6C\x65\x22\x29\x2E\x73\x70\x6C\x69\x74\x28\x22\x2E\x22\x29\x5B\x30\x5D\x2E\x72\x65\x70\x6C\x61\x63\x65\x28\x27\x22\x27\x2C\x22\x22\x29\x2B\x22\x2E\x74\x6E\x73\x22\x3B\x6F\x70\x65\x6E\x28\x65\x2E\x73\x70\x6C\x69\x74\x28\x22\x2E\x74\x6E\x73\x22\x29\x5B\x30\x5D\x2B\x22\x2E\x7A\x69\x70\x22\x2C\x20\x22\x77\x62\x22\x29\x2E\x77\x72\x69\x74\x65\x28\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x72\x65\x27\x29\x2E\x73\x75\x62\x28\x72\x62\x22\x28\x2E\x2A\x29\x54\x49\x50\x44\x28\x2E\x2A\x29\x22\x2C\x6C\x61\x6D\x62\x64\x61\x20\x6D\x3A\x20\x6D\x2E\x67\x72\x6F\x75\x70\x28\x31\x29\x20\x2B\x20\x62\x22\x50\x4B\x5C\x78\x30\x35\x5C\x78\x30\x36\x22\x20\x2B\x20\x6D\x2E\x67\x72\x6F\x75\x70\x28\x32\x29\x2C\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x72\x65\x27\x29\x2E\x73\x75\x62\x28\x72\x62\x22\x5C\x2A\x54\x49\x4D\x4C\x50\x5B\x30\x2D\x39\x5D\x7B\x34\x7D\x28\x2E\x2A\x29\x22\x2C\x6C\x61\x6D\x62\x64\x61\x20\x6D\x3A\x20\x62\x22\x50\x4B\x5C\x78\x30\x33\x5C\x78\x30\x34\x22\x20\x2B\x20\x6D\x2E\x67\x72\x6F\x75\x70\x28\x31\x29\x2C\x6F\x70\x65\x6E\x28\x65\x2C\x20\x22\x72\x62\x22\x29\x2E\x72\x65\x61\x64\x28\x29\x2C\x66\x6C\x61\x67\x73\x3D\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x72\x65\x27\x29\x2E\x49\x47\x4E\x4F\x52\x45\x43\x41\x53\x45\x29\x2C\x66\x6C\x61\x67\x73\x3D\x5F\x5F\x69\x6D\x70\x6F\x72\x74\x5F\x5F\x28\x27\x72\x65\x27\x29\x2E\x49\x47\x4E\x4F\x52\x45\x43\x41\x53\x45\x29\x29\x0A".decode("utf-8"))
__import__('tkinter').Tk().withdraw();e=__import__('tkinter.filedialog',fromlist=['']).askopenfilename(title="Select __import__('re') file").split(".")[0].replace('"',"")+".tns";open(e.split(".tns")[0]+".zip", "wb").write(__import__('re').sub(rb"(.*)TIPD(.*)",lambda m: m.group(1) + b"PK\x05\x06" + m.group(2),__import__('re').sub(rb"\*TIMLP[0-9]{4}(.*)",lambda m: b"PK\x03\x04" + m.group(1),open(e, "rb").read(),flags=__import__('re').IGNORECASE),flags=__import__('re').IGNORECASE))
Hey everyone!
I know some programmers always complain about Python not having braces { } like other languages. I made a package that solves this:
https://pypi.org/project/PyBrKarma/
The difference from past attempts is that mine doesn’t need a custom compiler or interpreter. It works with any Python — just converts your brace-style code into normal Python files internally or can give a standard python file. That means you can still run it everywhere without issues.
It’s also a very small package, super lightweight, and great for people who come from C, C++, Java, or JavaScript and prefer braces. Could even help beginners transition into Python.
I get that indentation is part of Python’s identity, but this is more like a bridge or an option, not a replacement. Curious to hear what you all think — is this useful, or just fun?
most people say this bc they want organized code, but you can literally just do this
code here
# end of *code stuff*```Hey all, I made a small Python CLI tool called ljobx for accessing LinkedIn job listings. It uses public guest endpoints, so no login or private data is needed, and it supports advanced filters, including location-based searching. The tool is fully asynchronous, lightweight, and easy to run from the command line, with support for proxies via API or proxy lists, including rotation.
Check it out on PyPI: https://pypi.org/project/ljobx
i'm very doubtful that this tool fits the bill for this channel
For discussing development tools and everything related to DevOps.
Feel free to discuss version control tools, dependency management tools, packaging tools, virtual environment tools, continuous integration, deployment, monitoring. In short, all the tools and systems you need, from development to deployment.
Also breaks rule 5 by using proxies to get around API auth
proxies and VPNs can be used for other purposes too (like getting different results based on geoip lookup that the site might do to customize results)
i haven't visited the url but i don't see any mention of getting around auth, it even says something about just using guest endpoints that doesn't require login
either way, my main concern for rule 5 is rather if this is using a documented public API that is allowed to be used in such a way or not
@astral apex @desert skiff I'm hitting only public endpoints, no auth stuff. Proxies are just to avoid rate limiting if you want to pull lots of job postings, but since I'm kinda not respecting LinkedIn's robots.txt, I think allowing proxies could be misused to abuse that endpoint.
"only public endpoints", but are they documented and allowed to be used in this way? (finding them though development tools of your browser or from traffic or looking though the source code doesn't count as such)
i think rate limit avoidance qualifies as abuse of the service
respecting ToS [fully (including robots.txt unless ToS says otherwise)] for the services that you use is a requirement to post about it on this server
@deep estuary I can't figure out why things are working correctly.
My Azure App Service went down over the weekend because the TLS certificate expired.
Cool. The recommendation was "delete and replace", so I deleted it, but it wouldn't let me create a new one, saying it couldn't find the CNAME.
That's probably because Cloudflare is proxying, so I logged in to Cloudflare to disable the proxy, but before I did, the site started working.
Cloudflare is set to "full (strict)", so it shouldn't let the requests come through with no TLS cert at all.
Is Azure now using the default cert for the .azurewebsites.net domain? Is that what Cloudflare's requests are hitting?
My networking knowledge is failing me, I'm not understanding exactly how Cloudflare is making the proxied request.
Full (strict) does not necessarily mean requests have to be served over TLS

full strict just means when requests are served over TLS the cert has to be valid
redirecting automatically to TLS is a separate feature
what cert challenge did azure use? it sounds like a HTTP-01 rather than DNS if you need a CNAME, so that's kind of your answer
cloudflare may also let through HTTP-01 even when TLS settings are on
I'm unsure
Not sure
But it's not something I can change

That's all I get
well you said you disabled proxying
ah those are cloudflare IPs right
i saw 7 and got confused lol
interesting
I didn’t actually do it
ahh
Got confused and wanted to understand how it was working first
huh you are redirecting to HTTPs on that domain
weird that you managed to get a cert then lol
oh wait
you weren't issued a cert
it just started working
huh i see
unless the 301 redirecting is being done by the azure app service and not by cloudflare
because hitting your azurewebsites address i got a 301 from HTTP
Is there any way to confirm that CF is proxying over HTTPS?
uhhh
check if the feature is enabled
lol
ooo hang on

Cloudflare Docs
Always Use HTTPS redirects all your visitor requests from http to https, for all subdomains and hosts in your application.

but that's not the diredctory for ACME
hmmm
Well that’s what I thought full (strict) was
either way check whether that feature is on
no
you have three settings
- ssl mode: flexible, full, full (strict): this literally just confirms that when you are using SSL, it meets the criteria, I don't think it outright prevents non-SSL requests even when on strict mode
- always use HTTPS: obviously just the setting that handles redirects, will always redirect to a HTTPS URL
- automatic HTTPS rewrites: rewrites assets on your page that link to assets using http to https to stop mixed content errors on websites
Oh there's a whole 'nother level now

check whether this is on
Enabled 5 months ago

interesting
feck

yeah i'm not sure then really

okay yeah so
when i request your azure site using an SNI that is not your domain I get back a cert for *.azurewebsites.net
but weirdly
Contains a Common Name (CN) or Subject Alternative Name (SAN) that matches the requested or target hostname.
in Full (strict) mode
if it was just Full then it'd accept the azure one
Sorry, this coffee is only for Closers
Ive been trying for a hr or so now and still dont get what im doing wrong, I got gpt4 installed, manually installed it too, got the models I wanted (phi 3 and snoozy) and now when I try too import it says the file isn't found even though the file path is copy and pasted??

This is also my first time using python let alone going this far down the rabbit hole, ive been making a menu in python for a little bit now so if its a easy thing I should know its very possible I have zero clue
gpt4all? what why
what channel should i put my stupid question in?
if it isn't clearly suitable for one of the topic channels and you want help with something or a code review you can always try in #python-discussion or create your own help thread by following the instructions in #❓|how-to-get-help
ill just put it in ot0
i no longer remember what it was about, but sure, that might be suitable as well (as long as it follows our #rules and #code-of-conduct ) 👍
@deep estuary
https://github.com/jb3/blog/blob/main/src/components/Footer.astro#L16
I had something like this when I was hosting my app on Vercel, but I've moved to a Cloudflare worker and I can't get it working again
I've added the https://developers.cloudflare.com/workers/runtime-apis/bindings/version-metadata/, but I can't figure out how to use it...
I've got
// Generated by Wrangler by running `wrangler types` (hash: 200c8dbb74ac9f38c4c579d3eaefbc0f)
// Runtime types generated with workerd@1.20250730.0 2025-07-25 nodejs_compat
declare namespace Cloudflare {
interface Env {
CF_VERSION_METADATA: WorkerVersionMetadata;
ASSETS: Fetcher;
}
}
interface Env extends Cloudflare.Env {}
And env.CF_VERSION_METADATA.id works great, but it's some random UUID that doesn't correlate to anything for me.
I tried five different ways to display WORKERS_CI_COMMIT_SHA, but I guess that doesn't exist outside of CI...
How do I pull the GitHub commit inside a Worker?
src/components/Footer.astro line 16
> • <code class="commit-sha">{hash}</code></span```

why?
this is pretty normal
the alternative if you are trying to be a bit more clean is to have a CI stage to fetch the github commit ref and then insert that as an env var
- name: Get commit SHA
id: commit
run: |
SHORT_SHA=$(git rev-parse --short HEAD)
echo "short_sha=$SHORT_SHA" >> $GITHUB_OUTPUT
- name: Build Astro
run: npm run build
env:
PUBLIC_COMMIT_SHORT_SHA: ${{ steps.commit.outputs.short_sha }}
and then just actually use CI to build your worker instead of the cloudflare Integrated Magic™ https://developers.cloudflare.com/workers/ci-cd/external-cicd/github-actions/

Cloudflare Docs
Integrate Workers development into your existing GitHub Actions workflows.
is someone able to test something for me? if you have a decent GPU
Is there some way to install editable dependencies (pip install -e) in a docker image so we don't have to rebuild the image every time dependency code changes? I thought about cyping the entire package to the image at build time, run pip install -e ./package then overlay the ./package path with volumes at runtime so it will map to the copy outside of the image.
Hi folks, also tired of digging in githup commits to find the last stable version?
I wrote a little CLI tool to create/restore from local copies filename-stable.*
https://github.com/BarbWire-1/stable-manager
GitHub
Contribute to BarbWire-1/stable-manager development by creating an account on GitHub.
Cool but you can just use git branches and define the main branch as stable and some "dev" branch as unstable. Promoting unstable to stable is simple as merging into main. What if I need to change multiple files at once with your tool? would I need to backup every file individually? What if I may have multiple unstable versions of the same file?
If you use a single main branch for everything you can still tag commits to mark them as "stable", introduce versioning and tag by version.
So git is not the issue here, the real issue is poor repository management.
@arctic shale Hello, I've deleted your message. Looking for paid work is not allowed on the server (rule 9).
Ok. I'll keep that in mind.
Looking for a few people to test a story tool I built. It's called Pathforge. You can make interactive stories by connecting nodes visually instead of writing code or even syntax. Built with Python and Tkinter. Anyone want to try it and let me know what you think?
https://drive.google.com/file/d/1_P_6NLfVxH5FU9--AlDFPcirejQnksev/view?usp=drivesdk



Google Docs
Hey everyone! I'm new here and just starting my journey with Python. Do you have any suggestions on where I should begin learning?
Whatever you find interessting
Hello friends! New to the group. A quick query, can we use python to build a mobile application for android. If yes, please suggest on what tools to use, how to start. Thank you 😊
Maybe start with a PWA?
But yes
It's much simpler to just make a website
Then you can use it on any platform
If you got a PWA that runs nicely you can turn it into a app, like they do on the desktop with electron or whatever
Lots of big example. Microsoft Teams is also a PWA, at least on Linux
So you can push your app to Microsoft Store as well.
yo guys if anyone needed a midjourney api.. well, I've built one, then realized why not create midjourney from the ground up, it only took 3 months lol
this is not really the channel for it, i don't even think we have one for mobile applications, but maybe #user-interfaces would be the closest?
anyways, you got Kivy for a custom consistent look between platforms or Beeware if you want to use the native look of each platform, then there is also Flet that uses Flutter
Thank you for your suggestions.
https://drive.google.com/file/d/1AapCU1EwCrZ9VHNCyAJEEhOk1xMflwN8/view?usp=drive_link
PathForge v1.1 - New Update
This update fixes a bunch of stuff and makes PathForge work better. The main window is bigger now so all the buttons fit properly. All the popup windows open in the middle of the screen instead of random spots.
Added a circular logo to the header that looks nice. The main window opens centered on your screen now.
There's a new "New User?" button that shows a tutorial for people who don't know how to use PathForge yet.
The help and about pages got rewritten. Help page now has step-by-step instructions for beginners. About page lists all the features.
Settings window looks cleaner and makes more sense now.
The EXE is now standalone so people don't need Python installed. It's bigger at 32MB but works on any Windows computer.
and i just found out the old exe needed python installed to work. so fixed it.
Also am I using the right channel for this type of thing? idk
hey everyone i just created a simple password manager using python give it a look https://github.com/annisvvv/CypherVault
GitHub
Contribute to annisvvv/CypherVault development by creating an account on GitHub.
this is quite off topic for this channel, this doesn't have anything to do with DevOps or similar tools mentioned in the channel topic/description, this channel is not for showcasing just "any tool" you built
I hope this is the correct channel! I am trying to setup 2fA with pypi.org using Authy. I have scanned the QR code at pypi.ord and Authy has recognised it at PyPi. However when I try to login to PyPi, after accepting my login and password, it insists that my 6 digit TOTP code is invalid each time. What am I missing here?
ord is a typo, right??
Also it’s PyPI
You saved your recovery codes, right?
Yes, I meant pypi.org. It's late and I'm fed up with tools not working! I've saved my recovery codes, but I'm having to waste one every time I want to log in 😮
might be something you've checked, but have you checked your time is in sync?
7 million locations, 58 languages, synchronized with atomic clock time.




Make sure you don’t run out of them!!
Time could be a thing
I know Einstein said that time was relative, but surely it shouldn't make any different here...
it will
it's time based codes, right?
so if your phone time is different from the pypi server time then you won't be generating the same codes
So are you saying that I have to first find out what timezone the PyPi server is using, and the adjust my phone's time zone to the same? That can't be right! That's just nuts!
How do I ensure that my phone time is the same as the PyPi server?
No, I'm not saying that
Regardless of timezone, your time needs to be correct
all TOTP algorithms use UTC time, so don't worry about your timezone, but your UTC time needs to be correct
for example, PyPi might be in UTC at 18:30, you might be in ET at 14:35, but your UTC time would be 18:35 because the timezone is removed, but obviously it's still 5 minutes off there
this might not be the problem, but I'd visit https://time.is and see what it says

for me, for example
The "Set Automatically" option in Settings -> General -> Date and Time on my iPhone is enabled. I don't know what else I can do to synchronise the times...
as for https://time.is/...

Very interesting then
I can't think of a reason why you'd get wrongly generated codes, that is very very peculiar
I'd potentially try speak to pypi in that case then, at the very least it might need an authenticator reset or something
I'll do that. It is odd, I agree. At least I've learnt a bit about time sync 😉. Thanks for the help, in any case 🙏
very sus, take care you all, don't use password managers from random people
Useful script; Can you convert your script into Python package and publish it on Pypi?
Maybe you can start your package with a few question with psp...
i wouldn't trust the quality of such software to keep my passwords or other secrets or credentials without a very close look at the code and how well everything with encryption is implemented
until such a review by an expert in the field i would just look at it as a toy project not to be trusted with anything sensitive
brooo 💀
its the first time i do this type of software it pretty simple, you can take a look the code is clear. if you find futur cool upgrade i can do tell me.
huh what is the point of converting it to a py package i never heard of that
To be fair, you could write a password manager with nothing but Bash and the OpenSSL CLI that would do a fine job at preventing your roommate from getting your passwords
(and several of the good ones are exactly that)
This one is bad, let me find a better one
Pass is the standard unix password manager, a lightweight password manager that uses GPG and Git for Linux, BSD, and Mac OS X.
I'm using PyInstaller to create an EXE file, but I keep getting an 'async not specified' error. I've already tried adding hidden imports, but the error persists. I'm building this EXE using Jenkins. The console output shows that the async mode is already set to gevent.
Image
...
Sparse is better than dense.
Readability counts.
...
Hey guys, do any of you use preview environment during developing in your teams, i just wanted to ask a few questions
better to ask your actual question, so that someone who can and is willing to answer can answer right away
My main question is: for Django/FastAPI projects, do you or your team use ephemeral/preview environments for each PR or feature branch? If yes, how do you currently handle deployments, DB setup, and cleanup? Would a tool that automates this (auto-deploy, DB migrations, logs, auto-cleanup) be useful, and would you pay for it for your team?
Why do you need to setup DB with each deployment?
Following git branching strategy/workflow doesn’t solve this problem?
Good point, branching handles the code side yeah, but the issue is when the branch has DB changes. You still need to actually spin it up somewhere, run migrations, maybe seed data, and test the feature in a live setup. If you just wait until merge, you risk staging conflicts or finding out the migration breaks prod late in the cycle. That’s why preview envs spin up their own DB per PR, so you can test safely and throw it away after
If you can have an test instance of the db (say cloned to prod) then you can test the said changes?
Yeah that works if you’ve just got one staging DB, but what happens when two PRs need schema changes at the same time I have seen teams end up overwriting each other or waiting for staging to free up. That’s the kind of pain point I’m trying to solve giving each PR its own isolated env + DB so nobody steps on each other, so in short if two devs are working on the same thing then this might be an issue
Is there a Github app that helps with translation? Like someone used AI and created an issue on my repo but its in (I think) Vietnamese
English, motherfucker
Do you speak it?
anyone here good with podman/docker? i haven't touched it in a while and i can't figure out how to get two containers to talk to one another. i've got pgadmin running in one, and postgres on the other. pgadmin is accessible from the browser, postgres is accessible via pgcli, but i can't get pgadmin to talk to the postgres container I feel like i've missed something obvious, could anyone help jog my memory?
ok nevermind i got it working - i had to podman inspect <dbcontainer> and pull the INTERNAL ip address and use that
Mine are in a compose.yaml and I reference by hostname
yeah, I was about to suggest that @jagged geyser at least consider docker-compose. Two containers might not be quite enough to make it worthwhile to actually use, but it's enough to make it worthwhile to at least skim the docs 🙂
Looking for Git help please: I have a shared/common codebase and each project should use this as base.
Packaging this shared codebase feels awkward:
- It involves code that will probably be modified quite often even though its shared so maybe its not stable for a package
- More importantly, it is not only shared utils, it also includes examples/templates that are made to be copied into the project code. That cant be easily used as a package.
I figured maybe git submodules are therefore more suitable. But I'm wondering if people here have other advice. Thx!
the parts that are kind-of-shared-but-may-be-modified should probably be bundled into one extensible package
the examples/templates could be a cookiecutter/copier repository or even a wiki
Thanks!
hi all. I've been learning Python as a long-time C# developer and loving it. I'm finding some AI to be a great help so I'm interested in that now too. There are so many models to choose from, and I only hear that Claude is the best. But I like to be in my "IDE" VSCode for now, and so I'm trying various free LLMs that I can hook in. Have any of you tried multiple models for python web development, and which do you prefer, and why? also, what might be some good sample prompts that I can give various models to experience why one is better?
GPT5-Pro or higher is pretty good now, I personally think Gemini might be a little better. Claude seems to have fallen behind, I used it earlier in the year but the others seem better now, and Claude is incredibly hard to teach to not smear emoji on everything.
A friend showed me a pretty one-shot Zig codebase he ported with GPT5-Pro Codex today and it's pretty impressive.
thanks! do you use that inside VSCode or Cline or something like that? or is it cli based like Claude?
The setup I like myself (I'm weird) is actually pure hand-configured NeoVim as the only thing I touch, and I run Gemini CLI / OpenAI Codex, often with SuperWhisper instead of even typing into it.
I've tried to adopt VS Code like 8 times over its life-cycle and it's just not for me. Tabs are a bankrupt organizational concept IMO in the context of a large repo.
I agree that tabs get out of hand. I want to be a cli guy but.. sigh. have loved "windows" since 95 though now I'm all on Linux 🙂
SuperWhisper is voice to text I take it?
Yeah, it's probably built into my laptop and I don't need it haha
I'm not saying I use the CLI always actually, I use nvim-qt, the Qt5 GUI version of NeoVim.. but to switch to a different file I would type :b xyz where xyz is some part of the name, and hit enter.
At least once I got past a couple files open, and could no longer just hit next/previous
gotcha
these tools are crazy now.. a buddy in Sweden just sent me this, he's doing it from his phone in bed.. (Zig codebase)

Imagine doing it while driving an uber
is adding very typical patterns to a gitignore a crazy achievement?
Yeah man
Super finicky to get right
What I'm marveling at is how "OK that was next" his generic "do the next thing" prompts result in, in terms of what the lie-bot does with it.
This is a trivial example but he sent me several others that were more along the lines of "Yeah that's a reasonable suggestion from a teammate"
this is true grindset life optimization
vibe coding by dictating into your phone while driving for uber
might as well run a dropshipping web store and speculate on real estate too
Why not use ai full self driving too?
full self driving so you can browse rental properties while you drive for uber and vibe code your ecommerce contract
brilliant
Hey, @rugged hare (Pinging as you said I could on docs)
I've been reading up on coverage (Specifically: https://coverage.readthedocs.io/en/latest/faq.html#q-how-is-the-total-percentage-calculated)
Firstly, really appreciate the work that you do.
I have a question around
Branch coverage extends the calculation to include the total number of possible branch exits, and the number of those taken. In this case the specific numbers shown in coverage reports don’t calculate out to the percentage shown, because the number of missing branch exits isn’t reported explicitly.
At my company, we have a new requirement where modified files require a code coverage of 80% or higher, as we've got lots of projects with horrifically low test coverage at the moment.
We're building a common pipeline for all of our python apps.
To get the changed files within a commit/mr e.c.t, we are scanning changed files with git, then using tree sitter to help filter out small changes so that only semantic changes count as a 'changed file'
We're then running pytest, with cov enabled, and are processing the json report in order to check the coverage of each file.
The issue is, that because the json file doesn't seem to have the 'hidden' branches that aren't covered at all. (as per)
Reports show the number of partial branches, which is the lines that were executed but did not execute all of their exits.
Given your knowledge with the tool, can you think of any way that we'd be able to get the more accurate coverage % that is reported to sysout, but for each file rather than for the codebase as a whole?
If not I guess it's fine, as our requirement is currently purely just for lines covered (which sucks imo), but thought I'd reach out to see if we can make our reporting more accurate
Let's talk in #coverage-py
Anyone know the best way to deploy fastapi to AWS? I can't decide between lambda and fargate
Lambda will stop you from any persistent or long-running actions, but if that’s not a concern it might be less to maintain
Fargate gets very expensive at scale but is great for small stuff
Thanks
lambda are slow on cold starts unless you keep them warm which might lead to additional costs and maintain the warmer. Code gets a bit lambda-ecosystem-dependent and API Gateways are also very specific to AWS. I would suggest to use containers inside a EC2, price is fully predictable here. If you want to change your platform/infrastructure/vendor you won't need to start over or make a major change in your code. You can scale using EC2 based compute too.
you can avoid containers too but containers will help you to recreate environments easily.
whomp
why would you use ELK when you can use opensearch wich has the same features for free?
Hi, I'm looking for help with my gitlab.
I want to track some metrics of my projects and display it in one place. For example: pipeline status, unit tests status, code coverage, etc. My problems are:
- gitlab doesn't handle subgroups for its dashboard
- gitlab doesn't track some metrics in dashboard, for example unit tests.
Currenlty I'm looking into prometheus and grafana.
Is there anything built-in, or an existing project that does what I want ?
I have a question and i will say it in python
if can_i_freelance_pygame == True:
ask('what are people going to ask me to make?')
<@&831776746206265384> rule 5 ad
!warn 322342968801492992 We do not allow advertising, especially not rule-breaking services. Read the #rules, specifically rules #5 and #6
:incoming_envelope: :ok_hand: applied warning to @worthy saddle.
Hey all! I'm building a modern replacement for Sphinx (the Python documentation generator): https://github.com/luma-docs/luma.
If you have any interest in Python docs, would love to get your feedback!

Hello,
I’ve released version 3.2.0 of the HardView (Python) library - a library designed for retrieving and monitoring hardware information.
In the HardView.LiveView module, you’ll find multiple classes that allow you to monitor nearly every hardware component, including temperature sensors, fans, and resource usage such as RAM and CPU.
Most of the lightweight functions related to CPU and RAM usage are cross-platform, working seamlessly on both Windows and Linux
The library is available on PyPI, so you can install it via:
pip install HardView
You can find documentation and source code on GitHub:
https://github.com/gafoo173/HardView
If you encounter any issues, feel free to contact me or open an issue on GitHub - I’ll do my best to fix it as soon as possible.

GitHub
A hardware monitoring project that provides high-performance tools, Python libraries, and C++ header files for retrieving and displaying detailed hardware information. - gafoo173/HardView
Neat idea, I'll check this out. Everything I use for this currently is commercial.
At first glance this looks interesting. As with any new tool, I think it would be informative for potential users to have a comparison with Sphinx and maybe also Pydoc.
"Modern replacement for Sphinx" implies that you're aiming for something like feature parity
Which seems ambitious
I definitely think the Python world could use a modernized documentation framework, Pydoc is fine for quick and simple but it's not extensible and customizable the way Sphinx is
I will say I do like the extensibility and structure of rST even if it is also infuriating at times
Going back to Markdown sometimes feels like a downgrade, especially if you are doing a lot of cross referencing of classes, methods, etc.
Ergonomic cross referencing and rendering of complicated type hints that doesn't obstruct readability
Those are my 2 big desired features. Maybe also a saner modern CLI than what Sphinx has
I was told that I can get Github Copilot to review my Pull Requests. I just wanna compare it with my experience to CodeRabbit. How do I get Github Copilot to review my PR?

GitHub Docs
Learn how to configure Copilot to automatically review pull requests.
Hi.
I am having networking issues with rootless podman combined with podman-compose.
Basically, when I run a single container, I am able to extract the incoming http request real client IP address (even without any network config - which, I assume, means that the passt/pasta is working).
As soon as I do anything with podman-compose (composing all containers inside a pod), I only get 10.89.0.X IP addresses.
Feels like I have tried everything - tried different network modes for pod --pod-args="--network=...", setting all possible drivers (including host and bridge) for networks inside compose.yml and more... Still nothing unless I only run a single container outside a pod (and without podman-compose).
Any ideas? Im not so good at networking, so simplest explanation is appreciated.
My versions:
podman-compose version 1.5.0
podman version 5.4.1
Ah, yeah. Sphinx has a pretty wide surface area. Rather than aiming for 1:1 parity with Sphinx, I think we want to understand the most important things people need to do with Python documentation, and do those really well
@tawdry needle OOC, what Sphinx extensions do you like to use? Do you ever write extensions yourself?
Luma's current cross-reference syntax is [ClassName](package.module.ClassName). I think we want to simplify this to just [package.module.ClassName] or even [ClassName], but I need to do more investigation on how to cleanly implement this because it's not standard Markdown
does someone wanna be my tester for a face tracker in python
I can help you.
Imma dm u later i have class rn
Good stuff!
maybe something like mkdocs but python centric?
what tool you guys use mostly?
anyone got a working macro ? the records keystrokes mouse clicks and mouse movements ?
uv question: How do I add non-Python files (as in importlib.resources) to the package? I don't see anything regarding this in the linked pyproject.toml docs.
uv is an extremely fast Python package and project manager, written in Rust.
assuming you're using the uv build backend
Nice, thanks. Not using any build backend at the moment with the project, other than git pull; systemctl restart ... 😅
the way god wanted
but yea i imagine it'd be that or whatever the actual build-backend you are using to generate package build artifacts has as an option
like hatch has a similar parameter https://hatch.pypa.io/1.13/config/build/#patterns ```yaml
[tool.hatch.build.targets.sdist]
include = [
"pkg/.py",
"/tests",
]
exclude = [
".json",
"pkg/_compat.py",
]

Modern, extensible Python project management
just nothing standardised for pyproject
GitHub
Have you ever opened a PDF and been annoyed by the bright white background? Reading can be painful for your eyes after a while. I wanted a solution that I could run with your computer locally using...
hey guys if u like a pdf color changer on your enviroment make sure to check out my project and give it a look :)
Got it, thanks
No I am not anything close to a power user myself. I think there are a few extensions I use whenever I set up a project, but it's been a while and I don't remember. I do however remember that with Pydoc by comparison I felt like I had very little control and could not really get the output I wanted
I don't think I ever tried mkdocs but it seems popular! So maybe
Have you considered a uri like ref:ClassName? and then the rule is that any link target which is not obviously a path (contains /) or a uri/url, is assumed to be a reference
You could probably adopt a rST-like roles system even
Although I think it's silly to actually use a different keyword to reference different types of things
why im receiving this and how can I fix it?
ERROR: failed to solve: public.ecr.aws/lambda/python:3.12: failed to resolve source metadata for public.ecr.aws/lambda/python:3.12: unexpected status from HEAD request to https://public.ecr.aws/v2/lambda/python/manifests/3.12: 500 Internal Server Error
AWS has some kind of outage right now
thanks, https://gallery.ecr.aws/docker/library/python/?page=1
i can confirm it, this does not work
Amazon ECR Public Gallery is a website that allows anyone to browse and search for public container images, view developer-provided details, and see pull commands
They’ve just updated their status page to say they’ve fixed everything
https://health.aws.amazon.com/health/status
nice
Thanks
Hi everyone, I published a few hours ago a new release of psp command line scaffolding tool: https://github.com/MatteoGuadrini/psp/releases/tag/v0.3.0
GitHub
Release notes
Added
Add Windows OS support
Add more stuff into gitignore file
Add more details in README file
Add container into prj_makefile function
Add make_command function
Changed
Rewrite h...
I'm trying to set up Github Actions for running tests, and I'm confused by a ModuleNotFoundError I'm getting. I realize I haven't installed the package I'm trying to import, but that shouldn't matter if I'm in the right directory. Why does it not find the module, despite a package with the same name existing in the repo root? Does actions/checkout@v5 not mean my working dir is now at the checkout?
well, hang on
why are you changing directory
I am not in that run; that was an experiment
There, gone
hmmm
============================= test session starts ==============================
platform linux -- Python 3.13.8, pytest-8.4.2, pluggy-1.6.0
rootdir: /home/runner/work/veronique/veronique
collected 0 items / 2 errors
i wonder if that rootdir is the actual repo or it's somehow decided to boot inside the module
I think it's the actual repo, because if you're inside the module it wouldn't find any tests and exit with status 5.
so
(...I realise the proper way would be to actually build a package and pip-install it. But I want to understand why this doesn't work.)
interestingly
when I clone your repo and run pytest
I get the same error lol
does pytest work locally for you?
interestingly though ```
❯ pytest
======================================================================================================= test session starts =======================================================================================================
platform darwin -- Python 3.14.0, pytest-8.4.2, pluggy-1.6.0
rootdir: /Users/joe/scratch
configfile: pyproject.toml
collected 0 items / 2 errors
that rootdir is not where i cloned it
it's the parent
and if I create a pyproject.toml I get a new rootdir (but still for some reason get the ModuleNotFound errors)
❯ touch pyproject.toml
❯ pytest
======================================================================================================= test session starts =======================================================================================================
platform darwin -- Python 3.14.0, pytest-8.4.2, pluggy-1.6.0
rootdir: /Users/joe/scratch/veronique
configfile: pyproject.toml
collected 0 items / 2 errors
The error doesn't occur with a fresh clone for me either.
🤣
(Although I make and activate a venv first and install sanic and pytest in the venv)
that's what I've done
Let me try Python 3.14 or .13...
I get the same error on 3.13 and 3.14 with a venv for both
hahahaha
okay
it gets even funnier lol
if I create test/__init__.py
it works
🤣
o_O

:(
You're not even on a different OS..
What pytest version do you have?
Oh I see it. Same one..
🤣
DETERMINISTIC BUILDS !
I suspect the explanation is somewhere on here https://docs.pytest.org/en/7.1.x/explanation/pythonpath.html
without that __init__.py it's looking for veronique in sys.path but without that __init__.py it's looking for /Users/joe/scratch/veronique/test/veronique/
Running pytest with pytest [...] instead of python -m pytest [...] yields nearly equivalent behaviour, except that the latter will add the current directory to sys.path, which is standard python behavior.
aha
Somehow my Python setup locally makes it so that when I type pytest it still chooses the second option?
Yeah, once I changed pytest to python -m pytest in the workflow it worked. But I don't understand why it works locally then..
yea that is odd
i guess it's probably good that it's a local thing rather than something funky with the CI lol
How did you install Python?
(I'm confused because it also works on my work laptop running Ubuntu.)
homebrew
just using system python because it is patched to use homebrew native libraries
so brew install python@3.13 etc.
Okay, at least there's a difference, mine was via pyenv.
_Spent half a h*ckin' hour on that once _
Yeah, something like that!
We're not trying to build a generic static documentation generator. We're building a tool for Python and it's unique nuances (e.g., handling of type annotations, overloads, etc.)
@tawdry needle You mean a URI without any special syntax? For example, something like this?
For more information, see the ref:MyClass reference.
Yeah, I'm not sure what the original motivation for rST roles were. I don't think you can have a scenario where the same name refers to two distinct Python objects in the same scope. So, I think you could just infer the object type
i hvae the fix
What do you mean? Do you have a full explanation?
yes easy peasy
“Trust me bro”
heh - that's been used in a couple of our flaky sprint demos lately
hmm I am having a nonsensical issue with AWX and the python request library if anyone else has run into this.
Testing from my machine, both using the builtin uri module and ansible or using my own similar module this API call I have works fine. But when running from ansible tower I get the Error 36 filename too long.
Which doesnt make any sense as to why but is there some kind of way to get the request module to ignore the length limit? Because the uri is not actually 'too long' (like <120 characters entirely) so I am trying to figure out if this is masking some other error or if its just a false error. I dont have access to Tower to check/modify anything
edit* 'my machine' refers to Ubuntu in WSL, running the same version of python and ansible as Tower is.
try doing python3 filename.py instead of python filename.py
Hmm well the module should be using python3 already as part of the sensible install but I will see if I can force my own module to try and use python 3
yeah imagine if it's using python 2, that would be bad
or just pass, that error won't affect the code
this seems like an os limit rather than anything specific to requests
it's about file names and not uris
maybe you have some prefix or whatever that gets added, and on the other machine it's long enough to bump some path above (iirc) 255
Kinda agree TBH
This is what doesn't make sense to me as the only literal difference is the platform it runs on. Same exact playbook and uri. Same version of ansible so my only assumption is that tower has some silly file path length limit set really small. Because I run mine on Ubuntu and I think tower is on suse but even then the uri is only like 130 characters, it's a post method and all the data is json in the body so I'm not appending any just to it either
as said, I suspect it's not related to the url
do you have some stacktrace?
Hello, so I was just wondering and was very curious and got an project idea but it seems so complicated so I decided to ask here how someone would go by making a project as such. Basically, If someone would like to scrape the whole web and use discord to search for a certain keyword for example if they are having issues with programming something, they just use a discord bot and type their search query and the scraper tool will automatically give the best answer to solve that issue. How would someone go by making something like this and do you think it would be a good project to learn from? Just curious btw
what you are asking about is a search engine
Yea I figured it out. There was some stupid flag on ansible tower that would try and cache the request result in a file for some reason. And because it was some separate task and script it was obfuscating what was actually throwing the error.
I figured lol
How difficult would it be to make a search engine if i may be interested one day?
Flex fr ;-;
Not too hard to make a very basic implementation! You might find it interesting to look into the evolution of Google's scoring criteria over time.
https://en.wikipedia.org/wiki/PageRank is a classic
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. It is named after both the term "web page" and co-founder Larry Page. PageRank is a way of measuring the importance of website pages. According to Google: PageRank works by counting the number and quality of links to a page to determine a rough ...
Alright, thank you for the clarification and thank you @neon shard for the useful follow up.
Implemented a tool, if you are coming from some other language or want to see if a certain thing is available in python and in which module you can get it form here

It does a similarity search and tries to find similar keywords inside the language
which semantic search algo should i use
ParseInt should give int with 100% similarity
That doesn't sound like something easily automatable
(how do you automatically link e.g. f64 with float and Vec with list?)
maybe with some kind of LLM
e-graphs? :p
Hi everyone, I am using pyproject.toml with tox, but tox is not installing the dependancies from the project, only when I add the deps entry under the tox section i got them installed, i find that annoying as I need to duplicate those dependancies, btw I am not packaging I am doing a library, anyone knows how to tell tox to install the pyproject dependancies ?
Are you using dependency_groups?
@gentle solstice yeah but I use it just for dev dependancies, and I want install the app dependancies too
basically if I don't add the [build-system] it won't install the project normal dependencies
What if you add a dependency-group main?
Any reason you're not specifying a build backend?
Why don't you have a build system?
I am not building a distributal package, just an app
how do you do that ?
You said you have dev dependencies, right?
Set one anyway.
https://tox.wiki/en/4.32.0/user_guide.html#packaging
Otherwise, use the [dependency-groups] table instead of [project] and set the dependency_groups array in your env_run_base table.
See here: https://tox.wiki/en/4.32.0/config.html#dependency_groups
If you're using a project manager like uv, it might support installing the "main" group by default. https://docs.astral.sh/uv/concepts/projects/dependencies/#default-groups
Though I recommend using a build system
yeah I ended with the build system
you mean out everything from dependencies into the dependency-group:
dependencies = [
"requests == 2.32.4",
"dataclass_wizard == 0.35.0",
"boto3 == 1.38.33",
"python-dotenv == 1.1.0",
"pydantic_settings == 2.9.1",
"troposphere == 4.9.4",
]
[dependency-groups]
test = [
"pytest>=8.4.2",
"pytest-cov>=7.0.0",
"tox>=4.31.0",
"teamcity-messages",
"python-dotenv == 1.1.0"
]
lint = [
"ruff>=0.1.0",
"mypy>=1.0.0",
]
dev = [
{include-group = "test"},
{include-group = "lint"},
]
yeah, ok that's what I am doing
TIL that docker run rm does not automatically remove failed containers
And now my disk is full again
This will prune stopped containers, right?

including the failed ones this time
you can add volumes to that list too
i'd be slightly more wary of mass purging volumes automatically
if you're accruing unaccounted volumes en-masse something else is probably wrong with your setup
both from the perspective of it's risky to tear them down, but it's also not great that there isn't a better lifecycle and they're just hanging around until you do something with them
I'd say the same about images and containers tbh
yeah -- this is true
i'd just be slightly wary of wiping out stateful volumes vs. immutable images
with the exception of dev environments
I tend to just run docker rm if I've contributed to too many projects with docker containers at a time
looking at pydis bot
cursed.
for local dev you don't need to do pruning of individual stuff you can just do docker system prune --all --volumes
it's the best tool for easy and intuitive stateful app deployments
because it 1-to-1 maps with what you'd do administering via a shell, with some shortcuts for being more programmatic about workflows
I love ansible
Hi everyone, I am looking for a online GPU providers in US that I can rent 8*B200 instances
Anybody can let me know some good options for it?
Hi people, do you have some good recs which can help reduce runtime?
Hey everyone, do anyone working or have done some daemon designing for Linux based environment?
ask your question instead, this really goes for this whole server (and not just the #1035199133436354600 section)
how can i fix lagging vs code
probably by using another editor. vs code is not exactly known for good performance
!warn 1039032964845142027 Please don't advertise
 :ok_hand: applied warning to @lavish saffron.
:ok_hand: applied warning to @lavish saffron.
Isn't this channel the place to discuss tools?
It is. It's not the place to advertise tools.
ok
Can I talk about my project in the off-topic channel?
You cannot advertise it anywhere. You can talk about it, even here.
For further clarification feel free to contact @balmy mulch
ok
is this new?
github.com/org/repo / Settings / General

I see
New release 0.13.0 (lucky!) of logmerger (textual based TUI for viewing multiple log files with a unified timeline) comes with 10X data loading speedup, detailed loading progress bar panel, and "info" command to summarize the loaded log files, number of log entries, and covered time range. Use pipx install logmerger to access it as a terminal command anywhere on your system. Repo at https://github.com/ptmcg/logmerger.git
- time-based side-by-side or inline view
- includes some nice navigation features (jump forward/backward by number of lines or time interval, go to a line number or time stamp, and some simple searching)
- runs in the terminal (so even over SSH, without having to set up port forwarding, which I never can remember how to do)
- supports merging of .log with .pcap files
- auto-unpacks from .log.gz or .zip files
- textual-enabled vertical and horizontal scrolling (to view logs that are wider than your terminal screen)
#textual #logmerger #python #tui

GitHub
TUI utility to view multiple log files with merged timeline - ptmcg/logmerger
I need to plot a tree and then rotate it 180 degrees. The nodes should be defined with rectangles, like in the image, but they should be stacked on top of each other, and I don't know how. Could someone please help me?

You should be able to compare the leaves of each tree with each other
what do you have so far and what is blocking you?
Im actually working on something like this. It takes any domain type of dataset transforms it into leaves and builds a merkle tree up to a single root hash.
Whats the question?
What about a sentance transformer?
Okay, let me explore, but it must have a c/cpp interface.
I hope this is the right channel to ask:
Can someonep explain to me please, what the colors mean in Pycharm in the "Git Tab"? I added a branch, added a feature and delted the branch afterwards. Are the colors for different branches? Once I saw that the branch "forked" or branched off to another line, when does it happen and what is the difference?

Hi to everyone, I published psp to Pypi: https://pypi.org/project/psp-scaffold/
pip install psp-scaffold
Not sure if this is the right channel to ask, but if doing continuous integration and someone messes up on the main repository and wants to get rid of a commit, like you forgot to test locally and the tests failed on integration, is it normal to basically end up rewriting the history to get rid of it from main? Or... Are you supposed to be developing on a separate short lived branch, merging it after your tests pass, or removing it from that one if they fail.
Because I've been in the situation several times where I've wanted to remove a commit from main and jetbrains would not let me force push and I had to go through the git command and get credentials and so on (it considers it a protected branch or something), I think there's a setting I can change to fix it, but I don't want to walk into/continue an anti-pattern.
you normally develop and test in a branch and then make a PR to merge into main when it's ready for production
these things still happen, and if you end up with bad code in main you would typically just use git revert to an earlier commit and push that again to get back to a previous version of the code (but as a new commit), the bad code will still be in the history of the repo, but that shouldn't be a problem and is the recommended way of fixing such situations in a shared repo (or whenever the code has left your local git repo by pushing/publishing it)
the only situation that i would recommend to really go in and rewrite history in a shared repo like that (github/gitlab/gitea or whatever you are using) would be if you accidentality pushed any sensitive/secret data to the repo that you don't want to be left in the history of the repo, but that comes with side effects to anyone else that has checked out and have copy of the repo
a more detailed explanation of that and the consequences can be found at https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/removing-sensitive-data-from-a-repository
That makes sense. I misunderstood "don't branch" (though I do understand local development is technically like its own branch to begin with, and short lived branches are fine) and "the code should always be in a releasable state". So it's fine for it to be red at points in its history as long as the latest is returned to a working state quickly, and "reverting" is just adding a new commit to the history with the bad changes removed. If something sensitive is there and it has to be scrubbed history has to be rewritten and if there's been important commits since all the hashes people potentially rely on are about to become invalid and coordination required so that no one pushes those old changes again and or loses work.
I think the only times I rewrote it was when I did accidentally put somewhat sensitive information in a readme. I'm confused by the first part though, if I'm doing continuous integration I'd want to be working on the main branch and everyone integrating as soon as possible without waiting on review (just automated tests), did you mean in general or like one that you approve yourself or like an automated one that gets approved if the tests pass? (I have seen short lived feature branches are a thing). Thanks for taking the time to explain, and providing that resource. Right now for context I'm not working on any features explicitly, or planning far at all, I'm just taking the code one step at a time, exploring the problem, getting stuff further, and commiting and integrating frequently seeing the tests still passing on the repository.
it's worth noting that generally even post-rewriting a commit still exists in a repo
even post rewriting you're just changing what appeared on the branch at what time, the original commit that you've removed will still be in the reflog and is still completely accessible, so if you're truly looking to scrub secrets from a git repo deleting it is generally the only truly reliable option
there are things like https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/removing-sensitive-data-from-a-repository to try help remove stuff more permanently, but generally a simple rebase with a drop or something won't actually remove what happened in that commit from other places that git stores commits
for example if I have this commit history:
commit 05876e55b6d01768f763190d43aacd1203b24aa4 (HEAD -> main)
Author: Joe Banks <joe@jb3.dev>
Date: Fri Nov 21 14:47:18 2025 +0000
Add another file
commit a185ebe6d51605dbf0f46385c4852ecc73dd6e80
Author: Joe Banks <joe@jb3.dev>
Date: Fri Nov 21 14:47:04 2025 +0000
Some bad commit I added
commit 52bdd02776ea48fb47051dc26852f46936403837
Author: Joe Banks <joe@jb3.dev>
Date: Fri Nov 21 14:46:39 2025 +0000
Initial commit
and i use git rebase HEAD~2 and then drop the bad commit you can see it's still in the reflog

even though it's no longer in the log

and thus if I run git diff a185ebe~1 a185ebe (get the diff between whatever was before a185ebe and then a185ebe), you can still see the changes, even though that commit was dropped from the branch

a lot of this is only locally cached but github itself does also have caches that still allow you to sometimes see things that got force pushed away
you can expire the reflog etc. to fix local stuff but there's often ways that things end up on github that are accessible (like that time someone added yt-dl to the github dmca repo)
wasn't that exactly the page i already pointed to?
and yes, it's a bit more involved to truly scrub sensitive data from a repo reliably then "just" rewriting the history (which is definitely not enough)
sorry that's on me — I read the last bit of the above message, hadn't quite started the day yet
ah, early morrnings ☕ 🙂
What kind of caches does GitHub have that could expose this?
hello guys
!rule ad
this is not the place of this sort of thing
.
Ok can you explain
Please delete this.
👍
Same goes for you, advertising is not allowed here.
@coral scroll I've deleted your message. See above.
Nowhere
hmmm 🙁
Does anyone know of an automated check to flag code duplication across code base?
I know sonarqube does that. We have it implemented as a GH action, I only use ruff and ty locally, not sure if ruff provides that features though.
also, seems like pylint can do that too - https://stackoverflow.com/questions/60620262/how-to-detect-code-duplication-among-multiple-python-source-files

Stack Overflow
I have placed all python project sources in a single folder. Running the following pylint only seems to be looking and analyzing for duplicates within each source file and not across all which is w...
What benefits does ty provide
So u need to explicitly enable it I see
Rust
It also has incomplete features and more bugs.
Ty, as planned, has a more rich type system than mypy/pyright. For example it's going to support Intersection and Not
First time publishing docker images, what configuration causes these un/tagged sha256-* versions to appear? They're a bit noisy so I'd like to skip uploading them, but I couldn't find a relevant option in metadata-action or build-push-action:
https://github.com/thegamecracks/ministatus/pkgs/container/ministatus/versions
my workflow file: https://github.com/thegamecracks/ministatus/blob/main/.github/workflows/docker.yml
last runs: https://github.com/thegamecracks/ministatus/actions/workflows/docker.yml

How? from ty import Intersection? Or are they lobbying for stdlib inclusion?
from ty_extensions import Intersection, yes
Click on one and scroll down to past the "No description provided" to see the "Manifest"
"mediaType": "application/vnd.dev.sigstore.bundle.v0.3+json",
Sigstore publishes to the index
Try docker pulling one of them
You'll get an error saying application/vnd.dev.sigstore.bundle.v0.3+json isn't a valid mediatype
ahh that makes sense, maybe i'll leave those be then
is there another source code hosting platform like GitHub that offers free CI and a container registry? I don't need a lot of it. Just one action that publishes one docker image every month or so?
I'm looking to move a hobby project off of GitHub
okay, I tried gitea and that does not offer a similar service
I'd check gitlab
okay, thank you ill try that too
Gitlab and Codeberg are the names I keep hearing, but I don't know in detail what either offers.
me neither
for fun: https://tangled.org/
tightly-knit social coding
I am put off by any tool that introduces a ton of new jargon: "knots", "spindles", "Jujitsu change IDs"
also it's unclear what problem it's solving
knot/spindle and the like is just cutesy themed naming for their stuff
uh huh
change ids are ids that are stable over the evolution of a commit
The tool might be great. I'm just saying those terms are ... let's say pink flags.
Hi
e.g. if you amend (or even change the description) a commit in git you would have an entirely new identifier (the hash)
Oh like http://esr.ibiblio.org/?p=3872
jj has started popularizing them recently, and different services have started accomodating them
(at the very least not destroying them during upload/rebasing/whatnot)
gerrit has had this concept for a long time as well
aw man it's just a guid
it's really just some identifier
the one jj is popularizing is an identifier stored as k-z hex to easily disambiguate it from the usual git hashes and similar
but ultimately it tends to just be a randomly generated identifier you can use to refer to the change
but one that is stable over the evolution of a commit
what's the quickest way to test a script on multiple python versions
pyenv local version switch? uv?
Write automated tests and run them with a tox file setup to do them for different versions you have installed, maybe use UV to easily install the ones you want.
I use GitLab and quite like it, but there's a learning curve for the new config you'd have to learn. It's not hard (except in the "we have made YAML almost, but not quite, Turing complete" sense). Free CI if your project is a public open source project, and there's also some free allowance of CI minutes per month for personal projects... I think?
I've always preferred GitLab to Github, but that's just a personal preference. Nothing objective.
Unrelated: is there a formatter, even a does-this-one-thing-only type of tool, that can format long strings in code? I usually use black instead of ruff because of this, but it looks like black is reconsidering some of their string processing stuff.
Which is fine! I'm not complaining about a preview/unstable feature going away, in an open source project. But it might be a good time to look for another tool to do this, if one exists.
uv switches back to the same version again and again
it changes the env version for the moment
i've been using nox with uv backend, i think nox can pull python versions itself now too with some extra dep
Tox/nox in general
just or ahoy?
I have used ahoy in the past, is as simple as declaring a yaml.
what is the simpler/most used?
never heard of ahoy
I have grown fond of just, fwiw
you might be able to answer "which is most used" by (somehow) querying github. I don't know how to do that, but I assume it's possible
well
it's safe to say that just is the industry standard lol
thanks
ahoy?
Can I get a link?
I do prefer the yaml syntax than the makefile one
.ahoy.yml
yep

As a data format, yaml is extremely complicated and it has many footguns. In this post I explain some of those pitfalls by means of an example, and I suggest a few simpler and safer yaml alternatives.
I don’t want this happening to my CLI tools
how about docker compose?
I use it too much, so use YAML everywhere is better then multiple file formats
if yaml sucks so much, why is it used everywhere? like docker, k8s, etc
genuine question
dunno. Maybe everyone really wants to use JSON, but use YAML instead because it allows comments 🙂
nobody wants to handwrite JSON
Subject: Guidance on Setting Up Error Alerts
Hi,
Not sure if this is the best place to ask—feel free to redirect me if not.
I currently have Grafana + Loki logging all backend errors, but I don’t get any real-time alert when something goes wrong. Usually I only find out when someone reports the issue. I was considering adding a Teams webhook, but I’m worried about spamming the channel with too many notifications.
Looking for suggestions on how people normally set up alerting rules—especially around when to actually send alerts vs. when to just log errors.
Thanks
off the top of my head:
- have your Grafana or Loki or one of those guys scan each log message, and send an alert if and only if the text of the message matches some pattern that you know indicates something Bad®
- have Grafana or Loki count the number of errors in (say) the last 60 seconds, and send an alert if it exceeds some value
disclaimer: I have never found a reliable way to do this; there's always either too many alerts or not enough 🤷
so you can't use docker cp to copy between two containers, but if I understand correctly, you could just pipe two docker cp calls and let the tar flow from one to the other
in which case, why not just let docker cp natively do that?
maybe doing "cp" properly involves subtleties like permissions that they haven't figured out
IME, alerting on error logs can get quite noisy and unruly
normally you'd emit metrics which can be scraped by/written to a metric store like Prometheus/Graphite/InfluxDB/etc.
then configuring alert rules in Grafana/Alertmanager/etc. using those metrics is straightforward
@quasi storm, pinging since I accidentally turned that off when replying
Haha thanks , actually helped because of the ping
I'm guessing you have already considered (and rejected) Sentry?
I have no idea, it has a docker-compose file. It turned into a behemoth though, I think there's like >50 containers involved now?
We are in the process of updating from an ancient version of Sentry to a modern one, and I hear it's a bit of a headache.
Not sure how I feel about it needing 16GB RAM+swap
- 4 CPU Cores
- 16 GB RAM + 16 GB swap
- 20 GB Free Disk Space
Upside: bugsink is compatible with sentry apis
As is glitchtip, apparently
sentry is just the standard, isn't it
Hello guys
New here
Hello Sani
Hello Sani
Hey everyone! Looking for a review of my open-source MCP platform, please review it once. It’s for internal teams managing MCP servers across the company.
Currently easy to host on bare-metal; I’ve only tested on a single-node K3s setup. Can it run well on a multi-node bare-metal cluster? I’m about a month into Kubernetes, exploring internals.
It will act as an internal registry for your company. The platform is capable of hosting those mcp server, considering the scale is supported by the
cluster on which the platform is running, I am shipping a CLI to manage the platform, which includes UI as well, if users find it useful
I’ve used operators and CRDs, and I’m considering an admission webhook for some tasks. Please share any issues you see and suggestions to
improve it.
https://github.com/Agent-Hellboy/mcp-runtime

GitHub
A manager,registry,broker, and infrastructure to manage , deploy and use MCP servers. - Agent-Hellboy/mcp-runtime
!otn a let the tar flow
Hi! Hope a little bit of self-promotion is ok. I've just open-sourced a tool we've used internally to automate and codify development tasks (e.g., cleaning projects, syncing development databases, etc.). https://github.com/petersuttondev/cleek
GitHub
Simple task runner with automatic command line generation - petersuttondev/cleek
Cleek is a super-simple task runner that automatically generates CLI's using your function type-hints. Create a cleeks.py file in you project:
from cleek import task
@task
def greet(name: str = 'World') -> None:
print(f'Hello, {name}!')
$ pip install cleek
$ clk
┏━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Task ┃ Usage ┃
┡━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ greet │ clk greet [-h] [-n NAME] │
└───────┴──────────────────────────┘
$ clk greet -h
usage: clk greet [-h] [-n NAME]
options:
-h, --help show this help message and exit
-n, --name NAME default: World
$ clk greet -n Discord
Hello, Discord!
Were you inspired by click?
Ner, we used fabric for ages. If I remember right fabric didn't allow types, but we wanted type-safe code. So I made cleek. The main aims are 1) type-safety 2) shouldn't alter code so I can be used elsewhere (@task just returns greet() unchanged so I can be used like another other function) 3) low effort (we were already writting the type annotations).
Never seen fire before. It's half way between click and fire but using type-hints
if you don't share the code, no one can check
does anyone in here have experience with spiderfoot? im trying to manually edit the use case section (Footprint mode) to not run a specific module displayed in the modules directory for spiderfoot, the module is sfp_tldsearch.py, ive tried editing the file name to other names, editing the file contents, or moving it completley but i just get hit with a "Broken Pipe" error whenever i try and run a scan, anyone got any tips?
nevermind, i fixed this problem by editing line 29 from 'useCases': ["Footprint"], to 'useCases': [""],
Weird obscure tool: Connect:Direct.
TIL
Hello guys! I do not know this a right place to talk about my project.
I built a package Kaizo for automation and dynamic configuration execution. I used it personally for running and training ai models on servers. It is fully dynamic and pluggable. I wrote a hugging-face plugin to upload/download files onto hf servers.
You can write additional plugins for it for your usecases.
The full documentation is available here: https://naughtfound.github.io/kaizo
Repo: https://github.com/NaughtFound/kaizo
You can install it using pip.
Thanks.

GitHub
declarative configuration parser. Contribute to NaughtFound/kaizo development by creating an account on GitHub.
Hey guys , can someone explain Devops vs Site Reliability Engineer vs Cloud platform engineer .
I don't really know how to code python, but I brute forced a couple different chatbots to create a .exe file renaming program mostly to make my life easier on renaming folders with many pdfs, is there a place I can share my github link with the .py and my released .exe?
I struggled heavily through compiling it so I have the requirements.txt and .py because I'm betting the idea of running some unknown .exe isn't that great
But i'm not sure where/who I could share with to see if it works like I think on a different system
I love Python and long walks. Daydreaming about physics sim algorithms while completing a 32768-meter long section in my quest to connect every major Bay Area park and city on foot is sublime.
Walking every step between SF San Jose Antioch Felton and more so far has been one hell of an eye opener. Tents and RVs are everywhere! This is the highest homeless tech geek concentration in the ENTIRE WORLD, probably even edging out Seattle.
How can the homeless keep their files safe? Oops, their phone was stolen by thieves or police (can they even afford another phone, not so easily if they are saving up their wages for an actual apartment).
What about a WASM virtual machine that includes a compiler? The idea is they log on to any library computer (the abundance of homeless in libraries doesn't bother me, but the staff constantly waking them up was sad and distracting) with a single username-password and have a virtual Linux in their browser that includes a WASM compiler and they can type in pip install pygame etc. No need for any personal property whatsoever to use! For some people, such as the founders of Jazz, creative projects keep you going through tough times.
Oh and it would also be useful on days I don't want to lug my computer around...
BUT how does such a project stack up?
- Performace. Speed ratio vs native for CPU and GPU heavy tasks. How reliable such a ratio is, so that they have an idea of what native performance would be. How much GB of RAM you can actually access. Startup and server I/O latencies and download speeds.
- Feasibility How many wheels need to be invented vs how much can it be build just by bolting together bog-standard parts?
- Cost The servers have to store and deliver data. How many GB do people really need and how much does it cost? How many clients can one large cloud instance handle (or is at-home volunteer better)? It should be backed up. So the total $/person/month I don't know?
is there a tool like node version manager fpr python
I'm not certain what "node version manager" is or does, but I'd look into uv
uv is an extremely fast Python package and project manager, written in Rust.
I need advise on what projects to try out to learn devops? Azure or AWS, if you have recommendations on which is better that would be great. I currently only have experience with Django
https://github.com/nvm-sh/nvm
It's the pyenv of JS landia
Despite having a decent (NVMe, no pun intended) disk, nvm is somehow the worst offender in my shell startup, at 210ms without cache and 140ms with cache
somehow pyenv is faster at 75ms
Hi guys
How do people safely deploy to a VM from GitHub Actions?
I have a VM where my containers run. On each push, I want GitHub Actions to trigger a build on the VM and run docker compose up.
One approach I’m considering is storing SSH credentials in GitHub Secrets and having the action SSH into the VM and run a deploy script.
Is this the usual/recommended pattern, or are there safer / cleaner alternatives (agent on VM, webhooks, etc.)?
why build on the VM instead of building an image in CI, pushing the image to a registry (like GHCR), and notifying the server to pull that image (with the digest ideally)
you could also use https://containrrr.dev/watchtower/ for the last part
safe is situational and kind of subjective. You have to store an ssh key there if you want any form of server automation I'm pretty sure. Secrets and treating it like a highly privileged API key or anything else would be appropriate.
This specific approach doesn't sound usual imo but it seems relatively par for the course depending on what exactly you want to do. The weird part sounds like deploying with docker compose.
umm basically i build the image in vm and directly up the container from there
because the image is of around 2gbs
so thats why not keeping it in GHCR
Is this VM only used/going to be used for this piece of software you're deploying to it?
more or less
its prod vm
you could run a small HTTP server on the VM that only exposes the minimal surface of accepting requests to build the container image and restart the service
then send authenticated requests to it from GitHub Actions
just fwiw, watchtower is now unmaintained
podman has this functionality built in though https://docs.podman.io/en/stable/markdown/podman-auto-update.1.html
the way I do it is with:
- a VM that is on a tailscale network
- a github actions workflow that requires an approval (to prevent forks and PRs from having too much power) or a workflow that can only deploy from main (for prod deploys)
- use github environments to make available an SSH key when a specific environment is being deployed to
- finally, i use SSH authorized key restriction to control what commands those CI SSH keys can run