#tools-and-devops
1 messages · Page 19 of 1
heh. imo there aren't any
there are only horribly-complex ways, and less-complex ways
So python across the board was decided and I was hired. 😄
I still don't understand your setup, but if you're using an EC2 instance and nginx, then you should look into "lego" -- it's what I use

GitHub
Let's Encrypt/ACME client and library written in Go - go-acme/lego
cases like that make me scarried ever leaving current company. Sure... our code is written may be far from perfect way. (in python too)
But still we uphold a lot of things for dev comfort
It sounds... impossibly challenging to maintain system like you have.

that's the first thing I found that was simple enough for me to understand, and get working
the installation says to use docker, does it still work for AWS?

Let'sEncrypt seems to be good in general, but I haven't used it so can't say.
suggestions on installing docker?

It doesn't "say to use docker". It says you can use docker.
I am using it, without docker, but on AWS
it's just a program you run


It says Docker isn't running. It's already installed
lego is installed, what to do with it?
wait oh no, is there a way to get a free certificate?
also is this good pseudo code running the certificate?
lego --email="example-email@example.com" --domains="example.com" --dns="route53" --path="/path/to/store/certificates" run
Let's Encrypt
is AWS with or without shell access?
If you're at a company, maybe IT or some other department can provide you with a certificate. If it is a completely internal service, usually certificates are issued from the domains CA server. If it's external, you need to demonstrate that you own the domain.
In order to get a certificate for your website’s domain from Let’s Encrypt, you have to demonstrate control over the domain.

Caddy Web Server
Caddy is a powerful, enterprise-ready, open source web server with automatic HTTPS written in Go
I own a domain through NameCheap, how do i demonstrate it?
should i run cert bot as well?
sudo apt-get update
sudo apt-get install certbot
It depends on what resources you are asking about. You have shell access to EC2 instances, probably some other things
Certbot is generally a good idea unless you're using something else that takes care of it
We're working toward it. I know for sure we won't use Docker here, though. I'm not sure why. Someone that's been here longer than me hates it, I think.
https://letsencrypt.org/getting-started/ Read through the documentation. You're the one that's going to maintain this over time and it would be much more helpful to future you if you read the documentation. Certs have an expiry-time, so you're going to want to be familiar with the process of requesting/renewing them. It's not a one-time thing. When the certificate expires, the service is (likely) going to be inaccessible.
If there is a particular step you have issues with I can try to assist.
https://certbot.eff.org/instructions
Seems they have pretty good selection of instructions for different OS'es and webservers. Cool
read the docs
where is the documentation? also should i follow the ACME certbot instructions?


Yes. Under the section where it says With Shell Access you have the line Visit the Certbot site to get customized instructions for your operating system and web server.


Learning Documentation one sec
8000 is not a port you linked to http in your incoming ports, is it?
it is
if it returns an HTML document but it looks different check the DevTools->Network Tab for errors in the css requests.
i am following the cert bot instructions for nginx on pip, it is not going well
Doesn't seem to be an issue with the domain. It looks like you got the certificate and private key /etc/letsencrypt/live/harmonyapp.org/*.
The installer looked through the nginx-configuration and didn't find a serverblock listening to "harmonyapp.org", so it exited. It couldn't figure out where to put the configuration lines for the certificate.
Should i manually update the nginx configuration to include the necessary server block for harmonyapp.org and then configure certbot to use a configuration?
Yes, that's probably the easiest solution
wait heck what is the command for editing the conf.d?

wdym? isn't that vim?
i enables editing, :wq for write & quit
do i use http://harmonyapp.org or do i use www.harmonyapp.org
thank you
`
server {
listen 80;
server_name harmonyapp.org www.harmonyapp.org;
# Redirect HTTP to HTTPS
location / {
return 301 https://$server_name$request_uri;
}
}
server {
listen 443 ssl;
server_name harmonyapp.org www.harmonyapp.org;
ssl_certificate /etc/letsencrypt/live/harmonyapp.org/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/harmonyapp.org/privkey.pem;
#What do i add here?
}
`
any thoughts on proxy code?
i haven't edited nginx, probably Netherwolf can help you
i'd say this info should be easy to search though
paging doctor Netherwolf
Life happened so I'm a bit busy.
See https://docs.nginx.com/nginx/admin-guide/web-server/reverse-proxy/
You want to proxy all traffic from nginx to your webserver:port, otherwise nginx will think that it is responsible for serving the webpages.
trying to setup fuzzing and am confooz
fuzzing make me oof
okay so im trying to write fuzz tests
and the thing im fuzzing against
uses randomness in the function
😔
i feel like im just ranting here
How do I get the nginx to see the ssl certificate?



Does the nginx user have read access to that folder?
i will assume not since i do not remember doing that
did You guys ever automated configuration of the user profile and computer settings in windows with python ?
That's best done with powershell
well i do not know powershell and i would not like to use it
and yet it's ideally suited for maniuplating Windows, wheras python isn't 🤷
I myself hate and fear WIndows, and yet ... I have a gruding respect for Powershell.
powershell lets you cd into HKLM:\
registry keys are treated as files in powershell
stuff like that, ya
basically, microsoft saw linux and /sys and /etc/system and decided that was a good idea.
I have opened a folder in VSCODE and want to add it to github. Why is it stuck like that? With the commit button greyed out

what does staging even mean?
https://git-scm.com/book/en/v2/Git-Basics-Recording-Changes-to-the-Repository
staging is simply picking which new/changed/deleted files you want in your commit, normally done with the git add command
when it prompts you with a file to edit like that, it wants you to type something appropriate, save, and then close the file to perform an action
Why do we use -e .

When you install your package, it creates a copy of your code, so every time you edit it you have to install it again
Editable links to your current folder instead of making a copy
So you don’t need to install over and over again
they probably have some obscure folder/package structure
if u use flat structure. when at root folder u have package_name/__init__.py, u usually don't need -e because current folder is already... sensed as installed package
and if need to reuse your library in other application in real time edit, usually -e is not very convinient too because it does not propagate to docker environments.
Easy to use overshadowing trick, where u just mount volume your library into app project folder 😁 real time editing too then. compatible with docker (its own docker volumes could be utilized for this hack)
-e pretty much useful only if u develop applications straight in a current machine filesystem without extra complications
🤔 technically nothing really forbids using -e mod with docker, if volume forwarding appropriate library project to it
e for editable
question araises though, what is the benefit of using -e if u can just volume/mount forward library folder itself into end project folder and it will be already working as editable lib
say I have an executable c:\python\python.exe
how do I use pip to install to that specific python instance?
u are supposed to have active pip in current terminal...
...but if u wish to ensure... u could run it as c:\python\python.exe -m pip install smth like this
thank you!
stil no idea on how to fix this or what I should change in the config


Can anyone share their terraform script that deploys Django made in Docker to GCP or AWS?
python -m pip install ... @arctic flicker
basically creates a symbolic link to your project i.e adds it to the path
SO has a nice explanation https://stackoverflow.com/questions/42609943/what-is-the-use-case-for-pip-install-e

Stack Overflow
When I need to work on one of my pet projects, I simply clone the repository as usual (git clone <url>), edit what I need, run the tests, update the setup.py version, commit, push, build the
how do I save and test a config in AWS?

this answer is too broad in approaches
- u could just open it with
nano, it has obvious simple interface
- u could connect with program like
vscode, using plusin remote ssh stuff and edit in real time through vscode (assuming u know how to use ssh)
- u could learn how to use 👀 probably it is
vim? how to edit and save. i never bothered to remember. too over complex unintuitive program
- you could learn (i like the best option) running your nginx at your local environment for more rapid feedback
by just using Linux as main OS, or at least windows with WSL2 - you could apply local code to modify remote server by using things like ansible (or other configuration management tools), including terraform and etc
new error, I just need to chang redirect settings, idk

do i have to install these on the server? is the remote server a different server than the AWS server?
- if u wish to use
nano, u have to install it at remote sever(AWS server) vscodeshould be present only at your local dev machine- should be already present there
vimat remote - well, definitely installing to local environment different OS
- this can work from being installed at local machine only, but some of them require modifications at remote machine as well 😅
can these instructions help me fix the bad request error? because i fixed the server name error
also thank you as always oh honorable and knowledgeable Darkwind The Dark Duck : ]
bro theyre just ways to edit your nginx file and iterate quicker
like if u take some time to understand what he said...
i want these full number can tell me anybody

new error unlocked


you have an extra } don't you (edit, meant need an extra })
i dont think so?

i removed the }
and it gave me this
when i readd the } it gives me this still

there is a bracket mismatch, one } missing it indicates.
why aren't you using vscode with remote ssh?
chat gpt may find the error
I want to set up the server on AWS to keep it up with nohup
pre-commit is slow and is extra work to keep it's version synced with my pyproject
so I'm looking to find a decent replacement
something that can run ruff and mypy for me
oh yea pre-commit's mypy is an issue too so that's another reason
I use poetry
I have my editor do "ruff format" on every save; it's fast enough.
I only do "mypy" at the same time I do unit testing
am i doing something wrong then?

I have the ruff extension but it's not doing anything from what I can see
on every keystroke? That seems like overkill
Anyway that looks like Visual Studio Code, but I don't use that, so can't help with it
Just run pre-commit autoupdate
do i have to create the www, i am trying to set up nginx

Oh no that was just what the default showed. Setting it on save had the same issue
I don't even see a "format" on save
how do i use socket?

varwww is for apache httpd
Check the directory by looking at /etc/nginx/sites-enabled/default
It should look something like this. ```cfg
server {
listen 80 default;
server_name localhost;
access_log /var/log/nginx/localhost.access.log;
location / {
root /var/www/nginx-default;
index index.html index.htm;
}
wait do i not sudo vi /etc/nginx/sites-enabled/default?


how do it edit it?
use ls to list the files
There's nothing in there...
Ok, check /etc/nginx/nginx.conf

Do you have another instance of vi(m) running?
i think so, maybe, how do i check?
run pkill vi


seems to work

Thanks
Having a little trouble with a project. I made a script to webscrape product information from wholefoods site, but in the all products page there is a Load More button at the bottom and my current script using the Requests library I'm not sure how to get around this to pull all the data. Do I need to switch to selenium or is there a workaround?
Hello I am using lazyvim but I can't run my Python code due to this error:
Error invoking 'python_execute' on channel 3 (python3-script-host): Traceback (most recent call last): File "<string>", line 1, in <module> NameError: name 'caesar_cipher' is not defined
This is my caesar_cipher.py :
`#text = input("Enter your message: ")
#cipher = ''
#for char in text:
if not char.isalpha():
continue
char = char.upper()
code = ord(char) + 1
if code > ord('Z'):
code = ord('A')
cipher += chr(code)
#print(cipher)
Caesar cipher - decrypting a message.
cipher = input('Enter your cryptogram: ')
text = ''
for char in cipher:
if not char.isalpha():
continue
char = char.upper()
code = ord(char) - 1
if code < ord('A'):
code = ord('Z')
text += chr(code)
print(text)`
So what is wrong about this code and why can I not run it in lazyvim? In vscode it works fine, but not in lazyvim..
The correct solution is to use an API instead of scraping. I don't think Whole Foods has a public one, but Instacart does, so hopefully that has what you need.
Selenium is technically an option but usually against terms of service. If you go that route you won't get help here per the #rules
Sorry no that doesnt help. Instacart has different prices on their app than what whole foods has in store. Please help with my question
yes, you can't handle interactivity with a static /text version of the page
Can you help via Requests using the JSON link on the network page
it's a lot more hassle, just use a lib that's for the purpose, try selenium.
It ends in ...offset=0 and the number increases by 60 each iteration the iterations part im just having trouble figuring out
yeah it takes time to learn that. that's why you start easy.
Tells me the count of products 11348 on the site so I know I have to iterate the offset= number +60 until it reaches a number just above 11348
That's why im asking for help/guidance
i get it, but try selenium. in fact chatgpt probably can help a lot better
I would really prefer to use requests I just need a nudge in the right direction
There are 190 load more screens to reach the bottom of the all products list I dont want to click load more 190 times via selenium
Requests to the json api endpoint is ok. Assuming they allow it
but normally only requests initiated from the page's origin (the main domain name) are replied to, to avoid people stealing I guess @warm rock
new error? how to get websocket to work idk

idk what you mean with the websocket thing
this error is probably because epel 7 is EOL
how do it update it?
how did you arrive at the conclusion that you should run that command? the yum install amazonlinux.com etc
if im not sure whats your end goal it's hard to help
i have a Django project that i was to run on an AWS server, the project does not work because they server lacks the packages to make the websocket the project uses work. idk how to get the packages?
these are the rough steps i would take to do this:
- make sure you have python and a reasonably modern one (you can check with
python -V, i would say anything higher than 3.7 is fine) - create a virtualenv, preferably in the same folder as your code (
python -m venv venvfor example) - activate the virtualenv (
source venv/bin/activate) - im gonna assume you dont have a requirements.txt. if you do, ignore the next 2 steps and do
pip install -r requirements.txtinstead - try to run the program. you'll get an error like Could not find module django
- run
pip install djangoand keep trying to run the program and installing what's missing until it works
once you have it running, you need to figure out a way to leave it running even when your terminal dies. the easiest way is probably nohup, there are some fancier alternatives like creating a systemd service or using pm2
is the v suppose to be capital

also i have a venv already look at the side

that works too. idk your setup
is it already activated, is there a way to check that?

also requirements did not work?

Running the server does not run the Django project, instead it runs the ngxin conif. How do I change that?


It looks like you're not connecting to the app on the port 8000
nginx looks like it's serving port 80
You would most likely need to configure a reverse proxy to serve port 8000 to the webpage
At least that's what i've always done for things that use ports
Ex in your nginx domain config, your server block might look something like this:
server {
listen 80; # Listen on Port 80 for IPv4 Addresses
listen [::]:80; # Listen on Port 80 for IPv6 Addresses
server_name harmonyapp.org www.harmonyapp.org; # The domain of your website to include the www subdomain
location / {
proxy_pass http://127.0.0.1:8000; # The host:port combo Nginx should serve to the website on Port 80
include proxy_params;
}
}
This is configured for a non-SSL certified website. If you end up getting an SSL certificate, make sure to switch the listen port 80 to 443
While this guide is used for Ubuntu, it should apply to most flavors of *nix

This tutorial will demonstrate how to set up a reverse proxy using Nginx, a popular web server and reverse proxy solution. You will install Nginx, configure …
how do i configure my nginx domain config?
so run django on port 80
then reverse proxy it using proxy_pass
and then running django and daphne at the same time, turn them into systemd services


If you follow that guide it should tell you how to do it
ex nano /etc/nginx/sites-available/harmonyapp.org and then paste what I put above. Then hit CTRL + O and then enter to save and then CTRL + X to quit
nano's key bindings are so weird
Surround it in quotes or apostrophes
such as
first = float(input('What is your first number?'))
I personally can't stand VI lmao
I know it's super powerful, but I just don't find it to be efficient for me
I am having some trouble with the guide, what does it mean does not exist?

Looks like you didn't edit the command
on the ln -s ... command
You left it as your_domain
but then i reran it correctly
So it's looking for a file that has that filename
or did i not?
Yes, however nginx still things the other one is enabled
you mispelled the second time too though it looks like
harmonapp.org instead of harmonyapp.org
Oh i see
So open nginx.conf using nano /etc/nginx/nginx.conf and find that line that has your_domain
I don't use nginx on my server so I'm not sure what it's going to look like
here?


type rm -r sites-enabled/ right there
it worked?

Looks like it
Thought it was a directory
@heavy knot can you type ls /etc/nginx/sites-available/
thats not confusing

Alright now
ln -s /etc/sites-available/harmonyapp.org /etc/nginx/sites-enabled/
worked?

Yup, ln commands don’t give any output
Now try a systemctl restart nginx
Are there any errors?
where in the guide are we?

We kinda went off track of that to troubleshoot
You add some errors and typos and so we’re just kinda fixing that right now



Are you able to copy the contents of nginx.conf and put it in https://paste.pythondiscord.com/
i could do such a thing : ] https://paste.pythondiscord.com/5MIQ
Haha thanks I’m on my phone now so trying to help the best I can
Okay remove all of this
server {
listen 80;
listen [::]:80;
server_name harmonyapp.org;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
error_page 404 /404.html;
location = /404.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
Lines 39-55
i love you
We’re doing this because we have enabled the config in the sites-enabled directory. So we don’t want it in the main file
The line “include /etc/nginx/sites-enabled/*” is what’s letting nginx know we have that configuration available, just in another place
i got rid of the lines
i saved and exited the conf

Can you run that journalctl command?
ls /etc/nginx/sites-*

Alright let’s start over real quick.
rm -f /etc/nginx/sites-enabled/*
oh no

heck?

Use sudo on this one too
happy!

Beautiful
Let’s confirm nginx can be happy now. Restart it once more
It shouldn’t have anything conflicting
: ]

Alright, let’s confirm your original config. Let’s cat /etc/nginx/sites-available/harmonyapp.org

Looks fantastic
no u
Now let’s do that ln command again:
ln -s /etc/nginx/sites-available/harmonyapp.org /etc/nginx/sites-enabled/

This is creating what’s called a symbolic link. Anytime you edit the file in sites-available, it will make the changes to the file in sites-enabled
symbolic? what is this 6th grade english class? jk lol
Now let’s try restarting nginx once more.
womp womp?

Man wtf lmao
ran journalctlhttps://paste.pythondiscord.com/F7YQ
It's telling you where to check the log to see what's wrong. Any clues there?

You didn’t put the host:port combo
What stands out to me is: invalid URL prefix in /etc/nginx/sites-enabled/harmonyapp.org:8
No in the sites-available/harmonyapp.org file
Look for the line “proxy_pass”
See if you can find the issue


this me
i found it!

should this be 127:something something
or is this my private or public ip?
is my "localhost" 0.0.0.0?


how do i vertify this?
every host has this
It’s a standard/default address that points to your servers internal self if that makes sense lol
When you start the app it says it’s being hosted on 0.0.0.0:8000 right? You should be able to use 127.0.0.1:8000 or localhost:8000 to reference this
Since you’re not reaching out to a remote server
oh so i do not have to replace localhost in http://localhost:8000/ ? wack
No, keep it as localhost
saving and exiting

Remove the last slash on that line
I think discord automatically put that in
So just …:8000;



Everything should be good
You don’t have to redo the ln command, it already knows where to look.
If you restarted, it should be good.


I want to run django on port 80
then reverse proxy it using proxy_pass
and then running django and daphne at the same time, turn them into systemd services
how we gotten steps 1 and 2 done?
yes the django project is an app i made
it runs locally but the end result means it should work on a server
Yeah, the reverse proxy is what will make it be served on port 80
i think the daphne i need does not work, thoughts? how to enable http/2 what is that?

Anyone in this Discord an expert in Prefect/Prefect Cloud?
not sure what daphne does or is, or what the http/2 package is for
forgive me if my responses are delayed im in a class rn
ok i am back i got the package and now daphne works, do I have to log into the server through daphne or do i have to use the python manage.py runserver command?

At this point I'm not sure what else you have to do
nginx and reverse proxy is as far my knowledge goes for what you're working on - i don't know anything about djano or daphne
any idea how to solve dependecy issues, i am following this guide to deploy on gunicorn

what version of python are you on?
is ufw a requirement? Can you use firewalld instead?
That should be installed by default on amazonlinux
amazonlinux is based on redhat, so will use the redhat defaults.
https://www.redhat.com/sysadmin/firewalld-linux-firewall
Thanks for teaching me something new! I don't use AWS so I didn't know that but yeah, firewalld is a great thing to know
though I also read that amazonlinux has all ports open by default because you can use aws itself as a firewall
I used to use ufw for everything because I started on debian/ubuntu. I work in a RHEL environment now and all I use is firewalld now
look into setting up rules through the AWS security group
DevCoops
Protecting your EC2 instance can be accomplished in multiple ways, setting up rules through the AWS security group or installing a firewall directly on your EC2 instance. Today I’m going to show you how to install firewalld on Amazon Linux 2 and set up some basic rules.
(thats for you backup 🙂 )
I dont work in a cloud environment but it's good to know if I ever do
The recommendation is to not use a firewall, but to use aws security console to control what can access your server
a firewall adds overhead


so this tutorial stops working for me because: sudo ufw allow 8000 does not work

did i write the correct allowed hosts?

from what I'm reading, thats acceptable, but I don't think it does what you think it does
It looks like it protects from certain web vuln attacks
does not accept all hosts?
how do i determine what hosts i need?
I don't think that setting is applicable to the issue you're having
At what point did the website stop letting you connect?
sometime between when i make the directory for the venv and when i made the migrations for the directory
wait im confused you CTRL + C'd it
i copied the firewall?
is directory meant to be called gdirectory?
you can name it anything
copied the fw from where?
you need to configure the firewall in the aws console
projectdirectory
cause to me you stopped the django project from running
with CTRL + C
again i dont know django, just using t/s skills. unalive sounds more confident at this point than I do
have i not done that?

No, that's just instructions on how to stop
oh, I misinterpreted how it was written
ohhhh yeah i control c to stop the server but when it is suppsoed to be running it does not run
Can you connect via curl localhost:8000?
no

in a new terminal console, right?
i reopened the terminal yes
sometimes it times out
don't close the terminal
ok but if it hypothetically times out can i refresh it ?
keep it open by making a systemd service file
hard life backup
in the gdirectory or the regular venv i make in thought_sync_django-channels
here
are you familiar with systemd?
or here

i have used systemd before yes
but idk where to write commands because in the venv or not in the venv does different things
systemd service files go in /etc/systemd/system/

Follow this guide. https://www.digitalocean.com/community/tutorials/how-to-set-up-django-with-postgres-nginx-and-gunicorn-on-ubuntu
This tutorial walks you through the steps needed to set up Django with Postgres, Nginx, and Gunicorn on an Ubuntu machine.
skip what you don't need
So start at step 7
question about step 6
do i have to run this in gdirectory?
also what happens when i control c and close this, does it just not work?


This is just testing, so it won't matter.
oh ok

keep going

oh no
the preset in the guide is enabled
did i miss a step
Did gunicorn.service start?
Run systemctl staus again
interesting?

You only enabled the socket. You also need to start it

your service file may be invalid.
how do i fix?
share your service file.
cat /etc/systemd/system/gunicorn.service and share here

Use your own username
or make your own
All the boxed strings in the textbox should be replaced with your own
WorkingDirectory should be where your project is located.

ExecStart should be the fully qualified command to start your server
User should be your own user, like ec2-user

what does that mean python manage.py runserver 0.0.0.0:8000
Fix the working directory and exec start
we won't be using manage.py. gunicorn is used to start the server
/path/to/your/project/.venv/bin/gunicorn
You can run which gunicorn to get the full path
what does that start with? ec2/tsupdate/thought_sync_django-channels
^
are you familiar with how absolute paths work?
there's basically the root / which is the parent of all files. Your home directory is located at /home/yourname
That's the default directory when you log in
the absolute path is the path starting at root
^^

Ok run this. readlink -f $(which gunicorn)
i have to go home now but i sure be on in 2 hours : ] thanks for everything
I have returned, I shall run this command

Use that as the execstart
hey, 2 questions, what programming language does a keyboard use? like a normal laptop keyboard, and can i program it to behave like "Razer Huntsman Mini V3"
basically my computer can't even run shooter games ( could get proof of my bad laptop ) it just seems fun making it, if anyone does not know, ppl hate it because it helps on shooter games
i know that Razer Huntsman Mini V3 has other features that compliment and make the shooting better, but i'd like to focous on the key canceling and not allowing a and d be pressed at the same time
not only a and d, almost every key, might be interesting to see how it effects avarage typing and such
does github of this exist? seems like a good idea, ppl would like to use this for hacks
A lot here depends on the OS. Here's a note about fiddling with the Windows API with Python: https://stackoverflow.com/questions/71370107/how-to-change-input-keyboard-layout-programmatically-in-pyqt5
Stack Overflow
Is it possible to change the Input Keyboard Layouts by programmatically in Pyqt5?
My first and second text box accepts Tamil letters. IN Tamil So many keyboard Layouts available. By default in Wind...
Anyone have any good resources on git pipelines and how to do local dev and push to a remote prod environment?
oh this is neat! Would this work for a discord bot?
I like the scaling feature, not sure how that would work for a bot because I know they use shards. But I think Dokku sounds like it's the right track.
Is what I'm essentially doing is committing my changes to my GH repo, and then go sync it with the dokku container, it detects the changes and pushes them?
yes.
Hi guys now if we are creating a virtual env for a system , it would be conda create -n env python 3.8
This would available in the whole system right?
Now what if I want a virtual env in directory how do I that?
I have used the --prefix method , but each time I want to activate it wants me to put the path
Is there any way to replace that path with the env name?
don't spam every channel...
(this is the right one though, not the others)
did you read did you read https://docs.python.org/3/library/venv.html ? @burnt ginkgo

Python documentation
Source code: Lib/venv/ The venv module supports creating lightweight “virtual environments”, each with their own independent set of Python packages installed in their site directories. A virtual en...
is there a way in python where when running a script it prints out whether the machine it's running on is a phone, PC, tablet or some other type of device?
Is there a way to declare the build dependencies and dependencies to be installed locally for development purposes in the same place?
Right now I’m using setuptools in a venv and if I want my IDE to recognize the dependencies I have to install them with pip, which I’d do with a requirements.txt.
But if I do that I have to list the dependencies in two places (pyproject.toml and requirements.txt). Is there another way?
if anybody wants to suggest conda I don’t want to use conda
If you have dependencies required for build, they should go inside the requires in the [build-system].
Then they’ll automatically get installed when building your package.
A somewhat common way to add dev dependencies is to add them as optional dependencies
For example — https://github.com/letsbuilda/imsosorry/blob/main/pyproject.toml#L19-L25>
Then you install them with pip install -e .[dev]
One thing to keep in mind is that if you publish your package to PyPI that dev extra will be included, but it’s only installed if people explicitly ask for it, so it doesn’t affect anything.
pyproject.toml lines 19 to 25
[project.optional-dependencies]
dev = [
"pip-tools",
"pre-commit",
"ruff",
"mypy",
]```Thanks.
How can I install runtime dependencies into the development environment?
You start with pip install .
The . installs your pyproject.toml, it will use the requires to build your package, and then also install everything in dependencies [under [project]], all of your runtime dependencies should be in there.
Then if you also want to install your dev dependencies, you add [dev] to your ., and you get pip install .[dev]
You can install more than one at a time too, for example I put my docs building dependencies in a different group, so I would use pip install .[dev,docs]
Can I install the runtime dependencies without building the package? I just need them so mypy etc. can find them while I code.
That’s not really a thing currently
Some people are arguing for it
Most people say there’s no reason to not just let your project be installed too
You need your project to be available for mypy too
You can kinda hack it with Hatch if you really want it
Why do I need my project to be installed in the venv for mypy to work?
It has worked fine before (but I didn't package anything then)
But if I do that I have to list the dependencies in two places (pyproject.toml and requirements.txt). Is there another way?
we use the choice of project building through setup.py. and just read requirements.txt file into its configuration 😉
as well as making dynamic reading of current README.md and changing version
can't poetry do that?
poetry doesn't require the dependencies to be in two places -- they're just in pyproject.toml (well OK they're also in poetry.lock, but that's autogenerated)
I meant symlinking the project without building it, so it 'live updates' i.e editable mode. But that too.
where should I store Python CI scripts that are called from a GH workflow?
Generally scripts go in a scripts/ folder
If they’re only used by CI, some projects create a ci folder
https://github.com/pandas-dev/pandas/tree/main/ci
I am considering Hatch
does anybody have experience with it and would like to en- or discourage that choice?
hatch is a fine choice.
It's great if you're looking for a modern alternative to setuptools
among other features
i have a new error this week! i have no idea what to do

here are my settings if that helps

We have Jenkins CI running various pipeline via Docker images. These pipelines require numerous and sometimes conflicting Python packages from public and private repos. There's a recent push to solely install these requirements at runtime, but previously we were just baking them into the image at build time. What would be best practice here?
- IMO more time on build vs. run always makes sense and there's increased reliability since sometimes access to these repos can be flaky. There are different opinions in the org that images should be as small as possible which would remove the baking of these packages in.
- Additionally, we're looking to utilise a shared cache for these Python packages across pipelines. Our first iteration of this just uses a
pip install --dry-runto warm the cache, but since we have some conflicting requirements we need a better way to do this. My first thought was to set up a local pypi server within the image for pip to install from. Is this a common usecase? Can you see this working?
We have Jenkins CI running various pipeline via Docker images. These pipelines require numerous and sometimes conflicting Python packages from public and private repos. There's a recent push to solely install these requirements at runtime, but previously we were just baking them into the image at build time. What would be best practice here?
The whole point of Docker images is creating frozen artifacts u can build once, test, check in stagng and be sure it will be the same running in prod now and at multiple servers and in few months.
So when u build new image and deploy it, and u screwed it up, u could rollback to previous docker image that was built before and everything will be okay (so u could relax and fix bugs for new version at your own temp, instead of rushing to fix prod bugs forward only right away at evenings)
You forfeitted THE Biggest point of Containerization.
TLDR: u are supposed to bake all dependencies on build
Well said, that makes things a lot clearer. I think this is known but the reason it’s being suggested is because of a high frequency of these requirements changing combined with a long build time for our C software (which is also baked into the image).
mm... let me copy u instruction i wrote how to take care of it...
We speed up all our CI by reusing already built Docker image layer where they are already installed.
Our CI pipelines only write layers with code usuaally, and Heavy dependencies are all the time reused by pulling already built version from docker registry. We achieved it with this algo (Multi stage building pretty much, where first build stage has calculated hash based on used dependencies in Pipfile.lock, and pulled in every CI if exists first, and if it does not exist for this Pipfile.lock only then it is built and saved again to remote docker registry for reusage across all CI)
our CI in a nutshell:
- Calculate md5 hash from dependencies file lock onto libraries. Whatever your language is. Lets call the value as
builder_base_hash(we do it by python in Github Actions run 😉 )- Pull image image
{{ builder_base_hash }}if it exists in docker registry, if not then build up to stage --builder. Save result to docker registry under tag{{ builder_base_hash }}
(Thus we implemented speed up twice for CI), as we are were able to cache half of longest CI in a way that its CI jobs can run at different runners, as we use remote for persistence- run full building of an image, til the code capable to run unit tests and push to docker registry under tag
build_${{ github.run_id }}- at unit test stage: pull the image
build_${{ github.run_id }}and run unit tests and other tests- if it passed them, than save the image as
service_name_{{ github.run_number }}as fit for deployment 🙂, also mark it aslatestand etc whatever tags u need
So we used approach to cache building docker image stage through Docker Registry.
feels like i should write article about it 🤔
That’s a very interesting approach. Using that approach, you’re, in a sense, splitting the requirement on that CI image being rebuilt into multiple parts. I can see that improving CI times quite a bit depending on where those “split” stages are defined. Presumably the effectiveness would be maximised at points of low dependency from one stage to the next.
Alternatively would a shared cache not offer the same benefit as your dependencies-are-installed image would?
Alternatively would a shared cache not offer the same benefit as your dependencies-are-installed image would?
sharing cache could but it is bothersome to setup working reliably and very CI provider depended. And Also default shared cache is not having ability to propagate for reusage across multiple CI runners.
Our solution is pretty much CI agnostic, will work the same at any CI tool. And works great for our autoscaled self hosted github runners
last time i tried using cache in Gitlab CI at least, it worked very unreliably, and the problems of cache persisting on same host only is an issue too, nullifying the benefits of caching
may be today it is different and shared cache became useful normally, at some of CI providers
The caching I’m thinking of is more language-specific rather than some OOTB CI-provided tool e.g. ccache, pip cache, Python build cache. But I can see the value in rolling your own in the way you’ve described. Thanks for sharing.
I’ll definitely be more forward about the potential value being lost if we were to go forward with runtime installs.
wait can daphne run in venv?
I am in the project
I login into the server
i cd tsupdate
cd thought_sync_django-channnels
pipenv shell
and then i am in the project
would the directory be:
ec2-user@ip-172-31-19-47 thought_sync_django-channels
or ec2/tsupdate/thought_sync_django-channels?

Checkout rye maybe
I still don’t understand why mypy needs to have the project installed? In my experience it has worked fine without…
I like the ci folder solution, thanks
how do i sudo yum install django, do i need epel? how do i install epel?

why do you want epel? you were asking the same thing the other day
should i want epel? i want django to work lol
if you have python+pip installed already, you could just install it with pip, e.g. pip install django outside a venv (or do it inside a venv and source it before starting ur server)
Pip install Django is not working
try
py -m pip install django
i guess django already works?

then why can i not reach my server?

django works as a server, having it installed is not the same thing as having it running
im not very familiar with django but i think you should have a file called manage.py in your project
once you find it, try running python manage.py runserver
same error


okay that's an improvement
my bet is that your instance doesn't have the right firewall port open
if you open another terminal on the same instance (or connect via ssh), can you run curl localhost:8000?
if it works, problem is most likely firewall and you'll have to open the port
Help in solving error in python
hi dangi, welcome to the server. as a friendly note, remember that asking for (or offering) paid work in this discord is against the rules
GitHub
Contribute to python-screen-builder/python-screen-builder development by creating an account on GitHub.
no i can not:
$ curl -v 'http://harmonyapp.org' curl: (7) Failed to connect to harmonyapp.org port 80 after 259 ms: Couldn't connect to server
run it as i wrote it
that also failed:

did you close this process to run the command? you need 2 terminals open, one with the process and another one running curl
how to i open two AWS terminals?
well you either open two tabs or connect with ssh instead of the web interface
the error is too large to copy
um
how do i share a message over 2000 words?
i think discord can convert it to a file when you paste it
otherwise pastebin or something like that
as a general comment, you should think about what you're trying to do and how the system works before doing anything. us feeding you commands and you copy pasting is not going to translate to any useful skill if you dont understand why each step is necessary
that is not an error, it's the website you want
this means that the django service is running properly and you can reach it locally. now it's a matter of being able to reach it from the outside
outside meaning aws config? what do i do next?
outside meaning from your computer, or anyone's computer
ok, so how do i do that?
give this a try
why can you access it locally but not remotely?
idk but i can i guess?
sure, guessing is fine
i think it is because it works locally but something is wrong with the AWS settings
science is basically coming up with a theory and then giving it a try
i do know however it works locally and not in AWS so that is a start
yes, good
i have limited time and therefore limited tries : [
your EC2 instance in amazon is in it's own network. AWS calls this VPC, and restricts their inputs/outputs
this is done with something called security groups, which are basically a firewall. my theory is that your instance's firewall doesn't have the right input port open (8000)

second to last group seems correct to me. is this security group applying to your instance?
yes, this is the security group inbound rules used on the server
outbound is "all"
can you show me the network tab of the instance? i dont remember the exact name of the tab, but it's on ec2 -> instances -> your instance
this thing?


i cant see whether the security group is applying to the instance here
oh that would be in security

firewall seems fine
new theory: django doesn't bind to external ip by default
should be easy to test. run it with python manage.py runserver 0:8000 instead
im not sure if this has security implications, for the final setup it might be better to setup a reverse proxy instead


👋 Hey all, would anyone be able to help setting up traefik on kube? I've been stuck on it for the past 4 hours and I desperatly need help. I can't for the life of me get the traefik dashboard working with HTTPS. I always get errors with ingressRoutes or something else which is extremely frustrating 😦
Have fun 🤣 😭
i would say, tough up and debug step by step where it is working
i enjoy using kind instrument for local debugging
That's what I've been doing for the past day...
and k9s to navigate rapidly over kubernetes things and seek the clues
Yeah I already am using k9s it's awesome
obviously though ingress will not work in kind unless u apply metallb btw
error: resource mapping not found for name: "traefik-dashboard" namespace: "default" from "ingressroute.yaml": no matches for kind "IngressRoute" in version "traefik.containo.us/v1alpha1" -> Which leads me to try and define IngressRoute but then other errors ensue ...
dev env for kubernetes requires too many things, i just use kind in terraform-opentofu locally 😋
That helps me locally to go through all issues before i try to intergrate it working in our staging (and facing new arrays of problems)
And when I try to do another type of ingress for the traefik dashboard it just doesn't work...
resolving those issues can indeed take a whole 4h or smth
it is just literally beyond the... limits of this channel 😅
we try to help in a reasonable some time
but debugging such issues can indeed take 4 hours and more 🥲
Yeah I know, that's what I've been stuck on since this morning 🥹
hey Darkwind if you are available my server is not running and i do not know why?

that totally depends on type of your deployment strategy/target (where u deploy it)
I am deploying a Django project in AWS EC2
okay then it makes it compatible with my ways. i am using AWS too 😅
curllocalhost of your website from within EC2 sever within and check if it works
- check that u binded Django server to 0.0.0.0 for public exposure
- it does not: https://paste.pythondiscord.com/LBUA
- check that your EC2 security stuff configurations allow traffic from IPs to ports u wish
- check that your EC2 is even having public IP
what is biniding, is that not security groups?
- check any other custom networking that u touched for it
i think they do, so i have to ssh into port 80, i can only ssh into port 22

it has an elastic IP
i dont think i did that but idk
gunicorn your_app.smth -p 0.0.0.0 (rough example, or python3 manage.py runserver -p 0.0.0.0)
smth like that stuff exists, if you bind your web python server to 127.0.0.1, it will be acessable locally only
if using 0.0.0.0, it will be exposed beyond host network to all attached networks to the host
what do i have to change?

that is a rough example
u are supposed to fix it where u launch your app inside host
to check to which port u binded
ergh... u can actually validate it by googling to which port/ip my app is binded and making scan over your host if desired (through the found commands)
what are we looking for?

we can see from this stable your app running at 0.0.0.0:80 ip listening to everything
so your are good at this department
also it listens to all ipv6 too (potential screw ups to be prepared, there are always some kind of screw ups with ipv6 😅 )
what does this mean? run it at port 80?

new error lets go!

only sudo level users can access ports below 1000 or smth like that
login as sudo if u wish binding to 80
sudo -s
does that not take me out of the venv?

it does take you out of a venv. relogin to venv again source path_to_venv/bin/activate
or run your app as path_to_venv/bin/python3 manage.py runserver (if wishing running with venv without its activation)


you haven't used the commands I provided
u made mistakes both times in missing parts
what did i miss?
u haven't wrote source the first time
and u wrote python with space in the beginning the command to be path_to_venv/bin/ python instead of requested path_to_venv/bin/python3
are you able to read english directly hmm? 🤔
new error!

u managed to make mistake once again in executing my initial request to use one thing or another one (but not both at the same time!)
#tools-and-devops message
#tools-and-devops message
i have to go now, gl
is it activated?


what is my endpoint ID?

@rapid sparrow since we talked about it earlier: https://github.com/traefik/traefik/issues/10986

GitHub
Welcome! Yes, I've searched similar issues on GitHub and didn't find any. Yes, I've searched similar issues on the Traefik community forum and didn't find any. What did you do? I am...
Hey if I want to get going with spark, should I deploy all the spark, kafka, zookeeper etc in docker images? Someone once told me to always do kafka in docker never local, is it the same for others as well?
even the database?
why does epel-release not install normally?
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ sudo yum install epel-release
Last metadata expiration check: 1 day, 2:29:14 ago on Tue Aug 6 17:53:05 2024.
Error:
Problem: conflicting requests
- nothing provides redhat-release >= 7 needed by epel-release-7-14.noarch from epel
(try to add '--skip-broken' to skip uninstallable packages)
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ sudo dnf install epel-release
Last metadata expiration check: 1 day, 2:32:09 ago on Tue Aug 6 17:53:05 2024.
Error:
Problem: conflicting requests
- nothing provides redhat-release >= 7 needed by epel-release-7-14.noarch from epel
(try to add '--skip-broken' to skip uninstallable packages)
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$
how do i install for centos7?
You broke your repos
how do i fix them?
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ sudo yum install epel-release-7-14.noarch
Last metadata expiration check: 1 day, 9:36:12 ago on Tue Aug 6 17:53:05 2024.
Error:
Problem: conflicting requests
- nothing provides redhat-release >= 7 needed by epel-release-7-14.noarch from epel
(try to add '--skip-broken' to skip uninstallable packages)
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ sudo dnf install epel-release-7-14.noarch
Last metadata expiration check: 1 day, 9:36:20 ago on Tue Aug 6 17:53:05 2024.
Error:
Problem: conflicting requests
- nothing provides redhat-release >= 7 needed by epel-release-7-14.noarch from epel
(try to add '--skip-broken' to skip uninstallable packages)
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ python install epel-release-7-14.noarch
python: can't open file '/home/ec2-user/tsupdate/thought_sync_django-channels/install': [Errno 2] No such file or directory
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$ python3 install epel-release-7-14.noarch
python3: can't open file '/home/ec2-user/tsupdate/thought_sync_django-channels/install': [Errno 2] No such file or directory
(thought_sync_django-channels) [ec2-user@ip-172-31-19-47 thought_sync_django-channels]$
Repos are configured in /etc/yum.repos.d
what should i add to the repo?

You are on amazonlinux. No epel for you
then what is wrong with the server?


i have i think?

You didn't activate your venv after becoming root
i ran pipenv shell? should i run something else?
did i do it wrong?




Stop installing epel


You should provision a new vm
Hey, where should i ask questions regarding Big data like Apache Hadoop or Spark?
what does that mean? make the venv somewhere else? where?
kill your ec2 vm and recreate it
it needs to be put out of its misery
i can kill a port how does one kill a vm?
delete it

my live reaction to this
two in the heart, one in the head
wait so i get into my venv using:
cd tsupdate
cd thought_sync_django-channels
and then running
pipenv shell
where in this process do I run
rm -rf somethingsomething how do i path to the venv?
do you know the difference between a vm and venv?
oh virtual machine versus venv
how do i kill a vm then? i am on a vm? is that not the instance? you mean terminat the instance i make a new instance?
do it in the ec2 console
is there a virtual machine killing option?

terminate?


now is there a specific type of instance i should make?

like know that i know more is amazon linux the best option?
just stick to amazonlinux
are my security groups good? i think it might be reverse proxy but idk how to do that, should i get nginx?



Using aws dns needs to use port 80
Stack Overflow
I've developed a simple Node.js/Socket.Io server running on EC2 instance on port 3000.
There is a load balancer setup for that instance and an elastic IP pointing to it too.
However I've added t...
Try using the ip
export the security group?
connect to the ip:port
in the terminal or in here?



it working

now we have to get daphne and redis working
daphne is up
redis is not working

lmao
What's the difference between the cloud and the arrows in VS Code? I pushed both branches, and I can see both of them in my GitHub account. When I pushed the master branch I used the -u command (git push -u origin master), and when I pushed ap, I didn't use it.
As I understand, -u makes git remember the branch as the default branch to push future commits to. I didn't want to make ap the default branch, so I didn't use -u.
By the way, when I created my first repository through VS Code's GUI, it called the main branch main, and when I used git init in a different repository (the one in the screenshots), it called it master 🤔
yeah, some code that uses git has changed the name of the default branch from "main" to "master". There's nothing significant about that; it's just a convention
If you don't push with -u, vscode won't know there's a remote tracking branch, so it will offer to "publish" the branch.
Run git config --global init.defaultBranch main
is there a way to hide config file which includes my API key ( i didnt push the files in yet) in my repository on github? i heard about gitignore but idk how to implement it
is that bad, or can I ignore it?
Use .env file, read about environment variables on internet
Aight
No.
Like make it not tracked by git? Then create file .gitignore in root of your repo and create entry there with your config file path
If you want to have that in GitHub or similar there are options to store keys secure in secrets or something like that can't remember exactly the name now. By doing that. These keys are then available to GitHub actions.
I wanted help making a dependabot.yml file that would update workflows and also make a pull request when packages need to be updated
where would be ask to this?
packages should be specifically pull requested
workflows can be automatically updated
version: 2
updates:
- package-ecosystem: "devcontainers"
directory: "/"
schedule:
interval: "monthly"
- package-ecosystem: "github-actions"
directory: "/"
schedule:
interval: "monthly"
groups:
ci-dependencies:
patterns:
- "*"
- package-ecosystem: "pip"
directory: "/"
schedule:
interval: "monthly"
groups:
python-dependencies:
patterns:
- "*"
I have this rn but I want it to make a pull request for package updates.
But I want it to update when a workflow is changed
The reason why I want dependabot to automatically update workflows is because it's harder for me to update them but package updates is something I myself can do so I tend to do it myself
some people recommend changing the default terminal in VS Code to git bash. why? how is it better than powershell?
Git Bash installs Bash on Windows, but then it also installs a bunch of really useful command line tools that aren’t available on Windows.
However
Windows has WSL now, which is the same thing but a million times better, and you should use that instead.
I didn't really understand what you mean here
could you rephrase your question?
the wolf/dog guy above helped me out thankfully
GitHub
Api version of Connie Melody Skye. Contribute to JDJG-Holding-Team/Melody-Api development by creating an account on GitHub.
okay
what's automatic in that?
also, isn't that the same Dependabot config you already shared?
how do I trigger a GH actions, on a cronjob or if the commit message contains some word?
I found this to accomplish the latter, but how can I integrate it with my cronjob?
Stack Overflow
I need to make sure to test with github action, if a commit has previously been made that contains the word build.
If the commit does not contain the word build then tests with github action should...
on:
schedule:
- cron: "15 4,5 * * *" # <=== Change this value
GitHub Docs
if u use hackery like this for if conditions, then u need to create two Workflow files.
one that is working on commit, and uses this if condition
and second one working on cronjob
they both can be reusing same shared workflow code
jobs:
check-translation-fuzzy:
name: Prevent fuzzy translation
uses: Orgname/actions/.github/workflows/check-fuzzy.yml@master
as example
the reusable workflow will need to have permission being called on workflow_call
name: Checks .po files for fuzzy translations
on:
workflow_call: {}
jobs:
lint:
name: Prevent fuzzy translation
runs-on: ubuntu-latest
steps:
- name: Check out source repository
uses: actions/checkout@v2
- uses: Orgname/actions/locales-check-fuzzy/@v4
I see, so basically 3 files. one for the actual job definition, and two for each condition
didnt think about that solution
are there any alternatives tho?
yes
u can do it with a single workflow file
if u change your regarding if: "!contains(github.event.head_commit.message, 'build')"
Replace it with stuff like
on:
release:
types: [published]
or
on:
release:
types: [created]
GH has special trigger to run on Github Releases created
probably on tag creation exists too
https://docs.github.com/en/actions/writing-workflows/choosing-when-your-workflow-runs/events-that-trigger-workflows
Check options there
GitHub Docs
we in company use running build creation/deployment of a library on git release published)
Then u will be able to merge your conditions into a single workflow file
on:
schedule: your cron schedule
release:
types: [published]
I dont get it, how can you include everything in the same file? here you are not checking if the commit contains the message? (and if you add the check then it will fail on cronjob ...)
I need smth like
on:
schedule:
- cron: '0 7 * * *'
push:
branches:
- master
jobs:
build:
if: "!contains(github.event.head_commit.message, 'abcd') or is_cronjob(...)"
i said do not check if the commit contains the message
use alternative optional triggers
through on Git Tags or on Github Release creation instead
on:
push:
tags:
- v1.**
Git tags are git native solution that u can create with git alones
oh so smth like on: push: tags: - "trigger actions"
yup. That is assuming u need to build only on releases of your app (besides cron)
Alternatively if your optional trigger stuff is not tied to product releases at all... then just use workflow_call, for human allowed CI trigger from GUI (probably usable from gh cli too)
through githooks it can be triggered then automatically on specific commit message 😁https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks
I think this is what I'm looking for.
cuz sometimes I want to test the actions after a commit (but not always).
the issue is that on the website if you run a workflow manually it runs on the same commit ref, not the latest one, so it accomplishes nothing in my use case
with git filter-repo, after I run the command to rewrite the history, how do I publish to the remote? (git status says there are no changes )
git push
if u rewrote then git push --force-with-lease
I'm missing something:
$git push --force-with-lease
fatal: No configured push destination.
Either specify the URL from the command-line or configure a remote repository using
git remote add <name> <url>
and then push using the remote name
git push <name>
okay then set remote first then
git remote add origin git@github.com:browserpass/browserpass-extension.git for example
u can clarify what u have set with git remote -v
once u configured remote origin, then u can normally use git push (the first one will be with extra flag potentially though)
it says to do git push --set-upstream origin master, but then rejects the push because "the tip of your current branch is behind its remote counterpart"
git push --set-upstream --force origin master
this will overwrite history of remote
with also setting remote as its remote target
be careful in its usage)
thanks so much it worked
after u do it once, next time it will be just git push
now I just gotta hope I didnt mess anything up

really thanks for the help
Please tell me about your favorite plugins you use in pycharm, I want to customize my workflow
try asking in #editors-ides, instead
I'm trying to learn AWS features in prep for an interview, but I don't know how to create a database without costing me. It says it's in free tier, but both options for configuring Dynamo and RDS are saying they'll cost me. Any help?
dynamo is so cheap that I wouldn't worry about it.
RDS is a whole different story -- I considered using it for a toy project, and the cheapest I could find was I think $70/month
!rule ad
I am setting up elastic cache to use redis service, any recommendations on how to change the settings?

- changing settings in AWS with terraform is recommended
- Serverless is many times more expensive for such types of infra than using persistent server

Hi all, I put together a dead simple pulumi (python flavor) gist to configure daemon sets to multiplex GPUs by configuring the nvidia-device-plugin: https://gist.github.com/MMMarcy/8f8bc3f660e01eb46cf28c654d373a62 .
It's helping me to run several small LLMs and embedding models on the same GPU from my minikube instance. Not sure this is the correct space, but hopefully it's useful for someone messing around with LLMs/K8s like I am doing

Gist
configure nvidia-device-plugin in K8s using pulumi - example.py
How I am supposed to access terraform, is it free?
Yes, there is a community version. There is also OpenTofu.
is there any specific settings I should be concerned with changing?
I am not sure I understand the goal. You can create an ELK stack and a REDIS service in a lab for free. Is this for educational purposes, or is there some other goal?
i need the REDIS service to function for an AWS server that is deploying a Django app
@heavy knot So, you have Django inside an EC2 instance?


If the Redis service is strictly for Django, I would run as a service in your EC2 instance. Then the site can talk to it using localhost. I am not sure how the cost would compare. I would think just a service on the EC2 instance would be less expensive than the Redis service offering. Have you considered that as an option? https://serverfault.com/questions/1127483/how-to-install-and-configure-redis-server-on-amazon-linux-2023-al2023

Server Fault
Amazon Linux 2023 is loosely based on Fedora 34, 35 and 36 as per aws:
https://docs.aws.amazon.com/linux/al2023/ug/relationship-to-fedora.html
However redis package is not available in AL2023, inst...
the whole point of getting redis service to work is so that the websocket works for user interaction, how do i test that this installation of the service works by using postman to test the websocket?
You would need to edit the redis config after installation. You could set permissions and access rules in it. Once you have that defined, you can use whatever tool you want to verify that the endpoint is reachable. https://stackoverflow.com/questions/19091087/open-redis-port-for-remote-connections
Stack Overflow
I can ping pong Redis on the server:
redis-cli ping
PONG
But remotely, I got problems:
$ src/redis-cli -h REMOTE.IP ping
Could not connect to Redis at REMOTE.IP:6379: Connection refused
In co...
You can limit it by IP on your firewall if you know what IPs need access.
8001 is for daphne, 8000 is for the server, is there some port redis service uses?
By default it is 6379, but you can set it to whatever in the config file in the /etc/ directory. By default it will bind to loopback but you can change it to your IP address or 0.0.0.0 to bind to all interfaces.
this explains that i need a config file but does not explain what should be in the config file: sudo nano /etc/redis6/redis6.conf
Most of the defaults are probably fine, this is the section that configures whether it will listen to an interface other than localhost. Here is some reference docs, too. https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/install-redis-on-linux/

How to install Redis on Linux
should i use administration, security, or replcation for Redis?
I don't think you need any of that on a single node install. You can just set the bind address list and start the service with systemctl.
Maybe this is helpful? My config is just at /etc/redis.conf

i found this online, would this work?

Yeah, try firing it up at the command line with something like this. It will tell you if there is an issue. I gotta step away for a bit, be back in an hour or so. You can find the binary like this...


So, /usr/bin/redis-server /path/to/config.file, something like that.
darn, what did i do wrong with my settings?
#Redis will listen on this port
port 6379
#Bind to all network interfaces. For better security, consider binding to specific interfaces.
bind 0.0.0.0
#Enable or disable TCP keepalive
tcp-keepalive 300
# Number of databases. By default, Redis has 16 databases.
databases 16
# Maximum memory usage. Redis will start evicting keys if this limit is reached.
# Uncomment and set the value to a specific amount of memory.
# maxmemory 2gb

# Eviction policy when memory limit is reached. Options: noeviction, allkeys-lru, volatile-lru, allkeys-random, volatile-random, volatile-ttl
# Uncomment and set the value as needed.
# maxmemory-policy noeviction
# Save the database on disk every 900 seconds if at least 1 key changed
save 900 1
# Save the database on disk every 300 seconds if at least 10 keys changed
save 300 10
# Save the database on disk every 60 seconds if at least 10000 keys changed
save 60 10000
# Append only file (AOF) configuration
# Enable AOF persistence (recommended for durability)
appendonly yes
# AOF rewrite policy, options: always, everysec
appendfsync everysec
# Set the name of the AOF file
appendfilename "appendonly.aof"
# Enable Redis to write a disk snapshot every time it is saved
rdbcompression yes
# Enable Redis to use rdb files for persistence
rdbchecksum yes
# Log level: debug, verbose, notice, warning
loglevel notice
# Path to the log file
logfile "/var/log/redis/redis-server.log"
# Daemonize the Redis server (run in the background)
daemonize yes
# Set the Redis server PID file
pidfile /var/run/redis/redis-server.pid
# Security configurations
# Require clients to authenticate with a password (uncomment to enable)
# requirepass yourpassword
# Use a Unix socket for local connections (optional, enable if needed)
# unixsocket /var/run/redis/redis.sock
# unixsocketperm 700
# Enable protected mode (recommended for security)
protected-mode yes
# Disable commands that could be harmful if exposed to the public
# Uncomment the following to disable dangerous commands
# rename-command CONFIG ""
# rename-command SHUTDOWN ""
# rename-command FLUSHDB ""
# rename-command FLUSHALL ""
# Specify the server's time zone (optional)
# time-zone "UTC"
# Include additional configuration files (optional)
# include /etc/redis/redis-user.conf
# Path to the Redis server binaries
/usr/bin/redis-server /path/to/config.file
./redis-server /path/to/redis.conf
Change daemonize to no for more output, set loglevel to debug, for troubleshooting, also, try running as root or with sudo to see if it is permissions. One of those should give more insights on the issue.
Oh, and if the log file that is listed is empty, it could lack write permissions to that or something similar.
what should i write to the log file? also what does this warning mean?

is it just this but in /var/log/redis/redis-server.log?
logfile "/var/log/redis/redis-server.log"
loglevel debug
Try this one... this gives the redis user access to the directory it uses to store stuff by default.

survey says: "no". hmmm what user besides sudo would there be?

Sudo is not a user
Sudo changes the currently logged in account from your user to the root account, and then executes the command you gave it
If the redis user doesn't exist, you will need to create it
I'm surprised the installation didn't create it, which makes me wonder if it was installed correctly
Normally, it gets created during package install, but maybe the Amazon Linux instance has a minimal package of some sort? You can check the service definition to verify that it is trying to run as redis, and if it is, create a redis user using the useradd tool.
This shows the service definition file

Command to view contents of file is sudo cat /usr/lib/systemd/system/redis.service
Contents will look something like this, showing the user. You can view users on the system with sudo cat /etc/shadow This gives info on adding a user. https://www.geeksforgeeks.org/useradd-command-in-linux-with-examples/

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
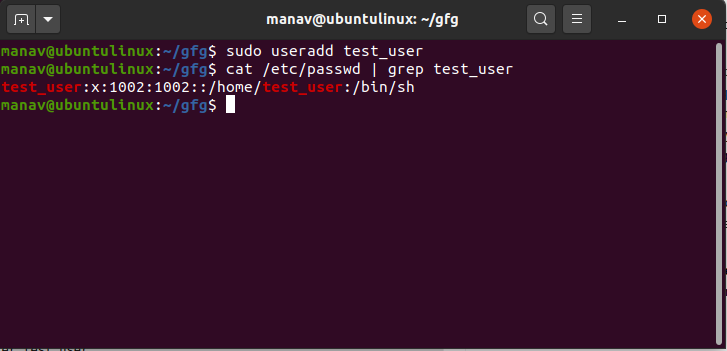

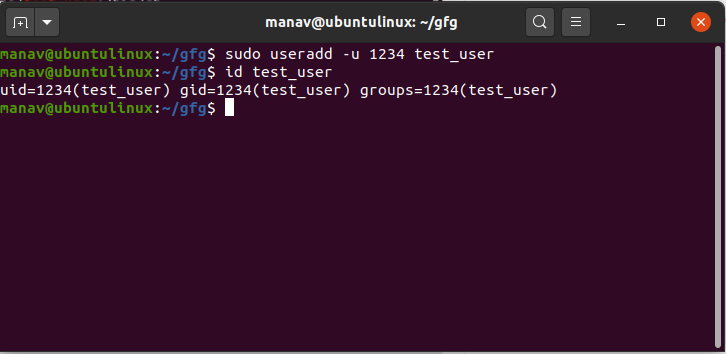
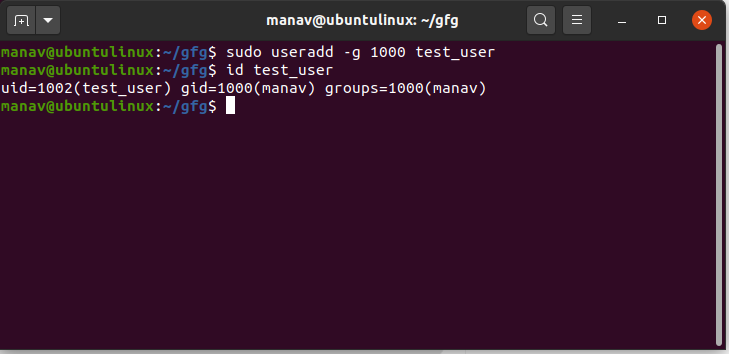
do i already have a user or do i have to set one up?

Looks like it is redis6, try running that command again with redis6:redis6 instead of redis:redis. I bet it is running as that user.
Those errors about /etc/nginx being a directory are because cat is for files. You can view what's in a directory with ls.
seems to work but i get a similar error?

sudo cat /etc/systemd/system/redis.service

Try editing that file and change it to redis6, then run sudo systemctl daemon-reload , then restart the service again.
Edit with sudo nano /etc/systemd/system/redis.service or whatever text editor you like to use.
hmmm

is there something else wrong with my settings
sudo cat /etc/redis/redis.conf
? why can it not mkdir?

Where is your config file? sudo ls /etc/redis sudo ls /etc/redis6 ?


Your service file /etc/systemd/system/redis.service is pointed at /etc/redis/redis.conf, but your config is /etc/redis6/redis6.conf. You could copy the file or update the service, I think I would update the service definition. It seems the installer package had some settings from redis6 and some from a previous version??
sudo systemctl status redis6 Is there another service called redis6?
less errors but differnet?

sudo systemctl stop redis && sudo sytemctl disable redis
sudo systemctl enable --now redis6 && sudo systemctl status redis6
we have green?

Maybe there was a different version installed by default. not sure, but it looks like you have two versions installed, but that's fine, the other one is disabled now.
thank you for everything you have been very helpful!!!
your patience knows no bounds
if you want to stick around I think I am going to get an app to run right about now 😪
if this does not work back to the chair (coding) for me
what should be my daphne settings, my websocket is not connecting?

we need to connect websocket

Not sure off hand, what do you get when you run this command curl -k http://localhost:8001

What's the error? Or are you sending me a link?
if that pastebin does not work let me know
the error is large
i could not fit it all on in the paste bin
but you get the idea
html stuff for daphne?
nani?
sudo dnf install lynx -y && lynx http://localhost:8001
we opened a portal to hell!

the portal to hell closed itself?

So, this fails daphne -b 0.0.0.0 -p 8001 django_project.asgi:application with whatever your app is, I assume at the end?
it dose not "fail" it can not connect

if it would work this would say "Connected"

Lynx is a text web browser, sometimes useful to check html pages in a terminal session. https://en.wikipedia.org/wiki/Lynx_(web_browser)

Lynx is a customizable text-based web browser for use on cursor-addressable character cell terminals. As of 2024, it is the oldest web browser still being maintained, having started in 1992.
what does the html page know?
I got you, so we are getting ahead of ourselves. Is the app configured to only respond to certain requests? I mean if you were on the computer that is running the app, should you be able to load the web page? I am trying to make sure it loads locally before I connect over a public IP.
i am not sure what the app if properly configured to respond to? I think the server? here is the repo if would like to see: https://github.com/K2GHub/tsupdate.git
Does it matter what version of Django or Python?
i would assume not but maybe
Alright give me a bit, I will see if I can get it to load.
I will have to afk for about an hour brb
Ran this, then verified it is loading with Lynx internally by runnning lynx http://127.0.0.1:8000/auth I ran on port 8000, and the page loads locally, so that's good.


So, now, probably all about firewalls, VPC, security groups, etc.
What's this look like? sudo firewall-cmd --list-all. Oh, and press "q" to get out of lynx when you are done browsing pages.
I have returned


sudo firewall-cmd --add-port=8001/tcp --permanent
sudo firewall-cmd --reload
yay

That should add port 8001 to firewall exceptions. I believe you are running on port 8001 so you should be trying to connect on http://127.0.0.1:8001 with lynx, not 8000.
? am I snytaxing wrong

I am not familiar with where you are connecting from. Does your ec2 instance have a public IP assigned?
yes: PublicIPs: 3.217.114.187
Have you registered that domain name?
Did you add an allow rule to your security group in AWS?
Use security groups and security group rules as a firewall to control traffic to and from your EC2 instances.
If you know where you are connecting from, you can add an exclusion just for your IP, so you don't open to the whole world.
You can get your public IP for your home Internet at https://ipchicken.com
If you add the security group exception, the next test would be attempting to connect via https://3.217.114.187:8001/auth or whatever page for the last part.
If that works, then you can check if your domain name is correct by doing a lookup of the IP for harmonyapp.org

The domain does look correct.



nvm, big lag spike. is the format correct for /auth

Hey peeps, sharing with you my Pixi, Flask, Jupyter, and Docker template for your new project https://github.com/mshaaban0/pixi-docker-template.git
(should get you started with one command if you have docker installed) hope it helps someone 🪓
GitHub
A Python project boilerplate template for new projects with Pixi, Flask, Jupyter Notebook and Docker Compose. - GitHub - mshaaban0/pixi-docker-template: A Python project boilerplate template for n...
Looks like it, maybe missing the SG rule? Something is blocking the inbound request.
There should be a spot in the console where you can make exceptions for inbound traffic. It should look something like this.

what should the source be?

Well, you could set it to 0.0.0.0. That will let the world access that port, or for testing, it's often better to narrow that so you don't get many unwelcome visitors. You can usually determine the IP you use on the public internet by visiting https://ipchicken.com and refreshing it a few times to see if your IP is fairly predictable.
Also, I'm pretty sure you are hosting on port 8001. If you are unsure, you can also enter a port range. You use the hyphen to denote a range like this. Eventually, you will want to configure SSL and possibly limit to relevant IP ranges, as well as monitor for any security vulnerabilities in Daphne/Django, etc.

not only did it not help websocket it stopped the server? I tried 0.0.0.0 and My IP, what is wrong?

What does your inbound exception look like, and did you try port 8001? I am pretty sure your API is on 8001.
oh wait redis is not working:

Aren't you using the redis6 service?
you are right

wait does "active running" mean i should run a command like daphne?

or maybe it is not the problem
is inbound exception different than security groups?
Inbound Exception tab in the Security Group.
also daphne is inactivate?


What do these referenced entries look like?

like this?


Yep, that should definitely open it up. Run the daphne command that starts the service. daphne -b 0.0.0.0 -p 8001 whatever
It's up..

You are going to want to restrict that soon. People are going to start trying to hack at it before too long if you leave that open like that.
but somehow the websocket does not work?

Is the websocket an internal connection? Is the app supposed to connect to a service running on the same server? Should it be pointed at localhost? Maybe the API doesn't need to be exposed? It depends on how the application is architected. Also, what is the UI you are using to test? Is that Postman? I am not that familiar with Postman.
the websocket and the server are not connected. i do not know the answer to the rest of the questions, here is my repo if you would like to view it: https://github.com/K2GHub/tsupdate.git
What happens if you try to connect to Google in that tool you are using?
oh, am i using it wrong?

I'm not sure; maybe I will read about it. I will let you know if I find something.
Some Googling makes it sound like you need to create the Websocket in your code, but I don't see any references to websocket creation in the code. https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_client_applications


MDN Web Docs
WebSocket client applications use the WebSocket API to communicate with WebSocket servers using the WebSocket protocol.
Could be that http:// and https:// are not valid for the Websocket King tool.

It looks like you need to configure a secure connection if you want to use Websocket King to troubleshoot and send POSTs to the endpoint.

new information: www.google or https.google ar enot websockets. websockets are essentialy connections that need to be made betwene users witihn the app using their user ids: their format is:
ws://IPorDOMAIN:PORT/ws/home/94be4db4-c018-43e7-9c44-c0bb8854129d/
therefore they should look like:
ws://3.217.114.187:8001/ws/home/94be4db4-c018-43e7-9c44-c0bb8854129d/
or
ws://harmonyapp.org:8001/ws/home/94be4db4-c018-43e7-9c44-c0bb8854129d/
If you try to use Websocket King, you still get the error. It sounds like you need to configure SSL before you can use Websocket King for testing.

how do i configure SSL? let's encrypt?
also what should my daphne group be? how should I config daphne?: https://pastebin.com/PAJ2PpDS

how do i make nginx publicly accessible?

Any apps, programs or scripts that can export a USDX format txt file to a midi or kar file?
https://youtu.be/RsPDDozg_PA?si=B4glvmjzgj7Ut49J
"I think it would be fairly easy for someone to make it. "
Says someone who only knows html, php
Any apps, programs or scripts that can export a USDX format txt file to a midi or kar file?
USDX - UltraStar Deluxe
USDX, My Little Karaoke, Performous, Vocaluxe
Might be a more universal name for the format.
Many goes from midi to the proper format but not the other way.
Part of txt file..
#COVER:cover.jpg
#BPM:320
#GAP:35200
F 0 0 0
F 8 6 6...
forward port 80 in your aws security console
and port 443 if you use https
Like this? This does not work so idk what to do? I also need to get daphne service functioning, and set up SSL certificate, and correctly select a group for daphne
