#data-science-and-ml
1 messages · Page 392 of 1

Hey guys
So I have a dataset which contains like 28 records.
Is it feasible to run ANN on this dataset?
It's a regression problem
oh man i should just take a bayesian class tbh 
honestly im not even trying to go too far into bayesian stats. i only listened to that podcast bc one of my favorite podcasters was a guest on that show
but thanks for the guidance
i bookmarked the references anyway
depending on the problem/data, maybe it would be ok with a small network (small number of features and hidden nodes)
but 28 is really small. like maybe even small for traditional linear regression
depending on what you actually want to do, you might want to take a more statistical approach to solving your problem
Hmm okay
Thank you my sir
[0, 1, 3, 5, 21, 22, 22, 24, 25, 25, 26, 27, 31, 32, 34, 40, 40, 42, 43, 44, 47, 50, 52, 55, 56, 56, 57, 58, 58, 59, 60, 63, 74, 76, 76, 80, 83, 84, 84, 86, 86, 87, 88, 90, 91, 91, 95, 97, 97, 100]
okay so I have a sorted array like this: to get half of it I do
half_data = data[:len(data)//2]
but for getting all the data after the half
like the first half of data gets cancelled
Um how do I get the second half of the data? or well 24th index
got it
What was the problem that was happening?

maybe just say "Missions", not "Total Missions" on the y axis
also the graph makes sense but it's pretty ugly data for a histogram
what is the bin size? you should state that imo
with small datasets, histograms are really sensitive to the bin size
i'd suggest maybe adding a "rug plot" to the bottom showing all the individual missions

A rug plot is a plot of data for a single quantitative variable, displayed as marks along an axis. It is used to visualise the distribution of the data. As such it is analogous to a histogram with zero-width bins, or a one-dimensional scatter plot.
Rug plots are often used in combination with two-dimensional scatter plots by placing a rug plot o...
Hi I keep trying to run my code but its not running properly ```import scipy.integrate
import numpy as np
from matplotlib import pyplot as plt
from scipy.constants import G
from scipy.constants import m_e
from scipy.constants import m_p
from scipy.constants import c
from scipy.constants import hbar
#defining constants
C=0.86
#h_bar = 1.05457266e-34
Ye =[ 6/12,26/56] #carbon-12 nuclei and iron-56 nuclei
#c= 2.99792458e8#speed of light
#G=6.67259e-11#gravitational constant
#me = 9.1093897e-31#mass of electron
#mp = 1.6726231e-27 #mass of proton
h_bar=hbar
mp=m_p
me=m_e
rh0_0 = (mpme**3c**3)/(3np.pih_bar)#natural unit for density
#define scaling functions
R0Val=[]#natural unit of length
#cycling through the 2 values of Ye the number of electrons per nucleon
for i in Ye:
R0=np.sqrt((C3imec**2)/(4np.piGmprh0_0))
R0Val.append(R0)
#defining first order ODE's
def rhs3(x, p):
dpdx = np.zeros_like(p)
M = p[0]
q = p[1]
g=q2/3/(3*(1+q2/3)1/2)#gamma factor us a function of q
dpdx[0] = 3qx2
dpdx[1] = -(CqM)/g*x**2
return dpdx#return the two coupled 1st order ODE's
sol = scipy.integrate.solve_ivp(rhs3, [0,1], [0,1], dense_output=True)
x=np.linspace(0,1,1000)
M=sol.sol(x)[0, :]
q=sol.sol(x)[1, :]```
thanks so much for your help on all my questions last few days man. Been super clutch, now going to write my 5 page report. Cheers
Does anyone know any good ways to share my Jupyter Notebooks? I know the company probably wants instructions on how to use it
you can share the .ipynb file as-is and they will be able to see the outputs you saved to it
you can also use nbconvert to export it to an html file or even pdf
so in my instructions they ask for "we’d also like you to include any code you wrote along the way to generate it."
Is it still okay to share the .ipynb or are they wanting something different
Make a readme for this
and code can be inside a jupyter notebook
man thank you for reminding me!!!!
Hi, I have a question: Why I got different version of PyTorch?

@bold timber must be different virtual environments
How to fix that?
you need to start the jupyter notebook using the same virtual environment for the pip call on the left. unfortunately it would be very difficult to walk you through this remotely.
you can run import sys; print(sys.executable) in the notebook, and which pip in the terminal, and see if they're in the same folder.
I am trying to write a helper function for this json tuple that i am currently working with
i tried to unpack the tuple
but it doesn't appear to be working
strings = []
for row in r.json():
strings.append(json.dumps(row))
strings
tooples = []
for row in strings:
tooples.append((row,))
tooples```this is the conversion i did
i want to pull the entire row based on race
however my attempts at unpacking this are falling short so i'm not sure what i'm forgetting in trying to access this data
i'm using sqlite3
no one is going to want to look at this. if you paste a few lines of it into the chat as text, that would be sufficient to establish what is happening.
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Any context? :) @pseudo wren
yes!
so
i converted this dictionary to be able to put into my sqlite3 server
i converted it into a tuple
and now i want to write a helper function that will parse through the "race" section and return rows based on race
i also want to be able to return rows based on year
i'm new to using sqlite3 with python
so i'm not super sure how to execute this. I tried to unpack it like a regular tuple, but it didn't work.
Oh. I'd normally just use pandas, so I don't really know
I did import pandas
But this is like
A tuple
With a string of dictionary inside
So i’m trying to figure out the best approach
When I want to import torch it did happen. How to fix this?

Maybe get the string tuple and split it from the commas?
the ipynb is the code. but you should at least also list the packages you installed that are required to run it.
did you try looking into "restart jupyter notebook kernel"?
your question about why your torch versions were different is fine as there weren't any obvious leads for how to resolve it. but if you ask "how do I fix this?" every time something goes wrong, you won't really develop any debugging skills.
anyone help plz

this question belongs in #tools-and-devops
ty
It needs the commas to be read the correct way
!e
data = (1, '{"year": "2019", "leading_cause": "Alzheimer\'s Disease (G30)", "sex": "Female", "race_ethnicity": "Asian and Pacific Islander", "deaths": "50", "death_rate": "7.719849741", "age_adjusted_death_rate": "6.207494885"}')
import json
def tuple_unpacker(data):
(tuple1, tuple2) = data
dictionary = json.loads(tuple2)
return dictionary["race_ethnicity"]
# function call
tuple_unpacker(data)
@misty flint :warning: Your eval job has completed with return code 0.
[No output]
ah shoot; forgot to print
well it returns this

but the thing is
this is just for unpacking for one row (but you can loop through it, etc.)
if you want it to return rows by race_ethnicity or by year, i recommend 1) unpacking and then 2) sending it to either an actual SQL database or pandas dataframe
so you can use the groupby function on it
otherwise you would have to create some sort of sorting algorithm if you try to do it all in one place
which does not sound like fun to me
but i mean you could do it if you want
i guess if its already unpacked, you could do a lot of things to it already

Lmao coffee bribe
why is logistic regression a classification model?
hey not sure if this is the right channel for this question, but what kind of graphs do you guys suggest if im trying to display frequency of data by location?
for example imagine a square separated into 3x3 sections. Each section has a numerical data associated with it, and I'd like to see which section gives me a high/low/most often etc
I have a question
For sufficiently complex feature mappings, what problematic issue will we encounter that is particular to Logistic Regression
2D histogram
Thanks! I'll give it a try, from pictures looks like something that's really applicable for my case
Its a binary classifier
Actually used that once lmao
does it output a number between 0 and 1? so logistic regression cannot be used with more than 2 groups? couldn't you use any regression model for binary classification?
Two groups only
Ok regression can be done with two groups if we set a threshold value
so
features... binary value
1 x y z 1
2 a b c 0
...
In statistics, the logistic model (or logit model) is used to model the probability of a certain class or event taking place, such as the probability of a team winning, of a patient being healthy, etc. This can be extended to model several classes of events such as determining whether an image contains a cat, dog, lion, etc. Each object being d...
Says Mathematically, a binary logistic model has a dependent variable with two possible values, such as pass/fail which is represented by an indicator variable, where the two values are labeled "0" and "1"
So binary class
is the output of logistic regression a binary class, or a decimal between 0 and 1; will it say 0, or something like 0.21?
source: https://www.analyticsvidhya.com/blog/2020/11/popular-classification-models-for-machine-learning/

Classification is a basic type of problem every data scientist must know. Let's have a look at various classification models in ML.
If it is a binary logistic regression 0 or 1 ...if plain logistic regression it can have intermediate I think
So least squares in linear regression vs sigmoid in logistic regression

In this step-by-step tutorial, you'll get started with logistic regression in Python. Classification is one of the most important areas of machine learning, and logistic regression is one of its basic methods. You'll learn how to create, evaluate, and apply a model to make predictions.
Sample there did binary class
Typical logistic regression use
Because they did a "common case of logistic regression applied to binary classification"
Dont cry it wont fix your code lmao
It is linear classifier like linear regression if the relationship between the variables are non linear or complex the model wont be too accurate
yeah but that's not particular to logistic regression, that's in linear regression too


If distribution is gaussian use linear regression if binomial use logistic regression...using logistic regression where the distribution doesnt match will hurt model accuracy
how do you get the coefficients and intercept for multiple linear regression?
is jupyter notebook recommended for data science / machine learning?
Medium
In my last article https://medium.com/@subarna.lamsal1/linear-regression-normally-vs-with-seaborn-fff23c8f58f8 , I gave a brief…
Jupyter notebook good for EDA and small scale...if you are going to deploy your model to prod avoid it
Stochastic Gradient Descent updates the weight n-times.
n = sample size /number of observation.
So if your data has 5000 rows, the sample size = 5000. SGD updates the weight per each sample ; i.e in our case here 5000 times. So it updates your weight per each number of sample observation in your data.
The main difference between Gradient Descent & SGD is just how the algorithm updates the weight.
Gradient Descent takes in the data and update weight just once. (This usually don't escape getting stuck in the local minima) so using SGD helps us to avoid getting stuck in local minima
There's also Mini-Batch Stochastic Gradient Descent.
They are all variants of Gradient Descent. The major difference to me is just how each algorithm updates the weight.
I usually use JNB for modelling part, then switch to VSCode for deployment.
Makes sense...
By calling model.coef_ for weights (slope in Statistics) and
model.intercept for bias (in ML lingo) 😀
How do i get pandarallel to work? it just runs for hours without any error messages, the progress bars shows 0.00%. code: https://pastebin.com/WTHKDDSp
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
how does this code give me a negative values of y?
x=np.arange(0,100)
y=x**5
plt.scatter(x,y)
plt.show()

@drowsy hemlock thanks for giving a reproducible example! looks like the problem is that your integers are overflowing. if you do x = np.arange(0, 100).astype(float), the problem should go away.
the orange line is when I converted everything from integers to floats

!e
import numpy as np
result = np.arange(0, 100, 10) ** 5
print(result)
@serene scaffold :white_check_mark: Your eval job has completed with return code 0.
001 | [ 0 100000 3200000 24300000 102400000 312500000
002 | 777600000 1680700000 3276800000 5904900000]
hmmmmmm, bad example, I guess
ok thanks a lot.....
so will .astype fix overflow error while handling large datasets
the problem is the size of the numbers, not the size of the dataset
i ment large numbers in the datasets😅
Hi everybody i have quick question maybe someone has an idea. I am trying to learn what kind of model name branding different company are using. quick example
apple: iphone 13s, iphone 8s, iphone 12 pro…
Samsung: galaxy S21, galaxy A52, galaxy note…
so if a new modelname (G note 54)occurs without its brand my model should guess the most probable brand.
i know its quite easy here but this is just for explanation.
My main issue is idk how to transform my modelnames into a vector for the ml algorithm to use.
All i find are libraries for real text document classification but in my case its not really a whole text but only different modelnames i want to tranform and be able to transfer new occuring modelnames in the same way.
i am trying ascii encoding right now but idk if this is the smartest way
Make a python progarm that continuasly asks the user for a postive interger greater than 0. For every number enetered , your program must display pass if the sum of the of the squars of even digits is less then the sum of the sqaures of odd digits otherwise it must display fail. No input checking is required
I’m stuck on this question
Can anyone help me
@lavish rune this isn't a data science question, so try a help channel. see #❓|how-to-get-help
you can't really do this in a generalized way. knowing that something is the "iPhone 12" only tells you the brand and the order it was put on the market. those are two features. the names of Samsung phones tell you different things (there's the S series and the A series, whereas iPhone just has one series)
Thanks for the reply. But my problem was more that people just consider mini-batch GD as SGD
Some people just use them as synonyms which is confusing :/
.bm
@odd meteor @mild dirge the point i was making is that they are synonymous because they have the same properties. it's just scaling the batch size from 1 to "N".
yes, smaller batches => more weight updates and smaller (but possibly more erratic) update steps
batch size is a parameter to the optimization algorithm, just like learning rate is
oh okay but wont the model learn model names including iphone is more likely apple and a modelname including galaxy or note its a samsung?
well, iPhone is always apple.
these aren't things you need ML for.
you can do that, yes. you can tokenize the model name into words and even just look at a frequency table. most model names will uniquely identify a company.
like i said its just an simplified example but thats what i am generally trying to do
the best you can do for forecasting is just incrementing the number at the end 😆
Hello guys, i have a question. So, i was working in a dataset and it something has caught our attention. We are working in a dataset from spotify where we want to predict the music popularity. We are know on the phase of data preparation and we saw the some songs are duplicated. However, we can't call the fuction of duplicated() because there are songs with the same name but not with the same values(In other words, they just have the same name, but songwriter are another or is it a cover). In the screenshot that i post, you can see six rows, where four of them are repeated and the others aren't. The only thing that changes are the values of the song popularity, however they are the same song because they all the same value in the other features. We want to keep the highest values or a mean of it and remove the rows that are duplicating. What line of code can i do?

it's not clear if they're actually doing NLP or if they're just trying to encode the product names as features for some other purpose
copying my response from the help channel:
a song is not uniquely identified its name. you can have 2 songs of the same name by 2 different artists
they might be 2 different versions of the same song, or they might be 2 completely different songs that have the same title. you can have 2 different versions of the same song by the same artist that are substantially different. you can have 2 cover versions of the same song that are more or less interchangeable from a listener's perspective.
so my first question is: why do you even want to deduplicate at all? what does "unique" actually mean in your project?
and copying your reply:
Oh i didn't notice that u had channel for data science. sorry. However, if you notice the columns, there are various columns that make us understand if there was any change. Some of them are completely different songs and we can check it by looking in the values ( I just noticed that my printscreen didn't catch any of it) but other just change a value in song popularity and we can understand that is duplicated! But i apreciate your answer, because it make me thinking of it !
maybe its actually encoding as features because i want to find the neareast neighbour of an unknown modelname afterwards to guess the brand then
so you intend to use the genre scores to detect duplicates, that is a great idea @compact rose
you can't really solve this with one line of code though
you can use scipy.spatial.distance.pdist to compute the pairwise differences of all rows in an array, and then set a threshold on distance
or you can use hdbscan or hierarchical clustering
you could even manually label pairs and train a model, but that seems like overkill in this case
you can make this a lot faster if you apply the distance operation within groups of song titles, because songs with different titles probably aren't duplicates
of course you might need to do some text processing on the song titles first
Yeah, but notice that it would change the values of columns. If one was live, the value in liveness columns would increase. If was from another person, it would change at least a decimal value in speechiness. I just want to perfect it and learn how we can change it 😄
btw where did you get this dataset? seems interesting to work with
what do you mean "from another person"? what is each row in this dataset exactly?
Check the rows in 4,5,6 and 7. In that rows, you can check that all values are the same except in song popularity. If it was from another person, the speechiness would change because it measure the speech-like. And we also can look for the column with the name song duration, where it represents the time of each song. This is an assumption, but i think most of the songs that have a cover or a remake or something similar, have at least one more second or a milisecond
It is a class project. I am learning python and this is for a predictive model. However, if you look for predictive dataset spotify, you can check it ^^ I can also pass you the dataset if you wish
I found a maths function that might be useful as a error function, should I show?
maybe I didnt find it, but its cool
Yes that's true.
so each row is one user's judgement of a song? as in, it's their opinion of how the song sounds?
or each row is one song on spotify?
yes, song duration is also a good indicator of similarity. maybe good enough that you don't need to mess with the genre stuff
i see a lot of spotify datasets compiled from their web api
It would be a spotify song, at least that is the information that we had. However, one of thing that our teacher make us understand is that dataset have always many error and most of the projects that we are going to work, we are going to use 75% of our resources in data preparation. So saying that, we think it maybe some values that professor put in purpose so we can learn how to solve it ! 😄
I can't say it is , however the columns are very similar to it. We have done some research and we could find there what would be the acceptable values for each column
I think it is the best. At least that is how we are going to support the purpose of deleting some rows in these dataset
75% of our resources in data preparation
yep, that is to be expected
sounds like you are going in the right direction then
Thank you a lot! It means much to hear that! Sometimes, i find myself looking hours in how to do one thing that is so simple, however I think it is the learning curve talking to me ^^ But i have a question, would you guys recommend learning from Datacamp? I have been spending some time there since our professor apply us as 'premium' members and I have been using my free time in learning there. I am know learning more things to do in python, but i also want to learn SQL and Power BI. Do any of you guys have any reference from it ^^
jupyter notebook vs jupyter lab?

I guess you can replace the Nones with ints
why not just use .head()?
By the way, I wanna have a solid understanding of data preparation, got any resources? i'd appreciate that.
please help i want to get started with ml but i dont knwo where to start
did you learn about k nearest neighbors yet?
not yet i want to start ffrom the begining
that pretty much is the beginning. it's one of the simplest kinds of classifiers.
let him first understand what is ML and followed by Supervised and Unsupervised learning you know
yea
where can i do that?
i havent fond a good tutorial yet
if i have a dataframe like this, how could i plot a line graph with 10 different lines, with date on the x axis and streams on the y?

the 10 different lines for 10 different artists
could u possibly provide an example?
not familar with seaborn


hai
can someone tell what is .values[0] here? I checked the documentation but their they use only .values not .values[] with any index
thank you, i take it flights is the name of the df?
yep
is there any projects or teams where I could join to learn some stuff about this topic?
its fetching the first value from the array that you get after .values
there is only one value being fetched by the code
without values[0]
@tough frigate
lol your code is weird, it says, if your income's first value is less than 35000 than return the gender's first value or else return male
no @tough frigate ...its just picking a random row from dataset
then checking if this random's income is less than 35000
what are you trying to do there?
may be you misread
its just a question in my course
and this values[0] thing confused me
its a quiz
basically
.values results in an array of income, and if you do .values[0] that means it fetches the first value from your income column
@tough frigate ...thanks
it was just unrequired in this code
thats what was confusing
@tough frigate im trying to rotate the x-axis labels but i get this output

lol i dont remember every stuff, just go through the documentation
yep found it, is it possible to show specific ticks like for each month and not the individual days without adding them together for the month?
cos i was a little unsure how to go about adding all the values for each month
for a df like this, how could i add all the streams for each month for each artist?

what is the difference between a framework and a libary. For example Open CV and tenserflow
from what i understand, a framework is more "opinionated" than a library - that is my loose working definition
does anyone have any simple projects to get comfortable with the basics of tensorflow?
just finished a few of google's tutorials on it
MNIST is a very popular dataset to get into neural networks
TensorFlow
Though I'm not sure if you're comfortable with the level of programming they're doing for this
But definitely a classic to try out whenever you can
wonderful
thanks

(tuple1, tuple2) = x
dictionary = json.loads(tuple2)
return dictionary["race_ethnicity"]```helper_function_1(tooples)
so i am trying to unpack my tuple in order to access the race and ethnicity section of the dictionary housed inside of it
however when i call the helper function i wrote, it says too many values to unpack
how should i go about fixing this
libraries have functions and classes that you can import and use however you'd like. frameworks tend to have a bunch of parts that partially implement some solution, and you supply a few key parts, and it uses them to achieve the rest.
it's also sort of a matter of perspective. the two neural network libraries are library-like when you're just making tensors and using them, but start to behave more like frameworks if you use the Sequential class to make a model, since that involves saying what layers you want, and it manages passing data through it.
CC @misty flint ^
Give more variables when you unpack, first learn what parameters does that function have and what output does it throw
start to behave more like frameworks if you use the Sequential class to make a model, since that involves saying what layers you want, and it manages passing data through it.
def 100% agree with this perspective part; i can see this making sense for both pieces
i should explain a bit better
so right now i am experimenting with my first sqlite3 server
to put it in the server i had to pack it into a tuple
stelercus, if you had a substack, i would subscribe and read it tbh @serene scaffold
i am now trying to unpack the tuple to manipulate the data inside
i created the function to unpack the tuple to access the data
i thought if i tried entering my toople variable as a parameter, it would work
what is that
can i ask python pipeline related questions here ?
I don't think that's how it works, if your tuple has 3 elements, so when unpacking you either create three different variables or use asterisk to get thr remaining elements inside a single variable making it a tuple
I'm getting this : Attempting to weight transformer "elo_offensive_1", but it is not present in transformer_list.
sounds like you're doing a deep learning thing. try showing the whole error message from Traceback and the relevant code in a markdown block
!traceback
i understand the number of arguments has to be equal to the number of elements
however this would be an inconvenient way to solve this
as this is an entire data set with thousands of elements
can i share the entire colab notebook instead ? cuz i don't know what are relevant in this case
so what i'm looking for is a way to pass an argument that will unpack the entire thing
you can put the link to it here, but people are more likely to help when the question is distilled.
Try using * after or before your variable, coz maybe this should work, there is a way to unpack all thr element in a single variable
oooh i see
what is a substack? heres an example https://technically.substack.com/

Technically explains software and hardware in a simple and engaging way so you can impress your boss. Click to read Technically, by Justin, a Substack publication with tens of thousands of readers.
and they usually are sent to your emails too
so you get articles in your inbox
this 'Technically' guy is hilarious tbh

ValueError Traceback (most recent call last)
<ipython-input-188-caa54ef5dede> in <module>()
1 #fitting
----> 2 pipeline.fit(df_train_test, y_oh)
6 frames
/usr/local/lib/python3.7/dist-packages/sklearn/pipeline.py in _validate_transformer_weights(self)
1059 if name not in transformer_names:
1060 raise ValueError(
-> 1061 f'Attempting to weight transformer "{name}", '
1062 "but it is not present in transformer_list."
1063 )
ValueError: Attempting to weight transformer "elo_offensive_1", but it is not present in transformer_list.
pipeline.fit(df_train_test, y_oh) : the line of code with problem
how is it different from a blog
pipeline = Pipeline([
# Feature Union to concatenate features
('union', FeatureUnion(
transformer_list=[
# Pipeline elo scores team 1
('elo_scores_1', Pipeline([
('elo_sc_1', ItemSelector(key=['elo_offensive_1','elo_defensive_1', 'elo_home_offensive_1',
'elo_home_defensive_1'])),
('MinMaxScaler', MinMaxScaler()),
])),
# Pipeline elo scores team 2
('elo_scores_2', Pipeline([
('elo_sc_2', ItemSelector(key=['elo_offensive_2','elo_defensive_2', 'elo_away_offensive_2',
'elo_away_defensive_2'])),
('MinMaxScaler', MinMaxScaler()),
])),
],
# 1.0 for all
transformer_weights={
'elo_offensive_1': 1.0,
'elo_defensive_1': 1.0,
'elo_home_offensive_1' : 1.0,
'elo_home_defensive_1' : 1.0,
'elo_offensive_2': 1.0,
'elo_defensive_2': 1.0,
'elo_away_offensive_2' : 1.0,
'elo_away_defensive_2' : 1.0,
},
)),
#Classifieur
('Classifieur', LinearSVC(random_state = 1, verbose=1)),
])
#LinearSVC(random_state = 1, verbose=1)
#RandomForestClassifier(n_estimators = 100, max_depth = 4, min_samples_split = 500)
Does anyone know how i could add the streams for each day for all the months for each artist?

My df looks like this
anyone know of any good resources for how to work with the apply() method on a dataframe?
# Evaluating the Model Performance
from sklearn.metrics import r2_score
r2_score(y_test, y_pred)
in the sklearn library, with these lines of code, is what calculated the r-squared value or the adjusted r-squared value?
step 1: don't
jokes aside, look up pandas dataframe apply and check the documentation. That said, you should avoid using it as much as possible - pandas supports many operations in a way that will be much faster than whatever you want to use apply() for
!d sklearn.metrics.r2_score
sklearn.metrics.r2_score(y_true, y_pred, *, sample_weight=None, multioutput='uniform_average')```
\(R^2\) (coefficient of determination) regression score function.
Best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value of y, disregarding the input features, would get a \(R^2\) score of 0.0.
Read more in the [User Guide](https://scikit-learn.org/stable/modules/model_evaluation.html#r2-score).Note that r2_score calculates unadjusted R² without correcting for bias in sample variance of y.
Thanks! too funny...I'm often the person telling people not to use apply() 😂 so I definitely get it. In my case though, since I'm working with parsing and evaluating strings series/columns, it seems like the most appropriate route.
depending on what it's for, you might be able to just use string accessor methods, maybe with a bit of regex
sadly, that's not going to work in this case.
but you're right about the pandas docs...which I usually find fairly helpful! but for apply, they really aren't.
I'm definitely looking to dig more into complicated apply
does anyone have a good vtk tutorial ?

Looking at some lecture slides concerning deep Q learning/network (DQN), and the slide says the following:

I don't fully understand what the difference is between expected maximum value, and maximum expected value
Found some explanation online, but that did not really clarify it
This explanation

Could someone maybe give an example or a more intuitive explanation*?

ah i see
hmm idk if i can explain it over mobile tbh
i might sketch something if i was on desktop
maybe someone else can help
Yeah dw, I'm going to sleep, if someone replies i'll be able to see it tomorow, but would appreciate it, thanks in advance 🙂
Hey anyone can give me a quick help ? I am using StandardScaler() on a dataframe, it works well but it return a ndarray. I lose index but also also other information
I found this post : https://stackoverflow.com/questions/35723472/how-to-use-sklearn-fit-transform-with-pandas-and-return-dataframe-instead-of-num

Stack Overflow
I want to apply scaling (using StandardScaler() from sklearn.preprocessing) to a pandas dataframe. The following code returns a numpy array, so I lose all the column names and indeces. This is not ...
Which mentioned sklearn_pandas library
You shouldn't really care about losing that metadata
if you need of it back later, pass it when creating another dataframe
I have a df containing some columns that are continious and named attr_cont = ['col1', 'col2', etc..]
but usually you should not do any further manipulation with it as a dataframe after scaling
But I think the DataFrameMapper() expect a pd.Index(['col1', 'col2', etc..]) object
and return those weird columns name

why do you care about losing the index etc?
I am seeing no documentation on how to create such Index([]) object from a list
Because the index are linked to categorical attribute contained in dataset
And that it have already been through train_test_split()
if the index itself is a feature, use df.reset_index() to throw it into a column
Index isn't a feature
if it is "linked" to another feature, you probably should not keep it anyway
but df= df[attribute_continuous] + df[attribute_categorical]
and i want to scale only the continuous attribute
use a ColumnTransformer instead of separating it yourself
scikit-learn
Examples using sklearn.compose.ColumnTransformer: Release Highlights for scikit-learn 1.0 Release Highlights for scikit-learn 1.0, Time-related feature engineering Time-related feature engineering,...
(maybe also look into Pipelines while you're at it, they allow for you to define the model - including pre-processing steps - as one single thing instead of applying multiple steps yourself)
Thanks, teacher just told us : "use standard scaler on continuous attribute on a new dataframe, then use the two dataframe to train again model...."
I don't think they even realize the sort of problem this cause..
on the data itself ..
Thanks I will look into it
Can someone help me with this?
https://stackoverflow.com/questions/71704956/running-evaluation-on-tensorflow-object-detection-api-memory-allocation-issue
Stack Overflow
I'm using Tensorflow Object Detection API and I am trying to evaluate my efficientdet_d2 model from Tensorflow Model Zoo. My evaluation TFRecords files have 8880 samples in total and when I run:
!p...
You don't need this package now, look up ColumnTransformer
It returns np array and don't transform df itself. I am digging deeper into it rn
There is this solution but it imply to go through a Pipeline with the last step being :
("pandarizer",FunctionTransformer(lambda x: pd.DataFrame(x, columns = ["x", "y"]))

Data Science Stack Exchange
I am having issues with scikit-learn converting dataframes to numpy arrays.
For instance, the following code
from sklearn.impute import SimpleImputer
import pandas as pd
df = pd.DataFrame(dict(...
Expected value of a die is 3.5, roll that die a bunch of times and take the max, that value is probably above the expected value (overestimated).
So in Q-learning, the values are pretty bad at first and so it will probably overestimate badly. So it will explore a bunch of overestimated state space making learning slow at first, and even after a long time, it's still generally an overestimation (not as bad as it is at first).
Expected-max, and max-expected, the order matters (you can try with a die).
(Which will probably be larger?)
classifier = LogisticRegression(random_state=0)
changing the random state value on this line does not seem to do anything to my results - would anyone happen to know why?
Random state says no matter how many times you run your model, it will take the same observations to get you the same results. So removing that parameter will result in some change.
Geez, these bank datasets are awful, alot to clean there
https://imgur.com/a/3W9Hmfk guys what could i say about this image, its a web servers data in splunk
with what appears to be their assets/pages
and i did the least common ones
could i argue these are the ones that may have the least bugs/or most bugs because nobody visits them to try and exploit them?
Hello, guys is there a problem solved on concepts Perspective projection, weak projection, orthographic projection.
@tough frigate
import numpy as np
def add_to_neg_elements(mat, num):
mat[mat<0] = mat[(mat<0)+num]
return mat
Can you tell whats wrong with this code? Im getting an error : IndexError: index 101 is out of bounds for axis 0 with size 4
I think you want
mat[mat<0] = mat[mat<0] + num
there are plenty of random states to set in python to get exact result, depends on lib as well
how to pop rows from a pd df? first 5 rows.. then next 5 rows and so on
from what i can tell there is no easy way to pop rows from a df?
I want to run the model Neural Network, but the kernel is always dead like this. What happened? How to fix this problem?

Try to find a log, it might help you understand why the kernel died. A common cause is not enough RAM to support the loaded data
❓ how to pop rows off a df ❓
can you guide me to handle this? my ram is 16gb and it still doesn't work

Try to see if you can access the Kernel logs from here
that's a column pop
Ohh yes, you're right
hmm, there doesn't seem to be an inbuilt function to do this
I found this df.T.pop(index)
and then you can transpose back to the original dataframe
First try to just lower the data you load in (lower batch size) see if that works
Try like 10 or something if it's images
At least then you can pretty much confirm it's a memory issue
Hello,
Is Prophet better or NeuralProphet?
what does this loss actually represent? (this is an artificial neural network for regression) is there a good thumb rule to determine how many hidden layers and how many neurons in each hidden layer in an artificial neural network?

the loss is an aggregate measurement of how far off your model is from getting it right. it looks like your loss is the same after each epoch, so your model is no longer learning.
the decrease in loss is incredibly slow from 30 to 100; should i just stop the epochs at 30?
once the rate of change for the loss gets this slow, you might as well stop, yes.
I don't know that there is
it says 'Adding the input layer and the first hidden layer' but there is just one line of code in that cell. Is this code incorrect? Could you please explain?

Previously I use batch_size = 128, then I try to use 64 and still doesn't work. Why did it happen?
ann is a Sequential network, which just means that for any data that goes into it, it's a straight pass through the sequence of layers. Then you have two dense layers that the data passes through. and then the output layer is the one with the answer, so to speak.
Did you try a really low amount like 10 or 5?
but where is the first input layer created in the lines of code? and where is the first hidden layer created? there is one line of code but two things are created?
that might actually be a mistake in the code. I only see three layers created here.
so only the input layer is being created here?

as far as I can tell, that's the first/input layer, and is thus not a hidden layer. where did you get this notebook?
you can do len(ann.layers) to see how many layers it has. but make sure you've run each cell exactly once when you do that, or you'll get an incorrect answer.
ok - they say that the input layer is automatically created depending on the number of features; ill check it with what you have advised to do
output of this is 3
then I guess the notebook is wrong
How could i create a legend and have it in this format for a seaborn plot?

Hello,
Is Prophet better or NeuralProphet?
I recently try to use 10 for batch size, but doesn't work
Try updating your libraries maybe
is this matplotlib?
Yep
ive currently got my graphs set out like this for all 6 sub plots

i tried that but i wanted to have it on its own not in a graph
handles, labels = ax.get_legend_handles_labels()
fig.legend(handles, labels, loc='upper center')
Stack Overflow
I am plotting the same type of information, but for different countries, with multiple subplots with matplotlib. That is, I have 9 plots on a 3x3 grid, all with the same for lines (of course, diffe...
There is also a nice function get_legend_handles_labels() you can call on the last axis (if you iterate over them) that would collect everything you need from label= arguments:
you basically make them into one big axes and it pulls the legend from them all into one
@vestal ocean
So would i need to change the code structure of mine?
yes,
you would need to make them into subplots
ax1
ax2
etc
I have a question for people that work with LSTM models
I am trying to predict asset prices from 60 days into the future
and it takes historical data and trains based off that data
but i have a problem with over fitting
ill show you
Epoch 1/500
237/237 [==============================] - 12s 52ms/step - loss: 3.8080e-04
Epoch 100/500
237/237 [==============================] - 11s 44ms/step - loss: 1.3932e-04
Epoch 200/500
237/237 [==============================] - 11s 45ms/step - loss: 1.1043e-04
Epoch 300/500
237/237 [==============================] - 11s 46ms/step - loss: 7.9581e-05
Epoch 400/500
237/237 [==============================] - 11s 47ms/step - loss: 6.8104e-05
Epoch 500/500
237/237 [==============================] - 11s 47ms/step - loss: 5.6542e-05
as you can see it goes from 1-4 untill like 275 then it skyrockets and hovers around 9
any idea how i could move it to take the place of the empty plot?

idk why my model is over fitting
to replace the first subplot with the legend?

the reason its there is because ther fig.legend
its applying to the full figure
you would need to apply it only to the subplot you want it in
ill look online for some examples to make myself more clear
Stack Overflow
I would like to put legends inside each one of the subplots below.
I've tried with plt.legend but it didn't work.
Any suggestions?
Thanks in advance :-)
f, (ax1, ax2, ax3) = plt.subplots(3, sha...
this is for multiple legends so one for each subplot
so far thats all i can find
but I think that if you apply the full legend to a single subplot of your choice it should work
my LSTM stock prediction model
If anyone has the time to tell me why its over fit please dont hesitate to dm me
yo can someone help me find a dataset which has different graphs like straight line, parabola, hyperbola, etc for a ML program (couldn't find anything on kaggle 😭)
Hey @thin palm!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
If i have a graph like this that is currently showing the streams for the top 10 global artists, could anyone recommend a way of having the top 10 european artists on the same plot?

Preferably not as the same line format and may reduce from top 10 to top 5 so its cleaner
instead of a line plot you could do dash plots
so European artists will be noticed
Do u mean do a combination of both?
Like line for global and dash for european?
like this?

Hi all, I was wondering what the best way (resources) to learn AI using Python; is there any books, videos, courses or modules that you guys can recommend me with?
I am currently studying Computer Science A-Level (College-equivalent).
In my final year and will be heading off to Uni this year soon.
Awesome. I'll start with those then, thank you so much 🙂
This is also an option, also you could do a scatter plot and define the hue by counrtries
Hi, I was trying to install Face_Recognition using PIP, but an error occur. I found out the issue, but was wondering if it is fine to install again; will it override old file or do I have to do something so that they don't collide?
Nvm, it just says satisfied for files already installed. But a new error has occured. I will be using one of the help channels :_
🙂
yes in general it will uninstall before installing, eg if you upgrade versions
Hi guys, i have a question, do you know how many items at most the apriori algorithm supports in python?
I would think this depends on the memory of your computer rather than a set limit in the code.
really interesting read if youre into RecSys and Personalization https://eugeneyan.com/writing/patterns-for-personalization/

eugeneyan.com
A whirlwind tour of bandits, embedding+MLP, sequences, graph, and user embeddings.
the tl;dr


it's nice to have a tldr with actual use cases for various things
right? i need everything like this
i am working on a time series problem to predict sales could someone point me to a resource that helps me break down the problem ?
Hey anyone got some time?
I've got some query about Reinforcement Learning that I want to ask
Hoping anyone with knowledge of generating animated graphs with matplotlib can help me figure this out
My program takes in a CSV with one column for timestamps, and another for values recorded at those timestamps
I currently animate it in a way to show 60 timestamps of data, and it scrolls from left to right to show the next timestamp and recorded piece of data
Problem is that the timestamps are variable, and my current function to graph the data points in an animated way doesn't work for that
def init_line():
line.set_data([], [])
return (line,)
def animate_line(i):
line.set_data(x.array[:i], y.array[:i])
ax.set_xlim(x.array[i] - x.array[60], x.array[i] + x.array[60])
return (line,)
anim = animation.FuncAnimation(
my_fig,
animate_line,
init_func=init_line,
frames=length,
interval=float(100/6),
blit=True,
save_count=50,
)```
So what happens is that 1 data point is plotted per video frame (at 60fps that's 0.16667 seconds), which is not accurate to how far apart the data points are (which range from 0.08s to 0.2s)
How would I go about making it so my data points are put into the video at the same point that the timestamp is?What cooks distance is classed as an extreme outlier
4/n is just non extreme right?
You can track the time elapsed in the update function (adding dt = 100/6 to the time each frame), and only move the window when the time reaches the next timestamp.
so something like
dt = 100/6 # the interval
t = 0
shown = 0
def animate_line(i):
global t, shown
t += dt
if shown < len(x.array) and t >= x.array[shown]: # time for next point!
shown += 1
# update the data:
line.set_data(x.array[:shown], y.array[:shown])
ax.set_xlim(x.array[i] - x.array[60], x.array[i] + x.array[60])
return (line,)
Hiya, I'm training a cnn on the MNIST dataset. I'm doing k-fold cross validation right now, and i've noticed that the loss varies quite a bit between each fold. Is that something I should be worried about?
Score per fold
> Fold 1 - Loss: 0.1064145416021347 - Accuracy: 97.18992114067078%
> Fold 2 - Loss: 0.05745554342865944 - Accuracy: 98.25581312179565%
> Fold 3 - Loss: 0.0768362432718277 - Accuracy: 97.86821603775024%
> Fold 4 - Loss: 0.09651391208171844 - Accuracy: 97.86821603775024%
> Fold 5 - Loss: 0.07439924031496048 - Accuracy: 98.06201457977295%
> Fold 6 - Loss: 0.1636662632226944 - Accuracy: 96.60852551460266%
> Fold 7 - Loss: 0.10331138223409653 - Accuracy: 97.48061895370483%
> Fold 8 - Loss: 0.06524728238582611 - Accuracy: 98.44810962677002%
> Fold 9 - Loss: 0.07992955297231674 - Accuracy: 97.47817516326904%
> Fold 10 - Loss: 0.09972762316465378 - Accuracy: 97.47817516326904%
------------------------------------------------------------------------
Average scores for all folds:
> Accuracy: 97.67377853393555 (+- 0.5145294907723429)
> Loss: 0.09235015846788883
what will you be working on
im learning how to implement deep learning
notebook should be fine
when would you use lab over notebook? and when would you use some ide like spyder?
now that I look at it, looks like lab might be nice to display graphs in cause you can move them around in a separate window
I might have to look into that myself
yeah spyder might be nice too
yeah, just started with that
It doesn't seem to vary that much tbh
You already have a high accuracy, so you only guess a few cases wrong. And if you guess one more or one less wrong, the loss will be quite a bit different
haha yeah you might be right. The problem is that I'm trying to tweak some parameters, and it's difficult to tell if It's improving or not
how many test samples?
And as long as the average loss over the folds does not have a very high deviation, it should be a good (or at least stable) measure
Alright
you get a more accurate measure with higher number of folds*
there's even leave-one-out cross validation
I'll look into that
Do you think I should revert back to a model where I haven't tuned the rest of the parameters yet? That should make training a bit faster too
And then once i've found what works best, combine all of the best parts and see where we're at
I think I might do thatr
from pycoingecko import CoinGeckoAPI
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from datetime import datetime
cg=CoinGeckoAPI()
# print(cg.get_price(ids="bitcoin",vs_currencies="eth"))
class crypto:
def __init__(self,crypto,currency):
self.x_cords=[]
self.y_cords=[]
self.crypto_curr=crypto
self.vs_currency=currency
plt.title(self.crypto_curr)
def getName(self):
return self.crypto_curr
def insertion(self):
self.x_cords.append(datetime.now())
self.y_cords.append(cg.get_price(ids=self.crypto_curr,vs_currencies=self.vs_currency)[self.crypto_curr][self.vs_currency])
def plotting(self):
plt.plot(self.x_cords,self.y_cords)
def start(self):
plt.gcf().canvas.manager.set_window_title(f"Live Plotting {self.crypto_curr}")
plt.tight_layout()
FuncAnimation(plt.gcf(),self.plotting,interval=1000)
plt.show()
Btc=crypto("bitcoin","usd")
Btc.insertion()
Btc.plotting()
Btc.start()
plot lines are not showing
can someone help me
Well the combinations is what give good results
you can keep other params constant and tune one, and then the next etc.
But this might not give the most satisfactory results
My thinking is that it should make the difference more obvious when I'm tuning if it's not already a good model
Yeah, but you can't be sure it's the best parameter value
since the other values will be different
It should make more mistakes between each model
What I've been doing is combining them once I've found a good parameter
There are more efficient grid search methods though I believe
so maybe look into that instead
Yeah I'm kind of worried about that
and MNIST should not* take a monstrous model, so training/testing shouldn't take too long per iteration right?
What are you using?
density = itertools.permutations([16, 64, 128, 256], 2)
for a, b in density:
print(a, b)
model = Sequential()
model.add(Conv2D(24,kernel_size=5,padding='same',activation='relu', input_shape=(28,28,1)))
model.add(MaxPool2D())
model.add(Conv2D(64,kernel_size=5,padding='same',activation='relu'))
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(a, activation='relu'))
model.add(Dense(b, activation='relu'))
model.add(Dense(10, activation='softmax'))
k_fold(model, 10)
that's keras right?
yeah
are you running on cpu or gpu?
cpu, I have an amd gpu
ah dang
bummer
that saves a lot of time 😛
so yeah maybe it doesn't take too long
but I have those convo layers in there which add a bit
There is something called halving grid search btw
and I'm doing each permutation of [16, 64, 128, 256]
and then 10 folds on top of that
You could always just pick out the best results after grid search with 10 folds, and then run the best results with more folds
When choosing the best model should I be looking at loss or accuracy?
Hm I guess if I'm not seeing improvement, that means it's not worth changing
is there any tool to visualise machine learning models in 3D?
How should I learn maths for data science
?
Any method or way to study maths for data science
what math do you already know?
Integration, differentiation etc which I learn till 12th standard
so you need to learn linear algebra next
Ok
can you run .py files in jupyter lab?
you have to turn them into notebooks, I think
Hello, I'm not a coder but I want to learn, but I have this idea and I just want to ask if it is possible. The question: Is it possible to predict the number generator generating 1-20?
But should I learn maths with Machine learning algorithms or differently?
you can get a high-level understanding of how the algorithms work without the math, but if you want to make a career out of it, you should probably know the math.
Ok, thanks for your help ✌️😊
are tensorflow and keras linked?
https://www.simplilearn.com/keras-vs-tensorflow-vs-pytorch-article yes, Keras is more limited in scope but easier to use than Tensorflow though
hi, would it be possible for chatbot to learn messaging like an user just by his private conversations? Or does it need really big amount of information?
big info
I'm aksing in general not some specific
most state of the art natural language processing models use the entirety of wikipedia and then some
If it's already learned from big data, would it be much easier to learn writing type or is it amount of information that decides more?
Like learning messanging from all kinds of users and then learning specific one
I'm sure there's some models that write like a specific person
that would probably use transfer learning
Thanks, i'll google it
@dense creek there might be a way to fine tune a language model that has learned from an exceptionally large corpus to sound like a specific author. I'm not sure how, though.
Hello guys, I have a problem that make me frustrating. Why my code is stuck in epochs = 3

@bold timber is this in colab? You might be maxing out your free compute resources, I guess.
in jupyter notebook
yes gpt-3 can do this if you have enough examples
When I try to use num_workers = 1, it works. Why did happen?
I'm not sure why that made a difference, but what that does is set the number of CPUs that you're using to one.
Thank you 🙂
Can someone help me , how can I take the images and divide into non-overlapping patches?

I am using the Fashion-mnist
28x28 images
i get i have to use unfold, but struggling to implement this
Hello
I am trying to understand the PolyCollection by trying a very minimal example to plot a square (I know there are already patches/artists for that) but I would like to understand how should I specify the vertices
I have tried the following:
import matplotlib.pyplot as plt
from matplotlib.collections import PolyCollection
import numpy as np
verts = [[0.0,0.0],[1.0,0.0],[1.0,1.0],[0.0,1.0]]
verts = np.array(verts)
print(verts.shape)
poly = PolyCollection(verts, facecolors = 'blue', edgecolors='k', linewidth=1)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_xlim(-1.5, 1.5)
ax.set_ylim(-1.5, 1.5)
ax.add_collection(poly)
plt.show()
but I get the following error:
ValueError:
'vertices' must be 2D with shape (M, 2). Your input has shape (3,).
How can I format my verts in the format expected by PolyCollection?
Possibly a deadlock issue with multiprocessing. Maybe a bug in the library, maybe a bug in your code. Setting to num workers = 1 probably disables multiprocessing entirely. If you share your code as text (not a screenshot) i can see what you are doing better
!paste read below for sharing code:
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Does anyone have a code for back propagation ?
Is there an actual python code where I can copy paste in my compiler and put different values and check the results ?
There's pytorch code
I want to write a research paper that wouuld be very interesting to mention in grad application.
Something related to computer vision is what i like.
Which direction should i look towards?
I made a video comparing some of the different file formats used to store data with python/pandas. Love to hear any feedback: https://www.youtube.com/watch?v=u4rsA5ZiTls

In this video we discuss the best way to save off data as files using python and pandas. When you are working with large datasets there comes a time when you need to store your data. Most people turn to CSV files because they are easy to share and universally used. But there are much better options out there! Watch as Rob Mulla, Kaggle grandmast...
lol, i never used pickle this way, might try it out later
You should also check out parquet and feather while you're at it. They have a lot of advantages over pickle files (at least when saving pandas dataframes)
i watched this before you posted it here lol since it was on my feed
coincidentally, i just listened to a podcast the other day about data serialization 
Wanted to come back to thank you for that info - it certainly worked!
I tweaked it a bit just cause the indenting was a bit off, so mine looks like this:
interval = float(100 / 6)
t = 0
shown = 0
def animate_fps(i):
nonlocal t, shown
t += interval
if shown < len(x.array) and t >= x.array[shown]:
shown += 1
line.set_data(x.array[:shown], y.array[:shown])
ax.set_xlim(x.array[i] - x.array[60], x.array[i] + x.array[60])
return (line,)
I use 4 spaces per indent, hence the difference
hi people. so i am new to python and coding
so i was installing pycharm and saw CONDA in the drop down list while creating new project
(learning about creating virtual environments using Conda)

does it mean Conda is already installed with python, and i dont need to install it separately?
because im looking at Conda website, and it says Conda with Python 3.9 is 510 mb download
anaconda is 510mb download. for leaner version you could look into miniconda, which comes with conda and it's dependencies. then if you need any lib lika numpy, pandas, you would need to install it with conda
miniconda requires terminal download
im not good with it at the moment, so prefer GUI installation
but why does pycharm show Conda there?
when i havent installed it yet?
do i even need to install it? if its already there in pycharm
I do too but discord's tab is 2 spaces so when I paste code here I just go with that
4 space tabs ftw
on windows tehre is exe installer. just double click and it installs conda/miniconda. not sure but perhaps in pycharm there should be some visual conda package manager. was some time ago since i used pycharm.
if it shows conda option for you you can try to create a new env and see if that works
ok sure. will try that
thanks miwojo
yeah so it seems there is visual package installer with conda/pip in pycharm: https://www.jetbrains.com/help/pycharm/installing-uninstalling-and-upgrading-packages.html#interpreter-settings
and it seems you have to install anaconda or miniconda separately: https://www.jetbrains.com/help/pycharm/conda-support-creating-conda-virtual-environment.html
so i need to install separately if i wanna create virtual environments?
but package installations can be done from conda inside pycharm?
Yes correct. Yiu can create conda Virtual environments and install packages using UI in pycharm. You need conda installed in your system by anaconda or miniconda installer
This is my code:
#TRAINING MODEL
def loop_fn(mode, dataset, dataloader, model, criterion, optimizer, device):
if mode == 'train':
model.train()
elif mode == 'test':
model.eval()
cost = correct = 0
for feature, target in tqdm(dataloader, desc = mode.title()):
feature, target = feature.to(device), target.to(device)
output = model(feature) #feedforward
loss = criterion(output, target) #count loss
if mode == 'train':
loss.backward() #backpropagation
optimizer.step() #update weight
optimizer.zero_grad() #zero gradient
cost += loss.item() * feature.shape[0]
correct += (output.argmax(1) == target).sum().item()
cost = cost / len(dataset)
acc = correct / len (dataset)
return cost, acc``` train_cost, train_score = loop_fn('train', train_set, trainloader, model, criterion, optimizer, device)
with torch.no_grad():
test_cost, test_score = loop_fn('test', test_set, testloader, model, criterion, optimizer, device)
#Logging
callback.log(train_cost, test_cost, train_score, test_score)
#Checkpoint
callback.save_checkpoint()
#Runtime Plotting
callback.cost_runtime_plotting()
callback.score_runtime_plotting()
#Early Stopping
if callback.early_stopping(model, monitor='test_score'):
callback.plot_cost()
callback.plot_score()
break`
train_set = datasets.ImageFolder('data/train/', transform= transform, num_workers = 2)
trainloader = DataLoader(train_set, batch_size= bs, shuffle=True)
test_set = datasets.ImageFolder('data/test', transform=transform, num_workers = 2)
testloader = DataLoader(test_set, batch_size= bs, shuffle=True)```Actually, I'm already to fix this when I don't use the number of num_workers or by default num_workers =0. But why did happened?
Can i do this kind of thing on Python?
https://www.youtube.com/watch?v=goePYJ74Ydg

Brilliant: http://www.brilliant.org/primer
Papers:
- https://www.researchgate.net/publication/41910312_Altruism_Spite_and_Greenbeards
- https://www.reed.edu/biology/professors/srenn/pages/teaching/2007_syllabus/2007_readings/a13_Keller_1998.pdf
For discussion and updates
- Discord: https://discord.gg/NbruaNW
- Reddit: r/primerlearning
- Twitte...
I'm pretty sure that Python holds a lot of libraries to do a lot of wierd things related with AI and Neural, but I'm not sure about this
hi guys is there a way of generating ground-truths of images (grey images) via automatic segmentation techniques using python?
Currently looking at the paper "attention is all you need", mainly focussed on positional encoding atm. It uses this formula to encode the position of the word:

Giving a result like this:

I was just wondering why we need this convoluted method of encoding the position of the word. Is it not just possible to add like an extra value to the word vector, and give that a value of 0 to 1 based on its position?
Might just not understand fully how or why this is done
Yes.
Did you have any of librarie that I can use as a reference?
Panda3D/Ursina. Numpy/Numba.
Anyone have tips to improve pandas query performance? Long story short, I have some code that needs to query pandas often, and for 'reasons' can't switch to something more appropriate for the job like sqlite, can't really find anyone talking about pd.query performance
Imagine you add one extra value between 0 and 1 for the position in the sequence. When looking at that one value the ANN can easily distinguish between 0 and 1. And 0 and 0.5, or 0.5 and 0.7, etc.
But what if the sequence is long? Then moving just one word might be like 0 and 0.0001. And ANNs have a hard time with small changes like this, not as easy to separate.
So how about two inputs? One between 0 and 1 for the whole sequence, and another that goes from 0 to 1 every 5 words.
The first can tell you where in general the position is, and the second gives a more precise answer in combination with the first.
Now do it with a bunch and you have a bunch of sin/cos waves that form a unique position encoding when combined.
That is easy to distinguish.
There are other position encoding methods, but they just decided to go with that one, and it's a pretty good way to do it, similar to how the brain actually does it (encode positions).
How often do data scientists use ML
(Also related to Fourier analysis)
Do they use it on a daily basis? When I look up data science, ML is always in there but I talked with a software engineer at NVIDIA and he said they rarely use it if not at all. They are more of a statistician
show your code, explain the current performance, and explain why it isn't meeting your requirements. also, how big is the dataframe?
its a much neater way, but you don't really need positional encodings in a transformer
its neater because you preserve shape of the encodings/embedded vector to be added/concatted as per need
You can also just combine it rather than add more dimensions. ^
Do you multiply those positional encodings with the original word vectors or something?
Or is it a separate vector?
yep, but their embedded version is used in the actual attention calculation
They add them I believe, specifically. But they could be combined in other ways technically.
since the token indices are discrete and of variable sizes - which you don't want because that would require recomputing the computing graph at each step, making things slow AF
atleast in TPUs/XLA. I believe CUDA handles dynamic shapes more smartly
If you are interested in this way of encoding positions and such. I recommend learning about grid cells to see how the brain does it (in 2D). And how it can integrate motion into it to update the position (and sensory info).
there are imo two different definitions of "ML":
-
the problem domain of building automated systems that learn from data in order to interact with the real world somehow.
-
the broad category of "non-statistical" techniques for building models. many of these techniques were developed in service of (1) and are often used in that context, hence the name.
whether you do (1) depends on the job you have and the industry/field you practice in. whether you do (2) is a matter of what tools make the most sense for the job, and what your background/expertise is. a statistician's expertise would probably be wasted spending too much time on (2), but you can certainly use statistics in service of (1). or you can use (2) in service of other problems, such as forecasting and even exploratory analysis to some extent.
so the answer is "it depends", but hopefully what it depends on is clearer now. i'd say that the average practicing "front line" data scientists in industry use ML techniques use (2) somewhat frequently and very often act in service of (1). when they aren't using (2) ("ML techniques"), they are using "advanced undergrad" level statistics: not much more advanced than the basics, but deployed judiciously and with a deep understanding of the business problem at hand.
note that true advanced-level statisticians are significantly rarer than generalist data scientists, in part because (imo) advanced statistics is harder to apply to real problems, and moreover tends to be deployed in the face of harder problems.
I'll look it up thx, learning for an exam. the prof did not really explain attention in that much detail
But that kinda leaves us just confused with what everything means
and why stuff is done
(But it also does the direct sin/cos wave stuff in your ears, even more similar (Fourier analysis more or less biologically (this is where spiking neurons really shine and show why you want them rather than the crude approximation used now)))
Im trying to have OpenCV use my Nvidia T4 gpu for YOLOv3 inference. Do I need to compile it from source to have it make use of the GPU (instead of cpu) or should it work out of the box installing opencv-python
As I am getting very mixed answers from googling it.
Yeah pretty cool stuff, how evolution just manages to converge to useful mathematical functions hehe
Using opencv dnn to be more specific
I think you have to build OpenCV with CUDA support
I think opencv dnn comes with a cuda flag that you can enable?
*To add further, there is this thing called thousand brains theory that expands on the idea of grid cells / this position encoding to encode arbitrary objects (including language). It's a general theory of how the brain works.
Ok so for inference using a GPU CUDA is what I need right?
thats what I picked up from google but its very confusing 😅
hey! me too
*And it's what i'm working on now.
You need CUDA and CUDNN
just follow the instructions and you'll be fine
are you working on colab or on your machine?
EC2
Colab isnt great for inferencing as far as I know
im finding this resource really helpful atm https://jalammar.github.io/illustrated-transformer/
awesome thx, i'll take a look at that too
that's kinda how DL is, most things look very abstract and convoluted
it requires heavy mathematical knowledge just to scratch the surface - otherwise it just becomes learning formulas
I really wish we had some assignments that went more in-depth on certain topics
Instead most of the profs just cover like every single possible topic in the field
So you get the same stuff repeated like 10 times, very shallowly
but its interesting in a way as there's plenty of opportunity to explore why it works
that sounds like undergrad. we go pretty in-depth here
doing masters :/
oof
For example, what if I don't use that position encoding method?
masters AI to add to that lol
well, profs probably dont like talking about things that theyre not interested/specialized in
What if it's learned rather than static?
coincidentally, the model learns it automatically
hey me too 
there's a paper published just today about it
So positional encoding is not that useful?
transformers learn everything - implictness is key
positional encoding will remain well relevant
but its not explictly required
All because a model learns something without it being explicit (which is often the case), you probably still want the explicit stuff especially if you don't have much data. Because it takes time to learn it implicitly and it may not end up doing so.
you don't see that many people posting their research paper results on twitter haha
but pretty cool
its a retweet BTW, guy's not the author 🙂
However, it's an interesting find, because it says something about language / what it was trained on.
yep, its just spending params and FLOPs for that. interesting that it can actually do stuff on its own
Honestly i'd probably rather go into the computer vision area
RNNs have mostly confused me up to so far
If you find your model learns something implicitly, maybe consider making it explicit.
well, I'm interested in AGI so I like transformers a lot
deep learning seems really nice and interesting
thats so funny bc im the opposite
but tbh mainly bc i hated convolutions
idk I dont like explicitness
I got bad news for you. Image tasks being treated as sequences are winning out.
(For now)
ive seen transformers being applied to image tasks more and more yeah
They're called videos, and they're beneath me
I have more bad news - transformers are SOTA in every field, except linear regression
No I mean single static image. You feed the pixels as a sequence (or sections of the image).
really?
yeah
any paper on that?
Yup. Transformers are used.
by every, I mean every. animation, images, text, audio, medical, tabular, RL like AlphaGO etc.
just tabular is left to xgboost
Turns out, treating things as sequences makes it work out better.
Which the human brain does too*
or more accurately, transformers are just a superior architecture due to scalability
so bad news, guess you gotta learn transformers
When you look at an image, your eyes saccade around turning it into a sequence of small patches.
Which are "high quality" and around it, it's fuzzy.
well yes, but treating things as sequences isn't really helpful on its own. its the scalability/parallelizability of transformers
Yeah.
The human brain is ofc different, so for normal computers (von neumann), you want that scale/parallelization in that way.
True.
"An Image is Worth 16x16 Words", seems like an interesting paper title haha
would be cool if there were some advances in neuro-computing
or at least something different from the transistors
Did my bachelor project on something called memristors, and how they could be used in a neural network
sounds dope dude
Looking back on the project now, I was absolutely clueless with what I was doing
with python and neural networks in general
I remember reading the "attention is all you need paper" for it back then
Still don't fully understand it
oh wait squiggle talked about memristors before
i remember bc my search history said so
Can you elaborate on number 1. What type of fields would do automation and.
Hello, I want to learn python for financial analysis application (due to the growing demand in this skill). I wanted to know some good resources that can direct me towards understanding python in finance. I would like something specific towards that field if possible but also be beginner based. In an ideal world it would be a data analysis/financial analysis course aimed at finance professionals/majors with no experience in coding.
If you have absolutely zero coding experience, I would maybe start with a beginner course to at least familiarize yourself with coding/Python.
You need to know basic data structures and syntax etc. before you can start using a code language in a specific field imho
is there a beginner friendly IDE that I can download and mess around w/ as i learn?
I Believe Thonny is a beginner friendly one, IDLE is also common for beginners
@fading thunder
if you're a beginner, you can also just use a plain text editor and run your code at the terminal, but it would be up to you to catch syntax and name errors.
ok ty. any recommendations on free course that are good?
for data science, or general Python usage?
in either case, you can filter for free courses on the resources page
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
How to handle the outlier in Dataframe? Since outlier making the regression model is weird
I never check the description seems like the loss must exist in the model
nope, i am new in machine learning
This is my model summary which exist outlier

ys, with polynomial function with degree 2
i wanted to make a recommendation system. I also found a suitable dataset for the same
what are the things I need to understand before building this?
def gram_schimdt(basis):
"""
basis => basis of current subspace
returns np array of new vectors and concated basis
"""
actual_basis = np.copy(basis)
new_basis = []
shapes_left = basis.shape[0] - basis.shape[1]
for _ in range(shapes_left):
vec = np.random.rand(1, 8)
projs = get_projection(vec, basis)
vec = vec - projs
vec_normalized = np.transpose(vec/np.linalg.norm(vec, axis=1))
new_basis.append(vec_normalized)
# print(vec_normalized.shape)
basis = np.concatenate((basis, vec_normalized), axis=1)
return np.squeeze(np.array(new_basis)), basis
a, b = gram_schimdt(q)
I made this to find new orthonormal vectors
can this be more vectorized
i am concerned about that outer for loop. but can't find a way to make it vectorized from iterative
Hello everyone,
I'm working with time series data forecasting and I'm trying to forecast with LSTM.
Preparing for LSTM
### Three month moving window size
#I splitted by 0.5
values = reframed.values
n_train_months = 255
train = values[:n_train_months, :]
test = values[n_train_months:, :]
# split into input and outputs
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
(255, 1, 15) (255,) (1090, 1, 15) (1090,)
After preparing my data for LSTM , I ran this following code which shows me error as below:
# make a prediction
yhat = model.predict(test_X)
test_X = test_X.reshape((test_X.shape[0], n_months*11))
# invert scaling for forecast
inv_yhat = concatenate((yhat, test_X[:, :-1]), axis=1)
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:,0]
# invert scaling for actual
test_y = test_y.reshape((len(test_y), 1))
inv_y = concatenate((test_y, test_X[:, :-1]), axis=1)
inv_y = scaler.inverse_transform(inv_y)
inv_y = inv_y[:,0]
# calculate MSE
mse = mean_squared_error(inv_y, inv_yhat)
print('Test MSE: %.3f' % mse)
ValueError Traceback (most recent call last)
<ipython-input-68-c36cb3d27f69> in <module>()
1 # make a prediction
2 yhat = model.predict(test_X)
----> 3 test_X = test_X.reshape((test_X.shape[0], n_months*11))
4 # invert scaling for forecast
5 inv_yhat = concatenate((yhat, test_X[:, :-1]), axis=1)
ValueError: cannot reshape array of size 16350 into shape (1090,33)
Feels like I'm slicing train_x and train y wrong. Can anyone help me fixing this mistake ?
Any statistician here?
Hello, im no programmer and still beginner and trying to learn python, what are your thoughts on this: there's a game that im playing that spits out random numbers, how are you going to approach this problem to predict what numbers will come out next? This idea is my motivation to learn i dont know, machine learning stuff neural networks
I'm using matplotlib and i cant see any grids or axis or labels why?

Ask your question. I want to believe there are lots of statisticians here
anyone??
there's no grid by default. I think the axes here might just be hidden on your background. Try plt.style.use("dark_background") before plotting.
Seems not
That's quite strange. Did you remove the axis from showing? Also, which IDE is this? Colab?
looks like VSCode
hmm, probably not, it does look very different
i was expecting something like this

guys any idea with this warning? is it safe to ignore?
WARNING:absl:Buffer deduplication procedure will be skipped when flatbuffer library is not properly loaded
305805732
this worked ...cheers!
generated while i run this code
converter = tensorflow.lite.TFLiteConverter.from_keras_model(gt_model)
tflite_model = converter.convert()
open("gt_model.tflite", "wb").write(tflite_model)
is there a way i could get something like this
@runic zodiac
It likely worked because dark_background's settings replaced your broken ones
Try doing mpl.rcParams.update(mpl.rcParamsDefault) instead, maybe? That should be matplotlib's default
You might want also to reload the kernel (to unset the dark background style) and check
import matplotlib as mpl
from pprint import pprint
pprint({k:v for k,v in mpl.rcParamsDefault.items() if mpl.rcParams[k]!=v})
That'll show all changes from default parameters in the broken parameters that your matplotlib defaults to. You can then track down where they come from.
If it's random numbers you need crystal ball rather than machine learning to predict next number. Supervised Machine learning for example needs training data for train
Really nice explanation, thanks for that!
bro your resource also helped me with my assignment, so thanks for that as well!
Any statisticians in chat? I have a question about transforming data for linearity
It's best to just ask. "Does anyone know about x" is basically the same as "I have a question about x" but not saying what the question is.
If you find the assumption of linearity is violated from a box Tidwell test and using quadratic term doesn’t work, can you cube it?
Found this. Basics of Neural Network with Tensorflow with a project - https://medium.com/coders-mojo/day-41-60-days-of-data-science-and-machine-learning-series-d0b6649587c9

this is pretty cool https://blog.google/technology/health/check-up-ai-developments-2022/

Google
At Google Health’s event, we shared new areas of research and development that look at how AI can improve healthcare around the world.
especially the focus on global health and low-resourced areas that cant afford healthcare or have access to it
what are the free sources to learn ML? can anyone help please
I like fast.ai courses course.fast.ai
You can also check python discord recommend resources page
im working on a network that predicts the rotation around the up axis of objects. Because 359 degrees is almost the same as 2 degrees but would be punished very hard with a standard loss function, up until now i have worked with the sin and cos of the angle as the 2 output values. This works decently. Does anyone think it would be better to only have 1 output value (the actual angle from 0-360 normalized to 0-1 or something) and write a custom loss function that can work with the cyclic nature of the angle (so 0.99 prediction when actual value is 0.01 does not result in great loss)?
my favorite intro class is https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS

YouTube
Cornell class CS4780. Written lecture notes: http://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/index.html Official class webpage: http://www.cs.cornel...
wow so may free lectures, that's what I want
thanks
hi
So i have been learning about creating virtual envs to work in python
and was while trying to create one in VSC, encountered this error.

the venv is created, but while trying to activate it, it throws an error
@fleet musk you might have to run powershell as an administrator
close powershell
right click powershell
select "run as administrator"
this is vsc
powershell is a program that comes with windows. you can just search for it at the Windows search bar.
and you'll get a command prompt that is the same one that you might get embedded in VCS
you are not encountering a VSC issue. the issue you are having is strictly with powershell. the fact that the powershell window you were using was embedded in VSC has no effect.
guys
run the same command as before
you're unable to. can you be more specific?
my project is in D drive. so i need to change directory and go there first
then activate
i see a bunch of arrays in debug mode but they are not in my code
so use the cd command to change directory

see if you can figure out how to use the cd command to change to a directory in the D drive. I can't show you the command because I'd have to manually retype the content of your screenshot, which I am not willing to do.
hmm understandable
i have all these arrays that come up when i run code in debug mode. but none of these arrays are in my code. i want to export values of one of these arrays to excel but whenever i do some code it says cannot find array.

ok im in. ill try that command to activate
there's over 200 lines of code that aren't in your screenshot, and any one of them could define the arrays that you claim are not in your code
!paste
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
i dont think any of the arrays are in my code but my code makes loads of arrays
so i dont know what name to refer to them and how to export

what am i doing wrong
any ideas
I'm sorry but I don't know what the problem is 
try setting your default terminal as command prompt
why do i know this because i run into this problem everytime i set up a new venv in vscode
so now i just save that link in one of my notion docs
so i need to repeat above process everytime i have to create new venv?
🥲
you should be able to just set your default terminal as command prompt
and you should be good
i think i had to do it in multiple places
thats why i saved it
why multiple? is there no permanent solution
laptop, desktop, etc. just try the solution bro
you will thank me afterwards
yeah. im going thru ur link. looking at option 2
also found something on stackof
Stack Overflow
I am trying to run a cmd file that calls a PowerShell script from cmd.exe, but I am getting this error:
Management_Install.ps1 cannot be loaded because the execution of scripts is disabled on this
wait why did you not pick option 1
i even said to select the default terminal as command prompt
just do it
then set it
and forget it
😂
tbh stuff like this is why i hate windows
ok you should do it and then understand afterwards

thanks. love ur emojies

im new to programming, and python, so lot of head scratching
its ok this is only the beginning
better than me when i started out tbh
Help what is this

add me 😄
@frank acorn Did u miss a bracket
Also cool story I accidentally deleted this file so I need to type it out painstakingly again :}
I don't think I did, the error was at a comment
Wait why
Where 👀
I tried that but it became part of the comment
Oh the second last line is part of the third last line
No prob 😂
It started working :D
I have eagle eye
See you, going to fill in the other 200 subplots
Good luck
This is why I always get an error  👍
👍

any simple tutorial of 5-10 min explaining ai play games generation shit?
like for example flappy bird and learning how to make the ai start random and select the best guy
Can someone explain the details of this plot?

training loop problems - you are iterating infinitely
how do you fix it?
debug
looks seasonal
thats tqdm if you want some leads
please help how can i get started with ml i cant find a good tutorial or course
You have asked this here several times, and I suspect that everyone who has an answer has already provided it.
i know i have and i am sorry that i am asking this again but the i swear this is the last time, can someone please provide me with a good tutoriial
a single tutorial isn't going to be enough. I've heard a lot of people recommend the Andrew Ng course, but I have not taken it. I do recommend the free data science resources on our website
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
ty
what?
also
i like that there are DS resources now
always have been  🧑🏻🚀
🧑🏻🚀

{kind=link}
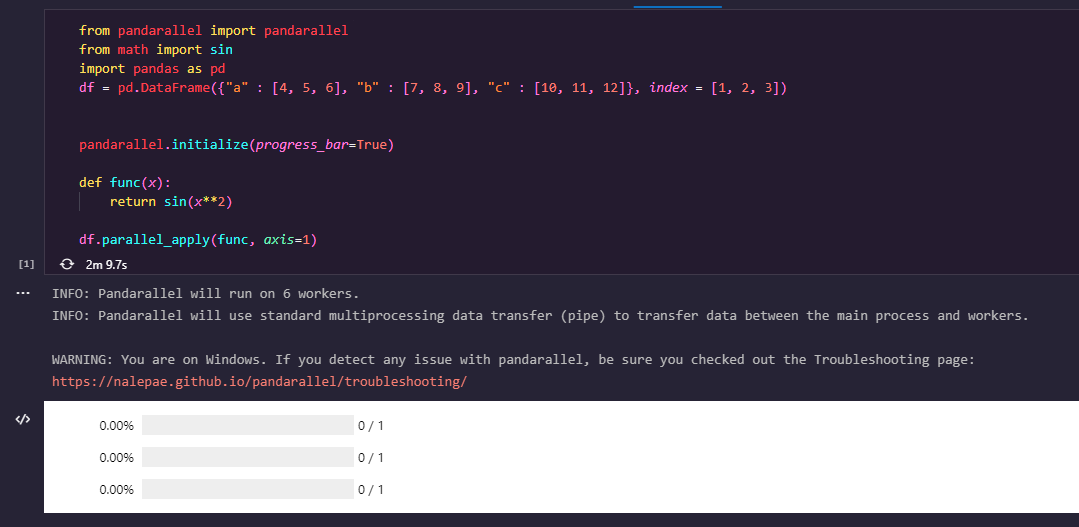{kind=link}
but you can put a topic after the !resources command now to pre-filter them in the URL
?
If there were a 5-10 min video about that, you couldn't recreate it after watching that if you don't know anything about ai or evolutional algorithms
yt videos are really mostly good for getting intuition

Pattern Recognition and Machine Learning (Information Science and Statistics)
just updated my tf version and now this problem is fixed!
anyone know details on how fingerprint identification like touch id works?
I presume it uses some sort of CNN/classifier but it amazes me that the false positive rate is only 1/50,000 according to apple
I think something that could work is predicting a transformation (scale + rotation + translation) and then verify the transformed captured image against one of the enrolment images
You can just use https://en.wikipedia.org/wiki/Harris_corner_detector to extract keypoints and check for a match. Can be done with just built-in OpenCV stuff.
The Harris corner detector is a corner detection operator that is commonly used in computer vision algorithms to extract corners and infer features of an image. It was first introduced by Chris Harris and Mike Stephens in 1988 upon the improvement of Moravec's corner detector. Compared to the previous one, Harris' corner detector takes the diffe...
i'm not trying to do it personally
Nothing crazy needed with CNNs and whatever.
just looking for more detail on how the high tech ones work 😄
https://data-apis.org/ interesting stuff
Just some extra denoising and stuff. They could start using CNNs and such, but probably don't need to.
Yeah it's what is followed to make stuff like numpy, cupy, and such consistent.
i figured you would know about it if anyone would