#data-science-and-ml
1 messages · Page 368 of 1
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Can someone solve this ?
i did this solution
def solution(logbook):
length = []
for i in logbook:
length.append(abs(ord(i[0]) - ord(i[1])))
return max(length)
Hi
I am also a coder and i code Computer Vision and Robotics Programs
I have made an Advacned app, and also i have made a video demonstrating the features of it
is here someone with plotly/dash knowledge and willing to help me?
I am more in computer Vision and ROobtics
Anyone would be interested to see my Computer Vision advanced Project ?
Scikit-learn data preprocessing:
Hi, I wonder wheres the best place to put data preprocessing functions: Before the scikit learn pipeline implemented in own functions or within the scikit-learn pipeline writing the data cleaning in my own transformer class?
Hi, i am getting this issue while installing tensorflow can anyone help me with this

Hi Friends
I wanto to share
something with you guys
I have made an Advanced AI and Computer Vision Project , would you mind checking it out and raiting it ?
I think it would be better if people would watch the code instead of just the video lol.(just my opinion ofc)
yes i will give the source code
and i have made it as an app,you want to see the GUI ?
This is how the GUI looks

can someone share some books from where i can learn ML/DL
i want to learn it's math not just code
if you want to learn DL, i like the series of andrew ng on coursera.
moreover he also has videos of CNN on youtube(assuming you want to learn cnn too)
i like the way he explains things.
.
How is this ?
Hello need help
any time you need help, you have to ask a question. no one will offer to help until they know what your question is.
How to update files?
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
@cerulean vapor
First issue I don't get .csv files
In referenced directory
Result is that just

I mean I assume it is tmp file since it's not downloaded yet and you closed the driver. While I'm not sure if this would work or not, but for now remove all other links and for one instance just do it for one, and don't close the driver, then find a way to handle it in a way that it does not close before it's downloaded completely.
@cerulean vapor
Also I'm not sure if this breaks TOS of the site since you are using the information, I would like you to make sure it's not breaking it, since, if it is, then we cannot help you.

or I'll just dm @sonic vapor to make sure lol.
no not breaks
alright no issues. just confirmed with mod too.
if a+b = 2
and a = 0.5
isnt that the same as:
lim (a+b)=2
a->0.5
??
@lapis sequoia help pls
How do you approach recognizing multiple symbols in one sequence with Pytorch? So like instead of predicting images with a single digit (i.e 7) , you predict multiple digits (i.e 8271)?
I have a program that can recognize digits on images with only one digit, but I can't get it to work with multiple digits in the images
Seems like more of an issue of properly dividing the image into single digits and then combining the results per digit
Is that easier than just using the entire image at once?
So like instead of image data being

It would be



?
The problem space seems a bit too big to have a class for each number
yeah you would break it up like that first
Is their a help forum for pandas specifically anywhere?
What if they overlap?
For pandas specifically no, you can ask here or open a help channel #❓|how-to-get-help
I mean a lot of people here are good at pandas but stackoverflow has lots of answered questions
I'll ask here then! Thank ya'll so much. I checked stackedoverflow but can't really articulate in google what I want. It's a simple problem, but I only have foundational pandas and Python experience so I'm a bit stuck
How much overlap?
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
Like i can't just divide at a specific place, cause each image has a slightly different positioning of the symbols
You can still separate them relatively well. You might want to look into detection and not just classification.
For this specifically you might still be able to do it with some heuristics like eroding it first and then finding connected components
can anyone plz help me with this issue

I'll look into this thanks ❤️
I have a dataframe in Pandas that is just 2 columns. I only needed one column so I wrote code for that:
Then, I got help for a regex expression that removed all PERIODS and NUMBERS from this list of email. The list is 22 million distinct emails.
for x in test:
new_email = re.sub(pattern, "", x)
print(new_email)
So that block of code works and does what it is supposed to do, but now my problems are this:
-
When I execute the block of code, their are so many emails that pop up that the text ends up overlapping itself and eventually causing Jupytr Notebook to crash
-
I don't know how to export my results to a .csv. If the results were in a dataframe I'd know how to do it, but from the for statement -> output -> to .csv I have no clue. I imagine you'd have to update the dataframe somehow but no idea how to do that here
it should be df["email"] no?
or df.email
Sorry, you're correct. I am writing this manually as it's on my work computer
okay. lemme read it and see if i can help.
okay that is expected. why are you printing them?
also I'll show you how you can save them
Thanks! I was printing them because the origial person helping me said that needed to be in there, and I also needed to ensure the code worked. Luckily, it did. Any help you can give it appreciated
you can print .head() if its too much data.
uhm
!d pandas.DataFrame.to_csv
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', ...)```
Write object to a comma-separated values (csv) file.@grizzled stirrup check this out
Thanks for this, but where to I actually utilize print.head() or export it to .csv after this 'for loop' statement? That is what I am stuck on, because the for loop is exporting results that don't appear to be in a dataframe if that makes sense
that kinda didn't make sense
That is my last line of code

first, don't use forloop.
forloops are slow and not pandas way. give me a minimal example.
Okay thanks! I am new and didn't know that.
Really I am just needing a regex statement that removed periods and numbers from this series of emails. So if the email was mr.prashant111@gmail.com, the regex statement would be mrprashant@gmail.com
ah beautiful. gimmi a sec.
!e
import pandas as pd
df = pd.DataFrame(['mr.prashant111@gmail.com'], columns=['P'])
df['P'] = df['P'].str.replace(r'\d|\.', '', regex=True)
# now you can save it by that function
print(df)
@lapis sequoia :white_check_mark: Your eval job has completed with return code 0.
001 | P
002 | 0 mrprashant@gmailcom
@grizzled stirrup
let me give this a go! Thanks so much for all your help
no issues. happy to help.
also i think your regex is wrong or you're expecting wrong result. it gives mrprashant@gmailcom
sorry archer pinged by mistake
That is the output I needed. The @ symbol can stay, but I just need any periods or numbers to go away 🙂
oh alright.
give this a go and ping me if you need me.
also df['P'] = this part is needed since you need to reassign it
Omg this worked! Your rock, my friend. I am still learning lots about Python and Pandas, but people like you really help motivate me to continue. I appreciate your help so much
Happy to help:D
I'll remember not to use FOR LOOPS in Pandas as much
haha nice!
Can a model output a shape of (513, 1)?
yes
to a sequential model?
what was the shape of the tensor you passed to it?
my x is (2534, 513, 26, 1) and my y is (2534, 513, 1). My final dense layer has 513 variables and a linear activation
When I passed my y with the third dimension, I received an error message due to dimension mismatch at the last layer. So I reshaped my y to (2534, 513) and the model started to fit, but the results are subpar
loss: 0.0032 - accuracy: 0.0020
This is the model result for the last epoch
I'd have to know the architecture of the network to know why you ended up with (513, 1) specifically, but it's unsurprising that you'd end up with (n, 1) for an n that is the length of one of the input's dimensions.
I am following a tutorial and I don't understand myself why I have a shape of (513, 1), I managed to manifest it by understand what I can. Right now I am just experimenting with the concept to see if I can make sense of it
this actual answers your query of why is it like this.
you have 2534 inputs of shape (513, 26, 1) and 2534 outputs of shape (513, 1)
so ofc output is gonna have that shape
ofc you could flatten X and Y and make it (2534*513, 26, 1) and so on (same for Y) you could have singular Y but that really depends on what data is and is that what you want.
I am working with spectrograms of audio data. the x is the spectrogram of the mixture, and the y is the spectrogram of the vocals. The goal is for the model to be able to separate vocals from instruments. I have succeeded in making a voice activity detection model using the same dataset, but for the source separation model I am having issues, mainly because the article I am following is not as descriptive about this part.
Did I understand this right - when there is a lot of data, training take longer, because of that, it's good to use distributed training. In data parallelism, models are replicated on different devices and data is split between them - then each worker communicate what his model learned to other models and they update weights accordingly - is that right?
Also, can someone explains asynchronous training?
hello
i have trained my model with 50 epochs and the accuracies keeping changing
should i choose the final val_acc as the one i get on the last epoch or should i choose the best val_acc for my final model??
Probably best val_acc and then make test to see if it performed well on just subset for which it learned weights
Hey everyone,
Is there a way with to get a specific desktop application "window" that is open? I'm looking to grab by title (with a wildcard flag) as there can be several instances of this application open at one time.
Guys, real quick. What does k actually mean? I always see it in algorithm such as k mean clustering and k nearest neighbour
it is just an integer value, in k means it means k cluster or k groups..example 2 clusters where k=2
and similarly for knn where k is the number of nearest data points, i.e the nearest neighbors
so should i keep restore_weights=true?
in k means you take 3 means, hence creating 3 clusters.
oh yes as @wicked grove explained.
Don't know what you mean by that exactly, but you should use ModelCheckpoint callback with save_best_only=True
heyy, i have doubt...so i am training a vgg19 model and have used k-fold cross validation with 10 splits except for one of the splits the other accuracies are p consistent tho they kinda keep changing. I was watching a video where they told i can treat 10 folds as 10 separate models. so can i save the 'best model'.
ohh okayy,is that better than early stopping?
not sure really, have not done it practically.
You use what I mentioned to save model
what do you do when you have varying accuracies after using say 50/100 epochs??
just saying, it does not work this way, we use it to validate which model is better, you don't really kinda say you have 10 models.
you do it over say vgg19 and some lets other NN model.
You compare THEM by it. not 10 models.
also this link answers this very nicely
https://stats.stackexchange.com/questions/52274/how-to-choose-a-predictive-model-after-k-fold-cross-validation

Cross Validated
I am wondering how to choose a predictive model after doing K-fold cross-validation.
This may be awkwardly phrased, so let me explain in more detail: whenever I run K-fold cross-validation, I use K
and if it does not increase a lot, one way would be trying more epochs.
and I think people do use more epochs.
yeahh but only one of the folds gives me a bad accuracy and the rest are fine,idk what i should do now
then it is good.
The thing with that fold should be,
the data very crucial to your feature to output function was put in testing so it made your model have kinda not good function.
for mine after 50 epochs it begins to overfit, so should i choose the best accuracy outof 50 or should i average it out
wait what you mean average accuracy over here.
yess i came across this link!!
ill show you an example?
Hey @wicked grove!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
yess
so like you can see these are my val_acc, should i choose the best one or use an earlystopping...also do i restore the weigjts?
okay so you got to understand one thing.
what exactly will you get by taking average?
let me ask you this question.
say you are learning how to guess if there is a dog in some images.
you guess it and it has some n1% accuracy
In 2nd time it has n2% accuracies
and it will increase since you will understand
now will the average matter at 50th epoch or will the end result?
about restoring weight for Nth epoc, I'm not sure.
the end result will only matter
exactly! hence taking average is in a way meaningless.
and taking the best?
uhm, well it would help(again I'm not sure if they store weights of each epoc)
also taking best may fall into overfitting as you know.
but yeah it could help. yes.
Hello I'm stuck with something that it's driving me crazy since yesterday afternoon and I wonder if you could lend me a hand. Basically I want to change the value of predictable column to 1 whenever a cityTown/startDate combination from preditable_incidences dataframe matches a multi-index from the original dataframe df.
df['predictable'] = 0
df['startDate_dupli'] = pd.to_datetime(df['startDate']).dt.strftime("%Y-%m-%d")
predictable_incidences = df[df['incidenceType'].isin(['Event', 'Labour'])]
df.set_index(['cityTown', 'startDate_dupli'], inplace=True)
predictable_incidences['startDate_dupli'] = pd.to_datetime(predictable_incidences['startDate']).dt.strftime("%Y-%m-%d")
zipped_list = list(zip(predictable_incidences['cityTown'].to_list(), predictable_incidences['startDate_dupli'].to_list()))
print(zipped_list)
df.loc[zipped_list, 'predictable'] = 1
print(df)
can you give a small df to explain this?
I'll go crazy if i tried understand what you did(no offense lol).
Sure
So according to this and the example you gave even the best fold to be saved as a model isn't correct
Cause only on one hold out set does model perform poorly which is ig due to outliers
This is where i saw it tho
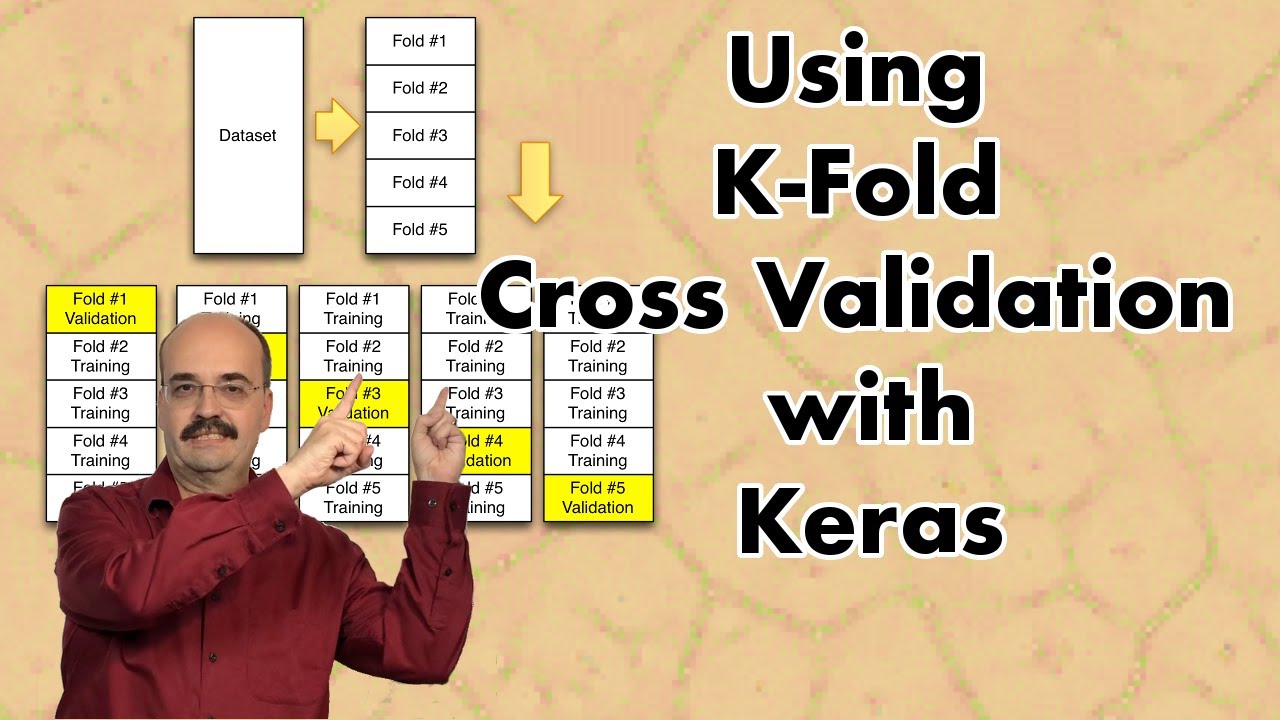
K-Fold cross validation is an important technique for deep learning. This video introduces regular k-fold cross validation for regression, as well as stratified k-fold for classification. Cross-validation can be used for a wide array of tasks, such as error estimation, early stopping, and hyper-parameter optimization.
Code for This Video:
ht...
I may be wrong
seems like a logical explanation. it can be because of that. I'm just not 100% sure if that would be the only case causing it.
but yeah that explanation is not incorrect.
Sorry for the delay, but it takes some time to execute everything, so here is a small set of the df.

So basically the dataframe that I'm using contains traffic incidences. Depending on the incidenceType, some of them are considered predictable and the rest non-predictable. Basically what I wanna do is remove those predictable incidences from the dataframe after setting the predictable_incidences flag to 1 for those non-predictable incidences that has predictable incidences for that day and city.
Does it make any sense?
Here is the code I'm using for that
According to the docs, it is possible to pass in a list of multi-indexes to df.loc[zipped_list, 'predictable'] = 1 so that this code should change the rows that match the multi-index, but it changes all the possible combinations within that list.
zipped_list = [('Zarautz', '2020-01-01'), ('Santurtzi', '2021-02-03')]
It should change two rows if found:
- 'Zarautz', '2020-01-01'
- 'Santurtzi', '2021-02-03'
It sets all the possible combinations to 1 instead: - 'Zarautz', '2020-01-01'
- 'Santurtzi', '2020-01-01'
- 'Zarautz', '2021-02-03'
- 'Santurtzi', '2021-02-03'
I want to use Movenet in unity
I was thinking to use barracuda
I converted tf movenet to onnx and tried to use it gave error
Unsupported default attribute `split` for node sequential/keras_layer/StatefulPartitionedCall/StatefulPartitionedCall/unstack:0 of type Split. Value is required.```
Click Here for more : http://tiny.cc/th7auz
#DMW #LSTM #AR #ARIMA #ArVsArimaVsLSTM #Python
Time to start talking about some of the most popular models in time series: AR, ARIMA, LSTM models.
It is my DMW Project Demonstration.
Check my apps on the play store:
Gravity 4: https://play.google.com/store/apps/details?id=com.dev.gravi
Please don't f...

So this is ETL process
I don't understand what's exactly extracting, downloading dataset and putting it on disk?
hey guys, which one do you recommend for data science, Intel iris xe or Nvidia. does even data science demand a specific kind of GPU or it doesn't matter?
Thank you soo much😁 so should i save one of the fold for k fold cross validation or im so confused idk how i can increase the accuracy
I tried retraining 4 layers of vgg 19 but the accuracy dropped
I added 3 extra dense layers,but that didn't help a lot
https://paste.pythondiscord.com/sejaluluje.http i need help with finding my erro here
nvidia is pretty much the default choice for high performance ML model trainning, as most if not all main stream ML frameworks use CUDA to accelerate training. While CUDA lib itself is open source you do need physical CUDA cores to use/take advantage of the various other libraries iirc. And if you are just starting out i would recommend that you try out things like Google Collab which provides free GPU and CPU for you to train models etc all you need to do is just go to Google Collab website and start coding
there are ways to bypass the CUDA requirement on AMD GPUs for example but it requires some setup which im not that familiar with
also for Nvidia RTX GPUs you get Tensor cores in addition to CUDA cores so those could also help when training models etc
so I have this class. Does anyone know why it would fail if I try to subtract it from a np.ndarray?
class Vector3(np.ndarray):
@property
def x(self): return self[0]
@x.setter
def x(self, value): self[0] = value
@property
def y(self): return self[1]
@y.setter
def y(self, value): self[1] = value
@property
def z(self): return self[2]
@z.setter
def z(self, value): self[2] = value
I get this, but they're both 1d arrays with length 3
Traceback (most recent call last):
File "/persist/safe/home/user/persist/sortme/rasterizer/./magic.py", line 124, in <module>
c.draw_poly([[100,100,100], [100,200,100], [200,200,100], [200,100,100]], (255,0,0))
File "/persist/safe/home/user/persist/sortme/rasterizer/./magic.py", line 74, in draw_poly
points = list(map(self.transform_point, points))
File "/persist/safe/home/user/persist/sortme/rasterizer/./magic.py", line 65, in transform_point
x = self._transformation.dot(np.array(point) - self.position)[:-1]
ValueError: operands could not be broadcast together with shapes (3,) (0,0,0) `
I constructed it as Vector3([0,0,0])
oh wait do I have to use something other than __init__ for that
nvm, got it.
def __new__(cls, val):
return np.array(val).view(cls)
This isn't strictly a python problem, but what sort of comparison/correlation analysis/method should I use when comparing how two different algorithms perform when compared to one another?
For some additional context, on one dataset I expect to see a major difference in performance and in another dataset I expect to see no difference in performance. Here performance means arriving at the right number, it has nothing to do with speed.
Like classification or?
No, not a classification problem. Maybe something more like... looking at a person in the distance and guessing how tall they are
like mean squared error or something?
That might be a good test
and you could use k-fold for validation method
and average over all the folds over multiple runs
So, validation data is used for updateing hyperparameters, right? I am interested how does that work. So let's say we specify batch of 32. Then, model will do prediction, with new parameters that are not used before (?), if it get better accuracy then it had before, then model will update hyperparameters?
Validation data in general is used* to see how well a model performs
You can validate your model for multiple different hyper parameter values and see which one performs best
Can be done with a gridsearch f.e.
scikit-learn
Hyper-parameters are parameters that are not directly learnt within estimators. In scikit-learn they are passed as arguments to the constructor of the estimator classes. Typical examples include C,...
Anyone here familiar with exporting xarrays as GRIB files?
@mild dirge I had to write that I am interested how does it works in Tensorflow 2
Never used tf2, but I assume you could just:
- split the data into training and testing (making sure the data is balanced for both)
- train on the training data with a given set of hyper parameters
- predict on the test data
- compare the test data desired outcomes with your predictions (with like MSE or accuracy)
- go to step 2, but choose different hyper parameters and check which parameters give better performance
This entire process is pretty much 1 or 2 lines using sklearn btw
@mild dirge Yeah, I am aware of that. Also, there is thing called hyperparameter search, but I am interested how does validating works for TF2
validation is done by splitting the data into train and test
test is your validation set
you validate your model on it
so I'm at an internship which requires me to write a paper and program an agent to play the game "nim with cash"
NIM(a1, ..., ak; n) is a 2-player game where initially there are n stones on the board and the players alternate removing either a1 or ... or ak stones. The first player who cannot move loses. This game has been well studied. For example, it is known that for NIM(1, 2, 3; n) Player II wins if and only if n is divisible by 4. These games are interesting because, despite their simplicity, they lead to interesting win conditions. We investigate an extension of the game where Player I starts out with d1 dollars, Player II starts out with d2 dollars, and a player has to spend a dollars to remove a stones. This game is interesting because a player has to balance out his desire to make a good move with his concern that he may run out of money. This game leads to more complex win conditions then standard NIM. For example, the win condition may depend on both what n is congruent to mod some M1 and on what d1 - d2 is congruent mod some M2. Some of our results are surprising. For example, there are cases where both players are poor, yet the one with less money wins. For several choices of a1, ..., ak we determine for all (n, d1, d2) which player wins.
how should I approach this?
should I use a monte carlo algorithm? or just something like alpha zero
any input is appreciated!
does anyone know anything about the olivetti face dataset?
What's the problem?
im messing with that dataset and trying out unsupervised learning to put faces in different clusters. Well I wanna see how accurate it was by taking the number of clusters that had only the same faces in it, but i'm not sure where to get started. I've looked around online to see if people have tried it and i cant find anything lol
Well unsupervised clustering can cluster them on anything
Doesn't have to mean it will cluster them based on identity
"how accurate it was by taking the number of clusters that had only the same faces" Here you say "same" but that can be based on a lot of stuff, not just identity 😉
oh okay. well that might be my first mistake lol
So if you want to cluster them based on identity, you want to use some supervised clustering algorithm
But you should probably just make a regular classifier, like a convolution neural network
Or use SIFT to extract kepoints from the images and use those to identify the different faces
Lots of different ways to go about this
okay. yeah maybe i should try it another way haha. thanks
Need some thoughts - I have a data frame with names, dates, and hotel codes. I'm using this to look up data using selenium, and save some of the results, but I'm not sure of the best way to iterate through the data frame. Lookup speed will be slow anyway so performance matters little.
What python packages are you using? https://towardsdatascience.com/400x-time-faster-pandas-data-frame-iteration-16fb47871a0a


Selenium, lookup of each takes a few seconds at least so it doesn't need to be fast. But I do want to add the lookup values to the data frame.
supposed to be black and white
Ùse a different colormap
I'm trying itertuples to put the columns into lists but it's hurting my soul. It feels so dumb. 😂
Note on some of the terms above: test set and validation set sometimes are synonymous to some people, but some people also use it in the following way:
- Training set is a the set which trains the model(s).
- Test set is a set which is held out of the training and which is used to tune [hyper]-parameters for the model(s).
- The validation set is a set which is held out of training and which is used to test a model which has specified [hyper]-parameters.
In the case of NNs, for example, you should not be using the test set to determine if fully-specified model 1 or fully-specified model 2 is better, that is the job of the validation set. You should use the test sets to help determine the hyperparameters of each model.
This is just so no one gets confused if they hear validation set being used in either way (as a synonym to test set or as the latter thing.)
binary_r seems to do it - thanks a ton!
Are you using only selenium or other packages too?
Pandas for managing the data, that's about it.

Stack Overflow
so I have done data extract from a table using library BeautifulSoup with code below:
if soup.find("table", {"class":"a-keyvalue prodDetTable"}) is not None:
table = parse_table(soup.
:incoming_envelope: :ok_hand: applied mute to @granite cape until <t:1642556873:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
I have a question related to GitHub. On this link: https://github.com/GoogleCloudPlatform/dialogflow-integrations/tree/master/spark#readme, I was trying to integrate my Diagflow chatbot to Spark. Then I ran into this problem: "In your local terminal, change the active directory to the repository’s root directory." Can anyone tell me how do I change the active directory to the root directory on GitHub?

GitHub
Dialogflow integrations with multiple platforms including KIK, Skype, Spark, Twlio, Twitter and Viber - dialogflow-integrations/spark at master · GoogleCloudPlatform/dialogflow-integrations
I am traing a lane keeping RC car however i have alot of images and if I try to load them into memory (i run out of memory)
I need a solution that loads data from directory instead of memory
TensorFlow / Keras
does anyone have issues with OpenCV being locked to screen refresh rate?
- when i am capturing my screen
I'm sorry I slept, well vgg is already very deep, I don't think 3 dense layers would make a lot of difference. why don't you try pretrained and lock it's initial weights for some layers?
heyy no probelm.pretrained? i should start retraining after how many layers?
could anyone point me in some directions, been stuck on this for a few days
you can try h5py but i am not too sure cause im facing the same issue,i had to resize my images and buy colab pro
hmm okai ill try colab.. ah the annoying part is i have to keep going on diff detours to fix one problem haha
]
yeahh same:// i still havent figured a solution but if the image size is big you gotta downscale else you will run out of memory
also how much ram do you have ?
just a small, warning, colab allows you to use TPU for only some specific hours of day.
yes and colab only gives 12 gb ram and the pro allocates 25
lemme think. I have not done it myself in a long time.
oh okayy
also if my data is 3390,512,512,3 of images and i have 25GB of memory...is there anyway i can use this efficienty on colab? can i use the cpu ram and then the gpu ram or something like that cause my session crashes when i do train_test_split cause i run out of memory
using CPU or GPU is in your hands. but as much i know you can only use one of them since tensors get data structure of such thing.
also I asked a friend of mine about how much layers should be still changable.
He said its more of a hyper parameter and you gotta do a bit of trial and error. but he said last 2 or 3 layers should be good.
ohh okayy thank you so much, i tried 5 layers lol the accuracy dropped a lot
haha yeah, I mean that's the thing, if they are images, we don't much need to change previous layers. And if we do change them, we need A LOT of data to have better results.
so its good to let them be frozen since they have already been trained on ALOT of data.
ohhh alrightt, got itt:))
alright!
8 gb on a mac lol . . .
oh okai thanks. I am just doing a proof of concept. Gonna have maybe 30 of video first attempt. Just wanna get my first project down and see if my approch is somewhat working
Honestly, i think? new to this stuff, on gpu training of about 50k greyscale images shouldnt take more than few hours? well see
it shouldn't yeah. also their CPU is more than what you have right now lol, so in both cases you're in good hands. just make sure to save the model on drive since they stop the process after 9 to 12 hours i think.
ah okai thanks alot for the heads up!
any one train self driving rc car; quick question
should i sort my train data as left turn images, stright images, right train images
and get "category" (0, 1, 2)
OR just have shuffled imgs
Your car, it only has input via a camera?
yes
just one camera, and loss is caculated steering angle
angle in my case is just -1, 0, 1
turn left, stay mid, turn right
i wanna say 10ms
not an issue cause im not trying to make my rc car go full speed, maybe half
just right or left realy
So what do you want to track on? A thing or a group of things. Within a border or nothing discernable as such?
i.e. How are you currently determining a path forward
gonna have paper on the ground, collect data driving on the paper track
On that paper what, a sharpie line?
just paper
and the goal is stay on?
yes
How wide is the vehicel?
abput 70%-80% of track width
How heavy?
the whole contraption?
Yes
if i use a wired webcam then maybe 300g if i stick my laptop on top(dont judge me here) then about pound and half
mac book air so not that heavy
20cm/sec sounds good
~>= half pound. great.
Got a pi?
Also, how are you controlling the engine?
motor, whatevre
I am using my laptop since im still learning; I wanna get to the proof of concept; once i have a super basic model. (one that is even 70% accurate) then ill invest in things
So my whole set is janky but here it goes; i will have a webcam/laptop on top of the car; OpenCV will extract a frame, that frame is preprocessed and sent to the model, the pridicticion is sent to arduino via serial port, the arduino then turns a servo pressing the button the the remote of the toy car
I was wondering is it more effective to to sort the training data as left turns, middle right turn directories or just shuffle it all and feed it while training
i belive second one is better, just trynna get some outside opinion
Hello
hi
lol okai?
here i asked a question about sorting training data
Heyy,when i fine tuned at 20,i.e retraining 2 layers the accuracy jumped to 98
Is that a glitch due to the internet or colab
Or am i doing something wrong
you mean by changing last 20 layers?
wait what do you mean by 20?
hello
So you mean you're confused why accuracy got this nice?
Yeahh,i think it's way too much and like no paper has mentioned it either
Plus when my friend tried she got an accuracy of 35 so idk
See theorizing speaking the initial weights are kinda very good for any picture. And the weights you've put on have been there by training on a lot of data(unlink your 3000 or something images)
So a very good result in fine tuning can be expected.
I suppose there is difference in weights you both took? And why don't you retrain just to make sure if it's not a bug in colab or something.
Alrightt will do, but then are bugs are common in colab cause we faced one a few days back as well
Oh you did? Well I never did yet, but again I play around on colab for other purposes and not usually deep learning.
suppose I have a dataset with 500 rows out of which 60 dont have column value ["price"], How can I drop first 20 rows having ["price"] as null?
You only want to drop 20? Not all of them?
only first 20, not all
import pandas as pd
import numpy as np
col_a = np.random.rand(100)
col_b = np.random.rand(100)
# Every 2nd value in ``col_a`` is NaN.
col_a[::2] = np.nan
df = pd.DataFrame({"a": col_a, "b": col_b})
# Get the first 20 row indices for the nulls, then drop them.
first_20_nan_idxes = df[df["a"].isnull()].index[:20]
df.drop(first_20_nan_idxes , inplace=True)
Just out of curiosity, why do you only care about dropping the first few NaNs, Vetpo?
Thanks a lot @stone marlin
now study Data Science for data reprocessing. so, i wanna data reprocessing part of books. can you some recommend the books?
Reprocessing or Preprocessing?
reprocessing.
What type of reprocessing are you doing? As in, getting a new model and re-processing data?
Can you give me an example, the term "reprocessing" has a few different ways it can be used.
use ML before data reprocessing some thing value. so, data something another value in the NaN, or text make token.
sorry. i confuse the word. i now talk about preprocessing.
It's okay, that's why I was making sure --- not too many people ask about reprocessing, but preprocessing is very popular!
Honestly, I know it's not a whole book, but the sklearn docs are fairly good for this kind of thing. https://scikit-learn.org/stable/modules/preprocessing.html . This also seems good: https://www.kdnuggets.com/2020/07/easy-guide-data-preprocessing-python.html
If you want an actual book, https://www.amazon.com/dp/B01M0LNE8C I remember being fairly good in general. Other than that, some others may have other suggestions.
scikit-learn
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream esti...

KDnuggets
Preprocessing data for machine learning models is a core general skill for any Data Scientist or Machine Learning Engineer. Follow this guide using Pandas and Scikit-learn to improve your techniques and make sure your data leads to the best possible outcome.

Introduction to Machine Learning with Python: A Guide for Data Scientists
Traceback (most recent call last):
File "C:\Users\esben\Desktop\Bob the Chatbot\bot.py", line 6, in <module>
['chatterbot.logic.BestMatch'])
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\chatterbot\chatterbot.py", line 28, in __init__
self.storage = utils.initialize_class(storage_adapter, **kwargs)
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\chatterbot\utils.py", line 33, in initialize_class
return Class(*args, **kwargs)
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\chatterbot\storage\sql_storage.py", line 20, in __init__
super().__init__(**kwargs)
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\chatterbot\storage\storage_adapter.py", line 23, in __init__
'tagger_language', languages.ENG
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\chatterbot\tagging.py", line 26, in __init__
self.nlp = spacy.load(self.language.ISO_639_1.lower())
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\spacy\__init__.py", line 27, in load
return util.load_model(name, **overrides)
File "C:\Users\esben\AppData\Local\Programs\Python\Python36\lib\site-packages\spacy\util.py", line 139, in load_model
raise IOError(Errors.E050.format(name=name))
OSError: [E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.``` how do i fix this error?i get somewhat the same error no matter what package i use
its always error loading
ive tried like 9 different chatbot packages
they all have problem loading
i just wanna make a simple chatbot, can anyone help me fix this error?
@glossy terrace the problem is that spacy is trying to load a model called en, but spacy models usually have names like en_core_web_sm.
so how do i fix this?
the part where you have self.language.ISO_639_1.lower() is wrong because it returns a string that isn't the name of a spacy model.
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
my_bot = ChatBot(name='Bob', read_only=True,
logic_adapters=
['chatterbot.logic.BestMatch'])
small_talk = [
"Hello",
"Hi there!",
"How are you doing?",
"I'm doing great.",
"That is good to hear",
"Thank you.",
"You're welcome."
]
list_trainer = ListTrainer(my_bot)
for item in(small_talk):
list_trainer.train(item)
i dont think i have that part in my script
this is just the basic script i got from following tutorial
yet it doesnt work for some reason
user_input = input()
if user_input == "Hi ":
print("Hello")
if user_input == "What ":
print("Im just a nameless test")
i also tried making this test
but i cant figure out how to make it recognise repplies to only the root of the input
ex. user_input 2, if i type Whats your it will just say error
and i would also like to know how to log it
like how to create new patterns and words in the training
e.g i type add.pattern and it will say like
Type user root:
and then when i type it says
Type bot repply:
and then it saves the new changes in the code file
Where can I ask for help in python question
there are instructions in #❓|how-to-get-help
Ok
@glossy terrace while your stated goal is to build a chatbot, it looks like you're currently struggling with general Python usage. I would ask for help debugging in a general help channel (also see #❓|how-to-get-help)
well i do understand the basics of python the problem is i dont understand packages and logging
and user inputs i understand just not how to set a root
it still isn't a data science question.
can someone teach me how to code
I have a pandas related question, I am trying to lookup values held in df1, that are in df2, would the best way of doing this be using the df.merge()?
pls can some teach me how to code i wanna make my own games
can you be more specific? merging is for SQL-style joins. If you're trying to check if a value from one Series is in another, you can use the isin method.
sure one sec, let me draw up an example
are monte carlo tree search and minimax (including alpha-beta pruning) about the only algorithms available for boardgames like othello or are there other algorithms available too?

so you're trying to get just the rows of df2 where the Ref_code is in df1['Code']?
What I would like to do, is lookup the "Ref_code" column in df2, using df1['code'], and append the appropriate code based on the description
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)```
Merge DataFrame or named Series objects with a database-style join.
A named Series object is treated as a DataFrame with a single named column.
The join is done on columns or indexes. If joining columns on columns, the DataFrame indexes *will be ignored*. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on. When performing a cross merge, no column specifications to merge on are allowed.you will need to use left_on= and right_on= because code and Ref_code are different names.
Cheers, I thought it might be pd.merge(). Will take a look at the docs now
no problem. you have permission to ping me about this specific question if you get stuck.
thanks, much appreciated!
is there anywhere to do the merge, but retain any missing values not in the lookup list?
Updated


yes, you have to change the "how" to a different kind of join. (remember that pandas uses the word "merge" to refer to what's called a "join" in general.) the types of joins are inner, outer, left, and right. see if you can figure out which is the one you want.
the different types of joins are about how to handle missing values, depending on which side they're missing on.
thanks, let me take a shot, at it
i'm confused i am trying to process a 2.7 GB file and it's taking forever
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
it still won't work and idk how to fix it
guys
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
idk what i should be using
Hey, i am looping a graph data structure in for loop i made it using a dictionary and i want to access its contents in a range for example dictionary is from A to Z and i only want to access its values from A to N i am really confused how i should approach it, is there any simple way to do it?
Hi I need a help
Hey @lapis sequoia!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
this was dumb
HIIIIIIIIIIIIIIIIIIII
hi
Why am I getting this error?

idk what chunksize to use
can't tell if 10 or 10,000 is the better option
it just takes forever to load and then i can't even see the first 5 rows of the dataframe
hello everyone! i am currently giving my 12th grade exams (A level). i was thinking of pursuing a career in AI. I just wanted to know from a few people in this field, or who are planning to be a part of this field. lets say im above average at coding, and fairly okay at network theory, can i pursue this field?
like, do i have to amazing at coding from get go or do i get to learn better along the way?
Does anyone use gini coefficient for feature selection in classification models?
If you are just trying to dummy encode the gender variable to be binary, I would just use pandas.get_dummies('gender', drop_first=True)
yeah idk how to get this csv file into chunks
nothing works
idk how to figure out this chunk size ugh
How big is the file?
2.7 GB
pandas can handle up to 5 gb
which is why i'm so confused as to why it wouldn't work
whats the error say?
there is no error
"ParserError: Error tokenizing data. C error: Expected 5 fields in line 2351587, saw 20"
@hollow sentinel have you tried using dask? they even have an example to determine the block size https://docs.dask.org/en/latest/generated/dask.dataframe.read_csv.html
you might want small chunks
I was going to suggest Dask, but for 2.7 GB it's not going to be very efficient
Maybe also try clearing up some memory on your machine?
why not?
Dask is usually recommended for datasets that are 100+ GB. When I tried to use it to parallel process a 50GB file it doubled my run time on everything
i tried using dask before
did not work that well
b'Skipping line 2351587: expected 5 fields, saw 20\n'
b'Skipping line 4779945: expected 5 fields, saw 20\n'
b'Skipping line 7110934: expected 5 fields, saw 20\n'
b'Skipping line 8319025: expected 5 fields, saw 20\n'
b'Skipping line 9111768: expected 5 fields, saw 20\n'
b'Skipping line 11291243: expected 5 fields, saw 20\n'
b'Skipping line 13551809: expected 5 fields, saw 20\n'
b'Skipping line 15830804: expected 5 fields, saw 20\n'
b'Skipping line 18116907: expected 5 fields, saw 20\n'
b'Skipping line 20293404: expected 5 fields, saw 20\n'
b'Skipping line 21406069: expected 5 fields, saw 20\n'
b'Skipping line 22166634: expected 5 fields, saw 20\n'
b'Skipping line 24241527: expected 5 fields, saw 20\n'
b'Skipping line 26589319: expected 5 fields, saw 20\n'
b'Skipping line 28809780: expected 5 fields, saw 20\n'
# chunksize = 10000
# for chunk in pd.read_csv(path, chunksize = chunksize,error_bad_lines=False, warn_bad_lines=False):
# print(chunk)
data = pd.read_csv(path, chunksize = 10000, error_bad_lines = False)
df = pd.concat(data, ignore_index = True)
df.head(1)
idk why it's giving me such an issue
dask is great for anything that normally wouldn't fit in memory
even when i used like chunk size 10
can the csv have weird data like 20 fields instead of 5? have you checked those lines?
if it has less columns you can use csv module. the good thing about it is it will simply let you read line by line.
can you open on a text readeer?
I processed a csv of 5/6 GBs earlier(with csv module).
I think it would crash too
idk what to do here
i just wanna see the first 5 rows
of the dataframe
i can't see the amt of cols
just wonna see?
then switching to csv is my suggestion, it won't be tough. bit long if things are complex but it will not crash.
(assuming you're not using readlines ofc)
it already is a csv
oh
you mean not using a dataframe?
i mean i want to process the data
i was just looking at the first 5 rows for now
what crashes?
for downloading a file?
yes
ah then i have no clue
should my computer be able to handle a 2.7 gb csv?
yes
it should download and if you use dask you can loaded without a problem
with dask you don't need to free memory before doing a .compute()
np
so dask should be able to comfortably read 2.7 gb files
easily
it's only when using the compute method that the memory is allocated
fully allocated*
when should I use a Monte Carlo tree search?
@hollow sentinel the dask docs say Dask is convenient on a laptop. It installs trivially with conda or pip and extends the size of convenient datasets from “fits in memory” to “fits on disk”.
i have an idea
i will save it locally on my machine
take a smaller portion of it
w excel
and see what's going on
but then would crash excel no?
gotta try something
good luck - you have my 2 cents on how i'd go about it 🙂
ok so excel is defo not gonna work
just uploading the csv into my jupyter notebook
/Users/rahuldas/opt/anaconda3/lib/python3.7/site-packages/dask/core.py:118: DtypeWarning: Columns (1) have mixed types.Specify dtype option on import or set low_memory=False.
args2 = [_execute_task(a, cache) for a in args]
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
how hard is it to implement a Monte Carlo tree search?
hey guys i am interested in text to speech with a human face speaking the text, can anyone recommend me anything that can help me with this
yes.
what process do you mean exactly? can you be lil bit detailed if possible?
i figured it out nvm
anyone have any ideas?
what kinda of questions is that - just look up implementations online 🤷♂️
how would I implement it for my own game?
r u using python?
yeah
I have to implement it myself not using a library for the Monte Carlo search tree
do it then
idk how for my specific game
google it 🤷♂️ learn it 🤷♂️ copy the code and implement it 🤷♂️
I don't see what you gain by asking whether its difficult or not thrice. if you have to do it anyways, what difference does it make?
:incoming_envelope: :ok_hand: applied mute to @lapis sequoia until <t:1642622654:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
Does anyone have expierence translating numpy code to cupy (https://cupy.dev/) ? Is it mostly just a 1:1 translation or is cupy much less featureful due to GPU limitations?
any data viz person know how to add labels in subplots (for each one)?
for i in range(1, columns*rows+1):
fig.add_subplot(rows, columns, i)
plt.imshow(eval(f'img_{i}'), cmap='binary_r')
plt.show()
eval(img.. is for variable names (don't ask)
@iron basalt: Thanks. It seems to have most of the features I like.
It also has some functions that simplify numpy code slightly as atleast_3d. I defenitly will look into this!
I am running a model in which the accuracy and loss remain relatively constant i.e the model doesn't seem to learn. Could it be because I have selected a wrong loss function? could that drastically affect the models' ability to learn?
Hey there! Can some1 help me with data representation (I'm new to DS)? I have class that describe some game, that contains array of players (player number = const, player data - additional info about player (e.g game_result flag, player name, etc.)). What is the best way to represent the data to see for example player win rate?
P.S: game and player data are dataclasses
It will be nice, if you can DM me and explain with an my code
pasting from #career-advice
I'm pretty good at python. I use it a lot for my web projects. Even built a complex desktop app with tkinter. But haven't explored data science much. Except pandas. I know pandas well. I wish to use my 13 years of field experience in oil/gas with my new coding skills to maybe bag some DS projects or even a position.
How long would it take to learn other python DS libraries for someone at my skill level? And which ones should I aim for?
I'd recommend starting off with the "non-Neural Network" type things. Sklearn is the usual library that people use for standard classifiers + regression models.
A lot of DS at the beginning is understanding what you can do, what you're looking for, and what math / techniques / whatever can you apply to things. It's also fairly dependent on the data and task at hand.
I'd go through three things in your case, since you've got the basics down:
-
Read over a Data Science textbook or do an intro to DS course, just to learn about the terms we use in the field.
-
Go through the tutorial for Sklearn to see how approximately to interact with Sklearn. With pandas, it's very easy now-a-days.
-
Get a dataset and mess around with it. This is very general but, honestly, it's the best way to learn. You can get some of these from kaggle, but even taking some standard datasets and trying to do things with them is fine. For example, taking the diabetes dataset and trying to think about how to represent the features, etc. OR, getting a weather dataset and messing around with that a bit.
I'm not exactly sure what type of oil/gas data you'd be working with w/rt your existing skills, so it's hard to give you something exact to focus on. But I'd say the above should take something like a month to get pretty decent at, and then a few months or so to really solidify your understanding of the basics.
tl;dr: learn sklearn.
Note: The reason I explicitly note above about NNs is that while they are WELL-represented in this channel, they often are "black boxes" which may not teach you DS as well as the classical non-NN methods. Additionally, for "practical" work in the fields, many datasets are still best served using the classical methods due to interpretability of the model. Neural Nets are fun, but I'd make them a "thing to learn later" after you're very comfortable with classical classifiers and regressors.
frankly i'd focus less on "learning libraries" and more on "learning stats and probability"
even if you don't care about latin square experiments and just want to jump into classifying cat pictures, without at least a basic understanding of those things you'll struggle to be useful in most organizations
but you can definitely have fun without them
you will also eventually need to learn calculus and linear algebra, but as long as you know how to do basic matrix and vector arithmetic you should be ok at the beginning
that said, in python specifically i agree that scikit-learn is high on the priority list, along with matplotlib and maybe seaborn
if you know excel, that can be a great "shortcut" to doing things that you otherwise might not know how to do in python
even if you are an experienced data scientist or data engineer, sometimes the most valuable skills are the "stupid" skills like being handy with excel and having a basic understanding of experimental design and statistical sampling
so it depends a lot on your goals
data science is a huge field, imo significantly bigger than programming with respect to the number of things you'd consider "core" competencies
programming usually you can get away with loops and ifs and a basic grasp of OO
i don't say all that to be discouraging. but i don't want people to go into it thinking that they'll be a senior data scientist from nothing in 3 years
you can of course get started with kaggle stuff, and imo it's a good way to feel like you're "doing something" while you fill in whatever gaps you might have in your math and stats knowledge
Excel / Sheets takes care of so many ezpz problems. Parenthetically, there's also a DS book --- I think called Data Smart? --- that goes over basic DS stuff using only Excel. It's pretty nice to not worry about the "language" and just look at the concepts, for those students who are unfamiliar with Python.
What university/college program do you guys recommend a high school student to become a data scientist
don't think the name of the university really matters
and as far as the name of the degree/major is concerned, it varied significantly across the country/university
some universities offer DS under CS, some offer it entirely separately
e.g. at my university it's under faculty of IT
I ended up figuring it out using a df.at[index,'column'] solution, just had to add the new blank columns to the dataframe. No goofy iterrows.
That’s great!
yeah, feel good! It's just automating data lookup on an internal web app, but I learned a lot. Gonna apply what I learned to some of the web based part of my job next.
I wouldn't have done it if there had been an internal database table with all that info on it.
thank you so much for that detailed response.
thanks. sounds like a long road. I did calculus and algebra in engineering so maybe that helps.
If by algebra you also mean linear algebra, then you are well set up for DS. You just need statistics, lots of statistics (but don't get too lost in the details of it all, the general ideas of why stats does things the way it does them matters more). As for programming, get comfy with libraries that let you implement/view the stuff from stats, like numpy, scikit (all of its various libraries), matplotlib, pandas, jupyter notebook, etc. Though the path might be something like: do it in excel first -> do it in python with pandas, numpy, etc -> let some library do it for you like scikit stuff.
Beyond that, there is stuff like neural networks, and other crazy things.
(Actually you can add another step in front of the "do it in excel first" part, do it by hand first)
I made a lot of neural network transfer art with copy pasta repos.
*There is also just the general ability to get data and mess around with it, whether that's from a database or other form (maybe even web scraping).
but stats are cool :'( you can get lost
Yeah, but that can take a lot of time, as you need to sort of push through it to the end, because if you pull out in the middle of the journey you can be more confused than just not knowing all the details.
haha true. still saying, it's a good jungle to get lost 😄
Yeah, all math is, just a warning of not spending all your time going through wikipedia article link jumping hell (what do all these random math words mean?).
(Because there is no end to it, and meanings are context specific, unfortunately math is not a context free language (it shows in papers))
true. there is literally no end lol.
as long as we know we are okay getting lost and have enough time to get lost, it's a fun process.
but the domain is just never ending.
This is also why I recommend getting a book on whatever math topic, the "intro to X" kind. Because even if you don't read it or only use it sometimes, its table of contents will let you know when you have gone too far (the thing you are looking at is not in the table, and not even adjacent to something in the table). But this only applies if you care about time management, and the multi-arm bandit problem of learning new stuff.
it's a good problem. I like the reference.
(*I use machine learning concepts to inform my own learning process)
How to implement FID score and Precision and Recall in DCGAN using tensorflow Keras
is it possible to make an ai that can play minecraft on different servers?
does anyone know how to make seaborn legend to be horizontally presented and stacked (n entity per row)

g=sns.lmplot(x='comp_1',
y='comp2',
data=data,
fit_reg=False,
height=10,
legend_out=False,
hue='user_name',
scatter_kws={"s":50,"alpha":0.9})
plt.legend(loc=8,title="Name")
plt.title("title")
plt.xlabel("dimension 1")
plt.ylabel("dimension 2")
can anyone tell me what im doing wrong here

since seaborn uses matplotlib, i suggest you to look at how you do it in that.
this may be relevant(https://www.delftstack.com/howto/seaborn/legend-seaborn-plot/) (Not totally helpful tho), but I think you will need to go in details in matplotlib docs or api refs to do it.
Delft Stack
This tutorial demonstrates how to add or customize the legend of a seaborn plot.
but since you are doing plt.legend you are on the way(If it is possible)
try delimiter = ',' instead of sep once
(again not sure, just looking through some similar questions)

uhm try \,
same problem😢
ah jesus

Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
just a few of the first lines
hm. alright gimmi a while
sure(:
Huh, that's strange, it works fine for me when I copy from this pastebin.
df = pd.read_csv("sample.csv", encoding="utf-8")
df.head(5)
What about this? (Where sample.csv is whatever you called yours.)
@stone marlin this error kinda suggests to me that something may be off with the data when they are using sep.
but if sep is not at all needed then i think pandas will handle ""
The default sep is ,, so that shouldn't be it. I'm also able to literally copy-paste the pastebin into a new file and correctly parse it.

it says there is strings
Okay, coolio, so you can just get rid of those double-quotes and it should work out.
Yes i have it, thx guys
from matplotlib import pyplot as plt
g=sns.lmplot(x='comp_1',
y='comp2',
data=data,
fit_reg=False,
height=10,
legend=False,
hue='user_name',
scatter_kws={"s":50,"alpha":0.9},
facet_kws={"legend_out": True})
plt.legend(loc=8,title="Name",ncol=5)
plt.title("...")
plt.xlabel("dimension 1")
plt.ylabel("dimension 2")
I able to make it get below and in several column
but i still unable to make it below the chart

How do you take a dataframe with column ['image data','labels'] and make it to a PyTorch dataset with DataLoader?
nvm, change it into like this
plt.legend(loc='lower center',title="Name",ncol=5,bbox_to_anchor=(0.5, -0.6))
How do you convert a column of integers to tensors?
Can i train my object detection model on another machine and run on the other?
yes
Yes.
hi i need some help with dataframes in pandas
Share the question.
Hi, I am facing some issues with getting the headcount for a month is anyone able to help?
The issue is
people are leaving and rejoining
and the algorithm is recounting the people who have already been counted
what is the difference between fig.show() and plt.show()
!paste this sounds like it might not be a "data science" problem specifically. at minimum, post your code and explain the context for this task (is it homework? something for a job?)
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
It is homework and I just need some guidance and not full help
I will post the code up as soon as I get back to my PC
How would you guys optimize a symbol/character recognizer? This is what i have after 100 epochs...

i didn't know the answer, but i was able to find the docs pages for both functions:
https://matplotlib.org/stable/api/figure_api.html#matplotlib.figure.Figure.show
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.show.html
the differences seem to be:
fig.showdoes not manage the graphical system that displays the plot; you are expected to already have e.g. a GUI window runningplot.showdoes set up and run the graphical system that displays the plot
in my experience, you can use them interchangeably inside a jupyter notebook, but in a command line console you can't use fig.show because the plot window will just close immediately, unless you take other steps to set up and run a GUI for displaying plots.
this would be a great stackoverflow question btw. i can post it if you don't feel comfortable
It's oscillating a lot too
Hello, i was wondering if anyone knows good resources about word encoding and decoding for neural networks, i'd like to kind of make basic encoding decoding system to learn how it works, I mostly want to make those 2 and test it with some sentences, I don't yet want to do the actual neural network that converts the words into a different sentence or anything mostly just the system that converts the words in a number and back
Does anyone know of any good resources for getting a better understanding of image recognition / object detection (and by extension machine learning as a whole)? I've followed some tutorials and it has worked, but I want to know why it works
sounds like you need to learn more about the math behind it all. is that something you're interested to do?
(a lot of people come to this channel excited about what they think AI is and leave disappointed when they realize that it's all math.)
anybody know how to concatenate dimensions within an array? Suppose I have a 2x2 array whose elements are 3x3 matrices. I want to concatenate them so the result is 6x6. reshape doesn't seem to work, since it just flattens. I'm trying to preserve the structure of the subarrays. Think of taking 4 photos and putting them side-by-side. Any help would be much appreciated.
Suppose I have a 2x2 array whose elements are 3x3 matrices
what is the shape of the whole array?(2, 2, 3, 3)?
keep in mind that arrays are "one thing".
so if you do print(array.shape), what you see is (2, 2, 3, 3)? we just need to be super clear on that, or I can't say anything useful.
yes
alright, let me think
I have a 2d array of 2d matrices and want to reshape without losing the structure. cheers
I have a 2d array of 2d matrices
that's not how it works. the array is one thing
you're talking about a single four-dimensional array
yes ik
anyway, the solution probably involves transposing before reshaping. still thinking.
x = np.array([[1,2,3],[4,5,6],[7,8,9]])
y = np.array([[x,x],[x,x]])
y.reshape(6,6), y
test code
ok got it
had to move axes to (2,3,2,3)
In [3]: np.arange(36).reshape(2, 2, 3, 3)
Out[3]:
array([[[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]]],
[[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]],
[[27, 28, 29],
[30, 31, 32],
[33, 34, 35]]]])
here's what we have
array([[ 0, 1, 2, 18, 19, 20],
[ 3, 4, 5, 21, 22, 23],
[ 6, 7, 8, 24, 25, 26],
[ 9, 10, 11, 27, 28, 29],
[12, 13, 14, 30, 31, 32],
[15, 16, 17, 33, 34, 35]])
this is what you want, right?
(I made this manually. still working out the code for it.)
I tried this: np.moveaxis(x, 1,2).reshape(6,6)
what is x
your array
In [10]: np.moveaxis(arr, 1, 2).reshape(6, 6)
Out[10]:
array([[ 0, 1, 2, 9, 10, 11],
[ 3, 4, 5, 12, 13, 14],
[ 6, 7, 8, 15, 16, 17],
[18, 19, 20, 27, 28, 29],
[21, 22, 23, 30, 31, 32],
[24, 25, 26, 33, 34, 35]])
well, that's not too far off.
yh
In [21]: arr.transpose(1, 2, 0, 3).reshape(6, 6)
Out[21]:
array([[ 0, 1, 2, 18, 19, 20],
[ 3, 4, 5, 21, 22, 23],
[ 6, 7, 8, 24, 25, 26],
[ 9, 10, 11, 27, 28, 29],
[12, 13, 14, 30, 31, 32],
[15, 16, 17, 33, 34, 35]])
I have done it
looks like the trick is to rotate the first three dimensions, but leave the fourth one in place
right, rotate not swap
this was an interesting question. Thanks 
thx 2u
hello, I am working on my code that has 5 ranges of 123 points and I want to export those points as numerical data on a csv but when I do, I get the columns right but the data are kinda compressed in only one cell and only up to 4 points of the ranges are shown in the cell as opposed to my desired results where they should be in separate cells as rows, can someone help me out? below is the code
heres what it looks like in print

Uhm if i remember correctly that method for einsum or something would also work
I'll mess around in #bot-commands and will let you knw
I have 30 GB ram currently but it crashes as the data is large
So i wanna increase the ram
And i found this
Is this correct? Does it increase my memory
what are some best research area in Deep Learning????
no, this is the opposite of what you want. this is just a very fast hard drive
Ohh, so it reduces my ram space?
no. it is like getting a bunch of extra ram sticks and using them as a hard drive
actually wait. yes
it does reduce your ram
You can allocate some of this memory to create a RAM disk
Ohh, 🤦♀️ thank youu:))
So if im using a hard disk i cant allocate memory and save variables?
maybe your machine learning framework allows you to do that?
are you using pytorch?
30 gb is a lot of stuff in memory at once
maybe you can restructure your training pipeline to use less memory
oh i mess around pretty half an hour, I think transpose part can be done with einsum too, but at the end we need reshape(if that is what OP wants)
https://pytorch.org/blog/efficient-pytorch-io-library-for-large-datasets-many-files-many-gpus/ the pytorch blog appears to recommend something called WebDataset which can help do i/o efficiently
einsum is like regex for arrays, it's always amazing what you can do with it
Tensorflow
Oh sorry not sure, I was bit messing around with stuff.
there are some suggestions here for reducing memory usage https://www.tensorflow.org/guide/data_performance#reducing_memory_footprint
Indeed. It's funny how it has A LOT OF functionalities together. btw, is it more efficient or similar? say for multiplication?
Hey guys could someone take a look at #help-dumpling, I would really appreciate it
as i understand it, einstein notation is a very compact notation for defining sequences and series with indexing into arrays. so you can use it for matrix transpose and multiplication, because both of those things can be expressed in terms of sequences and series with indexing into ararys
ah i see. I still need to see if it has anything to do with efficiency or not.
Hey I'm facing a weird error I'm not sure how to fix or go around: ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type numpy.ndarray).
Image
At first the error was a data adapter error and I found a solution online to turn it into a np.array, when that is done this is the new error I receive
Any help is much appreciated

Could this be a compatibility issue between sklearn and tensor?

i believe it can be more efficient than doing separate independent numpy operations, because you don't have to "round trip" with python and possibly make intermediate copies of data
do you need to convert the data to a tensor object first? or is keras supposed to accept plain numpy arrays as input?
All my data is stored in numpy arrays
Can i still follow this
I reduced the size of images it works fine, but i wanna try to improve the accuracy with a larger image size
ok, and are you loading the entire data into memory at once? if you are doing batch gradient descent, you should only need to load the images that are in the current batch
Yes I'm loading the entire data into memory at once
Im doing transfer learning using vgg19
maybe try the tensorflow data api as described in the document i sent
only load the data you need when you need it, don't load everything at once
that's what these data loader apis are for
ah makes sense
Ahhhh, just tried that out but my kernal died, will take me a sec to relaunch and run all again
Alrightt,thank youu:))
But i have a question ,since im doing transfer i need to pass the entire X_train and then split into xtrain and xtest
This is where all my memory goes
Can you please tell me how the api works here
I have a strange (?) question, when giving the model picture data, should all the picture follow the same format, like resolution and RBP compared to black and white?
I'm feeding it some COCO data, and not all pictures are in the same format
yep. as much i've seen yes. ( i mean I've never seen passing different res, or grayscale and rgb together)
Hmm maybe that's why I'm getting the error?

Going to need to try resize all the data then hmm
why don't you check the shape of them first.
may be they are same size lol.
also the error it shows in that case is different. about shapes.
(as much ive seen)
[array([[[ 33, 52, 59],
[ 44, 60, 73],
[ 51, 65, 83],
...,
[155, 166, 194],
[128, 139, 161],
[ 74, 85, 105]],
[[ 48, 66, 77],
[ 49, 65, 81],
[ 40, 56, 73],
...,
[151, 158, 185],
[154, 159, 184],
[110, 114, 139]],```Different
Unless I am missing something here
I had a project like this with normal Excel data, but this is proving to be much harder
What do you think about creating a set resolution bigger than all images and giving the pictures that aren't acceptable black filler borders?
You could ask for help in the #cybersecurity channel.
i am not talking about encryption i mean encoding words as in one hot encoding or embedding or something like [0,0,1] for house and [0,1,0] for cat, from what i have seen
thanks for your insight. I've posted the question on stackoverflow as per your advice
I think what you're referring to is a Natural Language Processing (NLP) problem. I'd advice you to read up on that
yeah, but that was my question i was wondering if someone knows good resources about the specific topic i meant
oh, you could do the intro course to nlp on datacamp
I'll be doing that. Plus, there's a course by deeplearning.ai on nlp available at Coursera
Specific to the topic of encoding-decoding tokens, you may want to check out the evolution of the idea if you haven't already:
- https://en.wikipedia.org/wiki/Byte_pair_encoding Compression also used in NLP.
- https://leimao.github.io/blog/Byte-Pair-Encoding/ This interesting article on implementing this process.
- A general overview of the landscape: https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/
[Note: these resources are from an ex-coworker who does more NLP than I do now, I haven't completely vetted them.]
thanks i will look into it
Hey guys, I'm getting the error ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 400, 400, 3), found shape=(None, 400, 3). Even though I'm resizing the images for training and predicting the exact same
The training: new_image = image.resize((400, 400))
The prediction: im_pil = image.resize((400, 400))
and then predicting with prediction = model.predict(np.asarray(im_pil))
I'm not sure how it can find a shape of (none, 400, 3)?
@primal shard i think a lot of machine learning still uses "bag of words", in that each word is converted to a vector embedding before feeding into something like a transformer
even if the sequence of the words/tokens is preserved, the word is more likely to be represented as a dense real-valued 100-vector than a sparse binary-valued 10k-vector (or however big your vocabulary is)
another common choice is tf-idf, or variants of tf-idf like bm25
tfidf doesn't provide any dimension reduction though
Could someone explain the error please? What does "shape" mean exactly?
like shape = (1D, 2D, 3D) ?
Do I need to reshape in some sort of way?
I think that the problem is that you have to use img.reshape(400,400,3)
The error is that the model is expecting an image that is 400 in width, 400 in height and 3 channels (RGB -red green and blue.)
And for some reason the shape is 400 and 3 when inputting it into the model. Would you mind sharing your code so I can get a better idea at whats going on?
Hi, somebody knows wich tool i can use to do something similar to this? :C i chequeck seaborn, matplotlib and pandas

yes of course! I've uploaded some code in #help-mushroom if you can take a look, thank you so much
oke thanks
Please only post your question once per channel, if you need to you can go back and edit your first post. Let me look for a minute, I've seen these plots before but I can't remember where.
I'm sorry, it was accidental 😁 , thanks a lot!
Has anyone tried to implement TPU support for Tacotron training? I am fighting with waveglow for TPU, but training doesn't seem to work
I am getting this error: NotImplementedError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: Unknown device for tensorexpr fuser
Should I use help channel for it?
For the charting, so far I've only found something "sorta" similar in Altair: https://altair-viz.github.io/gallery/trail_marker.html#gallery-trail-marker I'm still looking at the matplotlib/seaborn docs.
Pret much what you'd do, I imagine, is plot x = year, y = ranking, and the thickness is something like popularity. If this was generated, I'm guessing that they did something with the error bars to make it the popularity volume or something.
Lemme real quick look at mpl tho.
Ah, okay, I think I tracked down how they're doing it. https://observablehq.com/@russellgoldenberg/variable-thickness-band It's a d3js thing.

It is quite common to encode the thickness of a line to some variable. In d3, this typically means using d3.area. Here are some examples from NYT, Bloomberg, Axios (all whose work I love dearly), and myself at The Pudding. The image below is some kind of bump chart / streamgraph, but it appears as if Brazil's imports shrink to a tiny amount then...
:incoming_envelope: :ok_hand: applied mute to @deep ridge until <t:1642714819:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
Thanks a lot! 
that's kind of it, yes. the array [[1,2,3,4], [5,6,7,8], [9,10,11,12]] has shape (3, 4). it has 2 axes (shape has length 2). the first axis has size 3. the second axis has size 4.
we loosely say "2-dimensional", but you have to be careful because this isn't really the same meaning of "dimension" as is used in linear algebra
it maybe would be more precise to say "an array with 2 axes", but the term "axes" is a numpy-specific usage here
Im a little bit confused
whats the difference between yolov5 by ultralytics(pytorch), yolov4 (tensorflow) and yolov4 darknet?
what's better
Hello, I'm using Selenium to automate a purchase on a website. I'm not trying to automate captcha or anything, I just want to be able to input the captcha and then for it to move on.
Currently, I'm using ImplicitWait, but after completing the hCaptcha, it leaves me on the same page.
This may be better in a webdev room, I'm not sure this is data science or ai.
ah ok, thank you
it might still also be against ToS even if you are not bypassing the captcha
eg. if this is a sneaker bot or something like that, it might still violate rule 5
What's a good beginner's level project to start working with machine-learning or AI? Any tips?
@lapis sequoia i have a doubt in transfer learning. The first time i train vgg19 by removing the top layer with a dense layer and softmax,it learns weights for the final layers. When i fine tune i.e., retrain the last two layers of vgg 19 on the same dataset wouldnt it have already learnt the weights and thus would be overfitting?
or do i relearn cause i use model.compile again?
:incoming_envelope: :ok_hand: applied mute to @fierce bronze until <t:1642748880:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
:incoming_envelope: :ok_hand: applied mute to @split basin until <t:1642748881:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
Hi, Can someone suggest some tools/libraries to analyze and clean an image dataset specifically for instance segmentation purposes
Hey guys, So I wanted to use YOLOv4 for object detection, I was following a video where they showed how to install Darknet(using vcpkg). I tried following that but my PC ran into an error (Blue screen after which the computer restarts) in the mid-process of preparation of vcpkg for darknet installation using Powershell after reaching '-- Building ffmpeg for Release' (this line in the powershell). I also followed Medium's steps (https://medium.com/analytics-vidhya/installing-darknet-on-windows-462d84840e5a) but again the same problem occurs. now what do I do
Can anyone help me?
I also tried installing using CMake
still doesnt work
shows the same error

Youtube
The answer is Reply layer or Relu(cuz RELU is an activation dk if counts as a layer)
can you direct me to a channel which can teach me?
Hmm, i didnt learn in very deep, those concepts. just a brief idea of the layers. I learnt from CodeBasics
if you are preparing for interviews and all then go for books
oh
i just need to know the basics and fundamentals
youtube on playback 1.5x should be the best imo
Yea then i think you can watch CodeBasics
what about freecodecamp?
I tried watching their's but I didnt understand much, could be different in your case so try watching first 10-20 mins and then decide if you should continue watching the video
Someone? HELP me with this
Hey guys, I made a NN for the MNIST data set. However the accuracy of my NN is really bad and I cant figure out what I am doing wrong. Also the cost function works decent for [64,32,10] NN structure but structures with too many nodes and structures with more than 3 layers do poorly for some reason. Here is my code
https://github.com/MachineLearningEnthusiast/Neural-Network-Project-using-MNIST-data-set cheers

GitHub
Contribute to MachineLearningEnthusiast/Neural-Network-Project-using-MNIST-data-set development by creating an account on GitHub.
Hey I'm doing presentation on mathematics in Machine Learning. Can you suggest me which basic concepts should I cover? I was thinking about Linear Algebra: Matrix multiplications, and Calculus: Stochastic Gradient Descent
What level are you presenting to? High school? College? General Public?
??
I'd say its on college level. Just basic concepts. I should clarify, that for Calculus part I will be just covering gradient of a function (not SGD algorithm), as I do not have much time for presenting this concepts
I just need few topic to cover them in less than 7 minutes
Requesting someone to answer 🙏
A great project for linear algebra which utilizes eigen vector level theory, in particular diagonalization properties, is PCA and SVD. PCA should be pretty simple to write code for from scratch. SVD a fair bit harder.
I want some numpy projects for beginners 😶
idk man, i feel like there isnt much to numpy
i would just think of math things and carry out the calculations, like matrix calculations i have used alot
I've done this a lot, But I found a video parsing project using NumPy and OpenCV
Fortunately for me, I'm starting to learn OpenCV
You mean I read the array from a file?
no, matrix profile is a technique for time series
Well, I will look for it and do it
if you want to see how it works: https://renato145.github.io/matrix_profile/
The matrix profile is a data structure and associated algorithms that helps solve the dual problem of anomaly detection and motif discovery. It is robust, scalable and largely parameter-free.
that actually sounds really useful
what do they mean by help find anomalys in data?
like noise
?
imagine you have a time series where a pattern is repeating every 20 steps, but at some point something is different from that pattern, that will be an anomaly
so an example of time series is stock price of a particular stock over a time period?
yes
the term anomaly to me means like a data point which seems very extreme
like noise
so you basically use matrix profile to eliminate anomalies?
but it can only spot anomalies in series, that is a specific pattern?
with matrix profile you compare windows of data (euclidean distance between 2 windows), if very different than all other windows that will be an anomaly pattern
if you compare single data points or very small windows, that will probably capture noise
nop you use it to spot anomaly and common patterns
well if you spot an anomaly you want to remove it right ?
no, in this case you want to spot anomalies in the real data
also what is a window of data?
if you have a window of 100, you will be comparing groups of 100 data points
right and a use of finding the anomaly would be to excluding it from our training data set?
what is a window? whenever i search it up it comes up with windows, even when i try and nail it down
No, you detect an anomaly and report it because that may be a malfunction (if you are monitoring a machine or something for eg)
window or slide of data, if you have 1000 data points the 1st window is [0:100] the 2nd [1:101], [2:102], ... [n-100,n]
right, lets say i have a huge amount of data and i apply this matrix profile technique to spot anamolies. I have found all anomalies and decide to remove them from the data set to train an ML program. Would you say this is a decent use of matrix profile?
i am interested in application
thats all
that will not be a good use, because those anomalies are important in the data, they are not noise
imagine you have a lot of sales data, and you want to do a quick analysis, you can use matrix profile to find anomalies (the right term is discords in time series literature), and quickly spot points in time where sales went very different (like black friday)
I think that varies a lot depends on the domain you are working in
Its usually the domain that defines what can be considered noise
yeah that would make sense
and some times that can be very difficult to tell
i would assume
Can someone recommend me some techniques and tools to practice and become a pro at python(related to data science only)?
If I want to change specific parts of a csv file every 5 minutes, or every time a update comes through, should I use scheduling clocks and if so does it occupy a thread?(for each 5 min) the reason I ask is because the 5 minutes for each specific one could be off timed and would result in false data if I did it all every 5 minutes
and would it be better to use another file type of sorts for this? It’s a settings/ dashboard view program
Manages 20 branches which in turn manage a total of 300+ bots
usually git is good, check https://simonwillison.net/2020/Oct/9/git-scraping/
Is there a website where I can read more about classifier model? I need to do 3 model of yes and no model but I have no idea which one is which
I have a largish 1d array, scores, representing scores for players in a game. So the score for player i is scores[i]. If I want to make an overall leader board for the game then e.g. leaderboard = (-scores).argsort() gives me the players in order of score. But I also have a number of subsets of players represent as 1d arrays of player ids, say one such is l. To get the leaderboard for l I can do _, l_lb, _ = np.intersect1d(leaderboard, l, assume_unique=True, return_indices=True) gives what I want (I'm not sure if the order of l_lb is guaranteed, but it seems to work). But if I want to get, say just l_lb[:10] then it's potentially quite inefficient when l is large to compute all of l_lb - it should be possible to directly just get the first n members from leaderboard and l without computing the whole of l_lb. Any suggestions?
it sounds like an array isn't the best data structure here. it sounds like you generally want to be able to query arbitrary sub-collections of scores, sorted by score?
i actually don't understand how intersect1d even gives the correct result... if leaderboard is [5000, 4000, 3000, 2000] and l is an array of player ids [4, 2], then what does the intersection even provide? the intersection would just be empty
!e ```python
import numpy as np
leaderboard = np.array([5000, 4000, 3000, 2000])
player_ids = [3, 1]
print(np.sort(leaderboard[player_ids])[::-1])
@desert oar :white_check_mark: Your eval job has completed with return code 0.
[4000 2000]
but this sounds more like a #algos-and-data-structs question
maybe you are expected to explicitly do a groupby/count operation
i figured it out
can you clarify your question?
i was about to say, i just found value_counts https://docs.dask.org/en/stable/generated/dask.dataframe.Series.value_counts.html
that makes sense, dask operations are "lazy", like spark/pyspark
yeah i just instantly ran to the doc
wow numpy is good for checking lin alg work
leaderboard isn't the scores - it comes from argsort, so it's the positions of the relevant scores
oh, i misunderstood
is l already sorted, or no?
(this still sounds like a #algos-and-data-structs question)
I think it probably is in practice - it doesn't change so could be sorted anyhow
or at least changes infrequently
yeah - maybe wrong channel, but it's numpy specific...
yeah fair enough. numpy questions usually make more sense here, but in this case "how to do it in numpy" seems less important than "how to do this efficiently in general"
@warm jungle do i understand correctly? leaderboard are the player ids, sorted by player scores. l is some subset of player ids in unknown/arbitrary order. and you are asking for the best way to sort the contents of l by player scores, and get the top N of those, e.g. top 10.
maybe you can do something like check the position of each element of l in the original leaderboard?
could be a good stackoverflow question
yeah, although like I say, l can easily be in a specific order as it won't change often compared with
leaderboard. I'll write it up with some examples. I have a working solution, I'm just not sure it's the best...
!e ```python
import numpy as np
scores = np.array([5000, 4000, 3000, 2000])
leaderboard = (-scores).argsort()
leaderboard_positions = {
player_id: position
for position, player_id
in enumerate(leaderboard.tolist())
}
players_subset = np.array([3, 2])
players_subset_positions = np.array([
leaderboard_positions[player_id]
for player_id
in players_subset
]).argsort()
print(scores[players_subset[players_subset_positions]])
@desert oar :white_check_mark: Your eval job has completed with return code 0.
[3000 2000]
@warm jungle ☝️ does that work for you? because you say that players_subset changes infrequently, you can pre-construct players_subset_positions ahead of time.
maybe you can figure out a way to only take the top 10 from that list, but i feel like there is no way to get the top 10 without sorting the whole thing
model_mlp = MLPClassifier(hidden_layer_sizes=(100,), max_iter = 300, activation='relu', solver='adam', random_state=0)
# fitting on training data
model_mlp.fit(X_train, y_train)```
I got this error when i ran the code above
```D:\Anaconda\lib\site-packages\sklearn\neural_network\_multilayer_perceptron.py:582: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (300) reached and the optimization hasn't converged yet.
warnings.warn(```Maximum iterations (300) reached and the optimization hasn't converged yet.
socratic question: what do you think this means?
Thanks - I'll take a look later, gotta go out soon
you should increase them
i suppose i should increase it then, it confuse me because this only has 150 rows while my 1k rows works fine with lower iterations
right, it's having a harder time optimizing with fewer rows because there's less information. it's probably bouncing around a lot
try decreasing learning rate if you can
ah i see, thanks
Hey all just wondering, since I cant find a clear answer in the docs, but is there a way to use df.query with .unique() in for one column or .drop_duplicates in pandas?
df.query('...').drop_duplicates(subset='x') like this?
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.drop_duplicates.html if you want to get distinct rows according to a few specific columns, use the subset option
i don't think .query supports this, nor can i imagine how it would without being overly complicated
yeah, kinda of wanted to avoid the long codes when using the traditional:
df_filt = df[df['column'] == "x" & df['column'] == "y"]
is this a good place to talk about trading bots?
yes, although i don't think we have too many experts on that subject here
What's up Python gang, I'm trying to take this columns with addresses and display their LAT and LONG but for some reason it's not working on my dataframe columns. I've tested it with other columns and it seems to work. Can some one help: here's the code:
#Turn our new coordinates column into Lats and Longs
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="myApp")
df[['location_lat', 'location_long']] = df['coordinates'].apply(
geolocator.geocode).apply(lambda x: pd.Series(
[x.latitude, x.longitude], index=['location_lat', 'location_long']))```
Here's the error I getAttributeError: 'NoneType' object has no attribute 'latitude'
the error message suggests that geolocator.geocode returned None for some inputs. it's looking for x.latitude, but x is None
i'd recommend writing a standalone function for this, if only to make debugging easier:
import warnings
import pandas as pd
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="myApp")
def geolocate(address):
result = geolocator.geocode(address)
if result is None:
warnings.warn(f'Failed to geocode: {address}.')
return pd.Series({
'location_lat': result.latitude,
'location_lon': result.longitude
})
df = pd.DataFrame({
'address': ['10528 Duke Ave SW,Albuquerque,NM,87121'],
})
df[['location_lat', 'location_lon']] = df['address'].apply(geolocate)
also, here's a tip: whenever you query an API in bulk, save the raw output
don't just save the processed output
you never know when you'll need to process the data differently. and if you didn't save the raw output, you possibly just wasted a bunch of time and money
still getting this error
AttributeError: 'NoneType' object has no attribute 'latitude'
it's 128 lines in that column
that's because i forgot to return something inside the if after emitting the warning
don't copy and paste code without understanding it!
True, for me it made sense I still dont understand the None part tbh
what part of that don't you understand? it's just checking if the result was None
all the addresses are valid that's why I'm confused
that's why I wrote the code that prints a warning
that way you can at least see which address causes the problem
gotcha, I assumed it was fixing my error haha
thanks though salt rock lamp, appreciate it
well like i said, don't copy and paste without understanding what the code does!
import warnings
import pandas as pd
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="myApp")
def geolocate(address):
result = geolocator.geocode(address)
if result is None:
warnings.warn(f'Failed to geocode: {address}.')
return pd.Series({
'location_lat': None,
'location_lon': None,
})
else:
return pd.Series({
'location_lat': result.latitude,
'location_lon': result.longitude,
})
df = pd.DataFrame({
'address': ['10528 Duke Ave SW,Albuquerque,NM,87121'],
})
df[['location_lat', 'location_lon']] = df['address'].apply(geolocate)
found the error address, thank you sm @desert oar
Is this the right table to ask about REST API and retrieving data from API?
In general I'm looking for suggestions for references, books, sites, or even terms I can research.
I have an API which says things like "Using bla-bla API end point data can be linked to bla-bla API endpoint through the LocationID field"
TOtally new to this.
and the different syntaxes for making queries through the URL
The API is accounting info from R365
I'm trying to implement an extension field of the rationals, in a way compatible with Numpy. Specifically, I need to extend the rationals with the golden ratio. After reading a little, I came to the uncertain conclusion that a custom array container would be the way to go (https://numpy.org/doc/stable/user/basics.dispatch.html#basics-dispatch) as opposed to a subclass of numpy.ndarray (https://numpy.org/doc/stable/reference/arrays.classes.html). I've got the code started but I wanted to see examples of how other people have handled extension fields and/or Numpy custom array containers. (Or subclasses of Numpy arrays -- I'm not sure.)
So, googling for this a bit, I instead encountered Sympy. My overall goal is to perform fast, exact calculations involving rationals and the golden ratio. Is Sympy a good option, or should I stay on the Numpy array container track?
I'd expect to be able to find someone at least implementing rational numbers as a custom array container, but I can't seem to find it.
hey Chic-chicago, i found this chapter very useful, is it possible if you could send me the rest of the chapters for this book or where to find them? cheers
Hey @copper grotto!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
I've got a partial implementation now but I'm getting an error I'm not sure what to do about. https://paste.pythondiscord.com/akoxuwijas.py
The exception is:
numpy.core._exceptions._UFuncNoLoopError: ufunc 'gcd' did not contain a loop with signature matching types (dtype('float64'), dtype('float64')) -> dtype('float64')
This seems to have something to do with a potential for loopy behavior, where my class would punt taking the gcd to Numpy but Numpy would think it has to pass responsibility back to my class. But, I definitely want Numpy taking the gcd; otherwise most of my operations would end up way too slow.
Hello, so i was trying to install some libraries using conda
and this showed up
How do i solve this?
I am following this video: https://www.youtube.com/watch?v=Iw3tducClFw
to install darknet

any idea on how i can solve this problem?
Pls someone help, i have been trying to install darknet since 4 days
So now which version should i install
don't freeze versions i guess
yes
tensorflow-gpu==2.3.0rc0 means you are requesting for version 2.3.0rc0 and nothing else
so remove the ==* bit
actually i am following a video
or if you need a particular version then remove the rc0
so if i dont install the same version, then there could be some issues
Okay, thanks i will try
do you know how to install darknet
and what is this error
@royal crest
there is a darknet discord server if you are interested
thx
what is this error tho
zSq8rtW
it doesn't say it's an error
its trying to solve something idk what
probably some dep hell
hmm, okay
M
so i wanna make an ai
that can write an essay for me
example you give it a topic and it just searches google and finds info about that topic and then writes an essay about it
how can i achieve this?
:incoming_envelope: :ok_hand: applied mute to @jaunty lotus until <t:1642842550:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).