#data-science-and-ml
1 messages · Page 310 of 1
Yes, if you lower the quality 1000 should be ok
Make a try
Anybody know of a library that produce PNG files from data points?
Well data points for line graphs or candle stick gtaphs
ah, then matplotlib
Matplotlib makes PNG files?
of course
just plt.savefig("*.png")
Do u have an idea of how GANs could converge?
https://www.reddit.com/r/MachineLearning/comments/n7lv1o/oc_phand_gesture_recognition_play_pause_control/
I am more impressed that he used windows

reddit
502 votes and 35 comments so far on Reddit
that's too less. even using the DeiT recipie wouldn't yield much
What do you mean by converge?
does anyone know how to control the number of clusters here (https://scikit-learn.org/stable/auto_examples/cluster/plot_affinity_propagation.html#sphx-glr-auto-examples-cluster-plot-affinity-propagation-py)

i was hoping for 7-9 clusters but it doesn't seem to separate them far enough
For this you should use k-mean clustering
Training a good discriminator while a better generator that fools D at the same time?
will this work if i don't know the number of clusters beforehand?
from what i recall this was why i didn't use k-mean in the first place
the K in k-means is a hyperparameter I think
Well, I don't think a GAN could ever converge
No, unfortunately k-mean clustering has a fixed size
Maybe you could try DBSCAN
If I don't go wrong scikit learn has DBSCAN implemented
I am not quite familiar with the general training scheme of GANs. Do D and G both start from scratch or is D initialized with a good enough checkpoint?
They both start from scratch
does this return the cluster center? i can't seem to find how in the documentation
I think you have to calculate it by yourself
But
Once you have all the points in a cluster
quote from Stackoverflow

You can do the mean of all the xs and the mean of all the ys
So you have the center
@shy ember
I'm assuming you mean "better counterpart" as GPT-3, but that's a private beta, so what else can I use?
maybe BART?
What's BART?
auto-regressively pre-trained models are generally better at generative tasks like convo
State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0. 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-be...
A whole bunch of pre-trained models here
Basiclly BART = BERT (as encoder) + GPT (as decoder)
Checkout this new article 😃

These 8 NLP libraries in Python are a must know for anyone working with text data.
hey everyone, how do i read a folder of images in github through python in google colab?
ehh, that kind of stuff is always shite. There aren't any "must-to-know" libs ever - only those that are basic (numpy, pandas). It's absolutely useless to "learn" a library. you have to learn concepts, not libraries. in NLP, you do get some use out of those for basic processing, but I would rather say the person learns "TF/Pytorch" (i.e understand the practical terminology and API usage rather than just a lib) to use NLP models since most ML tools don't do good in real-world NLP tasks.
You'd find much more better blogs on Medium than Analytics Vidhya tbh
Download them, put them on your google drive
And then open them via colab
Never did this but it seems pretty simple
@simple shadow
How does fbprophet work?
cause I gave it some dataset and the output it generated kind of follows true values, but when it went to the values it didnt see, the prophet kinda starts..sucking?

what I mean is, how does it predict something? why did it even predict the values it was trained on if thats what happened on screenie?
you can only gain so much performance with black-box methods.
wdym
exactly what I mean.....?
you can't expect something to work as perfect with minimal effort 🤷
i just want to know how does fbprophet make predictions and why it predicts whats already there
learn ML basics, then see RNN'S/LSTM
i want others to be able to run the google colab, wouldnt it not work if its on my google drive only?
Just create a shared google colab
*google account
cannot pickle 'weakref' object
anyone knows how to solve it? Saving model using joblib.dump
tag if answered please
Prophet is less of a black box than an lstm
Prophet is essentially regression, and this is a common problem in forecasting. See the "how prophet works" section https://research.fb.com/blog/2017/02/prophet-forecasting-at-scale/
Forecasting is a data science task that is central to many activities within an organization. For instance, large organizations like Facebook must engage in capacity planning to efficiently allocate scarce resources and goal setting in order to measure performance relative to a baseline.
Just eyeballing this output, it looks like the trend shifts after the big spike, and prophet tries to continue the flatter trend at the end of the time series. If you are aware of additional features that could have caused the flatter period, you should add them to the model
Basically, in order to predict a change in trend, the change either needs to be cyclical, or there needs to be some external feature that can indicate the trend is changing, and in what direction
Otherwise really the only reasonable thing a model could do is to continue the previous trend
Makes sense
That said, it might be doing the wrong thing here in that what should be an unusual deviation from trend appears to be a change in trend
Maybe there are some configurable parameters that can help with this issue
Also, it would help if you drew a vertical line where the training data ended and the test data began
Yeah, I did draw one after posted but im not on pc now
Give me a sec
Should me something like that

oof
Yeah that's pretty much what I figured
that won't be very high accuracy, but I guess it gets the job done
Neural networks have shown themselves to be pretty lackluster in time series modeling compared to other domains
not true in practice tho
I believe it if you are doing something like classifying 1000 different time series
you can check out kaggle's jane street, and everyone is running nets (I think the winner too, not sure tho)
For time series prediction on a single series? I haven't seen good results but I am obviously willing to be proven wrong
jane street is stock prediction BTW
Yirun's Solution (1st on 2021-03-29): Training Supervised Autoencoder with MLP
ahh, and a blend of xgboost
Cross-Validation (CV) Strategy and Feature Engineering:
5-fold 31-gap purged group time-series split
Remove first 85 days for training
Forward-fill the missing values
Transfer all resp targets (resp, resp_1, resp_2, resp_3, resp_4) to action for multi-label classification
During inference, the mean of all predicted actions is taken as the final probability
Deep Learning Model:
Use autoencoder to create new features, adding along with original features to the MLP
Train autoencoder and MLP together in each CV split to prevent data leakage
Add target information to autoencoder (supervised learning) to force it generating more relevant features, and to create a shortcut for backpropagation of gradient
Add Gaussian noise layer before encoder for data augmentation and to prevent overfitting
Use swish activation function instead of ReLU to prevent ‘dead neuron’ and smooth the gradient
Batch Normalisation and Dropout are used for MLP
Train the model with 3 different random seeds and take the average to reduce prediction variance
Only use the models (with different seeds) trained in the last two CV splits since they have seen more data
Only monitor the BCE loss of MLP instead of the overall loss for early stopping
Use Hyperopt to find the optimal hyperparameter set
Ahh, the mind of grandmasters works in different ways than the rest of use mortals can comphrehend
Yeah I have no doubt that eventually we will figure out useful general purpose neural network models that offer incremental improvements over regression-based methods
But for now it's a mischaracterization to suggest that a regression model like prophet will be inherently less effective than something based on an LSTM
if prohpet hasn't yielded much in a comp for 100,000$ - I think we can safely rule it out imo
The Jane Street problem is also a lot more sophisticated than forecasting a single series 🤷♂️
I'm not trying to say this particular model is the best thing since sliced bread either
Neural networks I would expect to perform much better on a complicated evaluation task like this
it seems forcasting is the second stage of the comp - it will end up in 3 months. I bet for NNs to rule
!remindme
Missing required argument
expiration
I have no doubt that the winning forecast will at some point use deep learning somewhere along the way
uh-huh
refreshing question
Hi, does anyone have any good info on how to interpret the output of the critic/discriminator module in a Wassertstein GAN (WGAN-GP)? I am struggling to interpet whether a large number means 'normal' or a small number means normal and looking around online im seeing conflicting info?
Would love for some clarification
I'm using xml.sax to parse a 200GB XML file and I'm trying to get byte offsets so I can seek back. Is there a way to do this? The Locator interface only provides line/column numbers that are useless for seeking
200GB... geez
yeah it's been a pain
I'm using xml.sax which has a push API, so I read some bytes, feed them to the XML parser, and it calls callbacks where I handle the XML elements
so like I feed 16k bytes to it, one of the event is interesting and I want to note the file position, and I don't know how to do that
If I count bytes when I push data in, I know where the 16k buffer is, but I don't know where exactly in the buffer the event happens
Way over my head, wish I could help
The object event though
what happens when you print(blah.dir())
print(blah.__dir__())
Where blah is the obj
Even better, use ipython so you can tab out on the obj
unfortunately the parser's internals are in C so I can't really get at the internals
Its still an obj is it not?
i.e.
blah blah your code blah blah
x = your callbacks obj at the event level that is interesting
Now you just need to see what properties x has
So to do, you can tab it out if you make x available to you in ipython
In [1]: f = str()
In [2]: f.casefold
capitalize() format_map() isnumeric() maketrans() split()
casefold() index() isprintable() partition() splitlines()
center() isalnum() isspace() replace() startswith()
count() isalpha() istitle() rfind() strip()
encode() isascii() isupper() rindex() swapcase()
endswith() isdecimal() join() rjust() title()
expandtabs() isdigit() ljust() rpartition() translate()
find() isidentifier() lower() rsplit() upper()
format() islower() lstrip() rstrip() zfill()
function()
Like that. I tabbed out and all the things f can do or has, pop up 🙂
Oh yeah there's stuff, just not useful stuff
(Pdb) p parser
<xml.sax.expatreader.ExpatParser object at 0x7f393cee4430>
(Pdb) p dir(parser)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bufsize', '_close_source', '_cont_handler', '_decl_handler_prop', '_dtd_handler', '_ent_handler', '_entity_stack', '_err_handler', '_external_ges', '_interning', '_lex_handler_prop', '_namespaces', '_parser', '_parsing', '_reset_cont_handler', '_reset_lex_handler_prop', '_source', 'character_data', 'close', 'end_element', 'end_element_ns', 'end_namespace_decl', 'external_entity_ref', 'feed', 'getColumnNumber', 'getContentHandler', 'getDTDHandler', 'getEntityResolver', 'getErrorHandler', 'getFeature', 'getLineNumber', 'getProperty', 'getPublicId', 'getSystemId', 'notation_decl', 'parse', 'prepareParser', 'processing_instruction', 'reset', 'setContentHandler', 'setDTDHandler', 'setEntityResolver', 'setErrorHandler', 'setFeature', 'setLocale', 'setProperty', 'skipped_entity_handler', 'start_doctype_decl', 'start_element', 'start_element_ns', 'start_namespace_decl', 'unparsed_entity_decl']
Ok I wrote untractable code that records the byte offset of the buffer and the line number inside that buffer
What's the logic that goes into selecting a loss function
how else would you optimize your gradients?
do you mean selecting a loss function or why do we use one?
I mean, what loss function should I choose
Yeah, selecting one, I worded that badly lol
Like atm I'm doing an MLP sequential model for recognising numbers, what loss function should I be choosing?
classification on multi-class --> cross entropy
I mean, there aren't that many options are there?
What's the difference between that and the sparse variant?
the sparse accepts one-hot encoded labels I think - not sure tho
Then why use it
If you want to provide labels using one-hot representation, please use
CategoricalCrossentropyloss
Do you have a decision tree for this?
but in SO, Im pretty sure I read it as sparse loss for sparse labels
yup, it seems sparse_categorical_crossen is for labels that are NOT sparse.
https://stats.stackexchange.com/questions/326065/cross-entropy-vs-sparse-cross-entropy-when-to-use-one-over-the-other
that's a weird convention

Cross Validated
I am playing with convolutional neural networks using Keras+Tensorflow to classify categorical data. I have a choice of two loss functions: categorial_crossentropy and sparse_categorial_crossentrop...
The sparse_categorical_crossentropy is a little bit different, it works on integers that's true, but these integers must be the class indices, not actual values.
Ahh, that makes sense in the terminology, if it does represent indices
Yeah it really helps not having to keep one-hot distributions in memory for potentially multiple batches
I don't think it represents that significant of a overhead
How can I use the transformers lib bert model to continue a conversation (and basically be a chatbot)
I've got this code, but I don't know how to turn it's output into usable text.
tokenized = tokenizer.tokenize(message.content)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized)
tokens_tensor = torch.tensor([indexed_tokens])
tokens_tensor = tokens_tensor.to('cpu')
model.to('cpu')
outputs = model(tokens_tensor)
encoded_layers = outputs[0]
The encoded_layers is just a buncha random numbers
@lapis sequoia I can look at this tomorrow. However I believe the tokenizer can decode the "random numbers".
I know they're not random, they're outputs of the... neurons, I think they're called?
I know you know they're not random. Bert uses transformers and I don't believe that transformers use neurons.
ah
Hi, I think this might be a stupid question but I'm stuck. How do I train KNNRegressor from scikit using my entire dataset and then predict a target feature from 1 outside observation?
i asked my question more indepth in help-pretzel
but one has responded yet
anyone able to help?
RuntimeError: mat1 and mat2 shapes cannot be multiplied (256x1 and 128x32)
Anyone familiar with this error. An using Resnet by modifying nn.Linear. The error is thrown when trying to evaluate
def predict_single(input, target, model):
inputs = input.unsqueeze(0)
predictions = model(input)
prediction = predictions[0].detach()
print("Input:", input)
print("Target:", target)
print("Prediction:", prediction)
Will work for almost anything other than image classification
we do need to do some stuff in resnet in order to pass previous data to next to next. usually shapes are not exactly perfect and that seems to be case here.
a simple solN would be having the layers kinda same dimensions instead of reducing
Hey folks! I'm trying to detect motion and people with opencv and deploy it with fastapi, but I'm having some trouble integrating the two. Details are in #help-potato. Could someone pop in and help out?
Hello everyone!
So for a CNN (Convolutional Neural Network) , I am using Tensorflow . and I have Conv2d for the first 4 layers, a flatten , and then some dense layers with the last dense layer being Dense(3) with relu activation in ALL of them . My input image is loaded with CV2 and is B&W (the shape is (480, 640, 1)) and the output should be a number, for each image . The number should be either 0, 1 , or 2 . But with my Input (x values) looking something like :
[array([[213, 212, 212, ..., 149, 149, 149],
[212, 212, 211, ..., 151, 151, 151],
[211, 211, 211, ..., 150, 150, 150],
...,
[ 27, 27, 27, ..., 18, 18, 18],
[ 27, 27, 27, ..., 17, 17, 17],
[ 27, 27, 27, ..., 17, 17, 17]], dtype=uint8), array([[212, 212, 212, ..., 150, 150, 149],
[211, 211, 211, ..., 152, 151, 151],
[211, 211, 211, ..., 152, 151, 151],
. . .
And my output (y values) looking like :
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2]
It gives the following error :
ValueError: Failed to find data adapter that can handle input: (<class 'list'> containing values of types {"<class 'numpy.ndarray'>"}), (<class 'list'> containing values of types {"<class 'int'>"})
Why though? Because the types don't match? But when I turn the y values into np.array (like all of them) , I still get an error, telling the input sizes don't match . Anyone knows why?
What's the input shape of your model? Is it (480, 640, 1) or (480,640)? I think you can check with .input_shape.
My input shape is (480, 640, 1)
I can send you the model code if you want
If that's the case, the input shape for multiple images should be (N,480,640,1) (a single tensor/numpy array)
Oh, N being the count?
Yup
Lemme try
It looks like you're passing a list. If you convert that list to a numpy array, what's the shape and dtype?
sorry my laptop crashed
after running the code with input shape of N
so uhm, Im waiting for it to load
Okay so
Um
It doesn't show the dtype

@tidal bough Should I convert EVERY element into one np array?
The entire thing you pass to the model should be a single numpy array.
.dtype will show it. And what is this, the input? Shouldn't it be a lot bigger than this?
This is for testing purposes , just wanted to practice
That's the output
The input is images
Images , loaded by cv2, grayscaled
!e
import numpy as np
arr = np.arange(100).reshape(5,10,2)
print(arr.shape)
print(arr.dtype)
@tidal bough :white_check_mark: Your eval job has completed with return code 0.
001 | (5, 10, 2)
002 | int64
check the shape and dtype of what you're passing to the model
kk
uint8, (19, 1, 480, 640) is the shape
So I'm guessing ... the input shape should be (19, 480, 640, 1)?
Yup, if the input shape of your model is (480, 640, 1).
Presumably it will complain about shape if you pass this tensor to it.
So I should just add the 19 as the first one?
model.add(Conv2D(20, (5, 5), (2, 2), input_shape=(19, 480, 640, 1), activation='relu'))
Is this alright as the first layer?
If your shape is (19, 1, 480, 640), you can make it (19, 480, 640, 1) using .transpose([0,2,3,1])
What would be the best way to append a column of 1s as the 0th column to a numpy array
X = ([4,5,6,7,8,9],
[4,5,6,7,8,9],
.
.
.
X should then be:
X = ([1,4,5,6,7,8,9],
[1,4,5,6,7,8,9],
[1, ..
[1, ..
.
.
.
Oh right
No, your input shape of the model should describe one sample, I believe.
So (480,640,1) is right.
yeah, I think so
Lemme try
np.hstack([np.ones((X.shape[0],1)),X])
np.ones((X.shape[0],1)) is a (n,1)-shape array where n is X's number of rows.
Thanks @tidal bough , really appreciate it!
wait, you can force Convolutionals layers to find horizontal/vertical patterns?

does anyone know the research/technical term behind this?
you mean having different kind of filters in same layer?
yes. you can look out for inception network.
how can you have different types of filters in the same layers?
how do i install pyaudio?
there is a model made for that.
which one?
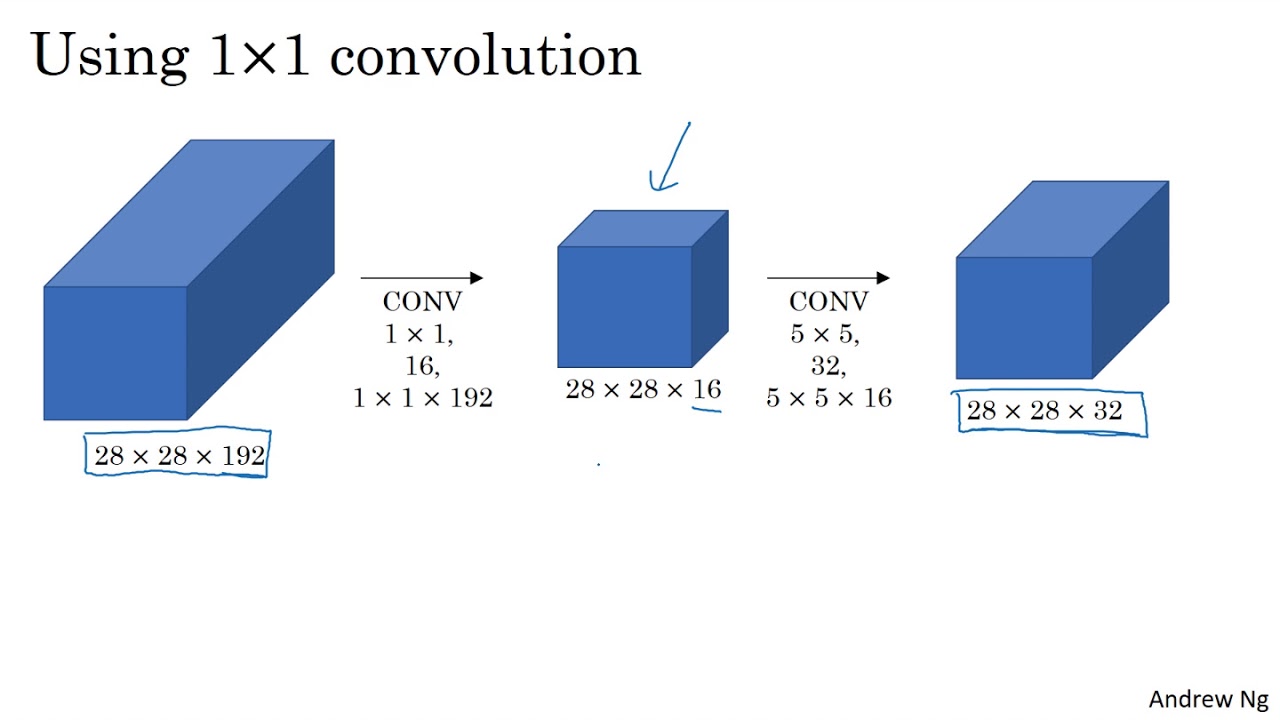
Take the Deep Learning Specialization: http://bit.ly/39thYn3
Check out all our courses: https://www.deeplearning.ai
Subscribe to The Batch, our weekly newsletter: https://www.deeplearning.ai/thebatch
Follow us:
Twitter: https://twitter.com/deeplearningai_
Facebook: https://www.facebook.com/deeplearningHQ/
Linkedin: https://www.linkedin.com/com...
..
inception network.
inception model is just composed of inception modules. and the architecutre I describes was sequential VGGish
i was just implying that if it is like that then it is possible.
well it's not, that's why its to mysterious
and the guys who described it looked like they had written it all in 10 mins
alright. thats why i kinda asked question as i was not 100% sure about it.
ref?
literally fucking one statement "Musically motivated CNN". I mean, why publish a paper when you can't even write out it's whole architecutre
their official paper is 1.5 pages of everything
so you can guess what's on it
ahh, why didn't they link the repo with this paper?
like that paper should have been the first thing in the repo
well, their technique is interesting, but severely outdatted
uh-huh. on top of that, they have custom layers for temporal and spatial, didn't even run NAS on it
A mediocre submission, but I guess it's 5 years old so I have to cut them some slack.
I was thinking of using LeVit. Just gotta convince them to gimme more GPU's
wow i need to learn a lot in data science.
imo I like Vit a lot, but it's main drawback is the fact that it requires labelled data for pre-training
There was a new technique called BYOL, but I haven't got around to understanding it or it's results + it's highly experimental. the advantage for it is that it can use random unlabelled images from the task and pre-train on that, just like in NLP
have there been any advances in gans since wgan-gp?
Hey could someone help me define a function which computes average of every last 50 ints for every point?
it's honestly quite confusing to keep advances in something. I guess you can check benchmarks 🤷
Should I be one hot-encoding the training set as well (if possible) or just the labels?
Hello all. I want to ask if there is any good tutorial to transfer learn VGGNet or Facenet with own-build datasets for production level architecture? Since i need to retrain it for specific face recognition task while cut production time. I search on Medium or anywhere there're lack of these kind of tutorial.
hi, my code is run, but the voice of my AI is speak too fast
here is my code:
import speech_recognition
import pyttsx3
from datetime import datetime
now = datetime.now()
name = input("Please enter your name before using this: ")
today = now.strftime("%B %D, %Y")
robot_ear = speech_recognition.Recognizer()
robot_mouth = pyttsx3.init()
robot_brain = ""
with speech_recognition.Microphone() as mic:
print("Robot: I'm listening")
audio = robot_ear.listen(mic)
print("Robot:...")
try:
you = robot_ear.recognize_google(audio)
except:
you = ""
print("you: " + you)
if "":
robot_brain = "I can hear you, try again."
elif "hello" in you:
robot_brain = "Hello " + name
elif "today" in you:
robot_brain = today
elif you == "WWDC 2021":
robot_brain = "WWDC 2021 will start from June 7 to 11. You can see details in https://developer.apple.com/wwdc21/"
else:
robot_brain = "Sorry, we not supported this question."
print("Robot:", robot_brain)
robot_mouth = pyttsx3.init()
robot_mouth.say(robot_brain)
robot_mouth.runAndWait()
@serene scaffold if you have some time, I woke up and can do this now
Did you look at what methods the tokenizer has?
I can't figure out how to look at the methods it has
I tried decode but there was an error, lemme try it again
The docs
I did the Tensorflow 2 for Deep Learning course on Coursera which is pretty good, goes into a fair amount of detail and uses VGG
The error is that encoded_layers is a list, and int can't convert it to a number (for tokenizer.decode)
Ah, I think I need to call convert_tokens_to_ids on the encoded_layers, then feed it to decode, possibly
I'll be at my desktop in like 15



Trying convert_ids_to_tokens seems to return something that decode can't handle, and convert_tokens_to_ids and putting it through decode returns [UNK]
the course got updated, lets goooooooooo..................!!!!!!!!!!!
You need to make sure your output layer and your labels layer are the same shape
What's your output layer?
No worries I fixed it
Cool
@lapis sequoiadid you try this one? https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.batch_decode
A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most of the tokenizers are available in two...
No, I haven't, let my try that
Feeding batch decode the output directly: TypeError: int() argument must be a string, a bytes-like object or a number, not 'list'
Feeding batch decode convert_ids_to_tokens: ValueError: only one element tensors can be converted to Python scalars
Feeding batch decode convert_tokens_to_ids:

what line caused that error?
output directly:
Traceback (most recent call last):
await coro(*args, **kwargs)
File ".\public-chatbot02.py", line 28, in on_message
msg_out = tokenizer.batch_decode(encoded_layers)
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils_base.py", line 3019, in batch_decode
for seq in sequences
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils_base.py", line 3019, in <listcomp>
for seq in sequences
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils_base.py", line 3055, in decode
**kwargs,
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils.py", line 731, in _decode
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils.py", line 706, in convert_ids_to_tokens
index = int(index)
``` `convert_ids_to_tokens`: ```
Traceback (most recent call last):
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\discord\client.py", line 343, in _run_event
await coro(*args, **kwargs)
File ".\public-chatbot02.py", line 28, in on_message
token_ids = tokenizer.convert_ids_to_tokens(encoded_layers)
File "C:\Users\owenp\AppData\Roaming\Python\Python37\site-packages\transformers\tokenization_utils.py", line 706, in convert_ids_to_tokens
index = int(index)
ValueError: only one element tensors can be converted to Python scalars
This is how I get encoded_layers
outputs = model(tokens_tensor)
encoded_layers = outputs[0]
Thats awesome
@lapis sequoia this is a program where I use BERT. https://github.com/swfarnsworth/pseudobert/blob/ner/pseudobert/pseudofiers/base_pseudofier.py#L70
pseudobert/pseudofiers/base_pseudofier.py line 70
def _call_bert(self, text: str, start: int, end: int) -> t.Generator[t.Tuple[str, float], None, None]:```see if that gives you any leads.
Should I be one hot-encoding the training set as well (if possible) or just the labels?
Hello, I'm doing object detection using darknet yolo, how would I write conditional statements based on the information in the image, like "if object in image, do this"
if model.predict(image) == 'tree': do_something
Depends heavily on the type of information you want to capture
honestly, in reality there are very few times that you ever want to one-hot encode your x array
Guys a cross-entropy loss basically runs soft-max on the losses?
hmm, that's what I thought, the issue is I'm running running the model through the exe, like sending the image over command prompt to the image.
def darknet(note):
os.chdir("C:/Users/Denis/FinalProject/Carla/darknet-master/build/darknet/x64")
process = popen_spawn.PopenSpawn("darknet.exe detector test data/obj.data cfg/yolov4.cfg yolov4.weights")
print(note)
return process
note = "Darknet Ready"
darknet_process = darknet(note)
def car_recogniser(new, detected_car_loop, sensor_name_image):
global darknet_process
carla_image_exists = os.path.isfile(f"C:/Users/Denis/FinalProject/Carla/carla/temp/{sensor_name_image}.jpg")
if carla_image_exists:
carla_image = (f"C:/Users/Denis/FinalProject/Carla/carla/temp/{sensor_name_image}.jpg").encode()
darknet_process.send(carla_image+b"\n")
its just terminology used by people that softmax loss refers to cross-entropy loss which is an actual technical term
like what exactly?
Hm
I posted the code above what i'm doing, I'm running the model through an executable, its not within the script. The model itself isn't written in the script, I wasn't sure how I could incorporate the official darknet model in a pyscript
so you don't know how run inference on the model?
I guess? My method does seem kinda jank
Guys is it necessary to memorize/understand all the loss , or generally, formulas that Machine learning has? Considering you use something like Tensorflow though
You can use machine learning without knowing anything about it
Pay attention about the fact that I worte "use"
Well
Because, if you use some auto ml, like autokeras, you don't really get equal results
But you can still do a lot
I can somewhat write a model in keras, without knowing what the frick the formulas mean
I suggest you to use autokers
But I wonder, can I continue like this?
autokeras? what's that
Why not? I won't need them, do I?
A library that automate all the model buildingh
*building
Training
Ecc.
You give it data, and it create and train a suitable model
Oh cool . But isn't the model building itself fun, and generally the whole point?
I seuggest you to start with autokeras, move to keras and then move to pytorch
*suggest
I am already using keras ig
I understand conv2d, dense, maxpooling, dropout, and flatten. I guess that's enough for image classification
When you deal with advanced stuff, you need to understand what you're dealing with
Yes
Oh I see ... Well AI isn't gonna be my job, but I would do projects in it , which would be pretty fun . So yeah , I guess I won't even be an advanced data scientist
I see
Anybody use Chatterbot? How can I recover the author of a message?
hello, could anyone please help me understand an issue i'm having with a model i'm building for predicting customer defaults on loan repayments
would really really appreciate it
How can i learn about machine learning in Python? :P
You should state the issue directly and people might be able to help you with it
I am applying a weight of evidence function to a train data set, however around half of my variables are categorical and have been split into their sub-categories which are using binary 1,0 to say whether that sub category was selected. my WoE however are extremely low and I think I haven't dealt with the categorical variables correctly so just need and advice on how to do so
i thought weight of evidence only worked on categorical features anyway?
nope
what's the target of the model? yes/no if the loan defaulted?
yes
dont people just bin numerical features to compute weight of evidence?
then it's just the weight of evidence in each bin
it's an assignment
and they have given us data with loads of variables
so I can't imagine we are meant to leave out all of the categorical variables
thats not what im saying
as there are so many, like education type, housing type, contract type etc
im saying that weight evidence only works on categorical variables
and that non-categorical variables need to be binned into categories
well that can't be true because I'm following tutorial and they only have numerical variables exclusively
what tutorial?
Cs50 ai is a nice course for learning ai with python
link to the tutorial if you can
a lab session
I can't link it it wont allow access

here is a sample
all of those variables are numerical in the data set
what's this sc module?
yes
?
I mean none of those variables are categorical in the dataset they are all numerical values
Alright! Thanks!
i think i'm misunderstanding something about categories maybe
what is sc?
oh
where is this woebin_ply function from?
is this a publicly available package?
yes
i am pretty sure that the "bin" in that name means that the numerical features are divided into "bins", in order to produce categories
maybe im wrong

either way I have so many and it just looks wrong because all the sub categories have been given their own column
i just dont know what to do
because in the examples they only deal in numerical variables
can you link to this scorecard package? the one i found does not appear to be correct
so they never discuss what to do with categorical ones
were you ever actually taught how WoE is calculated?
is it in a textbook? course notes?
well if you cant link to the package somewhere on the web, and you can't post the definition that you've been given, there isn't much i can say other than what i've already said
it looks like bins_adj were calculated by sc.woebin
i.e. those are "bins" calculated from the numerical features
which are themselves categories
that's a good idea to do. but don't use zscore on anything categorical, it doesn't make sense to do it.
and thats when i saw the split in the df
it looks like sc.woebin supports categorical features naturally, according to the docs http://shichen.name/scorecard/reference/woebin.html
woebin generates optimal binning for numerical, factor and categorical variables using methods including tree-like segmentation or chi-square merge. woebin can also customizing breakpoints if the breaks_list was provided. The default woe is defined as ln(Pos_i/Neg_i). If you prefer ln(Neg_i/Pos_i), please set the argument positive as negative va...
woebin generates optimal binning for numerical, factor and categorical variables
yeah i can't understand that page it's way above what i'm doing
i'm following their tutorial and applying the functions to the provided data set
no where do they explain how to deal with categorical variables 😦
(this is also the R docs i think)
what i would do is this:
- make sure that your categorical features are either
pd.Categoricalor otherwise not a numeric type (e.g. int, float) - use
sc.woebinandsc.woebin_plyas normal
just try it
use a small sample of the dataset
pick 2 categoricals and 2 numerics
i dont know how
you dont know how to select columns from a pandas dataframe?
actually you dont even need to, it takes whole dataframes
dt: A data frame with both x (predictor/feature) and y (response/label) variables.
y: Name of y variable.
x: Name of x variables. Default is None. If x is None,
then all variables except y are counted as x variables.
if you're using jupyter, go into a new cell and type ?sc.woebin
it will show you the docs
i'm using colab
what am i meant to be reading I honestly am very new to this i can't understand what this is saying to me
you need to be learning basic python then, and basic pandas usage, as well as the fundamental vocabulary that people use to talk about data
im sorry if they didnt teach you this and you were expected to figure it out
thats not good teaching style and its counterproductive to learning
:/
what kind of course is this? something actuarial?
business analytics
i see
can you at least show the previous code sections
just copy and paste the code i dont need the text
i can try to give a very quick explanation of what it is doing
there is quite a lot
i don't know how far to go back
I just need to know how to deal with these categorical variables because my WoE are so low they are useless
I don't understand why they didn't use categorical variables in any of the examples


have about 20 graphs like that
some look like this which seems wrong


that's all that's relevant I think
It's the first time i've seen weight of evidence and information value lol. It looks intersting and easy to calculate, especially IV, but WoE...I dont think i'm getting what it intends to represent
the nagative or positive impact of the variable relative to your target I guess
I'm not too familiar either
towards data science tends to do a good job explaining stuff

Medium
Using the Titanic data set to explain and implement both the concepts step-by-step. A great opportunity to also code in Julia!
yeah thank you i'll have a look
sadly i'm just going to have to continue modelling even though I know what I've done is incorrect
can't figure this out right now and have a llot more to finish
Hi everyone, woudl this be a place to talk about a decison i need to make by tmrw morning. I have to decide if I am going to move forward with my CS masters degree or if I am making the switch to a MS in Data Science. Are any of you professional data scientists?
you should probably go to #career-advice
I am there now, I guess i should have just asked if anyone did Data Science as a job right now. I have some basic questions about that
@twin fiber it doesn't look like they only used numeric variables
gender is not a numeric variable
they even had random numbers in the excel file for the address
I know but they used numbers in the excel file to replace
i have tried their code on my data
that is how i'm at this stage
what i'm saying is in their examples they are only applying the code to numeric values
whereas I have categories and subcategories
and I don't know to deal with them
I have used pandas.get_dummies()
which is meant to handle the categorical variables, but that has just divided the categories into the respective sub categories and assigned a 1 or a 0
im telling you not to use that pd.get_dummies or anything like it
just run it on the data with the categorical features, without trying to transform them
the docs clearly state that the default "tree" method works on both
I'm just following the code
from me lectures
so I feel like it must be done this way surely
the code says to use pd.get_dummies on the categorical features?
it will certainly work
in fact it should be equivalent to not doing it, now that i think about it
not explicitly on categorical variables
so what exactly is the problem that you are encountering
the problem is that my data just seems wrong
well pd.get_dummies makes no sense to use on numeric features
that's probably because the splits were wrong
type of job
and within that variable the customers can answer 5 different options
so my pd.get_dummies has split that into 5 columns
1 for each job
and assigned a 1 if it was selected

this slides along, there are just too many columns
and they say to remove any info_values below 0.1

all of mine are below 0.1 so I know it's wrong
can you just show the code that you ran
import pandas as pd
import scorecardpy as sc
df = pd.DataFrame([
{'gender': 'f', 'weight_lbs': 120, 'is_adult': 1},
{'gender': 'f', 'weight_lbs': 130, 'is_adult': 1},
{'gender': 'f', 'weight_lbs': 60, 'is_adult': 0},
{'gender': 'm', 'weight_lbs': 50, 'is_adult': 0},
{'gender': 'm', 'weight_lbs': 70, 'is_adult': 0},
{'gender': 'f', 'weight_lbs': 30, 'is_adult': 0},
{'gender': 'f', 'weight_lbs': 45, 'is_adult': 0},
{'gender': 'm', 'weight_lbs': 175, 'is_adult': 1},
{'gender': 'm', 'weight_lbs': 163, 'is_adult': 1},
])
bins = sc.woebin(
df,
y='is_adult',
x=['weight_lbs', 'gender'],
breaks_list={'weight_lbs': [100]},
)
df_woe = sc.woebin_ply(df, bins)
print(df_woe)
this works. i had to manually specify a break point for the weight_lbs column, not entirely sure why, maybe not enough data for the tree splitting algorithm. but it works.

ok, none of that looks offensive. pd.get_dummies will ignore numerical columns and only convert the categorical ones, so that should be fine
however it looks like you never actually used the z-scores you created
hmm
you'd have to do something like customer_data[zscores.columns] = zscores to replace the numeric columns in the customer data with the z-score versions
i guess i didn't see them use it in their code
(ideally you wouldn't replace them, you'd make new columns, but it sounds like you're already struggling w/ the python basics and at this point you just need to get it working)
maybe they use it later in the code?
well the first lab was preprocessing
it ended with zscore function to normalize the data
now the second lab goes straight to WoE
and they don't use the zscores created previously
they just do the WoE stuff I'm trying to do now
but my results are just terrible
its also not that big a deal if you dont use the z scores
what code did you use to compute the WoE scores
that is what i am interested in
because that is where we might be able to identify the problems and misunderstandings
evidently you were never taught what WoE actually is or how to use python. which makes me upset and frustrated on your behalf, but that's not something we can change now.
yeah it's been an insane few days
so i want to at least see specifically what you did that generated the bad output, so i can try to at least patch up your understanding enough to survive your exam
the zscore line took me 3.5 hours yesterday
to get to work and remove the right columns LOL
it's an assignment due tomorrow at 4, luckily no exam
but i have so much more to try and learn
im sorry to hear that. learning is always slow at first, but having poor instruction makes it that much worse.

and how did you compute bins_adj

well first it was this

and then used that other function to manually adjust some of them
for the WoE plots, I have quite a few that look like this

that can't be right
ok, and how did you compute breaks_adj
what do you mean?
it looks to me like this data is highly imbalanced. where you only have a small % of "bad" cases
when you compute bins_adj there is a variable called breaks_adj. how did you create breaks_adj?
i just used the function
sc.woebin_adj
and it has a little input box to manually play with bins
and i just tried different bins to try and get some of the unintuitive plots to be monotonic
which is what was advised in the lectures slides
**My biggest mystery in ML is: **
HOW IN THE HOLY FUCK CAN I GET BETTER ACCURACY IF I TRAIN A MODEL FROM SCRATCH THAN PRE-TRAINING
local minima

but I tried all the LR's 😦
it means that there is 1 column that has all the same data in every entry
no, it is not something to worry about
it really would help if you at least listed the steps that you took to get from "a dataframe" to "the final output"
i imagine you did something like this:
- load the data
- apply
woebintodfand gotbins - apply
woebin_adjtobinsand gotbreaks_adj - apply
woebintodfwithbreaks_adjand gotbins_adj - apply
woebin_plytodfwithbins_adjto get the final bad output
is that close enough?
and you are worried because the output seems like it's so low-quality that you think you did something wrong
give me a sec i will close frames and then show code
you can also use our code posting site https://paste.pythondiscord.com to post your code
it would be easier to read that way anyway
notebook cells? i dont know if you can in colab. i hate colab.
@desert oar ok, then how do I do this
One classic technique is to gradually reduce the learning rate, then increase it and slowly draw it down, again, several times.
it just sounds like random Learning rates with extra steps
you can share notebook in colab to work on it in real time
i agree. i like that they make all the libraries and models available and i like that you get free gpu compute, but the interface is hot garbage.
i can't and i don't want to, it's through their school
yeah learning rate stuff is kind of black magic. but initialization also matters a lot, it made sense to use imagenet for initialization but i guess if your data is very different then it also makes sense that it wouldnt work
no, like I initialized with imagenet, then fitted on big dataset. then again, with no changes, I recompiled my model slightly (increased regularization to prevent overfitting) and re-fitted. well, the accuracy on base dataset and small one is similar 😐
I have never expereienced such shit in my life please send help
thank you for helping
so do you think that any of these features should have a strong predictive effect on the target?
maybe this data is just crap for this task
if you selected the data yourself then it's very very possible that it's just not a good dataset

look at my IV values on the right

so all of my variables have no impact?
and 1 has very weak impact
i've obviously done something wrong
What level of python do I need to learn opencv?
Right, so basically I have a NN with an efficientnet + some Conv layers. Initially, I initialize the effnet with imagenet weights and then train from scratch on a pretty big dataset.
Next, I increase the regularization of the whole Net and re-fit to another smaller dataset. so the weights of all layers would be used again. the mystery is that this whole method performs much better than if I freezed my base network (effnet) and pre-trained on the small dataset.
I need theories on this. Any idea what could have happened?
@twin fiber personally i think that IVs are fucked up because you used pd.get_dummies. for a variable like NAME_HOUSING_TYPE, you need to be adding up the IVs across all the individual columns created by pd.get_dummies
are you very very certain that they told you to use WoE and IV on the output from pd.get_dummies?
Please help
what do you mean level? like your personal experience level?
What are the things I should know about
umm
at minimum: functions, modules, reading and writing files, numpy basics, how to use pip
maybe not but I don't understand why we would go throuhg a whole preprocessing stage
in the previous lab
and then ignore it and use fresh data
are you sure they werent just showing you various ways to process your data
Alright thanks
actually I don't think i did apply it to the output from pd.get_dummies
it looks like you did, based on the column names
from my messing around with this module, it doesnt look like it "splits" columns for you into separate columns, one per category. however get_dummies definitely does that
oh i did yes
im not sure i follow the 2 different procedures here
what do you mean how do i do that
they aren't 2 different procedures; first is just training the model again with new data (keeping old weights) and second is the proper pre-training --> freezing base model, then training the F.C on new data
i have to step away for a while... @twin fiber maybe go take a break and get some fresh air. sounds like you've been at this nonstop for hours.
hello
i have been but sadly I don't have time to stop as it's due tomorrow and I have a lot more stuff to do r.e. applying models

I want to get a list of players data here.
for generating code with AI, why don't we have masked "code modules" with special tokens for variables, chars (language specific subtleties etc.) and apply the masking LM recipie to get a good (kind of advanced) code autocompleter?

hey guys, I am training a graph GAN that consumes a lot of RAM. what are the tricks to reduce its usage ?
uh, what part consumes a lot of ram?
you can lazily load in data, saving you some memory on the input side... if your backprop graphs are too large to fit in memory, you can do gradient checkpointing
if you need to use a large batch size, but not enough space locally, maybe distribute over multiple nodes
your graph representation could also be really inefficient-- are you storing entire adjacency matrices, or just lists?
lots of things you can try
but you should learn how to use a profiler first, to figure out memory usages of each part
if i am lacking images on my data set, how good/bad would be using a GAN to generate more images? 🙂
do i need cuda installed locally after I build pytorch from source w/ CUDA support? I know that building CUDA-enabled pytorch requires CUDA, but what about running that build?
After you finish Machine learning
Because you will need Train Test Split and everything to run detection
Helloooo,a basic question I have,why do we mutiply input with weights?

Udemy
Learn how to use NumPy, Pandas, Seaborn , Matplotlib , Plotly , Scikit-Learn , Machine Learning, Tensorflow , and more!
can i start this course to get knowledge in ml
Hey there ! i was looking into the math behind neural nets, can anyone suggest some resources where they explain how they actually work ?
I would also like an answer to this question
i need some suggestion about face recognition with transfer learning method. Let say if i have a hundred unique person but i only one image per person as the source. The task is to identify who's face is this. Is is feasible if i use image generator to make train test and valid images for each person?
since what i have now is one image per person
you can read deep learning PDF e book from Ian Goodfellow which is give brief explanation about math behind the nets
Lan goodfellow, will remember that, thanks
Ian Goodfellow
you're wellcome
I typically use GPU's via Google Collab notebooks for my grad courses. You need to verify cuda is available and you need to place the features and targets on the selected device. Here is the cuda documentation: https://pytorch.org/docs/stable/cuda.html
The easiest way is to do "torch.cuda.is_available()" for verification or just something like "device = torch.device("cuda" if torch.cuda.is_available() else "cpu")" and then during training and testing you place the features and targets on the device (i.e. device.to() call).
I would watch Sentdex machine learning course on YouTube. He walks through all the more basic machine learning models and implements them line by line with clear cut explanations. plus it is free! I used that to get started and it helped build up my foundational knowledge. Link: https://www.youtube.com/playlist?list=PLQVvvaa0QuDfKTOs3Keq_kaG2P55YRn5v

YouTube
Has anyone here used Named-Entity-Recognition to categorize streamed data and then perform sentiment analysis with BERT or VADER or some other pretrained model? I have only done sentiment analysis but am trying to also use NER, so I don't have to query my streamed data prior and can just analyze all of it real-time. Any help would be greatly appreciated!
I trained a logistic regression model with some scraped data and saved the model. Now im trying to import it and im trying to predict the test data from my school project but I keep getting the message could not convert string to float:
My code looks like this right now.
test_data = df["text"]
# loading the vectorizer
vect_name = open("ml-vectorizer/tldf-vectorizer.sav", "rb")
Xtest = vectorizer.transform(test_data)
# loading the model
model_name = open("ml-models/sentiment-model.sav", "rb")
model = joblib.load(model_name)
model.predict(test_data)```
I have no clue where to look...Does anyone know where I can find a tutorial of how to do this using python and tensorflow?

X = teamid_matches.loc[:, ['home_team', 'away_team', 'home_team_cup', 'away_team_cup']]
X = np.array(X).astype('int32')
res_filter_drop = res_filter.drop(['date', 'home_score', 'away_score', 'tournament', 'city', 'country', 'neutral'], 1)
# Append data: simply exchange 'home team name' with 'away team name', 'home team championship' with 'away team
# championship', and replace the result
_X = X.copy()
_X[:, 0] = X[:, 1]
_X[:, 1] = X[:, 0]
_X[:, 2] = X[:, 3]
_X[:, 3] = X[:, 2]
y = res_filter_drop.loc[:, ['Winner']]
y = np.array(y).astype('int32')
y = np.reshape(y, (1, 900))
y = y[0]
_y = y.copy()
for i in range(len(_y)):
if (_y[i] == 1):
_y[i] = 2
elif (_y[i] == 2):
_y[i] = 1
X = np.concatenate((X, _X), axis=0)
y = np.concatenate((y, _y))
# Shuffle and split test, train
X, y = shuffle(X, y)
Guys I dont understand this piece of code right here why did he concatenate the columns for this prediction using svm
he uses some library which i doesn't even know
read the error message word by word you will find why
oh good math
I am a pendejo, thanks I just noticed I am using the wrong variable
So i;ve come up with this diagram for a single-layer perceptron network:

Sigma is the summation function, phi is the activation function, x are the inputs, y are the outputs
Would this be the correct diagram for a multi-layer perception network with one hidden layer?

Basically just checking if you have layers of activation functions:? Or is it only the output layer that has them?
Anyone having access currently to coursera deep learning specisialisation :course 2 ...plz dm?......theres a small help i need....please and thank you
if i have two correlated variables like sqft_living (house sqft) and sqft_above (upstairs sqft), is it necessary or beneficial to get rid of one of the two?
hey guys, which is better tensorflow or pytorch?
most likely depends on the use case
^
i personally like pytorch better
its more pythonic
but for getting started using keras with tensorflow is easier
@austere swift
i have a question
im pretty much a beginner but how did you get started with ai/ml?
i know dumb quesiton but i just wonder
i just started out doing some projects and learning about it
you have to have a good math background first though
linear algebra and calculus mainly
did you study it by yourself?
yes
i made a simple neural network from scratch using only numpy
when i first started
What level of education are you at? An online course might be the way to go. There are several excellent free online courses on Edx, Coursera, and MIT OCW.
that way i can learn more about it
I actually started by taking an online course run by Berkeley. It's what got me into computer science and programming.
i am currently in 8th grade but i dont live in uk/us so it means a bit different thing
oh okay
do you think khan academy is a good resource?
Khan Academy is great!
agreed
I don't think they have much on AI, but their math content is really good.
That would be a great way to get your math up to the level required to really understand what you're doing in AI/ML.
yeah thats fine because i enjoy maths anyway xd
On the practical side, you might want to check out Kaggle: https://www.kaggle.com
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
i mean you can probably do ai without actually understanding the math much but i want to know what am i doing
oh neat
is it free?
Yeah, I was about to say actually, it would be fine to get started trying out AI even if you don't yet have the math prerequisites. I personally paid far too much attention to the theory of AI relative to the practical side.
and one more thing
if i want to get started with making a basic neural network from scratch should i use numpy?
I believe Kaggle has free courses. Edx and Coursera courses can usually be audited for free (i.e. you have access to all the materials but don't get a certificate at the end).
Indeed 🙂
There's one text-book I recommend above all others for AI, and thats Artificial Intelligence: A Modern Approach by Russell and Norvig. It provides a pretty comprehensive overview of the subject.
No prob 👍
hey guys hows it going
how do i increase the bar space in matplotlib in graphs
in barchart
AttributeError: 'Rectangle' object has no property 'rwdith'
``` also got this errorTypeError: barh() got multiple values for argument 'width'
For anyone who needs to use scipy on Big Sur/Apple Silicon:
https://github.com/scipy/scipy/issues/13102#issuecomment-733988544
oh god, I joined this Ai server on discord and it's absolute shite. they think AGI is just a task, like classification
You would think an Ai-focused server would be better than a channel in the python server
I am pretty sure half of your messages are promotions for PyTorch. Seriously guys, TF/Keras is not that bad 🙂
Are you sponsored by FAIR to spread Pytorch?
😛
oof, I hate all these stupid dependencies
Tell me about it
I just hate numba. it f-ups all my stuff
any Idea?
ValueError: Input 0 of layer sequential is incompatible with the layer: expected axis -1 of input shape to have value 96 but received input with shape (32, 1)
I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
and that one
what do you think the error means?
Hello guys!
soooo I am like 14 and I want to learn AI
can anyone recommend any vids?
Anyone?
Does the memory / cpu required to drop a column from a dataframe scale with the amount of records in the column?
what is a data pipeline? is this similar to a ci/cd pipeline?
ik a pretty good class this summer
its berkeley coding academy
its pretty good and helpful
what has that got to do with data?
Hmm, good question. I'd assume that it's O(1), but best idea is to test it.
Wait I'm disabled, why not just... not load useless columns
then I don't have to drop it
big brain time
well, I don't know - I'm not sure what a data pipeline is
also this helped significantly with the source problem, not the main question

Medium
Watch Other Interesting Data Science Topics and my other medium articles
I have a pipeline where I need to send data, but should I yield data as a single object or send it in a list of hashes?
k thanks!
.
Can you elaborate
how do I properly build the following pipeline where all my data sources shares the same structure ?? https://dpaste.org/knNX#L1,15 the example: https://avleonov.com/wp-content/uploads/2017/05/home-grown_vulnerability_database.png
I need currently like a chat where a user sends a message then the other party recieve that data and save it
my approach
- celery for task queue (2 tasks one each 24 hours, and another each hour)
- node manger that acts as a chat to stream data
- scrapers streaming data to node manger
- node manager saves data < I am not sure if a list of dicts or single json object = many queries to db
I am trying to create a chatbot, I have a simple keras using intents, should I spend time adding information to that json, or try to find an already made one, or should I use a different method?
for any of the more experienced guys here, do you think joining a kaggle competition and getting a decent score (even if not top of the leaderboards) would good to showcase some python / DS proficiency?
quick stats-related question - in AP statistics we learn to estimate with confidence with methods that are optimal as long as we are sampling less than 10% of our population. I read somewhere that if we can sample over 10%, then there are more optimal statistical procedures to estimate parameters (a confidence interval, for example). how do these methods differ from the ones used?
Anyone here who knows of a good and free AI module/API? except Chatterbot
Anyone knows the difference of ggplot between python and R?
do 'interpretable machine learning' and 'explainable artificial intelligence' mean the same thing?
Yes, pretty much
what are the different types of scenarios of when a NN overfits/underfits?
kind of yeah. most people in the industry realize the worth of kaggle and other competeions
low data, low model power respectively
that is model power - the number of parameters
Do hyperparms also affect over/underfitting?
ofc
Ok but would this depend on the data or is there a general explanation for each hyperparam?
I recommend you read up the topic on the net - it's too deep to communicate via chat
knowledge about your hyperparameters would also help a lot
Kl could you share a useful link
🤷 I did this a long time ago, so I don't remeber any resources. I guess google overfitting and underfitting and read every single article you get your hands on
anyone have any luck installing pandas on an m1 mac?
when the number of samples is less than the number of features does this mean we are prone to underfitting?
not always - it could simply be that most of your features are useless, and only a few are useful that have a linear relationship (which can be easily mapped).
what are you trying to overcome exactly?
~~ google lords, forgive me for sinning,~~ but Is it just me, or is pytorch very easy to ....... debug?
previously, I only did tensor manipulation with PT. but now, I am running a pytorch model repo which is basically shit - and I am finding it far easier to edit the files rather than change it on my side; which is smthing I would have never dared to do with TF
yes it is @grave frost
anyone?^
anyone have any leads on this type of output tensor(-0., device='cuda:0', grad_fn=<NegBackward>) I am unable to locate the reason and the particular code
I assume it has something to do with my model gradients, since it seems to be at 0 validation accuracy
Hmm...I will try pre-processing my data again
I just want to make sure what I have done so far makes sense, because it looks like I can't use any of the generic test train split method such as from sklearn.
My goal is to detect which user is typing based on samples from a typing test which captures key press and release times. There is a warmup prompt, then a real test. Regardless, all of the data for each user is put in one file, and looks like this:
1620322580238912200::1620322580342812900::h
1620322580421799400::1620322580502047400::e
1620322580559144700::1620322580677672600::l
1620322580741669700::1620322580861339900::l
1620322580878105600::1620322580967490900::o
1620322580984171600::1620322581046345000::
1620322581103447000::1620322581181768700::r
1620322582151222600::1620322582230004600::backspace
1620322582215080400::1620322582309995200::w
1620322586805930900::1620322586941929800::o
1620322587061273700::1620322587149182600::r
1620322587125172800::1620322587245511000::l
1620322587285746100::1620322587365764900::d```
`timeUp` and `timeDown` are in nanoseconds time.For each user, I calculate what the text ended up looking like when they were finished with the prompt. I won't go into detail but I'm sure the algorithm that does this works as intended. I just want to give an overview of my whole process.
I put each user's table of data in a pd.DataFrame, and calculate the following:
- timeDown of first key to timeUp of same key
- timeUp of first key to timeDown of second key
- timeUp between two consecutive keys
- timeDown between two consecutive keys
- count of times key was pressed
I add this info to a group of lists, organized by character typed. For example 'l' in the above example was pressed twice, so the following dictionary entries would be made:
'l_d_d_avg': [1620322580741669700 - 1620322580559144700, 1620322580878105600 - 1620322580741669700]
'l_d_u_avg': [1620322580677672600 - 1620322580559144700, 1620322580861339900 - 1620322580741669700]
'l_u_u_avg': [1620322580861339900 - 1620322580677672600, 1620322580967490900 - 1620322580861339900]
'l_count': 2```All these calculations are stored as key-value pairs in a dict.
All users will not type exactly the same count of each character, but each dict entry is supposed to be a column. That means different users will give me different number of columns. So after looping through all the data, I replace the lists with average(list) , which greatly reduces the chance of not getting each character's stats. In other words, our attributes are character-focused, not key-event-focused. Any missing columns from this approach are unlikely, but can be imputed.
Now that I've shared all that, I can discuss what I want verification on. I want to make sure I'm splitting the train and test in a logical way. Because I need consecutive rows for my calculations, I can't just randomly split the rows for train and test, because consecutive rows may not be consecutive keystrokes if I do that, and it will throw off my calculations.
My Solution:
Currently, I take a percentage of unique, random indices (sampling without replacement) of the input rows before I start getting the character stats. Then while looping, I keep track of the index. If the current index is in that sample of indices, I copy the stats for that iteration to test_dict. If not, I copy them to train_dict. That way, train and test can both have averages from accurate data, but they will be computed from mutually exclusive data points.
sklearn or tensorflow?
https://www.youtube.com/watch?v=O1aZmy_YuL4&t=190s does anyone know where I can learn how to recreate this

@lapis sequoia sklearn
https://github.com/topics/gpt2-chatbot
Anyone here who can help me set this up so that, it acts like a simple chatbot?
GitHub
GitHub is where people build software. More than 65 million people use GitHub to discover, fork, and contribute to over 200 million projects.
Ping me if u do plz
hi all.. I've been studying on hyperparameter tuning . Of course my helper is youtube and datacamp videos.
But I came up with a question here;
grid = GridSearchCV(estimator= rfc, param_grid = param_grid, cv=3, n_jobs=2, verbose=2)
That's my code for gridsearchCV
Should I use all my dataset for fit or still need to train_test_split the data again? If I need to split it again, what does cv=3 do?
Thanks in advence
*advance
Hello everyone, I just found the Python server and I am really excited to see how many channels there are. I was wondering if there is an equivalent server for R, I tried searching for it but I couldn't find it. Thanks in advance
{
"hi": "hello"
}
how can i get hi by the value hello in json
idk if this is the right channel lmao
I just designed my first Neural Network Model with a CNN architecture, it is meant to detect masked faces.
I've just trained it through 10 epochs, but can anyone explain these values to me such as accuracy and val_accuracy? I understand pretty well what they mean but what should I be aiming for with those values?
1st epoch

10th epoch
isn't it bad that the val_accuracy stays at around 78%, whereas the accuracy has increased from 71% to 98%
btw I did test the model with 6 images and got 50% accuracy so far
you model is overfitting. you should aim for the highest val_accuracy and your accuracy should be around 4-6% your val accuracy
okay, I heard that term before, but what does it mean 😅
it's when it fits the data well but can't make good predictions with new data right?
it means that your model is basically "memorizing" your input data
which is not good, we want it to find the pattern
also did you mean it should be around + or - 4-6%, e.g. if i have 70% val accuracy i should have 65-75 accuracy
so what's the best way to fix this? Better training data or improving the model?
more data is an option, but it's infinitely easier to reduce the model complexity
I think I'll learn more from the latter, so will try that 😄
my models really basic though

it might be, but it seems to be more than enough for your task
or you can add dropout layer
you can read up more about it on net, it's pretty easy to implement
okay, you think that might fix it alone? or is that on top of simplifying the model
it should. if it doesn't then you can simply increase the effectiveness of dropout. that would def do it
Okay 👍
tbh I thought it was just cuz my training data sucked, so that's good I don't have to find more
nah, it's fine if the network can overfit. Data scientists always first overfit on the data to see everythin works, then gradually increase the complexity of the model
But you said I have to reduce the complexity of the model, why is it different in my case?
ah, ignore that part
I was just describing a debugging flow for Models. you can leave it
Anyways, anyone who used ChatterBot library before?

the earlier algo was trained on regular birds that are often seen
so why am i wrong if i marked option 1?
is it because i would still have lower examples
this is a weird question because presumably data augmentation is part of your model training pipeline, so #2 would imply #1
It's also a weirdly high-level question
ya but #1 seems correct (only drawback is we are only getting couple of thousand example......thats very less
so what would be the the perfect out of thenm
The city expects a better system from you within the next 3 months
Better get a telephoto lens and start birdwatching 😛
haha
The question says "which should you do first" (emphasis mine), which maybe helps narrow it down. What is option 3? is there an option 4+?
I wonder if option 2 is inherently wrong because you should be putting 800 of the images into train and 200 into test
4
yep, that. that's the correct answer
that's what i would personally want to do first
then you can answer the question of "how bad is our model at predicting these birds if we only have 1000 of them?"
2 are rulled out
what's the full statement of #3
also i assume this is a graded assignment from the past and you arent sneaking around rule 5 🙂

{kind=link}

this is true ya
yeah pedantically the right answer is #3 - make sure your evaluation metric takes the new bird species into account, before trying to actually do anything with the new bird data
its a weird question though
what is the main reason to rule out # 1
because it's not what you do first
it's part of the process, but not the first thing you should do
yeah but is it still acceptable solution later on?
ok
this is actually a good question and as you can see it tripped me up too. it almost seems designed for you to get it wrong and then learn from your wrong answer.
rather, the question is badly phrased but the intent behind it is good
so almost all are right but we first try new eval matrix to know if we can tweak the code and work without changing data sets?
ya thanks
i think the idea is, if you add the new bird species to your evaluation metrics for the current model, you will have 2 things happen:
- the model will no longer appear to (erroneously) underperform on known birds
- the model will be total useless shit on the new birds
yeah
then you can iterate towards improving 2 while maybe accepting some decrease in 1 (e.g. if the birds are similar or they happen to look similar in pictures)
so we work after checking what initially we can do with what made earlier
i think that is the idea, yes. something like test-driven development but for machine learning.
presumably also you still care about overall accuracy too, so you might be looking at multiple metrics even if you're only using 1 metric in your cross val loop
ok got it ....i am quite sure it was beyond syllabus....but andrew did say it will be worth the thinking and experience
multiple metric parameter?
or literally multiple matric(wont that create multiple f1scores)
yeah maybe you want to at least keep track of accuracy, f1, and brier score
👍 brier score is still left to be covered by me
some references:
https://www.fharrell.com/post/classification/
https://www.fharrell.com/post/class-damage/
https://stats.stackexchange.com/q/312780/36229
https://stats.stackexchange.com/q/359909/36229
https://neptune.ai/blog/brier-score-and-model-calibration
https://machinelearningmastery.com/probability-metrics-for-imbalanced-classification/
thank you very much
I think honestly, we can still make an AI that can code very well without reaching the AGI mark
since code would just be a set of instructions, we have an easy one-to-many relationship to map code with instructions performed. Once we have this loss metric, then it becomes easier to arrange research in a way to minimize that metric
the point won't be to write code fully autonomously, but to understand what a dev has already written and help them write much much more thereby reducing the programmers required, effort and money put in by companies for projects.
code is avaiable in plentiful, and we already have automatic documenter that can document each function so there's that
I think coding itself is ripe for automation 🤑
anyone happen to be good with SQLAlchemy?
ofc it is, there are plenty of no-code tools that can easily challenge or nullify the skills of 50% of devs
does it replace all devs? Not even close, just as a "coding AI" wouldnt make all devs obsolete either.
but id be surprised if a FAANG wasn't working on something like that
you think too narrowly, my friend
I don't mean no-code; I mean generating most of the code
I want my AI powered genetically engineered foxgirls.
Is that broad enough? 😳
mostly, the reason why I think we can acheive automated programming before AGI is that you can't really measure effectiveness of AGI - it's not a simple task to test and achieve best results on. But for automating coding, we can easily create a loss function. what's left is just to optimize it
so it's just the modelling part. and seeing the ingenuity from transformers, it does seem like a possibility
'easy loss function' for coding what
What losses would you be considering for that?
All losses essentially describe the structure of perfection and I'd say it's quite difficult to describe what is 'perfect code.'
Even if you just want the structure of something 'good enough' - what is 'good enough' code?
something that works well, and a loss that incorporates Big O wouldn't be too bad
mostly, something that runs. you guys are missing the point - the aim is not to fully automate the developers but drastically reduce the amount of developers required. this strategy plays out in almost every innovation and no reason for it to not work this time too
That's somewhat true, but despite Humans Need Not Apply being released in 2015, I feel like the economic revolution hasn't happened or would happen soon
humans always overestimate future; and CGP grey is not an AI expert
I would be willing to bet my every nickel that it would happen in my lifetime
FWIW, I think a no-licenses-required GPT-3 will transform the whole industry, especially as I think it's very end-user friendly
It can do stuff like "give me this website design" or "make sure no contrast decisions are bad"
Which is already quite a lot of freelance work I'd say?
it def would not; it suffers too much from biases. it would require some regulation but yeah, your general hypothesis is correct imo
again, you overestimate capabilities of GPT3
it's just a giant overfitted model
it's not supposed to be for techncial CS tasks or medical ones
only simple languages - and their usage
I'm not talkingn technical CS or medical
Simple language and simple work is a lot of work
Deploy this webapp, make a website showcasing X
yeah, GPT3 can do that. give it notes on news, and you have a news article for that news in the style of a editor
I mean the fact is most work is boring work
And GPT3 has the capability to replace that
yeah, it can. and it has happened
a lot of newspapers have these AI-generate low-level articles at the end (for testing)
what's your point? it seems you are proving my own point to demonstrate what models are taking over specific industries
Just discussion
ahh. and consider the fact that oh, "LAnGUaAgEs aRe HaRD" by the non-technical people few years back. they overestimated the complexity of language. while GPT-3 can't write deep books or win a nobel, it can take over quite a few jobs.
I suspect the same thing is gonna happen. programmers think their coding is pretty complicated task, but then it might later turn out that it wasn't as much as you though - tho by the time most realize, they would jobless 🤷
if companies are paying for 10 experts at 100,000$, and that product saves them the seats of 5, then they only have to pay like half a million rather than a whole million
What about human problems like https://www.youtube.com/watch?v=y8OnoxKotPQ

it's because of the way our backend works
tl;dw, weird deprecation issues, and also possibly weird architected systems
Also it's just funny so I like posting lol
I know next to nothing about web-dev but I really don't see why same AI can't generate code to interface with microservices??
again, I said that NOT ALL PROGRAMMERS would be replaced - only the bulk. that's how new products come into markets. but even say, a 20% loss in jobs can drastically decrease your salary
you have to compete with 20% more people who would work more at lower salary, so bye-bye money and perks
Hello, I need a bit of help with a kaggle project
First of all, this was supposed to take the Phrases and cut them down into words then put it in the same row, so why is it different?

hey
import os
import random
import tensorflow as tf
def process_text(text: tf.Tensor, cutoff_len: int = 300, word_len: int = 100, pad: str = 'asdf') -> tf.Tensor:
print(text, text.numpy())
initial = tf.strings.lower(tf.strings.substr(text, 0, cutoff_len))
no_special = tf.strings.regex_replace(initial, r'[^\w\s*]', '')
brs_removed = tf.strings.regex_replace(no_special, r'<br\s*/?>', ' ')
split_up = tf.strings.split(brs_removed)[:-1][:word_len]
# tf.pad(split_up, [[0, max(0, word_len - len(split_up))]], "CONSTANT", constant_values=tf.constant(pad))
return split_up # remove the trailing word because it might be cutoff
raw_data = ([[[1, 0], open(f'data/aclImdb/train/neg/{f}', encoding='utf-8').readline().strip()]
for f in os.listdir('data/aclImdb/train/neg')] +
[[[0, 1], open(f'data/aclImdb/train/pos/{f}', encoding='utf-8').readline().strip()]
for f in os.listdir('data/aclImdb/train/pos')])
random.shuffle(raw_data)
values = [d[0] for d in raw_data]
reviews = [d[1] for d in raw_data]
data = tf.data.Dataset.from_tensor_slices((values, reviews))
data = data.map(lambda v, r: (v, process_text(r)))
(the /neg and /pos) directories are just a bunch of txt files
so it's some simple strings
the thing is, i get this weird error: AttributeError: 'Tensor' object has no attribute 'numpy'
i googled it, and they said eager execution should solve this, but they also say tf2 (which is the one i'm using) has eager execution enabled by default so
wrap the map argument in tf.py_function
yeah i tried that, but what should i pass to input and outputT
passing a raw tf.Tensor doesn't seem to work
Hello everyone, everything good?
Could someone guide me to solve a problem?
I have a text (recipes) where I need to identify the words that are the ingredients within it, how can I solve this problem? Could someone guide me?
Thanks!
if you didn't already know, the problem you are trying to solve is called "named entity recognition". That might give you an entry point for finding more resources.
Thank you so much!!! I didn't know !! This will help me a lot to start research!
do you indicate any specific reading? Any material or website for this?
I'm not sure
quick stats-related question - in AP statistics we learn to estimate with confidence with methods that are optimal as long as we are sampling less than 10% of our population. I read somewhere that if we can sample over 10%, then there are more optimal statistical procedures to estimate parameters (a confidence interval, for example). how do these methods differ from the ones used?
they are probably referring to the "finite population correction" that can be applied to certain situations
https://stats.stackexchange.com/q/401763/36229
https://web.ma.utexas.edu/users/mks/M358KInstr/TenPctCond.pdf
Cross Validated
In an introductory stats book by Nicole Radziwell "Statistics the easy way with R" , an assumption used for nearly every statistical test (e.g.t-tets, anova, etc) is that the sample size should no...
whoa holy crap I feel old. I havent seen this correction in nearly a decade hahaha
do you remember the criterias for determining finite or infinite populations? I only ever saw it i the context of manufacturing and populations are assumed infinite always (you dont have a production ceiling)
the a 10% rule mentioned above is as good as any, i think
i don't think i've ever had to use the FPC "in anger" although in hindsight i probably should have in some cases
read the posts, but i'm still a bit confused. does it basically mean that, because we are sampling without replacement, this can be harmful to the independence of each sample?
i think that's where the bit about infinity comes in, if N = infinity then this isn't a problem
so the finite population correction can take care of this in confidence intervals by multiplying the "original" margin of error by sqrt((N - n)/N) i think, right?
short story, yeah something like that.
hey all, I'm working on building a text classifier using nltk and was hoping to get some guidance from someone. is anyone free to talk a bit about it?
Hello,
I have a 2d numpy array, and I would like to evaluate the following equation.
Is there a numpy like(vectorized) way to implement this evaluation rather than just iterating over the values?
Bonus question, is there a way(vectorized again) to save each result of the product inside a new 1d numpy array?
Thanks in advance

I am using keras, tensorflow to make a simple AI bot, can u recommend any better data processing method?
I need to make a simple chatbot that ll interact with the user, keep a conversation... Is that process ok? Can I achieve that by adding more data to my training session?
>>> x = np.array([1, 2, 3, 4, 5])
>>> y = np.array([1, 2, 3, 4, 5])
>>> m1 = x[1:] * y[:-1]
>>> m2 = x[:-1] * y[1:]
>>> s = 0.5 * np.sum(m1 - m2)
Where s is the final half sum result, m1 is the first elementwise-multiplication and m2 the second.
Thanks, I think that would probably work.
Though, I was thinking that m1, m2 should look something like:
m1= x[:-1] * y[1:]
m2 = x[1:] * y[:-1]
yeah the ranges are flipped for x and y
Anyone know why there are 3 conv layers in a row; this is Alexnet?

Hi everybody
How do i rename these columns in pandas? Im using pandas.read_json() to read the data.json { "c": [ 120.57, 120.52, 120.54 ], "h": [ 120.75, 120.63, 120.75 ], "l": [ 120.54, 120.46, 120.48 ], "o": [ 120.74, 120.58, 120.53 ], "s": "ok", "t": [ 1615302420, 1615302480, 1615302540 ], "v": [ 483063, 498590, 516948 ] }
I have a question: How I know 'spain' equal to [0.0 0.0 1.0 27.0 48000.0]?

whether a binary number place as a randomly? Please give me the clue. I'm so confuse to understand it
so basically OHE transforms your spain into a matrix
one good example would be if we have a list of variables
list = ['a', 'b', 'c']```if we pass it through enc it gives us
a
will be
[1, 0, 0]
it basically takes all your strings and tranforms them into a matrix
so what in reality you are seeing is this
(don't mind this just a line filler)
[0, 0, 1, 27, 48000]
^ ^ ^ ^ ^ ^ ^^^^^^^^
Spain Age. Salary
btw for a started I'd recommend never to use fit_transform as it might confuse you
just use fit and then transform
what is 'enc'?
Why i get two 0 at the first place in 'Spain'?
Hello everyone, i am new for data science (2 month studied claning data and simple machine learning, and little bit streamlit)
Anyone had a suggestion simple project for portofolio ?
In LeNet from 6x14x14 ---> 16x10x10 via convolution, would the total number of parameters be 16x((6x14x14) + 1) where 6x14x14 is the dimension of each kernel?