#data-science-and-ml
1 messages · Page 305 of 1


im also not sure how continuesly prompt for a book. i think i would have something to do with creating a main and having it loop the enitre program until exit is typed, but when i try to use def main(): it gives me an EOF parsing error. not sure if that is becuase i am using jupyter notebook. this assignment is due tonight at midnight, and i have been trying to solve it for a few days. if anyone could possibly assist with one on one time i would much appreciate it.
most of the eof parsing errors ive had are just missing a bracket
do u have your main code?
the images is the gist of the main code
its kind of a 3 part question/error lol
well most wont go 1 on 1
but ya never know
just ask your specific questions and maybe someone can help
i figured it was a long shot.
question 1: how do i get my program to loop until the user types 'exit' as an input.
question2: how do i get my model to display which author (as a string) it thinks wrote the input book.
question 1: use a while loop
while true:
run program
if input == exit
dont run program
yeah
or
while input != exit:
run program
question 2 depends on what your model returns
so pseudo the program is this:
read in 12 .txt files
store each .txt file as its own string
store each string in a list
booklist = [book1 , book 2, book3, ect]
count vectorize booklist
tfdif booklist
then :
as user to input a .txt file name
read in .txt and store it as a string
predict author using:
multinomial naive bays
svm
algorithm3
algorthim4
well what im trying to say is what does your model return currently?
if i chose bays prediction
what does that currently output

Does anyone know an easier way to let me use my GPU for training? Too many steps 😫
yea that does work as well thanks
AMD or Nvidia?
Nvidia
You could install Linux and use the Nvidia docker containers. Should be plenty if guides and generally easier overall.
That sounds like a hustle as well. Im not good with that type of stuff.
I've forgotten how many stuff i've downloaded now
Try google colab then or a cloud based solution. Google cloud gives out free credits to start. Those will have everything already setup
😂 all ready done that. It kept crashing so I switched to pycharm
but now its really slow so I need to use the GPU
its literally one line to install CUDA, TF and Keras lolol
install anaconda (just like clicking an .exe)
go to command prompt and type conda install -c anaconda tensorflow-gpu
and that's it
Just a general question. For regression problems, is it important to have all features scaled within the same range? And if they are not scaled to the same range what would this mean for how the network interprets it later downstream?
And following that. Is it more ideal to have a "flatter" scaled curve? I imagine this would allow the network to differentiate between values more easily. So just off of shape, would the red curve be more ideal than the blue?

Its important in the sense that most ML algos work better in ranges from 0 to 1, or so.
I normally do this (even when it has nothing to do eith ML)
Find descripte stats
"Observe data distribution"
Find outliers
Manage outliers
Then "normalize" data
Regression (ridge, lasso, etc) should really work fine even without scaling as long as the data is lineal.
But some preprocessing is needed to clean it up
I more meant after the scaling happens. Depending on the initial range (of nonscaled) the domain of the scaled data will be different. Is there any reason to try to align all of the scaled data to exist with the same bounds? So for the above plot...if you take off the chunk at 0 (which is false data I have injected into the set) there is a clear difference between the N_CII (top panel) which ranges from ~.3 : 1 and ZnII (bottom) continuous over entire range.
I dunno if I can get away with not scaling the data.
I think that's somehwat difficult to answer without seeing the data and its context lol
also it depénds.
is the data bounded in reality? or are you trying to bound it for convenience? its not the same.
i know it is pre trained, but ive seen you give a picture to it and the label, and following picture of that label will be predicted correctly
They are definitely bounded in reality. Looking at metals in intergalactic/galactic absorbers. So elements like Silicon should definitely be more prevalent and have a wider range than say Zinc or Iron. @exotic maple
why do you say that?
yes, so you want to make something like that? it will take 2-3 years with a cluster of 50 GPUs and about a million $ in development
specifically this
Regression (ridge, lasso, etc) should really work fine even without scaling as long as the data is lineal.
I havent documented myself about other regression methods, but "standard" lineal regressions shouldnt have a problem with multiple variables and different values as long as they are lineal and not highly correlated no? in the form -> y = a + bx + bz + bp.... etc
any method that uses some form of distance metric is going to depend on the scale of the variables
so non-regularised regression will be fine
but e.g. ridge will not
As far as I know anaconda uses some pretty old cuda versions which may not support newer GPUs. I had to go through more hoops to get cuda 11.2 for my 3090 this time. If you have a 10 series or older Conda should work fine
now that you mention that, i think Lasso WOULD have a problem
yes, because it uses a distance metric
too low coefficients would render it null
the L1 norm
yeah
what do you mean by that
doesn't make any point upgrading packages for a GPU that only like 10 people in the world posess
Lasso has a threshold below which it sets coefficients to 0 no?
no...
that's not how it works...
ok let me check because im sure it does
2000 series as well. Cuda 9.2 is pretty old
it can perform feature selection
its not...CUDA 9.2
by zeroing out some coefficients
its def 10
it's not like "if this would be below 0.01 it'll get clipped to 0"
that's fundamentally not correct
Unless their docs are wrong https://docs.anaconda.com/anaconda/user-guide/tasks/gpu-packages/
I stand corrected.
I expressed myself incorrectly

Well, that is certainly interesting. I personally got 10.2 for my 1050ti
lemme dig some more
@stiff barn here, TF 2.4 with CUDA 11 https://towardsdatascience.com/install-tensorflow-with-cuda-cudnn-and-gpu-support-in-4-easy-steps-954f176daac3 🤷 🤷
are the docs old or smthing?
Yeah probably. It could be a newish update or something.
@robust charm take a look at that above
Also, whenever I use minmax, the val_loss is always offset by a fairly stable constant relative to loss. Any ideas why that may be?
That should help you if you have a newer GPU and that’s your problem
Unfortunately i dont remember. I know the differences in their cost function (L2 and L1), but why, i dont know
I keep reading L1 and L2 as lagrange points
it would be a good thing to find out 😉

im seeiing that explanation
which relates it to the derivative
I found the explanation here very good @velvet thorn https://stats.stackexchange.com/questions/176599/why-will-ridge-regression-not-shrink-some-coefficients-to-zero-like-lasso

Cross Validated
When explaining LASSO regression, the diagram of a diamond and circle is often used. It is said that because the shape of the constraint in LASSO is a diamond, the least squares solution obtained m...
last post
I can't explain it better than the math of the bottom answer :p
thanks for the correction 🙂 I understand it a lot more now! I think I have some intuition about it now.
Lasso would definitely need some normalization lol
another space enthusiast? lol
Yeah I still get confused occasionally with those haha
https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a This articles answer your question in detail, and also gave me light about what @velvet thorn mentioned.
althought i still prefer the math of the stats exchange post
easier to "see"
How to install pytorch and cuda without a GPU on a mac?
Its my job currently, so not much I can do about it on that end haha. But also not denying it haha. I appreciate the article though!!
how to create a conscious AI?
Step 1, steal the mind stone

Step 2, ???
Create a code to make the AI learn what it sees.
You should give it tons of data to learn from. (From the most basic to the most complex, like whether a person is sitting or standing to finding what he/she would be thinking)
More data more better AI
(neural networks)
i have this basic basic code, with multiple inputs and multiple outputs. It doesn't use any libraries.
The net error loss even after 100k iterations is still barely decreasing. I don't know why
https://github.com/ZerothVector/BasicLearning/blob/main/nn2-with-issue.py
The problem is net loss decreases very slowly even after 100k iterations.
I tried decreasing the learning rate to 0.00001. doesn't seem to do much of a change.
I don't know why this happens?

GitHub
Contribute to ZerothVector/BasicLearning development by creating an account on GitHub.
can anyone help me wrap my head around einsums?
np.einsum('ik,kj->kij', np.exp(A), B)
What does this do exactly in "normal" np functions?
i don't understand what K being repeated actually does
in this case, the corresponding row/column in the input arrays are going to be dotted
i thought they are only dotted if they do not appear on the right of the ->
like im trying to figure out "how" i would do this without einsum
i saw examples of for loops online but that usually didn't include 2 -> 3 variable einsums
Anybody have experience with petastorm?
If I want to use sharding with petastorm. Is it correctly understood that I need to create a reader(call make_reader() or make_batch_reader()) for each shard I want?
you're right this is a weird one, you can see how the extra dimensions are formed here though, hopefully:
In [21]: a
Out[21]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [22]: np.einsum('ik,kj->kij', a, a)
Out[22]:
array([[[ 0, 0, 0, 0],
[ 0, 4, 8, 12],
[ 0, 8, 16, 24],
[ 0, 12, 24, 36]],
[[ 4, 5, 6, 7],
[ 20, 25, 30, 35],
[ 36, 45, 54, 63],
[ 52, 65, 78, 91]],
[[ 16, 18, 20, 22],
[ 48, 54, 60, 66],
[ 80, 90, 100, 110],
[112, 126, 140, 154]],
[[ 36, 39, 42, 45],
[ 84, 91, 98, 105],
[132, 143, 154, 165],
[180, 195, 210, 225]]])
In [23]: a[0], a[:, 0]
Out[23]: (array([0, 1, 2, 3]), array([ 0, 4, 8, 12]))
In [24]: a[1], a[:, 1]
Out[24]: (array([4, 5, 6, 7]), array([ 1, 5, 9, 13]))
In [25]: a[2], a[:, 2]
Out[25]: (array([ 8, 9, 10, 11]), array([ 2, 6, 10, 14]))
yes it's weird because without k it would just be matrix multiplication right?
yeah
do you know what this would look like in terms of regular (non einsum) functions?
it's easier for me to reason about
why do you output In [23]: a[0], a[:, 0]
like i don't really understand where each element in the resulting matrix comes from
(array([0, 1, 2, 3]), array([ 0, 4, 8, 12])) if you multiply each element of the first array with the entire 2nd array, and concat you'd get the first level
ohhh
In [27]: 0 * col0
Out[27]: array([0, 0, 0, 0])
In [28]: 1 * col0
Out[28]: array([ 0, 4, 8, 12])
In [29]: 2 * col0
Out[29]: array([ 0, 8, 16, 24])
In [30]: 3 * col0
Out[30]: array([ 0, 12, 24, 36])
and those are the columns of the first level
similar for the other levels, with the arrays i printed
so each element in the first matrix multiplies an entire column in the second?
hmmm
ahh i see
wait is this even possible with regular np?
from what i see matmul don't work
i can do it with a bunch of concats
i don't know a clean way to do it, there may be one
this is really weird i see someone use this
i've only used einsums to do internal dot products
so this is a weird use, but a neat one
np.sum(np.einsum('ik,kj->kij', a, a), axis=0)
is there like an intuitive meaning to this?
probably, but i don't know it
darn ok
a while back i stumbled on a long post about einsums, maybe i can find it
thanks that'd be every useful
i'm not sure this was it, but it looks well-done in any case https://rockt.github.io/2018/04/30/einsum
oh, this was it https://rajatvd.github.io/Factor-Graphs/
The factor graph is a beautiful tool for visualizating complex matrix operations and understanding tensor networks, as well as proving seemingly complicated properties through simple visual proofs.
this is a nice way to try to visualize everything

Hey! Is there anyone who has done Andrew Ng's ML course or Google ML Crash Course? If yes, I wanna know that what approach does both of these course uses, Top-Down or Bottom-Up.
quick question what are the cases in which removing outliers will benefit the model?
@rough otter some models are sensitive to outliers. For instance, regression, gaussian and naive bayes. You could say the presence of outliers poison the model
For tree based models outliers are not an issue
ah okay tysm
Hello there!
How can I compare the similarity between two words using nltk?
Example: "Pregao Eletronico" and "Pregão Eletrônico"
Levinshtein distance would do
Altho you might want to clean the strings first. Eg. Remove space
Levinsthtein is this method?
nltk.edit_distance()
Ok, thanks :)!
vectorize then euclidean
How would you get Euclidean distance of words? 🤔
Isnt Jaccard a preferable metric for NLP?
ED of vectors, not words
Yeah I know. I just cant mentalize it. Every word is a dimension in CountVect and its value its Count, no?
Do you mean distance as sqrt(w12 + w22)?

In mathematics, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
It can be calculated from the Cartesian coordinates of the points using the Pythagorean theorem, therefore occasionally being called the Pythagorean distance. These names come from the ancient Greek mathematicians ...
check out the fuzzywuzzy library
https://github.com/seatgeek/fuzzywuzzy

GitHub
Fuzzy String Matching in Python. Contribute to seatgeek/fuzzywuzzy development by creating an account on GitHub.
This is perfect, thanks
No problem 🙂
what are the best resources to learn to ML algos?
YouTube?
Depends where you are starting from. I quite like https://www.youtube.com/channel/UCZHmQk67mSJgfCCTn7xBfew videos

YouTube
I make videos about machine learning research papers, programming, and issues of the AI community, and the broader impact of AI in society.
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.lin...
If just starting out I would recommend spending time on stats/probability first and ease into different models from there
This is probably the most canon book for AI, also http://aima.cs.berkeley.edu/
WTF is this?
memes with ML????
Yeah, some of it is just for fun, but most of it is education. Most of his channel is just going over recent papers

#memes #science #ai
Antonio and I critique the creme de la creme of Deep Learning memes.
Music:
Sunshower - LATASHÁ
Papov - Yung Logos
Sunny Days - Anno Domini Beats
Trinity - Jeremy Blake
More memes:
facebook.com/convolutionalmemes
Links:
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https:/...
ngl the second one got me tho
hello
What would be a fun simple python AI to get started with?
pick up a copy of bishop's "pattern matching and machine learning" and read it straight through, doing the exercises and following references
You can't really merge object detection models right?
Like if I have one model that can detect dogs and on that detects cats, you can't just put them together and detect both without retraining
It needs to train on images with both dogs and cats in them at the same time
You can use knowledge distillation, but that does involve retraining yes.
I'm trying to think of a type of model where there would be a clear way to do this and coming up blank- if you had an ensemble model like random forests you can just merge your forests somehow but that doesn't feel like true to the problem. It's probably possible for some models but I've never seen it done. Would make a paper I'd read
hmmm...theoretically, if the architectures are same, then wouldn't a simple metric to merge weights work decently enough?
The most obvious problem with that (assuming this is a NN) is just that the output head is going to be binary for either, so you need to split that into two heads. Plus you're just mashing all the representations coming out of each layer together- which would most likely confuse layers downstream
It might not be a bad place to start transfer learning from
from which base model?
I was trying to train a model with a large amount of classes with yolov5. I wanted to train it for the classes in groups of 5, and save the weights along the way
But when I added new sets of classes it would forget the old ones
you would have to re-learn the optimizer 🤷
Because I imagine it needs to see examples of the old classes compared to the new ones
no, Yolo5 was pre-trained on that specific domain that encompasses both your target classes, which is not the case with your model that is limited to one particular domain
You probably want to train on all of the classes you care about together. If you train on just a few of them the model has no incentive to not disrupt the accuracy of the other ones when training on your subset of 5
This is one of the reasons why people usually randomize their dataset ordering before batching- having many batches of just one class can cause some problems
yeah I was doing 5 at a time because my resources are limited
When you say 5 at a time, is that like 5 per session of training, or 5 per batch?
5 classes in the training dataset, so it could learn what those 5 look like before moving onto more
opposed to doing all classes at the same time
Are you loading the whole dataset into memory altogether? Larger models are usually trained such that only the current batch, and maybe a few batches in advance are loaded from disk and into memory at a time, then released after use. This way you can train on as much data as you can fit on your hard drive, so long as you can fit just a batch (and associated overhead) into volatile memory.
If you are using tf/keras for image classifcation this is usually the goto
https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator
TensorFlow
Generate batches of tensor image data with real-time data augmentation.
But you can also write custom generators for tf/keras
I'm not as familiar with pytorch but I'm sure there's something equivalent
yeah the problem was the size of the dataset because I wanted to make sure there was enough data for the number of classes
so I tried splitting the classes up for training
but next time I'll try using all the classes and smaller datasets for each training session
I know what Euclidean distance is lol. What mean is, can this work for word Vecotrs? pretty much all values ar e 0 in their columsn except their own counts
so you will end up with sqrt ( count12 + count22)
import requests
import pandas as pd
import numpy as np
raob_stations = requests.get("http://www.raob.com/assets/downloads/raob.stn.txt").text.splitlines()
new_stations = []
for station in raob_stations[10:]:
new_stations.append([i.strip() for i in station.split(",")])
new_stations_header = ["WMO", "ICAO", "NAME", "LOC", "ELEVATION", "LAT", "HEMI_LAT", "LON", "HEMI_LON"]
df = pd.DataFrame(new_stations, columns=new_stations_header)
df.replace("----", np.nan, inplace=True)
Is what I have so far, the problem is that all of the LAT/LON values are positive, and I want the ones either South of the Equator or West of the Prime Meridian to be negative instead, so I don't need the N/S/E/W columns. Is there an easy way to do that?
The dataframe is fairly large, it is the set of all upper-air balloon stations on Earth.
output of df.head(n=10)

Is it be enough 100 labeled data and 25 for testing to classify object? This object actually have two states, i want to predict this states
nah, i want to build my dataset and train model to it with CNN
i would recomend making nice spiders
what is spiders?
yeah
spiders are good for stealing data from HTML
you could just use bs4 for that, no?
the is just load with some http some are able to navigate the entire site searching for data
bs4 never heard of
parsing python lib
sooo, spider will search data alone? without any help?
if wel made year
sites like trivago uses sider in other hotel sites
very common pratice to build datalakes
man i found bs4 is for beautiful soup that alone is ok but not enough for self navigation and all spiders use bs4 also
Why wouldn't it work then? euclidean distance will work regardless of sparsity
if a vector exists, it would still have a distance with other vectors, regardless of the magnitude
I know you "can" but as a similarity measure i think its odd
what's it's advantage over lets say, Jaccard distance?
you can use cosine similarity then 🤷
because with Jaccard to say "Awesome" and "awesomer" are "similar"
I dunno about jaccard distance, but it seems to measure the similarity of elements in a set
If we go straight to vectors, yeah it doesnt
but i mean Words BEFORE converting to countvectorizer
thats only for its statistical similarity rather than context based similarity
see, a word may be spelled similar (like vodka and voda) but it means different things in different contexts
first is wine, second is water. but with Jaccard, you would get a high coefficient
vector doesnt hold any context similarity meaning either (as far as I know=
the vector is literally just the count of the word in the corpus
yeah, you are right. not full context, rather it focuses more on meaning. however, model embeddings do preserve context
I'd have to read about model embeddings, but i'll trust your word there :p

Medium
Dives into BERT word embeddings with step by step implementation details using PyTorch
just read the intro, rest is coding shit
it depends
on the process of vectorisation
bag of words counts is the simplest
preserving little semantic meaning
ancient ⚰️
Hey guys, quick question
how do you get it to show every year on the x axis instead of 5?

lucky. I've been fighting with MPL for a while now lmao
and i just got that done on my side

!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
ax = plt.gca()
ax.set_xticks("lowerbound", "upperbound", "step"));
Ok thanks man. I will have dinner and try it out
that's... amazing. I love you

infinitely more beautiful omg. thanks @velvet thorn you know it all lol
this is the other part I want to do but holy crap MPL documentation aint the best guide...
yw 👋
I'll probably spend all night trying to get the multicolor working lol
i want to use cpu parallelisation to compare the costs of individual arrays and overwrite an array with the best ive seen so far. i dont really know what to do to synchronise:
from copy import copy
@njit(parallel=True)
def cpu_simulation(base_array):
best_cost = sum(base_array)
best_array = copy(base_array)
for thread_ in prange(somelen):
# do some mutation to basearray
base_array[2] = random_number
if sum(base_array) < best_cost:
best_array = base_array
return best_array
HELP
anyone here good with openCV / face recognition and stuff
Go ahead and ask your question. I don't know about those technologies, but maybe someone else does.
So idk much about what well preprocessed data shapes SHOULD look like....I guess minmax is supposed to just kinda uniformly distribute the data between 0-1. I am injecting in a negative constant to train it for missing user input. My prof is apparently a big fan of minmax so it keeps coming back to using it......but this to me just looks like (especially with the injected no data mask) it is not going to produce good results.....am I wrong in thinking this? Data just seems too compressed.
Raw data more resemble slightly skewed gaussians

Does anyone know how to grid an image and check which grid has the most white pixels with OpenCV-Python and Numpy

Hello everyone! I made my very first Plotly.express program today (yay me). And I thought I would ask. Which library would you recommend for plotting 3d points in space from a csv. Imagine tracking satellite in the solar system. (IE: I want to visualize small objects in a solar system)
please feel free to "reply", DM, or ping me so i can see this in the morning! Thank you all for all the awesome help you've been thus far in my quest to learn python
matplotlib is probably the most popular data visualization library.
though let me ask my astronomer friend
Thank you so much!
he's working on his dissertation so it may be a while before he responds 😛
I know a few people doing that lol
My question may be way less complicated then what I tired explaining.
matplotlib lets you plot points in 3D space. But there might be a way that better supports planets and stuff idk
I just want to create a 3d rendering of a "custom" solar system and be able to plot random coordinates that represent other items
and the system is based of x,y,z coordinates

This is what i managed to get in plotly
in matplotlib, I think you have to provide points in 3D as a three-dimensional array
huh, that looks cool tbh
thanks 😛
I wish i could figure out how to do "real time" rendering
but i think i'll have to switch languages for that
btw, my friend hasn't replied yet but he did tell me once that there's a library called astropy https://www.astropy.org/
Astropy. A Community Python Library for Astronomy.
I have no idea what it does
or if it's even remotely useful for what you want to do
i don't think its useful, but its wicked cool!
hello, I'm a newbie to ML world and was recently studying about Decision Tree Regression. And if you actually understand the algorithm, you might know that the algo, for each node of the tree, iterates through all the values of all the features trying to find the split that decreases the SSR the most. At each iteration the algo considers only 2 points at a time, takes their average, makes the split at that average, and then makes predictions using that split and calculates the SSR. And then selects the split which decreases the SSR the most. I was wondering, does the number of observations considered at the time of a split (i.e. 2 right now) affect the model in any way. I believe its a trade-off between speed/time taken by model to train and accuracy of the model. So I wrote a notebook for testing it out whether this trade-off is significant enough to be considered. But I'm having 2 issues rn and I can't seem to proceed further. Would anyone mind looking at my notebook and help me out?
Just using a simple OLS ML algorithm, one of the features is an order of magnitude larger than the other features. Would standardising the data allow for the model to train more easily?
@tender hawk my friend said that astropy has some tools for making 2d plots, and in his opinion a combination of 2d plots is better than a 3d plot. Not sure why he feels that way--I'm not an astronomer
also the plotting tools in astropy are just a wrapper around matplotlib 😛
as a rule of thumb, standardizing data works (and increases accuracy) in most cases
i thought so, I just wanted to make sure i wasn't talking out of my arse in my report! Thank you :)
For OLS in simple linear regression, feature standardisation (0 mean and unit variance) does not affect your results. It does however drastically increase the interpretability of your data. I am unsure if it would decrease running times of your model however. (Note that if you utilise an algorithm that uses regularisation then feature standardising does affect your results)
Sigproc guys, any recommendations to a SOTA note segmentation python lib? the one I found is like 3 years old
so it wouldn't create a more "accurate" model if you standardised it?
it depends on your algorithm/model
for NN, you can't use without it
for NB, no need
and so on
anyone knowledgeable on how to use Spacy and is willing to give a few moments of time?
just ask the question
no need to preface it other than saying it's Spacy related
Sorry, NN and NB?
The model I'm using is basic af it's just an ordinary least squares regression model
Hi I have a large astrophysics dataset (with missing values). I've been told to use an autoencoder and then use the autoencoder to carry out anomaly detection. I have five astrophysics features and I was wondering how I should get started with this.
how would i go about using the phrase matcher feature on a list of about 150,000 termed
terms
was also told to “serialize” and not sure what that is
Neural Network and Naive Bayes
Oh! That makes sense then!
What’s the best way to format results in a dataframe for a report?
Anyone know how to shorten the output of a HuggingFace summarization using T5?
I'm a huge noob to this and can't figure out what the max_length parameter actually does
because it sure doesn't shorten the output
NLP question involving scispaCy and sklearn: I am working with medical text. I used one of the specialized scispaCy libraries (en_core_sci_sm) to recognize biomedical entities within the corpus. I am now trying to create a term-document matrix in which each column is an entity. I've used CountVectorizer without success--either the entities are split into individual words (e.g., "malignant melanoma" become "malignant" and "melanoma") or not recognized as words at all. I learned this when I tried 1) inputting multi-word entities unchanged and 2) inputting multi-word tokens with the words separated by underscores (e.g. "malignant_melanoma" and "diabetes_mellitus"), which were split into single words, or 3) by squishing the words in an entity together by removing the space (e.g. "malignantmelanoma") which CountVectorizer did not process because the words were unrecognizable. What advice do you have? Is there a way to modify CountVectorizer so that it can use the scispaCy library or preserve multiword entities? Is there another package you would recommend. Thanks.
I've adjusted the ngram variable in countvectorizer from (1,1) to (1,3) so that it can take it trigrams. This looks promising. If anyone has a better idea let me know.
Hey there!
I made a video where I try to explain and implement the article "Growing neural cellular automata". It is a niche topic, however, I find it fascinating. My TLDR for those who are not familiar with this topic: Trying to learn simple rules using DL that give rise to complex structures. Hope some of you could find it interesting and helpful.
My video: https://youtu.be/21ACbWoF2Oo

In this video, I implement the Growing Neural Cellular Automata article. It is a biologically inspired deep learning pipeline that generates update rules that are applied to a grid of pixels. It uses heavily the convolution operation together with multiple other techniques - alive masking and stochastic update.
Implementation from the video: ht...
what do compute engineers o?
that's too broad of a question, nor is it related to AI. better luck #career-advice
So I concatenated 2 dataframes, and have them both use a Date column as index. One of the dataframes is now displaying a timestamp after the date. How can I edit this columm to just display the date?
most things that people self-post here is hot trash
this is super cool however, thank you!
reminds me of "neural gas" models (part of this theme of self-organizing nets)
whenever people ask about math for ai they say it's important for understanding how it works
is understanding how it works important for creating the machinelearning/ai?
How are you gonna tell your model what you want, when you don't understand what math is relevant to solving your problem of interest?
Also, if your model gave you data, how are you going to interpret it?
oh arlight got it
You can turn them into a pandas date object and call the method .dt.date I believe, just to call the date.
Yeah, just found the stack's post I read before.
@main fox
https://stackoverflow.com/questions/16176996/keep-only-date-part-when-using-pandas-to-datetime
Thanks
I managed to figure out what the problem was.
When using yfinance to get stock data and save it into a dataframe, by default it makes the Date column the index of that dataframe. Also, since it uses a groupby operation when creating the dataframe, the index becomes inaccessible. So I had to reset the index before doing the concatenation, and after concatenating I could do pd.to_datetime().dt.date
And set that column back as index
If you're grouping then you should read for Pietro Battiston's answer in the same post and use the
df['dates'].dt.floor('d')
I'll see if I can clean up my code doing it that way. Thank you for your reply
ouch
troubleshooting my df problem before asking anything further thanks unpingable
Anyone have experience with Dash? I keep receiving this error when trying to start it up OSError: [Errno 49] Can't assign requested address
Hello, is there a way to value_counts() for column values that I already have made bins for? eg I have a bin for values < 3 and the total count. I want to create a stacked bar chart
is any1 here familiar with probability and statistics
Wow, I appreciate that!! I find the topic fascinating:)
hi!! i'm in let's try!
Can I ask neural network stuff here?
yeah, machine learning is in the description among other things
Oh I didn’t see the description

I’m getting a number really small but I should be getting a 0,1
Hello! I am looking for smaller datasets where I can perform some pre-processing, carry out exploratory analysis,
build and evaluate machine learning models. Any help is appreciated.
Kaggle has datasets: https://www.kaggle.com/datasets
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
you're probably predicting probability instead of predicting label.
A really small number denotes that the probability of it being class 1 is really small so its actually label 0
To convert prob to label you can do labels = (prob < 0.5).astype(np.int)
guys, what went wrong? I haven't touched R studio in a day and now when I try to run my script I get an encoding error
attempt to use zero-length variable name```
Can't really find anything right now and my assignment is due in 1 hourare you using rmarkdown? the error should be pop up pretty much where the error exists
where does the error pop up
no specific line
source('~/.active-rstudio-document', encoding = 'UTF-8', echo=TRUE)
have you tried stack overflow?

Stack Overflow
When i generate a new rmarkdown file (or open existing rmarkdown-files) and try to run a rmarkdown chunk, i get this error: "Error: attempt to use zero-length variable name".
I have Win10 and did a...
does anyone know how to import a keras trained ml model into opencv dnn?
For some reason the web won't load. In the case the answer Yugen provided is not the solution I think you should still try to explain what your code should do and what's the expected output and the process you're trying to achieve, what have you tried to fix and whatnot. That'll help others reach the issue faster.
I'm trying to predict whether the review is good or bad(1/0) and the expected output should be either 1 or 0 but right now when I try to print the predicted value it gives me a really small number :/
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
hi
im installing pytorch
with cuda 11.1
which is already installed in the system
so will it install again?
No, as long as it's in the same environment and the version matches requirement. (you do use environments, right?... No? Well you should 😅)
thx
Is there any way to stop Pandas from exploding a dict of dicts into a MultiIndex table?
it's taking one of my nested dicts and assigning it to the index which misrepresents the data

what do you expect the result to be
when creating models is it a standard to always normalize the distribution of all the variables, and if not, in which cases would you normalize the distribution?
the solution was to use orient='index' instead of columns
Hi guys. If i have a pre trained model, can i keep training it without losing all the knowledge achieved? like, it classifies classes, but soemtimes it fails
can i keep training making sure what he has learnt it remains?
what model?
So i need to perform simulations for a given probability question and compare the simulated result with the theoretical one

do you know what type 1 and type 2 errors are
yea


Hi, i am workind on sentiment anlaysis of financial news/reports/tweets . Iam building my embedding model so i was following few tutorials on Tensorflow. So I was preparing my data for word2vec where i was sampling postiive and negative skip-grams samples. But when i was fitting it to my dataset I didn t understand :
- when building sampling table , am i building it from whole dataset? because its based on zipfs law and when i have one word sentence i didn t see the point of doing probabilistic of frequent words on that type of sentences. Following tutorial they have static size of sampling table and also vocabulary
- which leads me to another question . Is vocabulary builded on one sentence( thats how i ve done it , how i ve understand it from tutorial, but now i not sure) or make vocabulary from whole dataset(thats where some logic hit me 😄 why would i want vocabulary for each sentence)?
I was following few steps from this tutorial https://www.tensorflow.org/tutorials/text/word2vec i would be very grateful i am a bit stuck and confused because it look like they were doin it on large texts , big corpus i have just one sentence for each row
You mean a for loop?
https://en.wikipedia.org/wiki/For_loop
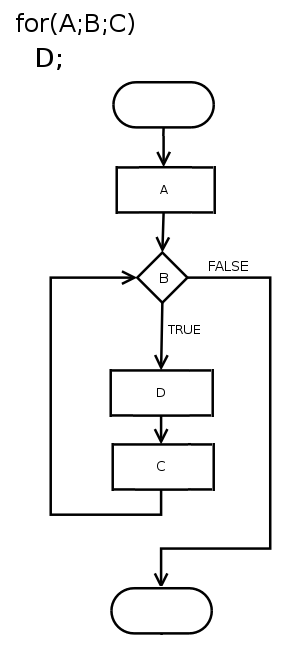
In computer science, a for-loop (or simply for loop) is a control flow statement for specifying iteration, which allows code to be executed repeatedly. Various keywords are used to specify this statement: descendants of ALGOL use "for", while descendants of Fortran use "do". There are other possibilities, for example COBOL which uses "PERFORM V...
I don't really know lol. I just want to know the name of using the "for" and "in" syntax. For example:
for i in var:
print(i)
That's a for loop. You call it with that structure
for [iterator] in [iterables]:
[do something]
oh, thank you so much!!
[iterables] would be a something that has a bunch of elements grouped in a sequence.
say for example, a python list of integers
int_list = [1,3,7,10]
[iterator] is an item on that list. You declare the variable name in the same for loop meaning that you don't have to declare it outside it, but you must use it at the [do something] part.
For example, if I want to add +2 to each element on that list and print the result, you could do something like
for n in [1,3,7,10]:
print(str(n + 2))
oh wow, thanks. This helps alot. I'm going to write this down lol.
And welcome to programing @pulsar karma Things might get complicated from time to time, but keep going, keep revisiting what you're learning and most importantly get your hands dirty. Experiment with everything you're learning until it breaks (then you learn on how to look for the solution at stackoverflow) lol
xD
thanks, I'll do my best
:)
So, I'm currently learning ML for a project at my workplace, and I'm watching tutorials, reading docs and stuff. But there is a thing I don't quite understand as far as implementation goes.
Say, for example, I want to make an AI that classifies an investor as either bullish or bearish, based on his sells and buys during a period of time of two years.
So you'd have something like, 200 rows, across this guy's investing history, each with 12 columns (whether it was a buy or sell, the opening price of the stock on the day he bought/sold it, the closing price, the price he sold/bought it for, etc)
I don't exactly know how to express this in a way that isn't completely wrong or very confusing, but.
Can you actually have this? Where you'd pass many arrays of data as input to get a singular output at the end?
Or is there some sort of requirement that I flatten the data into a singular array that is then passed to the model to classify?
yes
1 sec

Tired of searching for your Uber?
Trying to get a better idea of who’s stealing your car park?
Just want an awesome Computer Vision project to try out using Python?
Well, ANPR might just be the perfect thing for your to try out! In this video we’ll go through a full blown walkthrough of performing Automatic Number Plate Recognition (ANPR) usi...
see the vid above, its very ez to understand
@median dove heres a full code
will u plwese tell me about python pandas
It's a library to wrangle data. Based on numpy. What exactly do you want to know?
Bruh right now I'm trying to build my own deep learning framework and it sucks
maybe build it on top of something like jax?
something that will do autodiff and gpu stuff for you
Hi everyone
I scraped data from a forum about new cars and offers people get for them from dealerships. So the entries are like:"i got offered xx k for an xx brand xx model car from xx dealership." but because of this being a forum not all of them are in an order like this and not all of them contains information i want(most of them are trash). I want to see cars, their prices and the dealerships name on a table using the data i have. My question is which library or what kind of approach would be the best for this purpose?
the attempt itself is very admirable
Currently, I have built dense layer, activation functions, network to concatenate the layers, and confusion matrix
Forward and backpropagation are working perfectly, I just have to figure out how to properly calculate loss, and combine them into a single training function
Next, I'm looking to make convolution & pooling, then maybe an automatic bootstrap function; after that, I'll have to somehow make an optimization function
Hi there, i have been using python in vscode for a while and now i am interested in using it for data science. Can someone please kindly explain what anaconda is and if it is necessary for me to install it since ive already been using python? Or do i just need jupyter notebook?
Anaconda Is a toolbox for data science. It contains Jupiter. You can decide if you Want to install anaconda or just Jupiter on your computer
#data-science-and-ml I am new to Python and data science. I am currently working on a project with linear regression modeling. My question is: should I perform my log transformations before or after I split the data into train/test? If so, how do I do that since the split has occurred? Also, since I will be encoding categorical data prior to the split, do I need to perform .groupby on certain column after the split?
Oh i see. When i downloaded the python extension in VS code, it says that it comes with jupyter as well so that we dont have to download it
then would that mean that it is not necessary for me to install anaconda?
If i do, would there be some overlap or conflicts with my performance?
I don't Remember exactly but I think that you Need to install anaconda First. Than from there you can install Just Jupiter
I don't think that could be a problem
You're welcome
Hello 🙂
I was wondering if you guys when doing text pre-processing
remove words (including those with smaller length) then perform stemming
or Stem first then remove words ( such as those with smaller length)
depends on what you are doing but basically you need to remove stopwords
stop words first, stem later
hello, i need help! for a bagging classifier would accuracy of 0.99 on training data be considered overfitting? accuracy on test data is 0.89
(still learning)
but if you are doing some project where context is important i do not recommend removing words with smaller length they might be important when you ll be working on dependency parsing/embedding/whatever you ll use after that because they might be a part of a phrase. Also the part with a stemming. if you are doing lemmatization ( i used library to do that) the word could be one of the stopwords so thats why you need to remove stopwords first and then doing lemmatization/stemming
(i am still learning lol)
thank you for your advice i will probably have a look into the smaller length words in the contextual for analysis
does anyone know why pd.concat would suddenly drop one of your rows
i'm concatting a list of single line dataframes
and the list is 1 longer than the output DF
Hey there, im using the anaconda interpreter in vscode now! But i am a bit confused, do i still need to make a venv for my projects?
If anyone else can answer this too please feel free
Usually for non data science projects i make create a venv so that i can pip install modules
i'm not sure how to move forward once i've selected the anaconda interpreter
hello guys I'm making a psychologist chatbot and need dataset for it. All I found is data from couselchat.com and a large dataset from crisistextline.org which is unreachable for me because of their requirements. Can anyone find a dataset with conversations between psychologist and client or give a working way to get the one from crisistextline.org?
inception or anyone
NVM let me re-write this
Depending on what you intend or how to transform your data, you should do encoding or MOST transforms based ONLY on training data. Basically, (for something like OneHotEncoder or StandardScaler) you want to fit them to your training data.
Then, you transform your training data with the fit transformers (For example your numerical variables are all set in a range between -1 & 1, categorical variables through sparse columns, etc)
Later your train your model / ensemble with your transformed training set.
Finally, you transform your test set data and then perform your evaluation metrics.
At least those are the steps I've followed so far.
Hello Guys, I am having an issue while running a Dataflow Pipeline. I am declaring my options: parser.add_argument(
"--origin_path", help='origin_path. ex: gs://PROJECT/reception with our without "gs://"', default="gs://my-bucket", dest="origin_path", )
doing the same for blob name.
Then i want to :
p
| "Read file" >> beam.io.ReadFromText(f"{args.origin_path}/{args.blob_name}")```
but my dataflow is not overwinding that value and is always reading the file that I used to "compile" my template.
I can see the args values in the Dataflow monitoring and they are correct, so the dataflow is getting the info but not using it to read the file.
Any idea why? and or how to solve this?
Thank you!!!I need help with NMF decomposition algorithm
how do you actually intialize H and W matrices? random? or from data_x and y ?
Anyone with experience in PyTesseract?
Hey, im trying to get face recognition to work, but am getting really low fps for some reason.
how do i show code its to large
too*
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
when i run it its good fps until it detects a face
then it gets really bad
i also have a pretty powerful pc so im not sure whats happening
anyone here used OpenAI Gym with custom environments before?
i'm trying to create a simple basketball simulation
hello
anyone have any good videos on backpropagation
i am soooooooooooooooooooooooooo confused on the equations happening
I am able to find derivatives using f(x, y, z) easily on my own. But when it comes to the chain rule, and translating it to code eveyrthing just starts to not make sense lol
not really a video person but
feel free to ask specific questions if you have any
Check out 3Blue1Brown's video
hey, can someone help me figure out why my legend is only showing up with one label?

anyone knows whats the answer to this ?

if anyone could do this please dm me thanks!
...that defo looks like homework
!rule 4
4. This is an English-speaking server, so please speak English to the best of your ability.
5. Do not provide or request help on projects that may break laws, breach terms of services, be considered malicious or inappropriate. Do not help with ongoing exams. Do not provide or request solutions for graded assignments, although general guidance is okay.
y must have at least 2 data points```
the ml_data variable in question is a 400x2000 matrix, unsure how to proceed - anyone able to provide guidance?i am currently working on a project that calculates the similarity between certain keywords.
I am using custom data to calculate this, but not quite sure how to store the data (the data I pull from various news websites, contains title + body). This is the first time me working on bigger data, any suggestions?
Like do I separate the articles to sentences or use it as a whole?
@errant portal That looks really nice! You might want to correct that drop at the sides of the latitude though.
It's because the KDE calculation doesn't wrap around - it doesn't know that the data for -179 should also be counted as the data for 181.
I think you can fix that by manually wrapping your data around - as in:
- Extend your data to, say, a whole 720 degrees by duplicating the halves. That is, append to the end of the data the first half of the data, and to the beginning the second half. Something like
data_wrapped = np.concatenate([data[n//2:],data,data[:n//2]]). - Estimate the KDE for that
- Crop the KDE to the original part.
- Make sure to compare it to the one you've been getting before - hopefully, it should only majorly differ on the ends.
Genius! I had considered that the KDE would be a little weird on the edges, that's an excellent fix, thank you again.
anyone? I'm literally at my wit's end I don't get how it doesnt see data points
maybe you can show more of your code, instead of only the error?
Does anyone understand why I am getting
RuntimeWarning: invalid value encountered in double_scalars
r = np.array([-1.01994684 ,-0.59759477 ,-0.37829003])
x = np.product(1 + r) ** (1 / len(r)) - 1```negative number to a fractional power
Yeah I think it's giving you a very very low near 0 value and it can't do math with it
It's essentially dividing by zero in the np.product
@tidal bough negative numbers can be raised to a fractional power
in this instance it is raising to (1/3)
so the cubed root
@errant portal thanks I believe so as well
mathematically, only to rational powers, and using floats, it's hard to quantify that
np.cbrt(np.product(1 + r)) works. Hmm, how'd you do that in the general case...
np.product(1 + r) is just -0.00499028733552394 here
nothing too low
Oh neat, I'm not a math guy I shouldn't comment haha just speculation
np.cbrt(-0.00499028733552394) gives -0.17088680007841156, but
(-0.00499028733552394)**(1/3) gives a complex number when using Python floats, and an error when using numpy floats
is this, the same operation?

nah
Ah then I fundamentally misunderstand, haha deal with bt, not me B )
first you take the product of the elements + 1, then you cuberoot it, then subtract 1
nth root of the product of n numbers is the geometric average
not sure what the subtractions/additions are about
@tidal bough thanks,I see whats happening. Is there a good way to prevent nan
didnt seem like rounding before the calc worked
len(r) will always be 3
oh, then just use np.cbrt
@carmine iron Actually, one simple solution is to remove the sign and reassign it later. So you can use a wrapper like:
def nth_root(num,n:int):
if num<0:
if n%2==0:
raise ValueError("Even power root of a negative number")
return -((-num)**(1/n))
return num**(1/n)
and similarly for arrays
@tidal bough thanks, your solution is great
wait, I totally forgot about even roots
np.cbrt is probablly all i need
fixed
prior to this
r =np.array([np.product(1+x) -1 forx in np.split(r,len(r)/12)])
where r is a 6 X 6 matrix of floats
Playing with this a bit, I believe I'd need the "halves" that get appended to be increased by 180+ and decreased by 180, is there a way to just do that simple math to all the values in the array?
So that the furthest value is like -360 and 360
is there a way to just do that simple math to all the values in the array?
if it's a numpy array, as simple as doing that operation on the array
Hello Im having a very hard time just trying to load a keras model i trained in colab to my pycharm. i have tried saving the model as the folder a .h5 and a .hdf5
model = tf.keras.models.load_model('img_model.hdf5')
Yeah I've got it seperated, so longitude gets the 360 and latitude is only the 180* still
I've got a few NaN values inside my regression model's training data. Unfortunately, I only have 20 elements (a pitiful amount I know), so removing them will mean getting rid of a decent chunk of my training data. Getting more data is impossible, would I be justified in replacing these NaN data with the mean?
I think it depends on what you want to do with the data, I'm reading varying sources on the usefulness of Mean Imputation
There seems to be some other more useful options here: https://scikit-learn.org/stable/modules/impute.html
Aren't those detailing the method in replacing the NaNs, not what to replace them with?
Missing values can be imputed with a provided constant value, or using the statistics (mean, median or most frequent) of each column in which the missing values are located.
Ah i suppose for multivariate feature imputation it's a bit different
That's the one I was looking at, there seems to be some debate if Mean Imputation is good maths - mostly that it'll throw off trends and underestimate standard error
Surely it depends on how many NaNs you have?
So, for example, I will have like 1 or 2 rows that have NaNs in them, with only 3 features
Deleting the row would destroy a sad chunk of my data
But i feel that i could be justified in just plopping the mean in and assuming it won't change how the model trains too drastically
Yeah! I bet it would, I think pandas.DataFrame.fillna has a limit in it for that reason?
Also pandas.DataFrame.dropna has the thresh(old) argument
wait you think it would drastically change how the model trains?
Oop, no I mean it would depend on the amount of non-values
ah right right
Maybe worth a shot? Haha if the alternative is not training the model
There's probably some critical number, a threshold like you said, where the trade-off is not worth it
Well the model isn't training at all tbh, the data is garbage
Just my entire final year project at stake 🙂
Yeah that's way beyond me, I'm sure there's a way to quantify it though, there normally is
I could probably do an experiment to find that out, where you increase the number of NaN data for some nicely correlated data and watch how it destroys the accuracy
I think for machine learning though, it would come down to what the NaN values mean? And if a mean would be an appropriate substitute
Sort of a meta thing to the scenario
Like if it represented a failed experiment, a mean might not be appropriate but, a 0 might? Or something
Oh that's a good shout, i should ask where these NaN values have come from actually
thank you !
Yeah! It's not my area of expertise but science is science haha, good luck
I wonder why my KDE is so low on this graph?

Right hand that is
Compared to the actual data it's running on

Hey there,
I wanted to ask what's the good algorithm for finding a meaning of a sentence for specific topic and see how much related it is in machine learning? I'm kind of new to this and trying to see what are the commonly used algorithms that is used for understanding a sentence and see how much related the sentence is to the topic that I choose.
I appreciate any help
so the thing with ml is it makes its own mapping algorithm you can look into tf-idf term frequency–inverse document frequency for a less ml approach. what kinda documents are you working with?
does anyone know how to save and load models with keras that use experimental layers like image augmentation i cant load my model
you can use nlp, but models im not really sure
seq2seq
So I wanted to prove to my supervisor how important large data sets are for ML, to do so I created this plot using make_regression() from sklearn.datasets with a noise value of 15:

This is what i would have expected to happen to the value of "score" as the number of data points increase:

But what I actually see is:

This fluctuation between 0 and 1. Why is this? I'm using my own algorithm, but it should be doing exactly the same sklearn's linearregression algorithm. Is this typical behavior? Why does this happen?
I want to start a project with self recognizing AI. Where do I even start? Is there any research on this?
hey, so I made a line graph, why is it always straight? i want it to like kinda look like this:

it currently looks like this:

code:
@commands.command()
async def line(self, ctx, numbers: commands.Greedy[float]):
fig = plt.figure()
plt.plot(numbers, numbers, marker='o')
buf = io.BytesIO()
plt.grid(True)
plt.savefig(buf)
buf.seek(0)
await ctx.send(file=discord.File(buf, 'thing.png'))
...because all your points happen to lie on the same line? 
And that in turn is hardly surprised, considering:
plt.plot(numbers, numbers, marker='o')
...you are plotting numbers against itself.
...plot what you want to plot, rather than this? Not sure what else I can say.
ok
Just so it doesn't get lost: #data-science-and-ml message
Yeah this is really stumping me, I'm sure my model is coded correctly...
why does extra data in linear regression gurantee a large accuracy increase?
if you training sample is representative of the real-world test data, then more data wouldn't do much to help that
the only time you need more data is when you model is struggling to identify the relationship correctly.
if you want to prove, try using Neural Nets. then the resultant curve would be somewhat like that
hmmm i think it's because the data I have currently doesn't have enough for the model to properly learn a correlation. So I was trying to show that if it had more data it would eventually learn

I guess that explains the very first sharp jump from a negative score to a positive one then?

So perhaps this would be a better graph to show my supervisor, since the number of data points I have rn is around 30 (and the correlation won't be as good as with this dummy data, the noise level would be higher)
this much data is absolutely fine - you can even randomly drop out points and it would still result in a decent fir
*fit
that data is dummy data i created to try and demonstrate this. The actual amount of values I have to work with from real data in total is 30
Which means my training data is tiny
thank you! mind if i dm you? Or would you want me to ask here?
nope, not too bad
would work with 30 as long as the relationship is indeed linear
that's just another name for 'hell'
From what I can see, it doesn't seem to work for my data despite the relationship being linear
plot?
gimme a sec

So the line is different colours right? The blue is the testing data and the yellow is the training data
how.....is that a linear relationship?
From the physics, the x axis is literally defined from the y axis
this is experimental data
so it should be a linear relationship
if you were considering the first 2 points, then it would be fine. but seeing the rest - it def does not seem like that
what formula?
It's just that the tensile strength is defined from the failure point
ie. the x is defined from the y
nope. how is that linear?
this is experimental data, there's lots that can go wrong in an experiment
alright, but from physics point of view - how is that linear?
Because in the theory it is like saying that:
Failure = some constant X strength
which is a linear relationship
I don't have a formula, it's more like a definition. I'll show you with a sketch one sec

So we have this material, it breaks at the top right of the curve. The failure extension is what i've called the "failure" in the graph before
The strength is defined as the value of stress, \sigma_0, that this failure occurs at
(i understand the x axis is strain and not length, the sketch showcases lots of physics at once, i'm just highlighting this part)
very good. and tell me, is the breaking point always directly proportional to the stress applied? is there, say some other factor also?
There are nuances to the material that will change the amount of stress that it takes to break a material
So these nuances will vary between materials
In the case of the data i've got, it's all for one material
however one of those nuances could be the way in which the material is cut. Which is why I suspect that the data doesn't look as linear as it should, hence the "noise"
If i had a shit tonne of data though, that would probably end up smoothing out some of the noise
are you aware of young's modulus?
well, let me put this another way. does the material of the object remain same throughout the experiment? (along with the temperature)
yes
well, any other factors? length, thickness? are they all constant?
uhhh temperature might not, no. Since some work will be done on the material. It shouldn't be a significant temp change
all are as constant as can be made
like to the point where I can assume theyre constant
perfect. then can you tell me why for the same object you have different points of fracture?
it's this bit basically
the different samples have been cut from different parts of the base material
as long as the required constants are not changed, it shouldn't matter
eh it's not like quite like that, this material is a film. So the edges of the film may have slightly different (weaker) properties to the centre of the film
let me explain via analogy - if you have a wire and keep applying consecutive force, (1N, 5N, 10N ....) would the wire break everytime at the same force value?
(assuming the appropriate constants are respected)
about the same, you'd be limited by the precision of your equipment. But it would also depend on the composition of the wire as well
well, then can you tell me why your y-axis is jumping aroung so much?
at a specific strength application, it should always break at that point - right?
could easily be due to the precision of the equipment
This graph doesn't have error bars, because the data i've been given hasn't got them
I would rather think there is something fundamentally wrong with the experiment
having done plenty of experiments like this, plenty of shit goes wrong with experimental data hahaha
the frustrating thing is i wasn't the one who conducted the experiment, so i simply don't know
you can try a Neural Network that might be able to map the noise too (the relation might be spurious tho, so watch out)
unfortunately i simply don't have the time hahaha it's a shame
Thank you for your help though, honestly you've helped me put things into words so that will all go into my report !!
Hello am making an algoritme for intrusion detection , I've been assigned to do it with K-means , am looking for an open source algorithme for k-means that I can modify (since this is my first time doing smth in machine learning ) am using the K NSL data,
And I would love to know if I can find the detailed k-means of the sklearn library anywhere
Guys, i Just started my studies about data science, and i have a doubt If I should use the integranted jupyter notebook in vscode or should i use powerBI to provide the data visualization? Which of those frameworks will provide more tools and market possibilities for me? I want to be a data analist
cough analist
if you're just talking visualization, learn tableau or something to make dashboards, that's better for a data analyst path
Hey, I am trying to do face recognition with python using the face_recognition library from github.

GitHub
The world's simplest facial recognition api for Python and the command line - ageitgey/face_recognition
.
.
My problem is that the code works fine when not detecting a face, but when it does the fps drops to around 2.
i think it's pretty normal to drop fps's, ptyhon is not really efficient to do this kind of stuff in real time
maybe try to use recognition every few frames
When presenting your progress to other people in the data team it's okay to show them in the notebook, as you can interact with it live if it's necessary. However when creating a product that's goint to be used by "non-techy" people it is better to use Tableau, PowerBI or similar.
and you can also run it in colab so you'll be sure that's not issue with your pc
@untold ingot im pretty sure the script already only does 2 frames per sec and my pc is pretty powerful so im sure its not the issue
but droping to 2 frames is really unusual
i could help more if you'd post your code in notebook
that's why i told you about colab
you could share it with others
colab works like venv
Ok, ill try that if its better for you

ok ive made a new notebook
just paste the code now?
in the code?
Nice, and about the methods tô get the data, os easier getting data from a database within vscode working with jupyter or os easier with powerBI? Becausa i want to work since fetching the data untill show the data which im gonna work with after being reorganized and filtered
nvm i got it
Ultimately it comes down to what you like the most. As for me I like python to read data and do the preprocessing, cleaning, all that stuff. You can then save the data in a convenient format -csv, xlsx or whatever- and use the cleaned data directly into your visualizations.
You can do all that in any BI tool, no problem, but I just find it to be more complicated.
for me notebook is ultimate tool to showing your data to someone else
Big lets say i Will apply tô a job in a bank, and my competitors Also use the jupyter tô show the storytelling graphics. If I have the knowledge in BI, It Will be a great factor to Help me get the job or wont make almost any diference?
And thanks anyway for Help, i'm little Lost about what frameworks use to study
Would anyone have any recommendations for beginner/intermediate level data science projects? I would like to work on something outside of my classes that will further my knowledge of using python and allow me to get better.
It depends on what the specific position is searching for. Do not overthink on frameworks or technologies, pick one and stick with it until you are confident. Try and build your portfolio.
jupyter, numpy, pandas and matplotlib are really good and will take you further than one might think.
really fun projects to do is any work with geographical data
you can use for it geopandas/folium
for example you can get covid data and try to visualise it with folium
Hello! I'm learning pytorch, not because of preference, just because I had to start from something. But I was wondering is there performance differences from two similar trained models in Tensorflow and pytorch? Perhaps someone could point me in the direction of an article or something, thx!
AFAIK there is no obvious answer to this, both end up calling the same (or similar) cuda code. Giving a fair comparison is near impossible as it would have to be done across many CPUs, GPUs, GPU driver versions, Pytorch versions, and Tensorflow versions. If there was an obvious difference in performance people would probably all be using one and not the other.
Thx, that was very clarifying. No obvious answer is an answer. Hehe. I read somewhere that pytorch was mostly for researchers because it had no good production deployment options, but I guess it's not the case anymore. I think they are used almost in the same proportion today.
How easy it is to distribute the stuff is another thing separate from performance. Currently distributing software is harder and harder as operating systems and hardware gets more overly complex (for no real good reason IMO). But I can't imagine pytorch being significantly more difficult to use in production than tensorflow.
So, given the hardware, cuda version, etc., are fixed, the same for both frameworks, there is no obvious winner?
Yeah, though you will find as is typical, long essays on the internet about why their "side" is better.
This was an article from 2017 I read, as I'm new to those frameworks I was thinking that if there was an obvious winner I would not waste time on the other.
tbf... it isn't hard to switch if you end up dissatisfied, or a particular model isn't written in your framework of choice
This is also true ^
just pick one and learn it
Both pytorch and tensorflow also just have tons of people using / working on it, so if something is not there, it probably will be there soon.
hii anyone use virtual box?
anyone have any idea plz share how to connect net in virtual box

afaik, the only real difference is if you care about probabilistic programming (which you should)
I got that feeling.
at which point they have wildly different design points
(may want to use a probabilistic programming language though, but idk if there any good ones yet TBH)
Didn't reach that stage yet...
only reason to use a standalone PPL is if you want to do infinite nonparametric models (dirichlet processes), afaik
and even so, a lot of research supports building DSLs for this (kiselov-chen, finally tagless, etc)
Idk, it's not just capabilities, but also how nice it's to work with it (the entire point of a programming language). But yeah, DSLs work fine too.
shrug i've worked with anglican before and i've wanted to blow my brains out
I have not really found a good PPL yet.
i'm a pytorch guy, but that's mostly because of work preferences
i suspect none exists yet
I prefer pytorch. Purely preference, would not be bothered if asked to use TF.
Thx for the time!
On Reddit, I believe there is a lot of hate for TF, and much more preference for pytorch, one of the main reason is "pytorch syntax is more pythonist", what are your thought and can you share it with me?
a lot of that stuff is with the comparison between tf 1 and pytorch
tf 2 is better, but I still prefer pytorch
i just find the syntax easier to use imo
theres also keras, which is easier than both
Well I can use keras better with tf so I like it more
My preference is for TF - but that's mostly because a lot of stuff is already implemented and makes any project much easier with no headaches.
Even then, I have used PyTorch frameworks like fairseq and there aren't a whole lot of concepts that can't be transferred when debugging them.
if someone has an extremely in-depth understanding of the models they use, then its better for them to use Pytorch all the time
@pulsar karma hey could you state the question in another cell
cell?
like chat cell
?
just state the question clearly now
oh kk
So uh, is there a difference between the 2 identical codes?
like
i get an error on one the first identical one
but the second code, is fine.
so, i want to know if there is a difference and what I'm missing
hey could you tell the error type
uh wdym. Sorry, I'm a beginner lmao
are you executing this in jupyter-lab?
no
I'm executing this line of code in dataquest's terminal. Its like a learning thing for data science
The place where they show the output should display the error
oh, yeah I'll grab it.
OK, it says there is an error and dthat error says that the N in Nums is an invalid syntax...
:|
Hey try to think about it and try modifying the code and rerunning it (its the best way to learn)
oh, ok thank you so much!
I have experienced that ml workflow consist a big chunk of debugging
oh wow. I'll look into that.
and you forgot to close parenthesis in the line before
for i in data:
Var = float(i[1:]
Num = Num + Var
average = Num / 7123
for i in data:
Var = float(i[1:])
Num = Num + Var
average = Num / 7123
ah yes, thanks for that.
welcome
Suppose I collect data from a population of 1000 gymgoers and determine how many of them take steroids. I then put all of them on some treatment protocol (maybe inform them on the harms of steroids), and after a month I collect data again on how many of them take steroids. I'm confused which hypothesis test I would use here.
It doesn't seem like it would be a large sample z test for 1 sample proportion, because I have two proportions and I want to compare them.
It also doesn't seem like it would be a large sample z test for a difference in proportions, because they aren't independent.
So what hypothesis test do I use?
This might be more stats than DS but I figured I would ask just in case
Aight so guys can one of you explain to me how update gradients in NNs work?
It would be great help
you are implementing like the autograd mechanism in torch?
No as in I am building a deep learning framework for a regular feed forward NN from scratch in python
well, then just figure out the math and write a backward function?
Yeah thing is, I dont really know the actual math behind it
Because the highest level of math education I have is 3/4 of high school trigonometry
I think there're plenty of tutorials online, maybe just google it lol
Yeah, this type of stuff is sorta a pain when your math knowledge is limited
Good thing I still have like 2 years of HS to learn math left
ive been trying to find a way of turning "[[6,-5,-7,4,-4],[-9,3,-6,5,2],[-10,4,7,-6,3],[-8,9,-3,3,-7]]" into a np.array or even just a list
but every time i try to google it it shows me [['1','2','3'],...] to an array of ints
which is not what im looking for, so idk if anyone can help with this
Have you even defined a hypothesis there? Because I dont see it.
For example, you can do a hypothesis test for proportions. (% of people who use steroids vs your hypothesis)
just np.array([[6,-5,-7,4,-4],[-9,3,-6,5,2],[-10,4,7,-6,3],[-8,9,-3,3,-7]]) ?
the real string is very very long that comes from a file and it changes too fast to manually copy and paste into code
I see
you can use eval
suppose getting the string in a variable str
eval(str) returns a list
oh nice
hmm...then I suppose you haven't implemented backpropogation too?
it works perfectly @crude fable ! thanks
np~
this seems to be a good referring point if you want to have a an idea on a toy problem https://machinelearningmastery.com/implement-backpropagation-algorithm-scratch-python/
(he also implements backprop too if you haven't done so)
use ast.literal_eval
eval is unsafe and should only be used if you really know what you’re doing IMO
For this task, one could even just use json.loads
indeed, eval may lead to injection attacks
Is this the right channel to ask pandas related questions?
trying to manipulate some sample data to better learn
It is
ok, bear with me, lol. Im trying to figure out how I can do some calculations over a data frame with groupby, but using my own function. So using apply(). Im working with stock market data just because its easy to play with, to try and learn. I have sample data that has multiple symbols, and then normal items like trade_date, close, volume. Using pandas i can easily do something like calculate a moving average via:
quote_data['sma'] = quote_data.groupby("sym")["close"].rolling(window=5, center=False).mean().droplevel(0)
But if I want to do a calculation like RSI, I tried this:
def calc_rsi(df):
rsi_arr=np.array(df)
RSI = talib.RSI(rsi_arr, timeperiod=14)
#print(RSI)
#print(type(RSI))
return(RSI)```And I see that it prints valid data, and the type is a numpy array. But the column doesn't get added back to the data frame.
Im not sure how to do that, any ideas?
I believe that .apply, despite what the name implies, isn't in fact inplace.
(I suffered from that too 😅 )
you need to assign the result back
ok, because I am grouping by symbol, how would I go about assigning it back in place so it knows which rows are associated with the proper symbols?
appreciate the help
uhh, no idea 😅
groupby always confused me
ok
I'd consider how you want the result to look like
Yeah, i have this:
sym trade_date close sma
AAPL 2021-04-15 14:42:00 134.790 134.676375
AAPL 2021-04-15 14:43:00 134.600 134.685875
AAPL 2021-04-15 14:44:00 134.570 134.697250 ```And i want this:
AAPL 2021-04-15 14:42:00 134.790 134.676375 45
AAPL 2021-04-15 14:43:00 134.600 134.685875 45
AAPL 2021-04-15 14:44:00 134.570 134.697250 44```if my memory serves me right you shouldnt be using apply with a groupby
but instead
use .agg()
and pass your custom function instead of an in-built function
so for example
groupby("COLUMN").agg("FUNCTION)
I'm 99% sure you can
hmm, ValueError: Must produce aggregated value
that's probably a problem in your funciton, because the documnetation says it is supported

if it can be used with .apply, i can be used with .agg
it
yeah understood. ok
Hi, given a set of coordinates (such as x and y coordinates) and a value at those coordinates, is there a way to get pairwise differences between the value at each coordinate and its "adjacent" coordinates? Ideally it would return a list of coordinates between each pair of coordinates and the difference. I understand "adjacent" is poorly-defined, I was hoping that would be part of the algorithm. I understand if this doesn't already exist, but if it did I am not sure how to go about finding it.
I am aware of "diff", but that is the difference between samples in an array, while I am trying to use continuous coordinates.
Not sure to understand, do you want something like that ?
[0,0] - [1,1] = [-1,-1]
I know it doesn't work, but just an example to understand
I've taken a try at solving the second task of this:
https://xkcd.com/135

My results are:

is the plot of distance-ran-before-getting-eaten by angle
and this is an animation of one of the two optimal solutions:
by running at 54 degrees to the wounded raptor, you can make it almost 21.5 meters away before getting eaten by two raptors!
Isn't data beautiful?
Here's it at half realtime speed, it shows the velocities involved better:
So say I have a sequence of x,y coordinates, e.g.
[[0.28711064, 0.40451254],
[0.96784655, 0.0861019 ],
[0.68484285, 0.65096231],
[0.36623231, 0.63256963],
[0.91743885, 0.48476299],
[0.1396792 , 0.47512985],
[0.86345159, 0.83123037],
[0.60607383, 0.95506412],
[0.62010063, 0.05366763],
[0.68581617, 0.45793593]]
and values for those coordinates:
[0.84841442, 0.38087733, 0.98125056, 0.68496461, 0.63671769,
0.43368263, 0.8256275 , 0.83164562, 0.70654633, 0.52013433]
Say the algorithm says the first two points are "adjacent to" each other, it would give the coordinate directly between those two points, [0.8263446, 0.0861019], and the difference between the value at those two coordinates, -0.46753709.
Basically, it is the extension of "np.diff" to irregular arrangement of points.
Anyone know why dataframe.max() would be ignoring my max values??

So it shows the max value for NII as 18.8.....the histogram clearly shows otherwise...and I can find actual samples where the value has been set to 99. But the .max() as well as the actual training does not reflect that I've added this mask
How did you get [0.8263446, 0.0861019] in it would give the coordinate directly between those two points, [0.8263446, 0.0861019]
Are you asking how to implement it at all, or how to implement it efficiently?
Yeah this makes zero sense to me. How can a dataframe take on two separate values?

huh. Were those cells executed right after each other?
or maybe the dataframe was changed from one cell to the other
yup...
from the top cell where I enter the mask from my defined function "feature_mask"
then I printed the second cell and immediately the third cell
hi i want to share with you my data science project template . note: a dockerfile and docker-compose will be added
any advices!!?

idk somehow it had to do with the first line where I pop out the y_data.
Still think its super weird that the dataframe takes on two separate values for the same index...
Hello. I have a problem if anyone can help me please?
I am trying to run pytorch in a Jetson Nano with Cuda, (first time trying GPU, CUDA, etc...)but when I try to run my code, I get allways :
"AssertionError: Torch not compiled with CUDA enabled"
Also when I do:
"torch.cuda.is_available()"
I allways get FALSE.
Any help or orientation would be very apreciated.
Thanks in advance
As the message implies, it means you're using a build without CUDA. How did you install pytorch?
Hello @tidal bough first I did it with pip3... then I downloaded the wheel torch-1.8.0-cp36-cp36m-linux_aarch64.whl ...But get the same answer
Hello everyone,
I'm new to spark and python. I'm trying to use this lambda function:
contributions = JoinRDD.flatMap(lambda x, y, z : (x, y/z))
However, I keep getting this error: TypeError: <lambda>() missing 2 required positional arguments: 'y' and 'z'.
Any ideas on how to fix?
You're supposed to follow the instructions here (after selecting what version you want using the buttons):
https://pytorch.org/get-started/locally/
An open source deep learning platform that provides a seamless path from research prototyping to production deployment.
it uses +cu<something> at the end of the version to specify a cuda-enabled one
For my requirements is:
pip3 install torch torchvision torchaudio
So it should be:
pip3 install torch+cu102 torchvision+cu102 torchaudio+cu102 ?? Right
My Cuda installed is 10.2
Not quite I think, copy the one there
Hi, no, I got the same answer...still
torch.cuda.is_available()
False
Hmm, do you have CUDA itself installed?
Yes...its in /usr/local...and I tryed some examples that come with it, and run well
Sorry, I did the second and third point, not the first and second.
I was hoping there was some established way to do it, or even what the operation would be called. If there isn't I can probably come up with my own solution.
I don't think so, no. But it seems to me you can do it efficiently by adding together two copies of your array, the second one shifted by 1 position, and dividing by two.
or just writing the naive algorithm that iterates over the array and speeding it up with numba. Not sure what'd be faster - probably the numpy solution.
No, you can't do a z test for difference in proportions. The samples have to be independent for that, and they aren't independent in the scenario.
As for my hypothesis, I'm sorry I didn't specify it. Here it is:
Null: The lecture on steroid harms has no effect on the proportion of steroid users.
Alt: The lecture on steroid harms has an effect on the proportion of steroid users.
I didnt mean he could actually do that one, but that it was a possibility.
That said, whag you mention is correct
I think the McNemar would be appropriate after a bit of looking into it
works for matched samples
Does anything like paired z sample for priportion exists? Because thats definitely a z test for proportions.
But it also reminds me of a paired t test
I'm having trouble with setting up a convolutional neural net in pytorch. Could I have some advice please?
RuntimeError: Given groups=1, weight of size [24, 28, 5, 5], expected input[2, 3, 224, 224] to have 28 channels, but got 3 channels instead
I am mostly just going through various values for in_features and out_features, right now as well as stride and padding
But I am pretty lost
I can understand it better later, but right now I just want to get it to work
@tidal bough and @exotic maple setting a series index ended up fixing my issue earlier
def calc_rsi(series):
rsi_arr=np.array(series)
RSI = talib.RSI(rsi_arr, timeperiod=14)
rsi_series=pd.Series(RSI,series.index)
return(rsi_series)```somewhere, you configured your model to accept 28 channels (or incorrectly shaped your data) while you are feeding it 3 channels (R,G,B)
Can I show you what I have?
class ConvolutionalNeuralNet(nn.Module):
def __init__(self):
super(ConvolutionalNeuralNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=24, kernel_size=(5,5), stride=1)#, padding=1)#, stride=2)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=8, kernel_size=5, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=3*224*224, out_features=50)
self.fc2 = nn.Linear(in_features=50, out_features=9)
self.fc3 = nn.Linear(in_features=9, out_features=67)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 3*224*224)
x = self.fc1(x)
x = nn.ReLU(self.fc2(x))
x = self.fc3(x)
return x
this is why named tensors should be the standard in ml...
any thoughts?
there's a lot of confusion on proper sizing of kernels/inputs going on
i suggest you read this paper: https://arxiv.org/pdf/1603.07285.pdf on sizing convolutional layers and pooling
probably print out a copy and keep it with you at all times when writing CNNs... it's probably one of the most annoying things people deal with
digression: this repeated x = pattern is actually disgusting IMO
Is there a way to put like a pdb stopping command inside of a model if you wanna check around during the training process?
I'll definitely look into it, thanks. But I am in a rush to get this to work now. Is it possible you could offer some advice?
I also have an issue with my feedforward nn haha
It runs, but the accuracy is insanely low
And so is the loss, counterintuitively
So I think I am doing something really wrong
what do you want to check?
why are yuo in a rush?
More just a general question for if I did wanna look around or anything. But specifically atm trying to figure out how to index specific layers for a custom loss function.
Hi, I'm stuck and confused.
I'm supposed to calculate the median and the mean of a column. That column has NaN values. After googleing, it says that the output would be NaN if we calculate it as is, but I had result with actual number.
After searching again, I found the way: df.dropna(subset=['my_column_name']. But, it seems to be deleting the whole row. It's not a problem if I don't need to calculate the other columns, but I have to.
The other thing is that, with and without df.dropna(), the result of my median and mean is the same. What is actually happening? I don't understand.
Problem solved using pokemon.dropna(inplace=True). Thanks.
Good free course for learning data science in python
I have data as follows
Date,3AVG,3STD,5AVG,5STD
2020-01-01,0.0001516753626573417,4.312318533850928e-05,0.0001238381056464277,5.1544752917263285e-05
2020-01-02,8.940538989716313e-05,1.6553091501380443e-05,7.256192446220667e-05,3.0730320385990164e-05
2020-01-03,9.843248982279976e-05,2.6553840606630725e-05,0.00010043714893981816,5.002368550421968e-05
2020-01-04,7.060501876468252e-05,2.788075943272748e-05,6.0957247260375876e-05,2.9456213115351173e-05
2020-01-05,8.333993577657061e-05,1.2844978651636427e-05,7.349029838223941e-05,1.6037215969701733e-05
2020-01-06,0.0001618258473980758,3.314910335308243e-05,0.00011460499285021796,4.8313801065293874e-05
Does anyone have any idea what all charts can be created, that will help me in exploring the data
almost all pandas methods return copies
I see thanks
does anyone know how to use/set up 'experiments' on azure ml?
rn i'm just using notebooks and using it as a virtual machine but i'd rather use the full potential of azure
Does anyone know why creating a BeautifulSoup object using lxml is so slow? It takes 0.012 seconds with lxml parser but only 0.001 seconds using xml parser (just to put it in perspective - I know it's not a real comparison). Creating a Selector object using Parsel (library used in Scrapy) takes only 0.002 seconds even though Parsel is also using lxml.
debugging
ooh, I didn't even know that existed. will dig if that's present in TF!
I am trying to render a R 3d plot on google colab is it even possible on commandline
hello anyone here good with data manipulation and is free?
please
I need instant help
Hello, is there any book reference for forecasting with linear regression using Python (or just linear regression is ok)? I've searched on Google but I've found nothing, or if I found, the explanation was too few. Thanks in advance!
Haha, I just found a guy on Stack Overflow saying he has long experience in Deep Learning. The framework? tesseract 🤣
oof
please
Can somebody help me with this error?
File "D:/!Code/папкипитона/!!!Project stock_market/RL.py", line 3, in <module>
from stable_baselines.common.vec_env import DummyVecEnv
File "D:\!Misc\C++\lib\site-packages\stable_baselines\__init__.py", line 7, in <module>
from stable_baselines.deepq import DQN
File "D:\!Misc\C++\lib\site-packages\stable_baselines\deepq\__init__.py", line 1, in <module>
from stable_baselines.deepq.policies import MlpPolicy, CnnPolicy, LnMlpPolicy, LnCnnPolicy
File "D:\!Misc\C++\lib\site-packages\stable_baselines\deepq\policies.py", line 2, in <module>
import tensorflow.contrib.layers as tf_layers
ModuleNotFoundError: No module named 'tensorflow.contrib'```ModuleNotFoundError: No module named 'tensorflow.contrib'
Anyone know how I can plot multiple dataframes on the same graph?
you are following a tutorial in TF1, while you are using TF2
so what do i do
do i have to change python version tf version and reinstall all libraries
Make a new env for TF1.x
Hi, I have AI subject next year and Im already frigthened, can you give me little guides?
wdym new env
use anaconda or pyenv to make a new env, and install OR use a different machine/colab
I want to resize this dataframe to (16672, ) for doing a matrix multiplication.
I am kinda new to this. Can someone help me on how to upscale this kind of data?

i'm running tensorflow 2.4.1 with gpu support (on kubuntu 20.04)
but here's the thing
when i run it in intellij it gives this error message: https://paste.pythondiscord.com/ziqukuyuma.apache
but when i run it in the terminal it goes just fine:
https://paste.pythondiscord.com/vozaqehofu.apache
does anyone know why this is happening?
in intellij is it in some sort of virtual environment

Explore and run machine learning code with Kaggle Notebooks | Using data from Brain MRI Images for Brain Tumor Detection
its my best project
how?
is it just me, or do every kaggle kernels have the same sort of code structure, coding style, and formatting?
every
because there are 4 or 5 libraries. the logic is the same in all of them
no, it's the system interpreter
is matplotlib short for math or matrix