#data-science-and-ml
1 messages · Page 161 of 1
This gets into details that don't really matter.
Yeah.
and how come python is the preferred language over c++
even if c++ is more efficient
is it just cause of simplicity
Because C++ came from the 9th ring of hell.
lol
for real the people who made python are doing gods work
using a diabolical language to make a not diabolical language
Also, you won't be doing any of this manually, but instead using something like Pytorch, which while technically is also there in C++ (just Torch), there won't be any difference except extra pain from using C++.
So since you have a giant loop in plain Python, the solution is to either find a way to get rid of it by turning into some Numpy stuff, or reduce the iteration bounds (make it smaller).
for i in range(50000): is a red flag for Python performance.
It's written in C, which is more manageable (in terms of learning and all that (it only adds to C's insanity)), just often slower in terms of productivity.
i see
but isn't it necessary cause that's all the training examples
and it's different for each image cause it depends on that image's activations
Well first, are you actually using this value in your updates? If it's just there to give you a measurement to print while training you don't need to compute this every iteration.
Also in that case it does not need to be exactly correct, you can do less than all of them since it's just to give you a feel.
the value i was referring to was the partial derivatives for the gradient
cause i gotta get an average across all training examples
also the model will still train even if my pc goes into sleep mode due to inactivity right
You don't have to, you can do less, or even 1. See plain old SGD vs batching vs mini-batching.
i've been away from my computer for a while
how would only 1 work though
if i only do 1 then wouldn't it just always classify everything as the number that is in the one training example
No, let put it this way. If I had a program that took in a bunch of 2d points that are arranged in a Gaussian around some center, like this:

i see
oh wait what
bell curve?
oh wait i see what you mean
the peak of the bell curve is where the cluster is
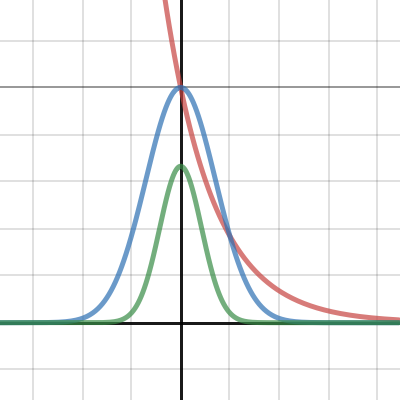
Desmos
I'm describing how these points where spawned, they tend to be mostly near the center.
And falls off exponentially.

So given these points are your dataset. Initially you may have say a single point estimate, randomly chosen, so you can imagine there is some green point in this plot somewhere. And through many iterations, we adjust this a little bit each time. During each iteration, which get a random point, and move our point a little bit towards it (interpolation by alpha amount of the distance between them). Now if you keep doing this where do you think the green point will end up roughly?
i'm not understanding
do you mean that you start off with these datapoints, plus your random estimate, and then you get a random point which you move your estimate towards?
Yeah, we start with our own random point, and each time it gets pulled towards some randomly chosen point from the data.
(i'm not gonna lie, i don't know how that works)
like i kind of guessed it and kind of see how it would make sense
It's pretty intuitive, that is why I chose simple 2D points.
but i don't really fully understand how that results in an exact average
or is this an approximate
oh wait yeah that makes sense now
If you only do like 3 iterations, probably way off.
yeah not sure why i didn't see it completely before
so it converges towards the average
And note what happens when you pull too hard towards a point too.
If I pull with max strength, basically setting our point to the random one, it will just keep jumping everywhere, the result is not really a mix of all the points.
So instead we say like, move about 0.001 of the way there.
Like a small % of the way there.
and how much we pull towards each point is our learning rate
Yes.
Not a neural network really, more broad.
so it's more so just a way of averaging across large datasets more efficiently
man sometimes i worry
like earlier when i didn't see right away how it converges to the average
now i feel like that's just common sense
but i couldn't think of it
Well, now let me ask this, if you have a neural network with a single neuron, and you are "pulling" based on one of two labels (binary classification problem), rather than input point itself, could you use this idea? What would "pulling" be in this case? When we were pulling towards other points we relied on some idea of "distance" or "difference" between the points (where we currently are and some kind of "target"), and moved part of the way towards it.
well if it's a binary classification then we would probably have a threshold similar to that for an svm right
so then it would be pulled toward a side
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on...
it runs on only cpu, when gpu is a lot quicker for stuff like matmul
oh so what i said isn't bullshit
man sometimes i feel that even if im able to figure things out, there's this slight feeling that what i'm saying is meaningless yap
i see
I gotta go, but one more thing to ponder. In that random point thing we did. I said that each iteration we get a random point to move toward from the set. But what if it's not randomly picked? What if we took all the inputs and sorted them by x and y (in that order)? And then iterated over them in that order. Would it still end up giving a nice estimate in the end? What about with infinite iterations?
(Hint, imagine just two input points (or a bunch in each corner) on opposite ends of the image, where would the estimate end up?)
(With and without random picking)
well it would still converge to the average, it would likely take longer to get closer though, but with infinite iterations it still would converge to the average
also is this feeling likely just because i'm new to all of this
You can also just try simulating it yourself in Python.
nah i mean in general
how would i get ai into python?
what does this question even mean
Search GitHub for API keys and export results to CSV. https://github.com/SanshruthR/GrepVault

GitHub
Search GitHub for API keys and export results to CSV. - SanshruthR/GrepVault
I assume pandas
df[ df['LRank'] > df['WRank'] ]
have any good project on gitHub you guys recommend to me
Hi
hello guys, i'm new to this server.
i'm here because i'm doing a uni project, i would like to know how to start learn ML, it would be of great help if you could recommend me some sources
i am not looking to make an LLM or anything of that sort, just something that looks at a few numbers and judges the severity of a situation, and prompts a few actuators
which framework is easy to learn for CNN
There is no easy way to learn about neural networks.
PyTorch is the most popular framework for implementing neural networks.
Can anyone give me review of Deep learning by ian goodfellow book? Is good to read?or too depth and time waste?
Hey guys, I manually wrote a simple neural network with each mathematical operation. it is my first attempt to create something like this so I wanted to share it here. I am open to be critiqued! 🙂



That's impressive fr
I mean I'm a beginner, I wanted to code a nn from scratch I tried but it was tough so I kinda left that in the middle
Hope to redo it someday
why do i have a type errorhttps://paste.pythondiscord.com/H22A
check sentdex
he had great blog on it
i remember it used to be free but now he is monetising it with a book ig
What is the error that I'm missing if all the entire video that was using and reread everything over and over and over
Isn't that the same code Wendigo had?
Also just from looking at it, your forward pass doesn't do anything
Yes I'm starting to try and learn convolution I couldn't find any tutorials and I know that if I try looking on Amazon for a book that doesn't have what I need it's going to take longer so I knew that Wendigo posting some code nothing we're working on convolution and I thought well I know that there's an error but if I can find out or at least have somebody guide me maybe they would learn if they came back to #data-science-and-ml
I know but it gives me an error for inputs which was already part of the original code
Here is the video wendigo used: https://youtu.be/pDdP0TFzsoQ?si=-qKX0vOd8VB5TU9j

New Tutorial series about Deep Learning with PyTorch!
⭐ Check out Tabnine, the FREE AI-powered code completion tool I use to help me code faster: https://www.tabnine.com/?utm_source=youtube.com&utm_campaign=PythonEngineer *
In this part we will implement our first convolutional neural network (CNN) that can do image classification based on the ...
he's videos are really helpful, i recommend too.
How did I miss that? Thank you sor....
He is I don't know how I missed the feed forward I hope to not repeat the same mistake in the future
implementing something you just learnt is always tough, but trust me it will make you have a very good understading of nn's
yo guys for a simple feed forward neural network, what learning rate range should i be using
you can start with like .05 and decrease it by an order of magnitude if things aren't converging
i'm not sure what's going on, but everytime it only decreases the lowest element in the cost
like for one of the digits the average cost will be like 0.9 and it just won't even touch that
but then it goes for the one that's 0.07 or something
Guys is break dataset good for training my chatbot?
idt there is such thing as a "good" learning rate as it really depends on the data you are training on
if you want to optimize for convergence, i prop would recommend implementing an optimization algorithm like adam and also using some sore of initialization like kaiming if u r using relu and xavier for sigmoid
has anyone used paperspace gradient? im considering subscribing to it but it sounds a bit too good(?)
Modal is better imo
oo ill check that
How do you give an ai a reward system
In my opinion 0.01 is a good starting point
That’s reinforcement learning 🤭 . You should read about that
typically how do i avoid falling into valleys/local minima that are far from the actual minimum and ending up "trapped"
i think that's the main issue i'm currently having
That’s where stuff like Adam and other optimization algos come in to play
would this be called feature engineering?
or is that something different
nah its more like the algos for backprop
oh i see
so there's multiple backprop methods
does the activation function also have a decent impact on this
https://arxiv.org/pdf/1412.6980
idk how strong u are with math but recommend reading this, a monumental paper
ye there many diff optimization algos
not too strong, just basic linear algebra and multivar calc
but i'll definitely look into it still
recently i've just been learning as i go when it comes to math
it does but i dont think u should worry about it at ur level
so it's just the backprop algorithm i should be worried about for right now
i think it's worth considering implementing cuz u can implement it without knowing the math behind this cuz u just need to copy formula
stochasthic optimization, or anything that has stochastic in it just means having to do with uncertainty right
yeah in a sense for stochastic gradient descent ur taking a random subset of the data and using that to updae ur params
oh i see
so the purpose of taking a random subset rather than the whole thing is just for computational efficiency right
i remember 3blue1brown talking about creating groups of data and then doing backpropagation on each group separately, then averaging the results
not sure if that's exactly what it was, was something like that though
Hi! I have joined somewhere as an intern and have to start working from next monday in the field of data science i only have knowledge in numpy pandas matplotlib seaborn till intermediatry level so should I focus on machine learning more or should I make my understaning in the libraries more robust...
could anyone provide any advice
I don't work in the field but other people will probably be able to help you better if you gave a more detailed job description.
Did they tell you what you will actually be doing on the job? "data science" is pretty vague
I got a Pandas dataframe with lot of rows, but every pair of rows should be combined:
1 a x 50.0
1 a y 60.5
2 b x 10
2 b y 10.3
=>
1 a 50.0 60.5 21
2 b 10 10.3 3
What are my options to achieve this? Groupby, agg, transform or apply?
is it a good idea to label a small subset of data for image captioning task ?
maybe you want to use groupby?
on that first column after the index
Strategic Debate Arena: Words fuel your chess moves. https://github.com/SanshruthR/DebateMate

GitHub
Strategic Debate Arena: Words fuel your chess moves. - SanshruthR/DebateMate
is super().__init__() required in pytorch models' __init__ function?
I'm sold at pawn b4 - but I'd just be a spectator as I'm too lazy to debate
Hey guys, am still new to ML I just finished building my first supervised model but am still learning, am currently using collab and when I tried using CSV file not from the course I was following its not working am trying to upload it straight from my pc but it ain't working. If anyone met with this issue I would love you help
Hi I'm training a cnn model, with like custom conv layers
Everything is fine just consecutive epochs the accuracy and everything turns 0
Please help me
I CAN HELP U
probably ur messing up ur forward pass bro
googles accuracy
"Neural network accuracy, a measure of how often a model correctly predicts outcomes"
yes bro it sounds like ur overfitting
or some other world ending phenominon
like gradient vanishing cause u have like 5 layers of conv nets
and no dropout (ds0nt is currently drunk and getting into troubles)
help sent
ohh, how you got this idea??
Yes thank you! I managed to do what I wanted using groupby, agg and transform. 👍
Next is a jupyter notebook question. Can I with a for loop output text and plots interleaved?
for i in (1,2,3):
print(i)
plot(i)
Outputs
1
2
Plot1
Plot2
Whereas I would like
1
Plot1
2
Plot2
lmao that's a good question

So, I used to read a lot of comics and watch a shit tonne of cartoon as a kid. In many of those marvel comics, the superior beings used to pretend that all of the heroes and the villains were just pieces
and everything was just a grand game

This is amazing 😍
I figured out I should show my figures explicitly with fig.show() 👍😊
thank you sm 😄
I just realised I should use ml algos instead of dl
Taking reference from existing kaggle notebook
Why to complicate things when it can be done easily
10 conv layers for a dataset containing 1000 items will obviously cause overfitting
anyone know how make click farm for youtube if yes dm
What is dl?
Bro do you know how mak click farm
The rules and guidelines that apply to this community can be found on our rules page. We expect all members of the community to have read and understood these.

So condescending 😂
are we talking about data science?
What am I supposed to say
oki
what's haskell used for
I've never used it but I feel it's something mathematical
11 years professionally 🙂
Sir 🙏🙏
Rather call you Mr David instead of "Bro"
🙏
yes 💯
must give due respect
he's a veteran programmer
always great to meet an expert
How do you organize your files? I took a bunch of courses and now getting into data projects, but I have file all over the place. Some are python venv, some art jupyter, some pull from different data sets, some are just trying new methods. some are a continuous lists of hypotehsis test. is there a best practice or recommended way or organizing this?
Make a main projects/datascience/ folder, then each project gets its own folder with things like data/, notebooks/, and models/. use a venv for each project and git to track changes, that'll keep things tidy
atl that works for me
you are using vscode or jupyter ?
i use both occasionally, you can also use any of the above, the folder structure being neat is all the matters
https://www.thinkingondata.com/how-to-organize-data-science-projects/ this one felt a little skimpy ...

Managing the organization of a data project means evaluate what are the objetives of your organization system, how do you want to structure your data, the way that you want to have a backup system and a version control and finally how to document all your processes.
https://github.com/drivendataorg/cookiecutter-data-science this one feels better, but a tad over complicated..

GitHub
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. - drivendataorg/cookiecutter-data-science
actually, maybe it's just right. - after thinking about it
Is it possible to run a regular python file as a jupyter notebook? I don't see why it couldn't with just a few markers for cell division.
from jupyter import MADE_UP_THING as next_cell
print(1)
next_cell()
print(2)
Technically yeah, you could create a tool to parse Python files and insert cell division markers. However, it's not a standard feature you'd essentially be building a custom conversion script.
Rough. 🤔
ikr
yes, small labeled subsets are fine for bootstrapping. use active learning or pseudo-labeling to expand the dataset efficiently.
where can i finetune llm online?
I am trying to finetune around 8B parameter models like llama
I tried on google collab but its slow and very limited
I find it hard to understand the pricing range for gpu renting
modal is good imo
at that point why not just put it into a notebook file lol
found runpod about 2x cheaper. however modal offers 30$ credit, worth a try
You might not be able to get that much computation power and time for free.
Oh you're willing to buy credit
settled for runpod and modal they seem like a good option
Several issues:
- Contains binary data
- Requires jupyter notebook
It would be neat to have them runable standalone as well. As to easier share them with other developers and git them as is. Also allow simpler editing with any editor.
But maybe this is exactly what jupytext is! Is it? 🤗
Hey guys so I was playing around with RNN using the imdb dataset, so initially I added a maxlen of 50 for the pad_sequences,I just made my input vocabulary to 10000 and then followed this architecture
model.add(Embedding(input_dim=10000,output_dim=2,input_length=50))
model.add(SimpleRNN(32,return_sequences=False))
model.add(Dense(1,activation='sigmoid'))
I did get an accuracy of 75 on the validation set , but then this time , I did these changes to the architecture
model.add(Embedding(input_dim=88364,output_dim=80,input_length=2943))
model.add(SimpleRNN(32,return_sequences=False))
model.add(Dense(1,activation='sigmoid'))
and I am only getting a constant accuracy of 50% , how do I increase it? Is it possible to achieve 75%+ accuracy using SimpleRNN
%run file.py
the drastic accuracy drop likely stems from the increased vocabulary size and sequence length. with a larger vocabulary (88364), the embedding layer's weight matrix becomes significantly larger, making it harder to train effectively, especially with a simple rnn. similarly, the extended sequence length (2943) can lead to vanishing gradients, hindering learning. try reducing the vocabulary size, lowering the sequence length, or using lstm or gru layers, which handle long sequences better. also, experiment with different learning rates and optimizers, and consider adding regularization techniques like dropout. finally, verify your data preprocessing and ensure no unintended data leaks.
yeah, jupytext sounds like what you need. it lets you pair .py and .ipynb files for easier editing and sharing. i'm not sure about binary data, but it's worth checking out.
Isit possible to know why did the AI/llm give certain answer??
yeah kinda, they give answers based on patterns they’ve seen during training. not always clear why exactly, but it's not random.
I mean if i ask an AI "what is 2+2" and it replies 5 all i can say is it did so bcz it saw this in training data, and not exactly know "WHY" it replied with 5 , right?
yeah exactly, llms don’t really “understand” in the human sense. they generate outputs based on learned statistical patterns from training data. if it says “2+2=5,” it’s likely due to token prediction errors, spurious correlations, or overfitting to noisy data. no true symbolic reasoning or logical grounding behind the answer.
explainability is a whole sub field of its own
read the anthropic blog post on golden gate claude if you haven’t already
Thanks i will
there are many out there already, but you could also try
finetuning other llms to fit to the task you need (what type of programming etc)
or you could also train the model on a code dataset and add an interface to it
yeah XAI and all that
hello i am new i wanna learn about ai so from where should i start plz guide me
start with basic ai concepts (ml, dl), then learn python and key libraries like numpy and scikit-learn. take online courses, build practical projects, and explore deep learning frameworks like tensorflow or pytorch. join online communities, and keep learning through blogs and papers. hands-on practice is crucial.
check coursera (andrew ng), fast.ai, scikit-learn's site, and tensorflow/pytorch docs. for youtube, try 3blue1brown, sentdex, or Lex Fridman. consistent practice is key
thank you
im thinking about starting to make a resume and upload projects, what are all the avenues. Github Repositories, Resume, anything else?
please only ask the same question in one place, to avoid duplicating effort. You asked this in #career-advice
from 0? with a lot of money and data
How to prevent seaborn from drawing multiple plots on top of other plot? I didn't have this issue before, it suddenly started to happen 🥴
likely because you plotted two axes-level functions wo creating a new axes in between (or something else that makes the two draw on different axes)
eg you could do
fig, axs = plt.subplots(ncols=2)
sns.scatterplot(..., ax=axs[0])
sns.lineplot(..., ax=axs[1])
or like
sns.scatterplot(...)
plt.subplot()
sns.lineplot(...)
It was enough to do
sns.stripplot(...)
sns.barplot(...)
Without any ax, I think. But I might misremember
(because I was doing ax stuff at some point)
All of this state-machinery in matplotlib is so confusing. 😕
matplotlib sucks
just use plotly
What's the correlation? Completely independent things? Which is newer?
Seaborn is quite big and looks nice and is on top of matpotlib. It's also big and scary 😝
@serene scaffold
first learn what ai is
Oh so due to the vanishing gradients , RNN becomes useless in this case . I see... Thanks for the info
I missed to reply you @serene scaffold
not sure what you mean by correlation, but plotly doesn't share any code with matplotlib.
is it possible to build an llm from scratch? I do have the data and i do have graphical power to some extend
is it possible in general? yes--otherwise the ones that already exist would not.
is it possible to do it with the hardware and amount of training data that you have? very probably not.
Yeah that's what I meant. Thanks.
Oh so we as a team , wanted to make llm that only answers questions regarding medicine , is fine tuning the way?
you should probably use an existing LLM and RAG, without any fine-tuning.
But it shouldnt leak the author name or the publishers name , or else we would be sued
Is it possible to achieve that using fine - tuning
Ah, and plotly is not tied to python. Seems good 👌
fine-tuning can't guarantee that that won't happen
Did I just waste a week doing matplotlib stuff? 😱😝
So how to combat that issue
can anyone help me build a RAG on prem with python. thinking of using railway app
yw
there's no way to guarantee that an LLM will or won't do something. You can include instructions in the prompt to do things a certain way, and if the LLM is good at following explicit instructions ("don't include any personal names in your response"), it probably never will. but if this is a situation where you're worried about getting sued, you need to include some post-processing on the LLM's response that will deterministically guarantee that the rule is followed.
if you spent a week trying to learn matplotlib, you increased your tolerance for suffering.
That tolerance is already extremely high 😅
First hurdle, quick question: Does plotly need internet connection to show plots?
No
Ok good, I got an empty browser screen on my first try with some Javascript loading... So got scared.
https://paste.pythondiscord.com/R3OQ
Did I do anything wrong I am using what @unkempt wigeon
I keep on getting an input error
you’ve got a stray self.conv1() in __init__, remove it, it’s trying to run the layer without input.
also your test loop accuracy logic could use some fixing,
But it does seem like I need to do some special stuff: https://foongminwong.medium.com/plotting-data-with-plotly-offline-mode-in-an-air-gapped-environment-5844df874537#:~:text=Plotly's offline mode overcomes this,analysis without compromising security protocols.

Medium
When conducting demos in secure locations or areas with limited or no internet connection, displaying interactive visualizations of…
Which line?
Probably not done today. But thank you for the help
just remove
x = self.conv1()
from the ConvNet __init__
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
hopefully that solves the issue.
why is that there i dont see anything
tell me what line
41-51
ywyw
in your test loop
if (labels == pred):
should be comparing each label, not the full tensors, so just replace it with
if label == pred:
Line 111
I already changed that a long time ago
acc = 100.0 * n_class_correct[i] / n_class_samples[i]
It's giving me this error
0 division error float division by zero
Ywyw?
your welcome,
Ty I don't use abriveations often so thank you so much
From what I can see on my screen the accuracy looks like it should but it's giving me an error zero division error
fixed it overall,
with torch.no_grad():
n_correct = 0
n_sample = 0
n_class_correct = [0 for _ in range(10)]
n_class_samples = [0 for _ in range(10)]
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
n_sample += labels.size(0)
n_correct += (predicted == labels).sum().item()
for i in range(len(labels)):
label = labels[i].item()
pred = predicted[i].item()
if label == pred:
n_class_correct[label] += 1
n_class_samples[label] += 1
acc = 100.0 * n_correct / n_sample
print(f'Overall Accuracy: {acc:.2f}%')
for i in range(10):
if n_class_samples[i] == 0:
acc = 0.0
else:
acc = 100.0 * n_class_correct[i] / n_class_samples[i]
print(f'Accuracy of {classes[i]}: {acc:.2f}%')
Just added a zero check,
also, that error means that n_class_samples[i] is 0 for at least one class.
so recheck that,
Could've happened cuz of if (labels == pred): error
because you were comparing the entire labels tensor to a single pred, the condition was likely never true --> so n_class_correct[label] was never incremented, and in some cases, n_class_samples[label] wasn't either if it crashed
Would you like to chat about this and voice chat zero?
cant vc, could chat
the first problem in your code was that you were like running a layer with NO INPUT BTW in __init__ where we define layers so that's what was causing that
and the second error arose by using the WHOLE tensor instead of indivisual comparison, which obv would result in 0 then, and then /0
Are you able to get on to voice chat because it'll make everything a whole lot faster if you can just listen and type also I did something bad to my visual code Studio key bindings so I guess I'm going to have to go to idle
And what about voice chat when it's not being used I'm sorry
clarity?
F-zero is array being used one doesn't have anyone in it so therefore it won't be able to be used unless you would be comfortable with something else
Ah, you mean class 0 didn’t appear in the test set, so n_class_samples[0] stayed zero? Makes sense right, that’s why the division by zero happened
How can I fix that division error?
adding a zero check, like I did
for i in range(10):
if n_class_samples[i] == 0:
acc = 0.0
else:
acc = 100.0 * n_class_correct[i] / n_class_samples[i]
print(f'Accuracy of {classes[i]}: {acc:.2f}%')
and fixing if (labels==pred): to
if label == pred:
hi im learning neural networks, in the first two screenshots i learned how to use polynomial transforms to add nonlinearities to the linear regression,
im trying to understand why it's said that you cant do this same thing for the hidden layers in neural networks, and the first solution is to perform sigmoid transformation on the data (it might be something obvious im misunderstanding)




i understand why the sigmoid one works to calculate logistic loss on a logistic regression but can you not use that synthetic feature from the first examples on the hidden layer and leave the equations linear?

apparently it makes it an 'activation layer' tho so ima continue reading but id appreciate feedback
do I need visual code Studio to process torch
according to openai it sounds like the poly transform of crossing to features is just one example and the NN finds the best one on its own?

ok i get it now

what do you mean by process torch?
polynomial transformations in linear regression help add nonlinearity by expanding the feature space, but neural networks need activation functions (like sigmoid or ReLU) to introduce nonlinearity in each layer. without activations, the network would just be stacking linear equations, limiting its ability to learn complex patterns. activation functions allow the model to adapt and find the best features during training. it's not just about adding nonlinearity; it's about learning the right transformations for each layer.
I put into the regular ide and it gave me it could either find it even though I know don't loaded into the system because I've managed to make a feed forward Network using torch
Which regular IDE, IDLE?
Python
The installation ide
you don't need visual studio code to use pytorch; you just need the right python environment set up. make sure you have pytorch installed in your environment. you can check that by running pip show torch in your terminal or command prompt. if it's not installed, you can install it with pip install torch. let me know if you're still having trouble
the non-linearity in nns is added thru activation functions; sigmoid's one of them, but nowadays ReLU (which is just max(0, value)) is more popular
why it's said that you cant do this same thing for the hidden layers
assuming you mean, why not more complex functions in neurons instead of simple weighted sums
the latter is very easy to compute, makes backprop a lot easier, and they can universally approximate anyways
appreciate that
thank u too
my current project require libtorch-gpu, onnxruntime, cuda-toolkit and cudnn, and the overall image size is so big, any ideas?
pls reply
You might wanna use cloud for this instead of running it on your local machine.
your wlecome
yeah classic ml would be fine for the uni proj, try google’s ml crash course or kaggle's beginner stuff to get hands-on fast. use sklearn for basic models like logreg or decision trees. also check "intro to ml with python" if you like coding while learning. lmk if you get stuck!
you could try using a lighter base image like nvidia cuda runtime instead of the full devel one, and only install the exact libs you need. libtorch and onnxruntime both have minimal builds too. also try multi stage docker builds to keep only runtime dependencies in the final image. if it's still too big, micromamba or conda-pack inside an alpine base can help shrink it further.
thank you
if it's still too big, micromamba or conda-pack inside an alpine base can help shrink it further.
I dont know anything about this
no prob,micromamba is a super lightweight conda replacement, good for small docker builds. conda-pack lets you zip up a prebuilt env and move it into a smaller image. both help avoid bloated installs.
you should elaborate more about your project
smart water monitoring system basically, an iot project
We could use a normal algorithm or threshold but we decided to go for bonus point using ML
Can a label be in a folder?
take a reference from available projects
label as in what?
yo that’s clean , def go w/ unsupervised anomaly detect (iso forest or lstm) on flow/pressure/time. catch leaks + weird usage w/o fixed thresholds. bonus if u add turbidity/pH + do dirty water classify too.
thanks a lot dude, will inform on the status soon!
your welcome, looking forward to it.
For the images cuz I might add some of my own data to the network after it's been training
like image classification?
Yes
if yes then yea ofc thats how most people do it
Any idea about the best / the most common image preprocessing techniques for the further use in CNNs? 🥲
preprocess what kind of images for a CNN that does what?
basics like resize, center crop, normalization, random flip, rotation, color jitter, maybe even blur,
mostly light unless youre training BIG time, then it'll be more complex
If you're using a pre-trained model you should use the same preprocessing that was used during training
Typically whatever package you're using will have that readily available for the model you're using
Thanks !
Medical image data. CNN that will extract features from the images
your welcome,
You can use a marimo notebook instead
if you're on vscode w/ the jupyter extension, you can do this in a .py file
# %%
print('cell 1')
# %% [markdown]
# # Header
# some md text
# %%
print('code cell 2')
Never heard about 😲
You should check it out, it's great. I'm actually hosting a marimo workshop next month in this server.
Then definitely use the preprocessing from the pretrained model you’re using
And if you’re not using one, you probably should 😄
consistency, optimal performance, avoiding errors
as for why to use pretrained models,
faster dev, better perfromance, resource efficiency
Hyper is right about using pretrained models. You should almost always try to work with pretrained models unless you have access to a bunch of A100s and a shit tonne of data. By the rule of thumb, you should never try to reinvent the wheel
Pretrained models and fixed architectures exist for a reason
People almost always use Adam, Nadam or SGD
and as I like to say, the inventor of wheel must've got paid nothing, but the owner of ferrari does
Facts
I like the analogy that the first part of training CNNs is just about teaching it what elementary features are
So instead of starting from 0, take one that is pretrained and continue training that one to fit it to your domain
Like detecting edges in an image, for example?
guys i have a question
is this result okay for my work
its a "pv panel image segmentation with ai" project, 1st images are panel images, 2.s are my masks and 3rds are model prediction results.
I got > 0.96 dice_coef and > 0.95 accuracy with 30 epoch on around 200 train images. please mention me in your reply, thanks.
end goal is making true masks and model predictions close as much as possible

Hello, I am starting in ML, I would like to work in a project to improve, send me DM
Probably a Resnet would help I believe
we can talk if you think you can help my question above
So intially in a CNN , we have a convolution operation(just another matrix multiplication task). In this operation , a small kernel or filter is slided across the image , thereby this filter helps to detect the edges of the image
and after detecting edges , we tend to get a lil higher level features
is your train accuracy and val_accuracy at 95% accuracy? or only train?
binary_accuracy: 0.9755 - dice_coef: 0.9494 - loss: 0.0506 - val_binary_accuracy: 0.9624 - val_dice_coef: 0.9227 - val_loss: 0.0842
Correct
I have a folder with tens of thousands of training images, and sometimes I just want to quickly scroll through and visually inspect them in windows to make sure nothing odd showed up in the pipeline. Windows doesn't seem to really like managing extremely large folders. It can take a minute or two for the folder to even open. Is there something I can download that makes navigating these files a bit easier in the same way someone might use voidtools instead of the default Windows search.
fr
yeah it's like adopting a fairly smart child
🔥 solid results! you're hitting high accuracy and dice
looks like your model’s generalizing well.
try XnView MP or IrfanView , both are lightweight image viewers that can handle massive directories super fast
you can also check out FastStone Image Viewer if you want a clean UI + quick scrolling. way smoother than default explorer.
yea
bet dm
This looks like exactly what I needed thanks
your welcome!
If anyone is interested in YOLOv12 and comparing its performance with YOLOv11 and YOLOv8 in real-world scenarios, I made this

GitHub
Real-time monitoring, object tracking, and line-crossing detection for CCTV camera streams. - SanshruthR/CCTV_SENTRY_YOLO12
Yay! I made it 🙂
yup
ooh, I have a project similar to this coming up, will look into it.
is it easy to get into making like AI bots for games, or anything realistically?
No, it's very hard
Unless you want to use existing APIs that don't require you do know anything about AI. But then that's a software development effort, not an AI one.
ai bots are very hard for 2 reasons
1st is you need an interface that connects to the game or make a similar game yourself
2nd is depending on the game the amount of variables is too much. Obviously if you are doing pacman or pong its gonna be not that hard, but if its anything 3d for example its gomna become impossible to properly manage and calculate the inputs for the ai model.
this may be niche, but how can get a pdb file (protein data bank) structure into embeddings for a huggingface model?
I know that I can turn it into a set of coords and perform dimensionality reduction and then embed it as text, but I feel like that there is something more advanced that can truly capture the complexities of protein structure
the alpha-helices, beta-pleated sheets, cysetine bonds, etc
btw ping or dm me
i'll be off maybe
totally , coords + dim red miss key stuff. better to use gnns (residues as nodes), or 3d grids. combine with seq models like esm2/protbert. use biopython/torchdrug to parse pdbs. depends on your goal, happy to help more!
April 12 from 11 AM to 12 PM PST, it'll be announced shortly as well
for data science, without going into any further detail, at what point should I move on to R
yoo chat, i learnt langchain and thought cool, now i can build projects, but recently everyone started to bash langchain and are moving to llamaindex or PydanticAI, I need to get a job ASAP, I'm strong with fundamentals but struggling with these gazzillionn frameworks..some one please help and i need a production ready project to start applying for stuffs..
Depends on your definition of hard then. You could always train an RL agent to play a game. You could also do a finite state approach which is how most NPC from back in the day worked.
I doubt he wants sth as sophisticated as like NPCs from MGSV, or MW 2022, or TLOU 2.
He could try making the ghosts from PACMAN.
gym has environments for most of those OG games for which you can make agents for.
Uhh, python is enough. R for me is a matter of preference, not objective advantage in a certain aspect.
In python you have matplotlib, you have pandas, you have scipy, you have numpy, all of which are amazing tools for datascience and even basic AI/ML (for when you want to make a NN from scratch).
That's my 2 cents on it. You can of course see if R has any advantage depending on what you want to do in specific.
guys not to interrupt but can anyone tell me if these are good regression evaluation metrics for real estate predictions?

given that the mean house prices are over 1,200,000
They seem rather large. Lower is better.
Sth I usually like is just checking the accuracy on train and test datasets.
It's a percentage, it takes your dataset into consideration (thus context), and is easier to debug for model performance.
Thanks
My pleasure. I'm curious to see what your acc is too now.
Vanishing gradients go burrrr

💀
When you train tensor networks, you really start to feel orthogonality catastrophe.
tensor flop
This is reaching that okay accuracy on a rather tiny tensor network. I wanted to keep it to a simple, global optimization approach, but that leads to orthogonality catastrophe, and that leads to vanishing gradients, and that leads to poor convergence as my networks get larger in size.
I have a love/hate relationship with it. I like how it makes sense, but don't like how inconvenient it is.
kind of my entire relationship with hyperparameter tuning
Yeeep.
focus on building a real-world project with what you know
try a chatbot, recommendation system, or an AI-driven web app
that'll show solid fundamentals and real production-ready work
if you're comfortable with Python and libraries like pandas, numpy, and scikit-learn, stick with it for now
move to R if you hit complex statistical analysis or need its specialized packages (e.g., ggplot, caret)
otherwise, Python is more versatile for most data science tasks
if you're doing some niche statistics, R might have better support than python in some cases
example: in my very limited experience, if you want to do SEM, lavaan is more feature complete than semopy
yep, that’s true
R shines for niche stats like SEM (lavaan) or bio stats
python’s catching up, but R’s libraries still lead in some areas
so if you’re deep into stats, R’s worth considering
also another thing to consider: you can use both together
RMarkdown is like jupyter notebooks but you can run both R and python snippets; packages like reticulate also allow you access your pd.DataFrames in R code to bridge the gap
yeah, exactly!
RMarkdown + reticulate is a great combo
lets you mix R and Python seamlessly, so you get the best of both worlds
perfect for projects that need both languages
if I have android, adobe, google
how can I cluster them
like distance between adobe and google is smaller than between android and adobe
make vectors from words and see in visualization
is it possible to do?
then I would have cluster with tech and cluster with companies
I think they would not be placed as I expect
use an embedding model, which turns text into vectors, then you can use say cosine similarity to compare the vectors
yes I know it in theory ok I check it in practice thanks
maybe also inter and intra cluster (forgot was distance?)
and wcss
tho I just ran a quick test with all-MiniLM-L6-v2, a bit old, but it thinks that android and google are closer, prob cause the former is a product of the latter
actually I have android and adobe words, google is just hypothetical
I did pos tagging on words now I have nouns and want to filter it further
yes closer of course example not good because complicates things
maybe other example algebra, android, adobe
Corresponding to math, tech, company
but I dont have any labels
also I have 700 words
yep, you can create word vectors for "android", "adobe", and "google" and calculate the distances between them. once you do that, you can use a technique like t-SNE to visualize them in 2D or 3D. you'll likely see clusters form, but they might not match your exact expectations
thanks man!
i really needed this, tryna do my first independent paper
ywww
🙏😁
the thing is i get really good ideas which are overly completed and requires me to learn complex stuffs, or else I get very basic no use ideas.. and i have decided to just make the shitty ideas, till i get comfortable with pushing the boundaries
push your boundaries dude dw
get complicated ideas but then dedicate on manifesting them
btw, how do I then tokenize the GNN for my huggingface model?
idk if i mentioned it or not tbh
you can tokenize the gnn by first converting the graph structure into a format that huggingface can handle, like a sequence of node features or a graph-based input. you can use libraries like torch-geometric or dgl to handle graph processing, then extract node features and adjacency information. from there, you can tokenize the node features and edges into a suitable input format (e.g tensors) and feed them into the huggingface model. if you're using esm2/protbert, you might want to integrate the graph structure with the sequence model’s embeddings, but thats just imo
i'm using protbert for the seq btw
should I also learn some graph theory?
besides i'm learning discrete maths as abase for learning ml
yeah, learning some graph theory would definitely help
especially since you're working with graph-based models like GNNs. understanding concepts like graph representations, adjacency matrices, and node embeddings will make it easier to work with graph data and integrate them into your models. discrete math is a great base for this, as it covers the fundamentals you’ll need to grasp graph theory and more advanced ML concepts down the road
nice!
hello
someone here can explain me how works the dialogflow IA?
to capture the text and directs to the correct intent
dialogflow works by using nlp to match user text to the closest intent you’ve set up. you define sample phrases per intent, and it uses ML to detect which one fits best. once matched, it can trigger a response or webhook to handle logic. you can access the raw user input too if needed.
any data scientist aspirant bangali here?
Always include your follow up question in the first question.
let's learn together
Hey Guys, I need some help with an automation project using Pywinauto. I'm stuck on a crucial part—analyzing tabular data inside a Pane. The problem is that this data doesn’t appear in the control identifiers, so I can't access it directly.
To work around this, I tried capturing an image of the table and using Tesseract OCR to extract the text. However, the accuracy is only around 80%, and some important data is being extracted incorrectly.
Would AI-based OCR be a better approach? Or is there another way to extract this data more reliably? Any suggestions would be appreciated!
(tesseract is AI, but that's neither here nor there.)
table data isn’t exposed in the ui tree, so pywinauto can’t access it directly. use paddleocr instead of tesseract, it’s ai-based and much better at reading structured tables. also try inspecting with inspect.exe or pyuiautomation to see if deeper elements can be accessed
Thanks i will try these tomorrow!
late here but in addition to what others said about using R for stats stuff, I think EDA is easier in R and the plots in R are easier/better
*plotting using ggplot2 package
if you end up using R, dplyr is usually recommended as the go to package for cleaning/manipulating data but i recommend data.table instead
syntax is less intuitive but it is much faster for big data sets
disclaimer: i actually did data science stuff in R before I learned python. however, R was not my first programming language
can I do DL on an rtx 4060 laptop?
depends on what you mean
like say a simple mnist classifier CNN isn't really resource intensive
on the other hand, small & usable LLMs eat at least a few gbs
I'm training an image classifier model using pytorch , in each epoch accuracy of training change from 0.08% then to 0.0%, what could be the most probable cause to oscillate training accuracy like this
a learning rate that's too high, a batch size that's too low, could be any number of things
learning rate too high means like 0.001 or 0.1?
.1 would generally be too high for any large model, .001 could work for a lot of models but the point is not the actual number that you set but the scheduling you're doing
usually to avoid the model jumping around right when it's about to reach convergence people will decay the learning rate
batch size also matters though, regardless of your learning rate that could cause a problem by giving poor gradient estimates
got it
Gemini 2.0 flash create image sounds look very powerful, what do you're thinking about that
yeah def, an rtx 4060 laptop can handle most dl tasks pretty well. you can train cnn models, run transformers, even fine-tune small llms if you manage vram smartly. just keep an eye on thermals and maybe use mixed precision where you can.
could be high lr, bad data, broken loss function, or something like all labels being one class. try lowering the lr, double-check the dataset, and print a few batches to make sure labels make sense
yeah so 0.1 is usually too high for anything deep
0.001 is often a good starting point, but best to test + use schedulers like reduceonplateau or cosine decay to avoid bouncing near convergence
looks promising yeah. flash models seem focused on efficiency and fast generation, especially for multimodal stuff. would love to see how it stacks up to sdxl or dalle when it comes to detailed image quality and prompt control
Yo so like, yolo object detection, yay or neigh? And why is CV so limited with deep learning or something?
yolo? yay for speed, def. real-time object det like a beast. but kinda trades off accuracy vs slower models like faster rcnn. as for cv being “limited”, not really, it's just that most DL cv models need hella data + can't reason like humans (yet)
Hi, if i have list of integer with arbitrary duplications as following {1,2,3,3,4,5,6,6,6,7,...,10000} and I sliced the list into sub lists with varing lengths so that there's no duplicate values in different sub lists. The sliced list is like this: {1,2,3,3} {4,5,6,6,6} {7,...} ... {..., 10000}
My question is, is there a simple mathematical function subID = F(x), where x is value of arbitrary element, subID is the identify number of the sub list that x is categorized to?
Hopefully this is a really simple question but I have a line chart with a table of the values beneath it. It would be really nice for the first cell in each row to have the little symbol showing which line it is. Can this be done?
(example is from excel)

Guys I need help , I am building a chat bot using RAG : the problem is that I feed data through pdfs , but I need to fetch that data directly from the website (url) , so it answers with the updated information from the website. Is that possible ?
so you are feeding data through pdf, so where does that pdf goes?
on that website which you are referring?
so that there's no duplicate values in different sub lists. The sliced list is like this: {1,2,3,3} ...
doesn't{1, 2, 3, 3}contain duplicates?
or ig, you mean that for all sublists, no item in sublist_i can be in sublist_j
but then you don't have a unique way to do that, e.g. you could've cut it into
{1, 2, 3, 3, 4, 5}, {6, 6, 6, 7}, ...
yo so if the sublists are made by grouping duplicates together, like all same numbers stay in same sublist (and appear only once per sublist),
then nah, there’s no simple math function F(x) that maps x -> subID directly unless u track how many unique values showed up before x in the full list.
u basically need either a dict mapping x → subID (if slicing is done already),
or build F(x) by knowing the slice rules (e.g sublist ends when next dup shows up)
so unless the sublist pattern is strict + predictable, can’t define clean F(x),
excel doesn’t auto-sync chart markers into tables, so u gotta manually color + symbol-code the first cell to match the line chart legend
instead of feeding static PDFs, u can scrape + chunk text live from the URL.
just use something like bs or newspaper3k to extract content from webpages, then pass it into your retriever like u did with pdfs.
Hello, good day to you. I need help. I'm having troubles in paste values of formula in python, how should I do this? I would want to loop all xlsx in a folder and paste as values all of the live formula included in files of the folder. 🙏
Thanks in advance 🙏
Hi! i am new with the data analytics and want to practise as i have gone throught the libraires like numpy pandas matplotlib seaborn -> but practise is what i lack so could anyone tell me which kaggle dataset or code i can use or what to do in this situation...
Remember to show code
I don't have any code because I don't know how to do this :(
I'm hoping somebody can help me make the code to do it
Where do you want these tables to appear?
...
On my computer screen?
In a notebook? On a web page? As a PNG?
Not sure I understand what you mean
In a word document? In a pdf?
In a notebook I guess but maybe we will export to png

Died from laughter? 😂
Do you want to add something into your excel sheet?
Or do you want to draw the graph and the table data using python + jupyter notebook?
nah died from tomfoolery
cause bro what 🙏
Ah I see the confusion -
I'm just trying to mimic what Excel is doing.
I've already got a line graph in seaborn and a matching table in matplotlib
Basically everything works except inserting these legend symbols into the cells
Do you have some existing code now to print the table to share?
I have never seen legend icons repeated in table, but it does some like a great convenience for the reader 👍👍👍
Ya lemme bring it up. Thank you btw!
Ooh I'd be interested too on legend icons repeated in the table
in the table sounds like a hassle
either you somehow put the string representation of what you want into a new column, or you hack jupyter's html to display what you want
(or maybe there's a 3rd way unknown to me)
Here's the full script, looks like you can remove the comments to make it a notebook again
Please react with ✅ to upload your file(s) to our paste bin, which is more accessible for some users.
That's doable tbh as long as its not necessary to change stuff every time I want to do new data. Ideally this is all automated beyond pasting some data
The text I would guess is already in the table. The question is how to get an icon there that matches the legend's style. I think it would be A LOT of work
rip
how come its not a lot of work to get it in the seaborn legend???
surely its just a bunch of shapes???
for a digital camera pipeline should i be using opencv
Did someone delete their own message?
does anyone know why normalization made V3 column clone V2

yea me i just resent it
you can use openpyxl to load each .xlsx file, evaluate the formulas, and replace them with their values
grab a beginner-friendly Kaggle dataset like Titanic (predict survival), Netflix Movies & TV Shows (EDA practice), Superstore Sales (sales insight, great for visuals), Spotify Dataset (music features, good for plotting/correlations)
imo best way to become is to scrape ur own data
i find kaggle is way too simple most of the time and more interesting data comes from data one sources themselves
Wondering if anyone familiar with NLP has come across a similar problem and can offer alternative approaches.
I was recently tasked with extracting evidence of a certain medical condition from PDFs. These PDFs are very non-standard in their form. They sometimes span hundreds of pages.
The particular evidence in question is valid if a patient has had a related screening in the last two years.
The dates of service for these procedures are also very non-standard. They can by yyyy-MM-dd, or of the form "Jan 12, 2025", etc.
Sometimes the patient refuses to have the procedure, so some sort of "assertion" needs to happen to check this. Also sometimes the evidence is related to a family member.
I ended up building a rule based program that just looks for keywords, parses dates using regex, looks if certain words like "refused" are present in a small context window. Being just regex/word matching, it runs very fast, and I know exactly how it works. But it can definitely miss charts that have valid evidence.
yo that's a super common real-world nlp challenge
messy, domain-specific docs w/ inconsistent formats. honestly, your rule-based setup sounds solid for precision + speed. to boost recall, maybe try a hybrid setup: keep ur regex for speed, but add a lightweight ML/LLM layer (like a distilBERT fine-tuned on examples of positive/negative evidence chunks) to catch edge cases. you can also use spaCy’s dependency parsing for better assertion logic (e.g. link “refused” to the right subject). also worth extracting & normalizing dates w/ dateparser, it handles weird formats better than custom regex
ripping text out of PDFs is a whole problem, regardless of what kind of text it is or what you plan to do with it.
We have OCR in place that is very accurate
I'll have to look more into spaCy
It wasn't until after I built the program that I noticed medspacy has something called "ConText" for the assertion part
Handwritten notes are definitely a mess sometimes
The rest of the text, including text in tables, is extracted with good accuracy
Medspacy is still a thing?
I'm at the creator of it in like 2018
I met*
He was trying to decide if you wanted to build on my platform or start something new
And he built something new
holy shit im dumb
Idk if it's relevant, but it came up when I was googling for how to handle assertions/negations
What platform you got? 👀
Hi , so I tried to train a model using colab , now after training the model , if I run the model.fit cell again , does it further train the same model
and if i want to train the model from scratch , should i restart the session?
sklearn? then no, .fit retrains the model
if you want something that can continue training, look for models that have .partial_fit
a neural network
the method .partial_fit is not avaiable in keras
wouldnt you increase epochs to train it further?
and just set the params to the latest results
just to make sure
can you check the mean and variance of both columns
maybe the correlation is 1
Hi guys ,
I’m a beginner
hello and welcome to our wonderful data science channel.
Hii Bro! Can u give me some advice regarding deep learning how can i deep dive in deep learning?
Thanks
I wanna be a Data scientist what should I do as a beginner?
don't start with deep learning. start with simpler models and work your way up.
focus on learning concepts, not tools.
you'll need a degree to get a job.
start by doing data exploration with datasets from kaggle.
@stuck tapir your message was removed for seeking an employee, which is not allowed.
oh dang mb
i'd disagree if u ok at math
like if u know basic linear and what convexity is
u basically have enough to make most models by just copying architecture
for stuff that has a little bit more math like vae u can learn the stats on the way
the people who ask for help in this channel are usually complete beginners. if someone isn't a complete beginner, it's incumbent on them to say where they're at.
Thanks
also the best python channel
I want to study LLM, but all the books and materials are theses. I want to find books and materials, so please recommend some.
Read attention is all u need paper
Then read gpt2
Once uread this try to load the weights and try to perform inference
humm..okey.
do youu know if a nlp model like this is easy to create? like if i want to create my own dialogflow appliocation?
Ok, GridsearcCV hyperparameter tuning with cv=4; the roc_score and the accuracy score from that is not the same from using sklearn.metrics for accuracy and the roc auc score, right?
yea it was, it was a frequency (amt of times donating blood), and monetary ($ earned donating blood) i wasnt thinking
any pandas users here know how to run map() while retaining references to the current row and column of each element?
I have a data format where I have dozens of columns with categorical IDs, i.e.
incident_type, materials_type, human_factors
102, 50, 3
140, 42, 5
and each of those integers matches a lookup table where incident_type:102=STRUCTURE FIRE, materials_type:50=COMPRESSED GAS, etc
so I need to know what column I am on while doing an applymap so I can sub in the correct lookup table value
this may be a trivial question, but do people generally prefer importing individual methods or modules, or just importing the whole library and having to type out everything (not wildcard import, don't worry i'm not that stupid)
You can't import methods, you can only import the class they belong to.
It also sounds like you're confusing modules and libraries
I think what you meant to ask was "do people prefer importing modules or importing individual classes and functions?"
we can't?
i mean like the "from ... import ..."
yeah this is what i meant
is a module not a group of methods?
like for example with numpy, there's the linalg module
No. It sounds like you think "function" and "method" mean the same thing
A method is a function that belongs to a class. All methods are functions, but not vice versa
wait yeah my bad i meant function
i gotta get rid of the habit of saying methods and parameters and instead say functions and arguments
it's less common to need to distinguish between parameters and arguments
and also @hidden cloud
https://www.pythondiscord.com/resources/?topics=data-science
http://introtodeeplearning.com/
https://deep-learning-drizzle.github.io/
https://kidger.site/thoughts/just-know-stuff/
https://github.com/aprbw/ArianDLPrimer (I made the last list myself)
https://github.com/EleutherAI/cookbook does cook book counts as a book?
GitHub
Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
So what's the answer?
I'm actually curious too
I usually just import the modules.
But I see a lot of codes that does otherwrise.
Is it just personal preference, or there is a a best practice I am missing?
And what you do personally?
It's pretty much a matter of preference and what feels right for the situation.
it is also typically influenced by example code
like if I see that they import the module with an alias, I'll probably do the same in my code
if I see them importing specific names from a module, I'll also do that most likely
how can i stop my language model ai from just using punctuation spamm to get cheat the system
my current debug to show yall the sample generation
Click here to see this code in our pastebin.

did it
Nice!
deriving the bbox position and spacing of the seaborn legend from the cell heights of the table, I am able to fake it
I am such a clever boy I deserve a treat
I know
as a little treat, I will take back the holy land from the nonbelievers
I can see it now - a holy war spreading across the land like unquenchable fire
fanatical legions worshipping at the shrine of my skull
a war in my name
everyones shouting my name
Heyyy guys I have a dissertation to make , could you recommend some problem statements that i should be working on ?
im making a ai and its already questioning me
Generated text after epoch 8:
<user> Hi how are you? <bot> '' what did you know ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? to do ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
what model are you using??
What do you mean? uh i here i let you look
model = Sequential([
Embedding(
vocab_size,
embedding_dim,
weights=[embedding_matrix],
input_length=CONFIG["max_sequence_len"],
trainable=True # Fine-tune embeddings
),
Bidirectional(LSTM(lstm_units, return_sequences=True)),
Dropout(dropout_rate),
LSTM(lstm_units, return_sequences=True),
Dropout(dropout_rate),
LSTM(lstm_units),
Dropout(dropout_rate),
Dense(vocab_size, activation='softmax')
])```im still learning but is this labeling accurate? or are those not layers

dense might be just the activation layer before output
yes thats correct,,, i think? wait no yes no i think each of those is its own model? yes i think your right
ya i think each model computes their own layers, atleast thats what it looks like
I made a chatbot that is powered by Google Gemini. How do I track and limit it so that it doesn't make me go broke?
Hey guys, I need help.
I started my journey in Data Science in 2022 and have been working with classical ML algorithms since then. Now that I have some time, I want to upgrade my skills and stay up to date with the latest tech stack. I need guidance on where to start and the best resources to learn from.
I have question what is the best course to learn python data analysis maven Analytics course or Jose Portilla course??
Me too
I wanted to replicate a project from github which translates sign language to English and vice versa. I can't even run the original project, let alone create a new one. Appreciate your patience and time.
Here's the repo link: https://github.com/kevinjosethomas/sign-language-processing
GitHub
✌️ An ASL fingerspell recognition and semantic pose retrieval interface (arXiv, GitHub, YouTube) - kevinjosethomas/sign-language-processing
anyone here know of any good resources to look up on setting up a digital camera pipeline
Opencv is decent
Hi, hopefully this is the right channel but I'm sure someone around might have an idea about this. I'm working on a project where I'm receiving the position data from a sensor (x, y). I'm now looking into the Kalman filter to better forward predict the position of the sensor with a couple of milli seconds (~100-300ms).
I've been reading up on the Kalman filter and trying to implement it. I'm curious if someone around has done this before and might want to help me a bit.
The Kalman filter I want to create should keep track of the estimate with [x, y, vx, vy]. What I'm especially curious about is how I setup the state covariance matrix (P) ? Should I simply come up with some values for the P-matrix?
is there any way to detect and correct lens distortions of an image with just that image or do i need multiple images with different perspectives
Hello 🙂 could someone give me some clues on how to do my homework please 🙂 Apologies if this isn't the right place to post!




message me if you can maybe give me some clues - I want to figure it out for myself but I'm just needing a little push haha
I did manage to help some help from my classmate on task 2 in the end - i sort of understand it now

Click here to see this code in our pastebin.
pls check this out
@rich moth how did you manage to get your graphs to work
do you know of any good resources to learn the theory behind it
lol youtube
all the youtube videos i've been finding either just give a very basic overview or they just straight up show the code (which i don't want, i want to be able to code it myself after learning the theory)
it wasn't like that for neural networks, i was able to find in depths theory videos for that, which allowed me to implement it myself using just numpy
This is ok primer to classical cv
oh wait this is exactly what i was referred to by someone else lol
i could not understand the first part of 2.1 though
i must be stupid or something
after the homogenous vector part i just did not know where things were coming from
Hm
I’d focus on getting good at linear first
A lot of ml will be painful if u don’t know linear and stats well
i see
i know linear to an extent, but it could definitely be better
part of it thought was just that i didn't know where some of the equations were coming from
like for example with this

i get that lambda is a diagonal matrix (it is right?) but i have no clue as to what this is being used for
Is lambda constrained to 0 to 1?
yeah
so that gives us r = mew * p + lamba * q
I'm still not sure what do you want?
Do you need help to find more dataset than 600k?
Do you need help to refine the 7k instance?
Are you showing one project outcome and asking for feedback on this "report"?
Are you asking for another project idea?
Do you have more info about the dissertation? Any topic limitation?
Maybe show us some problem statements you have think about, and we can give you feedback it is too easy or too hard.
Maybe tell us your interests?
The input layers could have been multiple layers. Have to double check with the definition of the Embedding class. But it seems to be a single layer, since there is only one embedding_matrix. but looks like it is expecting a list, so it could have been multiple layers.
The output layer is most probbably not just an activation layer, because the name of the class is Dense, which is usually a linear layer.
Check which part you are comfortable with, and then just skip it and go for the next one.
also @pearl barn
https://www.pythondiscord.com/resources/?topics=data-science
http://introtodeeplearning.com/
https://deep-learning-drizzle.github.io/
https://kidger.site/thoughts/just-know-stuff/
https://github.com/aprbw/ArianDLPrimer (I made the last list myself)
why can't you run it?
You got an error?
Copy paste the error?
Yes, you initialize it with your best guess.
If your guess is far-off, then it just takes more time/steps/data until your filter starts working better.
This is a very tricking question, and the answer might range from "it is mathematicaly impossible with just one image" to maybe few lines of codes, depending on the details of your camera setup and what you are trying to do.
are there any part of this function that you still do not understand?
No. @glacial root Lambda is not constaint, it ranges from -infinity to infinity
just scroll to the end of the page. It says so.
If you want a 3D line, then there is no constraint
if you want a 3D line SEGMENT, then you should constraint it

No. Lambda is litereally just a number, not a matrix.
clue: it is not bold.
more technically, it is a variable belonging to a set of real numbers, functioning as a parameterisation of the line.
oh wait yeah i forgot only bolded items are matrices
If you think that you are travelling from P to Q, then lambda just is the "percentage" of your travel.
at lambda = 0, you are at P
at lambda = 1, you are at Q
at lambda = 0.5 you are halfway between P and Q
etc2.
at lambda =-1, you are travelling the wrong way, you are as far aways as P is from Q, but on the wrong way
at lambda = 2, you have travelled past Q
@glacial root I made some edit
bolded are vectors i think
I just edited my explanation above, does it make sense now?
how can there be multiple input layers? do you mean nodes
so in this screenshot of his, lambda basically represents x-axis (3d depth) with points plotted on y-axis and z-axis?

but lambda being x within the lines, like progression from point 1 to 2 as u explained

Thanks @quaint mulch !
I'm thinking about the prediction step of the Kalman filter: P' = APAᵀ + Q. I'm still trying to get a good understanding of why the Aᵀ is required there. If I got it right it's meant to make sure that the result of the multiplication ensures a symmetric covariance matrix. Am I right?
is this right place to ask about ai models?
sure
So I want to test some open source ai models and identify which ones can take max parameters + should be able to run without internet.
Am not familiar with using these models. Was suggested to find them on huggingface.
which ones can take max parameters
what does that mean
should be able to run without internet
any model you download and save on your pc should have the ability to be ran w/o internet, provided you have the correct software installed
Can somebody help me why my x axis looks like that ?

I am using matplotlib but the x axis value doesn't line up
show code
fig, ax = plt.subplots()
for width_val in fts:
x = [item[1] for item in width_val]
y = [item[2] for item in width_val]
ax.plot(x, y)
what's width_val and fts
it is a list of list with this format [[<width>, <x>, <y>]]
like some models have written 7b, 1.5b which can take these amount of parameters for training.
This is width_val
fts is just a list of width_val
>>> import matplotlib.pyplot as plt
>>> from random import random
>>>
>>> fts = [[[random()]*3 for _ in range(5)] for _ in range(3)]
>>> fts
[[[0.6070407867652481, 0.6070407867652481, 0.6070407867652481], [0.21341951630147704, 0.21341951630147704, 0.21341951630147704], ...
>>> fig, ax = plt.subplots()
>>> for width_val in fts:
... x = [item[1] for item in width_val]
... y = [item[2] for item in width_val]
... ax.plot(x, y)
...
[<matplotlib.lines.Line2D object at 0x000001E4EABC64B0>]
[<matplotlib.lines.Line2D object at 0x000001E4EABC6750>]
[<matplotlib.lines.Line2D object at 0x000001E4EABC6A80>]
>>> plt.show()
```cant reproduce your x-axis thing
wdym by "take max parameters" then
yes, e.g. 7b means that model has 7 billion parameters
I think I found the solution, the x is a string instead of float That's why the x isn't lining up
like model should be of small size (download size I guess? am not sure sorry xd) with more max parameters
I have not used any models so idk how to setup ,need help with that too
"max" of what
I'm not really understanding what you mean by "max parameters"
a 7b model has exactly 7 billion parameters
a 1.5 b model has exactly 1.5 billion parameters
uhm, idk tbh 💀
what are you trying to do exactly
just test few models
basically you want to chat with models without internet? (and compare differences of models you can run without internet)
yea
imo the easiest backends (the software used to run those models) are either ollama or koboldcpp
personally I prefer koboldcpp but the 2 are p similar in terms of ease of use
- download a version of koboldcpp from releases fit for your hardware
- download a model (that's stored in GGUF format), e.g. this; you'll see a lot of versions of the same model, e.g.
Q4_K_M,Q6_K, you don't have to worry too much about it rn and just download theQ4_K_Mone - open
koboldcpp.exe, select the file you downloaded, clickLaunch, and start chatting
so it is gui based ?
yes, koboldcpp has a built-in gui
What if I want to setup cli based?
then you can launch it without the gui
it sets up an endpoint at your localhost so you can send requests to it
if you have an AMD gpu and want to use specifically rocm, there's a fork
got rtx 3060
you should be able to run a 7-12b model with 16k context give or take
Did someone post here recently about an alternative to jupyter notebook?
I've been using it for 2 weeks and it doesn't feel like the sweet spot of persistent and dynamic so I'm just looking for experimenting if there are alternatives available.
someone probably mentioned marimo
Yes! I recognize the name, thank you 😁
there was also doing this in vscode
# %%
print('this is a code block')
# %% [markdown]
# # Title
# this is a markdown block
# %%
print('this is another code block')
What plugin of vscode would act on these comments? (I'm not a vscode user)

Working with Jupyter code cells in the Python Interactive window
there is also the option of just using the terminal directly, either literally running in the terminal (e.g. VSCode's shift + enter can send the line(s) of code you have selected to run in the terminal), or anything else like IPython
just the normal jupyter extension
I have ipython but haven't tried plotting with it. And I haven't tried launching scripts in it. Maybe that's a path to investigate as well. 👍
quarto
it has nicer formatting too and better vim support
Than marimo or than jupyter?
Hey 🙂 does anyone know anything about these functions? I'm so stuck on this...we have a dataset with the data being like 4000 bacterial strains in about 400 different conditions, and the correlation I've made with the conditions using .cor

this is something we did previously: - still not 100% sure what line 2 does, but I think it has something to do wth removing all the diagonals and repeated values

Don't know if i can ask it in this channel, but what's the recommended cloud hosted chatbot akin to GPT4 to assist with python code? Or is GPT4 the best at that currently?
How can I import a neural model into a simulation like a panda 3D or pie game
Got laid off - thinking of doing a masters in data science or AI. do any of you have any feedback on if such a degree would be helpful?
the most valuable DS or AI-related degrees are going to be in computer science. be skeptical of "Masters in Data Science" programs that emphasize how easy it is to get into the program or how much graduates of the program purportedly make.
yo guys does anyone know what i'm doing wrong here

i'm trying to convert this to a color image
and to do so aren't we supposed to just make each element an array or tuple of 3 of that number?
so pretty much just setting the rgb values all to the grayscale value
wait nevermind that would just keep it as the same grayscale
but how else would we turn it into color
you can't, information has been lost, there's no way back
you can only estimate and "guess"
in terms of deep learning, you can train a network to do that (or grab a pretrained model from huggingspace (which you could finetune if necessary ig))
either way, I found this paper on the topic and it seems pretty interesting if you wanna dive deeper in how they achieved https://www.mdpi.com/2073-8994/14/11/2295
obviously there are probably also free (and not so free) online services that can do this as well (unless you need to do this for a large dataset in which case it'd likely definitely cost something)
nah i mean converting raw sensor data to an rgb image
this is the overall assignment

i'm so lost on all of this
is there anyone who could perhaps help me a little with this? my goal is to be able to code this myself but i just need some help finding the right direction in terms of concepts and some directions on how i would implement this
Skipping step 1, you need to learn the RAW sensor data format.
A camera raw image file contains unprocessed or minimally processed data from the image sensor of either a digital camera, a motion picture film scanner, or other image scanner. Raw files are so named because they are not yet processed, and contain large amounts of potentially redundant data. Normally, the image is processed by a raw converter,...
A camera raw image file contains unprocessed or minimally processed data from the image sensor of either a digital camera, a motion picture film scanner, or other image scanner. Raw files are so named because they are not yet processed, and contain large amounts of potentially redundant data. Normally, the image is processed by a raw converter,...
What you need to do depends on the camera and its settings.
Also this may be helpful https://stackoverflow.com/questions/71834629/how-do-i-convert-matrix-of-raw-values-to-matrix-of-rgb-values-in-code
Also Bayer filter

Stack Overflow
I have a bunch of values that seem to be 12-bit numbers. If I put them in a matrix and scale each one to a value 0-255 and then show them as an image, I get something that looks like a photo, but ...
Whether or not it's using Bayer etc depends on the camera. I'm assuming since this is an assignment they have certain assumptions for you to make. Otherwise you need to enumerate all possibilities and that is why there are big camera libraries.
For example https://en.wikipedia.org/wiki/Foveon_X3_sensor captures directly to RGB.
The Foveon X3 sensor is a digital camera image sensor designed by Foveon, Inc., (now part of Sigma Corporation) and manufactured by Dongbu Electronics.
It uses an array of photosites that consist of three vertically stacked photodiodes. Each of the three stacked photodiodes has a different spectral sensitivity, allowing it to respond differentl...
Not color filter array, and therefore no Bayer.
But it still needs some processing since it's not in sRGB, which is probably what is meant when they ask for "RGB."
the assignment suggests loading a colored image and converting it to RAW grayscale
so, I would presume Bayer
Likely, but technically could not be (or no CFA at all as I linked).
(what I've learned in my quick research on this is that this is a deep spot in this area of the field and I'm glad we have abstractions over it 😁)
Color is a huge rabbit hole.
And all the other parts too, like there are multiple ways to convert to grayscale, and you may need to use a different one depending on what you are doing with the result.
(Video game graphics programmers will know about this stuff (as they need to enter this rabbit hole for their work))
If I wanted to have a neural network control a puppet within a simulation do I have to make it so that can grab on to something like a blender ik bones
thank you, typically where/how would i find raw image data?
thank you
oh this definitely helps
i just need to find out about how to find raw bayer image data
ok so i found a raw image file on kaggle and tried using that, and i found a library called rawpy that processes the raw image file in just one line
it feels like cheating though
cause there's definitely a lot more work that goes into this

Is there any resources u can recommend on learning about agentic AI,
There are too many tools to learn so I need a reference as to what i should cover first.
Most videos I watch people just talk about theory like a lot of theory need something practical
And up to date
Agentic AI is an approach to networking different models together. What is your goal for learning about agentic AI?
creating custom AI agents,
For now something that can generate reports and charts from user prompt
Do you want to train the models, or just network existing ones?
By charts I mean
flow charts ERD diagrams and stuff like that
We call those plots. Or data visualizations.
I guess flow charts don't fall under plots.
firstly I probably want to network existing ones
If you ever plan to learn how to train models, it would make more sense to start there
Because if you want to network models together, you need to understand how data goes in and out of the model.
Yeah i want it to be general so like it shuld be ablt to create alot of stuff https://mermaid.js.org/
so basically if it can generate this memaid code That'll be a good start
^ so for something like this, it's still better to train your own model?
What will i train it on ? mermaid docs?
yo guys do you think working on an edge detection algorithm using just numpy is doable? i know it'll definitely be decently harder than just a plan feed forward neural network but still worth doing right
only place i think i'll use another library is for getting the matrices of images and converting the edge matrix to an image
absolutely doable yes, it sounds like a great project
excellent, looks like my next task is decided
creating one from scratch may be pretty hard, but implementing a widely used one should be relatively easy
by scratch i mean just without frameworks
i'll first watch some videos to learn the theory/math behind it
and then i'll try to implement it myself
it shouldn't be too hard to make a simple edge detection kernel and convolve it with your image
The event on marimo is coming up soon:
https://discord.com/events/267624335836053506/1350928346422186065
Hey everyone, I have a small question about clustering. I now have a distance matrix between samples, but how can I cluster based on this matrix? Any clustering method is fine.
As far as I know kmeans does not provide such a precomuted metric
this with metric='precomputed'
scikit-learn
Gallery examples: A demo of structured Ward hierarchical clustering on an image of coins Agglomerative clustering with and without structure Agglomerative clustering with different metrics Comparin...
does anyone know a good model for imputing a dataset with both categorical and continuous features? ive tried a couple but none have really worked. IterativeImputer from sklearn doesnt support categorical features, and MultipleImputer from autoimpute just throws a weird error
What formula do you want to use to impute them?
No matter what, the way that you impute categorical features will be different from continuous ones.

🌟 Excited to Share My Latest Project! 🌟
I’m thrilled to announce that I’ve successfully developed a chatbot powered by the advanced Google Gemini 2.0 LLM!…
Ideally mice, from what i read that works for both categorical and numerical no? Maybe i misunderstood something
Im guessing if i use two different formulas they can still use all features as inputs to impute right?
- how to tackle the outliers to further clean the datasets
- how to figure out which visualisation might help you to clean or explore the dataset
- how to choose which ml model will be best for random dataset
Thanks. But it is at Reputed Unis - Northeastern, and BU
links?
even reputed unis will have masters in DS or in AI that are separate from their CS department, where all the actual academic rigor is.
MS Data Science(https://www.bu.edu/cds-faculty/programs-admissions/ms-data-science/)
MS Artificial Intelligence (https://graduate.northeastern.edu/programs/ms-artificial-intelligence/)
a good place to look is at the admissions requirements. If they require prior coursework in computer science, that's a green flag.
The admissions requirements for northeastern are a red flag--you basically just have to send them unofficial transcripts, and they don't seem to care what courses you actually took.
also before doing this, should i first try implementing a convolutional neural network or is it pretty intuitive to implement that into the edge detector if i have tried a regular feed forward neural network
Interesting, thank you!!! Perspective is appreciated.
You are welcome
I'm getting ads for those universities now on other platforms.
ts so beautifull
i clicked an ad on IG for a data science program through caltech
decided it wasn't remotely worth, but i gave them some contact info and they have basically tried to flag me down a couple times lol
i was already not going to do it but it didn't inspire a lot of faith in the program
Hi guys, I'm a first year computer engineering student and I would like to approach the world of AI, could you recommend me handouts, forums or books to start studying AI from scratch?
Why are there many ways to create graphs in R and Python?
I think it depends on preference and use cases.
I recommend the Python and Programming Discord servers for forums. For handouts, I recommand the documentation and GeeksForGeeks.
Idk if this is the most appropriate channel but I'm trying to plot a confidence interval around a fit I did with scipy.optimize.curve_fit(). I asked chatgpt and it told me that I can do something like
var_f = J @ pcov @ J.T
Where J is the Jacobian. I don't need any help really I just want to make sure this is true bc i don't find it anywhere else other than chatgpt telling me
I'm looking to train a NN with mixed continuous/discrete input features AND mixed continous/discrete target features. What's a good place to start with this? I only really have experience with sklearn
Artificial Intelligence: A Modern Approach for an AI book.
yo guys i'm having an issue with grayscale conversion, isn't this the correct way to do it?



Don't round.
this is what i got when i don't round

Check your array's datatypes.
Pillow wants 8 bit pixels, grayscale.
oh wait yeah maybe that's the problem
it's probably set to float for me
for edge detection, typically do we just omit the outer layer
https://labelme.io/docs/export-to-yolo
is this command only for premium users? I tried to run it but it keeps failing:
usage: labelme [-h] [--version] [--reset-config] [--logger-level {debug,info,warning,fatal,error}] [--output OUTPUT]
[--config CONFIG] [--nodata] [--autosave] [--nosortlabels] [--flags FLAGS] [--labelflags LABEL_FLAGS]
[--labels LABELS] [--validatelabel {exact}] [--keep-prev] [--epsilon EPSILON]
[filename]
labelme: error: unrecognized arguments: /annotations --class-names waste```
Labelme - AI Image Annotation & Dataset Creation
Create private, flexible AI datasets with our offline annotation app. Save hours with AI-powered tools.
You need to start with learning PyTorch or other deep learning frameworks like TensorFlow, JAX etc.
If you ask me, I'd say, just zero in on PyTorch!
Once you've understood a bit about how PyTorch works and how to use it in training NN (there are nice videos on YouTube you can use to learn), then implement what you've learnt on your dataset.
You can use this video to learn PyTorch https://youtu.be/Z_ikDlimN6A?si=QtSTZSD7hc1SyFE8

Welcome to the most beginner-friendly place on the internet to learn PyTorch for deep learning.
All code on GitHub - https://dbourke.link/pt-github
Ask a question - https://dbourke.link/pt-github-discussions
Read the course materials online - https://learnpytorch.io
Sign up for the full course on Zero to Mastery (20+ hours more video) - https:/...
You can use the SimpleImputer from sklearn.
from sklearn.impute import SimpleImputer
How to go about the imputation depends on your choice of imputation strategy. See the docs below for a detailed guide.
https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
scikit-learn
Gallery examples: Release Highlights for scikit-learn 1.5 Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 0.23 Combine predictors using stacking Permutation Importance v...
-
You can use IQR approach
-
This comes with experience and exposure. In summary, you'll get better at it with more experience.
-
There's no special way to know. Remember, "all models are wrong but some are useful"... So you have to experiment a lot with different algorithms.
Thanks!!
hi does anyone know any good website to get datasets i have one from my uni assignment but i wanna experiment myself
Check Kaggle and HuggingFace
I’d suggest scraping ur own
It provides opportunity for a lot more interesting data
Guys I have a laptop with hybrid graphics which includes Nvidia graphics and whenever I'm trying to use pytorch from inside python it is not showing up over there so what is the issue
torch.cuda.is_available() is giving false
yo what are some intro computer vision projects i should work on
Maybe try fine tuning an existing
Model like yolo
Or efficientnet
would it be better to do this before or after implementing my own?
What are some alternatives to the browser-based jupyter notebook for running ipynbs. Currently I am using VSCode, but I open to other alternatives
now I generally prefer using this instead because it works way better w/ vcs
Working with Jupyter code cells in the Python Interactive window
Thanks!
Hey guys, I have a database of products from Amazon, but it's missing the "Date First Available" field. Does anyone know how I can scrape Amazon to get this information? Any tips or tools would be super helpful

hey guys i was searching for an ML project which is not trendy but very much useful, if anyone has any idea, do lemme know :pepeHype:
How did u originally scrape it?
i found it in kaggle
Do you think mcp servers is the next big thing?
what are mcp servers.

GitHub
a rag application to chat with library docs. Contribute to memopy/chat-with-docs development by creating an account on GitHub.
first (can be) useful project of mine
if you have any ideas for new features pls tell me
https://www.pythondiscord.com/resources/?topics=data-science
http://introtodeeplearning.com/
https://deep-learning-drizzle.github.io/
https://kidger.site/thoughts/just-know-stuff/
https://github.com/aprbw/ArianDLPrimer (I made the last list myself)
We're a large, friendly community focused around the Python programming language. Our community is open to those who wish to learn the language, as well as those looking to help others.

MIT Deep Learning 6.S191
MIT's introductory course on deep learning methods and applications.

Personal Website. Math, SciML, scuba diving!
GitHub
My personal list of what are the things to learn in deep learning. - aprbw/ArianDLPrimer
That is too vague for anyone to give a good feedback.
You can start by checking this website https://paperswithcode.com/sota
and find the closest setup to your setup and start from there.

12542 leaderboards • 5405 tasks • 11649 datasets • 159046 papers with code.
https://paperswithcode.com/datasets
https://datasetsearch.research.google.com/
https://archive.ics.uci.edu/

11649 datasets • 159049 papers with code.
Discover datasets around the world!
MNIST?
i've done that
It was actually a very specific question
but thanks for the link this looks interesting!
Well, you have finished the intro then haha, congrats.
You can browse this: https://paperswithcode.com/area/computer-vision
I also kinda like this: https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
Browse 1595 tasks • 3537 datasets • 5429
thank you, i'll take a look
also i think my implementation was just regular machine learning and not much computer vision involved since i didn't make it able to detect in real time
the only computer vision element to it is the fact that it's images, but in terms of the way the model was trained, it was just like any other extremely simple feed forward neural network
right now i'm trying edge detection, i've done the sobel operator part and i need to try canny, which i'm not yet sure how to do so i'll have to figure it out
sobel though was a lot simpler than i thought it would be, just a basic kernel convolution
and i might try implementing the AlphaDog attack
A = np.array([[1, 2, 3], [4, 5, 6]]) # Shape (2,3)
print(A)
A_expanded = A[:, :, np.newaxis] # Shape (2,3,1)
print("\nExpanded 3D Array:\n", A_expanded)
print("Shape:", A_expanded.shape) does it become tensor at this point? mathematically speaking where tensor is matrix but in higher dimension
im trying to get intuition behind np.newaxis
It just adds a new dimension. You had a 2d array (a matrix). Now it's a 3d array where it's a stack of matrices, but there's only one
Hey guys am 4 th year CSE student,
Am assuming to work on data science for my mini project,
So I need you guys to recommend me ideas on what to do ,
Beginner or medium level
Is it a good idea to make your own simulation or use something already pre-made for a neural network lets say a 3D parkour ai
Hey, guys!
I've been doing a research in natural language processing for conlangs and during the research I developed a framework called ALF-T5, which uses Google's T5 to adapt to any language for translation via fine-tune using transfer learning with PEFT 's LoRA technique. It serves as an universal language translator trainer, you can train ALF-T5 to any language translation pair and it will adapt, thanks to T5's language comprehension capabilities.
There's more info on the repository itself, which is available at: https://github.com/matjsz/alf-t5
If anyone wants to check it out, please don't forget to leave a star on the repository, it helps me a lot! Thank you for reading and have a nice day! :)
thanks for posting this. how did support for conlangs inform the design?
This started as a side-project to translate my own conlangs to English and vice-versa, thus creating the need for a bidirectional encoder-decoder structure, and kept evolving. The thing is that conlangs have scarce data, so it's not like a consolidated language, this way I was trying to find a way to train a encoder-decoder model to be able to translate even with few examples on the dataset
That's when I decided to use T5 as a base model, as it has the knowledge on natural language that I need and by applying transfer learning via fine-tuning, I could keep the capabilites from T5 that I needed and the data from the conlang that I wanted it to learn
Few shot learning was key on that, too
The framework was born from this and is key to perform the research now, so if this was useful for me, maybe it will be useful for someone else, too
so it's really for resource-scarce languages in general, including those that happen to be constructed.
Yes, exactly!
what conlangs are you most interested in?
I really like agglutinative ones, like Na'vi, but the one I was testing the framework on is one of my own, it's inspired by latin and is very straight-forward
I was reading the Na'vi PDF a couple days ago, boggled my mind
Those are really wild, but pretty interesting
does Na'vi have any phonemes that are impossible for humans?
I'm not really sure, to be honest, but it's sure difficult to learn
I couldn't tackle everything, but as it seems, the language has its similarities to some human languages
if there are "impossible phonemes", it would be because the Na'vi have different throat/mouth structures than humans. which is what I would expect.
That makes sense, since it was thought to be spoken by an alien species
Could it be possible?
To like, design a conlang that way
I never thought about that, to be honest with you
why wouldn't it be?
I'm a theoretical linguist who learned python. and then it just spiraled out of control from there.
Yeah, since we have the phonemes, we could think on some wild ones, that's right
Oh! That's awesome!
That explains a lot haha
I actually thought about pursuing a degree on linguistics, but choose CS instead
you made the right choice, unfortunately.
I really like both, so even if linguistics is a hobby, they are my main passions, but I don't have that much knowledge on linguistics, it's very dense, there's a lot to learn
It's a hard world for academics, and everything seems to be more and more corporate over time
But it's a fascinating field, really
It's really nice to know that there is another linguistics enjoyer here haha, with the difference that you are actually a professional. I just hopped in here, so I'm kind of getting the grip on the server, but it seems a nice place.
that's because we ban everyone who makes it not nice.
That's fair haha, seems to be working
hi anyone know how you are supposed to optimise an ANN?
i keep trying to train mine and it only ever reaches .14 r^2 score
but what ive read up already is that some areas might be undersampled?

but ive no way of going around this since most of the data sits between this 4 - 8 range