#data-science-and-ml
1 messages · Page 142 of 1
each image is the 'item'
each image is a random variables, and those variables are iid
Yeah mb
np, i appreciate replies :-)
If you flatten the image, is basically a big vector with can be considered as observation of random variables
thanks. in the wikipedia though are the x_i the inputs or outputs?
im confused, but i think it explains why one uses logs
more computationally efficient it says
x_i are generally the observation/value from a variable X so yeah the input
if one thinks of the cross entropy formula, imho there is smth off
i know its not the CE, but resembles it
i think it'd be P(y_i~theta)^y_ir
It's log likelihood you speaking about I think ?
Hmm not really

the power is P(y_ir), taking the log gives the cross entropy (image above.)
so i think x_i in Wikipedia can also be the outputs of the network (normally y_i), which can also be considered random variables
if that's correct, that would mean that the network is trying to fit the statistical distribution of the outputs (and that power/exponent P(y_ir), somehow.) ?
(note that the minus is because they are trying to maximise, one could add it and minimise i presume.)
gotta go
Bye!
the negative comes from the definition of shannon information
who the fuck is shannon
this is also not a proof, it's just a list of reasonable assumptions. none of them are correct, but they're often close enough for practical use
im ttryna do scipy.optimize.curve_fit
and when i give an initial guess for params, it literally doesnt change those params
when i give the default value for params, all 1, then it gives an overflow warning but at least it slightly changes it
anyone get this issue
There are entire categories of NNs that don't operate under an i.i.d. assumption. But "deep learning" (backpropagation based) does (there are some exceptions).
As Edd also wrote, it's an assumption. You often don't have a nice i.i.d. situation.
what function are you trying to fit? sadly, general non convex optimization has no guarantees and your success depends very strongly on your initial guess
It’s a custom function… basically I take like 37 Params and form them into a grid of 37 by 110, where in each column we have (1-1/p)^ column, and then convolve that grid with my data lol
I do have an extra parameter that I haven’t implemented how to fit yet, but it is still being passed into the fitter could that be a reason?
i don't get how you convolve that with the data
It’s numpy.convolve, I take a row of that grid and I take the corresponding row of my data (which is 36 by 37 by 110) and convolve the slice of the data and the row of the grid which is the kernel fully, so both inputs to convolve are array of length 110. Convolve fully and take the first 110 values
that sounds like a clever vectorization should let you use a pseudoinverse
if p and the column numbers are fixed, anyway
yeah
what would that do
get you back the parameters, so that your estimate is the application of the function to the parameters
i could get back to the parameters by doing 1/(1- kernel[:,1])
then what exactly are you trying to fit?
theres my simulated signal and an experimental signal, and if I apply the convolution to my simulated signal it should smooth out the signal, and we are trying to tune the constants of smoothing, our fitting parameters, such that it fits best to the experimental smoothness of signal
and the constants are those 37 params?
yea
doing this gives you back the parameters you chose, then. not the ones that fit the data
the pseudo inv should give you the best fit of the params to the data. at least with the model as you described it now, since you presented only linear operations (after reparametrizing the entries of the matrix, for clarity)
maybe i misunderstood though. if you can present the problem a bit more clearly, someone should be able to give more help while i go sleep
wait im confused, the function I pass to scipy.optimize.curvefit takes in 37 parameters, then in that function I tell it how to transform the list of paramaeters into the 37 by 110 grid, which then convolves it. so the final output of scipy.optimize,curvefit is 37 parameters which supposedly minimizes the nonlinear least squares from my simulated signal to experimental signal
yes
so i dont get how taking psuedoinv would help
what is p in the expression you gave above
the parameter
aha, there we go
sry
then no, pinv doesn't help
yeah that's a general nonlinear problem. things you can try include: giving curve_fit the jacobian and hessian explicitly, and running it several times with different initial conditions
aite thanks
since you have the function, you can get the derivatives fairly easily
i have absolutely no idea how to get the deriviatives 💀
idk how derivatives handle array splciing and indexing
kinda nastily tbh, each order of derivatives adds an extra dimension to the array (you can avoid this entirely by rewriting everything in sigma notation and differentiating component-wise, but it can be tedious)
but tbh since the problem is anyway nonlinear, i would take a look here https://docs.scipy.org/doc/scipy/tutorial/optimize.html#global-optimization
try some gradient-free optimization methods that use heuristics to try and find a global optimum (but have no nice guarantees)
the dual_annealing method is fairly standard
thanks,
the thing is this was previously impelemented in C using levenberg marqueete, which is relatively simpler than what I am reading here, however they did this all custom, and the convolution was defined recursively rather rather than absolutely
When looking at C code, it will often be all done manually, but also this manual implementation is often the result of a lot of upfront work elsewhere and that is just the end result written out which makes it hard to follow from the code alone. In Python you will usually find more high level functions called that just solve it for you.
Those high level functions have a ton of options, because they need to cover everything, take your time reading them.
the scipy curve fit func also uses levenberg marquart in the quasi-newton flavor (at least by default)
if you don't explicitly pass the derivatives, some finite difference approx is used for the jaco and hessian
i'm not sure what criteria it uses to choose a step size, i'm sure it's an issue for badly behaving functions though
alright lets go, whats everyones favourite data science python libraries
bonus points for libraries i havent heard of
can i use hugging face for this project to host the model ?

like can the model inside hugging face still can accept time-streaming data from my local machine?
the pipeline occur locally
Does anyone know the best models to generate similar images?
similar to what?
Similar to the original image duh
are you looking to build this from scratch or just for a tool to use?
I’m looking for some pre-trained models to use for my research project.
basically any autoencoder trained on images, especially images in a similar style to the ones you want to input, should work
you could just encode the image, add an extremely tiny bit of noise, then decode
VAE's specifically as this is kinda their bread and butter, might not even need extra noise from the variational nature of them
Traceback (most recent call last):
File "C:\Users\ekila\Downloads\Neural Network Framkework\main.py", line 247, in <module>
val_xdata = xdata[mask]
numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.66 PiB for an array with shape (387158016, 3, 448, 448) and data type float64
I think I need some more memory 💀
Theres a weird error with multiprocessing where you cant send data larger than 2gb back to the main thread, but im trying to train a large computer vision model, how can I overcome this limitation
anyone here use pycharm professional? you guys know how to enable the hugging face tool window on the left bar? i used to have it now its gone
nvm i was using the wrong env
why use pycharm over vscode? Genuinely curious ive been using vscode forever and love the extensions
Petabyte?
What the actual
nice section about ML-logistic regression https://en.wikipedia.org/wiki/Logistic_regression#Other_approaches

In statistics, the logistic model (or logit model) is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression (or logit regression) estimates the parameters of a logistic model (the coefficients in the linear or non linear combinations). In...
For binary class P(Y_i|X_i), none of Y_i|X_i is ||identically distributed||:
if X=age, and Y=disease or not, then Y will be a different distribution for each age. So Y_i are not identically distributed but ||they are independent.||; which is all that is used in the derivation (link above.)
visually it'd be like so:

So I'm getting the fabled expected 5 got 4 error. I imagine it's common?
hello, be sure to always show the whole error message and the code that caused it.
it just randomly started working and I have no idea why
which is even worse because now idk why I can't fix anything if it goes wrong
the biggest change I made was changing the python version
Which means the library I was using really was deprecated
Hate that
Nope that wasn't it. No idea why it worked
http://hollywood.mit.edu/GENSCAN.html
how can I make a similar model to this
i wan to host my model in hugging face but i wan it to be able to recieve live streaming data too
is it possible to do so ?
Hii anyone will someone volunteer themselves to guide me and my 2 friends to become a good data scientist
this is really cool, hadnt seen it before, i was wondering days ago whether gaussian radial activations were used anywhere
they are used in RBF https://en.wikipedia.org/wiki/Radial_basis_function_network
In the field of mathematical modeling, a radial basis function network is an artificial neural network that uses radial basis functions as activation functions. The output of the network is a linear combination of radial basis functions of the inputs and neuron parameters. Radial basis function networks have many uses, including function approxi...
imho the X-auto encoders should have less green neurons though, but it's a detail, and maybe im wrong.
Hello, I want to create a model that is able to take a picture of some clothing and return some parameters such as color, condition, type of fastener, etc. I have a rather large database with photos and parameters. Can I train a model this way in Keras? Or can I get something already trained?
check classification models
idk like logistic regression or KNN or anything ig
Would you say the AI has stopped improving? The average loss is not changing much
Epoch 23, Average Loss: 0.02855170254285137
Epoch 24, Average Loss: 0.027263049941716924
Epoch 25, Average Loss: 0.02655800049089723
Epoch 26, Average Loss: 0.027358725149598386
Epoch 27, Average Loss: 0.02881776740671032
Epoch 28, Average Loss: 0.027877019860574767
Hello 🤗
Which tools should I use for this?
idk anything
any library you are comfort to use
or even any language
Well, I'm a newbie on the DS topic, so I'd rather take something simple. I would also appreciate a literature recommendation, I've started read Deep Learning with Python about Keras, so I've thought it's right tool
@proper crag I've heard I should use CNN for this case, what do you think?
don ask me
i havent deploy my 1st model yet
let alone to suggest you anything
Okay, I get it
Hi matplotlibs. Could someone help me plot energy diagram? I got no idea how to achieve what I desire, been trying for quite a long time (three days) and without a success...
Give more details pls
I try to reproduce exactly something like this

What is the best coding environment for data science?
I use Jupyter notebook from anaconda. like the one it comes with. not jupyter lab.
my friend uses vs code,
im actually comfortable with jupyter notebook
it aint that bad
crude example

import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
a = 1 / np.arange(1, 6)
ax.scatter([1] * len(a), a, marker="_", s=5000, linewidths=2)
for y in a:
ax.annotate(str(y), (1, y), (1.01, y))
plt.show()
what is 's'?
in that graph, how long those lines are on the x axis
oh, got it
Yes, your AI propbably converged, which mean the loss value reached a minimum
I would say your problem is probably object detection, YOLO algo is SOTA in that field right now i guess
Does YOLO would by able to return things like kind of fabric, color etc?
Yes, if there are specific classes for them like: red cloth, yellow cloth, etc
is the hands-machine learning with sci-kit book enough to start of finetuning models? or are there any more pre requisites?
depend on what model you want to finetune
if all you want is fine tune
then I think reading a book is too much
just follow some online tutorial
I use vscode. The answer is whatever floats your boats
just use chatgpt?
CNN or ViT are good places to start.
If this is a job that you need to get done, just use chatGPT.
If this is a learning exercise, then yea, use CNN and then ViT
No because it's too expensive and too slow.
how slow?
ChatGPT is more like prompt-learning, there is no training
Eh for several reasons I don't want to use chatGPT
like ChatGPT in particular, or any multi modal LLM?
yea again right,
Is this a task that needs to get done? if it is, then it doens't matter if there are no training
We tried ChatGPT and it was kinda okay, but definitly too expensive. We haven't tried any other LLM
coz u have type of fastener, then you might need to do some fine tuning, hard to do zero shot stuff
Definitely, but the quality is not ensured so it's also depend on what you try to achieve.
Prompt-learning still got a long way to go and its performance is still not comparable to many SOTA models nowadays

exactly, really depends on what's the goal
Are they a hot topic right now or do you mean in the 90s?
yes, i meant in the 90s, sorry.
if you have sufficient amount of data, then go finetune an existing model. But the overhead is kinda big
overhead in terms of effort
multi modal is overkill if you don't need the text prompting part
this is the paper in case smone wants to give it a shot https://psycnet.apa.org/record/1991-32257-001
I just realized fn is not function, but functional lol
it's quite cited apparently
no like this isn't a one time thing i want to do, i have made simple projects and now want to try finetuning and get good at it
i think it's used in the same way, it's a function of functions
because of the hidden layers, a neural network would be a functional to some extent ig
If it is not multimodal, it is kinda hard to do zero shot asking about fastener types
really depends on what model have you made?
Any recommendations on the existing model and tools for this job? Probably I have to try this way
oh.. well its just a mnist reader, only difference i could say i have made is that i didn't use libraries so that i can understand the math, and implemented way to save the result of train curves and the model and loading pretrained models
There's this, but it is quite a jump https://github.com/EleutherAI/cookbook?tab=readme-ov-file#best-practices
GitHub
Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
i didn't know what else to make now, so i am making a review summarizer webapp, which scrapes reviews and then puts it through pipeline for zeroshot classification, and charts a graph of sentiment but for the summarization part i wanted to fine tune a base model instead of relying on pipeline@fiery bane
if im using the jupyter hub extension on vscode does anyone know if i can also use the vim one at the same time
alternatively does anyone have reccomendations for vim like extensions for fast keyboard shortcuts while using jupyter lab
wow... this is great, thanks a ton, visualising was a huge problem for me
something like this? https://github.com/google-research/vision_transformer?tab=readme-ov-file#available-vit-models
GitHub
Contribute to google-research/vision_transformer development by creating an account on GitHub.
vscode has them
also colab
like, that list link to this list https://github.com/stas00/ml-engineering
But maybe just go through the cookbook and see where you end up.
Also depends on your domain as well. This is geared towards llm.
You said you started with mnist, so do you actually care about cv or anything goes?
GitHub
Machine Learning Engineering Open Book. Contribute to stas00/ml-engineering development by creating an account on GitHub.
since i am in my 3rd sem of uni i was advised to set an upper limit to ml that would be up to fine tuning models but suggested that i explore horizontally, so far i have classified ml into two field one is more geared towards data science while the other is more of an ml implentation route, honestly i have no idea on the fields inside ml, none of my peers are really interested nor are my profs
i did mnist because i was told it was the "hello world" of ml
So do you recommend VIT instead of CNN?
Vision transformers are quite good apparently: https://paperswithcode.com/task/image-classification, also Efficient Net (CNN) https://arxiv.org/pdf/1905.11946
I don't have first hand experience, but from what I look around, it seems so
I think TRL is a better way to think about, rather than vertical / horizontal. or data science vs implementation https://github.com/ai-infrastructure-alliance/mltrl

GitHub
Repository for the ML Technology Readiness Levels framework - ai-infrastructure-alliance/mltrl
Great
thank you all for your help
this is a good list of the fields inside ML https://paperswithcode.com/sota

11372 leaderboards • 5047 tasks • 10460 datasets • 138538 papers with code.
so at my stage should would it be better to pick one and specialize? or are they interconnected enough that i can pursue more than one?
imo pick 1, but that's just my personal opinion
okay, thanks a lot for the resources

In mathematics (in particular, functional analysis), convolution is a mathematical operation on two functions (
f
{\displaystyle f}
and
g
{\displaystyle g}
) that produces a third function (
f
∗
g
{\display...
unexpected stuff
Adding up functions like this makes me think of Fourier Transform
because it is

they mentioned it, idk what either of those are though
you kinda use it all the time though
especially in the discrete case, the DFT/FFT is just a special case of matrix multiplication
Oh, makes a lot of sense
yeah i think im a bit lost
how are you doing with your matrix multiplication
normally either hadamard or dot product
the "with" there meaning your understanding of it
oh, no troubles so far
maybe i wasn't clear, i meant that i do not see the mapping between the discrete and continous part
there is no reflection (apparently that's not a big deal.) and im not sure the values should be allowed to be very separated
(for the integral and the sum to have a similar meaning, i think you need small intervals)

There is a reflection, if you see the parts I’ve circled in maroon, g is reflected on the y axis. Also for the part I’ve circled in purple, there appears to be no reflection because f is the function reflected and it is symmetrical
but there isnt in neural nets, that's what i meant
They usually use cross correlation
So the filter is applied directly to the input
Without reflection
What you’re referring to is convolution in the purely mathematical sense
When extracting data from a PDF, is there a method in pdfplumber to get rid of the headers and footers without figuring out the exact location of them?
https://github.com/jsvine/pdfplumber/issues/843 @shut shoal

GitHub
Please describe, in as much detail as possible, your proposal and how it would improve your experience with pdfplumber.
The PDF specification does not have concept of a header or footer; anything that looks like a header or footer is implemented by the particular software that is writing the PDF. For that reason, there is no generic solution for removing headers/footers (although there may be a specific solution for whatever specific PDFs you're working with).
so it's pretty much "styled body", you can either crop it or regex it ig

Appreciate it
i think the discrete and continuous convolutions could be mapped in certain way, as if the discrete were already bucketised areas

then the integral is a sum
For random forest regression, does anyone have a solid resource for a complete tutorial? I can't get my model over 71% r2 and feel like I might be missing something very simple because thats normally the case. I ran cv grid and even random. When I drop my only highly correlated variable, it drops to -0.001. I know that RFR isn't supposed to be sensitive to outliers and correlations but I'm sort of stuck. Switching from onehotencoding to LE increased my performance by 1% lol
This looks like a cave painting
There’s tons on YouTube
All will help
You'd think that, ha. I'll keep looking. YouTube is forcing the shorter visuals to the top. I'll select a longer vid duration.
from stable_baselines3.common.vec_env import vec_frame_stack whenever I add this I get a no module error ideas?
Are you following a tutorial/docs? If so, linking whatever you're following will probably help

Ever wanted to learn how to apply ML to games?
Here ya go!
What's happening team! This is a compilation of the RL tutorials for gaming in one mega course. In this course, you'll learn an absolute TON about best practices when training reinforcement learning models for games using Python and Stable Baselines 3.
Chapters
0:00 - START
1:07 - MA...
.
Ah, well I can't help with a video right now, sorry
Hopefully someone else can
alright its chill I'll figure it out
fixed it
it needed to reinstall stable baselines for whatever reason
Oh, nice
if I had a dollar for how many times I've had to install nad reininstall soemthing
I have to create presentation for evolution of computers for tools for data science
any tips
find survey papers
You have to be more specific then
What kind of presentation
And what are u trying to achieve
Thanks 🙂 Looks good, but certianley I'll need to change it
even someting similar to this would be nice

this would be a lot easier to make with latex + tikz than with matplotlib tbh
here's an example on how to do it with "raw" tikz https://tex.stackexchange.com/questions/124269/energy-level-diagrams-with-texhttps://tex.stackexchange.com/questions/124269/energy-level-diagrams-with-tex
and some other examples https://tikz.net/blackbody_oscillators/
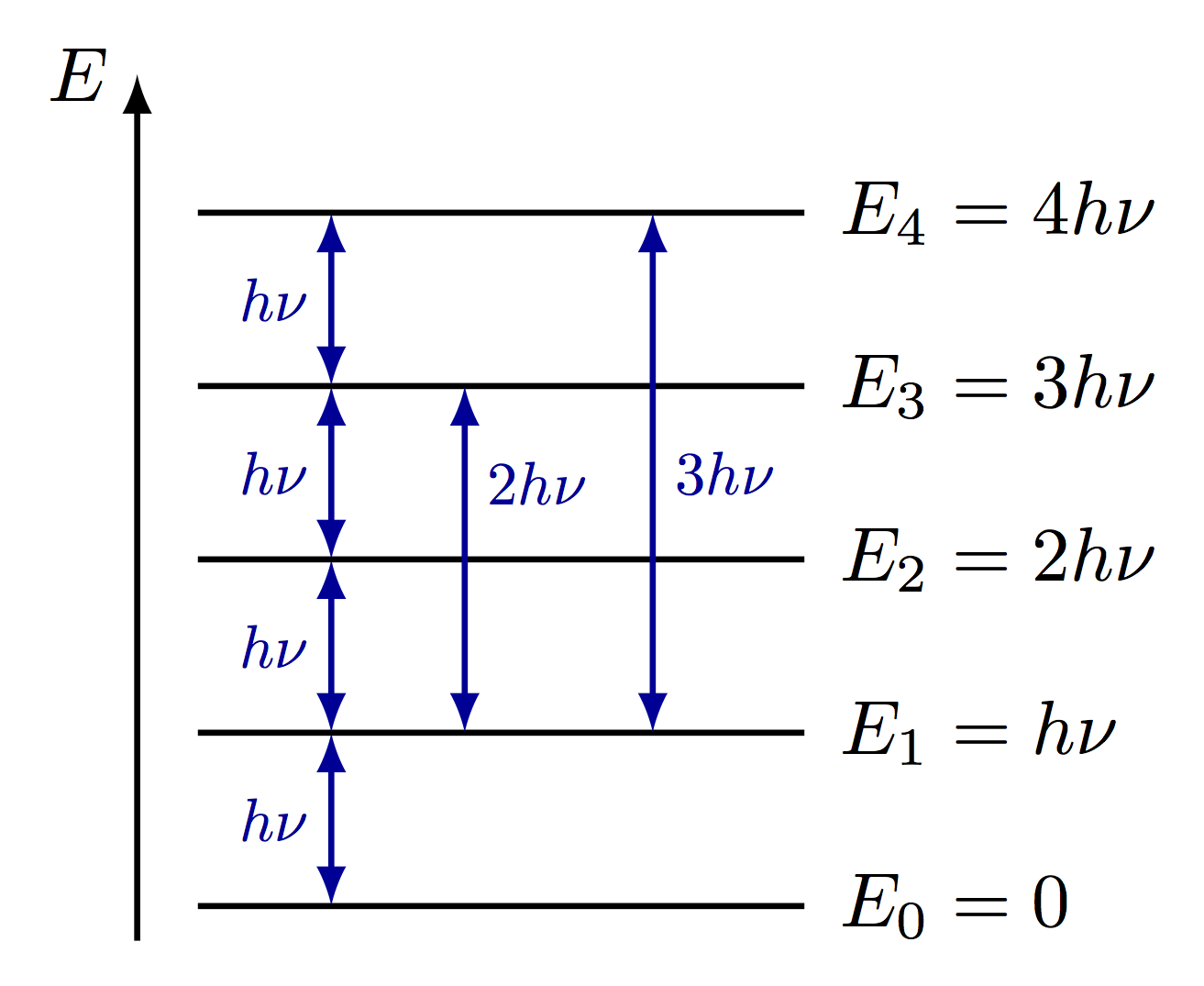
@wooden sail Link not found ;D
Not to say, Latex is a thing I don't know at all
i managed to do something like this in GNUplot but need some things that are more precisable in matplotlib

ok, so it absolutely has to be matplotlib?
what's a better option? i need to include arrows from the right of each red to the left of each blue
i would really say latex + tikz is the easiest... if you already know how to use them
but regardless of how you do it, that type of plot requires you to do a fair amount of math with the coordinates of the endpoints of the lines
but i dont 😅
never did anything with latex
then i would scavenge for people's projects that have already done this in matplotlib because doing it by hand is a mess
mpl is not a good tool for it
i searched for but they are not willing to share the code 😛
are you sure?
cuz i found some rn

GitHub
This is a simple script to plot energy profile diagrams using Python and matplotlib. - giacomomarchioro/PyEnergyDiagrams
i know this one
https://pypi.org/project/leveldiagram/
this one too

rather former than later, but I tried with the former and got some weird output given I have multielvels on the two categories
otherwise what purplys did is your best bet: trace lines working with their coordinates and doing some math to make arrows between points
okey, thank you
(don't be scared of tikz and latex, you can try it out on overleaf)
i'm guessing you're aware of it by now, but making pretty plots eats a ridiculous amount of time 😛
I see !
hello everyone , I'm starting to learn about polars, coming from pandas. There seems to be a lot of issues with this library. Has anyone tried working with polars?
There seems to be a lot of issues with this library
what specifically
heads up: polars isn't 'pandas but faster', if you just tried to e.g. line by line convert pd to pl code you won't have a good time
yes ofc appreciate the heads up
I think I found my issue lol
I was working with schema lazyframes
I just noticed you can't type cast the schema with numpy types. but instead you can only do it with numpy arrays
i just noticed also that my polars version wasn't updated to 1.0 and I was following the older version because for some reason pip installed a older version

Im kinda lost
Which is the correct channel for Machine Learning stuff?
here also for sure
Its me again
What libraries amd modules should I master to get started with TensorFlow ML?
Can you also suggest some projects that I should fi ish to get myself ready?
Its that Im really passionate about ML, and lost at the same timeIm kinda lost
Which is the correct channel for Machine Learning stuff?
I'm going to participate in SemEval 2025, which is just a NLP competition in a nutshell. Participants can publish a number of research papers (this can help boost your academic status) based on the number of tasks they took part in. I'm trying to find some partners interested in such tasks. If you are interested, maybe DM me and we could discuss further. Here is the information for the upcoming SemEval 2025: https://semeval.github.io/
fair, it's meant to describe how the two ways to calculate convolutions are conceptually equivalent.
there are packages directly to do those i think
im not sure if it achieves the same, but seems quite close. https://ftp.snt.utwente.nl/pub/software/tex/macros/latex/contrib/modiagram/modiagram_en.pdf
yeah there's probably several, i just didn't find them in 30 seconds of googling :p
It's College project,use of powerpoint can be done for presenting
why yes, but what are you doing specifically, like what is the description of the task ?, the input and the output ?, what methods are feasible ?
- TensorFlow is a framework specialized for deep learning, however, I would recommend Pytorch as an alternative since it's more popular nowadays so there are more documents about it.
- I advise you to get acquainted to basic ML concepts first like Linear Regression, Logistic Regression, Loss Function, Gradient descent, Regression problems, Classification problems, etc. Knowing all of them is probably enough for you to learn deep learning/neural network, but learning some other traditional ML algos like Decision Tree, Random Forest, SVM is also a great way to get familiar with ML in general.
- You can find some great ML courses on Coursera, I recommend the ML course and DL course taught by Andrew NG - one of the leading ML researcher.
- Your starting projects should be simple and get you acquainted with Regression problems and Classification problems (there are more types of problems, but those two are the most basic and common) like: House price prediction, Classify cat and dog, etc.
- Also math is the foundation of practically all ML methods nowadays, if you are good at math you will have an easier time understanding all the concepts, but it is not compulsory unless you want to do research in specific fields.
Pytorch more popular and less a pain in the ass too
I'm not sure if this is the right channel. I've created this using plotly and I'm wondering if there's a way to shift the neutral section into the middle and split it in half?

I'm a beginner in using plotly so I based my code from this thread https://community.plotly.com/t/need-help-in-making-diverging-stacked-bar-charts/34023/3

Plotly Community Forum
Thanks for posting this script. Successfully used with some of my own likert scale data. I’ve had real trouble changing the colours. I read the plotly documentation but I keep getting errors. Could you advise how we can implement gradient colours for each diverging stack (red for negative and green for positive responses)? Thanks
Wdym by shift to middle and split in half?
something like this if the shaded and bar blue are both neutral and its split in half by the line at x=0

I don't understand. Neutral has some value, so the neutral areas are not all the same width? Or are you saying you want neutral centered on 0?
i want neutral center on 0
Ok, paste your code for this chart ppz
import plotly.graph_objects as go
import pandas as pd
d = {'y-axis': ['TEIs and RCs S3', 'TEIs and RCs S2', 'TEIs and RCs S1', 'Socioeconomic Factors S2', 'Socioeconomic Factors S1', 'Learning Modality S2', 'Learning Modality S1'],
'Neutral': [2, 1, 1, 4, 5, 2, 0],
'Disagree': [0, 0, 1, 1, 1, 1, 0],
'Strongly Disagree': [1, 3, 2, 4, 4, 1, 0],
'Agree': [3, 3, 5, 5, 4, 5, 9],
' Strongly Agree': [7, 10, 8, 3, 3, 8, 8]}
df = pd.DataFrame(d)
fig = go.Figure()
for col in df.columns[1:4]:
fig.add_trace(go.Bar(x=-df[col].values,
y=df['y-axis'],
orientation='h',
name=col,
customdata=df[col],
hovertemplate = "%{y}: %{customdata}"))
for col in df.columns[4:]:
fig.add_trace(go.Bar(x=df[col],
y=df['y-axis'],
orientation='h',
name=col,
customdata=df[col],
hovertemplate="%{y}: %{x}"))
fig.update_layout(barmode='relative',
height=400,
width=700,
yaxis_autorange='reversed',
bargap=0.01,
legend_orientation ='h',
legend_x=-0.05, legend_y=1.3
)
fig.show()```thx though for trying
Try to add a loop for every data point then
please clarify, I've been trying to find the arg that allows me to set it at the middle of origin
Don't use relative, just set negative values for what you want on left
I think
(On mobile so my advice may be questionable)
I've noticed that but I can't find what can make it in the middle
its always left or right
Your problem seems to be way too specific to have any specific function for it. Try to find the middle point for each category then manually set the values' position with a for loop then. That's my method
Try to create the neutral bar by itself, first, with no other bar:
Oh, no, create two series: one above and one below x=0. So half of neutral is negative and half is positive
fig = go.Figure()
fig.add_trace(go.Bar(x=-df["Neutral"].values/2,
y=df['y-axis'],
orientation='h',
name="Neutral",
customdata=df["Neutral"],
xperiodalignment="middle",
hovertemplate = "%{y}: %{customdata}"))
fig.add_trace(go.Bar(x=+df["Neutral"].values/2,
y=df['y-axis'],
orientation='h',
name="Neutral",
customdata=df["Neutral"],
xperiodalignment="middle",
hovertemplate = "%{y}: %{customdata}"))
I've added this

I just need to find a way to merge both neutrals
can I set it to the same category or something like that?
Yah, I like that. Set the trace color to same, perhaps
And drop legend from one. Let me think about merging tho
I'd have to play with it a little, you could use a legend group to combine them
it technically worked

tysm @left tartan
I'll still try hunting for ways to do it more efficiently
my estimate is about 8 hours per plot.
tensorflow
i need idea
i wan to feed my model live streaming data
at 1st, i thot i wan to make network lab on a network simulator
but im a mac os user and most network simulator that their interfaces allow Wireshark to capture the .PCAP file isnt supported on ARM architecture
i wan to simulate works like the ETL pipeline, DMBS deployment and API while also deploying the model
Hello, does anyone have any advice on performing RAG on a CSV with a high number of columns? How would I go about doing it? I tried neo4j + Mistral 7B Instruct fine tuned for cypher generation but it does not work too well as the LLM does not generate the cypher query correctly, and sometimes gets it wrong.
Any tips please?
what does the CSV have to do with Cypher?..
that is the query language used for graph databases right?
I tried representing the csv attributes as nodes and relationships then i used llm to generate cypher query
what does your data looks like in first place? can you show some examples
and how do you plan to query/use it later (as in, which kind of prompt will the end user give to the model)
My data are about products - so there are attributes like name of product, use cases, and many other general information about it (cost, rating, dates etc)
The user query will be converted to a cypher query for querying the neo4j database, then returning the rsults as context for LLM to generate a reply
Which kind of queries exactly? How are you planning to evaluate how well it works?
For some cases you might want to just perform full text search over the product name, but if you use a Tool to search over it you might need to specify which values it can search in first place, e.g. provide an enum for the use cases
honestly I would provide a few options for the model to generate a JSON representing a query, then convert that JSON to the actual cypher query
cypher is kinda niche, if even using a fine-tuned model you are not getting valid queries, don't have the model generate cypher directly
Some user queries that I would like my RAG to do well in are generally aggregation type like e.g (which product is the least expensive for xx use case) and also general questions like (what are the available products for xx use case, what is the rating for xx product)
That is not the sort of question you would want to use a graph database to answer in first place
Yeah Im still experimenting. What would you recommend?
good old SQL
Text to sql?
you could try to have it generate SQL directly I guess, should work better than cypher, just make sure you're giving the model a read-only connection with properly configured permissions
I understand that we can feed the attributes (CSV schema) into the LLM to create a SQL statement.
What about the actual rows of the database? (My data is mostly text data + numbers mixed)
just run a SELECT query then feed the results directly as part of the query 
some frameworks have fancy ways of formatting tool calls and their outputs
Hmm for e.g query (what products has the highest rating), would give the sql query would be something like: select product top 1 sort(rating)
Thing is my attributes (e.g rating) is not sortable and not structured - because it is a mix of strings and numbers. Hence, would that mean i need to pass the entire column for the LLM to generate an answer?
Clean it first so that your ratings are proper numbers.
Any suggestions if cleaning is not feasible an option in the long run?
abort the entire project if cleaning the data before using it is not feasible
remember: if trash goes in, trash comes out
checking this i wonder if its used for ml in the web https://glmatrix.net/
wow ok i will see what i can do thanks
WebGL (Web Graphics Library) is a JavaScript API for rendering high-performance interactive 3D and 2D graphics within any compatible web browser without the use of plug-ins (...) makes it possible for the API to take advantage of hardware graphics acceleration provided by the user's device.
i think some of you may find this list interesting https://developer.mozilla.org/en-US/docs/Web/API/WebGL_API#libraries
you need classification model right for this?
as i understand bcua the model has to classify each data
and then create column corresponding the data
to put it differently,
apparntly you have a data cleaning project, not a data science project.
hmm okok
How could I fix this without removing the neccessary spaces? Everytime I make a function using re it seems like I remove the spaces that are needed to signify a new word.

pretty neat stuff https://en.wikipedia.org/wiki/Lp_space
appears in many ml papers
sounds like a regex question, not sure if this is the channel
just go one level more abstract and read https://en.wikipedia.org/wiki/Norm_(mathematics)
In mathematics, a norm is a function from a real or complex vector space to the non-negative real numbers that behaves in certain ways like the distance from the origin: it commutes with scaling, obeys a form of the triangle inequality, and is zero only at the origin. In particular, the Euclidean distance in a Euclidean space is defined by a nor...
What would be the correct channel?
I'm not sure either, try #1035199133436354600 ?
Awesome, thanks.

In mathematics, a metric space is a set together with a notion of distance between its elements, usually called points. The distance is measured by a function called a metric or distance function. Metric spaces are the most general setting for studying many of the concepts of mathematical analysis and geometry.
The most familiar example of a m...


Nice, how did you fix it?
ill take a look just trying to know what they mean here exactly

learnt up to l_p spaces
next is lebesgue measureable
we're gonna lose octobass to real and functional analysis before ever getting to ML
i'd really redirect to to vector norms on finite dimensional spaces unless you really wanna play with infinite dimensional spaces. if you've never heard of either, all the more reason
Is real analysis the field where you have to make proofs and things like that?
that's all of math
i would put it as "real analysis is the more formal version of calculus"
the flavor where you do go through all the proofs instead of being handed down the recipes
Ah, thank you
for most people not studying maths, linalg, real analysis, "intro to proofs", or "discrete mathematics" will be the first and possibly only time they ever have to fight against proofs and rigor
and the stuff they're discussing just above is several steps after that, which is a pretty bad idea for someone without a decent feel for maths just trying to get started with ml
added threshold as 0.1, because output images were on that range
also added batchnorm and dropout layers in model!
yeah, maths is very important for this field
What would be a good way to learn some stuff about proofs (at least as a high level overview, just for fun)? Intro to proofs sounds promising
I mean, lebesgue measurbale is literally in his screenshots
i see it, but i would still say that given the background and the questions they've been asking before, it's best to read something that.. they're more likely to understand at all 😛
everyone has to start somewhere
What I'm trying to say is, if see L_p spaces from the perspective of metric space, it would be easier to think about other stuff later on like KL div, or what contrastive learning is doing
read analysis is probably not that somewhere
Well, everyone has their own path. I don't like math, but it seems that some people want to take the more theoretical and fundamental path 1st, and I can appreciate that.
that's also my preferred path, but there are better reads to start from before jumping into lp spaces
starting from inner product spaces is more reasonable
i pretty much have no direction, but also no goal
then you are going nowhere, but also, you have arrived.
lol
pretty much how it feels indeed
you have win at life, congratz
shit happens , don't worry!, just keep going..
ty :)
why grokking ml has ofsetted operators?
its hard to read formulas
sth like instead of yhat - y
yhat y -
do you have too this issue?
I see more of this type in this book
with text no problem just some formulas

whats wrong with it?
Looks like some sort of formatting issue, is this a pdf? Maybe try a different pdf reader or something
maybe epub?
Yep tbh having to deal with Lp spaces and those are like heavy maths, depending on what you say on them it can be a master degree math topic lol
Like it's a Banach space with the associated norm blabla
Most ppl don't know shit about this and can still stay sota about ml DL, they eventually knew but only researcher mind about such things
thanks for the comments @spare forum
I have multiple tool data stored in different .txt files, which I have provided to my Langchain + OpenAI RAG model. The setup allows the user to input a prompt, and based on that prompt, the AI suggests the best tool accordingly. However, I've encountered an issue where the AI is recommending tools from inappropriate categories.
For example, if a user types 'I want to make a website,' the AI might still suggest tools related to video editing, which is incorrect. What should I do?
did you confirm that the RAG part of the pipeline picks the right txt files for the user's query?
yes its even working
if i write tools for video editing its showing proper
but sometimes its giving irravelent results. its showing video editing tool in "website building tool"
do you keep a record of the past conversations that are taken into account and then does this occur after talking about said irrelevant stuff or just talking with it for longer?
or does it happen to suggest something completely irrelevant on the first prompt as well?
if you don't keep a record of the past conversations, perhaps, you're fine-tuning the model instead? and over time it starts to pick up more of the more common stuff discussed
but I'm assuming here that it's only a per session thing
actually i dont keep the past conv
its like
when i ask it to give me tools for video editing, it gives proper tools. so for the tools with presentation. but when i asked to give the tools for website building, it gave me video editing tool. so some part it messes up
so what should i do to make it give proper and accurate results
what's the consensus on AI generated code?
it can be pretty effective for well-specified prompts. non-programmers often don't know what to ask for.
(that's my opinion, not necessarily the consensus. but I think I have more experience with generative language models than anyone else in this server.)
I was wondering if anyone here knew of a good textbook covering building transformers or other deep ML topics
check the pins
ooo thank you
yeah i'm just curious about how people feel about getting PRs that were generated using AI / how can they tell?
never trust anything AI generated before having a human double check it
it can seem to work great in small constrained toy examples, but often fails with real world larger & messier data - specially if the user doesn't properly understands how the system works
totally agree
if you've confirmed that the code does what you intend it to do, and it upholds all the standards of that project, then it doesn't matter if you used AI to create it.
if someone just started making a bunch of PRs with untested, AI-generated code, that person is draining the energy of open-source maintainers and should fuck all the way off.
If it's something that is commonly done it can work ok with a well crafted prompt(s).
It may fall under legal gray area though (i'm not a lawyer, look into it).
i'm just curious about how the maintainer can tell if something is AI generated (i'm not trying to fool anyone and don't use AI to blindly write code, just generally curious)
When the code quality is average or worse, has hallucinations, or other oddities that you would notice if you read a bunch of open source projects made by humans.
also, i've been sensing some kind of tension between newcomers (who are more like to use AI to write code) and experienced developers
newcomers should be honest about their capabilities and ask for opportunities to contribute at their skill level. a lot of repos have "good first issue" tags in their issue tracker.
However, the problem with this as a general answer is that it depends on which model, what it was trained on, and what it's being used to generate.
have any of you experienced someone submitting AI generated garbage lol
Yes. Including automated responses to PR comments.
are any of you sensing this tension too or is it just me lol
i wonder if this is going to reduce trust in newcomers contributions
There are also a bunch of better models that are not released publicly, nor scaled all the way up, but may already be used somewhere without anyone knowing.
No, this is a general problem present already. Just talk to them and you can tell, both if they are human and if they actually have read and understood the project or are trying to.
ah so you don't think AI is necessarily exacerbating this issue?
then i'm curious if you think it's going to have an effect on OSS at all
as of now AI cant write anything complicated enough to warrant an issue
Open Source has all kinds of issues, spam is annoying, but security issues are worse and ever growing.
security issues in general? or especially because of potential "bad" AI code
Intentional exploitation, not by AI bad code.
Is anyone interested in taking part in shared tasks ? Specifically the upcoming SemEval 2025
i saw online that around 60% of github users are using github copilot and they're mostly newcomers so just curious if this is going to affect the open source community, it seems like this channel mostly thinks that it won't have an effect
copilot also cannot write anything complicated any any decent code review will catch it
For any project I'm in charge in you can't submit copilot code. Potentional legal reasons.
is there some kind of check to make sure the code isn't generated by copilot? or is it based on your discretion?
I don't think that should be a problem as long as you don't blindly use it and treat it as a supporting tool rather than use it to do all the work for you
code review + tests
I can't tell always, I have to take their word at some point, but if I can tell it gets deleted and you are banned.
interesting. i'm curious if you've banned more people after copilot launched compared to before...
Tbf, those who don't use AI to help them write code nowadays are probably seniors with conspiracy theory. AI-generated code is not that bad lmao, just don't misuse it
yeah i guess but also it does hallucinate and it's annoying to keep checking code...
No, contributions are low in every OSS project beyond small changes. Most projects are driven by one or a few people.
Pick any OSS project on github, and look at the contributors page, the first one will probably have 80% of the code.
yeah 100% agree. is there a way to tell when someone has been banned by just looking at a repo's pr?
They are senior engineers for a reason.
I have just have my own ban list.
Its great for efficency like excel auitofil for repetitive code, just not actually designing applications
ok so @iron basalt basically what i'm getting is that from your experience there's 0 tolerance for AI code and it isn't a huge issue because the number of people contributing isn't super high so it's not that annoying. lmk if i misunderstood anything
totally agree
Yes
Yes, this is not like posting rage bait on Twitter to pay rent. Very few people actually want to contribute.
lol true
I don't deny their ability, but denying the convenience AI brings due to your skepticalism is pretty bias, dont u think ?
They understand from many years of experience of seeing new things that are there to provide convenience making things worse, trust their experience.
This is not like senior management, they are engineers.
If/when it's actually good enough, they will let you know.
I agree, I feel like senior engineers let their egos get in the way and claim that AI is nowhere near as good as them
I mean I'll tell you one thing,
That's wrong, just like how the old gen judges the new gens how easy their life is compared to them just because all the technology and stuff in real life
its a lifesaver if you dont wanna read through documentaiton
Again, this is not random old people yelling at clouds, they are people with decades of software development experience.
so do you think it's creating a tension between the seniors and juniors? have you experienced this?
I know that in modern culture it's the norm to disregard senior's advice in the context of politics and such, but this is not that.
I mean, Its with all levels of engineers. but I've definetly seen a correlation with ego and hate on AI
what do you mean by ego lol
And yes, what is the good in those experience when you don't even try to adapt to new things ? I've seen seniors said that AI "help" them do their job not actually "do" the job for them. Those deny AI convenience just have big egos and way too fixted without actually trying them first
because ai could technically save the managers time by making their subordinates check with the ai for answers before going to the manager?
I've seen profs in my school can't even code properly lmao
devs thinking they are just built diff
in the world of cs, you either have imposter syndrome or an ego
its very rare to find people without eirther
True lmao, could not agree more
Professors are not what i'm talking about. I mean decades of working experience.
You say profs dont have experience ?
Some do, many not so much.
Depends on if they wanted to stay in academia.
I don't get it, why are you so skeptical about an AI could autofil a "for loop" for you. You could even check it afterward
even then, depends on the experince
I know a lot of senior engineers that work for the goverment or another "slow paced setting" and they don't know anything outside of their very specific domain
Just don't tell that AI to build the whole system and u should be fine
and even their domain knoladge isent often impressive,
just saying, work experince does not translate to wisdom
This is fine and all, but now you are bordering on a snippet tool, which is not what many want to use it for.
Well, I disagree with that
with AI, comes integration hell
its pretty good at designing systems ngl and individually coding out components of the systems
its just
integration is the aids part, taking all the boiler plate based code and fitting it together like a puzzle
yeah i feel like not just integration but also with some repos having certain style guidelines - not sure how ai would match these guidlines and then maintainers can probably tell it's ai generated
It can if instructed
quite easilyt
for individual repos?
its one of the things it does best. As long as you specify the style guides
hmm i tested it out a while ago and it generated bs
you probably just need better prompt engineering my friend
lol
it seems like this channel has people on 2 opposite ends of the spectrum - fans and haters
i'm trying to be in the middle tho
Tbh, instructing AI is prompt-learning and its performance still not comparable to other types of learning
wdym
I do work on such systems, I just also understand the senior engineer's concerns.
Thanks to the rise of LLM, there is a new type of learning call prompt-learning. But here is the thing, u don't train or fine-tune the LLM, u just make prompts for it and make it do specific tasks like classification. And compared to other methods, the performance is really bad. It could achieve somewhat average results if the validation data is simple enough.
Ok i'm kinda new here, but is this channel the place where we discuss the theory behind AI and how to build it or do we just give comments and reviews about AI-based tools and the views around AI ?
This is generally about both the practice and theory of DS, including AI/ML. Debating AI tools like copilot is not really what's covered here, altho perhaps a well framed question might be on topic, I dunno.
why is my validation so spiky?

It seems like your model diverged at random epochs. It could have happened because of high learning rate, but it converged in the end so this shoud not be something that you worry about.
Guys, whats the best web scraping tool?
I want to get data on NVIDIA GPUS and compare them with Intel.
lol what
Now my validation loss is lower than my training 💀
I think my BatchNorm code may be incorrect because thats only part thats different during inference

Maybe its because I applied batch norm after every conv layer and deep layer
Why are you dreading over low loss ? Shouldn't you be glad ?
yeah but its still a little strange lol
ig it just has to do with the regularization
I've never seen regularization caused such problem
What is the value of ur learning rate then
learning rate of 0.00001
It could be some hardware problem too
and batch size of 32
perhaps
Ye, then i have no ideas, i've never dwelled too deep into regularization or normalization that much. But like i said, if it converges in the end, it works just fine, don't try to fix it lol
I have found somewhat of a feasible answer to ur problem: https://stackoverflow.com/questions/61287322/validation-loss-sometimes-spiking

Stack Overflow
i want to detect which one is genuine image and which one is spoof image. and i have +- 8000 dataset images (combine). so i trained the model with LR = 1e-4 BS = 32 EPOCHS = 100. and this is the re...
idk what's the size of your dataset, but you can pump up those a numbers a bit, maybe more stable
make sure you don't have a bigger batch size than the number of iter in epoch (just my own instict, no actual math here)
i know you are trying to do some sanity check.
make sure this is not a sign of a bigger issue.
Just redo it with 10 random seed, if they all 10 converge despite the spikes, then that's fine
alr thx for the tips
Hey
I'm trying to build a real time hand gesture pipeline
import React from "react";
import { createRoot } from "react-dom/client";
import App from "./App";
import "./style/index.css";
import * as tf from '@tensorflow/tfjs';
import '@tensorflow/tfjs-backend-wasm';
const root = createRoot(document.getElementById("root"));
tf.setBackend('wasm').then(() => {
root.render(
<React.StrictMode>
<App />
</React.StrictMode>
);
});
I have basically used this apprach to set the backend to wasm
But I get these errors

you have only one error failed to load resource
I mean other are labeled as warnings but have error word in text 🤔
I think rather javascript and webassembly related
hi im new here 🙂
i wrote an astrophoto ai denoise script in pyhton but i have small (big) problem with it, can someone help me out?
it denoises well, but i have really visible tile borders, where should i start to get rid of them?

tried doing overlap, changing stride and its still there
heres sourcecode: https://paste.pythondiscord.com/ATOQ
Hi, I am trying to load The Llama 3 model rom hugging face on my colab
on colab -
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B", low_cpu_mem_usage=True)
It takes forever and stops after running out of memory (Your session crashed after using all available RAM.)->
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 25%
1/4 [00:24<01:12, 24.10s/it]
It happens even tho I am using GPU
On my jupuyter notebook, this command -
! huggingface-cli login
takes forever to run
Ideally it should show something like this -
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
A token is already saved on your machine. Run `huggingface-cli whoami` to get more information or `huggingface-cli logout` if you want to log out.
Setting a new token will erase the existing one.
Is there any workaround to fix this?
I did try using this - low_cpu_mem_usage=True but still it crashes
What's ur ram size
Ideally it should be 16gb

Is this imbalance of 4 star and 5 star reviews over other classes bad for training?
somethings to keep in mind:
- be sure that you have a healthy amount of 1-5 classes in both training & testing sets, e.g. by setting
stratifyinsklearn.model_selection.train_test_split - using accuracy might not be the best idea
Gotcha, is there something equivalent for pandas or pytorch? I split it currently like this:
train_size = 0.8
train_dataset=df.sample(frac=train_size,random_state=200)
test_dataset=df.drop(train_dataset.index).reset_index(drop=True)
train_dataset = train_dataset.reset_index(drop=True)
And what do you mean by accuracy not being the best idea?
equivalent pytorch / pandas
off the top of my head, I don't think so... iirc last time I did something like this, I just grabbedtrain_test_splitorStratifiedKFoldfromsklearn
accuracy not good
imagine for simplicity, your have 1000 data points for reviews, 900 gave a 5 and 100 gave a 1.
simply by predicting everything to be a 5, you achieve 90% accuracy
though now that I look at it, is that kaggle? if so, just use whatever metric they use
Ahhh yeah that makes total sense. That wouldn't be a problem if each of the classes exist in equal quantities in the data set would it? I am actually not planning to use the entire 20k records. I have space to make each of the classes in equal amount
Yes, it is from kaggle
its 20 gigs RAM
pretty nice post showing logit and logistic are inverses https://math.stackexchange.com/questions/3252945/how-to-justify-the-logistic-function-is-the-inverse-of-the-natural-logit-functio
1st time reading about SVMs (and co), very neat idea, if anyone wants to discuss https://en.wikipedia.org/wiki/Kernel_method
one does get into moody waters fast https://en.wikipedia.org/wiki/Inner_product_space lol
???
nice image-summary of svms

from scratch? don't even try, the amount of data required isn't really accessible to individuals
otherwise, checkout huggingface
yeah I read about it in grokking ml
embed in 3d space and then project back
but before doing embedding move triangles up and squares down
how do you read or understand the 3d plot
I recommend kernel method section in grokking ml
in 2d, there's no line that'd separate the red from blue
the idea is, to use some function to transform those 2d points into higher dimensions, in this case 3d, then in that higher dimension, you might be able to find a hyperplane that can separate the data, which is what's shown in the 3d plot
yes at start there is not linearly separable but after kernel trick its seperable
Yeahhhh, thanks i understand now
it's separating each class according to the fitted plane
the dots are transformed using the kernel trick, from 2D to 3D.
true but I really wanna learn llms from scratch. I don't know what kind of datasets are used for this but I could prolly find a small one at least online.
I have heard using vectors that map words with values and multiple other ways, no idea which dataset I would need for this
hmm so unproject is same word for embedding?
nice explanation, i missed it
right now, most mainstream LLMs are built from a special DNN architecture called a transformer
map word -> values that's called the word embedding layer
also the kernel trick and SVMs are 2 separate things
it's just that usually you use them together
os.environ['pipeline'] = 'code'
# Verify that the environment variable is set
print(os.environ['pipeline'])
#Create the question answer pairs using groq api
def groq_qa_pairs(text):
#Create the client
groq_chat = ChatGroq(
#Keep the temperature low to maintain more precise question and answer
temperature = 0.3,
#Retreieve the key
groq_api_key = os.environ['pipeline'],
#Get the model type
model_name= "llama3-8B"
)
#Give the prompt
system_prompt = (
"You are an expert in the Indian legal system and your job is to summarize legal documents. You will be given text from real court cases"
"and you will need to generate what the underlying question was of that court case and the outcome of the court case. Here is an example"
"of the format I want you to follow: \n\n"
"Legal text: {t}"
"Q:\n"
"A: ").format(t = text)
#Get an output
response = groq_chat.generate(system_prompt)
return response
groq_qa_pairs(pdf1)
TypeError: Got unknown type Y
Why is this the error for me?
I'm pretty new on this stuff so I don't really know what really happened.
I have heard openai api providing embeddings, haven't looked into it. Embeddings generally in this field mean the mappings?
show the full traceback
kernel is map for svm
yeah, just non linear normally, i'd expect
svm are classically just linear
It's very long
in the general sense, embeddings are a compressed representation of data
usually they'll be vectors with a fixed size (determined by the model that produces it), and be normalized as floats in the range of -1.0 ~ 1.0
and you have rbf, polynomial, gausian kernel
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
but requires you to know a useful fn to map them
those are just transformation kernels for svms or wht do you mean? @verbal oar
cuz most are also activations in DNNs, thats a separate thing ig
I mean when you provide as parameter kernel=
in scikit learn for example
'poly', 'rbf' etc.
ig those are just doing rbf(x)=>x_t
and so on, so they are just specific $\phi$s in the wikipedia page (which is to my understanding a non-linear transformation, i.e like an activation in DNNs.)
thanks I'm understanding it!
i know it sounds stupid but can I go ahead to find an embeddings dataset to create an llm? I don't know how big they would be yet, I'll research on it
creating a LLM from scratch requires training on millions of data samples at least ; large models like Llama are trained on Trillions of tokens
take a look at https://github.com/karpathy/nanoGPT though, it is a bit more reasonable but won't be useful for much besides research/learning

GitHub
The simplest, fastest repository for training/finetuning medium-sized GPTs. - karpathy/nanoGPT
you can use an open source text encoder model to create your own embeddings though, look up the architecture of some popular open source models
embeddings are also frequently used for vector similarity search ; if two sentences carry a similar meaning, it is assumed that their embeddings will be similar. This can also be used for documents, images, videos etc. as long as you have a model that can encode that data (and there are even some multi-modal models which can encode multiple types into the same 'space')
random example of something I did for images
with text, that's commonly used as the first step in a Retrieval Augmented Generation pipeline
hmm idk, where did you get the code from?
I looked on examples on groq and based it upon there.
I can find the example I was basing it on.

GroqCloud
A simple application that allows users to interact with a conversational chatbot powered by Groq. This application is designed to get users up and running quickly with building a chatbot.
This was what I based it upon
my guess is that you're using an incompatible combination of model class / api provider / model name
What can I do to fix this?
that is entirely different from what you are doing
copy/paste from somewhere that works
either langchain's documentation or groq's documentation
it may be interesting to read the creator of SVMs
just realised he's in lex fridman
this is pretty cool summary ig:
In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the kernel trick, representing the data only through a set of pairwise similarity comparisons between the original data points using a kernel function, which transforms them into coordinates in the higher dimensional feature space.
Okay awesome
thanks! it's looking interesting so far as I'm reading it
I'll experiment on simpler embeddings first.
Also that website, I don't think the output is supposed to look like this

it is working as expected, it just does not works very well lol
oh, that is the example one
yeah it is very sensitive
Im finding everything except the exact same kanji

should be easier to find same ones than similar according to me, it's impressive btw
this worked for me, the angles and intersections are very important

I have heard the term huggingface a lot, what exactly is it? python module? some tool for creating text models?
it's a website, a bit similar to GitHub but for machine learning models and datasets
it also has a bunch of python libraries that makes it easier to access models hosted in their website
edit; oh yeah, it also has the Spaces that let you deploy python applications for free like the above 
article is pretty large, but so good. the math is overall quite digestible imho https://en.wikipedia.org/wiki/Support_vector_machine
sharing in case anyone wants to discuss
are the models free to use? can I use it to create new text models smarter than gpt2? (I have heard its the free fine tunable gpt)
if I see anything needs to be paid for I'm out

most models are free to download and you can run inference locally without additional costs besides your own compute/electricity, but you have to check their licenses (just like you would need to if you were downloading something from github, or installing from pypi)
some of them are free to use via their API or inside of Spaces
you cannot use Hugging Face to train models though, they focus on inference and deployment
for training you could try Google Colab or Kaggle if you want free cloud compute, and iirc that gpt repository I linked earlier is at least on the same level as GPT2 and can be trained in them
hello! im having some problems with very long html parsing times (talking about minutes for around 30 pages), is that normal?
idk but you could use multiprocessing and map those to your cpu cores in parallel, right? unless its only one html, a can't be splitted
ive got the code posted in #1035199133436354600 , wondering if u can have a look to see what i can do
is your 'time' including the request or just the parsing?
was the whole code so probably including the request
even so it takes a longer time compared to my other projects
oh, i think your first step should be to identify the bottleneck
yeah but otherwise we dont know what to fix
good to know free options exist, in the repo readme, they mentioned A100 CPU or GPU, I don't recall what exactly it was, is required to train them

ironically it's a gov website 🤷♂️
oh well - what are some ways to isolate the bottleneck?
training an AI takes a lot of computations
meaning that you need a pretty high tier gpu to have decent speeds
You don't need gpu to train models, you just need a cpu and at least 35 years.
just time each part
import time
start=time.time()
#code (reqquest)
end = time.time()
print(end-start)
#...
use a profiler, like line_profiler
if you're just running, then the requirements drop by a lot
personally I can run an 8b model pretty comfortably on a 4060 (8gb vram)
ain't gpu "graphics" pu, what's it doing to train text models
graphics involve a lot of matrix multiplications
neural nets just so happen to do a lot of mat muls
i see that's cost effective 👍🏻
lemme see how much A100 costs
10.18548583984375 request
0.7679240703582764 parsing
seems like its the request - is there any way i can increase the speed?
Deep learning specifically, other options can be trained on a CPU.
I should not have checked 💀
you don't want to know, and I don't think you can buy them anyways cause it's targeted at large companies
best you can get are consumer grade cards, so like the RTX 40 series
That is not its sole purpose, GPU can handle specialized computation way faster than CPU due to more specialized cores. Just like purplys said, those specialized computation happen to be mat mul
didn't know gpus can be used for computations
Kaggle offers free A100 30 hours a week, even dual T4 for the same period
if it's multiple documents,
https://www.reddit.com/r/learnpython/comments/woh54x/how_can_i_speed_up_python_requests/ ?
seems the first possibility.
this sends your requests sequentially but does not wait for replies (iirc.)
oh, I misremembered and underestimated GPT-2
yeah you're not going to be able to train something GPT-2 level without a pretty large budget
training from scratch takes a lot of compute
just heard i can use 30 hours free a100 👍🏻
I should try it out
Even google colab offers free T4 with limited time used
that's 60 hours a week
if you're willing to compromise, e.g. not train the entire thing from scratch, then the hardware reqs also drop significantly
it is P100, not A100
My bad then
here's an estimate from llama factory:
https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#hardware-requirement
Wait, isnt P100 better than A100 ?
no, not even close
maybe i should level down a bit.
either creating another type of model from scratch or start off from a checkpoint as Purplys said
Bruh, my bad again

any suggestions for other types of models I could build from scratch? I have already made image recognition ones(on limited objects), I want to go further
well as a reference, the only 'people' releasing models that are trained from scratch are basically all companies
example:
- llama: meta
- gemma: google
- qwen: alibaba
- nemo: mistral + nvidia
Yes, creating a LLM straight away is way too ambitous. I don't want to discourage you but even the predecessor of LLM - the PLM (pretrained langage model) - took a very long time to research and develop, not mention the amount of pretrained data (TBs of text) and computing units.
there are way more finetunes, i.e. take an existing model and tune it on some other data
or just try some classical ML like Kaggle's Titanic with sklearn instead of neural networks
if you step outside of LLMs, most ML architectures aren't that compute expensive to get started
Only big companies nowadays can afford to develop LLMs ngl
stares at stable diffusion yeahhh maybe "outside of generative ai" /s
I have used openai fine tuning, it doesn't give the feel of creating something, rather using a product
Guys Mtech CSE or Mtech AI and ML,which should I choose?
you can fine tune open source models like Gemma or Llama
alright I'll get into kaggle and try those out
what does that mean?
is it different somehow? isn't it simply providing conversation examples to get responses as per your style? or is it free?
Gemma and Llama are open source Largue Language Models (if that still makes no sense to you, think of it like free versions of ChatGPT)
fine tuning is a process through which you adapt a model to perform better on some specific tasks using your own data
oh its free
tbh, LLMs don't really 'feel' that magical if you just look at the code or something
most of the time's spent waiting for training
like I think I remember seeing the entire llama3 training file is just 300 lines of python
But I asked which specalization should I choose,either Mtech CSE or Mtech AIML,I'm studyin AI and DS 3rd year
Even fine-tuning LLMs require a behemoth amount of computing power. I tried inference only with a 7B params LLM from huggingface with google colab T4 and still i couldnt do it due to limited GPU RAM
I assumed that the part you were discontent with was just using an API versus actually running the training loop, never mind
yeah I was not replying to you in that first message 🙃
ahh mane
you're probably doing inference on the fully weighted model, which isn't really needed imo
somebody Welp
ah wait we don't use api here?
Wdym
I can run a 8b model with 16k context really comfortably on a 4060
with quantization
you could use an API, but the charm of open weights models is running them yourself
*well, you don't use an API as in not a HTTP rest API, you'll still be using some library API
Dude, its a goddamn 4060
I used free cloud GPU lmao
you said you used a T4, which has twice the vram a 4060 has
Around 15 gb
could you provide a reference on fine tuning llama with python?
yeah, 4060 has 8gb
there are 8GB and 16GB 4060s
isn't the 16gb only on 4060ti
that's a new color, we have purple names?
So what do you recommend how to do it tho
we don't, no
I do 
thanks! wonder why I didn't get that in results directly
#Create the question answer pairs using groq api
def groq_qa_pairs(text):
#Create the client
groq_chat = ChatGroq(
#Keep the temperature low to maintain more precise question and answer
temperature = 0.3,
#Retreieve the key
groq_api_key = os.environ['pipeline'],
#Get the model type
model_name= "llama-3.1-8b-instant"
)
#Give the prompt
messages = [
("system", "You are an expert in legal analysis."),
("user", "As an expert in legal analysis, your task is to read the following legal text and generate a corresponding question that reflects the key legal issue, followed by a concise answer that summarizes the outcome of the case. \n\n Legal text: " + text + "\n\n Q: What was the key legal issue addressed in this case?\n A: Please provide a summary of the court's decision.")
]
# Generate response
response = groq_chat.generate(messages)
return response
pdf1_res = groq_qa_pairs(pdf1)```
I keep getting "TypeError: Got unknown type system" and whatever I do to replace system it always returns some sort of an error.how ya get it I want 
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
run a quantized model (tho idk how to do this specifically on colab)
stuck with damn no color for 5 years
https://paste.pythondiscord.com/XLGQ
This is the full error
What do you mean by "quantized" ?
using 8-bit or 4-bit floating point precision instead of 16/32/64 bits
so usually each weight in the model is like 16 or 32 bit floats
quantization is trading precision for resources, so i.e. an algorithm might cut the weights' precision down to 8 bits, 4 bits, or even lower
Oh, there is a way to trim the params down like that ?
so em where's the model stored and where's the fine tuning part

yeah, you don't just truncate the weights to fit in range though (you can, but you can do better)
rn the quant techniques give more/less bits to some weights, so you end up with something like 4.2 bits on average for example
that image is only running inference, no fine tuning / training
it is downloaded from Hugging Face when you call from_pretrained iirc
generally you'll want to avoid using HF libraries for fine tuning, they're really focused on inference/deployment
When you call from_pretrained(model_name), huggingface will download the model for you if it has not been downloaded yet. And you fine-tune the downloaded model by training it with ur own data.
oh that clears it, thanks!
Man i wouldn't have to go find a bajillion ways to optimize such thing if i were not dirt poor. Doing research in CS is really not for everyone lmao
it's always le money
ah right gaussian rbf
anyone wants to join at reading this https://en.wikipedia.org/wiki/Neural_network_Gaussian_process
this one is quite neat as well https://en.wikipedia.org/wiki/Gaussian_process
Hi, by any chance can someone who has gotten a job as a data analyst/scientist look over my resume and give me feedback 🥹 ty
processed_dataset = pd.DataFrame()
def dataset_creation(qa_text):
q = ""
a = ""
answerHit = False
#Iterate through the data and make a dataset
for word in qa_text.split():
if answerHit:
# If "Answer" word is detected, start appending to answer
a += word + " "
else:
if word == 'Answer:':
# Switch to answer mode when "Answer" is detected
answerHit = True
elif word == 'Question:':
# Skip the "Question" word
pass
else:
# Append words to question before detecting "Answer"
q += word + " "
processed_dataset = pd.DataFrame([{"Question": q.strip(), "Answer": a.strip()}])
dataset_creation(pdf1_result)
print(processed_dataset)```
Why doesn't processed_dataset create a dataset? What am I doing wrong?hello, your dataset_creation function does not return anything.
you also should pretty much never create an empty dataframe.
can you guys suggest me some great projects for final year
of HS or College?
college
LLM without pytorch or tensorflow
will it be good for 200 marks
i havent seen a rubric so i have no idea
yhea understandable
i was going for predictive analytics
but llm from scratch is also kinda cool
thanks man
3d "image"/model classification
llm from scratch is basically impossible without compute & data inaccessible to individuals
Perhaps they meant a neural network from scratch which is actually possible
A fun idea (that's a bit out of style) is retraining the last few layers of large models. That might be a neat project. The old version was something like:
For a large image understanding model (like AlexNet) retrain the last few layers to predict something like a breed of dog. While AlexNet can do this itself, it's not really very good at it and you can fine-tune it for a specific use-case.
I think this is a really interesting aspect of LLMs that could be explored. How can we start with a pre-trained LLM and retrain it for a specific task.
finetune for specific usecase
sounds vaguely similar to lora (the actual technique is different I'm sure)
That does sound fun, I need to look into this sort of thing
both are easily obtained
A bit, LoRA is a combination of fine-tuning and optimization (often quantization, but I'm not super familiar if that's how LoRA is doing it). I think the fine-tuning is the easiest bit for something like this. It involves collecting data and training a model. Quantization or reduction then involves optimization that may be mathematically heavy for a project like this.
Go through kaggle, you'll get some ideas.
no, especially the compute as you would have to pay and college students might not be able to, and for the data there aren't good public datasets. you'd have to scrape it yourself (people training LLMs this way is what has prompted platforms like reddit to lash back against scraping and require paid API usage)
You can always fine-tune LLM for specific tasks. That is the point. LLM is just PLM (pre-trained language model), but large (of course), which is specifically need to be fine-tune for specific tasks. I think people keep mistaking that the only purpose for LLM is question answering.
I feel like deciding your own project is a very bad idea. If you are planning to work on a graduation thesis, find a mentor (MSc or PHD graduate) then do some research with them, they will give and validate your topic to fit the academic style. You can't just decide on your own with this sort of thing and consult strangers on the internet is a big NO NO because most (if not all) Unis/Colleges won't approve random projects for a thesis. This is a tedious process and you should start ideally a year in advanced.
But if you want to do projects for elective courses then this is fine i guess.
you are right
thanks man
interesting paper, ai in pharma (current open problems.) https://onlinelibrary.wiley.com/doi/epdf/10.1002/adhm.202401312
just pick one from this list https://paperswithcode.com/sota
11393 leaderboards • 5057 tasks • 10460 datasets • 138886 papers with code.
often quantization, but I'm not super familiar if that's how LoRA is doing it).
as far as i know, no
u guys agreeing to this?

Well, it depends on how you define "increasing aptitude", if you look at the last few years, they have become better, sure
Is it still increasing? If yes, how much and is it enough to worry about? I honestly don't know
The first part about creativity and critical thinking I agree with
how many of you use LLMs to summarise text?
(it's related to your 1st Q)
i think they are apt tool for the task, 95% of the time, for 95% of the people
I don't because
- I wouldn't trust it to be good enough (I'm quite pedantic)
- I like reading
(well, I also don't have a use case for it, I don't have a job or anything that forces me to read many texts I don't like)
I've done it a few times when reviewing a text outside my domain, and used it to find relevant search topics. I was recently looking at some particular financial math paper and was unfamiliar with the algorithms involved, and used GPT to summarize and find relevant search keywords (it came down to finding the right starting point for the topic)
I try to force myself to not rely on GPT to explain something, but it is useful as part of a search strategy
Using it for search can be useful yeah, I sometimes try googling something and don't find what I'm looking for (or anything close) within a few minutes because I don't know the topic/field at all
Asking an LLM gives you the keywords you can then google
interesting, i try to read as many things as i can fit in my head, and chatgpt is pretty much a coworker
think of it like paralellising reading XD
yeah outside of domain is neat, cause it presents a relevant 'glueing' of information
I disagree. It has never been an asset for any scientist, regardless of time.
could u expand?
The problem I have with it is the incompleteness: I need to see the forest, not just the trees. A summary of a passage by itself doesn't help me understand the big picture. (Even if it were accurate)
very rarely
I mostly use it to write
I cannot find a time/scenario where a scientist, young or old, have to memorize stuff. Except maybe, in cases where their labs burned down / got bombed etc2
i mean those scenarios are pretty much everywhere
how do you think a lab scientist conducts itself in a laboratory? is 90% memory
Ah, I didn't get your point on first read. You disagree with the premise of the passage.
IDK lol, I'm a computer scientist, I just SSH to my labs.
I imagine they write notes???
i dont see an llm as different from automation a computer does, but certainly ppl are segregated in the opinon space
And they can consult notes too?
yea haahah. There are things i like and don't like about llm, but replacing scientist memory just sounds weird.
you have to memorise a lot of stuff, especially during your training, that may be unnecesary, i think that's the point
like asking to know what the -p flag is for accesing through ssh
by training, do you mean like, highschool and bachelor and course work?
yes, anything that requires memorising should be reduced in place of tools
that's how i interpret it
would you be ok mastering a task that a robot can do?
like, the docs are always there if you forgot, you can always do man in the shell.
and if you use it often enough, you will memorize it
(better and faster than yourself.)
Yes, LLMs are getting more and more effective, but certainly cannot replace real engineers at the moment, those who tend to hate LLMs are probably senior devs who are too skeptical to try new things, and they r probably too paranoid that they think AI will take their jobs one day
i agree with that ^
orrr the seniors devs who have to fix things up when they broken because the junior devs are misusing and abusing llm?
I think LLMs just haven't been around long enough to be used in the same way as some other automation tools IMO, with time people will find (and invent) more sophisticated ways to use them despite their limitations and tradeoffs vs other tools
There's some infrastructure missing around LLMs is what I think. RAG is a good example of an enhancement that could make LLMs much more useful for a specific purpose, and as people come up with more enhancements like that (and continuously improve them), things will get better
I believe LLMs encourage lazy learning, doing the minimum / seeing the tree rather than understanding / seeing the forest
how many senior devs would you need knowing kernels in the future i.e this ones: https://en.wikipedia.org/wiki/Kernel_(image_processing)
sp how to hand-craft them.
In image processing, a kernel, convolution matrix, or mask is a small matrix used for blurring, sharpening, embossing, edge detection, and more. This is accomplished by doing a convolution between the kernel and an image. Or more simply, when each pixel in the output image is a function of the nearby pixels (including itself) in the input image,...
not just memorising, but only a few minutes should be spent in the concept / idea, then move on
yeah that's great criticism imho
That is my point, i said they are not good enough to replace real engineers at the moment. Even SOTA AIs can only execute like 17% of the engineer's tasks. A pathetic number so don't misuse it
That has always been the purpose of new techonologies. They make your life easier or encourage "laziness" as someone says.
The difference here is: the goal in education is not the task, but the learning. You're supposed to pick up the bigger picture along the way. At best, an LLM might help you with your project, but at the cost of the journey.
I see, I agree with that
So what you were mentioning is the process, not the goal
this seems to agree with the paragraph though, as long as one accepts that education is mostly about 'regurgitating information'
Huh? I and the passage are saying the opposite
yeah but you are not the education system
Learning is not about memorization, but understanding
"An LLM can help you get there, but cost you the journey" I'm gonna put that on a plaque above my oven in your honor.
To remind you not to use an LLM while cooking?
Why above oven?
or to not buy meals but preparing them
I agree this is a problem: incentives. If your incentive is to pass a course with a good grade, an LLM may help. But you'll be a weaker candidate than those who learned.
however, i do use a chopper, haven't regretted it.
(and an oven, as opposed to making a fire outside.)
imho it's very important to look at what aspects have already been replaced by technology
Hey, you're welcome to aim for mediocrity. More jobs for the rest of us.
BillyBobby gives me cooking advice
BillyBobby is an LLM confirmed
That was perhaps a lot of snark. My point is: you're not going to land a DS or Ml job without understanding the low levels
lol, now where's the #cooking
yeah, i mean, i didn't clarify cause it was fun
but we are talking about the opposite aspects of the education system
im saying that one should remove the aspects that are repetitive, you are saying one should not remove the learning
those not always overlap
nah, understanding is still low-level, one must apply, evaluate, analyse, create
(a la Bloom's revised taxonomy)
I'm actually curious how LLMs and education will converge; how we'll see LLMs incorporate into learning systems.
Any beginner book for stats?
possibly relevant

complete beginner? No stats course ever?
kinda
let me check
This can depend on your goals and background. Statistics by David Freedman is a decent book it you're at highschool level math, for example.
well i need for postgraduate i just forget all stats like probablity distribution and statsitical inference
Oh, so you want a calc based stats college level course?
Maybe find a recent syllabus from your Uni and grab that text?
well i have stats and queueing theory as a subject
Try Statistical Inference by Casella and Berger
is there any good resource where i can learn more about attentions with it's math?
i want to implement it on unet
the orginal paper?
Attetion mechansm has long been a concept in NLP, dating back to RNN. I assume you want to learn about the most recent type of attention, Multi-head attention, which is the most prominent factor contributing to the success of Transformer. Then try to google transformer concept in general, you will learn about multi-head attention eventually. I also believe StatQuest made an excellent video explaining the Multi-head attention concept
is this comment AI-generated?
Bruh, are you that skeptical
videos would be good😄
actually i want to learn mathematics behind attention
Tbh, i was suprised that the math behind Multi-head attention is just a bunch of matrix multiplications
ohk
what is attention
yeah i too was surprised
Imagine this ok. You want to translate a piece of text. What are you gonna do. Read each sentence then translate them 1 by 1 or translate the whole text all at once.
i found that it's easier application on unet
It's usually the first scenario so you pay attention to each sentence then translate them rather than the whole text. It's a rough explanation but in NLP the math behind it works somewhat like that. Each token will be affected more by adjacent tokens, and less by far away tokens
Yes, it originated from NLP
ohh,i get itt
Ngl lads, Dr Andrew NG gives a better explanation than me, and it has been too long since i last checked it
actually my core concern is on attention gate. I'm trying write attention gate which will use remote sensing techniques on input image. Attention unet has simpler architecture.
That's why i'm trying to learn it for scratch especially mathematics part
What you are saying seem to be related to Computer Vision, which is apparently not the field of my expertise, I don't know about attention mechanism in CV then, sorry.
Ok np. Actually it's part of deep learning.
just looking for resource of attention
Have you done any projects using CV?
Yes, but just basic ones. I delve deeper into NLP
so you expert in nlp

Every common ML models are DL nowadays
I try to
ok
I mean, I find if you want to learn the math, then go to the paper is the best way lol.
If you wnat video, maybe this? https://www.youtube.com/watch?v=-QH8fRhqFHM

AI/ML has been witnessing a rapid acceleration in model improvement in the last few years. The majority of the state-of-the-art models in the field are based on the Transformer architecture. Examples include models like BERT (which when applied to Google Search, resulted in what Google calls "one of the biggest leaps forward in the history of Se...
Guys.
I use the classic jupyter notebook for coding
I recently learnt about poetry package
how to install it so that i can use in jupyter notebook?
do you guys use package/envs managers?
When you install python, u have pip as a default package manager. But install anaconda for virtual envs
(I strongly recommend not using anaconda)
what do i use then
Is there better alternative ?
You can usually just use regular virtual environments. Poetry is intended to make environments easier to reproduce.
Just regular virtual environments.
Anaconda was created when native virtual environments were less mature. The use case for anaconda is pretty much deprecated, but a lot of people just haven't moved on.
Wut ? How do you create virtual env without conda ? Am i missing something ?
I dont get it
Python comes with the ability to make virtual environments with venv.
Oh
so you wnat us to use venv instead of conda
Yes
if we use venv, can we use poetry?
I work for an AI company, and anaconda is banned at my company. And we all get along just fine.
Why do you think you need to use poetry
I see
people told me that its a good package manager
i liked it when they told me about
Native virtual environments are the default assumption. Just use those unless there's a specific limitation of them that you need to overcome.
Tbh, just use whatever you are comfortable with. It's just package managers, not maleware
(I treat anaconda as malware)
jupyter notebook comes with anaconda
Eh, someone on stack overflow treat pip as malware too so my stand is always neutral until I've tried all the new tech out
is jupyter notebook malvare too
You have it backwards
crazy
LMAO MY BAD
Notebooks are fine as long as you understand how they manage state
what is a state
also coming back to my doubt
lets say i use venv to manage my envs
but i still use anaconda to launch my notebook
is it fine or not?
Yes, i have used it for so long without any issue.
i personally like classic jupyter notebook too
i dont prefer vs code
even though it has some good features
Umm, u can install jupyter notebook in VS code
like the classic jupyter notebook?
Yes, with all the VS code benefit
Download the jupyter notebook extension then u can use it
will it look like this

@serene scaffold what notebook do you use
like vscode?
does pycharm support notebooks
also you use vscode notebooks?
is this the right channel for a doubt i have regarding saving the final image after running K means clustering on it?
yes it is
Yes, save me the hassle with manually turning on the notebook with conda prompt
but you can also ask in #1035199133436354600
fair enough
alright. sorry for the spam coming up then 😅
how do you manage envs or install packages in vscode?
i have never used vscode
im familiar with pycharm though
Not community version
I'm currently working on running K-means clustering on a thermal map image of a waterbody. While the clustering itself is working fine, I'm not able to save the clustered image correctly.
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import cv2
from sklearn.cluster import KMeans
img = mpl.image.imread("ipv2/resources/processed/thermal_image.png")
plt.imshow(img)
img.shape
X = img.reshape(-1, 3)
X.shape
kmeans = KMeans(n_clusters=1000)
kmeans.fit(X)
clustered = kmeans.cluster_centers_[kmeans.labels_]
clustered = clustered.reshape(img.shape)
plt.imshow(clustered)
clustered = np.clip(clustered / 255.0, 0, 1).astype(np.uint8)
# clustered = clustered/255
cv2.imwrite("clustered_1.png", cv2.cvtColor(clustered, cv2.COLOR_RGB2BGR))
so professional version supports notebooks?
Y