#data-science-and-ml
1 messages · Page 125 of 1
Okay, I was slower than expected but the RAG project is as good as done now
Spent too much time on the UI
I used sveltekit. It's what I know the best
This is what I went with. I put in mock data because it doxes me

Honestly. I'd never want to build a BIG frotend project
I don't pay enough attention to data flow
Yup. I can imagine. It's the same with my frontend code but I honestly don't care there
I think to do frontend well you need a checklist of how to manage state
yo am i allowed to ask for help for my python script?
I kind of mentally do it, I have some heuristics about which state solution goes where. I also try and keep as much out of the FE framework as possible
definitely, ask away
so i dont have any background in coding ok. i have to make a scoreboard for project and its so annoying bc my teacher my program to have file handling
the script i have theres something wrong
Maybe if it's something like this you should make a help channel #❓|how-to-get-help
can any one help me my computer vision task?
Just ask the question. Don't ask if you can ask the question please. A lot of us work etc. and while we are we might look at discord and prefer to just answer a question one off straight
I am making a software aka web app to segment floor and apply pre-made texture. The texture will be in png formate and square shape tile.
Now by using segmentation model I segmented the floor, but now it time to apply texture in cm with dept in image that where i am stuck from many days the linear look of texture dosent look real so we need to do pov scale (near tile bigger further tile smaller) but here issue is of room direction again please sugggese me what I do in this
I tried prespective scaling but room direction is another issue i tried using inpainting but they never listen to prompt and never took my texture as parameter
huuuh wdym 
how can we identify that out input image is in PIL or numpy ?
I mean mostly they are in PIL right? if we didn't convert into numpy!
hugging face is also not loading!!
but hey I didn't tried DDOS
wdym on the last part ayo
he said possible reasons might be , I tried DDOS on that site, ( in simple visiting same IP from multiple PC on same location )
but I didn't do that
use a vpn trust
This can be good for UX but also bad. It depends. What I know is that this is for #web-development 😄
i have to calculate vanishing points?
I didn't know openai has vector stores 👀
Means I could've been done with my project even faster
Yes but it's not just that
I could've ran a cron job on my raspberry pi to fill the vector store and then I could've done basically all the rest client side on gh pages without having a backend (if I used bring-your-own-key)
u mind if u dm u?
At the expense of vendor lock-in
Rn I have a bunch of other concerns like hosting the backend and the ELT pipelines on my server (which isn't hard, I basically reuse the same CI/CD)
But it's still there
so look at real image and the texture my s/w applied I need to make that texture in tile shape like 30x30 cm repeating all over floor creating3d effect in image


yes but some one else need in tile shape
i am stuck for 1 week
Vendor lock in as in, right now I'm doing my embeddings and generation with OpenAI but in my code they're decoupled / behind an interface. I could switch the embedding models to ones that understand code better if I want
Or with a larger context window
like using prespective transform? function
Ah, yeah like that
My CI isn't that advanced lol. I just SSH into my server and build the container
I'm not using specific cloud services
No, a VPS
It sounds messy but I pay a fixed fee per month to host all of my projects

It's very simple
in this the issue is if the floor area is less then floor also leak out of this 2 lines
It's worth trying this workflow btw
see this picture

in this picture the lines and point wont align and floor will leak out?
I wanted to do it old school and just "rent" a server full time
I wanted predictable pricing
But for GPUs I'd do what you're doing ofc
If you're hosting basic web apps you could get away with €40-50 per year
Especially since the things I rewrote in rust use so little resources
Your data stuff I just work on-prem
Or idk databricks
def load_image(image_path):
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image_rgb
def preprocess_image(image):
if not isinstance(image, Image.Image):
image = Image.fromarray(image)
input_tensor = preprocess(image).unsqueeze(0)
return input_tensor
image_path = "/content/drive/MyDrive/lane_detection/original/002136-R.jpg"
image = load_image(image_path)
input_tensor = preprocess_image(image).to(device)
so now things are getting clear to me
but one thing is
after doing
preprocess_image(image), why we are doing .to(device)
are we using cpu/gpu for this function?
okay then it's fixed that .to(device) is use to do all operations on device which will be either cpu or gpu
@final kiln
hey do you remember I asked about deeplabv3 model few days ago
now I have learned this, so now you can clear the parameters
because it is only predicting left truck
Does anyone here work as a data analyst that ends up having to do things waaaaay above your pay grade ?
I’m working as a data analyst to support myself through uni and I started out just doing basic dynamic reports and answering business questions for the execs
But nowadays I find myself having to create forecasting models, clustering of clients to help my boss bring new products etc..
I feel like I’m learning a lot but I’m also doing a lot more than my colleagues which are doing simpler stuff
I’m the youngest one by about 10 yrs
then it's good sir!!
why you want to focus on money then?? , you are learning more as compare to others!
I asked you about deeplabv3 few days ago!!
I was having issues regarding output
see I have come this far

now the question is why all objects are not segmenting?
sry but where did I check only truck channel?
in my final mask output?
yup!!
I think there maybe 20 channels !!
but is this possible to combine all of this into one masked image
hmm? and how to do this?
changing in argmax?
ohh
then what ?
how can we get that output tensor?
wait that output variable has it
right?
ohh my bad sorry
yup I print that output variable and now got tensor
yeah clear now
output_predictions = output_predictions.cpu().numpy()
do I Need to do this for 'output' variable as we have now removed 'output_prediction' variable completely?
ohh let me try then
hmm got it
yup got it !!
here all classes are different
so yeah we have from 0 to 20 classes here
no
it's
21, 512, 512
strange
but how did you find out that we don't need argmax because I read about it and it is usefull for getting indices of tensor
did not understand this!!
okay in code right okay
help(model) is professional info I guess
but nice thing
okay so that's why the only truck was segmenting
they all got segmented in traning phase , but when using argmax only one class is indexing ? right
inference? what's that
okay
yeah got it !! fundamentals
wait wait, but it does return the index of the largest value
The argmax is one of the functions that PyTorch provides. By using the argmax function, we can get the maximum value of elements from the tensor as well as we can also get the indices of the tensor. In PyTorch, we have another function to return the second-highest elements from the input tensor.
I did this with for loop

wtf did happen here
wait I used colormap by the way
I did this with claude's code!!
means?? class 6?
ohh heatmap
right?
no it loooks scary now

what do you think about this?
it's AI generated ignore
so what now??
I need to learn about thresholding then !!
claude gives more accurate code than gpt
yup sir always!!
what this called as first of all
all the heatmaps and all other maps
I use that for only plotting
it is color map!!
I guess
should I try for different image?
okay
IOU
GitHub
I am new to Keras so sorry if the question is silly. I found here https://keras.io/examples/vision/deeplabv3_plus/ the deeplabv3+ model to perform multiclass semantic segmentation. I need to adapt ...
this is becoming interesting now
challenging but need to do research
okay one question,
this loss function is used in last layer right?
yeah got it!!
the way we normalize the input tensor
so which loss function to use??
okay thanks for the time !! gentlemen
then what to do??
softmax activation sorry
go for the interview!!
Can someone help me with RL? specifically either DQN and custom environments
just ask the question!!
I mean elaborate more!
I want to create a model that generates a tensor of input shape(X, Y, Z) for example 3, 3, 3
[['0', '0', '0'],
['0', '0', '0'],
['0', '0', '0']],
['0', '0', '0'],
['0', '0', '0'],
['0', '0', '0']],
['0', '0', '0'],
['0', '0', '0'],
['0', '0', '0']]]
into [
[7, 4, 12],
[2, 16, 9],
[10, 15, 5]
],
[
[14, 3, 11],
[6, 8, 1],
[17, 13, 7]
],
[
[8, 6, 3],
[11, 2, 16],
[4, 12, 15] something like this, then we validate the tensor based on some rules I've set (I have the function in place already) if the tensor generated is valid, we give it a score based my scoring function (higher is better)
I've googled and it seems DQN is the best option for this, but all the DQN tutorials I've seen include openai-gym games, but I want my custom environment here
@final kiln
do you think I should try YOLO8?
becasue I tried using softmax but still not getting proper output
because I think it can't predict about lanes
wait lemme search that
how was interview??
15 is for person
wait I am searching
still finding which class belongs to which object
yup I also find out this
These weights were trained on a subset of COCO, using only the 20 categories that are present in the Pascal VOC dataset. Also available as DeepLabV3_ResNet101_Weights.DEFAULT.
whole dataset??
it's 4gb
hmm searching now
it's available on kaggle
and it was created in 2012
here they have specified 20 classses
and yeah there is not lane marks here only some car detection and birds
is this is the reason that only left truck was detecting?
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/dbstats.html
here we go I found that
Anyone help?
yeah just ask
^
what about YOLO8?
yeah he is the same guy!!
I don't even know about fundamentals of RL so sorry!
there is a dedicated discord server for RL you can ask there
I thought you have deal with that anyways!
Where?
reinforcement learning discord
search this on browser
and you will get that
and yeah dont take pressure!

They are dead mate
no
Yes
Obviously
what about Learn AI Together?
you are there
so ask there!!
maybe first ask in general discussion
I'll try
Best book on machine learning?
pinned msg!
Means?
always sir!
what you not found?
pinned msg or boooks in pinned msg?
Book in pinned msg
okay are you begineer?
Yes
what you know in coding?
and what about you interest in ML?
NLP?? , Self driving Cars?? , healthcare, finance??
or pure data science , handing with data?
if you don't know then it's okay
maybe start with
-> types of ML
-> algorithms in each type
then you need to read more articles!!
just read whatever you can read about AI and ML
if by "ai" you mean the stuff that's mega advertised these days, look into neural networks and pytorch (they call it "deep learning" but that's just a buzzword for big neural nets)
though it might be better to start off with more fundamental stuff, e.g. you'll at least be working with numpy, and sklearn has many "classical" (read: not neuralnet) algos that are also interesting
Okey !
Pandas important?
yeah for data!!
what about you maths??
pandas is if you actually do like preprocessing, data cleaning, etc.
if you're just fed a good dataset, you can skip it (though this almost never happens, it's a dream scenario really)
I read a lot about calculus
if you go to pytorch's website, they do load one of these datasets and train on it as an example(MNIST or smthn I forgor), and you don't see pandas there
Hmm
yup MNIST
Then suggest me now, I just complete a playlist on basic python..... What should I do next?
algorithms!!!
first types of ML
and then each algorithms in each ML
maybe try atleast 3
and why we use that!!
Algorithm mean supervised learning and unsupervised learning?
they are types and in that types we have bunch of algorithms!
try to write something
having watched someone else do it, doesn't mean you can do it
doesn't have to be something complicated, heck even just try making something that appeared as an example in the videos you watched, without going back to re-watch them
Okay 👌
this is helpful for me also , thanks!
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems,
I found this book trending in machine learning
No... This is a name of a book
I get it, I'm just saying that TensorFlow is on the decline, sooo
Ohh
Now I start learning algorithm.... Any suggestion ?
check the pinned messages in this channel
Where is it? 😅
new things

now adjusting confidence levels
the more it goes like 0.9 and all it stop segmenting
and less it goes like 0.1 or 0.01 it tries to segment road as a car ( maybe because box )
so I think 0.128 is best I read about this in github issue post
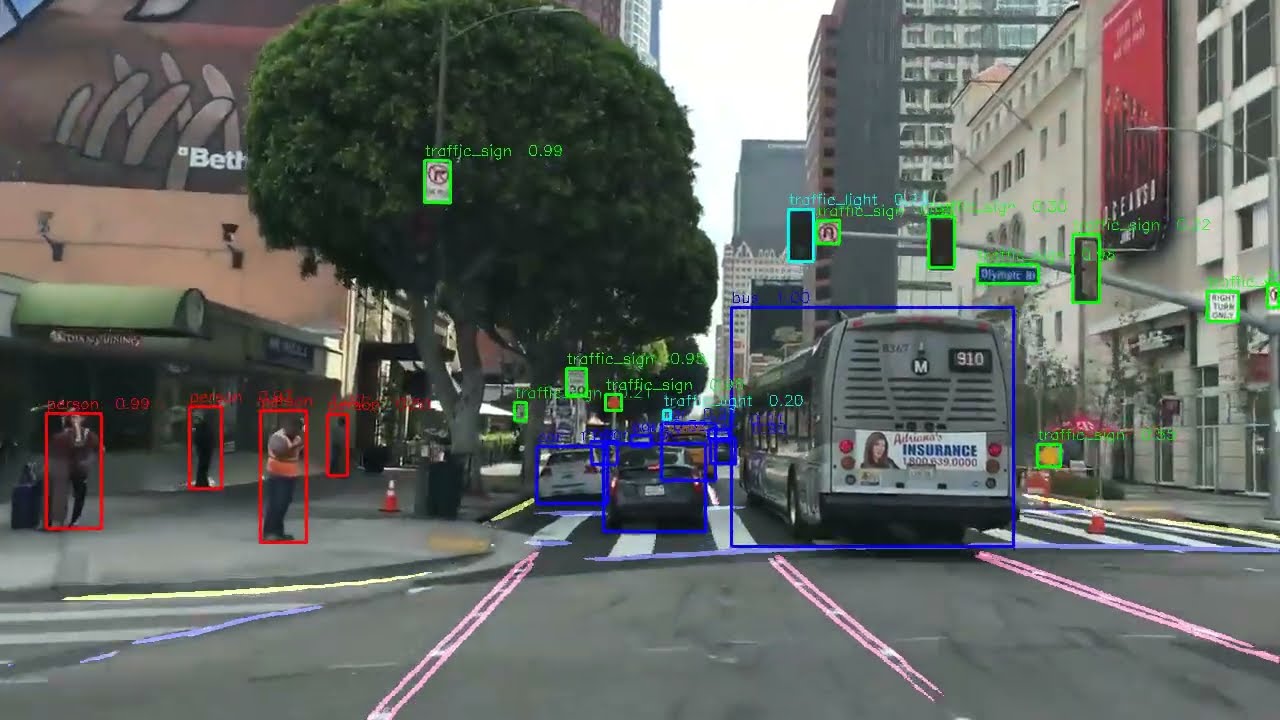
Multitask YOLOv8 (YOLOv8x++) for Object and Lane Detection
Model Architecture: YOLOv8x++ (YOLOv8x + Lane Detection Model)
Input Resolution: 960x960
GFLOPs: 693.67
Parameters (M) : 77.92
Dataset: Only BDD100K (without any other datasets)
Task : Object and...
he is able to do this!!
Alright ! It works. ```import torch
import torch.nn as nn
import torchaudio
from scipy.io.wavfile import write
import re
import matplotlib.pyplot as plt
Device Configuration
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Audio Configuration
SAMPLING_RATE = 22050
HOP_LENGTH = 256
Load Pre-Trained Models
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp32').to(DEVICE).eval()
waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp32').to(DEVICE).eval()
waveglow = waveglow.remove_weightnorm(waveglow)
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
Text Normalization Function
def normalize_text(text):
text = text.lower()
text = re.sub(r"[^a-zA-Z0-9\s]", "", text)
text = re.sub(r"\s+", " ", text).strip()
return text
Save Mel-Spectrogram to an Image
def save_mel_spectrogram(mel, filename):
plt.imshow(mel, aspect='auto', origin='lower')
plt.colorbar()
plt.title("Mel Spectrogram")
plt.savefig(filename)
plt.close()
Text-to-Speech Synthesis Function
def text_to_speech(text):
text = normalize_text(text)
sequences, lengths = utils.prepare_input_sequence([text])
sequences, lengths = sequences.to(DEVICE), lengths.to(DEVICE)
with torch.no_grad():
mel_outputs, _, _ = tacotron2.infer(sequences, lengths)
mel_outputs = mel_outputs.squeeze(0).cpu().numpy()
save_mel_spectrogram(mel_outputs, "mel_spectrogram.png")
mel_outputs = torch.FloatTensor(mel_outputs).unsqueeze(0).to(DEVICE)
audio = waveglow.infer(mel_outputs, sigma=0.8)
return audio
Save the Audio to a File
def save_audio(audio, filename="output.wav"):
audio_numpy = audio.cpu().numpy().squeeze()
write(filename, SAMPLING_RATE, audio_numpy)
Main Execution Block
if name == "main":
text = "Hello, how can I assist you today?"
audio = text_to_speech(text)
save_audio(audio, "output.wav")
This ones a little more natural.
Oh yeah I’m not complaining about the learning part, it’s more so that I have way too many responsibilities and I feel like my academic performance is suffering because of that.
It sucks because I really need this job to pay for university 😦
Also being the only one with intimate knowledge of many of our datasets (by virtue of working with them a lot) means I’m usually the main guy higher ups go to for business questions
I guess I showed a little too much initiative 😦
yooo that's fire
where can you guys find text corpus to train natural language models?
in txt file if you know
to train it to do what
LLMs in general need a metric fuck ton of data to train from scratch
to do what?
For typing assistance, so like something like gmail’s autocomplete when writing emails, but really any large text corpus from a tv show script will be great too
but you don't want to use an existing language model? why not?
because any language model that you can make on your computer will suck
(compared to "large" language models)
also for the record
you are probably better (for your local use case) to not use AI
it is a common thing to do algorithmically
something like Symspell can do compound aware completion, it just requires loading a dictionary, and the rest you can realistically do with a trie and set of common phrases and terms within emails
I just built something simple to generate unique text and I want to try it out with bigger text corpus
[Davies] 1.1 billion word corpus of American English, 1990-2010. Compare to the BNC and ANC. Large, balanced, up-to-date, and freely-available online.
Appreciate it
This is super crazy. It's evident my system posses some kind of transfer and recursive learning. It's learning and applying that knowledge dynamically in real-time. It then saves in a conversation database which is embedded and vectorized for later use.

Ngl that screenshot of a wall of text generally means not much to most people
also from the text in that screen shot... It looks like it is largely regurgitating nonsense
How would I sort a multi-level dict like this by name?
a = {'abc': [{'name': 'fro'}, {'name': 'lucky'}], 'def': [{'name': 'Leyda'}]}
I know its already sorted, but in case it wasn't, how would I do that via sorted()
While keeping memory efficiency in mind. Imagine if this dictionary was 1GB for example.
This doesnt work sorted(a.values(), key=itemgetter('name'))
just sorting the lists inside the values?
you can make a dict comprehension that does that
into a single list
"flatten" how?
there's two lists potentially in .values()
'abc' is a list of dicts and 'def' is also a list of dicts
flatten as in only return a single list
and sort all values regardless of key (abc, def)
so one sorted list result from a multi-level dict?
yes
but without loading everything into memory (if possible) and using generators when possible
sorted() would need to load everything into memory anyway, but..
i guess an itertools.chain of a comprehension of generators from a.values() would work
sorted(itertools.chain.from_iterable(map(itemgetter('name'), list_) for list_ in a.values()))
how would I keep all the values in the dict not just 'name'
how would i sort by a specific key, lets say not name but another key?
using itemgetter(key) as the key?
ty I think I got it?? return sorted( chain.from_iterable(set(map(itemgetter(*values), list_)) for list_ in price_comparison_map.values() ), key=lambda x: x[-1], reverse=reversed)
values = ('key1', 'key2', 'etc')
does the key= actually work?
it seems like it's indexing a set
reverse keyword argument expects a boolean value btw
obviously reversed will work too, but it's just... well, for one it can be confusing, for two, it's semantically incorrect
is i t better to catch a datetime strptime conversion error or do some if checks
Is this a good practice?
# Ensure we are in the correct date
try:
effective_date = datetime.strptime(row['Effective Date'], "%m/%d/%Y")
except ValueError:
continue
else:
if effective_date.year != year:
continue```The idea is to skip the given row in the CSV if we failed to parse the effective date
def sort_nested_dicts(data):
for key, name_dicts in data.items():
data[key] = sorted(name_dicts, key=lambda x: x['name'])
return data
a = {'abc': [{'name': 'fro'}, {'name': 'lucky'}], 'def': [{'name': 'Leyda'}]}
sorted_a = sort_nested_dicts(a)
print(sorted_a)
I asked my AI system for you 🙂
Is doing two sorted() calls to get top 10 increases and top 10 decreases better to do with two separate sorted() calls? Or is it faster to just call sorted once and then reverse it via [::-1] instead to get both?
Yes, its generally faster. Some situations where reversing a single sort list much be the prefered method like very small list.
Is this a type of scoring system?
# Function to sort a list of dictionaries based on the 'value' key and get top increases and decreases
def sort_by_value(data):
sorted_data = sorted(data, key=lambda x: x['value'])
# Get top 10 increases
top_10_increases = sorted_data[-10:]
# Get top 10 decreases
top_10_decreases = sorted_data[:10]
return top_10_increases, top_10_decreases
# Function to sort nested dictionaries by a specified key
def sort_nested_dicts(data, sort_key='name'):
for key, name_dicts in data.items():
data[key] = sorted(name_dicts, key=lambda x: x[sort_key])
return data
# Function to flatten and sort a multi-level dictionary by a specified key
def flatten_and_sort(data, sort_key='name'):
# Use itertools.chain to flatten the lists
flattened = chain.from_iterable(data.values())
# Sort the flattened list by the specified key
sorted_flattened = sorted(flattened, key=lambda x: x[sort_key])
return sorted_flattened
# Sample data for sorting by 'value'
data = [
{'name': 'item1', 'value': 10},
{'name': 'item2', 'value': 30},
{'name': 'item3', 'value': 20},
{'name': 'item4', 'value': 25},
{'name': 'item5', 'value': 15},
# Add more items as needed
]
# Sample nested dictionary for sorting by 'name'
a = {'abc': [{'name': 'fro'}, {'name': 'lucky'}], 'def': [{'name': 'Leyda'}]}
# Sort the data based on 'value' and get top 10 increases and decreases
top_10_increases, top_10_decreases = sort_by_value(data)
# Print the results
print("Top 10 Increases:", top_10_increases)
print("Top 10 Decreases:", top_10_decreases)
# Sort the nested dictionary based on 'name'
sorted_a = sort_nested_dicts(a)
# Print the sorted nested dictionary
print("Sorted Nested Dictionary:", sorted_a)
# Flatten and sort the multi-level dictionary by 'name'
sorted_flattened = flatten_and_sort(a)
# Print the flattened and sorted list
print("Flattened and Sorted List:", sorted_flattened)```hey yall, im trying to setup chatgpt 3.5 turbo api in python and just getting errors out the ass, can't even get one good answer from following official docs and yt videos to get the damn thing to properly supply an answer based on user string input
ive even paid $5 for usage credits lol
NEVER MIND FIXED THIS AND CAN USE GPT4 OMNI NOW
Hey, I don't suppose anyone can help me implement the Esoteric Pull kernel in python/cupy
I understand the algorithm, but I'm a little at a loss on how to write the kernel
I need a data structure which is (X,Y, 9) and then for each X,Y, I want to touch specific neighbors
I'm a little at a loss
Actually, I'll just try to explain it to chatGPT 😄
Apparently I can do it like this
kernel_code = '''
extern "C" __global__
void esotericKernel(float* data, int X, int Y) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x >= X || y >= Y) {
return;
}
float sum = 0.0;
int count = 0;
// Add (X,Y,0)
sum += data[(x * Y + y) * 9];
...
That more or less solves my confusion
GPU programming seems so magical, but slowly peeling back the layers
lmao based
I'm going to have chatgpt explain and provide "example" code for my own C assignments when i retake in the fall lol
Yeah I commonly use it in my hobby projects. It's pretty great except when you start trying to do something no one has done before
I was getting pretty frustrated for a few weeks that my cupy code was so slow. Moving to c++ kernel is doing the trick
u guys really need to use cuda in ai case? for me it's just a wrapper, only caring about the python level api
cuda is not needed at all, however it's like 100000000000x faster with so it's recommend
id say
i mean for example in the pytorch case should we care about the cuda level api? we just use the torch's api, we do not have to write cuda code
well in pytorch the code with cuda and without is basically identical, you just need like one or three extra lines telling the program to use cuda
I'm actually doing something that isn't AI, I'm just using the same tech stuff, so yeah you don't need to do what I'm doing
I'm implementing the Esoteric Pull algorithm for Lattice Boltzman Method fluid simulation on GPU
we can disagree about this
image you are loading a model across different gpu devices, you have too deal with how the vram are arranged
pardon?
https://github.com/KushalBKusram/AdvancedLaneDetection/tree/master
I watched a video on youtube and then found this repo
GitHub
An Advanced Lane Detection program highlighting lane area - KushalBKusram/AdvancedLaneDetection
and now he is able to do lane detection
yeah but I meant like.. if you use one gpu it's the same
that make senses
I'm currently building a machine learning model for a classification task. Right now, I'm at the stage of imputing missing values. Below is the code I'm using to fill in missing values for categorical data:
# Categorical columns
cat_cols = ['Gender', 'Married', 'Dependents', 'Education',
'Self_Employed', 'Credit_History', 'Property_Area']
# Impute categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
cat_imputer.fit(train_df[cat_cols])
train_df[cat_cols] = cat_imputer.transform(train_df[cat_cols])
test_df[cat_cols] = cat_imputer.transform(test_df[cat_cols])
When I run the code above, I get this error:
TypeError: Argument 'a' is not recognized as numeric. Support for input that cannot be coerced to a numeric array was deprecated in SciPy 1.9.0 and removed in SciPy 1.11.0. Please consider 'np.unique'.
How can I fix this error?
Can you enlighten me what does that error means?
What confuses me is why I got an error when I try to impute categorical data
These are the packages I'm using:
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
what should I do?
How can I determine the suitable version of Scipy to handle this issue?
hey Lisan
just see this
nice? so quick or what?
I am thinking now that I will label my data using this method
because YOLO8 is segmenting cars and trucks properly\
but not Lanes
but I have seen some videos of some people that they are using YOLO8 to detect lanes also!!
but how?
have they finetunned that ? or they trained the same YOLO8 model for lane detection also?
what do you think?
But I don't understand what the sentence "Please consider np.unique" in that error means. Can you explain its meaning?
and unique is unique
simple!
https://github.com/qinnzou/Robust-Lane-Detection
I found one
GitHub
Contribute to qinnzou/Robust-Lane-Detection development by creating an account on GitHub.
hey @final kiln
the above code is appropirate I guess becaause he is using CNN ( U-NET ) to train the dataset
and that other guy which I provided above this is just using ROI ( Region Of Interest ) and some mathematicals term to derive lanes?
so what do you think which method should I follow, I mean I also want to learn the architecture
it is in tensorflow what about pytorch
the main goal of mine is to create my own model, so that I can learn more things
that's why I am simply labelling my data first to train it
but to label I need some pre-trained models
yeah but my goal is not just segmenting images and lane detection so that I can use pre-trained model
I wanna make my own model!!
yup, but data ?
you mean labelled data with object segmented parts and lane and stuff?
like cars, trucks
so that my model can understand this things
but that data is not labelled right?
so it will be hard for me ( my model ) to understand things
yup using architecture and stuff
so you are telling me that , I shall build a model like them
and train on dataset
yeah
like how original image ( data ) is being transformed into new image, in which image the model is segmenting cars, trucks and lanes ?
I have a dataset which contains 1000 images ( both left lane and right)
you mean first create one or use pre-trained?
ohhhh got it!!
so I can take reference how other people have done that already and create/write my own
right?

GitHub
Contribute to qinnzou/Robust-Lane-Detection development by creating an account on GitHub.
but how??
okay then it's scratch process
got it
yeah
I was thinking I would take reference from other people how they builld and then same I will build my own
yup now make sense
and what about image segmentation like cars, trucks ,YOLO8 is doing that perfectly do you think I should spend time for creatiing my own for this task
or I should only do it for lane detection
Lane Detection!!
yeah
GitHub
Contribute to qinnzou/Robust-Lane-Detection development by creating an account on GitHub.
this guy litterally did this already!!
okay got it!!
I was just giving reference
yeah got it , but with only CNN it will be hard
then starting with reading paper good idea I guess?
yeah !! I have watched that
so general question is ,
CNN retrieves features from input images
then how it identify such features as lane markings on road?
yeah I watched yt video about this
when you started coding?
that's readigng and undeerstanding of whole architecture!
no it was different shape I guess
it's trapezoid
but then I need figure out how many number of max pooling layers, and CNN layers all that
Why plotly is not working with ipywidgets?
y_pred = model.predict(tf.expand_dims(X_test, axis=-1))
y_pred
So im getting an error when I try to add tf.expand_dims to the X_test, and when I dont it gives me an error that Dense layers are incompatible with rank 1 tensors.
ValueError: Creating variables on a non-first call to a function decorated with tf.function.
nvm fixed it was a colab problem
In what way is it not working?
for the final performance of each fold in cross validation, do you consider the average accuracy and loss or just accuracy and loss of the best epoch?
I think you're confusing a few concepts. You want to look at the performance of each fold and see how much variation there is
I agree with steler if the data has outliers or so, then you should look at all folds individually. If not you should take the average.
imagine not agreeing with me
basically what i did for each fold was plot the loss, accuracy, sensitivity across the epochs. Now do I calculate the average for each fold and then compare between the folds?
But I do 😄
If you have enough data the average perf on the folds will be similar so take the mean. if you have very very little data you can do leave-one-out-CV and then you probably don't want to look at n-1 folds
how do i start learning scikit learn?
There's not a lot to learn in scikit learn 😄
You call .fit on models to train them .predict to ... make a prediction. Aside from that you use ColumnTransformer to apply preprocessing (OneHotEncoder, StandardScaler) to one or more columns. After you have all these you assemble multiple things with a Pipeline. If you're working on tabular data you should typically use HistGradientBoostingRegressor or the classifier version.
The hard part isn't the code (so, learning how to use scikit learn) but rather conceptual understanding.
To learn it I did some projects with it and read the user guide https://scikit-learn.org/stable/user_guide.html a couple of times end-to-end
tysm!
I would say scikit learn is unending, just like say numpy and pandas.
It's important to know what you want to implement and know the necessary sklearn models you want to use.
Overtime you become familiar with it.
As for how the particular model works, you can take out time to look into them.
Trust me there are a thousand and one things that even experts ml scientists don't know in sklearn.
Im learning the basic machine algorithms in Scikit learn.
I have learnt numpy, pandas, matplotlib, and seaborn
Just finished with Linear Regression.
I saw some people on kaggle. They do EDA first. Then they fit the data to different regression model, then find out the r2 score. They pick up the one with the highest accuracy or score, and then they tune it's hyper parameter. If the score was 0.76 they would try to enhance it to somewhat 0.81 (for example)
Is that the actual and the usual way people do it????
😃 😄 . Yeah yeah, they fine tune in order to make their models perform at its best, just like you would probably hit the gym to be at your best. As for R2 score, mean squared error and the rest, they are just ways to determine the error of your model or how accurate your model is performing.
The closer r2 score is to 1, the more accurate your model is.
Ohhh okieee
Thanks a lot buddy 👍😄
Btw I have learned linear regression and it's types, the ones for the regularizations, cross validation and grid search as well to adjust the hyper parameter
😭😭😭 Now there are a bunch of other algos that I gotta learn... (My patience is dying)
😃 😀 😄 😁. Its perfectly fine, I've so much to learn as well and my patience dies so many times. But it's a lifestyle and there's no escaping it haha
 😄ohhh nice
😄ohhh nice
Btw nice to meet ya
Same ✌️
I need help learning the finer optimizations of .h5 caching with python and processing
hey @final kiln
how can I determine correct number of input/output channels for CNN?
wait there is a pdf regarding to this
the input at the very beginning depends on your dataset, pretty much whether you have a greyscale image or a coloured image
the output at the very end is usually the same channels as the input at the very beginning
the hidden size is pretty much a hyperparameter though, it's similar to linear layers in that regard
guys ive downloaded the llama3 model from meta but dead ass have no idea how to run it with python as a chatbot.. anyhelp?
like man how tf do i run this shit 😭
fr ran torchrun --nproc_per_node 1 example_chat_completion.py \ --ckpt_dir Meta-Llama-3-8B-Instruct/ \ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \ --max_seq_len 512 --max_batch_size 6 like acording to the docs and it says "failed to create process."
am i acoustic or something?
Some guys in my college are directly jumping over tensorflow
Im doing Scikit learn first... Will do TF later... Is that alright
everything is alright if you have strong fundamentals!!
Okieee 👍
Check this out. https://github.com/oobabooga/text-generation-webui
GitHub
A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
yeahh but the thing is i need it all in terminal for my project so
Ahh
i downloaded the model with the download.sh from meta and now im trynna run it with transformers cuz docs didnt work and im missing config.json so now i requests ascess to hugginface, hope it works
I'll help show me what you got when you are initializing the model.
well first i tried
https://github.com/meta-llama/llama3
and now i am trying https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
"Transformers AutoModelForCausalLM"

downloaded from meta with download.sh

so in general my input image is of shape [3, 128, 128]
and same for the output
and for CNN we will get
conv1 = 3 input , and what about output then??, kernel let's say 3x3 and stride for 1
I ask the same question to gpt and now he develops whole CNN
shi bet acess granted
from transformers import LlamaForCausalLM, LlamaTokenizer, LlamaConfig
Load the Meta-Llama model
llama_model_name = "Meta/Llama-3-8B-Instruct"
llama_model = LlamaForCausalLM.from_pretrained(llama_model_name)
llama_config = LlamaConfig.from_pretrained(llama_model_name)
llama_tokenizer = LlamaTokenizer.from_pretrained(llama_model_name, padding_side="left", config=llama_config)
tru to init it like that.
wait where?
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
At the top there.
at the imports and replace everything after = with what I wrote and add the config.
what about the output? you want to calculate the size of the image after the convolution? there's a formula for that
or do you want to know how many channels it should output? that's pretty much up to you, I mean, you can look at some papers and see what they used, but like generally it's similar to just linear layers, just pick some power of 2 and go with it, lol
wait what?
sorry am confused
wait figured it out with ma 2 braincells
I DM'ed you the code
both fighting for third place?
now I just need to detect lane!
I was thinking applying some filters at preprocessing step, so that lanes ( typically white ) would get highlighted
yeah I read that , just adjust these parameters randomly
so crazy
encoder = OneHotEncoder(sparse_output=False)
y_train_re = np.array(y_train).reshape(-1, 1)
y_test_re = np.array(y_test).reshape(-1, 1)
y_train_encoded = encoder.fit_transform(y_train_re)
y_test_encoded = encoder.fit_transform(y_test_re)
model = Sequential()
model.add(Dense(64, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.01),
metrics=['accuracy', 'Recall'])
history = model.fit(
X_train,
y_train_encoded,
epochs=75,
batch_size=32,
validation_split=0.2,
verbose=1
)
results = model.evaluate(X_test, y_test_encoded)
print("Test Loss, Test Accuracy, Test Recall:", results)
my first model with MLP
Should all images of Vision Transformer be of the same format?
mkay so what's the problem exactly?
By format I mean either jpg or png, not size
well no but it's recommended to have the same format
I need a higher recall
id say convert em all
Test Loss, Test Accuracy, Test Recall: [0.9047948122024536, 0.5376852750778198, 0.5376852750778198]
what type of data are you training it on?
intrustion detection @keen comet

it suffers significantly from imbalanced labeling
So I started with ensemble methods
since they are more resiliant against imbalanced data
no, it doesn't matter, just make sure that they are loaded with the same value range, I remember that loading pngs with plt.imshow returned an array of floats in range [0, 1], whereas with jpegs it was an array of integers in range [0, 255]
or something like that
just a heads up in case you run into some weird issues, but otherwise... ehhh, shouldn't really matter
also be careful of the channel count as pngs could have 4 channels
it's probably easier to just convert them though, yeah
unless you've got a ton of them
hullooo
Is plotnine still actively used, and are there dark themes somewhere? I've experimented with https://pwwang.github.io/plotnine-prism/ but it seems that many themes dont work
Does anyone ever done some object detection stuff on orange pi devices
Hey! Just asking out of quriosity, has someone used this service before? https://github.com/Avaiga/taipy
GitHub
Turns Data and AI algorithms into production-ready web applications in no time. - Avaiga/taipy
What has your experience been like so far, if you've used it?
Hi, im wondering for what is the NPU used? I want to use such hardware to run my object detection code: http://www.orangepi.org/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-5-plus-32GB.html and im having a trouble understanding for what is NPU used. Can I run my model on it? Is it faster than GPU? Can I utilize both of them?

import torch.nn as nn
import torch.nn.functional as F
class LaneDetectorCNN(nn.Module):
def __init__(self):
super(LaneDetectorCNN, self).__init__()
# conv2d ( input, output, kernel, stride )
self.conv1 = nn.Conv2d(3, 16, 3, 1)
self.conv2 = nn.Conv2d(16, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
# suppose input image is [ 3, 128, 128 ]
# so here output from conv3 which is 3D is getting converted into 1D
self.fc1 = nn.Linear(64 * 14 * 14, 128)
self.fc2 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 64*14*14)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# -> for conv
# output_size = ( Input_size - Kernel_size + 2 * Padding / stride ) + 1
# -> for max pooling
# output_size = Input_size / stride
model = LaneDetectorCNN()
so as per the code the output is of tensor with shape [1, 2], in simple they are 2 values!!
but what are those 2 values now?
hey @final kiln need some help , I am confused here!!
Suggest some good books to learn DS
Python Data Analysis by Wes Kinney. Used that to learn the basics of data analysis with python. Free book as well
So for two of my input features (out of ~30), the skew resides around 70-80 after appling log/boxcox transformation, would it be reasonable to remove the features from the dataset?
AFAIK NPUs are specialized hardware that excel at model inference, they apparently have higher peak performance compared to TPUs, but they're not as suited for model training. Essentially, if you have a model and you want to like start using it, an NPU appears to be the best choice. Apparently the iPhone 15 some models come with an NPU, yk, the new Apple Intelligence stuff
Do you know any way to utilize it with rocketchips
I Need to use i with onnx runtime using this pice of hardware ^
nope
I don't even know what the N stands for, lol
wait, it's probably Neural
I need help in choosing a good embedding model,
Documents are medical related and searching those documents can be like sentence search or just keywords so
What embedding model Opensource would be great for this?
if I have trained a model with TensorFlow on datasets of single eye images, how can i further use it to detect and track eyes on casual images of a person?
I'm not sure that you can. the model that you currently have: what exactly does it do?
given a cropped picture of a single eye, it tells if its closed or pointed at right/ left/center direction
you will probably need to start over with a dataset of the kinds of images you actually want the model to use.
is there any alternatives you're aware of to implement this?
do basically the same thing you already did, but with images that include "everything", not just cropped to the eye.
i need to simply track eye in any kind of image, be it a person taking a selfie or having breakfast or in a scenery. I don't think training on such images can help detect eyes
the training data needs to reflect the actual use case. not something so idealized that it's ultimately unrelated to the real use case.
-
- can we not do Black Mirror level creepy stuff?..
-
- in general your model can only do what it's been trained for
if you have a model that has only ever been trained on images of eyes, everything that isn't an image of an eye--and only an eye--is meaningless to the model.
how exactly are facial recognition models built then?
if the model has only ever seen closely cropped images of eyes, there's nothing in the model that could be construed as knowledge of what eyes are, or where they exist in relationship to anything else in the world (like faces)
in theory you could use some image segmentation model that can detect eyes on an image, and feed the cropped eyes into your model, but it'd probably be both simpler and more effective to train your model on real images.
I imagine the images would need to be very high resolution, so the cropped-to-eye part is as detailed as the training data for that part.
how does that work?
lemme clear some confusion !!
so currently that CNN has 2 neurons at last layer okay!!, so the thing here is how we are using that neurons, because we just want that lane lines pixels to be detected right?, so I was confused that , are only 2 neurons are sufficient for this task ? because when I ran that code the output values was both negative e.g [-0.9xx, -0.8xx ]
so what this values are trying to say to us??
yeah I search about how to visualize output of CNN , but it was ambigious for me!
what??, converting those 2 last layer's neurons into 512?
yeah got it now!!
but hey, will it break the structure of CNN, because I was spending some valuable time understanding maths behind max_poooling and conv operations
# output_size = ( Input_size - Kernel_size + 2 * Padding / stride ) + 1
# -> for max pooling
# output_size = Input_size / stride```
like thisit's interesting
wait lemme change those values and see the results firsts!! curious now....
what are hyperparameters here?
for example?
new output is interesting also ( no it's not it just tensor or vector )
so what we can do with that now??
torch.Size([1, 512])
can I ask how?
should I convert that into numpy as see as image , for fun!!
but is our approach correct??
and why did you choose 512 neurons?
because out input image is of size 128 so why big number?
okay interesting give me some time to read this !!
because I converted that into 128
transform = transforms.Compose([
transforms.ToPILImage(), # no need of this if image is already in PIL
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
look here
yeah it's clear now
but 512 will expand those?
anyways lemme try atleast , and yeah how can this transform.Normalize value are only 0.5
A transposed convolutional layer, on the other hand, is usually carried out for upsampling i.e. to generate an output feature map that has a spatial dimension greater than that of the input feature map. Just like the standard convolutional layer,
that's why are we using 512 neurons??
so what do you think? 256 or come back to 128
yeah! but for now??
because input is 128
okay back to reading now!
-> torch.Size([1, 3, 128, 128])
let it be for now !!
wait how this text got bigger size??
because of -> ???
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
X is input tensor , for me it's output of CNN
what about K ( kernel tensor )
how can I get that
wait , kernel values are out weight values right??
for each layer, for example here we defined 3 conv2d layers so 3 kernel values
so we have 3 kernel values now??
right?
??
we have 3 kernel here? as per 3 conv2d layeres
self.conv1 = nn.Conv2d(3, 16, 3, 1)
self.conv2 = nn.Conv2d(16, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
so which one?
I think I am also getting confused
is there any article of docs regarding this?
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
lemme clear then now!
the in_channels are output of our current cnn right?
in_channels (int) – Number of channels in the input image
channels are what layers??
no it's not
yup reading about that
input.shape = [3, 128, 128]
so here 3 channels, 128x128 width and height
so our output has shape of this torch.Size([1, 512])
so what does this mean?
1 channel with 512 values?
yup
so now question is how can we convert this?

in what ??
hmm,
[1, 512, 512] ??
but that's not possible
ohh hooo
we want to create tensor right to represent it as a image
and we have only 512 values!! ( vector )
so what will be size, lemme do calculation
1 is fixed in .shape() because it's channel
what about width and height
22*22 ??
23*23
exact shape not found !
ohh god
come on give me a hint atleast
is channel should be 1 only??
is it fixed?
bro I got different shapes
16 channels with 4, 8
32 channels with 4, 4
hey but we need only one right?
so how can I reshape this now?
yeah reading docs now
a = torch.reshape(output, ())
which value to give in this tuple?
and store in which variable, the name should be relevant?
okay what's next now, we got tensor now !! yeah!!
why batch is -1 here?
-1 represents flat vector values right?
and now I am getting confuse with those short names
x_bchw as x_batch weights
x_b1d what??
okay got it
now what's next?, encoder or what?
as per images
so it's batch size
yeah so D is out model's output
and B is .....
yeah!
I am now veery much confuse but anyways new things are always like this
😂
output.reshape(32, 4, 4)
so suggest a name for this now and then we will move to encoder part
explain it also please!!
and x ??
yeah I know thaty
okay now encoder right!
so what is out output is being now??
what it represents to us?
x_chw
it's tensor !
but for what
now encoder how can I implement that with out x_chw?
quick question!!
x_chw = output.reshape(32, 4, 4)
does this 32 channels represent as masks?
I mean the same masks which acts as features extractors from original image?
so is it we got 32 feature_masks?
I am wrong I guess?, because we have just converting 4, 4 into 32 channels!!
yeah so 4, 4 rectangles ( feature masks )
and they are 32
how can I implement this?
in pytorch
heh??, but on what size?
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
tconv(X)```we still need K value..
so from where we can get this value?
K value
we need this to pass into t_conv
here X is out x_chw
right?
hmm, got it
yeah
what about kernel size , we used 2x2 in conv2d !!
okay and what about input and output
output is fixes now, because we are using 32 channels right?
and in out input image the channels are 3
why?
but we reshaped into 32 right?
so we got different 32 feature_mask
okay so only reason we converted them to convert vector into tensor
what about stride shall we keep it as 1?
yeah sort of
but those were not images, those were feature masks
okay!
stride = ??
explain latent space in simpler words!! please
okay whatever!!, let's not focus onto that
m = nn.ConvTranspose2d(3, 1, 2, stride = 1)
what about this?
series? but why? and of what size ?
okay okay got it
we need final image as 128x128
so I need some layers probably again 3 to convert this into 128
hehehe
is decoder needed for out task?
now I am gonna confuse you so be ready
tconv1 = nn.ConvTranspose2d(3, 1, 2, stride = 1)```here we define fist tconv
with 3 input and 1 output!!
wait litterally 3 input channels are goint to convert into 1
where the heck maths gone?
1 output channel becaus we convert 32 of "x_chw" into 1 because it make sense
so how can I define input and output channels of tconv2
because out goal is 128
yeah I am keeping this on second tab
it's number of input channels in image
so for tcon1 it's just our raw original image which has 3
3, 128, 128
ohh for conv1 ??
shit again wrong
then for what
1, 512
which we convert into 32, 4, 4
okay
make sense now!
arite ? what's this now?
😂
okay now next?
we pass this shape to tconv1
right?
we are decoding now!
are you still calulating?
let's do parallelly!!
GPT wrote a code for this !!
self.tconv1 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
self.tconv2 = nn.ConvTranspose2d(16, 8, 3, stride=2, padding=1, output_padding=1)
self.tconv3 = nn.ConvTranspose2d(8, 3, 3, stride=2, padding=1, output_padding=1)
wtf did he wrote?
converting 32 into 16 into 8
and our goal is to get 128
import torch.nn as nn
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
# Assuming the encoder output is a vector of size 512
self.fc = nn.Linear(512, 32 * 4 * 4) # Fully connected layer to reshape the vector
# Transposed convolutional layers to upsample the data
self.tconv1 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
self.tconv2 = nn.ConvTranspose2d(16, 8, 3, stride=2, padding=1, output_padding=1)
self.tconv3 = nn.ConvTranspose2d(8, 3, 3, stride=2, padding=1, output_padding=1)
def forward(self, x):
# Reshape the vector back to a 4D tensor
x = self.fc(x)
x = x.view(-1, 32, 4, 4) # Reshape to (batch_size, 32, 4, 4)
# Pass through transposed convolutional layers
x = self.tconv1(x)
x = self.tconv2(x)
x = self.tconv3(x)
return x
# Example usage:
# Initialize the decoder
decoder = Decoder()
# Example input (compressed representation from encoder)
input_vector = torch.randn(1, 512) # Batch size of 1
# Decode the input vector
output_image = decoder(input_vector)
print(output_image.shape) # Should print torch.Size([1, 3, 128, 128])
Nope its wrong it prints 1 3 32 32
for reference only
then where is the wrong part
They are good but he need to refine them, I often point out mistakes to it.
atleast tconv are good
I got it now,
our original's image was of 3 channels
which out encoder converts into 32 to create feature_masks
now out task being decoder is to reverse this thing
yeajh!! I got it now!
now shape is out problem
lemme try some values
What was it?
It works! ```import torch
import torch.nn as nn
class Decoder(nn.Module):
def init(self):
super(Decoder, self).init()
# Assuming the encoder output is a vector of size 512
self.fc = nn.Linear(512, 32 * 4 * 4) # Fully connected layer to reshape the vector
# Transposed convolutional layers to upsample the data
self.tconv1 = nn.ConvTranspose2d(32, 16, 4, stride=2, padding=1, output_padding=0)
self.tconv2 = nn.ConvTranspose2d(16, 8, 4, stride=2, padding=1, output_padding=0)
self.tconv3 = nn.ConvTranspose2d(8, 4, 4, stride=2, padding=1, output_padding=0)
self.tconv4 = nn.ConvTranspose2d(4, 3, 4, stride=2, padding=1, output_padding=0)
self.tconv5 = nn.ConvTranspose2d(3, 3, 4, stride=2, padding=1, output_padding=0) # Final layer to reach 128x128
def forward(self, x):
# Reshape the vector back to a 4D tensor
x = self.fc(x)
x = x.view(-1, 32, 4, 4) # Reshape to (batch_size, 32, 4, 4)
# Pass through transposed convolutional layers
x = self.tconv1(x)
x = self.tconv2(x)
x = self.tconv3(x)
x = self.tconv4(x)
x = self.tconv5(x) # Adding the final layer
return x
Example usage:
Initialize the decoder
decoder = Decoder()
Example input (compressed representation from encoder)
input_vector = torch.randn(1, 512) # Batch size of 1
Decode the input vector
output_image = decoder(input_vector)
print(output_image.shape) # Should print torch.Size([1, 3, 128, 128])
How to talk it throughI guess it needed another laye
in decoder?
layer, geez my typing is lazy today :\
lemme understand this code first
```py
btw
self.fc = nn.Linear(512, 32 * 4 * 4) # Fully connected layer to reshape the vector
why you add this
we can done this in outside of class
model = LaneDetectorCNN()
output = model(input_image)
print(output.shape)
# so here we are converting simple 1d vector (output) into tensors
# so 32 channels tensors size of 4x4
x_chw = output.reshape(32, 4, 4)
```like thisIf you omit the fully connected layer, the 512-dimensional vector cannot be directly reshaped into a 4-dimensional tensor because the dimensions would not align correctly. Transposed convolutional layers cannot operate on a 1-dimensional vector; they need 4-dimensional input.
well, a linear layer would also learn stuff
That's what Im learning.
interesting
AI is great for alot of things, its been an awesome tutor. It might not always be right, but you paste entire documents in it and figure shit out together.
yeah , but always read docs!
then you will misunderstood
and in lot of time, it becomes habit to just copy and paste from that GPT
but eventually it not works here!
I agree its a double side blade, it has pros and cons
that's why I ask the same GPT to explain same code line by line and then I again read some artciles arount it
why would you even consider using cgpt for this 
lazy >?
Nah, its a tool like anything else. If pride keeps you from using it, youll get left in the dust eventually.
why this reaction?
cuz the pride month
lol nice
Pride mentioned.
right, it's a tool, but when all you've got is a hammer, everything looks like a nail
😂
now I am confusing which lines to add in my existing decoder code , need to read now
so what do you think , shall I keep that as it is ( outside class )
or create a layer for just reshaping?
I concur
in decoder?
I don't care if our output image is good with lane markings
which will eventually take some time to re-adjust our hyper parameters

but yeah he is right
Let me ask
no !!
lol
ask here lol!😂
latent spaces and stuff, he he
self.tconv4 = nn.ConvTranspose2d(4, 3, 4, stride=2, padding=1, output_padding=0)
self.tconv5 = nn.ConvTranspose2d(3, 3, 4, stride=2, padding=1, output_padding=0)
can you explain about this/
it's basically upscaling
we go from 16 to 8
and then 8 to 4
okay so we need in multiplies in 2?
yeah I use only 3
but here he uses 4th one
which converts 4 into 3
so should I use 4 in decoder??
in encoder
we did
3 -> 16
16 -> 32
32 -> 64
so what about decoder now?
we have in 32 shape already
so
32 -> 16
16 -> 8
yeah that's what I am thinking
heh?
so again (32, 4, 4) ??
then?
and with 2x2
Im trying to understand this too.
yeah becaue then it produce 256
torch.Size([1, 512])
yeah it's before
hey?
model = LaneDetectorCNN()
output = model(input_image)
print(output.shape)
look at this
because it's vector which our last layer gives us
how can I print that now?
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 64*14*14)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
```you mean here?that's the catch!
is X referring to the visual structure there?
so, with that latent embedding, how exactly do you train word embeddings with it? using sth like cosine similarity as the loss function? like how do you bring the word vector closer to the image vector?
cosine similarity, dot product, etc
like, do you embed the words and images in the same space?
I get that, but how do you tie in labels with that?
there are different encoders and decoders models that use different similariys
Wouldnt those want to match the hidden embedding layers?
or prompts, yeah, like what vq-vae does (realizes that I could just go and find the paper on those...)
lol
I was asking AI bout our chat and it wrote the whole dame code what you were asking. It alinged the image and text using a triplet loss function and ensuring silar embeddings
I ran it seems to work

Honeslty! There have been numerious "AH, HA" moments where I knew it was wrong and explained it, sure its not right, but these conversations is really how I pick up a lot. Critical thinking is key, i get what you mean.
Right, but understand what its spewing out is important otherwise were gonna have generations of braindead people lol
copilot is no bueno. Claude Opus. You should give that one a shot., or Just clade in general.
I guess DML is one way to achieve it, but it's not what VQ-VAE does I don't think
Deep Metric Learning, but like, VQ-VAE apparently indexes the embedding table, it seems I'll have to reread it a couple times till I understand it, lol, but yeah, it's not exactly triplet loss
well, yeah, but VQ-VAE tries to combine an image embedding and token embedding
I think... I'm still reading the dam paper, lol
wasn't that your plan with that new approach to transformers 
SOTA go brrrt
Look at this

This describe my entire system I build, I automatically load, preprocess and indexed datasets directly from hugging face into the ESDB, everything is embedded in a 768 dim, so I use models from hugging face that use the same dim.
Heres the diagram of it

interesting, this is actually what I considered at the very first when I mentioned embedding images and labels, I just knew that VQ-VAE doesn't do that
so you can try embedding an image and a token in the same latent space and bring them closer and such
Nice! I build a Conversation DB, and Two types of memory for summarys of conversations and and transcripts from other models, it gets ranked by scores, and the top answers get embedded back ito the conversation index.
I use cosline similarys on the memory to extract knowledge its learned from querys.
Combine with its ability to seach online and extracts information the same way, so its a type of transfer learning, but I swear the more I play with it the more it feels recursive learning too.
Heres what I mean.

I will put it up on github in a couple days, maybe you guys take a look at it
That would awesome. I would need a hand with that though, I made a front end and backend for it, just really simple but it worked locally.
great idea! let me go research this ill be back
Hi, im having an issue when converting my onnx model to rknn format. I need to make my model produce smaller output, how i can do this?

Thats my model

You can download it here https://www.easypaste.org/file/xqYJMfw0/license.plate.detector.onnx?lang=en
license_plate_detector.onnx
You guys gave me an idea from earlier. I combined VQ-VAE and CLIP to make a tool for learning and leveraging discrete latent representations of images that are aligned with textual descriptions.
I a full model ready to train on it. I think I got the learning rate dailed in after playing with it for a bit.

Ill share it with you guys if you want.
I gotta take a break. I got this far but I got fix the padding issue.

So it uses (VQVAE) with a CLIP model to work with both images and text. The VQVAE compresses images into compact representations and then reconstructs them, while the CLIP model ensures that these image features align well with corresponding text descriptions. During training, it optimizes a loss that includes image reconstruction error, quantization loss, and a CLIP loss measuring image-text similarity. I got it loaded with the flickr30k dataset.
how is the loss 150%
That was kinda high for the first one.
and it doesn't look like it's improving either
that's not how losses work
the value itself is rather meaningless
ye just thought it was silly
what's silly?
Decreasing loss durning training is a good sign.
Usually the first epoch from my understanding should be taken with a grain of salt.
nvm
For my understand but please correct me if im wrong
I don't think it's normal for my computer to random restart from nowhere when put in sleeping mode
Maybe a device is waking it up
I don't think it would do a full reboot for that
I don't understand what that means frankly (I understand the idiom...)
The model is train to learn off the data, theres nothing to learn first until it process a few epochs.
where's the test loss btw?
that's not true, it learns as soon as you run it pretty much, after every batch, it learns something
Not sure yet,, I have it setup for test and validation but I need to fix the padding error.
Technically your right but im talking about measuring it learning progress.
would it be better to fine-tune an LLM with my own data (dynamic data that can change every year or so) or just do RAG on it?
it's a customer support AI
from my limited knowledge of this from an API-usage standpoint, it seems that fine-tuning is quite an expensive process actually and you say it's dynamic data... that likely means you'd have to retune the model every year, that's certainly not cost effective the way I see it. I'd suggest RAG
thanks
i have the following einsum:
np.einsum('nsd,jd->njs', x, y, out = z)
d = 10, n = 1500, s = 100+, j = 200.
It's slow, because it's single-threaded. is there a multi-threaded matrix operation i could do that would accomplish the same thing?
i know matmul is multithreaded, but it seems difficult to accomplish that operation with matmul.
Can you use numpy and concurrent.futes to parallleize it ?
so, you can do this
import numpy as np
x = np.arange(1500 * 100 * 10).reshape((1500, 100, 10))
y = np.arange(200 * 10).reshape((200, 10))
e_sum = np.einsum('nsd,jd->njs', x, y)
dot_transpose = (x @ y.T).transpose(0, 2, 1) # <- this
assert e_sum.shape == dot_transpose.shape
assert np.array_equal(e_sum, dot_transpose)
print(e_sum.shape, dot_transpose.shape)
but it didn't really seem that much faster
nvm, it is faster
!e
from timeit import timeit
import numpy as np
N = 10
# reduced to 150 because otherwise this would take forever, lol
x = np.arange(150 * 100 * 10).reshape((150, 100, 10))
y = np.arange(200 * 10).reshape((200, 10))
print(timeit("""
np.einsum('nsd,jd->njs', x, y)
""", number=N, globals=globals()))
print(timeit("""
(x @ y.T).transpose(0, 2, 1)
""", number=N, globals=globals()))
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 0.3833521939814091
002 | 0.243569937068969
it would be best if I didn't have to instantiate x @ Y.T before the transpose. as is my understanding, merely instantiating an array that large requires a fair amount of time. i've created an array that will get written to over and over as inputs change. That said, i'll give it a shot.
I'm not sure if you saw the timing results but despite the dot product having to create a new array, it was still faster
oh absolutely. i'm not disputing that. But in a model run, i have to do that operation at least 20k times, so i'm trying to eke out as much speed as I can.
this is faster than my original solution, so i'm absolutely implementing it.
This is a beginner question:
Can I fine tune a ViT model one time with one dataset, and fine-tune it the ohter time with another dataset that has different labels?
My internet was gone , that's why I went offline , now need to go college then will do this!!
well, you have to combine the labels (like, if they are different then label with index 1 from the first dataset is gonna be with index 1, but label with index 1 from the other dataset can't also be index 1 in the embedding table (unless they're the same label)), otherwise you'll mess up the embedding table, does that make sense?
as for the images, it probably doesn't matter that much, though you probably are gonna need to match their sizes if they're not the same
Both datasets are similar on regard to the fact that they're the same gestures but from different sign languages. My idea was to add an underscore (+ name of the sign language) to differentiate the labels from each other... Would that be correct?
oh wait, you're not gonna embed the labels anyway... this is for classification, right? does same gestures also mean that the labels are identical? cuz like obviously different gestures could mean the same thing... hmmm
I think to be safe, it'd be better to just concatenate the labels, so basically, when you train both datasets your output is the concatenated array of labels from both datasets, for example
ds1_labels = [1, 2, 3]
ds2_labels = [1, 2, 3, 4]
combined = [1, 2, 3, 1, 2, 3, 4]
so when you train them, your output is of the combined size, that's the final output after softmax, it's 7 values in this example, the first 3 are for the 1st dataset and the next 4 are for the 2nd dataset, but otherwise you proceed as normal, you just need to know that when you're actually predicting and you get the max value from that array and it's the 2nd dataset, you need to subtract the number of labels in the first dataset from that max index to get the index for your actual label
for example, you're training the second dataset and this is your output for an image
[0.0, 0.0, 0.1, 0.1, 0.7, 0.0, 0.1]
the max index here is 4, but since it's the combined labels, you need to subtract 3, so you get 1 as the index for the label in the 2nd dataset
now, a concern of mine here is what to do if it predicts the label from the other dataset... now, one option I guess would be to assign a much greater loss to such cases
honestly, this is a bit of a tough one (btw, do take what I say with a bit of a grain of salt, not an expert yet 😁)
I mean, tbf, this does kinda make sense, it's basically the equivalent of merging the two datasets into one
I finally got it training. I did 20 epochs might take a bit but we can test the results

OMG! Its working better than I though lol

so image encoder of the VQVAE first extracts features from the input image. These image features are then concatenated with the text embedding obtained from CLIP, forming a joint representation. This joint representation is fed into the VQVAE's quantization layer and subsequently used for image reconstruction.
Wow.. look at the difference in loss.

holy shit lol
loss on its own doesn't convey much of a story, you should add some additional metrics and some sample visualisations and stuff, yk, so that you can somewhat see what the network is actually doing
I agree, I'd like to get some help on it, I can put it on github if you guys wanna see if we can crack this together
the idea is that it could identify the differences of those gestures since gestures vary between sign language. so i thought with different labels would be better. it's my first time ever doing this project so idk how good this methodology this is. i'm an emergin researcher
i didnt understand quite well the merging of the labels. the 4 would represent the label that is not from the other dataset, right?
i mean the thing is that it has the same amount of labels in both dataset, but what it's different is the type of sign language
mmmm
so the amount of labels would be 48?
jesus fucking christ is that feasible stiill
wdym?
i mean those are too many labels
not really, no
what?
why would it be too many?
what do you mean? so it's not feasible to do this? like, actually train the thing?
oh idk if it would affect the training
if you have enough samples for each class I don't see the issue
like language models have vocabularies that are in the 10s of thousands of tokens and stuff
so anyway, basically my idea boils down to essentially merging the two datasets and adding those prefixes to differentiate the datasets
but you can train one dataset first and then the other one, you just have to then merge the labels of both datasets
by merging here I just mean concatenation
like it's easier to visualize it as just merging the two datasets completely, adding those prefixes to the labels, so now you have like all the labels you could possibly predict, but then you first train with only one dataset and all of those combined labels and afterwards you train with the other dataset and again all the combined labels
now, as I understand you just want to do simple classification? so basically you give it an image of a gesture and it tells you what the gesture is, right?
I mean, you said you want it to identify the differences, but I assume it just means that you want the model to be able to differentiate different gestures itself
ValueError('shape too large to be a matrix.')
_<
the operation i specified before, with the dimensions i'm working with.
should become a 1566 by 240 by 200 output array
okay, that's a different shape, can you provide all the specs again? the shapes and what you're doing and like the code that causes this error and such
np.einsum('nsd,jd->njs', X, Y, out = Z)
with n=1566, j =200,s=240,d=10. (actual dimensions now; i was guessing before).
You had suggested (x @ y.T).transpose(0, 2, 1)
i tried implementing with np.matmul, which @ calls (i think), and it gave that error. so i tried @ directly, and it still gave that error.
so weird.
er..to be clear, einsum works but is slow. i was hoping to replace with a more performant option.
right, so if you do (X @ Y.T).transpose(0, 2, 1), what happens?
uh, the error message i posted.
so, if you replace this line with
Z = (X @ Y.T).transpose(0, 2, 1)
you get an error?
cuz it works just fine for me
!e
import numpy as np
x = np.arange(1566 * 240 * 10).reshape((1566, 240, 10))
y = np.arange(200 * 10).reshape((200, 10))
e_sum = np.einsum('nsd,jd->njs', x, y)
dot_transpose = (x @ y.T).transpose(0, 2, 1) # <- this
assert e_sum.shape == dot_transpose.shape
assert np.array_equal(e_sum, dot_transpose)
print(e_sum.shape, dot_transpose.shape)
:x: Your 3.12 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 6, in <module>
003 | e_sum = np.einsum('nsd,jd->njs', x, y)
004 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
005 | File "/snekbox/user_base/lib/python3.12/site-packages/numpy/core/einsumfunc.py", line 1371, in einsum
006 | return c_einsum(*operands, **kwargs)
007 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
008 | numpy.core._exceptions._ArrayMemoryError: Unable to allocate 573. MiB for an array with shape (1566, 200, 240) and data type int64
good one... well, anyway, as you can see, that's a memory error
you're not getting a memory error, so it's some other thing
to be clear, it worked fine for you? (not the eval bot)
yes
weird.
maybe it's my version of numpy?
i'm using an older version for compatibility with tensorflow.
does this specific piece of code work for you?
hmm
yes. then that opens up another question.
my issue is my implementation, i guess.
wow, damn it numpy
type(X) returns np.matrix
f-ing nonsense.
putting in np.asarray(X) in place of X makes it work
try float32 instead of 64
wish python actually did proper typechecking. all my functions are properly typed, but the only good that does is helping linting.
It is no longer recommended to use this class, even for linear algebra. Instead use regular arrays. The class may be removed in the future.
https://numpy.org/doc/stable/reference/generated/numpy.matrix.html
good riddance. i didn't even realize i was using a matrix.
data is now coerced to an array on initialization of the model
Im adding metrics after its done training 20 epochs. Im adding PSNR and SSIM for metrics and some visual metrics next.
does np.ndarray.reshape cost time?
You dont see this as a good sign though?

well, it certainly costs some time, yes
no, the change in loss is quite nice, I mean, from this I would expect the other metrics to really improve as well, but I can't be sure about that until I actually see those metrics
Ok ill work on, thanks
cuz for all I know, it could've been terrible initial values or some stuff like that, or the accuracy might be only say 60% despite the loss
ofc, it's a good sign that the loss is dropping, but it doesn't really convey much on its own
roger makes sense, we need more data!
Im learning all the traditional ML algorithms in Scikit learn.
We do standardization of the X_train and X_test in the start, before training.
Once the model is trained, once we have tuned the hyper parameters to get the best result and error metrics, when we finally go for training the final model on the entire dataset, do we need to fit the final model with the scaled X too?
And if I am deploying the final model, then do I need to deploy the scaler object too?
Any ideas how to make model output smaller??
Will market still be demanding AI ML engineers after 20 years
20 years? I mean, if there will still be a market... or humans for that matter left, maybe, it's really hard to say, 20 years is quite a long time
suppose the cycle continues as it has been going thus far and assuming we don't all go extinct, there will likely be demand for AI engineers, though it may be different AI, not necessarily ML
I got it setup and running.

Compared to the first image its really coming into shape
looks fantastic
thank you, im going hit the sack. ill let you guys know how it did it the morning, thanks for the advice
Anyone know how to resize that output?
Which career?
!rule ad
@past meteor what's the name of that book for ML + python that you often recommend? a friend is asking for a suggestion and that's the first that came to mind
where can I find some assistance on ai training task?
This channel
I am a good maths student. I am learning all the traditional ML algorithms and their practical implementation with sklearn (I have learnt numpy, pandas, matplotlib, seaborn). Even if I understand the underlying maths properly, at some points I am so confused or burnt out. I'm starting to doubt myself.
~ Just wanna code real awesome nueral networks in tensorflow one day and build do projects... but now i doubt myself so much
The way I learn it
Hmm... 🤔
I have a course of Jose portilla....
I learn stuff from there...
See code on kaggle
I also refer to the documentation...
That's how I learn... And I do try to implement that into real world dataset too
Is there any other or better way I could learn the ml stuff??? Plz tell 😓
Okieee
Alright 👍
One last question...😓😅
A few guys from my college are directly getting into tensorflow and neural networks....
They just know the theoretical and mathematical part of all the traditional machine learning algorithms... Is it possible to go into tensorflow just by knowing that much knowledge, without even implementing stuff with sklearn?
for some people, knowing how to code and understanding the math is enough to be able to implement the stuff. not for others. some will be fine with jumping into TF/pytorch immediately, and others won't. that's up to you
oh alright
Introduction to statistical learning?
Hello where do I learn Neural networks? like youtube or textbooks? recommend me some pls.
I have very basic understanding of NNs and some common ML algos (Thats just my current level knowledge)
Dive into deep learning. Look for it on arxiv
!res
I don't exactly feel qualified handing out such advice, but if you want to go into software development I guess you can start by learning a language, like Python, see the resources in the linked page
for career-related questions you can also go to #career-advice
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
But don't u need to learn those generic ml algorithms...first ...?
Really? ☠️☠️☠️
U sure?
Okk
☠️ Thank for the info
Im new in this field... That's I don't have that much knowledge ☠️☠️
Ik I sound so stupid but yeah
Yeah
It learnkng Scikit learn was not a time waste ...ik that... But still I could have started with tensorflow
(btw, instead of tf, go with pytorch)
Isn't that more into the research side
by what?
ah, sure, at some point that will happen probably, yeah, le cycle of software or whatever, lol
It'd be hard for that godlike API to exist in Python but there's a lot of possibilities in dependently typed languages
Or ones with very strong compile time programming
Does anyone as to why do we use a bias term in perceptron?