#data-science-and-ml
1 messages · Page 49 of 1
you'll want to have this as the .gitignore file in the root of your repository: https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore
it decided not to recognise the files
i had to use a hacky workaround but meh it's uploading
anyone wanna help me turn a folder of rgb images with the same shape into a tensor for ml? i think i have to turn each image into an np array and concat them to a dataframe but i am not sure
you don't need the images in a dataframe, no
dataframes are strictly two-dimensional, albeit with multiple levels of indexing
whereas each RGB image is already a 3d array/tensor
arrays and tensors are isomorphic, I guess.
but idk what you're trying to do. turning an image into an array is just a way of saying "load the image", basically.
i want to use the images with sklearn models
like which
classifiers
name a specific one
logistic regression i think?
my pictures are 128** so one which works well with a lot of features
it looks like each sample has to be one-dimensional
scikit-learn
Examples using sklearn.linear_model.LogisticRegression: Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.0 Release Highlights fo...
so i want to flatten each image
idk how well that will work outside of very simple use cases like the MNIST digits
i can't import skimage because match case only works with 3.10 and skimage is only compatible with 3.6 or so
apparently x.flatten().reshape(100, 2000) is lossless for rgb images
wdym by lossless
you haven't done anything to the data. reshaping an array doesn't change its contents
preserves pixel data
sure, you haven't changed the data in any way
you keep talking about sklearn classifiers in general, but that's not how it works. each one is different.
do any sklearn classifiers natively accept np.asarray(rgb_image)?
for the LogisticRegression classifier, the X data has to be a 2d array where rows are samples and columns are features.
beyond that, the LogisticRegression classifier doesn't know or care how those arrays came to be, or what you intend for them to represent.
just flatten() would make it a 1d array
gotcha 🙂 thanks
Does anyone here is familiar with the toric code in quantum computacion?
you'll usually never get an answer if you ask "does anyone know about x" -- you have to ask the actual question.
hello im getting errors with sklearn pipeline,
im trying to set up my pipeline for a data in this format:
[text,rating] for example : [['i love this'],5].
my pipeline should :
do lemmatizer on first index then do tfidfvectorizer and normalize data on second index
this is my pipeline:
transformers = [ ('lemmatizer',Lemmatizer(), [0]),('tfidf',PrebuiltTfidfVectorizer(tfidf_model,columns_drop=remove),[0]),('norm',Normalizer(), [1])]
transformer = ColumnTransformer(transformers=transformers)
pipeline = Pipeline(steps=[('preprocess', transformer), ('model',model)])
but when i do pipeline.fit() i get error from my lemmztizer that i cant do regex on bytes like object
class Lemmatizer(BaseEstimator):
def __init__(self,stop_words=None):
self.lemmatization = WordNetLemmatizer()
if stop_words == None:
self.stop_words = stopwords.words('english')
else:
self.stop_words = stop_words
def fit(self, x, y=None):
return self
def transform(self, x):
x = map(self.lemmatize_sentence, x)
x = np.array(list(x))
return x
def lemmatize_sentence(self,sentence):
text = re.sub('[^a-zA-Z]',' ',sentence)
text = text.lower()
text= text.split()
text = [self.lemmatization.lemmatize(word) for word in text if word not in set(self.stop_words)]
text =' '.join(text)
return text
oh nvm i did print statement
and it looks like pipeline is accounting for 2d array but in tutorial i follow they used 1d i not sure why
What can be the reason for validation being very slow(on CPU intensive task), but not crashing?
CPU seems to be filled but why doesnt it crash? it just slows down
Hey, the thing is still slow as hell. Do you need the code?
free -g:

takes 1 day to output metric scores, but doesnt crash, just slows down
its a GPU cluster server, could it be because when some other user do CPU intensive task it slows down?
train time*10 = test time
literally
How big is your test data? And is it the training time of an entire epoch, or just a single batch?
its a transformer,
test size 700 videos 30 second
i suspect tokenization the problem(CPU intense)
and i do 10 validation per epoch, nightmare for me
I wouldn't know sorry
np
Maybe a dumb question, but did you check if it is actually using your gpu?
Like if cuda is available
Yes, it's using it.
Do you have a really old cpu or something? cpu is normally still used for loading in data and some transformations
Hello Guys
I'm trying to convert a column using pandas to_numeric function yet it keeps getting me this error
Here's my initial code
data = pd.read_excel('Energy Indicators.xls', na_values=None, thousands=' ')
Energy = data.copy()
Energy.drop(['Unnamed: 0','Unnamed: 1'], axis=1, inplace=True)
Energy.drop(index=Energy.index[:17], axis=0, inplace=True)
Energy.rename(columns = {'Unnamed: 2': 'Country','Unnamed: 3':'Energy Supply','Unnamed: 4':'Energy Supply per capita','Unnamed: 5':'% Renewable'}, inplace=True)
Energy.drop(index=Energy.tail(38).index, axis=0, inplace=True)
Energy['Energy Supply'] = Energy['Energy Supply'].apply(lambda x:x*1000000)
Energy.Country = Energy.Country.str.replace('\d+', '') #Removing numeric values next to Country's name
Energy.set_index('Country', inplace=True)
#Smoothening Country Names
Energy.rename(index={"Republic of Korea": "South Korea",
"United States of America": "United States",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"China, Hong Kong Special Administrative Region": "Hong Kong",
"Bolivia (Plurinational State of)":"Bolivia",
"Switzerland17":"Switzerland",
"Falkland Islands (Malvinas)":"Falkland Islands",
"Iran (Islamic Republic of)":"Iran",
"Micronesia (Federated States of)":"Micronesia",
"Sint Maarten (Dutch part)":"Sint Maarten",
"Venezuela (Bolivarian Republic of)":"Venezuela"}, inplace=True)
Energy.reset_index(inplace=True)
Energy.loc[lambda Energy:Energy['Energy Supply'] == '...'] = np.NaN
Energy.iloc[3]=np.NaN
Energy.dropna(inplace = True)
Energy['Energy Supply'] = Energy['Energy Supply'].apply(pd.to_numeric)
Any help please?
I have an i8 cpu
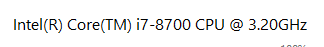
Running it in a notebook?
Nope.
I'm running it all locally
Are you 100% positive that the code is the exact same, including same versions for python and all packages?
Same version, Python version 3.8
And you just straight up copied the repository to your pc, installed the requirements and ran it?
I'm asking this because it is very hard to believe that all software aspects are the exact same, your hardware is better, and you get worse performance.
Did your friend mean 40k batches after 6 hours, instead of 40k epochs?
40k steps, they said. Yes, I copied the repo to my PC, installed all the requirements, tried to fiddle with both the batch size and num_workers... and still it's slow.
I don't know, they didn't say.
Try AdamAI: The first AI-powered Video Search Engine. Try our Beta Version: https://adamaivideosearch.streamlit.app/

Streamlit
This app was built in Streamlit! Check it out and visit https://streamlit.io for more awesome community apps. 🎈
All I know is that the epochs pass by slower than my friend. It takes like... 10 minutes for it to get to 100 Epochs for me, while it takes them 10-20 minutes for them to get to 800 steps.
Yeah but we really need to make sure that 800 steps mean epochs, otherwise we are chasing a unicorn 😛
coz I think its relevant its a python AI project ?
You'd probably have to ask in modmail, I'm just a helper
I'm going to make the gander that it's indeed such
Do you have any working theories?
I got nothing. I would probably have to go over the entire code to get an idea of what could be a bottleneck for different machines. But maybe even then I'd personally find nothing.
in online chats, it's better to just give people information than wait for them to say that they want it, and then have you wait to see that that they asked, and then have them wait for you to provide it.
hello, i would like to please ask
im trying to check if my CountVectorizer has been fitted with this snippet code and it says it hasnt ```py
from sklearn.utils.validation import check_is_fitted
check_is_fitted(tfidf_model,'The tfidf vector is not fitted')
whats strange is i saved my CountVectorizer model with pickle and when i load it i get nothing is fitted, why is this happening and how can i save the fitted model?
i fitted my model then saved it with pickle but when i load it nothing happens
!codeblocks
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
'A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set padding_side='left' when initializing the tokenizer.'

hello im running this code:
from sklearn.utils.validation import check_is_fitted
check_is_fitted(tfidf_model2,'The tfidf vector is not fitted')
and i get tfidf vecotrizer is not fitted
but i have this:
tfidf_model2=TfidfVectorizer(max_features=max_features)
tfidf_model2.fit(clean_data)
#tfidf_model2.fit_transform(clean_data)
i not sure why i getting this error
hey guys, I have a dataset with 3 classes. does anyone know how i"d make a classifier that predicts whether an input image is 1 of those 3?
Hello guys, this is an equation of input into decoder in Seq2Seq attention. I'm confused about what is alpha and h(t') mean. Can you guys enlighten me on this?

I am a bit unsure but I think it is the bars in the first equation represent subscripts.
Explain your issues and we will see how we can help you out : )
Do the zeros and ones in sklearn.datasets.make_circles() stand for whether it's red dot or blue dot?
no but it shows according to their docs
''Scale factor between inner and outer circle in the range (0, 1)."
I see
And, what does a nn.Linear() actually do? Say I want to visualize a circle made with sklearn.datasets. The in_features will equal to 2 since it has 2 shapes but when we set out_features to 5 for example, what does it actually mean?
I'm not good with pytorch but from keras background, it's like input dims? So a tensor of shape let's say 25000 rows, 3 y, 5 z. (25000, 3, 5). My input dims will be (3,5)
yeah but what's the duty of nn.Linear() here?
And how does it upscale the features?
Ohh I gotcha now
Thanks man
is it a problem if i share names between variables and function parameters?
it's like 'this variable goes here'
that shouldn't be a problem
function parameters' names only exist in the scope of the function
yeah 🙂 i mean for readability
well it's obvious, but still refer to the for variables snake naming convention
aye
your function should have a capital letters while variables are lowercase with underscore as a general rule
it's ok but working on different projects and teams people want to read your code lol
i dunno, you can tell it's a function by the brackets imo
Sometimes i want a function to be wrapped inside a function and that may fuck thing up imo
Again it's ok for small projects but working with a team may confuse stuff
yeah, fair enough
i wanna land a junior dev role but i think the first thing i'd do is ask for a style guide
well pep-8 uses lower case for funcs
don't matter 😄 take care
cheers 🍺
Hey guys, about GPT-2 and Unsupervised Learning in Language Models...
If the idea is that the model will try to minimize the information entropy in the input, then should I include Embedding layers in my unsupervised transformer model? I mean, the Embedding layer will be optimized at each iteration, which means that the vectors assigned to the inputs will change, thus, the input entropy will also be changing constantly, right?
https://paste.pythondiscord.com/saxuyevuzi
https://paste.pythondiscord.com/ifazaliyav
The first one is train.py and the second one is config.json. I hope these help. If that doesn't help...
https://github.com/effusiveperiscope/so-vits-svc/tree/eff
Here is the link to the code itself as a whole.

GitHub
so-vits-svc. Contribute to effusiveperiscope/so-vits-svc development by creating an account on GitHub.
my image classifier is not quite predicting as well as i'd hoped
should i use tensorflow or pytorch for audio recognition (to be deployed on iOS and android)
If you're gonna create a model, I think both might do fine, as both allows for memory handling. Unless tensorflow's tensors(which I think are numpy arrays in practice) and Pytorch tensors use different amounts of memory.
But tensorflow is a lower level API, so you probably might need to know more what you're doing
i'm gonna go with pytorch, thankss
is it correct implementation of hard mined triplet loss:
def loss(anchor, positive, negative):
sim_pos = nn.CosineSimilarity(anchor, positive)
sim_neg = nn.CosineSimilarity(anchor, negative)
# Compute the hardest negative sample for each anchor sample
hardest_neg = torch.max(sim_neg)
# Compute the weights for the negative samples
neg_weight = torch.exp(0.5 * (sim_neg - hardest_neg))
# Normalize the weights
neg_weight = neg_weight / torch.sum(neg_weight)
# Compute the triplet loss with hard negative mining and weighted sampling
curr_loss = torch.mean(torch.relu(sim_pos - 1.0*hardest_neg + margin) * neg_weight)
RuntimeError: Calculated padded input size per channel: (2). Kernel size: (3). Kernel size can't be greater than actual input size```I have no idea what to do here.
It says that it can't be greater than the input size... but what does that mean in terms of what I'm trying to do?
Like, I have audio files. There are 48 of them, the biggest one is 5 seconds long.
Could that be it?
Based from the error
Reduce your kernel size?
No need for a large kernel size for a small dataset
Well the embedding layers just turns your tokenized/preprocessed words into vectors. Based on the vocab_size. So they are necessary.
Most of those NLP uses some kind of a attention mechanism
This allows to solve some kind of contextual meaning of the word. Like "bank on the river" vs "bank as a financial institution". This is done by adding one hidden layer that computes probability (markov chains related) on target context based on the overall sentence.
Where is that? As in, where is the kernel size supposed to be?
And what is it supposed to be?
I cant seem to find a layer here here which should have access to the kernel size and our input dims. Is this a predefined model?
My guess is that we need to do some padding on the data. Like on those 48 sound files make it so that they are the same length?
I'm using a predetermined hubert model to put in the f0 and hubert stuff.
Should I bring up my config file and py file for adding the f0/hubert stuff?
Hmm no i think this a preprocessing problem. Try padding the data first.
Padding? They're already five seconds EACH.
If I make them longer, they''ll probably train slow as hell.
Hello Guys,
im playing with Energy supply dataset and im trying to create a linear regression model to predict the enery supply per capita
here is the correlation between the data check photo
and i initiated a 70% 30% train test split
the scores are
train: 0.5423702218150828
test: -52.99527792224533

can someone help me identify if the model is good or bad?
Oh i thought they are not the same length because you said one of the biggest lengths are 5 seconds long
My mistake. But like... what would I need to change? Where? I tried opening the checkpoint hubert thing, and it wasn't editable.
Shit... i think the input data needs somekind of a reshaping. Is it already a tensor?
No...?
I don't think so? They're wav files.
Basically the steps are: converting them into 44k hz audio samples, then categorizing them along with making the config file, and then the hubert/f0 thing.
I'm just confused as to what to do.
Reshaping?
hello hello
how are we today fellas how to one hot encode without increasing columns
TensorFlow
Converts a class vector (integers) to binary class matrix.

Create a numpy array of zeros, assign 1 to the desired position(the one that will be 1), multiply by your array to be one-hot encoded
because i am using get dummies python aand its increasing the columns by insane amount
Well...yes...that's how one-hot encode works
It creates columns with N classes, where all classes except one have value 0, and this remaining one has value 1
ah and if you are later doing dot product how are you suppose to reshape it?
its impossible to do
If just a single column will have a proper value(while the others will have value 0), you can simply sum all columns
And you'll have an array with a single column and your value
whats the method for that/
np.sum()
np.sum?

and this works for dataframe?
Oh, for dataframe...
df = pd.get_dummies(wd, columns=[1,2,3,4,5,6,7,8,9,10,11,12,13], drop_first=True)
For dataframe I don't know, but it's possible to create DataFrames from arrays, so...
this is what i currently have with the dataset wine.data

Wait
After reading the docs do you put your 48 files under different speakers?
ah thaat pandas is not it

Fuck tbh kinda give up sorry m8, but this is far as I go https://github.com/facebookresearch/fairseq/issues/2953#issuecomment-736837999

GitHub
Code sample nohup python fairseq_cli/hydra_train.py task.data=/datadrive/ASR/training_data model.w2v_path=/datadrive/ASR/model/checkpoint_best.pt --config-path /home/rashwan/ASR/fairseq/examples/wa...
Hey im looking for help for a naive bayes program with 3 data sets train,test and meta, i am able to use nampy and pandas but no sk learn
what have you tried so far?


so my menu works where it reads all data i just can't classify from string to integer, with the ability to than consider using x_train,x_test to solve for the accuracy
wdym when you say you can't classify?

that doesn't mean anything to me 😛
yea im realising that i dont think i know how to ask this question
ill figure it out nvm
can someone help? cuda isn't enabled even though I have a GeforceRTX 3070
user@e2fdf045-3a78-4315-8829-d11b952beb95:~/vits$ python3.6 -m pip install torch==1.6.0+cu101 torchvision==0.7.0 --no-cache-dir -f https://download.pytorch.org/whl/torch_stable.html
Looking in links: https://download.pytorch.org/whl/torch_stable.html
Collecting torch==1.6.0+cu101
Downloading https://download.pytorch.org/whl/cu101/torch-1.6.0%2Bcu101-cp36-cp36m-linux_x86_64.whl (708.0 MB)
|████████████████████████████████| 708.0 MB 52.4 MB/s
Requirement already satisfied: torchvision==0.7.0 in /home/user/.local/lib/python3.6/site-packages (0.7.0)
Requirement already satisfied: numpy in /home/user/.local/lib/python3.6/site-packages (from torch==1.6.0+cu101) (1.18.5)
Requirement already satisfied: future in /home/user/.local/lib/python3.6/site-packages (from torch==1.6.0+cu101) (0.18.3)
Requirement already satisfied: pillow>=4.1.1 in /home/user/.local/lib/python3.6/site-packages (from torchvision==0.7.0) (8.4.0)
Installing collected packages: torch
Attempting uninstall: torch
Found existing installation: torch 1.6.0
Uninstalling torch-1.6.0:
Successfully uninstalled torch-1.6.0
WARNING: The scripts convert-caffe2-to-onnx and convert-onnx-to-caffe2 are installed in '/home/user/.local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed torch-1.6.0+cu101
user@e2fdf045-3a78-4315-8829-d11b952beb95:~/vits$ python3.6
Python 3.6.15 (default, Apr 25 2022, 01:55:53)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
t>>> torch.cuda.is_available()
False```
need to use torch 1.6 since https://github.com/jaywalnut310/vits/blob/main/requirements.txt
please always give text as text. people might need to copy parts of the error message to help you.
Has anyone here worked with Haiku. I thik I might have some memory leaks, and maybe Haiku was causing it
i'm honestly not sure which parts would be helpful to google
there aren't any error messages aside from the warning
but that's unrelated
you don't have to. you just have to give the text so that other people can.
if you give whatever text is in the screenshot as text in your next message, I will try to help.
edited it
please run nvidia-smi | grep Version and give the text
also, why are you using Python 3.6?
on the repo a pre-req was Python >= 3.6 so I assumed they programmed in py3.6
and so I didn't really want to mess anything up by choosing a higher py version
user@e2fdf045-3a78-4315-8829-d11b952beb95:~/vits$ nvidia-smi | grep Version
user@e2fdf045-3a78-4315-8829-d11b952beb95:~/vits$```keep in mind that I will not look at any screenshots; they are a waste of time to post.
3.6 is past end-of-life, so you might not be able to find a PyTorch wheel for 3.6 for your CUDA version.
Can you run nvidia-smi again, and give the whole output, without any screenshots?
user@e2fdf045-3a78-4315-8829-d11b952beb95:~/vits$ nvidia-smi
Failed to initialize NVML: Driver/library version mismatch```interesting
try cat /proc/driver/nvidia/version
NVRM version: NVIDIA UNIX x86_64 Kernel Module 525.60.11 Wed Nov 23 23:04:03 UTC 2022
GCC version: gcc version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04.1)```i'm going to reboot this machine
that's what I was going to suggest next 😄
oh lmao 😅
ok that fixed it, thanks for the help!
Traceback (most recent call last):
File "train.py", line 290, in <module>
main()
File "train.py", line 50, in main
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
File "/home/user/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 240, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/user/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 198, in start_processes
while not context.join():
File "/home/user/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/home/user/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/home/user/vits/train.py", line 62, in run
dist.init_process_group(backend='nccl', init_method='env://', world_size=n_gpus, rank=rank)
File "/home/user/.local/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 754, in init_process_group
store, rank, world_size = next(rendezvous_iterator)
File "/home/user/.local/lib/python3.8/site-packages/torch/distributed/rendezvous.py", line 246, in _env_rendezvous_handler
store = _create_c10d_store(master_addr, master_port, rank, world_size, timeout)
File "/home/user/.local/lib/python3.8/site-packages/torch/distributed/rendezvous.py", line 169, in _create_c10d_store
raise ValueError(f"port must have value from 0 to 65535 but was {port}.")
ValueError: port must have value from 0 to 65535 but was 80000.```
😔i swapped to 3.8 to try some other stuff
it's telling you what the error is, you can only open ports with numbers 0 to 65535
i figured by the error message
kinda just modified the source to just hard code it to a random port
any better way though
i can't quite tell from the error message where the port is chosen. if it's something you are choosing, then sure. or just generate it from the valid range the error message gave you
if it#S something a python module is doing automatically, you could open an issue on their repository
Hey. Help me pls to find all the first column values that are not NaN in a Pandas dataframe
df.iloc[0]
id 236607
type message
date 2022-07-01T01:12:25
date_unixtime 1656612745
from ff3
from_id user4a2ffasd6
text text
text_entities [{'type': 'plain', 'text': 'text'}]
actor NaN
actor_id NaN
Name: 0, dtype: object
I take the first row to extract the values, but a few of the are NaN.
I'd like to filter NaN out to have all the values in a row exist.
Something like df.get_row().where(value != 'NaN)`
df[df['id'] != np.NaN]
they're called boolean masks but that's what I'd use
Yeah, it's pretty clear for a column, but I have no idea about how to put a mask on all the columns in one line of code
that's what the mask does
it'll go through every row literally looking for that column, in this case id
if i wanted to replace
"lost in space – verschollen zwischen fremden welten"
with
"lost in space: verschollen zwischen fremden welten"
cant i just do this with my df?
df_vd['Title']= df_vd['Title'].replace(' –', ':')
df_vd['Title_clean'] = df_vd["Title"].str.partition(":")[0]
?
You puted thell mask on all rows of a single column.
I'm looking for a way to put a mask on all the columns
I came up with an idea of sorting all the columns and take the first row
Hey all. Is there a place where I can get help optimizing one numpy operation?
this would be the place
Cool! So I have a numpy array of strings (type: object). Imagine: arr = np.array(['Hello', 'World'], dtype=object) and I want to, as quickly as possible, do np.equal('Hello', arr). I tried char arrays, but they were slow. This is the slowest op I have in my code because of the object type
so you want to elementwise check which elements of the array are equal to "hello"?
yep
i'm afraid np.equal and simply doing == are about as fast as it gets
so what I was hoping for is to type convert the arr to something numpy native and go from there
just a thought
Also, @patent lynx My goal is to get a result array np.array([True, False]), not whether it is in
What it returns it here in the docs @spring echo
element = 2*np.arange(4).reshape((2, 2))
element
array([[0, 2],
[4, 6]])
test_elements = [1, 2, 4, 8]
mask = np.isin(element, test_elements)
mask
array([[False, True],
[ True, False]])
element[mask]
array([2, 4])
you could try using dtype bytes or str
if those don't help, i'm not sure there's much to do. the operation is essentially a for loop done in c. the only gains here would be from how the object is stored in memory, making the jumps memory-adjacent
this isn't the kind of operation that is usually problematic 😛
I see, I judged too quickly @patent lynx . My apologies.
doesn't the object dtype stay in Python land and never enter C?
well, something has to be done to it though, since arbitrary types won't exist in c
i'm not sure what exactly it does though for objects
I think object simply stays in Python
sure, but what is passed to C?
nothing afaik
that could be the case, but idk. you CAN make dtype object numpy arrays and they'll have all the restructions of any other dtype
so memory is being allocated for them in c arrays
at any rate, if changing the dtype doesn't help you much, there isn't really much to do here. are you sure this part is where your code is too slow? have you tried profiling it?
yep! I profiled it and it is the majority of the sink. For example I have some datetime <= and >= comparisons that are circa 8x faster
using line_profiler
and which dtype were you using for those?
datetimens[64]
aha, so, when using dtype object, what is passed to C are simply pointers back to the python objects
welp
so yeah, try checking the dtype of your array and if it's object, change it to str or bytes or smth like that, then try again
hopefully this will squeeze out some extra speed
https://stackoverflow.com/questions/29877508/what-does-dtype-object-mean-while-creating-a-numpy-array here's a quick read btw

Stack Overflow
I was experimenting with numpy arrays and created a numpy array of strings:
ar1 = np.array(['avinash', 'jay'])
As I have read from from their official guide, operations on numpy array are propaga...
If i want two vectors to be similar, their cosine similarity should converge to 1 correct?
sin is 0
if 0 is sin, does that mean grace is 1?
that would make them parallel/scaled versions of each other, yeah
cross product is 0
I created an image-classification ai following this tutorial: https://www.tensorflow.org/tutorials/images/classification
I've trained it now and want to test it with an png. How can I do this?
TensorFlow
I mean the tutorials say you can "predict on new data" section
sry didnt see that
@wooden sail You rock 🤟
hmm?
is having a G and a D pth file standard or it just something that some repos just do?
I'm playing around with VITs tts rn and they seem to be having these paths
but I have some vague recollection of seeing this kind of format in other tts libraries

I'm running some tests on Unsupervised Learning and self-learning and I've seen that I should apply supervised fine-tuning on low-data regime.
Thing is... much is "low-data regime"? Does it depends on the size of my complete dataset?
I mean...if I have a dataset composed of 10,000 samples, I understand that 10% of this dataset is quite few.
However, if I have a dataset composed of 1,000,000 samples, 1% of this dataset is quite many
I FINALLY figured out the issue. The program was running on both CPU and GPU, and I only want it to run on the GPU.

But when I try to make the computer focus on the GPU, I get this.
it sounds like it depends more on the size of the dataset the model was originally trained on than on how much data you have now, though I'm not 100% sure
Traceback (most recent call last):
File "A:\so-vits-svc-4.0\train.py", line 305, in <module>
main()
File "A:\so-vits-svc-4.0\train.py", line 43, in main
assert torch.cuda.is_available(), "CPU training is not allowed."
AssertionError: CPU training is not allowed.```Uh... I'm trying to train the model from scratch, actually
is all of your data labelled?
Yes, but I want to see how unsupervised configuration goes
I really doubt that unsupervised learning will get better results than just supervised learning on that case
maybe just go with 10% or a bit less, or wait for someone with more real experience to answer
though you might also want to ask in servers specially focused on machine learning
That's the thing, I want to see what the results will be
Though I've seen that self-learning with pseudo-labels tend to provide better results than actual supervised learning.
At least, the paper I'm reading shows that the performance should be comparable or even better than supervised
Hello I would appreciate feedback on my data science document/report of my project : its in the readme https://github.com/Simplyalex99/OpenReview

GitHub
Contribute to Simplyalex99/OpenReview development by creating an account on GitHub.
Please tag me when responding for feedback thanks!
does TripletMarginWithDistanceLoss also increases distance between anchor and positives other than corresponding positives?
Hey, I have a question related to training NN with images.
I need to train a VAE model to produce images. The problem is I want to build a single model that is trained on images of two sizes 54x30 and 44x44. I was told to use padding, but I am not sure what it means. Should I modify each of the images and add the 0 values of pixels (thus padding?) so each image is of size 54x44?
That’s exactly what padding is, filling in those images to achieve said size
You can center the image if feasible and then add padding uniformly around or push it to a specific region, I think you can even scale if it’s not proportional too. Different options. I’d train on different techniques and see what produced the best result.
Thanks, I was also told to build VAE with two channels, each for an image type
Do you know what it means?
Could be channel as in RGB(which would be 3), but I’m not 100% sure
Yea, I have no idea what he means by that. If I use padding there is just a single input of the common shape to the model
What if I did not use padding? He told me that in this case If I want to train VAE on images of different size I should have two model outputs and two loss sources, but how the input would look in that case?

My VAE implementation in RGB images only worked after I followed this. Careful with tutorials. VAE tutorials tend to be awful ||and Diffusion tutorials too||
Thanks!
Im getting an OOM error when I train my image recogitoin model wit cpu. What can ? do against it
I use the model explained in https://www.tensorflow.org/tutorials/images/classification but with a different dataset
TensorFlow
Is a trading bot with machine learning an AI ???
so im struggling to get an 83% in accuraccy from a test data, i get 79 im trying to solve naive bayes, but im not allowed to use sklearn any way i can have someone look at my code?
yes
hmm ok i did solve it so thats good to know
thought we arent allowed here but good for the heads up next time
does anyone mind helping me comprehend a stats problem

i'm confused in this case on what would be the null hypothesis/alternate hypothesis and what the test would be trying to prove
from what I see the p-value is the probability that the your results was happened by chance. The test is trying to solve whether your results of the gene mean expression happens by chance.
Our null hypothesis should be that the gene expression stays the same. The alternate hypothesis shows that our gene expression is different from the null.
whats the significance of the threshold value and the sample mean in this case?
so to do this i would need a population mean, so is the "threshold" value the population mean?
Umm no I think you could do a t test to estimate the p value.
no we are not looking the population threshold value, we just need to see whether our experiment results happens by chance or not
but there is a threshold for the p-value to either accept or reject our hypothesis, which is alpha. This alpha can be anything but the industry standard is 5%.
okay
why cant you find p value using z score
Well it depends
If your sample size is large greater than 50 and the population Sigma is known then it is safe to use Z
t test works well when you have less data and distributions with a 'fatter' tail
No, that's not really right.
The z-test is for when you know the population variance. The t-test is for when you don't.
In almost all cases, you don't know the population variance, so you should use a t-test.
However, there are times when you do know the variance. For example, if you have a bunch of yes-no questions, then those are Bernoulli trials, and you know the variance of a Bernoulli trial, so the z-test is appropriate.
The tricky part with these tests is that they are based on normal approximations to the actual sampling distribution.
so in this case, we don't know the population variance but it's still asking to conduct a z-test
how would that work
Right, probably because it's just simpler.
but they are giving us options in the questions haha
But doesn't the z test require population variance
It needs to be known, yes.
so how would one conduct a z test for this
well the assumption says you could use the sample level variance
otherwise use a t test according to the question
It says to assume the sample variance equals the population variance. So you can compute the sample variance and use that.
It's not really correct. It's just an approximation. A t-test is better.
But this is supposed to be an exercise. In reality, you don't implement these tests by hand; someone else does (e.g., R, SciPy) and you just use theirs.
What the Z-test really is is a test in which the test statistic is normally distributed under the null hypothesis.
(With known mean and variance.)
So you do need to know the population mean. But you also need a threshold (as the problem says).
And the threshold is what we use to find the z value?
It's what we compare the z-value to.
Here's a simple example. Suppose we flip coins. When the coin comes up heads, I give you a coin. When it comes up tails, you give me a coin.
Yeah
You want to know if the flips are fair.
The only thing you need to track is the difference between the number of times you win and the number of times I win.
If the flips are fair, this will average out to zero.
Right
However, that's only on average. If we've made, say, 5 flips, then it's not going to be exactly. It can't be.
yes
So there's some distribution. In fact it's a binomial distribution, but if the number of flips is large enough, then it's pretty close to normal.
We can calculate the variance of this distribution exactly.
Yes
E[X^2] = 1 and E[X]^2 = 0, so the variance is 1.
👍
So asymptotically (i.e., for large numbers of flips) we get a standard normal distribution.
Yes
So how do we tell whether the coin is fair?
After, say, 100 flips, we expect a difference around zero. But if it's one? Two? Three? Still probably okay.
Right
What we usually ask is: Suppose we fix a threshold. Call it alpha. It's going to be small, like 5%. We figure out, if we have a fair coin, what kind of extreme behavior would we see only 5% of the time?
It's possible that a fair coin could come up heads 100 times in a row, but it's a 1 in 2^(-100) event. If your coin does something that could only happen 1 in a million times if it were fair, you might reasonably infer that it's not fair.
What you do is you look at the distribution you'd get at random. We're assuming that's normal. And you ask, how far would you have to be away from the mean to be in that extreme 5% (or other choice of alpha) region?
That's your threshold.
So the threshold is how far away from the mean to be within the alpha region
Pretty much.
Alpha is the parameter you use to control your Type 1 error rate—the probability that you have falsely rejected the null hypothesis.
so in this example what would be the value we are comparing to the mean
The threshold?
Yes. You're going to compare the sample mean to the threshold.
and determine whether that threshold is in that 5% end of the distribution
In practice, you would need to know the population mean to set the threshold. But in this exercise, the threshold is given to you.
And where would I use the test-statistic
The test statistic is the sample mean in this case.
could you clarify what the test statistic is used for
It's the thing you compare to the threshold.
In the coin flipping scenario, it's the difference between your wins and my wins.
In the exercise, it's the sample mean.
So in the exercise, there is a distribution whose population mean is the same as the sample mean, which is the same as the test statistic?
In the exercise, you are given a threshold. Someone else has set that for you, and because of that, you don't need to assume anything about the population mean.
i thought the test statistic is the number of standard deviations from the sample mean to the theshold value
feel like this convo is going in circles, I think you need to get a good grip on the central limit theorem.
Yeah i have not done anything stats related in like 2 years thank you guys though sorry for so many questions
Can someone explain the concept of RNNs and how they work? I haven't really learned the required math for it and are having trouble understanding.
Can you explain how feed forward neural networks work?
It's good with sequential data
like time series or sentences that is needed to be processed.
aka any data with temporal features
the tricky part is that how they take inputs of data because it inputs sequences of repeated observations through time.

these observations can also be multivariate

so this differs from a typical ML approach

Here is a very simple RNN architecture:
# 0- Imports
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import layers
# 1- RNN Architecture
model = Sequential()
model.add(layers.SimpleRNN(units=2, activation='tanh', input_shape=(4,3)))
model.add(layers.Dense(1, activation="linear"))
# 2- Compilation
model.compile(loss='mse',
optimizer=Adam(lr=0.5)) # vhigh lr so we can converge a little with such a small dataset
# 3- Fit
model.fit(X, y, epochs=2000, verbose=0)
# 4- Predict
model.predict(X) # One prediction per city
however this returns:

so how do we want to predict this?

to return a sequence of predictions we can make this model and adjust return_sequences=True
model_2 = Sequential()
model_2.add(layers.SimpleRNN(units=2, return_sequences=True, activation='tanh'))
model_2.add(layers.Dense(1, activation='relu'))```
however the y_train needs to be a sequence too if a sequence needs to be predictedThe RNN is fed one observation at a time (forward in time).
It maintains an internal state h that is updated at each time step.


The RNN has a memory about past observations.
A RNN layer outputs its internal state at the last time step

y(t) is not a prediction/target
but rather a vector of size RNN_units used as an input to the Dense layer to compute the rain at time.
If I have 10 RNN units
will try to capture 10 interesting temporal features from the time-series
(maybe: mean, rate of increase, complex auto-regressive feature, etc)
and combine them into 1 value for our regression task
The number of units can be seen as the number of memories about features maintained in parallel.
So when RNN feeds forward:

Then backpropagates by its gradient in respect to w:

Teaching page of Shervine Amidi, Graduate Student at Stanford University.
anyone know if there's a standard framework for combining Python ML with JS frontend?
I find different things related to Flask API + Sklearn, but I wonder if there's more than just random Github projects
there are a bunch of libraries/services that can do the frontend for you and let you just focus on building the model, but if you are separating it yourself, then you might as well treat your backend the same you would on a non-ML project as far as the frontend is concerned
x,y = make_circles(1000,noise=0.03 , random_state=42)
x = torch.from_numpy(x).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
device = "cuda" if torch.cuda.is_available() else "cpu"
x_train,x_test,y_train,y_test = train_test_split(x,y, random_state=42)
model = torch.nn.Sequential(
nn.Linear(in_features=2,out_features=5),
nn.Linear(in_features=5,out_features=1)
).to(device)
loss_function = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
epochs = 100
for epoch in range(epochs):
model.train()
y_pred = model(x_train).squeeze()
#Cal loss
loss = loss_function(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.inference_mode():
test_pred = model(x_test).squeeze()
test_loss = loss_function(test_pred, y_test)
if epoch%10==0:
print(f"Epoch: {epoch}| Loss: {loss:.3f} | Test Loss: {test_loss:.3f}")
Epoch: 20| Loss: 0.693 | Test Loss: 0.695
Epoch: 30| Loss: 0.693 | Test Loss: 0.694
Epoch: 40| Loss: 0.693 | Test Loss: 0.695
So as you see, test loss falls down and rises up again. How is it possible? Shouldn't it fall down everytime epoch increases?
Well it has reach convergence
It's best to plot the history of your model
But generally means your model can only improve at that loss value
OK, this is so off the wall but, I am using a survey website to get rankings, but now I need to find averages of all of the entires, this is the data I have

Would it be possible to use Panda's and "rank" all of these and create averages across all entries? (I have 45 entries)
Hi, What would be the best python library and time series model for forecasting storage usage. I am completely new to time series data and I am not sure how to start and chose the right model. Kindly advise.
Hello, I need your help
I have 500 IDs for students in a csv file (I have only one column for IDs) and I need to find the reports (pdf files) for each student among the 2K pdf files. These files are in one folder. Finally, I want to move extracted files into a new folder
So how can I find the pdf file containing the specific ID and move it to a new folder?
I started with this code but got stuck
import fitz
import os
path= r'C:\path\pdf'
id_csv = r"C:\path\pdf\id.csv"
files = os.listdir(path)
with open(id_csv, "r") as i:
reader = csv.reader(i)
for file in files:
doc=fitz.open(path+'\\'+file)
I hope my question is clear
Thanks in advance
Loop through each row of the csv file and find the report in the specified folder. I'd do something like this:
import csv
import shutil
from pathlib import Path
with open(id_csv) as file:
reader = csv.reader(file)
for student_id in reader:
pdf_filename = get_pdf_report(student_id)
shutil.move(pdf_filename, target_dir)
Thank you @lapis sequoia, here you are looking for the IDs in the filename, right?
Can you explain the script more beacuse the id inside the pdf files
can anyone help me understand what random_state parameter exactly is? and what happens if i set it to 0
!e
import random
def f(seed):
if seed!=None: random.seed(seed)
return [random.randrange(100) for i in range(5)]
print(f(None))
print(f(None))
print(f(0))
print(f(0))
@tidal bough :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | [9, 63, 52, 38, 75]
002 | [16, 75, 29, 66, 88]
003 | [49, 97, 53, 5, 33]
004 | [49, 97, 53, 5, 33]
Random number generators start with a seed, usually taken from the system's secure randomness source. But you can give them a specific seed, and ensure consistent behaviour. This is useful when e.g. you want to distribute an example that uses random data, but want the output to be the same each run.
so if i set random_state=0, it is a seed that will run the same everytime?
but if i dont set the random_state it always be a different value?
Pretty much, sure
I see, thanks a lot!
This is an old problem in statistics. It has no clear answer, because to get any answer at all, you have to decide what the rankings represent and what kind of answer you're looking for. You can make those choices in more than one way. Because of that, there are multiple possible answers.
This question has been studied the most for paired comparisons. The best known example is the Elo rating system used in chess, which is closely related to the Bradley–Terry model. More generally, this is a question of ordinal regression. In fact, if I understand your data and goals correctly, what you want to do is precisely ordinal regression. Usually this is done with a "generalized linear model." There is an implementation of these in the statsmodels package.
guys
collab gpu crashed
and the checkpoints which i saved in a folder also vanished
any way to get the folder with the checkpont file?
help required
trained for a long time and it vanished!!!!1
Hey, so I am trying to apply a function to every row in a Pandas dataframe. Problem is, I am getting an ilocindex object instead of the row, how would I go about this?
papersDataframe["isCSS"] = papersDataframe.apply(lambda row: isCSSPaper(row))```I need the whole row
I'm pretty sure apply works by column instead of by row by default.
Any quick fixes to this then?
so you need, like, axis=1 at least.
😦 anyone??
Could I transpose?
Why not pass axis=1 instead? That seems like it'd be more performant.
It's an argument of apply. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html
Integrated circuit
how to build a recommendation system where you dont have ratings of the user? Like i am trying to make a recommendation engine for a real estate company, which recommends on the basis of color, and popularity. How can i make one?
If you don't have user ratings, it's not a recommendation system. All you're doing is ranking properties by popularity.
You can have indirect ratings, if that is what you mean? Like how long people view certian sites? Is that what you mean?
Is this how you get a log normal distribution from a normal one in Python?
Y_logNorm = np.exp(sigma*np.random.standard_normal(n))
how do i pass fit params to cross_validate using a random forrest inside a GridSearchCV?
Set up possible values of parameters to optimize over
p_grid = {"n_estimators": [10, 50, 100],
"criterion": ["gini"],
"max_depth": [5, 10, 20],
"min_samples_split": [2, 3],
"random_state": [RANDOM_SEED]}
rf_clf = RandomForestClassifier()
Choose cross-validation techniques for the inner and outer loops,
independently of the dataset.
E.g "GroupKFold", "LeaveOneOut", "LeaveOneGroupOut", etc.
inner_cv = KFold(n_splits=NUM_SPLITS, shuffle=True, random_state=RANDOM_SEED)
outer_cv = KFold(n_splits=NUM_SPLITS, shuffle=True, random_state=RANDOM_SEED)
Nested CV with parameter optimization
clf = GridSearchCV(estimator=rf_clf, param_grid=p_grid, cv=inner_cv)
Set up possible values of parameters to optimize over
cv_p_grid = {"estimator__n_estimators": p_grid["n_estimators"],
"estimator__criterion": p_grid["criterion"],
"estimator__max_depth": p_grid["max_depth"],
"estimator__min_samples_split": p_grid["min_samples_split"],
"estimator__random_state": p_grid["random_state"]}
print(clf.get_params().keys())
cv_results = cross_validate(
estimator=clf,
X=X,
y=y,
scoring={"score": scorer},
cv=outer_cv,
n_jobs=10,
fit_params={"param_grid": p_grid},
return_estimator=True
)
I keep getting this error: fit() got an unexpected keyword argument 'param_grid'
never mind i figured it out thanks!
Anyone interested in quant finance
why do you ask? what would you say if someone said yes?
Oh because I have a outline on how to break into quant finance
I am also well known in the quant finance twitter world
@weary lake here's the deal. We're not a recruitment forum, we are a learning resource. We help people with Python. We're not here to help people break into finance, quant or no quant
I am not looking to recruit people in the quant finance world,rather seeing if anyone is interested such world.
which is off-topic.
you've posted about this in two channels now with no clear connection at all to Python. I think you're recruiting.
If you want to discuss it in the context of how you think Python can help the statistical analysis, you'd probably find more positive reception here.
Sorry but to become a quant you need to be way more specialized than just being a programmer. I am not looking to recruit rather spread awareness of the quant finance world.
which is off-topic.
that's not the focus of this server, or this channel.
!off-topic - we have these channels for a reason.
Off-topic channels
There are three off-topic channels:
• #ot0-psvm’s-eternal-disapproval
• #ot1-perplexing-regexing
• #ot2-never-nester’s-nightmare
The channel names change every night at midnight UTC and are often fun meta references to jokes or conversations that happened on the server.
See our off-topic etiquette page for more guidance on how the channels should be used.
Yes, I think one can utilize python to create a basic statistical arb trading algo.
You seem to be missing the point.
Anyone here use kaggle? I find it useful to find ideas on there
Also optiver actually hold data science competition on there as well.
I wouldn't say I directly use it, but I've found myself dipping into some older competitions to see some solutions for similar problems that I'm brainstorming.
Interesting, (secret) utilize the data the prop firms provide on there rather using yahoo finance
Here is a interesting project idea to implement in python
This wouldn't happen to be your website would it?
Nope
hi guys, I got a question. I have two tensors of size (3,32,32) each. I want to append them to a new tensor in such a way that the new shape is (2,3,32,32). how can I do that?
hi torch.stack((a, b))
Docstring:
stack(tensors, dim=0, *, out=None) -> TensorConcatenates a sequence of tensors along a new dimension.
All tensors need to be of the same size.
Arguments:
tensors (sequence of Tensors): sequence of tensors to concatenate
dim (int): dimension to insert. Has to be between 0 and the number
of dimensions of concatenated tensors (inclusive)Keyword args:
out (Tensor, optional): the output tensor.
Type: builtin_function_or_method
i tried it, but outcome isnt as desired
empty_stack = torch.empty(size=(3,64,64))
for i in datas: #datas is list of image paths, not relevant to the question anyway
imag = data_transform(Image.open(i)) #imag is a tensor of size(3,64,64)
torch.stack((empty_stack,imag))
```it returns a new tensor unless you pass an appropriate thing to the out parameter
new = torch.stack(...)
or
new = torch.empty(...)
torch.stack(..., out=new)
first is better if you already don't have a preallocated array for some reason

thats right, just empty and the last one
so you'd like to stack these 5 or N many images each of shape X, Y, Z
to end up with N, X, Y, Z
right
so torch.stack expects a list-like of tensors to stack; you can build a list out of those N images, and pass that to torch.stack
accumulatingly stacking has some glitches to implement, e.g., as you faced, what image to start with, as empty_stack is not literally an "empty" tensor but a tensor filled with potentially garbage values
it also has some performance cost as stacking is not so cheap of an operation
so
building a Python list out of your tensors, and then passing that to torch.stack is clearer
building that list can be done with an explicit loop like you have, or with a list comprehension
fantastic it works now
img = [data_transform(Image.open(i)) for i in data] #list of images, all items inside list are tensors
new = torch.stack((img))
cool
thank you so much @untold bloom , appreciate your help
^^ each time you stack, it has to copy all the data again.
so the first stack operation needs to move 2 arrays' worth of data
then the next one does 3
then 4, then 5, etc.
in total for N arrays you need almost N²/2 copies
doing all of them at once just needs N copies
thats right, it would cost a lot of extra operations
hey guys, im trying to work out how to learn a representation of a 3d voxel grid - anyone have any ideas?
Try asking it to chatgpt
To answer the question you asked in my DMs: no. I was just inviting you to expand on your question, to increase the chances that someone will answer it.
I have an spike in my image classification model training diagram where accuracy goes down and loss goes up for i'd say 1 epoch. How can I explain that?
Hey @radiant anvil!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
How to build real time voice changer and redirect output ? Hello everyone, I currently have to work on a real-time voice modification project. My idea is to listen in real time with the microphone and send this input to an AI model deployed on Azure. Modify this voice now with the template and return it to a new device. Do you think it's doable? And would that be the best way? I'm completely dry right now and need some recommendations.
You could do that using a Generative Adversarial Network, or a Variational AutoEncoder. You can also consider a Flow model(like Flowtron)
If you can afford a pretty good hardware in Azure, you probably won't have problems with that. However, if you can't, you might need to limit the number of channels in the convolutions.
Those models are a bit slow to train because of the convolutions, but for evaluation they might be pretty fast.
(Diffusion Models are an alternative, too, but they tend to be a bit slow, even for evaluation)
does anyone know how to use the first 10 rows of a 2D array?
I did 2_Darray[::11], but not sure it actually returns what I want it to
my dataset has 10000 rows, and when I do that the length is 46
it doesn't, that keeps every 11th sample of your array
all righty. just for completeness: my_array[0:10, :]
sadly i do not
Is working with Excel, Power Queries, Power BI, Pivots etc a subset of the Data Science field, or can't they be compared?
perhaps not entirely a subset, but a lot of it is part of data science (or data analysis to be more specific)
thanks 🙂
having some difficulties wrapping my head around the differences between data science, data analysis, data engineer etc. as it sound each role does something different
data engineer -> databases and transffering huge amounts of data
data analysis -> visualisation, reports, usually smaller amounts of data
data science -> technically encompasses everything, but 'data scientist' jobs will oftentimes focus on AI/ML models
much obliged
(engineer, analysis, science) -- you switched from an occupation to concepts 😮
oops 
just used the same terms as in that message
sorry.. had to step away for a sec.. I meant data scientist. My bad
Out of curiosity...a job that deals mostly...maybe almost entirely...with AI/ML models...is it an AI/ML Engineer?
Somekind of a data QA team? they decide whether our model/preprocessing/packaged product are bullshit or not
I would say ML engineers are more dealing with ML/AI models. And data scientist role is for companies who don't know what they want.
Or they fall more under Analytics
In my view engineer roles ( ML/AI/MLOps Eng. ) will be closer to software engineering roles than data science roles.
They are closer to SWE.
How to make most of my google bigquery free trial?
Did anyone of you guys keep making free account?
import sklearn
import torch
from torch import nn
from sklearn.model_selection import train_test_split
data = torch.randn(10, dtype=torch.float)
class Model(nn.Module):
def __init__(self, input_features=2, output_features=1, hidden_units=8):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_features=input_features, out_features=hidden_units),
nn.Linear(in_features=hidden_units, out_features=hidden_units),
nn.Linear(in_features=hidden_units, out_features=output_features)
)
def forward(self, x):
return self.layer(x)
x_train, x_test, y_train, y_test = train_test_split(data,data,test_size=0.3,random_state=42)
model = Model()
loss_function = nn.L1Loss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(100):
model.train()
y_preds = model(x_train)
loss = loss_function(y_preds, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.inference_mode():
test_pred = model(x_test)
test_loss = loss_function(test_pred, y_test)
if epoch%10 ==0:
print(f"Epoch: {epoch} | Loss: {loss} | Test Loss: {test_loss}")
Output:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x7 and 2x8)
I double-checked and still everything seems correct to me. Can someone help?
input_features=2
How many features the data you feed in have? Is it even two dimensional? (no) Shouldn't it respect the "n_samples x n_features" scheme? (yes)
thank you for providing a reproducible example BTW, that's super extremely rare unfortunately, so i had the feel to thank
I was designing SPR sensors using python. At one place I had to use integration. I used scipy.integrate library and It took 5hrs to generate 1000 datasets. I had to switch to matlab. Is there any solution in python?
scipy integrate uses BLAS to do its numeric integration, so that is not the problem in itself. maybe you have some loops written around it that weren't so efficient. this isn't as much of a problem in matlab because it's jit compiled, but otherwise matlab will also use BLAS or MKL for its linear algebra. things like the definition of the function being integrated, for example, can make a big difference.
Oh never noticed that. Thank you!
Thank you for your kind words. I wanted to provide them to make my problem more understandable
I've a question stuck in my head. I don't want to go by heart and learn the logic behind the deep learning.
For some specific questions (e.g numerical models where we use linear regression), we specify a train test split and split the data into 4 groups: x_train, y_train, x_test and y_test.
So, x_train is a data group that a machine is supposed to learn whereas x_test comes afterwards into our scene. x_test is used for testing how much the machine learned.
On the other hand, we have y_test and y_train. What do these actually do? E.g (y_train). Is it like utopic data that the machine must learn and y_train is how it must look like if the machine learns it with 0 loss. Am i right in this case?
you can think of networks as functions. for each input, they have an output. the x values are the inputs and the y values are the outputs. you don't train with just x_train, you train with the pair x_train, y_train.
so that if the network is a function f, then f(x_train) = y_train
x_train -> our model forward pass -> y_train ?
and if it learned correctly, then we will also see that f(x_test) = y_test
yes
Ah
we can do a simple example right now
imagine we know we have a function ax = y. we are given x_test = 1, y_test = 3. we are also given x_train = 2, y_train = 6.
so a*x_train = y_train tells us that a*2 = 6. so a = 3
now we test it
a * x_test = 3 * 1 = y_test = 3, which is correct
we learned a correctly!
For example, we created an artifical intelligence model that tells us the names of animals we show it. I show the robot a cat picture. How will we determine the y_test? Will it check it for every animal and which fits the best, will say the name of it?
you have to tell it yourself
oh wait, sorry, i thought you had written y_train
yeah it's y_test
that question actually has no good answer, what exactly networks do is not well understood
it will do some math with the weird parameters it learned
how exactly it does that "check" with the animals will vary by network, and in some cases you can have the class be a direct output without having to compare all classes, for example
you can try to interpret the final layer of a classifier network as an argmax that picks out the class with the largest probability
but how the network reaches those probabilities is another matter
Your train dataset comes in pair.
Image of animal = X
Type of animal = y
X = 🐶
y = dog
Right. I can tell you that the code was same just syntax were according to the language.
yeah i dont have user ratings. What if i recommend on the basis of similiar color or content based filtering? would it be a recommendation engine?
i am trying to implement this in vr. This feature would be hard. Are there any other methods plss!!?
so is ml engineer role better than data scientist as per you
Yes, there are a billion ways to get indirect user ratings. I would imagine how long a user stays/looks at a certain property would be an easy thing to get from VR?
Otherwise you can have direct ratings like Netflix does?
Either way, you should probably read Charu Ahharwal's book on Reccommender systems
Aggarwal
@cold minnow I saw your help post but it got closed before I had the chance to respond. You can do this by making your labels an array of multiple values, corresponding to the 2 labels you're looking for, and making the output shape of the model equal to the amount of labels you have
it would work similarly to if you have a multiclass output, except rather than multiple classes you'd have multiple labels
No, that's not what I said at all. No role is inherently better than another role. That would be saying a fork is better than a knife, they have different functions.
A ML engineer role is more well defined compared to a "Data Scientist" role. A company seeking a ML engineer tends to know exactly what they want (i.e. they generally will already have a data science pipeline set up).
Where as Data Scientist role's responsibilities is more often muddy. Some companies look for a 'data scientist', when the role responsibilities itself lie closer to an analytics role. There are instances where companies list a job as 'data scientist', but the role itself is actually data engineering. Others simply expect data scientist to be able to do it all (i.e. A unicorn).
depending on what your labels are (if they're discrete, continuous, or a mix of both) you might have to choose your loss algorithm wisely for this
alternatively you can also branch your model and create a separate section to identify healthy or diseased, which might give better performance but is also more complex
You mean by doing a second training?
no, it's the same training loop you'd just have the model itself split into multiple branches (you can't do this with the basic keras Sequential model, you'd have to use the functional API)
but that's likely not necessary anyways
I see
you can pretty much just append the healthy/diseased label to the end of your species labels
if you're using sparse_categorical_crossentropy as your loss, you'd have to change that since that only works for one-hot encoded values (values which can only have 1 positive label)
Is there a way to do this? I can send you the part of my code that does the labels if you want
yes, that would be helpful
Get image labels
labels = []
for a in train_set.iterdir():
labels += [a.name]
print("labels : ",labels)
Get index for all plants
label_index = {}
for i, label in enumerate(labels):
label_index[label]= i
print(label_index)
Create lables for each image
all_image_labels = [label_index[path.parent.name] for path in list(train_set.glob("/"))]
print (all_image_labels[:5])
Create a tf.data.Dataset of labels
tf_labels = tf.data.Dataset.from_tensor_slices(all_image_labels)
for example in tf_labels.take(1):
print(example)
technically speaking, how hard would it be to create a wojack image generator that utilizes a database of pre-existing wojack drawings and uses the drawings to create a new image according to the users input?
i can't tell if the concept of this would be rlly easy or not
can you show me the output of the last line? (so I can get an idea of what your labels currently look like)
Let me start the code
Not sure what a wojack is, but generating new image based on original images isn't new. You can look into GAN (Generative Adversarial Network).
if you're gonna make them according to a user input you can use stable-diffusion or a similar model and retrain the model onto your wojack drawings

so those are integer encoded labels, which won't work for multilabel. It's pretty easy to convert them though, you can call the tf.keras.utils.to_categorical function on all_image_labels before it get's converted to a tf dataset
from there you can add the healthy/unhealthy labels to the end of each label
the one-hot encoded label version of the [0, 0, 1, 1, 2] you had before will look something like [[1, 0, 0], [1, 0, 0], [0, 1, 0], [0, 1, 0], [0, 0, 1]] (this is assuming you have 3 classes, if you have more each label vector will be longer)
By classes in this case you mean the species?
yes
Alrighty
Does anyone knows how to train and test model jointly in neural networks?
Hey one question: If you want to get results fast in working and training LLMs, are there any similar service that provides the infrastructure likw AWS SageMaker? And if yes, which one you prefer?
But can we build a recommendation system without even any ratings!? Cuz now the data which i have doesnt include user ratings at all. Like what other parameters can i include for building a recommendation system?
You have to indirectly get the user ratings then. It doesn't have to be explicit as mentioned. What data do you have?
i want to use cross modal transformer, is there a one line/ small block of code i can use in torch?
so that it auto maticaaly makes key, values, queries
so its basically like creating a recommendation engine for a real estate company(laminates)
They have only got the data like Design No, Finish Name, Page No and Assigned Value.
They also have got the images of laminates corresponding to the finish name. Now i am trying to make a recommendation sys, where i got these data only and NO RATINGS! and also its now not possible to get the ratings from user now.
Idk any approach to this, but thought of color. Like similar color and it recommends. but how would i do it? and also what else can i use for recommendation
Yeahh i guess i totally agree with you! I was told to make a recommendation engine. And with this info i think it comes under data scientist. But still i am unclear, what is the role of ml engineer?
Ohhh, I think I understand the issue.
You might not be making a reccommender system after all. It sounds like what you want is unsupervised learning for clustering similar products together.
Look into K means clustering for that.
You know...that's something that I'd like very much to discuss...why neural networks are seen as "black boxes" when they're, in the end, just math operations that could be done by hand.
but unfortunately my mind is not in good shape for that right now 
Oh...I think I get it now... In the hidden layers, the process to which each parameter will be defined in order to provide the correct output for the given input will vary for each neural network. Two models with the layers input_layer, hiddenA, hiddenB, hiddenC, output_layer might have the same values for the input_layer and for the output_layer in order to stablish a good relation input -> output, but the numbers(weights) in the hidden layers won't necessarily be the same, yet both models might have the same performance. Right?
This is not a recommender system in the usual sense. Recommender systems are about using past user data to recommend future user actions. If you don't have past user data, then you don't have a recommender system.
I'm guessing that the intended applications is something like: Suppose that a user clicks on a page for one product; you would like to be able to have, on that page, something that shows similar products the user might consider. Is that right?
Assuming it is, there's more than one way you can approach this. If your items are already in categories, then you could just show a random selection of items in the same category. If there aren't very many items, and they don't change frequently, then you could make lists of similar products by hand. If neither of those works, then you need to generate the lists of similar products automatically. This is a machine learning task. How you should approach it depends on exactly what the available data is. You said, "Design No, Finish Name, Page No and Assigned Value", but I don't know what those are. I don't even know if they're strings. You also said there are images. What kind of images? Like, is there a picture that simply shows the color and pattern without any background?
My inclination is to say that you should try to embed your data in a (possibly large-dimensional) vector space. To look up similar items, you'd do an approximate nearest neighbors search. But I'm not completely sure; it depends on a lot of things. Can you share your data (or is it proprietary)?
Hey, I'm using Pandas Dataframes to handle some data cleanup, one of the steps is resampling to a fixed time series (every 100ms) and interpolating any gaps. The source data has a long gap of no data between 2 events that we are interested in (the data describes liquid flow rate). At either end of the gap there are data points of zero for the flow rate (as well as one or two in the middle). Once I interpolate I get a funny sloping rise from one of the zero points to a point midway along the sharp rise... This makes no sense to me, and it doesn't appear to happen on every event. I'm trying to correct for this artifact, but can't for the life of me figure out what's the root cause...
The data is indexed via proper DateTime column.
The interpolation code I'm using is:
inDF.resample(interpolationPeriodString).mean().interpolate(method='time')
(interpolationPeriodString is '100ms')
I've tried without specifying method (linear being default) and a few others... Result is the same.
Attached are a couple screenshots of pre-interpolation source data, and post interpolation (the slope is described by hundreds of rising data points as if it's doing linear interpolation between the zero at midpoint, and the peak at the start of the next event, but there are intervening zero points still it seems to be ignoring)
If anyone has any suggestions/ideas I'd be very grateful 🙂 Thanks!


Is this channel for Jupiter notebooks? Questions ? Because I was wondering the major difference from excel and Jupuyter note books and also how many rows can you have max with juypter note books for data etc
Well I just wanted to do math and calculations have input box
Yeah I just want one stop shop and store all my data and be good to go
Going to use a lot of forumla and calculations and Statistics profit taxes etc and maybe more advance stuff later
jupyter doesn't store data though, you'd have to load the data and/or rerun all the cells every time you reopen it
And been having issues with excel and sheets calculating stuff and I just resorted in making a script and bam works good but I just need to always run script then put it in the input box I made
Oooh
@wooden sail ouch
it's just one way of displaying your code, nothing else. think of it like an editor or IDE
Yeah it’s just seems like there no limit for rows on Jupiter which google sheet has limit
same as just writing python in notepad or vsc or whatnot. the only difference being in line plots
Cells etc
sure, because it's not storing anything itself
cells are just blocks of text
code, markdown, plots, etc
you can't really do the thing of having the data and the math in the same place in python, unlike excel
you always have to reload the data. python's just a programming language
Calculate every time due to numbers data changing
But I love python that does math for you
I think pandas does advance stuff I forgot which library for math again that does a ton
Soya idk guys
there's no direct way to compare rows in spreadsheets to code
and cells and jupyter are just blocks of code, groups of lines of code. you can do everything you do with jupyter without it as well
Hmm
I wanted to automate my model lifecycle using prefect API
@task
def preprocess_new_data(min_date: str, max_date: str):
return preprocess(min_date, max_date)
@task
def evaluate_production_model(min_date: str, max_date: str):
return evaluate(min_date, max_date)
@task
def re_train(min_date: str, max_date: str, split_ratio: float):
return train(min_date,max_date, split_ratio)
@task
def transition_model(current_stage: str, new_stage: str):
# if old_mae> new_mae:
# print("Past Model is Better")
# else:
# print("New model is better, please switch to production")
return mlflow_transition_model(current_stage, new_stage)
@flow(name=PREFECT_FLOW_NAME)
def train_flow():
"""
Build the prefect workflow for the `taxifare` package. It should:
- preprocess 1 month of new data, starting from EVALUATION_START_DATE
- compute `old_mae` by evaluating current production model in this new month period
- compute `new_mae` by re-training then evaluating current production model on this new month period
- if new better than old, replace current production model by new one
- if neither models are good enough, send a notification!
"""
min_date = EVALUATION_START_DATE
max_date = str(datetime.strptime(min_date, "%Y-%m-%d") + relativedelta(months=1)).split()[0]
old_flow = evaluate_production_model(min_date, max_date).submit()
preprocess(min_date, max_date).submit(wait_for[old_flow])
new_flow = re_train(min_date, max_date, 0.02).submit(wait_for[old_flow])
old_mae = old_flow.result()
new_mae = new_flow.result()
if old_mae> new_mae:
print("Past Model is Better")
else:
print("New model is better, please switch to production")
transition_model('None', 'Staging')
Is this the correct way to do it?
because it is returning AttributeError: 'NoneType' object has no attribute 'submit'
Welp as a guy struggling to implement it, one solution is to host it into a backend or cloud database for the data. Like google bigquery or amazon aws. Train the models on the cloud to save computing power.
Then host the model in Mlflow to redeploy trained models. Finally some kind of a Ml workflow to keep track how the models are updated or put into production/staging.
Finally you can integrate it with django for the front end to interact with.
hey
Code: https://sharetext.me/tplinuacxv (that was too long for Discord)
Problem: I calculated the loss etc. and it was unbelievebly fine. So I wondered how it looks like and visualized it. Then I found out that it works wrong...

Why does that happen?
hello everyone
can someone give me a link to get the winutils.exe file to set up pyspark?
I have this winutils.exe file but pyspark refuses to recognise it
so I think there is a version mistmatch
*mismatch
hey hey, i'm working on generating Minecraft schematics using DL
right now i'm trying to train some block embeddings using a convolutional autoencoder, and i'm successfully outputting a tensor of (128, 128, 128) but all the values are near 0 or negative. do any of you guys have any ideas?
im wondering if it's because i need to try and capture signals at different scales, but id rather invest that time developing a transformer based approach
slightly arbitrary, but a sample tensor: python tensor([-0.0134, 0.0423, 0.0137]
where each value is expected to be a minecraft block id
AutoEncoder(
(encoder): Sequential(
(0): Sequential(
(0): Conv3d(1, 64, kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1))
(1): LeakyReLU(negative_slope=0.01)
(2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): Sequential(
(0): Conv3d(64, 128, kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1))
(1): LeakyReLU(negative_slope=0.01)
(2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
(decoder): Sequential(
(0): ConvTranspose3d(128, 64, kernel_size=(3, 3, 3), stride=(3, 3, 3), padding=(1, 1, 1))
(1): LeakyReLU(negative_slope=0.01)
(2): ConvTranspose3d(64, 32, kernel_size=(3, 3, 3), stride=(3, 3, 3), padding=(1, 1, 1))
(3): LeakyReLU(negative_slope=0.01)
(4): ConvTranspose3d(32, 1, kernel_size=(2, 2, 2), stride=(2, 2, 2))
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=128, bias=True)
)
)```depends on what you're after, i'd pursue some book suggestions from websites where people discuss like reddit https://www.reddit.com/r/datascience/comments/so7l3n/must_reads/
Aight thanksss
I just used linear, ridge, lasso and elastic regression to make some predictions on some weather data. I was wondering how do I plot this systematically. Can u guys pass some ideas or functions to use from pandas to do so? I just kind of entered data science and I am doing a comparitive study on these algorithms by using weather data so. Please help me out, thanks!

can you check this out
I think on the line that says preprocess(min_date, max_date).submit(wait_for[old_flow]) you meant to use preprocess_new_data
"As an AI language model, ...
...can someone take a look at my question
There's no guarantee that anyone will answer your question. Everything is voluntary.
Any book that gives a gentle introduction to ML (from the basics like the types of learning, statistics, etc) and is direct to the point?
We're a large, friendly community focused around the Python programming language. Our community is open to those who wish to learn the language, as well as those looking to help others.
I'm working on deepfake related project.
anyone here have done this before ?
if so then i really need help.
Anyone ?
just text me please
xD
what are you specifically after? not done deepfakes before but can give you pointers
it's better to directly ask your question here and wait for someone to get back to you
hi, i would love to try and make a really basic simple chatbot, nothing super hard, but something i can say "i made it"
i have no clear idea on how, nor where to start, and most videos are just "do this and this and this" without being real tutorials
i know making an "ai" inst that easy, but im willing to learn and try ^^
the first "chat bot" was a therapist that just invited you to elaborate on the previous thing that you said. you can do that with pretty basic string manipulation.
"I'm feeling sad."
"Why are you feeling sad?"
"Because a terrible thing happened."
"How long have you felt that a terrible thing happened?"
If i have a 3x5 matrix, is there a way to get all 5choose3 combinations of columns of the matrix?
itertools.combinations on the iterable of columns, I guess.
i mean, i wanna learn how to make "stupid" ais x3 and i would love to do it by making a simple project for a chat bot, i really dont know how to start
the AI learning curve is kind of steep, and a chat bot that isn't "stupid" is probably further along on that curve than you'd expect
I was going to suggest that, but I wonder if their end-goal could be accomplished with broadcasting.
not saying its easy or fast, i just wanna start, it's hard to do something without having a start point
it took me 3 months to learn react, and 2 months were only the "what to do"
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
mhm, ill give a look ^^
Can anyone enlighten me on what is S and NP in pos tagging?

I'm trying to validate my KNN function but following these instructions. I'm not sure if I've done any of it correct, could someone plese check my code for me?
def validateDataFormat(data, predicted):
formatCorrect = False
if not data:
return False
# check column names
expected_cols = ["Path", "ActualClass"]
if predicted:
expected_cols.append("PredictedClass")
if data[0][:len(expected_cols)] != expected_cols:
return False
# check that paths are valid
for row in data:
if not os.path.isfile(row[0]):
return False
# check that classes are valid
classes = get_classes()
for row in data:
if row[1] not in classes:
return False
if predicted and row[2] not in classes:
return False
# check that number of paths equals number of classes
if len(data) != len(classes):
return False
if predicted and len(data) != len(set([row[0] for row in data])):
return False
return formatCorrect

Probably "sentence" and "noun phrase". You should be able to find documentation on the particular tagset that corpus/tagger uses.
Hi guys, im trying to get a good understanding of these topics, so I'll go first with Filter Activation, as we can see in the first image i uploaded, if we feed an input image, using this tecnique we'll probably see what special part of the image looks for each filter that the conv2D layer has, so maybe the most "brighter" values means that zone is more important to that specific filter, isn't?

Now, here in Filter & Class "Maximisation", we probably focus on seeing what "input image" would make the model most sure of he is seeing a specific class, for example if we input a image with same patterns like the bear filter, the model will classificate it as a bear with most confidence, isn't? Thanks all!!


hey
import sklearn
import torch
from torch import nn
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs, make_circles
x,y = make_circles(noise=0.3,random_state=42)
x,y = torch.from_numpy(x).type(torch.float), torch.from_numpy(y).type(torch.float)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3,random_state=32)
class BinaryModel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_features=2, out_features=8),
nn.Linear(in_features=8, out_features=8),
nn.Linear(in_features=8,out_features=8),
nn.Linear(in_features=8, out_features=1)
)
def forward(self,x):
return self.layer(x)
model = BinaryModel()
loss_function = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 1000
print("First y train: " , y_train)
for epoch in range(epochs):
model.train()
logits = model(x_train).squeeze()
labels = torch.round(torch.sigmoid(logits)).squeeze()
loss = loss_function(logits,y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
with torch.inference_mode():
test_logits = model(x_test).squeeze()
test_labels = torch.round(torch.sigmoid(test_logits)).squeeze()
test_loss = loss_function(test_logits,y_test)
if epoch%100==0:
print(f"Epoch: {epoch} | Loss: {loss:.4f} | Test Loss: {test_loss:.4f}")
#print(x_test)
print(y_train)
break
I made this model for binary classification and wanted to see how the values change. I noticed that y values are same and x values change. Why does that happen?
Hey guys, I ran a Kmeans algoritm but now when I'm trying to run:
print(silhouette_score(scaledfeatures, kmeans.labels, metric='euclidean'))
it keeps running. It has been running for 25 minutes, is it normal that it's that slow?
25 minutes 😮
Crap thanks for the help
Hi everyone. When you create a boxplot using Matplotlib/Seaborn, is there no way to easily display the values of the boxplot (i.e. Q0, Q1, Q2, Q3, Q4)? I have been searching and cannot find anything. I'm wondering if there is something simple like how you would use the .decribe() method to get a summary.
Depending on how many features you're working with, yes.
Specially since the model is probably being run on your CPU
Brotip: use Colaboratory or Kaggle.
I just find it weird that the actual kmeans takes 30 secondes but the silhouette takes forever haha, thanks
whats a decent beginner tensorflow project that'll improve my skills?
hello pythonistas
i have an algorithm intended to trial blackjack games, and it takes about 0.5 ms per game
i need to trial around 1 billion games
do i need to refactor the code for a more performant algorithm?
i'm currently being limited to about 100 million games, which takes about 8 hours per trial of 100 million games
You should profile your code. The cProfile module is good for this.
If you don't understand why something is slow, or you want suggestions on how to make it faster, someone in this server may be able to help you. Post the slow code (as text please, not as a screenshot) and the relevant part of the profiler output and someone may have advice.
i'd also recommend kernprof
I'm having trouble using darknet packages. Has anyone ever used these specific packages? https://github.com/pjreddie/darknet https://github.com/AlexeyAB/darknet
GitHub
Convolutional Neural Networks. Contribute to pjreddie/darknet development by creating an account on GitHub.
GitHub
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ) - GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object ...
hello, I am trying to get some help understanding a fairly basic code, I know next to nothing so I tagged my post with with this tag, because I didnt know which one to pick and I had to pick one
nobody is responding so I dont really know what to do
I remember there were many help channels here in the past with people replying
Does anyone know how to labelencode a column inside a nested dataframe?
what I am trying to is better described here: https://stackoverflow.com/questions/75616635/how-to-use-label-encoder-in-a-dataframe-which-is-nested-in-another-dataframe
Stack Overflow
My dataset is:
https://www.kaggle.com/datasets/angeredsquid/brewers-friend-beer-recipes
I loaded like this:
import json
filename = 'recipes_full copy.json'
with open(filename, 'r') as f:
try:...
How can I install an new environment to Anaconda from the CMD? It is a yaml.file. I already try from the dashboard, but I don't know it is over an hour
Hey guys I have a question. Any idea how to fetch specific data from a text block using nlp. My professor gave me a blog written by a student. I have to write code that fetches parts of the blog where the student talks about their feeling before they started a school assignment vs. their feelings after they started doing an assignment. I did try sentiment analysis but that only fetches the specific emotion in a text block. I would like to fetch parts of the blog (like sentences) where the students are describing a particular feeling.
spacy is a great general-purpose NLP tool. it can break documents down into sentences (without mistakenly breaking sentences on things like "Mr.").
when you say that your sentiment analysis tool gave you a specific emotion for a text block, what exactly did it give you? a float between 0 and 1, or an emotion label?
does anyone happen to know why when i implement a basic chat history for my model.generate() function, after around 7 entries my pc just turns off
i've troubleshot the hardware and there is nothing wrong there so it must be the code
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.utils import logging
import torch
hfName = "Microsoft/DialoGPT-large"
logging.set_verbosity_warning()
tokenizer = AutoTokenizer.from_pretrained(hfName, padding_side='right')
model = AutoModelForCausalLM.from_pretrained(hfName)
# Let's chat for 5 lines
def run():
for step in range(5):
new_user_input_ids = tokenizer.encode(input("User:") + tokenizer.eos_token, return_tensors='pt')
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
print("UnnamedAI: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
new_user_input_ids = tokenizer.encode(input("User:") + tokenizer.eos_token, return_tensors='pt')
print("UnnamedAI: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
# run()
``` this is the test file that i have been using which keeps crashing my PCPlease who is familiar with geodatabases files on here, i need to convert it to csv
what format are your "geodatabases files" in?
i'm kind of new to it, let me send a screenshot. I used a qgis to open it and its more of a vector layer.
The files are in different formats
it looks something like this

Well, searching export in PyQGis docs, I find: https://docs.qgis.org/3.22/en/docs/training_manual/spatial_databases/import_export.html
Of the tools mentioned, ogr2ogr looks interesting to me. Looking at its docs, https://gdal.org/programs/ogr2ogr.html, I see that one of the output formats is PostgreSQL. So if it truly can dump all this data to a postgre database, you can then easily-ish export it as CSV using various tools.
Uh, actually I googled export qgis to CSV and there seems to just be a GUI option for this, too: https://opensourceoptions.com/blog/export-qgis-attribute-table-to-excel-and-csv/
is it possible to share what i'm trying to achieve
I actually need to download a TIGER/Line Shapefile but it seems its all contained in the .gdb file i downloaded from the website. And i need to then convert the Shapefile to csv file, its been what have been having issues with
yeah, after struggling with this for a while i had to download it to know what the data i'm working iwth looks like
i think this solution you proffered is better, i would give this a go. Would be gone for a while but would let you know the result of doing this
Hey so I was doing my research and apprently if I fine tune the BERTForSequence model my own dataset I could create a model that could take in two sentences as input and tell me which sentence happened first. Has anyone worked with the BERTForSequenceClassifucation model before?
yes. do you have a lot of labeled training instances?
I am trying to implement inception v3 with pytorch (transfer learning), but I am unable to turn trainable parameters to False for base layer. How can I do that guys?
Unfortunately that's where my next issues is. I have to find data. But my professor has asked me to suggest a solution and whatever I have right now technically counts as a suggestion. I will see what come south of it. Do uk any way I could find labelled datasets?
every time i try and run GPU accelerated anything using CUDA it tells me CUDA isn't installed, when i run nvcc -V it confirms that CUDA is installed but PyTorch wont recognise it
any suggestions?
How did you install pytorch
pip
the thing is the pytorch thingy shows a lower version number than my CUDA version
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
so it shows that but i have CUDA 12.1
i dont know if its backwards compatible
What is your os and python version
windows and python 3.10
Okay. I'm finishing lunch. Back in a few
it was 3.11 but i was having issues with transformers and pytorch in general with 3.11
alr
When isntalling pytorch, it installs cuda alongside with it. It does not generally use the cuda that you have installed yourself from what i've seen.
oh
well it doesn't do much anyways
it just says "CUDA" is not a module
or something liek that

{kind=link}
Did you install it using the command generated here?
imma jsut run my test script rq
yes
omg
OMG it works
it must have installed without cuda to begin with
this is going to make life so much easier
i can use my tensor cores instead of using my fucking haswell i5 that doesnt have hyper threading 😭
nice
lmao
my pc is so weird i have a shitty ass cpu and then an rtx 3000 series GPU

oh no

Maybe just make an entirely new venv if that's possible and then just use the one command generated by the link I sent you
It's probably because you used multiple different commands
i fixed it i just uninstalled torchvision and reinstalled it
its working as it should now
and its so much faster
and my pc doesn't sound like a helicopter
I need some ideas what to do now , i need smh a project or smth, im way ro stuck on smth else now, i dunno what to do now, some people told me to mostly stay away from kaggle or smth like that
i need help again 😩
now i am using cuda, how to i select a device
to use, i've done the .to(device)
wait acc my code would probably better to show
@meager fulcrum sorry for my delayed reply. looks like you got it working though
i did, it was the version of cuda that torch installed
was wrong
i need a bit of help with sigmoid neuron model with cross entropy loss function.
I am getting almost 93.33% accuracy with the training data and 100% on test data. Now i am second guessing myself if the code that i've written is correct or is it wrong.
Here's the code. Please do ping me when replying. I am fairly new to this. So do tell if i could improve on my methods.
class SigmoidNeuron:
def __init__(self):
self.w = None
self.b = None
def perceptron(self, x): #x here is the the raw data
return np.dot(x,self.w.T)+self.b
def sigmoid(self,x): #x here is the calculated data from perceptrom model
return 1.0/(1.0 + np.exp(-x))
def grad_w(self, x, y):
y_p = self.sigmoid(self.perceptron(x)) #rn, you are prediciting a value for y rn.
return (y_p - y) * x #this is a formula to find the gradient of w
def grad_b(self, x, y):
y_p = self.sigmoid(self.perceptron(x))
return (y_p - y)
def fit(self, X, Y, e=1, lr=1, initialize=True, display_loss = False):#learning algo and X and Y can have many rows
if initialize:
self.w = np.random.randn(1,X.shape[1])
self.b = 0
if display_loss:
loss={}
for i in tqdm_notebook(range(e),total = e, unit = "Epoches"):
dw,db=0,0 #the starting values of grad w and grad b
for x, y in zip(X,Y):
dw += self.grad_w(x,y)
db += self.grad_b(x,y)
self.w -= lr * dw;
self.b -= lr * db;
if display_loss:
Y_pred = self.sigmoid(self.perceptron(X)) #seeing the loss for every change in the parameters over the whole data set
loss[i] = self.error(Y_pred, Y)
if display_loss:
plt.plot(loss.values())
plt.xlabel("Epoches")
plt.ylabel("Cross Entropy")
plt.show()
def predict(self, X):
Y_pred=[]
for x in X:
Y_pred.append(self.sigmoid(self.perceptron(x)))
return np.array(Y_pred)
def error(self,Y_P,Y):
err=0.0
for y_p,y in zip(Y_P,Y):
err += -((1-y)* np.log(1-y_p) + y*np.log(y_p))
return err```alright i have another question
i have a natural language model, im using GPT Neo alr, that's a text generative model that predicts the next words iirc, how do i translate that to answer questions so i can ask it a question like what is the capital of belarus and it will reply with minsk, but so i can also ask it a question like what is asbestos
i like to think i have a good understanding of how it works but its confusing me
What does this kind of cosine similarity tell me about my model/data?
It converges nicely at first, then collapses and fails to reconverge.

It's a small 2 layer model (1024, 512 neurons)
Not really sure why this would happen
if anyone has any resources i can use for this lmk plez
hey guys could anyone help me with this? Thanks!!
Cosine similarity between what?
Can someone please help with this - #1080959291583897600 message
I will really appreciate it 🙂
Does normalizing (standardizing) your data speed up the calculations ?
No
Still use the same datatypes, having higher values does not mean the program will use float64 instead of float32 f.e.
Depends on the application.
What application would give faster calculation for lower values?
Linear Regression
And anything that uses Gradient Descent
Faster convergence?
Can you explain more or give some examples? My professor said that limitingthe range of your values (to : from 0 to 1 for example) would speed up the calculations but that doesnt make any sense to me, like you would still need a float32 so no storage advantage and no calculation speed up in my opinion
Stack Overflow
I am trying to train a very basic linear regression model to predict a linear equation Y = m*X + c
The Weight parameter is optimized to 5 but the Bias parameter is stuck at 0. Am I doing something ...
I think grisha implies that the convergence is quicker (need less epochs/steps) but the calculations themselves would be the same speed
And I'm not sure if that example is relevant, they scale the features such that they can increase the learning rate without giving overflows
The learning rate had to be increased or else it was taking too much time. In general gradient descent does need the values to be scaled, otherwise it's hard to learn ... imo
hi how i can i fix the dying relu probleme in resU-Net
why do image training models take up so much vram
the capture size is 640x640 but the image training data is like 100x100
I need help with the calculations for my lab please. Thank you.

This is not a datascience/ai question, you can make a help channel #❓|how-to-get-help @midnight girder
Because each image has 10,000 data points, and each data point occupies around 8 bytes, so in total 80,000 bytes = 80 Mb.
Stack Overflow
I'm using python to analyse some large files and I'm running into memory issues, so I've been using sys.getsizeof() to try and keep track of the usage, but it's behaviour with numpy arrays is bizar...
(Though I'm a bit surprised that each 64 float occupy 8 bytes, and not 8 bits...)
Ok so i have 600 labels and in total around 50k images
How come when im training
Its taking up 48 gb of vram
When in my calculations and online sources say it should take anywhere from 6-16
You might be passing the entire data at once...or using a batch size that is too big
64 float is 64 bit, thus 8 bytes
Oh...now it makes sense...
I thought a single byte was 1024 bits...
That's a kb
kilobit, not kilobyte?
Oh...
But you have 50k images of 100x100(x3)? @royal hound
Well 200x200 is already 4 times the amount of memory
The largest is 300x300
Alright, well 48 GB makes sense then
50k images of 100x100x3 with float64 would be around 12 GB
So if you have a good amount of images bigger, then 48 GB is expect
And most of the times you use float32, so there's probably quite some images bigger
I have a thumb drive that can hold that
Breakup the data to chunk sizes and train the model based on those chunks.
Though the latest chunks influence the weights most than the earlier ones. We can fix this with shuffling the data
Hey, quick question
Does anyone know how to change the label for a bokeh map on plotly express?
Hi, guys... I'm struggling with a temporal + spatial gap filling
This is my problem, I'm trying to impute missing data of snow cover, only snow cover decrease, I'm not trying to forecast snowfall. I want to use neighbors values of the same date, and temporal variation using a co-variable like temperature. So probably an ANN + LSTM mix could do the job, but I don't know if a model ensemble is the right approach for this

Guys why do we need xticks function if we can directly pass company string as an argument in bar function.
Good evening! I am trying to work on writing a code that will work with collecting real-time data using a search term. However, I am limited in the functionality that I can use due to only receiving a bearer token from my Professor to use. All of my searches have shown that streamer-type setups for the Twitter API require other tokens and secrets to stream the data in real-time. Does anyone know any ideas of how to assist in this setup?
code so far
# Define the API endpoint you want to access
url = "https://api.twitter.com/2/tweets/search/recent"
# Define the query parameters for your API request
query_params = {"query": "Machine","max_results": "100"}
# Set the authorization header with the bearer token
headers = {"Authorization": f"Bearer {bearer_token}"}
# Send the API request
response = requests.get(url, headers=headers, params=query_params)
# Print the API response
print((json.dumps(response.json(), indent=4)))
data=response.json()
for tweet in data["data"]:
print(tweet["text"])
with this code I can look retrospectively but not live like the professor is asking for
Scipy is having a terrible time trying to optimize this fitting. Data resolution is extremely low, am I just asking too much to try and reconstruct a bimodal gaussian from 10 data points?

Can anyone help me fix this error?
$ xmanager launch ./xmanager/examples/cifar10_tensorflow/launcher.py
...
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
I put protobuf==3.20.* in ./xmanager/requirements.txt, but it did not fix the issue.
Probably, yes. 10 data points is very low for any kind of density estimation.
(If you're really interested in the mathematical details, you might look at Scott, Multivariate Density Estimation. The actual error in a density estimate depends on a lot of factors which are unfortunately hard to estimate.)
I think the sound of having them redo the experiment sounds much nicer than giving that a read hahaha. I appreciate it though!
u need to download protobuf
pip install -v protobuf==3.20.1
or
pip install protobuf==3.20.*
Boom! now your code works!
how to learn to code high quality/ scalable/ production ready code?
for example recommendation algorithm, i know how they work but when it comes to speed/scalability i dont know what matters and what to avoid?
ah, cosine similarity between model output and ground thruth.
trying to align two latent spaces
so its just two 512 vectors
running for another 150 epochs seems to have solved the problem and it reconverges. Very confusing that it would collapse in the first place though. 150 epochs is half a billion datapoints!
i feel like thats a lot for a model with 250k parameters
Hi, have been able to dump the data from geodb to postgresql db but the data is not outlined like expected
Hello guys does anyone know how to make queries, read and use data converted from .gdb to postgresql db. I'm able to see it created a table on conversion but it doesn't have a readable format like a normal database does
Guys
Im getting this error
TypeError Traceback (most recent call last)
<ipython-input-118-3586c211752c> in <module>
28 )
29
---> 30 trainer.train()
8 frames
/usr/local/lib/python3.8/dist-packages/transformers/data/data_collator.py in <listcomp>(.0)
107
108 if not isinstance(features[0], Mapping):
--> 109 features = [vars(f) for f in features]
110 first = features[0]
111 batch = {}
TypeError: vars() argument must have dict attribute

Hello guys when i export data from a postgresql db which is postgis data to a csv file, i get a binary file instead. Is there any reason for this. This is the psql query ran:
\COPY (select * from current_congressional_districts) TO '/tmp/gis.csv' CSV HEADER;
and the output gotten when the .csv file is read is as in the image

Could someone please explain when we should calculate the sample std vs the population std? And why we subtract 1 from the denominator in sample std? I don't get it
This seems pretty intuitive

It does not show a proof, just intuitive explanation. I saw the proof why it is 1 in some book I read, but forgot the name of it.
@sleek harbor
Hello guys, do you know why I get an error when I try to use TensrFlow?
In this case I used AutoTokenizer from Hugging Face

"Any x value is going to be closer to x– that to u" - but why?
fairly good adjustment... as long as n isn't huge - sounds kinda unscientific.. actually sounds very unscientific.. does that mean that the bigger the sample - the less accurate the std? Makes no sense..
Bro...this is gorgeous
Except for the Stable Diffusion part

Yes, but I prefer much more the idea of comparing it with a GAN, since the brain has some nucleii that does the "creation" part and others that do the "filtering"
Because x- is the mean of your sample. The average of the data points will minimize the variance of these data points. But x- is not exactly equal to the population mean. The population mean will not minimize the variance of the sample, as it will be slightly different from the sample mean. Thus your calculated variance/std will be slightly lower than the true variance/std of the population.
@sleek harbor
I want to make a Text GAN someday based on that...I just have to figure an efficient way for that
Though one could argue that biological neurons also work with diffusion processes...
But I simply dislike diffusion models
And Yeah like I said, I agree it's not "very scientific" its just some random blog that tries to show the intuition. If you really want to find the proof, you have to look up Bessel's correction.
So I kinda understand this, but not really. I get that the samples mean won't be exactly the same as the populations.. but.. shouldn't it be ± the same? I mean, generate a list of 100000 random numbers from 1 to 100, and then select 1000 random elements.. shouldn't the mean be ± the same? If you do that a bunch of times, shouldn't the average population and sample mean be.. the same? Sorry if I'm dumb, but I really don't get it
So if the sample size is very large, then yeah the -1 wouldn't matter much as n grows big
But the adjustment is important for smaller sample sizes, I think 1000 elements is still small enough for the -1 to be relevant
But even if it's a small sample size.. I still don't get why we subtract instead of, say.. add a 1 😅
Is it just because the range of elements will turn out a bit smaller, since the sample won't grab the smallest and largest elements¿ Nah, I don't get it
We are trying to estimate the population variance. Ideally we would have the population mean, and then we calculate the squared distance of every sample from this population mean. This would give some number. But we do not have the population mean, we only have our sample mean, which is not equal to the population mean. The sample mean will in general be closer to all samples then the population mean, as it is "overfitted" to the sample. Therefore the distance to sample mean will be lower than the distance to population mean. But we want the distances to population mean ideally, so we correct for it by increasing this distance.
the reason you subtract a 1 for sample means is that if you don't you get a so-called "biased estimator". if you take the expectation of your estimate for the variance, it is on average wrong. you can explicitly compute the bias to be (n-1)/n, so you can correct it by multiplying by n/(n-1)
Dem.. I finally get it! That clicked, the overfitting part! But does this mean that, if we have the population mean, we can use it to calculate the std with our sample elements and then divide by just N, not N-1 (if we do have the population mean, but not the population elements, just the sample elements)?
If we actually know the population mean, then we would prefer to use that yes
And then we don't need to correct for the used mean being overfitted
Thanks a bunch! Somehow I couldn't find an understandable for me explanation with Google/YouTube 😅
the convential wisdom/takeaway from this is that nesting of estimators, even if they're unbiased, yields a biased estimator
This kinda went over my head. Seems like I got a long night of googling ahead.. :/
this particular proof is done step by step in wikipedia 😛 https://en.wikipedia.org/wiki/Bias_of_an_estimator
In statistics, the bias of an estimator (or bias function) is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: con...
you'll hear a lot about bias-variance tradeoff while working in ML, so you might as well take a read
Thanks! I'll read that
Has anyone got this error -
On branch main
Changes not staged for commit:
I know that I have many new changes added to the repo. But they just aren't getting staged.
@serene scaffold when dealing with the english language(US), what range is a reasonable size for a word vocabulary?
(I'm not really worried about stemming and lemmatization, neither about stopwords)
A quick search through Google tells me that the english vocabulary has an average of 250,000 words. Yet my vocabulary after extracting words on part of CC-100, provided me almost 4,5 million words, so now I'm planning on doing some proper filtering(like removing numbers), but I'd like to know what would be a reasonable size in general.
(The task is text generation)
I'm not sure. I haven't worked on text generation
I'm mostly concerned with classification and information extraction.
I see. Thanks anyway.
It seems that nouns are also going to be a problem with the vocab size. I wonder how ChatGPT deals with that...
I know that if I simply create a name, ChatGPT will also include that name in its response. But I don't know how to do that without adding that name to the vocabulary and falling at the risk of a possible "infinite vocabulary", since...well...someone could create any "noun" anytime...
Unless I simply delete that noun from the vocabulary after the iteration is over 
Start small and see how it goes: https://en.wikipedia.org/wiki/Wikipedia:Language_learning_centre/5000_most_common_words
These are 5000 of the most common words in American English in order of usage. This can be a particularly useful list when starting to learn a new language and will help prioritise creating sentences using the words in other languages to ensure that you develop your core quickly. This process will be sped up if creating sentences using multiple ...
Thanks. I probably should. The vocab size is making my last fully connected layer become a parameter nuke
The only downside is that I'd like to deal with unsupervised learning, entropy minimization, so...I don't know if perhaps I should prefer using many, many words...
It's possible to not really need a vocabulary in that sense. It can just insert a word it previously saw. It just learned the pattern of where to insert the name later (attention stuff).
For example, I could be given a bunch of sentences in another language (a dialog), and then from many samples, without knowing what any of it means, construct some fake dialog and know that I should probably insert certain words that previously came up (such as names, without actually knowing what a name is) just from the patterns alone.
Starting to sound like a GAN
I don't need to know what the words mean to do that, just where they show up (given where they previously where or where not).
To make the grammar not completely broken and janky I would need a lot of samples though and some very good memory...
(Humans can't handle that, they rely on knowing what the words actually mean (pulling in data from the physical world to make up for this (the structure of that)))
Hey all, does anyone have skills with opencv? I'm trying to align my scanned 8mm cinefilm to the horizontal plane