#data-science-and-ml
1 messages · Page 40 of 1
what are you calling variables?
the total number of singular values is equal to the number of variables if you haven't done any dimensionality reduction
what's the shape of your data?
Would anyone know how to make this hack work for more than 1 level? I am trying to remove duplicates post-groupby on 3 levels, so something like this:
bbb 1
bb aaa 1
B aa aaa 1
1
bb bbb
c aa aaa
bb bbb 1```
https://stackoverflow.com/questions/64797580/pandas-groupby-remove-duplicates/64797686#64797686
Stack Overflow
input: (CSV file)
name subject internal_1_marks internal_2_marks final_marks
abc python 45 50 47
pqr java 45 46 ...
Someone recently told me about Polars - that it is more efficient than Pandas, as Panda's needs to be done sequentially whereas Polars can be done in parallel. I wanted to ask for a confirmation of this, and if anyone can recommend a good website/video/resource for Polars.
EDIT to add there isn't any resources on here



has anyone used docker to build an app and ran into the issue of yml file not being found when installed
try asking in #tools-and-devops, but show the whole error message. a specific yml file not being found is not some generic docker problem.
actually, i fixed that. sorry now its 'Error: Invalid value: File does not exist: ./app/app.py'
still not a data science question. try going to that other channel and show the dockerfile as well, I guess.
im assuming ive screwed my dockerfile but really i did it to the book
yeah sorry not rly meta here
pandas speeds things up by building atop numpy arrays. I heard that polars is implemented in rust. but I've never used polars, and no one has submitted a polars resource for the resource page
if people need "pandas but with parallel computation", they usually use dask.
polars really looks like it has a nicer API - the problem is at work we have a ton of internal tooling that expects pandas DFs, so that's not really a good enough argument for adding it into the mix.
You might find the pandas tutorial in this channel very helpful https://www.youtube.com/@dataschool/videos

YouTube
Are you trying to learn data science so that you can get your first data science job? You're probably confused about what you're "supposed" to learn, and then you have the hardest time actually finding lessons you can understand!
Data School focuses you on the topics you need to master first, and offers in-depth tutorials that you can understan...
Polars uses parallel processing, yes. https://www.ritchievink.com/img/post-35-polars-0.15/db-benchmark.png (benchmarks are ofc always kind of cheated on / nonsense, so don't take this as absolute in any way (plus it's vague here))


Polars is a blazingly fast DataFrame library completely written in Rust, using the Apache Arrow memory model. It exposes bindings for the popular Python and soon JavaScript languages. Polars supports a full lazy execution API allowing query optimization.
Drop the id and the class column and use the rest as your input.
input_df = df.drop(['id', 'class'], axis = 1)
This should do the job now.
hello, is there any way in beautiful soup to get the class name string value sucha s below:
<span class="ui_bubble_rating bubble_10"></span>
``` and get the string value "bubble_10"?the class name is dynamic so i cant hardcode "bubble_10" it can change to "bubble_20" etc, so would like to get that string value
nvm just found i can do element['classname'] and it gives class name
Has anyone tried to use chatgpt using an unofficial api here?
I'm not sure where you're getting this information. Pandas is built off of Numpy, and numpy can be vectorized.
From another student taking the 100 Days of Code python course on Udemy. The example the showed me was really cool, but I wanted to get more information and confirmation of what they told me.
hi everyone!
Gotcha. Well, I found this: https://www.scaler.com/topics/pandas/parallelizing-your-pandas-workflow/ Looks like you can parrallelize Pandas computations in a single line of code
Scaler Topics
hi I am looking for data sets on California wildfire frequency by year
anyone know where I could find this stuff?
If you can't find such a thing by googling it or on Wikipedia, you might try .gov websites for California
hey do you known how to do a early fusion on two different size data sets
so that when we pass then through a classifier one dataset is not more dominant then the other
help please anyone
https://bitbucket.org/casmania/bestfriendbuilder/src/master/bestfriendmaker.py What do you guys think?
Hi all,
I have a file with a large list of grocery product names from two separate stores.
they each name their products slightly different.
Is it possible to compare the product from the two files & match them in order to correctly compare the prices of the two similar products?
How large is a large list? Depending on how they are named it could be easy, or you might be better off just doing it manually.
1000+ product Names
For example, these are two products from both files.
- Fresh Pink Lady Apples Each
- Pink Lady Apples | approx. 200g each
Same item obviously, just names slightly different.
my intention is to compare the two items for the best price
I dont think I can do that until I figure out how to 'match' the products to ensure I am comparing the same product
You can compare lists like that in excel. Match values by similarity.
hi, QQ: recommendations for text classification on complex abstractions with small datasets? i tried using SVM but the concept is too complex to do with simple machine learning(featuring word by word), and the dataset is too small for the text (2000 characters avg, only 250 samples) so applying models such as roBERTa or longformers doesnt work quite well.
I haven't heard of early fusion before but if what you're referring to is related to solving the problem of class imbalance in your data, then there are several techniques to handle that.
- SMOTE
- Resampling strategy
- Upsampling minority class
- Tunning the class weight hyperparameter of your classifier
- Doing Data Augmentation etc
In whatever approach you decide to take, if you have getting an optimum performance in mind, please avoid using SMOTE.
Depending on the project, you can use class weight or data augmentation.
No not really. You'll only need Django when you want to deploy your ML model. It's nice to know it though.
More so, you have plethora of options when it comes framework to use for your model deployment.
- Flask
- FastAPI
- Django
- Streamlit
- Gradio
- etc
I think an example of what you mean by complex abstractions on text would have helped me understand better.
However, since this is an NLP problem, maybe you should try using text augmentation to increase the sample size of your data with respect to the number of classes in your target column
its hard, because what im trying to achieve is to classify the stance of the document-length text on some political stance, i.e. this text is leaning towards conservative/progressive stance rather than neutral
the amount of labels is low (3 only) but the amount of data is not sufficing i think
thats why using some noised text or text augmentation methods wont work, because it would break the whole text idea
is this book good with theory? applying algos is easy, but I want to understand that 🙂

Hey so, I'm working on a college project where I'm using an LSTM model to try and predict stock prices. I have a few questions:
- How do you predict future stock prices? Most of the models I've seen don't actually predict future values - they just compare predicted versus actual prices, but only within the input dataset.
2)In my LSTM model, the results for 10 years of data are kind of strange - they seem too good to be true. I'm not an expert so basically I'm not sure if I'm doing this right LOL.
(I've attached the results)
3)Every time I rerun the model, the results seem to get worse(significantly). Is this normal?
I'd really appreciate any sort of help. Thanks!

-
Your model predicts the next value(s) given all (or part of) the previous data. You could give all the data you have to it, and it should predict the next value(s).
-
Are you testing it on a test set not used for training the model? If you test it on the data you used for training and it has very good results, it probably is overfitted. It will likely not work well on actual new data, but it has just memorized your training data.
-
Rerunning should not change the results of the model I'd think, LSTM should just be deterministic given the same data and initial hidden state.
Well, you won't be reprimanded, penalised, or persecuted for attempting such, yeah? 😊
If I were in your shoe, I'll definitely try meta learning vs text augmentation.
I'm certain you'll either see some reasonable improvement or discover something interesting in the process.
For text augmentation, I've always used TextAttack and I enjoy using the library. You might wanna check it out later https://textattack.readthedocs.io/en/latest/0_get_started/basic-Intro.html
Then, if you're still worried about the artificial perturbation that comes with augmentation, then you can proceed to carry out Adversarial Text Attack (which you can also do with the TextAttack library).
Finally, if you aren't pressed for time, you can scrap data online and add it to the current one you have (if you don't wanna do text augmentation).
If you're feeling generous enough, please do share with us what you were able to uncover after trying the two approaches.
Are you testing it on a test set not used for training the model? If you test it on the data you used for training and it has very good results, it probably is overfitted. It will likely not work well on actual new data, but it has just memorized your training data.
yeah i feel overfitting might be the issue, i haven't tried running the model on a different dataset, any suggestions on how i should go about fixing it?
Rerunning should not change the results of the model I'd think, LSTM should just be deterministic given the same data and initial hidden state.
It's frustrating cuz i have to rewrite the entire code again to get results close to the first run.
Anyone here ever taken harvards cs50 intro to comp sci?
Muzero model implemented using Pytorch and Gymnasium (previously gym) for single player game. If you want to benchmark against PPO or create new simulation environment to solve with it.
https://github.com/DHDev0/Muzero
GitHub
Pytorch Implementation of MuZero for gym environment. It should support any <Discrete> or <Box> configuration for the action space and observation space. - GitHub - DHDe...
havent personally but ive been told its not that great
i do think its worth the cert thou
Hmmm ok thanks
np
I was making a diffusion prototype to see if I can get how it works and I got a bit confused over the noising thing.
I have to make my model noise my image, passing the image as input and using a noisy version as label, right? And this is done through some time steps.
Should I follow certain pattern to apply this noise to the image? Or can I just randomly apply noise to randomly selected pixels and let the forward/backward noising steps do the trick?
I'm using 5 steps at the moment, each image has 64x64x3 pixels(so 12,288 in total), the first step has the image as input and the label has 1000 random pixels added. This label is passed as input for the second step, which has as label the same input image, but with 2000 random pixels, and so on.
The 5th step has the 4th label(8000 random pixels) as input, while the label is simply a random noise with shape 64x64x3.
The results I'm getting is...nothing. lr=1e-3 leads to vanishing gradients and black and white stripes on every output.
lr=1e-6 produces only gray squares.
looks promising. I wonder how soon javascript support will be available. could potentially be a gamechanger for JS backend
For kNN when inspecting the features of the dataset, I have done a histogram and boxplot to check for normality/skewness and outliers. Is there anything else I should be doing visually?
If you want to visually check normality, I suggest a Q-Q plot.
But kNN is a non-parametric method, so you don't need normality except for the warm fuzzy feeling.
Keep in mind that real data is never normal. It may be approximately normal; it may be so close to normal that you can't tell the difference. But real-world data always comes with complications of one kind or another, so it's never going to be exactly normal.
hi guys, does anybody know a way to schedule the execution of a google colab script? In a way that it runs once a week
Thank you, appreciate the help.
Hello everyone, I got some weird scenarios when testing some models here, but I couldn't really figure out where there's something wrong with the code (which I think there is because the values are way too off to make sense).
Currently, I'm sending different models to a run_model function so that I can have the results automated:
def run_model(model, X_train, y_train, X_test, y_test):
# Fit Model
model.fit(X_train, y_train)
# Get Metrics
preds = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, preds))
print(f'RMSE : {rmse}')
# Plot results
signal_range = np.arange(0, len(X_test) + len(X_train))
output = model.predict(signal_range.reshape(-1,1))
plt.figure(figsize=(12,6),dpi=100)
sns.scatterplot(y=df[df['wireless_number'] == 1]['data_used_in_gb'], x=np.arange(0, len(df[df['wireless_number'] == 1]['data_used_in_gb'])), color='black')
plt.scatter(x=signal_range, y=output)
I'm testing every type of regressor, linear, polynomial, random forest, etc. But a simple linear regression is looking like this after a grid search was applied:

Which is absolutely non-sense. Let me know if you guys spot anything weird there, I couldn't really figure it out.
So there is only 1 feature and 1 output? @novel python
yeah, exactly
The feature being the x-axis and the y-axis being the predictions?
yeah, but the feature is always the same because it's the data usage over the course of 30 days
so that's why I just used np.arange(0,30
to create them
And you are plotting the test data and the predictions?
I'm plotting the label data and the predictions for the whole data
Label data meaning the test data?
Is the feature discrete, like 1, 2, 3 etc. or can there be values inbetween?
nope, the whole 30 days. The test data is split between t
between the train_test_split function just to evaluate the RMSE
no values inbetween
X_train, X_test, y_train, y_test =\
train_test_split(df[df['wireless_number'] == 1]['data_used_in_gb'], np.arange(0, len(df[df['wireless_number'] == 1]['data_used_in_gb'])), test_size=0.1, shuffle=False)
yeah basically, 10% for the test
Do you have multiple values for the same day f.e.?
nope
Hmm okay
only 1 value per day
So if you are using simple linear regression, it should basically just go close to through the first 90% of points
yup, and it explodes right from the beginning
Well the linear regression will just give you a straight line
Did you in some way normalize any data?
nope, didn't use any scaling
Sorry for all the questions but really want to understand the full picture.
What was the rmse?
the linear regression don't even combine the first 2 points, it just go straight to heaven right from the start. That's the only thing that's confusing me
6.07
really high
considering that the max usage for that month was like 6.5ish
So there is already going something wrong at the fitting or predicting stage then
hmm
Is the model written by you?
nope, using sklearn ones
basically just doing model = LinearRegression(), for example.
and then passing it into the function
What shape is your training data
Looking at the fit description in the docs, it requires a 2d array of shape (n_samples, n_features)
Is yours 1d, might that be a problem?
I'm reshaping them with
X_train, X_test = np.array(X_train).reshape(-1, 1), np.array(X_test).reshape(-1, 1)
Yeah, that should be correct
oh, wait a minute... 1 sec
wn_eq_1 = df.loc[df['wireless_number'].eq(1), 'data_used_in_gb']
X_train, X_test, y_train, y_test = train_test_split(
wn_eq_1,
np.arange(len(wn_eq_1)),
test_size=0.1,
shuffle=False
)
FTFY
Does that give a different array, or is just just nicer pd syntax?
it's just nicer to read.
it's being done inside the function
It says it returns a fitted model in the docs
I just realized what was being done wrong and I feel stupid af now to say that in chat
model.fit both mutates itself and returns itself, afaik
but the X and y were reversed...
still, I'm going to use that
ty a lot!
I literally spent the last 2 hours trying to fix that
but once I started throwing it here I realized that halfway
You unpacked them in wrong order in the train_test_split line then?
don't worry. you'll spend many more two-hour blocks trying to debug things. for the rest of your life.
yeah
Ah makes sense haha
lmao
but do you spend more time debugging or bugging
Can anyone that understands coefficients for linear regression take a look of this when they get a chance?
#1061405019796152380 message
that's your first message in this channel in almost a year. Do you just check all the topical channels? 
only 6 topicals i check
Chat GPT can solve coding problems/prompts pretty well. How does this work? I mean, roughly. Does this mean ChatGPT was trained on a similar question and answer, or is ChatGPT "thinking" up new solutions.
What's interesting is that when you ask it to write something, what comes out is very generic sounding. But the code it produces seems very elegant in comparison.
depends on what you mean by "thinking", which is really a philosophical question. but it's all about what words are known to occur in proximity to each other. it doesn't have a "world model" that knows what things actually are in relationship to each other. At least, not that I know of.
it mutates itself but it returns a history object containing information about the training
oh cool
I’ve heard that every output is like a probability of what would come next.
Which makes sense with sentences. But with code, that seems way more difficult and error prone.
it often produces incorrect results for non-trivial programming problems, does it not?
You can trick it to fix itself
I haven’t used it enough to know.
If there's an error in the code or something wrong with the formatting where the results are off
You can ask it to "Do it again without using for loops"
as an example
And it'll find an alternative
yeah but sometimes it "fixes itself" by admitting its wrong, then sending a new code block that is also wrong
I've never had non-functioning code from chat gpt but depends on how advanced the exact code you're looking for is I guess
I don't remember who it was here that sent a snippet from chatgpt where they asked it to expect the outcome of some code, it did the addition wrong, then they told it "can you check your math" or something like that and it was like "oh yeah I was wrong, its actually *another wrong answer*"
I’m currently upset because I was working on a double recursive solution for a while, and was conceptually correct, but was having trouble crafting the code structure.
ChatGPT basically gave me exactly what I would have ended up with had I kept going for a few days
its rare for it to give syntactically incorrect code but it gets the usage of the code wrong all the time
Its crazy how it just knows how to write the code at all
Does it just ... analyze source files and their instructions, and make their own interpretation using what you ask?
I've had trouble finding code examples and chat gpt just spits it out like nothing
its trained on a bunch of code from all different sources, including github and s/o posts etc
that's why its responses can sometimes look like textbook s/o posts
I remember someone posted here a paper that could be related to ChatGPT...it has a Reinforcement Learning model running in paralel to the Transformer thing(in that paper, there was actually 3 models)
Which is interesting...until I ask it about Reinforcement Learning and all he can say is basically about PPO
Also, if anyone gets a chance to look at these coefficients for linear regression in this help channel would grately appreciate it 😅
#1061405019796152380 message
I mean, I could just ask Chat GPT lol
Yes, but bear in mind that it can produce wrong answers
He answered me some things about GANs that, when I tested them, it didn't work at all.
Or maybe I did something wrong...which I hope so, because if it worked it would be cool
this was written in tensorflow pytf.keras.layers.Conv2D(16, (3, 3), activation="relu", input_shape=(150, 150, 3)), does 3,3 refer to the kernel filter? and what's the 16?
16 is the number of filters, and the (3, 3) is the size of the filters
TensorFlow
2D convolution layer (e.g. spatial convolution over images).
so there's 48 filters total yeah?
no theres 16 filters, the (3, 3) is the size of the filters and doesnt affect how many filters there are
it's also called the kernel size or convolution window size sometimes
@serene scaffold ChatGPT kind of has a "world model" due to its use of RL, but it's a model of just the text (notably, not physical text that has position and such (the kind that humans read / work with (very different from a string in memory in a computer))) and human preferences (they trained it with human feedback on responses). It's not a "world model" of the real physical world like humans have. In addition, when people bring up "think" my assumption is that they are imagining conscious human thought, which ChatGPT is not mimicking. Conscious human thought (made up fuzzy definition here) is much more like "the video game in your head" which requires a "world model" of the physical world, which comes from multiple senses such as vision, touch, and sound (fusion). Human language is the association (see associative memory in neuroscience) of these things (including sequences of these things) (audio for spoken language and vision (or touch) for written / carved / etc). The way stuff like most deep learning being used works is more like unconscious human thought, it's fast / fuzzy probabilistic processes / functions that don't run a whole intent-guided simulation (but dialed up to 11 via lots of compute (also parts of conscious-like thought have been making their way more and more into these systems (e.g. attention))). However, conscious human thought can poke at / modify / make use / invoke those processes. Spoken language is particularly interesting since most of it is done unconsciously, we don't think of every word we are about to say before we say it, that would be too slow for day-to-day use. It's intent guiding / invoking those faster processes (we can switch to conscious mode / focus on it though and do it the slower way). There isn't a set definition of what "conscious" is, but I find this distinction to be useful.
This was typed by chatGPT*
*It turns out however, that one can get pretty far with just the text and preferences feedback. And humans are easily tricked into thinking that it came from something conscious, probably because it's an assumption. We assume other humans are conscious like us, and when something produces something we would only expect from a human our associative memory probably jumps to "is conscious". It's an important assumption that makes us attempt to learn from each other without being taught to do so (and empathy, etc).
That is unfortunately something that must considered now for all text on the internet. I hope that it does not result in too much spam and make things worse than they are.
(At some point we all probably need detection tools to get anywhere)
Also...uh...is there a type of Attention Layer developed specifically for images?
I've been testing one that I made here for some days now...but if a proper ML engineer developed one, it'll probably be way more effective than mine.
Well there's definitely something called an ARU-net (attention residual U-net), not sure what task you need it for.
I'm sure there are attention layers for simple image classification too.
The one that OpenAI uses for Stable Diffusion?
I'm not sure about that, I used it for a project once myself which is why I know it exists
Yes, it would be strange if there wasn't, considering how effective attention layers are in NLP...and they even appear in Waveglow, if I remember correctly
do you recommend any courses for learning this
most of the AI courses on the internet suck
they don't explain anything. they just tell you to write x and y but never why
I'm trying to make CNNs atm
I can tell squiggle wrote it due to the nested parentheticals
It's very good, It seems to be much better and much more useful than copilot for generation imo
Does Pytorch's .permute() command destroys RGB images or is it just my luck?
The transforms.ToTensor() transformed my CIFAR100 images into marvellous white squares with gray stripes
EDIT: I was using .view(), when using .permute(), things go on fine. Strange...
yep!
please don't ask to ask, or ping specific people. put a complete question in the chat that anyone can read, and start answering if they know. if people have to interview you to figure out the question, they won't.
There should be chatGPT based bot here to repeat this over and over 🙂
ChatGPT is just a different more limited version of GPT-3. I don't think you can actually use ChatGPT with OpenAI's API but you can use GPT3
Was just a joke but thanks for telling me 🙂
There are some services that use chatGPT for example youchat https://you.com/search?q=who+are+you&tbm=youchat

You.com is an ad-free, private search engine that you control. Customize search results with 150 apps alongside web results. Access a zero-trace private mode.
I don't think ChatGPT and GPT are the same, but I could be wrong. I think ChatGPT is an 'improved' version of GPT-3 but more limited because of public attention.
chatGPT is trained with Reinforcement learning from human feedback
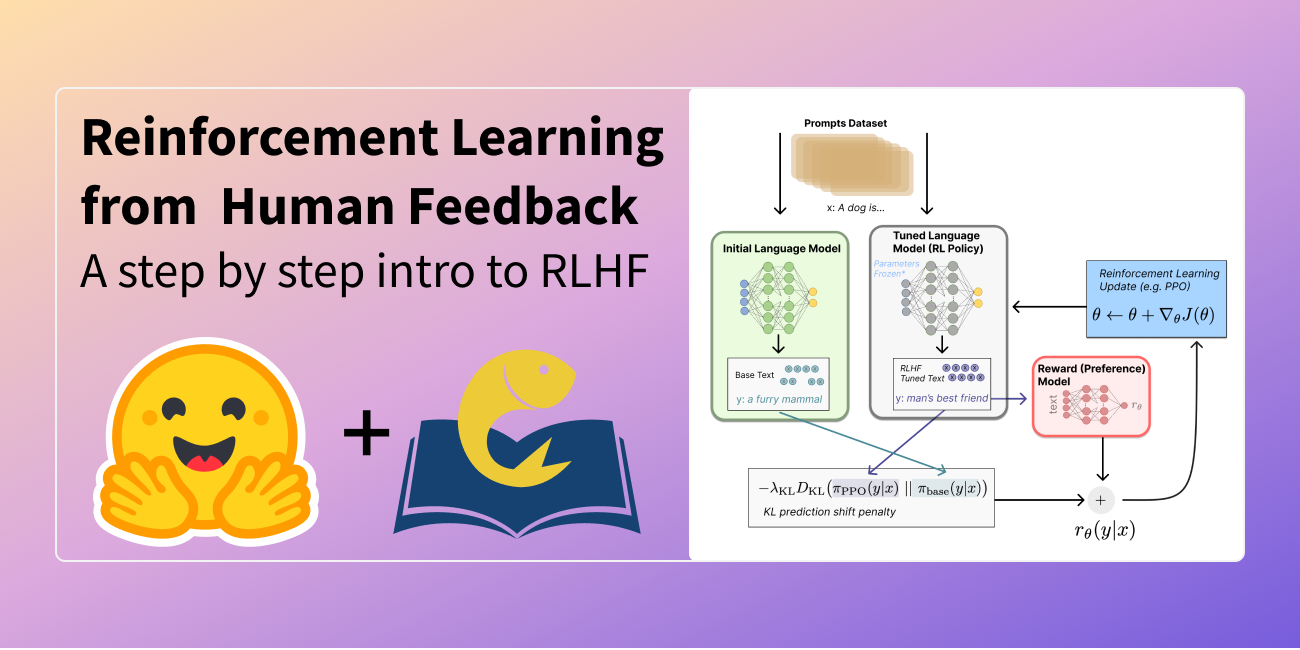
{kind=link}
I know
Our chat is almost like chatGPT:)
Why is it limited?
I'm sorry, I don't understand the question. Could you please rephrase it?
My jokes are terrible 😅
Because of the amount of public attention it got and the criticism of how easy it was to get it to say it supported the Taliban or similar.
By public attention you mean the RL part?
No, I mean ChatGPT has gained a lot of attention.
Not exactly RL as a whole.
But what do you mean by 'limited',?
hey evryone so I have these two different types of data
health data
and non health data
now I am trying to do late fusion
how do I do it
Could be shape of an array, for example RGB image will have 3 color channels and 512 size of the image, making it shape of 3 x 512 x 512. But there could be other meanings depends on the context
Train Score 0.6417617510601822
Test Score 0.6397783938389512
does this mean my model is good?
This is context dependent.
What is your task?
how can i change the name of a column?
This tutorial explains how to rename columns in a pandas DataFrame, including several examples.
thanks
to predict housing prices
from california housing list dataset
Hey there, is a pipeline part of the modeling process or the data preparation process?
I can do at the moment 2 things with my data:
- remove outliers
- append StandardScaler to all columns.
Now I am afraid that when I select my train, validate and test data the outliers removal goes a bit wrong resulting in uneven columns when appending my pipeline to the tr, val and tst data.
Ah, the Kaggle challenge 🤣
Hey guys. I just dive into SVMs and trying to solve some easy exercises but I struggle. Can someone give me some help ?
ok but how is the number of each innovation determined, is there an order for numbering each connection
Tbh it wasn't
I did it because it was the only dataset i could think of where I can use MLR
Nice to know about kaggle tho
I'll try practicing from there tyvm
Hello everyone I am a student hoping to get some idea for a AI project as that is something I have to do in my college for A-level. However, I am struggling to decide what AI project to make.
a chess game ai
A chess AI would probably be made by some students I also kinda need something Unique as I am also applying for Uni and trying to Include it for my personal statement for uni application
Insect classifiction?
what about a ai that you put in foods and fruits and it thinks about recipes for a fruit/protein smoothing using those items
thanks interesting idea
yea that can be really good as well
i like the insect idea too
no problem 💪
Can anyone suggest me something
I am new to machine learning thing and to show my results i generally use mathplotlib to make graphs but i get some error everytime like should be of same shape or something
I don't full understand the working of it so I'm a little confused
Can anyone help me with an in-depth guide of seaborne or math plot lib
I'm following two links on the internet but they aren't reliable and most of the code given there is either outdated or wrong
Also i don't want to use it's documentation
any avid flashtext users by chance?:
If you had this sentence:
sentence = "distributed super computer game"
and you wanted to extract these keywords:
{
"Distributed Super Company": ["distributed super company"],
"Super Computer": ["super computer"],
"Computer Game": ["computer game"]
}
Would you want the output of kp.extract_keywords(sentence) to be:
["Super Computer"] or:
["Super Computer", "Computer Game"]
hello
It's an sklearn method. Exactly what it does depends on model. See the docs.
okay but when it says fits x to y, what does that mean
how close the values of x are to y ?
It depends on model.
How are you constructing model?
def classification_model():
model = Sequential()
model.add(Dense(num_pixels, activation='relu', input_shape=(num_pixels, )))
model.add(Dense(100, activation='relu', ))
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model```using Keras
Oh, so that's not sklearn.
Well, then I think you should look in the Keras docs.
It should explain to you what model.fit does.
im coming from the docs bro
and it said x is input y is target. i started ml 2 days
It's constructing a function that approximately sends x to y. That's all.
The function is a neural network with some coefficients, and .fit chooses those coefficients so that the input data gets mapped to the target data, more or less.
The docs say quite a lot more than that:
https://keras.io/api/models/model_training_apis/#fit-method
Trains the model for a fixed number of epochs (iterations on a dataset).
...
epochs: Integer. Number of epochs to train the model. An epoch is an iteration over the entire x and y data provided (unless the steps_per_epoch flag is set to something other than None). Note that in conjunction with initial_epoch, epochs is to be understood as "final epoch". The model is not trained for a number of iterations given by epochs, but merely until the epoch of index epochs is reached
andepochsdefaults to 1 according to the signature.
nothing else from the description of x in that doc was useful/comprehensible tho
Do you know what backpropagation is?
I know the general term yes. But in simple terms I'm wondering what fit (x,y) does
It splits the dataset into batches of 32 (by default) datapoints, runs backpropagation on each according to the model's optimizer (Adam in your case), until the entire dataset gets trained on this way (which is called a single epoch).
does every instance of fit do backprop?
like fit as a method itself is always backprop?
Not sure what you mean by that. One needs to do backpropagation to determine how to alter the model's weights to decrease loss. How exactly it does it, though, depends on the optimizer - it can be just gradient descent (if using the SGD optimizer), or something fancy like Adam, like in your case.
Hey guys, about Reinforcement Learning...
I'm trying to understand Policy-based algorithms, according to ChatGPT:
In policy-based reinforcement learning, the goal is to learn a policy that directly maps states to actions, rather than learning a value function that predicts the expected return for each action. The agent's policy is typically represented by a probability distribution over the action space, which specifies the probability of selecting each possible action given a particular state.
So, if I want to make a policy-based algorithm, would I have to actually make 2 models: one to receive the current state and predict the possible actions through a softmax, and another one that will receive the current state and predict the actual action?
If this is correct...then it feels like my agent model will be working together with a vectorizer model... The vectorizer receives a context(current state) and, based on that, generates vectors(actions probabilities), which will be the cross-entropy label for the agent output. 
Hey there!How are you doing?
İ need some help,how to use chatterbot now?İt owners are not upgrading that.İts an ai chat bot that's why im writing here.Do you know how to use this in 2023?
Assuming it's a new innovation or an existing on for that generation?
Uh... It seems that I found another type of neural network that is as unstable as a GAN
does epoch * batch size = total amount of data trained on?
if I have a dataset of 60k, 10 epochs and a batch size of 200, would that mean 2k images got trained on?
No, it means the amount of iterations in total
A single epoch is when you've iterated through the entire dataset(which is divided in batches)
Hey guys are there any models that are trained to estimate the size of insects and worms ?
Based on what
based on insects or worms image datasets
what's batch size in that context then?
It's a chunk of data, how many samples you'll be using at each forward/backward pass
If your batch is 64, then you'll be making your model deal with 64 samples at each pass
No, it's just the samples from your entire dataset
If your dataset has 60k samples and your batch size is 64, then you'll be selecting 64 samples from your 60k dataset to make the forward/backward pass.
Hey guys, I have a question, say I have two dataframes in Pandas, where one dataframe holds the name of something (call it value) and two other columns A and B. Now, I want to create a new dataframe, where the value of a new column X is based on the A and B columns, grabbing the value that belongs to it. How would I go about that?
See Policy Gradient Methods in the Sutton Barto book. You almost described something like actor-critic.
Oh...curious... I've never read that book...
I managed to make a model that tries to predict correctly the reward...but I'm still struggling to make it...like...try different actions, instead of blindly using the same one
It's the RL book.
Does it talk about this? Or is it just like ChatGPT telling me to use PPO?
Exploration? Yes.
It's not exactly exploration. I mean... The gradients generated through the MSE(predicted_reward, actual_reward) should generate different actions, shouldn't it?
You can take actions in different ways based on the predicted values.
(Or maybe you decide to ignore them entirely)
I'm currently trying something like:
state ----> features ----> action ---> reward
Shouldn't the backpropagation through the predicted reward change the actions?
Not necessarily. If you are estimating values, you can choose actions based on those, then yes, since your estimation is changing.
Well, the model estimate values based on actions...
Depends on the type of RL you are doing.
Directly / indirectly. Things get a bit weird in terminology and such, it's best to just read that book.
Ugh... I hate how people use different terminologies for this...
With RL you are dealing with feedback loops, so there is a loop between actions and values. So talking about it is a bit difficult.
*In general, which is why we talk about specific algorithms or things get difficult and then people make up their own terms and start just using math to more specific.
action selection over action values there is always an " probability of selecting a random
action. Of course, one could select according to a soft-max distribution based on action
values, but this alone would not allow the policy to approach a deterministic policy.
Instead, the action-value estimates would converge to their corresponding true values,
which would di↵er by a finite amount, translating to specific probabilities other than 0 and
1.```
Oh...so this explains why the softmax(possible_actions, true_action) didn't work for me...# Sample an action from the distribution
action = torch.multinomial(action_probs, 1).item()
(ChatGPT)
Oh...so my action is not necessarily the action with higher probability in the distribution?
Then, the predicted reward is not based on my action or in the state that gave origin to such action, but rather on the state that comes right after the model executed such action?
Or is it wrong?
My model is predicting both the action and, based on that, the reward. It's managing to make nice predictions, but the actions tend to be always the same.
Should I make it predict the action and, after the action has been executed, predict the reward?
I don't you have mentioned which RL method you are using. Unless you are making one up.
I don't really know the method. All I know is that my model receives an image and the previous actual reward as inputs.
Then, extracts features from the image and tries to predict the actions(this is then passed through a softmax).
It also passes the previous reward through a linear layer and concatenates the output to the actions(before softmax). With this concatenation, it tries to predict the reward.
Then the backpropagation is done exclusively through MSE(predicted_reward, actual_reward). Always using cumulative reward.
Trying to install TF from the source, how long is the PKG build process supposed to take?
It's been like, a solid 15 minutes
I'm new to ai and I'm trying to find some models that can classify if a sequence of heads or tails was computer generated or human written. I have a small dataset of labeled data and was wondering what kind of model would work. Would a LSTM rnn work for this?
What do you mean, a sequence of heads or tails?
Coin throw?
How would you hand write a coin throw?
like a sequence of thhhththh
"I have thrown a coin and got a sequence of Heads, Heads, Heads"

Basically a human trying to fake a random coin toss
You could try it with an lstm, I guess.
I don't think the solution would generalize very well.
Aw...my GAN doesn't want to converge anymore just because I'm using a lower batch size.
I didn't know the batch size was also a parameter to make a GAN converge... I thought it was just for better generated images.
I think for humans you can probably find some kind of relation between a coin flip and all previous coin flips, but when a machine does it, there should be absolutely no dependence @tough sun
So you should make an algorithm that can find out if there is a dependence between a coin flip and a certain amount of previous coin flips
I'm working on the interpretation of regression analysis but I get really confused about the characteristics of an approximately normal distribution
I have mean=42 mins, std dev = 3 mins
The shape of the probability distribution is roughly symmetric, the center would rest at 42 mins, what would be the variability?
Would the variability just be the standard dev so 3 mins? My statistical knowledge is minimal. I am also familiar with the normalCDF and invNorm functions if that is needed
thanks man, will do
Does anyone have any good resources for learning/exploring Polars (https://www.pola.rs/). Can be an article, book, video...just wondering if anyone has a resource they've personally found useful. I've watched some YT videos and also this article (https://kevinheavey.github.io/modern-polars/) just looking for other resources beyond just a YT or Google search. Thanks!
I've seen a few people request polars resources recently, but I haven't seen any resources. but what form would something "beyond YT or a Google search" take? an ebook?
@serene scaffold yeah, I mentioned that just to save people time doing a google/yt search which I've done. And let folks know the format wasn't super important to me if they found it useful. So really, a YT vid or Google result would work, but if it's in the top results, I've probably checked it out already 🙂
During 2022 I worked my way through Matt Harrison's "Effective Pandas" book and loved it. So a book (or e-book) recommendation would be good too.
Hi. I've been trying to use a CNN to identify sign-language in a jupyter kernel (3.9.13), but running this "from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.callbacks import TensorBoard" keeps on killing my kernel. Does anybody have any advice/ideas?
try running those import statements in a py file and see what error you get
@orchid mist we don't allow surveys here, sorry
This is the error:
ModuleNotFoundError: No module named 'tensorflow'

Install packages from within code
in the notebook, reset the kernel, and then run a cell that has only this
import sys
print(f'{sys.executable = }')
and say what the text is (no screenshots)
and then go back to the py file and add the same code, run it, and make sure it's the same.
sys.executable = '/Users/myusername/opt/anaconda3/bin/python'
the .py file still catches the error in the beginning and doesn't run this line
it raises the error without catching it.
put the two lines about sys first in the py file, so that they happen before the error is raised
Please provide the full traceback for your exception in order to help us identify your issue.
While the last line of the error message tells us what kind of error you got,
the full traceback will tell us which line, and other critical information to solve your problem.
Please avoid screenshots so we can copy and paste parts of the message.
A full traceback could look like:
Traceback (most recent call last):
File "my_file.py", line 5, in <module>
add_three("6")
File "my_file.py", line 2, in add_three
a = num + 3
~~~~^~~
TypeError: can only concatenate str (not "int") to str
If the traceback is long, use our pastebin.
^ this shows what is meant by "whole error"
/usr/local/bin/python3 /Users/username/Downloads/MeDetectionWHOA.py
(base) username@MyDevice ~ % /usr/local/bin/python3 /Users/username/Downloads/MeDetectionWHOA
.py
File "<fstring>", line 1
(sys.executable = )
^
SyntaxError: invalid syntax
I get this
looks like you didn't copy the two lines exactly
print(f'{sys.executable = }') is not (sys.executable = )
I copied this "import sys
print(f'{sys.executable = }')
", and I still keep getting this /usr/local/bin/python3 /Users/username/Downloads/MeDetectionWHOA.py
(base) username@DeviceName ~ % /usr/local/bin/python3 /Users/username/Downloads/MeDetectionWHOA
.py
File "<fstring>", line 1
(sys.executable = )
^
SyntaxError: invalid syntax
(base) username@Insanity ~ %
but I suspect it's going to print /usr/local/bin/python3, which is a different executable than /Users/myusername/opt/anaconda3/bin/python. so the things you have installed for anaconda won't appear when you use /usr/local/bin/python3
maybe you're using 3.7. sorry for doubting you
anyway, how did you start the jupyter notebook?
I found a youtube tutorial on sign-language
🙂
I have some python experience, but not much with ML
watching a video to reproduce all your steps is more than I'm willing to commit to. but if you can explain how you started the notebook, please let me know.
I just opened anaconda, clicked launch, and pressed new
I see
that's in jupyter
the error I sent was in the .py file
In jupyter I get. sys.executable = '/Users/myusername/opt/anaconda3/bin/python'
imo, anaconda shouldn't be used by beginners anymore. though I understand why it was in the past.
so, any advice on what I should do?
how much Python experience do you have prior to this? like what's the most complicated thing you've done?
Some stuff with arrays, loops, if-statements and strings
And some raspberry pi stuff
are you sure you're talking about arrays? because lists and arrays are different.
if you're not doing DS/AI/ML, you can get away with using "list" and "array" interchangeably. but for us, the distinction is critical, and using the wrong term could result in miscommunicating without realizing it.
oh
anyway, I'm not too sure how to get into DS as a Python beginner without learning bad practices. I learned Python first.
what would you suggest I focus on learning?
how Python environments work. the problem we're having is that you don't know how to run a py file using the same environment that controls your notebook
sounds good. sorry that I don't have an assignment that's more fun.
thanks!
I even got in trouble because I confused array with matrix...
My computer almost killed me because of that giant matrix multiplication...
The numpy matrix class was deprecated a long time ago
It's not that. I literally confused arrays with matrices. I only learned the difference (specially between operations) when I started learning C++
Do you think of matrices as something other than 2d (math) arrays? I don't see the connection with cpp
In C++, there's no matrices itself(unless I didn't actually get that), there's only arrays. Because of this, every time I tried to create a 2D array and apply a multiplication to make a neural network from scratch, the result was different than what I expected.
That's when I learned the difference.
Not sure why you said that
useful for python beginners
nvm didnt read the full sentence
my bad
i mean it depends on the user and their wants generally it has its pros and cons
anyone know if Python for Data Science and Machine Learning Bootcamp by Jose Portilla on Udemy is any good?
Hi all, I have two CSV data files that contain a large of grocery products (1000+ items) from two different grocery stores.
I am trying to compare the prices from each store to identify the best price.
To do this, I first need to match the products the best I can. I am struggling to find the best way to do this, I have tried multiple different methods to best match the product names together.
For example
Store1 names a certain apple as follows
'Fresh Pink Lady Apples Each'
Store2 names the same apple as follows
' Pink Lady Apples 200g each'
I have tried to use levenshtein fuzzy string matching
difflib
natural language processing
greedy algorithm
cant seem to get it precise enough to have something useful so I can move on to comparing the prices.
Any suggestions?
If all the examples are like the one you give, then a bag of words model might be appropriate. Maybe look into tf-idf models. Good luck; I think the difficulty of your question depends on how well the products are labeled, and they could be all over the place.
They are kinda all over the place.
Here is a sample of some of the products.
Kitchen Superfood Slaw Mix 350g
Granny Smith Apples Prepacked 1kg
Asian Buk Choy 1 bunch
Mini Sweet Pineapple 1 each
Kitchen Chicken Caesar Salad Bowl 180g
Yellow Nectarines 1 Kg
Kitchen Carrot Sticks 150g
Chives Punnet 10g
Spinach And Kale 300g
Snacking Carrots 200g
Roasted & Salted Cashews 400g
Kitchen law 200g
Kitchen Broccoli & Cauliflower Florets 150g
Brown Mushrooms Loose 200g
Mix-A-Mato Grape Tomatoes 300g
Flat Mushrooms loose 350g
Mediterranean Style Salad Bowl 185g
Fresh Red Entertain Peri Tomato 350g
Green Kiwifruit Prepack 6 pack
Roma Tomatoes Loose 100g each
Plums Prepacked 1kg 1 each
Roasted & Salted Pistachios 400g
Im starting to incorporate the pricing into matching. So if the prices differ by more than say 15%, it shouldnt be a match as generally grocery prices dont differ too greatly between stores
I have a csv file that has data that is not sequential, ie the each row doesnt comprise 1 entry, a single entry may be made of multiple rows
is there a pandas function to read this kind of csv file or do I manually have to read and parse it ?
(for legal reasons I cant really share the dataset)
Friends what is that technique called for testing a model where you e.g. Split it into 5 subsets and iterate through each one, using it as test data and the rest as training, then get the mean of the accuracies?
Nm just found it - it's k-fold cross validation
Greetings everyone, so I have a little question:
Its the first time I participate in a kaggle competition, I created a notebook where I worked on EDA then modeling then validation and I want to make my first submission. But since its a notebook only competition, it needs to run and give the submission file at the end. Thus it will run all the modeling code and take hours training and wouldn't use the model I just trained. So my question is how do people submit in those competition? Do I need to make two notebooks one for training and one for submissions (where I upload the model from the training notebook)?
Im following this tutorial online but when i try to replicate the results with their dataset , the math comes out wrong
when the author says "Reviews proportion" does he mean the quantity of reviews( an integer value)?
nvm
I think I got it, now.
I'm using Actor-Critic, using the same network as policy network and agent network. But not A3C, just a single model.
Now I'm just wondering...would it be better if my value function was given by MSE(predicted_reward, actual_cumulative_reward) or by MSE(advantage, imediate_reward), where advantage = predicted_reward - previous_reward?
Also, now I know that my true action is not necessarily the possible action with higher probability given by the policy network, but just a sampled action from those probabilities.
I just wonder if there's any Pytorch built-in function that can help be make a weighted sample...
Wait...I could make my model sample that action by itself 
I know how to use python and c++ to an intermediate level. Can someone help me with a book I can use to start learning about artificial intelligence
the book I recommend is "data science from scratch", which does cover AI/ML concepts.
what common problem does anaconda solve that isn't now solved by venv and pip? and whatever it is, is it worth creating a knowledge gap between DS/AI people and the rest of the Python community?
thnx
who is the book's author

O’Reilly Online Learning
What if I calculate the expected reward for each action in the probability distribution, and then make a weighted sample, where the weights are the expected rewards for each action?
I suppose this could mitigate the softmax tendency of always outputting the same action, right?
If an action probability is 0.15 and its expected reward is 10, the result would be 1.5, while if the best action is 0.55 and its expected reward is 1, the result would be 0.55, so the first action tend to be chosen...
But then, if the policy thinks action B is better than A, maybe the tendency is to reward for B to be way higher than A...even if the layer for predicting the reward is independent...I guess.
Probably you're right. I've been using conda exclusively for last several years. But i think you can install most if not all packages using pip these days. I wouldn't know how to install python without conda:)
How do you know what envs you have with venv. Do you use special folder for them ? Conda keeps them organized for you ...
where can i learn about how training process takes place when we use multiple GPUs?
each environment is a folder on your file system. usually, you make it a subfolder of the top-level directory for a project.
with what library? pytorch?
yes
I see. I was thinking to store them central something like conda in envs folder
So at least I know where they are lol
you can do that, too. but if you keep them with their respective projects, you can just name each one venv, and you don't have to come up with creative names.
Can you have different python versions installed in different venvs?
yes. a venv will always mirror whichever python version you used to create it. on windows, you can do py -3.x -m venv (for whatever x, provided you have it installed)
I'm not sure if linux has the py launcher. but if I'm on linux, I'm usually on a project-specific VM, and only install the python version I plan to use.
Nice thanks. Final question 🙂 how do you install python on Mac without conda? Brew?
I don't know. my work and gaming PCs are both Windows, and then I do most development on linux VMs.
but it's probably basically the same as on linux
so, probably with brew. or you could download it from python.org
Thank you. I will try this new way 🙂
let me know if you have any issues 😛 I might be able to help
good evening data boys and girls,
i want to generate a comparison like r^2 for ifft spectra based on the amplitude and frequency of the resulting curves.
Does one of u know if there is a lib for that?
Maybe librosa or torchaudio?
i never used those but arent they for audio, i mean yeh fft is broadly used in audio but still?
i was thinking about writing my own r^2 function for both amplitude and freq
I thought spectra = spectrogram...
measurement spectra
Oh, for light waves?
cant i compare the abs(fft)
I guess they might do...they have spectrograms in frequency x amplitude, so...
if i keep only 5 freq. i can compare the abs() of them and calculate a score on that i guessed
power (float or None, optional) – Exponent for the magnitude spectrogram, (must be > 0) e.g., 1 for energy, 2 for power, etc. If None, then the complex spectrum is returned instead. (Default: 2)
There might be something that uses frequency x amplitude that could be adapted to eletromagnetic waves, I guess...
I remember that Pytorch also has a built-in function for ifft, but it's not in torchaudio
@hasty mountain thanks ill give it a try tomorrow
Guys, I'm trying to implement PPO and I'm running into a problem with autograd.
It won't compute the gradients for my policy. I guess the problem is in the surrogate loss, but I don't know why.
possible_actions, true_action, predicted_reward = model(frame, reward_input)
advantage = predicted_reward - reward_input
# PPO updates the policy based on the previous policy parameters, which can also be seen as the previous policy outputs
ratio = (possible_actions.retain_grad().argmax()/previous_possible_actions)
ratio = torch.clamp(ratio, min=0.2, max=0.2)
surrogate_loss = ratio * advantage
value_loss = reward_loss(predicted_reward*uncertainty_factor, reward)
total_loss = surrogate_loss + (value_loss * 0.5)
total_loss.backward()
The gradients backpropagate through the layers that predict the reward and through the feature extraction layers, but the layer that generates the possible actions specifically has no grads computed.
Using print(possible_actions.grad) gives me this:
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead
But even with possible_actions.retain_grad().argmax() I'm having problems with this. Any tip on how to fix this?
Also, when I used print(surrogate_loss, ratio), it shows me that those variables have grads:
tensor([[0.0915, 0.0915, 0.0915, 0.0915, 0.0915, 0.0915, 0.0915, 0.0915, 0.0915,
0.0915, 0.0915, 0.0915, 0.0915]], device='cuda:0',
grad_fn=<MulBackward0>)
tensor([[0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.2000,
0.2000, 0.2000, 0.2000, 0.2000]], device='cuda:0',
grad_fn=<ClampBackward1>)
any interesting fun data science project ideas for a relative beginner? (know the theory but haven't done too much in practice)
preferably things related to neural networks
Try a classification problem with digits MNIST dataset, then try with CIFAR100.
And try plotting the outputs of your layers into images to see how your network is dealing with the data(this might be easier to do with Pytorch or tensorflow, rather than keras)
Then go to DCGAN using the classic CelebA
||And get crazy because GAN things||
Ok, can't use argmax() without losing my grads. But at least I found an implementation that uses one-hot encoding and then sum all numbers in the softmax.

Hello how would you guys find the best cut off mark for this type of data, so that anything below x is labeled as 0 and anything above is label as 1?
I thought of doing histoplot but i dont see that bell curve shape. So i dont think I can do IQR or normal distribution
One way i was thinking is just looking at my dataset and see a cut mark where it makes sense
thanks, but this is kinda the hello world of neural networks so i've already done that, looking for something a little more interesting
also as for your problem maybe try posting it in #1035199133436354600 that might draw more attention to it
Thanks for the suggestion, but I managed to solve it. Now I'm just having vanishing gradients
EDIT: Now it's crazy gradients
Try a GAN(enhancing DCGAN) or SuperResolution model, then
Or Transformer

Humble Bundle
We’ve teamed up with BPB Publications for our newest bundle. Get books like Think AI & Data Science with Machine Learning - Python. Plus, pay what you want & support charity!
30 books for 17 euro, all ml
Thinking if they wirth it, thats a lot of reading
hello. i have a question about RDD with statsmodels and seaborn. im kinda getting where i want to be. but im not sure what the end goal should be. im doing some covid dataset RDD. about the reopening of the schools back in august 2020 (canada)

i cant get the dates and the line to show properly.. like a line that breaks.. or follows the scatter more closely
that plot doesn't look like it would fit well with a linear model
you'd be better off using a polynomial function instead, which would be able to better match the curves of the plot
This may be more relevant in the #databases channel (to my limited knowledge), but if I were trying to create an entire database of actions in the sport of fencing (i.e. attack, retreat, lunge, etc.) is there any method that is more efficient than having to manually download and edit videos in order to create a few 100-1000 clips? I need to know whether or not there are more efficient methods because it may mean that I may focus on finding a new project that won't require a stupid amount of time 😄
your question is on-topic for this channel, and would be off-topic in databases. what you're trying to make is a dataset. and creating datasets is widely known to be an arduous and soul-crushing process.
Sorry I don't have better news.
for your reference:
a database is a data store that can be queried.
a dataset is a collection of data that can be used for ML.
the distinction will become more clear to you with time.
I wonder if someone has already tried implementing a RL algorithm that lets the model itself decide its reward
EDIT: I just remembered that this is what ChatGPT does. A separate model generates the reward for each text generated by the text generator...interesting...
Meh...maybe I'll try this someday. I just hope I don't have to waste that much time before realizing if my RL model is inefficient.
hi , can i know how can i learn python and data science what are the topics i need to complete
I am doing binary classification on highly imbalanced data. I have a good baseline model that gets 0.9 predictive equality at 50% True Positive Rate (TPR). I now want to do hyperparameter tuning to get the highest TPR at a predictive equality above 0.8. How can that be done?
I thought about the following:
Create two keras_tuner.Objectives:
- abs(0.8-predictive_equality), min
- TPR, max
Would that lead to what I think it would lead to or is my understanding of objectives wrong
highest tpr is achieved by classifying everything as positive 🙂
Thats why I use the second metric predictive equality that prohibits such behaviour
why not simply pad your dataset so that its balanced and use a normal objective
otherwise there's a free variable
namely the scaling factor between 1 and 2
hey there! can anyone help me with dqn using the keras package using it for an openai gym custom environment
sure
Thanks man! so am getting dimension based errors. In my custom environment the state space is a 4d. state = (fes_pos, Uav_pos, uav_energy, lost_person)
here, fes_pos , uav_pos and lost_person are lists of x and y coordinates whereas uav_energy is a 1d list
this is my model
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
states = env.observation_space.shape
actions = env.action_space.n
actions
def build_model(states, actions):
model = Sequential()
model.add(Dense(24, activation='relu', input_shape=(4,)))
model.add(Dense(24, activation='relu'))
#model.add(Flatten())
model.add(Dense(actions, activation='linear'))
return model
model = build_model(states, actions)
when i try to fit the model
dqn.fit(env, nb_steps=50000, visualize=False, verbose=1)
getting this error
ValueError: Error when checking input: expected dense_32_input to have 2 dimensions, but got array with shape (1, 1, 4)
states = env.observation_space.shape
build_model usually takes shapes as input?
ok
then you need to flatten or use reshape
flatten before you pass it to a dense layer
at the start
ie right after Sequential()
ive tried adding flattern. however somewhere in the middle. okay letme add it in the beginning
hey should i add it after sequential or after the first layer
" model.add(Dense(24, activation='relu', input_shape=(4,)))"
because im getting this error :/
ValueError: This model has not yet been built. Build the model first by calling build() or by calling the model on a batch of data.
Hey there, I have the following code:
p1 = Pipeline([('Lineair Regression', LinearRegression())])
p2 = Pipeline([("Scaler", StandardScaler()), ('Lineair Regression', LinearRegression())])
p1.fit(greenhouse_X_tr, greenhouse_y_tr)
test_preds = p1.predict(greenhouse_X_v)
test_score = p1.score(greenhouse_X_v, greenhouse_y_v)
print('p1: ' + str(test_preds))
print('p1: ' + str(test_score))
p2.fit(greenhouse_X_tr, greenhouse_y_tr)
test_preds1 = p2.predict(greenhouse_X_v)
test_score1 = p2.score(greenhouse_X_v, greenhouse_y_v)
print('p2: ' + str(test_preds1))
print('p2: ' + str(test_score1))
When printing the results, the standardscaler doesnt seem to append when checking the results.
p1: [19.06856434 18.27648482 20.56294229 ... 23.65166504 19.11782744
21.71606506]
p1: 0.9883787684006002
p2: [19.06856434 18.27648482 20.56294229 ... 23.65166504 19.11782744
21.71606506]
p2: 0.9883787684006001
https://michael-fuchs-python.netlify.app/2021/05/11/machine-learning-pipelines/
https://scikit-learn.org/stable/auto_examples/compose/plot_column_transformer_mixed_types.html
scikit-learn
This example illustrates how to apply different preprocessing and feature extraction pipelines to different subsets of features, using ColumnTransformer. This is particularly handy for the case of ...
after sequential
you can pass input shape to flatten layer
i think
okay added this after sequential()
model.add(Flatten(input_shape=(4,)))
the model could be built now. but still getting this error
ValueError: Error when checking input: expected flatten_9_input to have 2 dimensions, but got array with shape (1, 1, 4)
is my input_shape argument ok? :/
input_shape=(1,4)
No the argument input_shape should have 2 dimensions so,:it will be input_shape = (4, 1)
What do you mean by free variable?
ambiguity, something to decide on
A = ((2,2),(3,10),(5,5))
print(max(A))
How would this piece of code compute?
mmh, seems like a good idea. I have to look into it
Thanks but im still getting another error :l
ValueError: setting an array element with a sequence.
:/
after it tried to fit the model again
if you send me all the code i can try to get it running
if its a standard gym problem
okay sure!
maybe someone that has an answer on this one 🙂
Hey @sharp anchor!
It looks like you tried to attach file type(s) that we do not allow (.ipynb). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
A = ((2,2),(3,10),(5,5))
print(max(A))
How would this piece of code compute?
Hey @sharp anchor!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
ive copied the code there
@sharp anchor what has input shape (2, 1)
i dont suppose ive given anything with a (2,1) dimension?! can you point out which line youre talking about :l
can one of u explain me:
https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.coherence.html
i want to compare 2 irfft curves and therefore set the nfft=len(irfft_curve) which results in n // 2+1.
However i want to compare the coherence directly in the same plot as the 2 curves. So what i need are shared_x_axis_ticks
https://github.com/mwouts/jupytext
Jupytext is great for letting you write code in your editor-of-choice and hand it off as a notebook if that's the preferred format of colleagues. Much improved workflow for me

GitHub
Jupyter Notebooks as Markdown Documents, Julia, Python or R scripts - GitHub - mwouts/jupytext: Jupyter Notebooks as Markdown Documents, Julia, Python or R scripts
Welp... (Thank you though)
this looks pretty handy
let's see. by irfft you mean inverse real fft, yeah? this is in the time domain. however, the scipy function you shared for coherence is in the frequency domain, not time domain
What's the math behind gradient descent in deep learning? I learnt it but don't really understand
It's just some simple calculus.
according to the calculated loss, the algorithm simply upgrades the values of the weights and biases such that it converges to the minimum point for accurate prediction.
Gradient Descent is the workhorse behind most of Machine Learning. When you fit a machine learning method to a training dataset, you're probably using Gradient Descent. It can optimize parameters in a wide variety of settings. Since it's so fundamental to Machine Learning, I decided to make a "step-by-step" video that shows you exactly how it wo...
This might help.
hey anyone here use bert
please don't ask to ask. instead of asking "does anyone know x", ask your actual question about x. it's easier for everyone that way.
How to fine tune a pre trained model of bert for text to vector conversion
it would take a lengthy tutorial to answer this. do you have a dataset of text segments and the desired vector representation of those segments?
I have a dataset of text
Intially I just used transfer learning to generate the vectors
you can use BERT out-of-the-box to get vectors for each segment. are you sure you actually need to do any fine tuning?
yup
what will the fine-tuned BERT do that is different from what BERT already does?
I get those vectors and then pass them through different machine learning algorithms like svm for classification
use fine tune bert I am hoping to generate more acurate vectors
can you give an example of an instance that you would use to fine-tune BERT?
aranesp ug
1 aranesp ug
2 aranesp ug
3 problems with arterial cannula had to discard ...
4 aranesp ug
... ...
14866 arenesp
14867 aranesp, stopped early due to bleeding
14868 iron and rnsp infussion
14869 very good
14870 good
I have this dataset
I wanna fine tune bert
this isn't enough. you also need a target of some kind.
model = BertModel.from_pretrained('bert-base-uncased',output_hidden_states = True,)
oh the ouput is just yes and no
what does the yes or no mean?
its just the class of the sentence
so you're trying to use BERT as a classifier?
its basically a classification problem
no I am trying to use bert to generate vectors
then pass the vectors through different classifiers
@serene scaffold
okay, so you're using vectors produced by BERT without fine-tuning BERT. or you're fine-tuning BERT to use it as a classifier.
it might be that if you train BERT as a classifier, but then don't use the classification layer, then vectors from the next-to-last layer would be closer together for inputs that belong to the same class.
i did back and forth transformation 😄
Currently i exported the fft values (complex) and now try MSE to get some good error_score
but yeh im not yet convinced what is best for my approach of comparison
time to shamelessly plug in my jupyter notebook... in pdf form
that's basically all you need to know about deterministic gradient descent. some stats is needed for the stochastic flavor
I like how there's pages and pages of just latex until you get to the code.
even if you transform back, you'd get an estimate of the cross correlation function. the domain of this function is the "lag" domain, not the original time domain of the two functions you fed it
😌 dat math
this is notebook usage I can get behind
oh i didnt knew that thanks for informing me. what do u think of MSE for each freq. of the freq. domain?
so difference of predicted/observed
MSE is a commonly used performance indicator
whats ur opinion on pearson or coherence in that regard ?
that they measure different things
or numpy sqrt
MSE measures distance, coherence measures similarity as an angle
MSE measures orthogonal distance, at that
i struggle a bit to find a good approach in classifying my predicted curves vs observed ones
i think they are all suited for comparison but i dunno what is "best in slot"- if one wants to call it like that
coherence is good to show full overview
unfortunately there is no "best approach" here, it depends on what you wanna emphasize
MSE gives a good overall value for curve vs curve
sadge
hey does anyone the error here

what u think of this as an error_score:
n = len(predicted_fft)
diff = predicted_fft - observed_fft
mse = (1/n) * np.sum(diff**2)
r_square = 1 - mse/np.var(observed_fft)```looks like l is not a numpy array, but a scalar?
Hey @keen notch!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
idk, does it tell you anything you want to know? it's basically comparing the error energy vs the energy of the target signal. from the POV of optimization, this is exactly the same as just the MSE, as all you've done is scale and shift it
can't see where this would fix it
yeh i wanted a "score" which indicates conformity
well, this would certainly be one 😛
😛
1 good, 0 (and negative) bad
would u say its a sufficient approach to describe the relationship of 2 curves
is there something wrong in my code
if i split the complex value into .real and .imag part and calc. each score individual the resulting r^2's differ quiet a bit. does that only imply symmetry mismatching?
Hi, i'm trying scrape with selenium but i receive this message
"NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//a[@class='ui_button nav next primary ']"}"
, Any suggestion ? Thanks
Hi, open the url in the browser and inspect element. Then CTRL+F to open search bar and paste xpath. Check if it exists.
If the elements does not found in search try re selecting an element and copy its xpath
Else if element found, there may be delay in webpage loading, then wait for the element before accessing in selenium script
I tried a couple courses online for datascience, hyperskill, dataquest, pluralsight, 365 data science (trial )
I really like the interactivity, or "by doing" learning and text of dataquest.
I like hyperskill's intergration with intellij, however the courseware is lacking, questions are a bit... what on earth?
I like to figure out how to autosync dataquest, and use intellij as my editor while learning
Thank i'll try
@wooden sail since you're a mathmagic, can you help me with a crazy trick?
I want to make a Reinforcement Learning model that will predict every possible action given a certain state, and will also predict the reward for every possible action it might take in that state, sum those rewards and get the mean.
In order to preserve my hardware, I've divided my commands between 3 input types: command_type, action1 and action2.
Each input type will have its own feedforward layer to output the probability distribution.
However, I don't know exactly how to calculate the reward for each input type without having to create a monster variable var = command_type * action1 * action2 and having to iterate through each one.
I'm currently testing, by hand, the possibility of total_reward = reward_command_type + reward_action1 + reward_action2 and I noticed that, if the lenght of every input type is 2, I'll have 2*2*2 = 8 possibilities, and, if I mark each possibility by hand, I noticed that each input type repeats itself 4 times(Possibilities divided by input length, perhaps?)
Problem is...I don't know how to continue after this
i don't know anything about reinforcement learning tbh :x but wouldn't the possible actions given a state be something deterministic? why would it need to be predicted?
More or less. Depends on how the policy is trained. I'm using PPO.
But knowing RL is kinda irrelevant for the question. My problem is more with the math
I was thinking about
avg_command_type = reward_command_typeA + reward_command_typeB
avg_action1 = reward_action1A + reward_action1B
avg_action2 = reward_action2A + reward_action2B
avg_rewards = avg_command_type + avg_action1 + avg_action2
Makes sense to me, at least.
Taking the mean reward for all command_types, the mean reward for all actions1 and the mean for all actions2.
I just don't know if, after summing those means, would make sense to take the mean of those sums or not
off the top of my head, if i understand correctly, it's really an expected payoff. so it would be the sum of payoff for action i * probability of taking action i
Yes, that's exactly the idea. The expected payoff for each action. But the problem is that I'm simplifing the problem so I can think better, but my model will be dealing with inputs with size 2000, 1000...
So, instead of having to deal with a monster, I'm thinking about simply taking the mean reward for each input type separately, then summing those mean rewards up to get the final, expected reward.
how do the inputs interact with each other? or what are they
the command_type determines whether the controller is the keyboard or the mouse.
The action1 determines whether to press or release a keyboard key(determined by command_type) or it's an X coordinate if the controller is the mouse.
The action2 determines the keyboard key specifically or an Y coordinate.
and you get several of these, are they supposed to be sequential or?
Nah, they're a probability distribution
then i'm not sure what the problem is :x
based on the current state, a probability is assigned to each input independently, with the only restriction that the probabilities add up to 1 (which you can do as a normalization step afterwards)
or what did i miss
it's sleepy time for me so i might not be understanding your problem
Let me see...
if action1 = [x for x in range(1000)]
There's 1000 possible X coordinates, then the probability distribution is got through:
probs = feedforward_layer(inputs, len(action1))
output = softmax(probs)
mhm
output is a probability distribution over all possible action1, right?
softmax is a smooth approximation to argmax
it'll pick the event with highest probability
so output is either 1 action, or an array that tells you the index of the action you should pick
probs is the probability dist
import torch
test = torch.randn((1, 100))
softmax = torch.nn.Softmax(-1)
output = softmax(test)
print(output.size())
.eval()
Uh...what's the command?
hmm?
!eval()
!eval
Missing required argument
code
idk if the both has pytorch
!eval
import torch
test = torch.randn((1, 100))
softmax = torch.nn.Softmax(-1)
output = softmax(test)
print(output.size())
Uh...
anyway, softmax does not yield a probability
it yields a 1hot vector
(based on a probability or something similar)

as i said, a smooth approximation though
right
It's enough, I guess
Anyway, this is how it's implemented, so it's kinda prob distribution
it isn't
And I want to get the avg reward for every single possibility
you don't even need the softmax for that
all you need is the dot product of the payoff vector with the probabilities vector
the softmax is not a pdf
Ok, then let me correct myself:
the output is supposed to be the probabilities of the actions that can be taken, from the worst one to the best one.
Is this better?
nope
you had probabilities before taking softmax
once you took softmax, this has nothing to do with probabilities anymore
How I hate Sutton and Barto for creating different terms for RL...
copy paste here what they wrote
I'm currently using a code example in tensorflow
class Policy_net:
def __init__(self, name: str, sess, ob_space, act_space, activation=tf.nn.relu, units=64):
"""
:param name: string
"""
self.sess = sess
with tf.variable_scope(name):
self.obs = tf.placeholder(dtype=tf.float32, shape=[None, ob_space], name='obs')
with tf.variable_scope('policy_net'):
layer_1 = layer.dense_layer(self.obs, units, "DenseLayer1", func=activation)
layer_2 = layer.dense_layer(layer_1, units, "DenseLayer2", func=activation)
self.act_probs = layer.dense_layer(layer_2, act_space, "DenseLayer4", func=tf.nn.softmax)
if P.use_dual_policy_value:
self.v_preds = layer.dense_layer(layer_2, 1, "DenseLayer5", func=None)
else:
with tf.variable_scope('value_net'):
layer_1 = layer.dense_layer(self.obs, units, "DenseLayer1", func=activation)
layer_2 = layer.dense_layer(layer_1, units, "DenseLayer2", func=activation)
self.v_preds = layer.dense_layer(layer_2, 1, "DenseLayer5", func=None)
self.act_stochastic = tf.multinomial(tf.log(self.act_probs), num_samples=1)
self.act_stochastic = tf.reshape(self.act_stochastic, shape=[-1])
self.act_deterministic = tf.argmax(self.act_probs, axis=1)
self.scope = tf.get_variable_scope().name
Heads up for the self.act_probs = layer.dense_layer(layer_2, act_space, "DenseLayer4", func=tf.nn.softmax)
well, it's a pdf in the sense that it adds up to 1, sure
but this is enforcing a prior
it can only spit out limited flavors of pdfs if you choose that as an activation funct for the last layer of something predicting a pdf
seems pretty restrictive
do you know the payoffs for the actions?
well, if you predict them, you'll have a vector of payoffs
if these are in the same order as the vector of probabilities, the average payoff is their dot product
Yes, but the thing is that I have too many actions, divided in 3 (command_type, action1 and action2).
If I use all of then at once, I'll have more than 4 million possibilities, and the reward must be predicted based on each possibility
ah, i see where we had the misunderstanding. according to wikipedia, reinforcement learning usually uses extra parameters in the denominator of the exponent in the softmax, so this works like regulating the variance of pdfs in the exponential family. bleh
This is why I want to try to predict the reward for each command_type, for each action1, for each action2 and manipulate then so I can get the average reward for every possible action, without having to deal with 4 million possibilities directly
sadly the probabilities here do depend on each other. if you compute the pdfs by splitting the actions into disjoint groups, you have no guarantee you'll get the same pdf you would have gotten if you feed all of them at once
i don't have a good answer for you

Well, if the predicted command type is a keyboard command, and the action1 refers to a mouse, the model will simply do nothing, if this helps with anything.
The idea is to optimize the model so this won't be happening over time
I'll even use some Supervised Learning before the actual Reinforcement Learning to prevent this.
Hm... I tried considering 2 possible command_types, one with reward 0.5 and the other with reward 1. Also 2 action1 and 2 action2, with rewards 0.25, 0.5 and 0.25, 0.75
I've taken the average reward for command_types, for action1 and for action2 and then summed the 3 average rewards to get the total payoff.
But, unfortunately, the result was different than when I summed every possible combination and took the mean
C1, A1, A2 = 1
C1, A1, B2 = 1,5
C1, B1, A2 = 1,25
C1, B1, B2 = 1,75
C2, A1, A2 = 1,5
C2, A1, B2 = 2
C2, B1, A2 = 1,75
C2, B1, B2 = 2,25
sum = 13
avg = 1.625
C_avg = 0.75
1_avg = 0.5
2_avg = 0.625
sum_avg = 1.875
Do you know if I can mitigate this deviation in the averages somehow?
expectation can be represented as an integral. if you come up with an interesting parametrization, you could replace expectation with a handful of montecarlo trials (c.f. montecarlo integration)
but yeah just arbitrarily picking chunks and adding them up isn't gonna work
best of luck with that, i need to sleep
Ugh... Maybe if I can mitigate the error, somehow? Make it the lowest possible?
Okay, sweet dreams
then you're basically training a network to predict the expected payoff. you can try that too, idk what you'd use to train it though
The idea is to sample one action, get the reward for that action and check how advantageous taking that action is, compared to the average reward of the other actions
Hi everyone, I'm following a tutorial to train a neural network for nlp. I'm using google colab. I'm running out of memory in this part:
max_len_sequence = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_len_sequence, padding='pre'))
total_words = len(tokenizer.word_index)+1
predictors, label = input_sequences[:,:-1], input_sequences[:,-1]
label = ku.to_categorical(label, num_classes= total_words)
I believe the problem is when I use keras.utils.to_categorical.
Any ideas to solve this problem?
You could test this out by commenting parts out until you do not get the error, but the problem is probably that total_words is pretty big
Maybe a few thousands or even more, and the amount of labels you have might also be a lot
And the size of the resulting matrix is the product of these two integers, which might be really really big
So that is why you would not have enough memory
to categorical probably 1 hot encodes it, you might want to look into other methods of encoding the words
You could also convert the labels to one hot encodings in batches instead of all at once
The problem is in the to_categorical piece
This would be the simplest solution
could you direct me to an example ?
max_len_sequence = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_len_sequence, padding='pre'))
total_words = len(tokenizer.word_index)+1
predictors, label = input_sequences[:,:-1], input_sequences[:,-1]
# Edited part
batch_size = 64
for i in range(0, len(label), batch_size):
predictors_batch = predictors[i:i+batch_size]
label_batch = label[i:i+batch_size]
label_batch = ku.to_categorical(label_batch, num_classes= total_words)
# Do stuff with the batch of features and labels
Something like this
Typically you do not train the network with all of the data you have at once, since sometimes you have many gigabytes of data
thanks
does anyone know pulp optimization?
yes
im trying to do a pulp optimization model for reorder quantities
but im not sure how to work with it
Stock < Predictions:
Reorder Amount = Prediction - Stock
When Prediction > Stock: Use from Safety Stock
Reorder Amount = Stock + (Safety Stock - Prediction)
Prediction > Stock + Safety Stock:
Reorder Amount = Prediction
Increase Safety Stock level = Prediction - Stock
im trying to generate a reorder amount
but i cant really differentiate the objective function and the constraints
most examples that i find online are very straightforward while mine feels very conditional
import pulp as pl
''' SOLVER SETUP '''
date = data.index
sales = data['Sum']
stock = data['Stock (Yearly)']
safety = data['Safety Stock (Monthly)']
reorder = data['Reorder Level (Yearly)']
predictions = datapred['Predictions']
# Create a variable for the reorder quantities
x = pl.LpVariable.dicts('Date', date, 0, None, pl.LpInteger)
''' SET THE OBJECTIVE FUNCTION '''
problem = pl.LpProblem('Reorder Level', pl.LpMinimize)
'''CONSTRAINTS'''
if stock<predictions:
problem+= predictions - stock
elif predictions>stock:
problem+= stock+(safety-predictions)
elif predictions > stock + safety:
problem += predictions
this is what i have right now
but im pretty sure its completely off
data is my dataset
please edit your code sample to show the import statements.
the import statements are the ones that start with import or from.
like that?
the only one that was needed was import pulp as pl, since that's the only one that you use in the code.
think of it from the perspective of someone looking at your code sample: pl isn't defined, which means it could be literally anything, unless you show in the code where it comes from.
that's okay. now you know.
thank you for telling me
you are welcome
data

datapred

is there a way to "merge" these 2 dataframes but only move one column from datapred (Predictions) to data
you what to merge on what attribute? SKU?
"merge" is an official thing in pandas.
sku and date
so you'd do data.merge(datapred, on=['SKU', 'Date'])
You are trying to merge on datetime64[ns] and object columns. If you wish to proceed you should use pd.concat
sounds like your Date column has different types in each df.
also it looks like the date is the index of data
anyone know how to avoid Can't convert non-rectangular Python sequence to Tensor.
without losing data? If i understand it correctly tensor is trying to create dataset from senteces with different length which it cant use, so i need to either lobotomise sentences to correct length or filter them out.
and i woulndt like either option
Tensors have to be "rectangular". you could pad all but the longest subsequence with 0s, or something.
I want to build a basic ml app using TF just to get some exposure. My data are objects containing strings and ints. I just want the user to type some characteristic contained within the objects and the AI to spit out the correct object. Is there a good tutorial for this?
please say what the strings and ints are.
knowing the types of the data you have is important. but what they represent matters. that's why it's AI.
is there a way to convert datetime back to an object
why do you want to do that? datetimes are better than strings that look like timestamps.
im not sure how to merge
!docs pandas.to_datetime
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True)```
Convert argument to datetime.
This function converts a scalar, array-like, [`Series`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html#pandas.Series "pandas.Series") or [`DataFrame`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html#pandas.DataFrame "pandas.DataFrame")/dict-like to a pandas datetime object.use this to make sure that all your strings (which are objects) that look like timestamps are actual datetimes.

sorry not ints but floats rather
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
Airport = TypedDict(
'Airport',
{
'icao': str,
'iata': str,
'name': str,
'city': str,
'subd': str,
'country': str,
'elevation': float,
'lat': float,
'lon': float,
'tz': str,
'lid': str,
},
)
hey, so does the kernel of a CNN just basically extract the features of an image? and then later down the architecture, you add all the features (neurons) together, to recreate a meaningful portion of the image?
sounds like you get it, yeah
though I wouldn't say that subsequent layers "recreate meaningful portions"
The neurons kinda serve for the network to analyze the features it has available and then take a conclusion about them
so basically you're guessing the important parts of the image (features), reconstructing it down the line, and then using your final image to compare to the original image or whatever input data you're getting?
the kernel of a convolutional layer decides what that layer is looking for. and then subsequent layers figure out what to do with that information.
nothing is getting "reconstructed" or "recreated".
Not reaally reconstructing, just extracting relevant features
If you have a dataset composed of dog images, the conv layers will extract the most relevant features(what is a remarkable trait dogs use to show?), then the neuron layer will analyze those features and conclude if it's a dog or not
but where does the comparison happen
comparison between what things?
sorry, does the final layer compare itself to the original image or the input image
Nah, that's a GAN, not a simple CNN
it doesn't go without saying that the final layer of a neural network involves comparisons.
if you have a dataset of 10k dog images and 1 image you're using to see if it's a dog, after all the convolutions, does it use that 1 image and compare it to all the convoluted images?
and if you have an image classifier, there is no output image. the output is a class.
to determine if it's a dog?
there are no "convoluted images", at that point. the outputs of the convolutional layers are used to adjust the weights of the remaining layers, which don't represent images, or really anything in particular.
@verbal venture does this make any sense?
df_predicted = df_predicted(pd.to_datetime(df_predicted['Date']))
like that?
df_predicted['Date'] = pd.to_datetime(df_predicted['Date'])
my optimization model doesnt work at all as expected
im completely new to optimization and i cant find any solutions online similar to my situation online
is it okay if i pm u for guidance
no
do you have any suggestions then
i can describe my situation here
so in my data i have different products/items with its sales, stock, safety stock and predictions
so what i want to do is to create optimization model(s) to generate reorder quantities for the next few months
to my knowledge there are linear and non linear optimization models
and that depends on whether my items are linear or non linear
Stock < Predictions:
Reorder Amount = Prediction - Stock
When Prediction > Stock: Use from Safety Stock
Reorder Amount = Stock + (Safety Stock - Prediction)
Prediction > Stock + Safety Stock:
Reorder Amount = Prediction
Increase Safety Stock level = Prediction - Stock
and this is what im supposed to use to calculate my reorder amount
Try scaling or normalizing your data. The difference between the numbers is too big.
Python with no gil soon? https://peps.python.org/pep-0703/
Python Enhancement Proposals (PEPs)
Does anyone know how the weights of Stable Diffusion are initialized? I can't find anything but hype, hype and more useless hype.
I tried using median 0 and std=0.2 like GANs, but this leads to vanishing gradients.
Also...I'm testing a simple Diffusion model(not Stable, just a sketch), and I'm wondering if someone has an idea on how many complete diffusion steps it takes before generating some images.
i'm back to life. here's what i had mentioned before https://en.wikipedia.org/wiki/Monte_Carlo_integration you can use naive monte carlo integration to estimate the expected payoff

In mathematics, Monte Carlo integration is a technique for numerical integration using random numbers. It is a particular Monte Carlo method that numerically computes a definite integral. While other algorithms usually evaluate the integrand at a regular grid, Monte Carlo randomly chooses points at which the integrand is evaluated. This method i...
but also after mulling it over in bed, i don't think i've ever seen an example of reinforcement training that considers every pixel on the screen as a possible input, which is where your complexity comes from. i think that task lends itself better to computer vision instead
those are my final 2 cents
I'm using pre-trained PyTorch data models to classify pictures, and I can't very bad results
Anyone willing to help me understand why?
https://pastecord.com/revacahefo
Training model resnet18
Epoch 0, Train loss = 0.6610
Epoch 0, Test loss = 0.4550
Accuracy: 86.6359%
---------------------
Epoch 1, Train loss = 0.6618
Epoch 1, Test loss = 0.3809
Accuracy: 86.8664%
---------------------
Epoch 2, Train loss = 0.6235
Epoch 2, Test loss = 0.3852
Accuracy: 88.1336%
---------------------
Epoch 3, Train loss = 0.6400
Epoch 3, Test loss = 0.4629
Accuracy: 87.7880%
---------------------
Epoch 4, Train loss = 0.5870
Epoch 4, Test loss = 0.4349
Accuracy: 87.9032%
---------------------
Epoch 5, Train loss = 0.5756
Epoch 5, Test loss = 0.3587
Accuracy: 89.2857%
---------------------
Training model alexnet
Epoch 0, Train loss = 4.2033
Epoch 0, Test loss = 4.2741
Accuracy: 9.1014%
---------------------
Epoch 1, Train loss = 4.2003
Epoch 1, Test loss = 4.2859
Accuracy: 7.9493%
---------------------
Epoch 2, Train loss = 4.1948
Epoch 2, Test loss = 4.2790
Accuracy: 7.9493%
---------------------
Epoch 3, Train loss = 4.1934
Epoch 3, Test loss = 4.2813
Accuracy: 7.9493%
---------------------
Epoch 4, Train loss = 4.1921
Epoch 4, Test loss = 4.2732
Accuracy: 9.1014%
---------------------😦
Honestly, I am trying to use TensorFlow for the same thing, are you using a large enough data set?
I have 9000 pictures
And they are also random transformations for the training set
Yet the models seems to be overfitting
And I have no idea why
is it overfitting though? wouldn't overfitting manifest itself as train loss going down and test loss going up?
i haven't used these models before, so i can't really comment on why this is happening. but i would make sure your input is exactly how the model(s) expects it, specifically if there is any special treatment to the colour channels, you have to replicate that treatment.
There are only random flips and resizes to the training pictures
Plus the training pictures and the test pictures do need to be different
Plus the training pictures and the test pictures do need to be different
yes of course they need to be different. i didn't imply the contrary just in case you thought i did.
Oop, sorry, I misunderstood
I am just losing my mind over this issue
Anyone seeing an issue in the code?
any particular reason why you use transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])?
"Normalization helps get data within a range and reduces the skewness which helps learn faster and better. Normalization can also tackle the diminishing and exploding gradients problems." 🤷♂️
I have been instructed to do so
okay. i meant where did you get the values from?
From the dataset I got
wait actually i read your output wrong.
resnet18 looks pretty good, no?
https://pytorch.org/vision/stable/models.html#:~:text=Before using the,or incorrect outputs.
have a read here. i suspect your preprocessing for alexnet is not correct?
My accuracy goes back and forth between 88% and 91%, looks kinda bad to me
I don't know, I believe it is correct, I'm just doing basic transforms
And other models are giving me awful results
Training model vgg16
Epoch 0, Train loss = nan
Epoch 0, Test loss = nan
Accuracy: 5.4147%
---------------------
Epoch 1, Train loss = nan
Epoch 1, Test loss = nan
Accuracy: 5.4147%
---------------------
Epoch 2, Train loss = nan
Epoch 2, Test loss = nan
Accuracy: 5.4147%
---------------------
Epoch 3, Train loss = nan
Epoch 3, Test loss = nan
Accuracy: 5.4147%
---------------------
Epoch 4, Train loss = nan
Epoch 4, Test loss = nan
Accuracy: 5.4147%
---------------------88% to 91% is not bad at all.
Maybe it is, but why are other models so bad?
Training model squeezenet
Epoch 0, Train loss = 3.4460
Epoch 0, Test loss = 3.4808
Accuracy: 24.7696%
---------------------
Epoch 1, Train loss = 3.6549
Epoch 1, Test loss = 3.6978
Accuracy: 22.4654%
---------------------
Epoch 2, Train loss = 3.8187
Epoch 2, Test loss = 3.8768
Accuracy: 21.0829%
---------------------
Epoch 3, Train loss = 3.9259
Epoch 3, Test loss = 4.0139
Accuracy: 17.3963%
---------------------
Epoch 4, Train loss = 4.0195
Epoch 4, Test loss = 4.1126
Accuracy: 16.0138%
---------------------
Epoch 5, Train loss = 4.0796
Epoch 5, Test loss = 4.1778
Accuracy: 16.4747%
---------------------
Epoch 6, Train loss = 4.1304
Epoch 6, Test loss = 4.2190
Accuracy: 16.2442%
---------------------
Epoch 7, Train loss = 4.1559
Epoch 7, Test loss = 4.2428
Accuracy: 15.8986%
---------------------Accuracy going downhill just like my life
i would look into this further
the model itself is unlikely to be wrong.
the only moving part here is your training/test data
as people say... "shit in, shit out"
wrong link, edited
likewise for other models, https://pytorch.org/vision/main/models/generated/torchvision.models.squeezenet1_0.html#torchvision.models.squeezenet1_0:~:text=The images are resized to resize_size%3D[256] using interpolation%3DInterpolationMode.BILINEAR%2C followed by a central crop of crop_size%3D[224]. Finally the values are first rescaled to [0.0%2C 1.0] and then normalized using mean%3D[0.485%2C 0.456%2C 0.406] and std%3D[0.229%2C 0.224%2C 0.225].
they are slightly different.
yeah in particular let's look at vgg16.
The images are resized to resize_size=[256] using interpolation=InterpolationMode.BILINEAR, followed by a central crop of crop_size=[224]. Finally the values are first rescaled to [0.0, 1.0] and then normalized using mean=[0.48235, 0.45882, 0.40784] and std=[0.00392156862745098, 0.00392156862745098, 0.00392156862745098].
that's not what you did. you use drastically different normalisation transformation, which explains the poor performance (probably).
Has anyone got 5min to help me fit a regression model to my scatter plot?

MyCurveFit
An online curve-fitting solution making it easy to quickly perform a curve fit using various fit methods, make predictions, export results to Excel,PDF,Word and PowerPoint, perform a custom fit through a user defined equation and share results online.
Do you know any libraryt that could tell me by analizing a graph which regression i should use? in python compatible with matlop lib
i don't think such a thing exists
one usually uses either prior knowledge on the phenomenon, some method of model order estimation, and/or some method for measuring "goodness of fit" to pick the best model
Hello everyone! Can someone explain me why this tensor gets, an error? Ive imported TensorFlow and NumPy. I dont see any mistake in this syntax

import tensorflow as tf or import tensorflow? only the former is correct given you decided to use tf.constant
import tensorflow as tf is in my syntax yes @boreal gale
Is there an alternative for tf.constant??
make sure you actually have ran the code block that imports tensorflow, i assume you are using some sort of jupyter lab / code lab
@boreal gale you were right

So actually I have to import tensorflow as tf on every separated cel?
Thank you very much 😄
you don't, but you need to execute the cells in order
think of notebooks as an ipython terminal. every time you run a cell, it's the same as copying all the code from the cell and running it in ipython
if you haven't run the previous cell, tensorflow has not been imported
aah I see
the potential of running cells out of order is one of the biggest gripes i have with jupyterlab/codelab. which is a variant of the problem you had.
imagine you have x += 1 in a cell, and you randomly reran it by mistake and altered the state of x, sometimes you don't even realise it until it's too late.
jupyterlab is still super useful though 🤷♂️ just something you need to be aware of
@boreal gale @wooden sail Thank you guys!! I will screenshot all these tips if you dont mind, got to pick up my daughter from nursery now
Good luck and keep coding!! 😄
One thing I want to know: how can you remember all the arguments, modules in Ml Do I need to learn them all
for ex: in keras do I need to learn all the layers their arguments
imo don't forcefully remember things that's just a google search away unless there is a reason.
Woah, thanks!
I guess it's because the examples of Reinforcement Learning you see out there usually uses OpenAI's Gym, which already provides an environment and the state ready to process.
But Gym Retro, for playing Atari games, actually uses pixels. PPO for Gym Retro even has a CNN Policy for that
well but how does the CNN policy work?
I'm trying to make something more complex, to play Steam games rather than some Atari games.
Something like AlphaStar, but in a really, really small scale
that's already using image processing methods, as soon as it says cnn
I guess it was you who teached me about the importance of vectorization and why I couldn't assign an input map to an arbitrary number.
Well, the CNN Policy is basically a vectorizer model which uses, as a way to extract the context, an image
Based on that context, it tries to predict the better actions for that situation
for all your other inputs, including the directional keys, all you can do is change status from pressed to unpressed, for instance
but for the mouse you want to move the cursor all the way to a specific pixel, instead of telling the mouse to move some delta x or delta z
this is the reason your model has so many inputs
it's the wrong parametrization of the inputs for such large images
you're getting massively sparse inputs
Hm... I couldn't think of a better idea to get mouse commands
But...seems like an interesting idea... Instead of "move to X", using "move a bit more to the left"
this does have the limitation of how much you can move the mouse, depending on how fast your network is
i think there must be a clever way, something like slicing the input image interatively into quadrants, for example
then you should reach a pixel close enough to the destination in log(n) steps
hi guys, so im learning data scraping and just wanted to know if its profitable in 2023 as a freelancer?
because there are so many websites and organizations available now that are willing to scrape data so i was thinking why woudl anyone want to buy my services from fiverr or upwork etc
that, or compute an acceleration and a velocity vector and apply that to the cursor so that you follow some sort of trajectory to the target
that makes the mouse input a 2d vector, which is much more tractable
but requires thinking the physics out a little
idk, i'm just tossing ideas. maybe they won't work at all 👀
Well, I'm using a bottleneck with 100 weights before the layer that decides the mouse actions, so the number of parameters is 100*1920 = 192,000, which ain't much
This solves the problem of having a computationally expensive net, but I suppose it may affect how good the model can get in a game
In the way my model is structured right now, the real computation power goes to the feature extraction part, which is similar to VGG19
Though I suppose I should consider something like ResNet
i remember when stock buying/selling was done on nvidia cuda cards, and cuda was just released. it had a gateway that prevented losses on bad software. of the 270+ days of the year, that company only lost one day of trading and it was 11 million
then others started getting into HFT, then they started wiring fiber to the nasdaq exchange to datacenters. nano'seconds started counting soon after thant
we started with a 130 ms lag, and i think its now 50 nanoseconds trades
these trading bots on github should never be used.
guys so i have this simple script to
create numpy array ```import numpy as np
import os
import vocab
Read in vocab set from vocab.txt file
with open("vocab.txt", "r") as f:
vocab = set(f.read().splitlines())
def text_to_array(texts, vocab):
# Initialize an empty array with the same dtype as vocab
data = np.zeros((len(texts), len(vocab)), dtype=int)
for i, text in enumerate(texts):
for word in text:
if word in vocab:
data[i, vocab.index(word)] += 1
return data
Read in text files from /txt_source directory
texts = []
for filename in os.listdir("txt_source"):
with open(os.path.join("txt_source", filename), "r", encoding="utf-8") as f:
texts.append(f.read().split())
data = text_to_array(texts, vocab)
Save the resulting array as a .npy file
np.save("data.npy", data)```
but i keep geting 'charmap' codec can't decode byte 0x81 in position 1067: character maps to <undefined> error, the thing is every single file is encoded as utf-8
why cloning a repo and getting it to work a bigger pain in ass than writing my own code, lmao
try utf8 instead of utf-8?
nothing changed
File "C:\Users\Reny\PycharmProjects\crossoverwriter\raw_to_array.py", line 7, in <module>
vocab = set(f.read().splitlines())
File "C:\Users\Reny\AppData\Local\Programs\Python\Python310\lib\encodings\cp1250.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x81 in position 1067: character maps to <undefined>
this is how looks whole error
add it here with open("vocab.txt", "r") as f:
ok
it worked
thanks
now i haw new set of errors but i fight then on my own for a while
# Initialize an empty array with the same dtype as vocab
data = np.zeros((len(texts), len(vocab)), dtype=int)
for i, text in enumerate(texts):
for word in text:
if word in vocab:
data[i, vocab.index(word)] += 1
return data```
this part of the script is goint to be repated with every world in vocabulary right?yeah it does
i have vocab of over 81k words [*]
okey i got this
hello, im using madplotlib and im trying to figure out how to show more dates on my xaxis. i have 94 dates for x, but only 7 shows up on the plot.. is there a bin= argument or xticknumber that i overlooked?
i mean as labels for the x axis, sorry im not too clear
by adjusting the xticks property of your plot
if u wanted to display all 94 :
plt.xticks(range(0, 94), dates, rotation=90)
hears some documentation that might help, https://matplotlib.org/stable/api/pyplot_summary.html
Hi all, What would be the best way to pair wines with similar other wines. For example, I enter a wine I like & I am returned a small list of wines with similar Adjectives used in the falvour description, from the same country, the same variety of wine & the same year?
If you have a pandas data frame that contains all these information you can use different approaches to get that done.
Perhaps you could start with semantic similarity score, then filter the dataframe based on highest score. You could then subset the filtered dataframe by year etc
If you wanna build a recommendation engine, the best approach would be, to get a dataset that contains information about each wine's:
- flavours
- manufactured year
- company name
- country the wine was brewed
- perhaps the price etc
- a rating for each variety of wine.
More so, you even extend this by
-
building a function that takes in the recommendation from your recommendation engine.
-
Create a corpus and get the semantic similarity score of each recommended wine in #1 on the description of the wine you entered in your recommendation engine (presuming you have 'wine_description' column in your original dataframe for each wine)
-
Finally your function should then return names of recommended wine with their similarity score respectively (in descending order.)
PS: There could be another way to approach this, so feel free to explore other options.
Meanwhile, have fun while at it 😂
i see that in a research paper, for "same dataset" and "fine tuning" dataset, they report accuracies for "Zero-shot text-to-video retrieval" task and "text-to-video retrieval" task.
How could they have done that? I mean zero shot is when all classes is not given right?
Did they purposefully remove some classes to make it Zero-shot text-to-video retrieval. And for normal text-to-video retrieval task, did they use full dataset. Could it be that?
retrieval isn't classification -- the query and database are vectorized and then the database vector that is closest to the query vector is retrieved
yeah, but how would zero shot retrieval differ from just retrieval?
a database vector is retrieved that hasn't been trained on
i can think of only that corresponding labels might be imperfect
descriptive i mean
ie a database vector is retrieved that was never retrieved during training
much like a class that was never used during classification
except there are no special architecture modifications required
umm, yes according to theory, but i am lost at how it would work "differently"
really?
you don't use the output of the network for classification
you use the vectorization based on the hidden
i am familiar with similarity based constrastive loss that might be used IN NON-ZEROSHOT VERSION
is this step also in zeroshot version?
yes, it can be, it doesn't matter what loss is used, all that matters for it to be zeroshot is that the image was never retrieved during training
hey can you check why this isnt running, like no error, the program just feels stuck there
before displot function, it was running alright
heres the code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df=pd.read_csv('D:\\Python for Data Science and Machine Learning Bootcamp\\05-Seaborn\\dm_office_sales.csv')
# # plt.figure(figsize=(5,8),dpi=200)
sns.rugplot(x='salary',data=df,height=0.5)#height is total % of y axis
# # can be considered as 1 dimensional scatterplots
# # do not use distplot, its deprecated, use dstplot()
sns.set(style='darkgrid')#theme can be set darkgrid or whitegrid
sns.displot(x='salary',data=df,bins=100)#we can manipulate the number of bins as per need
plt.show()
print('hello')


while reproducing results, if batch_size doesnt fit,
we should decrease LR with batch_size, right?
and should we also increase the epoch ? because LR has been decreased
i have no prior experience with ai and want to wrangle stable diffusion into making pixel art
what would be a good place to research this shit?
I get a physical piece of paper like this and have to transcribe the rows and columns into an excel file. What's the best way to read text from an image of a piece of paper like this?

scanner -> pdf -> pdf to excel convertor
tho in this case copying by hand probably won't kill you
Is there like a defacto best scanner? I'm looking at Google Vision API rn
Btw I have no experience with any AI/ML
oh i meant like a physical one lol
there probably is some image to pdf shit but eh
oh lmaoooo a physical scanner i didnt even think of that
hey guys, so yesterday i created dataset in form on numpy array to train text generator in writing stories, now i wanted to write said generator but the more i look into it the more I see that i should use tenserflow and fine-tune already pre trained model.
So my question sounds, is there any pre-trained model that can be feed my numpy array without any conversions ?
i used numpy cuz tenserflow refused to work on my pc
You can use tensorflow with keras, which will accept numpy arrays directly (just make sure they're in the same format as the data the model was originally trained on)
you can get pretrained models from the huggingface transformers library, which can be loaded into keras to fine-tune
the thing is im unable to get tenserflow with keras to work, like 2 days ago i spend whole night, reinstalling and rebuillding it, cuz pycharm installed "light version" or something and in the end i gave up
hi,
i noticing a lot of architectures which mentions use of pre trained model, but the model they mention is usually just one component, such as in transformer followed by maybe some projection, the pre trained model could only be transformer part right. So what happens to initialisation of gradient of other parts of model?
And i am also wondering that assuming some part is still randomly initialised, are gradients of those part able to adjust in few epochs that model is often trained?
The Transformer has 2 components that are pilled together, the encoder and the decoder, but in the paper I guess they used 8 encoders and decoders pilled together, so I suppose if you use a pretrained transformer, you'll use the weights from those components.
And if you use more, then I suppose it'll be a projection...
Yes, but if it's just a small part that is randomly initialized, you'll need just some few epochs to properly adjust them
- OCR
- You can convert this paper to pdf and use any of your preferred python library to extract text from a pdf
- If this is all the data needed to copy, you can manually type it
- Feeling too lazy to use #3, then use Google Lens app on your android phone / any other equivalent app. This is pretty straightforward.
a) Ensure your pc is online and you're signed in on your pc to same google account on your phone.
b) Use Google Lens mobile app to grab all text, click on copy to computer on the app, then on your pc press control + V anywhere you wanna paste the copied text.
i see, i am talking about these projection, But yes they indeed seems to be a small part compared to whole architecture
Here author didnt explicitly mention what projection "are", i assume they are just some mlp.

in this paper aim was to make modalities such that they are represented using such vector which are close irrespective of modality
for example: pizza making sentence ~= pizza making audio ~= pizza making video IN ONE EMBEDDING SPACE
and they mention model was pretrained, but didnt mention what and how "projections" were initialised
Hello, I am a bachelor student in software engineering (second year). I already know the basics of python and I want to develop my skills outside of university. I would like to learn artificial intelligence (I don't know what subjects exactly). I thought about trying to create cool projects from scratch and gain knowledge as I go. My first idea was a trading bot in python. Do you have any books or resources you recommend (my plan is to build a basic bot and improve it over and over again at least until it is "decent" (mentionable on a resume, an "accomplishment" not in profit but in skill gain).
Projection... Maybe they repeated the vectors until they can get a specific shape?
To make sure all inputs have the same shape?
yeah probably "projection" seemed a fancy name, they only say modalities even after going through transformer(acting like a "encoder" here) are still a bit-different in representation(NOT close in 1 embedding space) so they have this projection here
Does anyone know if Reinforcement Learning has been tested with generative networks?
(Now that I think I managed to make a RL algorithm, I want to play a bit)
Perhaps a GAN where the Discriminator is actually a reward model?
In ML why do we have multidimensional arrays? why not just use 1d array to store all the data?
I don't know the technical, mathematical details, but... which one is easier: decomposing a X-Ray image of a hand into a single, flattened 1D array and then having to figure out which number corresponds to each coordinate(considering many numbers will be 0 and many will be 1), or simply storing that image in a 2D array without moving any pixel, thus, without having the chance of messing your data?
Hey im wondering what should i lookup to make my idea possible
I want to make ai that will show you what should u dress acording to current weather, i know i should make my own dataset but how csn my ai learn basing on images and text?
Are you trying to do inverse reinforcement learning?
I didn't even know such thing existed

But yeah, I was thinking about the Discriminator assigning a reward to the generator's output based on how fake or how real such output is
Uh... are those rollouts and observations human?
IRL is not being given an explicit reward function, but instead making one up to mimic some observed behavior.
The expert can be observed, which is what you want to mimic.
E.g. watching a human pick up a ball, and then mimicking that.
Hm... Seems like a tricky version of Supervised Learning...