#databases
1 messages · Page 173 of 1
for example
INSERT INTO linked_chat values ($1, $2)
then
ctx.guild.id, ctx.channel.id)
with variables like this
you still probaly need to use $1
with some stuff in front of it

🤔 alright, let's hope this works
it did!
😄
congrats 😄
I just need to find some who can help me setup psql
on my vps
I have no idea how to do that
🤔 I could probaly setup tmate for it
but they would give out my ip
and I don't want that lol
fair xD. just follow the official guide lol. i recall it being fairly straight forwards
hello anyone familiar with django?
i am trying to figure out to to print whats in a queryset but instead im getting an address
which is good, but how can i plain print whats in that address
i assume you did something like this? print(MyThing.objects.all())
a QuerySet is an "iterator" but not a list or any other "sequence". if you want to collect all the data in a list, you need to call list() on the query set
e.g.
all_things = list(MyThing.objects.all())
print(all_things)
can someone help me make a per server toggle using sqlite3? im making this for my discord bot, so if someone say !filter on it should set the toggle to true in the database and the opposite for !filter off. any idea how i can do this?
interacting SQL via python
hey in mongodb's find_one, i need to do find_one({"key": value}) but if i wanna find if the "key" is in the db or not how wold i do it
I mainly wanted to know what way suits better in sql.
This is what I feel, please corect me if I am wrong: Inserting multiple values at a time is more efficient than inserting one at a time, hence I thought of separating out insert/update data items
if you want to fetch only those documents with the key present then you can use this
db.mycollection.find({ 'any_key' : { $exists: true, $ne: null } });
eh whats that
If I understood your question properly, you are trying to fetch only those documents if any_key is available and with some valid data right?
hm i just wanna find if the guild id is already in the collection or not
thats all
In that case, I would import SQL Alchemy and Pandas. Convert the dictionary to a Pandas dataframe and send it to a staging table in your database. Create a stored procedure in your database that updates the target table if it has matching records in the staging table, insert records if they don't exist, and then delete from the staging table at the end. How often this task needs to execute and how many rows you're sending to the staging table will determine how to set this up, but that's how I usually do my pure Python ETL.
unfortunately we are not using SQL Alchemy, I am writing out raw queries from python to handle all transactions.
i understand this is not the best practice, need to update......!!!
But as said above, we are just using raw queries, need to decide between 15k entries which all should be inserted and whihch should be updated
to brief, in the below dict, 1&2 needs to be updated, 4 should be inserted
{ 1: { "Id": 1, "product": "xxx", "Status": "ACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", }, 2: { "Id": 2, "product": "yyy", "Status": "INACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", }, 4: { "Id": 4, "product": "abc", "Status": "ACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", } }
would it better to divide something like this
{ 1: { "Id": 1, "product": "xxx", "Status": "ACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", }, 2: { "Id": 2, "product": "yyy", "Status": "INACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", } }
&
{ 4: { "Id": 4, "product": "abc", "Status": "ACTIVE", "ShipDate": "2012-11-19", "coverageStartDate": "2019-03-01", "coverageEndDate": "2022-02-28", } }
hi, could you suggest me the better option
@static zealot do you know?
Anyone knows one to one function
how do i merge req_point, recommendation, remark, and Fail column from row 3 to 14 (where there is a value in number all the way 1 row before there is another value)

^ this is in pandas
exists should do it right?


o
How Do I merge these Column in Pandas?
The idea is to merge all the rows based on the number column since 3.1.1 all the way down until the row before 3.1.2 should be in one cell. The merge should be applied to all the columns.
When we merge, it should contain all the values in the cell. So for example:
A
B
would be
A
B
Hi
You've a dataframe 'df' and two columns: 'Year' and 'Month'. You can merge those like:
df["NewColumn"] = df["Year"].astype(str) + df["Month"]
hello

im referring to this image
im trying to merge row 3 to 14 for all column
but that is only because of the number column where it has a value followed by NaN.
row 15 would be another value and thats why we dont merge that
SQL or mySQL or postgreSQL ?
Which is the best to learn/most widely used, or at least the best one to learn first?
if you've never touched sql, i'd recommend sqlite
SQL is just the language you use to query the database
anyone have a vscode extension they like that does syntax highlighting for sql queries in """ """?
SQL is itself just a programming language, used by relational databases including MySQL and PostgreSQL. did you mean SQLite?
sqlite is probably the easiest to learn, postgres has the most features that are useful for small-medium-size applications, mysql is popular in certain areas in industry
for personal hobby stuff, learn sqlite. if you want to pick up database admin skills that will be useful in a job one day, learn postgres or mysql

Hi,
Is keeping a db connection alive better or open and closing the db connection when required?
The best solution is to use a connection pool
So the connection pool is keeping connection alive as long as the app is running? Correct?
Yes, the connection pool keeps a certain number of connections alive
What's wrong in opening and closing connections when required?
Opening and closing connections has some overhead which puts strain on your app and your db
We have set a db connection limit to 25 and I create 6 workers that runs my flask app(flask app has connectionpool size of 5).
If there were many requests coming up at the same instance, I run into an error "max connection reached".
Is there a way to solve this problem, other than increasing connection limit ?
I think you need to either of the following:
- increase the connection limit to 30 (6 workers * 5 connections)
- run 5 workers instead of 6
- decrease the connection pool size for each worker
So the situation is... we have a autoscale mechanism where we spin up a new server and we deploy a new worker based on the increasing incoming requests.
Let's say the we have 5 workers and all the workers/connections are occupied(all 25), now when we spin up a new app which would require 5 more db connections for auto scaling. We run into max connection issue.
How do you suggest we solve this kinda problem? Any thoughts.
What database are you using?
Mysql
I don't have any experience with mysql but for PostgreSQL you can use pgbouncer to setup connection pooling at the database level, I think that would work for you because it delegates the connection pool management to the database server which is independent of the number of app workers
I do not know if there is such a solution for MySQL, or if it would even actually work in practice
Amazing
I didn't know there was such a think
Will look into pgbouncer! Thanks for the hint
Happy to help, again I cannot guarantee that it will actually work in practice though
PgBouncer is only available for PostgreSQL though, so hopefully there's a similar MySQL implementation
Same thoughts
How can I delete a mongoDB document using just the document's key?
Ping me if someone can help 👍
Does anyone have any experience using sqlalchemy when importing panda data frames to a mssql DB? I’m getting a programming error: pyodbc.programmingerror 42s02
Invalid object name ‘<table name I am not referencing anywhere in the script>’
so like what is the purpose of .ravel for the label? Sometimes when i run models it says i have to do that can someone tell me why or point me to a direction where i can learn why
Question about MongoDB
I have documents in collection which have structure:
{key: {0: 2, 1: 5, 2: 100, 4: 15}}
I need to add pair key: value to dictionary. value may be anything. It doesn’t matter. But key must be the smallest integer that is not used in the dictionary as a key (starts from 0).
I can do it using python.
document = {key: {0: 2, 1: 5, 2: 100, 4: 15}}
new_key = 0 #key to insert in our dict
for i in range(max(document[‘key’].keys()) + 2):
if i not in document[‘key’].keys():
new_key = i
#update the document
document[‘key’][new_key] = value #value may be anything
How to do it using MongoDB? Is it possible?
Got this one asked in a Interview
Let's say I have the following query -
select id from emp where email_address = 'abc@mail.com'
Now since we have 10 million rows in emp table its taking more than desired time, how can we reduce it?
I know using indexing it can be done, but is there anything done in pure SQL query to make it better?
Why are you using a dictionary there instead of an array?
because I need to access data using a key
But the keys are just whole numbers
And that's the same as using indexes to access values from an array?
I try to create a warnings system for discord bot. Moderators can edit warns using ID’s (keys of the dictionary). They also can remove warns and warn members. When a moderator warns a member I need to add warning data to my dictionary and set ID.
guys i am a beginner in python and now i think i should also learn about database
so is it in python itself?
or another language
i have no idea about it
suggest me something pls
easy, reliable, efficient and versatile like python
an index is probably the right answer here
a database is either:
- a special file that you interact with using special functions, which can store and retrieve data without rewriting the entire thing
- a separate application (a "server") that you interact with, which stores its data in several special files that cannot be read by other programs
examples of (1) include dbm and sqlite. examples of (2) include mysql and mongodb.
when people say "database", most people mean a "relational database", which is where data is organized into several "tables", with rows and columns like a spreadsheet. usually, you use the SQL language to perform queries and operations on relational databases.
i think that learning to use a database is a valuable skill. i recommend starting with sqlite. a module to interact with sqlite database files is included in python, and i recommend https://sqlbolt.com for learning how to use it.
SQLBolt provides a set of interactive lessons and exercises to help you learn SQL
help please
@formal axle you'll need to read the dict into python and do it in python
the only other option is server-side javascript https://docs.mongodb.com/manual/core/server-side-javascript/
so I need to use 2 MongoDB queries?
yeah, or use server-side javascript
the latter option might be better, but then you're writing javascript and not python
so it depends on your tolerance for that kind of thing
guys i entered >>> user_1 = User(username='admin', email='admin@blog.com, password='password') to my db and its saying SyntaxError: unterminated string literal (detected at line 1)
am i blind or are there no syntax errors
as i expected, i was blind
In email there's a ' is missing
Inverted comma maybe, idk about punctuation much
😅
Thanks bro
yep it was the email '', me coding without a text editor in cmd is pain
Lol
Why don't you use ide
im trying to code a website right now, so im using cmd instead
:incoming_envelope: :ok_hand: applied mute to @jaunty stone until <t:1637688302:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
What is the best way to practice database only? How to do database related work very well with Python?
Well if you want to easily work with databases I'd recommend https://github.com/RobertCraigie/prisma-client-py
However, as the creator of the library, I am very biased
Thank you @grizzled wadi
Happy to help, if you do want to use it then feel free to message me if you have any questions
i have this isssue
await cursor.execute("Select userid, activitypoints from activity where guildid = ? ORDER BY activitypoints ASC",(ctx.guild.id))
Traceback (most recent call last):
File "C:\Users\reals\AppData\Local\Programs\Python\Python310\lib\site-packages\discord\ext\commands\core.py", line 85, in wrapped
ret = await coro(*args, **kwargs)
File "A:\projects\stealthybot\realstealthybot\cogs\activity.py", line 61, in leaderboard
await cursor.execute("Select userid, activitypoints from activity where guildid = ? ORDER BY activitypoints ASC",(ctx.guild.id))
File "C:\Users\reals\AppData\Local\Programs\Python\Python310\lib\site-packages\aiosqlite\cursor.py", line 37, in
execute
await self._execute(self._cursor.execute, sql, parameters)
File "C:\Users\reals\AppData\Local\Programs\Python\Python310\lib\site-packages\aiosqlite\cursor.py", line 31, in
_execute
return await self._conn._execute(fn, *args, **kwargs)
File "C:\Users\reals\AppData\Local\Programs\Python\Python310\lib\site-packages\aiosqlite\core.py", line 129, in _execute
return await future
File "C:\Users\reals\AppData\Local\Programs\Python\Python310\lib\site-packages\aiosqlite\core.py", line 102, in run
result = function()
ValueError: parameters are of unsupported type
The above exception was the direct cause of the following exception:
but it gives this error
i am 100% sure that both guild.id and ctx.guild.id are ints
any help would be greatly apprecatied just ping me if you have the answer or advice
Hi, what command do you use to share your code on black screen like this?
"Code Blocks"
Thanks for your help💯

!code @queen bloom @torn sphinx we have an instruction block that pops up if you type !code, see below:
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
The second parameter must be an iterable, so tuple or list:
..., (ctx.guild.id,))
or
..., [ctx.guild.id])```Do you guys know what's the issue here?


can someone please help => django.db.utils.IntegrityError: insert or update on table "Occupy_post" violates foreign key constraint "Occupy_post_user_id_7dca33ac_fk_auth_user_id"
DETAIL: Key (user_id)=(3) is not present in table "auth_user".
You are trying to insert a user ID which doesn't exist in other table and you have a foreign key constraint
Hello, I would like to ask if there is any possibility to fill the data set with data where there is a lack of continuity.
In my case, in more than 100,000 records of the data set, in which there are changes every 5 minutes, there are empty fields, which I do not know if it is possible to complete it at all. The purpose of this question is to maintain the continuity of the graph or data. The dataset is in csv, im using pandas etc.
Hi guys, if I have 100,000 rows of data and I want to render the data in some table with pagination, how can I efficiently query the database to improve the responsiveness of my web application?
Or what would be an efficient way to query the database?
this is a #data-science-and-ml question. but you should be more specific about what you mean by "continuity", and describe what % of fields are empty
Keyset pagination? https://use-the-index-luke.com/no-offset/banner

Banner and Pictures for the No-Offset movement: Prefer key-set pagination over OFFSET
Uhh this one https://use-the-index-luke.com/no-offset
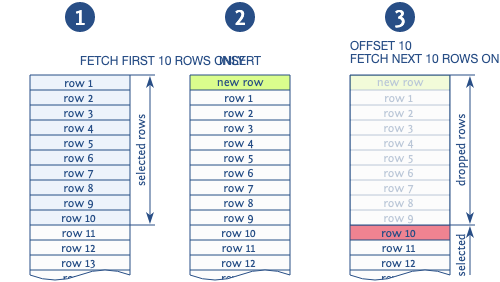
Pagination without OFFSET has many benefits but one problem: there is no tool support. Please help changing this.
🤐
Never saw this before, thanks
Hi does anyone have a python a script to terminate stuck pids in postgresql?
Guys, I have a question that might be silly (I am a beginner at databases and python). I was coding a python application and I used MySQL (installed in my machine) to store data and stuff. What I want to know is, let's suppose that I was a python freelancer and wanted to deliver the application, how would that happen (regarding the database part)?
I would have to deliver the .py and the client would have to have MySQL installed in their machine?
So the client could register info about users and stuff....
just put a couple of strings in readme.md that mysql should be installed or smth
and mention part in config that points to db connection params
.env variables or .conf file or smth
Depends what the customer wants
They might want you to setup their deployment in its entirety
Or just hand over source code
This is what I have been looking for. Thanks!
Is there a Motor MongoDB discord server?
guys..i need a database that my discord bot will read/write to and a windows app will read/write from it.
can i host mysql on my server (where discord bot is hosted) or buy a new databse cloud server.
I understand. But in the case the client is just a client, if he doesn't code or manage databases. In that case, I would have to install the MySQL in his machine (localhost connection) so the program could function 100% (since the focus of the program is storing data)?
Depends on what the app does or what the clients machine is used for.
Generally the database would be hosted on a server, and then you connect to it from your application. You can have it on his pc but this can come with certain problems.
You can host on the same server. By default the mysql installation would be listening on localhost so easy to configure as well when on the same server.
is there any good guide for it ? my server is linux ubuntu

DigitalOcean
MySQL is an open-source database management system, commonly installed as part of the popular LAMP (Linux, Apache, MySQL, PHP/Python/Perl) stack. It implements the relational model and uses SQL (Structured Query Language) to manage its data. This tuto
I see. Like, I see many freelance programmers on websites like fiverr
And they deliver the python code + database.
To their clients, and they are pretty must just regular clients that want basic stuff, like storing id of order, quantity of certain products and stuff like that on their machine.
So it is just localhost I guess, since it's just a supermarket business or something that has the same complexity.
If the client wants you to host, then its for you to manage and setup the database. If they want the source code, then you wouldn't deliver the database but the schema to set it up.
Yea, but in the case that I mentioned, like a supermarket application (for a super small local supermarket) and the client ordered the database itself (for you to setup) and the python program, the programmer would just install MySQL and run it on localhost, there is no need for a big thing like a server, right?
a better example would be a convenient store ig
Ask your client, what they want and how they will use the application. Its not something people other than your client can answer.
It was just a hypothetical scenario.
Whats a good db for a beginner
thanks...my bot is in the root folder...so should i install mysql in same folder
Doesn't make a difference, its installed on the server and will run as a service
will it interfere with the discord bot running ?
no
how i leave the venv on command line
isn't there a deactivate script/function?
Does anybody know a good tutorial for aiosqlite?
i got it now..cheers
SQLite
how can i fix sqlalchemy.exc.OperationalError ?
Hi, maybe you mean ORDER BY (?)
Is Redis Sentinel's consensus algorithm related to Raft in any way?
Should I choose mysql or mongodb for installation on my ubuntu server. It needs to be accessed from windows app
Strange question, but is there any way I can post/get data from my mongodb database while having my vpn on. I'm getting a ServerSelectionTimeoutError error whenever I attempt to.
why does it tell me 'sql' variable is referenced before its assigned?
async def automod(self, ctx, toggle):
db = sqlite3.connect(db_path)
with db:
c = db.cursor()
if toggle == "true" or "True" or "on" or "On":
c.execute(f"SELECT toggle FROM toxicity_filter_toggles WHERE guild_id = {ctx.message.guild.id}")
result = c.fetchone
if result is None:
sql = ("INSERT INTO toggle(guild_id, toggle) VALUES(?,?)")
val = (ctx.guild.id, toggle)
await ctx.send(f'Automod has been set to {toggle}')
elif result is not None:
await ctx.send('Automod is already turned on')
elif toggle == "false" or "False" or "off" or "Off":
c.execute(f"SELECT toggle FROM toxicity_filter_toggles WHERE guild_id = {ctx.message.guild.id}")
result = c.fetchone
if result is None:
sql = ("INSERT INTO toggle(guild_id, toggle) VALUES(?,?)")
val = (ctx.guild.id, toggle)
await ctx.send(f'Automod has been set to {toggle}')
elif result is not None:
sql = ("UPDATE toggle SET toggle = ? WHERE guild_id = ?")
val = (toggle, ctx.guild.id)
await ctx.send(f"Automod is already turned off")
else:
await ctx.send("Not a valid option")
c.execute(sql, val)
db.commit()
c.close()
db.close()
return result```its for a discord bot, hence the async function
did i mess up the indentation somewhere?
pg_orm
An ORM for Postgresql  written in python!
written in python! 
Features:
• Ability to interact with PostgreSQL databases using python OOP
• Create tables, create/delete/get rows with ease
• Asynchronous support
And much more!
Github: https://github.com/Rashaad1268/PostgreSQL-Python-ORM

GitHub
An ORM for PostgreSQL written in python. Contribute to Rashaad1268/PostgreSQL-Python-ORM development by creating an account on GitHub.
Hey, i have a problem relating to heroku where i get the following error at step 17 when i try to execute the code.
pgloader : The term 'pgloader' is not recognized as the name of a cmdlet, function, script file, or operable program

Heroku is a “platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud.” Heroku even offers a free plan. Here’s how to deploy your implement...
Why is the wrong data being commited to the database in SQLalchemy?
bookmark_obj = Bookmark(profile_public_key=profile_public_key,
owner=owner)
print(bookmark_obj.profile_public_key)
db.add(bookmark_obj)
db.commit()```
this prints something else and in the database other `profile_public_key` gets storedis it bad idea to allow mysql to connect to all ip addresses ? i need a database to communicate between me and the windows app used by various users/ how would i achieve that ?
The most common way to do this is to build an API server around the database
so that the database never actually gets hit by anything off the machine
This also allows you to modify the database schema as much as you want, while keeping the API the same
Opening a database directly to the internet isn't a good idea
FastAPI framework, high performance, easy to learn, fast to code, ready for production
using this ?
yup, that's quite a popular one
my discord bot run on this server ...can i run the api on it too ?
Yea, you can
or you could have your discord bot access the database
if that's of any use
yeah ibot need to take commands and write it to the databse and then windows app will execute them
so i can just use sqlite instead of mysql ??
since the databse will be only be accessed locally
i currently use sqlite databse for licenses
SELECT * FROM buildings
LEFT JOIN employees on Building_name = employees.building``` i just want to select some stuff from employees but idk how to do sohow do u install pgloader in windows VS Code? im tryna run a command but i get the following error:
pgloader : The term 'pgloader' is not recognized as the name of a cmdlet, function, script file, or operable program
try
SELECT e.field1, e.field2 FROM buildings b LEFT JOIN employees e ON Building_name = employees.building
is it possible with this way ?
read this, great article
https://blog.codinghorror.com/a-visual-explanation-of-sql-joins/
Coding Horror
I thought Ligaya Turmelle's post on SQL joins was a great primer for novice developers. Since SQL joins appear to be set-based, the use of Venn diagrams to explain them seems, at first blush, to be a natural fit. However, like the commenters to her post, I found that the
Left outer join produces a complete set of records from Table A, with the matching records (where available) in Table B. If there is no match, the right side will contain null.
with *, u are selecting everything
so all u need to do is just specify the columns/fields u want to select instead of "everything"
fair
how do u install pgloader in windows VS Code? im tryna run a command but i get the following error:
pgloader : The term 'pgloader' is not recognized as the name of a cmdlet, function, script file, or operable program
im tryna deploy my app to heroku but im stuck at step 17 where i convert my sqlite to postgres
https://cs50.readthedocs.io/heroku/
Heroku is a “platform as a service (PaaS) that enables developers to build, run, and operate applications entirely in the cloud.” Heroku even offers a free plan. Here’s how to deploy your implement...
can someone help me explain what AGG_FUNC does ?
@grizzled wadi are you the person behind https://github.com/RobertCraigie/prisma-client-py?

GitHub
Prisma Client Python is an auto-generated and fully type-safe database client - GitHub - RobertCraigie/prisma-client-py: Prisma Client Python is an auto-generated and fully type-safe database client
Yes I am, happy to answer any questions!
@lusty grail Can I ask how you found out about it? I'm always looking for new ways to spread the word
mhm I knew about prisma and started to look if it has python api 🙂
I was goinhg to look at sqalchemy and alembic for migrations but heard prisma is top for TS/JS
Ah I see, let me know if you try it out and if you have any questions
can i do migrations staying purely prisma py?
Yes
You don't need to do anything in TS/JS with the python client
The node Prisma CLI comes bundled with the python client

GitHub
Problem Many other Python ORMs have support for programmatically running migrations, i.e. each individual step in a migration is written to a python file that can be modified by the user. We should...
i asked bcs of this issue
not sure what kind of funcionality is missing there
Ah sorry, I need to add more information to that issue, by programmatic migrations I mean, migrations using a python script like
So Prisma migrations currently just generate raw SQL
For that issue, if it is possible I would add support for migrating using custom python scripts, this would be different than the standard Prisma migrations
Right now you can still use prisma migrate
For example, alembic is programmatic migration as migrations generate a python script that you can edit
isn't that what alembic or typeorm do also?
oh
Alembic generates a script that looks like this: ```py
"""empty message
Revision ID: 27c6a30d7c24
Revises: None
Create Date: 2011-11-08 11:40:27.089406
"""
revision identifiers, used by Alembic.
revision = '27c6a30d7c24'
down_revision = None
from alembic import op
import sqlalchemy as sa
def upgrade():
### commands auto generated by Alembic - please adjust! ###
op.create_table(
'account',
sa.Column('id', sa.Integer()),
sa.Column('name', sa.String(length=50), nullable=False),
sa.Column('description', sa.VARCHAR(200)),
sa.Column('last_transaction_date', sa.DateTime()),
sa.PrimaryKeyConstraint('id')
)
### end Alembic commands ###
def downgrade():
### commands auto generated by Alembic - please adjust! ###
op.drop_table("account")
### end Alembic commands ###
i see
but even without doing that prisma will generate sql, apply to DB and store some metadata do help with keeping in consistent right?
Yes, Prisma migrations are quite good
The reason you might need programmatic migrations is in case you need to also migrate data at the same time, this is currently difficult with Prisma migrations
How do I add a value inside an already existing document without changing what is already inside it?
do many tools support that? my understanding was that mostly its up to you to migrate data if you change schema a lot?
Honestly, I don't know, but my goal with the Prisma Client Python project is to make it the best possible ORM and supporting data migrations is a part of that
Also whenever I think of any improvement I make a new issue
i noticed
Yes there is a lot of open issues lol
ok. for some context, its for project at work. we are doing a major app rewrite from expres on js to nest and, we chose typeorm over prisma or seqelize. now we kinda regret as at a time we didnt know prisma and how good is it. now, i might take up a task of writing small python service and tools and we are thinking to give it own DB (or schema at least)
Can someone help me please, how can I add an array inside the 'info' without changing the lvl ?
when I use ( collection.update_one({'_id':author}, {'$set': {'info':{'XP':[]}}}) ), it deletes the lvl and adds XP

so we have like 3 options:
- keep schema migration centralized in typeorm
- use alembic or prisma
- use raw sql as it's, theoretically a small db
might be better of getting a help channel to be honest...
@grizzled wadi at first I thought to just straight go for alembic but, in past I didn't use ORMs or migration tools, so for me all are roughly the same in terms of learning curve
if we would chose prisma for node app too it would make for easy choice
but as we don't...
Yeah that's understandable, I would (obviously very biased) recommend using Prisma Client Python as it should be incredibly easy to learn due to the autocomplete support
You can use Prisma without using their migrations if you want to still use TypeORMs migrations
E.g. every time you update the database schema you can just run prisma db pull and that'll update the Prisma schema to match the database
well we are undecided right now 🙂
oh so I can easy hook it to existing db and get all schema>?
Yes you can
All you need to do is write a Prisma schema defining the db connection
e.g. ```prisma
datasource db {
provider = "postgres"
url = env("DATABASE_URL")
}
mhmh I need to play with it 🙂

Prisma
This page gives an overview of all available Prisma CLI commands, explains their options and shows numerous usage examples.
If you have any questions I'll be more than happy to help
btw do you collaborate with prisma devs?
it sounds like projct worth their attention
but their main focus is JS
To some extent, I have contact with them and I've actually appeared in an interview on their youtube channel
That is true but they are looking to expand into other languages too, they have an official Go client
so this has chance to become official py client?
I hope so, I have talked to them about it but their main focus at the time was the conference they hosted, so just waiting for them to get back to me
Which was only about a week ago
oh 🙂
i have a list of names of hospital, i need to find their location
does anybody know any API library where i can output the physical address from the name of a hospital all around the globe
(the global is not really necessary i just need turkey hospital loaction )
in a database form
Google maps api
they have an API?
.
is it free?

Google Developers
so no 😦
hey, anybody an idea how to find out if a connection and cursor have been closed when using cx_Oracle?
I found out, that for MySQL db there is a .open method for the connection, but I can not find a pendant for Oracle. Someone any idea?
Hello. I want to create a conditional statement that work like this: when sql_source1 is available, use source1, when it returns error, goes to source 2

How exactly should I code to make that work? thank you.
Hey!
I have an extension on mozilla from which I would like to get the data (https://github.com/cschiller/zhongwen)
I found the database, however when I read it, it seems impossible to decode it properly 😦 did someone have this issue before ?
import sqlite3
conn = sqlite3.connect('data.sqlite')
conn.text_factory = bytes
cur = conn.cursor()
sql_string = 'SELECT value FROM data WHERE key="wordlist";'
cur.execute(sql_string)
data = cur.fetchone()[0]
conn.close()
print(data)
# string = data.decode('UTF-8')
# print(string)
I got bytes that looks like this :
b'\xb9\xf5\x05\xf0C[{"timestamp":1619465676371,"simplified":"\xe4\xb8\x80\xe5\x8f\xb6\xe9\x9a\x9c\xe7\x9b\xae","traditional\t\x1d\x0c\xe8\x91\x89\xe9\x11\x1d\x98pinyin":"yi\xcc\x84 ye\xcc\x80 zha\xcc\x80ng mu\xcc\x80","defin\x05@\xf0[":"lit. eyes obscured by a single leaf (idiom); fig. not seeing the wider picture; can\'t see\t\x1d\x18ood for\x05\r\x1ctrees"},R\xf7\x00\x1043892:\xf7\x00$\xe6\x89\xa3\xe5\xb8\xbd\xe5\xad\x90">\xf4\x00.\x1a\x00\x15\xf14ko\xcc\x80u ma\xcc\x80o zi>\xe9\x00\x98to tag sb with unfair label; power wordZ\xa0\x00\x14436974:\xa0\x00\x14\xe9\xa2\x86\ ...
Hey @torn sphinx!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:

I tried all the solutions from SO like those:
https://stackoverflow.com/questions/22751363/sqlite3-operationalerror-could-not-decode-to-utf-8-column/43711347
If I set the text factory to str, I get the error :
Traceback (most recent call last):
File "D:/Thomas/Python/zhongwen-anki/new2.py", line 6, in <module>
cur.execute(sql_string)
sqlite3.OperationalError: Could not decode to UTF-8 column 'value' with text '���C[{"timestamp":1619465676371,"simplified":"������������"

Stack Overflow
I have a sqlite database with this row of information, the ù should really be a '-'
sqlite> select * from t_question where rowid=193;
193|SAT1000|having a pointed, sharp qualityùoften used to
I am using Sqlite3 in python script . where i am having 3 different python scipt in which 1 insert data from API to database , 2nd script use that data from same database and 3rd keep updating that database if new data is there it will updata that specific data value in database. I want to all those 3 script work together whithout interfering each other. what possiblely can go wrong and how i improve my code so that it will be efficient to work with database ... thank you 
HOw do I do correaltion analysis with a big dataframe?
Looks like pretty standard and general stuff so it's hard to give specific advise but it might be worth using an ORM like SQL Alchemy if you aren't already.
Is it possible to send data from html file to .db file?
Is there a particular channel that is best for sqlalchemy?
Here is good
Of course. What kind of db file, SQLite?
In that case, I'm trying to create some definitions in their own file, to make my code a little neater... the problem is that I've got a mix of declarations for tables, and I'm not sure how to import glossary_table from the definition file into the main app.
)
from sqlalchemy import Column, Integer, String, Boolean, ForeignKey, Table, Text
from sqlalchemy.orm import declarative_base, relationship, sessionmaker
__tablename__ = "book_table"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, nullable=False, index=True, unique=True)
def __repr__(self):
return f"The title is {self.title!r} and the id is {self.id!r}"
def __init__(self, title):
self.title = title
glossary_table = Table("glossary", Base.metadata,
Column("word_id", ForeignKey('word_table.id'), nullable=False, index=True),
Column("page_id", ForeignKey('page_table.id'), nullable=False, index=True)
```I can import book by going from defs import book, but how do I import glossary_table?
what package should i use to connect postgres with python ?
!d psycopg2
The module interface respects the standard defined in the DB API 2.0.
Well, that didn't work but yeah, psycopg2
I think you should be able to import the table the same way, what happens if you try?
.db, mongoDB
I think I'll have errors before that one.
After importing Book, I get an error when trying to run any query on an existing database, "no such table, "book_table". "
This works fine when Book is declared in the same file.
Hmm, nevermind. Seems to be working normally now.
Strangely, it has been imported just fine.
!d
can someone help me in #help-dumpling
Hey, is there anyone out there who could help me with general project mapping? I just need ideas of where to go with my first real world project and ideas where to take things



I posted a question in DS&AI but it may be better suited here.
I trained various models with different loss functions on the same dataset. I would like to use flask to create a web-app that can be used to compare any two models for a chosen sample. These images are saved as .npys. Essentially, I want to display images from multiple .npys in some kind of app.
Anyone know how to do this with flask? Or where I could start on this? I can't imagine it's too involved.
Hey. I'm trying to get output of this console, it's comming thru a pipe stdout, I'm trying to store it in an array to then get printed in chunks of 2000 characters, so instead of it printing 1 line at a time it would print chunks, anyway to do that?
Half the relevant details are missing from these screenshots. You might want to share complete code in a help channel #❓|how-to-get-help
hello
I installed older versions of Microsoft sql server (like 2014, 2017 etc.). somehow all installations stopped after computer saying missing some files. somehow latest version of mssql (2019) installed fine with mssql management studio. while installing mssql 2019, installer shows some old instances of mssql server ( 2014 / 2017 etc). I am not sure i uninstalled earlier versions of server using remove option of installer. problem is how can i remove those instances completely from my pc? next thing is, windows update kind of stuck and its trying to update security updates for those older mssql server instances. those updates just downloading only, they wont install. so windows update is kind a stuck too. removed whole files from softwaredistribution folder few times. how do i solve this problem?
import psycopg2
conn = psycopg2.connect(dbname="discord", user="postgres", password="my_pass")
cursor = conn.cursor()
x = cursor.execute("SELECT * FROM discord;")```ngl i'm new to pg
Hello this might seem like a dumb question but I am trying to store like number in my database to have it be sorted but I can't make a for loop or a while loop or it'll send a bad request error, is there a function or something I can use to have numbers one by one in-order from like 1-10 stored?
Sounds like you may need to learn the basics of SQL. A command like INCREMENT or ORDER will probably do whatever it is you are trying to accomplish
I'm not using SQL I'm using this cloud database called deta
SELECT works on tables, not databases. You can't select * from discord if your table name is lucid
i changed it to discord later on
How can I get the MySQL server connection ping?
hey guys how can i increase the memory (RAM) Usage for python ?
.bm
i want to push achievement to my list in other category, but i got error, how i can fix that?
.update_one({"_id": ctx.author.id}, {"$push": {"other": {"achievements":"❤️"}}})```https://cdn.aboutluc.xyz/images/i8s8e.png how can post all ImageUrl's that are in nft?

I need some help refactoring sqlalchemy. My queries are running at an unacceptably slow speed.
if w == None:
return "That word, '" + word + "' isn't recorded in the database."
else:
pa = w.page_appearances```
The pa = w.page_appearances bit returns Pages through a secondary relationship table, which has two cols: page_id and word_id. It's indexed on both, but it still takes 3.4 seconds to run 1000 queries.
wrong channel.
nope correct channe
That's a trigonometry problem, this is about databases.
I suggest you head for the help channels section, rather than the topical chat/help section.
Near the bottom you'll see a Python Help: Dormant section with a number of channels. They'll surely be eager to aid you there.
For best results, please check #❓|how-to-get-help
I've made multiple tables of the same SQL Alchemy Model, but now I can't find a way to query them.
def dynamicTxHistory(project_name):
DynamicBase = db.declarative_base(class_registry=dict())
class TxHistory(DynamicBase):
__tablename__ = f"tx_{project_name}"
entry_id = db.Column(db.Integer, primary_key = True)
price = db.Column(db.Integer)
sold_at = db.Column(db.DateTime)
listed_at = db.Column(db.DateTime)
tx_id = db.Column(db.String(64))
name = db.Column(db.String(30))
policy_id = db.Column(db.String(56), db.ForeignKey(Project.policy_id))
TxHistory.__table__.create(db.session.bind)
return TxHistory
Hi does anyone know how I can make a for loop to perform a loop to carry out this sampling many times and for each iteration I want to calculate the max value and return an interpolated x value given this y value x_1 = plot1.sample(frac = 0.7,random,replace=True) y_value=max(x_1['Y'])*0.7 x_value = np.interp(y_value, ret.Y, ret.X)
Whats a good async db
databases are usually neither strictly sync nor async - almost all of them technically support both ways
What you must think about is which connector / driver you use
how do i use placeholder in column names for fetching in postgres?
I see what do you recommend for async?
I'd recommend Postgres for anything 'classic'/relational
depending on what your data looks like, it could be better for you to use MongoDB or even something like Neo4J instead, but for most cases Postgres is a good fit
there's a library called asyncpg for Python. I wouldn't call anything a good starting project for databases though, just use them for something you'd previously use a csv for
if you really want to use them just for the sake of using them, find some data online and dump them into a local database then play around with some queries
they are, after all, a place to store data
Alr but what is asyncpg exactly?
check this channel's pins
alr thx
Sorry not python related but is anybody able to help with an SQL query, I am trying to count a column but I am struggling to do so
so like i have an id column in my database , is their a way to make it increase by 1 everytime something is added , or do i have to do it by hand ?
For relational dbs you can have auto increment
How can I check the date of saving files in Mongo?
my command: from flaskblog import db
the error: 'from' is not recognized as an internal or external command,
show your code

it looks like it, but it's not valid
how can I convert to a json file
i'm not sure, where'd you get this file from?
a_file = open("tweets.txt", "w")
tweets = []
def connect_to_endpoint(url):
json_file = open("tweet_json_file.json", "w")
results = []
response = requests.request("GET", url, auth=bearer_oauth, stream=True)
print(response.status_code)
print("Remaining rate limit: ", response.headers["x-rate-limit-remaining"])
if response.status_code == 200:
for response_line in response.iter_lines():
if response_line:
json_response = json.loads(response_line)
results.append(json_response)
if json_response["data"]["lang"] == "en":
json_file.write(json.dumps(json_response, indent=4, sort_keys=True))
I wrote some function to get api from twitter
yeah, that makes sense
accumulate the results into a list, then dump that, instead of writing each dict by itself
I'm not sure if the file is json. How can I change the code to make a json file? Thanks a lot, I'm new to python.
it's not valid, because a json file is only supposed to have 1 value in it
if you do what i told you to do instead, you'll end up with a valid file
you're writing each dict into the file, which is what makes it not valid
if you instead append the dicts into a list, then write the list into the file, it would be valid
Let me try. Thanks!
also if you've got a file object you can just do json.dump(your_object, the_file), you don't have to write manually into the file
wait, you're already putting the results into a list, just dump results at the end of the loop
i did
well, it's in the loop still
i meant after you've collected all the data, dump the list
So I need to dump the list after the loop?
yes
await cursor.execute(f"SELECT COUNT(user_id) FROM requests WHERE guild_id = {guild_id} AND user_id = {user_id}")
print(ticket_id)
ticket_count = await cursor.fetchall()
if ticket_count[0] > 2:```
Any ideas why this doesnt seem to be counting? just printing the id
you didn't close the file
also you should probably check the status code before that loop
status code is 200 which is fine

I just add json.dumps after json.file.write (comment out)
can someone explain what :value is used for in pdo im trying to conver this script from pdo to mysqli because im not good with pdo VALUES('".$tkn."', '".$user."', :gid, ".(time()+30).", 0);");
the :gid bit
i dont understand is it a auto increment
is there any place to host db for free (postgreSQL)
u can always use heroku, but i suppose it's NOT completely free
why? and any other than heroku?
https://towardsdatascience.com/deploy-free-postgresql-database-in-heroku-and-ingest-data-8002c574a57d?gi=2188a2188d95#:~:text=Deploy a new Heroku app and add PostgreSQL driver&text=The free plan allows you,20 connections to the database.
this is what im talking about it provides us with a limit The free plan allows you to have a maximum of 20,000 rows of data and up to 20 connections to the database

Medium
Deploy a PostgreSQL database for Free in Heroku and Ingest Data using Pandas and SQLAlchemy
okk
yup
can someone explain me what asyncpg.create_pool() what exactly create pool do and what is pool
nvm i got it what it means
save time to create connection again and again
but i still dont understand what transaction means

Railway
Railway is an infrastructure platform where you can provision infrastructure, develop with that infrastructure locally, and then deploy to the cloud.
i saw that alr
it have a $5 dollar/mo limit
ik i will not cross in any near future
but still any other than that?

You are going to be hard pressed to find free PostgreSQL with a higher limit than either of these two
ok
tnx
In PostgreSQL, if I were to implement something like an album tracklist, how could I atomically swap positions between two entries? I'm assuming something like
BEGIN;
UPDATE songs SET position = -1 WHERE position = 4;
UPDATE songs SET position = 4 WHERE position = 3;
UPDATE songs SET position = 3 WHERE position = -1;
COMMIT;
which would match how you would swap two variables in C; but is there a more idiomatic approach?
https://dba.stackexchange.com/a/131128 you can query for both at a time and use = case to do it all in one shot. idk if that is "more atomic" or safer or faster than the transaction

Database Administrators Stack Exchange
Consider a table test contains an attributes of id and name.
The values for that.
Id | Name
1 | Raj
2 | Kumar
From the above sample table, I know only the id, So through the Id I n...
the other answers are interesting too, eg a generalized solution with a CTE
I created a SEQUENCE in Postgres and using the \d+ command lists the size as 8192 bytes, isn’t that a bit big?
8129 bytes is 1024 64-bit integers, maybe it pre-computes some values?
that does seem big for what i would have guessed is a single integer and a counter
but maybe it isn't possible to "lazily" store sequence values since table order isn't well defined

did you create it with maxvalue or cache defined?
8192 bytes is the default page size for postgres, so may be related (because a sequence is like a table.. so likely takes up a page at minimum)
No, literally just has a name and the rest are default
This is probably why. Seems a bit odd tho
trying to forward engineer my tables and getting 1 error
Resetting connection with an active transaction <asyncpg.connection.Connection object at 0x000002C31268CD60>
I keep getting this error and I don't know how to fix it
I use tortoise orm if that helps
it just happens every time i access something in my db
I plan to design a system that can chain a bunch of logical expressions together using AND/OR operators. These expression chains need to be persisted in a relational database. Any ideas for how to model this in my database?
I read a suggestion that I should store the expression as text in some format that I can later parse. This would certainly make it easy from the database's point of view, but introduces complexity in writing a parser for these expressions. Granted, they are very simple so maybe I could restrict it to python syntax and use eval? What are your thoughts?
maybe just use "text" and we will ignore the errors :)))

Can somebody help me with this CSS sld on geoserver
mark:symbol('ttf://ESRI Business#39');
:symbol {
fill:#FF0000;
}
}
[activity_group_id = 20] [application_status = 'Payment-Done']{
mark:symbol('ttf://ESRI Business#39');
:symbol {
fill:#00FF00;
}
}
[activity_group_id = 20] [application_status = 'Work-Completed']{
mark:symbol('ttf://ESRI Business#39');
:symbol {
fill:#0000FF;
}
}
[activity_group_id = 20] [application_status = 'PreSanction-Received']{
mark:symbol('ttf://ESRI Business#39');
:symbol {
fill:#00FFFF;
}
}```this is working fine
but I want to simplify this using if-then-else
I'm stuck on this
as there are more than 30 unique 'activity_group_id' there
Maybe you have a better chance asking in #web-development
is that css?
print(query)
df = pd.read_sql_query(query, con = connection) ``` Can anyone help me me here? Its not creating a dataframe from the query. Not getting any errors so I got nothing to go by.what do you mean "not creating"?
You could maybe model it in a recursive tree-like structure, every row has two leaves (either values or references to another leaf) and an operator that defines how to join those (AND | OR)
It's a pain to query though, I think
must it be relational?
doesn't sound like a good fit for a relational database to me
assuming you want to store arbitrary expressions
the best you could do would be text, it seems to me
okay tbh I feel like you could use a JSON format?
json in postgres
s-expressions map somewhat nicely to json 😉
my vote is to stay with relational as long as possible until it's truly infeasible or nonsensical
if you have only one "non-relational" item in your database then don't leave relational
i wonder if there's some postgres extension to make an s-expression data type...
The expressions themselves don't necessarily have to be modelled in a relational way, but I do use a RDBMS and they need to go inside it somehow.
I do have other data that is relational. I need to have an FK that points to another table from which these expressions will reference values.
Though maybe I'll allow it to reference any table. But I'd still need to associate the expression with a user.
I am indeed using postgres so I will look into that, thanks. Will need to figure out a way to map it to JSON first.
@pure cypress Whats the use case? You could look into json logic which is commonly used, and there should be libs that parse it as well.
interesting idea https://jsonlogic.com/

Build complex rules, serialize them as JSON, share them between front-end and back-end
this pretty much is what you'd get with s-expressions so yeah i vote in favor of it
Use case is storing conditions for notifications e.g. if x is less than 2 and y is greater than 3 then send notification
At a glance, jsonlogic looks like it's exactly what I need
how can I create a connection pool for aiosqlite
Im using flask with sqlite. But sqlite won’t handle as much concurrent accesses as postgres so i want to switch. Anyone done that before ?
And the database has some complex relationships defined in flask-sqlalchemy
Will it be the same syntax and just the database location changing ?
Hi, I want to use a database for my public discord bot. I used to use mongodb but I was told that I shouldn't be using that, what else should I be using?
I accidentally deleted django_admin_log and now i can not use the django admin , i get this error => relation "django_admin_log" does not exist
LINE 1: ..."."app_label", "django_content_type"."model" FROM "django_ad...
whatever you're comfortable with. don't let other people tell you what to use
i personally use postgresql everywhere i can, but its really a matter of what you enjoy using
yes, you need to recover that table from backup
backuppp wow how can i acess that ?
based on your question you probably don't have one
so now you have a problem
if you don't care about your data the simplest is to recreate the entire database
if you care about your data, why do you not have backups?
i think you could somehow roll back all admin migrations and redo them, one moment
I cannot find the name of the django admin app at the moment, and i'm currently at dinner so I can't really check too far, but basically what you could do is
$ python manage.py migrate ADMINAPPNAME zero
$ python manage.py migrate ADMINAPPNAME
to wipe all data (for the admin application) and re-create all tables
another alternative is to check a database for a correctly working django app and pull the table definition for the table out of it
sorry just new to postgresql
admin and then my appname ?
uh thanks sorry didnt read the dinner part
django.db.utils.ProgrammingError: table "django_admin_log" does not exist
how can I create a connection pool for aiosqlite, I don't think I should be creating a connection to db every time when I run a command
You’d have to create your own pool. Look up the pool design matter for more info if you want to create your own. However, this is most effective when the cost/rate of initializing the database connection is high. For Sqlite connections are cheap unlike server based databases.
I make the connection quite a many times so I think it's worth a shot
And thank you!
Ive got a db that I'm not sure how its formatted, is there a way to display the whole thing rather than having to select specific tables?
Hey guys, so I’m using flask and SQLalchemy for my web application. Now I have a page where I’m rendering about 20 pieces of data, yet it takes about 3 seconds for the whole page to load and I’m assuming that it’s because their are unnecessary queries going on here. Does anyone know any good debugging tools to find out why queries my program is making?
Hi. Does anyone how to create ETL pipelines on Azure platform?
Hi, can someone help me with this
mysql.connector.errors.DatabaseError: 2014 (HY000): Commands out of sync; you can't run this command now
when I run it solo on a test script it works fine but in original script it throws this error
here's the code:
@make_query
def increment_login_success(bot_id):
query = """
UPDATE Bot
SET LoginCount = LoginCount + 1
WHERE BotId = %s;
"""
value = (bot_id,)
db_cursor.execute(query, value)
database.commit()
return```How can I upload a .db file to phpmyadmin?
Did you find an answer? I've been wondering about this, think SQL Alchemy will handle it pretty easily but I'm not certain
What db?
Azure offers several solutions for this, what is best to use depends on your need. Two examples that are used quite a bit as for as I know are Azure data factory and Databricks (which can be used in combination also). This however does not ensure they will work for your project.
My requirements are connecting Teradata with Databricks, for which I might also need data factory. However, this is my first DE project. Is there a tutorial where I can see how to create a databricks pipeline?
hi, in mongodb, how can i check that is there an existing data that have id = ctx.author.id?
I am using flask, SQLAlchemy and SQLite3. Is there a way to make sure that the primary key (set as an integer) always goes up, even if I delete the last object? For example, if i have a row with pk 5, if I delete it and add a new row, the primary key is again set as 5. How do I make it so that it will go to 6 even if pk 5 is not present?
It's not doing that by default? How are you defining the index (show your code)?
This is my model
class Account(db.Model):
__bind_key__ = 'data'
id = db.Column(db.Integer, primary_key=True)
account_name = db.Column(db.String(255), nullable=False, unique=True)
account_number = db.Column(db.String(127), nullable=False)
routing = db.Column(db.String(127), nullable=False)
active = db.Column(db.Boolean, default=True)
def __repr__(self):
return f'Account Name: {self.account_name}, Account Number: {self.account_number}'
yeah I thought it does that by default
i am trying to run a INSERT command and its giving this
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: OperationalError: table data has 5 columns but 2 values were supplied
i have 5 coloumns so i need to add none or 0 or NULL in each column?
help pls
Sounds right, did you try it?
Databricks is using apache spark, a quick google shows me that pyspark (the python api) for apache spark can connect to terradata database using the jdbc driver. From there on you should be able to request the data as done in any spark process. Databricks has documentation on pyspark (https://databricks.com/glossary/pyspark).
i havent researched about it yet. Will probably do very soon.
soo i am trying to make my discord bot update the database but its not updating these are codes
@bot.command()
async def start(ctx):
player = ctx.author
conn = sqlite3.connect('test.sql')
c = conn.cursor()
c.execute(f'UPDATE data SET start_used = start_used+{player.id} WHERE ID = {player.id}')
conn.commit()
if c.execute(f"SELECT * FROM data WHERE start_used={player.id}"):
return await ctx.reply("Command already used by this member.")
c.execute(f"INSERT INTO data VALUES ('{player.id}', 100, 0, 0, 0)")
conn.commit()
conn.close()
await ctx.send('you have started your journey with **100:nexus:** in your balance')```
and dis is the table
when i tried running !start with a 4th ID its saying "command already used"
help pls
anyone?
Hi
I need help creating a database in H2, with the sintaxis, its bad and i dont know how to fix it 😦
CREATE TABLE USER
(ID INT(11), PRIMARY KEY, NOT NULL);
user_email (Unique Index)varchar(50) Not null,
user_name VARCHAR(80), Not null,
user_password VARCHAR(50), Not null
Try adding autoincrement=True to the PK column. https://www.sqlite.org/autoinc.html
I've got a discord bot I've been running connecting to an Azure database using pyodbc. For some reason it always eventually stops being able to connect. I've tried to make it close an reopen the connection whenever it needs it, but that doesn't seem to have helped
how can I have the script running continuously without the sql calls failing
how do i use sql in python to make a database and put that in my code
i looked at sqlbolt tutorial or something
Thanks :). Yes after searching for a while, adding __table_args__ = {sqlite_autoincrement: True} solved the problem. I don't know if adding only autoincrement=True works (it might), but any such change in the column was not being captured by flask_migrate. So I manually deleted the whole table and added the table_args bit and it is working as intended now.
SQL Server
any help?
a single soul?
Your if statement is not checking the database. You just have a string your evaluating.
look at dis i updated the codes in someways
@bot.command()
async def start(ctx, user:discord.Member = None):
if user is None:
user = ctx.author
conn = sqlite3.connect('test.sql')
c = conn.cursor()
gg = c.execute(f"SELECT * FROM data WHERE ID = {user.id} AND start_used=TRUE")
if not gg:
return await ctx.reply("Command already used by this member.")
else:
c.execute(f"INSERT INTO data VALUES ('{user.id}', 100, 0, 0, 0,'TRUE')")
conn.commit()
await ctx.send('you have started your journey with **100:nexus:** in your wallet')
conn.close()
Use the fetchone method to get the value from the db
And your sql statement can be changed to check for existence instead of getting all data
@torn sphinx
df.values.tolist() giving me error
dataframe object has no attribute 'values', can anyone help?
Hello, everyone. I work with databricks and I have the following problem. I want to connect databricks cluster with my local machine I tried with Databricks connect but only the spark code execute on the cluster I want the entire code to execute on the cluster.
I got flask application that prints out a database, it has over 50 000 rows and takes forever to load, is there any smarter or faster way to print it out?
If I have already done flask db init for flask_migrate on a single db project, but later added multiple dbs , how would I initialize flask_migrate again? I can delete the migration files and do flask db init --multidb but is there a better way?


Good morning
I have an SQL question that I am stuck on, and not sure if it is solvable with just the standard sql syntax
I have a table that is outlined like below, and I'm trying to figure out how I can go through the table and grab every id that is changing e.g. ID 123 goes from 123 -> 234 -> 456 -> 567. I could use a list of CTEs to keep referencing the table, but I don't know how many times this ID will be updated i.e. it could be once, or it could be five times
id_old id_new
123 234
234 456
456 567
so output would be something like this...
ID_1 ID_2 ID_N
123 234 ...
it doesn't even have to be single row, but i'm basically keying off of two fields. The first one I'm using old to get new, then I'm using the id_new which is now referenced in the id_old field to get the newer id from id_new, and so on and so forth
So I am learning alembic and I got this doubt. How does the social media profile links stored in the database? Is it stored inside the users table or, people create separate table for it. I am asking because, the devs may want to add new social media networks every now and then right?
CREATE TABLE "id_list" (
id_old INTEGER,
id_new INTEGER
);
INSERT INTO id_list VALUES (123, 234), (234, 456), (456, 567), (1, 17), (17, 192);
WITH RECURSIVE new_ids(id, rev) AS (
VALUES(123, 0)
UNION
SELECT id_list.id_new, new_ids.rev+1
FROM id_list, new_ids
WHERE id_list.id_old = new_ids.id
)
SELECT * FROM new_ids;
Would there be a way to use something like sqlite with a class so whenever I do db.x = 5 it would write that to the file?
Basically make SQLite available without sql commands lol
what do i code if i want some like "if this id does not match up with anything in this data base, ignore/skip"?
use like?
that is called an ORM (object-relational mapping).
The best ORM for python is SQLAlchemy. Django also has its own ORM.
can someone help me with sqlite ?
Can someone help me please, how can I add an array inside the 'info' without deleting the lvl?
when I use (collection.update_one({'_id': author}, {'$set': {'info': {'XP': []}}})), it deletes the lvl and adds XP

Turn the info into an array of two arrays maybe
I'm confused why this INSERT statement is giving a syntax error. Does anyone have any input? INSERT INTO dbo.table (user,id) values(?,?) one 123
This is the error I'm getting Msg 102, Level 15, State 1, Line 1 Incorrect syntax near '?'.
which database r u using
?
that is sql i believe
tSQL, I was able to get the one insert statement to work but I'm working on inserting this in a for loop iterows() over a dataframe and that's where i'm getting issues currently.
this is the current error I'm getting ('42000', '[42000] [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]The incoming tabular data stream (TDS) remote procedure call (RPC) protocol stream is incorrect. Parameter 13 (""): The supplied value is not a valid instance of data type float. Check the source data for invalid values. An example of an invalid value is data of numeric type with scale greater than precision. (8023) (SQLExecDirectW)')
I'm trying to insert a NULL value
cursor.execute("INSERT INTO [dbo].[table] (user_id,campaign_id) values(?,?)" ,row.user_id,row.campaign_id)```The workaround that I did was to change the nulls to zeros, but if anyone knows the answer I'd be happy to know
hi, can anyone give a hint of querying a tree structure using recursion? my attempts are not working
Could someone explain what is meant by the second statement? It is not clicking for me

If your application needs all columns from your current table in the schema, then it may be tempting to use select *. Let's assume that's 3 columns. If your application is only expecting three columns, and the schema is updated and now has 4 columns, then your application could crash because you're doing select * instead of select var1, var2, var3
testing
select *
sorry, should have used the sql syntax 🙂
This now clicks. Many thanks!
Would anyone be able to help me with a SQLAlchemy related issue? I'm trying to insert records into a db and my id column wont autoincrement.
So I am creating a ER diagram from a table I saw and it has an ID for the first data that increments by one for each insert. Do I just have to give that data type the Auto increment category for it?
is there a way to drop tables that are not 'WordList'

hi, anyone tried traversing a graph node to build a tree? i' ma bit confused
Does this ER Diagram look correct or should the data types for my invoice table foreign keys be changed?

hi, how do recursively create nested html tags from a graph? I posted a question on SO. can you please give a hand ? https://stackoverflow.com/q/70213240/5713751
Wrong place to ask that question you are looking for #web-development
How do I get pandas.read_excel() to read empty cells as an empty string value instead of a "nan" float?
This is #databases for SQL or other database code your looking for #python-discussion or one of the python help channels
ah okay
Sorry if you asked the question somewhere else I couldn't find it. I do think there should be a pandas/numpy channel
df.read_excel(path , na_filter=False)
More options: https://stackoverflow.com/questions/26837998/pandas-replace-nan-with-blank-empty-string
Stack Overflow
I have a Pandas Dataframe as shown below:
1 2 3
0 a NaN read
1 b l unread
2 c NaN read
I want to remove the NaN values with an empty string so that it looks like so...
Gotcha, thank you!
your cardinality looks incorrect though I'm rusty on the theory. It seems invoice is implemented as a through table much like Membership is in this https://docs.djangoproject.com/en/3.2/topics/db/models/#extra-fields-on-many-to-many-relationships
I've got a data merge problem I can't seem to find a straight forward solution to. Datetime based records, main dataset every 5 minutes. Set to be merged is every 15 minutes and timestamps don't match exact. I want to merge with existing dataset filling in blanks with
average values. I know I want to use pandas, but I'm really new to that, only a couple months experience. DB is MySQL running on a Linux server. Main app is based on Flask everything else is "pure" Python. I'm good at following rabbit holes, but I could use some advice on where to start and a direction to go in.
can you be a bit more specific about what you're trying to achieve? maybe give some example data sets and show the result you would expect
For Example
Main Data Set:
datetime Val1 Val2 Val3
2021-10-15 3:15:03 100 120 ...
2021-10-15 3:20:02 110 100 ...
2021-10-15 3:25:01 120 120 ...
2021-10-15 3:30:03 100 130 ...
Merges with:
datetime Val3
2021-10-15 3:15:00 150
2021-10-15 3:30:00 160
Desired Result in Main Data Set:
datetime Val1 Val2 Val3
2021-10-15 3:15:03 100 120 150
2021-10-15 3:20:02 110 100 155
2021-10-15 3:25:01 120 120 155
2021-10-15 3:30:03 100 130 160
If that makes sense.
A bit new at Discord too. Please see my above post for an example. Main Data Set is a table in a MySQL database. Merge Data is in Excel. I really feel Pandas is the way to go, although I'm not opposed to other alternatives. I could just use Python and iterate over a cursor, but that was getting a bit ugly and I just keep feeling like Pandas has built in functions to do this, I just don't know what they are. I would also like to gain more experience with Pandas.
so what's the merging rule here? you want to merge with the closest timestamp that is +/- some range?
Yes. From looking at the data timestamps for merging would be within 10 seconds. For records that don't have a close match, I would be happy with with using an average of the before and after values. Probably a two step process.
Step 1:
datetime Val1 Val2 Val3
2021-10-15 3:15:03 100 120 150
2021-10-15 3:20:02 110 100 ...
2021-10-15 3:25:01 120 120 ...
2021-10-15 3:30:03 100 130 160
Step 2:
datetime Val1 Val2 Val3
2021-10-15 3:15:03 100 120 150
2021-10-15 3:20:02 110 100 155
2021-10-15 3:25:01 120 120 155
2021-10-15 3:30:03 100 130 160
i agree that sounds like a 2-step process
and yes you can do it either in mysql or pandas
In pandas you can use https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.merge_asof.html
use direction='nearest' and adjust tolerance= as needed
I will take a look at the link. I would really like to do this in pandas.
it sounds like the datetimes should be indexes
there is a time series example at the bottom
Looks like exactly what I was looking for! Any suggestion on Step 2?
can someone help me with ms sql instance problem?
Thanks for directing me to pydata.org. Awesome site. I think I'll be using that one quite a bit.
Does Value ('$621.97') work with DECIMAL(10, 2)?
Data type
asking because isn't $ a varchar data type?
Yes, I think that will work perfect. Once again, thanks! Not just for the specific direction but also for the website. This will come in very handy. I am finding myself doing quite a bit of data engineering lately. That's why I'm interested in getting better at pandas and I think this site will help me quite a bit.
Facing this issue INFO [alembic.autogenerate.compare] Detected removed table 'sqlite_sequence' while working with flask-sqlalchemy and flask-migrate. It should not be removed and sql_migrate should not ideally flag this.
@event.command()
async def participate(ctx):
player = ctx.author
conn = sqlite3.connect('list.sql')
c = conn.cursor()
if c.execute(f"SELECT * FROM list WHERE ID = {player.id}"):
c.fetchone()
await ctx.send('no')
else:
c.execute(f"INSERT INTO list VALUES({player.id})")
conn.commit()
await ctx.send('hm')
i am trying to connect dpy and sqlite3 the command ads User ID in a new record
but if the user id is already in the record it sends no but
even if the user ID isnt in the database it still says no
help
hi i have posted a qus in #help-apple
I fudged it. I think it is ugly but it works
con = sqlite3.connect(path)
cur = con.cursor()
table_drop_list = []
for row in cur.execute("""SELECT name, type FROM sqlite_master WHERE name != 'WordList' and type = 'table';"""):
table_drop_list.append(row[0])
for table in table_drop_list:
cur.execute("""DROP TABLE {}""".format(table))
con.close()
https://mystb.in/ColoredAdequatePrisoner.python
this displays the same rank for me and 2 others
that is #1
no errors
how do I make a function which picks a random record of a sql database?
SELECT *
FROM my_table
JOIN (
SELECT id
FROM my_table
ORDER BY RAND() LIMIT 10
) as my_table_rand ON my_table.id=my_table_rand.id
if you use postgres, you can use random sampling with TABLESAMPLE https://www.postgresql.org/docs/current/sql-select.html#SQL-FROM

PostgreSQL Documentation
SELECT SELECT, TABLE, WITH — retrieve rows from a table or view Synopsis [ WITH [ RECURSIVE ] with_query [, …
any idea why im getting a syntax error near the ")"??
c.execute(f"DELETE FROM afks WHERE author = {dbtype_authorid} AND guild_id = {dbtype_guildid}")
im using sqlite3
I've developed tenant architecture in my Cassandra DB. Can any one suggest me what's the best web socket for this DB? Right now I'm using channels-redis but it's utilise my CPU very high even on normal users load.
I don't think you can use f-strings with SQLite, it has its own syntax with ?
..
Hello! Is it possible to use server-side js with pymongo/motor?
Hello, I am using Flask and sqlite3 and I was wondering how I would go about creating a database USING SQL. I ask because this is a specific requirement I need to meet for a project. The code I have right now is app.config.from_mapping( SECRET_KEY='dev', DATABASE=os.path.join(app.instance_path, 'website.sqlite'), ) But I need it so the database is created using an sql statement. Any suggestions?
That code you share here is just configuring Flask to use an existing database, has nothing to do with creating one
if 'db' not in g:
sqlite3.register_adapter(shortuuid.uuid, lambda u :u.bytes_le)
g.db = sqlite3.connect(
current_app.config['DATABASE'],
detect_types=sqlite3.PARSE_DECLTYPES
)
g.db.row_factory = sqlite3.Row
return g.db```This might have something to do with it
Why isn't this working correctly?
I should be getting the Customer's First Name, Last name, and then the Employee with EmpID of 1's first name but instead I am getting the employee's first name then the customers last name and its completely leaving out the customers first name
As it says, your database may or may not exist. If you don't know whether and how it's being created, we can't determine that based on these code snippets you are sharing. Normally you should run flask db init to create a db and then flask db migrate to apply your migrations but if you're required to use SQL instead for some reason, then, do that
Have you confirmed the columns you are selecting all exist and contain data for these matching records?
@fading patrol I figured it out for some reason it got confused by the two similar FirstNames so I gave the employee First names an Alias and it worked.
async def info_message(ctx, content, guild_id):
something = cur.execute("SELECT channel_id FROM guild_config WHERE guild_id=?", (guild_id,))
result = something.fetchall()
print(result)
result = result[0]
print(result)
print(type(result))
channel = await client.fetch_channel(result)
print(type(result))
print(channel)
##await channel.send(content)
return()
Hello, This keeps returning me the 'guild_id'.
print(result) returns the database entry for guild_id. I need the channel_id. Why is the code broken?

What type of DB are you using?
SQLite
Can you share the schema with the following sqlite commands? I would like to try to recreate:
.headers on
pragma table_info(guild_config);
how do i show that output w/ python lol
Oh those are Sqlite commands - just drop them into your sqlite shell
damn im on windows rn, no sqlite shell
as i know of

there's my tables, pretty much same thing
Can you share the output of print(result) after you call fetchall()?



But 6903...192 is a channel_id
damn i did a fresh one maybe i pasted the server id...
guess i should code a fail-proof in for that...
lol wtf
Haha
I'd recommend checking out SQLAlchemy. Has a bit of a learning curve but can really simplify running queries and working with data models
Please help
It's in line 505
Result = await cursor.fetchone()
explain your issue in more detail. it's very vague what you're trying to do and what's happening
async def addinvites(ctx, member: discord.Member=None, *, amt: int):
if member == None:
await ctx.channel.send("specify a member")
else:
await bot.db.execute("INSERT OR IGNORE INTO totals (guild_id, inviter_id, normal) VALUES (?,?,?)",(ctx.guild.id, member.id, amt))
await bot.db.execute(f"UPDATE totals SET normal = normal + {amt} WHERE guild_id = ? AND inviter_id = ?", (ctx.guild.id, member.id))
await bot.db.commit()``` ok, so yall know doing f string here is bad, but how do I use a variable then?For 3 PPL it displays #1 as the rank but they are on diff levels with diff xps
bro, i don't understand what it is you are trying to do, only you do, what you said does not tell me what it is you're trying to do
I am tryn to display the members rank..
and how are you doing that
your code is long, realistically im not going to read that
Line 505
this is what i'm seeing,

nvm, i guess this is where your query starts
can you explain the logic of your query
Logic of my querey what?
the logic behind calculating the rank
Selects one row and arranges it.. idk how to explain tbh
Select COUNT(*) from users where ..m
That line
but COUNT counts the number of rows, so how exactly are you selecting a row and arranging it
Yes I got it rn
One sec lemme fix
I tried to run this luigi task but it says output() only takes in 1 positional argument but 2 were given, can anyone help

@jaunty spruce you're passing an argument to output and Python is passing self, too
so you're running the method with two arguments
you probably want something like
def output(self, path):
return luigi.localTarget(path)
but now it says
is json a good database? 🤔
json isnt a database
it has ways to be
still not considered as a db
also wouldnt recommend it being used as a db
hi. I'm having issues starting mongodb.service in GCP.
sudo systemctl status mongod
● mongod.service - MongoDB Database Server
Loaded: loaded (/lib/systemd/system/mongod.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: https://docs.mongodb.org/manual
Dec 05 18:30:53 mongodb-02 systemd[1]: /lib/systemd/system/mongod.service:11: PIDFile= references path below legacy dire
appreciate your help
File "./main.py", line 35, in <module>
import undetected_chromedriver.v2 as webdriver
File "/usr/local/lib/python3.6/dist-packages/undetected_chromedriver/v2.py", line 34
from future import annotations
^
SyntaxError: future feature annotations is not defined
DM me ($)
Seen a lot of people use JSON as an alternative to databases. I'm also told this isn't a good idea. What should I use? A database or a .JSON file.
in what situation?
JSON is nice because it's human readable and has high quality parsers written in pretty much every language. It can be a poor storage format for large amounts of data because the file size(s) will become very large.
I suggest using a format like parquet, feather, avro, etc if you need an efficient file format for storing data locally
the size isn't the bad part, it's the lack of ACID
So storing stuff like a list of hundreds of keys and their data isn't a good idea in JSON?
Right, as santa says, if you need to quickly update/remove/add rows of the data, then use a database
Alright, thanks for your help
Actually though if you just have a few hundred keys and values it's probably fine to just use a JSON file. It all depends on your use case. But a few hundred is very small. If you don't anticipate the size becoming larger then it's probably ok to use JSON as a simple solution
I suppose it's a okay way to go with for now, but I do want to expand on it eventually. So I think I'll probably just go for a database eventually.
Shelve is another option to consider, a bit more powerful then a JSON file but simpler then a db where appropriate https://docs.python.org/3/library/shelve.html
Good suggestion dowcet. I forgot about stuff like shelve, kyotocabinet, gdbm, etc. Those are good choices for when you do need the ability to update/delete/modify records as well as (relatively) quickly read. Much faster than reading/writing a json at least, and they stay on disk rather than in memory
isn't sqli dumping illegal :/
how to delete an entire row in sql?
i have 2 values stored in a row i want to delete all of them just by the user's id
and user id is stored
Error:
sqlite3.InterfaceError: Error binding parameter 1 - probably unsupported type.```
Code:
def get_rr(msg_id, emoji):
"""Get a specific rr's data"""
cursor.execute("SELECT * FROM rr WHERE msg_id = ? AND emoji = ?", (msg_id, emoji))
return cursor.fetchall()```
Usage:
data = get_rr(int(msgid), payload.emoji)```
does someone know about postgres here?
@bot.command(aliases=["regdb"])
async def registerdb(ctx):
def check(msg):
return msg.author == ctx.author and msg.channel == ctx.channel
try:
await ctx.reply("Enter your in-game name!")
msg = await bot.wait_for('message', check=check, timeout=60)
ign = msg.content
await ctx.reply("Enter your in-game Uid!")
msg = await bot.wait_for('message', check=check, timeout=60)
uid = msg.content
await bot.db.execute("INSERT OR IGNORE INTO users (user_id, uid, ign) VALUES (?,?,?)", (ctx.author.id, uid, ign))
await ctx.send("Registered")
except asyncio.TimeoutError:
await ctx.send(f"{ctx.author.mention} this process has timed out! Please use the command again if you wish to register!")```
• I have this command that should insert the Users and the uid and ign
• It gives no errors and i have raise error in my error handler
• it sends the message "Registered"
• After all this the issue is that it does not insert the things neededWhat’s the table structure. You have insert or ignore which might be ignoring conflict errors.
Do you have a question or just taking a survey?
Make sure to pass it valid data and one that sqlite supports.
Hi, I'm working on a small project, and don't really have past experience with database modelling. I'm working with django.
I want to create a database where for example I have a "Manufacturer" category, and for each "Manufacturer" I have "Car Models", and for each "Car Model" I have a list of mechanical parts used. So basically, Manufacturer --> Car Model --> Sort of a checklist for what all parts it uses from the ones available in the database. I can have multiple manufacturers, and each manufacturer can have multiple car models. Each particular car model uses some parts available (so I was thinking of having a separate table "Parts" which would store info about each part). What's the best way to model this relationship?
Please ping me if you reply
Can the same part be used for car models from different manufacturers?
yes
parts are common to all car models, I need to have sort of a check box for each car model saying that it used x,y,z parts
You’ve pretty much described the relationships in the above message so what are you stuck on? Are you not aware of the terms or what?
oops okay so how does this translate into code
Are you familiar with relationships and how foreign keys work to reference other tables?
when I'm querying, for a particular manufacturer I'll want to be able to list of all the car models and then I want to be able to go grab the list of parts used by that particular model as well
Um so I'll have a general Manufacturer table and another Car Model table with a foreign key to Manufacturer? So I also have a Parts table. What's the term for the relationship between a car model and parts called here
Many to many is the relationship type between car model and parts since a car can have many parts, and each part can belong to many car.
And yes, the foreign key will be in the car model, for manufacturer_id. For one to many relations the foreign key is on the table that acts as the many side.
right that makes sense, I think I was getting confused because I was doing this in my head
thank you
You can draw on paper or software to visualise. It helps.
I did try drawing something and I'm not sure why I got confused the first time, when you pointed out I already had the relationships down I somehow realised that I did know what to do sort of. But thank you
It worked... I had to do commit()
ok i did ig
@bot.command()
async def brackets(ctx, p:int):
while 0!=p:
data = await bot.db.execute("SELECT * FROM users ORDER BY RANDOM() LIMIT 2;")
dataa = await data.fetchall()
await ctx.send(dataa)
p-=1```
i want it like if dataa send in the first msg == dataa sent in the 2nd msg then it shud re do the dataa sent in the 2nd msg
how to do itwhy my sql database isnt getting updated in a github repo? i am using heroku for hosting
@app.route("/countviolations", methods=['get'])
def countviolations():
params = {
"roblox_id":request.values.get("id")
}
return str(violations.count_documents(params))```
***PYMONGO***
I want to return a count of all the documents that meet the requirements. There are some entries in the database, which should make it return a number above 0.
it always returns a 0.Your database isn't normally going to be storing anything as part of your code repository. What are you trying to accomplish?
how to change data in a table in sqlite3?
execute() / executemany() an UPDATE statement. Remember to commit() afterwards
Thanks
not 100% sure this belongs 🤷 but it's certainly DB-y: I'm looking for a really general python module that manages N rolling backups of a metadata file, ideally seamlessly automatically like:
with BACKUP_WRAPPER(open(f, 'w')) as fh:
...
does something like this exist?
@client.command()
async def test(ctx):
db = await aiosqlite.connect('database.db')
cursor = await db.execute('SELECT ticket FROM counter')
rows = await cursor.fetchall()
await db.close()
a = await ctx.reply(f'{rows[0]}')
await asyncio.sleep(5)
await a.delete()
await ctx.message.delete()``` In my database, I have `0` as the integer, how could I make rows send just the 0 rather than `(0,)`?anyone good at pygame?
Does anyone have experience with using delete-orphan in sqlalchemy? I have a situation where I want to create a one-to-many relationship between a crontab schedule and tasks such that when a task's crontab schedule is updated, the old schedule is deleted. My latest efforts are the following:
Task table
class Task(Base):
id = Column(Integer, primary_key=True)
name = Column(String(255))
crontab_id = Column(Integer, ForeignKey("crontabschedule.id", ondelete="CASCADE"))
crontab = relationship(
"CrontabSchedule",
cascade="all, delete-orphan",
backref=backref("schedule", uselist=False),
single_parent=True,
)
Crontab Schedule table
class CrontabSchedule(Base):
id = Column(Integer, primary_key=True)
minute = Column(String(64), default="*")
hour = Column(String(64), default="*")
day_of_week = Column(String(64), default="*")
day_of_month = Column(String(64), default="*")
month_of_year = Column(String(64), default="*")
Currently this does delete cascades (e.g., deleting a task also deletes its associated crontab schedule) however if I de-associate a task from its crontab schedule the schedule is not deleted. I haven't tried putting a relationship in the Crontab Schedule model back to the task table as I want to use it for tables other than tasks and would rather not put explicit relationships to all possible tables it can be associated to (unless necessary)
does someone know about postgres here? can someone help me?
just ask
Hi, I have a question if anyone could help out. I need to (1) create a code where 30 nucleotide base long sequence is randomly selected from a txt file, then (2) create a sequence with its' complimentary bases. (3) I have to repeat these pair of sequences 10 time (all random) and add them all into a txt file. I have done up to (2) but cannot figure out (3). Does anyone have an idea?
this is what I have so far

help me pleas

where is postgres running?
windows 10
can you
telnet 127.0.0.1 5432
from command prompt?
i have a discord bot with a command which updates the database
and even after user using the command the database isnt getting updated or showing the updated version in sqlite broweser

{kind=link}
{kind=link}
{kind=link}
hmm windows is strange, perhaps try opening cmd as admin
is MySQL faster than using a EXL file?
For what?
Excel is not a database so should not be compared
I want to store some data like name and something like that
I can use both db and exl file but I want to know which is faster to read?
Use a database to store data.
Hi, I'm using Google's Firestore database. How can I check if the field inside a document exists then return as True or False?
def check_locked(symbol):
locks = []
locked_return = ''
locked = db.collection('locked').where("symbol", "==", symbol)
for locks in locked.stream():
locked_return = locks.to_dict()for locks.key, locks.val in locked_return.items(): exec(key + '=val') if locked: lock_exists = True else: lock_exists = False return lock_exists
This one return as True if the value exists but throw error if it can't find the value.
NVM. I solved it with try and except. Thank you for my little space.
Please stop pinging me. Grab a help channel and share your code and hopefully someone can help you #❓|how-to-get-help
i am sorry but its been days since i am asking same question and you are the only person who responded to me
i have a question about database indexes
i have created some indexes on a DB2 database. One of the indexes is on a column with 1,000,000 distinct values, but when I looked at the index it says there is a cardinality of ~12,000. I know that the cardinality does not always equal the discount count, but how can these be so far off?
try:
if rank is None:
rankings = pstats.find().sort("MMR", -1)
else:
rankings = pstats.find({"Rank": rank.upper()}).sort("MMR", -1)
i = 1
embed = discord.Embed(title="6Mans Global Leaderboard:", color=0xE74C3C)
for x in rankings:
try:
temp = ctx.guild.get_member(x["id"])
temprank = x["Rank"]
tempmmr = x["MMR"]
tempwin = x["Wins"]
temploss = x["Losses"]
embed.add_field(name=f"{i}: {temp.name}", value=f"MMR: {tempmmr}\n Rank: {temprank}\n Win Ratio "
f"{round(tempwin / temploss, 2)}", inline=False)
embed.set_footer(text="CBell 6 Mans | Created by Heptix",
icon_url="https://i.imgur.com/1utxX7d.png")
i += 1
except:
pass
if i == 11:
break
await ctx.channel.send(embed=embed)
Anyone know why this code is not returning all the players on the leaderboard
(using mongo db)
Hello, could someone help me out with a small issue
I have columns that are a single number by name, and when I try to preform cursor.execute() it won't work
config.cursor.execute("INSERT INTO Loterij (date,1,2,3,colour) values(?,?,?,?,?)",
row.date, row.1, row.2, row.3, row.colour```If I try to run it I get the following error
^^^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?```Its also claiming config.cursor.execute() isn't properly closed
what's config.cursor?
ok, let me check something
did you try passing the parameters as a tuple?
@torn sphinx
How would i go about doing that?
just enclose your comma separated parameters in brackets
simple as that
Keep the commas or rmeove them?
wait nvm i think i got what u menat
New error now, but im not sure if it's worked
Sorry if I ask here first before looking it up, ive been working on this connection the whole day and ive sorta blown out
what does your original statement look like
You mean what its giving me the error for?
yes, like can I see what you ran originally
This
ive been running and working on this the whole time
Ive tried doing a pd.to_sql() aswell but thats not working either
is date a column in your table?
isn't date like a sql keyword
that might be the error but I'm just guessing
i could be wrong
I could honestly change the names aswel
because the query does work normally
if the name of the columns aren't fukkin 1, 2 and 3
And thats another whole 30 min of work and sorting out
But i think ill just do that
Thanks for the help tough, Android
Android? come on now
The methods worked fantastic! Started with over 23,500 values to update, after interpolation over 70,500. Used python and pymysql to iterate over the dataframe and do the db update. Ran the whole process form a jupyter notebook. Everything worked flawlessly. Thank you! Thank you! Thank you!
how do you replace one column value with another
for example i'm setting a for loop like:
for i in df['a']:
replace (df['a'], df['b']
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
https://pythondiscord.com/resources
Hello
Anyone one that has experience with SQLite?
I have a REAL simple question that I just cant seem to work out
sure, ask your question
How do you print out result to the python terminal?
Example
cur.execute("SELECT * FROM offense WHERE YRDS = 250")
this gives me the object
but it doesn't print out the result
I feel really dumb lol but am lost right now
I even added a variable and that only prints out the object
Above = cur.execute("SELECT * FROM offense WHERE YRDS = 250")
<sqlite3.Cursor object at 0x000001889A346C70>
print(cur.execute("your query").fetchall())
And my journey continues...Thank you! I owe you a cup of coffee!
no problem! 😅
Hey, everyone! I'm trying to get more people to try out https://github.com/RobertCraigie/prisma-client-py so I've created a PR to add the project to awesome-python https://github.com/vinta/awesome-python/pull/1890
GitHub
Prisma Client Python is an auto-generated and fully type-safe database client - GitHub - RobertCraigie/prisma-client-py: Prisma Client Python is an auto-generated and fully type-safe database client
GitHub
What is this Python project?
https://github.com/RobertCraigie/prisma-client-py.
An auto-generated, fully type safe ORM tailored specifically for your schema - works with SQLite, PostgreSQL, MySQL, ...
If anyone could approve the PR it would be greatly appreciated, thank you! :)
Hello folks,
Has anyone managed to connect to a google cloud sql postgres instance via SSL ?
It works just fine on windows and on using my ubuntu distro (WSL)
but when I deploy it to Pythonanywhere
it fails to connect
and i can't figure out why
for more contex: #help-potato
I'd appreciate the help 🙏
I cry :')
failing to connect to mssql via django app, here is the error
django.db.utils.OperationalError: ('08001', '[08001] [unixODBC][FreeTDS][SQL Server]Unable to connect to data source (0) (SQLDriverConnect)')
DATABASES = { 'default': { 'ENGINE': 'mssql', 'NAME': ***, 'HOST': ***, 'USER': ***, 'PASSWORD': ***, 'OPTIONS': { 'driver': "FreeTDS", }, } }
I would guess this is a firewall rule or something like that. If you didn't have to explicitly allow your IP on Google to get WSL working, then maybe the issue is on the PythonAnywhere side.
I didn't read this whole thread but I think someone describes the same error https://www.pythonanywhere.com/forums/topic/14179/
Forums : PythonAnywhere
anyone able to help? im currently trying to do an sql data base
I don't have to whitelist it because I'm connecting via SSL.
But I'll ready the thread! Thanks a lob !
The error?
Maybe date for the column name is a reserved keyword
And use parameter binding to avoid any issues with string formatting which might add unexpected characters to it
Yeah so like I said use parameter binding and not string formatting
Good Evening! Has any one ever encountered this this op error?
Here is my code
con = sqlite3.connect("Offense.db")
cur = con.cursor()
cur.execute("""CREATE TABLE stats (
SFPoints integer,
OPPoints integer,
FDs integer,
TYRDs integer,
PASS integer,
RUSH integer,
)""")
con.commit()
con.close()```Is there a way to use SELECT statement without getting a row object with sqlite3 and just get the value?
When I run it, this error appears
cur.execute("""CREATE TABLE stats (
sqlite3.OperationalError: near ")": syntax error```UPDATE message_history WHERE channel_id = X SET chat_history = X
Hello would this be the correct syntax for MySQL?
Looking at the example try:
SET chat_history = X
WHERE channel_id = X```@vocal cedarThanks i was missing ' 😄
My next question is now ive got it working it only enters the first message into the DB
messages = await ticket_channel.history(limit=None).flatten()
for i in messages:
chat_format = f"{i.author.name} | {i.content}"
print(chat_format)
db = await connect_to_sql_db('BanditBot')
async with db.cursor() as cursor:
await cursor.execute(f"UPDATE message_history SET chat_history = '{chat_format}' WHERE channel_id = '{ticket_channel.id}'")
await db.commit()
db.close()
Hoping someone chimes in on this one
Hey all -- I'm bulk inserting a bunch of data every evening into a Postgres table. There are a handful of duplicates on every transaction. Two solutions that come to mind are query first to see which records exist, exclude the ones that do, then insert, the other is to perform bulk insert but write a ON CONFLICT do nothing
The downside with ON CONFLICT is that it consistently increments my ids...
Any other viable solutions I'm not considering? Maybe using a temp table and inserting and just doing it query side?
what's wrong with that?
why can't the deduplication be done on the producer's side, incidentally?
I would assume over time it, the excess amounts of un-used ids if say we have 500+duplicates a day
The produce is a third-party api and they dont know what items are we storing daily or not
you should avoid f strings for queries
okay, so I'm guessing in your code you call the 3rd party API and then pass it to the DB?
so why can't you do it in the intervening step?
I'm getting ServerSelectionTimeoutError in MongoDB. Can anyone tell me why does that error occur? Please ping me when you reply
when i use my local system, it works. When i use it on EpikHost cloud, it gives error

is it due to pymongo version?
in my local system, it is 3.12.0
Hi all, does anyone know the newer version of From azure.storage.blob import BlockBlobService?
Hi guys, how do I make when a person leaves their email on my site, then the bot will send him an email, information that he bought on my site? If you can help me, I'll pay
That's what I'm suggesting in the 2ndary idea
When starting the program, construct a user table which is to be populated when a user Reigsters. Under that user, create 5 tables Books,TV,Movies,Albums,VideoGames. So each registered user will have five tables when a user object is created and that user object will have control over the management of these tables through functions such as add(), delete(), compare() for each of those tables. The user table will be a master table which is not associated with any objects in the codebase. Only the 5 Media-based tables will be associated with the user object and the user object will control it.
Can anybody point me towards how this can be done? I want a User Table where I store all Personal Details of the User and associated with that User I want 5 tables as mentioned. User is a class which I create instances of when any user registers. Also Books, TV, Movies, Albums and VideoGames are Classes whose instances are created when user wishes to add them to his library. Please suggest something how this can be designed. It would be wonderful if somebody could provide a database design schema.
You can take a look at my code here where I have created Python Classes: https://codeshare.io/9OYko8
@keen minnow I think we are far into offtopic for #career-advice 🙂
I though cassandra (and Scylla which is like fast cassandra) are open source?
well, I know it has some paid license and extra features
I guess that's what you mean by fake open sourcnes?
They are, but most of the committers are owned by an oligarchy
So the core is open source, but as soon as you need to take it to prod, then you will be missing crucial pieces
Thus, yes, they are open source, but are more akin to a dev freemium than an actual healthy open source project (ex: postgres)
The first target is anything related to management or security/DCs
If the committers don't do anything related to that on the open source parts and raise the bar too high for third party contributions, then they are effectively blocking it
And for cassandra specifically, if I recall correctly, most of the drivers aren't even in the apache parts
also I think that choosing cassandra over postgres in their case was blatantly wrong choice but this is no place to rant about that
depends on the scale too
well my understanding is that cassandra shines/excels at huge writing loads
but yeah, I recommend to always start with mysql/postgres first. You will have a lot of time before being stuck
i.e. chat, emails, iot sensor data from big network maybe
it does!
So does sharded mysql/postgres 😉
indeed
postgres is amazing really
when i was moved to this other product and it was postgres I was cautiously optimistic at first and now I am just happy about it 🙂
totally agree. And it still continue to progress at every release
I feel really bad for those guys with cassandra
there was a lot of struggle when I was there for short time and later as well bcs no one really knows cassandra very well there
with sql they would have much easier time
there is value in the well traveled path 🙂
does anyone here know of a python library that allows you to read a realm database?
i just need to read the data, not insert/create or update/edit or anything like that.
Alright Can someone help me setup a user and role(if needed) in postgresql?
cause I have no idea how to do this
and the one guide I used once
didn't help me
then connecting remotetly to the database?
I plan on using asyncpg btw
does anyone know how i can make heroku work with sqlite3 and not nuke the db every 24 hours? i currently cannot move to another db like postgre or move the hosting service
🤔 you need to use some external's host database, find a loophole(or do some anti-purge)
or get a better host
if you can, but I assume you can't really buy a beter host right? (if you could you would probaly not use heroku)
i mean, i do have the github student pack, is there any hosting service in it?
digitalocean, replit, there's more there
Is it possible to alter a string column to ARRAY(str) with pydantic ? I'm using sqlachemy
what does pydantic do?
oh sorry that was supposed to be alembic I have figured the issue out: https://stackoverflow.com/questions/14782148/changing-a-column-from-string-to-string-array-in-postgresql
op.execute(
"""
ALTER TABLE table
ALTER code DROP DEFAULT,
ALTER code TYPE text[] USING ARRAY[bu_code],
ALTER code SET DEFAULT '{}';
"""
)
Stack Overflow
The following is a snippet of a table called "containers".
Column | Type | Modifiers
--------------------+-----------------------------+-...
how do I pick a random record from a sql database
if you had any sense you'd read replies already made to you #databases message
How do I initialize a database locally (through visual studio code) in replit?
so im currently using heroku for a discord bot and the bot uses a sqlite database. the db gets wiped every 24 hours cuz its a file based one. i dont want to move to postgre since its a lot harder to learn, so i was wondering if there is a server based database with almost the same syntax as sqlite3 ???
you use SQL to query both postgres and sqlite
i'd say only the initial setup as such would be more difficult on postgres? after which it's not really hard
another small question: for heroku, will normal PostgreSQL work or will i have to use heroku postgre?