#databases
1 messages · Page 66 of 1
Set feels more appropriate if it's a number of unique queries.
Batch if it's like a number of queries performed during a particular time interval, or something.
I'm using MySQL connector on a MariaDB, one of the columns is the datetime on which something happened, how do I make it so that only things that happend x days ago are selected?
But in the query, I need to convert it to a string, and then It won't work?
Because in the database it's a datetime object, but to use it in a query, it'll have to be converted to a string?
what happens if you do cursor.execute('select * from mytable where date > %s', datetime.now())?
does that work?
if not you might need to either convert to unix epoch time
or use strftime to convert to string
before feeding to query
also please for the love of all that is sacred make sure you are using query params for this
i dont remember if mysql connector uses %s or ?
can you show your code
Checkpoint is datetime.now() - x days
Also it says time but it's really the date and time, ehh, not my database
I think it's ?
i thought you knew what i meant based on that
sorry
uhh one sec
query engines use placeholders in the query
instead of making you struggle w/ escaping and stuff
so instead of .execute('select * from foo where x = {x}'.format(x=1)) which is both cumbersome and dangerous (look up "sql injection") you do .execute('select * from foo where x = %s', (1,)) which lets the database engine correctly escape and process the input data
python lets database engines what to use for placeholder, e.g. %s or ?
note that %s is NOT the same as %s used by the % string operator
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
Oh ok
obviously thats not correct sql but
Neat, thanks
some query engines let you name the params
.execute('%(a)s %(b)s %(c)s', {'a':1,'b':2,'c':3}) but i dont remember which ones allow this
@harsh pulsar Everythings great, thanks for the help <3
Quick question, I know how to do "WHERE x IN (foo, bar)" but how do I do
"WHERE (foo) in x"
if x is a list in the second one
x is a column in the db?
cursor.execute('where %s in x', (foo,))?
wait
is this about string containment?
like you want to find a substring in a column?
One of the columns holds a list
I wanna check if one value is in that list
mysql.connector.errors.ProgrammingError: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near '<the column> at line 1
@harsh pulsar
im not a mariadb user, but afaik mysql doesnt support a native list/array datatype
i could be wrong
hey i just need some SQL help
SELECT * FROM table WHERE condition returns the correct row, but UPDATE table SET key = value WHERE condition just gives me UPDATE 0
i checked that the conditions are the same
is this that place to ask for help with sql queries?
This is our channel for questions related to databases, yes
Just doing an assignemnt and got this question:
"For each academic, give the acnum, givename, famname and the total number of papers s/he has written. Note that if an academic has not written any paper, his/her total should be zero. You can use or not use JOIN operators. "
i tried doing this:
SELECT academic.acnum, academic.givename, academic.famname, COUNT(author.panum)
FROM academic, author
WHERE academic.acnum = author.acnum
GROUP BY academic.acnum, academic.givename, academic.famname, author.acnum;
just confused how to add this:
"if an academic has not written any paper, his/her total should be zero"
Watch some videos on yt
@void otter any other specific suggestion?
You really can't learn databases alone
I learned a bit od sqlite while i was learning flask since i needed a db
„Watch some videos“ is bad advice
The PostgreSQL documentation has a great intro to SQL, including setting up Pg itself, see https://www.postgresql.org/docs/11/tutorial.html
hey sorry for a double post but there’s this, also its psql
or pg. whatever you want to call it
What do you guys think about using Google Sheets as a database? (Just in general, im curious!)
it's not a database
anything about 3000 rows and you start to experience latency issues
plus it can't handle special symbols and non locale languages when you try to send/receive json payloads
It has a lot of provision to be used as one certainly, but in the end it isn't
For lightweight stuff you could probably get away with it
But I really wonder why one would bother if one has the means to host a db themselves
I lead a clan in Warframe, and I have two groups of members: those who are in our discord server and those who are in our in-game clan. These groups partially overlap. I need to store some specific data on each member, like date of joining, clan points etc. How should I organize the database? Right now I see two solutions:
- One table, primary key is a simple self-incrementing id
- Two tables: one is for those who are in our discord with user id as primary key; the other is for the remaining in-game members with their aliases as primary key
Which one would be cleaner, easier to maintain and overall better? Maybe there are other solutions?
Will it let me insert values with NULL discord ids?
Yeah, gonna search that
It seems that I can exclude NULLs from the UNIQUE duplicate checking
what do you mean null discord IDs
everyone has IDs
and they are unique for each server arent they
I have two groups of members: those who are in our discord server and those who are in our in-game clan. These groups partially overlap
I mean some are in discord only, some are in clan only, but the majority is in both
ok I get it
you also arent tied to making the data a primary key, you can always leave that as some generic int and just set whatever fields you want to be unique, unique
and theres absolutely no problem inserting null values into columns
and two tables is definitely the right approach
if theres any mutuality in the data, you can always do a join
I think I'll try to put them all in one table with meaningless PK and unique discord ids / in-game names
thats fine as well
but just as a bit of a suggestion.
in the multitable example
you could for example have the warframe table just strictly represent the data available.
and then you could also include non-clan members in the dataset
and join on id = id, clan = myclan etc.
or get everyone to join the discord and avoid two sets of IDs altogether lol
its always convenient to keep the data in the same format it comes in as, and then manipulate it later. but thats completely your prerogative.
There are some lazy asses who don't want to be in discord, some just don't like it
Yeah, both categories need the same data stored. I want to move it from google sheets finally
It depends how much shared data they have
If there's a lot then I feel 1 table is better
Alright, thanks everyone. Now I just need to get myself a rpi and start using pgsql instead of sqlite
you can upload spreadsheet to bigquery
vrooom
No learning from that though, I want my own database
Another question. Right now clan ranks in the table are automated, thanks to the function that checks the date of joining and sum of points and shows the correct rank:
=IFS(AND(TODAY()-56>=F49, U49>=3),"4th Layer", AND(TODAY()-28>=F49, U49>=2),"3rd Layer", AND(TODAY()-14>=F49, U49>=1),"2nd Layer", ISBLANK(A49)=False,"1st Layer", True, "")
Can it be automated with triggers, or I need to run UPDATE daily?
Doesn't seem like triggers can handle that
For PostGreSQL I am trying to make it so I know how many collumns are in a table
length = await self.bot.pg_con.fetchrow("SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_catalog = 'Game Hub' AND table_name = 'users'")
print(length)```
This returns
``<Record count=12>``
So it is kinda what I want but is there a way I can have it be just be 12?Try len()
On the second thought, COUNT should return an interable with one value. Try length[0]
That works 😃 thanks
but one more thing i cant seem to figure out...
length = await self.bot.pg_con.fetchrow("SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_catalog = 'Game Hub' AND table_name = 'users'")```
How can I have this only return how many collumns are in a table thats values are true, so like
```python"length = await self.bot.pg_con.fetchrow("SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_catalog = 'Game Hub' AND table_name = 'users' AND ticket = $1", True)```when i do that it says that ticket is an unidentified column
How to move column from one table to other?
With one of JOIN queries I suppose
Try searching info about it, I'm on phone and don't remember the details besides there's multiple different joins
you can either go for joins if you need to just query the data
or you can do alter table and add the new column
Hey guys, I'm building a backend for a mobile app and I am trying to decide between GraphQl and a REST API. Any thoughts?
I'm a little concerned with version control. I don't want my app to break if someone uses an outdated version. Does anyone know if that is much of an issue? I.e., can Google Play/App Store push updates through instantly?
Moving columns != join queries, but moving columns sounds like XY. What are you trying to achieve?
guys? i created a database with a table and want to insert stuff but it isnt working it isn´t trowing errors.. but i also have nothing in my databse

@grizzled roost can u pls help me?
Well I'll be honest I've never worked with mysql and python in combination but shouldn't there be a way to "submit" a query?
I don't think you're doing that at this point, but I'll look at some docs
thx
ah
from looking at some examples from https://www.w3schools.com/python/python_mysql_create_table.asp
I found this line mycursor.execute("CREATE TABLE customers (name VARCHAR(255), address VARCHAR(255))")
so it does seem like you need to submit/execute a query like that
does this help?
maybe i think thx
and lastly, please don't tag helper randomly 🙂
dammm yes that explaines everything I needed to refresh my mysql stuff and forgott thast thx AAANNNDDD yes sry I wont do again thx for reminding not to ping u c:
@boreal shale your query in the screenshot wasn't terminated, sql needs to end in ;
yeah right also forgott that buuut it´s also working without
hello
i am trying to understand something regarding sqlalchemy
is it possible to query to return also the relationship?
I've set my .schema as the following:
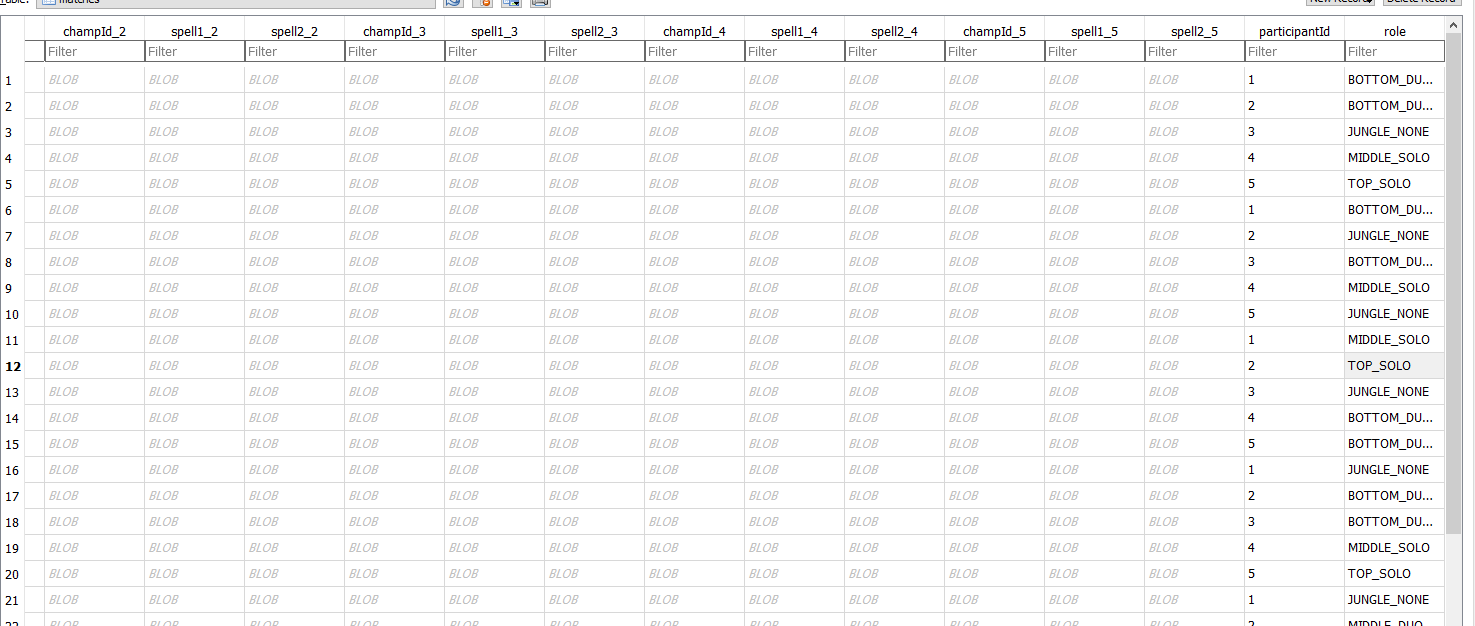
c.execute("""CREATE TABLE IF NOT EXISTS matches (champId_1 INTEGER,
spell1_1 INTEGER,
spell2_1 INTEGER,
champId_2 INTEGER,
but when I would look at it in DB Browser, I see that they are BLOB type, not INT
sqlite3
This is how I would INSERT
for row in blue:
print(row)
c.execute("INSERT INTO matches VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)", row)
conn.commit()
where row can be the following:
[412, 4, 14, 421, 11, 4, 145, 4, 7, 39, 4, 12, 24, 4, 12, 1, 'BOTTOM_DUO_SUPPORT']
Hello, I am using Google Firebase- Firestore
I want this:
doc_ref = db.document('GOPBOTdata', 'GOPBOTservers','Name of the server')
doc_ref.set({
u'WelcomeServerChannel': 458611220187054080,
u'ServerPrefix': True
})
It gives:
ValueError: A document must have an even number of path elements
So I tried:
doc_ref = db.collection('GOPBOTdata', 'GOPBOTservers','Name of the server')
doc_ref.set({
u'WelcomeServerChannel': 458611220187054080,
u'ServerPrefix': True
})
Gives:
AttributeError: 'CollectionReference' object has no attribute 'set'
How to fix this?
CollectionReference has add().
DocumentReference has set(), update() and delete().
Awesome thanks
hi I have this question
1.5) Return the acnum of academic(s) who wrote the largest number of papers. You must NOT use MAX. An SQL query that lists all academics in decreasing order of their total number of papers is incorrect.
how to di find out the largest number wihtout using max?
this is in oracle sql developer
what have you tried already?
for couchdb, is there an easy way to ipmort/export db from file?
so i can share the database on github with my collaborators
should i even be sharing the database on github?
Traceback (most recent call last):
File "main.py", line 16, in <module>
mydb = client["test"]
TypeError: string indices must be integers
@ionic pecan Can you help us?
the error tells you what you need to know - you're indexing a string with a string, can't do that
if test is a variable pointing to an integer, that would work, yes
@ionic pecan Im trying to create a new database in mongoDB
okay
Why isn't it working
can you show your full code?
client = os.environ.get("client")
print(client)
mydb = client['test']
mycol = mydb["customers"]
mydict = { "name": "John", "address": "Highway 37" }
x = mycol.insert_one(mydict)
myquery = { "address": "Highway 37" }
client = pymongo.MongoClient("mongodb+srv://######:###@ifuture-c5zf8.mongodb.net/test?retryWrites=true")
i'll need your full code, i'm not sure how these two snippets go together
Thats all the code I have that involves pymongo
you defined the client in an environment variable?
The environment is a file and I defined client in there
that won't really work that way
you'll need to define the client in your python code
Okay
Traceback (most recent call last):
File "main.py", line 16, in <module>
client = pymongo.MongoClient("mongodb+srv://####:##@ifuture-c5zf8.mongodb.net/test?retryWrites=true")
File "/home/runner/.local/lib/python3.6/site-packages/pymongo/mongo_client.py", line 524, in __init__
res = uri_parser.parse_uri(entity, port, warn=True)
File "/home/runner/.local/lib/python3.6/site-packages/pymongo/uri_parser.py", line 318, in parse_uri
raise ConfigurationError('The "dnspython" module must be '
pymongo.errors.ConfigurationError: The "dnspython" module must be installed to use mongodb+srv:// URIs
i don't quite know what you're trying to tell me with the traceback
any opinions on ORMs? thinking about trying out peewee
soo i have flask app on pythonanywhere and i cant connect to database which is on my vps
error is connectionrefused
i changed postgresql.conf listen_adresses = '*'
but still
maybe someone knows how to solve it
i read something. and people are saying that i should use sshtunneling
Forums : PythonAnywhere
but im still not sure
that post is for hosting postgres on pythonanywhere
do you have a firewall? if so, you need to add a rule that allows connections to port 5432 from the pythonanywhere host
i dont know if i have
im using ovh
2019-05-26 12:02:39,555: Error running WSGI application
2019-05-26 12:02:39,556: psycopg2.OperationalError: could not connect to server: Connection refused
2019-05-26 12:02:39,556: #011Is the server running on host "ip" and accepting
2019-05-26 12:02:39,556: #011TCP/IP connections on port 22?
2019-05-26 12:02:39,556:
2019-05-26 12:02:39,557: File "/var/www/stylus_pythonanywhere_com_wsgi.py", line 16, in <module>
2019-05-26 12:02:39,557: from flask_app import app as application # noqa
2019-05-26 12:02:39,557:
2019-05-26 12:02:39,557: File "/home/Stylus/mysite/flask_app.py", line 26, in <module>
2019-05-26 12:02:39,557: sql = """UPDATE cats
2019-05-26 12:02:39,557:
2019-05-26 12:02:39,558: File "/home/Stylus/.local/lib/python3.6/site-packages/psycopg2/__init__.py", line 126, in connect
2019-05-26 12:02:39,558: conn = _connect(dsn, connection_factory=connection_factory, **kwasync)```2019-05-26 15:08:57,057: Error running WSGI application
2019-05-26 15:08:57,062: psycopg2.OperationalError: could not connect to server: Connection refused
2019-05-26 15:08:57,062: #011Is the server running on host "x" and accepting
2019-05-26 15:08:57,062: #011TCP/IP connections on port 5432?
still
Hey does anyone know how to add music in pygame
with a #databases ?
Hey there :,)
I have doc_name, specialty_type and specialty.
I want to insert those values into a table doctors_specialties on a condition that a table doctors contains the value doc_name and that another table specialties contains the value specialty.
How would I do that in MySQL?
"Autonomous Databases" - Is this buzzwords like Blockchain or legit?
Gotcha, I'll look into that, thanks
Are there any good articles on safely caching database queries in memory?
Eg I write to table1 a few times a day, but need to query it several hundred times a day, and the table could potentially get big so I don't want to query the database directly every time
I just want to make sure I don't introduce race conditions or end up with a bad cache and start returning them direct results
I'm not terribly experienced in this area of programming so I don't have a great sense of what to even look out for
How/where do you want it to cache?
Hundred times a day does not sound like a load to the database
as long as you have proper indexes defined, it should not be an issue
Thats a good point. Not sure if it being sqlite matters
Was thinking of just caching in memory in python... like it would append to self.active_contracts whenever a new contract is proposed (a few times a day), and it would read off that list instead of querying for active contracts every time
And it would remove a contract from the list whenever it goes inactive
It seems like simple logic but i assume there are considerations im not aware of
well, you will need to limit cache size for sure, to not face out of memory error.
In addition to that if you are going to cache things in memory, you will need to make sure that are related to one specific entity are always hitting the same server.
also you might need a mechanism of cache invalidation and so on. If that is just an exercise then for sure you could/should try it.
No this is for a light duty hobby system but other people will use it and I don't want it to be unreliable
Right now the database is SQLite and the size of objects in cache will be small
But I see
It might be more complicated than it's worth
Well, just keep it simple, if you will actually see that your database becomes a bottle neck
then I would start thinking on how-to solve the problem
Good TY
I'm
maybe wait a bit more than 4 seconds to get a response, lol.
yh
I use PyQt5 for my project. I work on Sqlite3-based databases and I know that it includes QtSql, a database-related module, but I also know about Python's built-in sqlite3 module.
I kind of "accidentally" included methods from both modules in the project and that's because I would find an error or two when using one over the other in certain tasks. Both work fine for my very simple tasks and I don't want to edit them now, I just want some answers if possible
Are there solid reasons why should we prefer one over the other or what does each one miss that the other doesn't?
Qt SQL has integration with Qt, obviously
Like you could easily use a table as a provider for a model
I forget the correct term but hopefully you know what I mean with "provider"
The values need to be comma delimited
The values need to be separated by a comma
In your SQL
Yes
np
@pliant cedar please do not use the r-word in this server. Self-deprecating or otherwise.
Because it's derogatory, and thus inappropriate language to use here.
Any reason why the database is structured like this? https://github.com/ImagicTheCat/vRP/blob/master/vrp/base.lua#L20-L69

GitHub
FiveM (http://fivem.net) RP addon/framework. Contribute to ImagicTheCat/vRP development by creating an account on GitHub.
I don't see any advantage of using blob this case?
i'm using db browser for sqlite
is there a way to execute sql and export the given table to csv?
what are you querying.. do you just need the csv or do you need to maintain the database
<@&267628507062992896> <@&267629731250176001> <@&295488872404484098>
!ban 582962206849761299 Ping abuse
:incoming_envelope: :ok_hand: permanently banned @late olive (Ping abuse).
thanks :D
Wtf is happening
@plain radish I think these might be selfbots
It happened to me on another server
is safe to use accent for table name ?
don't do that
some systems won't detect that as a letter thingy
use english words
that's my advice
ok, also space in name is a bad idea too ?
👍
please help, how to write SELECT and assigment in MySQL
SELECT country_id = countries.id
FROM countries
WHERE codeName LIKE country_code;
this doesn't work
just do
SELECT country_id as countries.id FROM countries WHERE codeName LIKE country_code;
or isn't this what you mean?
@pliant oxide
SELECT country_id = countries.id
FROM countries
WHERE codeName IN country_code;
this doesn't work
why the country_id = countries.id ?
I want to find and assign country_id
I don't know how to do it properly
and this simple operation like "Find and store" is too difficult for me ;_;
SELECT country_id AS countries.id FROM countries WHERE codeName in country_code;
in what line?
36
but I mean underscore
countries_id? it doesn't make sense
don't get it, but how SELECT know that I need to store id?
what do you mean
you select something then you can store it later as something or insert it into a different table
I select only id, not entire row
can you paste the entire code
CREATE DEFINER=`root`@`%` PROCEDURE `add_airport`(airport_code VARCHAR(12), airport_name VARCHAR(128),
city_code VARCHAR(12), city_name VARCHAR(128),
country_code VARCHAR(12), country_name VARCHAR(128))
BEGIN
DECLARE city_id INT;
DECLARE country_id INT;
SELECT city_id = cities.id
FROM cities
WHERE codeName LIKE city_code;
IF city_id > 0 THEN
SELECT 'First IF';
INSERT INTO airports VALUES (NULL, city_id, airport_code, airport_name);
ELSE
SELECT 'SECONF IF';
SELECT country_id = countries.id
FROM countries
WHERE codeName LIKE country_code;
IF country_id > 0 THEN
SELECT '1 IF';
INSERT INTO cities VALUES (NULL, country_id, city_code, city_name);
ELSE
SELECT concat('2 IF', country_code);
INSERT INTO countries VALUES (NULL, country_code, country_name);
SELECT country_id = countries.id
FROM countries
WHERE codeName LIKE country_code;
INSERT INTO cities VALUES (NULL, country_id, city_code, city_name);
END IF;
SELECT city_id = cities.id
FROM cities
WHERE codeName LIKE city_code;
INSERT INTO airports VALUES (NULL, city_id, airport_code, airport_name);
END IF;
END
I'm working in workbench MySQL
the last END IF; is wrong just do END
I got error if I write "END" instead of "END IF"
There are 2 IF statements and we got two "END IF" what is wrong? :/
SET @something = NULL;
INSERT INTO eskycrawler_dev.countries VALUES (NULL, "PL", "Poland");
SELECT @something = countries.id
FROM countries
WHERE codeName LIKE 'PL';
SELECT @something;
This piece of code even doesn't work
it's simplified version
something is still NULL
this works
SET @something = NULL;
-- INSERT INTO eskycrawler_dev.countries VALUES (NULL, "PL", "Poland");
SELECT @something := countries.id
FROM countries
WHERE codeName LIKE 'PL';
wtf
SET @something = NULL;
INSERT INTO eskycrawler_dev.countries VALUES (NULL, "PL", "Poland");
SELECT countries.id AS @something
FROM countries
WHERE codeName LIKE 'PL';
try this
got solution
and know maybe why this works
if you want to know, I can write if you reply ;p
@something is like storing a variable
what is wrong here?
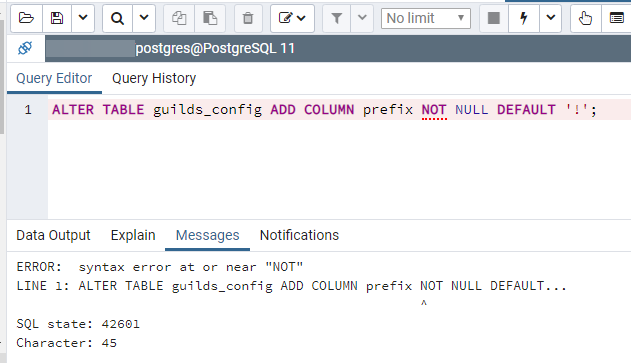
ALTER TABLE guilds_config ADD COLUMN prefix NOT NULL DEFAULT '!';
im gonna go crazy
where is the syntax error
help
wait
I forgot to specify the type of the column
im dumb, ignore me. thank you.
About how far does a mongodb scale before lacking in performance?
there is a way to get a dict or a tuple of (column, value) ?
From what?
from a sqlite3 database, select + cursor.fetchone
well, mb I missread the doc https://docs.python.org/3/library/sqlite3.html#sqlite3.Connection.row_factory
Well, it doesnt support it natively at least.
That is monkeypatching in a middleware to format the rows returned
better than nothing 🤷
Id imagine at least, i havent used it myself 😬
it work fine
and handler the case of there is no row
well, better than make a dict by myself
would anyone be able to help me set up a postgresql database on my linux server, Ive had a look at tutorials online but I just dk how to do it without the interface (im using ubuntu terminal)
If you have a more specific question about it in mind feel free to ask
here or in #unix if more appropriate
I just need help setting it up so I can use it as a leveling system for my bot. I just dk how to set up the database on linux because I cant see the interface you have on windows
Well the tutorials online should guide you through it
Why are you finding the tutorials to be inadequate?
Ive had a look but all of them were for the unbuntu you have a desktop on
I only have a terminal, which is why they dont work for me
I am just glancing at the tutorials. I see no reason why they wouldn't apply to your situation
They're all terminal commands
because the tutorials go through a desktop and app
I went here and clicked on a few tutorials
would u be able to link me some tutorials please ?
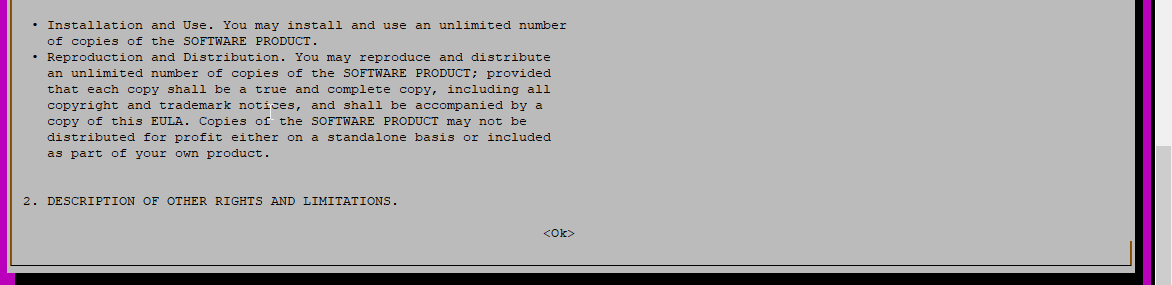
I did
scroll to the bottom and see what's there?
I exited full screen and its froze on this https://i.imgur.com/XgZvDR5.png

been froze like it for 5 minutes, tried restarting my server. Same result
Was that license coming from that package?
yes
So did you properly accept the license or what?
I had no way to accept the license , it went when I exited fullscreen
No I meant in the license thing
I honestly don't know cause I've never seen that sort of thing before
its not there anymore
it maybe the install im using
lemme restart my server and try again

DigitalOcean
Relational database management systems are a key component of many web sites and applications. They provide a structured way to store, organize, and access information. PostgreSQL, or Postgres, is a relational database management system that provides
I think ik why, its for ubuntu 16-04
ubuntu then?
Right at the top it shows a guide for 18.04
Here's the link then https://www.digitalocean.com/community/tutorials/how-to-install-and-use-postgresql-on-ubuntu-18-04

DigitalOcean
This tutorial provides instructions on how to install the PostgreSQL database software on an Ubuntu 18.04 server. It also includes instructions for basic database management.
thanks
https://i.imgur.com/5rtDpLj.png seems a bit better, its showing a progress bar
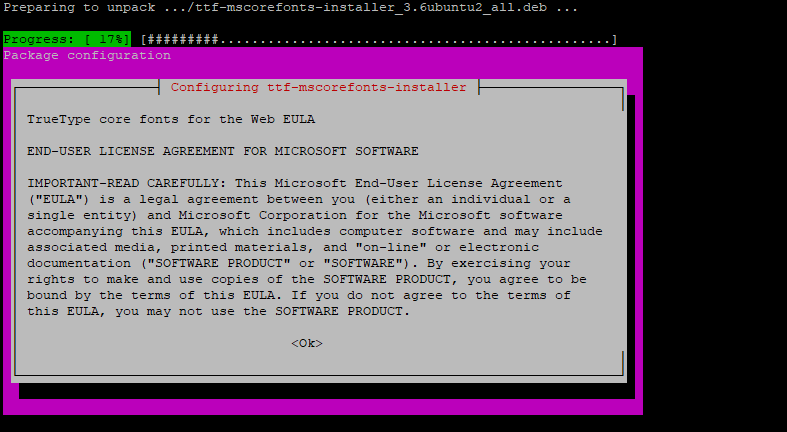
it seems to be freezing at a certain point, this point being 17%
Ok I found an answer for you https://askubuntu.com/a/16228/589656

Ask Ubuntu
After a recent update, ttf-mscorefonts-installer prompted me to accept its license agreement.
┌─────────────────┤ Configuring ttf-mscorefonts-installer ├─────────────────┐
│ ...
I'm surprised I haven't encountered this myself
how do I keep my database running ?
Using systemd to make it a service is probably the best way
does this look all good though ? https://i.imgur.com/VbPhh4u.png and Okay , ill read into it
Though I thought postgresql was already a service
Oh it may be, Its just on windows u have run it by default
https://i.imgur.com/vZ2JK9M.png is this what its meant to do ?

thats what it said to do on the website
That's a basic way of doing it
oh
read below and it shows how to make a service
I am pretty sure the command you used wont work out cause it will kill the process once you terminate the ssh connection
I dont see any other thing talking about service on that tutorial
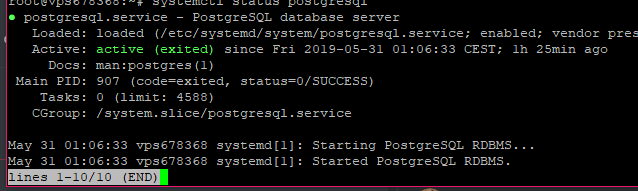
"When using systemd, you can use the following service unit file (e.g., at /etc/systemd/system/postgresql.service):"
Once you've got that going you can do sudo systemctl --now enable postgresql
https://i.imgur.com/ufz5xyN.png any reason I may have permissions denied when I have root access?
You're currently not the root user, you're the postegres user
You should be using sudo anyway to run your commands
https://i.imgur.com/XxjKl2w.png tried using sudo but this came up

Type exit so you leave the postegres user
I have a feeling you didn't even bother to create another user and just have root, which is bad...
I got told by my friend to just stay on root
No, while it may seem convenient, it's a security issue
o , Ill make a new account when I get all of this finished
https://i.imgur.com/qDcw1FY.png but this happened

You don't need to even run that command
Just make the service
All you need to do is create the service unit file in the directory they describe and then paste the contents below into the file
I used the service unit file but it said there was no directory
Do sudo touch /etc/systemd/system/postgresql.service
well I guess you don't need sudo since you're root...
then open the file in an editor and add the contents
I dont have an editor on terminal though ?
okay
Can you check if this file already exists? /usr/lib/systemd/system/postgresql.service
okay
I noticed that I already had it on my distro (Arch Linux)
no it does not
Ok so you do need to make it yourself I guess
continue with what I was saying before
okay
So you could try nano /etc/systemd/system/postgresql.service to open it in an editor
okay its opened in the editor
and ive copied all of the stuff from the docs into it

Yeah just press enter to confirm that filename
okay done
Now do systemctl --now enable postgresql and it should start up
To confirm that it's working, you can check systemctl status postgresql
https://i.imgur.com/R8RDWBf.png is this all good?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
yup 👍
thanks so much , im sorry im so slow. Im just not adapted to linux and how that all works yet
Now I gotta see if the database works with my bot x)
That's ok, you're getting the hang of it
so is it just running in the background now?
okay , lemme try it with my bot
oh damn
thats fancy , thanks for walking me through it<3
np
IMO I feel like the guide should have shown you how to do this 🤷
But they didn't bother I guess
tbh , sometimes I get lost in all of what its saying and find it hard to pick out whats relevant . Which is why ,in a second attempt, I came here for help to see if someone could guide me through it simper . Which they did 
I'm trying to connect to a mysql db with an ssh tunnel in a python flask app, I can connect with my desktop client (mysql workbench) with no issue, I'm however getting "Host 'my ip' is not allowed to connect to this MySQL server"), any clue?
app.config['SQLALCHEMY_BINDS'] = {'two' : 'mysql://{}:{}@{}/{}'.format(db_user, db_pw, host, db)}
tunnel = sshtunnel.SSHTunnelForwarder(
(host, 22), ssh_username=ssh_user, ssh_password=ssh_pw,
remote_bind_address=(localhost, 3306)
)
tunnel.start()
Can someone recommend a beginner guide for python and MySQL? (English or German)
I just learned python yesterday from this https://docs.python.org/3/tutorial/index.html
Just seen there is this channel so posting in here too.
I have a question on modelling data (I suppose it's not specific to python, but doing this in django). I always get confused with related models. How do I model a related table that can have only one at a time, but want to keep a historical record. Eg a user can have one address (not supporting multiple properties) but can have previous addresses in the past that we want to look up. What's the best way to model this?
You'll want to have unique keys not just on the unique column, but unique column + column tracking deleted records in a unique way (often the timestamp of deletion).
What I mean with this is
table: Users
columns: id INT
table addresses
columns id INT, user_id INT (FK), deleted_date
Unique key: (user_id + deleted_date)
Now the last thing to realise is that often, depending on your database, a NULL value in 2 different rows won't be seen as equal. so
addresses:
id | user_id | deleted_date
1 | 1 | NULL
2 | 1 | NULL
Would actually be valid for a lot of databases, even with a unique key over user_id + deleted_date.
So - depending on the database - you want to set a default value so it'll become
addresses:
id | user_id | deleted_date
1 | 1 | 0
2 | 1 | 0
Which the database would complain about.
To google for more, these " historical records" records you want, aka, not really deleting thigns is called "soft deletes".
database unique soft deletes should give you more articles with info.
Thanks, that's a lot to get my head around. I'll google for a bit more detail as you suggested. (I should have mentioned I'm using django and postgres)
Postgres indeed does not see 2 NULL values as equal.
Hmmm debating if I could just do a foreignkey to address and have the address have something like an occupied_from and left_on date (or a current flag) and that might be an easier implementation as typically users will only have a few prior addresses
How frequent is deletion vs changes?
if you're mainly doing changes, an "effective date" may be more efficient to query than "deleted date", though you'd need dummy records to represent being really deleted
@celest plank
since you can just find the row corresponding to the max value (or the max value less than a historical date being queried)
oh i see you came up with occupied_from, that's basically the same thing
Is there a type of local json database?
one that doesn't store in the cloud or anything
sorta like mongo
there you go lepto
I'm using a MariaDB and I print out the variable, but it formats it weirdly, does anyone know why?
what do you mean weirdly
print message: ('RedstoneDaedalus', 'Deathrohk', 'NoahLikesPi', 'lukecashwell')
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: ProgrammingError: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near ''(\'RedstoneDaedalus\', \'Deathrohk\', \'NoahLikesPi\', \'lukecashwell\', \'1All' at line 1
@void otter
Why the double '' and \s
try updating your packages
what do you mean? I'm using mySql-connector, update that?
Sorry, just went, I did it differently, I just selected everything and did an "if", probably not the best, but there's only like 50-100 records, so it's not that bad
does it work?
anyone here familiar with mongodb? if so, what's the maximum size for each document?
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="root",
database="mysql",
auth_plugin="mysql_native_password"
)
print(mydb)```mysql.connector.errors.NotSupportedError: Authentication plugin 'caching_sha2_password' is not supported
is that a question?
CREATE TABLE restaurant (id int, name text);
CREATE TABLE menu (id int, name text, restaurant_id int, foreign key (restaurant_id) references restaurant(id));
CREATE TABLE menu_item (id int, name text, menu_id int, foreign key (menu_id) references menu(id));
restaurant
-----------------
0|Limoncello
menu
-----------------------
0|limoncello menu|0
menu_item
----------------------
0|steak|0
1|chicken|0
@stone jacinth
seperate tables are more intuitive to a person, yeah. the issue is that if you want to add a new menu, you have to change the entire database, and apply a migration
An interesting
with a database, you want to group each "type" of item in its own table, whether they're 100% related or not, just so long as they have the same structure
so you have a table for restaurants, a table for menus, with each menu referencing the restaurant it belongs to, and a table for menu_items, with each menu referencing the menu it belongs to.
individual tables might seem intuitive, but then you're doing the db's work manually
could you just have your menu_item table reference the restaurant?
what's the benefit of the menu table?
most restaurants have multiple menus
lunch, dinner, specials, wine, etc
but if each only has one menu, then yeah, cut out the menu table :P
no problem!
how do you see what columns you have
I tried to do select * but number of columns was too much apparently..
lemme see if that works here
what database engine are you using
@lusty sandal In a relational database, you normally only want to store one "atomic" value per attribute/field of your database table
Otherwise, it will be difficult to filter the items by category, it's difficult to ensure the integrity of the data in the list, and so on
A way around that would be to create three tables:
- One with the items in question
- One with the possible categories
- One table that relates items to categories
If you have a fixed number of categories, then you could use something like a Boolean column for each category instead and go with just one (or two) tables.
there are arrays in certain SQL databases
sqlite doesn't
if category is actually just a string, and no other data you can just make use of arrays
That is true, so it depends on your specific database engine and your needs
However, they were talking of creating a comma-separated string manually in the help channel, which is probably not a good idea. So, if you have a db engine that supports arrays and those suit your needs, that's another option as well
@lusty sandal you can use a separate table with a foreign key for the categories
it will make easier to search which objects are in a certain category, really fast
Thanks for that. but actually each record will have multiple categories. how would that work? 😐 I'm not savvy with sql :/
It's called many to many relation. Just Google for it ;)
I've been trying to google every possible thing but I just can't seem to get where I want with any way other than having as value "category1,category2,category3"
I'm having a bit of a blank right now. I'm wanting to create a table, that has a one input for each category type, but then has multiple inputs for a final category. I'd like to make another table with these inputs because they have their own attributes as well... but I forget, do I use foreign keys for this? I will attempt to draw a diagram that makes more sense.
Like this, with banks for example.
A foreign key is for referencing records that are in another table
If that's what you wanted to do, then use a foreign key
Good evening folks. I'm trying to use pyodbc to connect to Oracle servers at work and it isn't letting me. I have spoken to a coworker and he said it might be because the server's version is too old to work with pyodbc. Does that make sense and what else should I try instead?
I have tried it but it also gives me errors when trying to connect.
And pyodbc works with the netezza servers.
Do you know which version of the db you're using?
I don't know about pyodbc, but cx_Oracle works with 11.2+
Actually, may be as far back as 9.2
Oracle Help Center
To get started with database administration, you must understand basic database concepts, such as the types of database users, database security, and privileges. You must also be able to complete basic tasks, such as submitting commands and SQL to the database and creating a ...
using sqlite, can I limit the number of different results and not limit the total results? an example of what I mean while limiting 3:
num15
num15
num15
num13
num13
num20
to show all available num15,num13,num20
if you're using python you can append the num3 once and the rest as many times as you want and than add the list as a value to a dict with for example key Num. and then use a pandas dataframe to make it into rows and columns
so
if num3 not in List1:
List1.append(num3)
else:
pass
that would work I think, I've used it before on my data
@lusty sandal
anyone got any tips for making databases. I've started learning it at school but a lot of the time i cant tell whether tables should have one to many or many to one links etc. Also i struggle with ensuring my databases are in 3rd normal form (Thats as high as we're told to go). Thanks 😃
hey querying optimization question. I have a query that does an outer join with the sole purpose of ordering by the joined table.create_date. Finding the outerjoin to be expensive, any way of avoiding this?
@pure cypress BTW I fixed my problem.
Anyone have any resources on best practices when it comes to cloud managed database solutions (e.g. AWS RDS, Google Cloud SQL)? Having a hard time figuring how if I should do my own backups outside of their prebuilt ones which only have PITR for 7 days
how do i send a sqlite server within a python response
mongodb atlas, how do i update items in an object without replacing the whole object ? ```dataUpdate = {
'Currencies':{
'Wood':woodData
},
'Profile':{
'Experience':expData
}
}
self.records.update_one({'userID':str(ctx.author.id)}, {'$set':dataUpdate})``` this is currently replacing my whole object
Hi. I am creating a network of GoT character. I have it all set up, but i am trying to display names instead of nodes. I nailed the names, now i am trying to display names in a way, so that their size depends on the character connection. I hope i was clear what the problem is. Can anyone help?
def network():
G=nx.Graph()
for i in range(len(intermatrix)): # ustvari vozle
G.add_node(i)
for i in range(len(intermatrix)): # doda povezave
for j in range(i+1,len(intermatrix),1):
if e[i,j]>0.0:
G.add_edge(i,j)
labels0 = [line.rstrip('\n') for line in open('characters.txt')] # uvozi imena
labels={}
for lll in range(len(labels0)):
labels[lll]=labels0[lll]
#lege=nx.spring_layout(G,scale=100,k=0.2)
lege=nx.fruchterman_reingold_layout(G,k=2.0/np.sqrt(len(intermatrix)))
nx.draw(G, lege, node_size=0, node_color='blue', alpha=0.9, linewidths=0.3, edge_color='grey', width = 0.4)
nx.draw_networkx_labels(G,lege,labels,font_size=4,font_color='k')
plt.gcf().text(0.06, 0.99, 'Character network', fontsize=9)
plt.axis('off')
'''plt.xlim(-0.15,1.15)
plt.ylim(-0.15,1.15)'''
filename='character_network.png'
plt.savefig(filename,dpi=200,bbox_inches="tight")
plt.show()
plt.close()```Maybe that's a question for #databases?
And if someone's going to help you they will
Just be patient
I'm sure you'll get the help you need
So I'm kind of getting mindfucked. I'm using sqlite3, and I'm trying to search for a var (which has assigned "discord" for example) in a column called PLATFORM in a table called DATA. And I can't seem the figure out the correct syntax to .execute it
I was thinking something like this:
transfer.execute("SELECT * FROM Data where PLATFORM = "+var+"")
But it gives this error: sqlite3.OperationalError: no such column: discord
var = "discord"
Try:
transfer.execute("SELECT * FROM Data WHERE PLATFORM = '{}';".format(var))
Strings typically need single quotes around them to execute properly.
I havent used sqlite3 though, that's how I would do it in MySQL
you shouldn't be using .format or + for sql queries, as that might open you up to injection vulns
That's true, if the variable is defined by a user.
@graceful nimbus transfer.execute("SELECT * FROM Data where PLATFORM = ?", (var,))
using parameterization has other advantages, not just sql injection prevention - it frees you from escape/quote hell, and can be optmized at query compliation level by the database @coral panther
Is there a way to alter a column name in sqlite3?
ALTER TABLE I think
Do you happen to know what specifically goes after the table name?
from the top of my head, no
I accidentally created an ambigious column name and now it won't accept it in my joined tables.
but it should be a google query away
you can prefix the column name with the source table name to resolve ambiguities in joins
ALTER TABLE mytable RENAME COLUMN badname TO goodname
SELECT table1.foo, table2.foo FROM table1 JOIN table2 ON table1.bar = table2.baz
Alright, thanks. I had found stuff for other SQL types but not sqlite.
Yikes. Still throwing an error.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
sqlite3.OperationalError: near "COLUMN": syntax error
I would sincerely hate to have to drop and remake this; it has 40000 some entries in it.
show your join @subtle galleon
I ended up dropping it. But I still have the join saved.
c.execute("SELECT sum(endos), regions.region_name FROM nations INNER JOIN regions ON regions.regionID = regionID WHERE regionID=? AND (status=? OR status=?)", (id,"WA Member", "WA Delegate"))
FROM nations INNER JOIN regions ON regions.regionID = nations.regionID
that is all you need
just prefix the ambiguous column with the name of the table
I did do that as well, but it was giving me operation errors still.
I can show a screenshot... if I can find it.
It's above 40000 some cursor objects.
by the way, you need sqlite version 3.25, and the version included with python is older than that; you'd need to run that query in the standalone sqlite3 client (outside python)
(the rename column one)
...oh. That's why.
Yeah, it's fairly impossible to find in the sea of cursor objects.
well, you don't have to rename columns to make joins, that would be hell
I have lots of tables with the same column and those are just the columns that I need to join
Not sure why it kept giving me syntax errors then.
Yesterday it worked fine when I had two different names.
otherwise I would run out of nice names fast
On the topic of sqlite3, how do I limit my query to the top 100 results, for future reference?
I tried SELECT TOP 100 (columnnames) FROM table but it didn't work.
Hey all, I am having an issue with a certain query i am running within my python script. For some brief context, my script pulls a bunch of data via an api, does some manipulation and then inserts it into a MSSQL Server database.
The issue i am having is with the following query when ever there is a name (first or last) that contains a single '
Query:sql MERGE looker.looker_scratch.namsortemp AS target USING (SELECT '{firstName}' AS firstName ,'{lastName}' AS lastName ,'{likelygender}' AS likelygender ,'{countryoforigin}' AS countryoforigin ,'{regionoforigin}' AS regionoforigin) AS source (firstName, lastName, likelygender, countryoforigin, regionoforigin) ON target.firstname = '{firstName}' and target.lastname = '{lastName}' WHEN NOT MATCHED BY TARGET THEN INSERT (firstName, lastName, likelygender, countryoforigin, regionoforigin) VALUES (?, ?, ?, ?, ?) WHEN MATCHED THEN UPDATE SET target.firstname = '{firstName}' ,target.lastname = '{lastName}' ,target.likelygender = '{likelygender}' ,target.countryoforigin = '{countryoforigin}' ,target.regionoforigin = '{regionoforigin}';
i understand the issue, given that when a name comes in with a ' it obviously confuses python
how can i alter the query above, or potentially a different spot in my code, to cater for this?
these are the variables that are being piped into the above query py firstName = genderdata['firstName'] lastName = genderdata['lastName'] likelygender = genderdata['likelyGender'] countryoforigin = origindata['countryOrigin'] regionoforigin = origindata['regionOrigin']
here is my code @pure scroll

A fast intuitive paste service.
it is very messy still as i just started putting it together, and i am by no means a python expert, so im sure there are plenty of other things that could be better
your problem is that you are mixing passing arguments and injecting them directly
most of the times you don';t want to inject parameters into the query string directly since that may open the doors to sql injection
I'm not really sure what your mysql python driver supports
but by the standart there should be a way to insert parameter by names
https://www.python.org/dev/peps/pep-0249/#paramstyle
Python.org
The official home of the Python Programming Language
that should do the job for you if you will replace all your f-string formatting with it
im not using mysql, im using MSSQL Server, not sure if that makes a difference
yeah it does not 😃
coolies
it's all about the library that you use
ill take a look at the article you showed me
it might that that it does not follow this standart so it has it's own way of inserting values into the template
ahh ok, well as far as im aware, the library im using for my database connection is the stock standard / most common one to use in my case, so hopefully it does
ill take a look and give it a go, appreciate it!
@pure scroll I assume this is me lacking some understanding here, but I would assume based off what i am already doing, and what it says in the document, that i would want to change those variables to ? same as i have for values, but then i obviously end up getting an error where i am now passing 17 values instead of 5
what am i missing here? I feel like its something painfully obvious
well it might accept named params, so you are able to pass them not by position by using ? but by name using :
if not then yeah, you would have to pass it more than just 5 times
makes sense, will give it a go thanks
Hello guys
can someone help me with sqlalchemy 😄
I'm trying to do something with association_proxy
This is the code in question
friends = association_proxy('a_friend', 'friend_b',
creator=lambda u: Friendship(friend_b=u))
Right now I can get friends back if its on the first col (friend_b). The problem rises that if it is on the second fol (friend_a) I don't get any result back
How do I go about doing a double check there without setting a different association_proxy
What's your model like?
Just this?
Friend 1..* ----- 0..* Friendship 0..* ----- 1..* Friend
class Friendship(db.Model):
__tablename__ = "friendship"
id = db.Column('id', db.Integer(), primary_key=True, nullable=False)
chatKey = db.Column('key', db.String(128), nullable=False)
friend_a_id = db.Column(db.ForeignKey('user.id'))
friend_a = db.relationship('User',
primaryjoin=friend_a_id == User.id,
back_populates='a_friend')
friend_b_id = db.Column(db.ForeignKey('user.id'))
friend_b = db.relationship('User',
primaryjoin=friend_b_id == User.id,
back_populates='b_friend')
messages = db.relationship('Message', backref='friendship_chat')
The table in question
I mean friendship table
this is user table
class User(db.Model, UserMixin):
__tablename__ = "user"
id = db.Column('id', db.Integer(), primary_key=True, nullable=False)
username = db.Column('username', db.String(128), nullable=False)
password = db.Column('password', db.String(128), nullable=False)
messages = db.relationship('Message', backref='user')
a_friend = db.relationship('Friendship',
primaryjoin=lambda: User.id == Friendship.friend_a_id,
back_populates='friend_a')
friends = association_proxy('a_friend', 'friend_b',
creator=lambda u: Friendship(friend_b=u))
rooms = association_proxy('a_friend', 'chatKey',
creator=lambda u: Friendship(friend_b=u))
b_friend = db.relationship('Friendship',
primaryjoin=lambda: User.id == Friendship.friend_b_id,
back_populates='friend_b')
I'm doing a chat app and its using self many to many relationship
a user will have many users as friends
and it should refer its class to get the users
one way works but if the user is found on the second col it doesn't get the friends.
I can fix it with another association_proxy col but I would like it to be on the same col as friends
ah yea I understand the issue now.
There are many way to do this but sqlalchemy docs is so confusing
I have yet to understand what association_proxy is doing
I don't think it applies in this case per se.
This code was implemented from a reddit post. I just changed a few variables to fix it (since it dind't work)
I have knowledge about sqlalchemy though
What you want is.. I guess mostly called a "self referencing many-to-many"
yeah thats how its called
I have googled a bit about that but no luck so far in implementing it properly. Most solutions didn't work for me and this one causes this issue
Found another way to make the ralationship 😄
How did you do it?
Cause I actually dont see a way to do this without having 2 friendship relations if both friends want to see each other as friend.
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(255))
friends = relationship('User',
secondary=friendship,
primaryjoin=id==friendship.c.user_id,
secondaryjoin=id==friendship.c.friend_id)
def befriend(self, friend):
if friend not in self.friends:
self.friends.append(friend)
friend.friends.append(self)
def unfriend(self, friend):
if friend in self.friends:
self.friends.remove(friend)
friend.friends.remove(self)
def __repr__(self):
return '<User(name=|%s|)>' % self.name
friendship = Table(
'friendships', Base.metadata,
Column('user_id', Integer, ForeignKey('users.id'), index=True),
Column('friend_id', Integer, ForeignKey('users.id')),
UniqueConstraint('user_id', 'friend_id', name='unique_friendships'))
much simplier
okay, so that essentially makes 2 friendships per relation between 2 users as I thought.
Now i just need a way to convert that Table into a class xD
@cerulean pendant That worked, thank you.
The association proxy could still be useful if you wish to get your friends often without caring about the friendship properties.
class User(Base):
__tablename__ = "users"
id = Column('id', Integer(), primary_key=True, nullable=False)
username = Column('username', String(128), nullable=False)
password = Column('password', String(128), nullable=False)
# messages = relationship('Message', backref='user')
friendships = relationship('Friendship',
primaryjoin=lambda: User.id == Friendship.friend_a_id,
back_populates='friend_a')
friends = association_proxy('friendships', 'friend_b',
creator=lambda friend: Friendship(friend_b=friend, chatKey=''))
def befriend(self, friend):
if friend not in self.friends:
self.friends.append(friend)
friend.friends.append(self)
# Without association proxy
def befriend2(self, friend):
if friend not in [friendship.friend_b
for friendship in self.friendships]:
self.friendships.append(Friendship(friend_a=self, friend_b=friend))
friend.friendships.append(Friendship(friend_a=friend,
friend_b=self))
def unfriend(self, friend):
if friend in self.friends:
self.friends.remove(friend)
friend.friends.remove(self)
class Friendship(Base):
__tablename__ = "friendships"
id = Column('id', Integer(), primary_key=True, nullable=False)
chatKey = Column('key', String(128), nullable=False)
friend_a_id = Column(ForeignKey('users.id'))
friend_a = relationship('User',
primaryjoin=friend_a_id == User.id,
back_populates='friendships')
friend_b_id = Column(ForeignKey('users.id'))
friend_b = relationship('User',
primaryjoin=friend_b_id == User.id)
# messages = relationship('Message', backref='friendship_chat')
befriend2 is what you'd need, kinda, without association proxy.
and then (with association proxy) user.friends will be a list of User objects. user.friendships will be a list of the friendship objects
@hazy crystal
Wouldn't that run into the issue of Userb not getting friends if it was initiated from UserA. Bcz you are doing one join in this case
the befriend methods will set the friendship in the other direction.
So if userA befriends userB, userB will also get A added to the friends
HI All! I'm working with pymysql to update a record in a MySQL database, and the variables are correct, but this runs without an error, but it doesn't update the row
cursor.execute("UPDATE places SET `longitude`=%s AND `latitude`=%s WHERE `id`=%s" , (long, lat, theID))
Any ideas?
Thanks, I'm a bit of a noob at Python, I confess
@mystic hedge do you commit the transaction?
You mean cursor.commit() ?
I saw that somewhere and I thought about it.. but no to answer your question, no
1 sec
I think .commit() is a method on the connection, not cursor
OH.. cause I just got an error: AttributeError: 'DictCursor' object has no attribute 'commit'
So, I just used the connection which is "db".. db.commit() .. and no dice..
I'm using pymysql.. could that be the issue?
Maybe you're referring to another package?
Then my guess is you don't have any entry with id equal to theID in the database - can you check that manually?
yeah, I do.. It's actually within a loop, and it's the first entry.. here's the output
-86.570008
34.783156500000004
1
Long, lat, and ID
do you do the insert and update in the same transaction?
I'm not inserting anything, I'm just updating
ah, I misunderstood the "within a loop" then
okay - if you do a ```py
cursor.execute("SELECT * FROM places WHERE id=%s", (theID,))
print(cursor.fetchall())
in the same program executing the update, does it print anything?Actually, that's the exact code that I have to create the for each loop (i'm sry, I don't know how to say it any other way)
I mean, iterate
Yea, it does do something, I do get the right data from that.. It's just when I get within that foreach iteration, I can't seem to commit the changes to the DB
hmmm
can you post your full code here? or on https://paste.pydis.com if it's too long
make sure to remove connection strings for the database
to check whether the values updated, do you check the output of this program via the print statements or some other way?
Hm. I have a feeling that Querious might see some old version of the data, is there some way to refresh the query result?
Yeah, I've refreshed it several times, and it's not changed at all
Again, the 'pymysql' package works, right?
it does if youre using python >=3.5 or python 2.7
i never use pymysql on its own, so i'm really not an expert, but i do notice that the pymysql quickstart and examples use context managers to commit in a transaction
So close first?
You could try moving the db.commit() below the loop and closing the cursor before running that - aside from that I'm out of ideas
you could always just use autocommit=True, but ehhhh
well i mean they also open it in a context manager using with
this i a good practice in general and since i dont know much about the library and since their own examples show it using this method, i would start with that
create the cursor inside a ctx manager with with db.cursor() as cursor:, execute whatver you need inside that block, then db.commit() once you're outside of that black. the cursor will have been closed propertly automatically and then it seems that's when to commit
all their docs and examples demonstrate this pattern which is not uncommon
there is almost certainly a way to do it without the context manager but you should not really bother trying to look for it
Ok, thx guys! i really appreciate it
Is there another library you
recommend?
Even with their example copied, with some modifications I'm still getting the same
I FIGURED IT OUT!
Before, the code was like this:
UPDATE places SET `longitude`=%s AND `latitude`=%s
It SHOULD have had a comma where I had AND
like this:
UPDATE places SET `longitude`=%s, `latitude`=%s
I'm sorry about that guys, I messed it
up
hahaha
love it
@mystic hedge it's okay one of my engineers spent 4 hours debugging what turned out to be a rogue .
still a good practice to use context managers and such
not a better mysql lib most likely but im a postgres guy in general. i do prefer to use a layer or two above raw sql in general though. either a full ORM or just a query builder but that's my preference
nice
i prefer to write things like: python db.table('videos').where('views', '>=', 500000).order_by('views', 'desc').first() or ```python
Video.update(is_public=False).where(Video.published_at.is_null())
Does anyone know which application in redhat I can use to open and edit sqlite3 databases?
Kexi didn't work
@ornate isle I totally agree. I come from the PHP world and we have lots of abstraction layers (and that snippet you gave looks almost like Laravel PHP) .. I appreciate your help!
@short holly install sqlitebrowser if you want a gui. sqlite3 on the command line obviously for doing it that way. never heard of kexi. 'dbeaver' is another free multi-db gui that would work. also almost anything commercial like datagrip will work with it
Hello everyone
Do you guys think 30 is too late to career change?
tech is such a cool industry
@stone jacinth that’s more of a question for #career-advice
length = await self.bot.pg_con.fetchrow("SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_catalog = 'Game Hub' AND table_name = 'users')```
So, right now this will grab how many columns are in my table but can I filter this? Like if I want it to only count values that fit a param (like if a value is true, then it will count it but if it is false it won't)just add it to where part of sql statement?
(f"INSERT INTO [table](type, executor, victim, reason, endtime) VALUES ('{what}', '{whom}', '{who}', '{why}', '{new_time}');")``` why does this give me an `ProgrammingError`?Hello there.
I've read through the documents, and I believe I have a question I would like to ask with respect to docker, sql lite, and migrations for testing my django app. However, I'm not sure the best way to do this
I have posted the question on stack overflow here

Stack Overflow
Problem
Honestly, I'm just firing this one into the dark because I have exhausted every possible avenue before asking this. I'm not sure what the problem is here.
I have a Django application that...
Is there someone who might be able to weigh in on this and correct any misunderstanding I have on how to achieve my goal?
2019-06-08T09:27:03.180820+00:00 app[worker.1]: Ignoring exception in on_message_edit 2019-06-08T09:27:03.182090+00:00 app[worker.1]: Traceback (most recent call last): 2019-06-08T09:27:03.182146+00:00 app[worker.1]: File "/app/.heroku/python/lib/python3.6/site-packages/discord/client.py", line 307, in _run_event 2019-06-08T09:27:03.182149+00:00 app[worker.1]: yield from getattr(self, event)(*args, **kwargs) 2019-06-08T09:27:03.182150+00:00 app[worker.1]: File "spark.py", line 461, in on_message_edit 2019-06-08T09:27:03.182152+00:00 app[worker.1]: channid = str(get_log_channel(before.server.id)) 2019-06-08T09:27:03.182156+00:00 app[worker.1]: File "spark.py", line 170, in get_log_channel 2019-06-08T09:27:03.182157+00:00 app[worker.1]: create_server_if_not_exists(server_id) 2019-06-08T09:27:03.182180+00:00 app[worker.1]: File "spark.py", line 134, in create_server_if_not_exists 2019-06-08T09:27:03.182182+00:00 app[worker.1]: c.execute("INSERT INTO Servers VALUES (%s, %s, %s, %s, %s)", (str(server_id), str(""), str(""), False, False, "")) 2019-06-08T09:27:03.182242+00:00 app[worker.1]: TypeError: not all arguments converted during string formatting```
The function that appears to be creating thses errors is:
```py
def create_server_if_not_exists(server_id: str):
c.execute("SELECT COUNT(*) FROM Servers WHERE ServerID=%s", (str(server_id),))
server_count = c.fetchone()[0]
if server_count < 1:
print("[Servers Table] Creating server with id " + str(server_id))
c.execute("INSERT INTO Servers VALUES (%s, %s, %s, %s, %s)", (str(server_id), str(""), str(""), False, False, ""))
db.commit()```
The table is created like this:
```c.execute("""CREATE TABLE IF NOT EXISTS Servers( ServerID BIGSERIAL, Logchannel TEXT, Welcomechannel TEXT, Welcomertf BOOLEAN, Logtf BOOLEAN, Joinrole TEXT)""")```
Please tag me when you awnser, thanks in advance@terse stump Could you help me please m8?
See how you have %s, %s, %s, %s, %s 5 places for strings but you pass (str(server_id), str(""), str(""), False, False, "" 6
and btw % formatting (which is terrible) already converts all args to strings
@torn sphinx Using Python format to condition quires provides anyone that can put something into your query full access to your database to do whatever they want with it
And anyway
You shouldn't be using %s for formatting
!tag f-strings
f-strings
In Python, there are several ways to do string interpolation, including using %s's and by using the + operator to concatenate strings together. However, because some of these methods offer poor readability and require typecasting to prevent errors, you should for the most part be using a feature called format strings.
In Python 3.6 or later, we can use f-strings like this:
snake = "Pythons"
print(f"{snake} are some of the largest snakes in the world")
In earlier versions of Python or in projects where backwards compatibility is very important, use str.format() like this:
snake = "Pythons"
# With str.format() you can either use indexes
print("{0} are some of the largest snakes in the world".format(snake))
# Or keyword arguments
print("{family} are some of the largest snakes in the world".format(family=snake))
That is not what I said
wait what driver are you using
I was going to use fstrings, I love em the dB system is old and I don't have the patience to rewrok it
sqlite? psycopg?
Whether or not you have the patience
Someone could wipe your entire db with the way you have it set up
If he uses pysqlite ? formatting is the best way
Be careful do you do not open your code to SQL injection
Your driver will have documentation on this
Using ? Is what I do
psycopg doesn't support ? iirc
I have never used it, should be some documentation on it
There you go @torn sphinx
Guys, I'm not sure if this question fits here as it's not a specific "database", but here's my question.
I made a really simple script to scrap some forum threads from time to time, and when the script finds a thread it fits the requirements, it interacts with it and also add the thread id to a .json to avoid duplicities.
I have the script gitted, in github, so I have it backed up, everything except the .json, how could I have it "updated" so if I lose the files I can recover the json?
I guess doing it in github would be a bad idea? as I would have to commit a lot of times per day
@scarlet cedar what site are you scraping?
Thanks for the input @indigo mason , but it's not anything illegal, just recollecting some data
@hazy mango It's a forum
It may not be illegal but it might break their ToS
Which forum @scarlet cedar that's what I meant
I don't wanna spam the channel, let's not diverge
Any PONY ORM users here? I am struggling with a TypeError.
"TypeError: Invalid value for attribute"
The attribute is set as Required(str) and the input to it is "Temperature" which should not give any issues from what I can tell. I have made multiple classes with relations and double checked them using https://editor.ponyorm.com without any luck in figuring out where the root of my problem comes from.
It's a script that should be used to load a CSV file into a db.
Im trying to dive into SQL (sqlite specifically) and im just browsing other code to try and understand foreign keys. my google searching has been exhausted!
more specifically trying to reverse engineer some code from "InstaPy"
SQL_CREATE_ACCOUNTS_PROGRESS_TABLE = """
CREATE TABLE IF NOT EXISTS `accountsProgress` (
`profile_id` INTEGER NOT NULL,
`followers` INTEGER NOT NULL,
`following` INTEGER NOT NULL,
`total_posts` INTEGER NOT NULL,
`created` DATETIME NOT NULL,
`modified` DATETIME NOT NULL,
CONSTRAINT `fk_accountsProgress_profiles1`
FOREIGN KEY(`profile_id`) REFERENCES `profiles`(`id`));"""
what does the fk_accountsProgress_profiles1 mean?
I know that profiles is another table but the 1 is confusing me
Hi all! Is there someone who might have the chance to help me with an issue using docker, django, and some failed migrations that only happen in the container
@tacit elk It's just the name of the constraint. Sometimes people don't bother naming their constraints and let the database automatically assign a name. In this case, they explicitly give it a name. I don't think the "1" at the end means anything
@void flower Just go ahead and ask your question
Ok
I have a stack overflow post here
Stack Overflow
Problem
Honestly, I'm just firing this one into the dark because I have exhausted every possible avenue before asking this. I'm not sure what the problem is here.
I have a Django application that...
But the gist of it, is that I can run migrations locally and run my tests locally perfectly fine
I'm using django and docker right now
When I run the code in docker thought my django system checks fail
That's their own comment
Yeah
@pure cypress ok so if I didn't add a constraint it would effectively do the same thing linking the foreign key?
that would fall in line with the documentation i've read
@tacit elk Yeah cause I think naming constraints is optional, at least for the databases I've worked with. By the way, if you didn't know, a "foreign key" is a type of "constraint" so that's how the two terms relate
yep 😉 hence why I was confused.. it looked like double dipping into the relationship
I'm pretty positive my issue has something to do with docker execution
I know that there isn't environment stored between layers
and that each docker layer is executed in its own shell
But that still doesn't make sense why it fails
There is an sqlite3 instance available in the container
So it fails when making migrations, not when applying them, right?
yes when, I make migrations
Specifically if I do the system checks that is what's failing
Do all your versions match up between local and the container?
Have you tried creating a docker image locally and testing with that?
Oh I see the comment says you've tried that
Yeah that's how I'm testing right now
I've completely removed the ci/cd from the equation and am just doing a local docker configuration
Can you show the dockerfile
It is very very simple
FROM python:3.7
COPY ./back_end /opt/back_end
WORKDIR /opt/back_end
RUN apt-get update -qy
RUN apt-get install -y python-dev python-pip
RUN pip3 install -r requirements.txt
RUN python3 manage.py makemigrations piano_gym_api
RUN python3 manage.py migrate
RUN python3 manage.py test
This moves the repository into the docker image
and then it installs the python tools set
and then it runs the migrations
@pure cypress The craziest thing about this
If I leave out the django migrations, and test commands
Then I run a docker comand to enter the container
The python django commands will work
However if those commands are run in the Dockerfile they fail
wtf
I agree
It makes no sense
That's why I have a theory this has to do with docker's layer's but I have no idea honestly
I'm not sure what commands you're referencing.
I'll look it up
$ django-admin <command> [options]
$ manage.py <command> [options]
$ python -m django <command> [options]```Those are the same
Another thing to try, especially if you think it's a layer issue
Just chain all the commands together with &&
so you get no intermediate layers that way
It's a private gitlab repo
But I'm more than happy to provide you access
If I concatenate all the commands into a single layer this is the output
Yeah ok this is me https://gitlab.com/Markkk

Ok one moment
@pure cypress I've given you access to https://gitlab.com/Hugbot/piano_gym/
I've made a branch for you on testing/branch_for_markk
From the root directory all you have to do for the image to build is run
docker build -t piano-gym-api -f Dockerfile_Piano_Gym_API .
That's not me
oh noes
3 k's
yes people take my name how dare they 
I do, but not to the code 🤔
one moment
The repository tab on the left does not exist
you're a developer now and should have access
👍
does this just use sqlite you said?
Yes it should just be sqlite
The first step is to get ci/cd supported
then I'll be migrating to postgres
oh dear
your image is already 1.13gb jeez
gb?
yeah'
oh lord
I was going to optimize later
It all started as "I'll just get some tests running"
I think you just ave a lot of python deps that's all
I'm glad you're able to reproduce it