#databases
1 messages · Page 41 of 1
Hmm I have seen some converter components already as part of pandas and qt6 so maybe I could go that route and just leave sql to do its basic thing since one part of the issue is display and the other part is the import. But the import I am massaging the data so much already it is easy to just adjust the input type to be an actual date for example.
Just be sure to read the datetime section here https://www.sqlite.org/datatype3.html
any1 know anything about aws dms endpoint creation?
when selecting RDS instance nothing shows up but i have rds aurora postgresql db
I was pondering this exact issue and decided to hop on here to ask. Saw this from a few days ago and it answered my question in full. Cheers mate!
Guys I am creating a legal document app which is using django.
I have permissions based on organization and subcategories within the document. A user is assigned to manage a subcategory.
Right now, my document is created using many foreign key. I can't denormalize it because of permissions etc.
I am using django with pgsql.
I am not sure which method to follow:
- Temporal database
- Django-simple-history (relation with history_id?)
- or any other approach that could be better would be appreciated!
What are you trying to do?
simple-history is great if you need a history of changes to a record.
If you share your models, someone might be able to help you figure out the relationships.
I could share it but I have app for authentication and the project itself.
I'll paste the model code in a github repo for you to have a look into
GitHub
Contribute to abubakar20-02/code development by creating an account on GitHub.
As for what I am trying to achieve, I mainly want subcategory field, organization_id to be a relation to allow my access control to work while also ensuring data is immutable.
Thanks for sharing! I haven't ever built anything similar to this, but it looks like you have some clearly defined requirements and constraints. A couple notes, might be worth adding the answer to some of these as doc strings:
- A User's organization can be null. Can a user exist without being a part of an organization?
- The TenantOwnedMixin defines an organization and an user field. A user can also belong to an organization. Can the organization ever be different from the user's organization? If not, consider a boolean field for is public or not instead.
- There are a lot of RFP models. What is the relationship cardinality between them? For example, if a GeneratedRFP can only have one SubmittedRFP, consider combining them into one model.
- Can GeneratedRFP.organization and FinalizedRFP.organization be different? If not, just keep one.
- On FinalizedRFP, if there can only be one per GeneratedRFP, consider using a is_finalized boolean field instead on GeneratedRFP.
- In ResponseRFP there are three boolean fields, and a status field. Are these all distinct pieces of data? Perhaps they can be combined into one status field.
- Instead of naming your foreign key fields to User,
user. A more descriptive name likecreated_byorownerwould be helpful.
Thanks for looking into my app.
- a standard user cannot exisit without being part of an organization.
- as for your second point if a data does not have organization_id attached to it, it becomes publicly available to all organizations.
- for your third point, I was expirementing different approaches and at that time, I had tried to create a denormalized copy. There is another tracking feature I was going to work on which required sql like behaviour.
- you are right here.
- I wanted the form to be immutable, hence why I created another table.
- you are right for the other 2 points.
Now for what I am trying and it does seem to be a better solution imo that temporalor history tables.
I have tried to containerize all relations in the rfp document- they have their own copy of relational data which then can be used to query using relations.
Do you think this would be a good approach at scale? I believe this should get rid of the mutable issue.
I think the different tables make it complicated by introducing a lot of redundancy. Instead I would use just one table for RFP, if you need to be able to view the same document at different steps of the process (submitted, accepted, finalized), then I would add one other table to hold the unique IDs and any constant data (user, organization). You can use composite unique constraints to enforce one finalized version per RFP for example.
I know I don't fully understand all your requirements and constraints, but maybe that's helpful.
I've made a dev tool db populator for dev testing, dropping the link here in case anyone’s interested and open to giving some feedback. Thanks!
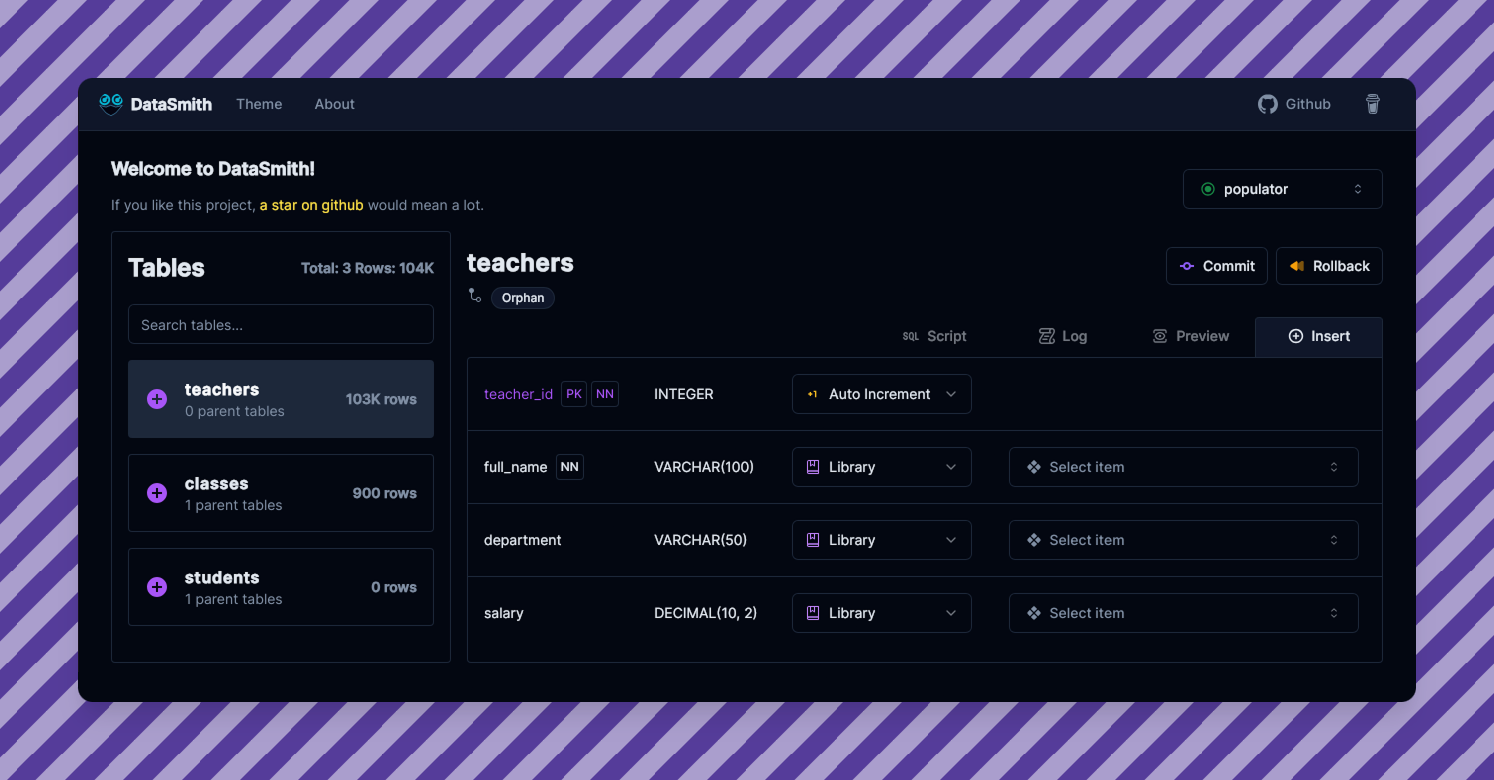
GitHub
DataSmith is a GUI tool to easily generate and insert custom sample data into your database. - MZaFaRM/DataSmith
I'm trying to use sqlalchemy and I'm really struggling with the typing from an IDE perspective

I'm on sqlalchemy version 2.0.42
Same thing when I just try and do this simple getting-started script

From what I can tell there is no maintained types lib for sqlalchemy?
Guys, i need some advice on something, basically im building a side project that involves storing a huge amount of chat messages (encrypted and embedded) for semantic search using ElasticSearch, my laptop isn’t quite powerful 16GB and 512GB storage, from a system design perspective, what is the most optimal why to store a huge amount of messages at once in seconds so that the user can’t wait that much?
Hello, I can help you using Elasticsearch. Ela is search and analytics engine to store big data and search data such as messages.
I am proficient in Elasticsearch indexes and documents.
You may use Ftp not in local
I want to learn some SQL, I do have mysql installed on wsl ubuntu but are there any massive databases I can connect to to practice on? Saves me making loads of tables and stuff, unless there is an easy way to do that
I use DuckDB with fairly large datasets all locally, downloaded as parquet files (there's many datasets out there). It's as easy as select * from myfile.parquet.
Kaggle is another good place to start as well
Hi, I want to use dbdiagram.io for my django webapp, idk how, can someone help me? When I coded the tables, how do I link them?
Have you created your models in Django? You can define the relationships using a ForeignKey field. https://docs.djangoproject.com/en/5.2/ref/models/fields/#django.db.models.ForeignKey
looking at deploying a python package directly from github action, pypi recommends publishing a new version to its test server for every commit? :monkacoffee: https://packaging.python.org/en/latest/guides/publishing-package-distribution-releases-using-github-actions-ci-cd-workflows/#separate-workflow-for-publishing-to-testpypi
seems like a waste
And it’ll publish any push to TestPyPI which is useful for providing test builds to your alpha users as well as making sure that your release pipeline remains healthy!
I don't get it, alpha users can download it the from the repo directly like pip install git+...
that is more on topic for #packaging-and-distribution than this channel
that said, for projects with multiple contributors you should never commit directly to the main branch - only merge PRs to it, and it is common to run tests + (when applicable) test that building and packaging and such works on each merge
having those versions available in a package index can make it a lot easier for users to help find regressions (bugs, performance issues, etc) without needing to manually install and bisect - pip install git+ requires building the project locally, which can be complicated for non-pure-python projects
Hi guys need help in mysql replication setup, any dedicated channel
here or #❓|how-to-get-help probavbly better
Is there any dedicated server for MYSql
possibly but you would have to google for it as this is the python one but there are certainly channels for common topic overlaps. So if you are using python and MySQL you could still just ask here, otherwise you can also try looking for another server. Best bet in finding one would likely be finding the subreddit for MySQL and seeing if they have a discord link. They probably do.
should I implement sqlite3 for my sproject that has a track of your all expenses??
ive heard database type of questions have been going out of date for interviews and similar envirements does that mean leetcode should be less useful for the newger generation of coders such as myself
I will likely give your tool a go, cool idea.
Yall how do I perform a ddos attack vía ftp protocol
Wrong channel and we can't answer anyways
you shouldn't perform any dos or ddos attacks period
as well as the statement above
but to be frank, there is no place for that question anywhere on this server
If I every day get zipfile with a bunch of data, I want to load this file into a database in a good way.
What the zip file is about ~2-3gb's of data, in a bunch of .json.
Currently loading this takes about ~45-60 minutes for me. Is this resonable?
it depends on sooo many factors, but i would say that it's not totally unreasonable, again depending on many many factors (hardware specs, is there networking between what is loading the data into the database and the database? indexes on the table, not too many i hop, and so on)
Well, its likely a mess, as im clueless, im just trying to get a baseline so I have some kind of a clue on what to aim for.
Currently im just running it all locally.
everything installed locally at least prevents any latency that the network could have introduced, but you might be a lot more hardware limited running locally compared with running it on enterprise server hardware
Im just more messing around, there's some loose plan it could be a public api at some point.
Then this question might apply.
If I have a zip with a bunch of data.
if I want to access data, I assumed I should load this data into a Database for fast access. Is this assumption correct?
As an example If I want the revenue of Apple 2023 i figured it would be faster to find that from within a database rather than sort of parsing through the .json in python.
is there any real association between each daily group of data? like is it daily data for the same thing, ala, daily revenue of Apple, or w/e The sort of storage format between just being json and importing it into a db kind of also depends on the relationship of the data in question.
consider that compressed data will generally be faster to read from disk then uncompressed data since it's less data to read from disk
but instead it will use more cpu to uncompress the data each time it needs to be read it and many compression formats and algorithms (but not all) requires you to read the file from the beginning to uncompress it until you have read and uncompressed the chunk that contains the data that you are looking for
some algorithms and formats can uncompress chunks directly without reading and uncompressing all of the proceeding chunks, but then you need to know where in the file the data you are looking for resides through some kind of index or similar, that is a challenge in itself
generally a database of some kind (one that is suitable for the sort of data and data structures you have) will probably be better to find data, especially if you can apply the right kind of index (for the sort of data in question) on the data
The "daily updates" is likly not going to be doing much latley, however there can be changes so i figure I need to keep it updated.
Well again it depends on what that data is tbh. If each day all the data is a fresh set and you dont need to reference the zip from the previous day then leaving it as json is likely more logical
ITs looking at forms submitted, so quarterly and annaual reports, however, there can be ammendments etc.
I am not sure if you are not fully understanding what I am saying or like just not sharing enough information but like what is the nature of the relationship between the data each day? Is every day like every single copy of every form ever submitted, and thus it is all the forms from the previous day plus the new ones or something completely different? Is it just a bunch of freeform text fields for every form or explicit details and maybe a 'comment' field or something? What is the goal of the data, like what do you want to do with it exactly?
leetcode isnt unique to database stuff, but also best asked in #career-advice
#Creating local temp table
source_conn.execute(f"""DROP TABLE if exists {temp_table};""")
source_conn.execute(f"""CREATE TABLE {temp_table} (LIKE {table} INCLUDING ALL);""")
source_conn.execute(f"""INSERT INTO {temp_table} SELECT * FROM {table};""")
Guys I wanna create copy of table in postgres
Is this the best way?
Seems quite slow
Goal is to send a table from local to remote. Without creating any downtime. To make it transactional

So I create a temporary table.
You can format code with triple backticks:
```python
code
```
In the past I've used duck db to copy a table between databases. That worked pretty well.
# Connect to the databases
duckdb.install_extension("postgres")
duckdb.execute(f"ATTACH 'host={source_db.host} port={source_db.port} dbname={source_db.db} user={source_db.user} password={source_db.password}' AS source_db (TYPE POSTGRES);")
duckdb.execute(f"ATTACH 'host={target_db.host} port={target_db.port} dbname={target_db.db} user={target_db.user} password={target_db.password}' AS target_db (TYPE POSTGRES);")
# Copy table
duckdb.execute(f"DROP TABLE IF EXISTS target_db.{table};")
duckdb.execute(f"CREATE TABLE target_db.{table} AS FROM source_db.{table};")
Is it transactional?
Okay so this is just a copy
Does duckdb have a full solution. To send a table from one db to another in a transaction?
As in a database transaction? Yeah that's supported by duckdb.
be careful with where you get the input from when interpolating variables in SQL statements like that so that you don't suffer a SQL-injection attack
SQL injection attacks include "I, the user, made a typo"
and by extension "I, the developer, did that"
I actually meant "developer" but yes to both
will you drop your database? unlikely. will your app crash with an error? likely.
I mean that all depends on whether you are testing with Little Bobby Tables or not 😉
last time I was in this situation I just made a value object for the table name and took that where needed, raised a value error in the constructor if it wasn't a valid table name, and added tests to it. It used regex internally and was simple enough.

I've done this too, it's just kind of annoying that database connector libraries don't provide this already
Snowflake works around it entirely with identifier() https://docs.snowflake.com/en/sql-reference/identifier-literal
Rightttt
with db.cursor() as c:
c.execte("DROP TABLE IF EXISTS identifier(%s)", table_fqn)
it's very very useful for this kind of thing
Yea I can see how that would make it as simple as writing any other SQL statement safely.
security, access control, data ownership, centralized storage, easier replication, syncing between devices?
Though many apps do store data locally, and Firebase is a thing
who has access to which parts of the data (be it per tables, columns or rows)
for single user applications, sure
for applications that must interact with data produced by others, you would either end up with a centralized database of some sorts or need to use some federation model, which can be annoying to work with
and yeah, by ownership I mean "(some) companies want to keep the user's data hostage, stored exclusively in their servers"
see also: discord messages
maybe take a look at ActivityPub and AtProto if you haven't heard about them before
not databases, but federation models to share data between different applications without one centralized server
-# the data is still stored in servers though, just not one server
(also don't forget that client-only applications exists, i.e. do not interact with any external servers at all, in which case you can just store everything in a sqlite file... or just store data locally and use APIs for whatever)
as long as you write it in a cross platform language/framework, you don't need to rewrite for each type of device?
no need to separate into a server
Is there a way to check a range of numbers?
I'm using a stack of if statements to check if int(input()) is 1-4 by doing
if input == 1:
** ** elif input == 2:
** ** elif input == 3:
etc....
What is the shortcut?
if input = (1-4)
?
Oh pshshhh
print("Valid Output")
. else:
. pass```yes, several ways, but this doesn't sound like a question that has anything to do with databases, which is the topic of this topic channel
but while i'm at it i'll answer you, but if you have follow-up questions or further questions of this general nature it's better to take it in #python-discussion or your own help channel #❓|how-to-get-help
with all that out of the way, the two most common ways of checking if an integer in a variable (let's call it x) is between two integers (inclusively), let's say 1 and 4 as in your example, are:
if x >= 1 and x <= 4:
print(f"{x} is between 1 and 4 inclusively")
```or a more mathematical and compact (and in my opinion more concise) way:
```py
if 1 <= x <= 4:
print(f"{x} is between 1 and 4 inclusively")
```and one last thing, don't call a variable `input` as that would "hide" the built-in function (or at least make it much less accessible) with the same name that is part of the core python languagebut it's also stuck on that device and many people use more then one device nowadays, so synchronization of data between that persons different devices and knowing which instance is the latest and correct might be a big issue
also, backup of the data will be all up to the person, and some people will be responsible for their data and back it up properly, but a lot of people today are so used to having that taken care of for them and if something happens with their device they can recover most of their data by just logging in to their apps
how would you solve synchronization?
Dealing with conflicts is a tough problem. Other interesting problems:
- How do your device A and B find each others?
- You login with device A. You do some work. Then A disconnects completely. Now you login with device B but device A is not available anymore to make available your latest changes
- Migration of schemas and generally dealing with difference of versions are gonna be more work to ensure a compatible path
All in all, you are creating a lot more work for yourself without a well define value
nextcloud is privacy first and they do use a server model
You can look into projects like anytype, they use server for data sync, but it's optional, and all of your notes are encrypted.
signal only allows for one device to be logged in to an account at a time and if you change device it is up to you to first migrate your information to the new device if you want to keep it
it's cumbersome to say the least
no, since you can't be logged in to any second device other then via web browser which is kind of a hack which has some security problems of its own
oh, yes the other party, they have their own copy for their account
it's not a sync, you send and they received, as it's messages
if one party deletes something it will still remain for the other party, it's not synced at all
no, it's not at all the same if we are talking databases
it's vastly different from messages
one needs consistency and the other doesn't
in that case you will have to look into "eventual consistency" that some database clusters use, but it can be extremely complex, especially for this kind of scenarios that we have been outlining above and can also be a less then satisfactory (and extremely confusing) user experience
and if a device which had the last update breaks before it can sync with one of your other devices that data is just gone forever
and this is very different then a database cluster where all nodes are more or less expected to be connected with one another at all times to exchange data continuously with only edge cases and failure scenarios where they wouldn't be for the wast majority of the time
that isn't at all true for user devices
also, Signal and WhatsApp transfer information between parties in the conversation using each platforms servers where it is stored temporarily in an asymmetricly encrypted form until the other party can pick it up, so it is not strictly local in that sense
if you want to keep it only local i mean
you also mentioned processing of the information server-side, then there is still the issue of user trust, gdpr and all of that
unless you strictly use homomorphic encryption (look it up) for the information that is sent to the server, which is a really cool technology but that is still being researched and can't be used for just any processing yet
GDPR compliance officers and lawyers probably beg to differ, as long as you process the information or even store it only in ram... it can still be leaked and you would be liable for that then
if there is no PII (if not even by reference) you should be safe from GDPR (but don't take my word for it, it's not legal advice)
yeah, discord isn't really a good reference, and they do store PII, e-mail, IP addresses and even the username or user ID (even the numerical one) counts as such
either way, i think an eventual consistency scheme with such sporadically interconnected and low number of nodes is ripe for data loss and extended times of inconsistent data and only partial data being available, will be the trade-off here, the question is if that is acceptable to users
at two years ago
I use
sqlite3
because
easy
comments
but
now
I use
mysql
because
faster (:
both of them are faster than one word per message I bet
Hey guys I want to learn data bases from scratch, I want to learn dbs for both data science and machine learning as well. I have good programming background as firstly I learned C language and I am working on python and it's libraries for previous 4 months. I want to be the suggested sources to learn dbs
Thanks bro
Also #databases message
Hey.
I have a bit of a specific scenario on my hand regarding a databse/how to handle it and i would like input from the a greater audiance 😄
Is anyone up for a quick discussion?
(I guess i will just get to it so if someone reads it later they are up to speed)
So. I am making a website for a friend.
It needs to hold several tests and their questions + data of the questions.
As of right now i opted to use 1 big database that holds all of the questions where the columns are.:
- question-id
- language
- text (The question itself)
- test (Which thest the question belongs to)
- tags (Future expandability/test specific things if any)
- revers (Boolean. Important for result calculation only)
- min_val
- max_val
- domain
- style
There is localization on the seite (Or at least planned to be) and the question id is going to be the same between the same questions just in different languages.
I am pretty happy with this setup so far but i talked with a friend and they did not like it at all and recommended that every test is it's own table and to hold the localized texts in the same row just in a differnt collumn.
And i am thorn.
Because my version holds a lot of metadata that is shared betwen questions (localized questions are basicly the same except 2 collumns)
But his proposal makes addition of a new language kind of a nigthmare and a new test means a new table.
more suiteable way would be to make a Questions table which hold all info except the text it will be a in Question content table with info about the language
You mean something like.:
QuestionMeta table that holds the meta data that is shared between localized questions
and
A Questions table that holds the language and the text for the question itslef while both have a shared question ID as a link?
let me show you

Okay.
And do i see it correctly that you propose to use the ID of the question table as the connector piece for the question_id?
yes
your welcome
For this approach I'd just use a flat document style of approach. Look up EAV schema and apply that to your mechanism, you could probably convert literally what you typed into classes in python, render their dictionary types to JSON and straight up stream upload to dynamodb / firebase / mongo
Or just use json with sql instead of a different db altogether 
This also is the way, depends how you like your ice cream I suppose in this context.
I personally avoid JSON with SQL, but I also play with very very large datasets
Document databases are not always correct, nor should my statement imply that, it's just a knee jerk response to your given scenario since transforming and mapping within a python ecosystem is much more user-friendly since you just apply your core methods to literal objects.
Certainly not worth using a different db in their case imo.
By the way, recommended solution looks fine.
The way you'd probably expand on this if you need multiple types of answers is to embed json into the Question table to hold the question type and it's parameters, e.g.:
{
"type": "number",
"expected": 42
}
{
"type": "string",
"expected": ["any", "of", "these"]
}
but you'll still bump into localization problem if you want your answers to be localized too
My experience with mongodb was mostly negative, maybe I wasn't using it correctly, but I think my brain just doesn't work that way after using SQL for a couple of years
In my case MongoDB was recommended by system architect for some reason, but I ended up just using postgres, sqlalchemy and embedded the document I needed into the sqlalchemy model/table, wrapping it into a pydantic model.
I had a similar time walking into mongo from a die hard sql background myself.
It took multiple projects leveraging both SQL and document db styles to realize the benefits of both.
It's actually really reminiscent of the paradigm of dynamic vs static programming as you get similar problems. Document drift is real and will indeed hurt you if your migrations do not respect previous versions, where in SQL you can process migrations with a stronger sense of confidence that you won't blow up your entire schema.
I don't see a lot of reason to use both sql and mongodb in the same project, at least if you have interact with both within a single transaction
I feel like that's completely irrelevant to probably 95%+ of projects
When you have hundreds of gigabytes of data you should probably be fine, and then you could think about using specific databases for your search functionality, if you end up needing them.
Depends on your field, and specific use case. For example building a search engine or needing to ad-hoc reference historical data on the fly that isn't cached. You can use a document style db for a lookup map to help optimize your SQL set.
There's a lot of use cases, but it really boils down to experience
I've also been doing data science for about 20 years
I'm very happy with using DuckDB to query json files, fwiw, rather than going the mongo route. I do everything I can to not use mongo
Also, all problems are  problems to me, anyway. (And I'll take parquet over anything else)
problems to me, anyway. (And I'll take parquet over anything else)
Yeah that's totally fair man - it does boil down to what you and your team prefer.
In the context of simplicity a lot of headaches for relational databases can be solved in document databases, but they swing on a pendulum of generating inverse problems due to being un-marshaled.
I can't say I use mongo all that often myself, I just live in cloud infrastructure these days and choose the path of least resistance when designing a schema for database problem.
the only reason why Mongo beats anything on indexing is because they still cheat and say your data is safe before it hits disk
I'm not sure I follow, additionally there's a lot more document style databases than mongo
afaik this https://www.openmymind.net/Demystifying-Write-Durability/
some other dbs also cheat in benchmarks similarly https://blog.cf8.gg/surrealdbs-ch/
#include <stdio.h>
#include "sqlite3.h"
//#include <sqlite3.h>
//main.c:2:10: error: 'sqlite3.h' file not found with <angled> include; use "quotes" instead
// 2 | #include <sqlite3.h>
// | ^~~~~~~~~~~
// | "sqlite3.h"
//1 error generated.
int main() {
sqlite3 *db; // указатель на базу данных
// открываем подключение к базе данных
int result = sqlite3_open("test.db", &db);
// если подключение успешно установлено
if(result == SQLITE_OK)
{
printf("Connection established\n");
}
else
{
// выводим сообщение об ошибке
fprintf(stderr, "Error: %s\n", sqlite3_errmsg(db));
}
// закрываем подключение
sqlite3_close(db);
}
//LINK : fatal error LNK1181: cannot open input file 'sqlite3.lib'
//clang: error: linker command failed with exit code 1181 (use -v to see invocation)
where is the python in this?

Oh sorry dude I thought I am in c channel
haha, wrong server?
Yeah😂
At least there is database stuff in my code
yeah 🙂
Hi
This is C alrigth?
Text Russ + C this is bad combination.
Why?
Is it because people will struggle to read it?
Because combining completely different letters can confuse someone, especially beginners. And the difference between Russian and English writing is significant.
No, just in order, although I'm using Python and I don't understand much because I hardly focus on the language.
Using Sqlite
It is habit to me as russian is my first foreign language;)
Oh that's the reason :0
Me use the English and my language Spanish for my codes. @placid crag
For easy
I thought it does not matter because advances coders do not need to read comments. I will try to avoid russian comments in english chats
Not only by order, but I am not experienced either. Imao
Aveces a mi se me da un poco largo el código y como algunas veces ahí un lado que necesito revisar y otro la verdad es más fácil poner eso.
Otras líneas están conectadas con otra línea se transforma en un problema de orden
Anyone experienced with neo4j? have some queries to ask
Experimenting on a UFC database to practise SQL queries and how to visualise data. The UFC database, I got from kaggle, contains the fight record and body statistics (i.e. height, reach, weight class) for every fighter. I want to make a query that sums up the wins accumulated per weight class. How would I go about it?
what have you tried
not tried anything yet. im thinking Ill create a view to join two tables (as one table contains the fight record and another contains the weight class). Then, maybe create a windows function to calculate the sum of wins per weight class. I could do this with python but, i want to improve my sql skills
/\ btw, I've managed to get an engineering apprenticeship but I still want to use what I've learnt from these past 2 years about data analysis and databases, into the apprenticsehip. Any advice on how I can try to improve further?
Start with a simple SELECT statement before going to a query. Also from what you have shared I don't see why a window function is necessary. Stick with GROUP BY and basic aggregations.
The website and content looks completely generated with AI. Are you affiliated with it?
this almost sounds/looks like advertising
besides, this is probably not even the right channel for this
#data-science-and-ml is more Pandas/Polars and data analytics territory
and don't go advertise in that channel as well now
not really an affiliate, lol 😛 , would like to if they have any such plans, but can't get hold of any such links yet.
I think they are very new.
I think it is AI generated, but very realistic case studies and datasets, I was trying to search for something to practice with this got up,
Try level 4 level 5 things, almost like a project
on this server we usually recommend Kaggle for learning Pandas and such as well as getting hold of example datasets
yes, but those are limited and not really business/ industry focused. what I liked here is business focus and application on real cases, I see a lot of free cases on that so, nothing bad with trying
Hello everyone,
I'm seeking assistance and feedback on my new open-source package, fastjson-db. It's a lightweight NoSQL database designed for speed and simplicity.
I would greatly appreciate any help with testing, code review, or general feedback on its functionality and usability. Your insights would be invaluable!
This is my first open-source package, so mistakes are expected. Feel free to open issues or pull requests.
Check it out here: https://github.com/MauricioReisdoefer/fastjson-db
Thank you in advance for your time and support!

GitHub
Contribute to MauricioReisdoefer/fastjson-db development by creating an account on GitHub.
I feel like if using SQLite is "overkill" for your project, you should either just use shelve or pydantic (whenever you serialize to & deserialize from JSON files directly, or use something like SQLModel)
Your examples do not feel very convincing either, pretty sure it would be simpler to do the same thing with other libraries? In particular:
- having to flush feels awkward, at least consider adding a context manager that does it automatically
- Either use a decorator or inheritance, requiring both for the user to inherit your model class and for them to use a decorator in the same class is odd
- Optionally combine "define a Table" and "add table to the Registry" into a single function call
also comments in Portuguese still make sense if all developers involved speak it, but keep the docstrings in English if you hope for international users to use it
if that was a serious project, I'd also recommend using an expression based way of querying things to chain all filters you need before loading data instead of calling get_all() in each JsonQuerier method
(see polars for a practical example)
lastly, that fixture is very weird: https://github.com/MauricioReisdoefer/fastjson-db/blob/main/tests/jsonquerier_test.py#L20
you should keep the code inside of the with tempfile context manager, as long you yield inside of it it'll only exit after the fixture is no longer being used so need is no reason to detele=False then delete it yourself, and you should use the Path it gives you directly instead of getting its name
(if it was for some reason like your library only accepting str and not Path objects, do add support for Path objects)
First of all, thank you for the feedback!
About the comparisons:
Using / substituting shelve or pydantic is not exactly the focus of my library. My goal is to build a lightweight NoSQL ORM/Database, closer in spirit to something like TinyDB (or even pymongo on a smaller scale). But your point is valid — other libraries already exist, and this project is mainly for my own learning process, including packaging and distribution. Who knows, maybe one day it could be genuinely useful.
About the structure:
Flush: I agree, having to flush manually is awkward. A possible solution is to create a base class that automatically flushes and also handles table definition + registry in one place.
Decorator + inheritance: only inheritance is required. The decorator I’ve been using mostly for style, but I’ll probably remove it from examples to avoid confusion. And now seeing in the documentation i said about them. It was mostly to tell it uses dataclasses. Because JsonModel is already a dataclass, you don't need to put the decorator again, but i didn't know exactly how to write that. Probaly i'll change that comment.
Comments/docstrings: the Portuguese comments were for my teachers, but I’ll soon translate everything to English to make it more accessible.
Query chaining: this is something I’d really like to add in the future, though I’m still figuring out how to design it. I’ll study projects like polars (like you said) for inspiration.
Testing/fixtures: you’re right, the fixture I made is unnecessarily complex. I’ll fix it by keeping the tempfile context and adding support for Path objects directly in the library.
Thanks again for the thoughtful feedback! I’ll work on these improvements and come back later with updates.
The flush system i thought would be a good idea when i saw the performance being completly trash. So i changed it to save everything in cache and later on "flushing" to .json files. Something like C buffers. And it actually helped with the performance, that's why i mantained it, but hiding this complexity would be good
Does this handle concurrent write and/or read?
"JSON + lightweight kv store" isn't new, eg TinyDB or doing it manually with shelve or dbm. But they aren't exactly a lot of options either, so I'm not going to doubt that there is room for innovation here. But it might be interesting to describe upfront how your thing differs from those things
For example shelve and dbm are very low level. And TinyDB is a Mongo-alike and that's not everyone's cup of tea
Alternatively, maybe the value proposition is precisely that your thing is a higher level wrapper over established lower level things. "I wrote this library so you don't have to write this boilerplate code yourself" that kind of a project
Provide some opinionated structure over what would otherwise be an open ended task
That's not a bad thing either
Thank you for the comment!
Currently, FastJson-DB doesn’t handle concurrent read/write operations yet — that’s planned for an upcoming release.
About positioning: you’re right — JSON + lightweight KV isn’t new. Libraries like shelve and dbm already cover the very low-level use case, while TinyDB is a more flexible “Mongo-like” approach. The idea behind FastJson-DB is to provide something in between: a lightweight NoSQL ORM-like system that offers some opinionated structure (dataclasses, typed models, organized tables) without being as heavy as a full database system.
I’m currently restructuring the core so it can be simpler, faster, and easier to use, while avoiding users having to deal with complexity. The roadmap includes a journaling + garbage collector system, (still not in github), which should keep performance high but still ensure file safety and consistency.
If you’re interested, I’d be happy to share how the next update will work so you can provide feedback.
Thanks again — your feedback helps a lot
(Note: the current version is just an early prototype and should be majorly discarded with a new structure — I even built a working forum on top of it — but it still needs a major reformulation. That’s what I’m working on now.)
Hey folks, I have a very open ended question. I've been using SQLAlchemy on and off for about 10 years, and the structure and features of the API just never clicks. I can't remember any of the semantics and I end up copy-pasting stuff from documentation (recently with the help of LLM:s). I think I should understand all the constituent parts by now -- sockets, SQL, serialization, modeling, async, etc, but the way SQLAlchemy is put together just doesn't make sense to me.
It all ends up feeling more like Java than Python, with a never-ending pyramid of wrapping classes and indirection. Maybe I don't understand why the abstractions are laid out the way they are, which creates a lot of cognitive overhead, and I find that I just want to drop down to a familiar raw SQL socket connection all the time. Reading the source code has helped me understand many other libraries, but trying that with SQLAlchemy kind of leaves me even more confused.
I don't mean to say the library is bad, I'm probably just a bit dumb. Did you guys have any point in time when SQLAlchemy finally "clicked"? Like, are there any deeper points I seem to be missing, or is it a matter of going wide enough?
sorry to say, i've never ever liked a single ORM i've encountered in any programming language through my years of programming and just think that SQL is so much easier (not that it is always easy, but still easier than the same functionality from most ORMs) and only use ORMs very seldomly, i'm mostly use raw SQL with bind variables/placeholders (to keep security intact)
but i'm also guessing it's not the fault of the ORMs but rather the failing is probably on my part 🤷
Try Django orm it is pretty straight forward
For me it took seriously reading through the docs a couple times. The tutorial has really been improved with 2.0 incase you haven't taken a look at it too recently: https://docs.sqlalchemy.org/en/20/tutorial/index.html
I have a problem achieving the data sets from my sql account
Hey guys, i am new in programming and i have reached out in the flask to the database could you recomomend me a stack to choose for the database and with the sources please
that very much depends on what you need (what you are going to use it for and how you are going to use it)
I have just started
then just build something like a prototype using something simple like sqlite3 to start with
first to learn and also to discover what requirements the project may have
how can I help you?
Hey guys, I just made ljobx, a Python CLI tool to explore LinkedIn jobs using public guest endpoints - no login needed. Fast, async, filterable, proxys/rotation support … built to make finding your next opportunity way easier.
it is not allowed to be cross posting about the same thing in multiple channels
this now crosses over to advertisement and spamming rather then much more innocent "look at my cool project that i made"
and this channel is definitely not applicable or related to your project, not even by mistake
I've started learning about SQL Databases :D
Best of luck!!!
How to learn python backend developer
Google, or just use a app ment for learning it.
I like sololearn, personally.
But it only give 5 mess ups aday.
could use this roadmap https://roadmap.sh/backend
and use your preferred LLM (gemini 2.5 pro is free on https://aistudio.google.com to teach you with a very good "guided learning" prompt)

<?php
// deploy_ftp.php
// Minimal PHP FTP deploy for a static site
$server = 'ftp.example.com';
$username = 'ftp_user';
$password = 'ftp_pass';
$localRoot = DIR . '/dist'; // change to your build/output folder
$remoteRoot = '/public_html'; // change to your web root on the server
$ftp = @ftp_connect($server);
if (!$ftp) {
fwrite(STDERR, "Could not connect to $server\n");
exit(1);
}
if (!@ftp_login($ftp, $username, $password)) {
fwrite(STDERR, "FTP login failed\n");
ftp_close($ftp);
exit(1);
}
// Passive mode often required behind NAT/firewalls
ftp_pasv($ftp, true);
function ensureRemoteDir($ftp, $path) {
$parts = array_filter(explode('/', trim($path, '/')));
$curr = '';
foreach ($parts as $p) {
$curr .= '/' . $p;
// Attempt to create; ignore if it already exists
@ftp_mkdir($ftp, $curr);
}
}
function uploadDir($ftp, $localDir, $remoteDir) {
if (!is_dir($localDir)) {
throw new RuntimeException("Local directory not found: $localDir");
}
ensureRemoteDir($ftp, $remoteDir);
$items = scandir($localDir);
foreach ($items as $item) {
if ($item === '.' || $item === '..') continue;
$localPath = $localDir . DIRECTORY_SEPARATOR . $item;
$remotePath = rtrim($remoteDir, '/') . '/' . $item;
if (is_dir($localPath)) {
uploadDir($ftp, $localPath, $remotePath);
} else {
$ok = @ftp_put($ftp, $remotePath, $localPath, FTP_BINARY);
if (!$ok) {
throw new RuntimeException("Failed to upload: $localPath");
}
echo "Uploaded: $remotePath\n";
}
}
}
try {
uploadDir($ftp, $localRoot, $remoteRoot);
echo "Deploy complete.\n";
} catch (Throwable $e) {
fwrite(STDERR, "Error: " . $e->getMessage() . "\n");
ftp_close($ftp);
exit(1);
}
ftp_close($ftp);
Ready to deploy
why are you just dumping php code in a python server?
Hi, I’m Francis 👋
Aspiring Data Engineer learning Python & SQL, currently building my first projects.
Excited to learn & connect 🚀
bro is not in the right discord server
What's the most lightweight ORM you guys would recommend? I'm just writing simple queries but don't wanna write raw SQL in code
I think it's not the most lightweight, but SQLAlchemy is pretty useful and easy.
Okay, I tried opening stuff on help but the bot just keeps closing, anyone that can help on https://discord.com/channels/267624335836053506/1419483771169669180
I tried opening another one and answering it on here but the bot also closed that one
the fix was to add an __all__ field with the model classes in the module I say where the models + not using the fastapi integration (it doesn't seem to be updated as it just silently explodes and using the previous method also doesn't work)
Hello i am new
Start in #python-discussion !
I’m a Full-Stack Developer ready to take on new project.
Let’s connect!
If you have a project that needs a reliable developer, message me
!rule ads
this space is not an ad board
Ammmmm

what was that supposed to be? it is not loading properly for me
sent a friend request....DM Me 👍🏽
Nodding face.
Would anyone be able to help me put together logic for this sql exercise?
I have a table called company_table
3 columns: department, num_of_emps, types_of_devices
types_of_devices has these values: phone,laptop, camera,tablet
In one table view I want the count of accounts and count of employees who have:
1)only phone
2) phone and laptop
3)phone and other devices (not laptop)
what have you tried so far?
Hi everyone, my name is Konstantin.
I have a huge favor to ask the server, my best friend recently got into an accident and now he cant finish his university thesis. Its a small python game that also uses q learning. I will present his thesis in his place and i also have to finish it. But unfortunately i am not very good at these stuff. If someone with a kind heart could help me. I would appreciate it so much!!
I have most of it ready, i need small help with the database and with the AI.
You can open a help thread or ask for help in #python-discussion . Ask a concrete question and you'll get an answer, but you won't find someone to do it for you on this server. And, we don't allow recruiting. But, we'll help by answering questions.
I finished with the database, but thank you very much!!!
im now trying to figure out why the car moves weird and the q-learning agent
Ok, definitely open a help thread if you get stuck!
yes sir!!
What is database?
its what we use to store data in. so it allows applications to query the saved database, creates new records in the database, updates the records in the database and deletes the records in the database.
Not necessarily online services. It can be done locally too. For example whenever you play any offline game, all your data is being saved into a database in your device and doesn't need to interact with any servers
Just the word on its own is so vague as to mean pretty much anything that plans to remember some data for you and give it back later. (Even if that place is just in RAM, and would go away if you rebooted, actually.)
Where it gets interesting is when you dive down into a "kind" of database. By default people usually mean "relational database" when they say the word on its own.
There are also "key/value" databases, "column-oriented" databases, etc, etc.
SQLite is a popular open source relational database to get started with, has easy Python libraries.
The "programming language" you talk to many databases with is called SQL, but there are others, especially for the more specialized kinds of databases.
The first database I worked with at a job was called IMS, an old IBM thing of a type we call a 'hierarchical database".
PostgreSQL 18 can do Index Skip Scans now. Pretty useful sometimes.
I'm no longer really a massive pgsql fan for my own work but it's all over etc, and it might be worth mentioning.
So, like, let's say you have:
CREATE INDEX idx_laser_face
ON staff_members (status, retires_at);
...and you want to do:
SELECT * FROM staff_members WHERE retires_at <= NOW();
...before this, the idx_laser_face index would be ignored, because the status column isn't being materialized.
Before PostgreSQL 18, this query was a TABLE SCAN!
In particular, FinTech db tables often need multi-column indexes to get any kind of plausible performance, and often end up extremely expensive to ALTER without complicated games. Always be careful setting up multi-column indexes in a table that might end up growing. Measure twice, cut once, etc.
This is pretty fun: https://github.com/dbohdan/sqawk
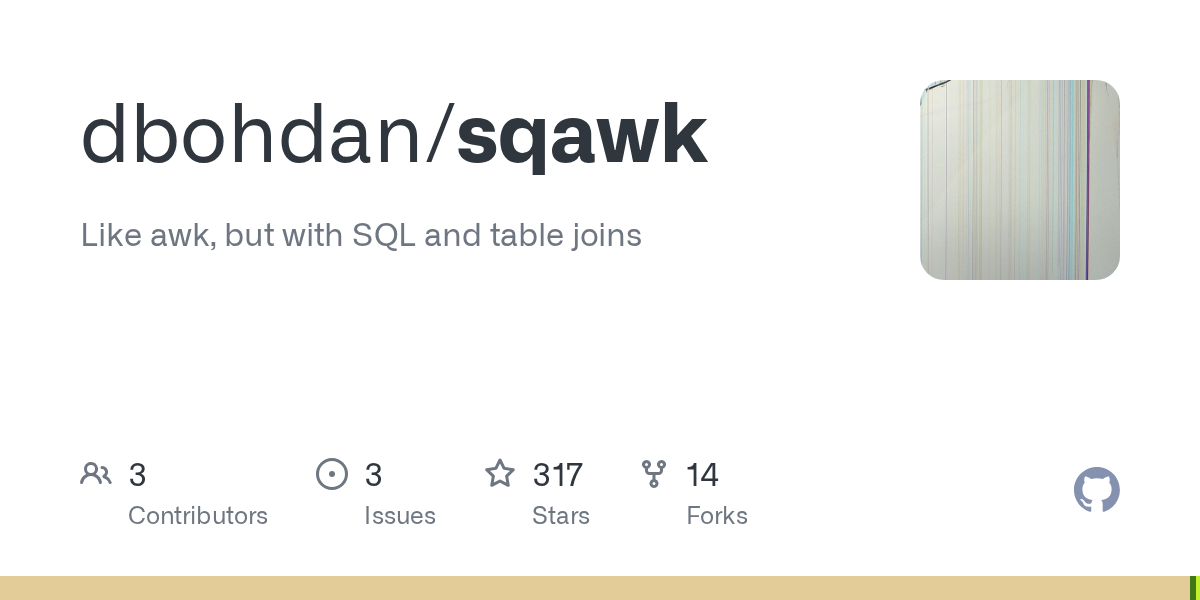
GitHub
Like awk, but with SQL and table joins. Contribute to dbohdan/sqawk development by creating an account on GitHub.
i think i want the opposite of this: let me use awk on my database 😆
I think PostgreSQL probably would let you plug that in haha
and actually, languages in the K family are basically THAT, and are used in finance land
K is wild
oh man that's a wild and great idea hahaha
and i never thought of awk as being like an array language
but in a way it kind of is
that's interesting too
I believe there's some kind of family tree relationship between Awk and APL, but maybe I am misremembering?
i'm not aware of one. i usually think of AWK as being an offshoot of the C/Unix development ecosystem
and I think of APL as its own distinct lineage
unless Iverson was connected to Bell Labs or something like that?

Indeed, Bell Labs is I guess the root of my memory here.
Both vectorized over interesting collections, both funky terse syntax, but I guess no direct ancestry.
yeah i never thought of AWK as vectorized
it's maybe a bit of a stretch but i think it's fair
Interesting, to me it's always been the vector tool kinda, just with lines as the default 'first class citizen'
Also with jq though I guess JSON top-levels can be {} as well as []
i was actually thinking about awk for the first time in a while today because there was a lobsters thread about the sam editor, and some of the commenters brought up awk
JSON top-levels can also be 1 and null
IMO this is a valid interpretation of the spec but not the only one.
Are there parsers that don’t?
Python’s does: #bot-commands message
Yeah, though maybe they are all old ones nobody uses anymore.
But I've run into more than one where {} and [] were the only valid toplevels, especially early ones to support 'streaming' processing modes.
I actually like that interpretation because IMO if you just want a number, use a different format
and same with null, what's the point of having a text file with 32 bytes to say null?
Anything that isn't an object or a list of things is degenerate IMO
they should have chosen nothingheretoseemovealong instead of null to save space in the repr.
mu would have been 1000x cooler.
It's one of those things where the spec imposes basically an arbitrary restriction that in practice costs everyone nothing to support
And while normally supporting something off spec opens up a risk of incompatibility across implementations, this one is so ambiguous it's hard to argue with not implementing it just as a courtesy to users
Postel's law and all
I feel the same way about comments, or at least line comments. But apparently that opinion is not widely shared enough to get the same treatment
IMO twice as many root node cases is not "nothing".
I guess but it's not like they're additional container types
While we are still kind of on the topic of AWK, you know what feature is amazing and should be in every database and data frame library? Snowflake match_recognize
It's regex for rows
It's an absolutely amazing feature
And it's something I personally have wanted for such a long time
Once I wanted it so badly that I almost resorted to manually translating row patterns to strings so I could run a regex search on it
I guess it's not that useful for transactional data
But for analytics, oh man
I love some of Snowflake’s ideas for sure. I never managed to get the performance I needed out of it, but I think they have great product ideas
What was the workload where you struggled with performance?
It definitely has some challenges when it comes to performance optimization
they keep coming out with various solutions for various cases, but sometimes you just have to deal with the fact that there are no indexes and your only optimization tool is clustering, which is not conceptually that different from dumb hive partitioning
But I'm curious what other peoples struggles are because I'm sure they are not the same as mine
I’m struggling to remember exactly, but what I can reveal of the application was a pretty scaled-up Dask Cloud-based worker setup, where we had a temporary very fast MySQL as working space, and were every morning trying to compute our “financial graph” data into “pre-computed” form so that the kinds of common answers our customers wanted didn’t have to be calculated on the fly. Lots of data though, $5T of financial records.
I think it was around how long Snowflake was taking to ingest that, but I might be misremembering and it was the other way around, getting it back out? I do like their security model and ability to “share” data with customers.
That's an interesting case. Getting data in and out is definitely not the fastest
It's like Spark in that regard
The slowest thing you can do is move lots of data around
Yeah definitely a weird application, pushing a lot of limits to get inside the necessary “pre-trade” T+1 window, which is why I don’t go around saying Snowflake is bad. I would still use it for a lot of stuff.
Especially “selling” datasets to customers.
My favorite way to export data from snowflake is by saving it directly to S3 via "external stage"
Definitely. I wish AWS gave us Hyperplane access so we didn’t have to use their panoply of garage private connection options.
I should be able to “know about” the relationship with Snowflake in the software defined networking layer
Privatelink and most of the others are awful
And the fully routable gateway option just pours money into their hands like crazy, you end up paying for the traffic like three times
I just want a dual-plane fully connected network of low-level shit to run something better than TCP/IP on with no overhead.
Time-Sensitive Networking (TSN) is a set of standards under development by the Time-Sensitive Networking task group of the IEEE 802.1 working group. The TSN task group was formed in November 2012 by renaming the existing Audio Video Bridging Task Group and continuing its work. The name changed as a result of the extension of the working area of ...
All I gotta say is, I have never even come close to thinking I might need anything resembling that 😆
At scale it’s easy to get on the chat with your AWS specialist and come up with an elegant design that turns out to cost more money than you could possibly justify
And sometimes the workaround you need is crazy complicated just to save money
Transit Gateways are like this. They do everything, but they multiply your network costs by a constant factor forever
I built a multi account design for our org at work a couple of years ago, initially around transit gateways, using really careful and IMO cool IP ranges so we didn’t have to coordinate between teams ever again
And we had to basically cripple it completely when we looked at the billing reports
At the time I had admin on $1.3M/month of AWS spending and we were like “oh naaaaaaah”
Speaking of databases for once, this one is cool https://duckdb.org

DuckDB
DuckDB is an in-process SQL OLAP database management system. Simple, feature-rich, fast & open source.
This is what I think we wish we would have done at that job I described above, but it wasn’t really mature enough at the time
Also this is sick https://github.com/sqliteai/sqlite-sync
(Though not applicable to OLAP as far as I can see)
But respectively I guess those are my current fave OLAP and OLTP dbs. CockroachDB is good too.
This is very very popular in data science and machine learning nowadays
Yeah, but this implementation is good and fast etc
And a lot of programmers like it too because you can kind of use it as a replacement for a "data frame", but with a more familiar API (SQL)
It's also really good at dealing with a whole variety of data formats
I’m about to start helping with a Rust “in process” config management library that looks great, in-process is often really useful
I like Cassandra for a bunch of reasons but administering it is awful
What do you mean by config management in this case?
Oh like Ansible or SaltStack or Chef or Puppet etc
Instead of a CLI, it’s a library with modules you can pick and choose from, and do from whatever piece of code you already have that makes sense to enhance.
And it can do every paradigm, from agentless like Ansible to fanout fancy “pull” agents with brokers and everything in between.
Which is cool because now you can use the same tool for simple stuff and silly hyper scale stuff
Used to be called “duxcore” but I joined his Discord as the 3rd member and now it is “regent” haha
Wait sorry there’s a better page with diagrams

GitLab
Embed an ansible-like automation engine right in your Rust code https://crates.io/crates/duxcore
This is a bad description because it is far from being as limited as Ansible in terms of “paradigm”
I’ve proposed this kind of pitch https://github.com/regent-project/

GitHub
The Regent Project - Multi-Paradigm Configuration Management as a Library - Regent Project
(Temporary logo I made, some kind of fun stylized crown seems like the right idea eventually)
(I think his robot arm looks like it is having a bad day and is a little depressed)
Nice. I feel like any nontrivial CLI should ideally expose an API as well
I like the circuit starburst logo
I use DuckDB extensively (professionally). Love it
Cool, we wanted to but it wasn't quite ready, it's good to hear that it probably would have worked out, because it's one of the things I would still recommend to someone etc.
How is it in handling rastor data for example multi dim arrays
No idea, at least not at the level of detail that would be useful to you. I think it should be OK at that but I haven't tested it.
2D only
It's a column oriented database meant for "analytics" type workloads
Imagine a workload where you have some business process that emits a JSON status output to S3 every 30 minutes from a fleet of 20,000 devices, assigned across dozens of customers. You want to generate a nightly report that, for each customer, displays a time series in a 6 month window as well as a few different moving averages and a moving standard deviation, and computes some aggregate per customer metrics.
You could do that all in Duckdb
There is a geospatial extension but I don't think it handles raster data
Okie that extension might be for vector data like boundaries and all
yes i know it does vector data for sure
points polygons etc
Correct c
I was working on creating a olap system for rastor data
So I was exploring different options
Have you explored this side of the domain?
I have not, I almost never work with raster data
i'll be learning DataBases in my 2nd semester - starting 13th Oct
Wishing u a good luck dude
Does atomic operations (update) guarantee concurrency? For example if multiple calls are made to update a db, will there still be a race condition?
thank you man
nice, i had them in Q1 (First sem.)
I have a community project called "Portfolio do <dev>". Our main goal is to bring together people who want to participate in complex projects that are difficult to complete alone and start developing projects as a team. This is not a paid work, it's a voluntary work, in the end of each project you will be able to show off yours skills and put that project on your portfolio. We're strongly focused on networking and team work, interacting and having fun while developing. Feel free to chat me on private
Is this meant as advertisment?
!rule 6
.
which of those are supported by Python?

are you going to use all of it?
I mean I want to know then search for best efficient db for Python
how do you know if a db is efficient? what is your metric of measurement?
Why not just pick the popular DB and go with it?
I mean fast with Python
They're all fast with Python
Dont overcomplicate yourself bro
all are supported?
You'll have to research if you wanna check if ALL of them are supported. But as I said, dont focus on that. Just pick ONE
also which one do u recommend for Python?
Alright ty
I would start with SQLite. Python does support it out of the box with an standard module.
I'm working on a project with a Postgres database and there is a 'pubdate' column with the type TIMESTAMP. Is there a way to make the DB convert this to a string in the query? The docs have different kinds of data conversion functions but I got kind of lost since I don't do db stuff much.
SELECT (colname::timestamp at time zone 'UTC', 'YYYY-MM-DD"T"HH24:MI:SS"Z"') I think?
something like that? I've been in MySQL land instead recently
Oh wow the second answer is CRAZY https://stackoverflow.com/questions/38834022/turn-postgres-date-representation-into-iso-8601-string
SELECT to_json(now())#>>'{}' zomg
which does force iso8601 so.. wild
thems the haxx, lads and lasses, wow
Lol yeah there is zero chance I would have figured that out on my own
the JSON stuff they added to pgsql is actually potent and worth learning
You can query for deeply-nested keys etc.
(I don't actually totally recommend this as a from-scratch idea, but it can make dumb things easy once you get there)
I use sqlalchemy with aiosqlite. Is there a way to completely ensure this doesn't happen? Or must I just implement a retry logic?

Or it's my code's problem? Let me know and I'll send snippets
iirc this means you have a read/write transaction that's taking too long to commit, so it's blocking other queries from executing
at least for that particular query, enabling sqlite's WAL mode should help alleviate read transactions from being blocked by other read/write transactions:
https://sqlite.org/wal.html
(see this sqlalchemy page for how to set pragmas: https://docs.sqlalchemy.org/en/20/dialects/sqlite.html#foreign-key-support)
Alright thanks
When do we rename this channel to #json-storage-engines? 
This isn't really a python thing, just sql, but I have a table with a bunch of TEXT columns I want to convert to VARCHAR.
ALTER TABLE Inventory MODIFY Description VARCHAR(MAX);
That's an error because mysql apparently doesn't like MAX;
ALTER TABLE Inventory MODIFY Description VARCHAR(65535);
Still no go, but progress. It is telling me the max size for a varchar is 16383. I guess that makes sense because it is 65535/4.
ALTER TABLE Inventory MODIFY Description VARCHAR(16383);
Well this isn't going to work either.
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
Now we all know nobody reads documentation, but I tried to find out how to fix this but I found nothing that made sense.
So I have several questions:
Why is the max row size 65535? Can that be made larger?
I have several other fields (a few ints, decimals, etc). How do I know how much space I have left over for VARCHAR fields?
I read somewhere that it is better to use VARCHAR(n) than TEXT. Is that true? I'm trying to switch because mysql is (for some inscrutable reason) returning BLOB types when I select a TEXT column.
You often want TEXT , MEDIUMTEXT, etc.
Yeah I was just really trying to get away from the TEXT types because they've been giving me trouble, but I might just have to work around it
As i known MySQL now I want learn with python should I learn MySQL-python+connector or sqlite3 library?
I'm using psycopg3. If I want to do a large amount of transactions, currently I find myself opening a context manager each time. If I call pyscopg.connect().execute() will it close the connection automatically as if it was a context manager after committing the transaction ?
Also I'd like to have a DB interface class, where I expose various operations through methods, and from a performance standpoint I think it'd be better to have a connection pool property of the instance. Since the use of a connection pool is through a context manager, how can I have a pool going as long as the instance exists ?
Another question; My bot's RAM usage, since I implemented DB usage, spikes from 100mb avg to around 230mb. Is that normal? There's no tons of DB entries or anything crazy.
if it's in discord.py, i'd assume it likely takes up most of that memory for caching channels, messages, members if that intent is enabled, etc., though you may want to do some memory profiling to know for sure (e.g. memray on linux)
Yeah I know about allat, just said it spiked in like 100mb after implementing DB usage
Are you talking about actually closing the database connection, or committing a transaction?
You can try contextlib.closing if you want to use a context manager to open and close the connection
you can set it up so that the connection pool instance is an init parameter. or use something like dependency injection, or contextvar, to provide access
The best way to set this up kind of depends on how your application is structured and how it actually works
I love context manager syntax and I love the context manager protocol, it's one of my favorite things about Python. But actually using context manager syntax is not always the best choice for long lived resources like a connection pool
Often you end up wanting something more like a dynamic scoped variable and passing around your resource as a function or class init argument gets clunky or infeasible
Hello everyone. I want to ask for advice to start with databases. For context, I only know that a database is a way to store data in a structured way. I have been using python for games, Tkinter applications and some maths problem solving/applications. I also know a bit of C and Cpp
First you should learn how to model databases, look into E/R modelling tutorials, there are plenty free resources online
After you practice a lot and feel confident with them, you can start learning any type of SQL you like the most, I highly recommend PostgreSQL tho. Then start transforming those E/R diagrams you have made in the previous steps into real database tables and after that, learn how to insert, delete and retrieve data from the DB using SQL

roadmap.sh
Comprehensive roadmap to learn SQL from scratch in 2025. From basic syntax to advanced querying, this step-by-step guide will equip you with the skills needed to excel in database management and data analysis.
And remember this: never forget your where clause when deleting
Thank you very much @chilly zealot
You are welcome, feel free to dm me any questions you have
I'm not a big fan of the 'roadmaps', as they're just a list of concepts. Check out some of these resources: A few SQL resources:
https://owencampbell.me.uk/sql_python_tutorial/pages/intro.html
https://sqlbolt.com/
https://selectstarsql.com/
https://www.datawars.io/
https://www.hackerrank.com/domains/sql
Thank you @coral wasp
Such nice resources
Hiii
I came across TiDB on youtube. How is it?

TiDB delivers strong consistency, built-in horizontal scalability, and cloud-native resilience for the most demanding workloads.
New to me, but interesting; we actually looked for something like this at my last job when picking tools for what we built pipeline-wise, and I guess it didn't exist yet.
Basically "MySQL plus non-sucky columnar mode". Never tried it, but it looks intriguing.
I'd still probably reach for https://duckdb.org first but this is going on my todo list somewhere.
DuckDB
DuckDB is an in-process SQL OLAP database management system. Simple, feature-rich, fast & open source.
I'm having fun with duckdb + iceberg + AWS S3 Tables
Learn about S3 Tables, an Amazon S3 storage solution that's purpose-built for tables and optimized for analytic workloads.
I've been eyeing this exact combo for making it easier to interoperate between snowflake and duckdb
S3 iceberg tables (possibly snowflake-managed/created) that you can then query from either snowflake or duckdb
Oh yah, that'd be huge
I'm curious how much I'll actually care. My workflows are well served by parquet
My use case is when there's an obvious partitioning structure and I only want to query a small subset of the data at a time
as far as I understand Iceberg is just a collection of parquet files, in a particular layout + particular metadata
but maybe I misunderstand what Iceberg is
To me the coolest thing about parquet is the zero-cost concatenation. Cool trick.
Yah, I generally deal with large-but-smaller-than-memory datasets. Not-too-big data
I've been in the "larger than any amount of RAM you can put in a server" scene recently, kinda fun also.
Not big data but "medium interesting data"
Which turns out to be, for example, what FinTech is about
Re: fintech, depends what you're doing. Not that many tabular datasets are larger than memory. Sure, ticks and documents may be, but most financial data sets are manageable, and everything can often summarize down unless you truly need order flow, level 2 or tick level stuff
We had $5T of private financial transaction data in our primary MySQL so yeah it was spicy
Lots of 'data products' to compute in parallel
The existing app was 'boiling the ocean' to calculate everything on the fly
So we built a thing that was three orders of magnitude cheaper to run haha
How large was the working set?
Dask is cool
Yah, I do like Dask
Uhh, can't quite remember but like.. a couple TB?
Tedious to restore but not impossible etc
Yah. Single digit TB is workable
Too bad we don't get paid based on cost savings 🙂
My dad did. :V
His gig was going to places like Dow Chemical, after finding them in the EPA's Toxics Release Inventory dataset and finding out how much they were paying to get rid of toxic waste.
Funny enough, that was my father's business model too.
And then he'd say "I can save you $X million per year on Process Z in exchange for a small percentage"
lol, my father did that with utility bills
He did that for Dow, Reliant, a bunch of other big things
These days what he was doing is called P2: "Pollution Prevention"
you have my sympathies using S3 tables lol
it's great right up until it isn't, where some parts and features just don't work
Tell me more!
Most of the AWS tooling doesn't properly work with iceberg on S3 tables, for example Athena & in particular views, break when using arrays.
Compaction is not very customisable, my co-worker knows more about the issues in detail as there was more, but we ended up just using iceberg manually on S3 with Spark and friends, because we could actually control it and debug things when it broke.
I also can't remember if this was a thing or not but I think we also had some issues of just not being able to view the buckets with normal CLI tooling and that caused other issues, something along those lines
That's generally how I end up doing things... I'd rather control more. I think I might use s3tables for more experimental stuff / non-prod
How do I change an existing table structure by providing a new table definition? For example,
`accounts` (
`username` VARCHAR(100) NOT NULL,
`email` VARCHAR(255) NOT NULL
);
``` I have this table already in the db, now I want to change `username` field to `VARCHAR(120)`, how do I do that with a new definition rather than using `ALTER TABLE`?can i help you
first creat the new table that inculding the struct
second copy the data from old table to new table
delete the old table
finally rename the new table with old table
r u understand? @lean walrus
hey, r u there? @lean walrus
if you want to more detail, send me DM
I don't think we can copy the foreign keys, index, autoincrement values, and other stuff by doing that though
no, u can do this
this is full code @lean walrus
CREATE TABLE accounts_new (
username VARCHAR(120) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO accounts_new (username, email)
SELECT username, email FROM accounts;
DROP TABLE accounts;
ALTER TABLE accounts_new RENAME TO accounts;
(I would ALTER TABLE accounts -> accounts_old vs. dropping it, myself, but yeah)
yea that probably works for simple table schema, what about a more complex definition:
CREATE TABLE product_order (
id INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
PRIMARY KEY(id),
INDEX (product_category, product_id)
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
) ENGINE=INNODB;
The foreign keys doesn't get copied since it is on a separate constraint, not column definition.
would be a burden if I changed like 20 columns in 10 different tables
Well, I've never seen that ever so yeah, don't do it then
Personally I would stand up a whole different database for such an evolution
I like how ORMs like django's ORM handle migration. IDK how to implement them using plain sql
It works the same way; you just do two steps:
first migration adds new columns etc but doesn't break the existing deployed code
next thing is a deploy of code that's aware of the new thing
you mean is about the primary key(id)?
then a second migration to drop the old etc
a clean migration needs to be decoupled from a 'cold deploy' that you might not ever be able to find the downtime for
how exactly do I perform that migration, using alter table manually in the production?
If you have very complex changes to make, an "ETL" tool might be the right choice vs. just migrations
Not manually, you check in the .SQL and version it with a sequential or timestamp-sequential file name etc
Rails and things inspired by it have an explicit framework for doing this
But you can script it yourself
hmm I've never touched those things
do u have any references I can look at?
Let me look, I've run into good blog posts about it before, just need to dig one up.
OK I found two that seem decent enough.

Updating a database schema without shutting down the application often requires a multi-step migration process. Here are the most common migrations steps.
and here's one written re: PostgreSQL but it's all equally applicable to MySQL or others: https://xata.io/blog/zero-downtime-schema-migrations-postgresql

Xata
Schema migrations are a pain. In this workshop we review the problem space and tools available to make reversible schema changes in production with zero downtime.
"expand and contract" seems to be a popular name for the pattern now
and video form: https://www.youtube.com/watch?v=-1aO6UznfI0

Schema migrations are a pain. They typically require multi-step playbooks to roll out in production and migrate your data over. In this workshop we review the problem space and tools available to make reversible schema changes in production with zero downtime.
Xata 🦋
This presentation was brought to you by Xata (https://xata.io/), the only s...
📘 T3 Stack Tutorial: https://1017897100294.gumroad.com/l/jipjfm
🤖 SaaS I'm Building: https://www.icongeneratorai.com/
✂️ Background Cutter: https://www.backgroundcutter.com/
💬 Discord: https://discord.gg/4kGbBaa
🔔 Newsletter: https://newsletter.webdevcody.com/
📁 GitHub: https://github.com/webdevcody
📺 Twitch: https://www.t...
(the two videos there seem to have very similar lists of things they cover, not sure which is better)
damn thanks a lot, I'll definitely look through them
the tl;dr is just..
- Expand schema with new stuff
- Deploy code that writes to both for now
- Switch the app to the new stuff as primary once the "backfill" finishes
- Deploy code/migration that drops the old stuff, now no longer used by your code, removing the 'legacy' if/else branch
It's work but it's the only thing you can do once you have enough data that the ALTER TABLE downtime isn't something you can fit in.
It would have taken two weeks of downtime to ALTER TABLE any indexed column in the main table at my last job.
(MySQL is super bad at online schema changes, even today)
yep, I watched one video and the idea is pretty great but still needed a lot of manual tweaking
is postgres any better?
Yes but it's also a LOT slower at some important things, so it can get very expensive in production
I like https://www.cockroachlabs.com and https://duckdb.org for their respective transaction / analytics use-cases.

CockroachDB is a distributed database with standard SQL for cloud applications. CockroachDB powers companies like Comcast, Lush, and Bose.
DuckDB
DuckDB is an in-process SQL OLAP database management system. Simple, feature-rich, fast & open source.
moving from MongoDB to PostgreSQL at Code Climate tripled our infrastructure costs.
(Admittedly we were using them pretty hard etc)
why is that though? I heard that postgres is good at handling large amount of data
Its transaction-per-second rate is terrible compared to MySQL at some important things (certain types of insert, etc), and it doesn't give you a way to "cluster" the data on disk in a way you control, it always re-organzies it.
So we had to run 3x as many servers to do what we'd been doing
clustering is powerful, you can say "I don't care what the primary key is, lay this table out on disk in "employee id order"", or whatever
Microsoft SQL Server is fantastic at it.
so is Oracle
clustering lets you achieve memory-locality, a thing that RDBMS normally suck at
but is crucial to speed on modern hardware
I don't love MySQL and never have, but I have seen it stand up for sure. The company I left earlier this year (since 2018), had $5 trillion of customer financial records in the single main MySQL db.
I see, my db isn't that big enough to worry about that kind of stuff lol
(I worked on the team using Python/Dask/NumPy/SQL to "offline" process that before the next day's market opened etc)
(Before that I was Senior Site Reliability there etc)
like without partitions and stuff?
Yeah
No partitions
(you need all the data at once to do certain calculations)
but I think MySQL popularity is decreasing and everyone starts using postgres instead
I haven't seen that myself
But maybe it's happening in certain sectors
I mostly see people moving from MySQL to Databricks rather than to another RDBMS
probably, every person I know and projects I have collaborated in uses postgresql
Grow your network 🙂
databricks is cloud-based right?
Cockroach is way better than pgsql to me
yeah I need to..
Yeah, I hate it, but it's incredibly powerful and organizations love it.
If you use it carefully you can process truly shocking amounts of data in parallel.
It's cloud but you can host it inside your own private AWS etc and just use a 'connector' out to their API as needed.
So they don't inherently 'see' your data unless you upload the results of your computations to them
It all runs on Spark, and I don't love Spark, but if you "phrase your problem right" to Spark, it's so fast.
The trick is figuring out how to do that, which isn't always obvious at all.
damn u really naming out every data platforms 😭
I’ve also used others, like Snowflake etc
(Snowflake is pretty nice actually)
Databricks offered us a huge discount though so we switched
Snowflake has a cool thing where you can create datasets and then sell them to customers through Snowflake directly without handling payments
Databricks is more powerful but I think Snowflake’s “product management” is better
Databricks seems to just constantly be adding 70 new features, no idea how they are going to maintain it all.
lol that's quite funny
Just the AWS accounts I had admin on were $1.3m/month, so when Databricks shows up and is like "Why don't you spend a bunch on us and move things off Amazon", executives start losing their minds
AWS networking is such a scam, it's SO expensive to plumb your databases up securely.
Often you end up paying for each packet 3 or 4 times.
especially if you need their Transit Gateway offering
"database behind transit gateway" probably makes a screen in AWS Sales's command center light up, and they pour a round of whiskey shots.
why would they do that...
that's bad
btw, how long have u been through this data ecosystem thing
Each NAT Gateway costs money per packet, each Transit Gateway is another, and a typical account-to-account setup using Transit Gateway is: [NAT in Account A] <-> [Transit Gateway in global networking account] <-> [NAT in Account B]
I started out working on a mainframe app for the State of Florida state government in 1997, so 28 years?
Under the hood of AWS networking is a software-defined-networking stack they call Hyperplane, and it could solve this pricing problem easily, but they don't let customers access it.
Hyperplane would just let you directly connect account services together etc.
So the network pricing thing is an obvious scam once you're aware of that etc.
Hyperplane would let you 'auto zero-trust' your whole networking layer etc.
It's aggravating. I don't use clouds for anything unless forced anymore.
My jam is https://oxide.computer/
The cloud you own. Hardware, with the software baked in, for running infrastructure at scale.
o damn, that's insane
Everything we were paying that $1.3m/month for runs easily on one rack-scale machine from Oxide.
And you can buy one for less than we were paying AWS every month etc.
They almost fired me for pitching Oxide instead of AWS haha
make sense, at that scale you probably wanna have your own dedicated cloud server right
Makes sense to ME, but I have not YET met a company that was down for it, even ones where I had the job title "Principal Architect"
blah blah "capex is harder than opex"
Eat it, this is where we keep the treasure
This is what CapEx is FOR
hahahah truee
hello
any resources to learn database
i have to connect it with flask
but i never used it
it's my first time using flask and database
i have to learn a lot
how much time would it take me to master both?
The flask tutorial has a chapter on how to connect to a database. I recommend you create a new project and follow the official tutorial so you understand how to connect, fetch, update, delete, etc to a database. https://flask.palletsprojects.com/en/stable/tutorial/
sure then i'll give it a go
thank you mate
do you recommend linode? that's what i've been using as a reverse proxy for a while now
It’s ok, I think it’s a little behind the curve and I currently like CloudFlare a lot
Yes I use CloudFlare too, the only bypass I was trying to reach was having reverse proxy ports that weren't just standard http(s) traffic
something lightweight that still got the job done; it's been roughly $20/mo for the instance
Hmm, can’t you route an arbitrary port to a Worker etc? Maybe I’m wrong
anyone a data or bi expert here
and from india
we need one person in this role for an agentic ai hackathon
HF?
Anybody tried this? https://github.com/probcomp/bayeslite
Video about the thing this is based on https://www.youtube.com/watch?v=-8QMqSWU76Q

Probabilistic inference is a widely-used, rigorous approach for processing ambiguous information based on models that are uncertain or incomplete. However, models and inference algorithms can be difficult to specify and implement, let alone design, validate, or optimize. Additionally, inference often appears to be intractable. Probabilistic prog...
this is new to me but extremely up my alley
also something i will probably never use in practice 😂
you might be interested in the "nondeterministic programming" frameworks that have popped up in the Lisp ecosystem, especially https://nikodemus.github.io/screamer/ (see eg https://www.youtube.com/watch?v=z7V5BL6W3CA)
Screamer

Today will be an introduction to screamer and nondeterministic Programming in Common Lisp
Screamer Docs: http://nikodemus.github.io/screamer/
and of course the weird and wonderful worlds of prolog and datalog, which i always wished i had more time to study
Which do you ultimately use for django
Postgresql
Same here,
Was considering oracle for a while
if you dont mind paying for the license, sure. I've not used Oracle in at least a decade. Not sure if there's a free version that can be used commercially
oracle is awful
That quite true
if i learn sqlite3 with localhost
do i still need to learn other like MySQL, MongoDB etc?
or server based?
Your question is a little confusing... for most database systems you would learn using localhost with your own instance running on your machine, regardless of if that's an in-memory database or a relational one saved to disk.
Connecting to an instance of a database on the server is not much difference really beyond the connection string and any authentication you need to do to a different address.
Your reason for learning different database setups would mostly depend on what you intended to use them for/build
if you learn sqlite3 with localhost, it gets easier to learn for other databases.
sqlite is an SQL database, and so is MySQL, so most of your SQL knowledge would carry over between those. But there are differences in how it's set up, configured and maintained that you would need to study.
MongoDB is not an SQL database, so the differences are larger there.
Deploying a production database, rather than a local dev installation, is a different matter, and requires additional knowledge about configuration and networking.
i learned CRUD operations in SQL using localhost, so am i already halfway there? Security, Configuration, and Networking - will it be difficult or a piece of cake like SQL?
i created a table, inserted, updated, indexed, deleted and other functions as well using sqlite3
Another philosopher...
is sql good or bad
lawful evil, I would argue

In the Dungeons & Dragons (D&D) fantasy role-playing game, alignment is a categorization of the ethical and moral perspective of player characters, non-player characters, and creatures.
Most versions of the game feature a system in which players make two choices for characters. One is the character's views on "law" versus "chaos", the other on "...
Or maybe chaotic good. I guess depends.
well since it is the language of the actual database, relational databases at least, it is definitely "good" and not "evil." and since it really boils down to "just a string" that would mean "chaotic" for sure. except there are "names parameters" and some people even just use sprocs. so anywhere on the "good" scale I'd say.
SQL feels more Lawful Neutral to me.
Not sure. Tough one.
Lawful Neutral is the "alignment of the dutiful sentry"
Lawful neutral in my book
Im trying to learn SQL and MongoDB but i dont know where to start (i dont have a laptop, im getting one in december), can anyone suggest resources with which i can learn in my phone
Learn how to make a discord bot that tracks data with mongoDB Atlas (cloud) (last time I checked, it was inclusive of a free small memory pool to use with an account)

MongoDB
Find out how the document model eliminates operational complexity while ensuring unmatched resilience, scalability, and enterprise-grade security through the Atlas cloud database.
PyCord or Nextcord (discord related frameworks for making bot projects) and SQL queries triggered with python
A few of the gotchas will be discord bot related, so if you want to do something more simple just make an account on Atlas and write a python program that uses SQL and Tkinter (a python library for simple UI stuff), or just is a terminal program that lets you change the data on MongoAtlas via an API key.



so can we use SQL on MongoDB?
or any other language for it
Very basic SQL is supported, but MongoDb uses its own very similar looking NoSQL language MQL
But the patterns of interacting with data are similar. Learning those patterns of interaction for ETL (export transform load) and beyond will adapt you to just about any data oriented language you desire 
Here's some resources that might help. Not mongo, they're sql:
https://owencampbell.me.uk/sql_python_tutorial/pages/intro.html
https://sqlbolt.com/
https://selectstarsql.com/
https://www.datawars.io/
https://www.hackerrank.com/domains/sql
Would anyone have a reccomendation on a legitimate SQL course to learn and implement alongside python? Straight-cut, covers the main fundamental portions.
SQLbolt looks cool so far. Very understandable for someone like me with little sql knowledge. Hard to type the code on my phone.. kinda wishing I was on my computer 😂
Awesome, ask questions if something doesn't make sense!
Much appreciated 🙏
ohh okay thank you
yeah sure ill try that out
damn thank you, datawars looks interesting
All relational databases can run ACID transactions
But not all of them have the postgreSQL sauce

Hey I have a question about databases. I have a process that reads rows from a pandas dataframe and processes them in a FIFO manner via a queue, the process needs to loop over each row in order to make a descision on wether it goes into the queue, or not (meaning marked with a status). I am doing this in a dataframe but thinking i could make such operations I/O bound by querying for a single database row in a FIFO manner?
It has completed ACID properties? Why do most companies rely on postgresql
why did nobody tell me about pgcli sooner, I've been stuck using psql like a caveman
The first question is always: Do you really want to loop over a dataframe? That's, more or less, an anti-pattern.
you can, it's just usually missing the entire point of having a dataframe. ie: If there's a status column, then do it in one operation.
I'm wondering if someone could help me diagnose a MySQL connection issue with a Python app? I'm building a v2 of a site I currently run. The old site uses MySQL, whereas I'm moving to Python/Postgres. Both versions are developed on docker compose. So when developing locally, the MySQL server is up on one docker network, with port 3306 exposed, while the Python app is on a separate docker network. As I'm on Linux, I have the extra_hosts config set up
extra_hosts:
- host.docker.internal:host-gateway
When I try to connect, I get a "Can't connect to MySQL server on 'host.docker.internal' ([Errno 111] Connection refused)" error. I am able to connect to the MySQL server via dbeaver (a db gui), on localhost, using the same credentials I'm feeding to python. The MySQL server is set up to listen on any address. Python is attempting to make an async connection via SqlAlchemy and asyncmy, but as far as I can tell, there is no config I'm supposed to set to support the connection. I'm using MySQL 8.4 and Python 3.13. I checked the grants, and theyre on *.* TO user@% WITH GRANT OPTION, which seems like is what it should be?
The challenge is that I am currently required to procees rows in a FIFO manner right now
You're not really giving us much info here, but sure, you can itertuples on the dataframe.
Yeah my apologies, the situation is that we have rows of data where each row needs to be processed in a FIFO manner, each row will go through a series of business logic. Some rows in the queue will be processed in different orders. I want to get away from looping over a dataframe. The issue is that vectorization is not easily translatable
im not a frequent user of pg, but nice to know this exists! FWIW im hosting a postgres server behind SSH, and apparently paramiko v4 broke sshtunnel which pgcli depends on:
https://github.com/pahaz/sshtunnel/issues/299
ended up working around it by using the linked pull request, #300: ruby $ uv tool install pgcli[keyring,sshtunnel] --with git+https://github.com/lglines/sshtunnel@7030d0c76c679c2934bdc27adc48ff5a84d1ae9a $ pgcli postgres://... --ssh-tunnel ...
i also tried connecting to it through my reverse proxy with SSL termination, but pgcli didn't work with that, and i couldn't find any "direct TLS" option to solve it...
I'm a bit confused.. shouldn't timediff() exist in Python's sqlite3?
Are not all functions available?
Oh.. It's sqlite version 2.6.0... then my next question would be: how do I find out which functions exist there?
!e ```py
import sqlite3
with sqlite3.connect(":memory:") as conn:
r = conn.execute("select * from pragma_function_list")
print(r.fetchall())
hmm
:white_check_mark: Your 3.14 eval job has completed with return code 0.
[('pow', 1, 's', 'utf8', 2, 2099200), ('group_concat', 1, 'w', 'utf8', 1, 2097152), ('group_concat', 1, 'w', 'utf8', 2, 2097152), ('json_type', 1, 's', 'utf8', 1, 2048), ('json_type', 1, 's', 'utf8', 2, 2048), ('julianday', 1, 's', 'utf8', -1, 2099200), ('ntile', 1, 'w', 'utf8', 1, 2097152), ('nullif', 1, 's', 'utf8', 2, 2099200), ('sqlite_compileoption_get', 1, 's', 'utf8', 1, 2097152), ('json_valid', 1, 's', 'utf8', 1, 2048), ('json_quote', 1, 's', 'utf8', 1, 2048), ('json_patch', 1, 's', 'utf8', 2, 2048), ('->', 1, 's', 'utf8', 2, 2048), ('json_array', 1, 's', 'utf8', -1, 2048), ('current_timestamp', 1, 's', 'utf8', 0, 2097152), ('power', 1, 's', 'utf8', 2, 2099200), ('sqlite_compileoption_used', 1, 's', 'utf8', 1, 2097152), ('json_remove', 1, 's', 'utf8', -1, 2048), ('json_object', 1, 's', 'utf8', -1, 2048), ('json_insert', 1, 's', 'utf8', -1, 2048), ('->>', 1, 's', 'utf8', 2, 2048), ('sin', 1, 's', 'utf8', 1, 2099200), ('sum', 1, 'w', 'utf8', 1, 2097152), ('quote', 1, 's', 'utf8',
... (truncated - too long)
Full output: https://paste.pythondiscord.com/DF3COG3WBRJBGW7AUHNT7UAQ4Q
Hmm, no timediff, but I guess I can subtract two results of juliandate(), should be enough for my purposes. Thanks!
Anyone mind pitching in on whether using json files as a digital assistants database format is an effective idea please?
@jade wing jsyk i despise the Method HOWEVER it has resulted in this so thank you for that
i'm still trying to figure out how to get the owner data to fill in

what method are you referring to?
for storage i would model this as two tables
one named attacks (if that is what it is and ifni remember it right) with the fields id, name, owner_id, damage, cooldown, damage_rate_ticks and ststuses
and another named owners with the fields id, name, love, badge, health, dodges and secret
and then be able to join the two tables on attacks.owner_id and owners.id
possibly create a ststusez table and a many-to-many connection table between the attacks and statuses if needed to be able to have several statuses associated with each each attack if that is a thing (i lack context here)
do these two lines work to form the one-to-many relationship (one owner will have many attacks but all attacks will have only one owner) ?
attacks = db.relationship('attack_model.owner_id', backref='owner') #part of charactermodel
owner_id = db.Column(db.Integer, db.ForeignKey('character_model.id'), unique=False, nullable=False) #part of attackmodel
guys i want help
i have bought a brand new pc
for
a database
but i only wanna use it for a database
using windows
and i want it to be available on my network + a vpn tunnel
could anyone help me with making a data flow diagram?
Not recommended for server hosting and similar, just noting
If you want a machine to function as only a database or similar but not general usage, you should've went for a Raspberry Pi-like machine IMO
Not a PC with Windows (though you can always just switch to Linux on it)
All of this is from my knowledge. I'm not stating super duper reliable facts but it's what I know
Ok
I will switch to ubuntu
unless @rigid pike want to use MS SQL Server for the database
but for MySQL, PostgreSQL and many more i agree that linux is a better choice in general
I want yo use postgresql
you can run it on windows but i would recommend running it on linux if you can
Hi, there!
I have a database which contains millions and billions as text 'Mln' and 'Md'.
I need to transform 'Mln' and 'Md' into numbers.
Python always gives me the wrong numbers.
Any suggestions, please?
The main problem is due to the coma conversion in dot.
In my country the float is coma not dot and millions and billions are dot
When I run I get 22.12.00
I could use spreadsheets but I'd like to know any solution in python
Which are currently considered the best ORMs in Python?
sqlalchemy is pretty popular
can you give us the source data that resulted in that?
Hey, thank for answering.
The source is this website
https://www.reportaziende.it/sonepar_italia_spa_pd_00825330285
Report Aziende, l'archivio delle aziende italiane
REPORT COMPLETO SONEPAR ITALIA S.P.A.. Guarda fatturato, utili, perdite, costo e numero dipendenti.
I want to get:
Fatturato
Utile
Costo personale
Numero dipendenti
The database i get is the follow picture



took me long enough...

 what's that for
what's that for
Please react with ✅ to upload your file(s) to our paste bin, which is more accessible for some users.
Well, my detective skills tells me it's a group chat that's all fun and games.
what does this have to do with #databases ?
Honestly, IDk
I'm coding a VCS with a command that encrypts a file using XOR encryption. It stores each users credentials in a separate JSON file. Only problem is I couldn't link a specific user. So once the file is encrypted, any other user could 'encrypt' the file with another key and corrupt the file. How can I fix this?
P.S - I have user verification system already
"XOR encryption" is the strongest there is and has been mathematically proven to be unbreakable, if but only if the key is as long as the data you encrypt and is made out of true randomness and is never ever reused again for encryption anything else, if you can't live up to those three stringent requirements "XOR encryption" isn't any good and can even be one of the weakest forms of encryption (in worst case scenario is almost like "Caesar encryption" or "ROT13")
with all of that out of the way, you need an ownership/permission system where you can tag a file with an owner and only let the owner have write access to such a file, as anyone with write access can otherwise overwrite the file with whatever they want (encrypting again with another key is just another way to overwrite it)
anyone here good with postgis? i've got a bunch of data that's using HK1980 northing/easting, and i'm under the impression that it should be stored in postgis by converting it to WGS84 (srid=4326) before storing it. is this correct? i want to be able to find the rows whose location is within a given radius of a point
(disclaimer: this is my first time working with GIS)
would you let me know if there is any resource to learn about Deploying a production database ? What kind of knowledge about configuration and networking do you think is required?
postgis doesn't require a particular coordinate system
if your data will all be in HK1980 it would be more accurate to keep it in HK1980
Honestly, I'm not sure. Whatever I know on this topic, which is not a lot, I've learned from co-workers and on the job. I can't think of any like guide, tutorial or book off the top of my head. Maybe someone else here can.
Can someone enlighten me on redis
Idk i havent used redis in my life
its a nosql database that stores data in a key-value based format, kind of like json. I've mainly seen people use it as a cache system and and have a relational db as the main db
if im not wrong they even updated thier license couple of years ago to paid if you're making commerical based application
even though they're open source
From what I understood yeah , for cache ,rate limiting..not for complex queries
thanks for the reply
Hi everyone.
I'm new here and a python rookie. Been learning for months now.
Just finished building a simple Expense Tracker in Python.
It handles income, expenses, and displays running balance using basic file operations.
Would love any feedback or improvement suggestions 👇
https://github.com/Variant1740/Expense_Tracker/blob/main/Expense_tracker.py
GitHub
A simple Python project for managing daily expenses - Variant1740/Expense_Tracker
you could probably get rid of the time.sleep or at least replace multiple calls to it by one long sleep. Also, in view_expense, you could use string alignment to make sure the output is neatly columnized
How do I possibly do that? The replacing time.sleep with one long sleep.
whats database
Wrote a python code for a mini store menu.
Open for recommendations and suggestions.
I'm a rookie in it though.
Been coding or learning python codes for months: nearly a year.
GitHub
A simple python code that recreates an online mini store menu - Variant1740/Mini_store.py
Whats the best database ( free) I can use to store json data?
can MongoDb store json? , if so can someone show how to do that?
postgres is free
Encountered two children with the same key, null. Keys should be unique so that components maintain their identity across updates. Non-unique keys may cause children to be duplicated and/or omitted — the behavior is unsupported and could change in a future version.
@app.post('/hangouts')
def create_hangout(hangout: dict):
cur = con.cursor()
cur.execute("""
INSERT INTO hangouts (activity, hour, minute, maxAttendees, location, description)
VALUES (?, ?, ?, ?, ?, ?)
""", (
hangout['activity'],
hangout['hour'],
hangout['minute'],
hangout['maxAttendees'],
hangout['location'],
hangout.get('description', '')
# no need for attendees because the default is one
)
)
con.commit() # for safety and control, think of this like git commit
# update to database and then give it to the frontend
new_id = cur.lastrowid
# fetch newly added hangout
cur.execute("SELECT * FROM hangouts WHERE id = ?", new_id)
new_hangout = cur.fetchone()
return dict(new_hangout)
getting this error in my Python code. think it is this function
figured it out
I am trying to log transform data but I could be sure if somethings is wrong

is this values normal for log transformed one?
I kinda get how skew() works but I didnt expect to negative values
If I have an API token stored in the database hashed with a salt (using bcrypt), how do I retrieve that row using the token in plain text form?
you don't
either you hash then retrieve based on the hash, or store some metadata in the token after hashing (e.g. account/token id) then fetch based on it
What problem would that solve for you?
I can't directly hash the plain text token and include it in the DB query since I need the salt to hash it (which is included in the hashed token header stored in the DB)
I have a table (e.g. instance) which has a column api_token (containing a hashed token bytes). Now, I want to retrieve details of a row just from a given token, which is passed in the Authorization header.
These hash functions are a one way street. You can't get that data from the hashed value.
So that means you could:
- Have your API specify the account id somewhere to you know how to link which API key it belongs to
- If your key is the secret, then you have a table somewhere that link API keys to an identity
- Your token is not just a hashed value. See for instance JWT tokens
then there is no way I can store the token in hashed form?
it would work with the second bullet
ok, pretend I have a table with two columns (user_id[str], api_token[bytes]). How would I get the user id from the db query if I only have the token in string?
If you store the hashed value of the token in the DB in that table, then you need to hash the incoming token and look for any row that contained that hashed value
the problem is that bcrypt needs salt to hash the token, I'll just probably take your solution and add a "salt" column in the table
- ts_in_delta
Select timestamp column (1-N): 1
2025-11-20 20:58:58,123 - INFO - Using ts_col='ts_event'
2025-11-20 20:58:58,123 - INFO - PASS 1: Creating UNSORTED parquet (no RAM usage)...
2025-11-20 21:03:37,466 - INFO - Pass 1 complete G:\quant\data\raw\datatbbo\datatbbo\converted\merged\ES_TBBO_CONTINUOUS_(04-12-2024- 09-22-2025)_UNSORTED.parquet
2025-11-20 21:03:37,467 - INFO - PASS 2: External disk-based sort...
2025-11-20 21:03:37,738 - ERROR - Merge failed: Invalid Input Error: Cannot change enable_external_access setting while database is running
❌ Merge failed: Invalid Input Error: Cannot change enable_external_access setting while database is running
❌ Merge failed
mr duckdb king
what does this mean
I'm a bit confused, are you disabling "enable_external_access " when you confiugure the db?
Seems like you're setting a bunch of duckdb settings (esp from the thread where you said you set the memory limit to).
When starting a back end app, what's your process like? I know you have to create an er diagram before coding and write documentation after it's done but what else?
first figure out the requirements. From there you can start to tease out the access patterns and data model
Your data model will be impacted by the access patterns and requirements
I start with writing tests and let the code serve as documentation. At this point I'll probably add a wiki if it is important enough. If there's something worth pointing out I'll put it in the readme, maybe utilize the wiki feature on GitHub to keep track of where we're at in terms of features.
For example I might add a comment to the locking code that says "it uses a table and select for instead of advisory locks because we want to use cockroachdb which doesn't support them", or highlight that somewhere another developer can read quickly.
Hey there, I'm planning to start learning postgresql could you guys recommend me any tutorial so that it will be good for me to get into web development(python) and data analysis ?
it depends on your current SQL knowledge and your task in web development. I would recommend reading introduction docs at first , I Tutorial part , learn about MVCC in postgres, if you don't know SQL well , may be you may also need a SQL part in docs a bit. If you wanna learn postgres architecture , you may watch this video. However, the best approach to learn certain topics so you would avoid tutorial hell is by practising them in your own web project , e.g if you are working with concurrency in your web application - you might wanna read more about Transaction Isolation , Explicit Locking and etc. So you may read a docs , solving a certain problem in your project and watch Hussein's channel

Creating a listener on the backend application that accepts connections is simple. You listen on an address-port pair, connection attempts to that address and port will get added to an accept queue; The application accepts connections from the queue and start reading the data stream sent on the connection.
However, what part of your application...
Try these #databases message
it stores stuff in a hashtable for rapid lookup
the main drive for the project is SPEED, but it limits you to unqiue key pairs, but its primarly a cacheing system to speed up requests
rather than work as a database
and it works 100% in memory
so you cant use it when you want a cache that you expect to have on disk lookups
Thank you
mostly its used as loadbalncer or head node. but you can use it as a raw DB, just kinda dont as powerloss makes you lose all data
this is not relevant for this channel whatsoever
and that smells more like self-promotion than anything else
Well, It is API monitoring tool , it is relevant to DB . I came across with it so i shared it here. If it feels promotional just remove it.
Thanks
!rule ad
please remove it yourself instead so that we don't need to call in moderators
!warn 1379302063292547155 Don't advertise, and listen to staff instructions.
:incoming_envelope: :ok_hand: applied warning to @devout nova.
!rule
The rules and guidelines that apply to this community can be found on our rules page. We expect all members of the community to have read and understood these.
Hi guys
I'm developing an Algorithm Trading bot. So I'm wondering what do you guys use in VS Code to visualize/analyse large base of data
hi, im new here and also in python, I know some basics, and im trying to make a code to help me with a study im making for my math class, can someone help me please?
HI, @ripe oasis
What is your math class problem?
I use dbeaver software for database visualization/management.
its free and open source
and has support for many kinds of db formats
Hi guys, is posting an open source Python project allowed here or is it considered advertising?
if you want some suggestions or feedback you can send your github link here
Hi there, how would postgres react on INSERT ON CONFLICT clause if we are doing a bulk insert and there are same rows in the insert statement? I suppose that if there are no unique constraint violation error it will only insert 1 example of row and ignore other duplicates, am I right?
Thanks! Here is the github link: https://github.com/manoss96/onlymaps
It's a micro-ORM, which means that you still get to write plain SQL queries to interact with a database either synchronously or asynchronously, while it takes care of mapping the results to Python objects. It also supports all major relational databases.
I believe that a micro-ORM was missing from the python ORM landscape, as most ORMs are pretty bloated feature-wise and come with their own OOP-like API.
Any questions/feedback is welcome.

GitHub
A Python micro-ORM. Contribute to manoss96/onlymaps development by creating an account on GitHub.
Probably yes, only non-conflicted rows would be inserted, but try it out just to be sure.
I heard that for document-like data e.g. ```json
{
"id": "page1",
"background": "#FFFFFF",
"elements": [
{
"id": "shape342",
"type": "rect",
"x": 100,
"y": 200,
},
{
"id": "text123",
"type": "text",
"content": "Hello world",
"x": 200,
"y": 150
}
]
}
Hi there , I am building web scraper of many websites and on each website there are specific time zone, e.g there could be both european , american websites with differn timezones. I am using postgres for a database , yet a local server with pgadmin app. As I know the preferred way to store data is in UTC timezone, however, my default value in postgres is specific timezone like Europe/(some city) , so the question is do I need to change the default value somewhere , if yes how? (set time zone (timezone) doesn't help as it is restarted with each new connection to the database )
And the preferred way is when I know the user's timezone using date postgres operators I should show the data using this certain time zone.
Example: date in the database
1999-01-08 04:05:06-8:00
query if user is from los angeles:
select created_at at time zone 'utc' at time zone 'america/los_angeles' from users;
Am I right with a concept? Or there are some misunderstandings?
there is an ISO standard for this

ISO 8601 is an international standard covering the worldwide exchange and communication of date and time-related data. It is maintained by the International Organization for Standardization (ISO) and was first published in 1988, with updates in 1991, 2000, 2004, and 2019, and an amendment in 2022. The standard provides a well-defined, unambiguou...
dont worry about the city, just do the offset
it may be important due to differences in DST (if and when it happens, as that changes the offset temporary) between locations within the same standard offset
the "continent/city" notation is the most correct when it comes to DST, but it's also the hardest to extrapolate unless you have that information about the user from a reliable source
thats done client side
generaly you dont care on the backend whats going on, and everything shoudl pretty much be done in 100% UTC
you can do customer stuff on their customer ID, or in their VIEW settings
if you 100% must put in customer specific cusomtization in you DB
but dont as almsot any app handles DST for you, hell the endpoint OS handles it
that depends on the context, on the web you can most of the time ignore it and just offload it to the client side
but if implementing this in a local application one might need to take care of that one way or another
and another reason you dont wanna deal with it in a DB, it changes year to year for alot of places
usally this is done in UX methods or the buiness logic methods
but generally, yes, i would just store everything in UTC in the DB and let the client application code deal with the local time if necessary
even if your doing this pure sqlite flat file you would do this in the program/app not the DB itself
youd just set that sucker to iso utc
because EVERY programing lang has stuff to handle it for you
any libary expects iso8601
i totally agree with you there
it's just that you might need to implement things in the presentation layer or business logic yourself if it is on you to implementing that side of things (i have had to do this a few times, last time was less then a month ago, but it is very special/specific cases only where you have to deal with this, for example when not dealing with timestamps right now but rather in the past or future)
one of the only ones ive come accross in a DB is an extra gps feild
but that is kind sketchy now due to data protection laws
so the most common way is to store timestamp obj (datetime if we speak about python ORM) in UTC format without an offset? talking of postgres
using only UTC for anything having to do with storage and calculation of timestamps or datetime data types are the most reliable way to handle things in general as well (not just in plostgres even if it applies there equally)
thx, bro! will apply it to my code.
yeah do all your customization in the buisness logic
ok, thx, i will convert all datetime to utc and store it in utc. and show according user's timezone. btw, banal , but not least interesting fact that timestamptz takes 8 bytes in postgres and date (without time) only 4 bytes. so earlier i used to store kind of birthday dates in timestamptz but today i have investigated the key difference. may be would be also useful for someone , you can find more about it in postgres docs
Professional Data Analysis Example
Coded by Aiko Lark
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
-----------------------------
1️⃣ Load dataset (example: sales data)
-----------------------------
data = {
"Month": ["Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug"],
"Sales": [1500, 1800, 1700, 1900, 2200, 2100, 2300, 2500],
"Expenses": [800, 900, 850, 950, 1000, 980, 1100, 1200]
}
df = pd.DataFrame(data)
-----------------------------
2️⃣ Data overview
-----------------------------
print("=== Data Overview ===")
print(df.head())
print("\nSummary Statistics:")
print(df.describe())
-----------------------------
3️⃣ Add new calculated column
-----------------------------
df["Profit"] = df["Sales"] - df["Expenses"]
-----------------------------
4️⃣ Analysis
-----------------------------
print("\n=== Profit Analysis ===")
print(df[["Month", "Profit"]])
Find month with highest profit
best_month = df.loc[df["Profit"].idxmax(), "Month"]
print(f"\nMonth with highest profit: {best_month}")
-----------------------------
5️⃣ Visualizations
-----------------------------
sns.set(style="whitegrid")
Line plot for Sales & Expenses
plt.figure(figsize=(10,6))
plt.plot(df["Month"], df["Sales"], marker='o', label="Sales")
plt.plot(df["Month"], df["Expenses"], marker='o', label="Expenses")
plt.title("Monthly Sales vs Expenses")
plt.xlabel("Month")
plt.ylabel("Amount ($)")
plt.legend()
plt.show()
Bar plot for Profit
plt.figure(figsize=(10,6))
sns.barplot(x="Month", y="Profit", data=df, palette="coolwarm")
plt.title("Monthly Profit")
plt.xlabel("Month")
plt.ylabel("Profit ($)")
plt.show()
#this is a tutorial for begginers
please put your code inside a code block like the embed above from the Python bot tells you how to do, so that it isn't so noisy in the channel
guys what app is best for data analysis in python should i use and also works in low end pc?
you can use Jupyter Notebooks with Pandas/Polars/PySpark
Hey guys good evening. I'm starting with this of python. Can anyone give some advice. Thanks
it’s lightweight, great for data analysis, and works well on low-end PCs. If you need a simple scientific IDE, Spyder is also a good choice. For quick experiments, Jupyter Notebook is ideal and runs directly in your browser.
does anyone use lightweight_chart in Python ?
In sqlachemy in a many to many relationship do I add associates/connection table after both tables the M:N tables have values? please ping on reply
Any pro dev in the house
pro tip, just ask your question instead
I've forgotten
When I remember I'll let you know
for next time then, skip asking for an expert or a pro or similar and just ask your question, that way you are more probable to get an answer and as a bonus you won't forget what you meant to ask in the first place 😉
idk
What's the best free provider for databases? Just in case I want to make a side project or something.
Supabase and fly.io provide hosted Postgres
AWS also has a free tier
I didn't know about AWS having free tiers. I assumed Amazon were thirsty for money.
iirc it is a free trial, not free tier?
or did they have an always-free offer
a few services (including databases) have an always-free offer with monthly limits on stuff like compute hours
for databases, Amazon Aurora DSQL and Amazon DynamoDB have an always-free offer
psql ot
Hi guy i need help with connecting into a database it dont let me connect it keep saying Error module not found
which module not found?
I cant connect the testconnetion into the mongo
they both in the same folder but dont work
can you share the full error message?
can i sent it here or in dm
here pls
% npm run test:db > node -r dotenv/config -r ts-node/register lib/testConnection.ts Error: Cannot find module '/Users//Desktop//lib/mongodb' imported from /Users//Desktop//lib/testConnection.ts at finalizeResolution
(node:internal/modules/esm/) at moduleResolve
(node:internal/modules/esm/) at defaultResolve
(node:internal/modules/esm/) at ModuleLoader.#cachedDefaultResolve
(node:internal/modules/esm/) at ModuleLoader.resolve
(node:internal/modules/esm/) at ModuleLoader.getModuleJobForImport
(node:internal/modules/esm/) at ModuleJob.#link (node:internal/modules/esm/)
{ code: 'ERR_MODULE_NOT_FOUND', url: 'file:///Users//Desktop//lib/mongodb' }
thats a nodejs error. probably need to install mongodb via npm but I'm not sure. Try asking in a JS server
ok ok
Hey 👋
I know this is probably a dumb question but oh well.
Let's say I have a database which stores information about discord guilds. And I want to display the information on a website.
How would I go about updating the information? (For example, server changes their icon and I want it to update on the site also)
(This is assuming that I have both the guild_id and icon_hash saved)
Well, the same way you got the info into the database in the first place, pretty much. You'd probably do an appropriate update query.
Won't constantly looking for updates drain resources? Or should it update every time the user does something? Like a login.
Bro pls look #career-advice probably i sent the wrong channel
Constantly looking for updates would be a bad idea (it's not even resources you should be worrying about, but API limits), yeah
Gotcha
Consider storing for each thing you look up (e.g. guild) the last lookup time, and periodically selecting one of the not-updated-for-longest-time records to update
Ohhh 😯
good
Hi all, have been facing a persistent issue with sqlalchemy/postgresql and multithreading, specifically regarding sqlalchemy throwing an “instance not persistent within this session” exception. Has anyone faced a similar issue and found a robust solution? This issue also occasionally happens under normal operation, primarily when long processes have been running for a while.
To clarify a bit, I just use a session factory to connect to the database at runtime, i.e. import the factory function per file and call it within the file to create a session, then use it as needed. This project may switch to using flask or Django in the near future, so this issue may end up being a moot point, but I have been banging my head on the wall with this for a while
Hi all, as a newcomer to Python programming, i was wondering if you know some nice websites with script templates for data science? I'm thinking of a premade script that will generate graphs or carry out multiple T tests by just copying in datasets and defining them. Thanks in advance 🙂
Anyone wanna help? Dms please
What kind of help
anyone can advice me before I try to make a program (I'm new to python and learning) to convert csv into bat into txt into etc. and vise versa, and along with that it supports a database using sql, it will save the data from those different types of files into the database. I will respect any advice and I need it if it helps. This is a project for a one shot to prepare for my exams fyi.
you can convert one data from one file type to another if that's what you're asking
how?
oh with pandas!!
tyy
alright np
Any thoughs on using json as a categorial database for a digital assistant?
If you're going to the effort of implementing a categorical database (I'm not actually too sure what this entails), I'd probably use a vaguely efficient backing storage like rocksdb.
Without outsourcing a purpose built database system.
in what cases i should use sqlalchemy
when you want to connect to a database and run queries against it
okay nothing else? i mean i can use queries. i was just asking is there anything i can do with sqlalchemy that i cannot do with query
It does alot more. It also does ORM so you can define your models easier, run sql migrations, sessions, etc. tbh you should definitely read the docs to see all of the nifty things it can do. https://docs.sqlalchemy.org/en/20/orm/
okay thanks
Hey guys, I'm new here. I started learning python so time ago, I created my frist mini-app in fastapi just to have something to show off and ask for an advice what to improve. If you could tell me what's wrong with the code I have, what I should change or never actually do. I'd be really glad and please be kind haha, I don't want to get discouraged.
https://github.com/dawidw-km/Mini-Library
GitHub
Contribute to dawidw-km/Mini-Library development by creating an account on GitHub.
The readme file is empty. I don't know what this is or how to use it.
its good
Hi guys, please check out dbzero. It's an open-source Python package which allows building blazing fast apps without any external database, ORM or cache. It's based on a principle of an "infinite memory" - just use your objects however you like. It's already tested in prod for several medium-size projects. We'd love to hear your feedback. https://github.com/dbzero-software/dbzero
GitHub
DISTIC (Durable, Infinite, Shared, Transactional, Isolated, Composable) memory system for Python 3.x - dbzero-software/dbzero
Hello guys, I have started learning Django some days now.I have some experience with Flask, I built a Quiz Website back then.Now, I want to build a website appointment system for a local haircut studio.The customers will be able to book for only one appointment and each appointment will have only one user.Furthermore the customers will be able to select haircut types they desire.It is my first time attempting to design database logic on my own.I know it might be very simple but I am still a begginner and I wanted to get your opinions in case I need to add/delete something.The problem is that I am a soo confused because: When I am thinking about the database logic I feel it seems alright the way I have divided the entities.But then I am thinking how are customers gonna select a haircut if they are not connected somehow (in the database section)? And what should I do with the form so that the haircuts can be added in my database while using ModelForms in Django? The last think that keeps getting me confused is how am I gonna keep the appointments clean in case an appointment is already booked and another user books at the same time.It seems like a whole mess in my head so if anyone can help I would appreciate it!

Polish guys! please DM me if you are free to chat.
halow
Assuming you are using Django to create the tables, this is a great start. I would consider extending the Customer model to the abstract user model so they can create logins/passwords.
A question that I’d have is the appointments, how are you blocking available and unavailable time?
As far as holding the appointment time, I would maybe create that in your form logic first, and then when the scheduling is verified and completed, have a is_taken bool so you can easily query for open slots.
Don't you need to identify who the hair stylist is assigned to that customer at the appointed time?
If you do need to identify the hair stylist, you will need to also check to make sure that the hair stylist doesn't get double booked at the same time for multiple customers
Can anyone suggest an embedded document-based database with a good Python API? Like if SQLite and MongoDB had a baby. I'll be doing more reads than writes. Long-term persistence isn't an issue, I'd be using it as an index to speed up some file generation
postgres?
Can I use it without expecting someone to spin up a Postgres server? And can I use JSON documents (as opposed to table rows) as the primary unit of data?
not fully sure but I don't think that anything embedded works great for that
if it's small enough to keep in memory, may as well just use a dictionary?
you can also store JSON in SQLite
Let me go into a bit more details about my problem, then. If you search my name on this server, you can see past discussions I've had, but I'll keep it to the salient points:
- I'm fetching data from a couple of web APIs and matching it locally with some data that's already in a repository. Specifically I'm matching game ROM data (e.g. the checksum of a ROM file) to game metadata (e.g. game genres, features, tags).
- The ultimate goal is to generate
.datfiles with this data to use within an app. - I was previously doing exactly what you describe, and pickling the Python objects to disk and back. But profiling revealed that that was a huge bottleneck, which was getting in the way of me iterating on the
.datfile generation -- even loading the pickled index I built manually took several minutes. - So I decided to store this info in an SQLite database in the hopes that querying would be faster. But dealing with SQLModel (Pydantic + SQLAlchemy) is proving to be a massive pain in the ass. Right now I'm just trying to store all the data I'm fetching from one service (including many-to-many relationship tables) in it.
- I don't want to require a database process because my use of databases isn't for any kind of persistent state; just as a cache to speed up local processing.
- I'm asking about document-based alternatives in the hopes that I can find something that's easier for me to get up and running
Also I'm trying to make this maintainable for people who aren't already heavy users of databases and Python
I'd just use raw SQLite tbh
I tried that but it got way too verbose specifying all those tables
The CREATE TABLE strings I hardcoded were longer than the classes themselves
So I hand-rolled some logic to create tables and column definitions based on type annotations, but I couldn't get relationships right. It then hit me that I was unwittingly creating my own ORM
do you need of all columns you were creating? you can include only the actually important ones, and leave the rest as part of a JSON object or even binary BLOB
Mostly. The data I'm fetching is already filtered (you can query from IGDB down to the level of individual fields)
May I ask, what is your university major?
I graduated with a Master's in computer science years ago, but I see my baby-face is as powerful as ever! 😊
Why do you ask?
it sounds like you just want to «stage» the data. just dump the tables raw. Without foreign keys, etc… that would solve your issue. If you want faster querying, create denormalized versions where the tables are joined. Also, duckdb is faster for this than sqlite
if you are trying to integrate data, you may want to create a star schema. Which is highly denormalized and optimized for querying. You still dump the data in a raw fashion, but then you update the star schema using MERGE
if you have a budget, and we are speaking larger amounts of data, you may want to consider apache spark (which is distributed processing) and a deltalake
if you are fetching data and you just want to dump it, then you don’t have to go through the pain of writing «create table». For example, you can use the pandas method to_sql() that will create the table for you
yoo thanks maan, didn't think about it appreciate the help
Yeah I was also thinking to make the logic in the form thanks for the advice appreciate it guys
Thoughts on https://sqlite.ai ?
SQLite AI transforms SQLite into a distributed AI-native database for the Edge—combining the simplicity of SQLite with cloud-powered scalability, fault tolerance, automatic backups, and powerful new extensions like SQLite-AI, SQLite-Vector, SQLite-Sync, and SQLite-JS to enable intelligent applications across devices, IoT, and mobile platforms.
ew
vector search is great, but the rest of their AI features sound awful
do they even have the permission to use the SQLite name that way?
I cannot imagine any compelling reasons to have LLMs integrated directly in the database, specially on edge devices
TTS and ASR are useful technologies, but again, keep it in the application layer instead of having the database deal with audio blobs or whatever you must do to get ASR working within SQLite
Hllo dm me I need data base
😭
This license seems super sus https://github.com/sqliteai/sqlite-vector?tab=License-1-ov-file#readme
OSI does not allow restricting fields of endeavor (such as "you can't use this commercially"), so it is impossible to incorporate this project into an open-source project. So the license is misleading at best.
there's no mention of this service on sqlite.org
Looks really interesting! Would I be able to use pydantic with a custom class? I haven't seen anything on this, but how do you store the state on disk? Can I load/copy/backup a specific state (at the next startup) ?
please check out dbzero https://github.com/dbzero-software/dbzero, it should satisfy your needs without any complex setup needed
in dbzero you just annotate your classes with @db0.memo and that's all - it handles persistence and caching transparently, allowing you to expand your program's working memory to virtually any scale. And for indexing purposes use the "tags" feature or db0.index then use db0.find to locate your data objects. Visit our documentation website for details and examples: https://docs.dbzero.io/
Get started with dbzero-enhanced programming in Python
Thank you fsade. Absolutely you can use pydantic. dbzero is Python-native so we made it to support most of the language features seamlessly (more extensions such as pandas integration coming soon). It can be used as a schema-on-write - when you enforce strict type validation or schema-on-read (no need to constrain yourself to rigid schemas). You can also use abstractions and polymorphism with your data objects.
State is persisted on disk automatially (default autocommit setting is 367ms - so roughly 3x every second). When you gracefully close the program - you can continue from where you left it (so indefinitely running programs are possible). If it crashes - it starts from the last consistent state. If you write REST API - and want to prevent data loss, use async locked feature to block response until there's a confirmation of data persistance (for high stake requests such as new signups or financial transactions), for most requests we don't recommend it.
Backups can be performed using copy_prefix() function - it works even if the process is actively modifying the state
And you can "time travel" to any past state of the process using db0.snapshot function
That sounds impressive...how did you implement that? How do you handle polymorphism? How do you handle references between objects for instance?
Okay, so I need to use python? I cannot use a backup program like restic or similar? Is it one file or multiple files? I guess going back to the implementation question 🙂
It's tightly integrated with CPython, when you wrap your class with @memo dbzero takes control of all the operations on the object. The references are stored as 64-bit identifiers and we manage ref-counts in the exact same way as Python does (so object stays alive for as long as it's referenced - note that tags also "reference" objects). The internals are quite complex - it's a lot of layers of C++ code but the source is available if you want to go deep 🙂
Yes, you need to use Python (but the function can be executed from another process, and it's just few lines of code). By default all goes to one file (we call it prefix) but you can split into many files by specifying either at a class level @memo(prefix = "settings") , @memo(prefix = "data") - or dynamically using db0.set_prefix function (in which case it must be the first instruction of the init method)
That's cool, I will try it out, thank you 🙂
Great, thank you :-). Let me know if you have any questions or problems.
In your intro video you mention that you are exploring other technologies? I presume other languages? Do you have a roadmap for this already?
we have a prototype version for JS, C/C++ SDK can be exposed quite easily I guess, but no specific roadmap yet - we'll listen to what the community says and navigate towards their needs (we still need to figure out what would be the best use-cases for dbzero)
anyone know good youtube videos guides for mysql
Consider reading the official docs instead https://dev.mysql.com/doc/connector-python/en/connector-python-installation.html
mumps (Massachusetts General Hospital Utility Multi-Programming System, aka M, has a whitespace-aware syntax where each line of code is syntactically significant. It integrates a built-in NoSQL hierarchical database, accessed using the same commands as local variables) + rag + py for fun i guess idk, as seen in screenshot running in my own html/skulpt based terminal.

{kind=link}
{kind=link}
Click here to see this code in our pastebin.
That's quite the project name, lol
Was there a question in here?
idk I just wanted peoples thoughts, using this syntax in py with rag has potential advantages: AI-driven healthcare: RAG on patient globals for semantic queries in telemedicine.
Legacy integration: Bridge old MUMPS systems (e.g., VA hospitals) with Python ML for predictive analytics. Knowledge graphs: Store/retrieve hierarchical AI data in edge computing for IoT.Hierarchical, schema-less storage for sparse data (e.g., medical records). Fast key-based access, global persistence.integrates MUMPS-like efficiency into Python apps without full DB switch. I have no experience in mumps or medical billing but what interested me is when I seen someone talking about EPIC has been using it since the 70s for reliable DB which exsists outside modern syntax. Epic uses MUMPS (Massachusetts General Hospital Utility Multi-Programming System) because it's a powerful, integrated language and database ideal for high-volume healthcare data, offering rapid development, scalability, reliability, and efficient, real-time data handling crucial for Electronic Health Records (EHRs) since its early days in hospital systems. Pairing this with PY and RAG is the innovation ive added, i'm just trying to find anyone familiar with mumps to maybe test it or weigh in, im trying to figure out what to build it into, its the template for something larger (no name yet Mumps and rag are just the DBs it uses within the py.)
the M (mumps) and RAG databases exsist indepdently from eachother i think right now, I want to enhance it for MCP functionality and API integration possible medical db data set training using a custom model
another advantage: niche syntax are less prone to cyber threats, (not that AI couldn't decrypt instantly ) just that people writing malicious software might overlook M syntax)
right, EPIC is loyal to MUMPS but likely for legacy reasons (they've been on the market since late 70-s). Same as Cobol is still prevalent in banking systems. Rewrites of such systems might cost billions so it's easier to train people in coding than taking on reimplementation and migration. Is there any specific reason you chose this particluar technology, aren't there any modern alternatives ? I understand the use-cases, just wanted to understand your motivation.
well the idea is to make mumps modern by supporting running in PY with RAG, thats essentially all i'm going for atm. old doesn't mean bad, it's known for its short CLI handling, which (conceptually) could speed up model training over larger data sets with less whitepsace and characters, while running in RAG/PY pipeline etc. thats my vision anyways
is this a client-server architecture or embedded ?
i thought about doing the same thing for cobol, i figure is not a way to eliminate old syntax, a way to revive them for modern use by more developers (idk if these companies that rely will be happy about this though)
embedded
That's a fair point. Old does not mean worse - but with so many alternatives on the market you need to demonstrate some real strong advantages to gain traction and later adoption in the mainstream. I think maybe it could fit into already existing ecosystem within hospitals (?) Just guessing. The market is really huge (it's 250M patients) - might be very interesting.