#databases
1 messages · Page 14 of 1
alright, forget about the replit part
alright ty
i will see if i can find a yt video on it

Python documentation
Source code: Lib/sqlite3/ SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows accessing the database using a nonstandard ...
thank you
the sqlite3 library itself is pretty small, learning to write sql queries is what takes time
i know some SQL already from previous like time@in school
but will have a look and learn this
thank you
data = info.find(sort=[('$natural', pymongo.DESCENDING)]).limit(1)
print(list(data))```
The output of this is `[{'_id': 9, 'user': 'test'}]`
How can I get the id I tried doing `list(data['_id'])`You should run your Django app on the same cluster as the database, rather than trying to connect into the cluster
but how would i test it locally then
use a local DB
Or use the port-forward command above if you want to run your tests against the production database. You'll need to install kubectl though
oof.
Doing setattr on SQLAlchemy object only changes it in memory right? As in the change is not commited to DB?
Yep
You have to add it to session and flush, and commit at some point so changes are persisted in db
Note that commit automatically flushes everything to db too
Assumed so, thanks!
I'm working with a Postgres database via Django Admin. I have only 700k items in a table and it takes roughly 700 seconds to load(on a very modern machine).
I hope to scale this to hundreds of millions. Can anyone direct me to some resources on howto optimize my database and or Django Admin panel to make it usable with my data?
What do you mean by "load"? Do you read the entirety of the records?
@fringe void
#1085255802111131679 message
it was pretty good. It was a little awkward to have to run the codegen step but I understand why it has to happen. I am pretty used to using the "active record" pattern because of django so I felt a little bit lost but I'm sure there are elegant ways to work with the data mapper pattern that I'm just not used to
Yes, Here's an example query:
SELECT COUNT(*) FROM table
Loading the table through djangos admin takes equally long.
Do you have the required indexes? Can you try the EXPLAIN command?
I've added all the fields for the table to an index using the class meta for the django model.
I'll run explain now.
EXPLAIN SELECT COUNT(*) FROM table_domain;
Finalize Aggregate (cost=3273350.21..3273350.22 rows=1 width=8)
-> Gather (cost=3273350.00..3273350.21 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=3272350.00..3272350.01 rows=1 width=8)
-> Parallel Seq Scan on table_domain (cost=0.00..3077165.60 rows=78073760 width=0)
JIT:
Functions: 5
Options: Inlining true, Optimization true, Expressions true, Deforming true
(8 rows)```Looking for some resources or clues on howto effectively query this data quickly, ideally still being able to use Django's Admin.
hey guys, how long is postgres 13 going to be supported?
because the oracle vm i'm using only has uh
13 on it
concerned that this will come & bite me in the back in the future
It's not all that bad, the rest of your Linux distribution will likely be unsupported too then
how is that good news
lol yeah sorry
Debian 11 "bullseye" goes end-of-life in 2024 if that's what you're using
3 years after its release in August 2021
oh i'm on oracle linux 9
Well then no need to worry
Hey guys, I am new to databases and am trying to setup my first database and server. I have postgres and valentina installed. Everything looks good but I cannot load my databases. Load SQL Dump: Unexpected SqlExecute() exception:: -- are the errors (4) , also same, that I get. Has someone encountered this issue pse and could point me in the right direction. I suspect my ports are not communicating properly because that is where I am not sure.
not sure if this is the right server, looking to disect nested json using python
hello, anyone available to help me?
title: Mapped[str] = mapped_column(String(50), nullable=False, unique=True)
im using sqlalchemy. seems like nullable isnt doing anything here, how can i fix?
Still slow, did you want an EXPLAIN of it?
what sort of query? literally the SELECT COUNT(*) or something else? because the answer really depends on your query pattern.
An join between relations R and S always includes all tuples from S in the result?
Hey guys, I'd like to add a column to my table, I know the command but I also know that this command (INSERT INTO <column's name> VALUES ( ... ) ) only works if the others are empty. Do you know a way to add a column to a table but with others full columns ? mention if you can help ! Thanks in advance !
That depends on a join
What's the problem?
Hi
( ! ) Warning: mysqli_num_rows() expects parameter 1 to be mysqli_result, bool given in C:\wamp64\www\contacts\select.php on line 13
Hey guys this is the error am getting when try to connect the database and the system
Can you share the code where this is coming from? Is this PHP or Python?
Like Doctor said it depends on the join. I think this picture explains it the best way:

not sure I understand your question. If you add a new column it will be added across all rows so the other columns will stay "full" with the values you inserted previously
Php but sure
await self.bot.db.execute('INSERT INTO lastfm VALUES ($1, $2) ON CONFLICT (author) DO UPDATE SET username = EXCLUDED.username', ctx.author.id, username)
any reason why this doesn't work?
please post stacktrace upfront next time, it provides important context for people who can help.
as for the reason why that didn't work, it's likely because you passed in ctx.author.id, username as args after the query instead of just a single iterable that contains ctx.author.id, username , but then again without stacktrace this is just a guess.
nvm fixed it, it wasnt working because i was tyrna select data first and then doing an if check for the data
cool
hi, I am having issues with mongo db with the database collecting the right info the on grab it grabs the right thing but decides to print the _id then t t p false
results = collection.find()
for result in results:
for query in result:
url = result["_id"]
print(url)
r = await session.get(url=url)
if r.status in list(range(100, 500)):
server = result[query]
channel = self.client.get_channel(server[0])
down_message = server[1]
auto_publish = server[2]
guild_id = server[3]
already_down = False
print(f"{result[query]} \n {down_message} \n {auto_publish} \n {guild_id} \n {already_down}")```
What am i doing wrong?
NOTE ALL IDS ARE FAKE

Hey guys I am trying to fetch a whole collection as a bson file, while I have figured out how to do that, it increases memory by 350mb as the file is 300mb~ I was wondering if I could somehow do it in chunks and save to the file so that memory usage doesnt go above 30mb~
I have tried using batch_size etc but either im doing something wrong or it just doesnt change anything
bruh code is inefficient af
explain?
the print shouldn't be there but i needed to find out the problem why it wasn't working right
results = collection.find()
for result in results:
r = await session.get(result ["_id"])
if r.status != 200:
for k, v in result.items():
if isinstance (v, list):
server = result[k][0]
something like this
for
get req
for
which is more efficient
for
for
get req
ok why i had todo it that way with the list is because the site may be live but might return an erros besides 200 such as a 403 or 404
but i'm checking for a 5xx
so how do I reput this into a collection update and grab the data i need to send a down message in that channel?
never seen it this way before
bro ur already using mongo why u have data stored like that its abuse of a db ;-;
make keys lol
wdym?
my goal is create a thing that checks a certain website then says it down without saying it multiple times because it keeps checking it
that is what already_down is for
but for some reason it is giving me a t t p False responce for the stuff
can you come back alive please?
best suggestion for betterhelp is to make a ticket in the #1035199133436354600
you will get further support directly from someone
ok thanks
Hi, Can can anyone help me with importing picture dataset from kaggle into google collab?
Is there a built-in way in sqlalchemy that can be used to dynamically create new tables with the same schema? I have different datasets and each dataset will be inserted into its own table with a systematic naming convention. All of the datasets have the same schema so I have created a sqlalchemy model class for that schema. Now, what I need is an appropriate pythonic way to create new tables dynamically for those datasets.
Why use different tables? 🤔
hey folks, i'm making a discord bot for my server exclusively, and i've run into a thought i can't get around. if i want to update a row in SQL, i could update multiple parts of the row, however i want to make it so that those parts are updated only if they are given a value to begin with within the query. for example
UPDATE db SET col1 = ?, col2 = ?, col3 = ?
i could update all those columns, but the user's query may only want col1 updated and just leave the others alone
i can put a lot of if statements and solve this but it's rather bruteforcy and i'd like to know if there's any better method to an idea like mine.
If that's a problem, you can use an orm like sqlalchemy that tracks what columns were changed 
!e I'm using a dictionary for the updated columns and build the statement, like:
def build_update_stmt(tbl_name, columns, *columns_id):
return (
f"UPDATE {tbl_name} SET {'=?,'.join(columns)}=?"
f" WHERE {'=? AND '.join(columns_id)}=?"
)
def update_from_dict(tbl_name, upd_colums, **id_colums):
columns, bind = zip(*[col_pair for col_pair in upd_colums.items()])
columns_id, bind_id = zip(*[col_pair for col_pair in id_colums.items()])
bind += bind_id
stmt = build_update_stmt(tbl_name, columns, *columns_id)
return stmt, bind
upd_columns = {
"first": 1,
"second": "2nd",
"third": "3"
}
user_id = 17
stmt, bind = update_from_dict("mytable", upd_columns, id=user_id)
print(f"{stmt = }, {bind = }")
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
stmt = 'UPDATE mytable SET first=?,second=?,third=? WHERE id=?', bind = (1, '2nd', '3', 17)
I am writing a plugin for a Python-based app (Joystick Gremlin) and I want to use the SQLite3 library. Because the app is running outside of the Python environment, I need to "install" SQLite3 in the app's directory. For other other libraries I simply moved the file or directory into the JG app directory. However, SQLite has files in many places in the Python environment (Lib, Library, DLL, etc.). What files are necessary for a "lite" packaging of SQLite? OR... is there an alternative? I want to maintain a very small stack-like data object where I want to add, delete, and search for records. It will have only a dozen records at most. A full db seems overkill, but it has the query features that a text file does not. An excel sheet maybe. Thanks for the suggestions.
If it's something simple maybe a json file would do I would generally advice from doing that but it may be a good enough solution for you
Thanks. Can you recommend a tutorial or package? I've never worked with them before.
Hi guys, I am currently digging into pandas and polars. I was wondering is this possible to use pandas as a sql_generator basically ?
You can use built-in json module
sql generator?
a query sql generator*
Hm, I never worked with polars or pandas, what do you need a sql generator for?
I'm not sure that json files will be dynamic enough. The purpose of my file is an event stack where several instances of a plugin can communicate what they are doing in real-time. Events will be pushed and popped off the top of the stack and records deeper in the stack will be removed when no longer relevant. That is why I was leaning toward SQLite, but hit the wall of installing it in to the app space. I really appreciate the new thought to research though. Do you still think a json file would work?
Ah, you said there would only be a couple of elements
If you need multiple instances of your plugin then sqlite should work better
How are you packaging your python app?
The app already exists and is not mine. I am writing a plugin that the app incorporates my code via a decorator. Because the app is already compiled, it runs independently of python. So, for my plugin to import libraries I have to have the library available in the app's directory. I have done this with simple 1 file or 1 folder libraries, but SQLite seems to have files all over the place in the python file structure (I am using Anaconda). I don't know which SQLite files to copy into the app directory, nor if I can put them all in a single folder. I wonder if I have to move over the SQLite dll or executable but have a python interface to them. It's all just out of my experience.
I don't think I will able to help with this, doesn't seem like it's related to databases too
Never worked with anaconda either
Nothing in particular, just wondering how we can directly use data that are store in databases and not in file for pandas/polars processing
but it seems that we have to use things like data lakehouse to be able to do so.
It is kind of a new pattern for me though, I need to dig further
If it needs to have some kind of integration with polars/pandas - I don't know of any, If you just need a query builder - there's a lot of orms and lower level toolkits
not sure if you're saying the app uses anaconda, but afaik with any cpython distribution there's three files required, _sqlite3.pyd, sqlite3.dll, and Lib/sqlite3/ (contained in python3**.zip if its an embedded version of cpython)
Yeah of course but an ORM is not what I am looking for. What is cool with polars/pandas is the ability to do intensive/advanced analytics without writing sql directly.
And you don't have to write SQL directly with orms 🤔
Yes of course but doing reporting for example is kind of a pain with an orm.
An orm is really for object relationnal mapping not for analytics
Sqlalchemy has a good query builder, but you essentially end up writing sql:
stmt = (
select(
func.max(Model.value),
func.min(Model.value),
Model.discriminator,
)
.group_by(Model.discriminator)
)
result = session.execute(stmt)
for max_, min_, discriminator in result:
...
Oh cool thanks, sql is not frightening me though, my point was more like is there an pandas transpiler to sql or something like that it could be cool
I think there was an intergation between pandas and sqlalchemy 🤔
But I think it was just for loading data, I don't know though
Thanks for your help I will try to dig further 🙂
That is awesome, thank you. What do you use in the import statement-- the pyd file?
if its set up correctly you just import sqlite3 like normal
Hmm. I copied _sqlit3.pyd, sqlite3.dll, and the sqlite3 folder into the app directory. When my code runs the import statement I get the error "DLL load failed: %1 is not a valid Win32 application". The application (Joystick Gremlin) is in the Program Files (x86) directory, does this all mean I need a 32-bit version?
at this point i think you should ask their community/devs, this seems like an uncommon setup
though i do remember seeing that error when i last tried to use cython in cpython 3.11 suggesting something was incorrect with my compiled extension, and _sqlite3.pyd is a compiled extension so as a random guess, perhaps your python version is mismatched with what they have?
Thanks for the suggestions. I really appreciate it.
create table emp(empno int auto_increment , name varchar(20), dept char(10), salary int);
what's wrong in it?
can someone help me i created a database but i cant open in in vs code

can you tell me the extension i need to download
Why do you wanna view it ?

ok thanks for the help i got it working different way @torn sphinx @mortal orchid
nah i got it working with an extention
ok
this is what it would look like

It's been a while I haven't used almebic but with sqlalchemy 2.0 I was wondering if it was a good idea to still use it for migrations
Also for some reason, using a get_url function messes with the --autogenerate command
Are there any other tools you'd use? 🤔
I don't have any that comes to mind that can be coupled with sqlalchemy 2.0
Except switching to peewee
the thing is, it refuses to autogenerate my models when I'm customizing the url like so:
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
def get_url(is_secret: bool = False) -> str:
url_obj = URL.create(
Settings().db_scheme,
username=Settings().postgres_user,
# plain (unescaped) text
password=Settings().postgres_password.get_secret_value(),
host=Settings().postgres_host_network
if Settings().in_network
else Settings().postgres_host,
port=Settings().postgres_port_network
if Settings().in_network
else Settings().postgres_port,
database=Settings().postgres_db,
)
return url_obj.render_as_string(hide_password=is_secret)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
from fastapi_elasticsearch_postgres.db.connectdb import Base # noqa
target_metadata = Base.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
config.set_main_option("sqlalchemy.url", get_url())
print(f"Migrations will be done at {get_url(is_secret=True)}")
I think it's just a problem with your url
I should probably just extract the url from the engine object instead
You can use the same url you provide to your engine
I had a data scaling question and database question, if i was storing json data and webpage html in a db, what is an efficient db backend to use plain old mysql redis or something else. I'd like to build this app to be scalable from the begining so I don't have to change anything later. it will mostly be used for a cache. Thanks for the guidance
HTML can be cached in redis, why do you need to store json though?
@paper flower caching calls to google serps api
Is there a column in Flask-SQLAlchemy that lets me pass a tuple or list?
How do I setup postgresql to work on a linux machine and can be accessed from docker?
Some databases have array type, but you in most cases shouldn't use it
https://discord.com/channels/267624335836053506/1087273880026107937 mysql problem connection
Thanks 👍
What do you need it for?
I was going to make an exam webpage which has a question with 4 options to choose from, I thought I could pass all 4 in a tuple/list in a Question model
You should use a relationship in this case, imo
Arrays are for storing scalar values, but I think you can use it here too 🤔
Support for arrays depends on DB iirc
I am using Flask's SQLAlchemy
Is there a way to visualize my database on a website or using a program?
@paper flower
What do you mean by visualize?
Maybe I can represent all the columns like how it is in excel, it's hard to visualize a relationship between two models in my head
There are GUI tools like DBeaver and pgadmin (if you use postgresql)
sqlite browser for sqlite, etc
What about SQLAlchemy (the one used in Flask)
What about it?
It's an ORM, it's not a db on itself
It serves as a layer between database and your application
How can I visualize it is what I was asking
^
So it's not possible to visualize it?
You can visualise schema of underlying database
How?
😐
My bad 🗿
np, it's just a bit annoying
You can google something like "SQL schema visualization tools"
So I have a basic SQL commandline interface
from atexit import register
import sqlite3
conn: sqlite3.Connection = sqlite3.connect("hoppeldihopp.sql")
cursor: sqlite3.Cursor = conn.cursor()
def main():
global conn
global cursor
print("Connection established\nType \"exit\" to exit")
while True:
inp: str = input("[exit/commit/fetch/SQL-Statement] >>").casefold()
if inp == "exit".casefold():
break
elif inp == "commit".casefold():
conn.commit()
elif inp.startswith("fetch"):
parse_fetch(inp)
else:
try:
conn.execute(inp)
except Exception as e:
print(f"An Error occured while executing the command: {str(e)}")
print("Connection terminated")
def parse_fetch(inp: str):
global cursor
splitted: list[str] = inp.split(" ")
if len(splitted) == 1:
print("Available commands: fetch one/fetch many <int>/fetch all")
else:
second_arg: str = splitted[1]
if second_arg == "one".casefold():
print(cursor.fetchone())
elif second_arg == "many".casefold():
try:
many: int = int(splitted[2])
if many < 0:
raise ValueError
except ValueError:
print(f"\"{splitted[2]}\" is not a valid number")
except IndexError:
print("No 3rd argument given")
else:
print(cursor.fetchmany(many))
elif second_arg == "all".casefold():
print(cursor.fetchall())
else:
print(f"Unknown argument \"{second_arg}\"")
if __name__ == '__main__':
main()
register(conn.close)
You can type "exit" to exit, "commit" to commit your transaction, "fetch" and then either "one", "many" and an int (like "fetch many 4") or "all" to fetch results of SELECTs, or plain SQL-Statements.
I already created a table `test`(`ID` BIGINT UNSIGNED PRIMARY KEY UNIQUE, `userid` BIGINT UNIQUE), and already inserted some Values into it.
Now if I type "SELECT * FROM `test`" it then "fetch all", it returns an empty list, no matter what. But it's in the database, since inserting 2 elements with the same ID results in an IntegryError
what should I do to make "fetch all" work?
def debug(inp: str):
global cursor
cursor.execute("SELECT * FROM `test`")
print(cursor.fetchall())
works if I call it in my commandline interface (I added a "debug" case) but why doesn't it work via "fetch all"?
You are doing a conn.execute(inp) and than a cursor.fetchall(), you'll need to do cursor.execute(inp) if you want to fetch it later (like you do in the debug()).
Thank you it works now
the cursor needs to execute the SELECT query in order for its fetch* methods to receive the rows, but you're using conn.execute() to run it instead
oh oops i thought the above answer was for a different question
got ideas on how to push an image into mongo database using python??
not 100% sure if it's the recommend way (might depends on how large the image files are and how often you want to retrieve them), but perhaps this https://pymongo.readthedocs.io/en/stable/examples/gridfs.html
https://www.mongodb.com/docs/manual/core/gridfs/
from what I remember reading around online, storing images in databases has historically been ill recommended but it is fine-ish nowadays, though you may still want to use something like a cdn instead
then can you tell me some other ways to store images, i want something where i can store and retrieve images for a facial recognition scan
like i want all the images to be in one place and then call 'em one by one
.
no clue, but try to look up whichever methods people are using for that - in anywhere from simple tutorials online from scientific papers - or ask in more specialised discord servers
there probably exist methods way more efficient than comparing images one at a time
thanks
hey is anyone able to help me with an SQL Question
maybe
whats the question
also ,
how do i select data from a row from a range of columns
I have 257 columns
2 i dont want to search through
255 i wanna search through
you want to search .... 255 columns .... for some value?
instead of spending time trying to shoehorn my own query builder it would be reasonable to move to something more suited for sql
Do you not put a id in each column ?
Then you would not have to search them all
I'm getting an error when trying to update mysql database from data over html forms, can someone help me?
Whats the difference between a Table and a Model in SQLAlchemy?
This is in app.py
def posts():
# comments = load_comments_from_db()
data = request.form
add_comments_to_db(data)
return render_template('first_blog.html', data=data)```
This is in database.py
```def add_comments_to_db(data):
with engine.connect() as conn:
query = text("INSERT INTO comments (id, postid, username, usercomment) "
"VALUES (:id, :postid, :username, :usercomment);")
conn.execute(query,
{
"id" : id,
"postid": 1,
"username": data["username"],
"usercomment": data["usercomment"]
}
)```
This is my html form
```<h4>Comment Section</h4>
<form action="/posts" method="post">
<div class="mb-2">
<label>Name</label><br>
<input type="text" name="username" placeholder="Enter your name here....."><br>
</div>
<div class="mb-2">
<label>Comment</label><br>
<textarea name="usercomment" placeholder="Start typing...."></textarea>
</div>
<input type="submit">
</form>
<h4>submitted comments</h4>
<b>{{data["username"]}}</b>
<p>{{data["usercomment"]}}</p>```
can someone explain why i'm getting:
```werkzeug.exceptions.BadRequestKeyError: 400 Bad Request: The browser (or proxy) sent a request that this server could not understand.
KeyError: 'username'```
error when trying to update data from forms to mysql databaseModel is a table mapped to a python object
They could be used to describe table structure too
So model is just a table but it's a python object
Yep
anyone know about Interactive Broker API for trading bots in python?
Is there good guides on implement PATCH endpoints? I'm finding this task particularly difficult with my database. I'm not using an ORM, so I'll essentially need to dynamically create a query depending on which parameters have been passed?
Surely there's a good practices pattern I can't come up with on my own, does anyone know some form of article or guide which details that?
Imo you shouldn't use flask-sqlalchemy
theres not a specified column im searching though
You can use a library like pydantic to parse json body and exclude arguments that weren't set, then you can do whatever you want with that dictionary
In case of an ORM you can use setattr
How can I do something similar to Panda's df.info() to get null counts for all columns in SQL? (Not sure which version of SQL, just know it's HUE Editor w/ presto/hive
Under the conditions that:
- I only know all the table names in the DB (Have a list) but not the column names?
- Wrapping this in python so it's automated.
Thinking something along the lines of
First querying for the all the column names per table, store them in a python list. Then second query for null counts for each column name in that list.
However, this would be a lot of queries. Wondering if there's some aggregated way in SQL I'm unaware of.
if you are using postgres and is comfortable with potentially stale stats
pg_stats table might help.
e.g.
poly_db=# select attname, null_frac from pg_stats where tablename='pois';
attname | null_frac
---------------------+------------
verified_polygon_id | 0.2518726
corrected_lat | 0.96881527
corrected_lng | 0.96881527
I'm not sure if this is postgres.
🤔 then i am not sure
Yea, I've been googling for a while now. I don't think it's possible without knowing the column names 
where is it from? as in what system/db are you working with?
Uh, all I know is it's in the HUE editor & it's accessible via hive/presto. Not sure beyond that or how to check.
oh hive/presto eh?
there should be some metadata storage that tells you what the columns names are 🤔
or a SHOW COLUMNS FROM table actually according to the docs
Yes, but the reason I say it's unknown is because I don't want to have to manually type in those column names into a list etc.
Like, panda's df.info() is a general command that is applied without knowing specifics on the dataframe. I was hoping there was something similar in SQL at a table level.
Looks promising, let me test it.
I think it technically works? But w/e reason, all the values end up being NULL.
Looks like I'll just have to just loop through one by one.
all the values end up being NULL.
waaat, how so? literally the null fraction is 1?
maybe you didn't run a ANALYZE and the statistics table is just super mega stale?
ref: https://prestodb.io/docs/current/sql/analyze.html
I ran SHOW STATS FOR DB.table

I'm guessing STATS command is based on something that needs to be run before hand, and isn't ran at time of being called.
Eh, by the time I figure this out, I would have already finished the for loops for running individual. I'm just going to loop and loop.
Yeah thanks, but the main issue for me is the part after this. Is there a smart SQL trick, something cool with sentinel values, is there some smart script?
Even with ORMs, I can't come up with a way of implementing PATCH in a satisfactory way 🤔
for key, item in pydantic_model.dict(exclude_unset=True):
setattr(orm_model, key, value)
🤔
I don't really like it since it's dynamic, but it works
If you use dataclasses you can set default value to a sentinel object()
Will this work? If not can someone help me correct it? Many thanks.

since you're using f-string, you should wrap your variable around with a pair of curly braces, like so
cursor.execute(f"SELECT * FROM rankbinds WHERE rank_id = {group_rankid} AND group_id = {group.id}")
Argl, NO! The f-string is not needed in this case, just remove the f, the binding parameters are the right way to do it.
!sql-fstring
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
Why not?
(if you said I should stop using it due to the error, I just fixed it 👍 )
It uses outdated techniques for defining models
That was the case for querying data too, but I think they moved to select 🤔
What should I switch to then
thx
thanks! I learn something
👍
Hey man, about displaying the questions and options. Right now I'm using a FlaskForm which grabs the question from my database using Question.query.all() and then uses a global variable which is incremented every time the user submits the form, so it goes to the next question.
question = StringField(q_list[current].content)
I don't think this is a good way and thought maybe you could suggest a better way to do this 👍
Sorry, I don't use flask 🤔
Dont know if any of you could help. But Im trying to get all MLB player salaries from 2016-2022. Lahman's baseball database only has salaries up to 2016.
QQ:
SELECT *
FROM table2
RIGHT JOIN table1
ON ...
This means I have this right?
(Table 1 (Table 1 & Table 2) Table 2)

Isn't it opposite because of the with statement?
here's the default Left Join

But since my table 1 and table 2 are flipped, I would need a right join?
Nvm, justified it myself. What I have coded is right for what I actually want.
ok nice
Left joins, right joins in SQL always confuses me.
Makes sense in pandas, since you order the dataframes.
But in SQL, with the backward reading and other  "Just SQL things" it becomes a pile of
"Just SQL things" it becomes a pile of 
I have a mongodb/PHP question, in Python I use "$match":{} to match everything, anyone have any idea what the equivalent syntax for this would be in PHP?
To answer my own question...
I used this array('$match' => (object)[]) and it appears to have worked.
Hey can someone help fix this? much appreciated
could you provide the stacktrace with if there is an exception please?
otherwise could you describe why do you think it's not working as intended?
Im more wondering if it will work
sorry i didnt explain
it looks fine to me!
but two comments
- you used a f prefix for your string (i.e. an f-string), but there is no actual string templating, i would remove the
f(also using string templating is generally frowned upon when it's a SQL query, due to possibility of SQL injection when working with user-generated input) - you used
SELECT *, normally people avoid this unless one really need all columns
Okay, thank you very much
is there any cons of using SELECT * that would affect the bots functions
other than it's using more bandwidth than absolutely necessary and a slightly increased RAM usage?
probably not.
i am just pointing that out because it's not a great habit to have. you can absolute ignore that if you want to!
alright, thx very much for the help i really appreciate it
np!
yoo doubt, mysql equi join how can u choose all columns
select * from table1,table2 where table1.primary_key = table2.foreign_key;```
is this possibleiirc select table1.*, table2.* from ... but I would strongly recommend against using select * at all
I'd also recommend using an explicit INNER JOIN ... ON ... statement for clarity instead of just from table1, table2
I just wanted to follow up on this. Keith Medcalf over at the SQLite forum (https://sqlite.org/forum/forum) is patient, kind-hearted genius. First, I had to confirm that the application was using python 3.6.3. Then I downloaded python-3.6.3-embed-win32.zip from python.org and extracted sqlite3.dll, _sqlite3.pyd, and the sqlite3 directory to save into the program directory. All works now.
SQL question for everyone! Is it possible to use a windowing function based on a difference between the value of a column in the current row? For example, if I had an auto-incrementing row number per week and wanted to get a rolling 52 number, I would want to partition by CUST order by WEEKRANK <current WEEKRANK values> between <current WEEKRANK> and <current WEEKRANK - 52>. I know you can do it based on rows, but there won't always be rows in this data every week for every year for every customer - so it will start windowing over years.
Hey guys, I have 50 parquet datasets (folders with 1 to 4 .parquet files) that I created with pyarrow, and in total they consume 136GB of storage,
now, my challenge is to somehow upload all of the records to MySQL, I could loop trough chunks from each dataset and perform a simple INSERT VALUES (...), or I could also use MySQL's LOAD DATA, but I would have to firstly convert all the parquet files to CSV and I can only imagine it will take much more storage, what should I do?
in PostgreSQL at least loading from CSV is much, much faster than using INSERT. I could imagine it's similar in MySQL. As for storage consumption, if you process one file after another or just process them in streaming fashion you should be good
Can't figure out this question,if there is no build-in function to create graphic object,then how pyplot does it using functions which consist of build-in functions in python?
This is probably something you could write in python. I mean it could inspect the table and do consecutive queries for columns based on user input. That's what I would do
Python can call into libraries that exist on box built in C, or binaries that are installed as a wheel pip package. That is how it installs database clients interfaces. You would need to look into the specific package pyplot to find out what it's installing
how exactly in python i can use library which are written in another language?
take a look at #c-extensions, it should have some relevant information pinned
That is a complex question that you need to research but there are several possible ways. 1 Write a rust or c module with python bindings and that will expose a function to python. 2 Call a system command with subproceas.popen and parse results. 3. Use webhooks or http protocol to interface with a javascript program. 4 is ironpython which runs in a mono interpreter on linux to interface multiple languages. This is .NET on windows platform.
Hye everyone, for a project I need to use Psychopy (of Python) but I still get a problem with running my experiment, can someone here help me?

I don't see how this relates. I am looking for a SQL-based solution, not an ETL change. Plus, (I didn't mention this) the source is Snowflake.
Sorry that was not meant for you. I was trying to reply to the post below yours.
did you try this using this https://pipes.datavirtuality.com/connectors/integrate/parquet-file/mysql/

Data Virtuality Pipes
Pipes allows you to automatically replicate your Parquet File data into MySQL on your defined schedule.
Just a hint here but you are going to have to be more descriptive about what the problem is. and this is database related channel. you might try #editors-ides channel.
How do I set my index to be of type "string"? using mongodb?
what database are you using? What does index of type string means for you?
Hi, I'm using PostgreSQL with asyncpg for my discord bot. It is quite a large bot with high usage. I use a singular connection pool for DB. The problem is that, between 6 hours or 2 days of uptime, the pool connection just cannot be used, like it goes stale. There is no error whatsoever in the terminal
there a website about university professor rating where you can rate, comment, add tags for any professor.
and I want to scrape it, but with a big amount of data I don't know the proper way to save it, I usually work on smaller data and save it as text/JSON.
any ideas? database to choose?
the data I want:
name
rating
tags
comment
comment votes
has mongodb got an upsert statement?
how do you figure out that it goes stale? where is the database the bot is connecting to?
looks like structured data so i would go with postgresql
did you try doing your own research before asking here?
I tried searching but couldnt find anything.
if there's a documentation on it I cant find it
what did you search for?
Like, the database functions don't complete and literally take forever. No fetch or adding to database functions and work and as such, all db related bot commands don't work
And database is in the same machine as the bot. Also, only the connection goes stale, database itself works fine through terminal
i see
is there anything in the logs?
how are you connecting to the database? over a unix socket or over the loopback address?
Sorry, but can you explain in a bit easier words?
sure: wherever you're calling asyncpg.connect, what's the value of the host setting?
localhost
that's good. okay, can you check if /run/postgresql contains something?
ls -l /run/postgresql
total 4
drwxr-s--- 2 postgres postgres 160 Mar 25 11:28 14-main.pg_stat_tmp
-rw-r--r-- 1 postgres postgres 4 Mar 20 11:17 14-main.pid
okay
when you run ls -al on it, it should contain something called .s.PGSQL.5432. That's a unix domain socket, a special type of network socket that doesn't need to use the regular network protocol
try passing host='/run/postgresql' to the asyncpg.connect function (or whatever builds your pool) that's gonna tell asyncpg to connect over the unix socket where I (personally) have never seen any connections going stale
let me know if that works. once that's done we can add some more changes to make these stale connections more unlikely
sure
The next things I'd recommend setting are:
- pass a
command_timeoutin your python bot because by default asyncpg will never timeout, set it to something that will far exceed any long-running query you have and only actually kill the stale connections - set
log_min_duration_statementin postgresql to 10-30 seconds to have it log slow queries - set
statement_timeoutin postgresql to some high value, a bit higher thancommand_timeoutabove (note this and the following settings are in milliseconds, not seconds) - set
idle_in_transaction_session_timeoutin postgresql to 1-3 minutes - set
idle_session_timeoutto a value higher thanmax_inactive_connection_lifetimein asyncpg (it defaults to 300 seconds there, so use, say,330000)
Hi. I tried doing this, but got this error
asyncpg.exceptions.InvalidAuthorizationSpecificationError: Peer authentication failed for user "user"
```sorry for bothering you.did you edit pg_hba.conf before?
No...
okay, so by default if we connect over that socket postgres will only allow us to connect if your database username is the same as your operating system username
so if your bot runs as user1 and the database user name is user2 it will reject it with that error
but we can tell it to verify this user with its password
open /etc/postgresql/14/main/pg_hba.conf in your favourite editor, read the introduction at the top to see what we're configuring, then you basically want to scroll down to this:
# "local" is for Unix domain socket connections only
local all all peer
and change it to
# allow bot user to connect with password
local all PUTYOURBOTUSERNAMEHERE md5
# "local" is for Unix domain socket connections only
local all all peer
with your bot username replaced of course
sudo pg_ctlcluster 14 main reload to load the new settings afterwards, then login should work
The bot user name as in database username?
Or the one I use to start the python file
on one hand yes, on the other hand the name of the user under which the bot is running
both
Hey, anyone know a data base that is stored on disc, and is good for key value pairs where both the keys and values are integers. I have around 200 million key value pairs, and I need to find the value associated with a key fast. I tried using a module called sqlitedict, and it doesn't have the speed i want. When i want to find the values for 100,000 different keys, this takes around 30-40 minutes. anyone know any alternatives?
so i was wondering is it good to use 4 processors then 1? cause i saw a yt video saying it boosts your performance and stuff so i went to run and typed in msconfig and then i went to “Boot” and selected “Advanced options” where it said”Numbers of processors” do i have it on max or 1?
how to store images in database and then like, display image in a web page from database?
Redis, KeyDB, DragonflyDB
Which database are you using? Postgres has a data type called bytea which can be used for this
Don't store images in database, use file system or S3 instead
postgresql can do it
with proper tuning
||how to do to translate only conversation in french please||
Thanks for this suggestion, im going to begen to research this! Would you happend to have any tips to implement this in python, and could you go into a little more detail with the propper tuning?
first you want to import it into the database, COPY is the fastest way (https://www.postgresql.org/docs/current/sql-copy.html) psycopg2 has a way to make use of it

PostgreSQL Documentation
COPY COPY — copy data between a file and a table Synopsis COPY table_name [ ( column_name [, ...] ) …
so create a table with two columns that fit your data (integer or biginteger, not sure if you have 32 bit or 64 bit integers), then first import it
these clarifying questions might change the answers slightly:
- do your data change over time? if so how often?
- does the key have any implicit meaning to it?
- are your lookup based on equality of key and not other form of comparison? (i.e. not substring, not
>or<but exactly=and nothing else)
Everyone knows that pickle is the best way to store data 😁
-
The data will never change.
-
I have 400,000 diffrent txt files with numbers in all of them. The values associated with the keys is how often each key apears in any of the txt files.
-
just equality. I want to look up an interger, and find out how often this interger apears
I can calculate this data, but it takes 2-3 hours to do each time. I want the data base so I can calculate this data once, then refer to the data base if I ever need the data again
re. 2. i am going to assume you already have a solution to computing the result in form of a bunch of key value pair
re. 3. great, good to know.
due to the disk-backed storage nature of your solution, postgres (like Volcyy suggested) seems suited for this
you will need to load your result into a table in postgres first
then you probably want to create an index over the column where you have stored your key, i would test performance of B-Tree index and that of HASH index, both are suitable because they enable quick lookup based on equality.
i would also check if some form of clustering in postgres would impact performance.
also beware of JIT in newer versions of postgres, sometimes they degrade performance more than actually helping you get faster execution, always do a EXPLAIN ANALYZE and check out the query plan.
now with postgres out of the way, i would also potentially look at redis. redis could be "disk-backed", i consider dumping a RDB file "disk-backed" in this case.
but this suggestion only applies if your RAM is big enough to hold the entirety of your results.
also i am not 100% sure this is actually faster than postgres in this use-case, but since redis is primarily a key-value store tech and it uses RAM, it probably is the case.
how are you doing this at the moment? i don't have a true grasp of the problem, but 2-3 hours seems rather excessive based on my gut feeling
I made a mistake, realized it should be 1-2 hours. Basicly I loop through each files. I then loop through each line per file. Then I have a dictionary. I try dictionary[num]+=1, and except a keyerror, then I set dictionary[num]=1
Also not all file are formatted the same, so my code has to figure out the way the file is formatted.
could you give me some examples of how it's formatted?
I'm about to get home, and I'll pull up some examples
We care about the second column of numbers. these are the onese that the keys repersent:
some are like this
0 0
1 1
2 1
3 1
4 2
5 1
they use spaces to separate columns
alot are like this:
#this is a comment that
#might take up two lines in the beginning
0 0
1 1
2 1
3 1
4 2
this has two comments in the beginning of the file
rarely they are like this:
#this is a comment that
#might take up two lines in the beginning
0 0
1 1
2 1# this is a comment on a row
3 1
4 2
this has a comment on a line
some have tabs or spaces on the beginning of every line. some others might rarely use tabs instead of spaces to sperate the columns
Also, some files might have a comment on top, but have no entries
def numbers(*args,show_comments=True):
lines=args[0]
seen_comment=False
for line in lines:
line=line.strip()
if not line:
continue
elif (line[0]=='#'):
continue
elif '#' in line:
if show_comments and not seen_comment:
print(f'in file {args[1]+1}, comment in line: ',line)
seen_comment = True
continue
else:
i=0
backwards_line=line[::-1]
while True:
try:
int(backwards_line[i])
except ValueError:
break
i+=1
value=backwards_line[:i][::-1]
yield value
this is the code i use to iterate through each file. args[0] is the lines of the file, and args[1] is the name of the file (which happens to be an integer).
oh that's a rather complicated parsing script, gimme a moment to see if there are alternative
also, some line might be empty, or the entire file could be empty besides comments at the top of the file
Does anyone know anything about flask and pytesting and from itsdangerous import TimedJSONWebSignatureSerializer
?
I use mysql
I'm actually writing the code for training so how would I go about doing it for free?
Also I heard something about CDN but couldn't really grasp it.
@torn sphinx Keep it simple, save the image to the filesystem, and store the path to the file in the database. Then whenever you need to use the image load it from the filesystem using the path saved in the database.
Ay ayy that sounds genuinely smart. Although I settled on a different solution earlier, I'll try this next time.
Its the most common way these days
What I did was convert image into bytes and then store as blob and convert into string
Also the other thing is, ik this ain't the right channel for asking this but what is jinja2 and why is me using flask variables inside js causing trouble?
sed -n 's/[a-zA-Z#]//g;/^[[:digit:]]/p' /tmp/input3.txt | cut -d' ' -f2 | sort | uniq -c
i tested this against your input, seems to work fine
sed -n 's/[a-zA-Z#]//g;/^[[:digit:]]/p' /tmp/input3.txt
is first stripping any word character and #, then only keeping lines that starts with a digit (completely empty lines are omitted by -n)
piped into cut -d' ' -f2 to extract the second column
sort is well sort.. we do this because uniq -c requires input to be sorted
uniq -c give occurrence count
input:
#this is a comment that
#might take up two lines in the beginning
0 0
1 1
2 1
3 1
4 2
output:
1 0
3 1
1 2
i.e. 1 instance of 0, 3 instances of 1, 1 instance of 2
combine this with parallel, and a small script to merge uniq -c output, i am pretty confident you can generate the result much faster
this is #unix territory, we can follow up there if you want
(edit: if you prefer to stick to python, i believe you can also optimise your script)
Its a templating engine, although ive never used it. Depends how you are trying to use the variables inside the JS, you should show some code. My guess is you are giving the incorrect format to JS.
What channel could I show in
not sure
maybe web development
You can simply store images on file system for now, if you're just learning and don't need to host multiple instances of your application
Have anyone heard of database management system?
Why are you asking?
I do not know about this thing and i got an assignment at my university so i am asking here please do help me
There's a lot of information about dbms and databases, what are you looking for specifically?
Hi, I'm trying to make a program that will take information from an api (Application Programming Interface) website, and from that, will make a spreadsheet using that information (the information is public, so this is not some sketchy project). I want it to do it automatically so it will need to access the information all the time (or in regular intervals). I would like to know how I can make my program access that information that's on the website.
Idk if this is the right text channel to ask this
b part
https://www.javaprogrammingforums.com/cafe/9544-problem-spoon-feeding.htmlhttps://www.javaprogrammingforums.com/cafe/9544-problem-spoon-feeding.html
recommending to read about spoon feeding and why it is wrong.
Also you can find advantageous to read guide how to ask good questions: https://pythondiscord.com/pages/resources/guides/asking-good-questions/
A guide for how to ask good questions in our community.
Short story told: Show effort you already tried to complete task, and ask question in places where you struggle. Nobody is going to solve homework for you
Answer b. The relational database schema of the er diagram is :
Course(CourseID, CourseName, NpOfPu)
Prerequiste(prerequiste_ID, courseID)
is this correct
If i know i didn't get zero
so i need help
relation b/w prerequsites and course is confusinng
looks correct to me 🙂
assuming we have read it correctly that Course has many Prerequisutes, which makes logical sense
btw, if one Prerequisute can be having Many Courses as well
so Many to Many relationship, then the answer was not correct 🙂
but it did not look like, looked l like just 1 to N
Elastic search 🙂
https://stackoverflow.com/questions/69797068/elasticsearch-find-similar-strings-in-string-array
https://www.elastic.co/blog/text-similarity-search-with-vectors-in-elasticsearch

Stack Overflow
I have a problem I'm not quite sure how to solve in elasticsearch.
I have a bunch of documents that have an array of names in them
{
...
"names":["name nameson", "e...

Elastic Blog
The Elasticsearch 7.3 release brings support for using vectors in document scoring. This post explores how text embeddings and vector fields can be used to support similarity search.
Yeah for web, u asked in database
Discord bot / sqlite is still web
Although sqlite can be used in desktop too
But discord is web 🙂
Therefore u have web app
Well... It will be tricky
U can find less optimal solution, if u have small amount of words
Some kind of local lib to match in memory of app
Elastic search is for scale, hundred thousands+
Then find lib that does in memory this matching similarity and that is it 🙂
Fuzzy match, find similar and etc
Definitely no
It has at most LIKE syntax, which supports wildcard matching
Hi i have these SQL queries
select *, Max(Years_employed) as Years_employed
from Employees;
How to remove the old Years_employed column?
i might be exaggerating when i say i have 100 column, but 15 column is not few right?
||especially when i mistype one of the column name, finding error over typo really grind my gears||
Maybe just select it under a different name?
Complex SQL windowing question for the brains trust. Is there a way to do a difference in value based on the value in a current row, rather than a difference in row numbers? I want to calculate rolling, but not every partition grouping will have every rank within it. In the attached example you can see why row numbers wouldn't work, so I'd want to do something like: sum(Value) over (partition by Cust order by Rank where Rank between <current value of Rank> and <current value of Rank + 52>). In the attached example, for the row highlighted in dark green, I'd want to only sum the Value from current and 2 previous rows.

I know it'd be pretty easy to do with a lambda function, but I don't have access to Python/Pandas in this use case.
I'm not using window functions a lot but this should work (definition from sqlite docu, that the RANGE is value specific):
select
*, sum(Value) over (partition by Cust order by "Rank" desc range 52 preceding)
from test
order by Cust, "Rank" desc
Legend! Thank you!
Had no idea there was even a range windowing type!
Hmm, looks like there's some Snowflake specific quirks with range and sum...
Yeah, Snowflake doesn't support sliding windows for range. Back to square 1.
Ugh, turns out the only way to achieve it in snowflake is cross joins or between clause on join, causing fun M:M junk.
Well, how about a sub-select, like:
select
*, (select sum(B.Value) from test as B where B.Cust = A.Cust and B."Rank" between A."Rank" and (A."Rank" + 52))
from test as A
order by A.Cust, A."Rank" desc```fuzzy string matching is not inbuilt, but it looks like you can do fuzzy string matching with an extension.
references:
https://www.sqlite.org/loadext.html
https://github.com/nalgeon/sqlean
https://github.com/nalgeon/sqlean/blob/main/docs/fuzzy.md
window frame syntax in snowflake is
<function> ( <arguments> ) OVER ( [ PARTITION BY <expr1> ] ORDER BY <expr2> [ cumulativeFrame | slidingFrame ] ) according to the docs.
where
cumulativeFrame ::=
{
{ ROWS | RANGE } BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
| { ROWS | RANGE } BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
}
slidingFrame ::=
{
ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND <N> { PRECEDING | FOLLOWING }
| ROWS BETWEEN UNBOUNDED PRECEDING AND <N> { PRECEDING | FOLLOWING }
| ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND UNBOUNDED FOLLOWING
}
so it's likely you want SUM(val OVER PARTITION BY Cust ORDER BY "Rank" ROWS BETWEEN 52 PRECEDING AND CURRENT ROW
I have the following table with some data. Each row stores either a debit or a credit for an account.
I want to write a query where for a given account_id i am able to select the following columns: id, debit, credit, balance. Balance is a calculated column and he's value will be the balance of the previous row plus the debit of the current row, or minus the credit of the current row.

Below is the result i am trying to achieve for account_id = 1. Any idea how i could do this?

I made a example table with the data structure here, https://www.db-fiddle.com/f/g3A8uKTUVxZfrZxUTuUbRc/0
An online SQL database playground for testing, debugging and sharing SQL snippets.
that's the perfect way to ask a question. kudos to you.
I thought a window function would work and tried it but just quite couldn't get it right.
and to answer your actual question,
there are two things you want to know:
- you first want to combine debit and credit column into one column, one column of net change to balance
- then you need to use window function to get cumlatively sum
updated here: https://www.db-fiddle.com/f/g3A8uKTUVxZfrZxUTuUbRc/1
An online SQL database playground for testing, debugging and sharing SQL snippets.
Oh thanks so much for the quick reply and explanation. I did not think of combining the column into one, was trying to work with the separate columns before. This looks perfect. Much appreciated. ❤️ ❤️
Data is sparse, not dense (not a row per week) so rows between doesn't work. Range would if Snowflake supported it for sliding windows.
i see. and you want the preceeding 52 weeks only, am i on the right track now?
ah, i have now actually looked at your original post, my bad for skipping over it. yes, doing a sub-query or a left join and aggregate would probably be the most sensible solution.
edit: actually just realised snowflake support lateral join, using that would also make sense.
Thanks! Will have a look into the concept. Haven't heard of it.
sqlite provides a few different versions of their FTS extension, ive used it myself for matching similar tags https://sqlite.org/fts5.html
Reporting back that lateral joins were the perfect solution, and so speedy too! Thank you for your guidance! 💜
awesome 🎉 lovely to hear that!
Is there any reason why accessing my db i can't see a table that i created in PGAdmin?
i'm trying to access my db via SQLAlchemy but it's unable to pickup on the new table i made
it added qoutes around the table name for someone reason and that's why it didn't pickup on the table name
guys when they say relational databases scale vertically and that theres a limit to it, how big can my application get before this starts to affect me?
you can get servers with up up to 128 cores and 2 TB easily (at a price). that’s enough for…… a lot
there’s no way to say “it scales until this many users”
Don't worry about it until u have many millions of records at least.
(Assuming u use indexes)
ah, the way people talk about it, it sounds like its functionality stops when you get around 10k users
which definitely seems sus cause i know a lot of big websites use postgre and mysql
anyways thanks
Way more will handle. Well it depends on amount of request per second, and how optimized your usage of it
Topic of different optimisations is very long one
i see
but if it does end up being a problem later on, you do have the ability to transfer data to another kind of database right?
Caching is quick way to speed up further
Message queue like celery to run some stuff in background after request, is another way too to optimize
If u use stuff like AWS RDS, u can easily migrate hardware limits without transfer of data.
It allows scaling same database with minimal effort
Migrations are always possible though too to another place, but u will probably never need it
i see, so this really isn't something i should worried about right now right? i should be able to use any kind of database right now and worry about either migrating the hardware or the database itself later on
i tend to over think a lot of the project stuff before even getting to a working prototype, anyways thanks for the help
Until u acquired your 1'000'000 users at least it is not issue
If it is became issue, it will be pleasant issue that your product is already successful and time to scale further
yea sounds like it wont really be a problem 😅
thanks btw
hey guys I kind of have a problem with a database I'm trying to setup, I'm doing this on a wsl machine running ubuntu
I'm sure mysql is running cause
sudo service mysql status
- /usr/bin/mysqladmin Ver 9.1 Distrib 10.6.12-MariaDB, for debian-linux-gnu on x86_64
Server version 10.6.12-MariaDB-0ubuntu0.22.04.1
Protocol version 10
Connection Localhost via UNIX socket
UNIX socket /run/mysqld/mysqld.sock
but when I try to check on what port it's listening and running it doesn't return anything
sudo netstat -tulpn | grep mysql
no output
the /etc/mysql/my.cnf looks like this
[client-server]
# Port or socket location where to connect
# port = 3306
socket = /run/mysqld/mysqld.sock```
so ig it should be using the default port 3306am I stupid
oh by the way I can connect to the db just fine
pandas html question. I'm using the following to add a button to each of my rows to be able to edit the data in the row.
product_metrics['check_box'] = '<button class="btn" hx-get="/metric_edit" hx-trigger="edit">Edit</button>```
Then I'm using this to turn my df into an html table:
```py
y = product_metrics[product_metrics['Metric Type'] == i].drop(columns=['id', 'product_id']).to_html(index=False)```
The issue I'm running into is, and this is a guess, that pandas is saving my button as a string, and when I call .to_html, it is using the string information for the html. For example:
```html
<td><button class="btn" hx-get="/metric_edit" hx-trigger="edit">Edit</button></td>```
Where '<' is being used instead of < and > is being used instead of >. To counter this, after turning my table into HTML, I'm using .replace():
```py
y.replace('<button','<button').replace('"edit">','>').replace('</button>','</button>')```
This works and gives me what I want, just wondering if there is built in pandas function/attribute I'm missing that might help. Thanks!Yeah... so working a problem at 2AM and then coming back at the next morning. Looking at the docs, https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_html.html... a couple lines down:
Convert the characters <, >, and & to HTML-safe sequences.```
so just adding "escape = False" to my code works. le sigh. Thanks to anyone who started working thisimagine you can save data in a file ^_^
what if instead of saving in a file, you save in a spercial service that does it for you, saves in files and allows to write and query data efficiently for millions of records of data.
database is usually available over network service (Sqlite3 is perfectly available locally as a file too though), that provides special language to structure how data will be inside, how to add and query from it records.
usually under databases understood SQL databases, like SQLite, or Postgresql in the first place
they also provide a way for data to be denormalized, where each unit of data is not repeated and connected with other units of data. With SQL Quering language you can query any complexity data that interconnects saved data and outputs necessary result (Like... how many passengers were flying to Dublin from London at tuesday after afternoon at airjet with model BJ3434). It is not a problem for SQL language to query such stuff by its design
so SQL database also takes away a considerable amount of complexity from your application, by making a lot lot of your code easier (in terms of saving and query any complexity data)
Thanks 🙂
Let R(A,B,C,D) be a relation schema with the following set of FD's:
F={AB→C,C→D,D→A}
(a). Find all the keys of R.
(b). Find all the superkeys of
R that are not keys.
Guys, it's there any reason to add indexing on many-to-many table with high I/O rate? but rows on this table won't exceed 100k
hi how i can make a code that make a data in row named role when the input = the data in the row who named username ,can anyone help me?
yes, to make searches faster
what have you tried already?
Im using DBbrowser / sqlite3 for my application at the moment (I am currently hosting it on my pc when i run it on my ide) , if i host my application on a vps will the data that will be stored while running become volatile ( The new data added to the DB will remain on there even if i stop hosting) and i can download the main.sqlite file that stores the data which will have the new data that was added while it was being hosted?
@fathom star
interested in the same question!
writing stored procedures for the first time in mssql, and when I try to call it, it just hangs?
I have this output from sp_who2
52 RUNNABLE sa localhost . comp3350 SELECT 1095980 1 03/30 15:26:11 SQLCMD 52 0
completely new to mssql, feel like I am missing a statement that tells the interpreter to do stuff. can post my procedure code if needed. do I need to be using BEGIN, END, and/or COMMIT? completely clueless
what’s the procedure?
Hi, looking for some help with inventory management for an rpg game I'm making
So, players can obtain food items that stack upto 6 items
I'm having trouble coding a logic that determines if they can obtain more items or not
So their inventory is 10 slots
Which means they can do a max of 60 food items, but of course there are other items they can obtain as well
This is on sqlite3
!code
'''py 1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit and manually define a default value in models.py.
Select an option: timezone.now
Please select a valid option: '''
How can i go implementing user with achievements.
A user will have multiple achievements.
I am thinking a achievement like
Achievement
name
image
threshold == some number
User
achievement list == (that have unlocked)
a user will have multiple achievement. a achievement will be unlocked for the user as the user reached the threshold of the achievement.
#1035199133436354600 #1091300844751818863 someone with powershell/python/API advice for this ?
Hey guys! Not sure if this is the right place to ask, but does anyone know if there is an efficient way to pull data directly to a Dask data frame in Python from Google Big Query? I want to avoid downloading locally, and the files I work with are pretty big so I’d rather not invest hundreds of parquet files.
Hey, how do i make it just print 2606427628 and not ('2606427628',)?

fetchall() returns a list of tuples so therefore e[0] gives you a tuple, if you wanted the first element of that tuple you would index it again, i.e. by writing e[0][0]
So the difference between fetchall and fetchone is that fetchall returns the whole row or?
think of a tuple as a single row, fetchone() gives you one row but fetchall() gives you every row from your query
col 1 col 2
row 1 123 456
row 2 789 123
row 3 456 789
>>> c.fetchone()
(123, 456)
>>> c.fetchall()
[(789, 123), (456, 789)]```Ok i get it now thx
Does this look good? Its a verification system to connect roblox accounts to discord accounts and i obviously dont want duplicates of the same robloxid and/or discord id in the database. @waxen finch

- using f-strings to substitute values generally puts your program at risk of SQL injection, you should be parameterizing those queries instead (same way you already did for your insert query)
- proper usage of primary keys will help you guarantee unique entries at the database level so you dont have to do it in your program
- if you do have your primary keys written correctly to reject duplicate rows, you can take advantage of "UPSERT" syntax for your database which combines an insert and update into one query
https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
interaction.user.id is the message authors ID so its no input and robloxuser.id is an API fetch so also no input
So theres no user input
in the f strings
there's really no good reason to not use parameters when you can, and you're trusting external libraries to never have vulnerabilities that can cause those attributes to be changed to maliciously crafted strings
Oh ok ill remove the f string
Also will what i select be printed in a list in order:
e.g
it will print (rankid here, nickname here, roleid here)
?
iunno, i dont see a print statement
If i added a print statement
im just wondering if i said print(res[0]) it would print rank_id?
and res[1] would print nickname?
etc
depends on what res is, if it came from fetchone() sure
yes it came from mycursor.fetchone()
btw mysql has support for unsigned bigints which is compatible with discord snowflakes, not sure what's expected of roblox user ids though
https://dev.mysql.com/doc/refman/8.0/en/integer-types.html
How do i can do SELECT card.*
when selecting from a table, is there a difference when putting '' around the table name?
to my knowledge "double quotes" are used to represent identifiers that would be misinterpreted as SQL syntax otherwise, e.g. if you had a table named user but in your database USER is a reserved keyword, you would need to quote it as "user" whenever you're referencing it
what if i did
"SELECT password FROM user WHERE user = 'Joe'"
you just do it, i guess?

sqlite> CREATE TABLE create (x);
Parse error: near "create": syntax error
CREATE TABLE create (x);
^--- error here
sqlite> CREATE TABLE "create" (x);
sqlite> INSERT INTO create VALUES (123);
Parse error: near "create": syntax error
INSERT INTO create VALUES (123);
^--- error here
sqlite> INSERT INTO "create" VALUES (123);
sqlite> SELECT x FROM create;
Parse error: near "create": syntax error
SELECT x FROM create;
^--- error here
sqlite> SELECT x FROM "create";
123```for sqlite, user isnt a reserved keyword so it would work without quotes there
How do you have 2 different firebase projects in one codebase in python ofc?
Hey guys! I need hand with a BCNF question on this assignment

I'm using an online BCNF calculator to check my work. Its telling that AD->E breaks BCNF. According to the definition in my notes, an FD breaks BCNF when it is both nontrivial, and its LHS is not a superkey for the relation
But AB is a superkey for R
Any idea what I'm missing?
can someone explain why this isnt detecting the collection in my MongoDB database
if "sample_airbnb.listingsAndReviews" in db.list_collection_names():
print("it's there")
else:
print("it's not there")
I am connected to the database, I just cant seem to detect the collections
resolved
between mongodb and postgresql, which is better?
mmh
They are completely different databases
use postgresql by default, if you don't know answer in detail to this question ^_^
postgresql is a very good average default which makes sense to use in general for most of cases.
guys can any one help me to know how use database
Why do i have to use Microsoft access for database management in school?
A) Microsoft propaganda to brainwash population into its products
B) it is easy to use as wordpress, easy to make solution for very small needs
Every solution has its own scalability limits and amount of necessary effort to apply.
For Microsoft Access amount of effort is not very far away from using Power Point and requires no special long education to receive full stack application in completely no code fashion with drag and dropping ^_^
It is within realm of non developer high level user to use it
I can program and im crying how bad the translation for hungaryan and it just feels like its really bad
Hi. For some reasons my asyncpg connections get stale after a bit of uptime
Like, they are still connected, but the functions never complete and run forever.
It's a discord bot, to be exact
It's a database issue, not specifically a discord bot issue.
Hello! Has anyone ever had such an issue, I've tried everything. I deleted python with the pip module and reinstalled it also I tried setting up a new virtual invironment but it did not solve this issue. Here's the code: ```PS C:\Users\Pavel\Desktop\Schule_2022-23\CCDE_Cloud\MillionaireFlask> sqlacodegen sqlite:///millionaire.sqlite3
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in run_code
File "C:\Users\Pavel\AppData\Local\Programs\Python\Python311\Scripts\sqlacodegen.exe_main.py", line 4, in <module>
File "C:\Users\Pavel\AppData\Local\Programs\Python\Python311\Lib\site-packages\sqlacodegen\main.py", line 11, in <module>
from sqlacodegen.codegen import CodeGenerator
File "C:\Users\Pavel\AppData\Local\Programs\Python\Python311\Lib\site-packages\sqlacodegen\codegen.py", line 9, in <module>
from inspect import ArgSpec
ImportError: cannot import name 'ArgSpec' from 'inspect' (C:\Users\Pavel\AppData\Local\Programs\Python\Python311\Lib\inspect.py)
you're probably trying to use inspect.getargspec (i made a research)
looks like sqlacodegen isnt compatible with 3.11, which is when ArgSpec/getargspec() got removed
that package also only has sqlalchemy 1.4 support (in their v3.0 release candidate), so if you're using sqlalchemy 2.0 it might be a better idea to handwrite your models instead
Why it giving await error ahdld i don't use async


🤔 from the documentation

Can anyone test my bot and see if it is vunerable to SQL injection? Would be super helpful
Tysm, you helped me out alot 🤝
if I have a vps server with postgresql installed, can I manage it remotely without using pgadmin, for example, with the help of code or applications such as datagrip, if so, how can I connect to it, what actions do I need to do on the server in order to everything worked, what host address will I need to register in order to connect to it?
Better if you use some tool like https://sqlmap.org/
as a choice -> creating admin user for external connections
getting into pg_hba.conf file, and allowing external connections for the user postgres to database
getting to postgresql.conf file, where you say postgresql to listen at port 0.0.0.0 for external connections
checking firewall allows access to database port
going and connecting ^_^ you can connect with using public IP address of a server (optionally u can assign domain address to your IP and connecting over domain name) (public IP is usually same u use for connecting to VPS over ssh... this can be simple or difficult topic depending on which provider u use)
here is instruction regarding listening port and hba file
https://www.bigbinary.com/blog/configure-postgresql-to-allow-remote-connection
BigBinary
Sometimes we need PostgreSQL to allow remote connection. This blog describes how to get that done.
Hello,
in SQLite if I have two threads both inserting a row into the same table at the same time. Will each thread get own last_insert_rowid() or both threads will get the same value?
Is there any other option how to get the rowid of the just inserted row (except SELECT a row based on all values used in previous INSERT)?
import aiosqlite as aio
async def getvar(id, table, key):
async with aiosqlite.connect("main.db") as db:
cursor = await db.cursor()
await cursor.execute(f"SELECT {key} FROM {table} WHERE id = {id}")
res = await cursor.fetchone()
return res[0]
getvar(1, "card", "power")
<string>:11: RuntimeWarning: coroutine 'getvar' was never awaited
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
HOW I AWAIT getvar what the f is saying
@formal cosmos
does your program actually need to be written with async/await?
but why are you using aiosqlite
ah ok
But this file is just for
from sqlfile import getvar
I want to make
getvar(some, some, some)
this is more of an #async-and-concurrency question then, but you should be calling your function from a place where you are able to await it
for example a main function: ```py
async def main():
await getvar(1, "card", "power")
await getvar(2, "card", "power")
asyncio.run(main())``` though this getvar() function doesnt seem that useful to have
if both threads are sharing the same connection then they will share the same last_insert_rowid(), though the Cursor.lastrowid is cached in memory so it won't immediately change between two cursors
I don't plan to use the same connection. Does it mean that each cursor has own lastrowid value based on the cursor's last insert?
judging from the source, cursors will always update its lastrowid with the sqlite3_last_insert_rowid() C-function regardless of what kind of query you make, unless you execute multiple statements at once
https://github.com/python/cpython/blob/v3.11.2/Modules/_sqlite/cursor.c#L964-L969
Modules/_sqlite/cursor.c lines 964 to 969
if (!multiple) {
sqlite_int64 lastrowid;
Py_BEGIN_ALLOW_THREADS
lastrowid = sqlite3_last_insert_rowid(self->connection->db);
Py_END_ALLOW_THREADS```!e ```py
import sqlite3
conn = sqlite3.connect(":memory:")
conn.execute("CREATE TABLE test (x)")
c1 = conn.execute("SELECT x FROM test")
c2 = conn.execute("INSERT INTO test VALUES ('abc')")
print("c1 SELECT, then c2 INSERT:", (c1.lastrowid, c2.lastrowid))
c1.execute("SELECT x FROM test")
print("after c1 SELECT:", (c1.lastrowid, c2.lastrowid))
c2.executemany("INSERT INTO test VALUES (?)", [["def"], ["ghi"]])
print("after c2 multiple INSERT:", (c1.lastrowid, c2.lastrowid))
c1.execute("SELECT x FROM test")
print("after c1 SELECT:", (c1.lastrowid, c2.lastrowid))```
@waxen finch :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | c1 SELECT, then c2 INSERT: (0, 1)
002 | after c1 SELECT: (1, 1)
003 | after c2 multiple INSERT: (1, 1)
004 | after c1 SELECT: (3, 1)
thank you!
Not database exclusive, could apply to many other situations.
I'm working on a custom async ORM for my discord bot.
In orm\__init__.py I have the orm classes, like ModelMeta, Model.
I also have a database.py with a Database class (just handles connecting/disconnecting).
Models need a connection object, which is created by await Database(...).connect().
However, I was thinking of defining the tables like so:
from .orm import Model
...
class MyTable(Model, tablename="MyTable", db_conn=connection):
...
but the connection hasn't been created yet.
How can I do this?
I'm pretty sure that you are supposed to pass the model to the connection (or an object created by the connection, e.g. a cursor), not the other way around
I want to do db calls like this:
# select rows
rows = await MyTable.select().where(...)
# insert a row
await MyTable(...).insert()
I've designed it so each model holds a reference to the connection
I've also thought about defining the tables as inner classes of Database
I could use __getattr__ to inject the connection 🤔
Would this work when importing the tables?
from .database.Database import MyTable
Need help. I made python program (exe) that work wirh sql server.
On my pc where ssms is installed it works, on server sql - works.
On other clienta machines - no.
- I cannot establish a problem since its exe file and i have no idea how to display error outside... unless i can use information window from tkinter.
- I dont want to install additional softwate on client machine unless its totally necessery for program operation.
Anyone have idea how to solve my issue?
you could try using SQLite instead of SQL Server but I'm not sure if I'd really recommend it
python isn't a particularly good language for creating compiled programs / desktop apps
I already know that. SQLite is not suitable for my program. Besides, it is not a serious tool.

So this is an error that occure.
I established that first it was driver problen just how i suspect.
I installed odbc driver, made changas in code so now i could get error in error window. Pretty neat right?
Anywho... problem still appeares. It seems like odbc driver do not trust server. I added string TrustServerCertoficate=True. Yet. No progress.. Wth is wrong with MS SQL?
can someone explain why this isnt detecting the collection in my MongoDB database
hey guys I'm working on self project to use much bigger size of dataset. when you initially load data to data warehouse after transformation, should i replace any nulls with something else or leave nulls as it is?
like, for example, i have columns called ImageID and PostText. ImageID has null value for some data, and i think they are null because they are regular posts without image. from real work perspective, should I change this to something else, like, "no" or "n/a" instead of "null"? because iirc, there's cleansing process in transformation which deals with bad data such as null and that got me confused.
broadly speaking, replacing nulls (actually missing / js undefined / commonly used null / python's None and such) with arbitrary strings like "no" is a terrible idea
cleaning does includes dealing with missing data, but that usually means dropping, getting the value that should be in these fields from a different source, filling in with a context-appropriate value (in some cases, could be something mean, median, min, max etc), or just taking note of it and leaving it as-is
in that case, it sounds like just leaving it null is a sensible approach
might be nearing 'rant' levels but some things you might want to consider:
- are there null fields?
- does it makes sense for that field to be nullable?
[in other words, does the field being null have a meaning, e.g. "there is no image in this post", compared to it almost definitely being an issue in the data, e.g. "this user hasn't got an ID" or "this user hasn't got a registration date"] - in the records in which that field is null, does it makes sense for that field to be null?
[consistent with other fields, particularly any fields that might be related to the one(s) that is|are null]
Thanks!
guys how do i prevent psycopg.errors.UniqueViolation:
i just want it to decline the duplicate
read up on ON CONFLICT in the insert statement, you can tell postgres to ignore it
Hello folks,
Was reading today about DuckDB, and I saw it coming also with a Python connector.
Has anyone around here already tested it?
Is it as good as it promise?
it seems intresting to me
Refering to my post earlier, I found a solution which some might use.
In connection string must be added next line:
Encrypt=No
Also, might help TrustServerCertificate=1
and finally make sure u have same version of driver since its declear in connection string.
There is lot of confusing crap of how to make a line right, so its been a hell of the quest for me. 🤫

farmer = farmerid, lname, fname, county and state
cow = farmer_id , tagno, breed, dob
is this right?
Code: https://paste.pythondiscord.com/enaxapipog
Error: Bot is showing one warnings when the user has been warned twice [asqlite]
looks good to me, not sure if you’re supposed to add a primary or yourself though
what have you tried already to fix it?
many things
but every of them inputs the same result
your user_id is set as UNIQUE and you ignore any error when inserting duplicate records
Can anyone help me normalize a set of tables to 5nf
async def setvar(id, table, key, value):
async with aio.connect("database.db") as db:
cursor = await db.cursor()
await cursor.execute(f"SELECT {key} FROM {table} WHERE id = {id}")
res = await cursor.fetchone()
if res == None:
if table == "coin":
await cursor.execute(f'INSERT INTO coin(id,bronze,silver,gold) VALUES({id},0,0,0)')
elif table == "sword":
await cursor.execute(f'INSERT INTO sword(id,min,max,crit,lvl,to,magic,shard,blood) VALUES({id},10,20,0,1,1,{None},1,0)')
elif table == "shard":
await cursor.execute(f'INSERT INTO shard(id,shard,blood,storm,fusion) VALUES({id},0,0,0,0)')
elif table == "armor":
await cursor.execute(f'INSERT INTO armor(id,power,lvl,to,magic,shard,blood) VALUES({id},10,1,1,{None},1,0)')
else:
await cursor.execute(f"UPDATE {table} SET {key} = {value} WHERE id = {id}")
``` why im getting here error if res == None its not insertibg into db 😭Pls help me
You're idle and i ping you
@jagged light
No
I can't give it
Ok
damn SQL
So messy
not the code but the use of it in python

You're using ... {None} ... which will be th string None which SQL doesn't know about. That's why you should use binding parameters like:
await cursor.execute('INSERT INTO armor(id,power,lvl,to,magic,shard,blood) VALUES(?,?,?,?,?,?,?)', (id,10,1,1,None,1,0))
Also testing for None equality should be done like: if res is None:
If the table and key can come from an unsafe source they should also be checked, maybe something like:
def check_sql_identifiers(table, column):
allowed_tables = {"coin", "sword", "shard", "armor"}
allowed_columns = {
"blood", "bronze", "crit", "fusion", "gold", "lvl", "magic",
"max", "min", "power", "shard", "silver", "storm", "to",
}
if table not in allowed_tables:
return False
if column not in allowed_columns:
return False
return True
async def setvar(id, table, key, value):
if not check_sql_identifiers(table, key):
print("Something wonderfull has happened, ...")
return
async with aio.connect("database.db") as db:
cursor = await db.cursor()
await cursor.execute(f"SELECT {key} FROM {table} WHERE id = ?", (id,))
res = await cursor.fetchone()
if res is None:
if table == "coin":
await cursor.execute('INSERT INTO coin(id,bronze,silver,gold) VALUES(?,?,?,?)', (id,0,0,0))
elif table == "sword":
await cursor.execute('INSERT INTO sword(id,min,max,crit,lvl,to,magic,shard,blood) VALUES(?,?,?,?,?,?,?,?,?)', (id,10,20,0,1,1,None,1,0))
elif table == "shard":
await cursor.execute('INSERT INTO shard(id,shard,blood,storm,fusion) VALUES(?,?,?,?,?)', (id,0,0,0,0))
elif table == "armor":
await cursor.execute('INSERT INTO armor(id,power,lvl,to,magic,shard,blood) VALUES(?,?,?,?,?,?,?)', (id,10,1,1,None,1,0))
else:
await cursor.execute(f"UPDATE {table} SET {key} = ? WHERE id = ?", (value, id))
I just realised what is problem theres no problem just i forget to use ```py
await db.commit()
Just im use this getvar and setvar its checker no needed for me but thanks anyways@grim vault
Im trying to understand here
!f-sql
😎 i'll try to pretend that i know of it
!sql
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
Sorry, couldn't remember the command
see above about sql-injection.
I love database
I have two pandas dataframes with multiple columns but let's keep it simple with 1. Dataframe A has data [1, 1, 2, 3, 10] and B has [1, 1, 1, 1, 2, 3, 4]
I want to do a kind of row specific merge, so I get [10] and [1, 1, 4].
Is there a name for what I'm trying to do?
So I want to make a layer of abstraction using a NLP for my database. Is there any good resources? This is what I currently have
guys I'm trying to connect to a postgresql from flask and flask_sqlalchemy.
I'm getting the following error:
The current Flask app is not registered with this 'SQLAlchemy' instance. Did you forget to call 'init_app'.
I have initialized the db using db.init_app(app). Is there anything else?
Hello, I can't find my question anymore, but thank you very much for your help ❤️



I am trying to get my Transaction table/relation to be in 3RD NF. I think there's a transitive dependency.
Note: I want PosType to keep the record made by the employee during that time. So if he was an HR employee that made a transaction and later got promoted to manager, keep it as HR employee.
For username, it should match the EMP_ID obviously, so I think that causes a transitive dependency, can anyone help me fix that?
How can I load JSON data into a custom object of mine?
I think this might help
Stack Overflow
I want to convert JSON data into a Python object.
I receive JSON data objects from the Facebook API, which I want to store in my database.
My current View in Django (Python) (request.POST contains ...
it does not bind it like i intended
only creates an object
i want something like: https://stackoverflow.com/questions/38636254/how-to-convert-json-to-java-object-using-gson
Stack Overflow
Suppose I have json string
{"userId":"1","userName":"Yasir"}
now I have a class User
class User{
int userId;
String userName;
//setters and getters
}
Now How can I convert above json string to...
Try reading this
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
i figured it out, thanks
you might want to consider Pydantic or dataclasses-json for your parsing needs
https://docs.pydantic.dev/
https://pypi.org/project/dataclasses-json/
im gonna use an alternate method, thanks
your welcome
Hey guys
In postgres 14.3 we do not have the functionality of merge query
So how do we bring the benefit of merge query in postgres 14.3 ??
Basically the merge imo helps in sequentially inserting or updating the record and deleted from source table
Whereas in 14.3 we need to perform a select *, inser or update on conflict and then perform a truncate on source
There is no way to ensure at which record the insert or update has failed here...
Ping me on reply
ideally by upgrading to postgresql 15
What do you mean?
postgresql 15 has MERGE
That's what I've mentioned
@ionic pecan
What additional benefit does this merge in postgres 15 have other than enhanced readability
Hey
I am trying to export data from a list to a json file
using the Json lib
The problem is that I also use the openpyxle in another func
so I am getting this errror
openpyxl.utils.exceptions.InvalidFileException: openpyxl does not support .json file format, please check you can open it with Excel first. Supported formats are: .xlsx,.xlsm,.xltx,.xltm
Anyone have an idea?
question to real life engieers: when you get petabytes of data, do you partition them to smaller size? if so, what's the average size of newly partitioned data?
when you get petabytes of data, do you partition them to smaller size?
yes, it's basically necessary if you are dealing with petabytes of data.
if so, what's the average size of newly partitioned data?
size of the partitioned data varies depending on the specific needs of your project, your tooling (e.g. your machines, your data processing framework and your network speed) and most of all the nature of the data itself.
i hate to pull out the "it depends" answer but it really does depend a lot on what you are doing.
it's also worth noting file size is not the only way to partition your data, it could be via some natural key (e.g. an identifier for each customer) or via time (e.g. a file per hour/per minute/etc)
if you are working with a specific project/issue, it might be best if you include more details for people to give a more comprehensive answer.
did you manage to know why it happend? currently facing this exact issue
and I'm LOST
@woven ice my previous statement about long-lived connections is a bit inaccurate in that deferred transactions also cause the same error, so here's a quick script testing the different sqlite transaction/journal mode combinations
https://paste.pythondiscord.com/acoxeyigap.py
basically if its only one query you should be fine, but if its multiple queries you need your transactions to start with BEGIN IMMEDIATE
... The WAL journaling mode is persistent; after being set it stays in effect across multiple database connections and after closing and reopening the database.
I always thought this means once WAL is set you can not change it to another one. Seems I was wrong.
Yes I figured it out
I cannot precisely determine what the issue without me seeing your code but basically you cannot chain session.begin() like that. If you want to immediately commit you have to use .commit() for that.
Because with session.begin which you may be aware, it will commit at the end of the context manager
Feel free to @ me if you have more questions and/or need more clarification
Congratulations on finding that btw
That’s an old post :P
I’m curious how you even found it
Here is a more detailed explanation #web-development message
it's in the #web-development channel
I'm facing the same issue, legit same error and it's driving me crazy lmao
i was like, let me try and just search for the error here, saw that you was the only one @rich current
Anybody know how to use MongoDB in a Flask page without refreshing? I’m trying to use MongoDB with the JavaScript but idk if that’s the best way.
Wdym? U can directly connect to mongodb with ur flask app
U should connect it from ur backend (server side), not frontend (client side)
Maybe u can clarify on the 'without refreshing' part
Yeah so I can definitely send data through Flask, but that's when the page loads.
For example, if I wanted to get data on a button click, I don't want the page to constantly reload every time it fetches data from MongoDB
Sounds like ure trynna live stream the data from mongo to the client
Connecting from the client side exposing the mongo URI seems like a bad idea regardless
U can try caching the data either on server or client side with some way to tell if a particular entry has been edited recently
yeah I'm thinking I'll just do this and have an async call to update the cache every 5 minutes.
sounds better for user experience anyway.
though actually, now that i think about it, i might have to do the calls somehow anyway. if my database becomes larger, it would be infeasible to do that
I assume this is for some sort of dashboard?
If it's actual large scale data, seem like a caching database like redis would be the solution
Essentially yes. That does sound interesting. I may take a look
Hello, how do i fix this error on SQLAlchemy (v 1.4) TypeError: 'NoneType' object is not callable
- this error only comes up when trying to insert into a table with foreign key
#1094742559399620628 message
Thanks a lot, I appreciate.
I was looking for about a solution like that for a long time ❤️
Is there any way to select rows with a null value in pgadmin 4? Been looking around and haven't found a clear answer that i understand
WHERE ColName IS NULL
Not sure coz I use mssql at work, postgres only for personal projects
Hello, I dropped a publication asking about dataframes, can anyone help me? 🙂
How to learn database with good practices
thank you! that was it
can sum1 plz tell me y my request.form.getlist isnt working
I have a seqlite db that stores raw bytes of images on each row that I read and creat image objects from, how do i multithread this process?
It's a pyqt application and the db read is already on its own qthread
Don't store files/images in sql databases
@paper flower i already have several db files in this format. changing it now is not feasible.
The file stays locally so i am not concerned with db management
sqlite is fine for storing images, lol. https://www.sqlite.org/fasterthanfs.html
In this case you're competing with fopen. (or equivalent of other OSes) you'll probably want a seperate db for images (vs any other configuration or relational data not tied to the images), but sqlite outperforms the filesystem at handling this, while allowing you to handle image data relationally.
@kindred rain@paper flower^
Small blobs*
it depends on what the image is going to be used for
if you're sending the image over a network pipe using a webserver like nginx, using sqlite will be much slower because nginx will use memory mapped files
(as an example)\
I'm aware, but the blanket "dont store files/images in sql databases" comment is unhelpful and could lead someone towards a worse option for their use case.
it's helpful because it's true 90% of the time
categorical statements that are wrong lead to people making poor decisions and not evaluating their options both now and in the future if they trusted the advice they got.
I try to assume that people are not complete idiots 🙂
Then try talking to them like they aren't and discuss the tradeoffs with them vs just giving a blanket "dont do x"
um when did I give a blanket "don't do x"?
you didnt specifically, you just jumped in and claimed
[the blanket statements ] "it's helpful because it's true 90% of the time" to which that statement still apllies.
to further answer your question, your original statement of it has you working with loading it into pyqt for local use. memory mapped files aren't going to come into play here, and you have a preference on keeping it in the DB already stated. I'd advise you read through this link (https://www.sqlite.org/fasterthanfs.html) for some details on the performance of files in sqlite.
overall, it's better for small files, and gets worse as blob sizes grow, but it takes extremely large blobs to be worse than the filesystem and there are real world applications using sqlite for much larger than "small files" without performance issues. (several major applications have used sqlite as a way to package application data into a single file, there's a list of this curated somewhere, but it's not all that important to this)
python's builtin sqlite3 objects are threadsafe in that they will (by default) prevent you from misusing them between threads, but are not safe to reuse in multiple threads (see: https://docs.python.org/3/library/sqlite3.html#sqlite3.threadsafety)
The ideal situation would be a pool of readers sized to the applications needs (This could be singular), and 1 thread for writes (if needed, but your use case indicates this might not be)
If you want something that works slightly nicer with threading, apsw (https://rogerbinns.github.io/apsw/) has a different API, but handles thread safety significantly better, and this allows more obvious ways to just toss background work into a thread pool.
thank you for your response. The application does no network requests. I intent to only do concurrent reads, writes doesn't seems to be too slow since i don't really update the image column often.
@rich current bump 😄
See here: #web-development message
Hi guys!
(context django) Is it bad to update the db by a background process like using celery? I want to run a function asynchronously as there are a lot of network operation and then update multiple rows in db
will this result in db lock?
please reply sooner if possible as I am in a rush
Why the rush?
In general, it's better to think through the implications. What if you go that way, then what would be the trade offs?
I have two CSVs.
The first is in the form
id,person_name
1,Bob
2,Amy
...
The second is in the form
id,interest_name
1,Cycling
1,Reading
2,Music
2,Card Games
...
The unique identifier for each person is the id. Bob is interested in Cycling and Reading for example. I believe that id would be called the Primary key in the person name table and a foreign key in the interest name table.
I am trying to insert these rows into MySQL tables.
My first question is: Into which table do I insert my rows first, the person name table or the interest name table?
Does the order matter in which I add the rows?
To my understanding, that depends on whether your foreign key constraint is deferred. Normally if your database supports it, you can set the constraint to be initially deferred on table creation or deferred during a transaction, in which case your second table's foreign keys won't be validated until the transaction is committed. However given the documentation, mysql always handles foreign keys immediately which means your person entries must be added before their interests
references:
mysql https://dev.mysql.com/doc/refman/8.0/en/constraint-foreign-key.html
sqlite https://sqlite.org/foreignkeys.html#fk_deferred
postgresql https://www.postgresql.org/docs/15/sql-createtable.html
Thanks for the insight.
this is python only? or ya guys help in other language too?
python and sql
Someone knows very well oracle sql? or any other database that let use regexp in the query?
just ask, plenty of databases support regex
whats the smartest database to use for a project that serves its purpose for a template (for an API) SQL? MongoDB?
Only has to serve as an example of how you would implement
SQLite?
easy setup, i would think SQLite
Yes, SQLite is the way if spinning up Postgres is not worth it
both SQLite and PostgreSQL are awesome
Heyo, I'm currently using json files to store basic item information for my game right now. Would it be a better idea to store them in a database?
Example:
"TOOLS_STARTER": {
"TOOL_AXE_starter": {
"name": "Starter axe",
"description": "A basic axe, meant for novice lumberjacks. You'll learn a lot from this axe, and it will learn a lot from you.",
"STAT_chopping_fortune": 1,
"STAT_chopping_speed": 1,
"price": 10000,
"sell_price": 0,
"can_sell": 0,
"can_trade": 0,
"rarity": "common",
"durability": -1,
"can_upgrade": 1,
"can_craft": 0,
"crafted_from": {},
"parent_items": ["TOOL_CHAINSAW_R1", "TOOL_AXE_R1"],
"child_items": []
}
I've tried scouring the internet for examples of how default item data is stored, but I can't seem to find the right search terms to find what I'm looking for
I suggest json for that
unless you have a shit ton of items that you need to query because most don't need to be in RAM at any one time
and by "shit ton", I mean 100's of thousands or more.
I see. I actually just discovered that Microsoft has a ton of documentation on Minecraft Bedrock editions code, so this is super helpful
I'm learning how they store data for different entities etc. and its actually pretty simple
For example, this is how they store the entity information for a cat
there's more advantages to a proper database than just better scaling, for example data integrity, consistency, and normalization if its a relational db
though having it in json or another text file format does mean you only need a text editor to update it
Yeah, that's true
I was really just curious what all the big games do to store item data
But every time I looked it up, it just gave me how it stores item data as in like players inventories etc
Not the default stuff
yes, but his data is for the "defaults", so it's static and won't need to be updated
right integrity is less relevant there
As a general software design principle, don't overcomplicate things. do the simplest thing possible until it stops working well. 80% of the time, that's enough.
choosing something too inflexible at the start also overcomplicates the project with technical debt, which is why its worth making a thorough decision ahead of time
sure, but many cannot because your requirements are unknown or will change
ERROR: attempt to write a readonly database what can I do against this? Since im on WSL i get this issue quite often and idk what to do about it
you need to provide more details and/or context
well im trying to access the db, currently trying to create tables but it only says this
not to sound like an a**hole, but I don't know squat about your project, what database you're using, what your code looks like, etc, etc. In short, I can't read your mind.
ah yeah, my bad xD
well i've fixed the issue with chown and chmod already but thanks for your help
?
Has anyone made this example work latley? https://dev.mysql.com/doc/connector-python/en/connector-python-example-cursor-select.html
I was helping a guy that could not get the select to work. I ran into it yesterday too.
I set him up with sqlalchemy and pymysql and all is fine but found this puzzling
could not get the select to work.
could not get the select to work in what way?
do you see anything? if so, is it some sort of error or a different result set from what you are expecting?
if you provide more context, i am sure people can lend a hand here.
I confirmed that not to work. Not sure why though
mysql docs makes me want to pull my hair out, navigating it is just an absolute pain.
https://dev.mysql.com/doc/connector-python/en/connector-python-api-mysqlcursor-execute.html
execute() returns an iterator if multi is True
that line there is probably the crux of the issue, as OP said
Im still getting NoneType is not iterable
the fix is:-
either set multi to True
or execute then fetchmany/fetchall to get an iterator over the result set
I have a task to create a release version of a database. I attempted to use Maven Apache and Python. I created a Python script that outputs all data from tables in my database. However, then I modified the pom.xml file and created a main class in Java. As a result, I compiled the sqlite-jdbc-3.41.2.1.jar file, but I am not sure if this is the release or not. When I run it, it simply writes 'Hello World' because I have this string specified in the Main class, but I don't understand what this means. Do I need to modify this main class so that it outputs the contents of the database when I run it, or is it just an indicator that the release file was compiled without errors? Can someone provide guidance or explain how I can create a release version of my database?
sqlalchemy problem here. First, why does my users variable show that all of them are admins even though only one (qwerty) should me admin.
Second, why does trying to do .where(User.admin == True) not work? It doesn't return any of the admin ones, nothing.


i think
User.admin == True is evaluated to False/True (probably False) within python
which is significantly different to User.admin = True which should translate to a WHERE user.admin within SQL
edit: nvm that's wrong
but User.admin = True won't work
especially in a function where it thinks it's an argument
== 1 maybe?
also, it tells us that it's like this

need to see how its passing that variable to the sql query being run

https://stackoverflow.com/questions/18998010/flake8-complains-on-boolean-comparison-in-filter-clause
Stack Overflow
I have a boolean field in the mysql db table.
table model
class TestCase(Base):
tablename = 'test_cases'
...
obsoleted = Column('obsoleted', Boolean)
To get the count of all t...
i think i found what u needed
is that sqlalchemy?
 i used psycopg2 when i learned flask
i used psycopg2 when i learned flask
this is how the model is defined

the above stack link shud answer ur ques doe
oh
i'm doing what it says already
even the users looks a bit odd, why is the second field all True for all users?
yeah that's also another problem
First, why does my users variable show that all of them are admins even though only one (qwerty) should me admin.
it would return the same thing because there are only four entries
it should say false or something falsy for the non-admins right?
it says True for each of them. only qwerty is the admin according to db
try setting default for the boolean admin col default = 0
how does that column look when u query the db directly?
Hey I am currently developing a python application using kivy, we are facing an issue while converting python file to apk, anybody would like to help please dm me
wdym
r u using postgres or
https://www.mysqltutorial.org/mysql-boolean/
so im thinking u can use == 1 for true and == 0 for false

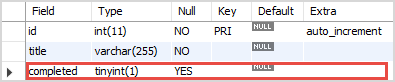
MySQL Tutorial
In this tutorial, you will learn how to use the MySQL BOOLEAN data type, which is the synonym of TINYINT(1), and how to manipulate Boolean values.
sqlite
SQLite does not have a separate Boolean storage class. Instead, Boolean values are stored as integers 0 (false) and 1 (true).
SQLite recognizes the keywords "TRUE" and "FALSE", as of version 3.23.0 (2018-04-02) but those keywords are really just alternative spellings for the integer literals 1 and 0 respectively.
i like integers more
clearer ig
also, ur admin column will change to int if u have more than 2 types of users beyond normal user and admin
so like 0 for admin, 1 for moderator, 2 for normal user
smth like that
I'd rather do flags there instead
so one new col for each new type of user?
no, bits? Like 1 << 2 would be admin and 1 << 3 would be moderator
that type of thing
i dont quite follow
Neither do I tbh, I’ve never seen someone use flags instead of integers for admin, moderator and normal
CREATE TABLE deck_themes (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
deck_id CHAR(22),
FOREIGN KEY deck_id
REFERENCES decks(deck_id),
theme_name TINYTEXT
)
I can't figure out what's wrong with this syntax. This is the error I get:
Error: '1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'REFERENCES decks(deck_id),
theme_name TINYTEXT
)' at line 5'
CREATE tABLe users (id BIGINT NOt NULL auto_increment primary key)
CREATE TABLE projects(
projectId INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
description VARCHAR(250),
others INT NOT NULL,
notes TEXT,
userId BIGINT NOT NULL,
CONSTRAINT fk_userId FOREIGN KEY (userId) REFERENCES users(id)
);
CREATE TABLE about(
pfp longblob,
bio VARCHAR(250) NOT NULL DEFAULT " ",
friends INT NOT NULL DEFAULT 0,
followers INT NOT NULL DEFAULT 0,
id BIGINT NOT NULL,
CONSTRAINT fk_id FOREIGN KEY (id) REFERENCES users(id)
);
Above is a similar version of yours
This is what I found about the error: Mariadb enforces that every auto_increment must be also primary key or unique constraint
As you can see in the second query.
Not sure I understand but I think that my AUTO_INCREMENT is a PRIMARY KEY.
Yes auto_increment must be equal/the same as your primary or foreign key
Do you maybe have like an manual of syntaxes within youre database server? Maybe you can find the right working syntaxes because it might not be working due to syntaxes not matching with your version of the server
So then what's the problem?
I'm using MySQL if that's what you're asking.
The error message with error code 1064 occurs due to the incorrect syntax of MySQL queries. In simple words, MySQL does not understand the commands that you have written. The commands are mistyped or misspelled within the MySQL environment which the database does not recognize.
So which part of my syntax is wrong?
I’m currently looking into it
Okay. Thank you.
But I have to do it on my phone cuz I’m not at home
Only downside is the error ‘1064 has many reasons why it appears. But I’m looking into it
Maybe I don't need to say "NOT NULL" because PRIMARY KEY implies NOT NULL?
What is your MySQL server version?
8.0.32
Thx
I checked the code
Unexpected beginning of statement. ```sql
CREATE TABLE deck_themes (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
deck_id CHAR(22),
FOREIGN KEY deck_id
REFERENCES decks(deck_id),
theme_name TINYTEXT
)
That is what it gave
An “unexpected beginning of statement CREATE TABLE deck_themes (…..
That's odd. I've created many other tables using the syntax CREATE TABLE table_name
Here's an example of one that works
CREATE TABLE deck_color_identities (
id INTEGER AUTO_INCREMENT PRIMARY KEY,
deck_id CHAR(22),
FOREIGN KEY (deck_id)
REFERENCES decks(deck_id),
color CHAR(1)
)
Oh I figured it out
I was missing parentheses around deck_id in the FOREIGN_KEY line.
Thank you for helping me.
You’re welcome
Any here use replit
Probably... If you have a question related to databases why not go ahead and ask it? If your question is just about replit maybe try #python-discussion
has anybody used panda for data analysis?
Many people have, especially in #data-science-and-ml .
Hi guys, which channel should I go to ask questions regarding Heroku + Redis issues? I have a flask application and currently experiencing connection timeouts but it is wierd because in my local development it connects fine...?
Sounds like #web-development
im inserting data into my database but i get this error:
mysql.connector.errors.ProgrammingError: 1054 (42S22): Unknown column '1NQ3keQkRSvtH3rSUdWmLNZh2qVVnERmfH' in 'field list'
this is my code:
cur.execute(f"INSERT INTO incoming (channelID, channel_owner_id) VALUES ({interaction.channel.id}, {interaction.user.id})")
there are columns in my databse which are as mentioned above so idk why im getting the error
!sql-fstring
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
Noob-ish question: How important is sanitizing your SQL queries if the user executing them has read-only (ala SELECT) priveleges?
if the user has read-only rights, the damage they can do is limitedreduced.
but it still not zero.
e.g. it should not be hard to craft an input that burn up all your database's CPU with some payload that does regex denial of service
another e.g. they can still get a dump of your users table containing hashes of pw
how does MySQL handle two or more rows being inserted at the same time to a table with an autoincrement column? will it cause a conflict, or will it Just Work?
pls could someone just let me know. i don’t want to be informed about the f strings, i find them easier to use and anyway i’m just testing
Please use the parameter form:
cur.execute("INSERT INTO incoming (channelID, channel_owner_id) VALUES (%s, %s)", (interaction.channel.id, interaction.user.id))
is that what the issue is?
@glass thunder and wrap quotes around the %s
that should fix it
NO, no quotes for parameter form!
Yes, depending on the variable type.
and if i had 4 values i wanted to input i would use %s, %s, %s, %s?
Yes, one %s per parameter.
And it's always a %s no matter the datatype.
okay
im wanting to get the first result that corresponds with interaction.channel.id, this is my code but i get an error:
cur.execute(f"SELECT * FROM incoming WHERE channelID='{interaction.channel.id}'")
resSQL = cur.fetchall()[0]```i get the error Index out of range
not sure why bcs channelID has a vlue in it
how do i run a query?
what database r u using?
heidisql
never heard of it, but theres proly something like pgadmin4 for it?
what is a query? what does it do

oh yea
How does one select rows where one column's value is in another column's value? Basically, I'm trying to select all rows in which the value of the subtype column is also present in the oracle_text column.
Here's an example
scryfall_id,subtype,oracle_text
1,Elf,Elf creatures you control get +1/+1
2,Bird,Flying
3,Brushwagg,Brushwagg creatures you control get +2/+2
I would like to select rows 1 and 3 from this table because Elf is in the subtype column and the oracle_text column for that row, and Brushwagg is in the subtype column and the oracle_text column for that row.
SELECT *
FROM Table1
WHERE colName in (SELECT colID
FROM Table2
WHERE colName2 = 'condition')```I think this would work if I knew the condition. But the condition will be different for each row.
Like for row 1, the condition would be "Elf IN oracle_text". And for row 2, the condition would be "Bird IN oracle_text". Do you see what I mean?
SELECT *
FROM Table1
WHERE subtype in (SELECT oracle_test
FROM Table2)
this should work if i understand correctly
maybe u can send some sample of the 2 tables and ur expected output?
Sure. One sec.
cards table
scryfall_id,card_name,oracle_text
1,Almighty Brushwagg,Brushwagg creatures you control get +2/+2.
2,Imperious Perfect,Elf Creatures you control get +1/+1.
3,Storm Crow,Flying
4,Pride Guardian,Defender
card_subtypes table
scryfall_id,subtype_name
1,Brushwagg
2,Elf
3,Bird
4,Cat
In this example, I want to select rows 1 and 2. The condition is that the subtype_name from the card_subtypes table is in the oracle_text column in the cards table. For example, "Elf" (the subtype_name) is in "Elf Creatures you control get +1/+1." (the oracle text). And "Brushwagg" (the subtype_name) is in "Brushwagg creatures you control get +2/+2." (the oracle text). I don't want rows 3 or 4 because the subtype_name is not in the oracle text. "Bird" is not in "Flying" and "Cat" is not in "Defender". @obtuse magnet
Yes
u can try something like this
hmm
WHERE col like '%Elf%'
but not sure how to do it for all
instead of writing it manually
Yes, I want to do this for all.
hmmm no idea rn
Okay. Thanks for trying.