#databases
1 messages · Page 4 of 1
import os,sqlite3
cn = sqlite3.connect(os.path.realpath(r'C:\Users\songq\Documents\PYTHON PROGRAMMING STUFF\Patchy\Playerstats.db'))
c = cn.cursor()
username = input("Input username: ")
sets_standing = 9
c.execute('''
UPDATE Stats
SET sets_standing = (?)
WHERE username = (?)
''',(sets_standing,username))```
Trying to input a variable into the table under the name 'tdeo', logic error occurs, and the sets_standing: 9 isn't inserted into the table
I don't see a cn.commit() after the UDPATE statement.
let me search it up, never saw it
thanks XD
Also, I have another thing that's relate to discord bot's slash commands
with the different choice, not all variables will be filled, so what's the way to make sure that existing data doesn't get wiped clean when there's no input
at the moment i can do like "if variable is filled then update that data from the variables, else move onto the next variable" but that's inefficient when I have 29 columns to choose from
How is SQLite compared to PostgreSQL?
simply put, "lite".
unlike others which just typically require a whole server or at least a fair bit of setting up, SQLite is operates almost like just a file format
it doesn't supports multiple connections as well, and is limited to the device the file is in, but it works fine if you only need to access that database from the program that created it and you have access to the file system (+ it is not ephemeral)
Using mysql connector for python, trying to select data from a statistics table.
db = mysql.connector.connect(host='localhost', user='admin', passwd='pwd', db='stats', charset='utf8')
cursor = db.cursor()
existsQuery = "SELECT * FROM all_time_stats WHERE id = %s"
cursor.execute(existsQuery, (userID,))
print(userID)
if cursor.fetchone() != None:
print(cursor.fetchall())
print(cursor.fetchone())
userID is printing the expected value
printing cursor.fetchone() prints None yet somehow its entering the if block, ive used this exact sql syntax and python cursor.execute syntax before with no issues, not sure what's happening
The first fetchone() (the one in the if) will consume the first row (if there is one) of the result set. The the fetchall() will consume the rest of it (2nd to the end) and the fetchone() inside the if will have no more rows to fetch.
Also comparing to None should be done with is None.
Hi, i have i Problem with PHPmyadmin. My database does not store tables. I had a look around and found this error. #1813 - Tablespace for table 'phpmyadmin.pma__bookmark' exists. Please DISCARD the tablespace before IMPORT.... But when I delete this file and try to fix the error by recreating it, it tells me to delete pma__bookmark even though I have already done that.
How do I sort on mongodb compass by latest added?
I remember I did it once
Please mention me if you reply
using asyncpg, if i make a BOOLEAN pgsql column, are its values set to false by default?
if not, how do i set them to false by default?
Hey, i had some doubt regarding pyscopg2 and sqlalchemy.
What should i use in my project? Which is better when using postgres as a database?
either one works
SQLAlchemy does a few more things that abstracts away having to write the queries directly. It works for a bunch of different databases as well
psycopg2 doesn't abstracts many things away, so you have to write all of the SQL queries yourself
you might as well use psycopg if you're doing it to learn / practice SQL - otherwise, it may be worthwhile to use SQLAlchemy instead
But Sqlalchemy isn't that fast as psycopg right?
the speed difference really shouldn't matter
It's a live project an e-commerce based..and i really don't know what to use
Hi, I'm doing some practice on nested SQL queries. Can anyone tell me if this is correct? I'm pretty sure I don't even need the Clinic table here?
Write a nested SQL query to find the names of doctors who work in the clinics
specified as follows.
The clinics must have at least 5 patients who live in the same city as the
doctor works.
--Find the names of the doctors who work in the clinics.
--The clinics must have at least 5 patients who live in the same city as the doctor.
Doctor(Dr_ID, Dr_Name, D_City, C_ID*)
Clinic(C_ID, C_Name, C_Addr)
Patient(P_ID, P_Name, P_City, C_ID*, Dr_ID*)
SELECT DISTINCT Dr_Name
FROM (
SELECT DISTINCT P_City, COUNT(P_ID) AS Number_of_Patients
FROM Patient
GROUP BY P_City
) x
WHERE D_City = P_City AND Number_of_Patients >= 5;
I'm pretty sure this isn't correct
- Cities probably can have multiple clinics
- You're not querying Doctor table in any way, so i'm not sure where Dr_Name even comes from
oh yeah of course, thanks
anyone know how to set up a postgres server for remote connections?
Look into pg_hba.conf 

PostgreSQL Documentation
21.1. The pg_hba.conf File Client authentication is controlled by a configuration file, which traditionally is named pg_hba.conf and is stored in …
I was looking at videos online regarding exactly that, but I don't fully understand them nor how to access the pg_hba.conf file especially on mac
I will take a look tho
It should be in directory where you installed postgres
Also just google "Where is pg_hba.conf"
I made my own Csv library for python
I know that there is a library for csv aldready, but i tried to make a better one. Pls try it and post bugs on the bug report!
My Module: https://pypi.org/project/ShanCsv/
Bug Reports: https://github.com/Ninjago77/ShanCsv/issues

GitHub
A Python Package for CSV File Parsing and Rendering - Issues · Ninjago77/ShanCsv
GitHub
A Python Package for CSV File Parsing and Rendering - GitHub - Ninjago77/ShanCsv: A Python Package for CSV File Parsing and Rendering
Hi!
While the enthusiasm is appreciated and I understand the excitement around sharing your work, you may want to avoid spamming and crossposting it.
It would go a long way to just pick one channel and sticking with it 😉
np
What is the best efficient way of processing operation of less 10^15 data between backend and Database Query?
Hi
when trying to do some first steps with flask + sqlalchemy, I would like to add a column to a model, like this:
db = SQLAlchemy(app)
# ...
class Dummy(db.Model):
text = db.Column(db.String(100))
# ...
The problem: db.Column() is not recognized and doesn't work. I've done everything according to flask-sqlalchemy documentation. What am I doing wrong?
I have a postgres question. I am storing number values and opted to use NUMERIC but then BIGINT. If I store 36,000,001 it will save and return fine. But if I store 1,000,00 it will save it as 1.0E+6... not the number 1 million. Anyone know how to fix this?
you sure it's not just your editor being helpful
1.0E+6 is the same as 1,000,000
it's just scientific notation for shorthand
Python displays large ints like this, and so do most editors
36,000,001 wont be displayed like that because it would be 3.6000001e7 which isn't any more readable than 36,000,001
python was saving the value as decimal and doing the conversion. Thanks.
You shouldn't be able to save null values in column that's declared as not null
You're either saving None as string or your column is still nullable
Well, None is a valid string
"" is still a valid string 🙃
If your column is declared as varchar not null it can't be null
Any strings such as "null", "" and "None" are still strings
Show how you're inserting data into your db
I assume user_full_name is none?
Can you share your table too?
I see, that really might be a sqlite specific behavior 🤔
But I'm not sure
Honestly I'd recommend you to switch to something like postgres
Unless you're writing an embedded/client side app
You could try enabling integriry check:
pragma integrity_check = on;
Maybe it's off by default
@paper flower sqlite doesn't actually check types by default, the column types are merely suggestive
Is it having a firebase database for a webapp a good choice? I dont know in what cases a firebase db is used, and how it is setup, because normally i dont setup security rules because I have my own private key to auth
im learning databases (mySQL) and trying to design on for a inventory management/ buying orders & products etc but i'm struggling to get something together my head just can't wrap around it D: is there anywhere that can help me with this for a beginners/ dummies lol
Fire base can be used as backend. See Google documentation
Worth nothing that Firebase can be slightly iffy with GDPR stuff around it's real time database. As it's only hosted in the US. (Other parts of it are able to be in the EU though so just check what parts you're using)
and yes yes, technically EU data can be stored outside of the EU providing it meets regulations, but i don't think the realtime DB actually does officially.
This is off memory though from a previous project we've had to move to different setups within firebase to avoid the GDPR stuff.
What do you have so far?
At I’ve got, products, products info, stores 😩😂
It would probably be easier to help if you had a diagram around of your schema 😉
This is what ive got so far, still early stages of learning but trying to learn on the go

my who idea of it is around amazon FBA, tracking individual items as well as overall order, sales, profits, expenses etc
any reason i shouldnt store my sqlite database as a .sql file instead of a .db file? only downside i can think of is longer initial load times which dont really matter to me... git cant diff the .db file
or it can but its just bytes for me
I think that .sql is used to store SQL Queries
What Program are you using?
sql workbench
git shouldn't be able to diff if even if you rename it to .sql, but you can use .sqlite iirc
no you can dump it to an .sql file with .dump
Why would you want to do this?
Also you generally don't want to add your db into git repository
Thanks guys
Nice!
But is there a specific question?
is the data static or dynamic? How big is it?
so im trying to restart my postgresql server on mac, but the terminal keeps telling me:
zsh: command not found: psql
any help?
Your psql isn't added to PATH, you can either add it or cd into postgres/bin
how do I do that
I cd'd into bin and ran the cmd and it still gave me the same error, is it bc i didn't install psql with brew? is there a way to restart my server with pgadmin?
Try ./psql
no luck, how do I add it to PATH?
would I have better luck uninstalling Psql and reinstalling with homebrew?
where is your postgres installed?
having some issues with sqlite3
@app.route("/checkUsername")
def checkUsername():
#Check if Username in table
username = request.args.get("q")
if username == "":
return "Valid"
#Connect Database and Create Cursor
DB = sqlite3.connect("final_project.db")
curs = DB.cursor()
userCheck = curs.execute("SELECT id FROM users WHERE username = ?", username)
if userCheck.fetchone() != None:
return "Username Taken"
return "Valid"
From what I'm seeing
it thinks that username is a table and I'm not supplying enough bindings for every value
how can I make it realize that its just a string
definitely not what's happening. the parameters must be a sequence of some kind, i.e. a list or tuple. you passed a string, which technically is a sequence. it's treating each character in the string as a separate parameter!
this is a common mistake when working with python database interfaces
you can also use named parameters and a dict if you prefer, it's described in the sqlite3 docs somewhere
it looks like library
what do you mean?
Is there anyway in sqlalchemy to have a dynamic schema for a json column ( ms sql server ). I have a request table that has the main request info as normal columns, and any request specific info as a json stored in a json column (pretty much nvarchar(max)). I would like to define the structure of the expected json per a request type. So for example Request A might have { "Name": "TEST", "Apple": Test }, Request B would have { "Orange": "Test", Bike: "TEST" }, so if request A use json structure A, if request is of type B, use json structure b for querying and validation.
You just want to enforce types on client side, correct? 🤔
I believe that is what it would be called. ( I am a data engineer, so this is my first foray in making a web app with a python backend )
Just want to make sure any required fields are there, that the json structure for each request type is consistent etc.
Values are what they are supposed to me etc
It's getting validated client side, but I want to validate server side as well.
I would generally advice you not to use json if your data is more or less structured
Also I feel like you always answer my questions doc lol
End goal would be to allow dynamic creation of requests.
Figured json would be the simplist way to store all the different possible schema's
otherwise I would need to do a table per a request, or something like a table were the fields are stored on per a row, and then having a column for request id to pull all fields
I think if you want to store different models in same column then that's not really doable
Maybe I just don't see a correct solution
As json, it doesn't matter as sql server is nvarchar, so the json can be whatever, but from the python side thats a different story.
I guess how would you store dynamic form fields
@late tinsel I would probably use pydantic here
from types import UnionType
from typing import Type
import pydantic
from pydantic import BaseModel
from sqlalchemy import select, create_engine, Column, Integer, TypeDecorator, JSON
from sqlalchemy.orm import sessionmaker, declarative_base
engine = create_engine(
"postgresql://user:password@localhost:5432/database-name",
future=True,
# echo=True,
)
Session = sessionmaker(
future=True,
bind=engine,
)
Base = declarative_base()
class MyType(TypeDecorator):
impl = JSON
cache_ok = True
def __init__(self, type_: Type | UnionType):
super().__init__()
self._type = type_
def process_bind_param(self, value: BaseModel, dialect):
return value.dict()
def process_result_value(self, value, dialect):
return pydantic.parse_obj_as(self._type, value)
class A(BaseModel):
a: int
class B(BaseModel):
b: int
class Model(Base):
__tablename__ = "model"
id = Column(Integer, primary_key=True)
data: A | B = Column(MyType(type_=A | B))
def main():
with engine.begin() as conn:
Base.metadata.drop_all(conn)
Base.metadata.create_all(conn)
with Session.begin() as session:
model_a = Model(
data=A(a=42)
)
model_b = Model(
data=B(b=77)
)
session.add_all([model_a, model_b])
with Session() as session:
models = session.scalars(select(Model)).all()
print(models, [model.data for model in models])
It would be a database design issue as much as python side no
Maybe 🤷♂️
You also should use pydantic's discriminated unions to parse models quicker
I know of a EAV ( Entity Attribute Value ), but was hoping to avoid that with json column
I watched a talk about using json/jsonb in postgres Their use case was to store a lot of additional information about objects, json was pretty much perfect for that case, otherwise you need to either create a table for each type of object or make a wide table

GitHub
Question Output of <: pydantic version: 1.7.2 pydantic compiled: True install path: /media/data/miniconda3/envs/pydeep/lib/python3.6/site-packages/pydantic python version: 3.6.11 | packaged ...
Hm this is along the lines of what i was looking for, and then the SQL alchemy side could stay as json but I could still have validation
Yea I didn't really know how to say that. I ended up passing it as a tuple with just 1 index which is the strinf
@late tinsel Why are you using sql server tho?
Does anyone know how to make a new collection in pymongo (MongoDB Atlas) using python?
@paper flower I am using sql server because thats what I have to use from my company. My other option was cosmosdb
I'm creating a discord bot, and I need a database. Do anyone have any suggestions?
For a small bot just for a couple servers, you can probably get away with using Sqlite, for anything else I'd say postgres is a solid option
Do I have install any of those on my computer? I'm trying to make a bot thru bot-hosting.net and I'm not sure what to do.
Sqlite is file based right? I tried it once on replit, but apparently files can't be edited while not being online there. Do you know if bot-hosting.net is the same?
@torn sphinx You probably want to change that password asap
Yeah, thanks.
I need advice regarding insertion of data in Postgres with multiple unique indices
I have a users table with unique phone, email and a few external ID columns. I need to be able to efficiently upsert rows in there, up to 5k for now but it could be even more later. I also need to get the IDs of the upserted entries to create relations in another table
So, how should I go about this? The simplest approach seems to be to upsert them one by one, trying different constraints or trying to fetch an existing user first and comparing it to the new one, but I don't see any solutions for bulk inserts here. Maybe it's better to drop the unique constraints and insert users freely, but implement a periodic data migration that would go over the table and join duplicate entries as well as change the dependent tables
yep can agree. I've been using Postgres for one of my discord bots and it's worked perfectly fine for me
SELECT score, name FROM guild ORDER_BY score DESC LIMIT 5 why is there a syntax errror
sqlite3.OperationalError: near "score": syntax error
oh underscore
hello! need some mysql help at #☕help-coffee thanks!
Hey guys, it´s a beginner question but I am struggling to get a list of objects from my models when I query my postgres db. I am using repr in the model class and it returns string. How can I have a list of objects so I can iterate later?
This is what I get to query my db:
users = db_session.query(Usuarios).all() return repr(users)
In pydantic, how would I go about validating a json column? I will be using discriminating unions to define the models for the various types of json in that column, but I am unsure of if I have to do anything special when validating them
can it literally be just any JSON value?
So the table is setup as RequestType, Department, Location, RequestSpecificJson. Request specific json structure will change based on the RequestType value ( I will have to nest this value in the json as well so that I can use descriminated unions as it seems I can't use a column in the parent model ). Other than being RequestType specific, the json will always follow some form of pre-define structure. If that answers your question
can you not make your base model just the abstract class
and then each specific request just inherits from the parent overriding the typehint
I am learning pydantic still, so not sure how that would look
reading docs now on abstract class
something along the lines of:
class MyBaseResponse(BaseModel):
status: int
message: str
class MySpecificResponse(MyBaseResponse):
data: str
class MyOtherSpecificResponse(MyBaseResponse):
data: Tuple[int, str, int]
the classes which inherit the base response will all still have the status and message fields. and then will have their specific relevant type for the data field
Would pydantic be able to tell the difference between the two responses when it gets data from an api? Or will I have to setup a different endpoint for each responce type?
in reality you should have them as separate endpoints unless your handling of each format is the same. In which case, yes you would just use a union type i.e
class MyBaseResponse(BaseModel):
status: int
message: str
data: Union[Model1, Model2, int]
class Model1(BaseModel):
foo: str
class Model2(BaseModel):
bar: str
for example
In essence, handling of them would be same, as they are just storing user input, the actual logic differences would be in approval piece, which is an endpoint of it's own.
status: 1,
message: "Success",
field1: "value1",
field2: 2,
field3: "1",
}
{
status: 1,
message: "Success",
field4: "value1",
fieldY: 2
}
// How I send the data now
{
status: 1,
message: "Success",
RequestSpecificJson: {
field4: "value1",
fieldY: 2
}
}```mmm a union type should be fine
End goal will be to allow for request building ( far out ), were a user can build a form and an approval process.
I was going to use jsonlogic for the approval process piece, so it can be dynamic based on conditions set by a user.
hi everyone. I'm working on putting together a simple site to be hosted locally on a small homelab setup I'm putting together to play around and learn with. I have the basic site put together and am using a sqlalchemy to build the database. Everything seems to work fine, except for my passive deletes for a little message board. The post are assigned id numbers, if i have 4 post with comments on each one the comments show up in the proper places, but if i delete say post id 2 out of the 4, the post deletes and it seems to work fine. But if all the post ate deleted and the id numbers start back at 1, new post made show up with comments from the old deleted post. I have looked through a few different sites and tried a couple different ways but the deletes still do not seem to be working.
class User(db.Model, UserMixin):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(150), unique=True)
email = db.Column(db.String(150), unique=True)
fname = db.Column(db.String(150))
lname = db.Column(db.String(150))
password = db.Column(db.String(150))
dob = db.Column(db.String(150))
date_created = db.Column(db.DateTime(timezone=True), default=func.now())
post = db.relationship("Post", backref="user", passive_deletes=True)
comments = db.relationship("Comment", backref="user", passive_deletes=True)
likes = db.relationship("Like", backref="user", passive_deletes=True)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
text = db.Column(db.Text, nullable=False)
date_created = db.Column(db.DateTime(timezone=True), default=func.now())
author = db.Column(db.Integer, db.ForeignKey('user.id', ondelete="CASCADE"), nullable=False)
comments = db.relationship("Comment", backref="post", passive_deletes=True)
likes = db.relationship("Like", backref="post", passive_deletes=True)
class Comment(db.Model):
id = db.Column(db.Integer, primary_key=True)
text = db.Column(db.String(200), nullable=False)
date_created = db.Column(db.DateTime(timezone=True), default=func.now())
author = db.Column(db.Integer, db.ForeignKey('user.id', ondelete="CASCADE"), nullable=False)
post_id = db.Column(db.Integer, db.ForeignKey('post.id', ondelete="CASCADE"), nullable=False
class Like(db.Model):
id = db.Column(db.Integer, primary_key=True)
date_created = db.Column(db.DateTime(timezone=True), default=func.now())
author = db.Column(db.Integer, db.ForeignKey('user.id', ondelete="CASCADE"), nullable=False)
post_id = db.Column(db.Integer, db.ForeignKey('post.id', ondelete="CASCADE"), nullable=False)```Sorry I dont know why the formatting got all messed up when it sent.
Your id's shouldn't reset if you delete all objects, also since you have ondelete="cascade" it should delete all the comments
well that has me even more confused, I guess I know less than I thought😆. I first noticed it when deleted all of the post that I made as a test. When i made a new post it showed up with id 1 and the old comments were there. Maybe its something in how I am calling my delete function. I'll look at some of the other files Im using for the site to see if I messed up one of them possibly.
Maybe you didn't migrate your database properly, so, ondelete just isn't there
I tried deleting the database and starting with a fresh one after everything was added and the issue still was there. I'm wondering now if maybe its in the way I am calling things in my views.py page, maybe the way I create the post or the way the delete function works. I'm looking through them now to see if anything obvious stands out.
I did notice in a new test a second ago, if there are say 4 post, if i delete post 4 and create a new post, it gets assigned post id 4 and keeps its comments from before. If i delete post 3 instead and leave post 4, then make a new post the new post gets id 5. So my current work around is just dont delete the last post
@login_required
def delete_post(id):
post = Post.query.filter_by(id=id).first()
if not post:
flash("Post does not exist.", category="error")
elif current_user.id != post.author:
flash("You do not have permission to delete this post", category="error")
else:
db.session.delete(post)
db.session.commit()
flash("Post deleted.", category='success')
return redirect(request.referrer)```What database are you using?
Sqlite3
Maybe that's the problem
That is my delete function, i dont see anything obvious standing out.
I'm not very familiar with sqlite but it has a lot of weird behavior and stuff like foreign key checks is disabled by default
ok, well if that's so then the problem is most likely exactly that. If its not doing the foreign key checks its not going to relate things properly then I would assume. Thank you, that gets me going in the right direction again!
So if I'm reading the sqlite documentation I need to make an sql statement PRAGMA foreign_keys=True; at run time. So if I add that statement to every block where I create and delete db entries, it should work, maybe.
You can create a listener that would execute these pragma statements when it connects to db, I'm not sure if they're preserved
I was just reading about that and trying to figure out how to build it into the site. I am pretty new to using databases, in the past I defaulted to saving everything to csv files and manipulating them that way. The sqlite doc says you need to pass the statement for every connection so I think a listener like you said should work.
Thank you for the guidance by the way!
You can also set up a different database like postgres
How can I set timezone for sqlite database? I want to timestamp in my timezone.
Can anyone help me, how to insert some things into a table? Is there something like %s I should have?
What's the problem?
Should it be ?,?,? or %s,%s,%s with aiomysql?
When in doubt: consult documentation
How to drop / remove a row from a table in mysql?
same way in your normal SQL dbs, DELETE FROM <table name here> WHERE <condition>
datetime('now', 'localtime')
best approach for many to many for 3 tables with 9 tables
hi
yo
in sqlite3, is it possible to add 3 values to a table constructed to contain 4 values?
sql = ''' INSERT INTO projects(name,begin_date,end_date)
VALUES(?,?,?) '''
cur = conn.cursor()
cur.execute(sql, project)
conn.commit()
```is this how i do it, if "projects" table is constructed to contain 4 values?why can this error:
conn = sqlite3.connect(db_file)
how can I alter my mysql procedure field type
So I have this codepy await c.execute("CREATE TABLE IF NOT EXISTS Tickets (channelid INT, ttype VARCHAR(50), memberid INT, membername VARCHAR(50), claimedby INT, created_on DATETIME, review_status BOOLEAN)") and when I run it I get ```py
/home/container/.local/lib/python3.8/site-packages/aiomysql/cursors.py:239: Warning: Table 'Tickets' already exists
await self._query(query)
even tho I have `IF NOT EXISTS` why?Documentation:```py
CREATE TABLE [IF NOT EXISTS]
:incoming_envelope: :ok_hand: applied mute to @abstract socket until <t:1662121911:f> (10 minutes) (reason: discord_emojis rule: sent 48 emojis in 10s).
The <@&831776746206265384> have been alerted for review.
!unmute @abstract socket
:incoming_envelope: :ok_hand: pardoned infraction mute for @abstract socket.
I think the bot might be seeing the timestampes with : as emoji
Sorry for extra data post here. I was posting data for better explaination to you guys
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
You can use this for now
No error, and it doesn't print c?```py
print("a")
await c.execute("INSERT INTO Categories (name, channelid) VALUES (%s,%s)", (i[1], i[0].id))
print("c")
:incoming_envelope: :ok_hand: applied mute to @abstract socket until <t:1662122079:f> (10 minutes) (reason: discord_emojis rule: sent 48 emojis in 10s).
The <@&831776746206265384> have been alerted for review.
!unmute 847052980770963486
:incoming_envelope: :ok_hand: pardoned infraction mute for @abstract socket.
😦
it thinks those colons are emoji
please use this ^
product_id | price | price last update datetime | datetime(truncate)
931 | 43.69 | ** | 2022-08-25 15:00:00
904 | 40.00 | ** | 2022-08-25 15:00:00
931 | 43.69 | ** | 2022-08-25 15:00:00
1026 | 59.99 | ** | 2022-08-25 14:00:00
931 | 43.69 | ** | 2022-08-25 14:00:00
904 | 40.00 | ** | 2022-08-25 14:00:00
931 | 43.69 | ** | 2022-08-25 14:00:00
** is the 2022-08-25 13:21:56.525869 +00
how to to use group_by in datetime(truncate) for multiple product id?
i don't know you guys can understand the question?
Hi, can someone tell me how I can order by full datetime?
format dd-mm-yyy hh:mm:ss
Result:
DESC LIMIT -1 -> 01-08-2022
DESC LIMIT 1 -> 31-08-2022
Data from:
23-07-2022 to 02-09-2022
why is it just looking in 08?
What do you mean by full datetime?
How do you store it in your database?
Which db?

No, I mean sqlite, mysql, etc
hmm
not sure, I have a database.db file and use python sqlite3 to write to the database
now to get the data I use php PDO
It's sqlite then?
ok
probably date(datetime here)
still the same problem
i just get 01.08 and 31.08
@tranquil shoal I don't quite understand what you want to do
I have data ranging from 07 to 09 and I would like to select the oldest row
But for some reason I get 01.08
can I just check something
are you reading the date the american way (month/day/year), or the way basically everyone else reads it? (day/month/year)
like Every one else
can you show the query you're using to get the data
and a screenshot of your rows if it's a small enough table would be good

Just using order by should work:
select * from some_table
order by some_column desc
limit 1
Can you show how you created your table? @tranquil shoal
afaik sqlite3 doesnt have a native datetime type so those are in reality stored as strings, and naively ordering them would do lexicographical ordering
CREATE TABLE "data" (
"user_id" TEXT NOT NULL,
"timestamp" DATETIME NOT NULL,
"username" TEXT NOT NULL,
"status" TEXT NOT NULL,
PRIMARY KEY("user_id","timestamp")
);
so it should be expected to be ordered by (day, month, year) as thats how the timestamps were formatted
This is the output:
DESC LIMIT -1 -> 01-08-2022
DESC LIMIT 1 -> 31-08-2022
They should be stored as numbers though
Maybe you could try wrapping your datetime column into datetime() call?
well, python's sqlite3 module uses an iso format-ish as a builtin converter for TIMESTAMP columns
tryed that
Solution to all sqlite problems: Don't use sqlite 😅
looking at https://sqlite.org/lang_datefunc.html i dont think there's any supported way to parse datetimes that arent in one of the expected formats like Y-M-D H:M:S
I'd say if your application isn't meant to be standalone just use something like postgres
easiest way is to correct the formatting so it orders lexographically correctly.
or just use unix timestamps
the latter is probably easier from a maintenance perspective.
Guess you can do:
...
order by julianday(
substr(timestamp, 7, 4) -- year
|| substr(timestamp, 3, 4) -- month including left and right hyphen
|| substr(timestamp, 1, 2) -- day
|| substr(timestamp, 11) -- space and time
)
!e You could also create a custom function for the conversion, like:
import sqlite3
import datetime as dt
conn = sqlite3.connect(":memory:")
conn.execute('CREATE TABLE "data"("timestamp" DATETIME NOT NULL)')
date_list = [
("01-08-2022 12:00:00",),
("10-08-2022 14:00:00",),
("03-08-2022 13:00:00",),
("03-08-2022 18:00:00",),
("17-08-2022 15:00:00",),
("01-09-2022 16:00:00",),
("01-09-2022 15:00:00",),
("02-08-2022 17:00:00",),
]
conn.executemany('INSERT INTO "data" VALUES(?)', date_list)
rows = conn.execute('SELECT * FROM "data" ORDER BY "timestamp"').fetchall()
print("\n".join(row[0] for row in rows))
print("-" * 75)
def datetime_to_unixepoch(text):
if text is None or len(text or "") != 19:
return None
return dt.datetime.strptime(text, "%d-%m-%Y %H:%M:%S").timestamp()
conn.create_function("datetime_to_unixepoch", 1, datetime_to_unixepoch)
rows = conn.execute('SELECT * FROM "data" ORDER BY datetime_to_unixepoch("timestamp")').fetchall()
print("\n".join(row[0] for row in rows))
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 01-08-2022 12:00:00
002 | 01-09-2022 15:00:00
003 | 01-09-2022 16:00:00
004 | 02-08-2022 17:00:00
005 | 03-08-2022 13:00:00
006 | 03-08-2022 18:00:00
007 | 10-08-2022 14:00:00
008 | 17-08-2022 15:00:00
009 | ---------------------------------------------------------------------------
010 | 01-08-2022 12:00:00
011 | 02-08-2022 17:00:00
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/fikalunesa.txt?noredirect
Anyone had issues in the past with App containers not recognising Redis container address in docker-compose?
i.e. Error -2 connecting to redis://redis:6379. Name or service not known
Why do I need to db.session.commit() for a query to pull current data from database instead of of the same results from the previous time the query was run: ```py
db.session.commit()
todays_events_query = TimekeeperEventModel.query.filter_by(user_id=user_id)
todays_events_df = pd.read_sql(todays_events_query.statement, todays_events_query.session.bind)
Is there a better or more standard way to ensure I querying the database and not retrieving some cached query object from the session?
probably should be redis://127.0.0.1:6379 if I remember correctly
you need to setup a docker network for hostname translation
hey, why can this error:py conn = sqlite3.connect(db_file)
i mean why do i have to put it in a try, except function
you're supposed to be committing after writing, not before reading
....but if I don't commit before the query, it just returns the results from the previous time it did that query.
I think it has to do with flushing?
are you also writing data inside this same db session? or just reading and expecting some external process to change the data?
Its flask-sqlalchemy and I am unsure how the sessions are managed. fwiw each write has its own commit: ```py
event_model = TimekeeperEventModel(user_id=current_user_id,
datetime=datetime.now(),
journal=form.journal.data,
clock_in_event=False)
db.session.add(event_model)
db.session.commit()
flask.flash("Successfully clocked out. Please, don't forget to log-out. Good-Bye.", 'success')
return flask.redirect(flask.url_for('main.home'))
huh, i'm not sure then. that's kind of weird and isn't what's supposed to happen
i've only used flask-sqlalchemy once and only for a very small task
hmm hmm. most of the tech peeps at my company are familiar with MSSQL but someone is leading a separate initiative to create a Snowflake DW
i know snowflake is similar to other columnar DBs like big query, teradata, etc.
should i warn peeps that the queries that they write on Snowflake will be different than a traditional, transactional DB system
especially since i know some queries would run up a lot of $$$
if you try using a SQL query based on a transactional, row-based DB like MSSQL

What is a good data visualization tool to use these days? I know this is "broad", just kind of curious.
I've got hundreds of thousands of data points I would like to visualize. Quite possibly topping 1 million in a given session, etc.
Graph or relational database?
There would be a poc that would highlight the differences and trade offs
Part of the outcome of that poc would include a "when should I use snowflake and when shouldn't I"
First sorry for my late sesponse this dose not work till now but you showed me something I did not know till now
I will look into it.
btw. right now I'm using php not python 😁
I'm using pdo to work with my databasem, what is the standart datetime format?
YYYY-MM-DD hh:mm:ss
or
DD-MM-YYYY hh:mm:ss
and if it is YYYY-MM-DD hh:mm:ss
if I cna somehow convert it
sqlite needs YYYY-MM-DD hh:mm:ss https://www.sqlite.org/lang_datefunc.html#time_values
ahh because because my format is DD-MM-YYYY hh:mm:ss this is prob. the reason why the oreder by date is not working
Yes. SQLite doesn't have a DATETIME or TIMESTAMP datatype. It's just a string and ordered like that.
You can use my example with the substr(...) to get it correct.
Oh lol I tried it but it didn't work but now it does THANKS! 😁
I was stuck for tolong
You can also try the user function way: https://www.php.net/manual/en/pdo.sqlitecreatefunction.php
I'm sure php does have some sort of strptime()
<?php
function mytimestamp_to_unixepoch($string)
{
$date = DateTimeImmutable::createFromFormat('d-m-Y H:i:s', $string);
return $date->format('U');
}
$db = new PDO('sqlite:sqlitedb');
$db->sqliteCreateFunction('my_ts2ue', 'mytimestamp_to_unixepoch', 1);
$rows = $db->query('SELECT * FROM data ORDER BY my_ts2ue(timestamp)')->fetchAll();
?>
hey guys can someone help me on how i could go about answering this question:
12. Display any guests in the hotel database that has never made an active booking. Show the
customer’s full name and email address
SELECT CONCAT(hguest.given,' ',hguest.surname) AS Guest_Name, hguest.email
FROM hguest
INNER JOIN hbooking
ON hbooking.guest_id = hguest.guest_id
WHERE hbooking.status = 'N'
ive got that atm but its showing every guest
ah okay that would be good

when using sql alchemy for updating records, do I need to create a pydantic schema for each type of update possible. Like if only 1 field is updated, will it only update that one field or will it try to replace the values in the data if I only send the updated fields?
Is there a way to order all the values in my table based on the ID column (ascending order) and I delete the first half or the first X number of records?
ID column? Row ID?
You want to order by, then create a rank column, then keep all records up until max_rank / 2
Sorry the opposite, you want to delete those
But you get the point 👍
alr ty
hi,
im wondering if calling functions too quickly (that do stuff in sqlite3) cause cause errors
my script does does:
-request.get for a page
-creates a list (lets call it "La Liste") of info i want to save in an sqlite3 database
-for each tuple containing the info in "La Liste" i run this
def create_connection(db_file):
conn = None
try:
conn = sqlite3.connect(db_file)
except Error as e:
print(e)
return conn
def updateValues(conn, liste, name, info):
list_value, list_demand, list_rarity, list_stability, list_status, list_OpUp = listItemsInfo(liste)
sql = f''' INSERT INTO itemsInfo({name},{list_value},{list_demand},{list_rarity},{list_stability},{list_status}, {list_OpUp})
VALUES(?,?,?,?,?,?) '''
cur = conn.cursor()
cur.execute(sql, info)
conn.commit()
#return cur.lastrowid
def saveToDb(liste, name, info):
database = 'cvb.db'
conn = create_connection(database)
with conn:
updateValues(conn, liste, name, info)
```my question is, because it goes through "La Liste" so quickly, could it cause an error with executing things in sqlite3if you don't async, you should be fine, SQLite runs into trouble if multiple threads attempt to write to it at same time
isnt that what my script does?
I don't see any Async
cause i doubt it saves a tuple before it goes to the next value of La Liste
also, Not sure why you have 3 functions, for simplicity sake, just wrap it into one
Also, you should use query parameters, not f-strings
oh yea, I totally missed that
whats that oof
Wait, I am wondering whether column names can be query parameters, I think they can't
yh its column names
I figured you had at least run the code
i have more to add to it, i was asking in case i change the structure
I wouldn't do 3 functions, if you are doing SQLite, it's likely tiny program, just shove it into single function
you probably have bigger problems
if your file system isn't available, you are big trouble
Unless it's already in use and doesn't share necessary file permissions, it should be
hi
im wondering if this could error sometimes
because i do executemany twice in a row 2 big lists containing like 1000 tuples each
i have to since i have different columns to fill```py
cur = con.cursor()
cur.executemany(''' INSERT INTO itemsInfo(name,sv_value)
VALUES(?,?) ''', List1)
cur.executemany(''' INSERT INTO itemsInfo(name,mv_value)
VALUES(?,?) ''', List2)
con.commit()
im doing this on a raspberry pi btw
using psql, asyncpg, does anyone know how i could get a table using a bot cmd, i mean like it would send he formatted table, as if you ran it in your own terminal
idk how id get the fancy table and not just a list
how would i format it..? is there a lib to help?
use sqlite
i don't think you want to do that
format it yourself
filter out some sensitive columns
Does anyone have experience with setting context.Configure for Flask-Migrate (or maybe even Alembic)? I'm having difficulty with the autogeneration (and thus upgrade) detecting an existing table that was created in the last migration.
class Log(db.Model):
__tablename__='logs'
__table_args__={'schema': 'logs'}
...
in env.py, I updated the online (not the offline) configuration:
import re
def include_name(name, type_, parent_names):
if type_ == 'schema':
if name == None:
return False
excludes = name in ['test', 'temp']
excludes = excludes or bool(re.search('^tmp\d', name))
includes = name in ['public', 'flask', 'api', 'app', 'logs']
return includes and not excludes
return True
def include_object(object, name, type_, reflected, compare_to):
if type_ == "table":
if object.schema == None:
return False
excludes = object.schema in ['test', 'temp']
excludes = excludes or bool(re.search('^tmp\d', object.schema))
includes = object.schema in ['public', 'flaskapp', 'api', 'app', 'logs']
return includes and not excludes
return True
def run_migrations_online():
...
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=process_revision_directives,
**current_app.extensions['migrate'].configure_args,
version_table='migrations', # special table for migration tracking
version_table_schema='app', # special schema for migration tracking
include_shemas=True,
include_name=include_name,
include_object=include_object
)
with context.begin_transaction():
context.run_migrations()
I'm seeing this in the logs, suggesting even the compare isn't detecting the existing table:
INFO [alembic.autogenerate.compare] Detected added table 'logs.logs'
All I've done is added a mixin to the existing table for some creation/update dates. So I was expecting to see an ALTER TABLE...ADD COLUMN query instead of CREATE TABLE in the migration (again)
Maybe I'm misunderstanding the include options. Is it forcing those migrations to be included always? Or is it forcing their evaluation (adding them to the search scope)?
I thought the latter, but now I'm thinking it's the former.
could someone help me parse some data from a small dataset. i'm having a hard time figuring out how to get the data i'm being asked for. DM please
That seems true (it seems to be a forced include/exclude) filter. So how can one say, "evaluate table in X schema for column changes, but only generate the migration if there are changes"?
which database?
For PostgreSQL your superuser, postgres, should be able to connect locally (e.g., psql postgres) and create additional users:
CREATE USER app_acct WITH PASSWORD 'app_pass';
GRANT CONNECT ON app_db TO app_acct;
Go to the pg_hba.conf and modify the connection permissions/methods:
host all all 127.0.0.1/32 password
host all all ::1/128 password
Notice those allow any account to connect on localhost with a password. You'll want to be more restrictive than this (also consider using something stronger than password authentication once you get it working).
host app_db app_acct <your IP> password
Restart the server and you should be able to connect.
I don't encourage using MySQL or MariaDB 🙂
... well that's true, but I don't know how to configure off the top of my head. Mine sit around and are set and forget. I'll look for my scripts to see if I have something on my other box.
For MySQL
CREATE USER IF NOT EXISTS 'app_user'@'localhost' IDENTIFIED BY 'app_pass';
GRANT SELECT ON *.* TO 'app_user'@'localhost';
FLUSH PRIVILEGES;
Your CREATE USER may need to be created with SSL, but your PhpMyAdmin should take care of all this connection stuff for you. If you do use the command line and localhost doesn't work (because it's a VPS), you can try using a wildcard % to accept any (again, this is much less secure).
Example:
CREATE USER IF NOT EXISTS 'app_user'@'%' IDENTIFIED BY 'app_pass';
GRANT SELECT ON *.* TO 'app_user'@'%';
FLUSH PRIVILEGES;
Hi, I got an error after trying to insert a value into the gender column. What could be wrong? Thanks.
After reading several docs, watching different videos, perusing Github issue boards, surveying Stack Overflow posts, and even creating a very barebones single-file Flask app (which worked as expected); by happen chance, I discovered include_shemas is not include_schemas . 🤦♂️ Hours wasted. You have to love spelling errors.
Everything works as expected and the include* functions are filters that stage for evaluation (and don't force). The spelling error caused the app to never consider my custom schemas for comparison evaluation.
Which database dialect?
Try using single quotes instead of double quotes:
INSERT INTO user_data (gender) VALUES ('test');
In MySQL double quotes may work, but in PostgreSQL double quotes are used to use use the literal name of database objects (e.g., database name, table name, column names) when they're defined with case sensitivity or include special characters (e.g., "Users" table). In MySQL, backticks are used for the same purpose.
In both cases, it's better to use single quotes to signify string values.
So then what is wrong with jt?
Again, I'd recommend changing "test" to 'test'
I have a new one for the Alembic/Flask users. I'm trying to insert a record and use its ID during a migration.
Example
from alembic import op
import sqlalchemy as sa
from datetime import datetime
from sqlalchemy.dialects.postgresql import insert
def upgrade:
admins = sa.table('admins',
sa.Column('id', sa.Integer),
sa.Column('handle', sa.String(64)),
sa.Column('email', sa.String(80)),
sa.Column('created', sa.DateTime)
schema='sys'
)
op.execute(
insert(admins)
.returning(admins.c.id)
.values(
handle='Admin',
email='Admin@sys',
created=datetime.utcnow
)
.on_conflict_do_nothing()
)
)
Questions
- I'm getting the following error:
sqlalchemy.exc.ProgrammingError: (psycopg2.ProgrammingError) can't adapt type 'builtin_function_or_method'
- How should the returning value be captured? Can I assign
op.executeto a variable and use that?
ad 1: missing () for datetime.utcnow?
I would suggest to use datetime.now(timezone.utc) to get an timezone aware timestamp.
Thank you @grim vault that was it, also thank you for the recommendation on how to set it. I'm still learning python and a lot of the content is a bit aged (2010-2013)
Apparently this old SO post also addressed this: https://stackoverflow.com/questions/2331592/why-does-datetime-datetime-utcnow-not-contain-timezone-information
So the blog or article I was following probably had a bad example is this has been known.

Stack Overflow
datetime.datetime.utcnow()
Why does this datetime not have any timezone info given that it is explicitly a UTC datetime?
I would expect that this would contain tzinfo.
@grim vault do you have any recommendation for capturing the returning() value nested in the op.execute()?
I'm trying to add a nullable=False column to a table in a migration. I'd like to use the new record's ID w/o using an additional SELECT query. It seems like value=op.execute() is always capturing None.
Sorry, I never used alembic or sqlalchemy.
My guess would be you need to fetch the data somehow.
It's challenging as it's nested in this Alembic migration process. I don't know if the statements are invoked in one db transaction (my hope) or separate transactions and how that might affect this.
Stack that on top of not knowing how op.execute behaves.
Haven't found the answer to op.execute, but the connection can be used to retrieve the value:
conn = op.get_bind()
response = conn.execute('INSERT INTO ... RETURNING ...').fetchall()
I wouldn't recommend doing that, alembic is primarily for schema migrations, not data migrations
Final update now that I have something working. I know this is the Python community and not the Alembic/Flask/SQLAlchemy community, but I wish that documentation was a little easier to follow for my edge case 🙂
Altering a column.
- BEFORE: nullable, string
- AFTER: not nullable, integer, foreign key
def upgrade:
# Custom schema name
app_schema='sys'
# Create a temporary data structures
admins = sa.table('admins',
sa.Column('id', sa.Integer),
sa.Column('handle', sa.String(64)),
sa.Column('email', sa.String(80)),
sa.Column('created', sa.DateTime)
schema=app_schema
)
resources = sa.table('resources',
sa.Column('resource', sa.String),
sa.Column('admin', sa.Integer),
schema=app_schema
)
# Find or create id of records to populate nulls for foreign key
# NOTE: be cautious with data migrations inside DDL migrations
conn = op.get_bind()
admin_id = conn.execute(admins.select().where(admins.c.username=='Admin')).scalar()
if not admin_id:
admin_id = conn.execute(
insert(admins)
.returning(admins.c.id)
.values(
username='Admin',
email='Admin@Sys',
created=datetime.now(timezone.utc)
)
.on_conflict_do_nothing()
).scalar()
# Add admin_id to table being modified (populate the nulls before making the column not-null)
op.execute(
resources
.update()
.where(resources.c.admin == None)
.values(admin=admin_id)
)
# Change column characteristics
op.alter_column('resources','admin',
type_=sa.Integer, #<-- trailing underscore is important
existing_type=sa.VARCHAR,
nullable=False,
existing_nullable=True,
schema=app_schema,
postgresql_using='admin::integer' #<-- important for Postgres
)
# Make column a foreign key
op.create_foreign_key(None, 'resources', 'admins', ['admin'], ['id'], source_schema=app_schema, referent_schema=app_schema)
Yes. In this case I'm going from a nullable to not-nullable, so I need to modify the data as part of the change. I could search for an existing record, but right now I wanted to assign it to something like "SYSTEM" to cleanup after the fact (assign to a true admin).
My example above isn't perfect, but I included the important bits which was the column's type conversion -- I still haven't found postgresql_using in the documentation and the autogenerator didn't create the existing_nullable key either (maybe because True is the default).
Update: Here's the little bit that exists on postgresql_using in the documentation. https://alembic.sqlalchemy.org/en/latest/ops.html#alembic.operations.Operations.alter_column.params.postgresql_using
Migrating existing data is fine but you don't need to insert any records
How would you propose doing this for a FK?
what project is this??
If you're adding new fk to a table then it's probably fine, but it looks then that your data model wasn't thought through 🤷♂️
If it's not in production then there's no need to create complicated migrations
It's a vanilla flask app that I'm learning Python/Flask with. I'm setting it up to follow the Rails MVC structure, which means making a lot of modifications and restructuring.
When developing it's easier to just remove old migrations and start from scratch
I have to approach this like someone may come behind me and make a change. Knowing the ins-and-outs of more complicated scenarios is actually a good thing to encounter now. My preference is to avoid anyone from altering the database directly so changes can be tracked in code and results are reproducible/recoverable.
That migration would be buried in 100 other revision files anyway
After this migration you'd likely have to manually adjust db anyway
Better solution would be to make that fk nullable and start using it in application code
Haha I hope not.
I'll add, the system I plan to develop is being thought out, but also is likely to change since we'll be prototyping.
There's a desire to normalize tables to at least 3NF, but performance, time, and maintenance considerations could modify that architecture.
When everything is migrated you can make it non-nullable
Same with other breaking changes
Yeah, this exercise was more about learning Alembic migrations. I actually created a Mixin after-the-fact to add creation and update timestamps to models -- in the future I'll set that up earlier on so it won't be an issue.
During this process I decided to change one unused field to a FK. This was mainly a learning experience in seeing how Alembic detects table changes -- initially I had issues with the tables being in a different schema.
I've overcome these various challenges and feel much better now. Still trying to get a feel for the environment contexts and when variables are are loaded, but I'll go read more of the docs.
Did you configure it to detect column changes?
I don't think I configured it for that. It's Flask-Migrate, so maybe it does some of that for me?
My initial issue that brought me here (way up above) is that I'm working out of a custom schema and it was encountering errors. Turns out I had a spelling error include_shemas -> include_schemas.
Tbh I'd recommend to use alembic and sqalchemy directly
It's configurable in env.py
src/alembic/env.py line 69
compare_type=True,```I'll have to check that out.
This is the env.py came over from the flask db init, which I think is mostly (if not completely) a copy/paste from Alembic:
def run_migrations_online():
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
# this callback is used to prevent an auto-migration from being generated
# when there are no changes to the schema
# reference: http://alembic.zzzcomputing.com/en/latest/cookbook.html
def process_revision_directives(context, revision, directives):
if getattr(config.cmd_opts, 'autogenerate', False):
script = directives[0]
if script.upgrade_ops.is_empty():
directives[:] = []
logger.info('No changes in schema detected.')
connectable = current_app.extensions['migrate'].db.get_engine()
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=process_revision_directives,
**current_app.extensions['migrate'].configure_args,
version_table='migrations', #<-- my addition
version_table_schema='app', #<-- my addition
include_schemas=True, #<-- my addition
include_name=include_name #<-- my addition (defined elsewhere)
)
with context.begin_transaction():
context.run_migrations()
I know you mentioned using SQLAlchemy (and not Flask-SQLAlchemy) as well. For my learning, I think it would have been better to learn from that angle. I prefer to work the native/core libraries first and then learn the time-saving methods after. This is the reverse.
I don't think flask-sqlalchemy does anything better
Please avoid spamming across channels
That's not productive and will only lead to negative feedback
im not intressetd to contunue this convo
You have been reported to moderators anyway. So you better stop
i did what the fcuk stop pinging me
shush
shush
I don't know enough to know better 🙂 I think I liked the syntax when setting up a class model:
class User(db.Model):
# vs #
class User(Base):
I didn't have to know anything about the declarative base or what it meant to set up an "engine". They're fairly simple concepts, but it's additional jargon when not familiar with the language or how the interpreter is loading files (e.g., app.py vs wsgi.py vs __init__.py).
engine is mainly configuring your db connection iirc
You can also check sqlalchemy docs for more info
I think I'm passed that point now. Was saying on initial introduction, it's a lot to learn and Flask cuts some of those corners.
Base is a metaclass to set up your tables declaratively by inheriting from it and defining columns on that class
I think flask db.Model is the same
src/db/models/book.py line 6
class Book(Base):```Right. Flask is a wrapper around SQLAlchemy and internally declares the base, while exposing access to it, but makes it so you don't have to do any of the upfront work. It also automatically names tables, which I might have used, but since I was specifying the schema via __table_args__, it didn't make sense not to also specify __tablename__.
You can create a mixin to name your tables too, but generally specifying table name it not a problem
I'll post this vanilla app and I expect the community to tear it to shreds over better ways to accomplish it =]. The joys of learning
Also if you're making an api then better use fastapi
hi- i have been using mysql workbench on windows 11 and have created a database on it while i was coding my python in windows. i have recently transitioned to wsl2 and i cant for the life of me figure out how to connect to query my database from wsl2? i essentially want to add a user to my current sql instance but all attempts for the past few hours have been futile. I am at a loss. anyone know how i can do this? (it says i am accessing from the my current user root- however when i go to make a db object in python with those creds i get this error: Authentication plugin 'caching_sha2_password' is not supported)

i updated the plugin to mysql_native_password nad still get the caching_sha2_password error


😿 😿
okay i have connected from wsl (i had to make a new user- named xxx_root but im not sure how to get the instance graphically showing in mySQL workbench)
when i tried to connect to the host with plugin changed to 'caching_sha2_password' i just got the error Access denied for user 'root'@'localhost' (using password: YES) )
i have to transfer the database from my windows server over to the wsl2 server aswell


god mysql is so freaken painful to use
you would think i could just access the same database from wsl2 that my local windows instance setup but ofcourse it cant- what am i missing?????
this is ridiculous honestly, shouldnt be this hard- i think im just going to use sqlite
Is there a reason you're using MySQL specifically? Postgres is quite easy to use and has many advantages over MySQL
nah no real reason just was using it because of the workbench for a gui. i am using no extra database features besides reading and writing tbh
In that case Postgres and MySQL are more trouble than they're worth. There's no point in running the entire server when SQLite should be just fine.
I encountered same problem on my Ubuntu 20.04. After installing MySQL server it’s running properly so I decided to install the workbench so I can use the GUI sometimes instead of CLI always buy since my work bench would start but can’t connect to database. I have tried several method to make it connect but nothing seems to be working out. What should I do ?
I am looking at storing data online using a relational database. I have looked at firebase, azure, aws, but not really sure which one would fit best? I am looking at users generating queries to gather information, so several calls a day, and possibly scaling up to 1000+ users. I do not know the cost comparison or the usefulness of each service. Do any of you have experience using these services for database hosting, or have any recommendations as to which direction I should look into?
I'm not familiar with these solutions but postgres db should do, 1k users isn't a lot
Heavily depends on your usecase and on the type of data you want to store
Do you need very low latency? Will your users directly run SQL queries? Will they need to interface with some specific softwares? Do you need to scale your db up and down? Do you need controllable costs before anything...?
"users directly run SQL queries" I don't think there is ever a time where this is a suitable situation to allow users to do that 🤣
Of course it does, in a Data Warehouse 🙂
How would you feed data to a population of Data Analysts then, or Data Scientists? Printing CSVs and sending by mail?
Mmmm true, although I'd argue under that situation I'd assume you're already plenty experienced in the database you choose to use unless any of your data can be freely accessible by absolutely everyone and even then there's so many risks around it that I couldn't really recommend doing it still to someone who appears to be quite new to this sort of thing
Exactly that's why I was asking. @naive urchin is not excluding the Data Warehouse use-case in the question. It could be for an app with a frontend, for users with experience, no experience, etc.
That's currently the point of any company that want to be data-driven: they need sources of data that the users (Employees with the right permissions ofc) can query and analyze in order to take data-driven decisions.
But I'm maybe just overkilling it and the need is just for something like mongodb here x)
Tbf I think the simplest solution is just asking what sort of app they're making lol
Depends, that could answer a lot of questions... or not at all :p
Hi everyone hope you guys are having a good day...I have got an error from the dbs using flask

i am not sure what does the error binding parameter 2 means...like which field is it referring to?
The <Team 1> looks like a class instance instead of an integer.
nevermind I have figured it out
I converted the class instance to an integer using team = Teams.query.get(x)# this will get a specific team
data = Players.query.filter_by(team_id=x) # this will get a specific player from a team
team_new_id = team.id
Controllable cost and low latency. The app will contain tables of data, users will have unique identifiers that allow them to view the data pertaining to them. It’s in relation to a shopping list. So say I have 20 items in my shopping list that are stored in the shopping list table. I need to query the data using my unique identifier, and receive my shopping list. I would need some way for the shopping list to update when synced with other users, so maybe a query call every 30s or something more clever. But in any case, there could be an infinite amount of rows to query from, and calls from users. I am not looking for high costs, so I am willing to sacrifice low latency.
it really depends on how comfortable you are with databases before hand.
- If you're relatively new and absolutely need the relational side of things. Postgres is a good option.
- If you're happy to sacrifice the relational side of things / can structure your data in a way that allows. Wide column DBs like ScyllaDB will be considerably more performance at scale. These databases came out of Amazon's DynamoDB paper which is the DB they made in order to original house user's shopping baskets.
- If you absolutely need the relational side of things, and it needs to be high availability and scale. YugabyteDB is probably the best option followed by cockroach.
Ok thanks 🙂 I’ll look into it
@naive urchin as you were looking at cloud solutions, I can recommend Cloud SQL (Google)
With postgres it's nice
Alright 🙂 I will look at that as well thanks!
hi, in sqlite3
is it possible to do something like this
example tuple1 = (value1, demand1, name)
name is PRIMARY KEY```py
sql = ('''
INSERT OR UPDATE INTO table VALUES(?, ?, ?)
''')
values = [tuple1, tuple2, ...]
cur.executemany(sql, values)
idk if its different when theres a primary key, but ik to update something you do```py
sql = ('''UPDATE table SET value = ?, demand = ? WHERE name = ?''')
values = [tuple1, tuple2, ...]
cur.executemany(sql, values)
```some context: "table" may not contain the name a tuple mentions
so it wouldnt work to simply do update, but others would already exist
if this is impossible, does it mean for each tuple i create (from web scraping) id have to insert/update it?
i wanted to avoid that cause i create 100 tuples per page i webscrape, so it wold do many executions in the database and thought an error could come out bc of the speed of the for loopHey guys can anyone tell me why i get this error "Fatal error: Uncaught Error: Call to undefined function mysqli_connect()" i've checked the php.ini file and the mysqli extension is already enabled.. I'm trying to connect to my database.. im using xampp and phpmyadmin.
EDIT(got it to work, it was a problem with the json settings of php.. it was not directed toward the php.ini file for some reason)

That would be called an UPSERT like:
sql = ("""INSERT INTO table(value, demand, name) VALUES(?, ?, ?)
ON CONFLICT(name) DO UPDATE SET
value = excluded.value,
demand = excluded.demand""")
values = [tuple1, tuple2, ...]
cur.executemany(sql, values)
I have this code, and it prints "a" but it never prints "b". When I print the fetched results is says <Future finished result=()> every time. What's wrong with the INSERT?```py
await c.execute("SELECT * FROM Categories")
print(c.fetchall())
print("a")
await c.execute("INSERT INTO Categories (name, channelid) VALUES (?,?)", (i[1], i[0].id))
print("b")
If you need to await the execute you'll also need to await the fetch.
Ty! Now it returns (), and it still isn't printing b. It's something wrong with the INSERT because the code stops there and nothing is inserted into the database.
Looks ok to me, which db module are you using?
aiomysql
According to the docs it should work I think, so I can't understand why it isn't
Doesn't mysql use %s instead of ? for parameter binding?
Someone said earlier because it's async, it can only do one thing at a time, and perhaps that it was doing something else, do you think that's right?
Now when I check the docs, do you think I need this loop?```py
loop = asyncio.get_event_loop()
loop.run_until_complete(test_example_execute(loop)
I'm not that familiar with async programming, depends on how your code is run I guess.
You can also try to make an extra cursor for the insert.
Do you think I need a loop in my connection?
do anyone know why sqlite3 creates a second record all the time my script is starting a new script file?
it creates a new record with 0 data in it
commit
I have this information, how to create a connection? (I've changed the password) (aiomysql)
thanks
i also saw something using ON DUPLICATE KEY UPDATE, though its in MySQL, ill do the upsert anyway
was just wondering what u think if i add a WHERE true before the ON CONFLICT to avoid ambiguity the sql documentation mentions

You have a VALUES statement not an SELECT, you can't add WHERE True that would be a syntax error.
Alright! So I have this code, and it isn't inserting anything to the database, it is printing A but not C.```py
async with self.bot.db.acquire() as con:
print("2")
async with con.cursor() as c:
print("3")
for i in ((bot_channel, "Bot Development"), (server_channel, "Server Creation"), (gfx_channel, "Graphic Effects"), (vfx_channel, "Visual Effects"), (market_channel, "Marketing"), (ticket_logging, "Logging"), (reviews, "Reviews"), (availability, "Availability")):
print("4")
if i[0]:
print("5")
await c.execute("SELECT name FROM Categories")
print("6")
data = await c.fetchall()
print("7")
if i[1] in data:
print("b")
await c.execute("UPDATE Categories SET channelid = %s WHERE name = %s", (i[0].id, i[1]))
print("D")
else:
await c.execute("SELECT * FROM Categories")
print(await c.fetchall())
print("a")
await c.execute("INSERT INTO Categories (name, channelid) VALUES ({},{})".format(i[1], i[0].id))
print("c")
:incoming_envelope: :ok_hand: applied mute to @night heart until <t:1662473119:f> (10 minutes) (reason: duplicates rule: sent 4 duplicated messages in 10s).
The <@&831776746206265384> have been alerted for review.
How about:
async with self.bot.db.acquire() as con:
async with con.cursor() as cur:
sel_stmt = "SELECT name FROM Categories WHERE name = %s"
ins_stmt = "INSERT INTO Categories (channelid, name) VALUES (%s, %s)"
upd_stmt = "UPDATE Categories SET channelid = %s WHERE name = %s"
for channel, channel_name in (
(bot_channel, "Bot Development"),
(server_channel, "Server Creation"),
(gfx_channel, "Graphic Effects"),
(vfx_channel, "Visual Effects"),
(market_channel, "Marketing"),
(ticket_logging, "Logging"),
(reviews, "Reviews"),
(availability, "Availability"),
):
if not channel:
print(f"no channel for {channel_name!r}")
continue
await cur.execute(sel_stmt, (channel_name,))
data = await cur.fetchone()
if data is None:
print(f"insert channel {channel_name!r}")
await cur.execute(ins_stmt, (channel.id, channel_name))
else:
print(f"update channel {channel_name!r}")
await cur.execute(upd_stmt, (channel.id, channel_name))
await con.commit()
print("done")
What’s your Favorite SQL database to use ?
I've only ever use SQLite or Postgres and have never had reason to try any other
Kind of a basic question but whats the best/fastest way to save and store a big matrix, Trying to store a graph matrix instead of creating it each run
matrix?
you could just pickle the object
but depending on the object, there might be easier solutions @cosmic lodge
Ok thanks
have stuck with Postgres and never rlly had a reason to switch
I'll use SQLite if it's a small program. But for larger ones like discord bots, typically I will use Postgres instead
What's the easiest way to write a query like this with django's ORM? sql SELECT MIN(column) FROM table WHERE condition ;
I know I can do something like this py records = Table.objects.filter(condition) value = min(record.column for record in records) but I really don't want to eagerly load all of the records (there are millions)
got it: py records = Table.objects.filter(condition) value = min(records.values_list('column'))
nvm
that pulls all of the records into memory
does this page help? https://docs.djangoproject.com/en/4.1/topics/db/aggregation/
Small async SQLAlchemy syntax question. I'm using it with asyncpg.
I have my async sessionmaker defined as this, copied from the asyncio ORM doc:
https://docs.sqlalchemy.org/en/14/orm/extensions/asyncio.html#synopsis-orm
async_session = sqlalchemy.orm.sessionmaker(
engine,
expire_on_commit=False,
class_=sqlalchemy.ext.asyncio.AsyncSession,
)
My issue with this is the following syntax:
async with async_session() as session:
async with session.begin():
session.add_all(
Is there no way to directly use the session object to .add objects? It does indeed not work when I call it directly.
Ok so I guess I was mistaking a sessionmaker for a context scope which is what I'd use in the past.
Is there a downside to defining an async context manager like this?
@asynccontextmanager
async def session_scope() -> sqlalchemy.orm.Session:
"""
Provide a transactional scope around a series of operations
"""
async with async_session() as session:
try:
yield session
await session.commit()
except Exception as e:
# Bare except don’t look good but make sense here to not become blocking in the database
await session.rollback()
raise e
finally:
await session.close()
I guess committing and closing sessions only matter when writing and this will result in a decrease of performance when only doing reading?
Sorry if the question sounds stupid
Your async_session is just a configuration on how to create a new session, similar to functools.partial, it's not the session itself.
Also rollbacks should occur automatically and there's a shorthand for beginning transactions:
async with async_session.begin() as session:
...
Creating a contextmanager like yours woulbe kind of wasteful since sqlalchemy does all of this under the hood
I see, the context manager used to be recommended in the dock hence why I used it
Thanks for the tips! Should I just always use .begin() then, even when I only intend to read data?
No, since there's no need to commit anything, but I'm not sure if it matters in case of sqlalchemy
hello, does anyone know how I can view a data table in pgAdmin 4?
I googled it for you: https://www.pgadmin.org/docs/pgadmin4/development/editgrid.html
pgAdmin - PostgreSQL Tools for Windows, Mac, Linux and the Web
I have read that already, it doesn't say how I can view the data table
It couldn't be more direct. What part are you having trouble with?
"To view or modify data, right click on a table or view name in the Browser tree control. When the context menu opens, use the View/Edit Data menu to specify the number of rows you would like to display in the editor panel."
"right click on a table" how am I supposed to do that when I can't display the table?
can someone give a code that will arrange 5 numbers that a user inputs into ascending order?
it couldn't be less direct
How to use asyncpg in cogs?
Don't you have a Browser on the left side which you can unfold? like here: https://www.pgadmin.org/static/COMPILED/assets/img/screenshots/pgadmin4-viewdata.png
yeah but I got it at the bottom
Ok, so in this view you should find your table list where you can right click over the table name as described.
no it's not there
Maybe you need to connect to your server to get the list? I'm no user of pgAdmin, so I'm out.
I don't know what list you are talking about, but anyways do you know any good alternatives for pgAdmin?
Hi, I'm getting this error after trying to insert something into the database:
def insert(self, table_name: str = "", columns: List[str] = None, values: List[str] = None):
"""
Args:
table_name: The table name that you want to insert something.
columns: These are the sql columns, where you can add something.
values: It should be the values of the table.
"""
if columns is None:
columns = []
if values is None:
values = []
try:
with self._conn_singleton() as conn:
with conn.cursor() as cur:
if slorm_detector.insert_check(table_name, columns, values):
cur.execute("""INSERT INTO {0} ({1}) VALUES ({2})""".format(table_name, ', '.join(columns), ", ".join(values)))
except:
raise InsertError(table_name=table_name, columns=columns, values=values)
Someone can help?
Thanks

As it's says: You tried to insert NULL into the column ident which is defined as NOT NULL.
And you shouldn't use .format() for values.
thank so then you have any tips, what string formatting type should I use?
Something like:
cur.execute(
"INSERT INTO {0} ({1}) VALUES ({2})".format(
table_name, ",".join(columns), ",".join(["%s"] * len(values))
),
values
)
This will make the SQL ... VALUES(%s, %s, %s) and the acuall values list as second parameter to the execute() for the binding of those ?
thanks, I understand, but I getting this error now:
raise ex.with_traceback(None)
psycopg.ProgrammingError: the query has 0 placeholders but 1 parameters were passed
During handling of the above exception, another exception occurred:
Do you have any tips?
Could be that psycopg uses %s instead of ? for the placeholder?
Stack Overflow
This might be a rather silly question but what am I doing wrong here? It creates the table but the INSERT INTO doesn't work, I guess I'm doing something wrong with the placeholders?
conn = psycopg2.
I updated <#databases message>
another error

That's the NOT NULL again, you only can solve that if you provide a value for the ident column or set a default values for it at the create table statement.
Do I have to provide a default value when I create them?
I don't know your database design or data requirements.

If a column in a table has the constraint NOT NULL you must provide a value at insertion time, except if the column also has an DEFAULT value which is not null.
this is my table things, so If I remove the not null, and provide a default value then is it going to work, right?

remove the NOT NULL will do, you don't need a default if it can be NULL.
But if you want the NOT NULL you need to add an default value.
I got too many connections error, which means that I've tried it too many times, right? 😄
Can't tell. If the program terminates it should close all connections. Do you still have some other programs running?
okay so I think it works now


If you use the placeholder method you don't need the quotes inside the string. values = ["test"] will do.
Thanks, I will modify that.
Thanks @grim vault!
I'm getting a SQL syntax error. Can someone look at this and see if there's something that I'm missing?
with engine.connect() as conn:
conn.execution_options(autocommit=True).execute("""
MERGE INTO [dbo].[calls] AS t
` USING (SELECT id=?) AS s
ON t.id= s.id
WHEN MATCHED THEN
UPDATE SET id=s.id
WHEN NOT MATCHED THEN
INSERT (id) VALUES (s.id);""",
(row['id'],))```what is the error?
Oh gosh, I see what it is. There's a backtick on line 5. It said there was an issue with the AS.
did you solve it?
Yes, that was the issue. Thank you for being willing to help. I was just staring at the code too long.
no problem
How to use asyncpg in cogs?
im trying to load a json file of course items into a dynamodb database. I am getting an ResourceNotFoundException when it is loading the items through a loop. Does anyone know what is wrong? (code incoming)
def load_data():
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Courses')
with open('files/courses_data.json') as json_file:
courses = json.load(json_file)
print('Populating table...')
for course in courses:
CourseID= 1
Subject= course['Subject']
print(Subject)
CatalogNbr= int(course['CatalogNbr'])
print(CatalogNbr)
Title= course['Title']
print(Title)
NumCredits= int(course['NumCredits'])
print(NumCredits)
print("Loading course: ",CourseID)
table.put_item(
Item={
'CourseID': CourseID,
'Subject': Subject,
'CatalogNbr': CatalogNbr,
'Title': Title,
'NumCredits': NumCredits
}
)
CourseID = CourseID + 1
json file is:
[
{
"Subject": "CMIS",
"CatalogNbr": "141",
"Title": "Introductory Programming",
"NumCredits": 3
},
{"Subject": "CMIS", "CatalogNbr": "242", "Title": "Intermediate Programming", "NumCredits": 3},
{"Subject": "CMIS", "CatalogNbr": "320", "Title": "Relational Database Concepts and Applications", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "300", "Title": "Building Secure Web Applications", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "325", "Title": "Detecting Software Vulnerabilities", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "350", "Title": "Database Security", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "360", "Title": "Secure Software Engineering", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "400", "Title": "Secure Programming in the Cloud", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "425", "Title": "Mitigating Software Vulnerabilities", "NumCredits": 3},
{"Subject": "SDEV", "CatalogNbr": "460", "Title": "Software Security Testing", "NumCredits": 3},
{"Subject": "CMSC", "CatalogNbr": "495", "Title": "Current Trends and Projects in Computer Science", "NumCredits": 3}
]
i basically put the print between each item so I know that it is gathering the correct data, and it seems to be doing everythig fine on the first loop
I get:
Make a selection: 1
Populating table
CMIS
141
Introductory Programming
3
Loading course: 1
but then that is where the error occurs
botocore.errorfactory.ResourceNotFoundException: An error occurred (ResourceNotFoundException) when calling the PutItem operation: Requested resource not found
Hello! I'm using mysql in python. Should i pass my cursor object or connection object to functions? Thanks!
I don't think there is a specific best practice
im thinking the error is somewhere in the table.put_item block, but I cannot figure out what is going wrong
currently have a help topic open but i feel like asking here as well
i want to fetch everything from a column but .fetchall is just not gonna cut it (size of database)
but fetchmany doesnt do what i want it to do since it keeps fetching the same ones over and over and over again
how would i go by going thru each value one by one
or any other method that would get the job done
No idea what database and/or ORM you're asking about but here's the general idea: https://stackoverflow.com/questions/7389759/memory-efficient-built-in-sqlalchemy-iterator-generator
Stack Overflow
I have a ~10M record MySQL table that I interface with using SqlAlchemy. I have found that queries on large subsets of this table will consume too much memory even though I thought I was using a b...
sqlite3
This might work https://stackoverflow.com/questions/41852393/python-loop-over-sqlite-select-with-fetchmany-until-no-entries-left
Stack Overflow
I need to retrieve results from my sqlite3 database 160 rows at a time, and repeat that until there are no rows left for my query, this is what I have:
conn = sqlite3.connect("C:\Users\%s\AppDa...

Well, did you create the table first? And, btw, your CourseID = 1 must be before the for loop to work, otherwise each ID is 1. You can also use enumerate() for this, like:
...
for CourseID, course in enumerate(courses, start = 1):
...
hey I've been using BigQuery and had no problem to save results as csv on google drive. The past days it takes ages and usually it leads to an error. How can I tell why is that?


img is a string and you need to convert it into bytes 🤔
Also it's generally not recommended to store images in a database

You didn't create that table
Yeah the table is created, and yes good point about the id outside the loop
I am using dynamodb
You can use alembic that should come with flask-sqlalchemy or use Base.metadata.create_all
thx
Hi, how can I encrypt the database connection in my python application? I am afraid of stealing the database data through HTTP Debugger.
Depends on the database
it's mysql phpmyadmin
You should check mysql documentation for that
Ok so usually I'm ok at debugging SQLAlchemy queries but here I'm stumped.
Running the exact query written in SQLAlchemy logs works. Any clue what to do in that situation?


Code for reference:
from_hour = sqlalchemy.func.DATE_TRUNC(
"hour", db.models.InOutCount.timestamp_from
).label("hour")
hourly_query = (
sqlalchemy.select(
from_hour,
sqlalchemy.func.SUM(db.models.InOutCount.fw_count).label("sum"),
)
.group_by(from_hour)
)
I've already made the query as simple as possible to debug, at this point I'm not sure what to do
I run the query with:
async with db.connection.async_session() as session:
hourly_data = await session.execute(hourly_query)
Which works for all my other aggregate queries or for running the raw SQL query.
Ok so changing group_by(from_hour) into group_by(sqlalchemy.text("hour")) works. It seems this is a known bug for SQLAlchemy/asyncpg.
hey, I have a BigQuery question: I have a unique customer_id, a label column and a date column. The label for each customer changes, but it can go back to a previous one e.g. customer Jim, label 2->2->3->3->4->2. I want to find for each customer the min and max date they were in each label. If I simply groupby then for a label that repeats a previous one after a change the min date represent the min date of the first occurrence and the max the max date of the last occurrence. Is there a way to distinguish between these? My idea was to get a counter for each customer where their label changes but I don't know how to do that
it sounds like you want to group by contiguous label values, right?
i don't know specifically for bigquery, but i would probably end up solving this in general with a self-join: https://stackoverflow.com/a/1611246/2954547
Stack Overflow
How can I return what would effectively be a "contiguous" GROUP BY in MySQL. In other words a GROUP BY that respects the order of the recordset?
For example, SELECT MIN(col1), col2, COUNT(*) FROM ...
not sure how that scales up to "data warehouse" scale though
thanks I'll have a look
I am working on a project using API and after sending a GET request I stored the data in this JSON file. Before storing I did response.json() but this data is giving error. Can someone tell me what's wrong? I used python request to get the data.
What do you mean "this data is giving error"? What exactly are you doing with the data and what error are you getting?
It depends
for python?
It doesn't really depends on a language but on what kind of data you want to store and what you want to do with it
imo you should not use mongodb unless you have a specific reason to use it. it falls into the category of "if you have to ask, you probably don't need it"
which database is better then
If sqlite3 comes built-in with python why would you need to install it manually? All I can think of is if you need to use a different version.
I just got the “process failed to start: argument file cannot be empty.”error. I fixed it by running this command in bash.
‘’’bash
sudo apt install sqlite3
‘’’
Im not sure why that is needed if sqlite3 is already included with python. I’d just like to understand this as it seems like something I’d come across again.
Any sql database should be fine
I'd prefer postgres
The Python library and the command line utility are kind of two different things... I'm guessing that's the underlying confusion here
hmm...I'm going to ask what is probably a stupid question. I'm trying to run sqlacodegen to auto-generate the classes in an existing oracle DB, but when I do connect to it, I've been manually initiating the oracle client in my python script. Is there a way for me to do that so sqlagodegen can actually connect to the DB?
(either that or is there a way to export the class definitions from sqlalchemy automap to a python file)
Sorry for not being clear, you can see this image. As I plan to parse the JSON object to extract some information, I assumed this might raise an error. I am getting 13 errors!

You need to look at the details. They could be anything, including false positives
I am not getting any particular message, instead this part of json seems to be the reason behind these errors.
Can you mouse over for details? Whatever you're using to validate the JSON might not like the URLs, probably doesn't matter
response = requests.request("GET", url, headers=headers, params=querystring)
file = open("fetched_data.json", 'w')
json.dump(response.json(), file)
These are the 13 errors and code

I need some help. I am making a database with google sheets and for some reason it is not working. I get an error on the last line saying it takes two positional arguments but 3 were given.
import gspread
from oauth2client.service_account import ServiceAccountCredentials
from pprint import pprint
scope = ["https://spreadsheets.google.com/feeds",'https://www.googleapis.com/auth/spreadsheets',"https://www.googleapis.com/auth/drive.file","https://www.googleapis.com/auth/drive"]
creds = ServiceAccountCredentials.from_json_keyfile_name("credentials.json", scope)
client = gspread.authorize(creds)
sheet = client.open("Discord Armed Forces Database").sheet1
data = sheet.get_all_records()
col = sheet.col_values(1)
last_ID = int(col[-1])
last_ID += 1
b = input("What is the exact name of the user?: ")
c = input("What is their rank?: ")
d = input("What is their branch? (put None if none): ")
e = input("What is their division? (put None if none): ")
insertRow = [last_ID, b]
sheet.add_rows(insertRow, 1)
From the data you sent here, it looks like you might have appended some content at the end of the file?
If you format the file and check the last line, you'll see some cut off json data.
From the gspread documentation you can see add_rows only takes in one argument, "rows" - You are passing two
https://docs.gspread.org/en/v5.4.0/api/models/worksheet.html?highlight=add_rows#gspread.worksheet.Worksheet.add_rows
Also, I really don't recommend using google sheets as a database...
Its not going to be a big database, its just like a small community.
So what can I do to fix it?
^
So I put this and I get a type error, last_ID is a int so I turn it into a string and the rest is already a string and now I get a type error, with and without me changing the last_ID into a string
insertRow = [str(last_ID), b, c, d, e]
sheet.add_rows(insertRow)
@proven wagon
As provided in this screenshot -https://discordapp.com/channels/267624335836053506/342318764227821568/1018154041546645576. What should I do to rectify this error?
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Can you delete the file and try again?
Send the error
How can I skip duplicated entries with insert_many using pymongo?
r_list = User.query.where(id > 10).all()
SQLAlchemy,
I am getting an "AttributeError: 'BaseQuery' object has no attribute 'where'" error 😦
how fast is retrieving data from an sqlite database? would performance become an issue if i were retrieving data, say, 3 times a second?
As fast as Filesystem can keep up, 3 times a second, unless it was really really really big and not held in RAM cache, probably not
SQLalchemy to the best of my knowedge has uses filter instead of where. so your code would be
r_list = User.query.filter(User.id > 10).all()
works like a charm. Thanks!
( got confused by this then I guess 😄 https://docs.sqlalchemy.org/en/14/tutorial/data_select.html#the-where-clause )
filter is an alias to where actually
ah
Might have something to do with that they're using a wrapper and not sqla directly
hmm, tried Where with a sample projected I had on hand and it worked fine, honestly I think the issue above was the fact that their where clause was id> 10 rather than User.id > 10.
error is clearly has something to do with base query, but that is also a problem
It's better to use 2.0 style api now
I think that API would be removed in 2.0
The biggest visible change in SQLAlchemy 2.0 is the use of Session.execute() in conjunction with select() to run ORM queries, instead of using Session.query().
Hmm, that makes sense. I'll have to get read up on the changes to SQLA 2.0
I have a table like this having composite keys...i want to update the table having values(id=1,role_id=R4,depth=0,last_stage=false)...
Then the table should update accordingly means the depths of the other role_id should also increase

After update it should look like this

Yup did that, now it's not raising any error. Can you tell me why it was raising error earlier?
I'm working with a database using sqlite3. I'm at the very beginning here, learning as I go. I'm using a jupyter notebook at this point. When I run a select query on a table, the result comes out as what appears to be a list of tuples, if I understand the output correctly? It's in this format:
[('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data')]
To make it easier on me, how could I get the results to print out to the screen in this format:
[('data', 'data', 'data'),
('data', 'data', 'data'),
('data', 'data', 'data'),
('data', 'data', 'data')
I'm guessing I probably have to use a for loop, yes?
OK, so yeah, a for loop works nicely, but now I'm wondering (and this is more of a f-string formatting question I guess) how to get the data columns to line up?
print(f"[{list[0]},\n{list[1]},\n{list[2]},\n{list[3]}]")
@wicked flax The above code should work
that's quite a lot of 'hardcoding' though, with the fixed indexes
In the code, list stands for the name of the list
!e you can use : (fillchar?) direction min_len - for example```py
names = ['bob', 'arthuor the second', 'etrotta']
scores = [20, 1000, 0]
for name, score in zip(names, scores):
print(f'{name:<20} {score:>4}')
@storm mauve :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | bob 20
002 | arthuor the second 1000
003 | etrotta 0
!format
String Formatting Mini-Language
The String Formatting Language in Python is a powerful way to tailor the display of strings and other data structures. This string formatting mini language works for f-strings and .format().
Take a look at some of these examples!
>>> my_num = 2134234523
>>> print(f"{my_num:,}")
2,134,234,523
>>> my_smaller_num = -30.0532234
>>> print(f"{my_smaller_num:=09.2f}")
-00030.05
>>> my_str = "Center me!"
>>> print(f"{my_str:-^20}")
-----Center me!-----
>>> repr_str = "Spam \t Ham"
>>> print(f"{repr_str!r}")
'Spam \t Ham'
Full Specification & Resources
String Formatting Mini Language Specification
pyformat.info
check the String Formatting Mini Language Specification link
Cool
Wow guys, thank you!
I don’t mind the hard coding for now as I’m doing a lot of checking to make sure the queries did what they should have done.
!e How about pprint — Data pretty printer
from pprint import pprint
rows = [('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data')]
pprint(rows)
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | [('data', 'data', 'data'),
002 | ('data', 'data', 'data'),
003 | ('data', 'data', 'data'),
004 | ('data', 'data', 'data')]
How can i get my employees from database into this listbox? when i click example F and click search to show my employee?

dataList = [('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data'), ('data', 'data', 'data')]
print([f"{items},\n" for items in dataList])
I may not be going about this the right way.
I'm running a query against a SQL server, then taking the results of that and modifying the results with some data from a table in Excel.
I understand how to take a dataframe and import that into a table in sqlite3, but what I don't know is how to set the primary key of that table during, or after, the import. How is that done?
you're talking about sql server, excel, data frames (pandas?), and sqlite3 here.... can you explain what you actually want to do? this sounds way over-complicated.
I'm running a production forecast for our pipeline gathering system. To do this, I need to gather information on what meters in the field are active, which have been deactivated, and what pipeline they're attached to.
SQL gives me data on which meters are active. The table in Excel gives me data on which pipeline they are attached to; the table is manually updated by me. I combine those tables and then create a production forecast based on [insert a very long explanation here].
All this stuff ends up in Excel, updated once per month.
I have something created already that depends way too much on Excel formulas (index/match) and is frustratingly complicated to maintain. I realized that doing this using a database would be much, much easier, and easier to maintain.
sqlite3 just creates a local database file as I cannot be creating/updating/manipulating the data in the SQL server. So I pull what I need from there and I can do whatever I want with it locally.
My limited understanding is that when I run the SQL query it creates a pandas dataframe. My limited undersanding of sqlite and databases in general is that if you have a couple tables, you need a primary key in each table if you want to run any queries.
Sorry for the long post; just trying to be accurate here. Hopefully the information helps.
What's the problem with PK?
I don’t know how to create one when I convert the data frame to a table in the SQLite db.
Doesn't your exported data has some kind of id?
Or any other identifier
The results from the SQL query have at least two columns which are unique. However, only one of them should be used as the PK in the table created in SQLite. To my knowledge, simply importing a data frame into SQLite doesn’t automatically create a PK. does it? If so, and it’s the index of the df, that is NOT what I want.
So how do I find out if one of the fields in a table in SQLite has been assigned as a primary key?
I want the primary key to be the meter number, aka “meterID”. How do I make that the primary key?
I didn't work with pandas and I'm not sure if composite primary keys are supported in sqlite 🤔 Maybe you could use a different db?
SQLite does support composite primary keys and index. But I read it like that each column by it's own is unique, not in combination.
hi . i have my pgadmin and postgres run on docker and works fine and i could create database from both side . but i can't connect to it with python script .
i've changed my host in python script and set it to localhost and tried to make an connection to one of my database in local host and it worked well . but i don't know why i can't connect to my db in docker
Not sure I follow, is it that you can connect to your DB from inside but not outside your container? If so, the most obvious question is whether you opened the port on your container
You may get better advice if you share actual details of your configuration. You might also check the logs
I never mentioned composite keys. One pk, that I define. How is that done. Is this a really unusual thing? To take a table of values that’s in a variable and make that a table in a database??
I’ll try to rephrase everything…
I have a table of values in a variable. It has column header names. How do I define a primary key when creating a SQLite table using that variable?
It's not clear to me what you're trying to do without seeing any code or data. Is your intention to run a CREATE TABLE statement via Python? What does it look like so far?
def df_to_db_table(table: str, df: pd.DataFrame, cn: sqlite3.Connection):
"""Creates a table in a sqlite db from a named dataframe
Parameters:
table (str): The name of the database table to be created
df (DataFrame): The data from which to create the table
cn (Connection): The connection string for the database
Returns:
True or False if the conversion was successful
"""
try:
with cn:
df.to_sql(table, cn, if_exists="replace")
return True
except sqlite3.Error as e:
print(e)
return False
The dataframe can be anything. What I'm not sure of is if sqlite automatically creates a primary key based on the index of the dataframe. How does one check a "table structure" in sqlite? How can I determine if a primary key exists in a table? How can I change that primary key to some other field in the table?
OK, I did find this query which is telling me that there's no pimary key:
SELECT l.name FROM pragma_table_info("Table_Name") as l WHERE l.pk = 1;
It returns [] on the table created from a dataframe.
My limited understanding is that when I run the SQL query it creates a pandas dataframe.
this is only true if you are using pandas to perform the sql queries. the built-insqlite3module only returns lists of tuples, no data frames.
My limited undersanding of sqlite and databases in general is that if you have a couple tables, you need a primary key in each table if you want to run any queries.
not true in general, but generally databases should be designed so that each row can be "uniquely identified" somehow, i.e. with one or more primary key columns
sqlite3 just creates a local database file as I cannot be creating/updating/manipulating the data in the SQL server. So I pull what I need from there and I can do whatever I want with it locally.
what's your end goal? you want to replace the excel sheet with a piece of software, or you want to do some of the data manipulation up-front in a python script instead of having a big pile of complicated formulas?
ok, it does look like you are using pandas. that's a 3rd party library that isn't always used in conjunction with databases. so you need to specify.
sqlite in particular is a bit weird in that rows implicitly all have a "row number", and if you create a column of type integer autoincrement primary key it becomes an alias for the internal row number. but you can also create tables that have the internal row number disabled.
i would avoid fussing too much about it, and just make tables that make sense for your application. that usually means uniquely-identifiable rows, with the unique identifier also being the primary key
that said, what's the purpose of using sqlite at all? it sounds like maybe you just need to write a python script that loads data from sql server and then emits the desired excel books. setting up your own ad-hoc mirror/cache of the sql server database in sqlite seems like way more complexity and work than is needed
it sounds like you are really mixed up about what these various technologies do and how they do and don't interact
i suggest starting small: write a python script that simply pulls data from sql server, puts it into a pandas dataframe, and then emits an excel sheet. don't do any data manipulation. take the "walk, crawl, run" approach. especially because it sounds like you have a lot to learn about these topics.
I've done that many, many times already. 🙂 What's next?
One of the columns is called "MeterID". How do I take the table in Excel, create a table in sqlite3 from that table, and define which column (I always called them 'fields' when referring to tables?) is the primary key? I don't want to use the 'index'.
this is a deep XY question. forget the specifics of using this or that tool. what are you actually trying to do?
OK, how about this. I have the dataframe, how do I define the primary key?
I am trying to create a table from a pandas dataframe with a defined primary key.
def df_to_db_table(table: str, df: pd.DataFrame, cn: sqlite3.Connection):
"""Creates a table in a sqlite db from a named dataframe
Parameters:
table (str): The name of the database table to be created
df (DataFrame): The data from which to create the table
cn (Connection): The connection string for the database
Returns:
True or False if the conversion was successful
"""
try:
with cn:
df.to_sql(table, cn, if_exists="replace")
return True
except sqlite3.Error as e:
print(e)
return False
df.to_sql is a pandas routine, I understand.
if you really are just asking how to set the primary key when using DataFrame.to_sql.... i actually don't know if you can do that. try setting your primary key column as the index of the dataframe. if that still doesn't work try creating the table in advance using create table, and set if_exists="append" instead.
Great. What's the syntax? I searched the internet and I haven't been able to find the syntax.
the syntax for what?
the syntax to do this "hey sqlite, please make a table with this data, and use this field as the primary key"
the sqlite CREATE TABLE syntax is described in the sqlite docs https://www.sqlite.org/lang_createtable.html
getting off the train, going to go radio dead for a few minutes here
and the sqlite3 python api (not pandas) is described here https://docs.python.org/3/library/sqlite3.html
you would use the sqlite3 module to create the table, and then use pandas to write to the table you created
@wicked flax ping so you see this after you get off the train, in case the channel moves
PING! Reading the link... Being an "advanced beginner" I still have trouble interpreting the python docs. 😄
:incoming_envelope: :ok_hand: applied mute to @oblique badge until <t:1662994177:f> (10 minutes) (reason: duplicates rule: sent 4 duplicated messages in 10s).
The <@&831776746206265384> have been alerted for review.
i think the sqlite3 module is a good place to get more acquainted with the python docs. everything you need to know is in there or in pep 249. but the writing style in both docs is a bit "conversational", which is not atypical for the python docs, especially the older ones. imo, learning to wade through the prose while extracting the relevant pieces of information will be time well spent.
!d sqlite3
Source code: Lib/sqlite3/
SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows accessing the database using a nonstandard variant of the SQL query language. Some applications can use SQLite for internal data storage. It’s also possible to prototype an application using SQLite and then port the code to a larger database such as PostgreSQL or Oracle.
The sqlite3 module was written by Gerhard Häring. It provides an SQL interface compliant with the DB-API 2.0 specification described by PEP 249, and requires SQLite 3.7.15 or newer.
This document includes four main sections:
!pep 249
**PEP 249 - Python Database API Specification v2.0**
Status
Final
Created
29-Mar-2001
Type
Informational
@harsh pulsar So after reading those docs and then doing some additional searching, it looks like there's really no way to specify a primary key using the pandas method df.to_sql. Not easily anyway. The other method is apparently to rename the table, create a new table with the same fields, specifying which field should be the primary key, then copying all the records over to that new table and then dropping the renamed old table. Reference link for the description/method: https://www.sqlitetutorial.net/sqlite-primary-key/

This tutorial shows you how to use SQLite PRIMARY KEY constraint to define the primary key for a table.
And this is supported by questions/answers at stackoverflow.
So what I'll have to do is:
- Get the column names from the dataframe
- Create the db table
- Create another db table using the list of column names, specifying which should be the primary key
- Copy all the records from the first table into the second table
I'm sure there's a way to insert all records from a dataframe into an existing sqlite database table, so when I figure that out, if it's not a pain, I can skip the 2nd and 4th steps above.
@harsh pulsar ok, found this, this should hopefully do it:
df = pd.DataFrame({'MyID': [1, 2, 3], 'Data': [3, 2, 6]})
with sqlite3.connect(db) as con:
df.to_sql('df', con=con, dtype={'MyID': 'INTEGER PRIMARY KEY AUTOINCREMENT'})
With the exception that my primary key is a string....
i think my solution is less ugly. create table using plain sql and just write your data to that table using pandas.
you also get the bonus result of having more precise control over the table schema and column names.
Is this a good spot to discuss some sort of data analysis/pattern recognition?
So making sure I understand your suggestion fully:
- Get the column names from the dataframe into a list
- Execute a
CREATE TABLEstatement using that list, specifying the primary key which would require manipulating the list in some way to insert thePRIMARY KEYstatement into the list at the appropriate location. - Insert the dataframe into the table that was just created
Do I understand that correctly?
My solution is like, one line. I don't see how yours is simpler? I apologize for being so obtuse.
ignore my previous assertion, this is the best/correct way to do it
i missed your second message!
hey guys need some help, I'm on bigquery doing something like this:
SELECT username,
CASE WHEN category in ('abc', 'asd2', 'sdf') then 'b1'
WHEN category in ('asdf', 'gfdg' , 'gfdgd') then 'b2'
else 'b3' END as category_new,
label,
min(col1) as min_col1,
max(col1) as max_col1,
min(col2) as min_col2,
max(col2) as max_col2
FROM table
WHERE date > 'xxx'
GROUP BY username, category_new
but I need to use
DENSE_RANK OVER (PARTITION username, category_new ORDER BY date) as rank
and group by username, category_new, rank
there is some conflict with the category_new variable and how I cannot groupby with rank. I tried putting the category_new case in from but I can't get it to work in the end. Any tips how to structure it correctly?
can you be a little more specific about the "some conflict"? it sounds like maybe you need a nested query
also did you forget the () after dense_rank? or does bigquery not require the ()?
i did forget, i just wrote that now so it's not exactly what I have
SELECT
*,
dense_rank() OVER (
PARTITION BY t.username, t.category_new
ORDER BY t.the_date
) AS rank
FROM (
SELECT ... FROM ... WHERE ... GROUP BY ...
) AS t
if you find the above annoying... welcome to sql
It's also missing the label column in the group by.
yes it's just an example - not very accurate
are you getting an error message or something?
I will try yours, but I think I tried something similar
You can't use a window function for grouping, you'll need a nested select like salt wrote, but the other way around.
initially i was getting 'you can't have analytical bla bla in the group by'
oh yeah that's probably what berndulas is saying. create the columns you need on the inner query, then do the group by on the outer query
does bigquery support cte's? might be a lot easier to do it that way
yes I tried something like that but didn't manage to pull it off
Ah ok, cool! I really appreciate your patience and all the time you took to give me those resources and so forth. Thank you!
i think so
select
*, dense_rank() over (...)
from (
select *
from (
select
*,
case
when category like 'a%' then 'A'
else 'B'
end as category_new
from foobar as fb
where fb.thedate > '123'
) as t1
group by username, category_new
) as t2
lol
as i said... welcome to sql
with fb as (
select
*, case
when category like 'a%' then 'A'
else 'B'
end as category_new
from foobar as fb
where thedate > '123'
)
, t1 as (
select username, category_new, min(...) as m1
from fb
group by 1, 2
)
select
*, dense_rank() over ( ... )
from t1
there's the cte version
I'm quite a noob but I manage so far with googling - though i have no interest
i thought it's gonna need something like many selects but thought that must not be the best way
will try now
actually I'm a bit confused as I need to groupby the output of the dense_rank()
this doesn't do that, does it?
no. i suggest maybe spending some time with sql fundamentals
hmm ok thanks will try a bit more
import sqlite3
class database():
def __init__(self, con):
self = self
self.con = con
db = database(sqlite3.connect("database.db"))
is this the right way doing a global db connection?
you don't need the database class at all. most people will just use the connection object directly
yeha, but how could I maintain a connection permanently?
in a single-threaded application, db = sqlite3.connect('data.db') is fine
it's often good software design to have a separate function that takes care of "accessing/loading resources" upon app initialization, but for simple stuff it's not important
yes!
sqlite3 lets you use execute directly on the connection object, which returns a cursor, so you usually don't have to explicitly create cursors with .cursor()
alright, thanks!
print(x)
delete="DELETE FROM Stocks WHERE ticker='%s'"
cur.execute(delete,x)
db.commit()
error: mysql.connector.errors.InternalError: Unread result found ```i need to delete rows in my database, without having to type in actual value for a row to be deleted.For example delete all the rows that has a certain value (coming from a list i created) how should i do it?
You need to SELECT in parenthesis I think... https://stackoverflow.com/questions/4562787/how-to-delete-from-select-in-mysql
Stack Overflow
This code doesn't work for MySQL 5.0, how to re-write it to make it work
DELETE FROM posts where id=(SELECT id FROM posts GROUP BY id HAVING ( COUNT(id) > 1 ))
I want to delete columns that d...
Is there a downside to creating a unique index on a database that is the entire set of columns?
My setup is that I have a table with key, type, and content columns. There can be multiple uses of type for unique values in content and duplicate content between unique key values.
Not sure if a CREATE UNIQUE INDEX contentIdx ON table(key, type, content) is what I want or if multiple indices would be better. 
i dont have id in that table
So select with what you do have, same idea
this should work but you don't need the '' around the interpolation place holder. ticker=%s not ticker='%s'. The library will do the formatting for you based on the value in x.
didnt work, however, when print(x) , value shows up as ('ACRO',) , shouldnt it show up as 'ACRO'
No, x needs to be a sequence so ('ACRO', ) is a tuple which is good.
The library will pull the contents of x and use each, in order, where you have a %s.
So what do you mean "it didn't work"? Can you expand on that a little?
mysql.connector.errors.InternalError: Unread result found
def commands():
cur.execute('SELECT ticker FROM Stocks')
for x in cur:
print(x)
delete="DELETE FROM Stocks WHERE ticker=%s"
cur.execute(delete,x)
db.commit()```That's odd... what uses this cursor prior to this? I notice you aren't making a fresh cursor for the delete.
refer to code again
it isnt even deleting one item. if i hard code the value in %s it succesfully deletes it but wont do it through looping
so it has something to do with the %s value
Oh, I see what's going on. You're pulling from the cursor results and trying to delete using the same cursor. Doesn't quite work that way. You should do a fetchall() from your select query and loop through that result, emptying the cursor.
That or you could use two cursors I suppose?
The error basically means "Cursor is in use, can't do anything else right now".
i havent done this before so its hard to undertand what you just, could you copy and edit my code ?
Rewriting your code for you isn't going to help you a ton if the reason why it is breaking isn't clear yet.
A cursor object is how one interacts with a database. On the first line of you function you use this cursor to get a query from the database (the SELECT statement). The cursor runs the query and then waits for you to tell it what to do next.
You then use the cursor in a for x in cur: statement which, I'm guessing, is just like a cur.fetchone() but in a loop. This is fine but you've started pulling that query but haven't pulled all of it. Let's say it returned 2 results, you've only read 1.
This leaves that cursor in a spot where it can't run the DELETE because it thinks you are interesting in the results it has from the SELECT but haven't finished reading them. It throws an error: Unread result found
It is saying "Hey! If I do this DELETE I'll forgot all the stuff that you haven't fetched already and that sounds bad".
cur.execute('SELECT ticker FROM Stocks')
list_data=[]
for x in cur:
print(x)
list_data.append(x)
list_data=tuple(list_data)
print(list_data)
delete='DELETE FROM Stocks WHERE ticker=%s'
cur.executemany(delete,list_data)
db.commit()```this worked
Cool!
list_data=[]
for x in cur:
print(x)
list_data.append(x)
This part here? You read all of the cursor content before running another query. see?
ohhh, yeah i get it
roles = await self.bot.db.fetch(
"SELECT role_id FROM autorole WHERE guild_id = $1",
ctx.guild.id
)
content = discord.Embed(color=0x303135)
rows = []
for record in roles:
rows.append(f"<@&{role_id}> [`{role_id}`]")```
Returns "SELECT 1" (yes i'm still struggling with this"If it's a constraint you want to enforce - yep, not sure if you need and index here
Another option might be using these columns as primary key but that's harder to create FKs for
I think I'll roll with the single unique index.
CREATE UNIQUE INDEX IF NOT EXISTS match_key ON match(key, match_name, match_value);
Seems to fit the need and if I hit issues with it in the future that will be fun for future me.
Hey guys what would be the best database to use to store transaction data?
rows = []
for record in roles:
rows.append(f"<@&{role_id}> [`{role_id}`]")
Where does the role_id come from here? Shouldn't that be:
rows = []
for record in roles:
rows.append(f"<@&{record['role_id']}> [`{record['role_id']}`]")
# or with comprehension
rows = [f"<@&{record['role_id']}> [`{record['role_id']}`]" for record in roles]
So i want to store stock prices everyday. I would like to calculate prices changes for each stock and for example this is how my queries would look like - provide a list of days and stocks when any stock was up over say 10% percent in past. How would you suggest i design/store the data? This is my first official fun SQL project i am working on
please dont question a question unless i didnt make my question above clear enough
Just store the data as it is - datetime it was fetched, stock, stock price and some additional info if you need it
You can run aggregate queries later on that
PostgreSQL does support the RETURNING statement for INSERT, so you can do like:
last_id = await conn.fetchval("INSERT INTO tablename(col1, col2) VALUES('what', 'ever') RETURNING id")
where id is the column name of the serial.
So i want to write a relational database with sqlite, my first practice project, the goal is to monitor grocery prices. I'm designing the tables now, one will be unique for the store, another will be for items. I'm stumbling over how to track online price vs in-store price, 2 tables for items?
a single price table with store key and item key, with 2 columns for price perhaps
you are having multiple stores, and multiple items?
and same items can be sold in multiple stores while having different prices?
correct
if yes, then better having three tables
store, items, and prices (which contains foreign key to store, foreign key to item, price online, price in store, and having combined constraint for unique pair FK to store and item)
that was my final thought, thanks
can you elaborate on the constraint?
is there a simple process?
uh, clarify your database type/engine?
anyway, in general constraint is thing like...
if you have constraint unique Primary Key ID
it would give error, if you try creating record with same ID number that already exists in table
sqlite automatically numbers entries
combined constraint on two fields will prevent creating object with there is already object having those two IDs in pair
I understand
this is just an example, not important
I'll have to figure out how to impliment it
sqlite has limited constraints support, but looks like having actually https://www.tutorialspoint.com/sqlite/sqlite_constraints.htm
SQLite - Constraints, Constraints are the rules enforced on a data columns on table. These are used to limit the type of data that can go into a table. This ensures the accuracy and
a key with multiple values
i am not sure if combined constraints are supported in sqlite
I imagine it can be done programmatically
anyway, constraints are to ensure better data integrity of your SQL database, and really good tone to have it
no no, that is wrong way to do that. you are supposed to have it at SQL engine level
it ensures fastest.... run check of those conditions without drop of performance
I understand, i don't believe sqlite supports it though
https://stackoverflow.com/questions/2701877/sqlite-table-constraint-unique-on-multiple-columns
CREATE TABLE a (
i INT,
j INT,
UNIQUE(i, j) ON CONFLICT REPLACE
);
good says it potentially does
https://www.sqlitetutorial.net/sqlite-unique-constraint/
CREATE TABLE table_name(
...,
UNIQUE(column_name1,column_name2,...)
);
found in more specializaed docs for sqlite

In this tutorial, you will learn how to use the SQLite UNIQUE constraint to ensure all values in a column or a group of columns are unique
very cool, ty!
u a welcome. Also protip: use Data Entity Diagram objects in tools like https://app.diagrams.net/ to visualize table design, makes things easier to grasp 🙂

Traceback (most recent call last):
File "C:\Users\Person1\Desktop\python\website\db_funcs.py", line 138, in <module>
add_ip('', True)
File "C:\Users\Person1\Desktop\python\website\db_funcs.py", line 69, in add_ip
cursor.execute('INSERT INTO ips VALUES (?, ?)', (ip, int(blacklisted)))
sqlite3.OperationalError: database is locked``` what does this mean?did you .close?
yes
that issue is solved now
i have another
when my app is running, rows are being added to the database. everything is working fine
🙂 sqlite3 is not allowing multiple inserts sessions at the same time by default. It allows only multiple readings at the same time
Enable WAL support for allowing multiple inserts https://sqlite.org/wal.html . or change your db to postgresql
sqlite3 by default makes block to write(and possibly to read as well?) to records undergoing insert already
when i close it, the database is resetted and everything is empty
yes
sqlite3 does support compound primary keys by writing it as a table constraint py CREATE TABLE user_guild_settings ( user_id INTEGER, guild_id INTEGER, -- some columns... PRIMARY KEY (user_id, guild_id) ); official documentation: https://sqlite.org/lang_createtable.html
although as per section 3.6 in the same page, primary keys and unique constraints are implemented with unique indexes aside from a couple exceptions so UNIQUE (c1, c2, ...) is basically equivalent syntax
nvm i found the issue
Hello #databases members.
I'm trying to understand SERIALIZABLE transaction.
Is it correct to say that a serializable transaction does NOT fail if its result matches one of the many possible results of all the concurrent transactions run in order ?
Or is it instead correct to say that a serializable transaction fails if all the possible results of the concurrent transactions run in order are NOT the same ?
Which library should I use, if any of python's for this use case:
-I will make an in house app with python. (not sure which framework yet)
-It needs to access a database of our inventory of parts. There might only be a few dozen rows.
-We currently use excel... So anything is an improvement
I see a lot on sqlalchemy
Oh and bonus points for using frameworks that employers of the future might love
Hi, I have a question, do you think is a valid way to do something like this:
@router.get("/test-slorm")
def test_slorm_select(self):
data = slorm.select("test_data", "*")
return {"data": data}
...
def select(self, table_name: TableName = "", condition: Condition = "") -> Sequence[List]:
"""
Args:
table_name("str"): Name of the table.
condition: A simple sign(str) or statements, shows what data you need, it works like a filter, if the filter behavior appears in th tables, then you going to get them.
"""
try:
with self._conn_singleton() as conn:
with conn.cursor() as cur:
cur.execute("""SELECT {0} FROM {1}""".format(condition, table_name))
selected_items = cur.fetchall()
return selected_items
except:
raise SelectError(condition, table_name)
Thanks
i am getting issue with heroku postgreSQL idk why when i run my website on local server i am able to get data from db and able to login and every process easily but on host it gives an error with same website
i am able to use website but db related things are not loading
can anyone help me in this?
what kind of app? gui app that runs on people's desktops? a highly interactive web app? a web api? a static webpage that updates nightly?
and serious question: what's wrong with excel? it doesn't make sense to store data there (excel is not a database!), but there's absolutely nothing wrong with analysts doing a sql query to generate a csv and loading that into excel for further processing and report generation
Maybe this is better suited for one of the help channels, but it's database/sqlalchemy related, Is it terrible practice to have a 1:1 relationship where both items have a column referencing the other? In my current use case I have one computer to one modem relationship and the way every sqlalchemy documentation seems to do it doesn't have a column referencing to the modem, only modem to computer.
You do not want foreign keys on both tables pointing to each other. It's unnecessary, inefficient, and then what if an update fails and the two become inconsistent?
I had a feeling there was a reason, but I don’t do much with database design. Is there a way to reference computer.modem or does the orm only know the one direction?
I mean is it not a stupid thing, correct and clean to use it?
Yes, for SQL Alchemy anyway, it's spelled out here: https://docs.sqlalchemy.org/en/14/orm/basic_relationships.html#one-to-one
Up to me I suppose, but the minimal viable product is an app that lets a user select a SKU, access the current inventory database, and relay a result on how to make the SKU to the person on the factory floor.
Coworker did want a web-app, but that seems like a level of complexity not needed, at least for a prototype, not to mention security concerns.
Oh no, the inventory database is stored in excel. Tho I don't expect it to be too hard to readtable into a database.
Well, if I am to stick with python, it seems like sqlAlchemy is what I want. Anyway, I'm not quite to the point of implementing a database in my algo/app, but I wanted to get a headstart
Part of the struggle with python is that there are 100 different libraries/frameworks that do basically the same thing. I just want to one that is most generally-useful and all else being equal favored by future employers lol
Yeah, SQL Alchemy is generally worth learning. If your project is really simple though it might be easier to just use raw SQL (which library depends on what db)
if after one minute not clicked button upload time in the database raspberry pi. Does someone know how to do this?
There's around 5 (I guess?) major python orms, but sqlalchemy is one of the best
I do really want to get my head around the full capabilities of sqlalchemy sometime. I know the very basics (setting up a model, creating tables, inserting/updating/selecting using those models) but I know that there is a lot more.
(incidentally, is sqlmodel anygood? I heard its combined sqlalchemy and pydantic)
Imo you generally don't need that

GitHub
Config files for my GitHub profile. Contribute to Snooz4pm/-PASSWORD-GENERATOR-SECURITY development by creating an account on GitHub.
Enjoy 😉
the problem is that you're not focused on a particular task, so you see 100s of libraries all intended for various specific tasks and it just looks like a huge stew of options. that's not how you're supposed to go about it! i wouldn't even start by worrying about an ORM here like sqlalchemy. all you need to connect python to a database is the relevant database "connector" library, and imo that's where you should start. anything else is introducing more complexity than you need at your level. you might also want to use Pandas (or even OpenPyxl, which Pandas uses internally) to read the XLSX files, but that's it.
and if you're using the Sqlite database (which you might want to do for a prototype), you don't even need to install a database connector. sqlite databases are literally just files, and all you need to work with them is a library that knows how to read and edit those files. and python actually comes with one by default
!d sqlite3
Source code: Lib/sqlite3/
SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows accessing the database using a nonstandard variant of the SQL query language. Some applications can use SQLite for internal data storage. It’s also possible to prototype an application using SQLite and then port the code to a larger database such as PostgreSQL or Oracle.
The sqlite3 module was written by Gerhard Häring. It provides an SQL interface compliant with the DB-API 2.0 specification described by PEP 249, and requires SQLite 3.7.15 or newer.
This document includes four main sections:
and if you export the xlsx files to csv first, you can literally do it all with the python standard library
!d csv
Source code: Lib/csv.py
The so-called CSV (Comma Separated Values) format is the most common import and export format for spreadsheets and databases. CSV format was used for many years prior to attempts to describe the format in a standardized way in RFC 4180. The lack of a well-defined standard means that subtle differences often exist in the data produced and consumed by different applications. These differences can make it annoying to process CSV files from multiple sources. Still, while the delimiters and quoting characters vary, the overall format is similar enough that it is possible to write a single module which can efficiently manipulate such data, hiding the details of reading and writing the data from the programmer.
pandas will have you a lot of annoyance, but it's also a really big library with its own learning curve
so i suggest not looking at any "frameworks" until you actually know what the hell you want
Hello, guys 👋🏻
I really need your help
after I click on the button, the fields that are filled in are not added to the database. Probably there is an error in the add_record function, but I can't figure out which one, please help
👇🏻👇🏻👇🏻
https://paste.pythondiscord.com/begoreyeyi
PS Tkinter App
The SQL looks good, but does 'Naim': naim_vid_product.get(0, END), (line 31) work? Don't you get a traceback?
I also hope the customers table has 24 columns.
if I leave maim_vim_product.get() empty, I get the error Tkinter TypeError: get() missing 1 required positional argument: 'index1'
Hey guys! I am using Peewee and I've got a really weird issue. I am using a 'key' and 'value' table for my settings and stuff like that. However, this function, replaces all values of that Settings table.
Settings.update(value=name).where("key" == "plex_name").execute() Settings.update(value=plex_url).where("key" == "plex_url").execute() Settings.update(value=plex_token).where("key" == "plex_token").execute() Settings.update(value=libraries).where("key" == "plex_libraries").execute() Settings.update(value=overseerr_url).where("key" == "overseerr_url").execute()
This causes everything in the Table Settings to be replaced with the value, hence resulting in "overseerr_url" replacing everything (as it is the last one executed)
I cannot for the life of me undestand why this is happening
I meant the database table, not the tkinter one. And I don't know tkinter, the ...get(0, END) just seems different than all the other ones, it was just a guess.
I get you, friend, it's just a feature of tkinter. The problem is that the request is correct but the function does not work it is very strange
How else do you think i can write the same query?
If you don't get an sqlite error it should work. You can't change much with. Only use ? as placeholder and use a tuple instead of a dictionary but that shouldn't matter.
Could the problem be that I'm using placeholde in entry boxesr, what do you think?
No, that shouldn't be a problem.
Thank you very much for trying to help me
How do I get the correct id from flask-sqlalchemy when autoincrement id from def init() in flask-sqlalchemy?
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
hashed_password = db.Column(db.String(128), nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
confirmation_email = db.Column(db.Boolean, default=False, nullable=False)
reset_email_password = db.Column(db.Boolean, default=False, nullable=False)
def __init__ (self , id: int, username: str, email: str, plaintext_password: str, confirmation_email=False, reset_email_password=False):
self.id = id
self.username = username
self.email = email
# Hashing the password ( bytes, salt)
plaintext_password = 'pojkp[kjpj[pj'
self.hashed_password = bcrypt.hashpw(plaintext_password.encode('utf-8'), bcrypt.gensalt())
self.confirmation_email = confirmation_email
self.reset_email_password = reset_email_password
Start by quering the database with with id = 1 then get the all the ids in a variable called user. Then using ````number_of_ids = len(user.id), Then use this code new_user_id =number_of_ids+1 . Will this work? Also can I just go self.id = idindef_init__()```
Also since Icould have 0 users at this point, I will put this in a try.
This is for pytesting and I will be deleting the information eventually. I posted this online and someone mentioned that" What if 2 records are created at the same time?" When would 2 records be created at the same time?
what is the use of a database?
Storing and organizing data
Hi, does anyone know how to get the latency of my pymongo connection?
Is there a way to connect to and download data from a ReportServer using a .atomsvc file?
is it possible to execute sql queries from .sql file using asyncpg
I mean, just read it and execute it?

GitHub
Would it be possible to add sql file support into asyncpg? It could work something like this: with open('setup.sql', 'r') as queries: await conn.execute(queries) Or ...
There's no reason to include file support into a db driver imo
You can use aiofiles, cache, etc to avoid synchronous operations
so if i just read and execute it should work right?
Yes, why not?
Also why really use files?
just don't want to clutter my py files
i didn't try i was thinking if it was possible in school rn 😔
I'd say raw sql is kind of limited and it's easier to use a query builder like sqlalchemy, at least for me
yeah tbh pandas seemed fine enough.
So now I'm asking stuff I can learn with a few hours of reading, but the terms "database connector" and "database" might have me confused.
A database should have backups and be secure, yes? XLSX is sorta not cutting it.
I will avoid sqlalchemy if it overcomplicates things.
Pandas almost seems good enough for what I want, and I am using it to simulate a fake database atm.
I'll look at OpenPyxl, which seems to be just a file reader.
So...
- Use sqlite database
- sqlite3 to read and edit files
- pandas to manipulate files when read?
Idk, I'll keep looking into this
but like, having production files and inventory on an excel file seems bad
but thanks I think I'll look into sqlite3 python library and sqlite database
oh but for a remote sort of database, "database server" I could then upgrade to MySQL
This would put the user inside the users dictionary of the guild:
guild_key = str(guild.id)
data2[guild_key]['users'] = {}
for user in Sleeper.get_all_members():
user_key = str(user.id)
if user_key not in data2[guild_key]['users']:
data2[guild_key]['users'][user_key] = {'open_tickets': 0}
thank you veyr much
Does anyone know if pymongo has a latency variable I could use to know the latency between my app's connection to the database?
Hello
I have a doubt related to sql




I found the answer for it on chegg but it is wrong

where can I learn json of python nicly
not really related to databases, but this link is a good start:
https://realpython.com/python-json/
1-3 seem totally correct. a "database connector" is a stupid overcomplicated term for "a library that talks to your database and transfers data back and forth". usually databases (other than sqlite) are servers that listen for and respond to requests over a network.
openpyxl is a lower-level tool. pandas uses it internally to read xlsx files
What's a really elegant way that I can remove duplicates from a relational DB table based on a semantic similarity of a given column?
Stack Overflow
Table A has records with duplicate entities with subtle string variations. There is no unique key that would uniquely identify an entity. Field "ID" identifies record inside the table, but not an e...
Ideally, I'd actually want to use a BERT Transformer for maximal accuracy
!d fuzzywuzzy
Nah.
No documentation found for the requested symbol.
!pypi fuzzywuzzy

Fuzzy string matching in python
any1 using mysql here
i have a huge number of rows i want to inserrt into it from a csv file
what's the fastest way to do it
one column in csv file is unix time stamp so also have to convert it before inserting it into db
Honestly if your doing bulk uploads, load the data into a pandas dataframe and then df.to_sql that data
How does that work.
How do i connect to the database ?
For now i am using mysql.connector



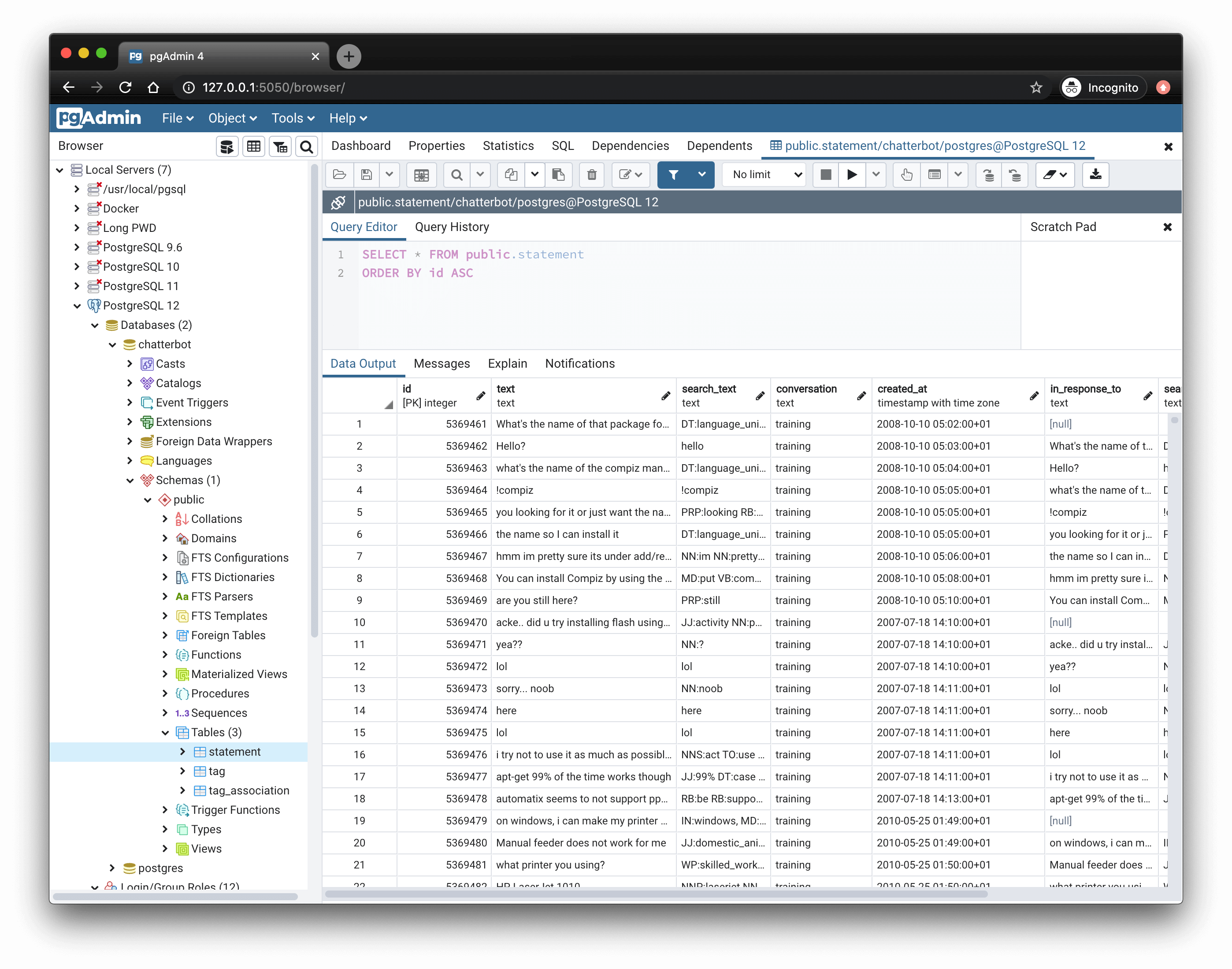{kind=link}
what is the issue? I can't able to connect my DB

hello 👋
i have a database like this:
Users
id, username, ...
Permissions
id, name
Roles
id, name
RolePermissions
id, role(fk), permission(fk), level
UserRoles
id, user(fk), role(fk)
the level is one of DENY, IGNORE, ALLOW.
im now thinking about how i would calculate the permissions, but ive come to a halt.
I dont know how i would add ordering to my roles, such that a higher ordered role can override a different roles permission.
so i basically want to iterate over all roles from the bottom, based on a hierarchy.
how is such an ordering implemented usually?
i dont seem to find information of how to structure my database anywhere
please ping on reply
I'm not sure I follow your exact intent but if you want to be able to iterate through roles in a specific sequence why not just add a sequence field to your roles table, and put appropriate integers there?
i want to append the already existing values from my table how will i do that
like for example i have bio written.. i just have to add iology to it
what will i do
So a filed called hierarchie where a higher integer indicates a higher position?
But then when I insert a role somewhere, i need to update all of the sequence indecies below or above the inserted one
What is a standard way of handling this.
Should I keep holes in the sequence so there can be values inserted
Good question, I don't really know but here are some ideas: https://stackoverflow.com/questions/4115053/how-to-keep-ordering-of-records-in-a-database-table
Stack Overflow
i am creating a database table that is going to store menu links that will ultimately show up on a web page.
My issue is that i want to control the order of the menu items. I could have a field c...
You can simply replace the old value with the new one
thats not gonna help in my case
So in a lot of NoSQL DBs this is quite easy because of their LSM nature.
But in SQL can you not just do this at query time with Order By?
a linked list seems promising
thank you very much
Not sure if this is the correct channel but is it possible to convert json as a python list? The project I'm working on is made to read lists and not dicts, and I need a way to save inputs to file so I thought I'd use json.
Question about MongoDB.
i have about ten document that look like this:
name: { first : 'GFDGDF', last: 'ASDADS'},
bdate: ISODate("1966-12-03T05:00:00.000Z"),
phones:['057153215'],
courses: [
{ccode: '334',cname:'C#',grade:55},
{ccode: '554',cname:'JS',grade:71},
{ccode: '224',cname:'JAVA',grade:65}
]
},
My teacher want me to
"Show all the students when each student is shown the ID card, a new field named full name will appear in it
The first name is concatenated with the last name with a space between them, a new field named year will contain the year of birth
of the student, a new field called age that will contain the student's age (for the purpose of calculating the age, please look at
subtract, $NOW,)$$the phone number field with one phone number, and a new field called 'courses' # whose value will be the number of courses the student has"
Now, since im really begginer i`m really not sure how to do so. how do i create a new field? with a new value?
all i understand here is that i have to use the find method
JSON supports lists, so I'm not sure I follow the question. You should be able to dump a Python list to JSON and read it back without doing anything special
I'm not trying to dump a Python list into JSON, I'm trying to read my json file as a list instead of a dict. If that makes more sense.
If your json file is a dict, then you will read it as a dict. But you can access dict.values() and/or dict.keys() as lists
Beyond that, not sure what you're trying to do, or what it would mean to access a dict as a list
The way I have my project set up is that I read keys: values from a list, and I need a way to add keys: values from user input. Which is why I've tried using json, but I think I should be able to just save it to a normal text file and format that as a list. Or reworking it so I can read keys: values from a dict 🤔
This is off topic to this channel but if you want to grab a help channel and share a link to your code you can ping me there and I'll see if I can understand what you mean
Hi is it possible to write/update value on a sql database ?
Because i tried it with a local servor (Mamp) and a mysql library for python, i simulate an update of a value but it shows me only in python.
When i go to my phpmyadmin it shows the default value
You'll probably have to show your code for anyone to have any idea why it's not working
sounds like your not committing your change
of course
how ?
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
if you have a cursor its usually something like cursor.commit()
>>> cursor.execute("INSERT INTO employees (first_name) VALUES (%s)", ('Jane'))
>>> cnx.commit()
I know it😂
I understand more better, so execute will change but only on the script and not really in the db ?
Commit changes directly on the db ?
thanks a lot
« Page not found »
nice

#3.Checking during which months people require car parking space
cmap = sns.cubehelix_palette(rot=-.2, as_cmap=True)
g = sns.relplot(
data=df,
x="country", y="arrival_date_day_of_month", size="required_car_parking_spaces",hue='arrival_date_year',
palette=cmap, sizes=(10, 200),
)
g.set(xscale="log", yscale="log")
g.ax.xaxis.grid(True, "minor", linewidth=.25)
g.ax.yaxis.grid(True, "minor", linewidth=.25)
g.despine(left=True, bottom=True)
plt.show()```
Hey! Im unable to figure out how to specify a country from my datasetis there a 'country' column in your dataframe?
...also this is the databases channel
couldnt find any channel that helps w seaborn or matplotlib specifically :/
my bad