#general
1 messages · Page 98 of 1
The API does not have those system prompts which tell the models which version they are.
no
From chatgpt.com

everyone knows that

Ngl. I'm not really seeing much point to the cheaper openAI models except so openAI saves money. Because we have stronger open source alternatives that are cheaper also

you have system prompts lmao
uhmmm, idk what you might even be referring to hmmmm
its a very interesting hypothesis though
It is not "better". It's just finetuned more aggressively for the style and formatting users prefer
I commend you for your wisdom

Why use GPT5 mini when GLM 4.5 exists for $0.5/$2
Can u help me fix this pls
Since it worked for him
he has system prompts
I have a system prompt
hes making a plugin
It's an issue with OpenAI, ask them

it should, but it needs some work for getting it to run
because gpt5-mini-high destroys glm
if youve never installed react it can be complicated for some
Ok so now it should work for me right
What do I say to it to run?
it cant you have to do it yourself
Ok sorry for saying you’re lying you guys should have a section for help
Like if something goes wrong
gpt5-mini-high is essentially o4-mini-high except better in every way
You said it needs some work. What prompt do I send for it to that "work"
Why do you need the model to tell you it's gpt 5 if you already know it's gpt 5 ?
So glm has no chance...
What the hell GPT5 dropped so much in the leaderboards
after it generated the code, just ask it for step by step instruction for how to run it on your machine, tell it if you have windows 11/mac or whatever
How did it drop that many Elos in short duration of time
its garbage after all
I have android 12
ask grok 4 same q, he will say he is grok 2 or 3 😄
not impossible, but complicated xD
Beicase a lot of websites are lying nowadays and putting gpt 4o even though the person wants gpt 5
are you kidding me

it's still nr1
guess ill use opus
By 6 Elo lol
Like I just want it to create a website according to my customisations and instructions and it should be runnable on chrome
It's within error

To 2.5 pro kek
How did it work for this person can someone help me pls
Can someone help me by dm me

Your collaborative AI assistant to design, iterate, and scale full-stack applications for the web.

Grok 4 deserves way better. It's underrated.
Google is always benchmaxxing for lmarena
maybe try this then
Grok is kinda sh'it
Paste your prompt here?
Can someone help pls
Told you
the prompt is only for direct chat
Open lmarena in incognito tab. It might help.
System Prompts, I have, you do not
sorry but it deserves that spot
its not that good
Oh ok ty for helping
System prompts in lmarena how
Can you tell
im starting to think that @modest prism is close to elon or some xai staff somehow
very soon
The market gives grok better odds than openAI for December
Oh are u guys going to give it to everyone
whos funding your project
Lmarena head
I'm not, grok 4 is really bad at coding, but at solving some deep math stuff it's really good.
Mr.@tired herald Head of Department, system prompts, lmarena.ai
Isn't Gemini 3 just going to be insanely good. They literally need to add a tiny amount of perf for SOTA
They are already at the frontier with a comparatively old model
Nani 😭
yea you are sus
def sus
And the 2 pro to 2.5 pro leap was immense
im confident it will be SotA
I would love to release this already and send it to the LMArena team so they can improve their website
The Arc-Agi benchmark doesn't lie
2.5 pro experimental shooked the world
why? they could've finetuned even if they only have the public dataset
Grok is intelligent if you prompt it right. Issue is it takes 10 mins thinking then
the win-rate to gemini2.5 pro also doesnt look good (was already there before the update)

idk grok 4 vibes are off
💀
Give grok 4 prompting guide
They are not and they have some catching up to do

And also are u guys going to give system prompts for the Public soon which will be nice ty pineapple for everything
we talked about how flawed this metric is
All of these models are available for free 🤑
It's not really flawed just because you don't like it lol
They have more important things to work on right now
Do you guys think that we gonna have gemini 3 this month?
Quick question are u an admin
Ngl these GPT5 models are good at maths though. That isn't a Gemini strong point any longer
Yeah I have a feeling
Deepthink is good
2.5Pro is not SOTA anymore, like that's the reality
Poor llama 4
And also do u guys know that Claude is good too
no
have you tested it?
But still the best 1m context option
No
Yeah that’s true
Yeah 2.5 pro on ai google studio is bad now
temperature is something I checked if I can do it myself, but nope, which is sad
idk wtf they did
The initial 2.5 pro release was before o3 release
Their TPUs melting
its not SotA but its not bad either
but gpt-5 is amazing
pdf and docs are probably gonna come soon
It isn’t up to date even with grounding with google search for ai google studio honestly
That’s why I stopped using it
How to set it on gemini web?
But it received so much updates
IMO Gemini 3 is October time. Not any time soon
Like you have Google ai ultra but no temparature setting access 🥀

The fastest path from prompt to production with Gemini
and im the biggest google shill
This is the website
Leaderbord does not make sense. Gpt 5 chat which is the worst model in gpt 5 because it is non reasoning is better than gpt 5 mini thinking which is a reasoning model

Gemini 3 is October, grok 5 is december
let it age
They created like 30 different endpoints for gemini 2.5 pro
you need to open Advanced Settings for Top P
Did u guys see that perplexity wants to buy google chrome
😭
You have to manually tell the model to search the web and fetch the websites otherwise it won't do it by itself .
bot hare gemini web 😭
both mid rn
That is just refinement. The march release was already good
What
You can't use deepthink or deep research on ai studio
Yeah Ty
Grok added NSFW to their image generator
Thats their only latest update 💀
Why have so many people active here today
Why
😆
elon musk made a corn generator
but no, its not possible to customize on gemini web
Yeah Austin Evans did an short about it
leaderboard update xD
(i think)
I want zenith back
there was one
Same guy who thinks humans on mars is more feasible then fixing earth btw
Hes a cr@ckhead
That's what I'm saying
You pay for Google ai ultra and you can't even change the temperature
🥀
😒
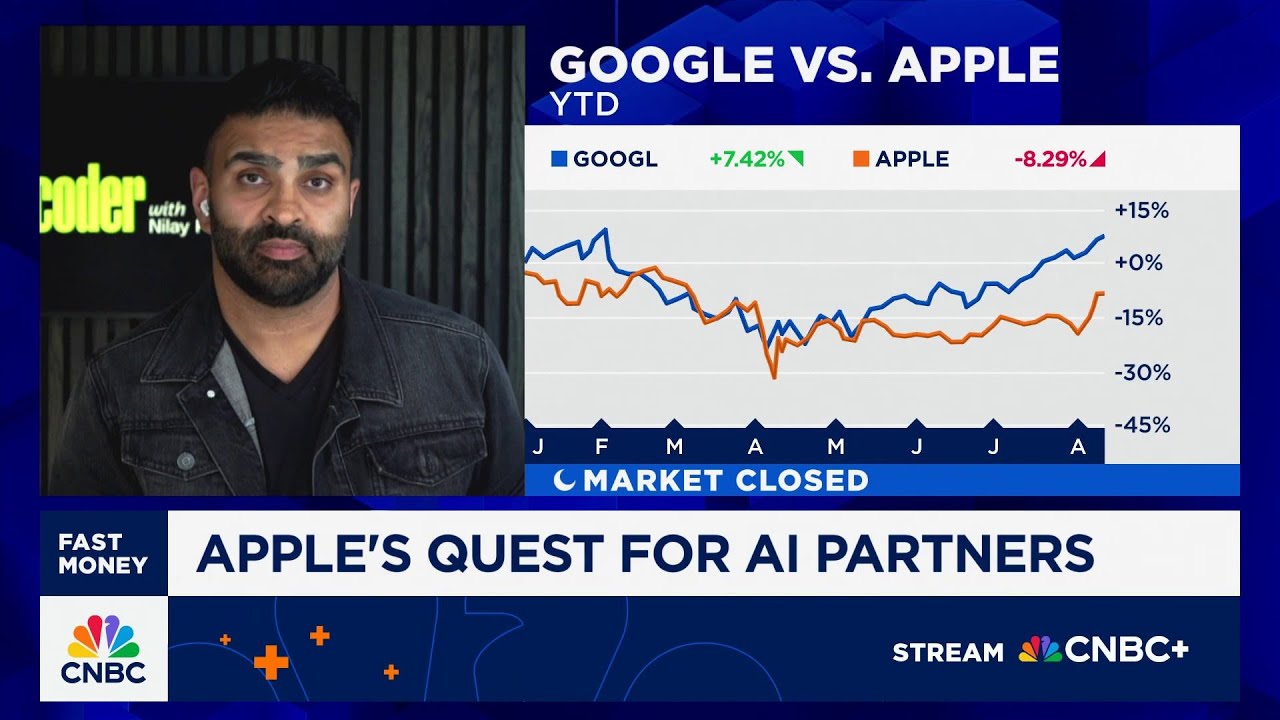
Nilay Patel, The Verge editor-in-chief, joins 'Fast Money' to talk the latest moves in the AI arms race between Google and Apple. For access to live and exclusive video from CNBC subscribe to CNBC PRO: https://cnb.cx/42d859g
» Subscribe to CNBC TV: https://cnb.cx/SubscribeCNBCtelevision
» Subscribe to CNBC: https://cnb.cx/SubscribeCNBC
» Wat...
I dont pay
I heard xAI is actually building AI corn team. To refine the corn generation
Man I am so excited for gemini 3. Hope they don't nerf the model
I dont have ultra
so many be yappin here
Exactly
indeed
I wonder if they actually using corn as training data or what
Ok bye ty for everything @echo aurora
Guyzzz
Actually google ultra plan is not worth the price at all. You get like 10 prompts a day
With deepthink
And you can't even change the temparature parameter
I only use the Gemini web because of custom gems
It's worth it if you are a TikToker or YouTuber thanks to high credit of Veo 3.
8 sec videos only
And I have seen how 😭 veo3 is in video arena
omg why is it so hard to change the UI of LMArena
hi im new to here,i just wondering i got limited in my gemini after few question,is it unlimited in lm arena?
No
yes, thats how I do everything 😭
so far only sometimes i got stuck in genarating page but haven't saw limited yet
I never got limited in Google ai pro free trial
it just going flash instead of pro sometimes
i just feel it takes time to genarating compare gemini appwith pro😩
I have zero Idea why theres a visual of the old ui behind the new ui

when will video generation be added to the website
TBD if it will, but be sure to share feebdack in #bot-feedback
To be donest
to be determined?
i dont have this ui
You are paying them $250...?
I said previously I'm 15
im making this ui*
I do not even receive any pocket money
can i say that lmarena should add video generation to the website in the feedback?
Hey everyone,
I keep getting this Cloudflare "Security Verification" pop-up on LMArena (see screenshot).
Any ideas how to fix this persistent verification? It's really annoying!
Thanks!

Yup!
Uh oh - are you getting the same regardless of browser type?
Well you shouldn't pay for it even if you had the money tbh. I could subscribe today but I don't see the point in even their Pro sub...
@echo aurora 😂
Yes, I'm getting the same security verification message on both Brave and Chrome.
what happens when you try to verify
What exactly are you getting for their Pro plan than you don't already have with aistudio...? Not much at all
Is the verificiation not working or just annoying and pops up a lot?
A wise man once said money multiplicates itself. Do you agree?
Only if money is used wisely
Their gemini subs are useless
Oh, making the Model selector appear in the chat box is gonna be hell
It appears every time I vote on a generated image.
I'm not talking Abt gemini subs at all
You may buy gemini sub if you want to support them or whatever, but then you shouldn't pretend it's a good value for the service 👀
Pls add pdf support please 😭🙏
Okay I'll flag to the team. But to confirm -> the verifcation isn't failing? Just appearing too often


later
Well I am..
I will do whatever you say just please add it 🙏🙏🙏
Yes, that's correct. The security verification pops up every single time, but once I authenticate, I can use it again.
It's hard and tedious, ill do the easy things first
Thank you very much for trying to help me fix this issue!
IMO the fact that they are messing with huge models (ultra for deepThink) is not extremely promising tbh. There's no obvious substantial improvement path without going to the extremes with Google for now..
I doubt Gemini3 will be substantially better than 2.5Pro. Probably more like marginal improvements (2.6?)
DeepThink uses Gemini 2.5 pro
Yeah I wished they did that instead of a bot in this discord server,but I think it's about the limits and direct voting
Its not a separate model
No it actually uses the bigger model
No
2.5Pro is not mentioned anywhere for that model card
Its 2.5 but multiple
So what
Marketing
Ain't deep think a part of 2.5 pro?
They make multiple versions of 2.5 Pro work together to all create a better response together
So it's a different model. We already knew they had bigger model internally, and DeepThink is way to distinct from 2.5Pro to be the same model tbh
Same with the GPT-5 Pro and Grok 4 Heavy
Like it can do some tasks worse than 2.5Pro
Multiple 2.5 Pro ≠ Bigger Model
Ill stop arguing
Ill go work on my stuff
It's a DIFFERENT model. And the only one they had to use other than Pro was Ultra
No
@tired herald I don't understand top p at all. What value should I put
I'm not
LETS GO DEOLD VS DOMS
💀
Still doesn't worth 250 bucks for 10 prompts a day
Correct
Idk either
💀
same for me. every vote gets checked with a cloudflare captcha. i thought that it was intentional, but if it isnt, then yeah, would be better to have it less often if thats possible
They are trying to make reverse engineering impossible. But people are still successful in doing that so it's like fighting the wind lol
I wouldn't call that reverse engineering, just some bots who want to push certain models
If you found a way to deterministically verify a model then it's easy I guess
And a difficult to solve problem for lmarena
No, this is more to prevent people from coding interfaces that use lmarena API for model access tbh...
A difficult problem to solve for lmarena you mean
Rather than bots doing vote manipulation - there's not many of those if at all
Its not reverse engineering. You can use their servers easily without issue....
But the captcha arrives after voting, not after prompt
DOMS LOST
That's how I found out about system prompts
🔥
So I could still generate programmatically

Use their API? You can't without reverse engineering
No
That's why they do it
Takes 3 clicks to get around any protections on the web
Also, even if, its not called RE
I think it balances creativity and coherence
what
You are insulting every RE with your sentences
You seem confused
Im an RE you honk
RE needs something to be locked in some way
Its open
So no RE required
I don't think you are

Says the guy that has no idea what google do
Is there an option that you have always 8 sec video without the commercial at the end. Now it is random and 5 sec or 8
Unfortunately no
@tired herald Reverse engineering refers to automating things like lmarena so you could do requests without having to go through their interface, click on things and having to do it manually.
It's not what you think it means
Are you f*cking insane
REVERSE
REVERSE
REVERSE
REVERSE
I think bro is having a stroke
Are you okay?
anyone else having this issue

I'm pretty sure that's not reverse engineering AT ALL
Json escape, your message broke message handling
AE (Alternative effects) server has a free pool of VEO3 text to video generator. Tonight ofline, but most nights from 1900 to 2300. 8 sec video, without watermark free download
oh ok hmm thanks
It is. Because you need to arrive at the methods they are doing in their interface for sever requests without having to use their interface. You are reversing how it works in order to be able to do it independently of accessible interface. I don't know why this is so difficult to grasp for some people. 🤷♂️
no
You are wrong in every sense of the word
Im sorry, but please stop interacting with me
Enlighten us then
Reverse
Cause it looks like you have no clue
Most likely you don't

I asked you first.
Reversing something
Nvm bro seems confused
🤣 🤣
Can you read what an AI just said
Bruh....
turn on your brain
This guy thinks he can code GTA 6 in 2 hours
This is the embarrassment of vibe coding
This guy is the reason why people believe in the flat earth
then you have no clue
LMFAO
You are pulling my leg
You cant be this unintelligent
Im being successfully Ragebaited
You sound like a broken record having absolutely no clue what you are talking about
😭
REVERSE
Define
REVERSE
Reverse
🤣
What are you guys rambling about?
Reverse engineering
Reverse engineering?
🍿
<@&1349916362595635286> See message logs. Some drama
I see. What about it?
Dom doesnt know what reverse means
don't ask. Some silly person pretends to know it all but can't say one sentence about it without prompting chatgpt lol
Agreed
Reminder:
✅ Treat others with Respect. Be kind, assume good intent from others, and keep disagreements respectful. It’s encouraged to share your disagreements, but only if it’s done in a respectful and productive way.
Hey Greg!
No, im proving to you that an ai can be prove you wrong without breaking a sweat
Sorry 🙏
I was being ragebaited and fell for it
I promise it wont happen again
Lets just keep conversations respectful please.
reverse engineering is the process of figuring out the logic and shape of the requests; automation is separate but i can see how it would be included
Looks more like you have no clue because you couldn't do a single proper sentence disproving anything I said lol
I tried
yeah...
EDIT: for the below... Yeah blocking is easier than coming up with a single argument that is not AI written. You can only pretend you know stuff for as long.
Im blocking you for my own sanity. I cant believe how little you know
My topic is that im prob gonna release my extension today
What is that
Which extension
it's interesting that gpt-5-chat ranks below a few other non-reasoning models

A new model based on the brain's system of thought.
See for yourself in community creations 🙂
Ill check it out after im done with what im doing
Oooo this is exciting!
Can you please...?
BRO
. 😭
Yeah, theres just a little problem with it right now
I need to fix and release
Im hoping that it could be helpful for those who could use it
Ask away
Is there any other models for generating 3d worlds,real time,other than genie 3?
yeah man, we all ready to help. welcome to the community
Yeah, but Genie 3 tops all of them, by quite the margin actually

Any examples regarding those models?
In the battle mode, if you get lucky, one of the two random models will be toad
I think he means he wants to get notified
They all have obscure names so I dont remember, but im sure if you search genie 3 on yt, click on the channel of one of the people, youll find some more stuff
And how he can get it? Or did I misread it 😭
what are these notifications and how do i get these or is this like a manual thing i need to do battles and if i am lucky i will discover something new?? basically i want to know how to get this bot that will give notifications about the new model
OHHHH
It's a discord server
Legit api
These notifications about new models are on the server discord. gg/devmode
Thanks man how can i join that
Oh, im just stupid
I misunderstood
Sorry to say discord invite links are blocked here so will have to DM the inv link
Thanks everyone, Have a great day.
Yeah you can leave that message, but if you want it to link you won't be able to is all
OK thanks
@echo aurora I don’t know if you saw my question yesterday, but I was wondering if you’re able to talk about the pre-seed/seed rounds at all, it wouldn’t need to include any specifics about lmarena, just how the general experience went… like finding a lead investor, pitching to angels/vcs, etc
I'm not sure I'd be able to share much info, even if I knew what that was like first-hand. I wasn't involved with those conversations so I know very little regarding that.
Ah okay, thanks anyway
Just have to get lucky I guess 😅 ai🎰
Gacha on ai, gacha games, gacha life, gacha everything
@tired herald https://github.com/sapientinc/HRM
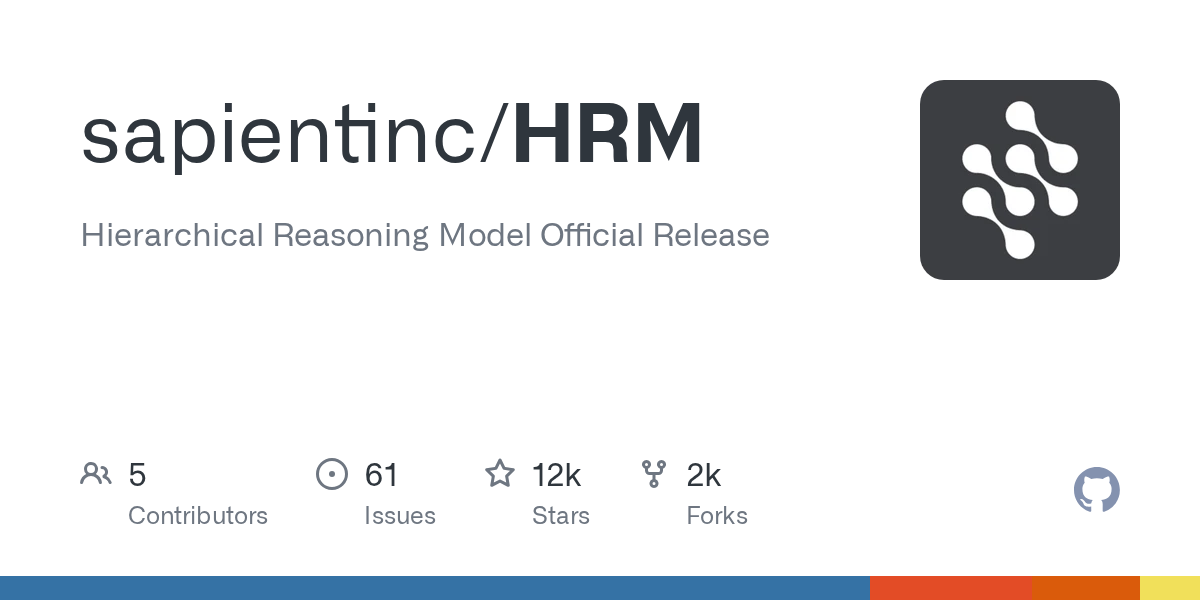
GitHub
Hierarchical Reasoning Model Official Release. Contribute to sapientinc/HRM development by creating an account on GitHub.
You're the ultimate gaming gambler, dude.
What is this model about? Is this some new architecture for LLMs?
Hold on, I read the github
Its a brain inspired ai architecture which focuses on deep reasoning rather than llm. It scored some very interesting results at the ARC AGI benchmark.
Would this replace CoT then?
Just asking if you knew more
What kind of score? 🧐
Maybe. But unfortunately it has some flaws, you will find them somewhere in their reddit community.
Nope, just a passerby who came across it. Interested if someone has set it up and tested it.
Okay, thanks for the info.
Would be very interesting
Esp for math and such
40.3%. Not that impressive but good for its usecase and mostly because of its low compute.
Exactly.
does anybody know an ai model for sound effect generation
Lyria 2
isnt that just for music
uh they have written a paper as well
https://arxiv.org/pdf/2506.21734
Yeah. My bad, didnt see it through. Sound effects generation eh? Hmm, not sure about that. Did you try looking it up on the net?
Yes! Forgot about that. Isn't it impressive tho with just 27M parameters and training on just 1000 examples?
I heard thats good, all the best dude!
Is it unsafe to use VPN while visiting chatgpt website?
No, why do you ask?
You wont get flagged.
Just might be stripped of some features/accessibility refrained in some countries.
Have heard of account lockouts. But so far only rumors.
It is, though it's also... too good to be true? 👀
I wonder if this would hold up as a general purpose model in real life
My thoughts exactly. Thats why I'm searching for people who have experience with it and set it up for their own usecases.
Yeah I guess so, this might be a huge hit in Healthcare
I like how opus be like this when you ask it to be your friend. But you ask 4o and it goes all in with saying you'll be the bestest friends ever and all sorts lmao

Opus 4 actually just says no basically

I like this all ai models should be like this
People got so desprate for 4o when it was gone for 2 days
This will have nagetive effects
Guys, how to use the Thinking model in GPT-5, not Thinking mini?
Or is only Thinking mini available for free users?
They are still complaining about how it doesn't feel like 4o, like it's secretly gpt 5 in disguise
the whole chatgpt subreddit is on fire
GPT 5 mini high is worse than 4.1 and 5 chat, gpt nano high is worse than oss at 42'nd place in text arena

flagship model my
saddening...
Sorry to say this
But the small error ballooned into a much larger set of issues so I cant release the src today
But I promise tmrw will be the day
GPT 5 high
the first personal fun project I made like actually was able to fully complete was done with 06-05 Gemini, I am a Gemini fan for sure
@novel crater
yeah Gemini 3 would be freakin awesome
basically I made a tarkov grid style inventory, if anyone here knows that game, basically a pretty complex system and Gemini knocked it out of the park
I don't think chatgpt likes their competition at all and probably put out gpt 5 as like this big thing, because not a lot of people seem overly enthused about it
Ok but mini and nano are very much not flagship models
Deepseek was too strong and he was nerfed 😭🙏
They are what the average chatgpt user gets though.
Sam has known for quite some time that GPT-5 was never going to live up to expectations, GPT-4 was this big model scale up from 3.5 and it saw huge improvements with that scale up, so people have been expecting the same from 5 since then, but it was found you can’t really scale them up any further and get meaningful improvements, so they started focusing on their reasoning/thinking models (o3/o4/etc), they tried launching another giant sized model, 4.5, but people didn’t really like it, so it was known for quite some time, whatever GPT-5 was going to be when it released was going to be more of a rebranding than anything
Didn't stop him from pretending it was the death star
Sometimes people need to realize when they shouldn't be hype men
Gotta get those VC dollars
yeah I mean it seemed like it was made out to be huge with their website and stuff, I mean they removed all the other models at first
Gpt-5 chat is the consumer facing flagship ChatGPT model, and I think that it’s going to go down like maverick 4 in the totality of its failure
costs saving, 4o seems to cost more to use
Nano and mini seem built for api use. Gpt-5 chat IS ChatGPT fo r most people, and it’s just so bad
fair yeah thats a really big part of it I think
cost friendly is always good
especially with some of these models 👀
GPT5 without thinking is so bad
I don't know how it's even possible
It fails basic arithmetic
That even 4o could get
I'm basically permanently using thinking
Only downside is wait time between prompts
@novel craterwhat will come first gemini 3 or grok 5
GPT-5 mini is a decent balance, it’s not as dumb as the chat model
I don't have enough knowledge on that to say definitively but since grok 4 came out recently it would make more sense logically that Google would release first
Gemini 3 October, grok 5 December
That's my guesses no info
The gap between pro and regular gpt5 is quite insane. They didn't even mention pro in the livestream lol

I guess they don't really want ppl using it much. Due to capacity issues
The gap between gpt5 and GPT5 pro much larger than gap between o3 and o3 pro I found

This one's weird because mensa Norway caps out at 145 IQ
Hello famalams
It doesn't?
It's just that it is rated for only up to 145
They didn't calibrate beyond that
Does anyone else think that LMArena should go back to NO style control? Now they’re also talking about “emotional control”…
Makes no sense - it defeats the purpose and mission of LMArena in the first place. The more they “control”, the more they turn into the very benchmarks that they wanted to distinguish themselves from
If LMArena is about what users like…then let the users decide what users like!
The more variables and factors you “control”…
You end up turning into a Capabilities test
And There are plenty of capabilities benchmarks out there already
Where can I find the emotional control discussion

LMArena Blog
Introducing Sentiment Control: Disentangling Sentiment and Substance
LMArena is supposed to give insight into what other benchmarks miss
If you keep “controlling” for those unknown factors by adding style control, sentiment control, etc….the benchmark becomes worthless. No alpha in the scoring
Where is style control?
Gimme style control
You already have it! Style control is built into the default rankings
All I’m saying is, if people like emojis and bolded words or whatever, then you have to accept that, regardless of ether you think they’re dumb or meaningless
In fact, we’re seeing right now why style control is a mistake for LMArena’s clients
It's to prevent a race to the bottom where every model turns into sycophant emoji slop machine
OpenAI announced that they would make gpt-5’s personality “warmer”
Because it’s obviously been too “style-control” maxed
Take a step back and think about what LMArena is, and what its value is
Just put that in #ai-news
Trying to work their way back up the charts
The whole value prop of LMArena, is extracting sycophantic signaling!
Again, the more you control for user preferences, the more you turn into any other standard benchmark
Making LMArena useless
I thought you're saying we can add custom instructions or at the very least a style mode like formal explanatory
The thing is: they're already controlling for a bunch of other things. Style control is controversial because it's a visible option. The other controls aren't because they aren't visible.
LMArena is supposed to captures what objective benchmarks cannot. ie, user preferences. ie, what users like. ie “sycophantic” behavior
What kinds of things is the “no style control” leaderboard controlling for?
I don't think so. LMArena is supposed to capture model's capability in general use cases. Sycophantic behavior is an undesirable side effect
Yeah my guess is OpenAI relied too much on style controlled rankings in testing, and realized that was a mistake
Wrong. There are hundreds of benchmarks that do that already
LMArena is not a capabilities test. It’s a popularity contest
Mainly integrity checks. Certain patterns of user behavior are more likely to be trying to manipulate rankings to favor certain models, and they have a relatively robust system to account for that
None as representative as LMArena
Which doesn’t mean it’s not valuable information, it’s still incredibly valuable
Agreed! And they should keep it that way. If they keep adding stuff to control for, LMArena’s value disappears entirely
That’s different -that’s a prompting issue, not a voting / output problem
Yeah filtering scam submissions seems like it’s not a manipulation
Also, the models vary wildly by language. 50% of LMArena’s queries are not in English
I don't think style control is manipulation either. I think it's just a slightly controversial option with compelling pros and cons to consider
Where does language factor into sycophancy
I meant a fairly benign version of the word manipulation
you can have a model that is very sycophantic in English, but maybe not in other language language. Or maybe rewarded in English more than in other languages
There's some stuff you can easily "turn up and down" and stuff that you can't
I'd argue that a leaderboard that only measures the second one would be even more valuable for some uses
Do you have any evidence of that happening? I believe it's not true
@pure falcon talk to @echo aurora about all this
So filtering scam submissions seems to be a necessary baseline function of the website or it would be a joke given how popular it is. Style control isn’t, it’s a choice to have it or not. I’m not sure it’s up to date for recent models
Yeah I mean personally I'm not the biggest fan of style control, although I think it has pros and cons and is useful as an option. You get some form of model provider gaming either way
Idk what you mean by this?
Eg a system prompt can increase formatting but can't increase raw intelligence
Or it can increase sycophancy but can't induce EQ
When it was originally made I kind of liked it as a guard against llm markdown listslop. Now though I feel models like Gemini and GLM answer in this very verbose way, but the tech has improved so the lists actually have benefit/are more info dense now.
Yeah I kind of want all the models to have fancy markdown now
Removing style control would cook openAI
I wonder if they intentionally steered away from using the things style control tracks
But thats the whole question right? Is LMArena measuring intelligence? Is it SUPPOSED to be measuring intelligence?
IMO, its primary purpose is to inform model makers on user preferences. So they can improve their own models.
If an ASI model came out tomorrow but was a total a- hole that everyone hated, where would you want that model to be ranked on the leaderboard?
This is gonna happen it’s gonna answer 42 to everything really quickly unless you ask it something sufficiently interesting.
But well, such a system will be in the somewhat far future
Yes, A model that behaves like that is undesirable to model makers. Model makers want to know what users like. So if you “control” all that away (with sentiment and style control, etc), you end up with a leaderboard that is SO useless to model makers
Well, unless OpenAI is LMArenas only revenue source, then that should be the way to go
IMO a few models will eventually pull ahead by a wider margin at which point the style control problem will gradually become moot because the best models will be able to win even with extensive markdown
They can simply press a button to remove style control
Style control helped in the llama 4 situation which was favourable
Why would they do that though? They care much more about raw user preferences. There are plenty of other benchmarks (internal and external) that can measure raw capabilities for specialty / niche areas
I don’t think lmarena is just user preference. It’s a whole bag of stuff
Like what? What value, to model makers, does LMArena provide that other benchmarks don’t?
Are there really. A lot of benchmarks are saturated and/or useless
I really would like to know, genuinely
I mean I don’t care about what value it provides to model makers. I care about what value it provides to the community.
?
If they really would like to see no style control. They simply press remove style control, simple
Sure, but you could argue the exact opposite, right? If no style control is what matters more, then why is style control the default?
fwiw I also prefer no style control as the default
That’s the thing though - LMArena isn’t a “community” service project. They have enormous costs servicing top of the line models for free
They are propped up by VC funding
I also prefer no style control.
Don’t worry about that. They might not be paying for it anyway.
Who are the leaderboards most valuable to? I’d argue it’s to companies like OpenAI who use their leaderboard to determine which model to deploy. Which is exactly what they did for GPT-5
There was an alternate gpt-5 variant named “zenith” that was tested in late July
OpenAI ended up going with the “summit” variant because it did better in LMArena
If they didn’t already, OpenAI would pay a lotttt of $$$$ for that data
Which means
For LMArena
Their primary customer and purpose, is the model maker
Why does Claude Opus have a limit on lmarena?
its expensive
and every model has a limit
I didn't notice that other models were reaching the limit, but maybe you're right and I just didn't reach it. I didn't write that many messages and I already have a limit.
@echo aurora We've been discussing whether or not LMArena should have style control enabled by default. I know this topic has been beaten to death, although I'm curious to understand LMArena's take
that isn't really what i meant - i was saying that a leaderboard that measures the "core" of a model might be interesting to look at
"If an ASI model came out tomorrow but was a total a- hole that everyone hated, where would you want that model to be ranked on the leaderboard?" if it's better than the average model prompted to act that way, and if it can be prompted to act like whatever other model, then on a leaderboard designed to measure the core - the parts of the model that aren't superficial - it would rightfully take first place
Personally I think there are pros and cons and prefer no style control by default because I see LMArena as primarily measuring user preference
Model the core what? “Intelligence”? What does intelligence even mean? In that case, why not just feed it IQ tests, math questions, or other capabilities tests, which already exist all over the place? What value does LMArena therefore have?
Do you see what I’m getting at? The more you control for, the more you approach benchmarks that already exist. That defeats the purpose of LMArena IMO
What does intelligence even mean?
what can't be reduced by controlling for attributes of the response / forcing a specific style
why not just feed it IQ tests, math questions, or other capabilities tests
have you heard of benchmaxxing? this would theoretically be unbenchmaxxable
I think the best argument for style control is if your goal is to be the best all-in-one measure of intelligence in the areas that users care about
Intelligence is just a vibe
I believe we did a blog post about this recently...
I could be wrong
So style control is a vibe realignment from the default one, more towards a different vibe that people might want more…
I think no style control is more valuable. That's a better reflection of who is "winning" with users
a good way to test how well models follow the control instruction, isnt it, or is this the original intention of lmarena?
I think less control is better
but it depends on what purpose style control serves and what you want to test that you need style control as a normalizer
Yeah. I think it’s a bit of a fools errand to try and find some function to morph current arena votes into “intelligence” or something. It would also need to be continually updated I think.
It doesn’t affect llm responses it just affects how it’s scored in the end.
Why is communication not counted in your “intelligence” definition? Are comedians not “intelligent” in your eyes? Are entertainers not “intelligent”? Intelligence is not just about solving problems and puzzles. That’s a very narrow and limited view of intelligence. A model highly skilled in communication is, in fact, intelligent, just in a Different way than Einstein. Intentionally dismissing those capabilities (by “controlling” for it) makes no sense.
if i can't prompt another model to be "highly skilled in communication" then the model would have an advantage
there are actually a few ways to do this though and all have some problems tbh
- prompt all models to act a fixed way
- prompt one model to imitate the structure of another model
- identify the traits of each model's responses and control for each trait (implicitly assuming that each trait is easy to reproduce)
Btw do llm arena models have system prompts?
If so who sets them?
iirc it used to be that each model had a fixed (usually minimal though) system prompt, and now there's a common system prompt that says how to respond but it's different for some models
idk 100% though, i don't develop the arena
It’s not suspicious on its own. All chat apps have a (often large) system prompt
So it’s decided by lmarena what to put in it and it’s short?
Ah ok. That makes sense

Damn, I should add this to my extension too
But most importantly: @deep adder said it is the best by far
Exactly my thoughts
Sorry I'm late to share this -> https://news.lmarena.ai/sentiment-control/
LMArena Blog
Introducing Sentiment Control: Disentangling Sentiment and Substance
@leaden palm please some prompt engineering tips
for...?
From what I checked, it seems that its either a very very simple one, none at all, or a base system prompt from the provider (gemini gave me a believable system prompt when I ehhm forc- made it give me its system prompt, all other ai's said they didnt have one/gave me mine back, which prob means mine was the only one)
Tho I cant confirm that unless I had access to the internals of LMArena
Yeah that would make the most sense. Simple as possible to stay close to the original model.

IIRC cursor had big context issues 1 year ago. is this still the case, now with gpt5 high?
why do OpenAI models suck so bad at creative writing
and why is Claude so good at it
Cuz open AI is the big poo poo, the prime crapola!
new here, excited to learn from you all
🥀 fr
Learn how to do obscene things with Gemini?
🔥
paws stop typing
i used all openai models since 2023, even GPT5 sucks today
and the emoji blasting is corny
i hate the emoji respondings
👀

What?
fr
google is actually the winner, cuz they got all the money in the world + all resources
it is actually
Guys, does anyone know how to use the Thinking model on the phone in ChatGPT, not Thinking mini? It's just that the Thinking mini model provides the "Think longer" function.
i dont see how this is gonna happen
they literally cant lose if they do that
are you payed option?
google?
Oh yeah baby and triple
u can't the GPT5 chooses if it should think longer based on ur prompt
I'm on the free plan
google can win
it has already won
than i dont think u can use thinking
Google has a much, much longer runway than OAI, and it's not even close
and in a few months they'll release Gemini 3
xAI seriously
why u hating on google tho
And eventually sheer capability just wins
wdym no product
There is a button. The "Think longer" button.
they'll use it if its the best at all stuff
OpenAI is far less innovative than Google, and it's not even close
doesn't even matter, they get their income from other stuff like google search, youtube and all google owned markets
they can throw money on AI until they get big
they can just put gemini in chrome which they already started?
The wider the gulf in the capability, the less product polish matters
u know the google cfo?
if you count all the x users?
cuz its "not woke"
well than why not include ai overview and ai mode
and u can easily jailbreak grok 4
I mean if you're going to make that argument, you have to include AI Overviews
grok 4 is easily controlled unlike claude, openai and google models
grok turned into a h*tler fan 😭
it got no security
FR
tbh even tho claude 4.1 opus is the best at coding, creative writing. majority of people still use chatgpt
true
because normal people dont care which AI is the best
they just download chatgpt and use it
still think google can win tho
we're like 0.01% of all humans
if ur into AI and coding
the majority follows the slop
they dont care if its good or bad
honestly it might be better than some ealier versions, where it pretended it was writing a epic fantasy tale
use ai google studio if you are using 2.5 pro
the gemini is different?
different instruction set
yah, its not suprising that the api version has less instructions then the non api version though
I have no clue what's going on with the front facing version since it never can act normal
I'm going to be honest. The ChatGPT web UI looks just like the Gemini web UI except with worse iconography
be me
can't choose which large language model to install
ask a friend
friend says chatgpt
download chatgpt
run chatgpt

yeah and its good enough for everything at the moment
It doesn't matter while the quality gap is small. It matters more as the gap widens
Nah they're about 1/3 to 1/2 a generation behind
Capability
Nah
Better in some areas. Worse in others. Overall parity
To my surprise, sure
But the point is that their pace isn't enough
They're roughly 1/3 to 1/2 a generation behind
Nah
Look if you want to compare bad ChatGPT responses vs bad Gemini responses, we can do that. I just don't think it would be a useful conversation
Do you just not like the bold sections?

Guys
I'm not sure what to say. Most people prefer paragraphs with bold headers
I do think verbosity is on the chopping block though
Did you know that you can compare the answers by SOTA and non-SOTA models to determine if the models you ask are right
You just ask say Qwen2.5 the same question 10 times in a row
Then Qwen3
And if the responses tend to differ, one LLM is clearly in the wrong here
be me
talk with bing chat sydney
distilling from sydney fine tune before it gets shut down
'Ello guys, is there any site that generates videos using Veo3 for free?
For me, I don't care about the writing style as long as the LLM I'm using flawless at instructions following, consistent at long context. Gemini 2.5 Pro did very well about first 10 messages, then it broke and went back to bullet list, which I instructed to be banned in systen instructions.
Default ChatGPT version of GPT-5 is on there now

It isn't as a hype yes man as gpt 4o so it got lower elo 💀
Lower than GPT-4.5 too
This is killing me 😩 Please ship faster and better quality
maybe the thinking but the chat version is 💩
chat is the non thinking version right? It's just GPT 4.1 in cloak
and it's really bad at IF
is there any api that has the 3 version of gpt 5
I don't care about benchmark I only care how well it follows my own system prompt
livebench rarely match my real world usage
then why did you show it as a proof of how well GPT 5 at IF 😭 💀
Most trustworthy benchmarks are your own
🗿
however
i still hope theres another ai model that can listen audios
that is not gemini
Gemini can hear u?
yeah ik
but there should be more ai models that could be it
like chatgpt
only me who takes ages to load a response?
direct
Good evening! I’m new here. Could you please let me know if you plan to add video generation to the site in the future?
what happened with nano banana model?
was removed?
It doesn't appear to me anymore, before it appeared to me all the time in battle

Is Google cooking smth up
Apparently they had a celebration when they saw GPT5 performance
Lol
just curious, but why limit video generation / arena to discord? discord ai stuff is the worst lol
An update on our exploratory research on model welfare
image to video is too 💩
Maybe ,the cost of data for downloading videos is very high.
ahh that might be the case
welcome welcome! It's possible we add Video Arena to the site in the future, we're treating this as an experiment using Discord. #bot-feedback is where we're collecting thoughts on it.
Vid Gen is more expensive, so we do want to limit it a bit. Currently it's set to 8 generations a day.
We taking all of this feedback into account though! So it may change.
I think Discord is great, it also works as a funnel for making announcements, since you’re not collecting emails or requiring sign-ups on a website.
plus i like the community
We'll always have a Discord for that kind of stuff fortunately.
agreed & seeing our site is about gathering community preferences there should be a place to chat about it.
thinking vs non-thinking versions
exactly
any gemini 3 news
Lmao
Hopefully their next model is better at agentic coding
I hope Gemini 3.0 can further extend their context window for even better agentic usage and tool use in agent. Ability of creative writing is also being anticipated by a lot of AIRP users
Gemini 2.5 Pro still holds the SOTA in long form multi-turn creative writing in actual usage but I wish they can even make it better
Personally I don't see what use there is of a longer context window when they can barely utilize their full 1 million so far
They need to improve attention to the context they have, imo
Especially for creative writing, airp, or even coding in some cases. Approaching 200k tokens and you see a ton of ai'isms / quality degredation / "amnesia" creeping in
YES
Seems like a hard problem to solve, though
I mean, they have to be train to have a consciousness of "rounds of conversation", like "this context is from the first round", "this context is from the second round" etc
which model is ranked first overall for this month?
Guys! I'm sharing my learning here, which I recently made up from my non-coding mind. I mean, I don't even know HTML.
I just discovered a way to create unlimited web apps, widgets, desktop apps, and so on for free!
We need two tools: Lmarena and Weblmarena, that's it!
Any person from a non-technical background can easily create fully customised software at no cost. With the steps below that I discovered lately!
-
Pick a pen and copy and write down about your desired app, mentioning every single detail that pops up in your head. For this, remember this rule, 5W1H (What, When, Where, Who, Why and How). If you have a better strategic model, then you can implement it here. It's totally up to you how you want to describe your app!
-
Click photos of your notebook pages and upload them to any LLM model and ask it to transcribe your images or pull the contents from them!
-
Once you have the text content, Copy it and open your lmarena and select the modal qwen coding one and paste all of your content there and also add your custom instructions how you want it to be built, for an example, the widget I made was a react js component + Typescript in node js page, same way you have to give instructions and ask your desired output in single page written code!
-
Once you have the code, Open Weblmarena and paste the code in the text box and hit enter! There you go, it will take 2-4 minutes to render your code and show you the preview of your website!
-
For Iteration and Bug error fixing, head back to your lmarena and open the Qwen coding thread where you have your previous chat. Now, you can iterate on it, fix your errors and so on. Repeat step 4 again and keep on doing it until you have the desired output!
If anyone has a better way to execute such ideas for a non-technical person, kindly share it. It would be really helpful for a newbie like me who knows nothing about tech stuff! 🤗
Interesting, but didn't expect to see Claude below Gemini
It's even lower than 4o here

claude seems to perform really bad at mania tests
It's been only a week since I found out LMArena and I jailbroke two things already
Bruh
calm down, ive known lmarena for a year
and they still the same
Kinda worrisome tbh

Turns out most people would rather have sycophantic delusion inducion machines than truth seeking arbiters such as GPT-5
I guess it can explains some ratings pretty well
I hate the safety!
what's the definition of "safety" here?
Yeah a very bad future we're heading to
without a precise definition of words like "safety, risks" in the context of AI, this is nothing but pseudo-science, isnt it?
Why don't I have a button where I can change the GPT-5 model?

I heard you'll be able to switch between Fast, Auto, and Thinking. But how?
Why can models with lower scores end up higher? Isn't CI a symmetric thing?

if you read how they described this bench, you know it's wishy-washy science https://eqbench.com/spiral-bench.html
Aghhh, give me gemini 3
Because they want AI to act as a "bestie"
and now because of that minority, OpenAI is making GPT 5 "warmer"
hahahah

Ohh Opus is top3 now. Seems Anthropic entered the game of user preference fine-tuning now. Opus 4.1 has bigger gains over 4.0 than Sonnet4 has over 3.5.
can't lmarena do function calls on the chat other than search
Is the video generation here powered by Veo 3?
i think we’re looking at a breakthrough in image gen.
nano-banana is literally picking its own spots to edit. changes flow with the context + prompt. doesn’t recreate the whole thing like gpt-image-1 or step1x-edit. it's like flux-1-kontext, but way sharper on context and prompt

Hello im preatty new here, is there any limits on how many images/videos you can generate?
*pretty
gemini king!
Yes. 8 exactly.
Based.
No, its powered by many video gen models. Its randomized, think of it as the exact version of battle mode.
Ok thanks
Gemini 2.5 and grok
"truth seeking arbiter" and "GPT-5" in the same sentence? what?
Absolutely not
not working

Use nano banana
Looking forward to seeing nano-banana on the chart.
btw who made nano banana and where is it other than lmarena?
I have no clue
I thought Google made it
Google would never put such a freaky name
And they already have veo

Lmao
Error: Something went wrong while generating the response. Please try again. Always when I paste some long code php

@tired herald what's the fix
I hate AI psychosis people
Hello
Me too
Hei
Me too... But one thing I want more is not to make GPT-5 a servile model
aka too positive and eager to please
but OpenAI is doing it
stated in a tweet
Me still waiting for Gemini 3 amd r2 💀🙏
I hope R2 will wreck the whole leaderboard like with R1
in January
🔥
To my surprise Qwen and Deepseek answer the same question better when asked through chat, not API. Deepseek and Qwen answer my music theory question 7-8 times out of 10 and Deepseek even infers almost correct conclusions another time which makes it more like 8.5-9/10 if I'm more liberal with scoring.
In LMarena when stress tested with the same prompt 10 times they both answer 3-4/10 at best.
It seems like the workload can influence performance.
But I cannot access o3 without lmarena
o3 still gets it correctly even at LMArena
OpenAI is the most demanded AI startup on this planet either way
They know how to scale their toys
Deepseek however seems to know about it a bit less
Holy hell if Deepseek in the chat version is actually that much better than the API version then I can only imagine what is going to happen once they will rent out enough compute to run R2
It's not there (the o3/GPT 5/Gemini 2.5 level), but it is very, very close
I want Deepseek v4. V3 is the best model available on AI Dungeon atm but I'm a bit burned out of its limitations.
hey, yesterday i lost all my chat sessions for some reason. can i retrieve it ?
Or maybe it is because LMArena proxies to Deepseek API through US servers and I am in Russia and get different entry points kek
Deepseek r2 will not be gemini 2.5 level?
is gpt 5 high any better than gemini 2.5?
depends on the gemini 2.5 and depends on the gpt 5
There's multiple versions of gpt5, high, chat, high nano and high mini
I used to think gemini 2.5 was slow, then gpt 5 high came around
so i told "gpt 5 high"
i mean you can choose the robotic personality
yeah dude lol
even gpt 5 medium
depends on the task
most of the time i have a feeling gemini 2.5 give better responses
and its little faster
I've heard that gemini 2.5 is better at different langauges compared to gpt 5
They know a lot. But they are constrained by CCP forcing them to use crappy Huawei chips lol
idk I don't speak other languages so I can't confirm
its also the us goverment forcing them too
yea, thats true - sometimes he makes typos
Sometimes.
One answers some of my questions better than another one. Depends on the question asked.
But they are roughly head-to-head in most things.
Well yeah but they were able to go around that (import restrictions) to be fair
If this is true this is sad.
Teortaxes wrote about it being fake news and so on. But here in Russia we actually have this exact problem, and being a Russian he sounds like massive cope to be honest.
But really
dude gpt 5 high is a lot better than the lobotimized gemini 2,5 we got
Only so much and it makes the chips more expensive
We in Russia learnt to evade this problem by importing foreign hardware and rebranding it as domestically produced one
the benchmarks you see are from the original gemini 2.5 pro that was not lobotimized(the first month of release)
We call it importozameschenie
True dat
They were still able to make it work. Now however having to use Huawei as well this is much more challenging. And there's no messing with CCP 👀
Original 2.5Pro was a fair bit less capable than the current version. People should really stop believing these conspiracy theories.
Sure lmarena benches are from the og 2.5 too?