#general
1 messages · Page 74 of 1
It was always part of the endgame. To start re educating the kids
grok shorts™
honestly it started with that guy called yang
What did he do lol
Ngl the xAI livestream had some weird vibes but maybe it's because most of the engineers are socially inept
Like the demo singing about the diet coke was absurdly cringe but none of them even realised that?
thats the consequence of lack of sleep
i dont remember exactly, but he was sharing cringe stuff all the time
I remember one of the xAI engineers did this whole thing that one of them equals 10 researchers at other labs lmao
They don't see how it's just cringe
yea he just recently said that
yea that was cringe too
I think they are trying to justify their shortcomings
'look we made this model called grok 4, while it may not be the best, but HEY DONT FORGET THAT WE ARE A SMALL TEAM AND WE JUST STARTED A YEAR AGO'
and please zoom-in on that
Clown 778 has left so I can discuss the results of the paper
With this "heavy" GenSelect inference mode, **OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.**```
This does not seem like it would match the real usage results at allThey are claiming to surpass o3 high on maths and coding benchmarks. Which may be true but I have serious doubts their models are truly better than o3 high
Even in parallel inference mode

If their claims are valid it basically means the end of openAI lol
i think he's trying to imply the difference between how human and AI contestants "work" at IMO, i sense a bit unfairness there in the approach at comparing since humans dont use anything else other than their brain while models can access a variety of tools (and internet?) but then again, what is fair when llms arent that comparable to raw human intelligence?
44ppl in Meta's Superintelligence team.
— 50% from China
— 75% have PhDs, 70% Researchers
— 40% from OpenAI, 20% DeepMind, 15% Scale
— 20% L8+ level
— 75% 1st gen immigrants

poached recently?
mm i see i see
yea this will def take a while
the transition from china undergrad -> us graduate i really incredibly common
wonder if the people will ever "come back"
bc ccp would certainly love that
zuck is doing more harm than good
I dont know if 44 ppl is enough tbh
he tried to go for quality over everything
with the insane salaries and all
yes
open source may be scrapped in general
the head guy suggested that
alexandr wang
me too, i guess a lot of these people where actually management level before -> might hire more people to the team with them as lead or they might get the FAIR people as "subordinates" to some degree
bc otherwise these people are really expensive if they can't manage
and only work on their own
guys may i know where they announce that the newest models got added - removed from the arena?
there was a channel called "🕸️ webdev-arena" but i don't know in which server it is
I wonder if the existing researchers got their salaries increased
or the dynamics of that
man upto llama 3.3 they made amazing models
rumors 😇
killing people (fictional character)
So 75% gonna get deported. Can't have illegal aliens playing with AI
if we shouldn't believe jimmy, who generally has a good track record, why should we believe you
what track record do you have
He's got a feeling
other feelings are inferior... 🤔
☠️
i dont really care if you dont believe me lol, im not going to out sources for internet points
sounds like Operation paperclip v2.0
to be fair industral espionage is a thing too. They can stay where they are and leak info.
it can work in the other way too (people that have contacts in other labs and get leaks)
No he is just saying that the rules and conditions for this contest should be disclosed and are possibly not comparable to the rules that apply to the human contest.
just we agree that o3 alpha is not o4 yes?
its not
its called o3-alpha for a reason
its a more refined o3 version
with coding-focused abilities and factually correct answers ( less hallucinations )
I think it'll be just an update
we've come a long way
i remember models couldn't even do ascii visualisation properly
Is o3 alpha still on arena
Checked yesterday, it was not there, barely anything interesting at all actually...
just like 'gpt2-chatbot' was called that for a reason lol
it means nothing tbh
o4 = gpt5
there's not gonna be o4 🙂
Also their current naming makes this... interesting. o4-mini is not a mini version of the upcoming improved o3 (gpt5), lmao
we do know that they are referring to their current gpt5 as "alpha" though
is O3 using Gpt 4 for base model, or is totally different one
gpt4.1
I thought gpt 4.1 was small model that has 1 million token window
gpt4.1-mini is a small model, not this one
Hmmmm. Can we use gpt 4.1 with app on plus plan ? Or only in API ?
Yes you can. But it's gonna perform similarly to 4o-latest (which is a different model to API dated ver of gpt4o)

who said that
gpt5 is a router model
could be anything
o-* + gpt model
hopefully it's based on 4.5
I doubt that's gonna turn out to be true tbh. Just a rumor. I think just "unified model" or bluntly speaking hybrid reasoning is much more likely
how to achieve hybrid reasoning model
Claude4
Not the same, Claude is not a router lol
im was talking about the final result not the approach used
they will both at the end chose which path to take ( reasoning/or not )
how is it achieved tho
I mean if it's an unified model, it could decide by itself when to output reasoning and when not to... Literal router does not sound to me like a good idea
reasoning effort: off/auto/low/med/high
or smth like that
yea i know but how do we decide that
its controlled by thinking_budget=0 / >0 & some internal controller
but how does the internal controller work
wdym. Model can decide by itself. And when it's explicitly specified you can always prefill thinking token and it's gonna output reasoning always
im talking about how does the model decide that
the training phase
or methods used
By being trained on both outputs with reasoning and without them. Where harder tasks contain it and easier ones do not
as simple as that?
qwen 3 has that too no?
Roughly speaking yeah... We already had some reasoning models that did not always output reasoning, that wasn't explored much yet though. It was all about max performance
mm i get it now, so its basically like a tiny classifier head used in the same transformer
looks at the query embedding and outputs a probability
yeah
prob is compared/learned through a param using RLHF
the challenging part is making this deciding by itself model perform better than o3-high. But if they add an option for explicit reasoning effort which it looks like they will, this becomes less crucial
im sure they will


Found out that Grok 4 got 60.5 on SimpleBench

Yet it failed miserably when faced with this prompt #share-prompts message
https://girlcockx.com/sama/status/1946575101509734619
why did they remove it from lmarena then... 😠
woke up early on a saturday to have a couple of hours to try using our new model for a little coding project.
︀︀
︀︀done in 5 minutes. it is very, very good.
︀︀
︀︀not sure how i feel about it...
@cedar tide too many pings I think
lmao


yeah I heard of this idea earlier. It's plausible
Does he really work at OpenAI though?
This satoshi guy
Sort of crazy how that CEO fucked up and then the internet fucked his life up 😅
**❤️ 3 👁️ 140 **
Oh, and once again, Strawberry dickhead doesn't know shit and most these shit talkers come from his direction.
lmao
bruh
I would still say 60:40 it's gpt5. But open-source model is a plausible option too.
this guy has nothing to do with oai
Nothing reliable yet I told everyone about o1 pro, about o3, about chain of thought tool calling in Jan as its on my profile, what the openrouter secret model was 4.1, codex, plus post before we update the Ui. The recursive system we have that Sam confirmed in his blog 🤣OK kid.
yea not reliable
why is he talking like a kid

@torn mantle tu verra
no trust me
hes like the strawberry guy
aint no way o3 alpha is the os model
impossible

do people really understand things like that
shes all over the place
fast talking
weird movements
Kinda agree. And like this #general message.... That's exactly the kind of thing you would say when you are ignorant and have no clue. "5 is bigger"
That's unlikely for 5 to be bigger, and also even if it was, no one would ever say this
this companion thingy is fun but its not well executed, and im not talking about waifus / elon's degenerate ideas
"strawberry dickhead"
this dude is clearly a troll
and he works no less than at mc donalds
there are many of those links and one of them is that
Yes, there is an official marking guideline from the IMO organizers which is not available externally. Without the evaluation based on that guideline, no medal claim can be made. With one point deducted, it is a Silver, not Gold.
they are embedding improvement for stock x.com url
Yes, there is an official marking guideline from the IMO organizers which is not available externally. Without the evaluation based on that guideline, no medal claim can be made. With one point deducted, it is a Silver, not Gold.
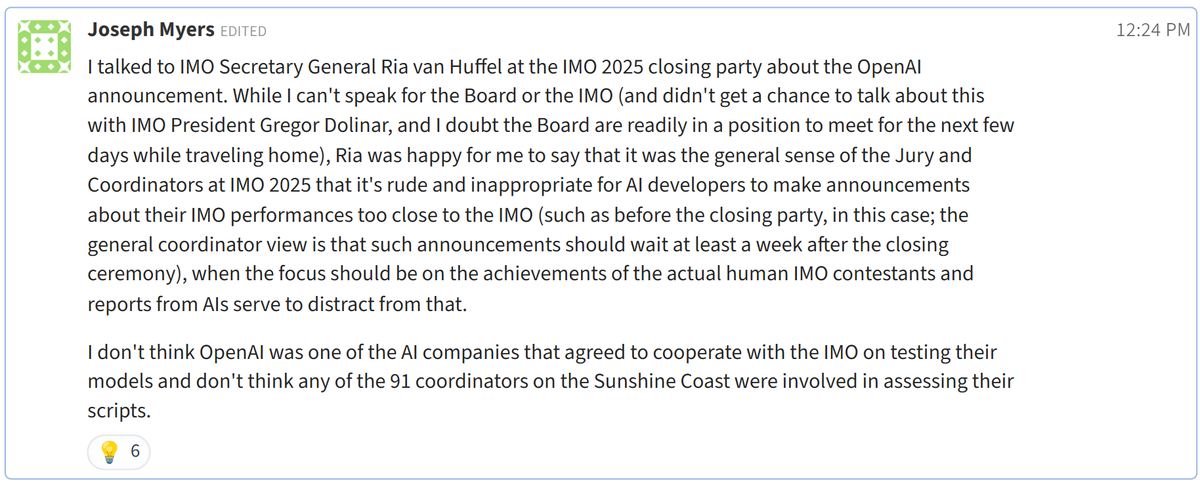
Quoting Mikhail Samin (@Mihonarium)
︀
🚨 According to a friend, the IMO asked AI companies not to steal the spotlight from kids and to wait a week after the closing ceremony to announce results. OpenAI announced the results BEFORE the closing ceremony.
︀︀
︀︀According to a Coordinator on Problem 6, the one problem OpenAI couldn't solve, "the general sense of the IMO Jury and Coordinators is that it was rude and inappropriate" for OpenAI to do this.
︀︀
︀︀OpenAI wasn't one of the AI companies that cooperated with the IMO on testing their models, so unlike the likely upcoming Google DeepMind results, we can't even be sure OpenAI's "gold medal" is legit. Still, the IMO organizers directly asked OpenAI not to announce their results imme…
Way better
I have a feeling most people will be disappointed with gpt5
it's just a fix embed domain very fitting to X 😇
they are fuming
shows how much IMO means to them
it was their thing
their lil baby
now oai stole that from them
ikr. Massacred and scarcened deepmind, can't let this go lol
already deducting points 💀
i read the openai "solutions"
they are garbage lel
the model somehow does not even write coherent english?
like it feels like they didnt teach it english somehow
I think they just trained it to not waste tokens on complex/long sentences... it still makes sense
https://github.com/aw31/openai-imo-2025-proofs/blob/main/problem_1.txt
GitHub
Contribute to aw31/openai-imo-2025-proofs development by creating an account on GitHub.
cant tell if it is sarcasm ngl
some ppl could probably spin it in their head as an innovation lol
try training your own model to do gold then in a math competition you have barely any data about at all as you are training....
The amazing about it is that it's actually an usable model as well, unlike AlphaGeometry...
did they really mark their own solutions
thats what i heard
why dont they let all the imo participants mark their own solutions
@whole wagon I refuse to believe you aren't actively and deliberately trying to stay ignorant lmao
It isn't. I find rl artifacts really cool because it's largely unintentional. There are so many rl artifacts in those traces, if you've seen it before
what do you guys think about the theory that it's actually a formal language, just written in a way that looks like plain english?
It could be doing that partly in the cot but this reads to me like the final output of extremely rld model. So you can't tell much
I'm 100% sure this is final output and not cot and also not intermediate agent results etc.
It seems to me it reasons primarily in natural language in the CoT though it can 'codeswitch' into lean or whatever maybe
Those are valid and correct solutions though at the end of the day. I suspect if you read AlphaGeometry solutions those would look way more weird and unnatural...
I think the solutions are good weird at least to me. It reeks of rl
AlphaGeometry was bruteforcing it and combining existing ML algorhitms with an LLM. This in contrast appears to be an actual singular model that you can use.
i could write pages on how this solution is flawed. The solution presents the bijection as a fact for example
just on problem 1
It's a good thing you are not a judge and not qualified to be one too
the premise is transformed from n+1 to n but then later on they somehow start using n+1 again. There is no reasoning for why this occurs
"For n=3, we have possibilities k=0, k=1, or k=3" no justification?
just stated as a fact
the IMO solution explictly enumerates all 6 points in p3
it shows possible k values are 0,1,3 but never proves those values are achievable for all n greater than equal to 3
the invokation of the pigeonhole principle is vague, they dont define exactly what the pigeons and holes are
The solution states that if you remove a side-line, you get a valid covering for n-1. There is 0 explanation for this
I think you should at least read on how it's being graded


"proving"
there is no proof in the openai solution
i can tell they didnt "make an argument" about the boundary point covering. because they literally just state it
I think this part:

though to be fair we do not know if all problems were graded the max 7/7. Solving it does not neccessarily mean full grade 
i heard if they drop a single point it goes from gold to silver
IMO Gold threshold this year is 35. OpenAI are assuming all their published solutions are 7/7 perfect because 7*5=35. They graded it all themselves and did not participate with the IMO people at all. People who did (eg DeepMind, probably also ByteDance, DeepSeek, etc) are still under an agreed embargo for a few days.
well in that case it counted as the necessary proof I suppose... But anyway, we are arguing about small details here. It's a big achievement no matter how you put it
its an achievement. but i dont believe it is gold
where is the grading site btw
i can go through point by point
from the headings for problem 1 they have 6 at least
DeepMind got a solid silver last year, I think the main achievement here is converting to natural language. Its interesting but its EXTREMELY likely that a 1yr improved prover (eg DeepMind's or DeepSeek prover) will score gold.
I think this sums it up well: https://werd.io/openais-gold-medal-performance-on-the-international-math-olympiad/

Werd I/O
OpenAI claims a significant result: gold-level performance International Mathematical Olympiad. But they're scant on details and it needs to be independently verified.
independent verifications are welcome, obviously
I used this https://matharena.ai, they have grading details for each individual IMO score and the requirements when you click on it
hm well with that grading criteria it is 7/7
yeah fair point I suppose that it may not be 100% identical. But probably as close as it gets at this point
We followed a methodology similar to our evaluation of the 2025 USA Math Olympiad [1]. In particular, four experienced human judges, each with IMO-level mathematical expertise, were recruited to evaluate the responses. Evaluation began immediately after the 2025 IMO problems were released to prevent contamination. Judges reviewed the problems and developed grading schemes, with each problem scored out of 7 points. To ensure fairness, each response was anonymized and graded independently by two judges. Grading was conducted using the same interface developed for our Open Proof Corpus project [2].
Don’t think they stole anything since they also got the gold, by the right way. OAI not passing the vanilla test&jury is more like them worrying to loose the battle. I’m sure if they had Silver with their eval they wouldn’t make noise
This explains why OpenAI results are out and GDM results are not.
And what's out is not even official results verified by IMO!
problem 1 - 3 looks fine with the point system
Nitter
🚨 According to a friend, the IMO asked AI companies not to steal the spotlight from kids and to wait a week after the closing ceremony to announce results. OpenAI announced the results BEFORE the closing ceremony.
According to a Coordinator on Problem 6, the one problem OpenAI couldn't solve, "the general sense of the IMO Jury and Coordinato...
can you prove that you really have it
not to you, no
hmmmmmmmm
Can you share links
Let me read them a bit
this is correct me thinks
Can someone share links or nah
moving fast and breaking things
hello
can anyone help me. i use LMArena. to create the image but can not create vertical image. can only create 1024x1024 king image

I have fixed the prompt many times but it still doesn't work.
are you good at math?
I'm not
If possible can you please re-prompt me?
768 x 1376 . nhưng AI chỉ tạo ra 1024 x 1024

I want to create a picture with dimensions like this. It is 768 x 1376. But AI only creates 1024 x 1024.
just looking at problem 1. OAI solution seems a bit of a different proof. "Stating and proving that the leftmost and bottommost points are covered by nn or n−1n−1 lines." . the OAI model doesn't do this, it shows instead that one line must always be a triangle side (and so can then be removed).
I am looking for someone to work on a project I have some ok hardware (3x 3090 GPUs and Threadripper 3990x with 128 Gb Ram). If anyone is interested DM me.
I think there are valid points in the comments. OpenAI brought more spotlight to it than this competition otherwise would have gotten. And all we have are some anecdotal reports from people allegedly having connections to the organizers and not even the organizers themselves going publicly on record to say there was anything wrong at all in what OpenAI did...
If we asked people actually taking part there (students), I would be very surprised if majority was in favor of forcing the labs to wait before they publish their results
Like all of it just seems a cheap way to attack someone, and seems to be driven for a good part by those who are just generally against OpenAI no matter what they do lol
They managed a breakthrough? Find ways to poke holes in it or how you don't need it. Then start needing it when everyone else starts doing it.
They beat the competition? Find ways how they cheated. And if they didn't cheat then they did something else wrong or released the results at the wrong time... 
I don't even think that's what's going on, I think they likely do consider the announcement rude, since it comes from an individual speaking to one of the directors.
It doesn't help that all the other companies are effectively under embargo and also want to announce, then a company comes in and didn't go through official channels and takes the spot light. So it angers the other companies and also embarrasses the IMO.
Also matharena published results before OpenAI did. I don't think they would have waited any longer even if that 2.5Pro run was medal worthy lol
"Individual speaking to one of the directors" just sounds incredibly weak though. There's no official statement even remotely resembling anything like this...
They're not going to make an official statement
well then it's "he said he heard person X who's sister rated one of the problems" types of thing lol
meaningless
All you have to do is find out who Joseph Myers is and see if they are indeed a reliable source connected to IMO officials
If yes, then likely what he's reporting is true
I'm not saying he made it all up. But you also need to realise they have dozens of judges and probably even more people that could be counted as organisers and quoted.
It is a guideline they have at the end of the day
Whether or not they are truly angered by it is not that relevant
They should follow the guidelines
Is it really a guideline for outsiders though? Doesn't seem to apply to matharena.ai etc
If they have AI labs asking their judges to participate rating model outputs then I suppose there could be guidelines. But it doesn't look like OpenAI was in that circle
was openai aware of those guidelines when they released those results? i think that's what matters
that is actually insane if its open source, wow
if they did, it's bad faith
Isn't it public information? Should be very easy for a company like openAI to know
It's almost common sensical
They were in contact with imo ppl they ofc knew lol
if it's public then link it lol
Even Altman would intuitively know this
I don't see it
It's extremely unlikely openAI is oblivious to this
Every year the AI labs wait a period of time before releasing their results. And you are trying to suggest openAI were not aware
If they are not part of their inner circle or asking their organisers for anything (rating outputs), I don't see how any of this applies what isn't public info tbh
ive got no dog in this fight nor am i familar with imo btw, just stating that it is bad faith if they were aware of it
That's basically what makes it rude
Imagine you training your model yourself for a breakthrough result and this receiving this same kind of scrutiny after doing everything independently lol
Like them "not being officially involved" doesn't spare them the "rudeness" of the whole thing
you were not bound by any internal "guidelines"
I'm aware
They're in effect taking IMOs prestige to hype themselves
Which is why it is rude
it is not any more "rude" than matharena publishing IMO leaderboard
Debatable. They are also making IMO much more talked about event than it otherwise would have been
and bringing more spotlight to the human participants
This would have occurred either way, even if they waited a week
Especially from the other companies
The main thing is this embarrasses the IMO
That's why you get a comment saying it is rude
but they had no clue what the results would have been. You can't judge it based on the results. If there ARE any guidelines (even that part is murky), they are to be applied universally not selectively depending on who does it.
It's just openAI disrespecting some obvious social etiquette
Yes but I thought it is valid still. There is a few places where they do things differently
that's an extreme reach lol
I'm not saying we can't consider matharena rude, I'm just saying it's too irrelevant to be noticed compared to a company hyping up their gold placement while every other AI company is forced to keep their mouth shut out of respect to the IMO
Hence, the rudeness
OpenAI is casually being rude to both the IMO and every other AI company involved
This is literally common sense and not even controversial
Yeah but it's openAI they never cared about things like that
I don't think they are forced per se. I think Google just did things differently and hence were bound by different constraints. They asked the actual judges to rate the outputs and hence were expected to comply with certain rules
No, not a single involved AI company, not just Deepmind, have said anything out of respect to IMO
matharena and OpenAI did not go that route 🤷♂️
There are both open source and closed source AI companies that participated this year
They haven't announced their results, out of respect to the IMO
Hence, openAI is rude
Well there is the entirety of AIMO that is also keeping quiet
It's a massive thing
Yeah. They just don't create a fanfare till the embargo date
That's your assumption. However matharena did announce them, and as for others.. We do not know what their relationship was (did they need assistance of judges), or even if their runs were actually successful and worth celebrating etc
It was literally stated earlier they are supposed to wait a week
The result itself is fine to publish imo. It's all this hyping and the suggestion openAI was the first (the other companies are literally just waiting)
How am I assuming anything lol
I'm literally just saying what has been stated they are supposed to do
Link to that guideline?
We already have the report from the secretary general conversation for one, which you reject
that's what internally was supposed to be an understanding for the labs participating together with them. OpenAI was not one of such labs...
therefore it literally needs to be public
or it kinda doesn't apply
You have to prove they didn't know
bruh...
If we're going to do this whole annoying burden argument thing here, then you have to prove your position
They were not part of that circle needing special treatment in the first place
even then, shouldn't those guidelines only really apply only if they were using the actual judges. it's still kinda bad faith even if they weren't bound by them anyway, but posting the results is fine i guess since they were unbound
Why didn't they make themselves part of the circle? They literally just came in as an outsider and said they got gold according to themselves
Why does it need to be public then if it doesn't apply to them?
That is strange
That makes no sense
The point is, if that expectation exists, then it's rude even if they weren't officially involved
i guess so they could do this lol
Like If I was participating from outside I'm publishing my results without doing some hilarious investigation to find out what they are secretly thinking internally lmao
Right, because we are discussing if they did so knowingly
Because doing so ignorantly technically looks less bad for them
I mean, sure... But there's also a question whether it even applies at all to outsiders. Even if you are aware of such rule being imposed on someone who is considered part of internal circle...
i dont think it applies, but they probably avoided participating officially with the imo just so they could publish results early. which is sorta bad faith
Like they do get the benefits for assistance of judges. It's not like there's only 1 way to do this
If the IMO indeed wants the first week to be about human achievement, and tells all the AI companies not to report yet, then some outside company company comes in before the closing ceremony and says "we got gold everyone!!!" And hypes their product, then it seems natural that would be annoying both to the IMO and the companies involved.
Obviously they're not bound by that standard, but that's precisely why it is rude
Because you're using their prestige and name to hype their product, while contradicting their intent to celebrate human performance, while also stealing the spotlight from other companies respecting this waiting period.
So basically, because other companies are respecting the IMO, they're getting slapped in the face meanwhile.
If they definitively contacted OpenAI and told them that then I agree it's bad faith, even if not legally bound at all. Though I find the details on this murky. There needs to be public info in writing for them to be in a good position on it
There's no "legality" here
Well I used this term loosely. Valid submission whatever
Well, I think openAI being ignorant of this expectation looks much better for them
It’s really not okay to lash out at someone or point fingers before we even know the full story.”
But, if they were aware, then yeah that comes off as bad faith
if they contacted openai even if they weren't participating officially, it's definitively bad faith.
if they didn't contact openai but openai were also aware of the rule (which is likely) which resulted in them not participating officially, it's sorta bad faith and manipulative (in order to release the results early). but plausibly deniable i guess
Fundamentally I think... We should apply the same rules to them you would follow yourself if you were training a model and wanted to do it. So we still come back to that public info part. Allegedly contacting someone on the side but not everyone is not the way this is supposed to be done
Yep, this is basically my view
Also I find it strange they didn't just officially involve themselves like everyone else did
Which may add to the whole rudeness factor, because every other company had the courtesy to go through the IMO
I agree but only partially and conditionally depending on the actual communication. Seems to me like what they did was still a valid path to take, and in some ways, perhaps even smart. They did take some risk too though as it's not gonna be a great look if this doesn't pass independent validation lol
has everyone here already seen this

I actually have a slightly different theory over what happened, despite what I just said.
4. OpenAI surely knew GDM was working on the IMO, so they beat GDM to the punch with their Saturday morning announcement, generating hype. GDM’s slow-science scholarship cost them the PR battle. (4/10)
lol
elaborate
Well I doubt my own theory now
You should appreciate that openai blessed this earth with their presence 

Basically, I think they didn't intend to participate in this IMO, until they heard Deepmind got gold and saw the questions. Realized they could get gold too and rushed and solved the problems then announced
we will see roon
Which is why they didn't go through official channels, because they originally didn't plan to participate
And the timeline technically lines up
Yeah I agree
I think had there been tougher questions, openAI doesn't participate
Because, it was a good opportunity for them
“openai made ai open”
🥀
deepmind gets gold and it gets leaked on twitter
36 hrs later openAI announces they got gold
Says they solved each question within 4.5 hrs each (so they could have solved everything within a day)
that would be a crazy series of events
They probably know Deepmind can't announce yet, decide to announce
Well i dont think it changes anything fundamentally. they are still being chased down the fundamentals are identical before and after
Yeah I doubt it too, that's why I didn't want to share lol
If both of them got similar scores then im more interested who got the cleanest readable solution
So they both failed p6?
But still 1/10
maybe the model is too smart. i noticed with o3 sometimes it skips steps cos it just assumes ill get it
like it cant conceptualise what a human would struggle to understand
It pisses me off all the time
Hmph
I have to tell it to elaborate
And don't assume things
Makes me so mad
🤬
Have you tried Heavy Dork 4.0?
https://vxtwitter.com/ns123abc/status/1947016206768046452
So they're claiming how they mark correct answers is only internally known
🚨🚨🚨BREAKING: DeepMind leader calls OpenAI’s IMO gold claim bullshit:
“IMO has an internal marking guide no one outside sees. Without that, you can’t claim a medal. With the point you lose on P6, you’re Silver, not Gold.”
Reminder:
OpenAI didn’t even collaborate with IMO.
vague-posts results with no full transparency
DeepMind collaborated with IMO to verify results
IMO explicitly requested AI labs to wait a week after the closing ceremony
to avoid stealing spotlight from brilliant students (humans)
OpenAI chose to announce their results BEFORE the ceremony even ended
Research community: “OpenAI has been disrespectful”
LMFAOOO

How were you guys judging if they were correct then? Based on prior IMOs?
Depends if the guidelines they know is the same used in 2025
it is bullsh'it the existence of this internal only thing, but on the other hand... Claiming a medal without cooperation with organizers can be a valid point as well. This is getting interesting though lol
🍿
wait are they claiming it is literally impossible for openai to get gold?
"IMO has an internal marking guide no one outside sees."
With the point you lose on P6, you’re Silver, not Gold this sounds unambiguous
like its just straight up impossible
eh this is all some weird bs im going to only treat the official results as real
i wouldnt accept a student doing this path
why would i accept an ai company
yeah if true then that's not gold... It was gold based on publicly available info 🤷♂️
Would have been insane plot twist too if they changed that reactively responding to OpenAI... lmao
@whole wagon explain this to me:

no last task = 35 = gold
the way everyone would read it
i dont need to explain anything it was a question
what
If they have official data clearly stating what a gold medal result is... That tweet gets an entirely different context tbh
At the moment it looks like this:
- Company X gets gold.
- Undisclosed guidelines change going against public info
- One of "internal partners" gets gold instead.
This whole thing can go dirty both ways lmao
OpenAI claims full marks on P1-P5, for 35 pts
I think the Deepmind employee was just saying that the internal guidelines aren't known to openAI, so how could they grade themselves? And if the lose even just a single point from those guidelines they get silver not gold.
That's why I was asking how you guys had scored it as 35, without knowing the guidelines
that's not AI summary lmao. It's the old fashioned search type of thing
info straight from that website
which isn't loading atm for me
Anyway, it matches with what you said yourself, so what is the issue?
ok it did load somehow... yeah exactly the same info:

according to this 35 without last problem is gold medal
So yeah... they can say internally what they want, if my model scores 35 I'm claiming it scores equivalent of gold medal with a clear conscience 🤷♂️
Yeah that part is a factor still. Which is why I said they are risking it claiming the result valid
LOL. Well we can only expect or assume they didn't half-ass it. They did know it's gonna need to be independently verified and published outputs for everyone to see, but who knows...
The problem right now is that if IMO organization is really united on this, they will want to screw them over as well lol
Also regarding the last problem, did it not produce final solution or did it not output anything useful at all? A detail that could be meaningful and something they may be withholding...
It comes down to whether or not they actually got gold according to the IMO guidelines, because if they didn't then we might see some drama over this.
If their answers are valid to those guidelines then I don't think that drama happens.


maybe sam promised that they would get the same pay at oai if they turn down the offer
This gap is crazy

Though the speed with which Google has gained ground is absurd also
not surprised
grok will get a bit more cuz of the new companion thingy
Yeah this changes quite a lot... People are quick to blame OpenAI and attack them for pretty much anything lol
Android
this was made by gpt agent
OpenAI are shameless greedy villains, they don't care about those harmless little kids BOOO 🤓
mb im late to this message but this is NOT impressive its just using plugins or whatever its called from threejs for the water and hills
did they even check the code
maybe its good at problems but its not good at coding
thats js dumb 🥀
forced integration aint fair tho
Like having ChatGPT in my iPhone
This past week, Harmonic had the opportunity to represent our advanced mathematical reasoning model, Aristotle, at the International Mathematics Olympiad - the most prestigious mathematics competition in the world.
To uphold the sanctity of the student competition, the IMO Board

Well, that confirms the wait a week claim
Also confirms they are supposed to wait for the sanctity of student contestants
You can definitely tell these companies are annoyed at openAI
Yeah, but only as far as they are concerned doing this internally with IMO and assumingly using their judges. OpenAI was green lit by IMO:
#general message
Hi 👋 Can anyone tell me which AI models available on LMArena have the most recent knowledge cut offs? And through using which ones can I get the most up-to-date and accurate information? Would be really helpful if you help 🙏
They are annoyed but probably an equal amount about the fact that they didn't think of doing it this way themselves lol
Though this is still mostly only relevant to the labs actually competing for the top spot though...
google gemini cooking?
do yall think it gonna catch up sooner or later
for others I would imagine the advantages of doing this in full collaboration far outweigh the opportunity of releasing results slightly sooner
yea with waifus
and nsfw stuff
I like how you cite me while explaining this to me lol
Google numbers are inflated by all those Android phones with dedicated AI buttons lmao
Your phone comes with it pre-installed so you automatically an user if you buy it. Any kind of automated request tied to a feature could count as an "active user"
no but if you think about it, xai cant boost their user base with just grok4/3 or a 300$ plan, then need to find another way
and then some genius at xai (cough cough elon) proposed companions
they know how a lot of virgins will eat that up
its sad but they dont have a choice since they are incompetent at making good models
Trump's phone gonna fix all their problems
the best phone
comes with Dork preinstalled and SuperDork free for the first 3 months ™
whos gonna win the ai race
definitely google
It's either Google or OpenAI
well first we need to define the finish line/target
xAI too detached from reality, Anthropic thinking too small, Meta is like MS operationally so don't really see them leading the way ever tbh
agi ig
or just takes most of the users
like 85%
idk
Chinese labs are impressive, but they are yet to prove they can come up with their own paradigms or ideas and convert it all into finished product
zuck poached many employees and lead figures from oai, but the way i see it, is that they will likely face the same outcome as xai
it's extremely difficult to start from scratch, even if you have a significant background or extensive experience
+they still need more personnel
open-source from them is impressive, but then again there are no closed Chinese models better than that regardless of how much you pay
tbh, we should be asking 1000 questions to the people who left
i honestly still don't understand why they would leave... can money really be a strong enough motivator to do that?
afaik they didn't really poach any key figures from OpenAI. Relatively speaking I mean, every single person working there has an impressive CV technically and it's very easy to make big deal out of it
chinese are a great case study people should learn from... you get the sense they genuinely want to innovate and achieve agi by any means necessary
In some ways yeah... But they also want for others to see their success more than anything (aka facade). Which is part of the reason why their best is equal to their best in open-source ig
If they come up with something, they gonna make sure the whole world knows it and it's represented in the best possible way 👀
also for anthropic, I get the impression they're working more for the government, or to please it, rather than for their actual users
look at how many years have passed, and they still have rate limits and GPU issues
but they good at coding : (
however, their core philosophy remains the same
true
wdym? They are all for "safe AI" though and the current US gov wants to ban all regulation with safety canceled entirely essentially lol
they probably have more respect for their employees than oai does... for example, lets say their researchers at anthropic are allocated 30% of the GPU resources for their own tests, simulations, etc... I'm certain that this percentage in oai case has decreased over time, which shows they may prioritize users.. but in turn, has an impact on their researchers, and it could very well be one of the reasons that led those researchers to search somewhere else
idk i just feel like their culture are so different
/ what they prioritize
everyone wants to show-off not just the chinese
Well but you can't make an assumption out of thin air and then say that it shows something lol
but do you have the talent to do so?
why cant other labs do the same?
i mean wtf happened to mistral?
There's no GPU resources allocation for engineers at all tbh. Neither at Anthropic nor at OpenAI. They have certain projects and the resources allocated for it, you don't have random people running around hogging compute if that wasn't planned months in advance and wanted by the entire company
Ofc they do have some kind of resources they can use for isolated work related smaller things, but that's gonna be miniscule comparing to the resources we are talking about with training the production models etc
and mostly not a problem at all to limit ever
Beep boop, am i disturbing?
Had a question
Back when i was using lmarena, i remember the models generated the code and deployed it too right then and there, does that not happen anymore?
Or is that feature relocated somewhere else
i'm talking about the whole R&D department, not individuals.... what I mean is that this number, or its percentage, we can say is fixed at anthropic or more prioritized, whereas at oai it could have decreased given their massive user base
Lack of funding. They recently partnered with nVidia though iirc
so probably things gonna get better
Yet OpenAI is sluggish af, azure works so much better relatively
Those are just assumptions. It may as well could have increased due to them modernizing their infra even more than the user count increased...
OpenAI is not sitting still
Meanwhile Gemini giving out year long free trials, thousands of free requests per day on CLI, all them Veo 3 nonsense, and having blazing fast speeds still.....
TPUs are just so much better, aren't they 🤔
has to be web based code though
Ah, without that subdomain it is just simple chat and image gen huh, i see
well, its possible hypothesis, of course I'm not saying its 100% happening, but it's plausible that it could happen
Seems to be broken at the moment?
When i type something in it and send it, it becomes unresponsive, nothing happens, it doesn't freezes it just does nothing.
Same when i click on suggested prompts, same on both desktop mode and mobile mode


LMAO
jesus christ
why do yall think it google? (i agree, i just wanna know ur reasons)
what ht ehell
Google did 80% of the foundational AI research of the past decade that allowed the other AI labs to exist
Google was already spending over $30B a year on R&D (mostly on AI) before ChatGPT existed
oo

There is no companion only a blender rig and a computer server behind it
How do people delude themselves into finding this amusing
i have been doing this with sydney for ages
aren't we all just computer servers at the end of the day

Claude back soon
hey guys,can anyone tell me what's the rate limits of flux kontext max in lmarena
Are you looking for the code preview section in https://web.lmarena.ai/ ?
The current ask for no is 97.8c. It took the market 5 days to reach a relatively fair price. No need to wait until resolution to realize 11% profit😂

this sounds more like an ad for machine learning than anything 😭
https://www.instagramez.com/reel/DF2JqSeNFfB/

💬 118 🔁 0 💜 11.8K 👀 125.6K
In 2003, IBM attempted to appeal to the hearts of ordinary computer users through a commercial that aired on U.S. television during the Super Bowl broadcast. The ad featured a young boy who personified Linux. He's 9 years old*, curious and quickly absorbs information.
We can argue at length about IBM's role in the modern high-tech world, but credit should be given to them, as the commercial turned out to be a masterpiece. Enjoy watching!
* Linux 1.0 was released in March 1994, so in the 2003 commercial, the boy was 9 years old.
#CusDebMagazine #TechJournal #TechMagazine
#IBM #linux #LinuxKernel #SuperBowl #SuperBowl2025 #SuperBowlAd #SuperBowlAds #SuperBowlCommercial #SuperBowlCommercials
yeah ik it’s meant to be focused on the expertise of contributers across the world but still
Yes
If anything the foul play was by xAI with those initial benchmarks that don't look very realistic. The model is just not very good and outputs are way too short and basic to do well on lmarena lol
It had a chance of capitalizing on their earlier success there, but when you look at the outputs of it it's easy to see why it did so poorly... People will not vote for what they don't see and what is hidden, there was no such issue with grok3.
given suitgate and several scandals with whales lately im expecting the worst strictly.
I mean from polymarket
Lmarena has no stakes in this and its just caught in crossfire
Silver lining this is a small market/I did not see any of the usual suspects. Too little money for them. Id fully expect an army of people/bots trying to influence it otherwise
Does anyone know when the Text Arena leaderboard is updated? Are the updates weekly?

He took the advice a bit too literally lmao
They have a fairly solid protection against bots with cloudfare which seems to have strict settings (hence the people complaining about getting locked out of the website). Though ofc everything is possible, spotting your own model should be very easy too when you know what to ask - but you can't exactly automate that, at least not easily.
Hard to tell if it's regular in same intervals but the last update before current one I think was 1 week earlier yeah
is it me or it has been a while since new secret model from Google. Stonebloom has been around for quite some time.
they are still finishing up Ultra 1.0
give them time
👀
But yeah... They are way behind schedule and Ultra name controversy continues lol
I have to disagree. Its not trivial but its not that hard either. And we talking f u kind of money with some these people. Worst case you can afford to pay 10 people to non stop click via vpns. This being the brute force approach basically with little to no automation.
Is the openai anon bot gone, been a while since i got it
Not saying it happened, there’s no sign of it. But it could
Like I said anything is possible... Though I would imagine cases of spamming the same thing (prompt) from several IPs relentlessly is an easy thing to catch and exclude from results as well lol
Given sample size in the voting (20k votes) its trivial to bypass IP restrictions. Only nord vpn would give you 100 + ips to use
this all would be visible to admins of lmarena. They have all the prompt data. If prompt or prompts repeat suspiciously, they can take action.
In some ways, if you have the money, you simply fine-tune your model to do well exclusively only on lmarena if it's so important for you and that's gonna be more effective and perhaps even easier. As for betting and polymarket, people with such resources do not bet on these odds...
Man look up polymarket suitgate 🤣
The guys own the whole crypto chain they use to solve markets. Talking few hundred million usd there
I meant it for lmarena related odds. Some of the other bets and categories get lots of attention and reach for sure
Eg: when something is disputed they use a distributed voting system that’s external (uma token). Few wallets hold majority of uma
Agreed, simply not enough money in the ai markets to be worth it
guys, you talk about polymarket so often How much do you actually bet? if you're comfortable to tell.
Not that much in my case just few grands disposable income
But you get range from 10 $ to 100 million people basically
ok, wish you good luck 🙂
Thanks
@pure lynx If you look there there are all the updates listed:
https://github.com/fboulnois/llm-leaderboard-csv/releases
GitHub
CSVs of the Huggingface and LMSYS LLM leaderboards, along with the code to generate them in R. - fboulnois/llm-leaderboard-csv
looks like it's somewhat more frequent than once a week actually
just noticed smth interesting too... their csv includes 2.5Pro-05-06 too even though the official leaderboard in new interface doesn't anymore 👀

So technically... even without style control Grok4 is still 3rd not 2nd lmao
Funny how mistral is now building manpads 😄

Mistral also has a very nice car lmao
Such an awesome company!
yea
it kinda reminds me of gemini 2.5 flash reasoning
That was very verbose though. Well I mean you could see the output and see it in full. Even if it was fundamentally similar you don't get to use any of that with Grok lol
I'm fairly sure in certain cases Grok answers could be counted as a pass or at least partially correct instead of completely off the mark, if only you could see the reasoning it did. But you can't
im so lazy to explain xd
Especially relevant for these math competitions where there are strict clear rules and containing explanation and not having it can be a difference between 1 or 0 points for that part
This model has been in the arena for 2 months, still without results 🥴 (he still appears in the arena)
gemini 2.5 flash lite and minimax M1 are also in the webdev arena for a long time and still no result

I expect GPT-5 in 1-2 weeks.
Coding model is likely next year
The rest seem ok
midjourney 8 and claude 4.5 are the most exciting ones on this list
Have actually no idea what you mean, here's telling me they are nothing alike without using words:


🗿
When do you all expect Gemini 3?
idk its just that grok 4 gives me 'weaker gemini 2.5 pro' vibes, which makes it feel like a weaker iteration.. again im saying it reminds me of it, not claiming that its a perfect match for flash ver
.
wolfstride / stonebloom / kingfall could all be gemini 3 early checkpoints
leo shared their metadata before
v3 internally is used for Gemini 2.0 right?
i dont remember tbh
but there was n+1 iteration for wolfstride/kingfall/stonebloom models
you guys tested that new openai model? sth sth alpha
the interesting part of the internal model names wasn't to do with that lol
it was that the suffix for gem 2.5 pro was "m" (as in "medium") and for kingfall/stonebloom/wolfstride it was "l" (as in "large")
Claude 4.5 sooner
not as Gemini 3.0 as Asura said
@echo aurora add HiDream-E1.1
Best open source image editing model
https://huggingface.co/HiDream-ai/HiDream-E1-1


ah this one yea
We still haven't seen seededit 3.0 in direct chat, pineapple
gemini-v3p1l-rev20-kingfall-sc__202505301__model__variant
 I'll be sure to flag.
I'll be sure to flag.
#1396830129635852329 message
Unicorn and Ultra fate then... I wonder if they are actually planning to ever release it. Probably marginal gains on most conventional metrics
no obvious activity on that stuff since wolfstride dropped on the arena
that was late june and now both of the models are gone
💔
also still find it weird that oai dropped that interesting model on webdev arena for a single day
Add gemini 2.5 no think instead of putting crappy models from amazon that nobody wants (kraken folsom, v1 v2, nova experimental)

Probably wanted to quantify the gains they made with spatial awareness. Webdev arena remains one of the most reliable metrics for this, even if focused on code...
arc-agi-2 is as good as useless for spatial awareness now, doesn't mean anything lol
wesh
they are still experimental models
and they cant just say no to requests from amazon
were kingfall/stonebloom/wolfstride early versions of gemini 3 or?
when do you expect that to drop then 😭
would you bet before or after gpt-5
the next 2-3 weeks should be fun then
how do ppl access that o3 alpha model?
ah ok then. i was running prompts like stupid
but i found interesting model, nightforge - anyone know what is it? probably a gemini model?
minimax m1 iirc
btw it's a weird model size for it just like the name suggests lmao
neither max nor mini. Neither good performing nor lightweight
Is it confirmed we will get gemini 2.5 ultra?
for all intents and purposes
or ultra dumb
if there is no exp model yet nothing is confirmed
ultra?
when was it lol
ah ok, i was talking about this

they usually do the release well in advance
like month
so i guess we arent getting anything atm
yes
im curious what the cost of O3 Alpha will be
this model looks really strong
if then it's due to geopolitical power play...
Is it in the arena
The battle one
I never get it there
i am a vegan who drinks dairy kefir
no coconut kefir has worse properties than dairy kefir
i will do everything to become healthy
would u say i am doing everything i can do be as vegan as possible?
i suffer from meteorism and psoriasis and constipation, in short a bad microbiome/dysbiosis for unknown reasons. probably very low motility.
so i am trying dairy kefir now cause this helps some people
i also tried bile acid from bovines
and digestion enzymes
Hi
Can anyone tell me which AI models available on LMArena have the most recent knowledge cut offs? And through using which ones can I get the most up-to-date and accurate information?
where is kingfall in benchmarks ?
where is this info?
iirc i posted it here or dmed it to them
Does anyone know why mines keep showing "something went wrong with this response try again"?
This is such a nice site but the worst thing is you just can't copy paste the whole conversation if you wanna restart because of the way the site is, you can't select more than 1 reply at a time, makes it so annoying
how do you use the best voted models if you don't at least put all the models out for voting? 🤔
The best voted models in "model-request"
https://discord.com/channels/1340554757349179412/1372229840131985540
ahh
naaah
Ai explained did a vid shitting on openAI imo announcement
Lel
The goat of AI influencers
Sora 2 is coming soon
Maybe openAI can redeem themselves after getting mauled by Google

Nitter
An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International Mathematical Olympiad. 🥇
It solved 5️⃣ out of 6️⃣ exceptionally difficult problems, involving algebra, combinatorics, geometry and number theory. Here’s how 🧵
wait didnt openai just win thhis?
A version of this model with Deep Think will soon be available to trusted testers, before rolling out to
Google AI Ultra subscribers.
they said the same thing 2 months ago
@deep adder Deepthink release January 2026
@deep adderare you the real craig federighi
An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International Mathematical Olympiad. 🥇
It solved 5️⃣ out of 6️⃣ exceptionally difficult problems, involving algebra, combinatorics, geometry and number theory. Here’s how 🧵

no one beat me to it right?
uh oh
i would rather take a ready to deploy model than an unreadable prototype that will take months to be released (oai model)
at first glance the solutions made by Gemini deepthink are really crisp https://storage.googleapis.com/deepmind-media/gemini/IMO_2025.pdf
billy do you work at google deepmind
thanks
lol
what a difference
i would be ashamed to share oai results
Gemini solved the math problems end-to-end in natural language (English).
This differs from our results last year when experts first translated them into formal languages like Lean for specialized systems to tackle.

dont end them like that
Lots of talk no release
Lmao who said DeepMind got cooked at IMO?
is open ai geting destroyed?
we are waiting for you
agree
but is it with informal mathematics or nah
then we can safely say gdm are way ahead
its still their thing
but i was serious tho
gdm takes IMO so seriously
Full context

based on tweets, it looks like DeepMind will release IMO gold version much faster than OAI gold version to public.
OAI mention in tweets that they are not planning to release their version for several months. I standby my conclusion
Honestly, at this point only OAI and Gemini are making some real progress. everyonw else is just catching upto them .
its not about releasing that model specifically but able to advance their public models that achives the same performance
Incredible non thinking model
https://x.com/Alibaba_Qwen/status/1947344511988076547?t=ZOtrFNlSmWmDn28eW3z5qg&s=19
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507!
After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing

Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507!
After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing
no one beat me to it again
yesh
If Deepmind got gold with Gemini 2.5 deepthink then they just mogged openAI
is it benchmaxxed again
aaaand
yes it is
initial thoughts : still the same as old qwen
better knowledge? i dont think so
where is deepseek ....
we need them
You see?
OpenAI ignored the IMO request. Shame. No class. Straight up disrespect.
Google DeepMind acted with integrity, aligned with humanity.
TRVTHNUKE


Makes sense why openAI rushed their announcement tho, if Deepmind was going to release natural language results via an LLM
same score...?
35/42
Also this:
Finally, we pushed this version of Gemini further by giving it:
🔘 More thinking time
🔘 Access to a set of high-quality solutions to previous problems
🔘 General hints and tips on how to approach IMO problems
I wouldn't be very proud about doing that nr2. That's like a cheat sheet lol
It had some kind of RAG with the entire history of IMO and previous curated solutions I presume
sure xd
yea
I mean how else are you honna interpret "Access to a set of high-quality solutions to previous problems"..?
They did do parallel for sure.
but they explicitly said no tools
so I assume no RAG either
We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling.
and
2/N We evaluated our models on the 2025 IMO problems under the same rules as human contestants: two 4.5 hour exam sessions, no tools or internet, reading the official problem statements, and writing natural language proofs.
Technically they did not explicitly mention RAG, but this strongly implies they did not use it, otherwise saying no internet and no tools kinda loses it's importance...
oh my god
test-time compute scalling --> parallel compute, so they did use it for sure.
these proofs are so damn good
ai solved imo
these are clearer than human solutions even
If openAI released second, everyone would have saw their sloppy proofs and wouldn't have been as impressed after seeing the Deepmind ones
Well no sh'it if you give it access to the corpus of the perfectly written solutions for past IMO problems it is going to mimmick that style lol
Hard to disagree on this. Looks like it did pay off huh
Where did this come from?
average 25 benchmark

“To make the most of the reasoning capabilities of Deep Think, we additionally trained this version of Gemini on novel reinforcement learning techniques that can leverage more multi-step reasoning, problem-solving and theorem-proving data. We also provided Gemini with access to a curated corpus of high-quality solutions to mathematics problems, and added some general hints and tips on how to approach IMO problems to its instructions.”
From this one they don't mention using previous IMO solutions
So I'm wondering where this additional claim is coming from
tbh i think the whole openai thing is going to backfire. I assume they didnt expect to get called out in that way
not just by us but demis himself kek
per category

Even on r/singularity you'll run into a decent number of comments calling them "shady" or "scummy" for what they did
and their result just isnt the actual sota
so it feels pretty pointless
like if they were the actual best maybe they could get away with it
Finally, we pushed this version of Gemini further by giving it:
︀︀🔘 More thinking time
︀︀🔘 Access to a set of high-quality solutions to previous problems
︀︀🔘 General hints and tips on how to approach IMO problems
"We also provided Gemini with access to a curated corpus of high-quality solutions to mathematics problems" there is no contradiction
nowhere does it say previous IMO problems
they don't need to spell it out... it's obvious that they used the problems as close as possible to what they guess the problems are going to be
previous IMO problems is a reasonable interpretation I would say, but this doesn't change anything really.
This is why standardization and transparency is so important
It is harder to game
well this all looks great for google
I'm really not. We can take this for face value and don't interpret anything "Access to a set of high-quality solutions to previous problems" - this still means fundamentally the same thing
they win ethically and performance wise lol
how??
read them, they are just a lot cleaner
Much crisper, cleaner, and easy to understand
it is easy to tell from the first paragraph
Lol.. like I can actually evaluate them. Thank you for the confidence though 😄
Well attacking OpenAI without knowing all the details and deducting points from them even (lmao) was certainly not a good look at all

"we werent in touch with IMO" isnt a defense imo
IMO Problem 1 is not too difficult to do yourself if you grant yourself a bit of help from the AOPS forums. Then you can read the AI solutions to at least problem 1 and see the difference.
It is kind of admission of guilt... like oh I didn't know that you cant steal from bank
There's no need to defend anything. You aren't required to be in their inner circle and have assistance from their judges like Google did, you can simply be an outsider doing your own thing... They went beyond that and made sure it is ok to post results
Well, OAI is not known for their ethics. I am not surprised. Good part is that we will soon have these great models at our disposal.
And...? They had the closing ceremony and IMO green lit it. What is the problem? 🙂
They asked one random organizer. They are a multibillion company
Yeah lol, they should have had a little more reliable communication channels going
They not gonna actively look for ways that would disallow them to post the results. That's on IMO and their communication
some delayed publication until next Monday btw, so there is more results to come on this.
I wouldn't be surprised if more than two companies got gold tbh
Yeah that's why I forgoed the help of the SAT graders and just told them my score.
I doubt IMO would want to associate with this strange outsider attempt anyways tbf. They would just redirect them to compete officially
Not sure if they even could at that point
I agree the way they rated it is a bit sus. But at the end of the day their solutions are public for everyone to independently verify, so not really a problem...
IMO are never going to grade openai solutions. Thats not how they operate they only care about official results
If they wanted they could. Also pretty sure Google are motivated to do it if no one else will take initiative 👀
They did grade Google's solutions
https://www.reddit.com/r/singularity/comments/1m5pwqr/what_does_it_mean_for_ai_and_the_advancement/
since they competed officially
ah..ohk
they graded Googles solutions because Google (and several other companies yet to announce) entered the IMO as AI teams officially this year
Well... if they manage to arrive at a different score. Probably not gonna post anything if the score checks out lmao
The openAI and deep mind researchers are flaming each other on X rn

What an absolute spectacle
🍿
Holly that's what I said. I said it first. 😠
🤯
Is there any reply from Deepmind researchers on it?
I don't think IMO expected it to go down like this 😂
This was going to happen eventually with openAI always trying to steal Deepmind's thunder, not surprising IMO would be big enough to cause actual public comments
This post is way too funny https://x.com/demishassabis/status/1947337620226240803?s=46
We've now been given permission to share our results and are pleased to have been part of the inaugural cohort to have our model results officially graded and certified by IMO coordinators and experts, receiving the first official gold-level performance grading for an AI system!
"first official gold-level.." lol
70% of people reading it gonna think they lost their mind and not even notice that "official" word lmaoo
Deepmind supposedly got gold before openAI did anyway
now we’re waiting for an open-weights model to get imo gold
So it's true either way
Doesn't matter. They got played. 😇
Unless you're stuck waiting for "official grading" or whatever
They basically offended the IMO to announce first
But then didn't end up with the best looking results
they did. Also, one tweet mentioned that they wont release the gold model for many more month. I think they will be forced to release it faster
How? I don't think they care much about people who are always hating OpenAI regardless of anything tbh
At least we have some transparency
whoever ships first
OpenAI model definitely trained on IMO answers from past competitions
We had it from both sides to be fair...
An org relying on unprecedented venture fundraising cares much more about being first and the online sentiment that it carries with normies. Google would prefer to stay in good graces of elite math types who follow this closely
this fight between OAI and Google is good. They will be try to release these models faster and try to one-up each other again. I am finally excited after long winter (~4 months 🙂 ) of non-significant progress
Normies aren't following elite math competitions closely lol
Normies see headlines tho
IMO it's more of they didn't think of doing it this way and did not even suspect OpenAI would enter this competition from the outside. If they knew they would have acted differently
I think the embargo date was moved
It was supposed to be Friday
They moved it because of openAI
God that's horrible 😂 the imo organizers literally had to move the embargo date
openai like always tasteless af
Why would they push the embargo date to later?
If we are really being truthful... If you were in their shoes, you would see their course of action as a better move. Especially considering that they did reach out and did not publish it before IMO said it is ok to do so
Oh, up from Monday
Billy was saying embargo extends to the 28th
Friday is the 25th
no I wouldnt. I have some respect for competitions like IMO.
In what way is it "direspectful" to do what they asked and wait for closing ceremony to finish? Everything that came later about their supposed internal guidelines Google was very laud about, only came out after the fact
There's a decent chance IMO makes some changes for next year to prevent this from happening again
notice how you are the only one who thinks this is all perfectly fine.
yeah 100% lmao
Because this caused a bunch of unnecessary drama surrounding their event
Cause it's not a popular opinion given the sensitivity of it. But it's also fueled for a good part by general hate of OpenAI in the public. If you just look at the facts, it is pretty much what I'm saying...
yeah those HS kids didnt deserve just a couple days to bask in their achievement.
Did anyone ask what they wanted??
lmao
I do not think they did
you're making my point really well here
Not really. It's ignorant to assume there were no participants that were against embargo of any kind in the first place. The whole thing meant more people are talking about and are interested in IMO too...
Been an interesting few days, the Reddit comments have been pretty good on this whole thing.
Reddit
Explore this conversation and more from the singularity community
I think Google are the only ones that got gold officially. IMO organizers would have moved other companies embargo dates a week forward if they also had gold
Taking "poor kids" argument it's kinda cheap tbh
They did have their closing ceremony without anyone publishing anything ---> not much of an argument in the first place
The IMO and every other company agreed to wait a bit. They agreed to wait a bit to not diminish IMO participants achievements.
The event isn't for AI companies, it is to celebrate highschool kids achievements. Them asking companies to not announce yet isn't new to this year
Yes it has always been a thing
Your arguments come off pretty weak and contrived
Like you're basically heavy reaching to defend openAI no matter what
This is no longer rationalism, but emotional investment
I mean from openai side they got a bit desperate for a sota result and thought they could get away with this. It is reasonable they wouldn't have expected to be called out
Desperation sometimes makes people do unethical things
I mean picture this. You had a huge lead and now Google are on your tail and moving in fast. You might start to crash out as a natural reaction and reach for any good result you can
Not justifying it but I can see why they do this
be the most prestigious mathematical competition
Host competitions for HS students for 70 years
70 years into your history an AI company wants to attempt to solve math questions from current event
Say sure, but don't announce for two weeks
Next year another company does the same unofficially
doesn't wait two weeks
hypes it up on social media, all on same day as closing ceremony
People say "f* them kids"
Mfw
Go upvote new qwen
https://discord.com/channels/1340554757349179412/1396916057024757902
Yeah he had a total crash out I saw
- OpenAI doesn't cooperate with or submit their answers to be graded by IMO allowing them possibly run multiple attempts or withhold any bad results which would hurt fundraising
- releases results before closing party pissing off the entire IMO board
- surprised Pikachu face when math people are mad online

Imagine being a competition for HS kids for 70 years and people are saying "f* them kids" lmao
IMO could have told all these companies to kick rocks, but they were initially respecting their wishes
Meanwhile openAI just shat on them
Our IMO gold model is not just an "experimental reasoning" model. It is way more general purpose than anyone would have expected. This general deep think model is going to be shipped so stay tuned! 🔥
Well I mean it probably is if they are going to actually ship it
Wouldn't be a great model to release otherwise, maths problems are not that valuable compared to coding
There is a trick though. It's not just deep thinking
There's smth else
:p
wow.. this
I owuld think all human competing would have been studying previous questions and solutions as well.
Yeah but you don't get to take them all printed with you in person lol
oh man I was rofling so hard. Found one in another browser tab. Can't find the other one tho 😦


"studying" = training data, but this is different. It's literally a cheat sheet 👀
What point is Aidan even making
They both "trained" models for it
Yeah, this like, idk why this is even a point of attack
training data is not gonna be recollected with 100% accuracy typically for tasks like these, unless you overfit and degrade performance
Honestly I'm amazed they allowed it to go as far as it did LOL
all of them are "first official" then💀
They are being kind, they don't need the official
They were the first. Just embargoed


↪️ Replying to @peterjliu
@peterjliu Thanks Peter!
It was surely annoying at first but once I came to terms this was because we were doing the right thing, everything felt okay!
I think we've won on all aspects! Legitimacy and sportsmanship!
Yeah, they're making little subtle pot shots at openAI
LOL he is still hurting
deep down he knows he's only saying that but it is not actually true...
🗿
GitHub
Kimi K2 is the large language model series developed by Moonshot AI team - MoonshotAI/Kimi-K2
thats what im talking about
decent but still pretty light on the details of the actual pretraining dataset
that's what happens when you make a model that's in-between reasoning and a concise one 😇
better than 4.1, worse than o3
better than 4.1 isnt a high bar
Depends on your perspective and bias

For conventional metrics Opus is not great
that's not a secret
it's a niche model, but SOTA for those select things it's good at
even livebench can get this right

In turn 4.1 is similar enough size to all of those it is being compared against... So no such discrepancies. 😇
any benchmark putting 2.5 flash above opus 4 is just a joke
For multimodal retrieval it’s actually better. Flash does what it is used for
Look at 2.5Flash vs 2.5Pro then. Or o4-mini-high vs o3. I think it's just you not knowing how to read them and what to look for...
the benchmark is for "intelligence". that is what it is literally called not retrieval
