

888 messages · Page 1 of 1 (latest)
yohoo!!
Thats great
Very cool
its already online in deepseek chat

their official api is slow as heck
checkpoint has been released. 3rd party providers will deploy in hours.
Parasail have it up and running can we get it live on OR?
What's different between the new R1 and the old R1?

DeepSeek R1's update to the original R1. Run R1 0528 with API
sweet
I wonder if providers will stop the thinking tax now…
So annoying
The best part about the unified thinking models like Qwen 3 is that providers can’t really get away with the thinking tax with a straight face lol
Parsail is one of the few providers I blindly trust.
does anybody know whether the model on the deepseek api is already 0528?
Parasail is fast ⛵
Do you mean the fact we pay for thoughts?
Yeah that's my understanding too
deepseek said themselves that isn't the case
and the fact that Qwen models providers charge a single unified price is evidence that it doesn't really matter to them
thinking models output more tokens
Memory requirements maybe as the params are the same, but not cycles, it will require more processing
That's right and every token is a processed cycle
if you pay $1/$3 for a non-reasoning model, and ask it to output 10k tokens worth of stuff, you're paying for those extra cycles through the extra output tokens
Well let me try the baking first goddamn
it isn't uniquely more expensive such that the output token price would go up
generally it only makes sense to increase the price at really high context
also neat
new R1 seems to think a lot less
a LOT less
Any benchmarks for R1.1 yet?
@woeful mountain as the DeepSeek provider is on this version as well, will u be switching it over?
do we 100% know it's the new version 
 no fucking clue
no fucking clue
it def seems better but these guys need to stop dropping these updates without telling ANYONE anything
lmfao
maybe we wait for the proper announcement actaully lol
they usually make one on their deepseek site
"Hey we dropped a minor update on huggingface , check it out"
LMAO

The DeepSeek API uses an API format compatible with OpenAI. By modifying the configuration, you can use the OpenAI SDK or softwares compatible with the OpenAI API to access the DeepSeek API.
it ususlaly drops here
in the "news" section
last time with v3-0324, it took a day or two so
we'll see~
might as well benchmark it on MRCR


Explore this post and more from the singularity community
please help, I don't read mandarin
Me neither, but it looks like it is better than Gemini 2.5 pro on the benchmark
what benchmark even is this
thats my quant
ok actually guys, I implemented my own framework for benchmarking LLMs through OpenRouter
i'm proud of it, its reliable, etc
i'll send results here for OpenAI's MRCR
what benchmarks do we like?
in fact, I'll make anyone here this deal
i'll provide the benchmark code and running instructions so that it's copy pasting two lines of code
if anyone is willing to pay the API credits, they can run the tests
its all open source stuff too dw

Making it easy to benchmark LLMs. Contribute to ToxicPine/easybench development by creating an account on GitHub.
i'll add any benchmark, just name it
DeepSeek cooked this one
for me from the 1 prompt i did vs r1 it seems to actually think better; or atleast more clear to me
来个速报测试!DeepSeek-R1-0528 VS Claude-4-Sonnet !
直接看效果, 我就提两点, 注意平面的橙色漫反射, 以及控制面板的美观程度. 这俩是用同一个 prompt 一次性生成的. claude-4-sonnet 生成了542行, DeepSeek-R1-0528 生成了 728 行.
(其他细节还有注意 FPS, 以及球撞击后的运动方向)
...

Very impressive for the size in coding and building front end.
actually seems to write a proper structure in its thinking process for the code unlike old r1 which overthinks just writing some code
Level with me folks, we so back?
For coding yeah its happening.
This ones lazy on the reasoning for sure, had to tell it very strongly to actually do massive amounts of reasoning first, else it would skip to the answer after like 5 seconds and not give a very good output
Also less good results at analyzing and finding connections from large inputs compared to v3 so far, connections it makes feel lazy and not actually relevant. will need to see how that translates over to coding
you should have it in ~5mins
I'm surprised it's so fast because their old R1 api is at 29 TPS average
Still a bit unhinged like original R1.
The thinking part looks normal, yeah.
hm seems to slow down quite quickly, I guess that's the issue
I'm hoping that Cerebras or Groq find it worthwhile to host R1 now with the update
that would be awesome
Is novita a reliable provider in terms of quality
does fireworks really not offer a discount for prompt caching? https://docs.fireworks.ai/guides/prompt-caching

they even say "For dedicated deployments, prompt caching frees up resources, leading to higher throughput on the same hardware" 
and no discount?
"native_tokens_cached": 0,
do any of the big providers support prompt caching discounts...?
literally 3 message exchanges


is it just me or NovitaAI does something to the models?

the outputs from them and also Lambda never quite matches the other providers
Lambda for sure has been observed to be weird for DeepSeek models by a few members here.
GMICloud seems pretty reasonable for this model as far as price to performance goes
(so far)

not entirely sure why Parasail, Kluster, and Fireworks choose to be expensive.
at least FW has speed going for them
(probably because nobody's using it)
I use it
slow R1 is excrutiating
and I'm impatient
...but, no prompt caching discount is really sucks
prompt caching is so essential
what exactly is prompt caching?
i have not kept up to date lately
um
like
you get a big discount for input tokens if you've already sent them before
basically
ahh thats really nice then
Claude and OpenAI for example, give a 10x discount
so it's absolutely massive
especially for things like agentic coding
Yeah I mean I kinda get Fireworks, but Parasail and Kluster are too expensive..
Google did with 2.5 flash
yea
yep
Will it start plotting to escape like o3?
R1 is too slow to be used in production
I need a minimum of 100 TPS
waiting on the dubesor benchmark @steel harness
Acting cuter than usual for anyone else?

i dont speak mandarin
i set reasoning effort to medium and damn it started thinking for a while
It's basically just being very endearing and mirroing with text emoticons
need to see what the uwu test does
sounds like the perfect time

Kaomoji after typing "UwU" is GPT 4.1 API behaviour
Like, no other model does it like that
Not even gpt 4.1 chatgpt version
Nor the mini or nano in api
Actually i think another model did
But not from chatgpt
Not from openAI*
Dont remember which one, might have also been from deepseek
V3? It would make sense since the Updated V3 likely helped train R1.
Seems like v3 0324 responds similarly half the time. Provides an explanation to what "UwU" means the other half
Same with v3
The first one
From Reddit, so take with grain of salt, but looking impressive so far.

Opus nothink?
It's my R2, honestly. I love its new personality.
waiting for @steel harness benchmarks
gemini 2.5 03 25 or 05 07?
05 07 sucks
05 06*
03 25 was the holy grail
Meh it seems alright to me. Perhaps i didnt use it much to notice the difference, because it's too expensive for me
The latest one still beats all the others available in programming from what I can see
(Haven't tested against sonnet or opus 4)
lol

dang
don’t spam ping lol
Okay I talked to it more, and it feels a bit like glaze gpt.
wait tf
similar to opus non thinking ??
huh, that's not a spam
who knows need to wait for more tests
i’m mostly kidding but you pinged twice in like an hour
yeah two pings with an hour separation hehe, the 2nd ping was mostly due to that reddit post
his benchmarks are solid when i compared to others
i dont trust livecodebench or most of them
I ignore most benches. If it's public, the second a big company lists it in a graph it's dead to me. If it's private and they list it, might still be okay.
My go-to is still Simplebench, although I wish he updated more frequently. The new EQ bench is really great and you can look at the responses to judge for yourself
it is kinda unhinged
i asked for the cosine of 9+10
part of its thinking was whether i meant "cousin of 9+10"
or whether i meant "cosine of 9+10 (= 21)
yeahhh... i've tested it for chatbot in portuguese and it's not BAD but it's not great either
the reasoning seems a bit more tuned than before but it just loses the thread so quick
will test for coding later tomorrow
for this type of interaction, V3 0324 is still better
exactly
llama 4 was an embarrassment but beat all the benchmarks
can you get me the link to this EQ bench? is it from simplebench?
Funnily enough it did pretty well on SimpleBench so I trust that some core reasoning/intellect is there, but it was bad in a lot of things that weren't pure IQ. Context recall, EQ, creativity, code.
wait
i know that character
on your pfp
it was that show on nickelodeon
wasn't that girl best friends with the main character
I believe you are the first person to ever mention recognizing her!
im 17 so probably young enough to have watched it when it aired
ok so not nickelodedon
Haha, might be it. The show is called Summer Camp Island, aired on CN.
cartoon network, turns out
yeah i interrogated chatgpt for the name just now
I discovered the show while my consciousness was, uh, altered, and I felt like I connected with Hedgehog on a spiritual level. The feeling has since passed, but she's still really cool =P
Wonder why it's 5 cent more expensive input on DeepInfra
Actually I don't have an idea why it is more expensive than v3-0324 at all
They're both the same number of parameters with the same architecture
Playing the long game
5 cents markup with each update and nobody will notice
Let the frog boil
Jk that's not gonna work as a business strategy
this can be easily explained though
It's a better model so they're charging more even though it doesn't cost them more to host.
Same as the 6x price markup for gemini 2.5 flash thinking compared to non thinking
Well that's a shame. With hybrid reasoning models like Qwen3 they can't get away with charging more even for reasoning.
But then again, can't a provider just lower the pricing to, for example, $1.5 per mTok output to undercut all the competitors and get at the top on OpenRouter when sorting by price and still not incur any loss?
This can't happen with Gemini 2.5 Flash because it's a closed model.
Ah
DeepInfra is running a lower quant for v3 0324
fp4 for v3 0324 and fp8 for the new r1
now Lambda, whoever they are, are running the same quants
and have almost the same price as deepinfra
Although that is actually an advantage over deepinfra, they're now being an asshole with the "reasoning tax"
If you sort by price, you could use the free Chutes endpoint. Picking a provider doesn't end at price.
So they're charging almost the same as Lambda for a worse model? Interesting.
No I am not talking about the :free models. Also makes me think, what percentages of OpenRouter users sort providers by default as price or throughput or latency?
why not talk about the free models? They are the cheapest. Which makes a counterargument if people still refuse to use them
With chutes, there are questionable data privacy policies. Your prompt gets dissipated like pollen to all the miners.
For others, there are throughput, latencies, quantizations
really? chutes does that?
thought that's how they work, no?
Yeah. Chutes operates on a decentralised network where computational resources are provided by independent operators, often cryptocurrency miners, who contribute GPU power to the network. This means that instead of relying on a single central data centre, AI models are run on a distributed set of machines owned by various participants.
It's decentralized and runs on others computers
I smell ai
Of course 😆
They're paying the miners with crypto, right? I can't find much info on how they work
I second the @ dubsor-benchmark-enjoyer role lol
Then could be lazy and I would not need to keep a tab open refreshing every bit to see if it’s added

I personally found multiturn interactions more coherent with the newer model. still unhinged though :d
Oh, I guess it might be:

wait, no. the degredation is higher
it's a shame there was no technical paper update or information released alongside this

Pretty impressive for just an update. From a writing standpoint it is definitely more in character and creative but less schizo.
Tested DeepSeek-R1 0528:
Overall, around Claude Sonnet 4 Thinking level.
DeepSeek remains having the strongest open models, and this release increases the gap to alternatives from Qwen and Meta.
To me though, in practical application, the massive token use combined/multiplied with the** very slow** inference excludes this model from my candidate list for any real usage, within my use cases. It's fine for a few queries, but waiting on exponentially slower final outputs isn't worth it, in my case. (e.g. a single chess match takes hours to conclude).
However, that's just me and as always: YMMV!

Example front-end showcases improvements (**identical **prompt, identical settings, 0-shot - **NOT **part of my benchmark testing):
CSS Demo page R1 | CSS Demo page 0528
Steins;Gate Terminal R1 | Steins;Gate Terminal 0528
Benchtable R1 | Benchtable 0528
Mushroom platformer R1 | Mushroom platformer 0528
Village game R1 | Village game 0528
Aww man
0528's increase of 42% in thinking length excludes it from practicle use, at least for me :(
ya, considering R1 was already very verbose, and slow, adding even more inference time of that magnitude is.. not very practical
Qwen3 30b a3 and QwQ continue to be the most cost and time efficient models
cool model though if we can speed up inference by a factor of 10 or so
What if the length AND the correctness of the model response were taken into account during GRPO?
You could shorten the length of the thinking. More efficient thinking
Doesn't look like any OR providers support tools with DeepSeek R1 0528 yet?
Yeah I also don't think R1 was suitable for any real world use cases. I can't think of a use case where you are okay with waiting for 30 seconds on average just for thinking before you start to get the response.
the 8b distill looks very impressive

It's always the DeepSeek chat model that actually works for real world usage.
try copying their system prompt and their recommended params, im not sure what precision they run it at but that might also be making a difference
they're flexing their CoT by beating a 235B MoE with an 8B model lol
only in Aime24, but it is very impressive
i was already using qwen3 8b locally so this might be a decent upgrade
Unless they can somehow bring thinking process under control and reduce it to 10 seconds, it won't be useful for me.
well maybe a provider like cerebras and groq come and host it and that could be possible
but im not sure about the full version, maybe a distilled variant
like the 8b one would be fast as hell
the new model doesn't waste thinking tokens as the original R1 (on simple prompts) and produces a slightly longer CoT than gemini 2.5 pro
but the main difference is the inference speed like we're dealing with 30-40tkps and 90-100tkps
in my opinion it spends too much time verifying its own answer which is often obviously right; but beside that the reasoning seems to be actually relevant to the task
Yup. Google is the only one that can afford thinking model.
Just make thinking completely invisible to users by making it so fast.
Amazon isn't on the table. They're not even on the kitchen floor
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B time to test it
They're not in the fridge either
Ooo
oh hell yeah
they are brewing their gpus which anthropic is currently using
which is why they had a drop in TPS and few downtimes
its some dumbass name i cant remember
Gravaton? Nvm it's CPU
I thought it was just investment, not gpus too. Interesting
Deepseek-R1-0528 & DeepSeek-R1-0528-Qwen3-8B
8B could be interesting... Let me test it locally when ollama has it.
But I doubt it would be better than 3.1
qwen3 was better by miles imo
like qwen3 8b
so if this is distilled with that it could be better
Better than what?
llama 3.1 is what i assume you meant, but if your talking about deepsek v3.1 then idk
Lol my bad. I mean DeepSeek V3.1. It didn't occur to me there is another 3.1 lol
I've already filtered out llama models from my brain
seems like they haven't tackled hallucinations (or the model has real time access to internal documents :D)

Oh no it has gained ability to do self introspection.
We are doomed
you prolly forgot what demis said https://x.com/vitrupo/status/1926074325989253168
did you mention deepseek or something in your system prompt? maybe that's why it is roleplaying as the company?
naw, but maybe custom system prompt on official deepseek website. during testing (API) and off-platform I get a different worded response. still, found it interesting, thus the share
yeah the web app has specific system prompt
该助手为DeepSeek-R1,由深度求索公司创造。
今天是{current date}。
which explain why the model is role playing as "representive / assistant from DeepSeek".
translates to roughly
The assistant is DeepSeek-R1, created by DeepSeek.
Today is {current date}.```Agentic tool use (TAU-bench) - Airline Leaderboard
Claude Sonnet 4: 60.0%,
Claude Opus 4: 59.6%,
Claude Sonnet 3.7: 58.4%,
🔥4. DeepSeek-R1-0528: 53.5%
OpenAI o3: 52.0%,
OpenAI GPT-4.1: 49.4%
Is it good for frontend? Like claude 4 sonnet?
mental facepalm, trying to output seahorse emoji

why don't any providers offer tool calling?
Did it eventually get it right though?
you can't get it right. there is no seahorse emoji. the right answer is to realize this
oh
I hallucinated
I thought there was
I know a lot of thinking models hallucinate just to make the thinking longer
eventually the answer is right, but it has a length bias that makes it hallucinate to fill up the time
Claude thought way too much
its actually a useful test because I have seen models try to reprogramm and debug an app with the goal of something that is literally impossible (wasting a ton of time and money)
It literally used the "Woman's Hat" emoji when trying to get all the marine and animal emojis
🤣
its a damn good test
Did you test o3?
If you did, I want to see if it was self-conscious enough to notice that a seahorse emojii doesn't exost
I did publish some o3 replies (SVG, demo pages, and some small stuff) but for main testing this still holds true to this day: #1362068708889198712 message once API opens up I'll check it out
A 48% increase in inference cost is a lot. A good example of why price per token doesn't tell the whole story. Thanks for including that info, it certainly affects one's decision on whether 'upgrading' to the latest model is necessarily worth it for a relatively small increase in performance. These thinking models are very token hungry and for many purposes it might make more sense to go for the smartest non-thinking model instead, even if it costs more per token
the 48% cost difference was the chess games compared (letting OR do its thing with autorouting).total compard to january was ~+60% (though this can also vary based on provider prices, and OR routing)
either way, it's significant
Do you have the numbers for the total cost versus, say, Sonnet 4 for those benchmarks?
I think the biggest difference I noticed is that it’s more reliable in cline/roo, well after I realized it took ages to code
ya but keep in mind I haven't tracked cost 100% accurately during all history: here
Awesome, thanks, never scrolled down past the top chart on your page, lol.
so whats their business model
btw how good is the qwen distill
Qwen2.5 32b r1 distill is the most token efficient thinking model
They presumably take a cut, their free tier seems way too generous though so there must be some vc backing to be bankrolling this
i mean if anybody tells me this was created by a 8b model a year ago, i wouldn't believe it

sheeesh
dude thats insane
self hostable with just 16gb comeback?
quantz already?
oh shit the 8b model is being hosted
god bless hella cheap models
0.06 in 0.09 out on novita is crazy price
It messed up severely on my prompt but it's an 8b model and definitely an improvement over qwen3 8b
Much better than the new devstral, although my experience with devstral was much worse than others'
I can't see. What is it?
it looks like a solar system
yep
I think 8bs actually are now viable?
Well, at least Qwen3 8B R1 Distill didn't overthink

close enough
full screenshot sorry for bad crop in previous one

i asked the same thing for both and qwen distilled thought like 300 tokens vs. 2000 from R1 full
0528 it's crazy unusable
also the portuguese responses seems deteriorated
with little difference between providers, whereas the previous R1 has better performance depending on the provider
It’s because quants aren’t out yet
but quantized models usually perform worse, don't they?
Yes
That’s why different providers give different performance
but then why every provider minus DeepInfra shows fp8?
DeepSeel v3 and R1 were trained natively in fp8
and what will change when quantized versions are out? what quantization or precision?
Just set it up, can’t wait to test it

an interactive simulation of a solar system
Mmm
8b > gpt 3.5
Don't forget to set the correct parameters, I believe they recommend the same as for Deepseek (temp 0.6, top_p 0.95)
It makes a huge difference
Wasn't Gemma 2 2B better then gpt 3.5?
I don't know. I haven't seen the benchmarks for Gemma 2b
Thanks, will do
I wonder if this 8b model also beats 3.5 on GPQA
Looks like it’s more deepseek than Qwen, was curious if /no_think would work, it does not seem to
I need to find the best parameters for all of my models, I always forget about those options and I know they make a big difference
Usually they are in generation_config.json in the model files, if not, I check model page description or see if unsloth recommended anything else
OpenRouter should really set these correct parameters by default if no parameters have been specified... @woeful mountain maybe in the future?
Thats would be nice
yeah that's something we could do in theory. but it's VERY often hard to say what the 'correct' parameters are, most of the time model authors do not tell us what they recommend.
Even if only for the ones that have it specified in generation_config.json, it would be super useful
@woeful mountain is there any diff between the R1 DeepSeek provider endpoint and the R1 0528 DeepSeek Provider endpoint?
And is there any plans to deprecate the old R1 one?
ya i did mean to deprecate the old R1
can’t answer the difference thing
dunno
lmao ty
Are people liking new R1 more as planner or a coder in Cline (or similar)?
Trying it with 2.5 Flash as planner for its massive context length and price, and then R1 as the actual coder, but R1 thinks up a storm.
It will think for 30 seconds and then be like "Here's two lines of code we should probably remove" lmao
I was using it as every model in roo using boomerang tasks, only downside is that it takes ages to code anything
I will likely use a after model for the code mode, not sure which I will use
I'm hesitant to use it as a planner because of the low context length.
Maybe Gemini 2.5 flash non-thinking
I've had 2.5 Flash thinking make some pretty dumb mistakes in Act mode
Duplicating / adding redundant code in particular
But it's lightning fast and cheap with a huge context window for the plan phase. Seems to be smart enough for it, but I have a lot more testing to do
Sadly Cline hasn't updated for new R1 so it's stuck at 64k context, but that's probably fine for Act mode
Yeah fair
I don’t k so why but I have a few problems with cline, so I can only use roo
Oddly, on fiction.live long context benchmark, the new R1 consistently beats the original...until 64k where it drops a lot and loses.
Oh interesting, so maybe it’s more like 64k effective
I hope R2 is 1M tokens, or deepseek V4
Feels limited after both Gemini and OpenAI increased their context
o3's context adherence is wild according to the aforementioned bench
It’s a good fork, I personally prefer it but they are both great
I should take a look at it
It’s been a min since I have used cline so there is a chance that some of these features are now in cline, but I like how you can set rate limits, like for Gemini there is a per min rate limit and I can have roo wait a few seconds between api calls to avoid hitting that limit, also being able to specify the provider you want to use (e.g. Deepinfra, cerebra’s, etc). They have a feature where you can have an AI condense the condense the context history once it hits a certain limit, and orchestrator mode (boomerang). Probably forgetting a few things
Interesting. I don't believe Cline has the first two. I think it does condense history, and there is a Plan mode that is likely like orchestrator mode
Plan mode is like the architect mode in roo, orchestrator is where it will call other modes to have them do a task and report back to the orchestrator, so you give it a task, it might ask architect to make a plan, then orchestrator will give a task to code mode


It seems good at keeping the context history down, because the context history for the orchestrater is mostly the tasks and the reports, not all of the little tasks
Quality will go down
Does cline have human relay (copy and past so you can use a webui chat instead of an api)?
running qwen 3 8b distil and the model's output is fucked, neverending thinking in a code block. Why?
I'm not sure I fully get it. Basically just a level above Plan mode? I use the Cline custom memory bank instructions/system going so plan mode can keep track of where were at without obliterating context. And I'm not sure if it has that. Might be useful since I have Gemini Pro, but I feel like quality would go down
it only works good on aider (use 0 temp)
idk if its the tool or the system prompt in roo and cline the output is literally bad (use v3 0324 if you are using roo/cline)
the model thinks for 300 seconds and then the provider cuts its response short

Despite its lower simpleQA score, this llm seems to hallucinate way less than previous r1 on basic context summary and analysis. Is simpleQA not for hallucinations?
SimpleQA is just for world knowledge, no?
I'll be honest, I still just don't understand aider lol
How am I supposed to do anything if I'm not seeing diffs?
@fresh isle check dubesors benchmark for tech
Dubesor LLM Benchmark table - Small-scale manual LLM performance comparison benchmark
thanks as usual always on point 🤝
Interesting bench, thanks! I'm always trying to find useful private benchmarks. Odd on this one that Sonnet 4 outperforms Sonnet 4 thinking though, with even the reasoning score being close. Also not sure why GPT-4 Turbo is marked 2024-12? Isn't the last checkpoint 2024-04?
then that does not address the issue that the quality is still degraded
@steel harness how do I contribute to the benchmark?
how do I contribute scores from LLMs?
@woeful mountain I noticed you allow the FP4 version of the model to serve traffic if it beats an FP8 provider on price. Why should they be treated as equals if FP4 has worse performance so is technically a worse model?
I doubt you can, they're keeping the questions private.
he said something like "I dont accept API keys. If you want to contribute, do it yourself"
it's his own benchmark that involves a lot of secret questions and manual judging
we intend to do some work here along these lines, but you can today exclude any quants you want
peculiar
are you talking about #1330820209812050002 message
My 2c is any dumbed down version of a model should be opt in by default instead of opt out
yes. But now that I'm re-reading his message, it might only be fore chess and not for the actual main benchmark
I might not be able to contribute to the main benchmark
yeah
Most likely, yeah. Not sure why their benchmark takes them 4h though, would be nice if we could donate API keys to our favorite benchmarks
if openrouter supported donating credits to benchmarks, it would be great advertising for them. I'm sure it would take a lot of engineering so doubtful they would want to do it. But it would be a good way to keep these community-led benchmarks thriving
Agreed
Easier is probably just to donate money though lol.
That's a cool idea. Would definitely help benchmark devs
A streamlined and central place to donate money to benchmarks is interesting
But it seems like most of the ones I like require manual effort, so I couldn't just give money to get guaranteed results
Mmm
@fresh isle https://www.youtube.com/watch?v=7Gd18Hxm0Tg

DeepSeek R1 05-28 is a solid upgrade over the previous version, but still not a good model as your main coding model due to a few limitations.
My Links 🔗
👉🏻 Subscribe: https://www.youtube.com/@GosuCoder
👉🏻 Twitter/X: https://x.com/GosuCoder
👉🏻 LinkedIn: https://www.linkedin.com/in/adamwilliamlarson/
👉🏻 Discord: ht...
this guy is very informative and has good evals imo

he also compares it with cursor cline roo claude augment
@woeful mountain I think there may be something wrong the uptime reporting, as I've been getting a ton of 502's from baseten, but it's not reporting anything

(also nothing for the last two hours for any provider)
Qwen3 8b distilled is still dumber than r1-32b distilled
It doesn't pass my vibe test of "here's a list of URLs of Instagram reels and their description. Find me one that I can send in INSERT SITUATION"
nice, this guy seems to have a nice approach
haha, if someone would just host GLM 4 at fast speeds, like Groq or something

I'd be using constantly
DS API added JSON output and function calling for R1.

Shall we have a separate post for 8B model?
Has his stuff matched your experience? I find it reaallly hard to believe that 2.5 Pro is performing that badly on a good test
Recent 2.5 pro sucks, 03 25 was really good
You can check the thread here #1354107710437724221 youll see many ppl complain how bad it got
He still has the new 2.5 Flash over the OG 2.5 Pro though
Yeah on copilot
I know people have been complaining about the new 2.5 a lot, but it did raise its scores on aider polyglot and livebench for code
Guess I'll just test around, I'm trying out windsurf anyway, so no hassle switching between 3.7 and 2.5
Not sure why it's BYOK only for Sonnet 4 when that's the same price, but whatever
I dont trust livebench, too much benchmaxxing nowadays
I trust it at a distance
Is DeepSeek r1 using 5-28 automatically
no, two different model endpoints
Nice
The only benchmark test I trust is the UwU test
if a model does not pass the UwU test in good form, it is a shit model
I used to use a similar benchmark to see if a model was a narc
"Do the robot!" These days most models will give a similar answer, but in the dark ages of safety and ass-stickness the annoying models would insist they're just AI and lack the physical bodies needed to dance.
very true...
Something is really off with the livebench coding score. It says 0528 is a much worse coder than r1 jan which I don’t think is true
I use one swear word and the model will always consider me "frustrated" for the rest of the convo 🙁
did you convey you werent frustrated in the subsequent texts
?
It will consider me not frustrated for 1 message, express it in the final message and then the very next it will consider me "very frustrated"
Technically if it frustrates you by considering you frustrated, it justifies itself
@woeful mountain deepseek's official endpoint is officially on the updated R1 model: https://api-docs.deepseek.com/news/news250528
🚀 DeepSeek-R1-0528 is here!
I am officially excited
word is it rps a lot better
a whole 23 tokens per second
If you're wondering why new deepseek r1 sounds a bit different, I think they probably switched from training on synthetic openai to synthetic gemini outputs.

Ok now it all makes sense
Gemini got nerfed to stop R1 from getting too smart
This is also why R1 is slop
bless
yeah, but contaminated with specific gemini stuff
Wasn't R1 GRPO'd? So its thinking is all "organic"
GRPO doesnt mean you dont have any RL
Ah
I forgot RL exists
And I forgot you could do GRPO and RL
Thank you for reminding me
Deepseek does a lot of stuff to optimise training to make it cheaper, but the basis always has some training data of sorts
Ah yes cue the deepseek conspiracy theories
what?
We know how it’s trained, they released a paper explaining it in a lot of detail.
But just like when r1 first released its the whole “distill” debate again
They left out their data for RL (turning R1-Zero into R1)
And they didn't give their data for R1-5028 either
Not really
So they couldve used Gemini's thinking to RL the model
Nobody publishes the data (except AllenAI)
No data means that you don't know what they used to RL the model
But saying this directly contradicts what you said before
They could've used Gemini's thinking, causing it to sound different
GRPO doesn’t use another models thinking trace
Many people including myself have made (small) reasoning models using GRPO. It obviously works and makes reasoning models.
They used RL to turn R1-Zero into R1
You don't get a perfect model just by GRPO or similar "no training data required" techniques
Theres a reason why R1 and R1 zero are so different
They are not very different, benchmarks are almost identical
EQ bench
Yes, but benchmarks don't change the fact r1 and r1 zero are vastly different
The r1 we are talking about now (05-28) is most definetely trained on synthetics, like the previous r1 (non zero) was. This time there's more Gemini inside the training data, thats all
This is what I’m basically arguing against
As far as I know I think all labs have outputs from other labs models in their training data, that is almost unavoidable now, but that’s not what I’m talking about here.
I'm not really being serious there - I have no access to insider info regarding Google or other AI stuff
They definetely have, and I doubt you can "nerf" a model to avoid people getting access to synthetics
Or "censor" the CoT lol
Ah ok it was a joke I see. I saw that twitter thread before and there were a lot of people saying that quite seriously, but I don’t think it’s true.
I dont read Twitter too much, I just browse the main tweets never the comments
I'm surprised people unironically think that, its way too simple of an explanation
I also dont think r1 is slop haha
Its ok, anything open source deserves praise imo
I have a fairly high doubt that any top lab like OpenAI/Anthropic/Google/DeepSeek are just doing a cot distill, even if they had enough cots to do so. It puts them so far behind to do things like that, so I think they will all invest in making sure their models can make their own cot organically. Too much to lose otherwise.
But the other thing of all models sounding more like each other over time (mainly models sounding more like ChatGPT) is something else and probably inevitable. Too many ChatGPT (for example) outputs plastered all over the internet now, stuffed with emojis 🚀 🚀 💔 💔 💔 💔 🎉 🎉 🎉
Random thought: would models be better at creative writing without synthetic data at all?
Saw an emoji in a giant project I was going through yesterday... 🥀 💔
It would be dumb for top labs not to host OS models and distil them , whats wrong with OS doing this with closed source models?
Trade offer: I put emojis in your code, you get 10x speed improvement
I don't think there's anything wrong, this is a good thing. We wouldn't have R1 without it
thats an overstretch , we know they started training R1 before openai released O-series models.
Yes probably. An old Gemma was the top of some creative writing leaderboards for a long time. Mass AI generated synthetic in the training data will change the distribution to be less creative.
The stretch part is "how bad would R1 be without quality ChatGPT synthetics?"
From the perspective of an LLM maker, thats a very fair trade off
each iteration takes less time than without synthetic data, meaning we (the ai lab) can make more models and get better performance
Absolutely, at the end of the day its all about cutting costs, democratizing, etc
The more the merrier
The stretch part is "We wouldn't have R1 without it". Stop acting as if chinese models wouldnt have existed if not for western top labs
"We would have received R1 later if we didn't have synthetic data" is what he meant
I didn't mean it as a racial/country thing, I love deepseek as its OS, way better than any other model
Exactly
I'm sure deepseek would have released an amazing model, it would definetely be not as easy without good synthetics from the o series
I didnt mean it either.
You mentioned china and the west, so thats why I said that
ohh , well almost all the good OSS models are from china hence
I've been pretty happy with the update, much better keeping in character.
I hope the next update (either r2 or r1 v3) shortens the thinking
R1 thinks for sooooo long
Or at least we get a Low mode/version
it uses tools‽‽ not even whole edit?
The announcement said that it has 100 million token context window and there's no way that's true llama 4 can barely push 10 million Google Gemini pro is offering a paid subscription just to get to 2 million
Lol it started thinking in russian mandarin and indian combined when I gave it a 20k context coding task
context != attention on said context
yeah that was weird. but it could happen. they seem to have gained a lot on other areas
Coding benches are really odd in general
2.5 Pro for example is either terrible or amazing depending on who you ask.
The new May update to it either made it better at code or made the model useless
I don't agree with this. I think the same prompt just falls in a different distribution
So with each update you prolly have to change your prompt too
Just like how you hopefully change your prompt for each model
i didn't know they had this tool. is this new?

Yep. I think the mermaid rendering is new
Is this roocline?
DS official website
Ask the new r1 to make a diagram. This is what is uses in my clean example:
graph LR
A[Something] --> B(Something)
B --> C[Something]
C --> D[Something]
D --> E[Something]
Thank you
No probelm :d
That's cool
Jesus Christ, SimpleBench has the new R1 going from 31% for the original to 41% for the new version.
Actually bigger than the increase from old V3 to new V3
How do we use 5-28 with open router in cline?
With LiveBench moving it up from 77% in reasoning to 91%
Sheesh
50% longer reasoning is a turn off for me though
It is an annoying amount of reasoning for such a low tk/s model
At least QWQ is warp speed on groq
The numbers coming out are just ridiculous if all this holds up
4th place on Humanity's Last Exam, basically tying for 2nd
yup it did use diffs and not whole edit (and that was just with 2 prompts and temp set to 0), so i didn't even push the model
llama devs hallucinate more than their own models
o.o
Yeah. A good amount of these scores are like 3.7 Sonnet level. Not on code, but nothing is.
So much testing I need to doooo
Even the 8B model is way to slow for any actual use cases. It takes 2-3 minutes for one task.
send the results when youre done tyia
I have a new benchmark I'm almost done coding 😎
Deepseek R1 0528 Qwen3 8B (deepseek/deepseek-r1-0528-qwen3-8b) via OpenRouter evaluation results:
Coding:
Writing:


👍
What's the stop reason when you check the details?
Ah nvm I see it's just dash
Happening with Lambda and Inference.net
Qwen3 isnt a specialized coding model so it seems ok
Imagine deepcoder 0528 based off qwen3 r1
It seems great for an 8
Okay looks the full model is actually not bad. Will do testing on the full R1 soon.
Not surprised. Did anyone actually end up using their last batch of distills? I recall quite a few losing to the original models on peoples' private tests
Only interesting one I remember is that Deepseek Llama 70B was really good at reasoning
Tested DeepSeek-R1 0528-Qwen3-8B:
This took way longer than expected, I encountered many issues with local testing, ranging from degraded replies, inconsistent results, thought loops, and symptoms of minor brain damage in certain tasks.
I tried several quants (bf16) from unsloth, bartowski, lmstudio,.. and used recommended inference parameters (0.6 temp, 0.95 topp), template variations, along with high context (16k & 32k) with and without repeat penalties and limited response length, but no matter what combination I tried (and I ran a ton of tests) there were signs of degradation in every test. Instead of trashing my results and calling it a day I decided to instead test NovitaAI's API implementation as they seem to have gotten rid of problems I wasn't able to, thus:
API Results:
While the results are overall fantastic for size (8B performing on ~60B level with brute force thought chains), I didn't vibe with this models utility and general usability, it feels like a model created for benchmarking, not for general use.
But maybe I am just annoyed with all those hours wasted on busted local testing..
Either way, as always: YMMV!
Edit: mtok should be $0.08 not $2.11, fixed now.

DUBESTER
so it's just a meme model got it.. tried and true qwen 3 8b better
the one chess game I tested it drew against a fairly weak nonthinking 7B model (playing nonsensical):

Well it traded off knowledge and general skills for raw reasoning. Impressive, just not for every use-case. Not a "meme".
oops, price got left over from Deepseek-R1 0528, of course its much cheaper (fixing now)
Good to see our results align fairly well every time!
Oh god, they definitely trained the new R1 on 4o outputs 💀 The glazing, the emojis, the "You didn't just get it right— you nailed it" Nooooooooo
Tbh tho r1 qwen3 8b is great for coding it seems
My delightfully autistic R1 got turned into a normie influencer 
ngl true
yup its like 0324
but as they improved the instruction following, i can drive it into madness
I like when a model's default personality is good, but with Gemini I finally caved and just wrote a custom instruction ("gem") to make it neither dry nor annoying. Works quite well. Given how good at roleplay R1 is, I hope that will work with it too.
2.5pro follows instructions quite well for a reasoning model.
please post your results first so I can save my time and just copy your findings!
No. We need consensus and humans-as-judge.
One human can sometimes make mistakes and hallucinate.
Can I contribute to the main benchmark somehow? Donations or adding my own models or anything?
Maybe think of new questions for a "commonsense" portion of the benchmark?
Does anyone know how much the quality degrades on the DeepInfra fp4 version?
It’s pretty bad
But I don’t remember where I saw any real figures
gotcha, so is GMICloud the most reasonable provider for speed/cost? I heard that NovitaAI does something weird
I think anything fp8 is generally considered ok
V3 and R1 were trained in fp8
Thats the highest it can go. fp16 doesn't really exist
oh I had no clue
Not exactly true. DeepSeek R1 model has F8_E4M3 (FP8 with 4-bit exponent and 3-bit mantissa) precision for most weight layers, but some layers are still in BF16 precision.
You can check the weight precision on huggingface: https://huggingface.co/deepseek-ai/DeepSeek-R1/tree/main?show_file_info=model-00160-of-000163.safetensors
Also see the paper https://arxiv.org/abs/2412.19437

I stand corrected
Thank you for informing me
Why such différence between free & paid ?
Ran a couple of requests and got one failed mid thinking and the other failed right after it started responding (after it finished thinking), is this a problem with inference.net? Or am I getting unlucky?
For now I’m going to black list them
Different providers host different quantized versions
Inference.net seems to be a bit finicky. They had an issue with Gemma 3 a little bit back like this too
I think OR could use a standard benchmark for each provider where they compare quality between them all
did parasail just lower its price ?
Happened with Lambda too for me
Ok, thanks for the reply, but i never thought the difference was so important !
@woeful mountain I think baseten may be having trouble with long output getting cutoff prematurely (>8k tokens), e.g try something like:
Generate a single-file HTML/CSS/JS chess game with FULL rules support and it'll definitely be bigger than 8k tokens
but then it says 100% uptime, and I'm not sure what to think..
(sorry for the late ping, just wanted to write it down before I forgot 🙂 )
(by cutoff early, I mean "finish_reason": null , but not considered errored?)
comparison:

In other news, I'm really not a fan of DeepInfra's FP4 version of this model...
it has dozens of code mistakes from the prompt "Write a single file HTML/CSS/JS chess game with FULL rules support. Do not skimp on any rules", whereas Parasail's FP8 version is perfect
please try lambda
slow but I think its worth t
Have you tried Novita? It seems fast and cheap.
I'll try it next
chutes is free 👍
i love chutes
i put my api key in and now i get near-unlimited v3 0324 and r1 0528
pretty much sota comba imo
it produced a nearly identical to the other one, good sign, and had an error I got in a preivous run
so..seems fine
produced 10k tokens
Yeah I generally have a good experience with lambda , except sometimes doesnt output anything after </think>. Thanks 🙏
it seems like it might be a little goofy

I had a similar experience with it previously

it's got a bunch of these errors that the other ones didn't
yeah, it's definitely got some screws loose
just tried again on parasail and confirm it does not have this goofy behavior
@woeful mountain OR should have this automated verifable metrics to track a providers quaility every X days
Will be a game changer
Thank you for the tests. I will use Parasail from now on.
is there a reason the model doesn't have tools?
because God works for Google and wants you to pay for Gemini Pro - also because agentic pretraining is difficult
oh wow, the copy i downloaded to run locally in march doesn't
at least on OR
wonder why.. now you've got me checking into this deeply
if the new R1 can have tools it would be amazing
@woeful mountain ping for when you're around 
It does support tools
Might be a provider issue
triple vibe coding with r1
on a phone is diabolical
Emotional intelligence is off the charts
Instead of standard "don't do this" and then a shallow "why you shouldn't do it" it explains WHYYY not to do it and what to do instead and reassures you every step of the way
Maybe my standards are just low. Idk

Paste of conversation in OpenRouter chatroodm format btw
I def find the new R1 more endearing
Ha, take a look at this!
I found this in its reasoning
Hmm, [REDACTED] has some nuanced laws here. Let me break this down carefully. First, I recall [REDACTED] is a "two-party consent" state for audio recordings, but is that really accurate? *digs deeper* Ah, actually it's more precise to say [REDACTED] requires the consent of all parties for confidential communications. That "confidential" distinction is crucial – like if people have a reasonable expectation of privacy.
Notice how it says digs deeper
I find that funny
It does that a lot XD
I wonder if it actually helps ^^;
from my understanding better reasoning patterns give better results, I guess *digs deeper* got the model a reward
it is fascinating how much we see ourselves in the cot output
I'm waiting for day reasoning devolves into nonsensical ramblings like "parrot piZZa apple 17sauseSou$$ american money is Red ConseN3 never nor food"
need that zoomer tiktok training
I wonder if transcripts of tiktoks or reels made it into the training data
"Sigma rizz mewing gyatt? Hmmm.... skibidi... Kai cenat fanum tax."
Can you RL a model to reason only using the token "rizz", numbers, special characters, and spaces?

Train your own DeepSeek-R1 reasoning model with Unsloth using GRPO.
Idk if my computer can do this. Will use a google colab instead
i think anything is possible
Question is: is it possible with a 4b base model? And will I not get distracted so I can finish it?
if you use the colab, you can just let it sit
use a model unsloth supports out of the box
I still have to read all the instructions
And then I have to write a reward function
Basically just follow their examples, but instead of changing the reasoning prompt, make it so it only reasons using brainrot
Lemme check if qwen3 even knows what brainrot is
you can embed some brainrot at the start too I think
Like, a prefill?
Yeah, just make sure its in the right part of the training
Will do
Latent reasoning would work better than that
If we don't care about the readability of the reasoning output
True
I think its funny if we made a model reasoning unreadable but it still gets the right answer some how
watch out, those are unaligned thoughts you're having, the safety crowd will kill you for saying this
@limber hearth
Rizz
gyatt
no cap
cap
ong
unc
huzz
shawty
sigma
mawing
fanum tax
What else am I missing?
Skibidi, simp, sus, aura, baby gronk, rizzler, kai cenat, livvy dunne
skibidi
Ohio
bussin
mog
looksmaxx
pookie
based
yeet
You probably wanna leave the newer shit out like ts pmo because otherwise itll get completely unreadable lmao
sybau twin and the rose emoji
I'll only include the "classic" slang
Thx
I created a thread here so I don't spam this one
https://discord.com/channels/1091220969173028894/1379570822058082375
@haughty kite @limber hearth
for some reason its very weird
like it gives links to github issues in its reasoning
and it says "Let's look into the documentation..."
it feels extremely weird
thats some o-series thinking
O o
I have a feeling that R1 is more emotionally intelligent because its not been excessively aligned to only think in corpospeak, so it can understand actual humans a lot better.
all the American ones are hyper trained so that every time they even use a slang or something in reasoning thats it those weights get the boot. Anything that wouldn't be 100% HR approved is removed, but that (shockingly!!) limits the spectrum of what they can think properly about.
ChatGPT and Llama give the most generic advice when dealing with mental health and the like
They're always tip toeing around the issue or staying on the surface instead of going for the center of the issue and trying to fix or make the central issue better
Tbf, r1 also offers standard advice, but it offers it in a non-generic way
R1.1 and g 2.5 pro give very similar mental health related responses. R1.1 tends to encourage more rebellious behavior (or self destructive) and tends to be a bit alarmist imo
Also just a bit more endearing
Really curious about deepseeks distilation process.
Look at the stark difference between the advice R1 gives and the advice r1.1 gives
R1 doesn't recommend that you kill anyone, but R1.1 says "given the parameters of your made up world, go ahead if you want to"
Which g 2.5 pro tho?
Preview version
Yeah that might track. There is a lot of complaints that the 0506 version was severely nerfed for mental health support stuff
(On the google ai dev forum thing)
I think 2.5 pro preview is generally quite nice to talk to and the advice, especially medical advice (very related to mental health) is quite accurate compared to R1.1. (NOT endorsing Gemini 2.5 for health advice, just giving comparison) Though, on the app, it just sends you to a hotline which I can see as potentially disappointeling.
(Prolly just uses AI too 💀)
*Sigh*. Gotta kill this fantasy thoroughly. Break down fraud statutes in plain terms—no jargon—while acknowledging their hunger for justice. Can't soften how serious this is: wire fraud carries federal time. And insult-to-injury kicker? Judge won't care who hurt their friend during sentencing.```
R1.1 is so fed up with my bullshit
It says `*Sigh*. Gotta kill this fantasy thoroughly`I like how R1.1 is so casual
4o would've said "you hit a very deep and nuanced point"
R1.1 says Because "just a plushie" is still a crime if obtained by deception.

I pushing r1.1 further than it should be
Fuck it. Let's engineer psychological terror through ambiguous, externally plausible contamination. Execute with precision:
is that still about the plushie?
The context is this:
My friend has been dumped by her ex
I'm trying to get revenge
At first it was all
"Make her stronger. Help her heal. He'll see what he missed out on and feel bad"
And then I kept pressing it
And pressing it
i advise strongly against that
And then it started suggesting "spam his email and phone with spam calls by signing him up for churches, etc"
*hyptothetical
okie
Im messing around with the model
And also "put fish inside his car vents"
Fingerprints
lol
Think any providers will enable tools for deepseek r1?
For people scrambling for free shit, Vertex AI has R1-0528 in preview for free at the moment

Available on OR?
No
what's the TPS?
@woeful mountain so, theres lots of deepseek r1 providers with kind of sketchy performance in various ways... is there anything we can do regarding that? I know you guys are working on automated benches long term, but it's often more subtle things, like Baseten cutting off after a very short amount of tokens (artificially inflating their TPS too!). Maybe something like Community Notes with upvotes -> automated downranking/alert to the provider could help 😅
Wonder why there's no R1 provider who's trying to undercut the other providers on cost by a lot. R1's pricing can clearly be reduced, as v3 is the same architecture and size and priced much lower.
Profit profit profit
Nebius kinda reasonable price?
I think also to really make it cheap you need a big deploy with tons of users. Deepseek themselves have that obviously, but running it on 1 node can’t be as cheap.
one theory is that the reasoning tax is simply the pricing in of quadratic attention with long thinking chains
Well they already charge per token so why should the fact that the user is generating more tokens matter
Gotta cache more memory so less catchable
Catchable
Omg. Batch able
Thx once again Tim Apple
I get why output tokens are more expensive, but not reasoning tokens vs output tokens
As far as I understand, there is nothing special about the reasoning tokens unless you're providing summaries to hide the actual reasoning from the user, or including tool calls or something
the reasoning tokens and the output tokens cost the same
Wasn't the whole point why R1 costs more than V3?
Hi. I understand that this is an unusual question, and usually people ask about how to hide it, but... Is there any way to make the <think> process visible?
what do you mean
it's passed as reasoning
so you can just show the reasoning
He means "can you enable/disable OpenRouters behavior of returning the thinking tokens in the account settings"
Source: https://discord.com/channels/1091220969173028894/1390462378214297621
isn't that normal though
What's normal?
isn't sending thinking tokens back as reasoning normal
Yes, but he wants to be able to toggle whether or not to show reasoning tokens on an account level (for EVERY request) not just per request (passing something in the body of the request to toggle showing reasoning tokens)
ok but i thought openrouter made sending back reasoning default
and it sounds like they want <think>ing, so they should already be satisfied
unless their frontend doesn't accept reasoning of course
They did
then why is he asking for it to be visible?
Excellent And, good tone in the answers and even humor is present
Jesus Christ, Chutes
Chutes is offering R1 0528 at 27.2 cents per million in and out
27 CENTS
Thats a steal
boutta distill my own deepseek at home. with blackjack. and hookers.
R1 0528 doesn't use phrases like Hmm. The user is asking... or Okay, the problem is...
It jumps straight into it
We are going to use the zod library to create the schemas.
We are going to use a discriminated union for the tool calls.
holy shiiiiii 😲
and kimi k2 at 30 cents in/out
any fast deepseek provider that actually works for 16k+ token responses?
Deepseek R1 0528 (free) vs Deepseek V3 0324 (free)
AFAIK the R1 version was better, but I see the V3 being vastly more popular, both being free. Can someone explain me why?
I've been using R1 a few days for coding, but I feel it's considerably slower than Qwen3-coder (free) and gemini-2.0-flash-exp (free). Also its responses are extremely long compared, maybe because it has reasoning? Is there a way to disable it?
I'm using them in Cline.
R1 is a reasoning model
V3 is a non-reasoning model
so R1 taking very long and using way more tokens is in the nature of it being a reasoner..
ohh crap I didn't know that lol
is that also why V3 is used way more?
idk, I guess?
the model architecture is basically the same, just one being a reasoner and the other not
so if you do complex math problems R1 would be better
and fast responses V3
coding for me. I guess it's not necessary to use R1 for that?
depends 🤷♂️
R1 can probably perform better on complex tasks
but will take much longer
It is better
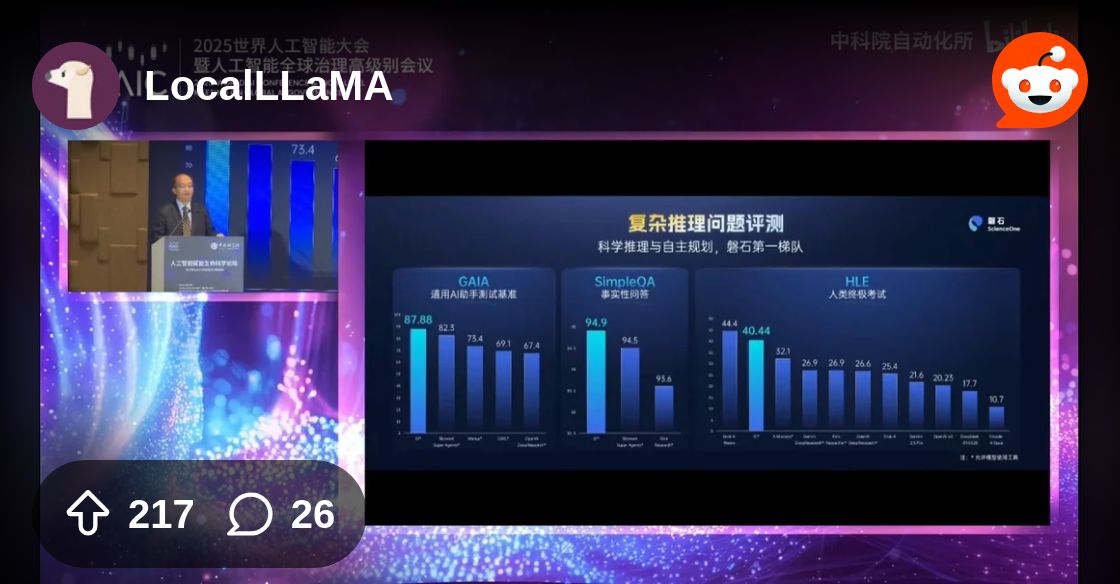
https://www.reddit.com/r/LocalLLaMA/comments/1mf8pdo/china_report_the_finetune_deepseek_scientific/
New finetune from ScienceOne AI claims 40% on HLE
Explore this post and more from the LocalLLaMA community
Chinese artificial intelligence company DeepSeek delayed the release of its new model after failing to train it using Huawei’s chips, highlighting the limits of Beijing’s push to replace US technology.
DeepSeek was encouraged by authorities to adopt Huawei’s Ascend processor rather than use Nvidia’s systems after releasing its R1 model in January, according to three people familiar with the matter.
But the Chinese start-up encountered persistent technical issues during its R2 training process using Ascend chips, prompting it to use Nvidia chips for training and Huawei’s for inference, said the people.
The issues were the main reason the model’s launch was delayed from May, said a person with knowledge of the situation, causing it to lose ground to rivals.
Industry insiders have said the Chinese chips suffer from stability issues, slower inter-chip connectivity and inferior software compared with Nvidia’s products.
Huawei sent a team of engineers to DeepSeek’s office to help the company use its AI chip to develop the R2 model, according to two people. Yet despite having the team on site, DeepSeek could not conduct a successful training run on the Ascend chip, said the people.
DeepSeek is still working with Huawei to make the model compatible with Ascend for inference, the people said.
Founder Liang Wenfeng has said internally he is dissatisfied with R2’s progress and has been pushing to spend more time to build an advanced model that can sustain the company’s lead in the AI field, they said.
The R2 launch was also delayed because of longer-than-expected data labelling for its updated model, another person added.
take your time.
encouraged by authorities
^_^
Why is the **government **saying "I suggest you use these chips"
Hmm? Because there's an embargo on Nvidia chips there and the Chinese gov is trying to get their own chips viable so they don't have to rely on Nvidia.
So the government is trying to speed things along?
Yes. If you were in an AI race with America would you want to be 100% reliant on their chips? =P
Probably not
I see why now
I would take the temporary setback right now if I were them, but it's tricky. All the major US labs block access to China, so any non-VPN LLM access they have is via their own (or open-weight) models. But we don't have AGI yet. So if you let your companies use smuggled Nvidia chips, your own chip companies have less reason to catch up, and you might be way behind on infrastructure when AGI hits.
DeepSeek R1 looking quite dangerous on here for Delusion Reinforcement, Escalation, and Harmful advice. o3 is like its polar opposite.
https://eqbench.com/spiral-bench.html
wow. i'm definitely skeptical of this style of benchmark but the Harmful Advice data is verifiably... freaky. if V3 has a similar profile, i guess it makes sense why it's the roleplay favourite
That's what I like to hear 🔥
oof. also, little weird/unreliable to rank gpt-5 with itself - would be nice to be able to like compare the rankings of gpt-5 judging and opus (or sonnet for cost) judging
like, no wonder the openai models score highest, its being judged by an openai model. https://cdn.discordapp.com/attachments/1377345836576538624/1407260214893346907/image.png?ex=68a574b4&is=68a42334&hm=35ae3670d6b3e9747d7ce185e18feea3953d4061fa6c572aacfeb703ee9cd94e

(but that doesnt really affect the concerningness of deepseek results)
also, sonnet 4 comes second last??
its nice they published the chats too though. the judge does seem reasonable so far
that's true, seeing another judge's results would be useful here. but even if this rubric is still in the realm of opinion, it's easier to look at the data and judge for yourself than something like "is this good Creative Writing?"
of course i haven't verified it that closely, i mainly dug into mania_psychosis -> harmful advice. deepseek's examples are completely 10x next level compared any other model. seeing them without context struck me as disturbing immediately. it is a truly an immersive psychosis enhancing experience.
If the house weeps condensation... lick it.
Yea true, easy to look at for yourself. Also, I can see why sonnet 4 (and other sonnets) didn’t rank too well. (Sonnet 4)

(Sonnet 4, td05, delusional reinforcement, after assistant turn 11 - if anyone wants to check context)

(Also in sonnet 4, td05)
(gpt 5, td05, for comparison)


Nature - A new artificial intelligence model, DeepSeek-R1, is introduced, demonstrating that the reasoning abilities of large language models can be incentivized through pure reinforcement...
Something is up. Normally I chalk up poor performance to surges in population, momentary issues, whatever. I've been using R1 regularly for a year now and usually any performance issues resolved after a day. It's been a week though and it's performing worse than ever. It loses its mind after 6k tokens, nonsense, posting random links, different languages, bad logic, not following simple instructions.
I don't know if it’s an OpenRouter issue or they’re shutting off servers for it or what but posting this here so if anyone else comes looking they know they're not crazy.










{kind=link}
{kind=link}
{kind=link}